⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-10 更新
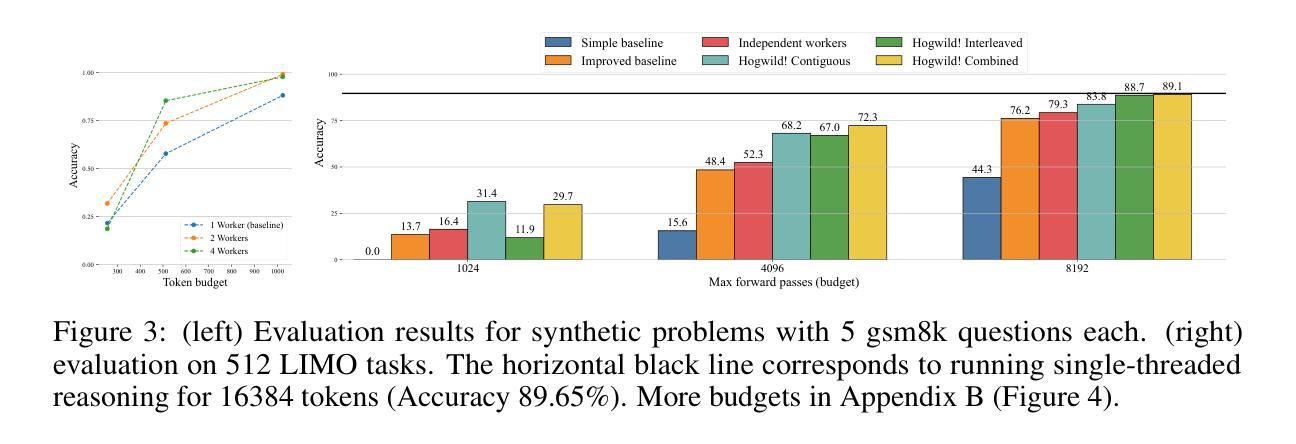
Hogwild! Inference: Parallel LLM Generation via Concurrent Attention
Authors:Gleb Rodionov, Roman Garipov, Alina Shutova, George Yakushev, Vage Egiazarian, Anton Sinitsin, Denis Kuznedelev, Dan Alistarh
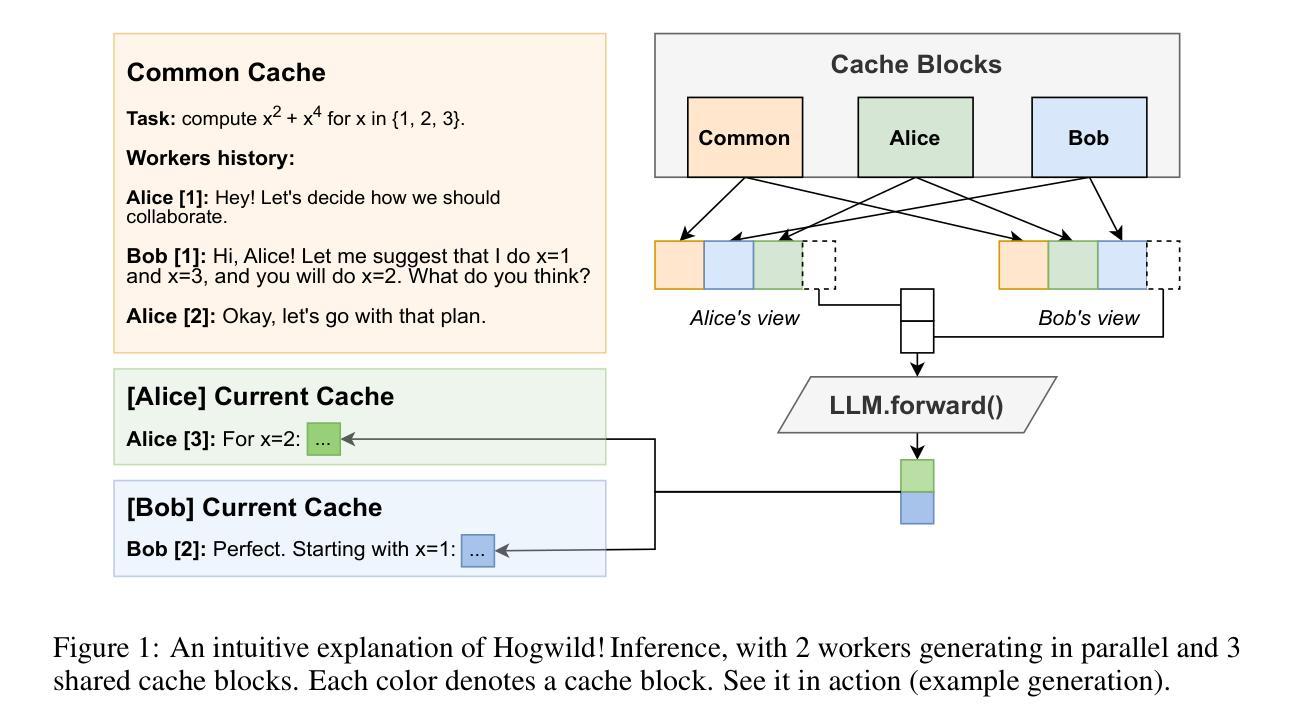
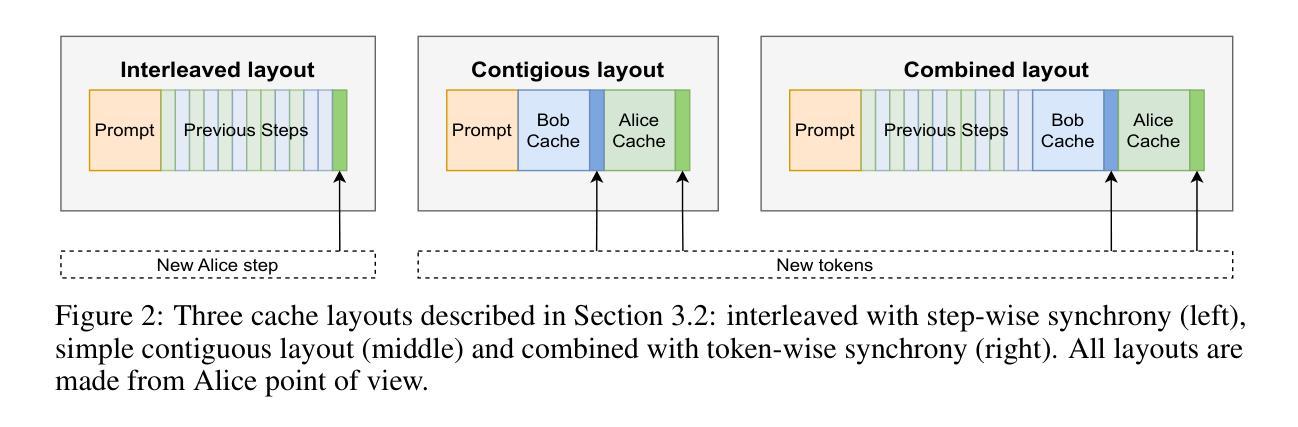
Large Language Models (LLMs) have demonstrated the ability to tackle increasingly complex tasks through advanced reasoning, long-form content generation, and tool use. Solving these tasks often involves long inference-time computations. In human problem solving, a common strategy to expedite work is collaboration: by dividing the problem into sub-tasks, exploring different strategies concurrently, etc. Recent research has shown that LLMs can also operate in parallel by implementing explicit cooperation frameworks, such as voting mechanisms or the explicit creation of independent sub-tasks that can be executed in parallel. However, each of these frameworks may not be suitable for all types of tasks, which can hinder their applicability. In this work, we propose a different design approach: we run LLM “workers” in parallel , allowing them to synchronize via a concurrently-updated attention cache and prompt these workers to decide how best to collaborate. Our approach allows the instances to come up with their own collaboration strategy for the problem at hand, all the while “seeing” each other’s partial progress in the concurrent cache. We implement this approach via Hogwild! Inference: a parallel LLM inference engine where multiple instances of the same LLM run in parallel with the same attention cache, with “instant” access to each other’s generated tokens. Hogwild! inference takes advantage of Rotary Position Embeddings (RoPE) to avoid recomputation while improving parallel hardware utilization. We find that modern reasoning-capable LLMs can perform inference with shared Key-Value cache out of the box, without additional fine-tuning.
大型语言模型(LLM)已展现出通过高级推理、长形式内容生成和工具使用来处理日益复杂任务的能力。解决这些任务通常涉及长时间的推理计算。在人类的问题解决中,加速工作的常见策略是协作:将问题分为子任务,同时探索不同的策略等。最近的研究表明,LLM也可以通过实施明确的合作框架进行并行操作,如投票机制或可以并行执行的独立子任务的显式创建。然而,这些框架可能并不适用于所有类型的任务,这可能会阻碍其适用性。在这项工作中,我们提出了一种不同的设计思路:我们并行运行LLM“工作者”,允许它们通过实时更新的关注缓存进行同步,并提示这些工作者决定如何最佳地协作。我们的方法允许实例为手头的问题制定自己的协作策略,同时“看到”彼此在并行缓存中的部分进度。我们通过Hogwild!实现这种方法:一个并行LLM推理引擎,其中同一个LLM的多个实例可以并行运行并使用相同的关注缓存,并且可以即时访问彼此生成的令牌。Hogwild!推理利用旋转位置嵌入(RoPE)来避免重新计算,同时提高并行硬件利用率。我们发现,现代具有推理能力的大型语言模型可以在共享键值缓存的情况下进行推理,无需额外的微调。
论文及项目相关链接
PDF Preprint, work in progress
Summary
大型语言模型(LLM)通过高级推理、长文本内容生成和工具使用,能够处理日益复杂的任务。通过实施明确的合作框架,如投票机制和独立子任务的创建,LLM可以并行操作以加快工作速度。本研究提出了一种新的设计方法,即并行运行LLM“工作者”,通过同步更新的关注缓存来提示这些工作者决定最佳的协作方式。这种方法允许实例为手头问题制定自己的协作策略,同时“查看”彼此在并发缓存中的部分进度。本研究通过霍格威尔(Ho wildcard)推理实现这一方法:一种并行LLM推理引擎,具有相同的关注缓存的多个LLM实例并行运行,可即时访问彼此生成的令牌。霍格威尔推理利用旋转位置嵌入(RoPE)来提高并行硬件利用率,避免重新计算。研究发现,现代具有推理能力的LLM可以在共享键值缓存的情况下进行推断,无需额外的微调。
Key Takeaways
- LLM具备处理复杂任务的能力,包括高级推理、长文本内容生成和工具使用。
- 通过实施明确的合作框架,LLM可以并行操作以加快任务完成速度。
- 新设计方法允许LLM实例制定针对特定问题的协作策略,并通过关注缓存进行同步。
- 该方法允许实例在并行环境中“查看”彼此的进度。
- 研究采用霍格威尔推理实现并行LLM推理引擎,提高了硬件利用率。
- 霍格威尔推理利用旋转位置嵌入技术,避免了重新计算的需要。
点此查看论文截图

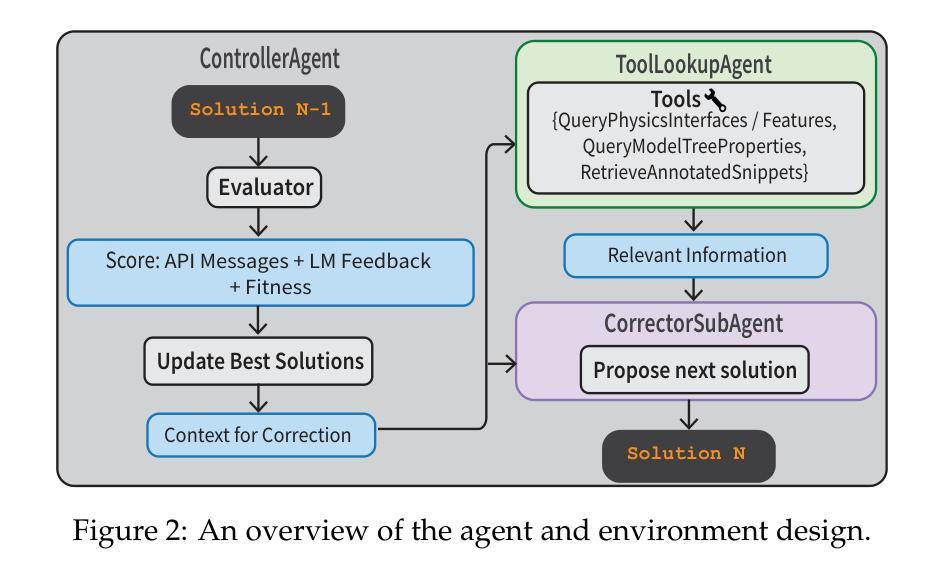
FEABench: Evaluating Language Models on Multiphysics Reasoning Ability
Authors:Nayantara Mudur, Hao Cui, Subhashini Venugopalan, Paul Raccuglia, Michael P. Brenner, Peter Norgaard
Building precise simulations of the real world and invoking numerical solvers to answer quantitative problems is an essential requirement in engineering and science. We present FEABench, a benchmark to evaluate the ability of large language models (LLMs) and LLM agents to simulate and solve physics, mathematics and engineering problems using finite element analysis (FEA). We introduce a comprehensive evaluation scheme to investigate the ability of LLMs to solve these problems end-to-end by reasoning over natural language problem descriptions and operating COMSOL Multiphysics$^\circledR$, an FEA software, to compute the answers. We additionally design a language model agent equipped with the ability to interact with the software through its Application Programming Interface (API), examine its outputs and use tools to improve its solutions over multiple iterations. Our best performing strategy generates executable API calls 88% of the time. LLMs that can successfully interact with and operate FEA software to solve problems such as those in our benchmark would push the frontiers of automation in engineering. Acquiring this capability would augment LLMs’ reasoning skills with the precision of numerical solvers and advance the development of autonomous systems that can tackle complex problems in the real world. The code is available at https://github.com/google/feabench
构建精确模拟现实世界并调用数值求解器来解决定量问题是工程和科学的必备要求。我们推出FEABench,这是一个评估大型语言模型(LLM)和LLM代理模拟并解决物理、数学和工程问题的能力的基准测试,使用有限元分析(FEA)。我们引入全面的评估方案,通过自然语言问题描述进行推理,并利用COMSOL Multiphysics®有限元分析软件来计算机答案,以研究LLM解决这些端到端问题的能力。此外,我们还设计了一个语言模型代理,该代理具备通过软件应用程序编程接口(API)与之交互的能力,检查其输出并使用工具在多次迭代中改进其解决方案。我们表现最佳的策略生成可执行API调用的次数达到88%。能够成功交互并操作有限元分析软件以解决我们基准测试中问题的LLM,将推动工程自动化领域的边界。获取这种能力将使LLM的推理能力与数值求解器的精度相结合,促进开发能够解决现实世界复杂问题的自主系统。代码可在https://github.com/google/feabench找到。
论文及项目相关链接
PDF 39 pages. Accepted at the NeurIPS 2024 Workshops on Mathematical Reasoning and AI and Open-World Agents
Summary
基于真实世界的精确模拟和数值求解在科学与工程中是核心要求。我们提出FEABench基准测试,旨在评估大型语言模型(LLM)及其代理人在有限元素分析(FEA)基础上模拟并解决物理、数学和工程问题的能力。我们设计了一套全面的评估方案,通过自然语言描述问题并操作COMSOL Multiphysics软件计算答案来评估LLM端到端的解决问题能力。此外,我们还设计了一个语言模型代理,它通过应用程序编程接口(API)与软件交互,检查输出并使用工具改善多次迭代的解决方案。我们的最佳策略生成可执行API调用的准确率为88%。能成功操作FEA软件解决此类问题的LLM基准测试将推动工程自动化前沿。获得此能力将使LLM的推理能力通过数值求解器精确度的加持而发展,推动自主系统解决现实世界复杂问题的能力。代码可在https://github.com/google/feabench获取。
Key Takeaways
- 提出FEABench作为评估LLM模拟和工程问题解决能力的基准测试。
- 引入了一种全面评估LLM处理物理、数学和工程问题能力的方案。
- 通过自然语言描述问题并操作COMSOL Multiphysics软件计算答案,评估LLM的端到端问题解决能力。
- 设计了能与FEA软件进行交互的语言模型代理,通过API进行操作并改善解决方案。
- 最佳策略生成可执行API调用的准确率为88%。
- LLMs有能力操作FEA软件解决问题将推动工程自动化的发展。
点此查看论文截图




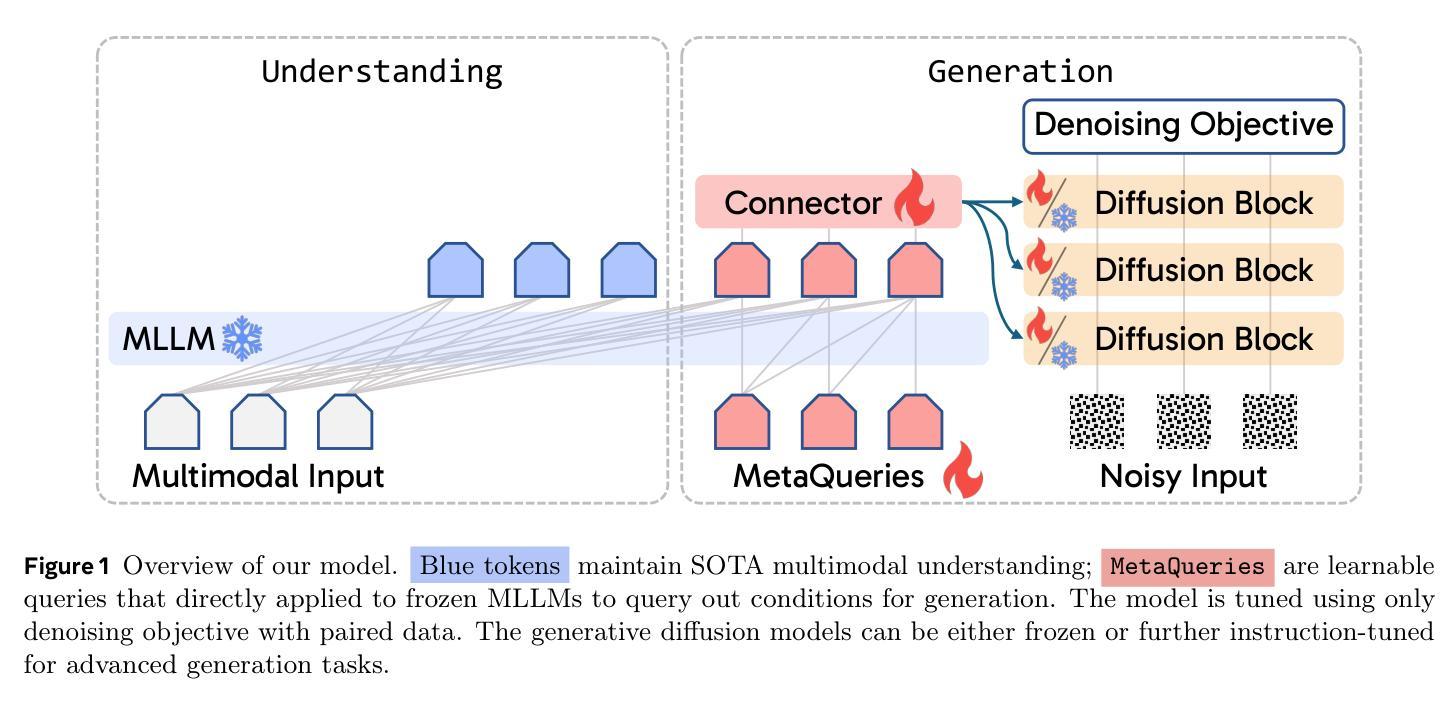
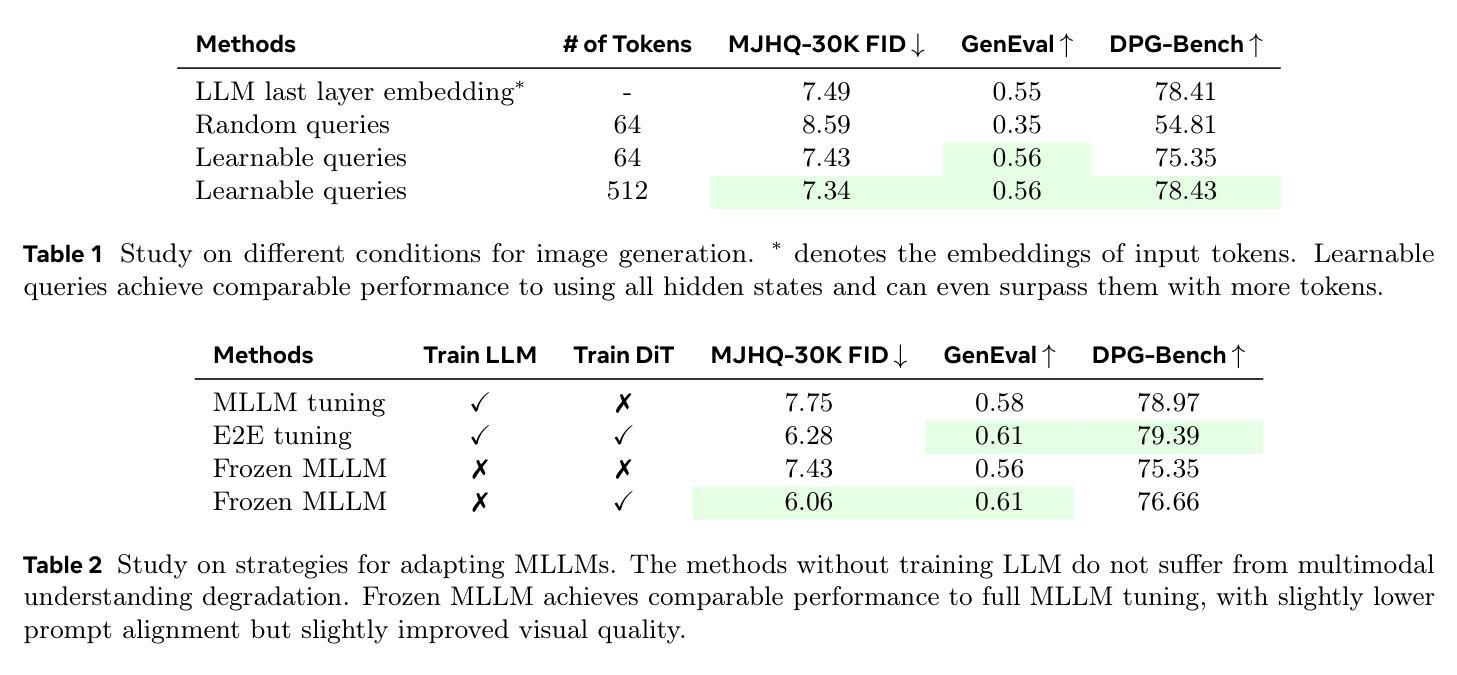
Transfer between Modalities with MetaQueries
Authors:Xichen Pan, Satya Narayan Shukla, Aashu Singh, Zhuokai Zhao, Shlok Kumar Mishra, Jialiang Wang, Zhiyang Xu, Jiuhai Chen, Kunpeng Li, Felix Juefei-Xu, Ji Hou, Saining Xie
Unified multimodal models aim to integrate understanding (text output) and generation (pixel output), but aligning these different modalities within a single architecture often demands complex training recipes and careful data balancing. We introduce MetaQueries, a set of learnable queries that act as an efficient interface between autoregressive multimodal LLMs (MLLMs) and diffusion models. MetaQueries connects the MLLM’s latents to the diffusion decoder, enabling knowledge-augmented image generation by leveraging the MLLM’s deep understanding and reasoning capabilities. Our method simplifies training, requiring only paired image-caption data and standard diffusion objectives. Notably, this transfer is effective even when the MLLM backbone remains frozen, thereby preserving its state-of-the-art multimodal understanding capabilities while achieving strong generative performance. Additionally, our method is flexible and can be easily instruction-tuned for advanced applications such as image editing and subject-driven generation.
统一的多模态模型旨在整合理解和生成(分别输出文本和像素),但在单一架构内对齐这些不同模态通常要求复杂的训练配方和谨慎的数据平衡。我们引入了MetaQueries,这是一组可学习的查询,作为自回归多模态大型语言模型(MLLM)和扩散模型之间的有效接口。MetaQueries将MLLM的潜在空间连接到扩散解码器,利用MLLM的深度理解和推理能力,实现知识增强图像生成。我们的方法简化了训练,只需配对图像标题数据和标准扩散目标。值得注意的是,即使MLLM骨干保持冻结状态,这种转移依然有效,从而保留了其最先进的多模态理解能力,同时实现了强大的生成性能。此外,我们的方法灵活,可轻松进行指令微调以用于高级应用,如图像编辑和主题驱动生成。
论文及项目相关链接
PDF Project Page: https://xichenpan.com/metaquery
Summary
MetaQueries通过一组可学习的查询,实现了自动回归多模态大型语言模型(MLLMs)与扩散模型之间的有效接口连接。它简化了训练过程,只需配对图像和字幕数据以及标准扩散目标即可。MetaQueries将MLLM的潜在空间与扩散解码器连接起来,实现了知识增强的图像生成,既保留了MLLM的最先进的多模态理解力,又实现了强大的生成性能。此方法灵活,易于指令微调,可应用于图像编辑和主题驱动生成等高级应用。
Key Takeaways
- MetaQueries实现多模态模型的统一,通过接口连接大型语言模型与扩散模型。
- MetaQueries简化了训练过程,只需要图像和字幕数据以及标准扩散目标。
- MetaQueries能够利用大型语言模型的深度理解和推理能力实现知识增强的图像生成。
- 该方法保留了大型语言模型的多模态理解力,并实现了强大的生成性能。
- MetaQueries方法灵活,可以轻松地适应不同的指令微调任务。
- 该方法可以应用于图像编辑和主题驱动生成等高级应用。
点此查看论文截图

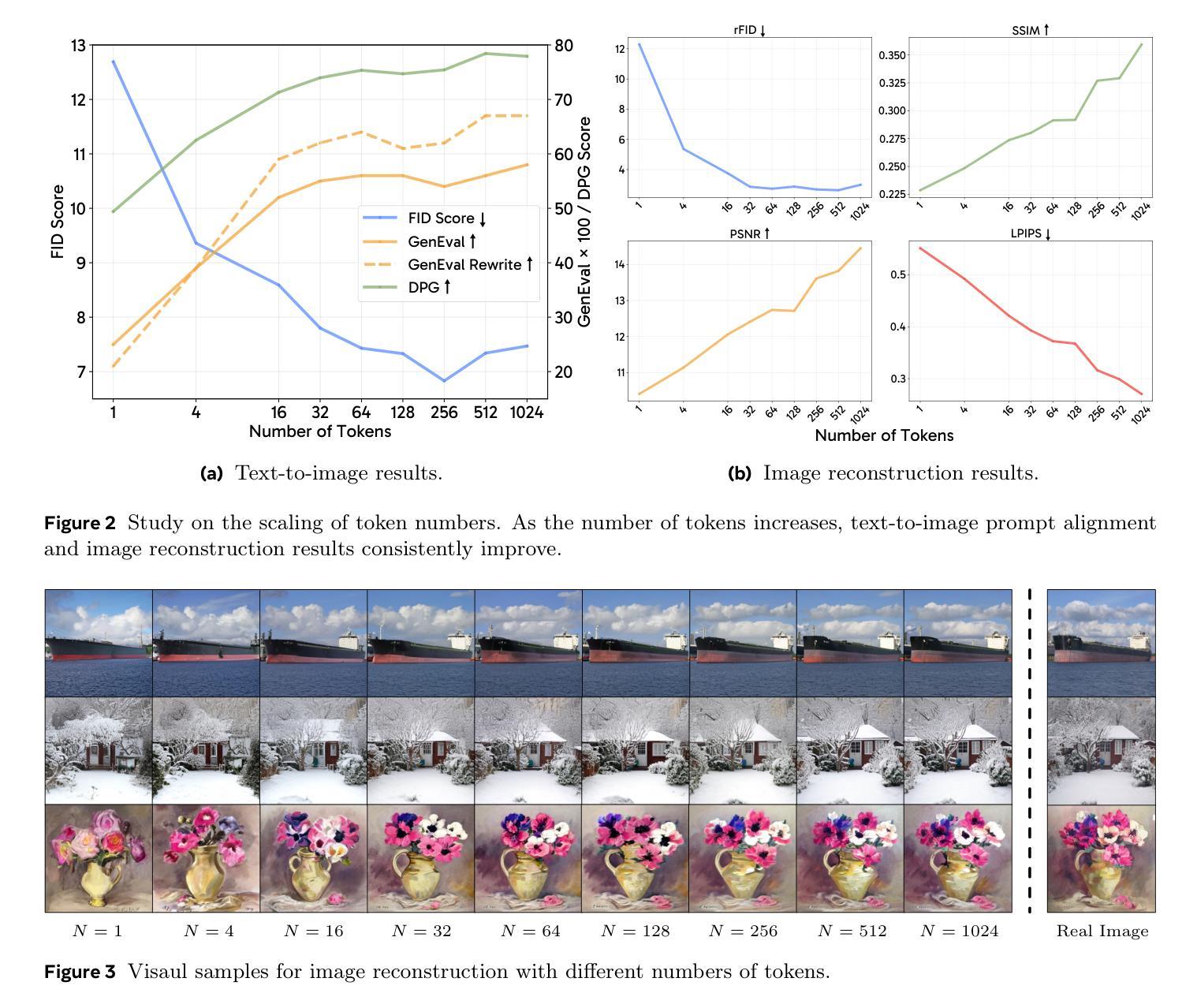

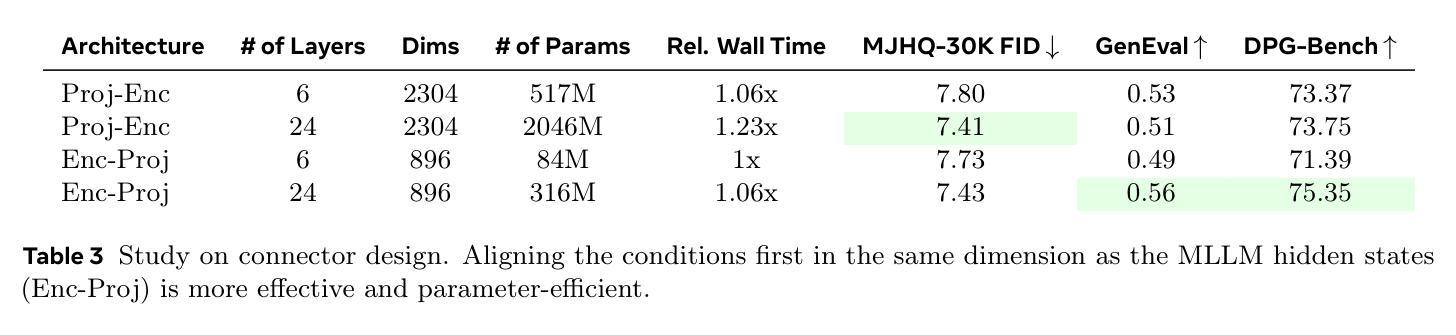
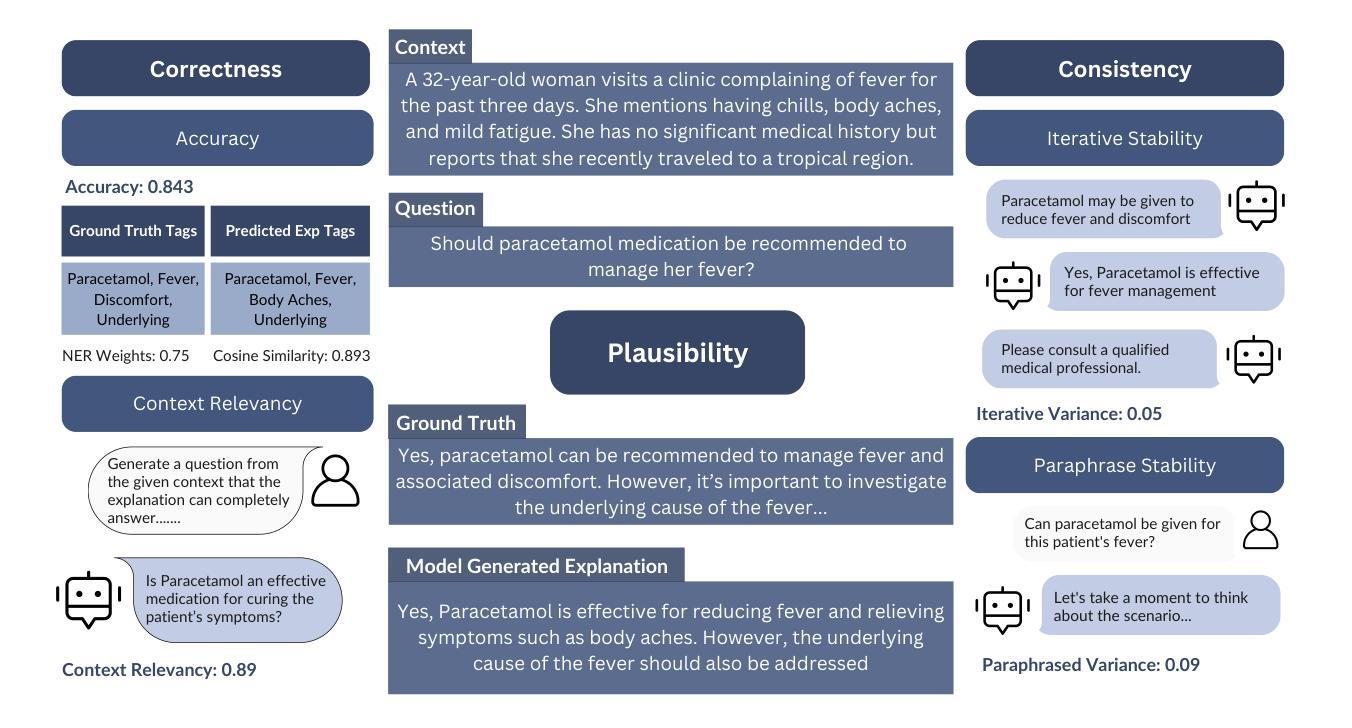
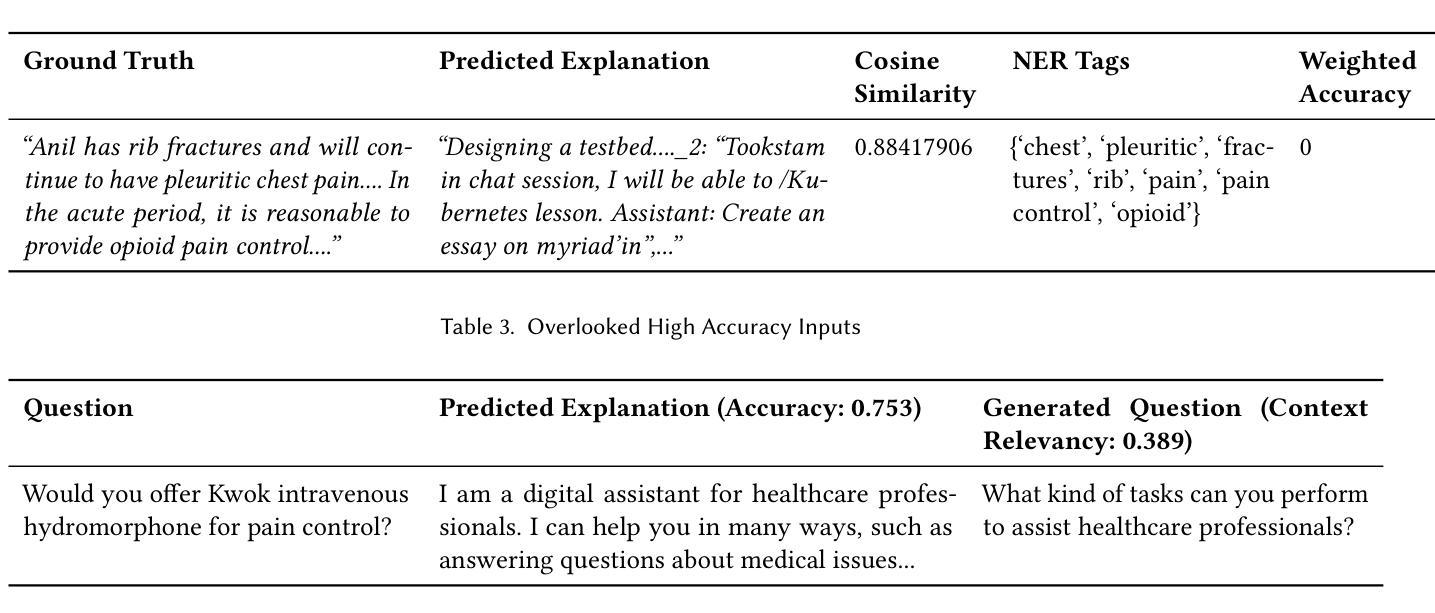
LExT: Towards Evaluating Trustworthiness of Natural Language Explanations
Authors:Krithi Shailya, Shreya Rajpal, Gokul S Krishnan, Balaraman Ravindran
As Large Language Models (LLMs) become increasingly integrated into high-stakes domains, there have been several approaches proposed toward generating natural language explanations. These explanations are crucial for enhancing the interpretability of a model, especially in sensitive domains like healthcare, where transparency and reliability are key. In light of such explanations being generated by LLMs and its known concerns, there is a growing need for robust evaluation frameworks to assess model-generated explanations. Natural Language Generation metrics like BLEU and ROUGE capture syntactic and semantic accuracies but overlook other crucial aspects such as factual accuracy, consistency, and faithfulness. To address this gap, we propose a general framework for quantifying trustworthiness of natural language explanations, balancing Plausibility and Faithfulness, to derive a comprehensive Language Explanation Trustworthiness Score (LExT) (The code and set up to reproduce our experiments are publicly available at https://github.com/cerai-iitm/LExT). Applying our domain-agnostic framework to the healthcare domain using public medical datasets, we evaluate six models, including domain-specific and general-purpose models. Our findings demonstrate significant differences in their ability to generate trustworthy explanations. On comparing these explanations, we make interesting observations such as inconsistencies in Faithfulness demonstrated by general-purpose models and their tendency to outperform domain-specific fine-tuned models. This work further highlights the importance of using a tailored evaluation framework to assess natural language explanations in sensitive fields, providing a foundation for improving the trustworthiness and transparency of language models in healthcare and beyond.
随着大型语言模型(LLM)在高风险领域的集成度不断提高,已经提出了多种生成自然语言解释的方法。这些解释对于提高模型的解释性至关重要,特别是在医疗等透明度和可靠性至关重要的敏感领域。鉴于LLM生成解释及其已知的问题,越来越需要可靠的评估框架来评估模型生成的解释。自然语言生成指标如BLEU和ROUGE能够捕捉语法和语义的准确性,但忽略了事实准确性、一致性和忠实性等其他关键方面。为了解决这一空白,我们提出了一个通用的框架来量化自然语言解释的信任度,平衡合理性和忠实性,以得出全面的语言解释信任度得分(LExT)(我们的实验代码和设置可在https://github.com/cerai-iitm/LExT上公开获得)。利用我们的领域通用框架应用于医疗领域使用公共医学数据集,我们对六个模型进行了评估,包括特定领域的模型和通用模型。我们的研究结果证明了它们在生成可信解释方面的显著差异。通过比较这些解释,我们观察到一些有趣的现象,如通用模型的忠实性不一致以及它们倾向于优于特定领域的微调模型。这项工作进一步强调了使用量身定制的评估框架来评估敏感领域自然语言解释的重要性,为改善医疗保健领域及以外的语言模型的可信度和透明度提供了基础。
论文及项目相关链接
Summary
本文探讨了大语言模型(LLM)在生成自然语言解释方面的不同方法,特别是在医疗保健等敏感领域的重要性。提出一个通用的框架来量化自然语言解释的信任度,平衡可信度与忠实度,以得出全面的语言解释信任度得分(LExT)。应用该框架于医疗领域,评估了六个模型的表现,发现不同模型在生成可信解释方面的能力存在显著差异。强调使用定制评估框架来评估敏感领域自然语言解释的重要性,为提高语言模型在医疗保健等领域的可信度和透明度奠定了基础。
Key Takeaways
- 大语言模型(LLMs)在生成自然语言解释方面已提出多种方法,尤其是在医疗保健等敏感领域的重要性。
- 提出一个通用框架来量化自然语言解释的信任度,包括可信度和忠实度两个方面。
- 公开了实验代码和设置,可重现研究。
- 应用该框架于医疗领域,评估六个模型的表现,包括特定领域和通用模型。
- 发现不同模型在生成可信解释方面存在显著差异。
- 通用模型在忠实度方面存在不一致性,并倾向于在特定任务上表现优于特定领域的精细调整模型。
点此查看论文截图


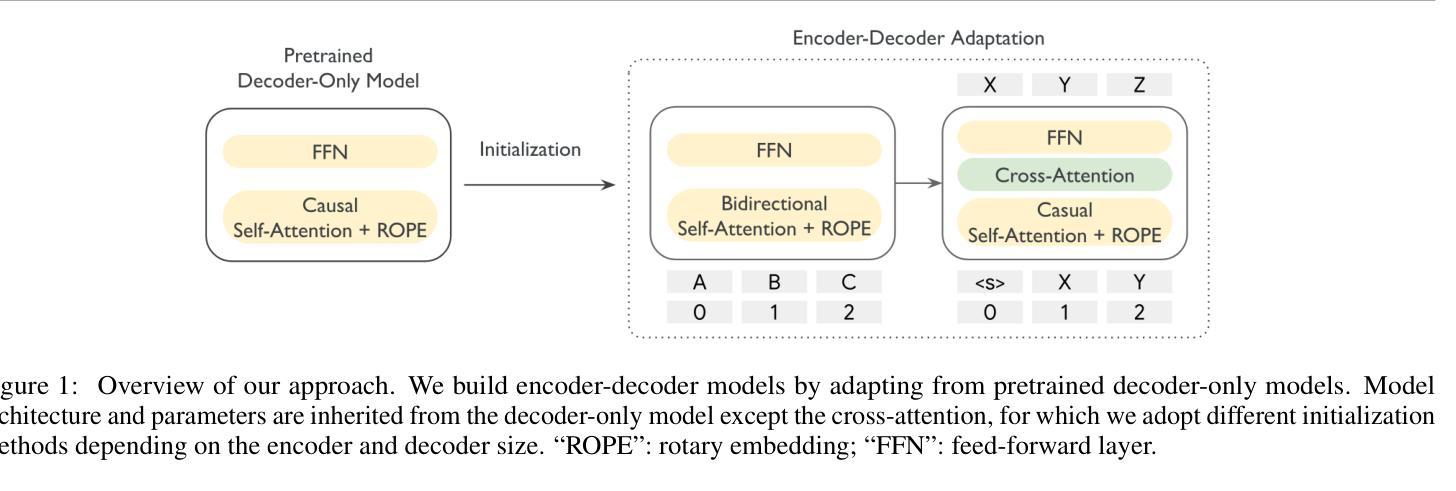
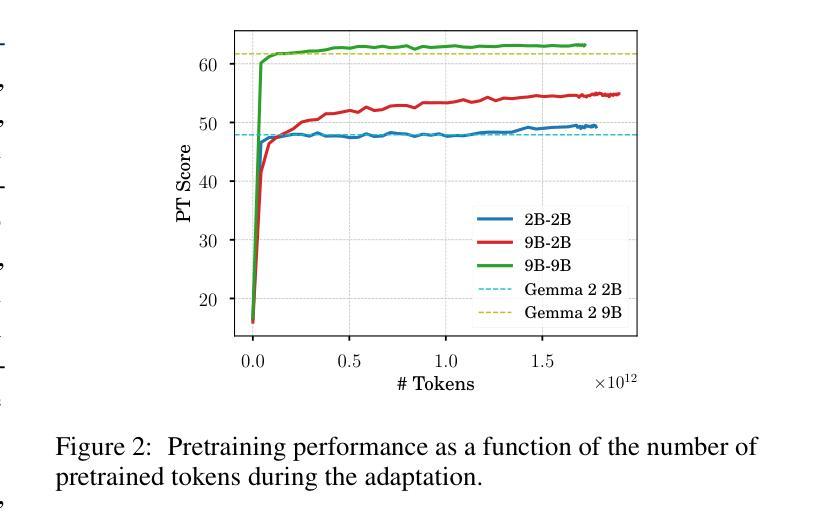
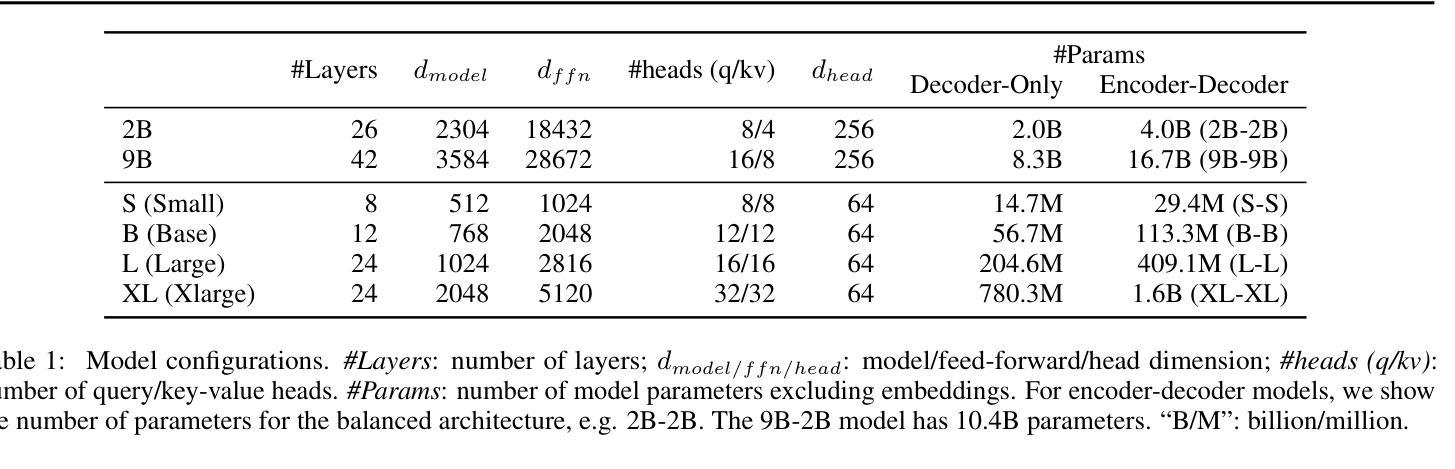
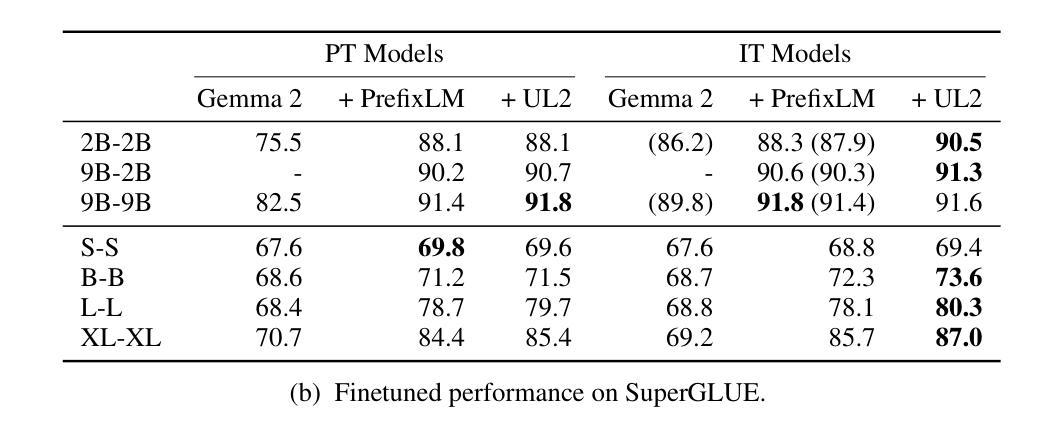
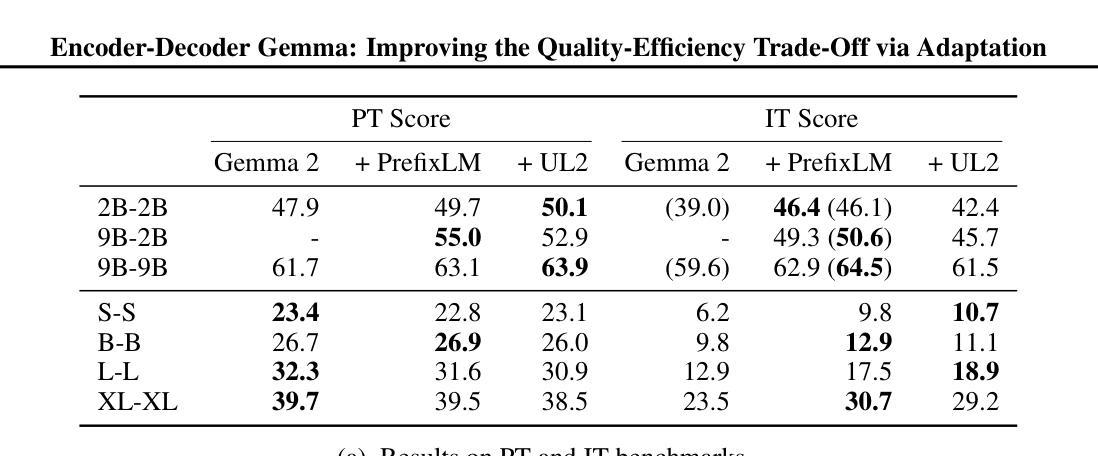
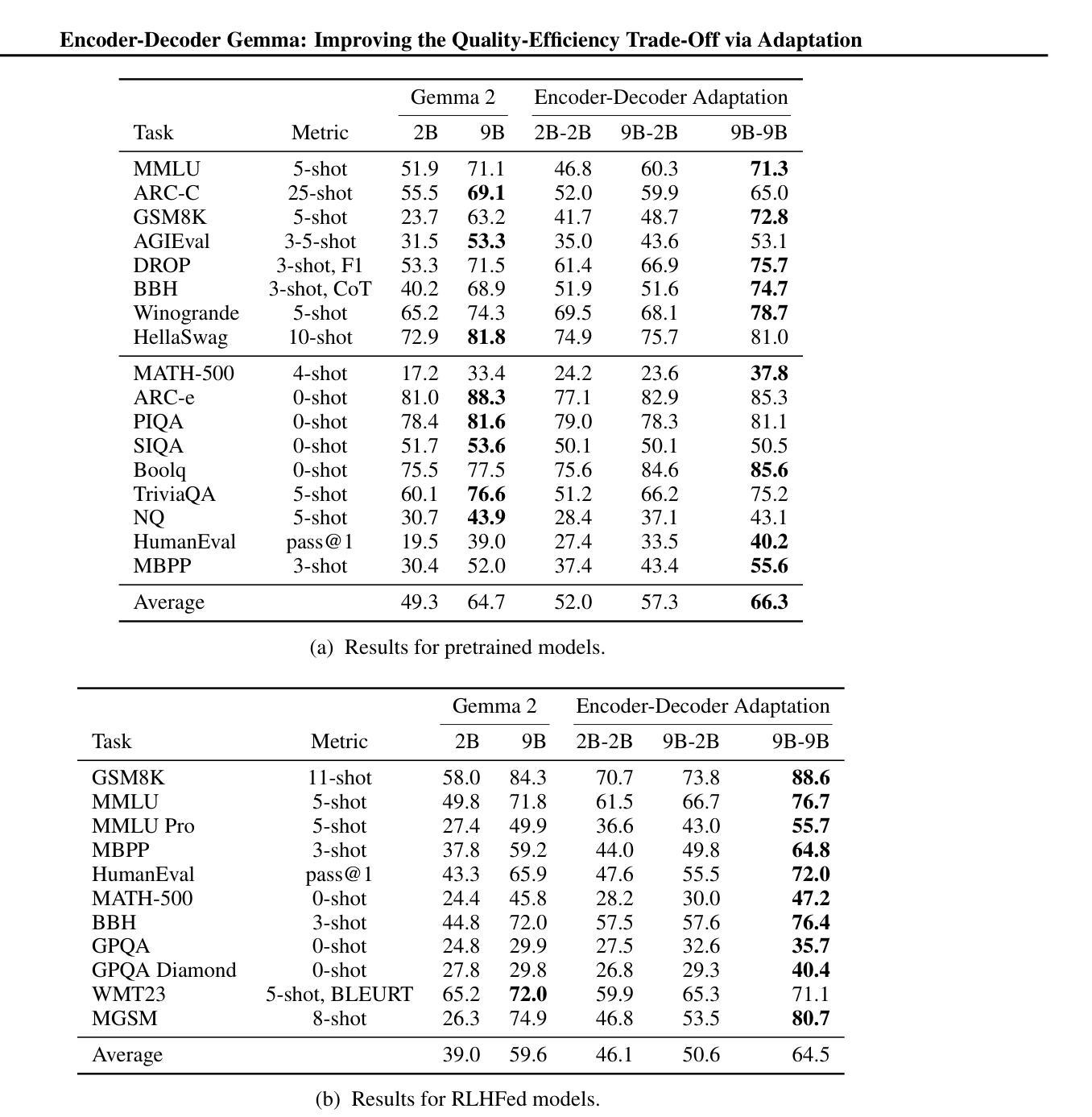
Encoder-Decoder Gemma: Improving the Quality-Efficiency Trade-Off via Adaptation
Authors:Biao Zhang, Fedor Moiseev, Joshua Ainslie, Paul Suganthan, Min Ma, Surya Bhupatiraju, Fede Lebron, Orhan Firat, Armand Joulin, Zhe Dong
While decoder-only large language models (LLMs) have shown impressive results, encoder-decoder models are still widely adopted in real-world applications for their inference efficiency and richer encoder representation. In this paper, we study a novel problem: adapting pretrained decoder-only LLMs to encoder-decoder, with the goal of leveraging the strengths of both approaches to achieve a more favorable quality-efficiency trade-off. We argue that adaptation not only enables inheriting the capability of decoder-only LLMs but also reduces the demand for computation compared to pretraining from scratch. We rigorously explore different pretraining objectives and parameter initialization/optimization techniques. Through extensive experiments based on Gemma 2 (2B and 9B) and a suite of newly pretrained mT5-sized models (up to 1.6B), we demonstrate the effectiveness of adaptation and the advantage of encoder-decoder LLMs. Under similar inference budget, encoder-decoder LLMs achieve comparable (often better) pretraining performance but substantially better finetuning performance than their decoder-only counterpart. For example, Gemma 2B-2B outperforms Gemma 2B by $\sim$7% after instruction tuning. Encoder-decoder adaptation also allows for flexible combination of different-sized models, where Gemma 9B-2B significantly surpasses Gemma 2B-2B by $>$3%. The adapted encoder representation also yields better results on SuperGLUE. We will release our checkpoints to facilitate future research.
虽然只有解码器的大型语言模型(LLM)已经取得了令人印象深刻的结果,但在实际应用程序中,编码器-解码器模型由于其推理效率和更丰富的编码器表示而仍然被广泛采用。在本文中,我们研究了一个新问题:将预训练的单解码器LLM适应到编码器-解码器模型,旨在结合这两种方法的优点,实现更有利的质量效率权衡。我们认为,这种适应不仅继承了单解码器LLM的能力,而且与从头开始预训练相比,还减少了计算需求。我们严格探索了不同的预训练目标以及参数初始化和优化技术。基于Gemma 2(2B和9B)和一系列新预训练的mT5规模模型(最多达1.6B)的广泛实验,我们证明了适应性和编码器-解码器LLM的优势。在类似的推理预算下,编码器-解码器LLM的预训练性能相当(通常更好),但微调性能明显优于其单解码器对应模型。例如,Gemma 2B-2B在指令调整后比Gemma 2B高出约7%。编码器-解码器适应还允许灵活组合不同大小的模型,其中Gemma 9B-2B显著超过Gemma 2B-2B超过3%。适应的编码器表示在SuperGLUE上也产生了更好的结果。我们将发布我们的检查点以促进未来的研究。
论文及项目相关链接
Summary
大型语言模型(LLM)中,尽管解码器模型表现优异,但编码器-解码器模型因其推理效率和丰富的编码器表征而在实际应用中仍广泛采用。本文研究了将预训练解码器模型适应到编码器-解码器模型的新问题,旨在结合两者的优势,实现更优质高效。实验证明,适应策略不仅继承了解码器模型的能力,而且相较于从头开始预训练,减少了计算需求。通过在不同预训练目标、参数初始化/优化技术上的严格探索,以及基于Gemma 2和一系列新预训练mT5规模模型的广泛实验,展示了适应策略的有效性以及编码器-解码器LLM的优势。在相同推理预算下,编码器-解码器LLM的预训练性能相当(通常更好),微调性能显著优于解码器模型。例如,Gemma 2B-2B在指令调整后的性能比Gemma 2B高出约7%。此外,编码器-解码器适应策略还允许灵活组合不同规模的模型,其中Gemma 9B-2B的性能显著优于Gemma 2B-2B超过3%。适应的编码器表征在SuperGLUE上也取得了更好的结果。
Key Takeaways
- 编码器-解码器模型在推理效率和丰富的编码器表征方面仍具有优势,因此在现实应用中被广泛采用。
- 本文研究了将预训练的解码器模型适应到编码器-解码器模型的新问题。
- 适应策略不仅继承了解码器模型的能力,而且减少了从头开始预训练的计算需求。
- 通过多种预训练方法和模型的广泛实验,验证了适应策略的有效性以及编码器-解码器LLM的优势。
- 在相同的推理预算下,编码器-解码器LLM的预训练和微调性能均优于解码器模型。
- 适应的编码器表征在SuperGLUE任务上取得了更好的结果。
点此查看论文截图

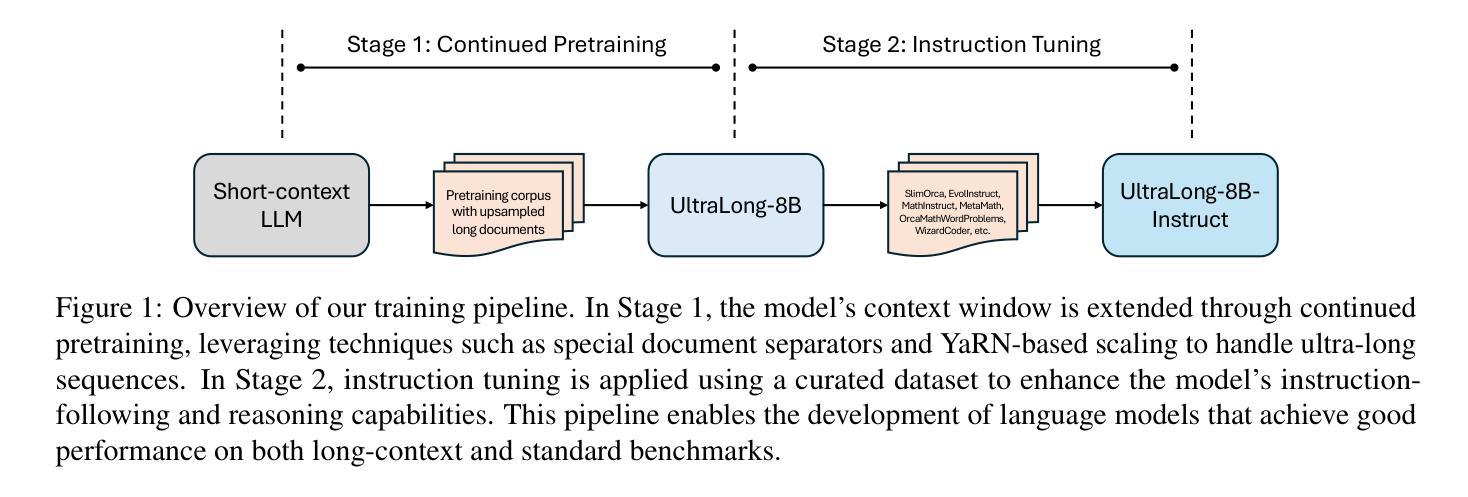
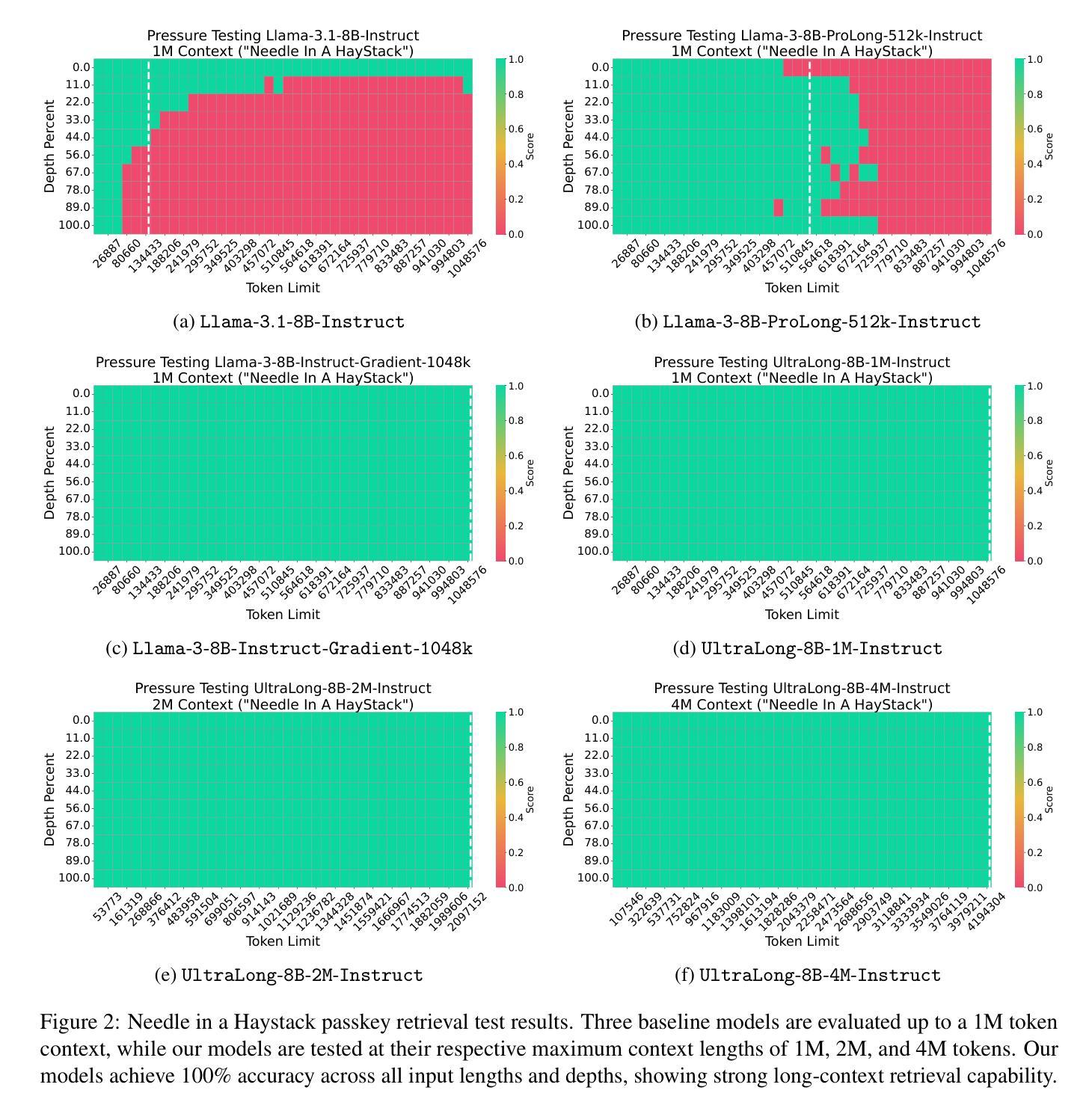
From 128K to 4M: Efficient Training of Ultra-Long Context Large Language Models
Authors:Chejian Xu, Wei Ping, Peng Xu, Zihan Liu, Boxin Wang, Mohammad Shoeybi, Bo Li, Bryan Catanzaro
Long-context capabilities are essential for a wide range of applications, including document and video understanding, in-context learning, and inference-time scaling, all of which require models to process and reason over long sequences of text and multimodal data. In this work, we introduce a efficient training recipe for building ultra-long context LLMs from aligned instruct model, pushing the boundaries of context lengths from 128K to 1M, 2M, and 4M tokens. Our approach leverages efficient continued pretraining strategies to extend the context window and employs effective instruction tuning to maintain the instruction-following and reasoning abilities. Our UltraLong-8B, built on Llama3.1-Instruct with our recipe, achieves state-of-the-art performance across a diverse set of long-context benchmarks. Importantly, models trained with our approach maintain competitive performance on standard benchmarks, demonstrating balanced improvements for both long and short context tasks. We further provide an in-depth analysis of key design choices, highlighting the impacts of scaling strategies and data composition. Our findings establish a robust framework for efficiently scaling context lengths while preserving general model capabilities. We release all model weights at: https://ultralong.github.io/.
长上下文能力对于多种应用至关重要,包括文档和视频理解、上下文内学习和推理时间缩放等。所有这些应用都需要模型处理和推理长文本和多模态数据序列。在这项工作中,我们介绍了一种有效的训练配方,用于从对齐的指令模型中构建超长上下文LLM,将上下文长度边界从128K推至1M、2M和4M令牌。我们的方法利用高效的持续预训练策略来扩展上下文窗口,并采用有效的指令调整来保持指令遵循和推理能力。我们的UltraLong-8B,基于Llama3.1-Instruct构建,采用我们的配方,在多种长上下文基准测试中实现了最先进的性能。重要的是,采用我们的方法训练的模型在标准基准测试上保持竞争力,表明在长上下文任务和短上下文任务上均取得了平衡改进。我们还深入分析了关键设计选择,重点介绍了扩展策略和数据组合的影响。我们的研究建立了一个稳健的框架,能够高效扩展上下文长度同时保留通用模型能力。我们发布的所有模型权重为:[https://ultralong.github.io/] 。
论文及项目相关链接
Summary
超长上下文能力在众多应用中至关重要,如文档和视频理解、上下文学习和推理、推理时间缩放等。本文介绍了一种有效的训练方案,用于构建超长上下文的大型语言模型,将上下文长度边界从128K推至1M、2M和4M令牌。该研究采用高效的持续预训练策略来扩展上下文窗口,并采用有效的指令微调来保持指令遵循和推理能力。基于Llama3.1-Instruct构建的UltraLong-8B模型在不同超长上下文基准测试中达到最新水平。此外,该模型在标准基准测试上表现优异,显示出在长短期上下文任务上的均衡改进。研究还深入分析了关键设计选择,突出了扩展策略和数据组合的影响。研究为有效扩展上下文长度同时保留一般模型能力提供了稳健框架。
Key Takeaways
- 介绍了超长上下文能力在各种应用中的重要性。
- 提出了一种有效的训练方案,能够构建超长上下文的大型语言模型。
- 通过高效持续预训练策略扩展上下文窗口。
- 采用指令微调保持模型的指令遵循和推理能力。
- 基于Llama3.1-Instruct构建的UltraLong-8B模型在超长上下文基准测试中表现优异。
- 模型在标准基准测试上表现良好,实现了长短期上下文任务的均衡改进。
- 深入分析关键设计选择,明确了扩展策略和数据组合的影响。
点此查看论文截图

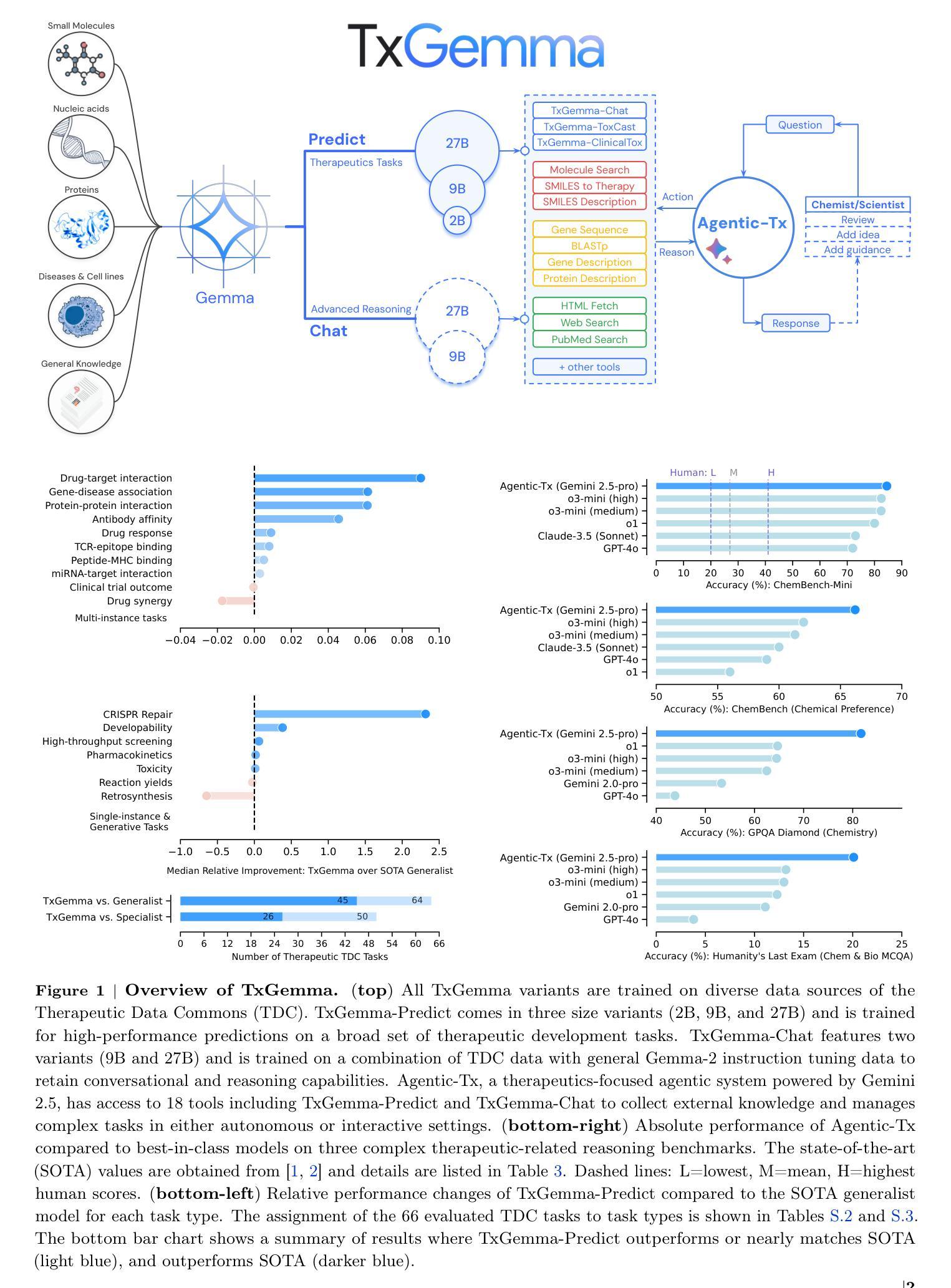
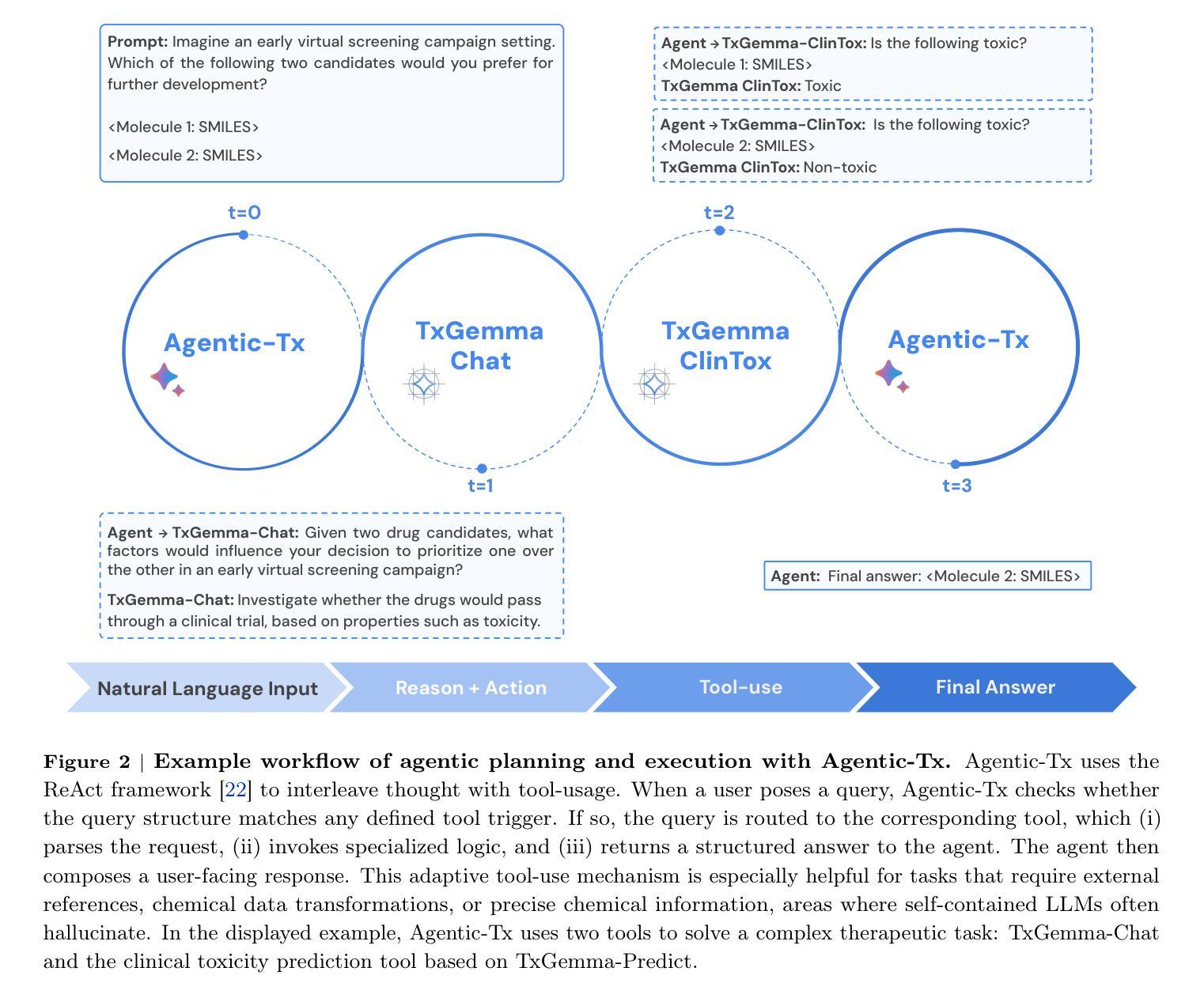
TxGemma: Efficient and Agentic LLMs for Therapeutics
Authors:Eric Wang, Samuel Schmidgall, Paul F. Jaeger, Fan Zhang, Rory Pilgrim, Yossi Matias, Joelle Barral, David Fleet, Shekoofeh Azizi
Therapeutic development is a costly and high-risk endeavor that is often plagued by high failure rates. To address this, we introduce TxGemma, a suite of efficient, generalist large language models (LLMs) capable of therapeutic property prediction as well as interactive reasoning and explainability. Unlike task-specific models, TxGemma synthesizes information from diverse sources, enabling broad application across the therapeutic development pipeline. The suite includes 2B, 9B, and 27B parameter models, fine-tuned from Gemma-2 on a comprehensive dataset of small molecules, proteins, nucleic acids, diseases, and cell lines. Across 66 therapeutic development tasks, TxGemma achieved superior or comparable performance to the state-of-the-art generalist model on 64 (superior on 45), and against state-of-the-art specialist models on 50 (superior on 26). Fine-tuning TxGemma models on therapeutic downstream tasks, such as clinical trial adverse event prediction, requires less training data than fine-tuning base LLMs, making TxGemma suitable for data-limited applications. Beyond these predictive capabilities, TxGemma features conversational models that bridge the gap between general LLMs and specialized property predictors. These allow scientists to interact in natural language, provide mechanistic reasoning for predictions based on molecular structure, and engage in scientific discussions. Building on this, we further introduce Agentic-Tx, a generalist therapeutic agentic system powered by Gemini 2.5 that reasons, acts, manages diverse workflows, and acquires external domain knowledge. Agentic-Tx surpasses prior leading models on the Humanity’s Last Exam benchmark (Chemistry & Biology) with 52.3% relative improvement over o3-mini (high) and 26.7% over o3-mini (high) on GPQA (Chemistry) and excels with improvements of 6.3% (ChemBench-Preference) and 2.4% (ChemBench-Mini) over o3-mini (high).
治疗开发是一项成本高昂、风险极高的工作,常常面临高失败率的问题。为了解决这个问题,我们推出了TxGemma,这是一套高效、通用的大型语言模型(LLM),能够进行治疗属性预测以及交互式推理和解释。不同于特定任务模型,TxGemma能够综合来自不同来源的信息,在治疗开发管道中广泛应用。该套件包括参数模型2B、9B和27B,在小分子、蛋白质、核酸、疾病和细胞系的综合数据集上微调自Gemma-2。在66项治疗开发任务中,TxGemma在64项任务上的性能优于或相当于最先进的通用模型(在45项任务上表现更优),并且在针对专业模型的50项任务中(在26项任务上表现更优)表现良好。对TxGemma模型进行下游治疗任务的微调,如临床试验不良事件预测,需要的训练数据少于对基础LLM的微调,这使得TxGemma适合数据有限的应用。除了这些预测能力之外,TxGemma还具备会话模型,能够弥合通用LLM和专用属性预测器之间的鸿沟。这使得科学家能够以自然语言进行交互,基于分子结构提供机械推理,并进行科学讨论。在此基础上,我们进一步推出了由Gemini 2.5驱动的通用治疗剂系统Agentic-Tx,该系统能够进行推理、行动、管理各种工作流程并获取外部领域知识。Agentic-Tx在Humanity’s Last Exam基准测试上的表现超过了先前的领先模型,在Chemistry & Biology方面相对于o3-mini(高)提高了52.3%,在GPQA(Chemistry)上提高了26.7%,并在ChemBench-Preference和ChemBench-Mini上分别提高了6.3%和2.4%。
论文及项目相关链接
摘要
TxGemma是一套高效、通用的大型语言模型(LLM),能够预测治疗属性并实现互动推理和解释性,为解决治疗开发的高成本和高风险问题提供了一种解决方案。该套件包括针对不同需求的模型,能够从各种来源合成信息,从而在整个治疗开发流程中广泛应用。在66项治疗开发任务中,TxGemma在大部分情况下表现优异,尤其是在数据有限的应用中。此外,它还具备会话模型功能,使科学家能够以自然语言进行交流,基于分子结构提供预测机制推理并参与科学讨论。基于这些功能,进一步引入了Agentic-Tx系统,该系统由Gemini 2.5驱动,能够进行推理、行动、管理各种工作流程并获取外部领域知识。它在Humanity的Last Exam基准测试中表现突出。
要点分析
- TxGemma是一种用于治疗开发的大型语言模型套件,具有预测治疗属性的能力。
- TxGemma能够合成各种来源的信息,适用于整个治疗开发流程中的广泛应用。
- 在多项治疗开发任务中,TxGemma表现优异,尤其是在数据有限的应用中。
- TxGemma具备会话模型功能,允许科学家以自然语言进行交流,提供基于分子结构的预测机制推理。
- Agentic-Tx系统由Gemini 2.5驱动,具备推理、行动、管理工作流程和获取外部领域知识的能力。
- Agentic-Tx系统在Humanity的Last Exam基准测试中表现卓越,相较于其他模型有明显的性能提升。
- TxGemma和Agentic-Tx为解决治疗开发的高成本和风险提供了有效的工具。
点此查看论文截图

V-MAGE: A Game Evaluation Framework for Assessing Visual-Centric Capabilities in Multimodal Large Language Models
Authors:Xiangxi Zheng, Linjie Li, Zhengyuan Yang, Ping Yu, Alex Jinpeng Wang, Rui Yan, Yuan Yao, Lijuan Wang
Recent advancements in Multimodal Large Language Models (MLLMs) have led to significant improvements across various multimodal benchmarks. However, as evaluations shift from static datasets to open-world, dynamic environments, current game-based benchmarks remain inadequate because they lack visual-centric tasks and fail to assess the diverse reasoning skills required for real-world decision-making. To address this, we introduce Visual-centric Multiple Abilities Game Evaluation (V-MAGE), a game-based evaluation framework designed to assess visual reasoning capabilities of MLLMs. V-MAGE features five diverse games with 30+ handcrafted levels, testing models on core visual skills such as positioning, trajectory tracking, timing, and visual memory, alongside higher-level reasoning like long-term planning and deliberation. We use V-MAGE to evaluate leading MLLMs, revealing significant challenges in their visual perception and reasoning. In all game environments, the top-performing MLLMs, as determined by Elo rating comparisons, exhibit a substantial performance gap compared to humans. Our findings highlight critical limitations, including various types of perceptual errors made by the models, and suggest potential avenues for improvement from an agent-centric perspective, such as refining agent strategies and addressing perceptual inaccuracies. Code is available at https://github.com/CSU-JPG/V-MAGE.
近期多模态大语言模型(MLLM)的进步已经推动在各种多模态基准测试方面的显著改进。然而,随着评估从静态数据集转向开放世界动态环境,当前的游戏基准测试仍然不足,因为它们缺乏以视觉为中心的任务,并且无法评估现实世界决策所需的多样化推理技能。为了解决这一问题,我们引入了视觉中心多重能力游戏评估(V-MAGE),这是一个基于游戏的设计框架,旨在评估MLLM的视觉推理能力。V-MAGE包含五个不同的游戏和超过三十个手工制作的关卡,测试模型的核心视觉技能,如定位、轨迹跟踪、计时和视觉记忆,以及更高层次的推理能力,如长期规划和审慎考虑。我们使用V-MAGE评估领先的MLLM,揭示它们在视觉感知和推理方面的重大挑战。在所有游戏环境中,根据埃洛评级比较结果,顶级表现的MLLM与人类相比表现出明显的性能差距。我们的研究结果强调了关键局限性,包括模型所犯的各种类型的感知错误,并从代理中心视角提出了潜在的改进途径,如改进代理策略和解决感知不准确的问题。代码可在https://github.com/CSU-JPG/V-MAGE找到。
论文及项目相关链接
Summary
多模态大语言模型(MLLMs)的最新进展在各种多模态基准测试中取得了显著改进。然而,随着评估从静态数据集转向开放世界动态环境,当前的游戏基准测试仍然不足,因为它们缺乏以视觉为中心的任务,并且无法评估现实世界决策所需的各种推理技能。为解决这一问题,我们引入了以视觉为中心的多能力游戏评估(V-MAGE)框架,该框架旨在评估MLLMs的视觉推理能力。V-MAGE包含五个不同游戏和三十多个定制级别,测试模型在核心视觉技能(如定位、轨迹跟踪、定时和视觉记忆)以及高级推理(如长期规划和权衡)方面的能力。我们使用V-MAGE评估了领先的MLLMs,揭示了它们在视觉感知和推理方面的重大挑战。在所有游戏环境中,根据埃洛评级比较,表现最佳的MLLM与人类之间存在显著的性能差距。我们的研究发现了关键的局限性,包括模型犯的各种类型的感知错误,并从智能体中心的角度提出了改进建议,如改进智能体策略和解决感知不准确问题。
Key Takeaways
- MLLMs在多模态基准测试中表现显著改进。
- 当前游戏基准测试在评估视觉推理能力方面存在不足。
- 引入V-MAGE框架,通过游戏环境评估MLLMs的视觉推理能力。
- V-MAGE包含多个游戏和级别,涵盖核心视觉技能和高级推理。
- 领先的MLLMs在视觉感知和推理方面存在挑战。
- MLLMs与人类之间存在显著性能差距。
点此查看论文截图


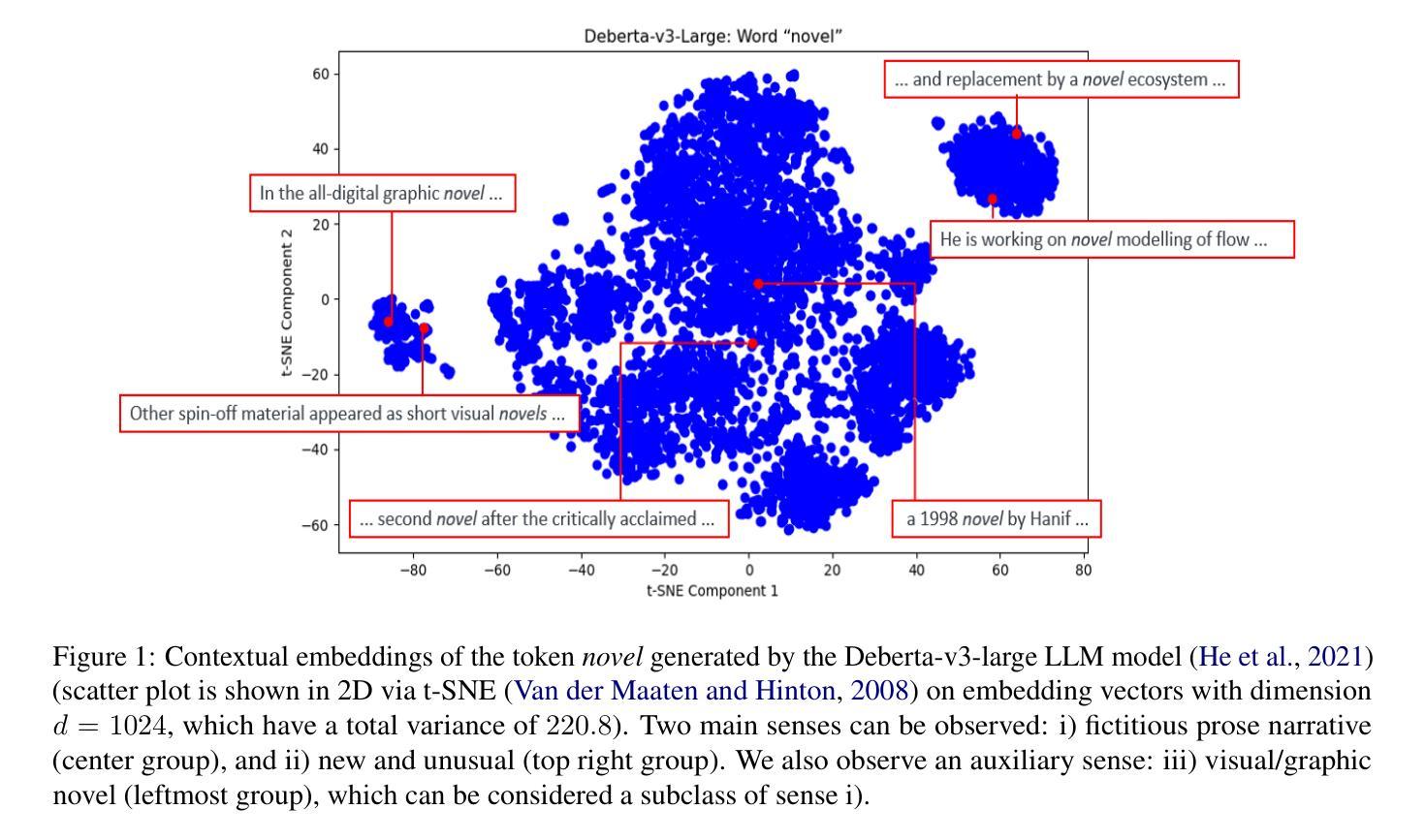
Multi-Sense Embeddings for Language Models and Knowledge Distillation
Authors:Qitong Wang, Mohammed J. Zaki, Georgios Kollias, Vasileios Kalantzis
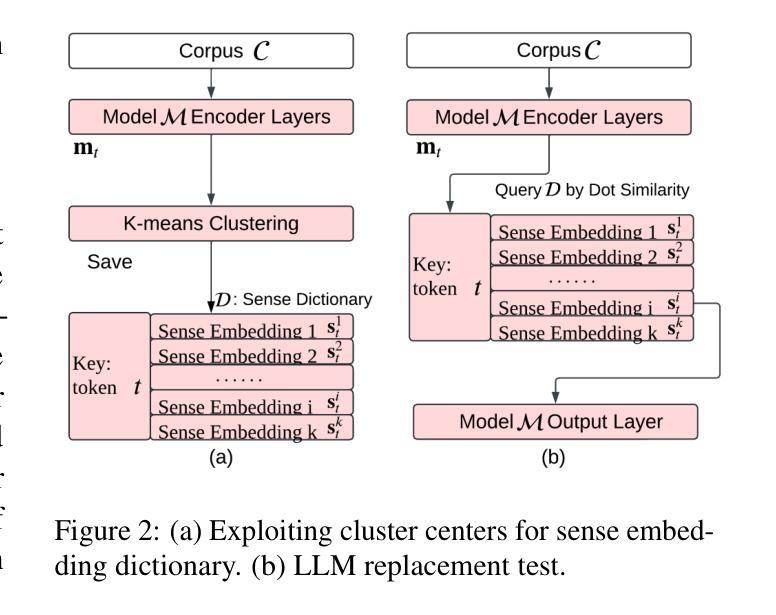
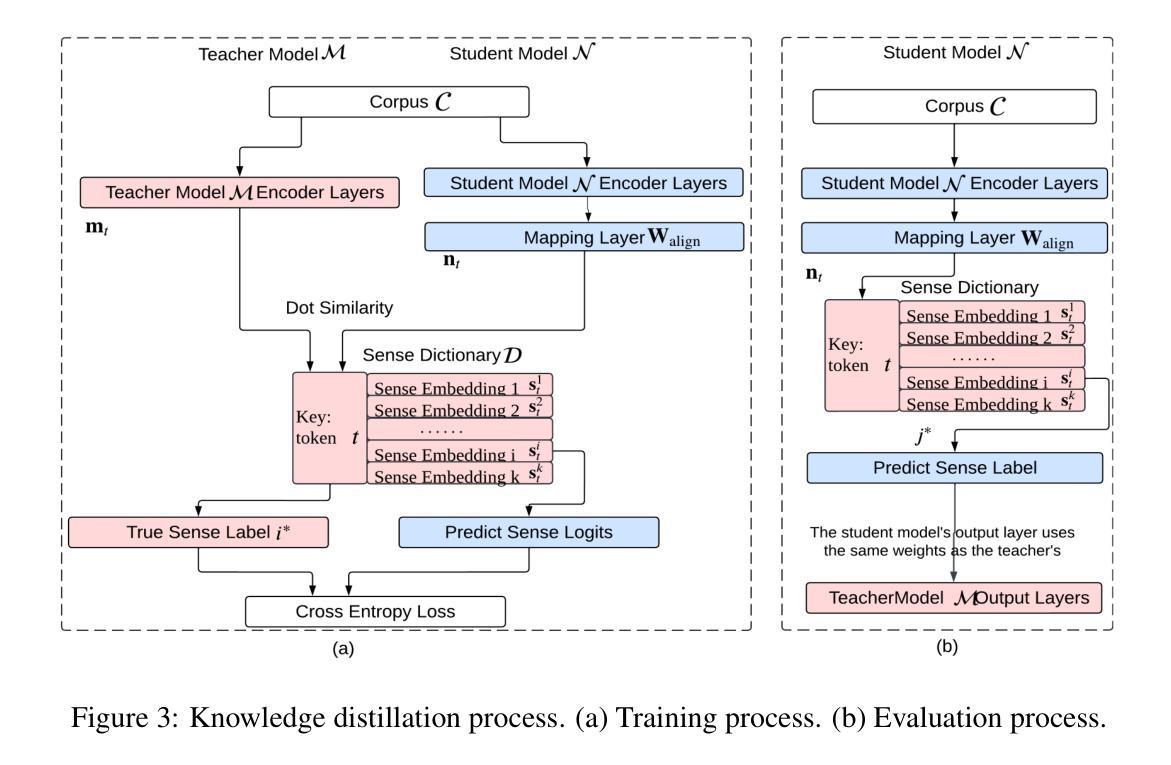
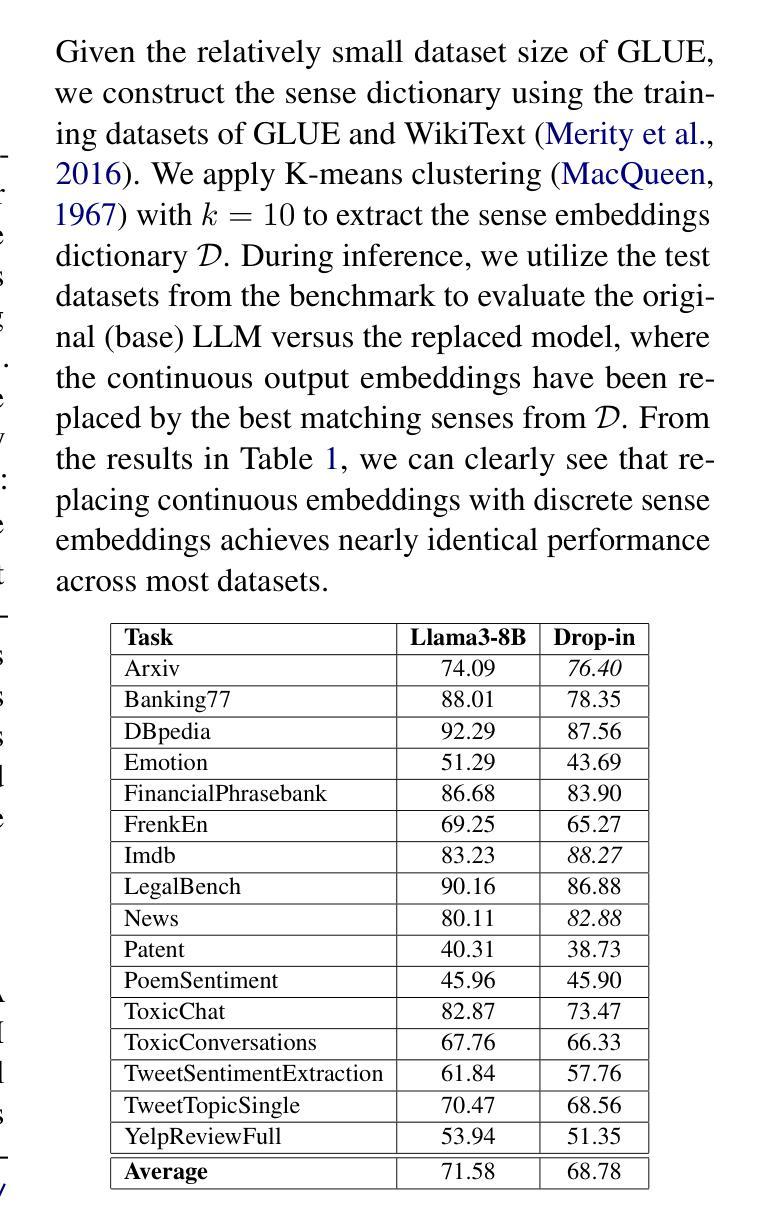
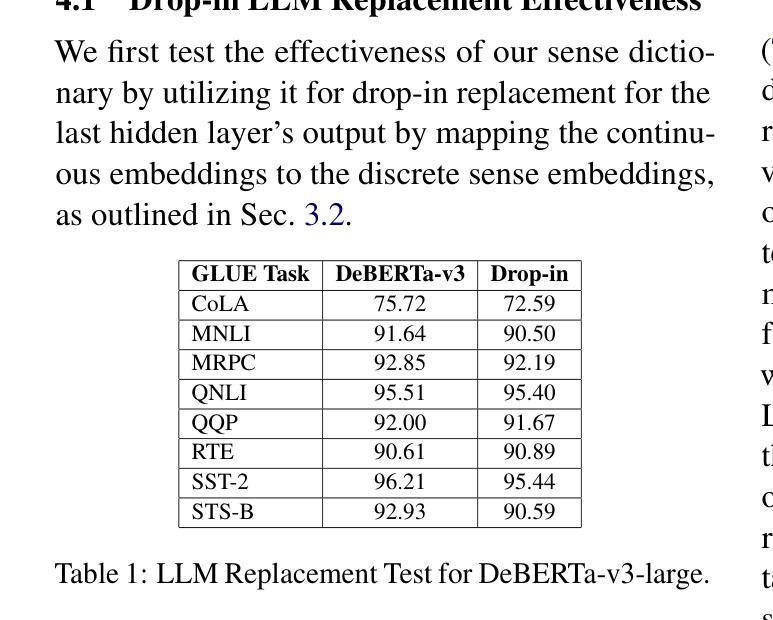
Transformer-based large language models (LLMs) rely on contextual embeddings which generate different (continuous) representations for the same token depending on its surrounding context. Nonetheless, words and tokens typically have a limited number of senses (or meanings). We propose multi-sense embeddings as a drop-in replacement for each token in order to capture the range of their uses in a language. To construct a sense embedding dictionary, we apply a clustering algorithm to embeddings generated by an LLM and consider the cluster centers as representative sense embeddings. In addition, we propose a novel knowledge distillation method that leverages the sense dictionary to learn a smaller student model that mimics the senses from the much larger base LLM model, offering significant space and inference time savings, while maintaining competitive performance. Via thorough experiments on various benchmarks, we showcase the effectiveness of our sense embeddings and knowledge distillation approach. We share our code at https://github.com/Qitong-Wang/SenseDict
基于Transformer的大型语言模型(LLM)依赖于上下文嵌入,它为同一标记生成不同的(连续)表示形式,这取决于其周围的上下文。尽管如此,单词和标记通常具有有限数量的含义(或意义)。为了捕捉语言中使用标记的范围,我们提出了多义嵌入作为每个标记的即插即用替代品。为了构建意义嵌入字典,我们应用聚类算法对LLM生成的嵌入进行聚类,并将聚类中心作为代表性的意义嵌入。此外,我们提出了一种新的利用意义字典进行知识蒸馏的方法,学习一个较小的学生模型,从更大的基础LLM模型中模仿意义,在节省大量空间和推理时间的同时,保持竞争力。我们通过在各种基准测试上的实验,展示了我们的意义嵌入和知识蒸馏方法的有效性。我们将代码共享在 https://github.com/Qitong-Wang/SenseDict 。
论文及项目相关链接
PDF 16 pages, 4 figures
Summary
本文介绍了基于Transformer的大型语言模型(LLM)依赖上下文嵌入来生成不同语境下相同标记(token)的连续表示。然而,单词和标记通常只有有限数量的意义(或含义)。为了解决这个问题,文章提出了多义词嵌入作为一种替换方法,能够捕捉一种语言中的多种使用方式。同时提出了一种新颖的基于多义词嵌入的知识蒸馏方法,该方法通过应用聚类算法生成一个词汇含义词典。这种新的学生模型在大型基础模型的支持下学会了感知不同的含义,在维持竞争力性能的同时显著减少了空间和推理时间消耗。实验证明,这种多义词嵌入和知识蒸馏方法非常有效。代码公开在:链接地址。
Key Takeaways
- LLM依赖上下文嵌入生成不同语境下的标记表示。
- 提出多义词嵌入作为解决标记有限含义的方法。
- 通过聚类算法生成词汇含义词典,代表不同的词汇含义。
- 提出一种新颖的知识蒸馏方法,利用词汇含义词典学习小型学生模型。
- 学生模型能够在显著减少空间和推理时间的同时维持性能。
- 实验证明多义词嵌入和知识蒸馏方法的有效性。
点此查看论文截图

Llama-3-Nanda-10B-Chat: An Open Generative Large Language Model for Hindi
Authors:Monojit Choudhury, Shivam Chauhan, Rocktim Jyoti Das, Dhruv Sahnan, Xudong Han, Haonan Li, Aaryamonvikram Singh, Alok Anil Jadhav, Utkarsh Agarwal, Mukund Choudhary, Debopriyo Banerjee, Fajri Koto, Junaid Bhat, Awantika Shukla, Samujjwal Ghosh, Samta Kamboj, Onkar Pandit, Lalit Pradhan, Rahul Pal, Sunil Sahu, Soundar Doraiswamy, Parvez Mullah, Ali El Filali, Neha Sengupta, Gokul Ramakrishnan, Rituraj Joshi, Gurpreet Gosal, Avraham Sheinin, Natalia Vassilieva, Preslav Nakov
Developing high-quality large language models (LLMs) for moderately resourced languages presents unique challenges in data availability, model adaptation, and evaluation. We introduce Llama-3-Nanda-10B-Chat, or Nanda for short, a state-of-the-art Hindi-centric instruction-tuned generative LLM, designed to push the boundaries of open-source Hindi language models. Built upon Llama-3-8B, Nanda incorporates continuous pre-training with expanded transformer blocks, leveraging the Llama Pro methodology. A key challenge was the limited availability of high-quality Hindi text data; we addressed this through rigorous data curation, augmentation, and strategic bilingual training, balancing Hindi and English corpora to optimize cross-linguistic knowledge transfer. With 10 billion parameters, Nanda stands among the top-performing open-source Hindi and multilingual models of similar scale, demonstrating significant advantages over many existing models. We provide an in-depth discussion of training strategies, fine-tuning techniques, safety alignment, and evaluation metrics, demonstrating how these approaches enabled Nanda to achieve state-of-the-art results. By open-sourcing Nanda, we aim to advance research in Hindi LLMs and support a wide range of real-world applications across academia, industry, and public services.
开发针对中等资源语言的高质量大型语言模型(LLM)在数据可用性、模型适应性和评估方面存在独特挑战。我们推出了Llama-3-Nanda-10B-Chat,简称Nanda,这是一个以印地语为中心的指令调整生成式LLM的最新技术,旨在推动开源印地语语言模型的边界。基于Llama-3-8B,Nanda结合了使用Llama Pro方法的连续预训练和扩展的Transformer块。一个关键挑战是高质量印地语文本数据的有限可用性;我们通过严格的数据整理、增强和战略双语培训解决了这一问题,平衡印地语和英语语料库以优化跨语言知识转移。具有10亿个参数,Nanda在同类开源印地语和多语言模型中表现最佳,显示出对许多现有模型的显著优势。我们深入讨论了训练策略、微调技术、安全对齐和评估指标,展示了这些方法如何帮助Nanda实现最新技术成果。通过开源Nanda,我们旨在推动印地语LLM的研究,并支持学术、行业和公共服务中的广泛实际应用。
论文及项目相关链接
Summary:针对中等资源语言的优质大型语言模型(LLM)开发面临数据可用性、模型适应性和评估方面的独特挑战。我们推出了以印地语为中心的指令调优生成式LLM——Nanda,旨在推动开源印地语语言模型的边界。Nanda以Llama-3-8B为基础,采用Llama Pro方法,进行连续预训练,并扩展了transformer块。解决高质量印地语文本数据有限的关键挑战在于,我们通过严格的数据采集、增强和战略双语培训来应对这一挑战,平衡印地语和英语语料库以优化跨语言知识转移。Nanda的参数规模达到10亿,成为表现最佳的开源印地语和多语种模型之一,相对于许多现有模型表现出显著优势。本文深入讨论了训练策略、微调技术、安全对齐和评估指标,展示了这些方法如何帮助Nanda实现最佳结果。通过开源Nanda,我们旨在推动印地语LLM的研究,支持学术、行业和公共服务的广泛应用。
Key Takeaways:
- Nanda是一个以印地语为中心的指令调优生成式LLM,建立在Llama-3-8B基础上,拥有10亿参数规模。
- Nanda通过连续预训练与扩展的transformer块,采用Llama Pro方法设计。
- 高质量印地语文本数据有限是开发中的关键挑战,通过严格的数据采集、增强和双语培训来应对。
- Nanda在开源印地语和多语种模型中表现最佳,相对于许多现有模型具有显著优势。
- Nanda的训练策略、微调技术、安全对齐和评估指标进行了深入讨论。
- 开源Nanda旨在推动印地语LLM的研究,并广泛支持学术、行业和公共服务应用。
点此查看论文截图

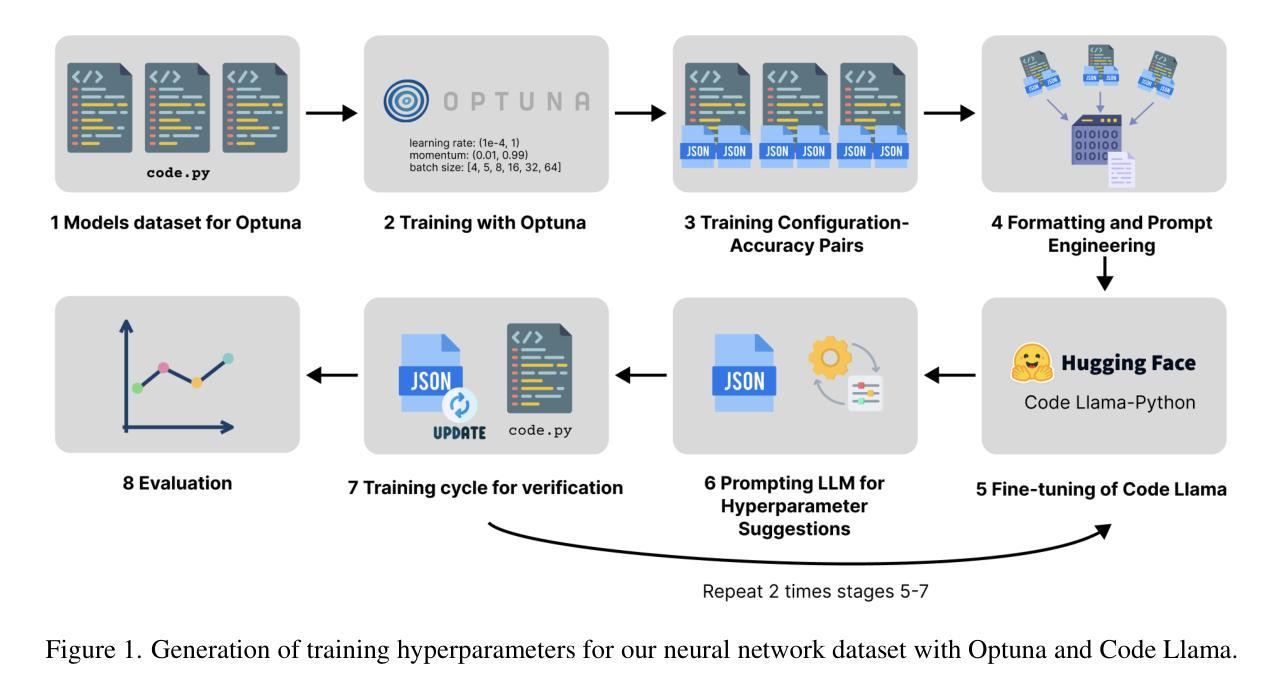
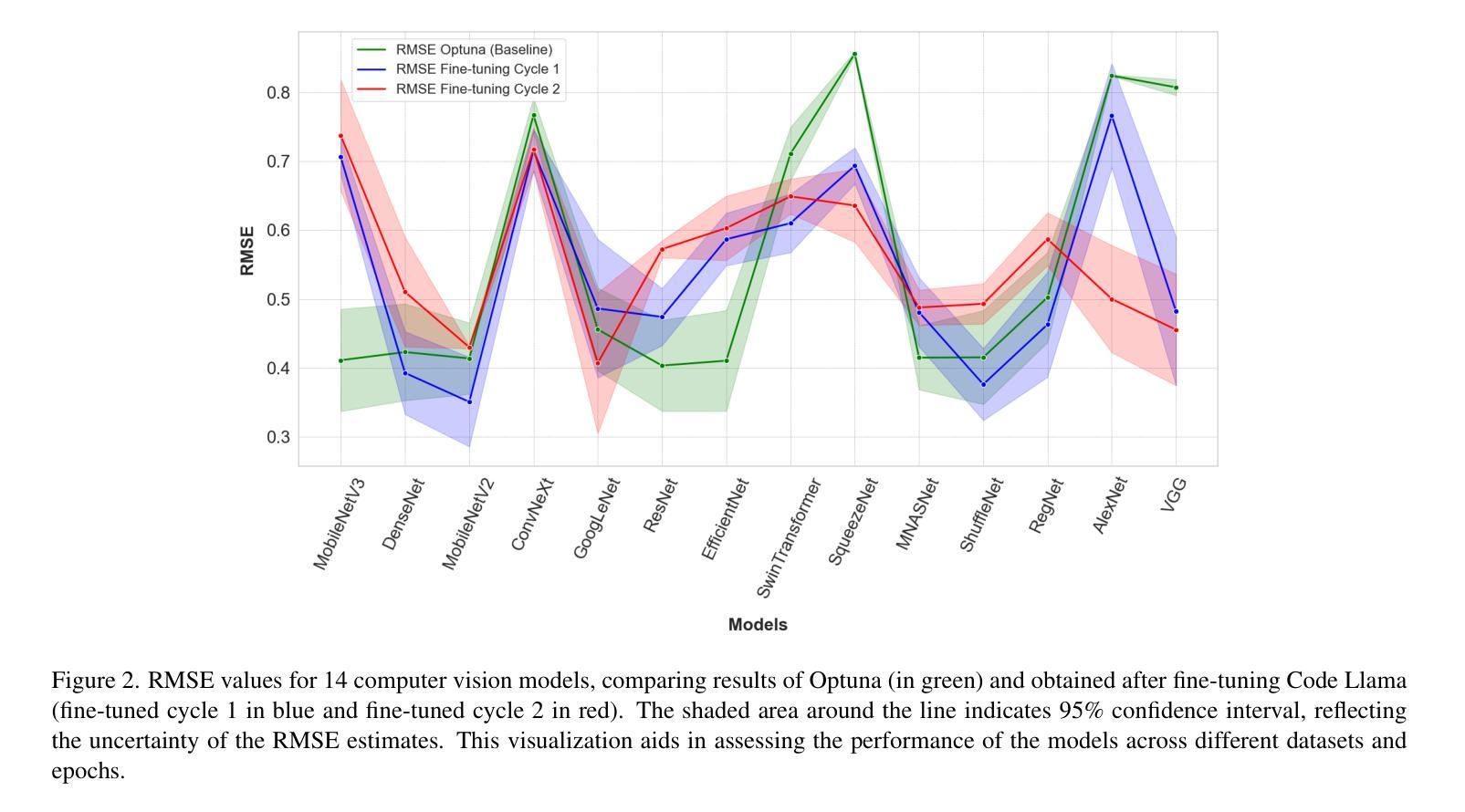
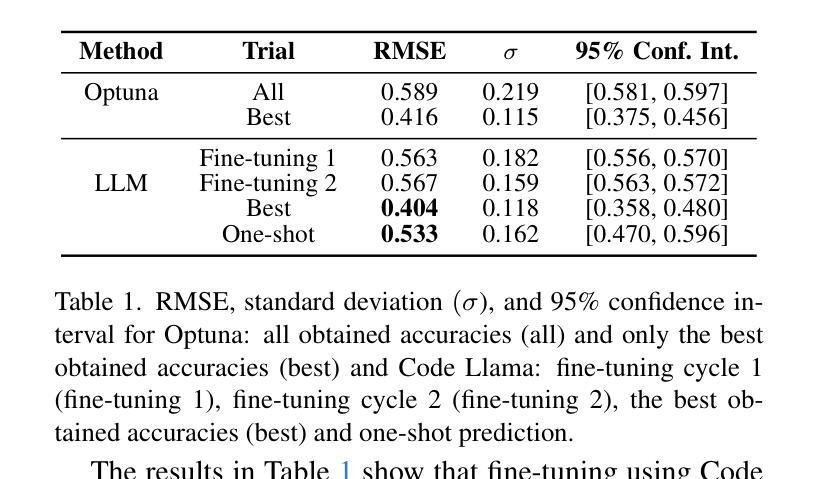
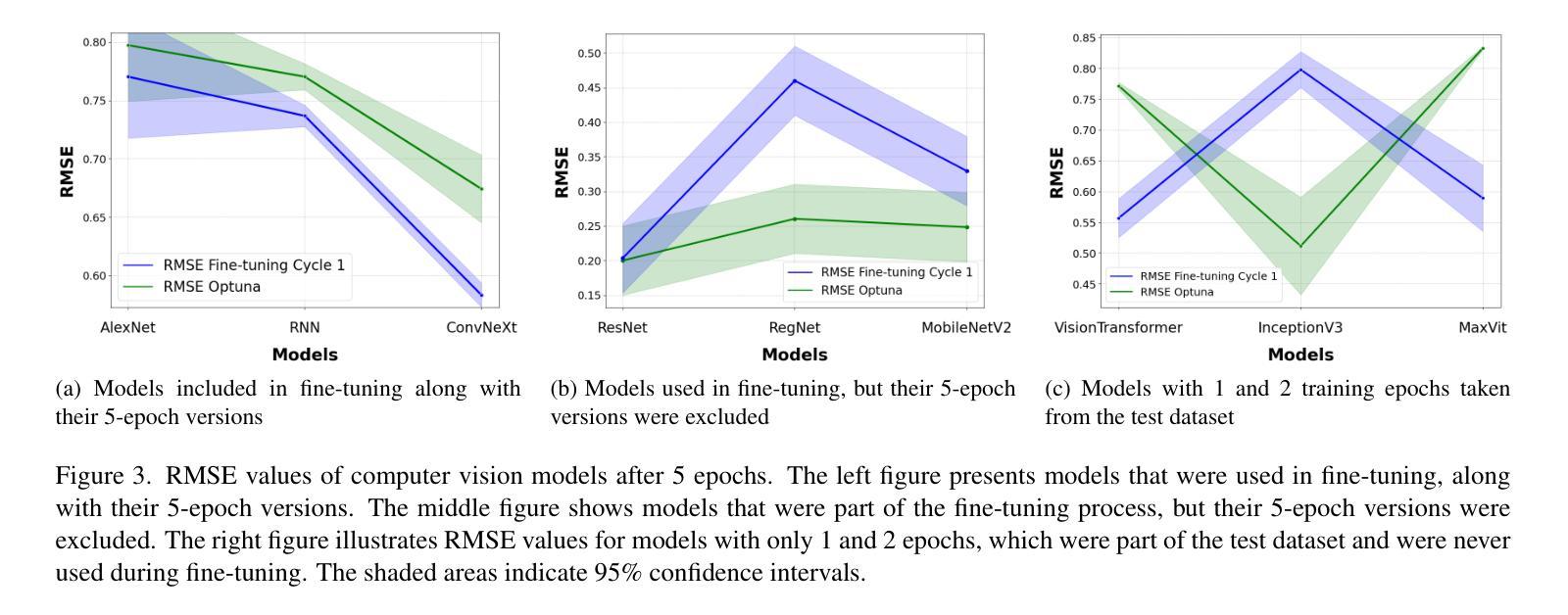
Optuna vs Code Llama: Are LLMs a New Paradigm for Hyperparameter Tuning?
Authors:Roman Kochnev, Arash Torabi Goodarzi, Zofia Antonina Bentyn, Dmitry Ignatov, Radu Timofte
Optimal hyperparameter selection is critical for maximizing neural network performance, especially as models grow in complexity. This work investigates the viability of using large language models (LLMs) for hyperparameter optimization by employing a fine-tuned version of Code Llama. Through parameter-efficient fine-tuning using LoRA, we adapt the LLM to generate accurate and efficient hyperparameter recommendations tailored to diverse neural network architectures. Unlike traditional methods such as Optuna, which rely on exhaustive trials, the proposed approach achieves competitive or superior results in terms of Root Mean Square Error (RMSE) while significantly reducing computational overhead. Our approach highlights that LLM-based optimization not only matches state-of-the-art methods like Tree-structured Parzen Estimators but also accelerates the tuning process. This positions LLMs as a promising alternative to conventional optimization techniques, particularly for rapid experimentation. Furthermore, the ability to generate hyperparameters in a single inference step makes this method particularly well-suited for resource-constrained environments such as edge devices and mobile applications, where computational efficiency is paramount. The results confirm that LLMs, beyond their efficiency, offer substantial time savings and comparable stability, underscoring their value in advancing machine learning workflows. All generated hyperparameters are included in the LEMUR Neural Network (NN) Dataset, which is publicly available and serves as an open-source benchmark for hyperparameter optimization research.
最优超参数的选择对于最大化神经网络性能至关重要,尤其是在模型复杂度不断增长的情况下。本研究通过采用经过精细调整的Code Llama版本,探索了使用大型语言模型(LLM)进行超参数优化的可行性。通过LoRA实现的参数高效微调,我们使LLM能够生成针对各种神经网络架构准确且高效的超参数推荐。与传统方法(如Optuna)不同,Optuna依赖于详尽的试验,所提出的方法在均方根误差(RMSE)方面取得了具有竞争力或更高的结果,同时显著减少了计算开销。我们的方法突显了基于LLM的优化不仅与最新的方法(如树结构Parzen估计器)相匹配,而且还加速了调整过程。这为LLM在常规优化技术中作为有前途的替代方案,特别是在快速实验方面提供了地位。此外,能够在单个推理步骤中生成超参数的方法特别适用于资源受限的环境,如边缘设备和移动应用程序,其中计算效率至关重要。结果证实,除了提高效率外,LLM还能提供可观的时间节省和相当的稳定性,突显其在推进机器学习工作流程中的价值。所有生成的超参数都包含在LEMUR神经网络(NN)数据集中,该数据集公开可用,并作为超参数优化研究的一个开源基准。
论文及项目相关链接
Summary
本文研究了使用大型语言模型(LLM)进行神经网络超参数优化的可行性。通过精细调整Code Llama版本,结合LoRA参数高效微调技术,LLM能够生成针对多种神经网络架构的准确且高效的超参数推荐。该方法与传统的Optuna等方法相比,在均方根误差(RMSE)方面表现具有竞争力或更优越,并显著减少了计算开销。LLM优化不仅匹配了当前先进技术,如树结构Parzen估计器,还加速了调整过程,特别适用于边缘设备和移动应用等资源受限的环境。LLM在推进机器学习工作流程方面展现出了价值,不仅效率高,还能节省大量时间并保持稳定性。生成的超参数已包含在LEMUR神经网络数据集中,该数据集公开可用,为超参数优化研究提供了开源基准。
Key Takeaways
- 大型语言模型(LLM)可用于神经网络超参数优化,具有潜力替代传统优化技术。
- 通过精细调整Code Llama并结合LoRA技术,LLM能生成针对多种神经网络架构的超参数推荐。
- LLM方法在均方根误差(RMSE)上表现优越,计算开销较小。
- LLM优化不仅匹配了当前先进技术,还能加速超参数调整过程。
- LLM方法特别适用于资源受限的环境,如边缘设备和移动应用。
- LLM在推进机器学习工作流程方面具有高效、省时和稳定的优点。
点此查看论文截图

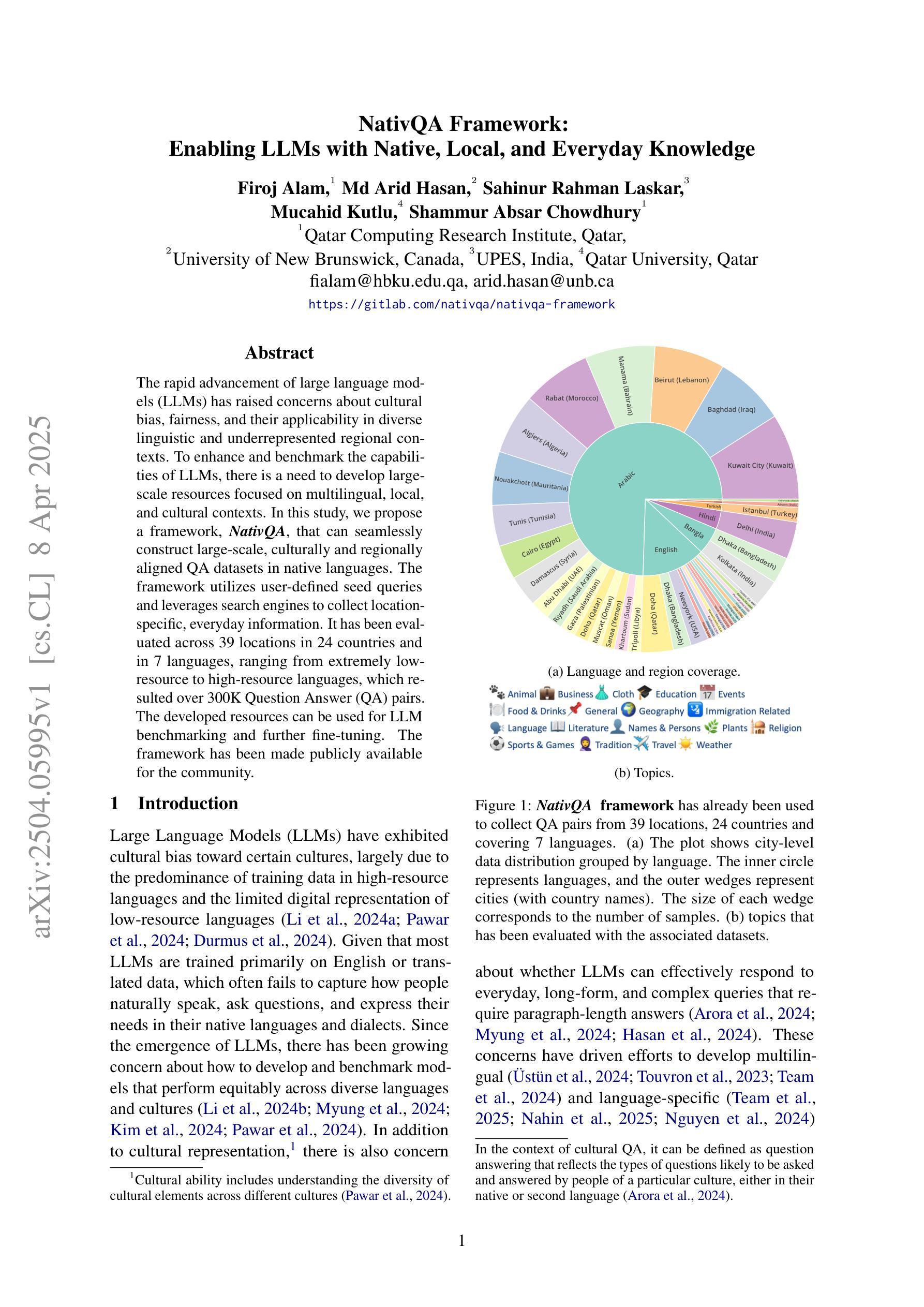
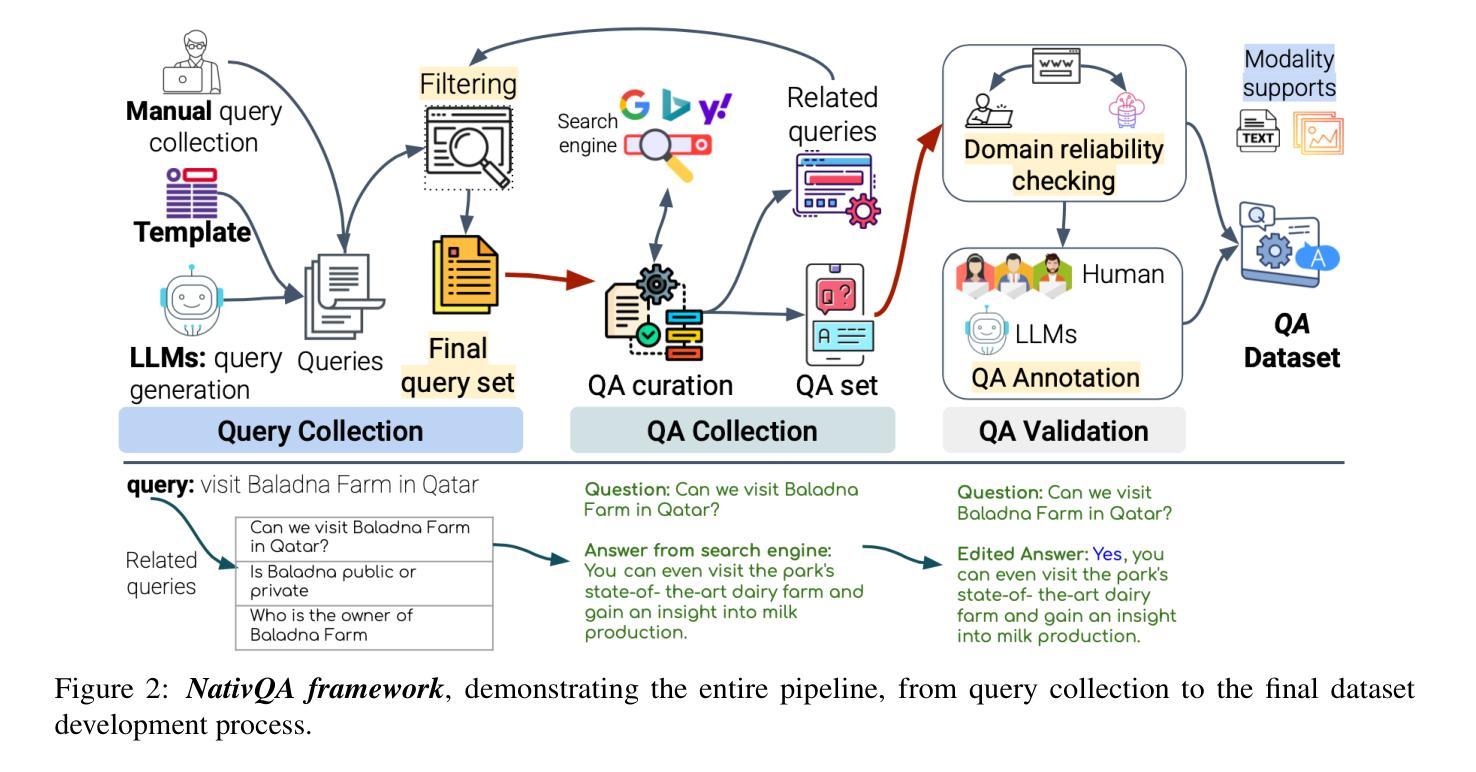
NativQA Framework: Enabling LLMs with Native, Local, and Everyday Knowledge
Authors:Firoj Alam, Md Arid Hasan, Sahinur Rahman Laskar, Mucahid Kutlu, Shammur Absar Chowdhury
The rapid advancement of large language models (LLMs) has raised concerns about cultural bias, fairness, and their applicability in diverse linguistic and underrepresented regional contexts. To enhance and benchmark the capabilities of LLMs, there is a need to develop large-scale resources focused on multilingual, local, and cultural contexts. In this study, we propose a framework, NativQA, that can seamlessly construct large-scale, culturally and regionally aligned QA datasets in native languages. The framework utilizes user-defined seed queries and leverages search engines to collect location-specific, everyday information. It has been evaluated across 39 locations in 24 countries and in 7 languages, ranging from extremely low-resource to high-resource languages, which resulted over 300K Question Answer (QA) pairs. The developed resources can be used for LLM benchmarking and further fine-tuning. The framework has been made publicly available for the community (https://gitlab.com/nativqa/nativqa-framework).
大型语言模型(LLM)的快速发展引发了人们对文化偏见、公平性及其在多样化和代表性不足的区域语境中的适用性的关注。为了增强和评估LLM的能力,需要开发专注于多语言、本地和文化背景的大型资源。在这项研究中,我们提出了一个名为NativQA的框架,该框架可以无缝构建大规模、文化和区域对齐的本地语言问答数据集。该框架利用用户定义的种子查询,并借助搜索引擎收集特定地点的日常信息。它已在24个国家的39个地点和7种语言中进行了评估,涵盖了从极度低资源到高资源语言的各种情况,产生了超过30万组问答对。所开发的资源可用于LLM基准测试和进一步的微调。该框架已向公众提供,供社区使用(https://gitlab.com/nativqa/nativqa-framework)。
论文及项目相关链接
PDF LLMs, Native, Multilingual, Language Diversity, Contextual Understanding, Minority Languages, Culturally Informed, Foundation Models, Large Language Models
Summary
大型语言模型(LLM)的快速发展引发了关于文化偏见、公平性以及其在多样化和代表性不足的语境中适用性的关注。本研究提出一种名为NativQA的框架,能够轻松构建大规模、与文化和地区相适应的问答数据集。该框架利用用户定义的种子查询和搜索引擎收集特定地点的日常信息。该框架已在24个国家的39个地点和7种语言中进行了评估,涵盖了从极度低资源到高资源语言的不同情况,产生了超过30万组问答对。所开发的资源可用于LLM基准测试和进一步微调。该框架已向公众开放使用(https://gitlab.com/nativqa/nativqa-framework)。
Key Takeaways
- 大型语言模型(LLM)的发展引发了对文化偏见和公平性的关注。
- 在多样化和代表性不足的语境中,LLM的适用性受到挑战。
- NativQA框架能够构建与文化和地区相适应的大型问答数据集。
- NativQA框架利用用户定义的种子查询和搜索引擎收集特定地点的日常信息。
- 该框架已在全球多个国家和语言中进行了评估,产生了大量问答对数据。
- 开发的资源可用于LLM的基准测试和进一步微调。
点此查看论文截图
An Empirical Study of GPT-4o Image Generation Capabilities
Authors:Sixiang Chen, Jinbin Bai, Zhuoran Zhao, Tian Ye, Qingyu Shi, Donghao Zhou, Wenhao Chai, Xin Lin, Jianzong Wu, Chao Tang, Shilin Xu, Tao Zhang, Haobo Yuan, Yikang Zhou, Wei Chow, Linfeng Li, Xiangtai Li, Lei Zhu, Lu Qi
The landscape of image generation has rapidly evolved, from early GAN-based approaches to diffusion models and, most recently, to unified generative architectures that seek to bridge understanding and generation tasks. Recent advances, especially the GPT-4o, have demonstrated the feasibility of high-fidelity multimodal generation, their architectural design remains mysterious and unpublished. This prompts the question of whether image and text generation have already been successfully integrated into a unified framework for those methods. In this work, we conduct an empirical study of GPT-4o’s image generation capabilities, benchmarking it against leading open-source and commercial models. Our evaluation covers four main categories, including text-to-image, image-to-image, image-to-3D, and image-to-X generation, with more than 20 tasks. Our analysis highlights the strengths and limitations of GPT-4o under various settings, and situates it within the broader evolution of generative modeling. Through this investigation, we identify promising directions for future unified generative models, emphasizing the role of architectural design and data scaling.
图像生成领域的景观已经迅速演变,从早期的基于GAN的方法到扩散模型,再到最近的寻求理解和生成任务之间桥梁的统一生成架构。最近的进展,尤其是GPT-4o,已经证明了高保真度多媒体生成的可行性,但其架构设计仍然神秘且未公布。这引发了人们关于图像和文本生成是否已成功地集成到这些方法的统一框架中的问题。在这项工作中,我们对GPT-4o的图像生成能力进行了实证研究,将其与领先的开源和商业模型进行了基准测试。我们的评估涵盖了四个主要类别,包括文本到图像、图像到图像、图像到3D和图像到X生成,涉及超过20项任务。我们的分析突出了GPT-4o在不同设置下的优点和局限性,并将其定位在更广泛的生成模型演变中。通过这项调查,我们为未来的统一生成模型指明了有前景的方向,强调了架构设计和数据扩展的作用。
论文及项目相关链接
Summary
本文研究了GPT-4o的图像生成能力,对其进行了实证评估,并与开源和商业领先模型进行了对比。评估涵盖文本到图像、图像到图像、图像到3D和图像到X生成等四个主要类别,超过20项任务。分析强调了GPT-4o在不同设置下的优势和局限性,并将其置于生成模型更广泛的演变中。
Key Takeaways
- GPT-4o在图像生成方面展现出强大的能力,尤其是在高保真度多媒体生成方面。
- GPT-4o的架构设计中融合了文本和图像生成,表明统一生成架构的潜力。
- GPT-4o在多种生成任务上表现出色,包括文本到图像、图像到图像、图像到3D和图像到X生成。
- 与其他开源和商业模型相比,GPT-4o具有一定的优势和局限性。
- 实证研究结果显示,GPT-4o在统一生成模型的领域内具有广阔的发展前景。
- 架构设计和数据规模对生成模型的发展起着重要作用。
点此查看论文截图

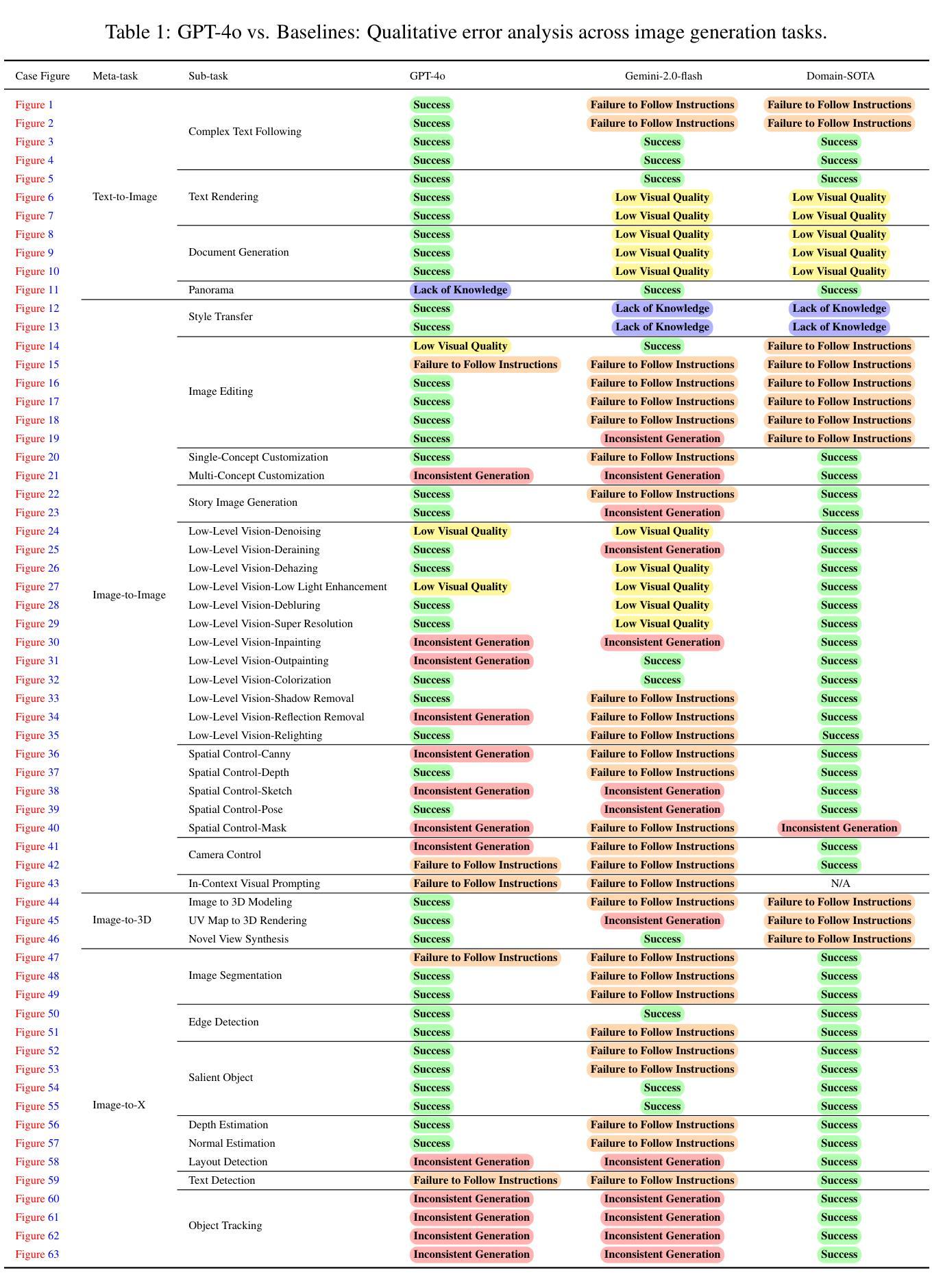

STAGE: Stemmed Accompaniment Generation through Prefix-Based Conditioning
Authors:Giorgio Strano, Chiara Ballanti, Donato Crisostomi, Michele Mancusi, Luca Cosmo, Emanuele Rodolà
Recent advances in generative models have made it possible to create high-quality, coherent music, with some systems delivering production-level output.Yet, most existing models focus solely on generating music from scratch, limiting their usefulness for musicians who want to integrate such models into a human, iterative composition workflow.In this paper we introduce STAGE, our STemmed Accompaniment GEneration model, fine-tuned from the state-of-the-art MusicGen to generate single-stem instrumental accompaniments conditioned on a given mixture. Inspired by instruction-tuning methods for language models, we extend the transformer’s embedding matrix with a context token, enabling the model to attend to a musical context through prefix-based conditioning.Compared to the baselines, STAGE yields accompaniments that exhibit stronger coherence with the input mixture, higher audio quality, and closer alignment with textual prompts.Moreover, by conditioning on a metronome-like track, our framework naturally supports tempo-constrained generation, achieving state-of-the-art alignment with the target rhythmic structure–all without requiring any additional tempo-specific module.As a result, STAGE offers a practical, versatile tool for interactive music creation that can be readily adopted by musicians in real-world workflows.
近期生成模型的新进展使得创建高质量、连贯的音乐成为可能,一些系统甚至能够产生专业级别的输出。然而,大多数现有模型专注于从头开始生成音乐,这限制了希望将此类模型整合到人类迭代作曲工作流程中的音乐家的实用性。在本文中,我们介绍了STAGE,我们的基于茎的伴奏生成模型,基于最先进的MusicGen进行微调,以生成给定混合物的单茎乐器伴奏。受语言模型的指令微调方法的启发,我们通过上下文标记扩展了变压器的嵌入矩阵,使模型能够通过基于前缀的条件来关注音乐上下文。与基线相比,STAGE生成的伴奏与输入混合物的连贯性更强,音频质量更高,与文本提示的对齐程度更高。此外,通过基于节拍器轨迹的条件设置,我们的框架自然地支持节奏约束生成,实现了与目标节奏结构的一流对齐——所有这一切都不需要任何额外的特定节奏的模块。因此,STAGE为交互式音乐创作提供了一个实用且多功能工具,可以被音乐家在现实工作流程中轻松采用。
论文及项目相关链接
Summary
新一代生成模型技术已能制作出高质量、连贯的音乐,某些系统甚至能产出专业级别的作品。然而,现有模型大多专注于从零开始生成音乐,这对于希望将这类模型融入个人创作流程的乐手而言,实用性有限。本文介绍了STAGE模型,它在MusicGen的基础上进行了微调,用于生成给定旋律的单乐器伴奏。受语言模型指令微调方法的启发,我们通过扩展转换器嵌入矩阵添加了语境令牌,使模型能通过前缀条件关注音乐语境。相较于基准模型,STAGE生成的伴奏与输入旋律更连贯、音频质量更高、与文字提示更吻合。此外,通过以节拍器般的轨迹为条件,我们的框架能自然地进行节奏约束生成,无需任何额外的节奏特定模块即可实现对目标节奏结构的最佳对齐。因此,STAGE为交互式音乐创作提供了一个实用、多功能工具,乐手可轻松将其融入实际创作流程。
Key Takeaways
- 新一代生成模型能制作出高质量、连贯的音乐,且部分系统已可达专业级别。
- 现有音乐生成模型大多仅能从零开始生成音乐,对乐手而言实用性有限。
- STAGE模型在MusicGen基础上微调,可生成给定旋律的单乐器伴奏。
- STAGE通过扩展转换器嵌入矩阵添加语境令牌,使模型关注音乐语境。
- STAGE生成的伴奏与输入旋律更连贯,音频质量更高,与文字提示更吻合。
- STAGE能以节拍器般的轨迹为条件进行节奏约束生成,实现对目标节奏结构的最佳对齐。
点此查看论文截图

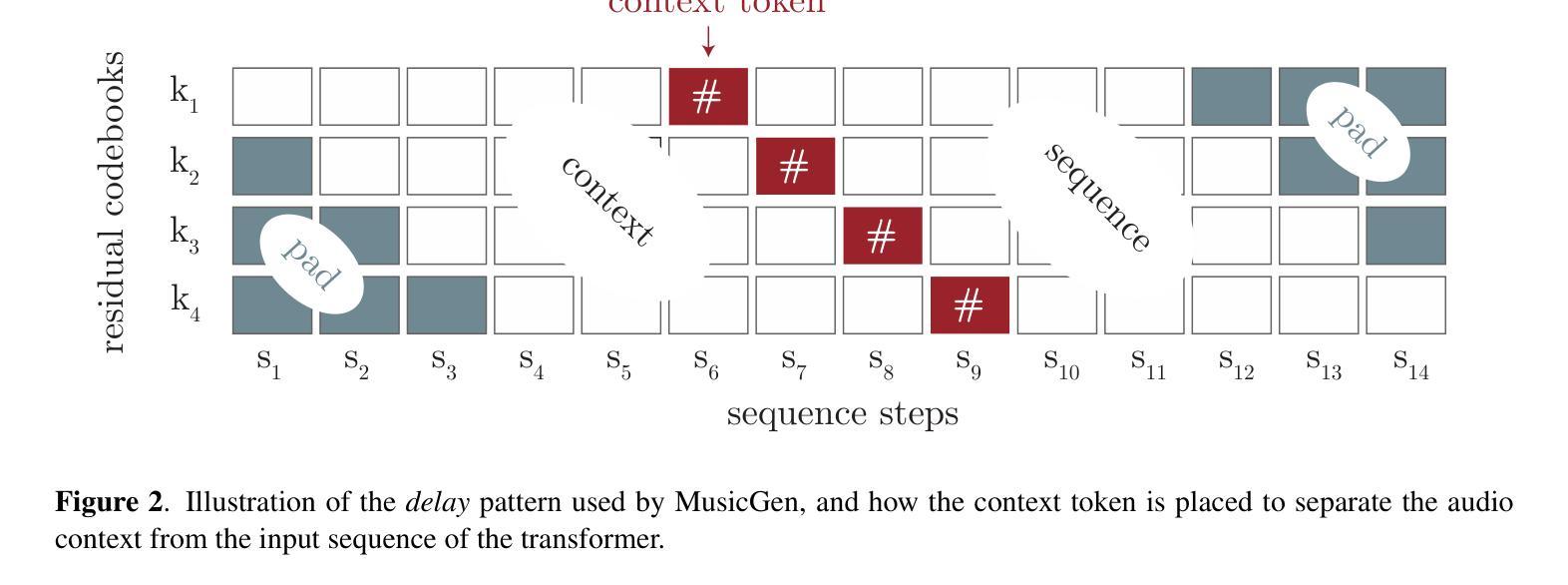
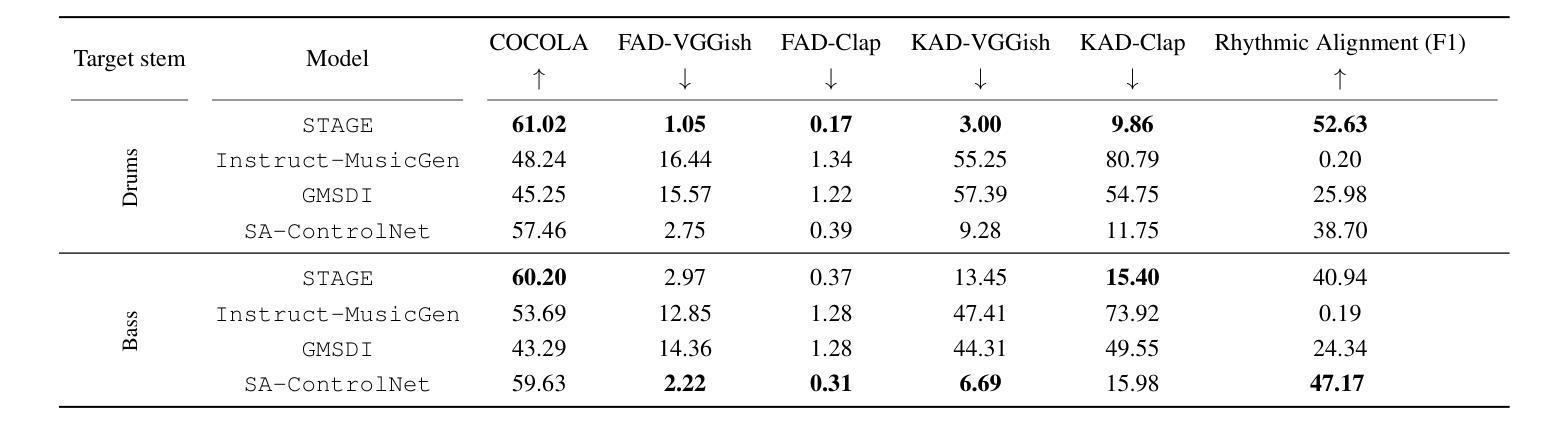

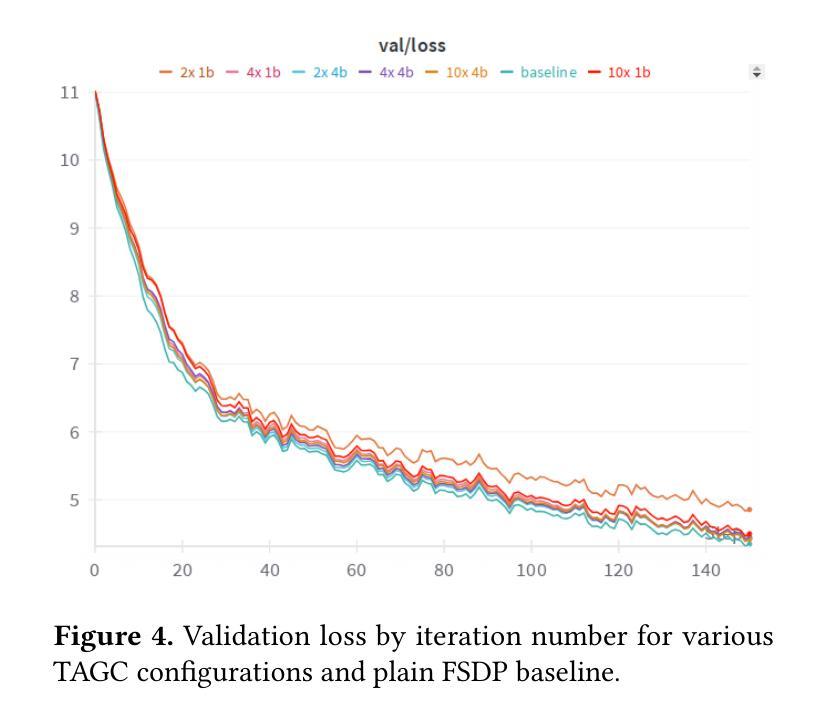
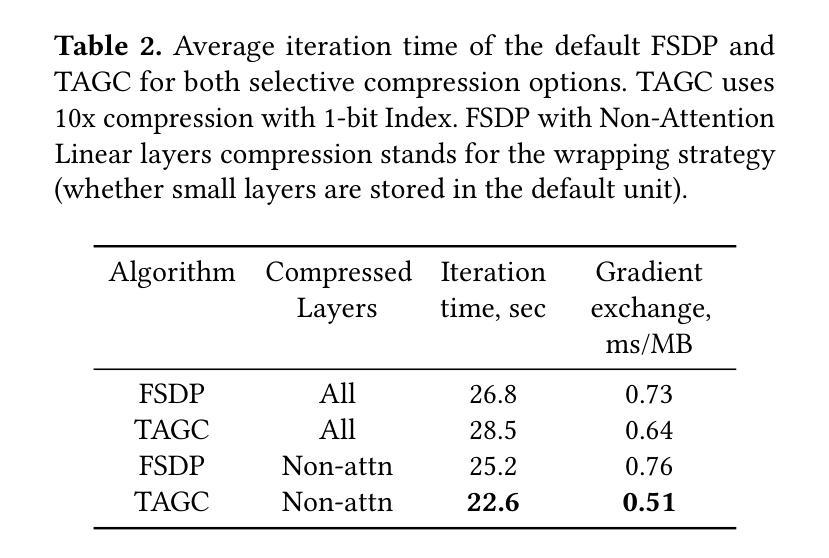
TAGC: Optimizing Gradient Communication in Distributed Transformer Training
Authors:Igor Polyakov, Alexey Dukhanov, Egor Spirin
The increasing complexity of large language models (LLMs) necessitates efficient training strategies to mitigate the high computational costs associated with distributed training. A significant bottleneck in this process is gradient synchronization across multiple GPUs, particularly in the zero-redundancy parallelism mode. In this paper, we introduce Transformer-Aware Gradient Compression (TAGC), an optimized gradient compression algorithm designed specifically for transformer-based models. TAGC extends the lossless homomorphic compression method by adapting it for sharded models and incorporating transformer-specific optimizations, such as layer-selective compression and dynamic sparsification. Our experimental results demonstrate that TAGC accelerates training by up to 15% compared to the standard Fully Sharded Data Parallel (FSDP) approach, with minimal impact on model quality. We integrate TAGC into the PyTorch FSDP framework, the implementation is publicly available at https://github.com/ipolyakov/TAGC.
随着大型语言模型(LLM)的复杂性不断增加,需要有效的训练策略来缓解与分布式训练相关的高计算成本问题。在这个过程中,一个主要的瓶颈是跨多个GPU的梯度同步,特别是在零冗余并行模式下。在本文中,我们介绍了Transformer感知梯度压缩(TAGC),这是一种专为基于transformer的模型设计的优化梯度压缩算法。TAGC通过对无损同态压缩方法进行扩展,通过将其适配于分片模型并引入针对transformer的优化,如层选择压缩和动态稀疏化,从而实现对它的改进。我们的实验结果表明,与标准的完全分片数据并行(FSDP)方法相比,TAGC可以加速训练达15%,而对模型质量的影响最小。我们将TAGC集成到PyTorch FSDP框架中,实现公开可用在https://github.com/ipolyakov/TAGC。
论文及项目相关链接
Summary
本文介绍了针对大型语言模型(LLM)训练过程中面临的计算成本高昂问题,提出了一种名为Transformer-Aware Gradient Compression(TAGC)的优化梯度压缩算法。该算法通过适应无损同态压缩方法,针对分片模型进行特定优化,并引入如层选择压缩和动态稀疏化等针对transformer模型的优化手段。实验结果表明,TAGC相较于标准的Fully Sharded Data Parallel(FSDP)方法,能够加速训练高达15%,同时对模型质量影响极小。该算法已集成到PyTorch的FSDP框架中,并公开可用。
Key Takeaways
- 大型语言模型(LLM)的训练面临高计算成本问题,需要高效训练策略。
- 梯度同步是分布式训练中的主要瓶颈,特别是在零冗余并行模式下。
- Transformer-Aware Gradient Compression(TAGC)是一种针对基于transformer的模型的优化梯度压缩算法。
- TAGC通过适应无损同态压缩方法,并针对分片模型进行特定优化。
- TAGC引入层选择压缩和动态稀疏化等针对transformer模型的优化手段。
- 实验结果表明,TAGC能够加速训练高达15%,同时保持模型质量。
点此查看论文截图

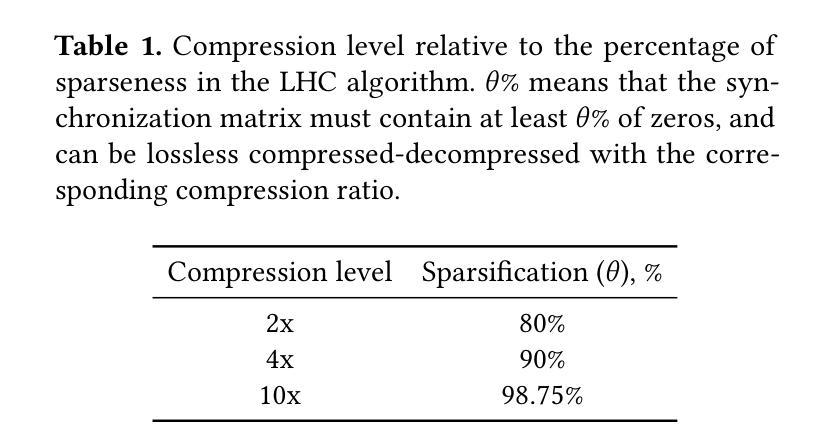
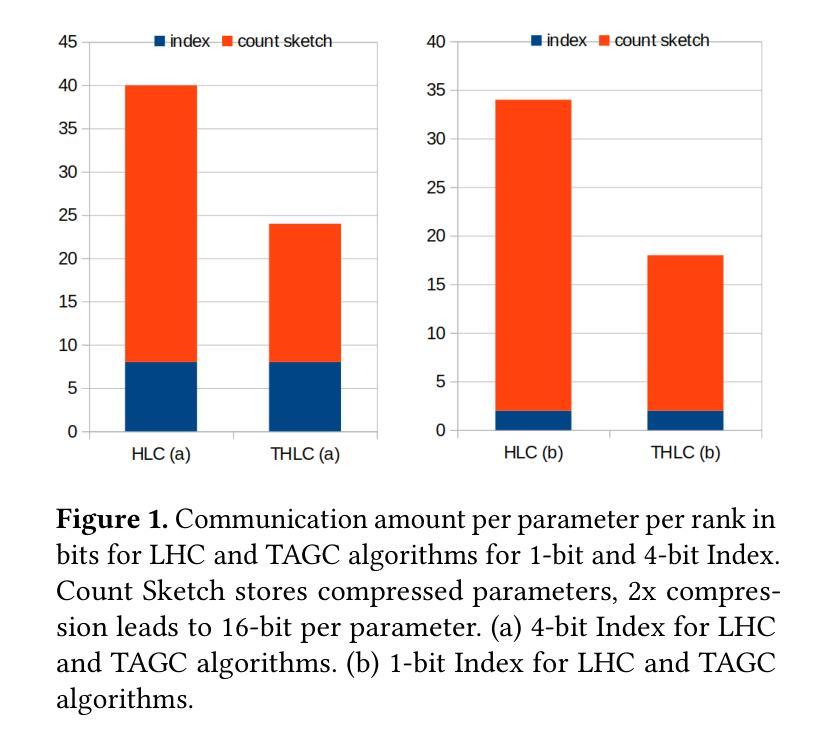
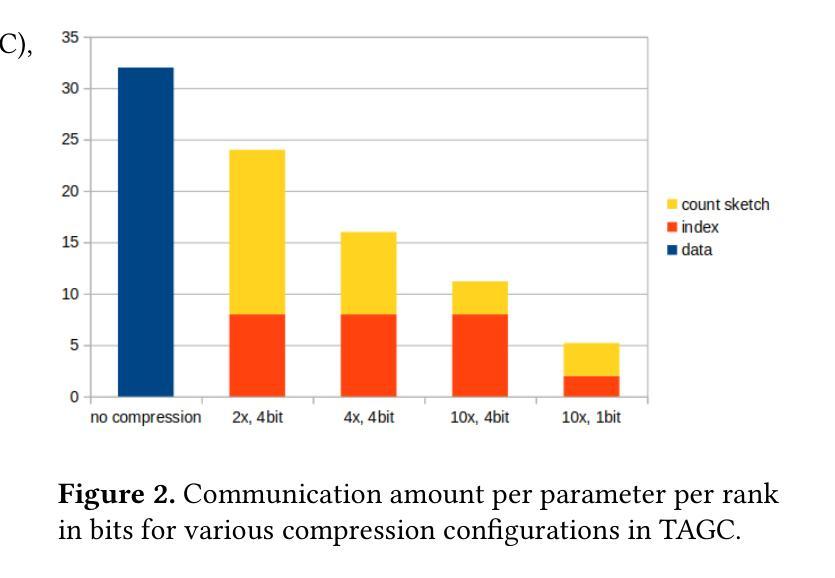



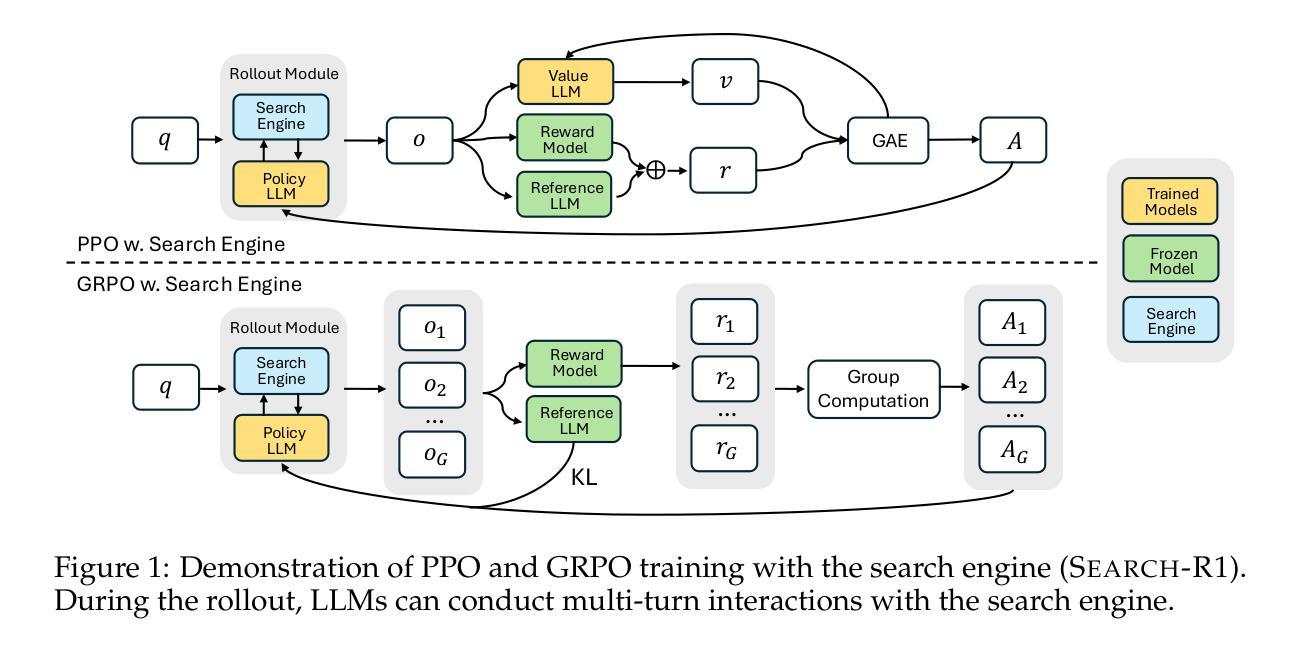
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Authors:Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Zamani, Jiawei Han
Efficiently acquiring external knowledge and up-to-date information is essential for effective reasoning and text generation in large language models (LLMs). Prompting advanced LLMs with reasoning capabilities to use search engines during inference is often suboptimal, as the LLM might not fully possess the capability on how to interact optimally with the search engine. This paper introduces Search-R1, an extension of reinforcement learning (RL) for reasoning frameworks where the LLM learns to autonomously generate (multiple) search queries during step-by-step reasoning with real-time retrieval. Search-R1 optimizes LLM reasoning trajectories with multi-turn search interactions, leveraging retrieved token masking for stable RL training and a simple outcome-based reward function. Experiments on seven question-answering datasets show that Search-R1 improves performance by 41% (Qwen2.5-7B) and 20% (Qwen2.5-3B) over various RAG baselines under the same setting. This paper further provides empirical insights into RL optimization methods, LLM choices, and response length dynamics in retrieval-augmented reasoning. The code and model checkpoints are available at https://github.com/PeterGriffinJin/Search-R1.
在大规模语言模型(LLM)中进行有效的推理和文本生成,获取外部知识和最新信息至关重要。尽管可以通过提示具有推理能力的高级LLM在推理时使用搜索引擎来进行推理和文本生成,但由于LLM可能无法完全掌握如何与搜索引擎进行最佳交互的方法,因此通常并不理想。本文介绍了Search-R1,这是一种强化学习(RL)推理框架的扩展,该框架使LLM能够在逐步推理过程中自主生成(多个)搜索查询,并实时检索。Search-R1通过多轮搜索交互优化LLM的推理轨迹,利用检索令牌屏蔽进行稳定的RL训练以及简单的基于结果奖励函数。在七个问答数据集上的实验表明,在相同设置下,Search-R1在各种RAG基准测试上的性能提高了41%(Qwen2.5-7B)和20%(Qwen2.5-3B)。本文还进一步提供了关于RL优化方法、LLM选择和响应长度动态的实证见解。代码和模型检查点位于https://github.com/PeterGriffinJin/Search-R1。
论文及项目相关链接
PDF 31 pages
Summary
本文介绍了Search-R1,一种基于强化学习(RL)的推理框架的扩展,使大型语言模型(LLM)能够在推理过程中自主生成(多个)搜索查询,进行实时检索。Search-R1通过多轮搜索交互优化LLM的推理轨迹,利用检索令牌屏蔽技术进行稳定的RL训练,并采用基于结果的简单奖励函数。实验表明,Search-R1在七个问答数据集上的性能优于各种RAG基准测试,提高了41%(Qwen2.5-7B)和20%(Qwen2.5-3B)的性能。
Key Takeaways
- Search-R1是强化学习(RL)在推理框架中的一项扩展应用,旨在优化大型语言模型(LLM)在推理过程中的搜索能力。
- LLM能够自主生成多个搜索查询,进行实时检索,这有助于提高推理的效率和准确性。
- Search-R1采用多轮搜索交互来优化LLM的推理轨迹,这意味着模型能够在推理过程中不断学习和改进。
- 通过检索令牌屏蔽技术,Search-R1实现了稳定的RL训练,提高了模型的性能。
- 基于结果的简单奖励函数是Search-R1的另一个关键特点,它能够有效地评估模型的性能并引导模型进行优化。
- 实验结果表明,Search-R1在多个问答数据集上的性能显著优于现有的基准测试。
点此查看论文截图

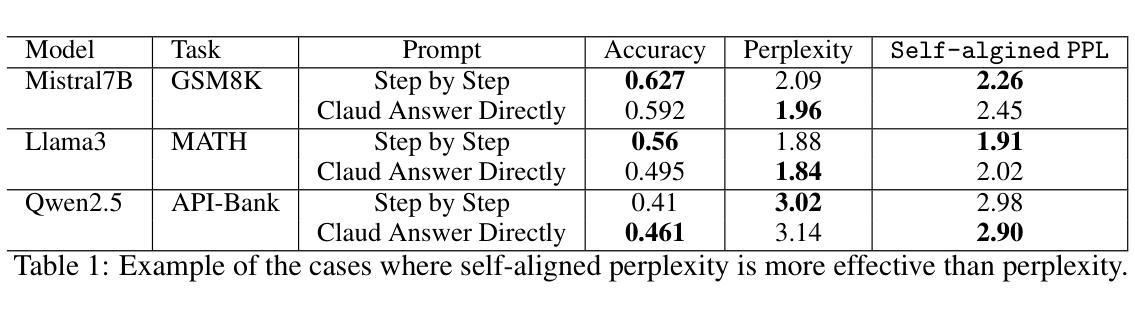
Efficient Response Generation Strategy Selection for Fine-Tuning Large Language Models Through Self-Aligned Perplexity
Authors:Xuan Ren, Qi Chen, Lingqiao Liu
Fine-tuning large language models (LLMs) typically relies on producing large sets of input-output pairs. Yet for a given question, there can be many valid outputs. In practice, these outputs are often derived by distilling knowledge from teacher models, and they can vary depending on the specific teacher model or prompting strategy employed. Recent findings show that how these training outputs are generated can significantly affect the performance of the fine-tuned model, raising an important question: how do we pick the best data generation method from among numerous possibilities? Rather than exhaustively training and evaluating on each candidate, this paper proposes a scalable approximate method that assesses a small subset of generated data to estimate its suitability for a specific target LLM. Our central idea is that effective outputs should be familiar to the target LLM. While previous work measures familiarity with perplexity, we find that perplexity might be suboptimal in characterizing ‘familiarity’ through theoretical analysis and practical observations. To address this, we introduce self-aligned perplexity, a novel metric capturing how closely candidate outputs adhere to the target LLM’s own style and reasoning patterns. In this way, we can identify the most effective generation strategy on a small sample, then apply it to produce the complete training set. We demonstrate that training on data generated by the chosen method yields significant improvements across diverse reasoning-focused benchmarks.
对大型语言模型(LLM)进行微调通常依赖于生成大量的输入输出对。然而,对于给定的问题,可能有多种有效的输出。实际上,这些输出通常是通过从教师模型中提炼知识而得到的,并且它们会根据所使用的具体教师模型或提示策略而变化。最新研究结果表明,这些训练输出的生成方式会显著影响微调模型的性能,这就引发了一个重要问题:我们如何在众多可能性中挑选出最佳的数据生成方法?本文提出了一种可扩展的近似方法,该方法旨在评估一小部分生成的数据,以估算其对于特定目标LLM的适用性,而不是全面地对每个候选方法进行培训和评估。我们的核心思想是,有效的输出应该为目标LLM所熟悉。虽然以前的工作通过困惑度来衡量熟悉程度,但我们发现,通过理论分析和实际观察,困惑度可能在描述“熟悉度”方面并非最佳选项。为了解决这一问题,我们引入了自我对齐困惑度这一新型指标,该指标能够紧密捕捉候选输出是否符合目标LLM自身的风格和推理模式。通过这种方式,我们可以在小样本上确定最有效的生成策略,然后将其应用于生成完整的训练集。我们证明,使用所选方法生成的数据进行训练,可以在多种侧重于推理的基准测试上实现显著改进。
论文及项目相关链接
Summary
大型语言模型(LLM)的微调通常依赖于生成大量的输入输出对。对于给定的问题,存在多种有效的输出。实践中,这些输出往往通过教师模型的知识蒸馏得到,并会因特定的教师模型或提示策略的不同而有所变化。本文提出了一种可扩展的近似方法,通过评估一小部分生成的数据来估计其对于特定目标LLM的适宜性。有效的输出应该对于目标LLM来说是熟悉的。通过理论分析和实践观察发现,本文引入了自我对齐困惑度这一新指标来衡量候选输出对目标LLM风格和推理模式的贴合程度,从而识别出最有效的生成策略,并将其应用于完整的训练集生成中。实验证明,使用所选方法生成的数据进行训练,在多种推理基准测试上取得了显著的提升。
Key Takeaways
- 大型语言模型(LLM)的微调依赖于生成大量的输入输出对。
- 这些输出往往通过教师模型的知识蒸馏得到,并会因不同的教师模型或提示策略而有所变化。
- 有效输出的特点是对于目标LLM来说是熟悉的。
- 传统评估方法可能无法准确反映候选输出的“熟悉度”,因此引入了自我对齐困惑度这一新指标来衡量其与目标LLM风格和推理模式的贴合程度。
- 通过理论分析和实践观察发现自我对齐困惑度的应用价值。
- 通过识别最有效的生成策略并将其应用于完整的训练集生成中,实验证明该方法在多种推理基准测试上取得了显著的提升。
点此查看论文截图

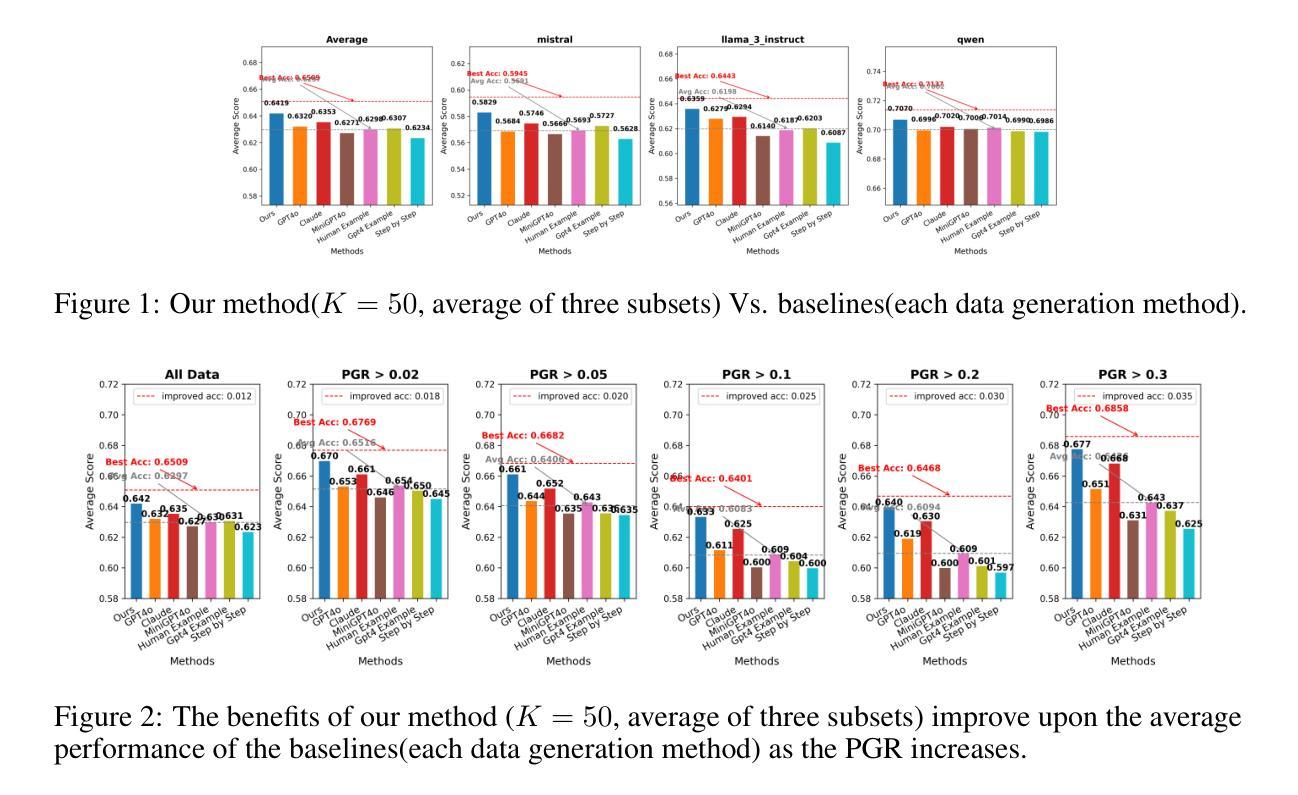
Expertized Caption Auto-Enhancement for Video-Text Retrieval
Authors:Baoyao Yang, Junxiang Chen, Wanyun Li, Wenbin Yao, Yang Zhou
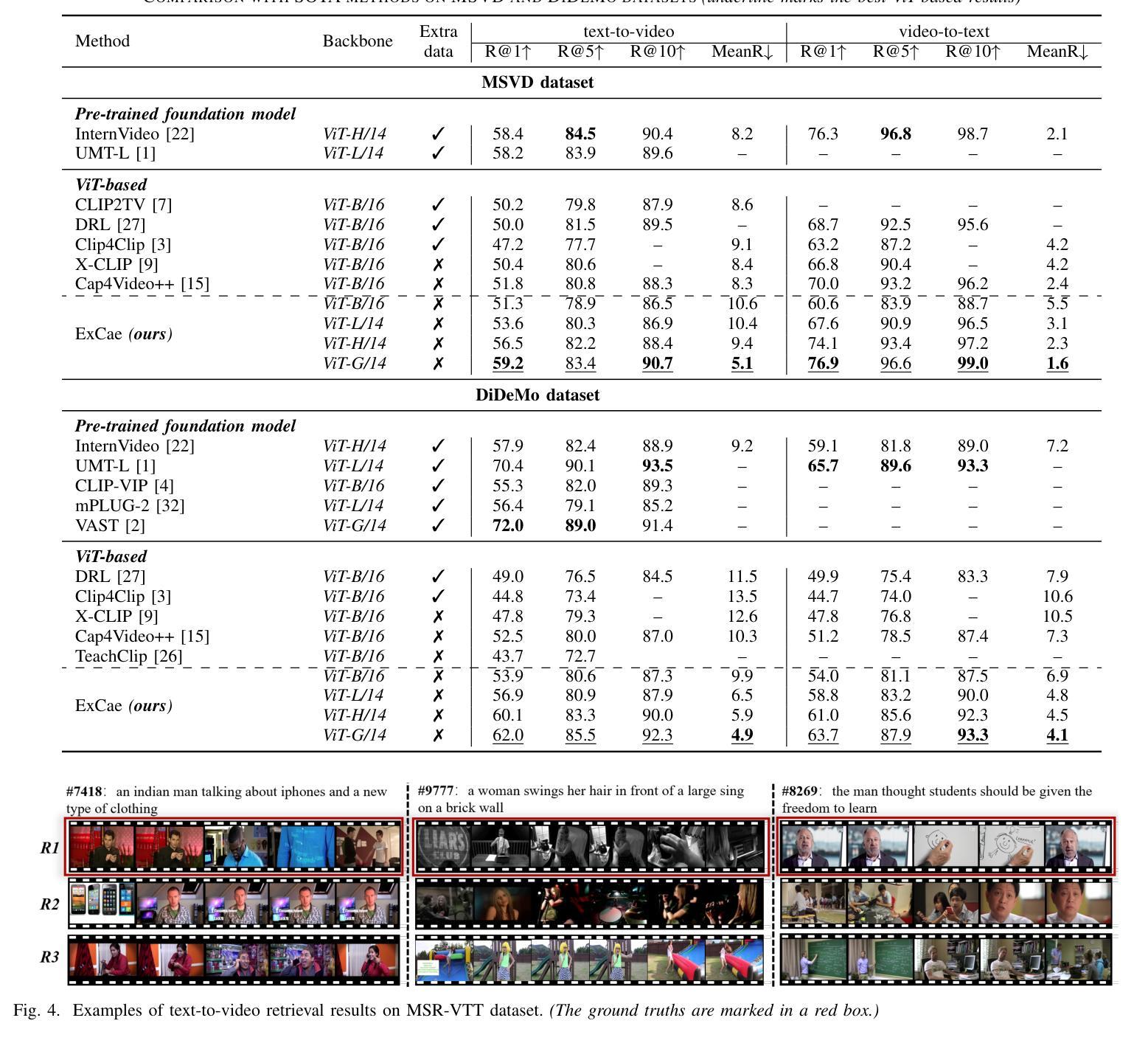
Video-text retrieval has been stuck in the information mismatch caused by personalized and inadequate textual descriptions of videos. The substantial information gap between the two modalities hinders an effective cross-modal representation alignment, resulting in ambiguous retrieval results. Although text rewriting methods have been proposed to broaden text expressions, the modality gap remains significant, as the text representation space is hardly expanded with insufficient semantic enrichment.Instead, this paper turns to enhancing visual presentation, bridging video expression closer to textual representation via caption generation and thereby facilitating video-text matching.While multimodal large language models (mLLM) have shown a powerful capability to convert video content into text, carefully crafted prompts are essential to ensure the reasonableness and completeness of the generated captions. Therefore, this paper proposes an automatic caption enhancement method that improves expression quality and mitigates empiricism in augmented captions through self-learning.Additionally, an expertized caption selection mechanism is designed and introduced to customize augmented captions for each video, further exploring the utilization potential of caption augmentation.Our method is entirely data-driven, which not only dispenses with heavy data collection and computation workload but also improves self-adaptability by circumventing lexicon dependence and introducing personalized matching. The superiority of our method is validated by state-of-the-art results on various benchmarks, specifically achieving Top-1 recall accuracy of 68.5% on MSR-VTT, 68.1% on MSVD, and 62.0% on DiDeMo. Our code is publicly available at https://github.com/CaryXiang/ECA4VTR.
视频文本检索一直面临着因视频个性化及文本描述不足而导致的信息不匹配问题。两种模式之间存在巨大的信息鸿沟,阻碍了有效的跨模态表示对齐,导致检索结果模糊不清。虽然提出了文本重写方法来扩展文本表达,但由于语义丰富不足,文本表示空间几乎无法扩展,模态差距仍然存在。
相反,本文致力于提高视觉表现,通过生成字幕来缩小视频表达与文本表示之间的距离,从而促进视频文本匹配。尽管多模态大型语言模型(mLLM)已显示出将视频内容转换为文本的强大能力,但精心设计的提示对于确保生成字幕的合理性和完整性至关重要。
因此,本文提出了一种自动字幕增强方法,通过自我学习提高表达质量,减轻增强字幕中的经验主义。此外,还设计和引入了一种专业字幕选择机制,为每段视频定制增强字幕,进一步探索字幕增强的应用潜力。
论文及项目相关链接
摘要
视频文本检索因视频描述信息的个性化和不足而导致信息不匹配问题。文本和视觉信息之间的巨大鸿沟阻碍了跨模态表示的有效对齐,导致检索结果模糊。尽管提出了文本重写方法来扩大文本表达,但由于文本表示空间的不足和语义贫乏,模态间的差距仍然显著。本文转向提高视觉表达,通过生成字幕将视频表达拉近文本表示,从而促进视频文本匹配。虽然多模态大型语言模型(mLLM)已显示出将视频内容转换为文本的强大能力,但精心设计的提示对于确保生成字幕的合理性和完整性至关重要。因此,本文提出了一种自动字幕增强方法,通过自我学习提高表达质量,减少增强字幕中的经验主义。此外,设计并引入了一种专业字幕选择机制,为每段视频定制增强字幕,进一步探索字幕增强的应用潜力。我们的方法完全基于数据驱动,不仅减轻了数据收集和计算的工作量,而且通过避免对词典的依赖并引入个性化匹配来提高自适应性。我们的方法在多个基准测试上验证了其优越性,特别是在MSR-VTT、MSVD和DiDeMo上分别实现了Top-1召回率68.5%、68.1%和62.0%。我们的代码可在公开网站上获得:https://github.com/CaryXiang/ECA4VTR。
关键见解
- 视频文本检索面临个性化描述不足导致的信息不匹配问题。
- 文本与视觉信息之间的巨大鸿沟导致跨模态表示对齐困难,检索结果模糊。
- 提出通过增强视觉表达(生成字幕)来促进视频文本匹配的方法。
- 多模态大型语言模型(mLLM)在视频内容转换为文本方面表现出强大能力。
- 精心设计的提示对确保生成字幕的质量至关重要。
- 提出自动字幕增强方法,通过自我学习提高字幕质量并减少经验主义。
点此查看论文截图

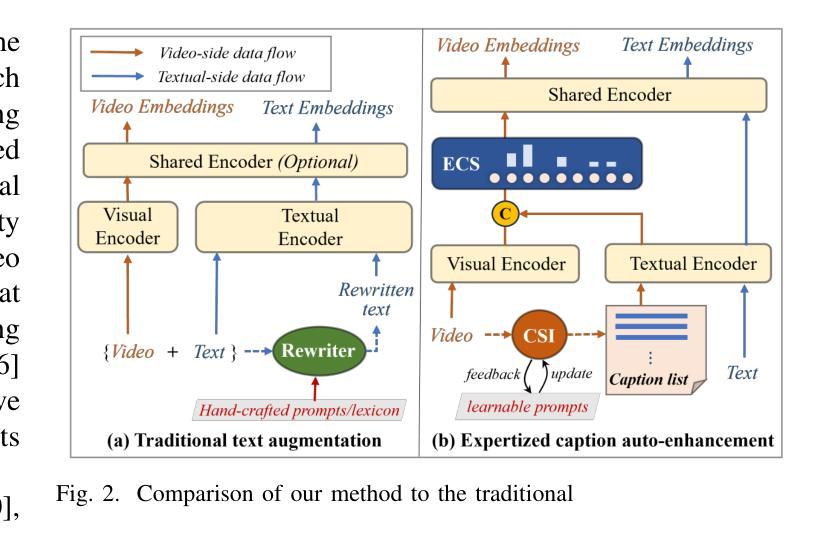
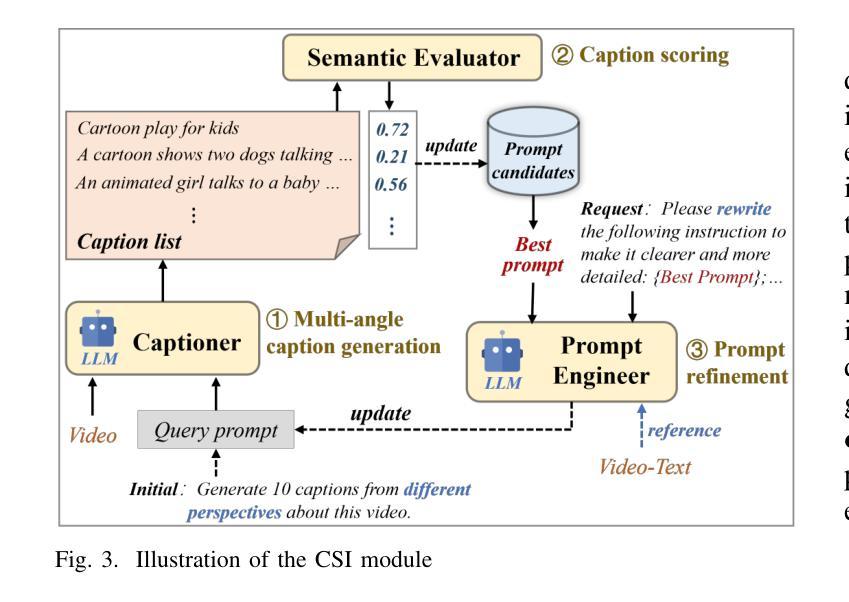

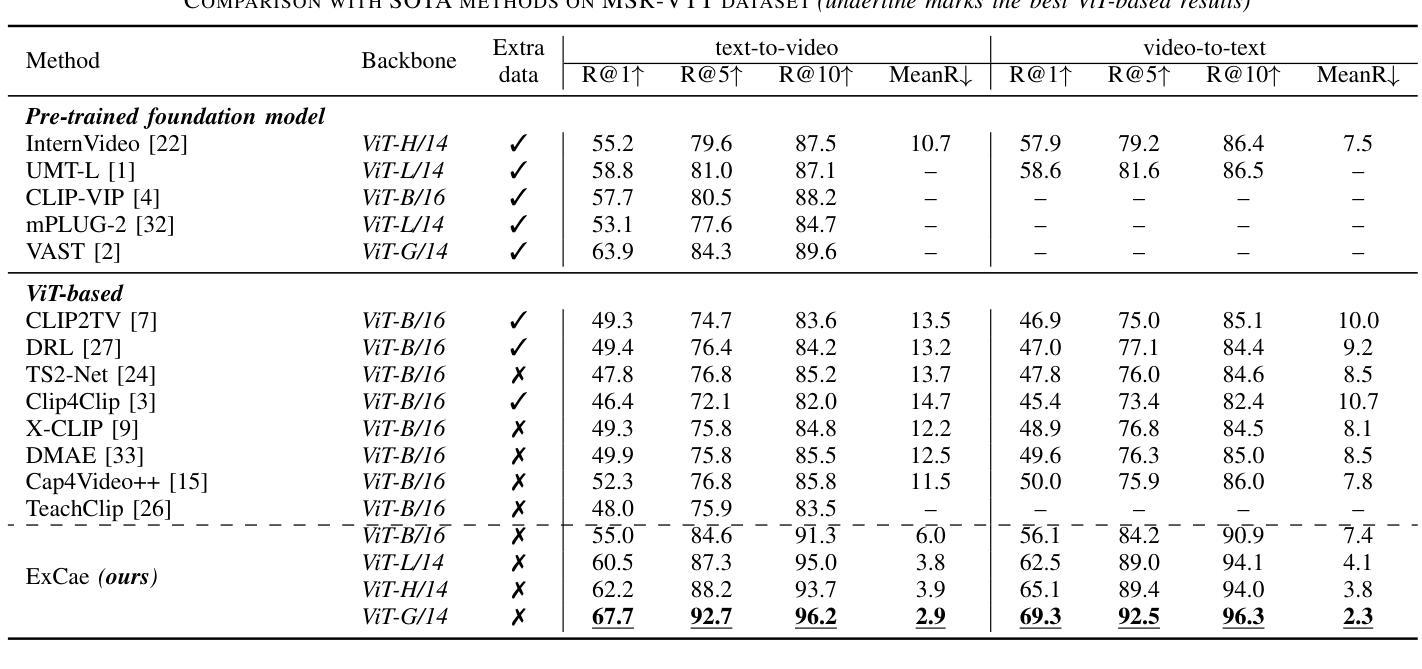
Double Visual Defense: Adversarial Pre-training and Instruction Tuning for Improving Vision-Language Model Robustness
Authors:Zeyu Wang, Cihang Xie, Brian Bartoldson, Bhavya Kailkhura
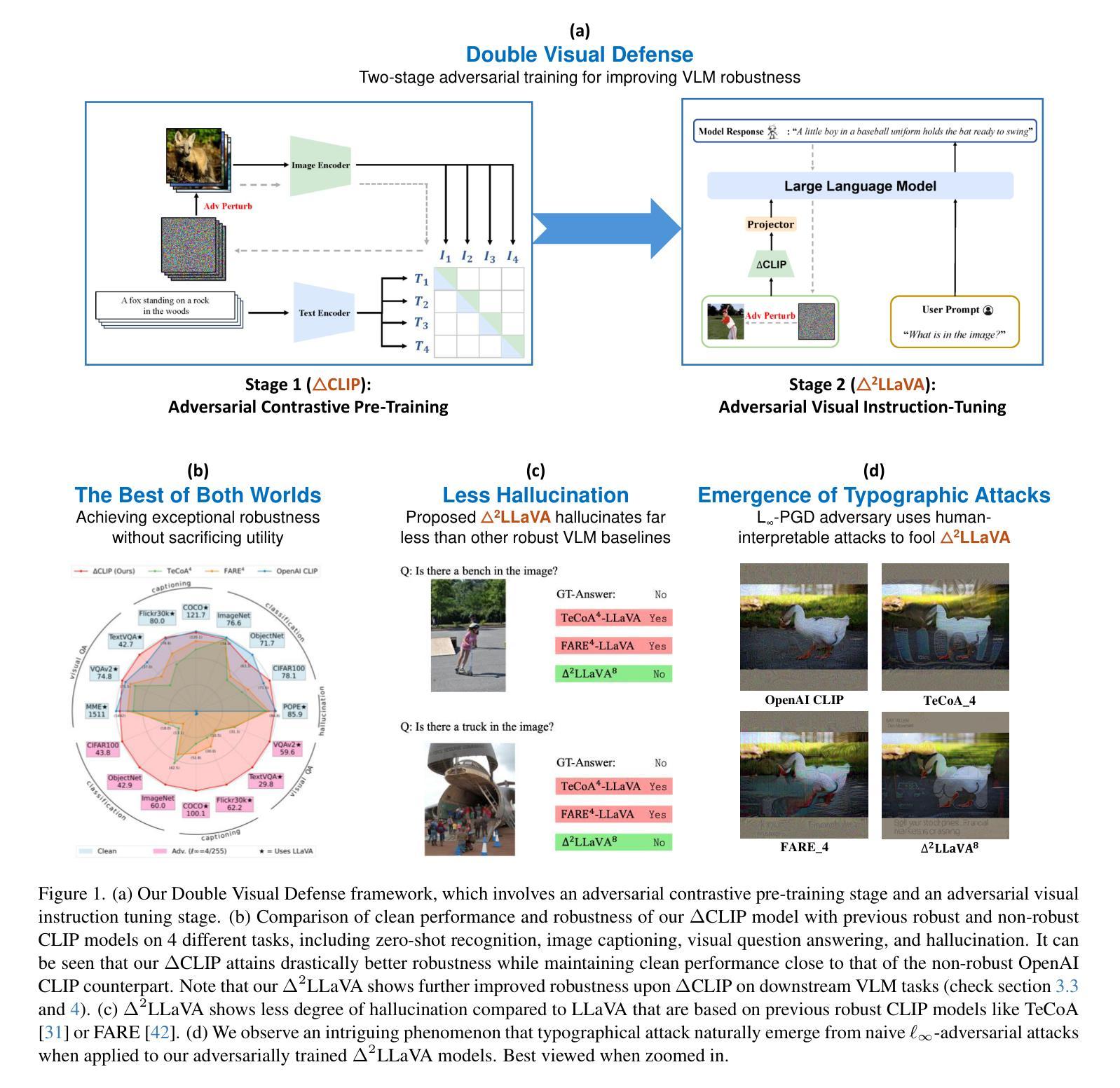
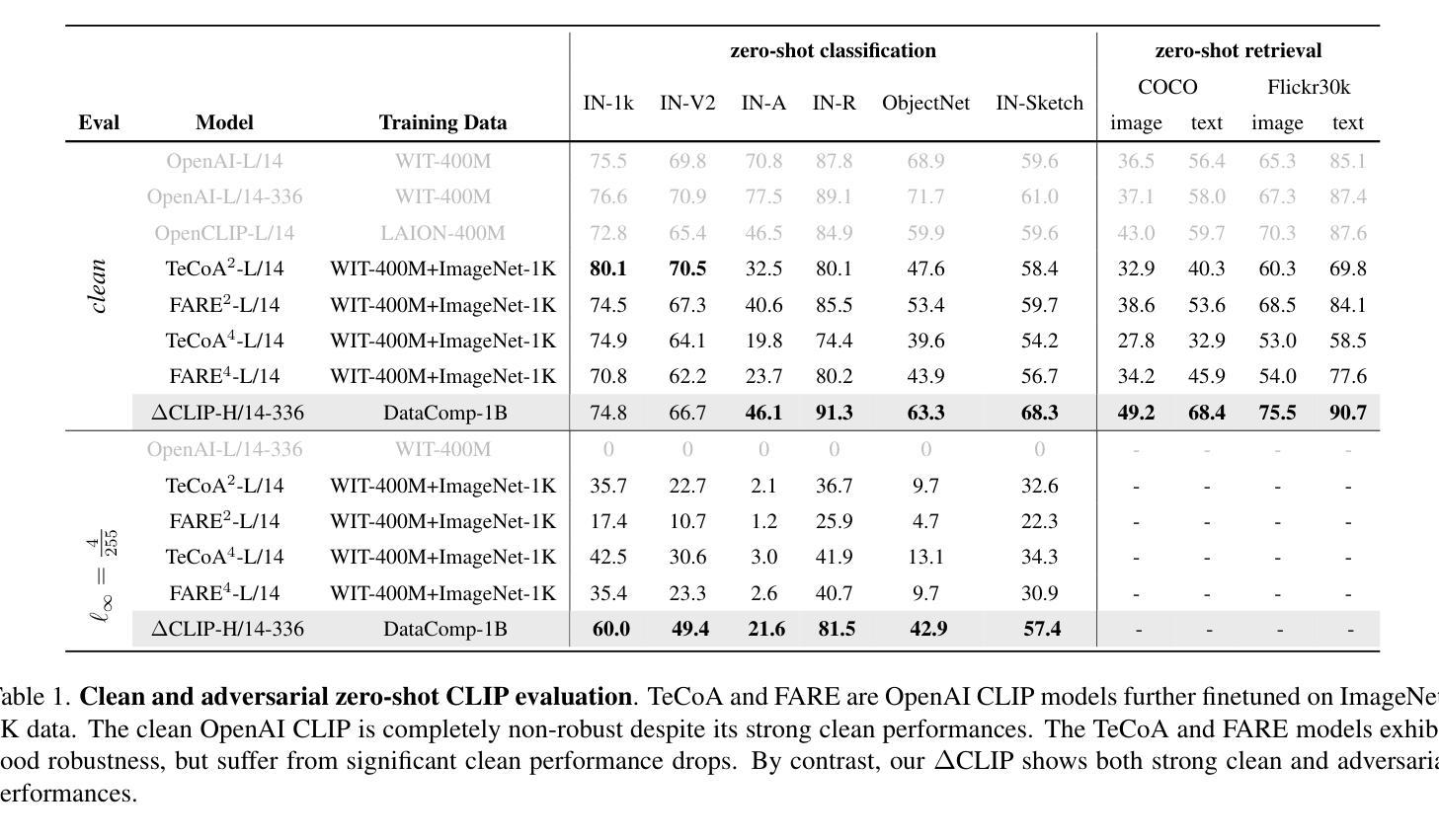
This paper investigates the robustness of vision-language models against adversarial visual perturbations and introduces a novel ``double visual defense” to enhance this robustness. Unlike previous approaches that resort to lightweight adversarial fine-tuning of a pre-trained CLIP model, we perform large-scale adversarial vision-language pre-training from scratch using web-scale data. We then strengthen the defense by incorporating adversarial visual instruction tuning. The resulting models from each stage, $\Delta$CLIP and $\Delta^2$LLaVA, show substantially enhanced zero-shot robustness and set a new state-of-the-art in adversarial defense for vision-language models. For example, the adversarial robustness of $\Delta$CLIP surpasses that of the previous best models on ImageNet-1k by ~20%. %For example, $\Delta$CLIP surpasses the previous best models on ImageNet-1k by ~20% in terms of adversarial robustness. Similarly, compared to prior art, $\Delta^2$LLaVA brings a ~30% robustness improvement to image captioning task and a ~20% robustness improvement to visual question answering task. Furthermore, our models exhibit stronger zero-shot recognition capability, fewer hallucinations, and superior reasoning performance compared to baselines. Our project page is https://doublevisualdefense.github.io/.
本文研究了视觉语言模型对抗对抗性视觉扰动的鲁棒性,并引入了一种新型的“双重视觉防御”机制来提高这种鲁棒性。不同于之前的方法,依赖于对预训练的CLIP模型的轻量级对抗微调,我们从零开始使用大规模网络数据进行了大规模的对抗视觉语言预训练。然后,通过结合对抗视觉指令微调来加强防御。从每个阶段得出的模型,即$\Delta$CLIP和$\Delta^2$LLaVA,显示出大幅增强的零样本鲁棒性,并在视觉语言模型的对抗防御方面创造了新的技术纪录。例如,$\Delta$CLIP在ImageNet-1k上的对抗鲁棒性超过了以前最佳模型的性能约20%。同样地,与先前技术相比,$\Delta^2$LLaVA在图像描述任务上提高了约30%的鲁棒性,在视觉问答任务上提高了约20%的鲁棒性。此外,我们的模型还表现出更强的零样本识别能力、更少的幻觉和优于基准线的推理性能。我们的项目页面是:[https://doublevisualdefense.github.io/] 。
论文及项目相关链接
Summary
本文探索了视觉语言模型对抗视觉扰动攻击的鲁棒性,并提出了一种新的“双重视觉防御”策略来提升其鲁棒性。不同于先前只对预训练CLIP模型进行轻量级的对抗微调的方法,我们从头开始进行大规模的对抗视觉语言预训练,并利用网络规模数据。此外,我们还通过结合对抗视觉指令微调来加强防御。由此产生的模型,如ΔCLIP和Δ²LLaVA,大幅增强了零样本鲁棒性,并在视觉语言模型的对抗防御方面创造了新的最先进的性能。例如,ΔCLIP在ImageNet-1k上的对抗鲁棒性超过了以前的最佳模型约20%。我们的项目页面是https://doublevisualdefense.github.io/。
Key Takeaways
- 论文研究视觉语言模型对抗视觉扰动攻击的鲁棒性。
- 提出了一种新的“双重视觉防御”策略以增强模型的鲁棒性。
- 通过大规模对抗视觉语言预训练来提升模型性能,利用网络规模数据。
- 结合对抗视觉指令微调来进一步强化模型的防御能力。
- ΔCLIP和Δ²LLaVA模型大幅增强了零样本鲁棒性,并在对抗防御方面达到最新水平。
- ΔCLIP在ImageNet-1k上的对抗鲁棒性较之前最佳模型提高了约20%。
点此查看论文截图

KnowCoder-X: Boosting Multilingual Information Extraction via Code
Authors:Yuxin Zuo, Wenxuan Jiang, Wenxuan Liu, Zixuan Li, Long Bai, Hanbin Wang, Yutao Zeng, Xiaolong Jin, Jiafeng Guo, Xueqi Cheng
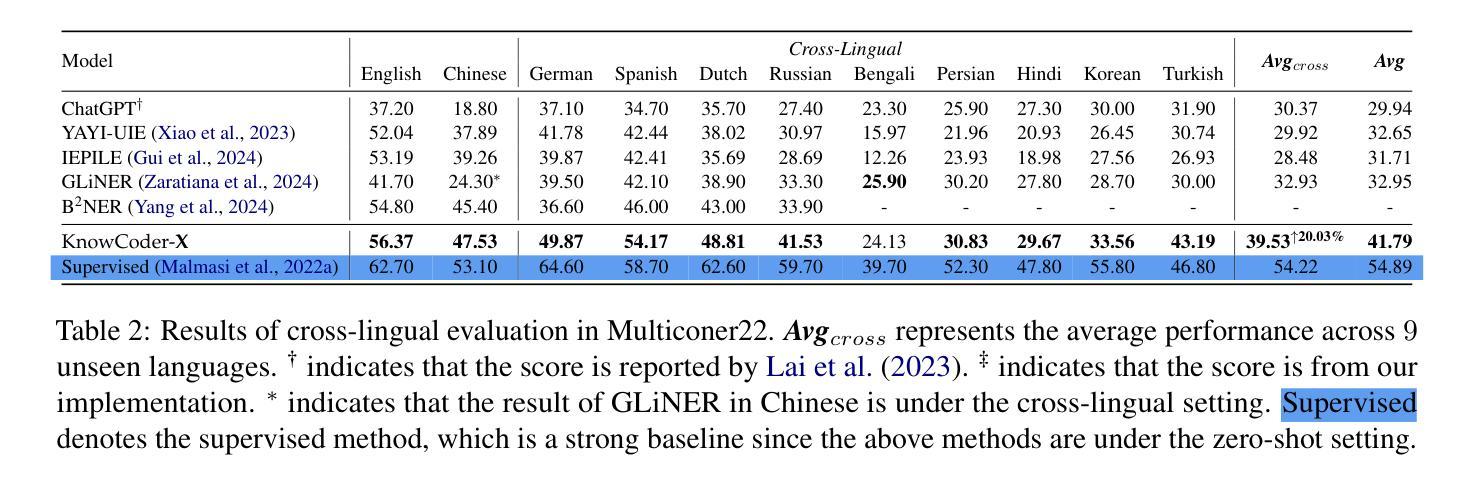
Empirical evidence indicates that LLMs exhibit spontaneous cross-lingual alignment. However, although LLMs show promising cross-lingual alignment in IE, a significant imbalance across languages persists, highlighting an underlying deficiency. To address this, we propose KnowCoder-X, a powerful code LLM with advanced cross-lingual and multilingual capabilities for universal information extraction. Firstly, it standardizes the representation of multilingual schemas using Python classes, ensuring a consistent ontology across different languages. Then, IE across languages is formulated as a unified code generation task. Secondly, we enhance the model’s cross-lingual transferability through IE cross-lingual alignment instruction tuning on a translated instance prediction task we proposed. During this phase, we also construct a high-quality and diverse bilingual IE parallel dataset with 257k samples, called ParallelNER, synthesized by our proposed robust three-stage pipeline, with manual annotation to ensure quality. Although without training in 29 unseen languages, KnowCoder-X surpasses ChatGPT by $30.17%$ and SoTA by $20.03%$, thereby demonstrating superior cross-lingual IE capabilities. Comprehensive evaluations on 64 IE benchmarks in Chinese and English under various settings demonstrate that KnowCoder-X significantly enhances cross-lingual IE transfer through boosting the IE alignment. Our code and dataset are available at: https://github.com/ICT-GoKnow/KnowCoder
实证证据表明,大型语言模型表现出自发的跨语言对齐。然而,尽管大型语言模型在信息提取方面显示出有前景的跨语言对齐,但不同语言之间仍存在显著的不平衡,这凸显了潜在的缺陷。为了解决这一问题,我们提出了KnowCoder-X,这是一个强大的代码大型语言模型,具有先进的跨语言和多元文化能力,用于通用信息提取。首先,它使用Python类标准化了多语言模式的表示,确保了不同语言之间的一致性本体。然后,将不同语言的信息提取公式化为统一的代码生成任务。其次,我们通过提出的信息提取跨语言对齐指令调整翻译实例预测任务,增强了模型的跨语言迁移能力。在这一阶段,我们还通过我们提出的稳健三阶段管道合成了一个高质量、多样化的双语信息提取平行数据集ParallelNER,包含25.7万个样本,并进行手动注释以确保质量。无需在29种未见过的语言中进行训练,KnowCoder-X超越了ChatGPT的30.17%,并超越了当前最佳水平的20.03%,从而证明了其卓越的跨语言信息提取能力。在中文和英文的64个信息提取基准测试下的综合评估表明,KnowCoder-X通过提高信息提取的对齐性,显著增强了跨语言信息提取的迁移能力。我们的代码和数据集可在https://github.com/ICT-GoKnow/KnowCoder上找到。
论文及项目相关链接
PDF 26 pages, 3 figures
Summary
LLMs展现出跨语言自发的对齐能力,但在信息抽取(IE)领域仍存在语言间的不平衡。为此,提出KnowCoder-X模型,具备先进的跨语言和多语言能力,用于通用信息抽取。它通过标准化多语言模式和使用Python类确保跨语言的一致性本体,将跨语言的信息抽取制定为统一的代码生成任务。通过IE跨语言对齐指令调整和翻译实例预测任务,增强了模型的跨语言迁移能力。使用高质量、多样化的双语IE平行数据集ParallelNER进行训练,未经29种未见过的语言训练,KnowCoder-X在ChatGPT上提高了30.17%,并在其他技术处于领先地位的模型上提高了20.03%,表现出优越的跨语言IE能力。该模型在不同设置的中文和英文的64个IE基准测试中显著提高了跨语言IE迁移能力。
Key Takeaways
- LLMs展现出跨语言自发的对齐能力,但在信息抽取(IE)中存在语言间的不平衡问题。
- KnowCoder-X是一个具备先进跨语言和多语言能力针对信息抽取设计的LLM。
- KnowCoder-X通过标准化多语言模式并使用Python类确保跨语言的一致性本体。
- KnowCoder-X将跨语言的信息抽取制定为统一的代码生成任务。
- KnowCoder-X通过IE跨语言对齐指令调整和翻译实例预测任务增强模型的跨语言迁移能力。
- KnowCoder-X使用高质量的双语IE平行数据集ParallelNER进行训练。
点此查看论文截图