⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-04 更新
High-Fidelity Diffusion Face Swapping with ID-Constrained Facial Conditioning
Authors:Dailan He, Xiahong Wang, Shulun Wang, Guanglu Song, Bingqi Ma, Hao Shao, Yu Liu, Hongsheng Li
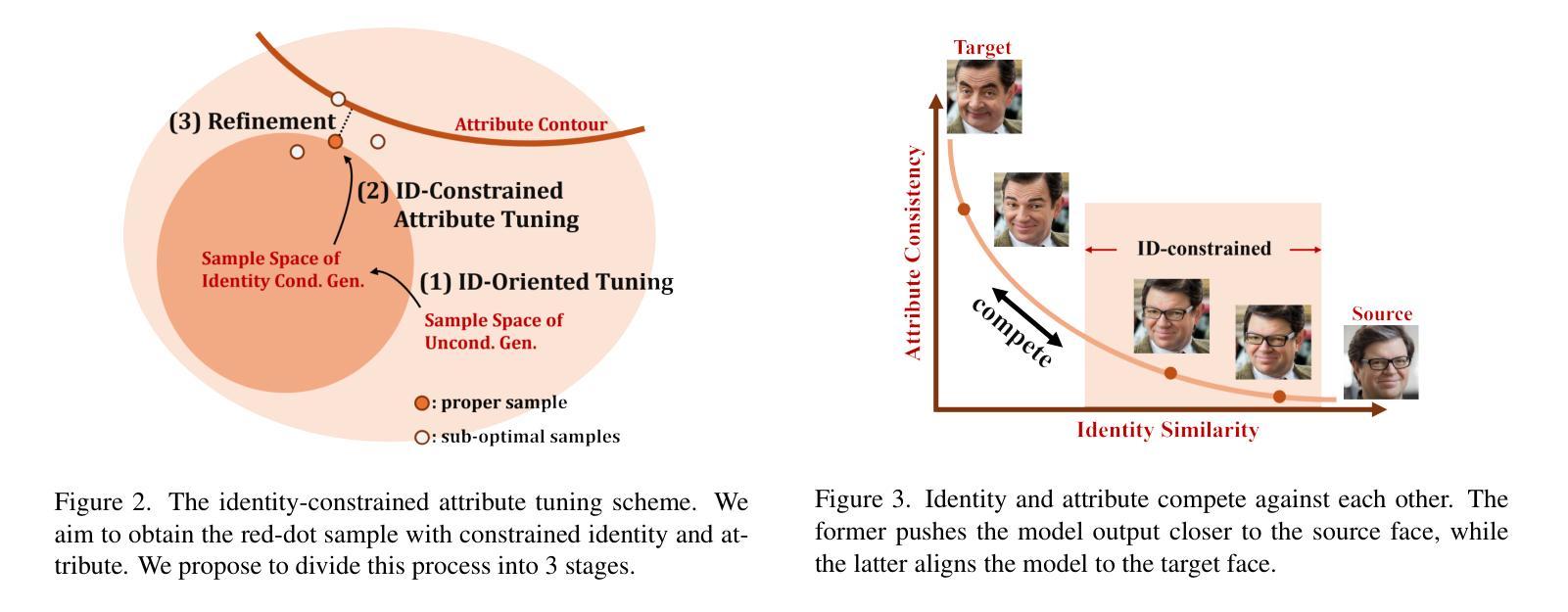
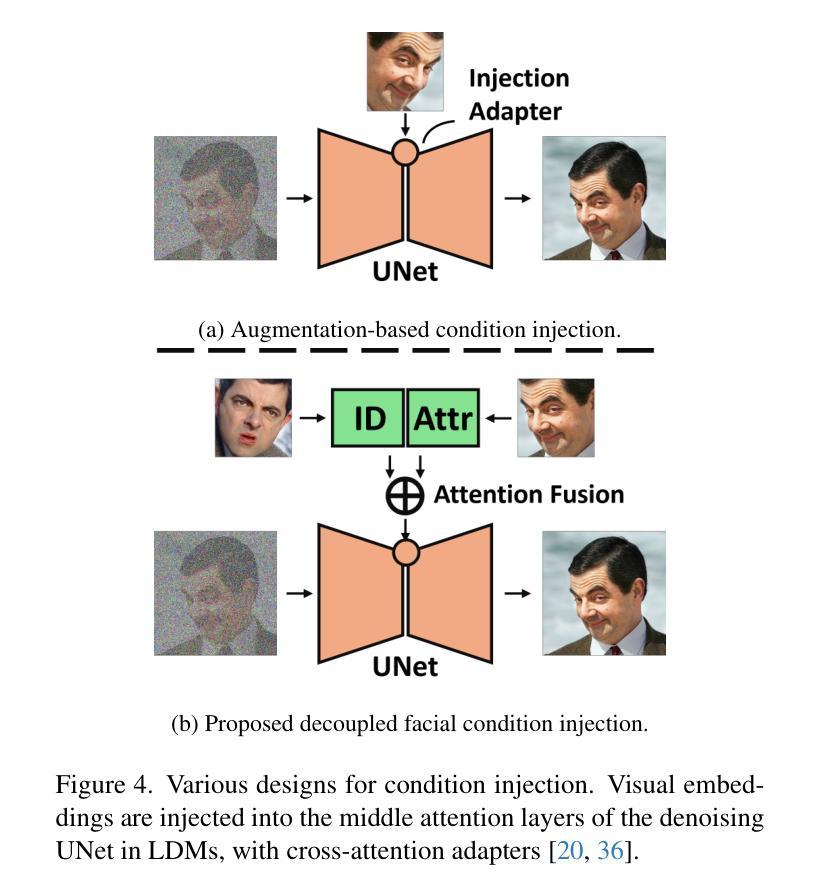
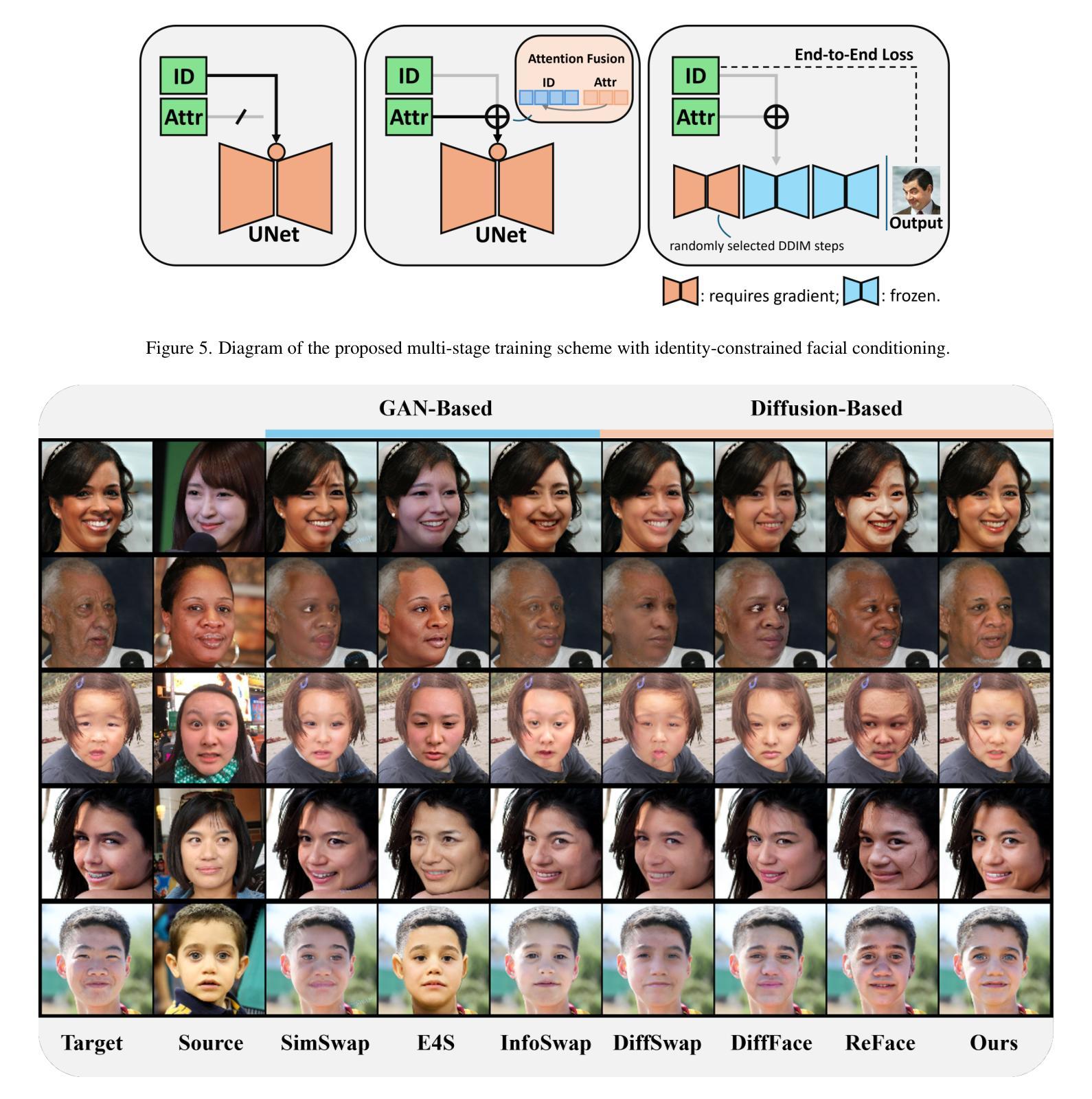
Face swapping aims to seamlessly transfer a source facial identity onto a target while preserving target attributes such as pose and expression. Diffusion models, known for their superior generative capabilities, have recently shown promise in advancing face-swapping quality. This paper addresses two key challenges in diffusion-based face swapping: the prioritized preservation of identity over target attributes and the inherent conflict between identity and attribute conditioning. To tackle these issues, we introduce an identity-constrained attribute-tuning framework for face swapping that first ensures identity preservation and then fine-tunes for attribute alignment, achieved through a decoupled condition injection. We further enhance fidelity by incorporating identity and adversarial losses in a post-training refinement stage. Our proposed identity-constrained diffusion-based face-swapping model outperforms existing methods in both qualitative and quantitative evaluations, demonstrating superior identity similarity and attribute consistency, achieving a new state-of-the-art performance in high-fidelity face swapping.
面部替换旨在将源面部身份无缝地转移到目标上,同时保留目标的姿态和表情等属性。扩散模型以其出色的生成能力而闻名,最近在提高面部交换质量方面显示出巨大的潜力。本文针对基于扩散的面部交换中的两个关键挑战:优先保留身份而非目标属性,以及身份与属性条件之间的固有冲突。为了解决这些问题,我们引入了一种用于面部交换的身份约束属性调整框架,该框架首先确保身份保留,然后通过解耦条件注入进行属性对齐的微调。我们通过在后训练优化阶段纳入身份和对抗损失来进一步提高保真度。我们提出的基于身份约束的扩散面部交换模型在定性和定量评估中都优于现有方法,表现出卓越的身份相似性和属性一致性,在高保真面部交换方面达到了最新的最佳性能。
论文及项目相关链接
Summary
本文介绍了基于扩散模型的面部替换技术的新进展。针对扩散面部替换中的两个关键挑战——身份优先于目标属性的保留以及身份与属性条件之间的内在冲突,提出了一个身份约束属性调节框架。通过首先确保身份保留,然后进行属性对齐的微调,实现了高保真面部替换的新水平。
Key Takeaways
- 面部替换旨在无缝地将源面部身份转移到目标面部,同时保留目标属性如姿势和表情。
- 扩散模型因其出色的生成能力而在面部替换领域显示出潜力。
- 本文解决了扩散模型面部替换中的两个主要挑战:优先保留身份和目标属性的冲突。
- 引入了一个身份约束属性调节框架,通过先确保身份保留再进行属性对齐的微调来解决这些问题。
- 通过在后训练细化阶段引入身份和对抗损失,进一步提高了保真度。
- 与现有方法相比,本文提出的基于身份约束的扩散面部替换模型在定性和定量评估中表现更优,实现了高保真面部替换的最新性能。
点此查看论文截图

Detecting Localized Deepfake Manipulations Using Action Unit-Guided Video Representations
Authors:Tharun Anand, Siva Sankar, Pravin Nair
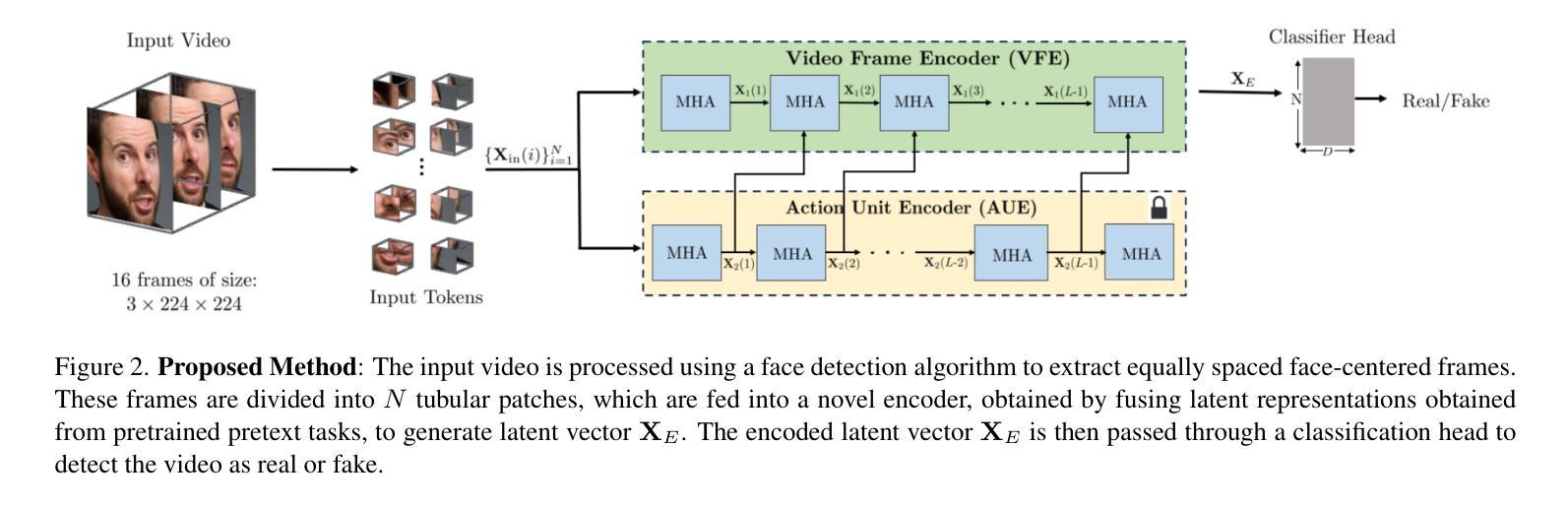
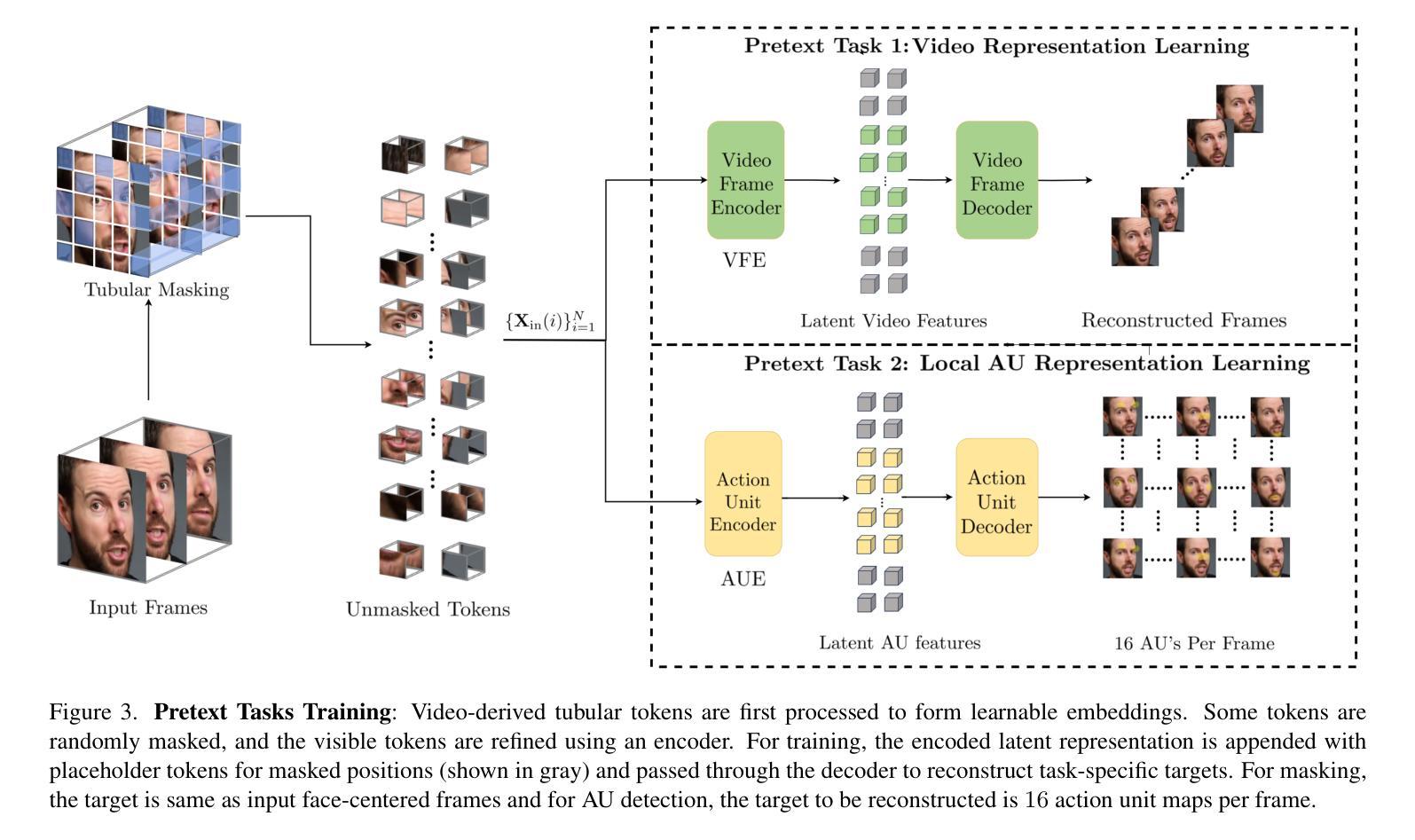
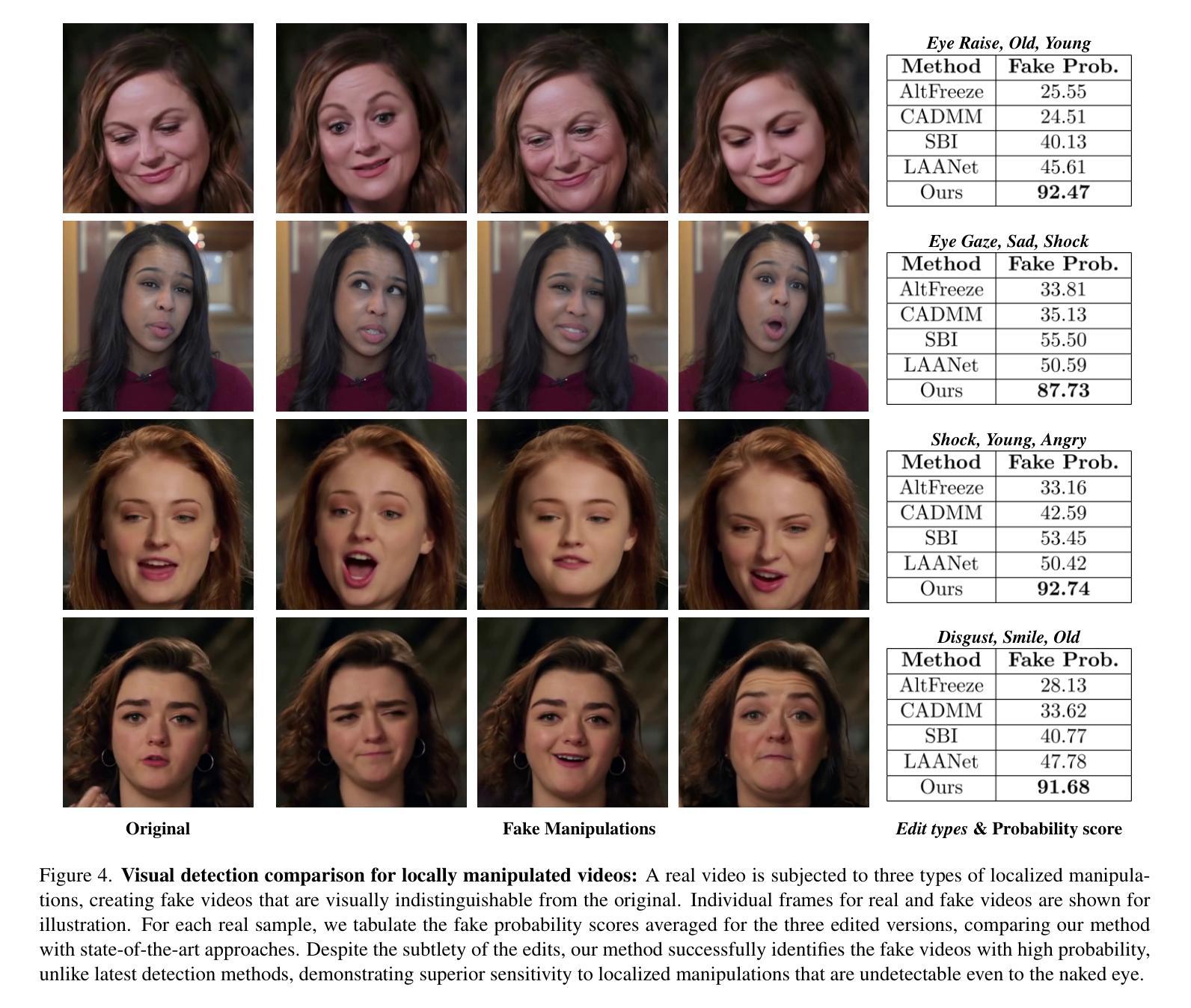
With rapid advancements in generative modeling, deepfake techniques are increasingly narrowing the gap between real and synthetic videos, raising serious privacy and security concerns. Beyond traditional face swapping and reenactment, an emerging trend in recent state-of-the-art deepfake generation methods involves localized edits such as subtle manipulations of specific facial features like raising eyebrows, altering eye shapes, or modifying mouth expressions. These fine-grained manipulations pose a significant challenge for existing detection models, which struggle to capture such localized variations. To the best of our knowledge, this work presents the first detection approach explicitly designed to generalize to localized edits in deepfake videos by leveraging spatiotemporal representations guided by facial action units. Our method leverages a cross-attention-based fusion of representations learned from pretext tasks like random masking and action unit detection, to create an embedding that effectively encodes subtle, localized changes. Comprehensive evaluations across multiple deepfake generation methods demonstrate that our approach, despite being trained solely on the traditional FF+ dataset, sets a new benchmark in detecting recent deepfake-generated videos with fine-grained local edits, achieving a $20%$ improvement in accuracy over current state-of-the-art detection methods. Additionally, our method delivers competitive performance on standard datasets, highlighting its robustness and generalization across diverse types of local and global forgeries.
随着生成模型的快速发展,深度伪造技术正在缩小真实视频和合成视频之间的差距,这引发了人们对隐私和安全的严重关注。除了传统的换脸和重新表演技术外,最近最先进的深度伪造生成方法中出现了一种新兴趋势,即进行局部编辑,例如对特定的面部特征进行细微操作,如挑眉、改变眼睛形状或修改口型等。这些精细的操纵对现有检测模型构成了重大挑战,这些模型在捕捉这种局部变化时感到困难。据我们所知,这项工作提出了第一个明确设计为适应深度伪造视频中局部编辑的检测方法,该方法利用面部动作单元引导的时空表征。我们的方法利用基于跨注意力的表示融合,这些表示是从随机掩码和动作单元检测等预训练任务中学习到的,以创建一个有效地编码微妙、局部变化的嵌入。在多种深度伪造生成方法上的综合评估表明,尽管我们的方法仅在传统FF+数据集上进行训练,但在检测具有精细局部编辑的深度伪造生成视频方面树立了新标杆,在准确率上较当前最先进的检测方法提高了20%。此外,我们的方法在标准数据集上表现出有竞争力的性能,突显了其在各种局部和全局伪造类型中的稳健性和泛化能力。
论文及项目相关链接
Summary
随着生成模型的快速发展,深度伪造技术不断缩小真实视频与合成视频之间的差距,引发了严重的隐私和安全问题。最新最先进的深度伪造生成方法出现了局部编辑的趋势,如对面部特征的微妙操作,如挑眉、改变眼型或调整口型等。这种精细粒度的操作对现有检测模型构成了重大挑战,难以捕捉这些局部变化。本研究提出了首个专门针对深度伪造视频中局部编辑设计的检测方法,通过利用面部动作单元引导的时空表征。该方法结合从随机掩蔽和动作单元检测等预训练任务中学到的表征,创建一个有效编码细微局部变化的嵌入。在多种深度伪造生成方法上的综合评估表明,尽管我们的方法仅在传统的FF+数据集上进行训练,但在检测具有精细粒度局部编辑的最近深度伪造视频方面却取得了突破性进展,较目前最先进的检测方法的准确性提高了20%。此外,我们的方法在标准数据集上的表现也颇具竞争力,突显了其对面部全局和局部篡改的稳健性和泛化能力。
Key Takeaways
- 深度伪造技术的快速发展导致真实视频与合成视频之间的差距日益缩小,引发隐私和安全问题。
- 最新趋势是在深度伪造生成方法中进行局部编辑,如面部特征的微妙操作。
- 这种精细粒度的操作对现有的检测模型构成挑战,难以捕捉局部变化。
- 提出了一种针对深度伪造视频中的局部编辑设计的检测方法,通过结合时空表征和面部动作单元。
- 方法通过结合预训练任务(如随机掩蔽和动作单元检测)的表征来创建嵌入,有效编码细微的局部变化。
- 在多个深度伪造生成方法上的评估显示,该方法在检测具有精细粒度局部编辑的深度伪造视频方面取得了显著进步。
点此查看论文截图

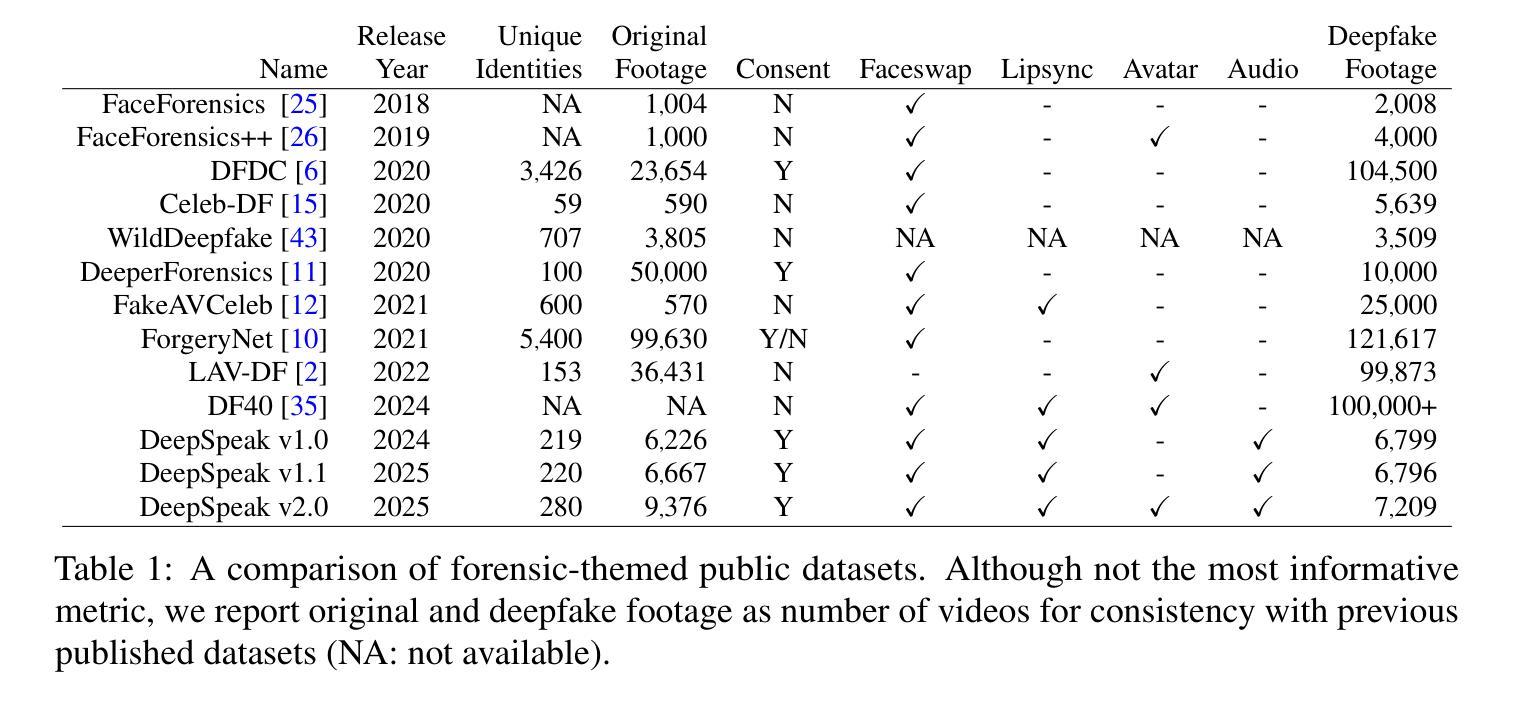
The DeepSpeak Dataset
Authors:Sarah Barrington, Matyas Bohacek, Hany Farid
We describe a large-scale dataset - DeepSpeak - of real and deepfake footage of people talking and gesturing in front of their webcams. The real videos in this dataset consist of a total of 50 hours of footage from 500 diverse individuals. Constituting more than 50 hours of footage, the fake videos consist of a range of different state-of-the-art avatar, face-swap, and lip-sync deepfakes with natural and AI-generated voices. We are regularly releasing updated versions of this dataset with the latest deepfake technologies. This preprint describes the construction of versions 1.0, 1.1, and 2.0. This dataset is made freely available for research and non-commercial uses; requests for commercial use will be considered.
我们介绍了一个大规模数据集——DeepSpeak,其中包含人们在其网络摄像头前说话和做手势的真实和深度伪造视频片段。该数据集的真实视频包含来自500个不同个体的总共50小时的片段。伪造视频则包含超过50小时的片段,涵盖各种不同的最先进的人形化身、换脸以及声音同步深度伪造技术,既有自然声音也有AI生成的声音。我们定期发布此数据集的更新版本,其中包含最新的深度伪造技术。这篇预印本描述了版本1.0、1.1和2.0的构建过程。该数据集免费提供给研究者和非商业用途使用;商业用途的请求将予以考虑。
论文及项目相关链接
Summary
本文介绍了一个大规模数据集DeepSpeak,包含真实和深度伪造的视频片段,展示人们在摄像头前说话和做手势。真实视频包含来自500个不同个体的总共50小时的视频素材。伪造视频则包含使用最新深度伪造技术制作的先进虚拟形象、面部替换和唇同步视频,时长超过50小时。数据集免费提供给研究者和非商业用途使用,商业用途的申请将会考虑。本文描述了数据集版本1.0、1.1和2.0的构建过程。
Key Takeaways
- DeepSpeak是一个大规模数据集,包含真实和深度伪造的视频片段。
- 真实视频素材包含来自500个不同个体的50小时内容。
- 伪造视频素材超过50小时,使用了多种先进的深度伪造技术。
- 数据集包含版本1.0、1.1和2.0的构建过程描述。
- 数据集免费提供给研究者和非商业用途使用。
- 商业用途的申请将会被考虑。
点此查看论文截图