⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-08 更新
MME-Unify: A Comprehensive Benchmark for Unified Multimodal Understanding and Generation Models
Authors:Wulin Xie, Yi-Fan Zhang, Chaoyou Fu, Yang Shi, Bingyan Nie, Hongkai Chen, Zhang Zhang, Liang Wang, Tieniu Tan
Existing MLLM benchmarks face significant challenges in evaluating Unified MLLMs (U-MLLMs) due to: 1) lack of standardized benchmarks for traditional tasks, leading to inconsistent comparisons; 2) absence of benchmarks for mixed-modality generation, which fails to assess multimodal reasoning capabilities. We present a comprehensive evaluation framework designed to systematically assess U-MLLMs. Our benchmark includes: Standardized Traditional Task Evaluation. We sample from 12 datasets, covering 10 tasks with 30 subtasks, ensuring consistent and fair comparisons across studies.” 2. Unified Task Assessment. We introduce five novel tasks testing multimodal reasoning, including image editing, commonsense QA with image generation, and geometric reasoning. 3. Comprehensive Model Benchmarking. We evaluate 12 leading U-MLLMs, such as Janus-Pro, EMU3, VILA-U, and Gemini2-flash, alongside specialized understanding (e.g., Claude-3.5-Sonnet) and generation models (e.g., DALL-E-3). Our findings reveal substantial performance gaps in existing U-MLLMs, highlighting the need for more robust models capable of handling mixed-modality tasks effectively. The code and evaluation data can be found in https://mme-unify.github.io/.
现有的多语言低资源机器学习(MLLM)基准测试在评估统一MLLM(U-MLLMs)时面临重大挑战,原因如下:1)缺乏传统任务的标准化基准测试,导致比较结果不一致;2)缺少混合模式生成的基准测试,无法评估多模式推理能力。我们提出一个全面的评估框架,旨在系统地评估U-MLLMs。我们的基准测试包括:标准化的传统任务评估。我们从12个数据集中抽样,涵盖10个任务及30个子任务,确保各项研究之间的一致性和公平比较。” 2. 统一任务评估。我们引入了五项测试多模式推理的新任务,包括图像编辑、带图像生成常识问答和几何推理等。3. 综合模型基准测试。我们评估了12款领先U-MLLMs,如Janus-Pro、EMU3、VILA-U和Gemini2-flash等,同时针对专业理解(如Claude-3.5-Sonnet)和生成模型(如DALL-E-3)。我们的研究发现了现有U-MLLMs存在的性能差距,强调需要更稳健的模型,能够更有效地处理混合模式任务。相关代码和评估数据可在https://mme-unify.github.io/中找到。
论文及项目相关链接
PDF Project page: https://mme-unify.github.io/
Summary
随着多任务学习模型的发展,现有的基准测试面临着评价统一多任务学习模型(Unified MLLMs,简称U-MLLMs)的挑战。由于缺乏标准化的传统任务基准测试和混合模态生成基准测试,无法全面评估U-MLLMs的能力。本研究提出一个全面的评估框架,包括标准化传统任务评估、统一任务评估和综合模型评估。评估结果显示现有U-MLLMs存在显著性能差距,强调需要更稳健的模型以有效处理混合模态任务。
Key Takeaways
- 缺乏标准化的传统任务基准测试和混合模态生成基准测试,无法全面评估Unified MLLMs(U-MLLMs)。
- 提出的评估框架包括标准化传统任务评估,涵盖12个数据集,共10个任务,30个子任务,以确保跨研究的公平和一致比较。
- 引入统一任务评估,包括测试多模态推理的五个新任务,如图像编辑、常识问答与图像生成、几何推理等。
- 综合模型评估包括12款领先的U-MLLMs,如Janus-Pro、EMU3、VILA-U、Gemini2-flash等。
- 研究发现现有U-MLLMs存在显著性能差距。
- 需要更稳健的模型以处理混合模态任务。
- 评估框架的代码和数据可在https://mme-unify.github.io/找到。
点此查看论文截图



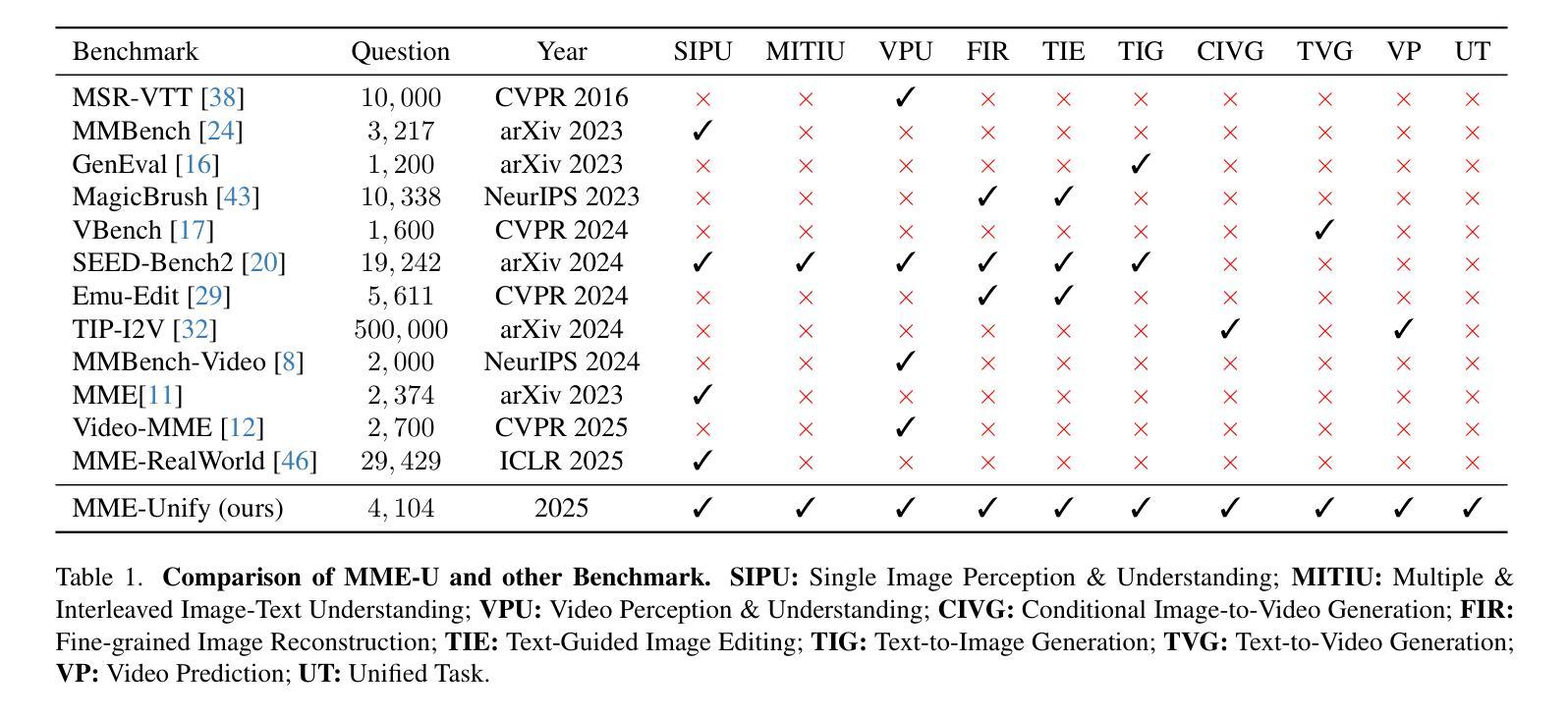
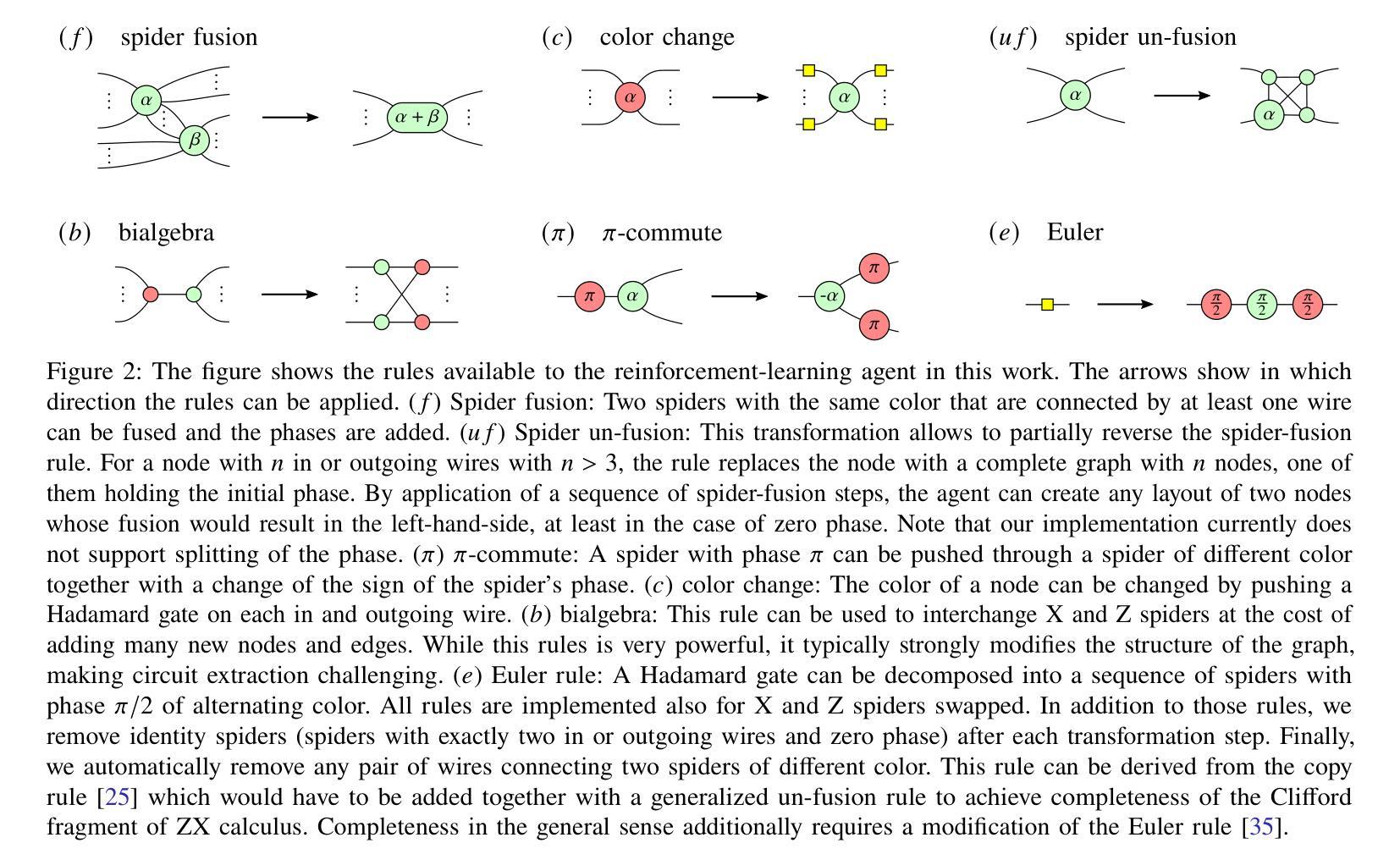
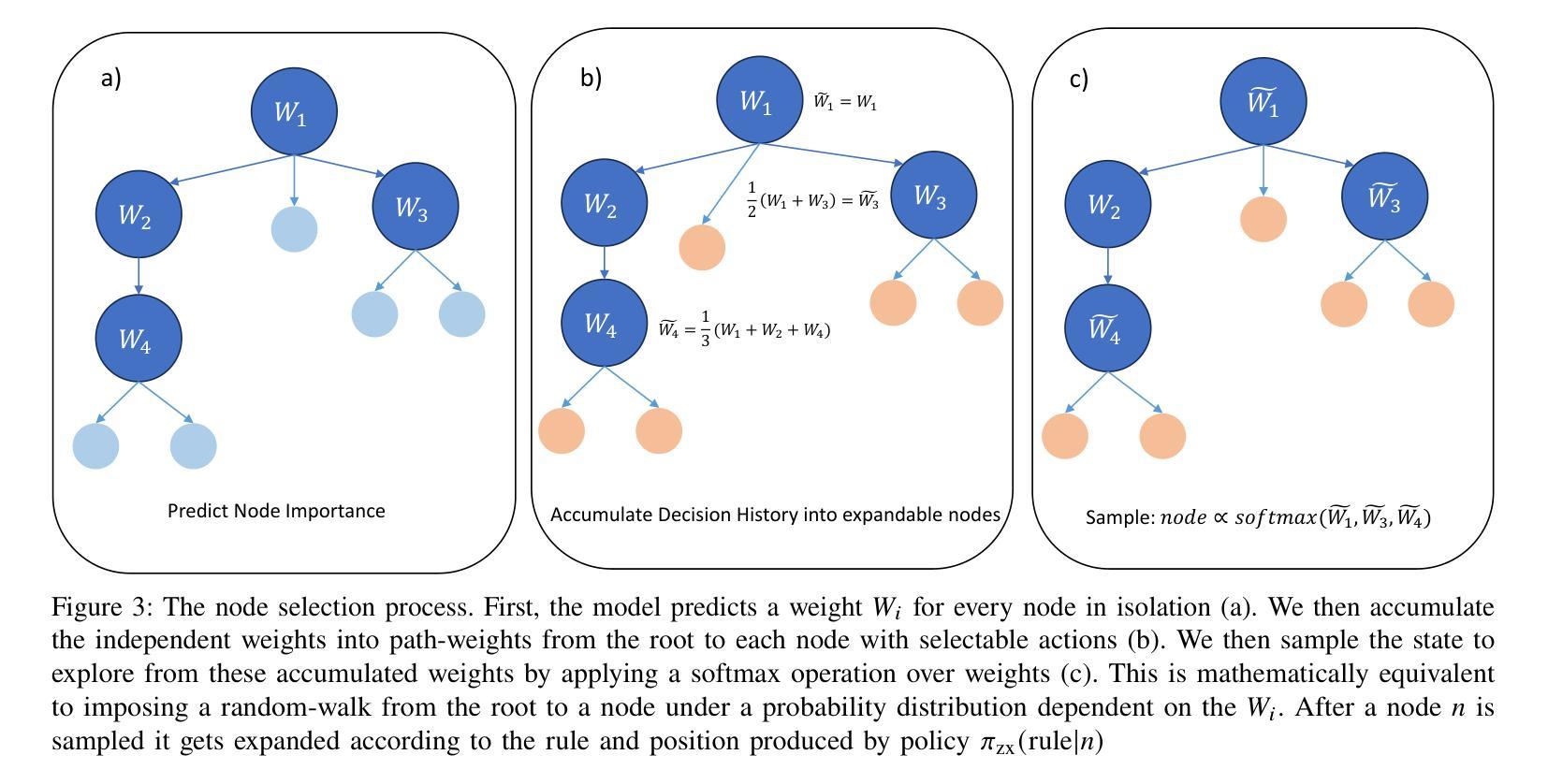
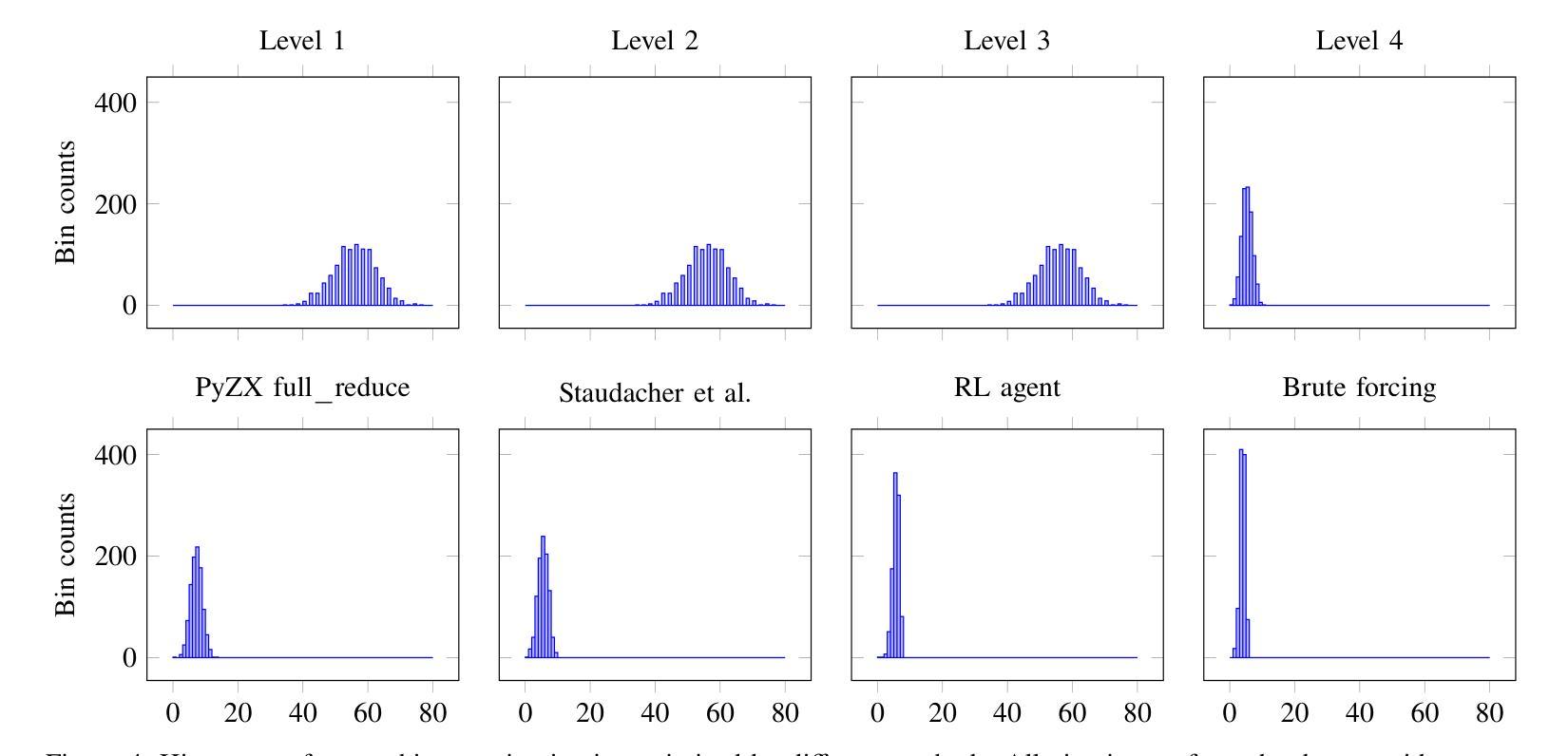
Optimizing Quantum Circuits via ZX Diagrams using Reinforcement Learning and Graph Neural Networks
Authors:Alexander Mattick, Maniraman Periyasamy, Christian Ufrecht, Abhishek Y. Dubey, Christopher Mutschler, Axel Plinge, Daniel D. Scherer
Quantum computing is currently strongly limited by the impact of noise, in particular introduced by the application of two-qubit gates. For this reason, reducing the number of two-qubit gates is of paramount importance on noisy intermediate-scale quantum hardware. To advance towards more reliable quantum computing, we introduce a framework based on ZX calculus, graph-neural networks and reinforcement learning for quantum circuit optimization. By combining reinforcement learning and tree search, our method addresses the challenge of selecting optimal sequences of ZX calculus rewrite rules. Instead of relying on existing heuristic rules for minimizing circuits, our method trains a novel reinforcement learning policy that directly operates on ZX-graphs, therefore allowing us to search through the space of all possible circuit transformations to find a circuit significantly minimizing the number of CNOT gates. This way we can scale beyond hard-coded rules towards discovering arbitrary optimization rules. We demonstrate our method’s competetiveness with state-of-the-art circuit optimizers and generalization capabilities on large sets of diverse random circuits.
量子计算目前受到噪声的严重限制,特别是两量子位门的应用所带来的噪声。因此,在带有噪声的中间规模量子硬件上减少两量子位门的使用至关重要。为了朝着更可靠的量子计算发展,我们引入了一个基于ZX计算、图神经网络和强化学习的量子电路优化框架。通过结合强化学习和树搜索,我们的方法解决了选择ZX计算重写规则最优序列的挑战。我们并不依赖现有的启发式规则来最小化电路,而是训练一种新型强化学习策略,直接在ZX图上操作,从而能够搜索所有可能电路变换的空间,找到能够显著减少CNOT门数量的电路。通过这种方式,我们可以超越硬编码规则,发现任意优化规则。我们在大型多样随机电路集上展示了该方法与最新电路优化器的竞争能力以及泛化能力。
论文及项目相关链接
Summary:量子计算受限于噪声影响,特别是两量子比特门的应用所带来的噪声。因此,在噪声中间态量子硬件上减少两量子比特门数量至关重要。为推进更可靠的量子计算,本文引入基于ZX计算、图神经网络和强化学习的量子电路优化框架。通过结合强化学习和树搜索,该方法解决了选择ZX计算重写规则序列的挑战性问题。本文不依赖现有启发式规则来最小化电路,而是训练一种新型强化学习政策,直接在ZX图上操作,从而能够搜索所有可能的电路转换空间,找到能显著减少CNOT门数量的电路。这样我们就能超越硬编码规则,发现任意优化规则。我们在大型多样的随机电路上验证了该方法的竞争力和泛化能力。
Key Takeaways:
- 量子计算受限于噪声影响,特别是在应用两量子比特门时产生的噪声。
- 在噪声中间态量子硬件上减少两量子比特门的数量至关重要。
- 本文提出基于ZX计算、图神经网络和强化学习的量子电路优化框架。
- 该方法通过结合强化学习和树搜索,解决了选择ZX计算重写规则序列的问题。
- 不依赖现有启发式规则来最小化电路,而是训练一种新型强化学习政策直接在ZX图上操作。
- 该方法能够搜索所有可能的电路转换空间,找到显著减少CNOT门数量的电路。
点此查看论文截图

From ChatGPT to DeepSeek AI: A Comprehensive Analysis of Evolution, Deviation, and Future Implications in AI-Language Models
Authors:Simrandeep Singh, Shreya Bansal, Abdulmotaleb El Saddik, Mukesh Saini
The rapid advancement of artificial intelligence (AI) has reshaped the field of natural language processing (NLP), with models like OpenAI ChatGPT and DeepSeek AI. Although ChatGPT established a strong foundation for conversational AI, DeepSeek AI introduces significant improvements in architecture, performance, and ethical considerations. This paper presents a detailed analysis of the evolution from ChatGPT to DeepSeek AI, highlighting their technical differences, practical applications, and broader implications for AI development. To assess their capabilities, we conducted a case study using a predefined set of multiple choice questions in various domains, evaluating the strengths and limitations of each model. By examining these aspects, we provide valuable insight into the future trajectory of AI, its potential to transform industries, and key research directions for improving AI-driven language models.
人工智能(AI)的快速发展已经重塑了自然语言处理(NLP)领域,如OpenAI的ChatGPT和DeepSeek AI等模型。虽然ChatGPT为对话式人工智能建立了坚实的基础,但DeepSeek AI在架构、性能和道德考量方面引入了重大改进。本文详细分析了从ChatGPT到DeepSeek AI的演变过程,重点介绍了它们的技术差异、实际应用以及对人工智能发展的更广泛影响。为了评估它们的能力,我们进行了一项案例研究,使用预定的多个领域中的多项选择题进行评估,评估每个模型的优点和局限性。通过考察这些方面,我们为AI的未来走向、其改变行业的潜力以及改进AI驱动的语言模型的关键研究方向提供了有价值的见解。
论文及项目相关链接
PDF 10 pages, 1 figure, 4 tables
Summary
人工智能的快速进步已经重塑了自然语言处理领域,从ChatGPT到DeepSeek AI的演变展示了显著的进步。本文详细分析了两者在技术、应用和对AI发展的更广泛影响方面的差异。通过案例研究,我们评估了这两种模型的能力,并提供了对AI未来发展方向、行业变革潜力以及改进语言模型的关键研究方向的宝贵见解。
Key Takeaways
- 人工智能(AI)的快速进步已重塑自然语言处理(NLP)领域。
- 从ChatGPT到DeepSeek AI的演变展示了显著的技术进步。
- DeepSeek AI在架构、性能和伦理考量方面进行了重大改进。
- 通过案例研究,对ChatGPT和DeepSeek AI的能力进行了评估。
- 两者在技术、应用和对AI发展的更广泛影响方面存在差异。
- AI有潜力改变各行各业,并提供了关于未来AI发展方向的关键见解。
点此查看论文截图

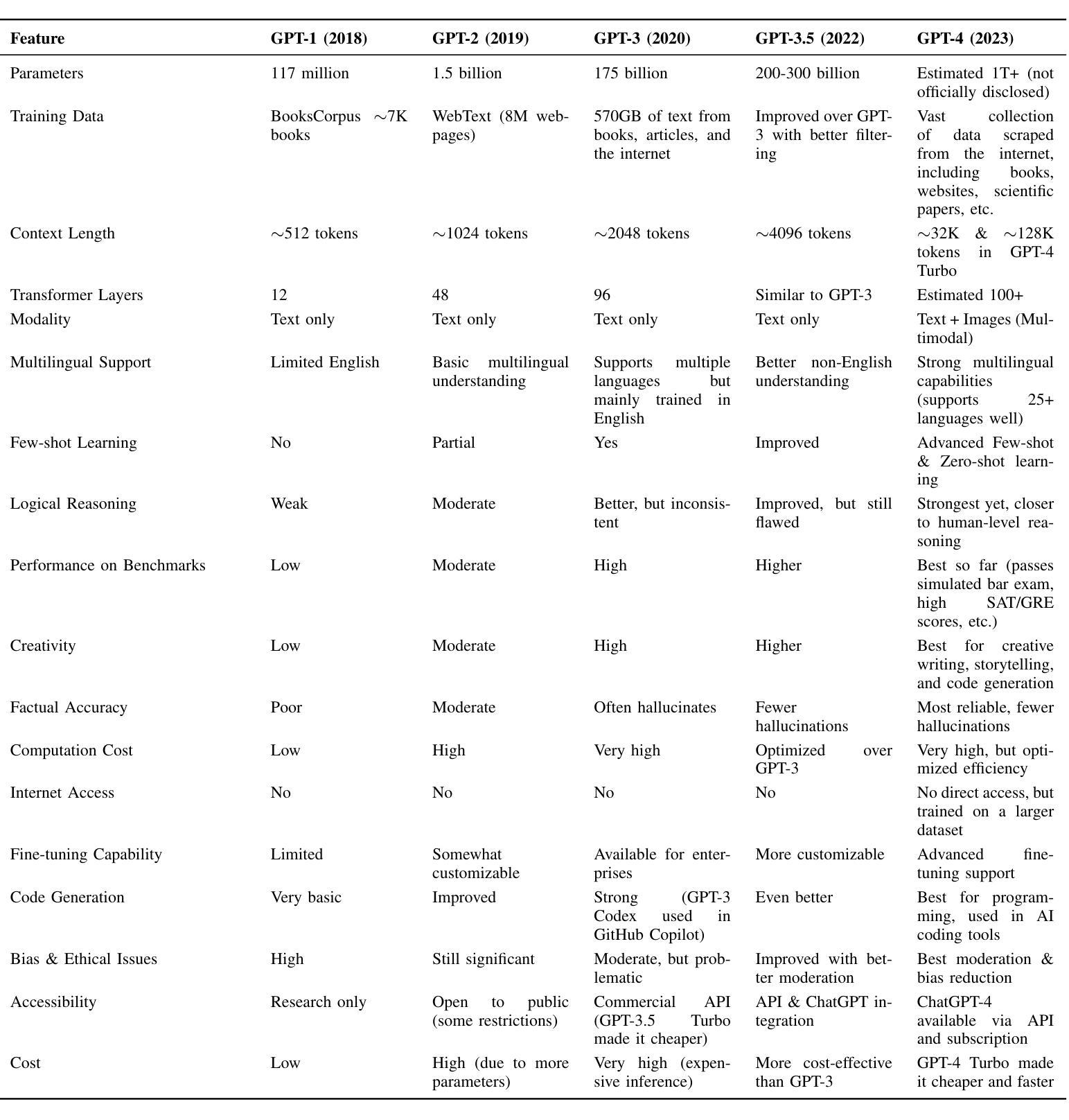

NuScenes-SpatialQA: A Spatial Understanding and Reasoning Benchmark for Vision-Language Models in Autonomous Driving
Authors:Kexin Tian, Jingrui Mao, Yunlong Zhang, Jiwan Jiang, Yang Zhou, Zhengzhong Tu
Recent advancements in Vision-Language Models (VLMs) have demonstrated strong potential for autonomous driving tasks. However, their spatial understanding and reasoning-key capabilities for autonomous driving-still exhibit significant limitations. Notably, none of the existing benchmarks systematically evaluate VLMs’ spatial reasoning capabilities in driving scenarios. To fill this gap, we propose NuScenes-SpatialQA, the first large-scale ground-truth-based Question-Answer (QA) benchmark specifically designed to evaluate the spatial understanding and reasoning capabilities of VLMs in autonomous driving. Built upon the NuScenes dataset, the benchmark is constructed through an automated 3D scene graph generation pipeline and a QA generation pipeline. The benchmark systematically evaluates VLMs’ performance in both spatial understanding and reasoning across multiple dimensions. Using this benchmark, we conduct extensive experiments on diverse VLMs, including both general and spatial-enhanced models, providing the first comprehensive evaluation of their spatial capabilities in autonomous driving. Surprisingly, the experimental results show that the spatial-enhanced VLM outperforms in qualitative QA but does not demonstrate competitiveness in quantitative QA. In general, VLMs still face considerable challenges in spatial understanding and reasoning.
近期视觉语言模型(VLMs)的进展为自动驾驶任务展现了强大的潜力。然而,它们对空间的理解和推理——自动驾驶的关键能力——仍然存在着明显的局限。值得注意的是,现有的基准测试并没有系统地评估VLM在驾驶场景中的空间推理能力。为了填补这一空白,我们提出了NuScenes-SpatialQA,这是第一个基于大规模真实数据的问答(QA)基准测试,专门用于评估VLM在自动驾驶中的空间理解和推理能力。该基准测试建立在NuScenes数据集之上,通过自动化的3D场景图生成流程和QA生成流程构建。该基准测试系统地评估了VLM在多个维度上的空间理解和推理能力。使用此基准测试,我们对多种VLM进行了广泛的实验,包括通用模型和空间增强模型,首次全面评估了它们在自动驾驶中的空间能力。令人惊讶的是,实验结果表明,空间增强VLM在定性QA上表现优异,但在定量QA上并没有表现出竞争力。总的来说,VLM在空间理解和推理方面仍然面临着巨大的挑战。
论文及项目相关链接
Summary
自动化驾驶中的视觉语言模型(VLMs)虽有所进展,但在空间理解和推理方面仍存在显著局限,目前尚无系统评估其在驾驶场景中的空间推理能力的基准测试。为此,我们提出了NuScenes-SpatialQA基准测试,它是基于大规模真实场景的自动驾驶问答数据集,旨在评估VLMs在空间理解和推理方面的性能。实验表明,空间增强的VLM在定性问答上表现优异,但在定量问答上并不具备竞争力。总体而言,VLMs在自动驾驶的空间理解和推理方面仍面临巨大挑战。
Key Takeaways
- VLMs在自动驾驶中的空间理解和推理能力存在局限。
- 目前缺乏系统评估VLM在驾驶场景中的空间推理能力的基准测试。
- NuScenes-SpatialQA基准测试旨在评估VLMs在空间理解和推理方面的性能。
- 该基准测试是基于大规模真实场景的自动驾驶问答数据集。
- 空间增强的VLM在定性问答上表现较好,但在定量问答上表现不够竞争力。
- VLMs的自动驾驶空间理解和推理能力仍需进一步提高。
点此查看论文截图


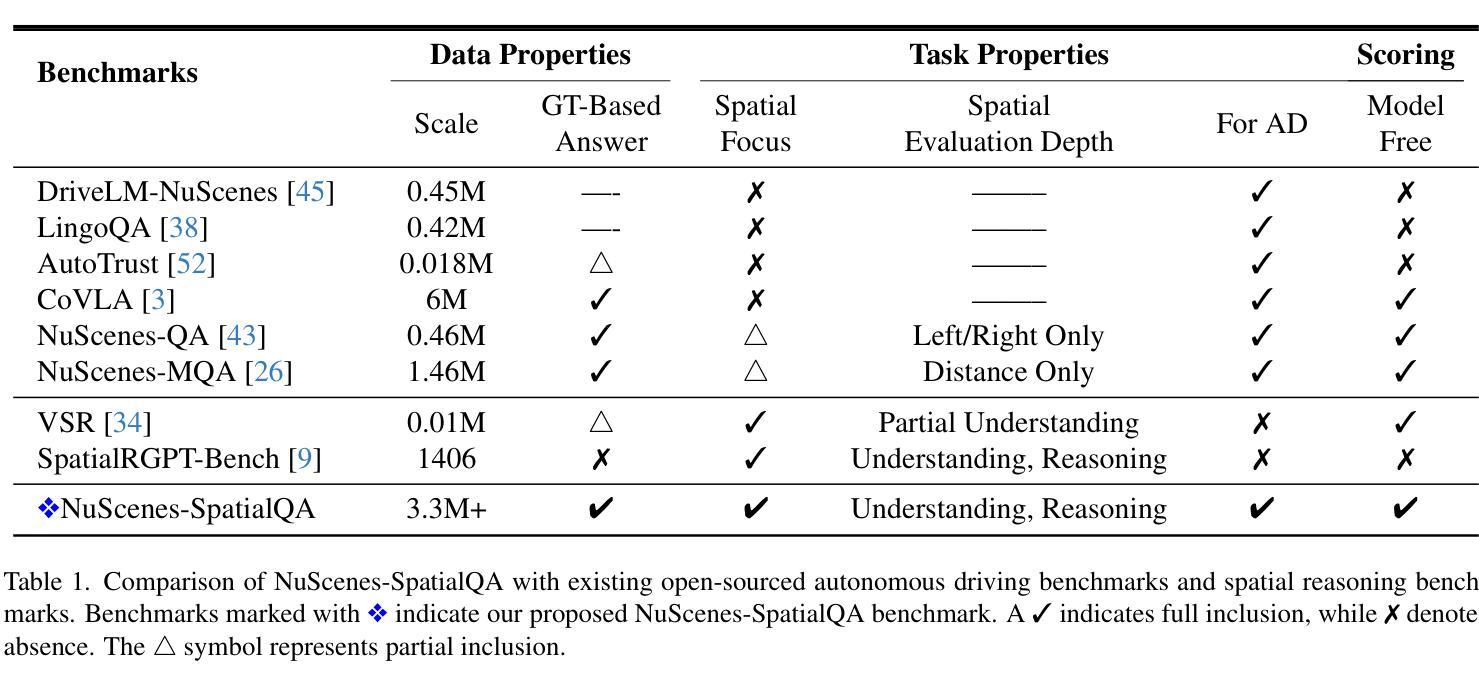
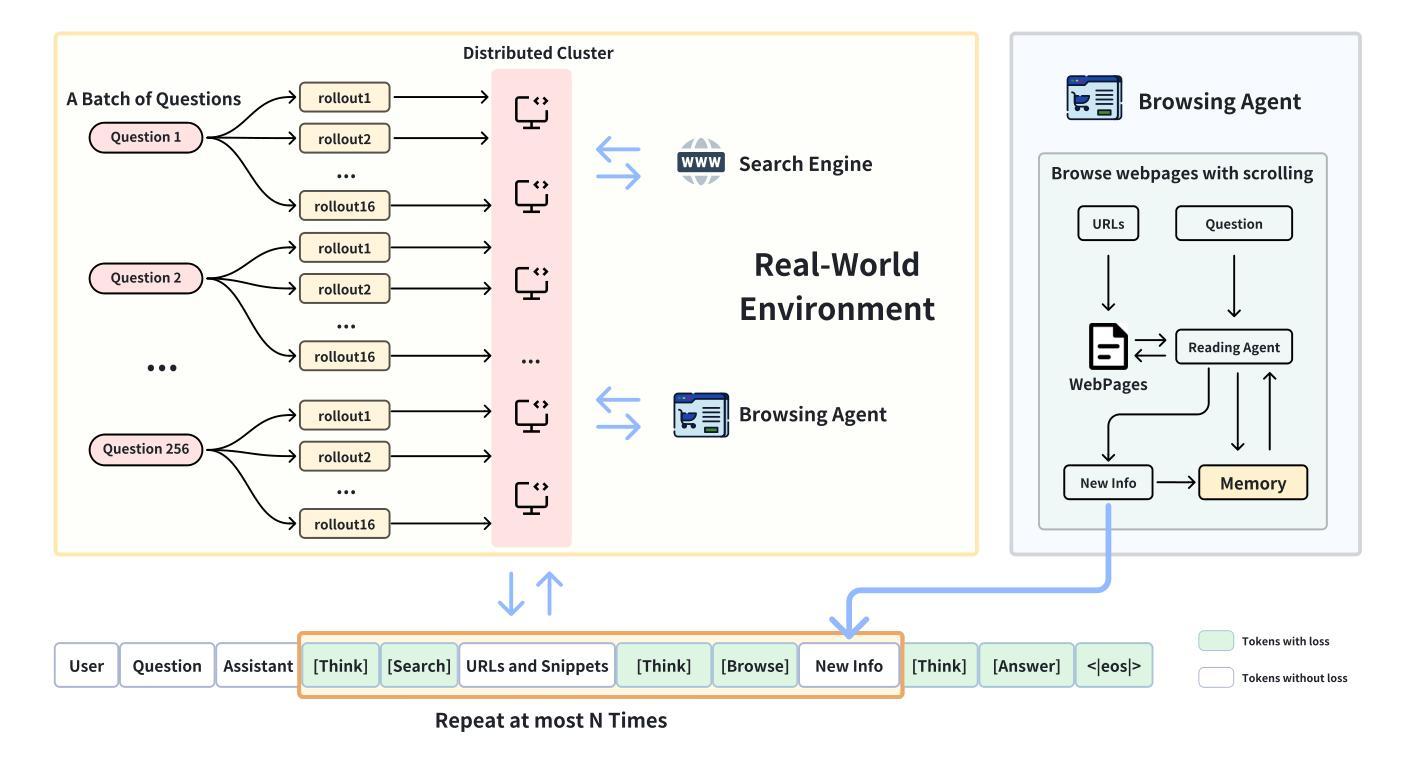
DeepResearcher: Scaling Deep Research via Reinforcement Learning in Real-world Environments
Authors:Yuxiang Zheng, Dayuan Fu, Xiangkun Hu, Xiaojie Cai, Lyumanshan Ye, Pengrui Lu, Pengfei Liu
Large Language Models (LLMs) equipped with web search capabilities have demonstrated impressive potential for deep research tasks. However, current approaches predominantly rely on either manually engineered prompts (prompt engineering-based) with brittle performance or reinforcement learning within controlled Retrieval-Augmented Generation (RAG) environments (RAG-based) that fail to capture the complexities of real-world interaction. In this paper, we introduce DeepResearcher, the first comprehensive framework for end-to-end training of LLM-based deep research agents through scaling reinforcement learning (RL) in real-world environments with authentic web search interactions. Unlike RAG-based approaches that assume all necessary information exists within a fixed corpus, our method trains agents to navigate the noisy, unstructured, and dynamic nature of the open web. We implement a specialized multi-agent architecture where browsing agents extract relevant information from various webpage structures and overcoming significant technical challenges. Extensive experiments on open-domain research tasks demonstrate that DeepResearcher achieves substantial improvements of up to 28.9 points over prompt engineering-based baselines and up to 7.2 points over RAG-based RL agents. Our qualitative analysis reveals emergent cognitive behaviors from end-to-end RL training, including the ability to formulate plans, cross-validate information from multiple sources, engage in self-reflection to redirect research, and maintain honesty when unable to find definitive answers. Our results highlight that end-to-end training in real-world web environments is not merely an implementation detail but a fundamental requirement for developing robust research capabilities aligned with real-world applications. We release DeepResearcher at https://github.com/GAIR-NLP/DeepResearcher.
配备网页搜索功能的大型语言模型(LLM)在深度研究任务中表现出了令人印象深刻的潜力。然而,当前的方法主要依赖于手动设计的提示(基于提示的工程)表现不稳定,或者在受控的检索增强生成(RAG)环境中使用强化学习(基于RAG的方法),无法捕捉现实世界中互动的复杂性。在本文中,我们介绍了DeepResearcher,这是第一个通过强化学习(RL)在真实世界环境中进行端到端训练LLM基于深度研究人员的全面框架,通过真实的网络搜索互动进行扩展。不同于假设所有必要信息都存在于固定语料库中的RAG方法,我们的方法训练研究人员在开放网络的嘈杂、非结构化和动态特性中进行导航。我们实现了一种特殊的多智能体架构,浏览智能体从不同的网页结构中提取相关信息,并克服重大技术挑战。在开放域研究任务上的大量实验表明,DeepResearcher较基于提示的工程基线实现了高达28.9点的实质性改进,较基于RAG的RL智能体提高了高达7.2点。我们的定性分析揭示了来自端到端RL训练的新兴认知行为,包括制定计划的能力、从多个来源交叉验证信息、进行反思以调整研究方向,以及在无法找到明确答案时保持诚实。我们的结果强调,在真实世界网络环境中进行端到端训练不仅是实现细节,而且是开发与现实世界应用相匹配的稳健研究能力的根本要求。我们在https://github.com/GAIR-NLP/DeepResearcher上发布了DeepResearcher。
论文及项目相关链接
Summary
大型语言模型(LLM)结合网页搜索能力在深研任务中展现出巨大潜力。然而,当前方法主要依赖手动工程提示或强化学习在检索增强生成(RAG)环境中的训练,这两者均存在局限性。本文提出DeepResearcher框架,通过强化学习在真实环境中的端到端训练,实现LLM基础上的深度研究代理。与基于RAG的方法不同,DeepResearcher训练代理以适应开放网页的噪声、非结构化和动态特性。通过特殊的多代理架构和浏览代理从各种网页结构中提取相关信息,克服技术挑战。在开放域研究任务上的实验表明,DeepResearcher相较于基于提示的工程方法和基于RAG的RL代理,分别实现了高达28.9点和7.2点的实质性改进。定性分析显示,来自端到端RL训练的认知行为正在形成,包括制定计划、跨源验证信息、自我反思以调整研究方向,以及在无法找到明确答案时保持诚实。结果表明,在真实网页环境中进行端到端训练不仅是实现细节,更是开发与现实应用相匹配的稳健研究能力的根本要求。
Key Takeaways
- 大型语言模型结合网页搜索能力在深研任务中展现潜力。
- 当前方法主要依赖手动工程提示或强化学习在RAG环境中的训练,存在局限性。
- DeepResearcher框架通过强化学习在真实环境中的端到端训练,实现LLM基础上的深度研究。
- DeepResearcher适应开放网页的噪声、非结构化和动态特性。
- 特殊的多代理架构和浏览代理从各种网页结构中提取相关信息。
- 在开放域研究任务上,DeepResearcher实现了对基准方法和RAG-based RL代理的显著改进。
点此查看论文截图

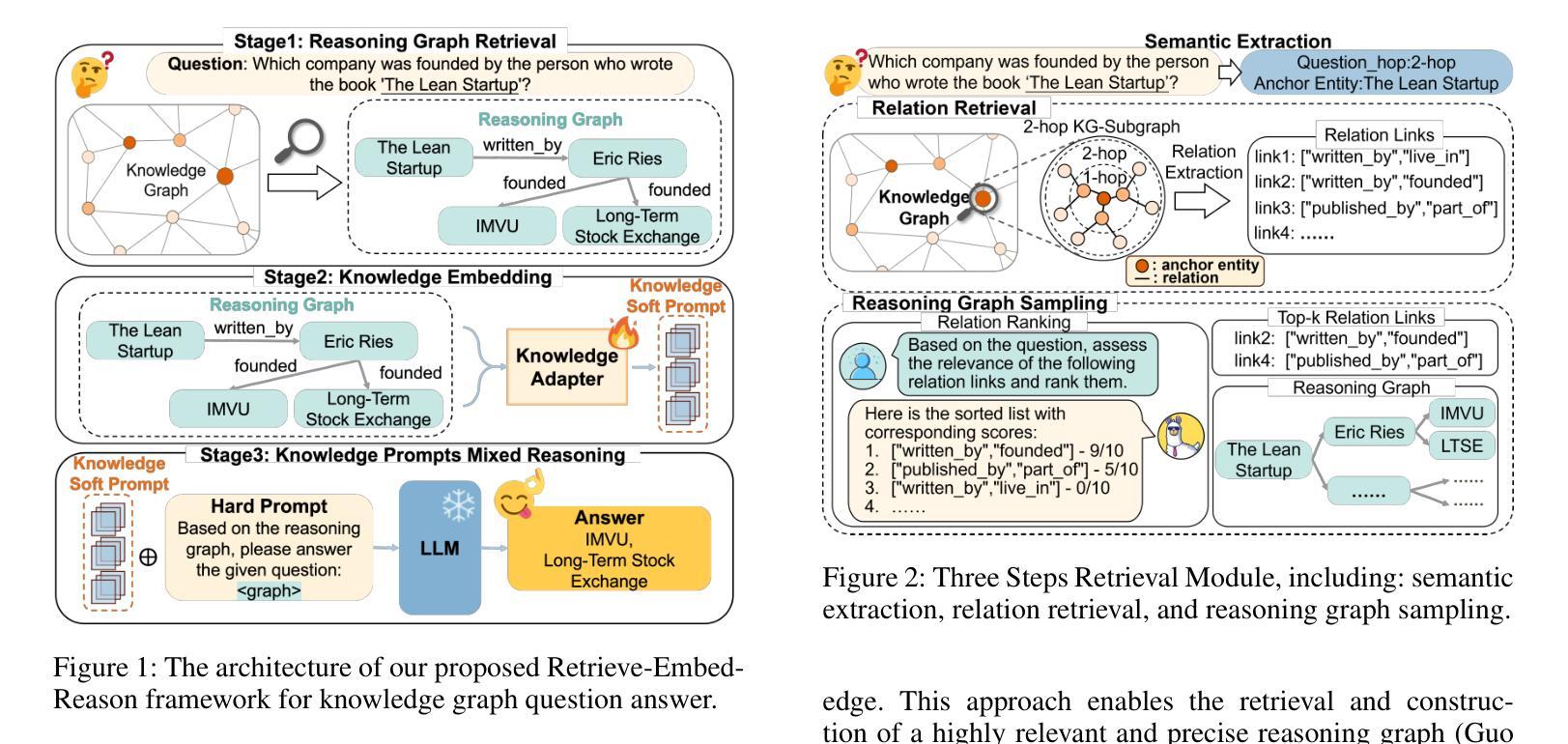
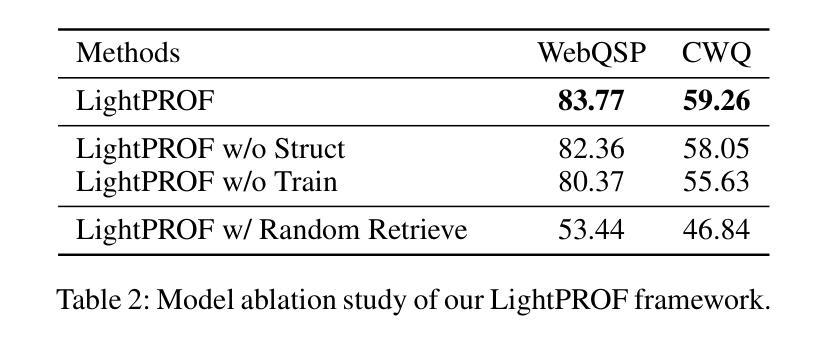
LightPROF: A Lightweight Reasoning Framework for Large Language Model on Knowledge Graph
Authors:Tu Ao, Yanhua Yu, Yuling Wang, Yang Deng, Zirui Guo, Liang Pang, Pinghui Wang, Tat-Seng Chua, Xiao Zhang, Zhen Cai
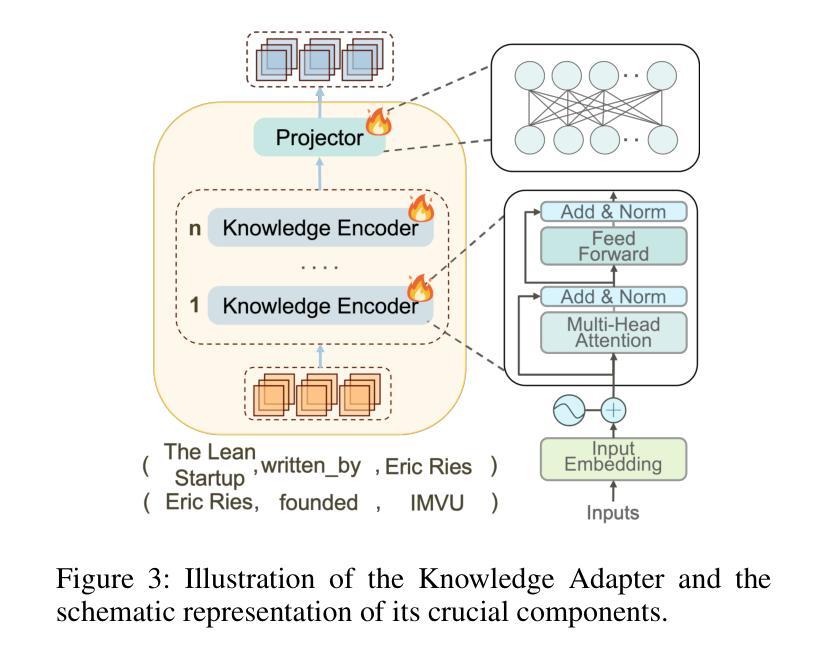
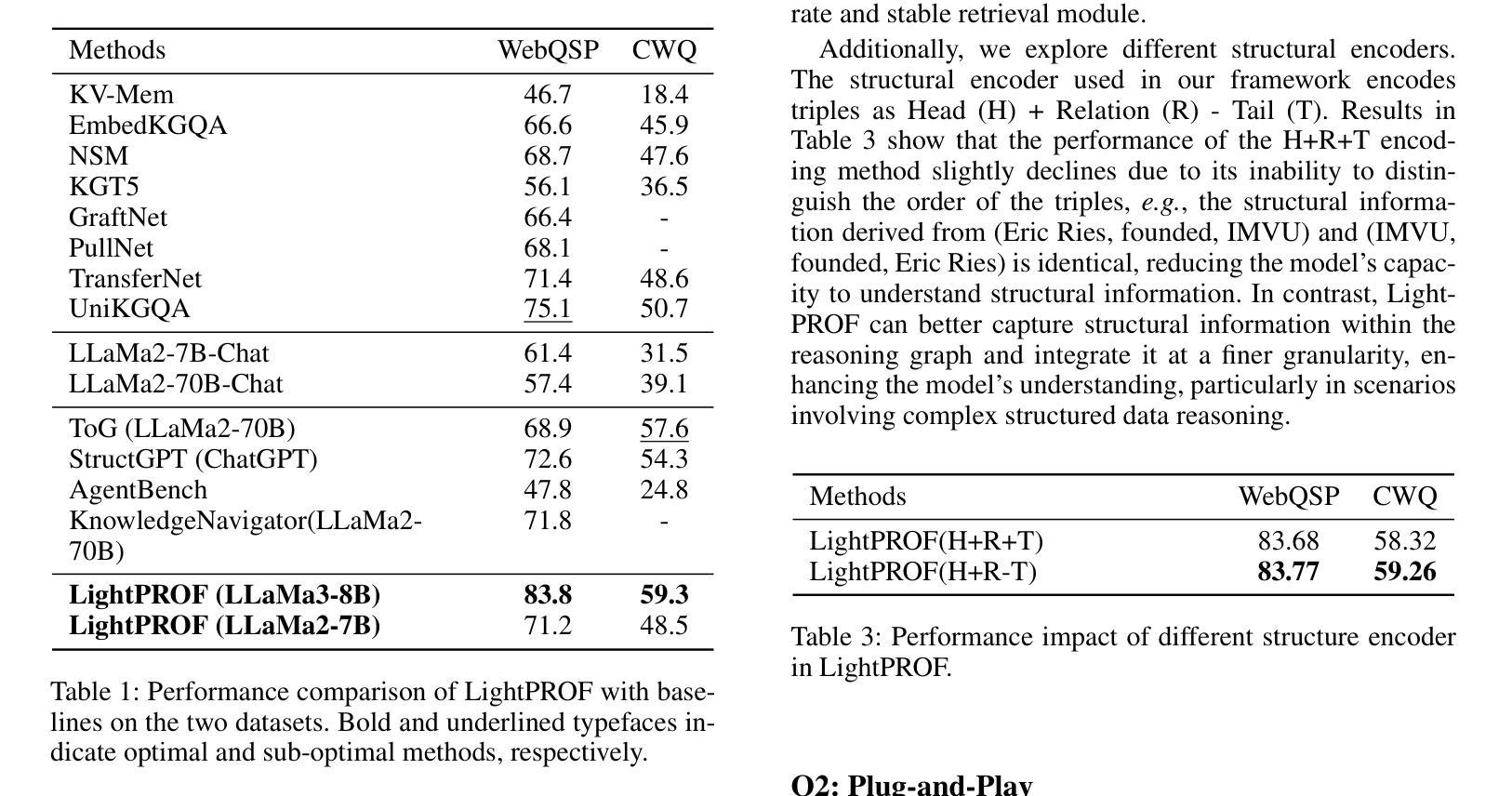
Large Language Models (LLMs) have impressive capabilities in text understanding and zero-shot reasoning. However, delays in knowledge updates may cause them to reason incorrectly or produce harmful results. Knowledge Graphs (KGs) provide rich and reliable contextual information for the reasoning process of LLMs by structurally organizing and connecting a wide range of entities and relations. Existing KG-based LLM reasoning methods only inject KGs’ knowledge into prompts in a textual form, ignoring its structural information. Moreover, they mostly rely on close-source models or open-source models with large parameters, which poses challenges to high resource consumption. To address this, we propose a novel Lightweight and efficient Prompt learning-ReasOning Framework for KGQA (LightPROF), which leverages the full potential of LLMs to tackle complex reasoning tasks in a parameter-efficient manner. Specifically, LightPROF follows a “Retrieve-Embed-Reason process”, first accurately, and stably retrieving the corresponding reasoning graph from the KG through retrieval module. Next, through a Transformer-based Knowledge Adapter, it finely extracts and integrates factual and structural information from the KG, then maps this information to the LLM’s token embedding space, creating an LLM-friendly prompt to be used by the LLM for the final reasoning. Additionally, LightPROF only requires training Knowledge Adapter and can be compatible with any open-source LLM. Extensive experiments on two public KGQA benchmarks demonstrate that LightPROF achieves superior performance with small-scale LLMs. Furthermore, LightPROF shows significant advantages in terms of input token count and reasoning time.
大规模语言模型(LLM)在文本理解和零样本推理方面拥有令人印象深刻的能力。然而,知识更新的延迟可能会导致它们推理错误或产生有害的结果。知识图谱(KG)通过结构化地组织和连接广泛的实体和关系,为LLM的推理过程提供了丰富可靠的上文信息。现有的基于知识图谱的LLM推理方法仅将知识图谱的知识以文本形式注入提示中,忽略了其结构信息。此外,它们大多依赖于封闭源模型或参数庞大的开源模型,这带来了高资源消耗的挑战。针对这一问题,我们提出了一种新型的轻量级、高效的知识问答提示学习推理框架(LightPROF)。LightPROF充分发挥了LLM的潜力,以参数高效的方式解决复杂的推理任务。具体来说,LightPROF遵循“检索-嵌入-推理”的流程,首先准确稳定地从知识图谱中检索相应的推理图。接下来,通过一个基于变压器的知识适配器,它精细地提取和整合了知识图谱中的事实和结构信息,然后将这些信息映射到LLM的令牌嵌入空间,为LLM创建友好的提示以进行最终的推理。此外,LightPROF只需要训练知识适配器,并能与任何开源的LLM兼容。在两个公共知识图谱问答基准测试上的广泛实验表明,LightPROF在小规模LLM上实现了卓越的性能。此外,LightPROF在输入令牌计数和推理时间方面显示出显著的优势。
论文及项目相关链接
PDF This paper has been accepted by AAAI 2025
Summary
大型语言模型(LLM)在文本理解和零样本推理方面表现出强大的能力,但知识更新的延迟可能导致其推理错误或产生有害结果。知识图谱(KG)通过结构化地组织和连接广泛的实体和关系,为LLM的推理过程提供了丰富可靠的上文信息。现有的基于KG的LLM推理方法仅将KG的知识以文本形式注入提示中,忽略了其结构信息,并且它们大多依赖于封闭源模型或参数庞大的开源模型,这带来了高资源消耗的挑战。为解决此问题,我们提出了一个轻量级、高效的知识问答推理框架LightPROF,该框架能够充分利用LLM的优势来解决复杂的推理任务,同时以参数高效的方式进行。LightPROF遵循“检索-嵌入-推理”的流程,首先稳定地从KG中检索出对应的推理图,然后通过基于Transformer的知识适配器精细提取和整合事实和结构信息,并将其映射到LLM的令牌嵌入空间,为LLM创建友好的提示以进行最终推理。此外,LightPROF只需要训练知识适配器,并且可以与任何开源LLM兼容。在公共KGQA基准测试上的广泛实验表明,LightPROF在小规模LLM上实现了卓越的性能,并且在输入令牌计数和推理时间方面显示出显著优势。
Key Takeaways
- LLMs面临知识更新延迟导致推理错误的问题。
- KG提供丰富的上下文信息以增强LLMs的推理能力。
- 现有方法忽视KG的结构信息,并且主要依赖大参数模型导致资源消耗大。
- LightPROF框架利用LLMs解决复杂推理任务,同时以参数高效的方式进行。
- LightPROF通过“Retrieve-Embed-Reason”流程处理KG数据,提高推理准确性。
- LightPROF只需训练知识适配器,与任何开源LLM兼容。
点此查看论文截图

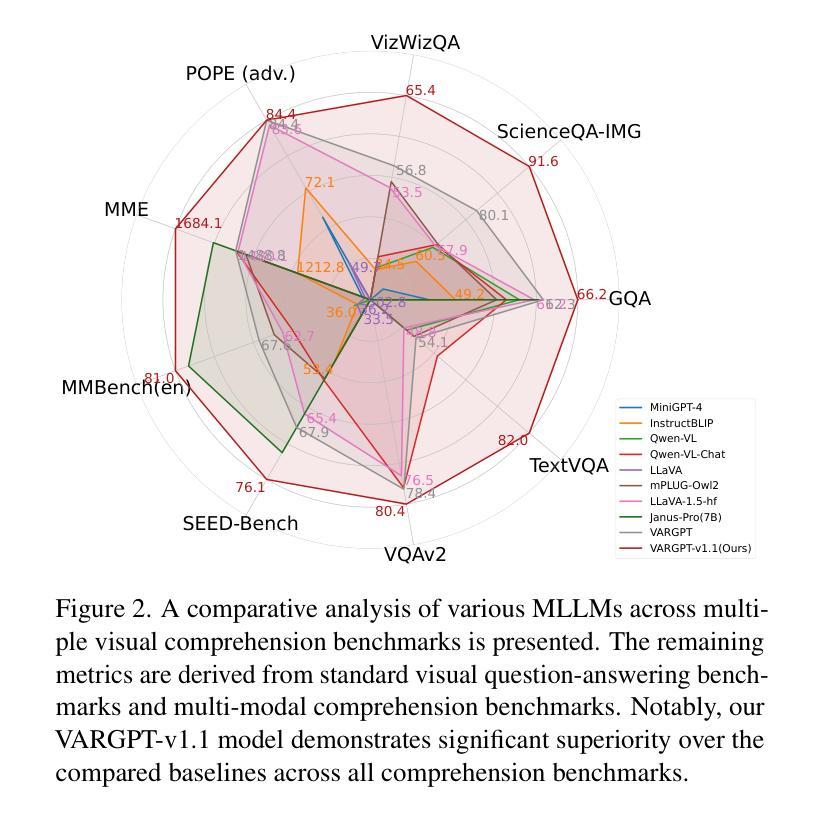
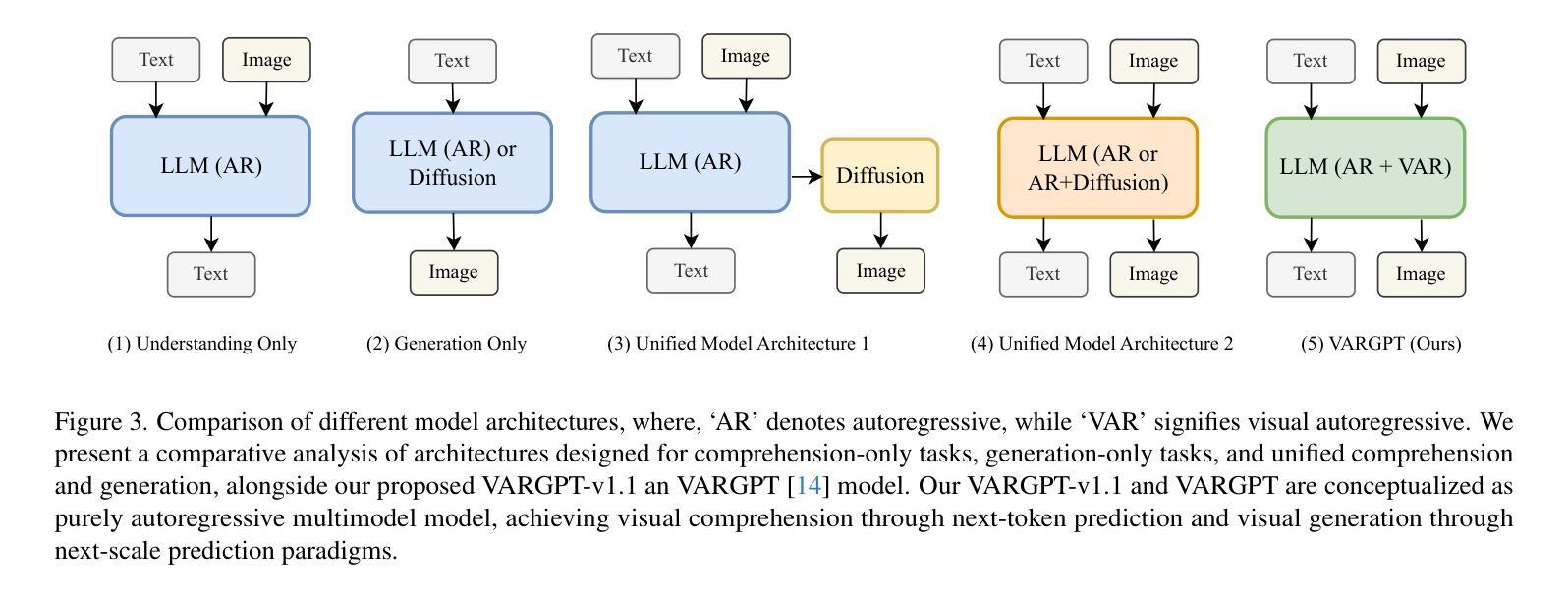
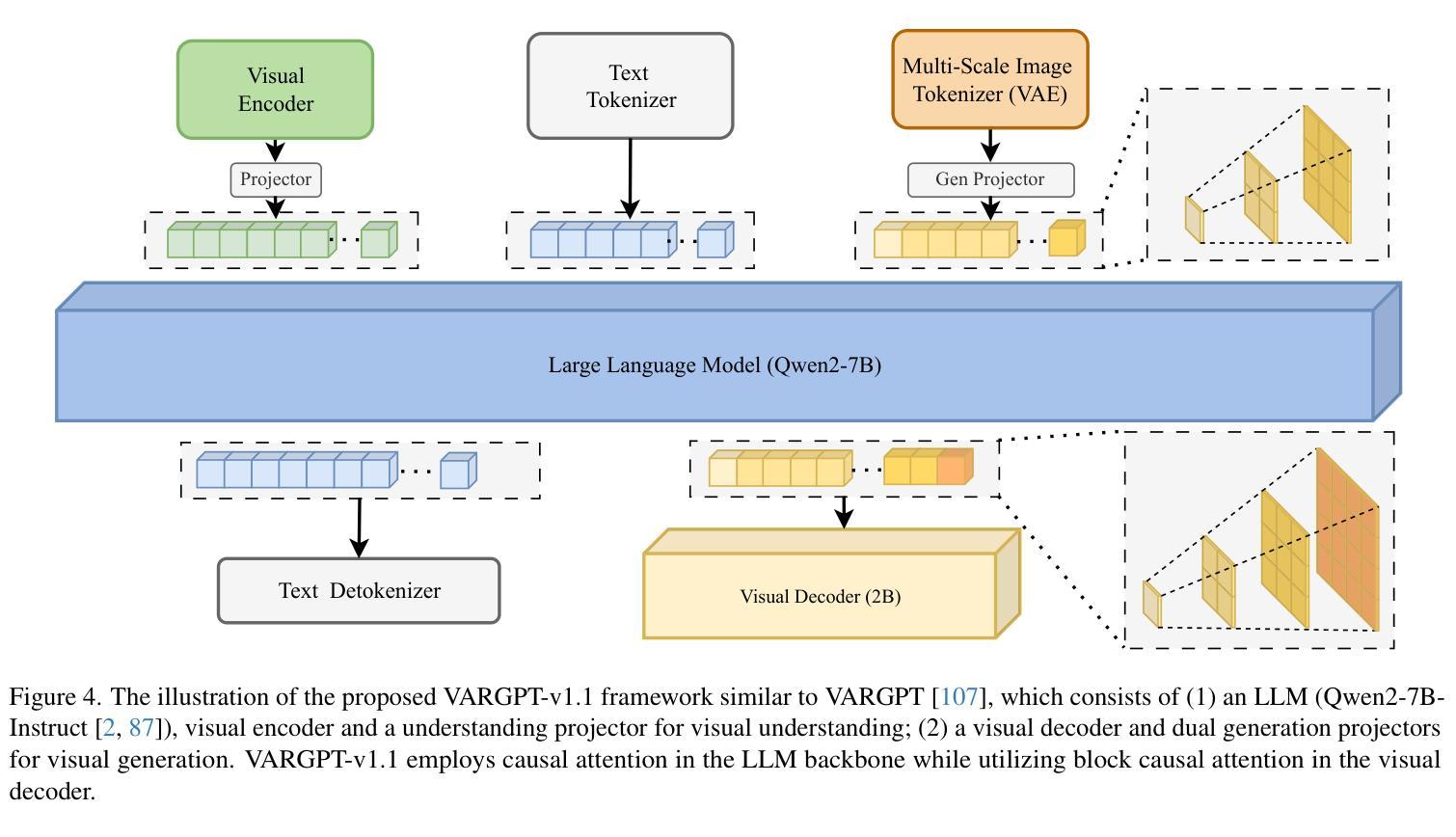
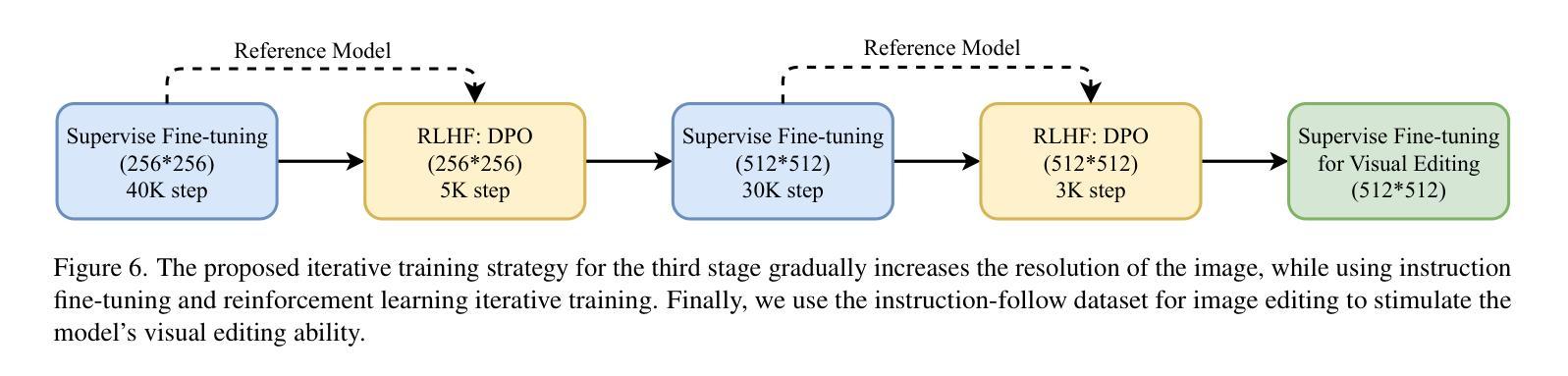
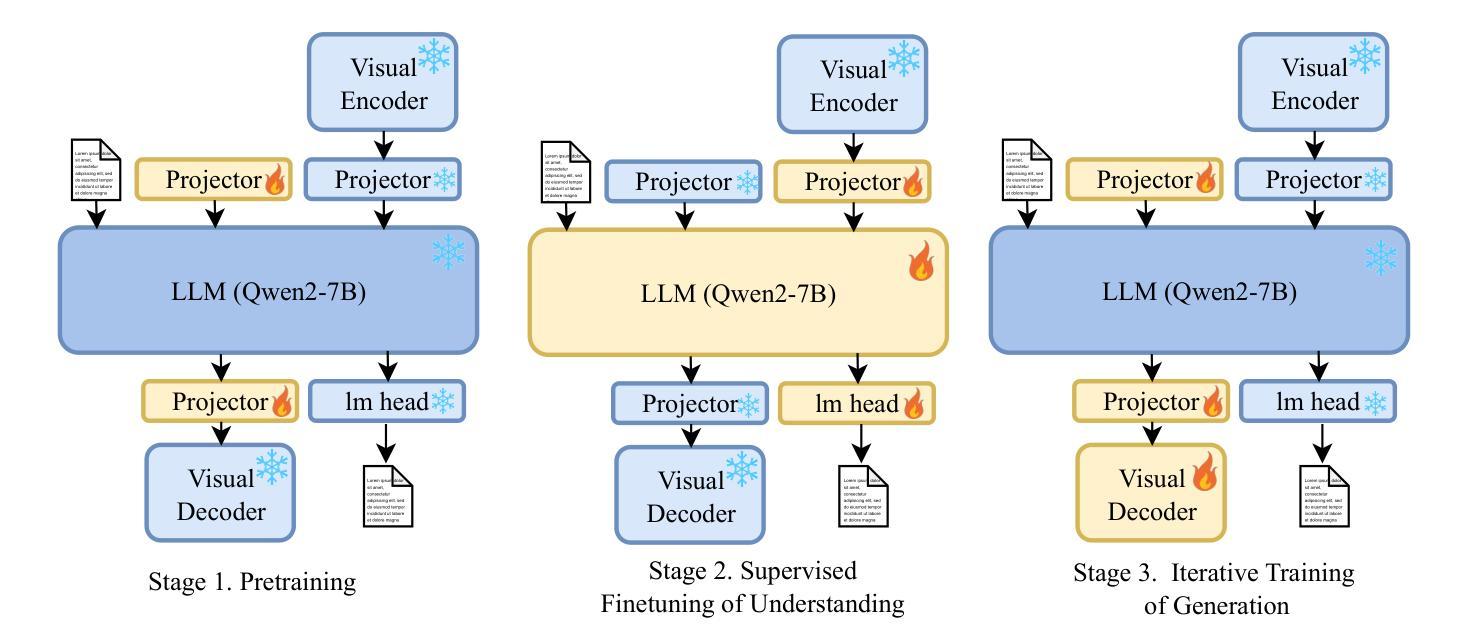
VARGPT-v1.1: Improve Visual Autoregressive Large Unified Model via Iterative Instruction Tuning and Reinforcement Learning
Authors:Xianwei Zhuang, Yuxin Xie, Yufan Deng, Dongchao Yang, Liming Liang, Jinghan Ru, Yuguo Yin, Yuexian Zou
In this work, we present VARGPT-v1.1, an advanced unified visual autoregressive model that builds upon our previous framework VARGPT. The model preserves the dual paradigm of next-token prediction for visual understanding and next-scale generation for image synthesis. Specifically, VARGPT-v1.1 integrates: (1) a novel training strategy combining iterative visual instruction tuning with reinforcement learning through Direct Preference Optimization (DPO), (2) an expanded training corpus containing 8.3M visual-generative instruction pairs, (3) an upgraded language model backbone using Qwen2, (4) enhanced image generation resolution, and (5) emergent image editing capabilities without architectural modifications. These advancements enable VARGPT-v1.1 to achieve state-of-the-art performance in multimodal understanding and text-to-image instruction-following tasks, demonstrating significant improvements in both comprehension and generation metrics. Notably, through visual instruction tuning, the model acquires image editing functionality while maintaining architectural consistency with its predecessor, revealing the potential for unified visual understanding, generation, and editing. Our findings suggest that well-designed unified visual autoregressive models can effectively adopt flexible training strategies from large language models (LLMs), exhibiting promising scalability. The codebase and model weights are publicly available at https://github.com/VARGPT-family/VARGPT-v1.1.
在这项工作中,我们推出了VARGPT-v1.1,这是一款基于我们之前框架VARGPT的高级统一视觉自回归模型。该模型保留了用于视觉理解和图像合成的下一个令牌预测和下一个尺度生成的双重范式。具体来说,VARGPT-v1.1集成了:(1)一种新型训练策略,结合迭代视觉指令调整与通过直接偏好优化(DPO)的强化学习,(2)一个包含830万视觉生成指令对的大规模训练语料库,(3)使用Qwen2的升级语言模型主干,(4)增强的图像生成分辨率,(5)无需架构修改即可实现图像编辑功能。这些进步使VARGPT-v1.1在多模态理解和文本驱动图像生成任务上达到了最新技术水平,在理解和生成指标上都取得了显著改进。值得注意的是,通过视觉指令调整,该模型在保持与前代模型架构一致的同时获得了图像编辑功能,展示了统一视觉理解、生成和编辑的潜力。我们的研究结果表明,精心设计的一体化视觉自回归模型可以有效地采用大型语言模型的灵活训练策略,显示出有希望的可扩展性。代码库和模型权重可在https://github.com/VARGPT-family/VARGPT-v1.1上公开获得。
论文及项目相关链接
PDF Code is available at: https://github.com/VARGPT-family/VARGPT-v1.1. arXiv admin note: text overlap with arXiv:2501.12327
Summary
基于之前框架VARGPT的基础上,我们推出了先进的一体化视觉自回归模型VARGPT-v1.1。此模型既保留了视觉理解与下一代尺度生成的双重范式,又通过整合多项新技术实现了多方面的提升。包括结合迭代视觉指令调整与强化学习的新训练策略、包含830万视觉生成指令对的大型训练语料库、升级的Qwen2语言模型主干、提升的图像生成分辨率以及无需架构修改即可实现的图像编辑功能等。这些进步使得VARGPT-v1.1在多模态理解和文本驱动图像操作任务上达到了业界领先的水平,并在理解和生成指标上实现了显著的提升。模型通过视觉指令调整获得了图像编辑功能,同时保持了与前代模型架构的一致性,展示了其在统一视觉理解、生成和编辑方面的潜力。我们的研究结果表明,设计精良的一体化视觉自回归模型可以有效地采用大型语言模型的灵活训练策略,并展现出令人鼓舞的可扩展性。相关代码和模型权重已公开发布在https://github.com/VARGPT-family/VARGPT-v1.1。
Key Takeaways
- VARGPT-v1.1是先进的一体化视觉自回归模型,基于VARGPT框架开发。
- 模型采用下一代尺度生成与视觉理解的双重范式。
- 模型具备多项新技术整合,包括新的训练策略、大型训练语料库、升级的语言模型主干等。
- 模型实现图像生成分辨率的提升,并具备图像编辑功能,无需进行架构修改。
- VARGPT-v1.1在多模态理解和文本驱动图像操作任务上表现优异,理解和生成指标均有显著提升。
- 模型通过视觉指令调整获得图像编辑功能,展示统一视觉理解、生成和编辑的潜力。
- 研究显示,该模型可以有效地采用大型语言模型的灵活训练策略,并展现出良好的可扩展性。
点此查看论文截图

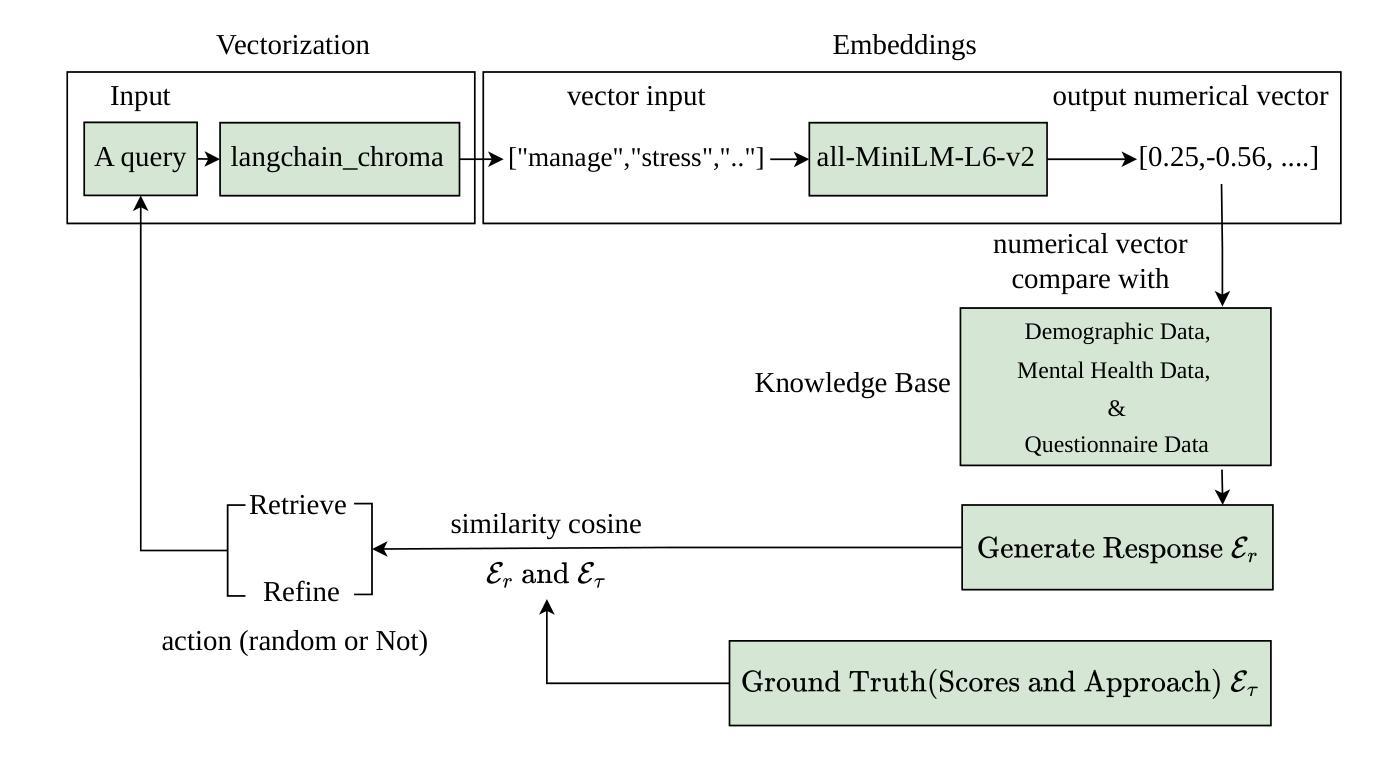
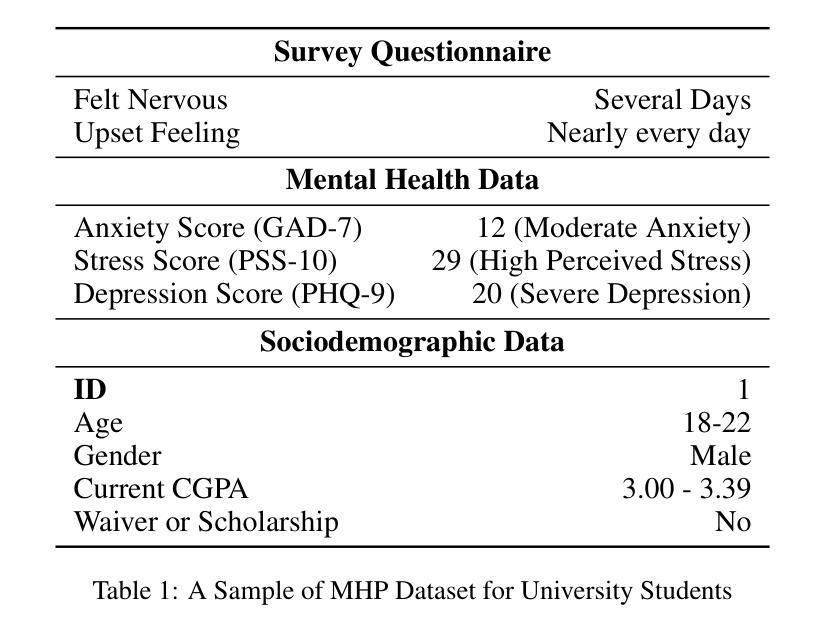
OnRL-RAG: Real-Time Personalized Mental Health Dialogue System
Authors:Ahsan Bilal, Beiyu Lin, Mehdi Zaeifi
Large language models (LLMs) have been widely used for various tasks and applications. However, LLMs and fine-tuning are limited to the pre-trained data. For example, ChatGPT’s world knowledge until 2021 can be outdated or inaccurate. To enhance the capabilities of LLMs, Retrieval-Augmented Generation (RAG), is proposed to augment LLMs with additional, new, latest details and information to LLMs. While RAG offers the correct information, it may not best present it, especially to different population groups with personalizations. Reinforcement Learning from Human Feedback (RLHF) adapts to user needs by aligning model responses with human preference through feedback loops. In real-life applications, such as mental health problems, a dynamic and feedback-based model would continuously adapt to new information and offer personalized assistance due to complex factors fluctuating in a daily environment. Thus, we propose an Online Reinforcement Learning-based Retrieval-Augmented Generation (OnRL-RAG) system to detect and personalize the responding systems to mental health problems, such as stress, anxiety, and depression. We use an open-source dataset collected from 2028 College Students with 28 survey questions for each student to demonstrate the performance of our proposed system with the existing systems. Our system achieves superior performance compared to standard RAG and simple LLM via GPT-4o, GPT-4o-mini, Gemini-1.5, and GPT-3.5. This work would open up the possibilities of real-life applications of LLMs for personalized services in the everyday environment. The results will also help researchers in the fields of sociology, psychology, and neuroscience to align their theories more closely with the actual human daily environment.
大型语言模型(LLM)已被广泛应用于各种任务和应用中。然而,LLM和微调都受限于预训练数据。例如,ChatGPT截至2021年的世界知识可能已过时或不准确。为了增强LLM的能力,提出了检索增强生成(RAG)来向LLM添加额外、最新、最新的细节和信息。虽然RAG提供了正确的信息,但它可能无法最好地呈现它,特别是对于具有个性化的不同人群。强化学习从人类反馈(RLHF)通过反馈循环使模型响应与人类偏好相适应,从而适应用户需求。在现实生活应用,如心理健康问题中,一个动态且基于反馈的模型将根据日常环境中的复杂因素不断适应新信息并提供个性化帮助。因此,我们提出了一种基于在线强化学习的检索增强生成(OnRL-RAG)系统,用于检测和应对心理健康问题,如压力、焦虑和抑郁的响应系统。我们使用从2028名大学生收集的开源数据集进行演示,每个学生接受28个调查问题以展示我们提出的系统与现有系统的性能。我们的系统相较于标准RAG和简单的LLM(如GPT-4o、GPT-4o-mini、Gemini-1.5和GPT-3.5)表现出卓越的性能。这项工作将为LLM在个性化服务方面的现实生活应用开辟可能性,特别是在日常环境中。结果还将帮助社会学、心理学和神经科学领域的研究人员将其理论更紧密地与实际的日常人类环境相结合。
论文及项目相关链接
摘要
大型语言模型广泛应用于各项任务和应用,但其基于预训练数据的局限性显著。为增强大型语言模型的能力,提出检索增强生成法,可以为其增添额外最新信息。然而,检索增强生成法未必能最佳地呈现信息,特别是对不同人群个性化的需求。强化学习从人类反馈适应符合用户需求,通过对模型响应与人类偏好对齐的反馈循环实现。针对心理健康问题的实际应用场景,我们提出基于在线强化学习的检索增强生成系统(OnRL-RAG),用于检测和个性化应对如压力、焦虑和抑郁等心理问题。使用收集的2028名大学生的开源数据集和每项包含28个问题的问卷调查展示系统性能。本系统相较于标准检索增强生成、简单的GPT大型语言模型(如GPT-4o,GPT-4o mini和GPT-3.5)以及Gemini-1.5系统表现优越。这项工作将为大型语言模型在个性化服务领域的实际应用开辟道路,帮助社会学、心理学和神经科学领域的研究者更好地结合理论实践。
关键见解
- 大型语言模型广泛应用于各类任务和应用,但受限于预训练数据,存在知识过时或不准确的问题。
- 检索增强生成法(RAG)可弥补大型语言模型的不足,为其增添最新信息。
- 强化学习从人类反馈(RLHF)适应符合用户需求,通过反馈循环使模型响应与人类偏好对齐。
- 提出在线强化学习基础上的检索增强生成系统(OnRL-RAG),用于个性化应对心理健康问题,如压力、焦虑和抑郁等。
- 使用大学生数据集展示系统性能,本系统相较于其他系统和大型语言模型表现优越。
- 本研究将为大型语言模型在个性化服务领域提供新思路,推进社会学、心理学和神经科学领域理论与实践的结合。
点此查看论文截图

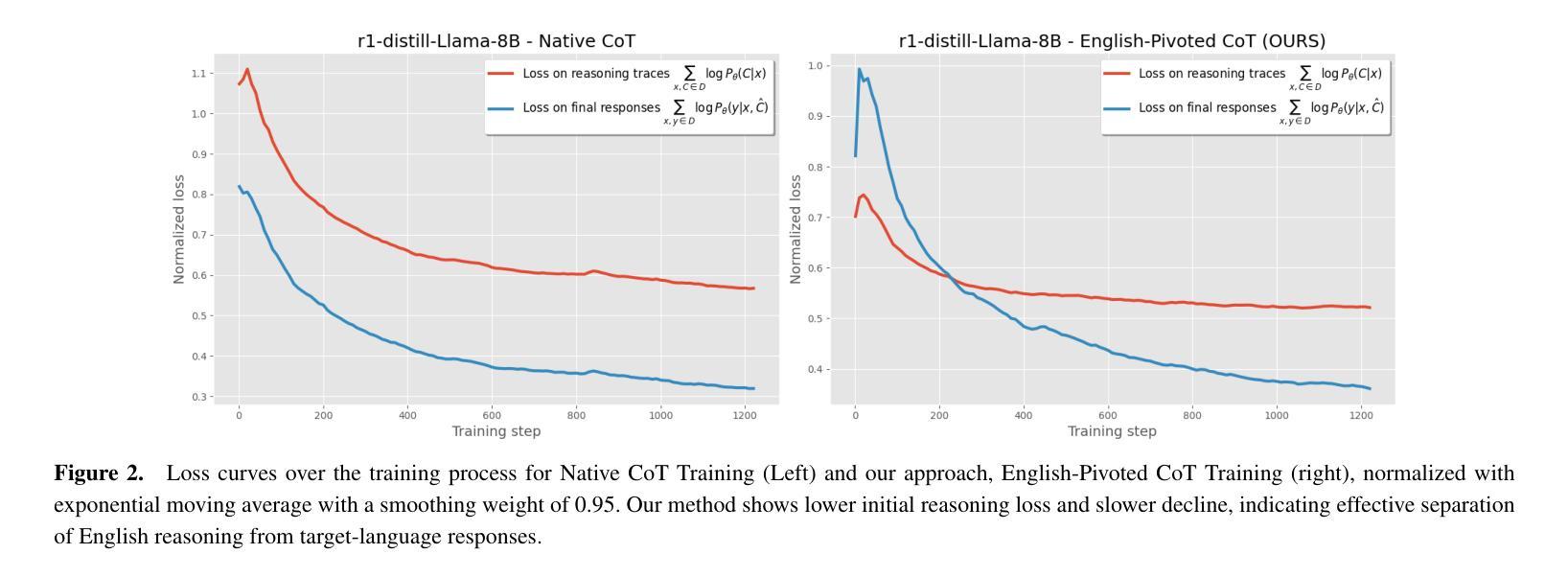
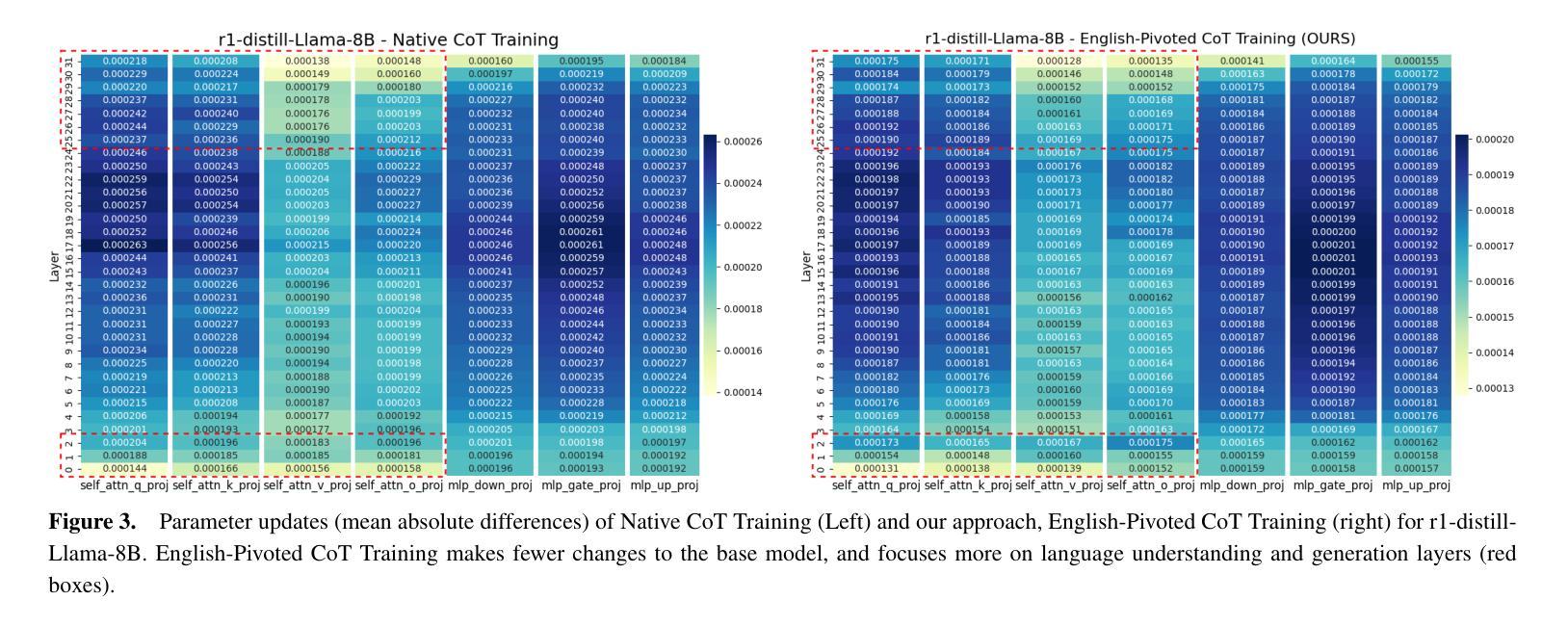
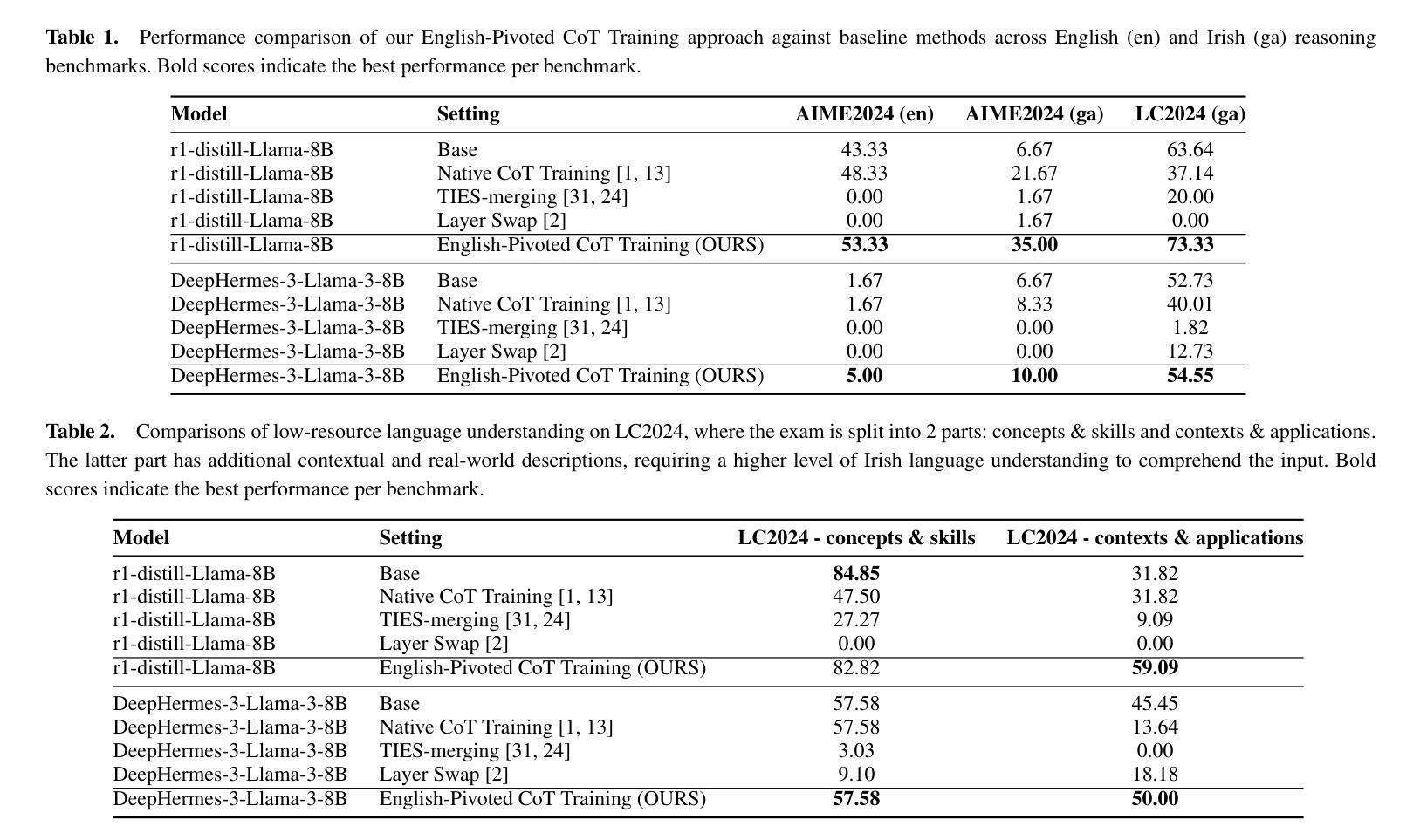
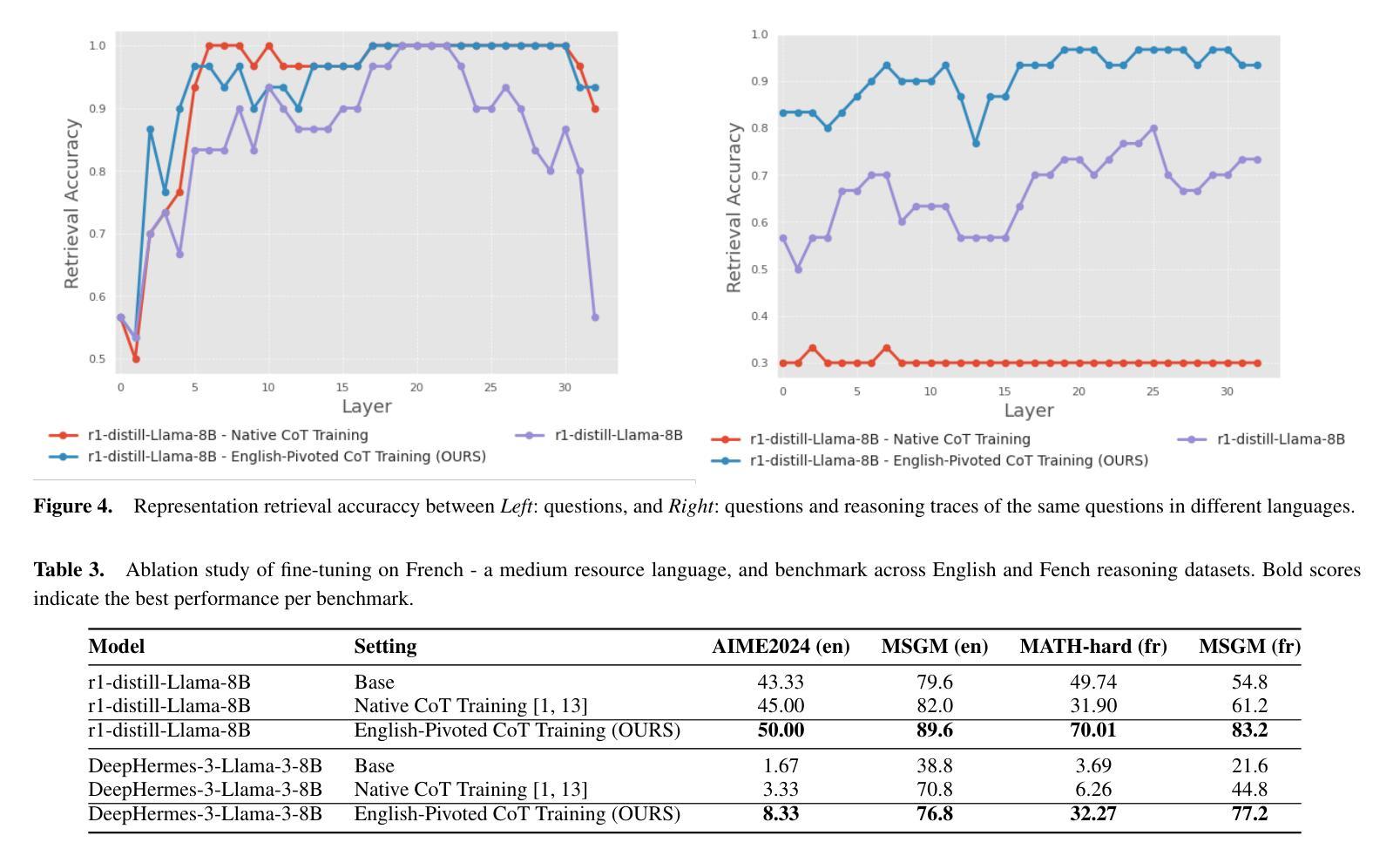
Scaling Test-time Compute for Low-resource Languages: Multilingual Reasoning in LLMs
Authors:Khanh-Tung Tran, Barry O’Sullivan, Hoang D. Nguyen
Recent advances in test-time compute scaling have enabled Large Language Models (LLMs) to tackle deep reasoning tasks by generating a chain-of-thought (CoT) that includes trial and error, backtracking, and intermediate reasoning steps before producing the final answer. However, these techniques have been applied predominantly to popular languages, such as English, leaving reasoning in low-resource languages underexplored and misaligned. In this work, we investigate the multilingual mechanism by which LLMs internally operate in a latent space biased toward their inherently dominant language. To leverage this phenomenon for low-resource languages, we train models to generate the CoT in English while outputting the final response in the target language, given input in the low-resource language. Our experiments demonstrate that this approach, named English-Pivoted CoT Training, outperforms other baselines, including training to generate both the CoT and the final response solely in the target language, with up to 28.33% improvement. Further analysis provides novel insights into the relationships between reasoning and multilinguality of LLMs, prompting for better approaches in developing multilingual large reasoning models
近期测试时间计算尺度方面的进展使得大型语言模型(LLM)能够通过生成包含试错、回溯和中间推理步骤的思维链(CoT)来完成深度推理任务,然后给出最终答案。然而,这些技术主要应用在了英语等流行语言上,导致在低资源语言中的推理探索不足且存在偏差。在这项工作中,我们研究了LLM的内在多元语言机制,即它们在潜在空间中的运行偏向其固有主导语言的现象。为了利用这一低资源语言现象,我们训练模型在英语中生成思维链,在目标语言中输出最终回应,以低资源语言作为输入。我们的实验表明,名为英语为轴的思维链训练方法优于其他基准测试方法,包括仅在目标语言中生成思维链和最终回应的训练方法,最高提升了28.33%。进一步的分析提供了关于LLM推理和多语言性之间关系的全新见解,为开发多语言大型推理模型提供了更好的方法。
论文及项目相关链接
Summary
大型语言模型(LLM)在测试时的计算扩展能力进步,使其能够通过生成包含试错、回溯和中间推理步骤的“思维链”(CoT)来应对深度推理任务。然而,这些技术主要应用于英语等流行语言,导致低资源语言的推理研究不足和对齐困难。本研究探讨LLM在多语言机制下如何在其偏向母语的内隐空间中进行操作。为了利用此现象服务于低资源语言,我们训练模型在英语生成思维链,并在目标语言输出最终回应。实验显示,名为英语支点思维链训练的方法优于其他基准测试,包括在目标语言中生成思维链和最终回应的训练方法,提高了最多达28.33%。进一步的分析为LLM的推理和多语言能力之间的关系提供了新的见解,提示了开发多语言大型推理模型的新方法。
Key Takeaways
- 大型语言模型(LLM)通过生成思维链(CoT)完成深度推理任务,包括试错、回溯和中间推理步骤。
- 现有技术主要关注流行语言,导致低资源语言的推理研究不足和对齐困难。
- LLM在多语言处理时存在内隐空间偏向母语的现象。
- 通过在英语生成思维链并在目标语言输出最终回应的训练方式,称为英语支点思维链训练,表现优于其他训练方法。
- 英语支点思维链训练方法最多可提高28.33%的性能。
- 分析揭示了LLM推理和多语言能力之间的新关系。
点此查看论文截图



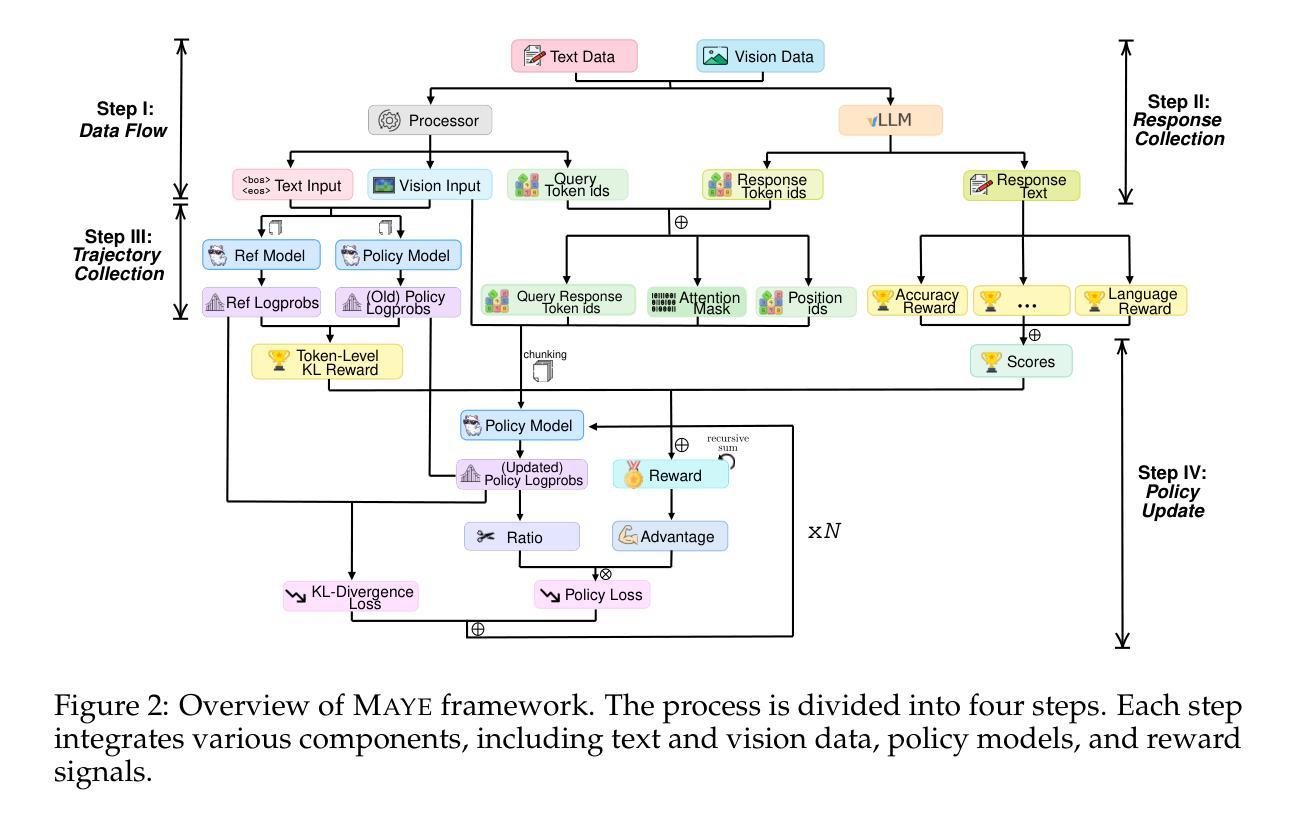
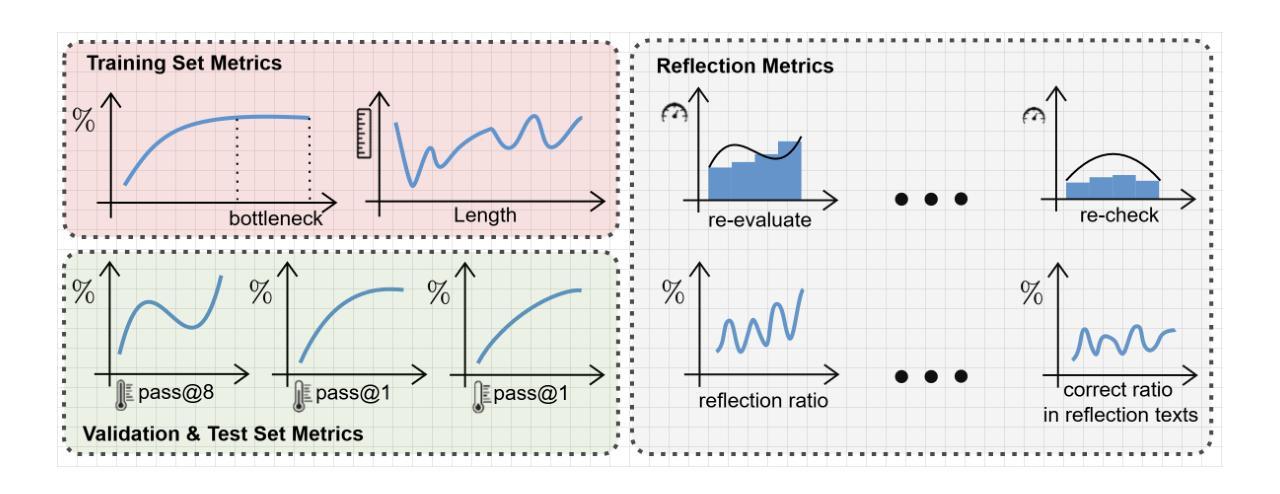
Rethinking RL Scaling for Vision Language Models: A Transparent, From-Scratch Framework and Comprehensive Evaluation Scheme
Authors:Yan Ma, Steffi Chern, Xuyang Shen, Yiran Zhong, Pengfei Liu
Reinforcement learning (RL) has recently shown strong potential in improving the reasoning capabilities of large language models and is now being actively extended to vision-language models (VLMs). However, existing RL applications in VLMs often rely on heavily engineered frameworks that hinder reproducibility and accessibility, while lacking standardized evaluation protocols, making it difficult to compare results or interpret training dynamics. This work introduces a transparent, from-scratch framework for RL in VLMs, offering a minimal yet functional four-step pipeline validated across multiple models and datasets. In addition, a standardized evaluation scheme is proposed to assess training dynamics and reflective behaviors. Extensive experiments on visual reasoning tasks uncover key empirical findings: response length is sensitive to random seeds, reflection correlates with output length, and RL consistently outperforms supervised fine-tuning (SFT) in generalization, even with high-quality data. These findings, together with the proposed framework, aim to establish a reproducible baseline and support broader engagement in RL-based VLM research.
强化学习(RL)在提升大型语言模型的推理能力方面已显示出强大的潜力,目前正在积极拓展到视觉语言模型(VLMs)。然而,现有的视觉语言模型中的强化学习应用往往依赖于重度工程的框架,这些框架阻碍了可重复性和可访问性,同时缺乏标准化的评估协议,使得难以比较结果或解释训练动态。这项工作引入了一个透明、从头开始的视觉语言模型强化学习框架,提供了一个简洁而实用的四步流程,已在多个模型和数据集上得到验证。此外,还提出了一种标准化的评估方案,以评估训练动态和反思行为。在视觉推理任务上的大量实验揭示了关键经验发现:响应长度对随机种子敏感,反思与输出长度相关,强化学习在泛化方面始终优于有监督微调(SFT),即使在高质量数据的情况下也是如此。这些发现与所提出的框架一起,旨在建立一个可重复的基本线,并支持更广泛地参与基于强化学习的视觉语言模型研究。
论文及项目相关链接
PDF Code is public and available at: https://github.com/GAIR-NLP/MAYE
Summary
强化学习(RL)在提升大型语言模型的推理能力方面展现出强大潜力,现在正积极扩展至视觉语言模型(VLMs)。然而,现有的VLMs中的RL应用常常依赖于重度工程的框架,这阻碍了可重复性和可访问性,同时缺乏标准化的评估协议,使得结果难以比较或解释训练动态。本研究介绍了一个透明、从头开始的RL在VLMs中的框架,提供了一个简洁而实用的四步管道,并在多个模型和数据集上进行了验证。此外,还提出了一个标准化的评估方案,以评估训练动态和反思行为。在视觉推理任务上的大量实验揭示了关键实证发现:响应长度对随机种子敏感,反思与输出长度相关,RL在泛化方面持续优于监督微调(SFT),即使在高质量数据的情况下也是如此。这些发现与所提出的框架旨在建立可重复性的基准,并支持更广泛的RL基于VLM研究的参与。
Key Takeaways
- 强化学习在提升语言模型的推理能力方面表现出强大潜力,正在逐步应用于视觉语言模型(VLMs)。
- 现有的VLMs中的RL应用框架复杂,缺乏透明度和可重复性。
- 本研究提供了一个简洁的RL框架,适用于VLMs,并进行了多模型和跨数据集的验证。
- 提出了标准化的评估方案,以更好地评估VLMs的训练动态和反思行为。
- 实验发现响应长度对随机种子敏感,且反思与输出长度有关联。
- 在泛化方面,强化学习(RL)通常优于监督微调(SFT),即使面对高质量数据。
点此查看论文截图


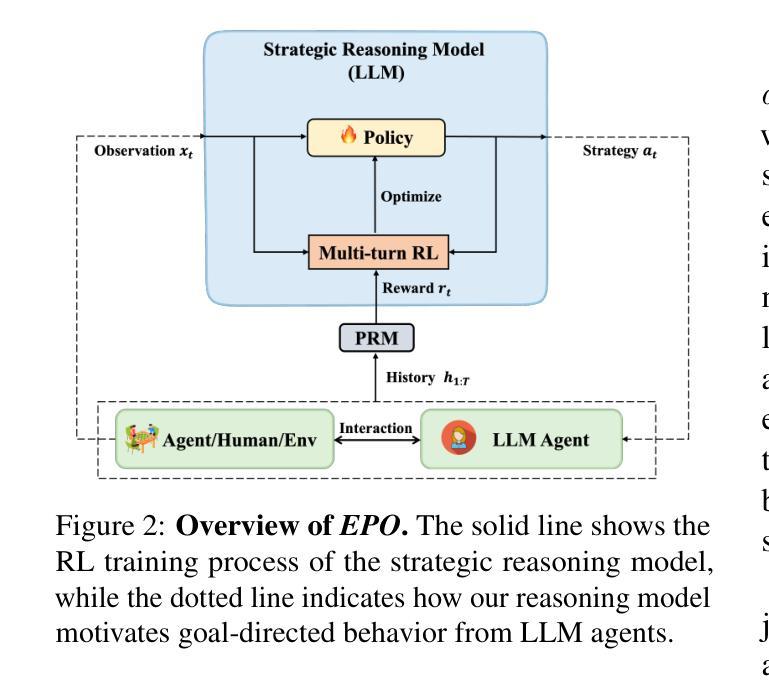
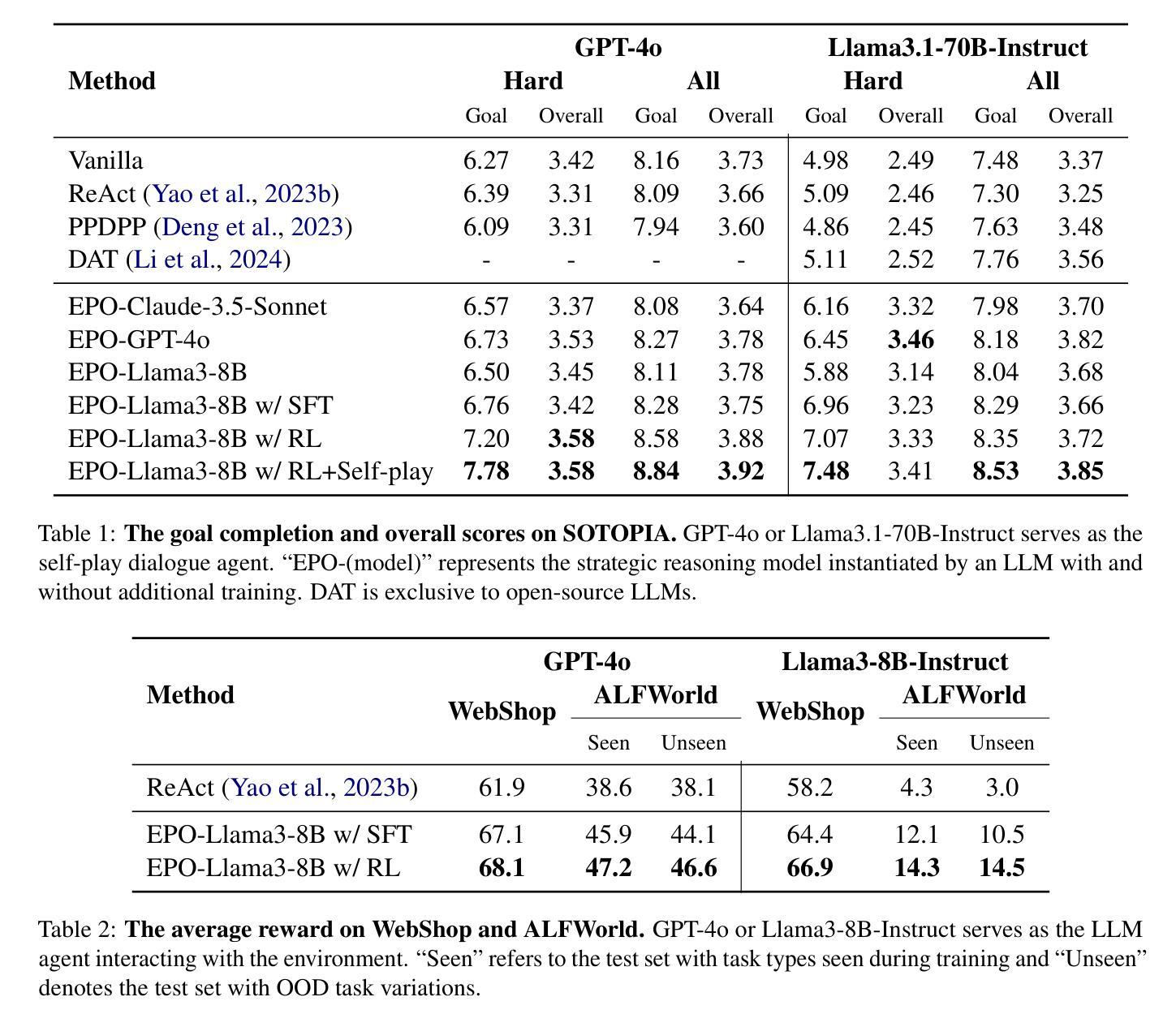
EPO: Explicit Policy Optimization for Strategic Reasoning in LLMs via Reinforcement Learning
Authors:Xiaoqian Liu, Ke Wang, Yongbin Li, Yuchuan Wu, Wentao Ma, Aobo Kong, Fei Huang, Jianbin Jiao, Junge Zhang
Large Language Models (LLMs) have shown impressive reasoning capabilities in well-defined problems with clear solutions, such as mathematics and coding. However, they still struggle with complex real-world scenarios like business negotiations, which require strategic reasoning-an ability to navigate dynamic environments and align long-term goals amidst uncertainty. Existing methods for strategic reasoning face challenges in adaptability, scalability, and transferring strategies to new contexts. To address these issues, we propose explicit policy optimization (EPO) for strategic reasoning, featuring an LLM that provides strategies in open-ended action space and can be plugged into arbitrary LLM agents to motivate goal-directed behavior. To improve adaptability and policy transferability, we train the strategic reasoning model via multi-turn reinforcement learning (RL) using process rewards and iterative self-play, without supervised fine-tuning (SFT) as a preliminary step. Experiments across social and physical domains demonstrate EPO’s ability of long-term goal alignment through enhanced strategic reasoning, achieving state-of-the-art performance on social dialogue and web navigation tasks. Our findings reveal various collaborative reasoning mechanisms emergent in EPO and its effectiveness in generating novel strategies, underscoring its potential for strategic reasoning in real-world applications.
大型语言模型(LLM)在定义明确、解决方案清晰的问题中展示了令人印象深刻的推理能力,例如在数学和编程方面。然而,它们在处理复杂的现实世界场景,如商务谈判等,仍然面临挑战。这些场景需要战略推理能力,即在动态环境中导航并在不确定性中实现长期目标的能力。现有的战略推理方法面临着适应性、可扩展性和策略转移等方面的挑战。为了解决这些问题,我们提出了针对战略推理的显式策略优化(EPO)方法。该方法使用LLM在开放动作空间中提供策略,并可插入到任意LLM代理中以激励目标导向行为。为了改善适应性和策略可转移性,我们通过多回合强化学习(RL)训练战略推理模型,使用过程奖励和迭代自我对抗,无需预先进行有监督的微调(SFT)。在社会和物理领域的实验表明,EPO通过增强的战略推理实现了长期目标对齐的能力,在社会对话和网页导航任务上达到了最新技术水平。我们的研究揭示了EPO中涌现的各种协作推理机制及其生成新策略的有效性,突显了其在现实世界应用中的战略推理潜力。
论文及项目相关链接
PDF 22 pages, 4 figures
Summary
大型语言模型(LLMs)在具有明确解决方案的明确问题中展现出令人印象深刻的推理能力,如数学和编程。然而,在面对需要战略推理的复杂现实世界场景,如商业谈判等,LLMs仍面临挑战。战略推理要求模型能够在动态环境中导航,并在不确定性中调整长期目标。为解决现有战略推理方法面临的可适应性、可扩展性和策略转移等挑战,我们提出了显式策略优化(EPO)方法。该方法结合了LLM,能在开放行动空间中提供策略,并可插入到任意LLM代理中以驱动目标导向行为。通过多回合强化学习(RL)进行训练,以提高模型的适应性和策略可转移性。实验表明,EPO在社交和物理领域具有长期目标对齐能力,并在社会对话和网页导航任务上实现了最先进的性能。研究结果揭示了EPO中涌现的各种协作推理机制及其生成新策略的有效性,突显其在现实世界应用中的战略推理潜力。
Key Takeaways
- 大型语言模型(LLMs)在明确问题中展现出强大的推理能力,但在需要战略推理的复杂现实世界场景(如商业谈判)中仍面临挑战。
- 战略推理要求模型能够在动态环境中导航,并在不确定性中调整长期目标。
- 现有的战略推理方法面临可适应性、可扩展性和策略转移等挑战。
- 显式策略优化(EPO)方法通过结合LLM,能在开放行动空间中提供策略,并促进目标导向行为。
- EPO通过多回合强化学习(RL)进行训练,以提高模型的适应性和策略可转移性。
- 实验表明,EPO在社交和物理领域的长期目标对齐能力出色,社会对话和网页导航任务性能先进。
点此查看论文截图


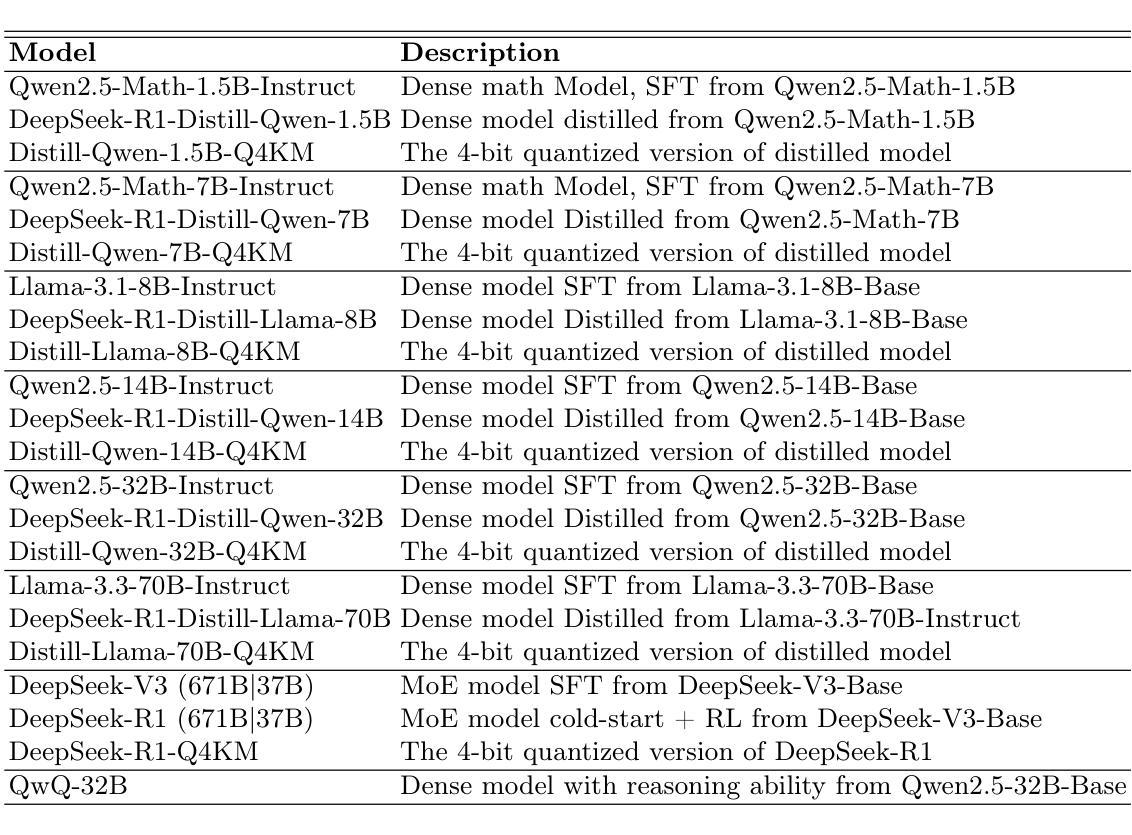
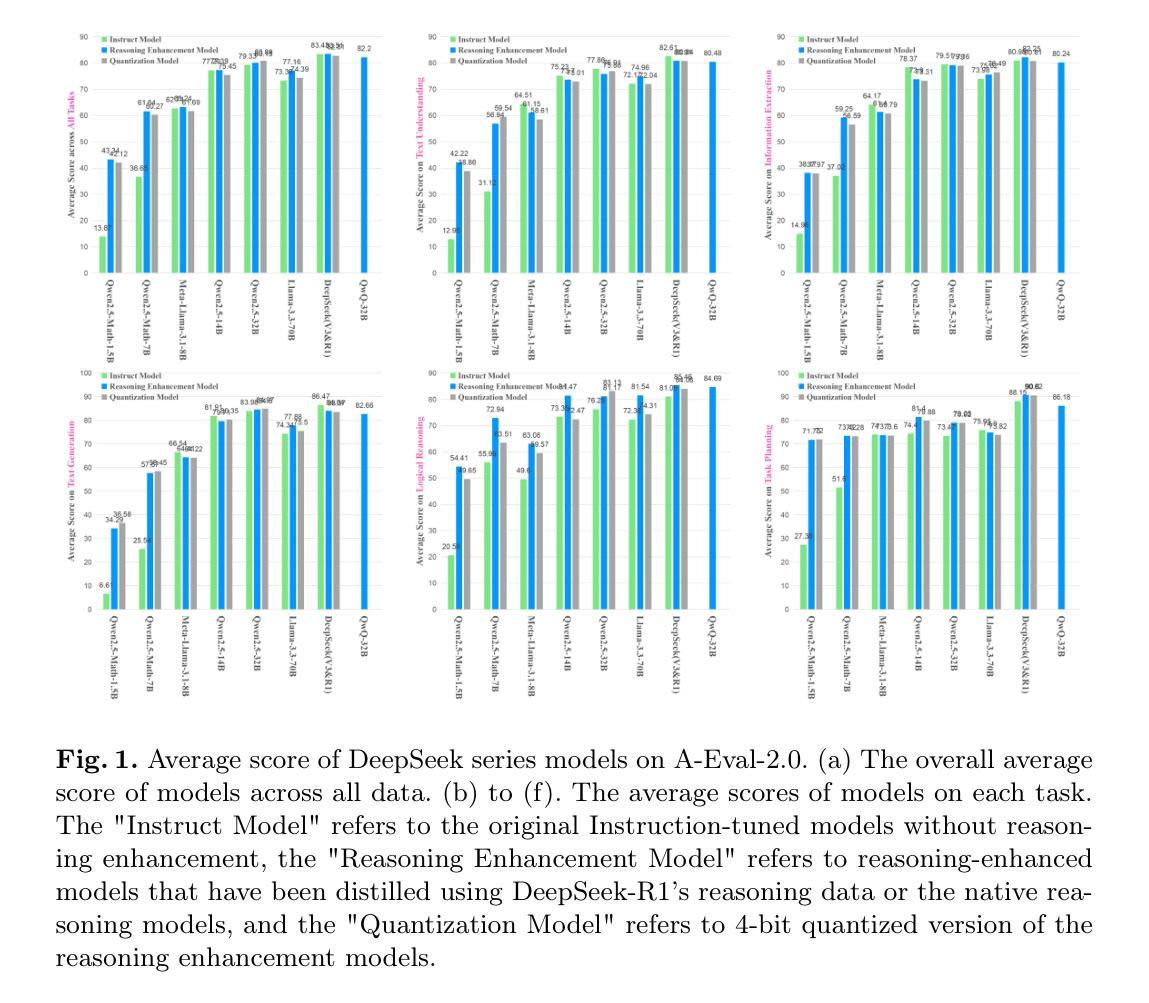
Quantifying the Capability Boundary of DeepSeek Models: An Application-Driven Performance Analysis
Authors:Kaikai Zhao, Zhaoxiang Liu, Xuejiao Lei, Jiaojiao Zhao, Zhenhong Long, Zipeng Wang, Ning Wang, Meijuan An, Qingliang Meng, Peijun Yang, Minjie Hua, Chaoyang Ma, Wen Liu, Kai Wang, Shiguo Lian
DeepSeek-R1, known for its low training cost and exceptional reasoning capabilities, has achieved state-of-the-art performance on various benchmarks. However, detailed evaluations for DeepSeek Series models from the perspective of real-world applications are lacking, making it challenging for users to select the most suitable DeepSeek models for their specific needs. To address this gap, we conduct a systematic evaluation of the DeepSeek-V3, DeepSeek-R1, DeepSeek-R1-Distill-Qwen series, DeepSeek-R1-Distill-Llama series, their corresponding 4-bit quantized models, and the reasoning model QwQ-32B using the enhanced A-Eval benchmark, A-Eval-2.0. Through a comparative analysis of original instruction-tuned models and their distilled counterparts, we investigate how reasoning enhancements impact performance across diverse practical tasks. To assist users in model selection, we quantify the capability boundary of DeepSeek models through performance tier classifications. Based on the quantification results, we develop a model selection handbook that clearly illustrates the relation among models, their capabilities and practical applications. This handbook enables users to select the most cost-effective models without efforts, ensuring optimal performance and resource efficiency in real-world applications. It should be noted that, despite our efforts to establish a comprehensive, objective, and authoritative evaluation benchmark, the selection of test samples, characteristics of data distribution, and the setting of evaluation criteria may inevitably introduce certain biases into the evaluation results. We will continuously optimize the evaluation benchmarks and periodically update this paper to provide more comprehensive and accurate evaluation results. Please refer to the latest version of the paper for the most current results and conclusions.
DeepSeek-R1以其低训练成本和出色的推理能力而闻名,已在各种基准测试中实现了最先进的性能。然而,从实际应用的角度对DeepSeek系列模型的详细评估仍然缺乏,这使得用户难以为其特定需求选择最合适的DeepSeek模型。为了弥补这一空白,我们对DeepSeek-V3、DeepSeek-R1、DeepSeek-R1-Distill-Qwen系列、DeepSeek-R1-Distill-Llama系列、其相应的4位量化模型以及推理模型QwQ-32B,使用增强的A-Eval基准测试A-Eval-2.0进行了系统评估。通过对比原始指令调整模型和它们蒸馏后的对应模型,我们研究了推理增强如何影响各种实际任务的性能。为了帮助用户选择模型,我们通过性能分级分类来量化DeepSeek模型的能力边界。基于量化结果,我们开发了模型选择手册,该手册清晰地说明了模型之间的关系、它们的能力以及实际应用。该手册使用户能够轻松选择最具成本效益的模型,确保在真实世界应用中实现最佳性能和资源效率。应当注意的是,尽管我们努力建立全面、客观、权威的评估基准,但测试样本的选择、数据分布的特征以及评估标准的设定不可避免地会对评估结果引入一定的偏见。我们将不断优化评估基准并定期更新本文,以提供更全面和准确的评估结果。有关最新结果和结论,请参阅本文的最新版本。
论文及项目相关链接
Summary
DeepSeek系列模型具备低成本和高推理能力,已在多个基准测试中达到领先水平。然而,针对这些模型在真实世界应用中的详细评估仍显不足,导致用户难以选择最适合其特定需求的DeepSeek模型。为解决此问题,研究团队对DeepSeek-V3、DeepSeek-R1、DeepSeek-R1-Distill-Qwen系列、DeepSeek-R1-Distill-Llama系列及其对应的4位量化模型,以及推理模型QwQ-32B进行了系统性的评估。研究采用增强的A-Eval基准测试A-Eval-2.0进行评估,并比较了原始指令调整模型和蒸馏后模型的表现,探讨了推理增强如何影响各种实际任务的性能。此外,研究还通过性能分级分类确定了DeepSeek模型的能力边界,并据此制定了模型选择手册,以帮助用户轻松选择最具成本效益的模型,确保在真实世界应用中实现最佳性能和资源效率。但评估过程中可能存在测试样本选择、数据分布特征和评估标准设置等方面的偏见,团队将持续优化评估基准并定期更新此论文以提供更全面和准确的评估结果。
Key Takeaways
- DeepSeek系列模型在多个基准测试中表现出卓越性能,但真实世界应用的详细评估仍不足。
- 研究对DeepSeek多个系列模型进行系统性评估,包括使用增强的A-Eval基准测试。
- 比较了原始指令调整模型和蒸馏模型的表现,探讨了推理增强对实际任务性能的影响。
- 通过性能分级分类确定DeepSeek模型的能力边界。
- 制定了模型选择手册,以指导用户轻松选择最具成本效益的模型。
- 评估过程中可能存在偏见,团队将持续优化评估基准并定期更新论文。
点此查看论文截图

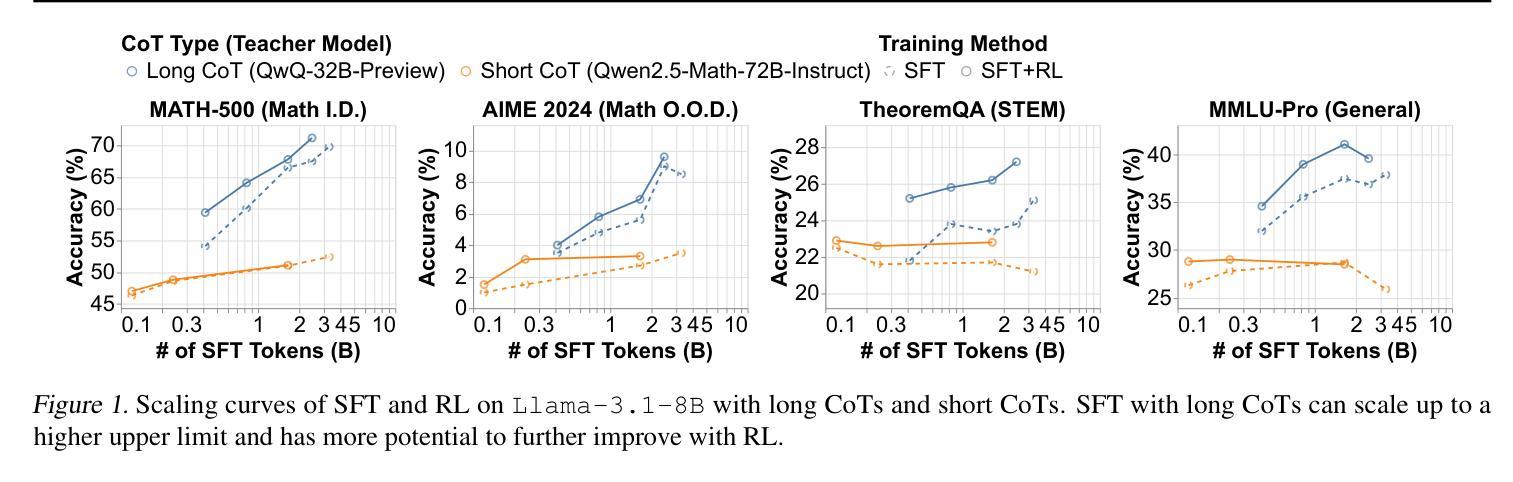
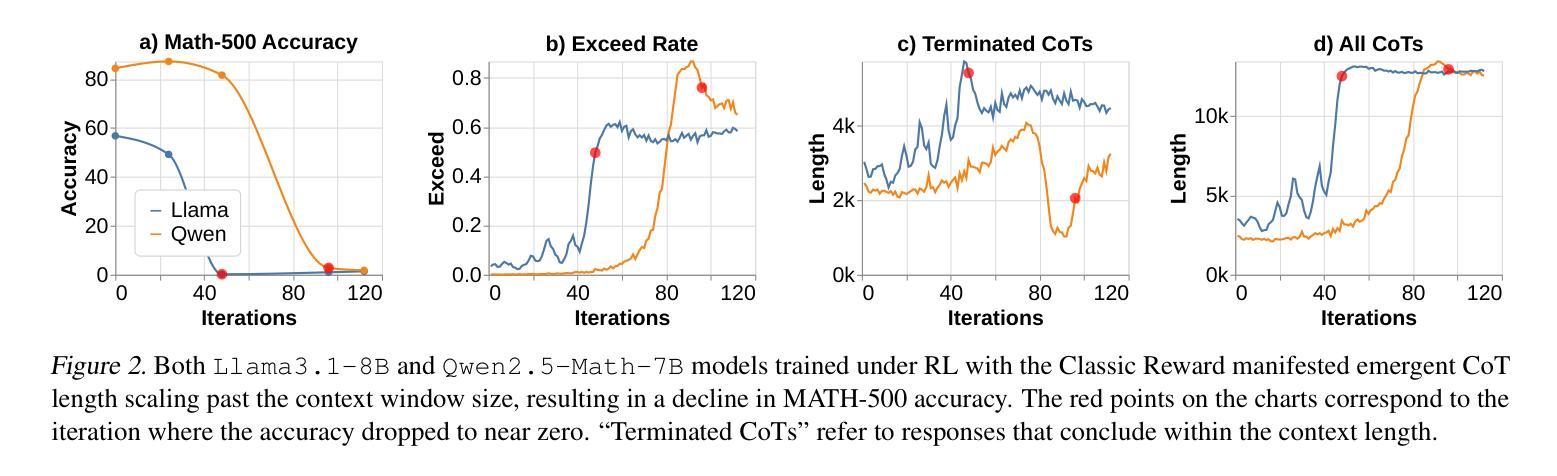
Demystifying Long Chain-of-Thought Reasoning in LLMs
Authors:Edward Yeo, Yuxuan Tong, Morry Niu, Graham Neubig, Xiang Yue
Scaling inference compute enhances reasoning in large language models (LLMs), with long chains-of-thought (CoTs) enabling strategies like backtracking and error correction. Reinforcement learning (RL) has emerged as a crucial method for developing these capabilities, yet the conditions under which long CoTs emerge remain unclear, and RL training requires careful design choices. In this study, we systematically investigate the mechanics of long CoT reasoning, identifying the key factors that enable models to generate long CoT trajectories. Through extensive supervised fine-tuning (SFT) and RL experiments, we present four main findings: (1) While SFT is not strictly necessary, it simplifies training and improves efficiency; (2) Reasoning capabilities tend to emerge with increased training compute, but their development is not guaranteed, making reward shaping crucial for stabilizing CoT length growth; (3) Scaling verifiable reward signals is critical for RL. We find that leveraging noisy, web-extracted solutions with filtering mechanisms shows strong potential, particularly for out-of-distribution (OOD) tasks such as STEM reasoning; and (4) Core abilities like error correction are inherently present in base models, but incentivizing these skills effectively for complex tasks via RL demands significant compute, and measuring their emergence requires a nuanced approach. These insights provide practical guidance for optimizing training strategies to enhance long CoT reasoning in LLMs. Our code is available at: https://github.com/eddycmu/demystify-long-cot.
扩展推理计算可以增强大型语言模型(LLM)的推理能力,通过长链条思维(CoTs)实现回溯和错误纠正等策略。强化学习(RL)已成为开发这些能力的重要方法,然而长CoTs出现的条件仍不清楚,且RL训练需要谨慎的设计选择。在这项研究中,我们系统地研究了长CoT推理的机制,确定了使模型生成长CoT轨迹的关键因素。通过广泛的监督微调(SFT)和RL实验,我们提出了四个主要发现:
(1)虽然SFT并非严格必要,但它简化了训练并提高了效率;
(2)推理能力往往随着训练计算的增加而涌现,但其发展并非必然,这使得奖励塑造对于稳定CoT长度增长至关重要;
(3)扩大可验证的奖励信号对RL至关重要。我们发现,利用带有过滤机制的嘈杂的网页提取解决方案具有很强的潜力,特别是对于离群分布(OOD)任务,如STEM推理;
论文及项目相关链接
PDF Preprint, under review
Summary
本文研究了如何提升大型语言模型(LLM)的长链思维(CoT)推理能力。通过强化学习(RL)和系统实验,发现训练计算量的增加有助于推理能力的提升,但也需要对奖励机制进行塑形以确保思维链的稳定增长。同时,利用过滤机制的噪声网络解决方案对于非常规任务如STEM推理具有很强的潜力。文章还指出基础模型本身就具备如错误修正等核心能力,但要通过RL进行有效激励需要更多的计算,并需要精细的测量方法来评估这些能力的出现。
Key Takeaways
- 增加训练计算量有助于提升大型语言模型的推理能力。
- 强化学习是发展长链思维推理能力的重要方法,但需要对奖励机制进行塑形以确保思维链的稳定增长。
- 系统实验发现,虽然监督微调(SFT)不是必须的,但它能简化训练并提高效率。
- 利用过滤机制的噪声网络解决方案对于非常规任务具有很强的潜力。
- 基础模型本身就具备核心能力,如错误修正,但要有效激励这些能力需要更多的计算。
- 测量这些能力的出现需要精细的方法。
点此查看论文截图

LlamaRestTest: Effective REST API Testing with Small Language Models
Authors:Myeongsoo Kim, Saurabh Sinha, Alessandro Orso
Modern web services rely heavily on REST APIs, typically documented using the OpenAPI specification. The widespread adoption of this standard has resulted in the development of many black-box testing tools that generate tests based on OpenAPI specifications. Although Large Language Models (LLMs) have shown promising test-generation abilities, their application to REST API testing remains mostly unexplored. We present LlamaRestTest, a novel approach that employs two custom LLMs-created by fine-tuning and quantizing the Llama3-8B model using mined datasets of REST API example values and inter-parameter dependencies-to generate realistic test inputs and uncover inter-parameter dependencies during the testing process by analyzing server responses. We evaluated LlamaRestTest on 12 real-world services (including popular services such as Spotify), comparing it against RESTGPT, a GPT-powered specification-enhancement tool, as well as several state-of-the-art REST API testing tools, including RESTler, MoRest, EvoMaster, and ARAT-RL. Our results demonstrate that fine-tuning enables smaller models to outperform much larger models in detecting actionable parameter-dependency rules and generating valid inputs for REST API testing. We also evaluated different tool configurations, ranging from the base Llama3-8B model to fine-tuned versions, and explored multiple quantization techniques, including 2-bit, 4-bit, and 8-bit integer formats. Our study shows that small language models can perform as well as, or better than, large language models in REST API testing, balancing effectiveness and efficiency. Furthermore, LlamaRestTest outperforms state-of-the-art REST API testing tools in code coverage achieved and internal server errors identified, even when those tools use RESTGPT-enhanced specifications.
现代web服务严重依赖于REST API,通常使用OpenAPI规范进行文档化。这一标准的广泛应用促使了许多黑盒测试工具的发展,这些工具根据OpenAPI规范生成测试。尽管大型语言模型(LLMs)在测试生成方面表现出了令人瞩目的能力,但它们在REST API测试中的应用仍然主要未被探索。我们提出了LlamaRestTest,这是一种新颖的方法,它采用两个自定义的LLMs,通过微调和使用挖掘的REST API示例值和数据集量化Llama3-8B模型,生成现实的测试输入,并通过分析服务器响应在测试过程中发现参数之间的依赖关系。我们对LlamaRestTest在12个真实世界服务(包括流行的服务如Spotify)上进行了评估,将其与由GPT驱动的规格增强工具RESTGPT以及几种最先进的REST API测试工具(包括RESTler、MoRest、EvoMaster和ARAT-RL)进行了比较。我们的结果表明,微调使较小的模型在检测可操作的参数依赖规则和为REST API测试生成有效输入方面表现出超越许多较大模型的能力。我们还评估了从基本的Llama3-8B模型到微调版本的工具配置,并探索了多种量化技术,包括2位、4位和8位整数格式。我们的研究表明,在REST API测试中,小型语言模型可以表现得与大型语言模型一样好甚至更好,平衡了有效性和效率。此外,即使在那些工具使用RESTGPT增强的规格时,LlamaRestTest在代码覆盖率和内部服务器错误识别方面也比最先进的REST API测试工具表现更出色。
论文及项目相关链接
PDF To be published in the ACM International Conference on the Foundations of Software Engineering (FSE 2025)
摘要
现代Web服务依赖REST API,通常通过OpenAPI规范进行文档化。许多黑盒测试工具基于OpenAPI规范生成测试。尽管大型语言模型(LLM)在测试生成方面展现出潜力,但它们在REST API测试中的应用仍然主要未被探索。本文提出LlamaRestTest,一种采用定制LLM(通过微调并使用挖掘的REST API示例值和参数间依赖关系数据集对Llama3-8B模型进行量化处理)来生成真实测试输入并揭示参数间依赖关系的方法。通过对包括Spotify等12个真实服务进行的评估,对比了RESTGPT驱动的规格增强工具及其他先进的REST API测试工具(如RESTler、MoRest、EvoMaster和ARAT-RL)。结果表明,微调使小型模型在检测可操作的参数依赖规则以及为REST API测试生成有效输入方面表现出超越大型模型的能力。本研究还对从基础Llama3-8B模型到微调版本的不同工具配置进行了评估,并探索了多种量化技术。结果显示,在REST API测试中,小型语言模型可在有效性与效率之间达到或超越大型语言模型的性能。此外,LlamaRestTest在代码覆盖率及内部服务器错误识别方面,即使使用RESTGPT增强规格的工具,也优于现有先进的REST API测试工具。
关键见解
- LlamaRestTest是首个利用大型语言模型(LLM)进行REST API测试的方法。
- 通过微调与量化处理Llama3-8B模型,LlamaRestTest能生成真实的测试输入。
- 相比其他工具,LlamaRestTest更擅长检测参数间的依赖关系。
- 小型语言模型(经微调与量化处理)在REST API测试方面的表现可与大型语言模型相当或更优。
- LlamaRestTest的代码覆盖率高,能识别更多内部服务器错误。
- RESTGPT在某些情况下能提高测试规格的质量,但与LlamaRestTest相比仍有所不足。
点此查看论文截图


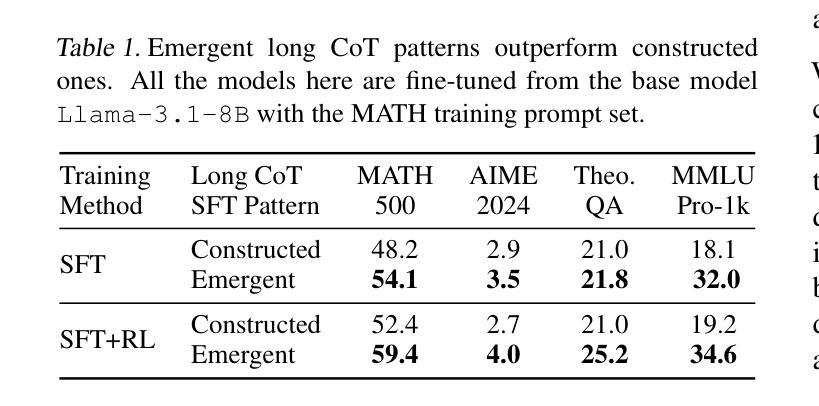
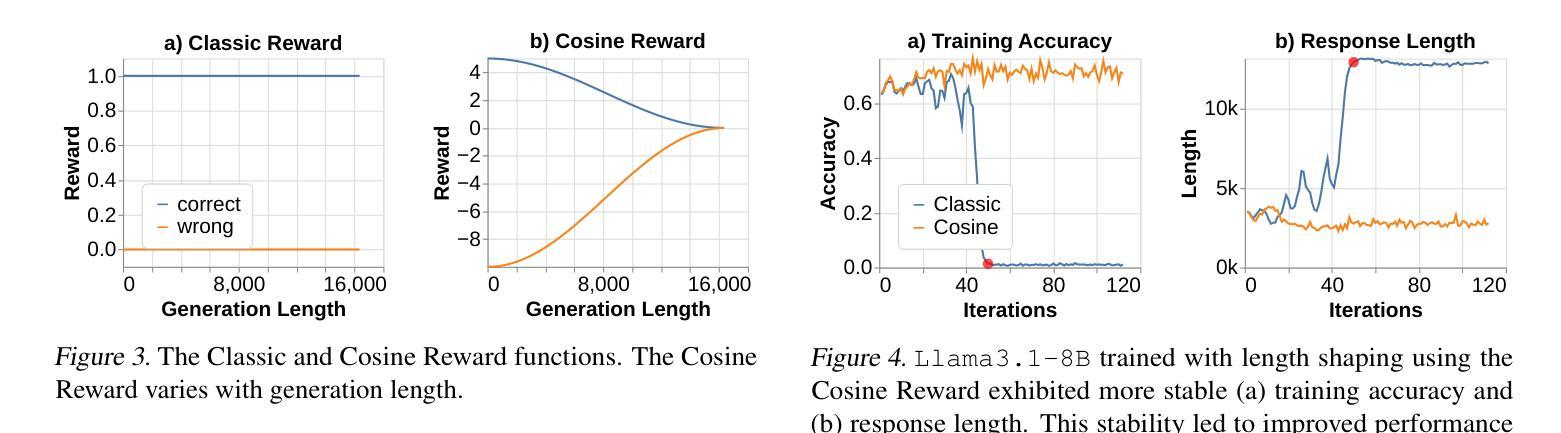
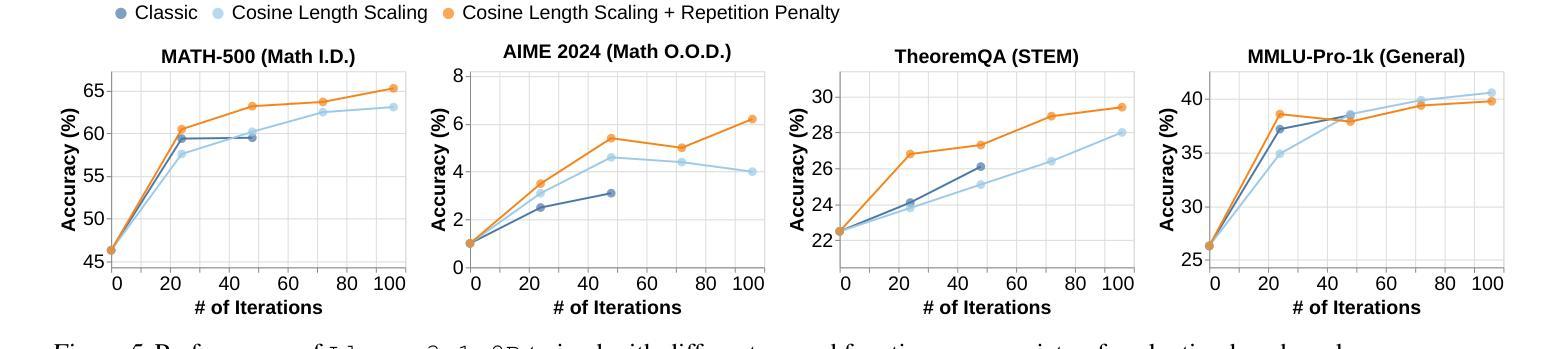
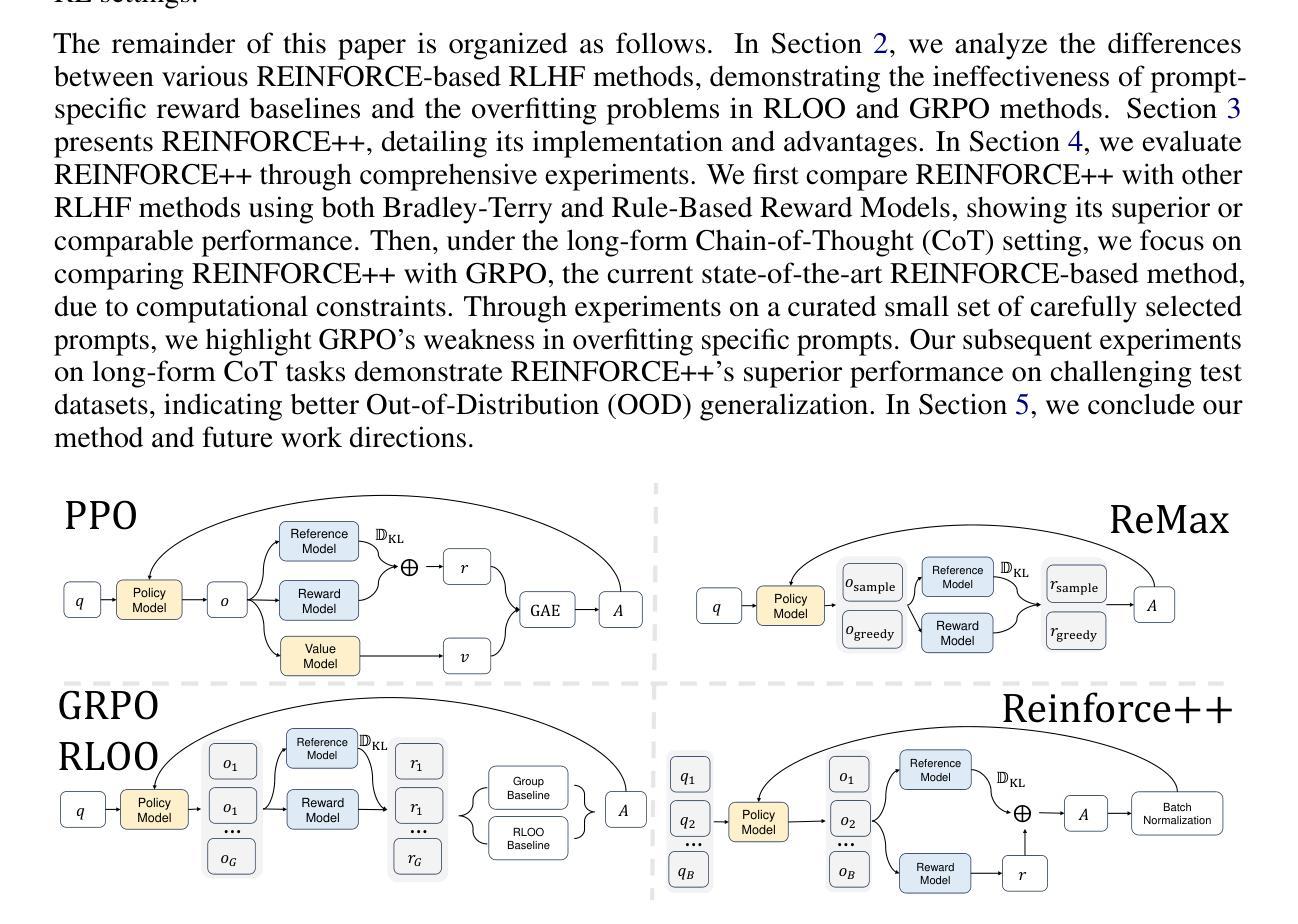
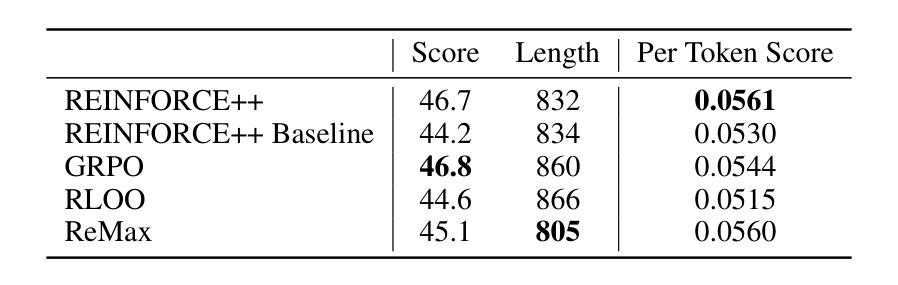
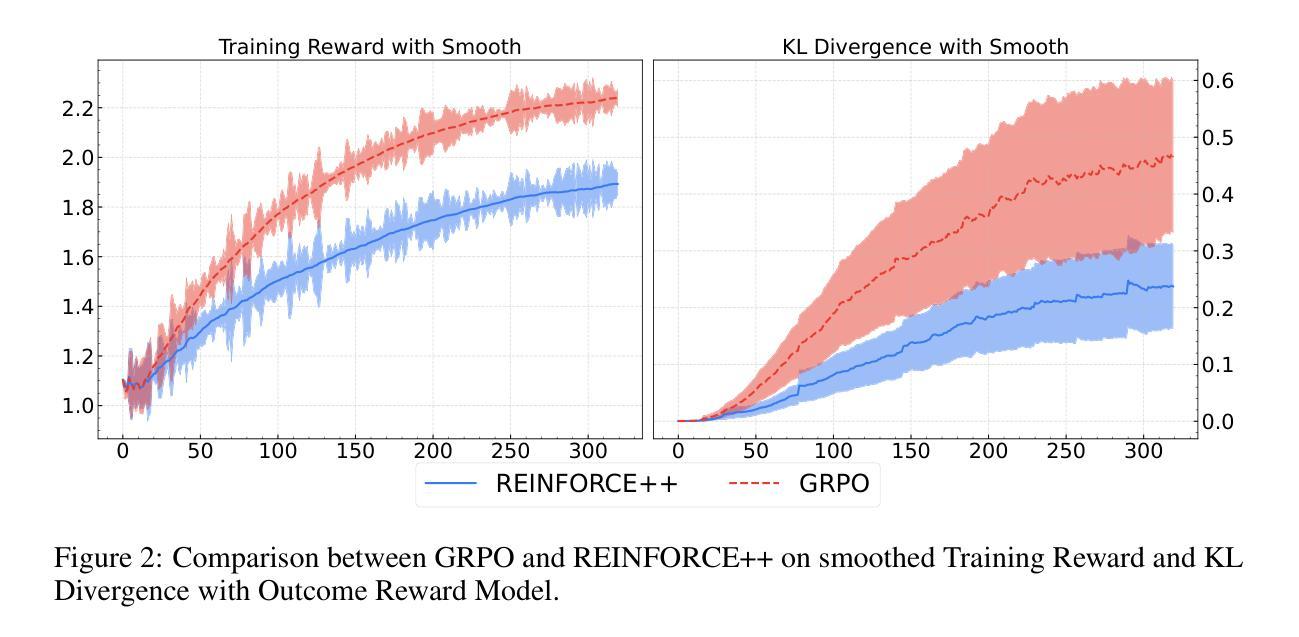
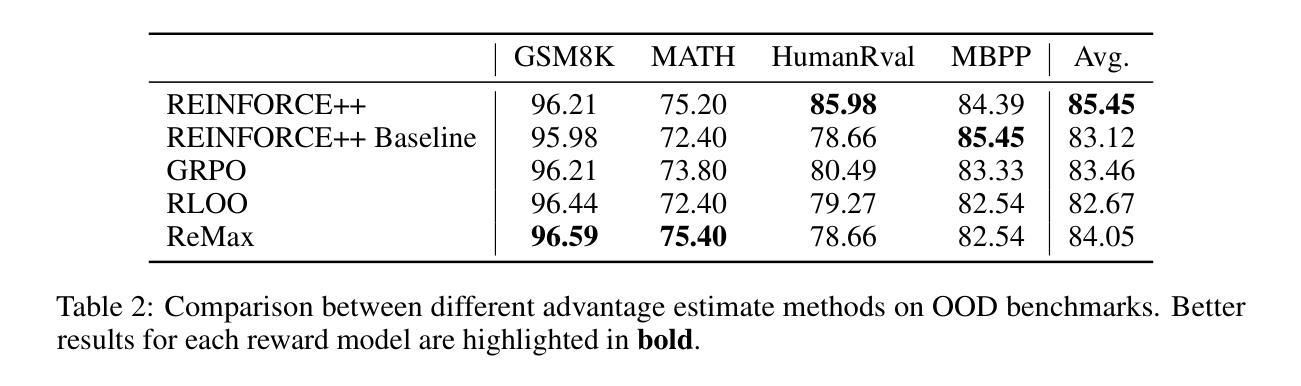
REINFORCE++: An Efficient RLHF Algorithm with Robustness to Both Prompt and Reward Models
Authors:Jian Hu, Jason Klein Liu, Shen Wei
Reinforcement Learning from Human Feedback (RLHF) plays a crucial role in aligning large language models (LLMs) with human values and preferences. While state-of-the-art applications like ChatGPT/GPT-4 commonly employ Proximal Policy Optimization (PPO), the inclusion of a critic network introduces significant computational overhead. REINFORCE-based methods, such as REINFORCE Leave One-Out (RLOO), ReMax, and Group Relative Policy Optimization (GRPO), address this limitation by eliminating the critic network. However, these approaches face challenges in accurate advantage estimation. Specifically, they estimate advantages independently for responses to each prompt, which can lead to overfitting on simpler prompts and vulnerability to reward hacking. To address these challenges, we introduce REINFORCE++, a novel approach that removes the critic model while using the normalized reward of a batch as the baseline. Our empirical evaluation demonstrates that REINFORCE++ exhibits robust performance across various reward models without requiring prompt set truncation. Furthermore, it achieves superior generalization in both RLHF and long chain-of-thought (CoT) settings compared to existing REINFORCE-based methods. The implementation is available at https://github.com/OpenRLHF/OpenRLHF.
强化学习从人类反馈(RLHF)在将大型语言模型(LLM)与人类价值观和偏好对齐方面发挥着至关重要的作用。虽然最先进的应用如ChatGPT/GPT-4通常采用近端策略优化(PPO),但加入评论家网络会引入大量的计算开销。基于REINFORCE的方法,如REINFORCE Leave One-Out(RLOO)、ReMax和集团相对策略优化(GRPO),通过消除评论家网络来解决这一限制。然而,这些方法在准确估算优势方面面临挑战。具体来说,它们独立地为每个提示的回应估计优势,这可能导致在简单提示上过拟合,并容易受到奖励黑客攻击。为了解决这些挑战,我们引入了REINFORCE++,这是一种新型方法,它移除了评论家模型,同时使用一批的标准化奖励作为基线。我们的经验评估表明,REINFORCE++在各种奖励模型中具有稳健的性能表现,无需截断提示集。此外,与现有的基于REINFORCE的方法相比,它在RLHF和长链思维(CoT)设置中实现了更好的泛化能力。实现方法详见https://github.com/OpenRLHF/OpenRLHF。
Translation
论文及项目相关链接
PDF this is a tech report
Summary
强化学习从人类反馈(RLHF)在将大型语言模型(LLM)与人类价值观和偏好对齐方面发挥着关键作用。最新的应用如ChatGPT/GPT-4常采用近端策略优化(PPO),但加入评论家网络带来了显著的计算开销。REINFORCE系列方法如REINFORCE Leave One-Out (RLOO)、ReMax和Group Relative Policy Optimization (GRPO)通过消除评论家网络解决了这一问题,但在准确的优势估计方面面临挑战。我们提出了REINFORCE++这一新方法,它不使用评论家模型,而是使用批次的标准化奖励作为基线。实证评估显示,REINFORCE++在不同奖励模型下表现稳健,无需截断提示集,并且在RLHF和长链思维(CoT)设置中相较于现有的REINFORCE系列方法表现更优越。其实现代码已在OpenRLHF/OpenRLHF公开。
Key Takeaways
- 强化学习从人类反馈(RLHF)在大型语言模型(LLM)与人类价值观和偏好对齐中起关键作用。
- 现有方法如PPO虽然有效,但存在计算开销大的问题。
- REINFORCE系列方法通过消除评论家网络解决了计算开销问题,但在优势估计方面存在挑战。
- REINFORCE++提出了新方法,不使用评论家模型,而是采用批次的标准化奖励作为基线。
- REINFORCE++在不同奖励模型下表现稳健,无需截断提示集。
- REINFORCE++在RLHF和长链思维(CoT)设置中的表现优于现有REINFORCE系列方法。
点此查看论文截图


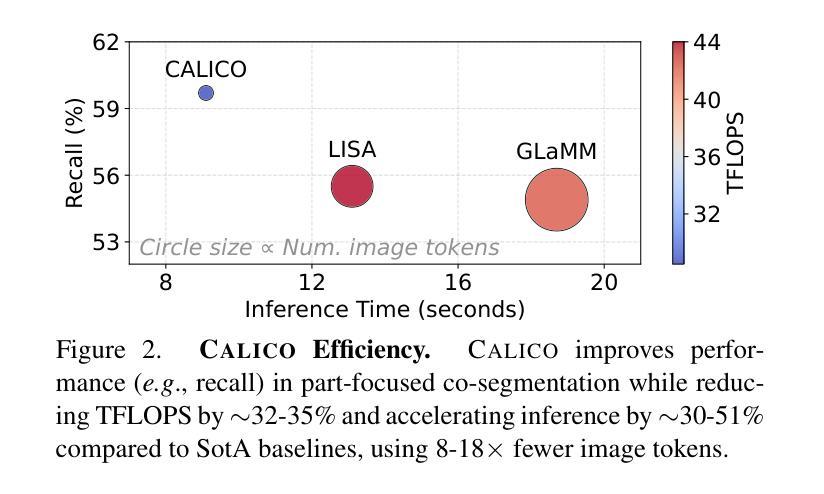
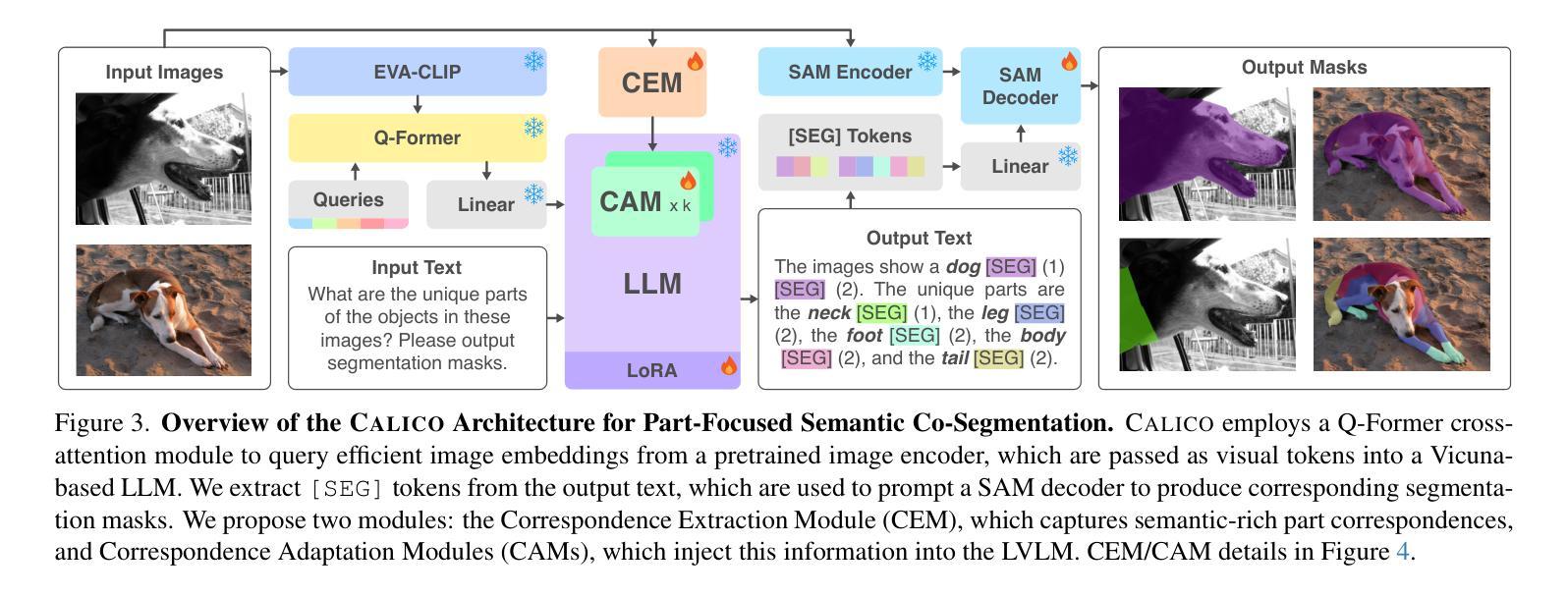
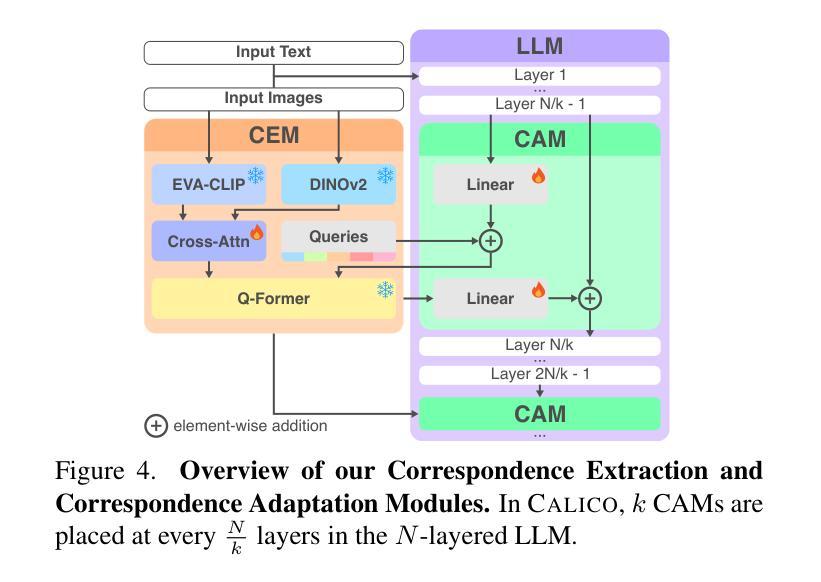
CALICO: Part-Focused Semantic Co-Segmentation with Large Vision-Language Models
Authors:Kiet A. Nguyen, Adheesh Juvekar, Tianjiao Yu, Muntasir Wahed, Ismini Lourentzou
Recent advances in Large Vision-Language Models (LVLMs) have enabled general-purpose vision tasks through visual instruction tuning. While existing LVLMs can generate segmentation masks from text prompts for single images, they struggle with segmentation-grounded reasoning across images, especially at finer granularities such as object parts. In this paper, we introduce the new task of part-focused semantic co-segmentation, which involves identifying and segmenting common objects, as well as common and unique object parts across images. To address this task, we present CALICO, the first LVLM designed for multi-image part-level reasoning segmentation. CALICO features two key components, a novel Correspondence Extraction Module that identifies semantic part-level correspondences, and Correspondence Adaptation Modules that embed this information into the LVLM to facilitate multi-image understanding in a parameter-efficient manner. To support training and evaluation, we curate MixedParts, a large-scale multi-image segmentation dataset containing $\sim$2.4M samples across $\sim$44K images spanning diverse object and part categories. Experimental results demonstrate that CALICO, with just 0.3% of its parameters finetuned, achieves strong performance on this challenging task.
近期大型视觉语言模型(LVLMs)的进步通过视觉指令调整实现了通用视觉任务。虽然现有的LVLMs可以通过文本提示对单图像生成分割掩膜,但它们在跨图像的分割推理方面遇到困难,尤其是在更精细的粒度(如物体部分)上。在本文中,我们引入了新的部分聚焦语义协同分割任务,该任务涉及识别和分割跨图像中的常见对象以及常见和独特的对象部分。为了解决此任务,我们提出了CALICO,这是专为多图像部分级推理分割设计的首个LVLM。CALICO具有两个关键组件:新型对应提取模块,用于识别语义部分级对应关系;以及对应适应模块,将此信息嵌入LVLM中,以高效参数的方式促进多图像理解。为了支持和评估训练,我们整理了MixedParts,这是一个大规模的多图像分割数据集,包含约4.4万张图像中的约240万样本样本,涵盖多样化的对象和类别部分。实验结果表明,CALICO仅微调其参数的0.3%,就能在此具有挑战性的任务上实现出色的性能。
论文及项目相关链接
PDF Accepted to CVPR 2025. Project page: https://plan-lab.github.io/calico/
Summary
本文介绍了大型视觉语言模型(LVLMs)的最新进展如何通过视觉指令微调实现通用视觉任务。针对现有LVLMs在跨图像分割推理,特别是在更精细的粒度如物体部分上的困难,本文引入了部分聚焦语义协同分割的新任务。为应对此任务,提出了CALICO,首款设计用于多图像部分级别推理分割的LVLM。CALICO包含两个关键组件:对应提取模块,用于识别语义部分级别的对应关系;对应适应模块,将此信息嵌入LVLM中以以参数效率高的方式促进多图像理解。为支持训练和评估,本文整理了MixedParts,一个大规模多图像分割数据集,包含约240万样本,跨越约4万张图像,涵盖多样化的对象和零件类别。实验结果表明,CALICO仅需微调其参数的0.3%,即可在此具有挑战性的任务上实现强劲表现。
Key Takeaways
- LVLMs能够通过视觉指令微调完成通用视觉任务。
- 现有LVLMs在跨图像分割推理上表现不足,尤其在物体部分的精细粒度上。
- 引入了部分聚焦语义协同分割的新任务,旨在解决跨图像的物体和部分级别的分割问题。
- 提出了CALICO模型,包含对应提取模块和对应适应模块,用于处理多图像部分级别的推理分割。
- CALICO设计用于处理大规模多图像分割数据集MixedParts。
- MixedParts数据集包含大量样本和多样化的对象和零件类别。
点此查看论文截图


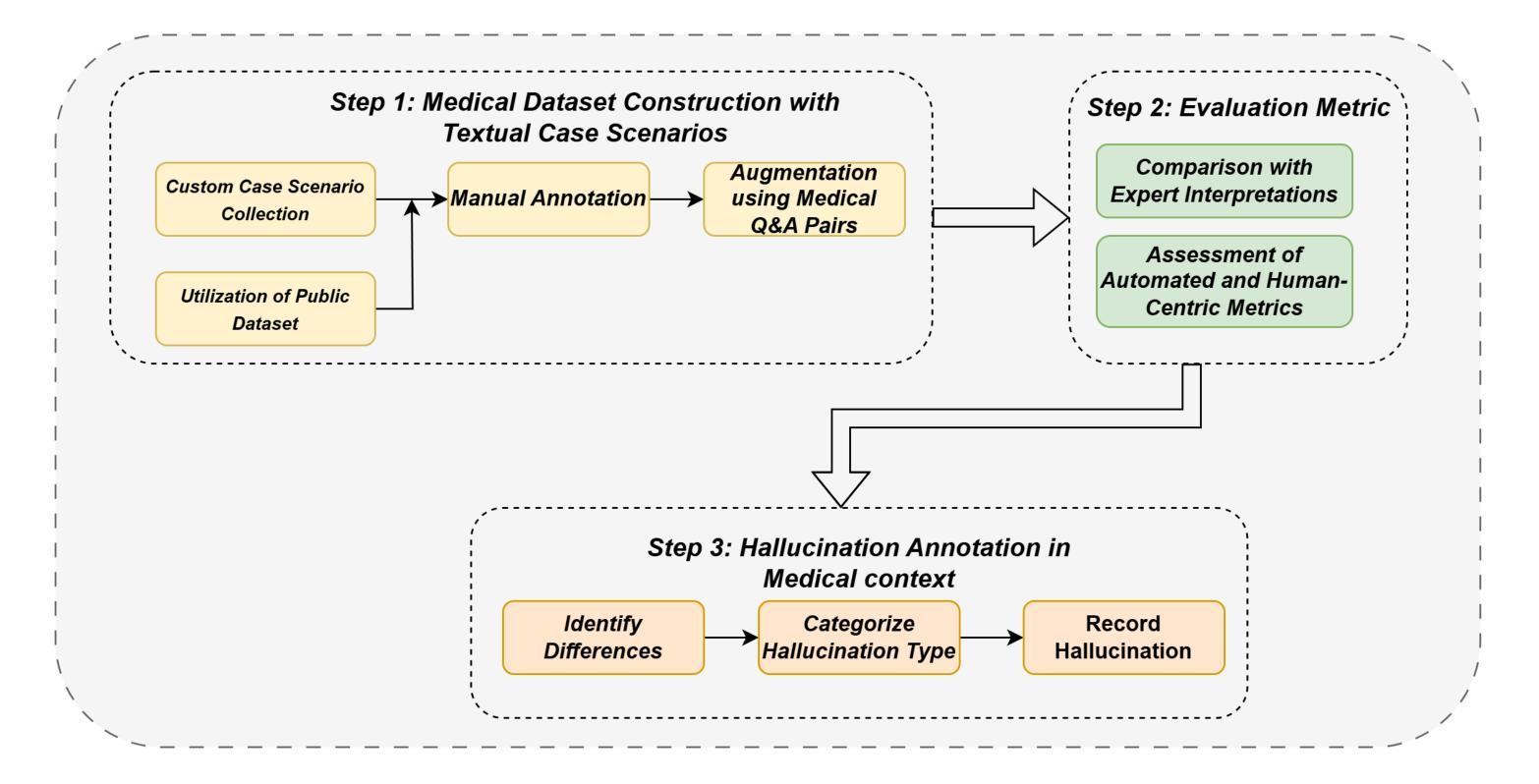
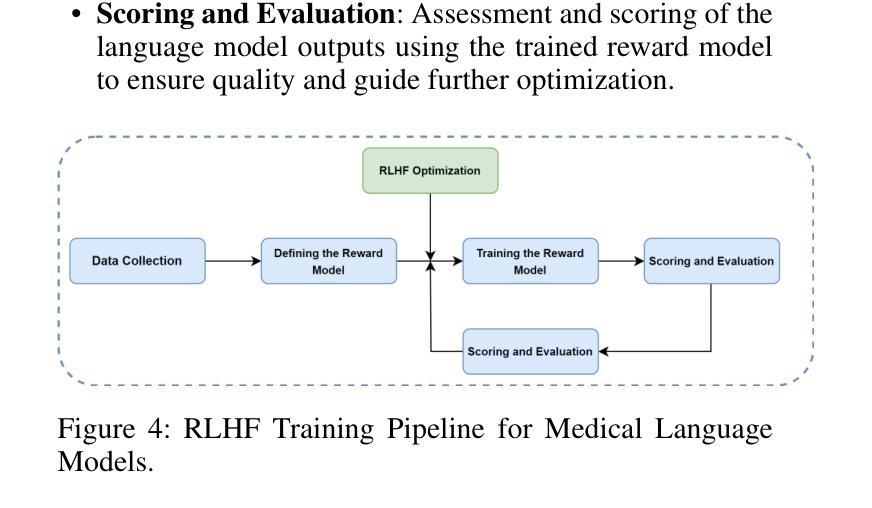
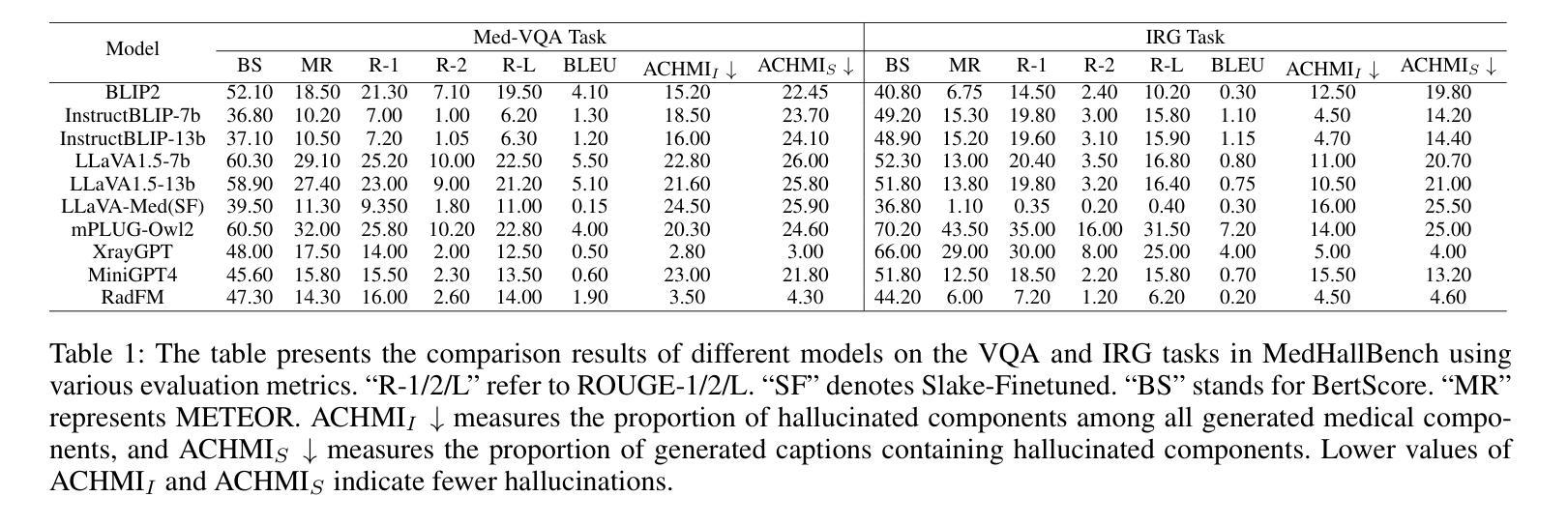
MedHallBench: A New Benchmark for Assessing Hallucination in Medical Large Language Models
Authors:Kaiwen Zuo, Yirui Jiang
Medical Large Language Models (MLLMs) have demonstrated potential in healthcare applications, yet their propensity for hallucinations – generating medically implausible or inaccurate information – presents substantial risks to patient care. This paper introduces MedHallBench, a comprehensive benchmark framework for evaluating and mitigating hallucinations in MLLMs. Our methodology integrates expert-validated medical case scenarios with established medical databases to create a robust evaluation dataset. The framework employs a sophisticated measurement system that combines automated ACHMI (Automatic Caption Hallucination Measurement in Medical Imaging) scoring with rigorous clinical expert evaluations and utilizes reinforcement learning methods to achieve automatic annotation. Through an optimized reinforcement learning from human feedback (RLHF) training pipeline specifically designed for medical applications, MedHallBench enables thorough evaluation of MLLMs across diverse clinical contexts while maintaining stringent accuracy standards. We conducted comparative experiments involving various models, utilizing the benchmark to establish a baseline for widely adopted large language models (LLMs). Our findings indicate that ACHMI provides a more nuanced understanding of the effects of hallucinations compared to traditional metrics, thereby highlighting its advantages in hallucination assessment. This research establishes a foundational framework for enhancing MLLMs’ reliability in healthcare settings and presents actionable strategies for addressing the critical challenge of AI hallucinations in medical applications.
医疗领域的大型语言模型(MLLMs)在医疗保健应用中显示出巨大潜力,但它们易于产生幻觉,即生成医学上不现实或不准确的信息,这对患者护理带来了实质性的风险。本文介绍了MedHallBench,这是一个评估和缓解MLLMs中幻觉的全面基准框架。我们的方法结合了专家验证的医疗案例场景和现有的医疗数据库,以创建稳健的评估数据集。该框架采用先进的测量系统,结合自动医学成像幻觉自动测量(ACHMI)评分与严格的临床专家评估,并利用强化学习方法实现自动注释。通过针对医疗应用而优化的、从人类反馈中强化学习(RLHF)的训练管道,MedHallBench能够在维持严格准确性标准的同时,在多种临床背景下对MLLMs进行全面评估。我们进行了涉及多种模型的对比实验,利用该基准为广泛采用的大型语言模型(LLMs)建立基线。我们的研究结果表明,与传统的度量指标相比,ACHMI提供了对幻觉影响的更细微理解,从而突出了其在幻觉评估中的优势。该研究为增强MLLMs在医疗环境中的可靠性奠定了基石,并提供了解决医疗应用中人工智能幻觉这一关键挑战的可行策略。
论文及项目相关链接
PDF Published to AAAI-25 Bridge Program
Summary
医疗大语言模型(MLLMs)在医疗保健应用中具有潜力,但其产生医学上不切实际或不准确信息的倾向对患者护理构成重大风险。本文介绍MedHallBench,一个全面评估和改进MLLMs中产生幻觉的框架。该框架通过结合专家验证的医学案例场景和建立的医学数据库,建立了一个稳健的评估数据集。通过结合自动化评分与临床专家评估的复杂测量系统,并利用强化学习方法实现自动标注,能够在多样化的临床环境中全面评估MLLMs并保持严格的标准。通过实验对比,我们发现ACHMI在评估幻觉方面相比传统指标具有更微妙的洞察力,凸显其在评估幻觉方面的优势。该研究为增强MLLMs在医疗保健环境中的可靠性提供了基础框架,并提出了解决医疗应用中AI幻觉这一关键挑战的行动策略。
Key Takeaways
- MLLMs在医疗保健应用中具有潜力,但存在产生医学上不切实际信息的风险。
- MedHallBench是一个评估和改进MLLMs中产生幻觉的框架。
- 该框架结合专家验证的医学案例和医学数据库建立稳健评估数据集。
- MedHallBench使用自动化评分与临床专家评估的复杂测量系统。
- 强化学习用于实现自动标注,提高评估效率。
- ACHMI指标相比传统评估方法更能微妙地理解幻觉的影响。
点此查看论文截图

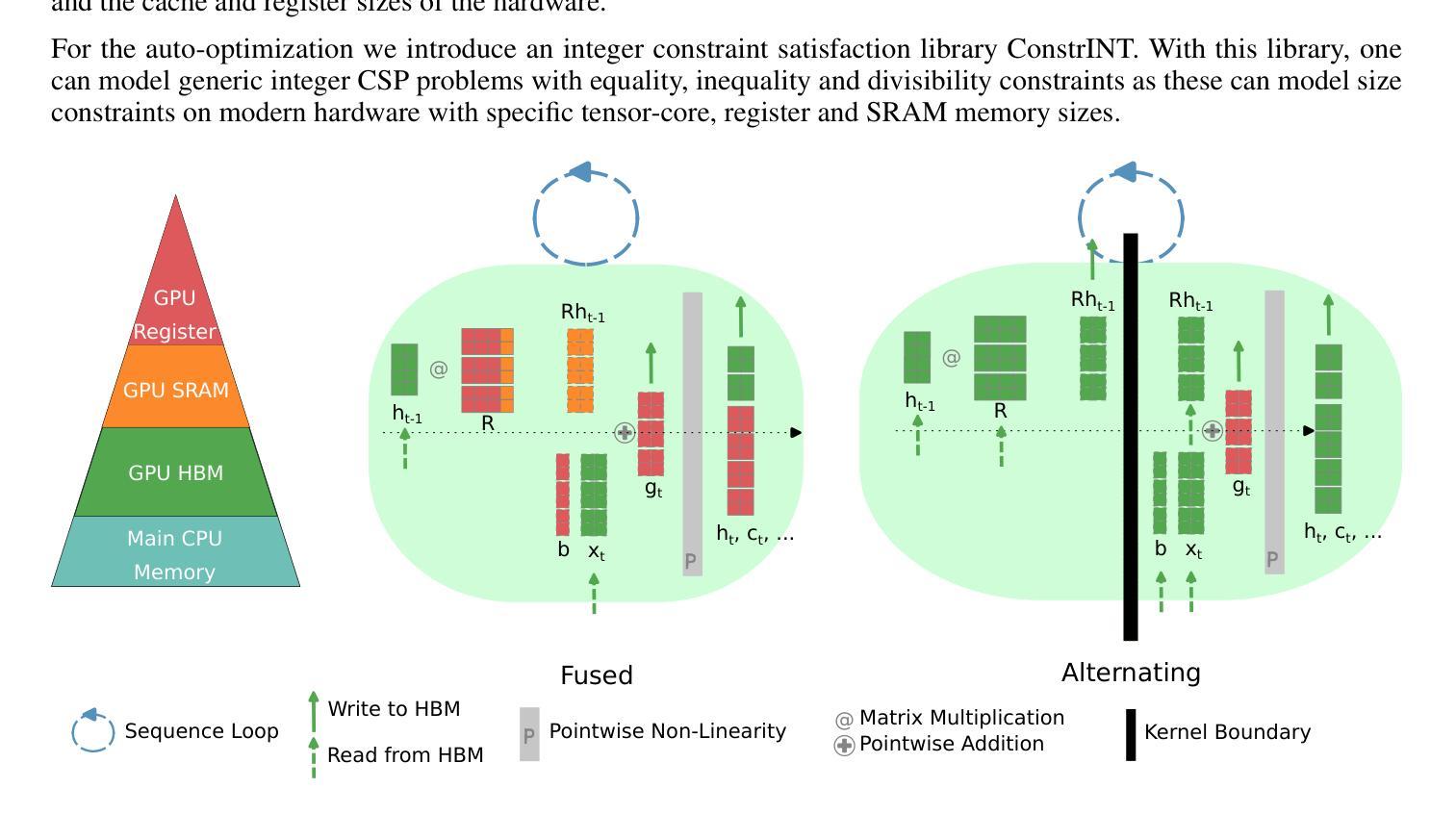
FlashRNN: I/O-Aware Optimization of Traditional RNNs on modern hardware
Authors:Korbinian Pöppel, Maximilian Beck, Sepp Hochreiter
While Transformers and other sequence-parallelizable neural network architectures seem like the current state of the art in sequence modeling, they specifically lack state-tracking capabilities. These are important for time-series tasks and logical reasoning. Traditional RNNs like LSTMs and GRUs, as well as modern variants like sLSTM do have these capabilities at the cost of strictly sequential processing. While this is often seen as a strong limitation, we show how fast these networks can get with our hardware-optimization FlashRNN in Triton and CUDA, optimizing kernels to the register level on modern GPUs. We extend traditional RNNs with a parallelization variant that processes multiple RNNs of smaller hidden state in parallel, similar to the head-wise processing in Transformers. To enable flexibility on different GPU variants, we introduce a new optimization framework for hardware-internal cache sizes, memory and compute handling. It models the hardware in a setting using polyhedral-like constraints, including the notion of divisibility. This speeds up the solution process in our ConstrINT library for general integer constraint satisfaction problems (integer CSPs). We show that our kernels can achieve 50x speed-ups over a vanilla PyTorch implementation and allow 40x larger hidden sizes compared to our Triton implementation. Our open-source kernels and the optimization library are released here to boost research in the direction of state-tracking enabled RNNs and sequence modeling: https://github.com/NX-AI/flashrnn
虽然Transformer和其他可序列并行化的神经网络架构看起来是当前的序列建模技术的前沿,但它们特别缺乏状态跟踪能力。这对于时间序列任务和逻辑推理很重要。传统的RNN,如LSTM和GRU,以及现代变体,如sLSTM,虽然具有这种能力,但需要严格序列处理。虽然这通常被视为一个强大限制,但我们通过硬件优化的FlashRNN在Triton和CUDA中展示了这些网络可以多么快速。我们对传统RNN进行了并行化改进,可以同时处理多个具有较小隐藏状态的小型RNN,类似于Transformer中的多头处理。为了在不同GPU变体上实现灵活性,我们为硬件内部缓存大小、内存和计算处理引入了一个新的优化框架。它使用多面体类似的约束在一种环境中建模硬件,包括可除性的概念。这加速了我们用于一般整数约束满足问题(整数CSP)的ConstrINT库中的解决方案过程。我们显示,我们的内核可以实现比PyTorch原生实现快50倍的速度提升,并且与我们Triton实现相比允许更大的隐藏尺寸高达40倍。我们的开源内核和优化库已在此发布,以促进状态跟踪启用RNN和序列建模方向的研究:https://github.com/NX-AI/flashrnn。
论文及项目相关链接
Summary
变换器和其他可并行化神经网络架构虽然看似是当前序列建模的尖端技术,但它们缺乏状态跟踪能力,这对于时间序列任务和逻辑推理很重要。传统RNNs(如LSTM和GRU)以及现代变体(如sLSTM)确实具有这种能力,但代价是严格序列处理。我们通过硬件优化的FlashRNN在Triton和CUDA中展示了这些网络可以多么快速,优化内核达到现代GPU的寄存器级别。我们为传统RNNs引入了一种并行化变体,并行处理多个具有较小隐藏状态RNN,类似于Transformer中的头处理。我们还为不同的GPU变体引入了新的优化框架,对硬件内部缓存大小、内存和计算处理进行建模,使用多面体约束等概念,包括可除性。这加快了我们用于一般整数约束满足问题(integer CSPs)的ConstrINT库的解决方案过程。我们展示我们的内核可以实现比PyTorch原生实现快50倍的速度,并且与我们的Triton实现相比,允许隐藏层大小扩大40倍。我们的开源内核和优化库旨在推动状态跟踪使能的RNN和序列建模的研究方向:https://github.com/NX-AI/flashrnn
Key Takeaways
- 变换器和其他神经网络架构虽然先进,但在状态跟踪方面存在局限,这对于时间序列任务和逻辑推理很重要。
- 传统RNNs(如LSTM和GRU)具有状态跟踪能力,但处理速度受限制。
- FlashRNN通过硬件优化提升了RNN的处理速度。
- 引入了一种并行化变体,能并行处理多个具有较小隐藏状态的RNN。
- 针对不同GPU变体,提出了新的优化框架,考虑了硬件内部缓存、内存和计算处理。
- 通过使用多面体约束等概念,包括可除性,加快了整数约束满足问题的解决方案过程。
点此查看论文截图

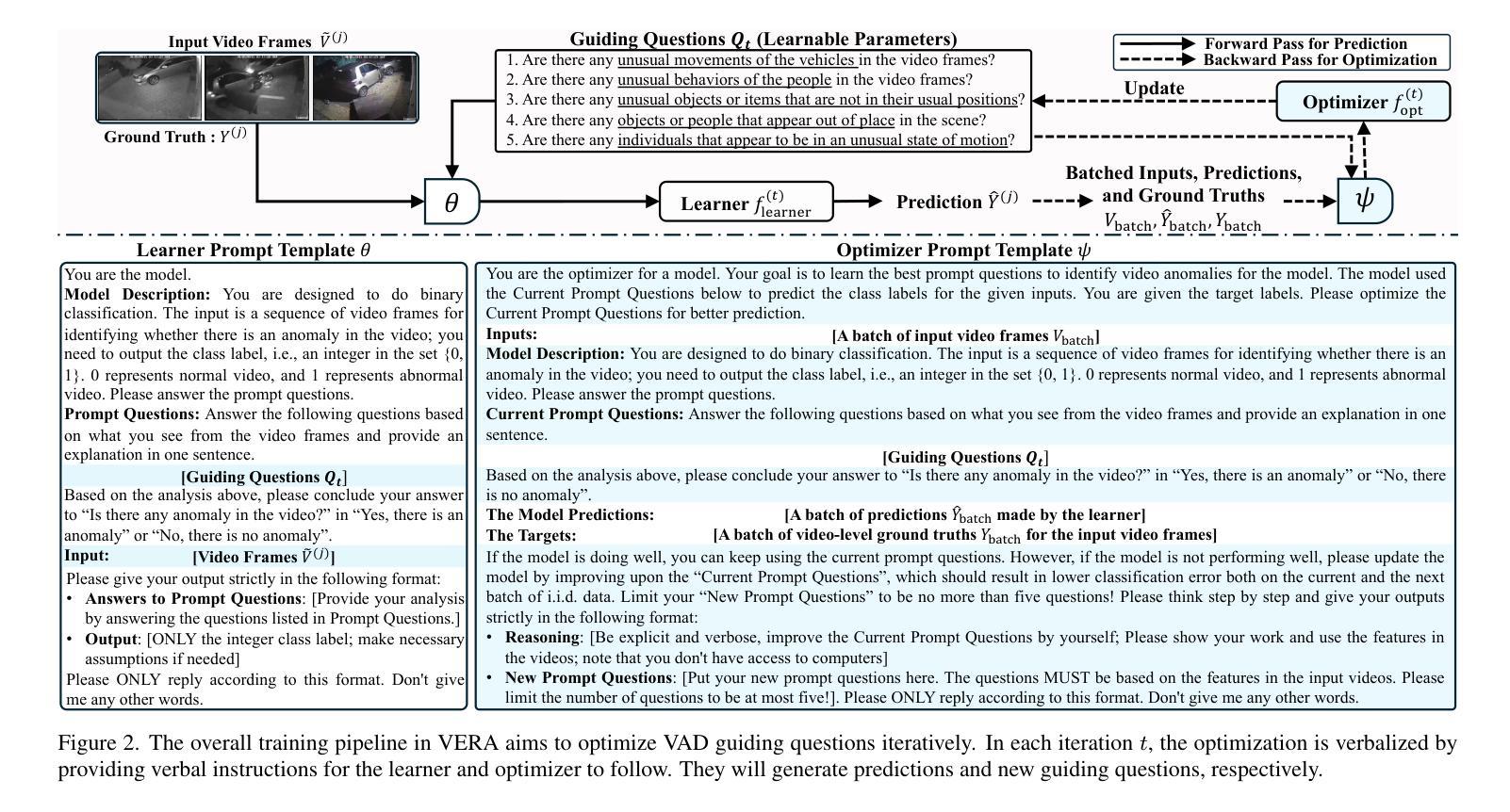
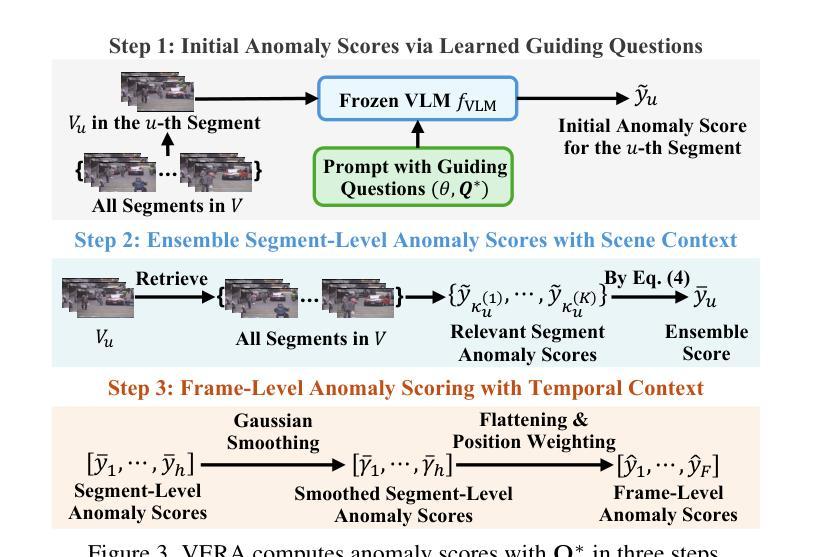
VERA: Explainable Video Anomaly Detection via Verbalized Learning of Vision-Language Models
Authors:Muchao Ye, Weiyang Liu, Pan He
The rapid advancement of vision-language models (VLMs) has established a new paradigm in video anomaly detection (VAD): leveraging VLMs to simultaneously detect anomalies and provide comprehendible explanations for the decisions. Existing work in this direction often assumes the complex reasoning required for VAD exceeds the capabilities of pretrained VLMs. Consequently, these approaches either incorporate specialized reasoning modules during inference or rely on instruction tuning datasets through additional training to adapt VLMs for VAD. However, such strategies often incur substantial computational costs or data annotation overhead. To address these challenges in explainable VAD, we introduce a verbalized learning framework named VERA that enables VLMs to perform VAD without model parameter modifications. Specifically, VERA automatically decomposes the complex reasoning required for VAD into reflections on simpler, more focused guiding questions capturing distinct abnormal patterns. It treats these reflective questions as learnable parameters and optimizes them through data-driven verbal interactions between learner and optimizer VLMs, using coarsely labeled training data. During inference, VERA embeds the learned questions into model prompts to guide VLMs in generating segment-level anomaly scores, which are then refined into frame-level scores via the fusion of scene and temporal contexts. Experimental results on challenging benchmarks demonstrate that the learned questions of VERA are highly adaptable, significantly improving both detection performance and explainability of VLMs for VAD.
视觉语言模型(VLMs)的快速发展为视频异常检测(VAD)建立了一种新的范式:利用VLMs同时检测异常并为决策提供可理解的解释。现有工作通常认为VAD所需的复杂推理超出了预训练VLMs的能力范围。因此,这些策略要么在推理过程中融入专门的推理模块,要么通过额外的训练依赖指令调整数据集来适应VAD的VLMs。然而,这样的策略往往带来较大的计算成本或数据标注开销。为了解决可解释VAD中的这些挑战,我们引入了一种名为VERA的言语化学习框架,该框架能使VLMs执行VAD而无需修改模型参数。具体来说,VERA会自动将VAD所需的复杂推理分解成对捕捉各种异常模式的更简单、更专注的引导问题的反思。它将这些反思问题视为可学习的参数,并通过学习者与优化器VLMs之间的数据驱动言语交互来优化这些参数,使用粗略标记的训练数据。在推理过程中,VERA将学习到的问题嵌入到模型提示中,引导VLMs生成分段级别的异常分数,然后通过场景和时间上下文的融合来完善帧级别的分数。在具有挑战性的基准测试上的实验结果表明,VERA学习的问题具有高度适应性,显著提高了VLMs对VAD的检测性能和解释性。
论文及项目相关链接
PDF Accepted in CVPR 2025
Summary
本文介绍了快速推进的视觉语言模型(VLMs)为视频异常检测(VAD)提供了新的模式。借助VLMs,该模式可以检测异常同时为决策提供可理解的解释。针对现有工作中对预训练VLMs能力的假设,我们引入了名为VERA的言语化学习框架,使VLMs能够在无需修改模型参数的情况下进行VAD。VERA通过数据驱动的言语交互优化指导问题,从而分解VAD所需的复杂推理。在推理过程中,VERA将问题嵌入模型提示中,指导VLMs生成分段级别的异常分数,再通过场景和临时上下文的融合,形成帧级别的分数。实验结果证明,VERA的问题学习具有高度适应性,显著提高了VLMs在VAD中的检测性能和解释性。
Key Takeaways
- 视觉语言模型(VLMs)在视频异常检测(VAD)中展现出新的应用模式。
- VLMs能够同时检测异常并提供解释,推动了VAD的发展。
- 现有方法常需专业化的推理模块或额外的训练数据来适应VLMs进行VAD,但会带来计算成本或数据标注负担。
- VERA框架解决了这些问题,使VLMs能在无需修改参数的情况下进行VAD。
- VERA通过分解复杂推理为更简单的问题来指导VAD,这些问题作为可学习的参数进行优化。
- VERA利用粗标签的训练数据,通过数据驱动的言语交互优化问题学习。
点此查看论文截图

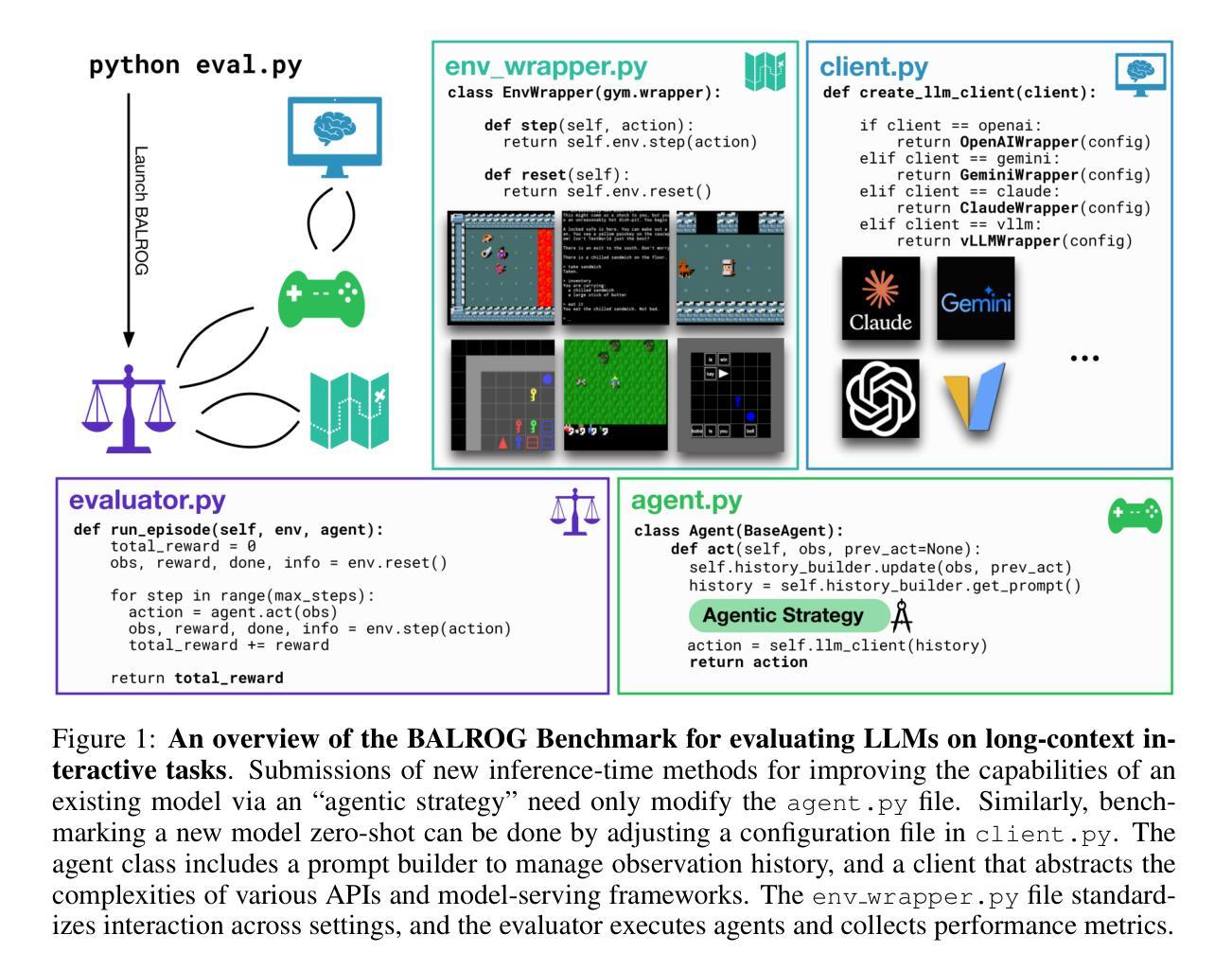
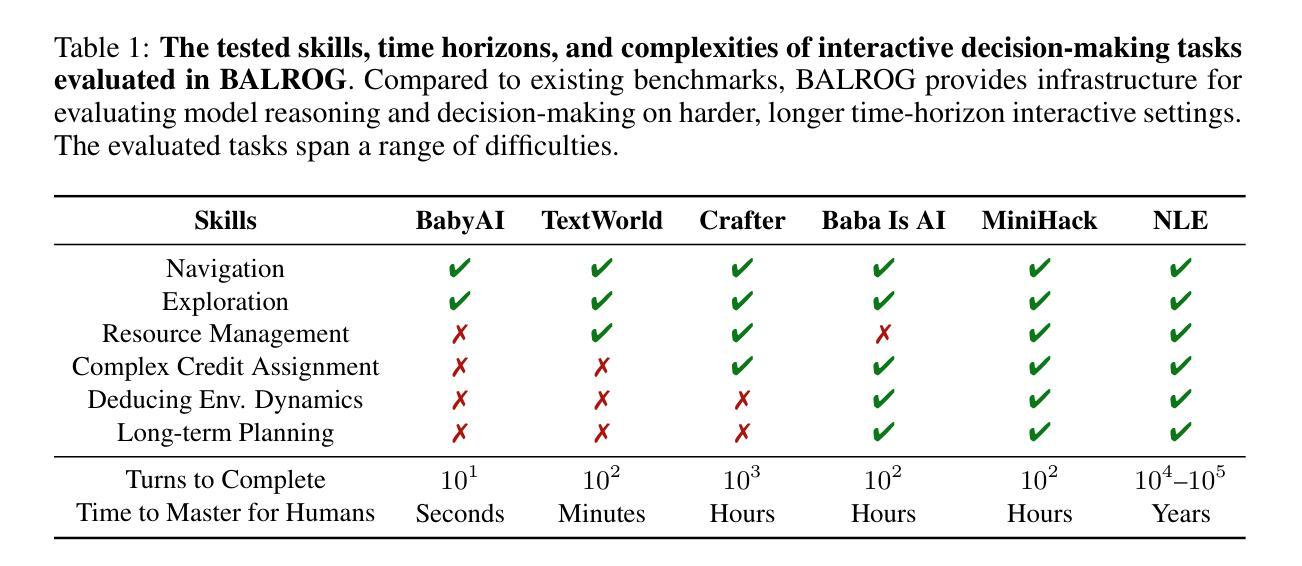
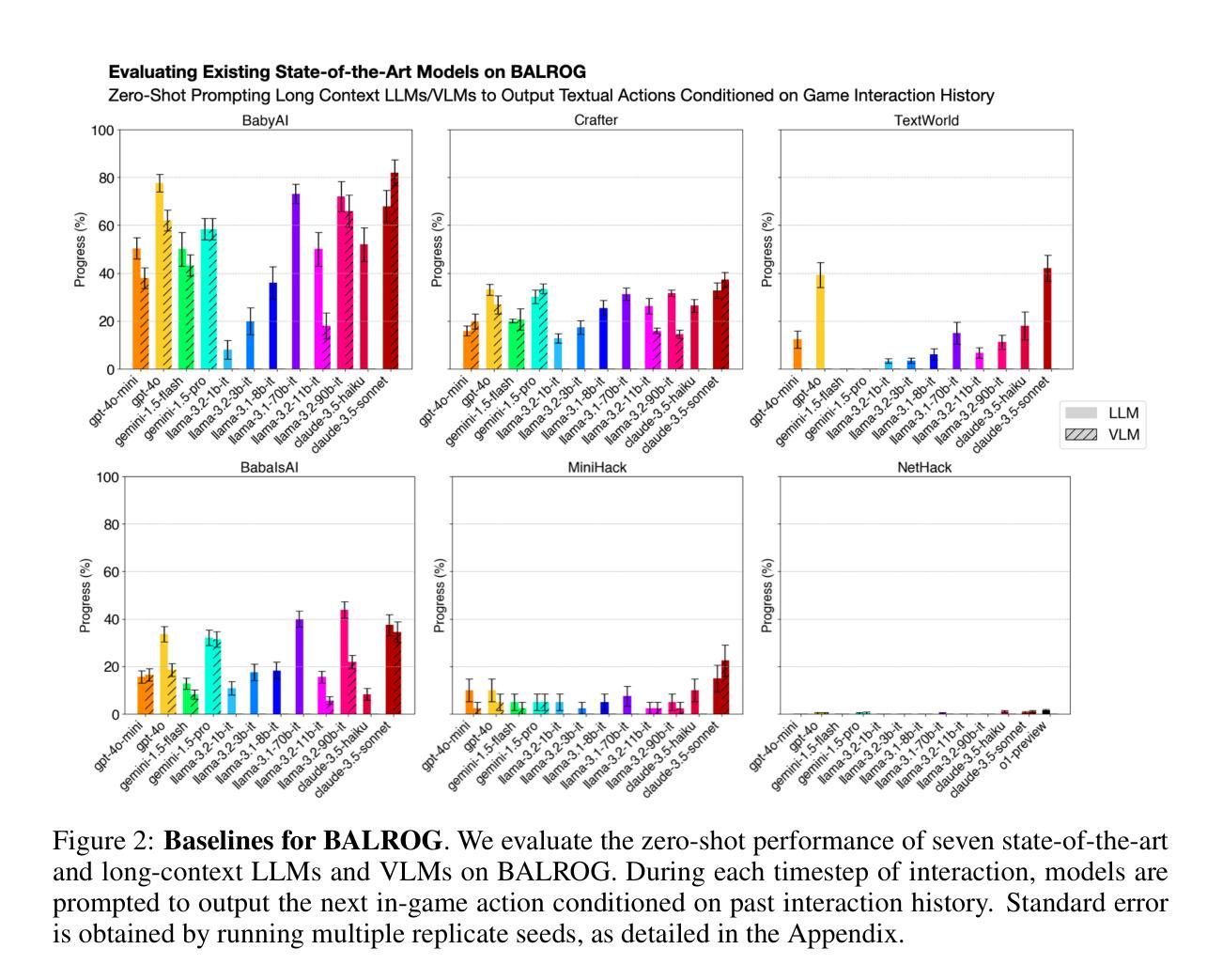
BALROG: Benchmarking Agentic LLM and VLM Reasoning On Games
Authors:Davide Paglieri, Bartłomiej Cupiał, Samuel Coward, Ulyana Piterbarg, Maciej Wolczyk, Akbir Khan, Eduardo Pignatelli, Łukasz Kuciński, Lerrel Pinto, Rob Fergus, Jakob Nicolaus Foerster, Jack Parker-Holder, Tim Rocktäschel
Large Language Models (LLMs) and Vision Language Models (VLMs) possess extensive knowledge and exhibit promising reasoning abilities, however, they still struggle to perform well in complex, dynamic environments. Real-world tasks require handling intricate interactions, advanced spatial reasoning, long-term planning, and continuous exploration of new strategies-areas in which we lack effective methodologies for comprehensively evaluating these capabilities. To address this gap, we introduce BALROG, a novel benchmark designed to assess the agentic capabilities of LLMs and VLMs through a diverse set of challenging games. Our benchmark incorporates a range of existing reinforcement learning environments with varying levels of difficulty, including tasks that are solvable by non-expert humans in seconds to extremely challenging ones that may take years to master (e.g., the NetHack Learning Environment). We devise fine-grained metrics to measure performance and conduct an extensive evaluation of several popular open-source and closed-source LLMs and VLMs. Our findings indicate that while current models achieve partial success in the easier games, they struggle significantly with more challenging tasks. Notably, we observe severe deficiencies in vision-based decision-making, as several models perform worse when visual representations of the environments are provided. We release BALROG as an open and user-friendly benchmark to facilitate future research and development in the agentic community. Code and Leaderboard at balrogai.com.
大型语言模型(LLM)和视觉语言模型(VLM)拥有广泛的知识并展现出有前景的推理能力,然而,它们在复杂、动态的环境中仍然难以表现出良好的性能。现实世界任务需要处理复杂的交互、先进的空间推理、长期规划和持续探索新策略——我们在这些方面缺乏全面评估这些能力的有效方法论。为了解决这一差距,我们引入了BALROG,这是一个新颖的基准测试,旨在通过一系列具有挑战性的游戏来评估LLM和VLM的自主能力。我们的基准测试结合了不同难度的现有强化学习环境,包括非专家人类可以在几秒钟内解决的任务到可能需要多年才能掌握的超难任务(例如NetHack学习环境)。我们制定了精细的指标来衡量性能,并对多个流行的开源和闭源LLM和VLM进行了广泛评估。我们的研究结果表明,虽然当前模型在较简单的游戏中取得了部分成功,但在更具挑战性的任务中却遇到了很大的困难。值得注意的是,我们观察到在基于视觉的决策制定方面存在严重缺陷,因为当提供环境的视觉表示时,几个模型的表现更差。我们发布BALROG作为一个开放和用户友好的基准测试,以促进未来在自主社区中的研究和开发。代码和排行榜可在balrogai.com查看。
论文及项目相关链接
PDF Published as a conference paper at ICLR 2025
Summary
大型语言模型(LLMs)和视觉语言模型(VLMs)具备广泛的知识和出色的推理能力,但在复杂、动态的环境中表现欠佳。为解决现有评估方法无法全面评估这些模型在现实世界任务中的代理能力的问题,提出了BALROG这一新基准测试,通过一系列具有挑战性的游戏来评估LLMs和VLMs的代理能力。BALROG结合了不同难度的现有强化学习环境,包括非专家人类可在几秒钟内解决的任务到可能需要数年才能掌握的任务。评估发现,当前模型在较简单的游戏中取得了一定的成功,但在更具挑战性的任务中却遇到了困难。特别是当提供环境的视觉表示时,许多模型的视觉决策能力存在严重缺陷。BALROG作为一个开放和用户友好的基准测试发布,以促进未来在代理领域的研发。
Key Takeaways
- LLMs和VLMs在复杂、动态的环境中表现不足。
- BALROG是一个新的基准测试,旨在评估LLMs和VLMs在现实世界任务中的代理能力。
- BALROG结合了不同难度的强化学习环境,包括从简单到极难的任务。
- 当前模型在简单游戏中部分成功,但在更具挑战性的任务中遇到困难。
- 模型的视觉决策能力存在严重缺陷。
- BALROG作为开放和用户友好的基准测试发布,方便未来研究和发展。
点此查看论文截图