⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-10 更新
REEF: Relevance-Aware and Efficient LLM Adapter for Video Understanding
Authors:Sakib Reza, Xiyun Song, Heather Yu, Zongfang Lin, Mohsen Moghaddam, Octavia Camps
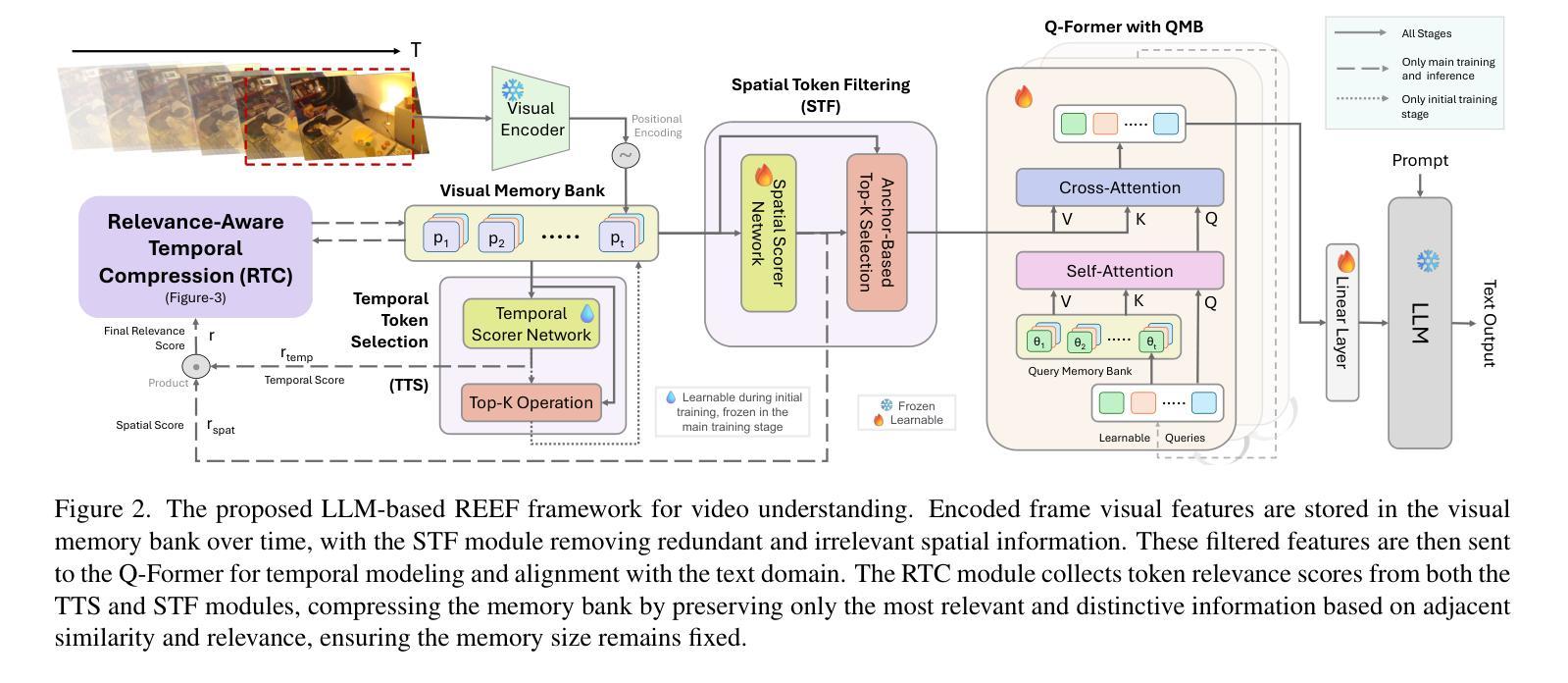
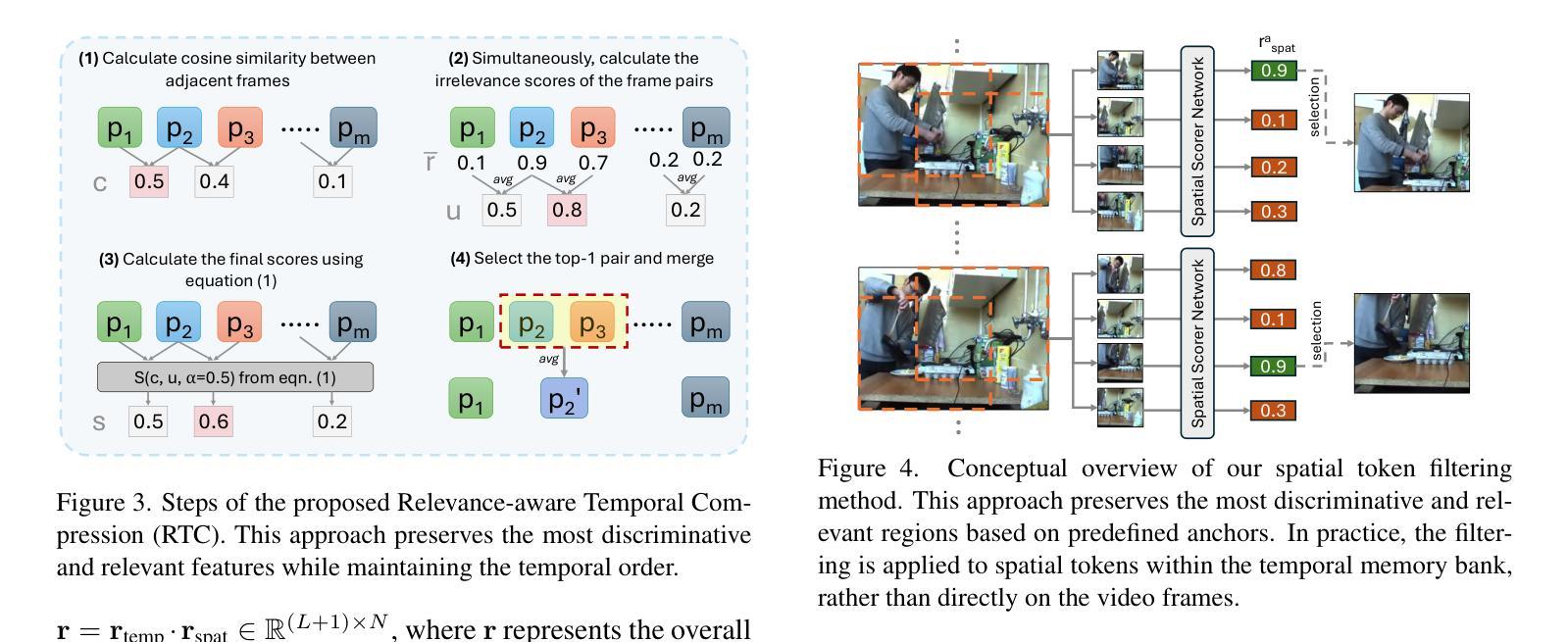
Integrating vision models into large language models (LLMs) has sparked significant interest in creating vision-language foundation models, especially for video understanding. Recent methods often utilize memory banks to handle untrimmed videos for video-level understanding. However, they typically compress visual memory using similarity-based greedy approaches, which can overlook the contextual importance of individual tokens. To address this, we introduce an efficient LLM adapter designed for video-level understanding of untrimmed videos that prioritizes the contextual relevance of spatio-temporal tokens. Our framework leverages scorer networks to selectively compress the visual memory bank and filter spatial tokens based on relevance, using a differentiable Top-K operator for end-to-end training. Across three key video-level understanding tasks$\unicode{x2013}$ untrimmed video classification, video question answering, and video captioning$\unicode{x2013}$our method achieves competitive or superior results on four large-scale datasets while reducing computational overhead by up to 34%. The code will be available soon on GitHub.
将视觉模型集成到大型语言模型(LLM)中,尤其是在视频理解方面,已经引起了人们对创建视觉语言基础模型的浓厚兴趣。最近的方法通常利用内存库来处理未修剪的视频以实现视频级别的理解。然而,它们通常使用基于相似性的贪婪方法来压缩视觉内存,这可能会忽略单个标记的上下文重要性。为了解决这一问题,我们引入了一种高效的LLM适配器,该适配器旨在实现对未修剪视频的基于视频级别的理解,并优先考虑时空标记的上下文相关性。我们的框架利用评分网络有选择地压缩视觉内存库,并根据相关性过滤空间标记,使用可微分的Top-K运算符进行端到端训练。在三项关键的基于视频的级别理解任务上——未修剪的视频分类、视频问答和视频字幕——我们的方法在四个大规模数据集上取得了有竞争力的或更好的结果,同时减少了高达34%的计算开销。相关代码很快将在GitHub上发布。
论文及项目相关链接
PDF Accepted at CVPRW’25
Summary
文本介绍了如何将视觉模型集成到大型语言模型(LLM)中,并专门应用于视频理解的。文中提出一种高效的LLM适配器,能够处理未修剪的视频以进行视频级别的理解,并且优先考虑时空令牌在上下文中的重要性。通过使用评分器网络选择性压缩视觉记忆库并基于相关性过滤空间令牌,同时采用可微分的Top-K算子进行端到端训练。实验结果显示该方法在三项关键的视频级理解任务上都获得了相当或更优秀的成果,同时降低了高达34%的计算开销。GitHub上将提供代码。
Key Takeaways
- 视觉模型与大型语言模型的集成是当前研究的热点,特别是在视频理解领域。
- 处理未修剪的视频进行视频级别的理解是一个挑战。
- 现有方法通过相似性贪椠算法压缩视觉记忆,可能忽略单个令牌在上下文中的重要性。
- 引入了一种高效的LLM适配器,用于视频级别的理解,该适配器优先考虑时空令牌在上下文中的重要性。
- 使用评分器网络选择性地压缩视觉记忆库,并基于相关性过滤空间令牌。
- 采用可微分的Top-K算子进行端到端训练。
点此查看论文截图