⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-08 更新
GraphSeg: Segmented 3D Representations via Graph Edge Addition and Contraction
Authors:Haozhan Tang, Tianyi Zhang, Oliver Kroemer, Matthew Johnson-Roberson, Weiming Zhi
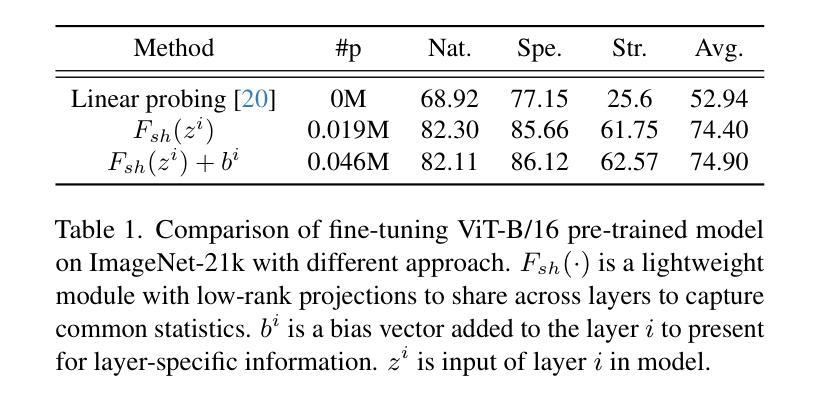
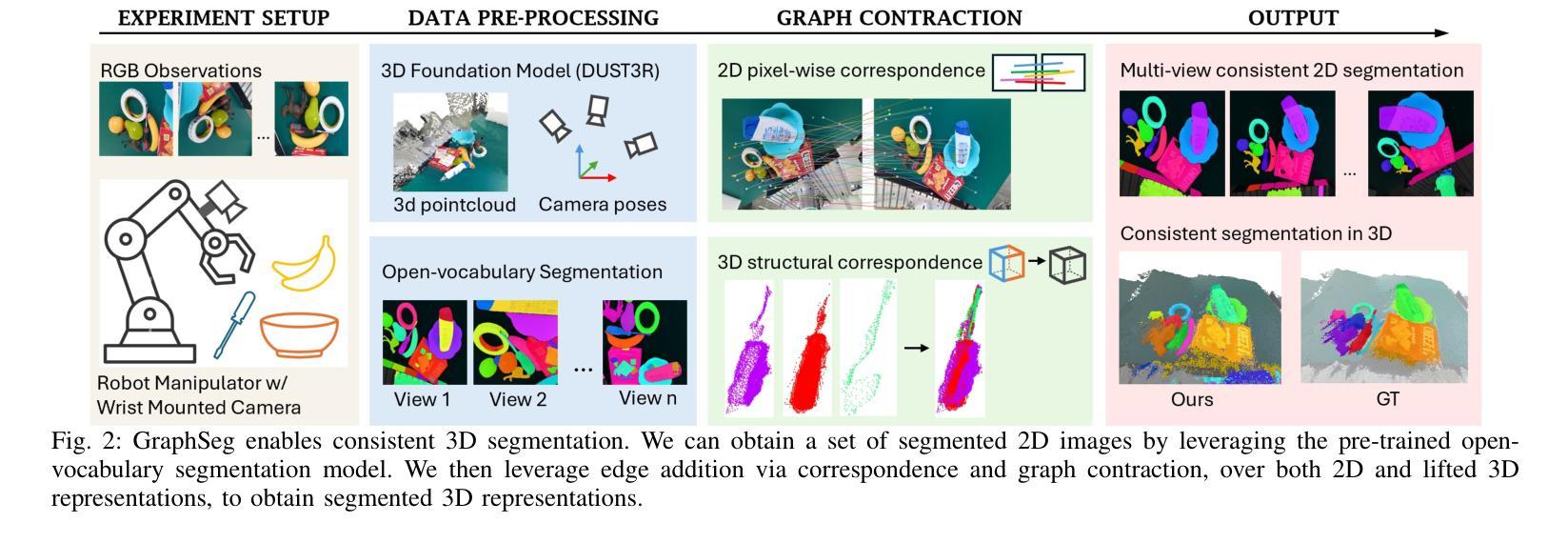
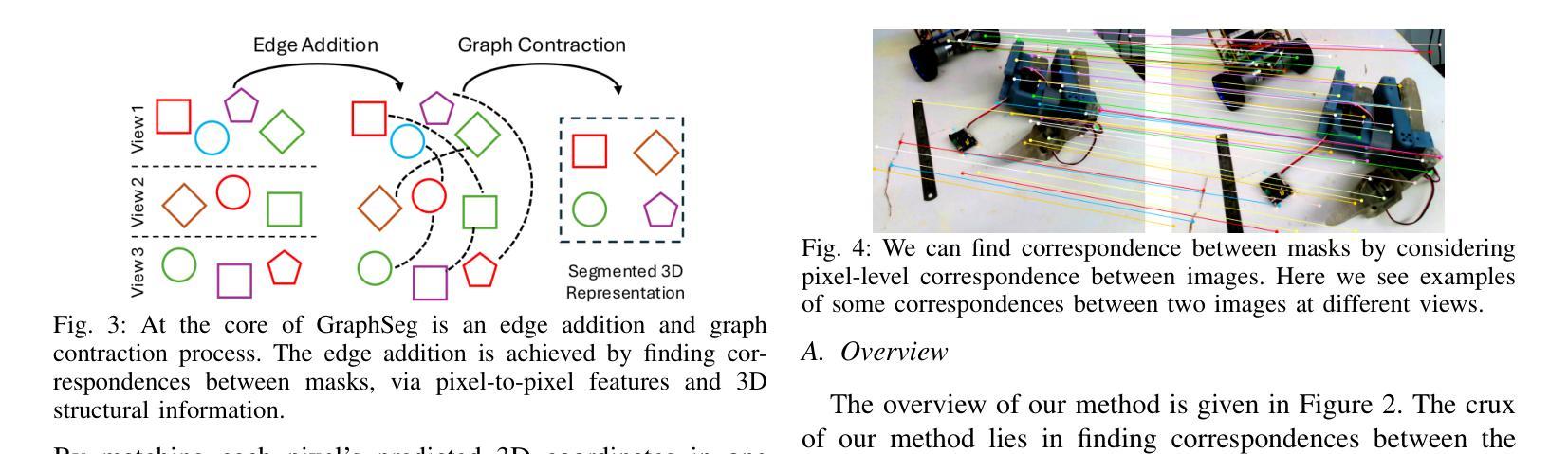
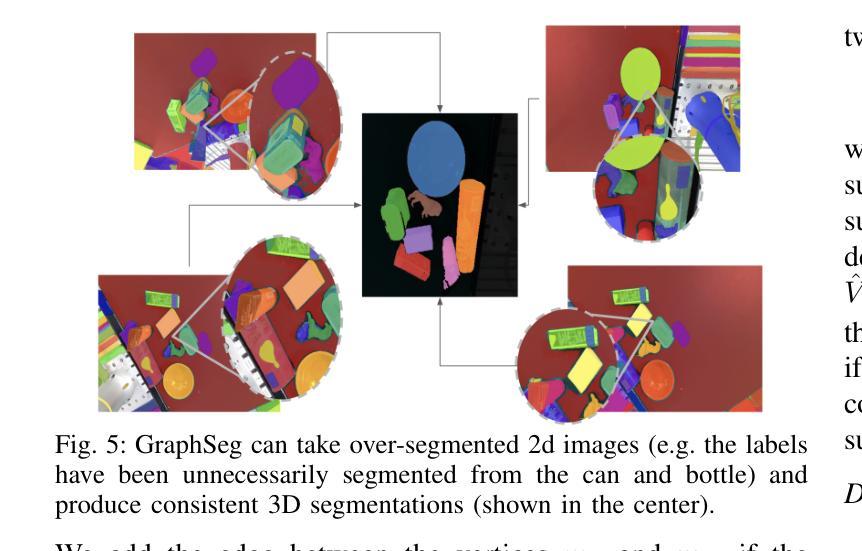
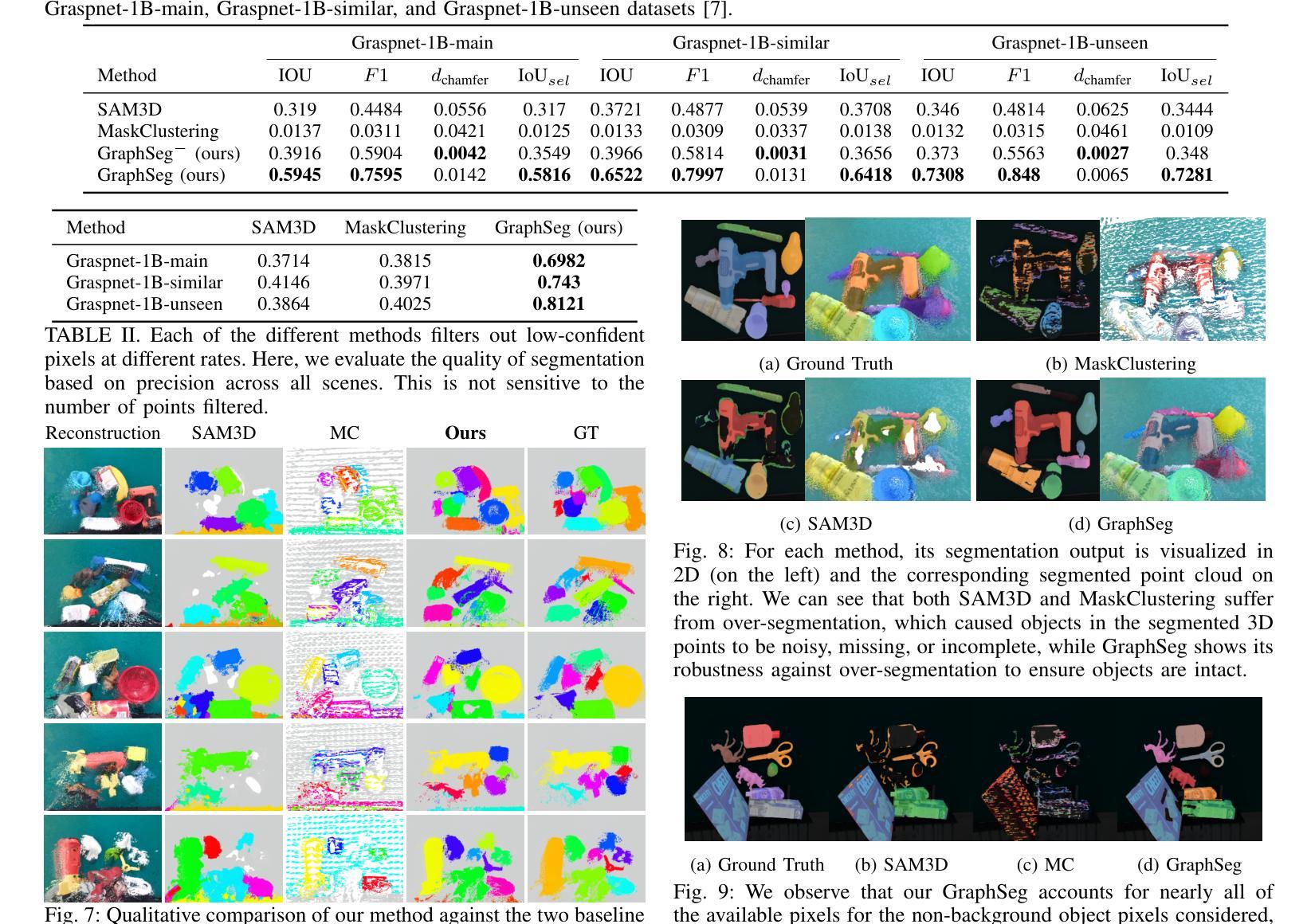
Robots operating in unstructured environments often require accurate and consistent object-level representations. This typically requires segmenting individual objects from the robot’s surroundings. While recent large models such as Segment Anything (SAM) offer strong performance in 2D image segmentation. These advances do not translate directly to performance in the physical 3D world, where they often over-segment objects and fail to produce consistent mask correspondences across views. In this paper, we present GraphSeg, a framework for generating consistent 3D object segmentations from a sparse set of 2D images of the environment without any depth information. GraphSeg adds edges to graphs and constructs dual correspondence graphs: one from 2D pixel-level similarities and one from inferred 3D structure. We formulate segmentation as a problem of edge addition, then subsequent graph contraction, which merges multiple 2D masks into unified object-level segmentations. We can then leverage \emph{3D foundation models} to produce segmented 3D representations. GraphSeg achieves robust segmentation with significantly fewer images and greater accuracy than prior methods. We demonstrate state-of-the-art performance on tabletop scenes and show that GraphSeg enables improved performance on downstream robotic manipulation tasks. Code available at https://github.com/tomtang502/graphseg.git.
在结构环境中操作的机器人通常需要准确且一致的对象级表示。这通常需要分割机器人周围环境中的单个物体。虽然最近的大型模型(例如Anything Segmenter(SAM))在二维图像分割方面表现出强大的性能,但这些进展并不能直接转化为在物理三维世界的表现,因为在物理世界中它们经常过度分割物体,并且在不同视角之间无法产生一致的掩膜对应关系。在本文中,我们提出了GraphSeg,这是一个从环境的稀疏二维图像集生成一致的三维对象分割的框架,无需任何深度信息。GraphSeg向图中添加边并构建双重对应图:一个基于二维像素级相似性,另一个基于推断的三维结构。我们将分割形式化为一个增边问题,然后进行随后的图收缩,将多个二维掩膜合并为统一的对象级分割。然后,我们可以利用“三维基础模型”来产生分割的三维表示。GraphSeg在显著减少图像数量和提高准确性的情况下实现了稳健的分割,超过了先前的方法。我们在桌面场景上展示了最先进的性能,并证明GraphSeg能改善下游的机器人操作任务性能。代码可用在https://github.com/tomtang502/graphseg.git。
论文及项目相关链接
Summary
本文提出了GraphSeg框架,用于从环境的稀疏2D图像集生成一致的3D对象分割,而无需任何深度信息。通过构建双重对应图,GraphSeg解决了从像素级别相似性推断的二维图和从推断的三维结构得到的图的边缘添加问题,随后通过图收缩合并多个二维掩膜,形成统一的对象级分割。该方法使用三维基础模型产生分割的三维表示,实现了稳健的分割,所需的图像数量更少,准确性更高。在桌面场景和下游机器人操作任务中均表现出卓越性能。
Key Takeaways
- GraphSeg解决了机器人在非结构化环境中操作时需要准确且一致的对象级表示的问题。
- GraphSeg框架能够从稀疏的二维图像集生成三维对象的分割。
- 该方法通过构建双重对应图(一个基于二维像素级相似性,另一个基于推断的三维结构)来工作。
- GraphSeg将分割问题转化为边缘添加和图收缩问题,合并多个二维掩膜以形成统一的对象级分割。
- 利用三维基础模型产生分割的三维表示,提高了分割的准确性和稳健性。
- 与现有方法相比,GraphSeg在桌面场景上的表现达到了最新水平。
点此查看论文截图


Real Time Animator: High-Quality Cartoon Style Transfer in 6 Animation Styles on Images and Videos
Authors:Liuxin Yang, Priyanka Ladha
This paper presents a comprehensive pipeline that integrates state-of-the-art techniques to achieve high-quality cartoon style transfer for educational images and videos. The proposed approach combines the Inversion-based Style Transfer (InST) framework for both image and video style stylization, the Pre-Trained Image Processing Transformer (IPT) for post-denoising, and the Domain-Calibrated Translation Network (DCT-Net) for more consistent video style transfer. By fine-tuning InST with specific cartoon styles, applying IPT for artifact reduction, and leveraging DCT-Net for temporal consistency, the pipeline generates visually appealing and educationally effective stylized content. Extensive experiments and evaluations using the scenery and monuments dataset demonstrate the superiority of the proposed approach in terms of style transfer accuracy, content preservation, and visual quality compared to the baseline method, AdaAttN. The CLIP similarity scores further validate the effectiveness of InST in capturing style attributes while maintaining semantic content. The proposed pipeline streamlines the creation of engaging educational content, empowering educators and content creators to produce visually captivating and informative materials efficiently.
本文提出了一种全面的流程,集成了最新的技术,以实现高质量的教育图像和视频的卡通风格转换。所提出的方法结合了基于反演的样式转移(InST)框架,用于图像和视频风格的风格化,预训练图像处理转换器(IPT)用于去噪后处理,以及领域校准翻译网络(DCT-Net)用于更一致的视频风格转换。通过对InST进行微调以适应特定的卡通风格,使用IPT进行伪影减少,并利用DCT-Net实现时间一致性,该流程生成了视觉上吸引人且教育有效的风格化内容。使用风景和纪念碑数据集进行的广泛实验和评估表明,与基线方法AdaAttN相比,所提出的方法在风格转移准确性、内容保留和视觉质量方面更具优势。CLIP相似度得分进一步验证了InST在捕获风格属性同时保持语义内容的有效性。所提议的流程简化了引人入胜的教育内容的创建过程,使教育工作者和内容创建者能够高效地产生视觉引人入胜且信息丰富的材料。
论文及项目相关链接
PDF 9 pages, images and videos with link
Summary
本文介绍了一条综合管道,融合了最先进的技术,实现高质量卡通风格转换,用于教育图像和视频。通过微调基于反转的风格转换框架实现图像和视频风格的卡通化,采用预训练的图像处理器变换器进行降噪处理,并引入领域校准翻译网络实现更一致的视频风格转换。实验证明,该方法在风格转换精度、内容保留和视觉质量方面优于基线方法AdaAttN。所提管道简化了引人入胜教育内容的创建流程,使教育工作者和内容创作者能够高效制作视觉吸引和富有信息量的材料。
Key Takeaways
- 融合多种先进技术实现高质量卡通风格转换。
- 利用反转风格转换框架进行图像和视频卡通化处理。
- 采用预训练图像处理器变换器进行降噪。
- 领域校准翻译网络实现视频风格转换的一致性。
- 实验证明该方法在风格转换精度、内容保留和视觉质量方面表现优越。
- CLIP相似性得分验证了风格转换中捕捉风格属性和保持语义内容的能力。
- 该管道简化了教育内容的创建流程,提高制作效率。
点此查看论文截图