⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-05 更新
OmniTalker: Real-Time Text-Driven Talking Head Generation with In-Context Audio-Visual Style Replication
Authors:Zhongjian Wang, Peng Zhang, Jinwei Qi, Guangyuan Wang Sheng Xu, Bang Zhang, Liefeng Bo
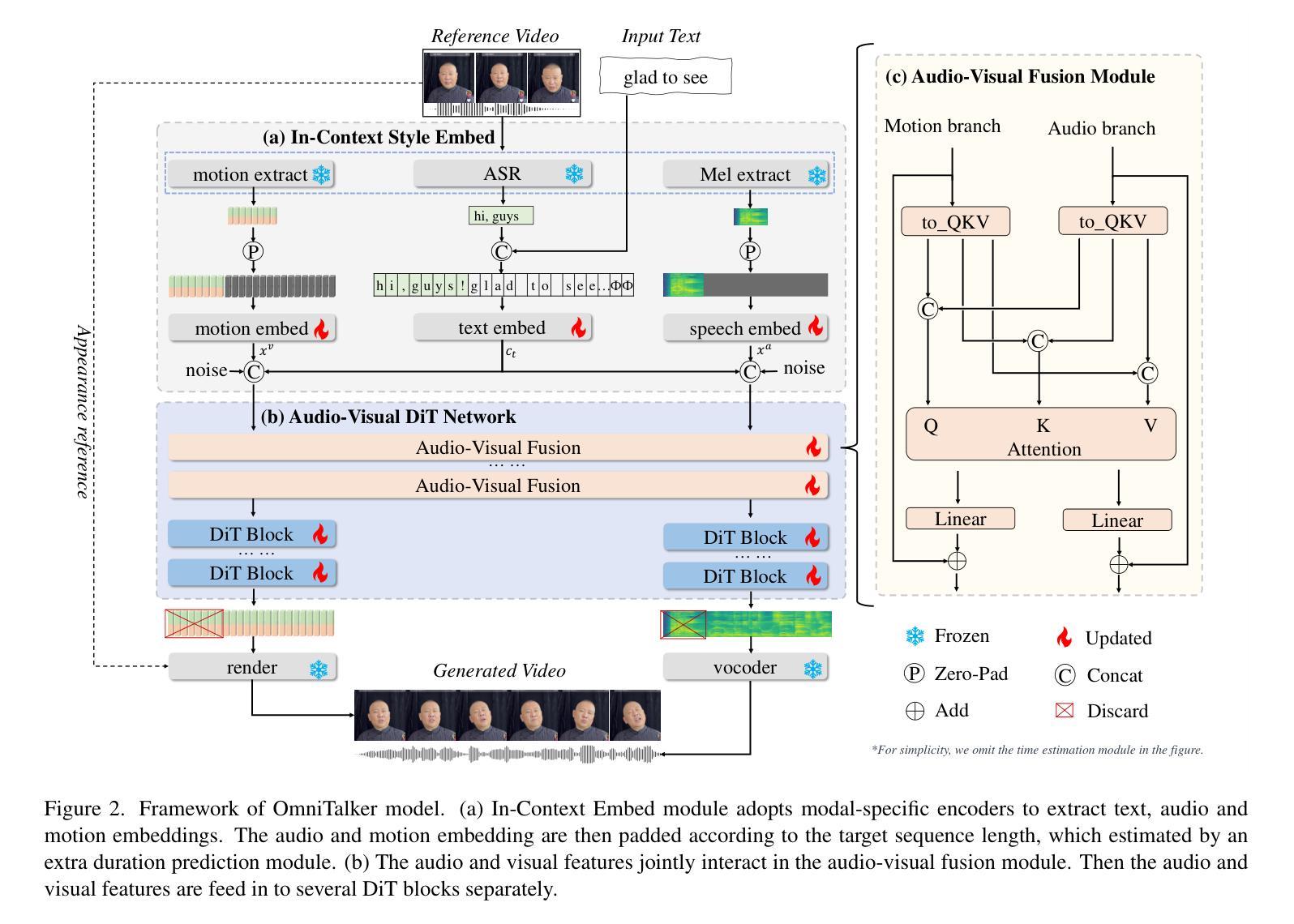
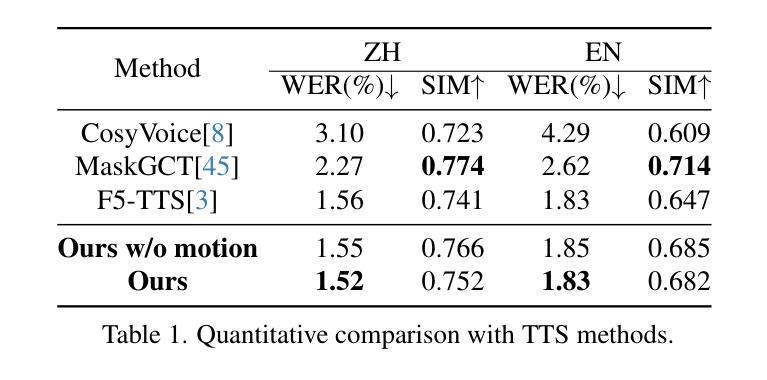
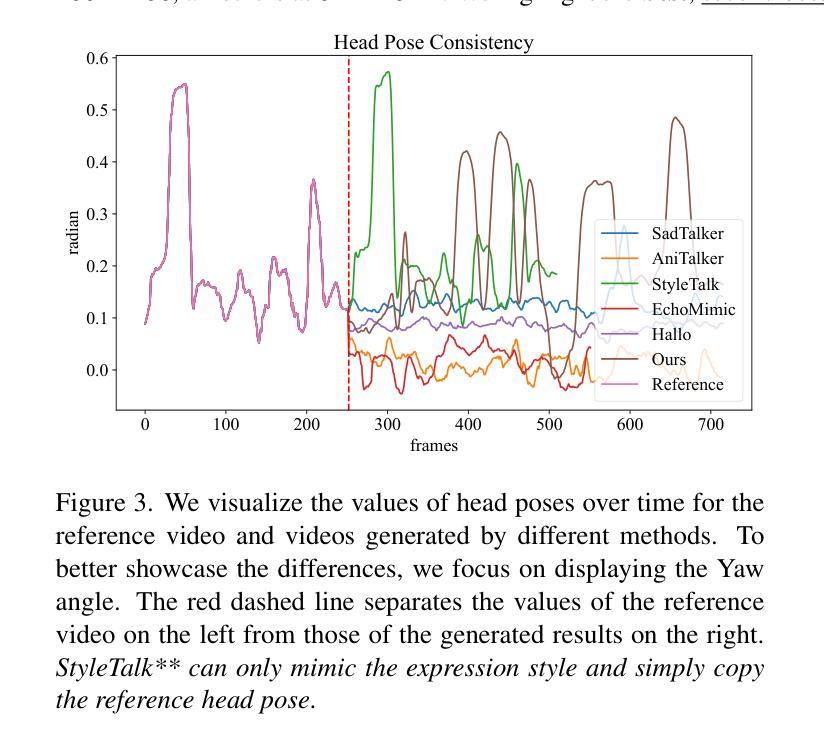
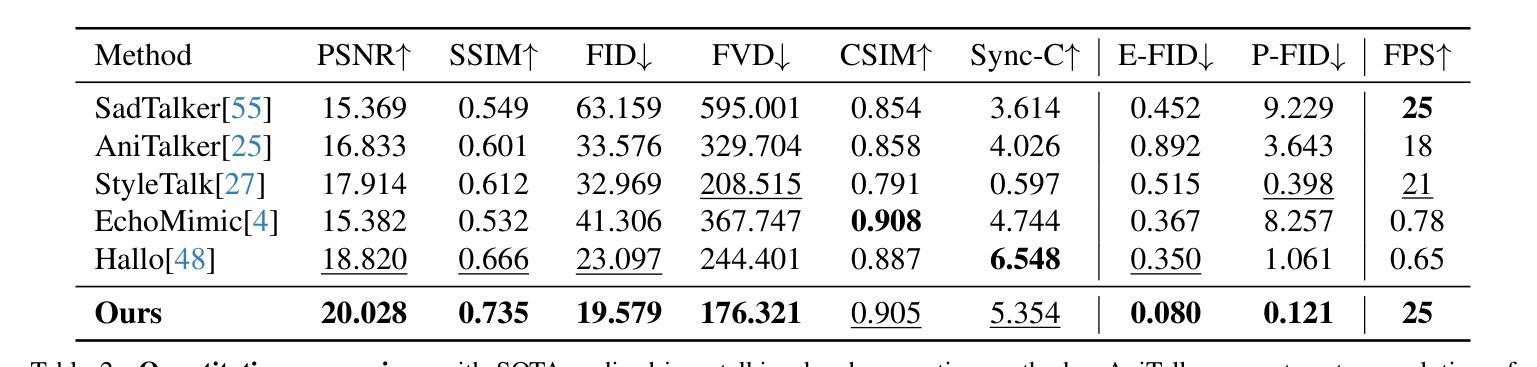
Recent years have witnessed remarkable advances in talking head generation, owing to its potential to revolutionize the human-AI interaction from text interfaces into realistic video chats. However, research on text-driven talking heads remains underexplored, with existing methods predominantly adopting a cascaded pipeline that combines TTS systems with audio-driven talking head models. This conventional pipeline not only introduces system complexity and latency overhead but also fundamentally suffers from asynchronous audiovisual output and stylistic discrepancies between generated speech and visual expressions. To address these limitations, we introduce OmniTalker, an end-to-end unified framework that simultaneously generates synchronized speech and talking head videos from text and reference video in real-time zero-shot scenarios, while preserving both speech style and facial styles. The framework employs a dual-branch diffusion transformer architecture: the audio branch synthesizes mel-spectrograms from text, while the visual branch predicts fine-grained head poses and facial dynamics. To bridge modalities, we introduce a novel audio-visual fusion module that integrates cross-modal information to ensure temporal synchronization and stylistic coherence between audio and visual outputs. Furthermore, our in-context reference learning module effectively captures both speech and facial style characteristics from a single reference video without introducing an extra style extracting module. To the best of our knowledge, OmniTalker presents the first unified framework that jointly models speech style and facial style in a zero-shot setting, achieving real-time inference speed of 25 FPS. Extensive experiments demonstrate that our method surpasses existing approaches in generation quality, particularly excelling in style preservation and audio-video synchronization.
近年来,随着对话头生成技术的显著进步,人机交互已从文本界面发展为逼真的视频聊天,这为该领域带来了巨大的潜力。然而,关于文本驱动对话头的研究仍然被忽视。现有的方法主要采用级联管道,将文本合成系统(TTS)与音频驱动的对话头模型相结合。这种传统管道不仅引入了系统复杂性和延迟开销,而且从根本上受到异步视听输出以及生成语音和视觉表达之间风格差异的限制。为了解决这些局限性,我们推出了OmniTalker,这是一个端到端的统一框架,可以实时从零场景中的文本和参考视频生成同步语音和对话头视频。同时保持语音风格和面部风格。该框架采用双分支扩散变压器架构:音频分支从文本中合成梅尔频谱图,而视觉分支预测精细头部姿势和面部动态。为了弥合不同模态之间的差距,我们引入了一种新颖的视听融合模块,该模块整合跨模态信息以确保音频和视频输出之间的时间同步和风格一致性。此外,我们的上下文参考学习模块有效地从单个参考视频中捕获了语音和面部风格特征,无需引入额外的风格提取模块。据我们所知,OmniTalker是第一个在零样本设置中联合建模语音风格和面部风格的统一框架,实现了25帧每秒的实时推理速度。大量实验表明,我们的方法在生成质量上超越了现有方法,尤其在风格保持和音视频同步方面表现出色。
论文及项目相关链接
PDF Project Page https://humanaigc.github.io/omnitalker
Summary
本文介绍了OmniTalker框架,该框架能够在零样本场景中实时从文本和参考视频中生成同步的语音和说话人头部的视频。它采用双分支扩散变压器架构,同时合成梅尔频谱图和精细头部姿态及面部动态预测。通过引入新型音频视觉融合模块,确保音频和视频输出之间的时序同步和风格一致性。此外,OmniTalker的有效之处在于,它能够通过单一的参考视频捕捉语音和面部风格特征,无需额外的风格提取模块。OmniTalker是首个在零样本设置中联合建模语音风格和面部风格的框架,实现了实时推理速度25帧/秒,且在生成质量上超越了现有方法,尤其在风格保持和音视频同步方面表现突出。
Key Takeaways
- OmniTalker是一个端到端的统一框架,能够实时地从文本和参考视频中生成同步的语音和说话人头部的视频。
- 该框架采用双分支扩散变压器架构,同时处理音频和视频生成任务。
- 引入新型音频视觉融合模块,确保音频和视频输出之间的同步和风格一致性。
- OmniTalker能够通过单一的参考视频捕捉语音和面部风格特征。
- 该框架实现了实时推理速度25帧/秒。
- OmniTalker在生成质量上超越了现有方法,尤其在风格保持和音视频同步方面表现优异。
点此查看论文截图

F5R-TTS: Improving Flow Matching based Text-to-Speech with Group Relative Policy Optimization
Authors:Xiaohui Sun, Ruitong Xiao, Jianye Mo, Bowen Wu, Qun Yu, Baoxun Wang
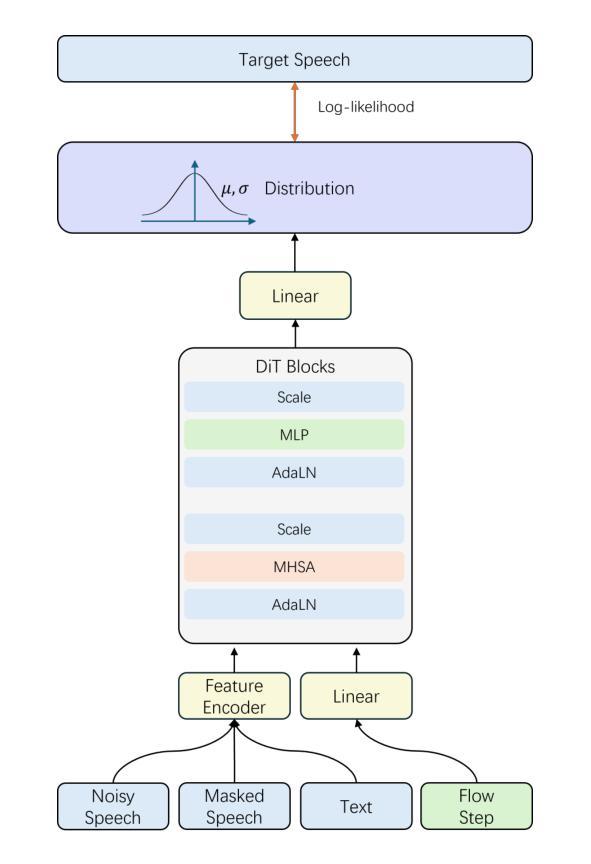
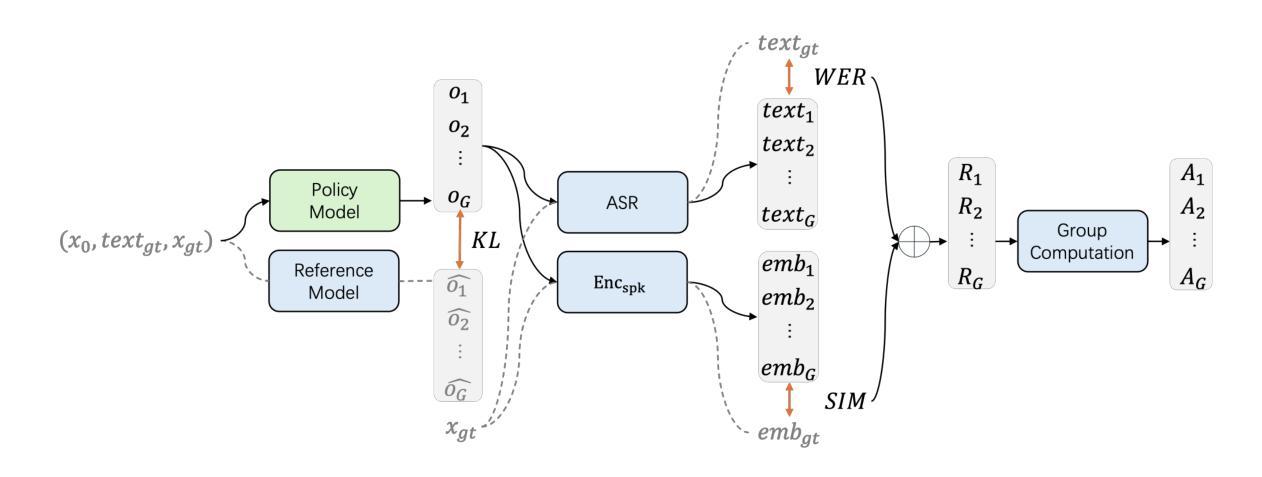
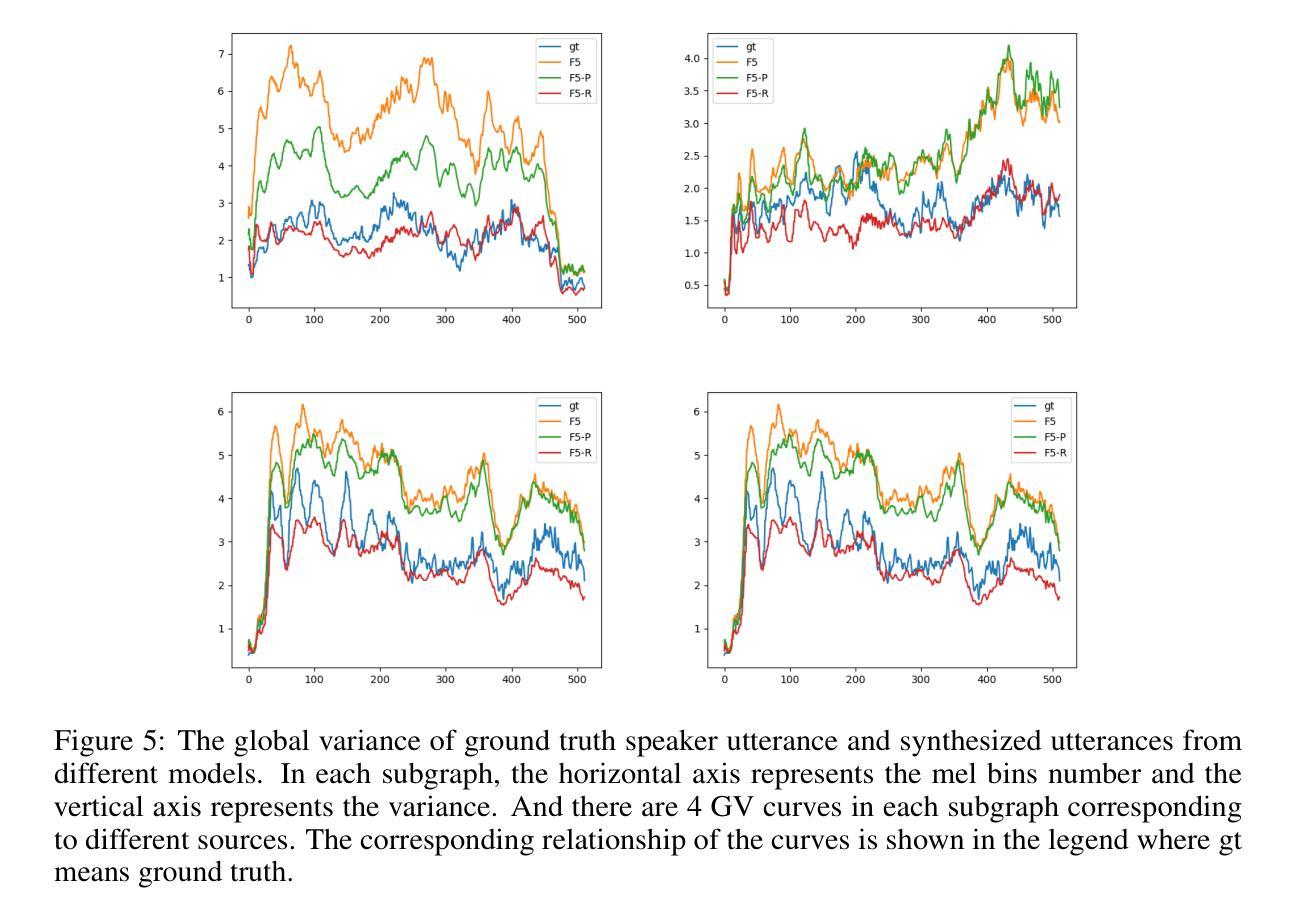
We present F5R-TTS, a novel text-to-speech (TTS) system that integrates Gradient Reward Policy Optimization (GRPO) into a flow-matching based architecture. By reformulating the deterministic outputs of flow-matching TTS into probabilistic Gaussian distributions, our approach enables seamless integration of reinforcement learning algorithms. During pretraining, we train a probabilistically reformulated flow-matching based model which is derived from F5-TTS with an open-source dataset. In the subsequent reinforcement learning (RL) phase, we employ a GRPO-driven enhancement stage that leverages dual reward metrics: word error rate (WER) computed via automatic speech recognition and speaker similarity (SIM) assessed by verification models. Experimental results on zero-shot voice cloning demonstrate that F5R-TTS achieves significant improvements in both speech intelligibility (relatively 29.5% WER reduction) and speaker similarity (relatively 4.6% SIM score increase) compared to conventional flow-matching based TTS systems. Audio samples are available at https://frontierlabs.github.io/F5R.
我们提出了F5R-TTS,这是一种新型文本到语音(TTS)系统,它将梯度奖励策略优化(GRPO)集成到基于流匹配的架构中。通过将以流匹配TTS产生的确定性输出重新表述为概率高斯分布,我们的方法能够实现强化学习算法的无缝集成。在预训练阶段,我们使用开源数据集对基于概率重新表述的流匹配模型进行训练,该模型由F5-TTS派生而来。在随后的强化学习(RL)阶段,我们采用GRPO驱动的增强阶段,利用双重奖励指标:通过自动语音识别计算的词错误率(WER)和通过验证模型评估的说话人相似性(SIM)。在零样本声音克隆方面的实验结果表明,F5R-TTS在语音清晰度方面实现了显著改进(相对降低了29.5%的WER),并且在说话人相似性方面也有相对提升(SIM得分相对增加4.6%),相较于传统的基于流匹配的TTS系统。音频样本可在https://frontierlabs.github.io/F5R获取。
论文及项目相关链接
Summary
F5R-TTS是一个结合梯度奖励策略优化(GRPO)的流式匹配文本转语音(TTS)系统。它通过概率化改革流式匹配TTS的确定性输出,实现了强化学习算法的无缝集成。在预训练阶段,使用概率化改革后的流式匹配模型进行训练,该模型基于开源数据集从F5-TTS衍生而来。在后续的强化学习阶段,采用GRPO驱动的增强阶段,利用双重奖励指标:通过自动语音识别计算的字错误率(WER)和通过验证模型评估的说话人相似性(SIM)。在零样本声音克隆的实验结果中,F5R-TTS在语音清晰度上实现了显著的改进(相对降低了29.5%的WER),并且在说话人相似性上也有相对的提升(SIM得分增加了4.6%),相较于传统的流式匹配TTS系统。
Key Takeaways
- F5R-TTS是一个新型的文本转语音(TTS)系统,结合了梯度奖励策略优化(GRPO)。
- 系统通过概率化改革流式匹配TTS的确定性输出,便于集成强化学习算法。
- 在预训练阶段,使用了概率化改革后的流式匹配模型,该模型基于F5-TTS并采用了开源数据集。
- 强化学习阶段采用GRPO驱动增强阶段,并使用了双重奖励指标:字错误率(WER)和说话人相似性(SIM)。
- F5R-TTS在零样本声音克隆的实验中表现出色,显著提高了语音清晰度和说话人相似性。
- F5R-TTS相对于传统的流式匹配TTS系统有明显的性能提升。
点此查看论文截图