⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-04 更新
Diffusion-Guided Gaussian Splatting for Large-Scale Unconstrained 3D Reconstruction and Novel View Synthesis
Authors:Niluthpol Chowdhury Mithun, Tuan Pham, Qiao Wang, Ben Southall, Kshitij Minhas, Bogdan Matei, Stephan Mandt, Supun Samarasekera, Rakesh Kumar
Recent advancements in 3D Gaussian Splatting (3DGS) and Neural Radiance Fields (NeRF) have achieved impressive results in real-time 3D reconstruction and novel view synthesis. However, these methods struggle in large-scale, unconstrained environments where sparse and uneven input coverage, transient occlusions, appearance variability, and inconsistent camera settings lead to degraded quality. We propose GS-Diff, a novel 3DGS framework guided by a multi-view diffusion model to address these limitations. By generating pseudo-observations conditioned on multi-view inputs, our method transforms under-constrained 3D reconstruction problems into well-posed ones, enabling robust optimization even with sparse data. GS-Diff further integrates several enhancements, including appearance embedding, monocular depth priors, dynamic object modeling, anisotropy regularization, and advanced rasterization techniques, to tackle geometric and photometric challenges in real-world settings. Experiments on four benchmarks demonstrate that GS-Diff consistently outperforms state-of-the-art baselines by significant margins.
近期,在3D高斯贴图(3DGS)和神经辐射场(NeRF)方面的进展,在实时3D重建和新型视图合成方面取得了令人印象深刻的结果。然而,这些方法在大型、无约束的环境中表现较差,其中稀疏和不均匀的输入覆盖、短暂的遮挡、外观变化和不一致的相机设置导致质量下降。我们提出了GS-Diff,这是一种由多视图扩散模型引导的新型3DGS框架,以解决这些局限性。通过生成以多视图输入为条件的伪观察结果,我们的方法将约束不足的3D重建问题转化为定位明确的问题,即使在稀疏数据的情况下也能实现稳健优化。GS-Diff还融合了多项增强功能,包括外观嵌入、单目深度先验、动态对象建模、各向异性正则化和先进的渲染技术,以应对现实环境中的几何和光度挑战。在四个基准测试上的实验表明,GS-Diff始终显著优于最新基线。
论文及项目相关链接
PDF WACV ULTRRA Workshop 2025
Summary
3DGS与NeRF的最新进展在实时3D重建和新型视角合成方面取得了令人印象深刻的结果。但在大规模、无约束的环境中,这些方法在面临稀疏和不均匀输入覆盖、临时遮挡、外观变化和不一致的相机设置等问题时表现欠佳。为此,本文提出GS-Diff,一种受多视角扩散模型引导的新型3DGS框架。通过生成基于多视角输入的伪观察值,GS-Diff将欠约束的3D重建问题转化为良好的问题,即使在稀疏数据情况下也能实现稳健优化。此外,GS-Diff还包括外观嵌入、单眼深度先验、动态对象建模、异向性正则化以及先进的栅格化技术等增强功能,以应对现实场景中的几何和光度挑战。在四项基准测试上的实验表明,GS-Diff显著优于最先进的基线方法。
Key Takeaways
- 3DGS与NeRF在实时3D重建和视角合成上表现出色。
- 在大规模、无约束环境中,现有方法面临多种挑战,如稀疏和不均匀的输入覆盖、临时遮挡、外观变化和相机设置不一致等。
- GS-Diff是一种新型3DGS框架,通过生成伪观察值解决上述问题,将欠约束的3D重建转化为良好约束的问题。
- GS-Diff采用多视角扩散模型引导,实现即使在稀疏数据下的稳健优化。
- GS-Diff集成了多种增强功能,包括外观嵌入、单眼深度先验、动态对象建模、异向性正则化和先进的栅格化技术,以应对现实场景中的几何和光度挑战。
- GS-Diff在四项基准测试上的实验表现优于最先进的基线方法。
点此查看论文截图


GaussianLSS – Toward Real-world BEV Perception: Depth Uncertainty Estimation via Gaussian Splatting
Authors:Shu-Wei Lu, Yi-Hsuan Tsai, Yi-Ting Chen
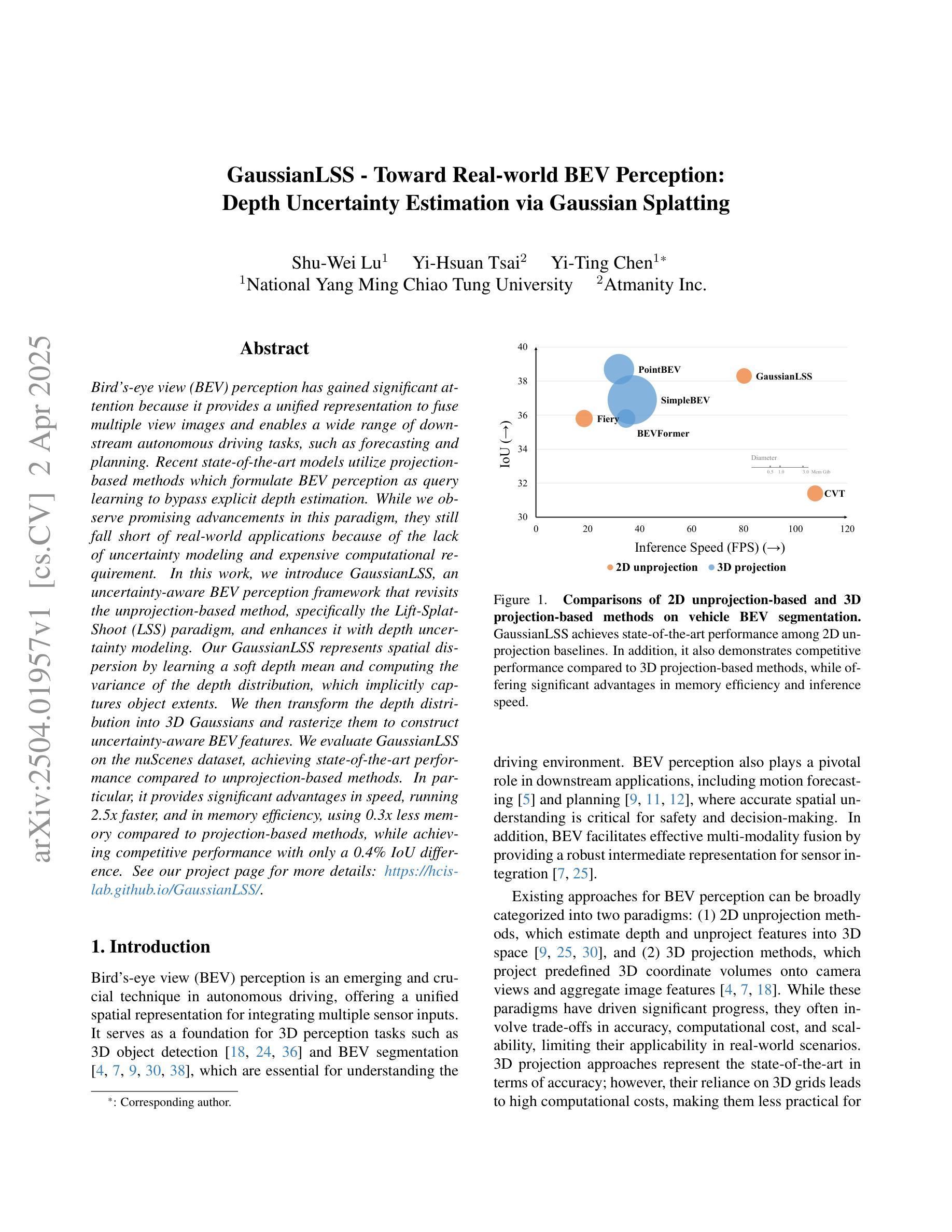
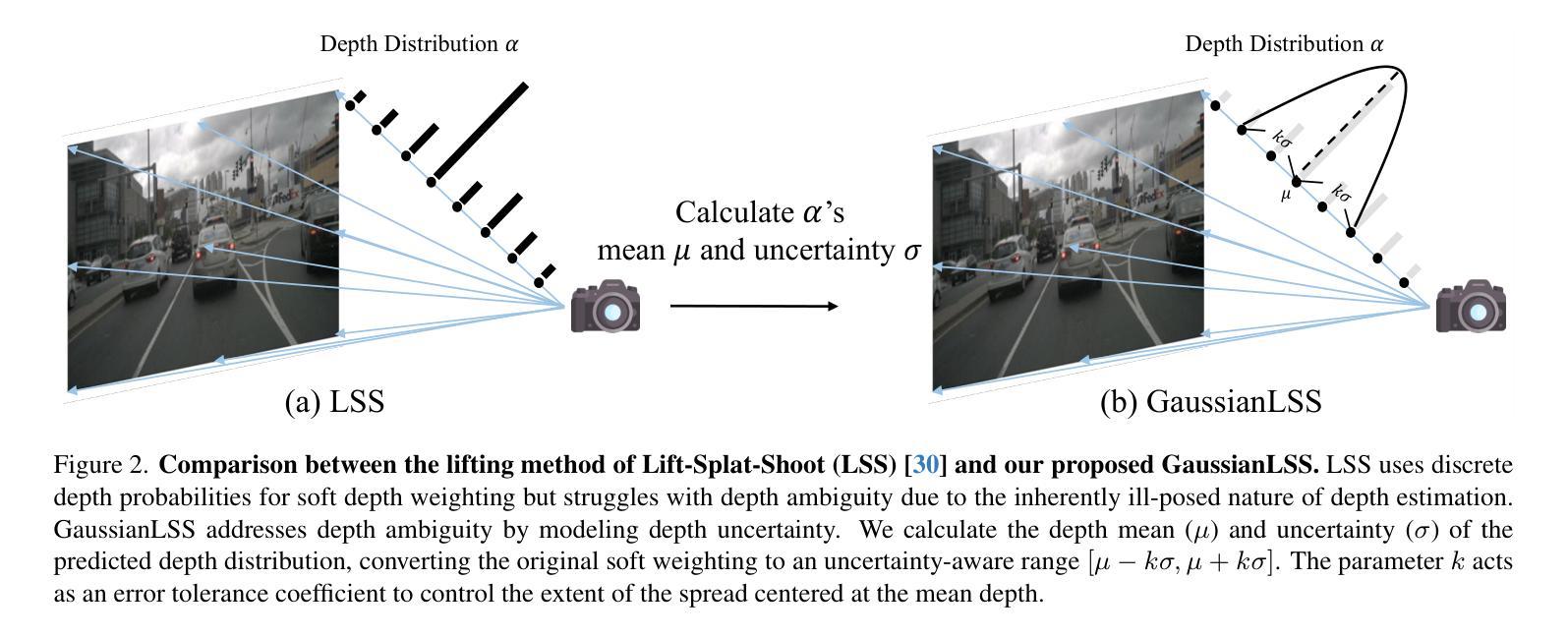
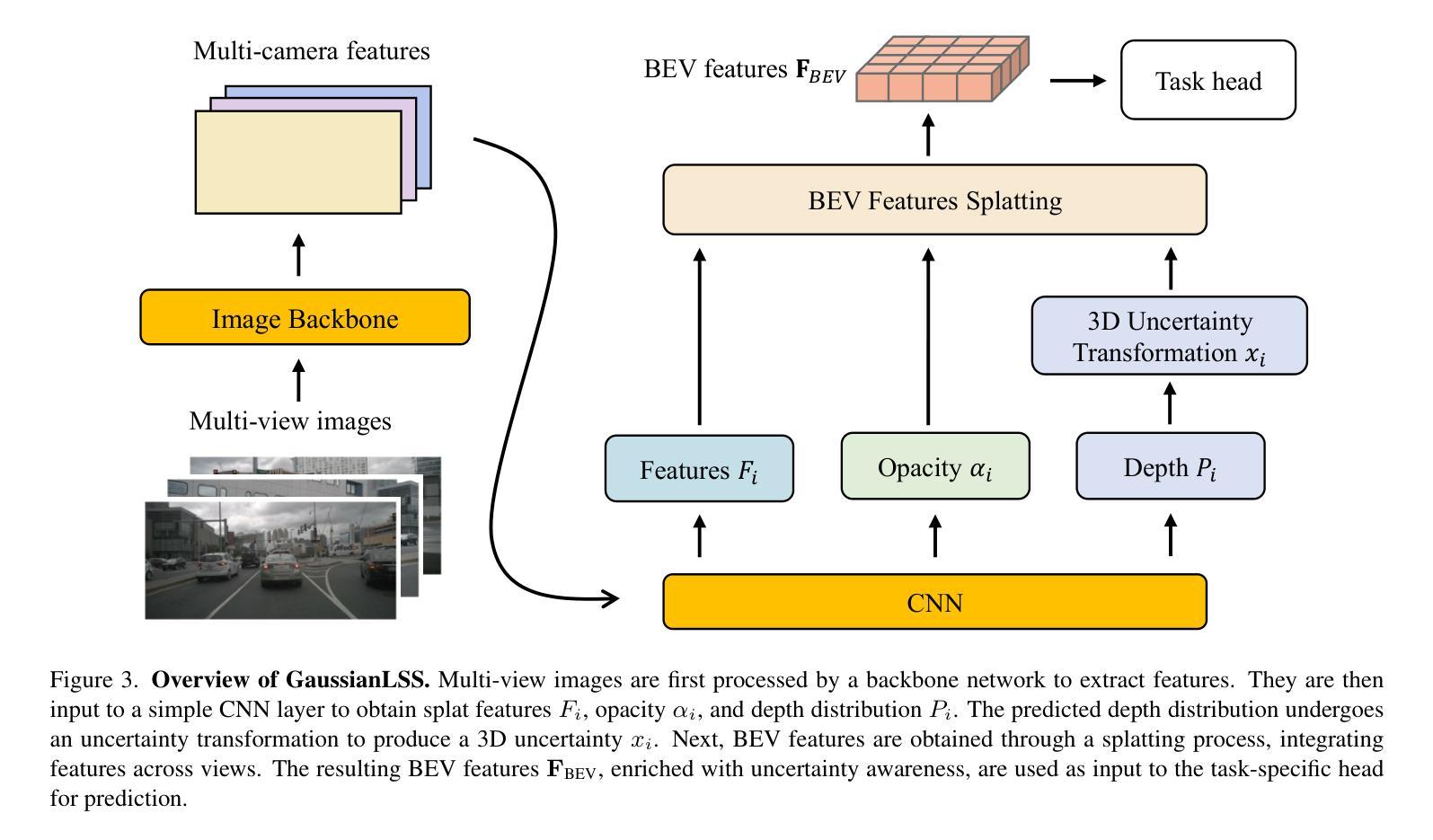
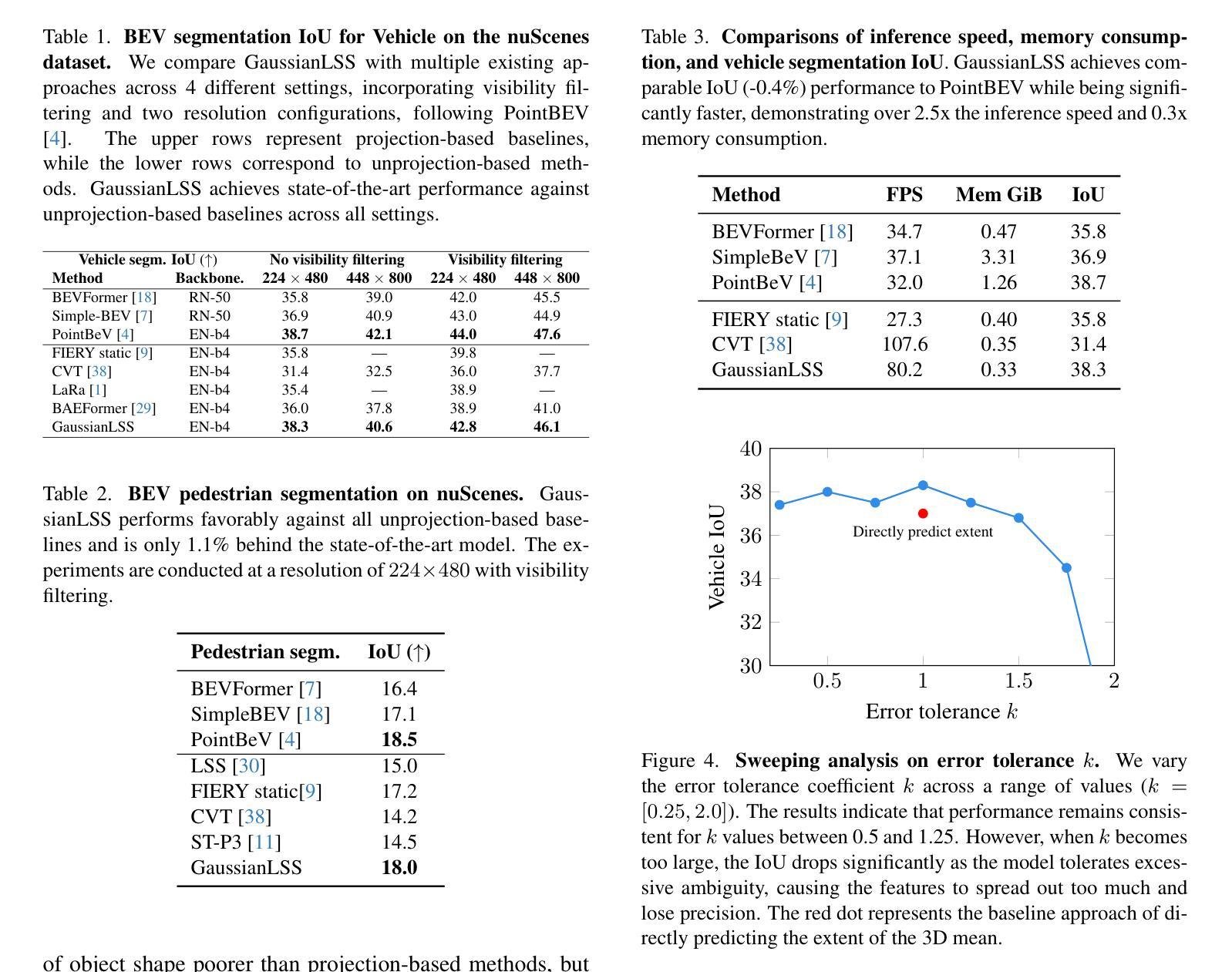
Bird’s-eye view (BEV) perception has gained significant attention because it provides a unified representation to fuse multiple view images and enables a wide range of down-stream autonomous driving tasks, such as forecasting and planning. Recent state-of-the-art models utilize projection-based methods which formulate BEV perception as query learning to bypass explicit depth estimation. While we observe promising advancements in this paradigm, they still fall short of real-world applications because of the lack of uncertainty modeling and expensive computational requirement. In this work, we introduce GaussianLSS, a novel uncertainty-aware BEV perception framework that revisits unprojection-based methods, specifically the Lift-Splat-Shoot (LSS) paradigm, and enhances them with depth un-certainty modeling. GaussianLSS represents spatial dispersion by learning a soft depth mean and computing the variance of the depth distribution, which implicitly captures object extents. We then transform the depth distribution into 3D Gaussians and rasterize them to construct uncertainty-aware BEV features. We evaluate GaussianLSS on the nuScenes dataset, achieving state-of-the-art performance compared to unprojection-based methods. In particular, it provides significant advantages in speed, running 2.5x faster, and in memory efficiency, using 0.3x less memory compared to projection-based methods, while achieving competitive performance with only a 0.4% IoU difference.
鸟瞰视图(BEV)感知已经引起了广泛关注,因为它为多视图图像融合提供了统一表示,并能够实现多种下游自动驾驶任务,如预测和规划。最近的最先进模型采用基于投影的方法,将BEV感知制定为查询学习,以绕过明确的深度估计。虽然我们在这一范式中看到了有前景的进展,但它们仍然因为缺乏不确定性建模和昂贵的计算要求而难以应用于现实世界。在这项工作中,我们引入了GaussianLSS,这是一个新型的不确定性感知BEV感知框架,它重新审视了基于非投影的方法,特别是提升-平铺-射击(LSS)范式,并通过深度不确定性建模增强了它们。GaussianLSS通过学习软深度均值并计算深度分布的方差来表示空间分散性,这隐含地捕获了对象范围。然后我们将深度分布转化为3D高斯分布并进行栅格化,以构建具有不确定性感知的BEV特征。我们在nuscenes数据集上评估了GaussianLSS的性能,与基于非投影的方法相比,它实现了最先进的性能。尤其值得一提的是,它在速度上具有显著优势,运行速度为基于投影的方法的2.5倍,在内存效率方面也具有优势,使用比基于投影的方法少0.3倍的内存,同时仅在IoU方面存在0.4%的差异便具有竞争力。
论文及项目相关链接
PDF Accepted to CVPR 2025
Summary
本文介绍了GaussianLSS,一种基于不确定性感知的鸟瞰图(BEV)感知框架。该框架重新审视了基于非投影的方法,特别是Lift-Splat-Shoot(LSS)范式,并通过深度不确定性建模进行增强。GaussianLSS通过学习软深度均值并计算深度分布的方差来表示空间分布,从而隐式捕获对象范围。然后,将深度分布转换为三维高斯分布,进行栅格化以构建具有感知不确定性的BEV特征。在nuScenes数据集上的评估表明,GaussianLSS相较于基于非投影的方法具有卓越性能,速度快2.5倍,内存效率提高0.3倍,同时与基于投影的方法相比,IoU差异仅0.4%。
Key Takeaways
- GaussianLSS是一种不确定性感知的鸟瞰图(BEV)感知框架。
- 该框架基于非投影方法,特别是Lift-Splat-Shoot(LSS)范式。
- GaussianLSS通过深度不确定性建模进行增强。
- 通过学习软深度均值和计算深度分布的方差来表示空间分布。
- 将深度分布转换为三维高斯分布,并进行栅格化以构建不确定性感知的BEV特征。
- 在nuScenes数据集上的评估显示,GaussianLSS具有卓越的性能和速度优势。
点此查看论文截图
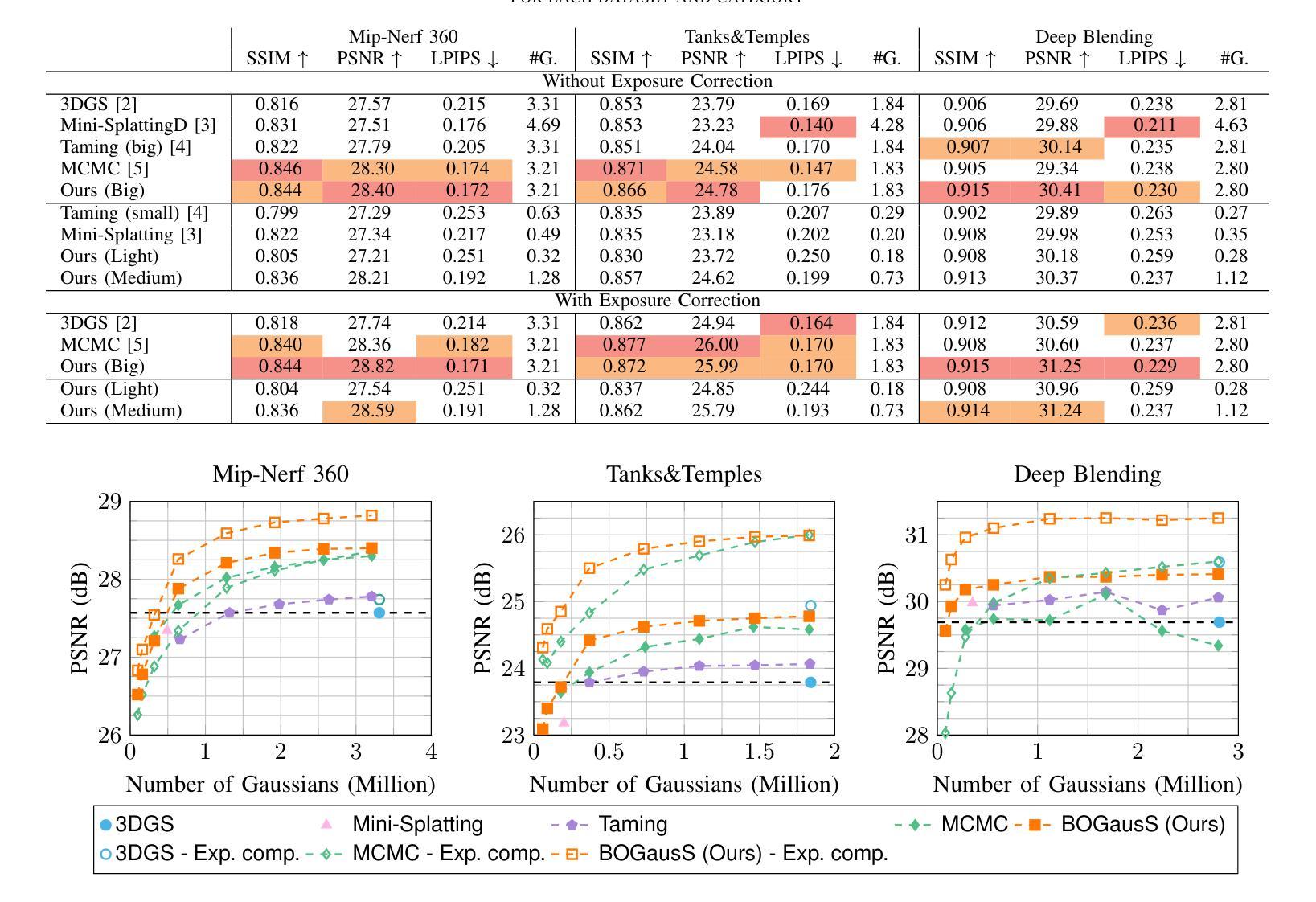
BOGausS: Better Optimized Gaussian Splatting
Authors:Stéphane Pateux, Matthieu Gendrin, Luce Morin, Théo Ladune, Xiaoran Jiang
3D Gaussian Splatting (3DGS) proposes an efficient solution for novel view synthesis. Its framework provides fast and high-fidelity rendering. Although less complex than other solutions such as Neural Radiance Fields (NeRF), there are still some challenges building smaller models without sacrificing quality. In this study, we perform a careful analysis of 3DGS training process and propose a new optimization methodology. Our Better Optimized Gaussian Splatting (BOGausS) solution is able to generate models up to ten times lighter than the original 3DGS with no quality degradation, thus significantly boosting the performance of Gaussian Splatting compared to the state of the art.
三维高斯喷溅(3DGS)提出了一种新颖的视点合成高效解决方案。其框架提供快速且高保真渲染。虽然相比于神经辐射场(NeRF)等其他解决方案,它的复杂性较低,但在不牺牲质量的情况下构建小型模型仍然面临一些挑战。在这项研究中,我们对3DGS训练过程进行了认真分析,并提出了一种新的优化方法。我们优化的高斯喷溅(BOGausS)解决方案能够生成比原始3DGS轻十倍的模型,同时不降低质量,从而极大地提高了高斯喷溅与最新技术的性能。
论文及项目相关链接
Summary
本文介绍了基于三维高斯贴图技术(3DGS)的创新视角合成解决方案。通过对其框架进行优化改进,研究提出了一种新的优化方法,即更好的优化高斯贴图(BOGausS)。这种方法能够在不降低质量的情况下,生成比原始3DGS模型轻十倍的模型,从而显著提高了高斯贴图技术的性能。
Key Takeaways
- 3DGS提供了一种高效的新视角合成解决方案,具有快速和高保真渲染的特点。
- 与其他解决方案(如NeRF)相比,构建较小模型的同时保持质量是一个挑战。
- 本文对3DGS训练过程进行了详细分析,并提出了新的优化方法——BOGausS。
- BOGausS能够在不降低质量的情况下,生成比原始3DGS模型轻十倍的模型。
- BOGausS显著提高了高斯贴图技术的性能。
- 此研究为三维图形渲染领域提供了新的优化思路和方法。
点此查看论文截图

3DBonsai: Structure-Aware Bonsai Modeling Using Conditioned 3D Gaussian Splatting
Authors:Hao Wu, Hao Wang, Ruochong Li, Xuran Ma, Hui Xiong
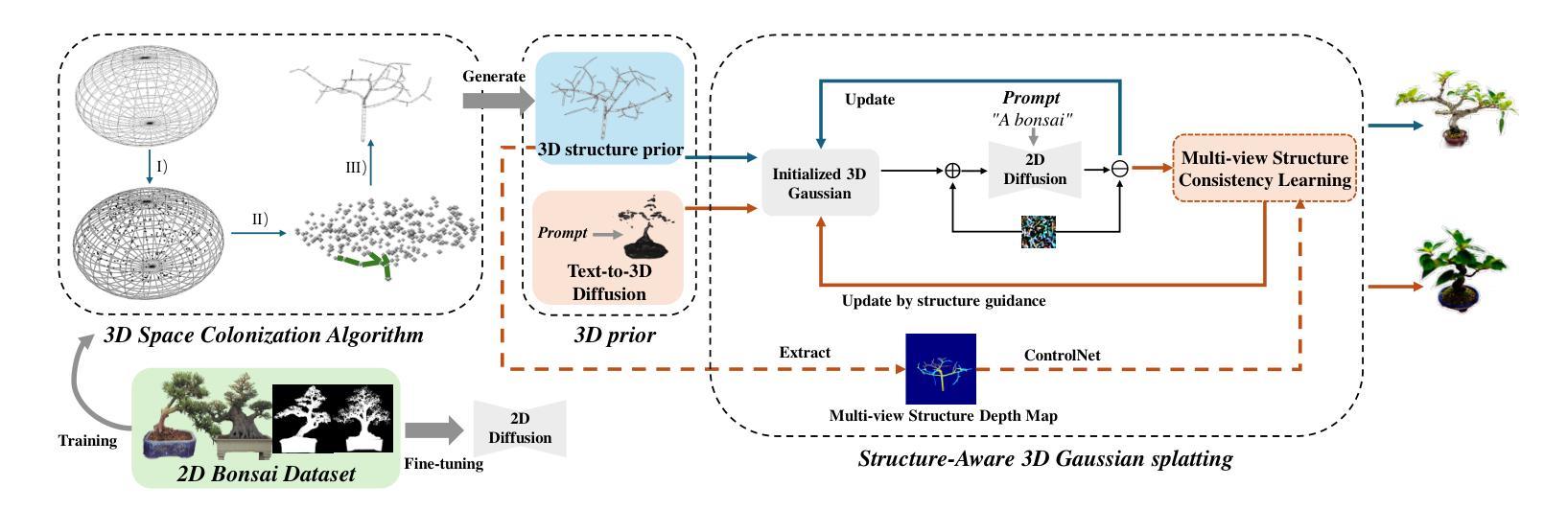
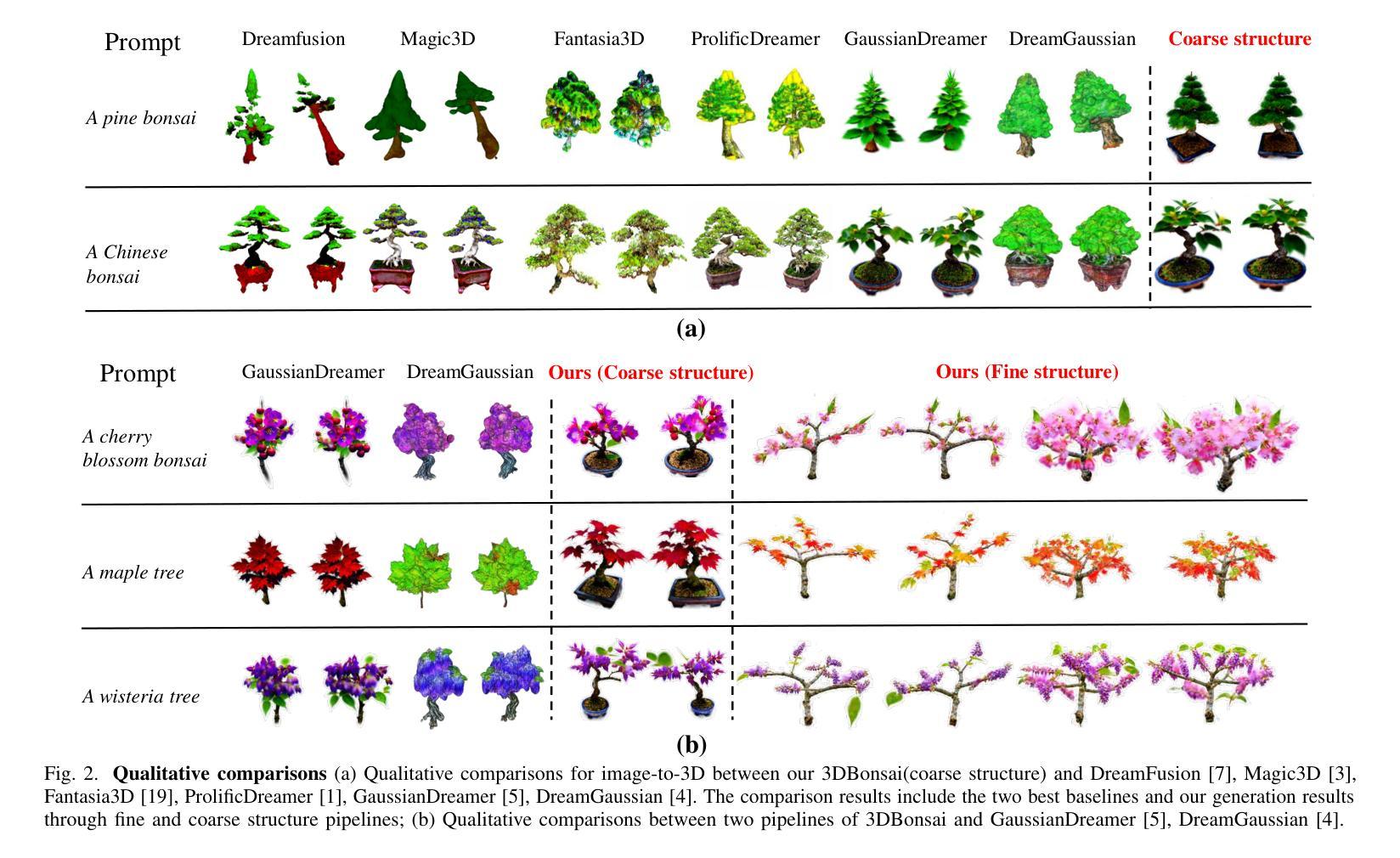
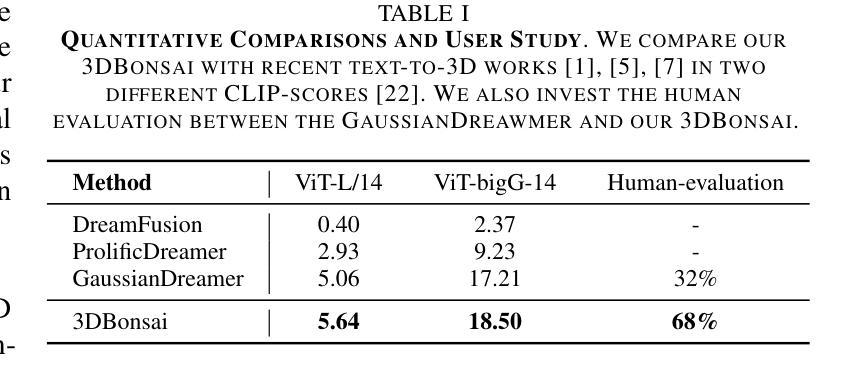
Recent advancements in text-to-3D generation have shown remarkable results by leveraging 3D priors in combination with 2D diffusion. However, previous methods utilize 3D priors that lack detailed and complex structural information, limiting them to generating simple objects and presenting challenges for creating intricate structures such as bonsai. In this paper, we propose 3DBonsai, a novel text-to-3D framework for generating 3D bonsai with complex structures. Technically, we first design a trainable 3D space colonization algorithm to produce bonsai structures, which are then enhanced through random sampling and point cloud augmentation to serve as the 3D Gaussian priors. We introduce two bonsai generation pipelines with distinct structural levels: fine structure conditioned generation, which initializes 3D Gaussians using a 3D structure prior to produce detailed and complex bonsai, and coarse structure conditioned generation, which employs a multi-view structure consistency module to align 2D and 3D structures. Moreover, we have compiled a unified 2D and 3D Chinese-style bonsai dataset. Our experimental results demonstrate that 3DBonsai significantly outperforms existing methods, providing a new benchmark for structure-aware 3D bonsai generation.
近期文本到3D生成的进展,通过利用3D先验和2D扩散的结合,取得了显著的结果。然而,之前的方法使用的3D先验缺乏详细和复杂的结构信息,仅限于生成简单物体,对于创建复杂的结构如盆景等带来了挑战。在本文中,我们提出了3DBonsai,这是一种新的文本到3D生成框架,用于生成具有复杂结构的3D盆景。技术上,我们首先设计了一种可训练的3D空间殖民化算法来生成盆景结构,然后通过随机采样和点云增强来增强这些结构,作为3D高斯先验。我们介绍了两种具有不同结构层次的盆景生成流程:精细结构条件生成,使用3D结构先验初始化3D高斯来生成详细而复杂的盆景;粗糙结构条件生成,采用多视角结构一致性模块来对齐2D和3D结构。此外,我们编译了一个统一的2D和3D中式盆景数据集。我们的实验结果表明,3DBonsai显著优于现有方法,为结构感知的3D盆景生成提供了新的基准。
论文及项目相关链接
PDF Accepted by ICME 2025
Summary
本文介绍了一种名为3DBonsai的新型文本到3D生成框架,用于生成具有复杂结构的3D盆景。该框架通过设计可训练的3D空间殖民化算法来生成盆景结构,并通过随机采样和点云增强技术来优化这些结构,将其作为3D高斯先验。文章还介绍了两种具有不同结构层次的盆景生成管道,分别是精细结构条件生成和粗略结构条件生成。实验结果表明,3DBonsai在结构感知的3D盆景生成方面显著优于现有方法,为相关领域提供了新的基准。
Key Takeaways
- 3DBonsai是一个用于生成具有复杂结构的3D盆景的新型文本到3D生成框架。
- 该框架利用可训练的3D空间殖民化算法来生成盆景的基本结构。
- 通过随机采样和点云增强技术优化生成的盆景结构,将其作为3D高斯先验。
- 文章中介绍了两种盆景生成管道:精细结构条件生成和粗略结构条件生成,分别适用于不同的需求。
- 3DBonsai编译了一个统一的2D和3D中式盆景数据集。
- 实验结果表明,3DBonsai在结构感知的3D盆景生成方面显著优于现有方法。
点此查看论文截图


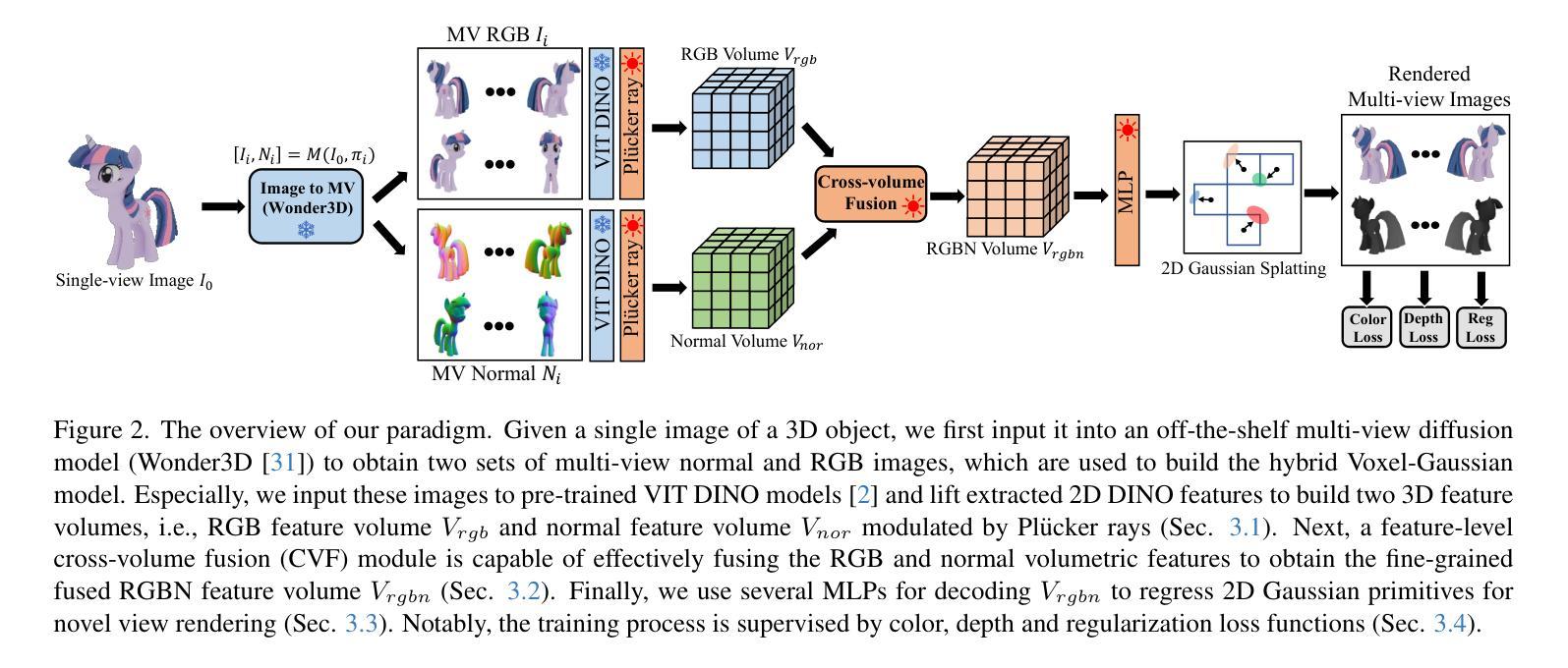
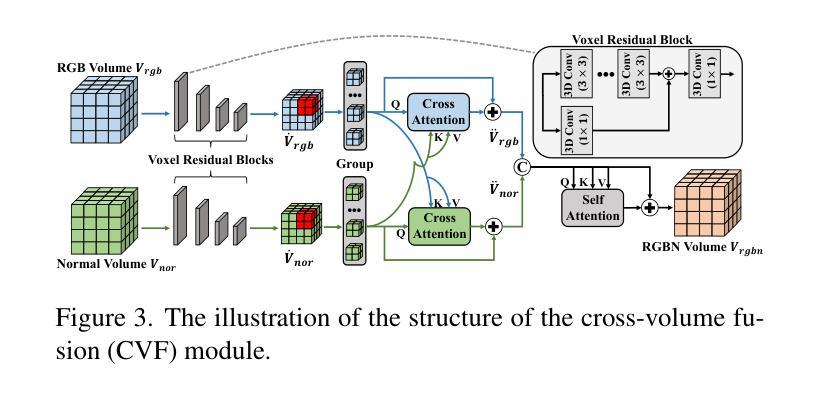
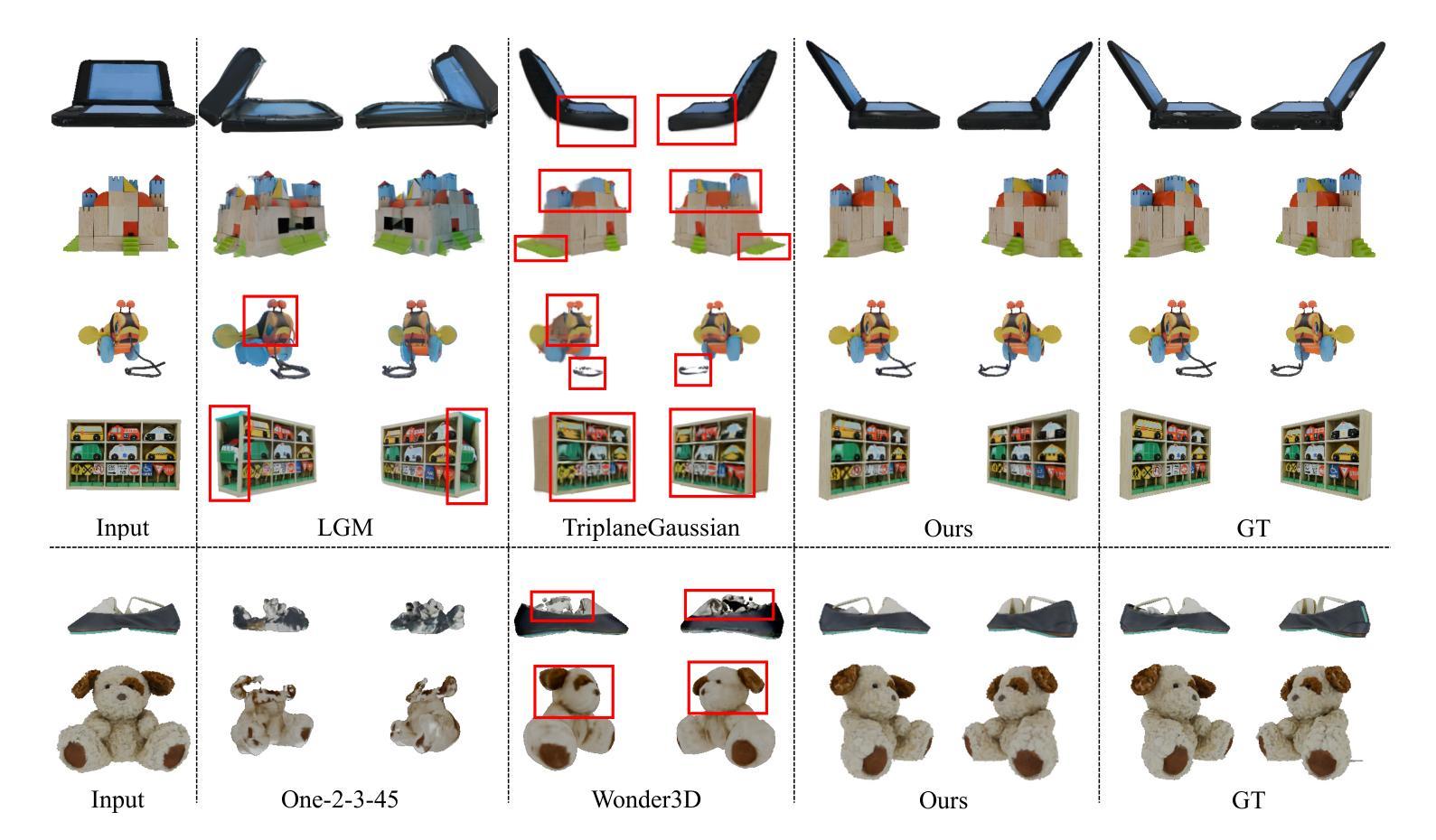
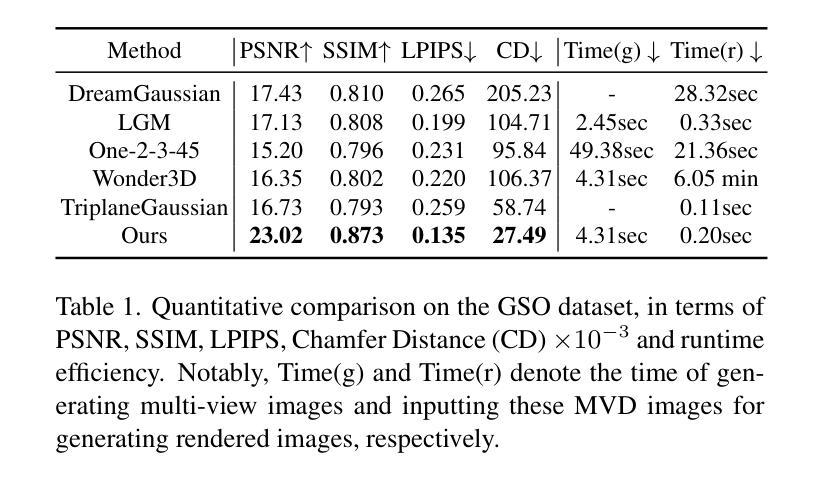
High-fidelity 3D Object Generation from Single Image with RGBN-Volume Gaussian Reconstruction Model
Authors:Yiyang Shen, Kun Zhou, He Wang, Yin Yang, Tianjia Shao
Recently single-view 3D generation via Gaussian splatting has emerged and developed quickly. They learn 3D Gaussians from 2D RGB images generated from pre-trained multi-view diffusion (MVD) models, and have shown a promising avenue for 3D generation through a single image. Despite the current progress, these methods still suffer from the inconsistency jointly caused by the geometric ambiguity in the 2D images, and the lack of structure of 3D Gaussians, leading to distorted and blurry 3D object generation. In this paper, we propose to fix these issues by GS-RGBN, a new RGBN-volume Gaussian Reconstruction Model designed to generate high-fidelity 3D objects from single-view images. Our key insight is a structured 3D representation can simultaneously mitigate the afore-mentioned two issues. To this end, we propose a novel hybrid Voxel-Gaussian representation, where a 3D voxel representation contains explicit 3D geometric information, eliminating the geometric ambiguity from 2D images. It also structures Gaussians during learning so that the optimization tends to find better local optima. Our 3D voxel representation is obtained by a fusion module that aligns RGB features and surface normal features, both of which can be estimated from 2D images. Extensive experiments demonstrate the superiority of our methods over prior works in terms of high-quality reconstruction results, robust generalization, and good efficiency.
近期,通过高斯贴片技术进行单视图3D生成的方法迅速兴起和发展。这些方法从由预训练的多视图扩散(MVD)模型生成的2D RGB图像中学习3D高斯分布,并为通过单张图像进行3D生成展示了前景。尽管已有进展,这些方法仍然受到由2D图像中的几何模糊和3D高斯结构缺失联合引起的不一致性的困扰,导致生成的3D对象失真和模糊。在本文中,我们提出通过GS-RGBN解决这些问题,这是一种新型的RGBN体积高斯重建模型,旨在从单视图图像生成高保真3D对象。我们的关键见解是,结构化的3D表示可以同时缓解上述两个问题。为此,我们提出了一种新颖的混合体素-高斯表示,其中3D体素表示包含明确的3D几何信息,消除了来自2D图像的几何模糊。它还在学习过程中对高斯进行结构化,使得优化更趋向于找到更好的局部最优解。我们的3D体素表示是通过融合模块获得的,该模块对齐RGB特征和表面法线特征,这两个特征都可以从2D图像中估计出来。大量实验表明,我们的方法在高质量重建结果、稳健的通用性和效率方面优于先前的工作。
论文及项目相关链接
PDF 12 pages
Summary
本文提出了一种新的RGBN体积高斯重建模型GS-RGBN,用于从单视图图像生成高保真度的3D对象。针对现有方法存在的几何模糊与高斯结构缺失的问题,该文采用了一种新的混合体素-高斯表示法,通过融合RGB特征和表面法线特征来构建结构化的三维表示,实现了高质量的三维重建结果。该方法优化了局部优化过程,并表现出优异的鲁棒性和效率。
Key Takeaways
- 单视图3D生成通过高斯拼贴方法快速发展。但是现有的方法仍存在由二维图像的几何模糊和高斯结构缺失引起的失真和模糊问题。
- 针对这些问题,提出了基于RGBN体积的高斯重建模型GS-RGBN来解决。
- 核心思路是采用混合体素-高斯表示法,将RGB特征和表面法线特征融合,构建结构化的三维表示。这种方法包含明确的几何信息并优化了高斯学习过程。这种方法有效地解决了二维图像中的几何模糊问题,并提高了生成三维对象的准确性。
- 通过融合模块获取三维体素表示法,该模块可以对RGB特征和表面法线特征进行对齐估算。
- 该方法在大量实验中表现优异,与传统方法相比具有更高的重建质量、更强的鲁棒性和良好的效率。
点此查看论文截图

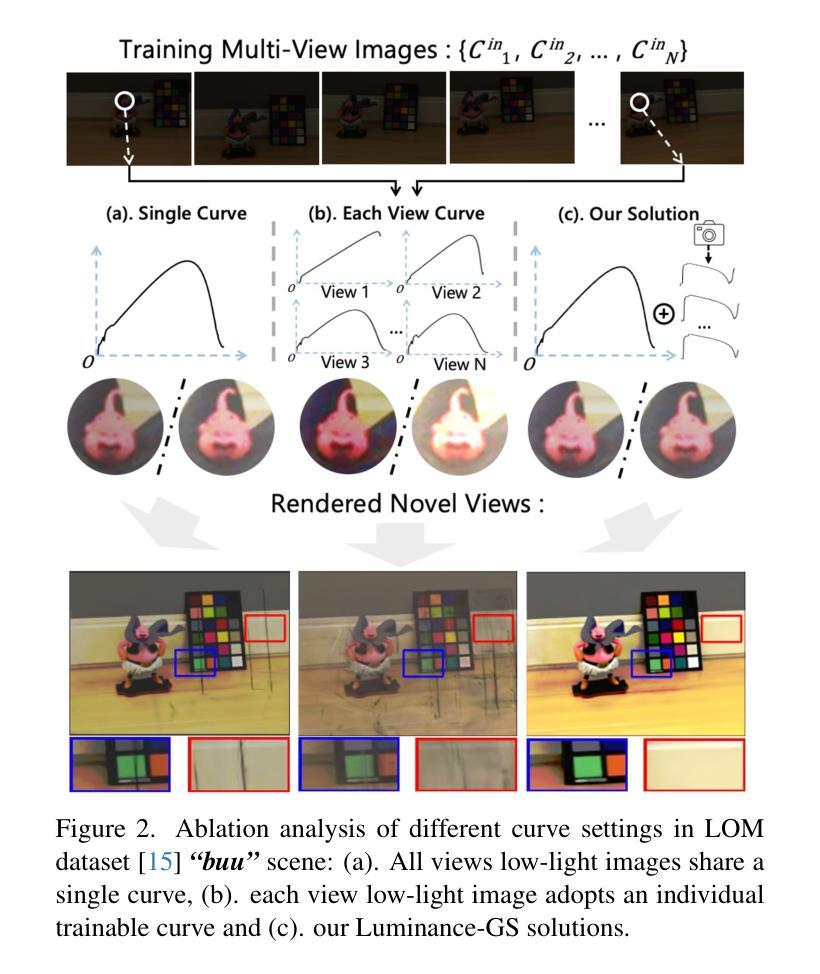
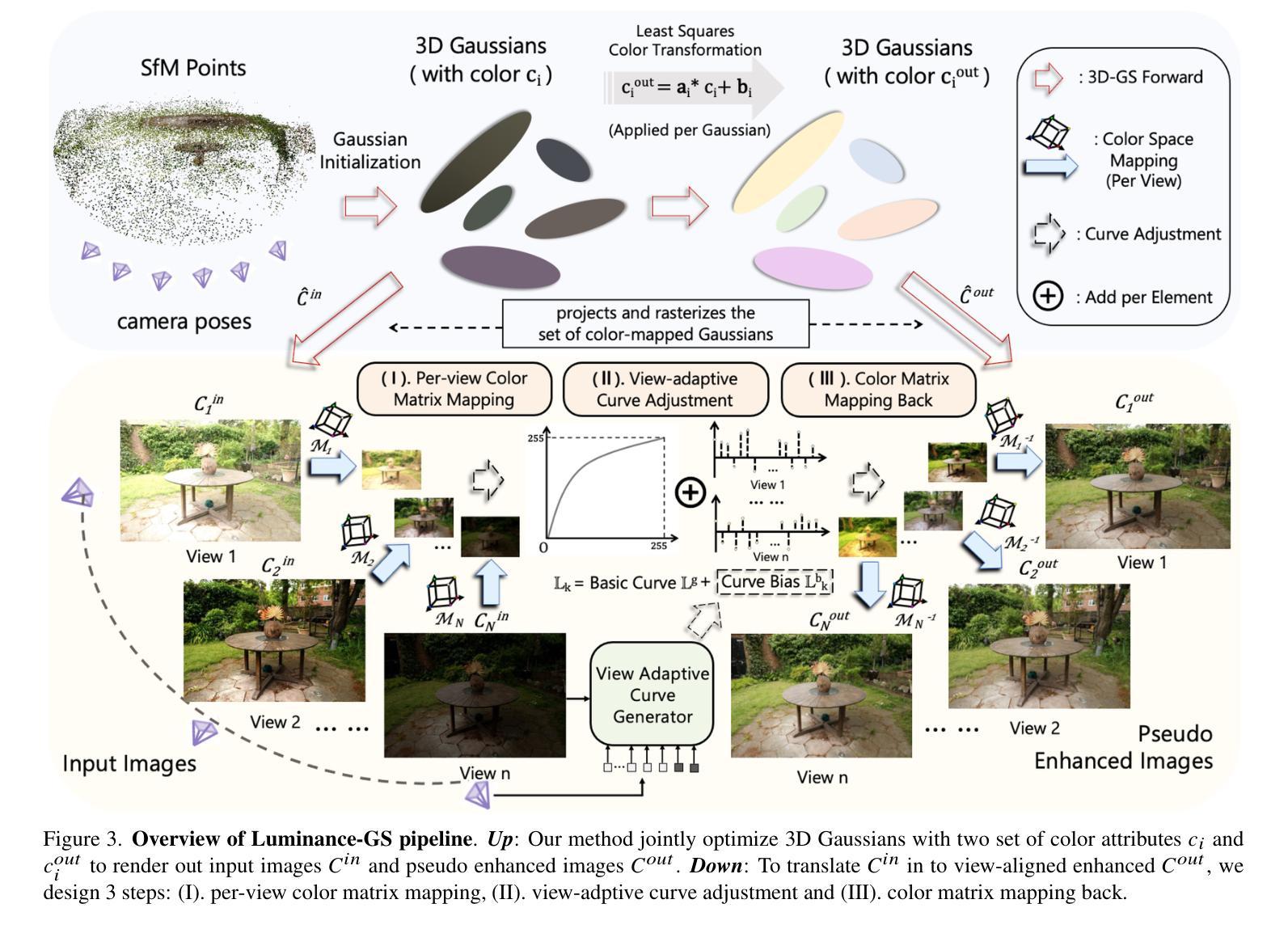
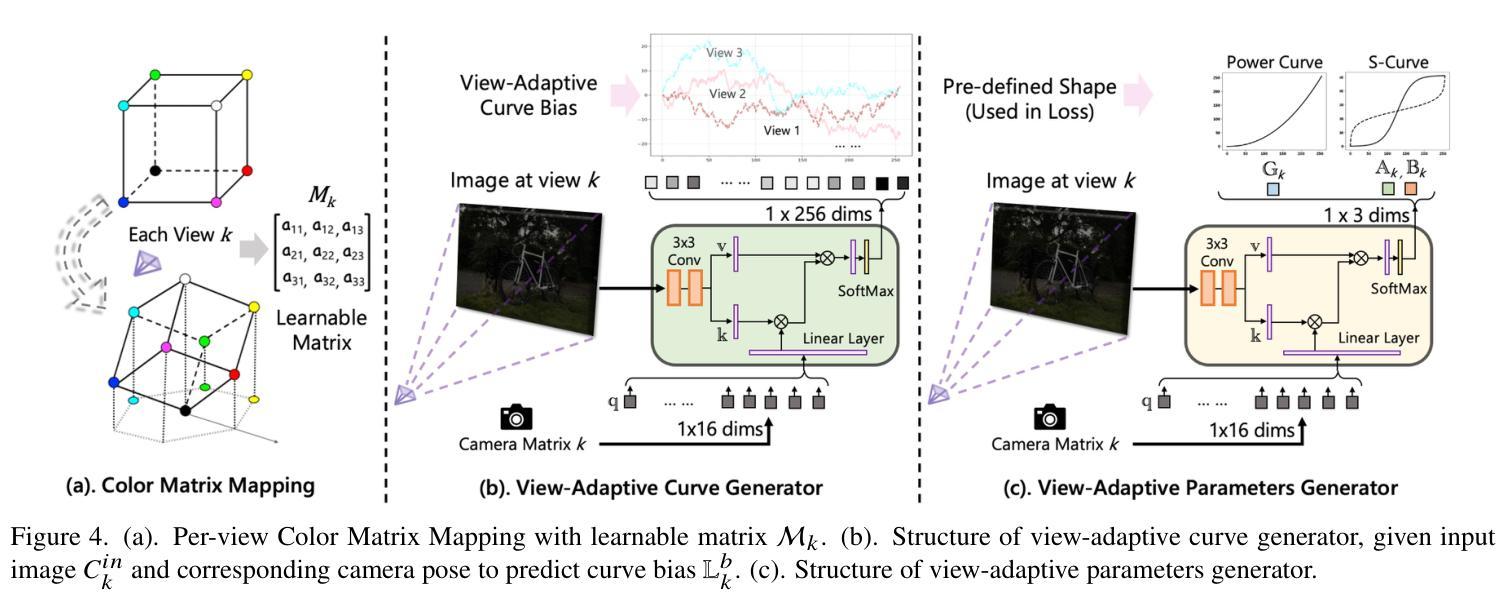
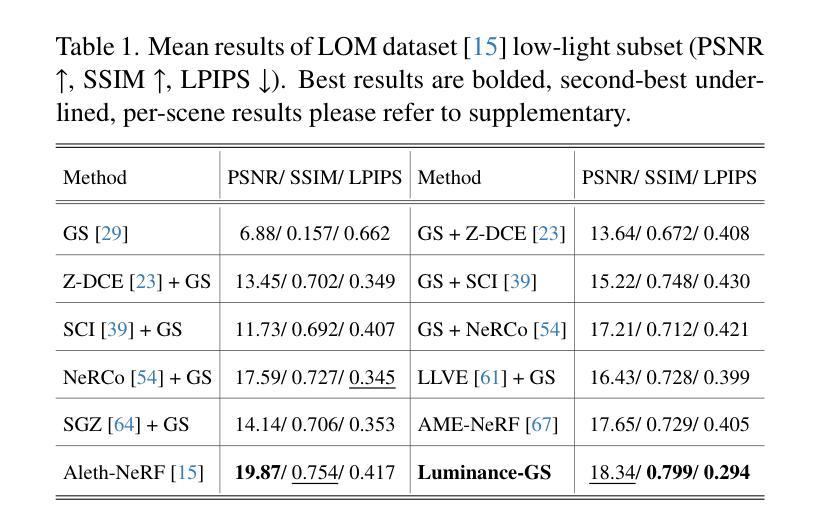
Luminance-GS: Adapting 3D Gaussian Splatting to Challenging Lighting Conditions with View-Adaptive Curve Adjustment
Authors:Ziteng Cui, Xuangeng Chu, Tatsuya Harada
Capturing high-quality photographs under diverse real-world lighting conditions is challenging, as both natural lighting (e.g., low-light) and camera exposure settings (e.g., exposure time) significantly impact image quality. This challenge becomes more pronounced in multi-view scenarios, where variations in lighting and image signal processor (ISP) settings across viewpoints introduce photometric inconsistencies. Such lighting degradations and view-dependent variations pose substantial challenges to novel view synthesis (NVS) frameworks based on Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS). To address this, we introduce Luminance-GS, a novel approach to achieving high-quality novel view synthesis results under diverse challenging lighting conditions using 3DGS. By adopting per-view color matrix mapping and view-adaptive curve adjustments, Luminance-GS achieves state-of-the-art (SOTA) results across various lighting conditions – including low-light, overexposure, and varying exposure – while not altering the original 3DGS explicit representation. Compared to previous NeRF- and 3DGS-based baselines, Luminance-GS provides real-time rendering speed with improved reconstruction quality.
在多样化的真实世界照明条件下捕捉高质量照片是一项挑战,因为自然光照(例如低光环境)和相机曝光设置(例如曝光时间)都会显著影响图像质量。这一挑战在多视角场景中尤为突出,其中不同视角的光照和图像信号处理器(ISP)设置变化会引入光度不一致性。这种光照退化和视角相关的变化给基于神经辐射场(NeRF)和3D高斯喷涂(3DGS)的新视角合成(NVS)框架带来了重大挑战。为了解决这一问题,我们引入了Luminance-GS,这是一种利用3DGS在多种具有挑战性的光照条件下实现高质量新视角合成结果的新方法。通过采用每视图颜色矩阵映射和视图自适应曲线调整,Luminance-GS在各种光照条件下实现了最先进的成果,包括低光、过曝和可变曝光,同时不改变原始3DGS的显式表示。与之前的NeRF和3DGS基准线相比,Luminance-GS提供了实时渲染速度,并提高了重建质量。
论文及项目相关链接
PDF CVPR 2025, project page: https://cuiziteng.github.io/Luminance_GS_web/
Summary
本摘要针对真实世界复杂光照条件下拍摄高质量照片的挑战,提出一种基于3DGS的新方法Luminance-GS,实现了不同视角的高质里合成图像。Luminance-GS利用视图色彩矩阵映射和视图自适应曲线调整技术,在多种光照条件下(包括低光、过曝光和曝光变化)取得了显著成果,同时保持了原始3DGS显式表示的完整性。与基于NeRF和3DGS的基线方法相比,Luminance-GS实现了实时渲染速度的提升和重建质量的改进。
Key Takeaways
- 高质量图像捕获面临挑战:真实世界复杂的光照条件和相机曝光设置对图像质量产生显著影响。
- 多视角场景中的光照变化引入光度不一致性,对基于NeRF和3DGS的新视角合成(NVS)框架构成挑战。
- 提出的Luminance-GS是一种利用视图色彩矩阵映射和视图自适应曲线调整技术的方法,解决了在不同光照条件下的高质量新视角合成问题。
- Luminance-GS在不改变原始3DGS显式表示的前提下,在多种光照条件下取得卓越成果。
- 与现有基于NeRF和3DGS的方法相比,Luminance-GS具有更快的实时渲染速度和更高的重建质量。
- 该方法具有广泛的应用前景,可用于改善真实世界复杂环境下的图像处理和渲染技术。
点此查看论文截图

3D Gaussian Inverse Rendering with Approximated Global Illumination
Authors:Zirui Wu, Jianteng Chen, Laijian Li, Shaoteng Wu, Zhikai Zhu, Kang Xu, Martin R. Oswald, Jie Song
3D Gaussian Splatting shows great potential in reconstructing photo-realistic 3D scenes. However, these methods typically bake illumination into their representations, limiting their use for physically-based rendering and scene editing. Although recent inverse rendering approaches aim to decompose scenes into material and lighting components, they often rely on simplifying assumptions that fail when editing. We present a novel approach that enables efficient global illumination for 3D Gaussians Splatting through screen-space ray tracing. Our key insight is that a substantial amount of indirect light can be traced back to surfaces visible within the current view frustum. Leveraging this observation, we augment the direct shading computed by 3D Gaussians with Monte-Carlo screen-space ray-tracing to capture one-bounce indirect illumination. In this way, our method enables realistic global illumination without sacrificing the computational efficiency and editability benefits of 3D Gaussians. Through experiments, we show that the screen-space approximation we utilize allows for indirect illumination and supports real-time rendering and editing. Code, data, and models will be made available at our project page: https://wuzirui.github.io/gs-ssr.
三维高斯曲面映射在重建逼真的三维场景方面显示出巨大的潜力。然而,这些方法通常将光照融入其表示中,限制了它们在基于物理的渲染和场景编辑中的使用。尽管最近的逆向渲染方法旨在将场景分解为材质和光照组件,但它们往往依赖于简化的假设,在编辑时这些假设会失效。我们提出了一种新方法,通过屏幕空间光线追踪为三维高斯曲面映射实现高效的全局光照。我们的关键见解是,大量的间接光可以回溯到当前视锥内可见的曲面。利用这一观察结果,我们用蒙特卡罗屏幕空间光线追踪来增强三维高斯计算的直接着色,以捕捉一次弹跳间接照明。通过这种方式,我们的方法能够在不牺牲计算效率和编辑便利性的情况下实现逼真的全局光照。通过实验,我们证明了我们所使用的屏幕空间近似允许间接照明并支持实时渲染和编辑。代码、数据和模型将在我们的项目页面提供:https://wuzirui.github.io/gs-ssr。
论文及项目相关链接
Summary
本文介绍了基于屏幕空间光线追踪技术的三维高斯贴图新方法,可有效实现全局光照效果。该方法结合三维高斯贴图的直接着色和蒙特卡罗屏幕空间光线追踪,捕获一次间接照明,具有计算效率高和可编辑性强的优点。实验结果证明该方法可实现实时渲染和编辑,支持间接照明效果。更多详情可访问项目页面:[链接地址]。
Key Takeaways
一、三维高斯贴图在重建真实感三维场景方面具有巨大潜力。
二、现有方法通常将照明融入其表示中,限制了其在物理渲染和场景编辑方面的应用。
三、逆向渲染方法旨在将场景分解为材料和照明组件,但在编辑时简化假设常常失效。
四、新方法通过屏幕空间光线追踪技术为三维高斯贴图实现了高效的全局照明。
五、关键洞察力在于大量间接光可以追溯回到当前视锥体可见的表面。
六、该方法结合了直接着色和间接照明,实现了真实感的全局照明,同时保持了计算效率和编辑性。
点此查看论文截图

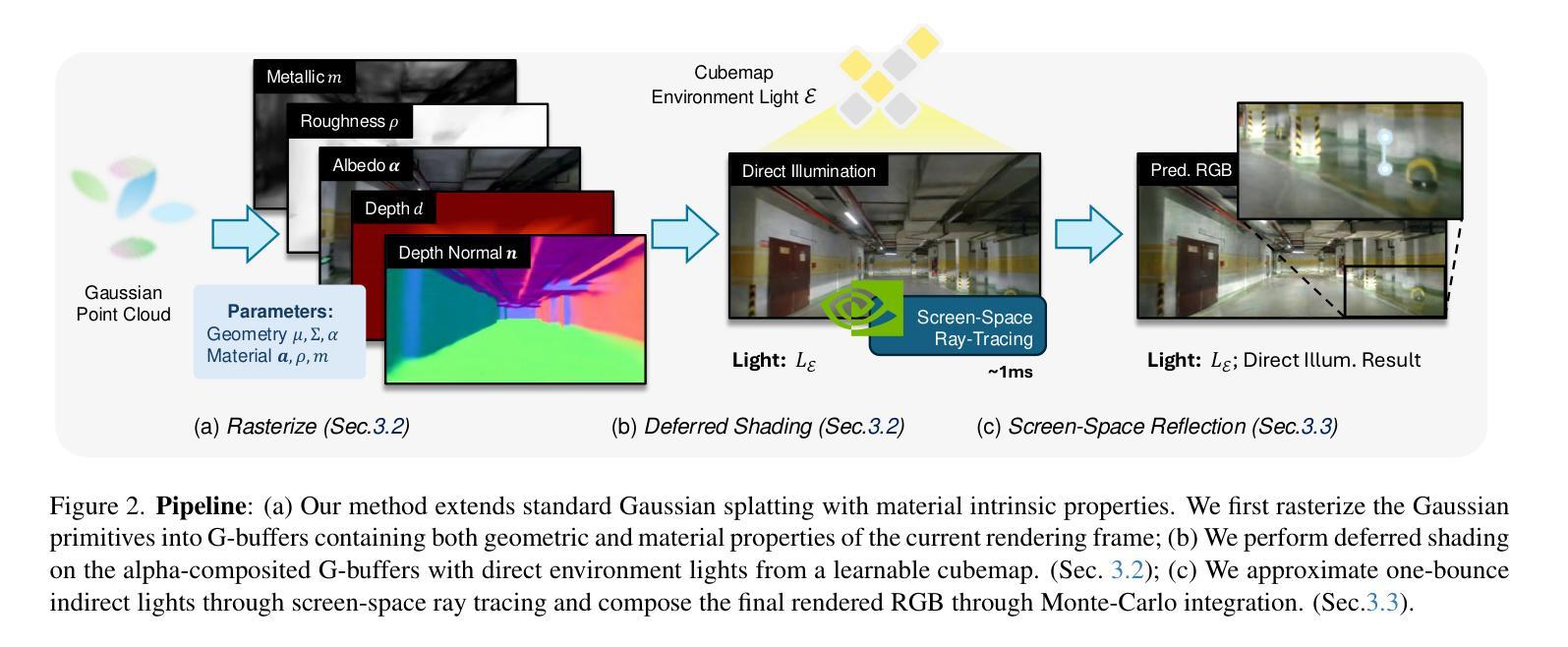
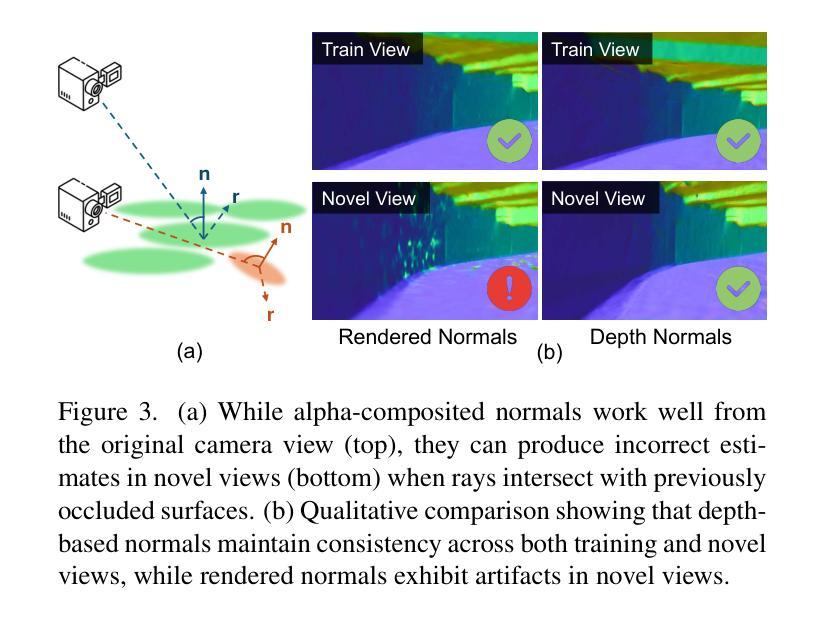
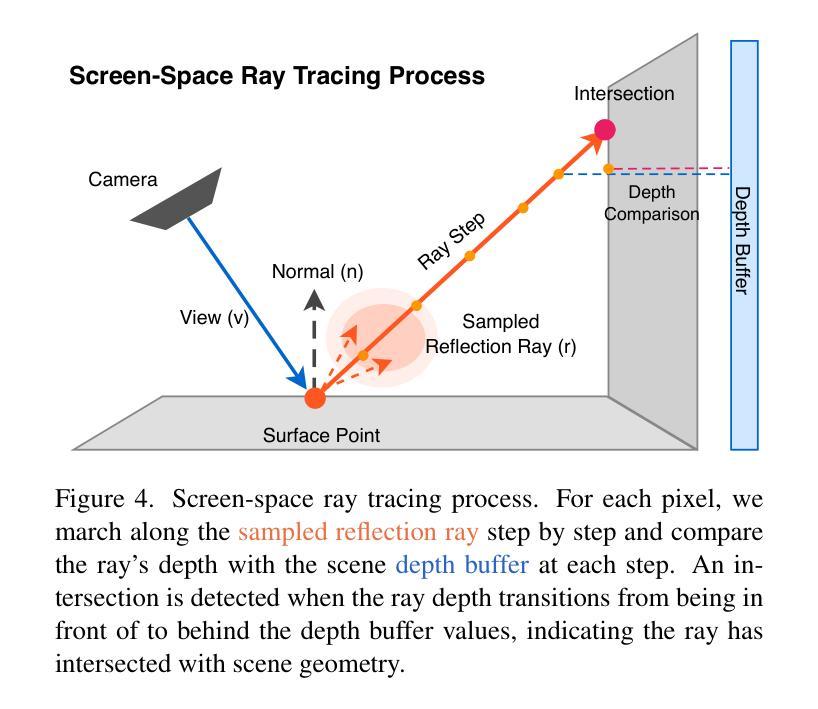
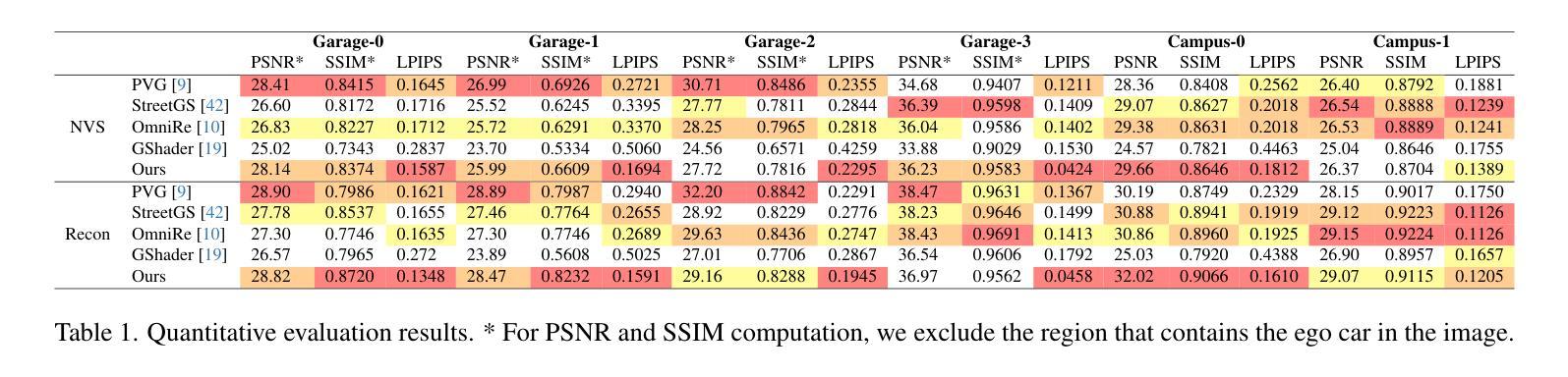
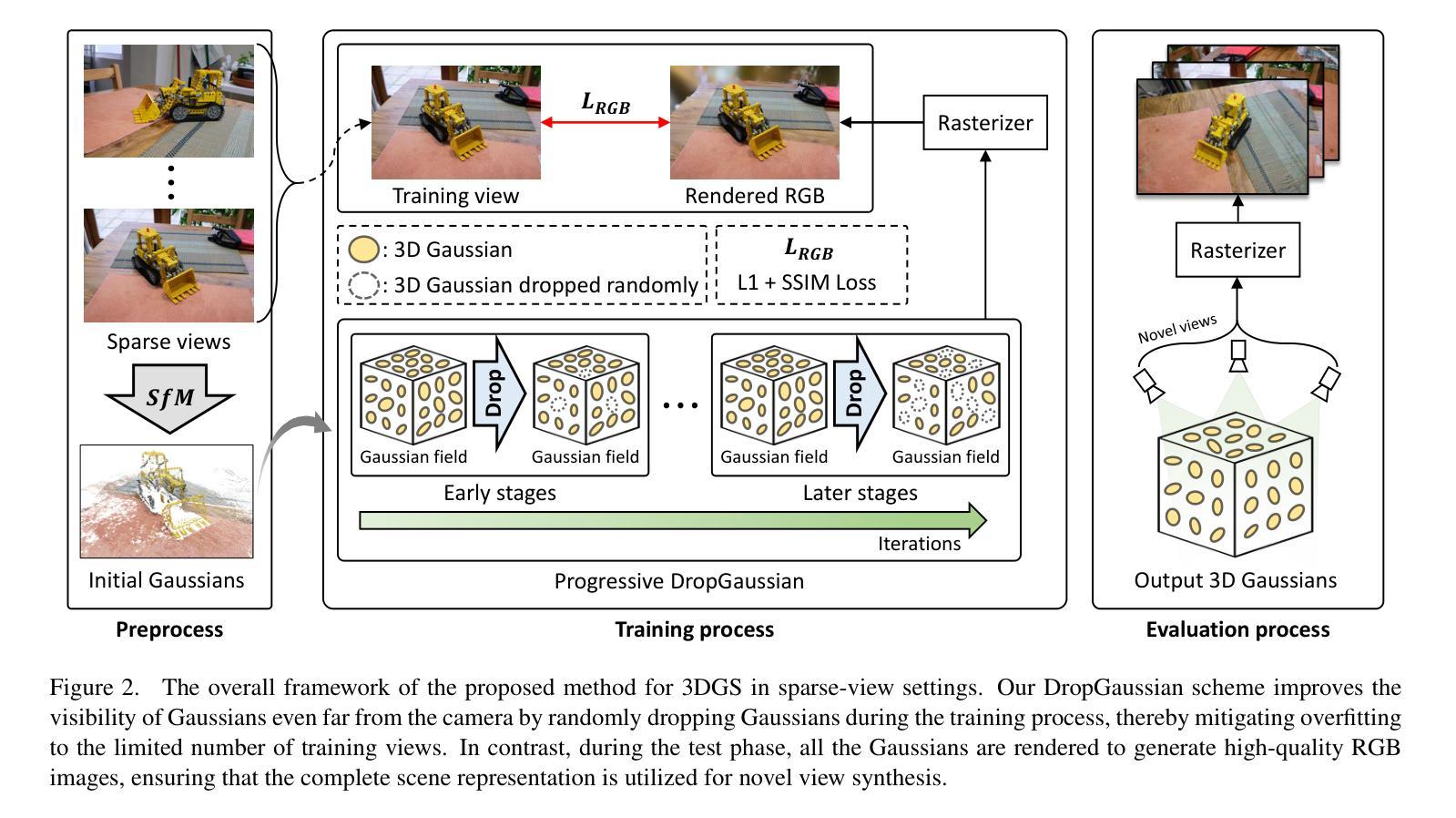
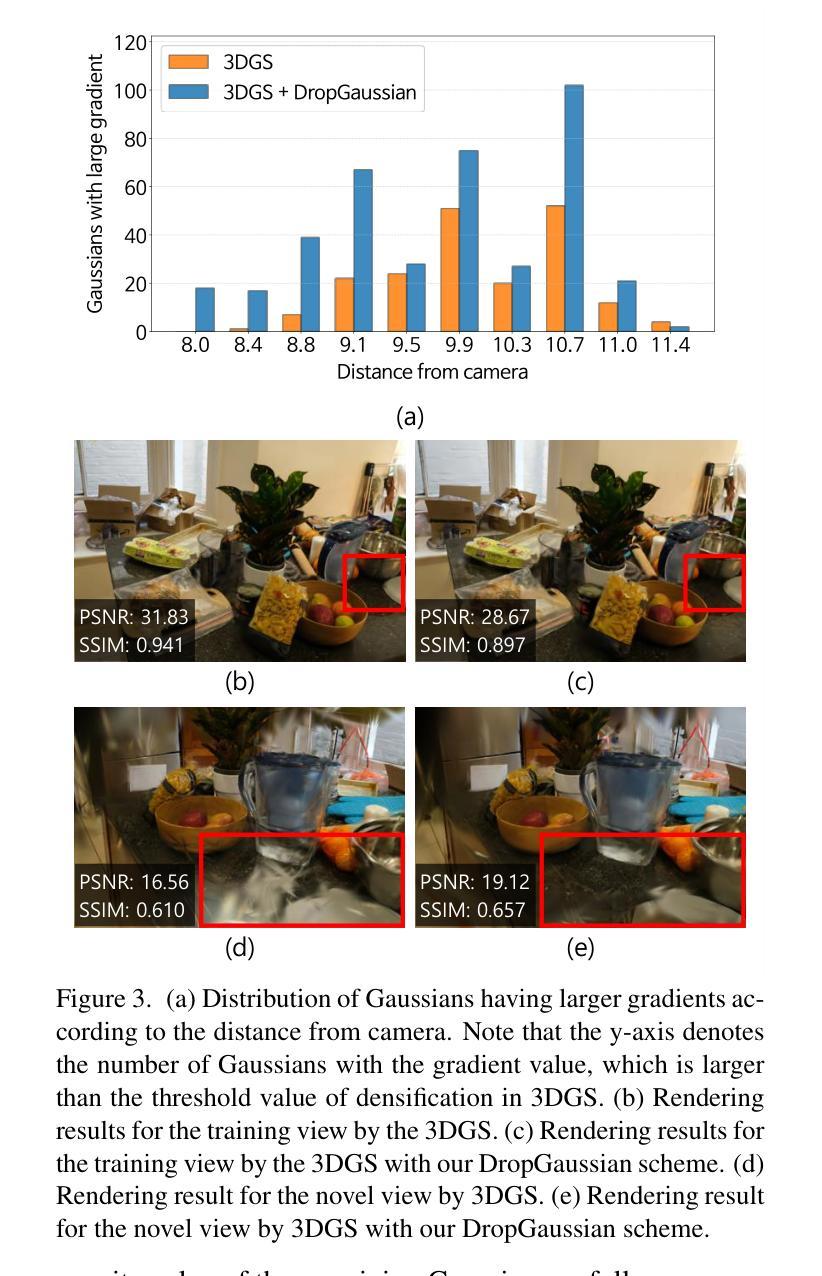
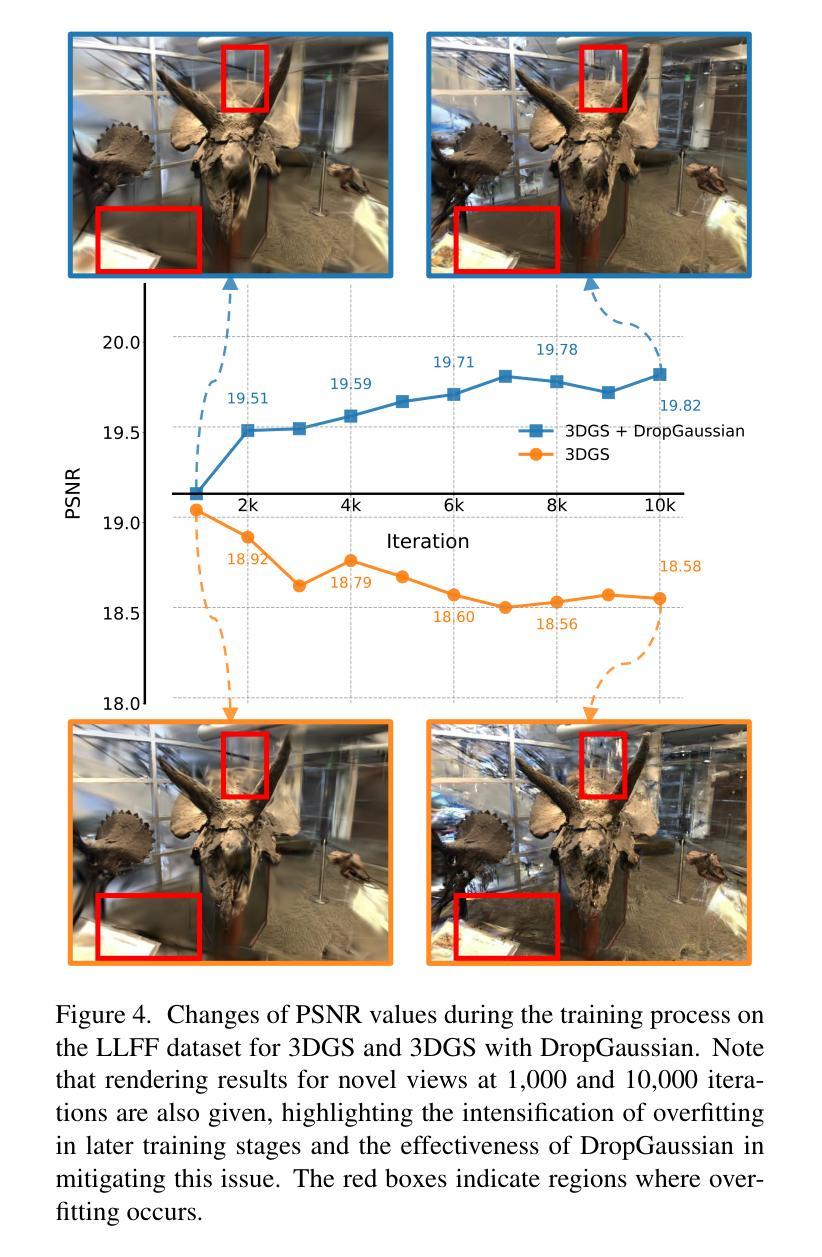
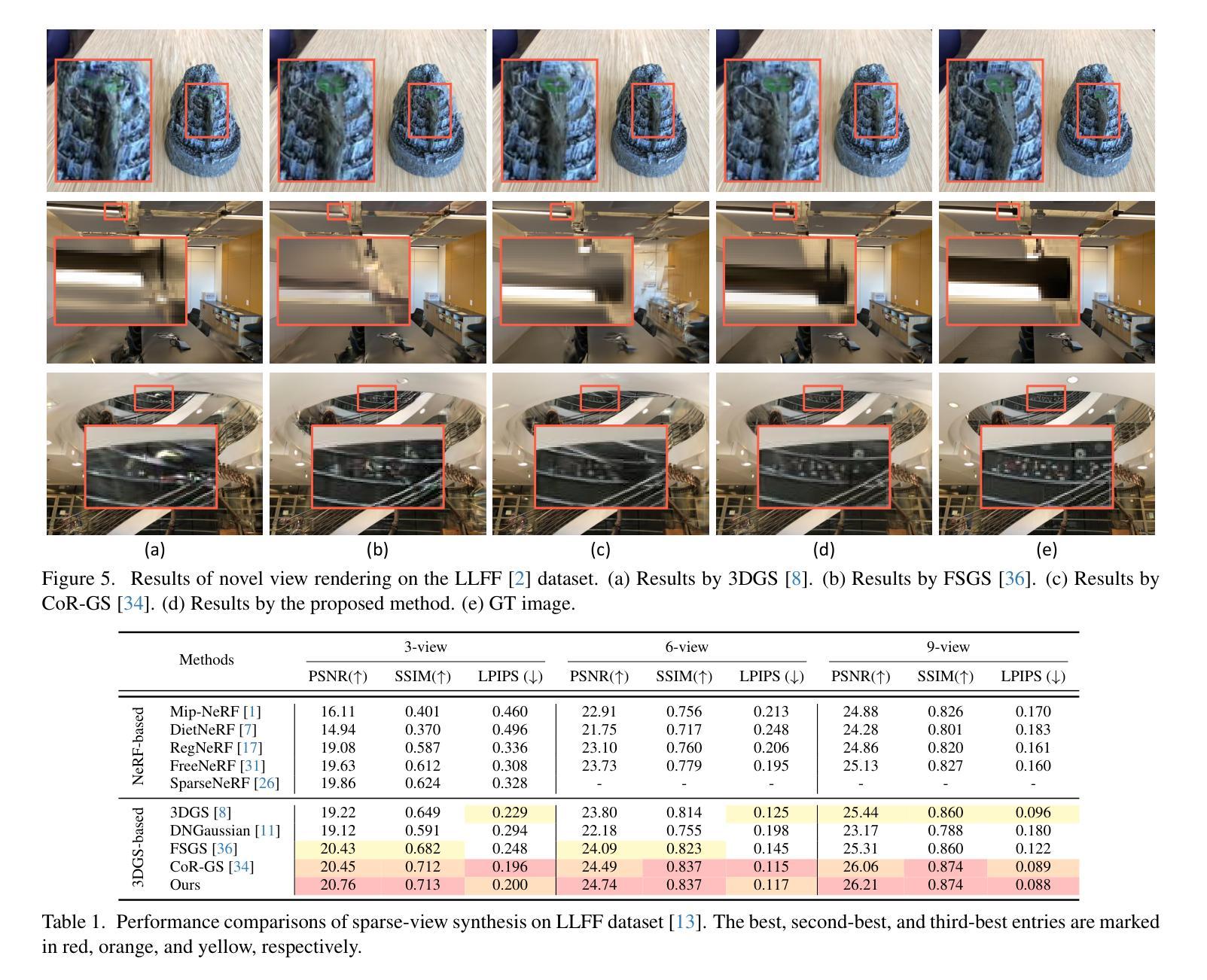
DropGaussian: Structural Regularization for Sparse-view Gaussian Splatting
Authors:Hyunwoo Park, Gun Ryu, Wonjun Kim
Recently, 3D Gaussian splatting (3DGS) has gained considerable attentions in the field of novel view synthesis due to its fast performance while yielding the excellent image quality. However, 3DGS in sparse-view settings (e.g., three-view inputs) often faces with the problem of overfitting to training views, which significantly drops the visual quality of novel view images. Many existing approaches have tackled this issue by using strong priors, such as 2D generative contextual information and external depth signals. In contrast, this paper introduces a prior-free method, so-called DropGaussian, with simple changes in 3D Gaussian splatting. Specifically, we randomly remove Gaussians during the training process in a similar way of dropout, which allows non-excluded Gaussians to have larger gradients while improving their visibility. This makes the remaining Gaussians to contribute more to the optimization process for rendering with sparse input views. Such simple operation effectively alleviates the overfitting problem and enhances the quality of novel view synthesis. By simply applying DropGaussian to the original 3DGS framework, we can achieve the competitive performance with existing prior-based 3DGS methods in sparse-view settings of benchmark datasets without any additional complexity. The code and model are publicly available at: https://github.com/DCVL-3D/DropGaussian release.
近期,由于其在提供出色图像质量的同时展现出高效的性能,3D高斯插值(3DGS)在新型视图合成领域引起了广泛关注。然而,在稀疏视图环境(例如三视图输入)中,3DGS经常面临过度拟合训练视图的问题,这显著降低了新视图的图像质量。许多现有方法通过利用强大的先验知识来解决这个问题,例如二维生成上下文信息和外部深度信号。相比之下,本文介绍了一种无需先验的方法,称为DropGaussian,它通过简单的改变3D高斯插值来实现。具体来说,我们在训练过程中随机删除高斯分量,类似于dropout的方式,这允许未被排除的高斯分量拥有更大的梯度并提高其可见性。这使得剩余的高斯分量对使用稀疏输入视图进行渲染的优化过程贡献更大。这种简单的操作有效地减轻了过度拟合问题并提高了新视图合成的质量。通过简单地将DropGaussian应用于原始3DGS框架,我们可以在基准数据集的稀疏视图环境中实现与现有基于先验的3DGS方法相当的性能,且没有任何额外的复杂性。相关代码和模型已公开在:https://github.com/DCVL-3D/DropGaussian发布。
论文及项目相关链接
PDF Accepted by CVPR 2025
Summary
本文介绍了名为DropGaussian的先验方法,通过随机移除训练过程中的高斯函数,改善了三维高斯采样在稀疏视图下的过拟合问题,提升了新视图合成的质量。此方法简单易行,只需应用于原始的三维高斯采样框架,即可在基准数据集的稀疏视图设置中,实现与现有基于先验的三维高斯采样方法相当的性能表现。
Key Takeaways
- 3D Gaussian Splatting(3DGS)在稀疏视图下会面临过拟合问题,导致新视图图像质量下降。
- DropGaussian是一种新颖的先验方法,通过随机移除训练过程中的高斯函数来解决这一问题。
- DropGaussian允许未被排除的高斯函数拥有更大的梯度,提升其可见性,使剩余的高斯函数对优化过程做出更大贡献。
- DropGaussian方法简单易行,能有效缓解过拟合问题,提升新视图合成的质量。
- DropGaussian能在不使用额外的复杂性的情况下,实现与现有基于先验的3DGS方法在稀疏视图设置中的竞争性能。
- DropGaussian的源代码和模型已经公开发布在相关GitHub链接上。对于公众可免费获取并使用这一资源用于学习和研究。
点此查看论文截图

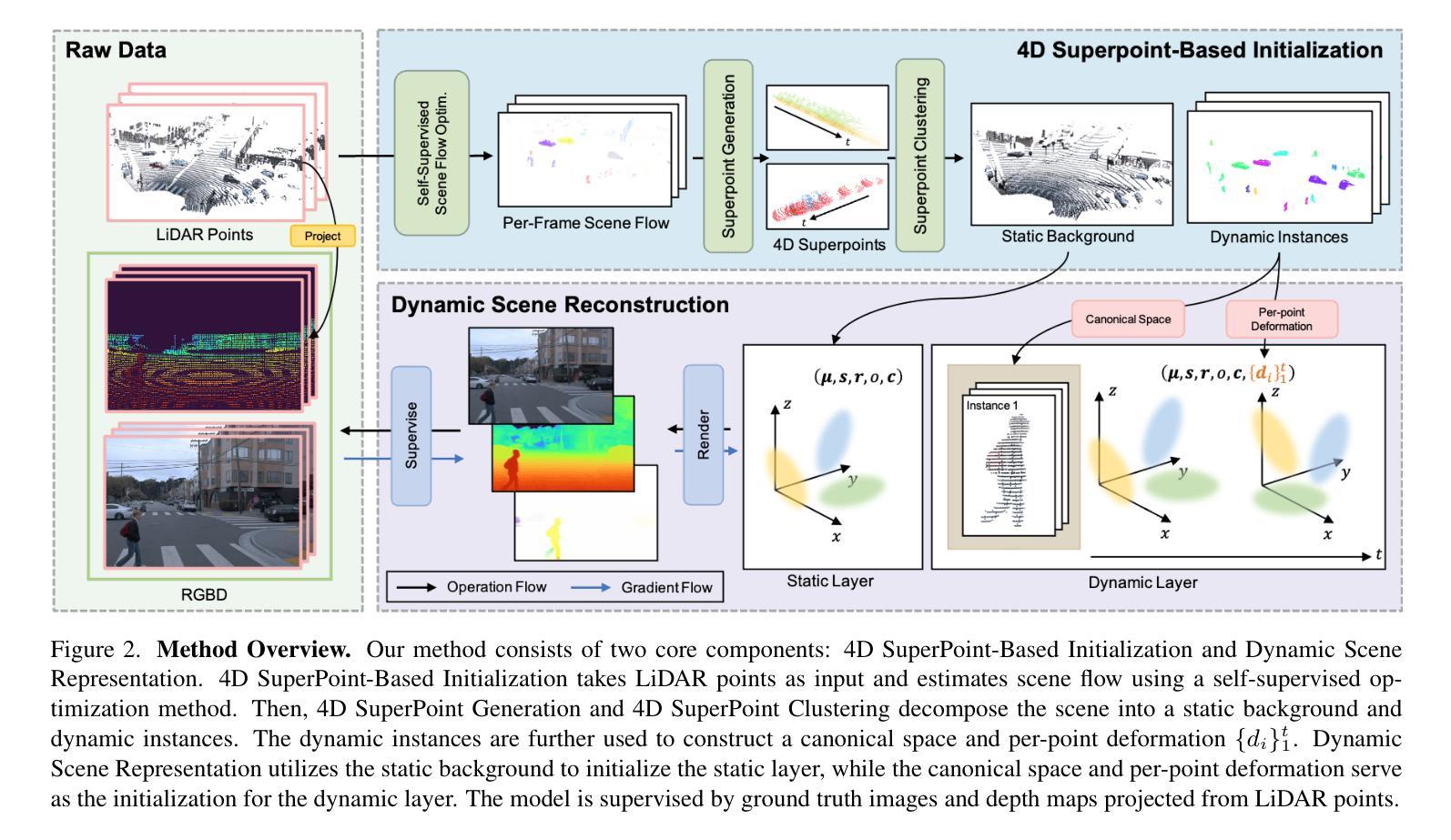
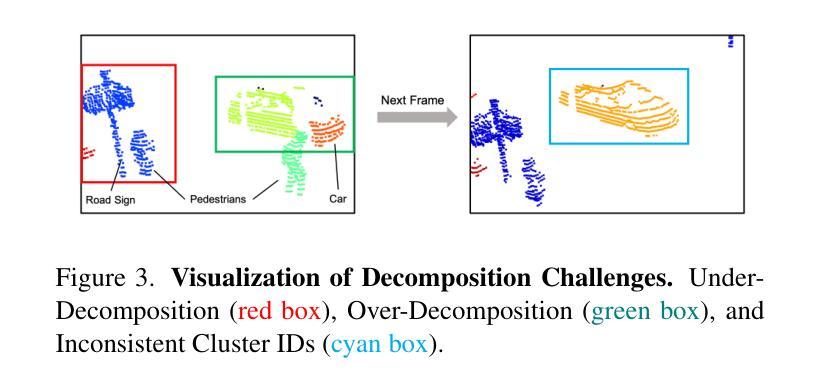
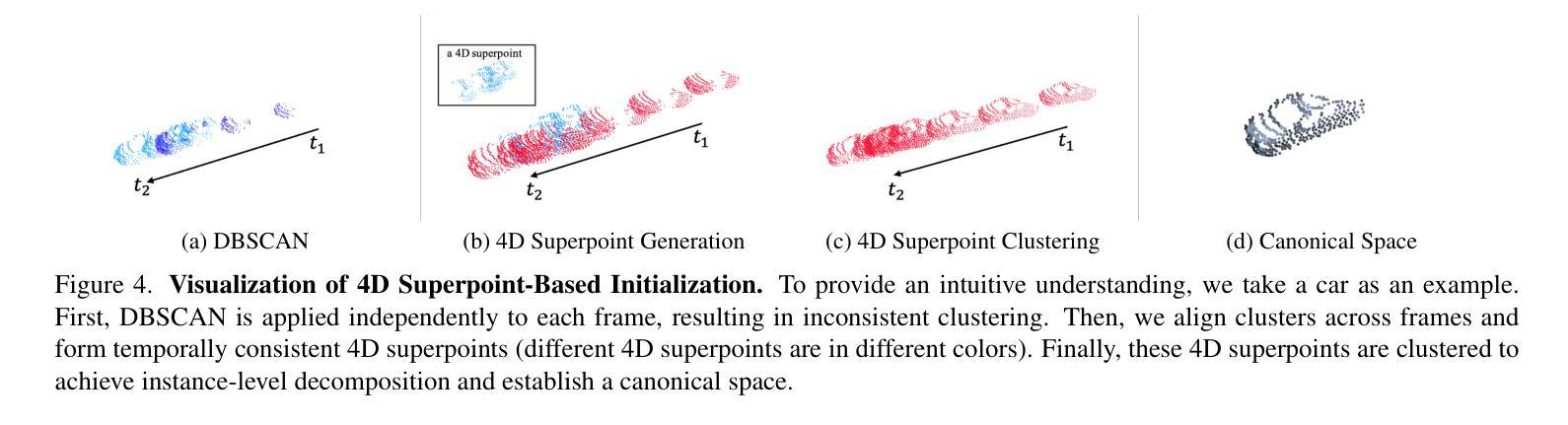
UnIRe: Unsupervised Instance Decomposition for Dynamic Urban Scene Reconstruction
Authors:Yunxuan Mao, Rong Xiong, Yue Wang, Yiyi Liao
Reconstructing and decomposing dynamic urban scenes is crucial for autonomous driving, urban planning, and scene editing. However, existing methods fail to perform instance-aware decomposition without manual annotations, which is crucial for instance-level scene editing.We propose UnIRe, a 3D Gaussian Splatting (3DGS) based approach that decomposes a scene into a static background and individual dynamic instances using only RGB images and LiDAR point clouds. At its core, we introduce 4D superpoints, a novel representation that clusters multi-frame LiDAR points in 4D space, enabling unsupervised instance separation based on spatiotemporal correlations. These 4D superpoints serve as the foundation for our decomposed 4D initialization, i.e., providing spatial and temporal initialization to train a dynamic 3DGS for arbitrary dynamic classes without requiring bounding boxes or object templates.Furthermore, we introduce a smoothness regularization strategy in both 2D and 3D space, further improving the temporal stability.Experiments on benchmark datasets show that our method outperforms existing methods in decomposed dynamic scene reconstruction while enabling accurate and flexible instance-level editing, making it a practical solution for real-world applications.
重建和分解动态城市场景对自动驾驶、城市规划和场景编辑至关重要。然而,现有方法无法在没有手动注释的情况下执行实例感知分解,这对于实例级场景编辑至关重要。我们提出了UnIRe,这是一种基于3D高斯喷溅(3DGS)的方法,它仅使用RGB图像和激光雷达点云将场景分解为静态背景和单个动态实例。在核心部分,我们引入了4D超点,这是一种新的表示方法,可以在4D空间中聚集多帧激光雷达点,基于时空相关性实现无监督实例分离。这些4D超点是我们分解的4D初始化的基础,即提供空间和时间的初始化,以训练动态3DGS,而无需边界框或对象模板。此外,我们在2D和3D空间中引入了平滑正则化策略,进一步提高了时间稳定性。在基准数据集上的实验表明,我们的方法在分解动态场景重建方面优于现有方法,同时实现了准确灵活的实例级编辑,使其成为现实世界应用的实用解决方案。
论文及项目相关链接
摘要
动态城市场景的重建和分解对于自动驾驶、城市规划和场景编辑具有重要意义。然而,现有方法无法在不依赖人工标注的情况下实现实例感知分解,这对于实例级别的场景编辑至关重要。本研究提出了UnIRe,一种基于3D高斯拼接(3DGS)的方法,仅使用RGB图像和激光雷达点云数据,将场景分解为静态背景和独立的动态实例。我们引入了4D超级点这一新型表示,通过时空相关性对多帧激光雷达点在4D空间进行聚类,实现了无需标注框或对象模板的任意动态类的动态三维重建。此外,我们在二维和三维空间中都引入了平滑正则化策略,进一步提高了时间稳定性。在基准数据集上的实验表明,我们的方法在分解动态场景重建方面优于现有方法,同时能够实现精确灵活的实例级别编辑,使其成为实际应用中的实用解决方案。
要点
- 动态城市场景的重建和分解对自动驾驶、城市规划和场景编辑至关重要。
- 现有方法缺乏实例感知分解的能力,需要手动标注。
- UnIRe方法基于RGB图像和激光雷达点云数据分解场景。
- 引入4D超级点表示,实现基于时空相关性的实例分离。
- 不需要标注框或对象模板进行动态三维重建。
- 在二维和三维空间引入平滑正则化策略提高时间稳定性。
点此查看论文截图

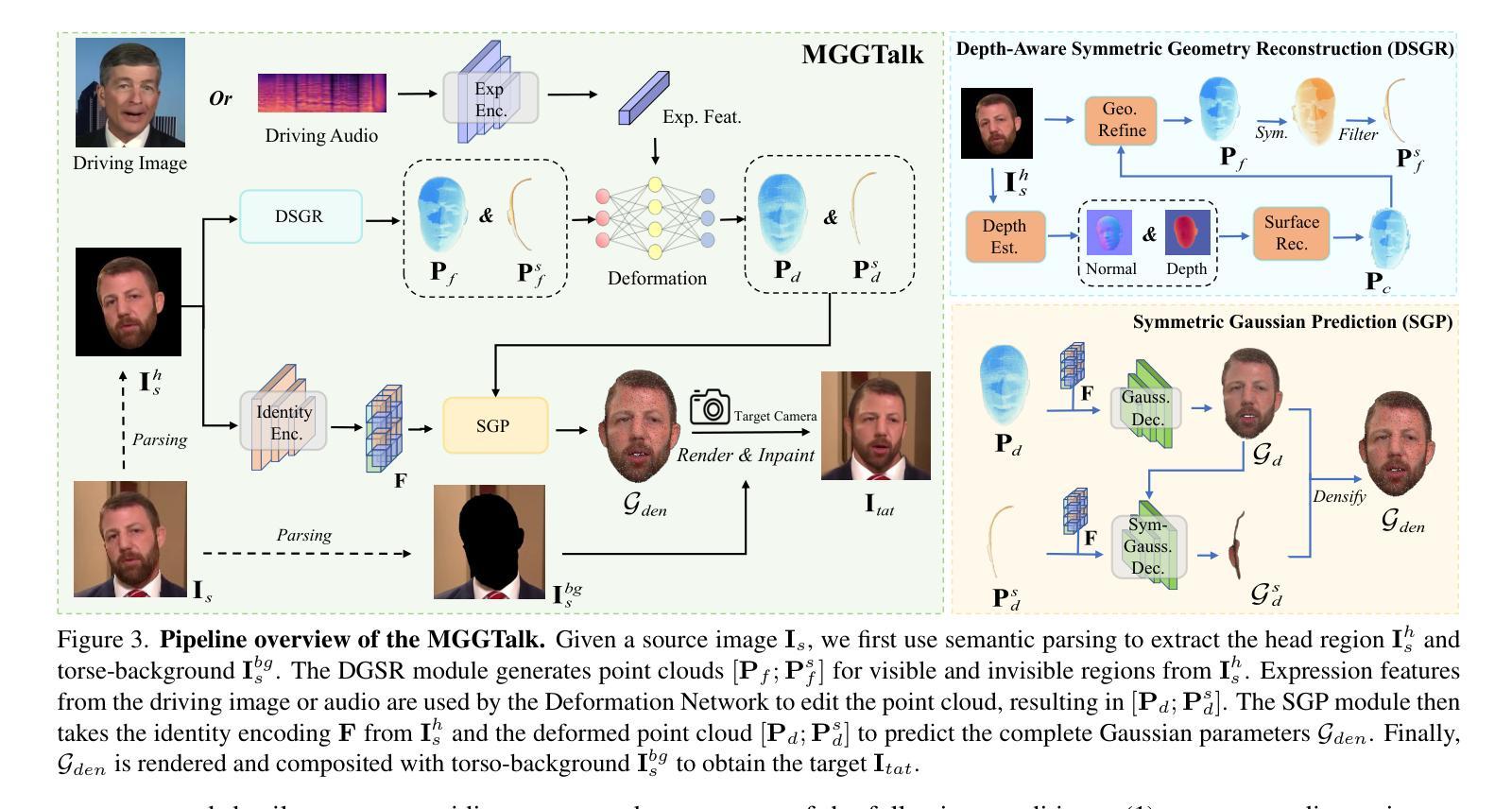
Monocular and Generalizable Gaussian Talking Head Animation
Authors:Shengjie Gong, Haojie Li, Jiapeng Tang, Dongming Hu, Shuangping Huang, Hao Chen, Tianshui Chen, Zhuoman Liu
In this work, we introduce Monocular and Generalizable Gaussian Talking Head Animation (MGGTalk), which requires monocular datasets and generalizes to unseen identities without personalized re-training. Compared with previous 3D Gaussian Splatting (3DGS) methods that requires elusive multi-view datasets or tedious personalized learning/inference, MGGtalk enables more practical and broader applications. However, in the absence of multi-view and personalized training data, the incompleteness of geometric and appearance information poses a significant challenge. To address these challenges, MGGTalk explores depth information to enhance geometric and facial symmetry characteristics to supplement both geometric and appearance features. Initially, based on the pixel-wise geometric information obtained from depth estimation, we incorporate symmetry operations and point cloud filtering techniques to ensure a complete and precise position parameter for 3DGS. Subsequently, we adopt a two-stage strategy with symmetric priors for predicting the remaining 3DGS parameters. We begin by predicting Gaussian parameters for the visible facial regions of the source image. These parameters are subsequently utilized to improve the prediction of Gaussian parameters for the non-visible regions. Extensive experiments demonstrate that MGGTalk surpasses previous state-of-the-art methods, achieving superior performance across various metrics.
在这项工作中,我们介绍了单目通用高斯说话人头动画(MGGTalk)技术,它只需要单目数据集,并能够推广到未见过的身份而无需个性化再训练。与之前需要难以获取的多视角数据集或繁琐个性化学习/推断的3D高斯涂抹(3DGS)方法相比,MGGTalk使实际应用和更广泛的应用成为可能。然而,在没有多视角和个性化训练数据的情况下,几何和外观信息的完整性构成重大挑战。为了解决这些挑战,MGGTalk探索深度信息以增强几何和面部对称特征,以补充几何和外观特征。首先,基于从深度估计获得的像素级几何信息,我们结合了对称操作和点云滤波技术,以确保3DGS的完整和精确的位置参数。随后,我们采用具有对称先验的两阶段策略来预测剩余的3DGS参数。我们首先对源图像的可见面部区域预测高斯参数。这些参数随后用于改进非可见区域的高斯参数预测。大量实验表明,MGGTalk超越了先前最先进的方法,在各项指标上实现了卓越的性能。
论文及项目相关链接
PDF Accepted by CVPR 2025
Summary
本文介绍了单目通用高斯说话人头动画(MGGTalk)技术,该技术基于单目数据集,可推广到未见过的身份而无需个性化再训练。与之前需要难以获取的多视角数据集或繁琐个性化学习/推断的3D高斯喷涂(3DGS)方法相比,MGGTalk具有更实际和更广泛的应用。为了解决缺乏多视角和个性化训练数据所带来的几何和外观信息不完整的问题,MGGTalk探索了深度信息以增强几何和面部对称特征,以补充几何和外观特征。通过深度估计获得的像素级几何信息,结合对称操作和点云过滤技术,确保3DGS的位置参数完整且精确。采用具有对称先验的两阶段策略来预测剩余的3DGS参数。首先预测源图像可见面部区域的高斯参数,然后用于改进非可见区域的高斯参数预测。实验表明,MGGTalk超越现有先进技术,在各项指标上实现卓越性能。
Key Takeaways
- MGGTalk是一种基于单目数据集的高谈说话人头动画技术,可推广到未见过的身份,无需个性化再训练。
- 与需要多视角数据集的3DGS方法相比,MGGTalk更具实际应用性和广泛性。
- MGGTalk通过探索深度信息来解决几何和外观信息不完整的问题。
- 采用像素级几何信息结合对称操作和点云过滤技术,确保3DGS位置参数的完整性和准确性。
- MGGTalk采用两阶段策略,利用对称先验来预测3DGS的剩余参数。
- MGGTalk通过预测源图像可见面部区域的高斯参数,进而改进非可见区域的高斯参数预测。
点此查看论文截图



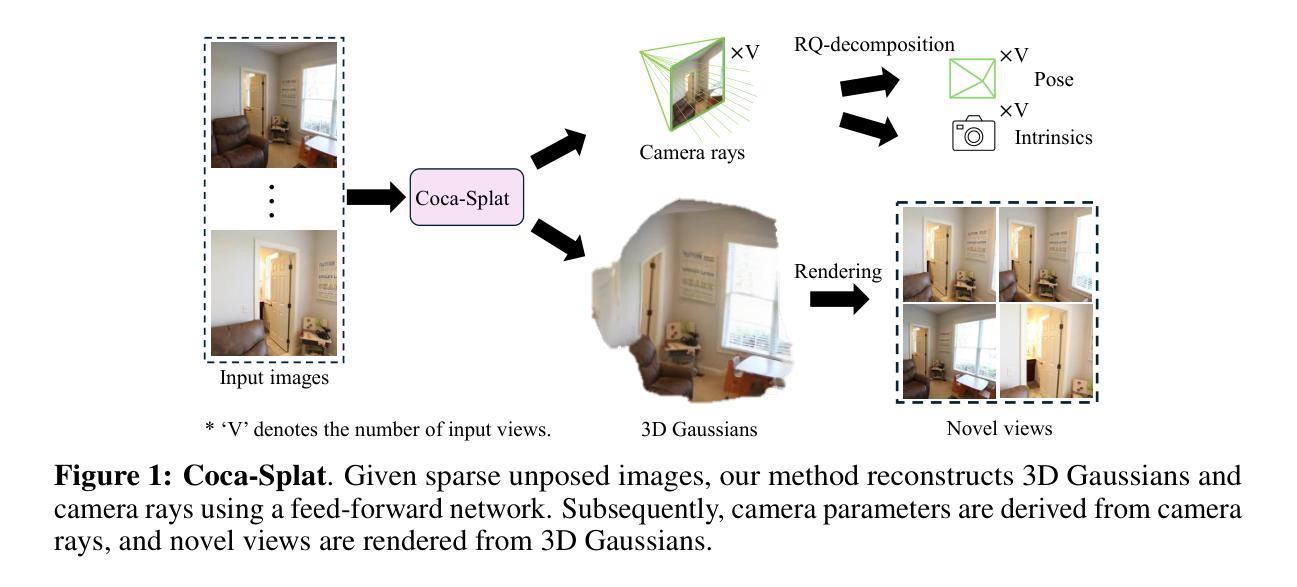
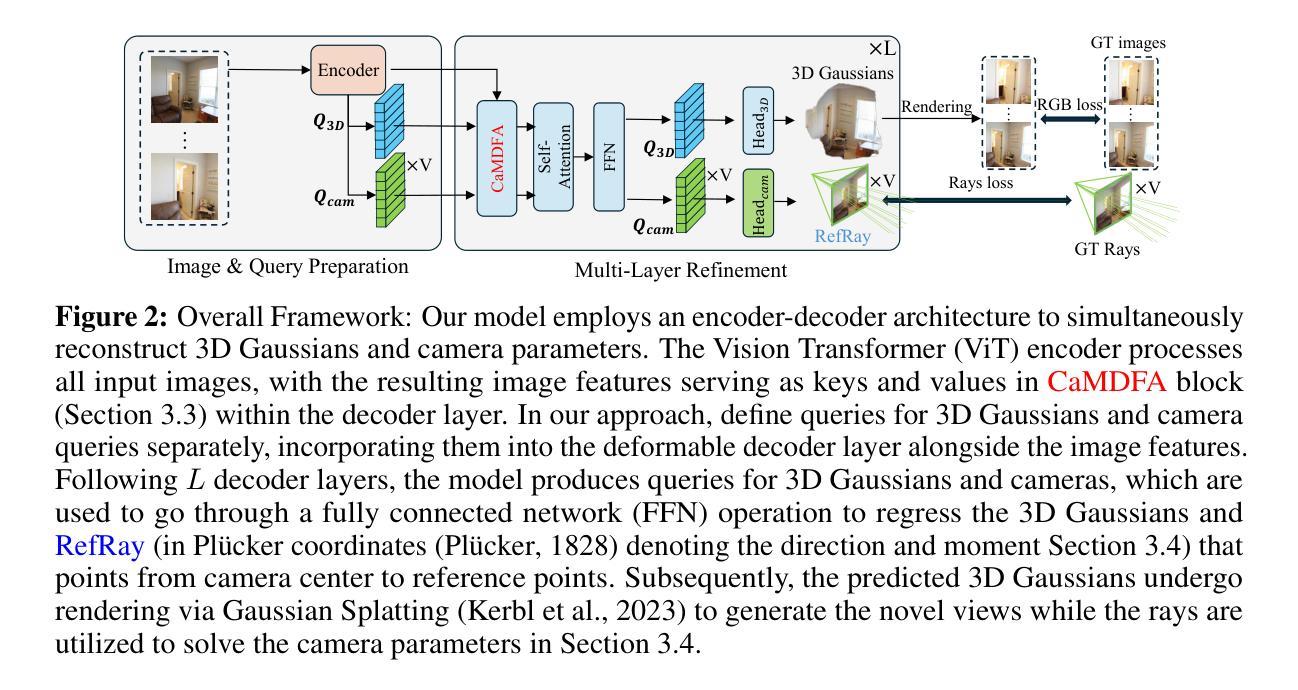
Coca-Splat: Collaborative Optimization for Camera Parameters and 3D Gaussians
Authors:Jiamin Wu, Hongyang Li, Xiaoke Jiang, Yuan Yao, Lei Zhang
In this work, we introduce Coca-Splat, a novel approach to addressing the challenges of sparse view pose-free scene reconstruction and novel view synthesis (NVS) by jointly optimizing camera parameters with 3D Gaussians. Inspired by deformable DEtection TRansformer, we design separate queries for 3D Gaussians and camera parameters and update them layer by layer through deformable Transformer layers, enabling joint optimization in a single network. This design demonstrates better performance because to accurately render views that closely approximate ground-truth images relies on precise estimation of both 3D Gaussians and camera parameters. In such a design, the centers of 3D Gaussians are projected onto each view by camera parameters to get projected points, which are regarded as 2D reference points in deformable cross-attention. With camera-aware multi-view deformable cross-attention (CaMDFA), 3D Gaussians and camera parameters are intrinsically connected by sharing the 2D reference points. Additionally, 2D reference point determined rays (RayRef) defined from camera centers to the reference points assist in modeling relationship between 3D Gaussians and camera parameters through RQ-decomposition on an overdetermined system of equations derived from the rays, enhancing the relationship between 3D Gaussians and camera parameters. Extensive evaluation shows that our approach outperforms previous methods, both pose-required and pose-free, on RealEstate10K and ACID within the same pose-free setting.
在这项工作中,我们提出了Coca-Splat这一新方法,通过联合优化相机参数与三维高斯分布来解决无姿态场景重建和新颖视角合成所面临的挑战。该方法灵感来源于可变形检测变压器(DETR),我们为三维高斯分布和相机参数设计了单独的查询,并通过可变形Transformer层逐层更新它们,从而能够在单个网络中实现联合优化。这种设计展示了更好的性能,因为准确渲染接近真实图像的视图依赖于对三维高斯分布和相机参数的精确估计。在这种设计中,三维高斯分布的中心通过相机参数投影到每个视图上,得到投影点,这些点被视为可变形交叉注意力中的二维参考点。通过相机感知的多视角可变形交叉注意力(CaMDFA),三维高斯分布和相机参数通过共享二维参考点固有地连接在一起。此外,从相机中心到参考点的二维参考点确定射线(RayRef)有助于通过射线得出的超定系统方程的RQ分解来建模三维高斯分布与相机参数之间的关系,从而增强两者之间的联系。大量评估表明,我们的方法在实地产10K和酸化剂的相同无姿态设置下,相对于以前的方法(包括需要姿态和不需姿态的方法)表现更优秀。
论文及项目相关链接
Summary
本文提出了Coca-Splat方法,这是一种针对无姿态场景重建和新颖视角合成(NVS)的挑战的新方法。该方法通过联合优化相机参数和3D高斯值来解决这些问题。通过可变形检测变换器(DETR)的灵感,为3D高斯值和相机参数设计独立的查询,并通过可变形变换器逐层进行更新,使两者在一个网络中联合优化。该设计因准确渲染依赖于两者精确估计的视图而表现出优越性能。设计将3D高斯值的中心通过相机参数投影到每个视图上,得到投影点,被视为可变形交叉注意中的2D参考点。通过共享这些参考点,相机感知的多视角可变形交叉注意(CaMDFA)将3D高斯值和相机参数内在联系起来。此外,通过定义从相机中心到参考点的射线,建立3D高斯与相机参数之间的关系模型,进一步增强了它们之间的联系。评估表明,在相同无姿态设置下,该方法在RealEstate10K和ACID上均优于之前的姿态要求和无姿态方法。
Key Takeaways
- Coca-Splat是一种解决稀疏视角无姿态场景重建和新颖视角合成挑战的新方法。
- 通过联合优化相机参数和3D高斯值来提高性能。
- 设计灵感来源于可变形检测变换器(DETR),为3D高斯值和相机参数分别设计查询,并通过可变形变换器进行联合优化。
- 通过投影3D高斯值的中心到每个视图上获得投影点,这些点被视为2D参考点。
- 通过共享2D参考点,将相机感知的多视角可变形交叉注意(CaMDFA)用于连接3D高斯值和相机参数。
- 通过定义从相机中心到参考点的射线来增强模型关系,进一步连接3D高斯值和相机参数。
点此查看论文截图


Distilling Multi-view Diffusion Models into 3D Generators
Authors:Hao Qin, Luyuan Chen, Ming Kong, Mengxu Lu, Qiang Zhu
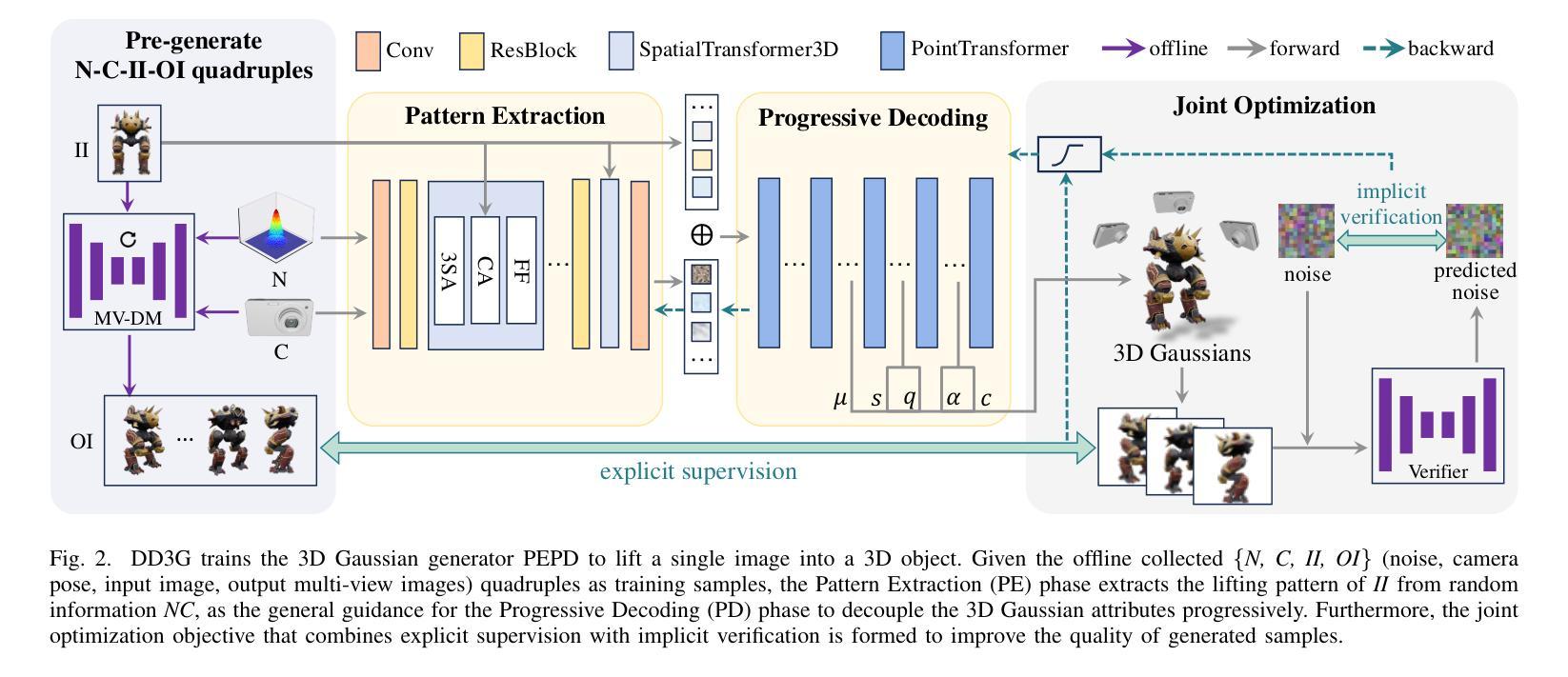
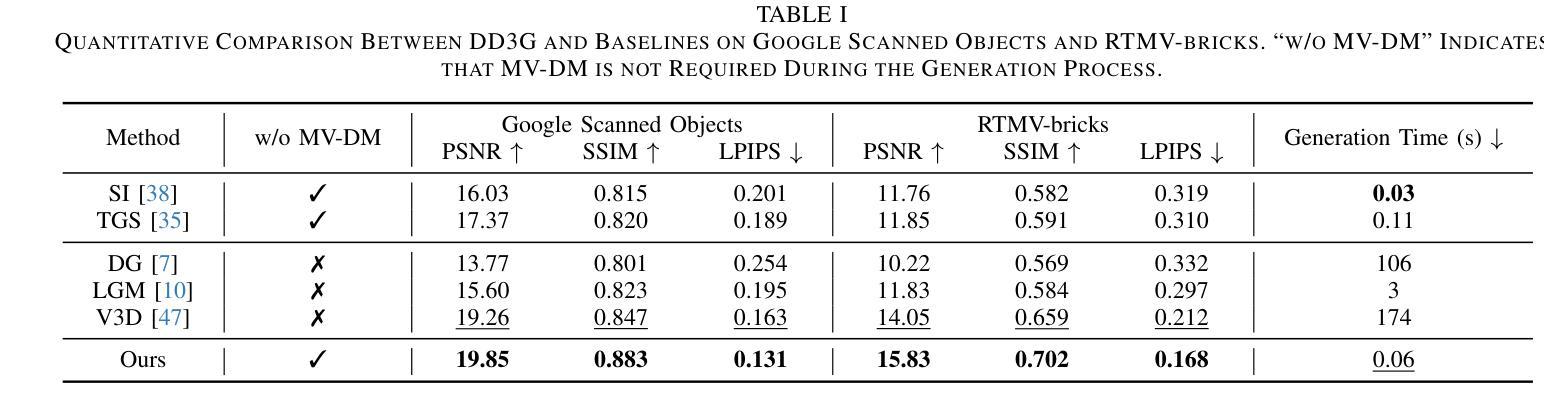
We introduce DD3G, a formulation that Distills a multi-view Diffusion model (MV-DM) into a 3D Generator using gaussian splatting. DD3G compresses and integrates extensive visual and spatial geometric knowledge from the MV-DM by simulating its ordinary differential equation (ODE) trajectory, ensuring the distilled generator generalizes better than those trained solely on 3D data. Unlike previous amortized optimization approaches, we align the MV-DM and 3D generator representation spaces to transfer the teacher’s probabilistic flow to the student, thus avoiding inconsistencies in optimization objectives caused by probabilistic sampling. The introduction of probabilistic flow and the coupling of various attributes in 3D Gaussians introduce challenges in the generation process. To tackle this, we propose PEPD, a generator consisting of Pattern Extraction and Progressive Decoding phases, which enables efficient fusion of probabilistic flow and converts a single image into 3D Gaussians within 0.06 seconds. Furthermore, to reduce knowledge loss and overcome sparse-view supervision, we design a joint optimization objective that ensures the quality of generated samples through explicit supervision and implicit verification. Leveraging existing 2D generation models, we compile 120k high-quality RGBA images for distillation. Experiments on synthetic and public datasets demonstrate the effectiveness of our method. Our project is available at: https://qinbaigao.github.io/DD3G_project/
我们介绍了DD3G,这是一种通过高斯拼贴技术将多视图扩散模型(MV-DM)蒸馏到3D生成器的方法。DD3G通过模拟MV-DM的常微分方程(ODE)轨迹,压缩并集成了大量的视觉和空间几何知识,确保蒸馏后的生成器比仅对3D数据进行训练的生成器具有更好的通用性。与之前的平均优化方法不同,我们将MV-DM和3D生成器的表示空间对齐,以将教师的概率流传输给学生,从而避免由概率采样引起的优化目标不一致。概率流的引入和3D高斯中各种属性的耦合给生成过程带来了挑战。为解决这一问题,我们提出了PEPD生成器,它由模式提取和渐进解码两个阶段组成,能够高效地融合概率流,并在0.06秒内将单幅图像转换为3D高斯。此外,为了减少知识损失并克服稀疏视图监督,我们设计了一个联合优化目标,通过显式监督和隐式验证确保生成样本的质量。我们利用现有的2D生成模型,编译了12万张高质量RGBA图像进行蒸馏。在合成数据集和公开数据集上的实验证明了我们的方法的有效性。我们的项目在:[https://qinbaigao.github.io/DD3G_project/]上可用。
论文及项目相关链接
Summary
本文介绍了DD3G方法,它通过模拟多视角扩散模型(MV-DM)的常微分方程(ODE)轨迹,将MV-DM压缩并转化为一个基于高斯填充的3D生成器。该方法利用确定性蒸馏技术,通过模拟MV-DM的ODE轨迹,整合视觉和空间几何知识,提高生成器的泛化能力。此外,本文提出了一种名为PEPD的生成器结构,以高效融合概率流并快速将单图像转换为三维高斯分布。同时,为了降低知识损失并克服稀疏视图监督问题,设计了一种联合优化目标,确保生成样本的质量。实验结果表明该方法的有效性。
Key Takeaways
- DD3G是一个基于多视角扩散模型的模拟并将其整合为3D生成器的方案。它使用了确定性蒸馏技术提高了生成器的泛化能力。
- DD3G使用模拟的常微分方程(ODE)轨迹来压缩和整合视觉和空间几何知识。它通过避免使用概率采样技术,实现了更好的模型对齐和优化目标一致性。
- PEPD生成器结构使得高效融合概率流成为可能,能够在短时间内将单图像转换为三维高斯分布。这种结构提高了生成过程的效率和质量。
点此查看论文截图


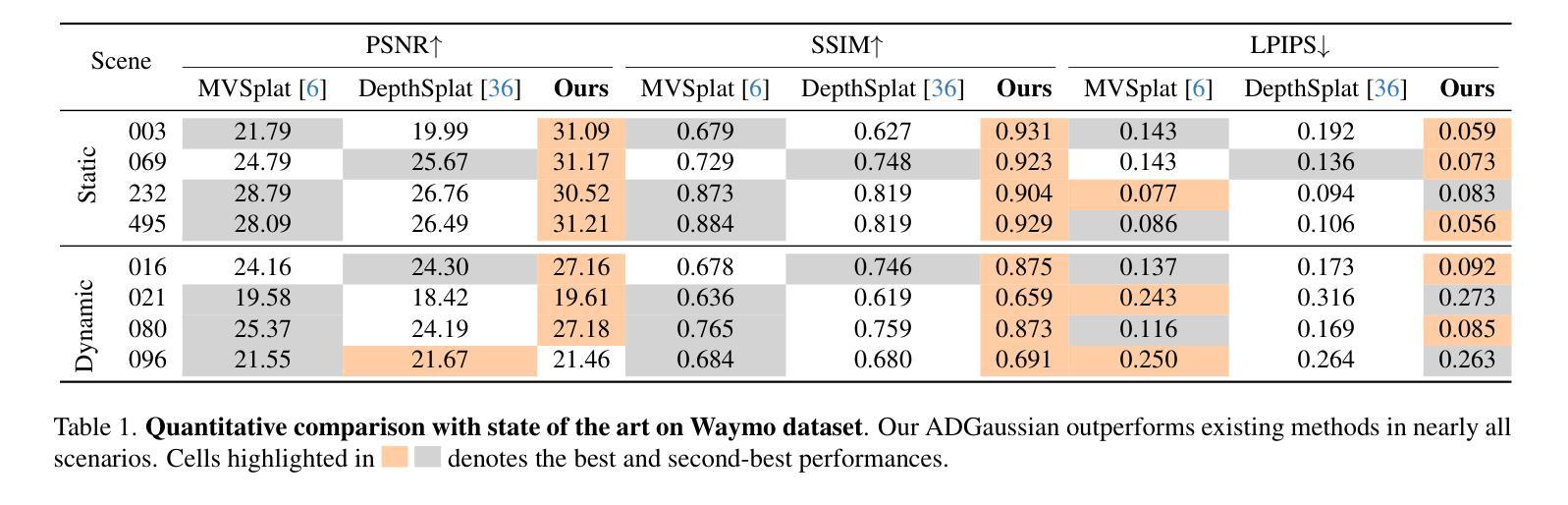
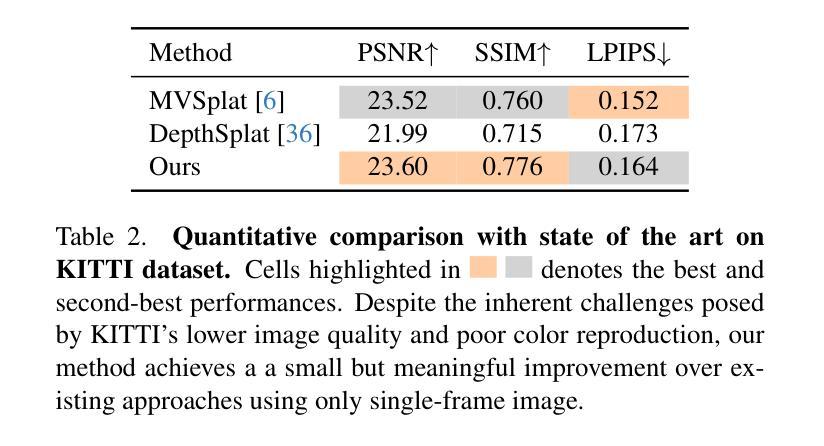
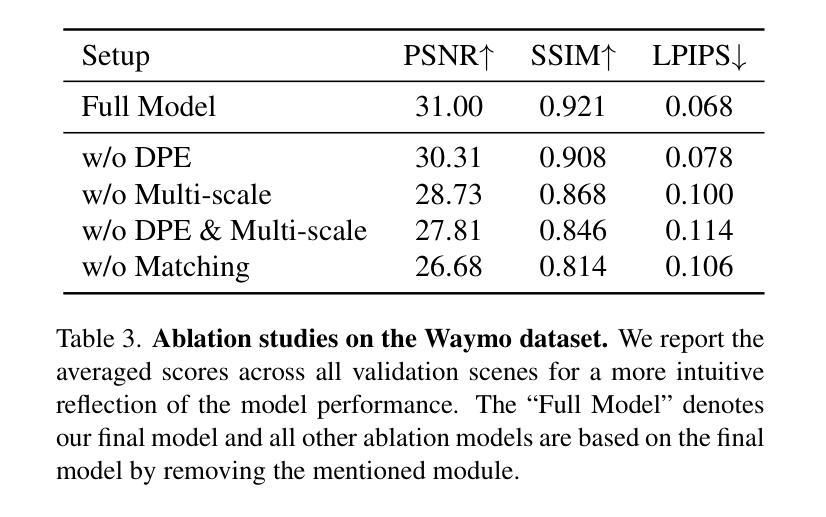
ADGaussian: Generalizable Gaussian Splatting for Autonomous Driving with Multi-modal Inputs
Authors:Qi Song, Chenghong Li, Haotong Lin, Sida Peng, Rui Huang
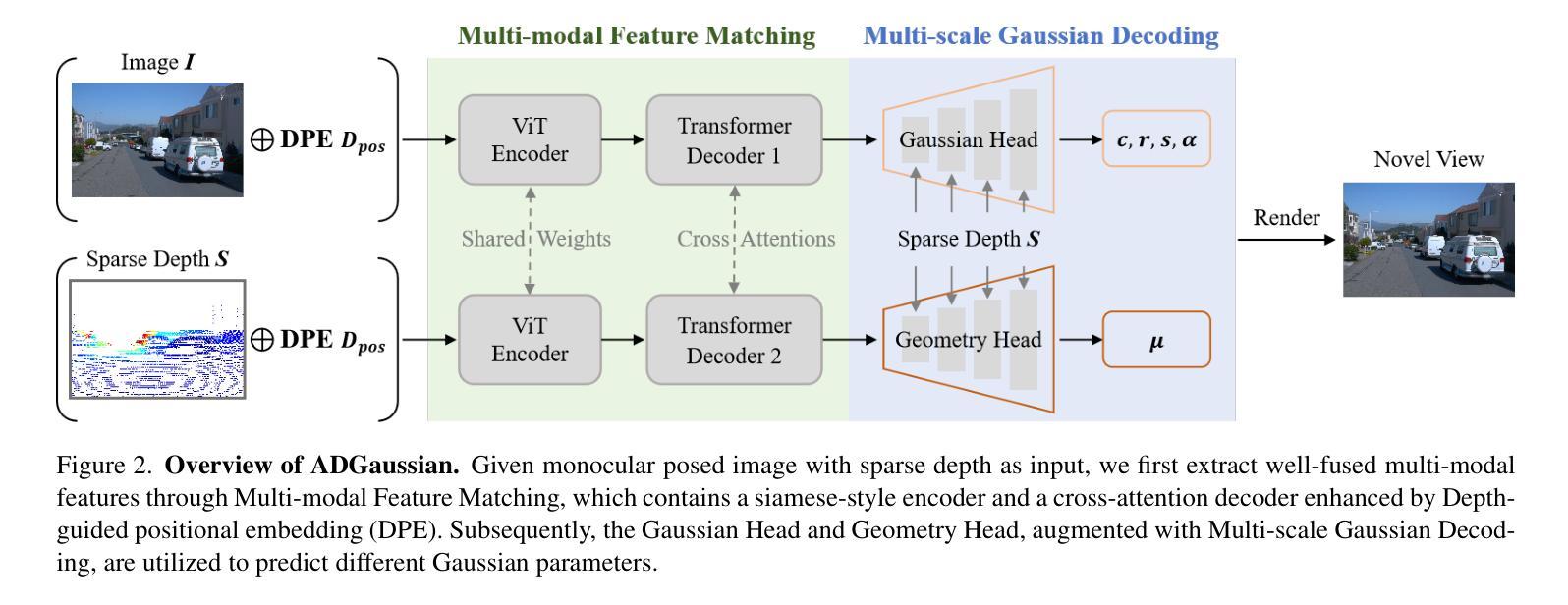
We present a novel approach, termed ADGaussian, for generalizable street scene reconstruction. The proposed method enables high-quality rendering from single-view input. Unlike prior Gaussian Splatting methods that primarily focus on geometry refinement, we emphasize the importance of joint optimization of image and depth features for accurate Gaussian prediction. To this end, we first incorporate sparse LiDAR depth as an additional input modality, formulating the Gaussian prediction process as a joint learning framework of visual information and geometric clue. Furthermore, we propose a multi-modal feature matching strategy coupled with a multi-scale Gaussian decoding model to enhance the joint refinement of multi-modal features, thereby enabling efficient multi-modal Gaussian learning. Extensive experiments on two large-scale autonomous driving datasets, Waymo and KITTI, demonstrate that our ADGaussian achieves state-of-the-art performance and exhibits superior zero-shot generalization capabilities in novel-view shifting.
我们提出了一种新的方法,称为ADGaussian,用于可泛化的街道场景重建。所提出的方法能够从单视图输入实现高质量渲染。与主要关注几何精化的先前的高斯Splatting方法不同,我们强调图像和深度特征联合优化的重要性,以实现准确的高斯预测。为此,我们首先纳入稀疏激光雷达深度作为附加输入模式,将高斯预测过程制定为视觉信息和几何线索的联合学习框架。此外,我们提出了一种多模式特征匹配策略,结合多尺度高斯解码模型,以增强多模式特征的联合优化,从而实现高效的多模式高斯学习。在Waymo和KITTI两个大规模自动驾驶数据集上的大量实验表明,我们的ADGaussian达到了最先进的性能,并在新型视角转换中表现出了卓越的零样本泛化能力。
论文及项目相关链接
PDF The project page can be found at https://maggiesong7.github.io/research/ADGaussian/
Summary
本文提出了一种新型的方法,名为ADGaussian,用于可泛化的街道场景重建。该方法能够实现从单视角输入的高质量渲染。不同于以往主要关注几何精修的Gaussian Splatting方法,ADGaussian强调图像和深度特征联合优化对于准确Gaussian预测的重要性。为实现这一点,引入了稀疏激光雷达深度作为额外的输入模式,将Gaussian预测过程公式化为视觉信息和几何线索的联合学习框架。同时,提出了多模式特征匹配策略和多尺度Gaussian解码模型,以强化多模式特征的联合优化,从而实现高效的多模式Gaussian学习。在Waymo和KITTI两个大规模自动驾驶数据集上的实验表明,ADGaussian达到了最先进的性能,并在新型视角转换中展现出卓越的零样本泛化能力。
Key Takeaways
- ADGaussian是一种用于街道场景重建的新型方法,可从单视角实现高质量渲染。
- 与其他方法不同,ADGaussian强调图像和深度特征的联合优化。
- 引入了稀疏激光雷达深度作为额外的输入模式。
- 将Gaussian预测过程公式化为视觉信息和几何线索的联合学习框架。
- 采用了多模式特征匹配策略和多尺度Gaussian解码模型。
- 在大规模自动驾驶数据集上,ADGaussian达到了最先进的性能。
点此查看论文截图


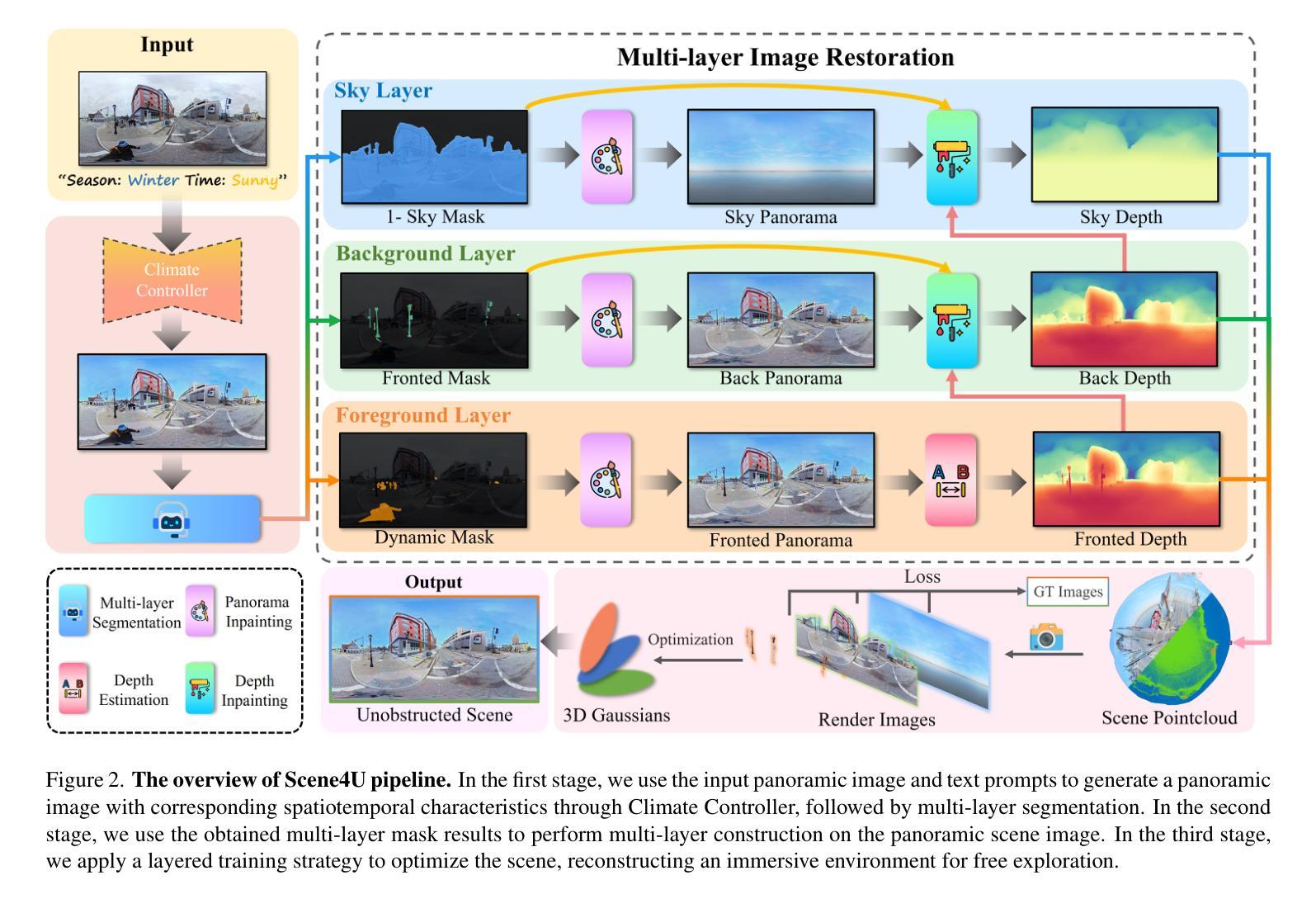
Scene4U: Hierarchical Layered 3D Scene Reconstruction from Single Panoramic Image for Your Immerse Exploration
Authors:Zilong Huang, Jun He, Junyan Ye, Lihan Jiang, Weijia Li, Yiping Chen, Ting Han
The reconstruction of immersive and realistic 3D scenes holds significant practical importance in various fields of computer vision and computer graphics. Typically, immersive and realistic scenes should be free from obstructions by dynamic objects, maintain global texture consistency, and allow for unrestricted exploration. The current mainstream methods for image-driven scene construction involves iteratively refining the initial image using a moving virtual camera to generate the scene. However, previous methods struggle with visual discontinuities due to global texture inconsistencies under varying camera poses, and they frequently exhibit scene voids caused by foreground-background occlusions. To this end, we propose a novel layered 3D scene reconstruction framework from panoramic image, named Scene4U. Specifically, Scene4U integrates an open-vocabulary segmentation model with a large language model to decompose a real panorama into multiple layers. Then, we employs a layered repair module based on diffusion model to restore occluded regions using visual cues and depth information, generating a hierarchical representation of the scene. The multi-layer panorama is then initialized as a 3D Gaussian Splatting representation, followed by layered optimization, which ultimately produces an immersive 3D scene with semantic and structural consistency that supports free exploration. Scene4U outperforms state-of-the-art method, improving by 24.24% in LPIPS and 24.40% in BRISQUE, while also achieving the fastest training speed. Additionally, to demonstrate the robustness of Scene4U and allow users to experience immersive scenes from various landmarks, we build WorldVista3D dataset for 3D scene reconstruction, which contains panoramic images of globally renowned sites. The implementation code and dataset will be released at https://github.com/LongHZ140516/Scene4U .
沉浸式与逼真的三维场景重建在计算机视觉和计算机图形学的各个领域都具有重要的实际意义。通常,沉浸式且逼真的场景应该不受动态物体的遮挡影响,保持全局纹理的一致性,并允许无限制的探索。当前主流的图像驱动场景构建方法通过移动虚拟相机对初始图像进行迭代优化以生成场景。然而,以前的方法在应对因相机姿态变化导致的全局纹理不一致问题时存在视觉不连续的问题,并且经常由于前景与背景的遮挡而导致场景空洞。为此,我们提出了一种新的全景图像分层三维场景重建框架,名为Scene4U。具体来说,Scene4U结合了开放词汇分割模型与大型语言模型,将真实全景图像分解成多个层次。然后,我们采用基于扩散模型的分层修复模块,利用视觉线索和深度信息恢复被遮挡的区域,生成场景的层次表示。多层全景图像被初始化为三维高斯飞溅表示,随后进行分层优化,最终生成具有语义和结构一致性的沉浸式三维场景,支持自由探索。Scene4U在LPIPS上提高了24.24%,在BRISQUE上提高了24.4%,同时达到了最快的训练速度。此外,为了证明Scene4U的鲁棒性并允许用户从各种地标体验沉浸式场景,我们建立了用于三维场景重建的WorldVista3D数据集,其中包含全球知名景点的全景图像。实施代码和数据集将在https://github.com/LongHZ140516/Scene4U发布。
论文及项目相关链接
PDF CVPR 2025, 11 pages, 7 figures
摘要
本文提出一种名为Scene4U的新型分层3D场景重建框架,该框架从全景图像出发,通过开放式词汇表分割模型与大型语言模型的结合,将真实全景图像分解为多层。利用基于扩散模型的分层修复模块,通过视觉线索和深度信息恢复遮挡区域,生成场景的层次表示。多层全景图像初始化为3D高斯喷溅表示,随后进行分层优化,最终生成具有语义和结构一致性的沉浸式3D场景,支持自由探索。Scene4U性能优越,在LPIPS和BRISQUE指标上分别提高了24.24%和24.40%,同时训练速度最快。为展示Scene4U的稳健性并让用户体验来自不同地标的沉浸式场景,建立了WorldVista3D数据集,包含全球知名景点的全景图像。
关键见解
- 沉浸式3D场景重建在计算机视觉和计算机图形学领域具有实际重要性。
- 当前主流方法通过迭代优化初始图像生成场景,但存在全球纹理不一致和场景空洞的问题。
- Scene4U框架采用分层重建策略,结合开放式词汇表分割模型和大型语言模型处理全景图像。
- 利用基于扩散模型的分层修复模块恢复遮挡区域,生成具有层次结构的场景表示。
- Scene4U在LPIPS和BRISQUE指标上显著提高,且训练速度最快。
- 为Scene4U框架建立了WorldVista3D数据集,包含全球知名景点的全景图像。
- Scene4U的稳健性得到验证,可广泛应用于不同地标的沉浸式场景体验。
点此查看论文截图



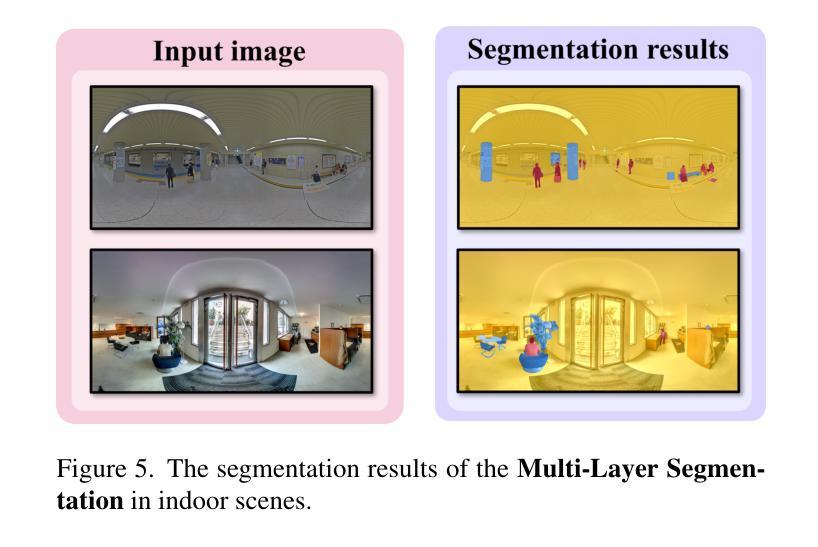
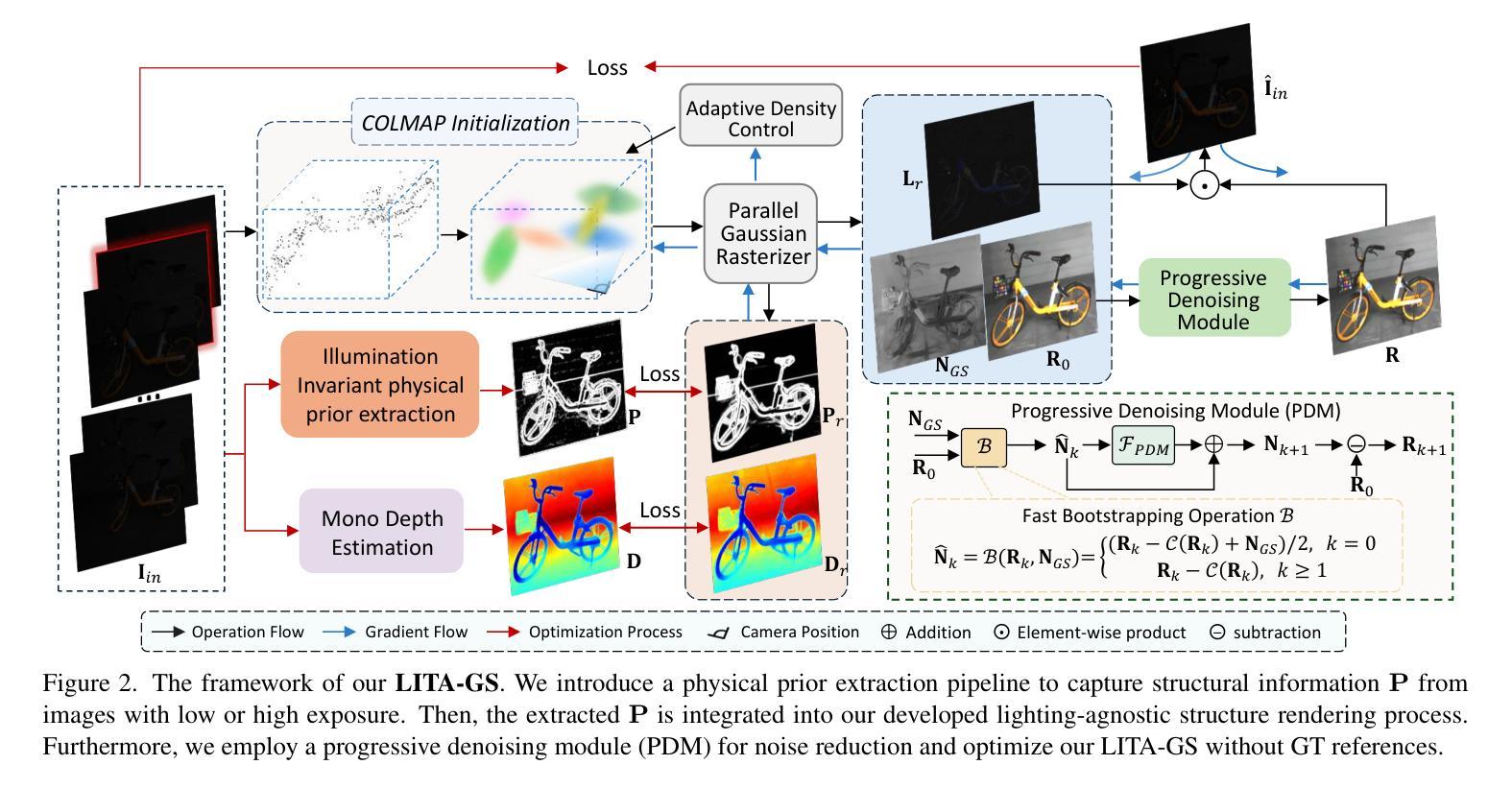
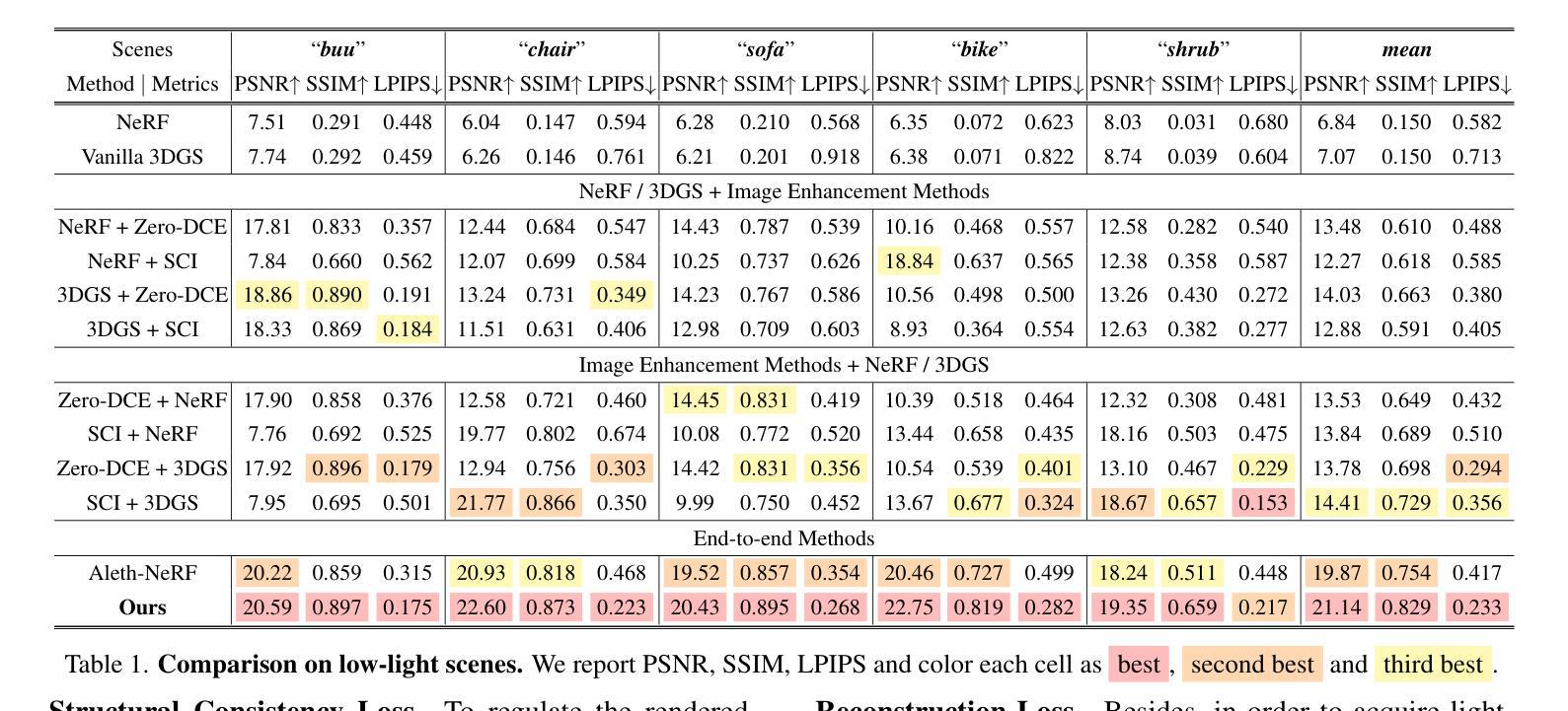
LITA-GS: Illumination-Agnostic Novel View Synthesis via Reference-Free 3D Gaussian Splatting and Physical Priors
Authors:Han Zhou, Wei Dong, Jun Chen
Directly employing 3D Gaussian Splatting (3DGS) on images with adverse illumination conditions exhibits considerable difficulty in achieving high-quality, normally-exposed representations due to: (1) The limited Structure from Motion (SfM) points estimated in adverse illumination scenarios fail to capture sufficient scene details; (2) Without ground-truth references, the intensive information loss, significant noise, and color distortion pose substantial challenges for 3DGS to produce high-quality results; (3) Combining existing exposure correction methods with 3DGS does not achieve satisfactory performance due to their individual enhancement processes, which lead to the illumination inconsistency between enhanced images from different viewpoints. To address these issues, we propose LITA-GS, a novel illumination-agnostic novel view synthesis method via reference-free 3DGS and physical priors. Firstly, we introduce an illumination-invariant physical prior extraction pipeline. Secondly, based on the extracted robust spatial structure prior, we develop the lighting-agnostic structure rendering strategy, which facilitates the optimization of the scene structure and object appearance. Moreover, a progressive denoising module is introduced to effectively mitigate the noise within the light-invariant representation. We adopt the unsupervised strategy for the training of LITA-GS and extensive experiments demonstrate that LITA-GS surpasses the state-of-the-art (SOTA) NeRF-based method while enjoying faster inference speed and costing reduced training time. The code is released at https://github.com/LowLevelAI/LITA-GS.
直接对不良照明条件下的图像应用3D高斯拼贴(3DGS)在实现高质量、正常曝光表示方面存在相当大的困难,因为:(1)在不良照明场景中估计的运动结构(SfM)点有限,无法捕捉足够的场景细节;(2)没有真实参考,大量信息丢失、显著噪声和颜色失真给3DGS带来很大挑战,难以产生高质量结果;(3)将现有曝光校正方法与3DGS相结合并未取得令人满意的效果,因为它们的个别增强处理过程导致从不同视点增强的图像之间照明不一致。为了解决这些问题,我们提出了LITA-GS,这是一种新型的无照明新型视图合成方法,通过无参考的3DGS和物理先验来实现。首先,我们引入了一种光照不变物理先验提取管道。其次,基于提取的稳健空间结构先验,我们开发了光照无关的结构渲染策略,有助于优化场景结构和对象外观。此外,还引入了一个渐进降噪模块,以有效地减轻光不变表示中的噪声。我们采用无监督策略对LITA-GS进行训练,大量实验表明,LITA-GS超越了基于神经辐射场(NeRF)的最新技术方法,同时拥有更快的推理速度和更短的训练时间。代码已发布在https://github.com/LowLevelAI/LITA-GS。
论文及项目相关链接
PDF Accepted by CVPR 2025. 3DGS, Adverse illumination conditions, Reference-free, Physical priors
摘要
采用3D高斯贴片技术对不良照明条件下的图像进行直接处理,难以实现高质量的正常曝光表示。主要由于以下几点:一是在不良照明场景中估计的有限结构光点无法捕捉足够的场景细节;二是由于缺乏地面真实参考,大量信息丢失、显著噪声和颜色失真给3DGS带来巨大挑战,难以产生高质量结果;三是现有的曝光校正方法与3DGS的结合并未达到预期效果,因为各自的增强过程导致从不同视角增强的图像之间照明不一致。为解决这些问题,我们提出一种名为LITA-GS的新型光照无关新型视图合成方法,采用无参考的3DGS和物理先验。首先,我们引入了一种光照不变物理先验提取管道。其次,基于提取的稳健空间结构先验,我们开发了光照无关的结构渲染策略,有助于优化场景结构和对象外观。此外,还引入了一种渐进降噪模块,可有效减轻光不变表示中的噪声。我们采用无监督策略对LITA-GS进行训练,大量实验表明,LITA-GS超越了基于NeRF的最新方法,同时拥有更快的推理速度和更短的训练时间。代码已发布在https://github.com/LowLevelAI/LITA-GS。
要点归纳
- 3D高斯贴片技术(3DGS)在不良照明条件下直接应用于图像时面临挑战,难以实现高质量的正常曝光表示。
- 挑战包括:结构从运动(SfM)点的估计不足、信息丢失、噪声和颜色失真等问题。
- 提出了一种新型方法LITA-GS,通过无参考的3DGS和物理先验解决上述问题。
- LITA-GS包含:光照不变物理先验提取管道、光照无关的结构渲染策略、渐进降噪模块。
- LITA-GS超越基于NeRF的当前最先进方法,具有更快的推理速度和更短的训练时间。
- 代码已公开发布在指定GitHub仓库。
点此查看论文截图


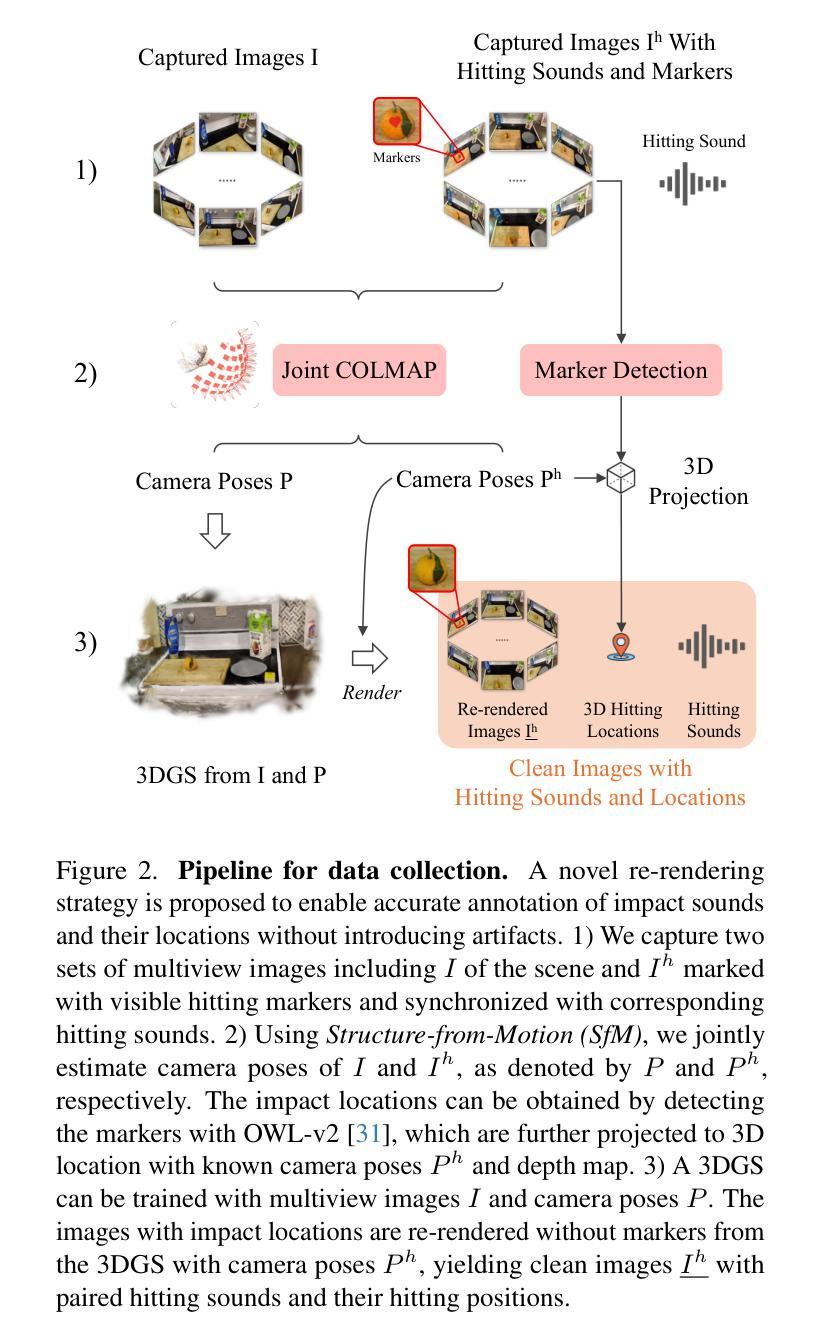
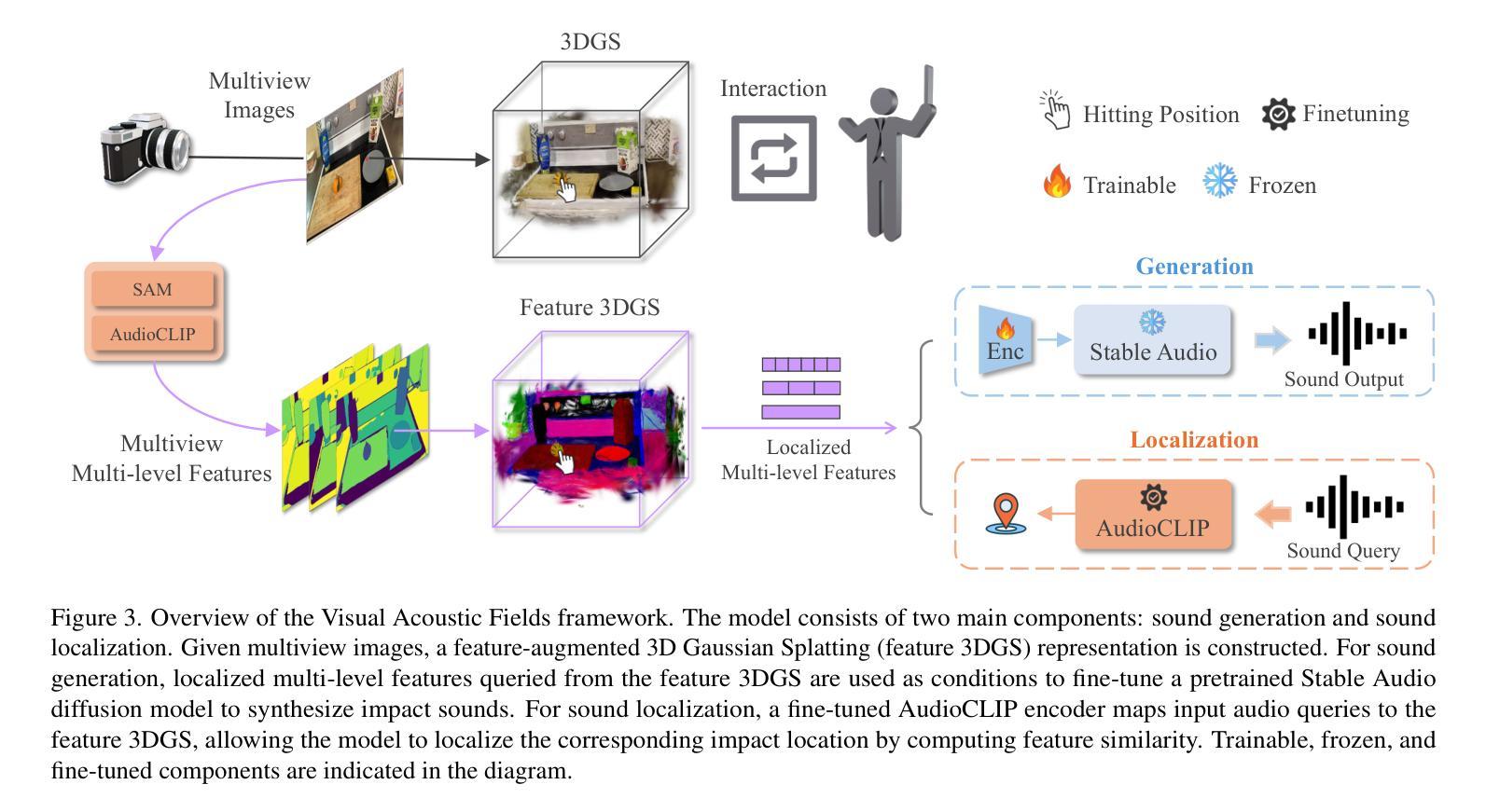
Visual Acoustic Fields
Authors:Yuelei Li, Hyunjin Kim, Fangneng Zhan, Ri-Zhao Qiu, Mazeyu Ji, Xiaojun Shan, Xueyan Zou, Paul Liang, Hanspeter Pfister, Xiaolong Wang
Objects produce different sounds when hit, and humans can intuitively infer how an object might sound based on its appearance and material properties. Inspired by this intuition, we propose Visual Acoustic Fields, a framework that bridges hitting sounds and visual signals within a 3D space using 3D Gaussian Splatting (3DGS). Our approach features two key modules: sound generation and sound localization. The sound generation module leverages a conditional diffusion model, which takes multiscale features rendered from a feature-augmented 3DGS to generate realistic hitting sounds. Meanwhile, the sound localization module enables querying the 3D scene, represented by the feature-augmented 3DGS, to localize hitting positions based on the sound sources. To support this framework, we introduce a novel pipeline for collecting scene-level visual-sound sample pairs, achieving alignment between captured images, impact locations, and corresponding sounds. To the best of our knowledge, this is the first dataset to connect visual and acoustic signals in a 3D context. Extensive experiments on our dataset demonstrate the effectiveness of Visual Acoustic Fields in generating plausible impact sounds and accurately localizing impact sources. Our project page is at https://yuelei0428.github.io/projects/Visual-Acoustic-Fields/.
当物体被击中时会产生不同的声音,人类可以根据物体的外观和材料属性直观地推断出物体可能发出的声音。受此启发,我们提出了视觉声学场(Visual Acoustic Fields)这一概念,通过三维高斯拼贴(3DGS)技术,在三维空间中架起击打声音与视觉信号的桥梁。我们的方法包含两个关键模块:声音生成和声音定位。声音生成模块采用条件扩散模型,以特征增强型三维高斯拼贴所呈现的多尺度特征为基础,生成逼真的击打声音。同时,声音定位模块能够查询由特征增强型三维高斯拼贴所表示的三维场景,根据声源来确定击打位置。为了支持这一框架,我们引入了一种新型管道,用于收集场景级别的视觉-声音样本对,实现捕获图像、冲击位置和相应声音之间的对齐。据我们所知,这是首个在三维环境中连接视觉和声音信号的数据库。在我们的数据库上进行的大量实验证明了视觉声学场在生成合理冲击声和准确定位冲击源方面的有效性。我们的项目页面是https://yuelei0428.github.io/projects/Visual-Acoustic-Fields/。
论文及项目相关链接
Summary
本文提出了Visual Acoustic Fields框架,该框架利用3D高斯延展(3DGS)技术,在3D空间中架起打击声音与视觉信号之间的桥梁。该框架包含两个核心模块:声音生成和声音定位。声音生成模块采用条件扩散模型,利用特征增强的3DGS生成逼真的打击声音。而声音定位模块则允许根据声音源查询由特征增强的3DGS表示的3D场景,以定位打击位置。为支持此框架,还引入了新型场景级视觉声音样本采集管道,实现了图像捕获、影响位置和相应声音之间的对齐。
Key Takeaways
- Visual Acoustic Fields框架结合了视觉和声音信号,在3D空间中模拟物体打击的声音。
- 该框架包含声音生成和声音定位两个核心模块。
- 声音生成模块采用条件扩散模型,利用3D高斯延展技术生成真实感的打击声音。
- 声音定位模块能根据声音源在3D场景中的特征进行定位。
- 引入了一个新型的场景级视觉-声音样本采集管道,实现了图像、影响位置和对应声音之间的对齐。
- 这是首个在3D环境中连接视觉和声音信号的数据库。
点此查看论文截图


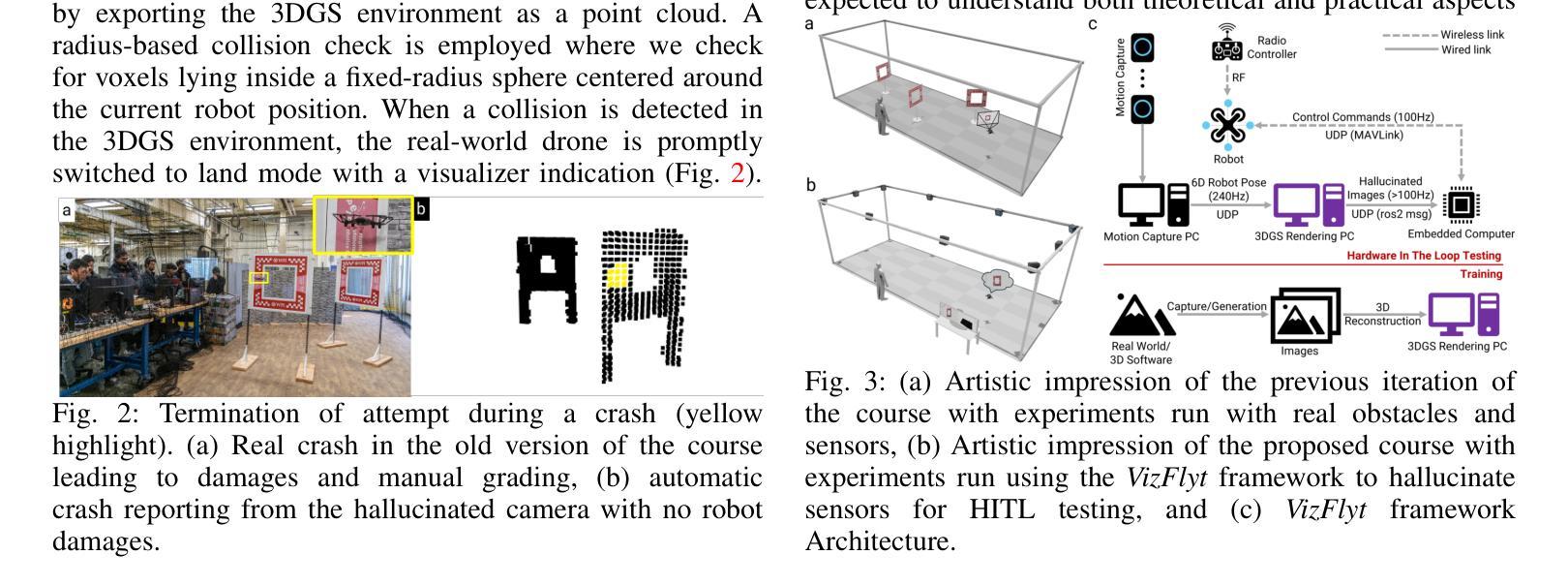
VizFlyt: Perception-centric Pedagogical Framework For Autonomous Aerial Robots
Authors:Kushagra Srivastava, Rutwik Kulkarni, Manoj Velmurugan, Nitin J. Sanket
Autonomous aerial robots are becoming commonplace in our lives. Hands-on aerial robotics courses are pivotal in training the next-generation workforce to meet the growing market demands. Such an efficient and compelling course depends on a reliable testbed. In this paper, we present VizFlyt, an open-source perception-centric Hardware-In-The-Loop (HITL) photorealistic testing framework for aerial robotics courses. We utilize pose from an external localization system to hallucinate real-time and photorealistic visual sensors using 3D Gaussian Splatting. This enables stress-free testing of autonomy algorithms on aerial robots without the risk of crashing into obstacles. We achieve over 100Hz of system update rate. Lastly, we build upon our past experiences of offering hands-on aerial robotics courses and propose a new open-source and open-hardware curriculum based on VizFlyt for the future. We test our framework on various course projects in real-world HITL experiments and present the results showing the efficacy of such a system and its large potential use cases. Code, datasets, hardware guides and demo videos are available at https://pear.wpi.edu/research/vizflyt.html
自主空中机器人正在我们的生活中变得越来越普遍。动手的空中机器人课程对于培养新一代劳动力以满足不断增长的市场需求至关重要。这样的高效和有吸引力的课程依赖于可靠的测试平台。在本文中,我们介绍了VizFlyt,这是一个用于空中机器人课程的以感知为中心的开源硬件在环(HITL)逼真测试框架。我们使用来自外部定位系统的姿态,通过3D高斯泼溅技术模拟实时和逼真的视觉传感器。这可以在无压力的情况下测试空中机器人的自主算法,避免了与障碍物的碰撞风险。我们实现了超过100Hz的系统更新率。最后,我们基于提供动手空中机器人课程的过去经验,以VizFlyt为基础,为未来提出一个新的开源和开放硬件的课程大纲。我们在现实世界的HITL实验中对各种课程项目测试了我们的框架,并展示了系统的有效性以及其巨大的潜在用例。代码、数据集、硬件指南和演示视频可在https://pear.wpi.edu/research/vizflyt.html找到。
论文及项目相关链接
PDF Accepted at ICRA 2025. Projected Page: https://pear.wpi.edu/research/vizflyt.html
Summary
可视化无人机飞行模拟平台(VizFlyt)作为感知为中心环节的硬件在环测试框架,为无人机课程提供了开放源代码的测试环境。该平台利用外部定位系统的姿态信息,通过三维高斯扩展技术模拟真实传感器视觉场景,实现对无人机自主算法的无障碍实时测试。系统更新率高达每秒百帧以上。此外,该研究还基于VizFlyt平台提出了开放源代码和开放硬件的未来课程设计思路。有关信息均可通过相关链接查询。该项目促进了对无人机的实际模拟研究,对推动无人机市场发展具有重要意义。
Key Takeaways
- 可视化无人机飞行模拟平台(VizFlyt)为无人机课程提供了重要测试环境。
- 利用三维高斯扩展技术实现实时传感器视觉模拟。
- 该平台支持无障碍测试无人机自主算法,降低测试风险。
- 系统更新率高达每秒百帧以上,保证测试效率。
- 基于VizFlyt平台提出了开放源代码和硬件的未来课程设计新思路。
- 提供在线访问教学资源及相关项目的指南,有助于无人机的教育及研发实践。
- 此框架验证了大规模使用潜能和对市场未来发展的重要作用。
点此查看论文截图


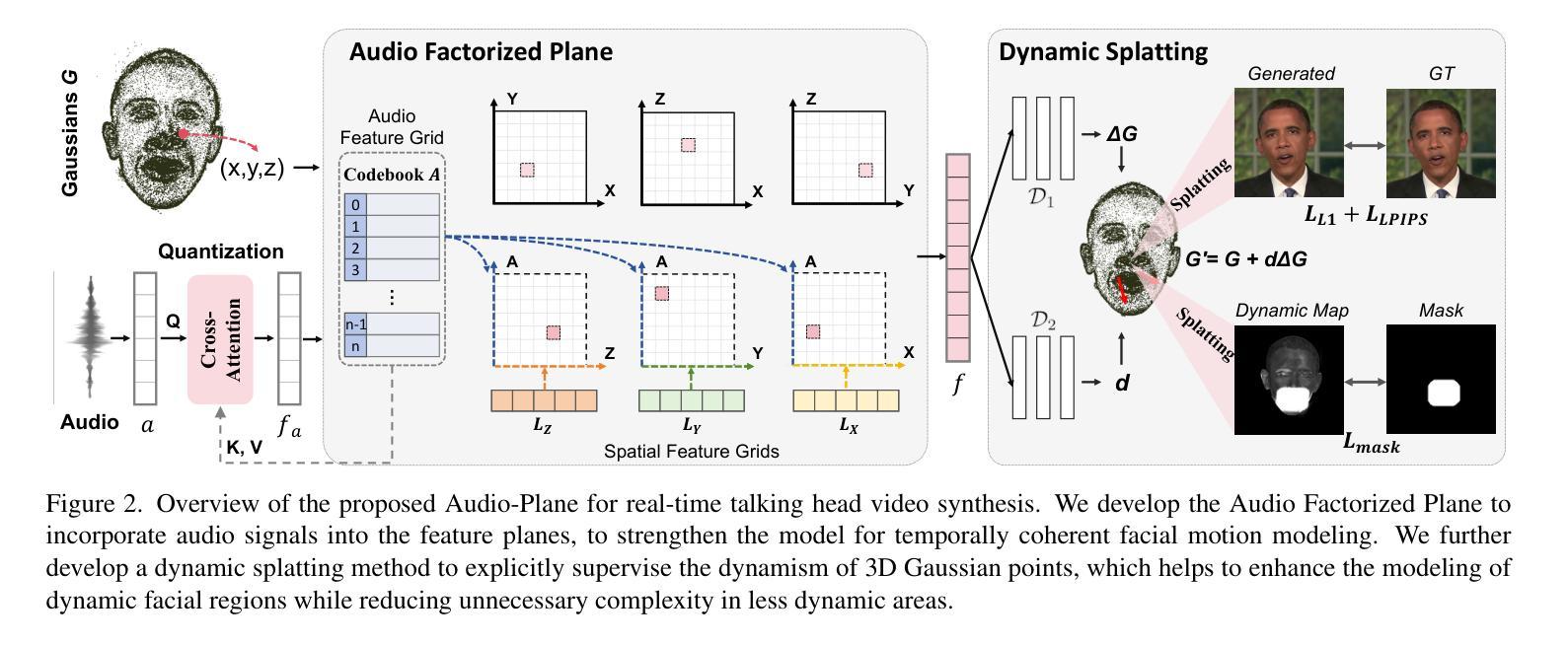
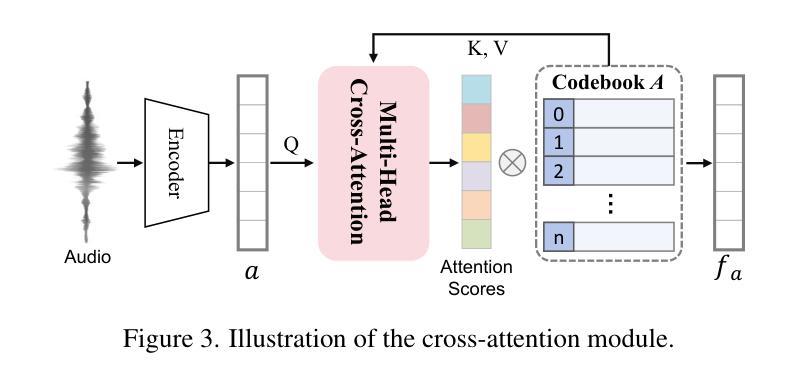
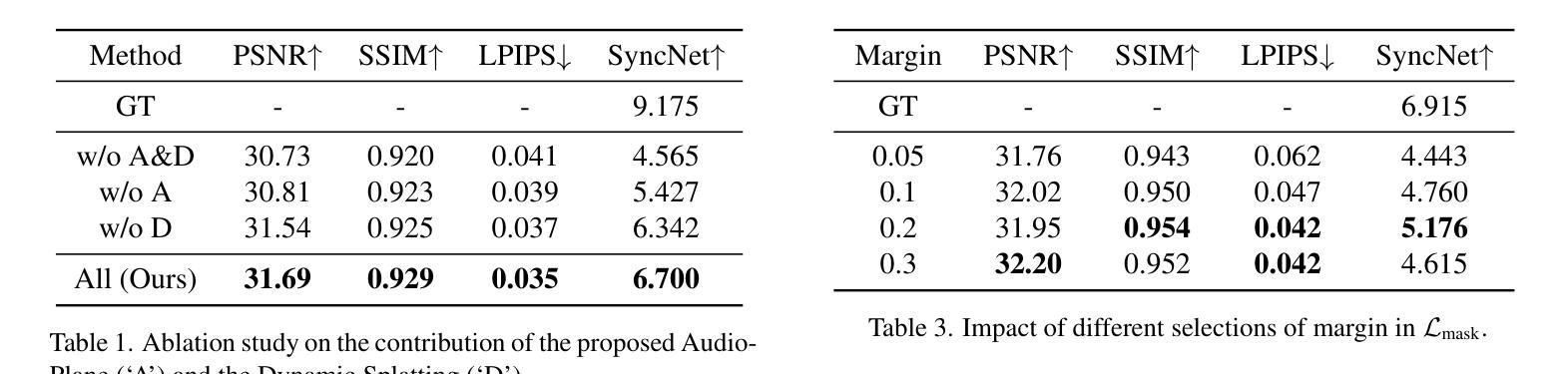
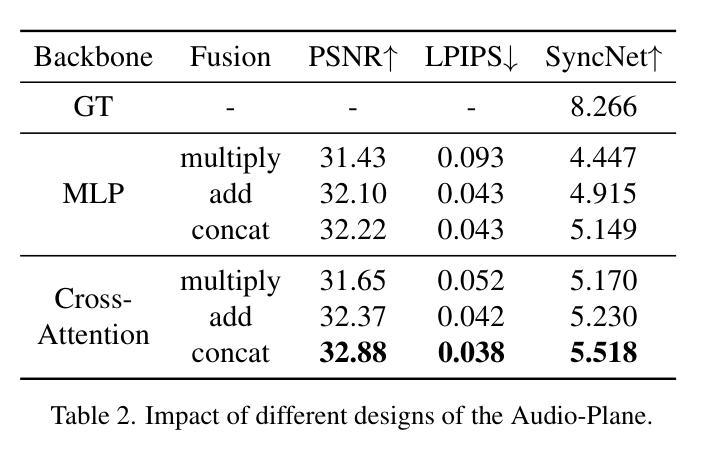
Audio-Plane: Audio Factorization Plane Gaussian Splatting for Real-Time Talking Head Synthesis
Authors:Shuai Shen, Wanhua Li, Yunpeng Zhang, Weipeng Hu, Yap-Peng Tan
Talking head synthesis has become a key research area in computer graphics and multimedia, yet most existing methods often struggle to balance generation quality with computational efficiency. In this paper, we present a novel approach that leverages an Audio Factorization Plane (Audio-Plane) based Gaussian Splatting for high-quality and real-time talking head generation. For modeling a dynamic talking head, 4D volume representation is needed. However, directly storing a dense 4D grid is impractical due to the high cost and lack of scalability for longer durations. We overcome this challenge with the proposed Audio-Plane, where the 4D volume representation is decomposed into audio-independent space planes and audio-dependent planes. This provides a compact and interpretable feature representation for talking head, facilitating more precise audio-aware spatial encoding and enhanced audio-driven lip dynamic modeling. To further improve speech dynamics, we develop a dynamic splatting method that helps the network more effectively focus on modeling the dynamics of the mouth region. Extensive experiments demonstrate that by integrating these innovations with the powerful Gaussian Splatting, our method is capable of synthesizing highly realistic talking videos in real time while ensuring precise audio-lip synchronization. Synthesized results are available in https://sstzal.github.io/Audio-Plane/.
论文摘要:说话人头部合成已成为计算机图形学和多媒体领域的一个关键研究点,然而现有的大多数方法往往难以在生成质量和计算效率之间取得平衡。在本文中,我们提出了一种新的方法,利用基于音频分解平面(Audio-Plane)的高斯涂抹技术来进行高质量实时说话头部生成。为了模拟动态的说话头部,需要采用4D体积表示。然而,直接存储密集的4D网格并不实际,因为成本高昂且对于更长时间的扩展性不足。我们克服了这一挑战,提出了音频平面,其中将4D体积表示分解为音频独立的空间平面和音频依赖的平面。这为说话头部提供了紧凑且可解释的特征表示,促进了更精确的声音感知空间编码和增强的音频驱动嘴唇动态建模。为了进一步改善语音动态,我们开发了一种动态涂抹方法,帮助网络更有效地专注于嘴部区域的动态建模。大量实验表明,通过将这些创新与强大的高斯涂抹技术相结合,我们的方法能够在确保精确音频-嘴唇同步的情况下,实时合成高度逼真的对话视频。合成结果可在https://sstzal.github.io/Audio-Plane/查看。
论文及项目相关链接
Summary
实时头部合成是研究计算机图形学和多媒体领域的一个关键课题。大多数现有方法难以平衡生成质量和计算效率。本文提出了一种基于音频分解平面(Audio-Plane)的高斯溅射法,用于高质量实时头部生成。通过分解四维体积表示为音频独立空间平面和音频依赖平面,克服了直接存储密集四维网格的不切实际和不可扩展的问题。这为头部提供了紧凑且可解释的特征表示,促进了更精确的音频感知空间编码和增强的音频驱动唇部动态建模。通过进一步的实验证明,结合高斯溅射法,该方法能够实时合成高度逼真的对话视频,同时确保精确的音频-唇部同步。合成结果可在链接查看。
Key Takeaways
- 实时头部合成是计算机图形学和多媒体领域的重要研究内容。
- 现有方法在生成质量和计算效率之间取得平衡面临挑战。
- 提出了基于音频分解平面(Audio-Plane)的新方法,用于高质量实时头部生成。
- Audio-Plane克服了直接存储四维体积表示的不切实际和不可扩展问题。
- 该方法提供了紧凑且可解释的特征表示,促进了音频感知空间编码和唇部动态建模。
- 结合高斯溅射法,实现了高度逼真的实时对话视频合成。
点此查看论文截图


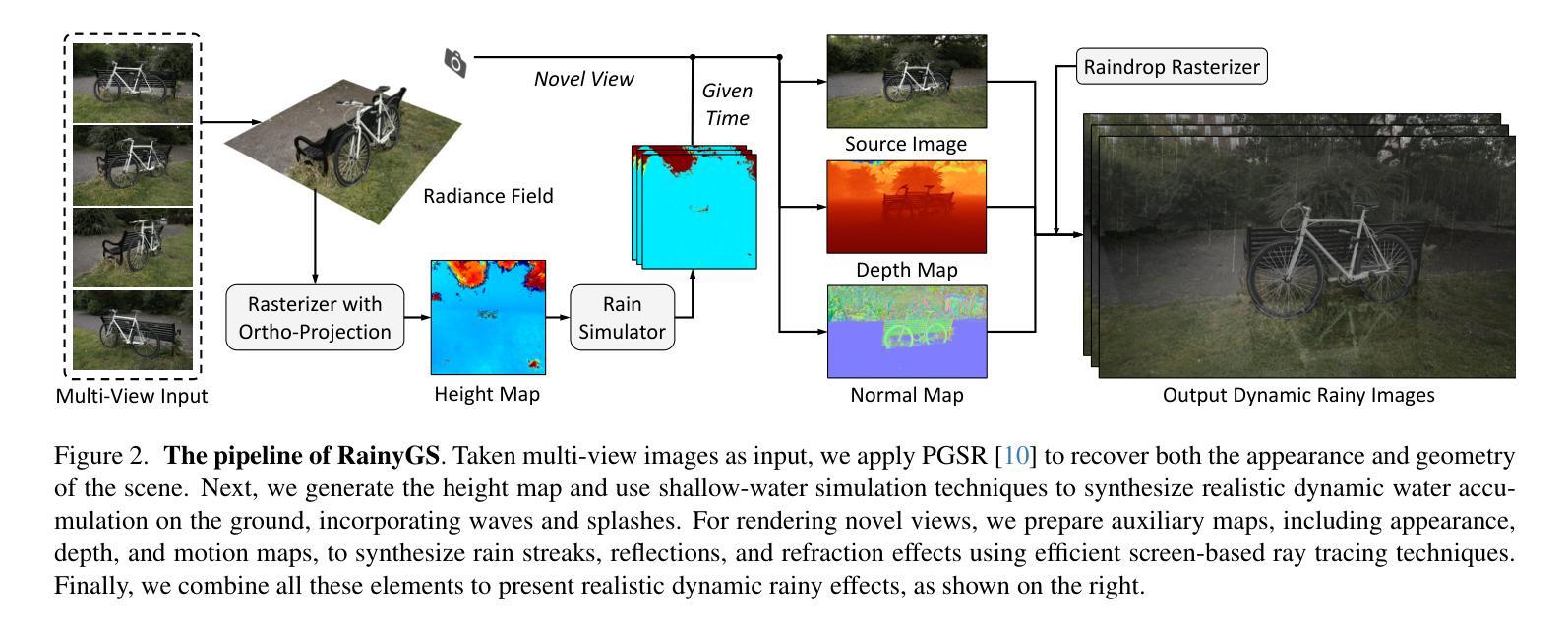
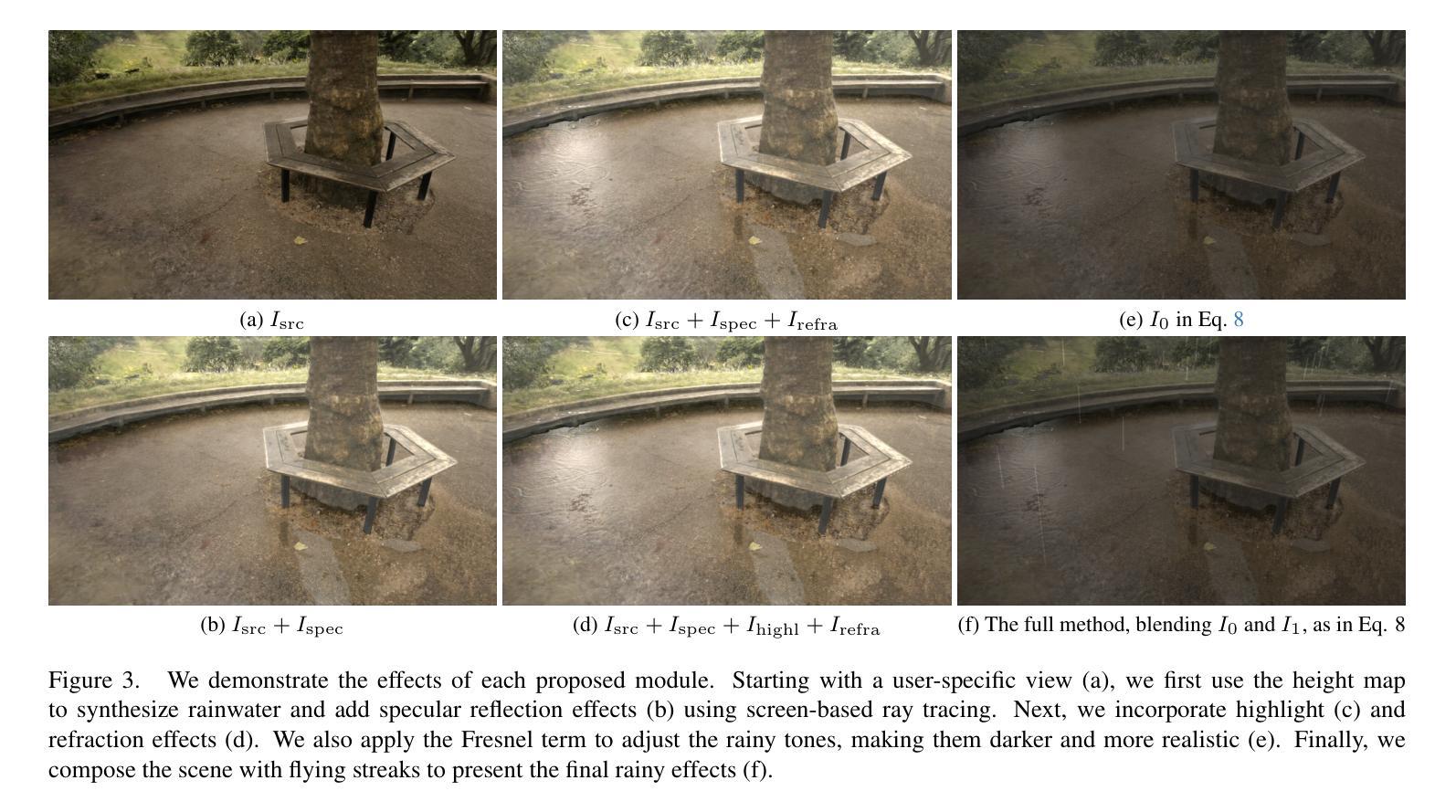
RainyGS: Efficient Rain Synthesis with Physically-Based Gaussian Splatting
Authors:Qiyu Dai, Xingyu Ni, Qianfan Shen, Wenzheng Chen, Baoquan Chen, Mengyu Chu
We consider the problem of adding dynamic rain effects to in-the-wild scenes in a physically-correct manner. Recent advances in scene modeling have made significant progress, with NeRF and 3DGS techniques emerging as powerful tools for reconstructing complex scenes. However, while effective for novel view synthesis, these methods typically struggle with challenging scene editing tasks, such as physics-based rain simulation. In contrast, traditional physics-based simulations can generate realistic rain effects, such as raindrops and splashes, but they often rely on skilled artists to carefully set up high-fidelity scenes. This process lacks flexibility and scalability, limiting its applicability to broader, open-world environments. In this work, we introduce RainyGS, a novel approach that leverages the strengths of both physics-based modeling and 3DGS to generate photorealistic, dynamic rain effects in open-world scenes with physical accuracy. At the core of our method is the integration of physically-based raindrop and shallow water simulation techniques within the fast 3DGS rendering framework, enabling realistic and efficient simulations of raindrop behavior, splashes, and reflections. Our method supports synthesizing rain effects at over 30 fps, offering users flexible control over rain intensity – from light drizzles to heavy downpours. We demonstrate that RainyGS performs effectively for both real-world outdoor scenes and large-scale driving scenarios, delivering more photorealistic and physically-accurate rain effects compared to state-of-the-art methods. Project page can be found at https://pku-vcl-geometry.github.io/RainyGS/
我们考虑以物理正确的方式为自然场景添加动态下雨效果的问题。最近场景建模方面的进展已经取得了重大突破,NeRF和3DGS技术作为重建复杂场景的强大工具而崭露头角。然而,尽管这些方法在合成新视角方面非常有效,但它们通常面临基于物理的下雨模拟等挑战性场景编辑任务时感到困难。相反,传统的基于物理的模拟可以产生逼真的下雨效果,如雨滴和飞溅的水花,但它们通常依赖于熟练的艺术家来仔细设置高保真场景。这个过程缺乏灵活性和可扩展性,限制了其在更广泛、开放世界环境中的适用性。在这项工作中,我们引入了RainyGS,这是一种利用基于物理的建模和3DGS优势生成开放世界场景中的逼真动态下雨效果的新方法,具有物理准确性。我们的方法的核心是在快速的3DGS渲染框架内整合基于物理的雨滴和浅水模拟技术,能够真实有效地模拟雨滴行为、飞溅和水面反射。我们的方法可以合成超过30帧/秒的下雨效果,让用户灵活地控制雨强度——从轻微细雨到倾盆大雨。我们证明RainyGS对于真实户外场景和大规模驾驶场景都表现有效,与最新方法相比,提供了更逼真和更物理准确的下雨效果。项目页面可在链接找到。
论文及项目相关链接
PDF CVPR 2025
Summary
本文介绍了一种名为RainyGS的新方法,该方法结合了基于物理的建模和3DGS技术,可在开放世界场景中生成具有物理准确性的高逼真度动态雨水效果。该方法通过快速3DGS渲染框架集成基于物理的雨滴和浅水模拟技术,实现了真实高效的雨滴行为、飞溅和反射模拟。该方法能够合成超过30帧的降雨效果,用户可以灵活控制雨强度,实现从轻雨到暴雨的模拟。RainyGS在真实户外场景和大规模驾驶场景中的表现得到了展示,与现有方法相比,它提供了更逼真和更准确的雨水效果。
Key Takeaways
- 本文提出了一种新的方法RainyGS,结合了物理建模和3DGS技术来模拟真实世界的降雨效果。
- RainyGS使用基于物理的雨滴模拟和浅水模拟技术,确保雨水效果的逼真度和物理准确性。
- 该方法能够在开放世界场景中模拟各种雨强度,从轻雨到暴雨。
- RainyGS通过快速3DGS渲染框架实现了高效模拟,可以合成超过30帧的降雨效果。
- 用户可以灵活控制雨强度,提供了丰富的模拟选项。
- RainyGS在真实户外场景和大规模驾驶场景中的表现得到了验证和展示。
点此查看论文截图

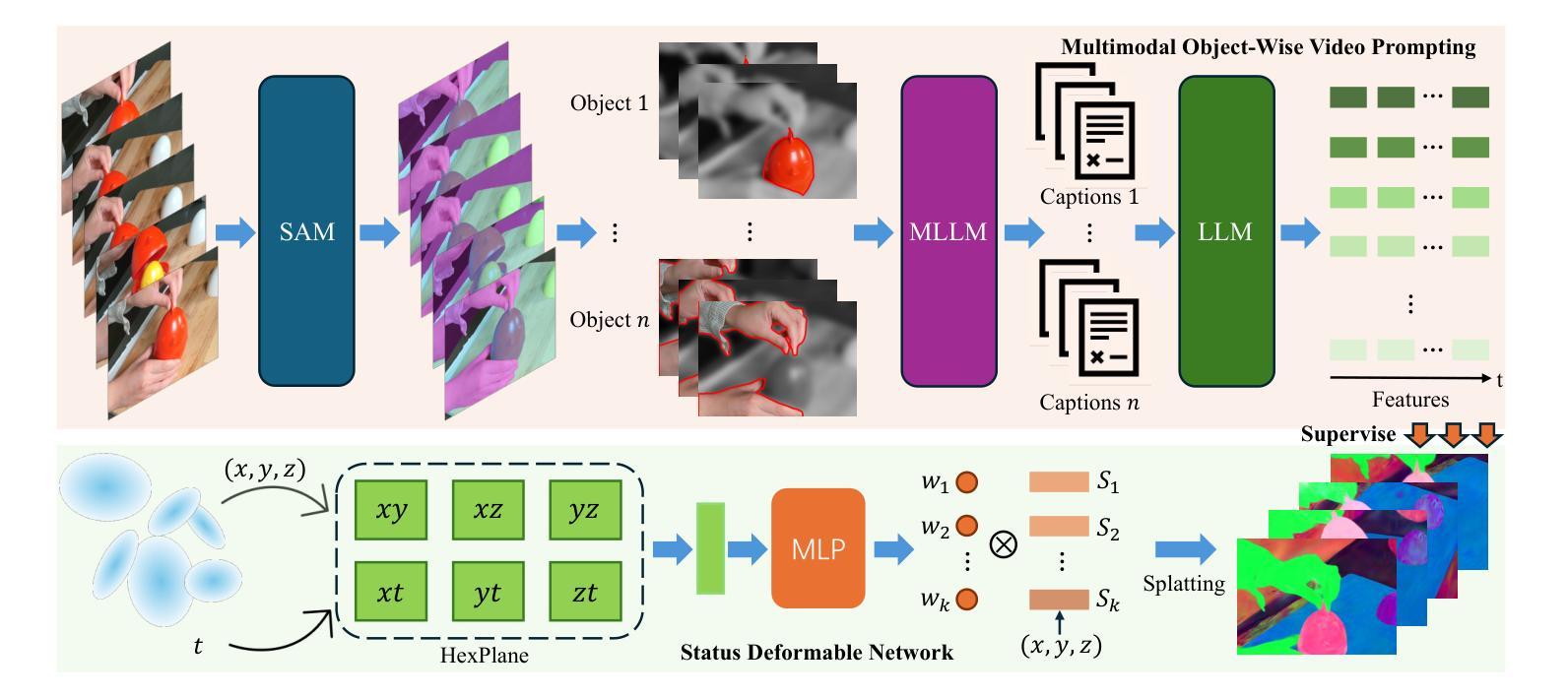
4D LangSplat: 4D Language Gaussian Splatting via Multimodal Large Language Models
Authors:Wanhua Li, Renping Zhou, Jiawei Zhou, Yingwei Song, Johannes Herter, Minghan Qin, Gao Huang, Hanspeter Pfister
Learning 4D language fields to enable time-sensitive, open-ended language queries in dynamic scenes is essential for many real-world applications. While LangSplat successfully grounds CLIP features into 3D Gaussian representations, achieving precision and efficiency in 3D static scenes, it lacks the ability to handle dynamic 4D fields as CLIP, designed for static image-text tasks, cannot capture temporal dynamics in videos. Real-world environments are inherently dynamic, with object semantics evolving over time. Building a precise 4D language field necessitates obtaining pixel-aligned, object-wise video features, which current vision models struggle to achieve. To address these challenges, we propose 4D LangSplat, which learns 4D language fields to handle time-agnostic or time-sensitive open-vocabulary queries in dynamic scenes efficiently. 4D LangSplat bypasses learning the language field from vision features and instead learns directly from text generated from object-wise video captions via Multimodal Large Language Models (MLLMs). Specifically, we propose a multimodal object-wise video prompting method, consisting of visual and text prompts that guide MLLMs to generate detailed, temporally consistent, high-quality captions for objects throughout a video. These captions are encoded using a Large Language Model into high-quality sentence embeddings, which then serve as pixel-aligned, object-specific feature supervision, facilitating open-vocabulary text queries through shared embedding spaces. Recognizing that objects in 4D scenes exhibit smooth transitions across states, we further propose a status deformable network to model these continuous changes over time effectively. Our results across multiple benchmarks demonstrate that 4D LangSplat attains precise and efficient results for both time-sensitive and time-agnostic open-vocabulary queries.
学习四维语言领域以实现动态场景中的时间敏感和无时限的语言查询对于许多实际应用至关重要。虽然LangSplat成功地将CLIP特性融入三维高斯表示中,实现了在三维静态场景中的精确性和高效性,但它无法处理动态四维领域,因为CLIP是为静态图像文本任务设计的,无法捕获视频中的时间动态。现实世界的环境本质上是动态的,物体语义会随时间演变。构建精确的四维语言领域需要获取像素对齐的、面向对象的视频特征,而当前视觉模型很难做到这一点。为了应对这些挑战,我们提出了四维LangSplat,它学习四维语言领域以高效地处理动态场景中的时间无关或时间敏感的无限制词汇查询。四维LangSplat绕过了从视觉特征中学习语言领域,而是直接从根据面向对象的视频字幕生成文本中学习,通过多模态大型语言模型(MLLMs)。具体来说,我们提出了一种多模态面向对象视频提示方法,包括视觉和文本提示,引导MLLMs为视频中的对象生成详细、时间一致、高质量的字幕。这些字幕使用大型语言模型编码为高质量的句子嵌入,然后作为像素对齐的、面向对象的特征监督,通过共享嵌入空间实现开放式词汇文本查询。我们认识到四维场景中的对象在状态之间呈现出平滑的过渡,因此进一步提出了一个状态可变形网络来有效地对这些随时间变化的连续变化进行建模。我们在多个基准测试上的结果表明,四维LangSplat对时间敏感和时间无关的无限制词汇查询都达到了精确和高效的结果。
论文及项目相关链接
PDF CVPR 2025. Project Page: https://4d-langsplat.github.io
Summary
本文介绍了学习4D语言字段的重要性,该语言字段可以处理动态场景中的时间敏感性和开放性词汇查询。虽然LangSplat成功地将CLIP特征融入3D高斯表示,但在处理动态4D字段方面仍存在局限性。为此,本文提出了4D LangSplat,它通过直接从由对象级视频字幕生成的多模态大型语言模型(MLLMs)学习语言字段,来解决这些挑战。文章还提出了一种多模态对象级视频提示方法,该方法包括视觉和文本提示,引导MLLMs为视频中的对象生成详细、时间一致的高质量字幕。这些字幕被编码成高质量句子嵌入,作为像素对齐的对象特定特征监督,通过共享嵌入空间进行开放式词汇文本查询。此外,本文还提出了一种状态可变形网络,以有效地模拟对象在4D场景中的连续状态变化。实验结果表明,4D LangSplat在时间和非时间敏感性的开放式词汇查询方面都取得了精确和高效的结果。
Key Takeaways
- 学习4D语言字段对于处理动态场景中的时间敏感性和开放性语言查询至关重要。
- LangSplat在3D静态场景中具有精确性和效率,但在处理动态4D字段方面存在局限性。
- 4D LangSplat通过直接从对象级视频字幕生成的多模态大型语言模型(MLLMs)学习语言字段。
- 多模态对象级视频提示方法生成详细、时间一致的高质量字幕。
- 对象级字幕被编码为句子嵌入,作为像素对齐的对象特定特征监督。
- 共享嵌入空间支持开放式词汇文本查询。
- 状态可变形网络用于模拟对象在4D场景中的连续状态变化。
点此查看论文截图