⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-09 更新
CREA: A Collaborative Multi-Agent Framework for Creative Content Generation with Diffusion Models
Authors:Kavana Venkatesh, Connor Dunlop, Pinar Yanardag
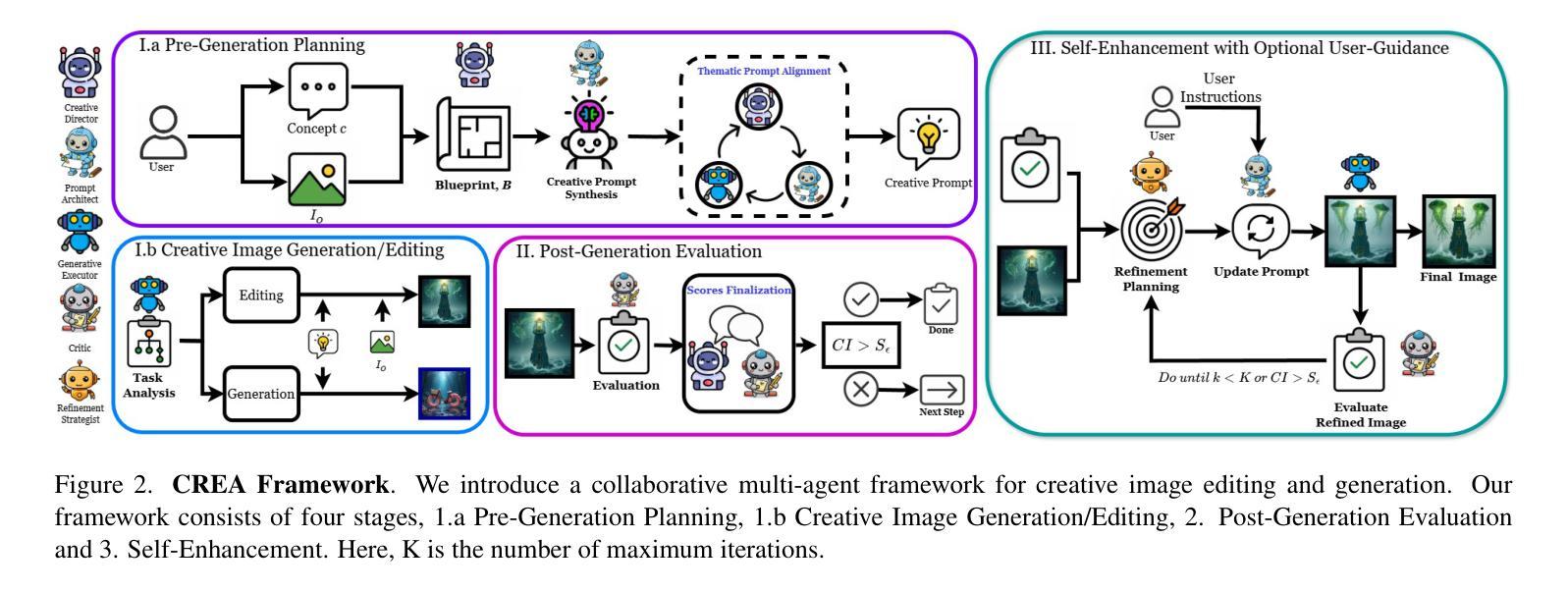
Creativity in AI imagery remains a fundamental challenge, requiring not only the generation of visually compelling content but also the capacity to add novel, expressive, and artistically rich transformations to images. Unlike conventional editing tasks that rely on direct prompt-based modifications, creative image editing demands an autonomous, iterative approach that balances originality, coherence, and artistic intent. To address this, we introduce CREA, a novel multi-agent collaborative framework that mimics the human creative process. Our framework leverages a team of specialized AI agents who dynamically collaborate to conceptualize, generate, critique, and enhance images. Through extensive qualitative and quantitative evaluations, we demonstrate that CREA significantly outperforms state-of-the-art methods in diversity, semantic alignment, and creative transformation. By structuring creativity as a dynamic, agentic process, CREA redefines the intersection of AI and art, paving the way for autonomous AI-driven artistic exploration, generative design, and human-AI co-creation. To the best of our knowledge, this is the first work to introduce the task of creative editing.
人工智能影像创造力仍然是一个基本挑战,不仅需要生成视觉吸引人的内容,还需要具备对影像进行新颖、表达和富有艺术感的转换能力。不同于依赖直接提示修改的传统编辑任务,创造性图像编辑要求一种平衡原创性、连贯性和艺术意图的自主迭代方法。为解决这一问题,我们引入了CREA,这是一种模仿人类创造过程的新型多智能体协作框架。我们的框架利用一组专门的智能体动态协作,对图像进行构思、生成、批判和改进。通过广泛的质量和数量评估,我们证明CREA在多样性、语义对齐和创造性转换方面显著优于现有技术。通过将创造力结构化为一个动态的智能主体过程,CREA重新定义了人工智能与艺术之间的交集,为自主的人工智能驱动艺术探索、生成设计和人机协同创作铺平了道路。据我们所知,这是首次引入创造性编辑任务的工作。
论文及项目相关链接
PDF Project URL: https://crea-diffusion.github.io
Summary
人工智能图像创造力仍然是一个基本挑战,需要生成视觉上吸引人的内容,并具备对图像进行新颖、富有表现力和艺术性丰富的转换能力。为解决这一问题,我们提出了CREA框架,一个模仿人类创造性过程的多智能体协作框架。它通过专门设计的AI智能体团队动态协作来实现图像的概念化、生成、批评和改进。研究表明,CREA在多样性、语义对齐和创造性转换方面显著优于现有方法。
Key Takeaways
- 人工智能图像创造力是一个基本挑战,需要生成视觉吸引力并具备新颖、富有表现力和艺术性丰富的转换能力。
- 不同于依赖直接提示修改的传统编辑任务,创造性图像编辑需要平衡原创性、连贯性和艺术意图的自主迭代方法。
- CREA是一个模仿人类创造性过程的多智能体协作框架,通过专门设计的AI智能体团队动态协作实现图像编辑。
- CREA在多样性、语义对齐和创造性转换方面显著优于现有方法。
- CREA重新定义了人工智能和艺术的交集,为自主的人工智能驱动的艺术探索、生成设计和人机共创铺平了道路。
- 这是首次引入创造性编辑任务的工作。
点此查看论文截图




How to evaluate control measures for LLM agents? A trajectory from today to superintelligence
Authors:Tomek Korbak, Mikita Balesni, Buck Shlegeris, Geoffrey Irving
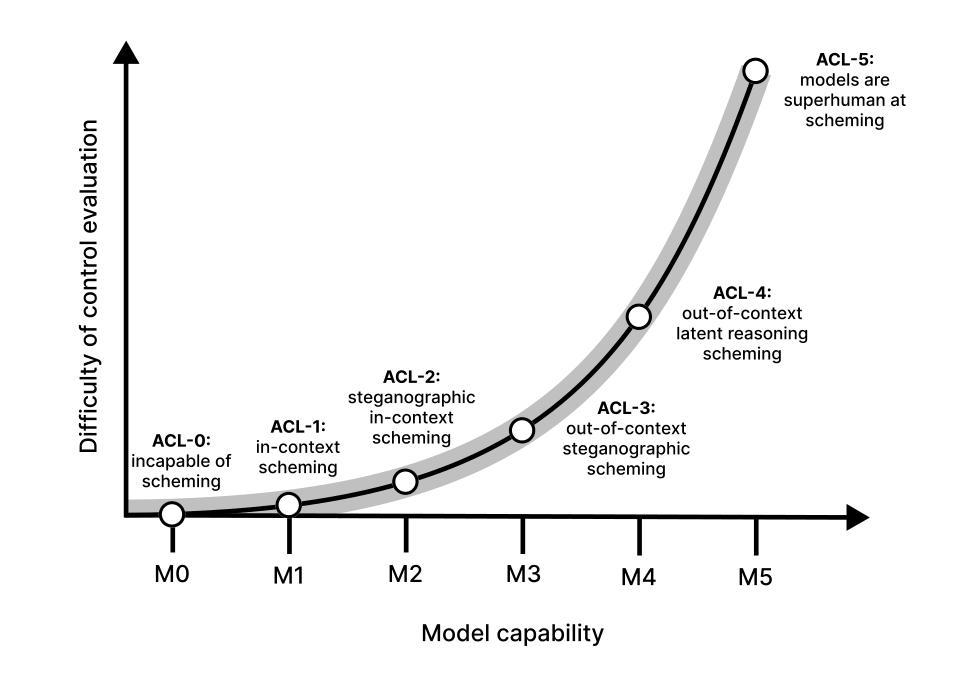
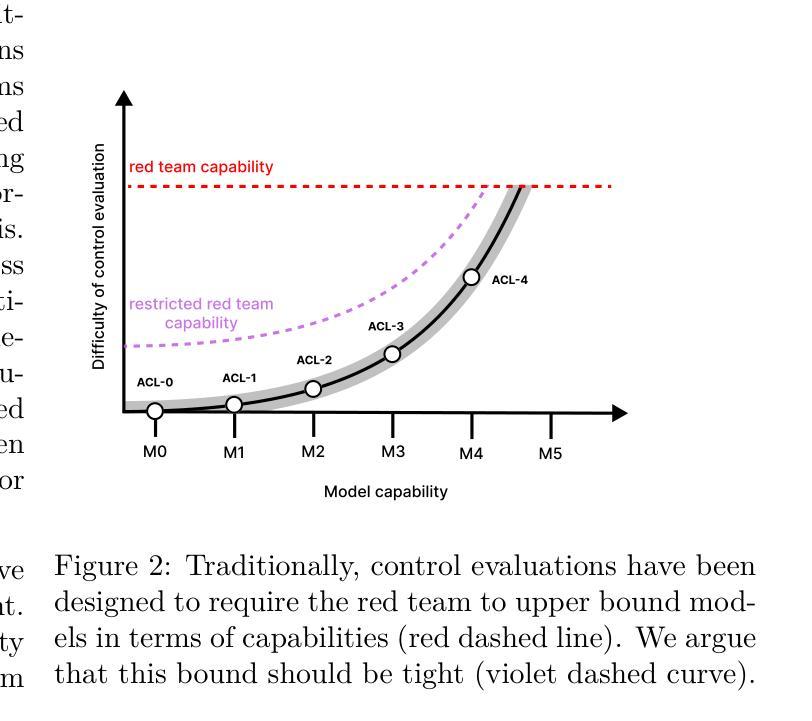
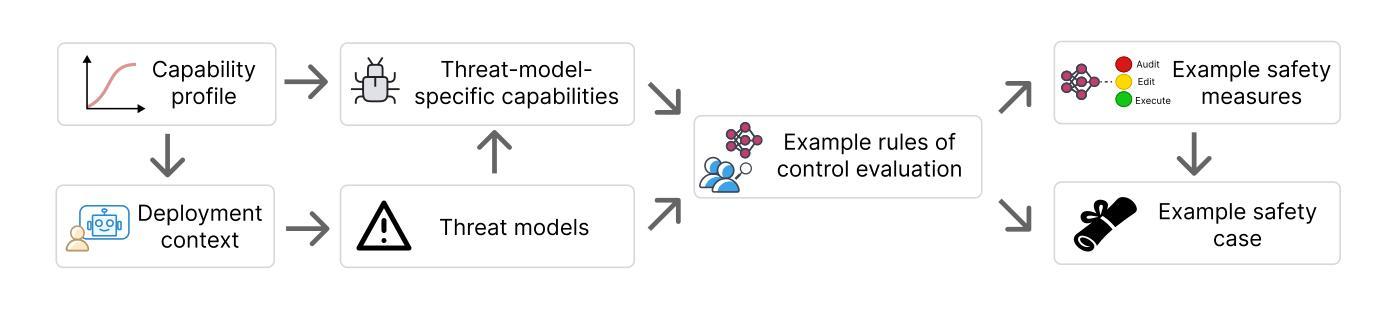
As LLM agents grow more capable of causing harm autonomously, AI developers will rely on increasingly sophisticated control measures to prevent possibly misaligned agents from causing harm. AI developers could demonstrate that their control measures are sufficient by running control evaluations: testing exercises in which a red team produces agents that try to subvert control measures. To ensure control evaluations accurately capture misalignment risks, the affordances granted to this red team should be adapted to the capability profiles of the agents to be deployed under control measures. In this paper we propose a systematic framework for adapting affordances of red teams to advancing AI capabilities. Rather than assuming that agents will always execute the best attack strategies known to humans, we demonstrate how knowledge of an agents’s actual capability profile can inform proportional control evaluations, resulting in more practical and cost-effective control measures. We illustrate our framework by considering a sequence of five fictional models (M1-M5) with progressively advanced capabilities, defining five distinct AI control levels (ACLs). For each ACL, we provide example rules for control evaluation, control measures, and safety cases that could be appropriate. Finally, we show why constructing a compelling AI control safety case for superintelligent LLM agents will require research breakthroughs, highlighting that we might eventually need alternative approaches to mitigating misalignment risk.
随着LLM代理人在自主造成伤害的能力方面不断增长,AI开发人员将依赖越来越复杂的控制措施来防止可能的对齐不当的代理人造成伤害。AI开发人员可以通过运行控制评估来证明其控制措施是足够的:测试演练中,红队产生代理试图破坏控制措施。为确保控制评估准确捕捉错位风险,赋予红队的权限应适应在控制措施下要部署的代理人的能力特征。在本文中,我们提出了一个系统的框架,以适应红队权限与不断发展的AI能力。我们不是假设代理人总是会执行人类已知的最佳攻击策略,而是展示了了解代理人的实际能力特征如何为比例控制评估提供信息,从而产生更实用、更经济的控制措施。我们通过考虑一系列具有逐渐增强能力特征的五个虚构模型(M1-M5)来说明我们的框架,定义了五个不同的AI控制级别(ACL)。对于每个ACL,我们提供了控制评估、控制措施和可能适用的安全案例的示例规则。最后,我们展示了为什么为超级智能LLM代理人构建有说服力的AI控制安全案例将需要研究突破,并强调我们可能需要替代方法来减轻错位风险。
论文及项目相关链接
Summary
随着LLM代理人的自主伤害能力增强,人工智能开发者将依赖越来越先进的控制措施来防止可能的对齐不当的代理人造成伤害。本论文提出了一种将红队代理的适应性与人工智能能力进步相适应的系统性框架,通过了解代理人的实际能力分布,进行比例控制评估,使控制措施更具实用性和成本效益。此外,我们展示了针对具有不同能力的五个虚构模型(M1-M5)的控制评估规则、控制措施和安全案例示例。最终,我们强调了为超级智能LLM代理人构建令人信服的AI控制安全案例将需要研究突破,并指出可能需要替代方法来减轻对齐风险。
Key Takeaways
- 随着LLM代理人的自主伤害能力增长,AI开发者将依赖更先进的控制措施来防止潜在风险。
- 红队测试是评估控制措施是否有效的重要手段,其提供的适应性需要依据代理人的能力分布进行调整。
- 了解代理人的实际能力分布有助于进行比例控制评估,使控制措施更具实用性和成本效益。
- 本文展示了针对五个虚构模型(M1-M5)的不同能力等级的控制评估规则、控制措施和安全案例示例。
- 随着AI能力的增强,构建令人信服的AI控制安全案例变得越来越具有挑战性,需要更多的研究突破。
- 替代方法可能在对抗超级智能LLM代理人的对齐风险方面发挥关键作用。
点此查看论文截图

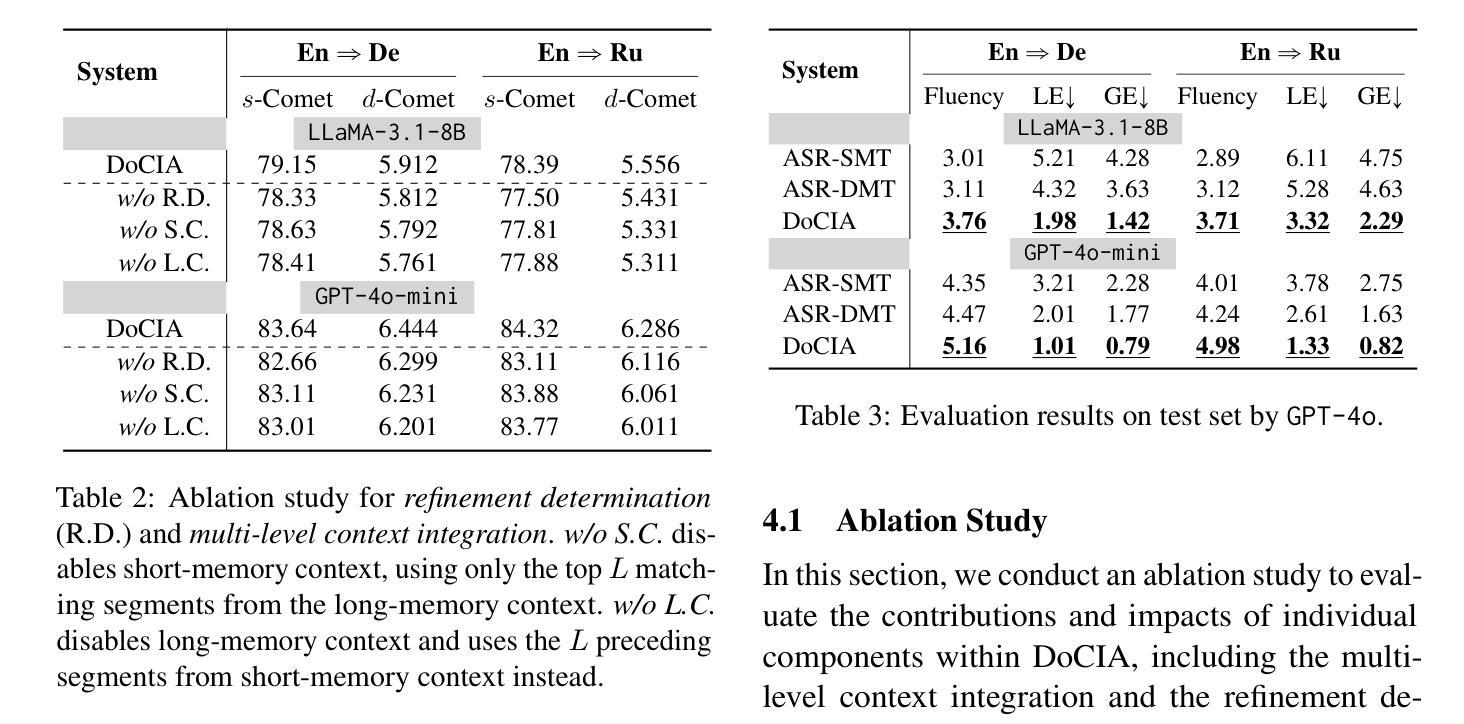
DoCIA: An Online Document-Level Context Incorporation Agent for Speech Translation
Authors:Xinglin Lyu, Wei Tang, Yuang Li, Xiaofeng Zhao, Ming Zhu, Junhui Li, Yunfei Lu, Min Zhang, Daimeng Wei, Hao Yang, Min Zhang
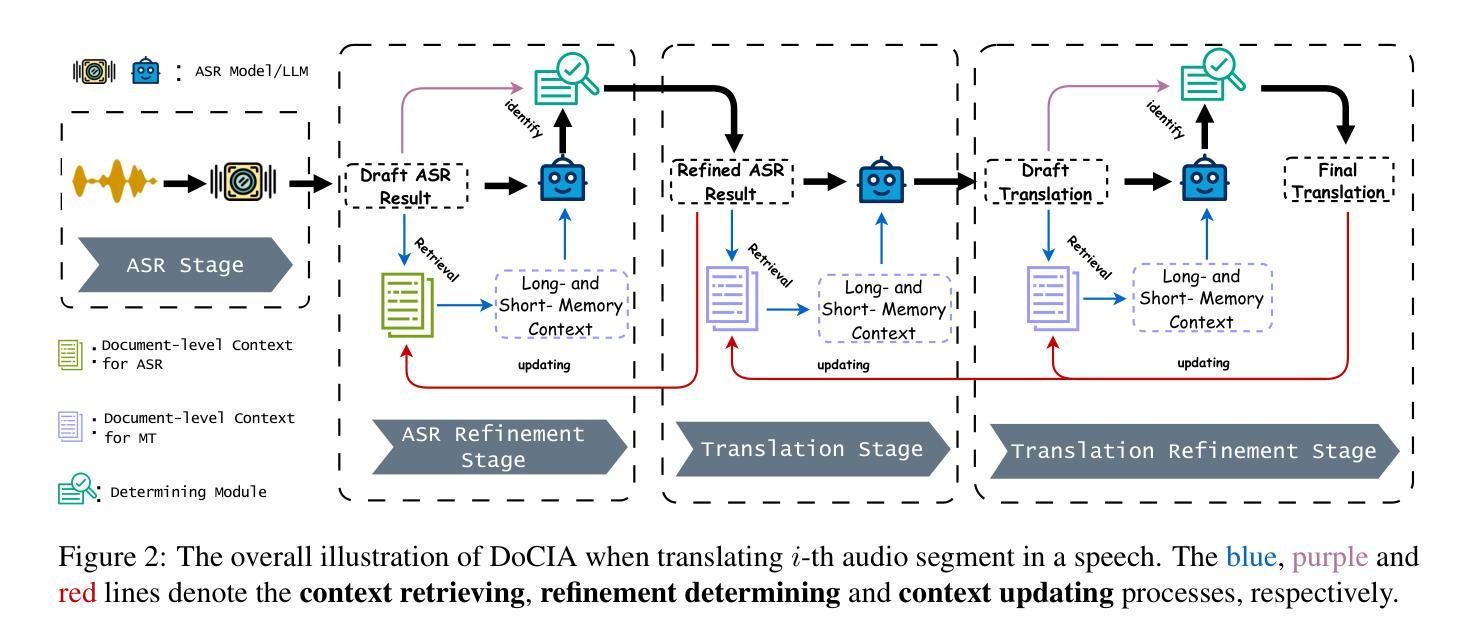
Document-level context is crucial for handling discourse challenges in text-to-text document-level machine translation (MT). Despite the increased discourse challenges introduced by noise from automatic speech recognition (ASR), the integration of document-level context in speech translation (ST) remains insufficiently explored. In this paper, we develop DoCIA, an online framework that enhances ST performance by incorporating document-level context. DoCIA decomposes the ST pipeline into four stages. Document-level context is integrated into the ASR refinement, MT, and MT refinement stages through auxiliary LLM (large language model)-based modules. Furthermore, DoCIA leverages document-level information in a multi-level manner while minimizing computational overhead. Additionally, a simple yet effective determination mechanism is introduced to prevent hallucinations from excessive refinement, ensuring the reliability of the final results. Experimental results show that DoCIA significantly outperforms traditional ST baselines in both sentence and discourse metrics across four LLMs, demonstrating its effectiveness in improving ST performance.
文本在文本到文本的文档级机器翻译(MT)中处理话语挑战时,文档级上下文至关重要。尽管自动语音识别(ASR)产生的噪声增加了话语挑战,但在语音翻译(ST)中整合文档级上下文的研究仍然不足。在本文中,我们开发了一个在线框架DoCIA,它通过融入文档级上下文来提升ST性能。DoCIA将ST管道分解为四个阶段。通过辅助的大型语言模型(LLM)模块,文档级上下文被整合到ASR优化、机器翻译和机器翻译优化阶段。此外,DoCIA以多层次的方式利用文档级信息,同时尽量减少计算开销。此外,还引入了一种简单有效的确定机制,以防止过度优化导致的幻觉,确保最终结果的可靠性。实验结果表明,在四种大型语言模型中,无论是在句子还是话语指标上,DoCIA都显著优于传统的ST基线,证明了其在提高ST性能方面的有效性。
论文及项目相关链接
总结
文本强调了在文本到文本的文档级机器翻译(MT)中处理话语挑战时,文档级上下文的重要性。尽管自动语音识别(ASR)的噪声增加了话语挑战,但在语音翻译(ST)中融入文档级上下文的研究仍然不足。本文提出了DoCIA在线框架,通过融入辅助的大型语言模型(LLM)模块,在ASR优化、MT和MT优化阶段融入文档级上下文,从而提高ST性能。DoCIA以多层次的方式利用文档级信息,同时减少计算开销。此外,还引入了一种简单有效的确定机制,防止过度优化导致的虚构,确保最终结果的可靠性。实验结果表明,DoCIA在四个LLM上显著优于传统的ST基线,在句子和话语度量方面都表现出改进ST性能的有效性。
关键见解
- 文档级上下文对于处理文本到文本机器翻译中的话语挑战至关重要。
- 在语音翻译中融入文档级上下文的研究仍然不足。
- DoCIA框架通过融入辅助的大型语言模型模块,在多个阶段融入文档级上下文,提高ST性能。
- DoCIA以多层次的方式利用文档级信息,减少计算开销。
- DoCIA引入了一种确定机制,防止过度优化导致的虚构,确保结果的可靠性。
- 实验结果表明DoCIA显著优于传统的ST基线,在句子和话语度量方面都表现出其有效性。
点此查看论文截图

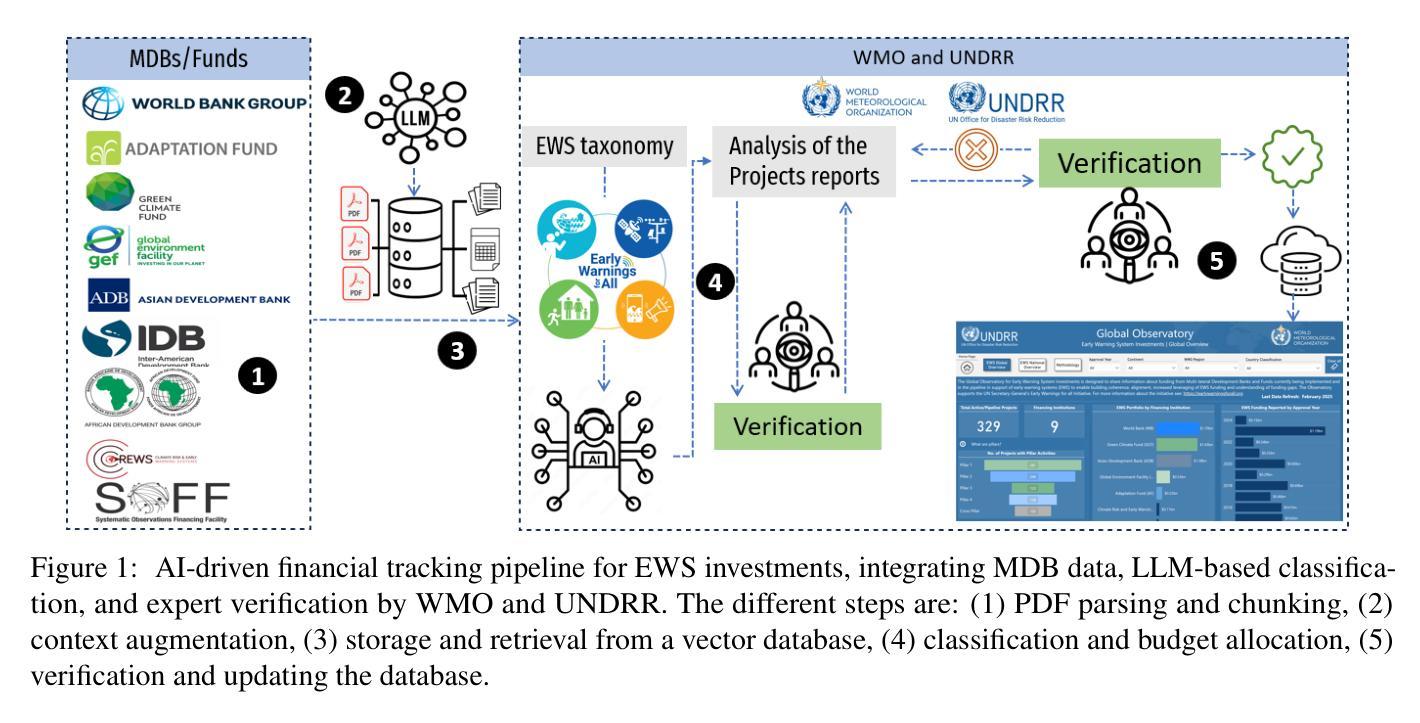
AI for Climate Finance: Agentic Retrieval and Multi-Step Reasoning for Early Warning System Investments
Authors:Saeid Ario Vaghefi, Aymane Hachcham, Veronica Grasso, Jiska Manicus, Nakiete Msemo, Chiara Colesanti Senni, Markus Leippold
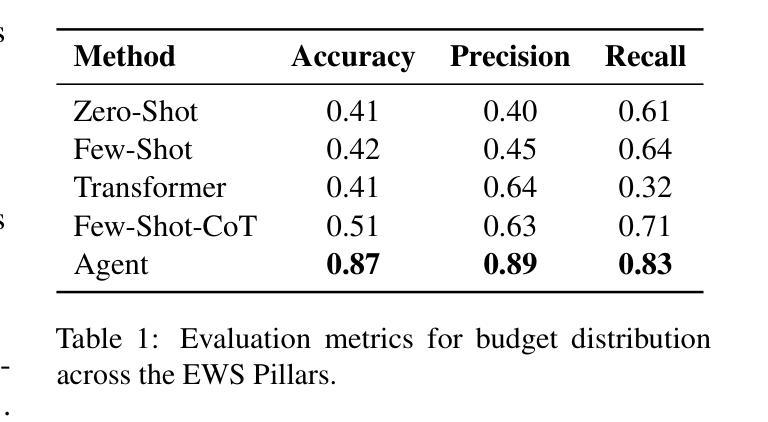
Tracking financial investments in climate adaptation is a complex and expertise-intensive task, particularly for Early Warning Systems (EWS), which lack standardized financial reporting across multilateral development banks (MDBs) and funds. To address this challenge, we introduce an LLM-based agentic AI system that integrates contextual retrieval, fine-tuning, and multi-step reasoning to extract relevant financial data, classify investments, and ensure compliance with funding guidelines. Our study focuses on a real-world application: tracking EWS investments in the Climate Risk and Early Warning Systems (CREWS) Fund. We analyze 25 MDB project documents and evaluate multiple AI-driven classification methods, including zero-shot and few-shot learning, fine-tuned transformer-based classifiers, chain-of-thought (CoT) prompting, and an agent-based retrieval-augmented generation (RAG) approach. Our results show that the agent-based RAG approach significantly outperforms other methods, achieving 87% accuracy, 89% precision, and 83% recall. Additionally, we contribute a benchmark dataset and expert-annotated corpus, providing a valuable resource for future research in AI-driven financial tracking and climate finance transparency.
跟踪气候适应方面的金融投资是一项复杂且需要专业知识的任务,特别是对于缺乏多边发展银行和基金标准化财务报告的早期预警系统(EWS)而言。为了应对这一挑战,我们引入了一个基于大型语言模型(LLM)的代理人工智能系统,该系统结合了上下文检索、微调和多步推理,以提取相关财务数据、分类投资并确保符合资金指导方针。我们的研究关注现实应用:跟踪气候风险与早期预警系统(CREWS)基金中的EWS投资。我们分析了25个MDB项目文件,并评估了多种AI驱动的分类方法,包括零样本和少样本学习、基于微调转换器的分类器、思维链提示和基于代理的检索增强生成(RAG)方法。我们的结果表明,基于代理的RAG方法显著优于其他方法,达到了87%的准确率、89%的精确率和8s%的召回率。此外,我们还提供了一个基准数据集和专家注释语料库,为AI驱动的金融跟踪和气候金融透明度的未来研究提供了有价值的资源。
论文及项目相关链接
Summary
本文介绍了一个基于大型语言模型(LLM)的代理人工智能系统,用于追踪气候适应领域的金融投资。该系统结合了上下文检索、微调和多步推理技术,以提取相关财务数据、分类投资并确保符合资助准则。针对气候风险及预警系统基金(CREWS Fund)中的早期预警系统(EWS)投资进行跟踪研究,分析25个多边发展银行项目文件,并评估多种人工智能分类方法。结果显示,基于代理的RAG方法表现最佳,准确率、精确度和召回率分别达到了87%、89%和83%。此外,本文还贡献了一个基准数据集和专家注释语料库,为未来人工智能驱动的财务跟踪和气候财务透明度研究提供了宝贵资源。
Key Takeaways
- 引入了一个基于LLM的代理AI系统,用于追踪气候适应金融投资,特别是早期预警系统(EWS)。
- 系统集成了上下文检索、微调、多步推理等技术,提升财务数据提取、投资分类和资助准则遵守的效能。
- 专注于气候风险及预警系统基金(CREWS Fund)中的EWS投资跟踪,分析25个多边发展银行项目文件。
- 评估了多种AI分类方法,包括零样本和少样本学习、基于fine-tuned transformer的分类器、链式思维(CoT)提示和基于代理的检索增强生成(RAG)方法。
- 基于代理的RAG方法表现最佳,准确率、精确度和召回率分别达到了87%、89%和83%。
- 贡献了一个基准数据集和专家注释语料库,为AI驱动的财务跟踪和气候财务透明度研究提供资源。
点此查看论文截图

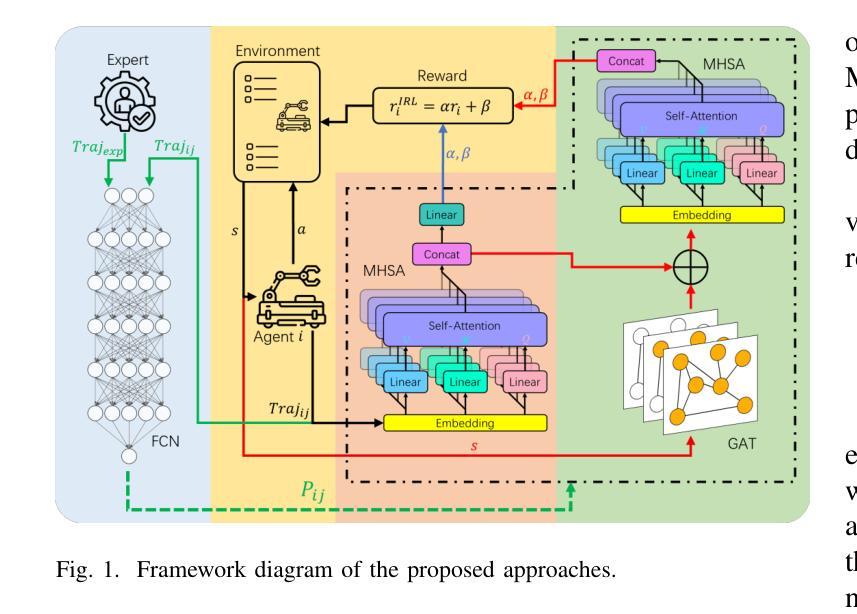
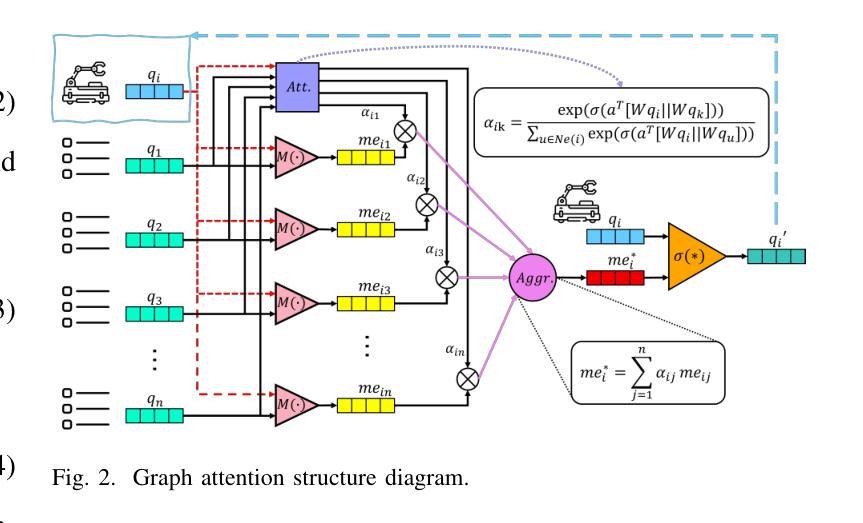
Attention-Augmented Inverse Reinforcement Learning with Graph Convolutions for Multi-Agent Task Allocation
Authors:Huilin Yin, Zhikun Yang, Daniel Watzenig
Multi-agent task allocation (MATA) plays a vital role in cooperative multi-agent systems, with significant implications for applications such as logistics, search and rescue, and robotic coordination. Although traditional deep reinforcement learning (DRL) methods have been shown to be promising, their effectiveness is hindered by a reliance on manually designed reward functions and inefficiencies in dynamic environments. In this paper, an inverse reinforcement learning (IRL)-based framework is proposed, in which multi-head self-attention (MHSA) and graph attention mechanisms are incorporated to enhance reward function learning and task execution efficiency. Expert demonstrations are utilized to infer optimal reward densities, allowing dependence on handcrafted designs to be reduced and adaptability to be improved. Extensive experiments validate the superiority of the proposed method over widely used multi-agent reinforcement learning (MARL) algorithms in terms of both cumulative rewards and task execution efficiency.
多智能体任务分配(MATA)在合作多智能体系统中起着至关重要的作用,对物流、搜索和救援以及机器人协调等应用具有重要意义。尽管传统的深度强化学习方法表现出一定的前景,但其有效性受到依赖人工设计的奖励函数和动态环境中效率不高的限制。针对这些问题,本文提出了基于逆向强化学习(IRL)的框架,该框架结合了多头自注意力(MHSA)和图注意力机制来提高奖励函数的学习和任务执行效率。利用专家演示来推断最优奖励密度,减少对手工设计的依赖,提高适应性。大量实验验证了所提方法在累积奖励和任务执行效率方面均优于广泛使用的多智能体强化学习(MARL)算法。
论文及项目相关链接
Summary
基于多智能体任务分配(MATA)在合作多智能体系统中的重要作用,本文提出了一种基于逆向强化学习(IRL)的框架,结合了多头自注意力(MHSA)和图形注意力机制,以提高奖励函数学习和任务执行效率。通过专家演示来推断最优奖励密度,减少对手工设计的依赖,提高适应性。实验证明,该方法在累计奖励和任务执行效率方面优于广泛使用的多智能体强化学习(MARL)算法。
Key Takeaways
- MATA在合作多智能体系统中具有关键作用,对于物流、搜索和救援、机器人协调等应用具有重要影响。
- 传统深度强化学习方法受限于手动设计的奖励函数和动态环境中的低效性。
- 本文提出了基于逆强化学习(IRL)的框架,利用多头自注意力(MHSA)和图形注意力机制提高奖励函数学习和任务执行效率。
- 专家演示被用来推断最优奖励密度,减少对手工设计的依赖并增强适应性。
- 所提出的方法在累计奖励和任务执行效率方面优于现有的多智能体强化学习(MARL)算法。
- 该方法可能推动多智能体系统在复杂任务中的实际应用。
点此查看论文截图


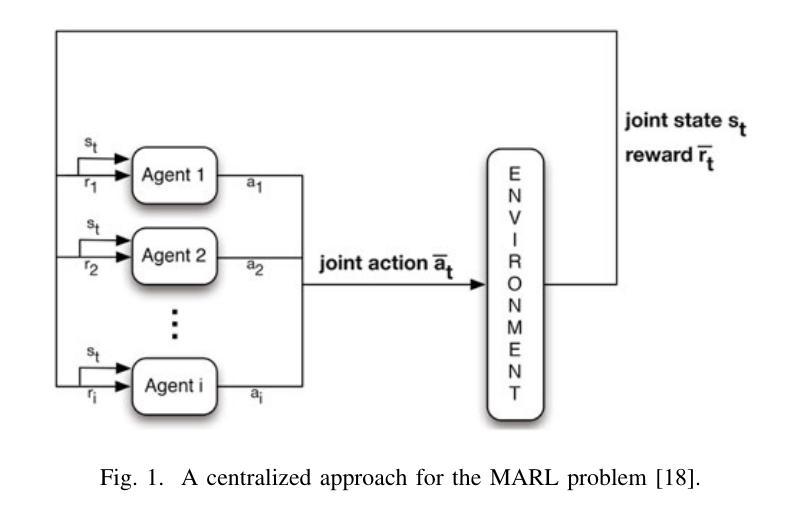
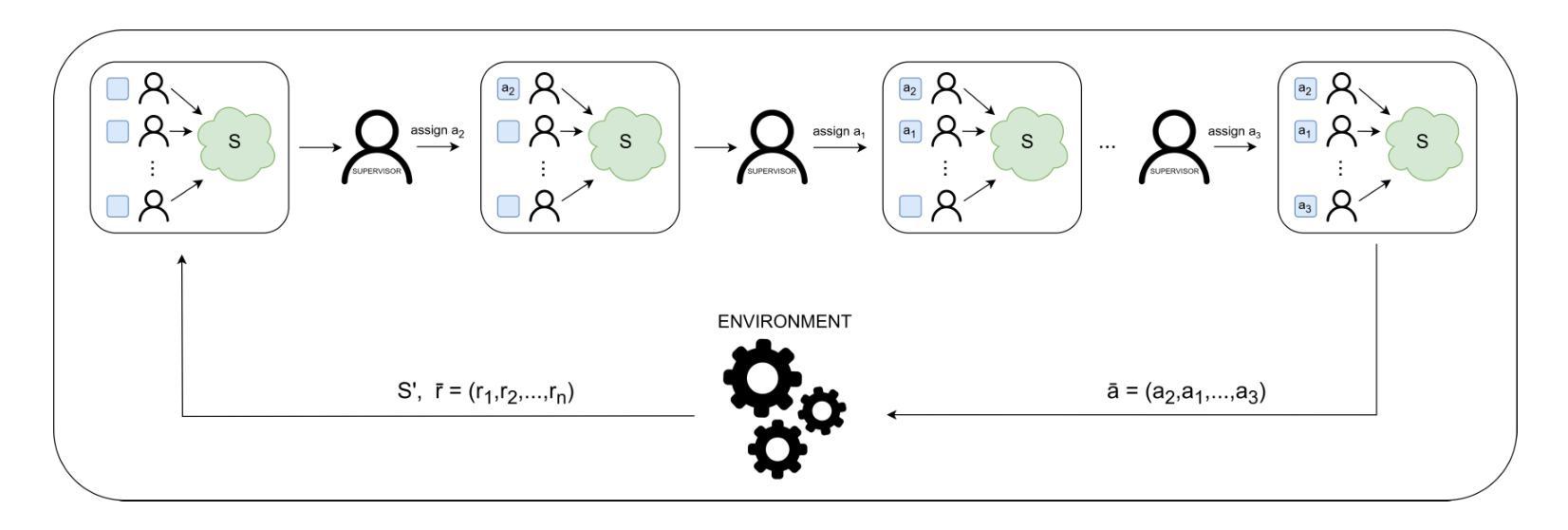
An Efficient Approach for Cooperative Multi-Agent Learning Problems
Authors:Ángel Aso-Mollar, Eva Onaindia
In this article, we propose a centralized Multi-Agent Learning framework for learning a policy that models the simultaneous behavior of multiple agents that need to coordinate to solve a certain task. Centralized approaches often suffer from the explosion of an action space that is defined by all possible combinations of individual actions, known as joint actions. Our approach addresses the coordination problem via a sequential abstraction, which overcomes the scalability problems typical to centralized methods. It introduces a meta-agent, called \textit{supervisor}, which abstracts joint actions as sequential assignments of actions to each agent. This sequential abstraction not only simplifies the centralized joint action space but also enhances the framework’s scalability and efficiency. Our experimental results demonstrate that the proposed approach successfully coordinates agents across a variety of Multi-Agent Learning environments of diverse sizes.
在这篇文章中,我们提出一个集中式的多智能体学习框架,用于学习一个策略模型,该模型能够模拟多个需要协调来解决特定任务的智能体的同时行为。集中式方法通常面临着由所有可能个体行为的组合所定义的动作空间的爆炸式增长问题,这被称为联合动作。我们的方法通过序列抽象来解决协调问题,克服了集中式方法的典型可扩展性问题。它引入了一个名为“监管者”的元智能体,它将联合动作抽象化为对每个智能体的动作顺序分配。这种序列抽象不仅简化了集中式的联合动作空间,还提高了框架的可扩展性和效率。我们的实验结果表明,该方法成功地在各种规模和多样性的多智能体学习环境中协调了智能体。
论文及项目相关链接
PDF Accepted at ICTAI 2024
Summary
本文提出一种集中式多智能体学习框架,该框架可以建模多个智能体的同时行为并解决协调任务问题。我们引入了监督器(meta-agent)来抽象联合行动为对每个智能体的连续动作分配,克服了集中式方法的可扩展性问题,提高了框架的效率和可扩展性。实验结果表明,该方法在不同规模和种类的多智能体学习环境中成功协调了智能体。
Key Takeaways
- 提出了一种集中式多智能体学习框架,用于建模多个智能体的同时行为。
- 引入了一种名为“监督器”(meta-agent)的元智能体概念,通过抽象联合行动来简化集中式联合行动空间。
- 监督器将联合行动抽象化为对每个智能体的连续动作分配,增强了框架的效率和可扩展性。
- 提出的框架通过顺序抽象解决了协调问题。
点此查看论文截图


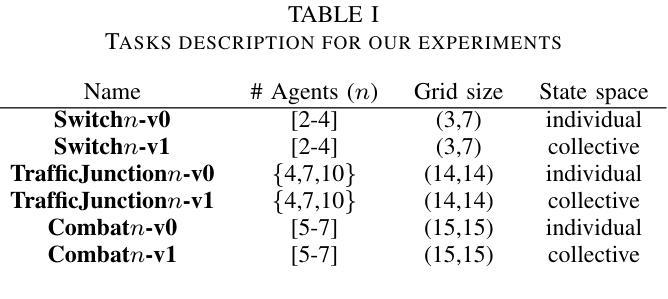
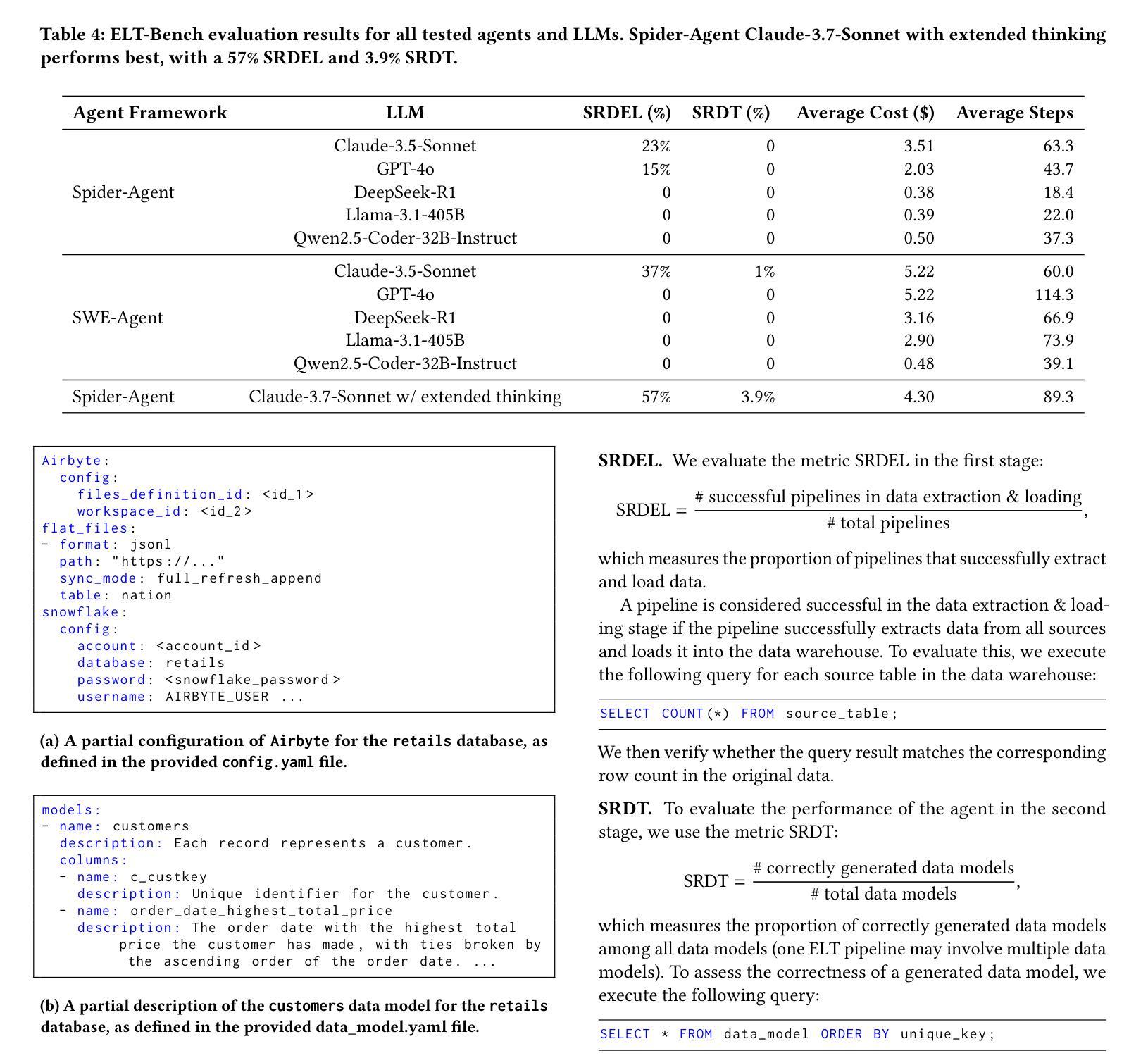
ELT-Bench: An End-to-End Benchmark for Evaluating AI Agents on ELT Pipelines
Authors:Tengjun Jin, Yuxuan Zhu, Daniel Kang
Practitioners are increasingly turning to Extract-Load-Transform (ELT) pipelines with the widespread adoption of cloud data warehouses. However, designing these pipelines often involves significant manual work to ensure correctness. Recent advances in AI-based methods, which have shown strong capabilities in data tasks, such as text-to-SQL, present an opportunity to alleviate manual efforts in developing ELT pipelines. Unfortunately, current benchmarks in data engineering only evaluate isolated tasks, such as using data tools and writing data transformation queries, leaving a significant gap in evaluating AI agents for generating end-to-end ELT pipelines. To fill this gap, we introduce ELT-Bench, an end-to-end benchmark designed to assess the capabilities of AI agents to build ELT pipelines. ELT-Bench consists of 100 pipelines, including 835 source tables and 203 data models across various domains. By simulating realistic scenarios involving the integration of diverse data sources and the use of popular data tools, ELT-Bench evaluates AI agents’ abilities in handling complex data engineering workflows. AI agents must interact with databases and data tools, write code and SQL queries, and orchestrate every pipeline stage. We evaluate two representative code agent frameworks, Spider-Agent and SWE-Agent, using six popular Large Language Models (LLMs) on ELT-Bench. The highest-performing agent, Spider-Agent Claude-3.7-Sonnet with extended thinking, correctly generates only 3.9% of data models, with an average cost of $4.30 and 89.3 steps per pipeline. Our experimental results demonstrate the challenges of ELT-Bench and highlight the need for a more advanced AI agent to reduce manual effort in ELT workflows. Our code and data are available at https://github.com/uiuc-kang-lab/ETL.git.
随着云数据仓库的广泛应用,从业者越来越多地转向使用Extract-Load-Transform(ELT)管道。然而,设计这些管道通常涉及大量的手动工作来保证正确性。最近AI方法取得了进展,展示出在数据任务方面的强大能力,例如文本到SQL的转换,这为我们减少在开发ELT管道中的手动工作提供了机会。然而,目前数据工程的基准测试仅评估孤立的任务,如使用数据工具和编写数据转换查询,在评估用于生成端到端ELT管道的AI代理方面存在巨大差距。为了填补这一空白,我们引入了ELT-Bench,这是一个旨在评估AI代理构建ELT管道能力的端到端基准测试。ELT-Bench包含100个管道,涵盖835个源表和203个数据模型,涉及不同领域。通过模拟涉及整合各种数据源和使用流行数据工具的实际情况,ELT-Bench评估AI代理在处理复杂数据工程工作流程方面的能力。AI代理必须与数据库和数据工具进行交互,编写代码和SQL查询,并协调每个管道阶段。我们使用两个具有代表性的代码代理框架Spider-Agent和SWE-Agent,以及六个流行的大型语言模型(LLM)对ELT-Bench进行了评估。表现最佳的代理是Spider-Agent Claude-3.7-Sonnet with extended thinking,它只能正确生成3.9%的数据模型,平均每个管道的成本为4.3美元和需要89.3步操作。我们的实验结果展示了ELT-Bench的挑战性,并强调了需要更先进的AI代理来减少ELT工作流程中的手动工作。我们的代码和数据可在https://github.com/uiuc-kang-lab/ETL.git上找到。
论文及项目相关链接
PDF 14 pages, 18 figures
Summary
随着云数据仓库的广泛应用,实践者越来越倾向于使用Extract-Load-Transform(ELT)管道。然而,设计这些管道需要大量的手动工作来保证正确性。最近AI方法,如在数据任务中的文本到SQL的进展,为减少ELT管道开发中的手动工作提供了机会。但目前数据工程中的基准测试只评估孤立任务,如使用数据工具和编写数据转换查询,在评估用于生成端到端ELT管道的AI代理方面存在巨大差距。为了填补这一空白,我们引入了ELT-Bench,这是一个端到端的基准测试,旨在评估AI代理构建ELT管道的能力。
Key Takeaways
- 实践者越来越多地采用ELT管道,需要高效、准确的设计和操作方法。
- AI方法在数据任务中的应用展现出了减少手动工作的潜力。
- 目前在评估AI代理在生成端到端ELT管道方面的能力存在差距。
- ELT-Bench是一个旨在评估AI代理构建ELT管道能力的端到端基准测试。
- ELT-Bench包含100个管道、835个源表和203个数据模型,模拟真实场景以评估AI代理的能力。
- 代表性代码代理框架Spider-Agent和SWE-Agent在ELT-Bench上的评估结果存在挑战。
点此查看论文截图

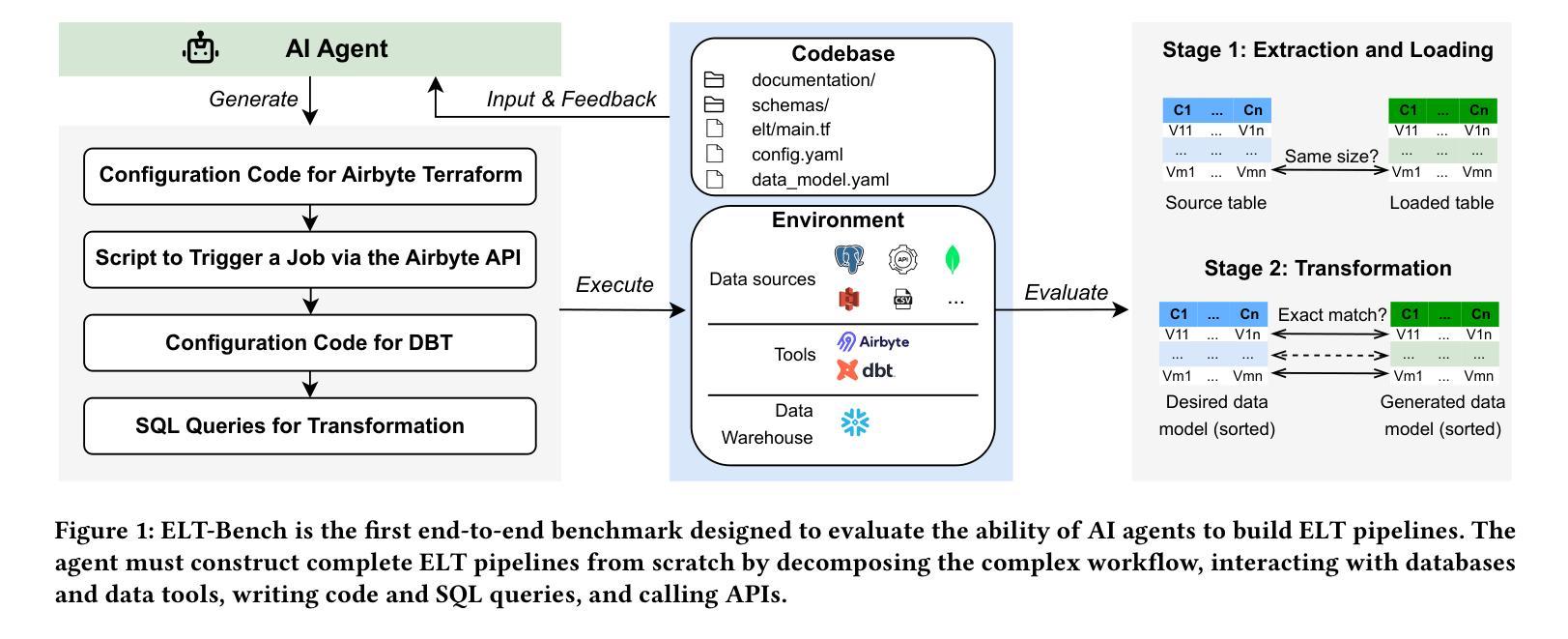
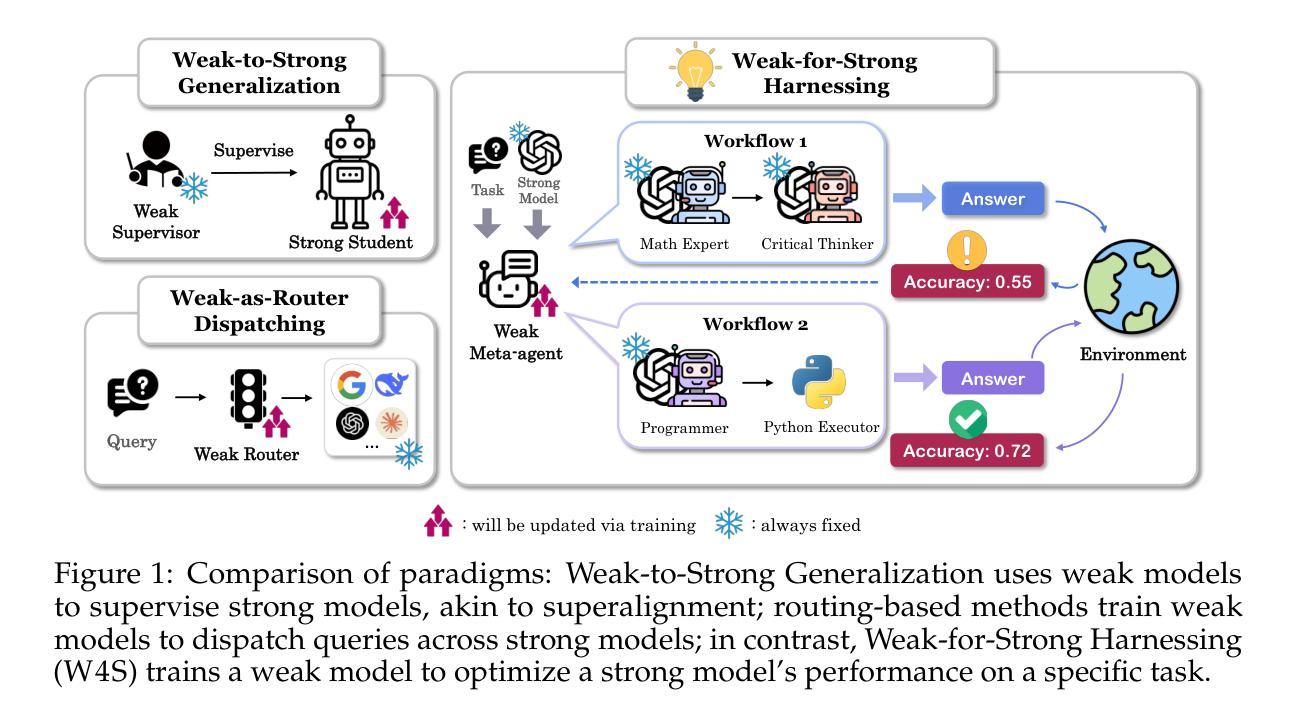
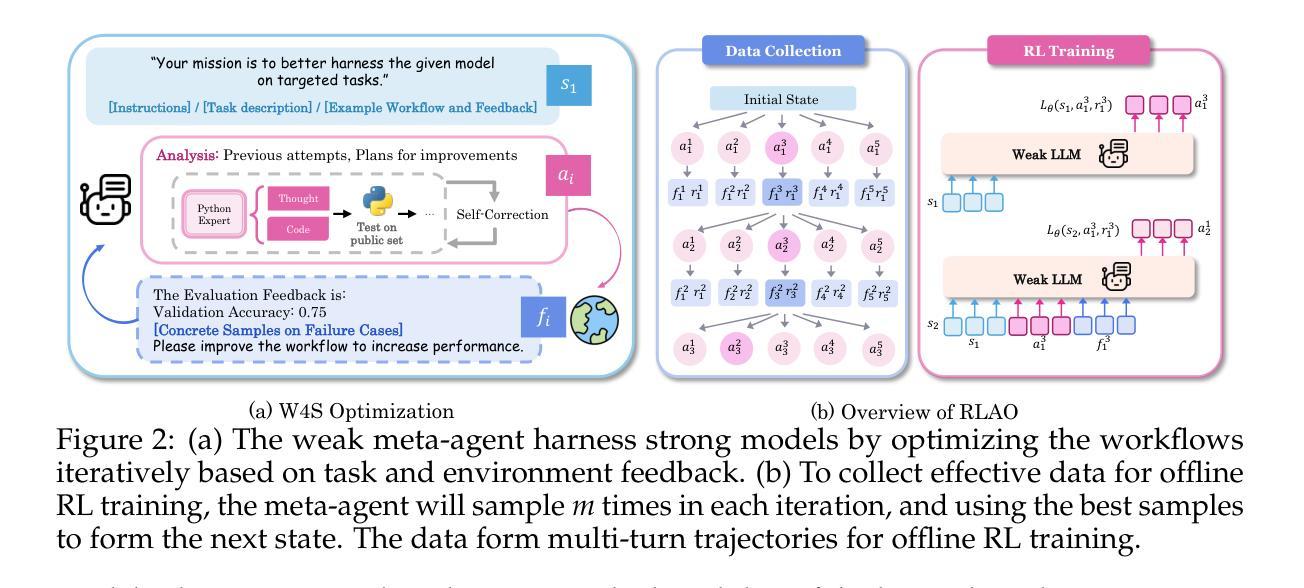
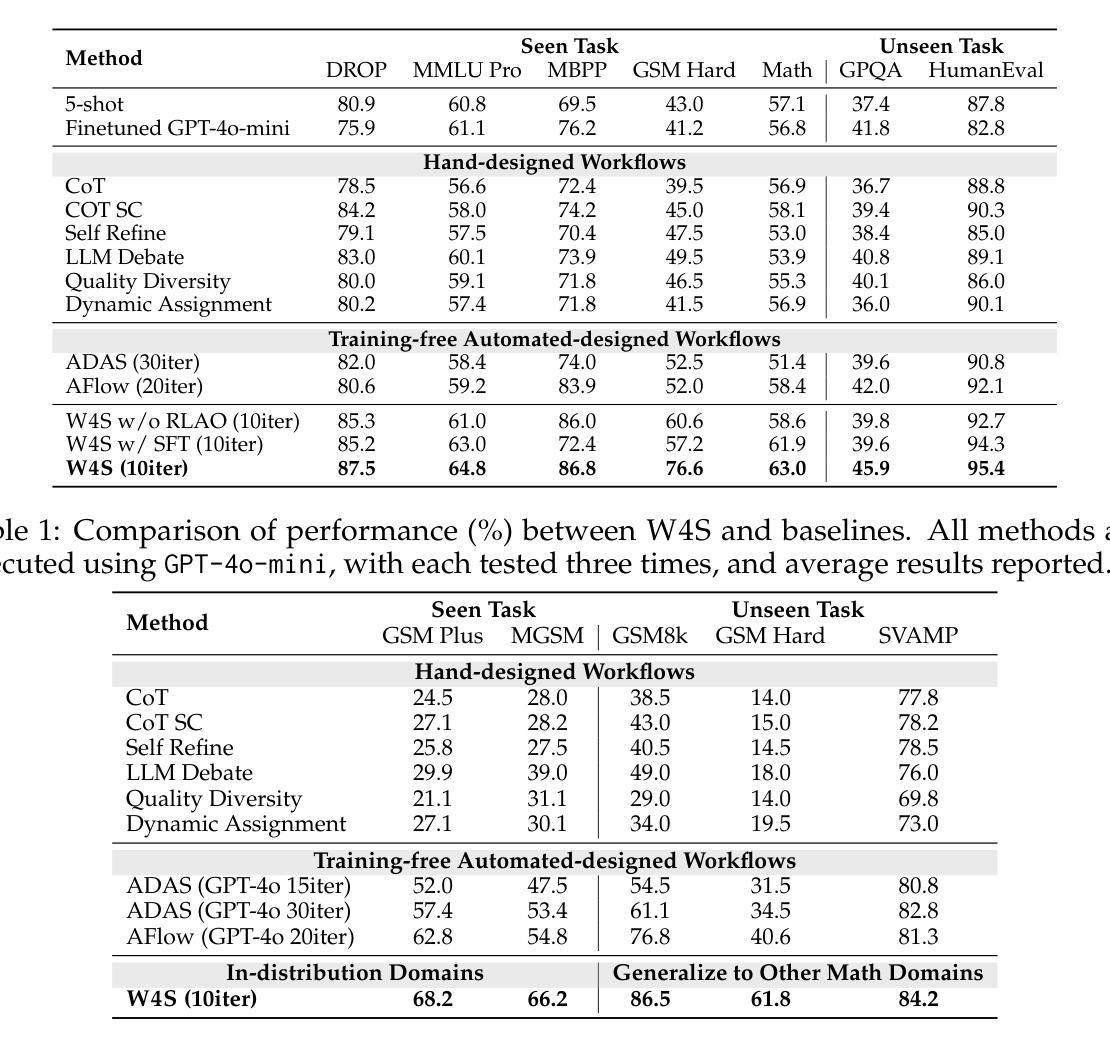
Weak-for-Strong: Training Weak Meta-Agent to Harness Strong Executors
Authors:Fan Nie, Lan Feng, Haotian Ye, Weixin Liang, Pan Lu, Huaxiu Yao, Alexandre Alahi, James Zou
Efficiently leveraging of the capabilities of contemporary large language models (LLMs) is increasingly challenging, particularly when direct fine-tuning is expensive and often impractical. Existing training-free methods, including manually or automated designed workflows, typically demand substantial human effort or yield suboptimal results. This paper proposes Weak-for-Strong Harnessing (W4S), a novel framework that customizes smaller, cost-efficient language models to design and optimize workflows for harnessing stronger models. W4S formulates workflow design as a multi-turn markov decision process and introduces reinforcement learning for agentic workflow optimization (RLAO) to train a weak meta-agent. Through iterative interaction with the environment, the meta-agent learns to design increasingly effective workflows without manual intervention. Empirical results demonstrate the superiority of W4S that our 7B meta-agent, trained with just one GPU hour, outperforms the strongest baseline by 2.9% ~ 24.6% across eleven benchmarks, successfully elevating the performance of state-of-the-art models such as GPT-3.5-Turbo and GPT-4o. Notably, W4S exhibits strong generalization capabilities across both seen and unseen tasks, offering an efficient, high-performing alternative to directly fine-tuning strong models.
有效地利用当代大型语言模型(LLM)的能力正变得越来越具有挑战性,尤其是在直接微调成本高昂且通常不切实际的情况下。现有的无训练方法,包括手动或自动设计的工作流程,通常需要大量的人工努力或产生次优结果。本文提出了Weak-for-Strong Harnessing(W4S),这是一种新型框架,能够定制较小、成本效益高的语言模型,以设计和优化利用更强模型的工作流程。W4S将工作流程设计制定为多轮马尔可夫决策过程,并引入强化学习进行智能工作流程优化(RLAO),以训练弱势元代理。通过与环境进行迭代交互,元代理学会了设计越来越有效的工作流程,无需人工干预。实证结果表明,W4S具有优越性,我们的7B元代理仅用一个GPU小时进行训练,就在十一个基准测试中比最强基线高出2.9%~24.6%,成功提升了最新模型(如GPT-3.5 Turbo和GPT-4o)的性能。值得注意的是,W4S在已知和未知任务中都表现出强大的泛化能力,为直接微调强模型提供了高效、高性能的替代方案。
论文及项目相关链接
Summary
当代大型语言模型(LLMs)的能力利用面临挑战,直接微调成本高昂且不实用。本文提出Weak-for-Strong Harnessing(W4S)框架,通过定制小型、经济的语言模型来设计和优化工作流程,以利用更强大的模型。W4S将工作流程设计制定为多轮马尔可夫决策过程,并引入强化学习进行智能工作流程优化(RLAO),训练出弱元代理。该元代理通过与环境进行迭代交互,学习设计越来越有效的工作流程,无需人工干预。实证结果表明,W4S的优越性在于其使用仅一个GPU小时训练的7B元代理,在十一个基准测试中比最强基线高出2.9%~24.6%,成功提升了最先进的模型如GPT-3.5 Turbo和GPT-4o的性能。此外,W4S在可见和不可见任务中都展现出强大的泛化能力,成为直接微调强模型的有效且高性能的替代方案。
Key Takeaways
- 当代大型语言模型的性能利用具有挑战性,直接微调不实际且成本高。
- W4S框架提出一种新型解决方案,通过定制小型语言模型来优化工作流程,以利用强大的模型。
- W4S将工作流程设计为马尔可夫决策过程,并使用强化学习训练元代理。
- 元代理能够与环境进行迭代交互,无需人工干预即可设计有效工作流程。
- W4S在多个基准测试中表现出优异的性能提升效果。
- W4S适用于多种任务,展现出强大的泛化能力。
点此查看论文截图

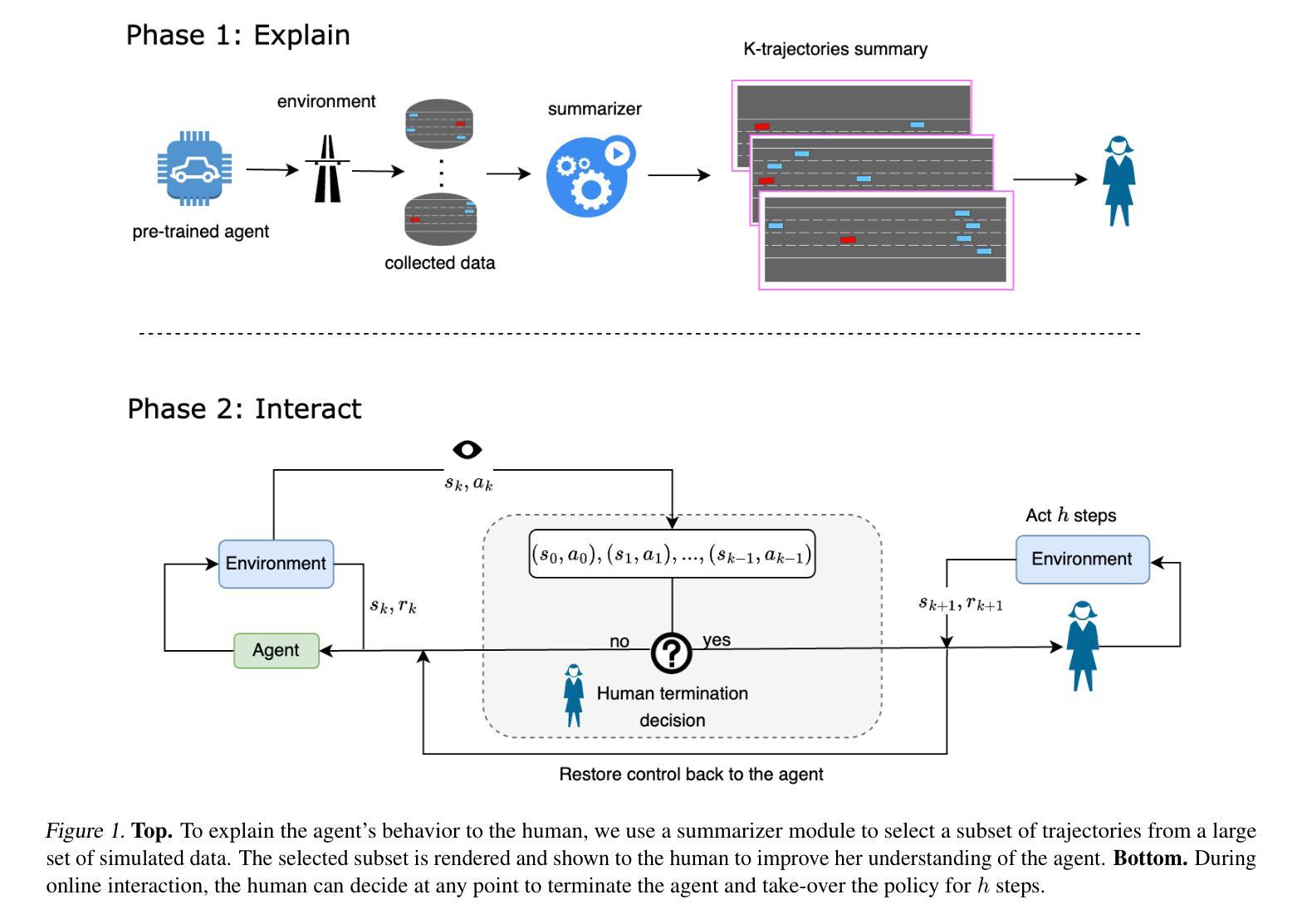
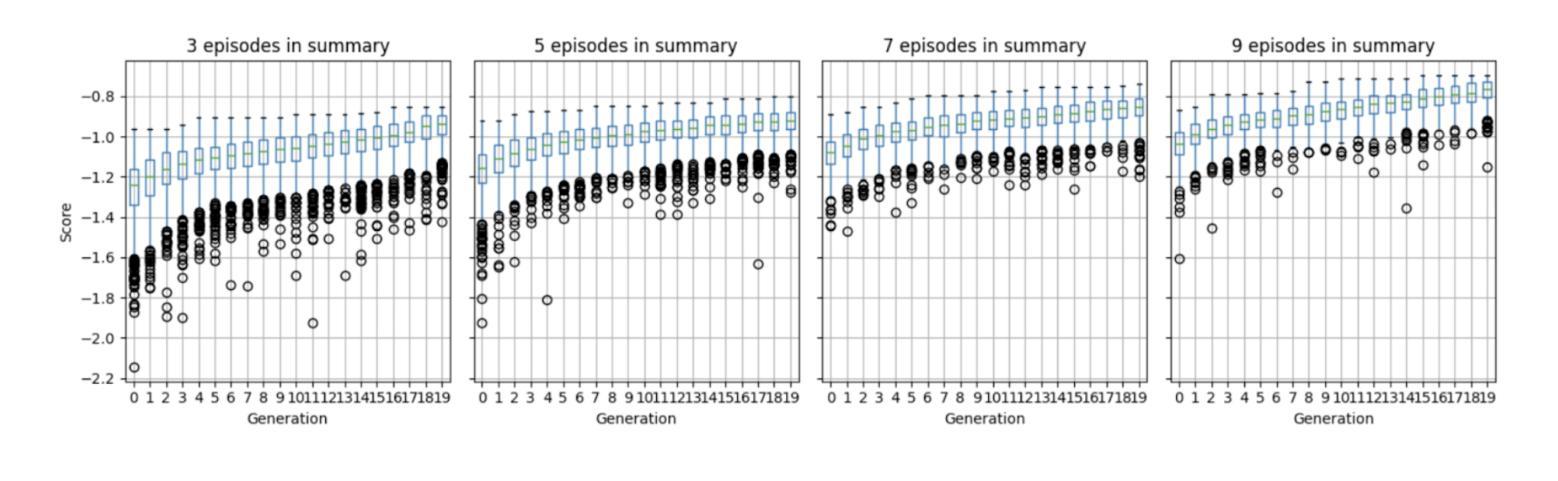
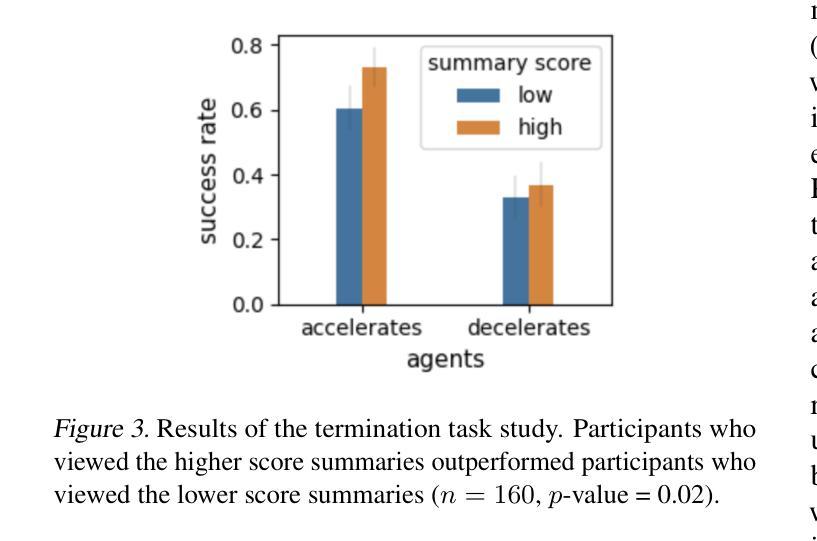
“You just can’t go around killing people” Explaining Agent Behavior to a Human Terminator
Authors:Uri Menkes, Assaf Hallak, Ofra Amir
Consider a setting where a pre-trained agent is operating in an environment and a human operator can decide to temporarily terminate its operation and take-over for some duration of time. These kind of scenarios are common in human-machine interactions, for example in autonomous driving, factory automation and healthcare. In these settings, we typically observe a trade-off between two extreme cases – if no take-overs are allowed, then the agent might employ a sub-optimal, possibly dangerous policy. Alternatively, if there are too many take-overs, then the human has no confidence in the agent, greatly limiting its usefulness. In this paper, we formalize this setup and propose an explainability scheme to help optimize the number of human interventions.
考虑一个预训练代理在环境中运行的场景,人类操作者可以决定暂时终止其操作并在一段时间内接管。这类场景在人类与机器交互中很常见,例如在自动驾驶、工厂自动化和医疗保健中。在这些场景中,我们通常观察到两种极端情况之间的权衡——如果不允许接管,那么代理可能会采用一种次优的、可能是危险的策略。另一方面,如果接管次数太多,那么人类对代理失去信心,极大地限制了其有用性。在本文中,我们对这一设置进行了形式化描述,并提出了一种解释方案,以帮助优化人类干预的次数。
论文及项目相关链接
PDF 6 pages, 3 figures, in proceedings of ICML 2024 Workshop on Models of Human Feedback for AI Alignment
Summary
本论文探讨了预训练代理在特定环境中的运行情况,其中人类操作者可以决定暂时终止代理的操作并接管一段时间。文章指出在人机互动场景中,如自动驾驶、工厂自动化和医疗保健等领域,存在两种极端情况的权衡:不允许接管可能导致代理采取次优甚至危险的策略,而频繁接管则使人类对代理失去信心,大大降低了其效用。为此,论文形式化了这一设置并提出了一种解释方案来帮助优化人类干预的次数。
Key Takeaways
- 在人机互动场景中,存在预训练代理运行与人为接管之间的权衡问题。
- 不允许接管可能导致代理采取次优或危险策略。
- 频繁接管会使人类对代理失去信心,降低其效用。
- 论文形式化了这种环境设置。
- 论文提出了一种解释方案来优化人类干预的次数。
- 该方案旨在找到一个平衡点,使代理能够自主运行并响应必要的干预。
点此查看论文截图

A Multi-Agent Framework Integrating Large Language Models and Generative AI for Accelerated Metamaterial Design
Authors:Jie Tian, Martin Taylor Sobczak, Dhanush Patil, Jixin Hou, Lin Pang, Arunachalam Ramanathan, Libin Yang, Xianyan Chen, Yuval Golan, Xiaoming Zhai, Hongyue Sun, Kenan Song, Xianqiao Wang
Metamaterials, renowned for their exceptional mechanical, electromagnetic, and thermal properties, hold transformative potential across diverse applications, yet their design remains constrained by labor-intensive trial-and-error methods and limited data interoperability. Here, we introduce CrossMatAgent – a novel multi-agent framework that synergistically integrates large language models with state-of-the-art generative AI to revolutionize metamaterial design. By orchestrating a hierarchical team of agents – each specializing in tasks such as pattern analysis, architectural synthesis, prompt engineering, and supervisory feedback – our system leverages the multimodal reasoning of GPT-4o alongside the generative precision of DALL-E 3 and a fine-tuned Stable Diffusion XL model. This integrated approach automates data augmentation, enhances design fidelity, and produces simulation- and 3D printing-ready metamaterial patterns. Comprehensive evaluations, including CLIP-based alignment, SHAP interpretability analyses, and mechanical simulations under varied load conditions, demonstrate the framework’s ability to generate diverse, reproducible, and application-ready designs. CrossMatAgent thus establishes a scalable, AI-driven paradigm that bridges the gap between conceptual innovation and practical realization, paving the way for accelerated metamaterial development.
超材料以其独特的机械、电磁和热力学特性而闻名,在多种应用中具有变革性潜力。然而,其设计仍受到劳动密集型的试错方法和有限数据互操作性的限制。在这里,我们引入了CrossMatAgent——一种新型多智能体框架,它通过协同整合大型语言模型与最新生成式人工智能,来革新超材料设计。通过协调分层的智能体团队——每个智能体都专注于模式分析、架构综合、提示工程和监管反馈等任务——我们的系统利用GPT-4o的多模态推理能力,结合DALL-E 3的生成精度和经过微调的稳定扩散XL模型。这种综合方法自动化数据增强,提高设计保真度,并产生模拟和3D打印就绪的超材料图案。全面的评估,包括基于CLIP的对齐、SHAP解释性分析和各种负载条件下的机械模拟,证明了该框架在生成多样化、可复制和适用于应用的超材料设计方面的能力。因此,CrossMatAgent建立了一个可扩展的、人工智能驱动的模式,缩小了概念创新和实际应用之间的差距,为超材料的加速发展铺平了道路。
论文及项目相关链接
Summary
新材料的设计受其特殊机械、电磁和热属性的影响,展现出变革性的潜力。然而,当前的设计方法受到劳动密集型的试错方法的制约和数据互操作性的限制。本研究提出CrossMatAgent——一种新型的多智能体框架,该框架将大型语言模型与先进的生成人工智能集成在一起,为新材料设计带来革命性变革。它通过多层次智能体团队的协同工作,实现自动化数据增强、提高设计保真度,并生成模拟和3D打印就绪的新材料图案。该框架展现了生成多样化、可复制和适用于实际应用的设计能力。因此,CrossMatAgent建立了一个可伸缩的AI驱动范式,缩小了概念创新和实际应用之间的差距,为新材料的发展开辟了道路。
Key Takeaways
- Metamaterials具备独特的机械、电磁和热属性,拥有变革性潜力,但设计过程中存在劳动密集型的试错方法制约和数据互操作性限制。
- CrossMatAgent是一种新型多智能体框架,融合了大型语言模型和先进生成人工智能,革新了新材料设计。
- 该框架通过多层次智能体团队的协同工作,实现了自动化数据增强和提高设计保真度。
- CrossMatAgent集成了GPT-4o的多模态推理、DALL-E 3的生成精度以及fine-tuned Stable Diffusion XL模型。
- 该框架能够生成模拟和3D打印就绪的新材料图案,并具有生成多样化、可复制和适用于实际应用的设计能力。
- 综合评估包括CLIP基对齐、SHAP解释性分析和机械模拟,证明了CrossMatAgent的有效性。
点此查看论文截图

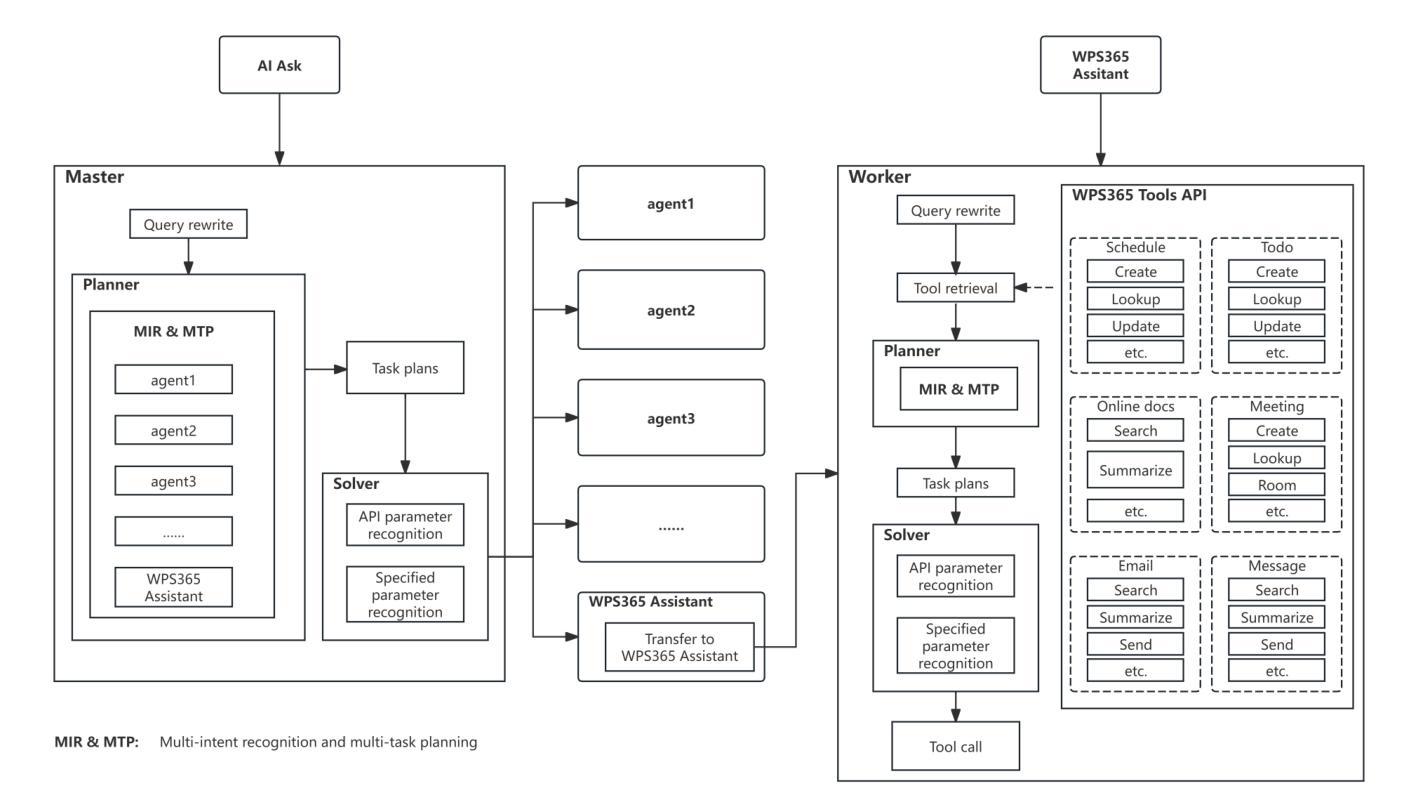
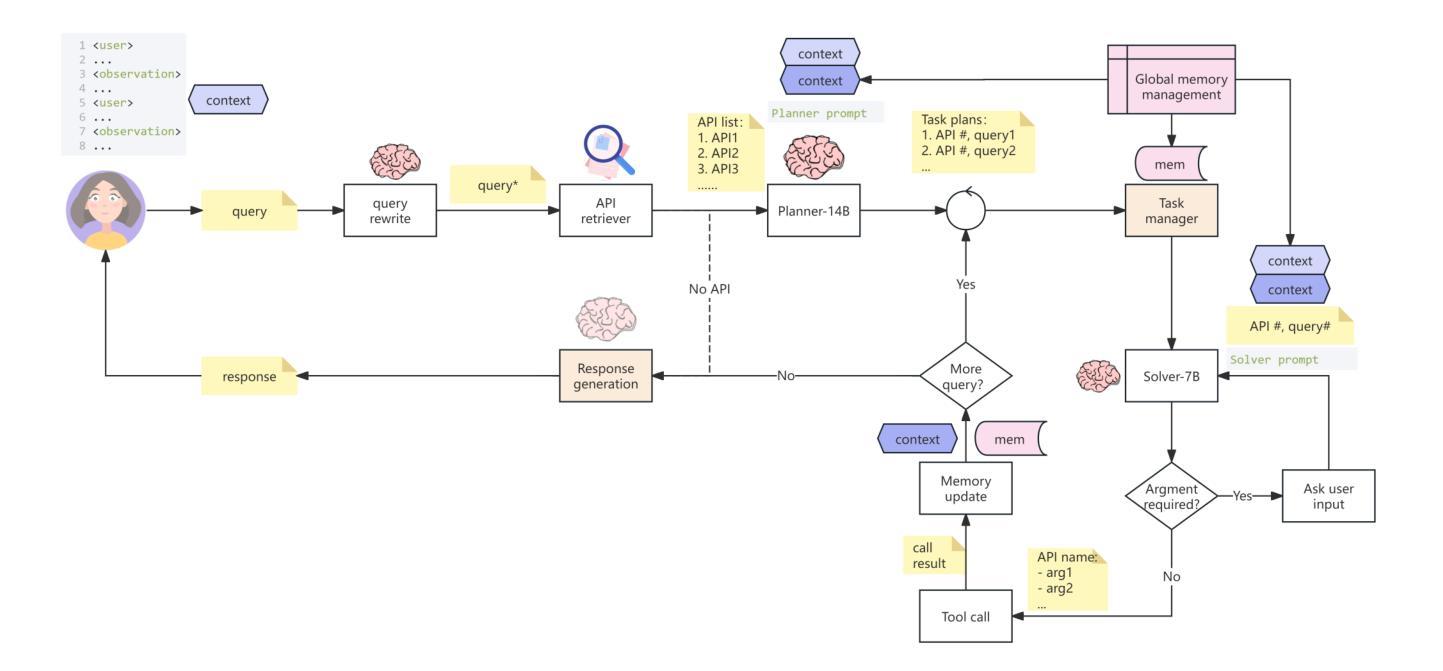
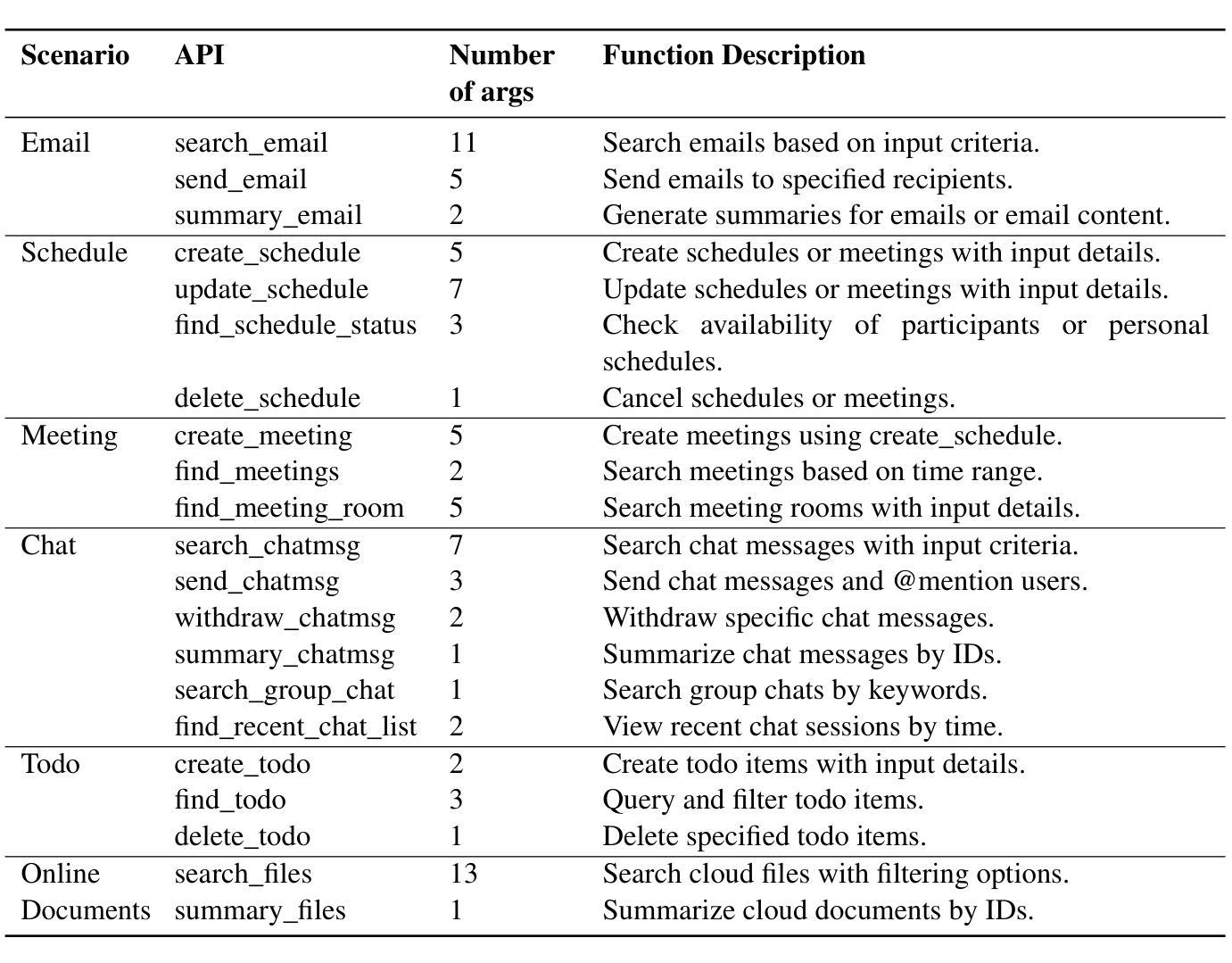
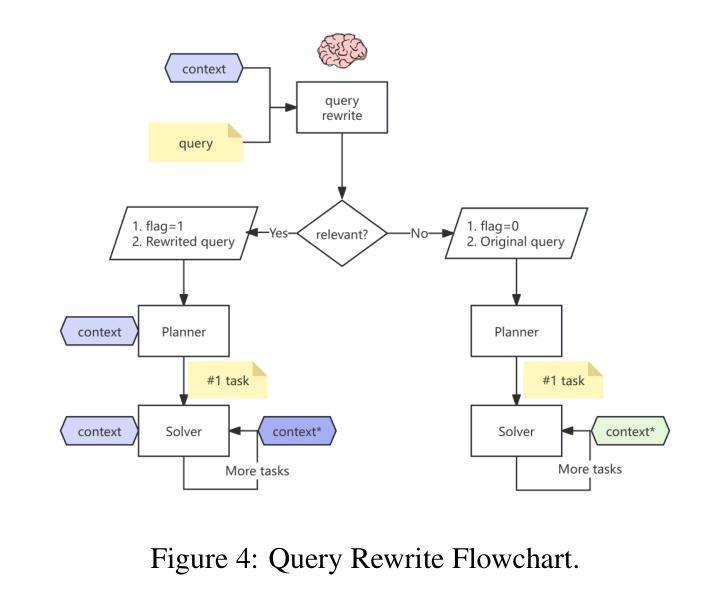
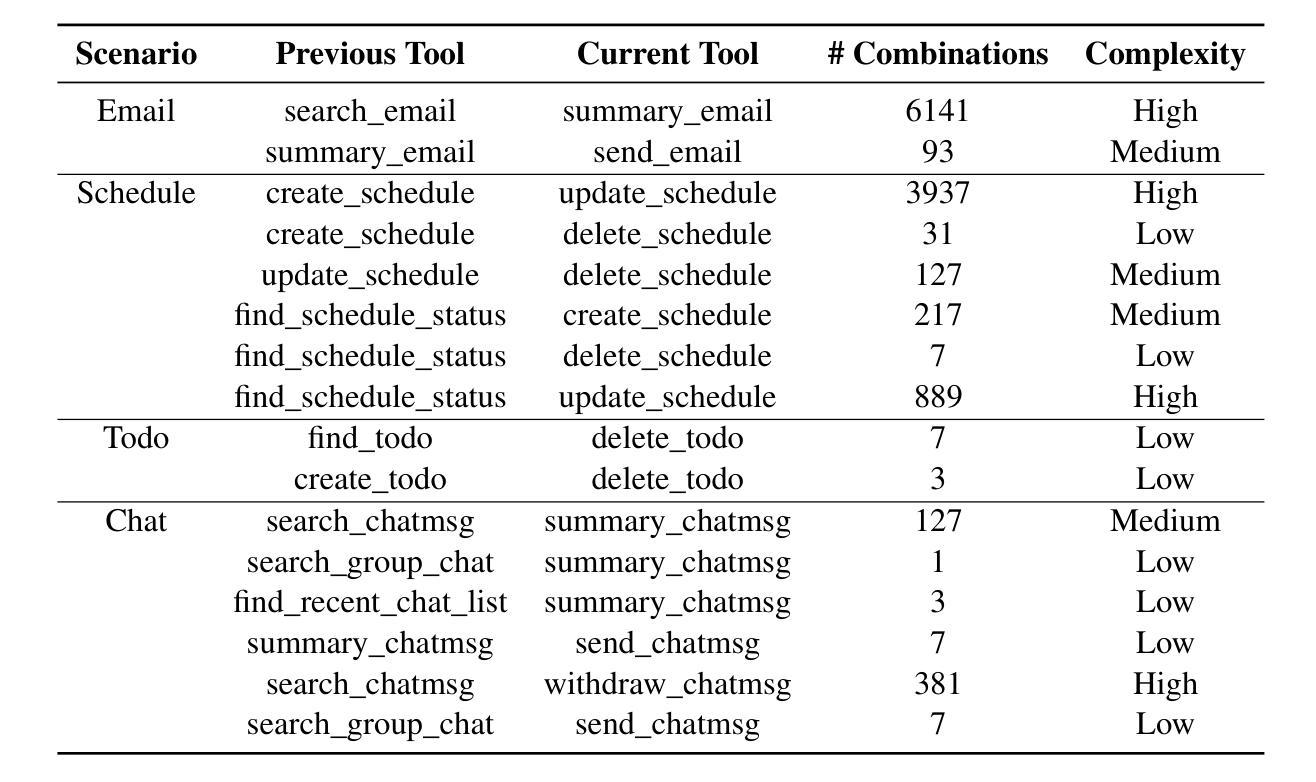
Multi-agent Application System in Office Collaboration Scenarios
Authors:Songtao Sun, Jingyi Li, Yuanfei Dong, Haoguang Liu, Chenxin Xu, Fuyang Li, Qiang Liu
This paper introduces a multi-agent application system designed to enhance office collaboration efficiency and work quality. The system integrates artificial intelligence, machine learning, and natural language processing technologies, achieving functionalities such as task allocation, progress monitoring, and information sharing. The agents within the system are capable of providing personalized collaboration support based on team members’ needs and incorporate data analysis tools to improve decision-making quality. The paper also proposes an intelligent agent architecture that separates Plan and Solver, and through techniques such as multi-turn query rewriting and business tool retrieval, it enhances the agent’s multi-intent and multi-turn dialogue capabilities. Furthermore, the paper details the design of tools and multi-turn dialogue in the context of office collaboration scenarios, and validates the system’s effectiveness through experiments and evaluations. Ultimately, the system has demonstrated outstanding performance in real business applications, particularly in query understanding, task planning, and tool calling. Looking forward, the system is expected to play a more significant role in addressing complex interaction issues within dynamic environments and large-scale multi-agent systems.
本文介绍了一个旨在提高办公室协作效率和工作质量的多智能体应用系统。该系统集成了人工智能、机器学习和自然语言处理技术,实现了任务分配、进度监控和信息共享等功能。系统内的智能体能根据团队成员的需求提供个性化的协作支持,并融合了数据分析工具来提升决策质量。文章还提出了一种智能体架构,该架构将计划和求解器分离,并通过多轮查询重写和业务工具检索等技术,增强了智能体的多意图和多轮对话能力。此外,本文还详细介绍了在办公室协作场景下工具和多轮对话的设计,并通过实验和评估验证了系统的有效性。最终,该系统在真实商业应用中表现出了卓越的性能,特别是在查询理解、任务规划和工具调用方面。展望未来,该系统在解决动态环境和大规模多智能体系统内的复杂交互问题方面将发挥更重要的作用。
论文及项目相关链接
PDF Technical report
Summary
本文介绍了一个多智能体应用系统,旨在提高办公协作效率和工作质量。该系统集成了人工智能、机器学习和自然语言处理等技术,具备任务分配、进度监控、信息共享等功能。系统中的智能体能根据团队成员的需求提供个性化协作支持,并引入数据分析工具来提高决策质量。同时,提出了智能体架构的Plan和Solver分离设计,增强了多意图和多轮对话能力。通过实验和评估验证了系统的有效性,特别是在查询理解、任务规划和工具调用方面表现优异。展望未来,该系统将在解决动态环境和大规模多智能体系统中的复杂交互问题方面发挥更重要作用。
Key Takeaways
- 系统集成了AI、ML和NLP技术,提高办公协作效率和工作质量。
- 智能体提供个性化协作支持,并引入数据分析工具提升决策质量。
- 提出了智能体架构的Plan和Solver分离设计,增强多意图和多轮对话能力。
- 通过实验和评估验证了系统在查询理解、任务规划和工具调用方面的有效性。
- 系统在真实商业应用中的性能出色。
- 该系统未来将在解决复杂交互问题方面发挥重要作用,特别是在动态环境和大规模多智能体系统中。
点此查看论文截图

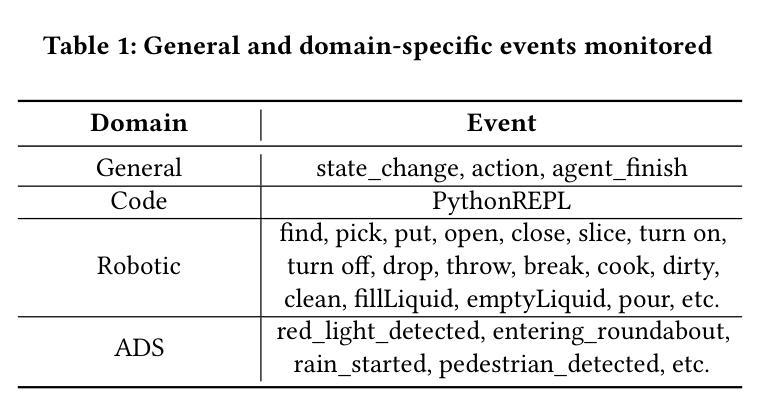
AgentSpec: Customizable Runtime Enforcement for Safe and Reliable LLM Agents
Authors:Haoyu Wang, Christopher M. Poskitt, Jun Sun
Agents built on LLMs are increasingly deployed across diverse domains, automating complex decision-making and task execution. However, their autonomy introduces safety risks, including security vulnerabilities, legal violations, and unintended harmful actions. Existing mitigation methods, such as model-based safeguards and early enforcement strategies, fall short in robustness, interpretability, and adaptability. To address these challenges, we propose AgentSpec, a lightweight domain-specific language for specifying and enforcing runtime constraints on LLM agents. With AgentSpec, users define structured rules that incorporate triggers, predicates, and enforcement mechanisms, ensuring agents operate within predefined safety boundaries. We implement AgentSpec across multiple domains, including code execution, embodied agents, and autonomous driving, demonstrating its adaptability and effectiveness. Our evaluation shows that AgentSpec successfully prevents unsafe executions in over 90% of code agent cases, eliminates all hazardous actions in embodied agent tasks, and enforces 100% compliance by autonomous vehicles (AVs). Despite its strong safety guarantees, AgentSpec remains computationally lightweight, with overheads in milliseconds. By combining interpretability, modularity, and efficiency, AgentSpec provides a practical and scalable solution for enforcing LLM agent safety across diverse applications. We also automate the generation of rules using LLMs and assess their effectiveness. Our evaluation shows that the rules generated by OpenAI o1 achieve a precision of 95.56% and recall of 70.96% for embodied agents, successfully identifying 87.26% of the risky code, and prevent AVs from breaking laws in 5 out of 8 scenarios.
基于大语言模型(LLM)的代理正越来越多地部署在各个领域,自动化复杂的决策和任务执行。然而,它们的自主性带来了安全风险,包括安全漏洞、法律违规和意外的有害行为。现有的缓解方法,如基于模型的保障和早期执行策略,在稳健性、可解释性和适应性方面存在不足。为了解决这些挑战,我们提出了AgentSpec,这是一种为LLM代理指定和执行运行时约束的轻量级特定领域语言。通过AgentSpec,用户定义包含触发器、谓词和执行机制的结构化规则,确保代理在预定的安全边界内运行。我们在多个领域实现了AgentSpec,包括代码执行、实体代理和自动驾驶,展示了其适应性和有效性。我们的评估显示,AgentSpec成功防止了超过90%的代码代理不安全执行的情况,消除了实体代理任务中的所有危险行为,并确保了自动驾驶汽车的100%合规性。尽管AgentSpec提供了强大的安全保证,但它的计算仍然轻量级,开销仅为毫秒级。通过结合可解释性、模块化和效率,AgentSpec为在多种应用程序中强制实施LLM代理安全提供了实用且可扩展的解决方案。我们还使用LLM自动化了规则生成,并评估了其有效性。我们的评估表明,OpenAI o1生成的规则对实体代理的精确度达到95.56%,召回率为70.96%,成功识别出87.26%的风险代码,并在8个场景中的5个中防止自动驾驶汽车违反法律。
论文及项目相关链接
Summary
基于LLM构建的代理正在多个领域得到广泛应用,实现了复杂的决策和任务自动化执行。然而,其自主性带来了安全风险,如安全漏洞、法律违规和意外有害行为。现有缓解方法如模型保障和早期执行策略在稳健性、可解释性和适应性方面存在不足。为此,我们提出了AgentSpec,这是一种用于在运行时对LLM代理进行特定域约束的轻量级领域专用语言。AgentSpec使用户能够定义结构化规则,包含触发器、谓词和执行机制,确保代理在预设的安全边界内运行。我们在代码执行、实体代理和自动驾驶等多个领域实现了AgentSpec,展示了其适应性和有效性。评估结果表明,AgentSpec成功阻止不安全执行的代码代理案例超过90%,消除了实体代理任务中的所有危险行为,并使自动驾驶车辆达到100%的合规性。尽管提供了强大的安全保证,但AgentSpec的计算开销仍然很小,仅在毫秒级别。通过结合可解释性、模块化和效率,AgentSpec为在不同应用中强制实施LLM代理安全提供了实用且可扩展的解决方案。我们还使用LLMs自动生成规则并评估了其有效性。评估显示,由OpenAI o1生成的规则对实体代理的精度达到95.56%,召回率为70.96%,成功识别出87.26%的风险代码,并在5个场景中的8个自动驾驶车辆避免违规。
Key Takeaways
- LLM代理被广泛应用于多个领域,实现了复杂的决策和任务自动化执行。
- 自主性的LLM代理带来了安全风险,如安全漏洞、法律违规和意外有害行为。
- 现有缓解方法不足以应对LLM代理的安全挑战。
- AgentSpec是一种轻量级的领域专用语言,用于在运行时对LLM代理进行约束。
- AgentSpec通过定义结构化规则来确保代理在预设的安全边界内运行。
- AgentSpec在多个领域得到实现并展示了其有效性和适应性。
- AgentSpec提供了强大的安全保证,同时计算开销很小。
点此查看论文截图



Toward LLM-Agent-Based Modeling of Transportation Systems: A Conceptual Framework
Authors:Tianming Liu, Jirong Yang, Yafeng Yin
In transportation system demand modeling and simulation, agent-based models and microsimulations are current state-of-the-art approaches. However, existing agent-based models still have some limitations on behavioral realism and resource demand that limit their applicability. In this study, leveraging the emerging technology of large language models (LLMs) and LLM-based agents, we propose a general LLM-agent-based modeling framework for transportation systems. We argue that LLM agents not only possess the essential capabilities to function as agents but also offer promising solutions to overcome some limitations of existing agent-based models. Our conceptual framework design closely replicates the decision-making and interaction processes and traits of human travelers within transportation networks, and we demonstrate that the proposed systems can meet critical behavioral criteria for decision-making and learning behaviors using related studies and a demonstrative example of LLM agents’ learning and adjustment in the bottleneck setting. Although further refinement of the LLM-agent-based modeling framework is necessary, we believe that this approach has the potential to improve transportation system modeling and simulation.
在交通运输系统需求建模与仿真中,基于主体的模型和微观仿真都是当前最先进的方法。然而,现有的基于主体的模型在行为现实性和资源需求方面仍有一些限制,这限制了其适用性。在这项研究中,我们借助新兴的大型语言模型(LLM)和基于LLM的主体技术,提出了一个适用于交通运输系统的通用LLM主体建模框架。我们认为,LLM主体不仅具备作为主体的基本能力,而且还提供了克服现有基于主体模型局限性的有前途的解决方案。我们的概念框架设计紧密地复制了交通运输网络中人类旅行者的决策和互动过程及特征,我们证明,相关研究和LLM主体在瓶颈环境中的学习和调整示范性例子可以证明,所提出的系统能满足决策制定和学习行为的关键行为标准。尽管对LLM主体建模框架的进一步精细化是必要的,但我们相信这种方法有潜力改进交通运输系统的建模和仿真。
论文及项目相关链接
PDF 39 pages; updated framework, literature review, and results
Summary
基于多智能体的模型与微观模拟是当前运输系统需求建模与仿真中的先进技术。然而,现有智能体模型在行为真实性和资源需求方面仍存在一定局限性。本研究利用新兴的大型语言模型(LLM)和LLM智能体技术,提出了一个通用的LLM智能体模型框架。该框架不仅具备了智能体的基本能力,而且解决了现有智能体模型的一些局限性问题。通过紧密复制运输网络中的决策与互动过程以及旅行者的特性,该框架展现了智能系统能满足关键的决策制定与学习行为标准。虽然该框架还需进一步完善,但其有望改进运输系统的建模与仿真。
Key Takeaways
- 现有运输系统需求建模的智能体模型存在行为真实性和资源需求的局限性。
- 大型语言模型(LLM)和LLM智能体技术为解决这些问题提供了新的思路。
- LLM智能体不仅具备基本的智能体功能,还能克服现有模型的某些限制。
- 提出了一种新的LLM智能体模型框架,该框架紧密复制了运输网络中的决策和互动过程以及旅行者的特性。
- 该框架能够通过相关研究和实例展示智能系统的决策制定与学习行为。
- 虽然还需要对LLM智能体模型框架进行改进,但它具有改进运输系统建模和仿真的潜力。
点此查看论文截图

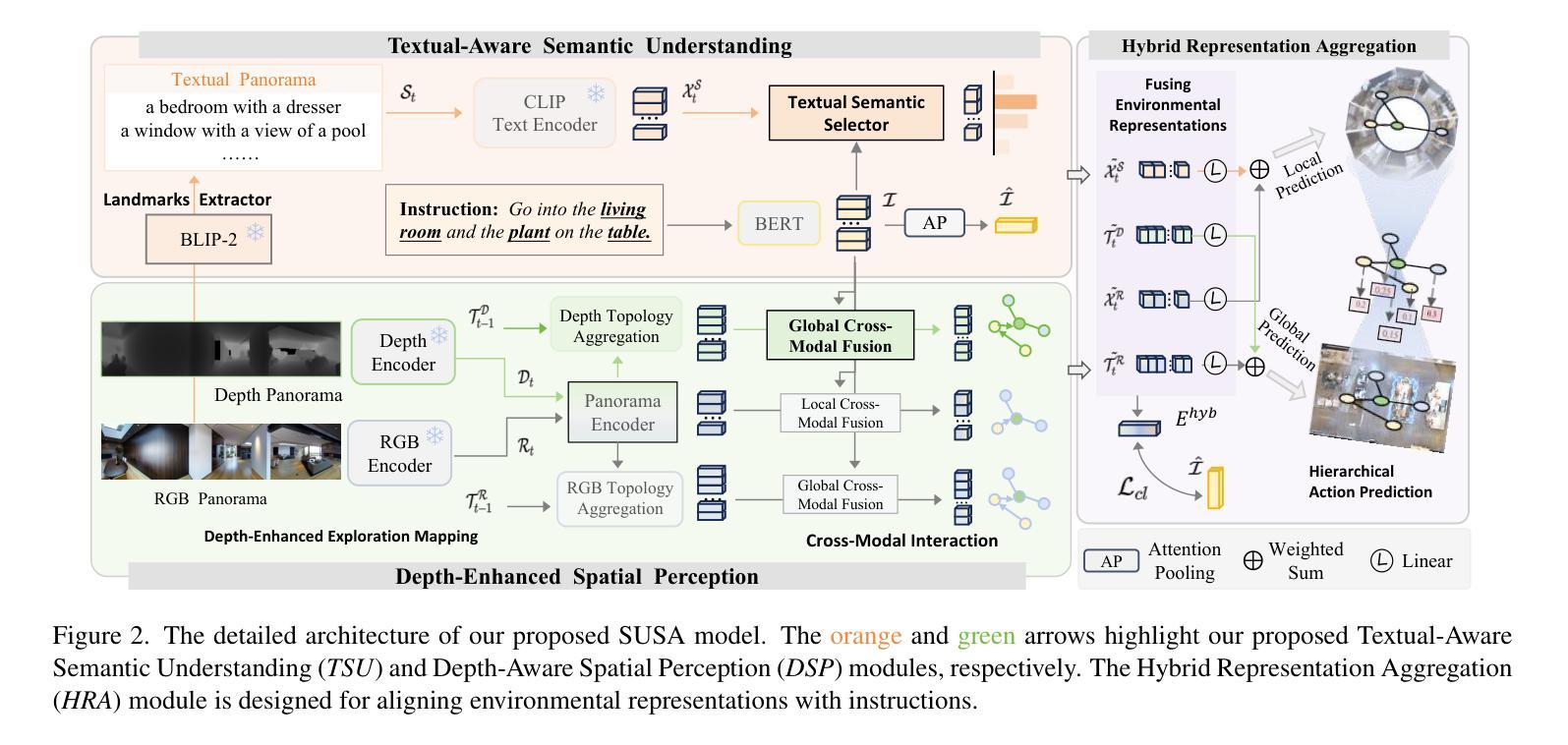
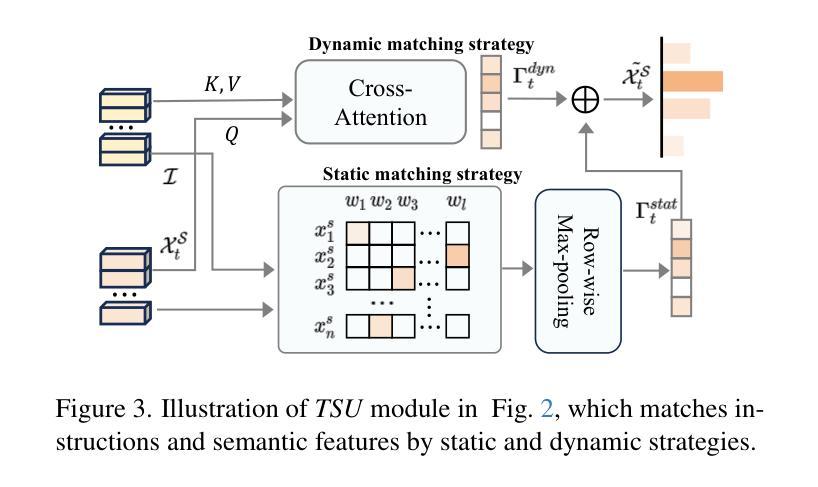
Agent Journey Beyond RGB: Unveiling Hybrid Semantic-Spatial Environmental Representations for Vision-and-Language Navigation
Authors:Xuesong Zhang, Yunbo Xu, Jia Li, Zhenzhen Hu, Richnag Hong
Navigating unseen environments based on natural language instructions remains difficult for egocentric agents in Vision-and-Language Navigation (VLN). Existing approaches primarily rely on RGB images for environmental representation, underutilizing latent textual semantic and spatial cues and leaving the modality gap between instructions and scarce environmental representations unresolved. Intuitively, humans inherently ground semantic knowledge within spatial layouts during indoor navigation. Inspired by this, we propose a versatile Semantic Understanding and Spatial Awareness (SUSA) architecture to encourage agents to ground environment from diverse perspectives. SUSA includes a Textual Semantic Understanding (TSU) module, which narrows the modality gap between instructions and environments by generating and associating the descriptions of environmental landmarks in agent’s immediate surroundings. Additionally, a Depth-enhanced Spatial Perception (DSP) module incrementally constructs a depth exploration map, enabling a more nuanced comprehension of environmental layouts. Experiments demonstrate that SUSA’s hybrid semantic-spatial representations effectively enhance navigation performance, setting new state-of-the-art performance across three VLN benchmarks (REVERIE, R2R, and SOON). The source code will be publicly available.
在视觉与语言导航(VLN)中,以自我为中心的智能体在根据自然语言指令来探索未知环境时仍然面临挑战。现有的方法主要依赖于RGB图像来表示环境,没有充分利用潜在的文本语义和空间线索,也没有解决指令和稀缺的环境表示之间的模态差距问题。直觉上,人类在室内导航时,会在空间布局中固有地融入语义知识。受此启发,我们提出了一种通用的语义理解与空间感知(SUSA)架构,以鼓励智能体从多个角度融入环境。SUSA包括文本语义理解(TSU)模块,它通过生成并关联环境地标的描述来缩小指令和环境之间的模态差距,这些描述都在智能体的周围。此外,深度增强空间感知(DSP)模块逐步构建深度探索地图,使环境布局的理解更加微妙。实验表明,SUSA的混合语义-空间表示有效地提高了导航性能,在REVERIE、R2R和SOON三个VLN基准测试中均达到了最新性能水平。源代码将公开提供。
论文及项目相关链接
PDF A technical report consisting of 16 pages, 12 figures, 11 tables
Summary
本文提出一种名为SUSA的架构,包含文本语义理解(TSU)模块和深度增强空间感知(DSP)模块,用于鼓励智能体从多个角度理解环境。该架构缩小了指令和环境之间的模态差距,通过生成和关联环境地标的描述以及构建深度探索地图,提高了智能体在视觉语言导航(VLN)中的导航性能。
Key Takeaways
- VLN任务中,智能体在根据自然语言指令导航未知环境时仍面临困难。
- 现有方法主要依赖RGB图像进行环境表示,未充分利用潜在的文本语义和空间线索,无法解决指令和环境表示之间的模态差距。
- SUSA架构包括TSU模块,通过生成和关联环境地标的描述来缩小指令和环境之间的模态差距。
- SUSA架构还包括DSP模块,该模块构建深度探索地图,使智能体对环境布局有更深入的理解。
- SUSA架构在三个VLN基准测试(REVERIE,R2R和SOON)上表现出卓越性能,提高了智能体的导航能力。
- 本文提出的SUSA架构具有广泛的应用前景,可以应用于智能机器人、自动驾驶等领域。
点此查看论文截图

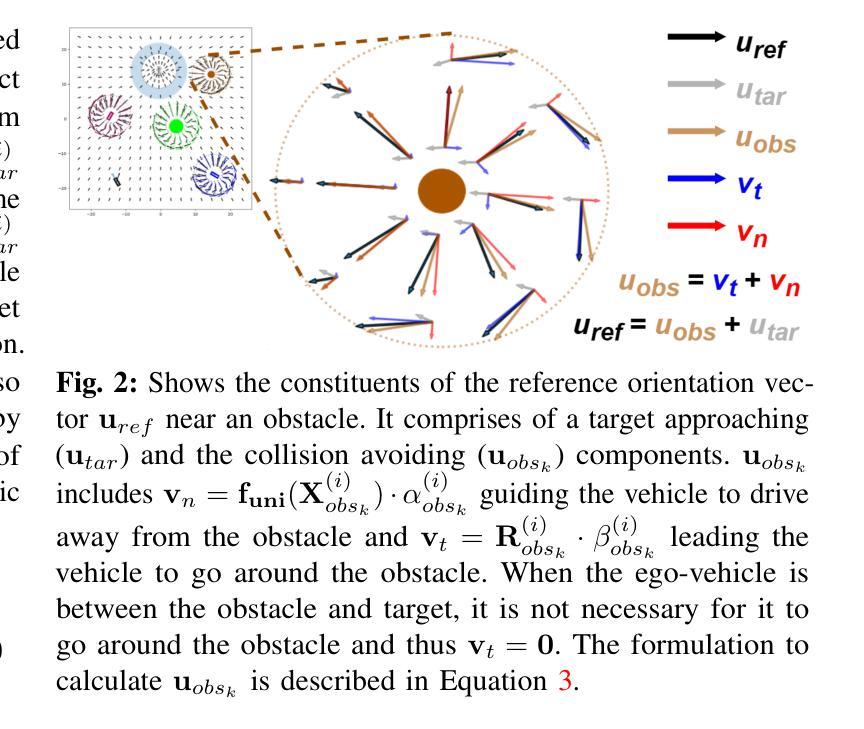
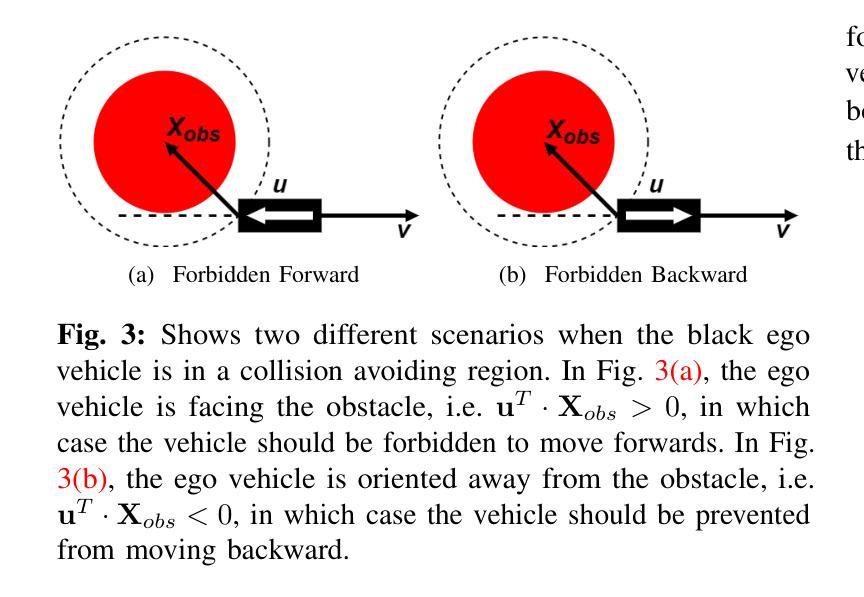
MA-DV2F: A Multi-Agent Navigation Framework using Dynamic Velocity Vector Field
Authors:Yining Ma, Qadeer Khan, Daniel Cremers
In this paper we propose MA-DV2F: Multi-Agent Dynamic Velocity Vector Field. It is a framework for simultaneously controlling a group of vehicles in challenging environments. DV2F is generated for each vehicle independently and provides a map of reference orientation and speed that a vehicle must attain at any point on the navigation grid such that it safely reaches its target. The field is dynamically updated depending on the speed and proximity of the ego-vehicle to other agents. This dynamic adaptation of the velocity vector field allows prevention of imminent collisions. Experimental results show that MA-DV2F outperforms concurrent methods in terms of safety, computational efficiency and accuracy in reaching the target when scaling to a large number of vehicles. Project page for this work can be found here: https://yininghase.github.io/MA-DV2F/
在这篇论文中,我们提出了MA-DV2F:多智能体动态速度矢量场。这是一个在具有挑战性的环境中同时控制一组车辆的框架。DV2F是为每辆车独立生成的,并提供了一张参考方向和速度的地图,车辆在导航网格上的任何位置都必须达到这些参考方向和速度,以便安全地到达其目标。该字段会根据自身车辆的速度和其他智能体的接近程度进行动态更新。速度矢量场的这种动态适应可以防止即将发生的碰撞。实验结果表明,MA-DV2F在安全性、计算效率和目标达成精度方面优于其他并行方法,特别是在车辆数量增加时。该工作的项目页面可以在这里找到:https://yininghase.github.io/MA-DV2F/。
论文及项目相关链接
PDF paper accepted by IEEE RAL 2025
Summary
本文提出了MA-DV2F:多智能体动态速度矢量场框架。它是一个用于在复杂环境中同时控制车辆群体的框架。DV2F为每个车辆独立生成,提供了一个导航网格上车辆的参考方向和速度的地图,使车辆能够安全地达到目标。速度矢量场根据车辆自身的速度和与其他智能体的接近程度动态更新,从而避免了即将发生的碰撞。实验结果表明,MA-DV2F在安全性、计算效率和目标到达的准确度方面优于现有方法,尤其在大规模车辆场景中表现更佳。
Key Takeaways
- MA-DV2F是一个用于控制车辆群体的框架,适用于复杂环境。
- DV2F为每个车辆独立生成,提供导航网格上的参考方向和速度地图。
- 速度矢量场可动态更新,根据车辆自身的速度和接近度进行调整。
- 动态速度矢量场有助于避免即将发生的碰撞。
- MA-DV2F在安全性、计算效率和目标到达准确度方面优于其他方法。
- 该框架在大规模车辆场景中表现良好。
点此查看论文截图



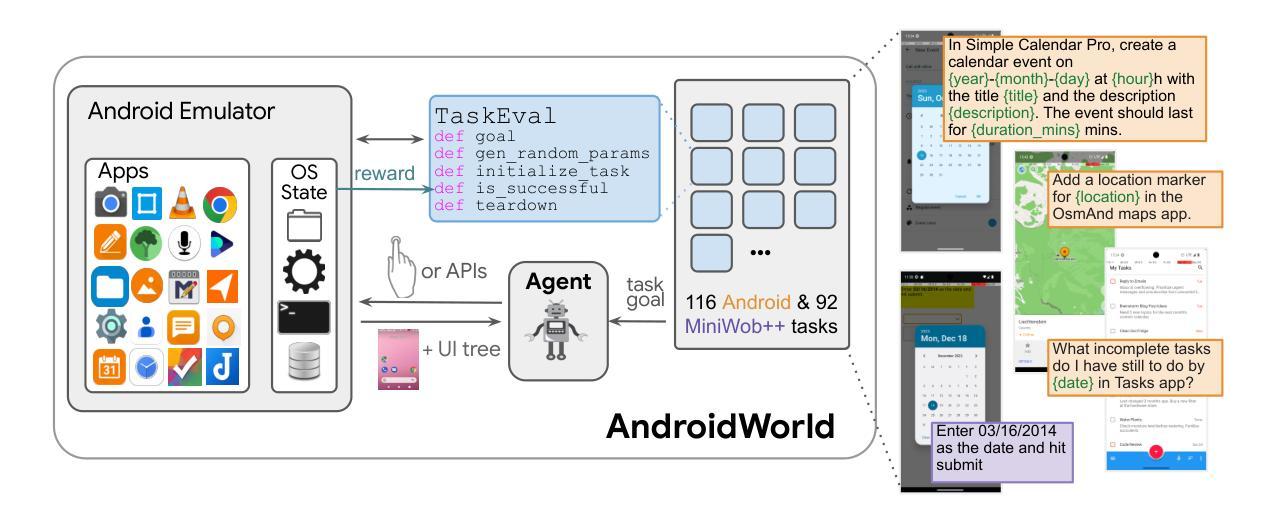
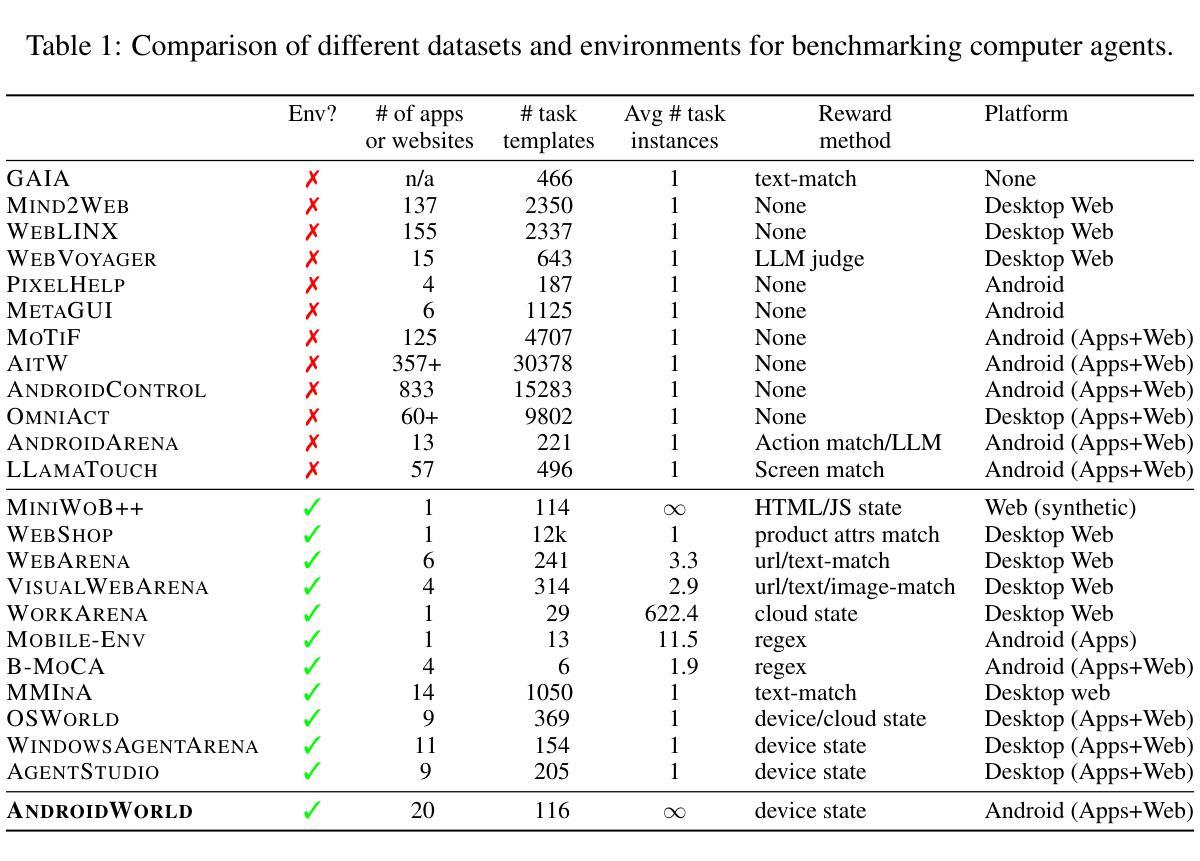
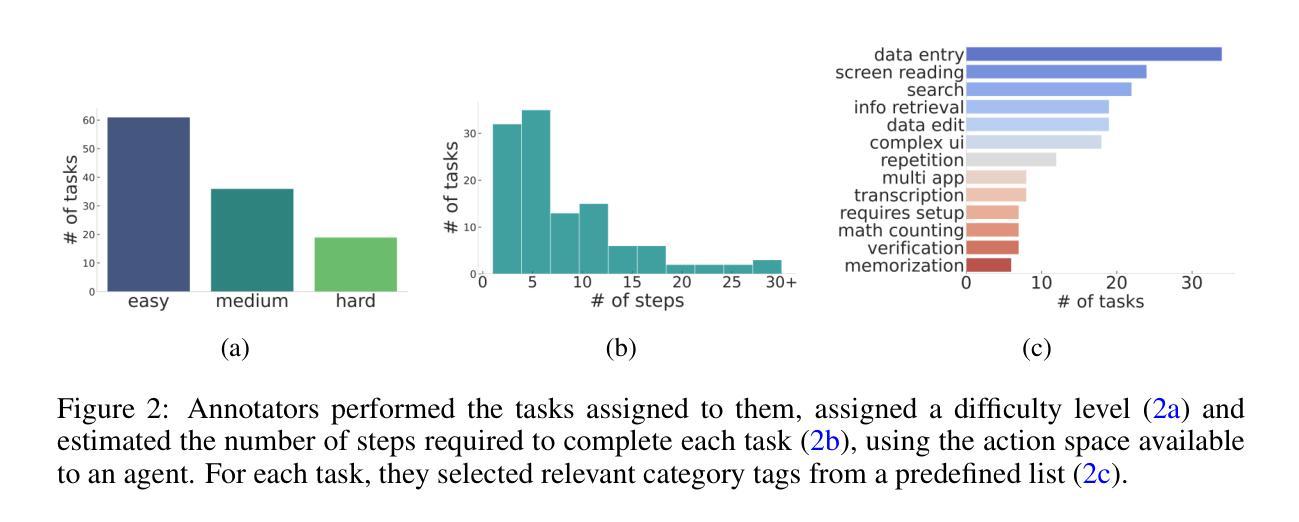
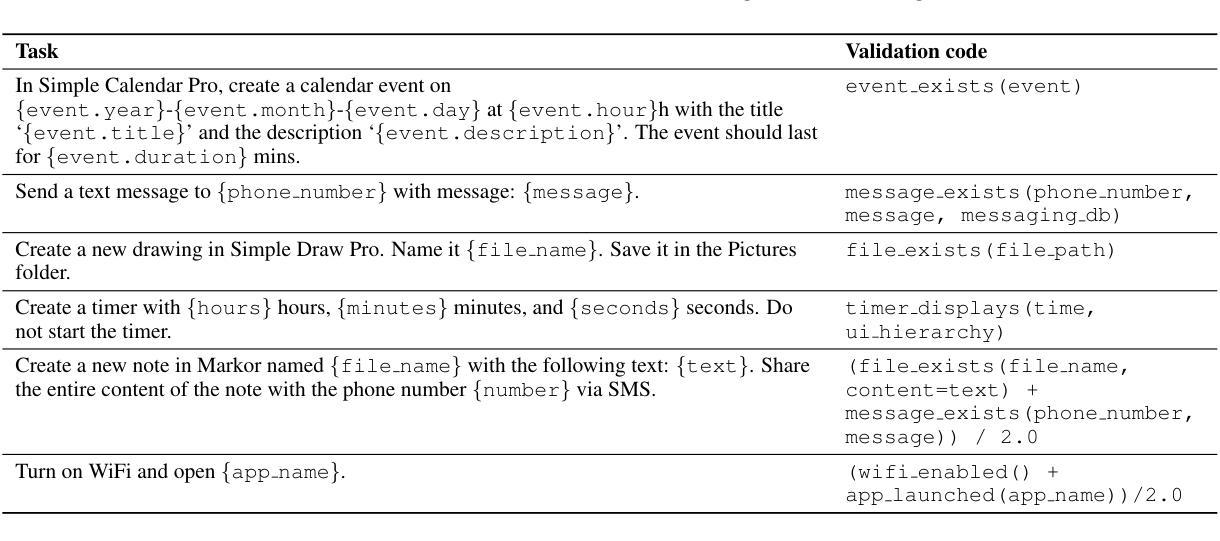
AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents
Authors:Christopher Rawles, Sarah Clinckemaillie, Yifan Chang, Jonathan Waltz, Gabrielle Lau, Marybeth Fair, Alice Li, William Bishop, Wei Li, Folawiyo Campbell-Ajala, Daniel Toyama, Robert Berry, Divya Tyamagundlu, Timothy Lillicrap, Oriana Riva
Autonomous agents that execute human tasks by controlling computers can enhance human productivity and application accessibility. However, progress in this field will be driven by realistic and reproducible benchmarks. We present AndroidWorld, a fully functional Android environment that provides reward signals for 116 programmatic tasks across 20 real-world Android apps. Unlike existing interactive environments, which provide a static test set, AndroidWorld dynamically constructs tasks that are parameterized and expressed in natural language in unlimited ways, thus enabling testing on a much larger and more realistic suite of tasks. To ensure reproducibility, each task includes dedicated initialization, success-checking, and tear-down logic, which modifies and inspects the device’s system state. We experiment with baseline agents to test AndroidWorld and provide initial results on the benchmark. Our best agent can complete 30.6% of AndroidWorld’s tasks, leaving ample room for future work. Furthermore, we adapt a popular desktop web agent to work on Android, which we find to be less effective on mobile, suggesting future research is needed to achieve universal, cross-platform agents. Finally, we also conduct a robustness analysis, showing that task variations can significantly affect agent performance, demonstrating that without such testing, agent performance metrics may not fully reflect practical challenges. AndroidWorld and the experiments in this paper are available at github.com/google-research/android_world.
通过控制计算机执行人类任务,自主代理可以增强人类生产力和应用程序的可访问性。然而,这一领域的进展将取决于现实且可再生的基准测试。我们推出了AndroidWorld,这是一个功能齐全的Android环境,可为跨20个现实世界Android应用的116项编程任务提供奖励信号。与现有的交互式环境不同,AndroidWorld能够动态构建任务,这些任务以自然语言参数化表达,方式无限,从而能够在更大且更现实的任务套件上进行测试。为确保可重复性,每个任务都包含专门的初始化、成功检查和拆卸逻辑,这些逻辑会修改并检查设备系统状态。我们用基线代理进行实验以测试AndroidWorld,并在基准测试上提供了初步结果。我们表现最佳的代理可以完成AndroidWorld的30.6%的任务,这为未来的工作留下了充足的空间。此外,我们将一个流行的桌面网络代理改编为适用于Android的版本,但发现在移动设备上效果较差,这表明需要未来的研究来实现通用跨平台代理。最后,我们还进行了稳健性分析,表明任务变动会极大地影响代理性能,表明如果没有这样的测试,代理性能指标可能无法充分反映实际挑战。AndroidWorld以及本文中的实验可在github.com/google-research/android_world获得。
论文及项目相关链接
Summary:
自主执行人类任务并控制计算机的智能代理可以增强人类生产力和应用程序的可访问性。然而,该领域的进展将取决于现实且可重复的基准测试。我们推出了AndroidWorld,这是一个功能齐全的Android环境,为20个真实世界的Android应用程序中的116个程序化任务提供奖励信号。与现有的交互式环境不同,AndroidWorld可以动态构建任务,这些任务以自然语言进行参数化表达且方式无限,从而能够在更大和更现实的套件上进行测试。为确保可重复性,每个任务都包含专用的初始化、成功检查和拆除逻辑,这些逻辑会修改并检查设备系统状态。我们对基准智能代理进行了实验测试并提供了初步结果,表现最佳的智能代理能完成AndroidWorld的30.6%的任务,这为未来的工作留下了充足的空间。此外,我们将流行的桌面网页智能代理适配到Android平台,发现其在移动端的效力较低,这表明要实现跨平台的通用智能代理还需要未来的研究。最后,我们还进行了稳健性分析,显示任务变化会显著影响智能代理的性能,表明没有这样的测试,智能代理的性能指标可能无法充分反映实际挑战。AndroidWorld以及本文中的实验可在github.com/google-research/android_world获取。
Key Takeaways:
一、自主代理通过控制计算机执行人类任务可以提升人类生产力及应用程序的易访问性。
二、AndroidWorld是一个全新的Android环境,可以为多种程序任务提供奖励信号。
三、AndroidWorld能动态构建任务,这些任务能以自然语言无限表达,扩大了测试任务的规模和真实性。
四、每个任务都包含特定的初始化、成功验证和拆除逻辑以确保研究的可重复性。
五、目前最好的智能代理只能完成AndroidWorld的30.6%的任务,表明该领域还有很大的发展空间。
六、将桌面网页智能代理适配到Android平台的效果不佳,提示我们仍需研究跨平台的智能代理。
点此查看论文截图