⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-05 更新
Re-thinking Temporal Search for Long-Form Video Understanding
Authors:Jinhui Ye, Zihan Wang, Haosen Sun, Keshigeyan Chandrasegaran, Zane Durante, Cristobal Eyzaguirre, Yonatan Bisk, Juan Carlos Niebles, Ehsan Adeli, Li Fei-Fei, Jiajun Wu, Manling Li
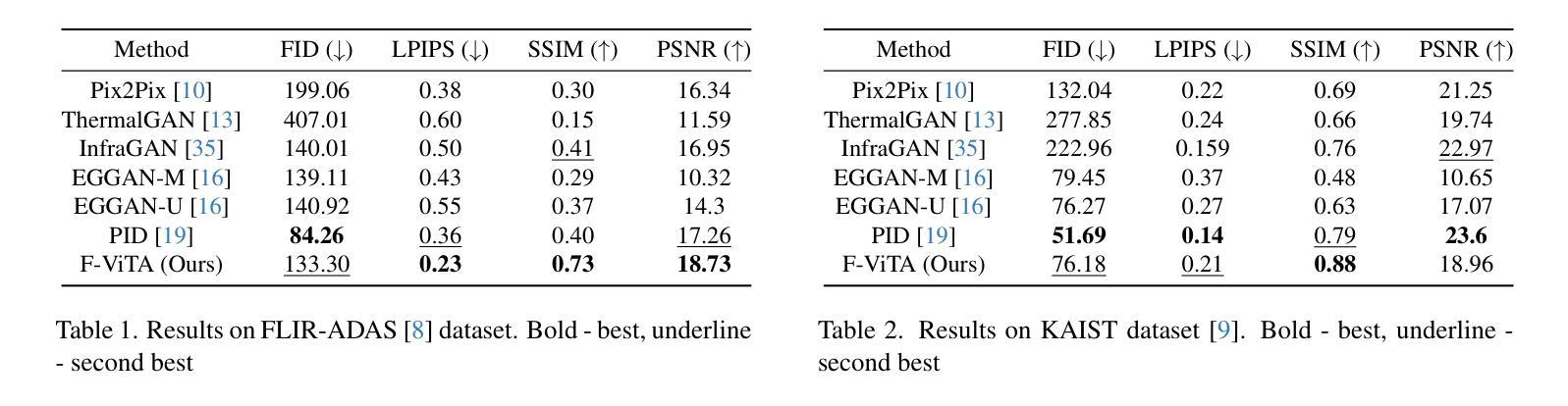
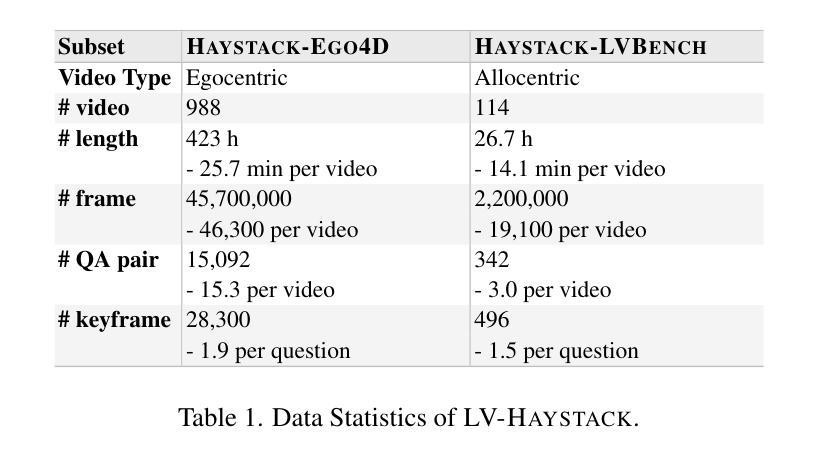
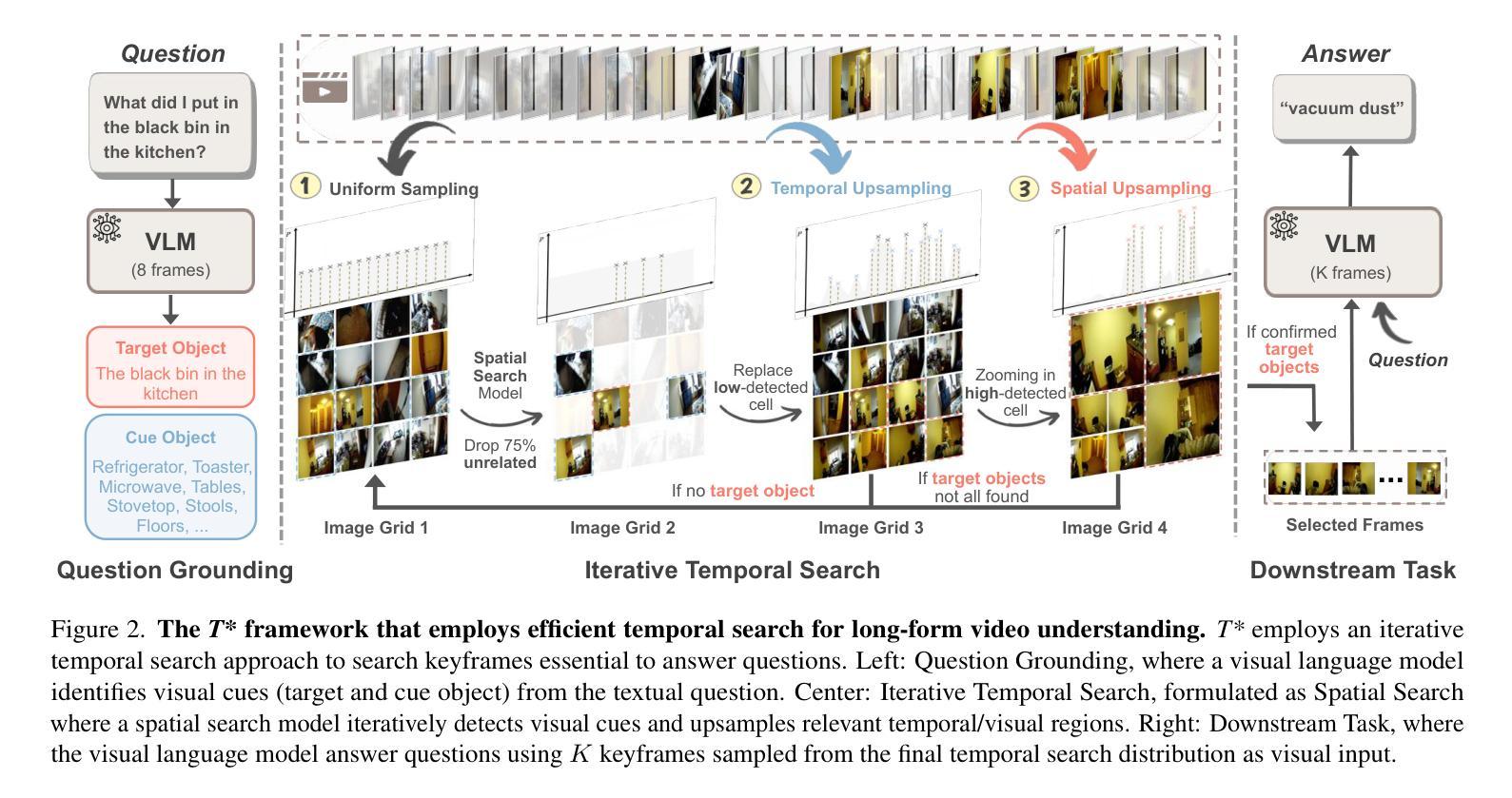
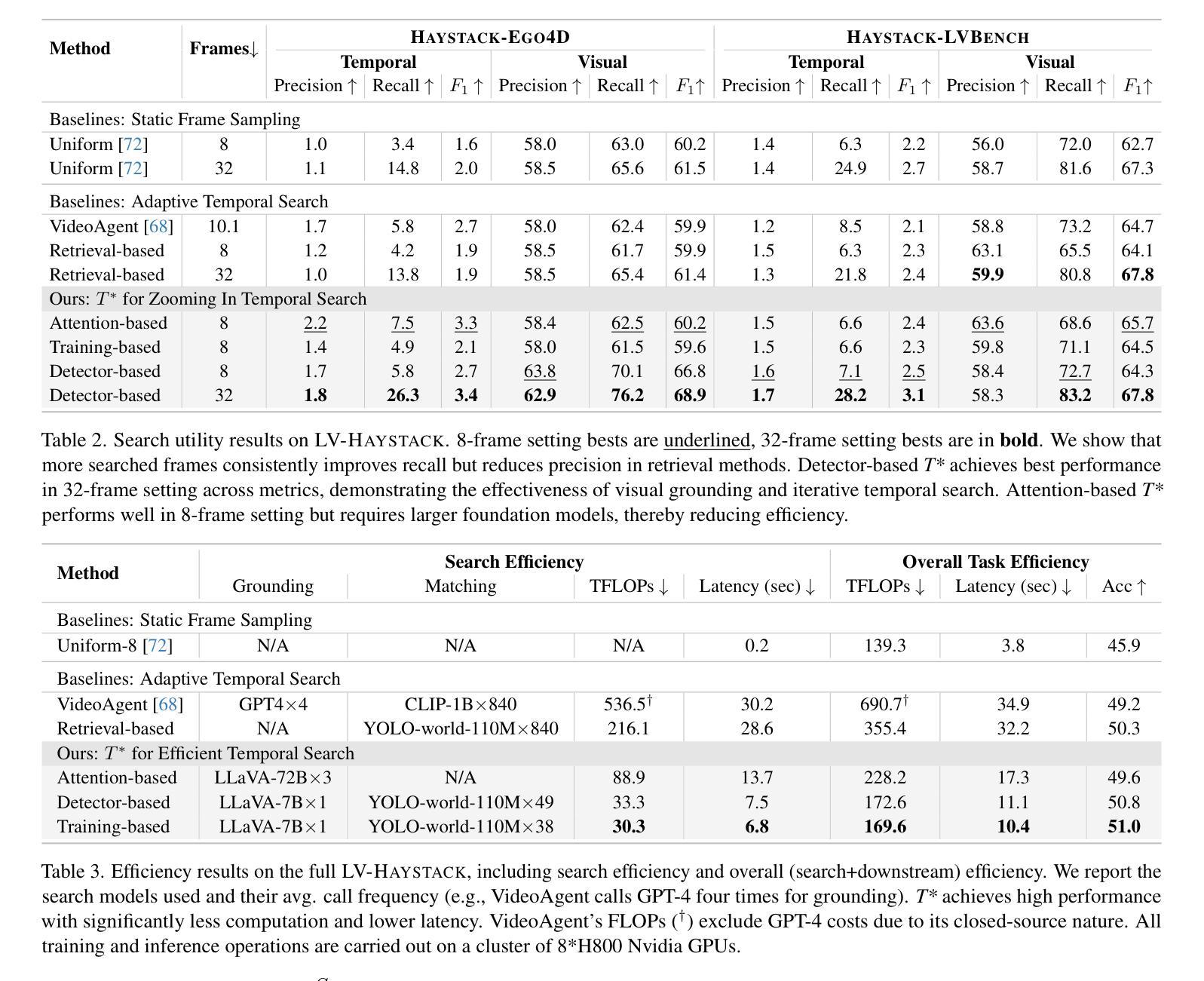
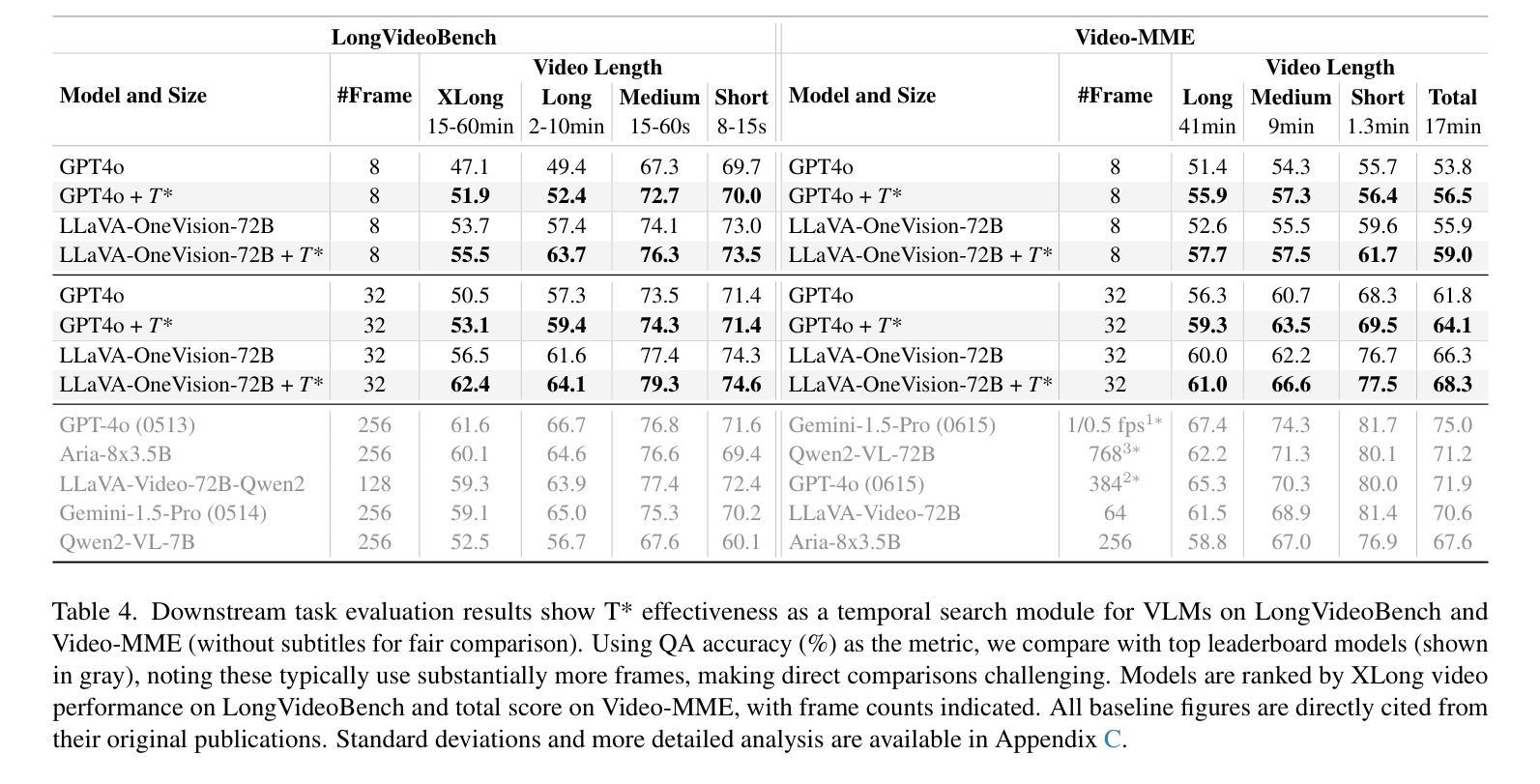
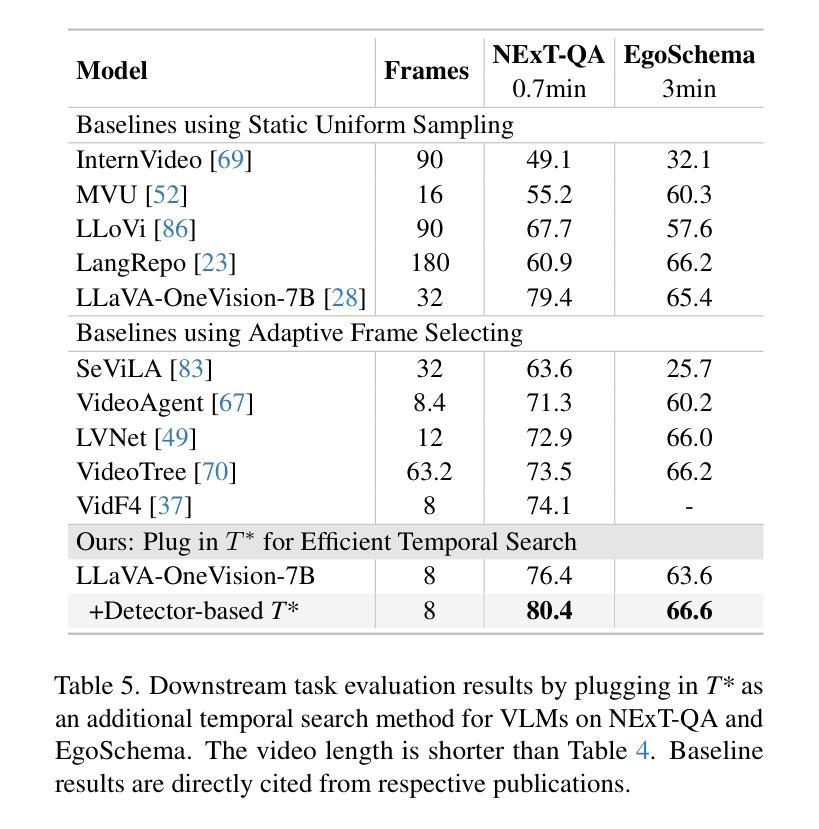
Efficient understanding of long-form videos remains a significant challenge in computer vision. In this work, we revisit temporal search paradigms for long-form video understanding, studying a fundamental issue pertaining to all state-of-the-art (SOTA) long-context vision-language models (VLMs). In particular, our contributions are two-fold: First, we formulate temporal search as a Long Video Haystack problem, i.e., finding a minimal set of relevant frames (typically one to five) among tens of thousands of frames from real-world long videos given specific queries. To validate our formulation, we create LV-Haystack, the first benchmark containing 3,874 human-annotated instances with fine-grained evaluation metrics for assessing keyframe search quality and computational efficiency. Experimental results on LV-Haystack highlight a significant research gap in temporal search capabilities, with SOTA keyframe selection methods achieving only 2.1% temporal F1 score on the LVBench subset. Next, inspired by visual search in images, we re-think temporal searching and propose a lightweight keyframe searching framework, T*, which casts the expensive temporal search as a spatial search problem. T* leverages superior visual localization capabilities typically used in images and introduces an adaptive zooming-in mechanism that operates across both temporal and spatial dimensions. Our extensive experiments show that when integrated with existing methods, T* significantly improves SOTA long-form video understanding performance. Specifically, under an inference budget of 32 frames, T* improves GPT-4o’s performance from 50.5% to 53.1% and LLaVA-OneVision-72B’s performance from 56.5% to 62.4% on LongVideoBench XL subset. Our PyTorch code, benchmark dataset and models are included in the Supplementary material.
对长视频的深刻理解仍然是计算机视觉领域的一个重要挑战。在这项工作中,我们重新审视了用于长视频理解的时序搜索范式,研究了一个与所有最新(SOTA)长上下文视觉语言模型(VLMs)相关的基础问题。特别是,我们的贡献体现在两个方面:首先,我们将时序搜索表述为长视频检索问题,即在现实世界的长视频中,给定特定的查询,从数万帧中找到一小部分(通常为一到五个)相关帧。为了验证我们的表述,我们创建了LV-Haystack数据集,这是第一个包含3874个人工标注实例的基准测试集,具有精细的评估指标,用于评估关键帧搜索质量和计算效率。在LV-Haystack上的实验结果表明,在时序搜索能力方面存在明显的差距,最先进的关键帧选择方法仅在LVBench子集上实现了2.1%的时序F1分数。其次,受到图像视觉搜索的启发,我们重新思考时序搜索并提出了一种轻量级的关键帧搜索框架T,它将昂贵的时序搜索转化为空间搜索问题。T利用图像中优越的视觉定位能力,并引入了一种自适应的缩放机制,该机制在时空维度上都能运行。我们的实验表明,与现有方法相结合时,T可以显著提高最先进的长期视频理解性能。具体来说,在预算为每推理处理32帧的条件下,T将GPT-4o的性能从50.5%提高到53.1%,将LLaVA-OneVision-72B的性能从56.5%提高到62.4%,这是在LongVideoBench XL子集上的表现。我们的PyTorch代码、基准数据集和模型都包含在补充材料中。
论文及项目相关链接
PDF Accepted by CVPR 2025; A real-world long video needle-in-haystack benchmark; long-video QA with human ref frames
Summary
本文探讨了长视频理解中的时间搜索问题,将其描述为“长视频堆栈”问题。文章提出并验证了LV-Haystack基准测试集,用于评估关键帧搜索质量和计算效率。文章还提出了一种轻量级的关键帧搜索框架T,将昂贵的时间搜索问题转化为空间搜索问题,并引入自适应缩放机制,在时间和空间维度上操作。实验表明,T与现有方法结合,显著提高长视频理解性能。
Key Takeaways
- 长视频理解中的时间搜索问题被重新定义为“长视频堆栈”问题,旨在从大量视频帧中找到与查询相关的关键帧。
- 引入了LV-Haystack基准测试集,用于评估关键帧搜索的质量和效率。
- 提出了轻量级关键帧搜索框架T*,将时间搜索问题转化为空间搜索问题。
- T*利用图像中的优秀视觉定位能力,并引入自适应缩放机制,在时间和空间两个维度上操作。
- 实验表明,T*显著提高了现有长视频理解方法的性能。
- T*在与GPT-4o和LLaVA-OneVision-72B等现有方法结合时,性能提升显著。
点此查看论文截图


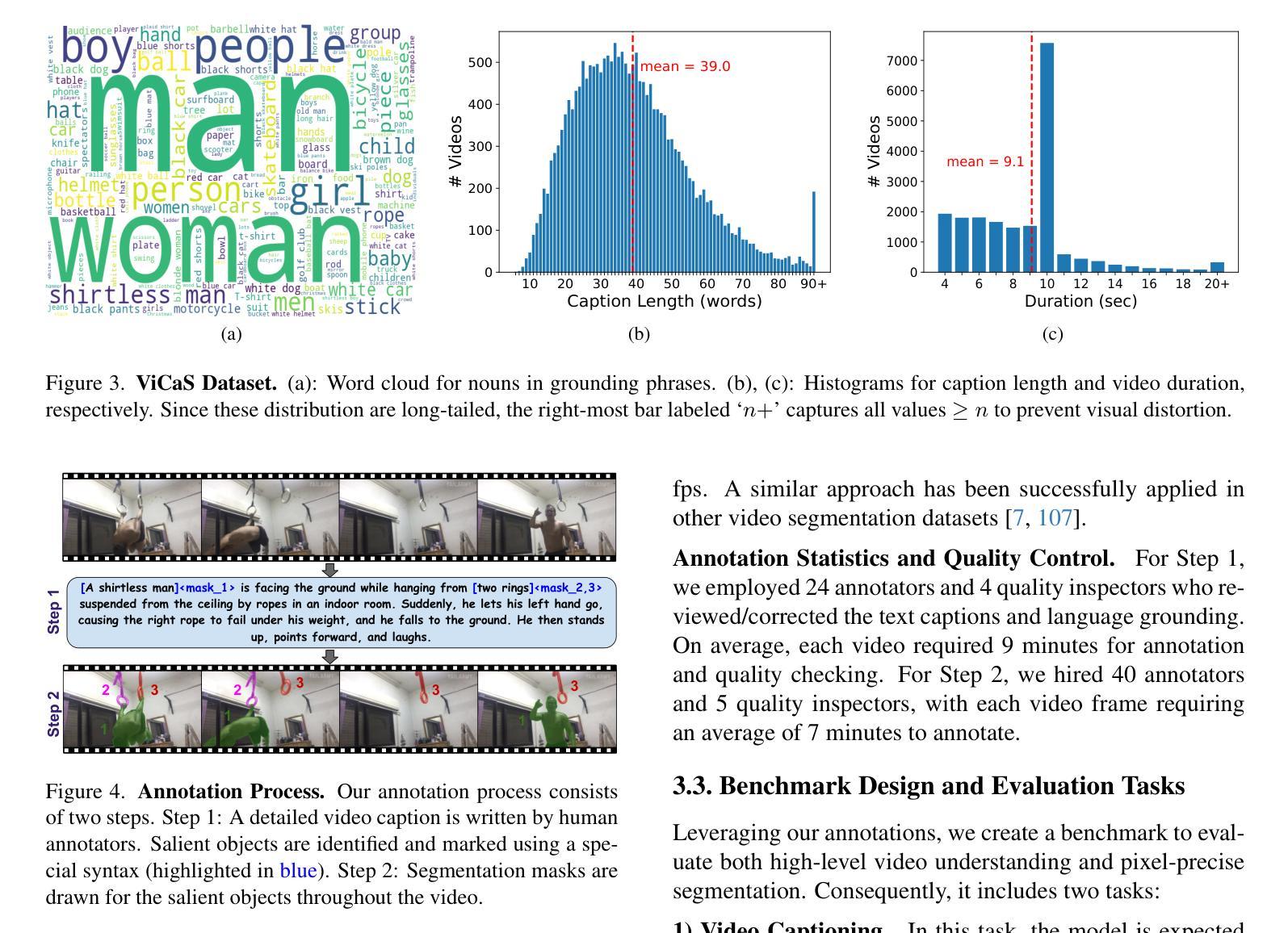
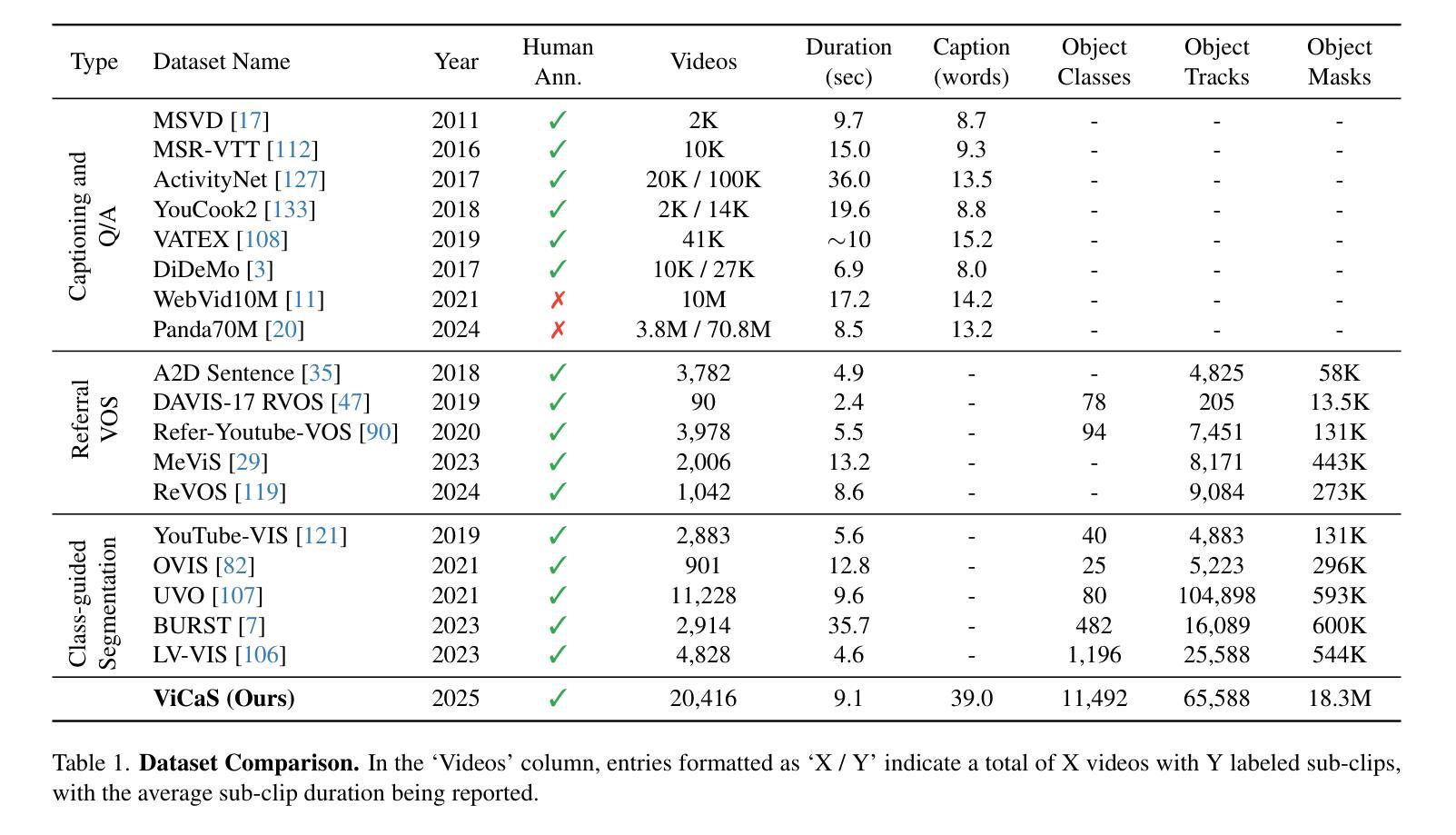
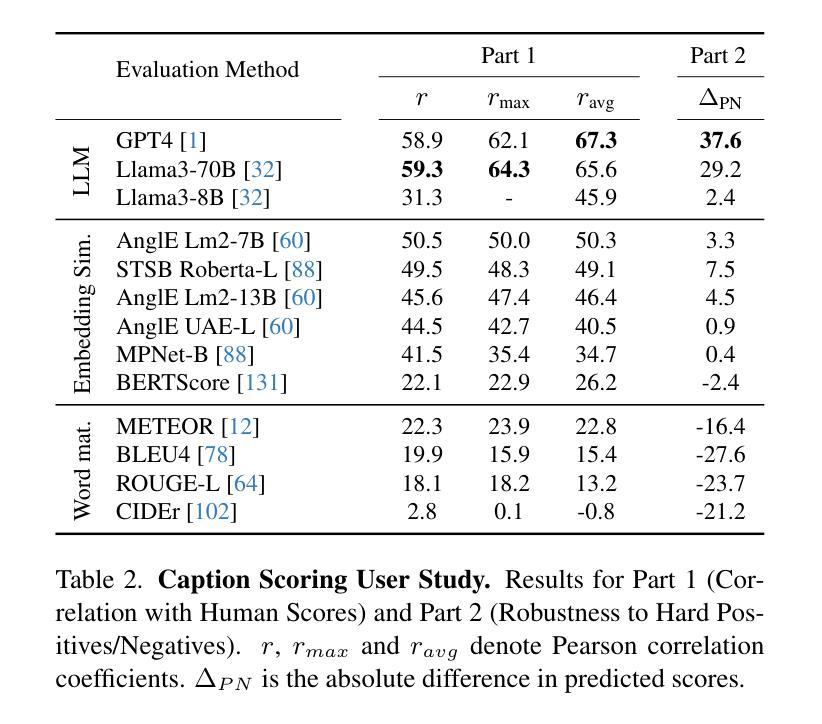
ViCaS: A Dataset for Combining Holistic and Pixel-level Video Understanding using Captions with Grounded Segmentation
Authors:Ali Athar, Xueqing Deng, Liang-Chieh Chen
Recent advances in multimodal large language models (MLLMs) have expanded research in video understanding, primarily focusing on high-level tasks such as video captioning and question-answering. Meanwhile, a smaller body of work addresses dense, pixel-precise segmentation tasks, which typically involve category-guided or referral-based object segmentation. Although both directions are essential for developing models with human-level video comprehension, they have largely evolved separately, with distinct benchmarks and architectures. This paper aims to unify these efforts by introducing ViCaS, a new dataset containing thousands of challenging videos, each annotated with detailed, human-written captions and temporally consistent, pixel-accurate masks for multiple objects with phrase grounding. Our benchmark evaluates models on both holistic/high-level understanding and language-guided, pixel-precise segmentation. We also present carefully validated evaluation measures and propose an effective model architecture that can tackle our benchmark. Project page: https://ali2500.github.io/vicas-project/
近期多模态大型语言模型(MLLMs)的进展推动了视频理解研究,主要集中在高级任务,如视频描述和问答。同时,较少的研究关注密集的像素精确分割任务,这通常涉及类别引导或基于引用的对象分割。虽然这两个方向对于开发具有人类水平视频理解能力的模型至关重要,但它们大多独立发展,具有不同的基准和架构。本文旨在通过引入ViCaS数据集来统一这些努力,该数据集包含数千个具有挑战性的视频,每个视频都经过详细的人类书写描述和与多个对象短语定位一致的时序一致、像素精确的掩膜标注。我们的基准测试对整体/高级理解和语言引导、像素精确的分割进行了评估。我们还提供了经过仔细验证的评估指标,并提出了可以有效应对我们基准测试模型架构。项目页面:https://ali2500.github.io/vicas-project/
论文及项目相关链接
PDF Accepted to CVPR 2025. Project page: https://ali2500.github.io/vicas-project/
Summary
视频理解领域的最新进展显示了对多媒体大语言模型的研究拓展,尤其是在高级任务(如视频标题编写和问题回答)上取得了突破。尽管还有更小范围的工作集中在密集的像素精确分割任务上,这些任务通常涉及类别引导或基于引用的对象分割。本文旨在通过引入ViCaS数据集统一这些努力,该数据集包含数千个具有挑战性的视频,每个视频都带有详细的人类书写标题和与多个对象短语定位一致的像素精确掩码。我们的基准测试评估模型在整体高级理解和语言指导下的像素精确分割方面的表现。同时提供了经过验证的评价指标并提出了一个有效的模型架构来应对我们的基准测试挑战。详情参见项目页面:链接。
Key Takeaways
- 多模态大语言模型在视频理解领域的进展迅速,特别是针对高级任务的研究如视频标题编写和问题回答等方向的研究显著增多。
点此查看论文截图