⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-08 更新
FRESA: Feedforward Reconstruction of Personalized Skinned Avatars from Few Images
Authors:Rong Wang, Fabian Prada, Ziyan Wang, Zhongshi Jiang, Chengxiang Yin, Junxuan Li, Shunsuke Saito, Igor Santesteban, Javier Romero, Rohan Joshi, Hongdong Li, Jason Saragih, Yaser Sheikh
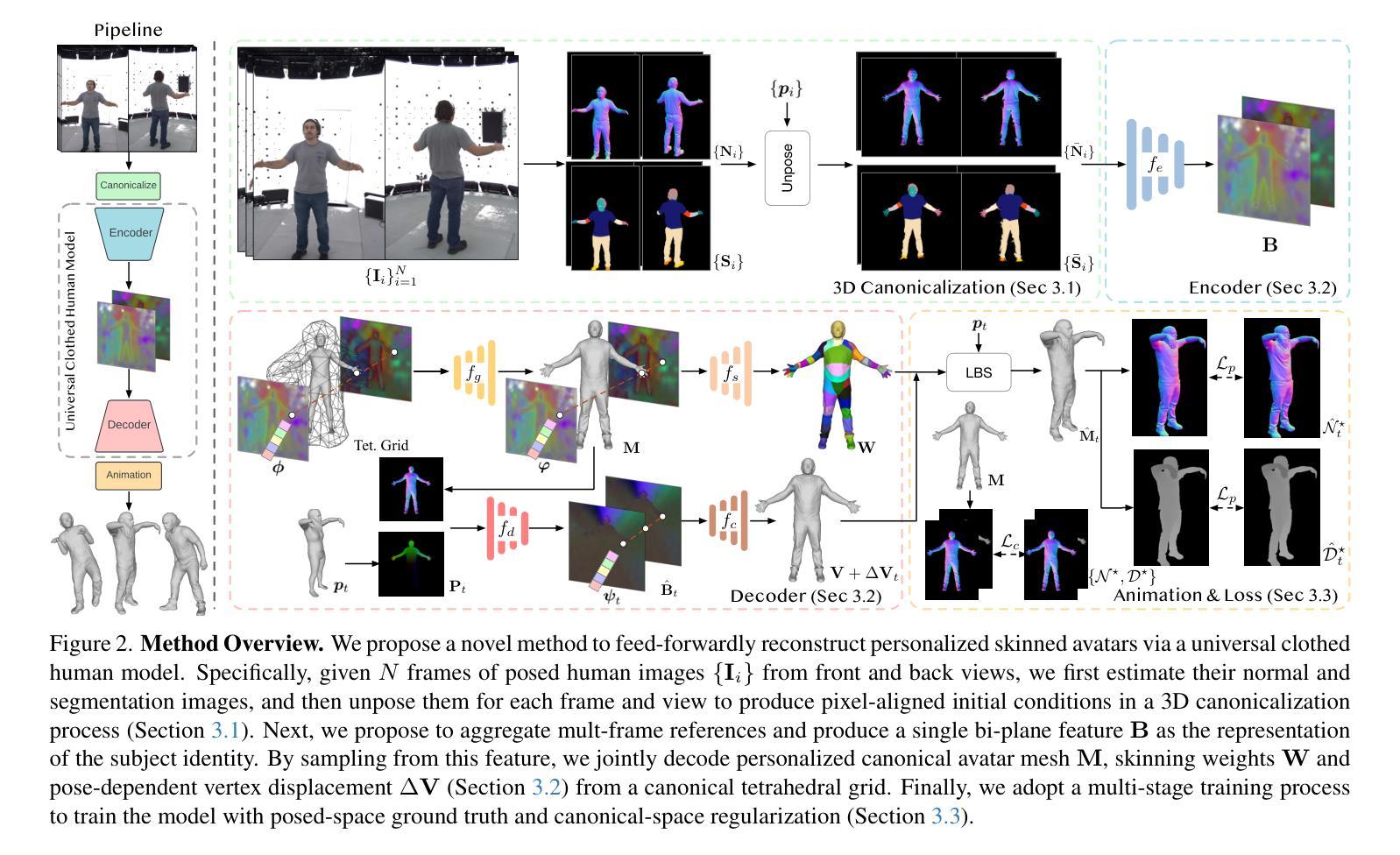
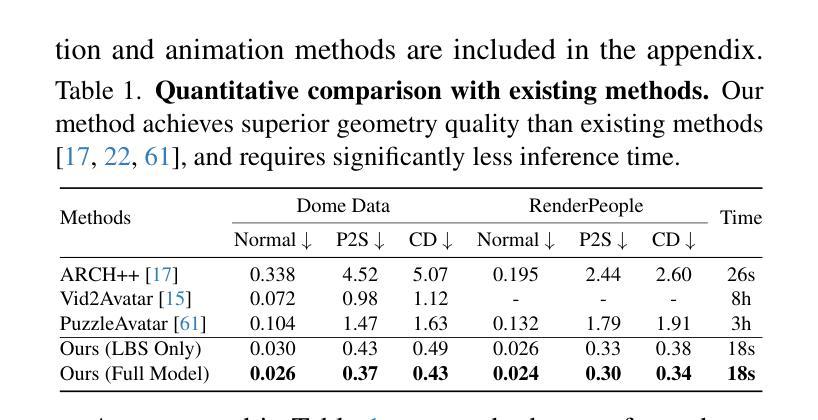
We present a novel method for reconstructing personalized 3D human avatars with realistic animation from only a few images. Due to the large variations in body shapes, poses, and cloth types, existing methods mostly require hours of per-subject optimization during inference, which limits their practical applications. In contrast, we learn a universal prior from over a thousand clothed humans to achieve instant feedforward generation and zero-shot generalization. Specifically, instead of rigging the avatar with shared skinning weights, we jointly infer personalized avatar shape, skinning weights, and pose-dependent deformations, which effectively improves overall geometric fidelity and reduces deformation artifacts. Moreover, to normalize pose variations and resolve coupled ambiguity between canonical shapes and skinning weights, we design a 3D canonicalization process to produce pixel-aligned initial conditions, which helps to reconstruct fine-grained geometric details. We then propose a multi-frame feature aggregation to robustly reduce artifacts introduced in canonicalization and fuse a plausible avatar preserving person-specific identities. Finally, we train the model in an end-to-end framework on a large-scale capture dataset, which contains diverse human subjects paired with high-quality 3D scans. Extensive experiments show that our method generates more authentic reconstruction and animation than state-of-the-arts, and can be directly generalized to inputs from casually taken phone photos. Project page and code is available at https://github.com/rongakowang/FRESA.
我们提出了一种新的方法,仅通过几张图片就可以重建具有真实动画的个性化3D人类化身。由于人体形状、姿势和服装类型的巨大差异,现有方法大多需要在推理过程中对每个主题进行数小时的优化,这限制了它们的实际应用。相比之下,我们从数千名穿衣者身上学习通用先验知识,以实现即时前馈生成和零样本泛化。具体来说,我们不是用共享的蒙皮权重来搭建化身,而是联合推断个性化的化身形状、蒙皮权重和姿势相关的变形,这有效地提高了整体几何保真度并减少了变形伪影。此外,为了规范姿势变化并解决规范形状和蒙皮权重之间的耦合模糊性,我们设计了一个3D规范化过程,以产生像素对齐的初始条件,这有助于重建精细的几何细节。然后,我们提出了一种多帧特征聚合方法,以稳健地减少规范化过程中产生的伪影,并融合保留个人特定身份的可行化身。最后,我们在一个大规模捕获数据集上,以端到端的方式训练模型,该数据集包含与高质量3D扫描配对的多样化人类主题。大量实验表明,我们的方法比最先进的技术产生更真实的重建和动画,并且可以直观地推广到来自随意拍摄的手机照片输入。项目页面和代码可在https://github.com/rongakowang/FRESA找到。
论文及项目相关链接
PDF Published in CVPR 2025
Summary
基于少量图像,我们提出了一种重建个性化3D人类阿凡达并实现逼真动画的新方法。由于人体形状、姿势和服装类型的巨大差异,现有方法大多需要在推理阶段对每个主题进行优化数小时,限制了实际应用。与之相比,我们从上千名穿着衣服的人身上学习通用先验知识,以实现即时前馈生成和零样本泛化。我们联合推断个性化的阿凡达形状、蒙皮权重和姿势相关的变形,有效提高整体几何保真度并减少变形伪影。
Key Takeaways
- 提出了一种基于少量图像重建个性化3D人类阿凡达的方法。
- 利用通用先验学习实现即时前馈生成和零样本泛化。
- 联合推断个性化阿凡达形状、蒙皮权重和姿势变形,提高几何保真度。
- 通过3D规范化过程解决姿态变化和耦合歧义问题,有助于重建精细几何细节。
- 采用多帧特征聚合技术,减少规范化产生的伪影,并保持个人身份特征。
- 在大规模捕获数据集上进行端到端框架训练,包含多种人类主题和高品质3D扫描配对。
点此查看论文截图

LAM: Large Avatar Model for One-shot Animatable Gaussian Head
Authors:Yisheng He, Xiaodong Gu, Xiaodan Ye, Chao Xu, Zhengyi Zhao, Yuan Dong, Weihao Yuan, Zilong Dong, Liefeng Bo
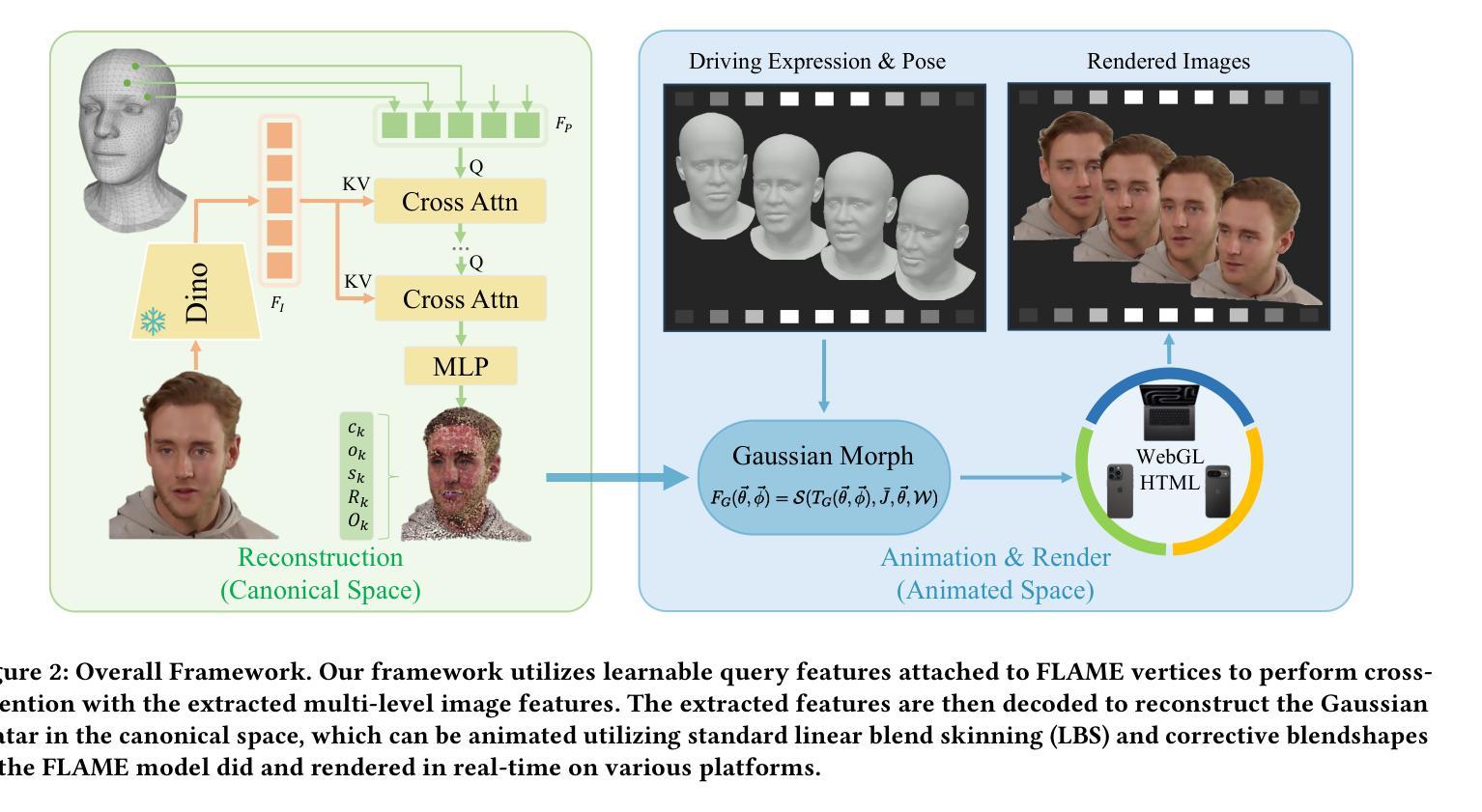
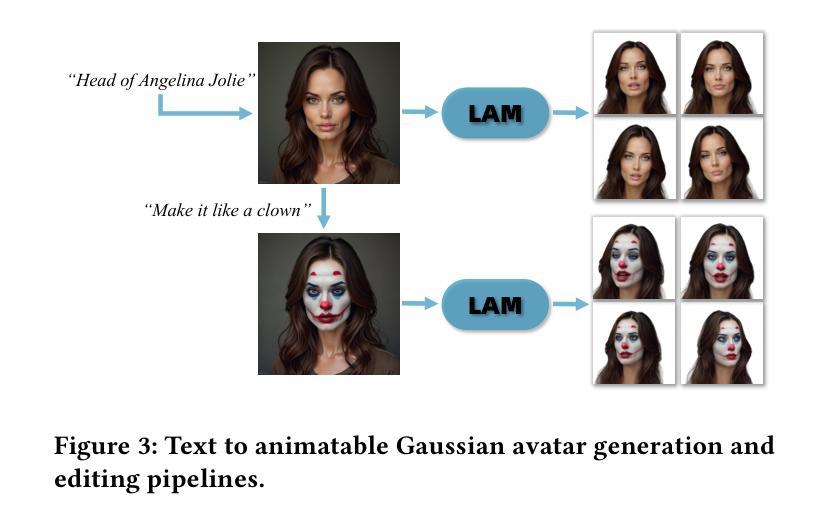
We present LAM, an innovative Large Avatar Model for animatable Gaussian head reconstruction from a single image. Unlike previous methods that require extensive training on captured video sequences or rely on auxiliary neural networks for animation and rendering during inference, our approach generates Gaussian heads that are immediately animatable and renderable. Specifically, LAM creates an animatable Gaussian head in a single forward pass, enabling reenactment and rendering without additional networks or post-processing steps. This capability allows for seamless integration into existing rendering pipelines, ensuring real-time animation and rendering across a wide range of platforms, including mobile phones. The centerpiece of our framework is the canonical Gaussian attributes generator, which utilizes FLAME canonical points as queries. These points interact with multi-scale image features through a Transformer to accurately predict Gaussian attributes in the canonical space. The reconstructed canonical Gaussian avatar can then be animated utilizing standard linear blend skinning (LBS) with corrective blendshapes as the FLAME model did and rendered in real-time on various platforms. Our experimental results demonstrate that LAM outperforms state-of-the-art methods on existing benchmarks. Our code and video are available at https://aigc3d.github.io/projects/LAM/
我们提出了LAM,这是一种用于从单张图像重建可动画的高斯头像的创新大型化身模型。与以往需要大量训练捕获的视频序列或依赖辅助神经网络进行推理过程中的动画和渲染的方法不同,我们的方法能够生成可立即动画化和渲染的高斯头像。具体来说,LAM通过一次前向传递创建可动画化的高斯头像,无需额外的网络或后处理步骤即可实现重演和渲染。这种能力可以无缝集成到现有的渲染管线中,确保在广泛的平台上实现实时动画和渲染,包括移动电话。我们框架的核心是规范高斯属性生成器,它利用FLAME规范点作为查询。这些点与多尺度图像特征通过变压器进行交互,以准确预测规范空间中的高斯属性。重建的规范高斯化身可以使用标准线性混合蒙皮(LBS)进行动画化,如同FLAME模型使用校正混合形状一样,并可在各种平台上实时渲染。我们的实验结果表明,LAM在现有基准测试上优于最先进的方法。我们的代码和视频可在https://aigc3d.github.io/projects/LAM/查看。
论文及项目相关链接
PDF Project Page: https://aigc3d.github.io/projects/LAM/ Source code: https://github.com/aigc3d/LAM
Summary
本文介绍了LAM模型,这是一种可从单张图像重建动态高斯头像的创新大型化身模型。不同于需要在对捕获的视频序列进行大量训练或依赖辅助神经网络进行推断时的动画和渲染的方法,LAM能够在单次前向传递中创建可动画化的高斯头像,实现无需额外网络或后处理步骤的重建、动画和渲染。这使得无缝集成到现有渲染管道成为可能,确保广泛平台(包括手机)上的实时动画和渲染。
Key Takeaways
- LAM是一种大型化身模型,可从单张图像重建动态高斯头像。
- 与其他方法不同,LAM在单次前向传递中生成可动画化的高斯头像。
- LAM不需要额外的网络或后处理步骤进行动画和渲染。
- LAM具有无缝集成到现有渲染管道的能力,适用于广泛平台。
- LAM的核心是规范高斯属性生成器,它利用FLAME规范点作为查询,通过Transformer与多尺度图像特征进行交互,以准确预测规范空间中的高斯属性。
- 重建的规范高斯化身可以使用标准线性混合皮肤(LBS)和修正blendshapes进行动画化。
点此查看论文截图

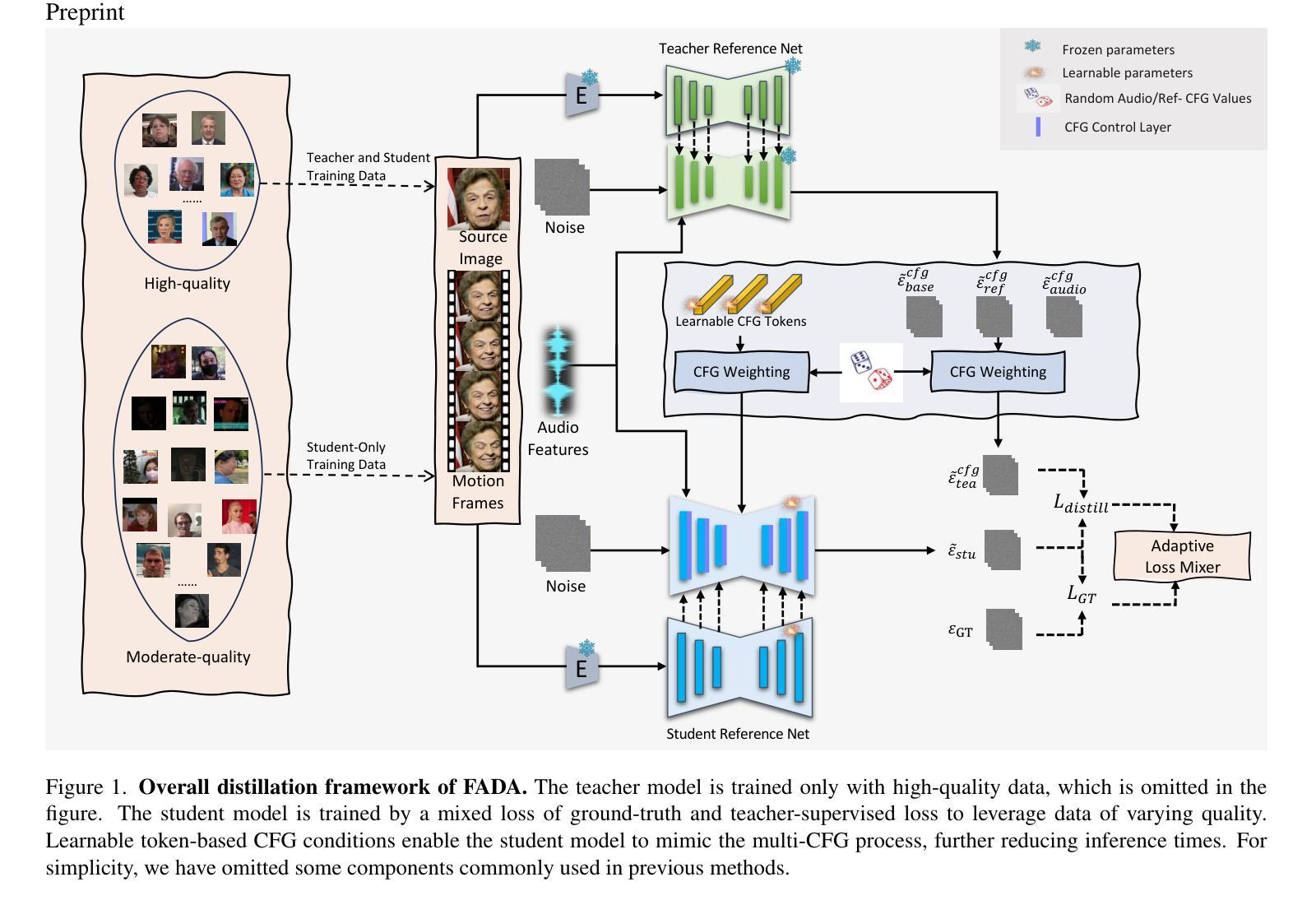
FADA: Fast Diffusion Avatar Synthesis with Mixed-Supervised Multi-CFG Distillation
Authors:Tianyun Zhong, Chao Liang, Jianwen Jiang, Gaojie Lin, Jiaqi Yang, Zhou Zhao
Diffusion-based audio-driven talking avatar methods have recently gained attention for their high-fidelity, vivid, and expressive results. However, their slow inference speed limits practical applications. Despite the development of various distillation techniques for diffusion models, we found that naive diffusion distillation methods do not yield satisfactory results. Distilled models exhibit reduced robustness with open-set input images and a decreased correlation between audio and video compared to teacher models, undermining the advantages of diffusion models. To address this, we propose FADA (Fast Diffusion Avatar Synthesis with Mixed-Supervised Multi-CFG Distillation). We first designed a mixed-supervised loss to leverage data of varying quality and enhance the overall model capability as well as robustness. Additionally, we propose a multi-CFG distillation with learnable tokens to utilize the correlation between audio and reference image conditions, reducing the threefold inference runs caused by multi-CFG with acceptable quality degradation. Extensive experiments across multiple datasets show that FADA generates vivid videos comparable to recent diffusion model-based methods while achieving an NFE speedup of 4.17-12.5 times. Demos are available at our webpage http://fadavatar.github.io.
基于扩散的音频驱动说话人偶方法因其高保真、生动、富有表现力的结果而最近受到关注。然而,它们较慢的推理速度限制了实际应用。尽管针对扩散模型开发了各种蒸馏技术,但我们发现简单的扩散蒸馏方法并没有产生令人满意的结果。与学生模型相比,蒸馏模型对开放集输入图像的稳健性降低,音频和视频的关联性也降低,这削弱了扩散模型的优势。为了解决这一问题,我们提出了FADA(带有混合监督多CFG蒸馏的快速扩散化身合成)。首先,我们设计了一种混合监督损失,以利用不同质量的数据,增强模型的整体能力和稳健性。此外,我们提出了一种带有可学习令牌的多CFG蒸馏,利用音频和参考图像条件之间的相关性,减少了多CFG引起的三倍推理运行,同时可接受质量降低。在多个数据集上的广泛实验表明,FADA生成的视频生动,与最近的扩散模型方法相当,同时实现了4.17-12.5倍的NFE加速。演示请访问我们的网页:FADA化身。
论文及项目相关链接
PDF CVPR 2025, Homepage https://fadavatar.github.io/
Summary
本文介绍了基于扩散模型的音频驱动说话人形象生成技术,虽然该技术能生成高质量、生动和形象的影像,但由于其推理速度较慢限制了实际应用。针对蒸馏技术在优化模型应用过程中的不足,作者提出了结合混合监督与多条件蒸馏技术的FADA方法,以提高模型的总体性能和鲁棒性,同时减少推理运行时间。通过多项实验证明,FADA生成的影像质量与扩散模型相近,而推理速度显著提升。具体详情可访问作者的网页。
Key Takeaways
- 扩散模型在音频驱动的说话人形象生成领域受到关注,因其能生成高质量、生动和形象的影像。
- 存在推理速度较慢的问题,限制了实际应用。
- 传统蒸馏技术对于扩散模型的优化效果不理想。
- 提出FADA方法,结合混合监督技术与多条件蒸馏技术。
- FADA设计混合监督损失,以利用不同质量的数据,提高模型的总体性能和鲁棒性。
- 通过提出的多条件蒸馏技术,减少推理运行时间并保持可接受的质量损失。
点此查看论文截图

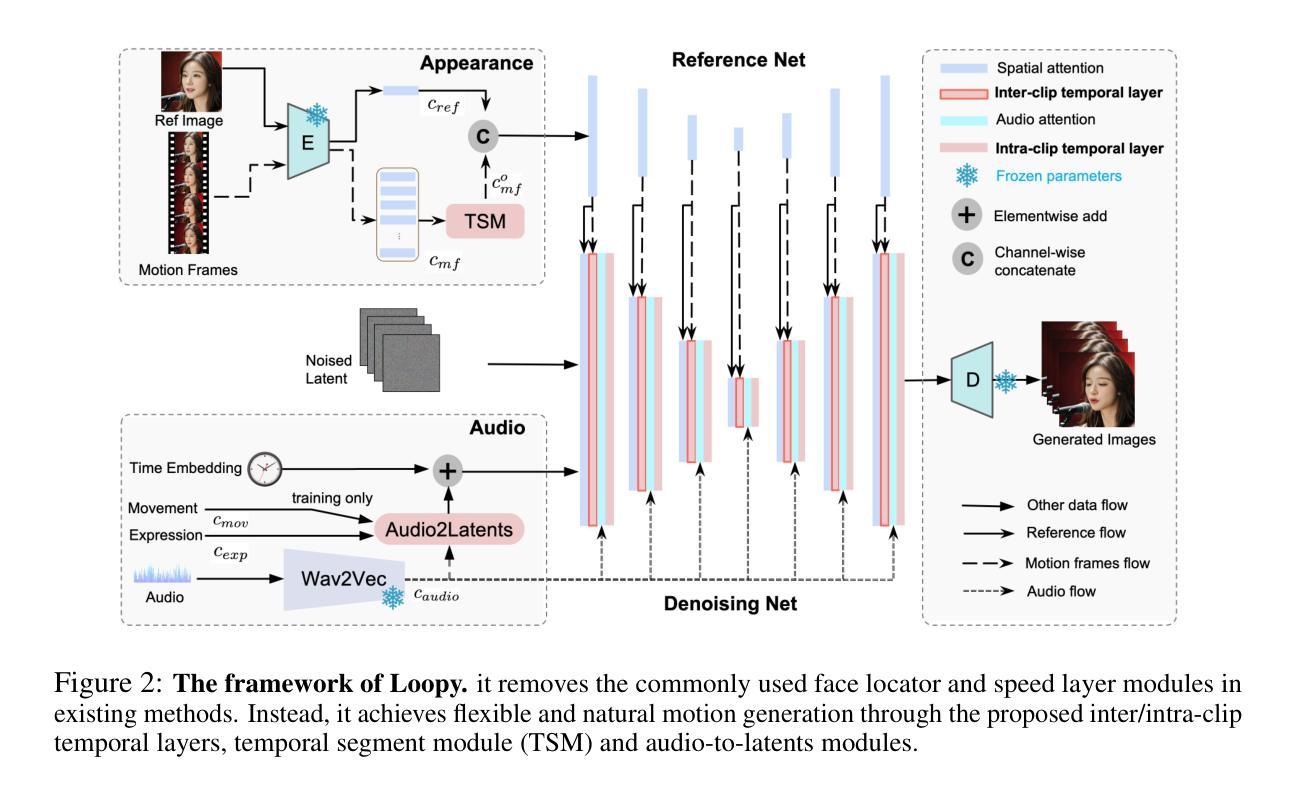
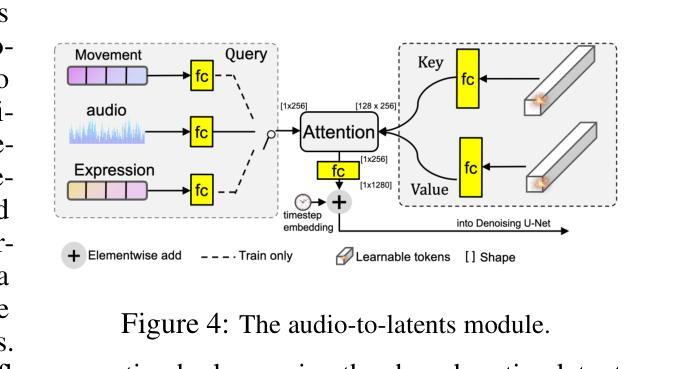
Loopy: Taming Audio-Driven Portrait Avatar with Long-Term Motion Dependency
Authors:Jianwen Jiang, Chao Liang, Jiaqi Yang, Gaojie Lin, Tianyun Zhong, Yanbo Zheng
With the introduction of diffusion-based video generation techniques, audio-conditioned human video generation has recently achieved significant breakthroughs in both the naturalness of motion and the synthesis of portrait details. Due to the limited control of audio signals in driving human motion, existing methods often add auxiliary spatial signals to stabilize movements, which may compromise the naturalness and freedom of motion. In this paper, we propose an end-to-end audio-only conditioned video diffusion model named Loopy. Specifically, we designed an inter- and intra-clip temporal module and an audio-to-latents module, enabling the model to leverage long-term motion information from the data to learn natural motion patterns and improving audio-portrait movement correlation. This method removes the need for manually specified spatial motion templates used in existing methods to constrain motion during inference. Extensive experiments show that Loopy outperforms recent audio-driven portrait diffusion models, delivering more lifelike and high-quality results across various scenarios.
随着基于扩散的视频生成技术的引入,音频条件下的视频生成在动作的自然性和肖像细节的合成方面都取得了重大突破。由于音频信号在驱动人类运动时的控制有限,现有方法往往添加辅助空间信号来稳定运动,这可能会损害运动的自然性和自由度。在本文中,我们提出了一种端到端的仅由音频驱动的视频扩散模型,名为Loopy。具体来说,我们设计了一个跨内剪辑的时间模块和一个音频到潜在特征的模块,使模型能够利用数据中的长期运动信息来学习自然运动模式,并提高音频与肖像运动的关联性。这种方法消除了现有方法中用于在推理过程中约束运动的手动指定空间运动模板的需要。大量实验表明,Loopy在多种场景下都优于最新的音频驱动肖像扩散模型,能产生更逼真、更高质量的结果。
论文及项目相关链接
PDF ICLR 2025 (Oral), Homepage: https://loopyavatar.github.io/
Summary
基于扩散的视频生成技术,音频驱动的人体视频生成在动作自然性和肖像细节合成方面取得了重大突破。为增强对音频信号的有限控制,现有方法常添加额外的空间信号来稳定动作,但可能影响动作的自然性和自由度。本文提出一种端到端的仅音频调节视频扩散模型Loopy,设计了跨内外剪辑的时间模块和音频到潜在特征模块,使模型能够利用数据中的长期动作信息学习自然动作模式,提高音频与肖像动作的相关性。该方法无需现有方法中用于约束推理过程中动作的手动指定空间运动模板。实验表明,Loopy在多种场景下表现优于最新的音频驱动肖像扩散模型,生成的结果更逼真、质量更高。
Key Takeaways
- 扩散视频生成技术使音频驱动的人体视频生成在动作和肖像细节方面取得突破。
- 现有方法使用额外的空间信号来稳定动作,但可能影响自然性和自由度。
- 提出一种名为Loopy的端到端音频调节视频扩散模型。
- Loopy设计了跨内外剪辑的时间模块和音频到潜在特征模块。
- Loopy能够利用数据中的长期动作信息学习自然动作模式。
- Loopy提高了音频与肖像动作的相关性,无需手动指定空间运动模板。
点此查看论文截图