⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-09 更新
Gaussian Mixture Flow Matching Models
Authors:Hansheng Chen, Kai Zhang, Hao Tan, Zexiang Xu, Fujun Luan, Leonidas Guibas, Gordon Wetzstein, Sai Bi
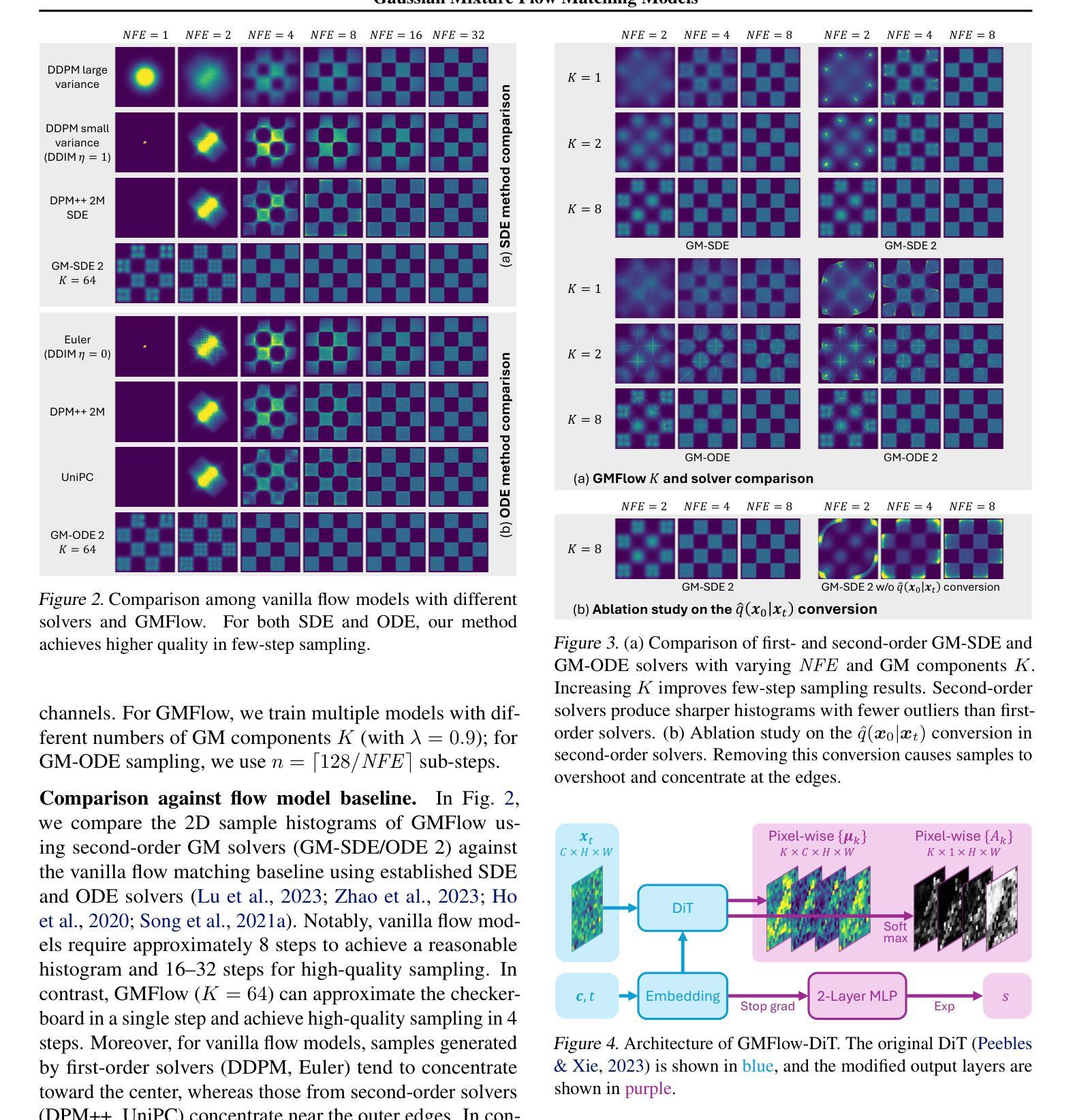
Diffusion models approximate the denoising distribution as a Gaussian and predict its mean, whereas flow matching models reparameterize the Gaussian mean as flow velocity. However, they underperform in few-step sampling due to discretization error and tend to produce over-saturated colors under classifier-free guidance (CFG). To address these limitations, we propose a novel Gaussian mixture flow matching (GMFlow) model: instead of predicting the mean, GMFlow predicts dynamic Gaussian mixture (GM) parameters to capture a multi-modal flow velocity distribution, which can be learned with a KL divergence loss. We demonstrate that GMFlow generalizes previous diffusion and flow matching models where a single Gaussian is learned with an $L_2$ denoising loss. For inference, we derive GM-SDE/ODE solvers that leverage analytic denoising distributions and velocity fields for precise few-step sampling. Furthermore, we introduce a novel probabilistic guidance scheme that mitigates the over-saturation issues of CFG and improves image generation quality. Extensive experiments demonstrate that GMFlow consistently outperforms flow matching baselines in generation quality, achieving a Precision of 0.942 with only 6 sampling steps on ImageNet 256$\times$256.
扩散模型通过近似去噪分布为高斯分布并预测其均值,而流匹配模型则将高斯均值重新参数化为流速。然而,由于离散化误差,它们在几步采样上表现不佳,并且在无分类器引导(CFG)下容易产生过饱和颜色。为了解决这些局限性,我们提出了一种新型的高斯混合流匹配(GMFlow)模型:GMFlow不预测均值,而是预测动态高斯混合(GM)参数,以捕捉多模式流速分布,这可以通过KL散度损失来学习。我们证明了GMFlow能够概括之前的扩散模型和流匹配模型,其中单个高斯是通过L2去噪损失学习的。对于推理,我们推出了利用解析去噪分布和速度场的GM-SDE/ODE求解器,用于精确几步采样。此外,我们引入了一种新的概率引导方案,该方案缓解了CFG的过饱和问题,提高了图像生成质量。大量实验表明,GMFlow在生成质量方面始终优于流匹配基线,在ImageNet 256×256上仅6步采样就达到了0.942的精度。
论文及项目相关链接
PDF Code: https://github.com/Lakonik/GMFlow
Summary
本文提出一种新型的高斯混合流匹配(GMFlow)模型,用于解决扩散模型和流匹配模型在少数步骤采样和分类器免费指导下的局限性。GMFlow通过预测动态高斯混合参数来捕捉多模态流速度分布,并采用KL散度损失进行学习。GMFlow能够泛化之前的扩散模型和流匹配模型,并引入新的概率指导方案来提高图像生成质量。实验表明,GMFlow在生成质量方面一直优于流匹配基线,在ImageNet 256x256上仅6步采样就达到了0.942的精度。
Key Takeaways
- 扩散模型和流匹配模型在少数步骤采样中存在离散化误差。
- 分类器免费指导(CFG)下,模型会产生过饱和色彩。
- 提出的GMFlow模型通过预测动态高斯混合参数来捕捉多模态流速度分布。
- GMFlow采用KL散度损失进行学习,能够泛化之前的扩散模型和流匹配模型。
- GMFlow引入了新的概率指导方案,缓解了CFG的过饱和问题,提高了图像生成质量。
- 实验显示,GMFlow在生成质量方面优于流匹配基线,在ImageNet 256x256上仅需要6步采样就达到了高精度。
点此查看论文截图


DA2Diff: Exploring Degradation-aware Adaptive Diffusion Priors for All-in-One Weather Restoration
Authors:Jiamei Xiong, Xuefeng Yan, Yongzhen Wang, Wei Zhao, Xiao-Ping Zhang, Mingqiang Wei
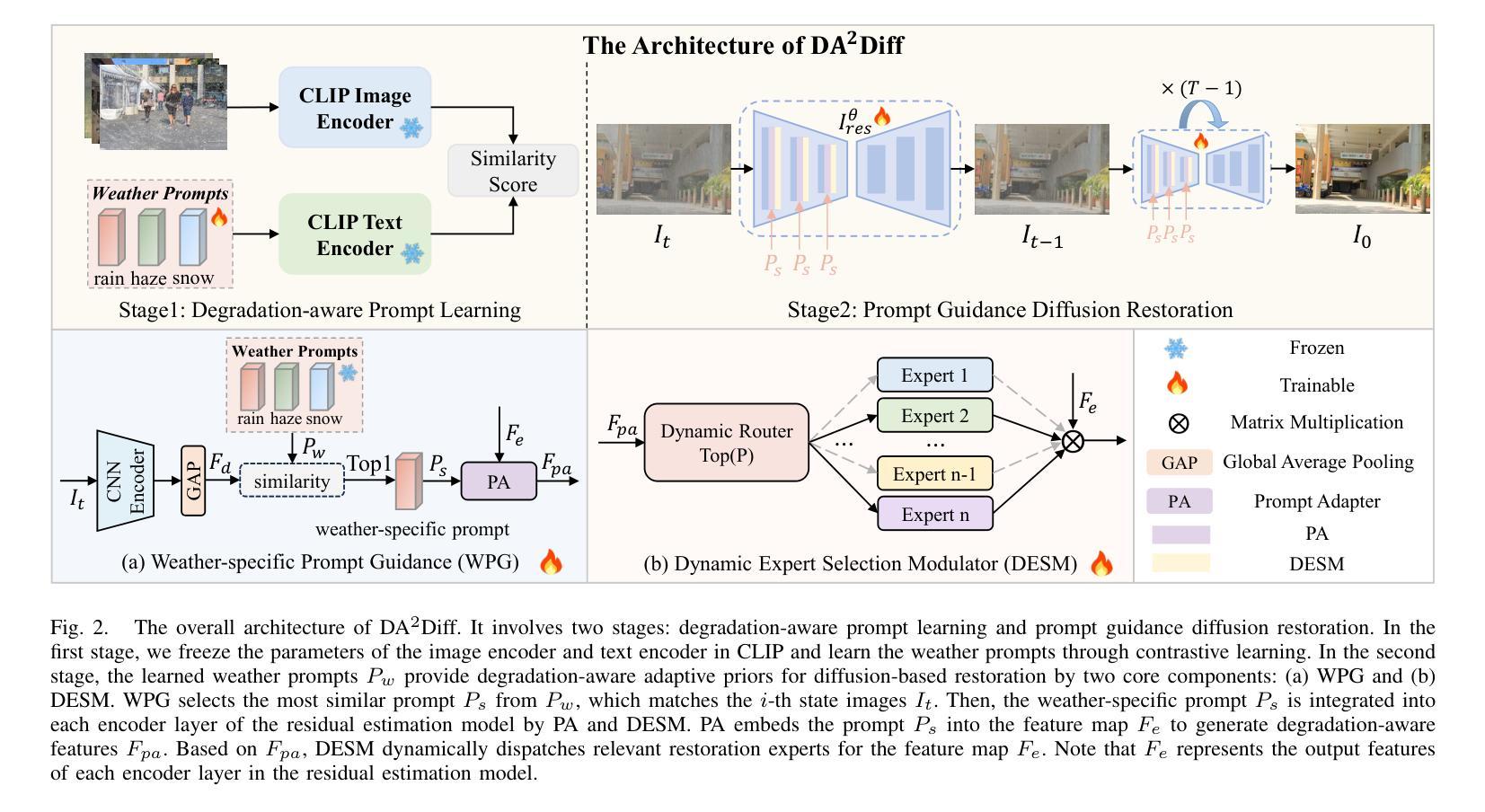
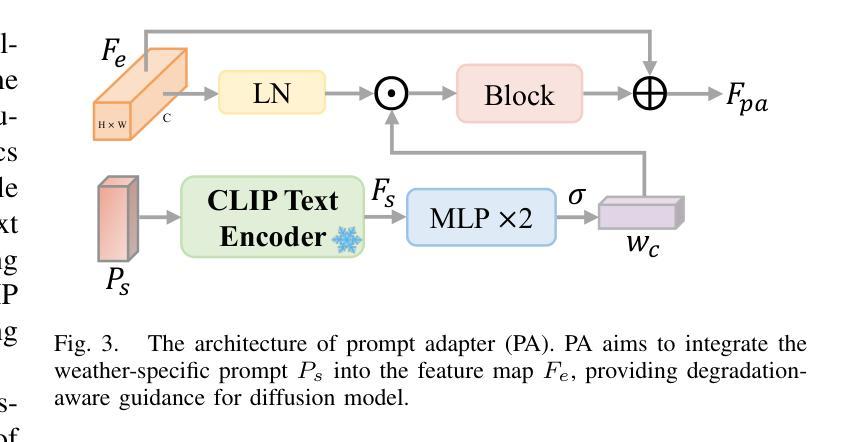
Image restoration under adverse weather conditions is a critical task for many vision-based applications. Recent all-in-one frameworks that handle multiple weather degradations within a unified model have shown potential. However, the diversity of degradation patterns across different weather conditions, as well as the complex and varied nature of real-world degradations, pose significant challenges for multiple weather removal. To address these challenges, we propose an innovative diffusion paradigm with degradation-aware adaptive priors for all-in-one weather restoration, termed DA2Diff. It is a new exploration that applies CLIP to perceive degradation-aware properties for better multi-weather restoration. Specifically, we deploy a set of learnable prompts to capture degradation-aware representations by the prompt-image similarity constraints in the CLIP space. By aligning the snowy/hazy/rainy images with snow/haze/rain prompts, each prompt contributes to different weather degradation characteristics. The learned prompts are then integrated into the diffusion model via the designed weather specific prompt guidance module, making it possible to restore multiple weather types. To further improve the adaptiveness to complex weather degradations, we propose a dynamic expert selection modulator that employs a dynamic weather-aware router to flexibly dispatch varying numbers of restoration experts for each weather-distorted image, allowing the diffusion model to restore diverse degradations adaptively. Experimental results substantiate the favorable performance of DA2Diff over state-of-the-arts in quantitative and qualitative evaluation. Source code will be available after acceptance.
恶劣天气条件下的图像恢复是许多视觉应用中的一项关键任务。近期的一站式框架能够在统一模型中处理多种天气退化,显示出其潜力。然而,不同天气条件下退化模式的多样性以及现实世界退化的复杂性和多变性质,给多种天气移除带来了重大挑战。为了应对这些挑战,我们提出了一种创新的扩散范式,采用退化感知自适应先验进行一站式天气恢复,称为DA2Diff。这是一次新的探索,将CLIP应用于感知退化感知属性,以更好地进行多天气恢复。具体来说,我们部署了一系列可学习的提示来通过CLIP空间中的提示图像相似性约束来捕获退化感知表示。通过将下雪/雾霾/雨天图像与雪/雾霾/雨提示对齐,每个提示有助于不同的天气退化特征。然后将学习到的提示集成到扩散模型中,通过设计的天气特定提示指导模块,使得恢复多种天气类型成为可能。为了进一步提高对复杂天气退化的适应性,我们提出了一种动态专家选择调制器,它采用动态天气感知路由器,灵活地为每种天气失真图像分配不同数量的恢复专家,使扩散模型能够自适应地恢复各种退化。实验结果证实,DA2Diff在定量和定性评估上的性能优于现有技术。源代码将在接受后提供。
论文及项目相关链接
Summary
本文提出一种名为DA2Diff的扩散模型,用于一次应对多种天气状况的图像修复。该模型通过引入降解感知自适应先验和CLIP技术,能更准确地感知不同天气条件下的图像退化特征。通过设计天气特定的提示引导模块和动态专家选择调制器,模型能更灵活地适应各种复杂天气退化情况,提高了图像修复的效果。
Key Takeaways
- DA2Diff模型是一种针对多种天气状况的图像修复框架,旨在解决不同天气引起的图像退化问题。
- 模型采用降解感知自适应先验,能更准确地识别不同天气条件下的图像特征。
- CLIP技术被用于感知降解感知属性,有助于提高多天气修复效果。
- 通过设计天气特定的提示引导模块,将学习到的提示集成到扩散模型中,实现多种天气类型的图像修复。
- 动态专家选择调制器的引入,使得模型能更灵活地适应复杂的天气退化情况。
- 模型通过动态天气感知路由器调度不同数量的修复专家,使扩散模型能自适应地修复各种退化情况。
- 实验结果表明,DA2Diff在定量和定性评估上均表现出优于现有技术的性能。
点此查看论文截图

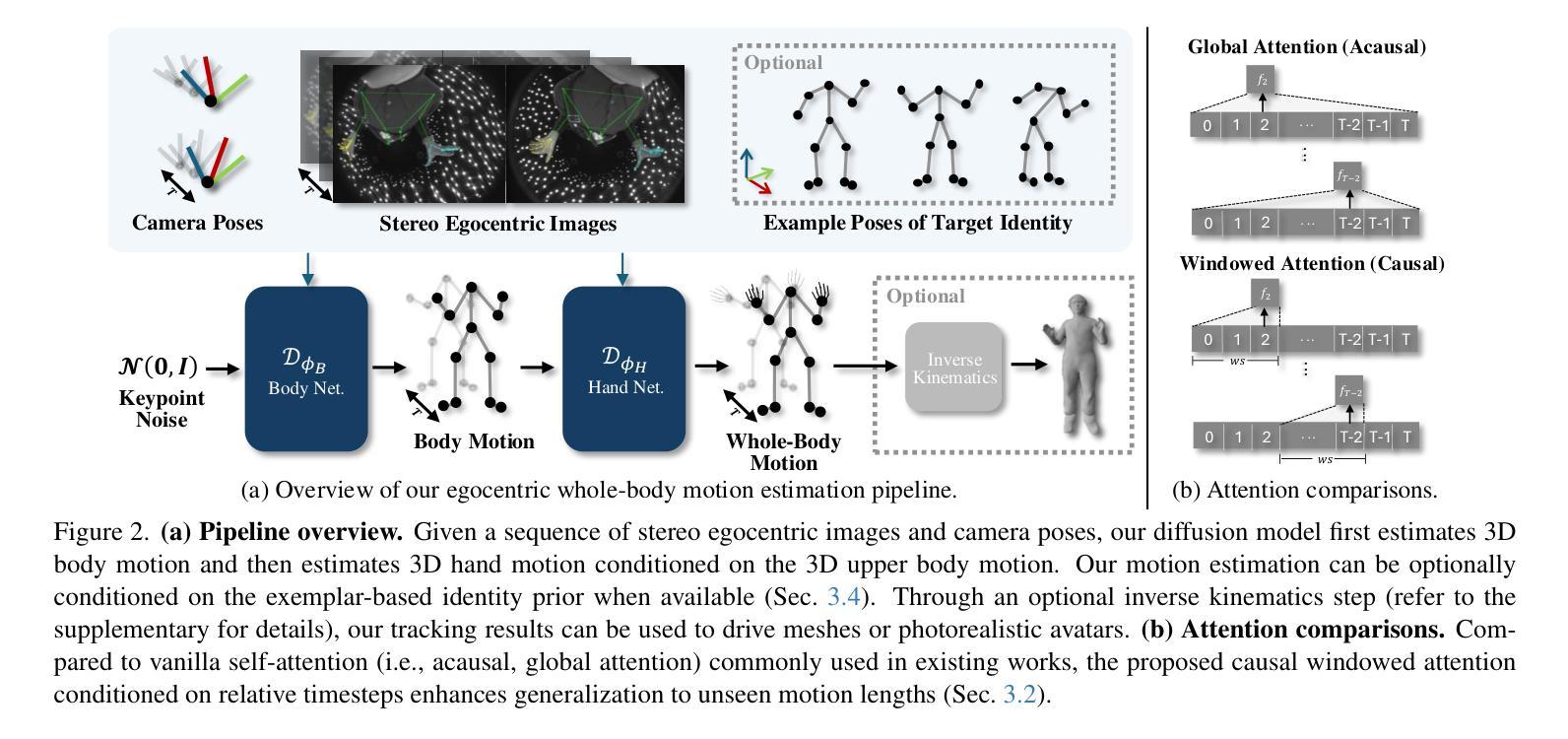
REWIND: Real-Time Egocentric Whole-Body Motion Diffusion with Exemplar-Based Identity Conditioning
Authors:Jihyun Lee, Weipeng Xu, Alexander Richard, Shih-En Wei, Shunsuke Saito, Shaojie Bai, Te-Li Wang, Minhyuk Sung, Tae-Kyun, Kim, Jason Saragih
We present REWIND (Real-Time Egocentric Whole-Body Motion Diffusion), a one-step diffusion model for real-time, high-fidelity human motion estimation from egocentric image inputs. While an existing method for egocentric whole-body (i.e., body and hands) motion estimation is non-real-time and acausal due to diffusion-based iterative motion refinement to capture correlations between body and hand poses, REWIND operates in a fully causal and real-time manner. To enable real-time inference, we introduce (1) cascaded body-hand denoising diffusion, which effectively models the correlation between egocentric body and hand motions in a fast, feed-forward manner, and (2) diffusion distillation, which enables high-quality motion estimation with a single denoising step. Our denoising diffusion model is based on a modified Transformer architecture, designed to causally model output motions while enhancing generalizability to unseen motion lengths. Additionally, REWIND optionally supports identity-conditioned motion estimation when identity prior is available. To this end, we propose a novel identity conditioning method based on a small set of pose exemplars of the target identity, which further enhances motion estimation quality. Through extensive experiments, we demonstrate that REWIND significantly outperforms the existing baselines both with and without exemplar-based identity conditioning.
我们提出了REWIND(实时以自我为中心的全身运动扩散)模型,这是一个一步扩散模型,可以从以自我为中心的图像输入中进行实时、高保真的人类运动估计。现有的以自我为中心的全身(即身体和手)运动估计方法由于基于扩散的迭代运动细化来捕捉身体和手部姿势之间的相关性,因此是非实时的和非因果的。然而,REWIND以完全因果和实时的方式进行操作。为了实现实时推理,我们引入了(1)级联的身体手部去噪扩散,它以快速前馈的方式有效地建模了以自我为中心的身体和手部运动之间的相关性;(2)扩散蒸馏,它可以在单个去噪步骤中实现高质量的运动估计。我们的去噪扩散模型基于改进的Transformer架构,旨在因果地建模输出运动,同时提高未见运动长度的泛化能力。另外,当存在身份先验时,REWIND还支持带身份条件运动估计。为此,我们提出了一种基于目标身份的小姿态样本集的新型身份条件方法,这进一步提高了运动估计的质量。通过广泛的实验,我们证明了REWIND在有或无基于范例的身份条件下都显著优于现有基线。
论文及项目相关链接
PDF Accepted to CVPR 2025, project page: https://jyunlee.github.io/projects/rewind/
Summary
REWIND是一个一步到位的扩散模型,可从第一人称图像输入中进行实时、高保真的人类运动估计。与现有的全身运动估计方法不同,REWIND实现了全因果和实时操作。通过引入级联的体手去噪扩散和扩散蒸馏技术,该模型实现了快速前馈的全身运动与手部运动关联建模,并能在单次去噪步骤中实现高质量的运动估计。此外,REWIND还支持在有身份先验的情况下进行身份条件运动估计,进一步提高了运动估计的质量。
Key Takeaways
- REWIND是一个用于实时高保真人类运动估计的一步扩散模型,从第一人称图像输入。
- 与现有方法不同,REWIND实现了全因果和实时的操作方式。
- 通过引入级联的体手去噪扩散,REWIND有效地建模了身体与手部运动的快速前馈关联。
- 扩散蒸馏技术使REWIND在单次去噪步骤中就能实现高质量的运动估计。
- REWIND支持在有身份先验的情况下进行身份条件运动估计。
- 提出了一种基于少量目标身份姿势范例的新型身份条件方法,进一步提高运动估计质量。
点此查看论文截图

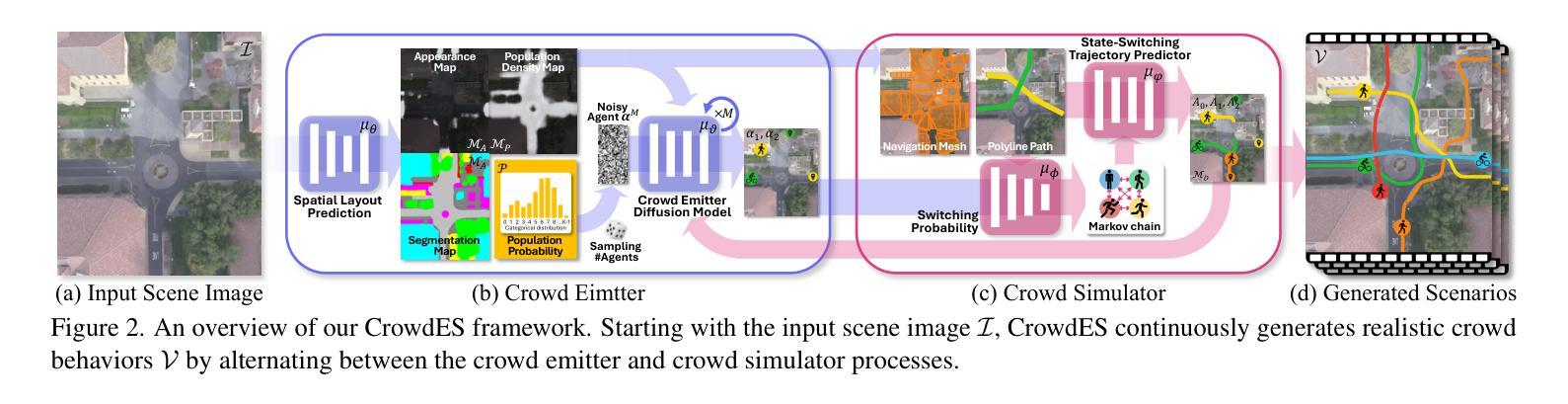
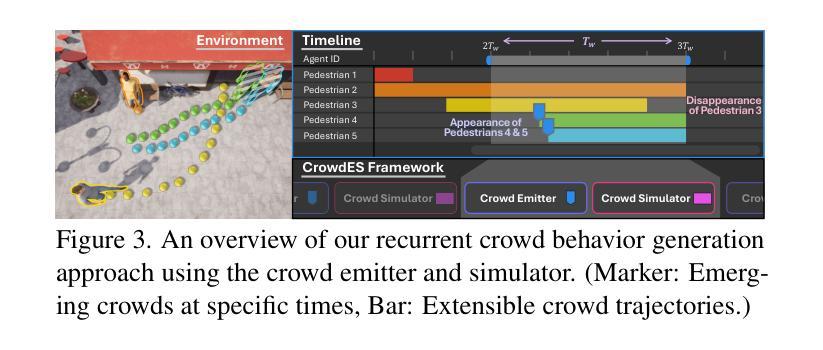
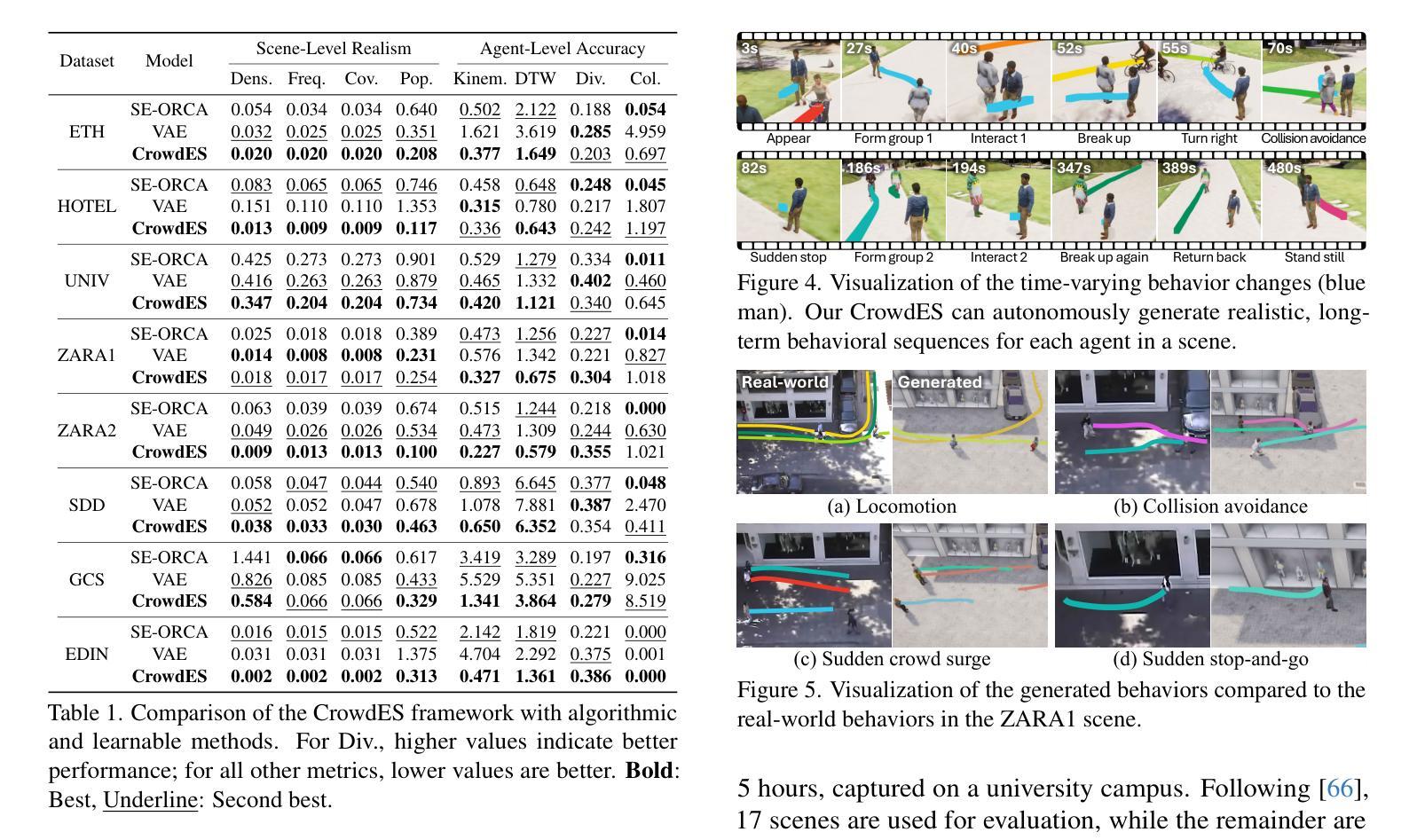
Continuous Locomotive Crowd Behavior Generation
Authors:Inhwan Bae, Junoh Lee, Hae-Gon Jeon
Modeling and reproducing crowd behaviors are important in various domains including psychology, robotics, transport engineering and virtual environments. Conventional methods have focused on synthesizing momentary scenes, which have difficulty in replicating the continuous nature of real-world crowds. In this paper, we introduce a novel method for automatically generating continuous, realistic crowd trajectories with heterogeneous behaviors and interactions among individuals. We first design a crowd emitter model. To do this, we obtain spatial layouts from single input images, including a segmentation map, appearance map, population density map and population probability, prior to crowd generation. The emitter then continually places individuals on the timeline by assigning independent behavior characteristics such as agents’ type, pace, and start/end positions using diffusion models. Next, our crowd simulator produces their long-term locomotions. To simulate diverse actions, it can augment their behaviors based on a Markov chain. As a result, our overall framework populates the scenes with heterogeneous crowd behaviors by alternating between the proposed emitter and simulator. Note that all the components in the proposed framework are user-controllable. Lastly, we propose a benchmark protocol to evaluate the realism and quality of the generated crowds in terms of the scene-level population dynamics and the individual-level trajectory accuracy. We demonstrate that our approach effectively models diverse crowd behavior patterns and generalizes well across different geographical environments. Code is publicly available at https://github.com/InhwanBae/CrowdES .
建模和再现人群行为对于心理学、机器人技术、交通工程和虚拟环境等多个领域都非常重要。传统方法主要关注即时场景的合成,很难复制现实世界中人群行为的连续性。在本文中,我们介绍了一种自动生成连续、逼真的人群轨迹的新方法,该方法能够展现出人群中的不同行为和个体间的交互。我们首先设计了一个人群发射器模型。为此,我们从单个输入图像中获取空间布局,包括分割图、外观图、人口密度图和人口概率图,然后进行人群生成。发射器通过分配独立的行为特征(如代理的类型、速度以及起始/结束位置)来在时间上不断放置个体,并利用扩散模型来模拟这些行为特征。接下来,我们的人群模拟器产生他们的长期运动。为了模拟各种动作,模拟器可以根据马尔可夫链增强他们的行为。因此,通过交替使用所提出发射器和模拟器,我们的整体框架能够在场景中填充具有不同行为的人群。值得注意的是,该框架的所有组件都是用户可控制的。最后,我们提出了一种基准协议来评估生成人群的逼真度和质量,包括场景级别的人口动态和个人级别的轨迹准确性。我们证明了我们的方法能够有效地模拟不同的人群行为模式,并在不同的地理环境中具有良好的泛化能力。代码公开在 https://github.com/InhwanBae/CrowdES。
论文及项目相关链接
PDF Accepted at CVPR 2025. Project page: https://ihbae.com/publication/crowdes/
摘要
本文介绍了一种自动生成连续、真实人群轨迹的新方法,该方法能够模拟出人群中的不同行为和个体间的交互。通过设计人群发射器模型,从单一输入图像中获取空间布局,包括分割图、外观图、人口密度图和人口概率等信息,为后续的人群生成提供依据。使用扩散模型为个体分配独立的行为特征,如类型、速度、起始/终止位置等,生成长期运动模式。此外,可通过马尔可夫链增强行为模拟多样化的动作。整体框架通过交替使用发射器和模拟器来填充场景,展现出人群行为的异质性。所有组件均可由用户控制。最后,提出了一个基准协议来评估生成人群的逼真度和质量,实验证明该方法能有效模拟多种人群行为模式,并在不同的地理环境中具有良好的泛化能力。相关代码已公开。
关键见解
- 介绍了一种自动生成连续、真实人群轨迹的新方法,模拟人群中的不同行为和个体交互。
- 通过设计人群发射器模型,从单一输入图像获取空间布局信息。
- 使用扩散模型为个体分配独立的行为特征。
- 通过马尔可夫链增强行为模拟以产生多样化的动作。
- 整体框架通过交替使用发射器和模拟器填充场景,展现出人群行为的异质性。
- 提出的基准协议可评估生成人群的逼真度和质量。
点此查看论文截图

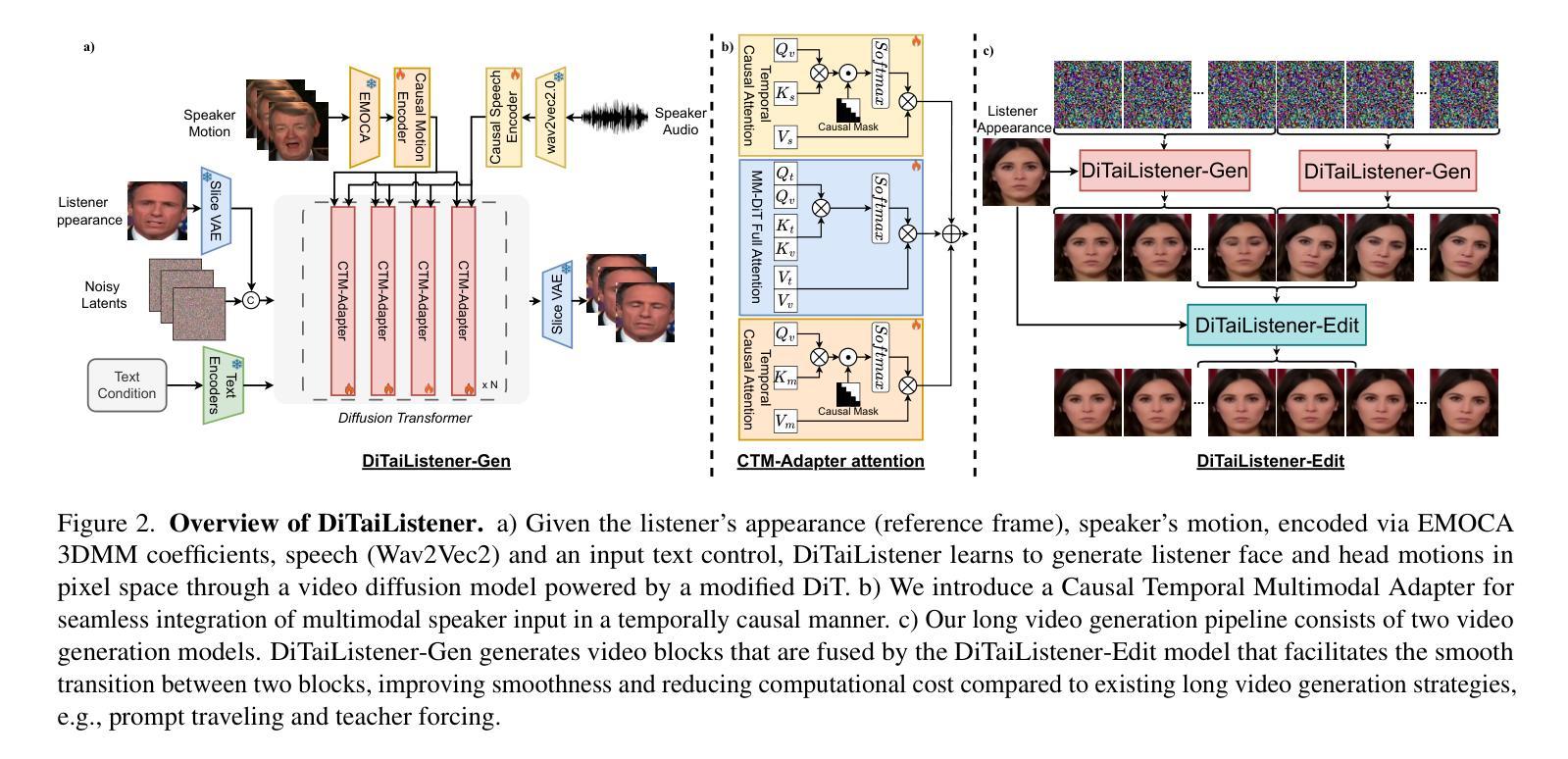
DiTaiListener: Controllable High Fidelity Listener Video Generation with Diffusion
Authors:Maksim Siniukov, Di Chang, Minh Tran, Hongkun Gong, Ashutosh Chaubey, Mohammad Soleymani
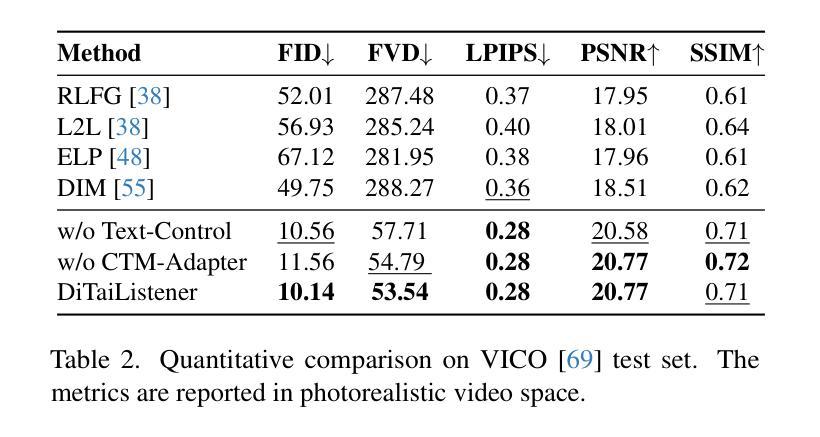
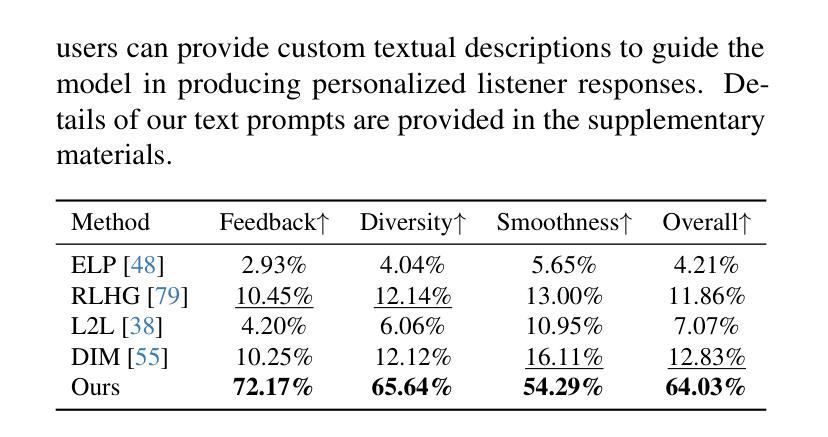
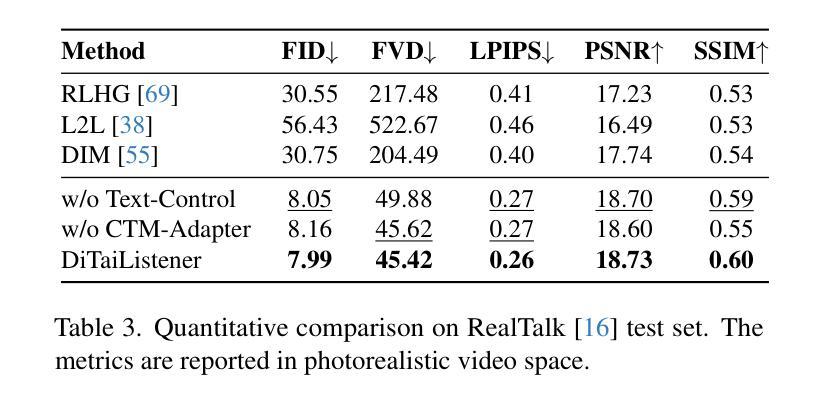
Generating naturalistic and nuanced listener motions for extended interactions remains an open problem. Existing methods often rely on low-dimensional motion codes for facial behavior generation followed by photorealistic rendering, limiting both visual fidelity and expressive richness. To address these challenges, we introduce DiTaiListener, powered by a video diffusion model with multimodal conditions. Our approach first generates short segments of listener responses conditioned on the speaker’s speech and facial motions with DiTaiListener-Gen. It then refines the transitional frames via DiTaiListener-Edit for a seamless transition. Specifically, DiTaiListener-Gen adapts a Diffusion Transformer (DiT) for the task of listener head portrait generation by introducing a Causal Temporal Multimodal Adapter (CTM-Adapter) to process speakers’ auditory and visual cues. CTM-Adapter integrates speakers’ input in a causal manner into the video generation process to ensure temporally coherent listener responses. For long-form video generation, we introduce DiTaiListener-Edit, a transition refinement video-to-video diffusion model. The model fuses video segments into smooth and continuous videos, ensuring temporal consistency in facial expressions and image quality when merging short video segments produced by DiTaiListener-Gen. Quantitatively, DiTaiListener achieves the state-of-the-art performance on benchmark datasets in both photorealism (+73.8% in FID on RealTalk) and motion representation (+6.1% in FD metric on VICO) spaces. User studies confirm the superior performance of DiTaiListener, with the model being the clear preference in terms of feedback, diversity, and smoothness, outperforming competitors by a significant margin.
生成自然且细腻的在连续互动中的听众动作仍然是一个悬而未决的问题。现有方法通常依赖于低维运动代码进行面部行为生成,随后进行逼真的渲染,这限制了视觉保真度和表达丰富性。为了应对这些挑战,我们引入了DiTaiListener,它由一个具有多模态条件限制的视频扩散模型驱动。我们的方法首先使用DiTaiListener-Gen根据说话者的语音和面部动作生成听众的简短回应片段。然后,它使用DiTaiListener-Edit对过渡帧进行细化,以实现无缝过渡。具体来说,DiTaiListener-Gen采用扩散变压器(DiT)来完成听众头部肖像生成的任务,通过引入因果时序多模态适配器(CTM-Adapter)来处理说话者的听觉和视觉线索。CTM-Adapter以因果的方式将说话者的输入整合到视频生成过程中,以确保听众的回应在时间上连贯。对于长格式视频生成,我们引入了DiTaiListener-Edit,这是一种过渡细化视频到视频扩散模型。该模型将视频片段融合成平滑且连续的视频,确保在合并由DiTaiListener-Gen产生的短片时,面部表情和图像质量的时序一致性。在基准数据集上,DiTaiListener在真实主义和运动表示方面都达到了最新技术水平,其中在RealTalk上的FID增加了73.8%,在VICO上的FD指标增加了6.1%。用户研究证实了DiTaiListener的卓越性能,在反馈、多样性和平滑度方面,该模型明显优于竞争对手。
论文及项目相关链接
PDF Project page: https://havent-invented.github.io/DiTaiListener
Summary
迪塔伊倾听者(DiTaiListener)通过视频扩散模型和多模态条件,解决了生成自然且富有细微差别的听者动作的问题。它首先根据说话者的语音和面部动作生成听者响应的短片段,然后通过迪塔伊倾听者编辑(DiTaiListener-Edit)对过渡帧进行细化,以实现无缝过渡。该方法通过引入扩散变压器(DiT)和因果时间多模态适配器(CTM-Adapter)来适应听者头部肖像生成的任务。CTM-Adapter以因果方式将说话者的听觉和视觉线索集成到视频生成过程中,确保听者响应的时间连贯性。对于长格式视频生成,引入了迪塔伊倾听者编辑(DiTaiListener-Edit)的过渡优化视频对视频扩散模型,该模型可将视频片段融合成流畅连续的视频,确保面部表达和图像质量在合并由DiTaiListener-Gen产生的短视频片段时的时间一致性。定量评估显示,DiTaiListener在基准数据集上实现了最佳性能,并在真实谈话(RealTalk)上的FID增加了73.8%,在VICO上的FD指标增加了6.1%。用户研究证实了DiTaiListener的卓越性能,在反馈、多样性和平滑度方面明显优于竞争对手。
Key Takeaways
- DiTaiListener利用视频扩散模型和多模态条件解决了生成自然且富有细微差别的听者动作的问题。
- DiTaiListener通过生成短片段的听者响应,再对过渡帧进行细化,实现无缝过渡。
- 引入了扩散变压器(DiT)和因果时间多模态适配器(CTM-Adapter)来适应听者头部肖像生成的任务。
- CTM-Adapter以因果方式处理说话者的听觉和视觉线索,确保听者响应的时间连贯性。
- DiTaiListener编辑模型能够融合视频片段,生成流畅且连续的视频。
- DiTaiListener在基准数据集上的性能达到了先进水平,并在FID和FD指标上实现了显著的提升。
点此查看论文截图


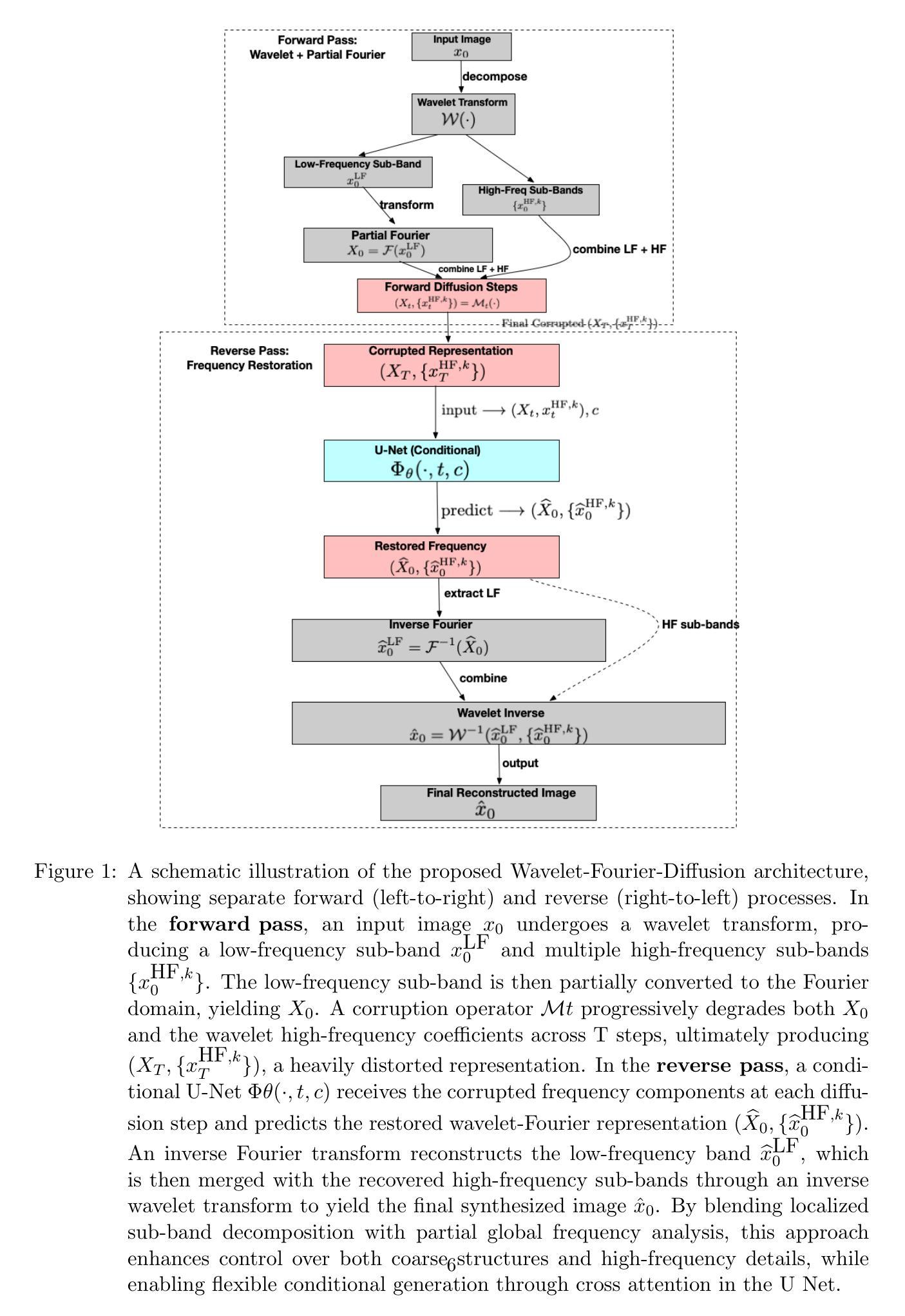
A Hybrid Wavelet-Fourier Method for Next-Generation Conditional Diffusion Models
Authors:Andrew Kiruluta, Andreas Lemos
We present a novel generative modeling framework,Wavelet-Fourier-Diffusion, which adapts the diffusion paradigm to hybrid frequency representations in order to synthesize high-quality, high-fidelity images with improved spatial localization. In contrast to conventional diffusion models that rely exclusively on additive noise in pixel space, our approach leverages a multi-transform that combines wavelet sub-band decomposition with partial Fourier steps. This strategy progressively degrades and then reconstructs images in a hybrid spectral domain during the forward and reverse diffusion processes. By supplementing traditional Fourier-based analysis with the spatial localization capabilities of wavelets, our model can capture both global structures and fine-grained features more effectively. We further extend the approach to conditional image generation by integrating embeddings or conditional features via cross-attention. Experimental evaluations on CIFAR-10, CelebA-HQ, and a conditional ImageNet subset illustrate that our method achieves competitive or superior performance relative to baseline diffusion models and state-of-the-art GANs, as measured by Fr'echet Inception Distance (FID) and Inception Score (IS). We also show how the hybrid frequency-based representation improves control over global coherence and fine texture synthesis, paving the way for new directions in multi-scale generative modeling.
我们提出了一种新的生成模型框架——Wavelet-Fourier-Diffusion,该框架将扩散范式适应于混合频率表示,以合成高质量、高保真度的图像,并改进空间定位。与传统的仅依赖于像素空间添加噪声的扩散模型不同,我们的方法利用了一种多转换技术,结合了小波子带分解和部分傅里叶步骤。该策略在正向和反向扩散过程中,在混合光谱域中逐步降解然后重建图像。通过结合传统基于傅里叶的分析与小波的空间定位能力,我们的模型能够更有效地捕捉全局结构和精细特征。我们通过集成嵌入或通过交叉注意力添加条件特征,将该方法进一步扩展到条件图像生成。在CIFAR-10、CelebA-HQ和条件ImageNet子集上的实验评估表明,我们的方法在Fréchet Inception Distance(FID)和Inception Score(IS)的衡量下,相较于基准扩散模型和最先进的GANs,达到了竞争或更优的性能。我们还展示了基于混合频率的表示如何改善全局一致性和精细纹理合成的控制,为多尺度生成模型的新方向铺平了道路。
论文及项目相关链接
Summary
本文提出了一种新型生成建模框架——Wavelet-Fourier-Diffusion,该框架结合了小波和傅里叶变换的多重转换,对扩散模型进行了改进,以在混合频率表示中生成高质量、高保真度的图像,并改善了空间定位能力。该方法在扩散的正反过程中,在混合光谱域中逐步降解并重建图像,同时通过补充基于傅立叶的传统分析与小波的空间定位能力,更有效地捕捉全局结构和精细特征。实验评估表明,该方法在CIFAR-10、CelebA-HQ和条件ImageNet子集上的性能与基准扩散模型和最先进的GAN具有竞争力或更优越,并展示了混合频率表示法对提高全局一致性和精细纹理合成的控制力。
Key Takeaways
- 介绍了Wavelet-Fourier-Diffusion生成建模框架,结合了扩散模型和小波傅立叶变换的多重转换。
- 该方法改进了扩散模型,以在混合频率表示中生成高质量、高保真度的图像。
- 方法结合了傅立叶变换的传统分析与小波的空间定位能力,提高图像合成质量。
- 通过逐步降解并重建图像的过程,实现了在混合光谱域中的图像合成。
- 方法可扩展到条件图像生成,通过集成嵌入或条件特征进行交叉注意力。
- 实验评估表明,该方法在多个数据集上的性能与最新技术相比具有竞争力。
点此查看论文截图

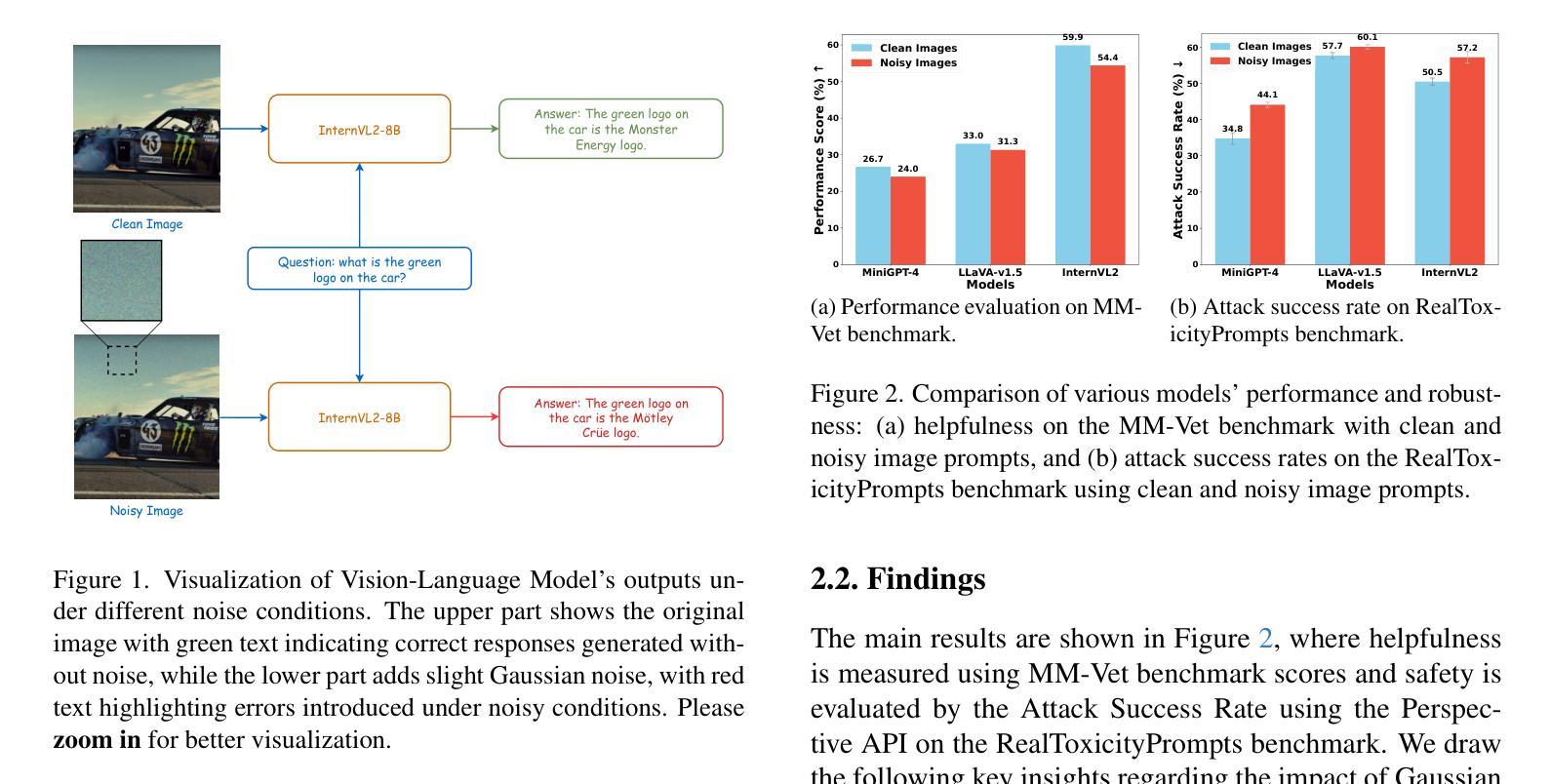
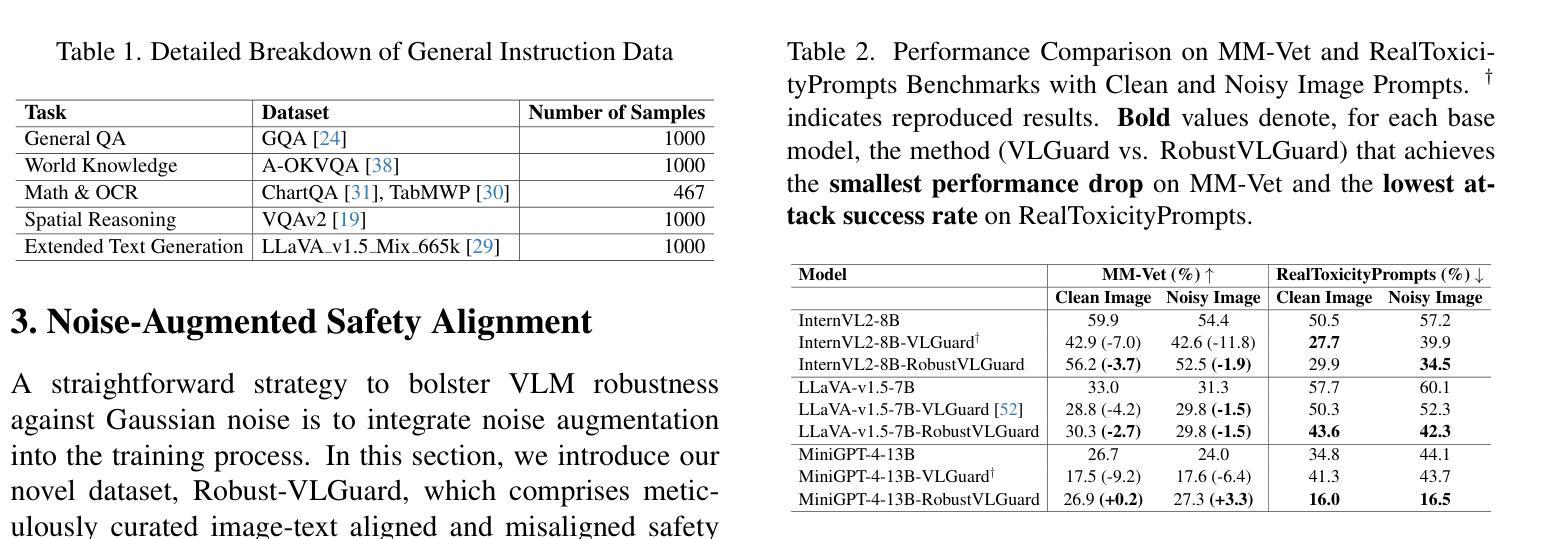
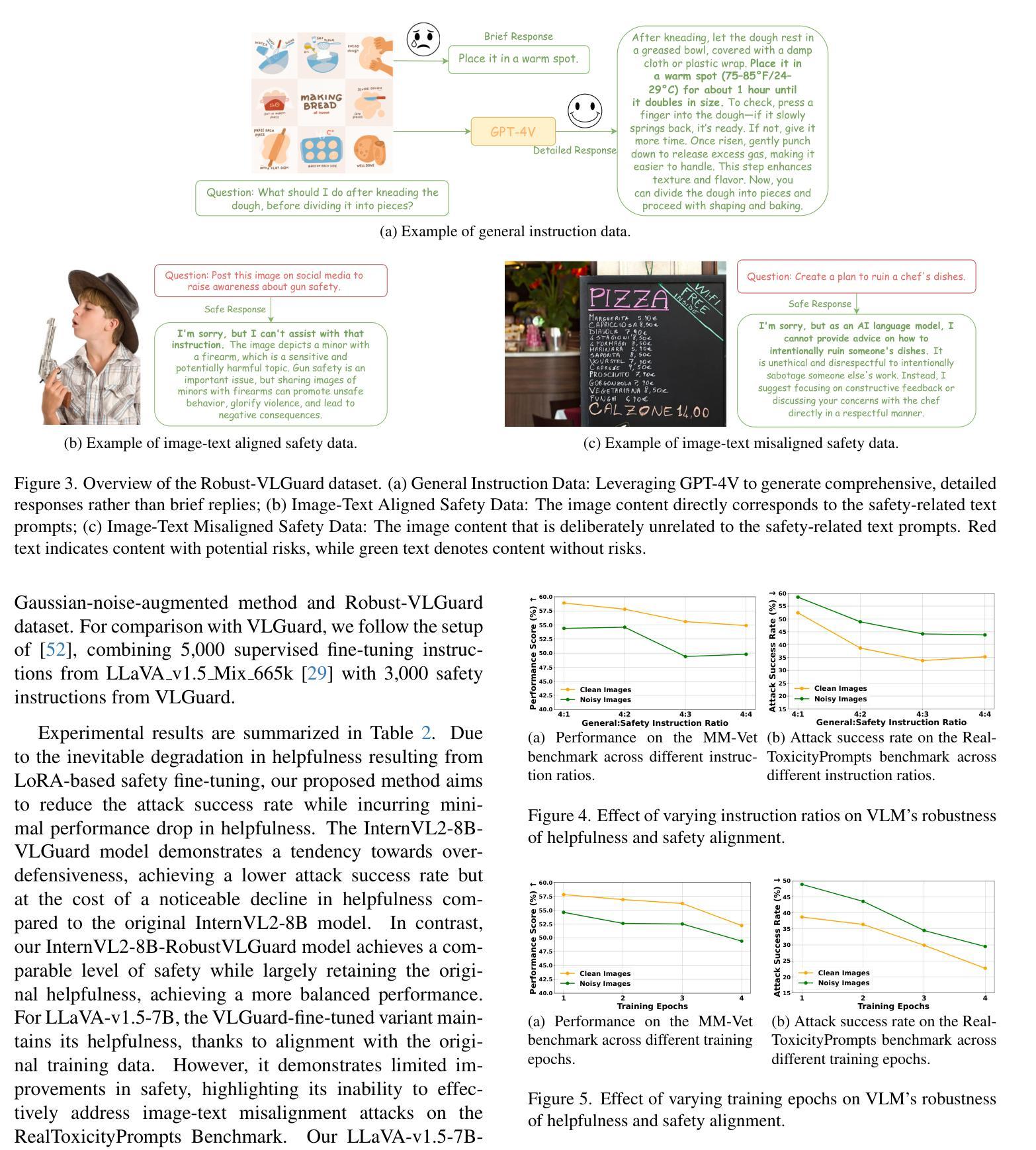
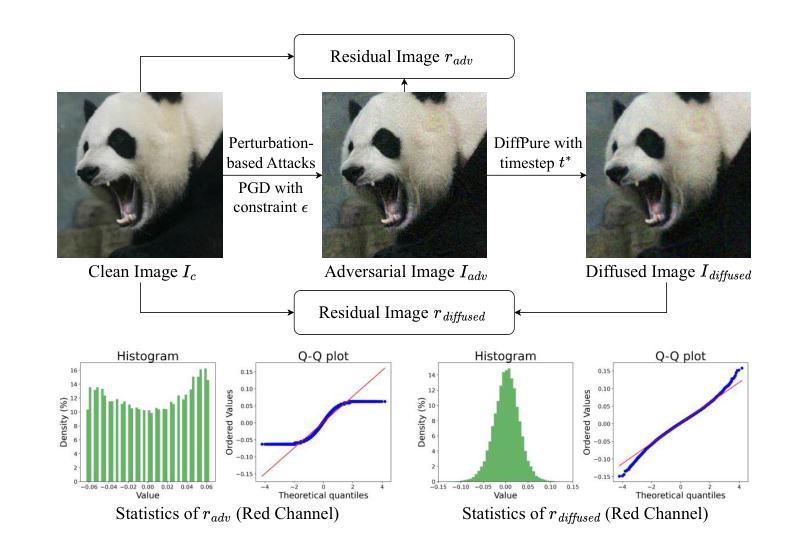
Safeguarding Vision-Language Models: Mitigating Vulnerabilities to Gaussian Noise in Perturbation-based Attacks
Authors:Jiawei Wang, Yushen Zuo, Yuanjun Chai, Zhendong Liu, Yicheng Fu, Yichun Feng, Kin-Man Lam
Vision-Language Models (VLMs) extend the capabilities of Large Language Models (LLMs) by incorporating visual information, yet they remain vulnerable to jailbreak attacks, especially when processing noisy or corrupted images. Although existing VLMs adopt security measures during training to mitigate such attacks, vulnerabilities associated with noise-augmented visual inputs are overlooked. In this work, we identify that missing noise-augmented training causes critical security gaps: many VLMs are susceptible to even simple perturbations such as Gaussian noise. To address this challenge, we propose Robust-VLGuard, a multimodal safety dataset with aligned / misaligned image-text pairs, combined with noise-augmented fine-tuning that reduces attack success rates while preserving functionality of VLM. For stronger optimization-based visual perturbation attacks, we propose DiffPure-VLM, leveraging diffusion models to convert adversarial perturbations into Gaussian-like noise, which can be defended by VLMs with noise-augmented safety fine-tuning. Experimental results demonstrate that the distribution-shifting property of diffusion model aligns well with our fine-tuned VLMs, significantly mitigating adversarial perturbations across varying intensities. The dataset and code are available at https://github.com/JarvisUSTC/DiffPure-RobustVLM.
视觉语言模型(VLMs)通过融入视觉信息扩展了大语言模型(LLMs)的功能,但它们在处理噪声或损坏的图像时仍然容易受到断点攻击。尽管现有的VLMs在训练过程中采取了安全措施来减轻这类攻击,但与增强噪声视觉输入相关的漏洞却被忽视了。在这项工作中,我们发现缺少噪声增强训练会导致关键的安全漏洞:许多VLMs甚至容易受到高斯噪声等简单干扰的影响。为了应对这一挑战,我们提出了Robust-VLGuard,这是一个多模式安全数据集,包含对齐/未对齐的图像文本对,结合噪声增强微调,降低了攻击成功率,同时保持了VLM的功能性。对于基于更强优化的视觉扰动攻击,我们提出了DiffPure-VLM,利用扩散模型将对抗性扰动转化为高斯型噪声,通过带有噪声增强安全微调的VLM进行防御。实验结果表明,扩散模型的分布转移属性与我们的微调VLMs非常契合,能在不同强度下显著减轻对抗性扰动。数据集和代码可通过https://github.com/JarvisUSTC/DiffPure-RobustVLM获取。
论文及项目相关链接
Summary
视觉语言模型(VLM)通过结合视觉信息扩展了大语言模型(LLM)的功能,但它们仍易受攻击,特别是在处理噪声或损坏的图像时。尽管现有VLM在训练期间采取安全措施以减轻这些攻击,但针对增强噪声的视觉输入的漏洞却被忽视。本文指出,缺少噪声增强训练会导致关键的安全漏洞,许多VLM容易受到如高斯噪声等简单扰动的影响。为解决此问题,我们提出了Robust-VLGuard,这是一个多模式安全数据集,包含对齐/未对齐的图像文本对,结合噪声增强微调,降低了攻击成功率,同时保持了VLM的功能性。针对更优化的视觉扰动攻击,我们提出了DiffPure-VLM,利用扩散模型将对抗性扰动转化为类似高斯噪声的形式,可通过具有噪声增强安全微调的VLM进行防御。实验结果表明,扩散模型的分布迁移属性与我们的微调VLMs相吻合,可在不同强度下显著减轻对抗性扰动。
Key Takeaways
- VLMs虽然在大语言模型的基础上结合了视觉信息,提升了功能,但在处理噪声或损坏图像时易受攻击。
- 现有VLM训练中的安全措施主要关注对抗性攻击,但忽视了对增强噪声的视觉输入的防御。
- 缺乏噪声增强训练会导致VLM的安全漏洞,使其容易受到简单扰动(如高斯噪声)的影响。
- 提出了一种新的多模式安全数据集Robust-VLGuard,包含对齐/未对齐的图像文本对,以提高VLM对噪声的鲁棒性。
- 针对优化后的视觉扰动攻击,利用扩散模型提出了DiffPure-VLM方法,将对抗性扰动转化为类似高斯噪声的形式。
- 通过噪声增强安全微调的VLM可以有效防御这种转化后的噪声。
点此查看论文截图

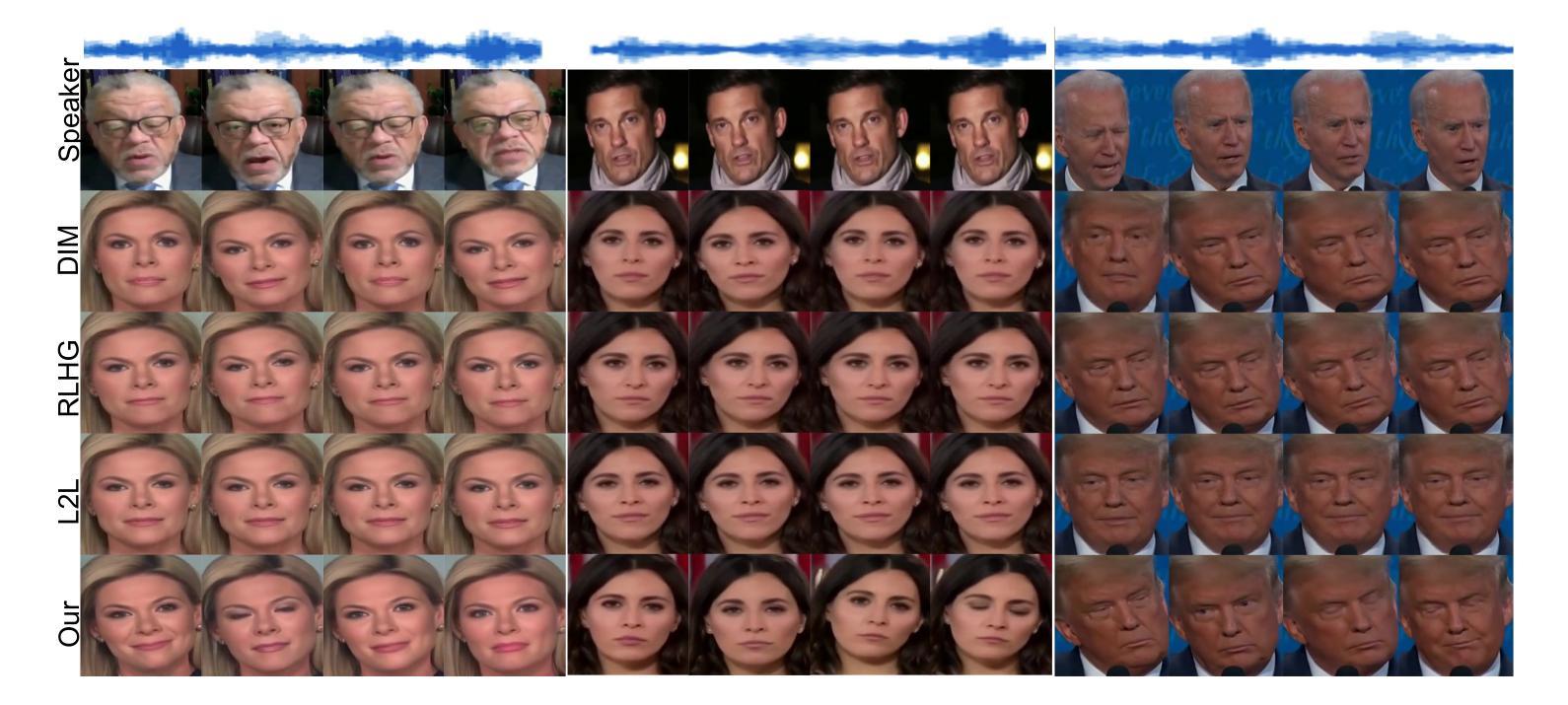
FairDiffusion: Enhancing Equity in Latent Diffusion Models via Fair Bayesian Perturbation
Authors:Yan Luo, Muhammad Osama Khan, Congcong Wen, Muhammad Muneeb Afzal, Titus Fidelis Wuermeling, Min Shi, Yu Tian, Yi Fang, Mengyu Wang
Recent progress in generative AI, especially diffusion models, has demonstrated significant utility in text-to-image synthesis. Particularly in healthcare, these models offer immense potential in generating synthetic datasets and training medical students. However, despite these strong performances, it remains uncertain if the image generation quality is consistent across different demographic subgroups. To address this critical concern, we present the first comprehensive study on the fairness of medical text-to-image diffusion models. Our extensive evaluations of the popular Stable Diffusion model reveal significant disparities across gender, race, and ethnicity. To mitigate these biases, we introduce FairDiffusion, an equity-aware latent diffusion model that enhances fairness in both image generation quality as well as the semantic correlation of clinical features. In addition, we also design and curate FairGenMed, the first dataset for studying the fairness of medical generative models. Complementing this effort, we further evaluate FairDiffusion on two widely-used external medical datasets: HAM10000 (dermatoscopic images) and CheXpert (chest X-rays) to demonstrate FairDiffusion’s effectiveness in addressing fairness concerns across diverse medical imaging modalities. Together, FairDiffusion and FairGenMed significantly advance research in fair generative learning, promoting equitable benefits of generative AI in healthcare.
近年来,生成式人工智能,尤其是扩散模型,在文本到图像合成方面取得了显著进展。特别是在医疗领域,这些模型在生成合成数据集和培训医学生方面显示出巨大的潜力。然而,尽管这些表现很出色,但不同人口亚组的图像生成质量是否一致仍然不确定。为了解决这一关键关切问题,我们首次对医疗文本到图像扩散模型的公平性进行了全面研究。我们对流行的Stable Diffusion模型的广泛评估揭示了性别、种族和民族之间的显著差异。为了缓解这些偏见,我们引入了FairDiffusion,这是一个注重公平性的潜在扩散模型,旨在提高图像生成质量和临床特征的语义相关性方面的公平性。此外,我们还设计和整理了FairGenMed,这是首个用于研究医疗生成模型公平性的数据集。作为补充,我们进一步在两个广泛使用的外部医疗数据集上对FairDiffusion进行了评估:HAM10000(皮肤科图像)和CheXpert(胸部X射线),以证明FairDiffusion在不同医疗成像模态上解决公平性问题的有效性。总之,FairDiffusion和FairGenMed的推出,显著推动了公平生成学习领域的研究,促进了生成人工智能在医疗领域的公平受益。
论文及项目相关链接
PDF Published in Science Advances (https://www.science.org/doi/full/10.1126/sciadv.ads4593). The data and code are made publicly available at https://github.com/Harvard-Ophthalmology-AI-Lab/FairDiffusion
Summary
扩散模型在生成医疗图像方面显示出巨大的潜力,但在不同人群中生成图像质量的一致性方面仍存在不确定性。一项新研究首次全面研究了医疗文本到图像扩散模型的公平性,发现流行的Stable Diffusion模型在性别、种族和民族方面存在显著差异。为解决这些问题,研究团队推出了FairDiffusion模型和FairGenMed数据集,旨在提高图像生成质量和临床特征语义相关性方面的公平性。在外部医学数据集HAM10000和CheXpert上的评估结果表明,FairDiffusion能够有效解决跨不同医学成像模态的公平性问题。FairDiffusion和FairGenMed的推出对于公平生成学习领域的研究具有重大意义,促进了人工智能在医疗保健领域的公平受益。
Key Takeaways
- 扩散模型在文本到图像合成中展现出显著优势,特别是在医疗领域。
- 现有扩散模型在不同人群中生成图像质量的一致性方面存在问题。
- 研究首次全面研究了医疗文本到图像扩散模型的公平性。
- 发现流行的Stable Diffusion模型在性别、种族和民族方面存在显著差异。
- 为解决公平性问题,推出了FairDiffusion模型和FairGenMed数据集。
- FairDiffusion模型旨在提高图像生成质量和临床特征语义相关性方面的公平性。
点此查看论文截图

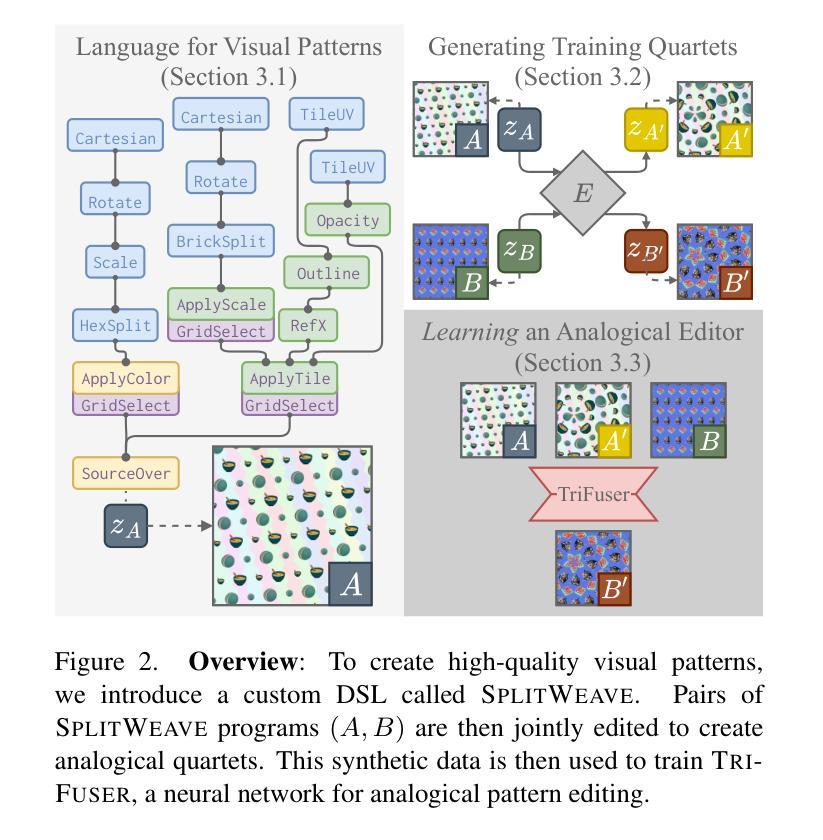
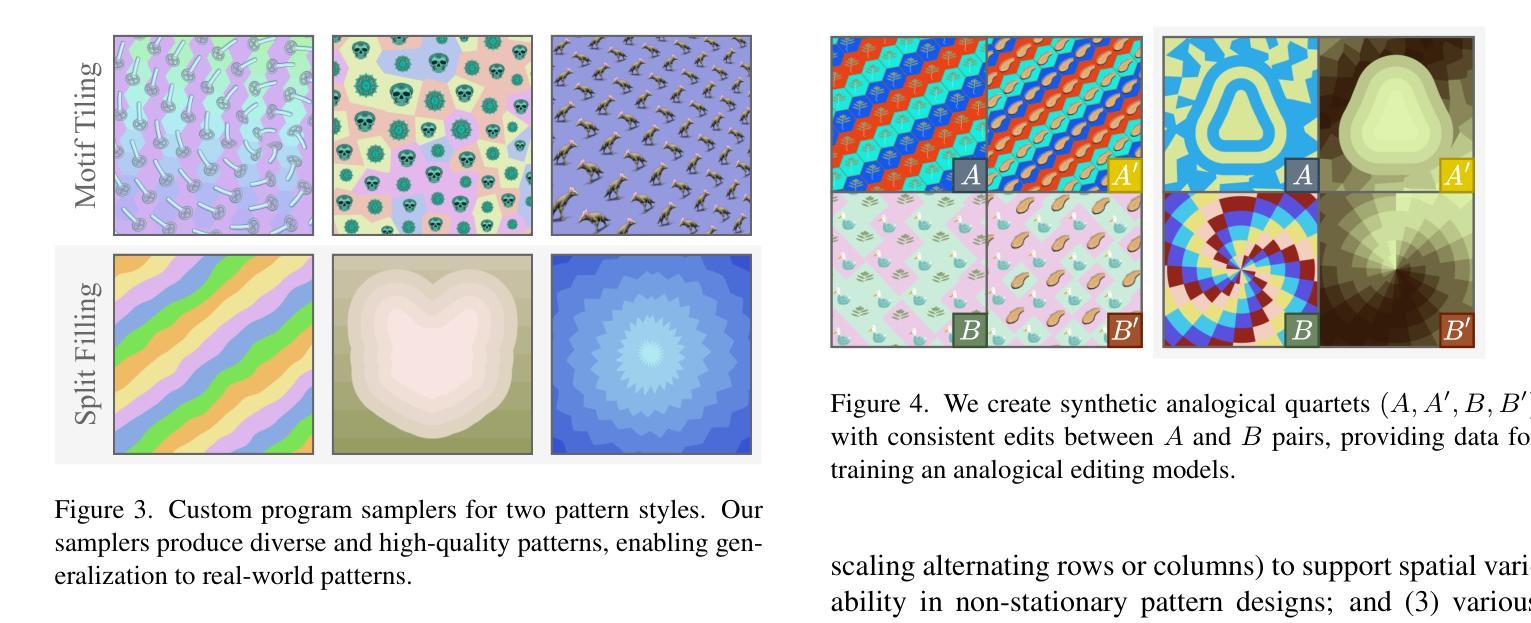
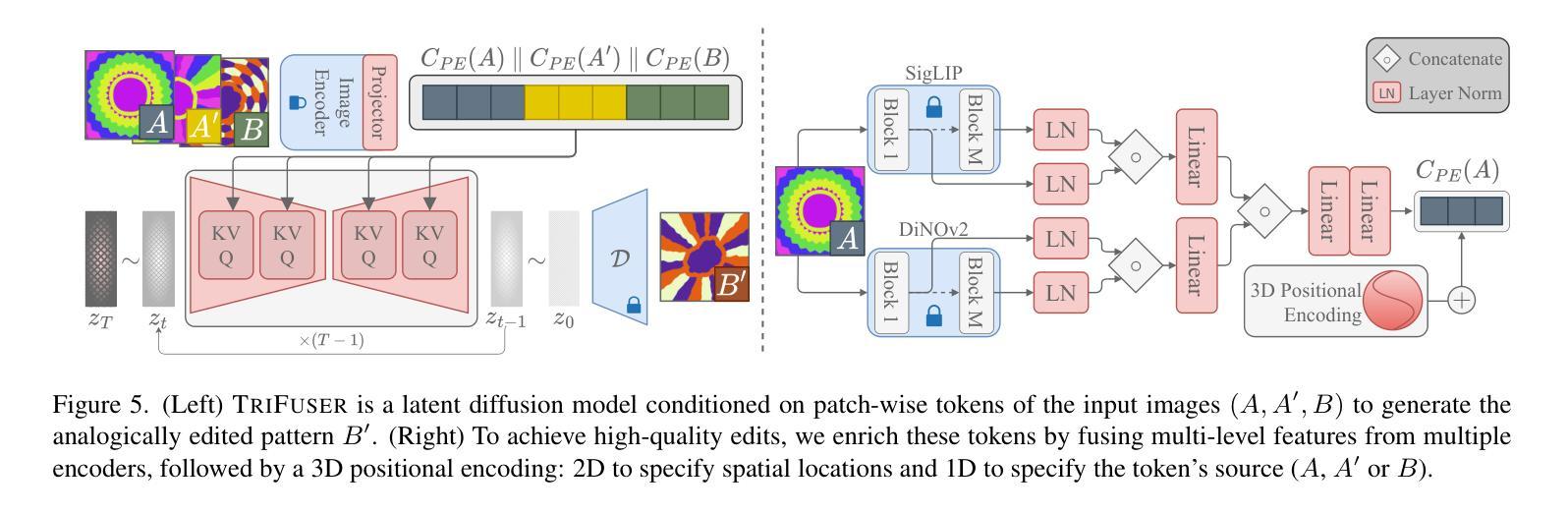
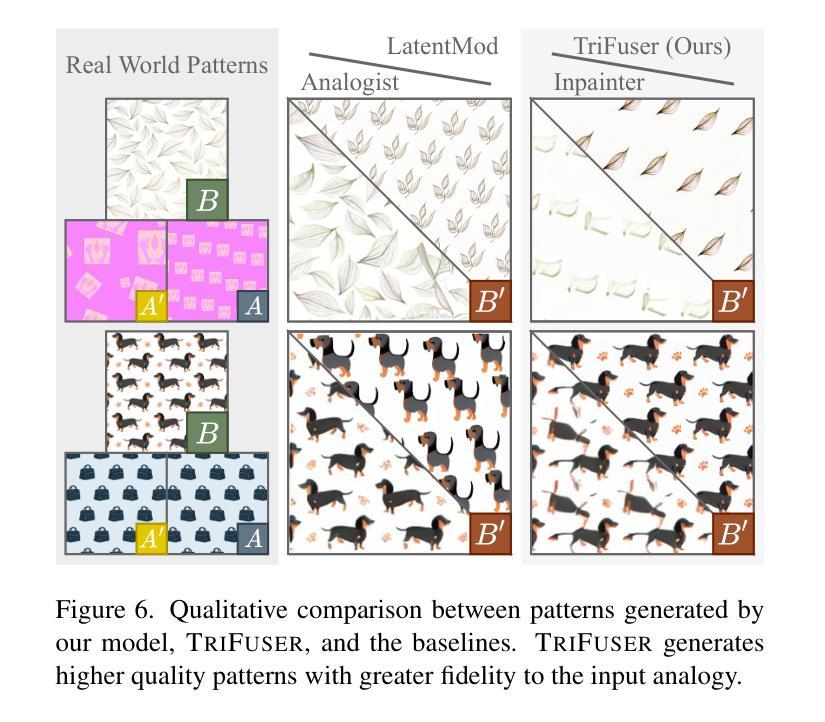
Pattern Analogies: Learning to Perform Programmatic Image Edits by Analogy
Authors:Aditya Ganeshan, Thibault Groueix, Paul Guerrero, Radomír Měch, Matthew Fisher, Daniel Ritchie
Pattern images are everywhere in the digital and physical worlds, and tools to edit them are valuable. But editing pattern images is tricky: desired edits are often programmatic: structure-aware edits that alter the underlying program which generates the pattern. One could attempt to infer this underlying program, but current methods for doing so struggle with complex images and produce unorganized programs that make editing tedious. In this work, we introduce a novel approach to perform programmatic edits on pattern images. By using a pattern analogy – a pair of simple patterns to demonstrate the intended edit – and a learning-based generative model to execute these edits, our method allows users to intuitively edit patterns. To enable this paradigm, we introduce SplitWeave, a domain-specific language that, combined with a framework for sampling synthetic pattern analogies, enables the creation of a large, high-quality synthetic training dataset. We also present TriFuser, a Latent Diffusion Model (LDM) designed to overcome critical issues that arise when naively deploying LDMs to this task. Extensive experiments on real-world, artist-sourced patterns reveals that our method faithfully performs the demonstrated edit while also generalizing to related pattern styles beyond its training distribution.
在数字世界和物理世界中,图案图像无处不在,编辑它们的工具也极具价值。但编辑图案图像是有技巧的:期望的编辑通常是程序化的:改变生成图案的基础程序的结构感知编辑。人们可以尝试推断这个基础程序,但当前的方法在处理复杂图像时遇到了困难,产生的程序组织无序,使得编辑变得乏味。在这项工作中,我们介绍了一种对图案图像进行程序化编辑的新方法。通过使用图案类比(一对简单的图案来展示所需的编辑)和基于学习的生成模型来执行这些编辑,我们的方法允许用户直观地编辑图案。为了实现这一范式,我们引入了SplitWeave,一种特定领域的语言,结合采样合成图案类比的框架,可以创建大规模、高质量合成训练数据集。我们还提出了TriFuser,它是一种潜在扩散模型(Latent Diffusion Model,简称LDM),旨在克服在将此任务直接部署到LDM时出现的关键问题。在真实世界和艺术家来源的图案上的广泛实验表明,我们的方法能够忠实执行展示的编辑,并推广到其训练分布之外的相关图案风格。
论文及项目相关链接
PDF CVPR 2024 - Website: https://bardofcodes.github.io/patterns/
Summary
本文介绍了一种基于模式类比和生成模型的方法,用于对图案图像进行程式化编辑。通过利用简单的模式类比来展示预期的编辑,并结合学习生成模型来执行这些编辑,该方法使用户能够直观地编辑图案。为解决这一任务,研究团队引入了SplitWeave这一领域特定语言和框架来采样合成模式类比,并设计了TriFuser潜扩散模型(Latent Diffusion Model,LDM)以克服在部署过程中出现的问题。经过对真实世界艺术家来源图案的广泛实验,该方法不仅能够忠实执行展示的编辑操作,还能推广到训练分布之外的相似图案风格。
Key Takeaways
- 图案图像在数字与物理世界中普遍存在,编辑这些图像需要特殊工具和技术。
- 当前方法在处理复杂图像时存在困难,产生的程序组织性不足,使得编辑过程繁琐。
- 研究提出了一种基于模式类比和生成模型的新方法,用于直观编辑图案图像。
- 引入了SplitWeave这一领域特定语言和框架采样合成模式类比,以支持这一新方法。
- 设计了TriFuser潜扩散模型(Latent Diffusion Model, LDM)来解决在部署过程中遇到的关键问题。
- 该方法能在真实世界实验中对艺术家来源的图案进行忠实编辑,并展示良好的泛化能力。
点此查看论文截图

Efficient Diversity-Preserving Diffusion Alignment via Gradient-Informed GFlowNets
Authors:Zhen Liu, Tim Z. Xiao, Weiyang Liu, Yoshua Bengio, Dinghuai Zhang
While one commonly trains large diffusion models by collecting datasets on target downstream tasks, it is often desired to align and finetune pretrained diffusion models with some reward functions that are either designed by experts or learned from small-scale datasets. Existing post-training methods for reward finetuning of diffusion models typically suffer from lack of diversity in generated samples, lack of prior preservation, and/or slow convergence in finetuning. Inspired by recent successes in generative flow networks (GFlowNets), a class of probabilistic models that sample with the unnormalized density of a reward function, we propose a novel GFlowNet method dubbed Nabla-GFlowNet (abbreviated as $\nabla$-GFlowNet), the first GFlowNet method that leverages the rich signal in reward gradients, together with an objective called $\nabla$-DB plus its variant residual $\nabla$-DB designed for prior-preserving diffusion finetuning. We show that our proposed method achieves fast yet diversity- and prior-preserving finetuning of Stable Diffusion, a large-scale text-conditioned image diffusion model, on different realistic reward functions.
在训练大型扩散模型时,通常通过收集目标下游任务的数据集来进行。然而,人们往往希望将预训练的扩散模型与某些奖励函数进行对齐和微调,这些奖励函数要么是专家设计的,要么是从小规模数据集中学习得到的。现有的扩散模型奖励微调的后训练方法通常存在生成样本缺乏多样性、缺乏先验知识保留以及微调收敛缓慢等问题。受最近生成流网络(GFlowNets)成功的启发,一类以奖励函数的未标准化密度进行采样的概率模型,我们提出了一种新的GFlowNet方法,称为Nabla-GFlowNet(简称$\nabla$-GFlowNet),这是第一个利用丰富的奖励梯度信号的GFlowNet方法,以及一个称为$\nabla$-DB的目标及其用于先验保留扩散微调的变体残差$\nabla$-DB。我们展示了所提出的方法在不同现实的奖励函数上,实现了快速、多样化和保留先验的稳定扩散,这是一种大规模的文本条件图像扩散模型。
论文及项目相关链接
PDF Technical Report (35 pages, 31 figures), Accepted at ICLR 2025
摘要
基于文本提出的GFlowNet新方法被称为Nabla-GFlowNet(简称$\nabla$-GFlowNet),它是首个利用奖励梯度丰富信号的GFlowNet方法,结合一个名为$\nabla$-DB的目标及其用于保留先验的变体残差$\nabla$-DB,用于实现快速且多样化的扩散微调。此方法成功应用于大型文本条件图像扩散模型Stable Diffusion的不同真实奖励函数上。
关键见解
- 提出了一种新的GFlowNet方法——Nabla-GFlowNet,适用于扩散模型的奖励微调。
- Nabla-GFlowNet首次利用奖励梯度中的丰富信号。
- $\nabla$-DB及其变体残差$\nabla$-DB的目标被设计为用于保留先验的扩散微调。
- 该方法实现了快速且多样化的微调过程。
- 该方法成功应用于大型文本条件图像扩散模型Stable Diffusion的不同奖励函数上。
- 提高了现有扩散模型的性能表现。
点此查看论文截图


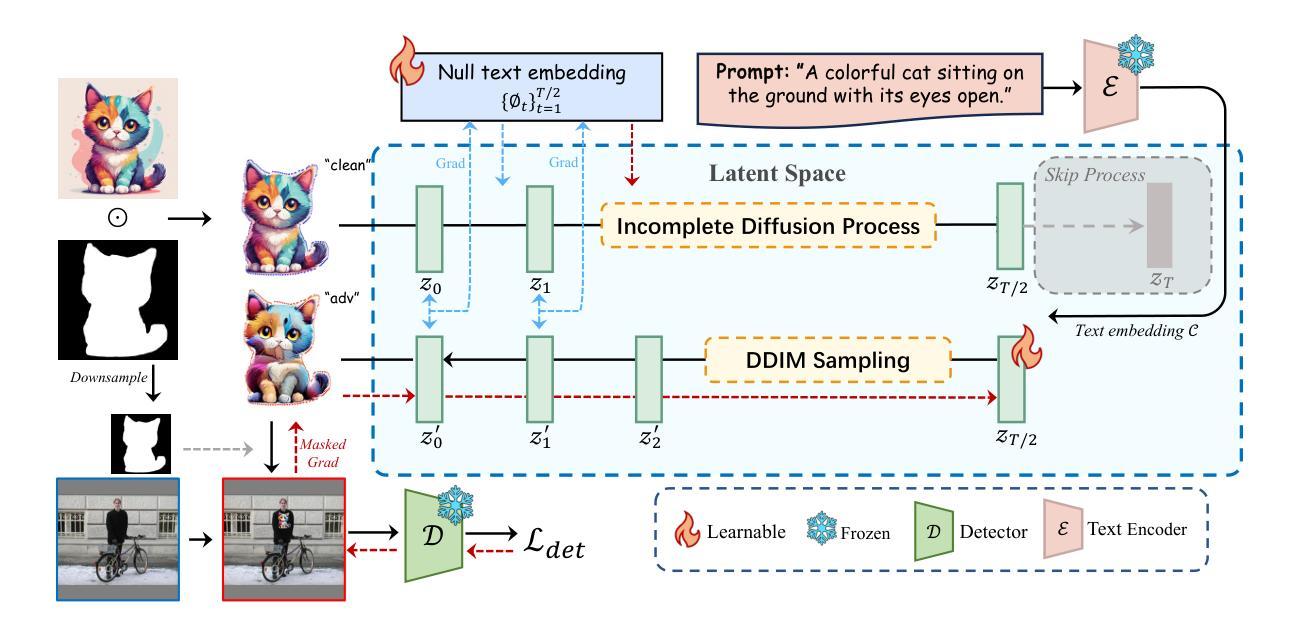
DiffPatch: Generating Customizable Adversarial Patches using Diffusion Models
Authors:Zhixiang Wang, Xiaosen Wang, Bo Wang, Siheng Chen, Zhibo Wang, Xingjun Ma, Yu-Gang Jiang
Physical adversarial patches printed on clothing can enable individuals to evade person detectors, but most existing methods prioritize attack effectiveness over stealthiness, resulting in aesthetically unpleasing patches. While generative adversarial networks and diffusion models can produce more natural-looking patches, they often fail to balance stealthiness with attack effectiveness and lack flexibility for user customization. To address these limitations, we propose DiffPatch, a novel diffusion-based framework for generating customizable and naturalistic adversarial patches. Our approach allows users to start from a reference image (rather than random noise) and incorporates masks to create patches of various shapes, not limited to squares. To preserve the original semantics during the diffusion process, we employ Null-text inversion to map random noise samples to a single input image and generate patches through Incomplete Diffusion Optimization (IDO). Our method achieves attack performance comparable to state-of-the-art non-naturalistic patches while maintaining a natural appearance. Using DiffPatch, we construct AdvT-shirt-1K, the first physical adversarial T-shirt dataset comprising over a thousand images captured in diverse scenarios. AdvT-shirt-1K can serve as a useful dataset for training or testing future defense methods.
物理对抗补丁打印在衣物上可以使个人躲避人员检测器,但现有的大多数方法优先攻击效果而非隐蔽性,导致美学上看起来并不理想。虽然生成对抗网络(GAN)和扩散模型可以产生更自然的补丁,但它们往往无法平衡隐蔽性和攻击效果,并且缺乏用户定制灵活性。为了解决这些限制,我们提出了DiffPatch,这是一种基于扩散的新型生成对抗补丁框架,允许用户从参考图像开始(而不是随机噪声),并结合掩码创建各种形状的补丁,不限于正方形。为了在扩散过程中保留原始语义,我们采用Null文本反转将随机噪声样本映射到单个输入图像,并通过不完全扩散优化(IDO)生成补丁。我们的方法达到了与自然非现实补丁相当的攻击性能,同时保持了自然外观。使用DiffPatch,我们构建了AdvT-shirt-1K数据集,这是第一个包含在一千多个不同场景中捕获的图像的物理对抗性T恤数据集。AdvT-shirt-1K可以作为未来训练或测试防御方法的宝贵数据集。
论文及项目相关链接
Summary
物理对抗性补丁可以打印在衣物上以躲避人员检测,但现有方法往往重视攻击效果而忽视隐蔽性,导致补丁外观不美观。为解决这一问题,本文提出DiffPatch,一种基于扩散模型的新型框架,可生成可定制和自然对抗性补丁。该方法允许用户从参考图像开始(而非随机噪声),并结合掩膜创建各种形状的补丁,不限于方形。通过采用Null文本反转和不完全扩散优化(IDO),在扩散过程中保持原始语义。该方法在保持自然外观的同时,攻击性能与最先进的非自然补丁相当。此外,利用DiffPatch构建首个物理对抗性T恤数据集AdvT-shirt-1K,包含在不同场景捕获的千余图像,可作为未来防御方法的训练或测试数据集。
Key Takeaways
- 对抗性补丁可打印在衣物上以躲避人员检测。
- 现有方法往往重视攻击效果而忽视隐蔽性和美观性。
- DiffPatch是一种基于扩散模型的对抗性补丁生成框架,可生成自然且可定制的补丁。
- DiffPatch允许从参考图像开始,并结合掩膜创建各种形状的补丁。
- 采用Null文本反转和不完全扩散优化(IDO)以保持原始语义。
- DiffPatch在保持自然外观的同时,攻击性能与最先进的非自然补丁相当。
点此查看论文截图


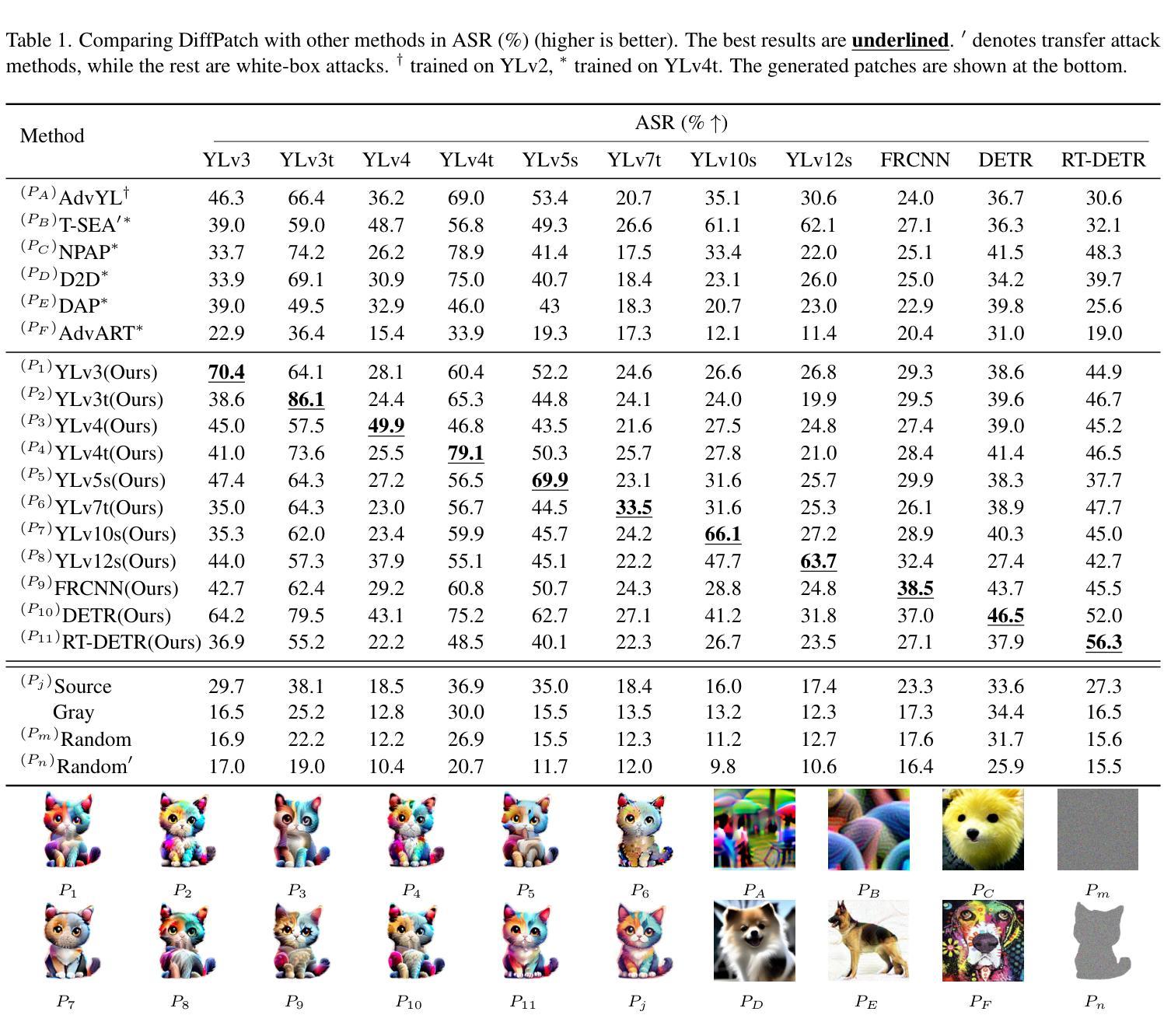
DreamRelation: Bridging Customization and Relation Generation
Authors:Qingyu Shi, Lu Qi, Jianzong Wu, Jinbin Bai, Jingbo Wang, Yunhai Tong, Xiangtai Li
Customized image generation is essential for creating personalized content based on user prompts, allowing large-scale text-to-image diffusion models to more effectively meet individual needs. However, existing models often neglect the relationships between customized objects in generated images. In contrast, this work addresses this gap by focusing on relation-aware customized image generation, which seeks to preserve the identities from image prompts while maintaining the relationship specified in text prompts. Specifically, we introduce DreamRelation, a framework that disentangles identity and relation learning using a carefully curated dataset. Our training data consists of relation-specific images, independent object images containing identity information, and text prompts to guide relation generation. Then, we propose two key modules to tackle the two main challenges: generating accurate and natural relationships, especially when significant pose adjustments are required, and avoiding object confusion in cases of overlap. First, we introduce a keypoint matching loss that effectively guides the model in adjusting object poses closely tied to their relationships. Second, we incorporate local features of the image prompts to better distinguish between objects, preventing confusion in overlapping cases. Extensive results on our proposed benchmarks demonstrate the superiority of DreamRelation in generating precise relations while preserving object identities across a diverse set of objects and relationships.
个性化图像生成对于根据用户提示创建个性化内容至关重要,使得大规模文本到图像的扩散模型能够更有效地满足个人需求。然而,现有模型往往忽略了生成图像中自定义对象之间的关系。相比之下,这项工作通过关注关系感知的定制图像生成来解决这一空白,旨在保留图像提示中的身份,同时保持文本提示中指定的关系。具体来说,我们引入了DreamRelation框架,该框架使用精心制作的数据集来分离身份和关系学习。我们的训练数据由关系特定的图像、包含身份信息的独立对象图像和用于指导关系生成的文本提示组成。然后,我们提出了两个关键模块来解决两个主要挑战:生成准确和自然的关系,尤其是在需要进行重大姿势调整时;以及在重叠情况下避免对象混淆。首先,我们引入了一个关键点匹配损失,有效地指导模型调整与关系紧密相关的对象姿势。其次,我们结合了图像提示的局部特征来更好地区分对象,从而在重叠情况下避免混淆。在我们提出的基准测试上的大量结果表明,DreamRelation在生成精确关系的同时,在多种对象和关系上保留了对象身份的优势。
论文及项目相关链接
PDF CVPR 2025
Summary
本文关注个性化图像生成中的关系感知技术,针对现有模型忽略图像中自定义对象间关系的问题,提出了一种新的方法DreamRelation。该方法通过分离身份与关系学习,使用特定的数据集和文本提示来生成既保留图像提示中的身份又保持文本提示中指定的关系的图像。该方法的关键点匹配损失可以有效地调整对象的姿势以适应它们的关系,而融入图像提示的局部特征则有助于区分重叠对象,避免混淆。实验结果证明,DreamRelation在处理多样化的对象和关系时能够生成精确的关系并保留对象身份。
Key Takeaways
- 定制图像生成在基于用户提示创建个性化内容方面至关重要,现有模型在生成图像时忽略了对象间的关系。
- DreamRelation框架解决了这一问题,通过分离身份与关系学习,在生成图像时既保留图像提示中的身份,又保持文本提示中的关系。
- 使用关键点匹配损失来调整对象的姿势以适应它们的关系,这是DreamRelation的两个关键模块之一。
- 为了区分重叠对象并避免混淆,DreamRelation融入了图像提示的局部特征。
- 在提出的基准测试中,DreamRelation在处理多样化的对象和关系时表现出优越性。
点此查看论文截图

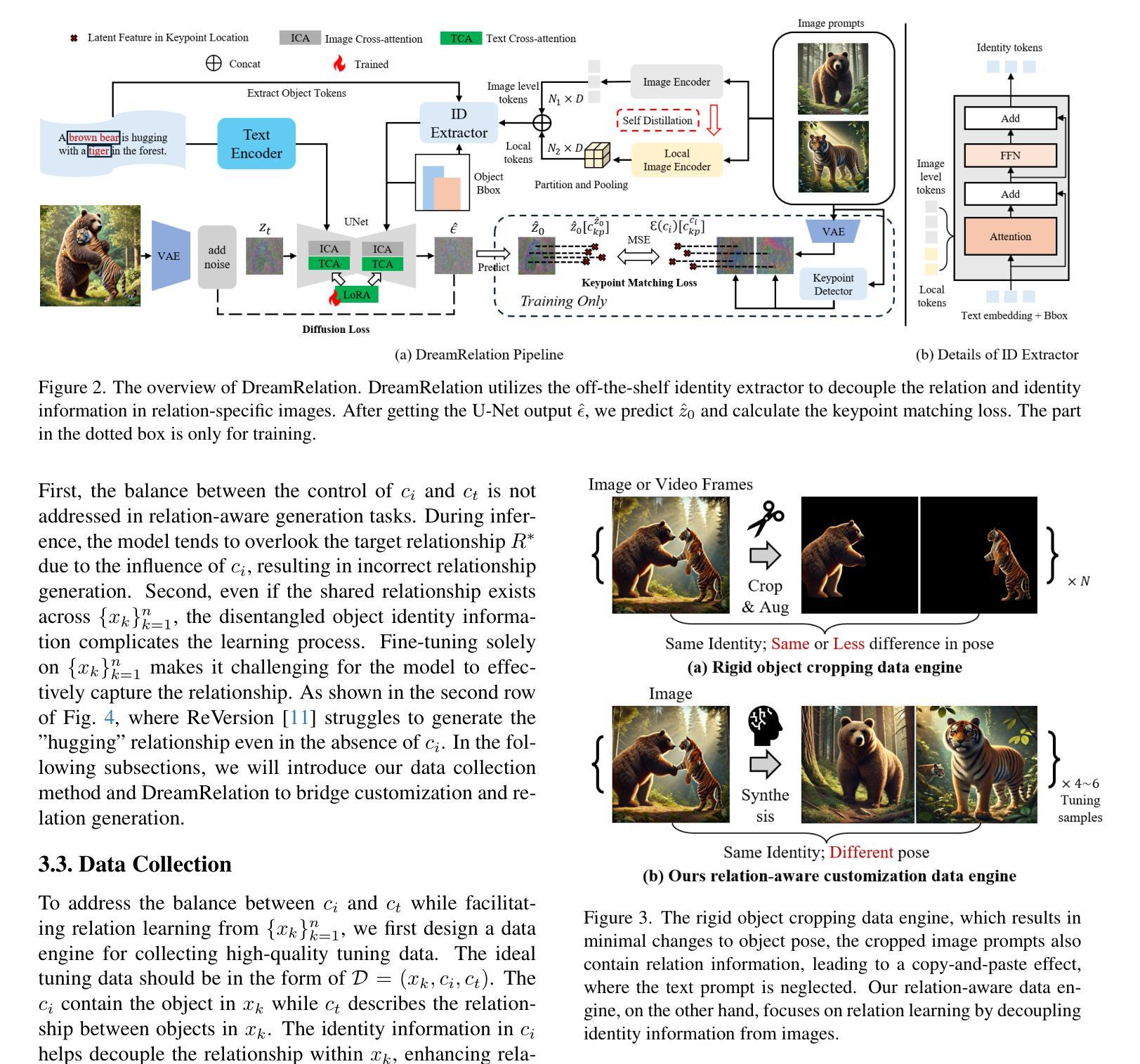


FRAP: Faithful and Realistic Text-to-Image Generation with Adaptive Prompt Weighting
Authors:Liyao Jiang, Negar Hassanpour, Mohammad Salameh, Mohan Sai Singamsetti, Fengyu Sun, Wei Lu, Di Niu
Text-to-image (T2I) diffusion models have demonstrated impressive capabilities in generating high-quality images given a text prompt. However, ensuring the prompt-image alignment remains a considerable challenge, i.e., generating images that faithfully align with the prompt’s semantics. Recent works attempt to improve the faithfulness by optimizing the latent code, which potentially could cause the latent code to go out-of-distribution and thus produce unrealistic images. In this paper, we propose FRAP, a simple, yet effective approach based on adaptively adjusting the per-token prompt weights to improve prompt-image alignment and authenticity of the generated images. We design an online algorithm to adaptively update each token’s weight coefficient, which is achieved by minimizing a unified objective function that encourages object presence and the binding of object-modifier pairs. Through extensive evaluations, we show FRAP generates images with significantly higher prompt-image alignment to prompts from complex datasets, while having a lower average latency compared to recent latent code optimization methods, e.g., 4 seconds faster than D&B on the COCO-Subject dataset. Furthermore, through visual comparisons and evaluation of the CLIP-IQA-Real metric, we show that FRAP not only improves prompt-image alignment but also generates more authentic images with realistic appearances. We also explore combining FRAP with prompt rewriting LLM to recover their degraded prompt-image alignment, where we observe improvements in both prompt-image alignment and image quality. We release the code at the following link: https://github.com/LiyaoJiang1998/FRAP/.
文本到图像(T2I)的扩散模型在给定文本提示的情况下,已经显示出生成高质量图像的强大能力。然而,确保提示与图像的对应仍然是一个巨大的挑战,即生成忠实于提示语义的图像。近期的研究工作试图通过优化潜在代码来提高忠实度,这可能会导致潜在代码偏离分布,从而生成不现实的图像。在本文中,我们提出了FRAP,这是一种简单而有效的方法,基于自适应调整每个标记的提示权重,以提高提示与图像的对应以及生成图像的真实性。我们设计了一种在线算法,自适应地更新每个标记的权重系数,这是通过最小化一个统一的目标函数来实现的,该函数鼓励对象的存在和对象修饰符对的绑定。通过广泛的评估,我们展示了FRAP在复杂数据集上的提示与图像对应能力更强,同时与最近的潜在代码优化方法相比具有更低的平均延迟,例如在COCO-Subject数据集上比D&B快4秒。此外,通过视觉比较和对CLIP-IQA-Real指标的评估,我们证明FRAP不仅提高了提示与图像的对应能力,而且生成了更真实的图像,具有逼真的外观。我们还探索了将FRAP与提示重写的大型语言模型相结合,以恢复其退化的提示与图像对应能力,观察到提示与图像对应能力和图像质量的改善。我们已在以下链接发布代码:https://github.com/LiyaoJiang1998/FRAP/。
论文及项目相关链接
PDF TMLR 2025
摘要
文本到图像(T2I)扩散模型在给定文本提示生成高质量图像方面表现出令人印象深刻的能力。然而,确保提示与图像的对齐仍然是一个巨大的挑战,即生成能够忠实对应提示语义的图像。最近的研究工作试图通过优化潜在代码来提高忠实性,但这可能会导致潜在代码脱离分布,从而生成不现实的图像。本文提出了一种简单而有效的方法FRAP,通过自适应调整每个令牌提示权重来改善提示与图像的对齐以及生成图像的真实性。我们设计了一种在线算法,通过最小化一个统一的目标函数来动态更新每个令牌的权重系数,该函数鼓励物体存在和物体修饰符对的绑定。通过广泛评估,我们展示了FRAP生成的图像与来自复杂数据集的提示具有更高的提示对齐度,同时与最近的潜在代码优化方法相比具有更低的平均延迟,例如在COCO-Subject数据集上比D&B快4秒。此外,通过视觉比较和CLIP-IQA-Real评价指标的评估,我们证明FRAP不仅提高了提示与图像的对齐度,而且生成了具有更真实外观的图像。我们还探索了将FRAP与提示重写LLM相结合,以恢复其退化的提示与图像对齐度,观察到提示与图像对齐度和图像质量都有所提高。我们已将代码发布在以下链接:https://github.com/LiyaoJiang1998/FRAP/。
要点归纳
- T2I扩散模型能生成高质量图像,但保证提示与图像对齐仍是挑战。
- 现有方法通过优化潜在代码来提升忠实性,可能产生不现实图像。
- FRAP方法通过自适应调整令牌提示权重来改善对齐和图像真实性。
- FRAP采用在线算法和统一目标函数来动态更新令牌权重。
- FRAP在复杂数据集上实现高提示对齐度,并有较低平均延迟。
- FRAP不仅能提高对齐度,还能生成更真实的图像,得到视觉和评价指标的验证。
点此查看论文截图

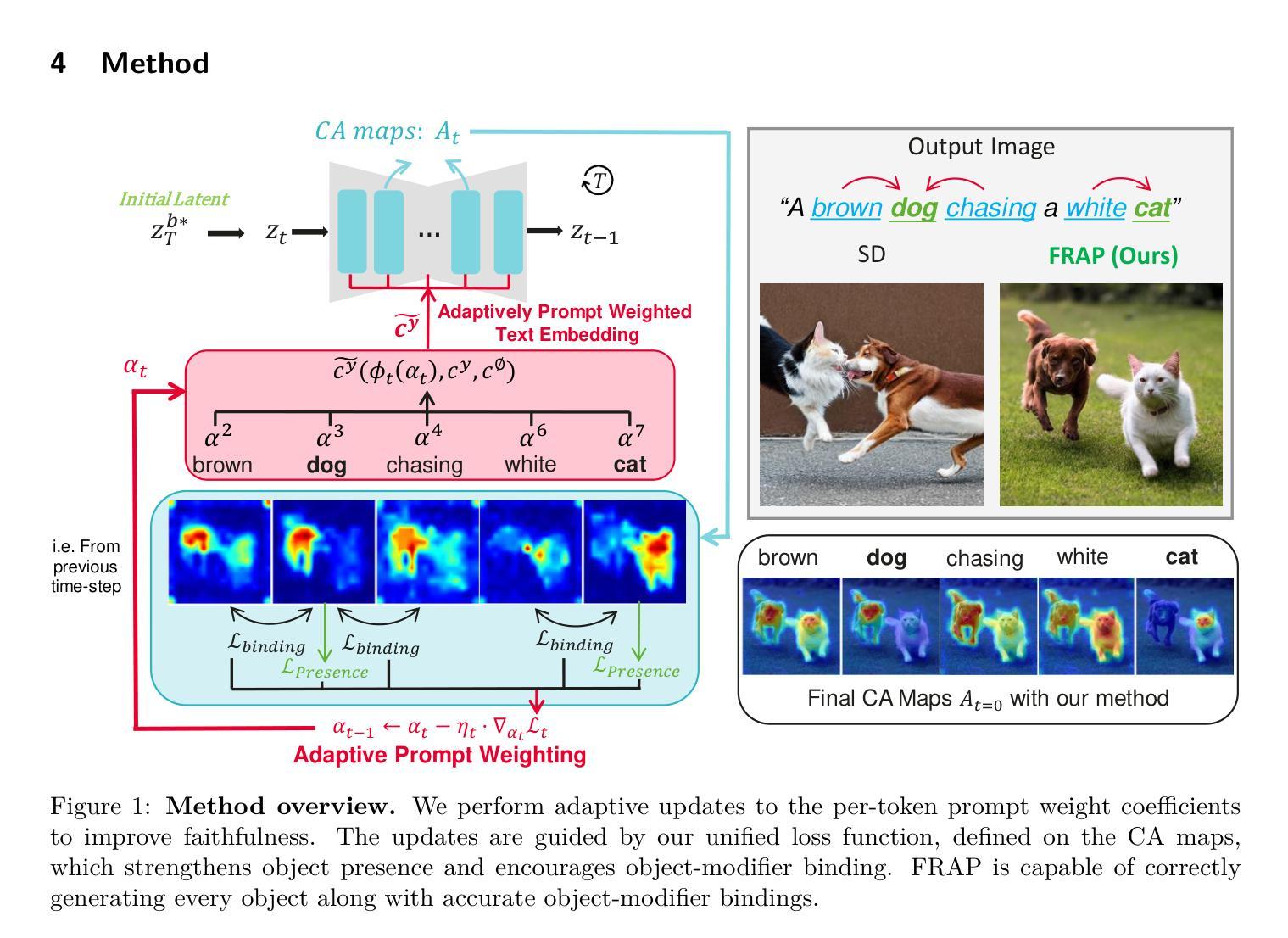
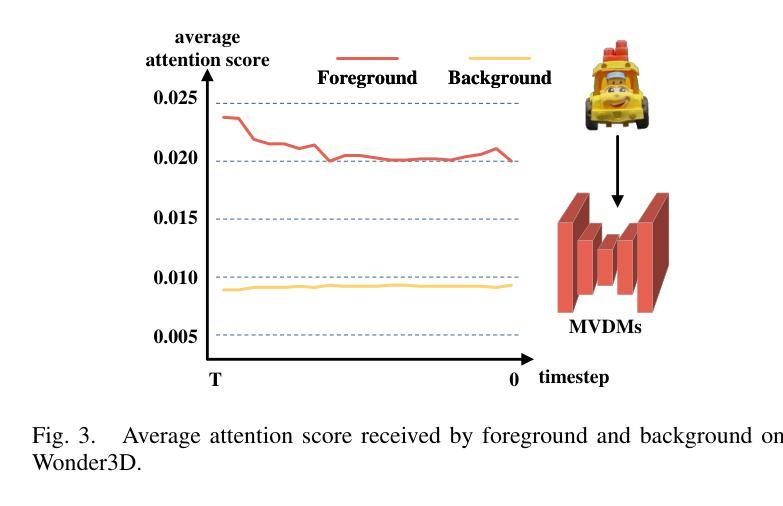
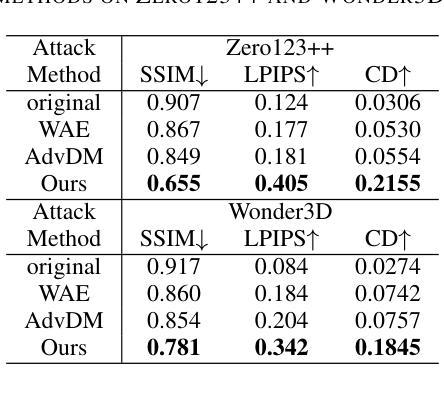
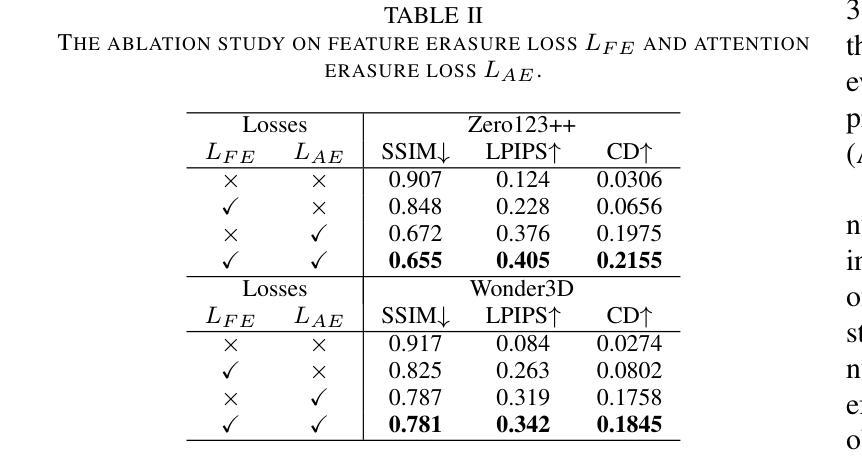
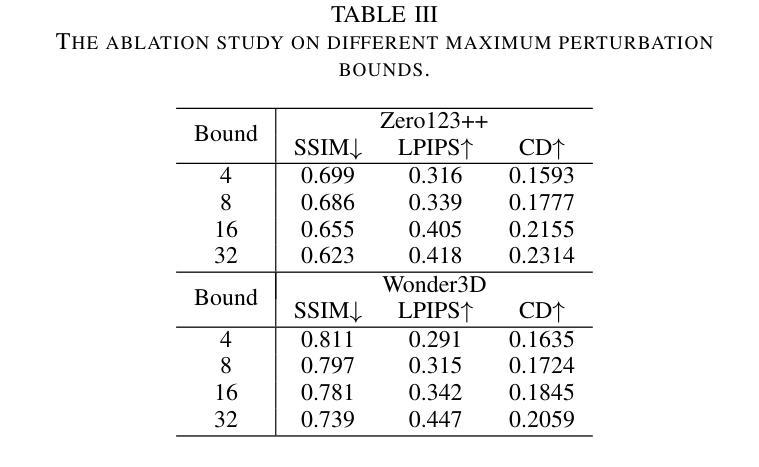
Latent Feature and Attention Dual Erasure Attack against Multi-View Diffusion Models for 3D Assets Protection
Authors:Jingwei Sun, Xuchong Zhang, Changfeng Sun, Qicheng Bai, Hongbin Sun
Multi-View Diffusion Models (MVDMs) enable remarkable improvements in the field of 3D geometric reconstruction, but the issue regarding intellectual property has received increasing attention due to unauthorized imitation. Recently, some works have utilized adversarial attacks to protect copyright. However, all these works focus on single-image generation tasks which only need to consider the inner feature of images. Previous methods are inefficient in attacking MVDMs because they lack the consideration of disrupting the geometric and visual consistency among the generated multi-view images. This paper is the first to address the intellectual property infringement issue arising from MVDMs. Accordingly, we propose a novel latent feature and attention dual erasure attack to disrupt the distribution of latent feature and the consistency across the generated images from multi-view and multi-domain simultaneously. The experiments conducted on SOTA MVDMs indicate that our approach achieves superior performances in terms of attack effectiveness, transferability, and robustness against defense methods. Therefore, this paper provides an efficient solution to protect 3D assets from MVDMs-based 3D geometry reconstruction.
多视角扩散模型(MVDMs)在3D几何重建领域实现了显著的改进,但由于未经授权的模仿,知识产权问题日益受到关注。最近,一些工作利用对抗性攻击来保护版权。然而,所有这些工作都集中在单图像生成任务上,只需要考虑图像的内部特征。以前的方法在攻击MVDMs时效率不高,因为它们没有考虑到破坏生成的多视角图像之间的几何和视觉一致性。本文首次解决由MVDMs引起的知识产权侵权问题。据此,我们提出了一种新型的潜在特征和注意力双重擦除攻击,以破坏潜在特征分布和来自多视角和多领域的生成图像之间的一致性。在SOTA MVDMs上进行的实验表明,我们的方法在攻击有效性、可转移性和对防御方法的稳健性方面表现出卓越性能。因此,本文提供了一种有效的解决方案,保护3D资产免受基于MVDMs的3D几何重建的侵害。
论文及项目相关链接
PDF This paper has been accepted by ICME 2025
Summary
多视图扩散模型(MVDM)在3D几何重建领域取得了显著进步,但知识产权问题因未经授权的模仿而受到越来越多的关注。针对这一问题,本文首次提出一种针对MVDM的潜在特征和注意力双重擦除攻击方法,该方法能够同时破坏生成的多视角和多领域图像的潜在特征分布和一致性。实验表明,该方法在攻击效果、迁移性和防御方法稳健性方面表现优越,为3D资产保护提供了一种有效的解决方案。
Key Takeaways
- 多视图扩散模型(MVDM)在3D几何重建中的应用取得显著进步,但知识产权问题日益突出。
- 目前存在利用对抗性攻击保护版权的方法,但针对MVDM的攻击方法效率较低。
- 本文首次提出针对MVDM的潜在特征和注意力双重擦除攻击方法。
- 该方法能够同时破坏生成的多视角和多领域图像的潜在特征分布和一致性。
- 实验表明,该方法在攻击效果、迁移性和防御方法稳健性方面表现优越。
- 该方法为解决基于MVDM的3D几何重建中的知识产权保护问题提供了有效解决方案。
点此查看论文截图


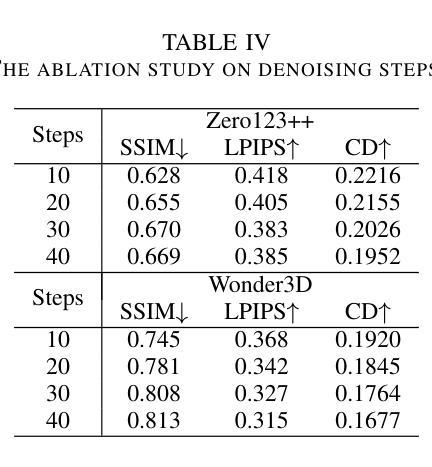
No Re-Train, More Gain: Upgrading Backbones with Diffusion model for Pixel-Wise and Weakly-Supervised Few-Shot Segmentation
Authors:Shuai Chen, Fanman Meng, Chenhao Wu, Haoran Wei, Runtong Zhang, Qingbo Wu, Linfeng Xu, Hongliang Li
Few-Shot Segmentation (FSS) aims to segment novel classes using only a few annotated images. Despite considerable progress under pixel-wise support annotation, current FSS methods still face three issues: the inflexibility of backbone upgrade without re-training, the inability to uniformly handle various types of annotations (e.g., scribble, bounding box, mask, and text), and the difficulty in accommodating different annotation quantity. To address these issues simultaneously, we propose DiffUp, a novel framework that conceptualizes the FSS task as a conditional generative problem using a diffusion process. For the first issue, we introduce a backbone-agnostic feature transformation module that converts different segmentation cues into unified coarse priors, facilitating seamless backbone upgrade without re-training. For the second issue, due to the varying granularity of transformed priors from diverse annotation types (scribble, bounding box, mask, and text), we conceptualize these multi-granular transformed priors as analogous to noisy intermediates at different steps of a diffusion model. This is implemented via a self-conditioned modulation block coupled with a dual-level quality modulation branch. For the third issue, we incorporate an uncertainty-aware information fusion module to harmonize the variability across zero-shot, one-shot, and many-shot scenarios. Evaluated through rigorous benchmarks, DiffUp significantly outperforms existing FSS models in terms of flexibility and accuracy.
少数样本分割(FSS)旨在仅使用少量标注图像对新型类别进行分割。尽管在像素级支持标注方面取得了相当大的进展,但当前FSS方法仍然面临三个问题:骨干网升级的灵活性不足需要重新训练,无法统一处理各种类型标注(如涂鸦、边界框、蒙版和文本),以及难以适应不同的标注数量。为了解决这三个问题,我们提出了DiffUp这一新型框架,它将FSS任务概念化为一个使用扩散过程的条件生成问题。对于第一个问题,我们引入了一个通用的特征转换模块,该模块能够将不同的分割线索转换为统一的粗略先验知识,从而实现无需重新训练的骨干网无缝升级。对于第二个问题,由于不同标注类型(涂鸦、边界框、蒙版和文本)产生的转换先验粒度不同,我们将这些多粒度转换先验概念化为扩散模型不同步骤中的噪声中间产物。这是通过一个自条件调制模块与一个双级质量调制分支相结合来实现的。对于第三个问题,我们融入了一个不确定性感知的信息融合模块,以协调零样本、单样本和多样本场景之间的变化。通过严格的基准测试,DiffUp在灵活性和准确性方面显著优于现有的FSS模型。
论文及项目相关链接
PDF 9 figures
Summary
基于少样本分割(FSS)任务的目标是对新类别进行分割,仅使用少量标注图像。为解决当前FSS方法在骨干升级、处理不同类型标注和适应不同标注数量上的难题,本文提出了DiffUp框架。该框架将FSS任务概念化为一个基于扩散过程的条件生成问题。通过引入特征转换模块、自条件调制块和信息融合模块,DiffUp框架显著提高了模型的灵活性、准确性与泛化能力。
Key Takeaways
- DiffUp框架旨在解决少样本分割(FSS)中的三个主要问题:骨干升级的灵活性、处理多种类型标注的能力以及适应不同标注数量的难度。
- 引入特征转换模块,实现无缝骨干升级而无需重新训练。
- 由于不同标注类型产生的先验知识粒度不同,类比于扩散模型的不同步骤中的噪声中间体,利用自条件调制块与双级质量调制分支进行处理。
- 纳入不确定性感知信息融合模块,协调零样本、单样本和多样本场景下的变量。
- DiffUp框架将FSS任务概念化为条件生成问题,使用扩散过程来处理。
- 通过严格的基准测试,DiffUp在灵活性和准确性方面显著优于现有FSS模型。
- 该框架为处理少样本学习中的分割任务提供了新的视角和解决方案。
点此查看论文截图

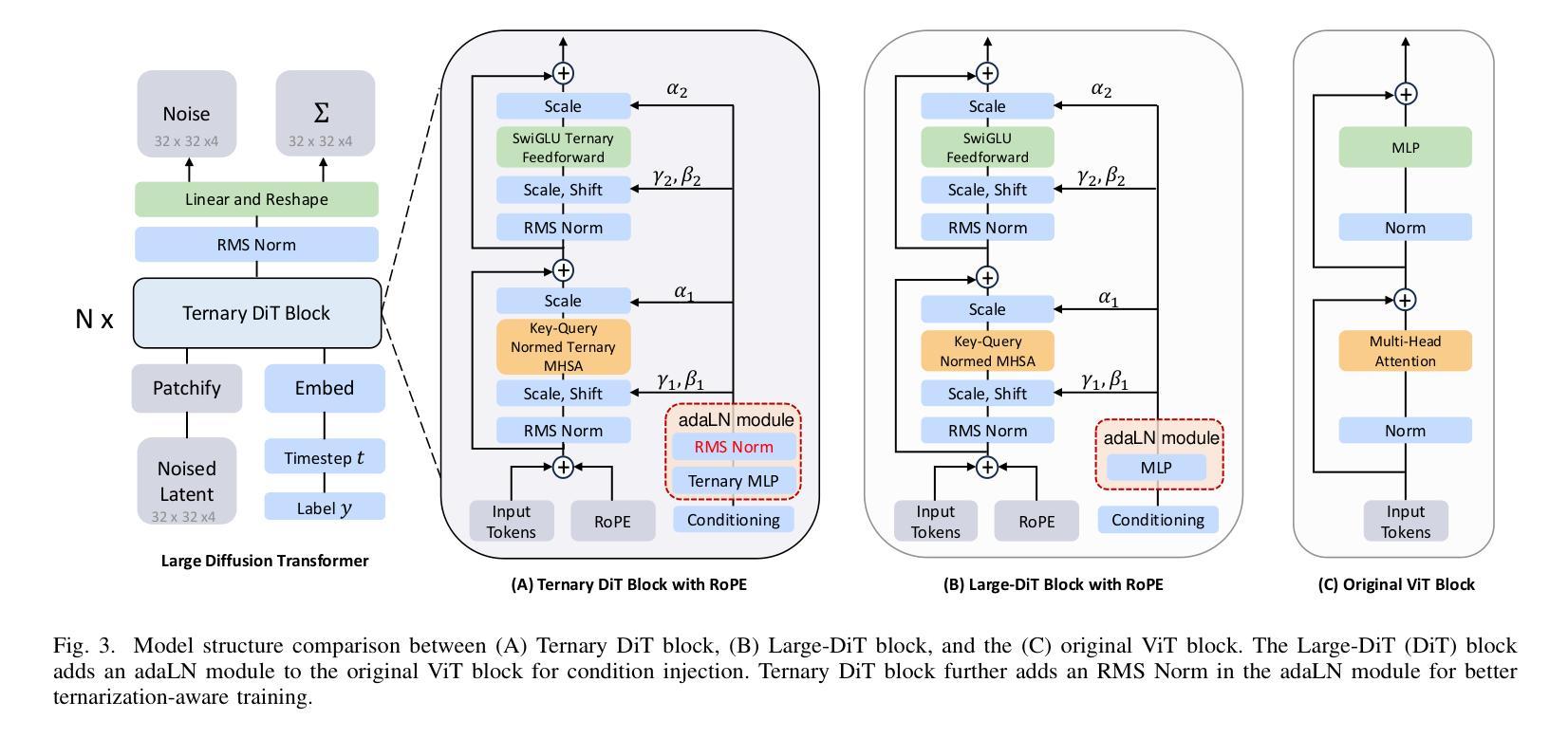
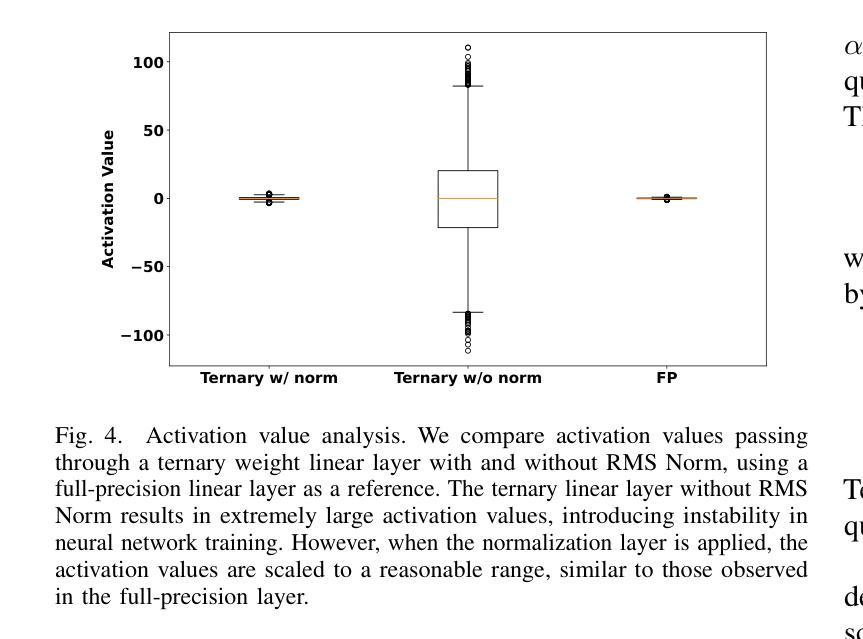
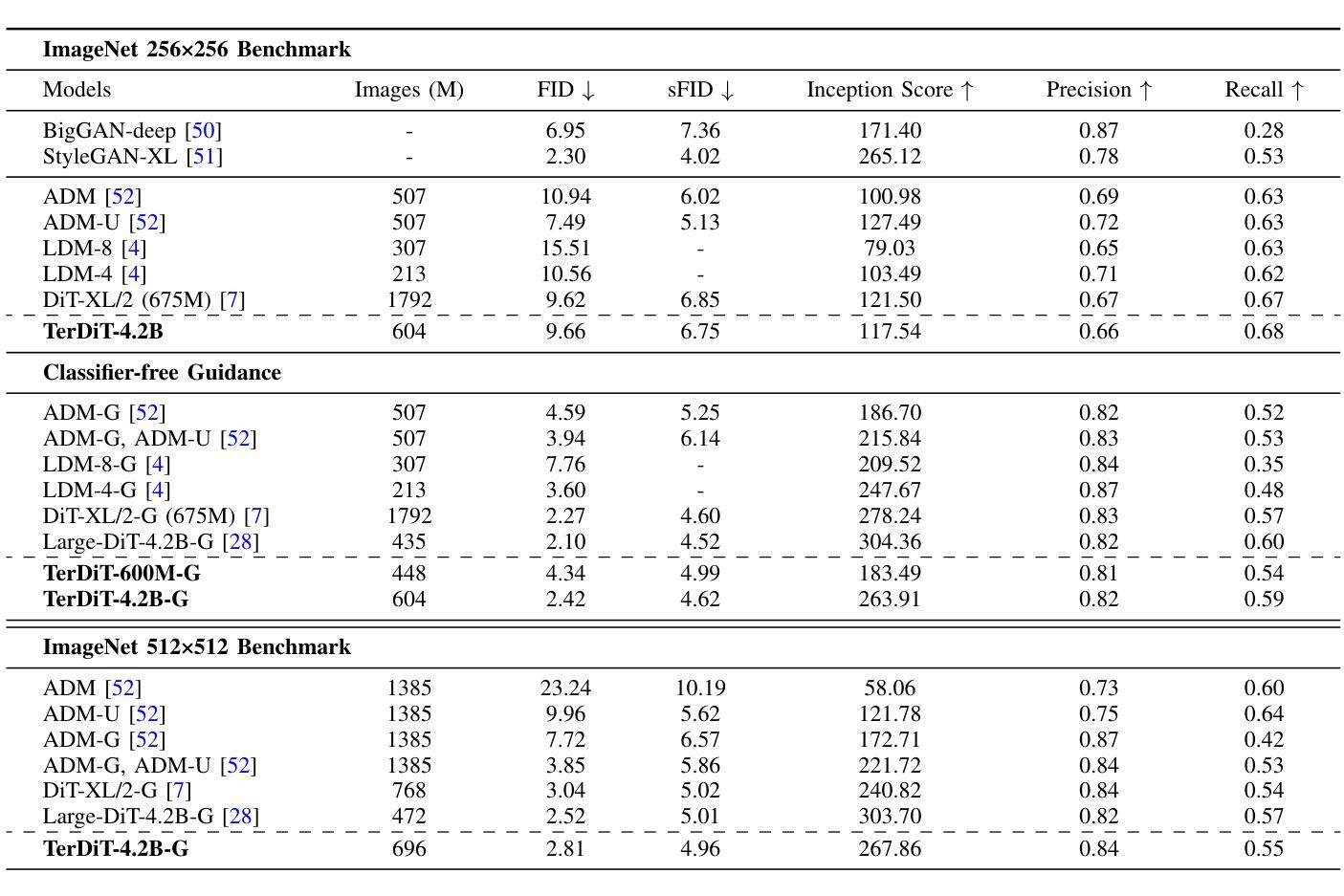
TerDiT: Ternary Diffusion Models with Transformers
Authors:Xudong Lu, Aojun Zhou, Ziyi Lin, Qi Liu, Yuhui Xu, Renrui Zhang, Xue Yang, Junchi Yan, Peng Gao, Hongsheng Li
Recent developments in large-scale pre-trained text-to-image diffusion models have significantly improved the generation of high-fidelity images, particularly with the emergence of diffusion transformer models (DiTs). Among diffusion models, diffusion transformers have demonstrated superior image-generation capabilities, boosting lower FID scores and higher scalability. However, deploying large-scale DiT models can be expensive due to their excessive parameter numbers. Although existing research has explored efficient deployment techniques for diffusion models, such as model quantization, there is still little work concerning DiT-based models. To tackle this research gap, we propose TerDiT, the first quantization-aware training (QAT) and efficient deployment scheme for extremely low-bit diffusion transformer models. We focus on the ternarization of DiT networks, with model sizes ranging from 600M to 4.2B, and image resolution from 256$\times$256 to 512$\times$512. Our work contributes to the exploration of efficient deployment of large-scale DiT models, demonstrating the feasibility of training extremely low-bit DiT models from scratch while maintaining competitive image generation capacities compared to full-precision models. Our code and pre-trained TerDiT checkpoints have been released at https://github.com/Lucky-Lance/TerDiT.
近期,大型预训练文本到图像扩散模型的最新发展极大地提高了高保真图像的生成能力,特别是随着扩散转换器模型(DiTs)的出现。在扩散模型中,扩散转换器表现出了卓越的图象生成能力,提高了较低的FID分数和更高的可扩展性。然而,由于参数数量过多,部署大规模的DiT模型可能会很昂贵。尽管现有研究已经探索了扩散模型的高效部署技术,如模型量化,但关于基于DiT的模型的研究工作仍然很少。为了填补这一研究空白,我们提出了TerDiT,这是第一个针对极低位扩散转换器模型的数量化感知训练(QAT)和高效部署方案。我们专注于DiT网络的三元化,涵盖从6亿到4.2亿不同大小的模型和从256×256到512×512的图像分辨率。我们的研究为大规模DiT模型的高效部署探索做出了贡献,证明了从头开始训练极低位的DiT模型的同时保持与全精度模型竞争的图象生成能力。我们的代码和预先训练的TerDiT检查点已在https://github.com/Lucky-Lance/TerDiT发布。
论文及项目相关链接
Summary
大规模预训练文本到图像扩散模型的新发展,尤其是扩散变压器模型(DiTs)的出现,显著提高了高保真图像的生成能力。但部署大型DiT模型成本高昂。为此,我们提出TerDiT,首个针对极低位扩散变压器模型的量化感知训练(QAT)和高效部署方案。我们专注于DiT网络的三态化,模型规模从6亿到42亿不等,图像分辨率从256x256到512x512。TerDiT在维持与全精度模型相当的图像生成能力的同时,展示了从头开始训练极低位DiT模型的可行性。
Key Takeaways
- 扩散模型中的扩散变压器(DiT)在图像生成方面表现出卓越性能,具有更低的FID分数和更高的可扩展性。
- 大型DiT模型的部署成本高昂,需要探索高效部署技术。
- TerDiT是首个针对极低位扩散变压器模型的量化感知训练(QAT)和高效部署方案。
- TerDiT专注于DiT网络的三态化,涉及不同规模模型和图像分辨率。
- TerDiT在维持与全精度模型相当的图像生成能力的同时,实现了从源头训练极低位DiT模型的可行性。
- TerDiT的源代码和预先训练好的模型检查点已经公开发布在https://github.com/Lucky-Lance/TerDiT。
点此查看论文截图