⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-08 更新
Audio-visual Controlled Video Diffusion with Masked Selective State Spaces Modeling for Natural Talking Head Generation
Authors:Fa-Ting Hong, Zunnan Xu, Zixiang Zhou, Jun Zhou, Xiu Li, Qin Lin, Qinglin Lu, Dan Xu
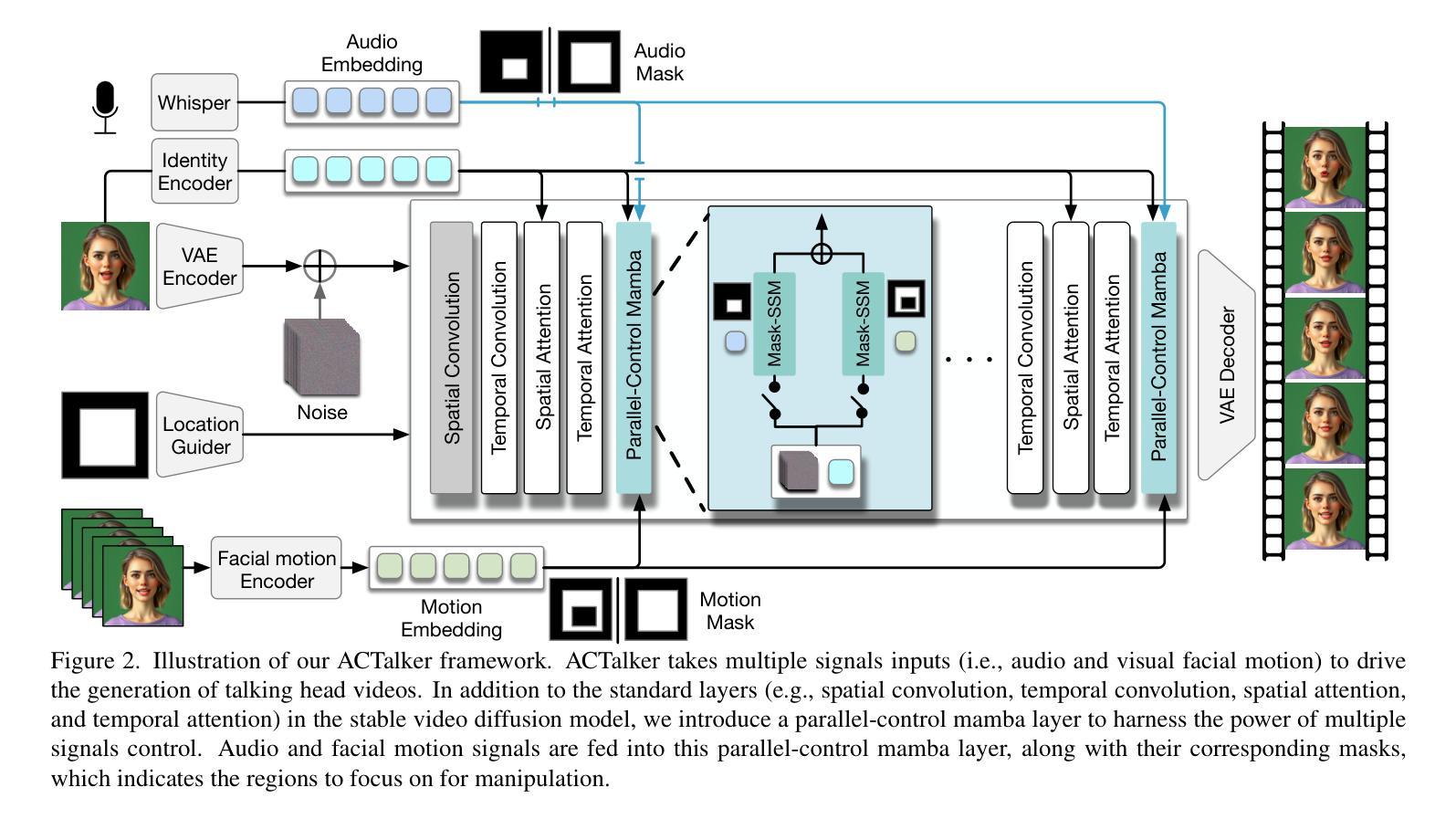
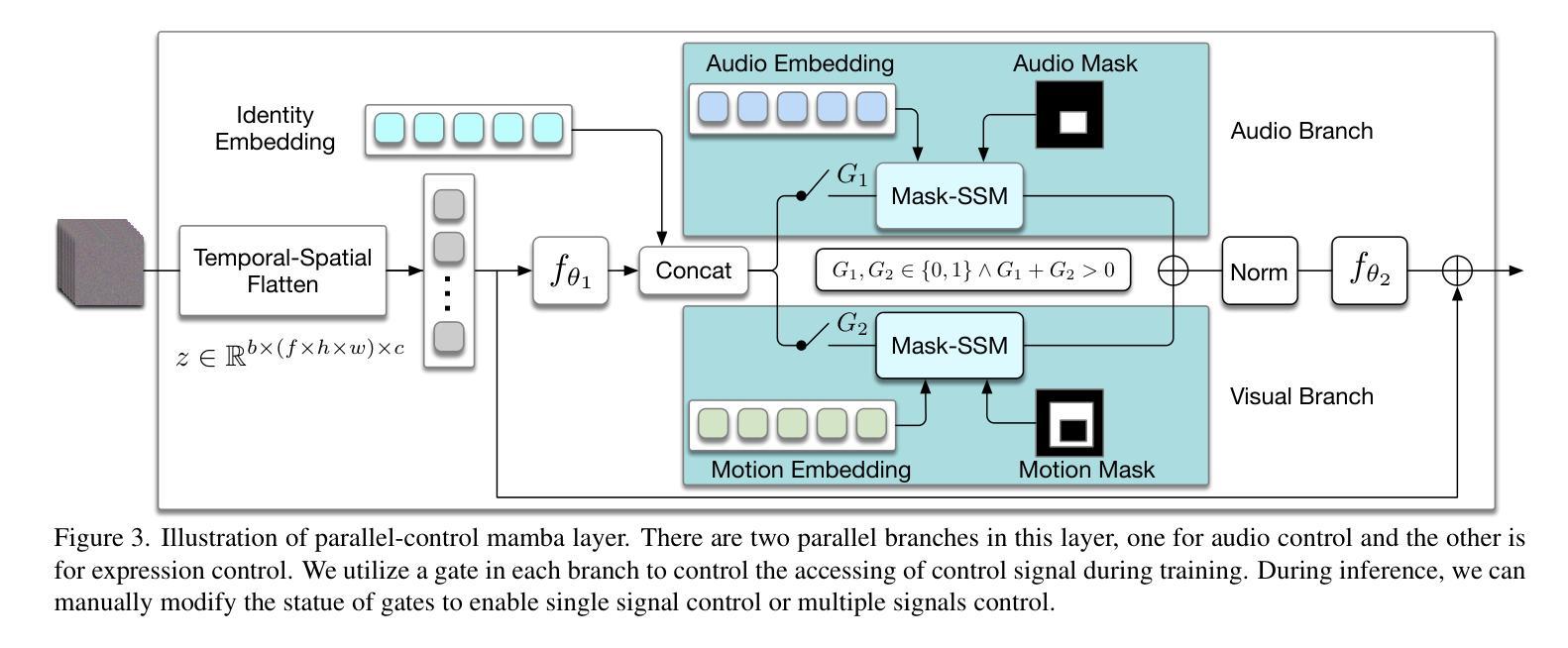
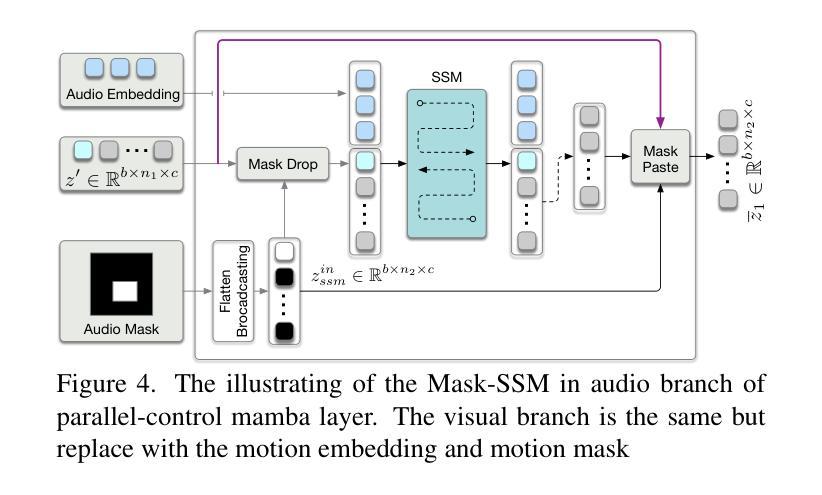
Talking head synthesis is vital for virtual avatars and human-computer interaction. However, most existing methods are typically limited to accepting control from a single primary modality, restricting their practical utility. To this end, we introduce \textbf{ACTalker}, an end-to-end video diffusion framework that supports both multi-signals control and single-signal control for talking head video generation. For multiple control, we design a parallel mamba structure with multiple branches, each utilizing a separate driving signal to control specific facial regions. A gate mechanism is applied across all branches, providing flexible control over video generation. To ensure natural coordination of the controlled video both temporally and spatially, we employ the mamba structure, which enables driving signals to manipulate feature tokens across both dimensions in each branch. Additionally, we introduce a mask-drop strategy that allows each driving signal to independently control its corresponding facial region within the mamba structure, preventing control conflicts. Experimental results demonstrate that our method produces natural-looking facial videos driven by diverse signals and that the mamba layer seamlessly integrates multiple driving modalities without conflict. The project website can be found at \href{https://harlanhong.github.io/publications/actalker/index.html}{HERE}.
头部谈话合成对虚拟化身和人机交互至关重要。然而,大多数现有方法通常仅限于接受单一主要模态的控制,从而限制了其实用性。为此,我们引入了ACTalker,这是一个端到端的视频扩散框架,支持多信号控制和单信号控制用于头部谈话视频生成。对于多控制,我们设计了一个并行mamba结构,包含多个分支,每个分支利用一个单独的驱动信号来控制特定的面部区域。所有分支都应用了门控机制,为视频生成提供了灵活的控制。为了确保控制视频的时空自然协调,我们采用了mamba结构,使驱动信号能够在每个分支的两个维度上操作特征令牌。此外,我们还引入了一种mask-drop策略,允许每个驱动信号独立控制在mamba结构内对应的面部区域,防止控制冲突。实验结果表明,我们的方法能够生成由多种信号驱动的自然面部视频,并且mamba层能够无缝集成多种驱动模式,无冲突。项目网站可在此处找到。
论文及项目相关链接
Summary
本文介绍了针对虚拟角色和人机交互的说话人头部合成技术。针对现有方法的局限性,提出一种名为ACTalker的端到端视频扩散框架,支持多信号控制和单信号控制下的说话头视频生成。通过设计并行mamba结构,实现对多个控制信号的并行处理,每个分支利用单独的驱动信号控制面部特定区域。同时引入门控机制,实现灵活的视频生成控制。mamba结构的应用确保了受控视频的时空自然协调性。此外,采用mask-drop策略,使每个驱动信号能独立控制对应的面部区域,避免控制冲突。实验结果表明,该方法能生成自然逼真的面部视频,适应多种信号驱动,mamba层能无缝集成多种驱动模式。
Key Takeaways
- ACTalker是一个用于说话头视频生成的端到端视频扩散框架,支持多信号控制和单信号控制。
- 通过并行mamba结构设计,每个分支可以独立处理并利用不同的驱动信号控制面部特定区域。
- 门控机制的应用提供了灵活的视频生成控制。
- mamba结构确保了受控视频的时空自然协调性。
- 采用mask-drop策略,避免不同驱动信号之间的控制冲突。
- 实验结果表明,ACTalker能生成高质量的、自然逼真的面部视频,适应多种信号驱动。
点此查看论文截图


FADA: Fast Diffusion Avatar Synthesis with Mixed-Supervised Multi-CFG Distillation
Authors:Tianyun Zhong, Chao Liang, Jianwen Jiang, Gaojie Lin, Jiaqi Yang, Zhou Zhao
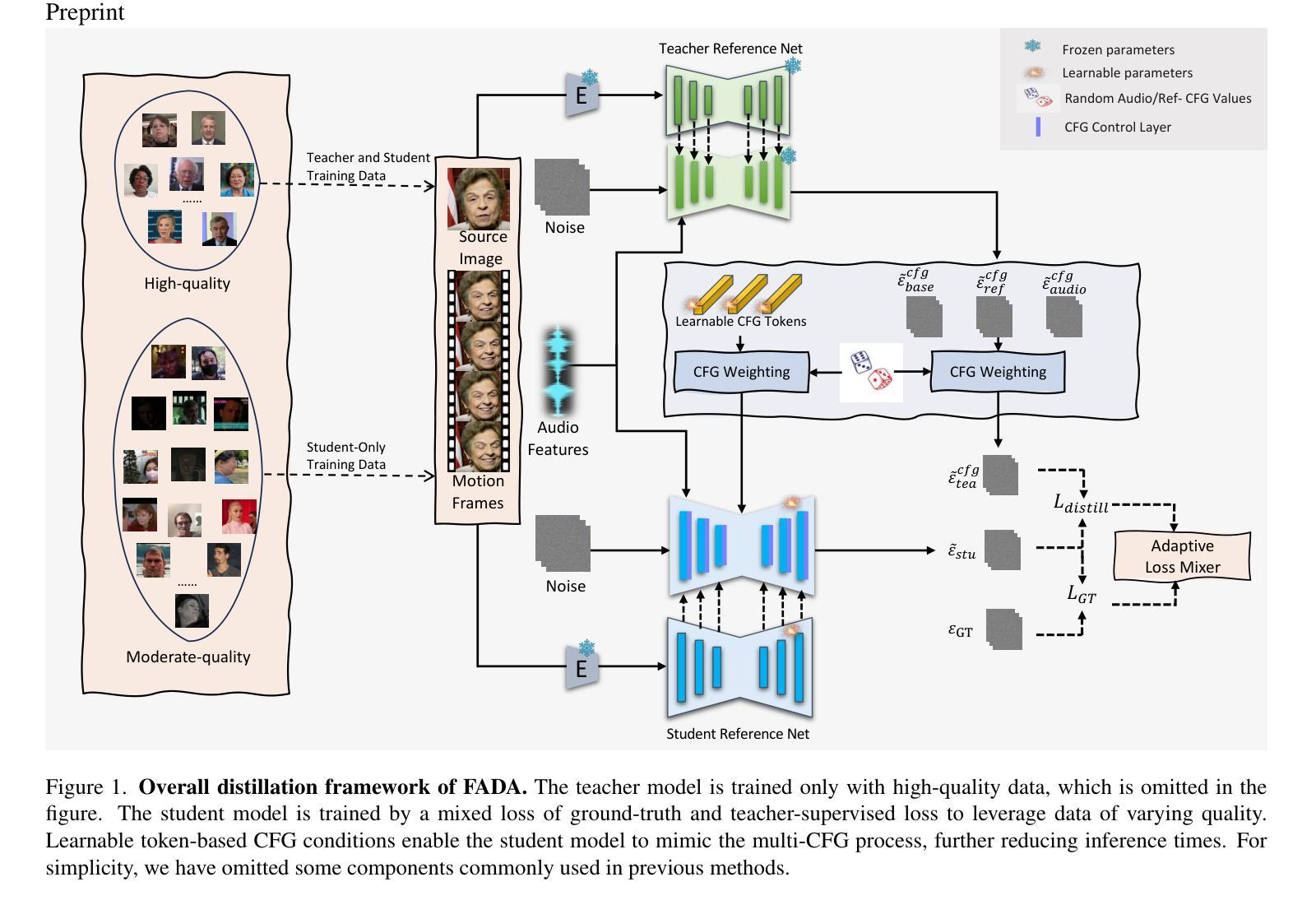
Diffusion-based audio-driven talking avatar methods have recently gained attention for their high-fidelity, vivid, and expressive results. However, their slow inference speed limits practical applications. Despite the development of various distillation techniques for diffusion models, we found that naive diffusion distillation methods do not yield satisfactory results. Distilled models exhibit reduced robustness with open-set input images and a decreased correlation between audio and video compared to teacher models, undermining the advantages of diffusion models. To address this, we propose FADA (Fast Diffusion Avatar Synthesis with Mixed-Supervised Multi-CFG Distillation). We first designed a mixed-supervised loss to leverage data of varying quality and enhance the overall model capability as well as robustness. Additionally, we propose a multi-CFG distillation with learnable tokens to utilize the correlation between audio and reference image conditions, reducing the threefold inference runs caused by multi-CFG with acceptable quality degradation. Extensive experiments across multiple datasets show that FADA generates vivid videos comparable to recent diffusion model-based methods while achieving an NFE speedup of 4.17-12.5 times. Demos are available at our webpage http://fadavatar.github.io.
基于扩散的音频驱动说话人偶方法因其高保真、生动、富有表现力的结果而最近受到关注。然而,它们缓慢的推理速度限制了实际应用。尽管为扩散模型开发了各种蒸馏技术,但我们发现天真的扩散蒸馏方法并没有产生令人满意的结果。与教师模型相比,蒸馏模型对开放集输入图像的稳健性降低,音频和视频的关联性降低,这削弱了扩散模型的优势。为了解决这一问题,我们提出了FADA(基于混合监督多CFG蒸馏的快速扩散人偶合成)。我们首先设计了一种混合监督损失,以利用不同质量的数据,提高模型的整体能力和稳健性。此外,我们提出了一种带有可学习标记的多CFG蒸馏,利用音频和参考图像条件之间的相关性,减少了多CFG引起的三倍推理运行,并实现了可接受的质量下降。在多个数据集上的大量实验表明,FADA生成的视频生动,与最近的扩散模型方法相当,同时实现了4.17-12.5倍的NFE加速。演示可在我们的网页上看到:http://fadavatar.github.io。
论文及项目相关链接
PDF CVPR 2025, Homepage https://fadavatar.github.io/
Summary
扩散模型驱动的音频对话生成技术近期受到广泛关注,其生成的音频与视频内容真实且生动。然而,由于其推理速度较慢,限制了实际应用。尽管有各类蒸馏技术应用于扩散模型,但直接使用蒸馏技术往往不能达到令人满意的生成效果。经过对比分析发现,蒸馏模型的稳健性有所降低,音频和视频间的关联性下降,这些都会影响模型的优点。针对这一问题,我们提出了基于混合监督和多配置组蒸馏技术的快速扩散头像合成方法(FADA)。通过设计混合监督损失函数,我们充分利用了不同质量的数据,提高了模型的总体能力和稳健性。同时,我们提出了基于学习标记的多配置组蒸馏技术,利用音频和参考图像之间的关联性,减少了多配置组带来的推理运行次数,并保证质量损失可接受。实验证明,FADA生成的视频生动真实,与当前流行的扩散模型相比有着明显的推理速度提升。具体详情可访问我们的网站:http://fadavatar.github.io查看。
Key Takeaways
- 音频驱动说话的头像生成技术近年来因高保真度和生动性受到关注。
- 扩散模型存在推理速度慢的问题,限制了实际应用。
- 直接使用现有的蒸馏技术在扩散模型上效果不尽人意,会降低模型的稳健性和音频与视频的关联性。
- 提出了一种名为FADA的新方法,结合了混合监督损失和多配置组蒸馏技术来解决上述问题。
- 混合监督损失能够利用不同质量的数据,提高模型的总体能力和稳健性。
- 多配置组蒸馏技术利用音频和参考图像之间的关联性,提升了推理速度并保证质量损失可接受。
点此查看论文截图

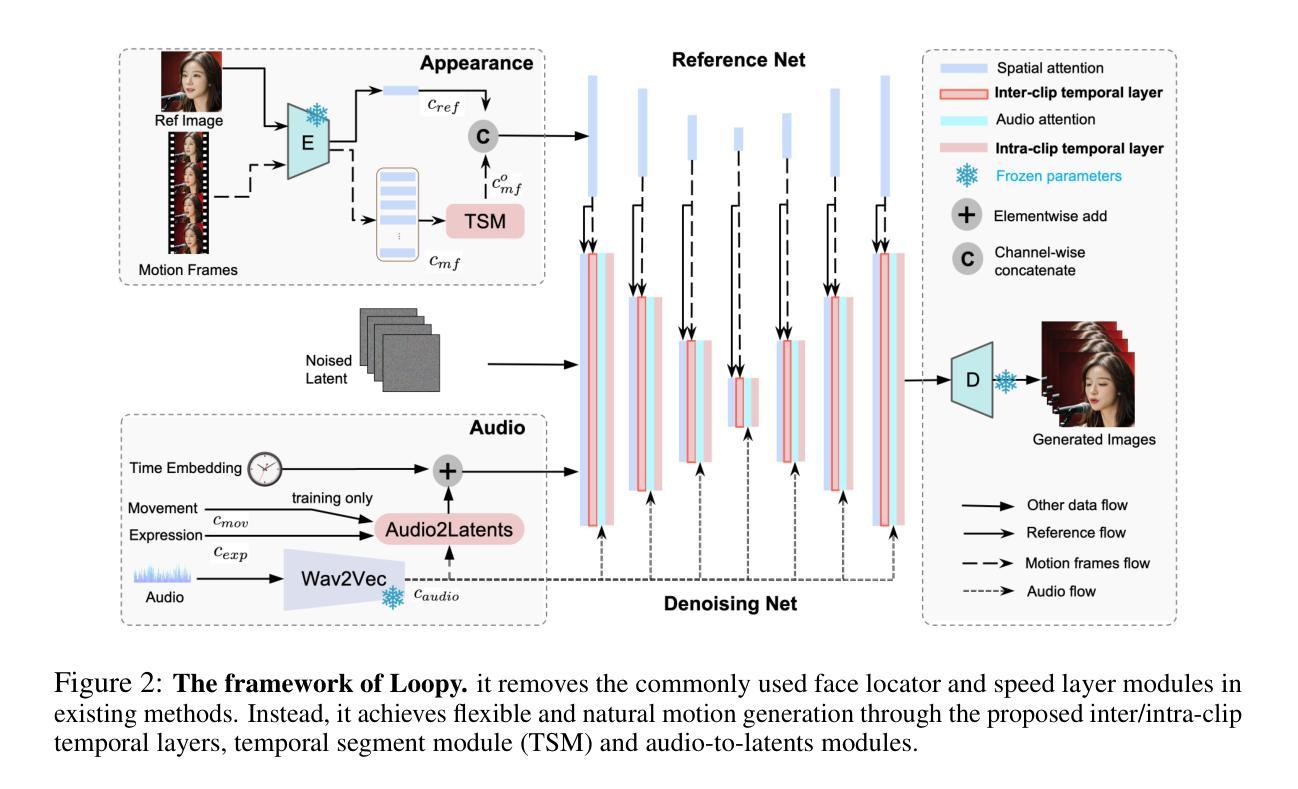
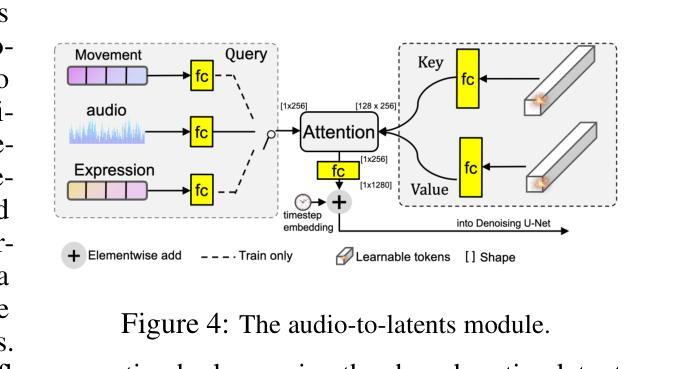
Loopy: Taming Audio-Driven Portrait Avatar with Long-Term Motion Dependency
Authors:Jianwen Jiang, Chao Liang, Jiaqi Yang, Gaojie Lin, Tianyun Zhong, Yanbo Zheng
With the introduction of diffusion-based video generation techniques, audio-conditioned human video generation has recently achieved significant breakthroughs in both the naturalness of motion and the synthesis of portrait details. Due to the limited control of audio signals in driving human motion, existing methods often add auxiliary spatial signals to stabilize movements, which may compromise the naturalness and freedom of motion. In this paper, we propose an end-to-end audio-only conditioned video diffusion model named Loopy. Specifically, we designed an inter- and intra-clip temporal module and an audio-to-latents module, enabling the model to leverage long-term motion information from the data to learn natural motion patterns and improving audio-portrait movement correlation. This method removes the need for manually specified spatial motion templates used in existing methods to constrain motion during inference. Extensive experiments show that Loopy outperforms recent audio-driven portrait diffusion models, delivering more lifelike and high-quality results across various scenarios.
随着基于扩散的视频生成技术的引入,音频控制的人类视频生成在动作的自然性和肖像细节的合成方面最近取得了重大突破。由于现有方法对人类动作驱动中音频信号的控制有限,通常添加辅助空间信号来稳定动作,这可能会损害动作的自然性和自由度。在本文中,我们提出了一种端到端的仅受音频条件的视频扩散模型,名为Loopy。具体来说,我们设计了一个跨剪辑和内剪辑的时间模块和一个音频到潜在特征模块,使模型能够利用数据中的长期运动信息来学习自然运动模式,并提高了音频肖像运动相关性。此方法消除了现有方法中用于在推理过程中约束运动的手动指定空间运动模板的需求。大量实验表明,Loopy超越了最近的音频驱动肖像扩散模型,在各种场景下生成了更逼真、高质量的结果。
论文及项目相关链接
PDF ICLR 2025 (Oral), Homepage: https://loopyavatar.github.io/
Summary
随着基于扩散的视频生成技术的引入,音频控制的人体视频生成在动作自然性和肖像细节合成方面取得了重大突破。现有方法由于音频信号对驱动人体运动的控制有限,通常添加辅助空间信号来稳定动作,这可能会损害动作的自然性和自由度。本文提出了一种端到端的仅由音频控制的视频扩散模型Loopy。通过设计跨内帧时间模块和音频到潜在特征模块,该模型能够利用数据中的长期运动信息来学习自然运动模式,并提升音频与肖像运动的关联性。此方法无需现有方法中手动指定的空间运动模板来约束推理过程中的运动。实验表明,Loopy在多种场景下表现优于近期的音频驱动肖像扩散模型,生成的结果更逼真、高质量。
Key Takeaways
- 扩散视频生成技术推动了音频控制人体视频生成的进步,在动作自然性和肖像细节方面取得重大突破。
- 现有方法依赖音频信号驱动人体运动存在局限性,需借助辅助空间信号稳定动作,可能影响动作的自然性和自由度。
- 提出的Loopy模型是一种端到端的仅由音频控制的视频扩散模型。
- Loopy通过设计跨内帧时间模块,能够利用长期运动信息学习自然运动模式。
- Loopy的音频到潜在特征模块提升了音频与肖像运动的关联性。
- Loopy模型无需手动指定的空间运动模板来约束推理过程中的运动。
点此查看论文截图