⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-08 更新
Mamba as a Bridge: Where Vision Foundation Models Meet Vision Language Models for Domain-Generalized Semantic Segmentation
Authors:Xin Zhang, Robby T. Tan
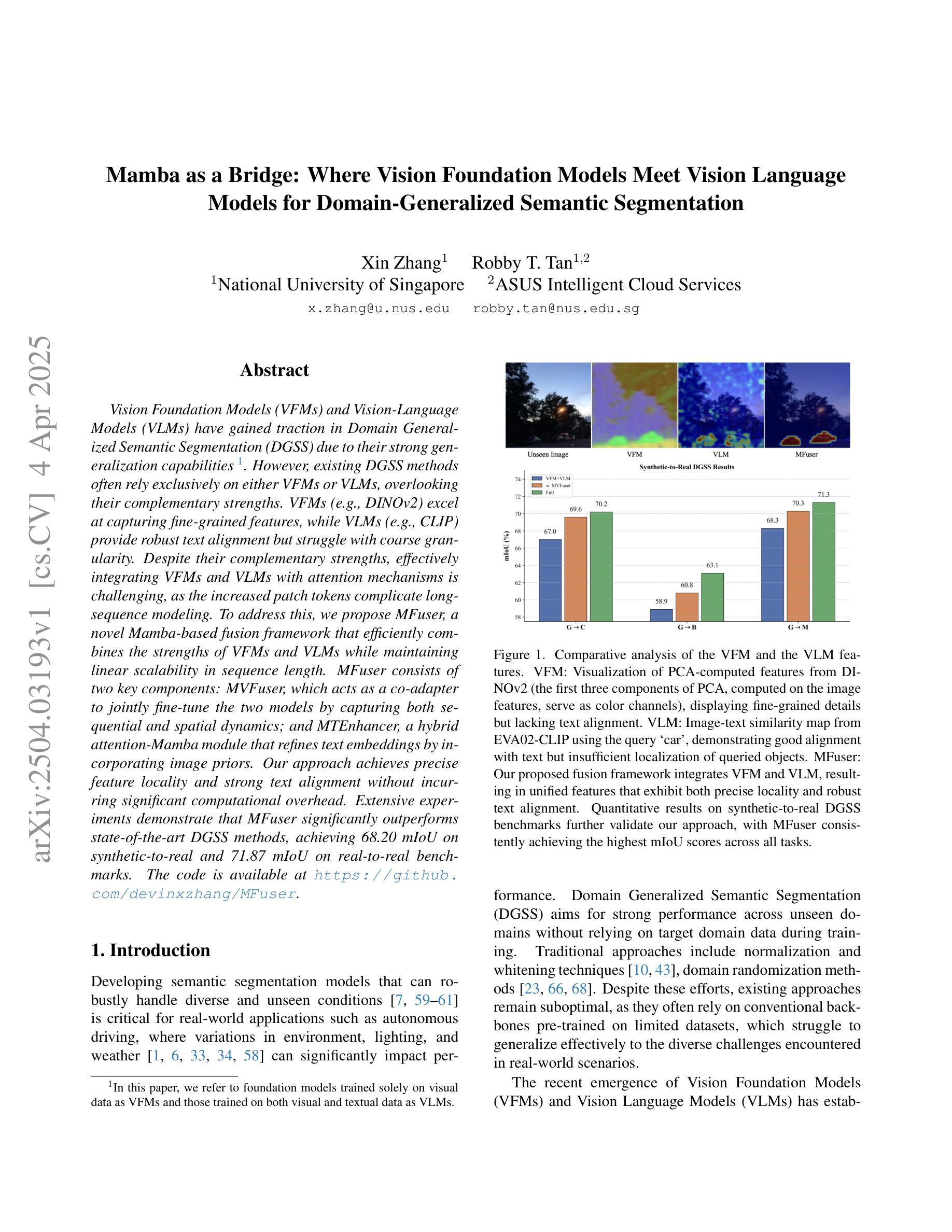
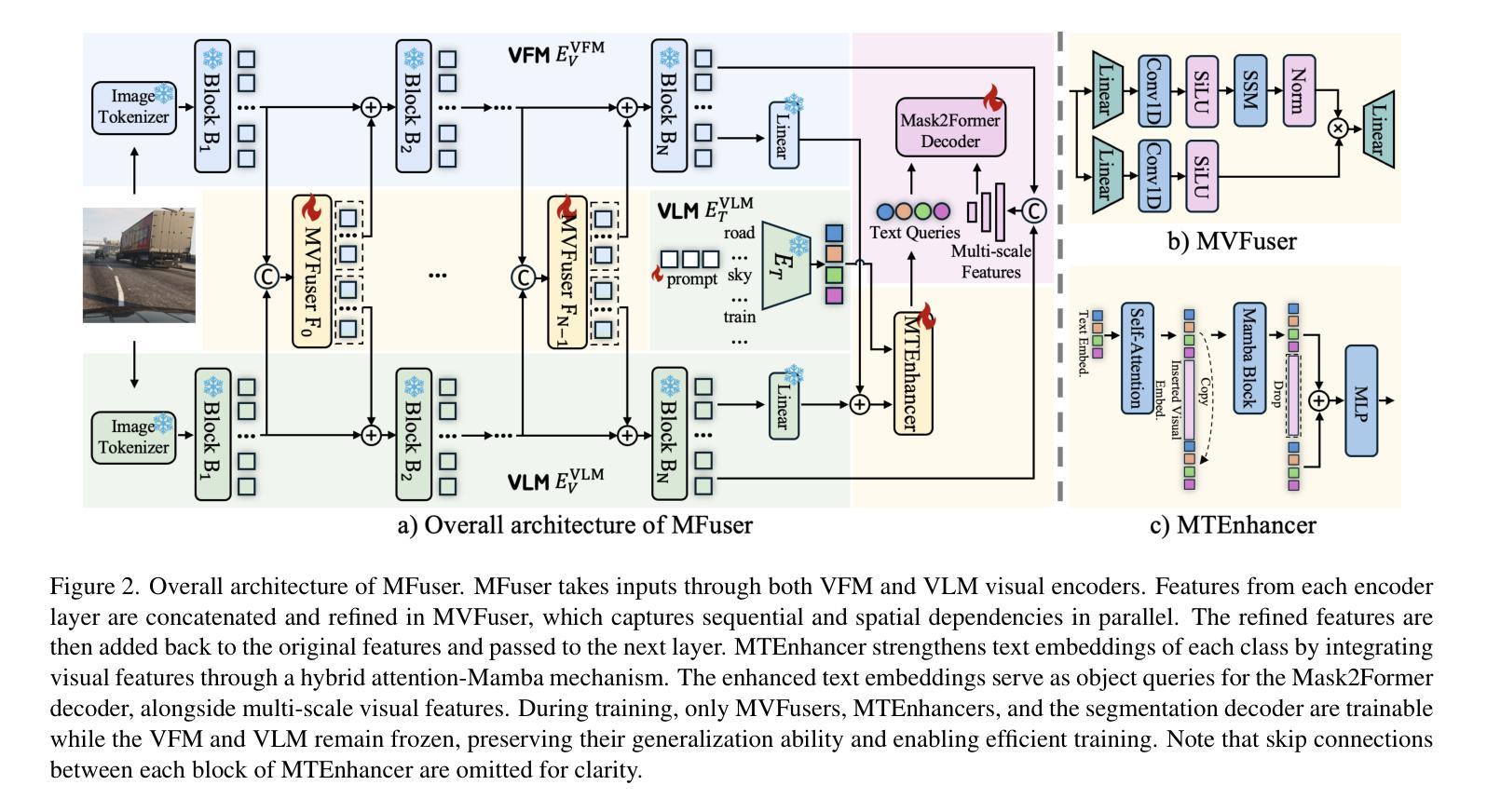
Vision Foundation Models (VFMs) and Vision-Language Models (VLMs) have gained traction in Domain Generalized Semantic Segmentation (DGSS) due to their strong generalization capabilities. However, existing DGSS methods often rely exclusively on either VFMs or VLMs, overlooking their complementary strengths. VFMs (e.g., DINOv2) excel at capturing fine-grained features, while VLMs (e.g., CLIP) provide robust text alignment but struggle with coarse granularity. Despite their complementary strengths, effectively integrating VFMs and VLMs with attention mechanisms is challenging, as the increased patch tokens complicate long-sequence modeling. To address this, we propose MFuser, a novel Mamba-based fusion framework that efficiently combines the strengths of VFMs and VLMs while maintaining linear scalability in sequence length. MFuser consists of two key components: MVFuser, which acts as a co-adapter to jointly fine-tune the two models by capturing both sequential and spatial dynamics; and MTEnhancer, a hybrid attention-Mamba module that refines text embeddings by incorporating image priors. Our approach achieves precise feature locality and strong text alignment without incurring significant computational overhead. Extensive experiments demonstrate that MFuser significantly outperforms state-of-the-art DGSS methods, achieving 68.20 mIoU on synthetic-to-real and 71.87 mIoU on real-to-real benchmarks. The code is available at https://github.com/devinxzhang/MFuser.
视觉基础模型(VFMs)和视觉语言模型(VLMs)由于其强大的泛化能力,在域通用语义分割(DGSS)中受到了广泛关注。然而,现有的DGSS方法往往仅依赖于VFMs或VLMs,忽略了它们的互补优势。VFMs(例如DINOv2)擅长捕捉细微特征,而VLMs(例如CLIP)则提供稳健的文本对齐,但在处理粗粒度数据时表现不佳。尽管它们具有互补优势,但如何有效地结合VFMs和VLMs的注意力机制仍然是一个挑战,因为增加的补丁令牌使得长序列建模变得复杂。为了解决这个问题,我们提出了MFuser,这是一个基于Mamba的新型融合框架,能够结合VFMs和VLMs的优势,同时保持序列长度的线性可扩展性。MFuser由两个关键组件组成:MVFuser,它作为协同适配器,通过捕捉序列和空间动态来共同微调两个模型;MTEnhancer是一个混合注意力Mamba模块,它通过融入图像先验来完善文本嵌入。我们的方法实现了精确的特征局部性和强大的文本对齐,而不会造成显著的计算开销。大量实验表明,MFuser显著优于最新的DGSS方法,在合成到现实的基准测试中实现了68.20 mIoU,在真实到真实的基准测试中实现了71.87 mIoU。代码可在https://github.com/devinxzhang/MFuser上找到。
论文及项目相关链接
PDF Accepted to CVPR 2025
Summary
本文介绍了在域泛化语义分割(DGSS)中,视觉基础模型(VFMs)和视觉语言模型(VLMs)的联合应用。现有方法往往只专注于其中一种模型,忽略了它们的互补优势。为此,本文提出了MFuser框架,该框架能够高效结合VFMs和VLMs的优势,并在序列长度上保持线性可扩展性。通过MFuser的两个关键组件——MVFuser和MTEnhancer,实现了精确的特征局部性和强大的文本对齐。实验表明,MFuser显著优于现有的DGSS方法,在合成到现实和真实到现实的基准测试中分别达到了68.20 mIoU和71.87 mIoU。
Key Takeaways
- VFMs和VLMs在DGSS中具有强大的泛化能力,但现有方法往往只专注于其中之一,忽略了它们的互补优势。
- VFMs(如DINOv2)擅长捕捉细微特征,而VLMs(如CLIP)提供稳健的文本对齐,但在粗粒度方面表现较差。
- MFuser是一个基于Mamba的融合框架,能够结合VFMs和VLMs的优势,并维持序列长度的线性可扩展性。
- MFuser包含两个关键组件:MVFuser用于联合微调两种模型,捕捉序列和空间的动态变化;MTEnhancer是一个混合注意力-Mamba模块,通过融入图像先验来优化文本嵌入。
- MFuser实现了精确的特征局部性和强大的文本对齐,且不会带来显著的计算开销。
- 实验结果表明,MFuser显著优于现有的DGSS方法,在特定基准测试中达到了高达68.20 mIoU和71.87 mIoU的性能。
点此查看论文截图
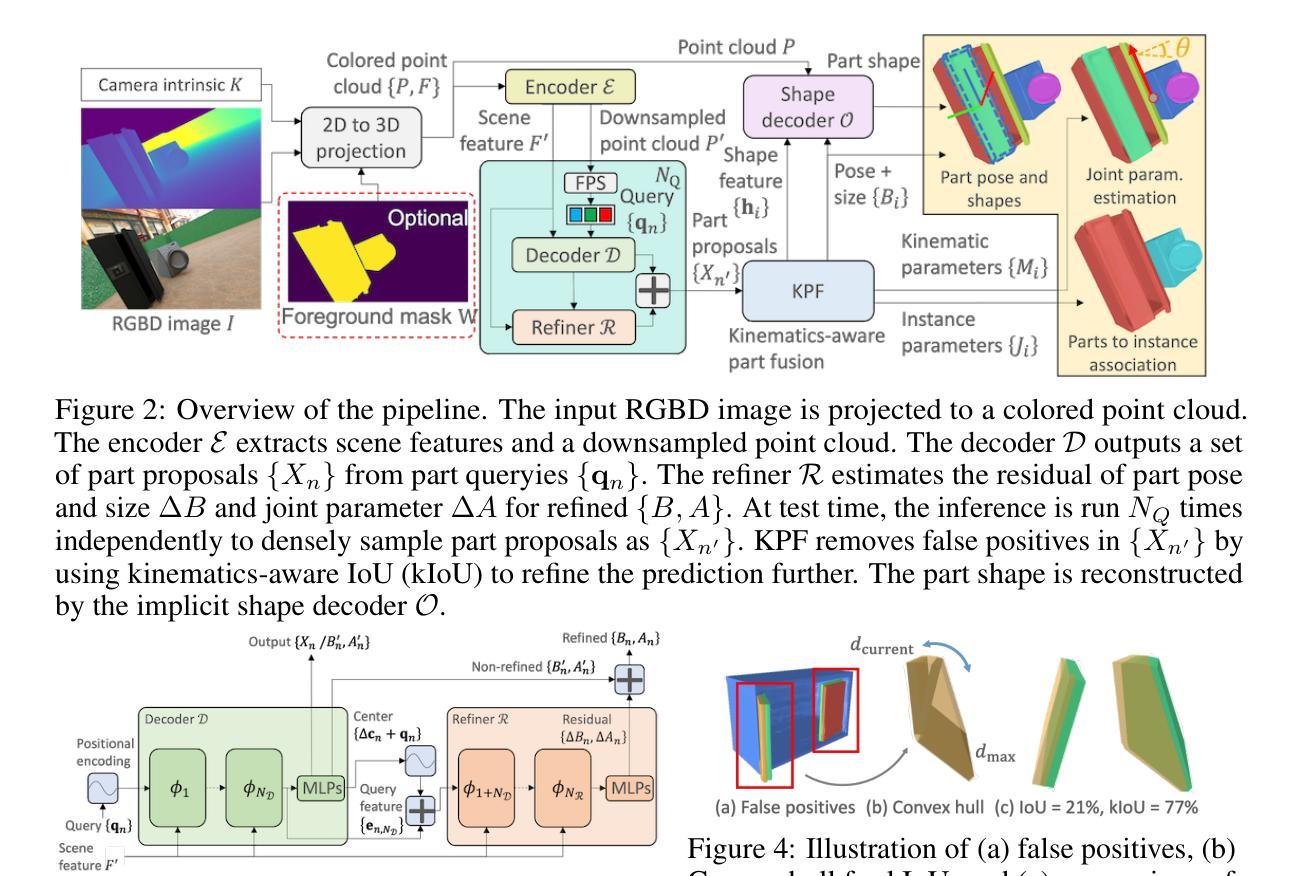
Detection Based Part-level Articulated Object Reconstruction from Single RGBD Image
Authors:Yuki Kawana, Tatsuya Harada
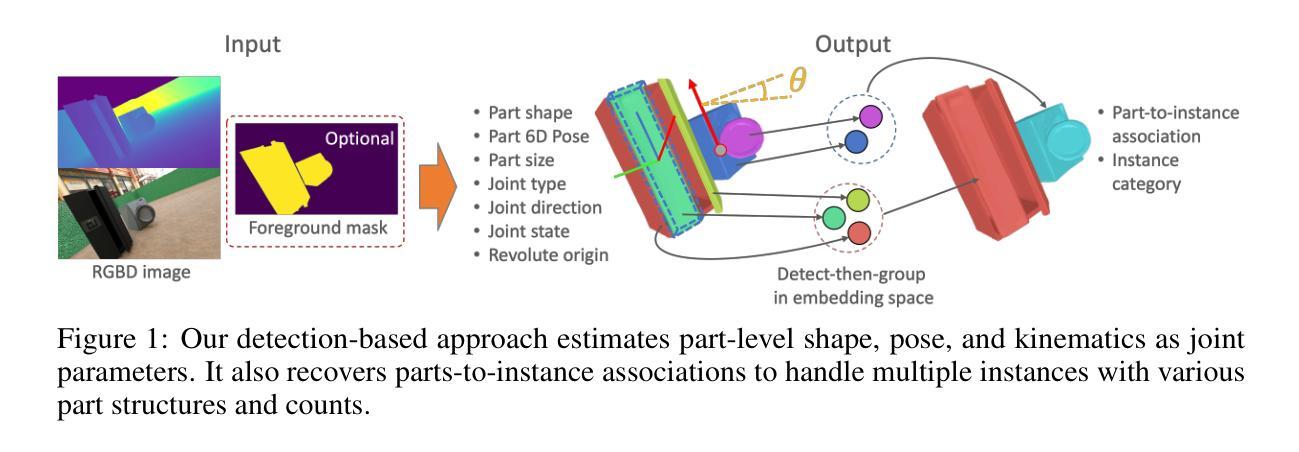
We propose an end-to-end trainable, cross-category method for reconstructing multiple man-made articulated objects from a single RGBD image, focusing on part-level shape reconstruction and pose and kinematics estimation. We depart from previous works that rely on learning instance-level latent space, focusing on man-made articulated objects with predefined part counts. Instead, we propose a novel alternative approach that employs part-level representation, representing instances as combinations of detected parts. While our detect-then-group approach effectively handles instances with diverse part structures and various part counts, it faces issues of false positives, varying part sizes and scales, and an increasing model size due to end-to-end training. To address these challenges, we propose 1) test-time kinematics-aware part fusion to improve detection performance while suppressing false positives, 2) anisotropic scale normalization for part shape learning to accommodate various part sizes and scales, and 3) a balancing strategy for cross-refinement between feature space and output space to improve part detection while maintaining model size. Evaluation on both synthetic and real data demonstrates that our method successfully reconstructs variously structured multiple instances that previous works cannot handle, and outperforms prior works in shape reconstruction and kinematics estimation.
我们提出了一种端到端可训练的跨类别方法,用于从单个RGBD图像重建多个人造关节对象,重点关注部分级别的形状重建和姿态及运动学估计。我们不同于以前依赖学习实例级潜在空间的工作,主要关注具有预定义部分数量的人造关节对象。相反,我们提出了一种新型替代方法,采用部分级别的表示形式,将实例表示为检测到的部分的组合。虽然我们的“先检测后分组”的方法有效地处理了具有不同部分结构和不同部分数量的实例,但它面临着误报、部分大小和比例不一以及由于端到端训练导致的模型大小增加等问题。为了解决这些挑战,我们提出了以下策略:1)测试时的运动学感知部分融合,以提高检测性能并抑制误报;2)用于部分形状学习的各向异性尺度归一化,以适应各种部分大小和比例;3)特征空间和输出空间之间的跨细化平衡策略,以提高部分检测的同时保持模型大小。在合成数据和真实数据上的评估表明,我们的方法能够成功重建以前的工作无法处理的结构各异的多个实例,并在形状重建和运动学估计方面优于先前的工作。
论文及项目相关链接
PDF Accepted to NeurIPS 2023
Summary
本文提出一种端到端可训练的跨类别方法,从单一RGBD图像中重建多个人造关节对象,重点关注部件级别的形状重建和姿态动力学估计。该方法采用部件级表示,将实例表示为检测到的部件的组合,有效处理具有不同部件结构和计数的实例。为应对检测中的误报、部件尺寸和尺度的变化以及模型尺寸增大等问题,提出测试时动力学感知部件融合、各向异性尺度归一化用于部件形状学习和特征空间与输出空间之间的平衡策略。评估表明,该方法在形状重建和动力学估计方面优于以前的工作,并能够成功重建以前无法处理的多实例。
Key Takeaways
- 提出一种从单一RGBD图像重建多个人造关节对象的方法,涵盖多种部件结构和计数的实例。
- 重点关注部件级别的形状重建和姿态动力学估计。
- 采用测试时动力学感知部件融合,提高检测性能并抑制误报。
- 实施各向异性尺度归一化,以适应各种部件尺寸和尺度。
- 提出特征空间与输出空间之间的平衡策略,改善部件检测同时保持模型尺寸。
- 在合成和真实数据上的评估显示,该方法在形状重建和动力学估计方面优于先前的工作。
点此查看论文截图


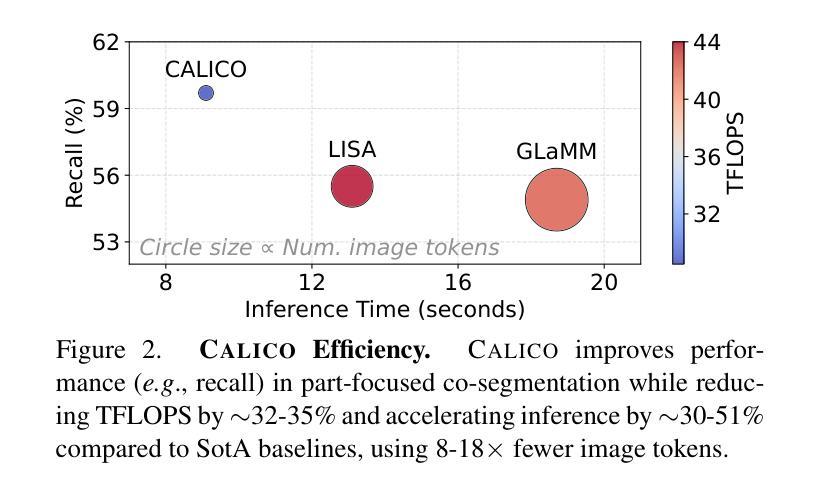
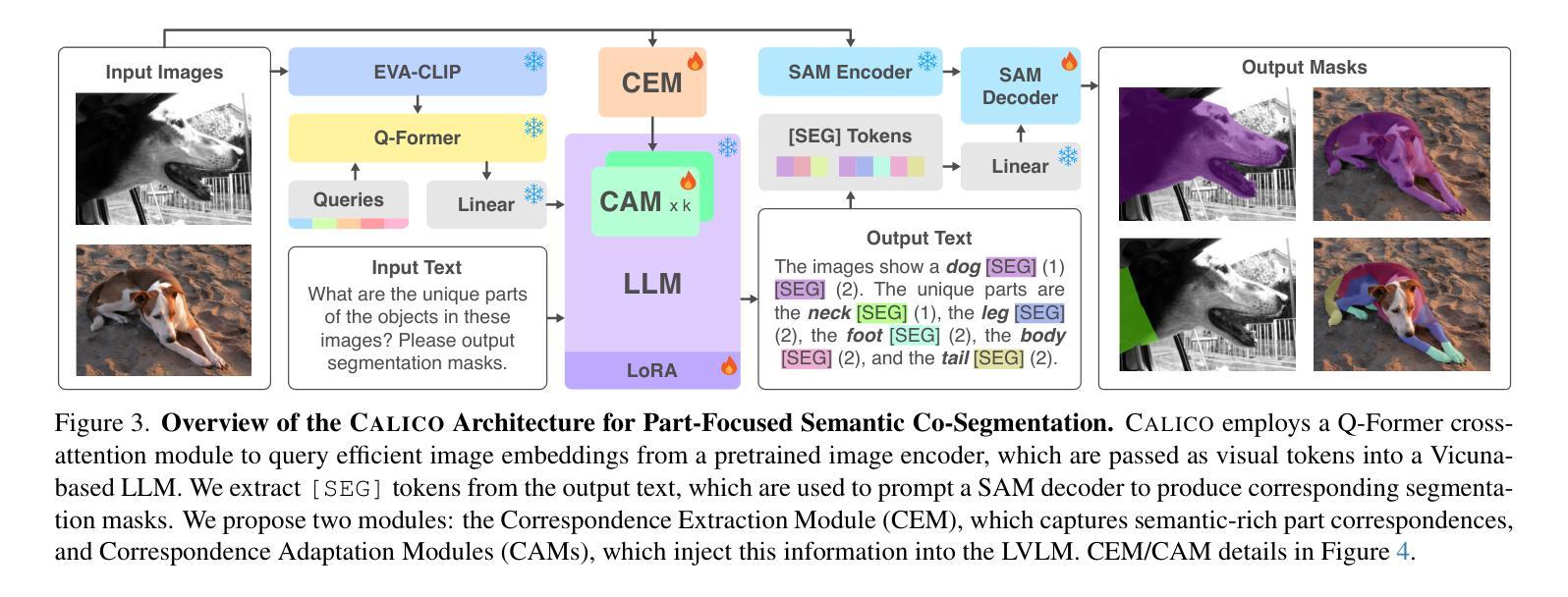
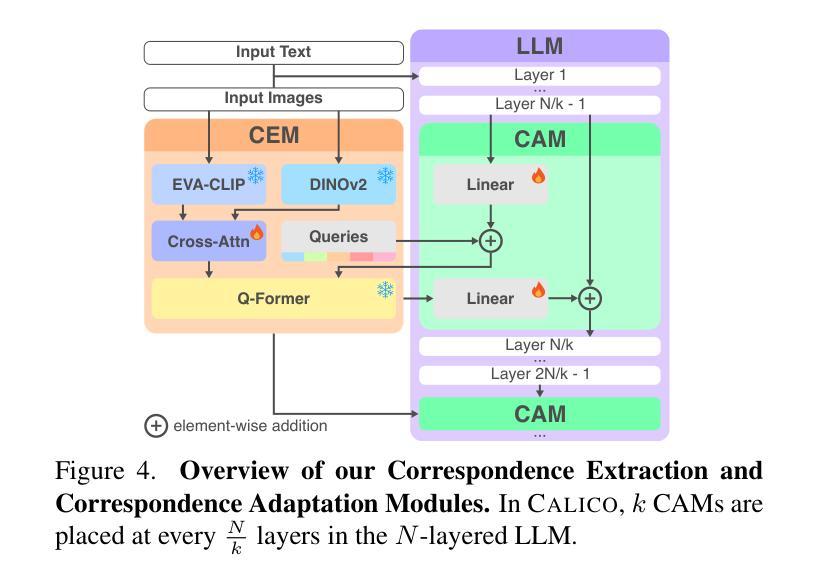
CALICO: Part-Focused Semantic Co-Segmentation with Large Vision-Language Models
Authors:Kiet A. Nguyen, Adheesh Juvekar, Tianjiao Yu, Muntasir Wahed, Ismini Lourentzou
Recent advances in Large Vision-Language Models (LVLMs) have enabled general-purpose vision tasks through visual instruction tuning. While existing LVLMs can generate segmentation masks from text prompts for single images, they struggle with segmentation-grounded reasoning across images, especially at finer granularities such as object parts. In this paper, we introduce the new task of part-focused semantic co-segmentation, which involves identifying and segmenting common objects, as well as common and unique object parts across images. To address this task, we present CALICO, the first LVLM designed for multi-image part-level reasoning segmentation. CALICO features two key components, a novel Correspondence Extraction Module that identifies semantic part-level correspondences, and Correspondence Adaptation Modules that embed this information into the LVLM to facilitate multi-image understanding in a parameter-efficient manner. To support training and evaluation, we curate MixedParts, a large-scale multi-image segmentation dataset containing $\sim$2.4M samples across $\sim$44K images spanning diverse object and part categories. Experimental results demonstrate that CALICO, with just 0.3% of its parameters finetuned, achieves strong performance on this challenging task.
近期大型视觉语言模型(LVLMs)的进步通过视觉指令调整实现了通用视觉任务。虽然现有的LVLMs可以通过文本提示对单图像生成分割掩膜,但它们在进行跨图像的分段基础推理时遇到困难,尤其是在较细的粒度(如物体部位)上。本文介绍了全新的部分聚焦语义协同分割任务,该任务涉及识别并分割跨图像中的常见物体以及常见和独特的物体部位。为了解决此任务,我们推出了CALICO,这是专为多图像部分级推理分割设计的首个LVLM。CALICO有两个关键组件:新型对应提取模块,用于识别语义部分级对应关系;对应适应模块,将这一信息嵌入LVLM中,以高效参数的方式促进多图像理解。为了支持和评估训练,我们整理了MixedParts,这是一个大规模的多图像分割数据集,包含约240万样本,跨越约4.4万张图像,涵盖多样化的对象和部位类别。实验结果表明,CALICO仅微调其0.3%的参数,就能在此具有挑战性的任务上取得强劲表现。
论文及项目相关链接
PDF Accepted to CVPR 2025. Project page: https://plan-lab.github.io/calico/
Summary
本文介绍了大型视觉语言模型(LVLMs)的最新进展,能够通过视觉指令微调完成通用视觉任务。针对现有LVLMs在跨图像分割推理方面的不足,特别是在对象部分的更精细粒度上的挑战,本文引入了部分聚焦语义协同分割的新任务。为应对这一任务,提出了CALICO,首款用于多图像部分级推理分割的LVLM。CALICO有两个关键组件:对应提取模块,用于识别语义部分级对应关系;对应适配模块,将信息嵌入LVLM,以高效参数的方式实现多图像理解。为支持训练和评估,我们整理了MixedParts,一个大规模多图像分割数据集,包含约240万样本,涵盖约4万张图像,涉及多种对象和部件类别。实验结果表明,CALICO仅需微调其参数的0.3%,就能在这个具有挑战性的任务上取得出色表现。
Key Takeaways
- 大型视觉语言模型(LVLMs)可通过视觉指令微调完成通用视觉任务。
- 现有LVLMs在跨图像分割推理方面存在不足,特别是在对象部分的精细粒度上。
- 引入了部分聚焦语义协同分割的新任务。
- 提出了CALICO模型,用于多图像部分级推理分割。
- CALICO包含两个关键组件:对应提取模块和对应适配模块。
- 为了支持训练和评估,整理了一个大规模多图像分割数据集MixedParts。
点此查看论文截图