⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-09 更新
A multidimensional measurement of photorealistic avatar quality of experience
Authors:Ross Cutler, Babak Naderi, Vishak Gopal, Dharmendar Palle
Photorealistic avatars are human avatars that look, move, and talk like real people. The performance of photorealistic avatars has significantly improved recently based on objective metrics such as PSNR, SSIM, LPIPS, FID, and FVD. However, recent photorealistic avatar publications do not provide subjective tests of the avatars to measure human usability factors. We provide an open source test framework to subjectively measure photorealistic avatar performance in ten dimensions: realism, trust, comfortableness using, comfortableness interacting with, appropriateness for work, creepiness, formality, affinity, resemblance to the person, and emotion accuracy. Using telecommunication scenarios, we show that the correlation of nine of these subjective metrics with PSNR, SSIM, LPIPS, FID, and FVD is weak, and moderate for emotion accuracy. The crowdsourced subjective test framework is highly reproducible and accurate when compared to a panel of experts. We analyze a wide range of avatars from photorealistic to cartoon-like and show that some photorealistic avatars are approaching real video performance based on these dimensions. We also find that for avatars above a certain level of realism, eight of these measured dimensions are strongly correlated. This means that avatars that are not as realistic as real video will have lower trust, comfortableness using, comfortableness interacting with, appropriateness for work, formality, and affinity, and higher creepiness compared to real video. In addition, because there is a strong linear relationship between avatar affinity and realism, there is no uncanny valley effect for photorealistic avatars in the telecommunication scenario. We suggest several extensions of this test framework for future work and discuss design implications for telecommunication systems. The test framework is available at https://github.com/microsoft/P.910.
高保真虚拟人是看起来像、移动和说话都像真实人类的虚拟人。基于PSNR、SSIM、LPIPS、FID和FVD等客观指标,高保真虚拟人的性能最近得到了显著提高。然而,最近的高保真虚拟人出版物并没有提供主观测试来测量虚拟人的可用性因素。我们提供了一个开源的测试框架来主观地测量高保真虚拟人在十个方面的性能:逼真度、信任度、使用舒适度、交互舒适度、工作适宜性、怪异感、正式程度、亲和力、与人的相似性以及情感准确性。在电信场景中,我们发现这些主观指标中的九个与PSNR、SSIM、LPIPS、FID和FVD之间的相关性很弱,情感准确度的相关性则适中。与专家小组相比,众包的主观测试框架在高度可复制和准确性方面表现良好。我们分析了从高保真到卡通式的各种虚拟人,发现一些高保真虚拟人在这些维度上已经接近真实视频的性能。我们还发现,对于达到一定现实水平的虚拟人,这八个衡量维度之间存在强烈的相关性。这意味着那些不如真实视频逼真的虚拟人在信任度、使用舒适度、交互舒适度、工作适宜性、正式程度以及亲和力方面会较低,并且与真实视频相比会有更高的怪异感。此外,由于虚拟人亲和力和逼真性之间存在强烈的线性关系,因此在电信场景中,高保真虚拟人不会出现诡异谷效应。我们建议未来工作对此测试框架进行扩展,并讨论电信系统的设计影响。测试框架可在https://github.com/microsoft/P.910获取。
论文及项目相关链接
PDF arXiv admin note: text overlap with arXiv:2204.06784
Summary:该文本主要介绍了高度逼真的头像(photorealistic avatars),并采用了客观指标对其进行衡量。然而,近期的研究并未涉及主观测试来衡量其人机交互的可用性。为此,提供了一个开源测试框架来主观衡量头像在十个维度上的表现,包括逼真度、信任度等。通过分析发现,主观指标与客观指标的关联度较弱,但对于情感准确度而言关联度适中。此外,对于达到一定逼真程度的头像,多数维度的衡量结果表现出强相关性。最后,强调了未来对该测试框架的扩展和讨论电信系统设计的影响。
Key Takeaways:
- Photorealistic avatars已得到显著发展,并采用了如PSNR、SSIM等客观指标进行性能评估。
- 现有研究缺乏主观测试来衡量头像在人机交互中的可用性。
- 提供了一个开源测试框架来主观评估头像在多个维度(如逼真度、信任度等)的表现。
- 主观指标与客观指标的关联度总体较弱,但情感准确度的关联度适中。
- 对于高度逼真的头像,多个衡量维度表现出强相关性。
- 头像的亲和力与逼真度之间存在强烈的线性关系,没有所谓的“怪异谷效应”(uncanny valley effect)。
点此查看论文截图

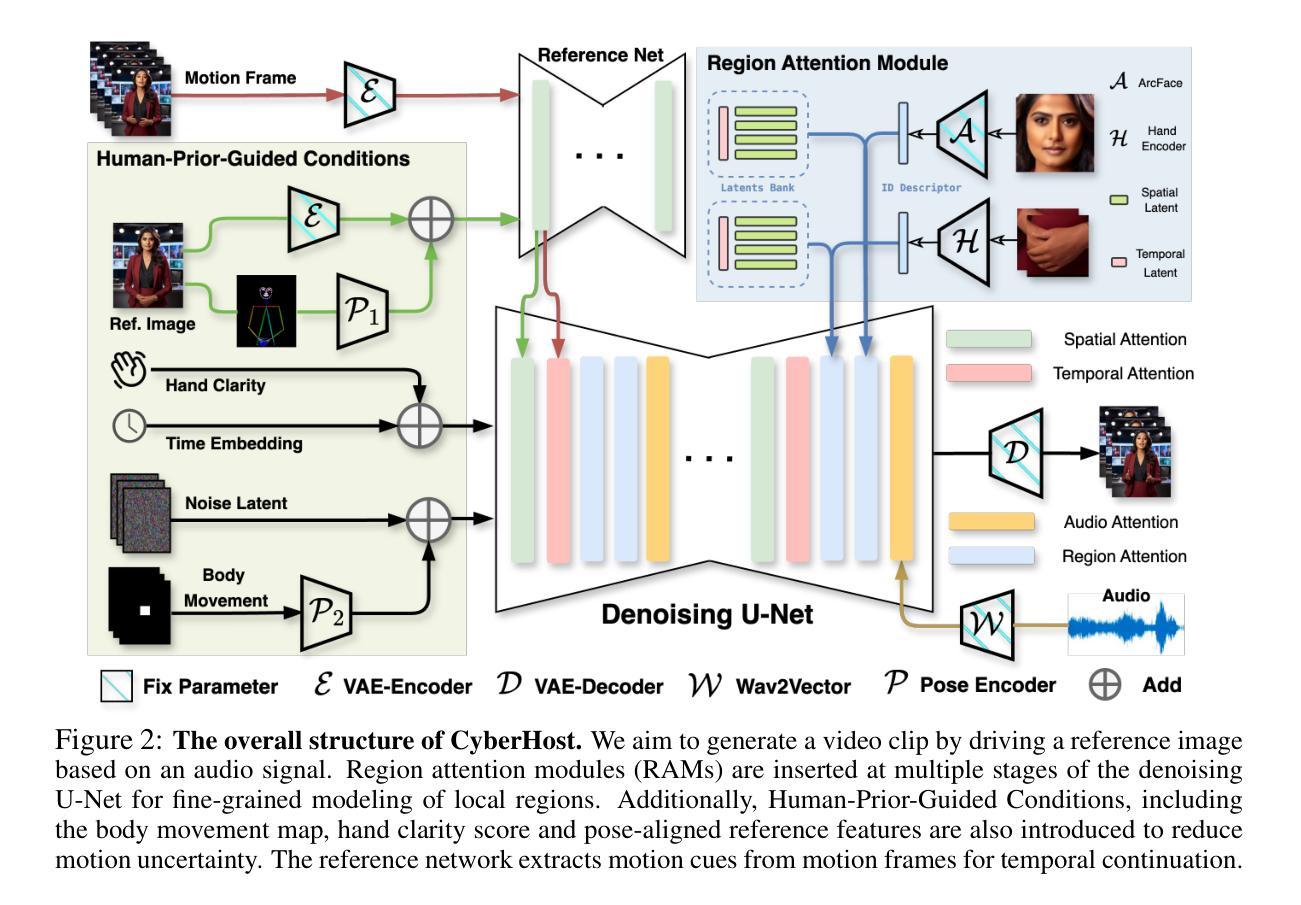
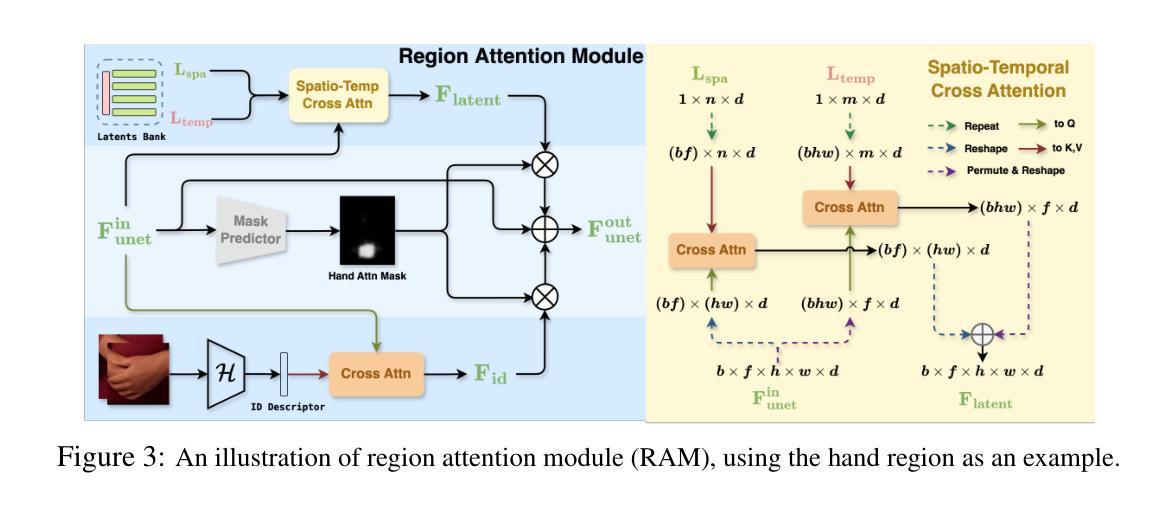
CyberHost: Taming Audio-driven Avatar Diffusion Model with Region Codebook Attention
Authors:Gaojie Lin, Jianwen Jiang, Chao Liang, Tianyun Zhong, Jiaqi Yang, Yanbo Zheng
Diffusion-based video generation technology has advanced significantly, catalyzing a proliferation of research in human animation. However, the majority of these studies are confined to same-modality driving settings, with cross-modality human body animation remaining relatively underexplored. In this paper, we introduce, an end-to-end audio-driven human animation framework that ensures hand integrity, identity consistency, and natural motion. The key design of CyberHost is the Region Codebook Attention mechanism, which improves the generation quality of facial and hand animations by integrating fine-grained local features with learned motion pattern priors. Furthermore, we have developed a suite of human-prior-guided training strategies, including body movement map, hand clarity score, pose-aligned reference feature, and local enhancement supervision, to improve synthesis results. To our knowledge, CyberHost is the first end-to-end audio-driven human diffusion model capable of facilitating zero-shot video generation within the scope of human body. Extensive experiments demonstrate that CyberHost surpasses previous works in both quantitative and qualitative aspects.
基于扩散的视频生成技术已经取得了显著的进步,催生了人体动画领域的繁荣研究。然而,大多数研究都局限于相同模式的驱动环境,跨模态人体动画的研究相对较少。在本文中,我们介绍了一个端到端的音频驱动人体动画框架——CyberHost,它确保手部的完整性、身份一致性和自然运动。CyberHost的关键设计是区域代码本注意机制,它通过整合精细的局部特征与学习的运动模式先验,提高了面部和手部动画的生成质量。此外,我们还开发了一套人体优先引导的训练策略,包括身体运动地图、手部清晰度评分、姿态对齐参考特征和局部增强监督,以提高合成结果。据我们所知,CyberHost是第一个端到端的音频驱动人体扩散模型,能够在人体范围内实现零样本视频生成。大量实验表明,无论是在定量还是定性方面,CyberHost都超越了以前的工作。
论文及项目相关链接
PDF ICLR 2025 (Oral), Homepage: https://cyberhost.github.io/
Summary
扩散式视频生成技术在人类动画领域取得了显著进展,但大多数研究仅限于同模态驱动设置,跨模态人体动画相对较少。本文介绍了一种端对端的音频驱动人体动画框架——CyberHost,它保证了手的完整性、身份一致性和自然运动。其核心设计是区域代码本注意机制,通过整合精细的局部特征与学习的运动模式先验,提高了面部和手部动画的生成质量。此外,还开发了一系列人体优先训练策略,包括身体运动图、手部清晰度分数、姿势对齐参考特征和局部增强监督,以提高合成结果。CyberHost是首个能够零样本生成视频的端到端音频驱动人体扩散模型。
Key Takeaways
- 扩散式视频生成技术在人类动画领域有重大进展,但跨模态人体动画研究仍相对较少。
- 提出了音频驱动的端对端人体动画框架——CyberHost,保障手的完整性、身份一致性和自然运动。
- CyberHost的核心设计是区域代码本注意机制,能提高面部和手部动画的生成质量。
- 开发了一系列人体优先训练策略,包括身体运动图、手部清晰度分数等,提高合成结果。
- CyberHost是首个能零样本生成视频的端到端音频驱动人体扩散模型。
- 实验表明,CyberHost在定量和定性方面都超越了以前的工作。
点此查看论文截图


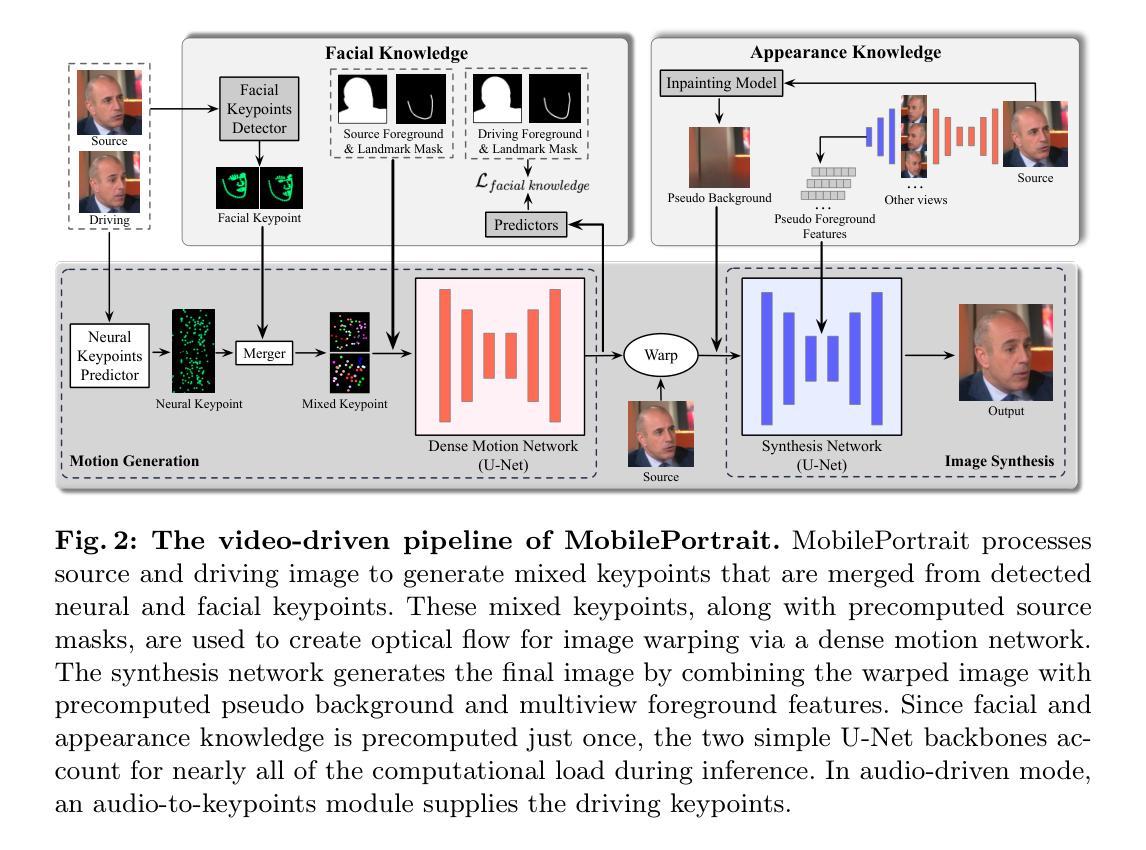
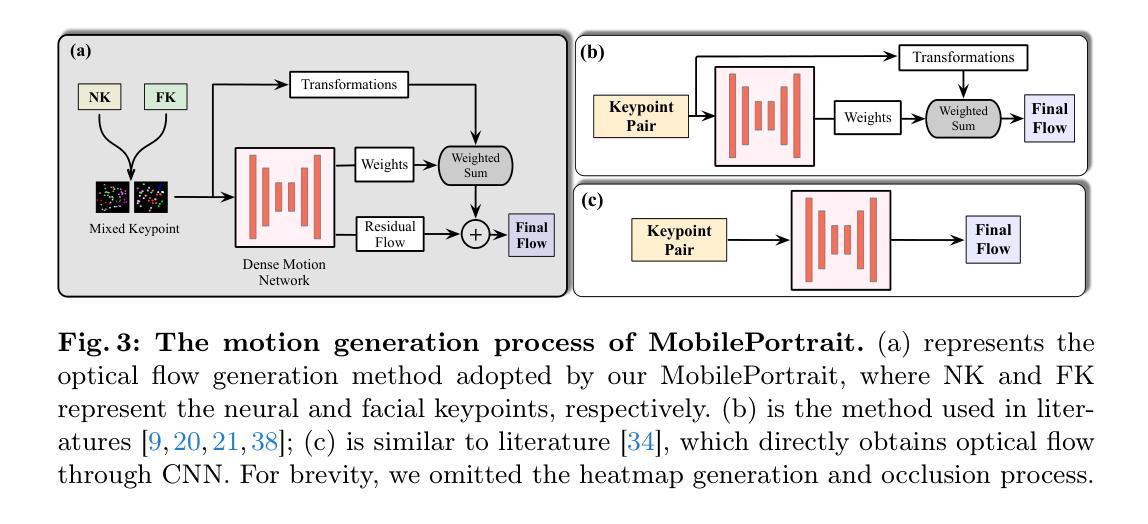
MobilePortrait: Real-Time One-Shot Neural Head Avatars on Mobile Devices
Authors:Jianwen Jiang, Gaojie Lin, Zhengkun Rong, Chao Liang, Yongming Zhu, Jiaqi Yang, Tianyun Zhong
Existing neural head avatars methods have achieved significant progress in the image quality and motion range of portrait animation. However, these methods neglect the computational overhead, and to the best of our knowledge, none is designed to run on mobile devices. This paper presents MobilePortrait, a lightweight one-shot neural head avatars method that reduces learning complexity by integrating external knowledge into both the motion modeling and image synthesis, enabling real-time inference on mobile devices. Specifically, we introduce a mixed representation of explicit and implicit keypoints for precise motion modeling and precomputed visual features for enhanced foreground and background synthesis. With these two key designs and using simple U-Nets as backbones, our method achieves state-of-the-art performance with less than one-tenth the computational demand. It has been validated to reach speeds of over 100 FPS on mobile devices and support both video and audio-driven inputs.
现有的神经头像方法已经在肖像动画的图像质量和运动范围方面取得了显著进展。然而,这些方法忽视了计算开销,而且据我们所知,没有设计用于移动设备运行的方法。本文介绍了MobilePortrait,这是一种轻量级的单镜头神经头像方法,它通过整合外部知识到运动建模和图像合成中,降低了学习复杂性,实现在移动设备上的实时推理。具体来说,我们引入了显式关键点和隐式关键点的混合表示来进行精确运动建模,以及预计算的视觉特征来增强前景和背景合成。通过这两个关键设计和使用简单的U-Nets作为骨干网,我们的方法在不到十分之一计算需求的情况下达到了最先进的性能。经验证,它在移动设备上的速度超过100帧每秒,并支持视频和音频驱动输入。
论文及项目相关链接
PDF CVPR 2024
Summary
该论文介绍了MobilePortrait技术,一种轻量级的一次性神经头部半身像方法,通过整合外部知识进入动作建模和图像合成,降低学习复杂度,实现了移动设备上的实时推理。采用明确的隐式关键点混合表示法和预计算的视觉特征,提高了动作建模和前景背景合成的准确性。使用简单的U-Nets作为骨干网,该方法在减少十分之一计算需求的同时达到了业界领先的表现。经验证,其在移动设备上的速度超过每秒100帧,并支持视频和音频驱动输入。
Key Takeaways
- MobilePortrait是一种轻量级的神经头部半身像方法,可在移动设备上实现实时推理。
- 该方法通过将外部知识整合到动作建模和图像合成中,降低了学习复杂度。
- 通过采用明确的隐式关键点混合表示法,提高了运动模型的精度。
- 预计算的视觉特征用于增强前景和背景合成的效果。
- 该方法使用简单的U-Nets作为骨干网,达到了业界领先的表现。
- MobilePortrait的技术在移动设备上的速度超过每秒100帧。
点此查看论文截图