⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-05 更新
Aligned Better, Listen Better for Audio-Visual Large Language Models
Authors:Yuxin Guo, Shuailei Ma, Shijie Ma, Xiaoyi Bao, Chen-Wei Xie, Kecheng Zheng, Tingyu Weng, Siyang Sun, Yun Zheng, Wei Zou
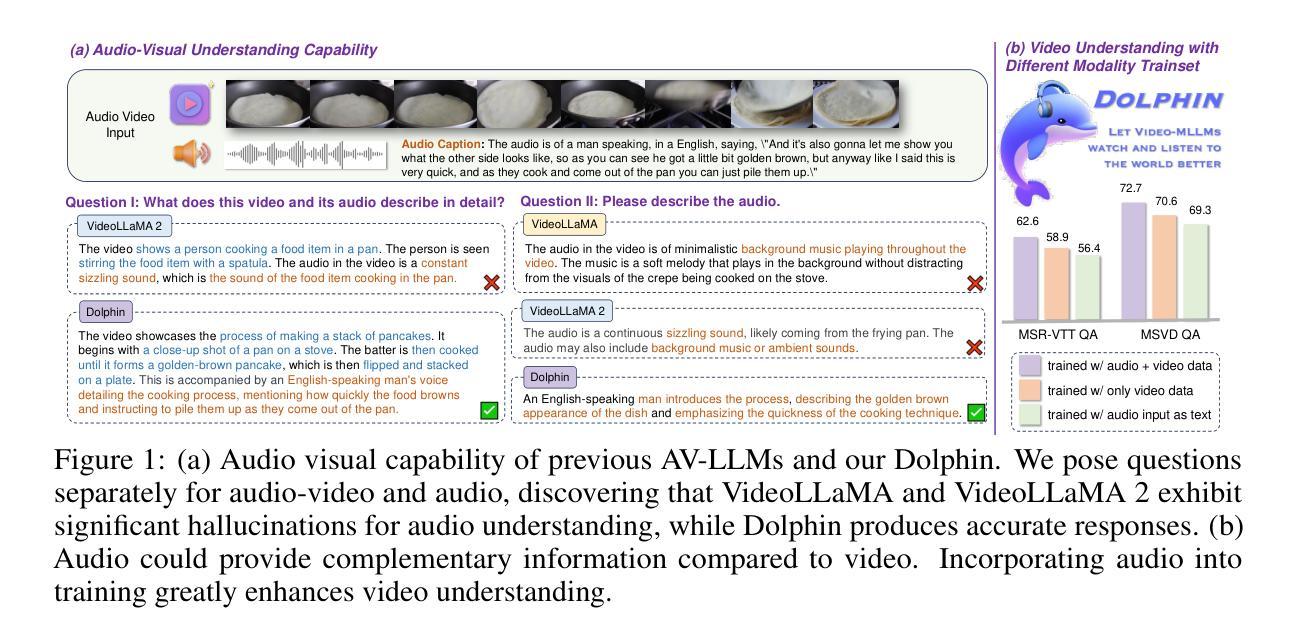
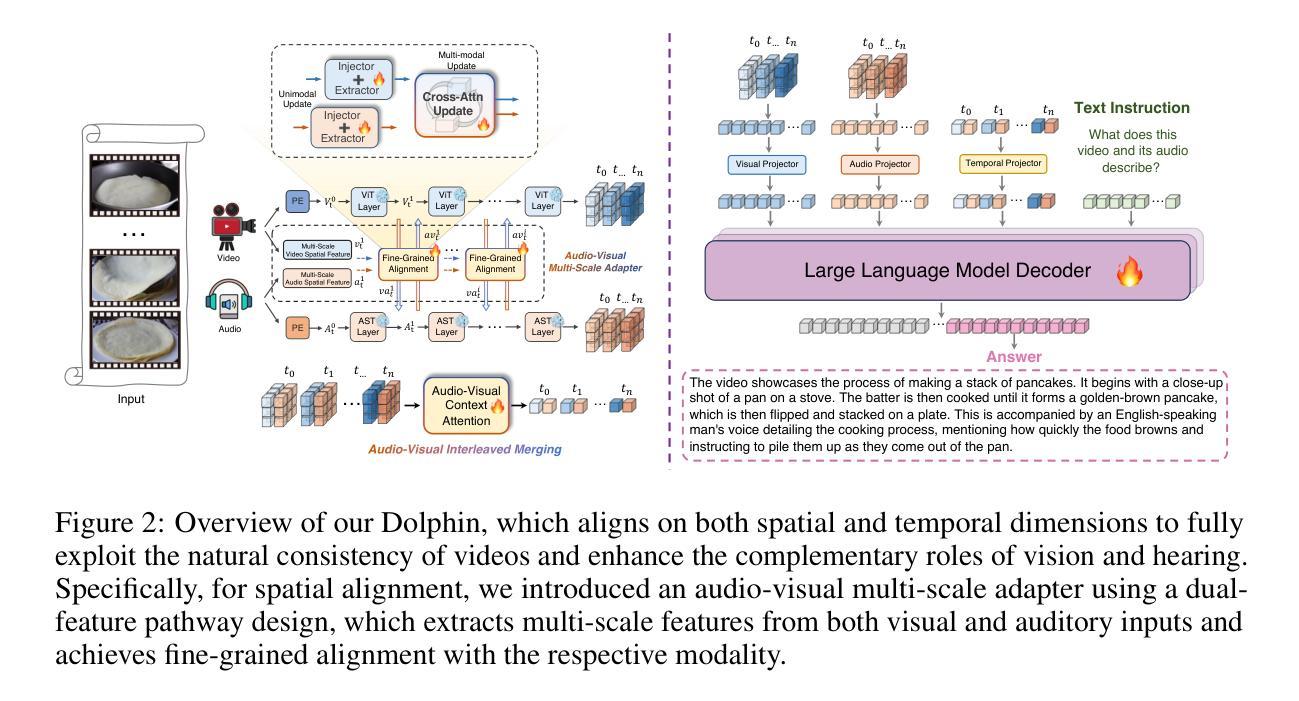
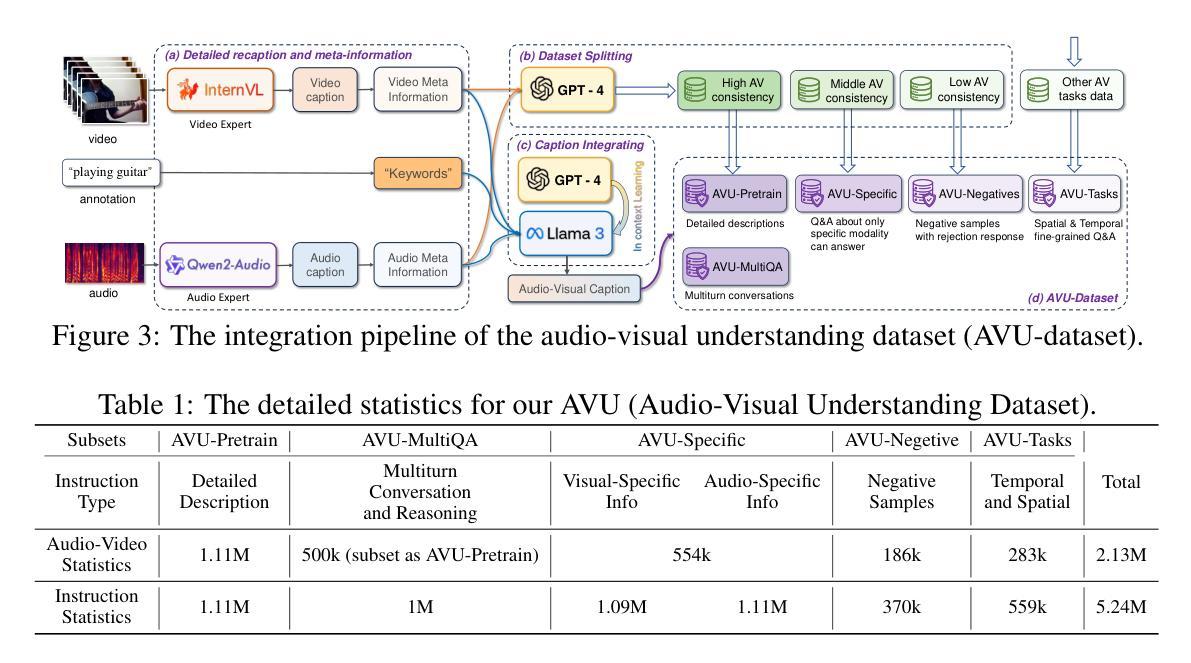
Audio is essential for multimodal video understanding. On the one hand, video inherently contains audio, which supplies complementary information to vision. Besides, video large language models (Video-LLMs) can encounter many audio-centric settings. However, existing Video-LLMs and Audio-Visual Large Language Models (AV-LLMs) exhibit deficiencies in exploiting audio information, leading to weak understanding and hallucinations. To solve the issues, we delve into the model architecture and dataset. (1) From the architectural perspective, we propose a fine-grained AV-LLM, namely Dolphin. The concurrent alignment of audio and visual modalities in both temporal and spatial dimensions ensures a comprehensive and accurate understanding of videos. Specifically, we devise an audio-visual multi-scale adapter for multi-scale information aggregation, which achieves spatial alignment. For temporal alignment, we propose audio-visual interleaved merging. (2) From the dataset perspective, we curate an audio-visual caption and instruction-tuning dataset, called AVU. It comprises 5.2 million diverse, open-ended data tuples (video, audio, question, answer) and introduces a novel data partitioning strategy. Extensive experiments show our model not only achieves remarkable performance in audio-visual understanding, but also mitigates potential hallucinations.
音频对于多模态视频理解至关重要。一方面,视频本身就包含音频,为视觉提供了补充信息。此外,视频大型语言模型(Video-LLMs)可能会遇到许多以音频为中心的场景。然而,现有的Video-LLMs和视听大型语言模型(AV-LLMs)在利用音频信息方面存在缺陷,导致理解不足和幻觉。为了解决这些问题,我们对模型架构和数据集进行了深入研究。(1)从架构的角度来看,我们提出了一种精细的AV-LLM,即Dolphin。音频和视觉模态在时间和空间维度上的并行对齐,确保了视频的全面和准确理解。具体来说,我们设计了一个视听多尺度适配器进行多尺度信息聚合,以实现空间对齐。对于时间对齐,我们提出了视听交替合并的方法。(2)从数据集的角度来看,我们整理了一个视听字幕和指令调整数据集,称为AVU。它包含了520万个多样、开放的数据元组(视频、音频、问题、答案),并引入了一种新的数据分区策略。大量实验表明,我们的模型不仅在视听理解方面取得了显著的成绩,而且减轻了潜在的幻觉问题。
论文及项目相关链接
PDF Accepted to ICLR 2025
Summary
本文强调音频在多模态视频理解中的重要性,并提出了一种精细的音视频大型语言模型(AV-LLM),名为“海豚”。该模型通过音频和视觉模态在时间和空间维度的并行对齐,实现了对视频的全面准确理解。同时,为了提升模型性能并减少潜在的幻觉,本文从数据集角度入手,创建了一个音视频字幕和指令调整数据集AVU。
Key Takeaways
- 音频对于多模态视频理解至关重要,提供了与视觉互补的信息。
- 现有视频大型语言模型(Video-LLMs)和音视频大型语言模型(AV-LLMs)在利用音频信息方面存在缺陷。
- 提出了一种名为“海豚”的精细AV-LLM模型,通过音频和视觉模态在时间和空间维度的并行对齐,提高视频理解能力。
- 在模型架构方面,引入了音视频多尺度适配器和音视频交替合并策略。
- 从数据集角度,创建了一个音视频字幕和指令调整数据集AVU,包含520万个开放式的数据元组。
- AVU数据集采用了新型的数据分区策略。
点此查看论文截图