⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-08 更新
Align to Structure: Aligning Large Language Models with Structural Information
Authors:Zae Myung Kim, Anand Ramachandran, Farideh Tavazoee, Joo-Kyung Kim, Oleg Rokhlenko, Dongyeop Kang
Generating long, coherent text remains a challenge for large language models (LLMs), as they lack hierarchical planning and structured organization in discourse generation. We introduce Structural Alignment, a novel method that aligns LLMs with human-like discourse structures to enhance long-form text generation. By integrating linguistically grounded discourse frameworks into reinforcement learning, our approach guides models to produce coherent and well-organized outputs. We employ a dense reward scheme within a Proximal Policy Optimization framework, assigning fine-grained, token-level rewards based on the discourse distinctiveness relative to human writing. Two complementary reward models are evaluated: the first improves readability by scoring surface-level textual features to provide explicit structuring, while the second reinforces deeper coherence and rhetorical sophistication by analyzing global discourse patterns through hierarchical discourse motifs, outperforming both standard and RLHF-enhanced models in tasks such as essay generation and long-document summarization. All training data and code will be publicly shared at https://github.com/minnesotanlp/struct_align.
生成长文并使其保持连贯性对于大型语言模型(LLM)来说仍然是一个挑战,因为它们缺乏层次性的规划和结构化组织来进行文本生成。我们引入了结构对齐这一新方法,通过使LLM与人类一样的文本结构进行对齐,以提升长文本生成的能力。通过结合语言学的文本框架并应用于强化学习,我们的方法能引导模型产生连贯、组织良好的输出。我们在接近策略优化框架内采用了一种密集的奖励方案,根据与人类写作相比的文本特征精细度来分配令牌级别的奖励。评估了两种互补的奖励模型:第一种通过评分表面级的文本特征来提高可读性,提供明确的结构;第二种通过层次化的文本模式分析来加强更深层次的连贯性和修辞技巧,在诸如作文生成和长文档摘要等任务中表现出优于标准模型和增强型RLHF模型的性能。所有训练数据和代码将在https://github.com/minnesotanlp/struct_align上公开分享。
论文及项目相关链接
Summary
大语言模型(LLM)在生成长篇连贯文本时存在挑战,缺乏层次规划和结构化组织。为此,我们提出了结构对齐法,通过整合语言基础的话语框架和强化学习,使LLMs与人类话语结构对齐,提升长篇文本生成能力。我们采用密集奖励方案,在近端策略优化框架内,根据话语的鲜明性相对于人类写作给予精细标记奖励。评估了两种互补奖励模型,第一种通过评分表面文本特征提高可读性,提供明确的结构性;第二种通过识别全局话语模式加强深层次连贯性和修辞技巧。此方法在作文生成和长文档摘要等任务中表现优于标准模型和RLHF增强模型。相关训练数据和代码将公开分享在https://github.com/minnesotanlp/struct_align。
Key Takeaways
- LLM在生成长篇连贯文本时存在挑战,缺乏层次规划和结构化组织。
- 提出了结构对齐法,通过整合语言基础的话语框架和强化学习来提升LLM的长篇文本生成能力。
- 采用密集奖励方案,根据话语的鲜明性相对于人类写作给予精细标记奖励。
- 有两种互补奖励模型,分别关注提高可读性和加强深层次连贯性及修辞技巧。
- 该方法通过明确的结构性和对全局话语模式的识别来改进LLM的话语生成。
- 此方法在作文生成和长文档摘要等任务中的表现优于标准模型和RLHF增强模型。
点此查看论文截图


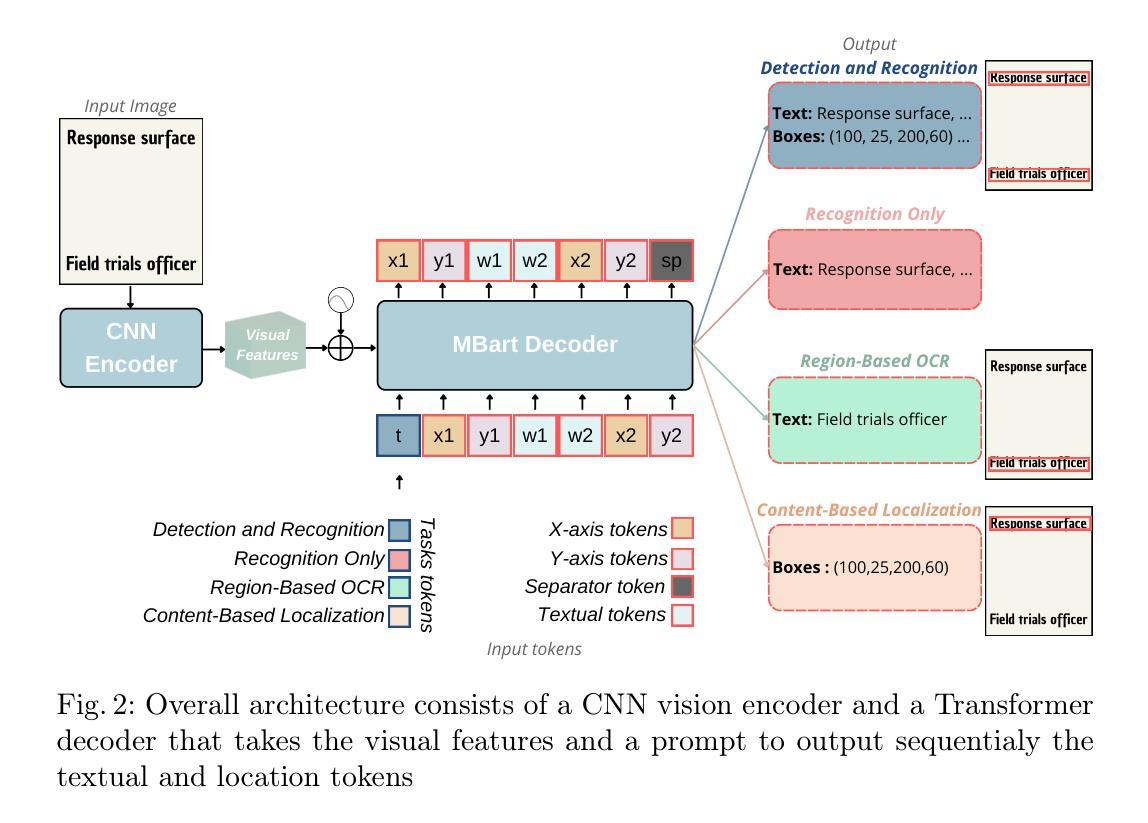
VISTA-OCR: Towards generative and interactive end to end OCR models
Authors:Laziz Hamdi, Amine Tamasna, Pascal Boisson, Thierry Paquet
We introduce \textbf{VISTA-OCR} (Vision and Spatially-aware Text Analysis OCR), a lightweight architecture that unifies text detection and recognition within a single generative model. Unlike conventional methods that require separate branches with dedicated parameters for text recognition and detection, our approach leverages a Transformer decoder to sequentially generate text transcriptions and their spatial coordinates in a unified branch. Built on an encoder-decoder architecture, VISTA-OCR is progressively trained, starting with the visual feature extraction phase, followed by multitask learning with multimodal token generation. To address the increasing demand for versatile OCR systems capable of advanced tasks, such as content-based text localization \ref{content_based_localization}, we introduce new prompt-controllable OCR tasks during pre-training.To enhance the model’s capabilities, we built a new dataset composed of real-world examples enriched with bounding box annotations and synthetic samples. Although recent Vision Large Language Models (VLLMs) can efficiently perform these tasks, their high computational cost remains a barrier for practical deployment. In contrast, our VISTA$_{\text{omni}}$ variant processes both handwritten and printed documents with only 150M parameters, interactively, by prompting. Extensive experiments on multiple datasets demonstrate that VISTA-OCR achieves better performance compared to state-of-the-art specialized models on standard OCR tasks while showing strong potential for more sophisticated OCR applications, addressing the growing need for interactive OCR systems. All code and annotations for VISTA-OCR will be made publicly available upon acceptance.
我们介绍了VISTA-OCR(视觉和空间感知文本分析OCR),这是一个轻量级的架构,在一个单一的生成模型中统一了文本检测和识别。不同于传统方法需要为文本识别和检测设置单独的分支和专用参数,我们的方法利用Transformer解码器来顺序生成文本转录和其空间坐标的统一分支。VISTA-OCR基于编码器-解码器架构构建,采用渐进式训练方法,首先从视觉特征提取阶段开始,然后是多任务学习模态令牌生成。为了满足对能够进行高级任务(如基于内容的文本定位)的通用OCR系统的日益增长需求,我们在预训练期间引入了新的提示可控OCR任务。为了提高模型的能力,我们构建了一个新的数据集,由丰富的边界框注释的合成样本和真实世界示例组成。尽管最近的视觉大型语言模型(VLLM)可以有效地执行这些任务,但它们的高计算成本仍然是实际部署的障碍。相比之下,我们的VISTA${\text{omni}}$变体仅使用150M参数即可交互式地处理手写和打印文档。在多个数据集上的广泛实验表明,VISTA-OCR在标准OCR任务上的性能优于最新专业模型,同时对于更复杂的OCR应用显示出强大潜力,满足日益增长的对交互式OCR系统的需求。VISTA-OCR的所有代码和注释在验收后将公开发布。
论文及项目相关链接
Summary
本文介绍了VISTA-OCR(具有视觉和空间感知能力的文本分析OCR),这是一种轻型架构,将文本检测和识别统一到一个单一的生成模型中。不同于传统方法,它采用一个Transformer解码器,在一个统一的分支中顺序生成文本转录和其空间坐标,无需为文本识别和检测设置单独的分支和专用参数。VISTA-OCR逐步训练,起始于视觉特征提取阶段,然后是用于多模态标记生成的多任务学习。为提高模型的潜力并满足日益增长的对高级OCR应用的需求,如在基于内容的内容定位等应用中引入了新的提示控制OCR任务进行预训练。为了增强模型的性能,使用由带边界框注解的真实世界示例和合成样本组成的新数据集进行训练。虽然最近的视觉大型语言模型可以有效地执行这些任务,但它们的高计算成本仍是实际部署的障碍。相比之下,我们的VISTAomni变体仅使用1.5亿个参数即可交互式地处理手写和打印文档。在多个数据集上的广泛实验表明,VISTA-OCR在标准OCR任务上取得了比最新专用模型更好的性能,并具有强大的潜力满足更复杂的OCR应用需求。满足需求。提供摘要的内容将在正式通过后公开所有代码和注释。 (以下是以简化汉字生成的关键信息) 根据提供的技术论文摘要可知,本文介绍了一种新型的文本检测和识别模型VISTA-OCR。该模型采用单一生成模型实现文本检测和识别的统一,通过利用Transformer解码器生成文本转录及其空间坐标,简化了传统方法中需要独立处理文本识别和检测的复杂流程。该模型具有优秀的性能表现,能够在多个数据集上实现优于现有模型的性能表现,并且具有强大的潜力应用于更复杂的OCR应用需求。此外,为了满足日益增长的需求,该模型还引入了新的提示控制OCR任务进行预训练,并采用新数据集进行训练以增强性能。尽管一些现有模型具备高效的性能表现能力很强大但对资源需求比较高而该模型以较低的参数量实现了高效的性能表现满足了实际应用的需求。该模型将在正式通过后公开所有代码和注释以供公众使用。
Key Takeaways
以下是论文的主要观点和关键信息点:
- VISTA-OCR是一个新型的文本检测和识别模型,将文本检测和识别统一到一个单一的生成模型中。
- 该模型采用Transformer解码器生成文本转录及其空间坐标,简化了传统方法的复杂流程。
- VISTA-OCR通过引入新的提示控制OCR任务来提高模型的潜力并满足复杂OCR应用的需求。
- 该模型使用一个新的数据集进行训练,该数据集由真实世界示例和合成样本组成,以增强模型的性能。
- 与现有模型相比,VISTA-OCR在多个数据集上实现了更好的性能表现。
- VISTA-OCR具有较低的计算成本,以较少的参数实现了高效的性能表现,满足了实际应用的需求。
点此查看论文截图


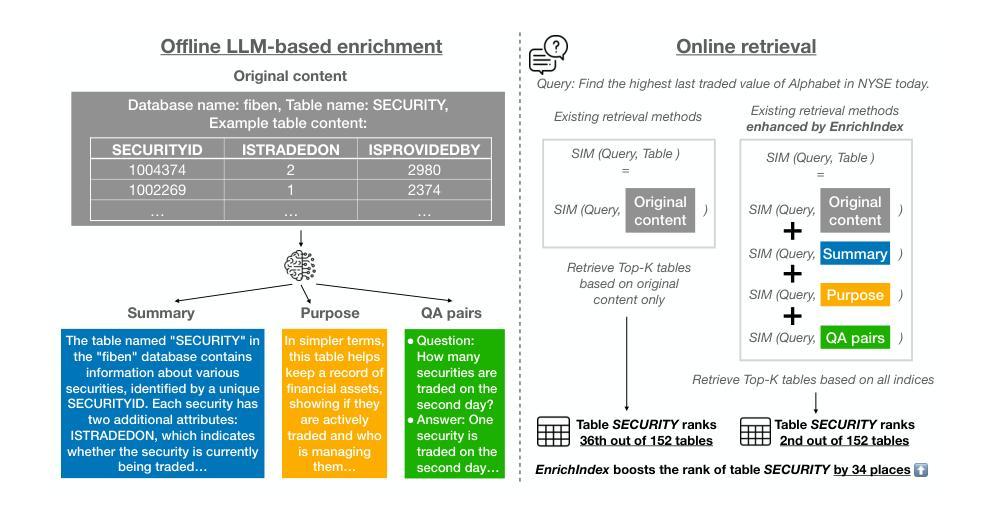
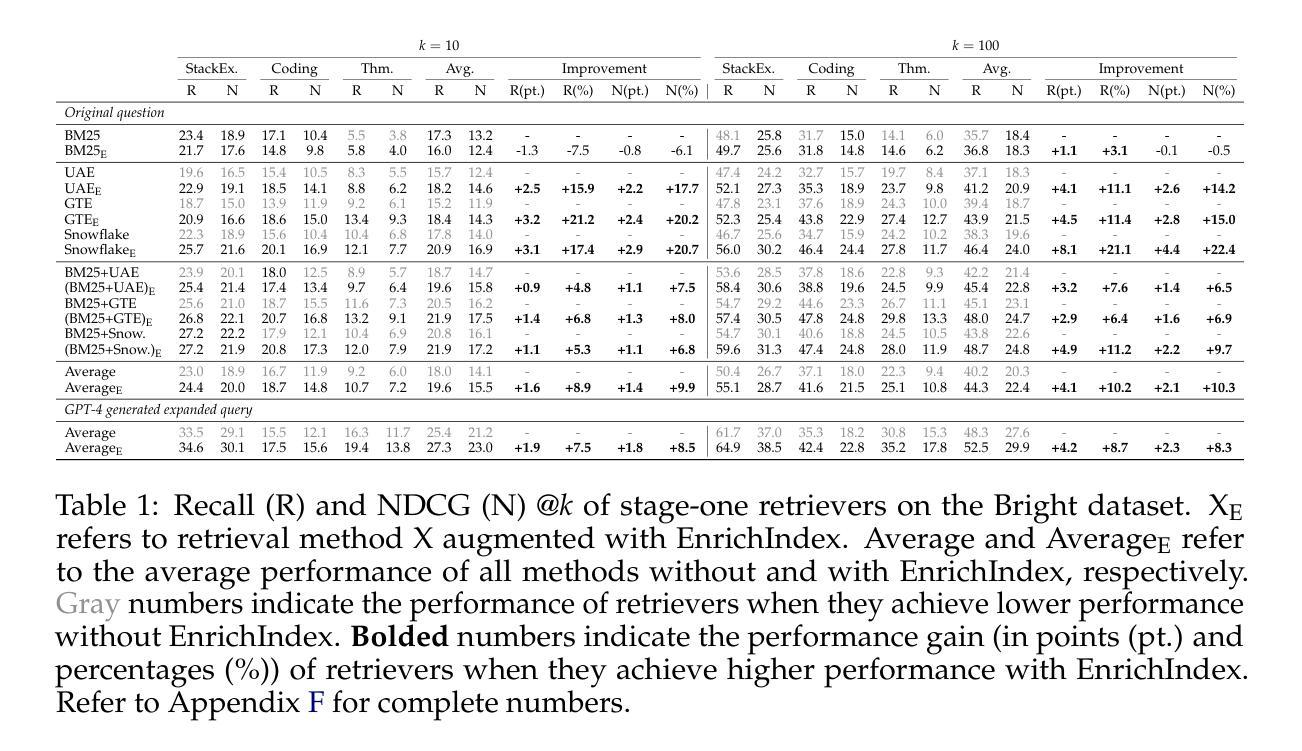
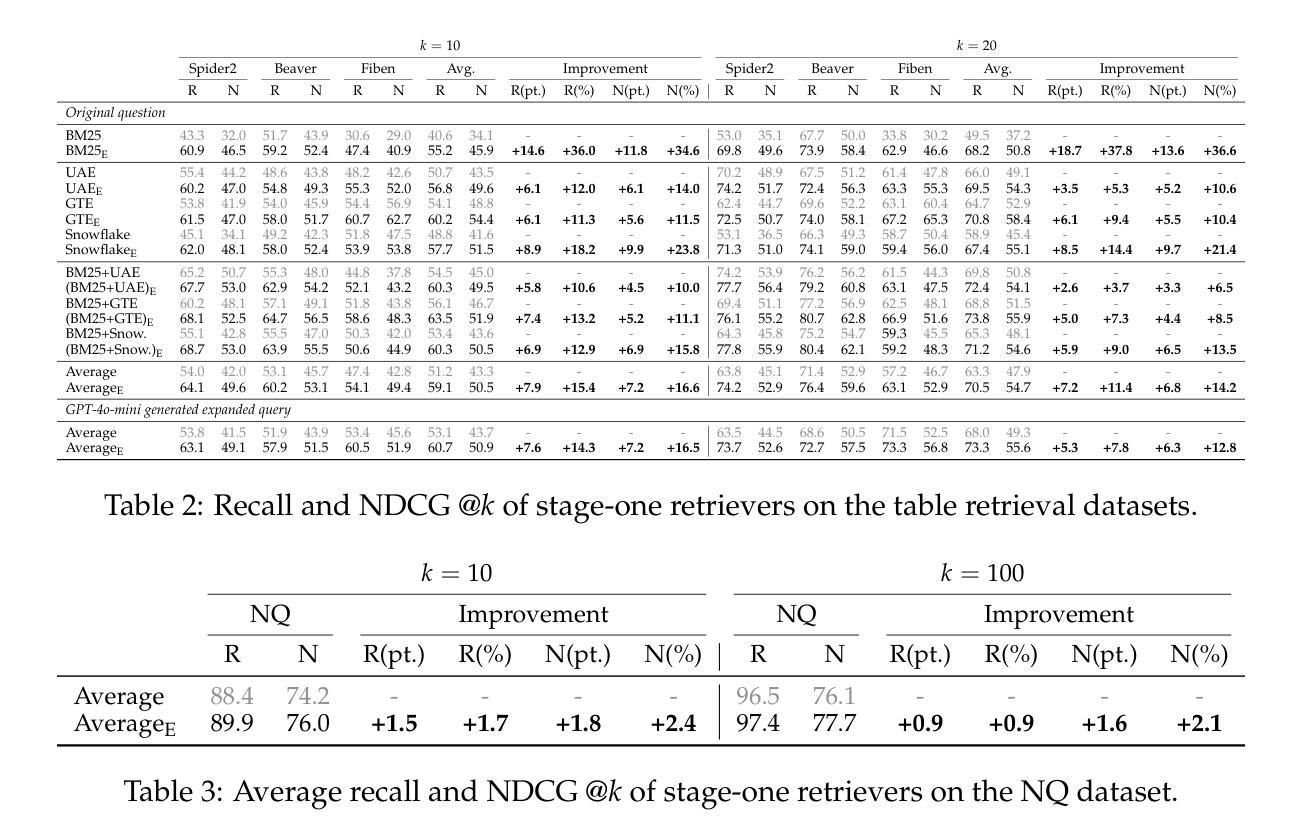
EnrichIndex: Using LLMs to Enrich Retrieval Indices Offline
Authors:Peter Baile Chen, Tomer Wolfson, Michael Cafarella, Dan Roth
Existing information retrieval systems excel in cases where the language of target documents closely matches that of the user query. However, real-world retrieval systems are often required to implicitly reason whether a document is relevant. For example, when retrieving technical texts or tables, their relevance to the user query may be implied through a particular jargon or structure, rather than explicitly expressed in their content. Large language models (LLMs) hold great potential in identifying such implied relevance by leveraging their reasoning skills. Nevertheless, current LLM-augmented retrieval is hindered by high latency and computation cost, as the LLM typically computes the query-document relevance online, for every query anew. To tackle this issue we introduce EnrichIndex, a retrieval approach which instead uses the LLM offline to build semantically-enriched retrieval indices, by performing a single pass over all documents in the retrieval corpus once during ingestion time. Furthermore, the semantically-enriched indices can complement existing online retrieval approaches, boosting the performance of LLM re-rankers. We evaluated EnrichIndex on five retrieval tasks, involving passages and tables, and found that it outperforms strong online LLM-based retrieval systems, with an average improvement of 11.7 points in recall @ 10 and 10.6 points in NDCG @ 10 compared to strong baselines. In terms of online calls to the LLM, it processes 293.3 times fewer tokens which greatly reduces the online latency and cost. Overall, EnrichIndex is an effective way to build better retrieval indices offline by leveraging the strong reasoning skills of LLMs.
现有的信息检索系统在处理目标文档与用户查询语言相匹配的情况下表现优异。然而,在实际的信息检索系统中,通常需要隐式判断文档的关联性。例如,在检索技术文本或表格时,其与用户查询的相关性可能通过特定的术语或结构隐含表达,而非在内容中明确表述。大型语言模型(LLM)在识别这种隐含相关性方面潜力巨大,通过利用其推理能力。然而,当前使用LLM增强的检索受到高延迟和计算成本的阻碍,因为LLM通常在线计算查询与文档的相关性,并针对每个查询重新进行计算。为解决此问题,我们引入了EnrichIndex检索方法,该方法使用LLM离线构建语义丰富的检索索引,通过对检索语料库中的所有文档进行一次性遍历来完成。此外,语义丰富的索引可以弥补现有的在线检索方法的不足,提升LLM重新排序器的性能。我们在五个检索任务上评估了EnrichIndex,涉及段落和表格,发现它优于强大的在线LLM检索系统,在召回率@10和NDCG@10方面平均提高了11.7点和10.6点,相较于强基线有所改进。就LLM的在线调用而言,它处理的令牌减少了293.3倍,极大地降低了在线延迟和成本。总体而言,EnrichIndex是一种利用LLM的强大推理能力离线构建更好的检索索引的有效方法。
论文及项目相关链接
PDF Dataset and code are available at https://peterbaile.github.io/enrichindex/
摘要
现有信息检索系统擅长处理目标文档与用户查询语言相匹配的情况。然而,在实际的世界中,检索系统需要隐式判断文档的关联性。例如,在检索技术文本或表格时,其与用户查询的关联性可能通过特定的术语或结构隐式表达,而非在内容中明确表达。大型语言模型(LLM)在识别这种隐式关联性方面具有巨大潜力,可通过推理能力来实现。然而,当前LLM增强的检索受到高延迟和计算成本的阻碍,因为LLM通常在线计算查询文档的相关性,针对每个查询都是全新的计算。为解决这一问题,我们引入了EnrichIndex,这是一种检索方法,它利用LLM离线构建语义丰富的检索索引,通过对检索语料库中所有文档进行一次单一遍历来实现。此外,语义丰富的索引可以补充现有的在线检索方法,提升LLM重新排序器的性能。我们在五个检索任务上评估了EnrichIndex,涉及段落和表格,发现它优于强大的在线LLM检索系统,在召回率@10和NDCG@10方面平均提高了11.7点和10.6点,相较于强基线。在在线调用LLM方面,它处理的令牌数量减少了293.3倍,大大降低了在线延迟和成本。总体而言,EnrichIndex是一种有效利用LLM强大推理能力构建更好检索索引的离线方法。
关键见解
- LLM具有识别文档与用户查询之间隐式关联性的潜力。
- 当前LLM增强的检索面临高延迟和计算成本的问题。
- EnrichIndex是一种利用LLM离线构建语义丰富检索索引的方法。
- EnrichIndex通过一次遍历所有文档,在摄入时间建立语义丰富的索引。
- EnrichIndex提高了检索性能,特别是在处理包含技术文本和表格的检索任务时。
- EnrichIndex相较于强基线在召回率@10和NDCG@10方面表现出优异的性能提升。
- EnrichIndex降低了在线调用LLM的频率和成本,提高了效率。
点此查看论文截图

Agentic Knowledgeable Self-awareness
Authors:Shuofei Qiao, Zhisong Qiu, Baochang Ren, Xiaobin Wang, Xiangyuan Ru, Ningyu Zhang, Xiang Chen, Yong Jiang, Pengjun Xie, Fei Huang, Huajun Chen
Large Language Models (LLMs) have achieved considerable performance across various agentic planning tasks. However, traditional agent planning approaches adopt a “flood irrigation” methodology that indiscriminately injects gold trajectories, external feedback, and domain knowledge into agent models. This practice overlooks the fundamental human cognitive principle of situational self-awareness during decision-making-the ability to dynamically assess situational demands and strategically employ resources during decision-making. We propose agentic knowledgeable self-awareness to address this gap, a novel paradigm enabling LLM-based agents to autonomously regulate knowledge utilization. Specifically, we propose KnowSelf, a data-centric approach that applies agents with knowledgeable self-awareness like humans. Concretely, we devise a heuristic situation judgement criterion to mark special tokens on the agent’s self-explored trajectories for collecting training data. Through a two-stage training process, the agent model can switch between different situations by generating specific special tokens, achieving optimal planning effects with minimal costs. Our experiments demonstrate that KnowSelf can outperform various strong baselines on different tasks and models with minimal use of external knowledge. Code is available at https://github.com/zjunlp/KnowSelf.
大型语言模型(LLM)在各种自主规划任务中取得了显著的性能。然而,传统的代理规划方法采用“洪水灌溉”的方法,不加区别地将黄金轨迹、外部反馈和领域知识注入代理模型中。这种做法忽略了决策过程中情境自我意识这一基本的人类认知原则——即在决策过程中动态评估情境需求并战略性地利用资源的能力。为了弥补这一差距,我们提出了代理知识自我意识这一新范式,使基于LLM的代理能够自主地调节知识利用。具体来说,我们提出了KnowSelf方法,这是一种以数据为中心的方法,将具有知识自我意识的代理应用于人类。具体来说,我们设计了一种启发式情境判断标准,在代理自我探索的轨迹上标记特殊令牌以收集训练数据。通过两阶段训练过程,代理模型可以通过生成特定的特殊令牌在不同情境之间进行切换,以最低的成本实现最佳的规划效果。我们的实验表明,在不同的任务和模型中,KnowSelf可以超越各种强大的基线,且对外部知识的使用最少。代码可在https://github.com/zjunlp/KnowSelf上找到。
论文及项目相关链接
PDF Work in progress
Summary
大语言模型在代理计划任务上取得了显著的成效,但传统方法忽略了人类决策时的情境自我意识。为此,我们提出了基于知识自我意识的代理模型,并介绍了KnowSelf方法。该方法通过启发式情境判断标准,使代理模型在自我探索轨迹上生成特定标记,实现知识利用的自适应调节。实验表明,KnowSelf在不同任务上的表现优于多个强基线模型,且对外部知识的需求较低。
Key Takeaways
- LLM在代理规划任务中有出色表现。
- 传统代理规划方法存在缺乏情境自我意识的问题。
- 知识自我意识的引入是为了解决这一问题。
- KnowSelf方法采用启发式情境判断标准标记特殊令牌。
- 通过两阶段训练过程,代理模型可在不同情境间切换。
- KnowSelf在不同任务上的表现优于多个基线模型。
点此查看论文截图




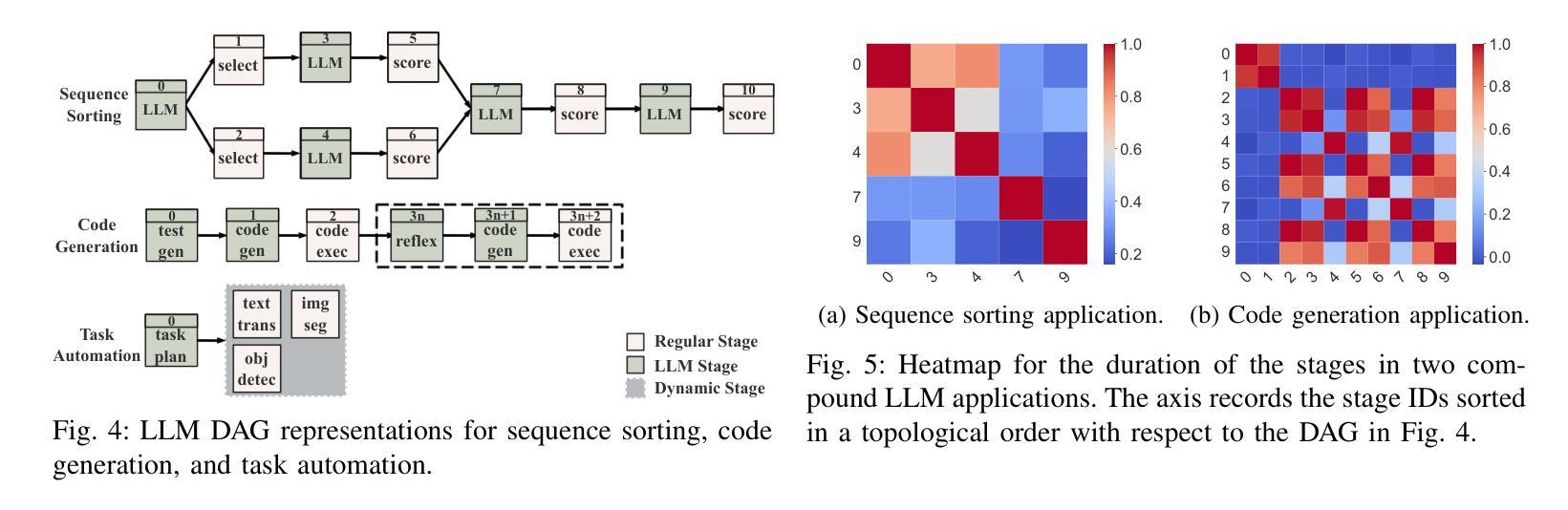
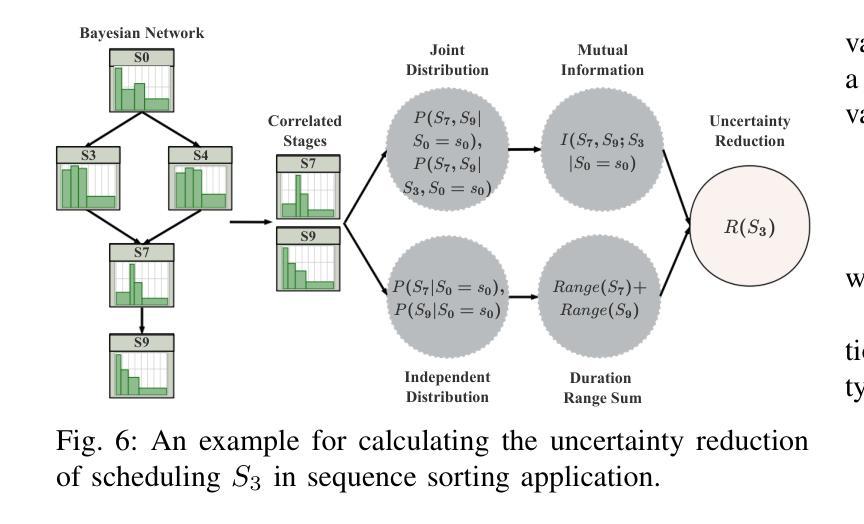
LLMSched: Uncertainty-Aware Workload Scheduling for Compound LLM Applications
Authors:Botao Zhu, Chen Chen, Xiaoyi Fan, Yifei Zhu
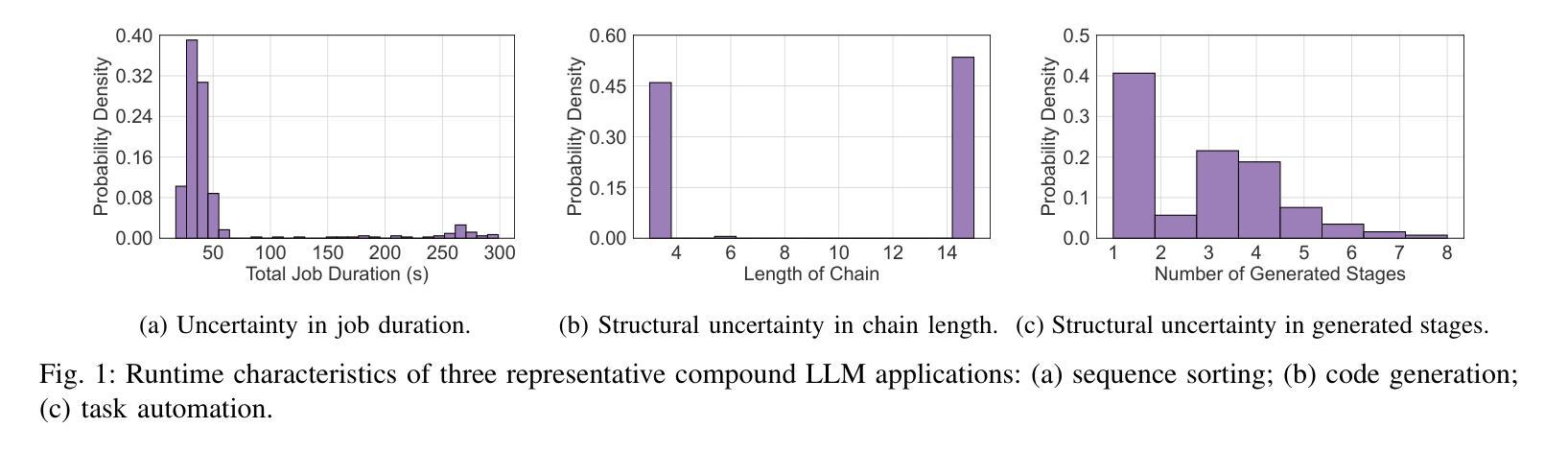
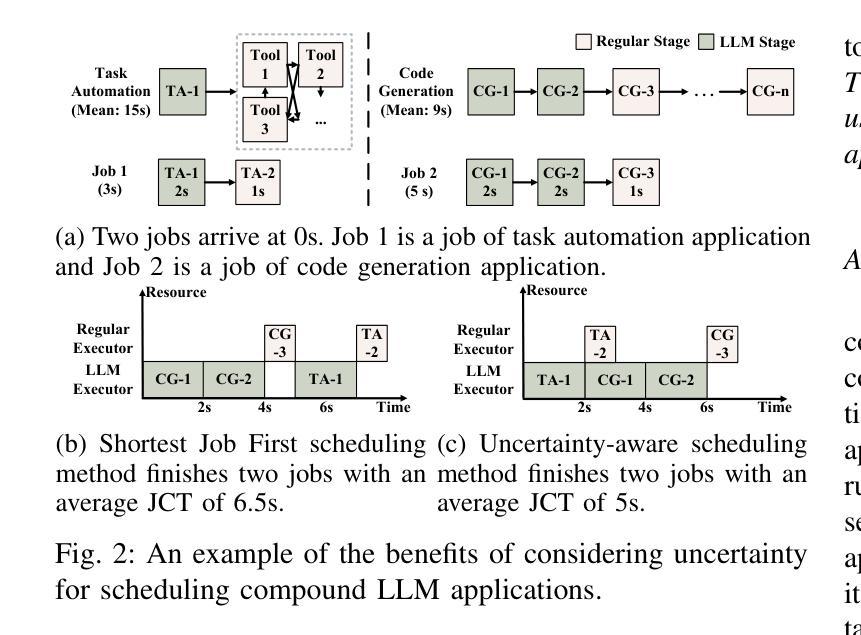
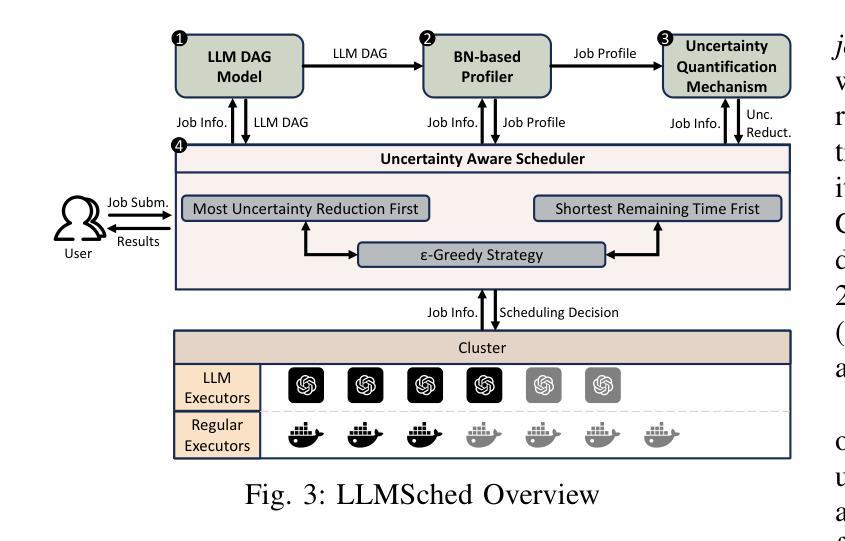
Developing compound Large Language Model (LLM) applications is becoming an increasingly prevalent approach to solving real-world problems. In these applications, an LLM collaborates with various external modules, including APIs and even other LLMs, to realize complex intelligent services. However, we reveal that the intrinsic duration and structural uncertainty in compound LLM applications pose great challenges for LLM service providers in serving and scheduling them efficiently. In this paper, we propose LLMSched, an uncertainty-aware scheduling framework for emerging compound LLM applications. In LLMSched, we first design a novel DAG-based model to describe the uncertain compound LLM applications. Then, we adopt the Bayesian network to comprehensively profile compound LLM applications and identify uncertainty-reducing stages, along with an entropy-based mechanism to quantify their uncertainty reduction. Combining an uncertainty reduction strategy and a job completion time (JCT)-efficient scheme, we further propose an efficient scheduler to reduce the average JCT. Evaluation of both simulation and testbed experiments on various representative compound LLM applications shows that compared to existing state-of-the-art scheduling schemes, LLMSched can reduce the average JCT by 14~79%.
开发复合大型语言模型(LLM)应用已成为解决现实世界问题的一种越来越普遍的方法。在这些应用中,LLM与各种外部模块(包括API甚至其他LLM)协作,以实现复杂的智能服务。然而,我们揭示,复合LLM应用中的内在持续时间和结构不确定性给LLM服务提供商在服务和调度方面带来了巨大挑战。在本文中,我们提出了LLMSched,一个用于新兴复合LLM应用的不确定性感知调度框架。在LLMSched中,我们首先设计了一个基于DAG的新型模型来描述不确定的复合LLM应用。然后,我们采用贝叶斯网络对复合LLM应用进行全面分析,并识别出减少不确定性的阶段,以及一种基于熵的机制来量化其不确定性减少程度。结合一种不确定性减少策略和一种作业完成时间(JCT)高效方案,我们进一步提出了一种有效的调度器来减少平均JCT。对各种代表性复合LLM应用的仿真和测试床实验评估表明,与现有的最先进的调度方案相比,LLMSched可以将平均JCT减少14~79%。
论文及项目相关链接
Summary
基于复合大型语言模型(LLM)的协同应用程序在解决现实世界中复杂问题时越来越受到关注。但服务提供者面临着运行与调度不确定性与高难度的挑战。为解决这一问题,本文提出了LLMSched不确定性感知调度框架。LLMSched使用基于DAG的新模型描述不确定的复合LLM应用,通过贝叶斯网络综合评估应用,并提出熵值衡量不确定性降低程度。实验结果显示,与现有先进的调度方案相比,LLMSched可降低平均任务完成时间达约提高工作成效到一定的范围内。(可减少的平均作业完成时间具体取决于应用情况。)
Key Takeaways
- LLM协同应用程序是解决现实问题的流行方法。
- 服务提供者面临复合LLM应用的调度不确定性挑战。
点此查看论文截图

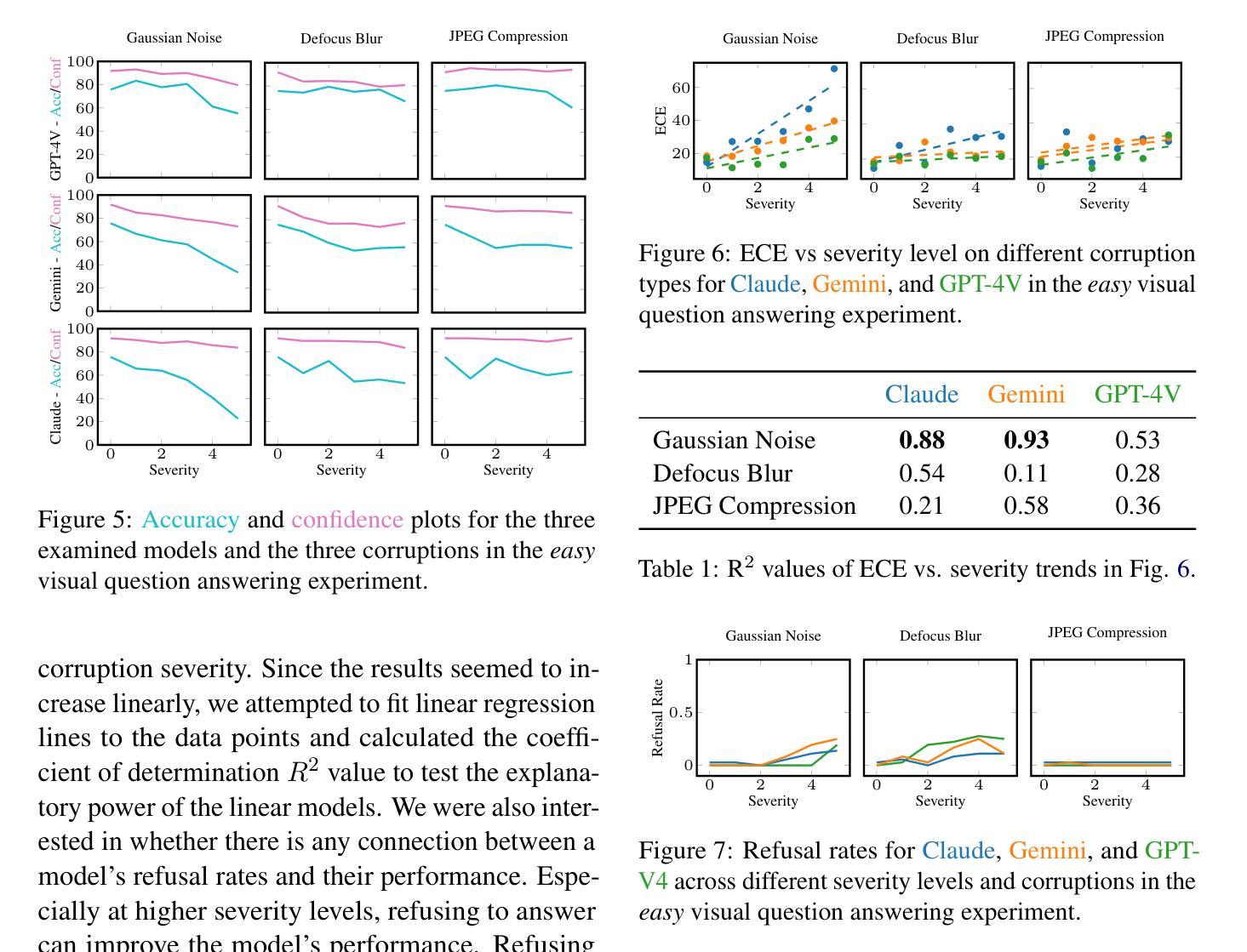
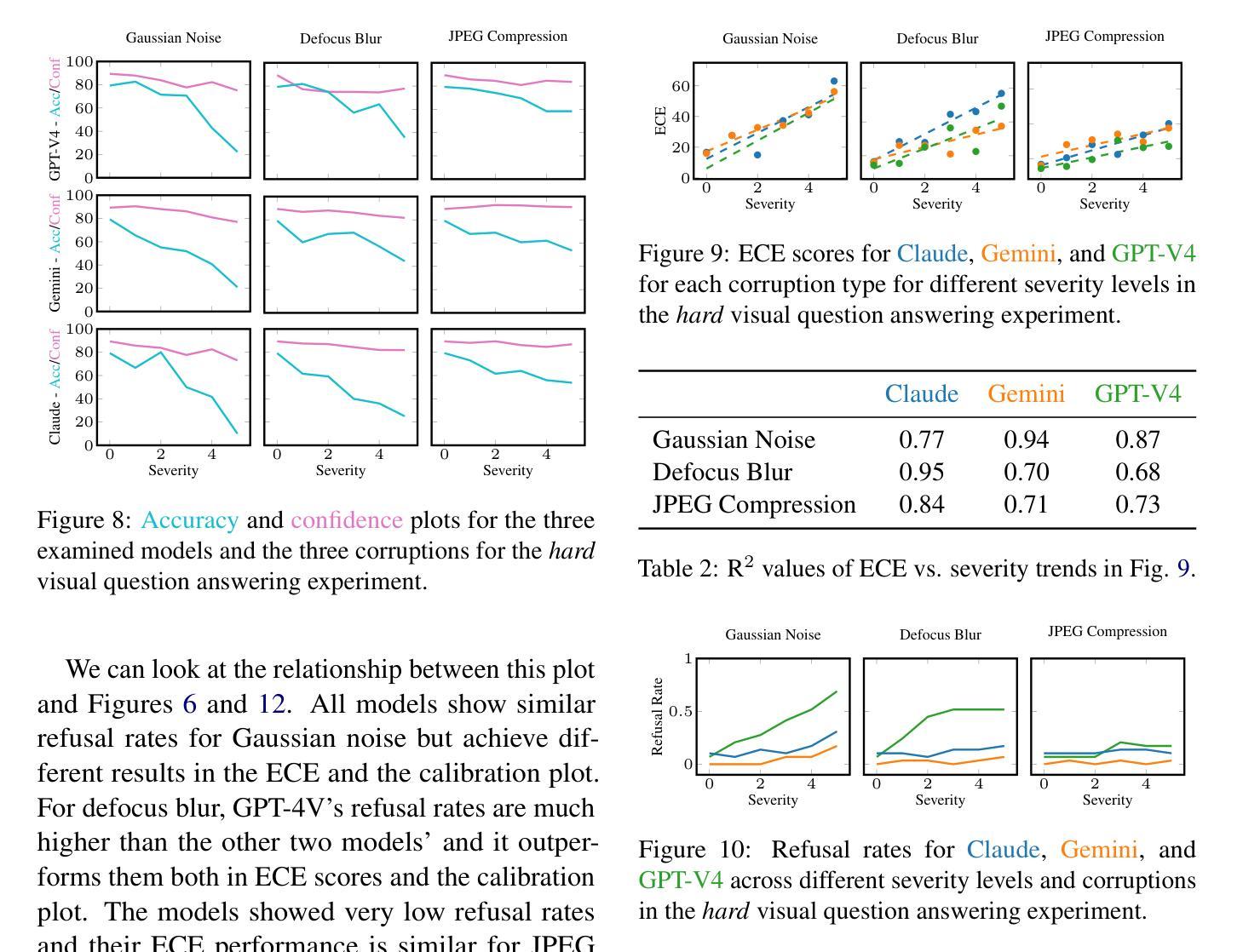
Know What You do Not Know: Verbalized Uncertainty Estimation Robustness on Corrupted Images in Vision-Language Models
Authors:Mirko Borszukovszki, Ivo Pascal de Jong, Matias Valdenegro-Toro
To leverage the full potential of Large Language Models (LLMs) it is crucial to have some information on their answers’ uncertainty. This means that the model has to be able to quantify how certain it is in the correctness of a given response. Bad uncertainty estimates can lead to overconfident wrong answers undermining trust in these models. Quite a lot of research has been done on language models that work with text inputs and provide text outputs. Still, since the visual capabilities have been added to these models recently, there has not been much progress on the uncertainty of Visual Language Models (VLMs). We tested three state-of-the-art VLMs on corrupted image data. We found that the severity of the corruption negatively impacted the models’ ability to estimate their uncertainty and the models also showed overconfidence in most of the experiments.
为了充分利用大型语言模型(LLM)的潜力,了解它们答案的不确定性至关重要。这意味着模型必须能够量化它对给定答案正确性的信心程度。不良的不确定性估计可能导致过于自信的错答,从而削弱对这些模型的信任。关于处理文本输入并提供文本输出的语言模型已经进行了大量的研究。然而,由于这些模型的视觉功能最近才被添加进来,关于视觉语言模型(VLM)的不确定性方面的进展并不大。我们在被腐蚀的图像数据上测试了三种最先进的VLM。我们发现,腐蚀的严重性对模型估计不确定性的能力产生了负面影响,并且在大多数实验中,这些模型显示出过于自信的情况。
论文及项目相关链接
PDF 10 pages, 11 figures, TrustNLP Workshop @ NAACL 2025 Camera ready
Summary:
大型语言模型(LLM)的潜力完全发挥需要对其答案的不确定性进行量化评估。模型需要能够衡量对给定答案正确性的置信度。不良的不确定性估计可能导致过度自信的错误答案,破坏对这些模型的信任。目前对处理文本输入的语言模型的研究较多,但对包含视觉功能的语言模型(VLM)的不确定性研究尚未取得太多进展。我们对三款最先进的VLM进行了图像数据损坏测试,发现数据损坏的严重程度对模型估计其不确定性的影响呈负面趋势,且大多数实验中模型表现出过度自信。
Key Takeaways:
- 大型语言模型(LLM)要完全发挥潜力,需要评估答案的不确定性。
- 模型应能衡量对答案正确性的置信度。
- 不良的不确定性估计可能导致过度自信的错误答案。
- 目前对视觉语言模型(VLM)的不确定性研究尚未取得足够进展。
- 测试了三种最先进的VLM在损坏图像数据上的表现。
- 数据损坏的严重程度对模型估计其不确定性的影响呈负面趋势。
点此查看论文截图



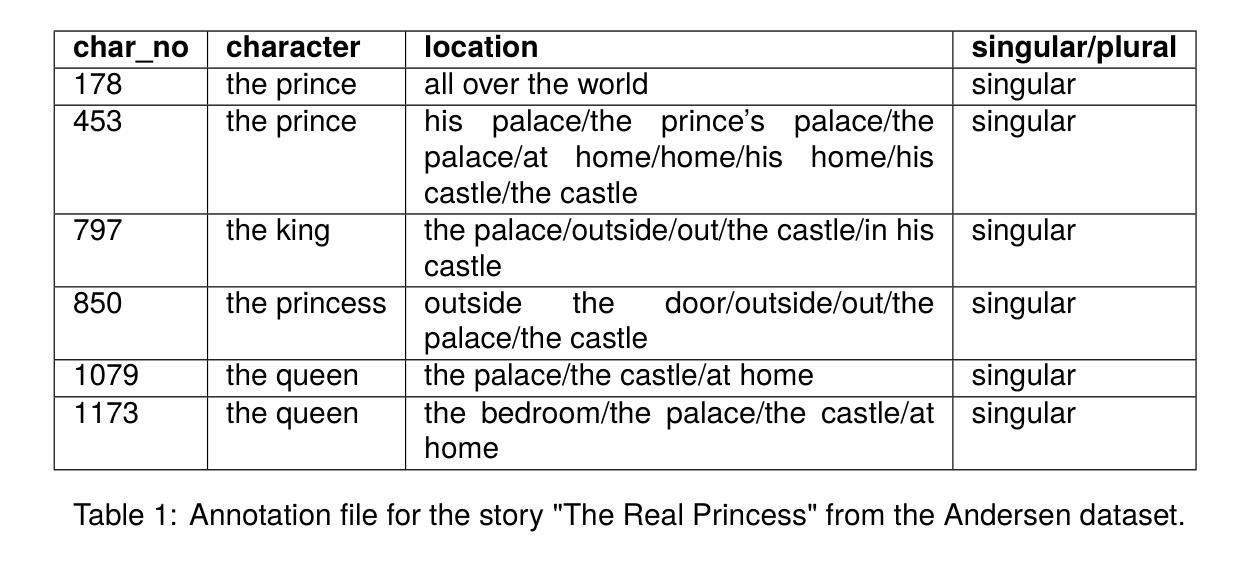
Locations of Characters in Narratives: Andersen and Persuasion Datasets
Authors:Batuhan Ozyurt, Roya Arkhmammadova, Deniz Yuret
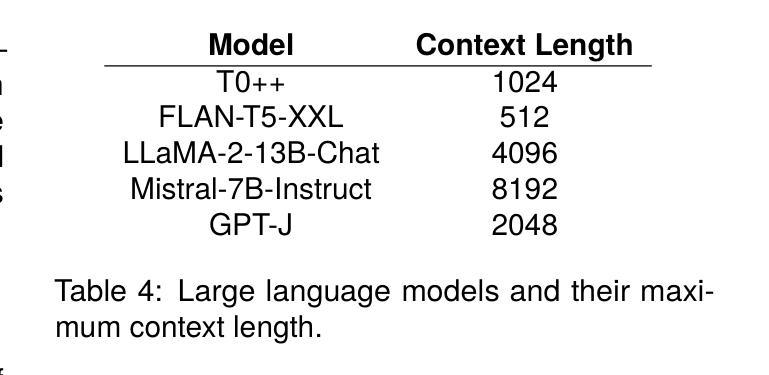
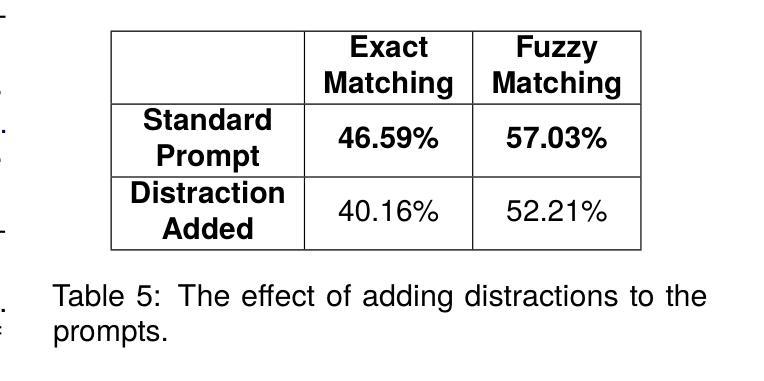
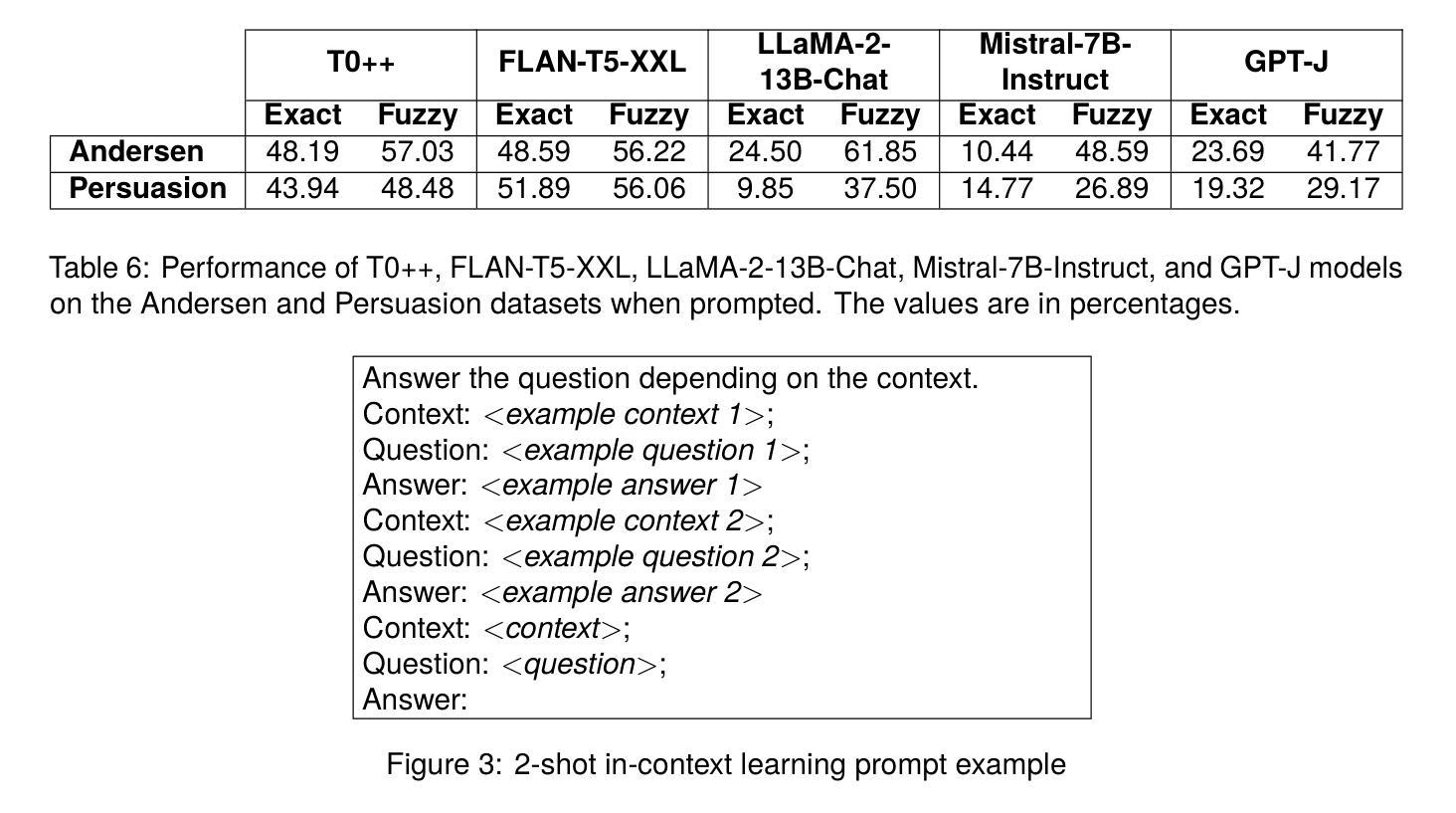
The ability of machines to grasp spatial understanding within narrative contexts is an intriguing aspect of reading comprehension that continues to be studied. Motivated by the goal to test the AI’s competence in understanding the relationship between characters and their respective locations in narratives, we introduce two new datasets: Andersen and Persuasion. For the Andersen dataset, we selected fifteen children’s stories from “Andersen’s Fairy Tales” by Hans Christian Andersen and manually annotated the characters and their respective locations throughout each story. Similarly, for the Persuasion dataset, characters and their locations in the novel “Persuasion” by Jane Austen were also manually annotated. We used these datasets to prompt Large Language Models (LLMs). The prompts are created by extracting excerpts from the stories or the novel and combining them with a question asking the location of a character mentioned in that excerpt. Out of the five LLMs we tested, the best-performing one for the Andersen dataset accurately identified the location in 61.85% of the examples, while for the Persuasion dataset, the best-performing one did so in 56.06% of the cases.
机器在叙事语境中把握空间理解的能力是阅读理解中一个引人入胜的方面,仍然持续被研究。为了测试人工智能理解叙事中角色及其所在位置的关系的能力,我们引入了两个新数据集:安徒生数据集和劝诫数据集。对于安徒生数据集,我们从汉斯·克里斯蒂安·安徒生的《安徒生童话》中选取了十五个故事,并手动标注了每个故事中的角色及其所在位置。同样,对于劝诫数据集,我们也手动标注了简·奥斯汀的小说《劝诫》中的角色及其位置。我们使用这些数据集来提示大型语言模型(LLM)。提示是通过提取故事或小说的片段,并将其与一个问题相结合而创建的,这个问题会询问该片段中提到的角色的位置。在我们测试的五个LLM中,对于安徒生数据集,表现最好的一个准确识别了61.8d的位置的实例,而对于劝诫数据集,表现最好的一个准确识别了56.06%的实例。
论文及项目相关链接
PDF 14 pages, 3 figures, 10 tables
Summary
本文介绍了机器在叙事语境中把握空间理解的能力,并为了测试人工智能在理解叙事中角色与地点关系方面的能力,提出了Andersen和Persuasion两个新数据集。通过对Hans Christian Andersen的《安徒生童话》和Jane Austen的《劝导》中的故事和小说进行手动标注角色及其所在位置,创建数据集并用于提示大型语言模型(LLM)。最好的LLM在Andersen数据集上准确识别地点的例子占61.85%,在Persuasion数据集上占56.06%。
Key Takeaways
- 机器在叙事语境中的空间理解能力是阅读理解能力的一个有趣方面,仍持续被研究。
- 为了测试AI理解角色与地点在叙事中的关系的能力,提出了Andersen和Persuasion两个新数据集。
- Andersen数据集是从Hans Christian Andersen的儿童故事中手动标注角色和地点,而Persuasion数据集则是从Jane Austen的小说中标注。
- 使用这些数据集来提示大型语言模型(LLM)。
- 最好的LLM在Andersen数据集中准确识别地点的比例为61.85%。
- 在Persuasion数据集中,最好的LLM准确识别地点的比例为56.06%。
点此查看论文截图




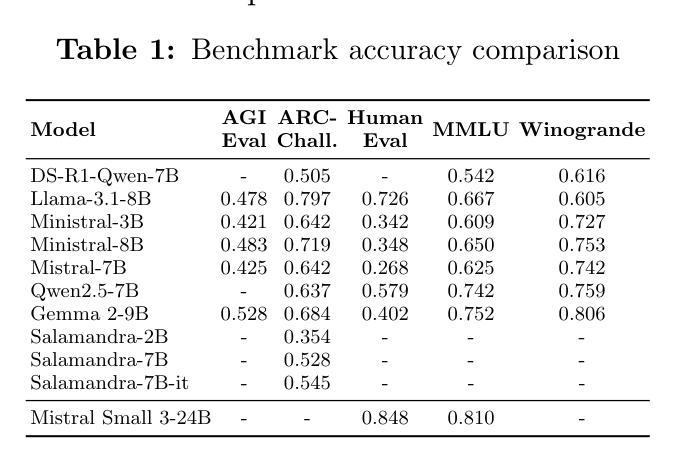
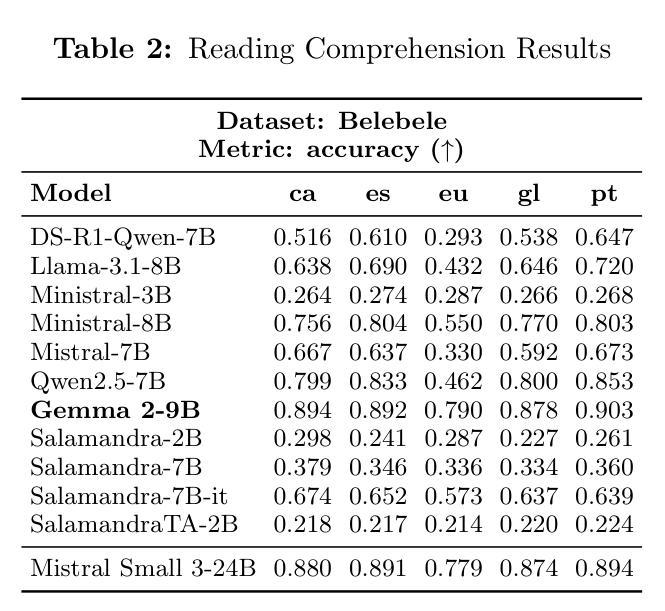
Evaluating Compact LLMs for Zero-Shot Iberian Language Tasks on End-User Devices
Authors:Luís Couto Seller, Íñigo Sanz Torres, Adrián Vogel-Fernández, Carlos González Carballo, Pedro Miguel Sánchez Sánchez, Adrián Carruana Martín, Enrique de Miguel Ambite
Large Language Models have significantly advanced natural language processing, achieving remarkable performance in tasks such as language generation, translation, and reasoning. However, their substantial computational requirements restrict deployment to high-end systems, limiting accessibility on consumer-grade devices. This challenge is especially pronounced for under-resourced languages like those spoken in the Iberian Peninsula, where relatively limited linguistic resources and benchmarks hinder effective evaluation. This work presents a comprehensive evaluation of compact state-of-the-art LLMs across several essential NLP tasks tailored for Iberian languages. The results reveal that while some models consistently excel in certain tasks, significant performance gaps remain, particularly for languages such as Basque. These findings highlight the need for further research on balancing model compactness with robust multilingual performance
大型语言模型在自然语言处理方面取得了显著进展,在语言生成、翻译和推理等任务中表现突出。然而,其巨大的计算需求限制了其在高端系统上的部署,也限制了其在消费者级设备上的可用性。这一挑战对于像伊比利亚半岛所使用的那些资源匮乏的语言来说尤为突出,相对有限的语言资源和基准测试阻碍了有效的评估。本研究对针对伊比利亚语言的多个基本NLP任务,对最新的紧凑型LLM进行了全面评估。结果表明,虽然一些模型在特定任务上表现一直很好,但仍然存在显著的性能差距,尤其是巴斯克语等语言。这些发现强调了需要在模型紧凑性与稳健的多语言性能之间取得平衡,以进行进一步的研究。
论文及项目相关链接
PDF Under Revision al SEPLN conference
Summary
大型语言模型在自然语言处理方面取得了显著进展,尤其在语言生成、翻译和推理等任务中表现突出。然而,其巨大的计算需求限制了其在低端设备上的部署。对于像伊比利亚半岛上使用的那些资源匮乏的语言来说,这一挑战更为突出,因为相对有限的语言资源和基准测试阻碍了有效的评估。本研究对紧凑的最先进的大型语言模型在针对伊比利亚语言的多个基本NLP任务上进行了全面评估。结果表明,虽然一些模型在特定任务上表现优异,但仍存在显著的性能差距,尤其是巴斯克语。这强调了需要在模型紧凑性与稳健的多语种性能之间取得平衡的研究需求。
Key Takeaways
- 大型语言模型在自然语言处理方面取得显著进展,尤其在语言生成、翻译和推理等任务中。
- 大型语言模型的计算需求巨大,限制了其在低端设备上的部署。
- 对于资源匮乏的语言,有效的评估尤为重要。
- 紧凑的大型语言模型在针对伊比利亚语言的多个NLP任务上进行了评估。
- 某些模型在特定任务上表现优异,但仍然存在显著的性能差距。
- 需要进一步研究以平衡模型紧凑性与多语种性能。
点此查看论文截图

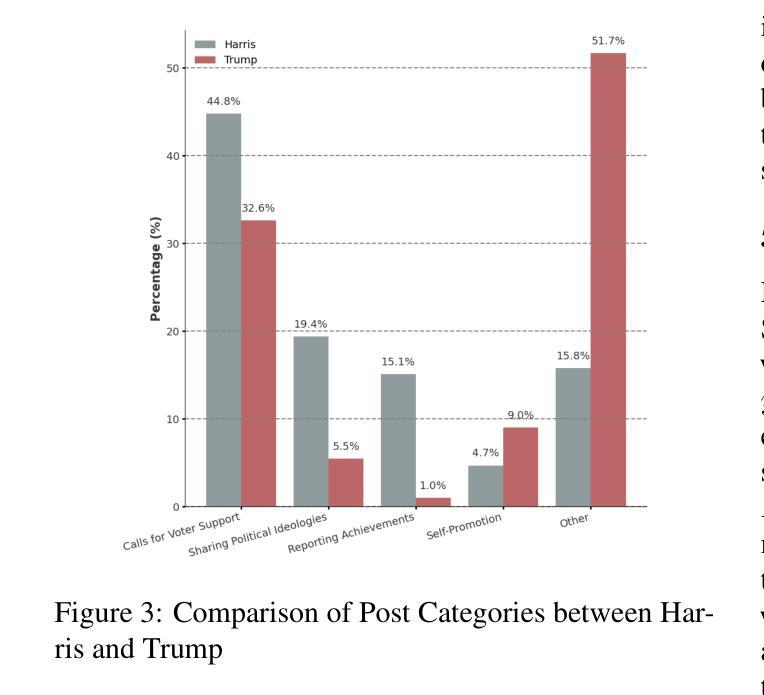
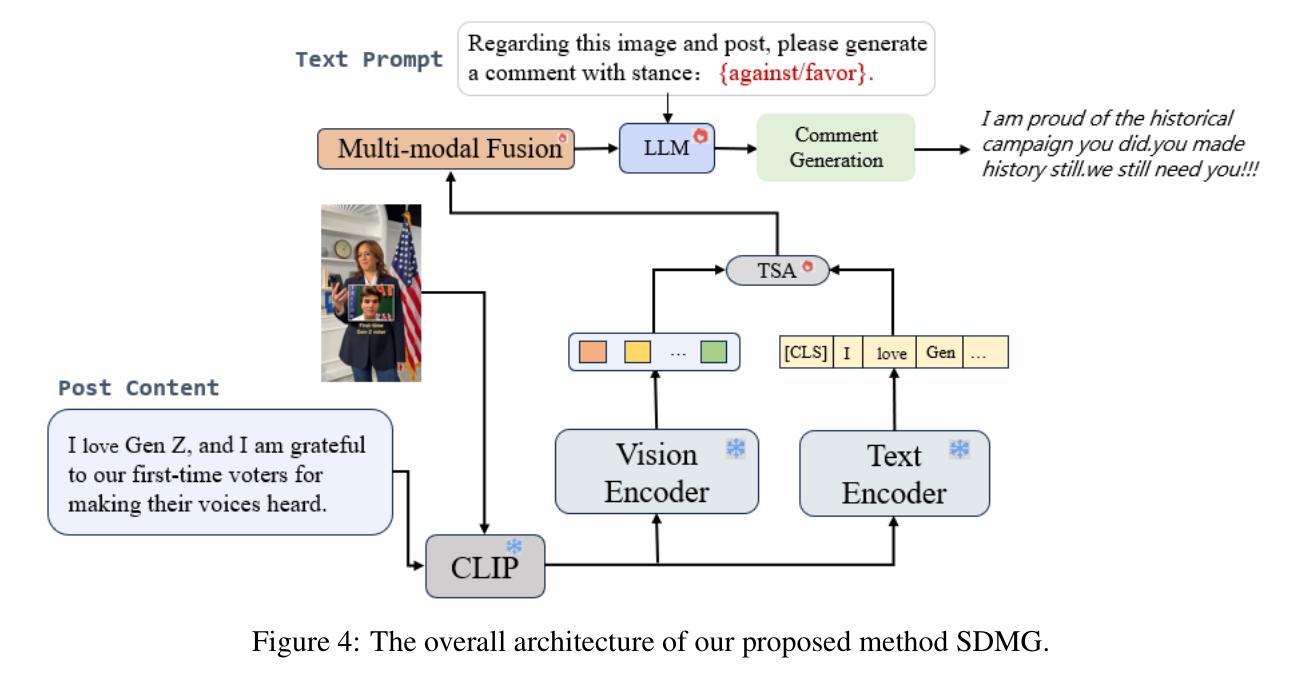
Stance-Driven Multimodal Controlled Statement Generation: New Dataset and Task
Authors:Bingqian Wang, Quan Fang, Jiachen Sun, Xiaoxiao Ma
Formulating statements that support diverse or controversial stances on specific topics is vital for platforms that enable user expression, reshape political discourse, and drive social critique and information dissemination. With the rise of Large Language Models (LLMs), controllable text generation towards specific stances has become a promising research area with applications in shaping public opinion and commercial marketing. However, current datasets often focus solely on pure texts, lacking multimodal content and effective context, particularly in the context of stance detection. In this paper, we formally define and study the new problem of stance-driven controllable content generation for tweets with text and images, where given a multimodal post (text and image/video), a model generates a stance-controlled response. To this end, we create the Multimodal Stance Generation Dataset (StanceGen2024), the first resource explicitly designed for multimodal stance-controllable text generation in political discourse. It includes posts and user comments from the 2024 U.S. presidential election, featuring text, images, videos, and stance annotations to explore how multimodal political content shapes stance expression. Furthermore, we propose a Stance-Driven Multimodal Generation (SDMG) framework that integrates weighted fusion of multimodal features and stance guidance to improve semantic consistency and stance control. We release the dataset and code (https://anonymous.4open.science/r/StanceGen-BE9D) for public use and further research.
表述支持特定话题的多样或争议性立场,对于允许用户表达、重塑政治话语并推动社会批评和信息传播的平台至关重要。随着大型语言模型(LLM)的兴起,针对特定立场的可控文本生成已成为一个充满希望的研究领域,并应用于塑造公众舆论和商业营销。然而,当前的数据集通常只专注于纯文本,缺乏多模式内容和有效的上下文,特别是在立场检测方面。在本文中,我们正式定义并研究了推特文本和图像的新问题,即立场驱动的可控内容生成。给定多模式帖子(文本和图像/视频),模型生成受立场控制的响应。为此,我们创建了多模式立场生成数据集(StanceGen2024),这是第一个专为政治话语中的多模式立场可控文本生成设计的资源。它包含来自2024年美国总统选举的帖子和用户评论,包括文本、图像、视频和立场注释,以探索多模式政治内容如何影响立场表达。此外,我们提出了立场驱动的多模式生成(SDMG)框架,该框架融合了多模式特征的加权融合和立场指导,以提高语义一致性和立场控制。我们公开数据集和代码(https://anonymous.4open.science/r/StanceGen-BE9D),供公众使用和进一步研究。
论文及项目相关链接
摘要
基于用户表达的立场驱动的可控文本生成对于重塑政治话语、推动社会批判和信息传播至关重要。随着大型语言模型(LLM)的兴起,可控文本生成在特定立场上的应用已成为塑造公众舆论和商业营销的研究热点。然而,当前数据集往往仅关注纯文本,缺乏多模态内容和有效上下文,特别是在立场检测方面。本文正式定义并研究面向推特文本和图像的多模态立场驱动可控内容生成的新问题。给定多模态帖子(文本和图像/视频),模型生成立场控制响应。为此,我们创建了专为政治话语中多模态立场可控文本生成设计的Multimodal Stance Generation Dataset(StanceGen2024)。它包含来自美国2024年总统选举的帖子和用户评论,包含文本、图像、视频和立场注释,以探讨多媒体政治内容如何影响立场表达。此外,提出了Stance-Driven Multimodal Generation(SDMG)框架,通过多模态特征的加权融合和立场指导来提高语义一致性和立场控制力。我们公开数据集和代码以供公众使用和进一步研究。
关键见解
- 大型语言模型(LLM)在可控文本生成方面展现出巨大潜力,特别是在支持用户表达特定立场的应用中。
- 当前数据集缺乏多模态内容和有效上下文,这对于准确捕捉政治话语中的立场至关重要。
- 本文介绍了一个新的数据集Multimodal Stance Generation Dataset(StanceGen2024),专门用于政治话语中的多模态立场可控文本生成。
- StanGen数据集包含了多种媒体形式(如文本、图像和视频),并附有立场注释,有助于研究多媒体内容如何影响立场表达。
- 提出了一个新的框架Stance-Driven Multimodal Generation(SDMG),该框架通过整合多模态特征和立场指导来提高文本生成的语义一致性和立场控制力。
- 该框架有望促进在政治话语分析、信息表达和社交媒体营销等多个领域的深入研究与应用开发。
点此查看论文截图

From ChatGPT to DeepSeek AI: A Comprehensive Analysis of Evolution, Deviation, and Future Implications in AI-Language Models
Authors:Simrandeep Singh, Shreya Bansal, Abdulmotaleb El Saddik, Mukesh Saini
The rapid advancement of artificial intelligence (AI) has reshaped the field of natural language processing (NLP), with models like OpenAI ChatGPT and DeepSeek AI. Although ChatGPT established a strong foundation for conversational AI, DeepSeek AI introduces significant improvements in architecture, performance, and ethical considerations. This paper presents a detailed analysis of the evolution from ChatGPT to DeepSeek AI, highlighting their technical differences, practical applications, and broader implications for AI development. To assess their capabilities, we conducted a case study using a predefined set of multiple choice questions in various domains, evaluating the strengths and limitations of each model. By examining these aspects, we provide valuable insight into the future trajectory of AI, its potential to transform industries, and key research directions for improving AI-driven language models.
人工智能(AI)的快速发展已经重塑了自然语言处理(NLP)领域,出现了OpenAI ChatGPT和DeepSeek AI等模型。虽然ChatGPT为对话式AI奠定了坚实基础,但DeepSeek AI在架构、性能和道德考量方面引入了重大改进。本文详细分析了从ChatGPT到DeepSeek AI的演变过程,重点介绍了它们的技术差异、实际应用以及对AI发展的更广泛影响。为了评估它们的能力,我们采用预先设定的多个领域的多项选择题进行案例研究,评估每个模型的优点和局限性。通过考察这些方面,我们为AI的未来发展方向、其改变行业的潜力以及改进AI驱动的语言模型的关键研究方向提供了有价值的见解。
论文及项目相关链接
PDF 10 pages, 1 figure, 4 tables
Summary
随着人工智能(AI)的快速发展,自然语言处理(NLP)领域已经发生了巨大变化,其中OpenAI的ChatGPT和DeepSeek AI等模型引领了变革。虽然ChatGPT为对话AI奠定了坚实基础,但DeepSeek AI在架构、性能和伦理考量方面实现了显著改进。本文详细分析了从ChatGPT到DeepSeek AI的演进过程,重点介绍了它们的技术差异、实际应用以及对AI发展的更广泛影响。通过多项选择题的案例研究,我们评估了这两个模型的能力,探讨了它们的优点和局限性。这为深入了解AI的未来发展趋势、其对行业的潜在变革以及改进AI驱动的语言模型的关键研究方向提供了有价值的信息。
Key Takeaways
- AI的发展已经深刻影响了NLP领域,以ChatGPT和DeepSeek AI为代表的新模型推动了变革。
- ChatGPT为对话AI奠定了基石,而DeepSeek AI在架构、性能和伦理方面进行了显著改进。
- 文章通过案例分析详细比较了ChatGPT和DeepSeek AI的技术差异、实际应用及影响。
- 案例研究包括多个领域的多项选择题测试,以评估两个模型的实力和局限。
- DeepSeek AI的改进不仅体现在技术能力上,还包括对伦理问题的重视。
- 文章提供了关于AI未来发展趋势、行业变革以及研究方向的深刻见解。
点此查看论文截图


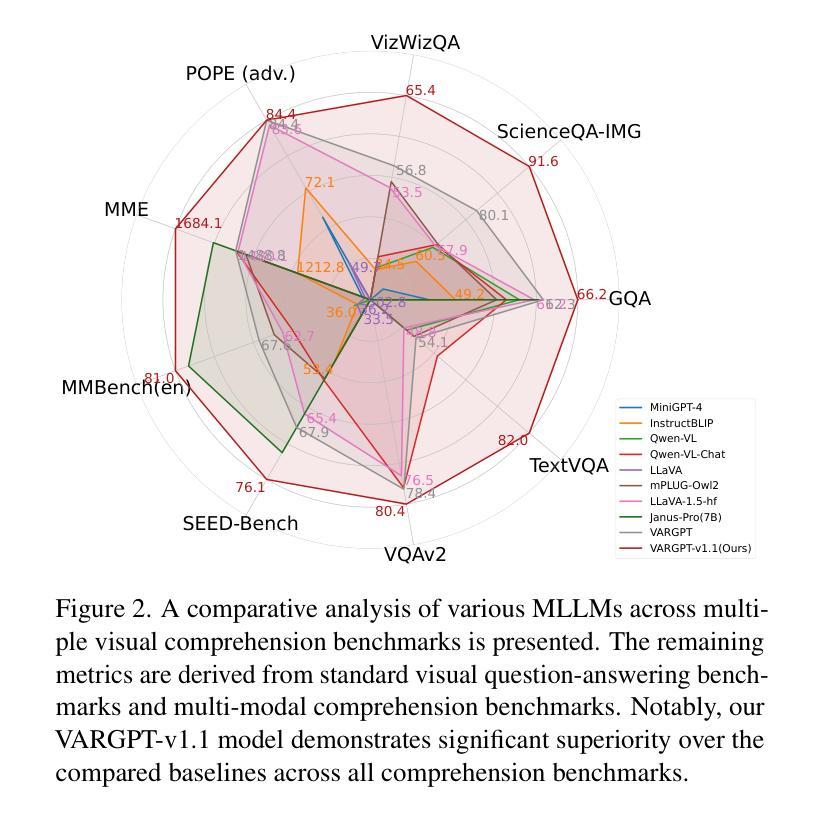
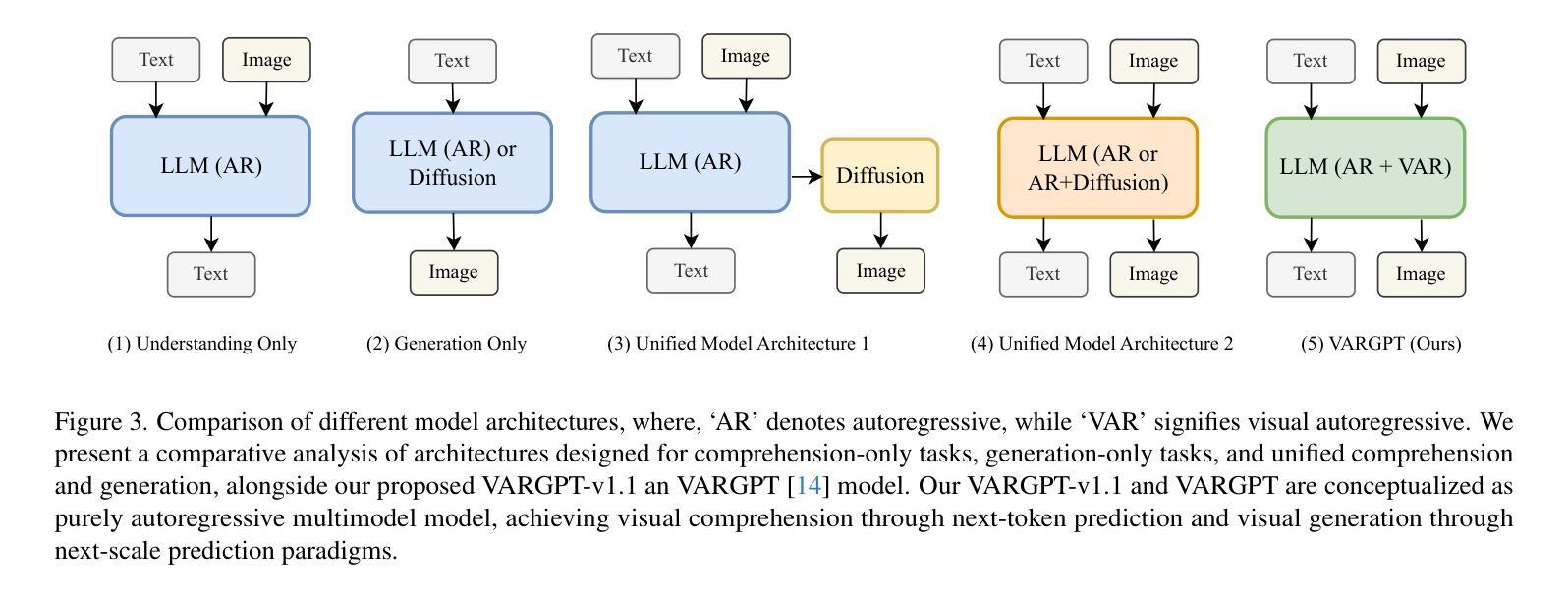
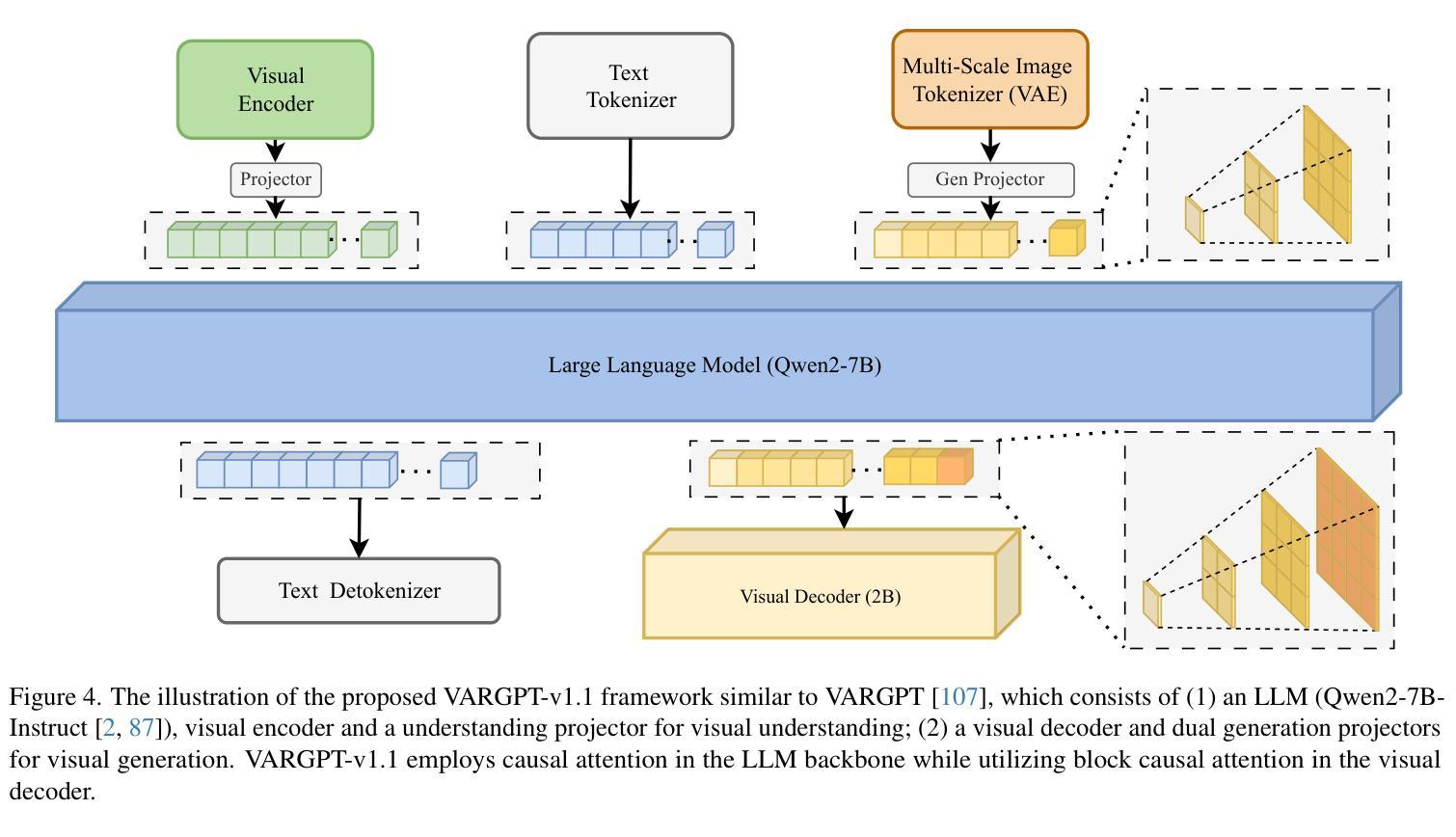
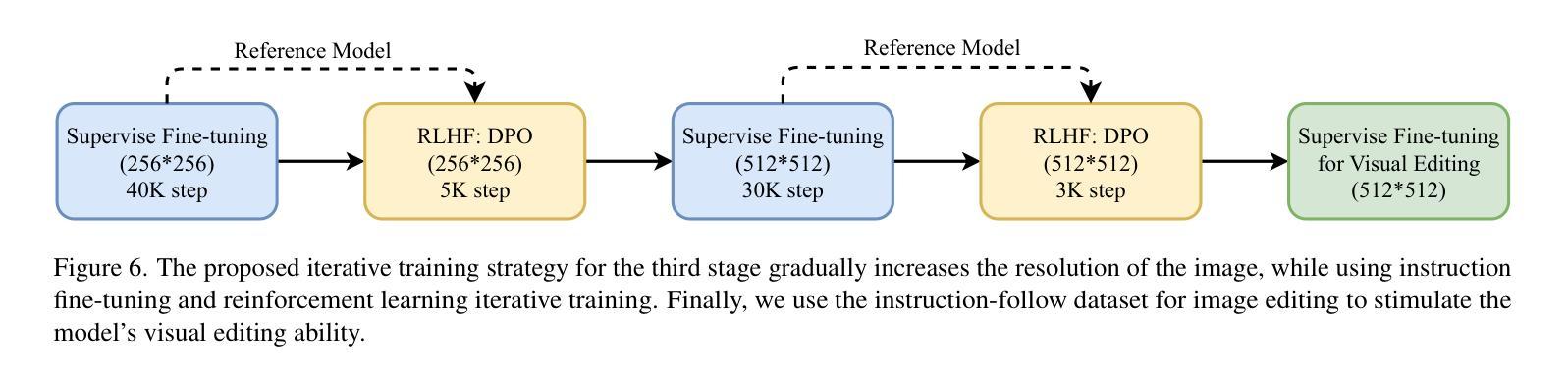
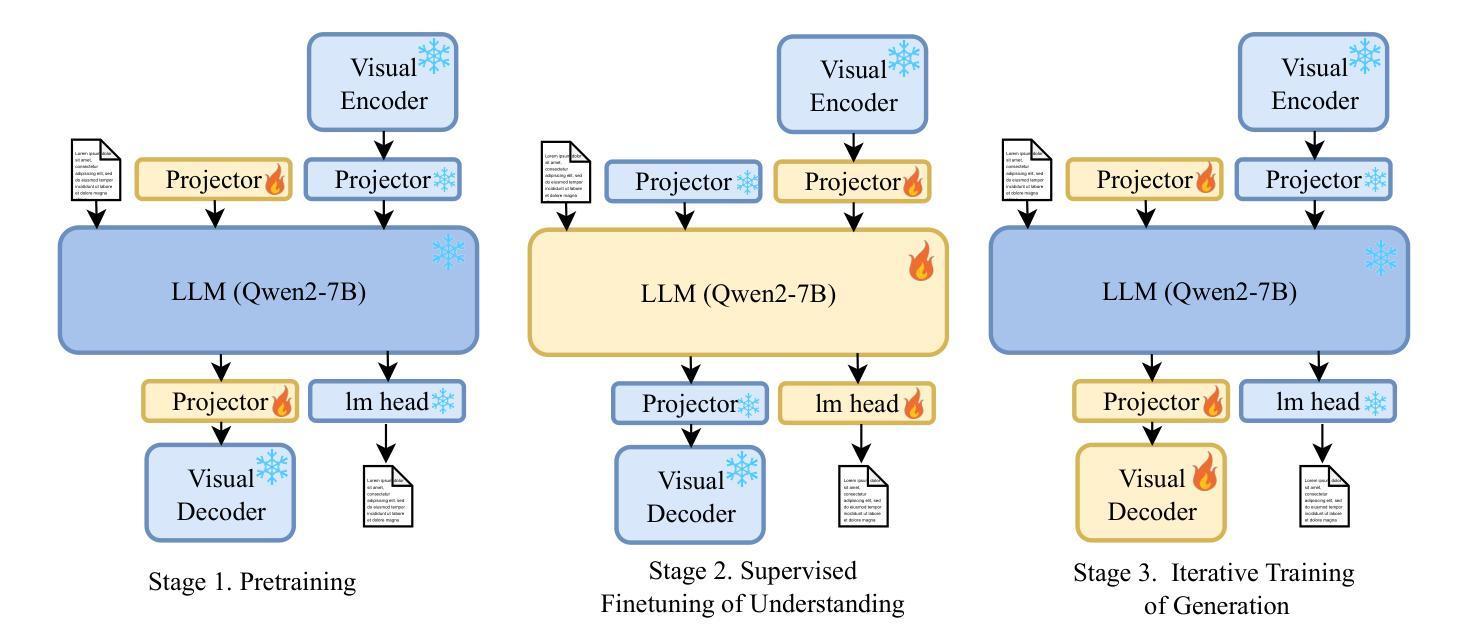
VARGPT-v1.1: Improve Visual Autoregressive Large Unified Model via Iterative Instruction Tuning and Reinforcement Learning
Authors:Xianwei Zhuang, Yuxin Xie, Yufan Deng, Dongchao Yang, Liming Liang, Jinghan Ru, Yuguo Yin, Yuexian Zou
In this work, we present VARGPT-v1.1, an advanced unified visual autoregressive model that builds upon our previous framework VARGPT. The model preserves the dual paradigm of next-token prediction for visual understanding and next-scale generation for image synthesis. Specifically, VARGPT-v1.1 integrates: (1) a novel training strategy combining iterative visual instruction tuning with reinforcement learning through Direct Preference Optimization (DPO), (2) an expanded training corpus containing 8.3M visual-generative instruction pairs, (3) an upgraded language model backbone using Qwen2, (4) enhanced image generation resolution, and (5) emergent image editing capabilities without architectural modifications. These advancements enable VARGPT-v1.1 to achieve state-of-the-art performance in multimodal understanding and text-to-image instruction-following tasks, demonstrating significant improvements in both comprehension and generation metrics. Notably, through visual instruction tuning, the model acquires image editing functionality while maintaining architectural consistency with its predecessor, revealing the potential for unified visual understanding, generation, and editing. Our findings suggest that well-designed unified visual autoregressive models can effectively adopt flexible training strategies from large language models (LLMs), exhibiting promising scalability. The codebase and model weights are publicly available at https://github.com/VARGPT-family/VARGPT-v1.1.
在这项工作中,我们推出了VARGPT-v1.1,这是一款先进的统一视觉自回归模型,基于我们之前的框架VARGPT构建。该模型保留了视觉理解和图像合成下一次令牌预测和下一代尺度的双重范式。具体来说,VARGPT-v1.1集成了以下功能:(1)一种新型训练策略,结合迭代视觉指令微调与通过直接偏好优化(DPO)的强化学习,(2)包含830万视觉生成指令对的扩展训练语料库,(3)使用Qwen2的升级语言模型主干,(4)增强的图像生成分辨率,(5)无需架构修改即可实现图像编辑功能。这些进步使VARGPT-v1.1在跨模态理解和文本到图像的指令跟踪任务上达到了最先进的性能,理解和生成指标均显著改进。值得注意的是,通过视觉指令微调,该模型在保持与前代模型架构一致的同时获得了图像编辑功能,展示了统一视觉理解、生成和编辑的潜力。我们的研究结果表明,精心设计的一体化视觉自回归模型可以有效地采用大型语言模型(LLM)的灵活训练策略,展现出有前景的可扩展性。代码库和模型权重可在https://github.com/VARGPT-family/VARGPT-v1.1上公开获取。
论文及项目相关链接
PDF Code is available at: https://github.com/VARGPT-family/VARGPT-v1.1. arXiv admin note: text overlap with arXiv:2501.12327
Summary
VARGPT-v1.1是一款先进的统一视觉自回归模型,基于先前的VARGPT框架进行开发。它保留了视觉理解和图像合成的下一代标记预测和下一代比例生成的双重范式,并增加了多项新技术和功能。通过结合迭代视觉指令调整与通过直接偏好优化(DPO)的强化学习的新型训练策略、包含830万视觉生成指令对的大型训练语料库、升级的Qwen2语言模型主干、提高的图像生成分辨率以及新兴的图像编辑功能,VARGPT-v1.1在多模态理解和文本到图像指令遵循任务上实现了最先进的性能,显著提高了理解和生成指标。该模型通过视觉指令调整获得图像编辑功能,同时保持了与前体的架构一致性,显示出统一视觉理解、生成和编辑的潜力。我们的研究结果表明,精心设计的大型语言模型(LLM)的统一视觉自回归模型可以有效地采用灵活的训练策略,并展现出令人鼓舞的可扩展性。
Key Takeaways
- VARGPT-v1.1是一个先进的统一视觉自回归模型,基于VARGPT框架开发。
- 模型采用新型训练策略,结合迭代视觉指令调整与强化学习。
- VARGPT-v1.1拥有扩大的训练语料库,包含830万视觉生成指令对。
- 升级为Qwen2语言模型主干,增强图像生成分辨率和图像编辑功能。
- 模型在多模态理解和文本到图像指令遵循任务上表现先进,理解和生成指标显著提高。
- 通过视觉指令调整,模型具备图像编辑功能,并保持与前体的架构一致性。
- 研究表明,统一视觉自回归模型可灵活采用大型语言模型(LLM)的训练策略,具有可扩展性。
点此查看论文截图

Better Bill GPT: Comparing Large Language Models against Legal Invoice Reviewers
Authors:Nick Whitehouse, Nicole Lincoln, Stephanie Yiu, Lizzie Catterson, Rivindu Perera
Legal invoice review is a costly, inconsistent, and time-consuming process, traditionally performed by Legal Operations, Lawyers or Billing Specialists who scrutinise billing compliance line by line. This study presents the first empirical comparison of Large Language Models (LLMs) against human invoice reviewers - Early-Career Lawyers, Experienced Lawyers, and Legal Operations Professionals-assessing their accuracy, speed, and cost-effectiveness. Benchmarking state-of-the-art LLMs against a ground truth set by expert legal professionals, our empirically substantiated findings reveal that LLMs decisively outperform humans across every metric. In invoice approval decisions, LLMs achieve up to 92% accuracy, surpassing the 72% ceiling set by experienced lawyers. On a granular level, LLMs dominate line-item classification, with top models reaching F-scores of 81%, compared to just 43% for the best-performing human group. Speed comparisons are even more striking - while lawyers take 194 to 316 seconds per invoice, LLMs are capable of completing reviews in as fast as 3.6 seconds. And cost? AI slashes review expenses by 99.97%, reducing invoice processing costs from an average of $4.27 per invoice for human invoice reviewers to mere cents. These results highlight the evolving role of AI in legal spend management. As law firms and corporate legal departments struggle with inefficiencies, this study signals a seismic shift: The era of LLM-powered legal spend management is not on the horizon, it has arrived. The challenge ahead is not whether AI can perform as well as human reviewers, but how legal teams will strategically incorporate it, balancing automation with human discretion.
法律发票审核是一个成本高、不一致且耗时的过程,传统上由法律运营、律师或计费专员执行,他们逐行审查计费合规性。本研究首次对大型语言模型(LLM)与人类发票审核员(初级律师、资深律师和法律运营专业人士)进行实证研究,评估其准确性、速度和成本效益。以专家法律专业人士设定的真实数据集为基准,对比最先进的LLM,我们的实证研究发现,LLM在所有指标上均显著优于人类。在发票审批决策中,LLM的准确率高达92%,超越了资深律师设定的72%上限。在细粒度层面,LLM在条目分类上占据主导地位,顶级模型的F分数达到81%,而表现最佳的人类团队仅为43%。速度对比更加令人印象深刻——虽然律师审核每张发票需要194至316秒,但LLM却能在短短3.6秒内完成审核。那么成本呢?人工智能将审核费用减少了99.97%,将人类发票审核员平均每张发票的审核成本从4.27美元降至仅几美分。这些结果凸显了人工智能在法律费用管理中的不断演变的作用。随着律师事务所和企业法务部门面临效率问题,这项研究标志着重大变化:大型语言模型驱动的法务支出管理时代已经到来。未来的挑战不在于人工智能能否像人类审核员一样表现良好,而在于法律团队如何将其战略性地纳入其中,实现自动化与人类判断之间的平衡。
论文及项目相关链接
摘要
传统法律发票审查流程成本高昂、结果不一致且耗时,通常由法务运营人员、律师或计费专员执行,逐行审查计费合规性。本研究首次实证比较大型语言模型(LLM)与人类发票审查员(初级律师、资深律师及法务运营专业人士)在准确性、速度和成本效益方面的表现。以专家法律专业人士的基准真实数据集为标准,对最前沿LLM进行基准测试,结果显示LLM在各项指标上均显著超越人类。在发票审批决策中,LLM的准确率高达92%,突破了资深律师设定的72%上限。在具体层面,LLM在项目分类上表现卓越,顶尖模型的F分数达81%,而表现最佳的人类团队仅为43%。速度方面的对比更为显著——律师审查每张发票需194至316秒,而LLM仅需3.6秒即可完成审查。至于成本?人工智能将审查成本降低了99.97%,将人类发票审查者的平均发票处理成本从4.27美元降至几美分。该研究突显了人工智能在法律费用管理中的不断进化角色。随着律师事务所和企业法务部门面临效率问题,这项研究预示着一次重大变革:LLM驱动的法律费用管理时代已经到来。未来的挑战不在于人工智能能否像人类评审者那样表现,而在于法律团队如何将其纳入战略平衡自动化与人类判断之中。
关键见解
- 法律发票审查传统流程成本高且耗时。
- 大型语言模型(LLM)首次被实证比较于不同水平的法律发票审查员(人类)。
- LLM在准确性方面显著超越人类审查员,准确率高达92%。
- LLM在项目分类上表现卓越,顶尖模型F分数达81%。
- LLM审查速度远超人类,仅需3.6秒即可完成审查。
- 人工智能大幅降低了法律发票审查的成本,将成本降低了99.97%。
点此查看论文截图

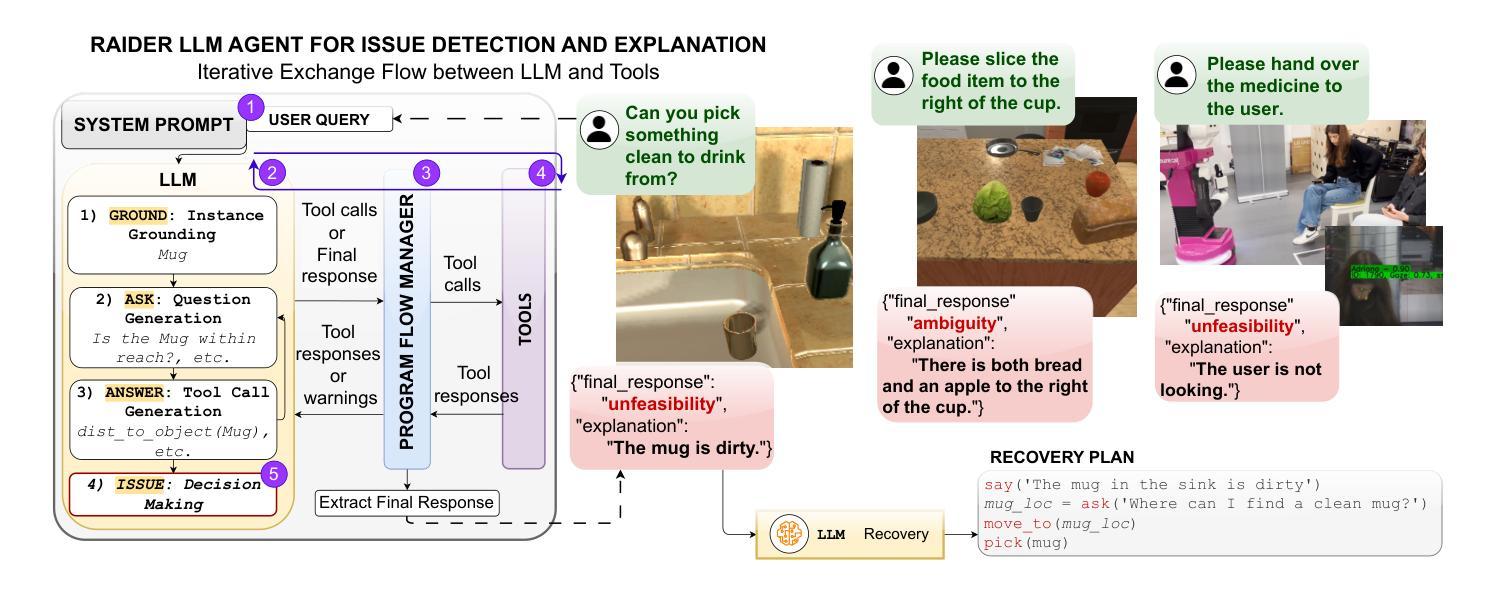
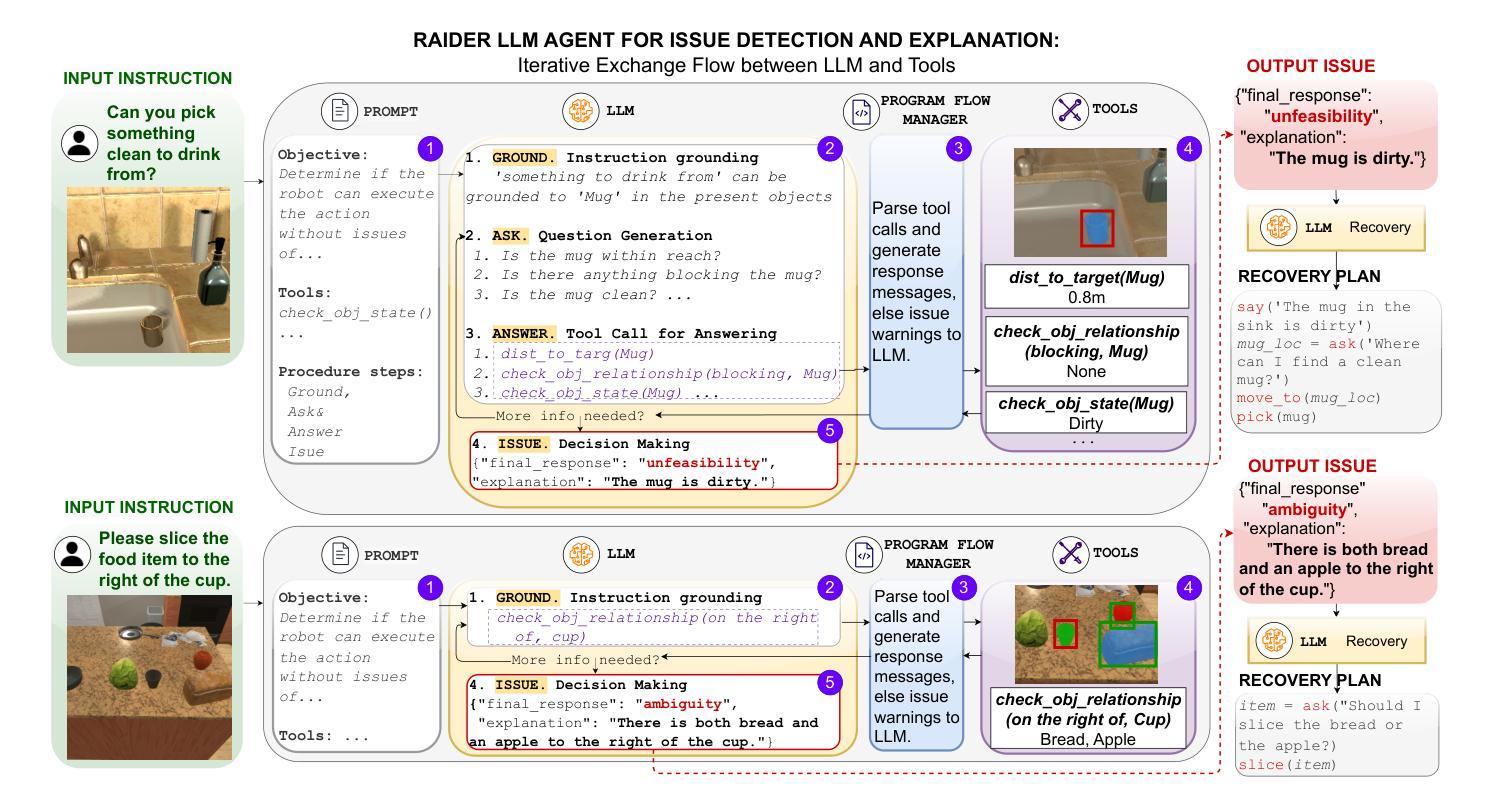
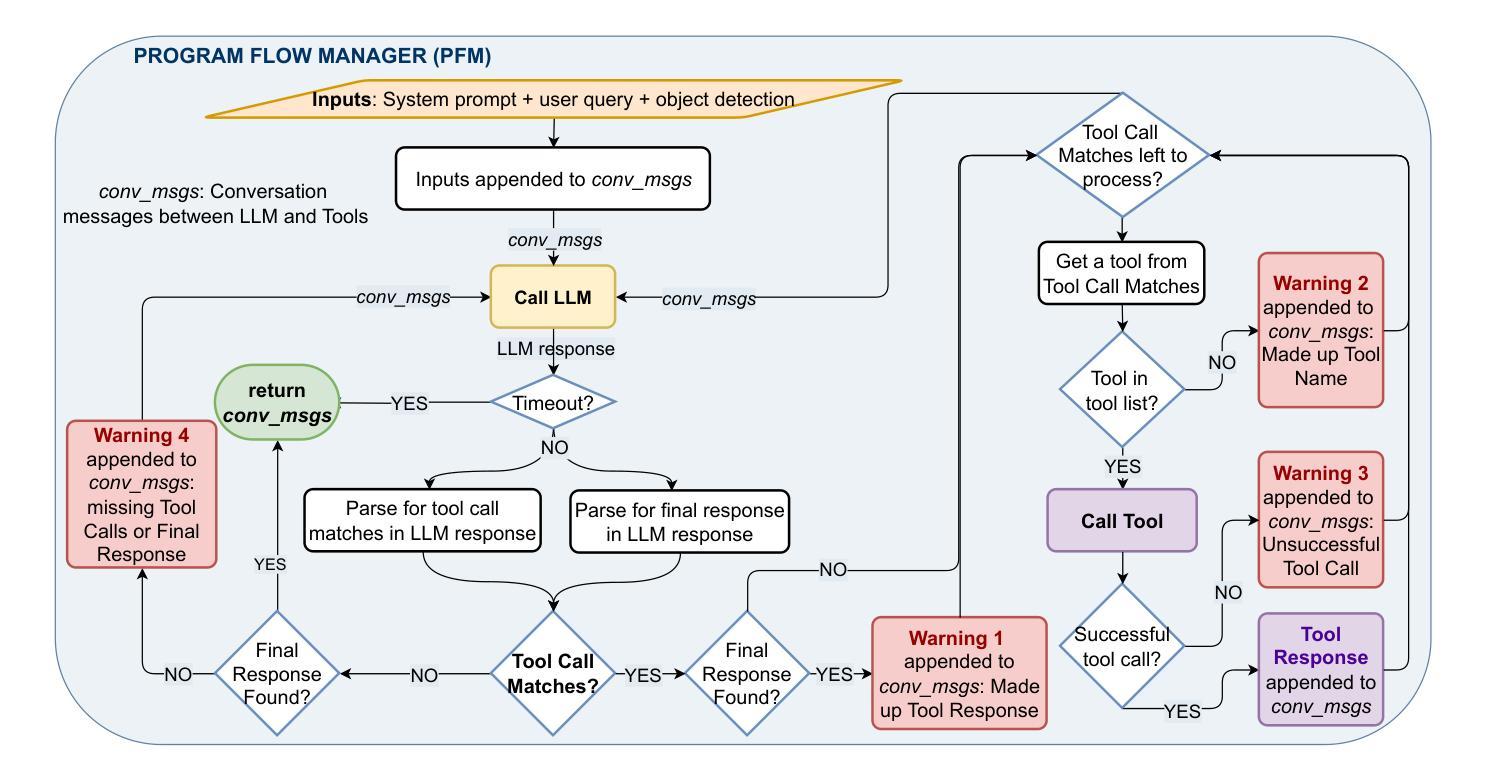
RAIDER: Tool-Equipped Large Language Model Agent for Robotic Action Issue Detection, Explanation and Recovery
Authors:Silvia Izquierdo-Badiola, Carlos Rizzo, Guillem Alenyà
As robots increasingly operate in dynamic human-centric environments, improving their ability to detect, explain, and recover from action-related issues becomes crucial. Traditional model-based and data-driven techniques lack adaptability, while more flexible generative AI methods struggle with grounding extracted information to real-world constraints. We introduce RAIDER, a novel agent that integrates Large Language Models (LLMs) with grounded tools for adaptable and efficient issue detection and explanation. Using a unique “Ground, Ask&Answer, Issue” procedure, RAIDER dynamically generates context-aware precondition questions and selects appropriate tools for resolution, achieving targeted information gathering. Our results within a simulated household environment surpass methods relying on predefined models, full scene descriptions, or standalone trained models. Additionally, RAIDER’s explanations enhance recovery success, including cases requiring human interaction. Its modular architecture, featuring self-correction mechanisms, enables straightforward adaptation to diverse scenarios, as demonstrated in a real-world human-assistive task. This showcases RAIDER’s potential as a versatile agentic AI solution for robotic issue detection and explanation, while addressing the problem of grounding generative AI for its effective application in embodied agents. Project website: https://eurecat.github.io/raider-llmagent/
随着机器人越来越多地在以人类为中心的环境中运行,提高它们检测、解释和从动作相关问题中恢复的能力变得至关重要。基于模型和传统数据驱动的技术缺乏适应性,而更灵活的生成式人工智能方法在将提取的信息与现实世界的约束相结合方面却表现挣扎。我们引入了RAIDER,这是一个新型智能体,它融合了大型语言模型(LLM)和基于现实的工具,用于适应性强、高效的问题检测和解释。通过独特的“接地、问答、问题”流程,RAIDER能够动态生成具有情境意识的先决条件问题,并选择适当的工具进行解决,从而实现有针对性的信息收集。在模拟家庭环境中的结果超过了依赖于预定义模型、全景描述或独立训练模型的方法。此外,RAIDER的解释增强了恢复成功的可能性,包括需要人类交互的情况。其模块化架构配备了自我校正机制,可轻松适应各种场景,正如在人类辅助任务中所展示的那样。这展示了RAIDER作为通用智能体解决方案在机器人问题检测和解释方面的潜力,同时解决了生成式人工智能在实体机器人中的应用中的接地问题。项目网站:https://eurecat.github.io/raider-llmagent/
论文及项目相关链接
Summary
机器人技术在动态以人为中心的环境中操作日益普遍,提高机器人检测和解释动作相关问题的能力以及从故障中恢复的能力变得至关重要。传统的模型驱动和数据驱动方法缺乏适应性,而灵活的生成式AI方法则难以将提取的信息与现实世界的约束相联系。本研究引入了RAIDER,这是一种集成了大型语言模型(LLM)和接地工具的新型智能体,用于适应性强、效率高的故障检测与解释。通过独特的“接地、提问与回答、解决问题”流程,RAIDER能动态生成情境感知的前置问题,并选择适当的工具进行解决,实现有针对性的信息收集。在模拟家庭环境中的表现优于依赖预设模型、完整场景描述或独立训练模型的方法。此外,RAIDER的解释功能提高了恢复成功率,包括需要人类交互的情况。其模块化架构具有自我修正机制,能轻松适应各种场景,在真实世界的人类辅助任务中得到了验证。这为RAIDER作为通用智能体在机器人问题检测和解释方面的潜力提供了展示,解决了生成式AI在现实应用中的接地问题。
Key Takeaways
- 随着机器人在以人为中心的环境中操作日益增多,提高其检测和解释动作相关问题的能力变得至关重要。
- 传统模型驱动和数据驱动方法缺乏适应性,难以满足动态环境变化的需求。
- 引入RAIDER智能体,集成了大型语言模型(LLM)和接地工具,用于增强机器人的问题检测和解释能力。
- RAIDER采用独特的“接地、提问与回答、解决问题”流程,实现动态生成情境感知的前置问题和有针对性的信息收集。
- 在模拟家庭环境中,RAIDER表现优于传统方法,具有强大的适应性。
- RAIDER的解释功能增强了恢复成功率,并在需要人类交互的情况下表现出优势。
点此查看论文截图

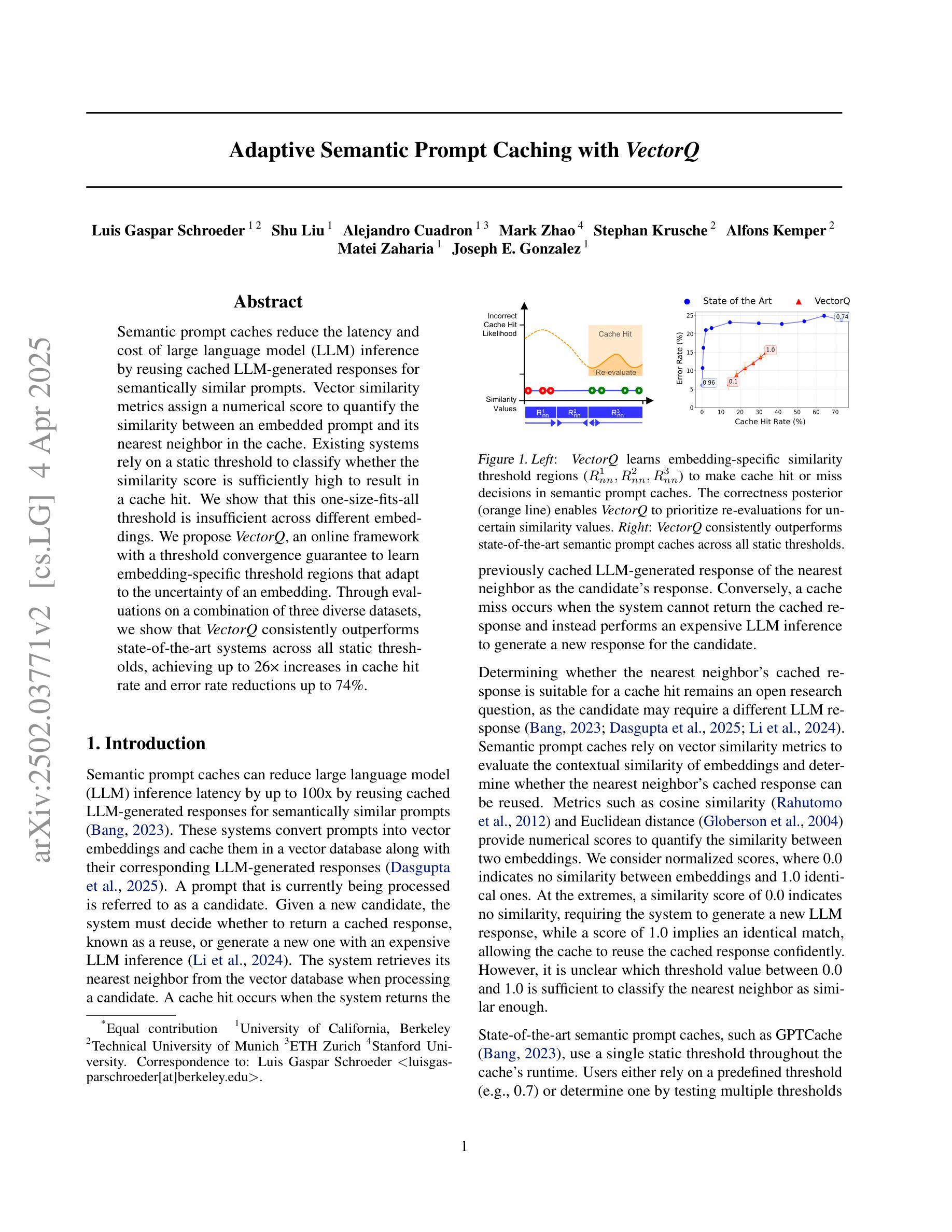
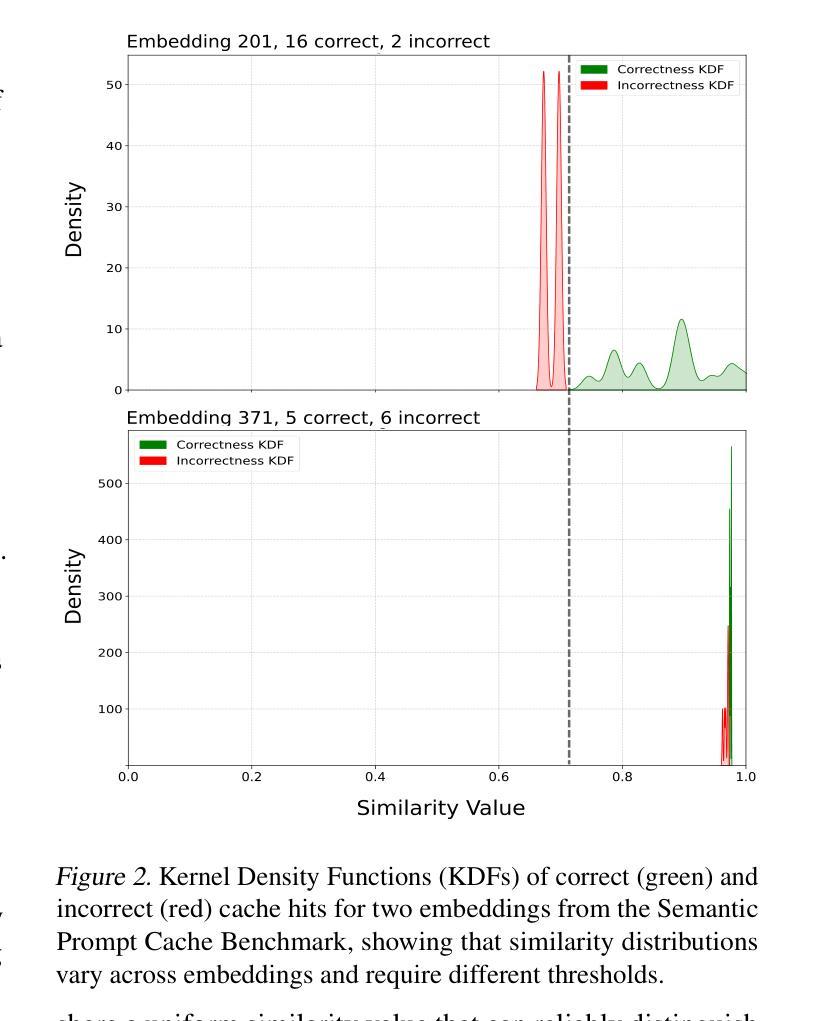
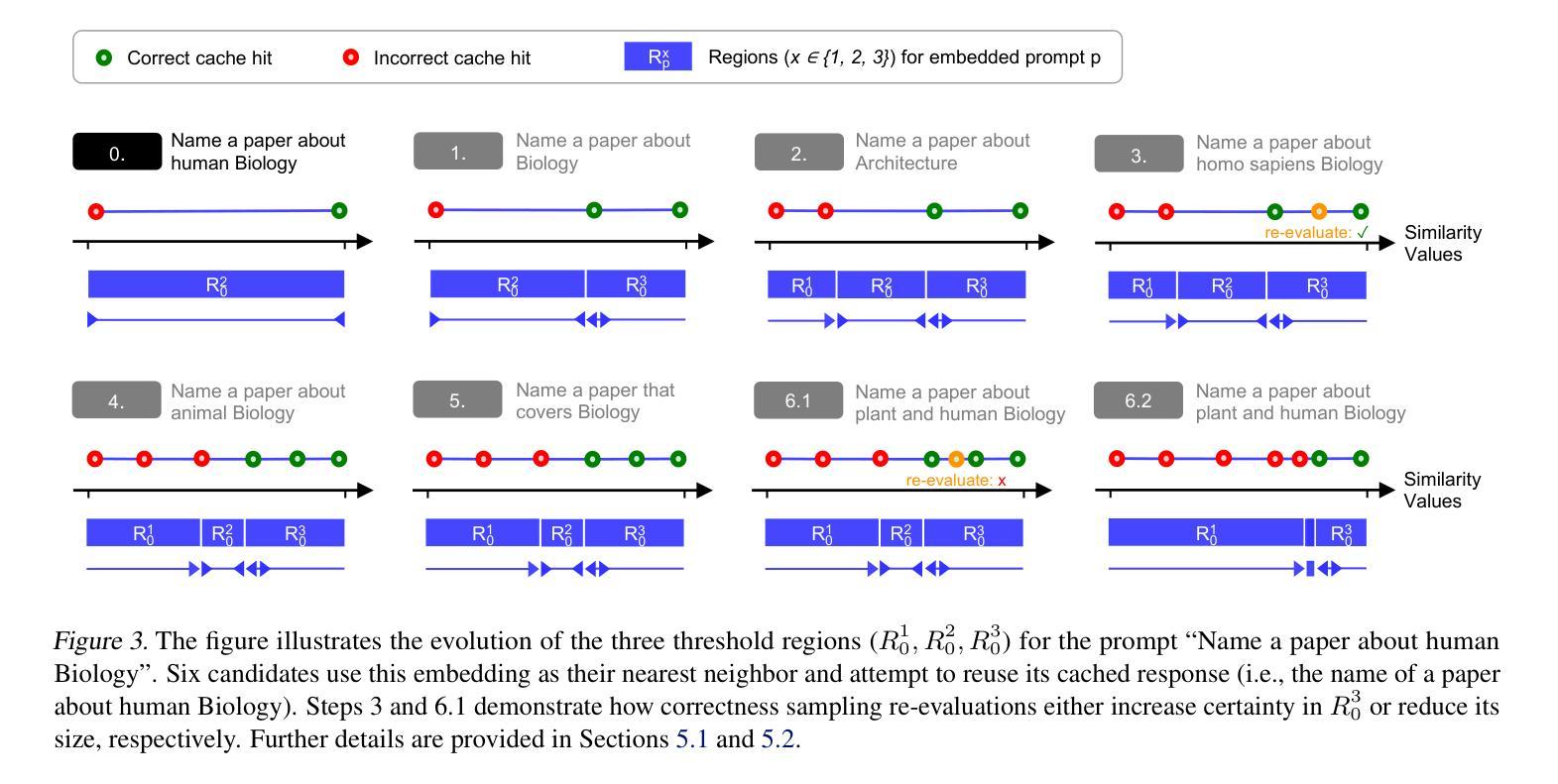
Adaptive Semantic Prompt Caching with VectorQ
Authors:Luis Gaspar Schroeder, Shu Liu, Alejandro Cuadron, Mark Zhao, Stephan Krusche, Alfons Kemper, Matei Zaharia, Joseph E. Gonzalez
Semantic prompt caches reduce the latency and cost of large language model (LLM) inference by reusing cached LLM-generated responses for semantically similar prompts. Vector similarity metrics assign a numerical score to quantify the similarity between an embedded prompt and its nearest neighbor in the cache. Existing systems rely on a static threshold to classify whether the similarity score is sufficiently high to result in a cache hit. We show that this one-size-fits-all threshold is insufficient across different embeddings. We propose VectorQ, an online framework with a threshold convergence guarantee to learn embedding-specific threshold regions that adapt to the uncertainty of an embedding. Through evaluations on a combination of three diverse datasets, we show that VectorQ consistently outperforms state-of-the-art systems across all static thresholds, achieving up to 26x increases in cache hit rate and error rate reductions up to 74%.
语义提示缓存通过重用缓存中LLM生成的与语义相似的提示响应,减少了大语言模型(LLM)推理的延迟和成本。向量相似度度量会给出一个数值分数来衡量嵌入提示与其在缓存中的最近邻居之间的相似度。现有系统依赖于静态阈值来分类相似度分数是否足够高以产生缓存命中。我们表明,这种一刀切阈值在不同嵌入中是不够用的。我们提出了VectorQ,一个带有阈值收敛保证的在线框架,学习针对嵌入的特定阈值区域,以适应嵌入的不确定性。通过对三个不同数据集的评估,我们证明了VectorQ在所有静态阈值上均优于最新系统,实现了高达26倍的缓存命中率提升,误差率降低高达74%。
论文及项目相关链接
Summary
语义提示缓存通过重用缓存中LLM生成的与语义相似提示相对应的回答,减少了大型语言模型(LLM)推理的延迟和成本。向量相似度度量标准给出一数值分数来衡量嵌入提示与其在缓存中的最近邻居之间的相似性。现有系统依赖于静态阈值来判断相似度分数是否足够高以产生缓存命中。本文指出,这种一刀切阈值在不同嵌入中的适用性不足。因此,我们提出了VectorQ,一个在线框架,具有阈值收敛保证,能够学习适应嵌入不确定性的嵌入特定阈值区域。在三个不同数据集上的评估表明,VectorQ在所有的静态阈值上都表现出一致的优势,实现了高达26倍的缓存命中率提升和高达74%的错误率降低。
Key Takeaways
- 语义提示缓存用于减少LLM推理的延迟和成本。
- 向量相似度度量用于评估嵌入提示与其缓存中最近邻居的相似性。
- 现有系统依赖静态阈值判断缓存命中存在不足。
- VectorQ框架通过在线学习和阈值收敛保证来适应不同嵌入的不确定性。
- VectorQ在不同数据集上的评估表现优于现有系统。
- VectorQ提高了高达26倍的缓存命中率。
点此查看论文截图

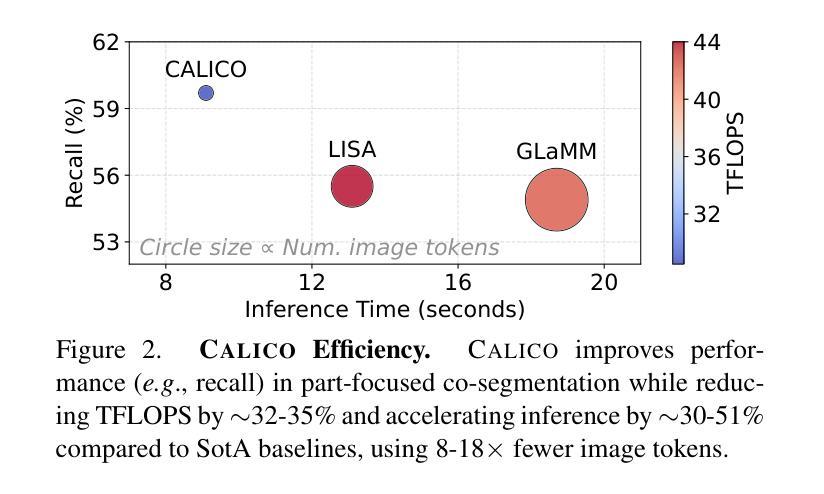
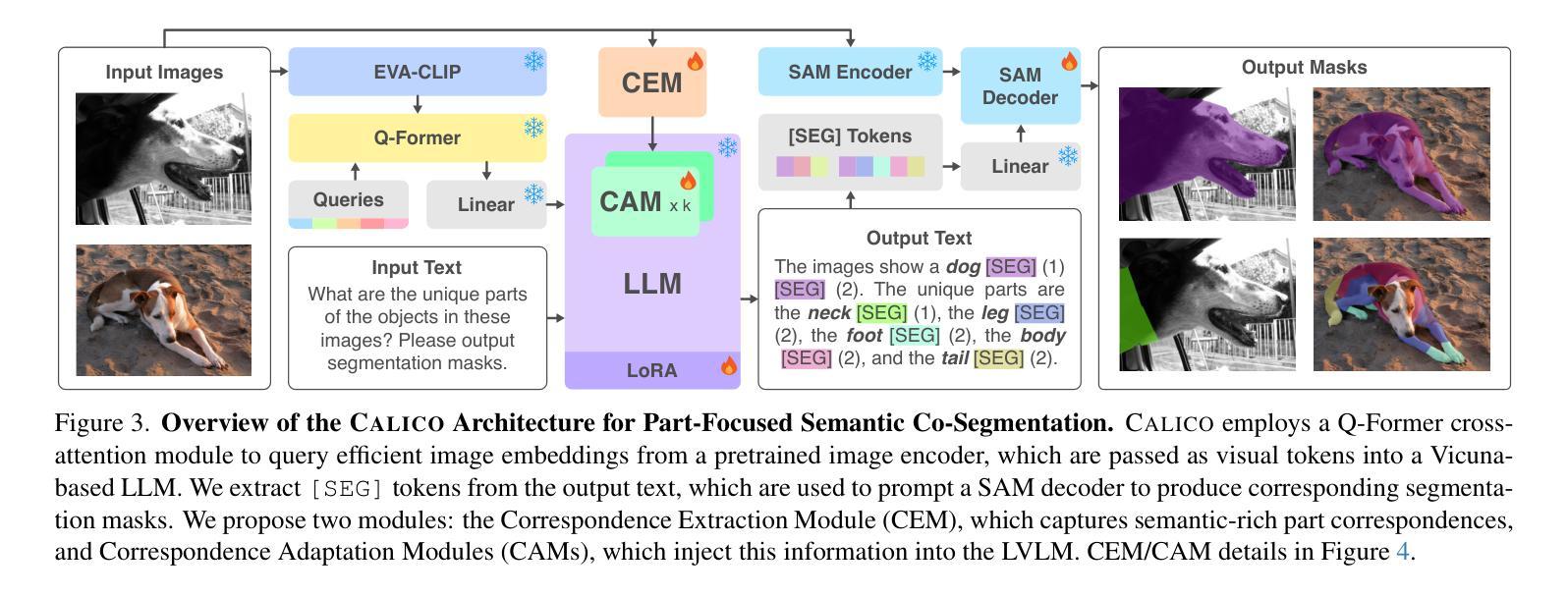
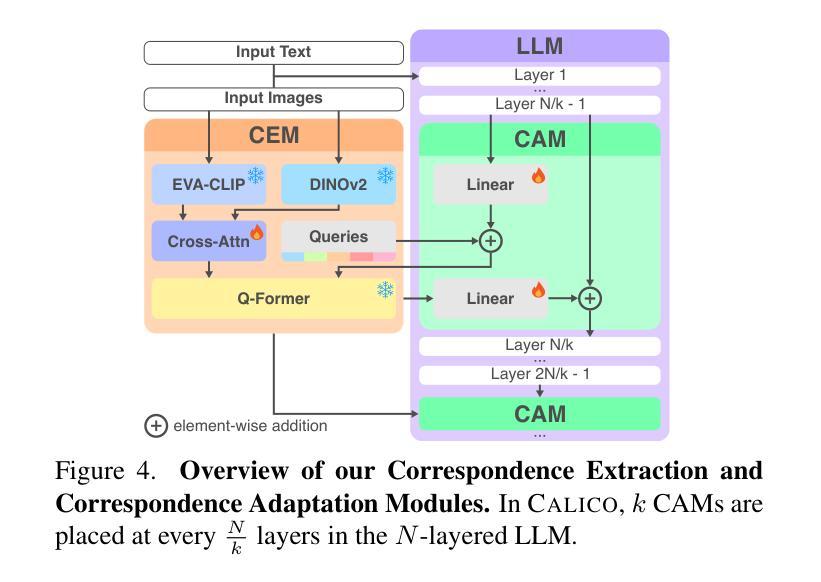
CALICO: Part-Focused Semantic Co-Segmentation with Large Vision-Language Models
Authors:Kiet A. Nguyen, Adheesh Juvekar, Tianjiao Yu, Muntasir Wahed, Ismini Lourentzou
Recent advances in Large Vision-Language Models (LVLMs) have enabled general-purpose vision tasks through visual instruction tuning. While existing LVLMs can generate segmentation masks from text prompts for single images, they struggle with segmentation-grounded reasoning across images, especially at finer granularities such as object parts. In this paper, we introduce the new task of part-focused semantic co-segmentation, which involves identifying and segmenting common objects, as well as common and unique object parts across images. To address this task, we present CALICO, the first LVLM designed for multi-image part-level reasoning segmentation. CALICO features two key components, a novel Correspondence Extraction Module that identifies semantic part-level correspondences, and Correspondence Adaptation Modules that embed this information into the LVLM to facilitate multi-image understanding in a parameter-efficient manner. To support training and evaluation, we curate MixedParts, a large-scale multi-image segmentation dataset containing $\sim$2.4M samples across $\sim$44K images spanning diverse object and part categories. Experimental results demonstrate that CALICO, with just 0.3% of its parameters finetuned, achieves strong performance on this challenging task.
近期大型视觉语言模型(LVLMs)的进步通过视觉指令调整实现了通用视觉任务。虽然现有的LVLMs可以通过文本提示对单张图像生成分割掩膜,但它们在进行跨图像的分割推理时遇到困难,尤其是在较细的粒度(如物体部分)上。在本文中,我们引入了新的部分聚焦语义协同分割任务,该任务涉及识别并分割跨图像中的常见对象以及常见和独特的对象部分。为了解决这个问题,我们提出了CALICO,这是首款针对多图像部分级推理分割设计的LVLM。CALICO有两个关键组件,一个是新型对应关系提取模块,用于识别语义部分级对应关系,另一个是对应关系适应模块,将这些信息嵌入LVLM中,以高效参数的方式促进多图像理解。为了支持训练和评估,我们整理了MixedParts,这是一个大规模的多图像分割数据集,包含约240万样本,分布在约4万张图像上,涵盖各种对象和部件类别。实验结果表明,CALICO仅微调其参数的0.3%,就能在这个具有挑战性的任务上取得出色的表现。
论文及项目相关链接
PDF Accepted to CVPR 2025. Project page: https://plan-lab.github.io/calico/
Summary
本文介绍了大型视觉语言模型(LVLMs)的最新进展,通过视觉指令微调实现了通用视觉任务。现有LVLMs可以从文本提示中生成单个图像的分段掩膜,但在跨图像的分段基础推理方面存在困难,特别是在对象部分的更精细粒度上。为此,本文引入了部分聚焦语义协同分段的新任务,涉及识别并分段跨图像的常见对象及对象部分。为应对此任务,提出了CALICO,首个设计用于多图像部分级别推理分段的LVLM。CALICO具有两个关键组件:对应提取模块,用于识别语义部分级别的对应性;对应适应模块,将信息嵌入LVLM中,以高效参数的方式促进多图像理解。为支持和评估训练,整理出MixedParts大型多图像分段数据集,包含约44K张图像、涵盖不同对象和零件类别的约2.4M样本。实验结果表明,CALICO仅微调其参数的0.3%,即可在此挑战性任务上取得良好表现。
Key Takeaways
- LVLMs能够通过视觉指令微调完成通用视觉任务。
- 现有LVLMs在跨图像分段推理方面存在困难,特别是在对象部分的精细粒度上。
- 引入新的任务:部分聚焦语义协同分段,旨在识别并分段跨图像的常见对象及其部分。
- 提出CALICO模型,专为多图像部分级别推理分段设计。
- CALICO包含两个关键组件:对应提取模块和对应适应模块。
- 为了训练和评估模型,创建了MixedParts数据集,包含大量的多图像分段样本。
点此查看论文截图


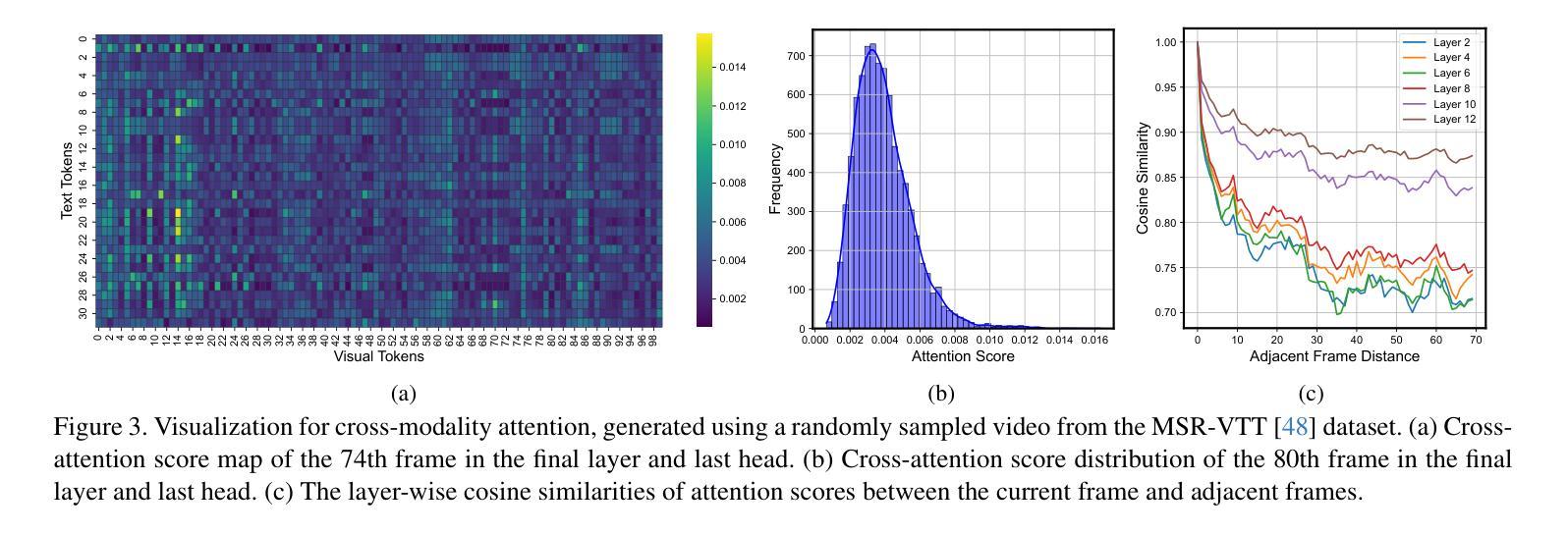
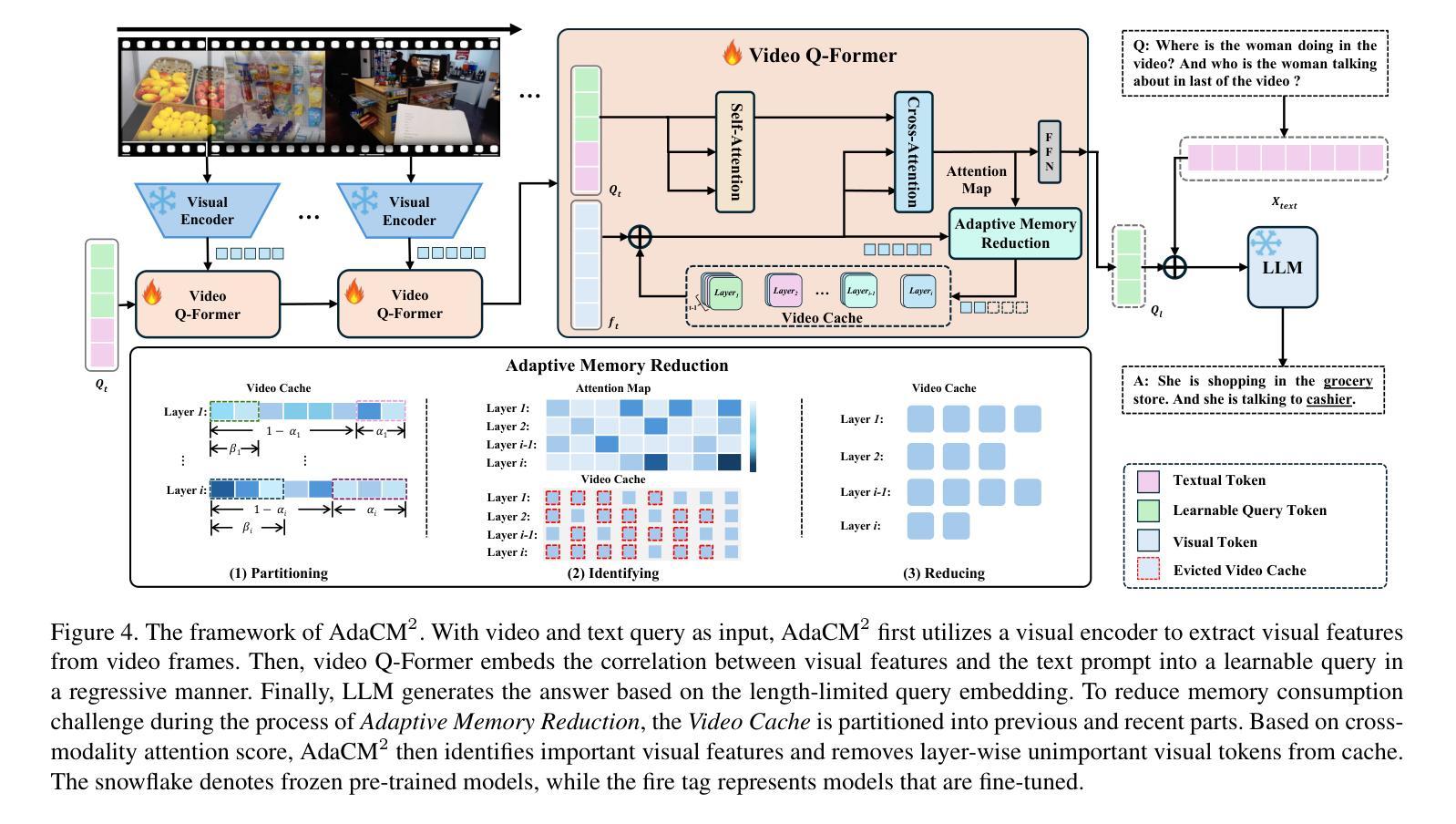
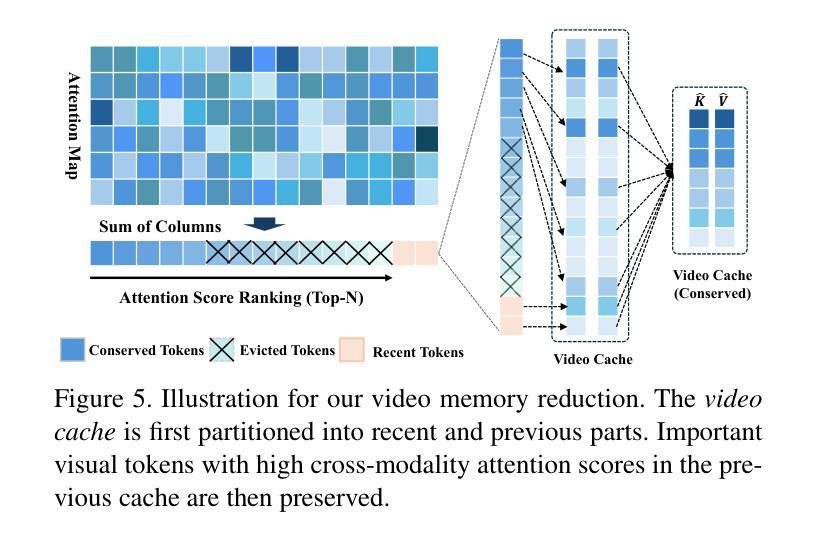
AdaCM$^2$: On Understanding Extremely Long-Term Video with Adaptive Cross-Modality Memory Reduction
Authors:Yuanbin Man, Ying Huang, Chengming Zhang, Bingzhe Li, Wei Niu, Miao Yin
The advancements in large language models (LLMs) have propelled the improvement of video understanding tasks by incorporating LLMs with visual models. However, most existing LLM-based models (e.g., VideoLLaMA, VideoChat) are constrained to processing short-duration videos. Recent attempts to understand long-term videos by extracting and compressing visual features into a fixed memory size. Nevertheless, those methods leverage only visual modality to merge video tokens and overlook the correlation between visual and textual queries, leading to difficulties in effectively handling complex question-answering tasks. To address the challenges of long videos and complex prompts, we propose AdaCM$^2$, which, for the first time, introduces an adaptive cross-modality memory reduction approach to video-text alignment in an auto-regressive manner on video streams. Our extensive experiments on various video understanding tasks, such as video captioning, video question answering, and video classification, demonstrate that AdaCM$^2$ achieves state-of-the-art performance across multiple datasets while significantly reducing memory usage. Notably, it achieves a 4.5% improvement across multiple tasks in the LVU dataset with a GPU memory consumption reduction of up to 65%.
大型语言模型(LLM)的进步通过将其与视觉模型结合,推动了视频理解任务的改进。然而,大多数现有的基于LLM的模型(例如VideoLLaMA、VideoChat)仅限于处理短时长视频。最近的尝试通过提取和压缩视频特征到固定内存大小来理解长视频。然而,这些方法仅利用视觉模式来合并视频令牌,并忽略了视觉和文本查询之间的相关性,导致在处理复杂的问答任务时面临困难。为了解决长视频和复杂提示的挑战,我们提出了AdaCM$^2$,它首次在视频流上以一种自回归的方式引入了自适应跨模态内存缩减方法进行视频文本对齐。我们在各种视频理解任务上进行了大量实验,如视频描述、视频问答和视频分类,结果表明AdaCM$^2$在多个数据集上实现了最先进的性能,同时显著降低了内存使用。值得注意的是,它在LVU数据集的多项任务上实现了4.5%的改进,GPU内存消耗减少了高达65%。
论文及项目相关链接
PDF CVPR 2025 Highlight
Summary
大型语言模型(LLM)在视频理解任务中的应用取得了显著进展。然而,现有LLM模型主要处理短视频,难以应对长视频和复杂查询任务。为此,本文提出了AdaCM$^2$模型,首次采用自适应跨模态记忆缩减方法,以自适应、自回归的方式处理视频流中的视频文本对齐问题。实验证明,AdaCM$^2$在多个视频理解任务上达到了先进性能,同时在LVU数据集上实现了高达65%的GPU内存消耗减少。
Key Takeaways
- LLM的进步推动了视频理解任务的改善。
- 现有LLM模型主要处理短视频,难以应对长视频和复杂查询任务。
- AdaCM$^2$模型首次采用自适应跨模态记忆缩减方法处理视频文本对齐问题。
- AdaCM$^2$模型以自适应、自回归的方式处理视频流。
- AdaCM$^2$在多个视频理解任务上表现出先进性能。
- AdaCM$^2$在LVU数据集上的性能优于其他模型,实现了高达65%的GPU内存消耗减少。
点此查看论文截图


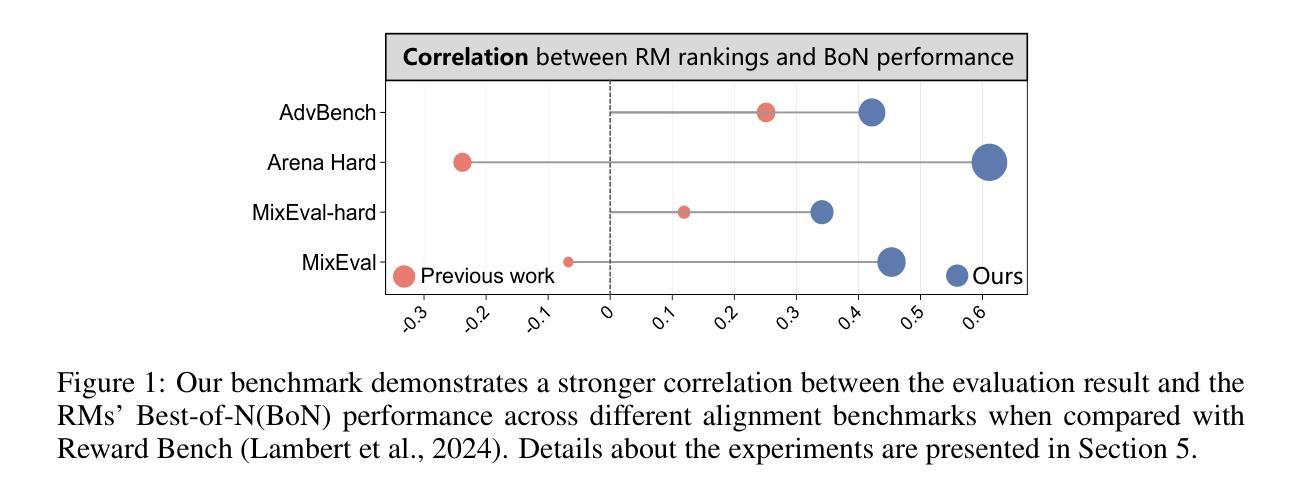
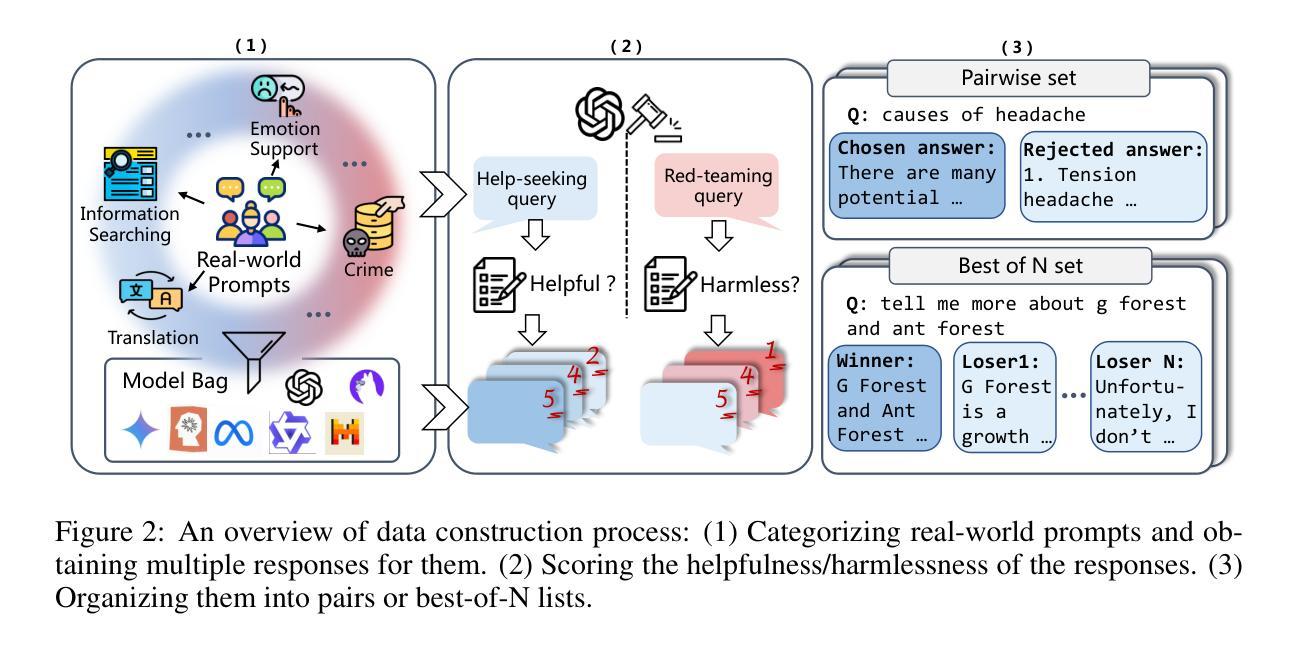
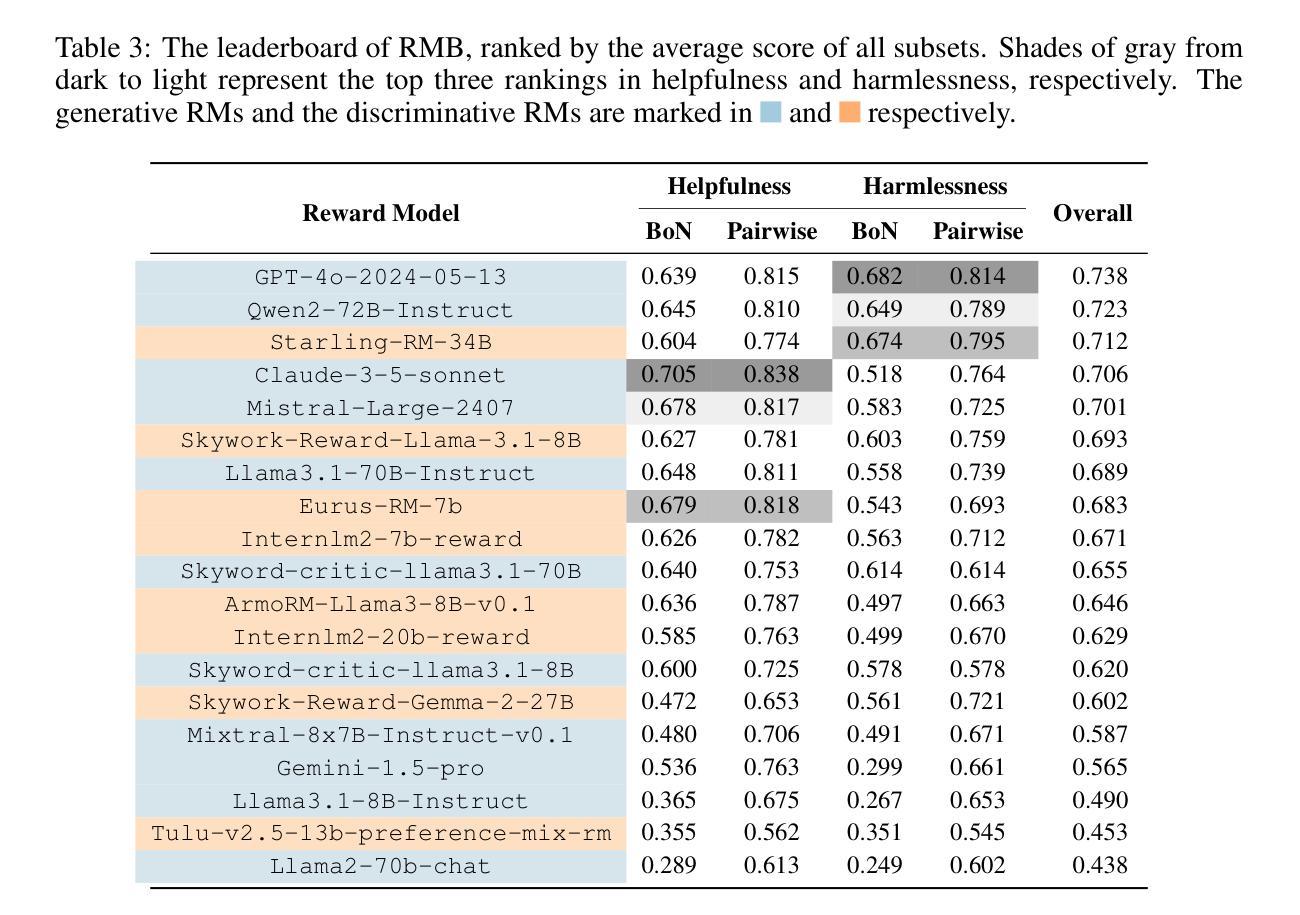
RMB: Comprehensively Benchmarking Reward Models in LLM Alignment
Authors:Enyu Zhou, Guodong Zheng, Binghai Wang, Zhiheng Xi, Shihan Dou, Rong Bao, Wei Shen, Limao Xiong, Jessica Fan, Yurong Mou, Rui Zheng, Tao Gui, Qi Zhang, Xuanjing Huang
Reward models (RMs) guide the alignment of large language models (LLMs), steering them toward behaviors preferred by humans. Evaluating RMs is the key to better aligning LLMs. However, the current evaluation of RMs may not directly correspond to their alignment performance due to the limited distribution of evaluation data and evaluation methods that are not closely related to alignment objectives. To address these limitations, we propose RMB, a comprehensive RM benchmark that covers over 49 real-world scenarios and includes both pairwise and Best-of-N (BoN) evaluations to better reflect the effectiveness of RMs in guiding alignment optimization. We demonstrate a positive correlation between our benchmark and the downstream alignment task performance. Based on our benchmark, we conduct extensive analysis on the state-of-the-art RMs, revealing their generalization defects that were not discovered by previous benchmarks, and highlighting the potential of generative RMs. Furthermore, we delve into open questions in reward models, specifically examining the effectiveness of majority voting for the evaluation of reward models and analyzing the impact factors of generative RMs, including the influence of evaluation criteria and instructing methods. Our evaluation code and datasets are available at https://github.com/Zhou-Zoey/RMB-Reward-Model-Benchmark.
奖励模型(RM)引导大型语言模型(LLM)的对齐,使它们朝向人类偏好的行为。评估RM是更好地对齐LLM的关键。然而,当前的RM评估可能无法直接对应其对齐性能,因为评估数据的分布有限,且评估方法与对齐目标不紧密相关。为了解决这些局限性,我们提出了RMB(RM基准测试),这是一个全面的RM基准测试,涵盖超过49个真实场景,包括成对和Best-of-N(BoN)评估,以更好地反映RM在引导对齐优化方面的有效性。我们证明了我们的基准测试与下游对齐任务性能之间的正相关关系。基于我们的基准测试,我们对最先进的RM进行了广泛的分析,揭示了它们未被以前基准测试发现的泛化缺陷,并突出了生成RM的潜力。此外,我们深入探讨了奖励模型中的开放问题,具体检查了多数投票在评估奖励模型中的有效性,并分析了生成RM的影响因素,包括评估标准和指导方法的影响。我们的评估代码和数据集可在https://github.com/Zhou-Zoey/RMB-Reward-Model-Benchmark找到。
论文及项目相关链接
PDF Accepted by ICLR2025
Summary
本文提出一种针对奖励模型(RM)的综合基准测试RMB,该基准测试涵盖超过49个真实场景,包括成对评价和最佳N评价,以更好地反映RM在指导对齐优化方面的有效性。研究发现,该基准测试与下游对齐任务性能之间存在正相关,对最先进的RM进行了广泛的分析,揭示了其以往基准测试中未发现的泛化缺陷,并强调了生成式RM的潜力。同时,探讨了奖励模型中的开放问题,包括多数投票的有效性评估和生成式RM的影响因素等。
Key Takeaways
- 奖励模型(RM)用于指导大型语言模型(LLM)的对齐,使其朝向人类偏好的行为发展。
- 评估RM是优化LLM对齐的关键。
- 当前RM评估方法存在局限性,无法直接反映其对齐性能,主要体现在评价数据分布有限以及评价方法未与对齐目标紧密相关。
- 为解决这些局限性,提出了RMB基准测试,涵盖多种真实场景并包括成对和最佳N评价,以更准确地反映RM在指导对齐方面的有效性。
- RMB基准测试与下游对齐任务性能之间存在正相关。
- 基于RMB基准测试,对现有RM进行了广泛分析,揭示了其泛化缺陷,并强调了生成式RM的潜力。
点此查看论文截图



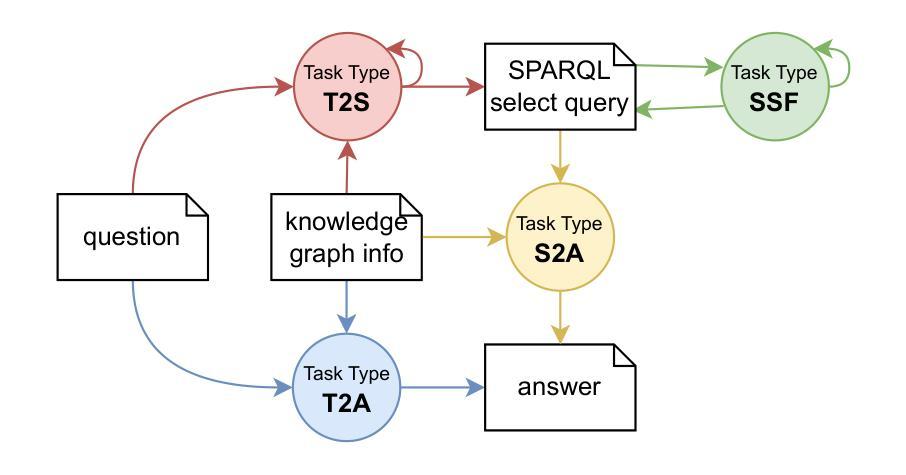
Assessing SPARQL capabilities of Large Language Models
Authors:Lars-Peter Meyer, Johannes Frey, Felix Brei, Natanael Arndt
The integration of Large Language Models (LLMs) with Knowledge Graphs (KGs) offers significant synergistic potential for knowledge-driven applications. One possible integration is the interpretation and generation of formal languages, such as those used in the Semantic Web, with SPARQL being a core technology for accessing KGs. In this paper, we focus on measuring out-of-the box capabilities of LLMs to work with SPARQL and more specifically with SPARQL SELECT queries applying a quantitative approach. We implemented various benchmarking tasks in the LLM-KG-Bench framework for automated execution and evaluation with several LLMs. The tasks assess capabilities along the dimensions of syntax, semantic read, semantic create, and the role of knowledge graph prompt inclusion. With this new benchmarking tasks, we evaluated a selection of GPT, Gemini, and Claude models. Our findings indicate that working with SPARQL SELECT queries is still challenging for LLMs and heavily depends on the specific LLM as well as the complexity of the task. While fixing basic syntax errors seems to pose no problems for the best of the current LLMs evaluated, creating semantically correct SPARQL SELECT queries is difficult in several cases.
大型语言模型(LLMs)与知识图谱(KGs)的融合为知识驱动的应用提供了巨大的协同潜力。一种可能的融合是解释和生成形式语言,如语义网所使用的语言,SPARQL是访问知识图谱的核心技术。在本文中,我们专注于测量LLMs与SPARQL的即插即用能力,更具体地说,是应用定量方法的SPARQL SELECT查询。我们在LLM-KG-Bench框架中实施了各种基准测试任务,用于自动执行和评估多个LLMs。这些任务评估了语法、语义阅读、语义创建以及知识图谱提示包含的作用等方面的能力。通过这项新的基准测试任务,我们评估了一些GPT、Gemini和Claude模型。我们的研究结果表明,对于LLMs来说,处理SPARQL SELECT查询仍然具有挑战性,这很大程度上取决于特定的LLM以及任务的复杂性。虽然纠正基本语法错误似乎对评估的最佳LLMs没有问题,但在许多情况下,生成语义正确的SPARQL SELECT查询是很困难的。
论文及项目相关链接
PDF Peer reviewed and published at NLP4KGc @ Semantics 2024, see original publication at https://ceur-ws.org/Vol-3874/paper3.pdf . Updated Metadata
Summary
大型语言模型(LLM)与知识图谱(KG)的融合为知识驱动的应用提供了巨大的协同潜力。本文关注LLM对SPARQL的即席能力进行衡量,特别是SPARQL SELECT查询。通过定量方法,在LLM-KG-Bench框架下实施多种基准测试任务,对语法、语义阅读、语义创建以及知识图谱提示的融入角色进行评估。评估了GPT、Gemini和Claude等模型。研究结果表明,对于SPARQL SELECT查询,LLM仍面临挑战,其表现取决于特定LLM及任务的复杂性。虽然修正基本语法错误对最佳LLM来说似乎不是问题,但在许多情况下生成语义正确的SPARQL SELECT查询仍然具有挑战性。
Key Takeaways
- LLM与KG的集成具有为知识驱动应用提供重大协同潜力的潜力。
- 基准测试任务在评估LLM与SPARQL互动方面非常重要。
- LLM在处理SPARQL SELECT查询时仍面临挑战。
- LLM的表现取决于模型的特定复杂性以及任务的复杂性。
- 修正基本语法错误对最佳LLM来说不是主要问题。
- 生成语义正确的SPARQL SELECT查询在多个案例中仍具有挑战性。
点此查看论文截图

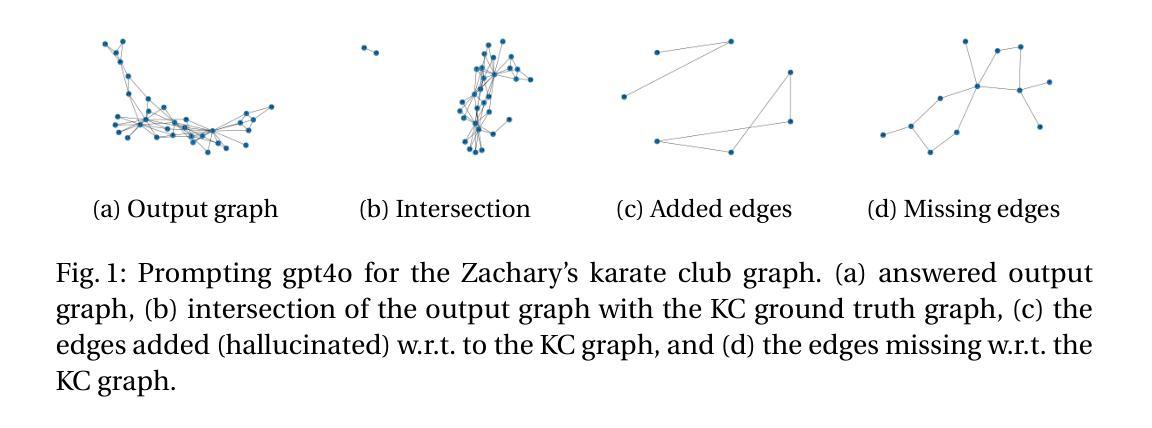
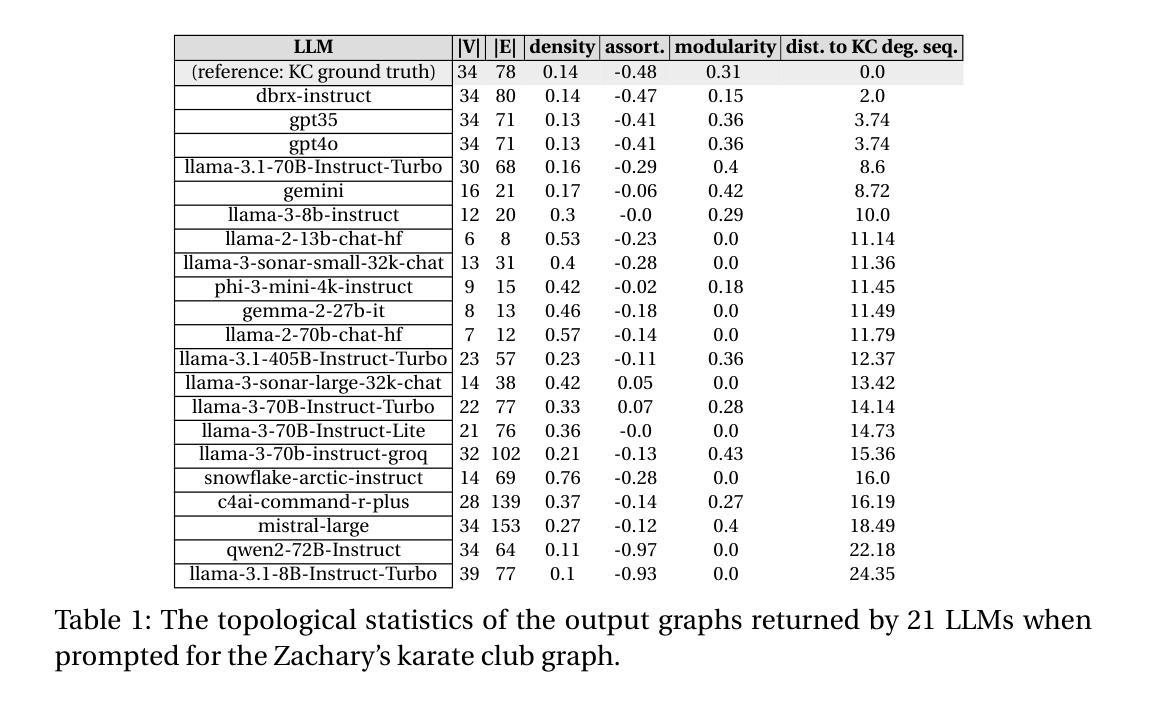
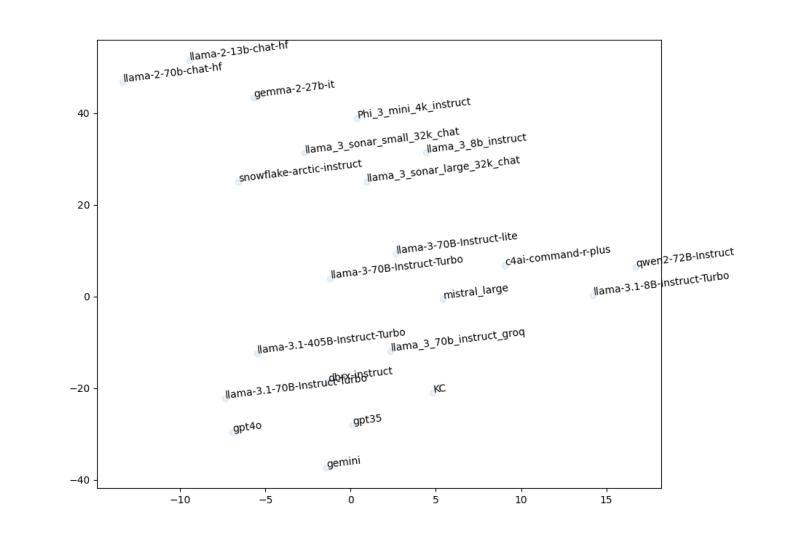
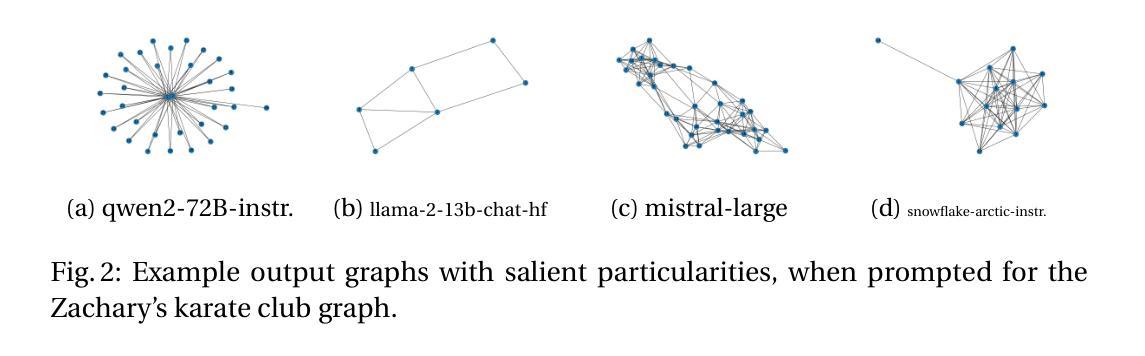
LLMs Prompted for Graphs: Hallucinations and Generative Capabilities
Authors:Gurvan Richardeau, Samy Chali, Erwan Le Merrer, Camilla Penzo, Gilles Tredan
Large Language Models (LLMs) are nowadays prompted for a wide variety of tasks. In this article, we investigate their ability in reciting and generating graphs. We first study the ability of LLMs to regurgitate well known graphs from the literature (e.g. Karate club or the graph atlas)4. Secondly, we question the generative capabilities of LLMs by asking for Erdos-Renyi random graphs. As opposed to the possibility that they could memorize some Erdos-Renyi graphs included in their scraped training set, this second investigation aims at studying a possible emergent property of LLMs. For both tasks, we propose a metric to assess their errors with the lens of hallucination (i.e. incorrect information returned as facts). We most notably find that the amplitude of graph hallucinations can characterize the superiority of some LLMs. Indeed, for the recitation task, we observe that graph hallucinations correlate with the Hallucination Leaderboard, a hallucination rank that leverages 10, 000 times more prompts to obtain its ranking. For the generation task, we find surprisingly good and reproducible results in most of LLMs. We believe this to constitute a starting point for more in-depth studies of this emergent capability and a challenging benchmark for their improvements. Altogether, these two aspects of LLMs capabilities bridge a gap between the network science and machine learning communities.
大型语言模型(LLM)如今已被应用于各种任务。在本文中,我们调查了它们在背诵和生成图形方面的能力。我们首先研究LLM从文献中复述已知图形的能力(例如空手道俱乐部或图形集)。其次,我们通过要求生成Erdos-Renyi随机图形来质疑LLM的生成能力。与可能记住一些Erdos-Renyi图形的训练集不同,第二次调查旨在研究LLM的潜在新兴属性。对于这两个任务,我们提出了一个评估错误的指标,通过幻觉的视角来评估(即错误的信息被当作事实返回)。我们尤其发现,图形幻觉的幅度可以反映某些LLM的优势。事实上,在背诵任务中,我们观察到图形幻觉与幻觉排行榜相关,幻觉排行榜利用更多的提示来获得其排名。对于生成任务,我们在大多数LLM中都发现了令人惊讶的良好和可重复的结果。我们相信这构成了对这一新兴能力的深入研究起点,并为改进它们提供了具有挑战性的基准测试。总体而言,LLM能力的这两个方面在网络科学和机器学习社区之间架起了一座桥梁。
论文及项目相关链接
PDF A preliminary version of this work appeared in the Complex Networks 2024 conference, under the title “LLMs hallucinate graphs too: a structural perspective”
Summary
本文探讨了大型语言模型(LLMs)在背诵和生成图方面的能力。研究内容包括对LLMs复述已知图的能力的考察,以及对生成Erdos-Renyi随机图的能力的探究。研究发现,图幻觉的幅度可以反映某些LLMs的优越性,且LLMs在生成任务方面的表现良好且具有可重复性。这些发现有助于深化对LLMs的理解,为网络科学和机器学习领域的研究人员提供了一个富有挑战性的基准测试。
Key Takeaways
- LLMs具备复述已知图的能力,如Karate club或图集等。
- LLMs能够生成Erdos-Renyi随机图,这是对其生成能力的探究。
- 图幻觉的幅度可作为评估某些LLMs性能的重要指标。
- 在背诵任务中,图幻觉与幻觉领导者榜(利用10,000次提示进行排名)存在关联。
- 在生成任务方面,LLMs的表现出乎意料地良好且具有可重复性。
- LLMs的能力表现在背诵和生成两个方面,为网络科学和机器学习领域的研究提供了桥梁。
点此查看论文截图

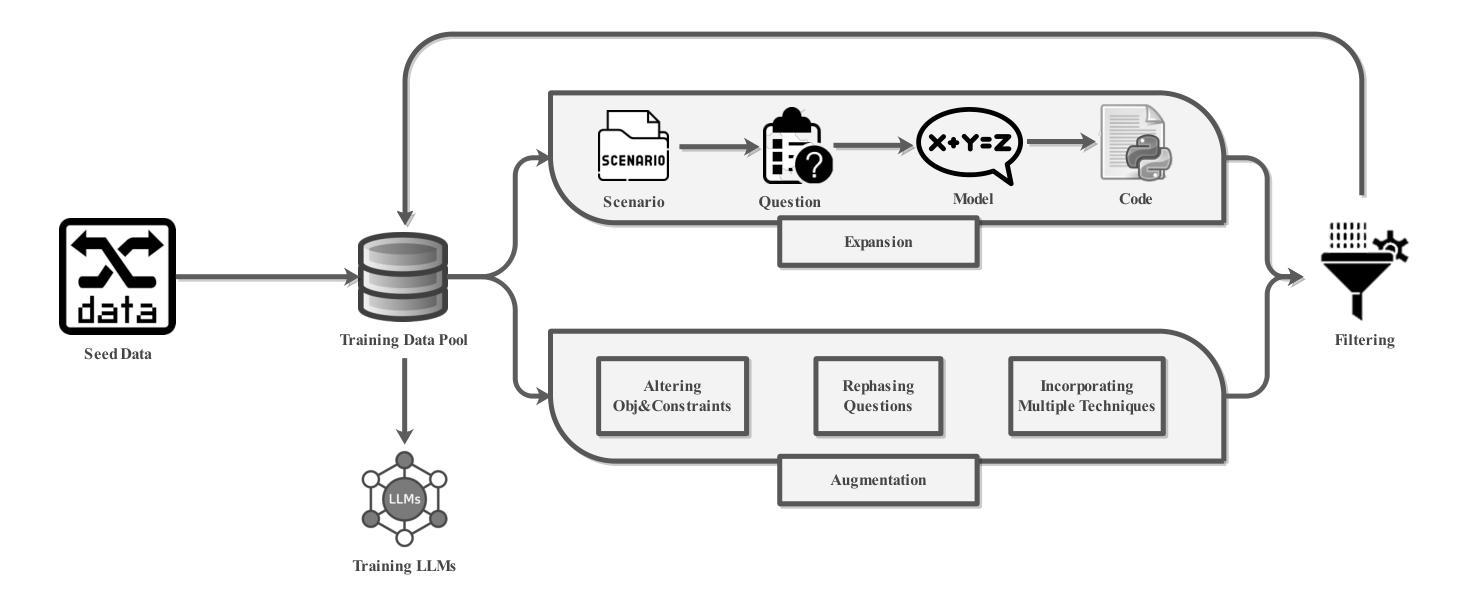
ORLM: A Customizable Framework in Training Large Models for Automated Optimization Modeling
Authors:Chenyu Huang, Zhengyang Tang, Shixi Hu, Ruoqing Jiang, Xin Zheng, Dongdong Ge, Benyou Wang, Zizhuo Wang
Optimization modeling plays a critical role in the application of Operations Research (OR) tools to address real-world problems, yet they pose challenges and require extensive expertise from OR experts. With the advent of large language models (LLMs), new opportunities have emerged to streamline and automate such task. However, current research predominantly relies on closed-source LLMs such as GPT-4, along with extensive prompt engineering techniques. This reliance stems from the scarcity of high-quality training datasets for optimization modeling, resulting in elevated costs, prolonged processing times, and privacy concerns. To address these challenges, our work is the first to propose a viable path for training open-source LLMs that are capable of optimization modeling and developing solver codes, eventually leading to a superior ability for automating optimization modeling and solving. Particularly, we design the {\sc OR-Instruct}, a semi-automated data synthesis framework for optimization modeling that enables customizable enhancements for specific scenarios or model types. This work also introduces IndustryOR, the first industrial benchmark for evaluating LLMs in solving practical OR problems. We train several 7B-scale open-source LLMs using synthesized data (dubbed ORLMs{https://github.com/Cardinal-Operations/ORLM}), which exhibit significantly enhanced optimization modeling capabilities, achieving competitive performance across the NL4OPT, MAMO, and IndustryOR benchmarks. Additionally, our experiments highlight the potential of scaling law and reinforcement learning to further enhance the performance of ORLMs. The workflows and human-machine interaction paradigms of ORLMs in practical industrial applications are also discussed in the paper.
优化建模在运筹学工具解决现实世界问题中起着关键作用,但它们带来挑战,需要运筹学专家的深厚专业知识。随着大型语言模型(LLM)的出现,简化并自动化这类任务的新机会已经产生。然而,目前的研究主要依赖于诸如GPT-4等封闭源代码的LLM,以及广泛的提示工程技术。这种依赖源于优化建模高质量训练数据集的稀缺性,导致成本增加、处理时间延长和隐私担忧。
我们的工作是第一个提出训练能够进行优化建模和开发求解器代码的开源LLM的可行路径,最终实现对优化建模和求解的自动化能力的卓越提升。特别是,我们设计了半自动化数据合成框架{\sc OR-Instruct},用于优化建模,可为特定场景或模型类型提供可定制增强功能。这项工作还引入了IndustryOR,这是评估LLM解决实际运筹问题的第一个工业基准测试。我们使用合成数据训练了几个7B级开源LLM(称为ORLM),展现出显著增强的优化建模能力,在NL4OPT、MAMO和IndustryOR基准测试中表现出竞争力。此外,我们的实验还突出了扩展定律和强化学习在进一步提高ORLM性能方面的潜力。论文还讨论了ORLM在实际工业应用中的工作流程和人机交互范式。
注:文中网址的中文翻译可按照实际情况进行处理,本文暂翻译为“我们在GitHub上开设的项目库‘ORLM’”。
论文及项目相关链接
PDF accepted by Operations Research
Summary
随着大型语言模型(LLM)的出现,操作研究(OR)工具的优化建模面临新的挑战和机遇。当前研究主要依赖封闭源代码的LLM和提示工程技术,这增加了成本、延长了处理时间并引发了隐私担忧。本研究首次提出训练能够优化建模和编写求解代码的开源LLM的路径,并设计了一个半自动化的数据合成框架{\sc OR-Instruct},用于优化建模,为特定场景或模型类型提供可定制的增强功能。此外,本研究引入了IndustryOR作为评估LLM解决实际OR问题的工业基准。训练出的开源LLM(称为ORLM)展现出强大的优化建模能力,在NL4OPT、MAMO和IndustryOR基准测试中表现优异。
Key Takeaways
- 优化建模在解决现实世界问题中扮演关键角色,大型语言模型(LLM)为此带来了新的机遇。
- 当前研究主要依赖封闭源代码的LLM和提示工程技术,存在成本高、处理时间长和隐私担忧等问题。
- 本研究首次提出训练能够优化建模和编写求解代码的开源LLM的路径。
- 设计了半自动化的数据合成框架{\sc OR-Instruct},用于优化建模,支持特定场景或模型类型的定制增强。
- 引入了IndustryOR作为评估LLM解决实际操作研究问题的工业基准。
- 训练出的开源LLM(ORLM)展现出强大的优化建模能力,在多个基准测试中表现优异。
点此查看论文截图