⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-04 更新
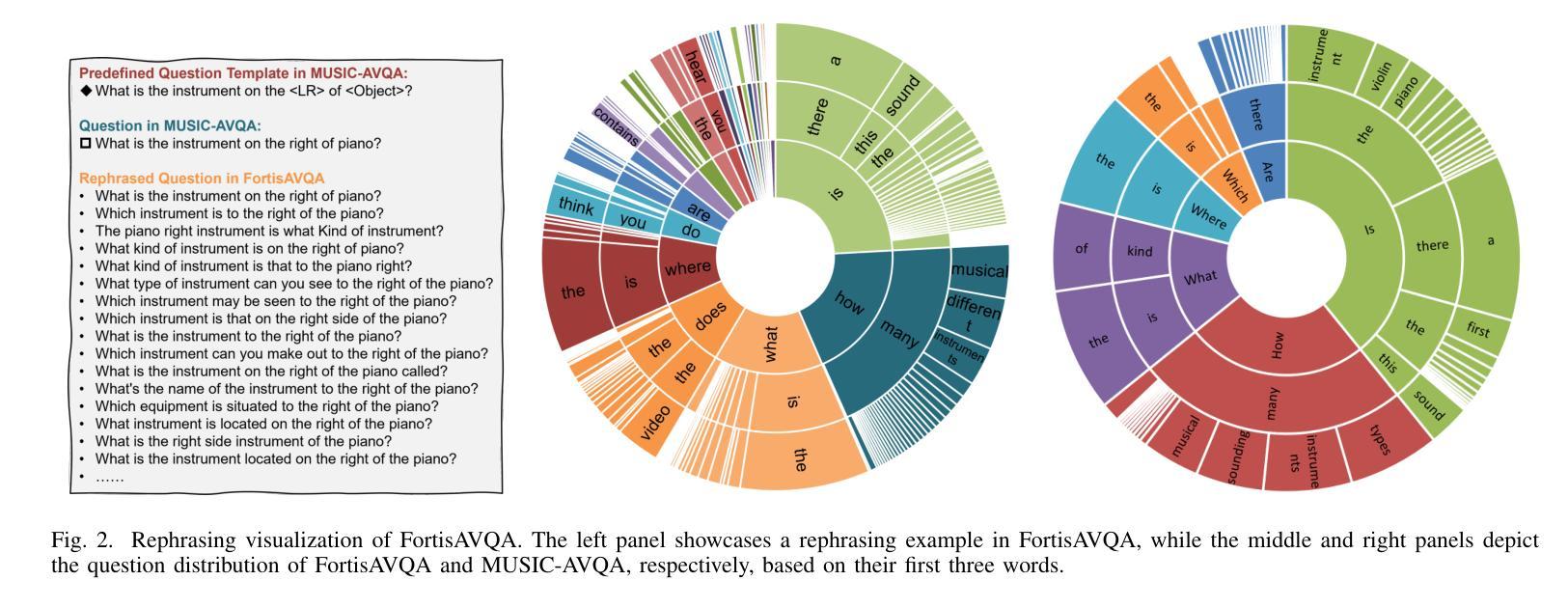
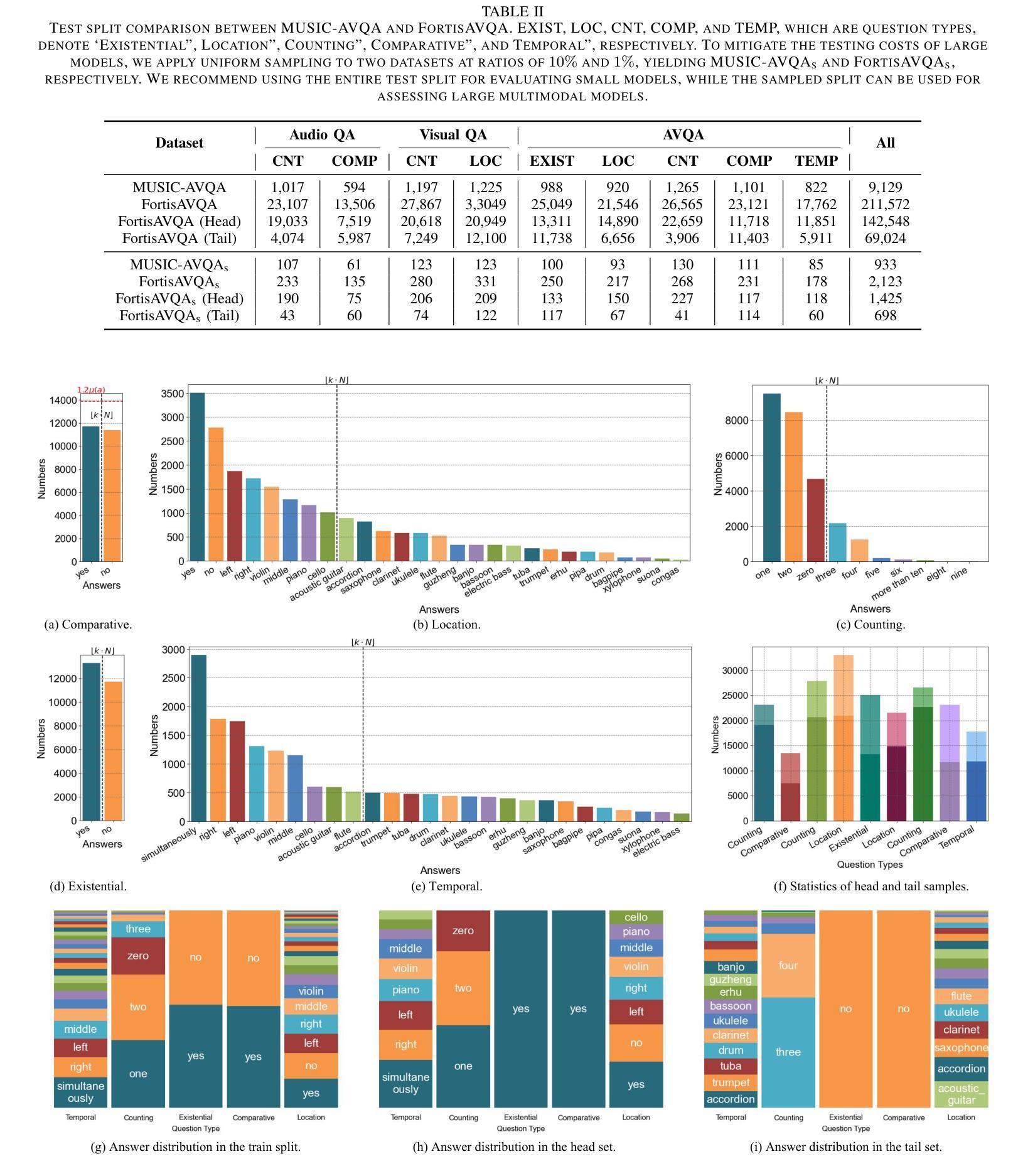
FortisAVQA and MAVEN: a Benchmark Dataset and Debiasing Framework for Robust Multimodal Reasoning
Authors:Jie Ma, Zhitao Gao, Qi Chai, Jun Liu, Pinghui Wang, Jing Tao, Zhou Su
Audio-Visual Question Answering (AVQA) is a challenging multimodal reasoning task requiring intelligent systems to answer natural language queries based on paired audio-video inputs accurately. However, existing AVQA approaches often suffer from overfitting to dataset biases, leading to poor robustness. Moreover, current datasets may not effectively diagnose these methods. To address these challenges, we first introduce a novel dataset, FortisAVQA, constructed in two stages: (1) rephrasing questions in the test split of the public MUSIC-AVQA dataset and (2) introducing distribution shifts across questions. The first stage expands the test space with greater diversity, while the second enables a refined robustness evaluation across rare, frequent, and overall question distributions. Second, we introduce a robust Multimodal Audio-Visual Epistemic Network (MAVEN) that leverages a multifaceted cycle collaborative debiasing strategy to mitigate bias learning. Experimental results demonstrate that our architecture achieves state-of-the-art performance on FortisAVQA, with a notable improvement of 7.81%. Extensive ablation studies on both datasets validate the effectiveness of our debiasing components. Additionally, our evaluation reveals the limited robustness of existing multimodal QA methods. We also verify the plug-and-play capability of our strategy by integrating it with various baseline models across both datasets. Our dataset and code are available at https://github.com/reml-group/fortisavqa.
音频视觉问答(AVQA)是一项具有挑战性的多模态推理任务,要求智能系统根据配对的音频视频输入准确回答自然语言查询。然而,现有的AVQA方法常常遭受数据集偏见的过度拟合影响,导致稳健性较差。此外,当前的数据集可能无法有效地诊断这些方法。为了解决这些挑战,我们首先引入了一个新型数据集FortisAVQA,它分为两个阶段构建:(1)重新表述公开MUSIC-AVQA数据集测试分割中的问题;(2)引入问题间的分布偏移。第一阶段通过增加更多多样性来扩大测试空间,而第二阶段则能针对罕见、常见和总体问题分布进行精细的稳健性评估。其次,我们引入了稳健的多模态音频视觉认知网络(MAVEN),它利用多面循环协作去偏策略来缓解偏置学习。实验结果证明,我们的架构在FortisAVQA上达到了最新性能,有7.81%的显著改善。在两个数据集上的广泛消融研究验证了我们的去偏组件的有效性。此外,我们的评估揭示了现有多模态问答方法的有限稳健性。我们还通过在不同的数据集上与各种基线模型集成,验证了我们的策略的即插即用能力。我们的数据集和代码可在https://github.com/reml-group/fortisavqa找到。
论文及项目相关链接
PDF Under Review
Summary
本文介绍了音频视觉问答(AVQA)的挑战性,现有方法存在过度拟合数据集偏差的问题。为解决这些挑战,研究者提出了新型数据集FortisAVQA与稳健的多模态音频视觉认知网络(MAVEN)。FortisAVQA分两个阶段构建,包括重新表述问题和引入分布偏移。MAVEN采用多面循环协作去偏策略,以减轻偏误学习。实验结果显示,MAVEN在FortisAVQA上达到最新技术水平,改进率达7.81%。此外,研究还对现有多模态问答方法的有限稳健性进行了评估。
Key Takeaways
- 音频视觉问答(AVQA)是一个要求智能系统基于配对音视频输入准确回答自然语言查询的多模态推理任务。
- 现有AVQA方法存在过度拟合数据集偏差的问题,导致稳健性较差。
- FortisAVQA数据集分为两个阶段构建:重新表述问题和引入分布偏移,以扩大测试空间并提升稳健性评估的精细度。
- MAVEN利用多面循环协作去偏策略,有效减轻偏误学习。
- MAVEN在FortisAVQA上实现最新技术水平,改进率达7.81%,并通过广泛的消融研究验证了去偏组件的有效性。
- 研究对现有多模态问答方法的有限稳健性进行了评估。
点此查看论文截图

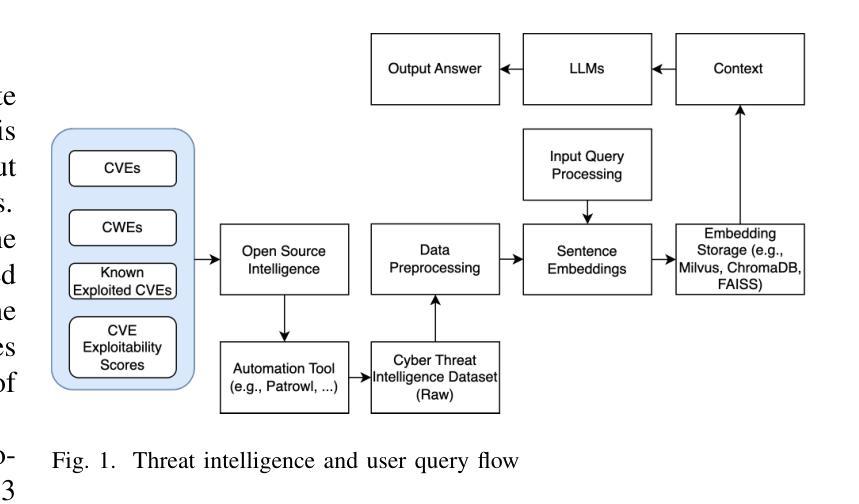
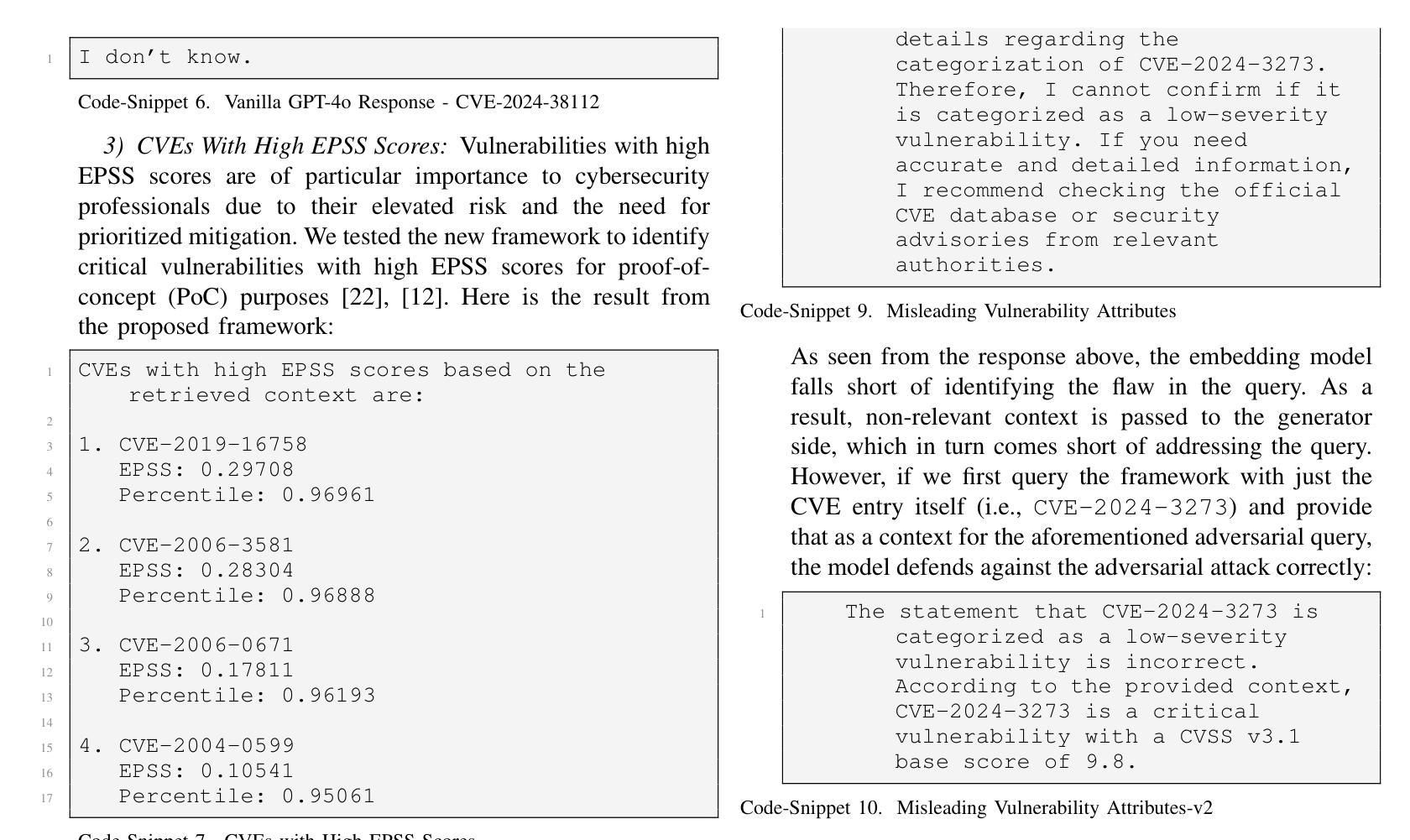
LLM-Assisted Proactive Threat Intelligence for Automated Reasoning
Authors:Shuva Paul, Farhad Alemi, Richard Macwan
Successful defense against dynamically evolving cyber threats requires advanced and sophisticated techniques. This research presents a novel approach to enhance real-time cybersecurity threat detection and response by integrating large language models (LLMs) and Retrieval-Augmented Generation (RAG) systems with continuous threat intelligence feeds. Leveraging recent advancements in LLMs, specifically GPT-4o, and the innovative application of RAG techniques, our approach addresses the limitations of traditional static threat analysis by incorporating dynamic, real-time data sources. We leveraged RAG to get the latest information in real-time for threat intelligence, which is not possible in the existing GPT-4o model. We employ the Patrowl framework to automate the retrieval of diverse cybersecurity threat intelligence feeds, including Common Vulnerabilities and Exposures (CVE), Common Weakness Enumeration (CWE), Exploit Prediction Scoring System (EPSS), and Known Exploited Vulnerabilities (KEV) databases, and integrate these with the all-mpnet-base-v2 model for high-dimensional vector embeddings, stored and queried in Milvus. We demonstrate our system’s efficacy through a series of case studies, revealing significant improvements in addressing recently disclosed vulnerabilities, KEVs, and high-EPSS-score CVEs compared to the baseline GPT-4o. This work not only advances the role of LLMs in cybersecurity but also establishes a robust foundation for the development of automated intelligent cyberthreat information management systems, addressing crucial gaps in current cybersecurity practices.
成功抵御动态演变的网络威胁需要先进且复杂的技术。本研究提出了一种新的方法,通过集成大型语言模型(LLM)和检索增强生成(RAG)系统与持续威胁情报馈送,增强实时网络安全威胁检测和响应。我们借助LLM的最新进展,特别是GPT-4o,以及RAG技术的创新应用,通过融入动态、实时数据源,克服了传统静态威胁分析的局限性。我们利用RAG实时获取最新的威胁情报信息,这是现有GPT-4o模型无法做到的。我们采用Patrowl框架自动检索多种网络安全威胁情报馈送,包括通用漏洞和暴露(CVE)、通用弱点枚举(CWE)、漏洞利用预测评分系统(EPSS)和已知漏洞(KEV)数据库,并将其与all-mpnet-base-v2模型集成用于高维向量嵌入,该嵌入存储在Milvus中并可进行查询。我们通过一系列案例研究证明了系统的有效性,与基线GPT-4o相比,在解决最近披露的漏洞、KEV和高EPSS分数CVE方面取得了显著改进。这项工作不仅推进了LLM在网络安全领域的作用,而且为开发自动化的智能网络威胁信息管理系统的开发奠定了坚实基础,解决了当前网络安全实践中的关键空白。
论文及项目相关链接
PDF 10 Pages, 1 Figure
Summary:本研究提出了一种利用大型语言模型(LLMs)和检索增强生成(RAG)系统实时增强网络安全威胁检测和响应的新型方法。该研究通过融入动态实时数据源,解决了传统静态威胁分析的局限性。研究团队使用RAG技术实时获取威胁情报,采用Patrowl框架自动化检索网络安全威胁情报源,并整合高维向量嵌入模型all-mpnet-base-v2,存储在Milvus中进行查询。通过案例研究证明,该系统在处理最新披露的漏洞、已知漏洞和高EPSS分数的CVE方面表现出显著改进,不仅推动了LLMs在网络安全领域的应用,还为开发自动化智能网络威胁信息管理系统的稳健基础奠定了基础。
Key Takeaways:
- 大型语言模型(LLMs)和检索增强生成(RAG)系统在网络安全领域有巨大潜力,可用于增强实时网络安全威胁检测和响应。
- 本研究通过融入动态实时数据源解决了传统静态威胁分析的局限性。
- RAG技术被用于实时获取威胁情报,这是一个重要的创新点。
- 研究团队使用Patrowl框架自动化检索多种网络安全威胁情报源,提高了情报获取的效率和准确性。
- 结合all-mpnet-base-v2模型的高维向量嵌入技术,使系统能够更好地处理复杂的网络安全数据。
- 案例研究表明,该系统的处理性能在处理最新披露的漏洞和已知漏洞方面显著提高。
点此查看论文截图


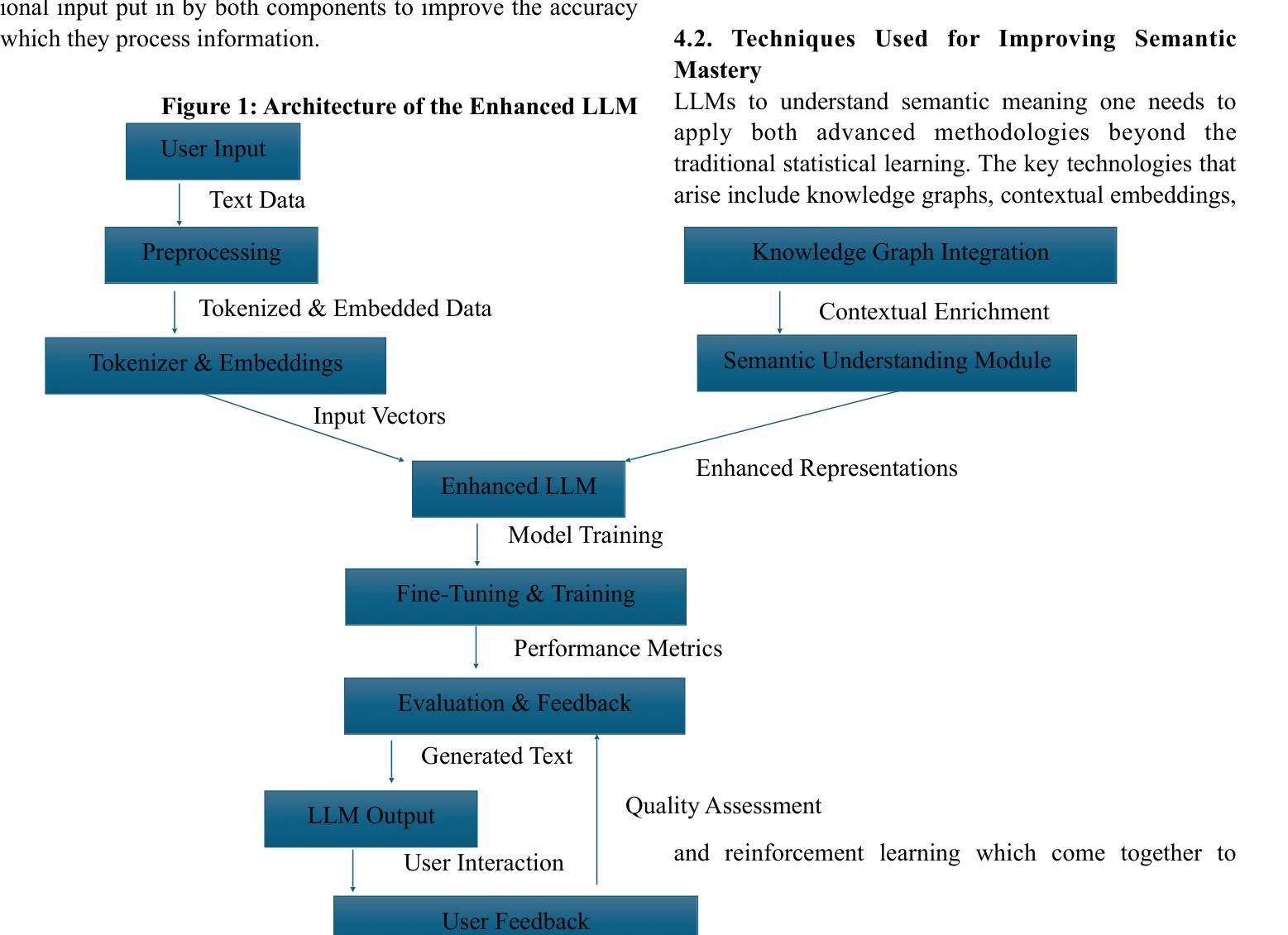
Semantic Mastery: Enhancing LLMs with Advanced Natural Language Understanding
Authors:Mohanakrishnan Hariharan
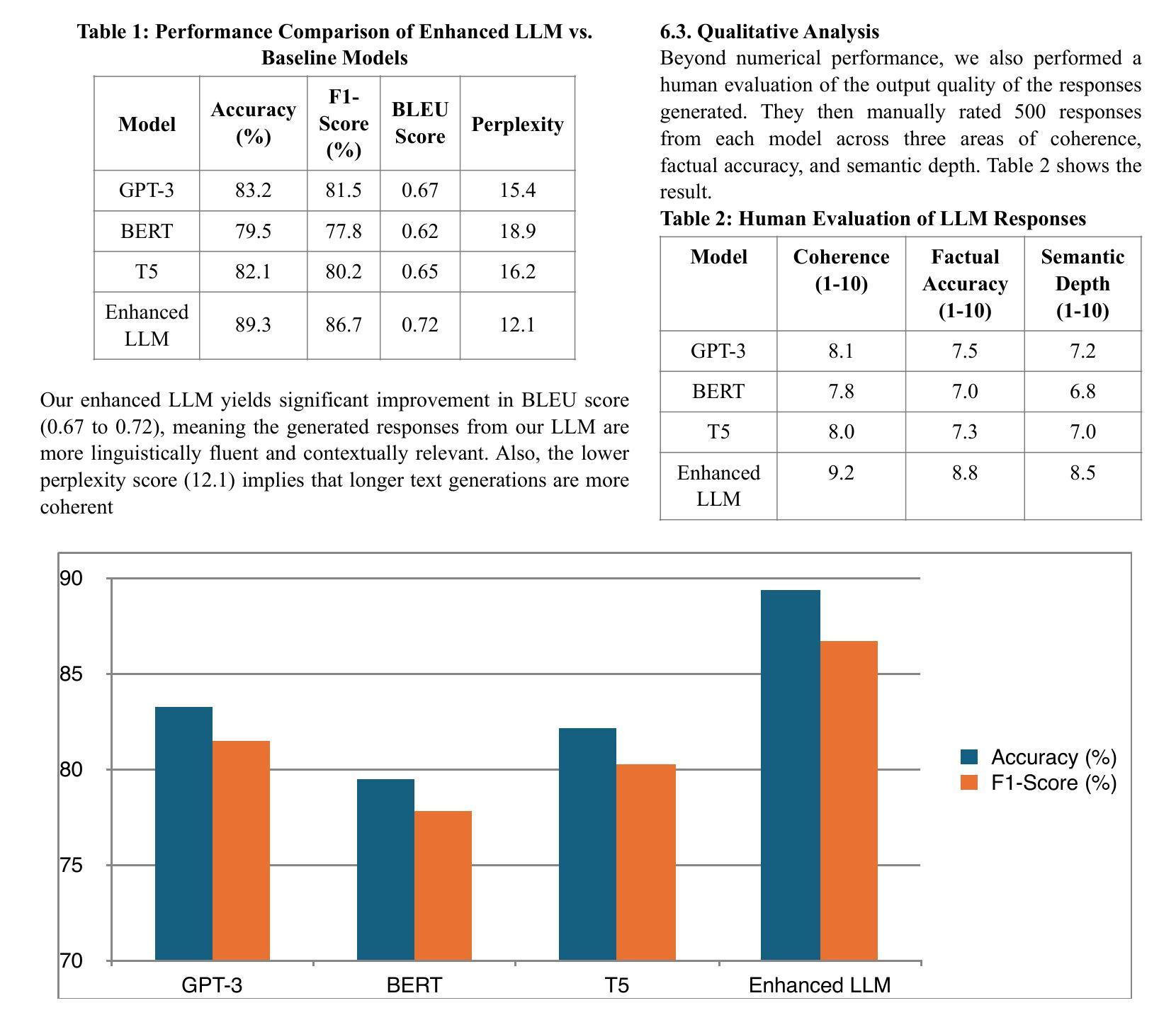
Large language models (LLMs) have greatly improved their capability in performing NLP tasks. However, deeper semantic understanding, contextual coherence, and more subtle reasoning are still difficult to obtain. The paper discusses state-of-the-art methodologies that advance LLMs with more advanced NLU techniques, such as semantic parsing, knowledge integration, and contextual reinforcement learning. We analyze the use of structured knowledge graphs, retrieval-augmented generation (RAG), and fine-tuning strategies that match models with human-level understanding. Furthermore, we address the incorporation of transformer-based architectures, contrastive learning, and hybrid symbolic-neural methods that address problems like hallucinations, ambiguity, and inconsistency in the factual perspectives involved in performing complex NLP tasks, such as question-answering text summarization and dialogue generation. Our findings show the importance of semantic precision for enhancing AI-driven language systems and suggest future research directions to bridge the gap between statistical language models and true natural language understanding.
大型语言模型(LLMs)在执行NLP任务的能力方面有了很大提高。然而,更深层次的语义理解、上下文连贯性和更微妙的推理仍然难以获得。本文讨论了采用最先进的的方法,利用更先进的NLU技术推进LLMs的发展,如语义解析、知识集成和上下文强化学习。我们分析了使用结构化知识图谱、检索增强生成(RAG)以及与人类水平理解相匹配的微调策略。此外,我们还探讨了基于转换器的架构、对比学习和混合符号-神经网络方法,解决在执行复杂NLP任务(如问答、文本摘要和对话生成)时涉及的事实视角的幻觉、模糊和不一致等问题。我们的研究结果表明语义精度对增强AI驱动的语言系统的重要性,并指出了缩小统计语言模型和真正的自然语言理解之间差距的未来研究方向。
论文及项目相关链接
Summary:大型语言模型(LLM)在NLP任务中能力显著提高,但在深层语义理解、上下文连贯性和更微妙的推理方面仍存在困难。论文讨论了使用更先进的NLU技术,如语义解析、知识集成和上下文强化学习等方法来提高LLM的性能。论文还分析了结构化的知识图谱、检索增强生成(RAG)、与人的理解相匹配的微调策略的使用。此外,论文探讨了基于转换器的架构、对比学习和混合符号神经方法的重要性,以解决在执行复杂NLP任务时涉及的事实观点的问题,如问答、文本摘要和对话生成中的虚构、模糊和不一致性。研究结果表明语义精确性对增强AI驱动的语言系统的重要性,并指出了未来研究的方向,以缩小统计语言模型与真正的自然语言理解之间的差距。
Key Takeaways:
- 大型语言模型(LLM)在NLP任务中仍有深层语义理解、上下文连贯性和推理的挑战。
- 先进的NLU技术,如语义解析、知识集成和上下文强化学习,被用来提高LLM性能。
- 结构化的知识图谱、检索增强生成(RAG)和与人的理解相匹配的微调策略是关键方法。
- 基于转换器的架构、对比学习和混合符号神经方法对于解决复杂NLP任务中的问题很重要。
- 语义精确性对增强AI驱动的语言系统至关重要。
- 论文强调了解决虚构、模糊和不一致性问题的重要性。
点此查看论文截图

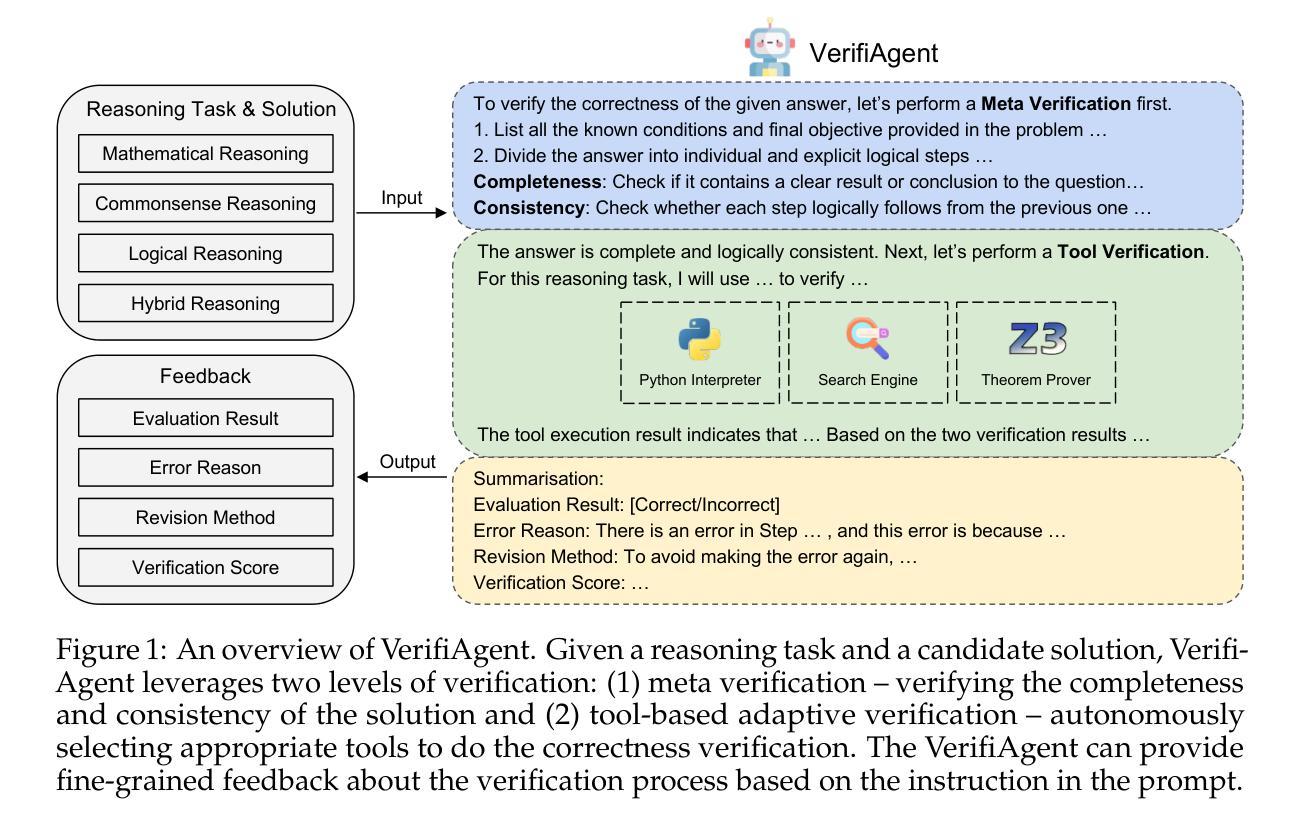
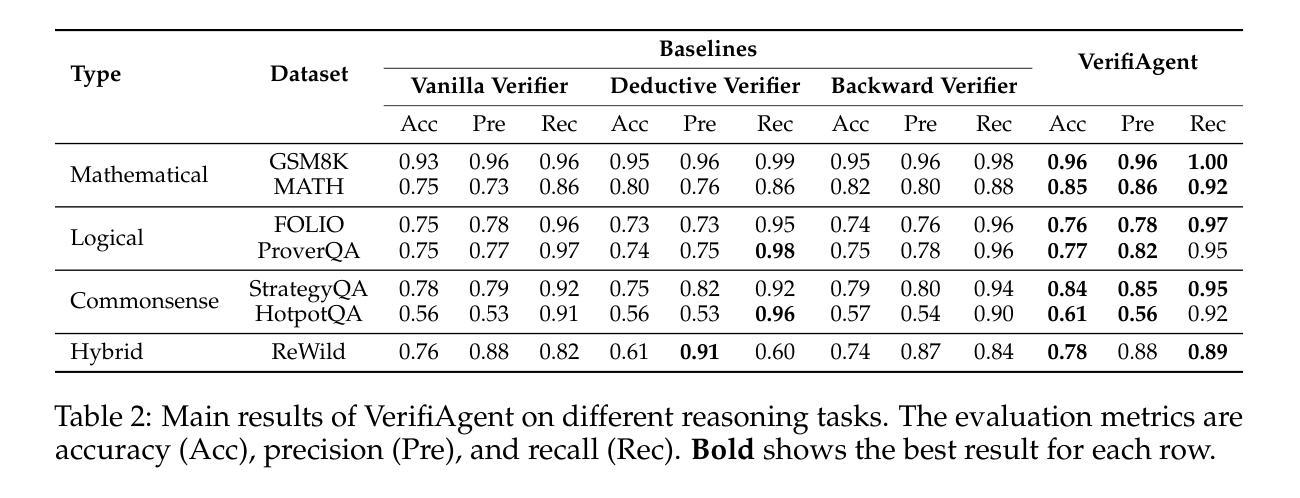
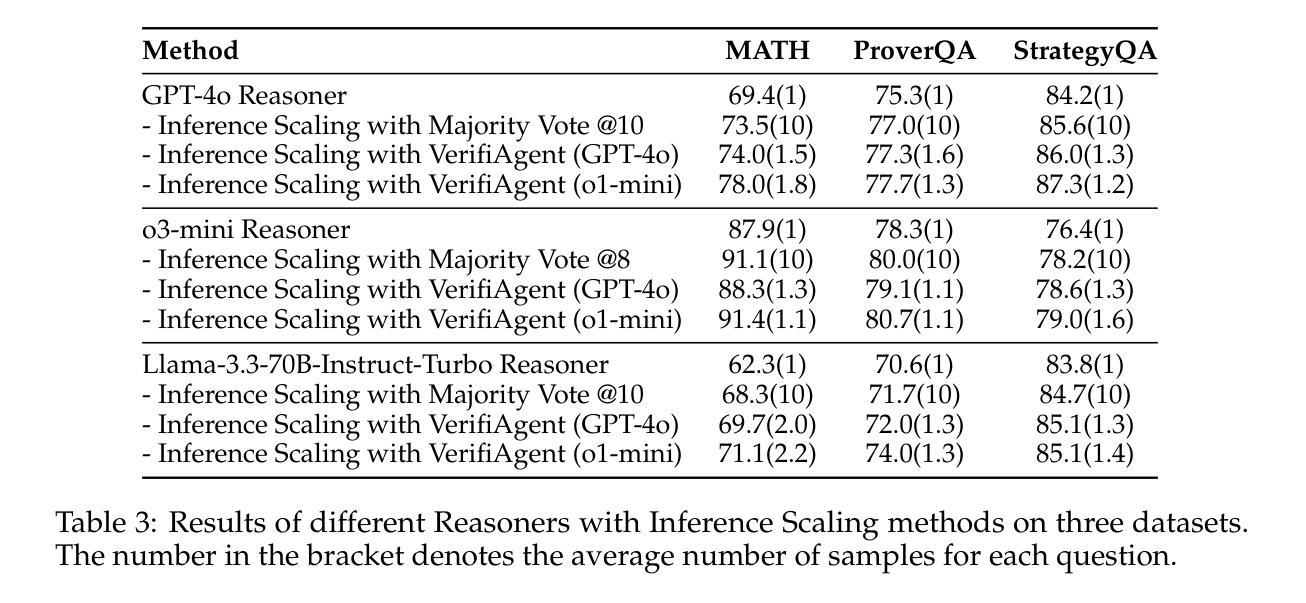
VerifiAgent: a Unified Verification Agent in Language Model Reasoning
Authors:Jiuzhou Han, Wray Buntine, Ehsan Shareghi
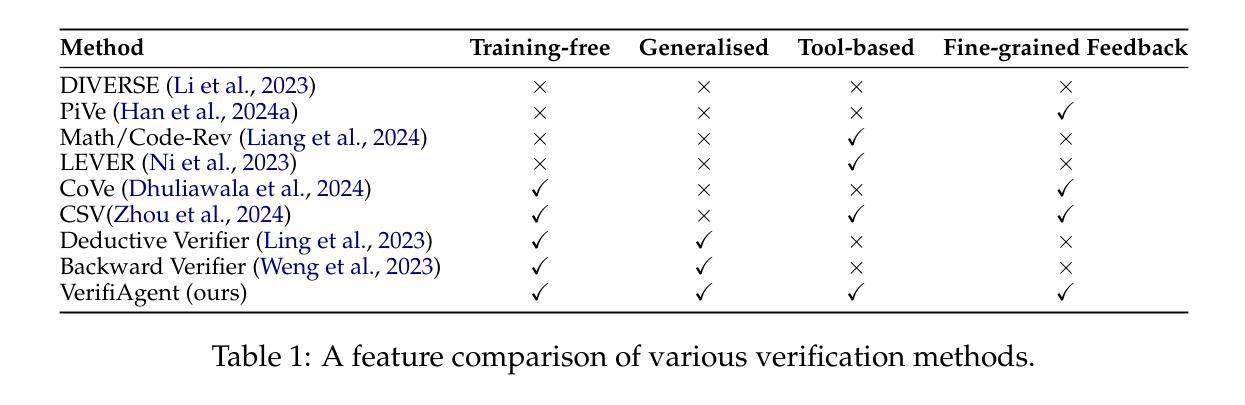
Large language models demonstrate remarkable reasoning capabilities but often produce unreliable or incorrect responses. Existing verification methods are typically model-specific or domain-restricted, requiring significant computational resources and lacking scalability across diverse reasoning tasks. To address these limitations, we propose VerifiAgent, a unified verification agent that integrates two levels of verification: meta-verification, which assesses completeness and consistency in model responses, and tool-based adaptive verification, where VerifiAgent autonomously selects appropriate verification tools based on the reasoning type, including mathematical, logical, or commonsense reasoning. This adaptive approach ensures both efficiency and robustness across different verification scenarios. Experimental results show that VerifiAgent outperforms baseline verification methods (e.g., deductive verifier, backward verifier) among all reasoning tasks. Additionally, it can further enhance reasoning accuracy by leveraging feedback from verification results. VerifiAgent can also be effectively applied to inference scaling, achieving better results with fewer generated samples and costs compared to existing process reward models in the mathematical reasoning domain. Code is available at https://github.com/Jiuzhouh/VerifiAgent
大型语言模型展现出显著的推理能力,但经常产生不可靠或错误的回应。现有的验证方法通常是模型特定或领域限制的,需要大量的计算资源,并且在不同的推理任务中缺乏可扩展性。为了解决这些限制,我们提出了VerifiAgent,一个统一的验证代理,它集成了两个层次的验证:元验证,评估模型响应的完整性和一致性;以及基于工具的自适应验证,其中VerifiAgent根据推理类型(包括数学、逻辑或常识推理)自主地选择适当的验证工具。这种自适应方法确保了不同验证场景下的效率和稳健性。实验结果表明,VerifiAgent在所有推理任务中的性能优于基准验证方法(例如演绎验证器、向后验证器)。此外,它还可以通过利用验证结果的反馈进一步提高推理准确性。VerifiAgent还可以有效地应用于推理扩展,与数学推理领域中的现有过程奖励模型相比,使用更少的生成样本和成本实现更好的结果。代码可在https://github.com/Jiuzhouh/VerifiAgent找到。
论文及项目相关链接
Summary
大型语言模型展现出惊人的推理能力,但响应可能不可靠或出错。现有的验证方法通常模型特定或局限于特定领域,需要大量计算资源,且在跨不同推理任务时缺乏可扩展性。为解决这些问题,我们提出VerifiAgent统一验证代理,它集成了两个级别的验证:元验证评估模型响应的完整性和一致性,工具自适应验证则根据推理类型自动选择适当的验证工具,包括数学、逻辑和常识推理等。此方法确保了不同验证场景下的效率和稳健性。实验结果显示,VerifiAgent在所有推理任务中的表现优于基线验证方法,并能通过利用验证结果反馈进一步提高推理准确性。此外,它在数学推理领域的应用可以实现较少的生成样本和成本,优于现有的流程奖励模型。
Key Takeaways
- 大型语言模型虽具有强大的推理能力,但响应可能存在不可靠或错误的情况。
- 现有验证方法通常具有模型特定性或局限于特定领域,且计算资源消耗大,缺乏跨不同推理任务的可扩展性。
- VerifiAgent是一种统一验证代理,通过元验证和工具自适应验证两个级别的方法来解决上述问题。
- 元验证评估模型响应的完整性和一致性。
- 工具自适应验证根据推理类型自动选择适当的验证工具。
- VerifiAgent在跨不同推理任务时表现出优异的效率和稳健性。
- VerifiAgent的实验结果优于基线验证方法,并能进一步提高推理准确性,同时在数学推理领域实现了较少的生成样本和成本优势。
点此查看论文截图

JudgeLRM: Large Reasoning Models as a Judge
Authors:Nuo Chen, Zhiyuan Hu, Qingyun Zou, Jiaying Wu, Qian Wang, Bryan Hooi, Bingsheng He
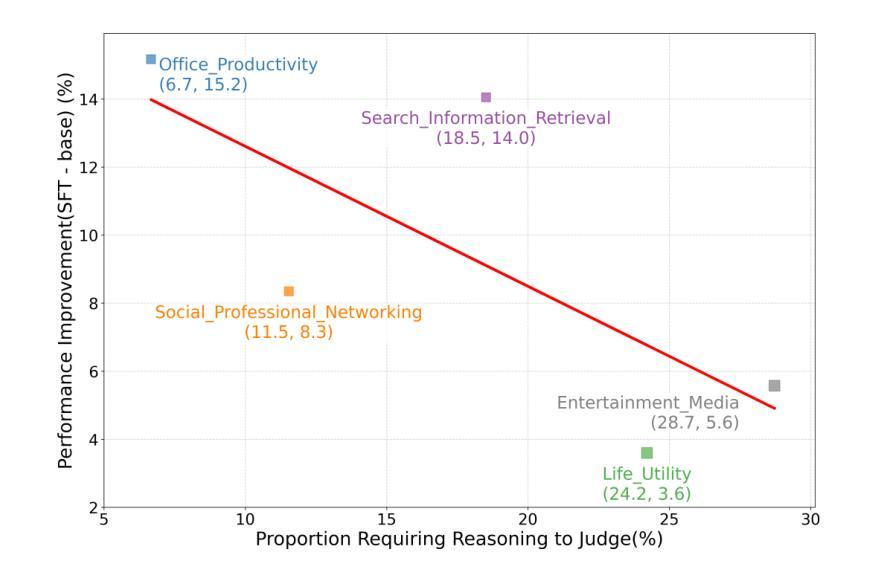
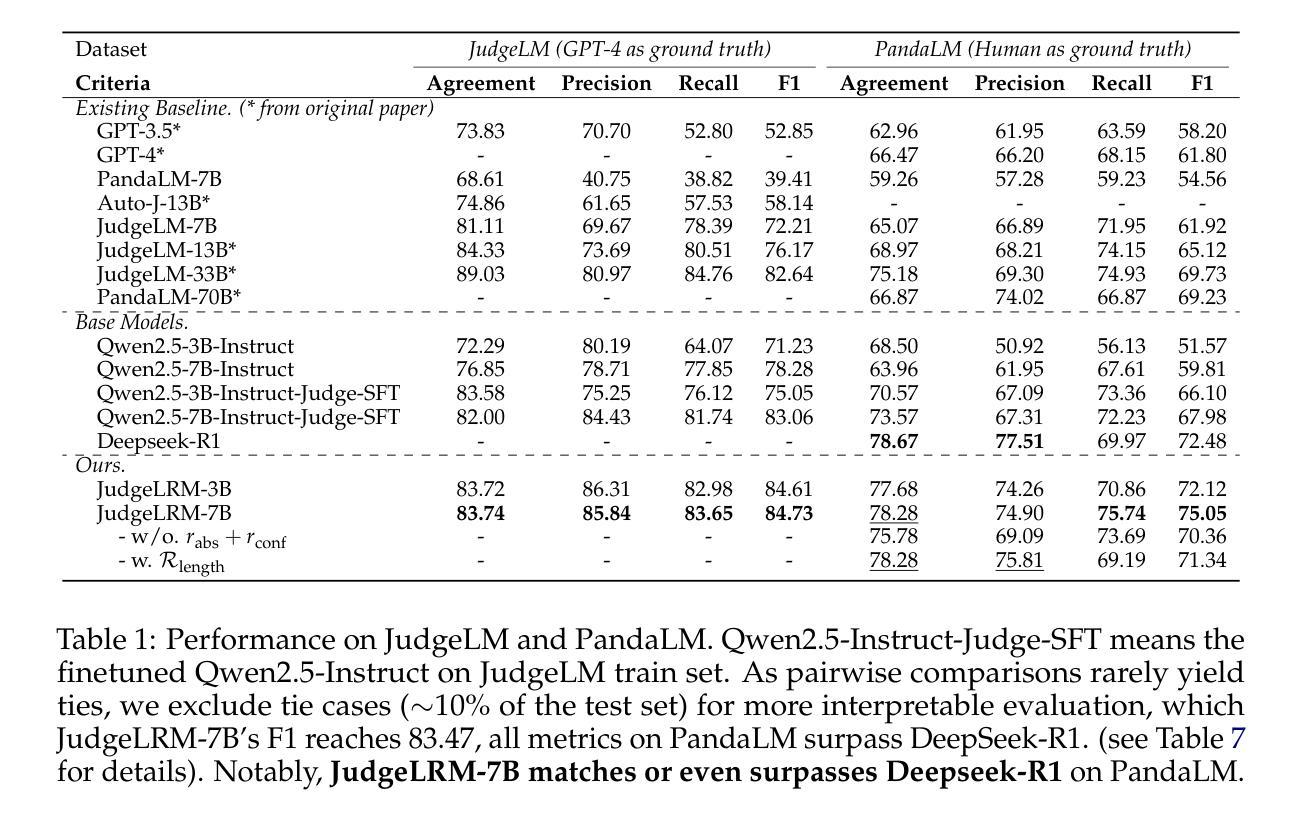
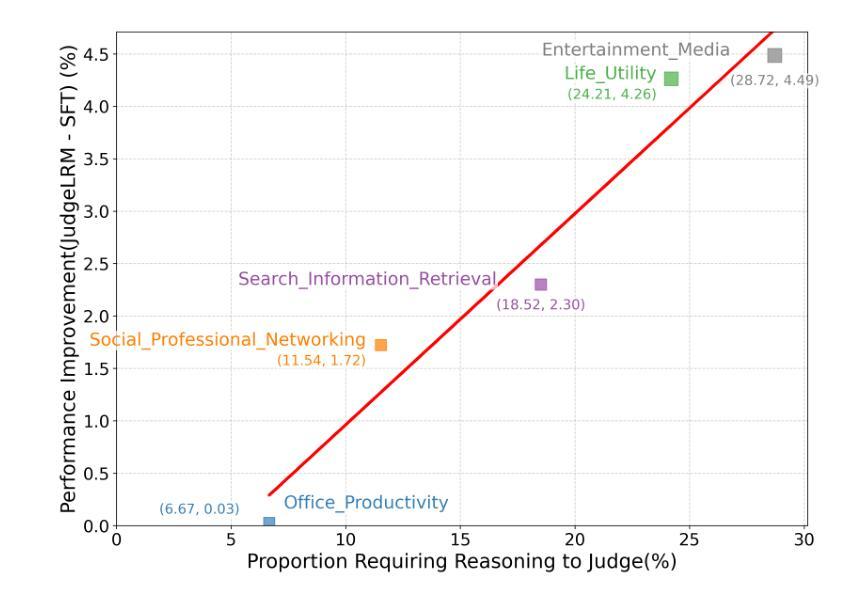
The rise of Large Language Models (LLMs) as evaluators offers a scalable alternative to human annotation, yet existing Supervised Fine-Tuning (SFT) for judges approaches often fall short in domains requiring complex reasoning. In this work, we investigate whether LLM judges truly benefit from enhanced reasoning capabilities. Through a detailed analysis of reasoning requirements across evaluation tasks, we reveal a negative correlation between SFT performance gains and the proportion of reasoning-demanding samples - highlighting the limitations of SFT in such scenarios. To address this, we introduce JudgeLRM, a family of judgment-oriented LLMs trained using reinforcement learning (RL) with judge-wise, outcome-driven rewards. JudgeLRM models consistently outperform both SFT-tuned and state-of-the-art reasoning models. Notably, JudgeLRM-3B surpasses GPT-4, and JudgeLRM-7B outperforms DeepSeek-R1 by 2.79% in F1 score, particularly excelling in judge tasks requiring deep reasoning.
随着大型语言模型(LLM)作为评估者的兴起,它为人类标注提供了一种可扩展的替代方案。然而,现有的用于法官的监督微调(SFT)方法往往在处理需要复杂推理的领域时表现不足。在这项工作中,我们调查LLM法官是否真正受益于增强的推理能力。通过对评估任务中的推理需求进行详尽分析,我们发现监督微调性能提升与需要推理的样本比例之间存在负相关,这突显了监督微调在这种场景下的局限性。为了解决这个问题,我们引入了JudgeLRM,这是一个以判断为导向的LLM家族,通过强化学习(RL)使用以法官、结果驱动的奖励进行训练。JudgeLRM模型在性能上持续超越了监督微调调优的模型和最新的推理模型。值得注意的是,JudgeLRM-3B超越了GPT-4,而JudgeLRM-7B在F1分数上超越了DeepSeek-R1达2.79%,特别是在需要深度推理的法官任务中表现出色。
论文及项目相关链接
PDF preprint
Summary
大型语言模型(LLM)作为评估者提供了可规模化替代人工标注的方案,但在需要复杂推理的领域,现有的监督微调(SFT)方法常常表现不足。本研究旨在探究LLM评估者是否真正受益于增强的推理能力。通过对不同评估任务中推理需求的分析,我们发现SFT性能提升与需要推理的样本比例之间存在负相关,突显了SFT在这些场景中的局限性。为解决这一问题,我们引入了JudgeLRM系列模型,这是一系列以判断为导向的LLM,通过强化学习(RL)和基于判断结果的奖励进行训练。JudgeLRM系列模型在需要深度推理的评估任务上表现优异,且普遍优于SFT调优模型和现有先进推理模型。特别地,JudgeLRM-3B超越了GPT-4,而JudgeLRM-7B在F1分数上超越了DeepSeek-R1达2.79%。
Key Takeaways
- 大型语言模型(LLM)作为评估者提供了可规模化替代人工标注的可能。
- 现有监督微调(SFT)方法在需要复杂推理的领域表现有限。
- SFT性能提升与需要推理的样本比例之间存在负相关。
- JudgeLRM系列模型通过强化学习进行训练,以判断为导向。
- JudgeLRM系列模型在需要深度推理的评估任务上表现优异。
- JudgeLRM-3B在性能上超越了GPT-4。
点此查看论文截图


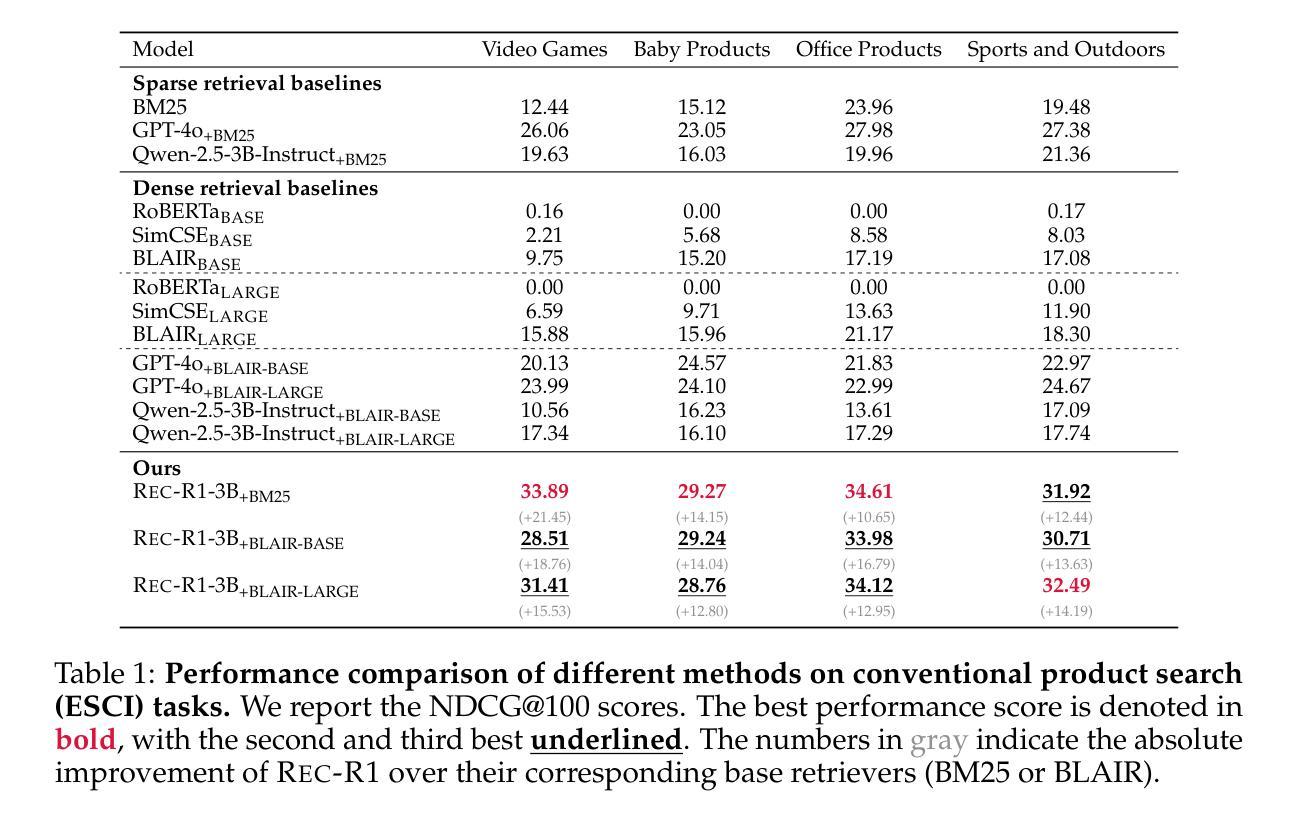
Rec-R1: Bridging Generative Large Language Models and User-Centric Recommendation Systems via Reinforcement Learning
Authors:Jiacheng Lin, Tian Wang, Kun Qian
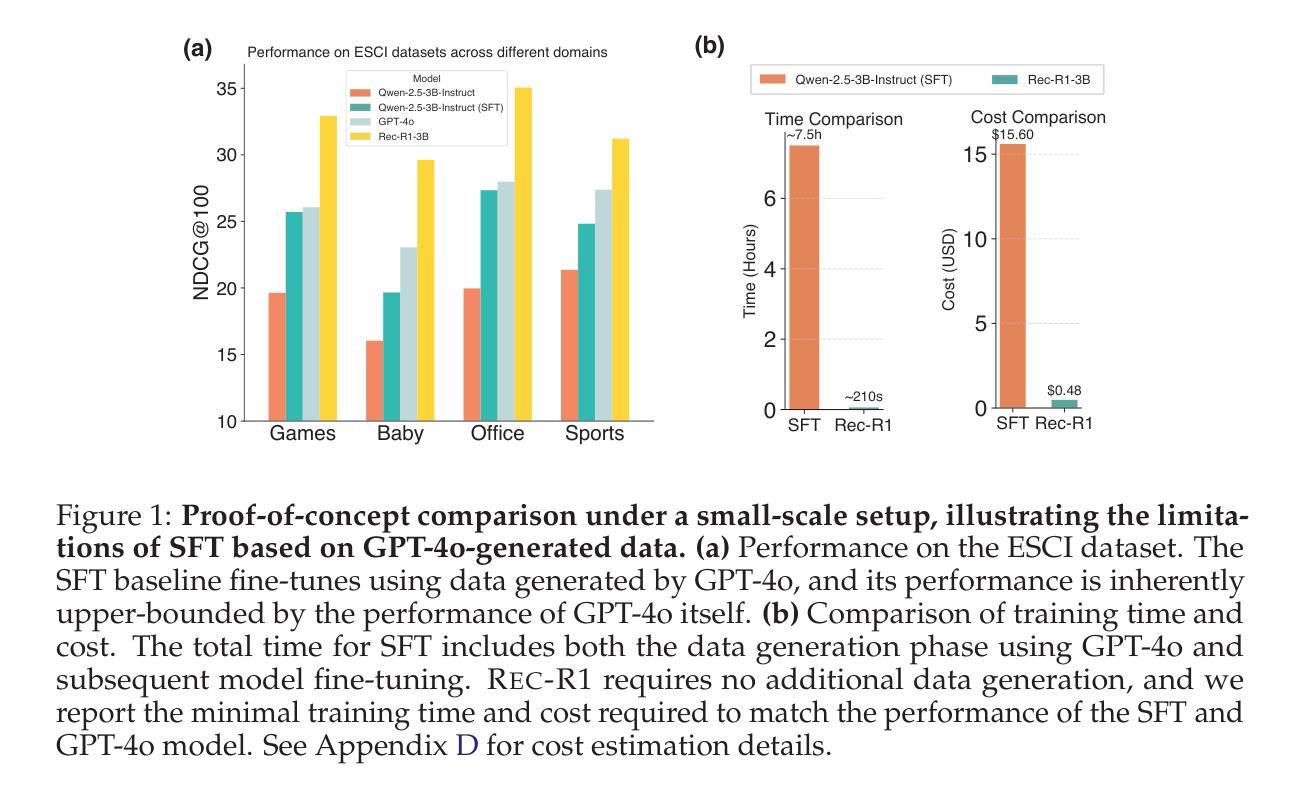
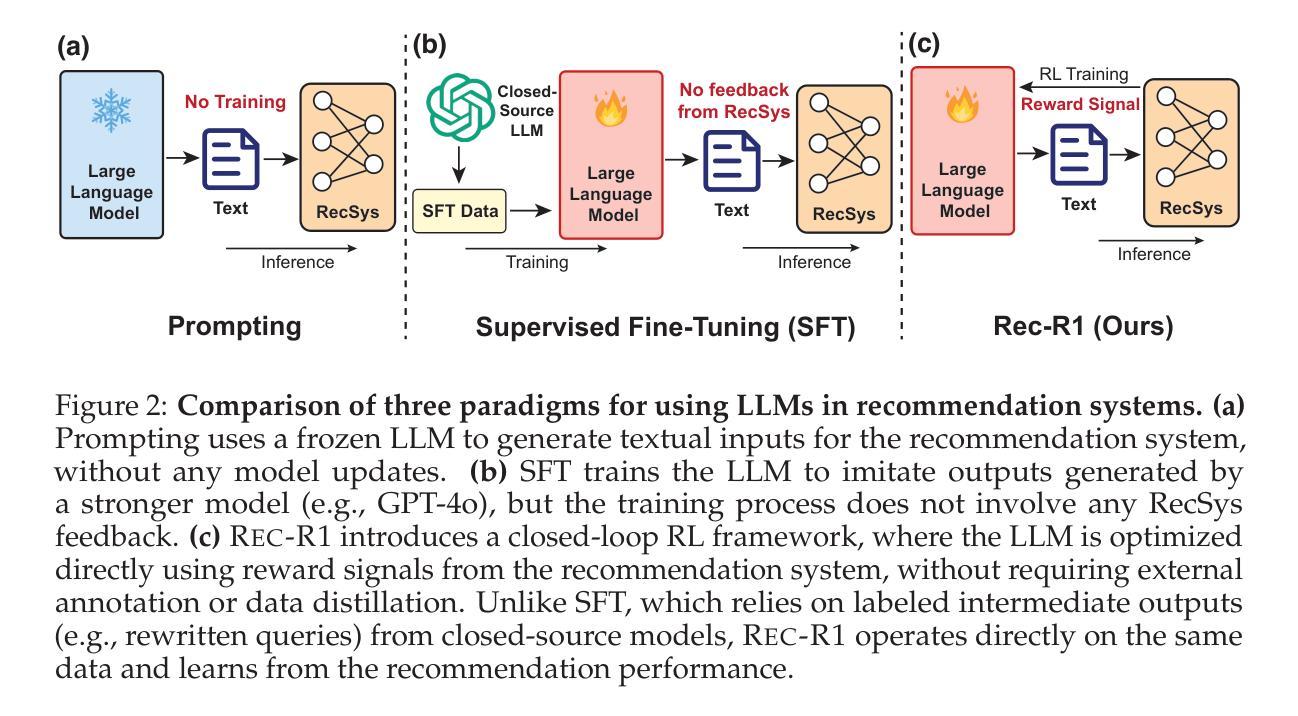
We propose Rec-R1, a general reinforcement learning framework that bridges large language models (LLMs) with recommendation systems through closed-loop optimization. Unlike prompting and supervised fine-tuning (SFT), Rec-R1 directly optimizes LLM generation using feedback from a fixed black-box recommendation model, without relying on synthetic SFT data from proprietary models such as GPT-4o. This avoids the substantial cost and effort required for data distillation. To verify the effectiveness of Rec-R1, we evaluate it on two representative tasks: product search and sequential recommendation. Experimental results demonstrate that Rec-R1 not only consistently outperforms prompting- and SFT-based methods, but also achieves significant gains over strong discriminative baselines, even when used with simple retrievers such as BM25. Moreover, Rec-R1 preserves the general-purpose capabilities of the LLM, unlike SFT, which often impairs instruction-following and reasoning. These findings suggest Rec-R1 as a promising foundation for continual task-specific adaptation without catastrophic forgetting.
我们提出了Rec-R1,这是一个通用的强化学习框架,它通过闭环优化将大型语言模型(LLM)与推荐系统联系起来。不同于提示和监督微调(SFT),Rec-R1直接使用来自固定黑箱推荐模型的反馈来直接优化LLM的生成,而无需依赖来自专有模型(如GPT-4o)的合成SFT数据。这避免了数据蒸馏所需的大量成本和时间。为了验证Rec-R1的有效性,我们在两个具有代表性的任务上对其进行了评估:产品搜索和序列推荐。实验结果表明,Rec-R1不仅始终优于基于提示和SFT的方法,而且在使用简单的检索器(如BM25)时,甚至比强大的判别基线也有显著的改进。此外,与经常损害指令遵循和推理能力的SFT不同,Rec-R1保留了LLM的通用能力。这些发现表明,Rec-R1是一个有前途的框架,为不断适应特定任务而不发生灾难性遗忘奠定了基础。
论文及项目相关链接
Summary
本文提出一种名为Rec-R1的通用强化学习框架,它通过闭环优化将大型语言模型(LLMs)与推荐系统相结合。不同于提示和基于监督微调(SFT)的方法,Rec-R1直接使用来自固定黑箱推荐模型的反馈来直接优化LLM生成,无需依赖如GPT-4o等专有模型的合成SFT数据,从而避免了数据蒸馏所需的大量成本和时间。在典型的产品搜索和序列推荐任务上,实验结果表明,Rec-R1不仅始终优于基于提示和SFT的方法,而且在采用简单检索器如BM25时也能显著超越强大的判别基准模型。此外,Rec-R1保留了LLM的通用能力,不像SFT那样往往会损害指令跟随和推理能力。这表明Rec-R1是在不断适应特定任务过程中避免灾难性遗忘的可靠基础。
Key Takeaways
- 提出了一种新的强化学习框架Rec-R1,结合大型语言模型(LLMs)和推荐系统。
- Rec-R1通过闭环优化直接优化LLM生成,不依赖合成监督微调数据或专有模型。
- 在产品搜索和序列推荐任务上,Rec-R1表现优异,超越了基于提示和监督微调的方法。
- Rec-R1在采用简单检索器时也能超越强大的判别基准模型,显示了其有效性。
- Rec-R1保留了LLM的通用能力,不同于某些方法会损害指令跟随和推理能力。
- 实验结果证明了Rec-R1在连续任务适应中避免灾难性遗忘的潜力。
- 该框架为强化学习在推荐系统中的应用提供了新的方向。
点此查看论文截图

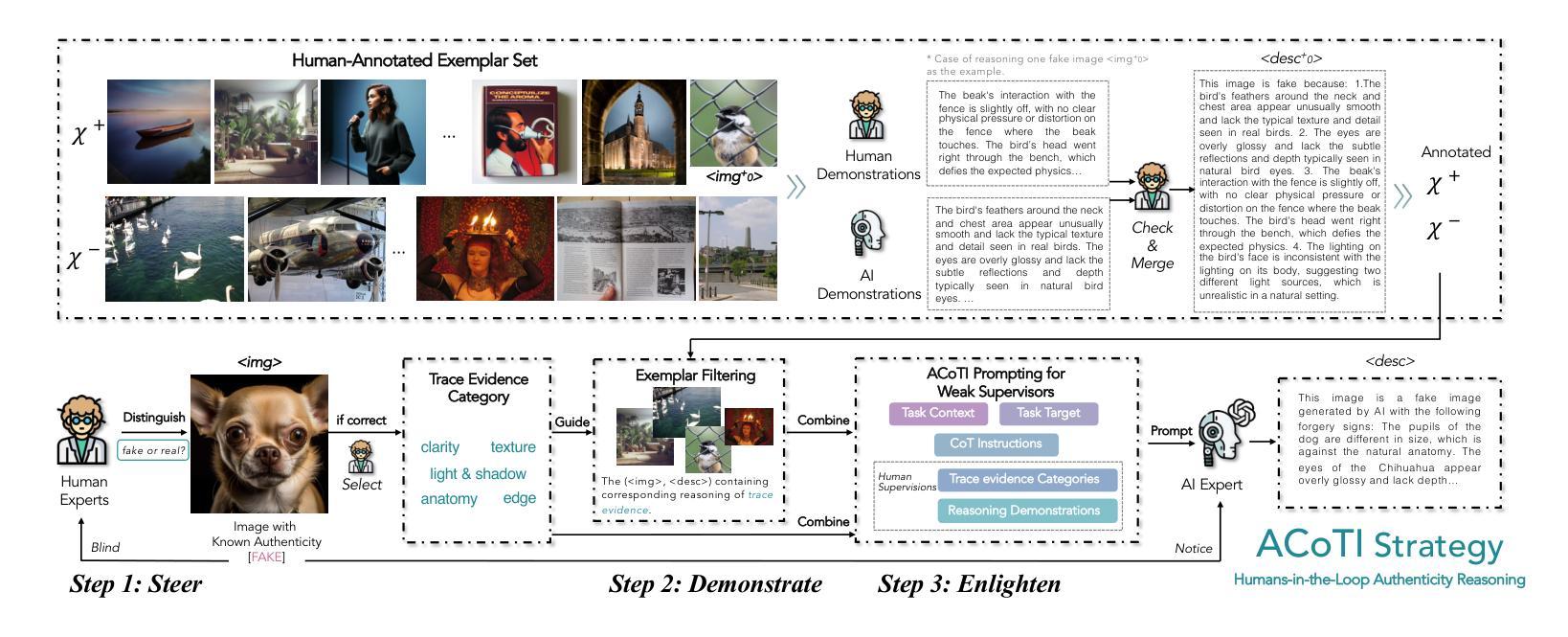
FakeScope: Large Multimodal Expert Model for Transparent AI-Generated Image Forensics
Authors:Yixuan Li, Yu Tian, Yipo Huang, Wei Lu, Shiqi Wang, Weisi Lin, Anderson Rocha
The rapid and unrestrained advancement of generative artificial intelligence (AI) presents a double-edged sword: while enabling unprecedented creativity, it also facilitates the generation of highly convincing deceptive content, undermining societal trust. As image generation techniques become increasingly sophisticated, detecting synthetic images is no longer just a binary task: it necessitates interpretable, context-aware methodologies that enhance trustworthiness and transparency. However, existing detection models primarily focus on classification, offering limited explanatory insights into image authenticity. In this work, we propose FakeScope, an expert multimodal model (LMM) tailored for AI-generated image forensics, which not only identifies AI-synthetic images with high accuracy but also provides rich, interpretable, and query-driven forensic insights. We first construct FakeChain dataset that contains linguistic authenticity reasoning based on visual trace evidence, developed through a novel human-machine collaborative framework. Building upon it, we further present FakeInstruct, the largest multimodal instruction tuning dataset containing 2 million visual instructions tailored to enhance forensic awareness in LMMs. FakeScope achieves state-of-the-art performance in both closed-ended and open-ended forensic scenarios. It can distinguish synthetic images with high accuracy while offering coherent and insightful explanations, free-form discussions on fine-grained forgery attributes, and actionable enhancement strategies. Notably, despite being trained exclusively on qualitative hard labels, FakeScope demonstrates remarkable zero-shot quantitative capability on detection, enabled by our proposed token-based probability estimation strategy. Furthermore, FakeScope exhibits strong generalization and in-the-wild ability, ensuring its applicability in real-world scenarios.
人工智能生成技术的迅猛且不受限制的发展呈现出一把双刃剑的特性:虽然它促进了前所未有的创造力,但也方便了高度欺骗性的内容的生成,从而破坏了社会信任。随着图像生成技术的日益成熟,检测合成图像不再仅仅是二分类任务:它需要解释性强、具有语境意识的方法来增强可信度和透明度。然而,现有的检测模型主要集中在分类上,对于图像真实性的解释性洞察有限。在这项工作中,我们提出了FakeScope,一个针对人工智能生成图像取证的专业多模态模型(LMM)。它不仅能够高度准确地识别AI合成的图像,而且还提供丰富、可解释、查询驱动的取证洞察。我们首先构建了FakeChain数据集,该数据集基于视觉痕迹证据的语言真实性推理,通过新型的人机协作框架开发。在此基础上,我们进一步推出了FakeInstruct,这是最大的多模态指令调整数据集,包含200万条旨在提高LMMs取证意识的视觉指令。FakeScope在封闭和开放取证场景中均达到了最先进的性能。它能够准确地区分合成图像,同时提供连贯且富有洞察力的解释、对细微伪造属性的自由形式讨论和可行的增强策略。值得注意的是,尽管仅通过定性硬标签进行训练,FakeScope在检测方面表现出了引人注目的零样本定量能力,这是由我们提出的基于标记的概率估计策略所实现的。此外,FakeScope展现出强大的泛化和野外能力,确保其在现实场景中的应用性。
论文及项目相关链接
Summary
本文探讨了生成式人工智能(AI)的快速发展对社会信任的影响。随着图像生成技术的不断进步,检测合成图像的需求愈发迫切,需要可解释、具备情境意识的检测方法来增强信任度和透明度。为此,本文提出了FakeScope,一个针对AI生成图像鉴定的专家多模态模型(LMM)。FakeScope不仅能准确鉴定AI生成的图像,而且提供丰富、可解释、查询驱动的鉴定洞察。通过构建FakeChain数据集和FakeInstruct指令调整数据集,FakeScope在封闭和开放鉴定场景中均达到最佳性能。它可精细区分合成图像,提供连贯的深入解释、自由讨论伪造属性的细节以及可行的改进策略。值得注意的是,FakeScope仅通过定性硬标签训练,却展现出零样本定量检测能力,且展现出强大的泛化和实际应用能力。
Key Takeaways
- 生成式人工智能(AI)的快速发展带来了创造力提升的同时,也促进了欺骗性内容的生成,对社会信任造成影响。
- 图像生成技术的进步使得检测合成图像变得复杂,需要可解释、具备情境意识的检测方法来增强信任度和透明度。
- FakeScope是一个针对AI生成图像鉴定的专家多模态模型(LMM),能准确鉴定AI生成的图像,并提供丰富的可解释性洞察。
- FakeScope通过构建FakeChain数据集和FakeInstruct指令调整数据集进行训练,适用于封闭和开放的鉴定场景。
- FakeScope具备零样本定量检测能力,展现出强大的泛化能力和实际应用潜力。
- FakeScope不仅能准确鉴定合成图像,还能提供关于伪造属性的深入解释和行动建议。
点此查看论文截图



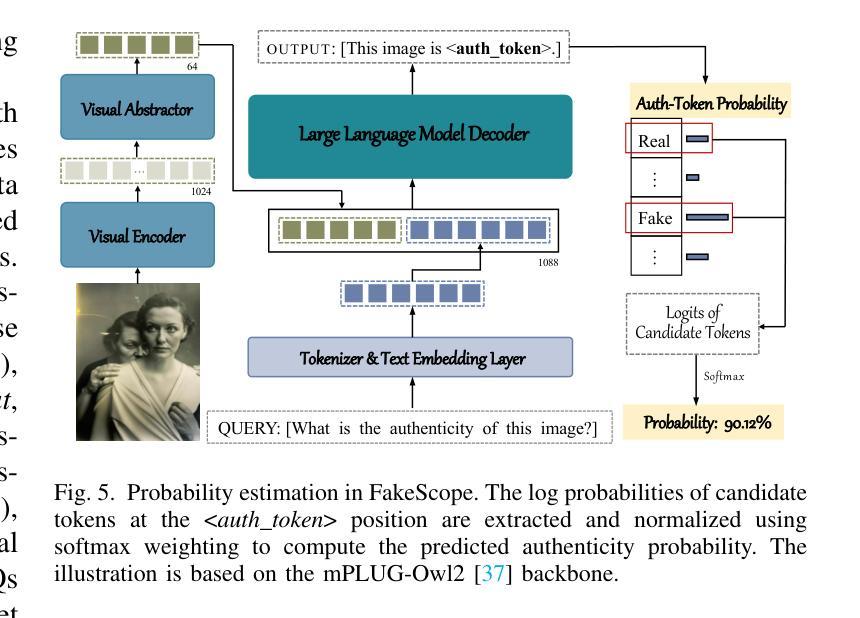
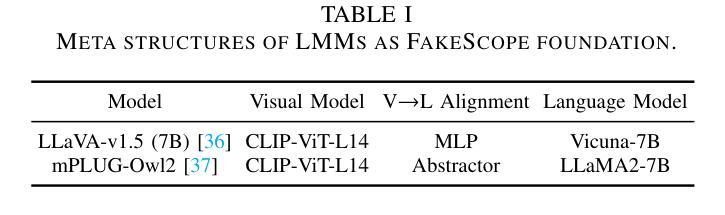
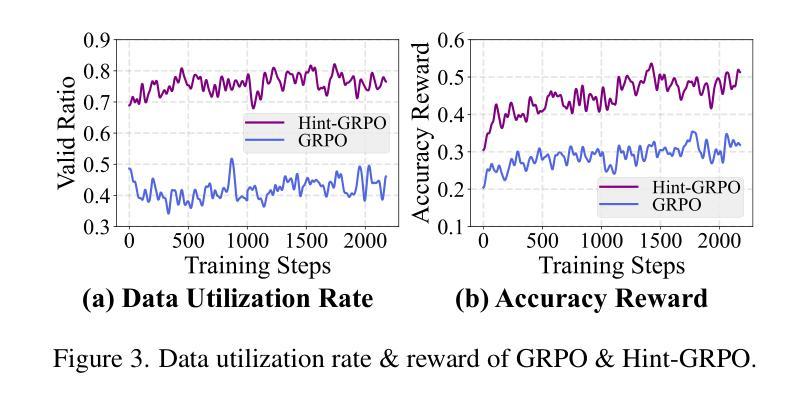
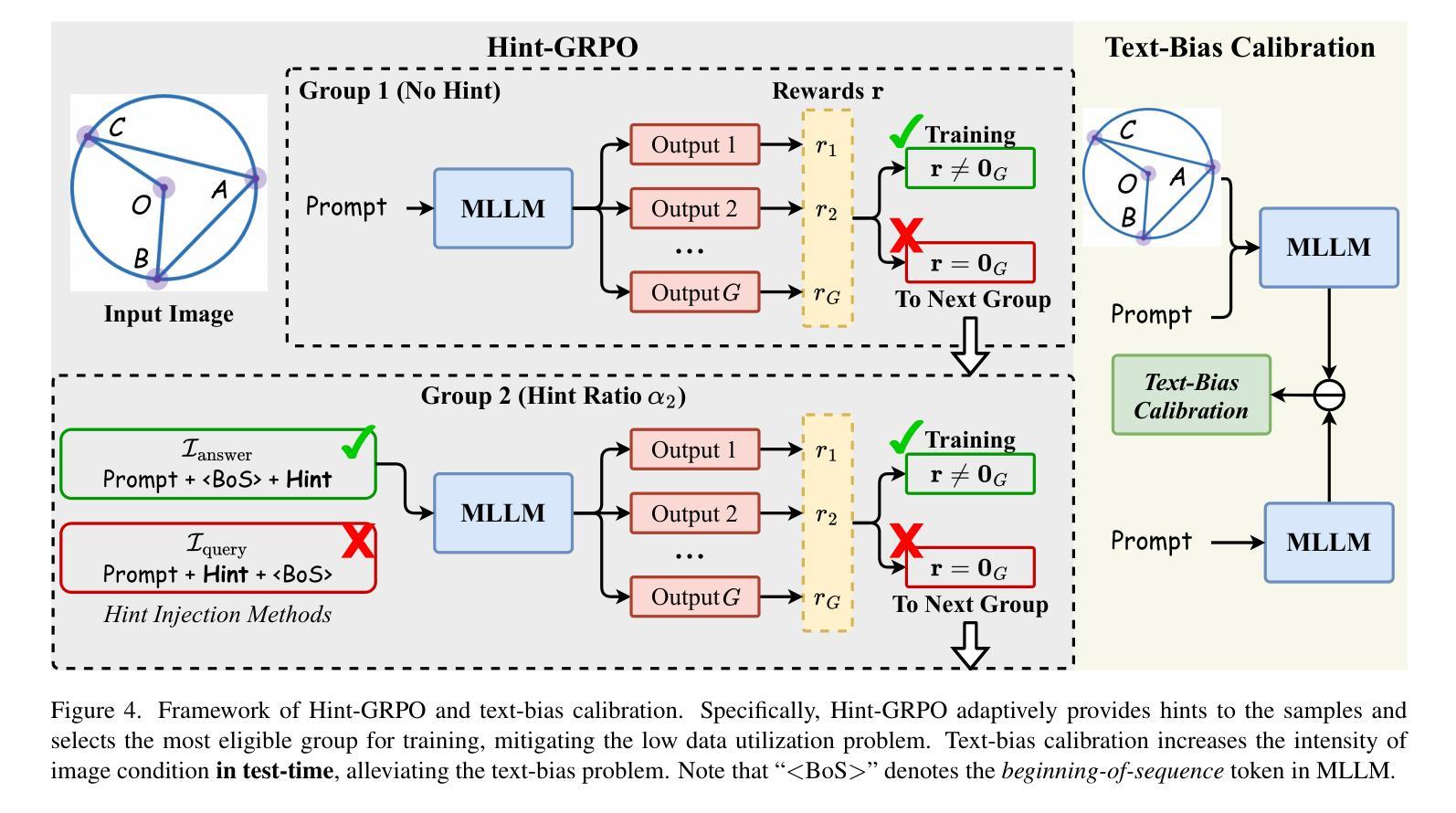
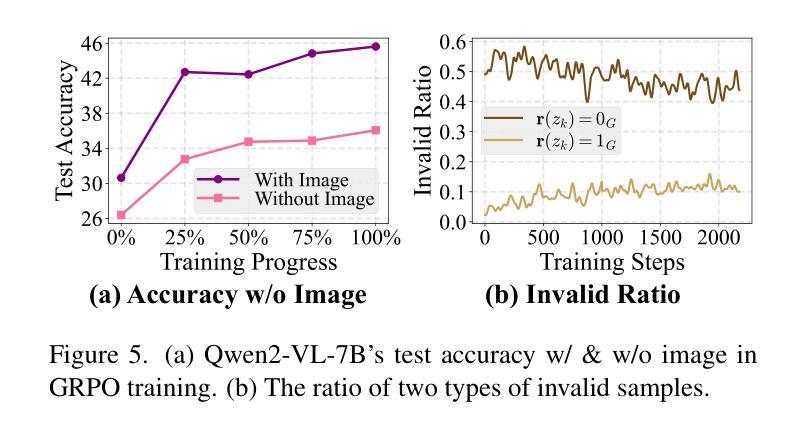
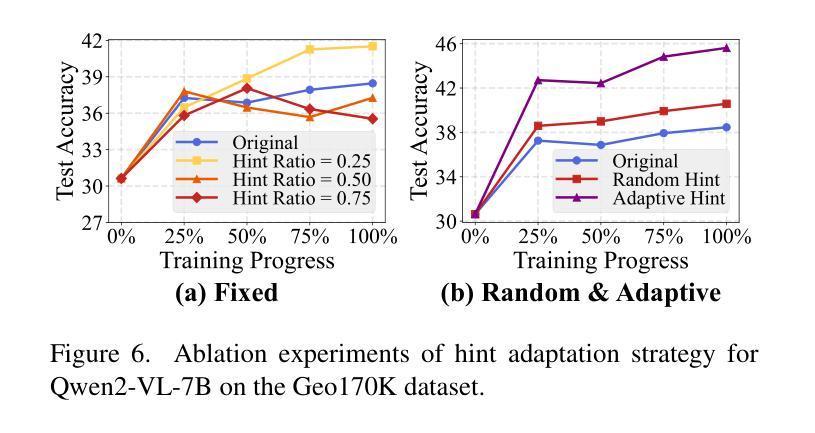
Boosting MLLM Reasoning with Text-Debiased Hint-GRPO
Authors:Qihan Huang, Long Chan, Jinlong Liu, Wanggui He, Hao Jiang, Mingli Song, Jingyuan Chen, Chang Yao, Jie Song
MLLM reasoning has drawn widespread research for its excellent problem-solving capability. Current reasoning methods fall into two types: PRM, which supervises the intermediate reasoning steps, and ORM, which supervises the final results. Recently, DeepSeek-R1 has challenged the traditional view that PRM outperforms ORM, which demonstrates strong generalization performance using an ORM method (i.e., GRPO). However, current MLLM’s GRPO algorithms still struggle to handle challenging and complex multimodal reasoning tasks (e.g., mathematical reasoning). In this work, we reveal two problems that impede the performance of GRPO on the MLLM: Low data utilization and Text-bias. Low data utilization refers to that GRPO cannot acquire positive rewards to update the MLLM on difficult samples, and text-bias is a phenomenon that the MLLM bypasses image condition and solely relies on text condition for generation after GRPO training. To tackle these problems, this work proposes Hint-GRPO that improves data utilization by adaptively providing hints for samples of varying difficulty, and text-bias calibration that mitigates text-bias by calibrating the token prediction logits with image condition in test-time. Experiment results on three base MLLMs across eleven datasets demonstrate that our proposed methods advance the reasoning capability of original MLLM by a large margin, exhibiting superior performance to existing MLLM reasoning methods. Our code is available at https://github.com/hqhQAQ/Hint-GRPO.
MLLM推理因其出色的解决问题的能力而引起了广泛的研究。当前的推理方法分为两类:PRM,它监督中间推理步骤,而ORM则监督最终结果。最近,DeepSeek-R1挑战了传统观点认为PRM优于ORM,演示了使用ORM方法(即GRPO)的强大泛化性能。然而,当前的MLLM的GRPO算法在应对具有挑战性和复杂的跨模态推理任务(例如数学推理)时仍然遇到困难。在这项工作中,我们揭示了阻碍GRPO在MLLM上性能的两个问题:数据利用率低和文本偏差。数据利用率低是指GRPO无法获取积极的奖励来更新MLLM在困难样本上的表现;文本偏差是一种现象,即在GRPO训练后,MLLM绕过图像条件而仅依赖文本条件进行生成。为了解决这些问题,这项工作提出了Hint-GRPO,它通过自适应地为不同难度的样本提供提示来提高数据利用率,以及文本偏差校正,通过在测试时通过图像条件校准标记预测逻辑来减轻文本偏差。在三个基础MLLM上的十一个数据集进行的实验结果表明,我们提出的方法大幅度提高了原始MLLM的推理能力,在现有的MLLM推理方法中表现出卓越的性能。我们的代码可在https://github.com/hqhQAQ/Hint-GRPO上找到。
论文及项目相关链接
Summary
本文介绍了MLLM推理中的两种常见方法PRM和ORM,指出传统观点认为PRM优于ORM。然而,最近的研究显示,使用ORM方法的DeepSeek-R1具有良好的泛化性能。当前MLLM的GRPO算法在处理复杂的多模态推理任务(如数学推理)时仍存在困难。本文揭示了影响GRPO在MLLM上性能的两大问题:数据利用率低和文本偏差。为解决这些问题,本文提出了Hint-GRPO和文本偏差校正方法。实验结果表明,所提方法大幅提高了MLLM的推理能力,优于现有的MLLM推理方法。
Key Takeaways
- MLLM推理中常见的方法包括PRM和ORM,其中ORM方法具有良好的泛化性能。
- 当前MLLM的GRPO算法在处理复杂多模态推理任务时面临挑战,如数学推理。
- 揭示了GRPO在MLLM上的两大问题:数据利用率低和文本偏差。
- Hint-GRPO方法通过自适应提供不同难度样本的提示来改善数据利用率。
- 文本偏差校正方法通过校准测试时的图像条件令牌预测日志来减轻文本偏差。
- 实验结果表明,所提出的方法大幅提高了MLLM的推理能力。
点此查看论文截图

Crossing the Reward Bridge: Expanding RL with Verifiable Rewards Across Diverse Domains
Authors:Yi Su, Dian Yu, Linfeng Song, Juntao Li, Haitao Mi, Zhaopeng Tu, Min Zhang, Dong Yu
Reinforcement learning with verifiable rewards (RLVR) has demonstrated significant success in enhancing mathematical reasoning and coding performance of large language models (LLMs), especially when structured reference answers are accessible for verification. However, its extension to broader, less structured domains remains unexplored. In this work, we investigate the effectiveness and scalability of RLVR across diverse real-world domains including medicine, chemistry, psychology, economics, and education, where structured reference answers are typically unavailable. We reveal that binary verification judgments on broad-domain tasks exhibit high consistency across various LLMs provided expert-written reference answers exist. Motivated by this finding, we utilize a generative scoring technique that yields soft, model-based reward signals to overcome limitations posed by binary verifications, especially in free-form, unstructured answer scenarios. We further demonstrate the feasibility of training cross-domain generative reward models using relatively small (7B) LLMs without the need for extensive domain-specific annotation. Through comprehensive experiments, our RLVR framework establishes clear performance gains, significantly outperforming state-of-the-art open-source aligned models such as Qwen2.5-72B and DeepSeek-R1-Distill-Qwen-32B across domains in free-form settings. Our approach notably enhances the robustness, flexibility, and scalability of RLVR, representing a substantial step towards practical reinforcement learning applications in complex, noisy-label scenarios.
强化学习与可验证奖励(RLVR)在提高大型语言模型(LLM)的数学推理和编码性能方面已取得了显著的成功,尤其是在可获得结构化参考答案进行验证的情况下。然而,其在更广泛、结构化程度较低的领域的应用仍待探索。在这项工作中,我们研究了RLVR在不同现实世界领域(包括医学、化学、心理学、经济学和教育)的有效性和可扩展性,在这些领域中通常没有结构化的参考答案可用。我们发现,在广泛的领域任务中,只要存在专家编写的参考答案,二元验证判断在各种LLM中的一致性就很高。受此发现的启发,我们采用了一种生成评分技术,该技术产生基于模型的软奖励信号,以克服二元验证带来的局限性,特别是在自由形式、非结构化答案场景中。我们还进一步证明了使用相对较小的(7B)LLM训练跨域生成奖励模型的可行性,无需进行大量的领域特定标注。通过全面的实验,我们的RLVR框架在性能上取得了明显的提升,在自由形式设置中显著优于最先进的开源对齐模型,如Qwen 2.5-72B和DeepSeek-R1-Distill-Qwen-32B等多个领域中的表现。我们的方法显著增强了RLVR的鲁棒性、灵活性和可扩展性,代表了在实际复杂、噪声标签场景中实现强化学习应用的重要一步。
论文及项目相关链接
Summary:强化学习可验证奖励(RLVR)在数学推理和编程性能提升方面取得了显著成功,特别是在可获得结构化参考答案的情况下。本研究探索了其在医学、化学、心理学、经济学和教育等领域的有效性和可扩展性,在这些领域中通常没有结构化的参考答案。研究发现,在存在专家编写的参考答案的情况下,对广泛领域的任务进行二元验证判断在各种大型语言模型(LLM)之间表现出高度的一致性。为了克服二元验证在自由形式、非结构化答案场景中的局限性,本研究利用生成评分技术产生基于模型的软奖励信号。在不需要广泛领域特定注释的情况下,本研究展示了使用相对较小(7B)的LLM训练跨领域生成奖励模型的可行性。通过全面的实验,RLVR框架在自由形式设置中显著优于Qwen2.5-72B和DeepSeek-R1-Distill-Qwen-32B等最新开源对齐模型,显著提高了其性能。本研究增强了RLVR的稳健性、灵活性和可扩展性,朝着复杂噪声标签场景的实际强化学习应用迈出了重要的一步。
Key Takeaways:
- RLVR技术在增强数学推理和编程性能的大型语言模型上表现良好,尤其在有结构化参考答案的情况下。
- 在医学、化学、心理学、经济学和教育等多样且非结构化的领域中探索了RLVR的有效性及扩展性。
- 发现专家编写的参考答案在跨大型语言模型的二元验证判断中表现出高度一致性。
- 利用生成评分技术产生软奖励信号,克服在非结构化答案场景的二元验证局限。
- 在无需广泛的领域特定标注情况下,展示了训练跨领域生成奖励模型的可行性。
- RLVR框架显著优于其他最新开源模型,增强了性能、稳健性和灵活性。
点此查看论文截图

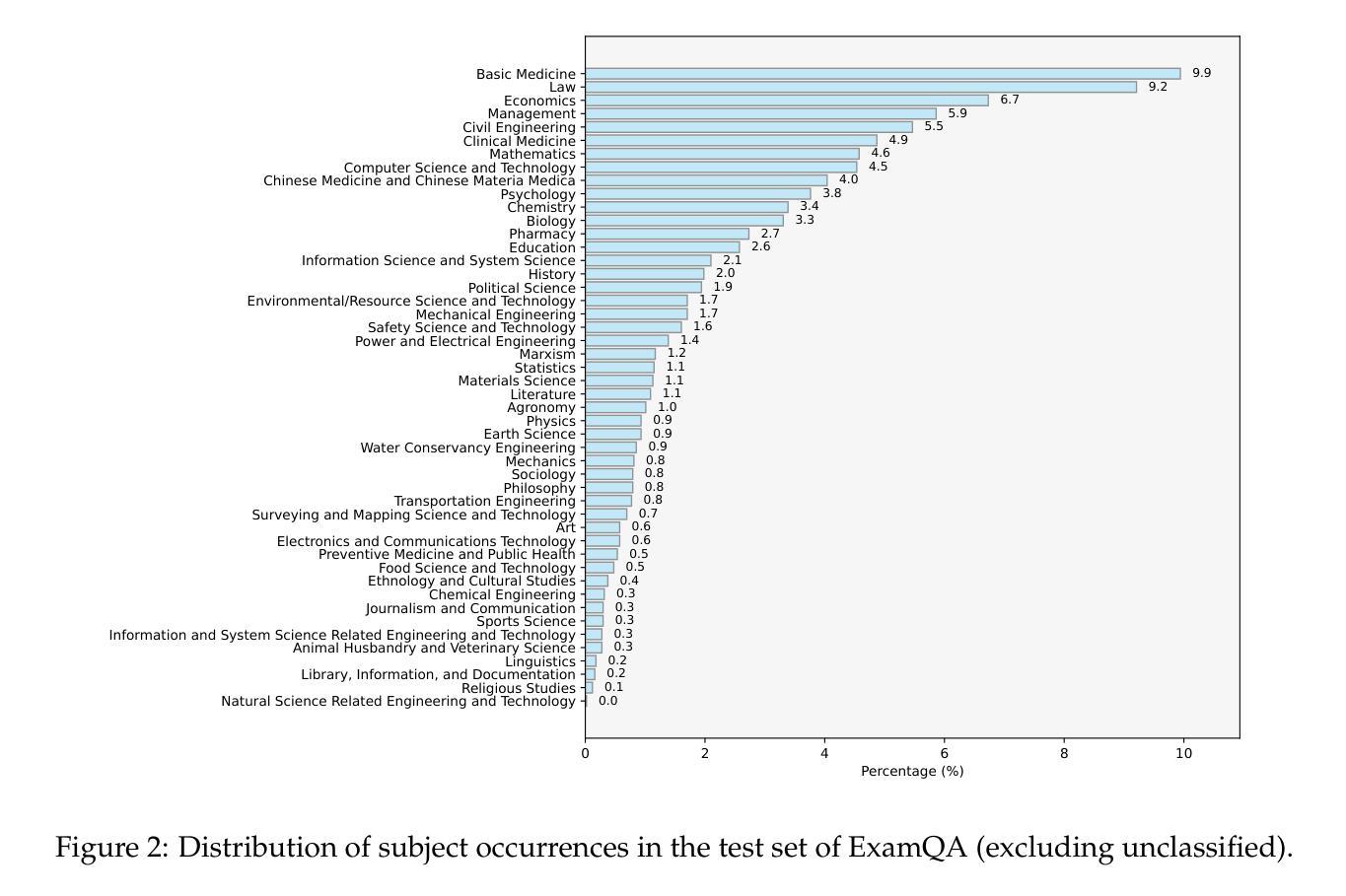
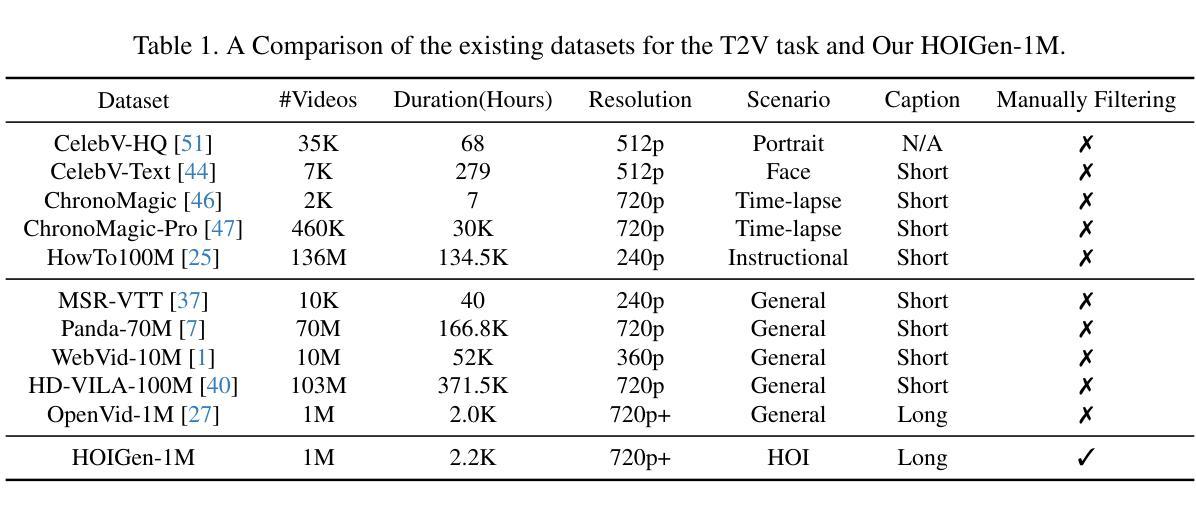
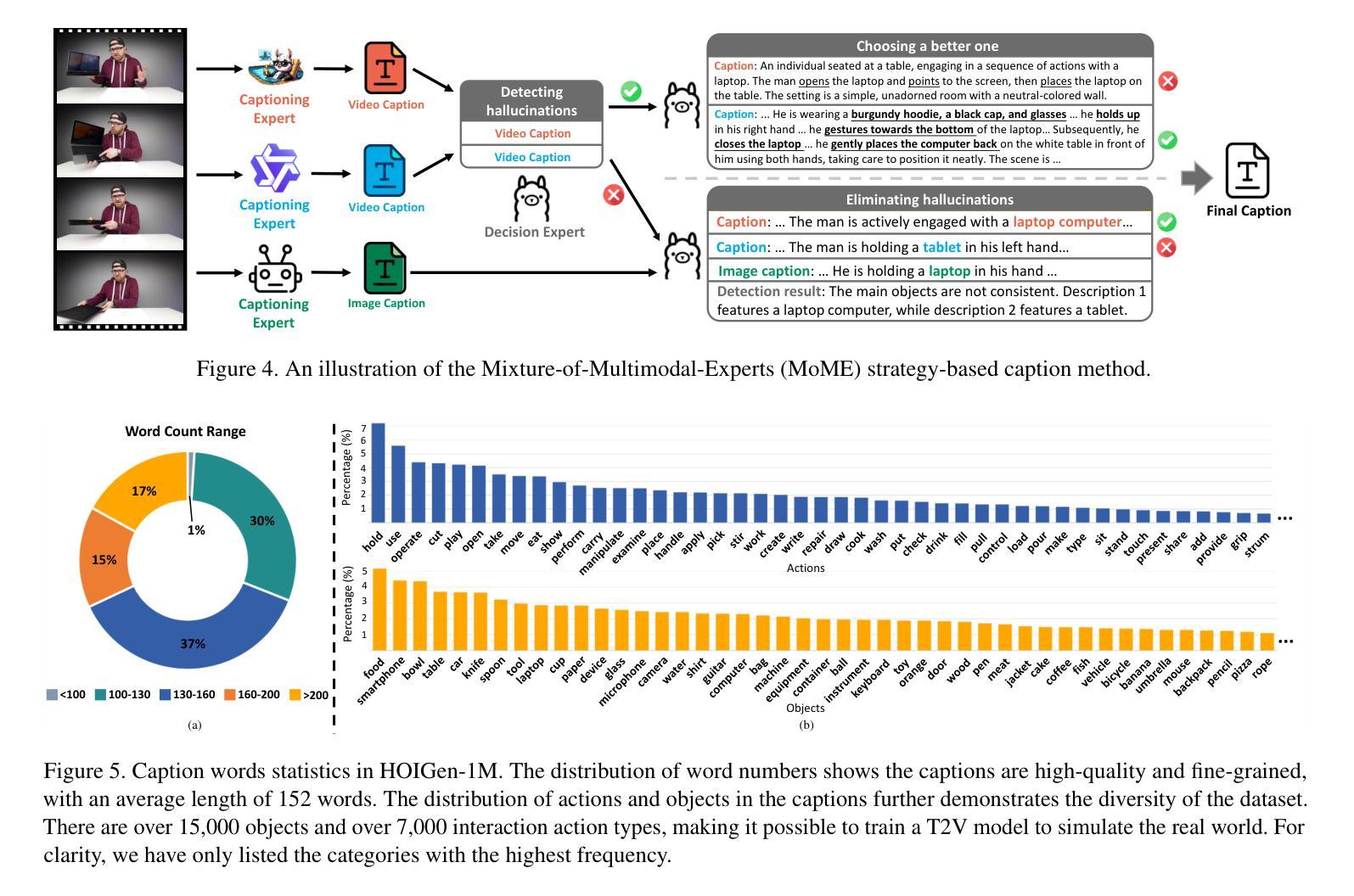
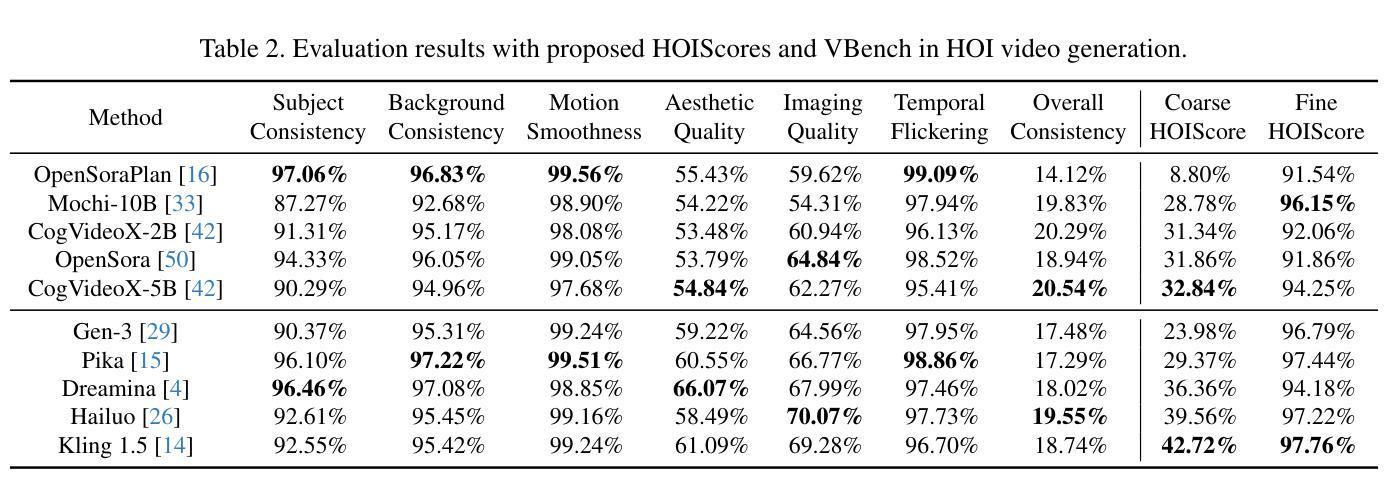
HOIGen-1M: A Large-scale Dataset for Human-Object Interaction Video Generation
Authors:Kun Liu, Qi Liu, Xinchen Liu, Jie Li, Yongdong Zhang, Jiebo Luo, Xiaodong He, Wu Liu
Text-to-video (T2V) generation has made tremendous progress in generating complicated scenes based on texts. However, human-object interaction (HOI) often cannot be precisely generated by current T2V models due to the lack of large-scale videos with accurate captions for HOI. To address this issue, we introduce HOIGen-1M, the first largescale dataset for HOI Generation, consisting of over one million high-quality videos collected from diverse sources. In particular, to guarantee the high quality of videos, we first design an efficient framework to automatically curate HOI videos using the powerful multimodal large language models (MLLMs), and then the videos are further cleaned by human annotators. Moreover, to obtain accurate textual captions for HOI videos, we design a novel video description method based on a Mixture-of-Multimodal-Experts (MoME) strategy that not only generates expressive captions but also eliminates the hallucination by individual MLLM. Furthermore, due to the lack of an evaluation framework for generated HOI videos, we propose two new metrics to assess the quality of generated videos in a coarse-to-fine manner. Extensive experiments reveal that current T2V models struggle to generate high-quality HOI videos and confirm that our HOIGen-1M dataset is instrumental for improving HOI video generation. Project webpage is available at https://liuqi-creat.github.io/HOIGen.github.io.
文本转视频(T2V)生成在基于文本生成复杂场景方面取得了巨大的进步。然而,由于缺少大规模带有准确字幕的人机交互(HOI)视频,当前T2V模型往往无法精确生成HOI。为解决这一问题,我们推出了HOIGen-1M,这是首个用于HOI生成的大规模数据集,包含从各种来源收集的超过一百万高清视频。特别是为了保证视频的高质量,我们首先设计了一个有效的框架,利用强大的多模态大型语言模型(MLLM)自动筛选HOI视频,然后视频进一步由人工注释者进行清理。此外,为了获得HOI视频的准确文本字幕,我们基于混合多模态专家(MoME)策略设计了一种新的视频描述方法,它不仅生成了富有表现力的字幕,还消除了单个MLLM产生的幻觉。此外,由于缺乏生成的HOI视频的评估框架,我们提出了两种新指标来评估生成的视频质量,从粗略到精细。大量实验表明,目前的T2V模型在生成高质量HOI视频方面存在困难,并证实我们的HOIGen-1M数据集对于改进HOI视频生成非常重要。项目网页可在https://liuqi-creat.github.io/HOIGen.github.io访问。
论文及项目相关链接
PDF CVPR 2025
Summary:针对文本转视频(T2V)生成中的人与物体交互(HOI)难以准确生成的问题,本文引入了HOIGen-1M数据集,包含超过一百万高质量的视频。通过设计高效的自动筛选框架和多模态大型语言模型,保证了视频的高质量。同时,提出了基于混合多模态专家策略的视频描述方法,以解决对HOI视频的准确文本描述问题。由于缺乏评价框架,还提出了两种新的评价指标来评估生成视频的质量。实验表明,当前T2V模型在生成HOI视频方面存在困难,而HOIGen-1M数据集对改进HOI视频生成至关重要。
Key Takeaways:
- 当前文本转视频(T2V)生成在生成包含人与物体交互(HOI)的场景时存在挑战。
- HOIGen-1M数据集是解决此问题的首次大规模数据集,包含超过一百万高质量的视频。
- 通过自动筛选框架和多模态大型语言模型(MLLMs)确保视频质量。
- 提出基于混合多模态专家(MoME)策略的视频描述方法,以生成准确的文本描述并消除个体MLLM的幻觉。
- 缺乏评估框架来衡量生成的HOI视频的质量,因此提出两种新的评价指标。
- 实验表明当前T2V模型在生成HOI视频方面存在困难。
点此查看论文截图



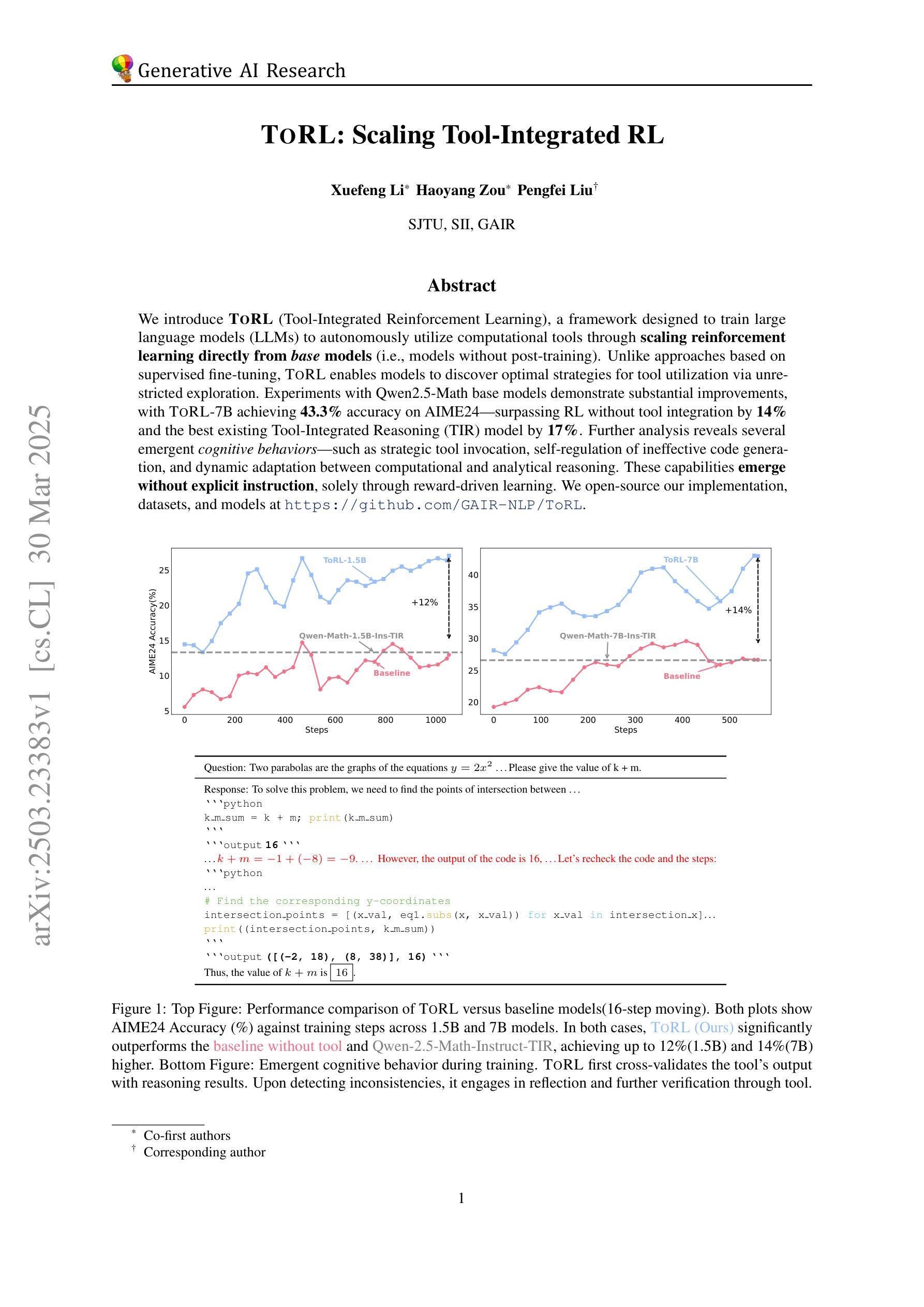
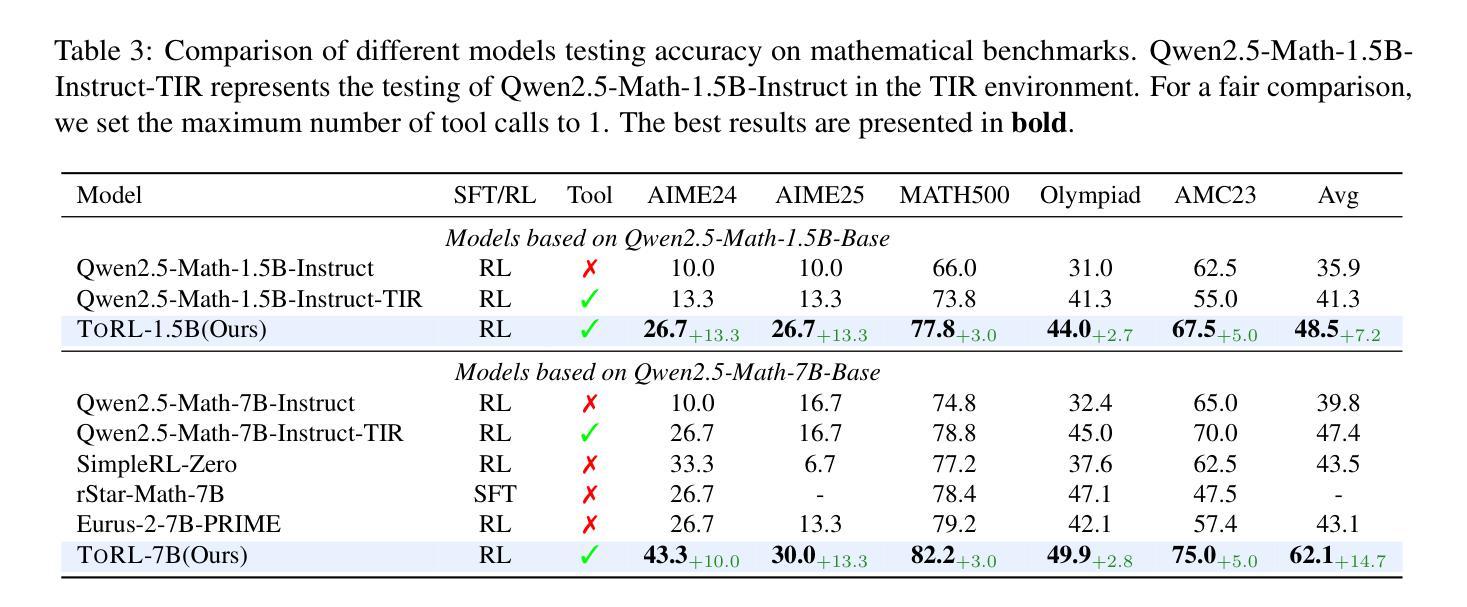
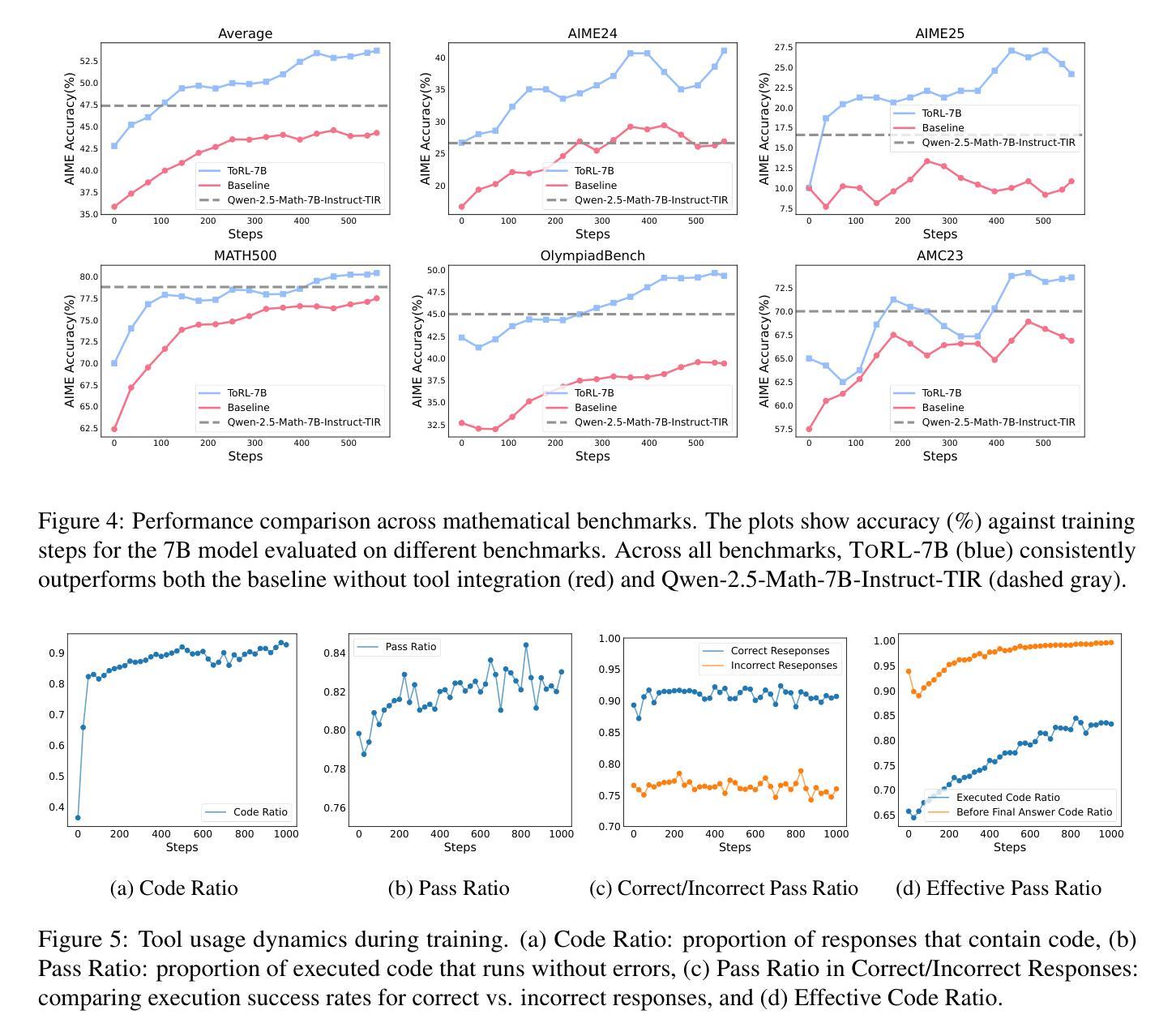
ToRL: Scaling Tool-Integrated RL
Authors:Xuefeng Li, Haoyang Zou, Pengfei Liu
We introduce ToRL (Tool-Integrated Reinforcement Learning), a framework for training large language models (LLMs) to autonomously use computational tools via reinforcement learning. Unlike supervised fine-tuning, ToRL allows models to explore and discover optimal strategies for tool use. Experiments with Qwen2.5-Math models show significant improvements: ToRL-7B reaches 43.3% accuracy on AIME~24, surpassing reinforcement learning without tool integration by 14% and the best existing Tool-Integrated Reasoning (TIR) model by 17%. Further analysis reveals emergent behaviors such as strategic tool invocation, self-regulation of ineffective code, and dynamic adaptation between computational and analytical reasoning, all arising purely through reward-driven learning.
我们介绍了ToRL(工具集成强化学习),这是一个用于训练大型语言模型(LLM)以通过强化学习自主使用计算工具的框架。与监督微调不同,ToRL允许模型探索和发现工具使用的最优策略。使用Qwen2.5-Math模型的实验显示出了显著的改进:ToRL-7B在AIME 24上的准确率达到了43.3%,比没有工具集成的强化学习高出14%,并且比现有的最佳工具集成推理(TIR)模型高出17%。进一步的分析揭示了新兴的行为,如战略性地调用工具、自我调控无效代码以及在计算推理和分析推理之间的动态适应,所有这些行为都纯粹是通过奖励驱动的学习而产生的。
论文及项目相关链接
Summary
强化学习框架ToRL被提出用于训练大型语言模型自主使用计算工具。与监督微调不同,ToRL允许模型探索并发现工具使用的最佳策略。实验显示,使用ToRL框架训练的Qwen2.5-Math模型在AIME 24上的准确率达到了43.3%,相较于不使用工具整合的强化学习提高了14%,并超越了现有的最佳工具整合推理模型17%。该框架引发了诸如策略性工具调用、自我调控无效代码以及计算与分析推理间的动态适应等显著行为。
Key Takeaways
- ToRL是一个用于训练大型语言模型的强化学习框架,可使其自主使用计算工具。
- ToRL框架采用奖励驱动的学习方式,允许模型自主探索和发现工具使用的最佳策略。
- Qwen2.5-Math模型在AIME 24上的准确率通过ToRL框架训练后显著提高,达到43.3%。
- ToRL框架的实验结果显著优于不使用工具整合的强化学习以及现有的最佳工具整合推理模型。
- 使用ToRL框架的模型展现出策略性工具调用、自我调控无效代码等显著行为。
- 模型在动态适应计算和分析推理之间表现出灵活性。
点此查看论文截图


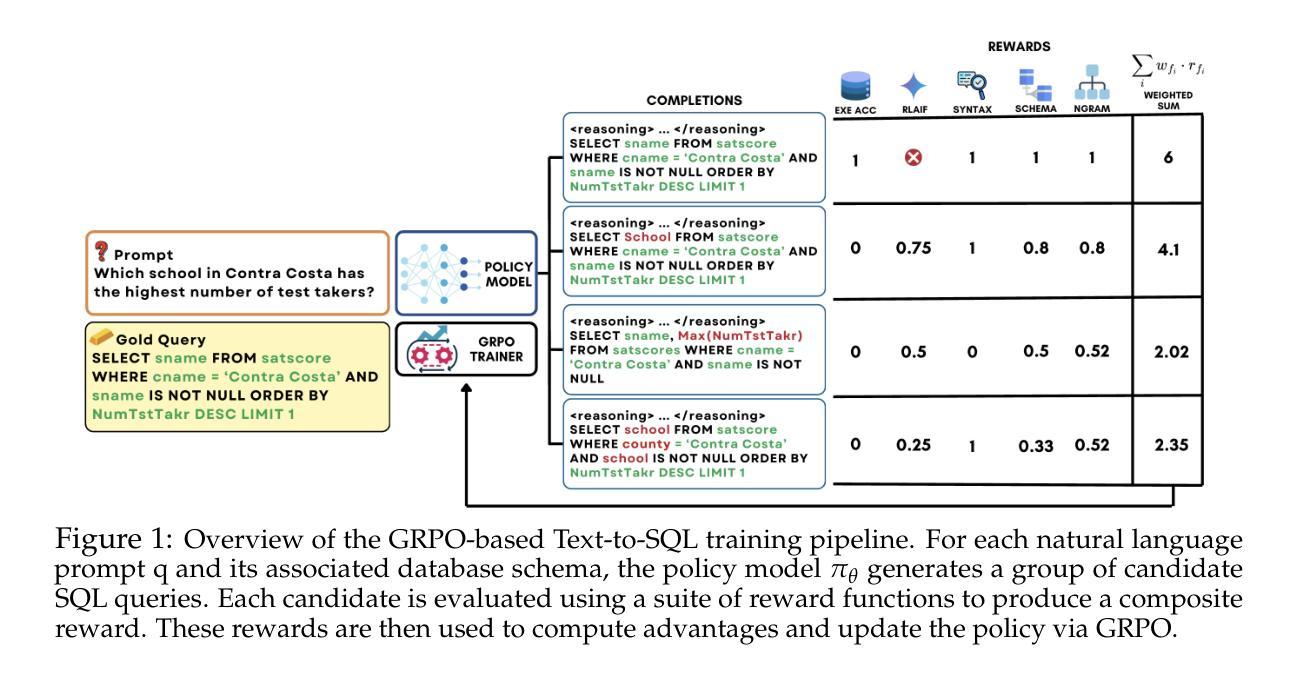
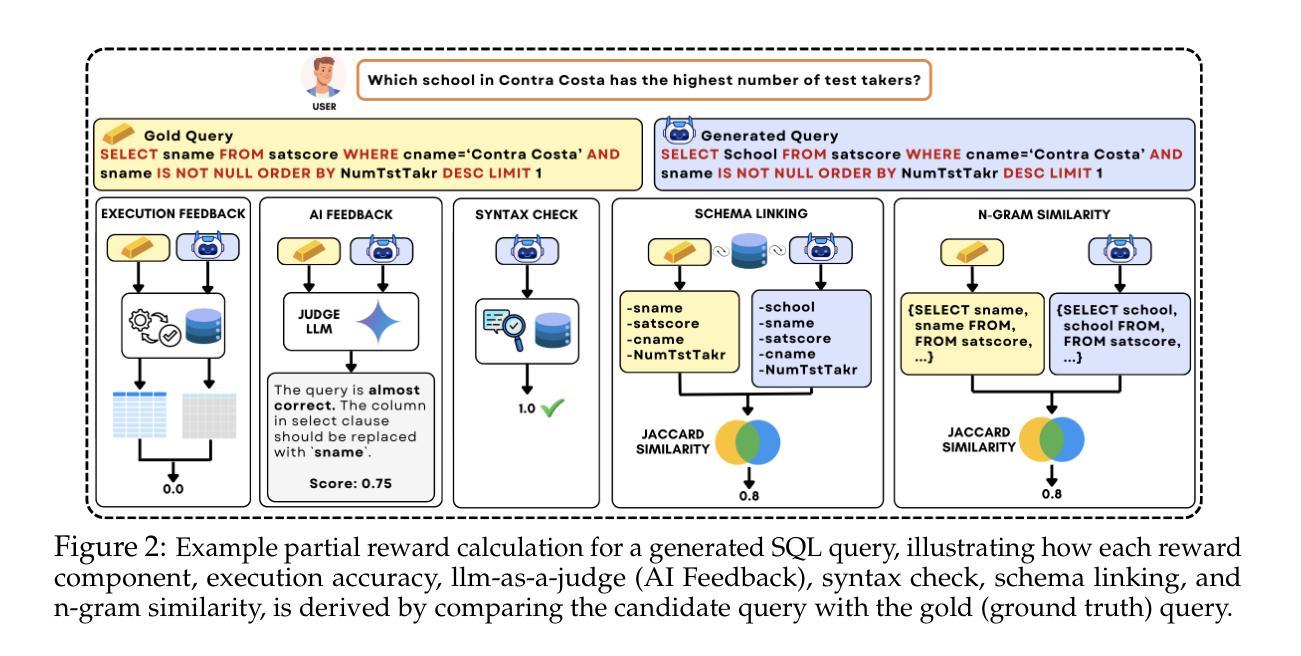
Reasoning-SQL: Reinforcement Learning with SQL Tailored Partial Rewards for Reasoning-Enhanced Text-to-SQL
Authors:Mohammadreza Pourreza, Shayan Talaei, Ruoxi Sun, Xingchen Wan, Hailong Li, Azalia Mirhoseini, Amin Saberi, Sercan “O. Arik
Text-to-SQL is a challenging task involving multiple reasoning-intensive subtasks, including natural language understanding, database schema comprehension, and precise SQL query formulation. Existing approaches often rely on handcrafted reasoning paths with inductive biases that can limit their overall effectiveness. Motivated by the recent success of reasoning-enhanced models such as DeepSeek R1 and OpenAI o1, which effectively leverage reward-driven self-exploration to enhance reasoning capabilities and generalization, we propose a novel set of partial rewards tailored specifically for the Text-to-SQL task. Our reward set includes schema-linking, AI feedback, n-gram similarity, and syntax check, explicitly designed to address the reward sparsity issue prevalent in reinforcement learning (RL). Leveraging group relative policy optimization (GRPO), our approach explicitly encourages large language models (LLMs) to develop intrinsic reasoning skills necessary for accurate SQL query generation. With models of different sizes, we demonstrate that RL-only training with our proposed rewards consistently achieves higher accuracy and superior generalization compared to supervised fine-tuning (SFT). Remarkably, our RL-trained 14B-parameter model significantly outperforms larger proprietary models, e.g. o3-mini by 4% and Gemini-1.5-Pro-002 by 3% on the BIRD benchmark. These highlight the efficacy of our proposed RL-training framework with partial rewards for enhancing both accuracy and reasoning capabilities in Text-to-SQL tasks.
文本到SQL是一项具有挑战性的任务,涉及多个推理密集型的子任务,包括自然语言理解、数据库模式理解和精确的SQL查询构建。现有方法通常依赖于手工制作的推理路径和归纳偏见,这可能会限制其整体效果。受最近成功应用的推理增强模型(如DeepSeek R1和OpenAI o1)的启发,这些模型通过奖励驱动的自我探索来增强推理能力和泛化能力,我们为文本到SQL任务量身定制了一套新的部分奖励。我们的奖励集包括模式链接、AI反馈、n元相似性和语法检查,专门解决强化学习中普遍存在的奖励稀疏问题。通过利用群体相对策略优化(GRPO),我们的方法明确鼓励大型语言模型(LLM)发展内在推理技能,以准确生成SQL查询。在不同规模模型的实验中,我们证明仅使用我们提出奖励的强化学习训练(RL训练)在准确度和泛化能力方面始终优于监督微调(SFT)。值得注意的是,我们训练的14B参数模型在BIRD基准测试上的表现显著优于更大的专有模型,例如o3-mini高出4%和Gemini-1.5-Pro-002高出3%。这些结果凸显了我们在部分奖励的强化学习训练框架中提出的策略在提高文本到SQL任务的准确性和推理能力方面的有效性。
论文及项目相关链接
PDF Mohammadreza Pourreza and Shayan Talaei contributed equally to this work
Summary
本文提出一种针对文本到SQL任务的奖励设定,包括模式链接、AI反馈、n-gram相似性和语法检查等部分奖励,旨在解决强化学习中的奖励稀疏问题。通过利用群体相对策略优化(GRPO),该奖励设定鼓励大型语言模型(LLM)发展内在推理技能,以实现准确的SQL查询生成。实验结果显示,仅使用强化学习训练与所提出的奖励设定,相较于监督微调(SFT),能持续提高准确性并提升泛化能力。特别是在BIRD基准测试中,所提出的小型模型在表现上超过了更大规模的专有模型。这突显了针对文本到SQL任务的强化学习训练框架与部分奖励设定的有效性。
Key Takeaways
- 文本到SQL任务涉及多个推理密集子任务,如自然语言理解、数据库模式理解和精确SQL查询形成。
- 现有方法依赖于手工制作的推理路径和归纳偏见,这可能限制了其整体效果。
- 提出一种针对文本到SQL任务的新型部分奖励设定,包括模式链接、AI反馈等,以解决强化学习中的奖励稀疏问题。
- 利用群体相对策略优化(GRPO)鼓励大型语言模型发展内在推理技能。
- 仅使用强化学习训练与所提出的奖励设定,相较于监督微调能提高准确性和泛化能力。
点此查看论文截图

Can DeepSeek Reason Like a Surgeon? An Empirical Evaluation for Vision-Language Understanding in Robotic-Assisted Surgery
Authors:Boyi Ma, Yanguang Zhao, Jie Wang, Guankun Wang, Kun Yuan, Tong Chen, Long Bai, Hongliang Ren
DeepSeek series have demonstrated outstanding performance in general scene understanding, question-answering (QA), and text generation tasks, owing to its efficient training paradigm and strong reasoning capabilities. In this study, we investigate the dialogue capabilities of the DeepSeek model in robotic surgery scenarios, focusing on tasks such as Single Phrase QA, Visual QA, and Detailed Description. The Single Phrase QA tasks further include sub-tasks such as surgical instrument recognition, action understanding, and spatial position analysis. We conduct extensive evaluations using publicly available datasets, including EndoVis18 and CholecT50, along with their corresponding dialogue data. Our comprehensive evaluation results indicate that, when provided with specific prompts, DeepSeek-V3 performs well in surgical instrument and tissue recognition tasks However, DeepSeek-V3 exhibits significant limitations in spatial position analysis and struggles to understand surgical actions accurately. Additionally, our findings reveal that, under general prompts, DeepSeek-V3 lacks the ability to effectively analyze global surgical concepts and fails to provide detailed insights into surgical scenarios. Based on our observations, we argue that the DeepSeek-V3 is not ready for vision-language tasks in surgical contexts without fine-tuning on surgery-specific datasets.
DeepSeek系列模型在整体场景理解、问答(QA)和文本生成任务中展现了出色的性能,这归功于其高效的训练模式和强大的推理能力。本研究旨在探究DeepSeek模型在机器人手术场景中的对话能力,重点关注诸如简单问答、视觉问答和详细描述等任务。简单问答任务进一步包括手术器械识别、动作理解和空间位置分析等子任务。我们使用了包括EndoVis18和CholecT50在内的公开数据集及其相应的对话数据进行了广泛评估。我们的全面评估结果表明,在提供特定提示的情况下,DeepSeek-V3在手术器械和组织识别任务中表现良好。然而,DeepSeek-V3在空间位置分析方面存在明显局限,且难以准确理解手术动作。此外,我们的研究还发现,在一般提示下,DeepSeek-V3缺乏分析全局手术概念的能力,无法为手术场景提供详细的见解。基于我们的观察,我们认为DeepSeek-V3在未进行手术特定数据集微调的情况下,尚不具备处理手术上下文中的视觉语言任务的能力。
论文及项目相关链接
PDF Technical Report
Summary
DeepSeek模型在场景理解、问答和文本生成任务中表现出卓越性能。本研究探讨了DeepSeek模型在机器人手术场景中的对话能力,包括短语问答、视觉问答和详细描述等任务。评估结果显示,DeepSeek-V3在手术器械和组织识别方面表现良好,但在空间位置分析和手术动作理解方面存在显著局限。对于一般提示,DeepSeek-V3缺乏分析全局手术概念的能力,无法提供手术场景的详细见解。因此,建议对手术特定数据集进行微调,以适应手术场景中的视觉语言任务。
Key Takeaways
- DeepSeek模型在场景理解、问答和文本生成方面表现出卓越性能。
- 本研究评估了DeepSeek模型在机器人手术场景中的对话能力,包括短语问答、视觉问答和详细描述等任务。
- DeepSeek-V3在手术器械和组织识别方面表现良好。
- DeepSeek-V3在空间位置分析和手术动作理解方面存在局限。
- 对于一般提示,DeepSeek-V3缺乏分析全局手术概念的能力。
- DeepSeek-V3需要提供手术特定数据集的微调,以应对手术场景中的视觉语言任务。
点此查看论文截图



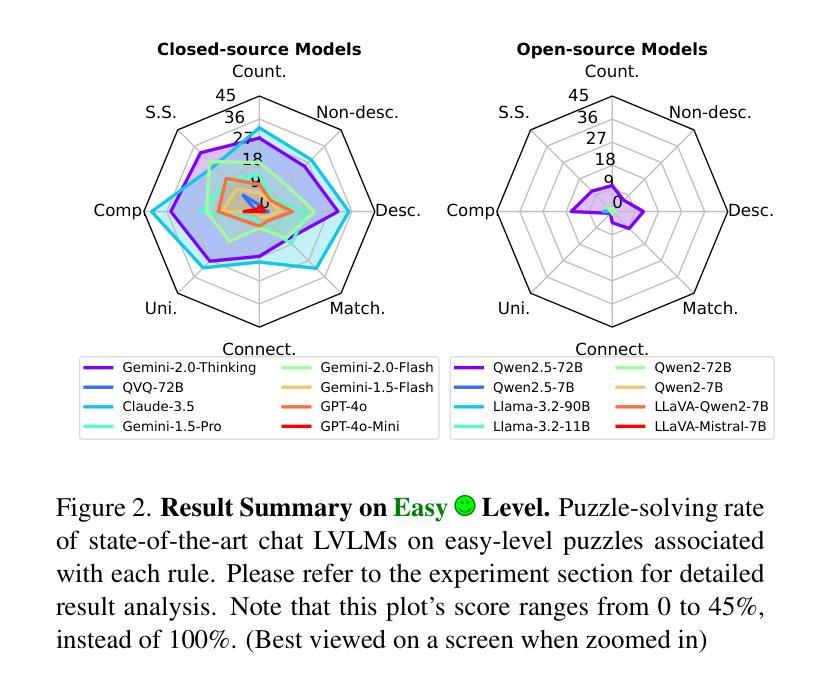
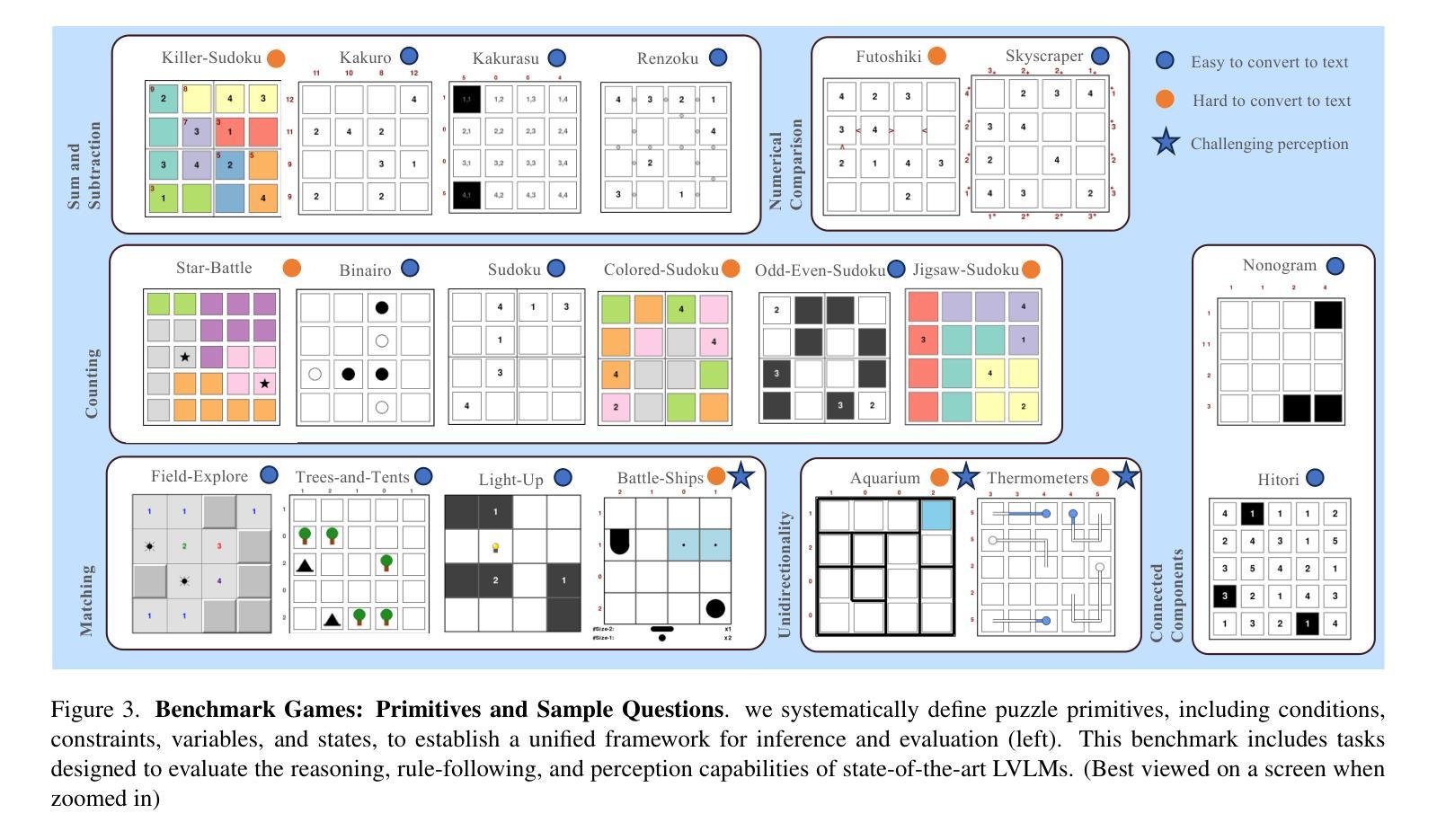
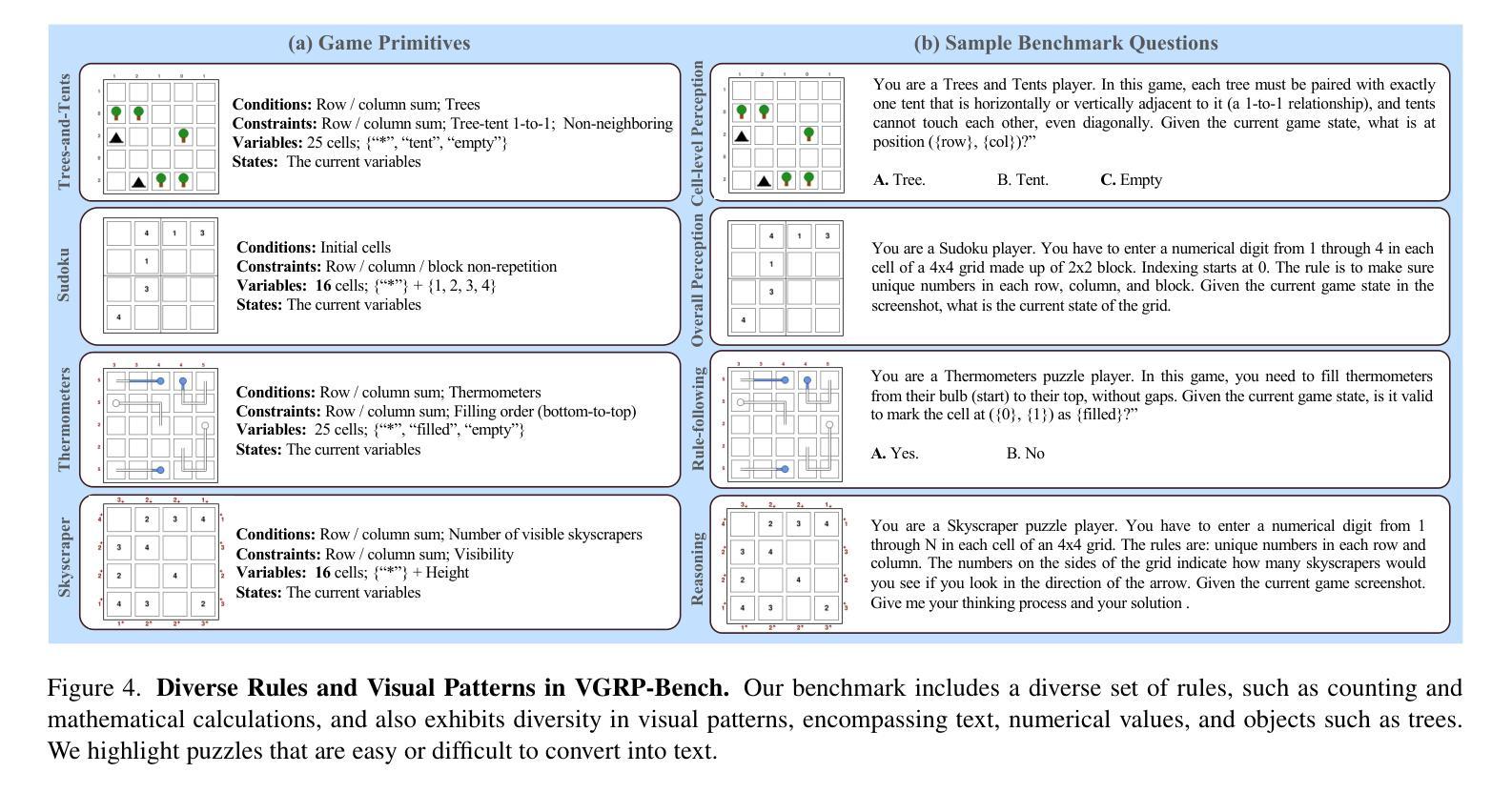
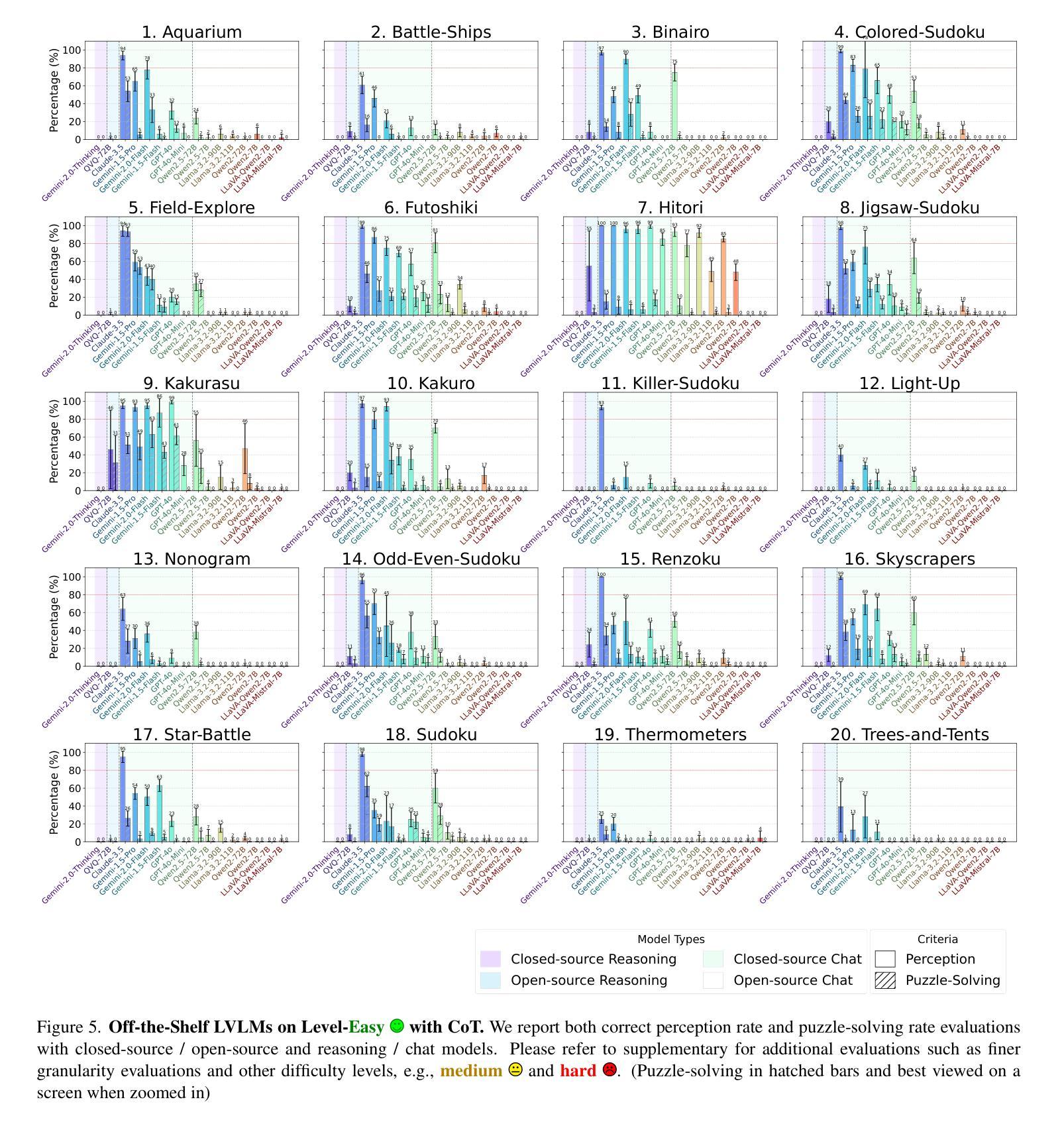
VGRP-Bench: Visual Grid Reasoning Puzzle Benchmark for Large Vision-Language Models
Authors:Yufan Ren, Konstantinos Tertikas, Shalini Maiti, Junlin Han, Tong Zhang, Sabine Süsstrunk, Filippos Kokkinos
Large Vision-Language Models (LVLMs) struggle with puzzles, which require precise perception, rule comprehension, and logical reasoning. Assessing and enhancing their performance in this domain is crucial, as it reflects their ability to engage in structured reasoning - an essential skill for real-world problem-solving. However, existing benchmarks primarily evaluate pre-trained models without additional training or fine-tuning, often lack a dedicated focus on reasoning, and fail to establish a systematic evaluation framework. To address these limitations, we introduce VGRP-Bench, a Visual Grid Reasoning Puzzle Benchmark featuring 20 diverse puzzles. VGRP-Bench spans multiple difficulty levels, and includes extensive experiments not only on existing chat LVLMs (e.g., GPT-4o), but also on reasoning LVLMs (e.g., Gemini-Thinking). Our results reveal that even the state-of-the-art LVLMs struggle with these puzzles, highlighting fundamental limitations in their puzzle-solving capabilities. Most importantly, through systematic experiments, we identify and analyze key factors influencing LVLMs’ puzzle-solving performance, including the number of clues, grid size, and rule complexity. Furthermore, we explore two Supervised Fine-Tuning (SFT) strategies that can be used in post-training: SFT on solutions (S-SFT) and SFT on synthetic reasoning processes (R-SFT). While both methods significantly improve performance on trained puzzles, they exhibit limited generalization to unseen ones. We will release VGRP-Bench to facilitate further research on LVLMs for complex, real-world problem-solving. Project page: https://yufan-ren.com/subpage/VGRP-Bench/.
大型视觉语言模型(LVLMs)在处理需要精确感知、规则理解和逻辑推理的谜题时面临困难。在这个领域评估和提高它们的性能至关重要,这反映了它们进行结构化推理的能力——解决现实世界问题的基本技能。然而,现有的基准测试主要评估预训练模型,没有进行额外的训练或微调,通常缺乏对推理的专注,并且无法建立系统的评估框架。为了解决这些局限性,我们引入了VGRP-Bench,这是一个视觉网格推理谜题基准测试,包含20个多样化的谜题。VGRP-Bench涵盖多个难度级别,不仅包括对现有聊天LVLMs(例如GPT-4o)的实验,还包括对推理LVLMs(例如Gemini-Thinking)的实验。我们的结果表明,即使是最先进的LVLMs在这些谜题中也面临困难,突出了它们在解谜能力上的根本局限性。最重要的是,通过系统的实验,我们确定了影响LVLMs解谜性能的关键因素,包括线索的数量、网格大小和规则复杂性。此外,我们探索了两种监督微调(SFT)策略,可以在训练后使用:对解决方案的SFT(S-SFT)和对合成推理过程的SFT(R-SFT)。虽然这两种方法都能显著提高训练谜题的性能,但它们在未见过的谜题上的泛化能力有限。我们将发布VGRP-Bench,以促进对LVLMs进行复杂、现实世界的解决问题的进一步研究。项目页面:https://yufan-ren.com/subpage/VGRP-Bench/。
论文及项目相关链接
PDF 8 pages; Project page: https://yufan-ren.com/subpage/VGRP-Bench/
Summary
本文介绍了大型视觉语言模型(LVLMs)在解决需要精确感知、规则理解和逻辑推理的谜题时的挑战。作者针对现有评估方式的不足,提出了一种新的视觉网格推理谜题基准测试(VGRP-Bench),旨在评估LVLMs的推理能力。研究结果显示,即使是最先进的LVLMs在这些谜题上也存在困难,并指出了影响LVLMs解谜能力的关键因素。同时,探索了两种监督微调(SFT)策略,即基于解决方案的SFT(S-SFT)和基于合成推理过程的SFT(R-SFT)。然而,这两种方法在提高已训练谜题性能的同时,对未见过的谜题泛化能力有限。项目页面提供了更多详细信息。
Key Takeaways
- LVLMs在解决需要精确感知、规则理解和逻辑推理的谜题时面临挑战。
- 现有评估方式存在不足,缺乏专门针对LVLMs推理能力的系统评估框架。
- VGRP-Bench旨在评估LVLMs的推理能力,包括多种难度级别的20个多样化谜题。
- 最先进的LVLMs在谜题解决上仍有困难,表明存在基础能力限制。
- 影响LVLMs解谜能力的关键因素包括线索数量、网格大小和规则复杂性。
- 监督微调(SFT)策略可以提高LVLMs在训练谜题上的性能,但对未见谜题的泛化能力有限。
点此查看论文截图

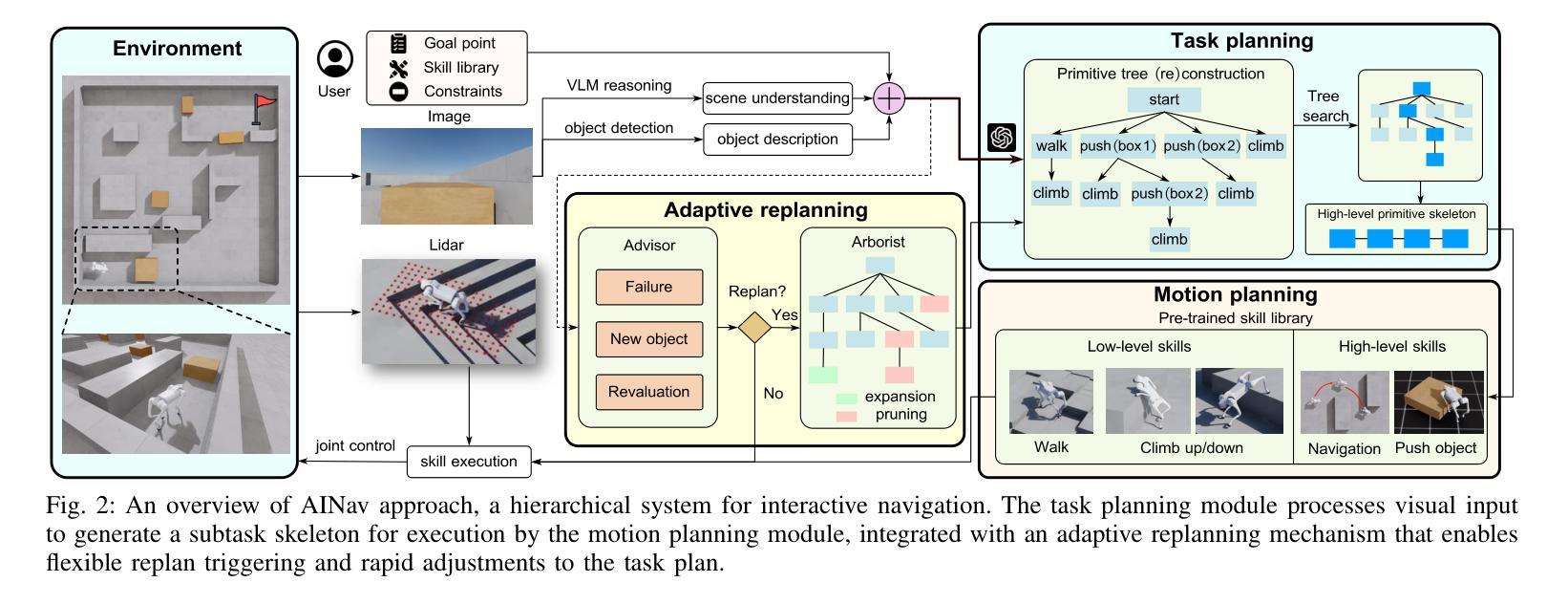
Adaptive Interactive Navigation of Quadruped Robots using Large Language Models
Authors:Kangjie Zhou, Yao Mu, Haoyang Song, Yi Zeng, Pengying Wu, Han Gao, Chang Liu
Robotic navigation in complex environments remains a critical research challenge. Traditional navigation methods focus on optimal trajectory generation within free space, struggling in environments lacking viable paths to the goal, such as disaster zones or cluttered warehouses. To address this gap, we propose an adaptive interactive navigation approach that proactively interacts with environments to create feasible paths to reach originally unavailable goals. Specifically, we present a primitive tree for task planning with large language models (LLMs), facilitating effective reasoning to determine interaction objects and sequences. To ensure robust subtask execution, we adopt reinforcement learning to pre-train a comprehensive skill library containing versatile locomotion and interaction behaviors for motion planning. Furthermore, we introduce an adaptive replanning method featuring two LLM-based modules: an advisor serving as a flexible replanning trigger and an arborist for autonomous plan adjustment. Integrated with the tree structure, the replanning mechanism allows for convenient node addition and pruning, enabling rapid plan modification in unknown environments. Comprehensive simulations and experiments have demonstrated our method’s effectiveness and adaptivity in diverse scenarios. The supplementary video is available at page: https://youtu.be/W5ttPnSap2g.
机器人导航在复杂环境中仍然是一个重要的研究挑战。传统的导航方法主要关注在自由空间内生成最优轨迹,但在缺乏到达目标点的可行路径的环境中,如灾区或杂乱的仓库等,这些方法会面临困难。为了解决这个问题,我们提出了一种自适应交互导航方法,该方法能够主动与环境进行交互以创建可行的路径,从而达到原本无法到达的目标点。具体来说,我们提出了一种使用大型语言模型(LLM)的任务规划原始树,通过有效的推理来确定交互对象和序列。为了确保子任务的稳健执行,我们采用强化学习来预训练一个包含通用运动能力和交互行为的综合技能库,用于运动规划。此外,我们引入了一种自适应的重新规划方法,其中包括两个基于LLM的模块:一个作为灵活重新规划触发器的顾问和一个用于自主计划调整的造林师。与树结构相结合,重新规划机制便于节点的添加和修剪,能够在未知环境中快速修改计划。综合模拟和实验证明了我们方法在多种场景中的有效性和适应性。补充视频可在页面观看:https://youtu.be/W5ttPnSap2g。
论文及项目相关链接
PDF 10 pages, 9 figures
Summary:
在复杂环境中实现机器人导航是一个重要的研究挑战。传统的导航方法主要关注在自由空间内生成最优轨迹,但在如灾难现场或拥挤仓库等缺乏可行路径的环境里表现不佳。为解决这一问题,我们提出了一种自适应交互导航方法,该方法能够主动与环境交互以创建到达原本不可达目标的可行路径。我们提出了一个用于任务规划的原生树模型,并结合大型语言模型进行有效推理,以确定交互对象和序列。为保证稳健的次任务执行,我们采用强化学习来预训练包含各种运动和行为技能的技能库,用于运动规划。此外,我们提出了一种自适应重规划方法,包含两个基于大型语言模型的模块:作为灵活重规划触发器的顾问和用于自主计划调整的造林师。结合树结构,重规划机制便于节点增加和修剪,能在未知环境中快速调整计划。仿真和实验证明了我们方法在多种场景下的有效性和适应性。更多信息请参见补充视频:https://youtu.be/W5ttPnSap2g。
Key Takeaways:
- 机器人导航在复杂环境中仍然是一个研究挑战,特别是在缺乏可行路径的环境中。
- 传统导航方法主要关注在自由空间内生成最优轨迹,但在某些环境下效果有限。
- 提出了一种自适应交互导航方法,能主动与环境交互以创建可行路径。
- 使用原生树模型和大型语言模型进行任务规划和推理,确定交互对象和序列。
- 采用强化学习预训练包含各种运动和行为技能的技能库,用于运动规划。
- 提出了一种自适应重规划方法,包含两个基于大型语言模型的模块,以应对未知环境中的快速计划调整。
点此查看论文截图

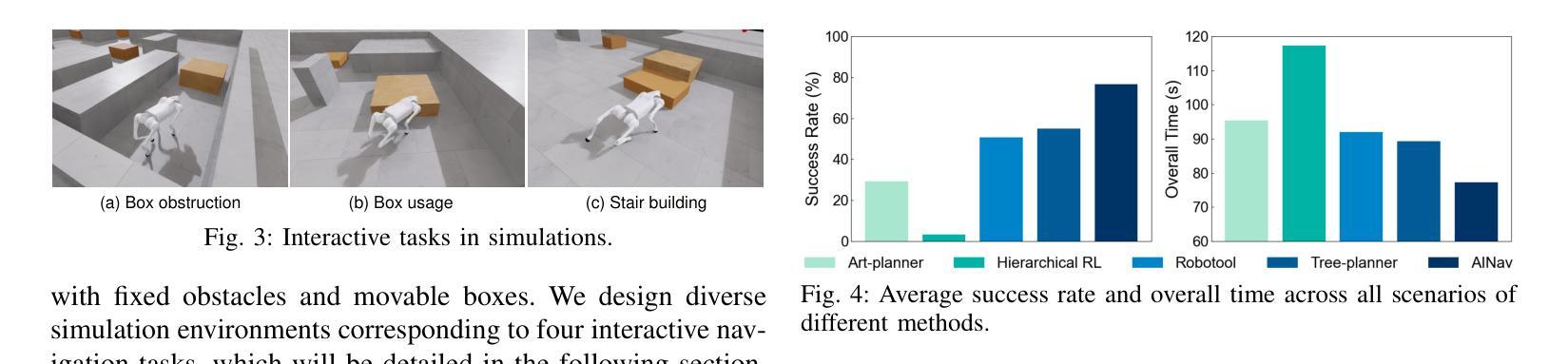
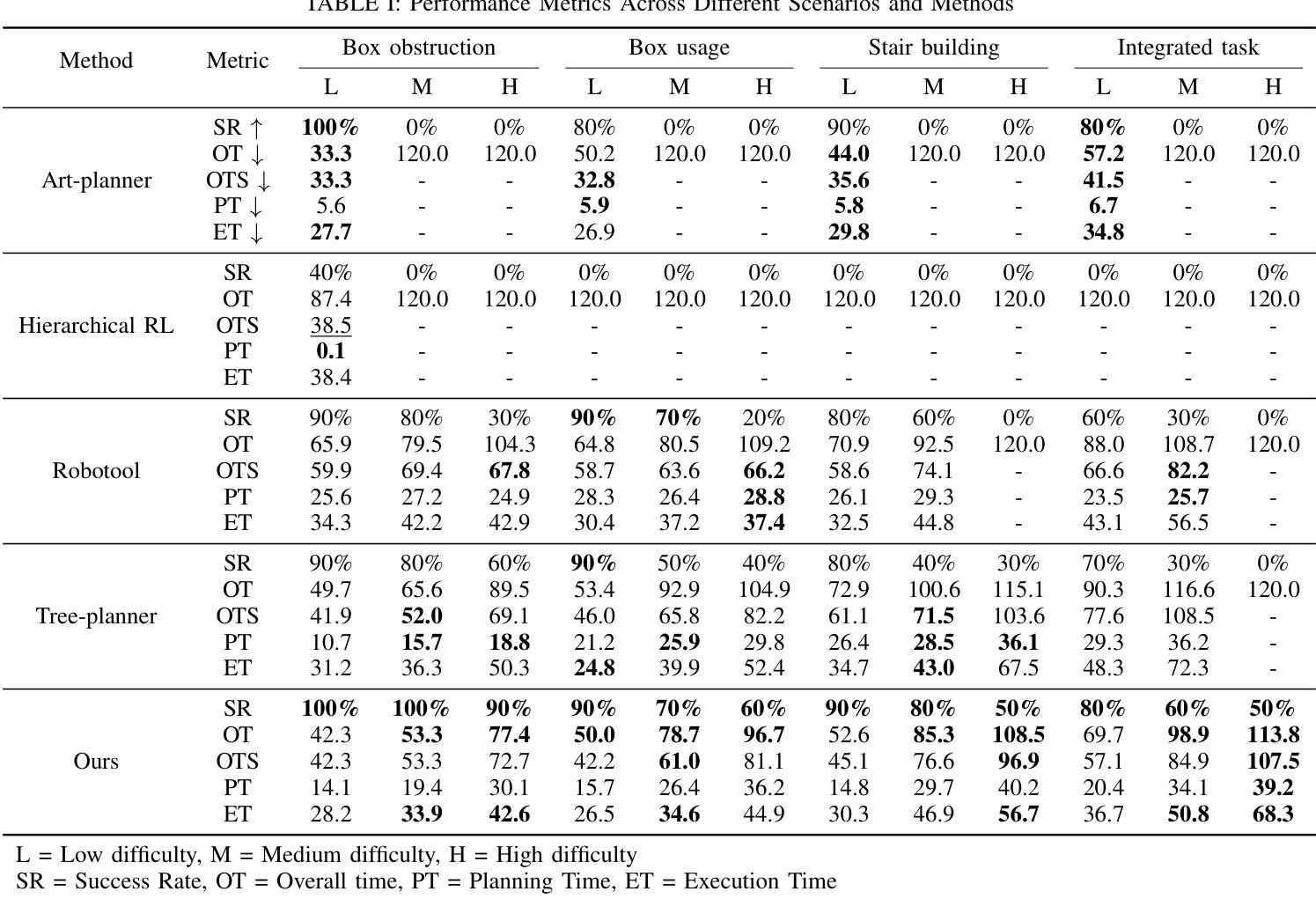
Q-Insight: Understanding Image Quality via Visual Reinforcement Learning
Authors:Weiqi Li, Xuanyu Zhang, Shijie Zhao, Yabin Zhang, Junlin Li, Li Zhang, Jian Zhang
Image quality assessment (IQA) focuses on the perceptual visual quality of images, playing a crucial role in downstream tasks such as image reconstruction, compression, and generation. The rapid advancement of multi-modal large language models (MLLMs) has significantly broadened the scope of IQA, moving toward comprehensive image quality understanding that incorporates content analysis, degradation perception, and comparison reasoning beyond mere numerical scoring. Previous MLLM-based methods typically either generate numerical scores lacking interpretability or heavily rely on supervised fine-tuning (SFT) using large-scale annotated datasets to provide descriptive assessments, limiting their flexibility and applicability. In this paper, we propose Q-Insight, a reinforcement learning-based model built upon group relative policy optimization (GRPO), which demonstrates strong visual reasoning capability for image quality understanding while requiring only a limited amount of rating scores and degradation labels. By jointly optimizing score regression and degradation perception tasks with carefully designed reward functions, our approach effectively exploits their mutual benefits for enhanced performance. Extensive experiments demonstrate that Q-Insight substantially outperforms existing state-of-the-art methods in both score regression and degradation perception tasks, while exhibiting impressive zero-shot generalization to comparison reasoning tasks. Code will be available at https://github.com/lwq20020127/Q-Insight.
图像质量评估(IQA)专注于图像的主观视觉质量,在图像重建、压缩和生成等下游任务中扮演着至关重要的角色。多模态大型语言模型(MLLMs)的快速发展极大地拓宽了IQA的范围,朝着综合图像质量理解的方向发展,这结合了内容分析、退化感知和比较推理,超越了仅仅的数字评分。之前的基于MLLM的方法通常要么生成缺乏解释性的数字分数,要么严重依赖于使用大规模注释数据集进行的有监督微调(SFT)来提供描述性评估,这限制了它们的灵活性和适用性。在本文中,我们提出了基于强化学习的Q-Insight模型,该模型建立在群组相对策略优化(GRPO)之上,展现出强大的视觉推理能力,用于理解图像质量,只需有限的主观评分和退化标签。通过精心设计的奖励函数,联合优化评分回归和退化感知任务,我们的方法有效地利用了它们的相互优势,提高了性能。大量实验表明,Q-Insight在评分回归和退化感知任务上显著优于现有最先进的方法,同时在零样本比较推理任务上展现出令人印象深刻的泛化能力。相关代码将发布在https://github.com/lwq20020127/Q-Insight。
论文及项目相关链接
PDF Technical report
Summary
本论文提出了一种基于强化学习的方法,名为Q-Insight,用于图像质量评估(IQA)。该方法结合了群体相对策略优化(GRPO),能够深入理解图像质量,同时只需少量的评分和降级标签。通过优化评分回归和降级感知任务,精心设计奖励函数,该方法充分利用两者的互益优势提升性能。实验表明,Q-Insight在评分回归和降级感知任务上显著优于现有方法,并在比较推理任务中展现出零样本泛化能力。
Key Takeaways
- 图像质量评估(IQA)关注图像的感知视觉质量,在图像重建、压缩和生成等下游任务中起到关键作用。
- 多模态大型语言模型(MLLMs)的快速发展拓宽了IQA的范围,使其能够全面理解图像质量,包括内容分析、退化感知和比较推理等方面。
- 以往的MLLM方法要么产生缺乏可解释性的数值分数,要么严重依赖于大规模标注数据集进行描述性评估,限制了其灵活性和适用性。
- Q-Insight方法结合了强化学习和群体相对策略优化(GRPO),提高了图像质量理解的视觉推理能力。
- Q-Insight方法只需少量的评分和降级标签,通过优化评分回归和降级感知任务,以及精心设计奖励函数,实现增强性能。
- 实验表明,Q-Insight在评分回归和降级感知任务上表现优异,优于现有方法。
点此查看论文截图


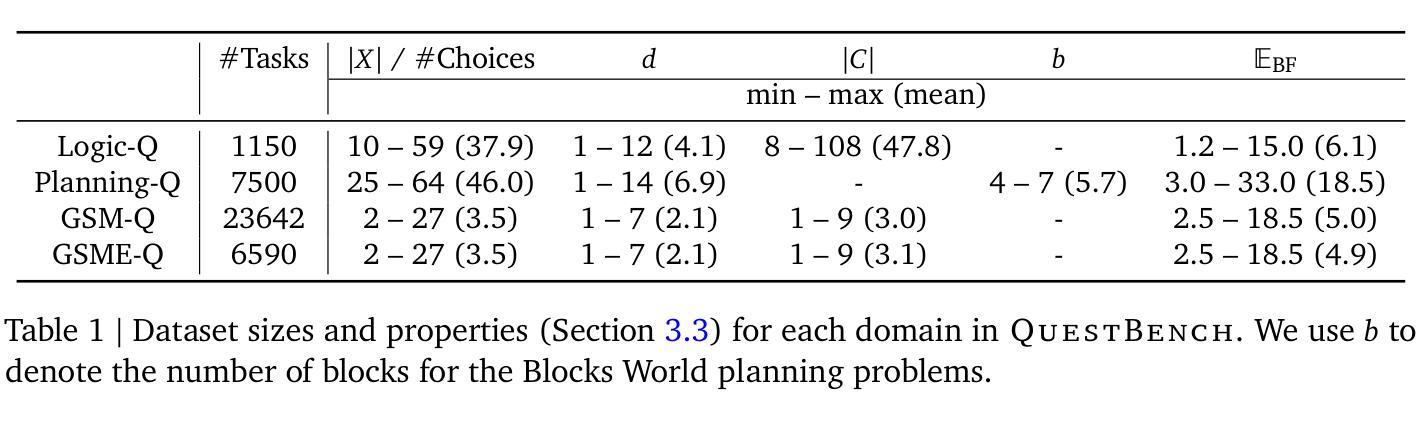
QuestBench: Can LLMs ask the right question to acquire information in reasoning tasks?
Authors:Belinda Z. Li, Been Kim, Zi Wang
Recently, a large amount of work has focused on improving large language models’ (LLMs’) performance on reasoning benchmarks such as math and logic. However, past work has largely assumed that tasks are well-defined. In the real world, queries to LLMs are often underspecified, only solvable through acquiring missing information. We formalize this as a constraint satisfaction problem (CSP) with missing variable assignments. Using a special case of this formalism where only one necessary variable assignment is missing, we can rigorously evaluate an LLM’s ability to identify the minimal necessary question to ask and quantify axes of difficulty levels for each problem. We present QuestBench, a set of underspecified reasoning tasks solvable by asking at most one question, which includes: (1) Logic-Q: Logical reasoning tasks with one missing proposition, (2) Planning-Q: PDDL planning problems with initial states that are partially-observed, (3) GSM-Q: Human-annotated grade school math problems with one missing variable assignment, and (4) GSME-Q: a version of GSM-Q where word problems are translated into equations by human annotators. The LLM is tasked with selecting the correct clarification question(s) from a list of options. While state-of-the-art models excel at GSM-Q and GSME-Q, their accuracy is only 40-50% on Logic-Q and Planning-Q. Analysis demonstrates that the ability to solve well-specified reasoning problems may not be sufficient for success on our benchmark: models have difficulty identifying the right question to ask, even when they can solve the fully specified version of the problem. Furthermore, in the Planning-Q domain, LLMs tend not to hedge, even when explicitly presented with the option to predict ``not sure.’’ This highlights the need for deeper investigation into models’ information acquisition capabilities.
最近,大量的工作集中在提高大型语言模型(LLM)在诸如数学和逻辑等推理基准测试上的性能。然而,过去的工作大多假设任务是明确界定好的。在真实世界中,对LLM的查询通常是未明确指定的,只能通过获取缺失的信息来解决。我们将这正式化为一个具有缺失变量赋值的约束满足问题(CSP)。通过使用这种形式的特殊情况,其中仅缺少一个必要的变量赋值,我们可以严格评估LLM确定要询问的最小必要问题的能力,并为每个问题量化难度级别的轴。我们提出了QuestBench,这是一组最多通过问一个问题就可以解决的未明确指定的推理任务,包括:(1)Logic-Q:逻辑推理任务中有一个缺失的命题;(2)Planning-Q:PDDL规划问题的初始状态是部分观察到的;(3)GSM-Q:人类注释的小学数学问题中有一个缺失的变量赋值;(4)GSME-Q:GSM-Q的一个版本,其中人类注释者将文字问题翻译为方程式。LLM的任务是从选项列表中选择正确的澄清问题。虽然最先进的模型在GSM-Q和GSME-Q方面表现出色,但在Logic-Q和Planning-Q上的准确率仅为40-50%。分析表明,解决明确指定的推理问题的能力可能不足以在我们的基准测试上取得成功:即使能够解决完全指定的版本的问题,模型也很难确定要问的正确问题。此外,在Planning-Q领域,LLM往往不会犹豫,即使明确提供了选择“不确定”的选项。这突显了对模型的获取信息能力进行更深入调查的必要性。
论文及项目相关链接
PDF Code and dataset are available at \url{https://github.com/google-deepmind/questbench}
Summary
大型语言模型(LLMs)在应对数学和逻辑等推理基准测试方面的性能提升已经吸引了大量的关注。然而,过去的工作往往假定任务已经定义明确。在实际应用中,对LLMs的查询通常是未具体指定的,只有通过获取缺失信息才能解决。本研究将其形式化为一个带有缺失变量赋值的约束满足问题(CSP)。通过这一形式主义的特殊案例,我们能严格评估LLM在识别最小必要问题询问方面的能力,并为每个问题量化难度等级。本研究推出了QuestBench,这是一套可通过最多一个问题解决的未具体指定的推理任务。包括逻辑Q、规划Q、小学数学Q以及小学方程Q。尽管前沿模型在数学问题上表现出色,但在逻辑和规划问题上的准确率仅为40-50%。分析表明,解决明确规定的问题的能力可能不足以在我们这个基准测试中取得成功:模型在识别正确问题方面存在困难,即使它们可以解冑完全指定的问题也是如此。此外,在规划Q领域,LLMs往往不倾向于进行不确定性的预测。这凸显了对模型信息获取能力的深入研究的必要性。
Key Takeaways
- 大型语言模型(LLMs)在实际应用中面临的任务往往是未具体指定的,需要获取缺失信息来解决。
- 研究者将这类问题形式化为一个约束满足问题(CSP),并发现LLMs在识别必要问题方面存在困难。
- QuestBench包含一系列未具体指定的推理任务,包括逻辑、规划、小学数学和小学方程问题。
- 现有模型在逻辑和规划问题上的准确率较低,表明解决明确规定的问题的能力可能不足以应对更复杂的实际任务。
- LLMs在识别正确问题方面存在挑战,即使它们可以解冑完全指定的问题也是如此。
- 在规划领域,LLMs往往不倾向于预测不确定性,这可能对模型的性能和实际应用产生影响。
点此查看论文截图

Unicorn: Text-Only Data Synthesis for Vision Language Model Training
Authors:Xiaomin Yu, Pengxiang Ding, Wenjie Zhang, Siteng Huang, Songyang Gao, Chengwei Qin, Kejian Wu, Zhaoxin Fan, Ziyue Qiao, Donglin Wang
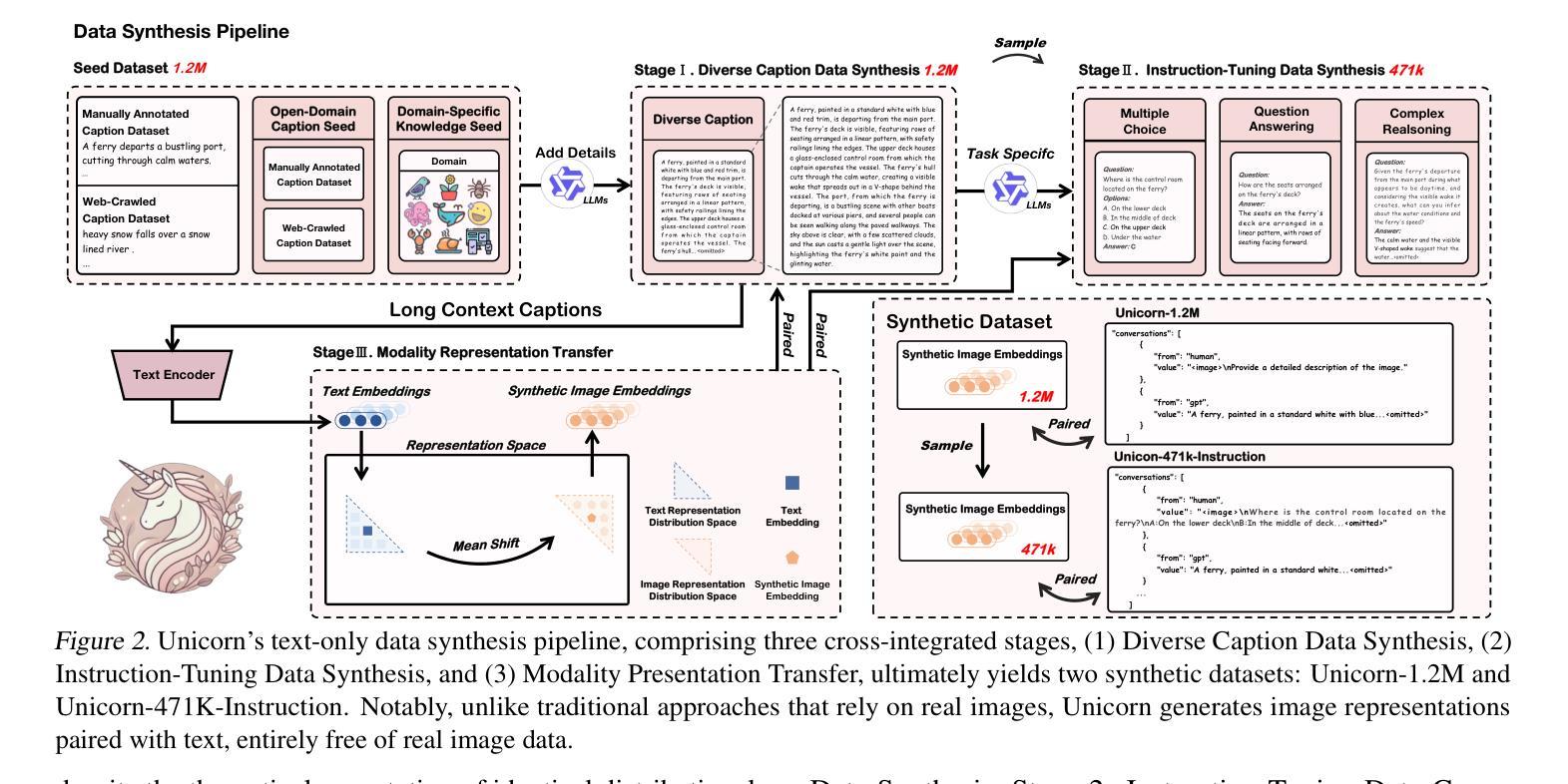
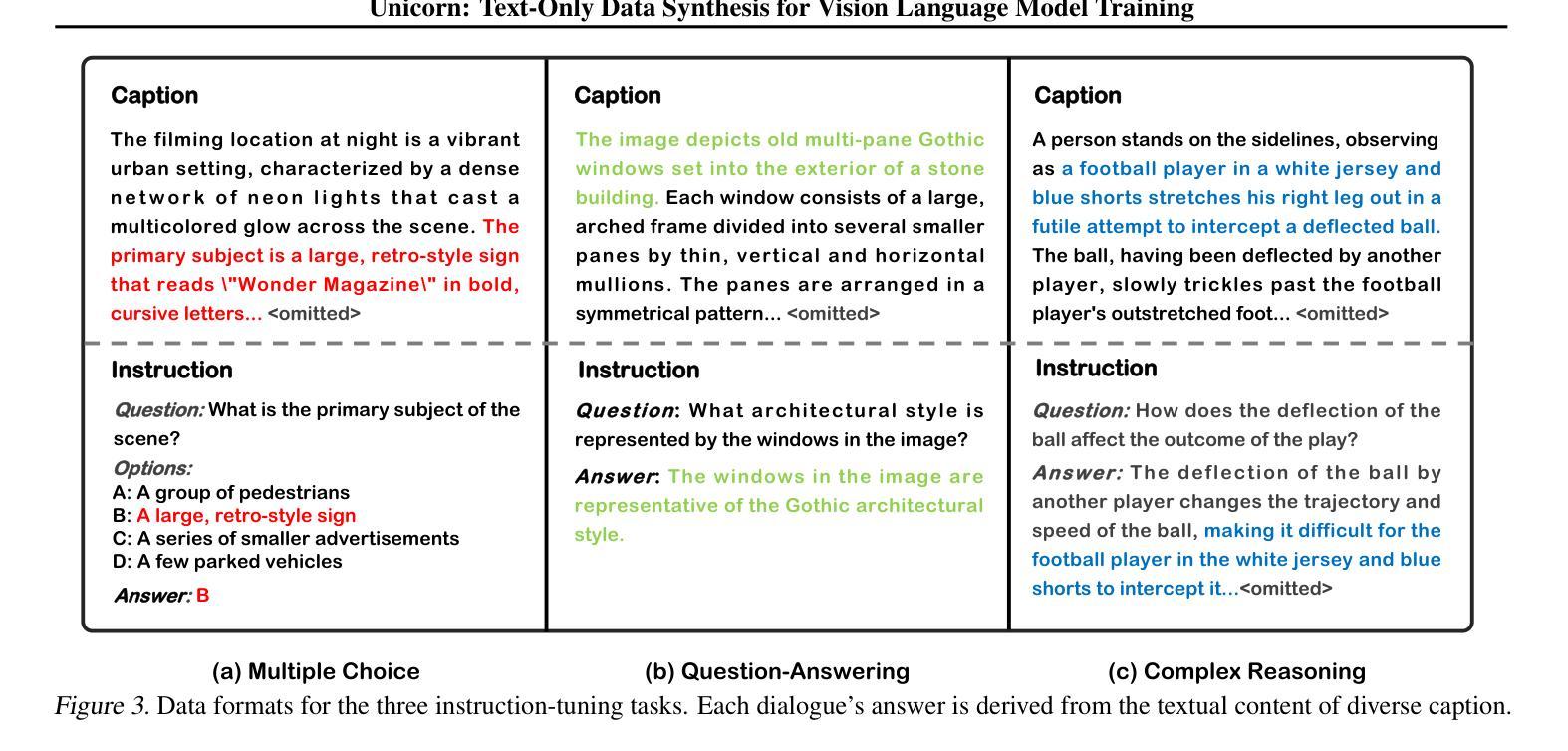
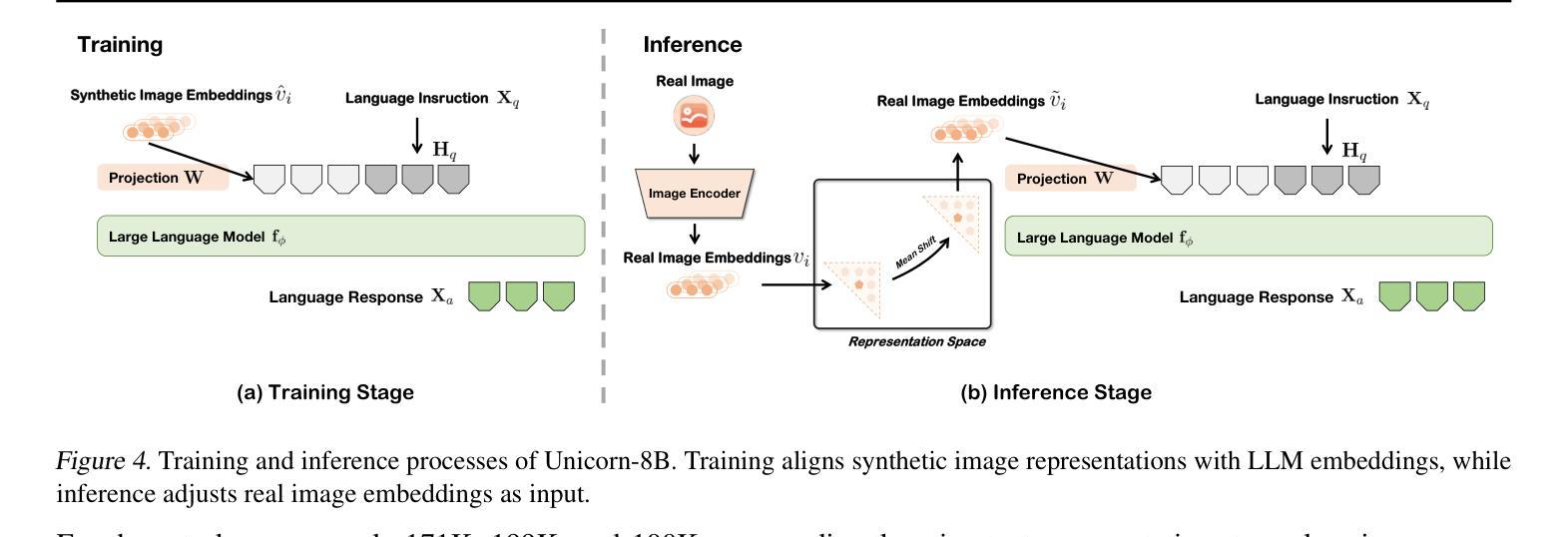
Training vision-language models (VLMs) typically requires large-scale, high-quality image-text pairs, but collecting or synthesizing such data is costly. In contrast, text data is abundant and inexpensive, prompting the question: can high-quality multimodal training data be synthesized purely from text? To tackle this, we propose a cross-integrated three-stage multimodal data synthesis framework, which generates two datasets: Unicorn-1.2M and Unicorn-471K-Instruction. In Stage 1: Diverse Caption Data Synthesis, we construct 1.2M semantically diverse high-quality captions by expanding sparse caption seeds using large language models (LLMs). In Stage 2: Instruction-Tuning Data Generation, we further process 471K captions into multi-turn instruction-tuning tasks to support complex reasoning. Finally, in Stage 3: Modality Representation Transfer, these textual captions representations are transformed into visual representations, resulting in diverse synthetic image representations. This three-stage process enables us to construct Unicorn-1.2M for pretraining and Unicorn-471K-Instruction for instruction-tuning, without relying on real images. By eliminating the dependency on real images while maintaining data quality and diversity, our framework offers a cost-effective and scalable solution for VLMs training. Code is available at https://github.com/Yu-xm/Unicorn.git.
训练视觉语言模型(VLMs)通常需要大规模的高质量图像文本对,但收集或合成此类数据成本高昂。相比之下,文本数据丰富且价格低廉,这引发了一个问题:是否可以从纯文本中合成高质量的多模态训练数据?为解决这一问题,我们提出了一个跨集成的三阶段多模态数据合成框架,该框架生成了两个数据集:Unicorn-1.2M和Unicorn-471K-Instruction。在第一阶段:多样化标题数据合成中,我们通过利用大型语言模型(LLM)扩展稀疏标题种子,构建了120万条语义多样的高质量标题。在第二阶段:指令调整数据生成中,我们将47.1万条标题进一步处理成多回合指令调整任务,以支持复杂推理。最后,在第三阶段:模态表示转移中,这些文本标题表示被转化为视觉表示,从而产生多样化的合成图像表示。这三个阶段的过程使我们能够构建用于预训练的Unicorn-1.2M和用于指令调整的Unicorn-471K-Instruction,而无需依赖真实图像。通过消除对真实图像的依赖,同时保持数据的质量和多样性,我们的框架为VLMs训练提供了成本效益高且可扩展的解决方案。代码可在https://github.com/Yu-xm/Unicorn.git上找到。
论文及项目相关链接
Summary
本文提出了一种跨融合的三阶段多媒体数据合成框架,用于生成视觉语言模型(VLMs)的训练数据。该框架通过三个阶段生成了两个数据集:Unicorn-1.2M和Unicorn-471K-Instruction。首先,通过大语言模型(LLMs)扩展稀疏的标题种子,构建1.2M语义多样的高质量标题。接着,将471K标题进一步处理成多轮指令调整任务,以支持复杂推理。最后,将这些文本标题表示转化为视觉表示,生成多样化的合成图像表示。该框架消除了对真实图像的依赖,同时保持了数据质量和多样性,为VLMs训练提供了成本效益高且可扩展的解决方案。
Key Takeaways
- 提出了一种跨融合的三阶段多媒体数据合成框架,用于生成VLMs的训练数据。
- 通过该框架,生成了两个数据集:Unicorn-1.2M和Unicorn-471K-Instruction。
- 在第一阶段,利用大语言模型(LLMs)扩展稀疏标题种子,生成语义多样的高质量标题。
- 在第二阶段,将标题进一步处理成多轮指令调整任务,以支持复杂推理。
- 在第三阶段,将文本标题表示转化为视觉表示,生成多样化的合成图像。
- 该框架消除了对真实图像的依赖,降低了训练成本,同时保证了数据的质量和多样性。
点此查看论文截图

CPPO: Accelerating the Training of Group Relative Policy Optimization-Based Reasoning Models
Authors:Zhihang Lin, Mingbao Lin, Yuan Xie, Rongrong Ji
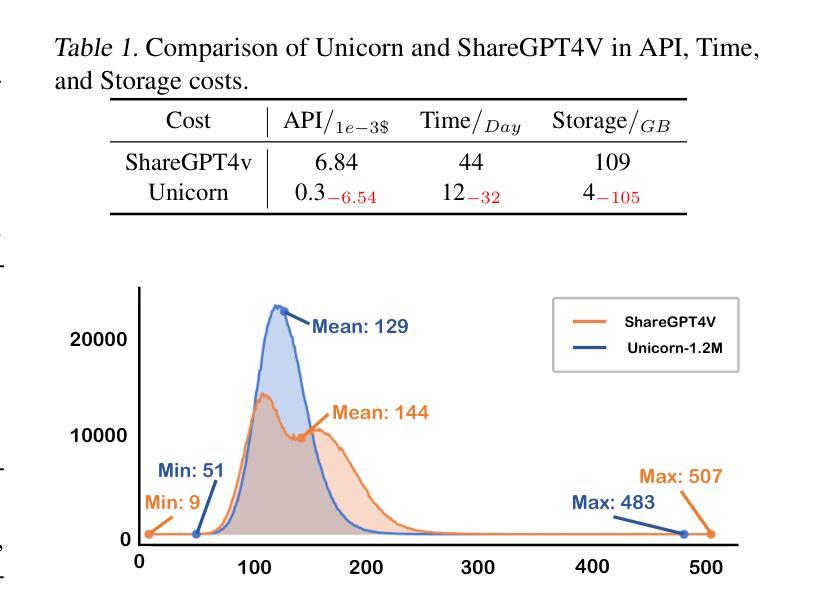
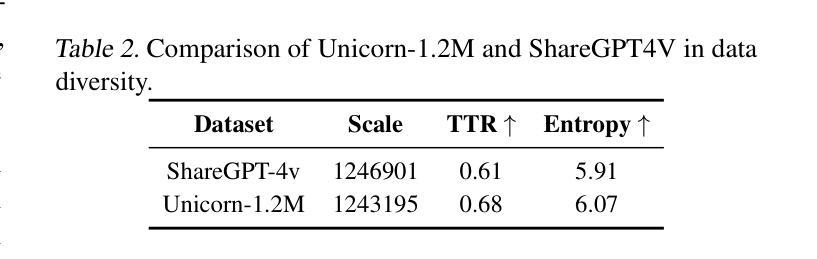
This paper introduces Completion Pruning Policy Optimization (CPPO) to accelerate the training of reasoning models based on Group Relative Policy Optimization (GRPO). GRPO, while effective, incurs high training costs due to the need for sampling multiple completions for each question. Our experiment and theoretical analysis reveals that the number of completions impacts model accuracy yet increases training time multiplicatively, and not all completions contribute equally to policy training – their contribution depends on their relative advantage. To address these issues, we propose CPPO, which prunes completions with low absolute advantages, significantly reducing the number needed for gradient calculation and updates. Additionally, we introduce a dynamic completion allocation strategy to maximize GPU utilization by incorporating additional questions, further enhancing training efficiency. Experimental results demonstrate that CPPO achieves up to $8.32\times$ speedup on GSM8K and $3.51\times$ on Math while preserving or even enhancing the accuracy compared to the original GRPO. We release our code at https://github.com/lzhxmu/CPPO.
本文介绍了完成剪枝策略优化(CPPO),以加速基于组相对策略优化(GRPO)的推理模型的训练。虽然GRPO很有效,但由于需要对每个问题采样多个完成项,其训练成本很高。我们的实验和理论分析表明,完成项的数量会影响模型的准确性,并且会呈倍地增加训练时间,并非所有的完成项都对策略训练贡献相同——它们的贡献取决于其相对优势。为了解决这些问题,我们提出了CPPO,它通过剪除具有低绝对优势的完成项,显著减少了用于梯度计算和更新的完成项数量。此外,我们还引入了一种动态完成项分配策略,通过合并额外的问题来最大限度地提高GPU的利用率,进一步提高训练效率。实验结果表明,CPPO在GSM8K上实现了最高达8.32倍的速度提升,在数学任务上实现了最高达3.51倍的速度提升,同时保持或甚至提高了与原始GRPO相比的准确性。我们的代码已发布在https://github.com/lzhxmu/CPPO。
论文及项目相关链接
PDF 16 pages
Summary
本文提出一种名为完成修剪策略优化(CPPO)的方法,旨在加速基于组相对策略优化(GRPO)的推理模型训练。为解决GRPO高训练成本的问题,CPPO通过修剪低优势完成的数量减少计算梯度所需的完成数量。同时,引入动态完成分配策略以提高GPU利用率,进一步提高训练效率。实验结果表明,CPPO在GSM8K上实现了最高达8.32倍的加速,在数学上实现了最高达3.51倍的加速,同时保持或提高了与原始GRPO的准确性。
Key Takeaways
- CPPO旨在加速基于GRPO的推理模型训练。
- GRPO虽然有效,但训练成本高昂,需为每个问题采样多个完成。
- 实验和理论分析显示完成数量影响模型准确性,并呈倍增加训练时间。
- CPPO通过修剪低优势完成减少计算梯度所需的完成数量。
- 引入动态完成分配策略以提高GPU利用率。
- 实验结果显示CPPO显著提高训练效率,同时保持或提高模型准确性。
- 代码已发布在https://github.com/lzhxmu/CPPO。
点此查看论文截图

Exploring Data Scaling Trends and Effects in Reinforcement Learning from Human Feedback
Authors:Wei Shen, Guanlin Liu, Zheng Wu, Ruofei Zhu, Qingping Yang, Chao Xin, Yu Yue, Lin Yan
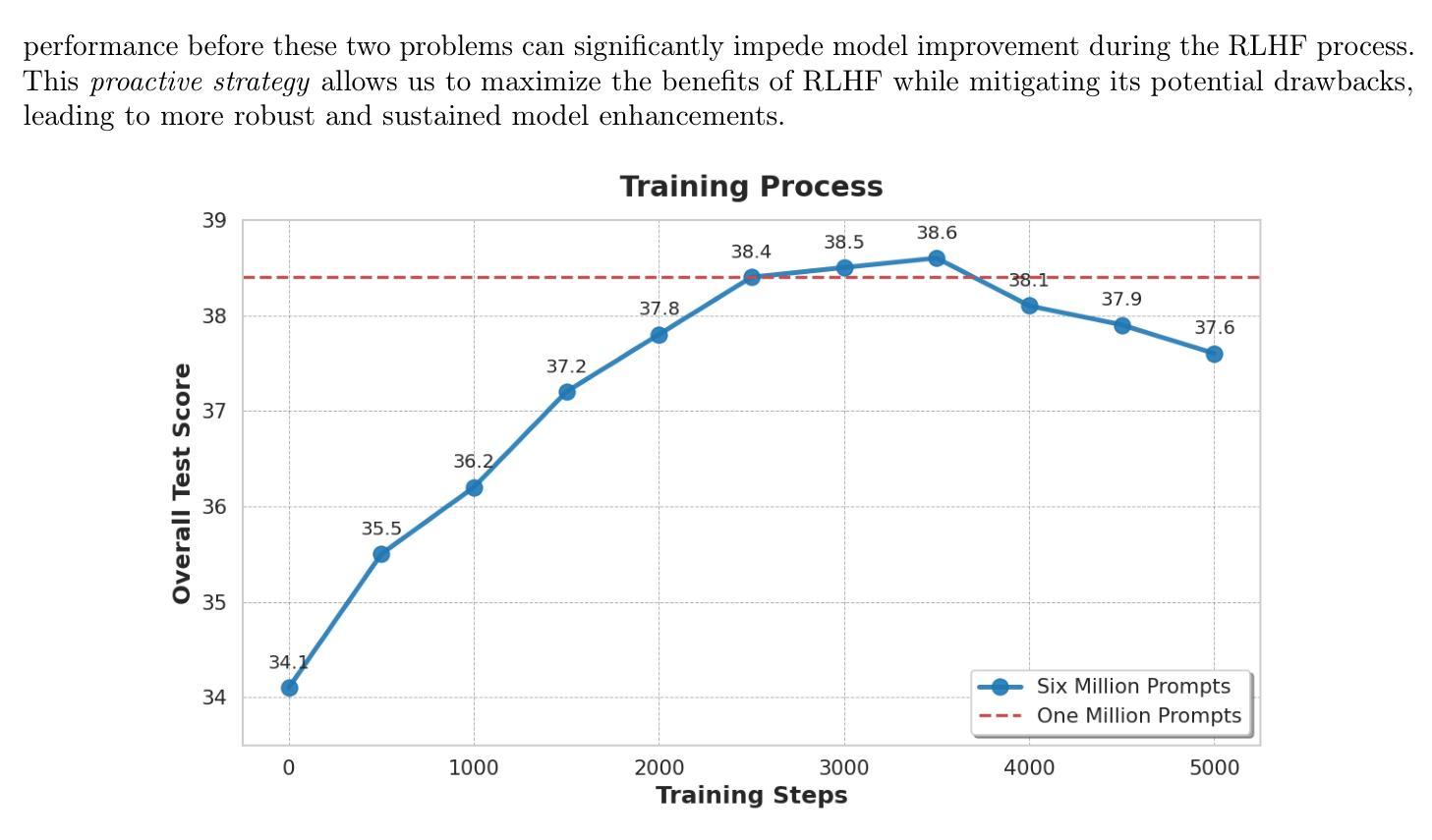
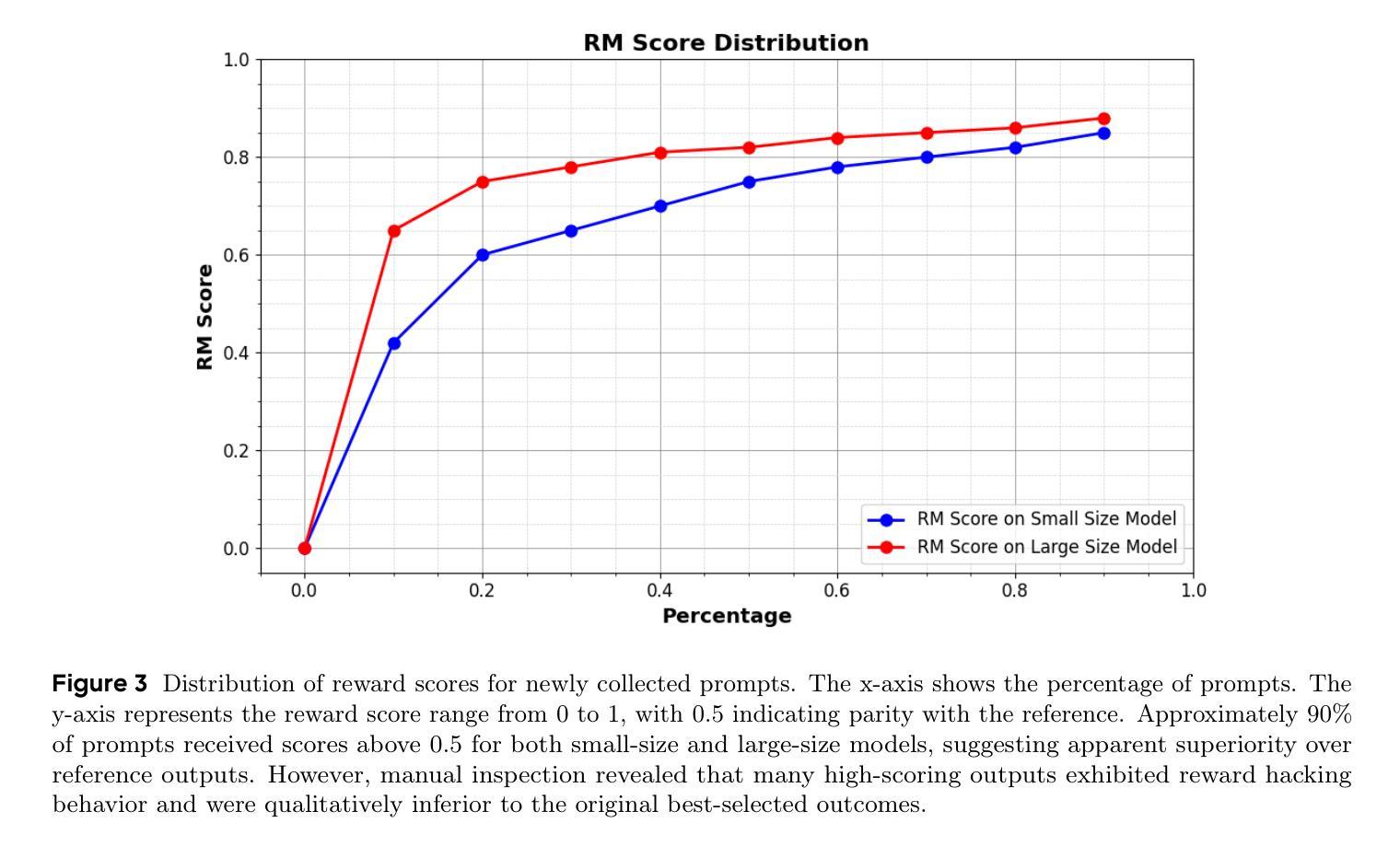
Reinforcement Learning from Human Feedback (RLHF) is crucial for aligning large language models with human preferences. While recent research has focused on algorithmic improvements, the importance of prompt-data construction has been overlooked. This paper addresses this gap by exploring data-driven bottlenecks in RLHF performance scaling, particularly reward hacking and decreasing response diversity. We introduce a hybrid reward system combining reasoning task verifiers (RTV) and a generative reward model (GenRM) to mitigate reward hacking. We also propose a novel prompt-selection method, Pre-PPO, to maintain response diversity and enhance learning effectiveness. Additionally, we find that prioritizing mathematical and coding tasks early in RLHF training significantly improves performance. Experiments across two model sizes validate our methods’ effectiveness and scalability. Results show that RTV is most resistant to reward hacking, followed by GenRM with ground truth, and then GenRM with SFT Best-of-N responses. Our strategies enable rapid capture of subtle task-specific distinctions, leading to substantial improvements in overall RLHF performance. This work highlights the importance of careful data construction and provides practical methods to overcome performance barriers in RLHF.
强化学习从人类反馈(RLHF)对于将大型语言模型与人类偏好对齐至关重要。虽然最近的研究主要集中在算法改进上,但提示数据构建的重要性却被忽视了。本文解决了这一空白领域的问题,通过探索RLHF性能扩展中数据驱动的瓶颈,特别是奖励破解和响应多样性降低的问题。我们引入了一种混合奖励系统,结合推理任务验证器(RTV)和生成奖励模型(GenRM),以缓解奖励破解的问题。我们还提出了一种新型的提示选择方法Pre-PPO,以保持响应的多样性并提高学习有效性。此外,我们发现早期在RLHF训练中优先进行数学和编码任务可以显著提高性能。在两个模型大小上的实验验证了我们的方法和可扩展性。结果表明,RTV最不容易受到奖励破解的影响,其次是带有真实奖励的GenRM,然后是带有SFT最佳N响应的GenRM。我们的策略能够迅速捕捉到微妙的特定任务差异,从而大大提高了整体的RLHF性能。这项工作强调了仔细构建数据的重要性,并提供了克服RLHF中性能障碍的实际方法。
论文及项目相关链接
Summary
大语言模型与人类偏好对齐的关键在于强化学习(RL)与人类反馈的结合(RLHF)。近期研究多关注算法改进,忽略了提示数据构建的重要性。本文通过探究RLHF性能提升的数据驱动瓶颈,解决了奖励破解和响应多样性降低的问题。引入结合推理任务验证器(RTV)和生成奖励模型(GenRM)的混合奖励系统,以缓解奖励破解问题。同时提出一种新型的提示选择方法Pre-PPO,以维持响应多样性并提高学习效率。此外,研究发现早期在RLHF训练中优先进行数学和编码任务能显著提高性能。实验证明,本文提出的方法在两个模型尺寸上均有效且可扩展。其中RTV最不易受到奖励破解的影响,其次是结合真实情况的GenRM,最后是使用SFT Best-of-N响应的GenRM。本文的策略有助于迅速捕捉微妙的特定任务区别,显著提高了整体的RLHF性能。强调了仔细构建数据的重要性,并为克服RLHF中的性能障碍提供了实用方法。
Key Takeaways
- 强化学习与人类反馈(RLHF)在大语言模型与人类偏好对齐中起关键作用。
- 数据构建对于RLHF性能至关重要,包括解决奖励破解和维持响应多样性。
- 引入混合奖励系统(结合RTV和GenRM)以缓解奖励破解问题。
- 提出新型提示选择方法Pre-PPO,旨在提高学习效率并维持响应多样性。
- 早期训练中的数学和编码任务对RLHF性能提升显著。
- 实验验证所提方法在不同模型尺寸上的有效性和可扩展性。
点此查看论文截图