⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-09 更新
Let it Snow! Animating Static Gaussian Scenes With Dynamic Weather Effects
Authors:Gal Fiebelman, Hadar Averbuch-Elor, Sagie Benaim
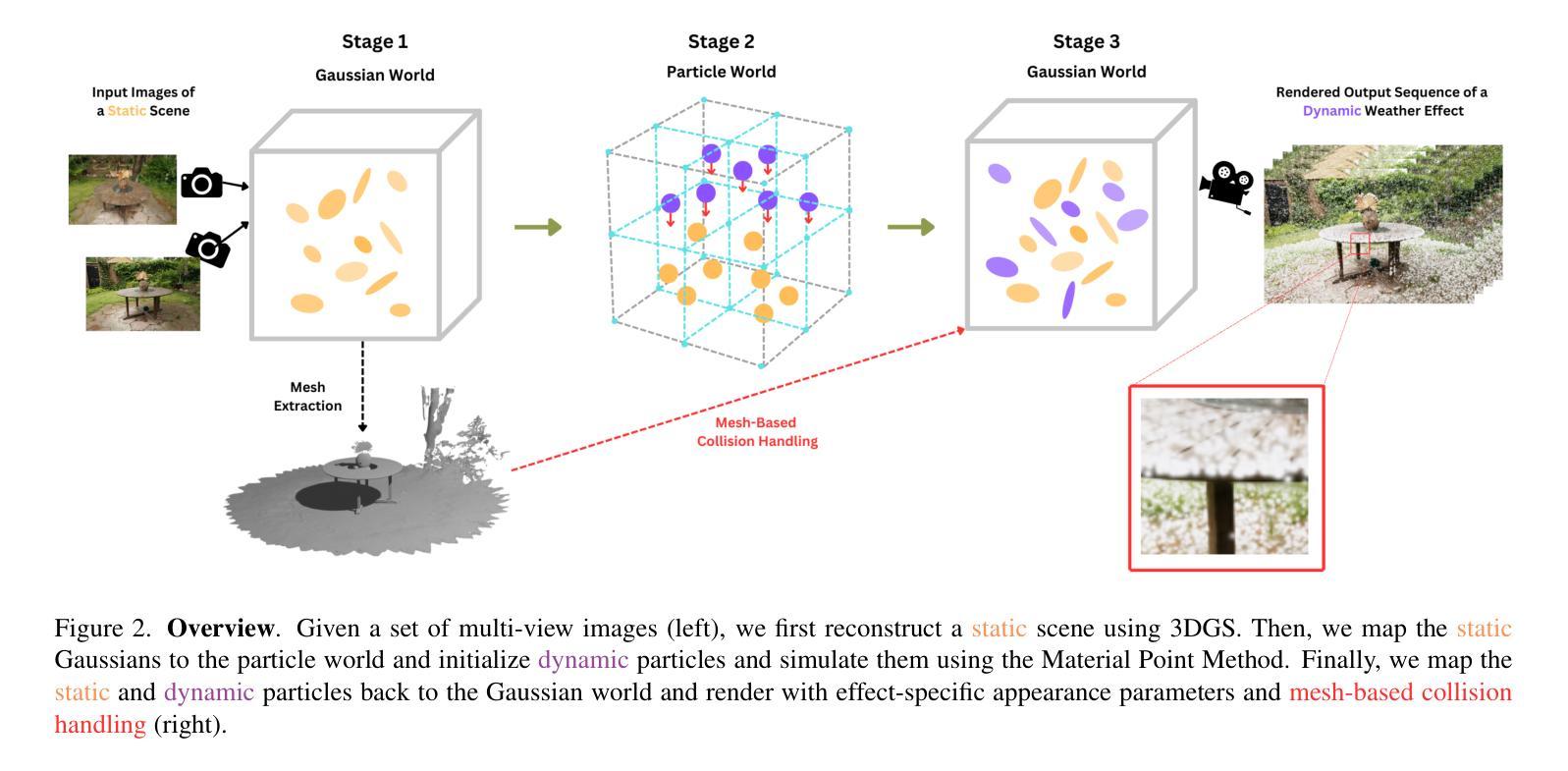
3D Gaussian Splatting has recently enabled fast and photorealistic reconstruction of static 3D scenes. However, introducing dynamic elements that interact naturally with such static scenes remains challenging. Accordingly, we present a novel hybrid framework that combines Gaussian-particle representations for incorporating physically-based global weather effects into static 3D Gaussian Splatting scenes, correctly handling the interactions of dynamic elements with the static scene. We follow a three-stage process: we first map static 3D Gaussians to a particle-based representation. We then introduce dynamic particles and simulate their motion using the Material Point Method (MPM). Finally, we map the simulated particles back to the Gaussian domain while introducing appearance parameters tailored for specific effects. To correctly handle the interactions of dynamic elements with the static scene, we introduce specialized collision handling techniques. Our approach supports a variety of weather effects, including snowfall, rainfall, fog, and sandstorms, and can also support falling objects, all with physically plausible motion and appearance. Experiments demonstrate that our method significantly outperforms existing approaches in both visual quality and physical realism.
3D高斯摊铺技术最近已经实现了静态3D场景的快照和逼真的重建。然而,引入能与这些静态场景自然交互的动态元素仍然是一个挑战。因此,我们提出了一种新型混合框架,它结合了高斯粒子表示法,将基于物理的全球天气效果融入到静态的3D高斯摊铺场景中,正确处理动态元素与静态场景的交互。我们遵循一个三阶段的过程:首先,我们将静态的3D高斯映射到基于粒子的表示法上。然后引入动态粒子,并使用物质点法(MPM)模拟其运动。最后,我们将模拟的粒子映射回高斯域,同时引入针对特定效果的外观参数。为了正确处理动态元素与静态场景的交互,我们引入了专门的碰撞处理技术。我们的方法支持多种天气效果,包括下雪、下雨、雾和沙尘暴,还支持下落物体,所有这些都具有物理上合理的运动和外观。实验表明,我们的方法在视觉质量和物理现实性方面都显著优于现有方法。
论文及项目相关链接
PDF Project webpage: https://galfiebelman.github.io/let-it-snow/
摘要
本文提出了一种结合高斯粒子表示法的新型混合框架,将基于物理的全球天气效应引入静态三维高斯贴图场景,并正确处理动态元素与静态场景的交互。该研究采用三阶段流程,首先,将静态三维高斯映射到基于粒子的表示法;接着,引入动态粒子并使用物质点法模拟其运动;最后,将模拟粒子映射回高斯域,同时引入针对特定效果的外观参数。为处理动态元素与静态场景的交互,研究引入了专业碰撞处理技术。该方法支持多种天气效应,包括降雪、降雨、雾和沙尘暴,还能支持落体物体,具有物理上合理的运动和外观。实验表明,该方法在视觉质量和物理真实性方面显著优于现有方法。
要点
- 3D Gaussian Splatting技术能快速重建静态3D场景,但引入自然交互的动态元素仍是挑战。
- 新型混合框架结合高斯粒子表示法,引入物理全球天气效应到静态3D场景中。
- 采用三阶段流程:映射静态高斯到粒子表示,引入动态粒子并使用物质点法模拟,再将粒子映射回高斯域并引入外观参数。
- 引入专业碰撞处理技术,正确处理动态元素与静态场景的交互。
- 支持多种天气效应和落体物体,具有物理上合理的运动和外观。
- 实验显示,该方法在视觉质量和物理真实性上优于现有方法。
- 该研究为动态元素与静态3D场景的交互提供了一种新的解决方案。
点此查看论文截图



PanoDreamer: Consistent Text to 360-Degree Scene Generation
Authors:Zhexiao Xiong, Zhang Chen, Zhong Li, Yi Xu, Nathan Jacobs
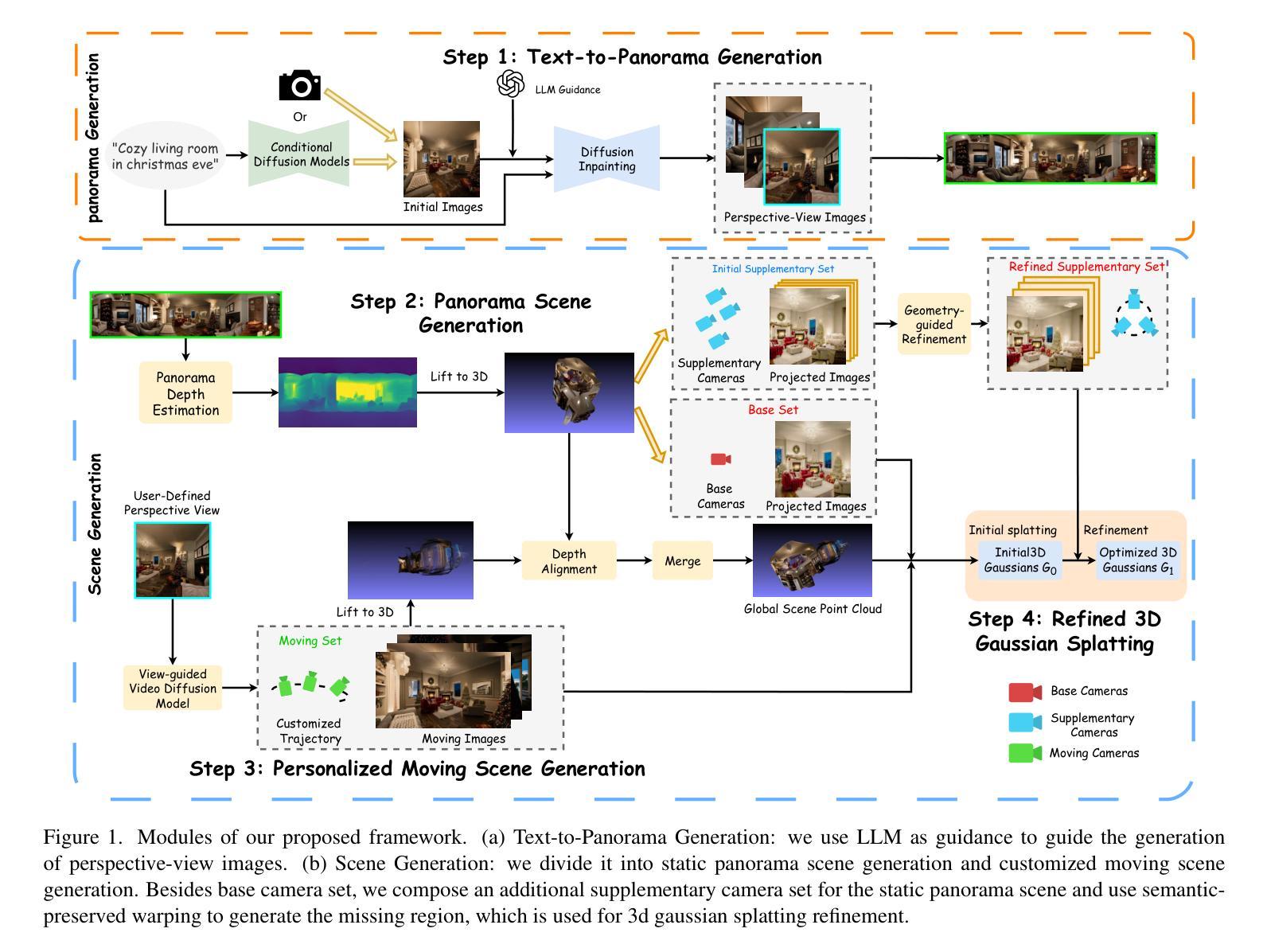
Automatically generating a complete 3D scene from a text description, a reference image, or both has significant applications in fields like virtual reality and gaming. However, current methods often generate low-quality textures and inconsistent 3D structures. This is especially true when extrapolating significantly beyond the field of view of the reference image. To address these challenges, we propose PanoDreamer, a novel framework for consistent, 3D scene generation with flexible text and image control. Our approach employs a large language model and a warp-refine pipeline, first generating an initial set of images and then compositing them into a 360-degree panorama. This panorama is then lifted into 3D to form an initial point cloud. We then use several approaches to generate additional images, from different viewpoints, that are consistent with the initial point cloud and expand/refine the initial point cloud. Given the resulting set of images, we utilize 3D Gaussian Splatting to create the final 3D scene, which can then be rendered from different viewpoints. Experiments demonstrate the effectiveness of PanoDreamer in generating high-quality, geometrically consistent 3D scenes.
通过文本描述、参考图像或两者结合自动生成完整的3D场景,在虚拟现实和游戏等领域具有显著的应用价值。然而,当前的方法往往生成低质量的纹理和不一致的3D结构。当超出参考图像的视野范围进行推断时,尤其如此。为了解决这些挑战,我们提出了PanoDreamer,这是一种具有灵活文本和图像控制的一致3D场景生成新框架。我们的方法采用大型语言模型和warp-refine管道,首先生成一组初始图像,然后将它们合成一个360度的全景图。接着将这个全景图提升为3D,形成初始点云。然后,我们使用几种方法从不同的视点生成与初始点云一致并扩展/细化初始点云的附加图像。根据所得的图像集,我们利用3D高斯摊铺技术创建最终的3D场景,然后可以从不同的视点进行渲染。实验表明,PanoDreamer在生成高质量、几何一致的3D场景方面非常有效。
论文及项目相关链接
PDF Accepted by CVPR 2025 Workshop on Computer Vision for Metaverse
Summary
新一代PanoDreamer框架通过结合文本和图像控制实现了高质量、一致的3D场景生成。利用大型语言模型和warp-refine管道,PanoDreamer通过构建初始全景图并结合不同视角的图像来创建3D场景,并采用多种方法来完善点云数据并生成最终的3D场景。该框架在虚拟现实和游戏等领域具有广泛的应用前景。
Key Takeaways
- PanoDreamer是一个新颖的框架,用于从文本描述或参考图像(或两者结合)自动生成完整的3D场景。
- 当前方法生成纹理质量低下且三维结构不一致的问题得到重视。尤其是在视野之外的场景外推上尤为突出。
- PanoDreamer采用大型语言模型和warp-refine管道,先生成初始图像集并组合成全景图,再转化为三维场景。
- 利用多种方法从不同视角生成与初始点云一致的图像,并对其进行扩展和优化。
- 采用3D高斯拼贴技术创建最终的3D场景,可从不同角度进行渲染。
- 实验证明PanoDreamer在生成高质量、几何一致的3D场景方面的有效性。
点此查看论文截图


Embracing Dynamics: Dynamics-aware 4D Gaussian Splatting SLAM
Authors:Zhicong Sun, Jacqueline Lo, Jinxing Hu
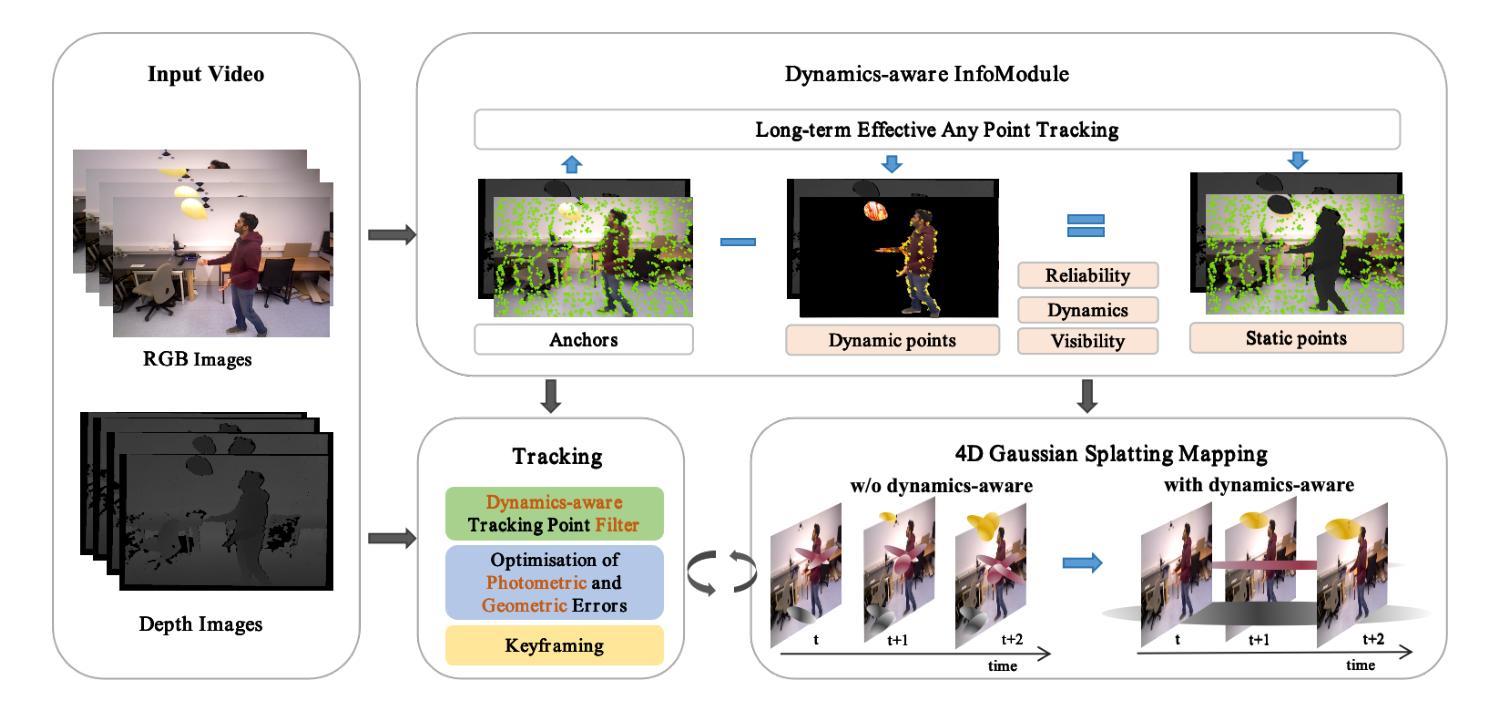
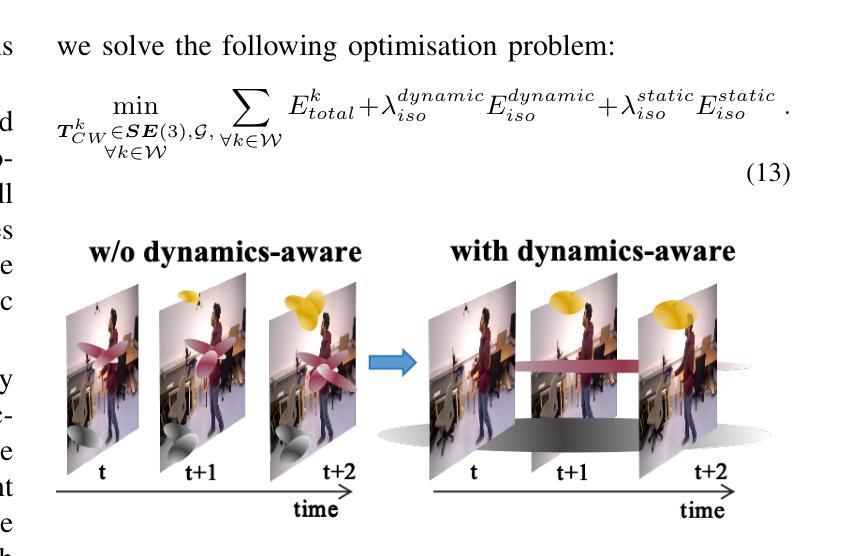
Simultaneous localization and mapping (SLAM) technology now has photorealistic mapping capabilities thanks to the real-time high-fidelity rendering capability of 3D Gaussian splatting (3DGS). However, due to the static representation of scenes, current 3DGS-based SLAM encounters issues with pose drift and failure to reconstruct accurate maps in dynamic environments. To address this problem, we present D4DGS-SLAM, the first SLAM method based on 4DGS map representation for dynamic environments. By incorporating the temporal dimension into scene representation, D4DGS-SLAM enables high-quality reconstruction of dynamic scenes. Utilizing the dynamics-aware InfoModule, we can obtain the dynamics, visibility, and reliability of scene points, and filter stable static points for tracking accordingly. When optimizing Gaussian points, we apply different isotropic regularization terms to Gaussians with varying dynamic characteristics. Experimental results on real-world dynamic scene datasets demonstrate that our method outperforms state-of-the-art approaches in both camera pose tracking and map quality.
由于3D高斯混合(3DGS)的实时高保真渲染能力,现在的同时定位与地图构建(SLAM)技术已经具备逼真的映射能力。然而,由于场景的静态表示,当前的基于3DGS的SLAM在动态环境中遇到了姿态漂移和无法重建准确地图的问题。为了解决这个问题,我们提出了基于四维高斯混合地图表示的动态环境SLAM方法——D4DGS-SLAM。通过将时间维度融入场景表示,D4DGS-SLAM能够实现动态场景的高质量重建。通过使用动态感知的InfoModule,我们可以获得场景点的动态性、可见性和可靠性,并据此过滤出稳定的静态点进行跟踪。在优化高斯点时,我们对具有不同动态特性的高斯应用不同的等距正则化项。在真实世界动态场景数据集上的实验结果证明了我们的方法在相机姿态跟踪和地图质量方面均优于现有先进技术。
论文及项目相关链接
PDF This paper is currently under reviewed for IROS 2025
Summary
基于三维高斯点云技术(3DGS)的实时渲染能力,现在的同步定位与地图构建(SLAM)技术可以实现逼真的地图构建。然而,在动态环境下,现有的基于3DGS的SLAM技术存在姿态漂移和无法准确重建地图的问题。为解决这些问题,我们提出了基于四维高斯点云表示(D4DGS)的SLAM方法。通过引入时间维度来表示场景,D4DGS-SLAM能够高质量地重建动态场景。采用动力学感知的InfoModule模块,可以获取场景点的动力学、可见性和可靠性,并据此过滤稳定的静态点进行跟踪。在优化高斯点时,我们对具有不同动态特性的高斯点应用不同的同构正则化项。在真实世界的动态场景数据集上的实验表明,我们的方法在主摄像的姿态追踪和地图质量上优于当前的主流方法。
Key Takeaways
- SLAM技术结合3DGS实现了逼真的地图构建。
- 现有基于3DGS的SLAM技术在动态环境下存在姿态漂移和地图重建不准确的问题。
- D4DGS-SLAM是首个基于四维高斯点云表示的SLAM方法,能够高质量重建动态场景。
- D4DGS-SLAM利用动力学感知模块获取场景点的动力学、可见性和可靠性信息。
- D4DGS-SLAM通过不同的同构正则化项优化具有不同动态特性的高斯点。
点此查看论文截图



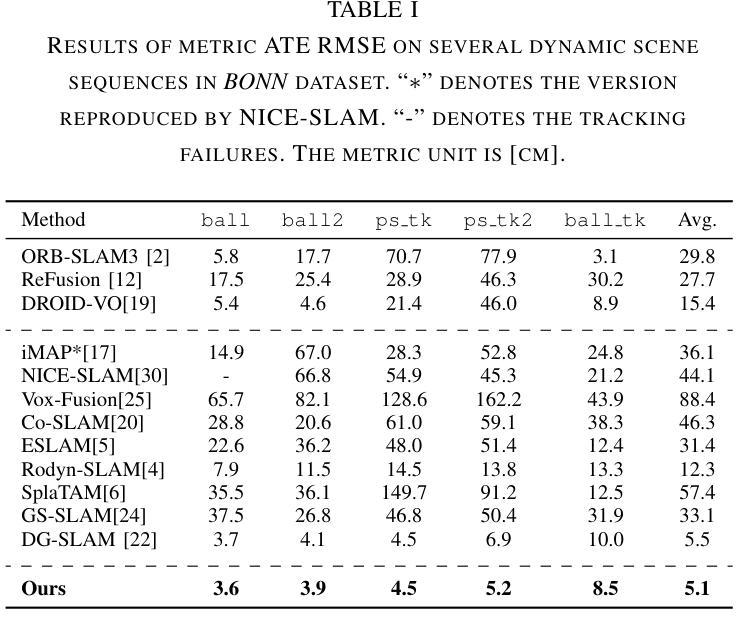


DeclutterNeRF: Generative-Free 3D Scene Recovery for Occlusion Removal
Authors:Wanzhou Liu, Zhexiao Xiong, Xinyu Li, Nathan Jacobs
Recent novel view synthesis (NVS) techniques, including Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) have greatly advanced 3D scene reconstruction with high-quality rendering and realistic detail recovery. Effectively removing occlusions while preserving scene details can further enhance the robustness and applicability of these techniques. However, existing approaches for object and occlusion removal predominantly rely on generative priors, which, despite filling the resulting holes, introduce new artifacts and blurriness. Moreover, existing benchmark datasets for evaluating occlusion removal methods lack realistic complexity and viewpoint variations. To address these issues, we introduce DeclutterSet, a novel dataset featuring diverse scenes with pronounced occlusions distributed across foreground, midground, and background, exhibiting substantial relative motion across viewpoints. We further introduce DeclutterNeRF, an occlusion removal method free from generative priors. DeclutterNeRF introduces joint multi-view optimization of learnable camera parameters, occlusion annealing regularization, and employs an explainable stochastic structural similarity loss, ensuring high-quality, artifact-free reconstructions from incomplete images. Experiments demonstrate that DeclutterNeRF significantly outperforms state-of-the-art methods on our proposed DeclutterSet, establishing a strong baseline for future research.
近期的新型视图合成(NVS)技术,包括神经辐射场(NeRF)和3D高斯拼贴(3DGS),在高质量渲染和真实细节恢复方面极大地推动了3D场景重建的发展。在保留场景细节的同时有效地去除遮挡物可以进一步增强这些技术的稳健性和适用性。然而,现有的物体和遮挡物去除方法主要依赖于生成先验,尽管可以填补空洞,但会引入新的伪影和模糊。此外,用于评估遮挡物去除方法的现有基准数据集缺乏现实的复杂性和视角变化。为了解决这些问题,我们引入了DeclutterSet,这是一个具有显著遮挡物的多样化场景的新数据集,这些遮挡物分布在前景、中景和背景中,并在不同视角之间表现出大量的相对运动。我们还介绍了DeclutterNeRF,这是一种无需生成先验的遮挡物去除方法。DeclutterNeRF引入了可学习相机参数的联合多视角优化、遮挡物退火正则化,并采用了可解释的随机结构相似性损失,确保从不完整图像中进行高质量、无伪影的重建。实验表明,在我们的提议的DeclutterSet上,DeclutterNeRF显著优于最先进的方法,为未来研究建立了强有力的基准。
论文及项目相关链接
PDF Accepted by CVPR 2025 4th CV4Metaverse Workshop. 15 pages, 10 figures. Code and data at: https://github.com/wanzhouliu/declutter-nerf
Summary
NeRF和3DGS等新型视图合成技术已在3D场景重建方面取得显著进展,但在去除遮挡物时仍面临生成先验导致的模糊和人工制品问题。为解决此问题,研究者引入了DeclutterSet数据集以及无需生成先验的DeclutterNeRF方法。DeclutterNeRF通过联合多视角优化学习相机参数、实施遮挡退火正则化并采用可解释的随机结构相似性损失,确保了从不完整图像进行高质量、无人工制品的重建。此方法在DeclutterSet上的表现显著优于现有方法,为未来研究确立了坚实的基准。
Key Takeaways
- NVS技术如NeRF和3DGS推动了高质量渲染的3D场景重建发展。
- 遮挡移除技术在NVS中仍面临挑战,尤其是引入生成先验导致的新问题。
- 提出了一个新的数据集DeclutterSet,涵盖了具有显著遮挡的多样化场景,并展现出视点变化的复杂性。
- 介绍了无需生成先验的遮挡移除方法DeclutterNeRF。
- DeclutterNeRF通过联合多视角优化相机参数,提高了遮挡处理效果。
- DeclutterNeRF采用遮挡退火正则化和可解释的随机结构相似性损失,确保高质量的重建结果。
点此查看论文截图

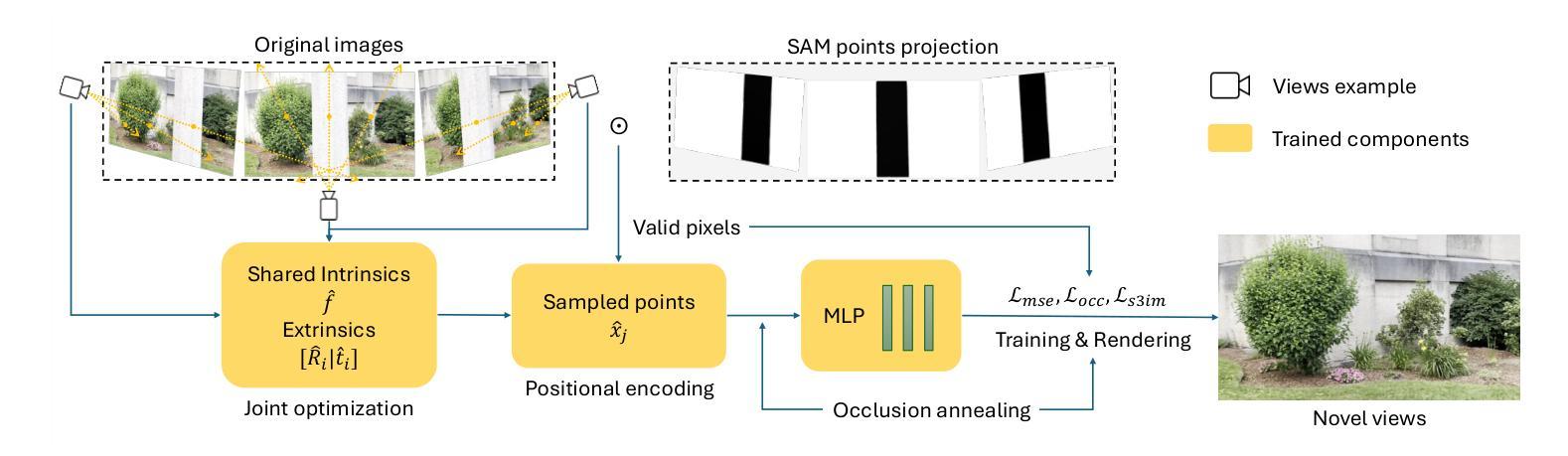
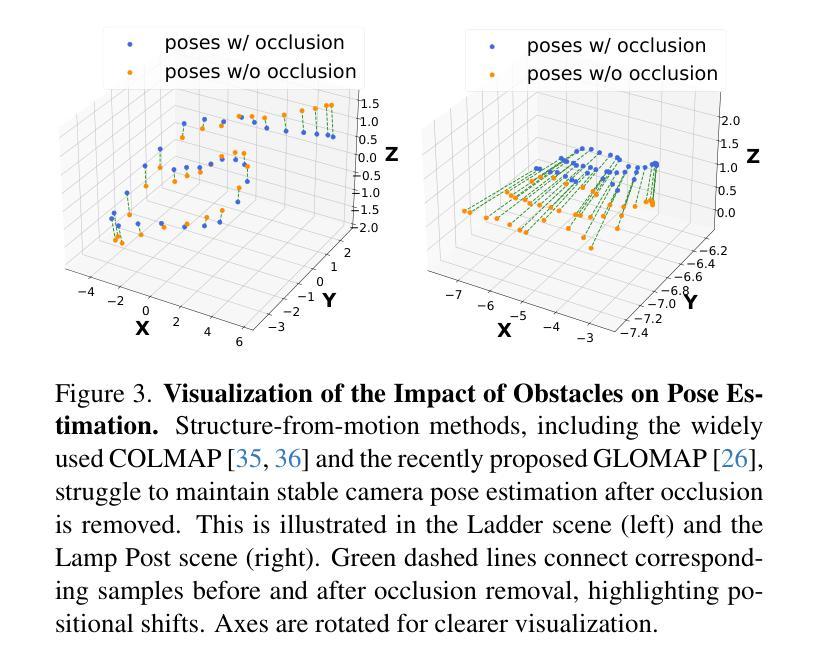
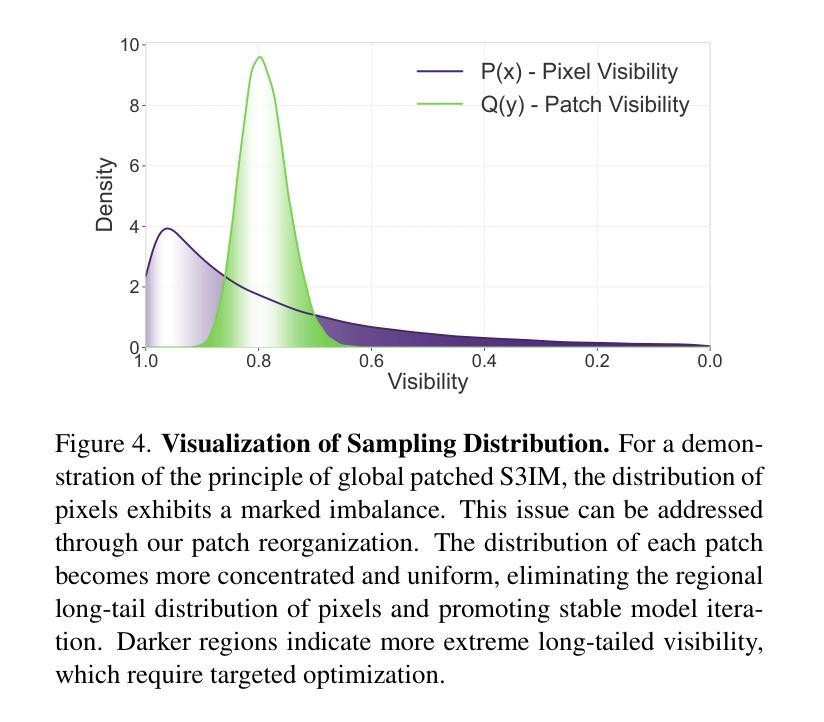

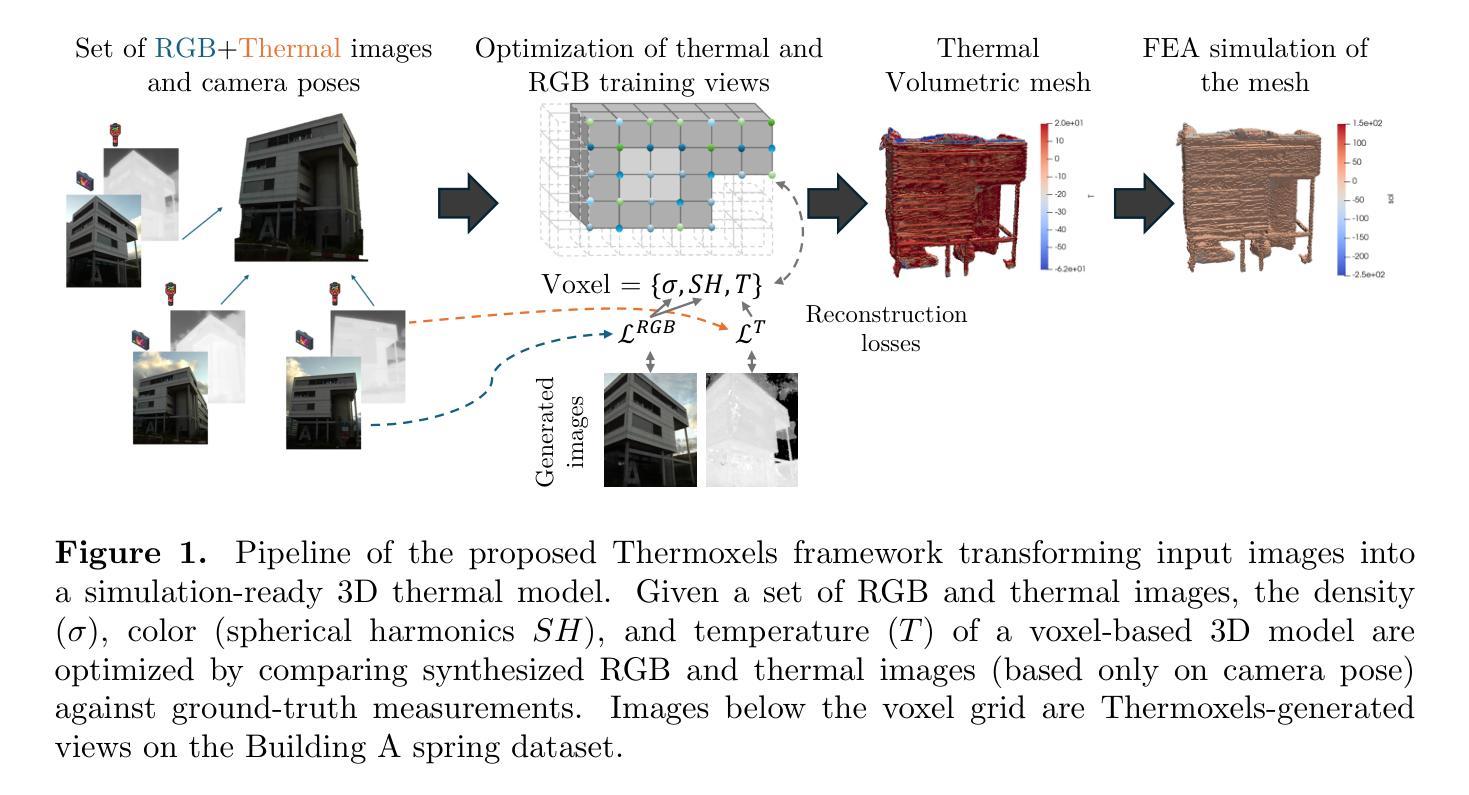
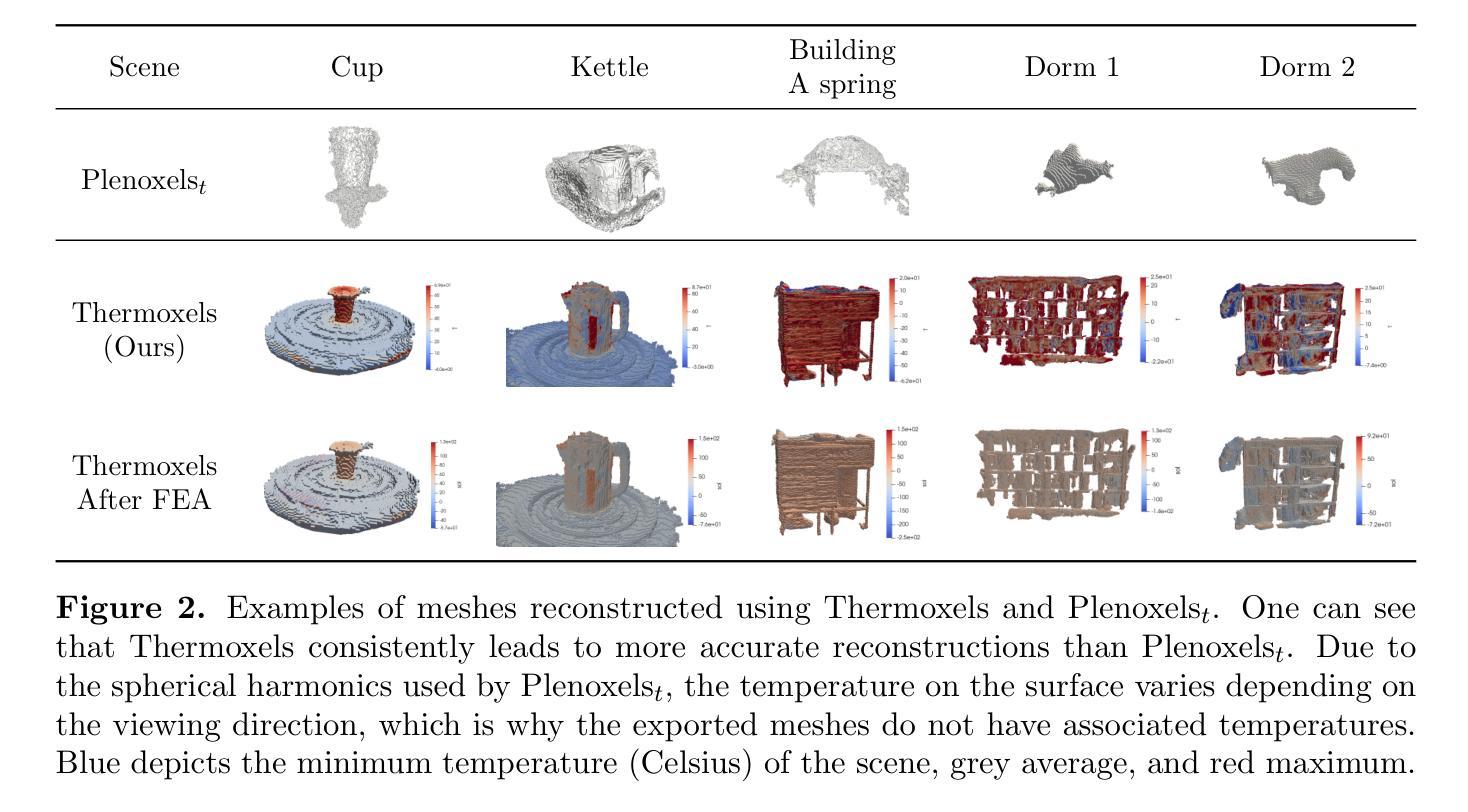
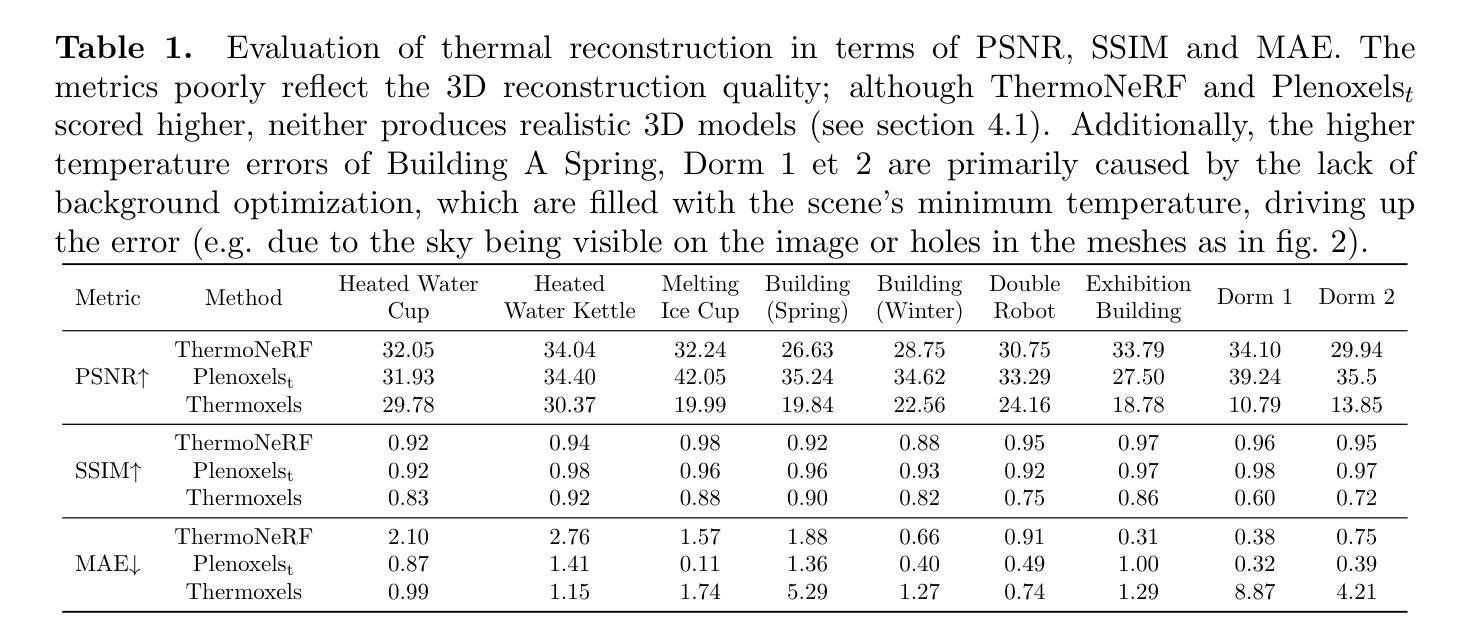
Thermoxels: a voxel-based method to generate simulation-ready 3D thermal models
Authors:Etienne Chassaing, Florent Forest, Olga Fink, Malcolm Mielle
In the European Union, buildings account for 42% of energy use and 35% of greenhouse gas emissions. Since most existing buildings will still be in use by 2050, retrofitting is crucial for emissions reduction. However, current building assessment methods rely mainly on qualitative thermal imaging, which limits data-driven decisions for energy savings. On the other hand, quantitative assessments using finite element analysis (FEA) offer precise insights but require manual CAD design, which is tedious and error-prone. Recent advances in 3D reconstruction, such as Neural Radiance Fields (NeRF) and Gaussian Splatting, enable precise 3D modeling from sparse images but lack clearly defined volumes and the interfaces between them needed for FEA. We propose Thermoxels, a novel voxel-based method able to generate FEA-compatible models, including both geometry and temperature, from a sparse set of RGB and thermal images. Using pairs of RGB and thermal images as input, Thermoxels represents a scene’s geometry as a set of voxels comprising color and temperature information. After optimization, a simple process is used to transform Thermoxels’ models into tetrahedral meshes compatible with FEA. We demonstrate Thermoxels’ capability to generate RGB+Thermal meshes of 3D scenes, surpassing other state-of-the-art methods. To showcase the practical applications of Thermoxels’ models, we conduct a simple heat conduction simulation using FEA, achieving convergence from an initial state defined by Thermoxels’ thermal reconstruction. Additionally, we compare Thermoxels’ image synthesis abilities with current state-of-the-art methods, showing competitive results, and discuss the limitations of existing metrics in assessing mesh quality.
在欧洲联盟,建筑物占能源使用的42%和温室气体排放的35%。由于大多数现有建筑在2050年之前仍在使用,因此改造对于减少排放至关重要。然而,当前建筑评估方法主要依赖于定性热成像,这限制了基于数据节能的决策。另一方面,使用有限元分析(FEA)的定量评估提供了精确见解,但需要手动CAD设计,这既繁琐又容易出错。最近的三维重建技术进展,如神经辐射场(NeRF)和高斯溅射(Gaussian Splatting),能够从稀疏图像进行精确的三维建模,但缺乏明确定义的体积和进行FEA所需的界面。我们提出Thermoxels,这是一种新型基于体素的方法,能够从稀疏的RGB和热图像生成与FEA兼容的模型,包括几何和温度信息。使用成对的RGB和热图像作为输入,Thermoxels将场景的几何表示为包含颜色和温度信息的体素集合。经过优化后,使用简单的过程将Thermoxels模型转换为与FEA兼容的四面体网格。我们展示了Thermoxels生成RGB+热网格的三维场景的能力,超越了其他最先进的方法。为了展示Thermoxels模型的实际应用,我们使用FEA进行简单的热传导模拟,从Thermoxels热重建定义的初始状态实现收敛。此外,我们将Thermoxels的图像合成能力与当前最先进的方法进行比较,显示了具有竞争力的结果,并讨论了现有指标在评估网格质量方面的局限性。
论文及项目相关链接
PDF 7 pages, 2 figures
Summary
提出了一种名为Thermoxels的新方法,通过稀疏的RGB和热图像生成有限元分析(FEA)兼容的模型,用于建筑的热性能评估。该方法能生成包含几何和温度信息的voxel模型,并转化为FEA兼容的四面体网格,实现精确的热传导模拟。
Key Takeaways
- 建筑在欧洲联盟中占据大量的能源使用和温室气体排放。
- 现有建筑到2050年仍将占据大部分,因此改造对于减少排放至关重要。
- 当前建筑评估方法主要依赖定性热成像,限制了数据驱动的节能决策。
- 定量评估使用有限元分析(FEA)提供精确见解,但需要手动CAD设计,过程繁琐且易出错。
- Thermoxels是一种基于voxel的新方法,能从稀疏的RGB和热图像生成FEA兼容的模型,包括几何和温度信息。
- Thermoxels模型可转化为四面体网格,用于精确热传导模拟。
- 通过与现有先进方法的比较,展示了Thermoxels在图像合成能力方面的竞争力,并讨论了评估网格质量现有指标的局限性。
点此查看论文截图

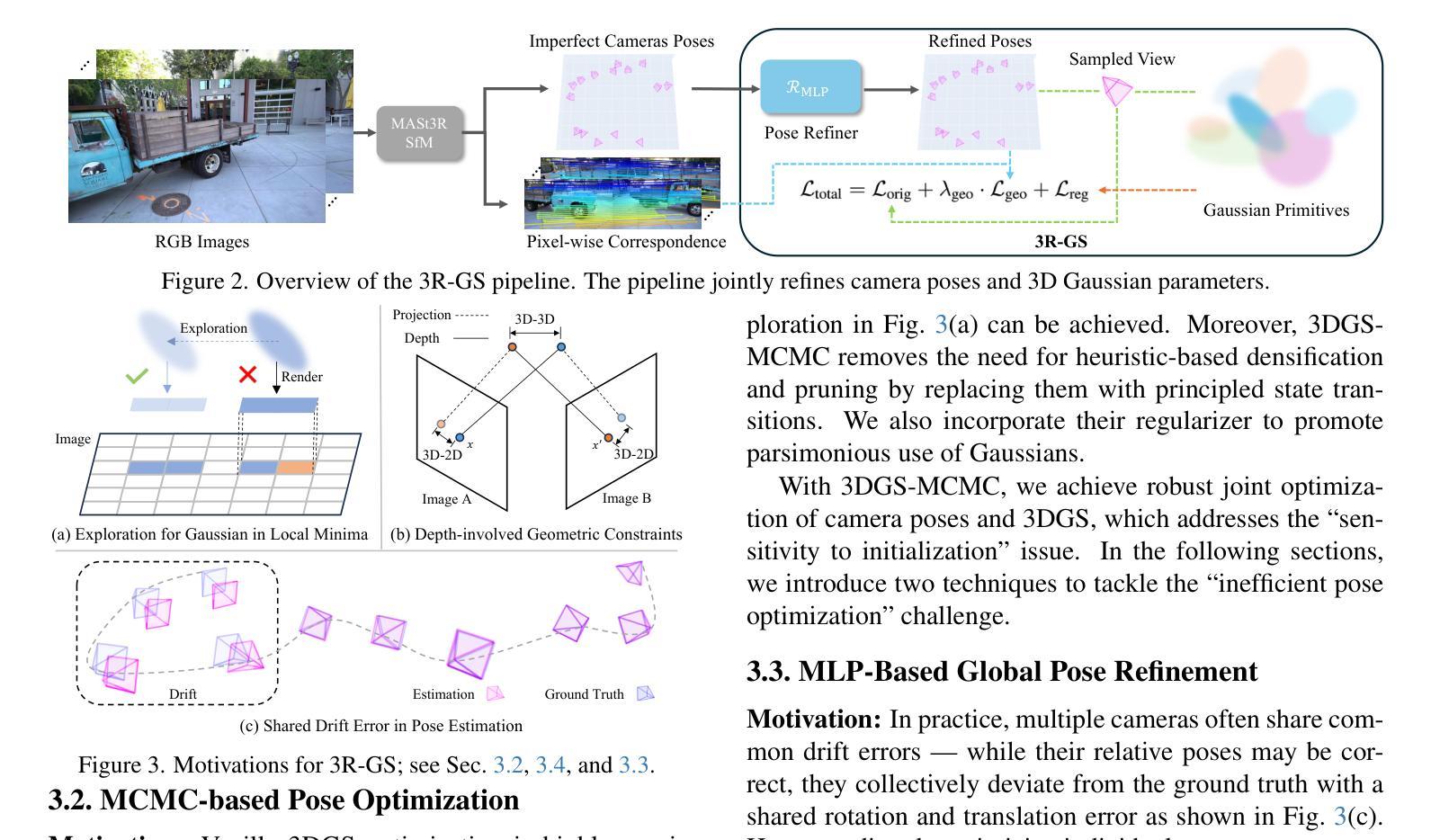
3R-GS: Best Practice in Optimizing Camera Poses Along with 3DGS
Authors:Zhisheng Huang, Peng Wang, Jingdong Zhang, Yuan Liu, Xin Li, Wenping Wang
3D Gaussian Splatting (3DGS) has revolutionized neural rendering with its efficiency and quality, but like many novel view synthesis methods, it heavily depends on accurate camera poses from Structure-from-Motion (SfM) systems. Although recent SfM pipelines have made impressive progress, questions remain about how to further improve both their robust performance in challenging conditions (e.g., textureless scenes) and the precision of camera parameter estimation simultaneously. We present 3R-GS, a 3D Gaussian Splatting framework that bridges this gap by jointly optimizing 3D Gaussians and camera parameters from large reconstruction priors MASt3R-SfM. We note that naively performing joint 3D Gaussian and camera optimization faces two challenges: the sensitivity to the quality of SfM initialization, and its limited capacity for global optimization, leading to suboptimal reconstruction results. Our 3R-GS, overcomes these issues by incorporating optimized practices, enabling robust scene reconstruction even with imperfect camera registration. Extensive experiments demonstrate that 3R-GS delivers high-quality novel view synthesis and precise camera pose estimation while remaining computationally efficient. Project page: https://zsh523.github.io/3R-GS/
3D高斯融合(3DGS)以其高效性和质量彻底改变了神经渲染,但与其他许多新颖的视角合成方法一样,它严重依赖于结构从运动(SfM)系统的准确相机姿态。尽管最近的SfM管道已经取得了令人印象深刻的进展,但仍存在如何进一步提高其在具有挑战性的条件下(例如无纹理场景)的稳健性能以及与相机参数估计精度同时提高的问题。我们提出了3R-GS,这是一个三维高斯融合框架,它通过优化三维高斯和来自大规模重建先验MASt3R-SfM的相机参数来弥合这一鸿沟。我们注意到,盲目进行三维高斯和相机的联合优化面临两个挑战:对SfM初始化的质量敏感,以及全局优化的能力有限,导致重建结果不理想。我们的3R-GS通过融入优化实践克服了这些问题,即使在相机注册不完美的情况下也能实现稳健的场景重建。大量实验表明,3R-GS能够实现高质量的新视角合成和精确的相机姿态估计,同时保持计算效率。项目页面:https://zsh523.github.io/3R-GS/
论文及项目相关链接
Summary
基于神经渲染的高效性和质量,三维高斯映射(3DGS)在视景合成方法中引发了革命。然而,其依赖于结构从运动(SfM)系统的精确相机姿态。针对SfM管道在具有挑战性的条件下(如纹理缺失的场景)如何进一步提高其稳健性能和同时提升相机参数估计精度的问题,本文提出了3R-GS方法。它通过联合优化三维高斯和来自大规模重建先验MASt3R-SfM的相机参数来解决上述问题。通过采用优化实践,即使在不完美的相机注册下也能实现稳健的场景重建。实验表明,与传统方法相比,这种方法不仅能进行高质量的新型视景合成,还能实现精确的相机姿态估计,且计算效率高。项目页面:链接。
Key Takeaways
- 介绍了基于神经渲染的三维高斯映射(3DGS)技术及其在视景合成中的重要作用。
- 指出了现有的结构从运动(SfM)系统在特定条件下如纹理缺失场景的局限性,如性能稳健性和相机参数估计的准确性。
- 介绍了通过联合优化三维高斯和来自大规模重建先验MASt3R-SfM的相机参数的解决方案——即新的方法“3R-GS”。
- 分析了新方法面临的挑战,包括初始化的质量和全局优化的能力限制,并解释了如何通过优化实践克服这些问题。
点此查看论文截图

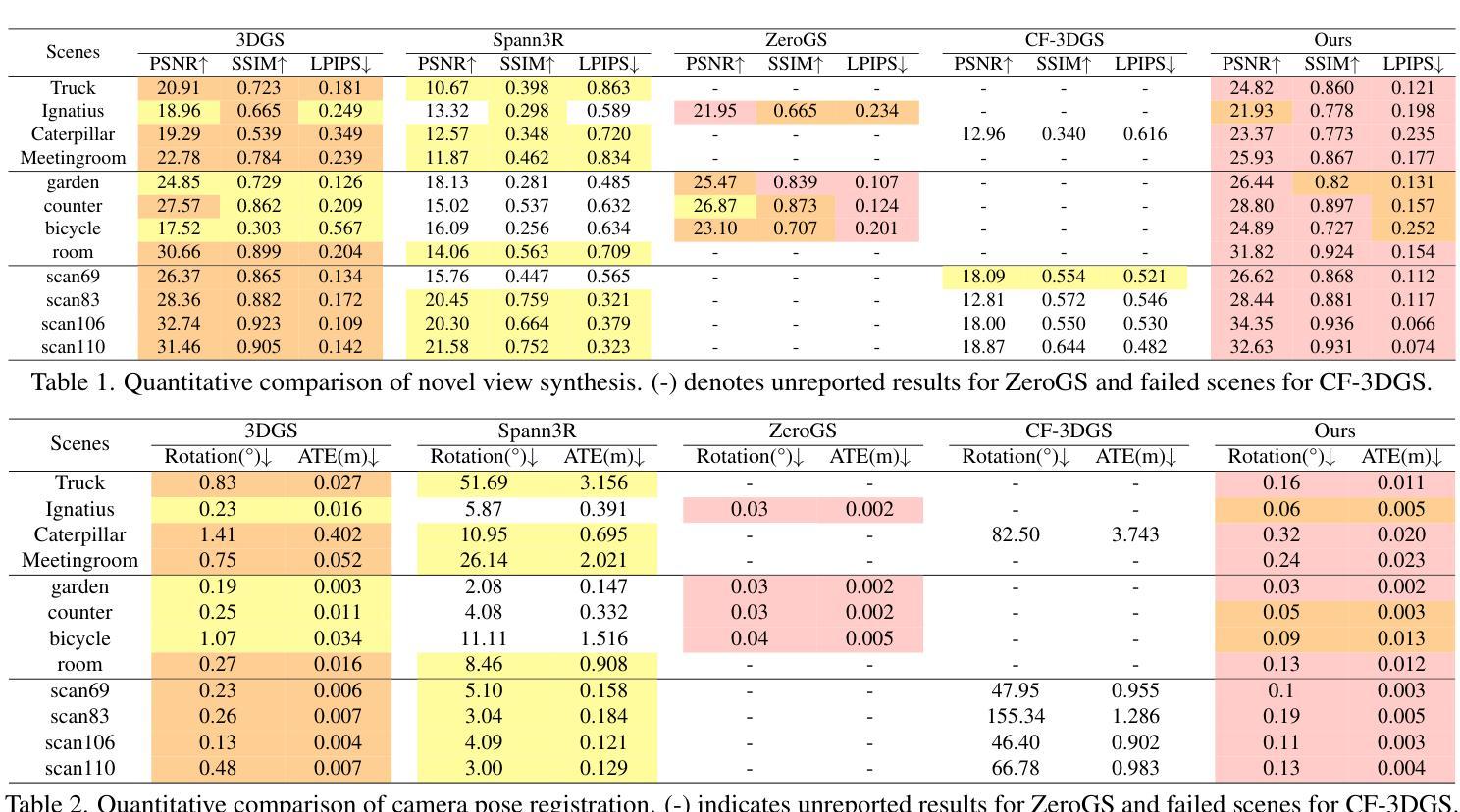
WildGS-SLAM: Monocular Gaussian Splatting SLAM in Dynamic Environments
Authors:Jianhao Zheng, Zihan Zhu, Valentin Bieri, Marc Pollefeys, Songyou Peng, Iro Armeni
We present WildGS-SLAM, a robust and efficient monocular RGB SLAM system designed to handle dynamic environments by leveraging uncertainty-aware geometric mapping. Unlike traditional SLAM systems, which assume static scenes, our approach integrates depth and uncertainty information to enhance tracking, mapping, and rendering performance in the presence of moving objects. We introduce an uncertainty map, predicted by a shallow multi-layer perceptron and DINOv2 features, to guide dynamic object removal during both tracking and mapping. This uncertainty map enhances dense bundle adjustment and Gaussian map optimization, improving reconstruction accuracy. Our system is evaluated on multiple datasets and demonstrates artifact-free view synthesis. Results showcase WildGS-SLAM’s superior performance in dynamic environments compared to state-of-the-art methods.
我们提出了WildGS-SLAM,这是一个稳健且高效的单目RGB SLAM系统,通过利用不确定性感知几何映射来处理动态环境。与传统的假设场景静态的SLAM系统不同,我们的方法结合了深度和不确定性信息,以提高移动物体存在时的跟踪、映射和渲染性能。我们引入了一个由浅层多层感知器和DINOv2特征预测的不确定性地图,以指导跟踪和映射过程中的动态对象移除。这个不确定性地图增强了密集捆绑调整和高斯地图优化,提高了重建精度。我们的系统在多个数据集上进行了评估,并展示了无伪影的视图合成。结果证明了WildGS-SLAM在动态环境中相较于最先进的方法具有卓越的性能。
论文及项目相关链接
Summary
本文介绍了WildGS-SLAM系统,这是一种用于处理动态环境的稳健高效的单目RGB SLAM系统。它通过利用具有感知不确定性的几何映射来增强跟踪、映射和渲染性能。该系统引入了一个由浅层多层感知器和DINOv2特征预测的不确定性地图,用于在跟踪和映射过程中引导动态对象移除。该不确定性地图增强了密集捆调整和高斯地图优化,提高了重建精度。在多个数据集上的评估结果表明,WildGS-SLAM在动态环境中的性能优于现有方法。
Key Takeaways
- WildGS-SLAM是一种用于处理动态环境的RGB SLAM系统。
- 系统利用不确定性感知的几何映射进行设计。
- 引入不确定性地图以增强跟踪、映射和渲染性能。
- 浅层多层感知器和DINOv2特征用于预测不确定性地图。
- 不确定性地图有助于提高密集捆调整和高斯地图优化的效果。
- WildGS-SLAM在多个数据集上的性能优于现有方法。
点此查看论文截图

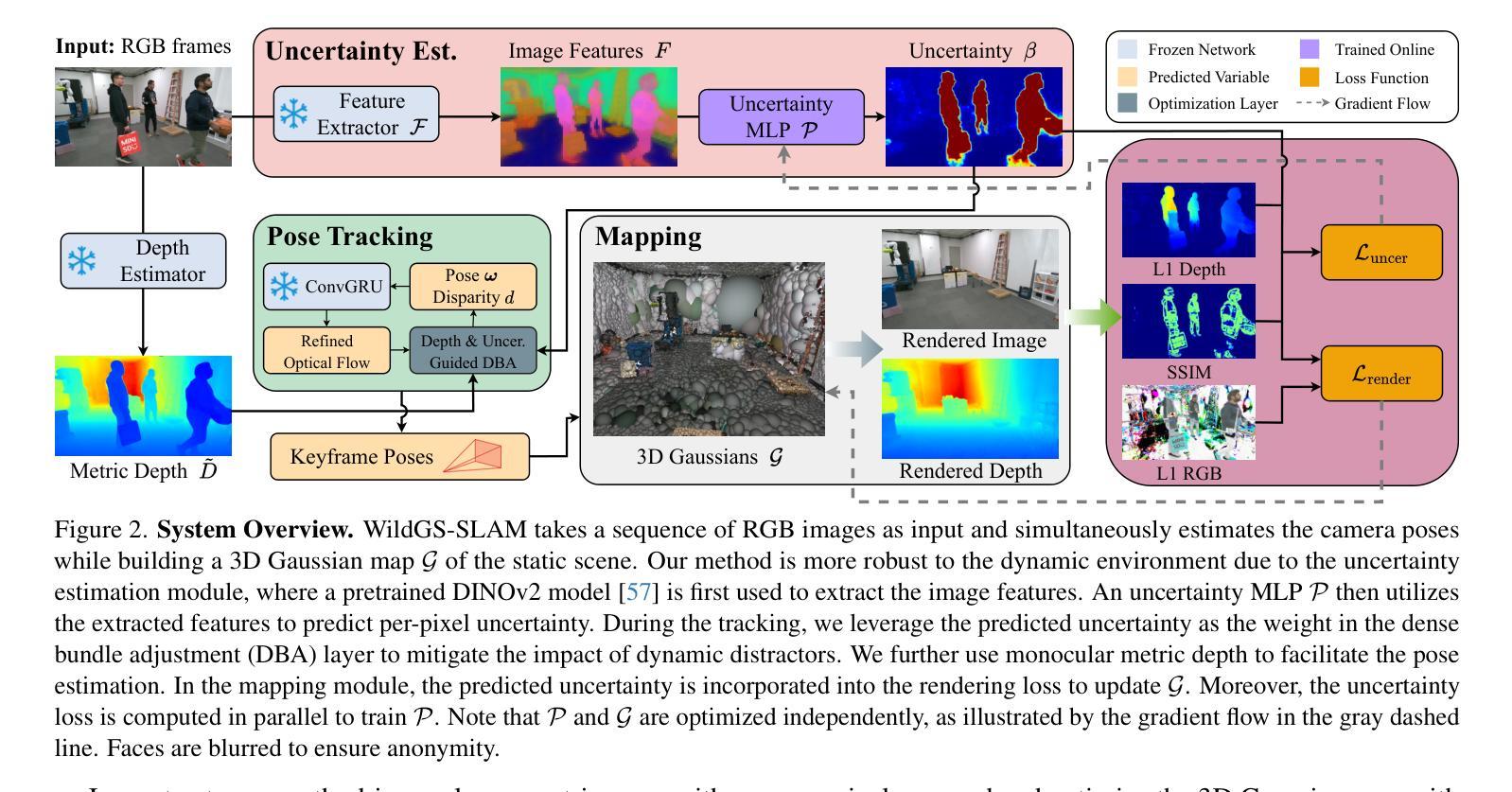
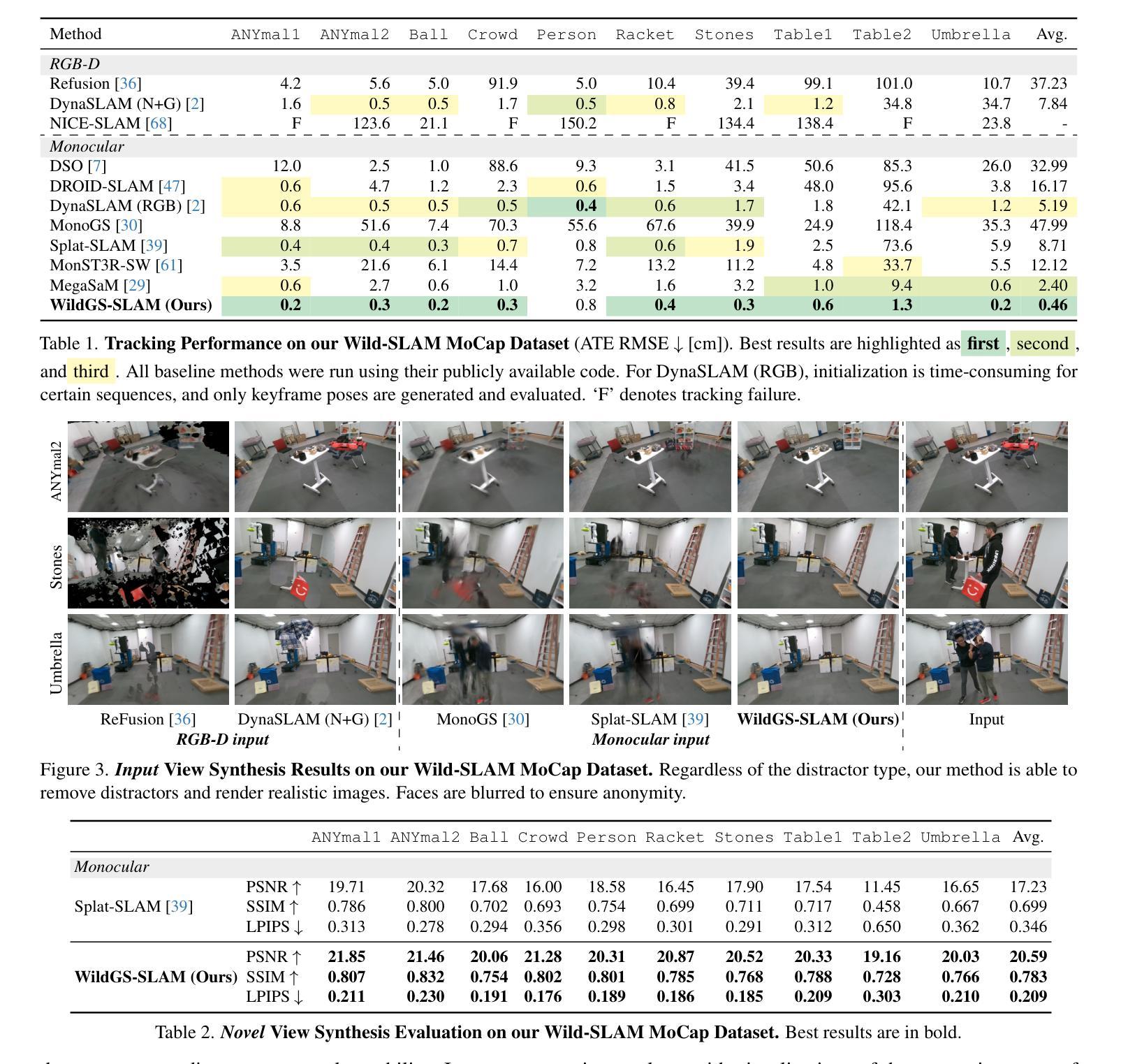
SelfSplat: Pose-Free and 3D Prior-Free Generalizable 3D Gaussian Splatting
Authors:Gyeongjin Kang, Jisang Yoo, Jihyeon Park, Seungtae Nam, Hyeonsoo Im, Sangheon Shin, Sangpil Kim, Eunbyung Park
We propose SelfSplat, a novel 3D Gaussian Splatting model designed to perform pose-free and 3D prior-free generalizable 3D reconstruction from unposed multi-view images. These settings are inherently ill-posed due to the lack of ground-truth data, learned geometric information, and the need to achieve accurate 3D reconstruction without finetuning, making it difficult for conventional methods to achieve high-quality results. Our model addresses these challenges by effectively integrating explicit 3D representations with self-supervised depth and pose estimation techniques, resulting in reciprocal improvements in both pose accuracy and 3D reconstruction quality. Furthermore, we incorporate a matching-aware pose estimation network and a depth refinement module to enhance geometry consistency across views, ensuring more accurate and stable 3D reconstructions. To present the performance of our method, we evaluated it on large-scale real-world datasets, including RealEstate10K, ACID, and DL3DV. SelfSplat achieves superior results over previous state-of-the-art methods in both appearance and geometry quality, also demonstrates strong cross-dataset generalization capabilities. Extensive ablation studies and analysis also validate the effectiveness of our proposed methods. Code and pretrained models are available at https://gynjn.github.io/selfsplat/
我们提出了SelfSplat,这是一种新型的三维高斯扩展模型,旨在从无姿势的多视角图像进行无姿态和无三维先验的可泛化的三维重建。由于缺少真实数据、学习到的几何信息,以及需要在不进行微调的情况下实现精确的三维重建,这些设置本质上是病态的,使得传统方法难以实现高质量的结果。我们的模型通过有效地将显式三维表示与自监督的深度和姿态估计技术相结合,解决了这些挑战,实现了姿态准确性和三维重建质量的相互提高。此外,我们引入了一个感知匹配的姿态估计网络和深度细化模块,以提高跨视图的几何一致性,确保更准确和稳定的三维重建。为了展示我们方法的表现,我们在大规模真实世界数据集上对其进行了评估,包括RealEstate10K、ACID和DL3DV。SelfSplat在外观和几何质量方面均达到了先前最先进的水平,并展示了强大的跨数据集泛化能力。广泛的消融研究和分析也验证了我们所提出方法的有效性。代码和预训练模型可在[https://gynjn.github.io/selfsplat/]找到。
论文及项目相关链接
PDF Project page: https://gynjn.github.io/selfsplat/
Summary
SelfSplat是一种新型3D高斯混合模型,无需姿势和先验信息即可进行多视角图像的通用化3D重建。它通过整合显式3D表示与自监督的深度和姿态估计技术来解决缺乏真实数据等挑战,提高了姿态准确性和重建质量。此外,还加入了匹配感知姿态估计网络和深度优化模块,确保跨视图几何一致性,实现更准确稳定的重建。在大型真实世界数据集上的评估显示,SelfSplat在外观和几何质量上均优于先前的方法,并具有强大的跨数据集泛化能力。
Key Takeaways
- SelfSplat是一种新的3D重建模型,可以在无姿势先验的情况下进行多视角图像的可泛化重建。
- 它通过整合显式三维表示与自监督的深度和姿态估计技术解决了无真实数据的问题。
- 模型包括匹配感知姿态估计网络和深度优化模块来确保跨视图的几何一致性。
- 在大规模真实世界数据集上的测试显示,SelfSplat在外观和几何质量方面表现出超越最新技术的优势。同时展示强大的跨数据集泛化能力。
- 该模型还实现了姿态准确性和重建质量的相互提升。
点此查看论文截图

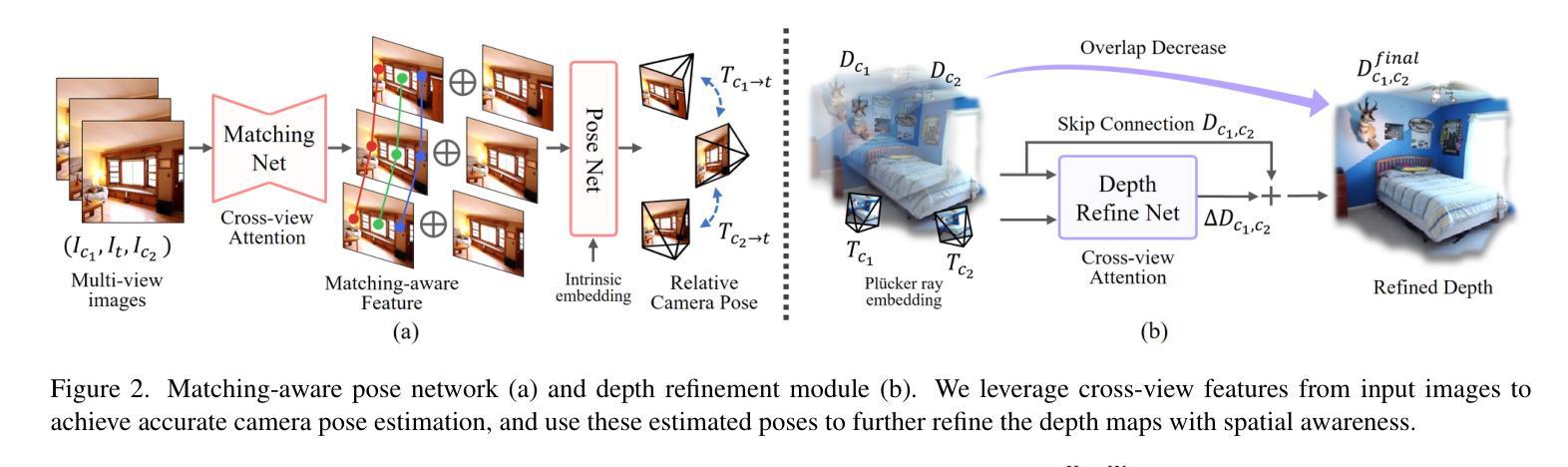




Gaussian Scenes: Pose-Free Sparse-View Scene Reconstruction using Depth-Enhanced Diffusion Priors
Authors:Soumava Paul, Prakhar Kaushik, Alan Yuille
In this work, we introduce a generative approach for pose-free (without camera parameters) reconstruction of 360 scenes from a sparse set of 2D images. Pose-free scene reconstruction from incomplete, pose-free observations is usually regularized with depth estimation or 3D foundational priors. While recent advances have enabled sparse-view reconstruction of large complex scenes (with high degree of foreground and background detail) with known camera poses using view-conditioned generative priors, these methods cannot be directly adapted for the pose-free setting when ground-truth poses are not available during evaluation. To address this, we propose an image-to-image generative model designed to inpaint missing details and remove artifacts in novel view renders and depth maps of a 3D scene. We introduce context and geometry conditioning using Feature-wise Linear Modulation (FiLM) modulation layers as a lightweight alternative to cross-attention and also propose a novel confidence measure for 3D Gaussian splat representations to allow for better detection of these artifacts. By progressively integrating these novel views in a Gaussian-SLAM-inspired process, we achieve a multi-view-consistent 3D representation. Evaluations on the MipNeRF360 and DL3DV-10K benchmark datasets demonstrate that our method surpasses existing pose-free techniques and performs competitively with state-of-the-art posed (precomputed camera parameters are given) reconstruction methods in complex 360 scenes.
在这项工作中,我们提出了一种无姿态(无需相机参数)的生成方法,用于从稀疏的二维图像集中重建360度场景。从不完整、无姿态的观察中进行场景重建通常是通过深度估计或三维基础先验进行正则化的。虽然最近的进展已经实现了具有已知相机姿态的大型复杂场景(前景和背景细节丰富)的稀疏视图重建,使用视图条件生成先验,但这些方法无法直接适应无姿态设置,即在评估期间无法使用真实姿态。为了解决这一问题,我们提出了一种图像到图像的生成模型,旨在填充缺失的细节并消除新型视图渲染和三维场景深度图中的伪影。我们通过特征线性调制(FiLM)调制层引入上下文和几何条件,作为交叉注意力的轻量级替代方案,并提出了一种新的三维高斯斑点表示置信度度量,以更好地检测这些伪影。通过以高斯SLAM为灵感的过程逐步集成这些新型视图,我们实现了多视图一致的三维表示。在MipNeRF360和DL3DV-10K基准数据集上的评估表明,我们的方法超越了现有的无姿态技术,并在复杂360度场景的重建方法与最先进的定位(预先计算相机参数已给出)重建方法中表现相当。
论文及项目相关链接
PDF Project page is available at https://gaussianscenes.github.io/
摘要
本文介绍了一种无需相机参数的360度场景重建方法,能够从稀疏的2D图像集合中进行场景重建。该方法通过深度估计或3D基础先验进行规则化。虽然最近的进展已经实现了在已知相机姿态下从稀疏视角重建大型复杂场景,但这些方法无法直接适应于没有地面真实姿态的评估时的姿态自由设置。为解决此问题,我们提出了一种图像到图像的生成模型,旨在填补缺失的细节并消除新视图渲染和深度图中的伪影。我们使用特征线性调制(FiLM)调制层引入上下文和几何条件作为跨注意力的轻量级替代方案,并提出了一种针对高斯splat表示的置信度度量来更好地检测这些伪影。通过渐进地整合这些新视图在高斯SLAM启发的过程中,我们获得了一个多视角一致的3D表示。在MipNeRF360和DL3DV-10K基准数据集上的评估表明,我们的方法超越了现有的姿态自由技术,并在复杂360度场景中与最先进的定位重建方法具有竞争力。
要点
- 本文介绍了一种无需相机参数的360度场景重建方法。
- 该方法通过深度估计或3D基础先验进行规则化。
- 提出了一种图像到图像的生成模型,用于填充缺失的细节并消除新视图渲染和深度图中的伪影。
- 引入特征线性调制(FiLM)调制层来处理上下文和几何条件。
- 提出一种针对高斯splat表示的置信度度量来检测伪影。
- 通过渐进地整合新视图,实现多视角一致的3D表示。
- 在基准数据集上的评估表明,该方法在姿态自由技术方面表现出色,与最先进的定位重建方法具有竞争力。
点此查看论文截图

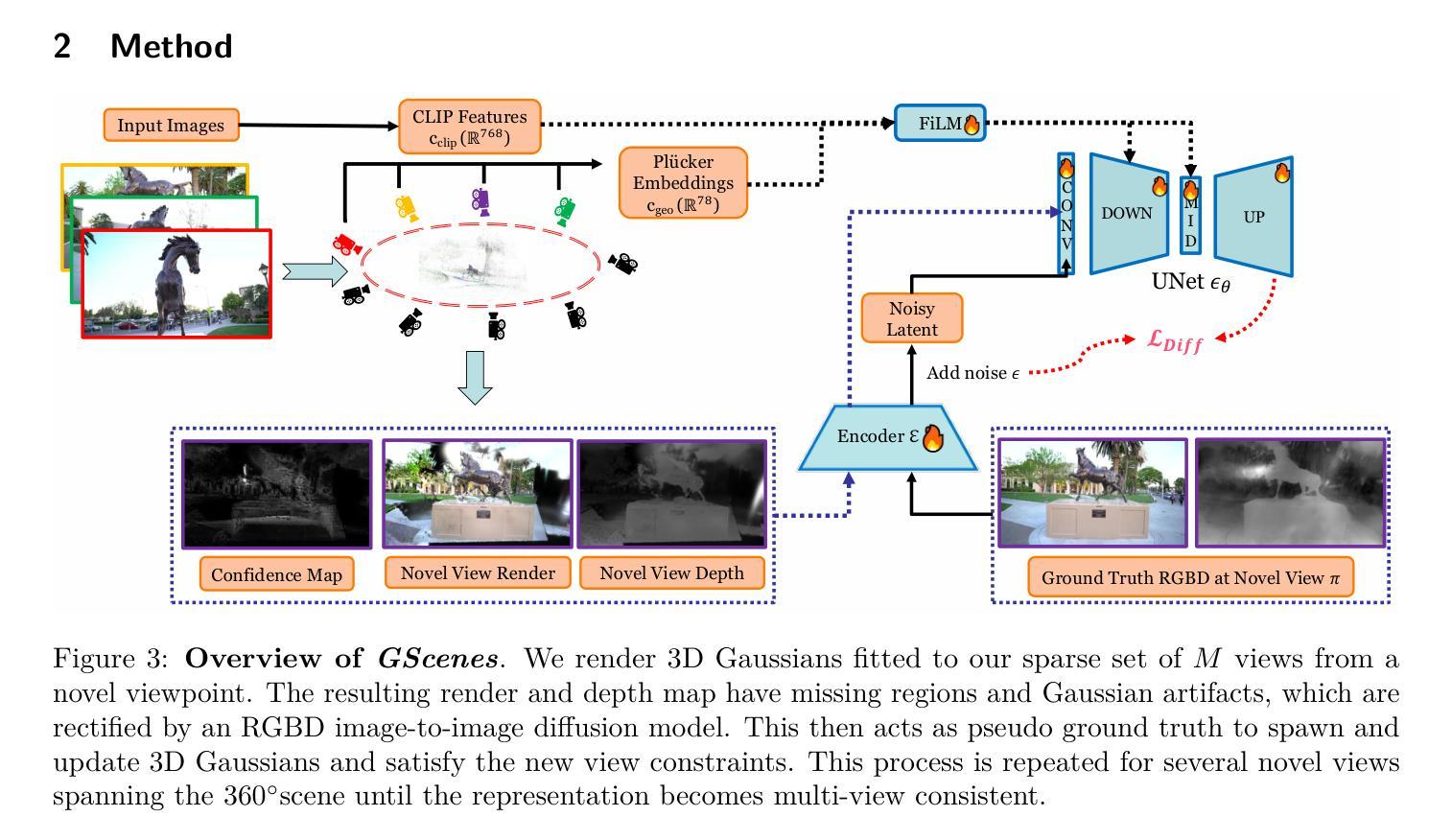


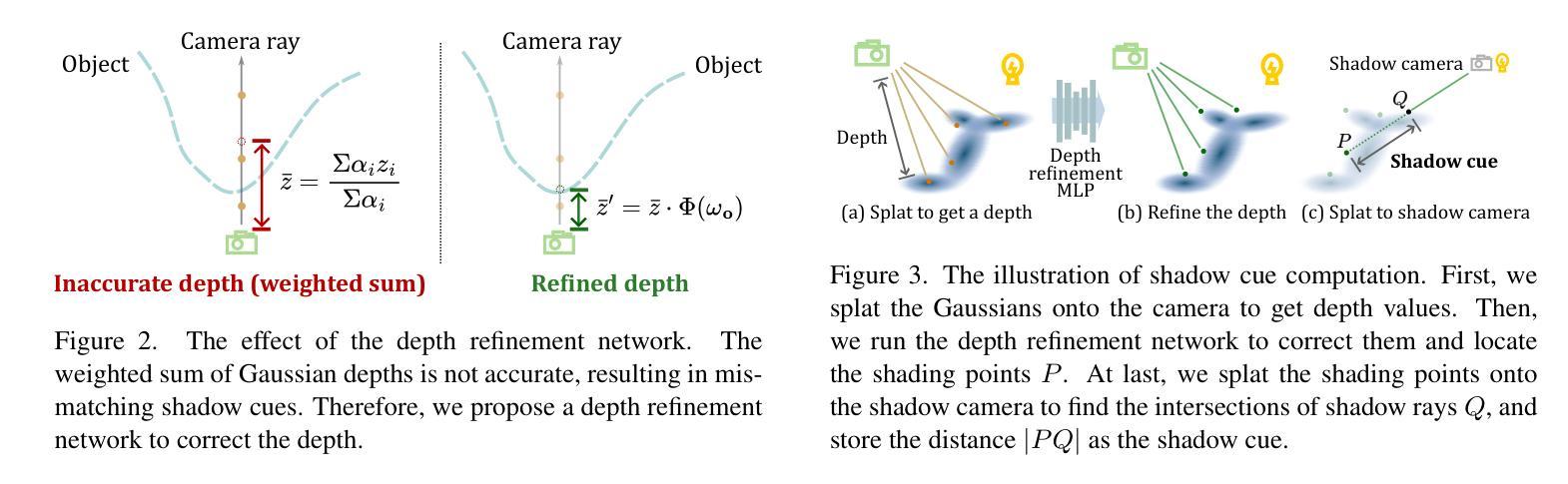
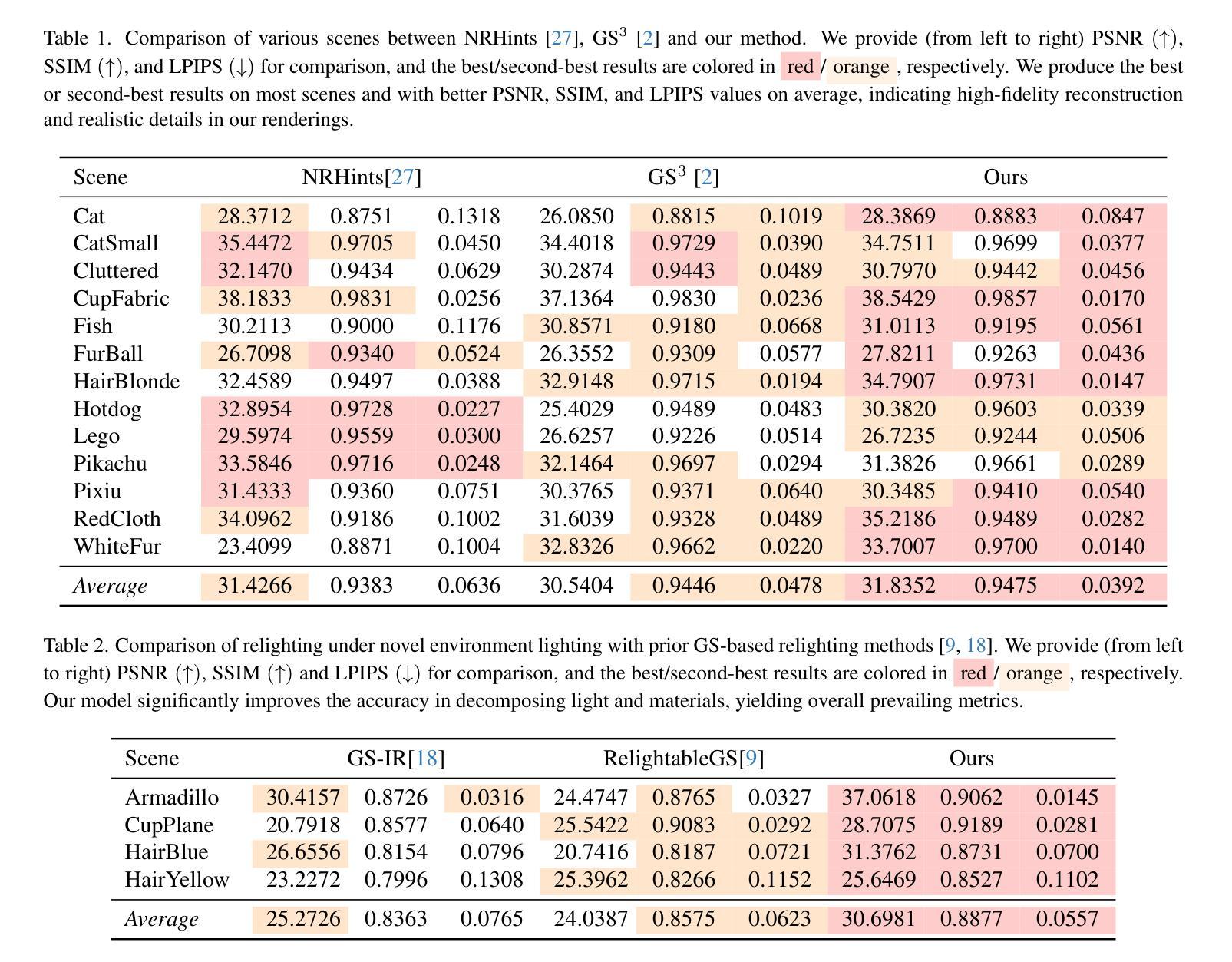
RNG: Relightable Neural Gaussians
Authors:Jiahui Fan, Fujun Luan, Jian Yang, Miloš Hašan, Beibei Wang
3D Gaussian Splatting (3DGS) has shown impressive results for the novel view synthesis task, where lighting is assumed to be fixed. However, creating relightable 3D assets, especially for objects with ill-defined shapes (fur, fabric, etc.), remains a challenging task. The decomposition between light, geometry, and material is ambiguous, especially if either smooth surface assumptions or surfacebased analytical shading models do not apply. We propose Relightable Neural Gaussians (RNG), a novel 3DGS-based framework that enables the relighting of objects with both hard surfaces or soft boundaries, while avoiding assumptions on the shading model. We condition the radiance at each point on both view and light directions. We also introduce a shadow cue, as well as a depth refinement network to improve shadow accuracy. Finally, we propose a hybrid forward-deferred fitting strategy to balance geometry and appearance quality. Our method achieves significantly faster training (1.3 hours) and rendering (60 frames per second) compared to a prior method based on neural radiance fields and produces higher-quality shadows than a concurrent 3DGS-based method. Project page: https://www.whois-jiahui.fun/project_pages/RNG.
三维高斯绘制技术(3DGS)对于新的视角合成任务已经取得了令人印象深刻的结果,该任务假设光照是固定的。然而,创建可重新照明的三维资产仍然是一个具有挑战性的任务,特别是对于形状不明确(如毛发、织物等)的对象。光线、几何形状和材料之间的分解关系不明确,特别是如果光滑表面假设或基于表面的分析着色模型不适用的话。我们提出了可重新照明的神经高斯(RNG),这是一种基于三维高斯绘制技术(3DGS)的新框架,可以实现对具有硬表面或软边界的物体的重新照明,同时避免了对着色模型的假设。我们将每一点的辐射量设置为视点和光照方向的条件。我们还引入了一个阴影提示和一个深度细化网络来提高阴影的准确性。最后,我们提出了一种混合的前向延迟拟合策略来平衡几何形状和外观质量。我们的方法与基于神经辐射场的先前方法相比,实现了更快的训练(1.3小时)和渲染(每秒60帧),并且与同期的基于三维高斯绘制技术的方法相比,产生了更高质量的阴影。项目页面:https://www.whois-jiahui.fun/project_pages/RNG。
论文及项目相关链接
PDF Camera-ready version. Proceedings of CVPR 2025
Summary
在光照固定假设下,基于神经网络辐射场的观点合成方法虽展现出惊人效果,但对于照明可调整的三维资产创建,尤其是形状不明确物体(如毛发、布料等)仍是一大挑战。本文对基于高斯插值的几何渲染(Geometry Splatting)提出一种改进方法——Relightable Neural Gaussians(RNG)。该方法能够针对具有硬表面或软边界的对象进行照明调整,无需对阴影模型进行假设。此外,我们还引入了一种阴影提示和一个深度修正网络来提高阴影的准确性。最终,通过一种混合的正向延迟拟合策略平衡几何和外观质量。我们的方法相较于基于神经网络辐射场的先前方法,训练时间显著缩短(仅1.3小时),渲染速度更快(每秒60帧),并且产生的阴影质量更高。相关项目页面可访问:链接。
Key Takeaways
- 3DGS在高光固定的假设下对于视点合成效果良好,但在照明可调整的三维资产创建上仍面临挑战。
- RNG框架解决照明可调整性问题,适用于硬表面和软边界物体。
- RNG不需要对阴影模型进行假设,通过引入阴影提示和深度修正网络提高阴影准确性。
- 混合正向延迟拟合策略实现几何和外观质量的平衡。
点此查看论文截图

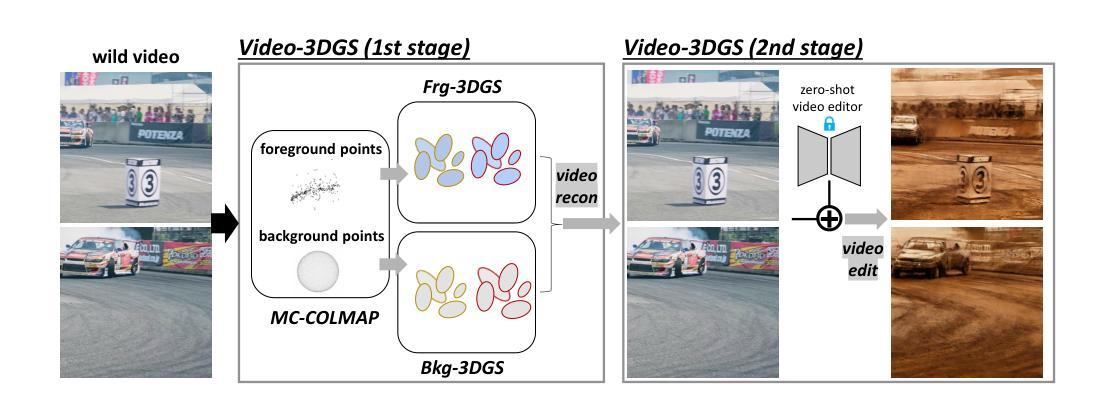
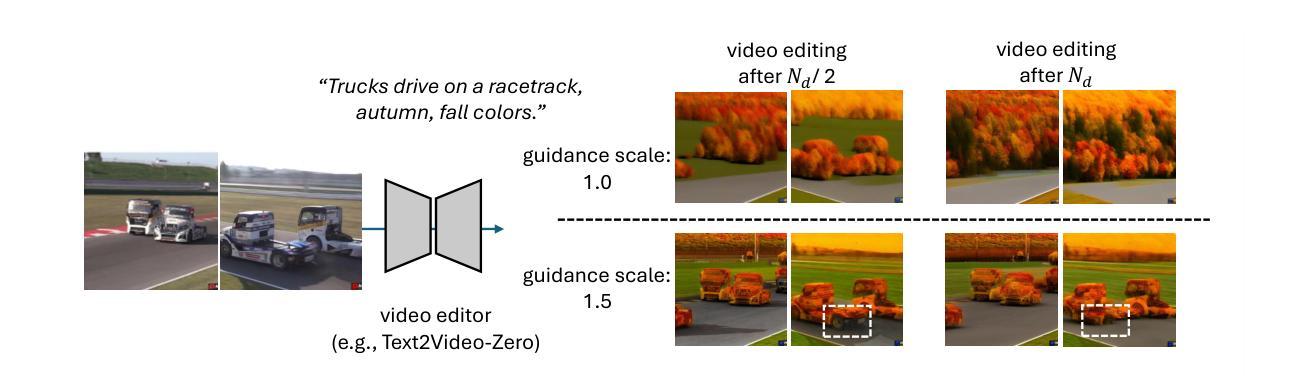
Enhancing Temporal Consistency in Video Editing by Reconstructing Videos with 3D Gaussian Splatting
Authors:Inkyu Shin, Qihang Yu, Xiaohui Shen, In So Kweon, Kuk-Jin Yoon, Liang-Chieh Chen
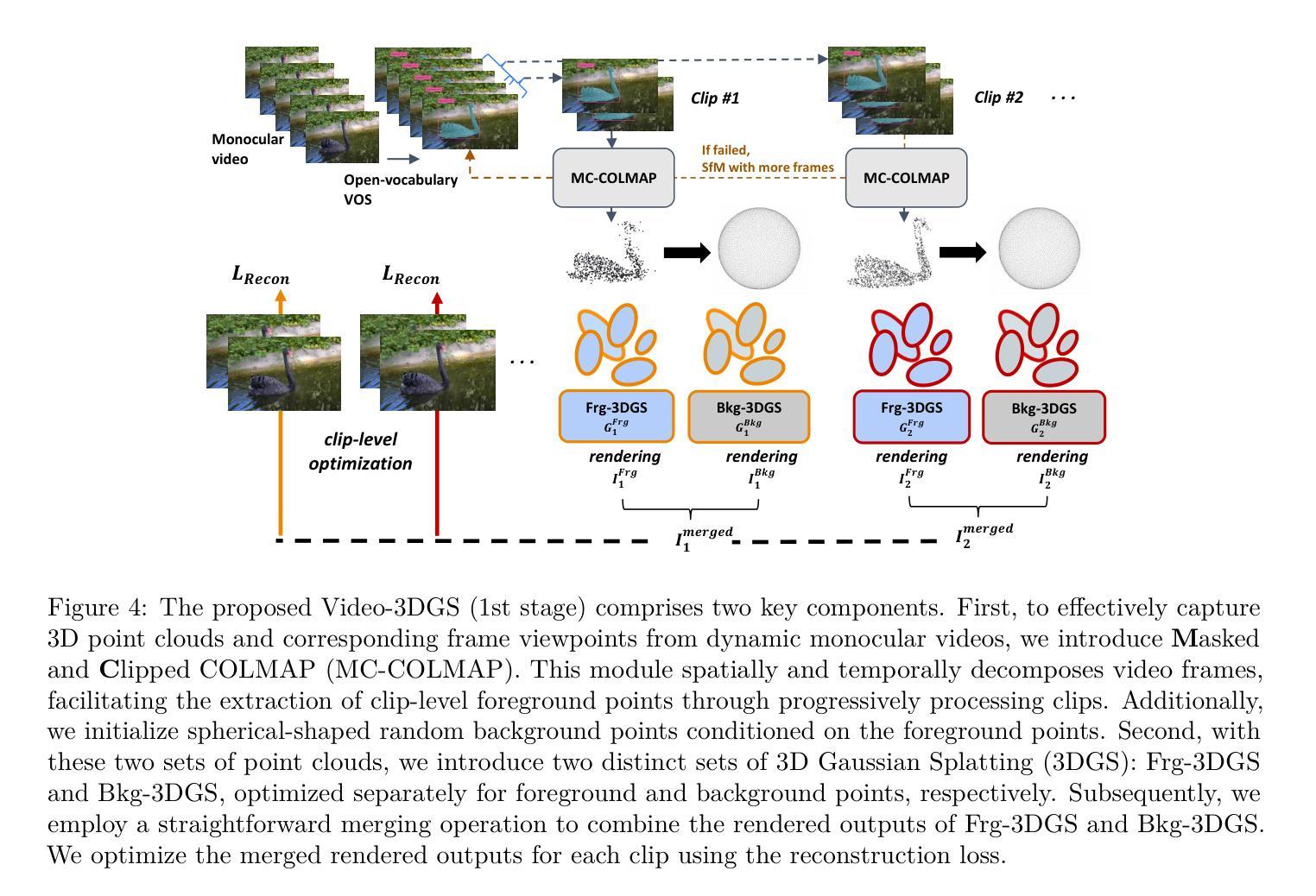
Recent advancements in zero-shot video diffusion models have shown promise for text-driven video editing, but challenges remain in achieving high temporal consistency. To address this, we introduce Video-3DGS, a 3D Gaussian Splatting (3DGS)-based video refiner designed to enhance temporal consistency in zero-shot video editors. Our approach utilizes a two-stage 3D Gaussian optimizing process tailored for editing dynamic monocular videos. In the first stage, Video-3DGS employs an improved version of COLMAP, referred to as MC-COLMAP, which processes original videos using a Masked and Clipped approach. For each video clip, MC-COLMAP generates the point clouds for dynamic foreground objects and complex backgrounds. These point clouds are utilized to initialize two sets of 3D Gaussians (Frg-3DGS and Bkg-3DGS) aiming to represent foreground and background views. Both foreground and background views are then merged with a 2D learnable parameter map to reconstruct full views. In the second stage, we leverage the reconstruction ability developed in the first stage to impose the temporal constraints on the video diffusion model. To demonstrate the efficacy of Video-3DGS on both stages, we conduct extensive experiments across two related tasks: Video Reconstruction and Video Editing. Video-3DGS trained with 3k iterations significantly improves video reconstruction quality (+3 PSNR, +7 PSNR increase) and training efficiency (x1.9, x4.5 times faster) over NeRF-based and 3DGS-based state-of-art methods on DAVIS dataset, respectively. Moreover, it enhances video editing by ensuring temporal consistency across 58 dynamic monocular videos.
最近的零样本视频扩散模型进展对文本驱动的视频编辑显示出巨大潜力,但在实现高时间一致性方面仍存在挑战。为了解决这一问题,我们引入了Video-3DGS,这是一种基于3D高斯拼贴(3DGS)的视频细化器,旨在提高零样本视频编辑器的时间一致性。我们的方法利用两阶段3D高斯优化过程,针对动态单目视频编辑而定制。在第一阶段,Video-3DGS采用COLMAP的改进版本,称为MC-COLMAP,它通过遮罩和裁剪的方法处理原始视频。对于每个视频片段,MC-COLMAP生成动态前景对象和复杂背景的点云。这些点云用于初始化两组3D高斯(Frg-3DGS和Bkg-3DGS),旨在表示前景和背景视图。然后将前景和背景视图与2D可学习参数图合并,以重建全景。在第二阶段,我们利用第一阶段开发的重建能力对视频扩散模型施加时间约束。为了证明Video-3DGS在两个阶段的有效性,我们在两个相关任务上进行了大量实验:视频重建和视频编辑。Video-3DGS在DAVIS数据集上与基于NeRF和基于3DGS的最先进方法相比,经过3k次迭代训练,显著提高了视频重建质量(+3 PSNR,+7 PSNR增加),并提高了训练效率(分别加快了1.9倍和4.5倍)。此外,它通过确保58个动态单目视频的时间一致性,增强了视频编辑效果。
论文及项目相关链接
PDF Accepted to TMLR 2025. Project page at https://video-3dgs-project.github.io/
摘要
近期零样本视频扩散模型在文本驱动的视频编辑领域展现出巨大潜力,但在实现高时间一致性方面仍面临挑战。为解决这一问题,我们推出Video-3DGS,一种基于3D高斯拼贴(3DGS)的视频精炼器,旨在提升零样本视频编辑器的时间一致性。该方法采用两阶段3D高斯优化流程,专门针对动态单目视频编辑。第一阶段,Video-3DGS采用改进版COLMAP(称为MC-COLMAP),通过遮罩和裁剪方法处理原始视频。MC-COLMAP为每段视频生成动态前景和复杂背景的点云,用于初始化两组3D高斯(Frg-3DGS和Bkg-3DGS),分别代表前景和背景视图。然后,前景和背景视图与2D可学习参数图合并,以重建全视图。第二阶段,我们利用第一阶段的重建能力,对视频扩散模型施加时间约束。为证明Video-3DGS在两个阶段的有效性,我们在两个相关任务(视频重建和视频编辑)上进行了广泛实验。在DAVIS数据集上,与最新基于NeRF和基于3DGS的方法相比,Video-3DGS经过3k次迭代训练,显著提高了视频重建质量(PSNR提高3点,提高7点),并提高了训练效率(分别提高了1.9倍和4.5倍)。此外,它还能确保在58个动态单目视频上的时间一致性,从而提高视频编辑效果。
关键见解
- Video-3DGS被引入以解决零样本视频编辑中的时间一致性问题。
- 引入两阶段3D高斯优化流程,适用于动态单目视频编辑。
- MC-COLMAP方法用于生成前景和背景的点云,初始化3D高斯。
- Video-3DGS在DAVIS数据集上的实验表明,相较于其他方法,它能显著提高视频重建的质量和训练效率。
- Video-3DGS通过确保时间一致性,提升了视频编辑的效果。
- 该方法在两个相关任务(视频重建和视频编辑)上均表现出优异性能。
点此查看论文截图


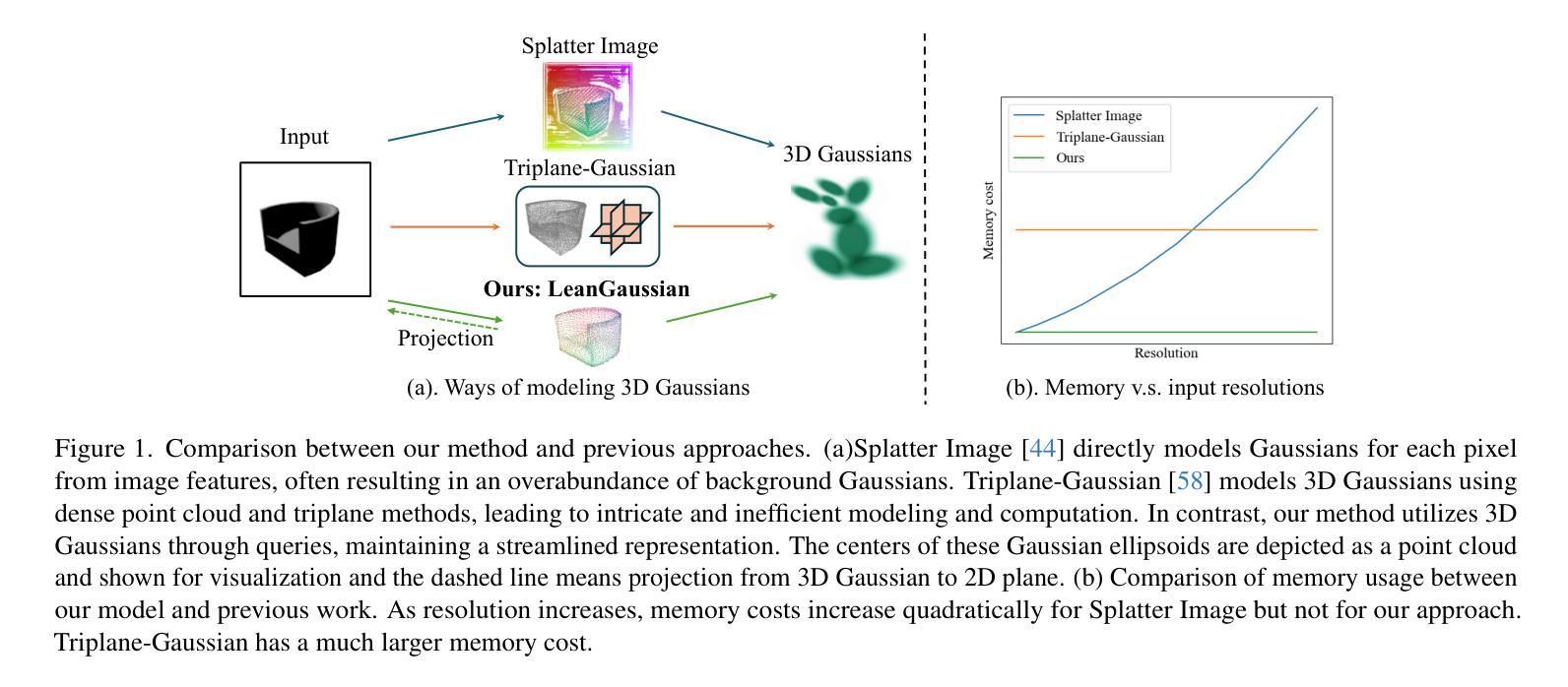
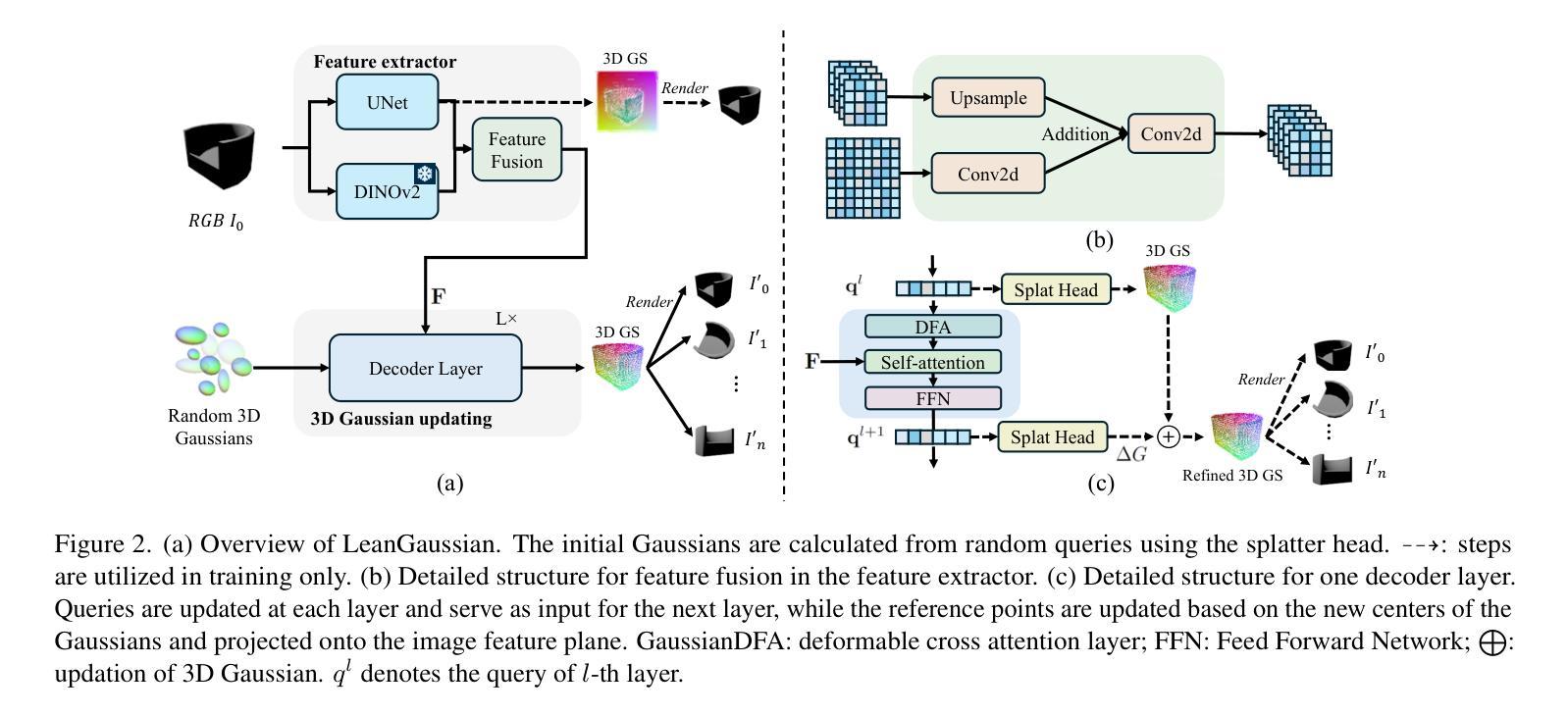
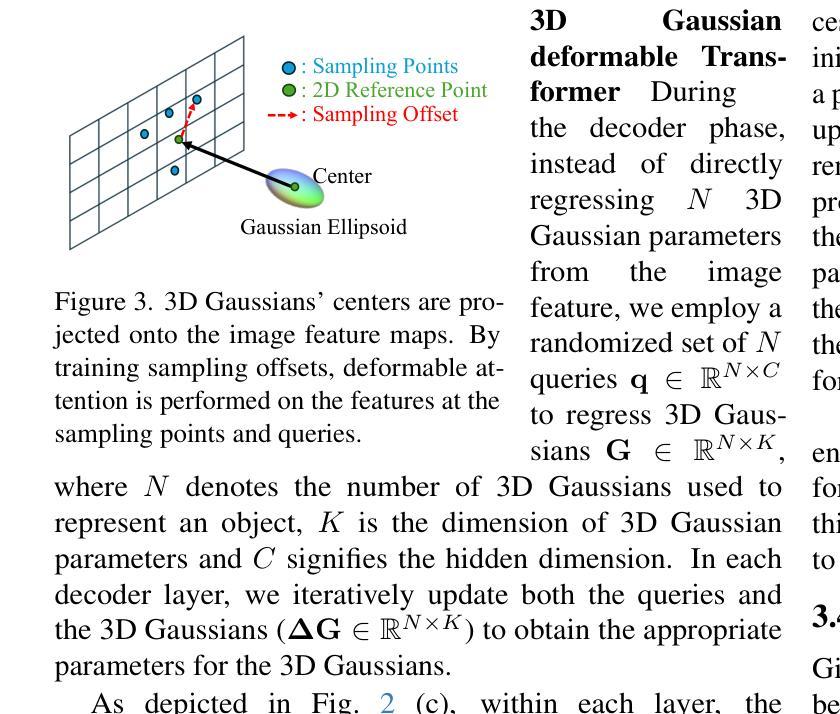
LeanGaussian: Breaking Pixel or Point Cloud Correspondence in Modeling 3D Gaussians
Authors:Jiamin Wu, Kenkun Liu, Han Gao, Xiaoke Jiang, Lei Zhang
Recently, Gaussian splatting has demonstrated significant success in novel view synthesis. Current methods often regress Gaussians with pixel or point cloud correspondence, linking each Gaussian with a pixel or a 3D point. This leads to the redundancy of Gaussians being used to overfit the correspondence rather than the objects represented by the 3D Gaussians themselves, consequently wasting resources and lacking accurate geometries or textures. In this paper, we introduce LeanGaussian, a novel approach that treats each query in deformable Transformer as one 3D Gaussian ellipsoid, breaking the pixel or point cloud correspondence constraints. We leverage deformable decoder to iteratively refine the Gaussians layer-by-layer with the image features as keys and values. Notably, the center of each 3D Gaussian is defined as 3D reference points, which are then projected onto the image for deformable attention in 2D space. On both the ShapeNet SRN dataset (category level) and the Google Scanned Objects dataset (open-category level, trained with the Objaverse dataset), our approach, outperforms prior methods by approximately 6.1%, achieving a PSNR of 25.44 and 22.36, respectively. Additionally, our method achieves a 3D reconstruction speed of 7.2 FPS and rendering speed 500 FPS. Codes are available at https://github.com/jwubz123/LeanGaussian.
近期,高斯喷溅技术在新型视图合成方面取得了显著的成功。当前的方法通常通过像素或点云对应关系回归高斯,将每个高斯与像素或3D点相关联。这导致使用大量冗余高斯来过度拟合对应关系,而非由3D高斯本身所代表的物体,从而浪费资源,并且缺乏精确几何或纹理。在本文中,我们介绍了LeanGaussian,这是一种新颖的方法,它将可变形Transformer中的每个查询视为一个3D高斯椭圆体,打破了像素或点云对应关系的约束。我们利用可变形解码器逐层迭代地细化高斯,以图像特征作为键和值。值得注意的是,每个3D高斯的中心被定义为3D参考点,然后投影到图像上进行2D空间的可变形注意力。在ShapeNet SRN数据集(类别级别)和Google扫描对象数据集(开放类别级别,使用Objaverse数据集进行训练)上,我们的方法较之前的方法高出约6.1%,分别实现了PSNR值为25.44和22.36。此外,我们的方法实现了3D重建速度为7.2 FPS和渲染速度为500 FPS。代码可通过https://github.com/jwubz123/LeanGaussian获取。
论文及项目相关链接
摘要
本文提出LeanGaussian方法,以3D高斯椭圆体处理变形Transformer中的查询,打破像素或点云对应的约束。利用可变形解码器逐层细化高斯,以图像特征为键和值。定义每个3D高斯的中心为3D参考点,投影到图像上进行二维空间的变形注意。在ShapeNet SRN数据集和Google扫描对象数据集上,该方法优于现有方法约6.1%,PSNR分别达到25.44和22.36。此外,该方法达到3D重建速度7.2 FPS和渲染速度500 FPS。
关键要点
- LeanGaussian方法引入3D高斯椭圆体处理变形Transformer中的查询。
- 方法打破像素或点云对应的约束,利用可变形解码器逐层细化高斯。
- 3D高斯中心定义为3D参考点,用于二维空间的变形注意。
- 在ShapeNet SRN和Google扫描对象数据集上,该方法性能优于现有方法约6.1%。
- LeanGaussian方法实现3D重建速度7.2 FPS和渲染速度500 FPS。
点此查看论文截图