⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-05 更新
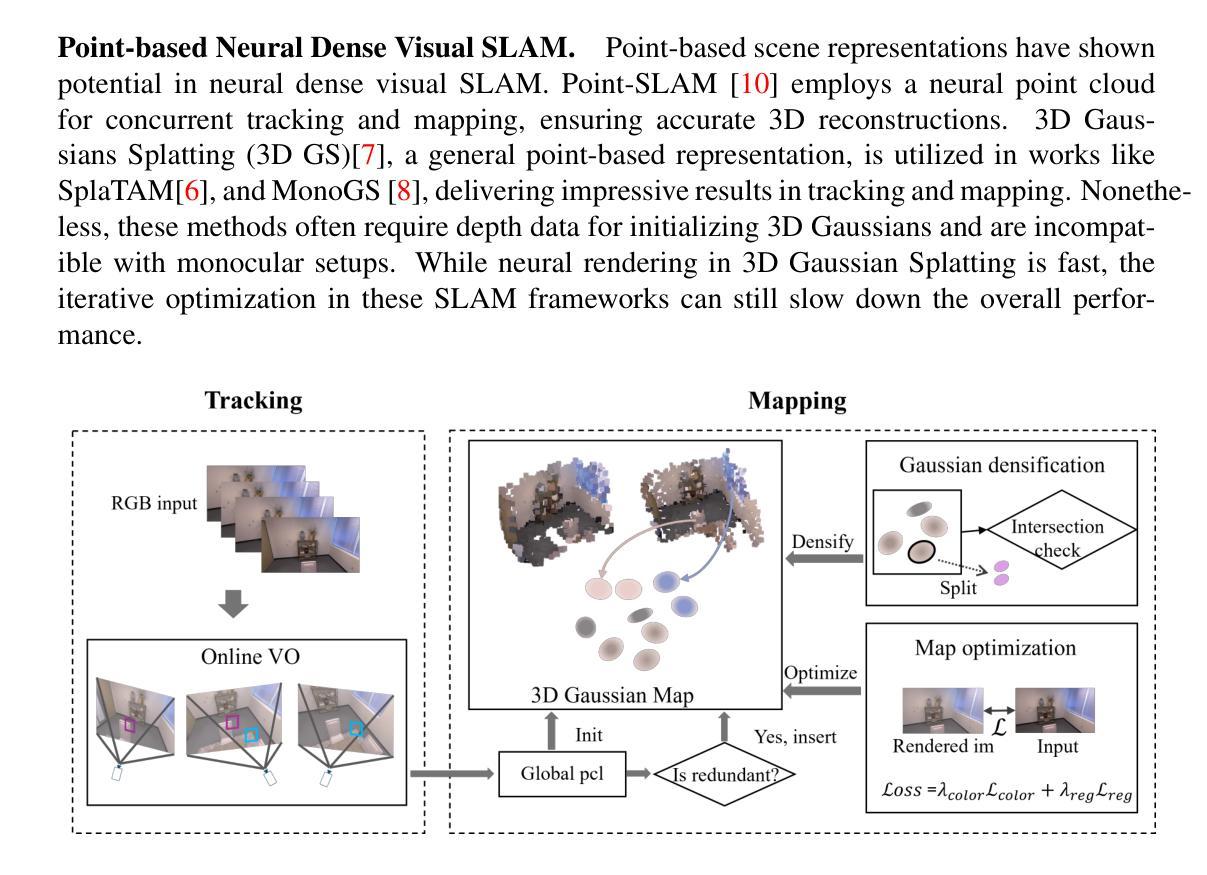
MonoGS++: Fast and Accurate Monocular RGB Gaussian SLAM
Authors:Renwu Li, Wenjing Ke, Dong Li, Lu Tian, Emad Barsoum
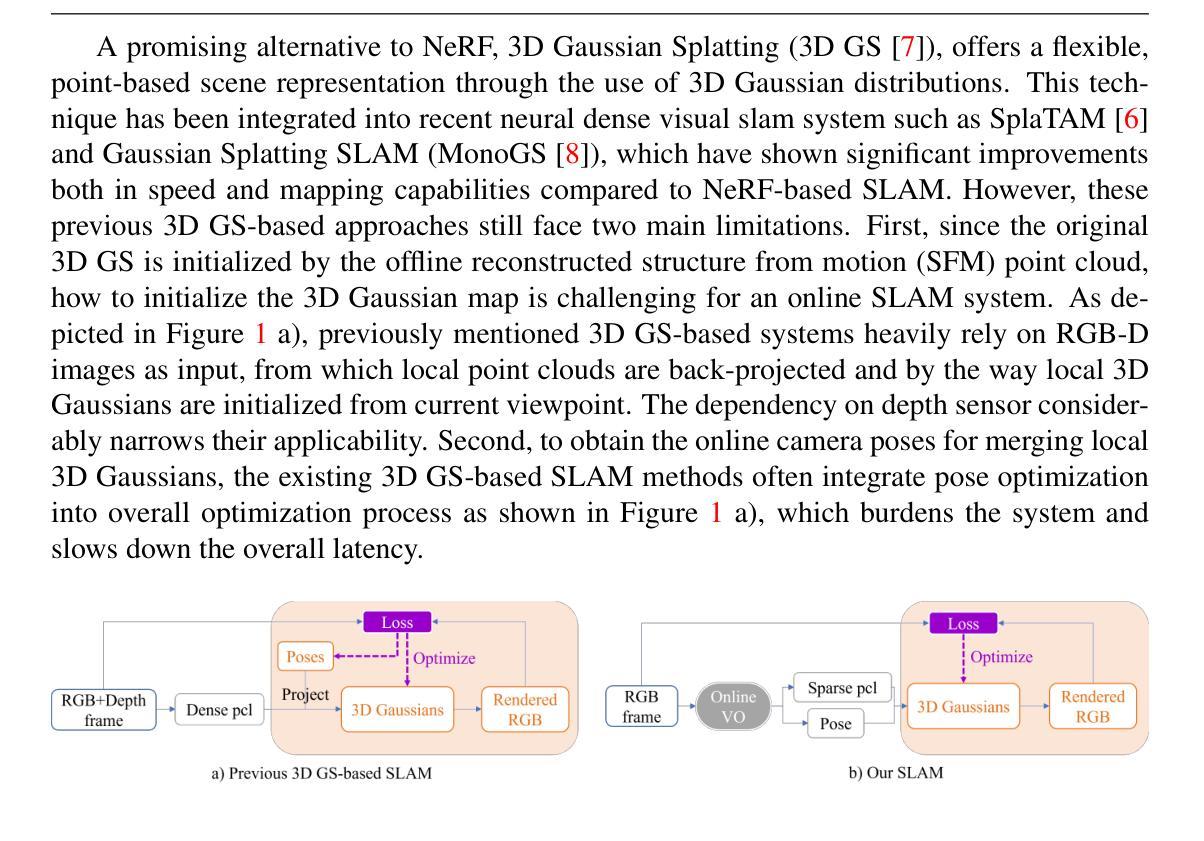
We present MonoGS++, a novel fast and accurate Simultaneous Localization and Mapping (SLAM) method that leverages 3D Gaussian representations and operates solely on RGB inputs. While previous 3D Gaussian Splatting (GS)-based methods largely depended on depth sensors, our approach reduces the hardware dependency and only requires RGB input, leveraging online visual odometry (VO) to generate sparse point clouds in real-time. To reduce redundancy and enhance the quality of 3D scene reconstruction, we implemented a series of methodological enhancements in 3D Gaussian mapping. Firstly, we introduced dynamic 3D Gaussian insertion to avoid adding redundant Gaussians in previously well-reconstructed areas. Secondly, we introduced clarity-enhancing Gaussian densification module and planar regularization to handle texture-less areas and flat surfaces better. We achieved precise camera tracking results both on the synthetic Replica and real-world TUM-RGBD datasets, comparable to those of the state-of-the-art. Additionally, our method realized a significant 5.57x improvement in frames per second (fps) over the previous state-of-the-art, MonoGS.
我们提出了MonoGS++,这是一种新型快速且精确的SLAM(Simultaneous Localization and Mapping,即时定位与地图构建)方法,它利用三维高斯表示,并且仅使用RGB输入进行操作。尽管先前的基于三维高斯拼接(GS)的方法在很大程度上依赖于深度传感器,但我们的方法减少了硬件依赖,仅需要RGB输入,并利用在线视觉里程计(VO)来实时生成稀疏点云。为了减少冗余并增强三维场景重建的质量,我们在三维高斯映射中实现了一系列方法上的改进。首先,我们引入了动态三维高斯插入,以避免在先前重建良好的区域中添加冗余的高斯。其次,我们引入了清晰度增强高斯细化模块和平面正则化,以更好地处理无纹理区域和平坦表面。我们在合成副本和真实世界的TUM-RGBD数据集上实现了精确的相机跟踪结果,与最新技术相比表现相当。此外,我们的方法在每秒帧数(fps)上较之前的最新技术MonoGS实现了5.57倍的显著提升。
论文及项目相关链接
Summary
本论文提出MonoGS++方法,这是一种新型快速且精确的SLAM方法,利用三维高斯表示,仅依赖RGB输入进行操作。相较于之前依赖深度传感器的三维高斯映射方法,该方法减少了硬件依赖,并借助在线视觉里程计生成实时稀疏点云。在三维高斯映射方面,该方法实现了多项改进以提升场景重建质量并降低冗余。测试表明,无论在合成Replica数据集还是真实世界TUM-RGBD数据集上,该方法的相机追踪结果都精确,且与现有技术相当。相较于上一代MonoGS方法,该方法每秒帧数提高了5.57倍。
Key Takeaways
- MonoGS++是一种基于RGB输入的快速且精确的SLAM方法。
- 该方法利用三维高斯表示进行操作,实现了对之前依赖深度传感器的三维高斯映射方法的改进。
- MonoGS++通过在线视觉里程计生成实时稀疏点云,减少了硬件依赖。
- 方法实施了多项改进提升三维场景重建的质量和降低冗余。
- 动态三维高斯插入避免了在已重建区域添加冗余高斯。
- 引入了清晰度提升的高斯密集化模块和平面正则化,以更好地处理无纹理区域和平坦表面。
- 在合成和真实世界数据集上的测试表明,MonoGS++的相机追踪结果精确,性能与现有技术相当。
点此查看论文截图

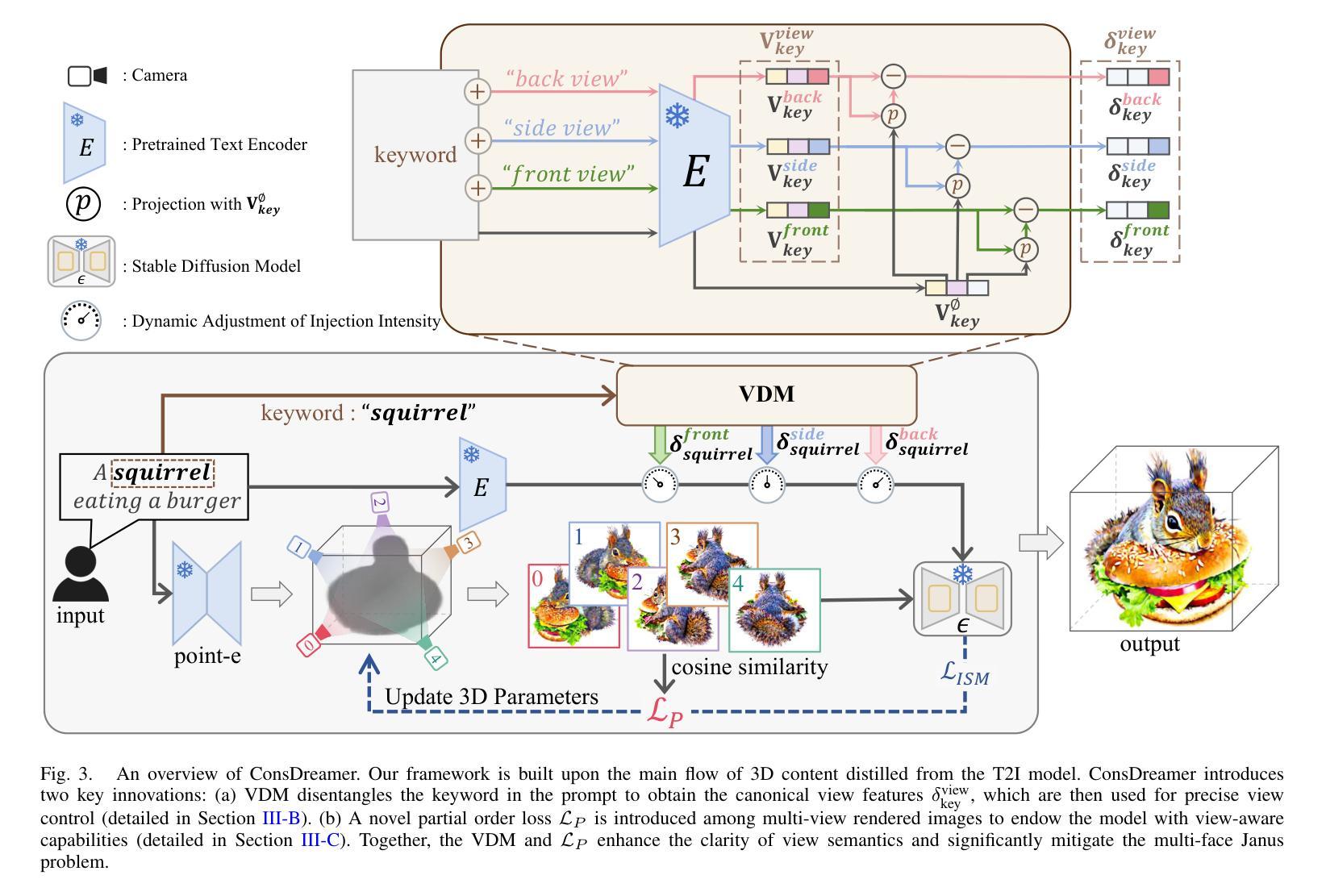
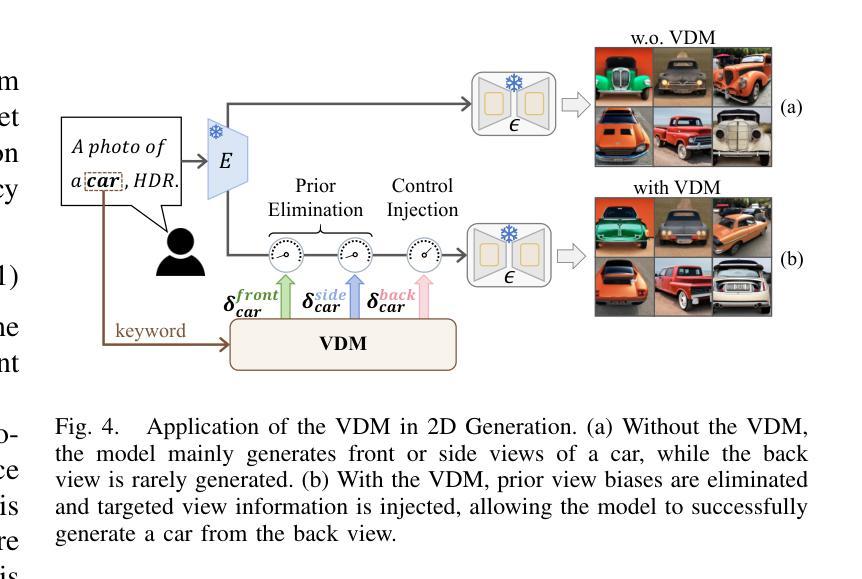
ConsDreamer: Advancing Multi-View Consistency for Zero-Shot Text-to-3D Generation
Authors:Yuan Zhou, Shilong Jin, Litao Hua, Wanjun Lv, Haoran Duan, Jungong Han
Recent advances in zero-shot text-to-3D generation have revolutionized 3D content creation by enabling direct synthesis from textual descriptions. While state-of-the-art methods leverage 3D Gaussian Splatting with score distillation to enhance multi-view rendering through pre-trained text-to-image (T2I) models, they suffer from inherent view biases in T2I priors. These biases lead to inconsistent 3D generation, particularly manifesting as the multi-face Janus problem, where objects exhibit conflicting features across views. To address this fundamental challenge, we propose ConsDreamer, a novel framework that mitigates view bias by refining both the conditional and unconditional terms in the score distillation process: (1) a View Disentanglement Module (VDM) that eliminates viewpoint biases in conditional prompts by decoupling irrelevant view components and injecting precise camera parameters; and (2) a similarity-based partial order loss that enforces geometric consistency in the unconditional term by aligning cosine similarities with azimuth relationships. Extensive experiments demonstrate that ConsDreamer effectively mitigates the multi-face Janus problem in text-to-3D generation, outperforming existing methods in both visual quality and consistency.
最近,零样本文本到3D生成技术的进展通过实现从文本描述到直接合成的转变,彻底改变了3D内容的创作方式。虽然目前最先进的方法利用3D高斯平铺和分数蒸馏技术,通过预训练的文本到图像(T2I)模型增强多角度渲染,但它们却遭受了T2I先验的固有视角偏差的影响。这些偏差导致了3D生成的不一致性,特别表现为多面 Janus 问题,即物体在不同视角下的特征相互冲突。为了应对这一基本挑战,我们提出了 ConsDreamer 这一新型框架,它通过改进分数蒸馏过程中的条件和无条件术语来减轻视角偏差:(1)视角分离模块(VDM),通过分离无关的视角成分并注入精确的相机参数,消除条件提示中的视角偏差;(2)基于相似度的部分顺序损失,通过调整余弦相似性与方位关系,在无条件术语中强制实施几何一致性。大量实验表明,ConsDreamer 有效地解决了文本到3D生成中的多面 Janus 问题,在视觉质量和一致性方面均优于现有方法。
论文及项目相关链接
PDF 13 pages, 11 figures, 3 tables
Summary
文本描述直接合成3D内容的方法取得了进展,但现有技术存在视图偏差问题,导致3D生成不一致,出现多面人问题。为解决此问题,提出ConsDreamer框架,通过改进条件和无条件术语中的评分蒸馏过程来消除视图偏差,包括视图分解模块和基于相似性的部分顺序损失。实验证明,ConsDreamer在文本到3D生成中有效解决了多面人问题,在视觉质量和一致性方面优于现有方法。
Key Takeaways
- 文本直接合成3D内容成为3D内容创建的革命性方法。
- 当前技术存在视图偏差问题,导致3D生成不一致。
- ConsDreamer框架旨在解决视图偏差问题,通过改进评分蒸馏过程中的条件和无条件术语。
- ConsDreamer包括视图分解模块(VDM),通过解耦无关视图组件并注入精确相机参数来消除视点偏差。
- ConsDreamer采用基于相似性的部分顺序损失,通过对齐余弦相似性与方位关系来确保几何一致性。
- 实验证明ConsDreamer在文本到3D生成中解决了多面人问题。
点此查看论文截图


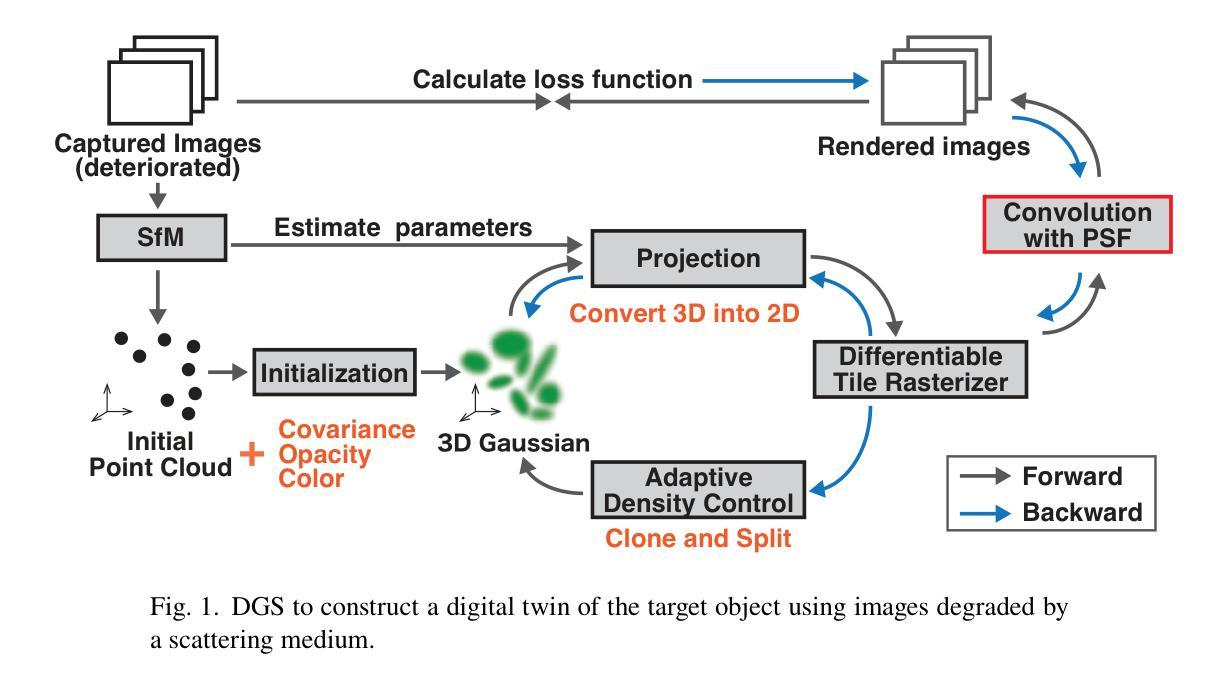
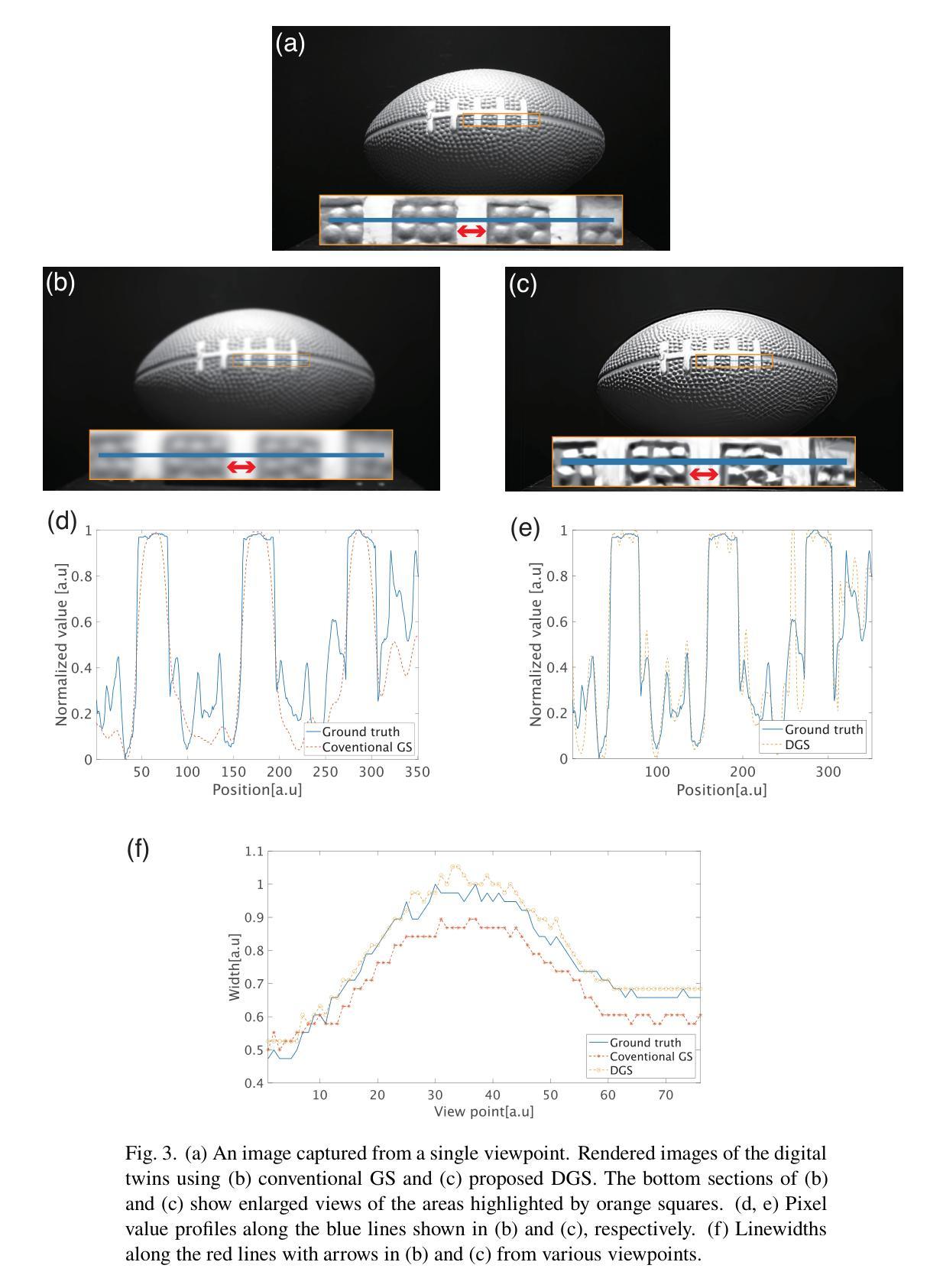
Digital-twin imaging based on descattering Gaussian splatting
Authors:Suguru Shimomura, Kazuki Yamanouchi, Jun Tanida
Three-dimensional imaging through scattering media is important in medical science and astronomy. We propose a digital-twin imaging method based on Gaussian splatting to observe an object behind a scattering medium. A digital twin model built through data assimilation, emulates the behavior of objects and environmental changes in a virtual space. By constructing a digital twin using point clouds composed of Gaussians and simulating the scattering process through the convolution of a point spread function, three-dimensional objects behind a scattering medium can be reproduced as a digital twin. In this study, a high-contrast digital twin reproducing a three-dimensional object was successfully constructed from degraded images, assuming that data were acquired from wavefronts disturbed by a scattering medium. This technique reproduces objects by integrating data processing with image measurements.
通过散射介质进行三维成像在医学和天文学中具有重要意义。我们提出了一种基于高斯展开的数字化双胞胎成像方法来观察散射介质后的物体。通过数据同化建立的数字双胞胎模型,模拟虚拟空间中的对象行为和环境变化。通过使用由高斯组成的点云构建数字双胞胎,并通过点扩散函数的卷积模拟散射过程,可以将在散射介质后的三维对象复制为数字双胞胎。本研究中,从退化图像成功构建了一个高对比度的三维数字双胞胎。假设数据来自被散射介质干扰的波前所获得的数据。此技术通过将数据处理与图像测量相结合来重现物体。
论文及项目相关链接
摘要
基于高斯喷涂的数字孪生成像方法可用于观测散射介质后的物体。通过数据同化构建数字孪生模型,模拟虚拟空间中对象和环境变化的行为。利用高斯点云构建数字孪生体,并通过点扩散函数的卷积模拟散射过程,成功构建出三维物体的高对比度数字孪生体。此技术通过将数据处理与图像测量相结合,实现对物体的重建。
要点
- 提出一种基于高斯喷涂的数字孪生成像方法,用于透过散射介质观测物体。
- 通过数据同化构建数字孪生模型,模拟虚拟空间中对象的行为和环境变化。
- 利用高斯点云构建数字孪生体,模拟散射过程。
- 成功构建出高对比度的三维物体数字孪生体。
- 此技术集成了数据处理和图像测量,实现了物体的重建。
- 此方法在医学和天文学等领域具有应用价值。
点此查看论文截图


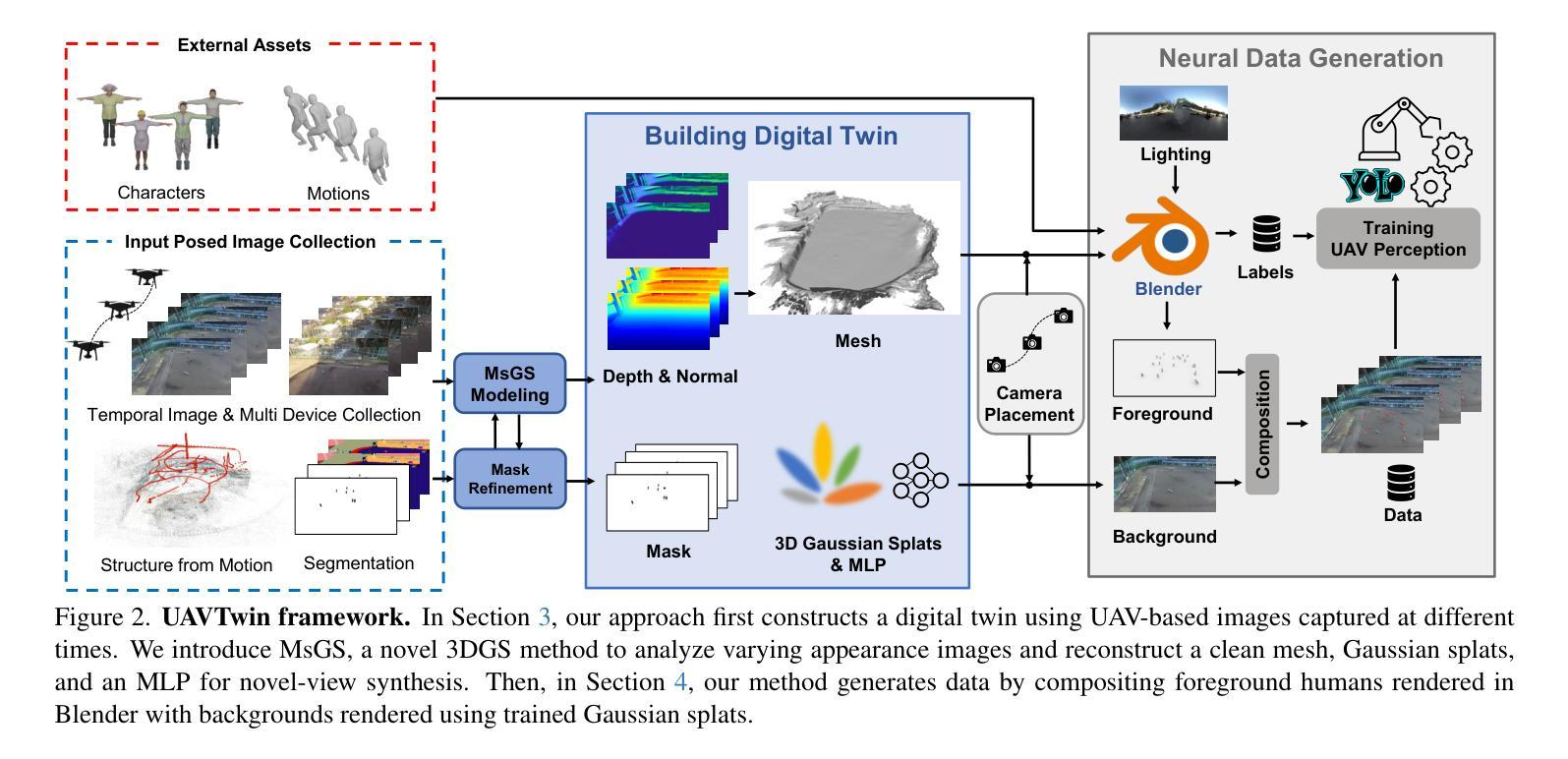
UAVTwin: Neural Digital Twins for UAVs using Gaussian Splatting
Authors:Jaehoon Choi, Dongki Jung, Yonghan Lee, Sungmin Eum, Dinesh Manocha, Heesung Kwon
We present UAVTwin, a method for creating digital twins from real-world environments and facilitating data augmentation for training downstream models embedded in unmanned aerial vehicles (UAVs). Specifically, our approach focuses on synthesizing foreground components, such as various human instances in motion within complex scene backgrounds, from UAV perspectives. This is achieved by integrating 3D Gaussian Splatting (3DGS) for reconstructing backgrounds along with controllable synthetic human models that display diverse appearances and actions in multiple poses. To the best of our knowledge, UAVTwin is the first approach for UAV-based perception that is capable of generating high-fidelity digital twins based on 3DGS. The proposed work significantly enhances downstream models through data augmentation for real-world environments with multiple dynamic objects and significant appearance variations-both of which typically introduce artifacts in 3DGS-based modeling. To tackle these challenges, we propose a novel appearance modeling strategy and a mask refinement module to enhance the training of 3D Gaussian Splatting. We demonstrate the high quality of neural rendering by achieving a 1.23 dB improvement in PSNR compared to recent methods. Furthermore, we validate the effectiveness of data augmentation by showing a 2.5% to 13.7% improvement in mAP for the human detection task.
我们提出了UAVTwin方法,它可以从真实世界环境中创建数字孪生体,并促进无人机(UAV)中嵌入的下游模型的数据增强。具体来说,我们的方法侧重于从无人机的视角合成前景组件,例如复杂场景背景中运动的多种人类实例。这是通过整合3D高斯拼贴(3DGS)来重建背景,同时控制合成的人类模型,以在多种姿势下呈现多样的外观和动作来实现的。据我们所知,UAVTwin是基于无人机的感知方法的首次尝试,它能够基于3DGS生成高保真数字孪生体。所提出的工作通过数据增强显著提高了下游模型在具有多个动态对象和重大外观变化的真实世界环境中的性能,而这两者通常在基于3DGS的建模中引入伪影。为了应对这些挑战,我们提出了一种新颖的外观建模策略和一个掩膜优化模块,以提高3D高斯拼贴的训练效果。我们通过在PSNR上实现1.23 dB的改进展示了神经渲染的高质量,与最近的方法相比。此外,我们通过在人检测任务上提高2.5%至13.7%的mAP来证明数据增强的有效性。
论文及项目相关链接
Summary
无人机数字双胞胎生成方法UAVTwin能够创建真实环境的数字双胞胎,并促进无人机嵌入式下游模型的训练数据增强。该方法通过整合三维高斯喷绘技术,重建背景并生成可控的合成人物模型,展现多样化外观和动作。UAVTwin可生成高质量的数字双胞胎并提升下游模型在面对具有多个动态物体和显著外观变化的实际环境中的性能。研究解决了传统建模中面临的挑战,并提出了改进模型策略和蒙版优化模块以提升模型训练质量。其神经渲染技术显著提高PSNR,同时在人检任务中的平均准确率提升了近三个百分点。本技术对未来无人机的环境感知有着重大意义。
Key Takeaways
一、研究介绍了一种基于无人机的新型数字双胞胎生成方法(UAVTwin),通过结合三维高斯喷绘技术(3DGS)创建真实环境的数字双胞胎。
二、UAVTwin方法可以合成前景组件,如复杂场景背景中的动态人物,为无人机提供更全面的感知信息。
三、研究首次提出使用合成人物模型在基于无人机的情况下实现高度真实的数字双胞胎生成,展示了良好的性能和实用性。
四、通过引入新的外观建模策略和蒙版优化模块,解决了在重建过程中可能出现的挑战和缺陷。
五、该研究通过数据增强技术显著提升了下游模型在真实环境中的性能,特别是在处理多个动态物体和显著外观变化方面。
六、神经渲染技术得到了显著提升,相比现有方法提高了PSNR值达到近三个百分点。
点此查看论文截图



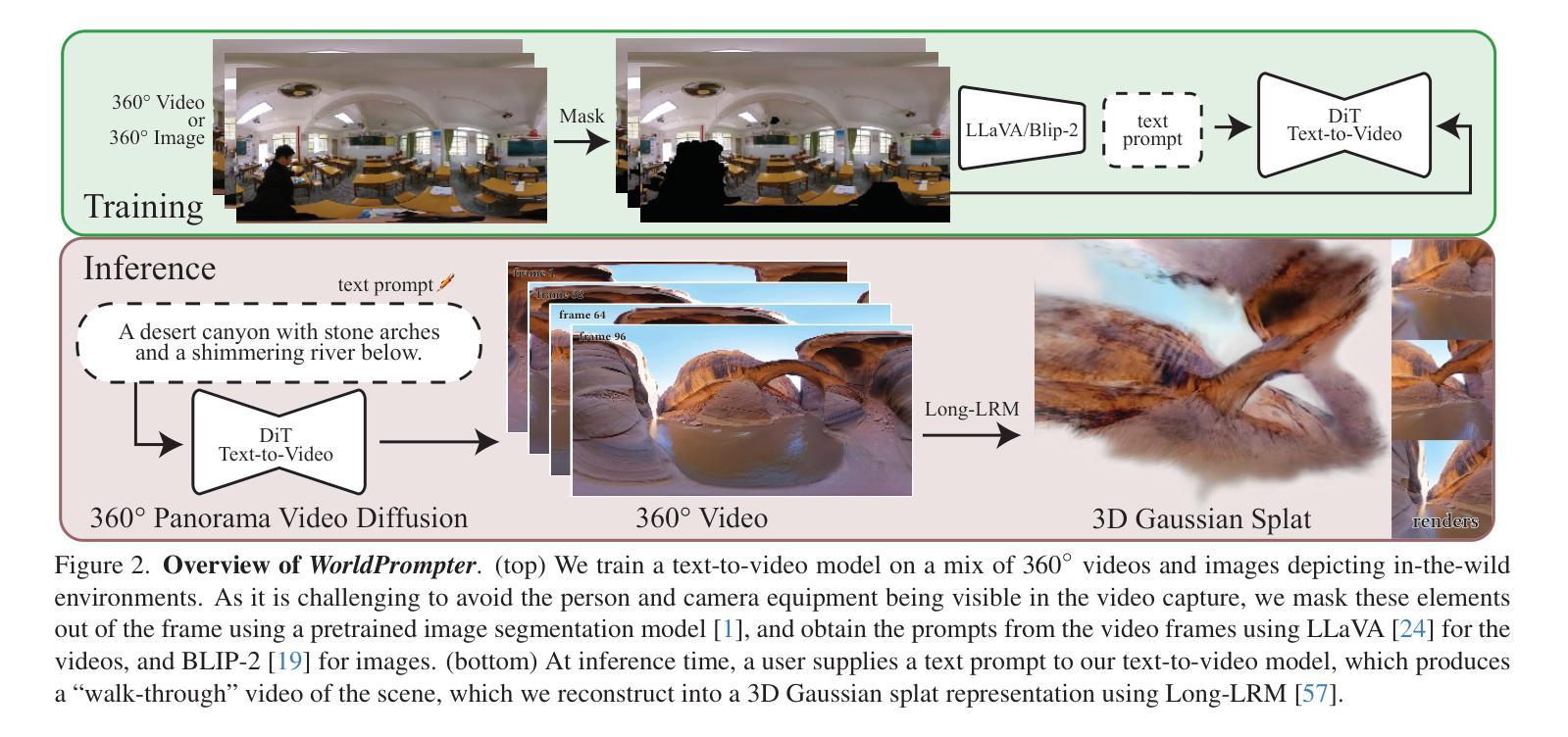
WorldPrompter: Traversable Text-to-Scene Generation
Authors:Zhaoyang Zhang, Yannick Hold-Geoffroy, Miloš Hašan, Chen Ziwen, Fujun Luan, Julie Dorsey, Yiwei Hu
Scene-level 3D generation is a challenging research topic, with most existing methods generating only partial scenes and offering limited navigational freedom. We introduce WorldPrompter, a novel generative pipeline for synthesizing traversable 3D scenes from text prompts. We leverage panoramic videos as an intermediate representation to model the 360{\deg} details of a scene. WorldPrompter incorporates a conditional 360{\deg} panoramic video generator, capable of producing a 128-frame video that simulates a person walking through and capturing a virtual environment. The resulting video is then reconstructed as Gaussian splats by a fast feedforward 3D reconstructor, enabling a true walkable experience within the 3D scene. Experiments demonstrate that our panoramic video generation model achieves convincing view consistency across frames, enabling high-quality panoramic Gaussian splat reconstruction and facilitating traversal over an area of the scene. Qualitative and quantitative results also show it outperforms the state-of-the-art 360{\deg} video generators and 3D scene generation models.
场景级别的3D生成是一个具有挑战性的研究课题,现有的大多数方法只能生成部分场景,提供的导航自由有限。我们引入了WorldPrompter,这是一种从文本提示合成可遍历的3D场景的新型生成管道。我们利用全景视频作为中间表示来建模场景的360°细节。WorldPrompter结合了一个条件性的360°全景视频生成器,能够生成一个模拟人走过并捕捉虚拟环境的128帧视频。然后,结果视频被快速前馈的3D重建器重建为高斯斑点,从而在3D场景中实现真正的可步行体验。实验表明,我们的全景视频生成模型在帧之间实现了令人信服的视图一致性,实现了高质量的全景高斯斑点重建,并促进了场景的某个区域的遍历。定性和定量结果也表明,它的性能优于最先进的360°视频生成器和3D场景生成模型。
论文及项目相关链接
Summary
本文介绍了WorldPrompter这一新型三维场景生成管道,其基于文本提示生成可导航的三维场景。利用全景视频作为中间表现形式来模拟场景的360度细节。通过条件360度全景视频生成器产生模拟人行走并捕捉虚拟环境的128帧视频。然后,通过快速前馈三维重建器将视频重建为高斯斑点,实现真正的场景内部可走动体验。实验证明,全景视频生成模型在帧间视角一致性方面表现出色,实现了高质量的全景高斯斑点重建,并促进了场景的遍历。相较于现有的360度视频生成器和三维场景生成模型,本文的方法具有优越性。
Key Takeaways
- WorldPrompter是一种新型的三维场景生成管道,可从文本提示生成可导航的三维场景。
- 利用全景视频作为中间表现形式,模拟场景的360度细节。
- 通过条件全景视频生成器产生模拟人行走的128帧视频。
- 快速前馈三维重建器将视频重建为高斯斑点,实现场景内部的可走动体验。
- 全景视频生成模型在帧间视角一致性方面表现出色。
- 该方法实现了高质量的全景高斯斑点重建,促进了场景的遍历。
点此查看论文截图



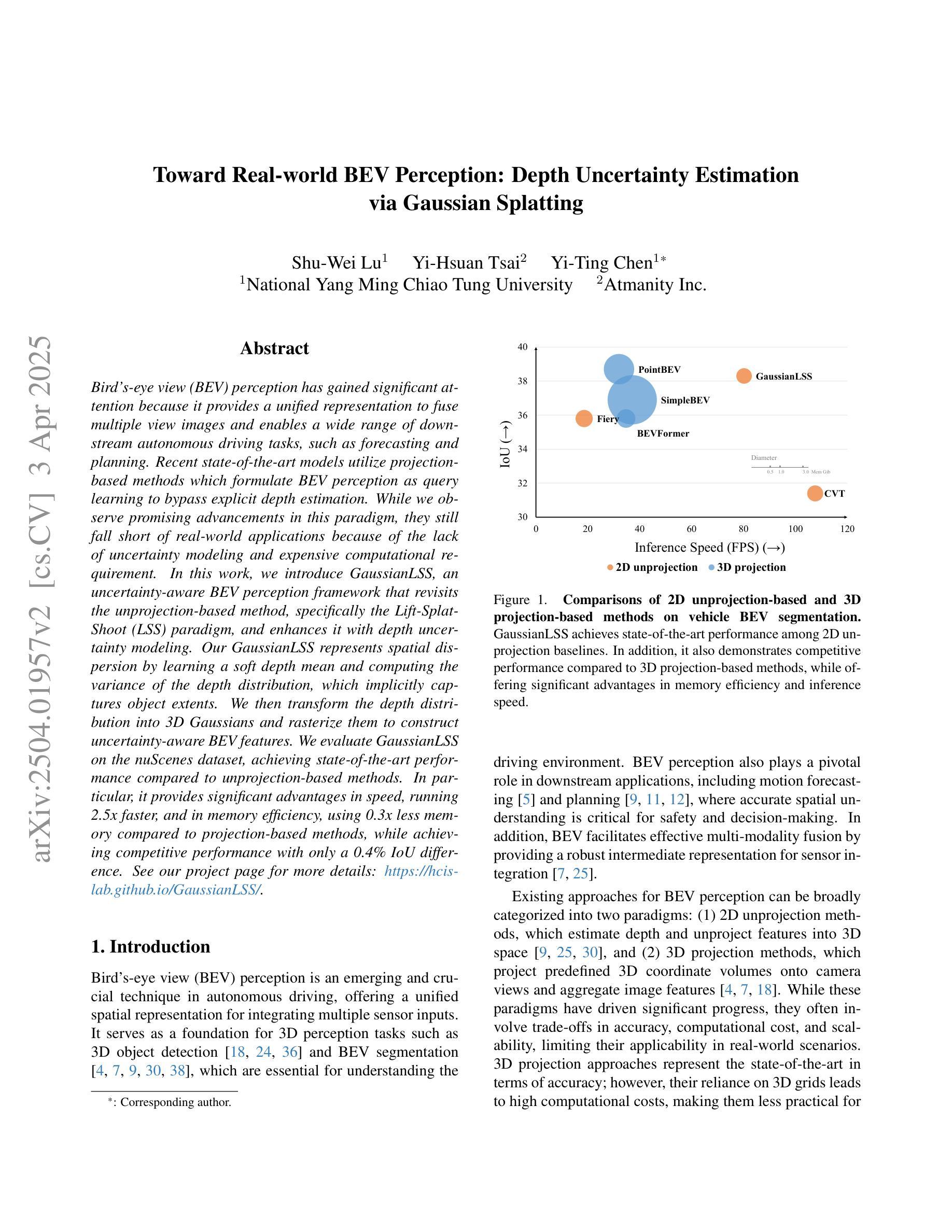
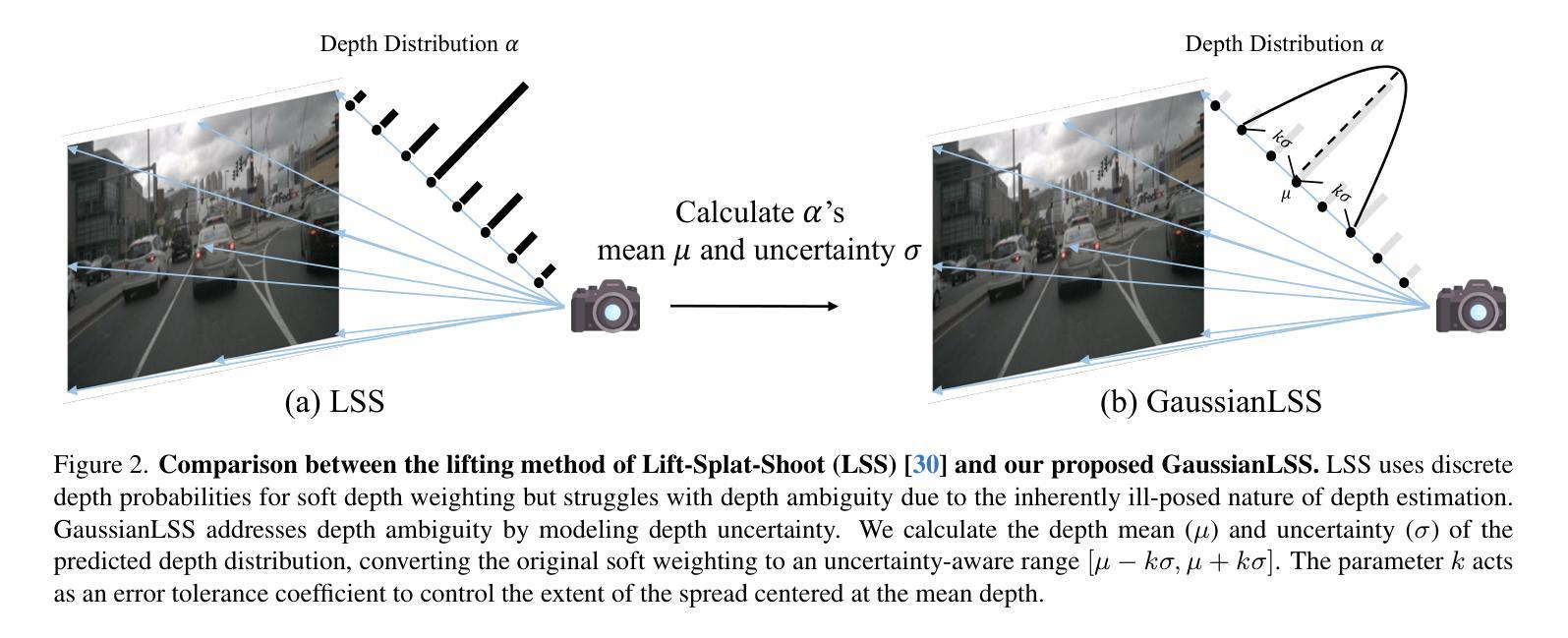
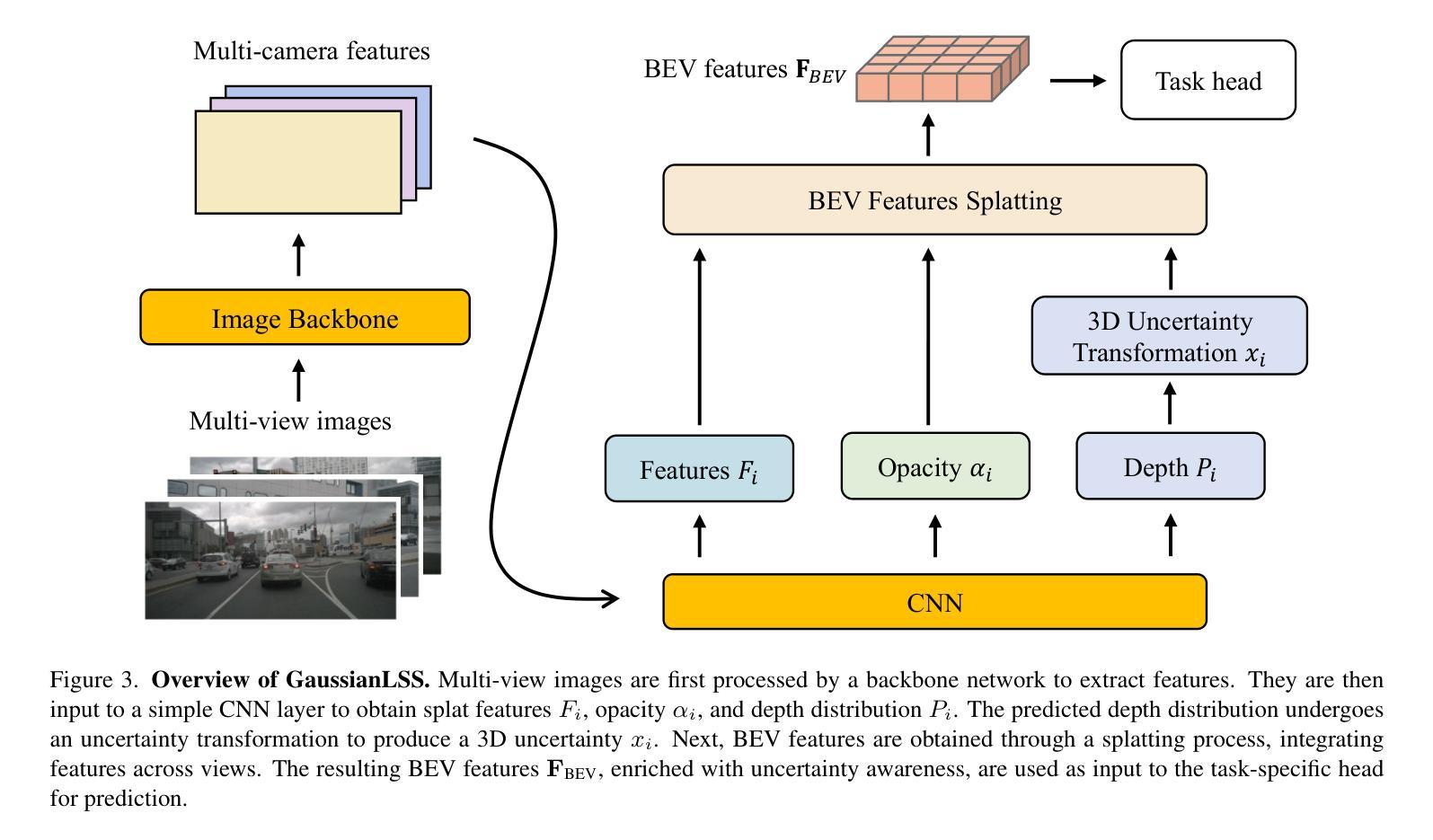
Toward Real-world BEV Perception: Depth Uncertainty Estimation via Gaussian Splatting
Authors:Shu-Wei Lu, Yi-Hsuan Tsai, Yi-Ting Chen
Bird’s-eye view (BEV) perception has gained significant attention because it provides a unified representation to fuse multiple view images and enables a wide range of down-stream autonomous driving tasks, such as forecasting and planning. Recent state-of-the-art models utilize projection-based methods which formulate BEV perception as query learning to bypass explicit depth estimation. While we observe promising advancements in this paradigm, they still fall short of real-world applications because of the lack of uncertainty modeling and expensive computational requirement. In this work, we introduce GaussianLSS, a novel uncertainty-aware BEV perception framework that revisits unprojection-based methods, specifically the Lift-Splat-Shoot (LSS) paradigm, and enhances them with depth un-certainty modeling. GaussianLSS represents spatial dispersion by learning a soft depth mean and computing the variance of the depth distribution, which implicitly captures object extents. We then transform the depth distribution into 3D Gaussians and rasterize them to construct uncertainty-aware BEV features. We evaluate GaussianLSS on the nuScenes dataset, achieving state-of-the-art performance compared to unprojection-based methods. In particular, it provides significant advantages in speed, running 2.5x faster, and in memory efficiency, using 0.3x less memory compared to projection-based methods, while achieving competitive performance with only a 0.4% IoU difference.
鸟瞰视图(BEV)感知已引起广泛关注,因为它为多视图图像融合提供了统一表示,并能够支持多种下游自动驾驶任务,如预测和规划。最近最先进的模型采用基于投影的方法,将BEV感知制定为查询学习,以规避明确的深度估计。虽然我们在这一范式中看到了有前景的进展,但它们仍然因缺乏不确定性建模和昂贵的计算要求而无法应用于现实世界。在这项工作中,我们介绍了GaussianLSS,这是一种新型的不确定性感知BEV感知框架,它重新审视了基于非投影的方法,特别是提升-平铺-射击(LSS)范式,并通过深度不确定性建模增强了它们。GaussianLSS通过学习软深度均值并计算深度分布的方差来表示空间分散性,这隐含地捕获了对象范围。然后我们将深度分布转化为3D高斯并进行栅格化,以构建具有不确定性感知的BEV特征。我们在nuscenes数据集上评估了GaussianLSS的性能,与基于非投影的方法相比,它实现了最先进的性能。尤其值得一提的是,它在速度上具有显著优势,运行速度为基于投影方法的2.5倍,并且在内存效率方面也有提高,使用了仅相当于基于投影方法0.3倍的内存,同时在IoU差异上仅相差0.4%,表现出了竞争力。
论文及项目相关链接
PDF Accepted to CVPR’25. https://hcis-lab.github.io/GaussianLSS/
Summary
本文提出一种名为GaussianLSS的不确定性感知鸟瞰图感知框架,该框架重新审视基于非投影的方法,特别是Lift-Splat-Shoot(LSS)范式,并通过深度不确定性建模进行增强。它通过学习软深度均值并计算深度分布的方差来表示空间分布,从而隐式地捕获对象范围。然后,将深度分布转换为3D高斯并将其栅格化,以构建具有感知不确定性的鸟瞰图特征。在nuScenes数据集上评估GaussianLSS,与基于非投影的方法相比,它实现了最先进的性能,具有速度快、内存效率高等优点。
Key Takeaways
- BEV感知融合多视角图像表示,促进自动驾驶下游任务,如预测和规划。
- 最新模型使用基于查询的学习方法绕过显式深度估计,但缺乏不确定性建模和计算成本高。
- GaussianLSS是一种不确定性感知的BEV感知框架,基于非投影方法(特别是LSS范式)。
- GaussianLSS通过建模深度不确定性增强性能。
- 该框架通过学习和计算深度分布的软均值和方差来表示空间分布。
- 将深度分布转换为3D高斯并栅格化,构建不确定性感知的BEV特征。
点此查看论文截图
Distilling Multi-view Diffusion Models into 3D Generators
Authors:Hao Qin, Luyuan Chen, Ming Kong, Mengxu Lu, Qiang Zhu
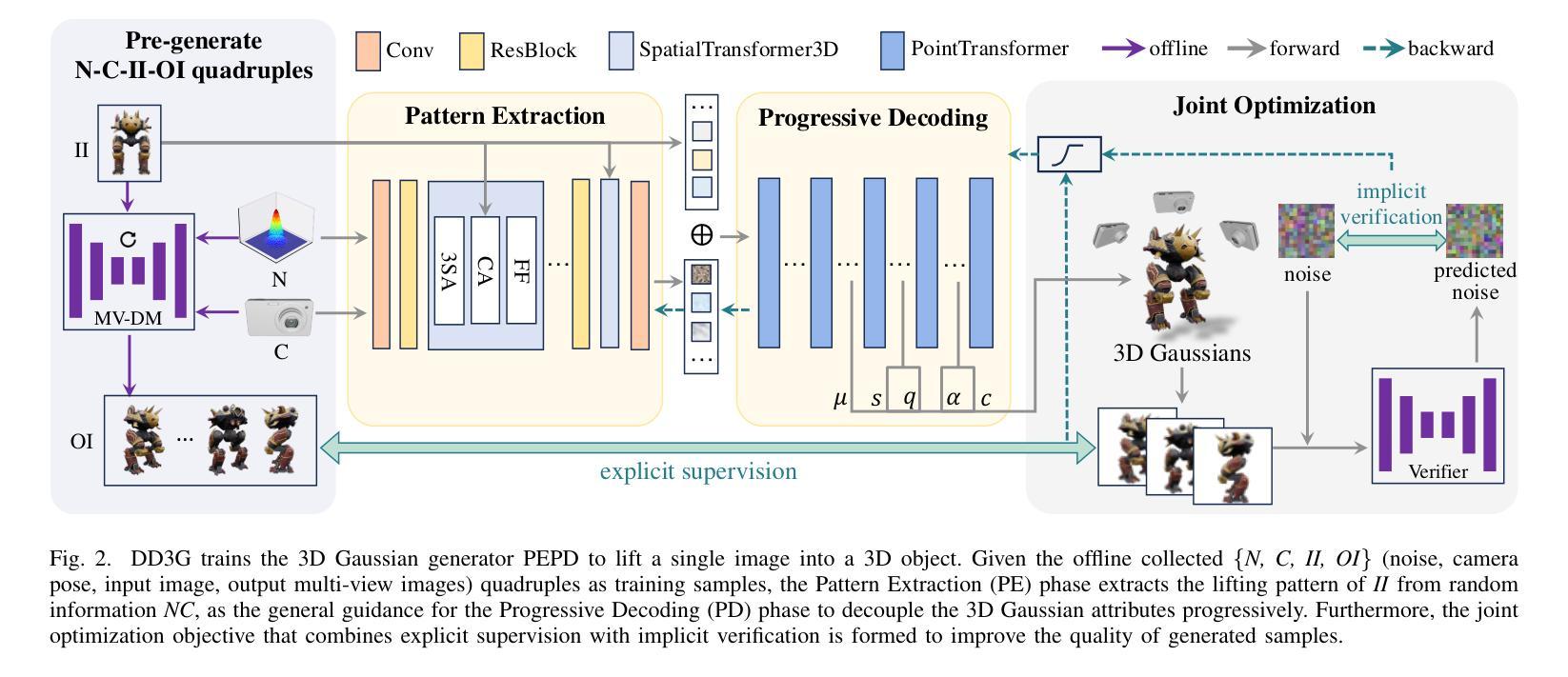
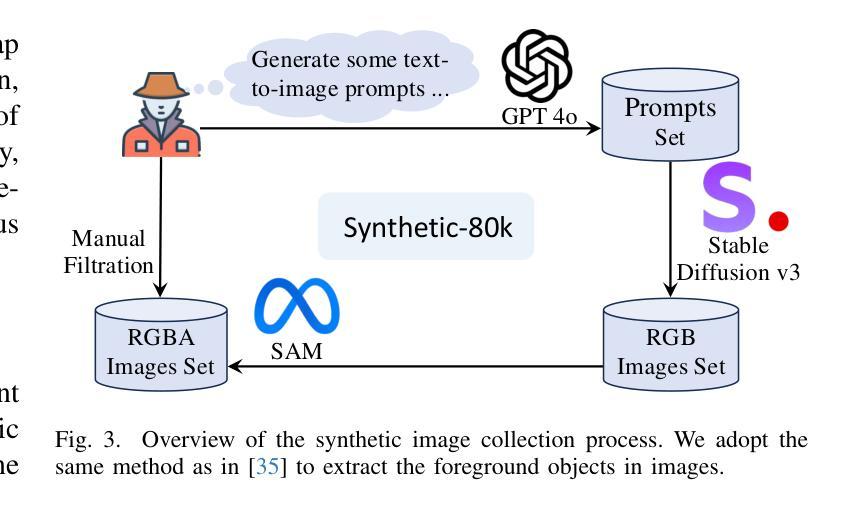
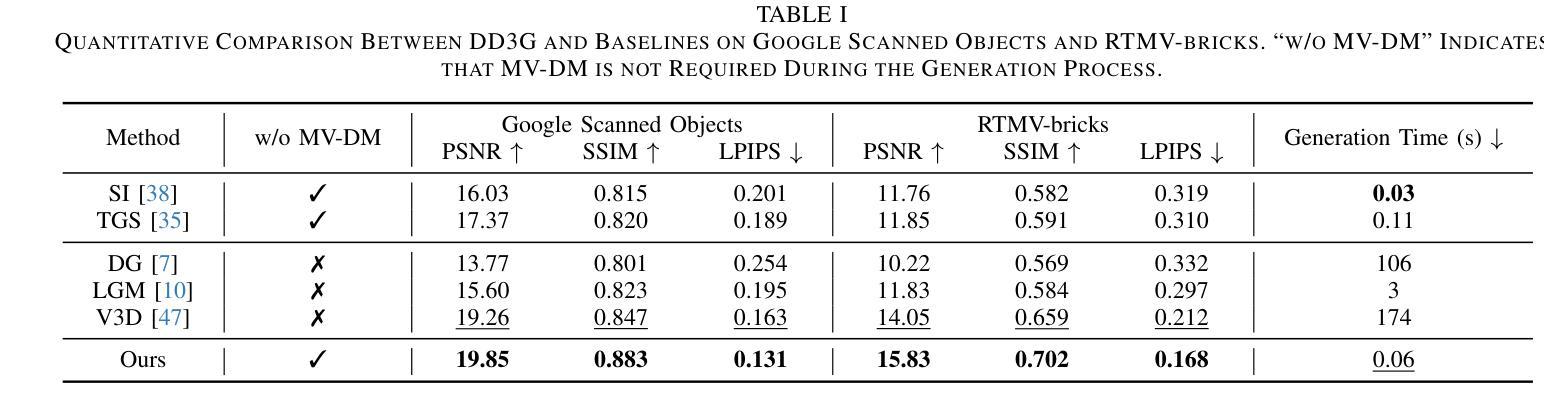
We introduce DD3G, a formulation that Distills a multi-view Diffusion model (MV-DM) into a 3D Generator using gaussian splatting. DD3G compresses and integrates extensive visual and spatial geometric knowledge from the MV-DM by simulating its ordinary differential equation (ODE) trajectory, ensuring the distilled generator generalizes better than those trained solely on 3D data. Unlike previous amortized optimization approaches, we align the MV-DM and 3D generator representation spaces to transfer the teacher’s probabilistic flow to the student, thus avoiding inconsistencies in optimization objectives caused by probabilistic sampling. The introduction of probabilistic flow and the coupling of various attributes in 3D Gaussians introduce challenges in the generation process. To tackle this, we propose PEPD, a generator consisting of Pattern Extraction and Progressive Decoding phases, which enables efficient fusion of probabilistic flow and converts a single image into 3D Gaussians within 0.06 seconds. Furthermore, to reduce knowledge loss and overcome sparse-view supervision, we design a joint optimization objective that ensures the quality of generated samples through explicit supervision and implicit verification. Leveraging existing 2D generation models, we compile 120k high-quality RGBA images for distillation. Experiments on synthetic and public datasets demonstrate the effectiveness of our method. Our project is available at: https://qinbaigao.github.io/DD3G_project/
我们介绍了DD3G,这是一种通过高斯拼贴法将多视图扩散模型(MV-DM)蒸馏到3D生成器的方法。DD3G通过模拟MV-DM的常微分方程(ODE)轨迹,压缩并集成了大量的视觉和空间几何知识,确保蒸馏出的生成器比仅基于3D数据训练的生成器具有更好的通用性。不同于之前的折中优化方法,我们将MV-DM和3D生成器的表示空间进行对齐,以将教师的概率流传输给学生,从而避免由概率采样引起的优化目标不一致的问题。概率流的引入和3D高斯中各种属性的耦合给生成过程带来了挑战。为解决这一问题,我们提出了PEPD生成器,它由模式提取和渐进解码两个阶段组成,能够高效地融合概率流,并在0.06秒内将单幅图像转换为3D高斯。此外,为了减少知识损失并克服稀疏视图监督,我们设计了一个联合优化目标,通过显式监督和隐式验证确保生成样本的质量。我们利用现有的2D生成模型,编译了12万张高质量RGBA图像进行蒸馏。在合成和公共数据集上的实验证明了我们的方法的有效性。我们的项目在https://qinbaigao.github.io/DD3G_project/上提供。
论文及项目相关链接
Summary
基于高斯喷溅技术,研究提出一种多视角扩散模型(MV-DM)到三维生成器(DD3G)的蒸馏方法。通过模拟MV-DM的普通微分方程(ODE)轨迹,DD3G整合并压缩了视觉和空间几何知识,使其生成的模型相较于仅依赖三维数据训练的模型更具泛化能力。不同于传统的折半优化法,研究通过将MV-DM和三维生成器的表现空间对齐,传递了教师模型的概率流给学生模型,避免了由概率采样带来的目标优化不一致问题。为解决概率流引入及三维高斯中的属性耦合带来的生成挑战,研究提出了包含模式提取和渐进解码阶段的PEPD生成器,能在0.06秒内实现概率流的融合并将单一图像转化为三维高斯图像。为减少知识损失并解决监督视图的稀疏性问题,研究设计了一种联合优化目标,确保生成样本的质量和可靠性。现有二维生成模型的应用和实验结果验证了研究的效用性。研究更多内容可通过网址https://qinbaigao.github.io/DD3G_project/ 进行查看。
Key Takeaways
- 利用高斯喷溅技术提出DD3G蒸馏公式。该公式基于MV-DM整合并压缩视觉和空间几何知识。
- 采用ODE轨迹模拟,使蒸馏后的生成器具有更好的泛化能力。
- 对齐MV-DM和三维生成器的表现空间,传递教师模型的概率流避免目标优化不一致的问题。
- 引入PEPD生成器处理概率流引入及三维高斯中的属性耦合带来的挑战。
- PEPD生成器可实现概率流的融合并将单一图像快速转化为三维高斯图像。
点此查看论文截图


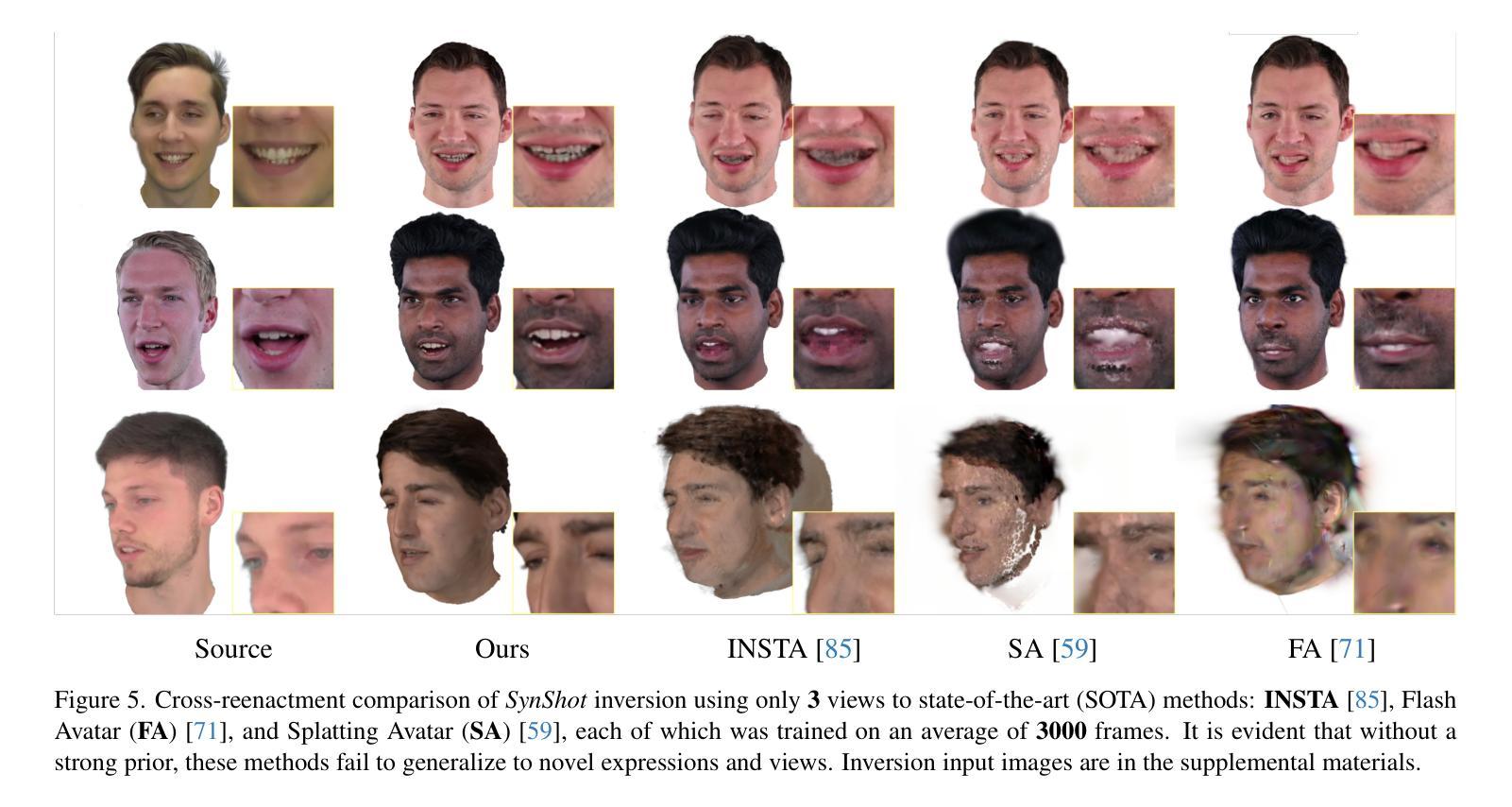
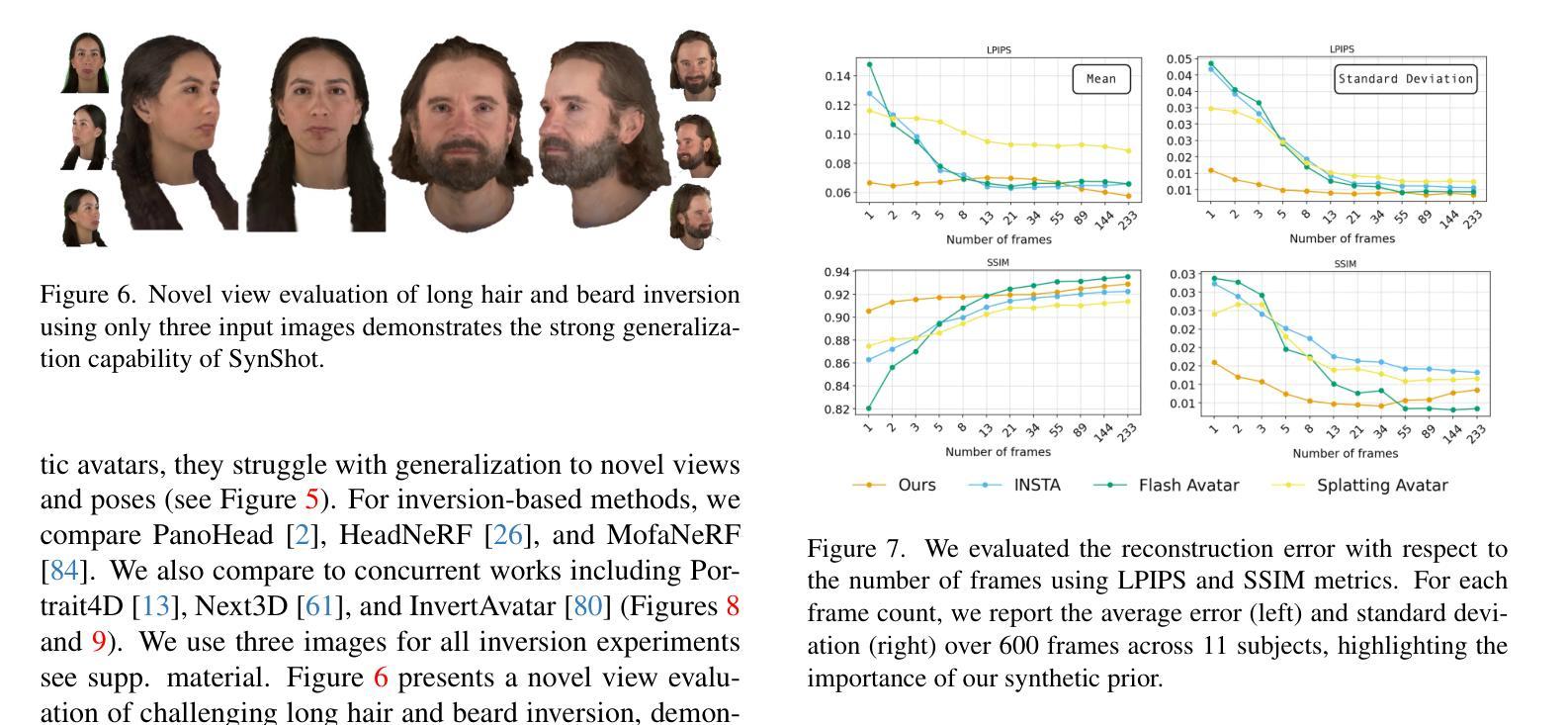
Synthetic Prior for Few-Shot Drivable Head Avatar Inversion
Authors:Wojciech Zielonka, Stephan J. Garbin, Alexandros Lattas, George Kopanas, Paulo Gotardo, Thabo Beeler, Justus Thies, Timo Bolkart
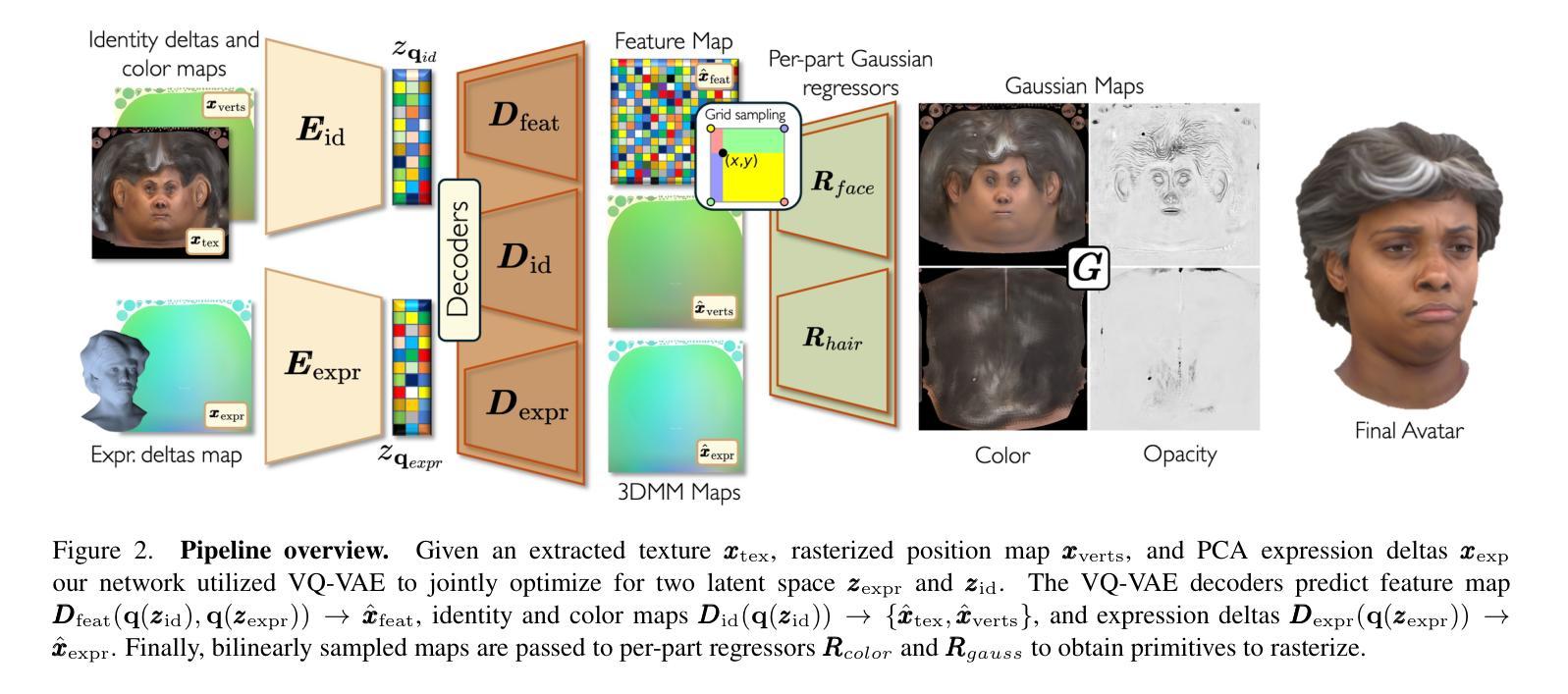
We present SynShot, a novel method for the few-shot inversion of a drivable head avatar based on a synthetic prior. We tackle three major challenges. First, training a controllable 3D generative network requires a large number of diverse sequences, for which pairs of images and high-quality tracked meshes are not always available. Second, the use of real data is strictly regulated (e.g., under the General Data Protection Regulation, which mandates frequent deletion of models and data to accommodate a situation when a participant’s consent is withdrawn). Synthetic data, free from these constraints, is an appealing alternative. Third, state-of-the-art monocular avatar models struggle to generalize to new views and expressions, lacking a strong prior and often overfitting to a specific viewpoint distribution. Inspired by machine learning models trained solely on synthetic data, we propose a method that learns a prior model from a large dataset of synthetic heads with diverse identities, expressions, and viewpoints. With few input images, SynShot fine-tunes the pretrained synthetic prior to bridge the domain gap, modeling a photorealistic head avatar that generalizes to novel expressions and viewpoints. We model the head avatar using 3D Gaussian splatting and a convolutional encoder-decoder that outputs Gaussian parameters in UV texture space. To account for the different modeling complexities over parts of the head (e.g., skin vs hair), we embed the prior with explicit control for upsampling the number of per-part primitives. Compared to SOTA monocular and GAN-based methods, SynShot significantly improves novel view and expression synthesis.
我们提出了一种名为SynShot的新方法,用于基于合成先验的少量驱动头部化身倒置。我们解决了三大挑战。首先,训练可控的3D生成网络需要大量的不同序列,而图像和高质量跟踪网格的配对并不总是可用。其次,真实数据的使用受到严格监管(例如,根据《通用数据保护条例》,当参与者同意撤回时,经常需要删除模型和数据)。不受这些约束的合成数据是一个吸引人的替代方案。第三,最先进的单眼化身模型很难推广到新的视角和表情,缺乏强大的先验知识,并且经常过度适应特定的视角分布。受只接受合成数据训练的机器学习模型的启发,我们提出了一种方法,该方法从包含各种身份、表情和视角的合成头部的大型数据集中学习先验模型。凭借少量的输入图像,SynShot对预训练的合成先验进行了微调,以弥合领域差距,并建立一个逼真的头部化身,能够推广到新的表情和视角。我们使用三维高斯平铺和卷积编码器-解码器来模拟头部化身,输出UV纹理空间的高斯参数。为了考虑头部各部分的建模复杂性(例如皮肤和头发),我们在先验嵌入中加入了明确的控制,以实现对每个部分原始数量的上采样。与最先进的单眼和基于GAN的方法相比,SynShot在新型视角和表情合成方面有了显著改善。
论文及项目相关链接
PDF Accepted to CVPR25 Website: https://zielon.github.io/synshot/
Summary
本文介绍了SynShot方法,这是一种基于合成先验的少数人头驾驶头像反转技术的新方法。该方法解决了三大挑战:缺乏多样序列图像和高品质追踪网格的训练数据、真实数据使用受到严格监管以及当前单眼头像模型难以泛化到新视角和表情。通过从大量合成头像数据中学习先验模型,SynShot能够在少量输入图像的基础上精细调整预训练合成先验,以弥补领域差距,从而建立能够泛化到新视角和表情的真实头像模型。该模型采用三维高斯拼贴技术和卷积编码器解码器输出UV纹理空间的参数。考虑头部不同部分的建模复杂性,SynShot采用具有显式控制的先验模型来模拟不同部分的细节特征。相较于其他先进的单眼模型和基于GAN的方法,SynShot显著提升了新视角和表情合成的性能。
Key Takeaways
- SynShot是一种针对驾驶头像少数情况下的反转技术的创新方法。
- 该方法解决了三大主要问题:缺乏多样训练数据、真实数据使用的监管挑战以及现有模型在新视角和表情上的泛化问题。
- 通过学习从大型合成头像数据集的先验模型,SynShot能够利用少量输入图像进行精细调整。
- SynShot采用三维高斯拼贴技术和卷积编码器解码器来建立真实头像模型,并输出UV纹理空间的参数。
- 为了模拟头部不同部分的复杂性,该模型提供了显式控制的先验模型来细化特征表达。
- 与其他先进技术相比,SynShot在新视角和表情合成方面表现出显著改进。
点此查看论文截图



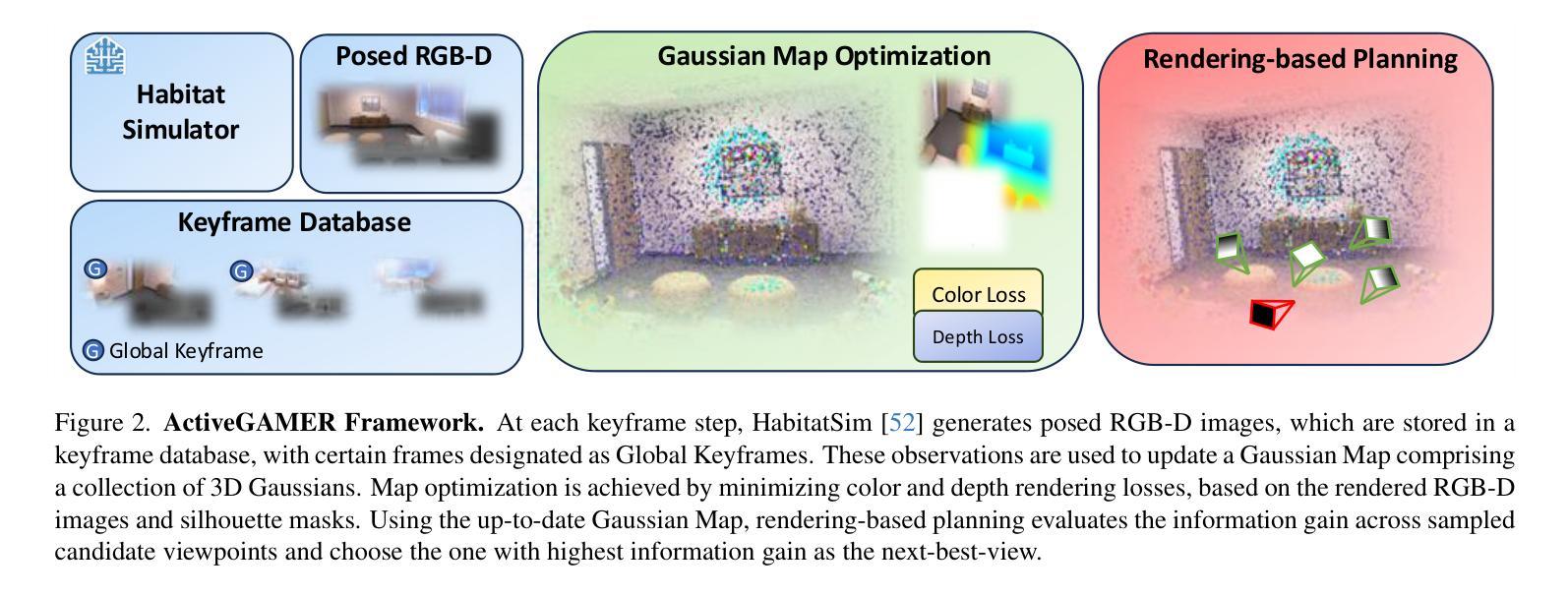
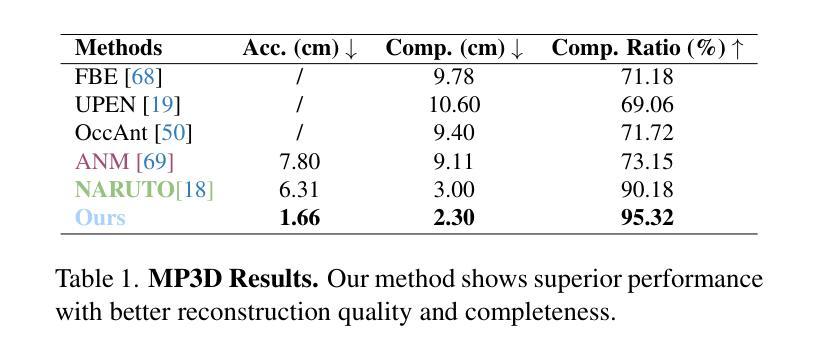
ActiveGAMER: Active GAussian Mapping through Efficient Rendering
Authors:Liyan Chen, Huangying Zhan, Kevin Chen, Xiangyu Xu, Qingan Yan, Changjiang Cai, Yi Xu
We introduce ActiveGAMER, an active mapping system that utilizes 3D Gaussian Splatting (3DGS) to achieve high-quality, real-time scene mapping and exploration. Unlike traditional NeRF-based methods, which are computationally demanding and restrict active mapping performance, our approach leverages the efficient rendering capabilities of 3DGS, allowing effective and efficient exploration in complex environments. The core of our system is a rendering-based information gain module that dynamically identifies the most informative viewpoints for next-best-view planning, enhancing both geometric and photometric reconstruction accuracy. ActiveGAMER also integrates a carefully balanced framework, combining coarse-to-fine exploration, post-refinement, and a global-local keyframe selection strategy to maximize reconstruction completeness and fidelity. Our system autonomously explores and reconstructs environments with state-of-the-art geometric and photometric accuracy and completeness, significantly surpassing existing approaches in both aspects. Extensive evaluations on benchmark datasets such as Replica and MP3D highlight ActiveGAMER’s effectiveness in active mapping tasks.
我们介绍了ActiveGAMER,这是一个利用3D高斯拼贴(3DGS)实现高质量、实时场景映射和探索的主动映射系统。与传统的基于NeRF的方法不同,它们在计算上需求较高,限制了主动映射的性能,我们的方法利用3DGS的高效渲染能力,能够在复杂环境中进行有效且高效的探索。我们的系统的核心是基于渲染的信息增益模块,该模块能够动态地识别下一个最佳视角的视点信息,从而提高几何和光度重建的准确性。ActiveGAMER还整合了一个精心设计的框架,结合了从粗到细的探索、后期优化以及全局局部关键帧选择策略,以最大化重建的完整性和逼真度。我们的系统以最新的几何和光度准确性和完整性,自主探索和重建环境,在这两方面都大大超越了现有方法。在Replica和MP3D等基准数据集上的广泛评估突出了ActiveGAMER在主动映射任务中的有效性。
论文及项目相关链接
PDF Accepted to CVPR2025
Summary
ActiveGAMER系统利用三维高斯投影技术实现高质量实时场景映射和探索。与传统的NeRF方法相比,该系统更高效且具有强大的渲染能力,可在复杂环境中进行高效探索。其核心是一个基于渲染的信息增益模块,能动态识别最具信息量的视点,从而提高几何和光度重建的准确性。此外,该系统结合粗到细的探索方式、后期优化和全局局部关键帧选择策略,旨在最大化重建的完整性和保真度。ActiveGAMER自主探索和重建环境,几何和光度准确性和完整性均达到业界领先水平,在基准数据集上的表现优于现有方法。
Key Takeaways
- ActiveGAMER系统利用三维高斯投影(3DGS)实现场景映射和探索。
- 该系统较传统NeRF方法更高效,具有强大的渲染能力。
- 基于渲染的信息增益模块可动态识别最具信息量的视点。
- 该系统能提高几何和光度重建的准确性。
- ActiveGAMER结合粗到细的探索方式、后期优化和关键帧选择策略,旨在最大化重建的完整性和保真度。
- 系统自主探索和重建环境,几何和光度准确性和完整性均达到领先水平。
点此查看论文截图


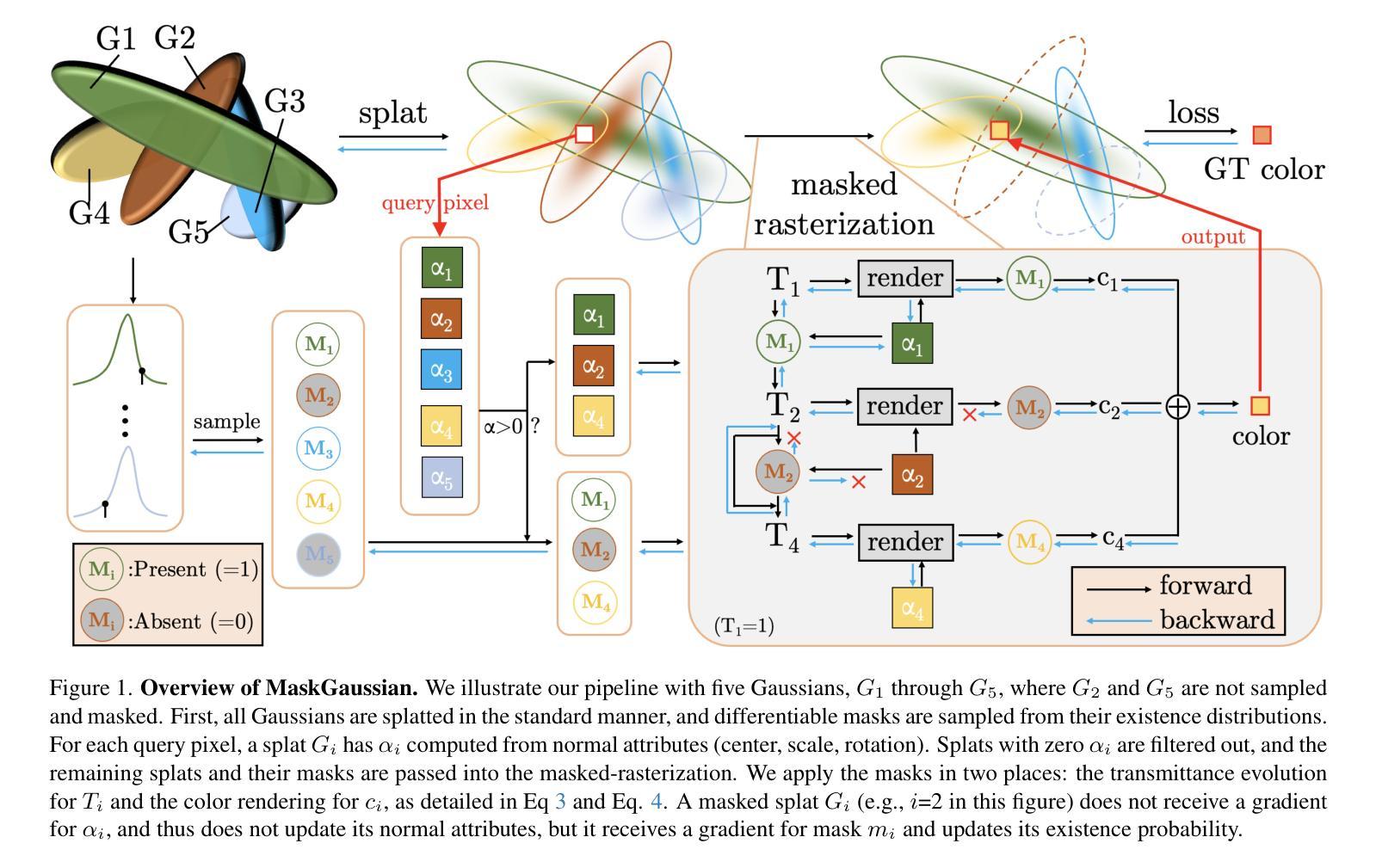
MaskGaussian: Adaptive 3D Gaussian Representation from Probabilistic Masks
Authors:Yifei Liu, Zhihang Zhong, Yifan Zhan, Sheng Xu, Xiao Sun
While 3D Gaussian Splatting (3DGS) has demonstrated remarkable performance in novel view synthesis and real-time rendering, the high memory consumption due to the use of millions of Gaussians limits its practicality. To mitigate this issue, improvements have been made by pruning unnecessary Gaussians, either through a hand-crafted criterion or by using learned masks. However, these methods deterministically remove Gaussians based on a snapshot of the pruning moment, leading to sub-optimized reconstruction performance from a long-term perspective. To address this issue, we introduce MaskGaussian, which models Gaussians as probabilistic entities rather than permanently removing them, and utilize them according to their probability of existence. To achieve this, we propose a masked-rasterization technique that enables unused yet probabilistically existing Gaussians to receive gradients, allowing for dynamic assessment of their contribution to the evolving scene and adjustment of their probability of existence. Hence, the importance of Gaussians iteratively changes and the pruned Gaussians are selected diversely. Extensive experiments demonstrate the superiority of the proposed method in achieving better rendering quality with fewer Gaussians than previous pruning methods, pruning over 60% of Gaussians on average with only a 0.02 PSNR decline. Our code can be found at: https://github.com/kaikai23/MaskGaussian
虽然3D高斯贴图(3DGS)在新型视图合成和实时渲染方面表现出卓越的性能,但由于使用了数百万个高斯,其高内存消耗限制了实用性。为了缓解这个问题,已经通过删除不必要的高斯进行了改进,方法包括使用手工制定的标准或使用学习到的掩膜。然而,这些方法根据删除时刻的快照确定性地删除高斯,从长远来看导致重建性能不佳。为了解决这一问题,我们引入了MaskGaussian,它将高斯建模为概率实体,而不是永久删除它们,并根据其存在的概率来使用它们。为了实现这一点,我们提出了一种掩膜栅格化技术,使未使用但概率存在的高斯能够接受梯度,从而动态评估它们对不断变化场景的贡献并调整其存在的概率。因此,高斯的重要性会迭代地改变,被删除的高斯选择也会多样化。大量实验表明,所提出的方法在使用较少的高斯实现更好的渲染质量方面优于以前的高斯删除方法,平均删除超过60%的高斯,而PSNR仅下降0.02。我们的代码可以在https://github.com/kaikai23/MaskGaussian找到。
论文及项目相关链接
PDF CVPR 2025; Project page:https://maskgaussian.github.io/
Summary
本文介绍了针对3D高斯融合(3DGS)在真实场景重建中存在的问题所提出的一种新的解决方案,名为MaskGaussian。此方案通过将高斯视为概率实体而非永久移除,利用掩膜技术动态评估高斯对场景变化的贡献,并调整其存在概率。相较于传统的修剪方法,MaskGaussian能在减少高斯使用数量的同时保持或提高渲染质量。
Key Takeaways
- 3DGS在新型视角合成和实时渲染中表现出卓越性能,但其高内存消耗限制了实际应用。
- 当前改善方法主要通过修剪不必要的Gaussians实现,但这些方法基于快照时刻确定性地移除Gaussians,从长远角度看会导致重建性能不足。
- MaskGaussian方案通过将Gaussians视为概率实体解决此问题,利用掩膜技术动态评估Gaussians的贡献并调整其存在概率。
- MaskGaussian采用了一种新型的masked-rasterization技术,允许概率存在的未使用Gaussians接收梯度,以便动态评估其对场景变化的贡献。
- MaskGaussian方法能够在减少Gaussians使用数量的同时保持或提高渲染质量,平均修剪超过60%的Gaussians,同时仅降低0.02 PSNR。
- MaskGaussian的代码可在公开代码库中找到,为相关研究和应用提供了便利。
点此查看论文截图


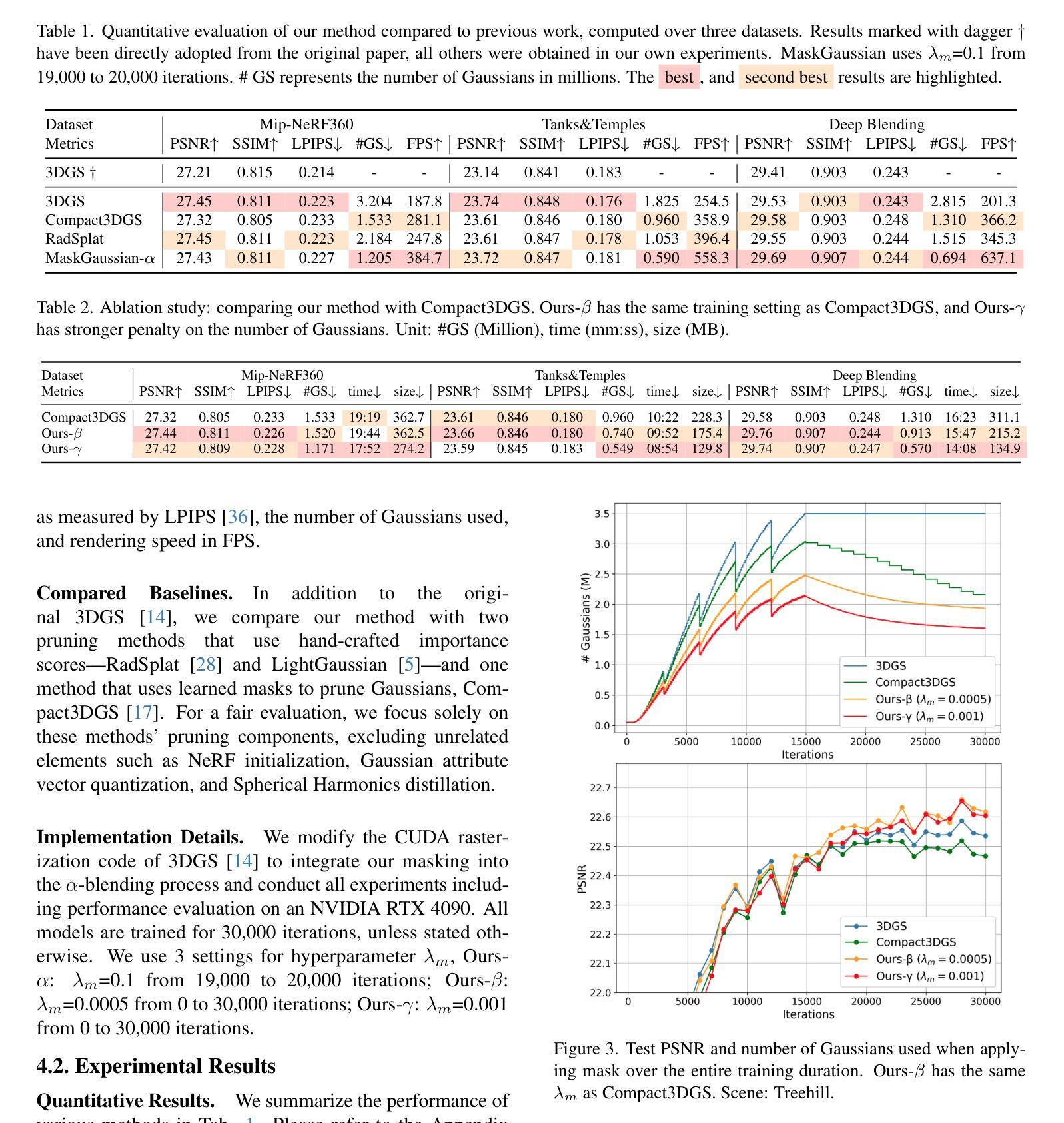
6DOPE-GS: Online 6D Object Pose Estimation using Gaussian Splatting
Authors:Yufeng Jin, Vignesh Prasad, Snehal Jauhri, Mathias Franzius, Georgia Chalvatzaki
Efficient and accurate object pose estimation is an essential component for modern vision systems in many applications such as Augmented Reality, autonomous driving, and robotics. While research in model-based 6D object pose estimation has delivered promising results, model-free methods are hindered by the high computational load in rendering and inferring consistent poses of arbitrary objects in a live RGB-D video stream. To address this issue, we present 6DOPE-GS, a novel method for online 6D object pose estimation & tracking with a single RGB-D camera by effectively leveraging advances in Gaussian Splatting. Thanks to the fast differentiable rendering capabilities of Gaussian Splatting, 6DOPE-GS can simultaneously optimize for 6D object poses and 3D object reconstruction. To achieve the necessary efficiency and accuracy for live tracking, our method uses incremental 2D Gaussian Splatting with an intelligent dynamic keyframe selection procedure to achieve high spatial object coverage and prevent erroneous pose updates. We also propose an opacity statistic-based pruning mechanism for adaptive Gaussian density control, to ensure training stability and efficiency. We evaluate our method on the HO3D and YCBInEOAT datasets and show that 6DOPE-GS matches the performance of state-of-the-art baselines for model-free simultaneous 6D pose tracking and reconstruction while providing a 5$\times$ speedup. We also demonstrate the method’s suitability for live, dynamic object tracking and reconstruction in a real-world setting.
高效且精确的目标姿态估计是现代视觉系统在许多应用中的关键组件,例如增强现实、自动驾驶和机器人技术。尽管基于模型的6D对象姿态估计研究已经取得了有前景的结果,但无模型方法受到渲染和推断实时RGB-D视频流中任意对象的一致姿态的计算负载的阻碍。为了解决这个问题,我们提出了6DOPE-GS,这是一种利用高斯平铺技术的新在线6D对象姿态估计和跟踪方法。得益于高斯平铺的快速可微分渲染能力,6DOPE-GS可以同时优化6D对象姿态和3D对象重建。为了实现实时跟踪的必要效率和准确性,我们的方法使用增量2D高斯平铺和智能动态关键帧选择程序,以实现对象的高空间覆盖并防止错误的姿态更新。我们还提出了一种基于不透明度统计的修剪机制,用于自适应高斯密度控制,以确保训练稳定性和效率。我们在HO3D和YCBInEOAT数据集上评估了我们的方法,结果表明,6DOPE-GS在无需模型的同时实现6D姿态跟踪和重建方面的性能与最新基线相匹配,同时提供了5倍的加速。我们还证明了该方法在真实环境中进行实时动态对象跟踪和重建的适用性。
论文及项目相关链接
摘要
高效准确的物体姿态估计是增强现实、自动驾驶和机器人技术等多个现代视觉系统应用中的核心组件。针对基于模型的6D物体姿态估计模型已取得良好结果,但无模型方法因在实时RGB-D视频流中呈现和推断任意物体的一致性姿态的计算负荷较高而受到阻碍。为解决此问题,我们提出一种名为6DOPE-GS的新方法,通过利用高斯涂抹技术的最新进展,实现利用单个RGB-D相机的在线6D物体姿态估计与跟踪。由于高斯涂抹的快速可微分渲染能力,6DOPE-GS可以同时优化6D物体姿态和3D物体重建。为实现实时跟踪所需的有效性和准确性,我们的方法采用增量式二维高斯涂抹和智能动态关键帧选择程序,以实现高空间物体覆盖并防止错误的姿态更新。我们还提出了一种基于不透明度统计的修剪机制,以确保训练稳定性和效率,实现对高斯密度的自适应控制。我们在HO3D和YCBInEOAT数据集上评估了我们的方法,表明6DOPE-GS在无需模型的同时实现了最先进的6D姿态跟踪和重建的匹配性能,同时提供了5倍的速度提升。我们还展示了该方法在真实环境中的实时动态物体跟踪和重建的适用性。
要点解析
- 对象姿态估计是现代视觉系统的核心部分,应用于多种领域如增强现实、自动驾驶和机器人技术。
- 当前模型基于6D的对象姿态估计已取得良好进展,但无模型方法的实时性能受到计算负荷的限制。
- 论文提出了名为6DOPE-GS的新方法,利用高斯涂抹技术实现RGB-D相机的在线6D对象姿态估计与跟踪。
- 6DOPE-GS结合了优化的对象姿态与3D对象重建任务,这是由于其可微分渲染能力的支持。
- 方法采用增量式二维高斯涂抹与智能动态关键帧选择,确保高效且准确的实时跟踪性能。
- 提出了一种基于不透明度统计的修剪机制来优化训练过程和提高效率。
点此查看论文截图

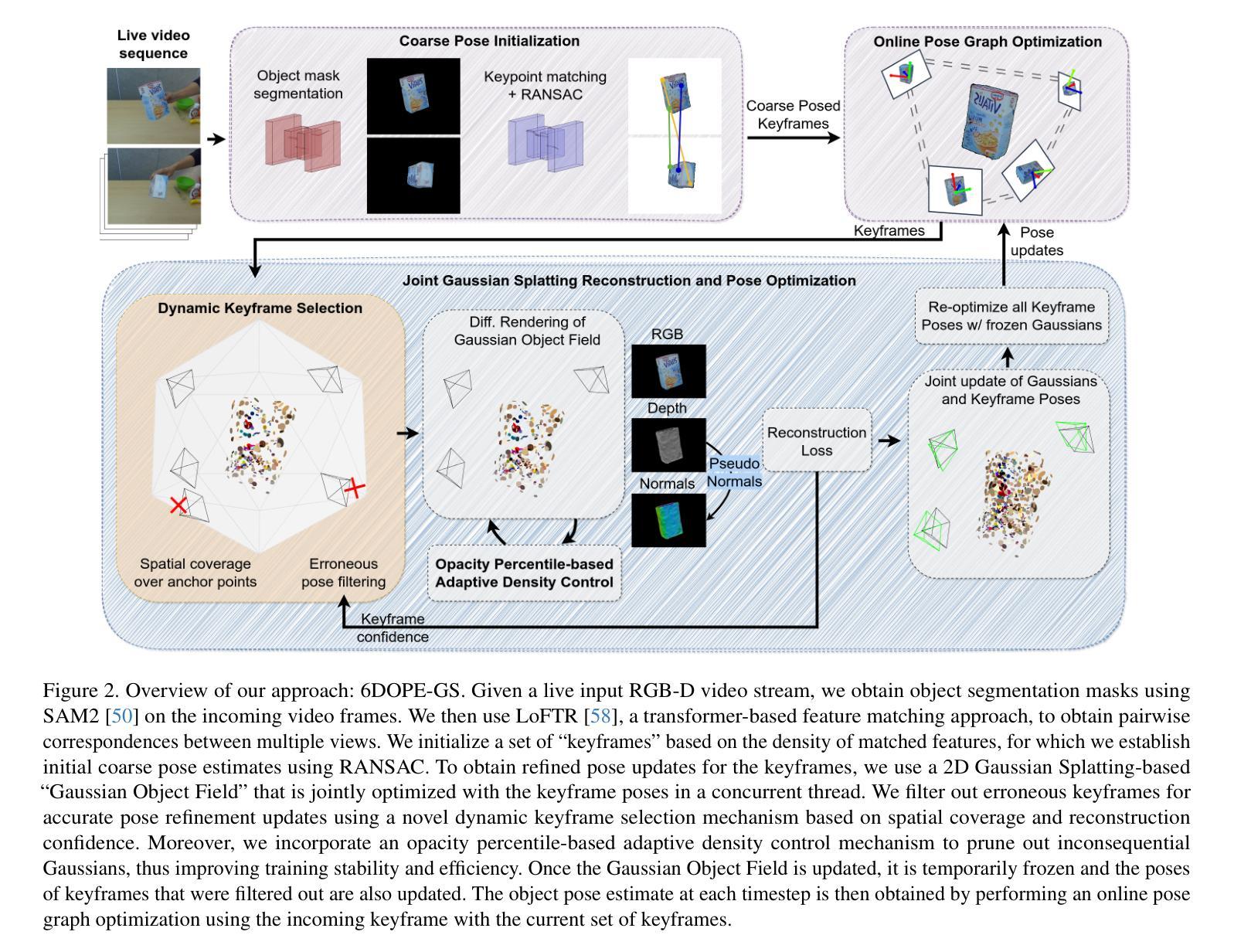

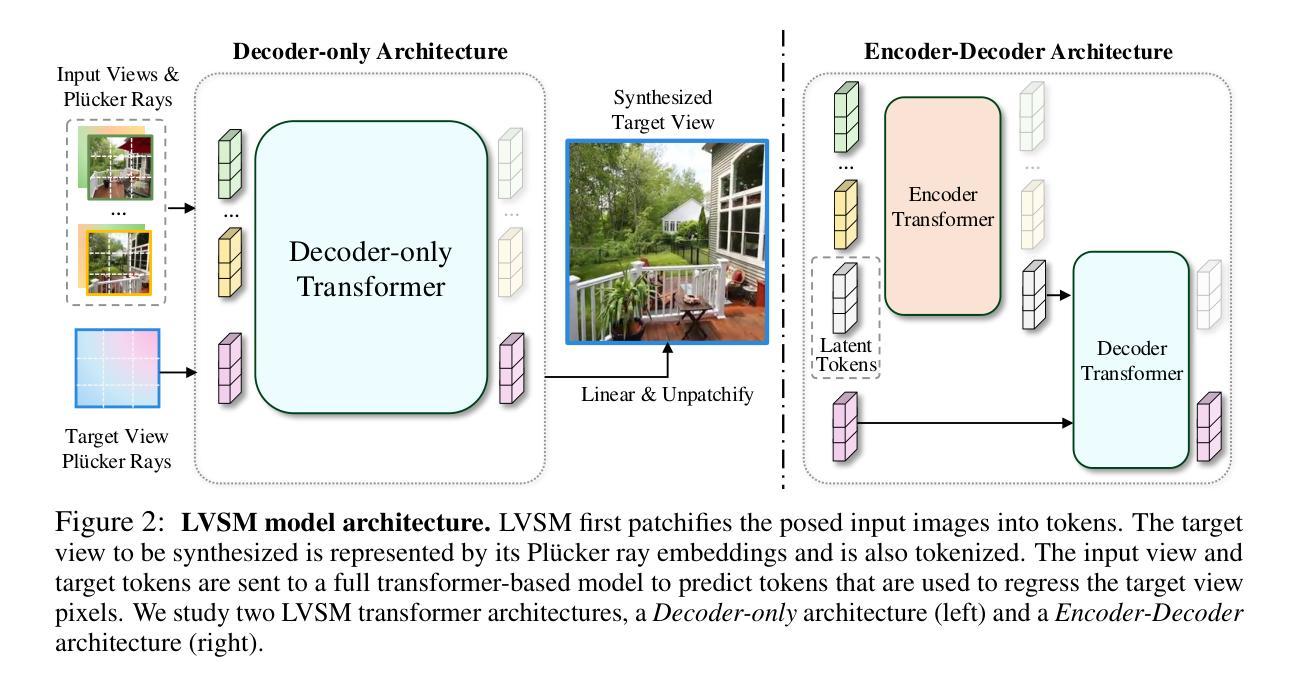
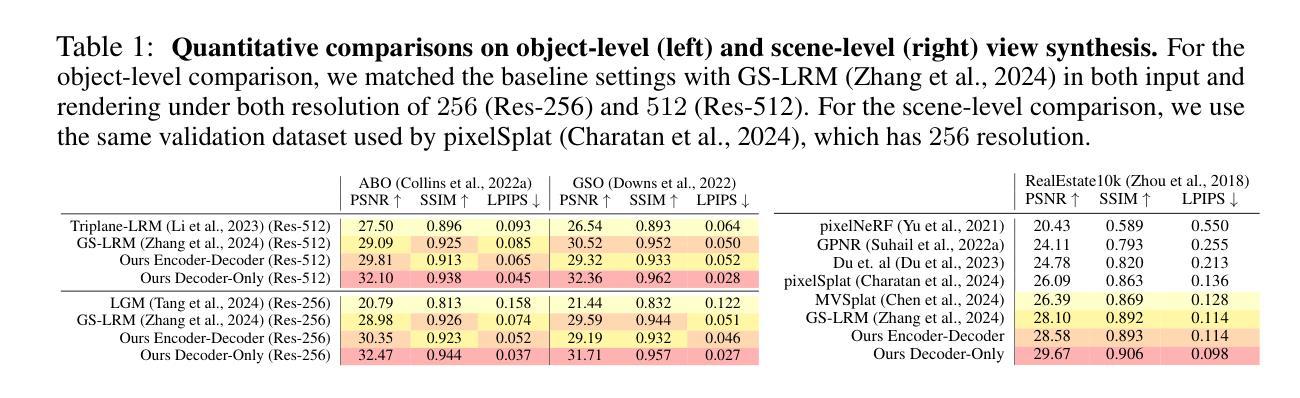
LVSM: A Large View Synthesis Model with Minimal 3D Inductive Bias
Authors:Haian Jin, Hanwen Jiang, Hao Tan, Kai Zhang, Sai Bi, Tianyuan Zhang, Fujun Luan, Noah Snavely, Zexiang Xu
We propose the Large View Synthesis Model (LVSM), a novel transformer-based approach for scalable and generalizable novel view synthesis from sparse-view inputs. We introduce two architectures: (1) an encoder-decoder LVSM, which encodes input image tokens into a fixed number of 1D latent tokens, functioning as a fully learned scene representation, and decodes novel-view images from them; and (2) a decoder-only LVSM, which directly maps input images to novel-view outputs, completely eliminating intermediate scene representations. Both models bypass the 3D inductive biases used in previous methods – from 3D representations (e.g., NeRF, 3DGS) to network designs (e.g., epipolar projections, plane sweeps) – addressing novel view synthesis with a fully data-driven approach. While the encoder-decoder model offers faster inference due to its independent latent representation, the decoder-only LVSM achieves superior quality, scalability, and zero-shot generalization, outperforming previous state-of-the-art methods by 1.5 to 3.5 dB PSNR. Comprehensive evaluations across multiple datasets demonstrate that both LVSM variants achieve state-of-the-art novel view synthesis quality. Notably, our models surpass all previous methods even with reduced computational resources (1-2 GPUs). Please see our website for more details: https://haian-jin.github.io/projects/LVSM/ .
我们提出了大型视图合成模型(LVSM),这是一种基于transformer的可扩展和通用新型视图合成方法,可从稀疏视图输入中进行合成。我们介绍了两种架构:(1)编码器-解码器LVSM,它将输入图像标记编码为固定数量的1D潜在标记,作为完全学习的场景表示,并从中解码出新的视图图像;(2)仅解码器LVSM,它直接将输入图像映射到新的视图输出,完全消除了中间场景表示。两种模型都绕过了以前方法中使用的3D归纳偏见,从3D表示(例如NeRF、3DGS)到网络设计(例如极投影、平面扫描),通过一种完全数据驱动的方法解决新的视图合成问题。由于独立的潜在表示,编码器-解码器模型提供更快的推理速度,而仅解码器LVSM在质量、可扩展性和零样本泛化方面表现更优越,比先前最先进的方法高出1.5至3.5 dB PSNR。在多个数据集上的综合评估表明,两种LVSM变体都达到了最先进的新型视图合成质量。值得注意的是,我们的模型甚至在减少的计算资源(1-2个GPU)的情况下也超过了以前的所有方法。更多详细信息请参见我们的网站:https://haian-jin.github.io/projects/LVSM/。
论文及项目相关链接
PDF project page: https://haian-jin.github.io/projects/LVSM/
Summary
提出Large View Synthesis Model(LVSM),采用新型transformer技术,实现稀疏视角输入的可扩展和通用化新视角合成。包含两种架构:一种为编码解码器LVSM,将输入图像标记编码为固定数量的1D潜在标记,作为完全学习的场景表示,并从中解码出新视角图像;另一种为仅解码器LVSM,直接将输入图像映射到新视角输出,无需中间场景表示。两种模型均绕过之前方法使用的3D归纳偏见,采用全数据驱动方法解决新视角合成问题。编码器-解码器模型具有更快的推理速度,而仅解码器LVSM在质量、可扩展性和零镜头泛化方面更胜一筹,较之前的最先进方法提高了1.5至3.5 dB PSNR。在多个数据集上的综合评估表明,两种LVSM变体均实现了最新颖的视图合成质量。
Key Takeaways
- 提出Large View Synthesis Model(LVSM),基于transformer的新方法用于稀疏视角输入的新视角合成。
- 包含两种架构:编码解码器LVSM和仅解码器LVSM。
- 编码解码器LVSM通过编码输入图像标记到潜在标记来实现场景表示和新视角图像解码。
- 仅解码器LVSM直接映射输入图像到新视角输出,无需中间场景表示,实现高质量、可扩展性和零镜头泛化。
- LVSM模型较之前方法提高了1.5至3.5 dB PSNR,实现了先进的新视角合成质量。
- 综合评估显示,两种LVSM变体在多个数据集上均表现优异。
点此查看论文截图

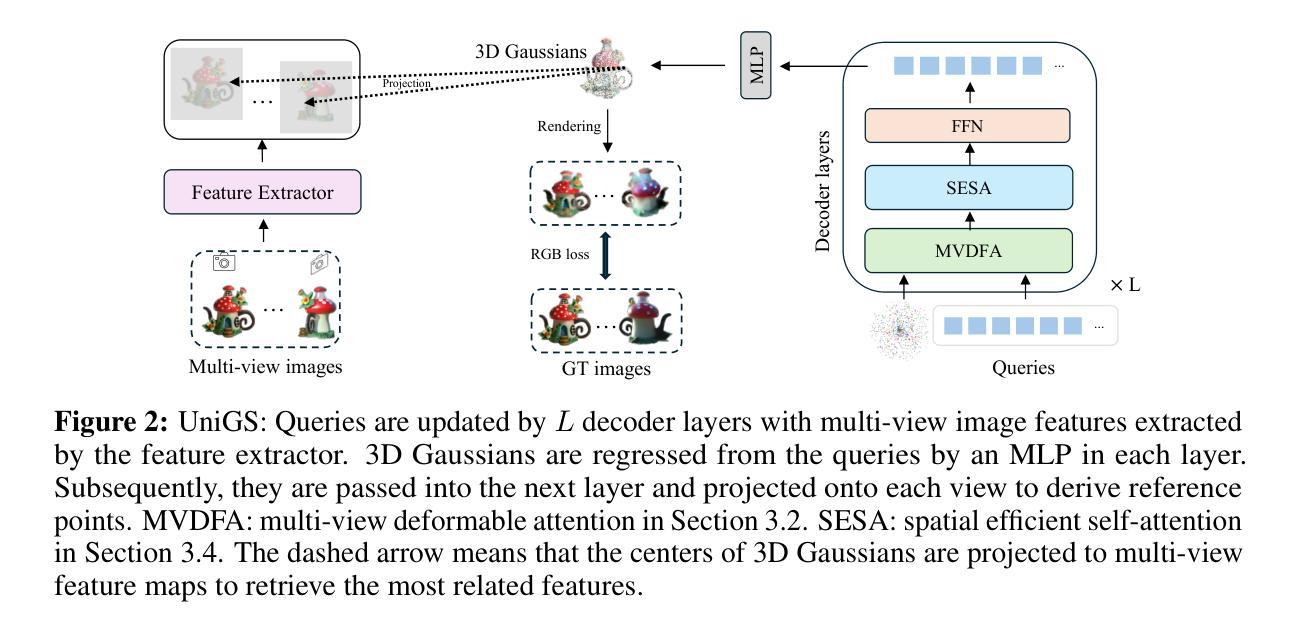
UniGS: Modeling Unitary 3D Gaussians for Novel View Synthesis from Sparse-view Images
Authors:Jiamin Wu, Kenkun Liu, Yukai Shi, Xiaoke Jiang, Yuan Yao, Lei Zhang
In this work, we introduce UniGS, a novel 3D Gaussian reconstruction and novel view synthesis model that predicts a high-fidelity representation of 3D Gaussians from arbitrary number of posed sparse-view images. Previous methods often regress 3D Gaussians locally on a per-pixel basis for each view and then transfer them to world space and merge them through point concatenation. In contrast, Our approach involves modeling unitary 3D Gaussians in world space and updating them layer by layer. To leverage information from multi-view inputs for updating the unitary 3D Gaussians, we develop a DETR (DEtection TRansformer)-like framework, which treats 3D Gaussians as queries and updates their parameters by performing multi-view cross-attention (MVDFA) across multiple input images, which are treated as keys and values. This approach effectively avoids `ghosting’ issue and allocates more 3D Gaussians to complex regions. Moreover, since the number of 3D Gaussians used as decoder queries is independent of the number of input views, our method allows arbitrary number of multi-view images as input without causing memory explosion or requiring retraining. Extensive experiments validate the advantages of our approach, showcasing superior performance over existing methods quantitatively (improving PSNR by 4.2 dB when trained on Objaverse and tested on the GSO benchmark) and qualitatively. The code will be released at https://github.com/jwubz123/UNIG.
在这项工作中,我们引入了UniGS,这是一种新的3D高斯重建和视图合成模型,能够从任意数量的定位稀疏视图图像预测出高保真度的3D高斯表示。之前的方法通常在每个视图的像素基础上局部回归3D高斯,然后将它们转移到世界空间并通过点连接进行合并。相比之下,我们的方法是在世界空间中建立单位3D高斯模型,并逐层更新它们。为了利用来自多视图输入的的信息来更新单位3D高斯,我们开发了一个类似于DETR(检测转换器)的框架,该框架将3D高斯作为查询,通过多视图交叉注意力(MVDFA)在多个输入图像(作为键和值)之间更新其参数。这种方法有效地避免了“重影”问题,并将更多的3D高斯分配给复杂区域。此外,由于用作解码器查询的3D高斯的数量与输入视图的数量无关,因此我们的方法允许任意数量的多视图图像作为输入,而不会导致内存爆炸或需要重新训练。大量实验验证了我们的方法的优势,在定量上展示了优于现有方法的表现(在Objaverse上进行训练,在GSO基准测试上进行测试时,峰值信噪比提高了4.2 dB),并在定性上也是如此。代码将发布在https://github.com/jwubz123/UNIG。
论文及项目相关链接
Summary
本文提出了UniGS,这是一种新的3D高斯重建和视图合成模型,可从任意数量的定位稀疏视图图像预测高保真3D高斯表示。与以往方法不同,UniGS直接在世界空间中对单位3D高斯进行建模,并逐层更新它们。为解决单位3D高斯更新的信息融合问题,研究团队引入了DETR(检测转换器)框架,将3D高斯视为查询,通过多视图交叉注意力(MVDFA)在多个输入图像(视为键和值)之间更新其参数。此方法有效避免了“幽灵”问题,并在复杂区域分配了更多的3D高斯。由于用作解码器查询的3D高斯数量与输入视图的数量无关,因此该方法允许任意数量的多视图图像作为输入,而不会造成内存爆炸或需要重新训练。大量实验验证了该方法相较于现有技术的优势,在定性和定量上均表现出卓越性能(在Objaverse上训练后在GSO基准测试上提高了4.2 dB的PSNR)。
Key Takeaways
- UniGS是一个新型的3D高斯重建和视图合成模型,可从任意数量的定位稀疏视图图像预测高保真3D高斯表示。
- UniGS在世界空间中对单位3D高斯进行建模并逐层更新,避免了以往方法中局部回归和合并的复杂性。
- 引入DETR框架来处理多视图输入,通过多视图交叉注意力(MVDFA)更新单位3D高斯参数。
- 该方法解决了“幽灵”问题,并在复杂区域分配更多3D高斯。
- 模型允许使用任意数量的多视图图像作为输入,且不会增加内存需求或需要重新训练。
- 实验结果表明,UniGS在定性和定量上均优于现有技术,特别是在GSO基准测试上的PSNR提高了4.2 dB。
点此查看论文截图



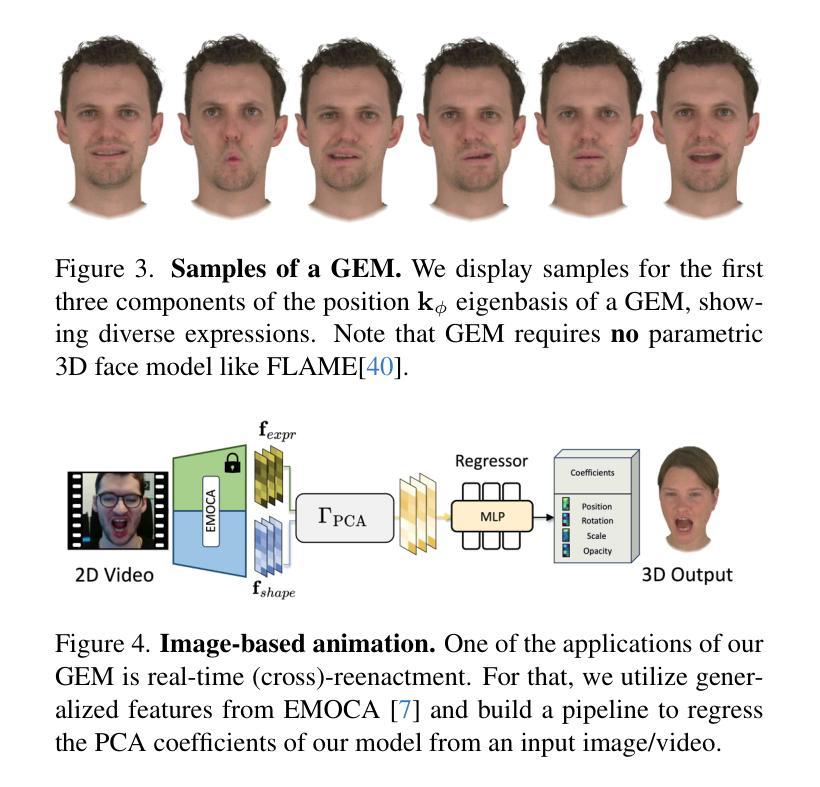
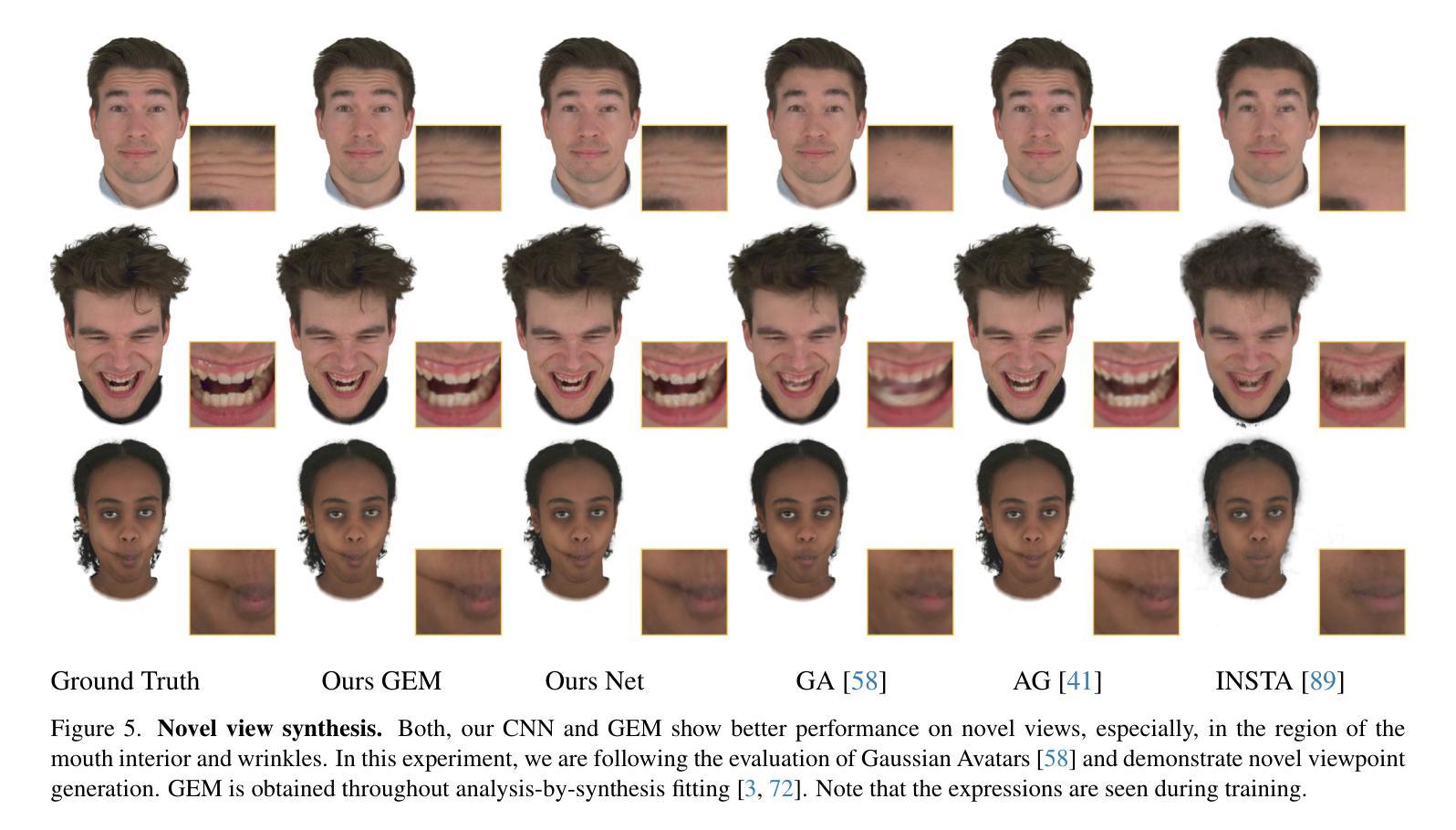
Gaussian Eigen Models for Human Heads
Authors:Wojciech Zielonka, Timo Bolkart, Thabo Beeler, Justus Thies
Current personalized neural head avatars face a trade-off: lightweight models lack detail and realism, while high-quality, animatable avatars require significant computational resources, making them unsuitable for commodity devices. To address this gap, we introduce Gaussian Eigen Models (GEM), which provide high-quality, lightweight, and easily controllable head avatars. GEM utilizes 3D Gaussian primitives for representing the appearance combined with Gaussian splatting for rendering. Building on the success of mesh-based 3D morphable face models (3DMM), we define GEM as an ensemble of linear eigenbases for representing the head appearance of a specific subject. In particular, we construct linear bases to represent the position, scale, rotation, and opacity of the 3D Gaussians. This allows us to efficiently generate Gaussian primitives of a specific head shape by a linear combination of the basis vectors, only requiring a low-dimensional parameter vector that contains the respective coefficients. We propose to construct these linear bases (GEM) by distilling high-quality compute-intense CNN-based Gaussian avatar models that can generate expression-dependent appearance changes like wrinkles. These high-quality models are trained on multi-view videos of a subject and are distilled using a series of principal component analyses. Once we have obtained the bases that represent the animatable appearance space of a specific human, we learn a regressor that takes a single RGB image as input and predicts the low-dimensional parameter vector that corresponds to the shown facial expression. In a series of experiments, we compare GEM’s self-reenactment and cross-person reenactment results to state-of-the-art 3D avatar methods, demonstrating GEM’s higher visual quality and better generalization to new expressions.
当前个性化神经头部化身面临权衡:轻量级模型缺乏细节和真实感,而高质量、可动画的化身需要巨大的计算资源,使其不适合普通设备。为了解决这一差距,我们引入了高斯特征模型(GEM),它提供高质量、轻便且易于控制的头部化身。GEM使用3D高斯原始图形来表示外观,并结合高斯拼贴进行渲染。基于基于网格的3D可变形面部模型(3DMM)的成功,我们将GEM定义为表示特定主体头部外观的线性特征基集合。特别是,我们构建了表示位置、比例、旋转和透明度的线性基。这允许我们通过线性组合基向量有效地生成特定头部形状的高斯原始图形,只需要包含相应系数的低维参数向量。我们提议通过提炼高质量的计算密集型CNN高斯化身模型来构建这些线性基(GEM),该模型可以生成与表情相关的外观变化,如皱纹。这些高质量模型是在主体的多视角视频上进行训练的,并使用一系列主成分分析进行提炼。一旦我们获得了代表特定人类可动画外观空间的基地,我们就学习一个回归器,它接受单张RGB图像作为输入,并预测与所示面部表情相对应的低维参数向量。在一系列实验中,我们将GEM的自我再演绎和跨人再演绎结果与最先进的3D化身方法进行比较,证明了GEM更高的视觉质量和对新表情的更好泛化能力。
论文及项目相关链接
PDF Accepted to CVPR25 Website: https://zielon.github.io/gem/
摘要
本文为了解决个性化神经头部化身面临的困境——轻量化模型缺乏细节和逼真度,而高质量、可动画的化身需要巨大的计算资源,不适合普通设备使用,提出了高斯特征模型(GEM)。GEM利用3D高斯原始特征表示外观,结合高斯贴图进行渲染,提供高质量、轻量化且易于控制的头部化身。基于网格的3D可变形面部模型(3DMM)的成功,定义GEM为特定的头部外观表示线性特征基集合。通过构建表示位置、尺度、旋转和透明度的线性基,通过线性组合基向量有效地生成具有特定头部形状的高斯原始特征。此外,提出了通过蒸馏高质量的计算密集型CNN高斯化身模型来构建这些线性基(GEM),可以生成如皱纹等表情相关的外观变化。这些高质量模型通过主体多视角视频进行训练,使用主成分分析进行蒸馏。在获得代表特定人类可动画外观空间的基后,学习一个回归器,以单张RGB图像为输入,预测与所示面部表情相对应的低维参数向量。一系列实验表明,与最先进的3D化身方法相比,GEM的自我再演绎和跨人再演绎结果具有更高的视觉质量和更好的新表情泛化能力。
要点
- 当前个性化神经头部化身面临困境:轻量化模型缺乏细节和逼真度,高质量模型则计算资源需求大。
- 提出高斯特征模型(GEM)解决此问题,实现高质量、轻量化且易于控制的头部化身。
- GEM利用3D高斯原始特征和高斯贴图进行渲染。
- 基于网格的3D可变形面部模型(3DMM)构建线性基来表示头部外观。
- 通过线性组合基向量生成特定头部形状的高斯原始特征。
- 通过蒸馏高质量的计算密集型CNN模型来构建线性基,能生成表情相关的外观变化。
点此查看论文截图


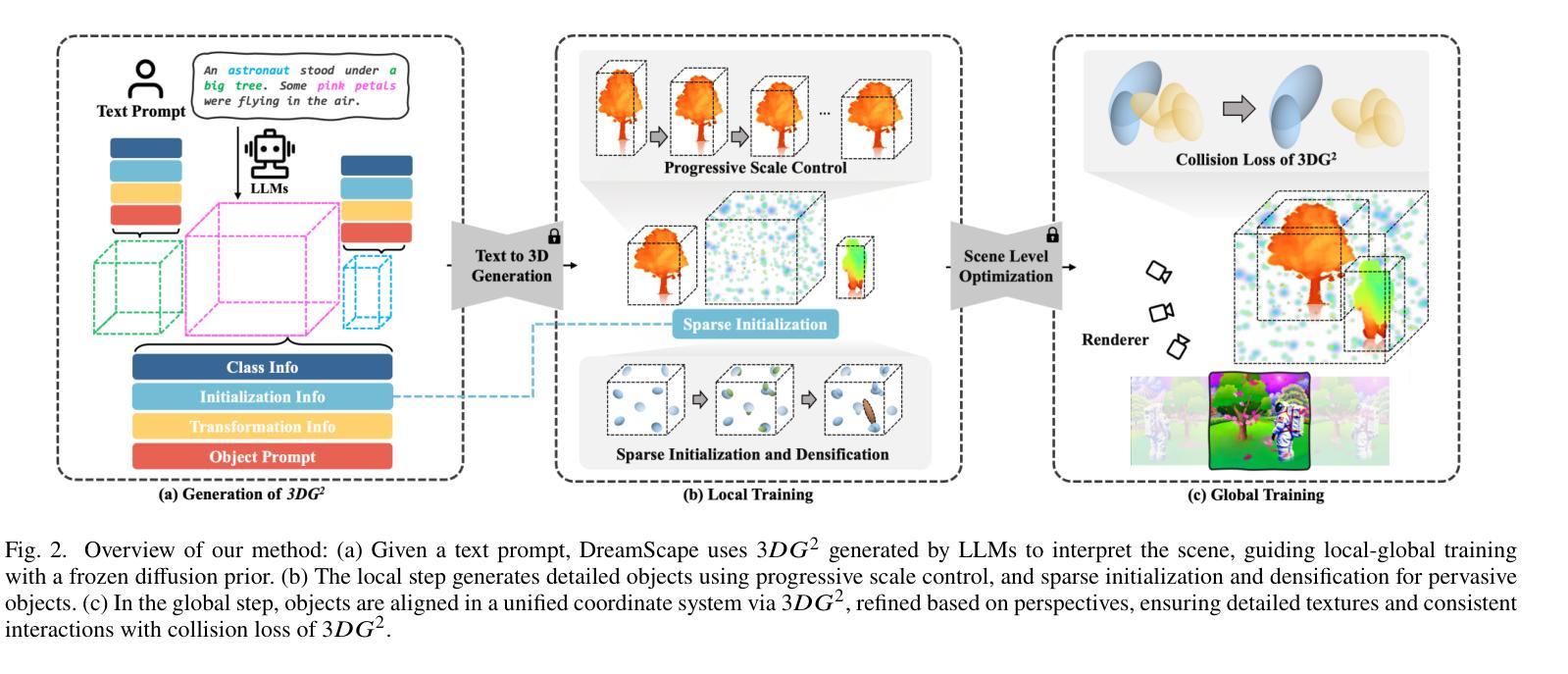
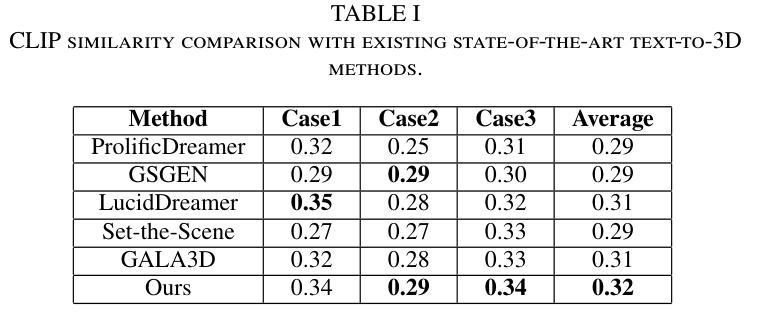
DreamScape: 3D Scene Creation via Gaussian Splatting joint Correlation Modeling
Authors:Yueming Zhao, Xuening Yuan, Hongyu Yang, Di Huang
Recent advances in text-to-3D creation integrate the potent prior of Diffusion Models from text-to-image generation into 3D domain. Nevertheless, generating 3D scenes with multiple objects remains challenging. Therefore, we present DreamScape, a method for generating 3D scenes from text. Utilizing Gaussian Splatting for 3D representation, DreamScape introduces 3D Gaussian Guide that encodes semantic primitives, spatial transformations and relationships from text using LLMs, enabling local-to-global optimization. Progressive scale control is tailored during local object generation, addressing training instability issue arising from simple blending in the global optimization stage. Collision relationships between objects are modeled at the global level to mitigate biases in LLMs priors, ensuring physical correctness. Additionally, to generate pervasive objects like rain and snow distributed extensively across the scene, we design specialized sparse initialization and densification strategy. Experiments demonstrate that DreamScape achieves state-of-the-art performance, enabling high-fidelity, controllable 3D scene generation.
最近的文本到3D创建技术进展将文本到图像生成的强大扩散模型先验知识整合到3D领域。然而,生成具有多个对象的3D场景仍然具有挑战性。因此,我们提出了DreamScape方法,一种从文本生成3D场景的方法。利用高斯涂抹法进行3D表示,DreamScape引入了3D高斯指南,该指南使用大型语言模型(LLMs)对语义原始信息、空间变换和关系进行编码,从而实现局部到全局的优化。在局部对象生成过程中进行了定制的渐进式尺度控制,解决了全局优化阶段简单混合所导致的训练不稳定问题。在全局层面建立对象间的碰撞关系,以减轻大型语言模型先验中的偏见,确保物理正确性。此外,为了生成如雨雪等广泛分布在场景中的常见物体,我们设计了专门的稀疏初始化和致密化策略。实验表明,DreamScape达到了最先进的性能,能够实现高保真、可控的3D场景生成。
论文及项目相关链接
Summary
基于文本到图像生成的扩散模型潜力,结合其在三维领域的应用,DreamScape方法实现了从文本生成三维场景的功能。通过高斯拼贴进行三维表示,并使用大型语言模型编码语义基元、空间转换和文本中的关系,DreamScape实现了局部到全局的优化。该方法解决了简单混合带来的训练不稳定问题,并在全局优化阶段采用渐进尺度控制。通过建模物体间的碰撞关系,确保物理正确性并减轻大型语言模型先验的偏见。此外,为了生成场景中广泛分布的如雨雪等常见物体,设计了一种特殊的稀疏初始化和密集化策略。实验表明,DreamScape取得了业界领先水平,能够实现高保真、可控的三维场景生成。
Key Takeaways
- DreamScape利用扩散模型整合文本到三维场景生成。
- 通过高斯拼贴进行三维表示,并采用大型语言模型(LLMs)编码文本中的语义和关系。
- 实现局部到全局的优化,解决简单混合带来的训练不稳定问题。
- 建模物体间的碰撞关系以确保物理正确性。
- 设计特殊策略生成场景中的普遍物体,如雨雪。
- DreamScape实验表现出卓越性能,达到业界领先水平。
点此查看论文截图