⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-10 更新
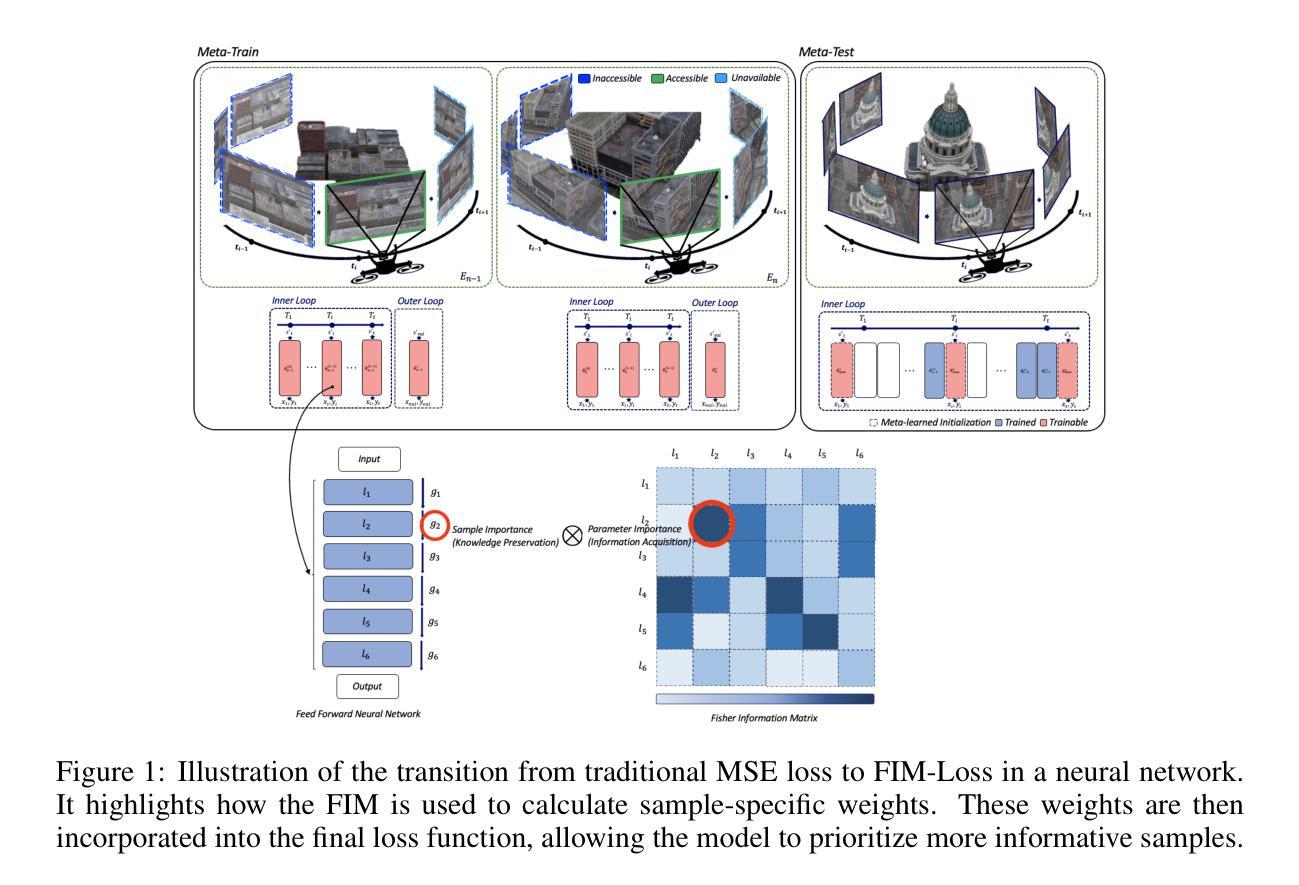
Meta-Continual Learning of Neural Fields
Authors:Seungyoon Woo, Junhyeog Yun, Gunhee Kim
Neural Fields (NF) have gained prominence as a versatile framework for complex data representation. This work unveils a new problem setting termed \emph{Meta-Continual Learning of Neural Fields} (MCL-NF) and introduces a novel strategy that employs a modular architecture combined with optimization-based meta-learning. Focused on overcoming the limitations of existing methods for continual learning of neural fields, such as catastrophic forgetting and slow convergence, our strategy achieves high-quality reconstruction with significantly improved learning speed. We further introduce Fisher Information Maximization loss for neural radiance fields (FIM-NeRF), which maximizes information gains at the sample level to enhance learning generalization, with proved convergence guarantee and generalization bound. We perform extensive evaluations across image, audio, video reconstruction, and view synthesis tasks on six diverse datasets, demonstrating our method’s superiority in reconstruction quality and speed over existing MCL and CL-NF approaches. Notably, our approach attains rapid adaptation of neural fields for city-scale NeRF rendering with reduced parameter requirement.
神经场(NF)作为一个多功能框架,在复杂数据表示中脱颖而出。本研究揭示了一个新的问题设置,称为“神经场的元连续学习”(MCL-NF),并引入了一种新的策略,该策略采用模块化架构并结合基于优化的元学习。我们的策略专注于克服现有神经场连续学习方法(如灾难性遗忘和收敛缓慢)的局限性,实现了高质量重建和显著的学习速度提升。此外,我们还引入了用于神经辐射场的Fisher信息最大化损失(FIM-NeRF),通过最大化样本级别的信息增益,以增强学习的泛化能力,并具有收敛性保证和泛化边界。我们在图像、音频、视频重建和视图合成任务上对六个不同的数据集进行了广泛评估,证明了我们的方法在重建质量和速度上均优于现有的MCL和CL-NF方法。尤其值得一提的是,我们的方法能够实现城市规模NeRF渲染的神经场快速适应,并降低了参数需求。
论文及项目相关链接
Summary
本文提出了一个新的研究问题——神经场的元连续学习(MCL-NF),并提出了一种采用模块化架构和优化元学习相结合的新策略来解决神经场连续学习的局限性问题,如灾难性遗忘和慢速收敛。同时,引入了Fisher信息最大化损失用于神经辐射场(FIM-NeRF),提高了学习的泛化能力,保证了收敛性和泛化边界。在图像、音频、视频重建和视图合成任务上的六个不同数据集进行的广泛评估表明,该方法在重建质量和速度上均优于现有的MCL和CL-NF方法。特别是在城市规模NeRF渲染方面,该方法实现了神经场的快速适应和减少参数需求。
Key Takeaways
- 引入新的研究问题——神经场的元连续学习(MCL-NF)。
- 提出一种结合模块化架构和优化元学习的新策略来解决神经场连续学习的挑战。
- 引入Fisher信息最大化损失(FIM-NeRF)以提高学习的泛化能力。
- 保证收敛性和泛化边界。
- 在多个数据集上进行了广泛评估,涵盖图像、音频、视频重建和视图合成任务。
- 在重建质量和速度上优于现有的MCL和CL-NF方法。
点此查看论文截图


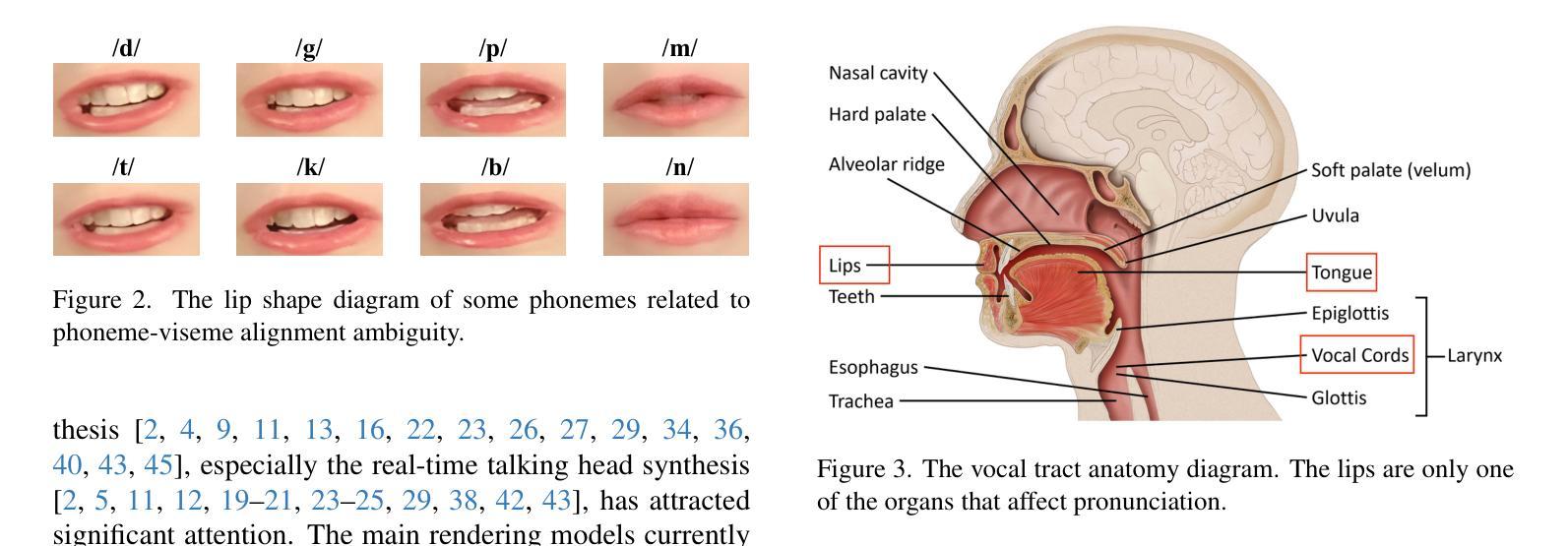
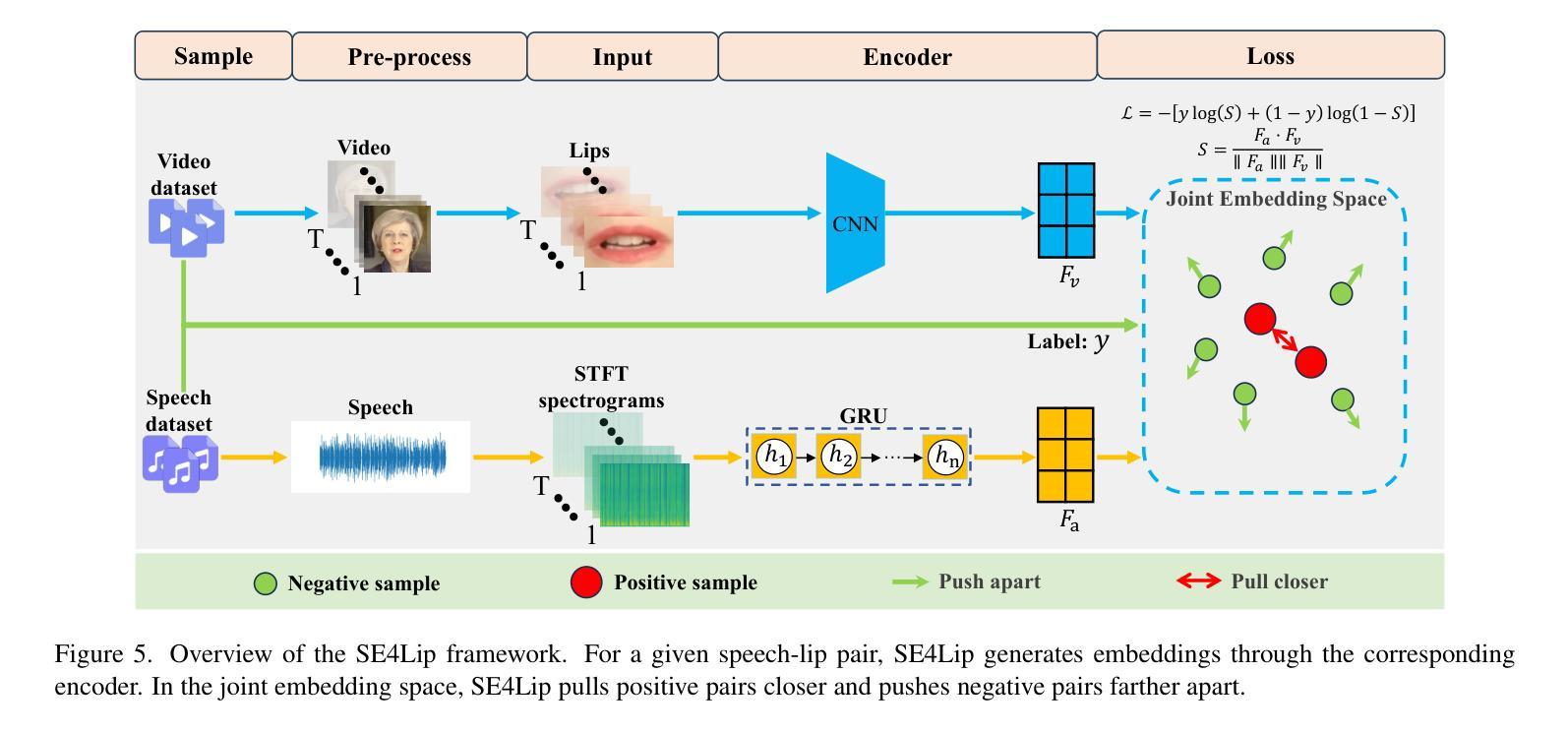
SE4Lip: Speech-Lip Encoder for Talking Head Synthesis to Solve Phoneme-Viseme Alignment Ambiguity
Authors:Yihuan Huang, Jiajun Liu, Yanzhen Ren, Wuyang Liu, Juhua Tang
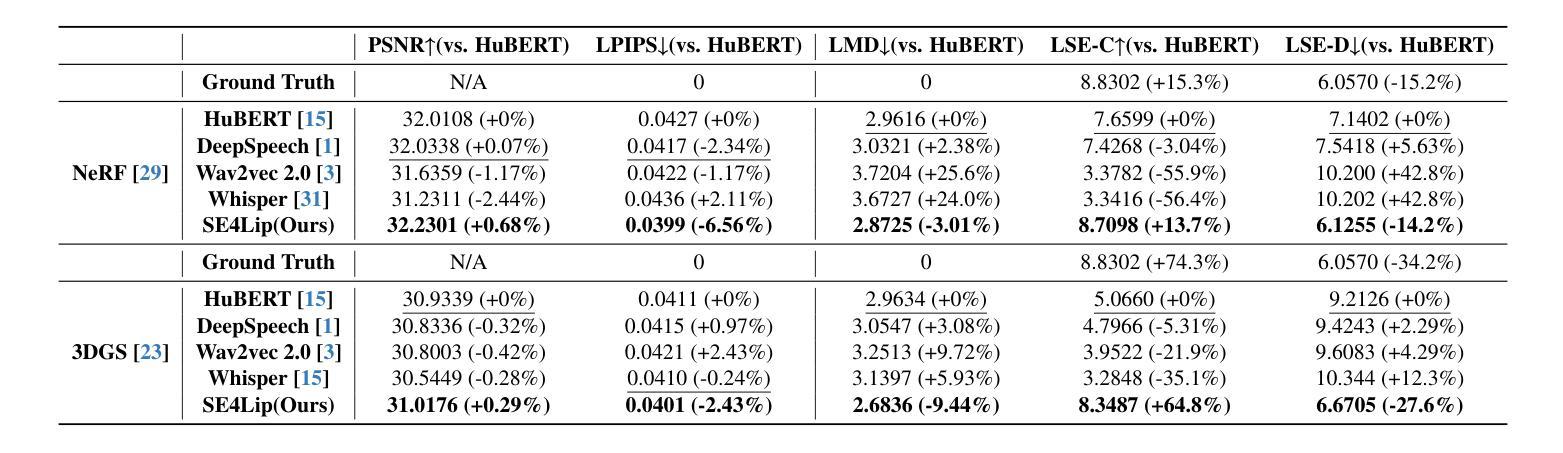
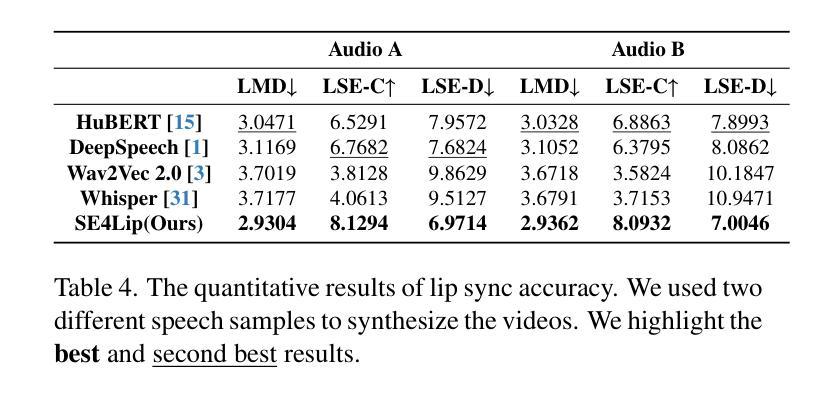
Speech-driven talking head synthesis tasks commonly use general acoustic features (such as HuBERT and DeepSpeech) as guided speech features. However, we discovered that these features suffer from phoneme-viseme alignment ambiguity, which refers to the uncertainty and imprecision in matching phonemes (speech) with visemes (lip). To address this issue, we propose the Speech Encoder for Lip (SE4Lip) to encode lip features from speech directly, aligning speech and lip features in the joint embedding space by a cross-modal alignment framework. The STFT spectrogram with the GRU-based model is designed in SE4Lip to preserve the fine-grained speech features. Experimental results show that SE4Lip achieves state-of-the-art performance in both NeRF and 3DGS rendering models. Its lip sync accuracy improves by 13.7% and 14.2% compared to the best baseline and produces results close to the ground truth videos.
语音驱动的人头合成任务通常使用一般的声学特征(如HuBERT和DeepSpeech)作为引导语音特征。然而,我们发现这些特征存在音素-唇形对应模糊的问题,即音素(语音)与唇形(唇)匹配的不确定性和不精确性。为了解决这一问题,我们提出了基于语音的唇形编码器(SE4Lip),直接对语音进行唇形特征编码,通过跨模态对齐框架在联合嵌入空间中对齐语音和唇形特征。SE4Lip采用基于GRU模型的STFT频谱图设计,旨在保留精细的语音特征。实验结果表明,SE4Lip在NeRF和3DGS渲染模型中均达到了最新技术水平。其唇形同步精度比最佳基线提高了13.7%和14.2%,并产生了接近真实视频的结果。
论文及项目相关链接
Summary
本文为了解决语音驱动头部合成任务中语音与唇动作(viseme)对齐的问题,提出了一个名为SE4Lip的唇特征编码模型。该模型能够直接从语音中编码唇特征,通过在联合嵌入空间建立跨模态对齐框架来实现语音和唇特征的精准匹配。实验结果显示,SE4Lip在NeRF和3DGS渲染模型上取得了最先进的性能,其唇同步精度相较于最佳基线模型提高了13.7%和14.2%,并且生成的结果接近真实视频。
Key Takeaways
- SE4Lip模型是为了解决语音驱动头部合成任务中的语音与唇动作对齐问题而提出的。
- SE4Lip模型能够直接从语音中编码唇特征。
- 通过在联合嵌入空间建立跨模态对齐框架,实现了语音和唇特征的精准匹配。
- SE4Lip模型采用了基于STFT的频谱图和GRU模型的设计,以保留精细的语音特征。
- 实验结果显示SE4Lip在NeRF和3DGS渲染模型上取得了最先进的性能。
- SE4Lip模型的唇同步精度相较于最佳基线模型有显著提高。
点此查看论文截图



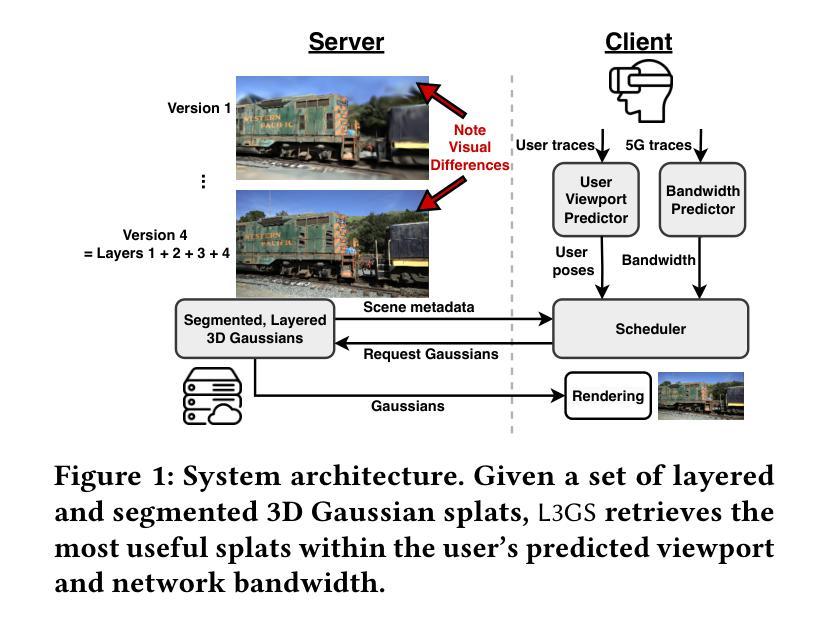
L3GS: Layered 3D Gaussian Splats for Efficient 3D Scene Delivery
Authors:Yi-Zhen Tsai, Xuechen Zhang, Zheng Li, Jiasi Chen
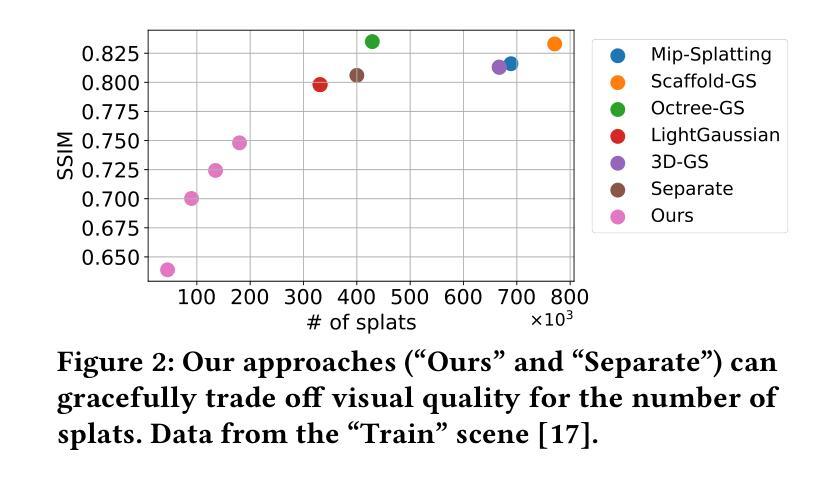
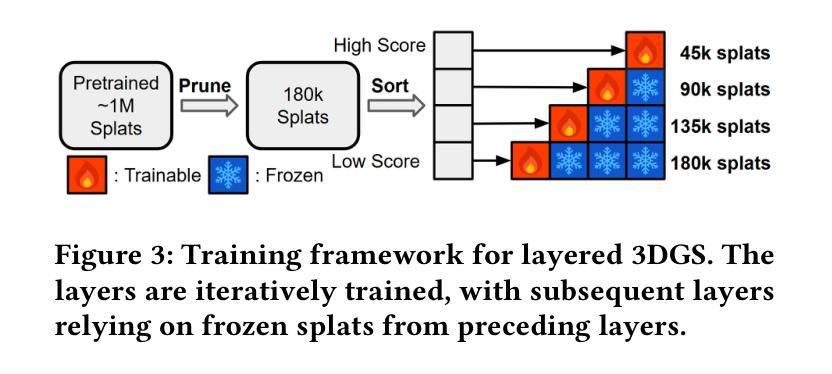
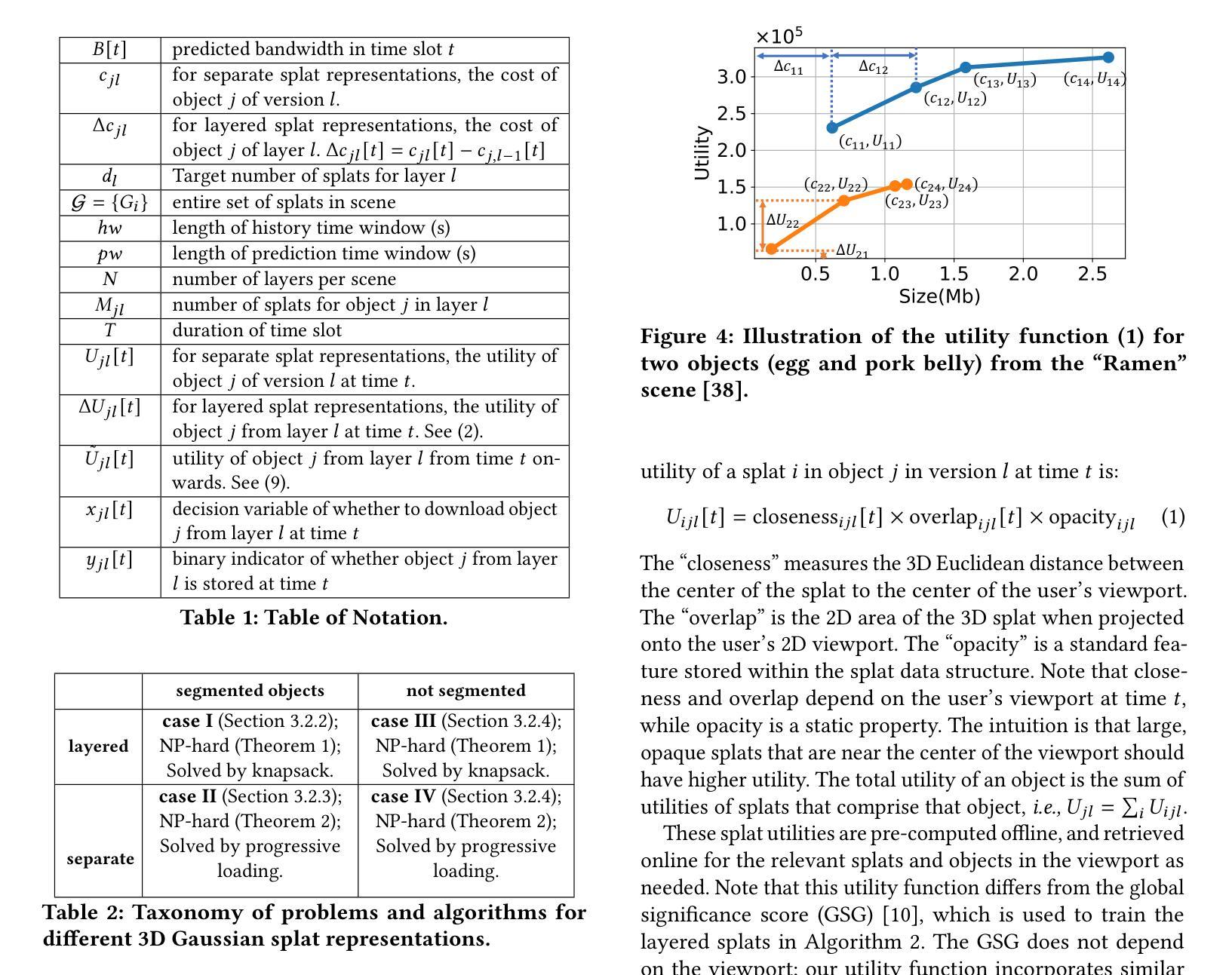
Traditional 3D content representations include dense point clouds that consume large amounts of data and hence network bandwidth, while newer representations such as neural radiance fields suffer from poor frame rates due to their non-standard volumetric rendering pipeline. 3D Gaussian splats (3DGS) can be seen as a generalization of point clouds that meet the best of both worlds, with high visual quality and efficient rendering for real-time frame rates. However, delivering 3DGS scenes from a hosting server to client devices is still challenging due to high network data consumption (e.g., 1.5 GB for a single scene). The goal of this work is to create an efficient 3D content delivery framework that allows users to view high quality 3D scenes with 3DGS as the underlying data representation. The main contributions of the paper are: (1) Creating new layered 3DGS scenes for efficient delivery, (2) Scheduling algorithms to choose what splats to download at what time, and (3) Trace-driven experiments from users wearing virtual reality headsets to evaluate the visual quality and latency. Our system for Layered 3D Gaussian Splats delivery L3GS demonstrates high visual quality, achieving 16.9% higher average SSIM compared to baselines, and also works with other compressed 3DGS representations.
传统3D内容表示包括消耗大量数据和网络带宽的密集点云,而较新的表示形式,如神经辐射场,由于非标准体积渲染管线而帧速率较低。3D高斯斑点(3DGS)可以被视为点云的概括,兼具两者之优点,即拥有高质量视觉效果和实时帧率的高效渲染。然而,由于网络数据消耗较高(例如单个场景高达1.5GB),从托管服务器向客户端设备传输3DGS场景仍然是一个挑战。本文的目标是创建一个高效的3D内容传输框架,允许用户使用3DGS作为基础数据表示来查看高质量3D场景。论文的主要贡献包括:(1)创建用于高效传输的新分层3DGS场景;(2)调度算法来选择何时下载哪些斑点;(3)使用佩戴虚拟现实头盔的用户进行追踪驱动实验,以评估视觉质量和延迟。我们的分层3D高斯斑点传输系统L3GS具有较高的视觉质量,与基线相比,平均SSIM高出16.9%,并且与其他压缩的3DGS表示形式一起使用也能发挥良好效果。
论文及项目相关链接
摘要
传统三维内容表示方法包括密集的点云,消耗大量数据和网络带宽,而新的神经辐射场表示方法则因非标准体积渲染流程而帧率较低。三维高斯点云可看作点云的泛化,兼具高质量视觉和高效渲染,实现实时帧率。然而,从主机服务器向客户端设备传输三维高斯点云场景仍面临高网络数据消耗的挑战(例如,单个场景高达1.5GB)。本文旨在创建一个高效的三维内容传输框架,允许用户以三维高斯点云为底层数据表示来查看高质量三维场景。论文的主要贡献包括:(1)创建用于高效传输的分层三维高斯点云场景;(2)调度算法选择何时下载哪些点云;(3)通过佩戴虚拟现实头盔的用户进行追踪实验,以评估视觉质量和延迟。我们的分层三维高斯点云传输系统L3GS具有高视觉质量,平均结构相似性指数(SSIM)比基线高出16.9%,并且与其他压缩的三维高斯点云表示方法兼容。
关键见解
- 三维高斯点云是点云的泛化,能结合高质量视觉和高效渲染,实现实时帧率。
- 现有三维内容表示方法如点云和神经辐射场存在数据消耗大和网络传输效率低的问题。
- 分层三维高斯点云场景创建为高效传输提供了解决方案。
- 调度算法选择何时下载哪些点云,优化数据传输效率。
- 通过佩戴虚拟现实头盔的用户进行的追踪实验验证了系统的视觉质量和效率。
- L3GS系统具有高视觉质量,平均结构相似性指数(SSIM)优于其他方法。
- L3GS系统与其他压缩的三维高斯点云表示方法兼容。
点此查看论文截图

Neural Pruning for 3D Scene Reconstruction: Efficient NeRF Acceleration
Authors:Tianqi Ding, Dawei Xiang, Pablo Rivas, Liang Dong
Neural Radiance Fields (NeRF) have become a popular 3D reconstruction approach in recent years. While they produce high-quality results, they also demand lengthy training times, often spanning days. This paper studies neural pruning as a strategy to address these concerns. We compare pruning approaches, including uniform sampling, importance-based methods, and coreset-based techniques, to reduce the model size and speed up training. Our findings show that coreset-driven pruning can achieve a 50% reduction in model size and a 35% speedup in training, with only a slight decrease in accuracy. These results suggest that pruning can be an effective method for improving the efficiency of NeRF models in resource-limited settings.
神经辐射场(NeRF)近年来已成为流行的3D重建方法。虽然它们能产生高质量的结果,但也需要长时间的训练,通常持续数天。本文针对神经修剪作为一种解决这些问题的策略进行了研究。我们比较了修剪方法,包括均匀采样、基于重要性的方法和基于核心集的技术,以减小模型大小并加速训练。我们的研究发现,基于核心集的修剪方法能够实现模型大小减少50%,训练速度提高35%,同时仅略微降低准确性。这些结果表明,修剪方法是在资源受限环境中提高NeRF模型效率的有效方法。
论文及项目相关链接
PDF 12 pages, 4 figures, accepted by International Conference on the AI Revolution: Research, Ethics, and Society (AIR-RES 2025)
Summary
神经网络辐射场(NeRF)近年来已成为流行的3D重建方法,虽然能产生高质量结果,但训练时间较长。本文研究了通过神经剪枝策略来解决这些问题,比较了均匀采样、基于重要性的方法和基于核心集的剪枝技术来减小模型大小并加速训练。研究发现,核心集驱动的剪枝可在保持轻微精度损失的情况下,实现模型大小减少50%,训练速度提高35%。这表明在资源受限的环境中,剪枝是提高NeRF模型效率的有效方法。
Key Takeaways
- NeRF是一种流行的3D重建方法,但训练时间长。
- 神经剪枝可作为解决NeRF训练效率和模型大小问题的方法。
- 均匀采样、基于重要性和基于核心集的剪枝技术是研究的重点。
- 核心集驱动的剪枝能在减小模型大小的同时,实现训练速度的提升。
- 核心集驱动的剪枝能在保持轻微精度损失的情况下,实现模型大小减少50%,训练速度提高35%。
- 剪枝策略在资源受限的环境中尤其有效。
点此查看论文截图

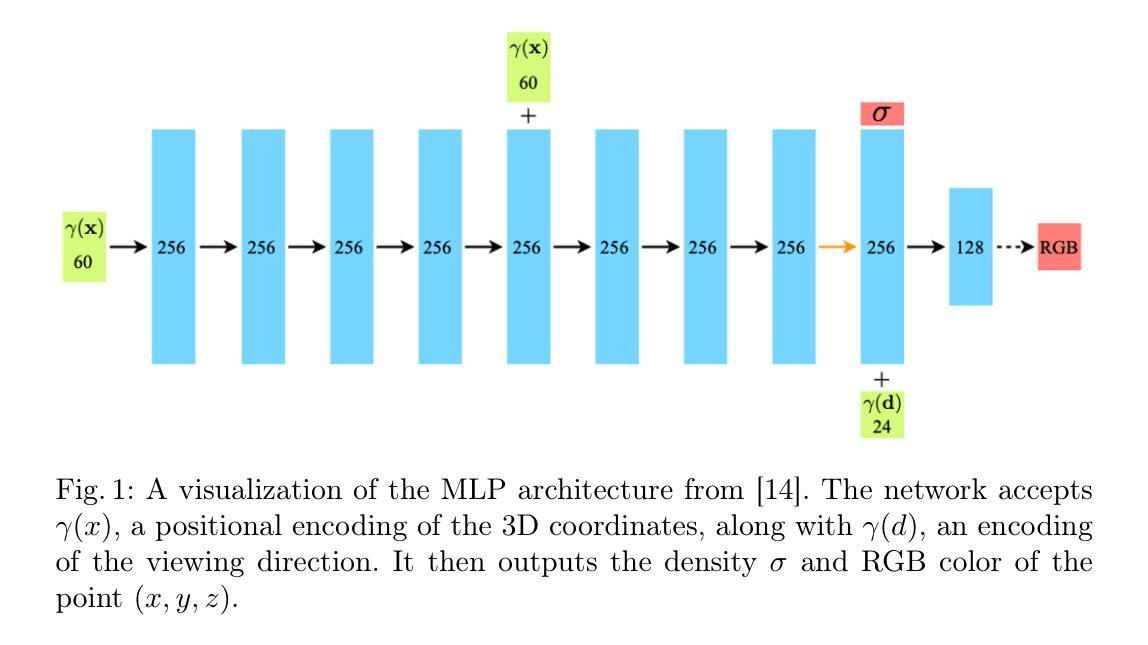
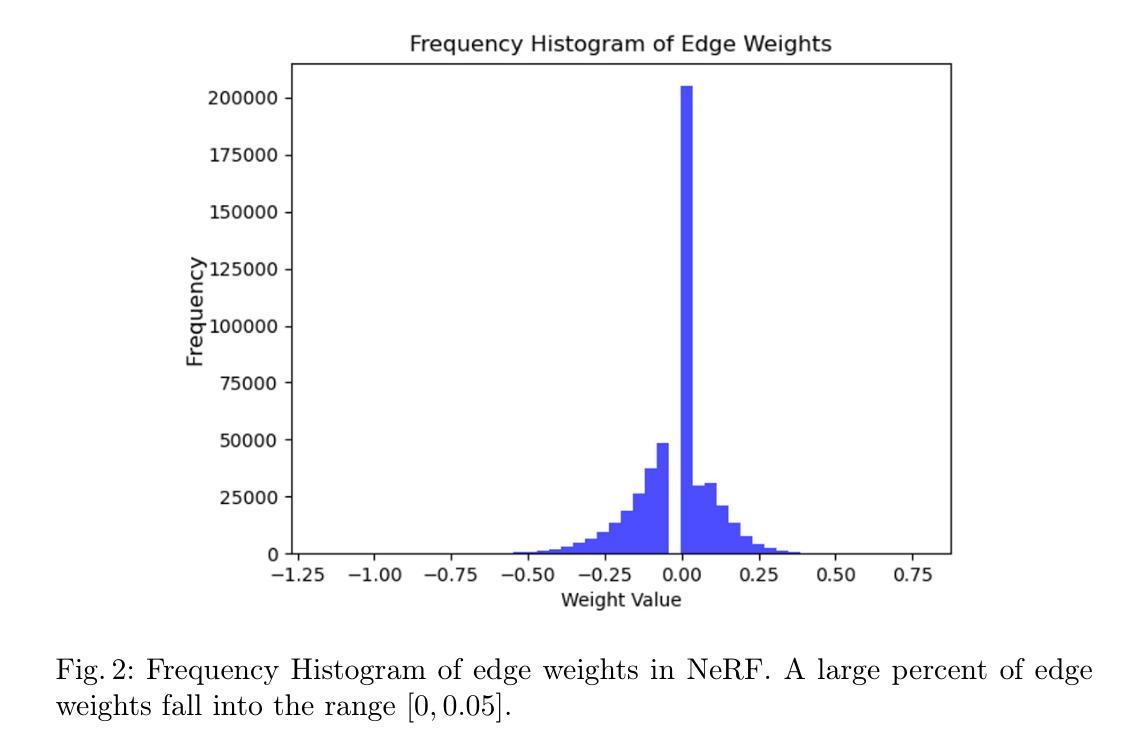

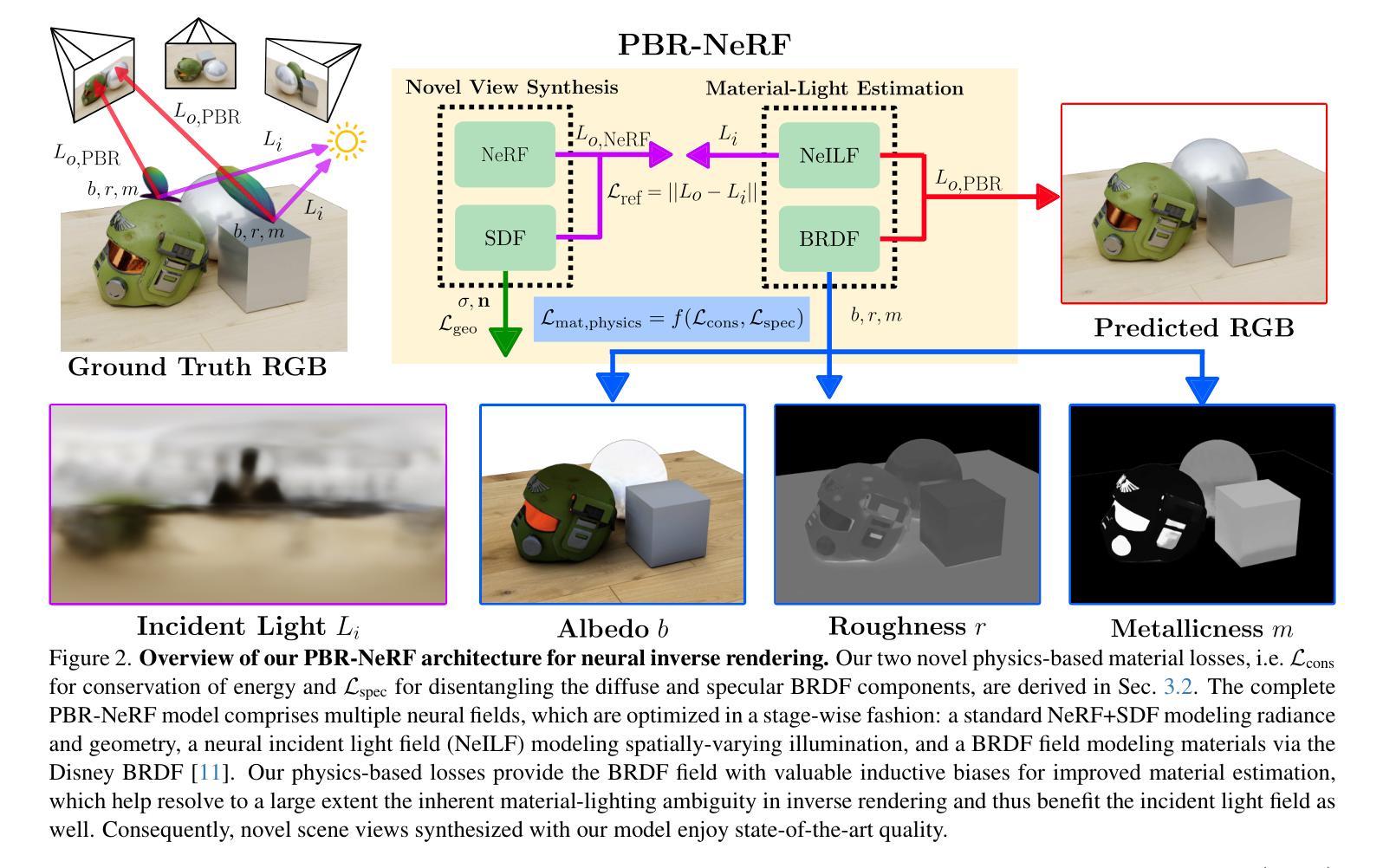
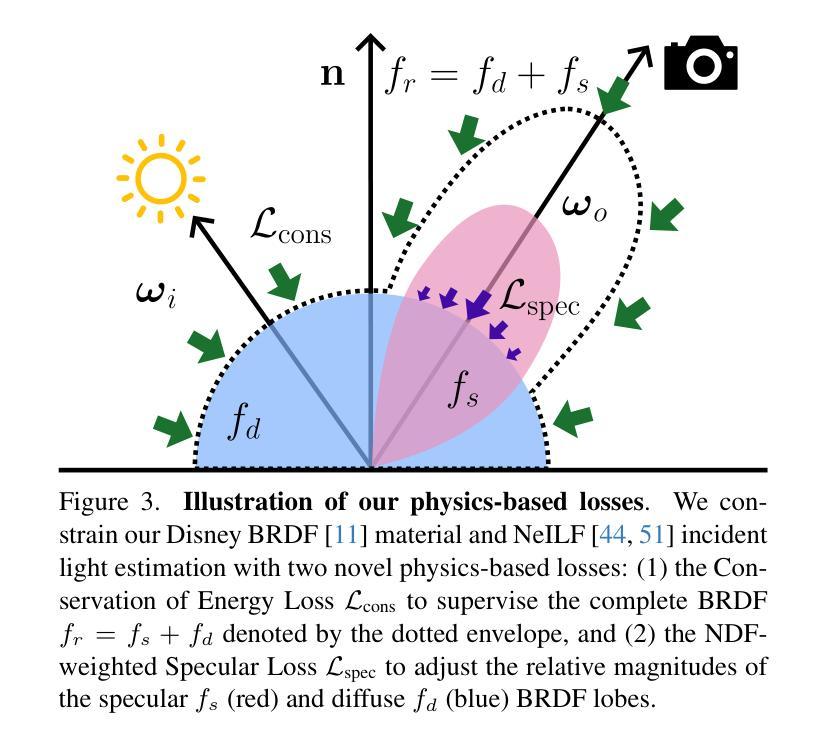
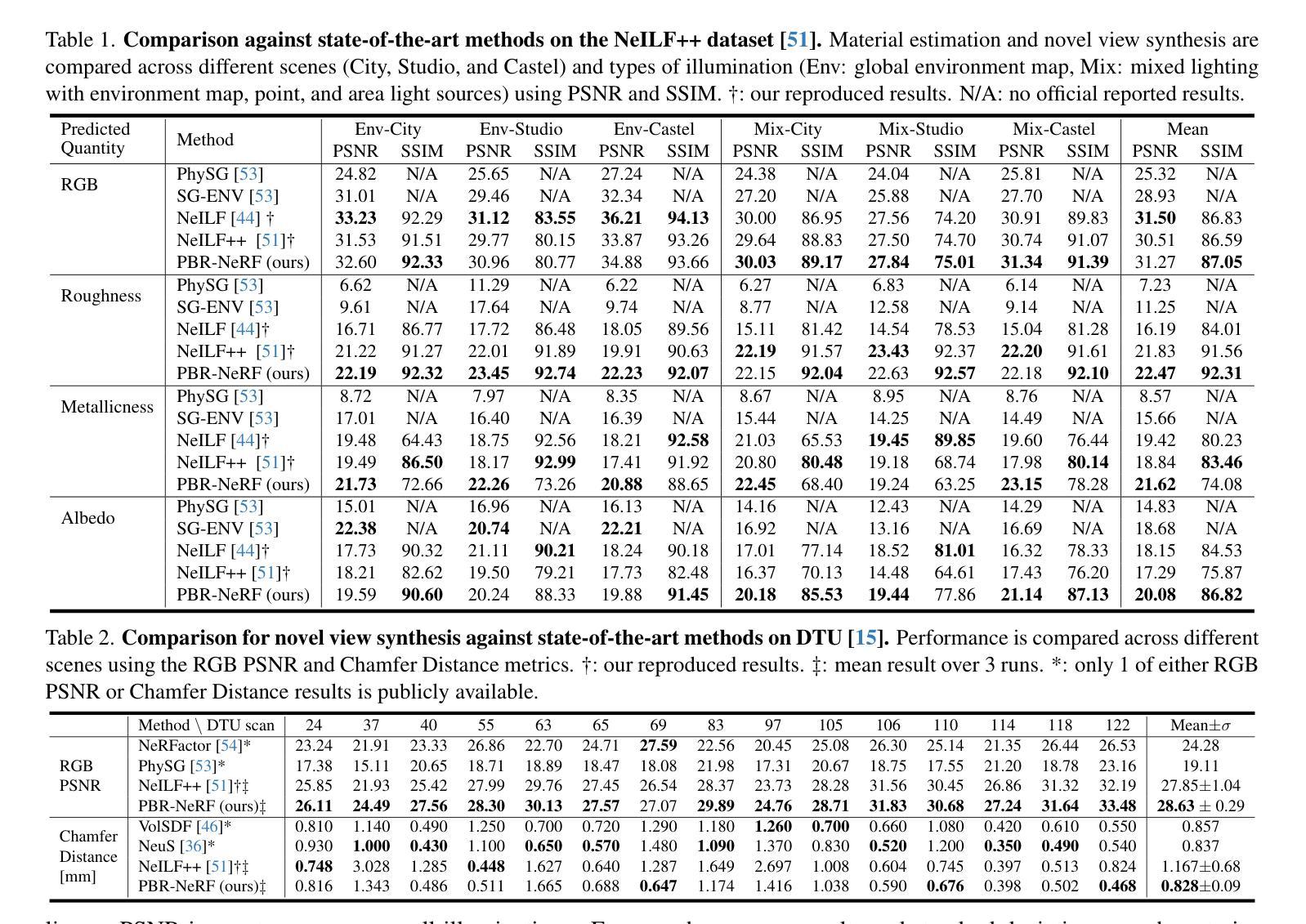
PBR-NeRF: Inverse Rendering with Physics-Based Neural Fields
Authors:Sean Wu, Shamik Basu, Tim Broedermann, Luc Van Gool, Christos Sakaridis
We tackle the ill-posed inverse rendering problem in 3D reconstruction with a Neural Radiance Field (NeRF) approach informed by Physics-Based Rendering (PBR) theory, named PBR-NeRF. Our method addresses a key limitation in most NeRF and 3D Gaussian Splatting approaches: they estimate view-dependent appearance without modeling scene materials and illumination. To address this limitation, we present an inverse rendering (IR) model capable of jointly estimating scene geometry, materials, and illumination. Our model builds upon recent NeRF-based IR approaches, but crucially introduces two novel physics-based priors that better constrain the IR estimation. Our priors are rigorously formulated as intuitive loss terms and achieve state-of-the-art material estimation without compromising novel view synthesis quality. Our method is easily adaptable to other inverse rendering and 3D reconstruction frameworks that require material estimation. We demonstrate the importance of extending current neural rendering approaches to fully model scene properties beyond geometry and view-dependent appearance. Code is publicly available at https://github.com/s3anwu/pbrnerf
我们采用基于物理渲染(PBR)理论的神经辐射场(NeRF)方法,解决了3D重建中的不适定逆向渲染问题,称之为PBR-NeRF。我们的方法解决了大多数NeRF和3D高斯拼贴方法的关键局限性:它们在估计视图相关外观时没有对场景材质和照明进行建模。为了解决这个问题,我们提出了一种逆向渲染(IR)模型,能够联合估计场景几何、材质和照明。我们的模型建立在最近的NeRF基IR方法之上,但关键地引入了两种新型基于物理的先验知识,更好地约束了IR估计。我们的先验知识被严谨地制定为直观的损失项,并在不损害新视图合成质量的情况下实现了最先进的材质估计。我们的方法可以轻松地适应其他需要材质估计的逆向渲染和3D重建框架。我们证明了将当前神经渲染方法扩展到完全建模场景属性(超越几何和视图相关外观)的重要性。代码已公开在 https://github.com/s3anwu/pbrnerf。
论文及项目相关链接
PDF CVPR 2025. 16 pages, 7 figures. Code is publicly available at https://github.com/s3anwu/pbrnerf
摘要
基于物理渲染(PBR)理论的神经网络辐射场(NeRF)方法解决三维重建中的逆向渲染问题,提出名为PBR-NeRF的方法。该方法解决了大多数NeRF和三维高斯涂抹方法的关键局限性:它们在估计视相关外观时没有建模场景材质和照明。为解决此局限性,我们提出了一种能够联合估计场景几何、材质和照明的逆向渲染(IR)模型。该模型建立在最近的NeRF基IR方法之上,但关键地引入了两个新的基于物理的先验知识,更好地约束了IR估计。我们的先验知识被严谨地制定为直观的损失项,实现了材料估计的最优状态,并且不会损害新颖视图合成的质量。我们的方法可以轻松地适应其他需要材料估计的逆向渲染和三维重建框架。展示了将当前神经网络渲染方法扩展到完全建模场景属性(超越几何和视相关外观)的重要性。
要点总结
- 提出一种名为PBR-NeRF的方法,利用NeRF和基于物理的渲染(PBR)理论来解决三维重建中的逆向渲染问题。
- 解决了现有NeRF和其他方法仅估计视相关外观而未建模场景材质和照明的局限性。
- 提出了一种逆向渲染(IR)模型,可联合估计场景几何、材质和照明。
- 引入两个新的基于物理的先验知识来约束IR估计,并实现材料估计的最优状态,同时保持视图合成的质量。
- 方法可轻松适应其他需要材料估计的逆向渲染和三维重建框架。
- 强调了完全建模场景属性的重要性,包括几何和视相关外观以外的因素。
点此查看论文截图