⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-05 更新
Charm: The Missing Piece in ViT fine-tuning for Image Aesthetic Assessment
Authors:Fatemeh Behrad, Tinne Tuytelaars, Johan Wagemans
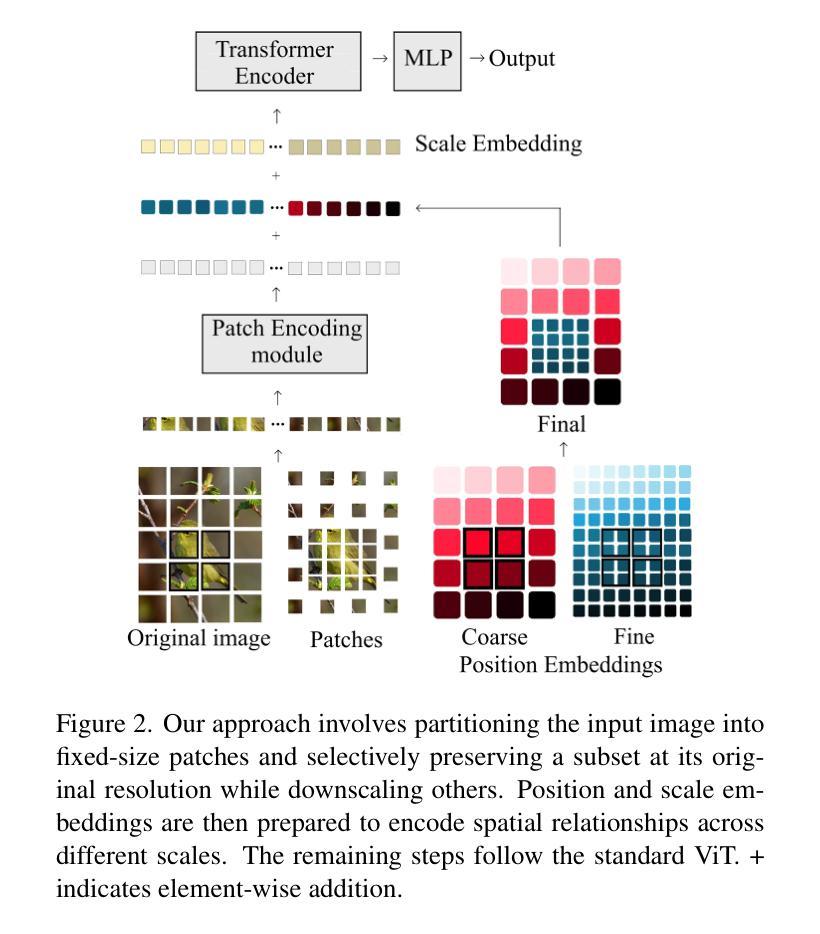
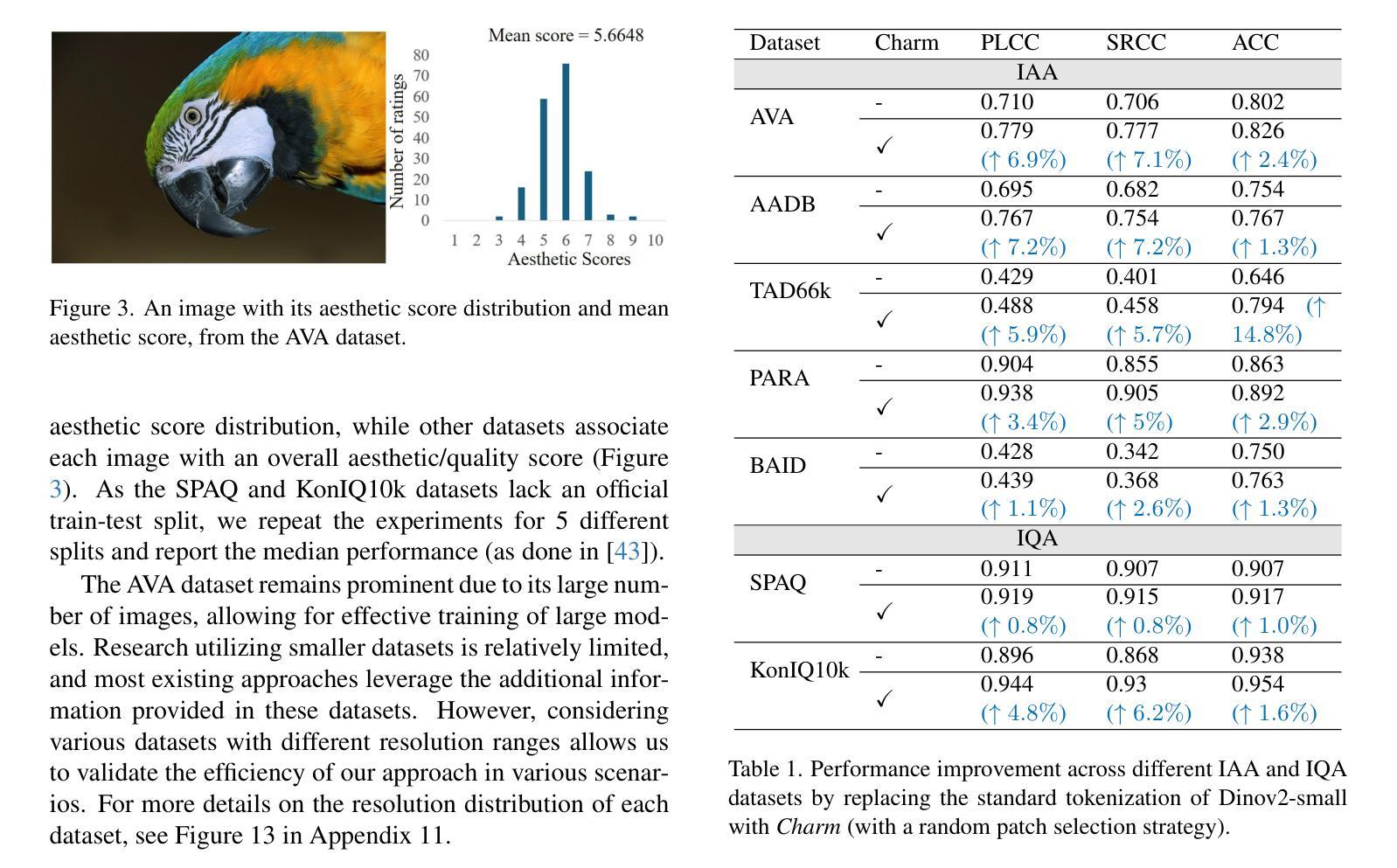
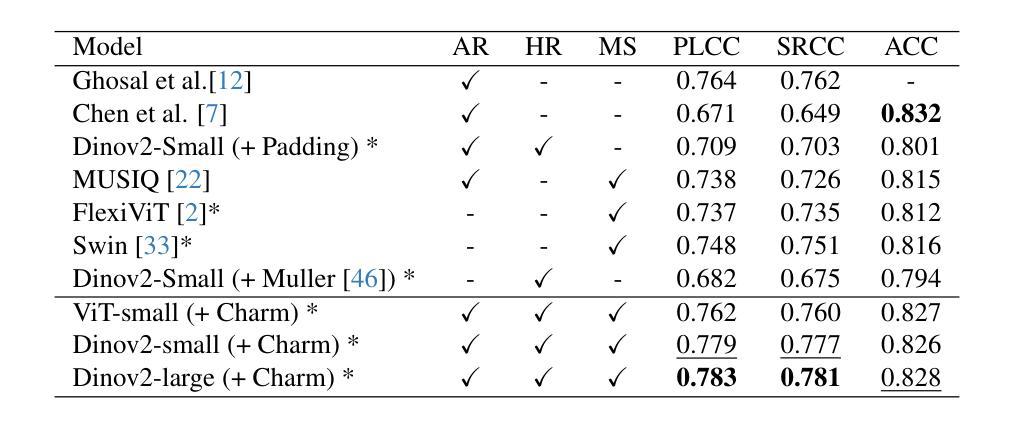
The capacity of Vision transformers (ViTs) to handle variable-sized inputs is often constrained by computational complexity and batch processing limitations. Consequently, ViTs are typically trained on small, fixed-size images obtained through downscaling or cropping. While reducing computational burden, these methods result in significant information loss, negatively affecting tasks like image aesthetic assessment. We introduce Charm, a novel tokenization approach that preserves Composition, High-resolution, Aspect Ratio, and Multi-scale information simultaneously. Charm prioritizes high-resolution details in specific regions while downscaling others, enabling shorter fixed-size input sequences for ViTs while incorporating essential information. Charm is designed to be compatible with pre-trained ViTs and their learned positional embeddings. By providing multiscale input and introducing variety to input tokens, Charm improves ViT performance and generalizability for image aesthetic assessment. We avoid cropping or changing the aspect ratio to further preserve information. Extensive experiments demonstrate significant performance improvements on various image aesthetic and quality assessment datasets (up to 8.1 %) using a lightweight ViT backbone. Code and pre-trained models are available at https://github.com/FBehrad/Charm.
视觉转换器(ViT)处理可变大小输入的能力通常受到计算复杂性和批处理限制的制约。因此,ViT通常在对通过缩小或裁剪获得的小而固定大小的图像上进行训练。虽然这些方法减轻了计算负担,但它们导致了信息的大量损失,对图像美学评估等任务产生了负面影响。我们引入了Charm,这是一种新型令牌化方法,可以同时保留组合、高分辨率、纵横比和多尺度信息。Charm优先处理特定区域的高分辨率细节,同时缩小其他区域,使ViT能够处理较短的固定大小输入序列,同时融入重要信息。Charm的设计旨在与预训练的ViT及其学习的位置嵌入兼容。通过提供多尺度输入并为输入令牌引入多样性,Charm提高了ViT在图像美学评估方面的性能和通用性。我们避免裁剪或改变纵横比,以进一步保留信息。大量实验表明,在各种图像美学和质量评估数据集上,使用轻量级ViT主干,性能得到了显著提高(最高达8.1%)。代码和预训练模型可在https://github.com/FBehrad/Charm找到。
论文及项目相关链接
PDF CVPR 2025
Summary
ViT在处理可变大小输入时的能力受到计算复杂性和批量处理限制的制约。通常,ViT在通过缩小或裁剪获得的小尺寸图像上进行训练。虽然减轻了计算负担,但这些方法导致了信息的大量损失,对图像美学评估等任务产生了负面影响。本文提出了Charm,这是一种新的tokenization方法,可以同时保留组成、高分辨率、纵横比和多尺度信息。Charm优先保留特定区域的高分辨率细节,同时缩小其他区域,使ViT能够处理更短固定长度的输入序列,同时融入关键信息。Charm的设计旨在与预训练的ViT及其学习的位置嵌入兼容。通过提供多尺度输入并引入各种输入令牌,Charm提高了ViT在图像美学评估方面的性能和泛化能力。通过避免裁剪或改变纵横比,进一步保留了信息。大量实验表明,使用轻量级ViT主干,在各种图像美学和质量评估数据集上的性能得到了显著提高(最多提高8.1%)。
Key Takeaways
- Vision transformers (ViTs)面临处理可变大小输入的挑战,受到计算复杂性和批量处理限制的影响。
- 当前方法如缩小或裁剪虽减轻计算负担,但导致信息损失,影响图像美学评估等任务。
- 引入Charm,一种新的tokenization方法,能同时保留组成、高分辨率、纵横比和多尺度信息。
- Charm优先保留高分辨率细节,同时使ViT能够处理更短固定长度的输入序列。
- Charm与预训练的ViT及其位置嵌入兼容,提供多尺度输入,提高ViT性能和泛化能力。
- Charm通过避免裁剪或改变纵横比来进一步保留信息。
点此查看论文截图

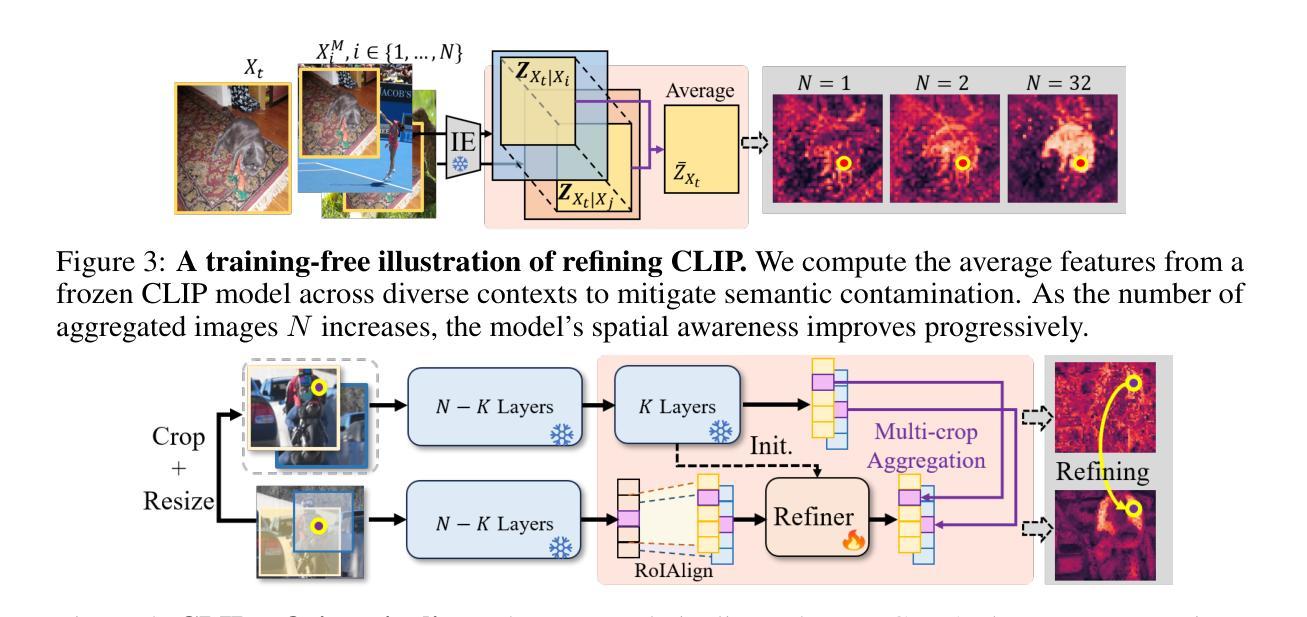
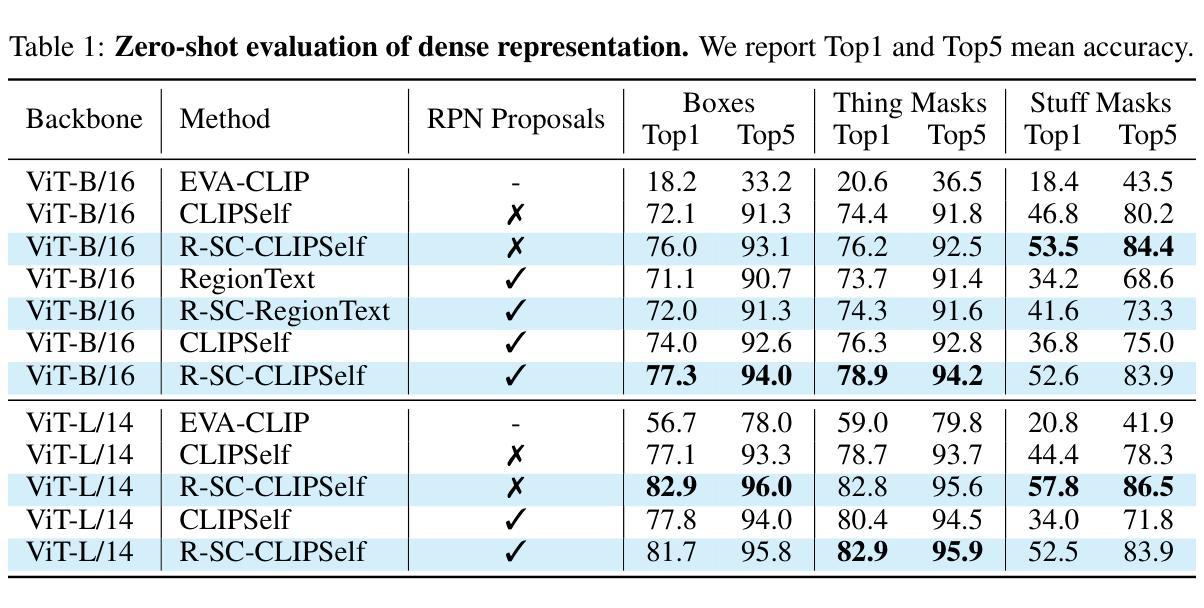
Refining CLIP’s Spatial Awareness: A Visual-Centric Perspective
Authors:Congpei Qiu, Yanhao Wu, Wei Ke, Xiuxiu Bai, Tong Zhang
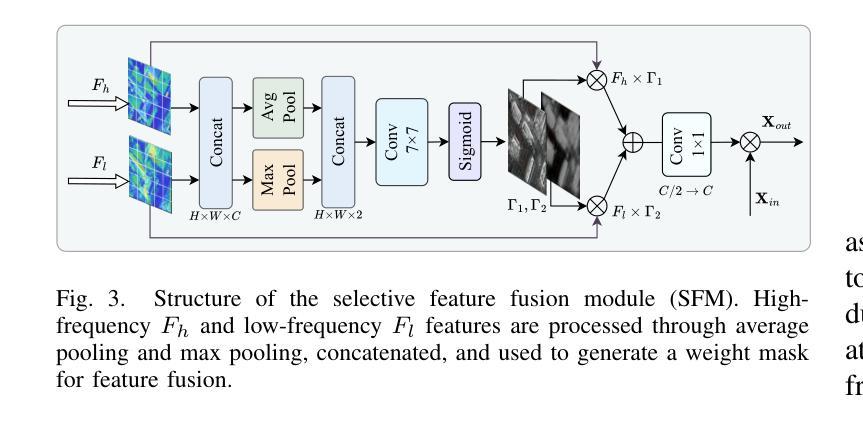
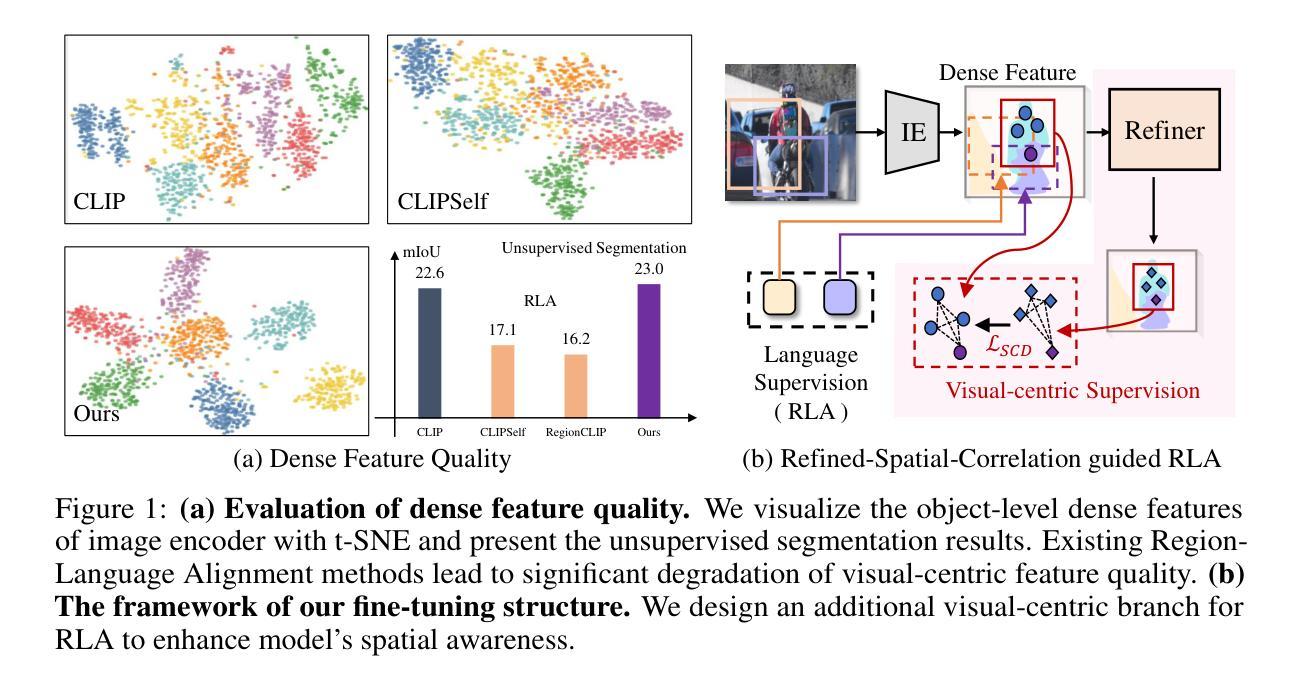
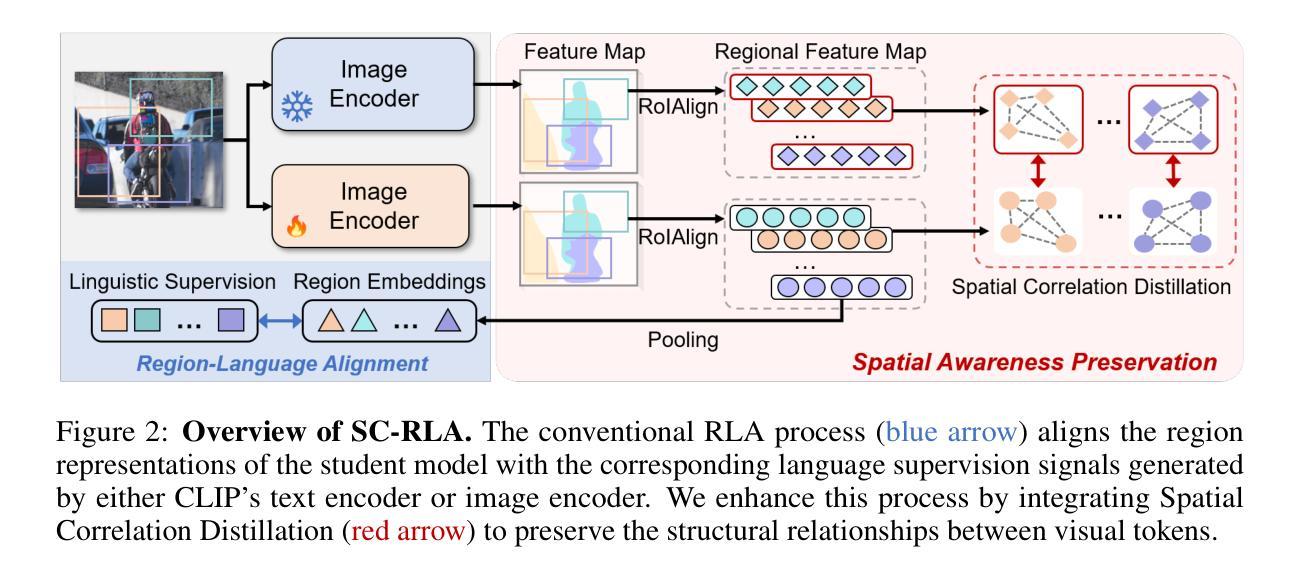
Contrastive Language-Image Pre-training (CLIP) excels in global alignment with language but exhibits limited sensitivity to spatial information, leading to strong performance in zero-shot classification tasks but underperformance in tasks requiring precise spatial understanding. Recent approaches have introduced Region-Language Alignment (RLA) to enhance CLIP’s performance in dense multimodal tasks by aligning regional visual representations with corresponding text inputs. However, we find that CLIP ViTs fine-tuned with RLA suffer from notable loss in spatial awareness, which is crucial for dense prediction tasks. To address this, we propose the Spatial Correlation Distillation (SCD) framework, which preserves CLIP’s inherent spatial structure and mitigates the above degradation. To further enhance spatial correlations, we introduce a lightweight Refiner that extracts refined correlations directly from CLIP before feeding them into SCD, based on an intriguing finding that CLIP naturally captures high-quality dense features. Together, these components form a robust distillation framework that enables CLIP ViTs to integrate both visual-language and visual-centric improvements, achieving state-of-the-art results across various open-vocabulary dense prediction benchmarks.
对比语言图像预训练(CLIP)擅长全局语言对齐,但对空间信息的敏感度有限,导致其在零样本分类任务上表现优异,但在需要精确空间理解的任务上表现不佳。近期的方法引入了区域语言对齐(RLA)以增强CLIP在密集多模式任务中的性能,通过对齐区域视觉表示与相应的文本输入来实现。然而,我们发现使用RLA微调过的CLIP ViTs在空间感知方面存在明显的损失,这对于密集预测任务至关重要。为解决这一问题,我们提出了空间关联蒸馏(SCD)框架,它保留了CLIP的固有空间结构并减轻了上述退化问题。为了进一步增强空间关联性,我们基于一个有趣发现——即CLIP能自然捕捉高质量密集特征——在将其送入SCD之前,引入了一个轻量级的精炼器来直接提取精炼后的关联性。这些组件共同形成了一个稳健的蒸馏框架,使CLIP ViTs能够同时融入视觉语言和视觉中心改进,在多个开放词汇密集预测基准测试中实现了最新结果。
论文及项目相关链接
PDF ICLR 2025
Summary
CLIP模型在全局语言对齐方面表现出色,但在空间信息敏感性上有所局限,导致在需要精确空间理解的任务上表现不佳。为提高CLIP在密集多模态任务中的性能,引入区域语言对齐(RLA)方法。然而,我们发现RLA微调后的CLIP ViTs在空间感知方面存在显著损失,这对于密集预测任务至关重要。为解决这一问题,我们提出空间关联蒸馏(SCD)框架,保留CLIP的内在空间结构并减轻上述退化问题。为进一步提高空间关联性,我们基于CLIP自然捕捉高质量密集特征的有趣发现,引入了一个轻量级的精炼器(Refiner),直接从CLIP中提取精炼后的关联并输入到SCD中。这些组件共同构成了一个强大的蒸馏框架,使CLIP ViTs能够结合视觉语言和视觉中心的改进,在各种开放词汇密集预测基准测试中达到最新水平。
Key Takeaways
- CLIP模型在全局语言对齐方面出色,但在空间信息敏感性上有限制。
- RLA方法被引入以提高CLIP在密集多模态任务中的性能。
- RLA微调后的CLIP ViTs在空间感知方面有显著损失。
- 提出空间关联蒸馏(SCD)框架以保留CLIP的内在空间结构并改善性能退化。
- 引入轻量级精炼器(Refiner)以提高空间关联性。
- CLIP自然捕捉高质量密集特征的有趣发现。
点此查看论文截图

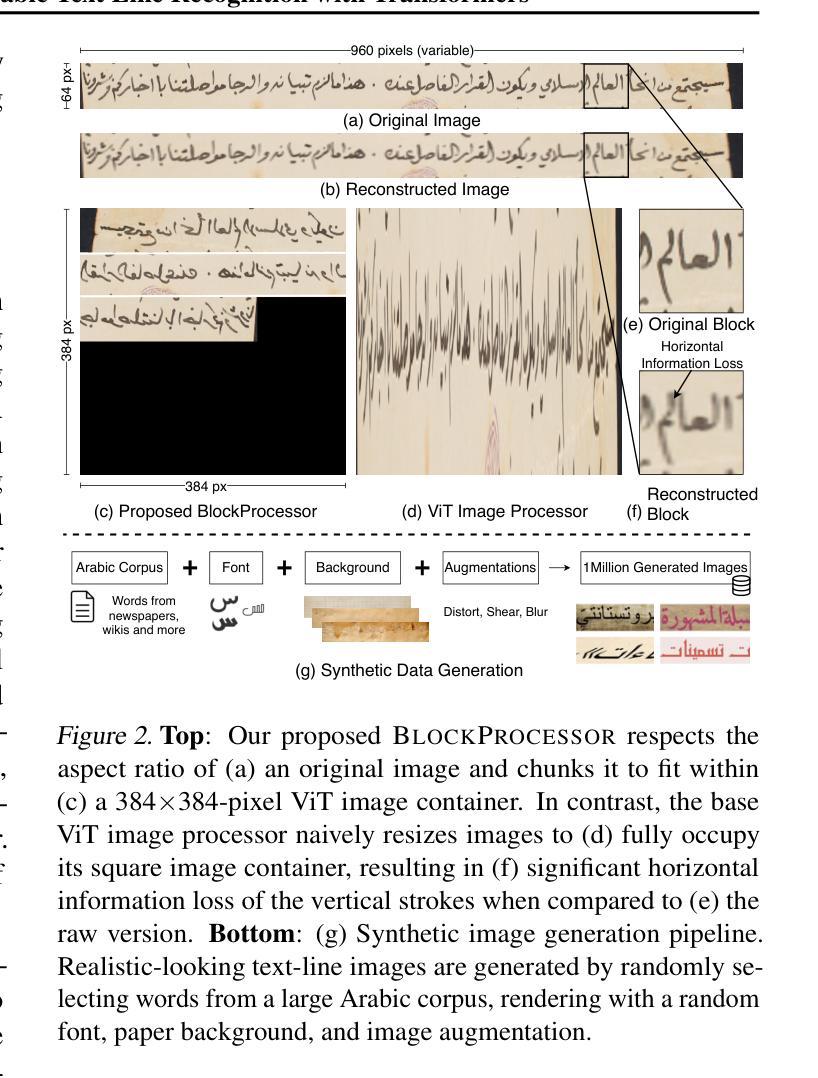
HATFormer: Historic Handwritten Arabic Text Recognition with Transformers
Authors:Adrian Chan, Anupam Mijar, Mehreen Saeed, Chau-Wai Wong, Akram Khater
Arabic handwritten text recognition (HTR) is challenging, especially for historical texts, due to diverse writing styles and the intrinsic features of Arabic script. Additionally, Arabic handwriting datasets are smaller compared to English ones, making it difficult to train generalizable Arabic HTR models. To address these challenges, we propose HATFormer, a transformer-based encoder-decoder architecture that builds on a state-of-the-art English HTR model. By leveraging the transformer’s attention mechanism, HATFormer captures spatial contextual information to address the intrinsic challenges of Arabic script through differentiating cursive characters, decomposing visual representations, and identifying diacritics. Our customization to historical handwritten Arabic includes an image processor for effective ViT information preprocessing, a text tokenizer for compact Arabic text representation, and a training pipeline that accounts for a limited amount of historic Arabic handwriting data. HATFormer achieves a character error rate (CER) of 8.6% on the largest public historical handwritten Arabic dataset, with a 51% improvement over the best baseline in the literature. HATFormer also attains a comparable CER of 4.2% on the largest private non-historical dataset. Our work demonstrates the feasibility of adapting an English HTR method to a low-resource language with complex, language-specific challenges, contributing to advancements in document digitization, information retrieval, and cultural preservation.
阿拉伯手写文本识别(HTR)是一项具有挑战性的任务,尤其是对历史文本而言,其原因在于写作风格的多样性和阿拉伯文脚本的内在特征。此外,与英文手写数据集相比,阿拉伯文手写数据集较小,这使得训练通用阿拉伯文HTR模型更加困难。为了解决这些挑战,我们提出了HATFormer,这是一种基于transformer的编码器-解码器架构,它建立在最先进的英文HTR模型之上。通过利用transformer的注意力机制,HATFormer捕获空间上下文信息,通过区分连笔字符、分解视觉表征和识别变音符号来解决阿拉伯文脚本的内在挑战。我们对历史手写阿拉伯文的定制包括用于有效ViT信息预处理的图像处理器、用于紧凑阿拉伯文本表示的文本标记器,以及考虑到有限的历史阿拉伯手写数据量的训练管道。HATFormer在最大的公共历史手写阿拉伯数据集上实现了8.6%的字符错误率(CER),比文献中的最佳基线模型改进了51%。HATFormer在最大的私有非历史数据集上也达到了可比的4.2%的CER。我们的工作证明了将英文HTR方法适应于资源匮乏的语言(具有特定语言的复杂挑战)的可行性,为文档数字化、信息检索和文化保存的进步做出了贡献。
论文及项目相关链接
Summary
阿拉伯手写文本识别(HTR)具有挑战性,尤其是历史文本,因为存在多种书写风格和阿拉伯文字本身的特性。此外,阿拉伯手写数据集比英文数据集小,难以训练通用的阿拉伯HTR模型。为应对这些挑战,我们提出基于transformer的编码器-解码器架构的HATFormer模型,该模型建立在先进的英文HTR模型之上。通过利用transformer的注意力机制,HATFormer捕获空间上下文信息,解决阿拉伯文字本身的挑战,包括区分连笔字符、分解视觉表征和识别变音符。我们对历史手写阿拉伯文的定制包括有效的ViT信息预处理图像处理器、紧凑的阿拉伯文本表示文本标记器,以及考虑到有限的历史阿拉伯手写数据的训练管道。在最大的公共历史手写阿拉伯数据集上,HATFormer实现了8.6%的字符错误率(CER),较文献中的最佳基线改进了51%。在非历史数据集上,它也能达到相当不错的4.2%的CER。我们的工作证明了将英文HTR方法适应于资源匮乏且语言特定挑战复杂的语言是可行的,为文档数字化、信息检索和文化保存领域做出了贡献。
Key Takeaways
- 阿拉伯手写文本识别(HTR)面临多样书写风格和阿拉伯文字特性的挑战。
- 阿拉伯手写数据集相对较小,使得训练通用模型更具挑战性。
- HATFormer模型基于先进的英文HTR模型,利用transformer的注意力机制解决阿拉伯文字的挑战。
- HATFormer通过区分连笔字符、分解视觉表征和识别变音符来应对阿拉伯文字的特性。
- 为历史手写阿拉伯文定制了图像处理器、文本标记器和训练管道。
- 在公共历史手写阿拉伯数据集上,HATFormer实现了较低的字符错误率(CER)。
点此查看论文截图