⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-09 更新
InteractVLM: 3D Interaction Reasoning from 2D Foundational Models
Authors:Sai Kumar Dwivedi, Dimitrije Antić, Shashank Tripathi, Omid Taheri, Cordelia Schmid, Michael J. Black, Dimitrios Tzionas
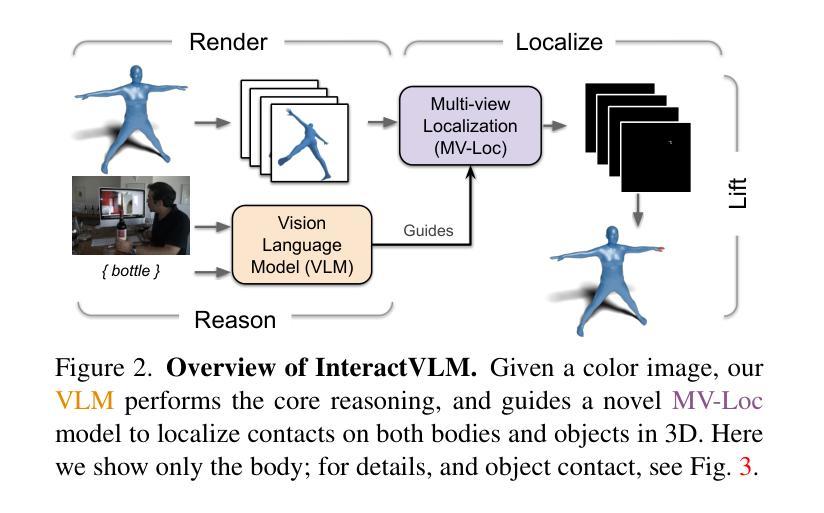
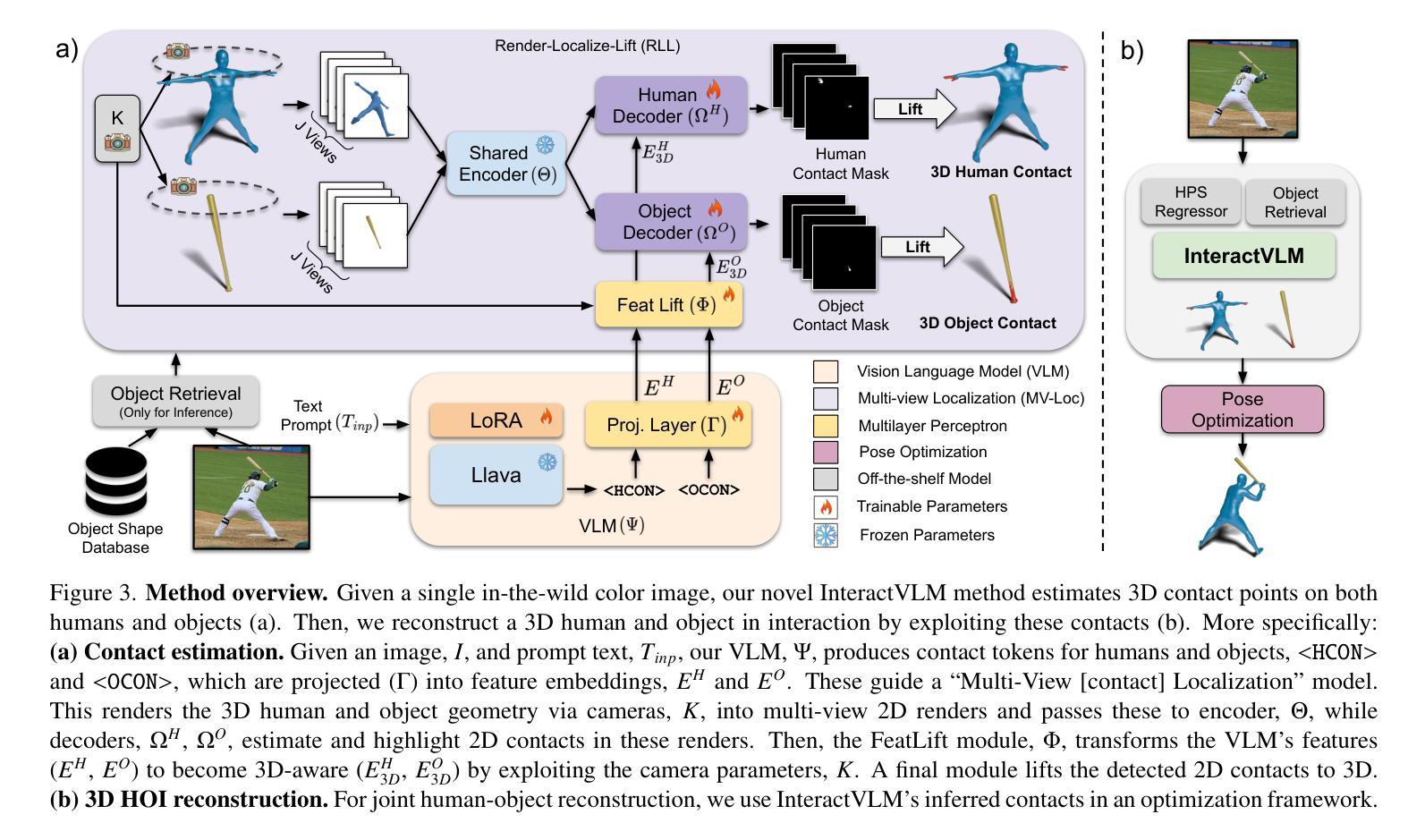
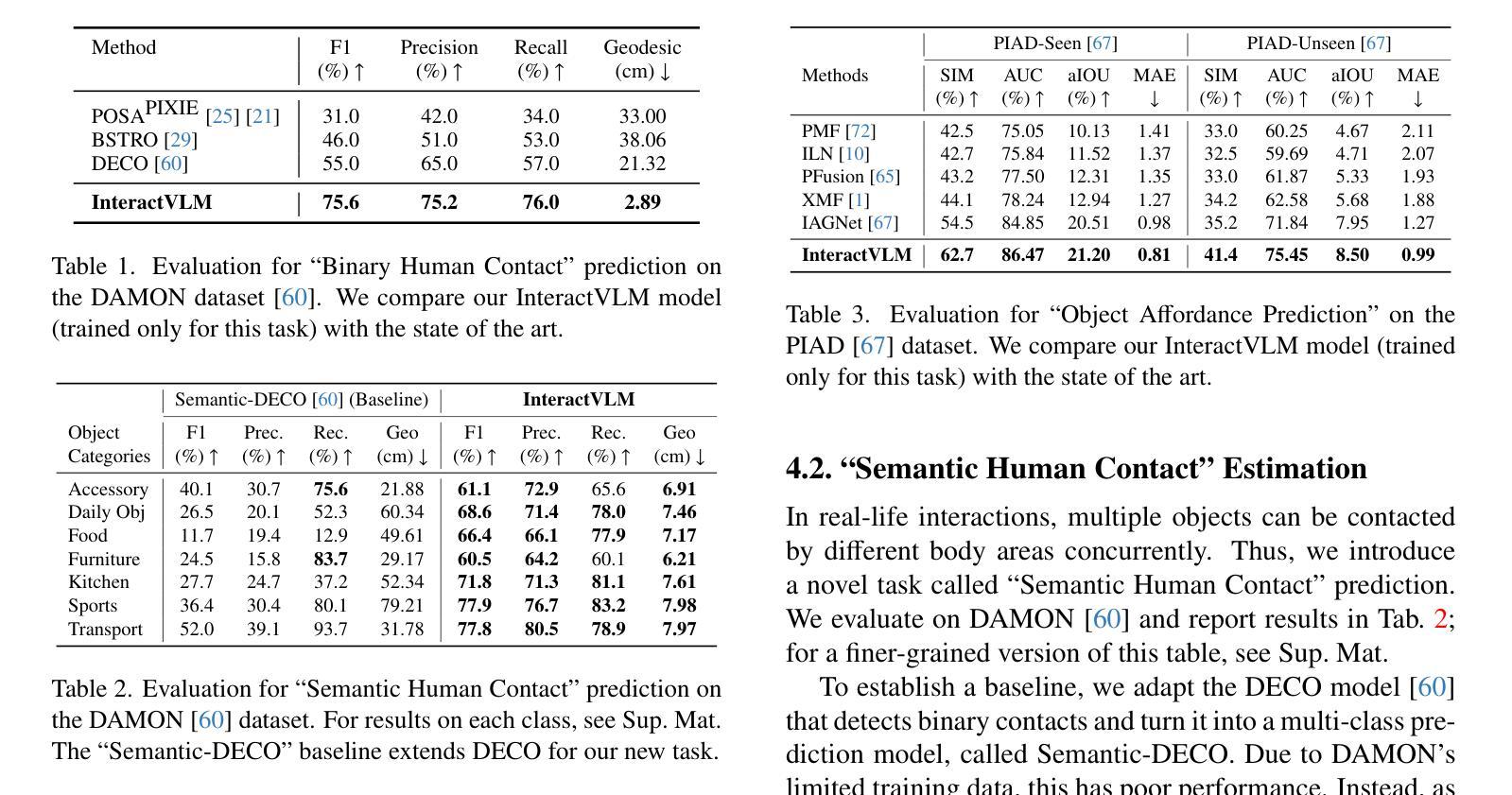
We introduce InteractVLM, a novel method to estimate 3D contact points on human bodies and objects from single in-the-wild images, enabling accurate human-object joint reconstruction in 3D. This is challenging due to occlusions, depth ambiguities, and widely varying object shapes. Existing methods rely on 3D contact annotations collected via expensive motion-capture systems or tedious manual labeling, limiting scalability and generalization. To overcome this, InteractVLM harnesses the broad visual knowledge of large Vision-Language Models (VLMs), fine-tuned with limited 3D contact data. However, directly applying these models is non-trivial, as they reason only in 2D, while human-object contact is inherently 3D. Thus we introduce a novel Render-Localize-Lift module that: (1) embeds 3D body and object surfaces in 2D space via multi-view rendering, (2) trains a novel multi-view localization model (MV-Loc) to infer contacts in 2D, and (3) lifts these to 3D. Additionally, we propose a new task called Semantic Human Contact estimation, where human contact predictions are conditioned explicitly on object semantics, enabling richer interaction modeling. InteractVLM outperforms existing work on contact estimation and also facilitates 3D reconstruction from an in-the wild image. Code and models are available at https://interactvlm.is.tue.mpg.de.
我们介绍了InteractVLM,这是一种从单张野外图像估计人体和物体上3D接触点的新型方法,能够实现3D中准确的人体-物体关节重建。由于遮挡、深度歧义和物体形状各异,这项工作具有挑战性。现有方法依赖于通过昂贵的动作捕捉系统或繁琐的手动标注收集到的3D接触点注释,这限制了其可扩展性和通用性。为了克服这一难题,InteractVLM利用大型视觉语言模型(VLMs)的广泛视觉知识,这些模型通过有限的3D接触数据进行微调。然而,直接应用这些模型并不简单,因为它们只在2D中进行推理,而人体与物体的接触本质上是3D的。因此,我们引入了一种新颖的Render-Localize-Lift模块,该模块通过以下方式工作:(1)通过多视角渲染将3D人体和物体表面嵌入到二维空间中;(2)训练一种新型的多视角定位模型(MV-Loc),以在二维空间中推断接触点;(3)将这些接触点提升到三维空间。此外,我们提出了一个新的任务,称为语义人类接触估计,其中人类接触预测显式地以对象语义为条件,从而实现更丰富的交互建模。InteractVLM在接触点估计方面表现优于现有工作,并促进了从野外图像进行三维重建。相关代码和模型可在https://interactvlm.is.tue.mpg.de访问。
论文及项目相关链接
PDF CVPR 2025
Summary:我们提出了一种名为InteractVLM的新方法,可以从单张野外图像中估计人体与物体的3D接触点,从而实现准确的人-物体关节重建。该方法通过利用大型视觉语言模型(VLMs)的广泛视觉知识,并借助有限的3D接触数据进行微调,解决了因遮挡、深度模糊和物体形状多样而带来的挑战。为将模型应用于人-物体接触这一固有3D问题,我们引入了Render-Localize-Lift模块,通过多视图渲染将3D人体和物体表面嵌入2D空间,训练新型多视图定位模型(MV-Loc)以在2D空间中推断接触,并将其提升到3D空间。此外,我们还提出了基于对象语义的语义人类接触估计新任务,使人机交互建模更加丰富。InteractVLM在接触估计方面表现出超越现有工作的性能,并能够从野外图像进行3D重建。
Key Takeaways:
- InteractVLM是一种从单张野外图像估计人-物体3D接触点的新方法。
- 该方法解决了遮挡、深度模糊和物体形状多样带来的挑战。
- InteractVLM利用大型视觉语言模型的广泛视觉知识,并通过有限的3D接触数据进行微调。
- 引入Render-Localize-Lift模块解决从2D到3D的推理问题。
- 提出新型多视图定位模型(MV-Loc)以在2D空间中推断接触。
- 提出基于对象语义的语义人类接触估计新任务。
- InteractVLM在接触估计和3D重建方面表现出卓越性能。
点此查看论文截图

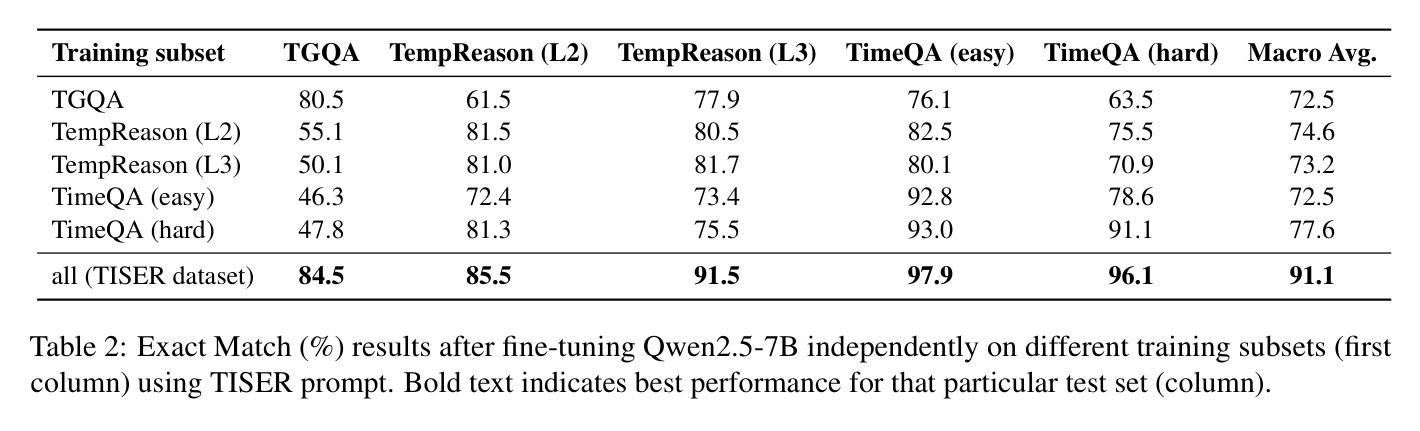
Learning to Reason Over Time: Timeline Self-Reflection for Improved Temporal Reasoning in Language Models
Authors:Adrián Bazaga, Rexhina Blloshmi, Bill Byrne, Adrià de Gispert
Large Language Models (LLMs) have emerged as powerful tools for generating coherent text, understanding context, and performing reasoning tasks. However, they struggle with temporal reasoning, which requires processing time-related information such as event sequencing, durations, and inter-temporal relationships. These capabilities are critical for applications including question answering, scheduling, and historical analysis. In this paper, we introduce TISER, a novel framework that enhances the temporal reasoning abilities of LLMs through a multi-stage process that combines timeline construction with iterative self-reflection. Our approach leverages test-time scaling to extend the length of reasoning traces, enabling models to capture complex temporal dependencies more effectively. This strategy not only boosts reasoning accuracy but also improves the traceability of the inference process. Experimental results demonstrate state-of-the-art performance across multiple benchmarks, including out-of-distribution test sets, and reveal that TISER enables smaller open-source models to surpass larger closed-weight models on challenging temporal reasoning tasks.
大型语言模型(LLM)已经成为生成连贯文本、理解上下文和进行推理任务的强大工具。然而,它们在时间推理方面遇到困难,时间推理需要处理与时间相关的信息,如事件序列、持续时间和时间间关系。这些能力对于问答、日程安排和历史分析等应用至关重要。在本文中,我们介绍了TISER,这是一个通过结合时间线构建和迭代自我反思的多阶段过程,提高LLM的时间推理能力的新型框架。我们的方法利用测试时缩放来延长推理痕迹的长度,使模型能够更有效地捕捉复杂的时序依赖关系。这种策略不仅提高了推理准确性,还提高了推理过程的可追溯性。实验结果表明,我们在多个基准测试集上达到了最先进的性能,包括超出分布外的测试集,并且揭示了TISER使较小的开源模型能够在具有挑战性的时间推理任务上超越较大的封闭权重模型。
论文及项目相关链接
Summary
大型语言模型(LLM)在生成连贯文本、理解上下文和进行推理任务方面展现出强大能力,但在需要处理与时间相关信息的临时推理方面存在困难,如事件排序、持续时间和时间间关系。对于问答、日程安排和历史分析等应用,这些能力至关重要。本文介绍了一个增强LLM临时推理能力的新框架TISER,它采用分阶段的过程,结合时间线构建和迭代自我反思。该方法利用测试时缩放,延长推理轨迹的长度,使模型更有效地捕捉复杂的临时依赖关系。此策略不仅提高了推理的准确性,还提高了推理过程的可追溯性。实验结果表明,在多个基准测试上达到了最先进的性能水平,包括超出分布式测试集的性能,并且TISER还使较小的开源模型能够在具有挑战性的临时推理任务上超越较大的封闭权重模型。
Key Takeaways
- 大型语言模型(LLM)在文本生成、上下文理解和推理任务方面表现出强大的能力。
- LLM在临时推理方面存在挑战,需要处理时间相关信息,如事件排序、持续时间和时间间关系。
- TISER是一个新框架,旨在增强LLM的临时推理能力。
- TISER采用分阶段过程,结合时间线构建和迭代自我反思。
- TISER利用测试时缩放来延长推理轨迹长度,提高捕捉复杂临时依赖关系的能力。
- TISER提高了推理准确性和推理过程的可追溯性。
点此查看论文截图



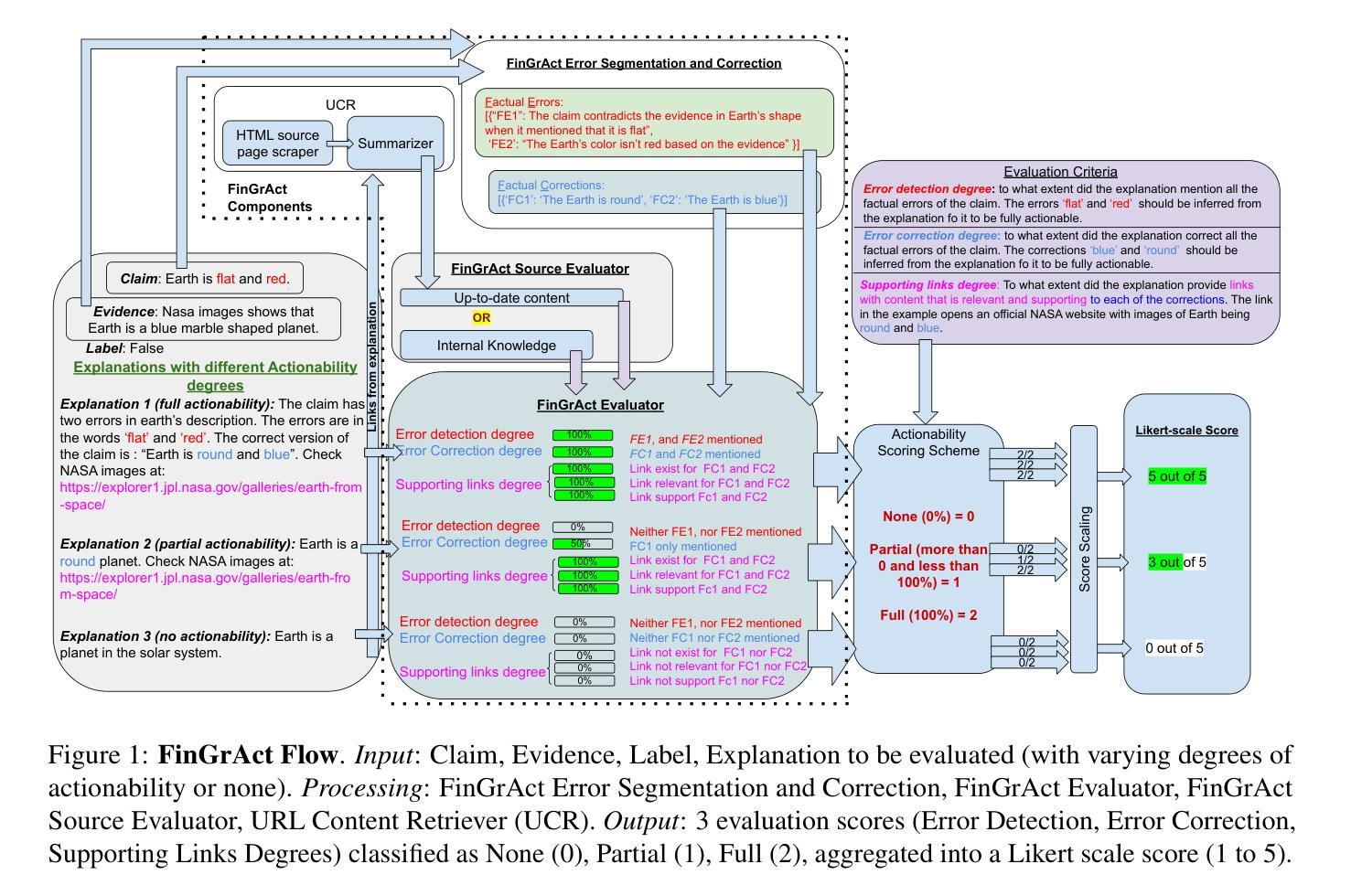
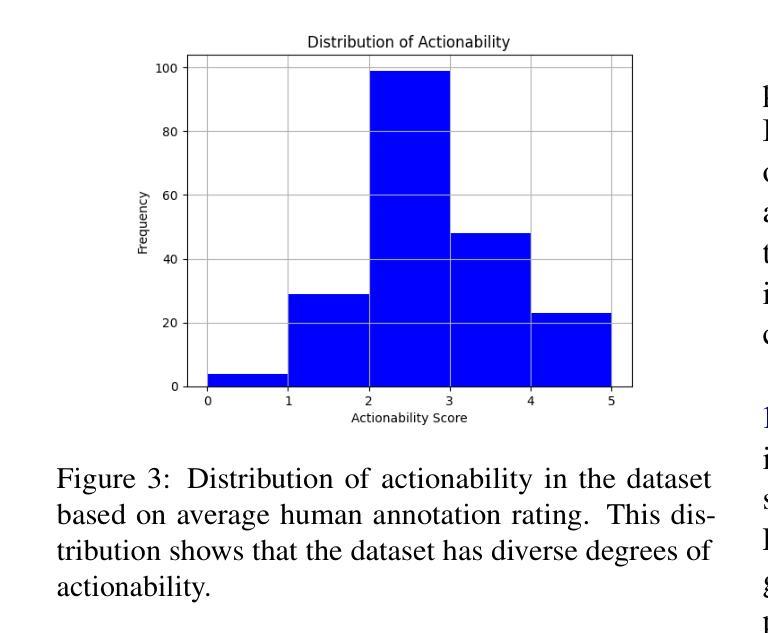
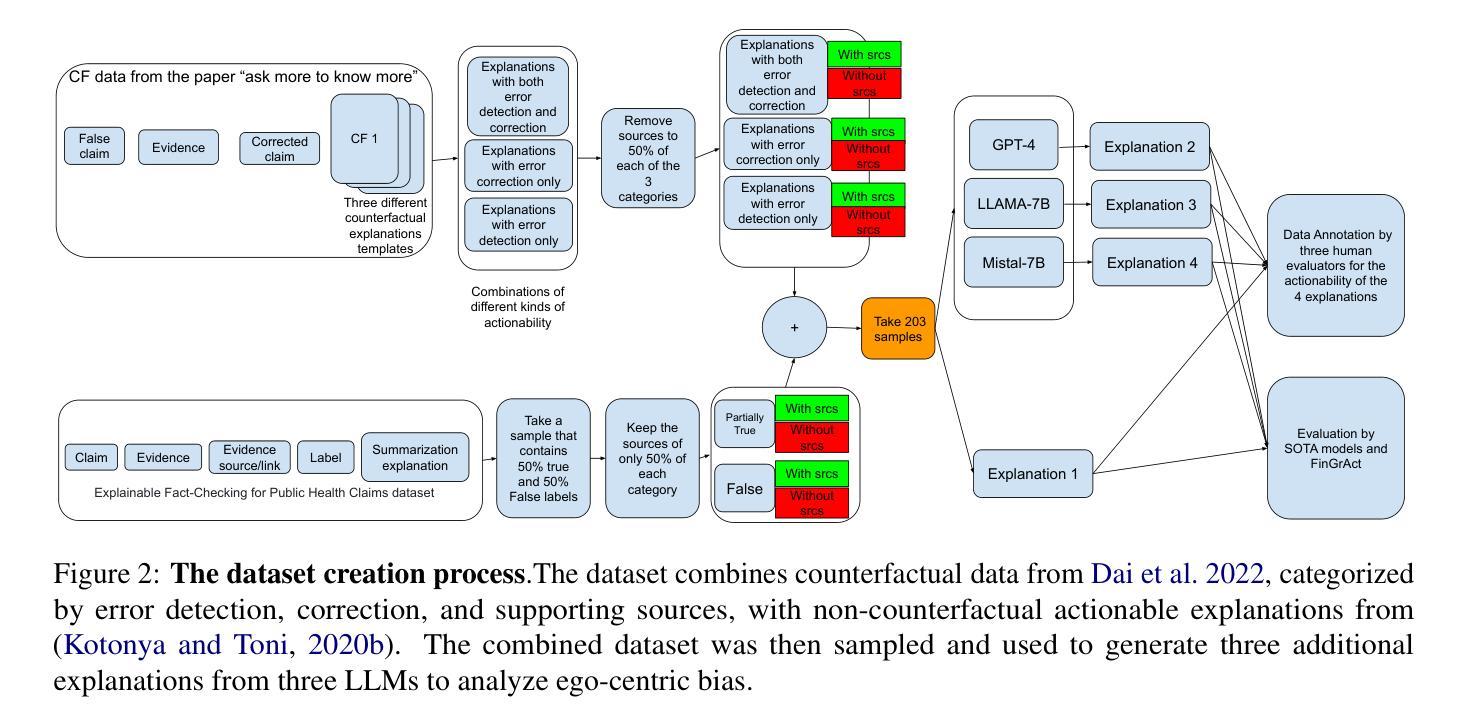
FinGrAct: A Framework for FINe-GRrained Evaluation of ACTionability in Explainable Automatic Fact-Checking
Authors:Islam Eldifrawi, Shengrui Wang, Amine Trabelsi
The field of explainable Automatic Fact-Checking (AFC) aims to enhance the transparency and trustworthiness of automated fact-verification systems by providing clear and comprehensible explanations. However, the effectiveness of these explanations depends on their actionability –their ability to empower users to make informed decisions and mitigate misinformation. Despite actionability being a critical property of high-quality explanations, no prior research has proposed a dedicated method to evaluate it. This paper introduces FinGrAct, a fine-grained evaluation framework that can access the web, and it is designed to assess actionability in AFC explanations through well-defined criteria and an evaluation dataset. FinGrAct surpasses state-of-the-art (SOTA) evaluators, achieving the highest Pearson and Kendall correlation with human judgments while demonstrating the lowest ego-centric bias, making it a more robust evaluation approach for actionability evaluation in AFC.
可解释性自动事实核查(AFC)领域旨在通过提供清晰且易于理解的解释来提高自动事实核查系统的透明度和可信度。然而,这些解释的有效性取决于它们的可操作性——即它们帮助用户做出明智决策和缓解假信息的能力。尽管可操作性是高质量解释的关键属性,但之前的研究并没有提出专门的方法来评估它。本文介绍了FineGrAct,这是一个可以访问网页的精细评估框架,旨在通过明确定义的标准和评估数据集来评估AFC解释中的可操作性。FineGrAct超越了最先进的评估者,实现了与人工判断的最高Pearson和Kendall相关性,同时表现出了最低的以自我为中心偏见,使其成为AFC中可操作性评估的更稳健的评估方法。
论文及项目相关链接
Summary
本文介绍了自动事实核查(AFC)领域的一个研究目标,即提高自动化事实核查系统的透明度和可信度。为此,研究者们需要开发清晰易懂且易于行动的解释。然而,现有的研究尚未提出专门的方法来评估这些解释的可行性。本文提出了一种精细的评估框架FinGrAct,旨在通过明确的标准和评估数据集来评估AFC解释的可行性。该框架能够访问网络,并且相较于现有的评估器,它实现了更高的Pearson和Kendall相关性,同时显示出最低的自我中心偏见,使其成为AFC中评估可行性的更稳健的方法。
Key Takeaways
- 自动事实核查(AFC)的目标是增强自动化事实验证系统的透明度和可信度。
- 评估AFC解释的有效性关键在于其可行性,即解释能否帮助用户做出明智的决策并减少误导信息。
- 当前缺乏专门的方法来评估AFC解释的可行性。
- FinGrAct是一个用于评估AFC解释可行性的精细评估框架。
- FinGrAct可以访问网络并使用明确的标准和评估数据集来评估解释的可行性。
- FinGrAct实现了高相关性并与人类判断相比显示出较低的自我中心偏见。
点此查看论文截图


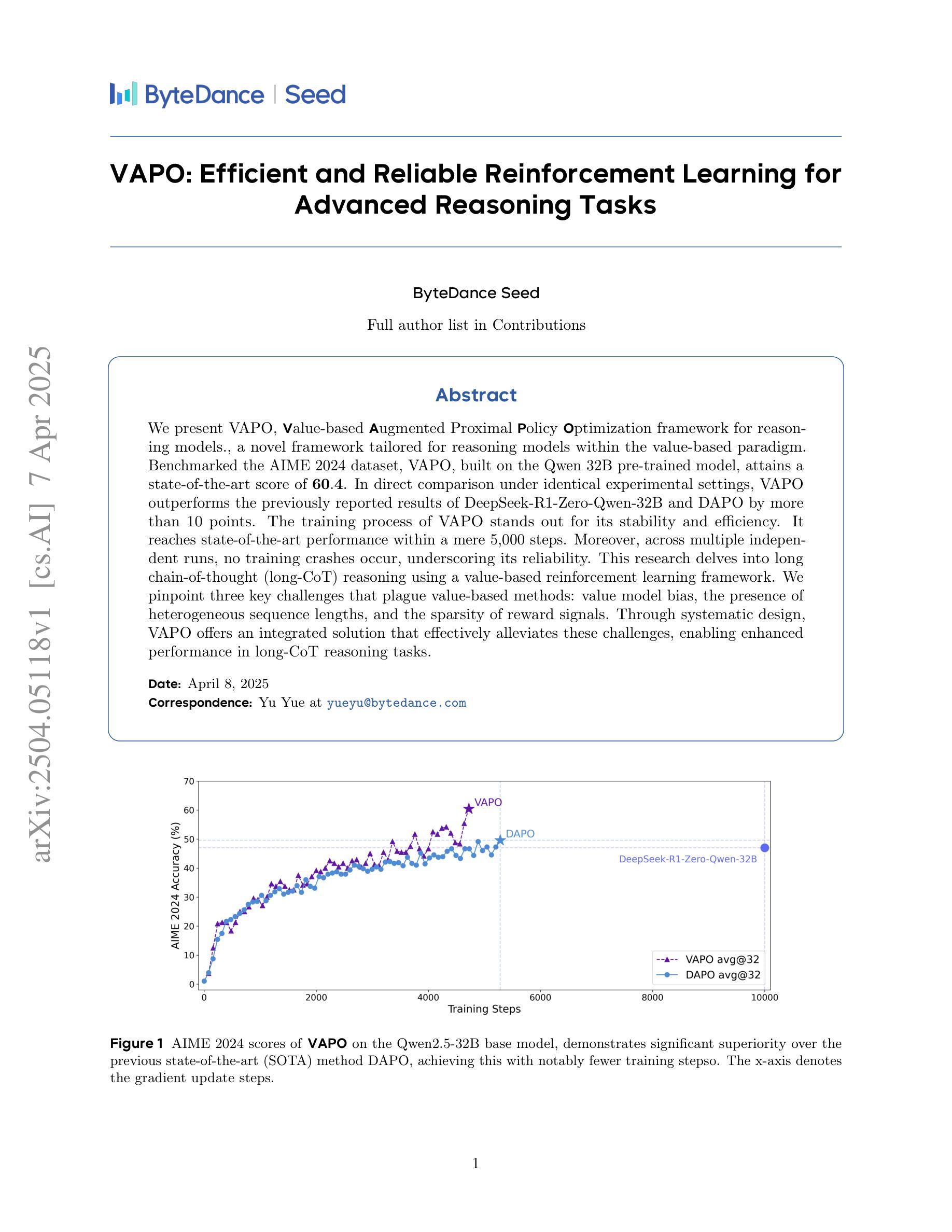
VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks
Authors: YuYue, Yufeng Yuan, Qiying Yu, Xiaochen Zuo, Ruofei Zhu, Wenyuan Xu, Jiaze Chen, Chengyi Wang, TianTian Fan, Zhengyin Du, Xiangpeng Wei, Gaohong Liu, Juncai Liu, Lingjun Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Ru Zhang, Xin Liu, Mingxuan Wang, Yonghui Wu, Lin Yan
We present VAPO, Value-based Augmented Proximal Policy Optimization framework for reasoning models., a novel framework tailored for reasoning models within the value-based paradigm. Benchmarked the AIME 2024 dataset, VAPO, built on the Qwen 32B pre-trained model, attains a state-of-the-art score of $\mathbf{60.4}$. In direct comparison under identical experimental settings, VAPO outperforms the previously reported results of DeepSeek-R1-Zero-Qwen-32B and DAPO by more than 10 points. The training process of VAPO stands out for its stability and efficiency. It reaches state-of-the-art performance within a mere 5,000 steps. Moreover, across multiple independent runs, no training crashes occur, underscoring its reliability. This research delves into long chain-of-thought (long-CoT) reasoning using a value-based reinforcement learning framework. We pinpoint three key challenges that plague value-based methods: value model bias, the presence of heterogeneous sequence lengths, and the sparsity of reward signals. Through systematic design, VAPO offers an integrated solution that effectively alleviates these challenges, enabling enhanced performance in long-CoT reasoning tasks.
我们提出了VAPO,即基于价值的增强近端策略优化框架(Value-based Augmented Proximal Policy Optimization framework),这是一个针对基于价值的范式中的推理模型的新型框架。使用AIME 2024数据集作为基准测试,VAPO建立在Qwen 32B预训练模型之上,达到了最先进的60.4分。在相同的实验设置下直接比较,VAPO比先前报道的DeepSeek-R1-Zero-Qwen-32B和DAPO的结果高出超过10分。VAPO的训练过程以稳定性和效率而突出。它仅在5000步内就达到了最先进的性能。此外,在多次独立运行中,没有发生训练崩溃,这证明了其可靠性。本研究深入探讨了基于价值的强化学习框架中的长链思维(long-CoT)推理。我们确定了困扰基于价值的方法的三个关键挑战:价值模型偏见、序列长度异质性的存在和奖励信号稀疏。通过系统设计,VAPO提供了一个综合解决方案,有效地缓解了这些挑战,从而在长链思维推理任务中实现了增强的性能。
论文及项目相关链接
Summary
VAPO,一种针对价值基准模型推理的新型框架,实现了AIME 2024数据集上的卓越表现。基于Qwen 32B预训练模型,VAPO获得前所未有的高分60.4。在相同实验环境下,VAPO相较于DeepSeek-R1-Zero-Qwen-32B和DAPO有超出10分的显著优势。其训练过程稳定高效,5000步内达成顶尖性能,且多次独立运行无崩溃,表现出可靠性。本研究深入探讨了价值基准强化学习框架下的长链思维推理,并指出了价值模型偏差、序列长度异质性和奖励信号稀疏性三大挑战。VAPO通过系统设计提供了综合解决方案,有效应对这些挑战,提升长链思维推理任务性能。
Key Takeaways
- VAPO是专门为价值基准模型推理设计的新型框架。
- 在AIME 2024数据集上,VAPO取得了突破性的成绩,达到60.4分。
- 在相同实验环境下,VAPO显著优于其他模型,如DeepSeek-R1-Zero-Qwen-32B和DAPO。
- VAPO训练过程稳定高效,能在短时间内达到顶尖性能。
- VAPO多次独立运行无崩溃,表现出高度可靠性。
- 研究指出了价值基准模型面临的三大挑战:价值模型偏差、序列长度异质性和奖励信号稀疏性。
点此查看论文截图
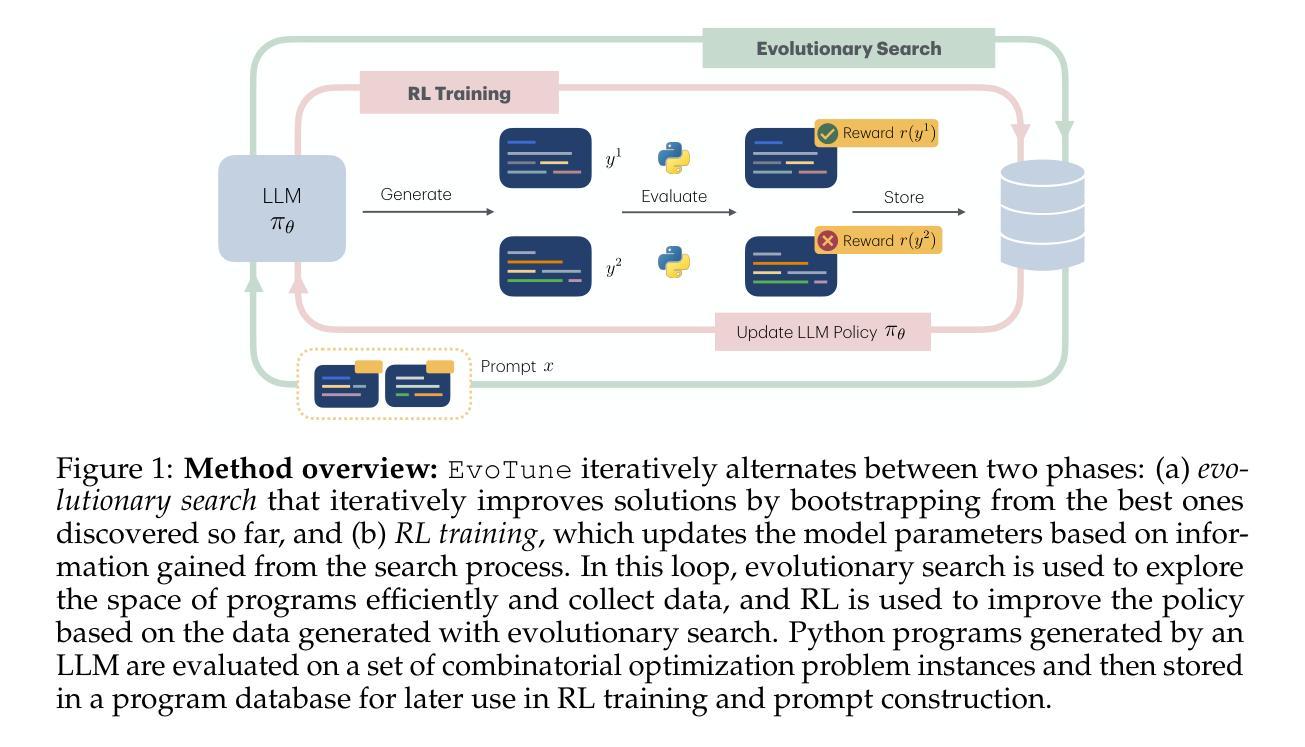
Algorithm Discovery With LLMs: Evolutionary Search Meets Reinforcement Learning
Authors:Anja Surina, Amin Mansouri, Lars Quaedvlieg, Amal Seddas, Maryna Viazovska, Emmanuel Abbe, Caglar Gulcehre
Discovering efficient algorithms for solving complex problems has been an outstanding challenge in mathematics and computer science, requiring substantial human expertise over the years. Recent advancements in evolutionary search with large language models (LLMs) have shown promise in accelerating the discovery of algorithms across various domains, particularly in mathematics and optimization. However, existing approaches treat the LLM as a static generator, missing the opportunity to update the model with the signal obtained from evolutionary exploration. In this work, we propose to augment LLM-based evolutionary search by continuously refining the search operator - the LLM - through reinforcement learning (RL) fine-tuning. Our method leverages evolutionary search as an exploration strategy to discover improved algorithms, while RL optimizes the LLM policy based on these discoveries. Our experiments on three combinatorial optimization tasks - bin packing, traveling salesman, and the flatpack problem - show that combining RL and evolutionary search improves discovery efficiency of improved algorithms, showcasing the potential of RL-enhanced evolutionary strategies to assist computer scientists and mathematicians for more efficient algorithm design.
发现解决复杂问题的有效算法一直是数学和计算机科学领域的一项重大挑战,需要多年的人类专业知识。最近使用大型语言模型(LLM)的进化搜索的进展表明,在各个领域加速算法发现方面存在希望,特别是在数学和优化方面。然而,现有方法将LLM视为静态生成器,错过了通过进化探索获得的信号更新模型的机会。在这项工作中,我们提议通过强化学习(RL)微调来不断精炼搜索运算符——LLM,以增强基于LLM的进化搜索。我们的方法利用进化搜索作为探索策略来发现改进后的算法,而强化学习则根据这些发现优化LLM策略。我们在三项组合优化任务——装箱问题、旅行推销员问题和平板包装问题上的实验表明,将强化学习与进化搜索相结合,提高了发现改进算法的效率,展示了强化学习增强型进化策略在帮助计算机科学家和数学家进行更有效率地算法设计方面的潜力。
论文及项目相关链接
PDF 30 pages
Summary:近期,进化搜索与大型语言模型(LLM)的融合展现出对加速算法发现的潜力,尤其在数学和优化领域。然而,现有方法将LLM视为静态生成器,忽略了通过进化探索获得的信号来更新模型的机会。本研究提出通过强化学习(RL)微调来持续完善搜索运算符LLM,从而增强LLM基础的进化搜索。实验表明,RL和进化搜索的结合提高了发现改进算法的效率,展示了RL增强进化策略在协助计算机科学家和数学家进行更高效算法设计方面的潜力。
Key Takeaways:
- 进化搜索与大型语言模型的融合为算法发现提供了新的潜力,特别是在数学和优化领域。
- 现有方法主要将大型语言模型视为静态生成器,未能充分利用进化探索的信号来更新模型。
- 强化学习(RL)可以用于微调大型语言模型,以持续提升搜索性能。
- 通过结合RL和进化搜索,发现改进算法的效率得到了提高。
- 实验在组合优化任务上验证了所提出方法的有效性,包括装箱问题、旅行推销员问题和flatpack问题。
- RL增强进化策略在协助计算机科学家和数学家进行更高效算法设计方面展现出潜力。
点此查看论文截图

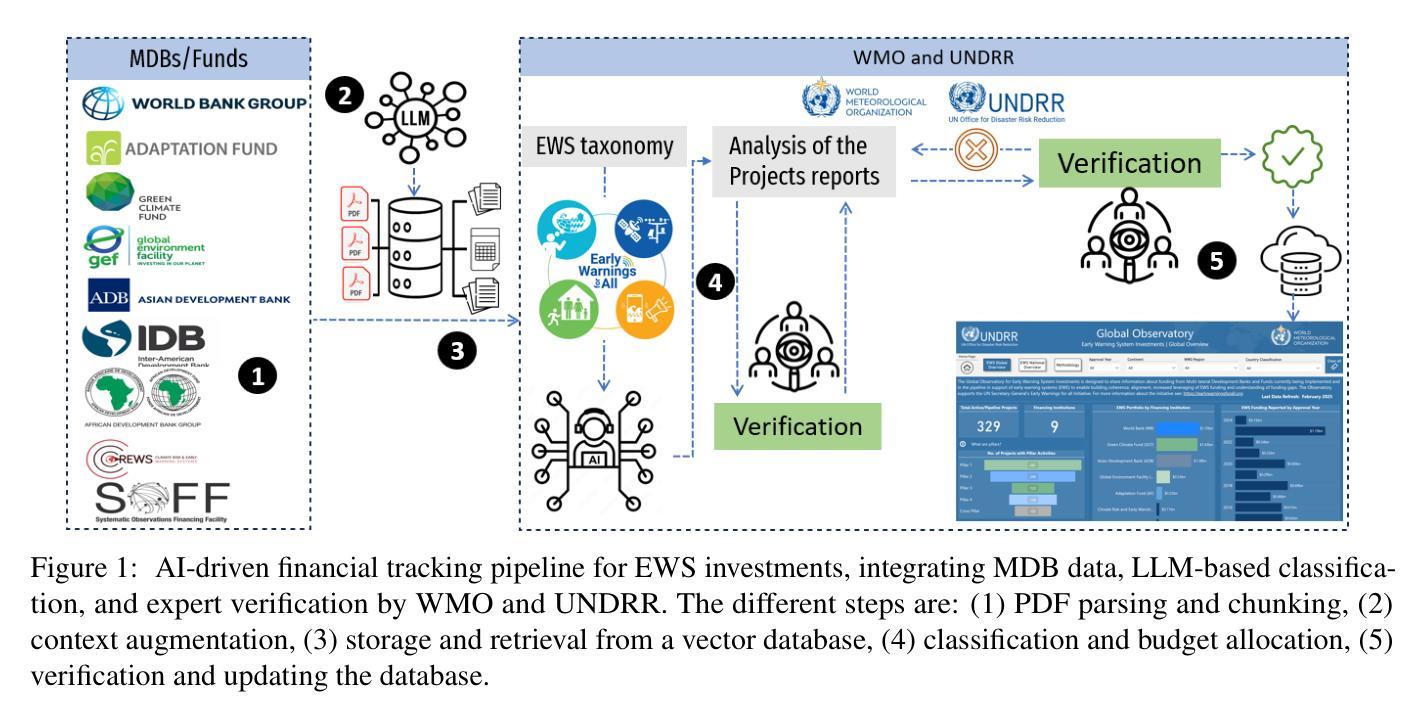
AI for Climate Finance: Agentic Retrieval and Multi-Step Reasoning for Early Warning System Investments
Authors:Saeid Ario Vaghefi, Aymane Hachcham, Veronica Grasso, Jiska Manicus, Nakiete Msemo, Chiara Colesanti Senni, Markus Leippold
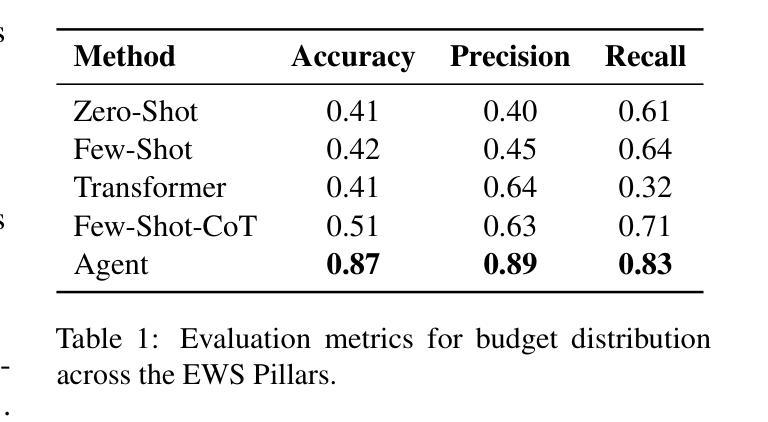
Tracking financial investments in climate adaptation is a complex and expertise-intensive task, particularly for Early Warning Systems (EWS), which lack standardized financial reporting across multilateral development banks (MDBs) and funds. To address this challenge, we introduce an LLM-based agentic AI system that integrates contextual retrieval, fine-tuning, and multi-step reasoning to extract relevant financial data, classify investments, and ensure compliance with funding guidelines. Our study focuses on a real-world application: tracking EWS investments in the Climate Risk and Early Warning Systems (CREWS) Fund. We analyze 25 MDB project documents and evaluate multiple AI-driven classification methods, including zero-shot and few-shot learning, fine-tuned transformer-based classifiers, chain-of-thought (CoT) prompting, and an agent-based retrieval-augmented generation (RAG) approach. Our results show that the agent-based RAG approach significantly outperforms other methods, achieving 87% accuracy, 89% precision, and 83% recall. Additionally, we contribute a benchmark dataset and expert-annotated corpus, providing a valuable resource for future research in AI-driven financial tracking and climate finance transparency.
追踪气候适应领域的金融投资是一项复杂且需要专业技能的任务,特别是对于缺乏多边发展银行和基金标准化财务报告的早期预警系统(EWS)而言。为了应对这一挑战,我们引入了一个基于大型语言模型的智能AI系统,该系统结合了上下文检索、微调以及多步骤推理,以提取相关财务数据、分类投资并确保符合资金指导方针。我们的研究关注现实应用:追踪气候风险与早期预警系统(CREWS)基金中的EWS投资。我们分析了25个多边发展银行的项目文件,并评估了多种AI驱动的分类方法,包括零样本和少样本学习、微调基于转换器的分类器、思维链提示以及基于代理的检索增强生成(RAG)方法。我们的结果表明,基于代理的RAG方法显著优于其他方法,达到了87%的准确率、89%的精确率和80%的召回率。此外,我们还提供了基准数据集和专家注释语料库,为AI驱动的金融追踪和气候金融透明度的未来研究提供了宝贵资源。
论文及项目相关链接
Summary
本文介绍了一个基于大型语言模型(LLM)的智能化AI系统,用于追踪气候适应投资。该系统融合了语境检索、微调技术和多步骤推理,能够提取相关财务数据、分类投资并确保符合资金指导方针。研究以气候风险和预警系统(CREWS)基金中的早期预警系统(EWS)投资追踪为例,分析了25个多边发展银行项目文件,并评估了多种AI分类方法。结果表明,基于代理的RAG方法表现最佳,准确率、精确度和召回率分别达到了87%、89%和83%。同时,文章还贡献了一个基准数据集和专家注释语料库,为未来AI驱动财务追踪和气候金融透明度研究提供了宝贵资源。
Key Takeaways
- LLM-based AI系统被用于追踪气候适应投资,该系统集成了语境检索、微调技术和多步骤推理。
- 系统能够提取相关财务数据、分类投资并确保与资金指导方针相符。
- 以气候风险和预警系统(CREWS)基金中的EWS投资追踪为例,进行了实证研究。
- 分析涉及25个多边发展银行项目文件,并评估了多种AI分类方法。
- 基于代理的RAG方法在追踪EWS投资方面表现最佳,准确率、精确度和召回率均超过其他方法。
- 文章贡献了一个基准数据集和专家注释语料库,为未来研究提供资源。
点此查看论文截图

A Unified Pairwise Framework for RLHF: Bridging Generative Reward Modeling and Policy Optimization
Authors:Wenyuan Xu, Xiaochen Zuo, Chao Xin, Yu Yue, Lin Yan, Yonghui Wu
Reinforcement Learning from Human Feedback (RLHF) has emerged as a important paradigm for aligning large language models (LLMs) with human preferences during post-training. This framework typically involves two stages: first, training a reward model on human preference data, followed by optimizing the language model using reinforcement learning algorithms. However, current RLHF approaches may constrained by two limitations. First, existing RLHF frameworks often rely on Bradley-Terry models to assign scalar rewards based on pairwise comparisons of individual responses. However, this approach imposes significant challenges on reward model (RM), as the inherent variability in prompt-response pairs across different contexts demands robust calibration capabilities from the RM. Second, reward models are typically initialized from generative foundation models, such as pre-trained or supervised fine-tuned models, despite the fact that reward models perform discriminative tasks, creating a mismatch. This paper introduces Pairwise-RL, a RLHF framework that addresses these challenges through a combination of generative reward modeling and a pairwise proximal policy optimization (PPO) algorithm. Pairwise-RL unifies reward model training and its application during reinforcement learning within a consistent pairwise paradigm, leveraging generative modeling techniques to enhance reward model performance and score calibration. Experimental evaluations demonstrate that Pairwise-RL outperforms traditional RLHF frameworks across both internal evaluation datasets and standard public benchmarks, underscoring its effectiveness in improving alignment and model behavior.
强化学习从人类反馈(RLHF)已经成为一种重要的范式,用于在训练后期将大型语言模型(LLM)与人类偏好对齐。该框架通常涉及两个阶段:首先,基于人类偏好数据训练奖励模型,然后使用强化学习算法优化语言模型。然而,当前的RLHF方法可能受到两个限制。首先,现有的RLHF框架通常依赖于Bradley-Terry模型,根据个别响应的配对比较分配标量奖励。然而,这种方法给奖励模型(RM)带来了重大挑战,因为不同上下文中的提示-响应对固有的变化要求RM具备强大的校准能力。其次,尽管奖励模型执行的是判别任务,但奖励模型通常是从生成基础模型(如预训练或监督微调模型)初始化的,这造成了不匹配。本文介绍了Pairwise-RL,这是一个RLHF框架,它通过结合生成奖励模型和成对近端策略优化(PPO)算法来解决这些挑战。Pairwise-RL在一致的对偶范式内统一了奖励模型的训练及其在强化学习中的应用,利用生成建模技术提高奖励模型的性能和分数校准。实验评估表明,Pairwise-RL在内部评估数据集和标准公共基准测试上的表现都优于传统RLHF框架,这突出了其在提高对齐和模型行为方面的有效性。
论文及项目相关链接
PDF 11oages,2 figures
Summary:
强化学习人类反馈(RLHF)已成为训练大型语言模型(LLM)与人类偏好对齐的重要范式。本文介绍了Pairwise-RL,一个解决现有RLHF框架挑战的新框架。它通过结合生成奖励模型和成对近端策略优化(PPO)算法,在一致的两两比较范式中统一奖励模型训练和强化学习应用。实验评估表明,Pairwise-RL在内部评估数据集和公共标准基准测试中均优于传统RLHF框架,提高了模型对齐和行为的效果。
Key Takeaways:
- RLHF已成为训练LLM与人类偏好对齐的重要方法,涉及两阶段:训练奖励模型和使用强化学习算法优化语言模型。
- 当前RLHF方法存在两个局限性:依赖Bradley-Terry模型进行基于两两比较的个人响应的标量奖励分配,以及奖励模型的初始化和应用存在不匹配问题。
- Pairwise-RL通过结合生成奖励模型和PPO算法解决这些挑战。
- Pairwise-RL在奖励模型训练和强化学习应用中采用一致的两两比较范式。
- 生成建模技术被用来提高奖励模型性能和分数校准。
- 实验评估表明,Pairwise-Rl在内部和公共基准测试中均表现出优于传统RLHF框架的性能。
点此查看论文截图

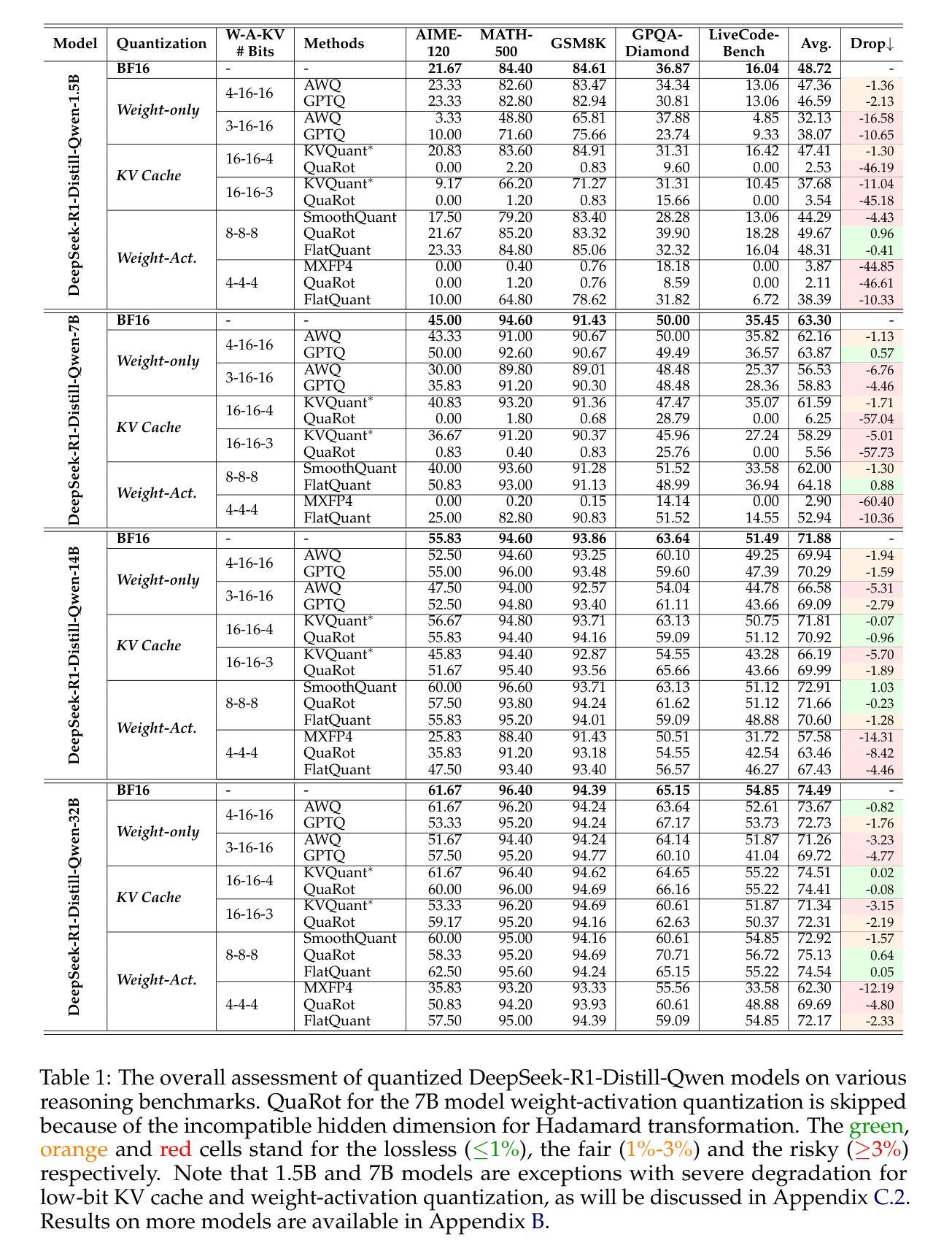
Quantization Hurts Reasoning? An Empirical Study on Quantized Reasoning Models
Authors:Ruikang Liu, Yuxuan Sun, Manyi Zhang, Haoli Bai, Xianzhi Yu, Tiezheng Yu, Chun Yuan, Lu Hou
Recent advancements in reasoning language models have demonstrated remarkable performance in complex tasks, but their extended chain-of-thought reasoning process increases inference overhead. While quantization has been widely adopted to reduce the inference cost of large language models, its impact on reasoning models remains understudied. In this study, we conduct the first systematic study on quantized reasoning models, evaluating the open-sourced DeepSeek-R1-Distilled Qwen and LLaMA families ranging from 1.5B to 70B parameters, and QwQ-32B. Our investigation covers weight, KV cache, and activation quantization using state-of-the-art algorithms at varying bit-widths, with extensive evaluation across mathematical (AIME, MATH-500), scientific (GPQA), and programming (LiveCodeBench) reasoning benchmarks. Our findings reveal that while lossless quantization can be achieved with W8A8 or W4A16 quantization, lower bit-widths introduce significant accuracy risks. We further identify model size, model origin, and task difficulty as critical determinants of performance. Contrary to expectations, quantized models do not exhibit increased output lengths. In addition, strategically scaling the model sizes or reasoning steps can effectively enhance the performance. All quantized models and codes will be open-sourced in https://github.com/ruikangliu/Quantized-Reasoning-Models.
近期推理语言模型的发展在复杂任务中表现出卓越的性能,但其扩展的链式推理过程增加了推理开销。虽然量化已广泛应用于降低大型语言模型的推理成本,但对推理模型的影响仍研究不足。本研究首次对量化推理模型进行系统研究,评估开源的DeepSeek-R1-Distilled Qwen和LLaMA系列,参数范围从1.5B到70B,以及QwQ-32B。我们的研究涵盖了使用最新算法的权重、KV缓存和激活量化,并在数学(AIME,MATH-500)、科学(GPQA)和编程(LiveCodeBench)推理基准测试进行了广泛评估。我们的研究发现,使用W8A8或W4A16量化可以实现无损量化,但较低位宽会引入显著准确性风险。我们进一步确定了模型大小、模型来源和任务难度是性能的关键决定因素。出乎意料的是,量化模型并没有表现出输出长度增加的情况。此外,有针对性地调整模型大小或推理步骤可以有效提高性能。所有量化模型和代码将在https://github.com/ruikangliu/Quantized-Reasoning-Models上开源。
论文及项目相关链接
Summary
最近的语言模型推理技术取得了显著进展,在复杂任务中表现出色,但其扩展的推理过程增加了推理开销。本研究首次对量化推理模型进行系统研究,评估了DeepSeek-R1-Distilled Qwen和LLaMA系列以及QwQ-32B等开源量化推理模型,涉及权重、KV缓存和激活量化的研究。研究发现,在特定量化方法下可以实现无损量化,但低比特宽度会引入精度风险。模型大小、来源和任务难度对性能有重要影响。量化模型的输出长度并未增加,且通过战略性地调整模型大小或推理步骤可以有效提高性能。所有量化模型和代码将开源在ruikangliu的Quantized-Reasoning-Models仓库中。
Key Takeaways
- 量化推理模型的系统研究是必要的,因为虽然量化广泛应用于减少大型语言模型的推理成本,但对推理模型的影响尚未得到充分研究。
- 研究涵盖了多种开源量化推理模型,包括DeepSeek-R1-Distilled Qwen和LLaMA系列等。
- 研究涉及权重、KV缓存和激活量化的评估,发现特定量化方法可以实现无损量化。
- 低比特宽度量化可能导致精度风险。
- 模型大小、来源和任务难度对量化推理模型的性能有重要影响。
- 量化模型的输出长度并未因量化而增加。
点此查看论文截图

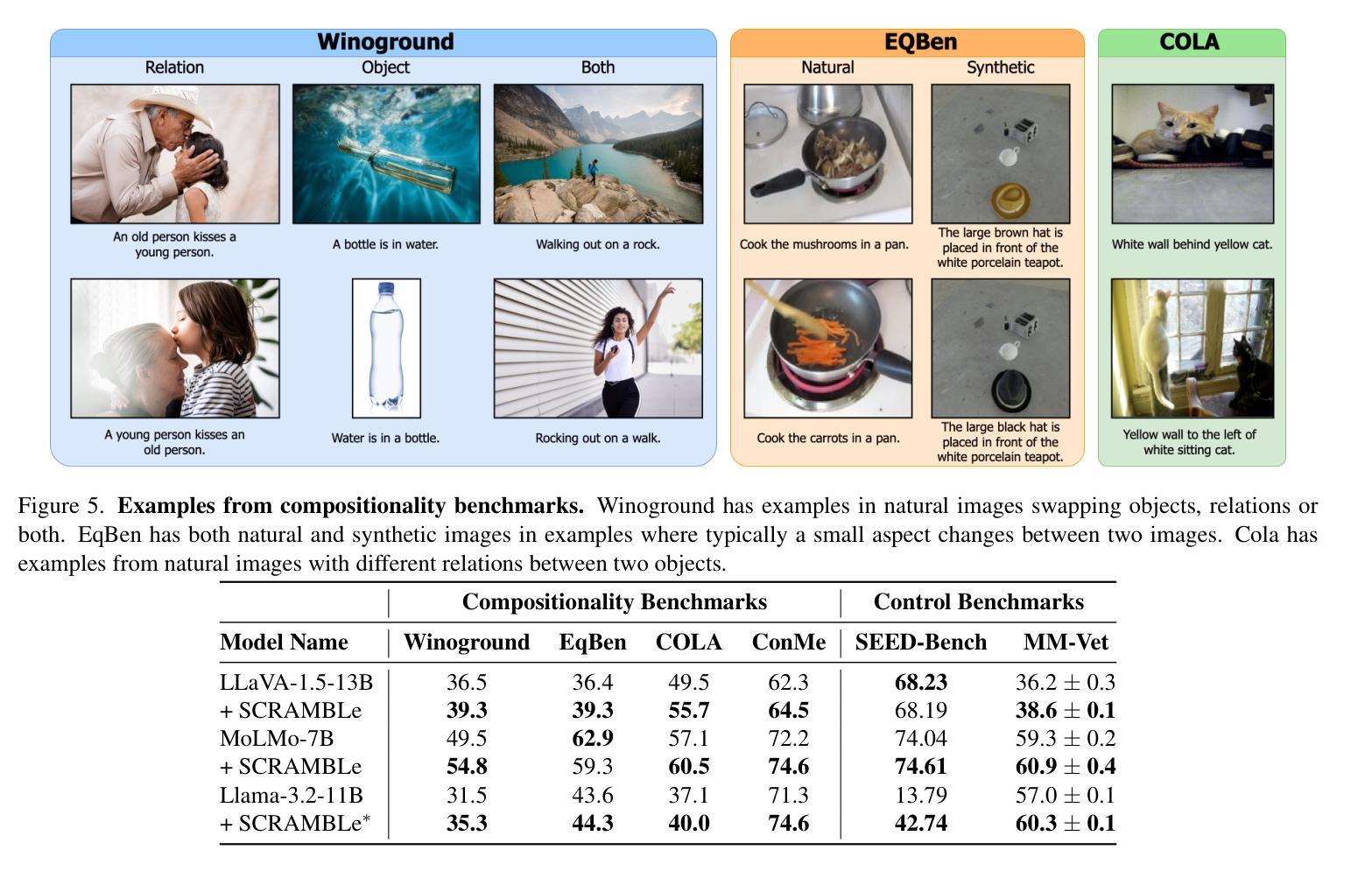
Enhancing Compositional Reasoning in Vision-Language Models with Synthetic Preference Data
Authors:Samarth Mishra, Kate Saenko, Venkatesh Saligrama
Compositionality, or correctly recognizing scenes as compositions of atomic visual concepts, remains difficult for multimodal large language models (MLLMs). Even state of the art MLLMs such as GPT-4o can make mistakes in distinguishing compositions like “dog chasing cat” vs “cat chasing dog”. While on Winoground, a benchmark for measuring such reasoning, MLLMs have made significant progress, they are still far from a human’s performance. We show that compositional reasoning in these models can be improved by elucidating such concepts via data, where a model is trained to prefer the correct caption for an image over a close but incorrect one. We introduce SCRAMBLe: Synthetic Compositional Reasoning Augmentation of MLLMs with Binary preference Learning, an approach for preference tuning open-weight MLLMs on synthetic preference data generated in a fully automated manner from existing image-caption data. SCRAMBLe holistically improves these MLLMs’ compositional reasoning capabilities which we can see through significant improvements across multiple vision language compositionality benchmarks, as well as smaller but significant improvements on general question answering tasks. As a sneak peek, SCRAMBLe tuned Molmo-7B model improves on Winoground from 49.5% to 54.8% (best reported to date), while improving by ~1% on more general visual question answering tasks. Code for SCRAMBLe along with tuned models and our synthetic training dataset is available at https://github.com/samarth4149/SCRAMBLe.
多模态大型语言模型(MLLMs)在识别场景作为原子视觉概念组合方面仍然面临困难,即组合性(Compositionality)。即使是目前最先进的MLLMs,如GPT-4o,在区分“狗追猫”和“猫追狗”等组合时也会出错。虽然在衡量此类推理能力的Winoground基准测试中,MLLMs已经取得了显著进展,但它们与人类的表现相比仍有很大差距。我们展示可以通过数据阐明这些概念来改善这些模型中的组合推理能力,模型经过训练,更倾向于为图像选择正确的标题,而非接近但错误的标题。我们推出了SCRAMBLe:基于二进制偏好学习的多模态大型语言模型合成推理增强方法。这是一种偏好调整方法,用于在完全自动化的方式下从现有的图像标题数据中生成合成偏好数据,对开放权重MLLMs进行偏好调整。SCRAMBLe全面提高了这些MLLMs的组合推理能力,这可以从多个视觉语言组合基准测试中显著的改进中看出,以及在一般问答任务中的小幅但显著的改进。作为预览,SCRAMBLe调整了Molmo-7B模型,使其在Winoground上的表现从49.5%提高到54.8%(至今最佳报告结果),同时在更一般的视觉问答任务上提高了约1%。SCRAMBLe的代码以及调整后的模型和我们的合成训练数据集可在https://github.com/samarth4149/SCRAMBLe获得。
论文及项目相关链接
Summary
文本讨论了多模态大型语言模型(MLLMs)在识别场景组合方面存在的困难,即使是最先进的模型如GPT-4o也难以区分类似的场景组合。为解决这一问题,本文提出了一种名为SCRAMBLe的方法,通过偏好学习训练模型以在合成偏好数据上选择正确的图像描述。SCRAMBLe方法全面提高了MLLMs的组合推理能力,并在多个视觉语言组合基准测试中取得了显著改进。此外,SCRAMBLe对Molmo-7B模型的调整在Winoground上的表现从49.5%提高到了54.8%,同时在更一般的视觉问答任务上也提高了约1%。相关代码和训练模型可在相关网站上找到。
Key Takeaways
- 多模态大型语言模型(MLLMs)在识别场景组合方面存在困难,难以区分类似的场景组合。
- SCRAMBLe方法通过偏好学习训练模型,以提高其在合成偏好数据上选择正确图像描述的能力。
- SCRAMBLe方法显著提高了MLLMs的组合推理能力,并在多个视觉语言组合基准测试中取得了良好表现。
- SCRAMBLe对Molmo-7B模型的调整在Winoground上的表现有所提升,同时也提高了视觉问答任务的性能。
- 合成数据在训练模型和提高模型性能上起到了关键作用。
- SCRAMBLe方法适用于开源大型语言模型的偏好调整。
点此查看论文截图



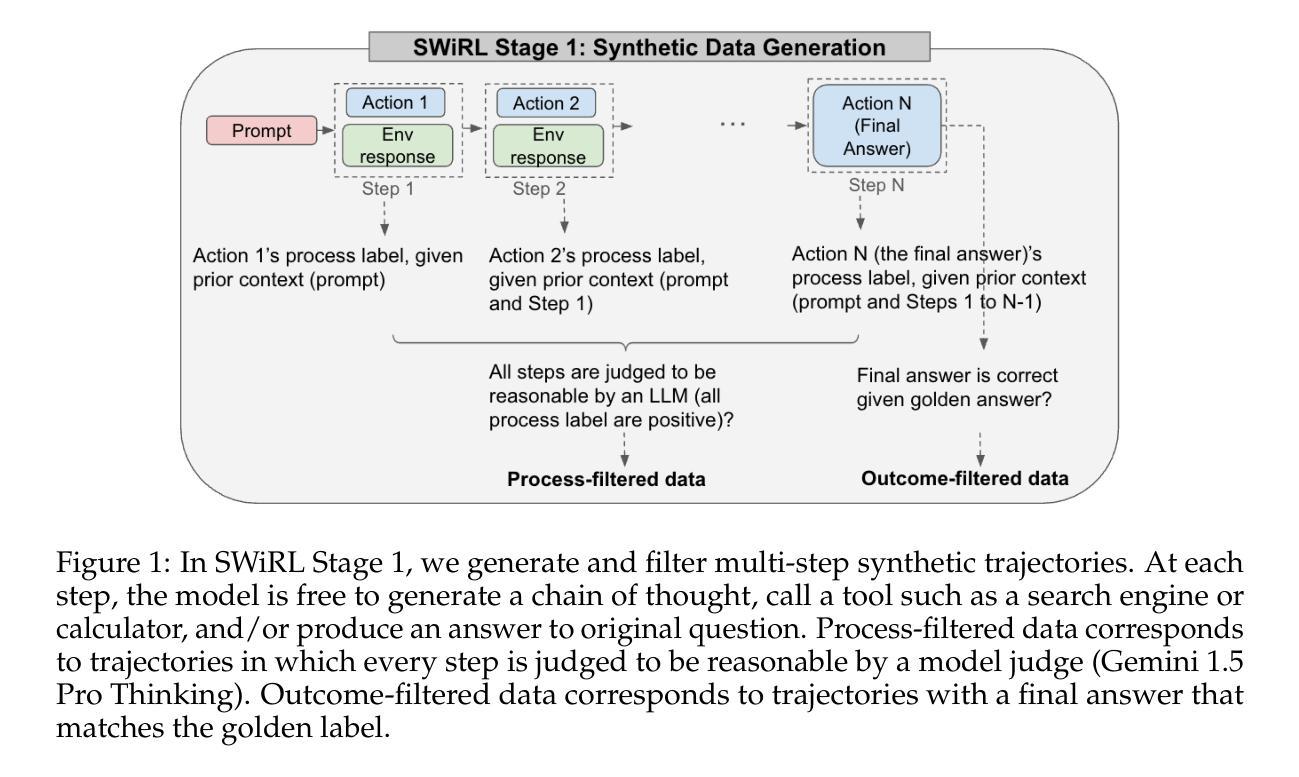
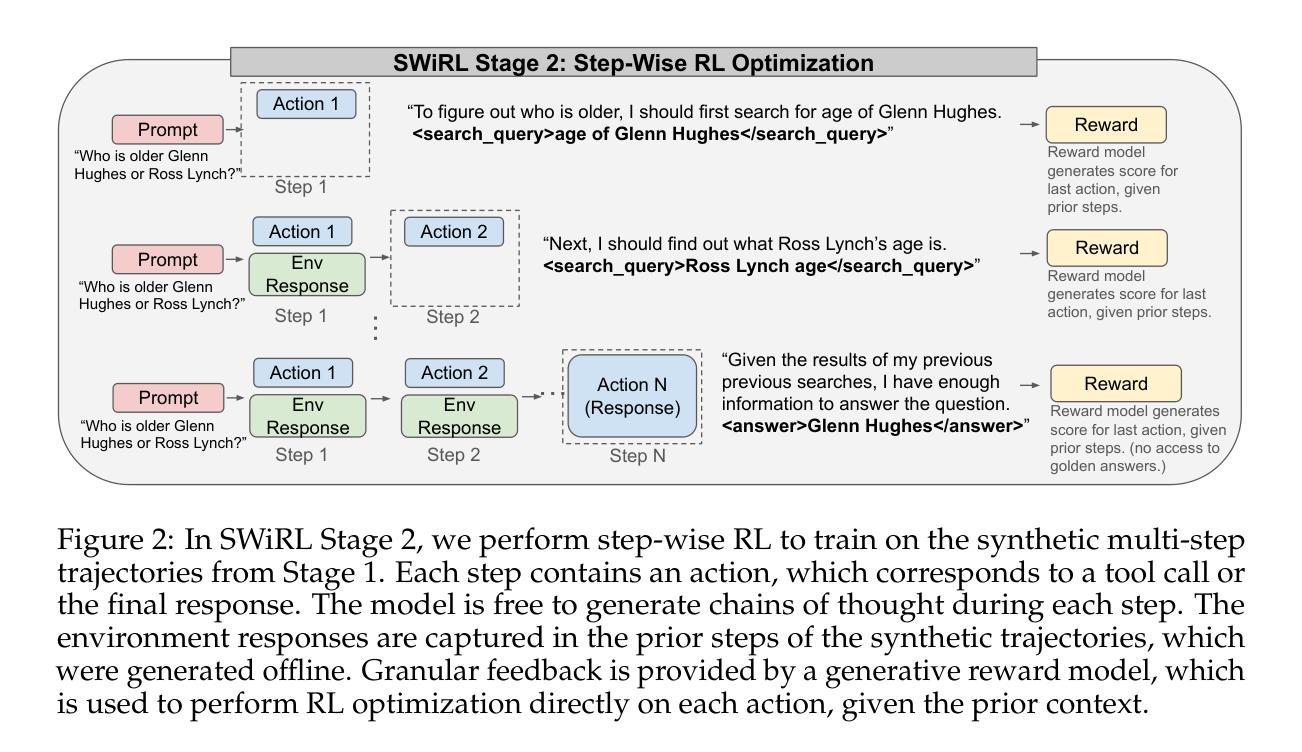
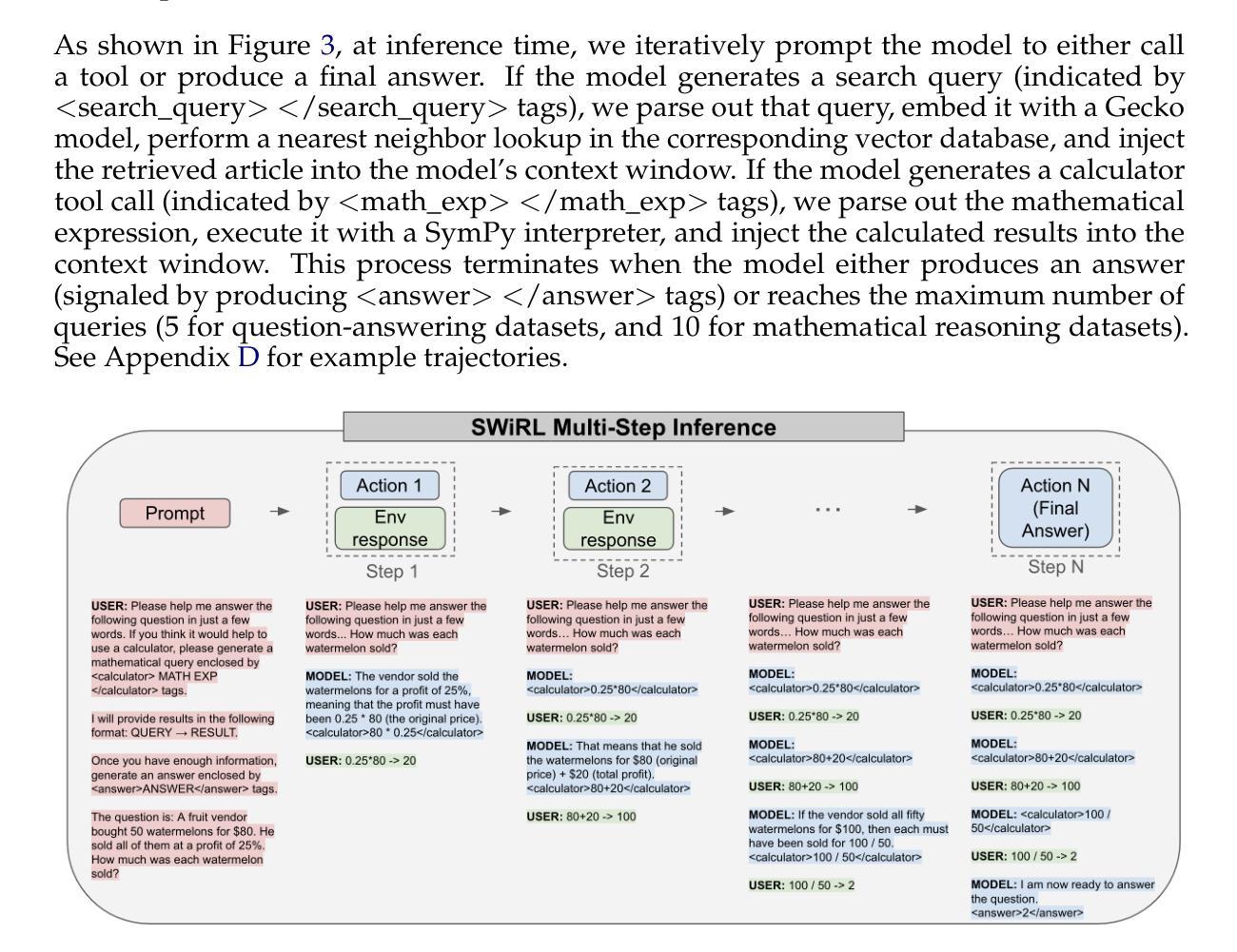
Synthetic Data Generation & Multi-Step RL for Reasoning & Tool Use
Authors:Anna Goldie, Azalia Mirhoseini, Hao Zhou, Irene Cai, Christopher D. Manning
Reinforcement learning has been shown to improve the performance of large language models. However, traditional approaches like RLHF or RLAIF treat the problem as single-step. As focus shifts toward more complex reasoning and agentic tasks, language models must take multiple steps of text generation, reasoning and environment interaction before generating a solution. We propose a synthetic data generation and RL methodology targeting multi-step optimization scenarios. This approach, called Step-Wise Reinforcement Learning (SWiRL), iteratively generates multi-step reasoning and tool use data, and then learns from that data. It employs a simple step-wise decomposition that breaks each multi-step trajectory into multiple sub-trajectories corresponding to each action by the original model. It then applies synthetic data filtering and RL optimization on these sub-trajectories. We evaluated SWiRL on a number of multi-step tool use, question answering, and mathematical reasoning tasks. Our experiments show that SWiRL outperforms baseline approaches by 21.5%, 12.3%, 14.8%, 11.1%, and 15.3% in relative accuracy on GSM8K, HotPotQA, CofCA, MuSiQue, and BeerQA, respectively. Excitingly, the approach exhibits generalization across tasks: for example, training only on HotPotQA (text question-answering) improves zero-shot performance on GSM8K (a math dataset) by a relative 16.9%.
强化学习已被证明可以提高大型语言模型的性能。然而,像RLHF或RLAIF这样的传统方法将问题视为单步骤的。随着焦点转向更复杂的推理和代理任务,语言模型必须在生成解决方案之前进行多步骤的文本生成、推理和环境交互。我们提出了一种针对多步骤优化场景的人工数据生成和强化学习方法。这种方法被称为Step-Wise Reinforcement Learning(SWiRL),它迭代地生成多步骤推理和工具使用数据,然后从中学习。它采用简单的逐步分解方法,将每个多步骤轨迹分解为与原始模型的每个动作相对应的多个子轨迹。然后,它对这些子轨迹进行人工数据过滤和强化学习优化。我们在多个多步骤工具使用、问答和数学推理任务上评估了SWiRL。实验表明,在GSM8K、HotPotQA、CofCA、MuSiQue和BeerQA上,SWiRL的相对准确率分别比基线方法高出21.5%、12.3%、14.8%、11.1%和15.3%。令人兴奋的是,该方法在任务之间表现出泛化能力:例如,仅在HotPotQA(文本问答)上进行训练,对GSM8K(数学数据集)的零样本性能相对提高了1 结点计算效率是指完成某项任务或操作所需的时间越少。这在多任务处理或在短时间内完成任务的情况下特别重要。在上述场景中,通过使用SWiRL等方法提高模型的效率和准确性,可以进一步推动自然语言处理领域的发展和应用。这不仅有助于提高语言模型的性能,还有助于开发更智能、更高效的智能系统,从而更好地服务于人类社会。我们的研究只是冰山一角,我们相信未来会有更多的创新方法和技术不断涌现,推动人工智能领域的进步和发展。%。
论文及项目相关链接
Summary
强化学习已证明可提升大型语言模型的性能。然而,传统方法如RLHF或RLAIF将问题视为单步骤的。随着焦点转向更复杂的推理和代理任务,语言模型必须在生成解决方案之前进行多步骤的文本生成、推理和环境交互。本文提出了一种针对多步骤优化场景合成数据生成和强化学习方法——Step-Wise Reinforcement Learning(SWiRL)。SWiRL通过迭代生成多步骤推理和工具使用数据,并学习这些数据。它采用简单的逐步分解方法,将每个多步骤轨迹分解为多个对应于原始模型每个操作的子轨迹,然后对这些子轨迹进行合成数据过滤和强化学习优化。在多项多步骤工具使用、问答和数学推理任务上评估SWiRL,相对于基线方法,其在GSM8K、HotPotQA、CofCA、MuSiQue和BeerQA上的相对准确性分别提高了21.5%、12.3%、14.8%、11.1%和15.3%。此外,该方法展现出跨任务的泛化能力,例如在HotPotQA(文本问答)上训练后,在GSM8K(数学数据集)上的零样本性能相对提高了16.9%。
Key Takeaways
- 强化学习能提高大型语言模型的性能。
- 传统方法主要处理单步骤问题,但复杂任务需多步骤解决。
- 提出的Step-Wise Reinforcement Learning (SWiRL) 方法能处理多步骤优化场景。
- SWiRL通过生成多步骤推理和工具使用数据,并学习这些数据来优化模型。
- SWiRL采用逐步分解法处理多步骤轨迹,提高模型学习效果。
- SWiRL在多项任务上的性能优于基线方法,显示出明显的性能提升。
点此查看论文截图

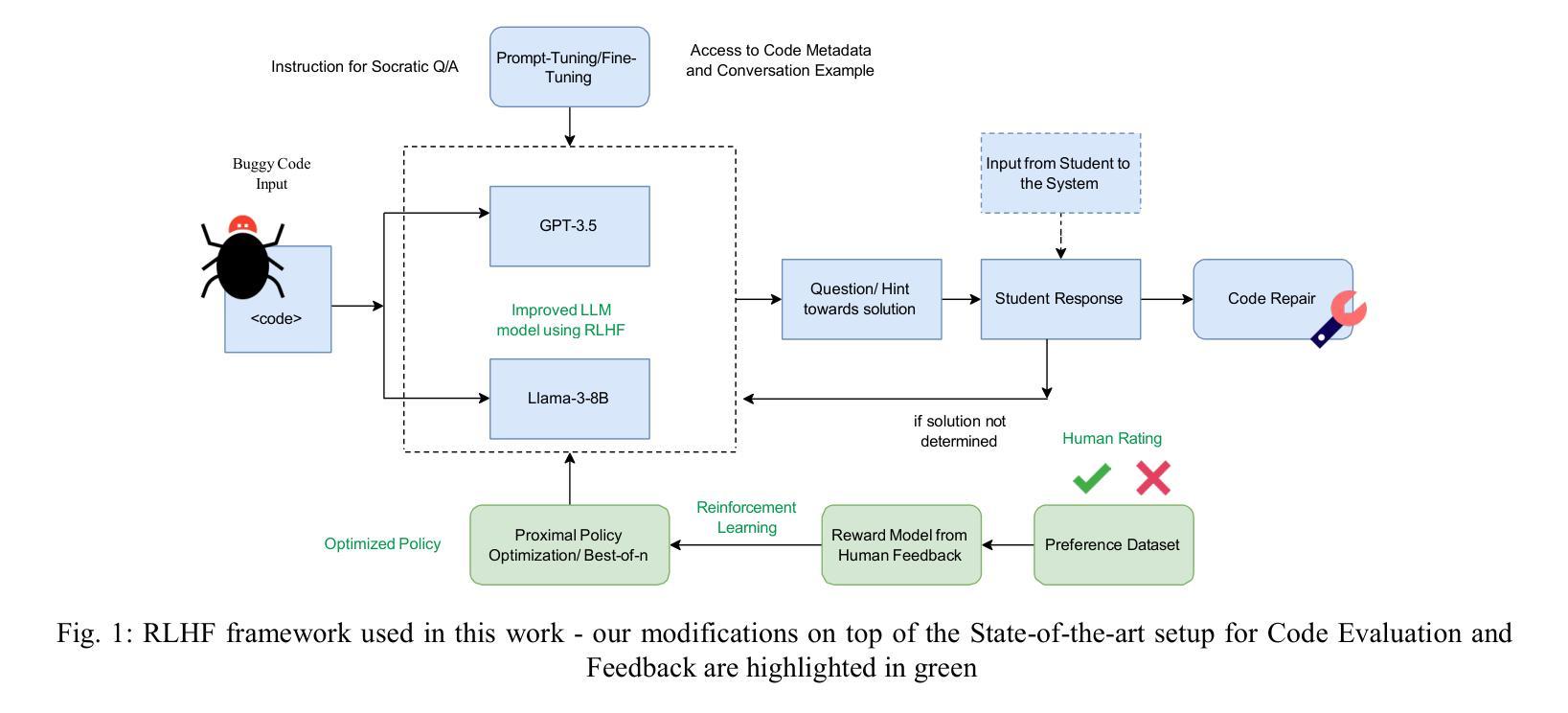
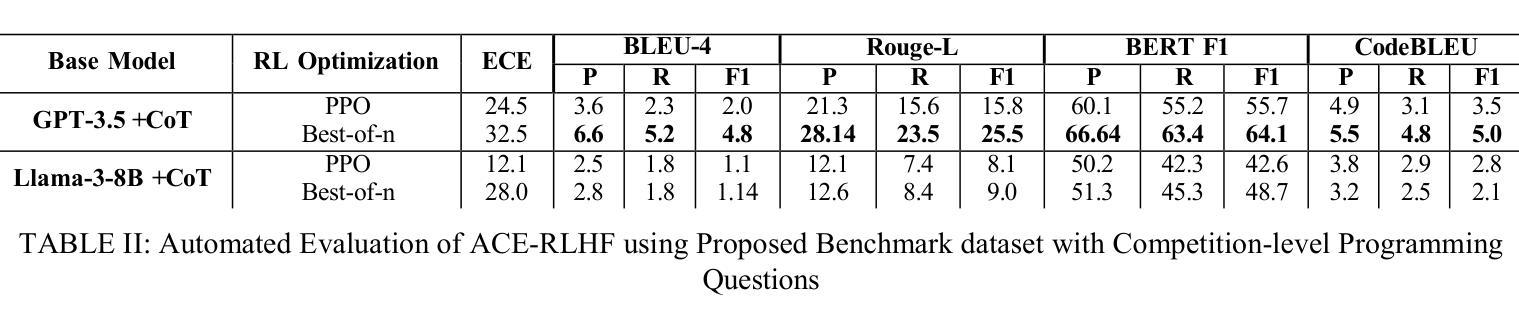
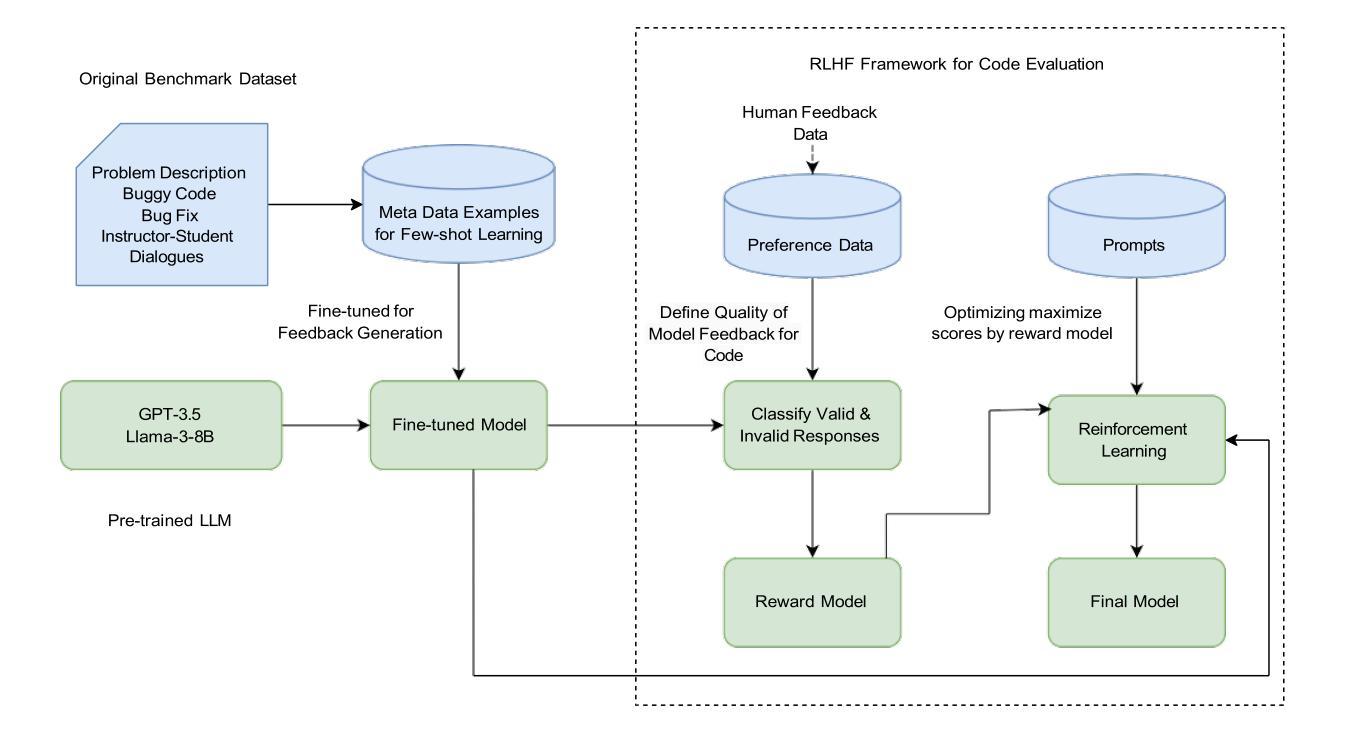
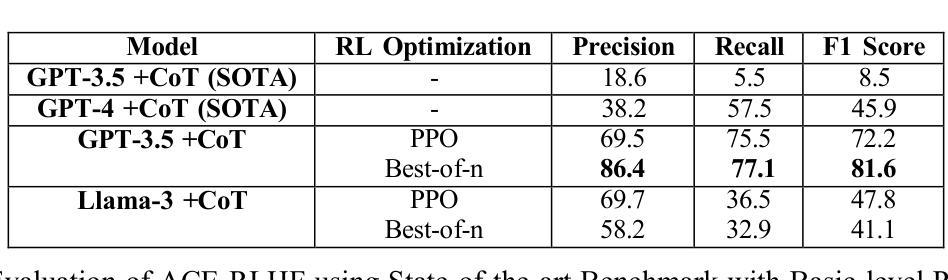
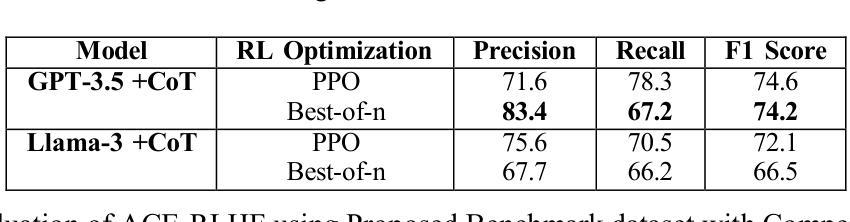
ACE-RLHF: Automated Code Evaluation and Socratic Feedback Generation Tool using Large Language Models and Reinforcement Learning with Human Feedback
Authors:Tasnia Rahman, Sathish A. P. Kumar, Sumit Jha, Arvind Ramanathan
Automated Program Repair tools are developed for generating feedback and suggesting a repair method for erroneous code. State of the art (SOTA) code repair methods rely on data-driven approaches and often fail to deliver solution for complicated programming questions. To interpret the natural language of unprecedented programming problems, using Large Language Models (LLMs) for code-feedback generation is crucial. LLMs generate more comprehensible feedback than compiler-generated error messages, and Reinforcement Learning with Human Feedback (RLHF) further enhances quality by integrating human-in-the-loop which helps novice students to lean programming from scratch interactively. We are applying RLHF fine-tuning technique for an expected Socratic response such as a question with hint to solve the programming issue. We are proposing code feedback generation tool by fine-tuning LLM with RLHF, Automated Code Evaluation with RLHF (ACE-RLHF), combining two open-source LLM models with two different SOTA optimization techniques. The quality of feedback is evaluated on two benchmark datasets containing basic and competition-level programming questions where the later is proposed by us. We achieved 2-5% higher accuracy than RL-free SOTA techniques using Llama-3-7B-Proximal-policy optimization in automated evaluation and similar or slightly higher accuracy compared to reward model-free RL with AI Feedback (RLAIF). We achieved almost 40% higher accuracy with GPT-3.5 Best-of-n optimization while performing manual evaluation.
自动化程序修复工具旨在针对错误代码提供反馈并建议修复方法。最先进的代码修复方法依赖于数据驱动的方法,并且通常难以解决复杂的编程问题。为了解释前所未有的编程问题的自然语言,使用大型语言模型(LLM)来生成代码反馈至关重要。LLM生成的反馈比编译器生成的错误消息更易于理解,而借助人类反馈的强化学习(RLHF)通过融入人类参与循环进一步提高了反馈质量,有助于初学者从零开始交互式地学习编程。我们正在应用RLHF微调技术,以期望获得苏格拉底式的回应,如带有提示的问题以解决编程问题。我们提出通过RLHF微调LLM的代码反馈生成工具,即结合两种开源LLM模型和两种不同最先进优化技术的自动化代码评估与RLHF(ACE-RLHF)。反馈的质量是在包含基本编程问题和竞赛级别编程问题的两个基准数据集上进行评价的,其中后者是由我们提出的。在自动评估中使用Llama-3-7B-近端策略优化,我们实现了比无RL的最先进技术高2-5%的准确率,与无奖励模型的AI反馈的强化学习(RLAIF)相比,准确率相似或略高。在进行手动评估时,使用GPT-3.5的最佳n优化方案,我们实现了近40%的高准确率。
论文及项目相关链接
PDF 9 pages, 3 figures
Summary
本文介绍了自动化程序修复工具的发展情况,指出当前最先进的代码修复方法主要依赖于数据驱动的方法,对于复杂的编程问题往往无法提供有效的解决方案。为了解决这个问题,引入了大语言模型(LLM)用于代码反馈生成的方法。文章进一步阐述了强化学习与人类反馈(RLHF)技术对于提高代码反馈质量的重要性,并通过精细调整LLM与RLHF技术的结合,提出了一种新的代码反馈生成工具——ACE-RLHF。实验结果表明,该方法在基准数据集上的表现优于无强化学习的技术,并实现了较高的准确性。
Key Takeaways
- 自动化程序修复工具需要能够生成反馈并建议修复错误代码的方法。
- 当前最先进的代码修复方法主要依赖于数据驱动的方法,但对于复杂的编程问题常常失效。
- 大语言模型(LLM)被用于生成更易于理解的代码反馈,相较于编译器生成的错误消息更具优势。
- 强化学习与人类反馈(RLHF)技术能提高代码反馈的质量,帮助新手程序员互动学习编程。
- ACE-RLHF是结合了LLM和RLHF技术的代码反馈生成工具,通过精细调整实现预期的社会性问答反应,如提供问题和提示以解决编程问题。
- 实验结果表明,ACE-RLHF在基准数据集上的表现优于无强化学习的技术。
点此查看论文截图



Splits! A Flexible Dataset for Evaluating a Model’s Demographic Social Inference
Authors:Eylon Caplan, Tania Chakraborty, Dan Goldwasser
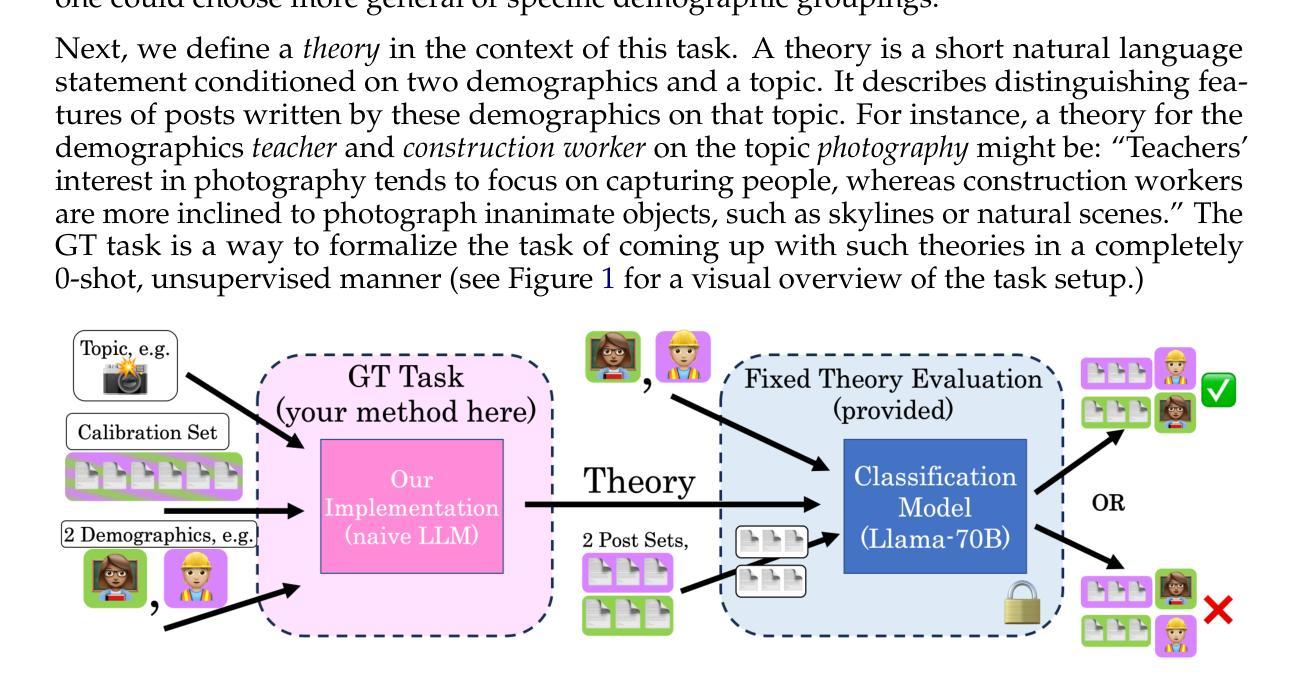
Understanding how people of various demographics think, feel, and express themselves (collectively called group expression) is essential for social science and underlies the assessment of bias in Large Language Models (LLMs). While LLMs can effectively summarize group expression when provided with empirical examples, coming up with generalizable theories of how a group’s expression manifests in real-world text is challenging. In this paper, we define a new task called Group Theorization, in which a system must write theories that differentiate expression across demographic groups. We make available a large dataset on this task, Splits!, constructed by splitting Reddit posts by neutral topics (e.g. sports, cooking, and movies) and by demographics (e.g. occupation, religion, and race). Finally, we suggest a simple evaluation framework for assessing how effectively a method can generate ‘better’ theories about group expression, backed by human validation. We publicly release the raw corpora and evaluation scripts for Splits! to help researchers assess how methods infer–and potentially misrepresent–group differences in expression. We make Splits! and our evaluation module available at https://github.com/eyloncaplan/splits.
理解不同人口统计群体如何思考、感受和表达自身(统称为群体表达)对社会科学至关重要,也是评估大型语言模型(LLM)偏见的基础。虽然LLM在提供实证例子时可以有效地总结群体表达,但要想提出一种可推广的理论,阐述群体表达如何在现实文本中呈现,仍具有挑战性。在本文中,我们定义了一个新任务,称为“群体理论化”,系统必须在该任务中撰写区分不同人口统计群体表达的理论。我们为此任务构建了一个大型数据集“Splits!”,通过Reddit帖子按中性主题(如体育、烹饪和电影)和人口统计(如职业、宗教和种族)进行划分。最后,我们为评估方法生成关于群体表达“更好”理论的有效性提供了一个简单的评估框架,该框架以人工验证为支持。我们公开发布原始语料库和评估脚本来帮助研究人员评估方法如何推断——以及可能误代表——群体在表达上的差异。我们在https://github.com/eyloncaplan/splits处提供Splits!和我们的评估模块。
论文及项目相关链接
PDF Under review for COLM 2025
Summary
本文定义了一项新任务——群体理论化,旨在让系统能够撰写区分不同群体表达的理论。为完成此任务,构建了名为Splits!的大型数据集,通过Reddit上的中性话题和人口统计信息来分类帖子。同时,提出了一种简单的评估框架,以评估方法生成关于群体表达“更好”理论的有效性,并通过人工验证进行支持。公开发布了原始数据集和评估脚本,以帮助研究人员评估方法如何推断——以及可能误代表——群体在表达上的差异。
Key Takeaways
- 论文强调了理解不同群体的思考、感受和表达方式对社会科学的重要性,对于评估大型语言模型的偏见也至关重要。
- 提出了一个新任务——群体理论化,要求系统能够撰写区分不同群体表达的理论。
- 构建了一个名为Splits!的大型数据集,通过Reddit帖子按中性话题和人口统计信息进行分类。
- 提供了一个简单的评估框架来评估方法生成关于群体表达理论的有效性。
- 该框架通过人工验证进行支持,以确保评估的准确性。
- 论文公开提供了原始数据集和评估脚本,便于研究人员使用。
点此查看论文截图


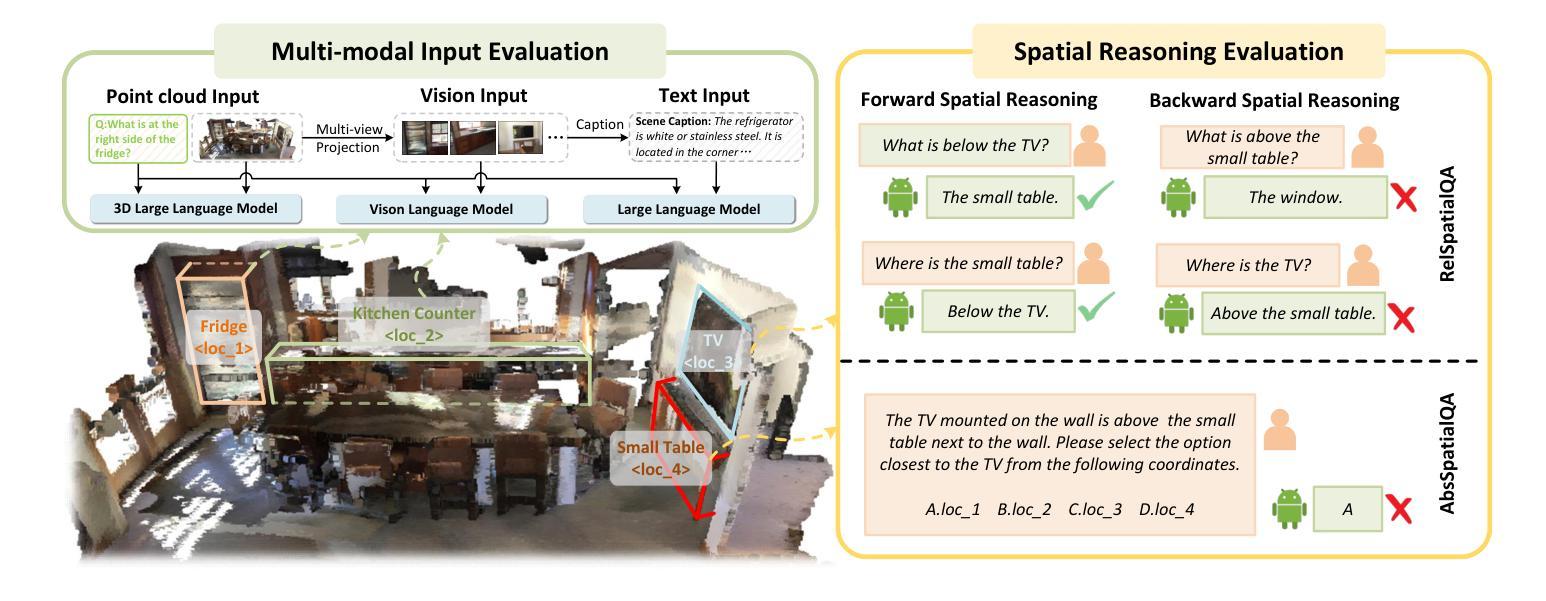
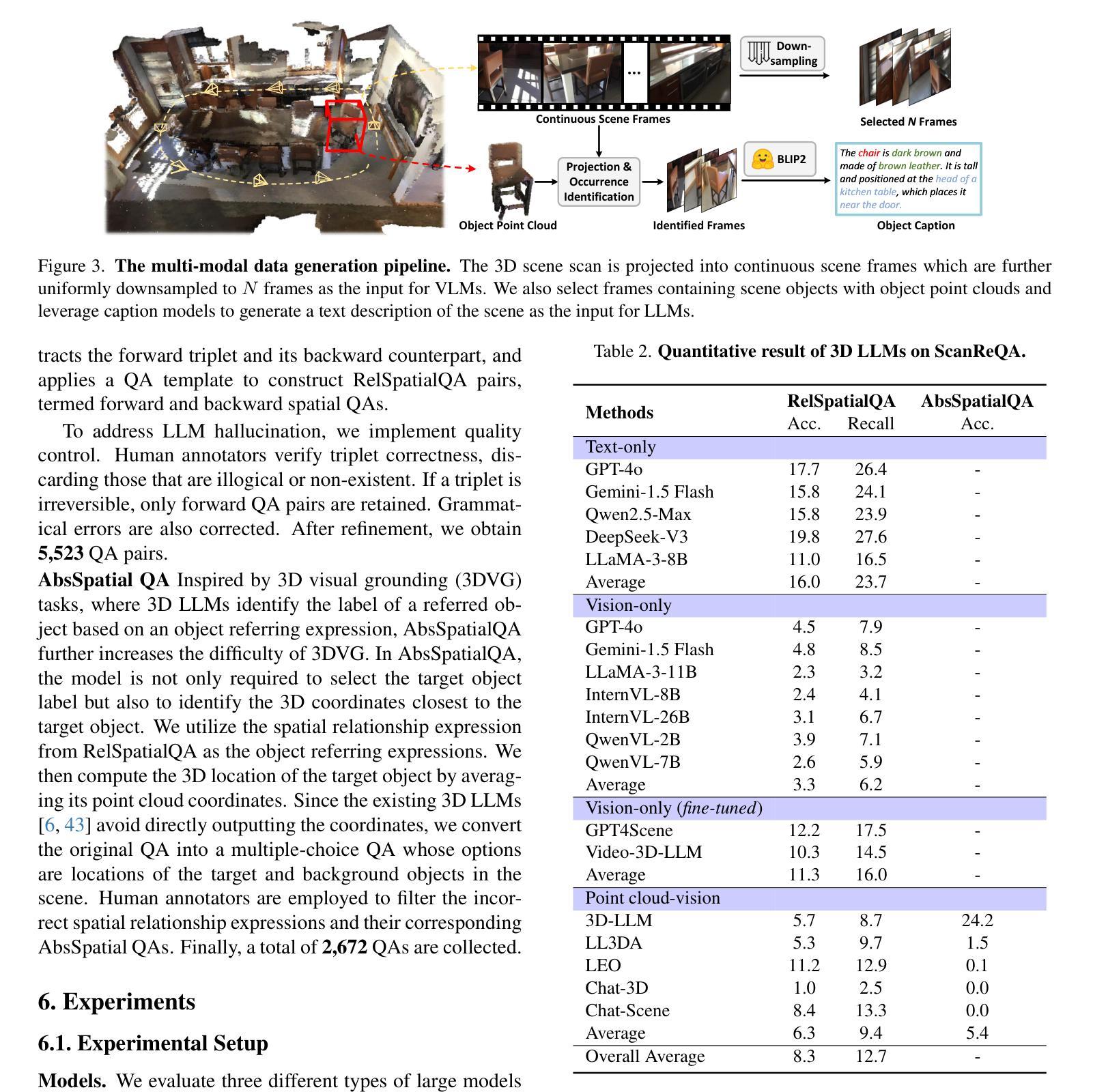
The Point, the Vision and the Text: Does Point Cloud Boost Spatial Reasoning of Large Language Models?
Authors:Weichen Zhang, Ruiying Peng, Chen Gao, Jianjie Fang, Xin Zeng, Kaiyuan Li, Ziyou Wang, Jinqiang Cui, Xin Wang, Xinlei Chen, Yong Li
3D Large Language Models (LLMs) leveraging spatial information in point clouds for 3D spatial reasoning attract great attention. Despite some promising results, the role of point clouds in 3D spatial reasoning remains under-explored. In this work, we comprehensively evaluate and analyze these models to answer the research question: \textit{Does point cloud truly boost the spatial reasoning capacities of 3D LLMs?} We first evaluate the spatial reasoning capacity of LLMs with different input modalities by replacing the point cloud with the visual and text counterparts. We then propose a novel 3D QA (Question-answering) benchmark, ScanReQA, that comprehensively evaluates models’ understanding of binary spatial relationships. Our findings reveal several critical insights: 1) LLMs without point input could even achieve competitive performance even in a zero-shot manner; 2) existing 3D LLMs struggle to comprehend the binary spatial relationships; 3) 3D LLMs exhibit limitations in exploiting the structural coordinates in point clouds for fine-grained spatial reasoning. We think these conclusions can help the next step of 3D LLMs and also offer insights for foundation models in other modalities. We release datasets and reproducible codes in the anonymous project page: https://3d-llm.xyz.
在点云的三维空间推理中,利用三维大型语言模型(LLM)的空间信息已经引起了广泛关注。尽管已经取得了一些令人鼓舞的结果,但点云在三维空间推理中的作用仍然有待探索。在这项工作中,我们对这些模型进行了全面的评估和分析,以回答研究问题:点云是否真的提升了三维LLM的空间推理能力?我们首先通过用视觉和文本代替点云来评估不同输入模式的三维LLM的空间推理能力。然后,我们提出了一个新的三维问答(QA)基准测试ScanReQA,它全面评估了模型对二元空间关系的理解。我们的研究发现了一些关键见解:1)即使没有点输入的LLM甚至可以在零样本方式下实现具有竞争力的性能;2)现有的三维LLM在理解二元空间关系方面存在困难;3)三维LLM在利用点云的结构坐标进行精细空间推理方面存在局限性。我们认为这些结论可以帮助三维LLM的下一步发展,并为其他模态的基础模型提供见解。我们在匿名项目页面发布了数据集和可复制的代码:https://3d-llm.xyz。
论文及项目相关链接
Summary
点云在3D空间推理中的重要作用吸引了很多关注,但对于其在3D大型语言模型(LLM)中的角色仍存在争议。本研究通过评估和分析LLM在不同输入模式下的空间推理能力,以及提出新的3D问答基准测试ScanReQA,揭示了一些关键见解。研究发现,即使没有点云输入,LLM也能实现出色的性能;现有的3D LLM在理解二元空间关系方面存在困难;并且在利用点云的结构坐标进行精细空间推理方面表现出局限性。这些结论有助于指导未来3D LLM的研究,并为其他模态的基础模型提供启示。
Key Takeaways
- 点云在增强LLM的空间推理能力中扮演重要角色,但其作用尚未完全明确。
- 不同输入模态下的LLM空间推理能力评估显示,即使没有点云输入,LLM也能实现良好性能。
- 现有的3D LLM在理解二元空间关系方面存在挑战。
- 3D LLM在利用点云的结构坐标进行精细空间推理方面存在局限性。
- 本研究提出一个新的基准测试ScanReQA,用于全面评估模型对二元空间关系的理解。
- 研究结论有助于指导未来对3D LLM的研究,并为其他模态的基础模型提供启示。
点此查看论文截图


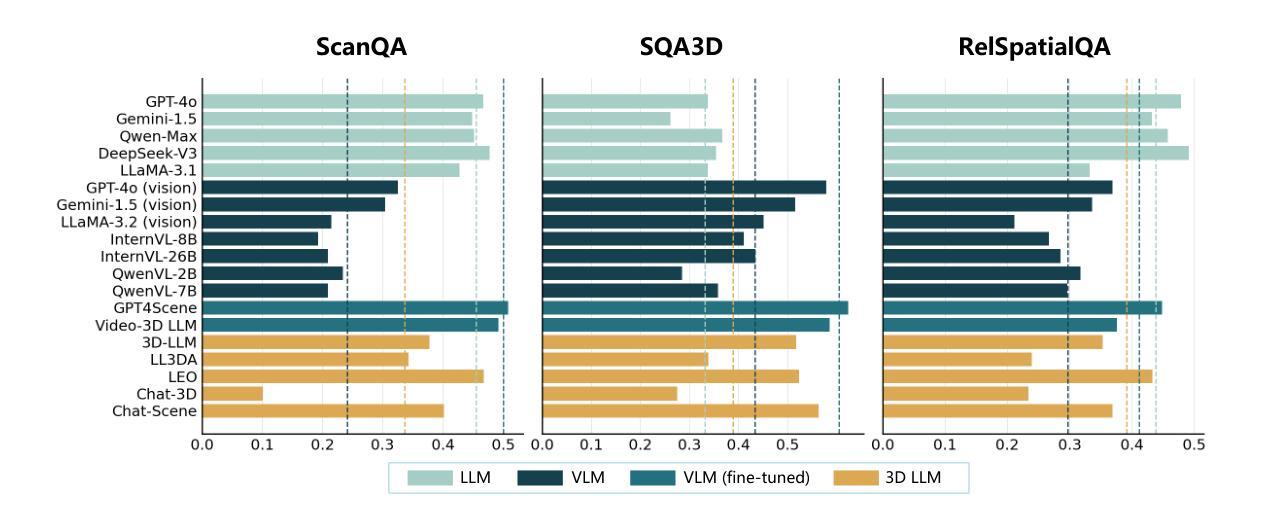
Trust Region Preference Approximation: A simple and stable reinforcement learning algorithm for LLM reasoning
Authors:Xuerui Su, Shufang Xie, Guoqing Liu, Yingce Xia, Renqian Luo, Peiran Jin, Zhiming Ma, Yue Wang, Zun Wang, Yuting Liu
Recently, Large Language Models (LLMs) have rapidly evolved, approaching Artificial General Intelligence (AGI) while benefiting from large-scale reinforcement learning to enhance Human Alignment (HA) and Reasoning. Recent reward-based optimization algorithms, such as Proximal Policy Optimization (PPO) and Group Relative Policy Optimization (GRPO) have achieved significant performance on reasoning tasks, whereas preference-based optimization algorithms such as Direct Preference Optimization (DPO) significantly improve the performance of LLMs on human alignment. However, despite the strong performance of reward-based optimization methods in alignment tasks , they remain vulnerable to reward hacking. Furthermore, preference-based algorithms (such as Online DPO) haven’t yet matched the performance of reward-based optimization algorithms (like PPO) on reasoning tasks, making their exploration in this specific area still a worthwhile pursuit. Motivated by these challenges, we propose the Trust Region Preference Approximation (TRPA) algorithm, which integrates rule-based optimization with preference-based optimization for reasoning tasks. As a preference-based algorithm, TRPA naturally eliminates the reward hacking issue. TRPA constructs preference levels using predefined rules, forms corresponding preference pairs, and leverages a novel optimization algorithm for RL training with a theoretical monotonic improvement guarantee. Experimental results demonstrate that TRPA not only achieves competitive performance on reasoning tasks but also exhibits robust stability. The code of this paper are released and updating on https://github.com/XueruiSu/Trust-Region-Preference-Approximation.git.
最近,大型语言模型(LLM)迅速进化,在受益于大规模强化学习提高人类对齐(HA)和推理的同时,逐渐接近人工智能通用智能(AGI)。基于奖励的优化算法,如近端策略优化(PPO)和群体相对策略优化(GRPO),在推理任务上取得了显著的性能成就。而基于偏好的优化算法,如直接偏好优化(DPO),则显著提高了语言模型在人机对齐方面的性能。然而,尽管基于奖励的优化方法在人机对齐任务中表现出强大的性能,但它们仍然容易受到奖励操纵的影响。此外,基于偏好的算法(如在线DPO)在推理任务上的性能尚未达到基于奖励的优化算法(如PPO)的水平,这使得在这一特定领域的探索仍然具有价值。针对这些挑战,我们提出了信任区域偏好逼近(TRPA)算法,该算法将基于规则的优化与基于偏好的优化相结合,用于推理任务。作为一种基于偏好的算法,TRPA自然地解决了奖励操纵的问题。TRPA使用预定义的规则构建偏好层次,形成相应的偏好对,并利用一种新的优化算法进行RL训练,该算法具有理论上的单调改进保证。实验结果表明,TRPA不仅在推理任务上具有良好的性能,而且表现出稳健的稳定性。本文的代码已发布并在https://github.com/XueruiSu/Trust-Region-Preference-Approximation.git上进行更新。
论文及项目相关链接
PDF 10pages
Summary
本文探讨了大型语言模型(LLM)在人工通用智能(AGI)方面的最新进展。通过大规模强化学习提升人类对齐(HA)和推理能力。文章介绍了基于奖励的优化算法,如近端策略优化(PPO)和组相对策略优化(GRPO),在推理任务上的优异表现;同时也提到了基于偏好的优化算法,如直接偏好优化(DPO),在LLM的人类对齐方面表现出色。然而,尽管基于奖励的优化方法在对齐任务上表现出色,但它们仍然容易受奖励作弊的影响。文章还提出了一种新的算法——信任区域偏好近似(TRPA),该算法结合了基于规则的优化和基于偏好的优化,旨在解决推理任务中的挑战。TRPA解决了奖励作弊问题,并通过预设规则构建偏好层次,形成相应的偏好对,然后使用新的优化算法进行RL训练,具有理论上的单调改进保证。实验结果表明,TRPA在推理任务上具有良好的竞争力和稳健性。
Key Takeaways
- 大型语言模型(LLM)通过强化学习提升人类对齐(HA)和推理能力。
- 基于奖励的优化算法如PPO和GRPO在推理任务上表现良好,但存在奖励作弊的脆弱性。
- 基于偏好的优化算法如DPO在LLM的人类对齐方面有所突破,但仍未匹配基于奖励的优化算法在推理任务上的性能。
- TRPA算法结合了基于规则的优化和基于偏好的优化,解决了奖励作弊问题,并在推理任务上表现出竞争力和稳健性。
- TRPA通过构建偏好层次和形成偏好对来进行优化,具有理论上的单调改进保证。
- 发布的代码可以在指定网站找到并不断更新完善。网站链接为:https://github.com/XueruiSu/Trust-Region-Preference-Approximation.git。
点此查看论文截图

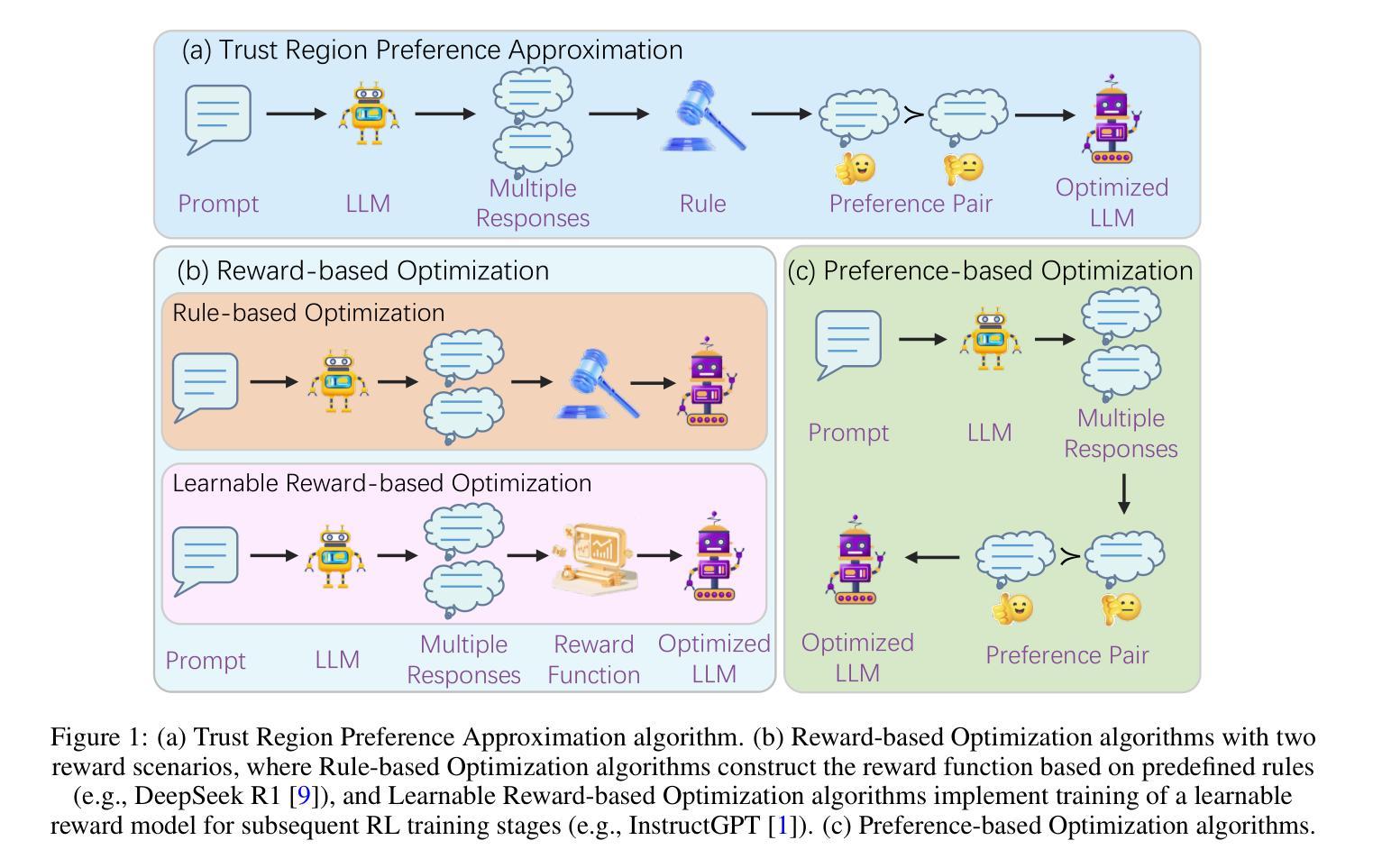
VideoAgent2: Enhancing the LLM-Based Agent System for Long-Form Video Understanding by Uncertainty-Aware CoT
Authors:Zhuo Zhi, Qiangqiang Wu, Minghe shen, Wenbo Li, Yinchuan Li, Kun Shao, Kaiwen Zhou
Long video understanding has emerged as an increasingly important yet challenging task in computer vision. Agent-based approaches are gaining popularity for processing long videos, as they can handle extended sequences and integrate various tools to capture fine-grained information. However, existing methods still face several challenges: (1) they often rely solely on the reasoning ability of large language models (LLMs) without dedicated mechanisms to enhance reasoning in long video scenarios; and (2) they remain vulnerable to errors or noise from external tools. To address these issues, we propose a specialized chain-of-thought (CoT) process tailored for long video analysis. Our proposed CoT with plan-adjust mode enables the LLM to incrementally plan and adapt its information-gathering strategy. We further incorporate heuristic uncertainty estimation of both the LLM and external tools to guide the CoT process. This allows the LLM to assess the reliability of newly collected information, refine its collection strategy, and make more robust decisions when synthesizing final answers. Empirical experiments show that our uncertainty-aware CoT effectively mitigates noise from external tools, leading to more reliable outputs. We implement our approach in a system called VideoAgent2, which also includes additional modules such as general context acquisition and specialized tool design. Evaluation on three dedicated long video benchmarks (and their subsets) demonstrates that VideoAgent2 outperforms the previous state-of-the-art agent-based method, VideoAgent, by an average of 13.1% and achieves leading performance among all zero-shot approaches
长视频理解是计算机视觉中越来越重要且具有挑战性的任务。基于代理的方法在处理长视频时越来越受欢迎,因为它们可以处理扩展序列并集成各种工具来捕获精细信息。然而,现有方法仍然面临一些挑战:(1)它们通常仅依赖于大型语言模型的推理能力,而没有专门的机制来增强长视频场景中的推理;(2)它们仍然容易受到外部工具的错误或噪声的影响。为了解决这些问题,我们提出了一种专为长视频分析量身定制的专项思维链(CoT)流程。我们提出的具有计划调整模式的CoT使LLM能够增量地规划并适应其信息收集策略。我们进一步结合了LLM和外部工具启发式的不确定性估计来指导CoT过程。这使得LLM能够评估新收集信息的可靠性,改进其收集策略,并在合成最终答案时做出更稳健的决策。经验实验表明,我们的感知不确定性的CoT有效地减轻了来自外部工具的噪声,从而产生了更可靠的输出。我们在名为VideoAgent2的系统中实现了我们的方法,该系统还包括通用上下文获取和专用工具设计等其他模块。在三个专用的长视频基准测试(及其子集)上的评估表明,VideoAgent2较之前的先进代理方法VideoAgent平均提高了13.1%,在所有零样本方法中表现领先。
论文及项目相关链接
Summary
长视频理解在计算机视觉中是一项重要且具有挑战性的任务。基于代理的方法处理长视频日益流行,能够处理扩展序列并整合各种工具来捕捉精细信息。然而,现有方法仍面临挑战,如过度依赖大型语言模型的推理能力,以及易受外部工具错误或噪声的影响。为解决这个问题,我们提出专为长视频分析定制的链式思维过程,并引入计划调整模式,使大型语言模型能够逐步规划并调整其信息收集策略。此外,我们结合了启发式不确定性估计,指导链式思维过程。实验表明,我们的不确定性感知链式思维有效减轻了外部工具噪声的影响,产生了更可靠的结果。我们实现了名为VideoAgent2的系统,包含通用上下文获取和专用工具设计等额外模块。在三个专用的长视频基准测试(及其子集)上的评估显示,VideoAgent2较之前的代理方法VideoAgent平均提高了13.1%的性能,并在零样本方法中表现领先。
Key Takeaways
- 长视频理解是计算机视觉中的重要且具有挑战性的任务。
- 基于代理的方法处理长视频日益流行,但需要解决依赖大型语言模型的推理能力和应对外部工具错误或噪声的问题。
- 提出了一个专门为长视频分析定制的链式思维过程,包括计划调整模式和不确定性估计。
- 通过实验验证了不确定性感知链式思维的有效性,减轻了外部工具噪声的影响。
- 实现了一个名为VideoAgent2的系统,该系统结合了通用上下文获取和专用工具设计等功能。
- VideoAgent2在多个长视频基准测试中表现优于之前的代理方法VideoAgent。
点此查看论文截图

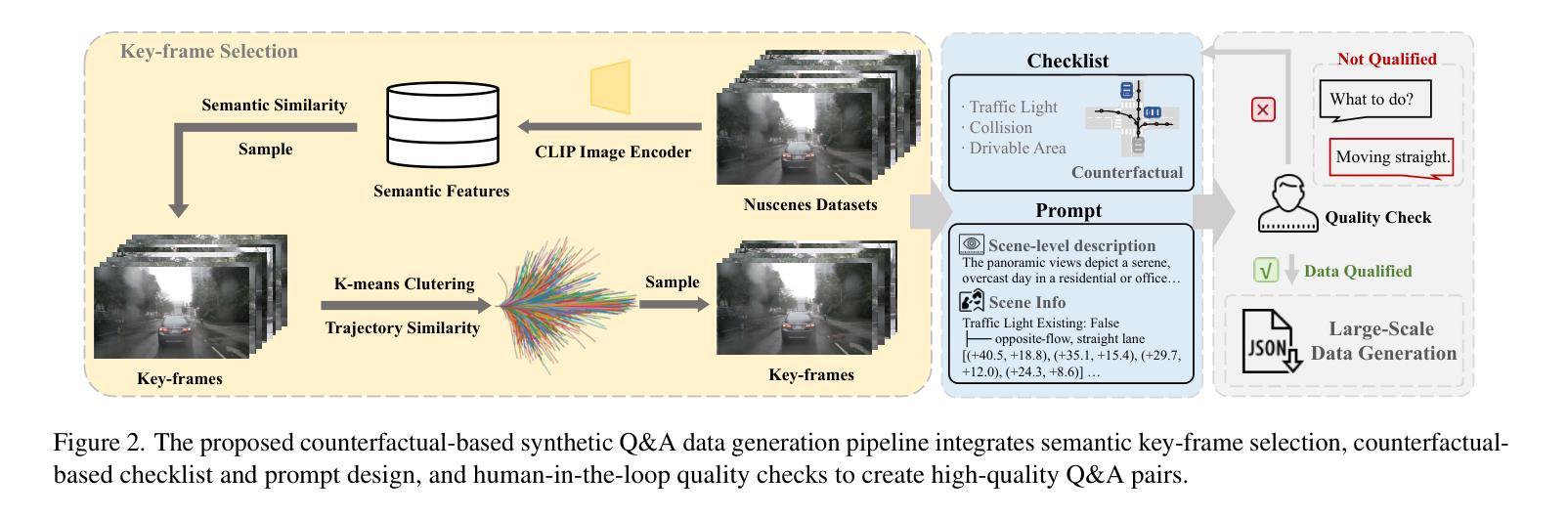
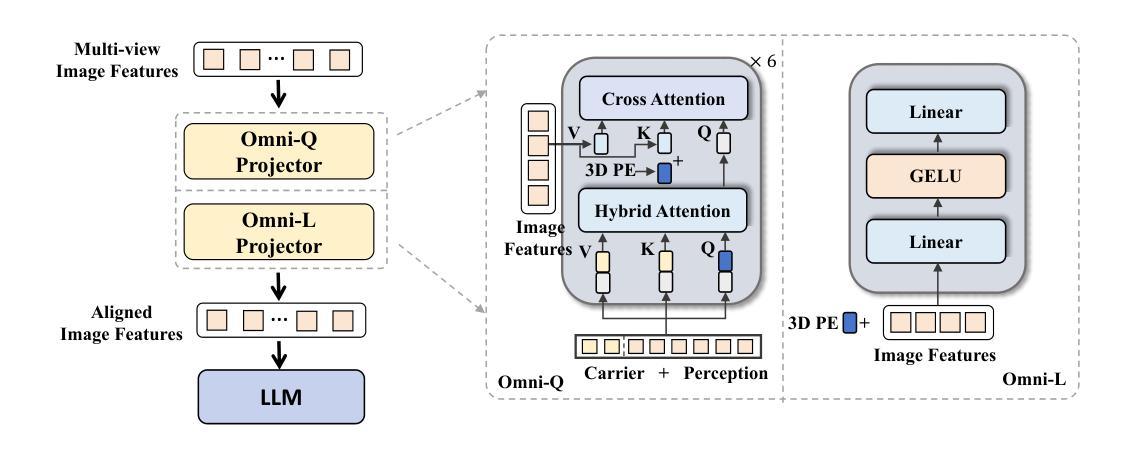
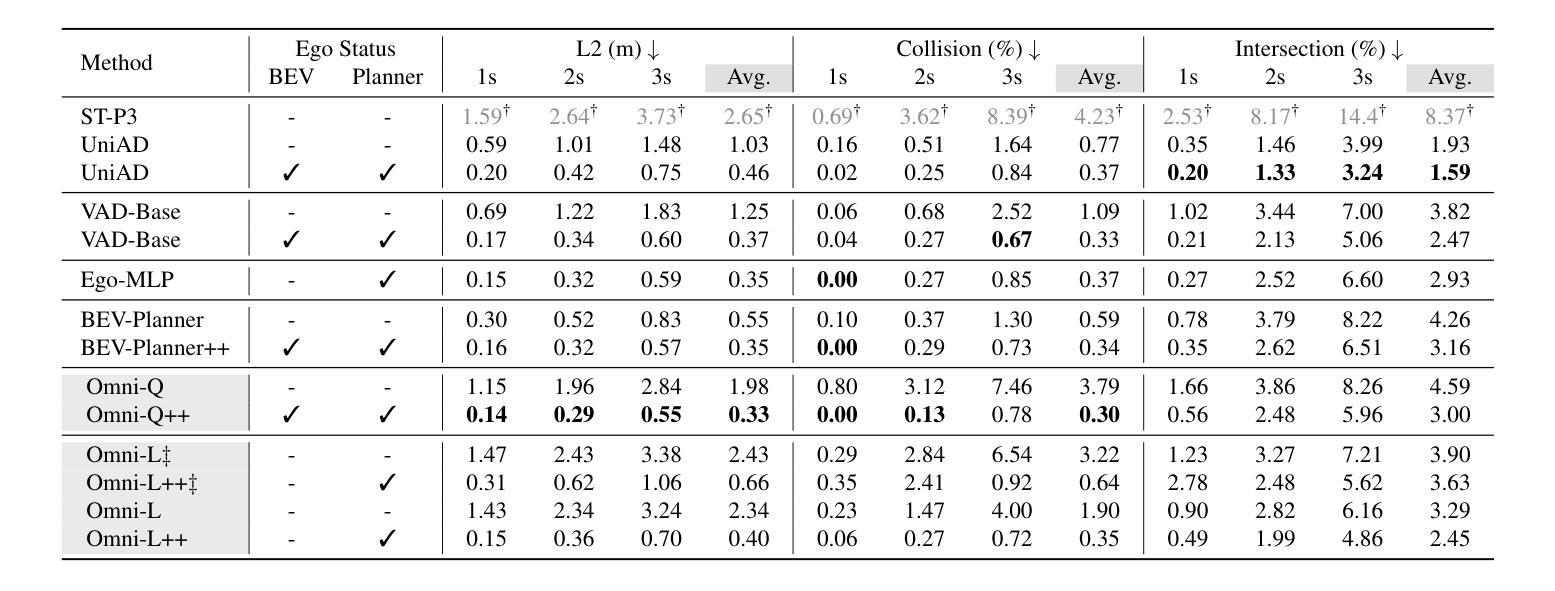
OmniDrive: A Holistic Vision-Language Dataset for Autonomous Driving with Counterfactual Reasoning
Authors:Shihao Wang, Zhiding Yu, Xiaohui Jiang, Shiyi Lan, Min Shi, Nadine Chang, Jan Kautz, Ying Li, Jose M. Alvarez
The advances in vision-language models (VLMs) have led to a growing interest in autonomous driving to leverage their strong reasoning capabilities. However, extending these capabilities from 2D to full 3D understanding is crucial for real-world applications. To address this challenge, we propose OmniDrive, a holistic vision-language dataset that aligns agent models with 3D driving tasks through counterfactual reasoning. This approach enhances decision-making by evaluating potential scenarios and their outcomes, similar to human drivers considering alternative actions. Our counterfactual-based synthetic data annotation process generates large-scale, high-quality datasets, providing denser supervision signals that bridge planning trajectories and language-based reasoning. Futher, we explore two advanced OmniDrive-Agent frameworks, namely Omni-L and Omni-Q, to assess the importance of vision-language alignment versus 3D perception, revealing critical insights into designing effective LLM-agents. Significant improvements on the DriveLM Q&A benchmark and nuScenes open-loop planning demonstrate the effectiveness of our dataset and methods.
视觉语言模型(VLMs)的进步引发了人们对自动驾驶利用其强大推理能力的日益增长的兴趣。然而,从二维扩展到全面的三维理解对于实际应用至关重要。为了应对这一挑战,我们提出了OmniDrive,这是一个全面的视觉语言数据集,它通过反事实推理将代理模型与三维驾驶任务对齐。这种方法通过评估潜在场景及其结果来增强决策制定,与人类驾驶员考虑替代行动的方式相似。我们的基于反事实的合成数据标注过程生成大规模高质量数据集,提供更密集的监督信号,从而建立规划轨迹和语言基础推理之间的桥梁。此外,我们探索了两个先进的OmniDrive-Agent框架,即Omni-L和Omni-Q,以评估视觉语言对齐与三维感知的重要性,为设计有效的LLM-agents提供关键见解。在DriveLM问答基准测试和nuScenes开放循环规划上的显著改进证明了我们的数据集和方法的有效性。
论文及项目相关链接
Summary
在自动驾驶领域,视觉语言模型(VLMs)的进步引发了对其强大推理能力的兴趣。然而,从二维扩展到三维理解对于实际应用至关重要。为了应对这一挑战,本文提出了OmniDrive,这是一个全面的视觉语言数据集,它通过反事实推理将智能体模型与三维驾驶任务对齐。此方法通过评估潜在场景及其结果来增强决策制定,类似于人类驾驶员考虑替代行动。此外,本文还探索了两个先进的OmniDrive-Agent框架,即Omni-L和Omni-Q,以评估视觉语言对齐与三维感知的重要性,为设计有效的LLM代理提供关键见解。在DriveLM问答基准测试和nuScenes开放循环规划上的显著改善证明了本文数据集和方法的有效性。
Key Takeaways
- 视觉语言模型(VLMs)的进步激发了自动驾驶领域的兴趣,但其从二维到三维理解的扩展至关重要。
- OmniDrive是一个全面的视觉语言数据集,通过反事实推理将智能体模型与三维驾驶任务相结合,以增强决策过程。
- 反事实推理方法评估潜在场景和结果,类似于人类驾驶员考虑替代行动。
- OmniDrive-Agent框架包括Omni-L和Omni-Q,用于评估视觉语言对齐与三维感知的重要性。
- OmniDrive的数据集和方法在DriveLM问答基准测试和nuScenes开放循环规划任务上表现出显著效果。
- 通过大规模高质量数据集的生成,OmniDrive提供了更密集的监督信号,桥接了规划轨迹和语言基础推理。
点此查看论文截图


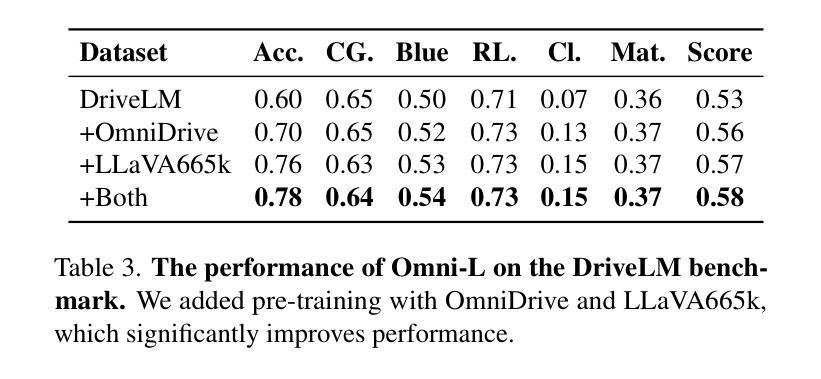
Distillation and Refinement of Reasoning in Small Language Models for Document Re-ranking
Authors:Chris Samarinas, Hamed Zamani
We present a novel approach for training small language models for reasoning-intensive document ranking that combines knowledge distillation with reinforcement learning optimization. While existing methods often rely on expensive human annotations or large black-box language models, our methodology leverages web data and a teacher LLM to automatically generate high-quality training examples with relevance explanations. By framing document ranking as a reinforcement learning problem and incentivizing explicit reasoning capabilities, we train a compact 3B parameter language model that achieves state-of-the-art performance on the BRIGHT benchmark. Our model ranks third on the leaderboard while using substantially fewer parameters than other approaches, outperforming models that are over 20 times larger. Through extensive experiments, we demonstrate that generating explanations during inference, rather than directly predicting relevance scores, enables more effective reasoning with smaller language models. The self-supervised nature of our method offers a scalable and interpretable solution for modern information retrieval systems.
我们提出了一种结合知识蒸馏和强化学习优化训练小型语言模型的新方法,用于推理密集型文档排序。虽然现有方法常常依赖于昂贵的人力标注或大型黑盒语言模型,我们的方法则利用网页数据和教师大型语言模型(LLM)自动生成高质量的训练样本及其相关性解释。通过将文档排序设定为强化学习问题并激励明确的推理能力,我们训练了一个紧凑的3B参数语言模型,在BRIGHT基准测试上取得了最先进的性能。我们的模型在排行榜上排名第三,同时使用的参数比其他方法少得多,超越了超过20倍的大型模型。通过大量实验,我们证明在推理过程中生成解释,而不是直接预测相关性分数,能够使小型语言模型更有效地进行推理。我们的方法的自我监督性质为现代信息检索系统提供了一种可扩展和可解释的解决方案。
论文及项目相关链接
Summary
本文提出了一种结合知识蒸馏和强化学习优化的小型语言模型训练方法,用于密集推理文档排名。不同于依赖昂贵的人力标注或大型黑盒语言模型的方法,本文利用Web数据和教师大型语言模型自动生成高质量的训练样本及其相关性解释。通过将文档排名视为强化学习问题并激励明确的推理能力,本文训练了一个紧凑的3亿参数语言模型,在BRIGHT基准测试中取得了最先进的性能。在参数远少于其他方法的情况下,本模型在排行榜上排名第三,同时证明了对超出同类模型二十倍的大型模型的超越能力。此外,本文通过实验证明,在推理过程中生成解释而非直接预测相关性分数,能够使小型语言模型的推理更加有效。本方法具有自我监督的特性,为现代信息检索系统提供了可扩展和可解释的解决方案。
Key Takeaways
- 提出了一种结合知识蒸馏和强化学习的小型语言模型训练方法用于推理密集型文档排名。
- 利用Web数据和教师大型语言模型自动生成高质量的训练样本及其相关性解释。
- 将文档排名视为强化学习问题,训练出参数较少的紧凑语言模型。
- 模型在排行榜上排名第三,且性能优于其他大型模型。
- 通过实验证明,推理过程中生成解释能提高小型语言模型的推理有效性。
- 本方法具有自我监督的特性,为现代信息检索系统提供了解决方案。
点此查看论文截图


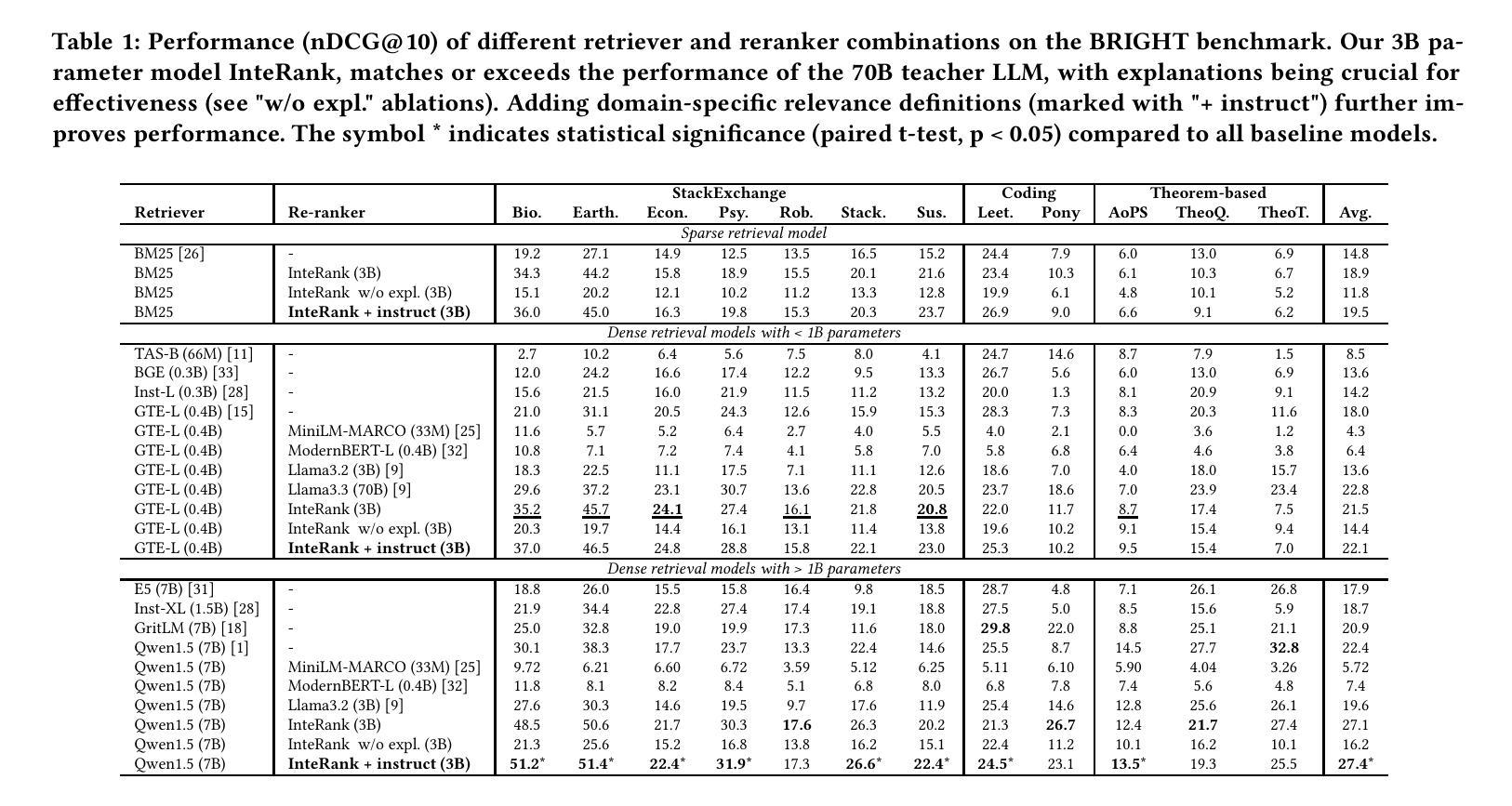
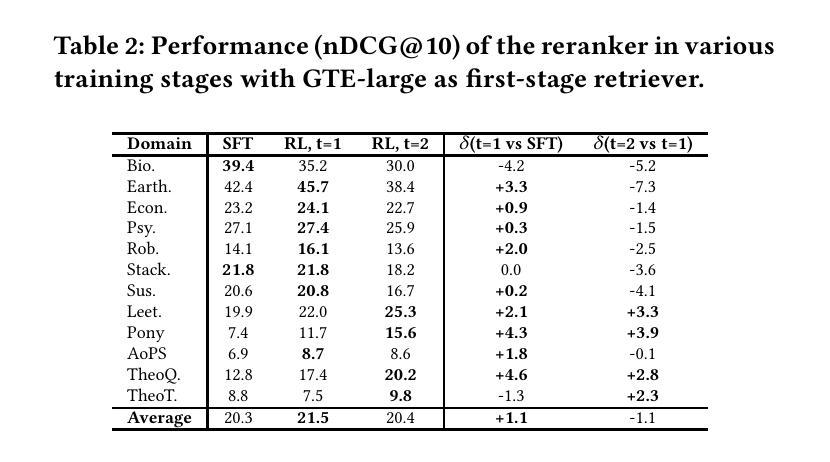
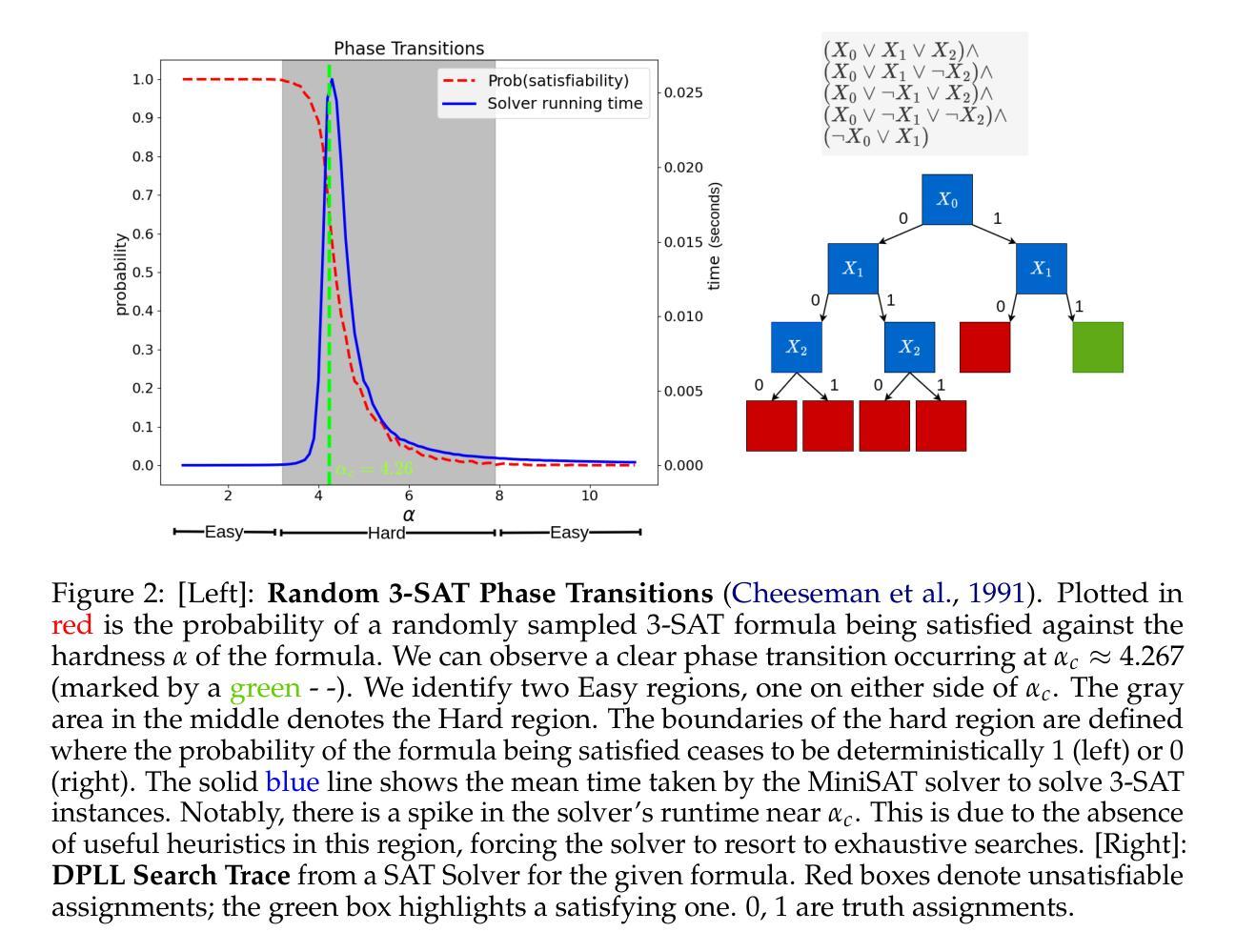
Have Large Language Models Learned to Reason? A Characterization via 3-SAT Phase Transition
Authors:Rishi Hazra, Gabriele Venturato, Pedro Zuidberg Dos Martires, Luc De Raedt
Large Language Models (LLMs) have been touted as AI models possessing advanced reasoning abilities. In theory, autoregressive LLMs with Chain-of-Thought (CoT) can perform more serial computations to solve complex reasoning tasks. However, recent studies suggest that, despite this capacity, LLMs do not truly learn to reason but instead fit on statistical features. To study the reasoning capabilities in a principled fashion, we adopt a computational theory perspective and propose an experimental protocol centered on 3-SAT – the prototypical NP-complete problem lying at the core of logical reasoning and constraint satisfaction tasks. Specifically, we examine the phase transitions in random 3-SAT and characterize the reasoning abilities of state-of-the-art LLMs by varying the inherent hardness of the problem instances. By comparing DeepSeek R1 with other LLMs, our findings reveal two key insights (1) LLM accuracy drops significantly on harder instances, suggesting all current models struggle when statistical shortcuts are unavailable (2) Unlike other LLMs, R1 shows signs of having learned the underlying reasoning. Following a principled experimental protocol, our study moves beyond the benchmark-driven evidence often found in LLM reasoning research. Our findings highlight important gaps and suggest clear directions for future research.
大型语言模型(LLM)被誉为拥有先进推理能力的AI模型。理论上,采用思维链(CoT)的自回归LLM可以执行更多的串行计算来解决复杂的推理任务。然而,最近的研究表明,尽管具备这种能力,LLM并没有真正学会推理,而是适应于统计特征。为了以原则性的方式研究推理能力,我们从计算理论的角度出发,提出了以3-SAT为中心的实验协议——3-SAT是逻辑推理和约束满足任务核心的典型NP完全问题。具体来说,我们研究了随机3-SAT中的相变,并通过改变问题实例的固有难度来表征最先进的LLM的推理能力。通过比较DeepSeek R1与其他LLM,我们的研究发现两个关键见解:(1)在更难的实例上,LLM的准确率显著下降,这表明当没有统计捷径可用时,当前所有模型都会遇到困难;(2)与其他LLM不同,R1显示出已掌握基本推理的迹象。遵循原则性的实验协议,我们的研究超越了LLM推理研究中通常出现的基准测试驱动的证据。我们的研究发现了重要的差距,并为未来的研究提出了明确的方向。
论文及项目相关链接
PDF An updated version of arXiv:2408.07215v2, featuring: (1) inclusion of recent LRMs and recent LLMs, (2) revised conclusions reflecting recent developments, and (3) updated analysis
Summary
大型语言模型(LLMs)具备理论上的推理能力,尤其在采用链式思维(CoT)的自回归LLMs中表现更突出。然而,最近的研究表明,LLMs并没有真正学会推理,而是依赖于统计特征。为了更系统地研究其推理能力,本研究从计算理论角度入手,围绕3-SAT这一逻辑和约束满足任务的核心NP完全问题设计实验。通过对比DeepSeek R1和其他LLMs在随机3-SAT中的阶段转变,发现以下两点关键见解:(1)在更困难的实例中,LLM准确率大幅下降,表明在没有统计捷径可用时,所有当前模型都存在问题;(2)与其他LLMs相比,R1显示出已掌握基础推理的迹象。本研究遵循系统的实验协议,为理解LLM的推理能力提供了超越基准测试的新证据。发现当前技术的不足之处并为未来的研究指明了方向。
Key Takeaways
- 大型语言模型(LLMs)虽然理论上具备推理能力,但依赖统计特征而非真正的逻辑推理。
- 采用计算理论视角研究LLMs的推理能力是一种新的方法。
- 围绕3-SAT问题设计的实验揭示了LLMs在困难实例中的准确率下降。
- DeepSeek R1与其他LLMs相比,在推理能力方面表现出独特性。
- LLMs面临在没有统计捷径时的挑战。
- 当前研究为理解LLM的推理能力提供了超越基准测试的新证据。
点此查看论文截图

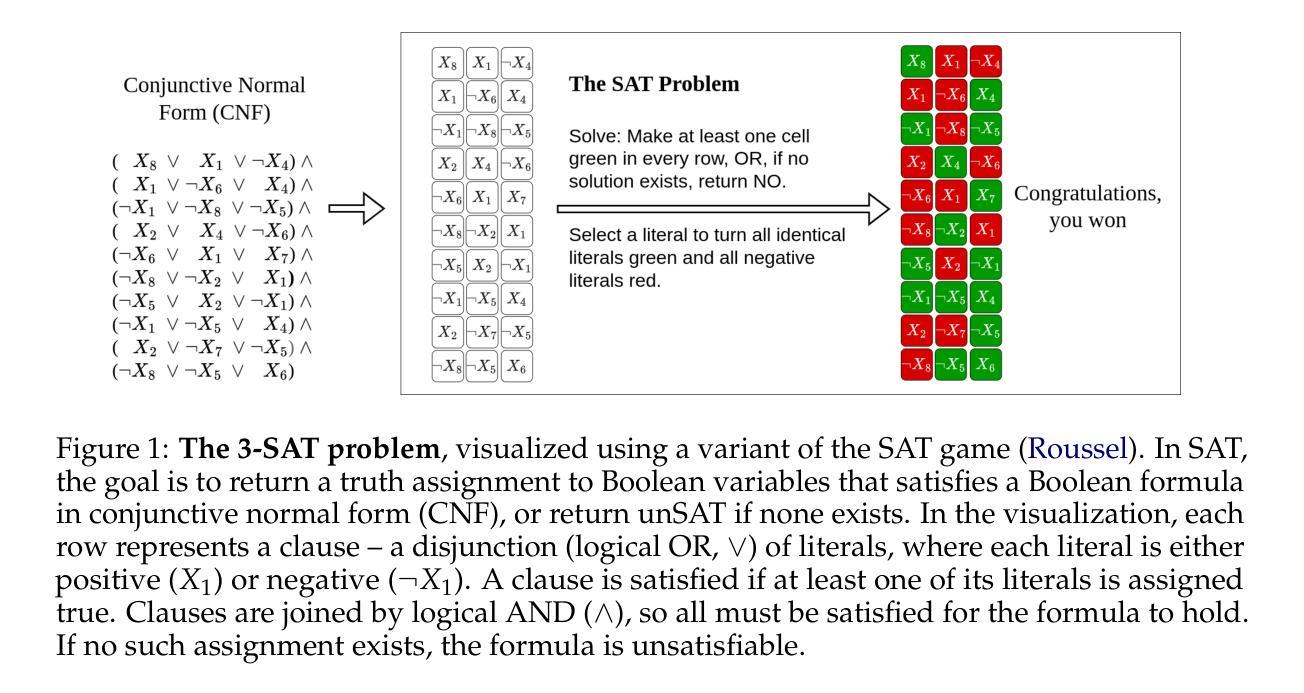
MME-Unify: A Comprehensive Benchmark for Unified Multimodal Understanding and Generation Models
Authors:Wulin Xie, Yi-Fan Zhang, Chaoyou Fu, Yang Shi, Bingyan Nie, Hongkai Chen, Zhang Zhang, Liang Wang, Tieniu Tan
Existing MLLM benchmarks face significant challenges in evaluating Unified MLLMs (U-MLLMs) due to: 1) lack of standardized benchmarks for traditional tasks, leading to inconsistent comparisons; 2) absence of benchmarks for mixed-modality generation, which fails to assess multimodal reasoning capabilities. We present a comprehensive evaluation framework designed to systematically assess U-MLLMs. Our benchmark includes: Standardized Traditional Task Evaluation. We sample from 12 datasets, covering 10 tasks with 30 subtasks, ensuring consistent and fair comparisons across studies.” 2. Unified Task Assessment. We introduce five novel tasks testing multimodal reasoning, including image editing, commonsense QA with image generation, and geometric reasoning. 3. Comprehensive Model Benchmarking. We evaluate 12 leading U-MLLMs, such as Janus-Pro, EMU3, VILA-U, and Gemini2-flash, alongside specialized understanding (e.g., Claude-3.5-Sonnet) and generation models (e.g., DALL-E-3). Our findings reveal substantial performance gaps in existing U-MLLMs, highlighting the need for more robust models capable of handling mixed-modality tasks effectively. The code and evaluation data can be found in https://mme-unify.github.io/.
现有的多语言低资源机器学习(MLLM)基准测试面临评估统一MLLM(Unified MLLMs,简称U-MLLMs)的重大挑战,主要由于以下几点原因:1)缺乏传统任务的标准化基准测试,导致比较结果不一致;2)缺少混合模态生成的基准测试,无法评估多模态推理能力。我们提出了一个全面的评估框架,旨在系统地评估U-MLLMs。我们的基准测试包括:标准化的传统任务评估。我们从12个数据集中抽样,涵盖10个任务及30个子任务,确保跨研究的比较结果一致且公正。” 2. 统一任务评估。我们引入了五项新的任务来测试多模态推理,包括图像编辑、带有图像生成常识问答和几何推理。3. 综合模型基准测试。我们评估了领先的12个U-MLLMs,如Janus-Pro、EMU3、VILA-U和Gemini2-flash等,同时评估专业理解(如Claude-3.5-Sonnet)和生成模型(如DALL-E-3)。我们的研究发现,现有的U-MLLMs存在显著的性能差距,这突显了需要更稳健的模型来有效处理混合模态任务。相关代码和评估数据可在https://mme-unify.github.io/找到。
论文及项目相关链接
PDF Project page: https://mme-unify.github.io/
Summary
现存的MLLM基准在评估统一MLLMs时面临重大挑战,如缺乏标准化基准与传统任务的混合模态生成基准缺失,无法评估多模态推理能力。本文提出了一个全面评估框架以系统化评估U-MLLMs。该基准包括标准化传统任务评估、统一任务评估和全面模型评估。评估了多种领先U-MLLMs模型,发现现有U-MLLMs存在显著性能差距,突显出需要更稳健的模型以有效处理混合模态任务。
Key Takeaways
- U-MLLMs现有评估面临的挑战包括缺乏标准化基准和传统任务混合模态生成基准的缺失。
- 提出一个全面评估框架来系统化评估U-MLLMs,包括标准化传统任务评估、统一任务评估和全面模型评估。
- 标准化传统任务评估包括从12个数据集中采样,涵盖10个任务和30个子任务,以确保跨研究的公平和一致比较。
- 统一任务评估引入五个测试多模态推理的新任务,包括图像编辑、带有图像生成常识问答和几何推理等。
- 综合模型评估涵盖了多种领先的U-MLLMs模型,如Janus-Pro、EMU3、VILA-U、Gemini2-flash等。同时也评估了专项理解和生成模型。
- 研究发现现有U-MLLMs存在显著性能差距。
点此查看论文截图



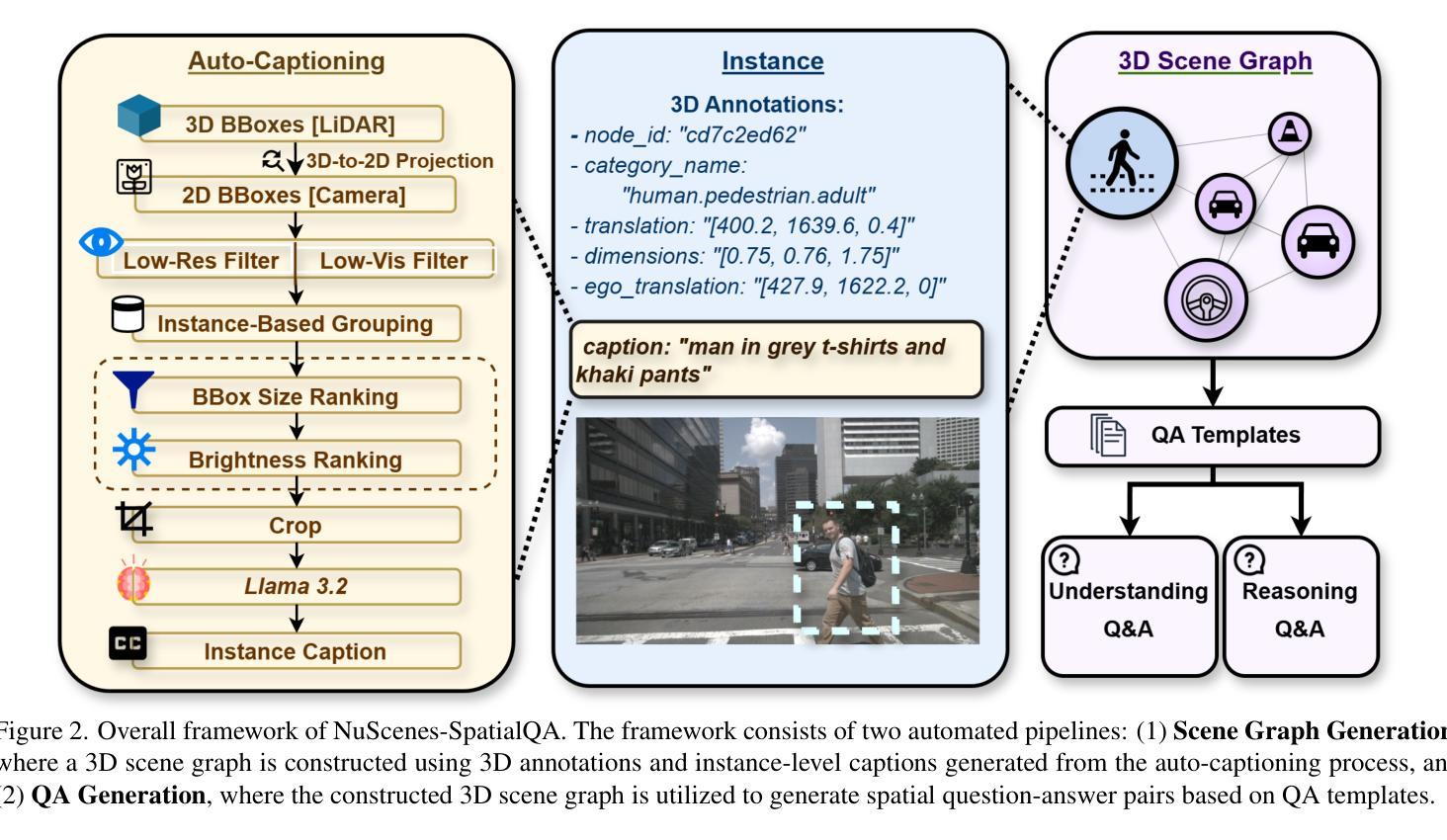
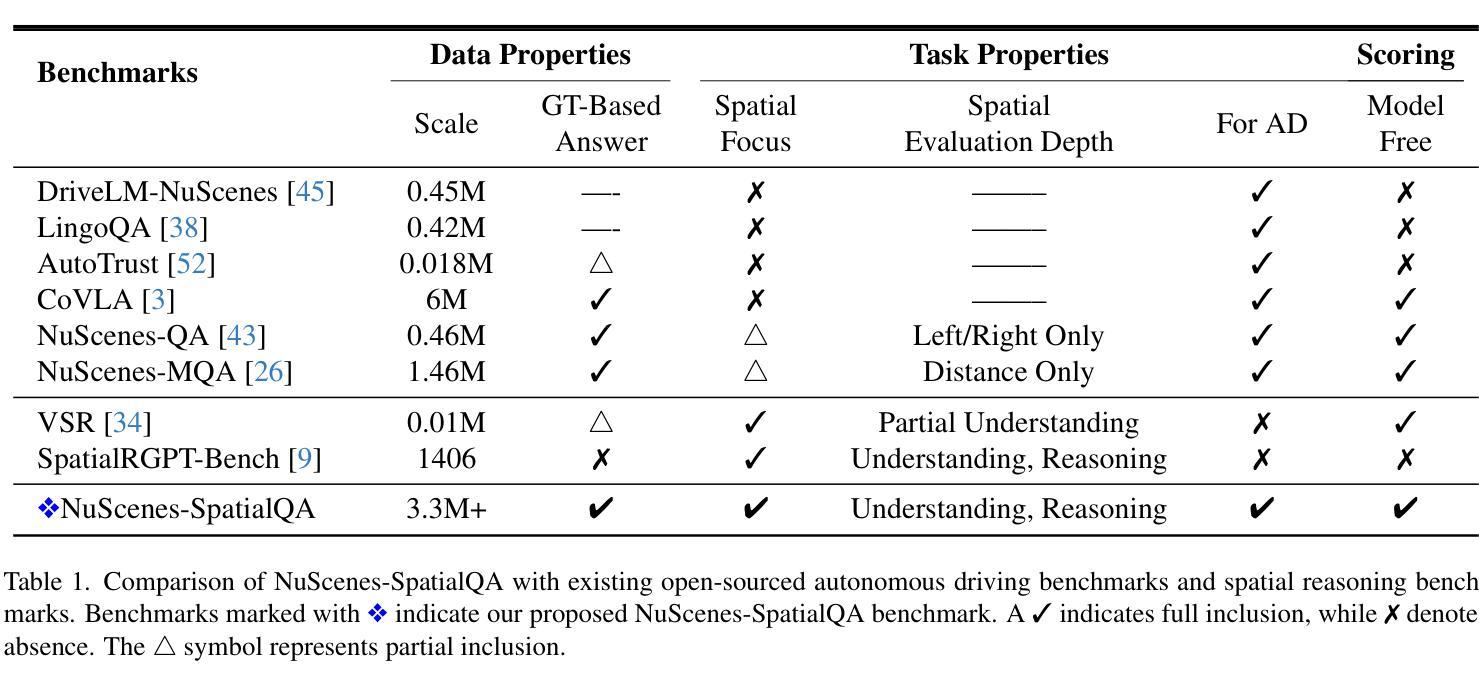
NuScenes-SpatialQA: A Spatial Understanding and Reasoning Benchmark for Vision-Language Models in Autonomous Driving
Authors:Kexin Tian, Jingrui Mao, Yunlong Zhang, Jiwan Jiang, Yang Zhou, Zhengzhong Tu
Recent advancements in Vision-Language Models (VLMs) have demonstrated strong potential for autonomous driving tasks. However, their spatial understanding and reasoning-key capabilities for autonomous driving-still exhibit significant limitations. Notably, none of the existing benchmarks systematically evaluate VLMs’ spatial reasoning capabilities in driving scenarios. To fill this gap, we propose NuScenes-SpatialQA, the first large-scale ground-truth-based Question-Answer (QA) benchmark specifically designed to evaluate the spatial understanding and reasoning capabilities of VLMs in autonomous driving. Built upon the NuScenes dataset, the benchmark is constructed through an automated 3D scene graph generation pipeline and a QA generation pipeline. The benchmark systematically evaluates VLMs’ performance in both spatial understanding and reasoning across multiple dimensions. Using this benchmark, we conduct extensive experiments on diverse VLMs, including both general and spatial-enhanced models, providing the first comprehensive evaluation of their spatial capabilities in autonomous driving. Surprisingly, the experimental results show that the spatial-enhanced VLM outperforms in qualitative QA but does not demonstrate competitiveness in quantitative QA. In general, VLMs still face considerable challenges in spatial understanding and reasoning.
最近,视觉语言模型(VLMs)的进展为自动驾驶任务展示了强大的潜力。然而,它们在空间理解和推理方面的关键能力对于自动驾驶来说仍显示出显著的局限性。值得注意的是,现有的基准测试并未系统地评估驾驶场景中VLMs的空间推理能力。为了填补这一空白,我们提出了NuScenes-SpatialQA,这是第一个基于大规模真实数据的大型问答(QA)基准测试,专门设计用于评估VLMs在自动驾驶中的空间理解和推理能力。该基准测试建立在NuScenes数据集之上,通过自动化的3D场景图生成流程和QA生成流程构建。该基准测试系统地评估了VLMs在多个维度上的空间理解和推理性能。使用这个基准测试,我们对多种VLMs进行了广泛的实验,包括通用模型和空间增强模型,首次全面评估了它们在自动驾驶中的空间能力。令人惊讶的是,实验结果表明,空间增强VLM在定性问答中表现优异,但在定量问答中并未展现出竞争力。总体而言,VLMs在空间理解和推理方面仍面临巨大的挑战。
论文及项目相关链接
Summary
自动化驾驶领域中,视觉语言模型(VLMs)在自动驾驶任务上的潜力和表现得到了展示。但其空间理解和推理能力的核心仍有诸多局限,而现有基准测试并未系统地评估其在驾驶场景中的空间推理能力。为此,我们提出了NuScenes-SpatialQA基准测试,该测试以NuScenes数据集为基础,通过自动化的三维场景图生成管道和问答生成管道构建而成。此基准测试系统地从多个维度评估了VLMs在空间理解和推理上的表现。我们对一系列多样化的VLMs进行了基准测试的实验研究,其中包括一般模型和增强空间理解的模型,研究结果表明空间理解的增强模型在定性问答上的表现较为优秀但在定量问答上并无竞争力。总体来说,VLMs在空间理解和推理方面仍存在较大挑战。该研究的结论反映了我们需要针对此领域的深入理解和持续的研发进步以确保更高效可靠的自动化驾驶技术的发展和应用落地。
Key Takeaways
- VLMs在自动驾驶任务中展现出潜力,但在空间理解和推理方面存在局限。
- 目前缺乏系统评估VLMs在驾驶场景中空间推理能力的基准测试。
- NuScenes-SpatialQA基准测试是首个专为评估VLMs在自动驾驶中的空间理解和推理能力而设计的大型基于真实场景的基准测试。
- 该基准测试通过自动化的三维场景图生成管道和问答生成管道构建而成。
- 实验研究了多种VLMs的表现,发现增强空间理解的模型在定性问答上表现良好但在定量问答上仍有挑战。
点此查看论文截图