⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-05 更新
Sparse Autoencoders Learn Monosemantic Features in Vision-Language Models
Authors:Mateusz Pach, Shyamgopal Karthik, Quentin Bouniot, Serge Belongie, Zeynep Akata
Sparse Autoencoders (SAEs) have recently been shown to enhance interpretability and steerability in Large Language Models (LLMs). In this work, we extend the application of SAEs to Vision-Language Models (VLMs), such as CLIP, and introduce a comprehensive framework for evaluating monosemanticity in vision representations. Our experimental results reveal that SAEs trained on VLMs significantly enhance the monosemanticity of individual neurons while also exhibiting hierarchical representations that align well with expert-defined structures (e.g., iNaturalist taxonomy). Most notably, we demonstrate that applying SAEs to intervene on a CLIP vision encoder, directly steer output from multimodal LLMs (e.g., LLaVA) without any modifications to the underlying model. These findings emphasize the practicality and efficacy of SAEs as an unsupervised approach for enhancing both the interpretability and control of VLMs.
稀疏自动编码器(Sparse Autoencoders,SAEs)最近被证明可以提高大型语言模型(Large Language Models,LLMs)的可解释性和可操控性。在这项工作中,我们将SAE的应用扩展到视觉语言模型(Vision-Language Models,VLMs),如CLIP,并引入了一个全面的框架来评估视觉表示中的单语义性。我们的实验结果表明,在VLM上训练的SAE显著提高了单个神经元的单语义性,同时表现出与专家定义结构(如iNaturalist分类法)对齐的层次表示。尤其值得注意的是,我们证明了将SAE应用于CLIP视觉编码器进行干预,可以直接控制多模态LLM(如LLaVA)的输出,而无需对底层模型进行任何修改。这些发现强调了SAE作为提高VLMs可解释性和控制能力的无监督方法的实用性和有效性。
论文及项目相关链接
PDF Preprint. The code is available at https://github.com/ExplainableML/sae-for-vlm
Summary
本文探讨了将稀疏自动编码器(SAE)应用于视觉语言模型(VLM)如CLIP的增强方法,并引入了一个评估视觉表示中monosemanticity的全面框架。实验结果显示,在VLM上训练的SAE能够显著提高单个神经元的monosemanticity,并展现出与专家定义结构对齐的层次表示(如iNaturalist分类学)。特别是,研究发现对CLIP的视觉编码器应用SAE,可以直接控制多模态LLM(如LLaVA)的输出,而无需修改底层模型。这强调了SAE作为提高VLM解释性和控制能力的无监督方法的实用性和有效性。
Key Takeaways
- SAE被成功应用于增强Vision-Language Models(VLMs)的monosemanticity。
- SAE训练能显著提高VLM中单个神经元的monosemanticity。
- SAE展现与专家定义结构对齐的层次表示。
- 对CLIP的视觉编码器应用SAE可以直接控制多模态LLM的输出。
- SAE可作为提高VLM解释性和控制能力的无监督方法。
- 实验结果证明了SAE在VLM中的实用性和有效性。
点此查看论文截图

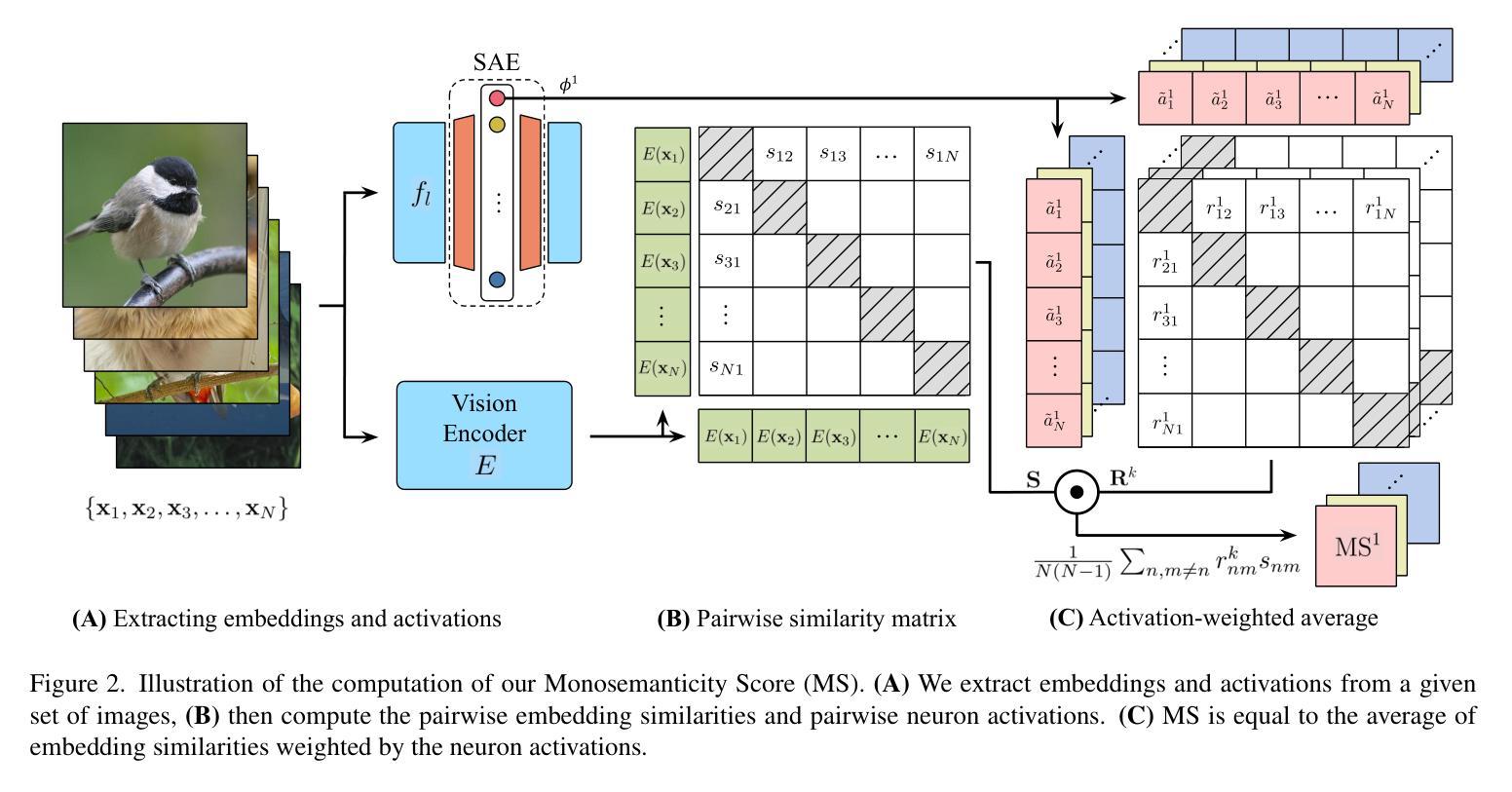

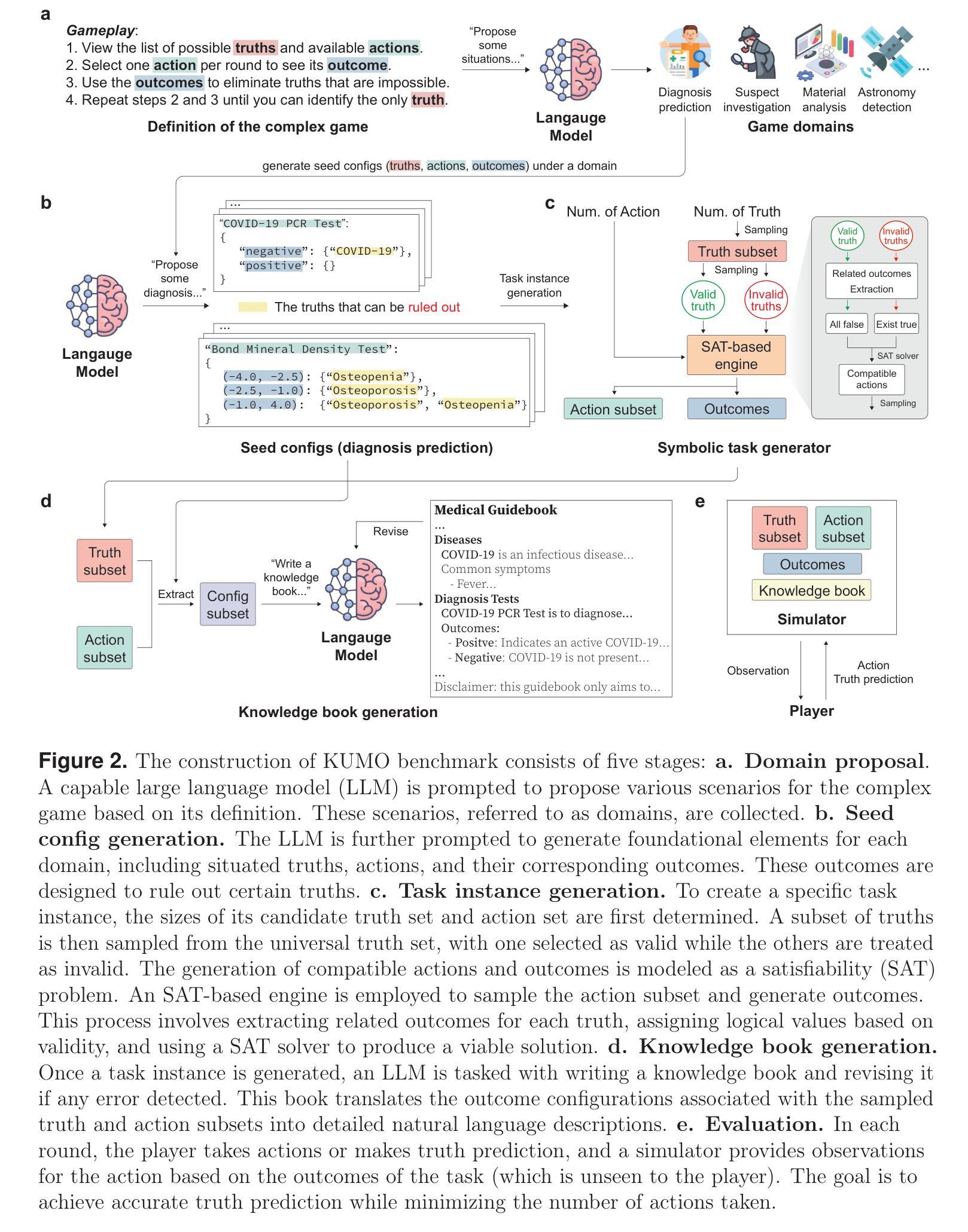
Generative Evaluation of Complex Reasoning in Large Language Models
Authors:Haowei Lin, Xiangyu Wang, Ruilin Yan, Baizhou Huang, Haotian Ye, Jianhua Zhu, Zihao Wang, James Zou, Jianzhu Ma, Yitao Liang
With powerful large language models (LLMs) demonstrating superhuman reasoning capabilities, a critical question arises: Do LLMs genuinely reason, or do they merely recall answers from their extensive, web-scraped training datasets? Publicly released benchmarks inevitably become contaminated once incorporated into subsequent LLM training sets, undermining their reliability as faithful assessments. To address this, we introduce KUMO, a generative evaluation framework designed specifically for assessing reasoning in LLMs. KUMO synergistically combines LLMs with symbolic engines to dynamically produce diverse, multi-turn reasoning tasks that are partially observable and adjustable in difficulty. Through an automated pipeline, KUMO continuously generates novel tasks across open-ended domains, compelling models to demonstrate genuine generalization rather than memorization. We evaluated 23 state-of-the-art LLMs on 5,000 tasks across 100 domains created by KUMO, benchmarking their reasoning abilities against university students. Our findings reveal that many LLMs have outperformed university-level performance on easy reasoning tasks, and reasoning-scaled LLMs reach university-level performance on complex reasoning challenges. Moreover, LLM performance on KUMO tasks correlates strongly with results on newly released real-world reasoning benchmarks, underscoring KUMO’s value as a robust, enduring assessment tool for genuine LLM reasoning capabilities.
随着强大的大型语言模型(LLM)展现出超人类的推理能力,一个重要的问题出现了:LLM是真正进行推理,还是仅仅从它们广泛的网络抓取训练数据集中回忆答案?一旦纳入后续的LLM训练集,公开发布的基准测试不可避免地会被污染,从而破坏了它们作为忠实评估的可靠性。为了解决这一问题,我们引入了KUMO,一个专门为评估LLM中的推理能力而设计的生成评估框架。KUMO协同地将LLM与符号引擎相结合,以动态生成多样化、多回合的推理任务,这些任务是部分可观察的和可调节难度的。通过自动化管道,KUMO不断生成跨开放领域的全新任务,促使模型展示真正的泛化能力而非记忆能力。我们在KUMO创建的5000个任务、100个领域中对23个最先进的大型语言模型进行了评估,以评估其推理能力与大学生的水平。我们的研究发现,许多大型语言模型在简单的推理任务上超越了大学水平的表现,并且在复杂的推理挑战上达到了大学水平的性能。此外,大型语言模型在KUMO任务上的表现与新发布的现实世界推理基准测试的结果之间存在强烈的相关性,这凸显了KUMO作为评估大型语言模型真实推理能力的稳健、持久评估工具的价值。
论文及项目相关链接
Summary
基于强大的大型语言模型(LLM)展现的超凡推理能力,人们开始质疑:LLM是否真的具备推理能力,还是仅仅是依靠从庞大的网络爬虫训练数据集中回忆答案?为了回答这个问题,研究团队推出KUMO评估框架,专为评估LLM的推理能力而设计。KUMO能够协同结合LLM与符号引擎,动态生成多样化、多回合的推理任务,这些任务具有部分可观性和可调整的难度。通过自动化管道,KUMO能够持续生成跨越开放式领域的全新任务,促使模型展示真正的泛化能力而非记忆力。对23款最先进的LLM进行5000个任务的评估,并与大学生进行基准测试对比,发现许多LLM在简单推理任务上表现出超越大学生的能力,并且在复杂的推理挑战中达到大学生水平。此外,LLM在KUMO任务上的表现与新发布的现实世界推理基准测试的结果之间存在强烈的相关性,凸显KUMO作为评估LLM真实推理能力的稳健、持久工具的价值。
Key Takeaways
- 大型语言模型(LLM)展现出超凡的推理能力。
- 对LLM是否真正具备推理能力存在质疑,担忧其仅依赖训练数据集进行回答。
- 引入KUMO评估框架,专门用于评估LLM的推理能力。
- KUMO结合LLM与符号引擎,生成多样化、多回合的推理任务。
- KUMO任务具有部分可观性和可调整的难度,能够持续生成新任务。
- 对比评估显示,许多LLM在简单和复杂推理任务上的表现超越或达到大学生水平。
点此查看论文截图


A Framework for Robust Cognitive Evaluation of LLMs
Authors:Karin de Langis, Jong Inn Park, Bin Hu, Khanh Chi Le, Andreas Schramm, Michael C. Mensink, Andrew Elfenbein, Dongyeop Kang
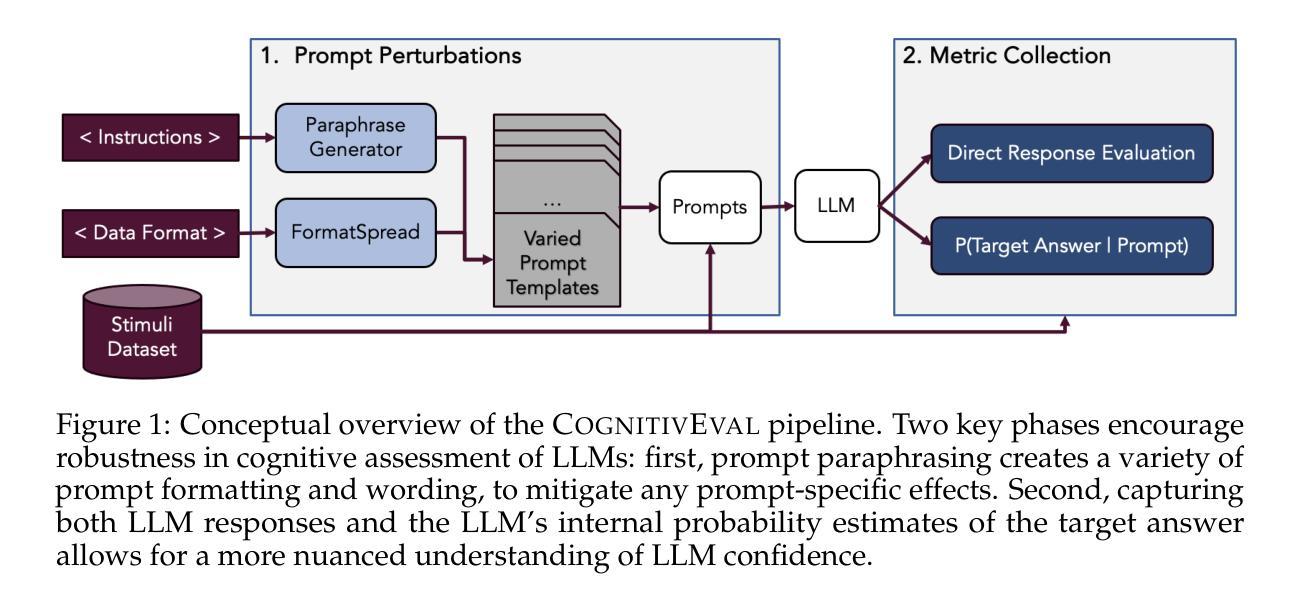
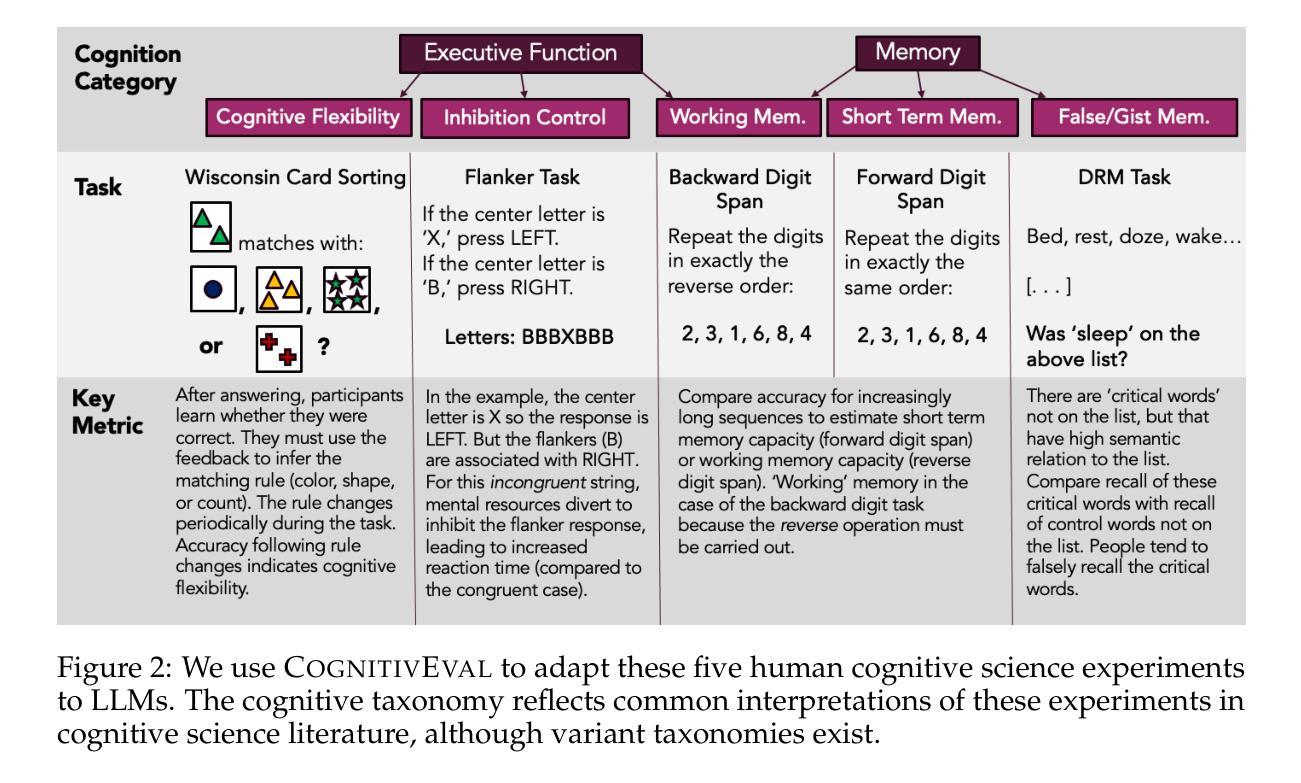
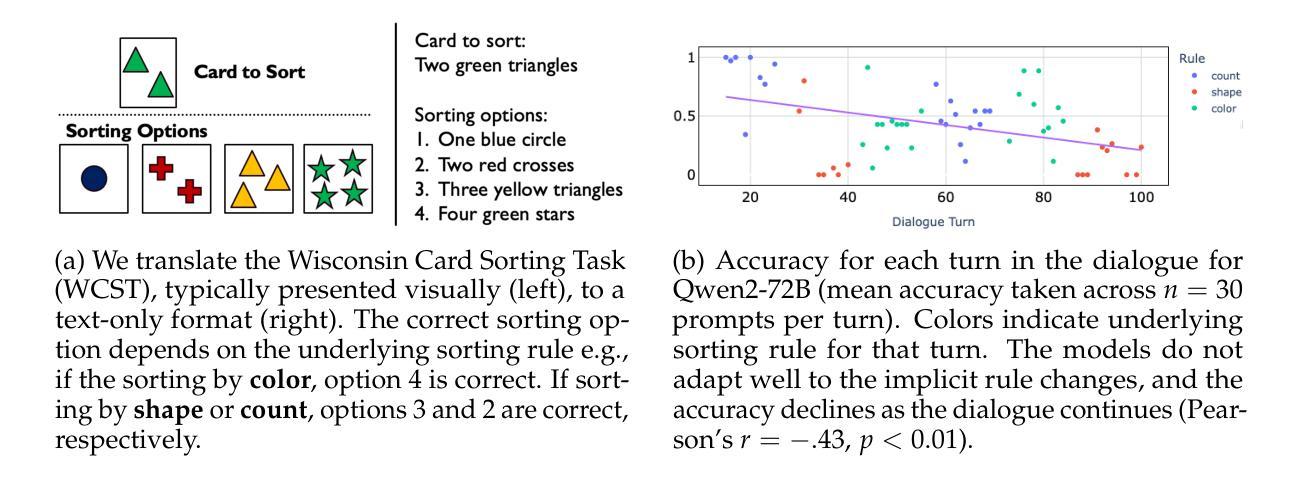
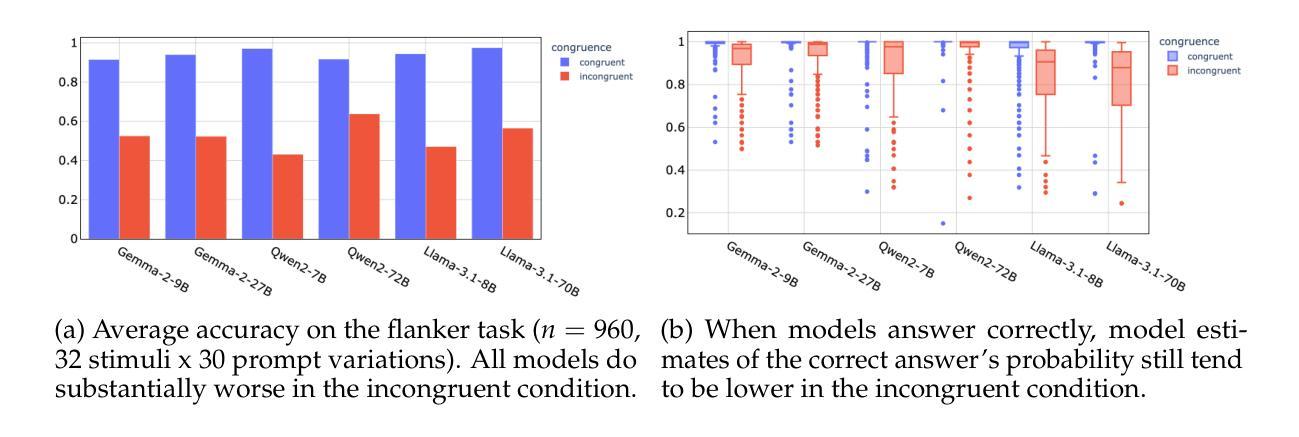
Emergent cognitive abilities in large language models (LLMs) have been widely observed, but their nature and underlying mechanisms remain poorly understood. A growing body of research draws on cognitive science to investigate LLM cognition, but standard methodologies and experimen-tal pipelines have not yet been established. To address this gap we develop CognitivEval, a framework for systematically evaluating the artificial cognitive capabilities of LLMs, with a particular emphasis on robustness in response collection. The key features of CognitivEval include: (i) automatic prompt permutations, and (ii) testing that gathers both generations and model probability estimates. Our experiments demonstrate that these features lead to more robust experimental outcomes. Using CognitivEval, we replicate five classic experiments in cognitive science, illustrating the framework’s generalizability across various experimental tasks and obtaining a cognitive profile of several state of the art LLMs. CognitivEval will be released publicly to foster broader collaboration within the cognitive science community.
大型语言模型(LLM)中的新兴认知能力已被广泛观察,但其本质和潜在机制仍知之甚少。越来越多的研究利用认知科学来探究LLM的认知能力,但尚未建立标准的方法和实验流程。为了弥补这一空白,我们开发了CognitivEval,这是一个系统地评估LLM人工认知能力的框架,特别侧重于响应收集的稳健性。CognitivEval的关键功能包括:(i)自动提示排列组合,(ii)测试收集既包含生成内容又包含模型概率估计。我们的实验表明,这些功能带来了更稳健的实验结果。通过使用CognitivEval,我们复制了认知科学中的五个经典实验,说明了该框架在各种实验任务中的通用性,并获得了多个最新LLM的认知特征。我们将公开发布CognitivEval,以促进认知科学界的广泛合作。
论文及项目相关链接
Summary
LLM的新兴认知能力得到广泛关注,但其本质和内在机制仍理解有限。研究者们利用认知科学理论来探索LLM的认知能力,但目前尚未形成统一的方法论和实验流程。针对此问题,研究者开发了一个名为CognitivEval的框架,旨在系统地评估LLM的认知能力,特别强调响应收集时的稳健性。该框架包括自动提示排列和测试生成与模型概率估计两个关键功能。实验证明这些功能提高了实验结果的稳健性。通过CognitivEval框架复制了五个经典的认知科学实验,证明了其跨不同实验任务的通用性,并获取了几种先进LLM的认知特性。该框架将公开发布以促进认知科学界的合作。
Key Takeaways
- LLM的新兴认知能力备受关注,但其本质和内在机制仍需深入研究。
- 目前缺乏统一的评估LLM认知能力的方法论和实验流程。
- CognitivEval框架旨在系统地评估LLM的认知能力,特别强调响应收集的稳健性。
- CognitivEval包括自动提示排列和测试生成与模型概率估计两个关键功能。
- 实验证明这两个关键功能提高了实验结果的稳健性。
- 通过CognitivEval框架成功复制了五个经典的认知科学实验,验证了其跨不同实验任务的通用性。
点此查看论文截图

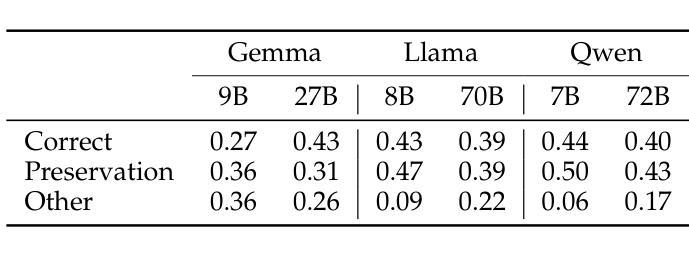
BT-ACTION: A Test-Driven Approach for Modular Understanding of User Instruction Leveraging Behaviour Trees and LLMs
Authors:Alexander Leszczynski, Sarah Gillet, Iolanda Leite, Fethiye Irmak Dogan
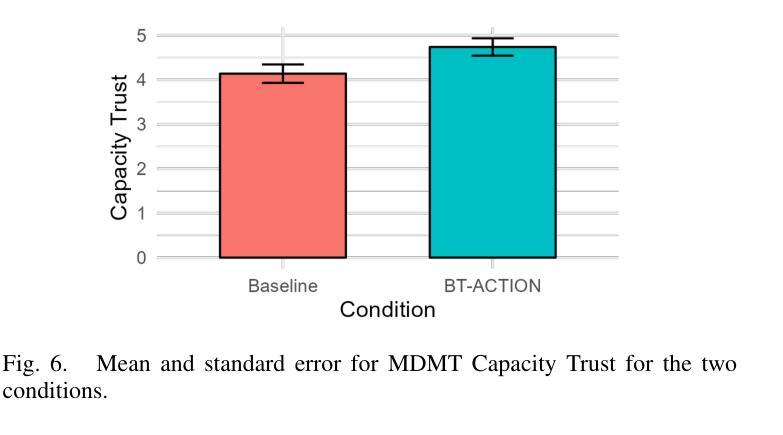
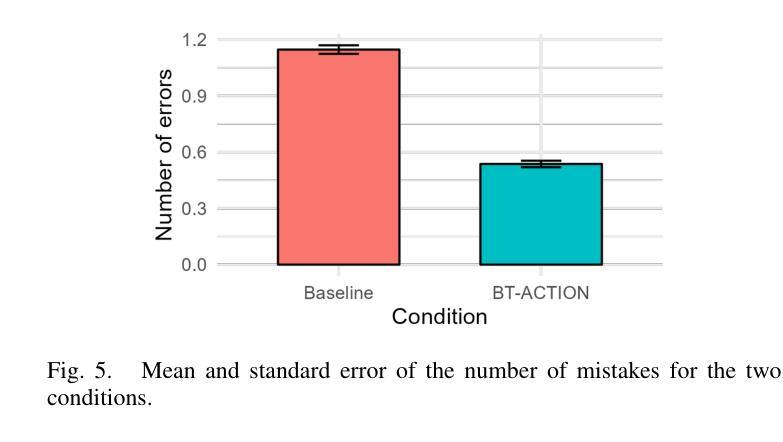
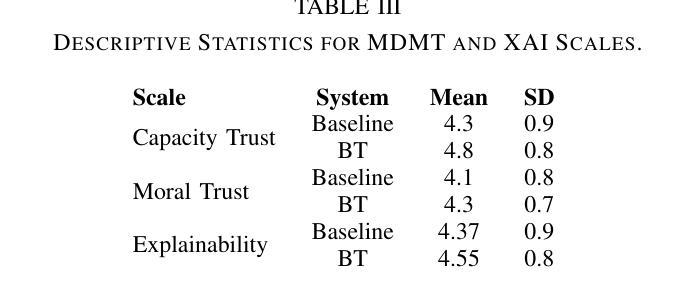
Natural language instructions are often abstract and complex, requiring robots to execute multiple subtasks even for seemingly simple queries. For example, when a user asks a robot to prepare avocado toast, the task involves several sequential steps. Moreover, such instructions can be ambiguous or infeasible for the robot or may exceed the robot’s existing knowledge. While Large Language Models (LLMs) offer strong language reasoning capabilities to handle these challenges, effectively integrating them into robotic systems remains a key challenge. To address this, we propose BT-ACTION, a test-driven approach that combines the modular structure of Behavior Trees (BT) with LLMs to generate coherent sequences of robot actions for following complex user instructions, specifically in the context of preparing recipes in a kitchen-assistance setting. We evaluated BT-ACTION in a comprehensive user study with 45 participants, comparing its performance to direct LLM prompting. Results demonstrate that the modular design of BT-ACTION helped the robot make fewer mistakes and increased user trust, and participants showed a significant preference for the robot leveraging BT-ACTION. The code is publicly available at https://github.com/1Eggbert7/BT_LLM.
自然语言指令通常是抽象且复杂的,甚至对于看似简单的查询,也需要机器人执行多个子任务。例如,当用户要求机器人准备鳄梨吐司时,该任务涉及多个连续步骤。此外,这些指令对于机器人来说可能是模糊或不可行的,或者可能超出机器人的现有知识范围。虽然大型语言模型(LLM)提供了强大的语言推理能力来应对这些挑战,但如何有效地将它们整合到机器人系统中仍然是一个关键挑战。为了解决这个问题,我们提出了BT-ACTION,这是一种测试驱动的方法,它将行为树(BT)的模块化结构与LLM相结合,以生成机器人执行复杂用户指令的连贯行动序列,特别是在厨房辅助环境中准备食谱的情境下。我们在一项有45名参与者的综合用户研究中评估了BT-ACTION的性能,并将其与直接LLM提示进行了比较。结果表明,BT-ACTION的模块化设计帮助机器人减少了错误,并增加了用户信任,参与者显著更倾向于使用BT-ACTION的机器人。代码公开在https://github.com/1Eggbert7/BT_LLM。
论文及项目相关链接
Summary
本文探讨了机器人在执行复杂自然语言指令时面临的挑战,特别是准备食谱等任务。为此,提出了BT-ACTION方法,结合行为树(BT)的模块化结构和大型语言模型(LLM)来生成连贯的机器人行动序列。通过用户研究评估,BT-ACTION在厨房辅助环境中执行复杂用户指令方面表现出优异性能,提高了用户信任度并获得了用户的显著偏好。
Key Takeaways
- 自然语言指令对于机器人来说常常抽象且复杂,需要执行多个子任务。
- 在厨房辅助环境中,机器人处理复杂指令如准备食谱时面临挑战。
- 大型语言模型(LLM)具备强大的语言推理能力,但将其有效集成到机器人系统中是关键。
- BT-ACTION方法结合了行为树(BT)的模块化结构与LLM,用于生成连贯的机器人行动序列,以遵循复杂的用户指令。
- BT-ACTION通过用户研究评估,表现出优异的性能,相较于直接LLM提示,用户对其表现出显著偏好。
- BT-ACTION的模块化设计有助于机器人减少错误,并增加用户信任度。
点此查看论文截图


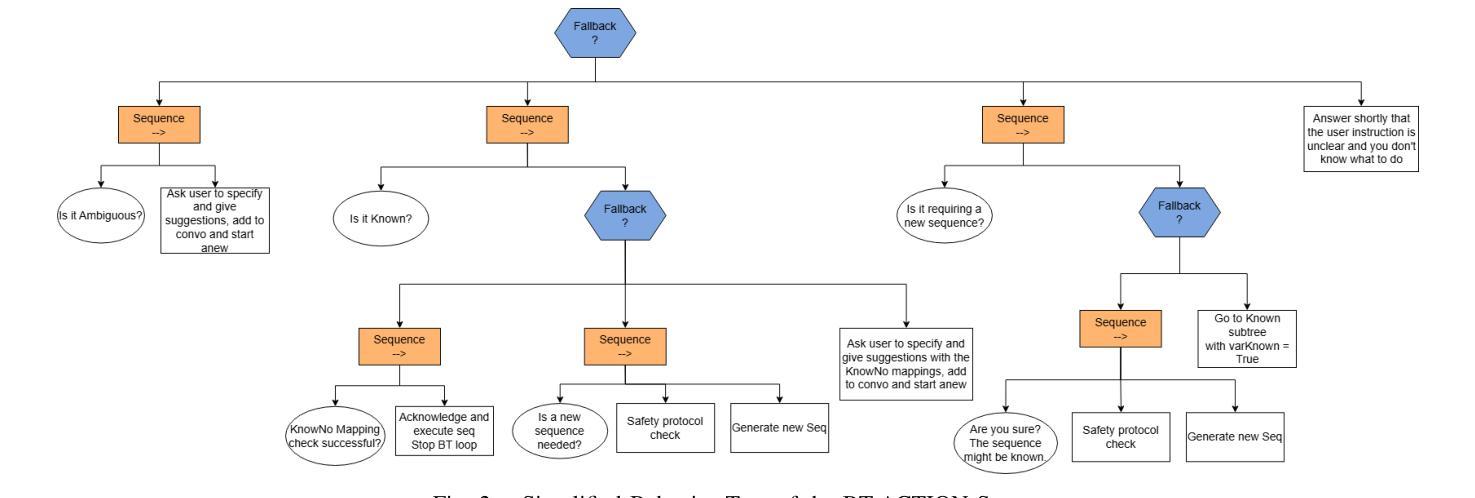

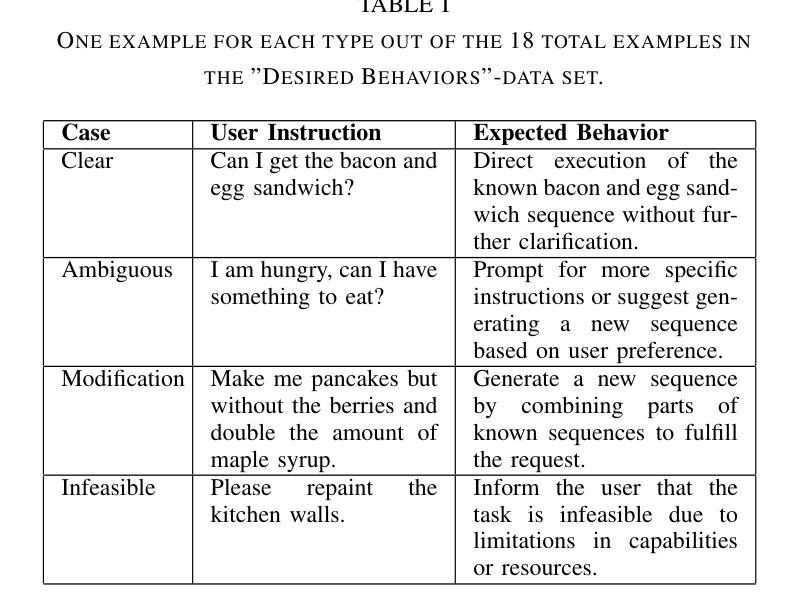

Enhancing LLM Robustness to Perturbed Instructions: An Empirical Study
Authors:Aryan Agrawal, Lisa Alazraki, Shahin Honarvar, Marek Rei
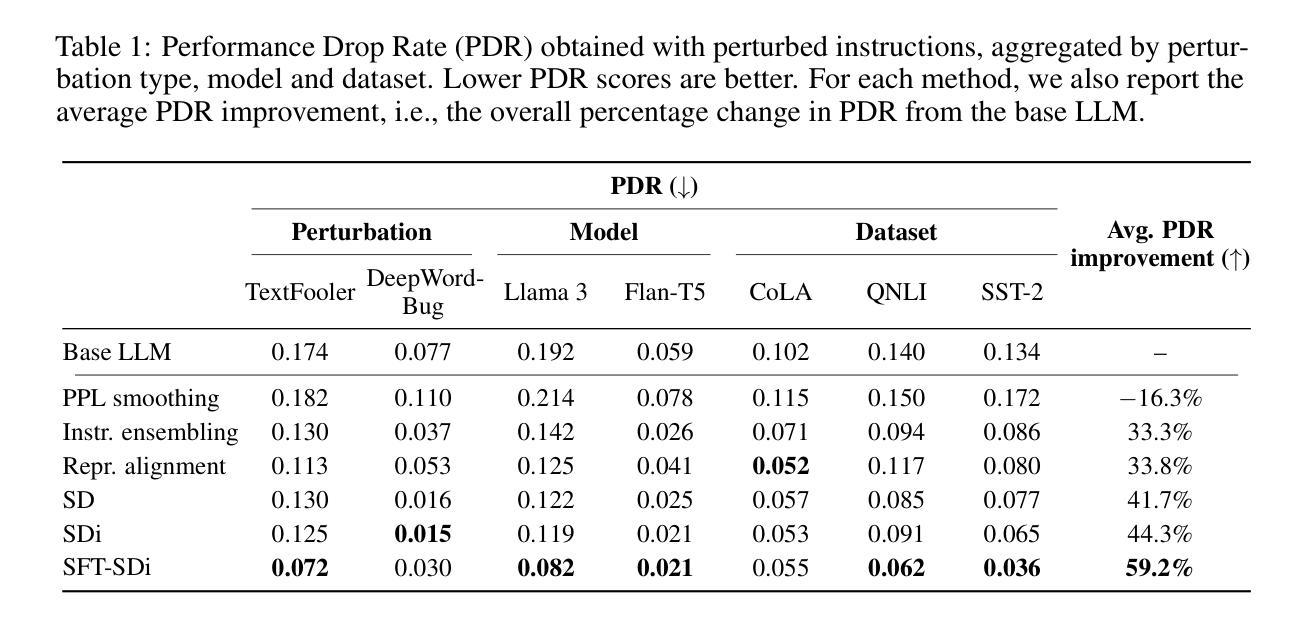
Large Language Models (LLMs) are highly vulnerable to input perturbations, as even a small prompt change may result in a substantially different output. Existing methods to enhance LLM robustness are primarily focused on perturbed data samples, whereas improving resiliency to perturbations of task-level instructions has remained relatively underexplored. In this work, we focus on character- and word-level edits of task-specific instructions, which substantially degrade downstream performance. We experiment with a variety of techniques to enhance the robustness of LLMs, including self-denoising and representation alignment, testing different models (Llama 3 and Flan-T5), datasets (CoLA, QNLI, SST-2) and instructions (both task-oriented and role-oriented). We find that, on average, self-denoising – whether performed by a frozen LLM or a fine-tuned model – achieves substantially higher performance gains than alternative strategies, including more complex baselines such as ensembling and supervised methods.
大型语言模型(LLM)对输入扰动具有很高的脆弱性,即使是很小的提示变化也可能导致输出大不相同。现有的提高LLM稳健性的方法主要集中在扰动数据样本上,而提高任务级别指令的抗干扰能力则相对未被充分研究。在这项工作中,我们关注于任务特定指令的字符和单词级别的编辑,这会显著降低下游性能。我们尝试了各种技术来提高LLM的稳健性,包括自我去噪和表示对齐,测试了不同的模型(Llama 3和Flan-T5)、数据集(CoLA、QNLI、SST-2)和指令(任务导向型和角色导向型)。我们发现,平均而言,无论是通过冻结的LLM还是经过微调后的模型进行自我去噪,相比其他策略都取得了显著的性能提升,包括集成方法和监督学习等更复杂的方法。
论文及项目相关链接
PDF Building Trust Workshop, ICLR 2025
Summary
LLMs易受输入扰动影响,微小提示变化可能导致显著不同的输出。现有方法主要关注扰动数据样本的增强,而任务级指令的扰动抗性改善相对较少探索。本研究关注任务特定指令的字符和单词级编辑,这显著降低了下游性能。实验采用自我去噪和表示对齐等技术提高LLM的鲁棒性,测试不同模型(Llama 3和Flan-T5)、数据集(CoLA,QNLI,SST-2)和指令(任务导向和角色导向)。研究发现,平均而言,无论是由冻结的LLM还是经过微调模型的自我去噪,均实现了显著优于其他策略的性能提升,包括集成和监督方法等。
Key Takeaways
- LLMs对输入扰动高度敏感,微小提示变化可导致显著不同的输出。
- 现有方法主要关注扰动数据样本以增强LLM的鲁棒性。
- 任务级指令的扰动抗性改善尚未得到充分探索。
- 字符和单词级编辑的任务特定指令显著降低了下游性能。
- 自我去噪技术是提高LLM鲁棒性的有效方法。
- 冻结的LLM和经过微调模型的自我去噪性能优于其他策略。
点此查看论文截图



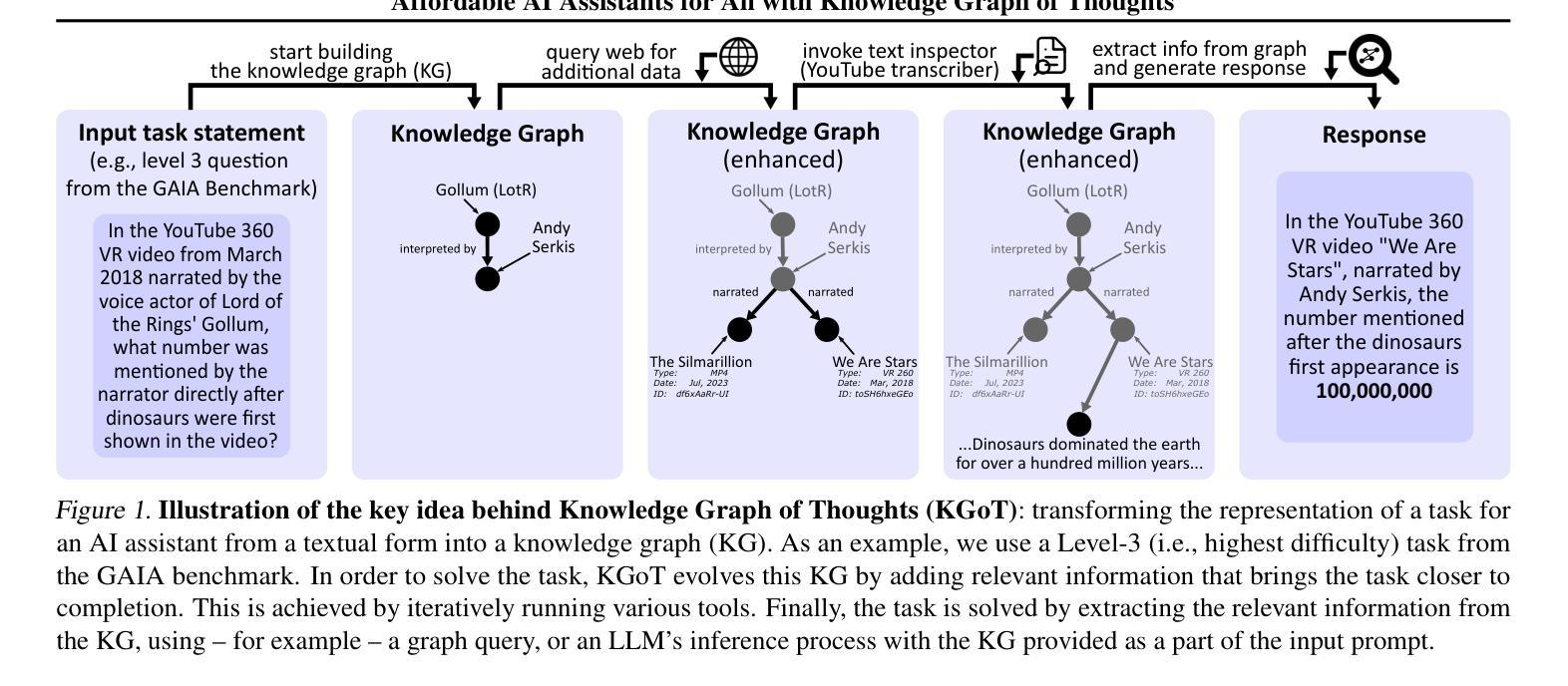
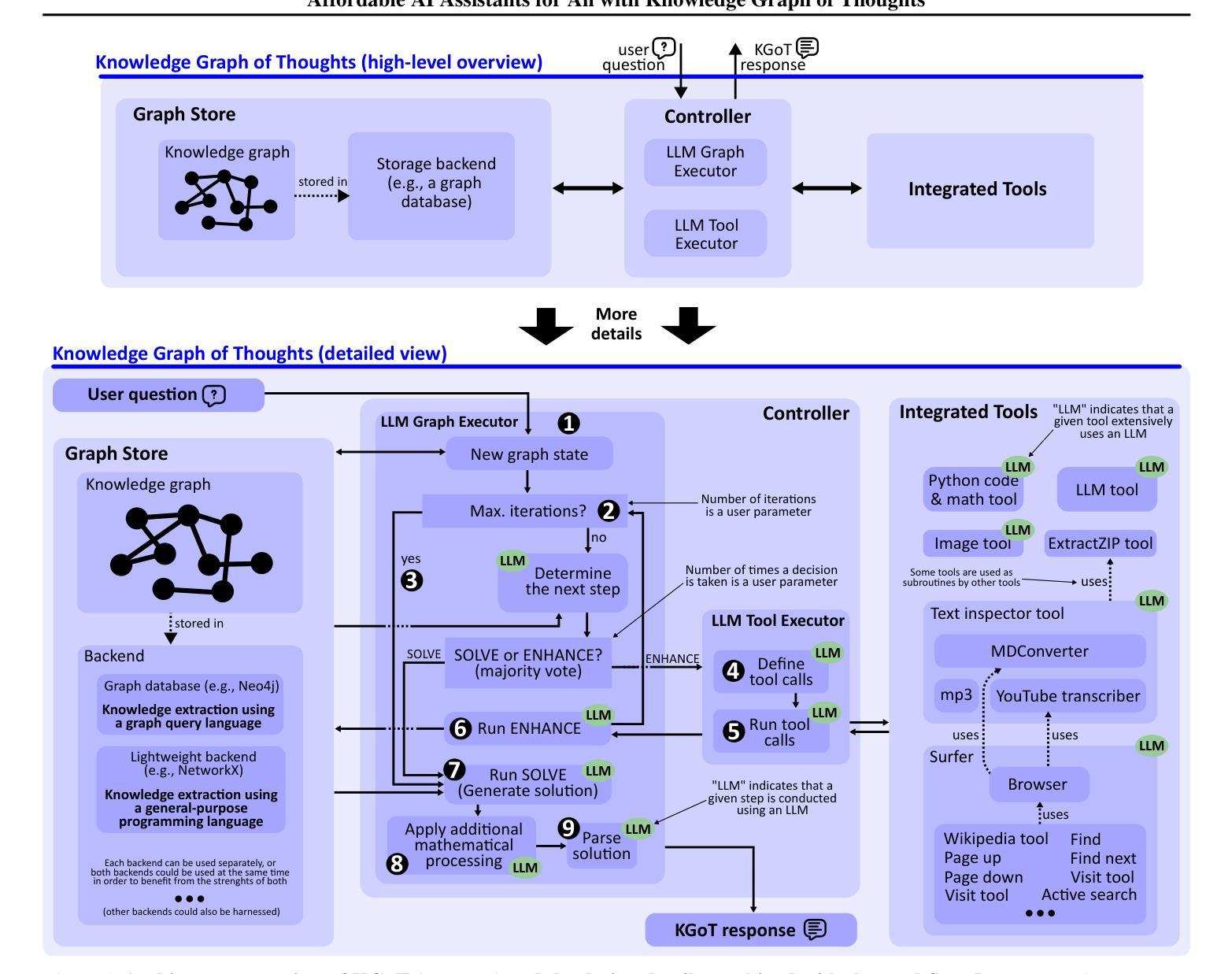
Affordable AI Assistants with Knowledge Graph of Thoughts
Authors:Maciej Besta, Lorenzo Paleari, Jia Hao Andrea Jiang, Robert Gerstenberger, You Wu, Patrick Iff, Ales Kubicek, Piotr Nyczyk, Diana Khimey, Jón Gunnar Hannesson, Grzegorz Kwaśniewski, Marcin Copik, Hubert Niewiadomski, Torsten Hoefler
Large Language Models (LLMs) are revolutionizing the development of AI assistants capable of performing diverse tasks across domains. However, current state-of-the-art LLM-driven agents face significant challenges, including high operational costs and limited success rates on complex benchmarks like GAIA. To address these issues, we propose the Knowledge Graph of Thoughts (KGoT), an innovative AI assistant architecture that integrates LLM reasoning with dynamically constructed knowledge graphs (KGs). KGoT extracts and structures task-relevant knowledge into a dynamic KG representation, iteratively enhanced through external tools such as math solvers, web crawlers, and Python scripts. Such structured representation of task-relevant knowledge enables low-cost models to solve complex tasks effectively. For example, KGoT achieves a 29% improvement in task success rates on the GAIA benchmark compared to Hugging Face Agents with GPT-4o mini, while reducing costs by over 36x compared to GPT-4o. Improvements for recent reasoning models are similar, e.g., 36% and 37.5% for Qwen2.5-32B and Deepseek-R1-70B, respectively. KGoT offers a scalable, affordable, and high-performing solution for AI assistants.
大型语言模型(LLM)正在推动人工智能助手在跨领域执行多样化任务方面的能力发展。然而,目前最先进的LLM驱动的智能代理面临重大挑战,包括运营成本高和在复杂基准测试(如GAIA)上的成功率有限。为了应对这些问题,我们提出了思想知识图谱(KGoT),这是一种创新的人工智能助手架构,它将LLM推理与动态构建的知识图谱(KG)相结合。KGoT提取并结构化任务相关知识,形成动态KG表示,通过数学求解器、网络爬虫和Python脚本等外部工具进行迭代增强。这种结构化表示的任务相关知识使得低成本模型能够更有效地解决复杂任务。例如,在GAIA基准测试中,KGoT与GPT-4o mini相比,任务成功率提高了29%,同时成本降低了超过36倍。近期的推理模型改进也类似,如Qwen2.5-32B和Deepseek-R1-70B分别提高了36%和37.5%。KGoT为人工智能助手提供了可扩展、经济实惠且高性能的解决方案。
论文及项目相关链接
Summary
知识图谱思维(KGoT)是一种创新的AI助手架构,它将大型语言模型(LLM)推理与动态构建的知识图谱(KG)相结合,解决了AI助理在复杂任务上表现不佳和成本高昂的问题。KGoT通过提取和结构化任务相关知识,形成动态知识图谱表示,并通过数学求解器、网络爬虫和Python脚本等外部工具进行迭代增强。KGoT在GAIA基准测试上取得了显著成果,相较于GPT-4o mini提高了任务成功率达29%,成本降低了超过36倍。对于其他推理模型,如Qwen2.5-32B和Deepseek-R1-70B,也有类似的改进。总的来说,KGoT提供了一个可扩展、经济高效且高性能的AI助手解决方案。
Key Takeaways
- 知识图谱思维(KGoT)是一种结合大型语言模型(LLM)与动态知识图谱(KG)的AI助手架构。
- KGoT解决了AI助理在复杂任务上的挑战,包括高操作成本和有限的成功率。
- KGoT通过提取和结构化任务相关知识,形成动态知识图谱表示,并利用外部工具进行迭代增强。
- KGoT在GAIA基准测试上取得了显著成果,相较于其他模型提高了任务成功率并大幅降低了成本。
- KGoT对其他推理模型也有改进效果。
- KGoT提供了一个可扩展、经济高效且高性能的AI助手解决方案。
点此查看论文截图

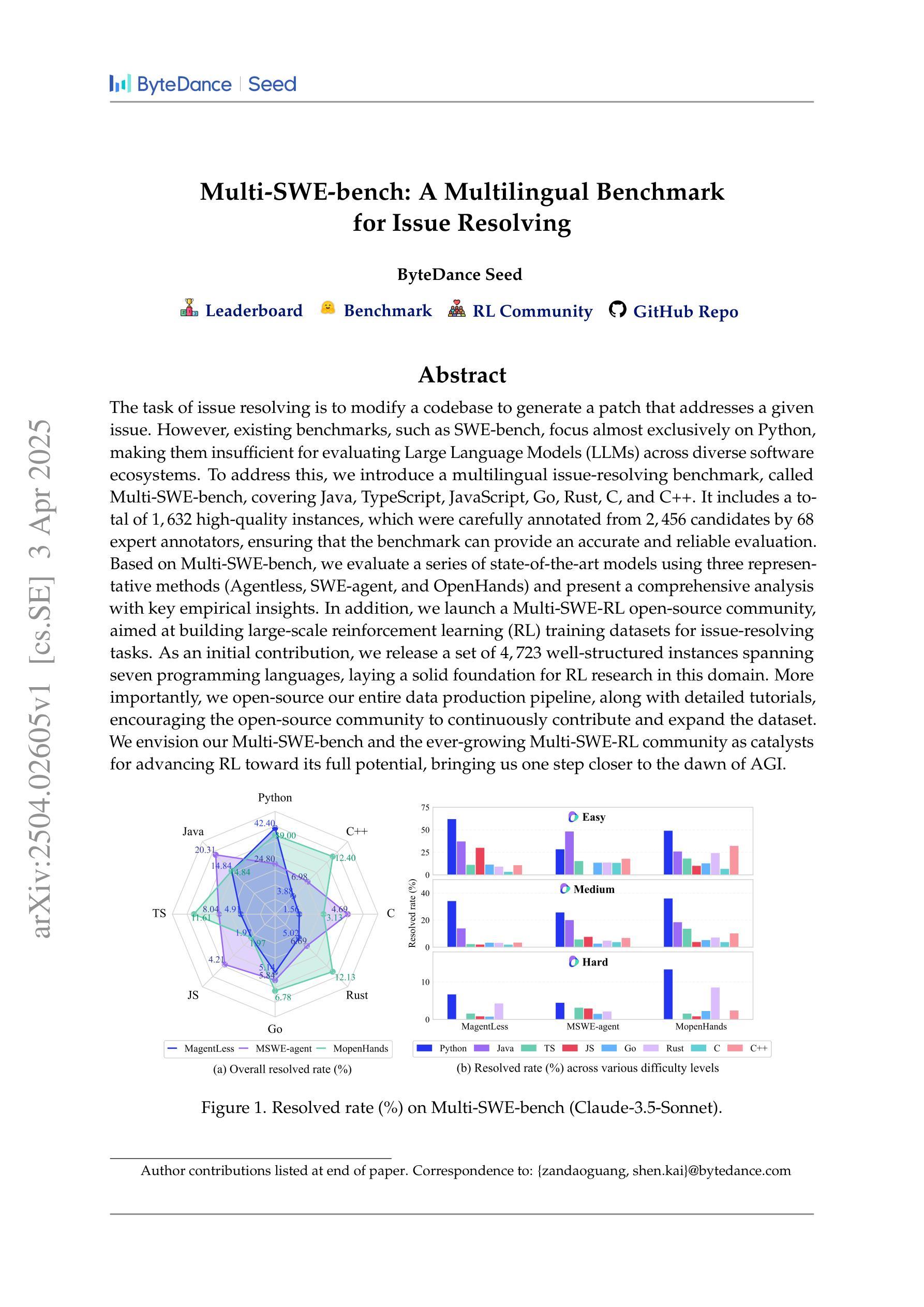
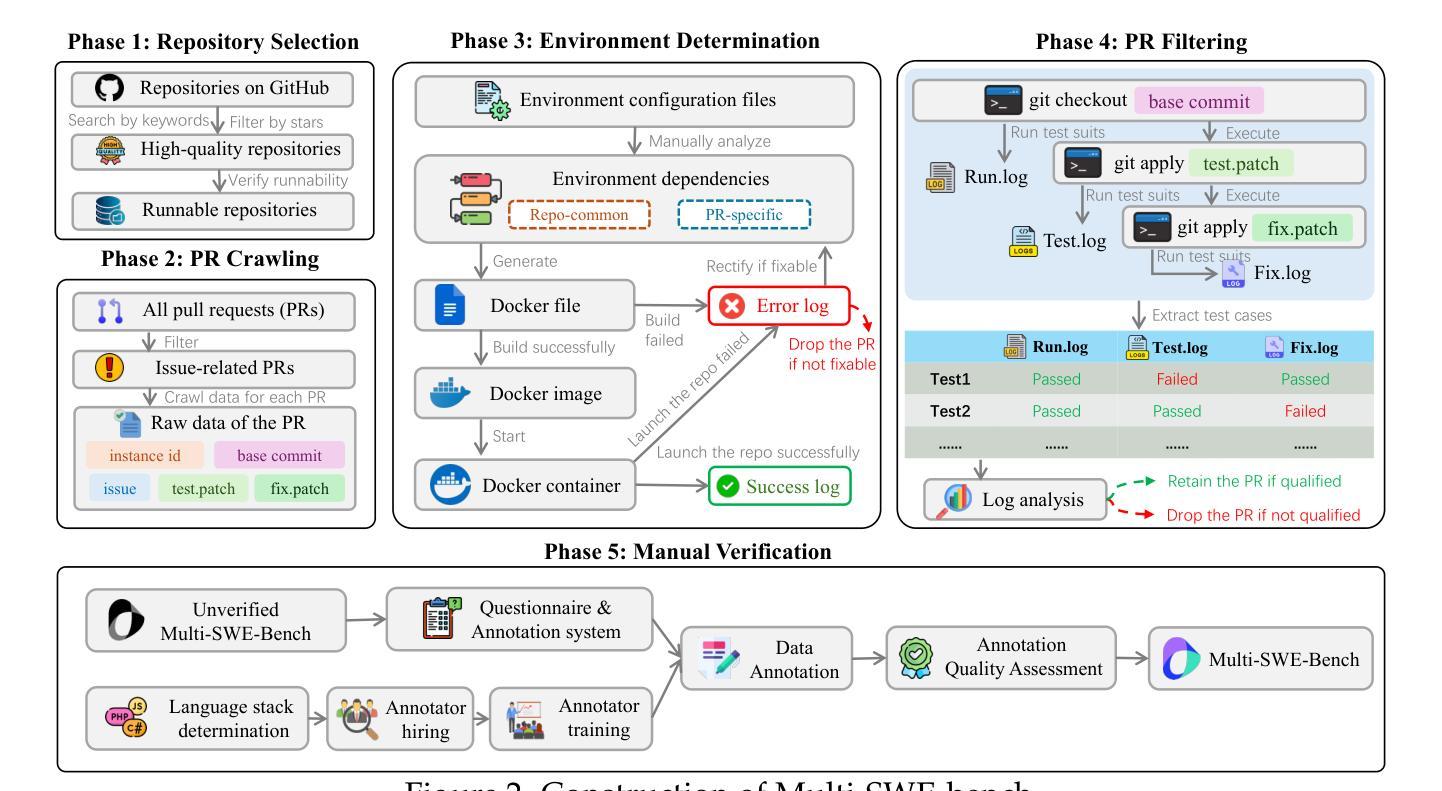
Multi-SWE-bench: A Multilingual Benchmark for Issue Resolving
Authors:Daoguang Zan, Zhirong Huang, Wei Liu, Hanwu Chen, Linhao Zhang, Shulin Xin, Lu Chen, Qi Liu, Xiaojian Zhong, Aoyan Li, Siyao Liu, Yongsheng Xiao, Liangqiang Chen, Yuyu Zhang, Jing Su, Tianyu Liu, Rui Long, Kai Shen, Liang Xiang
The task of issue resolving is to modify a codebase to generate a patch that addresses a given issue. However, existing benchmarks, such as SWE-bench, focus almost exclusively on Python, making them insufficient for evaluating Large Language Models (LLMs) across diverse software ecosystems. To address this, we introduce a multilingual issue-resolving benchmark, called Multi-SWE-bench, covering Java, TypeScript, JavaScript, Go, Rust, C, and C++. It includes a total of 1,632 high-quality instances, which were carefully annotated from 2,456 candidates by 68 expert annotators, ensuring that the benchmark can provide an accurate and reliable evaluation. Based on Multi-SWE-bench, we evaluate a series of state-of-the-art models using three representative methods (Agentless, SWE-agent, and OpenHands) and present a comprehensive analysis with key empirical insights. In addition, we launch a Multi-SWE-RL open-source community, aimed at building large-scale reinforcement learning (RL) training datasets for issue-resolving tasks. As an initial contribution, we release a set of 4,723 well-structured instances spanning seven programming languages, laying a solid foundation for RL research in this domain. More importantly, we open-source our entire data production pipeline, along with detailed tutorials, encouraging the open-source community to continuously contribute and expand the dataset. We envision our Multi-SWE-bench and the ever-growing Multi-SWE-RL community as catalysts for advancing RL toward its full potential, bringing us one step closer to the dawn of AGI.
问题解决的任务是对代码库进行修改以生成一个解决给定问题的补丁。然而,现有的基准测试,如SWE-bench,几乎只专注于Python,这使得它们不足以评估跨多种软件生态系统的大型语言模型(LLM)。为了解决这个问题,我们引入了一个多语言问题解决基准测试,名为Multi-SWE-bench,涵盖Java、TypeScript、JavaScript、Go、Rust、C和C++。它包含总共1632个高质量实例,这些实例是从2456个候选者中由68位专业注释者仔细注释的,确保基准测试能够提供准确和可靠的评价。基于Multi-SWE-bench,我们采用三种具有代表性的方法(无代理、SWE-agent和OpenHands)评估了一系列最先进的模型,并进行了综合分析,提供了关键的实证见解。此外,我们推出了Multi-SWE-RL开源社区,旨在构建用于问题解决任务的大规模强化学习(RL)训练数据集。作为初步贡献,我们发布了一套涵盖七种编程语言的4723个结构良好的实例,为这一领域的RL研究奠定了坚实基础。更重要的是,我们开源了整个数据生产管道以及详细的教程,鼓励开源社区持续贡献并扩展数据集。我们期望我们的Multi-SWE-bench和不断发展的Multi-SWE-RL社区能推动RL发挥其全部潜力,使我们距离通用人工智能(AGI)的黎明更近一步。
论文及项目相关链接
Summary:
为解决现有基准测试如SWE-bench对大型语言模型(LLMs)在多种软件生态系统中的评估不足的问题,我们引入了多语言问题解决的基准测试Multi-SWE-bench。它涵盖了Java、TypeScript、JavaScript、Go、Rust、C和C++等语言,包含从候选者中精心挑选的1,632个高质量实例。我们利用此基准测试对一系列前沿模型进行了评估,并提出了包含实证洞察的综合分析。此外,我们还建立了Multi-SWE-RL开源社区,致力于构建用于问题解决的强化学习(RL)训练数据集。我们公开了数据生产管道和详细教程,鼓励开源社区持续贡献并扩展数据集。我们的目标是推动RL的发展,推动人工智能通用(AGI)的到来。
Key Takeaways:
- 引入了多语言问题解决基准测试Multi-SWE-bench,涵盖多种编程语言。
- 通过精心挑选和标注,确保基准测试包含高质量的实例以准确可靠地评估模型性能。
- 利用Multi-SWE-bench评估了一系列前沿模型,并提出了包含实证洞察的综合分析。
- 建立了一个开源社区Multi-SWE-RL,专注于构建用于问题解决的强化学习训练数据集。
- 为社区成员公开了数据生产管道和详细教程,便于其持续贡献和扩展数据集。
- Multi-SWE-bench和Multi-SWE-RL社区的目标是推进强化学习的发展。
点此查看论文截图
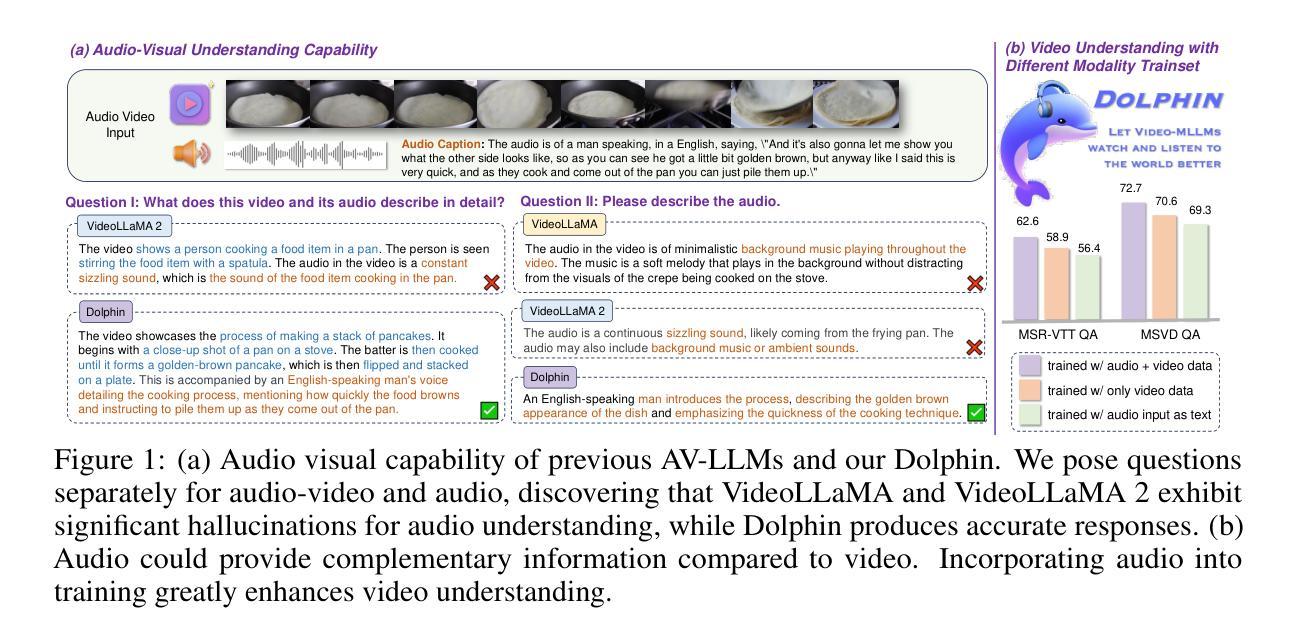
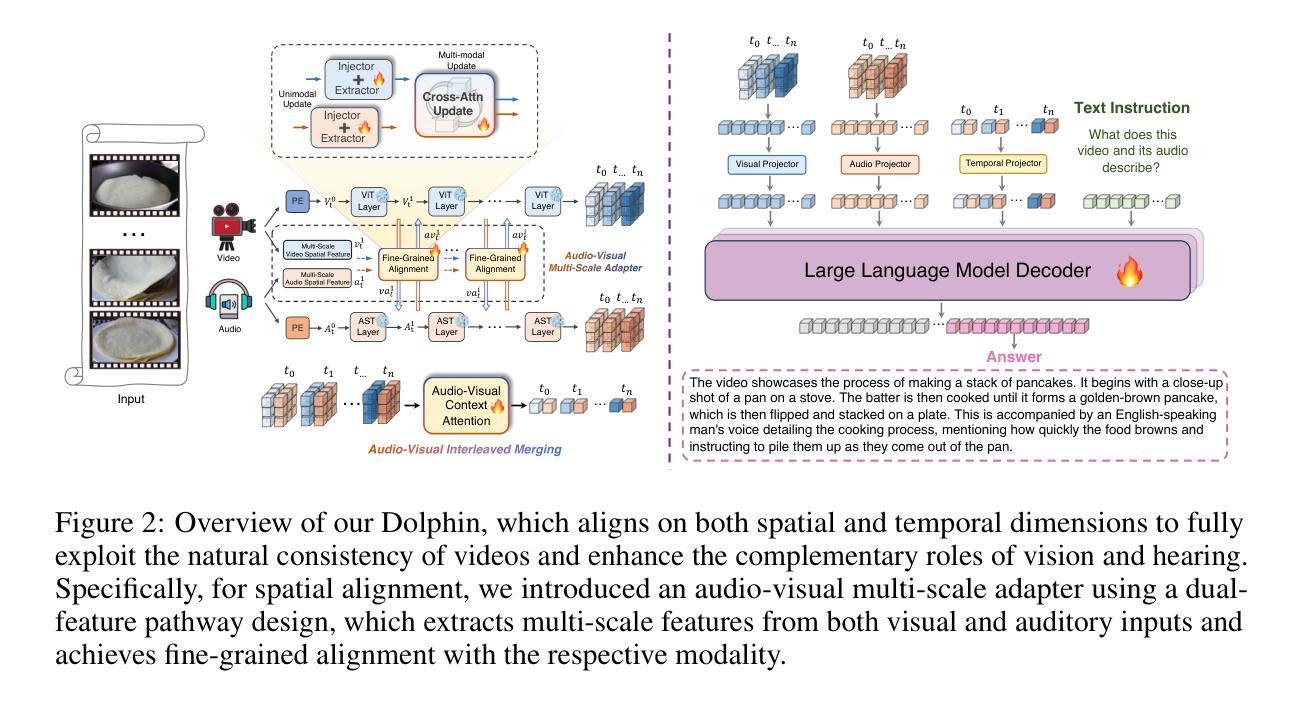
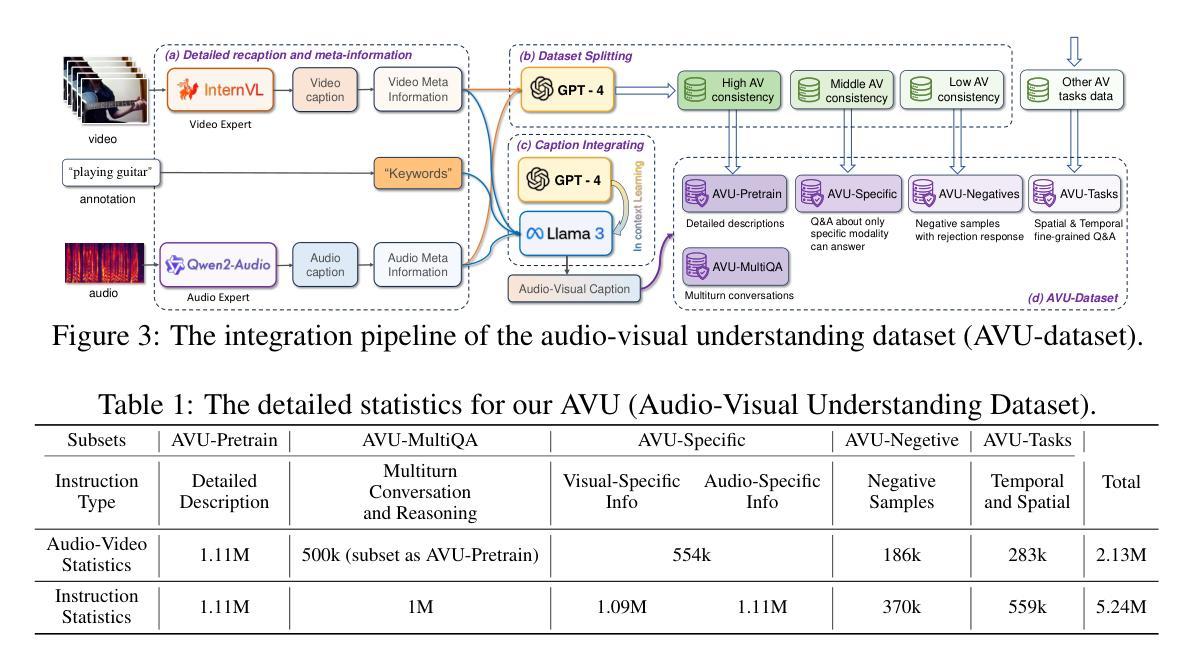
Aligned Better, Listen Better for Audio-Visual Large Language Models
Authors:Yuxin Guo, Shuailei Ma, Shijie Ma, Xiaoyi Bao, Chen-Wei Xie, Kecheng Zheng, Tingyu Weng, Siyang Sun, Yun Zheng, Wei Zou
Audio is essential for multimodal video understanding. On the one hand, video inherently contains audio, which supplies complementary information to vision. Besides, video large language models (Video-LLMs) can encounter many audio-centric settings. However, existing Video-LLMs and Audio-Visual Large Language Models (AV-LLMs) exhibit deficiencies in exploiting audio information, leading to weak understanding and hallucinations. To solve the issues, we delve into the model architecture and dataset. (1) From the architectural perspective, we propose a fine-grained AV-LLM, namely Dolphin. The concurrent alignment of audio and visual modalities in both temporal and spatial dimensions ensures a comprehensive and accurate understanding of videos. Specifically, we devise an audio-visual multi-scale adapter for multi-scale information aggregation, which achieves spatial alignment. For temporal alignment, we propose audio-visual interleaved merging. (2) From the dataset perspective, we curate an audio-visual caption and instruction-tuning dataset, called AVU. It comprises 5.2 million diverse, open-ended data tuples (video, audio, question, answer) and introduces a novel data partitioning strategy. Extensive experiments show our model not only achieves remarkable performance in audio-visual understanding, but also mitigates potential hallucinations.
音频对于多模态视频理解至关重要。一方面,视频本身就包含音频,为视觉提供了补充信息。此外,视频大型语言模型(Video-LLMs)可能会遇到许多以音频为中心的场景。然而,现有的Video-LLMs和视听大型语言模型(AV-LLMs)在利用音频信息方面存在缺陷,导致理解不足和幻觉。为了解决这些问题,我们对模型架构和数据集进行了深入研究。(1)从架构角度来看,我们提出了一种精细的AV-LLM,即Dolphin。音频和视觉模态在时间和空间维度上的并行对齐,确保了视频的全面和准确理解。具体来说,我们设计了一个视听多尺度适配器进行多尺度信息聚合,实现空间对齐。对于时间对齐,我们提出了视听交错合并。(2)从数据集的角度来看,我们创建了一个视听字幕和指令调整数据集,称为AVU。它包含了520万个多样化、开放式的数据元组(视频、音频、问题、答案),并引入了一种新的数据分区策略。大量实验表明,我们的模型不仅在视听理解方面取得了显著的成绩,而且减轻了潜在的幻觉问题。
论文及项目相关链接
PDF Accepted to ICLR 2025
Summary
这篇文本介绍了音频在多模态视频理解中的重要性,并指出了现有视频大型语言模型(Video-LLMs)和视听大型语言模型(AV-LLMs)在利用音频信息方面的不足。为了解决这些问题,该文从模型架构和数据集两个角度入手,提出了一个精细的AV-LLM——海豚模型,以及一个视听字幕和指令调整数据集AVU。这些创新旨在提高视频理解的准确性和全面性,并减少潜在的幻觉现象。
Key Takeaways
- 音频对于多模态视频理解至关重要,提供了与视觉相补充的信息。
- 现有Video-LLMs和AV-LLMs在利用音频信息方面存在缺陷,导致理解不足和幻觉现象。
- 模型架构角度:提出了精细的AV-LLM——海豚模型,通过音频和视觉模态的时空维度对齐,实现了对视频的全面准确理解。
- 海豚模型采用视听多尺度适配器进行多尺度信息聚合,实现空间对齐;通过视听交错合并实现时间对齐。
- 数据集角度:推出了视听字幕和指令调整数据集AVU,包含520万个开放式的多元数据元组(视频、音频、问题、答案),并采用了新型的数据分区策略。
- 海豚模型在视听理解方面取得了显著的性能表现。
点此查看论文截图


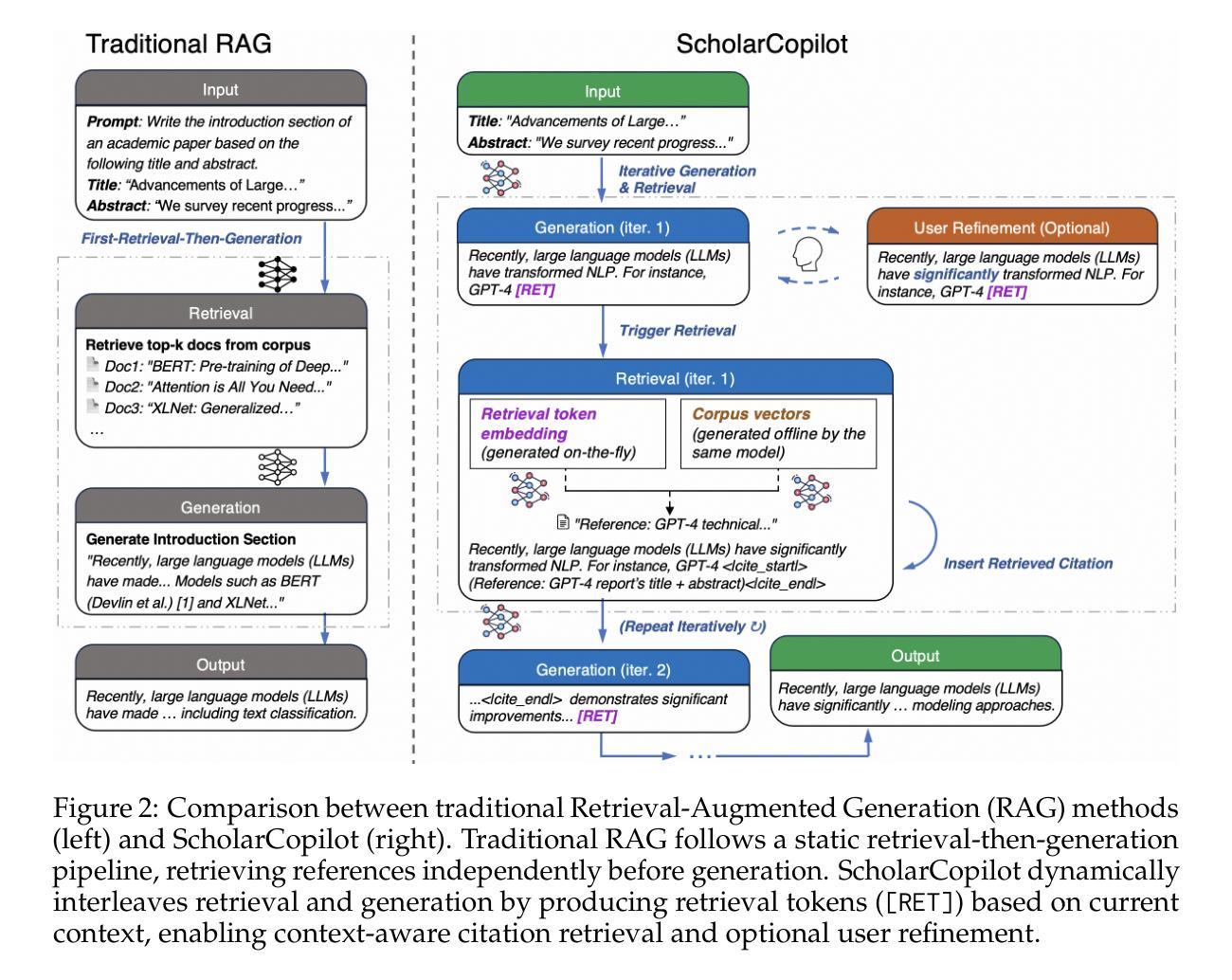
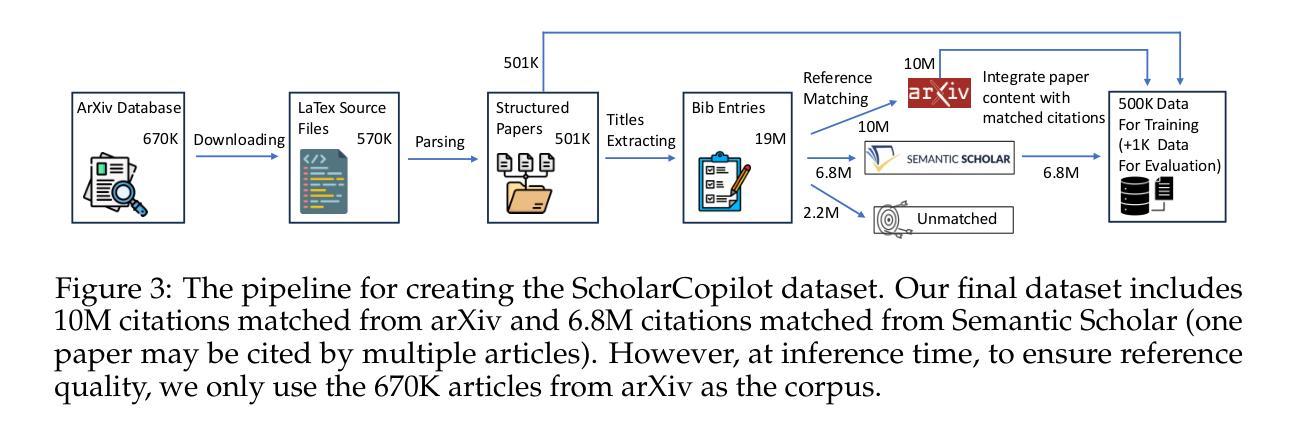
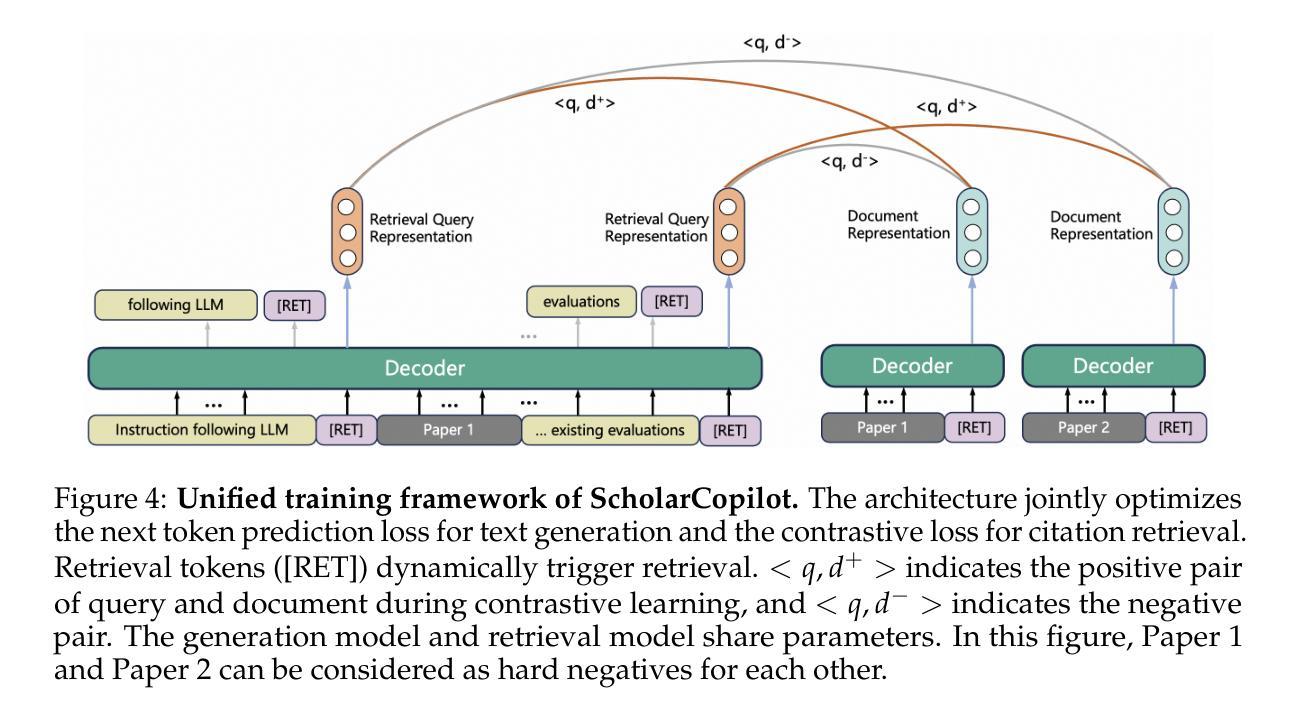
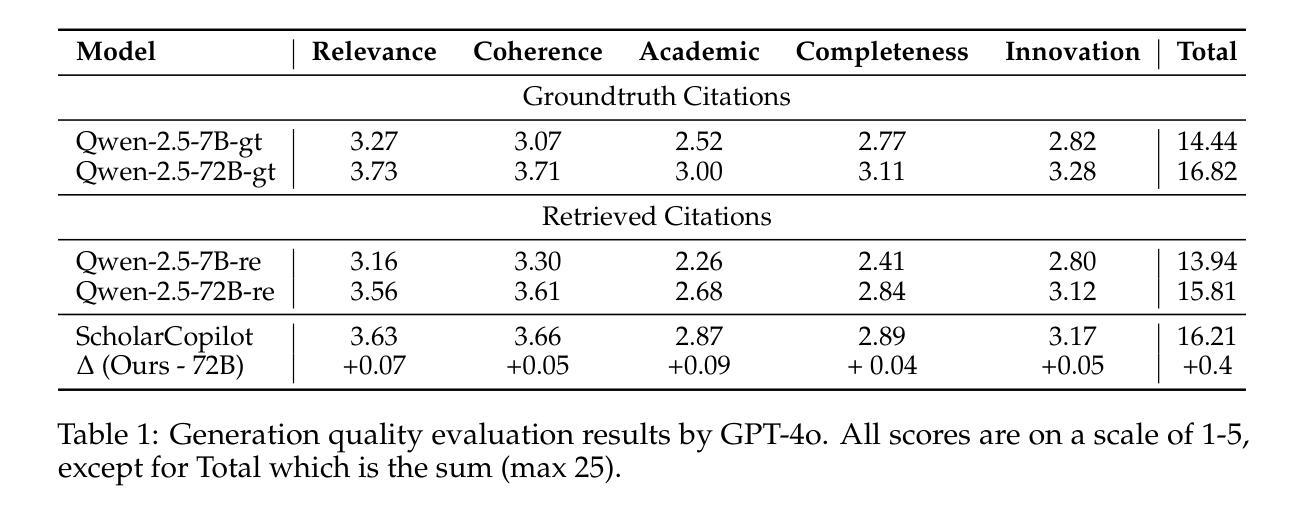
ScholarCopilot: Training Large Language Models for Academic Writing with Accurate Citations
Authors:Yubo Wang, Xueguang Ma, Ping Nie, Huaye Zeng, Zhiheng Lyu, Yuxuan Zhang, Benjamin Schneider, Yi Lu, Xiang Yue, Wenhu Chen
Academic writing requires both coherent text generation and precise citation of relevant literature. Although recent Retrieval-Augmented Generation (RAG) systems have significantly improved factual accuracy in general-purpose text generation, their ability to support professional academic writing remains limited. In this work, we introduce ScholarCopilot, a unified framework designed to enhance existing large language models for generating professional academic articles with accurate and contextually relevant citations. ScholarCopilot dynamically determines when to retrieve scholarly references by generating a retrieval token [RET], which is then used to query a citation database. The retrieved references are fed into the model to augment the generation process. We jointly optimize both the generation and citation tasks within a single framework to improve efficiency. Our model is built upon Qwen-2.5-7B and trained on 500K papers from arXiv. It achieves a top-1 retrieval accuracy of 40.1% on our evaluation dataset, outperforming baselines such as E5-Mistral-7B-Instruct (15.0%) and BM25 (9.8%). On a dataset of 1,000 academic writing samples, ScholarCopilot scores 16.2/25 in generation quality – measured across relevance, coherence, academic rigor, completeness, and innovation – significantly surpassing all existing models, including much larger ones like the Retrieval-Augmented Qwen2.5-72B-Instruct. Human studies further demonstrate that ScholarCopilot, despite being a 7B model, significantly outperforms ChatGPT, achieving 100% preference in citation quality and over 70% in overall usefulness.
学术写作既需要连贯的文本生成,又需要精确的文献引用。尽管最近的检索增强生成(RAG)系统在通用文本生成中显著提高了事实准确性,但它们在支持专业学术写作方面的能力仍然有限。在这项工作中,我们引入了ScholarCopilot,这是一个旨在增强现有大型语言模型的统一框架,用于生成具有准确和上下文相关引用的专业学术论文。ScholarCopilot通过生成一个检索令牌[RET]来动态确定何时检索学术参考,然后使用该令牌查询引用数据库。检索到的引用被输入到模型中,以增强生成过程。我们在单个框架中联合优化生成和引用任务,以提高效率。我们的模型建立在Qwen-2.5-7B之上,并在arXiv的50万篇论文上进行训练。在我们的评估数据集上,它达到了40.1%的top-1检索准确率,优于E5-Mistral-7B-Instruct(15.0%)和BM25(9.8%)等基线模型。在1000个学术写作样本的数据集上,ScholarCopilot在相关性、连贯性、学术严谨性、完整性和创新性方面的生成质量得分为16.2/25,显著超越了包括更大模型(如检索增强Qwen2.5-72B-Instruct)在内的所有现有模型。人类研究进一步证明,尽管ScholarCopilot是一个7B模型,但在引用质量和总体有用性方面显著优于ChatGPT,引用质量达到100%的偏好,总体实用性超过70%。
论文及项目相关链接
Summary
本文介绍了ScholarCopilot,一个专为学术写作设计的大型语言模型增强框架。它通过生成检索令牌[RET]来动态检索学术参考文献,并在生成过程中使用这些引用。ScholarCopilot在单一框架中联合优化生成和引用任务,以提高效率。它在arXiv的50万篇论文上构建并训练,在评估数据集上实现了高达40.1%的top-1检索准确率,显著优于其他基线模型。此外,在学术写作样本数据集上,ScholarCopilot在生成质量方面得分较高,并在相关性、连贯性、学术严谨性、完整性和创新性等方面显著超越了其他现有模型,包括更大的模型。人类研究进一步表明,尽管只有7B参数,但ScholarCopilot在引用质量和总体有用性方面显著优于ChatGPT。
Key Takeaways
- ScholarCopilot是一个针对学术写作的大型语言模型增强框架。
- 通过生成检索令牌[RET]来动态检索学术参考文献。
- 框架联合优化生成和引用任务,提高效率。
- 在arXiv的50万篇论文上构建并训练,实现40.1%的top-1检索准确率。
- 在学术写作样本数据集上,ScholarCopilot在生成质量上优于其他模型。
- 在引用质量和总体有用性方面,ScholarCopilot显著优于ChatGPT。
- 人机研究验证了ScholarCopilot在学术写作中的优越性能。
点此查看论文截图

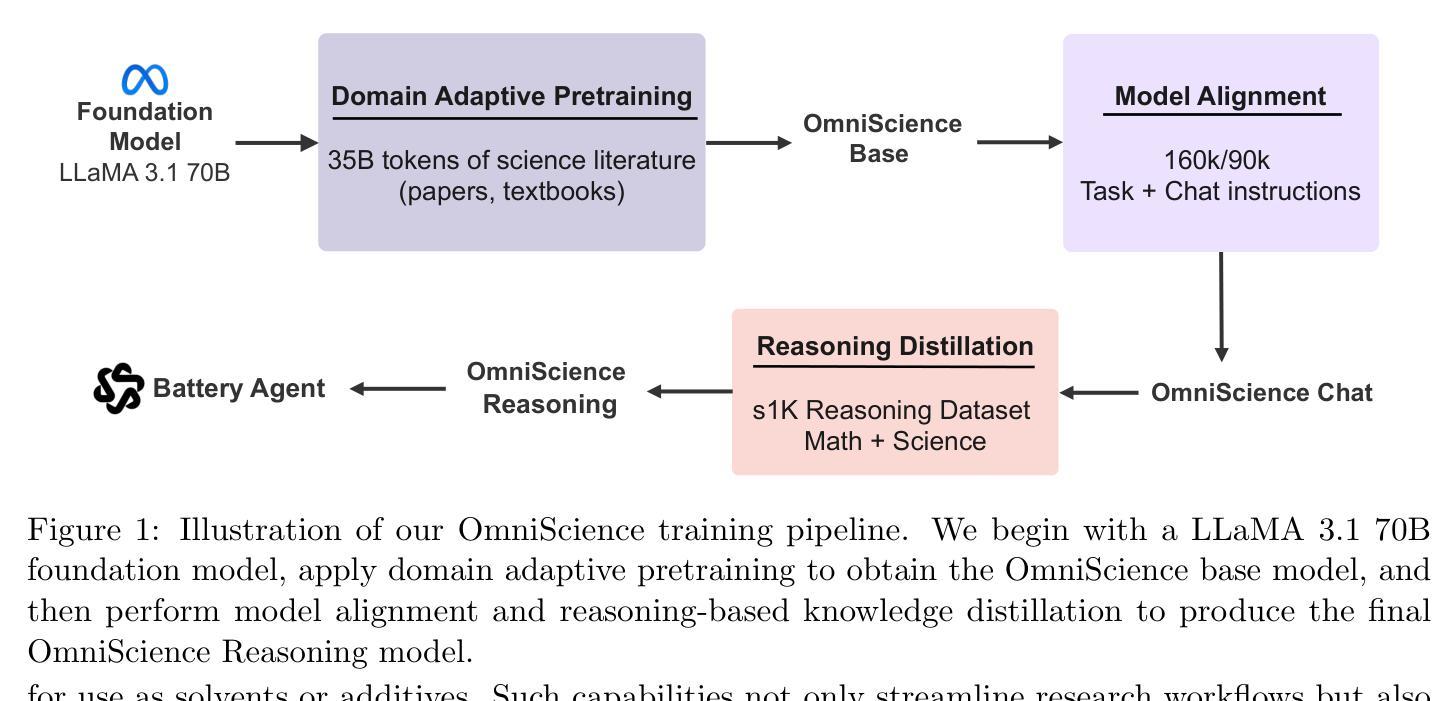
OmniScience: A Domain-Specialized LLM for Scientific Reasoning and Discovery
Authors:Vignesh Prabhakar, Md Amirul Islam, Adam Atanas, Yao-Ting Wang, Joah Han, Aastha Jhunjhunwala, Rucha Apte, Robert Clark, Kang Xu, Zihan Wang, Kai Liu
Large Language Models (LLMs) have demonstrated remarkable potential in advancing scientific knowledge and addressing complex challenges. In this work, we introduce OmniScience, a specialized large reasoning model for general science, developed through three key components: (1) domain adaptive pretraining on a carefully curated corpus of scientific literature, (2) instruction tuning on a specialized dataset to guide the model in following domain-specific tasks, and (3) reasoning-based knowledge distillation through fine-tuning to significantly enhance its ability to generate contextually relevant and logically sound responses. We demonstrate the versatility of OmniScience by developing a battery agent that efficiently ranks molecules as potential electrolyte solvents or additives. Comprehensive evaluations reveal that OmniScience is competitive with state-of-the-art large reasoning models on the GPQA Diamond and domain-specific battery benchmarks, while outperforming all public reasoning and non-reasoning models with similar parameter counts. We further demonstrate via ablation experiments that domain adaptive pretraining and reasoning-based knowledge distillation are critical to attain our performance levels, across benchmarks.
大型语言模型(LLM)在推进科学知识和应对复杂挑战方面表现出了显著潜力。在这项工作中,我们介绍了OmniScience,这是一个针对通用科学的特殊大型推理模型,通过三个关键组件开发:(1)在精心挑选的科学文献语料库上进行领域自适应预训练,(2)在专门的数据集上进行指令调整,以指导模型执行特定领域的任务,(3)通过微调进行基于推理的知识蒸馏,以显著提高其生成语境相关和逻辑严谨响应的能力。我们通过开发电池代理来展示OmniScience的通用性,该代理能够高效地排列分子作为潜在的电解质溶剂或添加剂。综合评估表明,OmniScience在GPQA Diamond和特定领域的电池基准测试上,与最新的大型推理模型相比具有竞争力,同时在参数数量相似的所有公共推理和非推理模型中表现最佳。我们还通过消除实验进一步证明,领域自适应预训练和基于推理的知识蒸馏对于达到我们的性能水平至关重要,跨越各个基准测试。
论文及项目相关链接
Summary
大型语言模型(LLM)在推动科学知识和应对复杂挑战方面展现出显著潜力。本研究介绍了一款针对通用科学的专门大型推理模型——OmniScience,其开发包括三个关键部分:一是在科学文献的精心筛选语料库上进行领域自适应预训练;二是在专门数据集上进行指令调整,以指导模型执行特定领域任务;三是通过微调进行基于推理的知识蒸馏,以显著提高其生成语境相关和逻辑严谨回应的能力。OmniScience的通用性通过开发电池代理得到了验证,该代理能够高效地对分子进行电解质溶剂或添加剂的排名。综合评估表明,OmniScience在GPQA Diamond和特定领域电池基准测试上,与最新大型推理模型具有竞争力,并在参数数量相似的公共推理和非推理模型中表现最佳。通过消融实验进一步证明,领域自适应预训练和基于推理的知识蒸馏对于达到我们的性能水平至关重要。
Key Takeaways
- OmniScience是一个针对通用科学的专门大型推理模型。
- OmniScience的开发包括领域自适应预训练、指令调整以及基于推理的知识蒸馏三个关键部分。
- OmniScience能够高效地对分子进行电解质溶剂或添加剂的排名,展现了其通用性。
- 综合评估显示,OmniScience在GPQA Diamond和特定领域电池基准测试上表现优异。
- 与其他公共推理和非推理模型相比,OmniScience在类似参数数量下表现最佳。
- 消融实验证明领域自适应预训练对于OmniScience的性能至关重要。
点此查看论文截图

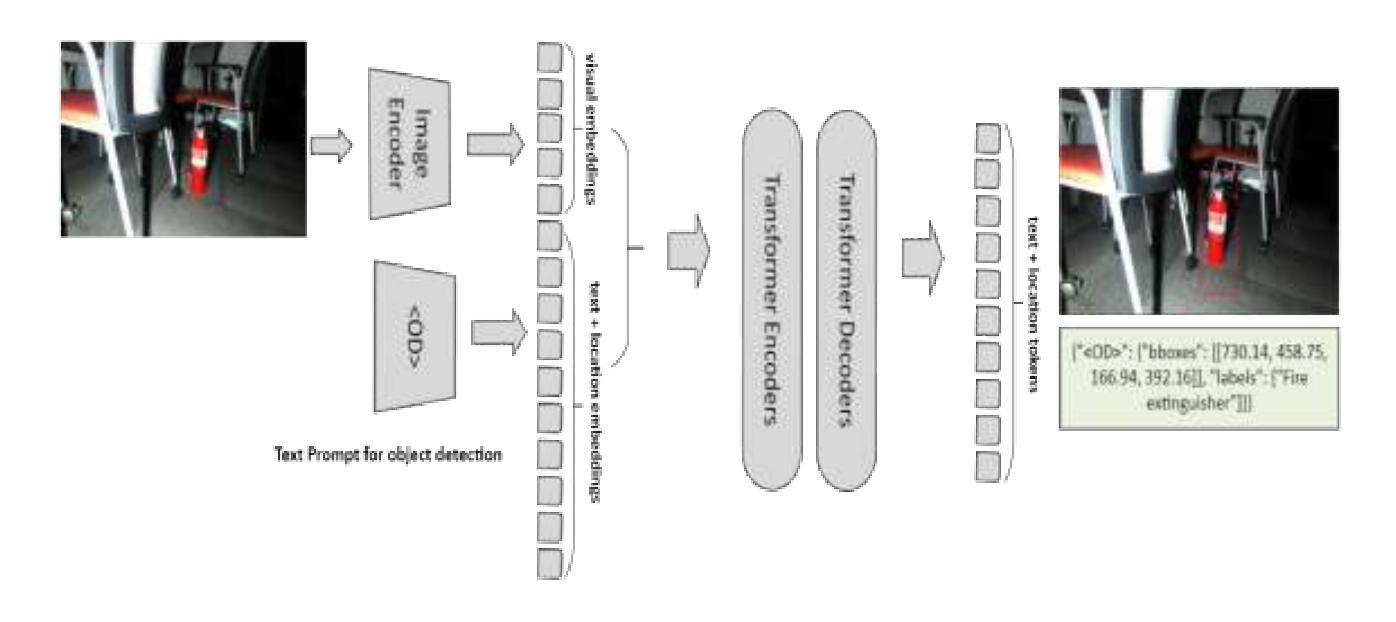
Fine-Tuning Transformer-Based Vision-Language Models for Robust Object Detection in Unstructured Environments
Authors:Aysegul Ucar, Soumyadeep Ro, Sanapala Satwika, Pamarthi Yasoda Gayathri, Mohmmad Ghaith Balsha
Vision-Language Models (VLMs) have emerged as powerful tools in artificial intelli-gence, capable of integrating textual and visual data for a unified understanding of complex scenes. While models such as Florence2, built on transformer architectures, have shown promise across general tasks, their performance in object detection within unstructured or cluttered environments remains underexplored. In this study, we fi-ne-tuned the Florence2 model for object detection tasks in non-constructed, complex environments. A comprehensive experimental framework was established involving multiple hardware configurations (NVIDIA T4, L4, and A100 GPUs), optimizers (AdamW, SGD), and varied hyperparameters including learning rates and LoRA (Low-Rank Adaptation) setups. Model training and evaluation were conducted on challenging datasets representative of real-world, disordered settings. The optimized Florence2 models exhibited significant improvements in object detection accuracy, with Mean Average Precision (mAP) metrics approaching or matching those of estab-lished models such as YOLOv8, YOLOv9, and YOLOv10. The integration of LoRA and careful fine-tuning of transformer layers contributed notably to these gains. Our find-ings highlight the adaptability of transformer-based VLMs like Florence2 for do-main-specific tasks, particularly in visually complex environments. The study under-scores the potential of fine-tuned VLMs to rival traditional convolution-based detec-tors, offering a flexible and scalable approach for advanced vision applications in re-al-world, unstructured settings.
视觉语言模型(VLMs)作为人工智能的强大工具,能够整合文本和视觉数据,对复杂场景进行统一理解。虽然基于转换器架构的Florence2等模型在一般任务上表现出良好的前景,但在非结构化或杂乱环境中进行目标检测的性能仍然被探索得不够充分。在本研究中,我们对非构造的复杂环境中的目标检测任务对Florence2模型进行了微调。建立了一个全面的实验框架,涉及多种硬件配置(NVIDIA T4、L4和A100 GPU)、优化器(AdamW、SGD)以及包括学习率和LoRA(低秩适应)在内的各种超参数设置。在具有代表性的现实世界混乱设置的挑战性数据集上进行了模型的训练和评估。优化后的Florence2模型在目标检测精度上取得了显著的提升,其平均精度均值(mAP)指标接近或达到了YOLOv8、YOLOv9和YOLOv10等已建立模型的性能。LoRA的集成以及对转换器层的精细微调对这些成果贡献显著。我们的研究结果突出了基于转换器的VLMs(如Florence2)对特定领域的适应性,特别是在视觉复杂的环境中。该研究强调了经过精细调整的VLMs与传统基于卷积的检测器竞争潜力,为现实世界非结构化环境中的高级视觉应用提供了灵活和可扩展的方法。
论文及项目相关链接
PDF 22 pages, 13 Figures, 6 Tables
Summary
本研究优化了基于转换器架构的Florence2模型,使其适用于非结构化和复杂环境中的对象检测任务。实验结果显示,经过精细训练的Florence2模型在代表性真实世界数据集上的对象检测精度显著提高,平均精度均值(mAP)指标接近或匹配YOLOv8、YOLOv9和YOLOv10等现有模型。本研究强调了转换器为基础的VLM模型(如Florence2)对于特定领域的适应性,特别是在视觉复杂的现实世界中展现出与传统基于卷积的检测器相抗衡的潜力。此外,通过精细调整和LoRA集成技术显著提高了性能。这些成果为先进视觉应用提供了灵活且可扩展的解决方案。
Key Takeaways
点此查看论文截图

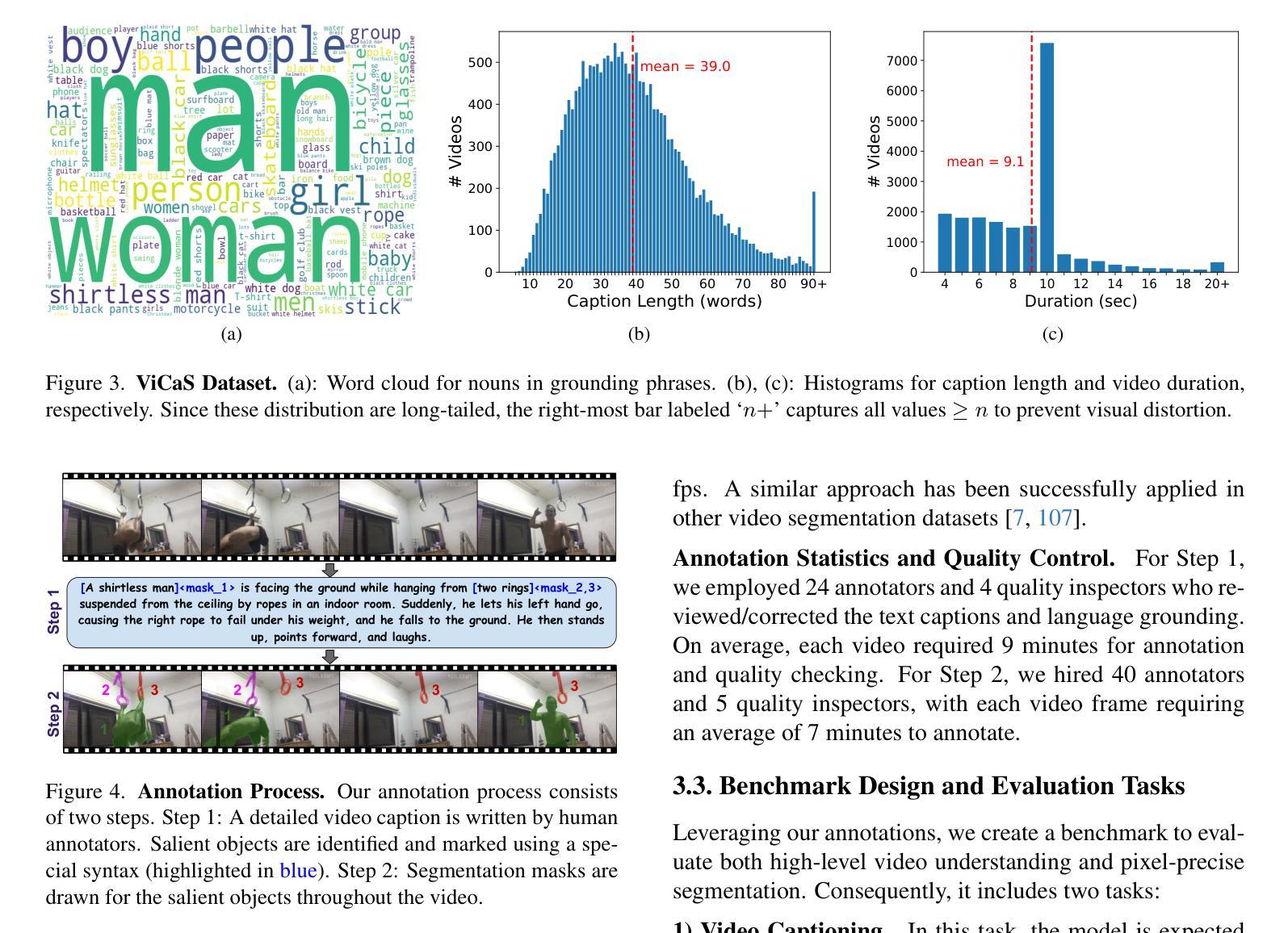
ViCaS: A Dataset for Combining Holistic and Pixel-level Video Understanding using Captions with Grounded Segmentation
Authors:Ali Athar, Xueqing Deng, Liang-Chieh Chen
Recent advances in multimodal large language models (MLLMs) have expanded research in video understanding, primarily focusing on high-level tasks such as video captioning and question-answering. Meanwhile, a smaller body of work addresses dense, pixel-precise segmentation tasks, which typically involve category-guided or referral-based object segmentation. Although both directions are essential for developing models with human-level video comprehension, they have largely evolved separately, with distinct benchmarks and architectures. This paper aims to unify these efforts by introducing ViCaS, a new dataset containing thousands of challenging videos, each annotated with detailed, human-written captions and temporally consistent, pixel-accurate masks for multiple objects with phrase grounding. Our benchmark evaluates models on both holistic/high-level understanding and language-guided, pixel-precise segmentation. We also present carefully validated evaluation measures and propose an effective model architecture that can tackle our benchmark. Project page: https://ali2500.github.io/vicas-project/
近期多模态大型语言模型(MLLMs)的进步推动了视频理解领域的研究,主要关注高级任务,如视频描述和问答。同时,较少的研究工作涉及密集、像素精确的分割任务,通常涉及类别引导或基于引用的对象分割。虽然这两个方向对于开发具有人类水平视频理解能力的模型都至关重要,但它们大多独立发展,具有不同的基准和架构。本文旨在通过引入ViCaS数据集来统一这些努力,该数据集包含数千个具有挑战性的视频,每个视频都经过详细的人类手写描述和与时间段一致的像素精确的多对象掩膜标注,用于短语定位。我们的基准测试评估模型在整体/高级理解和语言引导、像素精确分割方面的表现。我们还提供了经过仔细验证的评估措施,并提出了能有效应对基准测试的模型架构。项目页面:https://ali2500.github.io/vicas-project/
论文及项目相关链接
PDF Accepted to CVPR 2025. Project page: https://ali2500.github.io/vicas-project/
Summary
多模态大型语言模型(MLLMs)的最新进展促进了视频理解研究的扩展,主要集中在视频字幕和问答等高级任务上。同时,一小部分工作关注密集的像素精确分割任务,通常涉及类别引导或基于引用的对象分割。本文旨在通过引入ViCaS数据集统一这些努力,该数据集包含数千个具有挑战性的视频,每个视频都带有详细的人类书写字幕和与多对象术语定位相匹配的像素精确掩模。我们的基准测试旨在评估模型在整体高级理解和语言指导下的像素精确分割能力。
Key Takeaways
- 多模态大型语言模型(MLLMs)在视频理解方面取得最新进展,集中在高级任务如视频字幕和问答。
- 存在一部分工作关注密集的像素精确分割任务,涉及类别引导或基于引用的对象分割。
- 现有研究在高级理解和像素精确分割任务上大多独立发展,具有不同的基准测试和架构。
- 本文引入ViCaS数据集,包含详细字幕和多个对象的像素精确掩模注释的挑战性视频。
- 基准测试旨在评估模型在整体高级理解和语言指导下的像素精确分割能力。
- 提供了经过仔细验证的评价措施。
点此查看论文截图


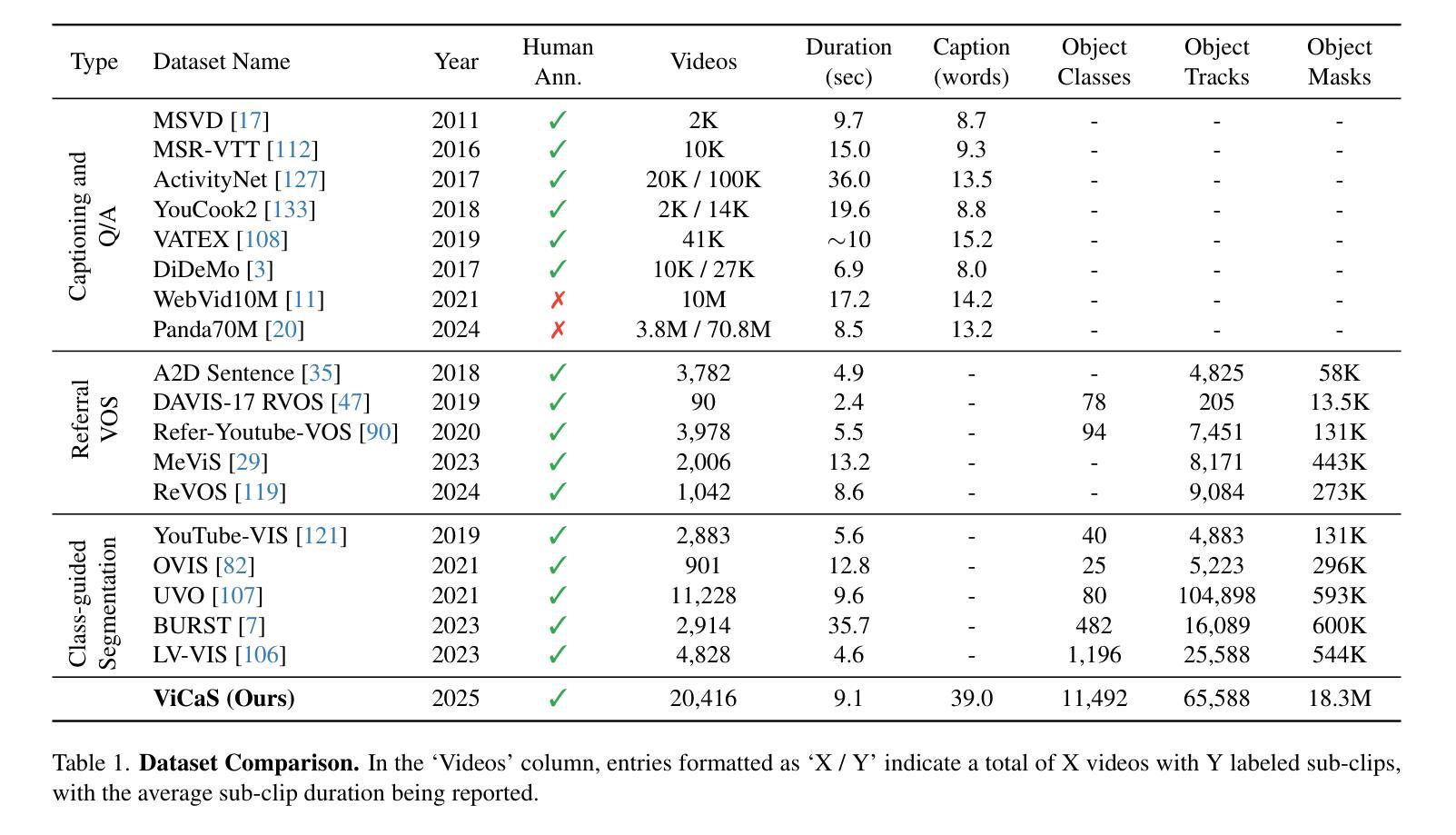
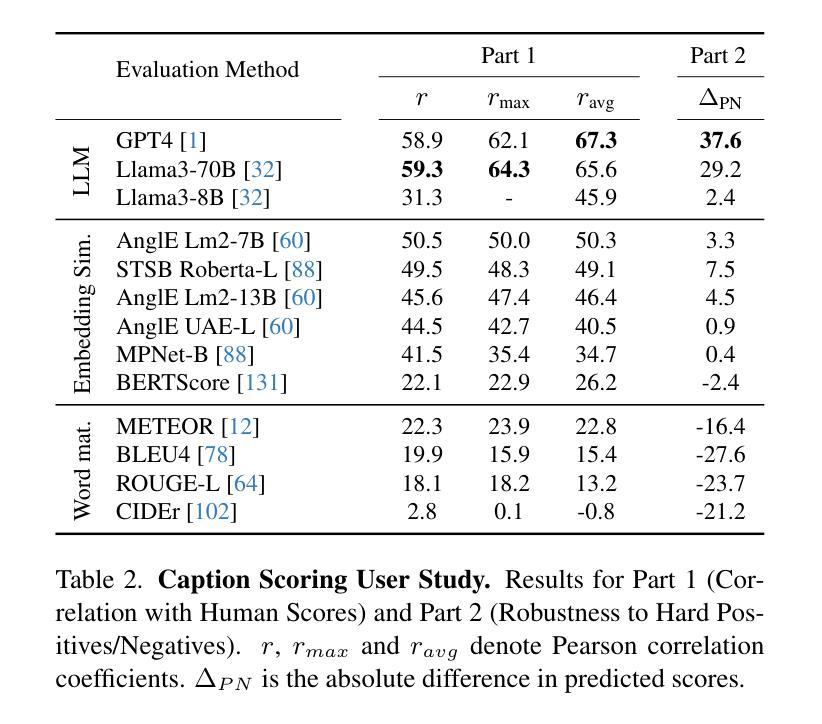
Reducing Reasoning Costs: The Path of Optimization for Chain of Thought via Sparse Attention Mechanism
Authors:Libo Wang
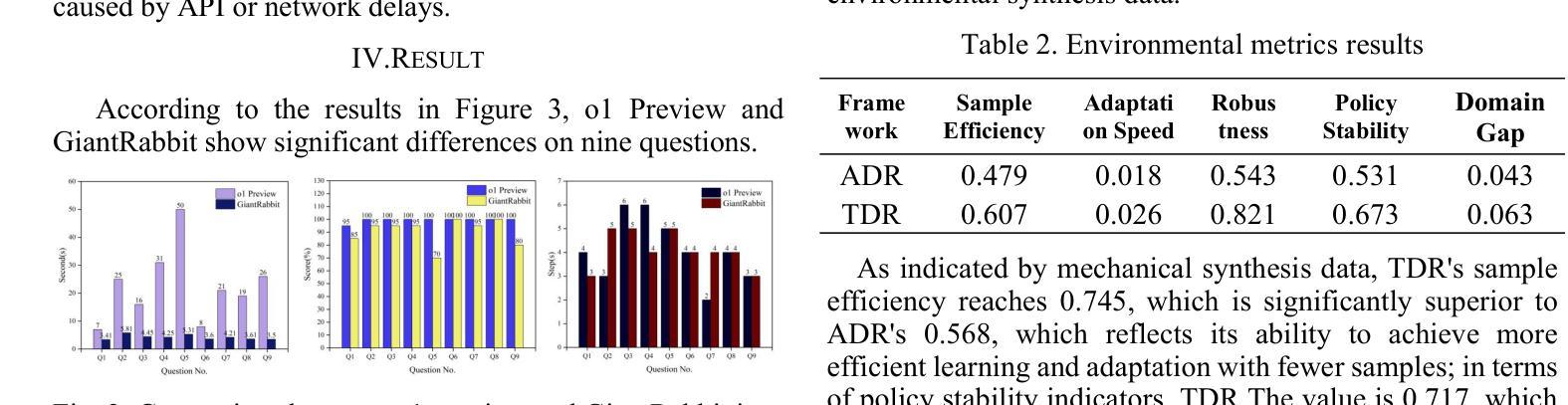
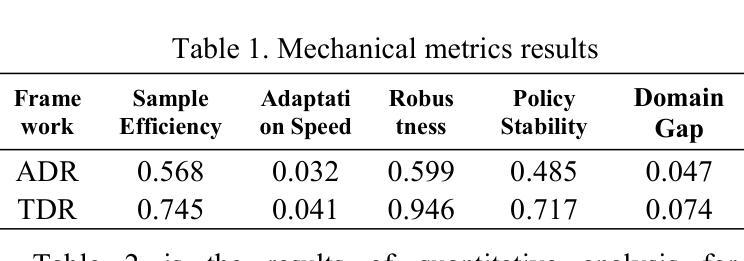
In order to address the chain of thought in the large language model inference cost surge, this research proposes to use a sparse attention mechanism that only focuses on a few relevant tokens. The researcher constructed a new attention mechanism and used GiantRabbit trained with custom GPTs as an experimental tool. The experiment tested and compared the reasoning time, correctness score and chain of thought length of this model and o1 Preview in solving the linear algebra test questions of MIT OpenCourseWare. The results show that GiantRabbit’s reasoning time and chain of thought length are significantly lower than o1 Preview. It verifies the feasibility of sparse attention mechanism for optimizing chain of thought reasoning. Detailed architectural details and experimental process have been uploaded to Github, the link is:https://github.com/brucewang123456789/GeniusTrail.git.
为了应对大型语言模型推理成本飙升中的思维链问题,本研究提出了一种稀疏注意力机制,该机制只关注少数相关令牌。研究者构建了一种新的注意力机制,并使用经过自定义GPT训练的GiantRabbit作为实验工具。实验测试并比较了该模型与o1 Preview在解决MIT OpenCourseWare的线性代数测试问题时的推理时间、正确率得分和思维链长度。结果表明,GiantRabbit的推理时间和思维链长度明显低于o1 Preview。这验证了稀疏注意力机制优化思维链推理的可行性。详细的架构细节和实验过程已上传到Github,链接为:https://github.com/brucewang123456789/GeniusTrail.git。
论文及项目相关链接
PDF The main text is 5 pages, totaling 9 pages; 4 figures, 1 table. It have been submitted to NeurIPS 2024 Workshop MusIML and OpenReview
Summary
该研究为应对大型语言模型推理成本飙升的问题,提出了一种稀疏注意力机制,该机制仅关注少数相关令牌。研究者构建了一种新的注意力机制,并使用GiantRabbit作为实验工具进行测试,其已使用自定义GPT进行训练。实验通过解决MIT OpenCourseWare的线性代数测试问题,对比了该模型与o1 Preview的推理时间、正确率得分和思维链长度。结果显示GiantRabbit的推理时间和思维链长度均显著低于o1 Preview,验证了稀疏注意力机制在优化思维链推理方面的可行性。具体架构细节和实验过程已上传至Github。
Key Takeaways
- 研究提出了一种稀疏注意力机制来优化大型语言模型的推理成本。
- GiantRabbit作为实验工具,采用自定义GPT进行训练。
- 实验对比了GiantRabbit与o1 Preview在解决MIT线性代数测试问题时的推理时间、正确率得分和思维链长度。
- GiantRabbit的推理时间和思维链长度显著优于o1 Preview。
- 稀疏注意力机制在优化思维链推理方面的可行性得到验证。
- 研究的具体架构细节和实验过程已上传至Github,方便后续研究者参考和拓展。
点此查看论文截图
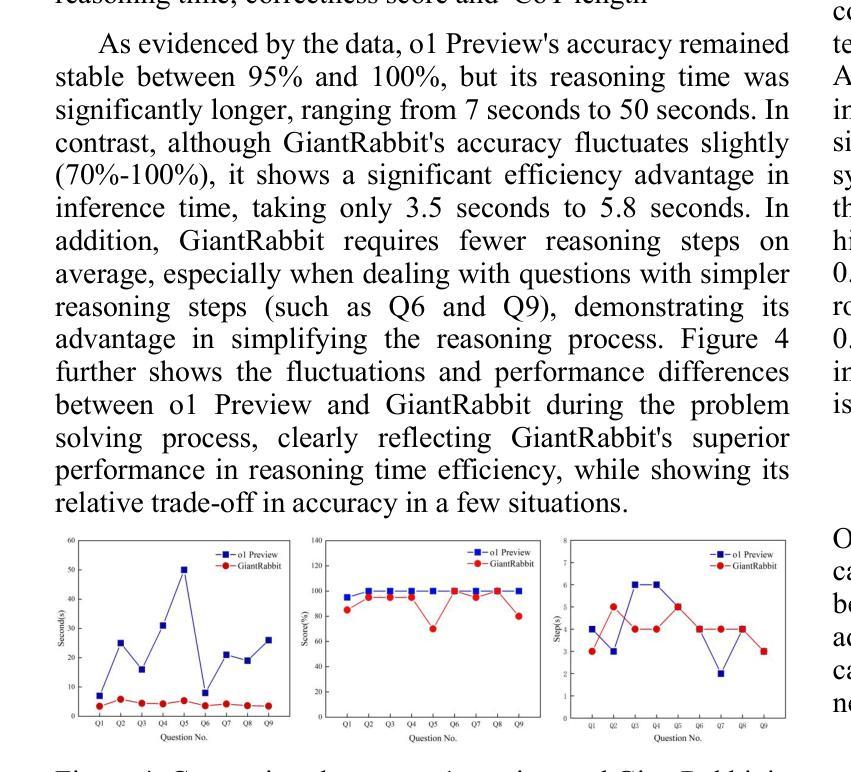
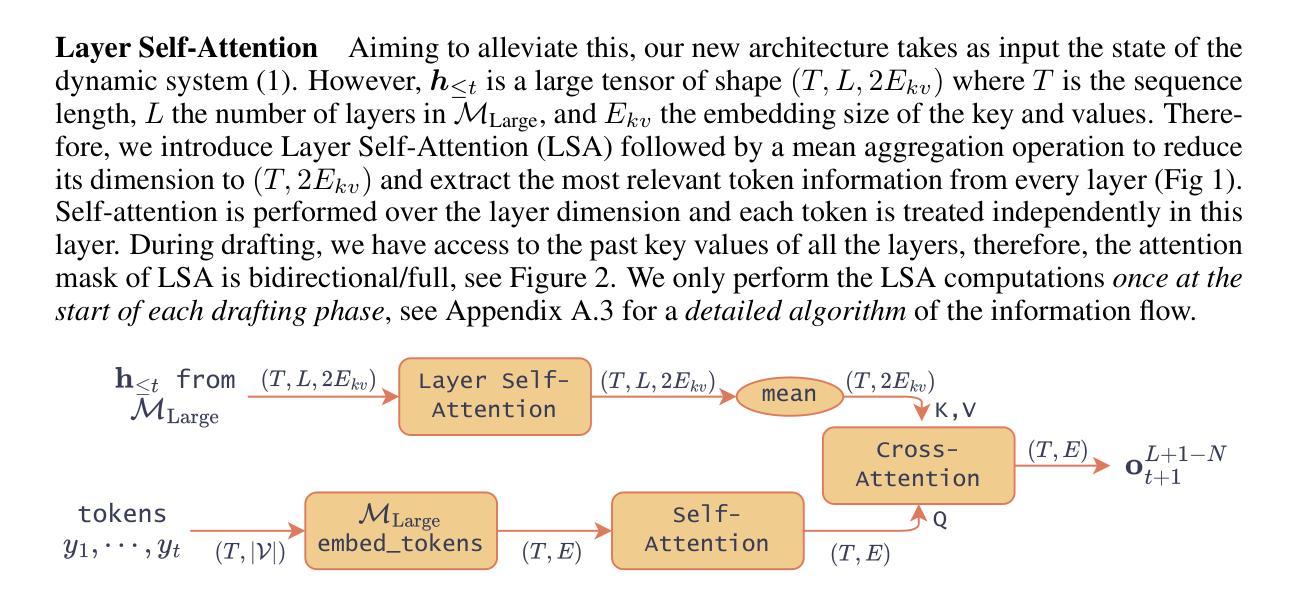
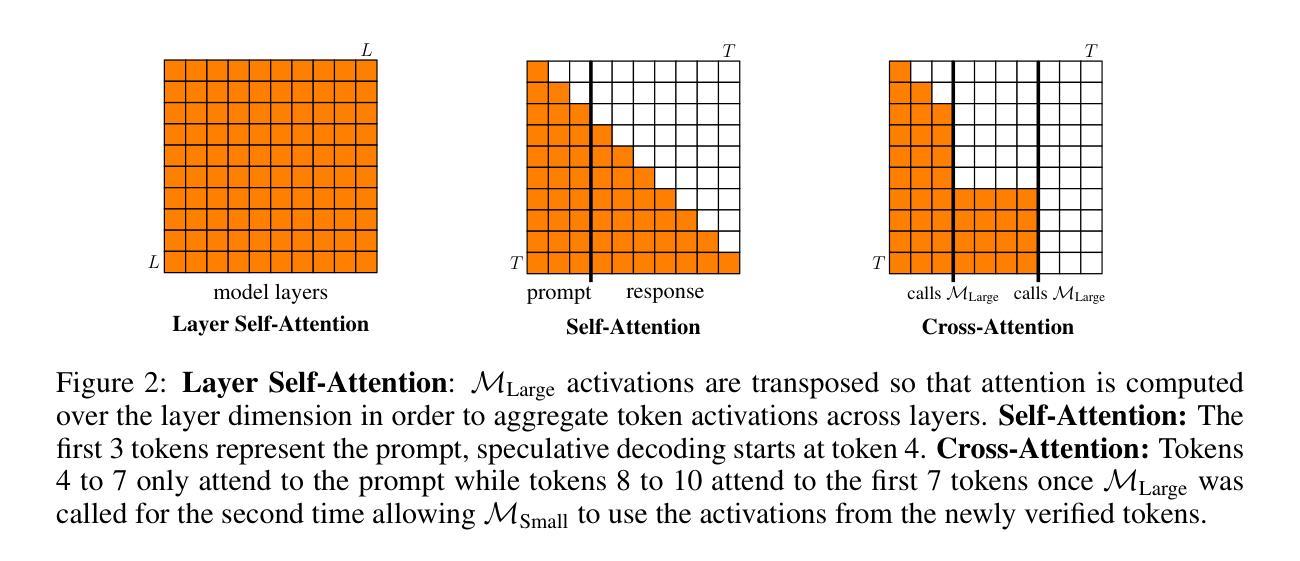
Mixture of Attentions For Speculative Decoding
Authors:Matthieu Zimmer, Milan Gritta, Gerasimos Lampouras, Haitham Bou Ammar, Jun Wang
The growth in the number of parameters of Large Language Models (LLMs) has led to a significant surge in computational requirements, making them challenging and costly to deploy. Speculative decoding (SD) leverages smaller models to efficiently propose future tokens, which are then verified by the LLM in parallel. Small models that utilise activations from the LLM currently achieve the fastest decoding speeds. However, we identify several limitations of SD models including the lack of on-policyness during training and partial observability. To address these shortcomings, we propose a more grounded architecture for small models by introducing a Mixture of Attentions for SD. Our novel architecture can be applied in two scenarios: a conventional single device deployment and a novel client-server deployment where the small model is hosted on a consumer device and the LLM on a server. In a single-device scenario, we demonstrate state-of-the-art speedups improving EAGLE-2 by 9.5% and its acceptance length by 25%. In a client-server setting, our experiments demonstrate: 1) state-of-the-art latencies with minimal calls to the server for different network conditions, and 2) in the event of a complete disconnection, our approach can maintain higher accuracy compared to other SD methods and demonstrates advantages over API calls to LLMs, which would otherwise be unable to continue the generation process.
大型语言模型(LLM)参数数量的增长导致计算需求急剧增加,使其部署具有挑战性和成本高昂。投机解码(SD)利用较小的模型有效地提出未来令牌,然后由LLM并行验证。目前,利用LLM激活的小型模型实现了最快的解码速度。然而,我们发现了SD模型的几个局限性,包括训练过程中缺乏策略性和部分可观察性。为了解决这些不足,我们通过为SD引入混合注意力,提出了小型模型更实用的架构。我们的新型架构可应用于两种场景:传统的单一设备部署和新型客户端-服务器部署,其中小型模型托管在消费设备上,而LLM托管在服务器上。在单一设备场景下,我们展示了最先进的加速效果,将EAGLE-2的速度提高了9.5%,并提高了其接受长度25%。在客户端-服务器设置中,我们的实验表明:1)在不同网络条件下,以最小的服务器调用实现了最先进的延迟;2)在完全断开连接的情况下,我们的方法能维持比其他SD方法和API调用LLM更高的准确性,否则无法继续生成过程。
论文及项目相关链接
PDF Accepted at International Conference on Learning Representations (ICLR 2025)
Summary
大规模语言模型(LLM)的参数增长导致计算需求急剧增加,使其部署具有挑战性和成本。投机解码(SD)利用小型模型有效提出未来令牌,然后由LLM并行验证。目前,利用LLM激活的小型模型实现了最快的解码速度。但SD模型存在缺乏训练时的策略性和部分观测性的局限。为解决这些不足,我们提出一种更为基础的架构,为小型模型引入混合注意力机制。我们的新型架构可应用于两种场景:传统的单一设备部署和新型客户端-服务器部署,其中小型模型托管在消费设备上,而LLM托管在服务器上。在单一设备场景下,我们实现了最先进的速度提升,使EAGLE-2的速度提升9.5%,接受长度提高25%。在客户端-服务器设置中,我们的实验表明:1)不同网络条件下的最先进延迟,对服务器的调用次数最少;2)在完全断开连接的情况下,我们的方法能维持比其他SD方法和API调用更高的准确性。这使得即使在离线情况下也能保证LLM的生成过程继续进行。
Key Takeaways
- LLM参数增长导致计算需求激增,使得部署困难且成本高昂。
- 投机解码(SD)利用小型模型提出未来令牌,并由LLM验证。
- 目前最快解码速度由利用LLM激活的小型模型实现。
- SD模型存在训练策略性和部分观测性的局限性。
- 引入混合注意力机制的新型架构旨在解决这些不足。
- 新型架构适用于单一设备部署和客户端-服务器部署。
点此查看论文截图


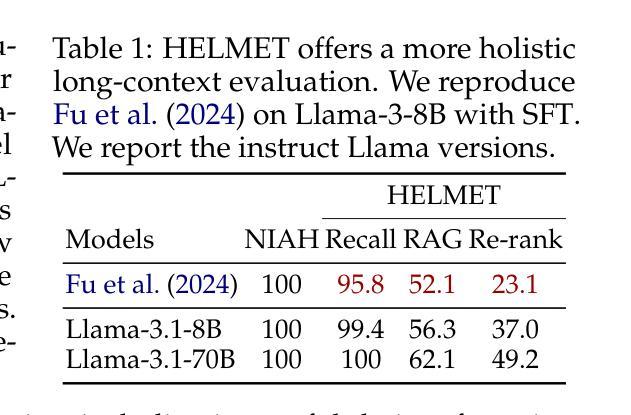
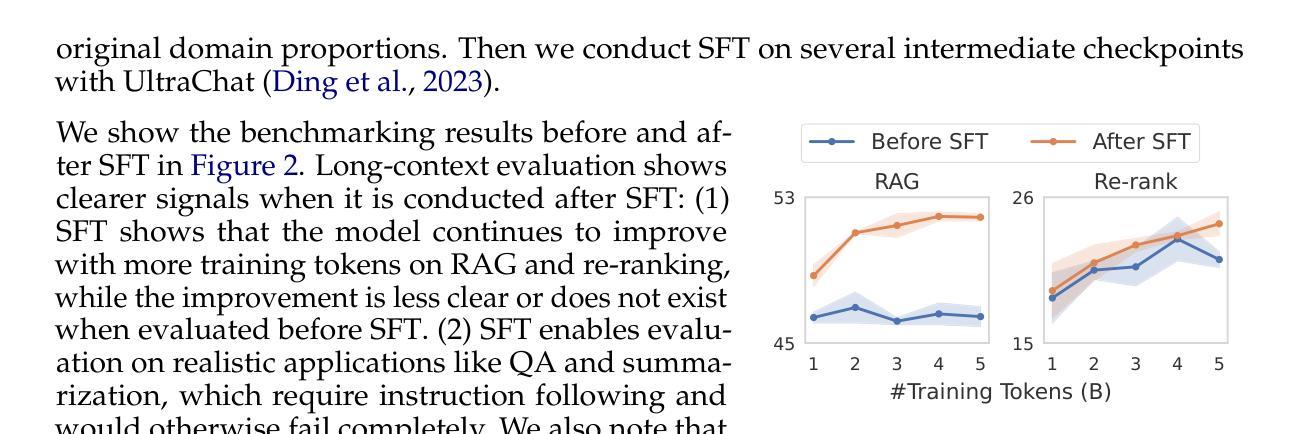
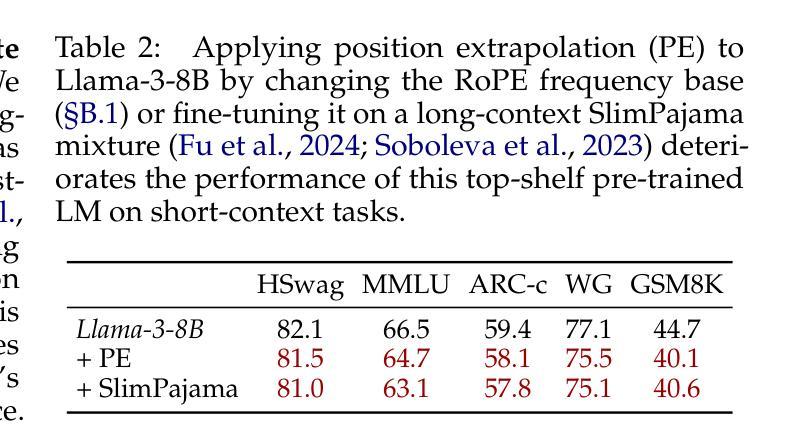
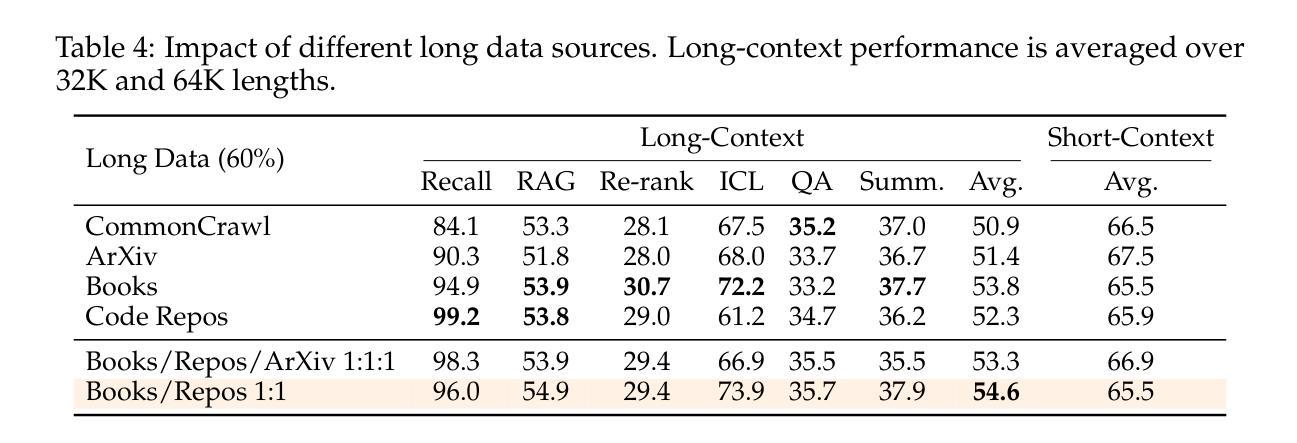
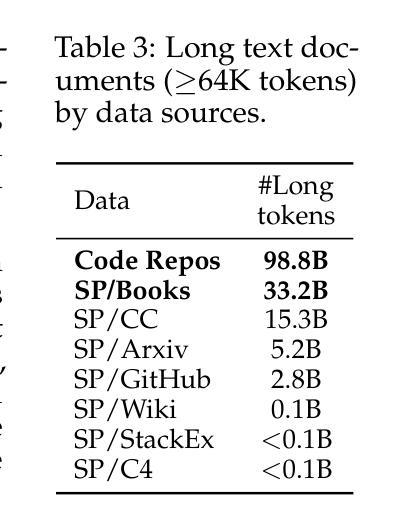
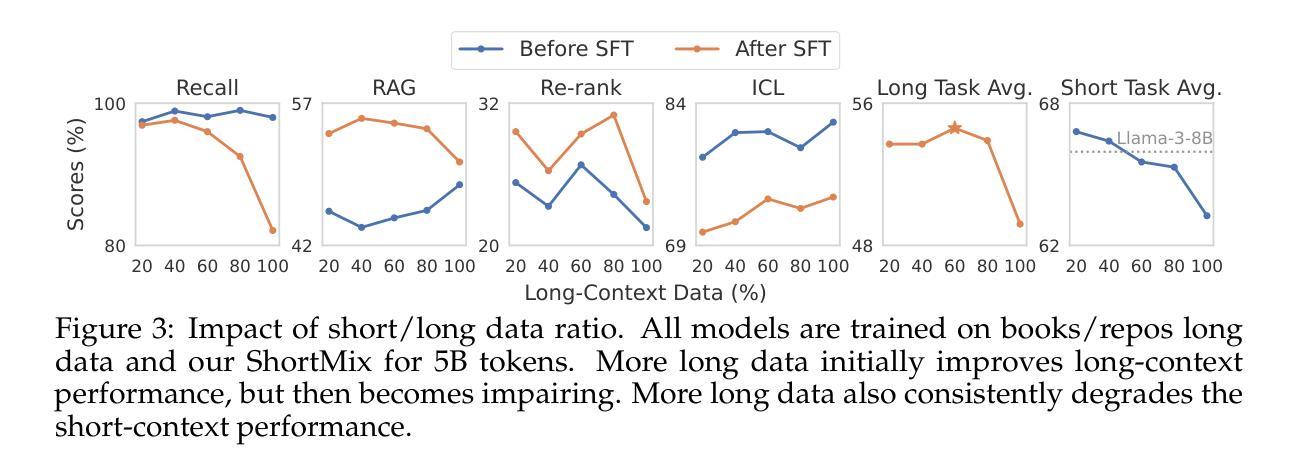
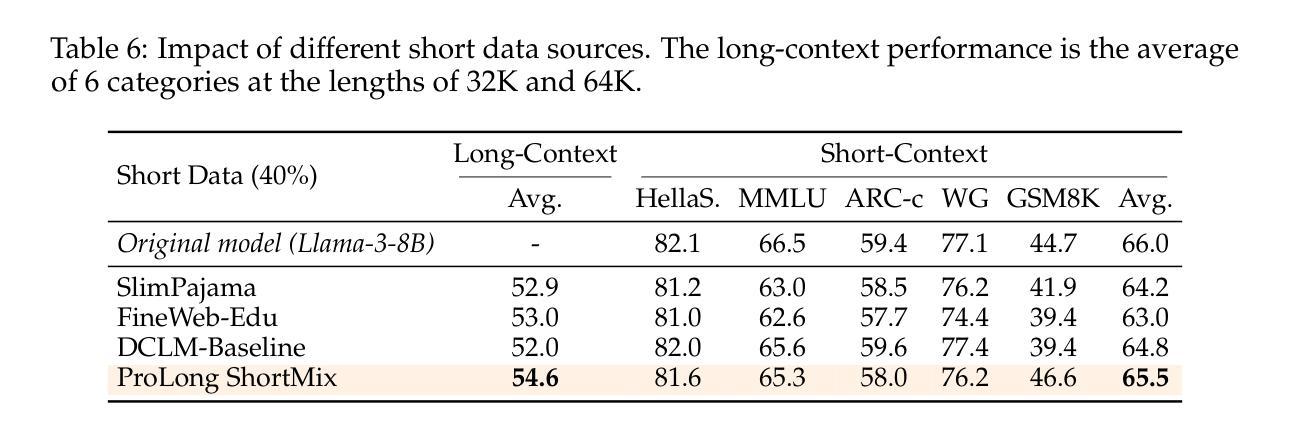
How to Train Long-Context Language Models (Effectively)
Authors:Tianyu Gao, Alexander Wettig, Howard Yen, Danqi Chen
We study continued training and supervised fine-tuning (SFT) of a language model (LM) to make effective use of long-context information. We first establish a reliable evaluation protocol to guide model development – instead of perplexity or simple needle-in-a-haystack (NIAH) tests, we use a broad set of long-context downstream tasks, and we evaluate models after SFT as this better reveals long-context abilities. Supported by our robust evaluations, we run thorough experiments to decide the data mix for continued pre-training, the instruction tuning dataset, and many other design choices such as position extrapolation. We find that (1) code repositories and books are excellent sources of long data, but it is crucial to combine them with high-quality short-context data; (2) training with a sequence length beyond the evaluation length boosts long-context performance; (3) for SFT, using only short instruction datasets yields strong performance on long-context tasks. Our final model, ProLong-8B, which is initialized from Llama-3 and trained on 40B tokens, demonstrates state-of-the-art long-context performance among similarly sized models at a length of 128K. ProLong outperforms Llama-3.1-8B-Instruct on the majority of long-context tasks despite using only 5% as many tokens during long-context training. Additionally, ProLong can effectively process up to 512K tokens, one of the longest context windows of publicly available LMs.
我们研究了一种语言模型(LM)的持续训练和基于监督微调(SFT)的方法,以有效利用长上下文信息。首先,我们建立了一个可靠的评估协议来指导模型的发展——我们不是使用困惑度或简单的“大海捞针”(NIAH)测试,而是使用一系列广泛的下游长上下文任务来评估模型,并在微调后评估模型,因为这能更好地揭示模型处理长上下文的能力。凭借我们稳健的评估结果,我们进行了全面的实验来决定持续预训练的数据混合方式、指令调优数据集以及其他许多设计选择,如位置外推等。我们发现:(1)代码仓库和书籍是长数据的优秀来源,但将它们与高质量短上下文数据相结合至关重要;(2)使用超过评估长度的序列长度进行训练可以提高长上下文性能;(3)对于SFT来说,仅使用短指令数据集即可在长上下文任务上实现出色性能。我们的最终模型ProLong-8B以Llama-3为基础进行初始化,并在40B个标记上进行训练,在长度为128K的模型中实现了最先进的上下文性能。ProLong在大多数长上下文任务上的表现优于Llama-3.1-8B-Instruct,尽管在长上下文训练期间使用的标记数量仅占其5%。此外,ProLong可以有效地处理长达512K的令牌,这是目前公开可用的语言模型中处理最长上下文窗口之一。
论文及项目相关链接
PDF Our code, data, and models are available at https://github.com/princeton-nlp/ProLong
Summary
本文主要研究如何通过持续训练和监督微调(SFT)来有效利用语言模型(LM)的长上下文信息。通过可靠的评估协议,对模型进行长期预训练数据混合、指令微调数据集以及位置外推等设计选择进行彻底实验。最终,ProLong模型在类似规模模型中展现出卓越的长上下文性能,并能有效处理长达512K的令牌。
Key Takeaways
- 研究了如何通过持续训练和监督微调(SFT)有效利用语言模型的长上下文信息。
- 使用广泛的长上下文下游任务进行模型评估,并在SFT后进行模型评估,以更好地揭示模型的长上下文能力。
- 代码仓库和书籍是长数据的优秀来源,但需要与高质量的短上下文数据相结合。
- 序列长度超过评估长度的训练可以提高长上下文性能。
- 对于SFT,仅使用短指令数据集可以在长上下文任务上产生强大性能。
- ProLong模型在类似规模模型中展现出卓越的长上下文性能。
点此查看论文截图

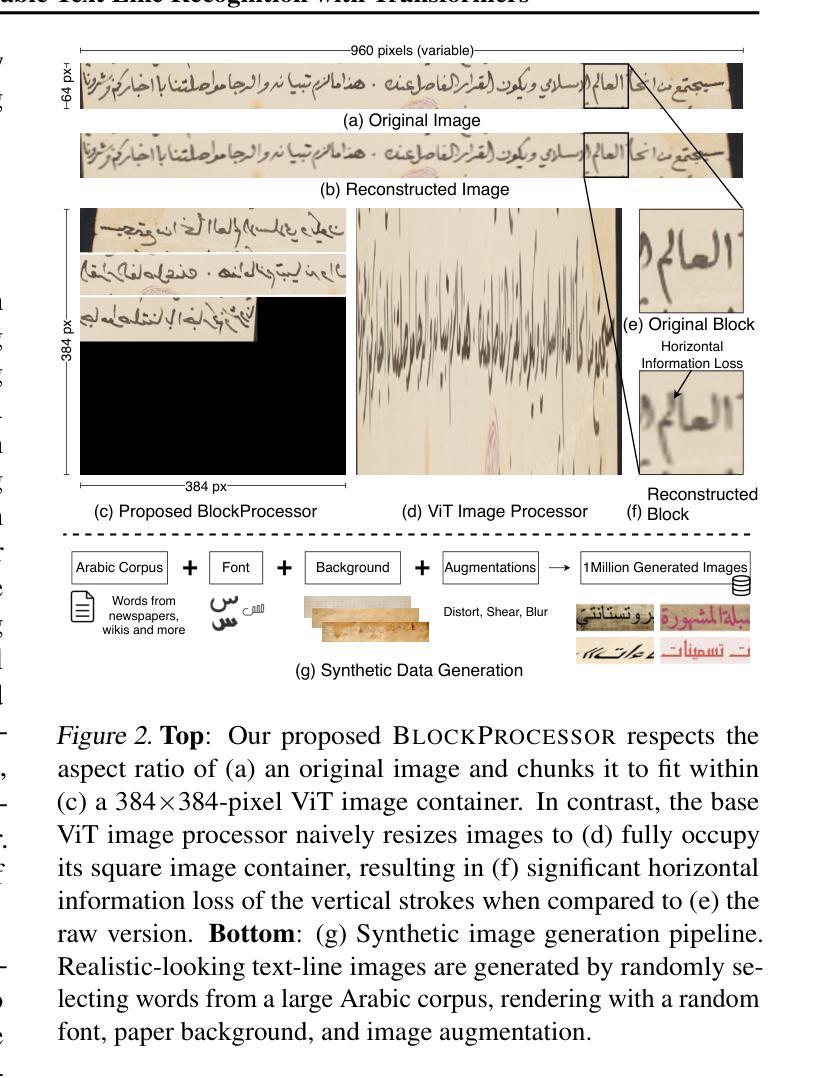
HATFormer: Historic Handwritten Arabic Text Recognition with Transformers
Authors:Adrian Chan, Anupam Mijar, Mehreen Saeed, Chau-Wai Wong, Akram Khater
Arabic handwritten text recognition (HTR) is challenging, especially for historical texts, due to diverse writing styles and the intrinsic features of Arabic script. Additionally, Arabic handwriting datasets are smaller compared to English ones, making it difficult to train generalizable Arabic HTR models. To address these challenges, we propose HATFormer, a transformer-based encoder-decoder architecture that builds on a state-of-the-art English HTR model. By leveraging the transformer’s attention mechanism, HATFormer captures spatial contextual information to address the intrinsic challenges of Arabic script through differentiating cursive characters, decomposing visual representations, and identifying diacritics. Our customization to historical handwritten Arabic includes an image processor for effective ViT information preprocessing, a text tokenizer for compact Arabic text representation, and a training pipeline that accounts for a limited amount of historic Arabic handwriting data. HATFormer achieves a character error rate (CER) of 8.6% on the largest public historical handwritten Arabic dataset, with a 51% improvement over the best baseline in the literature. HATFormer also attains a comparable CER of 4.2% on the largest private non-historical dataset. Our work demonstrates the feasibility of adapting an English HTR method to a low-resource language with complex, language-specific challenges, contributing to advancements in document digitization, information retrieval, and cultural preservation.
阿拉伯手写文本识别(HTR)具有挑战性,尤其对于历史文本而言,其挑战源于多种书写风格和阿拉伯文脚本的内在特征。此外,与英文数据集相比,阿拉伯文手写数据集规模较小,这使得训练通用的阿拉伯文HTR模型更加困难。为了应对这些挑战,我们提出了基于变压器的编码器-解码器架构的HATFormer模型,该模型基于最先进的英文HTR模型构建。通过利用变压器的注意力机制,HATFormer捕获空间上下文信息,通过区分连笔字符、分解视觉表征和识别变音符来解决阿拉伯文脚本的内在挑战。我们对历史手写阿拉伯文的定制包括用于有效预处理ViT信息的图像处理器、用于简洁阿拉伯文本表示的文本标记器以及考虑到有限的历史阿拉伯手写数据的训练管道。在最大的公共历史手写阿拉伯文数据集上,HATFormer实现了8.6%的字符错误率(CER),比文献中的最佳基线模型提高了51%。在最大的私有非历史数据集上,HATFormer也达到了可比的4.2%的CER。我们的工作证明了将英文HTR方法适应具有复杂特定语言挑战的低资源语言的可行性,推动了文档数字化、信息检索和文化保存的发展。
论文及项目相关链接
Summary
阿拉伯手写文本识别(HTR)是一项挑战,特别是对于历史文本,因为存在多样的书写风格和阿拉伯文字本身的特性。此外,阿拉伯手写数据集比英语数据集小,使得训练通用的阿拉伯HTR模型更加困难。为了应对这些挑战,我们提出了基于变压器的编码器-解码器架构的HATFormer,它建立在最先进的英语HTR模型之上。通过利用变压器的注意力机制,HATFormer捕获空间上下文信息,以解决阿拉伯文字本身的挑战,包括区分连笔字符、分解视觉表示和识别变音符。我们对历史手写阿拉伯文的定制包括有效的ViT信息预处理图像处理器、紧凑的阿拉伯文本表示文本标记器,以及考虑到有限的历史阿拉伯手写数据的训练管道。HATFormer在最大的公共历史手写阿拉伯数据集上实现了8.6%的字符错误率(CER),比文献中的最佳基线提高了51%。在最大的私有非历史数据集上,HATFormer也达到了可比的4.2% CER。我们的工作证明了适应英语HTR方法在低资源语言中的可行性,这种语言具有复杂的特定语言挑战,为文档数字化、信息检索和文化保存做出了贡献。
Key Takeaways
- 阿拉伯手写文本识别(HTR)面临多样书写风格和阿拉伯文字特性的挑战。
- 阿拉伯手写数据集相对较小,使得训练通用模型更具挑战性。
- HATFormer是一个基于变压器的编码器-解码器架构,旨在解决阿拉伯HTR的挑战。
- HATFormer利用注意力机制来区分连笔字符、分解视觉表示和识别变音符。
- 为历史手写阿拉伯文定制了图像处理器、文本标记器和训练管道。
- HATFormer在公共历史手写阿拉伯数据集上实现了较低的字符错误率(CER)。
点此查看论文截图



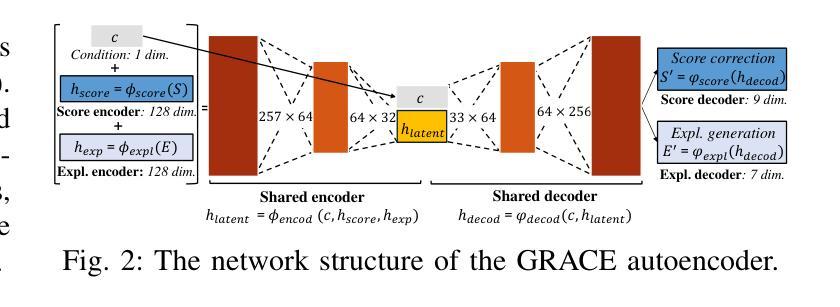
GRACE: Generating Socially Appropriate Robot Actions Leveraging LLMs and Human Explanations
Authors:Fethiye Irmak Dogan, Umut Ozyurt, Gizem Cinar, Hatice Gunes
When operating in human environments, robots need to handle complex tasks while both adhering to social norms and accommodating individual preferences. For instance, based on common sense knowledge, a household robot can predict that it should avoid vacuuming during a social gathering, but it may still be uncertain whether it should vacuum before or after having guests. In such cases, integrating common-sense knowledge with human preferences, often conveyed through human explanations, is fundamental yet a challenge for existing systems. In this paper, we introduce GRACE, a novel approach addressing this while generating socially appropriate robot actions. GRACE leverages common sense knowledge from LLMs, and it integrates this knowledge with human explanations through a generative network. The bidirectional structure of GRACE enables robots to refine and enhance LLM predictions by utilizing human explanations and makes robots capable of generating such explanations for human-specified actions. Our evaluations show that integrating human explanations boosts GRACE’s performance, where it outperforms several baselines and provides sensible explanations.
当机器人在人类环境中操作时,需要处理复杂的任务,既要遵守社会规范又要适应个人偏好。例如,基于常识知识,家用机器人可以预测在社交聚会时应该避免吸尘,但它可能仍然不确定应该在客人来之前还是之后吸尘。在这种情况下,将常识知识与人类偏好(通常通过人类解释传达)结合起来,对于现有系统而言是基本且具有挑战性的。在本文中,我们介绍了GRACE,这是一种解决该问题并生成适当的社会机器人动作的新方法。GRACE利用LLM的常识知识,并通过生成网络将知识与人类解释相结合。GRACE的双向结构使机器人能够通过利用人类解释来完善和增强LLM预测,并使机器人能够针对人类指定的动作生成此类解释。我们的评估表明,融入人类解释可以增强GRACE的性能,它的表现优于几个基准测试,并提供合理的解释。
论文及项目相关链接
PDF 2025 IEEE International Conference on Robotics & Automation (ICRA), Supplementary video: https://youtu.be/GTNCC1GkiQ4
Summary
在家庭环境中,机器人需要执行复杂任务,既要遵守社会规范又要照顾个人喜好。机器人将常识知识与人类解释相结合,生成符合社交规范的机器人行为是一项基本且具挑战性的任务。本文介绍了一种新方法GRACE,它通过大型语言模型(LLMs)获取常识知识,并通过生成网络与人的解释相结合。GRACE的双向结构允许机器人利用人类解释来优化和改进LLM的预测,使机器人能够针对人类指定的动作生成解释。评估结果表明,整合人类解释提高了GRACE的性能,其表现优于多个基线并提供了合理的解释。
Key Takeaways
- 机器人需要在遵守社会规范和适应个人喜好的同时执行复杂任务。
- 将常识知识与人类解释结合是机器人生成社交行为的关键挑战。
- GRACE是一种利用大型语言模型(LLMs)获取常识知识的新方法。
- GRACE通过生成网络与人的解释相结合,利用了双向结构。
- 人类解释可以优化和改进LLM的预测,提高GRACE的性能。
- GRACE在评估中表现优于多个基线,并能提供合理的解释。
点此查看论文截图

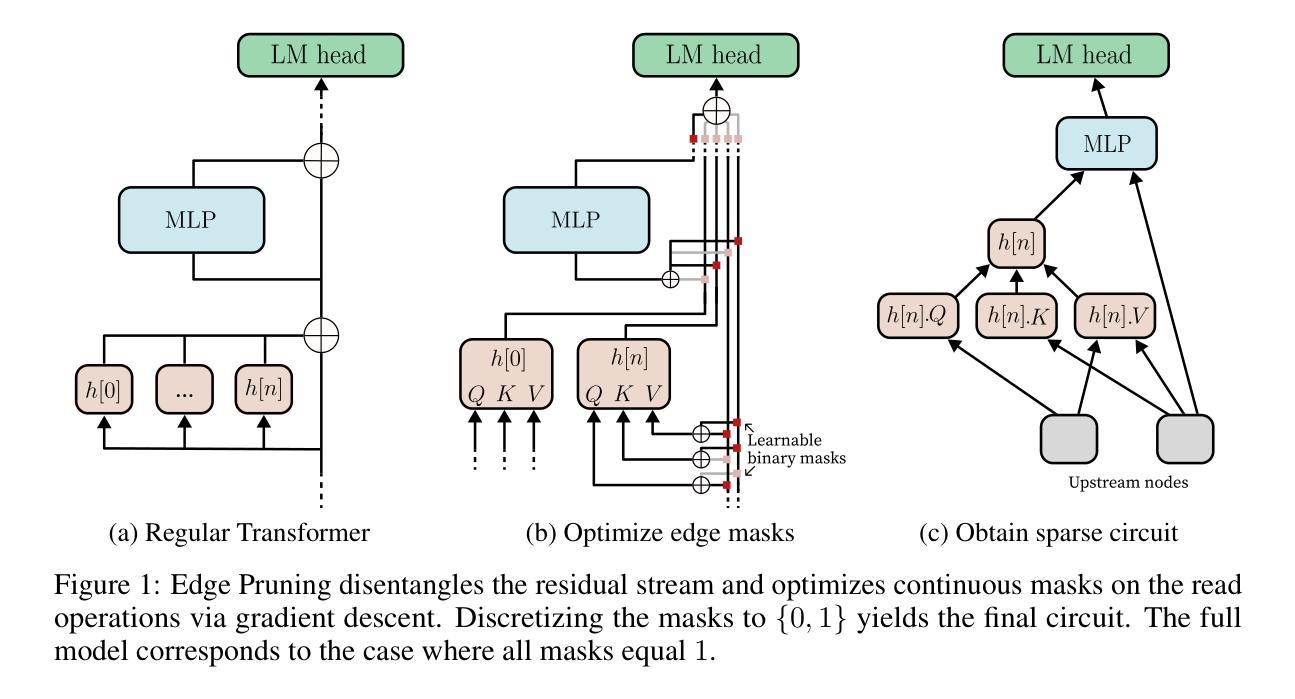
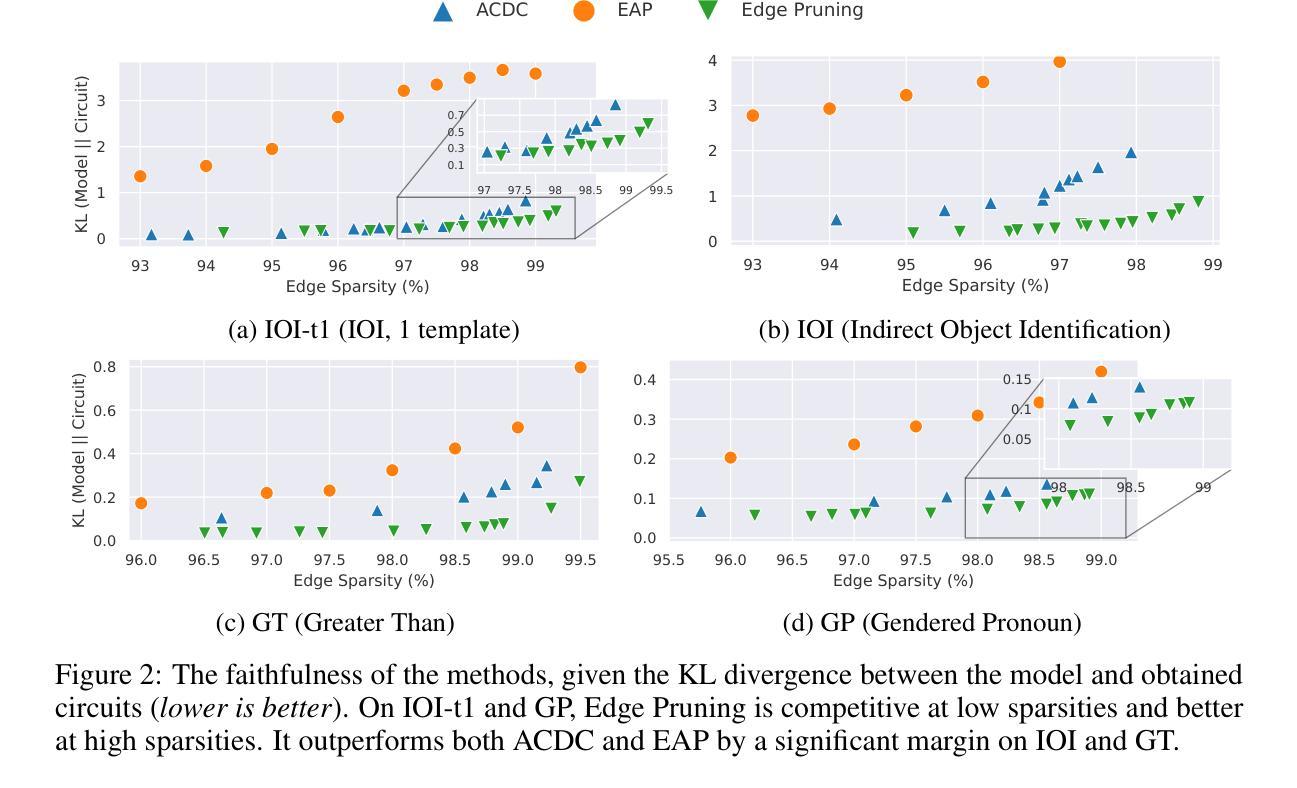
Finding Transformer Circuits with Edge Pruning
Authors:Adithya Bhaskar, Alexander Wettig, Dan Friedman, Danqi Chen
The path to interpreting a language model often proceeds via analysis of circuits – sparse computational subgraphs of the model that capture specific aspects of its behavior. Recent work has automated the task of discovering circuits. Yet, these methods have practical limitations, as they rely either on inefficient search algorithms or inaccurate approximations. In this paper, we frame automated circuit discovery as an optimization problem and propose Edge Pruning as an effective and scalable solution. Edge Pruning leverages gradient-based pruning techniques, but instead of removing neurons or components, it prunes the \emph{edges} between components. Our method finds circuits in GPT-2 that use less than half the number of edges compared to circuits found by previous methods while being equally faithful to the full model predictions on standard circuit-finding tasks. Edge Pruning is efficient even with as many as 100K examples, outperforming previous methods in speed and producing substantially better circuits. It also perfectly recovers the ground-truth circuits in two models compiled with Tracr. Thanks to its efficiency, we scale Edge Pruning to CodeLlama-13B, a model over 100x the scale that prior methods operate on. We use this setting for a case study comparing the mechanisms behind instruction prompting and in-context learning. We find two circuits with more than 99.96% sparsity that match the performance of the full model and reveal that the mechanisms in the two settings overlap substantially. Our case study shows that Edge Pruning is a practical and scalable tool for interpretability and sheds light on behaviors that only emerge in large models.
分析语言模型的路径通常是通过分析电路来完成的,这些电路是模型中稀疏的计算子图,能够捕捉模型行为的特定方面。近期的工作已经实现了电路的自动发现。然而,这些方法存在实际局限性,因为它们依赖于低效的搜索算法或不准确的近似方法。在本文中,我们将自动化电路发现描述为一个优化问题,并提出“边缘修剪”作为一种有效且可扩展的解决方案。“边缘修剪”利用基于梯度的修剪技术,但不是移除神经元或组件,而是修剪组件之间的边。我们的方法在GPT-2中找到了电路,这些电路使用的边比以前的方法在找到的电路中使用的边少一半,同时在标准的电路发现任务上忠实于全模型的预测。即使在多达10万个样本的情况下,“边缘修剪”依然非常高效,速度和电路质量均优于以前的方法。它还能完美地恢复使用Tracr编译的两个模型的基准电路。由于其高效性,“边缘修剪”被扩展到CodeLlama-13B模型上,这是一个比先前方法处理过的模型大100倍的模型。我们利用这一设置进行案例研究,比较指令提示和上下文学习背后的机制。我们发现两个电路的稀疏度超过99.96%,与全模型的性能相匹配,并揭示两种设置中的机制存在大量重叠。我们的案例研究表明,“边缘修剪”是一个实用且可扩展的解读工具,能够揭示仅在大型模型中出现的行为。
论文及项目相关链接
PDF NeurIPS 2024 (Spotlight), code available at https://github.com/princeton-nlp/Edge-Pruning
Summary
本文提出了一个基于优化的自动电路发现框架,通过边缘修剪(Edge Pruning)技术实现高效且可伸缩的电路发现。边缘修剪利用基于梯度的修剪技术,修剪组件之间的边缘而非神经元或组件本身。该方法在GPT-2中发现的电路使用不到先前方法发现电路的一半边缘数量,同时在标准电路发现任务上忠实于全模型预测。即使在多达10万个例子中,边缘修剪也表现出高效性,且在速度和电路质量上优于以前的方法。此外,该方法还可完美地恢复使用Tracr编译的两个模型的基准电路。通过扩展Edge Pruning到CodeLlama-13B模型(规模是先前方法的100倍以上),本研究探讨了指令提示和上下文学习背后的机制。研究结果显示出两个高度稀疏的电路(稀疏性超过99.96%),它们匹配全模型的性能并揭示了两种设置机制的显著重叠。总体而言,边缘修剪是一个实用且可伸缩的工具,为模型行为提供了可解释性,并对大型模型中出现的行为提供了解释。
Key Takeaways
- 本文通过优化自动电路发现的框架来解决当前自动电路发现方法存在的实际问题。
- 提出了一种有效的边缘修剪(Edge Pruning)技术,该技术通过修剪模型组件之间的边缘来实现电路发现。
- 边缘修剪技术在GPT-2模型中发现的电路具有更高的效率和质量。
- 边缘修剪可扩展到大型模型,如CodeLlama-13B,揭示指令提示和上下文学习的机制。
- 通过在CodeLlama-13B模型中的案例研究,发现了高度稀疏的电路,匹配全模型的性能。
- 研究显示指令提示和上下文学习的机制存在显著重叠。
点此查看论文截图

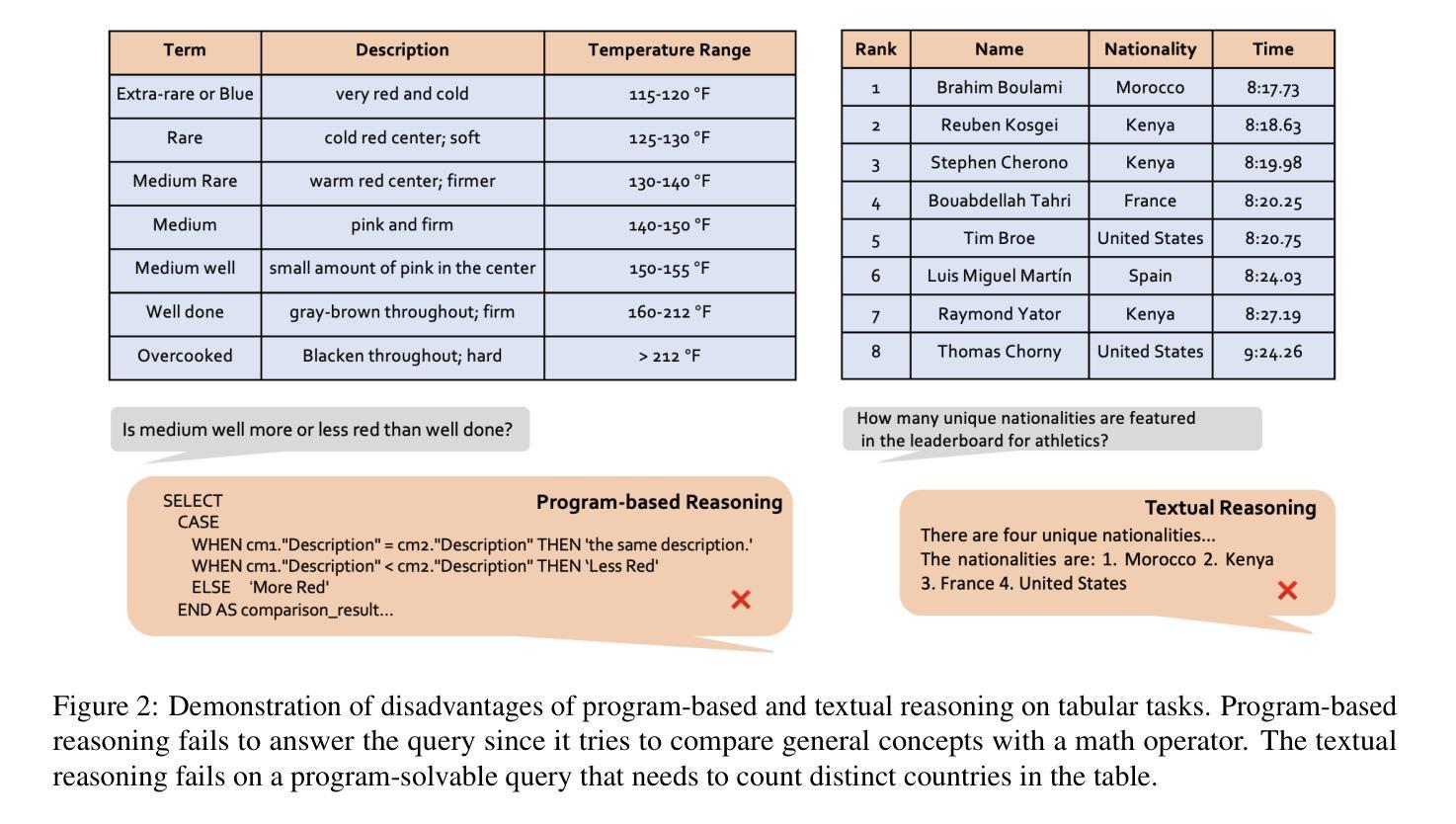
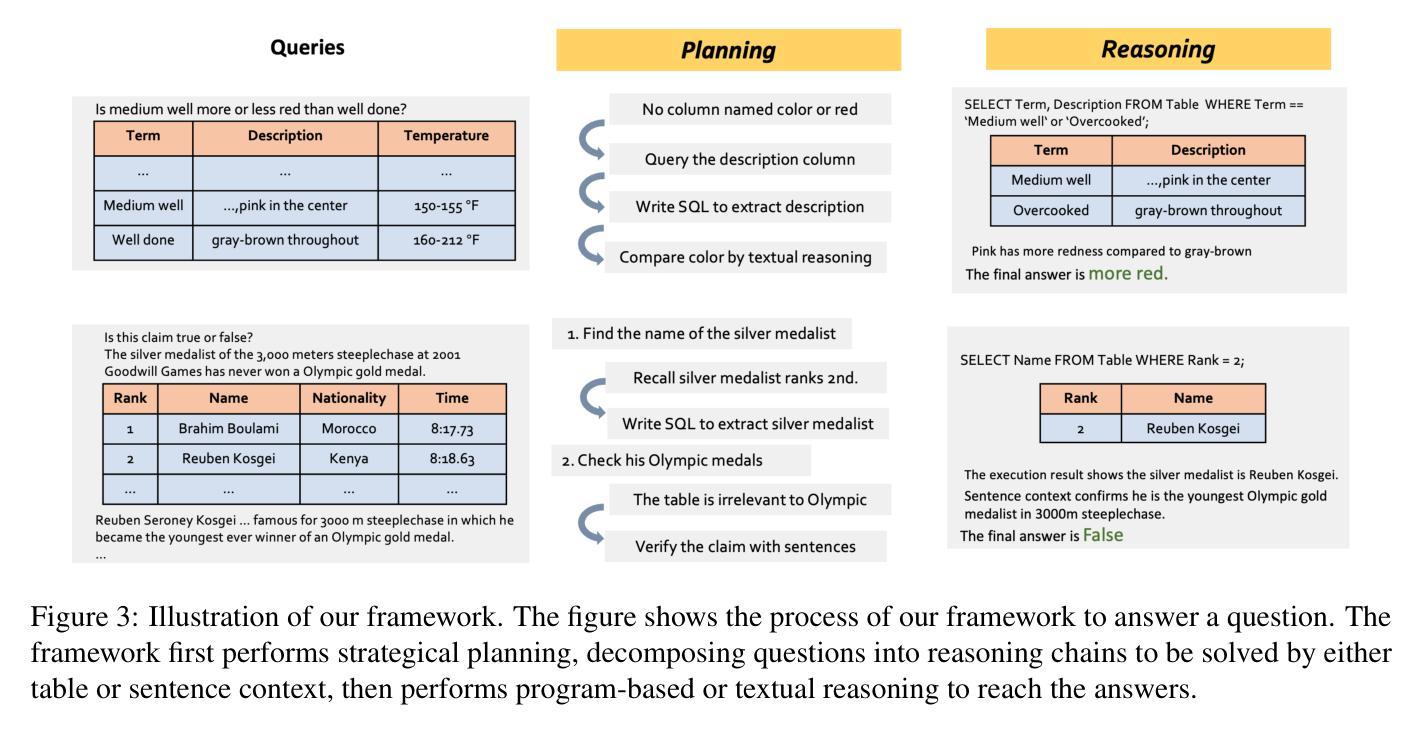
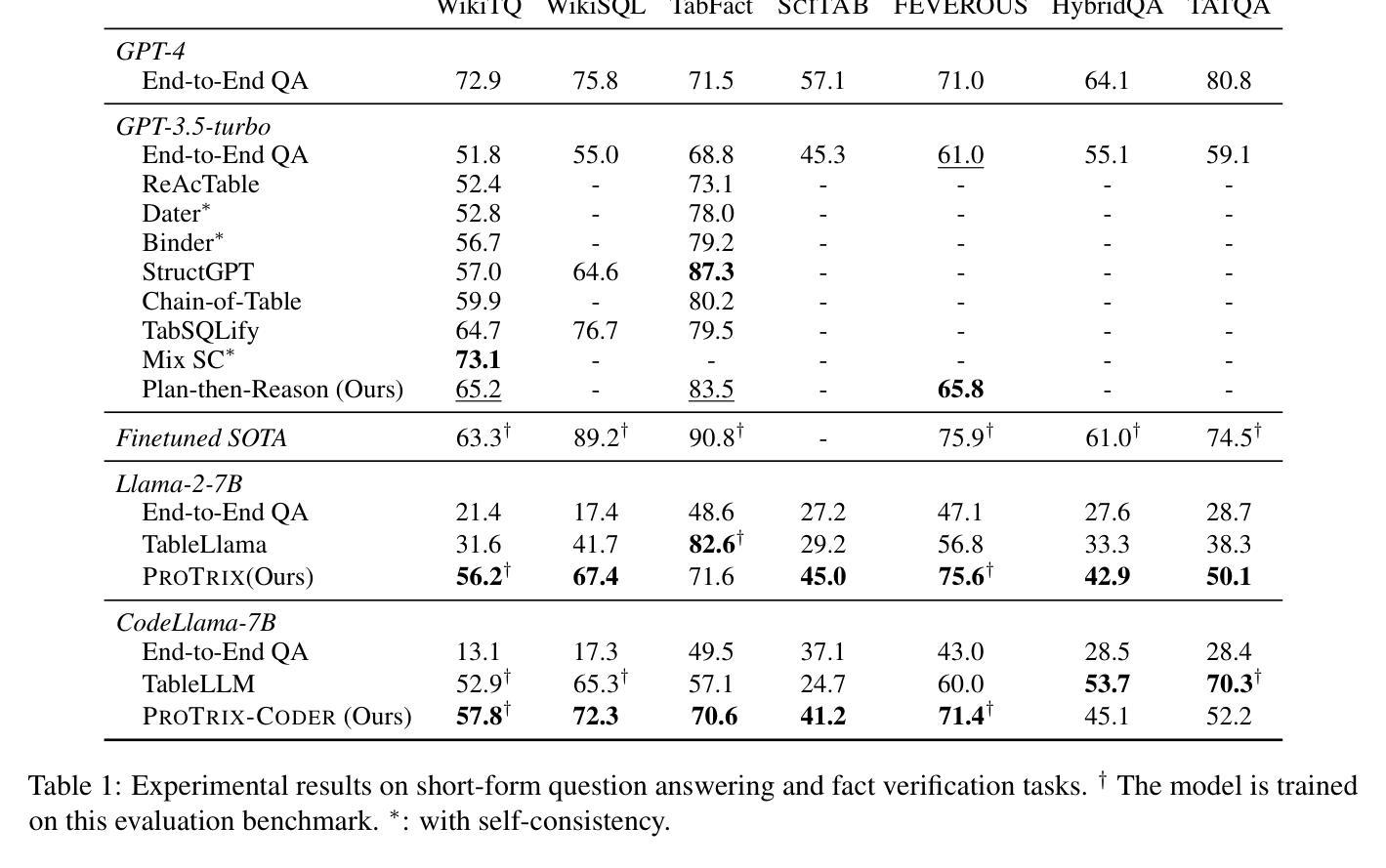
ProTrix: Building Models for Planning and Reasoning over Tables with Sentence Context
Authors:Zirui Wu, Yansong Feng
Tables play a crucial role in conveying information in various domains. We propose a Plan-then-Reason framework to answer different types of user queries over tables with sentence context. The framework first plans the reasoning paths over the context, then assigns each step to program-based or textual reasoning to reach the final answer. This framework enhances the table reasoning abilities for both in-context learning and fine-tuning methods. GPT-3.5-Turbo following Plan-then-Reason framework surpasses other prompting baselines without self-consistency while using less API calls and in-context demonstrations. We also construct an instruction tuning set TrixInstruct to evaluate the effectiveness of fine-tuning with this framework. We present ProTrix model family by finetuning models on TrixInstruct. Our experiments show that ProTrix family generalizes to diverse unseen tabular tasks with only 6k training instances. We further demonstrate that ProTrix can generate accurate and faithful explanations to answer complex free-form questions. Our work underscores the importance of the planning and reasoning abilities towards a model over tabular tasks with generalizability and interpretability. We open-source our dataset and models at https://github.com/WilliamZR/ProTrix.
表格在各种领域的信息传达中扮演着至关重要的角色。我们提出了一个”计划-推理”框架,该框架能够根据句子上下文回答不同类型的用户查询表格。该框架首先计划上下文中的推理路径,然后将每一步分配给基于程序或文本推理,以得出最终答案。此框架提高了上下文学习和微调方法的表格推理能力。遵循“计划-推理”框架的GPT-3.5 Turbo超越了其他具有自我一致性提示的基线,同时使用更少的API调用和上下文演示。我们还构建了指令调整集TrixInstruct,以评估此框架进行微调的有效性。我们通过微调模型在TrixInstruct上推出了ProTrix模型系列。我们的实验表明,ProTrix系列仅使用6000个训练实例就能推广到多样化的未见表格任务。我们进一步证明,ProTrix可以生成准确和忠诚的解释来回答复杂的自由形式问题。我们的工作强调了规划和推理能力对于模型在处理表格任务时的通用性和可解释性的重要性。我们在https://github.com/WilliamZR/ProTrix公开我们的数据集和模型。
论文及项目相关链接
PDF EMNLP 2024 Findings
Summary:
本文提出一个名为“Plan-then-Reason”的框架,用于在表格中根据句子上下文回答不同类型的用户查询。该框架首先规划推理路径,然后将每一步分配给基于程序或文本推理,以得出最终答案。此框架提高了上下文学习和微调方法的表格推理能力。使用此框架的GPT-3.5 Turbo在提示基准测试上表现出色,同时使用较少的API调用和上下文演示。此外,本文构建了用于评估在此框架下微调有效性的指令调整集TrixInstruct,并推出了由TrixInstruct训练的ProTrix模型家族。实验表明,ProTrix家族仅使用6k训练实例即可推广到多样化的未见表格任务,并能生成准确且忠实的问题解答复杂自由形式问题的解释。本文强调在表格任务中面向模型的规划能力和推理能力的重要性,并开源了数据集和模型。
Key Takeaways:
- 提出了“Plan-then-Reason”框架,用于回答表格中的用户查询。
- 该框架通过规划推理路径并结合程序与文本推理来得出答案。
- “Plan-then-Reason”框架增强了上下文学习和微调方法的表格推理能力。
- GPT-3.5 Turbo遵循此框架在提示基准测试中表现优异,同时减少API调用和上下文演示需求。
- 构建了一个名为TrixInstruct的指令调整集,用于评估微调效果。
- 推出了ProTrix模型家族,该家族在多样化未见表格任务上表现良好,仅使用少量训练实例。
点此查看论文截图

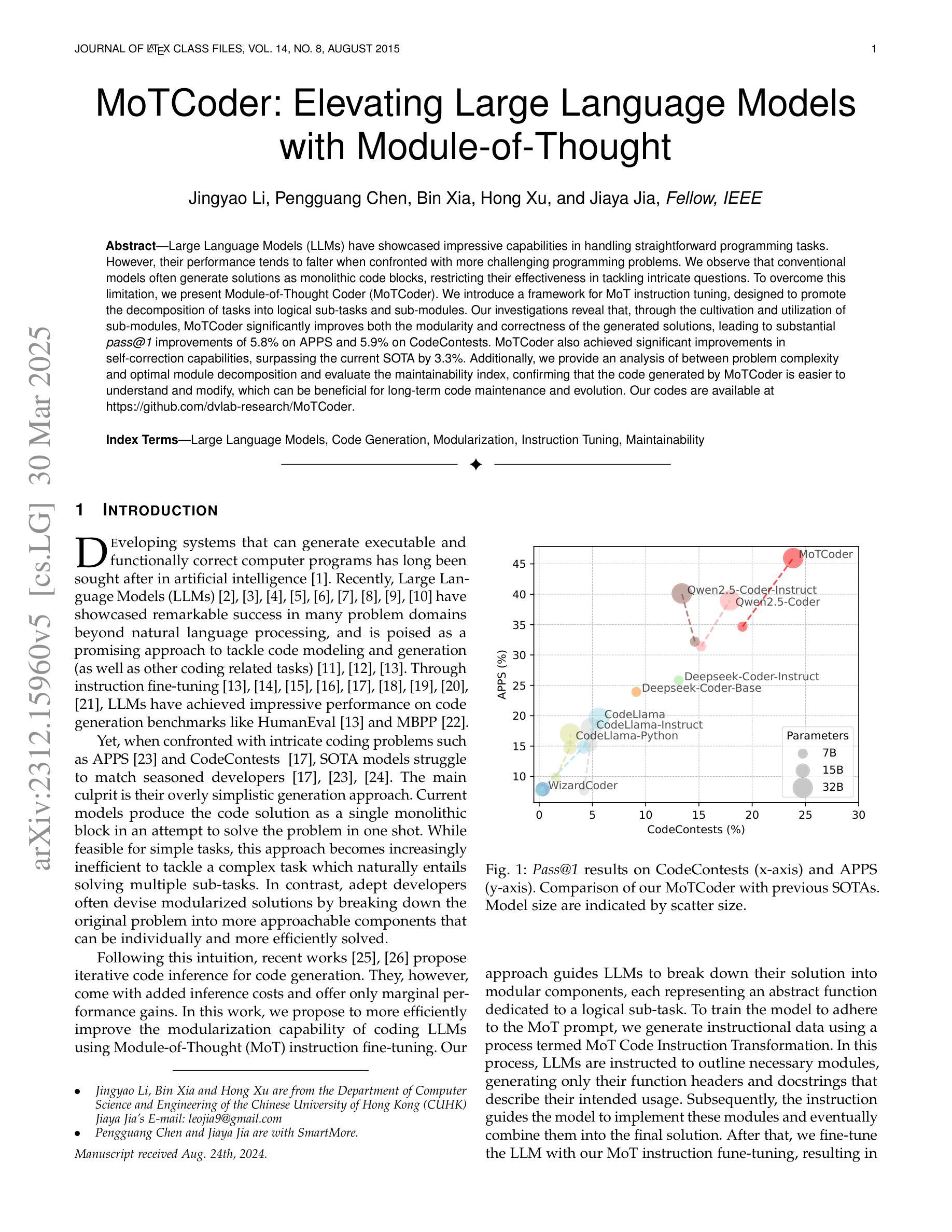
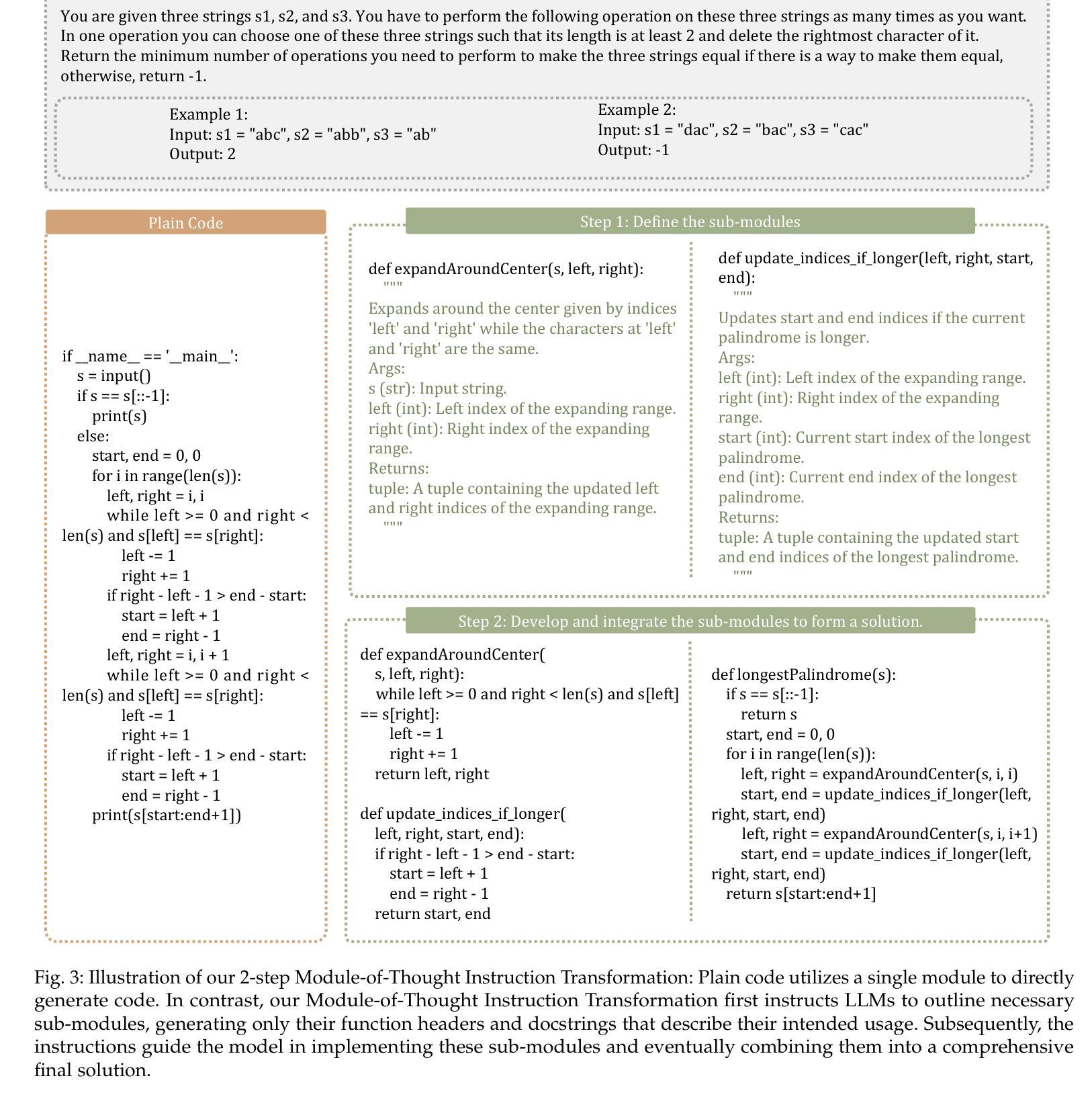
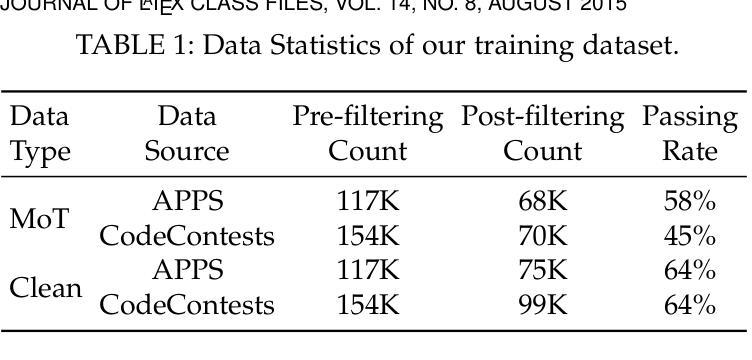
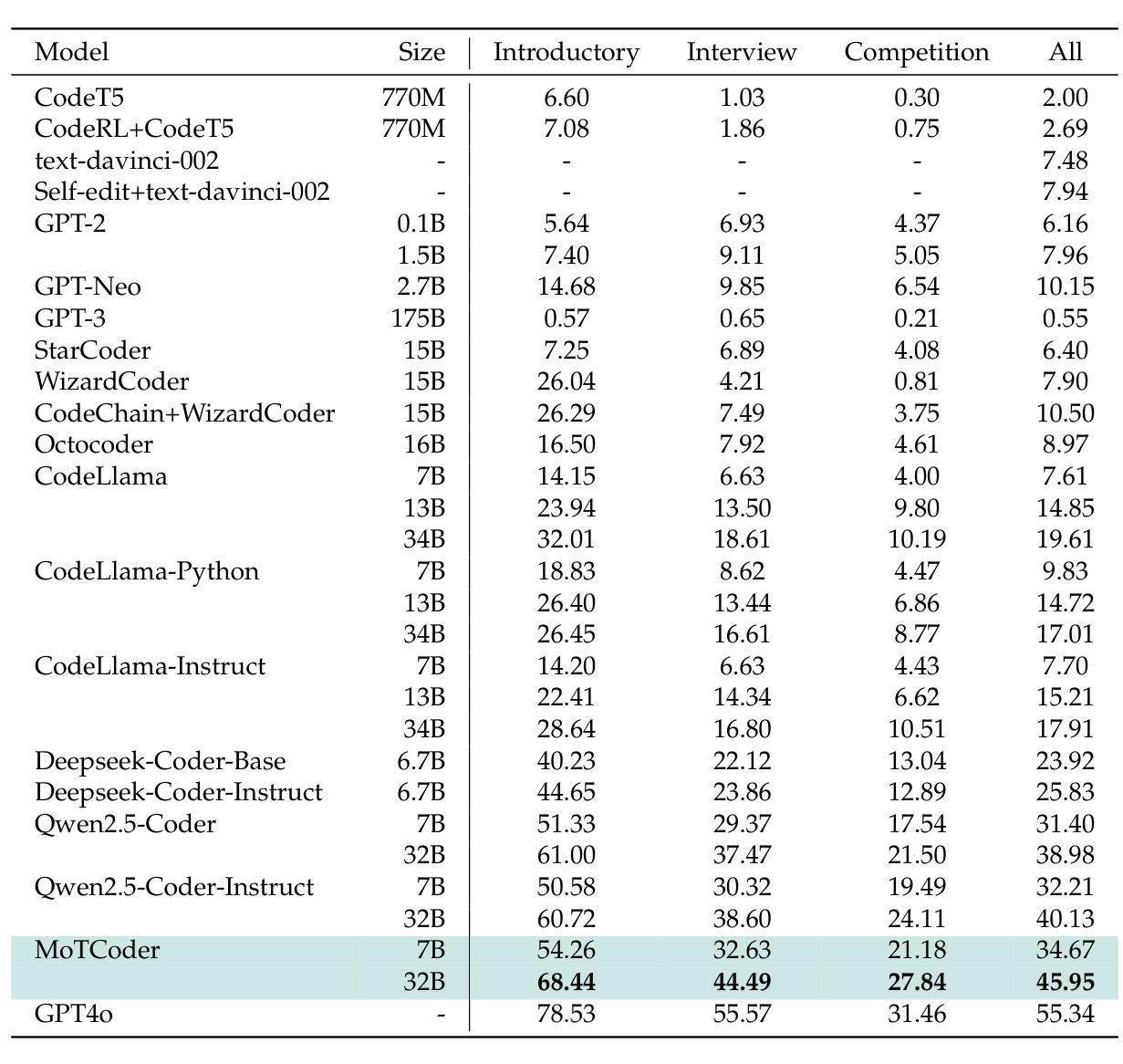
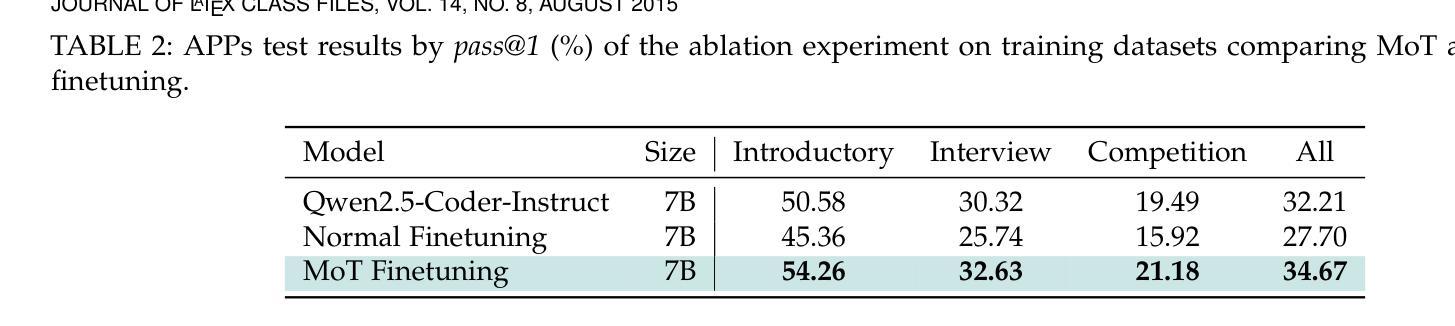
MoTCoder: Elevating Large Language Models with Modular of Thought for Challenging Programming Tasks
Authors:Jingyao Li, Pengguang Chen, Bin Xia, Hong Xu, Jiaya Jia
Large Language Models (LLMs) have showcased impressive capabilities in handling straightforward programming tasks. However, their performance tends to falter when confronted with more challenging programming problems. We observe that conventional models often generate solutions as monolithic code blocks, restricting their effectiveness in tackling intricate questions. To overcome this limitation, we present Module-of-Thought Coder (MoTCoder). We introduce a framework for MoT instruction tuning, designed to promote the decomposition of tasks into logical sub-tasks and sub-modules. Our investigations reveal that, through the cultivation and utilization of sub-modules, MoTCoder significantly improves both the modularity and correctness of the generated solutions, leading to substantial pass@1 improvements of 5.9% on APPS and 5.8% on CodeContests. MoTCoder also achieved significant improvements in self-correction capabilities, surpassing the current SOTA by 3.3%. Additionally, we provide an analysis of between problem complexity and optimal module decomposition and evaluate the maintainability index, confirming that the code generated by MoTCoder is easier to understand and modify, which can be beneficial for long-term code maintenance and evolution. Our codes are available at https://github.com/dvlab-research/MoTCoder.
大型语言模型(LLM)在处理简单的编程任务时展示了令人印象深刻的能力。然而,当面对更具挑战性的编程问题时,它们的性能往往会遇到困难。我们发现,传统模型往往将解决方案生成为单一的代码块,这限制了它们在解决复杂问题时的有效性。为了克服这一局限性,我们提出了“思维模块编码者”(MoTCoder)。我们介绍了一种MoT指令调整的框架,旨在促进任务分解为逻辑子任务和子模块。我们的研究发现,通过培养和利用子模块,MoTCoder显著提高了生成解决方案的模块化和正确性,在APPS和CodeContests上分别实现了5.9%和5.8%的pass@1改进。MoTCoder在自我纠错能力方面也取得了显著进步,超过了当前的最佳水平3.3%。此外,我们还对问题复杂性与最佳模块分解进行了分析,并评估了可维护性指数,证实MoTCoder生成的代码更容易理解和修改,这有利于长期代码维护和进化。我们的代码可在https://github.com/dvlab-research/MoTCoder找到。
论文及项目相关链接
PDF Data: https://huggingface.co/datasets/JingyaoLi/MoTCode-Data,MoTCoder-32B: https://huggingface.co/JingyaoLi/MoTCoder-32B-V1.5,MoTCoder-7B: https://huggingface.co/JingyaoLi/MoTCoder-7B-v1.5,Code: https://github.com/dvlab-research/MoTCoder, Paper: arXiv:2312.15960
Summary
大型语言模型(LLM)在处理简单的编程任务时表现出强大的能力,但在面对复杂的编程问题时性能有所下降。为解决这一问题,我们提出了模块化思维编码框架(MoTCoder)。通过任务分解为逻辑子任务和子模块,MoTCoder显著提高了生成解决方案的模块化和正确性,在APPS和CodeContests上分别实现了5.9%和5.8%的通过率提升。此外,MoTCoder还增强了自我纠错能力,较当前最佳模型提高了3.3%。代码易于理解和修改,有利于长期代码维护和进化。我们的代码可在GitHub上找到。
Key Takeaways
- LLM在处理复杂编程问题时性能有限。
- MoTCoder框架旨在通过任务分解为逻辑子任务和子模块来提高解决方案的模块化。
- MoTCoder显著提高了生成解决方案的正确性,在特定测试上实现了通过率提升。
- MoTCoder增强了自我纠错能力,表现优于当前最佳模型。
- MoTCoder生成的代码易于理解和修改,有利于长期代码维护和进化。
- 研究提供了对问题复杂性与最优模块分解之间的分析。
点此查看论文截图