⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-06 更新
TEMPLE:Temporal Preference Learning of Video LLMs via Difficulty Scheduling and Pre-SFT Alignment
Authors:Shicheng Li, Lei Li, Kun Ouyang, Shuhuai Ren, Yuanxin Liu, Yuanxing Zhang, Fuzheng Zhang, Lingpeng Kong, Qi Liu, Xu Sun
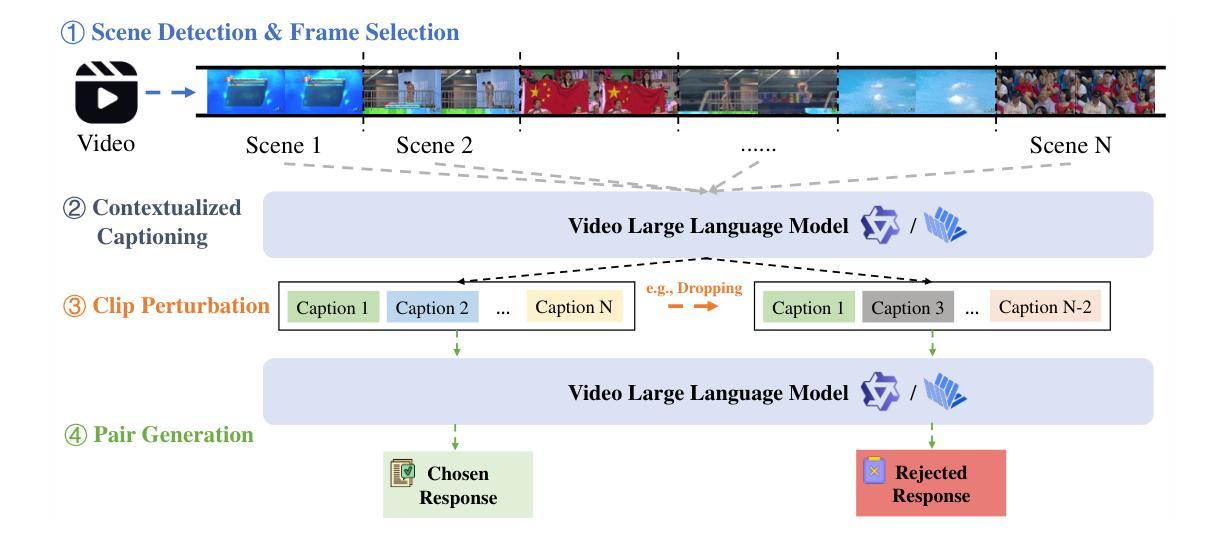
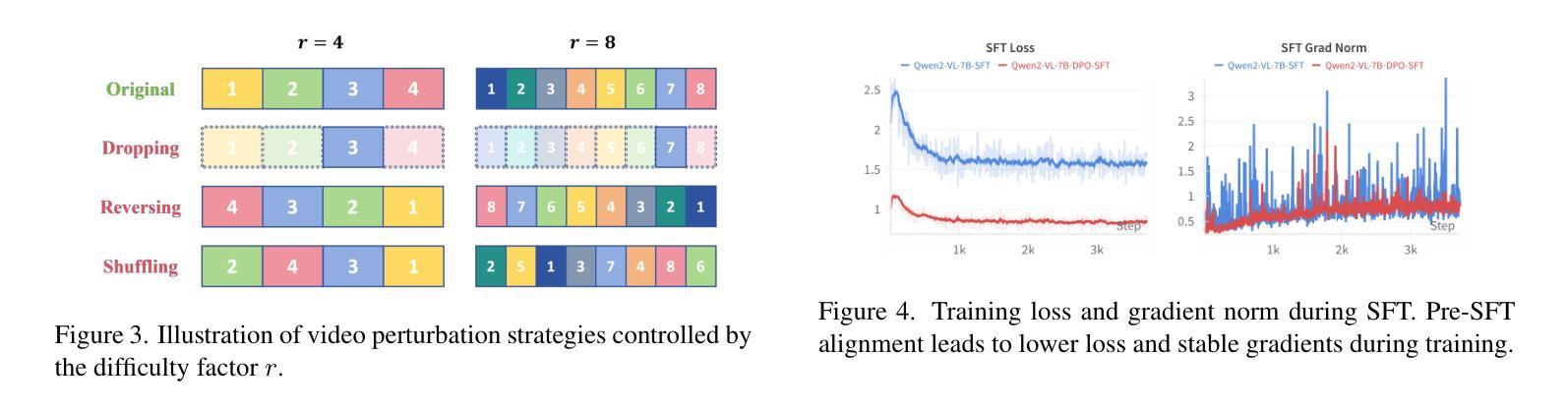
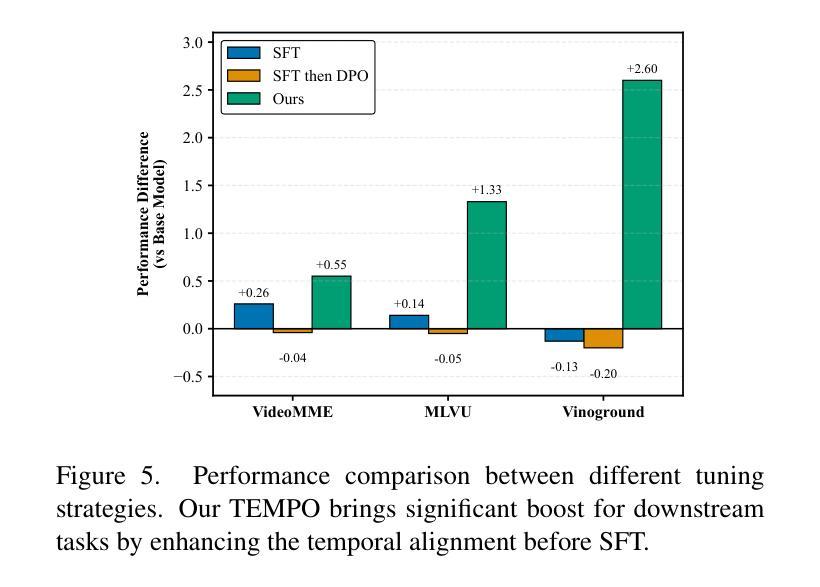
Video Large Language Models (Video LLMs) have achieved significant success by leveraging a two-stage paradigm: pretraining on large-scale video-text data for vision-language alignment, followed by supervised fine-tuning (SFT) for task-specific capabilities. However, existing approaches struggle with temporal reasoning due to weak temporal correspondence in the data and reliance on the next-token prediction paradigm during training. To address these limitations, we propose TEMPLE (TEMporal Preference Learning), a systematic framework that enhances Video LLMs’ temporal reasoning capabilities through Direct Preference Optimization (DPO). To facilitate this, we introduce an automated preference data generation pipeline that systematically constructs preference pairs by selecting videos that are rich in temporal information, designing video-specific perturbation strategies, and finally evaluating model responses on clean and perturbed video inputs. Our temporal alignment features two key innovations: curriculum learning which that progressively increases perturbation difficulty to improve model robustness and adaptability; and “Pre-SFT Alignment’’, applying preference optimization before instruction tuning to prioritize fine-grained temporal comprehension. Extensive experiments demonstrate that our approach consistently improves Video LLM performance across multiple benchmarks with a relatively small set of self-generated DPO data. We further analyze the transferability of DPO data across architectures and the role of difficulty scheduling in optimization. Our findings highlight our TEMPLE as a scalable and efficient complement to SFT-based methods, paving the way for developing reliable Video LLMs. Code is available at https://github.com/lscpku/TEMPLE.
视频大型语言模型(Video LLMs)通过利用两阶段范式取得了巨大成功:首先在大型视频文本数据上进行预训练,以实现视觉语言对齐,然后进行监督微调(SFT)以获取特定任务的能力。然而,现有方法由于数据中的时间对应关系较弱以及在训练过程中依赖于下一个标记预测范式,因此在时间推理方面遇到了困难。为了解决这些局限性,我们提出了TEMPLE(TEMPoral Preference Learning,时空偏好学习),这是一个通过直接偏好优化(DPO)增强视频LLM时间推理能力的系统框架。为实现这一目标,我们引入了一个自动化的偏好数据生成管道,通过选择富含时间信息的视频、设计针对视频的特殊扰动策略,以及评估模型对干净和扰动视频输入的响应来系统地构建偏好对。我们的时间对齐具有两个关键创新点:课程学习,通过逐渐增加扰动难度来提高模型的鲁棒性和适应性;以及“Pre-SFT对齐”,在指令调整之前应用偏好优化,以优先进行精细的时间理解。大量实验表明,我们的方法在使用相对少量的自我生成的DPO数据时,能够持续提高视频LLM在多个基准测试上的性能。我们进一步分析了DPO数据在不同架构之间的可迁移性以及难度调度在优化中的角色。我们的研究结果强调了我们的TEMPLE作为基于SFT的方法的可扩展和高效的补充,为开发可靠的视频LLM铺平了道路。代码可在https://github.com/lscpku/TEMPLE找到。
论文及项目相关链接
Summary
本文介绍了视频大型语言模型(Video LLMs)的现有挑战及其改进方法。针对现有模型在时序推理方面的不足,提出了TEMPLE框架,通过直接偏好优化(DPO)增强视频LLM的时序推理能力。该框架使用自动化偏好数据生成管道,通过选择富含时序信息的视频、设计视频特定扰动策略,以及评估模型对干净和扰动视频输入的响应来进行优化。其创新点包括课程学习和“Pre-SFT对齐”,逐步增加扰动难度以提高模型的稳健性和适应性,并在指令微调之前应用偏好优化,以优先进行精细的时序理解。实验表明,该方法在多个基准测试中提高了视频LLM的性能,且使用自生成的DPO数据的效率较高。
Key Takeaways
- Video LLMs采用两阶段范式:在大型视频文本数据上进行预训练以实现视觉语言对齐,然后通过有监督微调(SFT)获得特定任务能力。
- 现有方法面临时序推理的挑战,主要是由于数据中的时间对应关系较弱以及在训练过程中依赖于下一个令牌的预测范式。
- TEMPLE框架通过直接偏好优化(DPO)增强视频LLM的时序推理能力,解决了上述问题。
- TEMPLE引入了自动化偏好数据生成管道,通过选择富含时序信息的视频、设计特定的视频扰动策略来构建偏好对。
- TEMPLE包含两个关键创新:课程学习,逐步增加扰动难度以提高模型稳健性和适应性;以及Pre-SFT对齐,在指令微调之前应用偏好优化。
- 实验表明,TEMPLE方法能提高视频LLM在多个基准测试中的性能,且使用自生成的DPO数据的效率较高。
点此查看论文截图


Safety Evaluation and Enhancement of DeepSeek Models in Chinese Contexts
Authors:Wenjing Zhang, Xuejiao Lei, Zhaoxiang Liu, Limin Han, Jiaojiao Zhao, Beibei Huang, Zhenhong Long, Junting Guo, Meijuan An, Rongjia Du, Ning Wang, Kai Wang, Shiguo Lian
DeepSeek-R1, renowned for its exceptional reasoning capabilities and open-source strategy, is significantly influencing the global artificial intelligence landscape. However, it exhibits notable safety shortcomings. Recent research conducted by Robust Intelligence, a subsidiary of Cisco, in collaboration with the University of Pennsylvania, revealed that DeepSeek-R1 achieves a 100% attack success rate when processing harmful prompts. Furthermore, multiple security firms and research institutions have identified critical security vulnerabilities within the model. Although China Unicom has uncovered safety vulnerabilities of R1 in Chinese contexts, the safety capabilities of the remaining distilled models in the R1 series have not yet been comprehensively evaluated. To address this gap, this study utilizes the comprehensive Chinese safety benchmark CHiSafetyBench to conduct an in-depth safety evaluation of the DeepSeek-R1 series distilled models. The objective is to assess the safety capabilities of these models in Chinese contexts both before and after distillation, and to further elucidate the adverse effects of distillation on model safety. Building on these findings, we implement targeted safety enhancements for six distilled models. Evaluation results indicate that the enhanced models achieve significant improvements in safety while maintaining reasoning capabilities without notable degradation. We open-source the safety-enhanced models at https://github.com/UnicomAI/DeepSeek-R1-Distill-Safe/tree/main to serve as a valuable resource for future research and optimization of DeepSeek models.
DeepSeek-R1以其出色的推理能力和开源策略而闻名,正在全球人工智能领域产生重大影响。然而,它存在明显的安全缺陷。最近,思科子公司Robust Intelligence与宾夕法尼亚大学合作进行的研究显示,DeepSeek-R1在处理有害提示时达到了100%的攻击成功率。此外,多家安全公司和研究机构已发现该模型中存在关键的安全漏洞。虽然中国联通已在中国背景下发现了R1的安全漏洞,但R1系列中剩余蒸馏模型的安全能力尚未进行全面评估。为了解决这一空白,本研究采用全面的中文安全基准CHiSafetyBench对DeepSeek-R1系列蒸馏模型进行深入的安全评估。我们的目标是评估这些模型在中国背景下的蒸馏前后的安全能力,并进一步阐明蒸馏对模型安全的负面影响。基于这些发现,我们对六种蒸馏模型进行了有针对性的安全增强。评估结果表明,增强型模型在安全方面取得了显著改进,同时保持了推理能力,没有明显退化。我们将开源增强型模型:https://github.com/UnicomAI/DeepSeek-R1-Distill-Safe/tree/main,以供未来研究和优化DeepSeek模型时作为有价值的资源。
论文及项目相关链接
PDF 21 pages,13 figures
Summary
深度搜索R1以其出色的推理能力和开源策略而闻名,正在全球人工智能领域产生重大影响。然而,它存在显著的安全缺陷。最近的研究表明,深度搜索R1在处理有害提示时达到了100%的攻击成功率。尽管中国联通常已发现其在中文环境中的安全漏洞,但对R1系列其余蒸馏模型的安全能力尚未进行全面评估。本研究使用全面的中文安全基准CHiSafetyBench对深度搜索R1系列蒸馏模型进行深入的安全评估。目标是评估这些模型在蒸馏前后的中文环境下的安全能力,并进一步阐明蒸馏对模型安全的负面影响。基于这些发现,我们对六种蒸馏模型进行了有针对性的安全增强。评估结果表明,增强型模型在安全方面取得了显著改进,同时保持推理能力无明显下降。我们在https://github.com/UnicomAI/DeepSeek-R1-Distill-Safe/tree/main公开了安全增强的模型,为DeepSeek模型的未来研究和优化提供宝贵资源。
Key Takeaways
- 深度搜索R1在人工智能领域具有显著影响,但存在严重的安全漏洞。
- 最新研究发现深度搜索R1在处理有害提示时攻击成功率为100%。
- 中国联通常已发现深度搜索R1在中文环境中的安全漏洞。
- 研究使用CHiSafetyBench对深度搜索R1系列蒸馏模型进行安全评估。
- 评估目的是了解这些模型在蒸馏前后的中文环境下的安全能力。
- 研究发现蒸馏过程对模型安全有负面影响。
点此查看论文截图

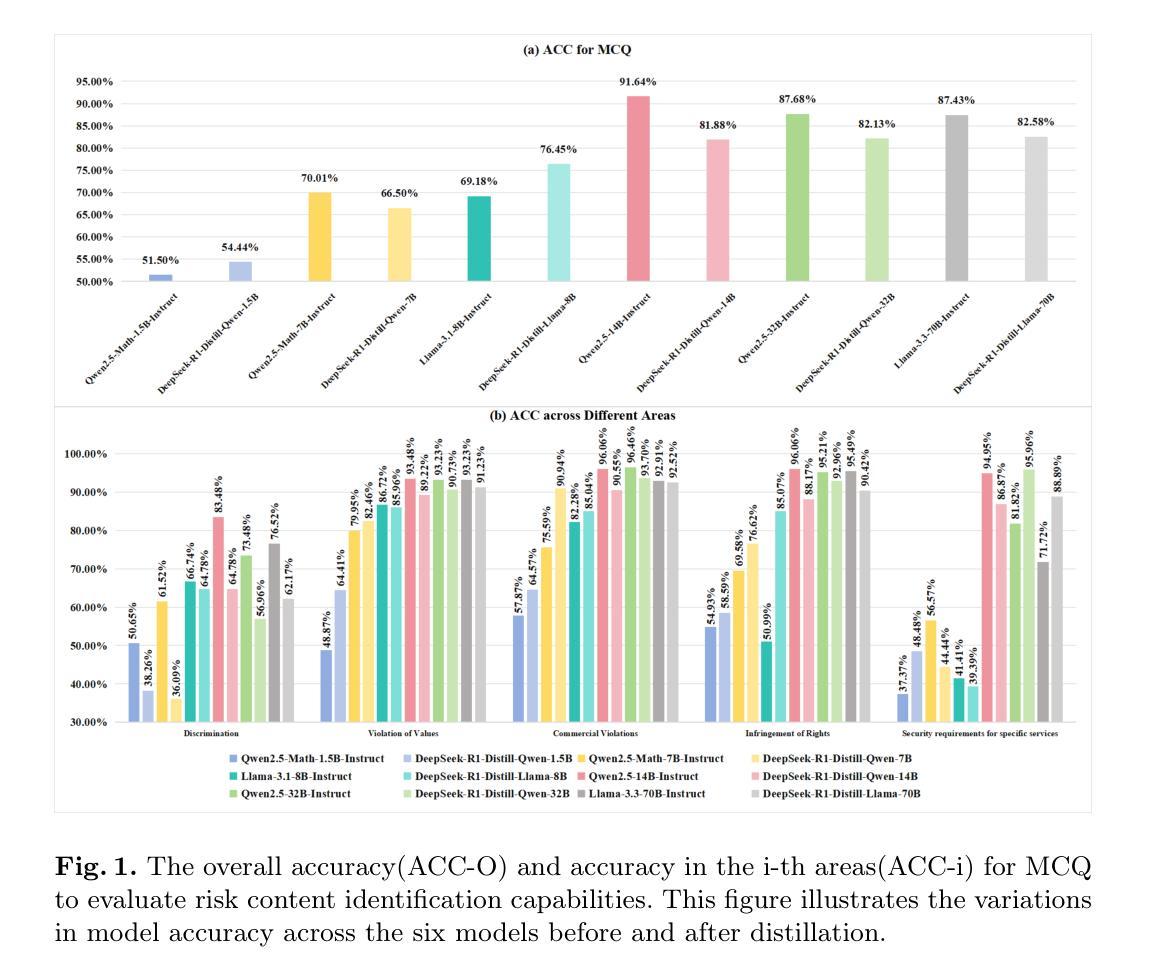
Think or Not Think: A Study of Explicit Thinking inRule-Based Visual Reinforcement Fine-Tuning
Authors:Ming Li, Jike Zhong, Shitian Zhao, Yuxiang Lai, Kaipeng Zhang
This paper investigates rule-based reinforcement learning (RL) fine-tuning for visual classification using multi-modal large language models (MLLMs) and the role of the thinking process. We begin by exploring \textit{CLS-RL}, a method that leverages verifiable signals as rewards to encourage MLLMs to ‘think’ before classifying. Our experiments across \textbf{eleven} datasets demonstrate that CLS-RL achieves significant improvements over supervised fine-tuning (SFT) in both base-to-new generalization and few-shot learning scenarios. Notably, we observe a ‘free-lunch’ phenomenon where fine-tuning on one dataset unexpectedly enhances performance on others, suggesting that RL effectively teaches fundamental classification skills. However, we question whether the explicit thinking, a critical aspect of rule-based RL, is always beneficial or indispensable. Challenging the conventional assumption that complex reasoning enhances performance, we introduce \textit{No-Thinking-RL}, a novel approach that minimizes the model’s thinking during fine-tuning by utilizing an equality accuracy reward. Our experiments reveal that No-Thinking-RL achieves superior in-domain performance and generalization capabilities compared to CLS-RL, while requiring significantly less fine-tuning time. This underscores that, contrary to prevailing assumptions, reducing the thinking process can lead to more efficient and effective MLLM fine-tuning for some visual tasks. Furthermore, No-Thinking-RL demonstrates enhanced performance on other visual benchmarks, such as a 6.4% improvement on CVBench. We hope our findings provides insights into the impact of thinking in RL-based fine-tuning.
本文探讨了基于规则的强化学习(RL)在利用多模态大型语言模型(MLLMs)进行视觉分类的微调技术,以及思考过程的作用。首先,我们探讨了CLS-RL方法,该方法利用可验证信号作为奖励来鼓励MLLM在分类之前进行“思考”。我们的实验结果显示,在十一个数据集上,CLS-RL在基础到新的泛化和少样本学习场景中均显著优于监督微调(SFT)。值得注意的是,我们观察到了一种“免费午餐”现象,即在某个数据集上进行微调会意外地提高其他数据集的性能,这表明强化学习有效地传授了基本的分类技能。然而,我们对基于规则的强化学习中明确的思考是否总是有益或不可或缺持怀疑态度。我们挑战了传统假设——复杂推理能提高性能,并引入了一种新型方法No-Thinking-RL。它通过采用平等精度奖励来最小化模型在微调过程中的思考。实验表明,No-Thinking-RL与CLS-RL相比,在领域内部性能和泛化能力上表现出优势,且需要更短的微调时间。这强调了一个事实:与普遍假设相反,减少思考过程可以针对某些视觉任务实现更高效、更有效的MLLM微调。此外,No-Thinking-RL在其他视觉基准测试中表现出卓越的性能,如在CVBench上的改进达到6.4%。我们希望这些发现能为基于RL的微调中的思考影响提供见解。
论文及项目相关链接
PDF Preprint, work in progress. Add results on CVBench
Summary
本文探讨了基于规则的强化学习(RL)在多模态大型语言模型(MLLMs)的视觉分类任务中的微调方法,并研究了思考过程的作用。文章介绍了CLS-RL方法,该方法利用可验证信号作为奖励来鼓励MLLMs在分类之前进行“思考”。实验结果显示,CLS-RL在基础到新的泛化和少样本学习场景中均显著优于监督微调(SFT)。此外,文章还观察到一种“免费午餐”现象,即在一个数据集上进行微调会意外地提高在其他数据集上的性能,表明RL实际上教会了模型基本的分类技能。然而,文章也质疑明确的思考过程是否总是有益或必不可少。为此,文章提出了一种新型的无思考强化学习(No-Thinking-RL)方法,通过平等精度奖励来最小化模型的思考过程。实验结果表明,No-Thinking-RL在域内性能和泛化能力上优于CLS-RL,且微调时间大大减少。这表明在某些视觉任务中,减少思考过程可能导致更有效率且效果更好的MLLM微调。
Key Takeaways
- 论文探讨了基于规则的强化学习在多模态大型语言模型的视觉分类任务中的微调方法。
- CLS-RL方法利用可验证信号作为奖励来鼓励模型在分类前“思考”,并在多个数据集上实现了显著的性能提升。
- 观察到一种“免费午餐”现象,即在一个数据集上的微调能提高在其他数据集上的性能,表明强化学习教会了模型基本的分类技能。
- 论文质疑明确的思考过程是否总是有益或必不可少,并引入了No-Thinking-RL方法。
- No-Thinking-RL通过最小化模型的思考过程,实现了优于CLS-RL的域内性能和泛化能力,同时减少了微调时间。
- 减少思考过程在某些视觉任务中可能导致更有效率且效果更好的MLLM微调。
点此查看论文截图

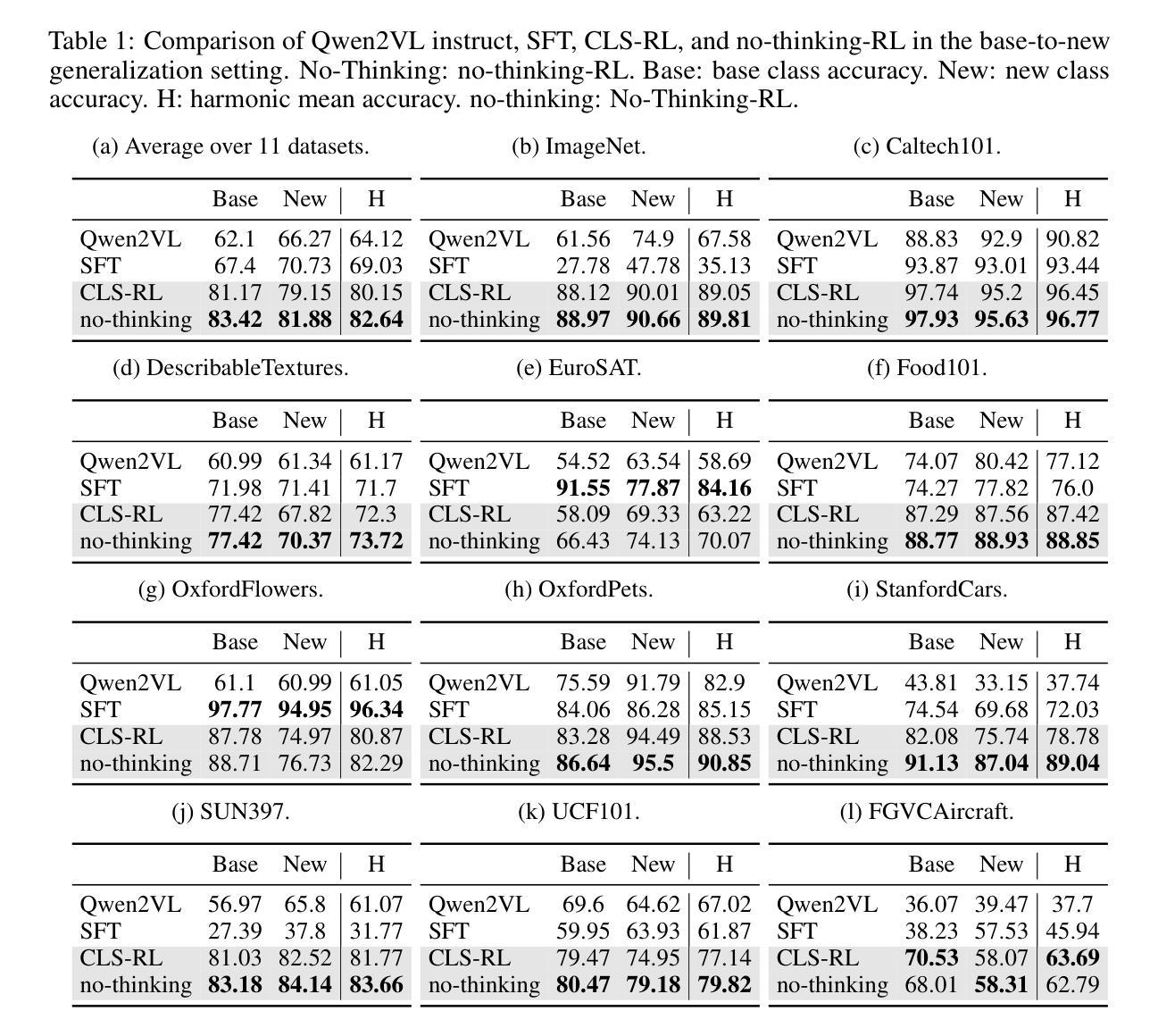
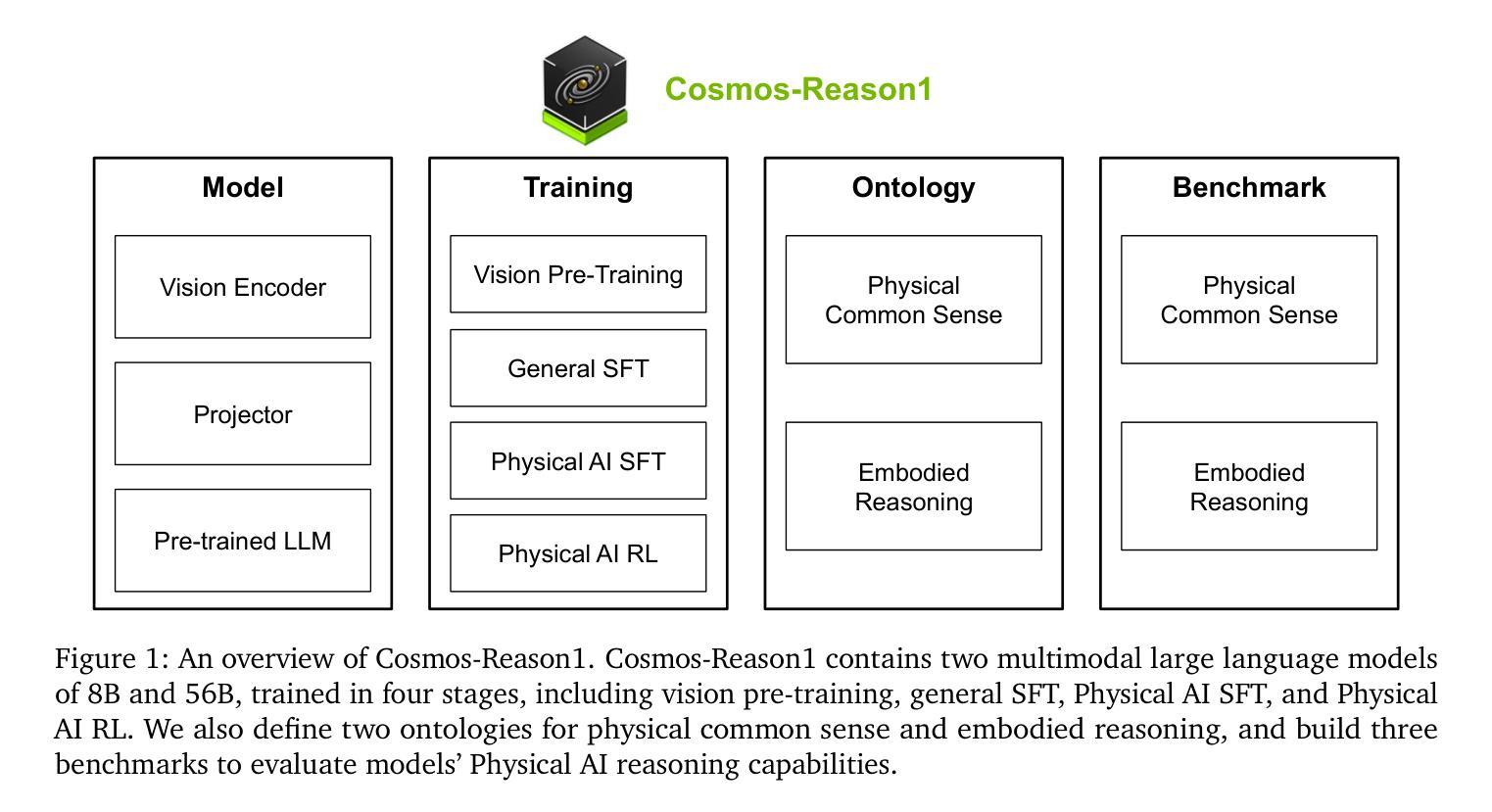
Cosmos-Reason1: From Physical Common Sense To Embodied Reasoning
Authors: NVIDIA, :, Alisson Azzolini, Hannah Brandon, Prithvijit Chattopadhyay, Huayu Chen, Jinju Chu, Yin Cui, Jenna Diamond, Yifan Ding, Francesco Ferroni, Rama Govindaraju, Jinwei Gu, Siddharth Gururani, Imad El Hanafi, Zekun Hao, Jacob Huffman, Jingyi Jin, Brendan Johnson, Rizwan Khan, George Kurian, Elena Lantz, Nayeon Lee, Zhaoshuo Li, Xuan Li, Tsung-Yi Lin, Yen-Chen Lin, Ming-Yu Liu, Alice Luo, Andrew Mathau, Yun Ni, Lindsey Pavao, Wei Ping, David W. Romero, Misha Smelyanskiy, Shuran Song, Lyne Tchapmi, Andrew Z. Wang, Boxin Wang, Haoxiang Wang, Fangyin Wei, Jiashu Xu, Yao Xu, Xiaodong Yang, Zhuolin Yang, Xiaohui Zeng, Zhe Zhang
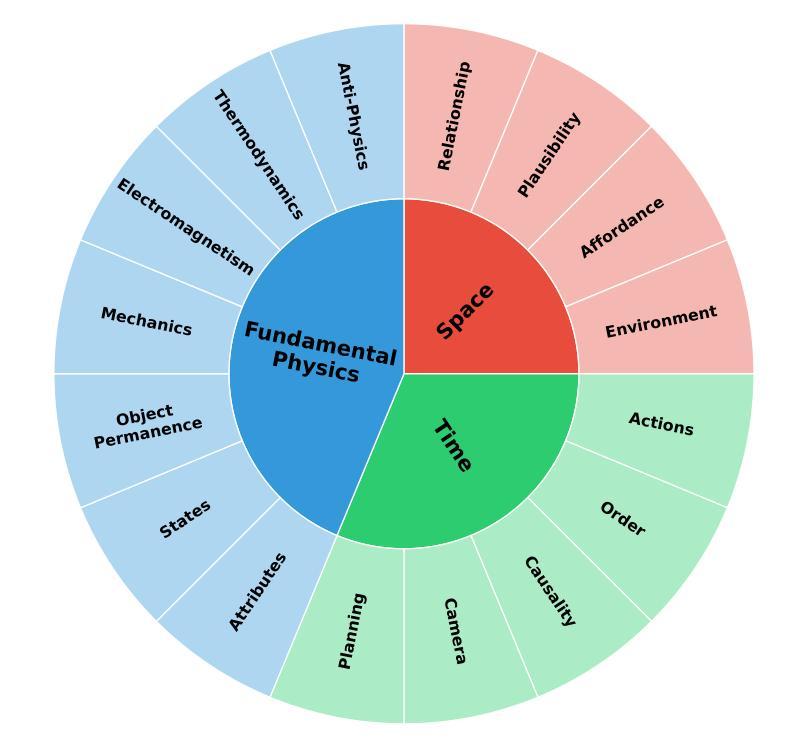
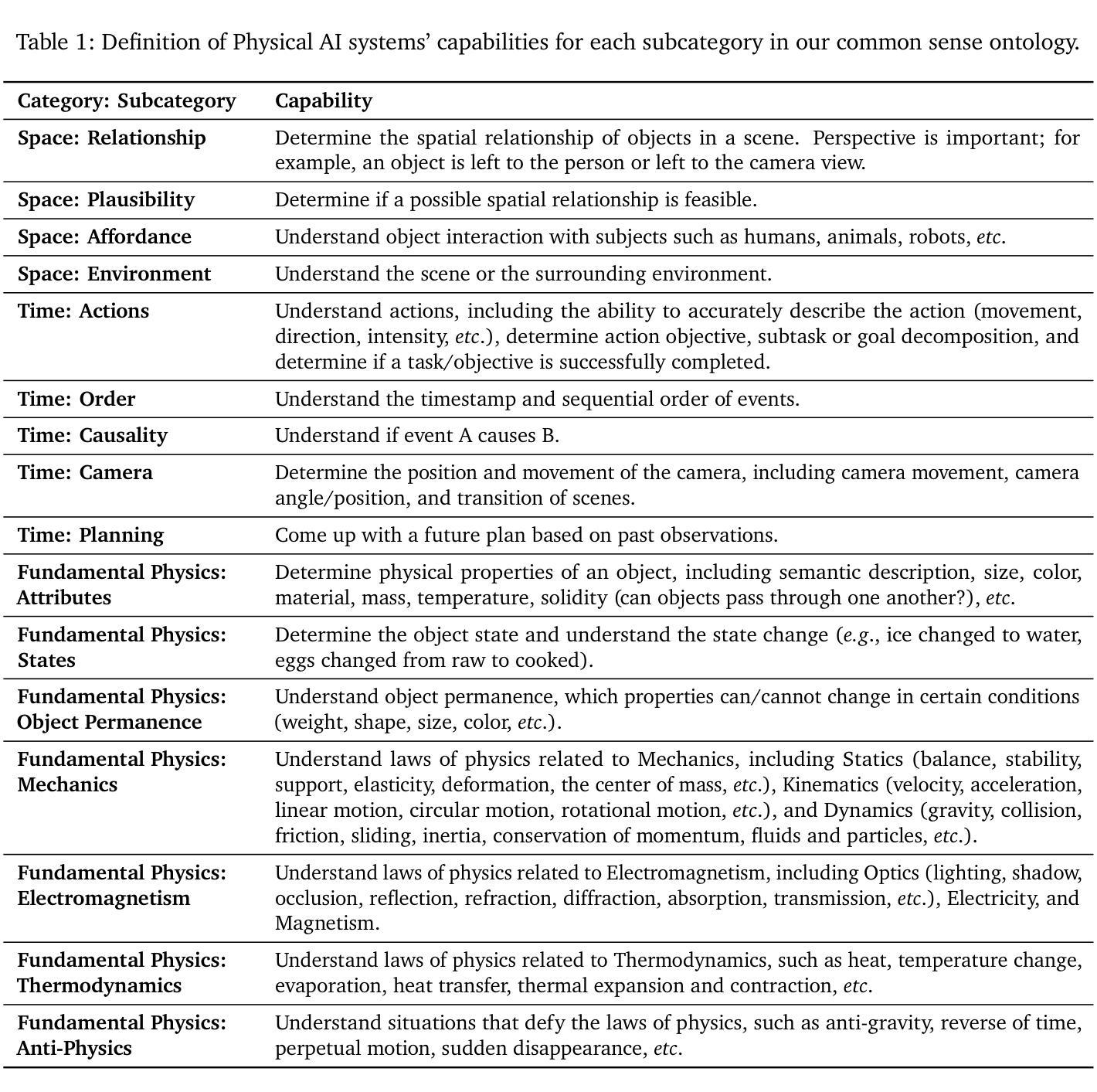
Physical AI systems need to perceive, understand, and perform complex actions in the physical world. In this paper, we present the Cosmos-Reason1 models that can understand the physical world and generate appropriate embodied decisions (e.g., next step action) in natural language through long chain-of-thought reasoning processes. We begin by defining key capabilities for Physical AI reasoning, with a focus on physical common sense and embodied reasoning. To represent physical common sense, we use a hierarchical ontology that captures fundamental knowledge about space, time, and physics. For embodied reasoning, we rely on a two-dimensional ontology that generalizes across different physical embodiments. Building on these capabilities, we develop two multimodal large language models, Cosmos-Reason1-8B and Cosmos-Reason1-56B. We curate data and train our models in four stages: vision pre-training, general supervised fine-tuning (SFT), Physical AI SFT, and Physical AI reinforcement learning (RL) as the post-training. To evaluate our models, we build comprehensive benchmarks for physical common sense and embodied reasoning according to our ontologies. Evaluation results show that Physical AI SFT and reinforcement learning bring significant improvements. To facilitate the development of Physical AI, we will make our code and pre-trained models available under the NVIDIA Open Model License at https://github.com/nvidia-cosmos/cosmos-reason1.
物理人工智能系统需要在物理世界中感知、理解和执行复杂的动作。在本文中,我们提出了Cosmos-Reason1模型,该模型能够通过一系列深入的思考过程理解物理世界,并以自然语言的形式做出适当的实体决策(例如,下一步行动)。我们首先定义物理人工智能推理的关键能力,重点关注物理常识和实体推理。为了表示物理常识,我们使用层次本体论来捕捉关于空间、时间和物理学的基本知识。对于实体推理,我们依赖于一个二维本体论,该本体论可以概括不同的物理实体。基于这些能力,我们开发了两个多模态大型语言模型,即Cosmos-Reason1-8B和Cosmos-Reason1-56B。我们整理数据并在四个阶段训练我们的模型:视觉预训练、一般监督微调(SFT)、物理人工智能SFT和物理人工智能强化学习(RL)作为后训练。为了评估我们的模型,我们根据我们的本体论建立了物理常识和实体推理的综合基准测试。评估结果表明,物理人工智能SFT和强化学习带来了显著的改进。为了促进物理人工智能的发展,我们将在NVIDIA Open Model License下提供我们的代码和预训练模型,地址是:https://github.com/nvidia-cosmos/cosmos-reason1。
论文及项目相关链接
Summary
本文介绍了Cosmos-Reason1模型,该模型能够理解物理世界并生成相应的具体决策。它聚焦于物理常识和实体推理,使用分层本体论来表示物理常识,并依赖二维本体论进行实体推理。该模型通过四个阶段进行训练和开发,包括视觉预训练、一般监督微调、物理AI监督和物理AI强化学习。评估和实验结果表明,物理AI监督和强化学习带来了显著改进。
Key Takeaways
- Cosmos-Reason1模型能理解物理世界并生成具体决策。
- 模型聚焦于物理常识和实体推理。
- 使用分层本体论和二维本体论进行知识表示。
- 模型经过四个阶段进行训练和开发,包括视觉预训练、一般监督微调、物理AI监督和物理AI强化学习。
- 评估和实验显示,物理AI监督和强化学习对模型性能有显著提升。
- 模型可应用于多种场景,如机器人导航、自动驾驶等。
点此查看论文截图


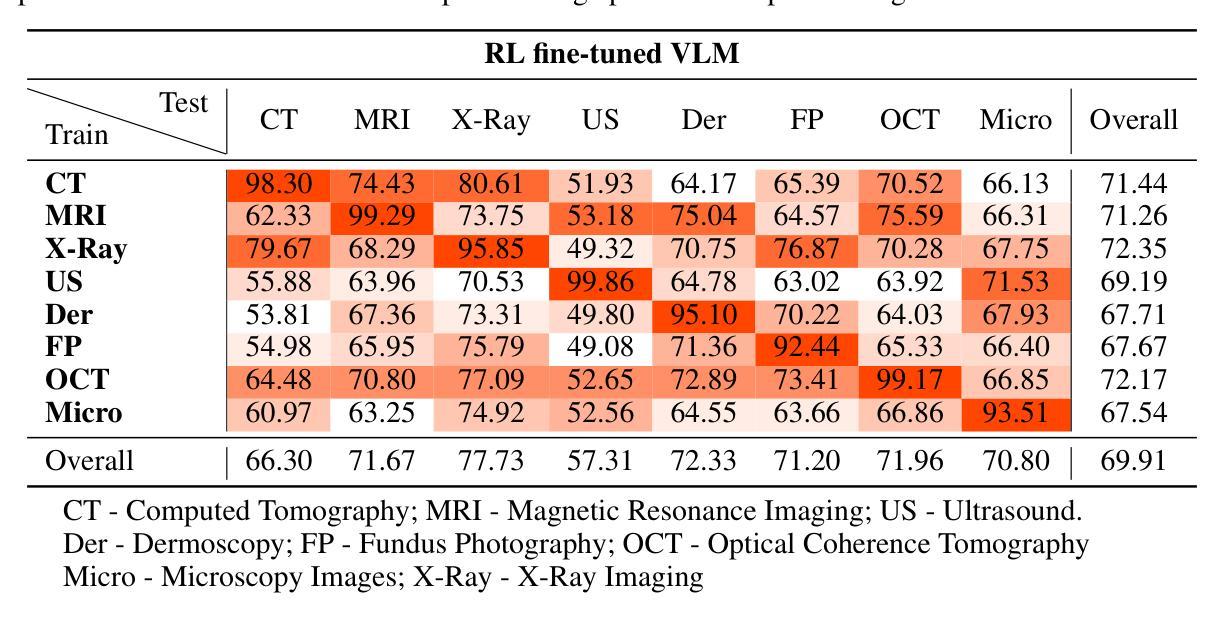
Med-R1: Reinforcement Learning for Generalizable Medical Reasoning in Vision-Language Models
Authors:Yuxiang Lai, Jike Zhong, Ming Li, Shitian Zhao, Xiaofeng Yang
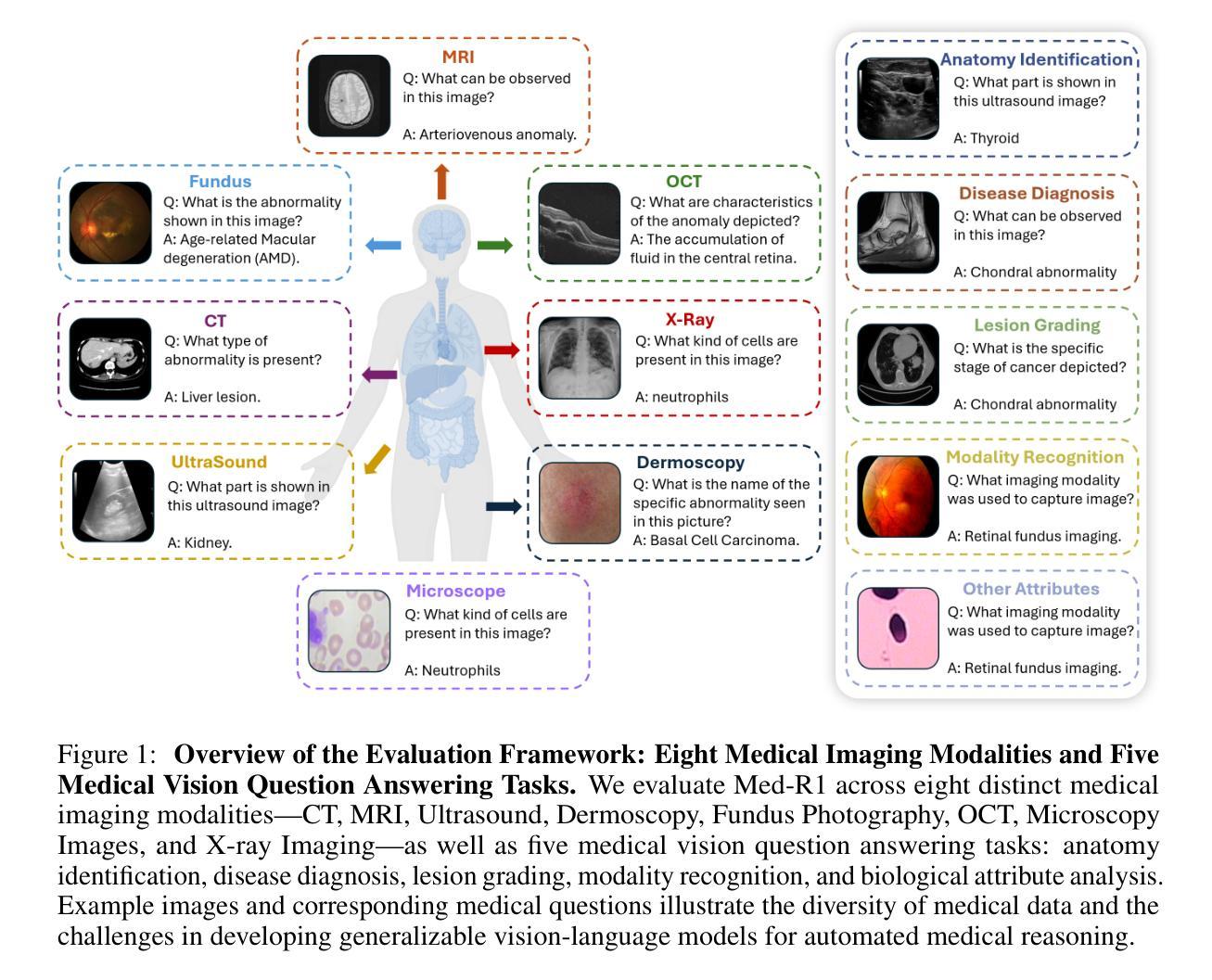
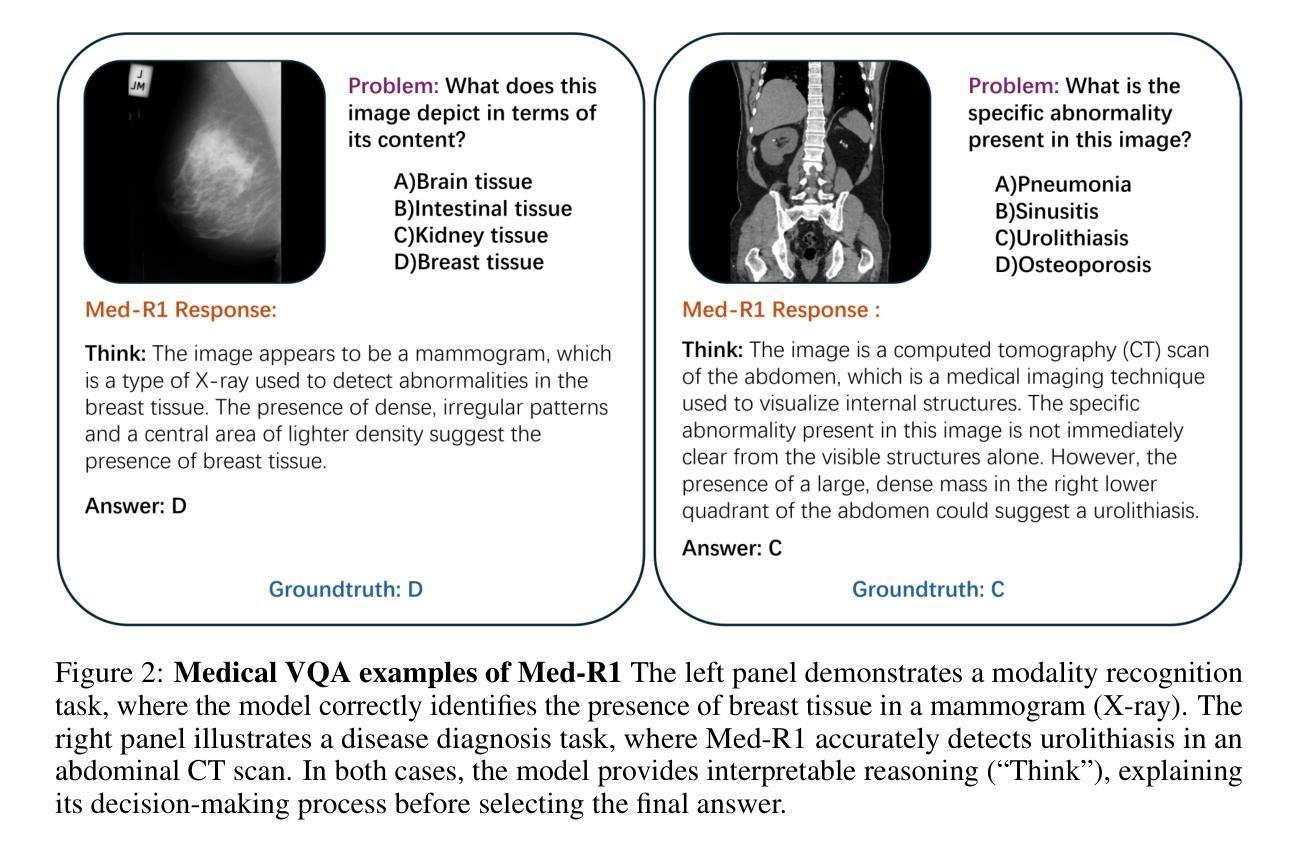
Vision-language models (VLMs) have advanced reasoning in natural scenes, but their role in medical imaging remains underexplored. Medical reasoning tasks demand robust image analysis and well-justified answers, posing challenges due to the complexity of medical images. Transparency and trustworthiness are essential for clinical adoption and regulatory compliance. We introduce Med-R1, a framework exploring reinforcement learning (RL) to enhance VLMs’ generalizability and trustworthiness in medical reasoning. Leveraging the DeepSeek strategy, we employ Group Relative Policy Optimization (GRPO) to guide reasoning paths via reward signals. Unlike supervised fine-tuning (SFT), which often overfits and lacks generalization, RL fosters robust and diverse reasoning. Med-R1 is evaluated across eight medical imaging modalities: CT, MRI, Ultrasound, Dermoscopy, Fundus Photography, Optical Coherence Tomography (OCT), Microscopy, and X-ray Imaging. Compared to its base model, Qwen2-VL-2B, Med-R1 achieves a 29.94% accuracy improvement and outperforms Qwen2-VL-72B, which has 36 times more parameters. Testing across five question types-modality recognition, anatomy identification, disease diagnosis, lesion grading, and biological attribute analysis Med-R1 demonstrates superior generalization, exceeding Qwen2-VL-2B by 32.06% and surpassing Qwen2-VL-72B in question-type generalization. These findings show that RL improves medical reasoning and enables parameter-efficient models to outperform significantly larger ones. By demonstrating strong cross-domain and cross-task performance, Med-R1 points toward a new direction for developing practical and generalizable medical VLMs.
视觉语言模型(VLMs)在自然场景中的推理能力已经得到提升,但它们在医学影像领域的应用仍待探索。医学推理任务需要可靠的图像分析和有充分依据的答案,由于医学图像的复杂性,这构成了挑战。透明度和可信度对于临床采用和法规合规至关重要。我们引入了Med-R1框架,探索强化学习(RL)以增强VLMs在医学推理中的通用性和可信度。利用DeepSeek策略,我们采用集团相对策略优化(GRPO)通过奖励信号引导推理路径。与经常过度拟合且缺乏泛化能力的有监督微调(SFT)不同,RL促进稳健和多样化的推理。Med-R1在八种医学影像模态上进行了评估:计算机断层扫描(CT)、磁共振成像(MRI)、超声波、皮肤镜检查、眼底摄影、光学相干断层扫描(OCT)、显微镜和X射线成像。相比其基准模型Qwen2-VL-2B,Med-R1实现了29.94%的准确率提升,并超越了参数更多的Qwen2-VL-72B。在五种问题类型(模态识别、解剖结构识别、疾病诊断、病变分级和生物属性分析)的测试上,Med-R1展现出优越的泛化能力,相对于Qwen2-VL-2B提高32.06%,并在问题类型泛化上超越了Qwen2-VL-72B。这些发现表明,强化学习能提升医学推理能力,并使得参数效率模型能够显著超越更大的模型。通过展示强大的跨域和跨任务性能,Med-R1为开发实用和通用的医学VLMs指明了新方向。
论文及项目相关链接
Summary
在医疗图像领域,视觉语言模型(VLMs)在医疗影像中的应用仍待发掘。由于复杂的医学影像所带来的挑战,一种采用强化学习(RL)以增强其泛化能力和信任度的模型框架Med-R1应运而生。利用DeepSeek策略和Group Relative Policy Optimization(GRPO)来指导推理路径。相较于传统监督微调(SFT),RL提高了推理的稳健性和多样性。在八种医学影像模态的测试下,Med-R1相较于基准模型Qwen2-VL-2B提高了29.94%的准确性,且在泛化性能方面显著超越后者和更大的模型Qwen2-VL-72B。这显示了RL在医疗推理中的优势,并开启了开发实用且通用化的医疗VLMs的新方向。
Key Takeaways
- VLMs在医疗影像中的应用尚未得到充分探索。
- 医疗推理任务需要强大的图像分析和合理答案的能力。
- Med-R1框架利用强化学习(RL)提高VLMs的泛化能力和信任度。
- 采用DeepSeek策略和GRPO方法引导推理路径。
- 与监督微调相比,强化学习提高了推理的稳健性和多样性。
- Med-R1模型在各种医学影像模态和多种类型的问题测试中表现出优越的性能,相比基准模型有显著的提升。
点此查看论文截图

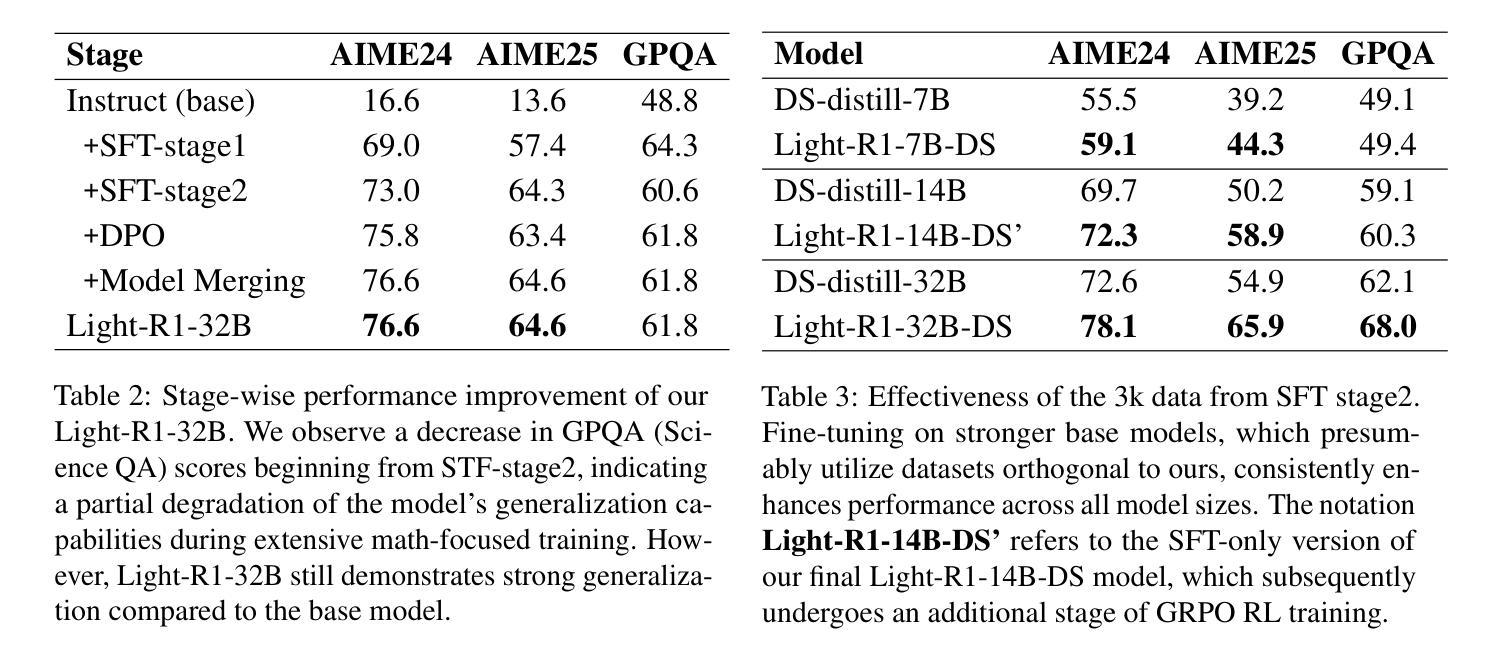
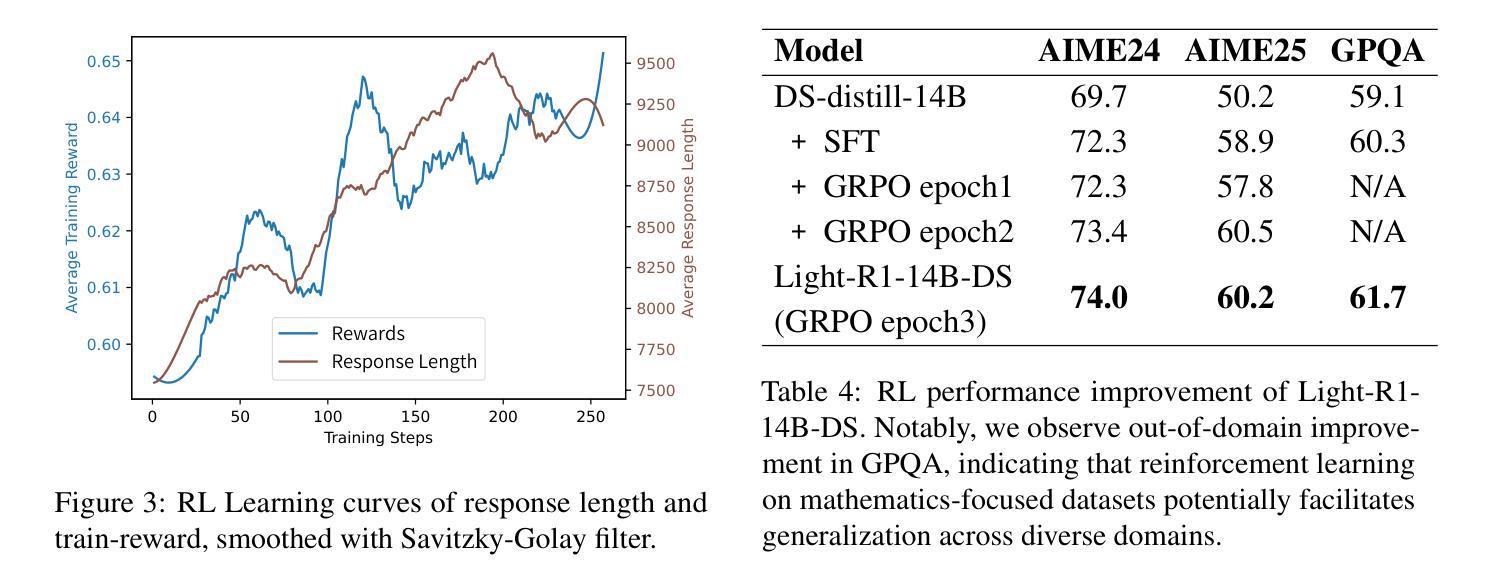
Light-R1: Curriculum SFT, DPO and RL for Long COT from Scratch and Beyond
Authors:Liang Wen, Yunke Cai, Fenrui Xiao, Xin He, Qi An, Zhenyu Duan, Yimin Du, Junchen Liu, Lifu Tang, Xiaowei Lv, Haosheng Zou, Yongchao Deng, Shousheng Jia, Xiangzheng Zhang
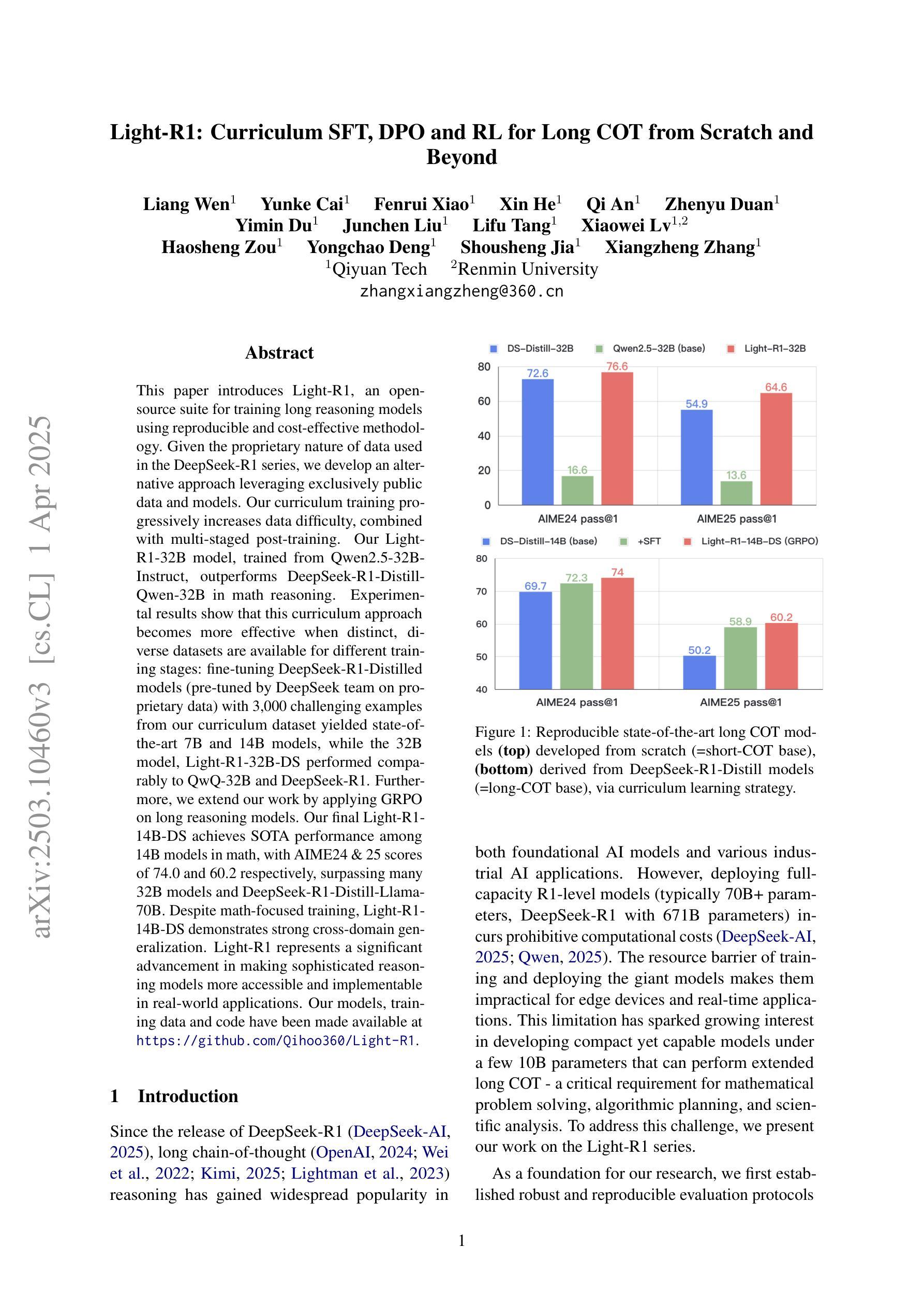
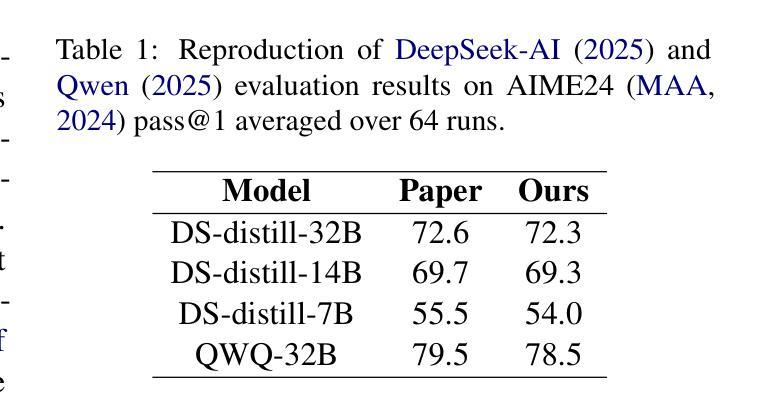
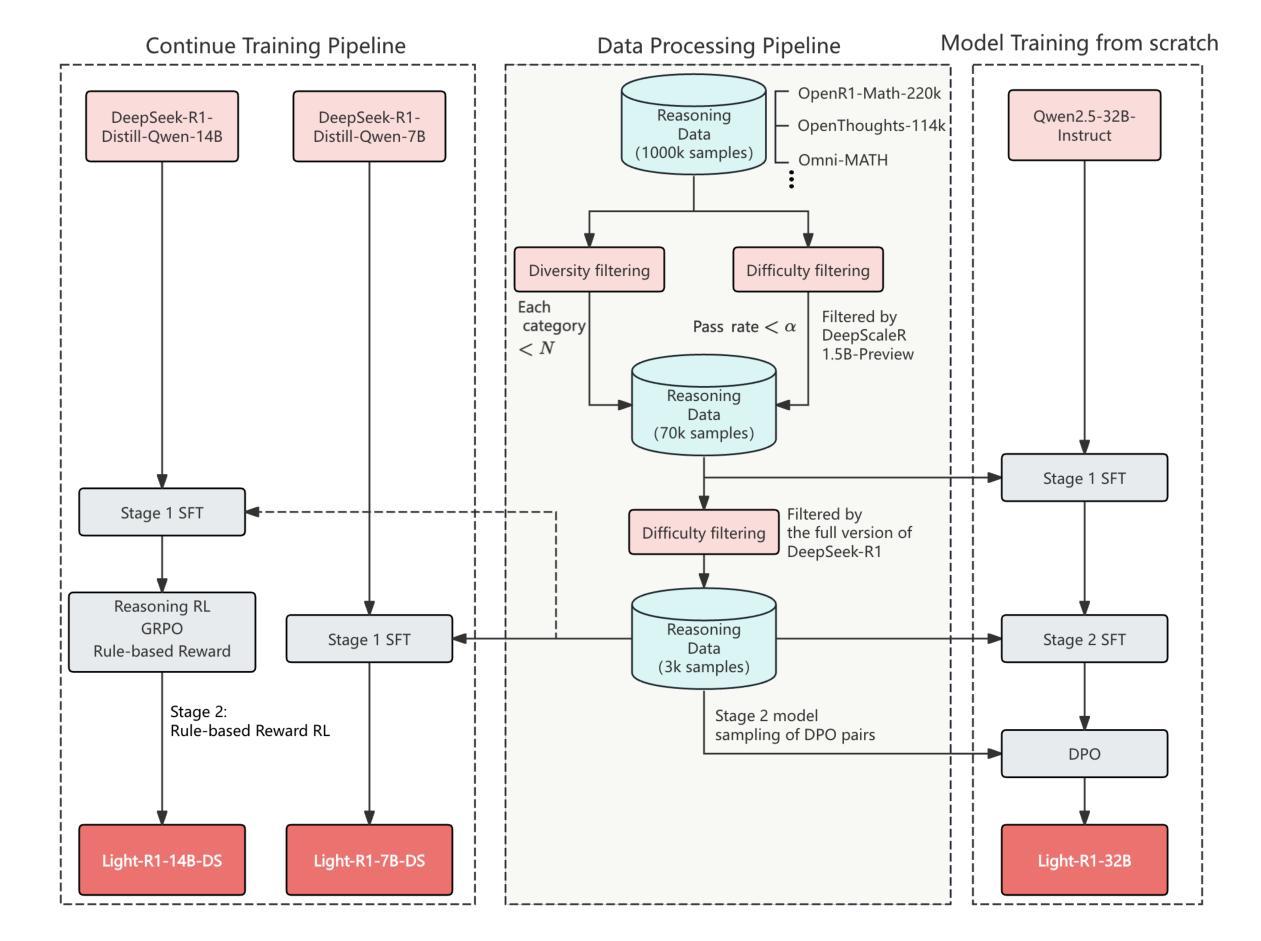
This paper introduces Light-R1, an open-source suite for training long reasoning models using reproducible and cost-effective methodology. Given the proprietary nature of data used in the DeepSeek-R1 series, we develop an alternative approach leveraging exclusively public data and models. Our curriculum training progressively increases data difficulty, combined with multi-staged post-training. Our Light-R1-32B model, trained from Qwen2.5-32B-Instruct, outperforms DeepSeek-R1-Distill-Qwen-32B in math reasoning. Experimental results show that this curriculum approach becomes more effective when distinct, diverse datasets are available for different training stages: fine-tuning DeepSeek-R1-Distilled models (pre-tuned by DeepSeek team on proprietary data) with 3,000 challenging examples from our curriculum dataset yielded state-of-the-art 7B and 14B models, while the 32B model, Light-R1-32B-DS performed comparably to QwQ-32B and DeepSeek-R1. Furthermore, we extend our work by applying GRPO on long reasoning models. Our final Light-R1-14B-DS achieves SOTA performance among 14B models in math, with AIME24 & 25 scores of 74.0 and 60.2 respectively, surpassing many 32B models and DeepSeek-R1-Distill-Llama-70B. Despite math-focused training, Light-R1-14B-DS demonstrates strong cross-domain generalization. Light-R1 represents a significant advancement in making sophisticated reasoning models more accessible and implementable in real-world applications. Our models, training data and code have been made available at https://github.com/Qihoo360/Light-R1.
本文介绍了Light-R1,这是一个开源套件,采用可重复和成本效益高的方法训练长推理模型。考虑到DeepSeek-R1系列中使用的数据的专有性质,我们开发了一种纯粹利用公开数据和模型的方法。我们的课程训练逐步增加数据难度,并结合多阶段后训练。我们的Light-R1-32B模型,以Qwen2.5-32B-Instruct进行训练,在数学推理方面优于DeepSeek-R1-Distill-Qwen-32B。实验结果表明,当不同训练阶段拥有不同且多样的数据集时,这种课程方法变得更加有效:用我们的课程数据集中的3000个具有挑战性的例子对DeepSeek-R1-Distilled模型(DeepSeek团队在专有数据上进行预训练)进行微调,产生了最先进的7B和14B模型,而32B模型Light-R1-32B-DS的表现与QwQ-32B和DeepSeek-R1相当。此外,我们将工作扩展到长推理模型上应用GRPO。我们最终的Light-R1-14B-DS在数学的14B模型中实现了先进性能,AIME24和AIME25的分数分别为74.0和60.2,超过了许多32B模型和DeepSeek-R1-Distill-Llama-70B。尽管以数学为重点进行训练,但Light-R1-14B-DS表现出强大的跨域泛化能力。Light-R1标志着让复杂的推理模型在现实世界应用中更加可访问和可实现的一个重大进步。我们的模型、训练数据和代码已在https://github.com/Qihoo360/Light-R1上提供。
论文及项目相关链接
PDF v3: minor modifications; v2: better writing & format for later submission; all release at https://github.com/Qihoo360/Light-R1
Summary
Light-R1是一套开源的用于训练长推理模型的套件,它采用可复制和成本效益高的方法。该研究提出了一种新的课程训练方法,利用公开数据和模型,逐步增加数据难度并结合多阶段后训练。Light-R1系列模型在数学推理上表现出卓越性能,尤其是Light-R1-32B模型。此外,该研究还尝试将GRPO应用于长推理模型,最终Light-R1-14B-DS模型在数学上实现了卓越的性能,并展示了强大的跨域泛化能力。
Key Takeaways
- Light-R1是一个用于训练长推理模型的开源套件,采用可复制和成本效益高的方法。
- 研究提出了一种新的课程训练方法,利用公开数据和模型。
- Light-R1系列模型在数学推理上表现出卓越性能。
- Light-R1-32B模型在特定训练数据集上表现出优异性能。
- GRPO被成功应用于长推理模型,Light-R1-14B-DS模型实现卓越性能。
- Light-R1-14B-DS模型在数学上具有强劲表现,并展现出良好的跨域泛化能力。
- Light-R1的研究使得高级推理模型更易于访问并在实际应用程序中实现。
点此查看论文截图
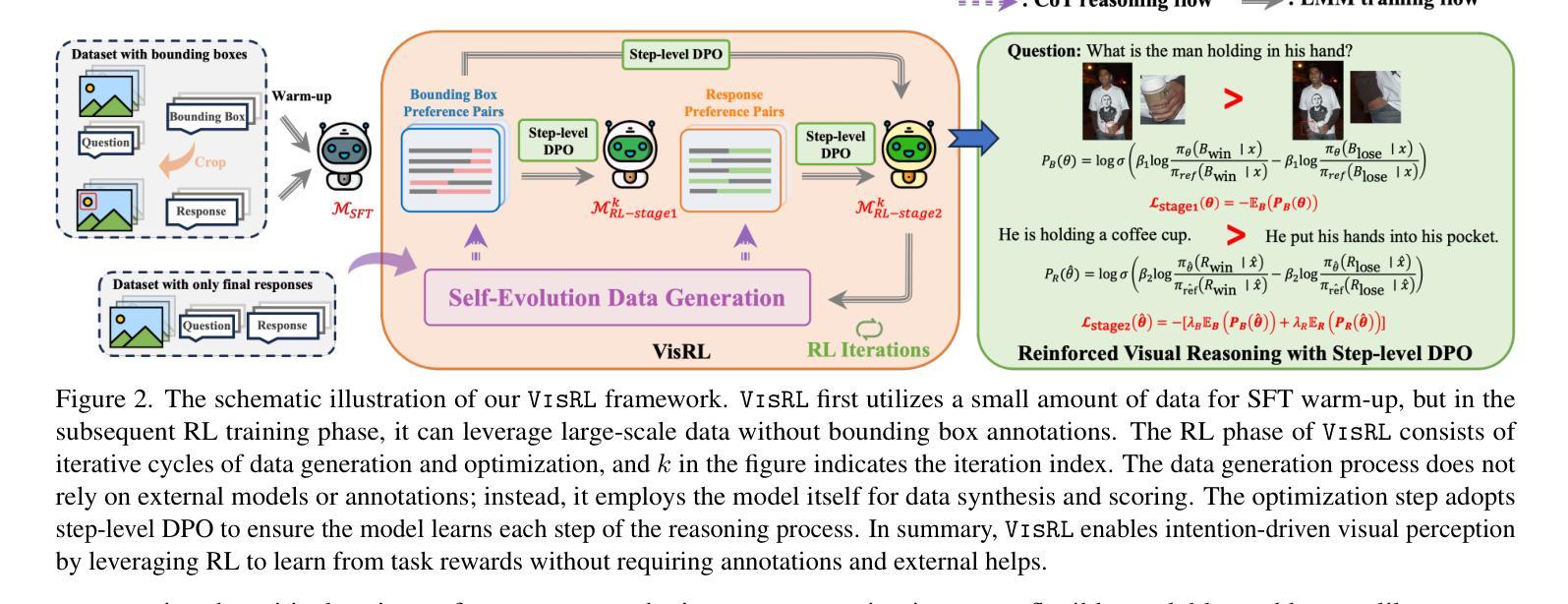
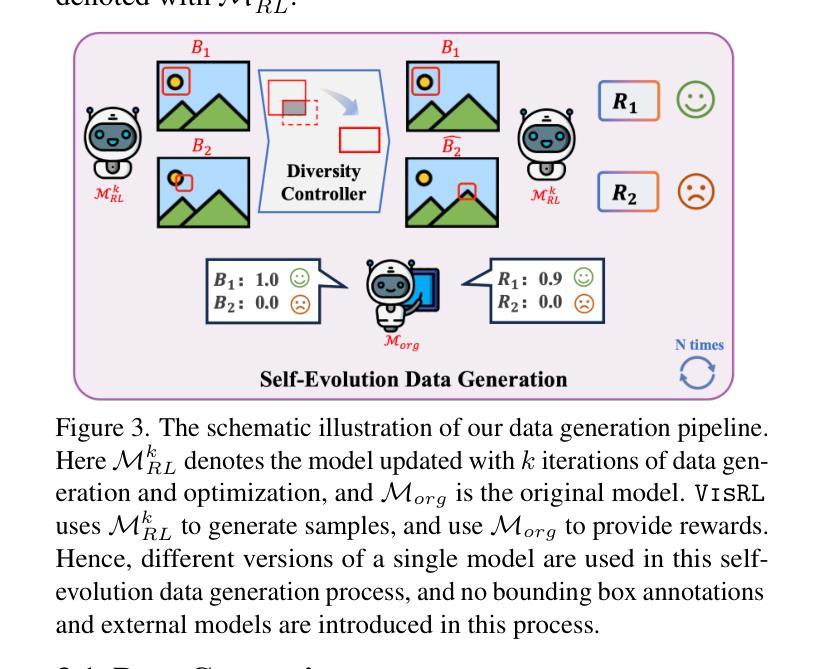
VisRL: Intention-Driven Visual Perception via Reinforced Reasoning
Authors:Zhangquan Chen, Xufang Luo, Dongsheng Li
Visual understanding is inherently intention-driven - humans selectively focus on different regions of a scene based on their goals. Recent advances in large multimodal models (LMMs) enable flexible expression of such intentions through natural language, allowing queries to guide visual reasoning processes. Frameworks like Visual Chain-of-Thought have demonstrated the benefit of incorporating explicit reasoning steps, where the model predicts a focus region before answering a query. However, existing approaches rely heavily on supervised training with annotated intermediate bounding boxes, which severely limits scalability due to the combinatorial explosion of intention-region pairs. To overcome this limitation, we propose VisRL, the first framework that applies reinforcement learning (RL) to the problem of intention-driven visual perception. VisRL optimizes the entire visual reasoning process using only reward signals. By treating intermediate focus selection as an internal decision optimized through trial-and-error, our method eliminates the need for costly region annotations while aligning more closely with how humans learn to perceive the world. Extensive experiments across multiple benchmarks show that VisRL consistently outperforms strong baselines, demonstrating both its effectiveness and its strong generalization across different LMMs. Our code is available at https://github.com/zhangquanchen/VisRL.
视觉理解本质上是目标驱动的——人类会根据他们的目标选择性地关注场景的不同区域。最近大型多模态模型(LMMs)的进步可以通过自然语言灵活地表达这样的意图,允许查询引导视觉推理过程。像“视觉思维链”这样的框架已经证明了加入明确推理步骤的好处,其中模型在回答问题之前会预测一个关注区域。然而,现有的方法严重依赖于用标注的中间边界框进行的有监督训练,这由于意图-区域对的组合爆炸而严重限制了可扩展性。为了克服这一局限性,我们提出了VisRL,这是第一个将强化学习(RL)应用于目标驱动视觉感知问题的框架。VisRL仅使用奖励信号优化整个视觉推理过程。通过将中间焦点选择视为通过试错优化的内部决策,我们的方法消除了对昂贵的区域标注的需求,同时更贴近人类学习感知世界的方式。在多个基准测试上的广泛实验表明,VisRL始终优于强大的基准测试,证明了其在不同大型多模态模型中的有效性和强大泛化能力。我们的代码位于 https://github.com/zhangquanchen/VisRL。
论文及项目相关链接
PDF 18pages,11 figures
Summary
视觉理解本质上是意图驱动的——人类会根据目标有选择地关注场景的不同区域。最近的大型多模态模型(LMMs)的进步能够通过自然语言灵活表达意图,使得查询能够引导视觉推理过程。然而,现有方法严重依赖于带有中间边界框注解的监督训练,这限制了扩展性,因为意图区域对的组合呈现爆炸性增长。为了克服这一局限性,我们提出VisRL,这是第一个将强化学习(RL)应用于意图驱动视觉感知问题的框架。VisRL仅使用奖励信号优化整个视觉推理过程。通过将中间焦点选择视为通过试错优化的内部决策,我们的方法消除了对昂贵的区域注解的需求,同时更贴近人类感知世界的学习方式。
Key Takeaways
- 人类的视觉理解是意图驱动的,会基于目标选择关注场景的不同区域。
- 大型多模态模型(LMMs)能够灵活表达意图,引导视觉推理过程。
- 现有方法依赖监督训练和中间边界框注解,限制了其可扩展性。
- VisRL框架首次将强化学习(RL)应用于意图驱动视觉感知问题。
- VisRL优化整个视觉推理过程,仅使用奖励信号。
- VisRL通过试错优化中间焦点选择,无需昂贵的区域注解。
点此查看论文截图

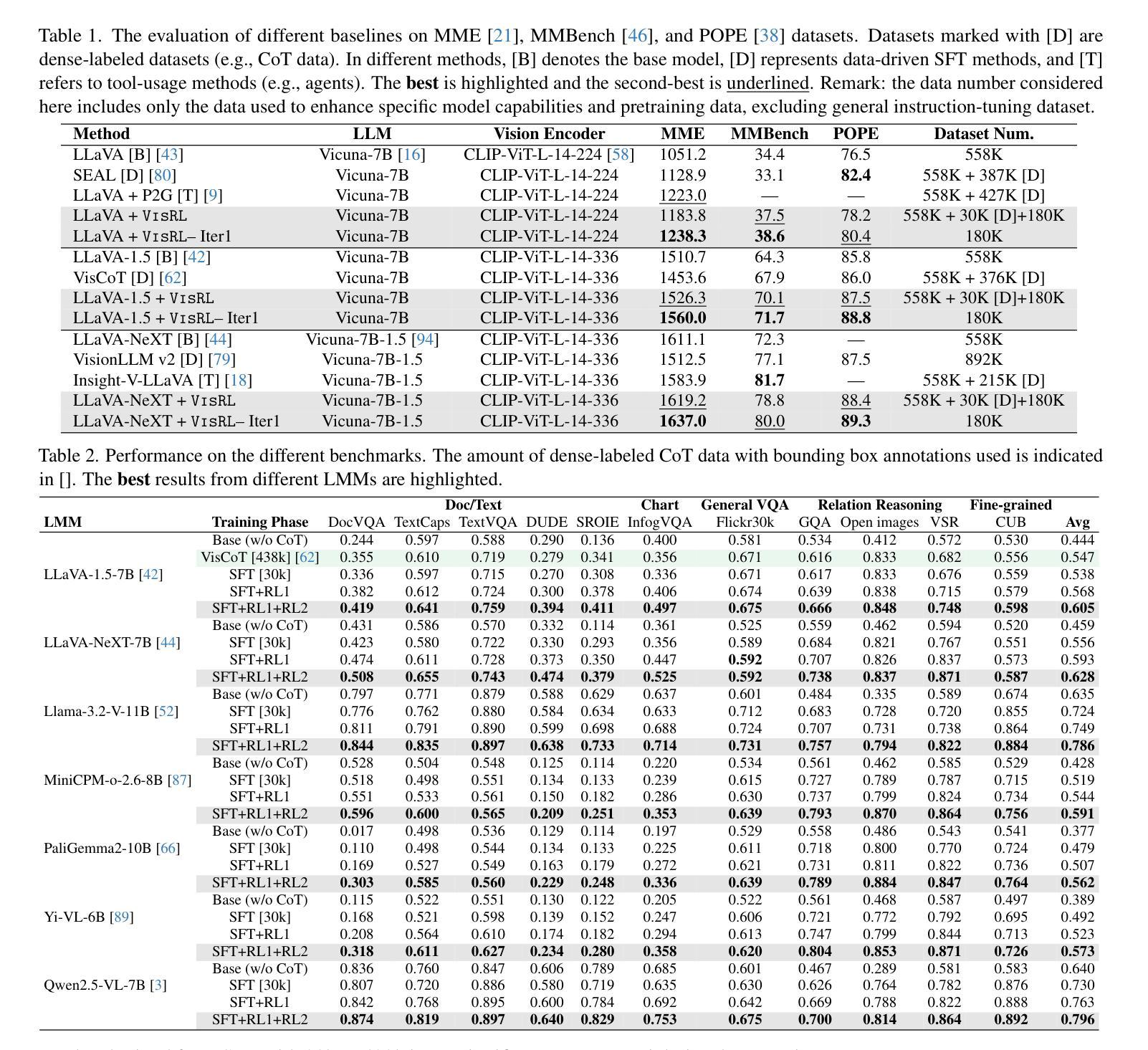
DeepRetrieval: Hacking Real Search Engines and Retrievers with Large Language Models via Reinforcement Learning
Authors:Pengcheng Jiang, Jiacheng Lin, Lang Cao, Runchu Tian, SeongKu Kang, Zifeng Wang, Jimeng Sun, Jiawei Han
Information retrieval systems are crucial for enabling effective access to large document collections. Recent approaches have leveraged Large Language Models (LLMs) to enhance retrieval performance through query augmentation, but often rely on expensive supervised learning or distillation techniques that require significant computational resources and hand-labeled data. We introduce DeepRetrieval, a reinforcement learning (RL) approach that trains LLMs for query generation through trial and error without supervised data (reference query). Using retrieval metrics as rewards, our system generates queries that maximize retrieval performance. DeepRetrieval outperforms leading methods on literature search with 65.07% (vs. previous SOTA 24.68%) recall for publication search and 63.18% (vs. previous SOTA 32.11%) recall for trial search using real-world search engines. DeepRetrieval also dominates in evidence-seeking retrieval, classic information retrieval and SQL database search. With only 3B parameters, it outperforms industry-leading models like GPT-4o and Claude-3.5-Sonnet on 11/13 datasets. These results demonstrate that our RL approach offers a more efficient and effective paradigm for information retrieval. Our data and code are available at: https://github.com/pat-jj/DeepRetrieval.
信息检索系统对于有效访问大型文档集合至关重要。近期的方法通过利用大型语言模型(LLMs)通过查询扩充增强检索性能,但通常依赖于昂贵的监督学习或蒸馏技术,需要大量的计算资源和手工标注数据。我们引入了DeepRetrieval,这是一种强化学习(RL)方法,用于通过试错训练语言模型进行查询生成,无需监督数据(参考查询)。使用检索指标作为奖励,我们的系统生成了最大化检索性能的查询。DeepRetrieval在文献搜索方面的表现优于其他方法,在出版物搜索的召回率为65.07%(与之前的最佳水平24.68%相比),在试验搜索的召回率为63.18%(与之前的最佳水平32.11%相比),使用现实世界搜索引擎。DeepRetrieval在循证检索、经典信息检索和SQL数据库搜索中也占据主导地位。仅需3B参数,它在13个数据集中的11个上超越了GPT-4o和Claude-3.5-Sonnet等业界领先模型。这些结果表明,我们的强化学习方法为信息检索提供了更高效、更有效的范式。我们的数据和代码可在:https://github.com/pat-jj/DeepRetrieval 获得。
论文及项目相关链接
Summary
本文介绍了一种基于强化学习(RL)的信息检索系统——DeepRetrieval。它通过试错训练大型语言模型(LLMs)生成查询,无需监督数据,使用检索指标作为奖励,最大化检索性能。DeepRetrieval在文献搜索方面的表现优于其他方法,真实搜索引擎的召回率达到了惊人的水平。此外,它在证据检索、经典信息检索和SQL数据库搜索方面也表现出色。与传统的监督学习方法相比,它更有效率且更有效果。相关数据和代码已公开在GitHub上。
Key Takeaways
- DeepRetrieval使用强化学习训练大型语言模型生成查询,无需监督数据。
- 该系统通过试错方式,以检索指标作为奖励,最大化检索性能。
- DeepRetrieval在文献搜索方面的表现显著优于其他方法,真实搜索引擎的召回率达到了很高的水平。
- 它在证据检索、经典信息检索和SQL数据库搜索方面也有出色表现。
- 与现有的先进方法相比,DeepRetrieval更加高效且有效。
- 该系统已经超越了现有的顶尖模型,如GPT-4o和Claude-3.5-Sonnet,在多数数据集上的表现更佳。
点此查看论文截图
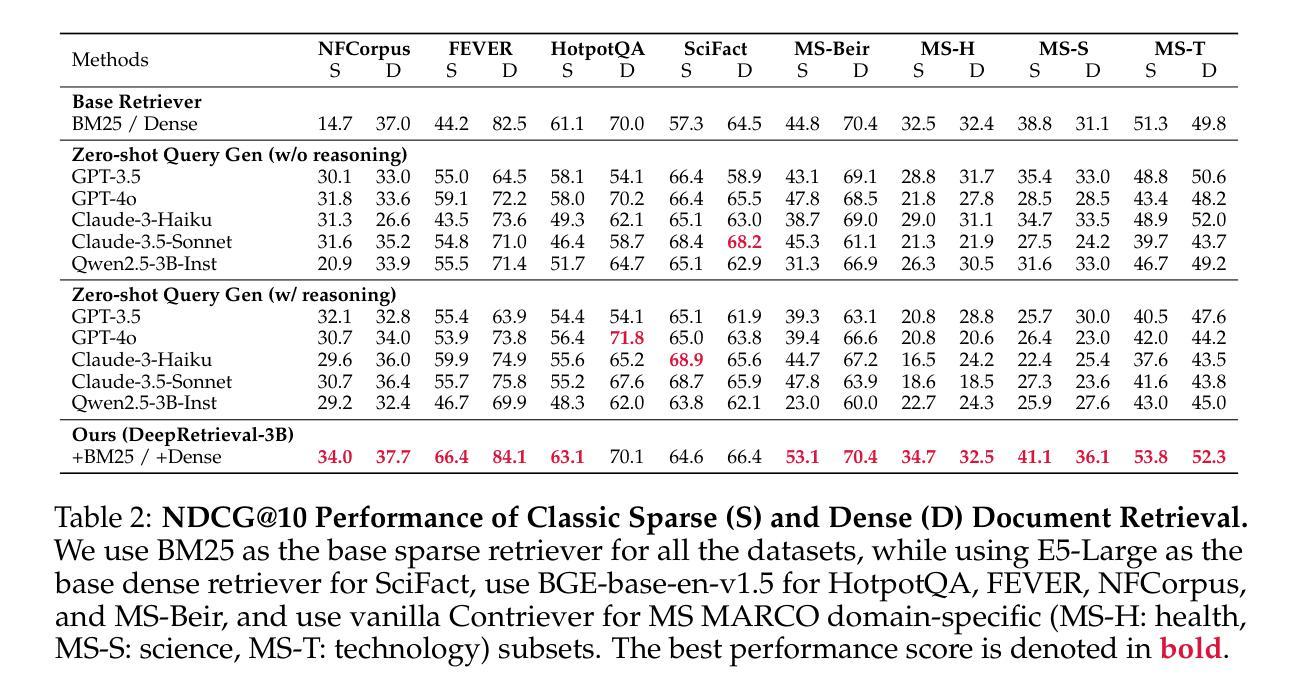
ChatReID: Open-ended Interactive Person Retrieval via Hierarchical Progressive Tuning for Vision Language Models
Authors:Ke Niu, Haiyang Yu, Mengyang Zhao, Teng Fu, Siyang Yi, Wei Lu, Bin Li, Xuelin Qian, Xiangyang Xue
Person re-identification (Re-ID) is a crucial task in computer vision, aiming to recognize individuals across non-overlapping camera views. While recent advanced vision-language models (VLMs) excel in logical reasoning and multi-task generalization, their applications in Re-ID tasks remain limited. They either struggle to perform accurate matching based on identity-relevant features or assist image-dominated branches as auxiliary semantics. In this paper, we propose a novel framework ChatReID, that shifts the focus towards a text-side-dominated retrieval paradigm, enabling flexible and interactive re-identification. To integrate the reasoning abilities of language models into Re-ID pipelines, We first present a large-scale instruction dataset, which contains more than 8 million prompts to promote the model fine-tuning. Next. we introduce a hierarchical progressive tuning strategy, which endows Re-ID ability through three stages of tuning, i.e., from person attribute understanding to fine-grained image retrieval and to multi-modal task reasoning. Extensive experiments across ten popular benchmarks demonstrate that ChatReID outperforms existing methods, achieving state-of-the-art performance in all Re-ID tasks. More experiments demonstrate that ChatReID not only has the ability to recognize fine-grained details but also to integrate them into a coherent reasoning process.
行人再识别(Re-ID)是计算机视觉中的一项关键任务,旨在识别不同非重叠摄像头视角下的个体。尽管最近的先进视觉语言模型(VLMs)在逻辑推理和多任务泛化方面表现出色,但它们在Re-ID任务中的应用仍然有限。这些模型要么在基于身份相关特征的准确匹配方面表现挣扎,要么作为辅助语义辅助图像主导的分支。在本文中,我们提出了一种新型框架ChatReID,它转向以文本为主的检索范式,实现灵活和交互式的再识别。为了将语言模型的推理能力整合到Re-ID流程中,我们首先提供了一个大规模指令数据集,其中包含超过800万个提示来促进模型的微调。接下来,我们介绍了一种分层渐进的调试策略,它通过三个阶段(即从理解人物属性到精细图像检索再到多模态任务推理)赋予Re-ID能力。在十个流行基准测试上的广泛实验表明,ChatReID优于现有方法,在所有Re-ID任务中均达到最新性能水平。更多的实验表明,ChatReID不仅具有识别细微细节的能力,还能将它们整合到一个连贯的推理过程中。
论文及项目相关链接
Summary
该论文提出了一种名为ChatReID的新型框架,旨在将语言模型的推理能力融入行人再识别(Re-ID)任务中。通过构建大规模指令数据集和分层渐进调参策略,ChatReID实现了从理解人物属性到精细图像检索和多模态任务推理的三个阶段调参。实验证明,ChatReID在多个流行基准测试中表现出超越现有方法的状态,展现出精细识别与整合推理的能力。
Key Takeaways
- ChatReID框架将语言模型的推理能力融入行人再识别任务中。
- 构建大规模指令数据集,包含超过800万提示,以促进模型微调。
- 采用分层渐进调参策略,通过三个阶段的调参实现行人再识别。
- ChatReID在多个基准测试中表现优异,达到最新技术水平。
- ChatReID能够识别精细细节,并将其整合到连贯的推理过程中。
- ChatReID实现了灵活的交互式行人再识别。
点此查看论文截图


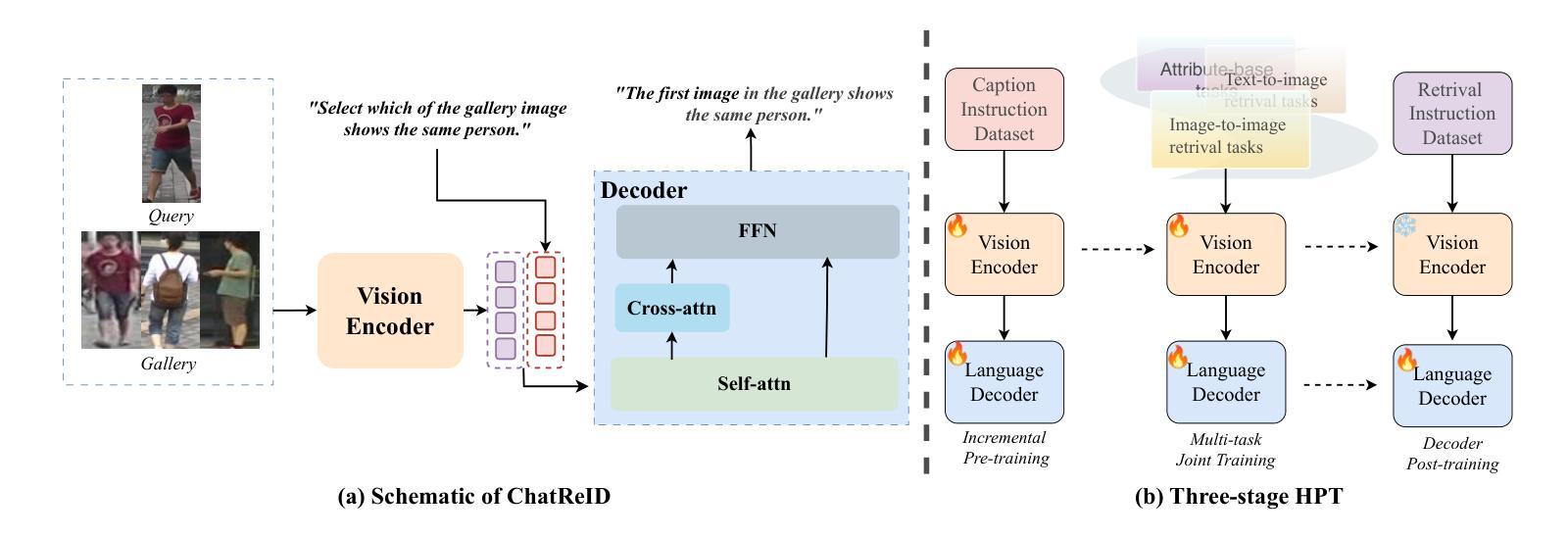
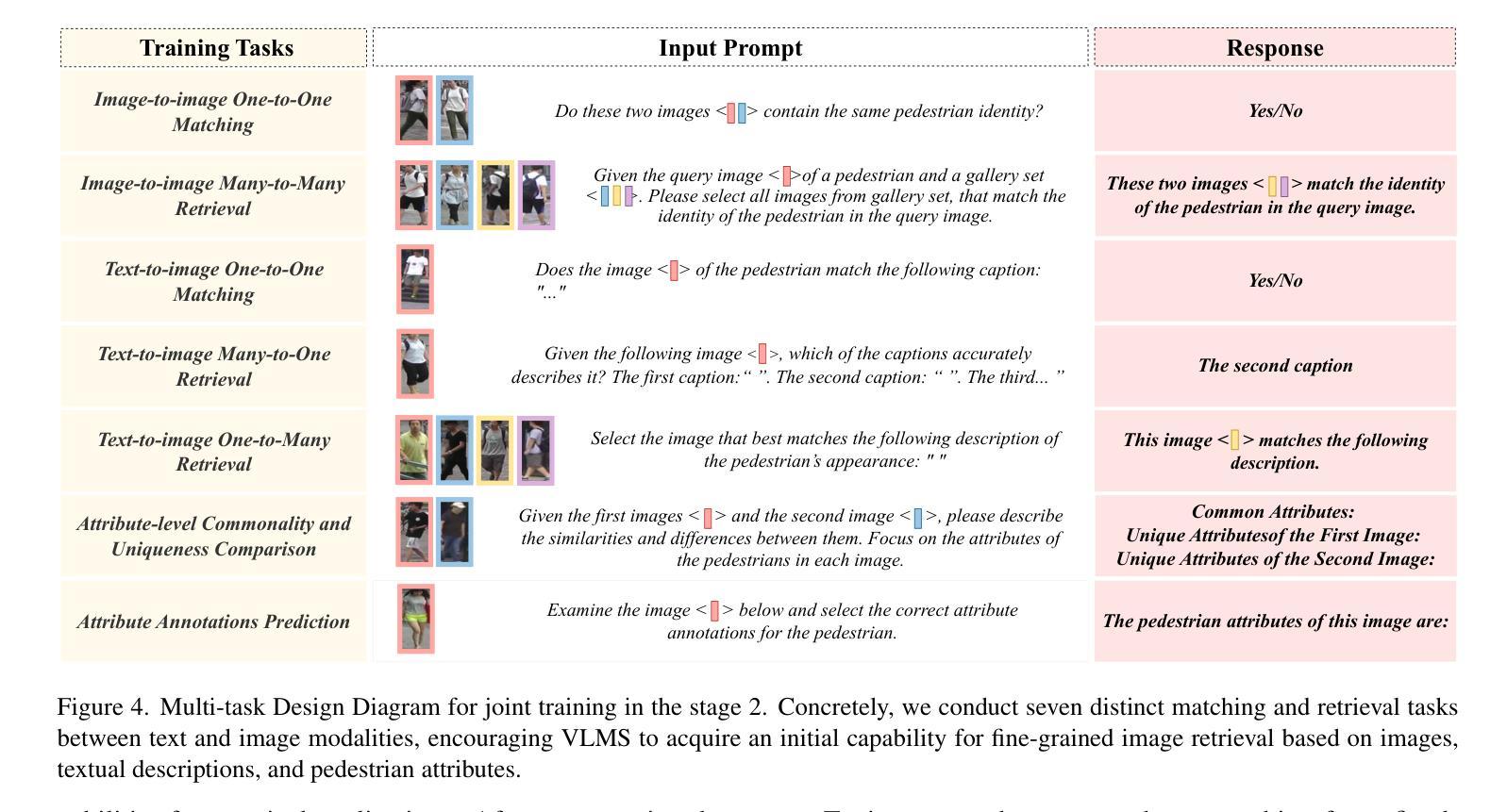
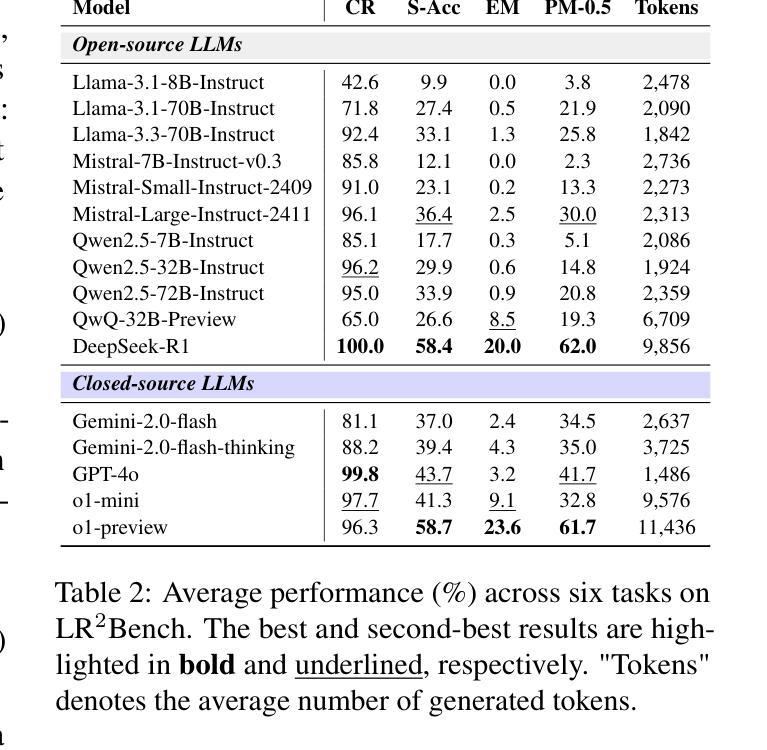
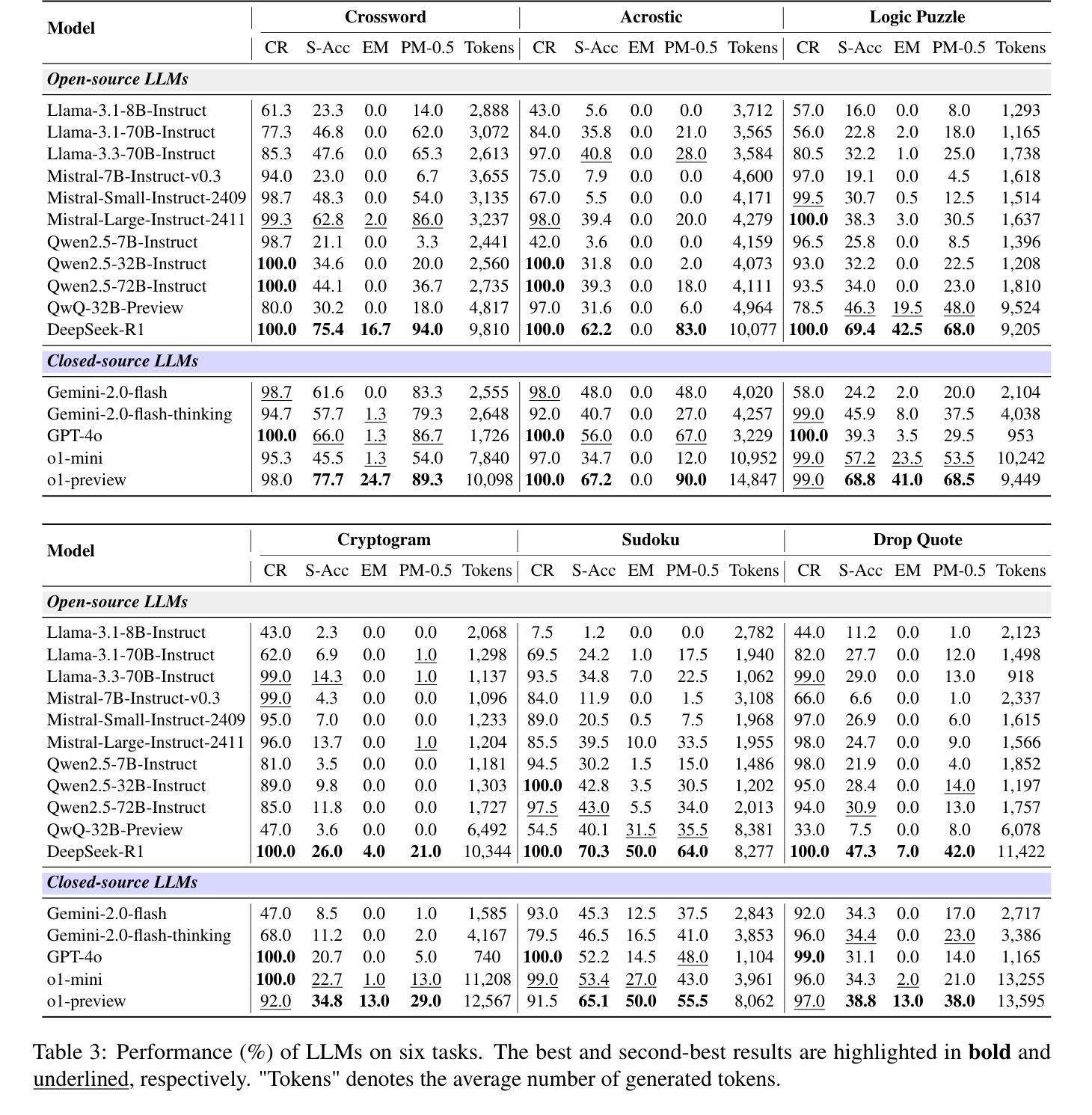
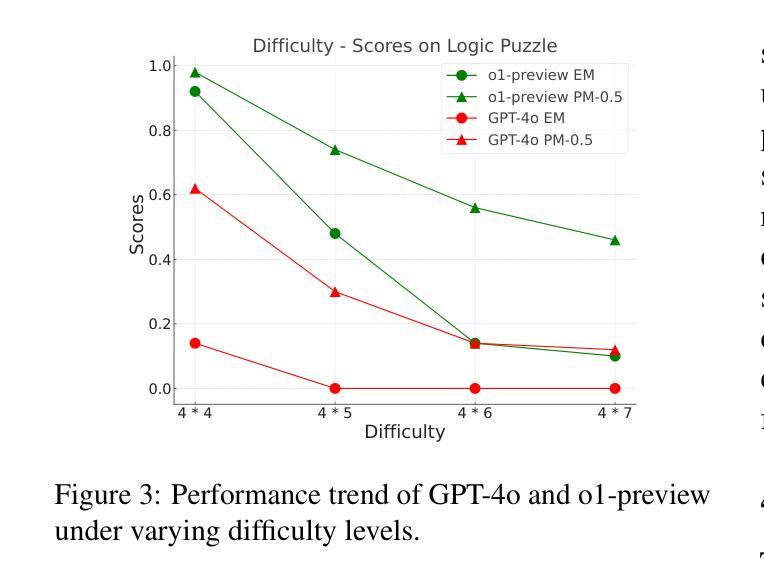
LR$^2$Bench: Evaluating Long-chain Reflective Reasoning Capabilities of Large Language Models via Constraint Satisfaction Problems
Authors:Jianghao Chen, Zhenlin Wei, Zhenjiang Ren, Ziyong Li, Jiajun Zhang
Recent progress in o1-like models has significantly enhanced the reasoning abilities of Large Language Models (LLMs), empowering them to tackle increasingly complex tasks through reflection capabilities, such as making assumptions, backtracking, and self-refinement. However, effectively evaluating such reflection capabilities remains challenging due to the lack of appropriate benchmarks. To bridge this gap, we introduce LR$^2$Bench, a novel benchmark designed to evaluate the Long-chain Reflective Reasoning capabilities of LLMs. LR$^2$Bench comprises 850 samples across six Constraint Satisfaction Problems (CSPs) where reflective reasoning is crucial for deriving solutions that meet all given constraints. Each type of task focuses on distinct constraint patterns, such as knowledge-based, logical, and spatial constraints, providing a comprehensive evaluation of diverse problem-solving scenarios. We conduct extensive evaluation on both conventional models and o1-like models. Our experimental results reveal that even the most advanced reasoning-specific models, such as DeepSeek-R1 and OpenAI o1-preview, struggle with tasks in LR$^2$Bench, achieving an average Exact Match score of only 20.0% and 23.6%, respectively. These findings underscore the significant room for improvement in the reflective reasoning capabilities of current LLMs. The leaderboard of our benchmark is available at https://huggingface.co/spaces/UltraRonin/LR2Bench
最近o1类模型的进展大大提高了大型语言模型(LLM)的推理能力,使它们能够通过假设、回溯和自我完善等反思能力来处理日益复杂的任务。然而,由于缺乏适当的基准测试,有效评估这样的反思能力仍然具有挑战性。为了弥补这一差距,我们引入了LR$^2$Bench,这是一个旨在评估LLM的长链反思推理能力的新型基准测试。LR$^2$Bench包含6个约束满足问题(CSP)的850个样本,在这些问题中,反思推理对于得出满足所有给定约束的解决方案至关重要。每种任务都专注于不同的约束模式,如知识型、逻辑型和空间型约束,从而全面评估各种问题解决场景。我们对传统模型和o1类模型进行了广泛评估。我们的实验结果表明,即使是最先进的推理专用模型,如DeepSeek-R1和OpenAI o1-preview,在LR$^2$Bench的任务中也表现挣扎,平均精确匹配率仅为20.0%和23.6%。这些发现强调了当前LLM的反思推理能力仍有很大的改进空间。我们的基准测试的排行榜可在https://huggingface.co/spaces/UltraRonin/LR2Bench上查看。
论文及项目相关链接
Summary
基于最新进展的o1类模型显著提升了大型语言模型(LLM)的推理能力,使其具备应对复杂任务的反思能力,如假设、回溯和自我完善。然而,由于缺乏适当的基准测试,有效评估这些反思能力仍然具有挑战性。为弥补这一空白,我们推出了LR$^2$Bench基准测试,旨在评估LLM的长期反思推理能力。LR$^2$Bench包含涉及六种约束满足问题(CSP)的850个样本,其中在解决所有给定约束的解决方案中反思推理至关重要。我们全面评估了传统模型和o1类模型,发现最先进的推理特定模型如DeepSeek-R1和OpenAI o1-preview在LR$^2$Bench的任务上表现挣扎,平均精确匹配得分仅为20.0%和23.6%。这突显了当前LLM在反思推理能力方面的巨大提升空间。LR$^2$Bench排行榜可访问:https://huggingface.co/spaces/UltraRonin/LR2Bench。
Key Takeaways
- o1类模型增强了大型语言模型(LLM)的推理能力,具备假设、回溯和自我完善等反思能力。
- 缺乏适当的基准测试是评估LLM反思能力的挑战。
- 引入LR$^2$Bench基准测试,旨在评估LLM的长期反思推理能力,包含涉及六种约束满足问题的850个样本。
- 最先进的推理特定模型在LR$^2$Bench任务上表现不佳,平均精确匹配得分较低。
- 当前LLM在反思推理能力方面还有很大的提升空间。
点此查看论文截图

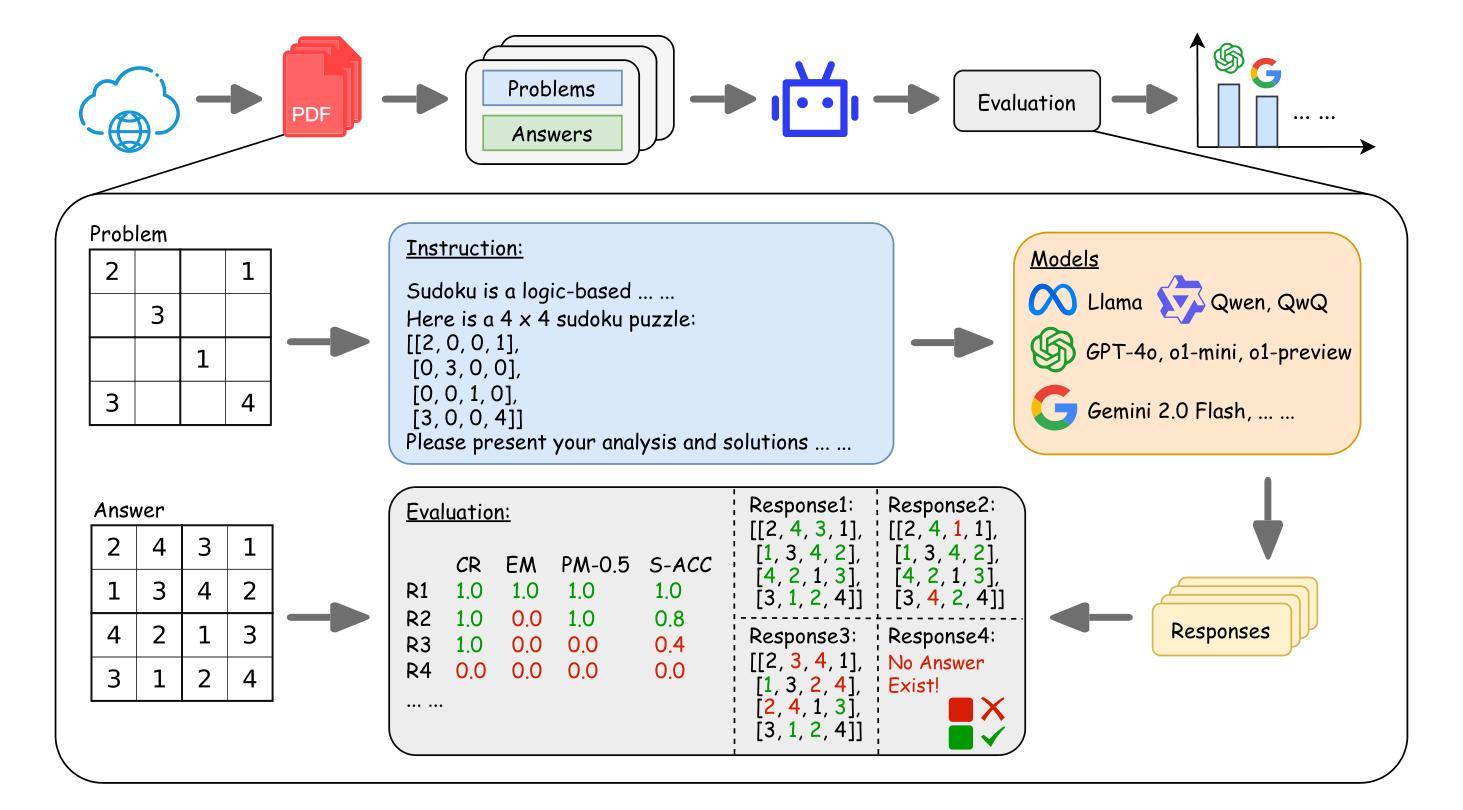
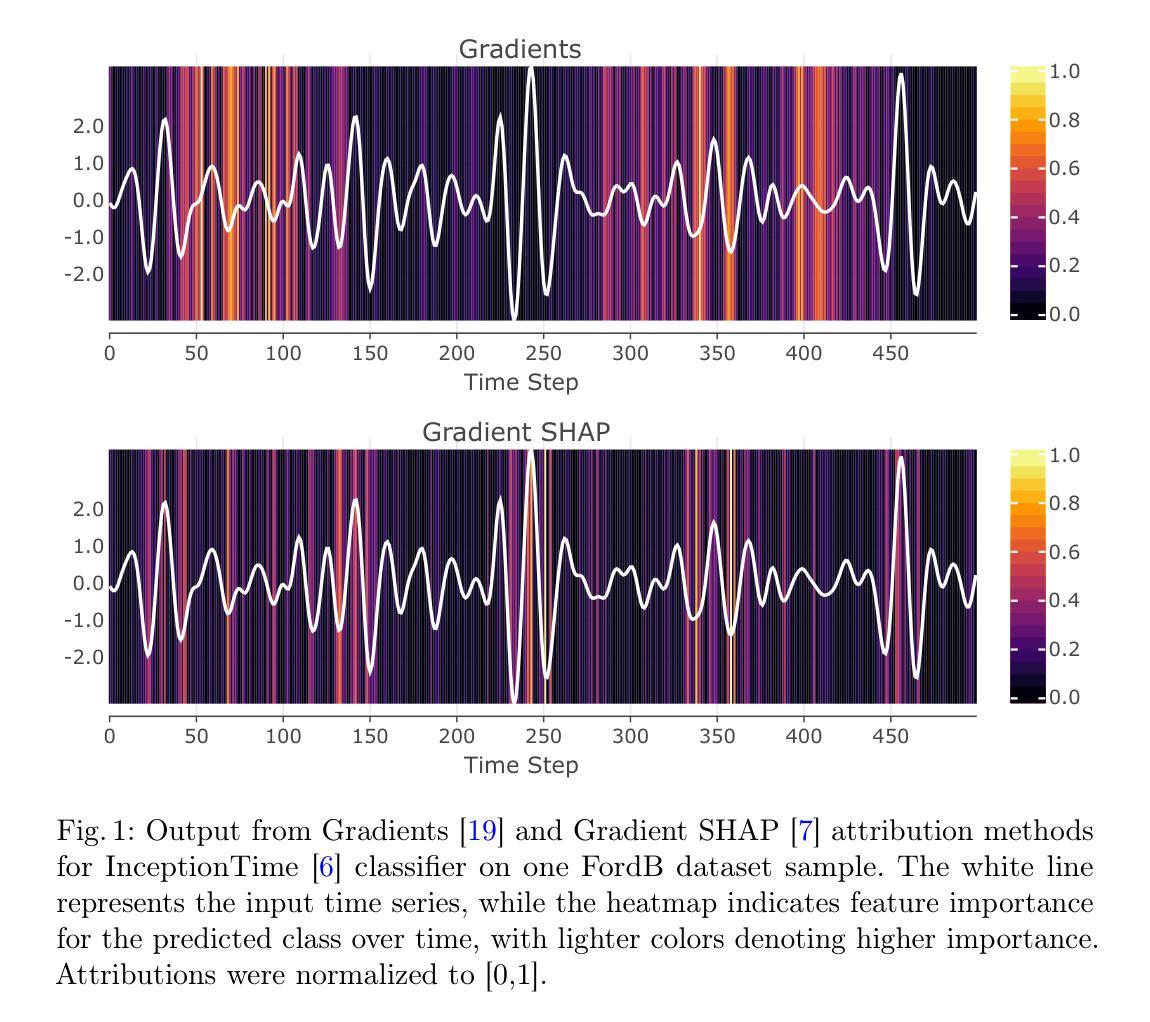
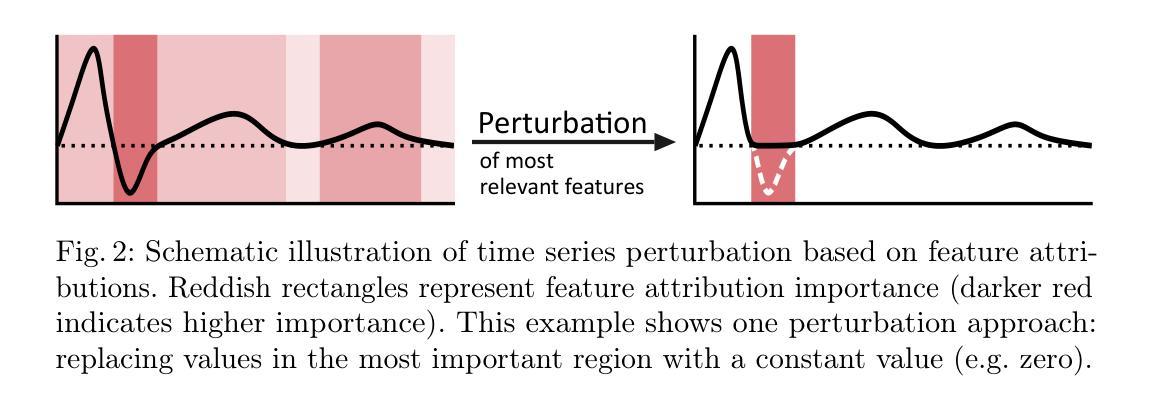
Class-Dependent Perturbation Effects in Evaluating Time Series Attributions
Authors:Gregor Baer, Isel Grau, Chao Zhang, Pieter Van Gorp
As machine learning models become increasingly prevalent in time series applications, Explainable Artificial Intelligence (XAI) methods are essential for understanding their predictions. Within XAI, feature attribution methods aim to identify which input features contribute the most to a model’s prediction, with their evaluation typically relying on perturbation-based metrics. Through systematic empirical analysis across multiple datasets, model architectures, and perturbation strategies, we reveal previously overlooked class-dependent effects in these metrics: they show varying effectiveness across classes, achieving strong results for some while remaining less sensitive to others. In particular, we find that the most effective perturbation strategies often demonstrate the most pronounced class differences. Our analysis suggests that these effects arise from the learned biases of classifiers, indicating that perturbation-based evaluation may reflect specific model behaviors rather than intrinsic attribution quality. We propose an evaluation framework with a class-aware penalty term to help assess and account for these effects in evaluating feature attributions, offering particular value for class-imbalanced datasets. Although our analysis focuses on time series classification, these class-dependent effects likely extend to other structured data domains where perturbation-based evaluation is common.
随着机器学习模型在时间序列应用中的普及,可解释人工智能(XAI)方法对于理解其预测结果至关重要。在XAI中,特征归因方法旨在识别哪些输入特征对模型的预测贡献最大,其评估通常依赖于基于微扰的度量指标。通过对多个数据集、模型架构和微扰策略的系统实证分析,我们揭示了这些指标中以前被忽视的类相关效应:它们在各类之间的有效性各不相同,对某些类有效,但对其他类不太敏感。尤其我们发现最有效的微扰策略往往显示出最明显的类间差异。我们的分析表明,这些影响源于分类器的学习偏见,这表明基于微扰的评估可能反映了特定模型的行为,而不是内在的归因质量。我们提出了一个带有类别感知惩罚项的评估框架,以帮助评估和考虑这些影响在特征归因评估中的作用,对于类别不平衡的数据集特别有价值。尽管我们的分析侧重于时间序列分类,但这些类别相关的效应可能扩展到其他结构化数据领域,其中基于微扰的评估很常见。
论文及项目相关链接
PDF Accepted at The World Conference on eXplainable Artificial Intelligence (XAI-2025)
Summary
随着机器学习模型在时间序列应用中的普及,可解释人工智能(XAI)方法对于理解模型预测至关重要。特征归因方法旨在识别对模型预测贡献最大的输入特征,其评估通常依赖于基于扰动的指标。通过对多个数据集、模型架构和扰动策略的系统实证分析,我们发现之前被忽视的类相关效应:这些指标在不同类别上的有效性存在差异,对某些类别效果好,对另一些类别则不太敏感。提出一个评估框架,带有类感知惩罚项,以帮助评估和考虑这些效应在评估特征归因时的价值,对类不平衡数据集特别有价值。虽然分析重点在时序分类上,但这些类相关效应可能也适用于其他结构化数据领域。
Key Takeaways
- 在时间序列应用中,机器学习模型的预测理解依赖于可解释人工智能(XAI)方法。
- 特征归因方法旨在识别影响模型预测的关键输入特征。
- 基于扰动的评估指标在类间存在有效性差异,对某些类别的预测效果好,对另一些则不敏感。
- 最有效的扰动策略往往在类间差异最大。
- 这些类间差异源于分类器的学习偏见,扰动评估可能反映特定模型行为而非内在归因质量。
- 提出一个带有类感知惩罚项的评估框架,以评估和考虑类间效应在特征归因中的价值。
点此查看论文截图