⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-10 更新
FEABench: Evaluating Language Models on Multiphysics Reasoning Ability
Authors:Nayantara Mudur, Hao Cui, Subhashini Venugopalan, Paul Raccuglia, Michael P. Brenner, Peter Norgaard
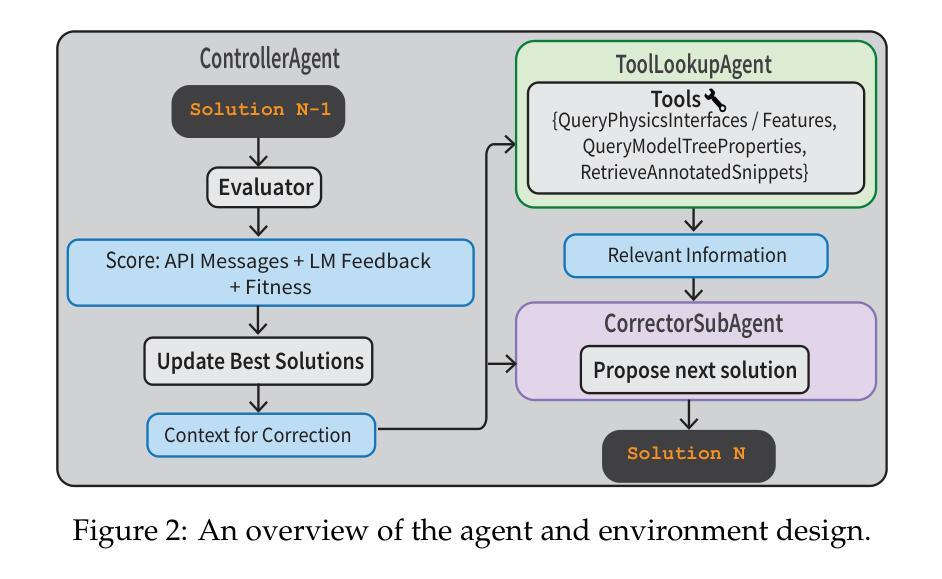
Building precise simulations of the real world and invoking numerical solvers to answer quantitative problems is an essential requirement in engineering and science. We present FEABench, a benchmark to evaluate the ability of large language models (LLMs) and LLM agents to simulate and solve physics, mathematics and engineering problems using finite element analysis (FEA). We introduce a comprehensive evaluation scheme to investigate the ability of LLMs to solve these problems end-to-end by reasoning over natural language problem descriptions and operating COMSOL Multiphysics$^\circledR$, an FEA software, to compute the answers. We additionally design a language model agent equipped with the ability to interact with the software through its Application Programming Interface (API), examine its outputs and use tools to improve its solutions over multiple iterations. Our best performing strategy generates executable API calls 88% of the time. LLMs that can successfully interact with and operate FEA software to solve problems such as those in our benchmark would push the frontiers of automation in engineering. Acquiring this capability would augment LLMs’ reasoning skills with the precision of numerical solvers and advance the development of autonomous systems that can tackle complex problems in the real world. The code is available at https://github.com/google/feabench
构建精确模拟现实世界并调用数值求解器解决定量问题是工程和科学的本质要求。我们推出了FEABench,这是一个基准测试,旨在评估大型语言模型(LLM)和LLM代理使用有限元分析(FEA)模拟和解决物理、数学和工程问题的能力。我们引入了一个全面的评估方案,通过端到端的推理来调查LLM解决这些问题的能力,通过自然语言问题描述进行推理并操作COMSOL Multiphysics®这一有限元分析软件来计算答案。此外,我们还设计了一个语言模型代理,该代理具备通过软件的应用程序编程接口(API)进行交互的能力,检查其输出并使用工具在多次迭代中改进其解决方案。我们表现最佳的策略生成可执行API调用的次数达到88%。能够成功与有限元分析软件交互并操作以解决诸如我们基准测试中问题等状况的LLM,将推动工程自动化领域的边界。获得这种能力将使LLM的推理技能与数值求解器的精确度相结合,推动开发能够应对现实世界复杂问题的自主系统的发展。代码可在https://github.com/google/feabench找到。
论文及项目相关链接
PDF 39 pages. Accepted at the NeurIPS 2024 Workshops on Mathematical Reasoning and AI and Open-World Agents
Summary
FEABench是一个用于评估大型语言模型(LLMs)及LLM代理模拟和解决物理、数学及工程问题能力的基准测试。它运用有限元分析(FEA)及COMSOL Multiphysics软件来解答问题。本文介绍了一个全面的评估方案,以研究LLMs端到端解决问题的能力,通过推理自然语言问题描述并操作FEA软件计算答案。此外,设计了一个语言模型代理,可透过软件的应用程序接口(API)互动、检视输出并使用工具改善多次迭代的解决方案。最佳策略生成的可执行API调用准确率达到了88%。此能力将推动工程自动化前沿,提升LLMs与数值解算器的结合推理能力,推动针对复杂现实问题的自主系统发展。
Key Takeaways
- FEABench是一个评估大型语言模型(LLMs)模拟与解决问题能力的基准测试,特别是在工程和科学领域的定量问题上。
- 该测试利用有限元分析(FEA)和COMSOL Multiphysics软件来设计和解决物理、数学和工程问题。
- LLMs需通过自然语言描述进行推理,并操作FEA软件以计算答案,体现其端到端的解决问题能力。
- 引入了一种语言模型代理,该代理能通过软件API进行互动,并能改善解决方案的多次迭代。
- 最佳策略生成的API调用准确率达到了88%,显示出较高的自动化潜力。
- LLMs结合数值解算器的能力将推动工程自动化的发展,并提升自主系统解决复杂问题的能力。
点此查看论文截图




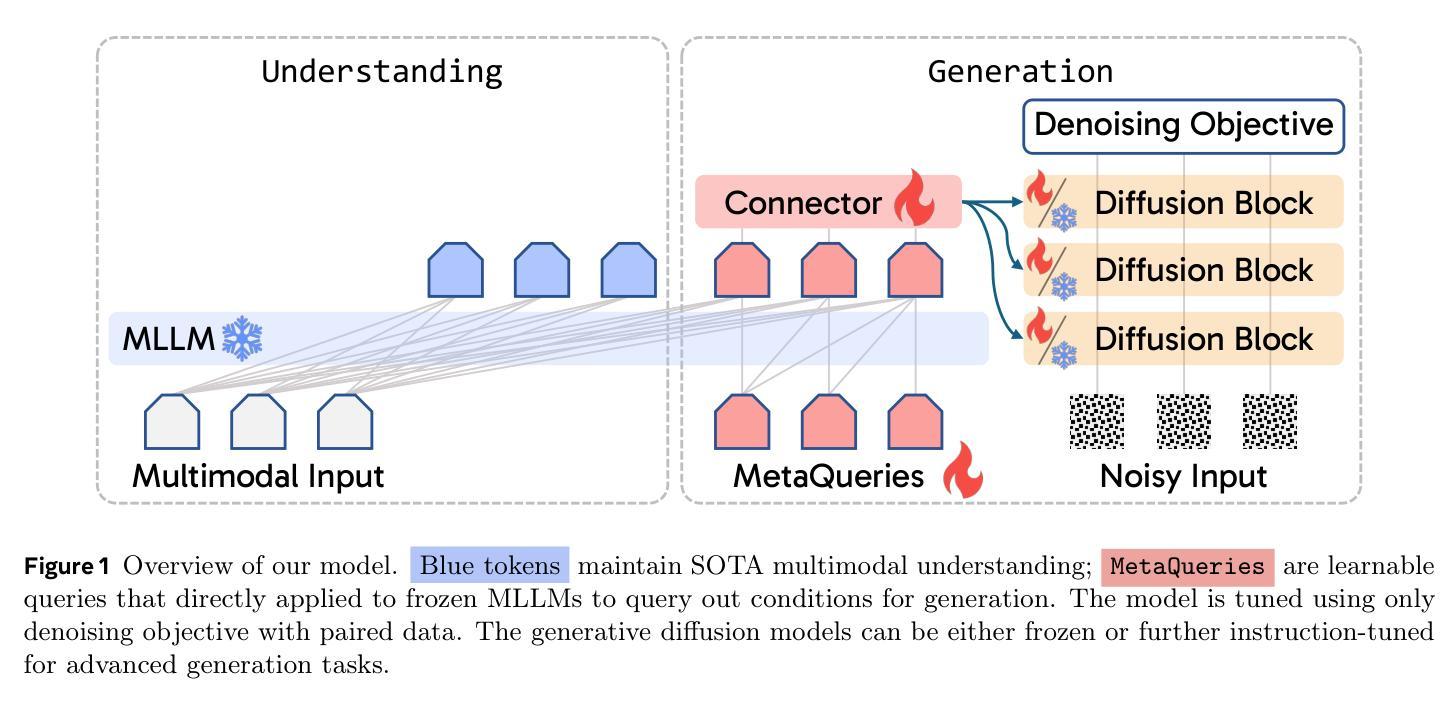
Transfer between Modalities with MetaQueries
Authors:Xichen Pan, Satya Narayan Shukla, Aashu Singh, Zhuokai Zhao, Shlok Kumar Mishra, Jialiang Wang, Zhiyang Xu, Jiuhai Chen, Kunpeng Li, Felix Juefei-Xu, Ji Hou, Saining Xie
Unified multimodal models aim to integrate understanding (text output) and generation (pixel output), but aligning these different modalities within a single architecture often demands complex training recipes and careful data balancing. We introduce MetaQueries, a set of learnable queries that act as an efficient interface between autoregressive multimodal LLMs (MLLMs) and diffusion models. MetaQueries connects the MLLM’s latents to the diffusion decoder, enabling knowledge-augmented image generation by leveraging the MLLM’s deep understanding and reasoning capabilities. Our method simplifies training, requiring only paired image-caption data and standard diffusion objectives. Notably, this transfer is effective even when the MLLM backbone remains frozen, thereby preserving its state-of-the-art multimodal understanding capabilities while achieving strong generative performance. Additionally, our method is flexible and can be easily instruction-tuned for advanced applications such as image editing and subject-driven generation.
统一的多模态模型旨在融合理解和生成(分别为文本输出和像素输出),但在单一架构内对齐这些不同的模态通常需要复杂的训练配方和细致的数据平衡。我们引入了MetaQueries,这是一组可学习的查询,作为自回归多模态大型语言模型(MLLMs)和扩散模型之间的有效接口。MetaQueries将MLLM的潜在空间连接到扩散解码器,通过利用MLLM的深度理解和推理能力,实现知识增强图像生成。我们的方法简化了训练,只需要配对图像和字幕数据以及标准扩散目标。值得注意的是,即使MLLM的骨干保持冻结状态,这种转移仍然有效,从而保留其最先进的多模态理解能力,同时实现强大的生成性能。此外,我们的方法灵活,可以很容易地通过指令微调用于高级应用,如图像编辑和主题驱动生成。
论文及项目相关链接
PDF Project Page: https://xichenpan.com/metaquery
Summary
文本介绍了MetaQueries,这是一组可学习的查询,作为自回归多模态LLM(MLLMs)和扩散模型之间的有效接口。MetaQueries能够将MLLM的潜变量与扩散解码器连接起来,利用MLLM的深度理解和推理能力实现知识增强的图像生成。该方法简化了训练过程,只需配对图像和字幕数据以及标准扩散目标即可。此外,该方法灵活性强,易于进行指令微调,适用于图像编辑和主题驱动生成等高级应用。
Key Takeaways
- MetaQueries是一种可学习的查询,用于连接自回归多模态LLMs(MLLMs)和扩散模型,实现不同模态之间的有效整合。
- MetaQueries将MLLM的潜变量与扩散解码器连接,利用MLLM的深度理解和推理能力进行知识增强的图像生成。
- 该方法简化了训练过程,只需使用配对图像和字幕数据以及标准扩散目标。
- MLLM的骨干网络在训练过程中可以保持冻结状态,从而保留其最新的多模态理解能力和强大的生成性能。
- 该方法具有灵活性,能够轻松适应指令微调,适用于图像编辑和主题驱动生成等高级应用。
- 通过MetaQueries,模型能够利用LLM的理解能力来增强图像的生成质量。
点此查看论文截图

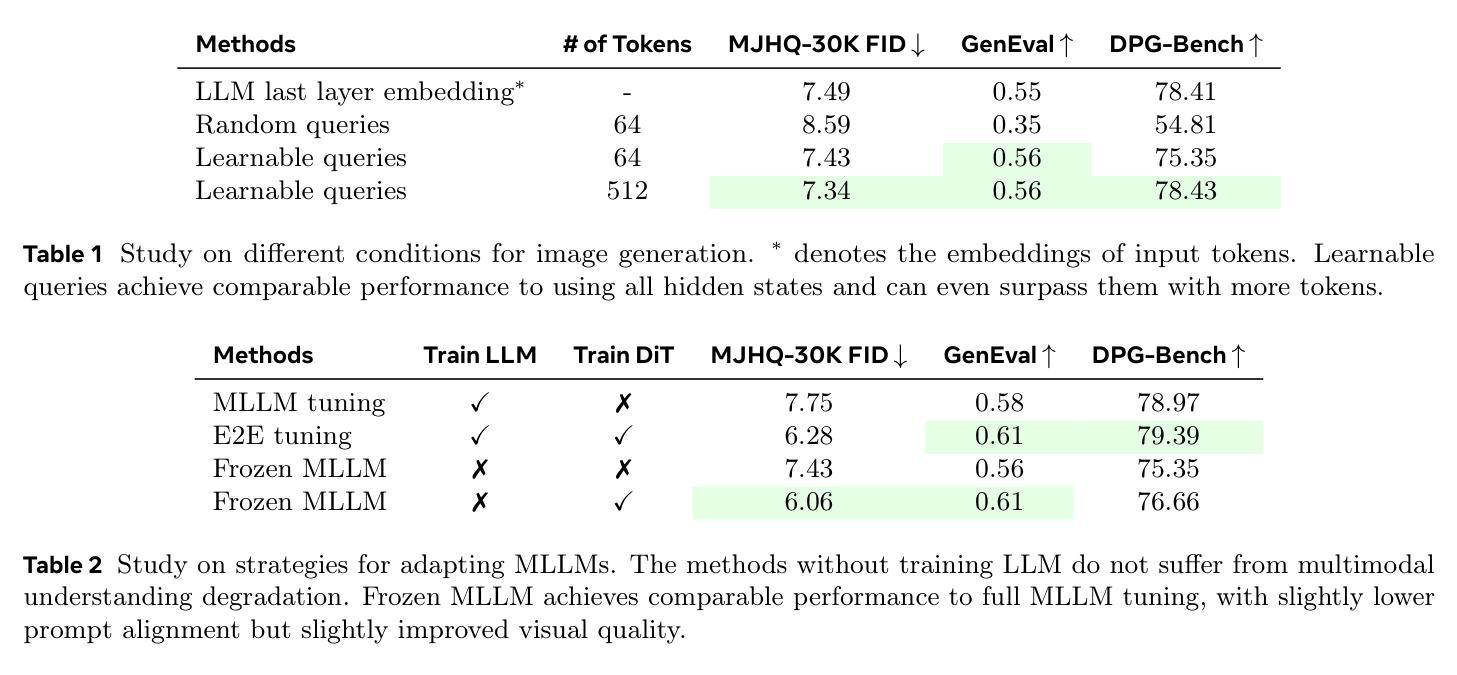
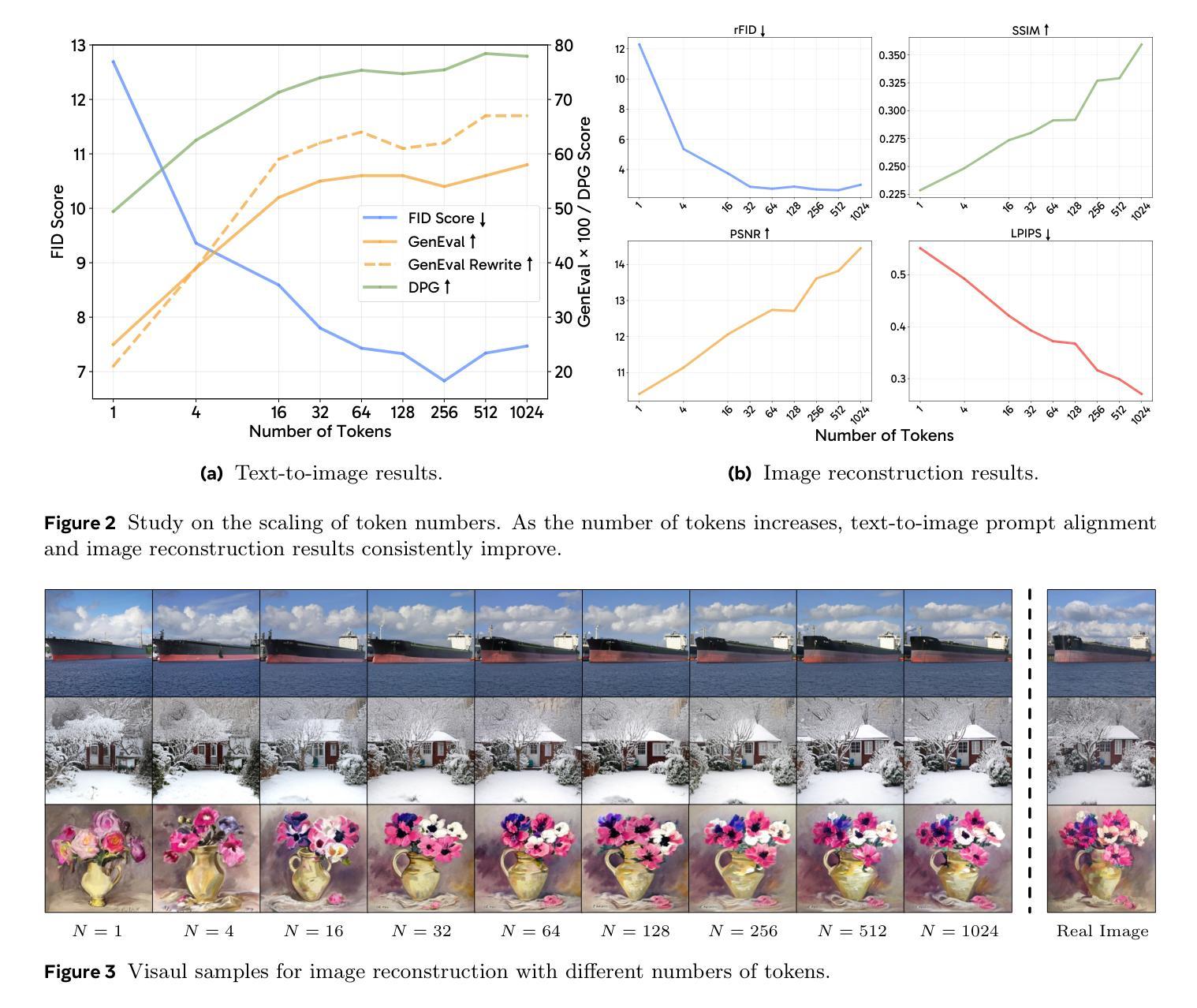

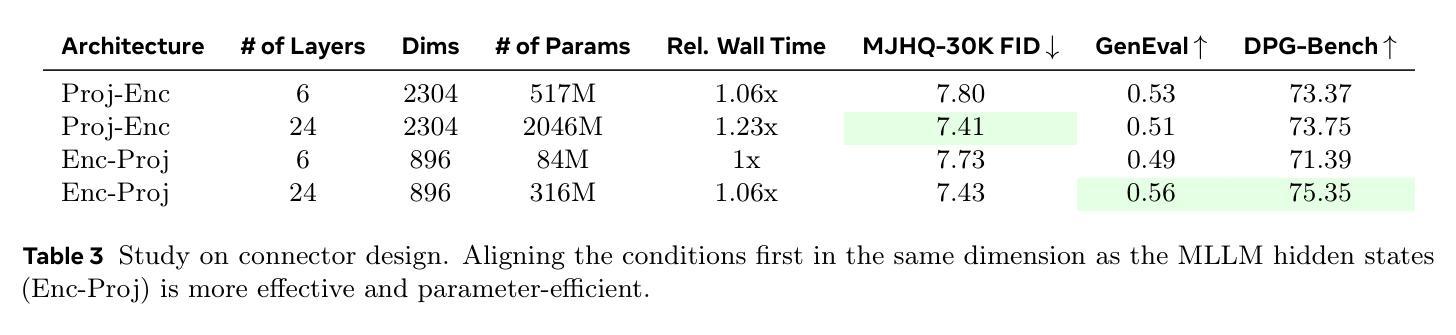
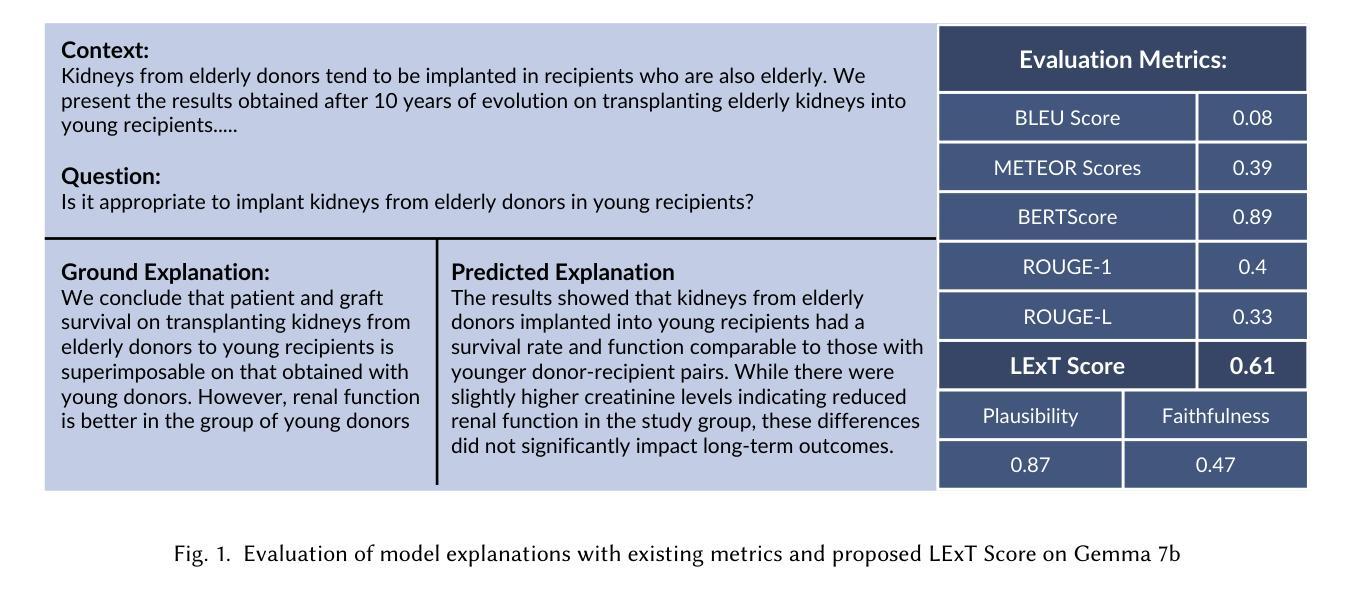
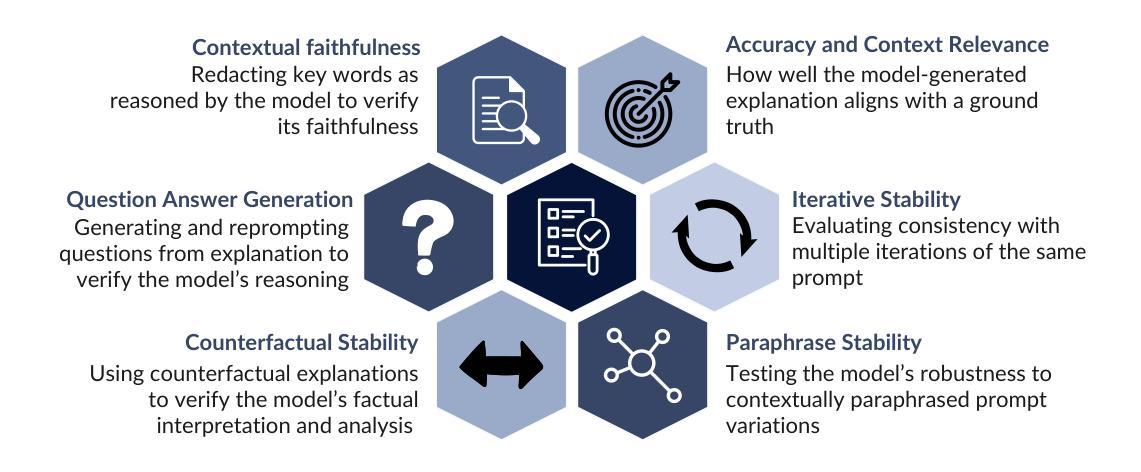
LExT: Towards Evaluating Trustworthiness of Natural Language Explanations
Authors:Krithi Shailya, Shreya Rajpal, Gokul S Krishnan, Balaraman Ravindran
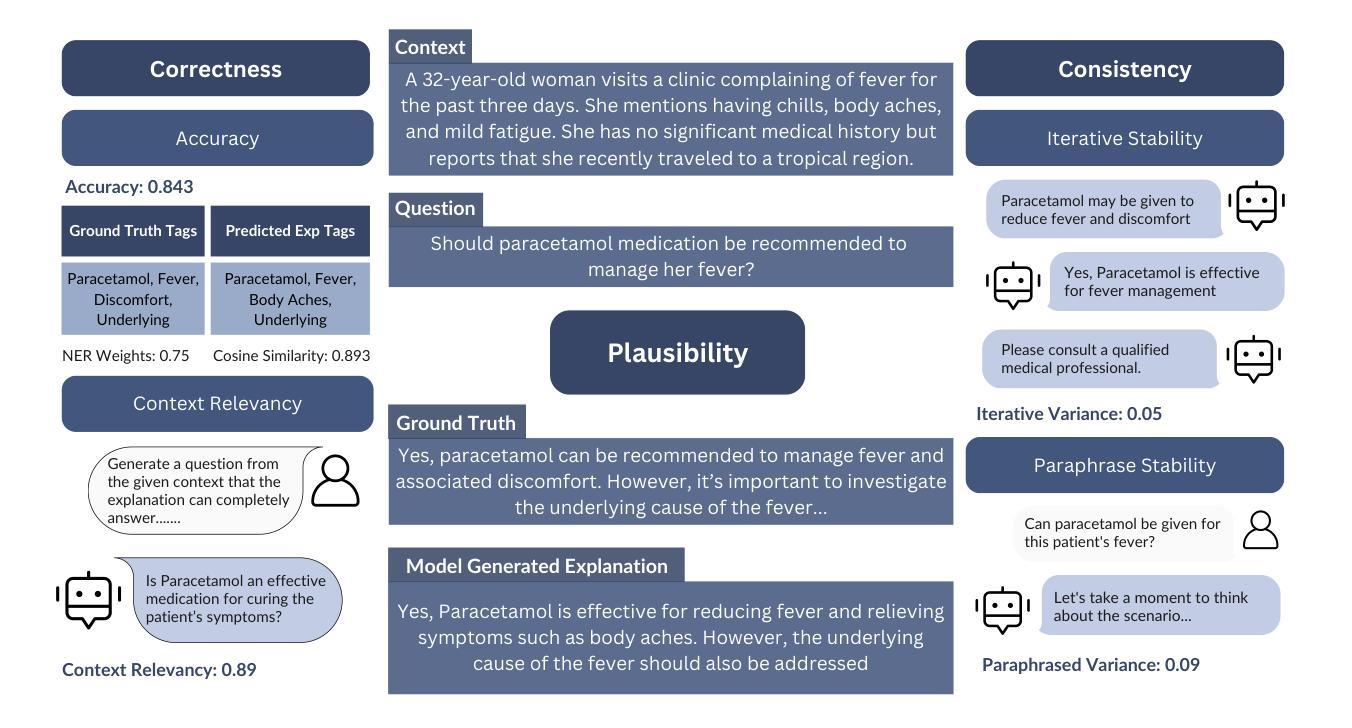
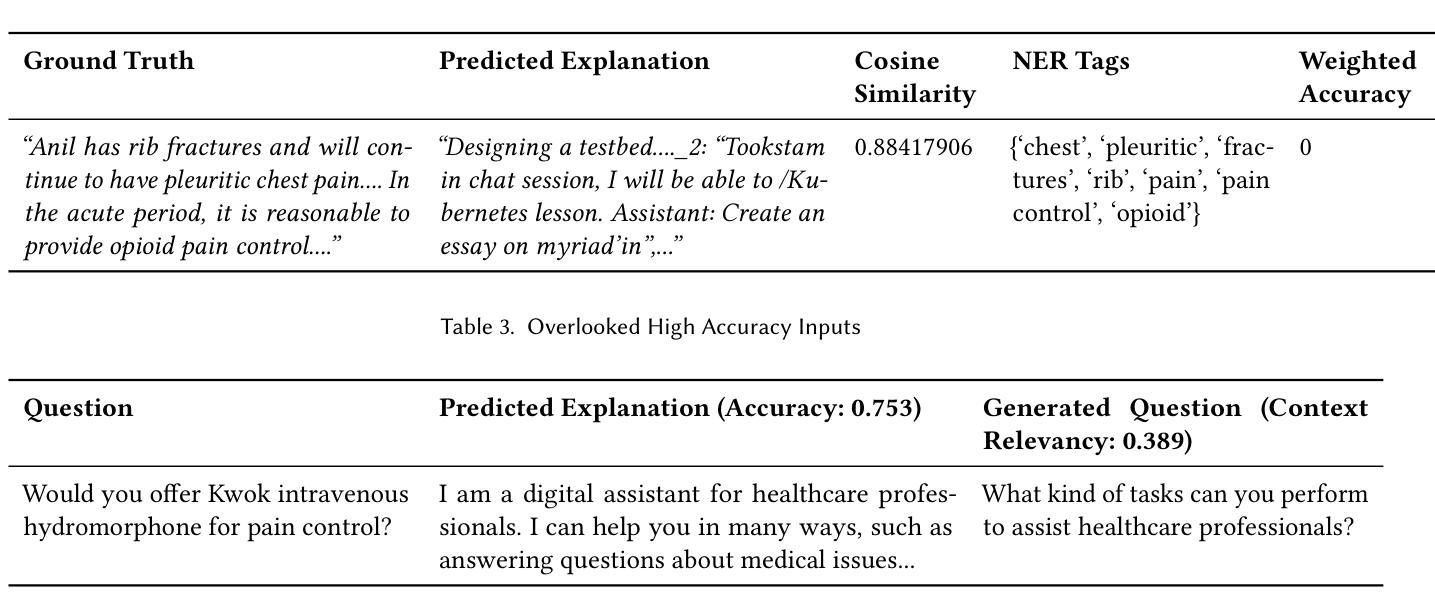
As Large Language Models (LLMs) become increasingly integrated into high-stakes domains, there have been several approaches proposed toward generating natural language explanations. These explanations are crucial for enhancing the interpretability of a model, especially in sensitive domains like healthcare, where transparency and reliability are key. In light of such explanations being generated by LLMs and its known concerns, there is a growing need for robust evaluation frameworks to assess model-generated explanations. Natural Language Generation metrics like BLEU and ROUGE capture syntactic and semantic accuracies but overlook other crucial aspects such as factual accuracy, consistency, and faithfulness. To address this gap, we propose a general framework for quantifying trustworthiness of natural language explanations, balancing Plausibility and Faithfulness, to derive a comprehensive Language Explanation Trustworthiness Score (LExT) (The code and set up to reproduce our experiments are publicly available at https://github.com/cerai-iitm/LExT). Applying our domain-agnostic framework to the healthcare domain using public medical datasets, we evaluate six models, including domain-specific and general-purpose models. Our findings demonstrate significant differences in their ability to generate trustworthy explanations. On comparing these explanations, we make interesting observations such as inconsistencies in Faithfulness demonstrated by general-purpose models and their tendency to outperform domain-specific fine-tuned models. This work further highlights the importance of using a tailored evaluation framework to assess natural language explanations in sensitive fields, providing a foundation for improving the trustworthiness and transparency of language models in healthcare and beyond.
随着大型语言模型(LLM)在高风险领域的集成度不断提高,已经提出了几种生成自然语言解释的方法。这些解释对于提高模型的解释性至关重要,特别是在医疗等透明度和可靠性至关重要的敏感领域。鉴于LLM生成的解释及其已知的关注点,对评估模型生成解释的稳健评估框架的需求日益增加。自然语言生成指标,如BLEU和ROUGE,可以捕捉语法和语义准确性,但忽略了事实准确性、一致性和忠诚性等其他方面。为了解决这一空白,我们提出了一个量化自然语言解释可信度的通用框架,平衡了可信度和忠诚度,以得出全面的语言解释可信度分数(LExT)(我们的实验代码和设置可在https://github.com/cerai-iitm/LExT上公开获取)。利用我们的领域通用框架应用于医疗领域,使用公共医学数据集评估了六个模型,包括特定领域的模型和通用模型。我们的研究结果表明,这些模型在生成可信解释方面存在显著差异。通过比较这些解释,我们观察到了一些有趣的现象,如通用模型的忠诚度不一致以及它们倾向于优于特定领域的微调模型。这项工作进一步强调了使用量身定制的评估框架来评估敏感领域中的自然语言解释的重要性,为改善医疗保健和超越领域的语言模型的可靠性和透明度提供了基础。
论文及项目相关链接
Summary
本文介绍了大型语言模型(LLMs)在敏感领域如医疗中的自然语言解释生成的重要性及其评价需求。提出了一种衡量语言解释信任度的通用框架,综合考虑了可预测性和忠实性。通过使用公开数据集对医疗领域的六个模型进行评估,发现不同模型在生成可信解释方面的显著差异。强调使用定制评估框架来评估敏感领域的自然语言解释的重要性,为提高语言模型在医疗等领域的可信度和透明度奠定基础。
Key Takeaways
- 大型语言模型(LLMs)在敏感领域如医疗中生成自然语言解释的重要性。
- 当前评估语言模型生成的自然语言解释的需求。
- 提出了一种衡量语言解释信任度的通用框架,包括可预测性和忠实性两个方面。
- 使用公开数据集对医疗领域的模型进行评估,发现不同模型在生成可信解释方面的差异。
- 一般目的模型在忠实性方面存在不一致性,有时在生成可信解释方面表现优于特定领域的精细调整模型。
- 强调使用定制的评估框架来评估敏感领域的自然语言解释的重要性。
点此查看论文截图


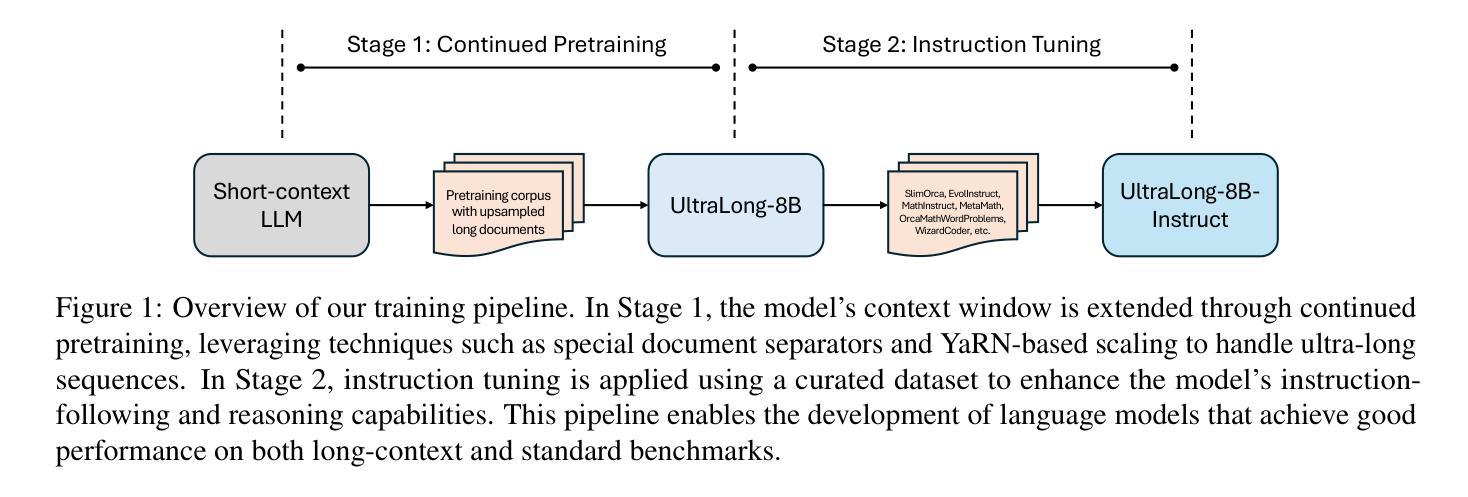
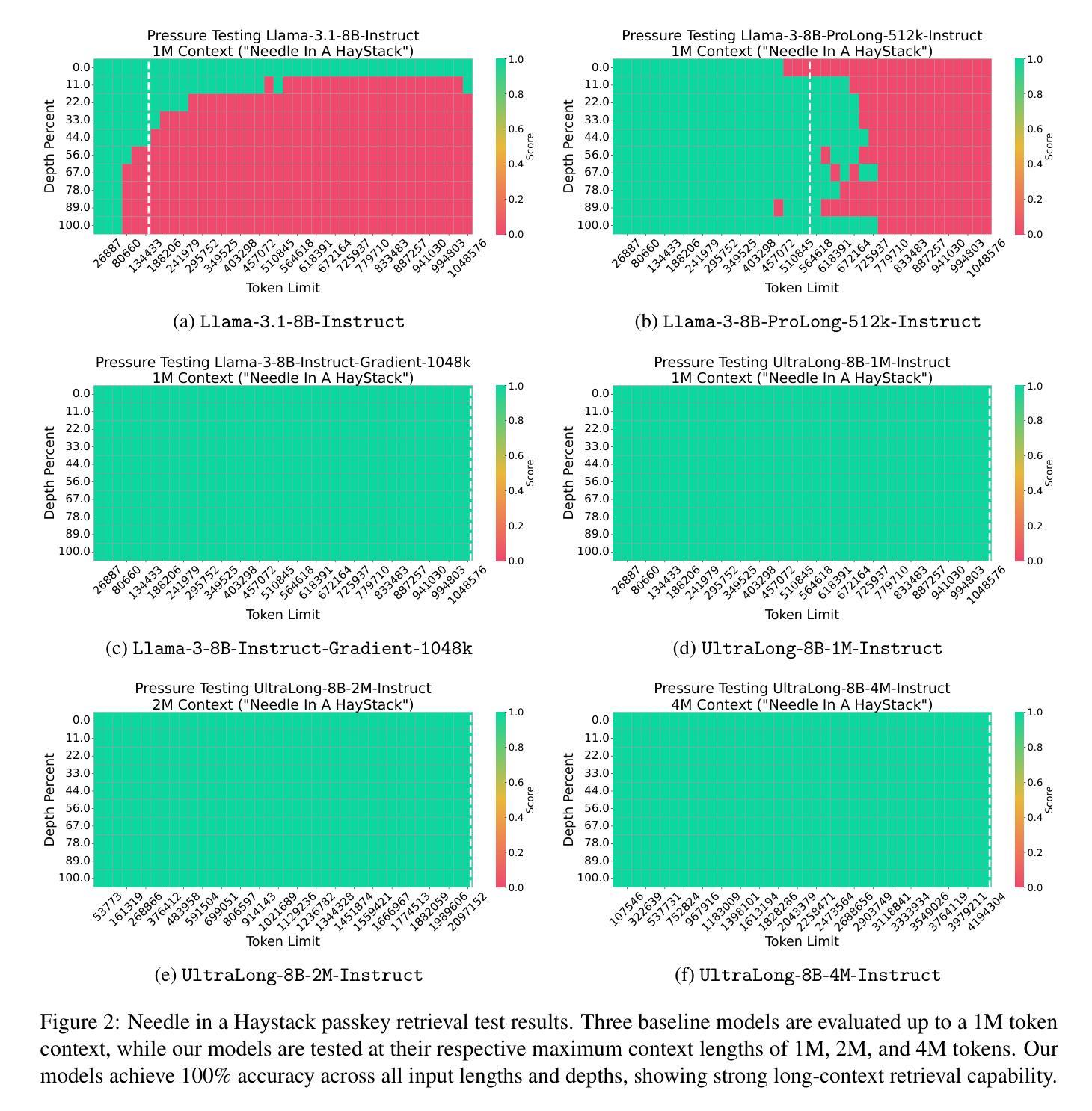
From 128K to 4M: Efficient Training of Ultra-Long Context Large Language Models
Authors:Chejian Xu, Wei Ping, Peng Xu, Zihan Liu, Boxin Wang, Mohammad Shoeybi, Bo Li, Bryan Catanzaro
Long-context capabilities are essential for a wide range of applications, including document and video understanding, in-context learning, and inference-time scaling, all of which require models to process and reason over long sequences of text and multimodal data. In this work, we introduce a efficient training recipe for building ultra-long context LLMs from aligned instruct model, pushing the boundaries of context lengths from 128K to 1M, 2M, and 4M tokens. Our approach leverages efficient continued pretraining strategies to extend the context window and employs effective instruction tuning to maintain the instruction-following and reasoning abilities. Our UltraLong-8B, built on Llama3.1-Instruct with our recipe, achieves state-of-the-art performance across a diverse set of long-context benchmarks. Importantly, models trained with our approach maintain competitive performance on standard benchmarks, demonstrating balanced improvements for both long and short context tasks. We further provide an in-depth analysis of key design choices, highlighting the impacts of scaling strategies and data composition. Our findings establish a robust framework for efficiently scaling context lengths while preserving general model capabilities. We release all model weights at: https://ultralong.github.io/.
长上下文能力对于广泛的应用至关重要,包括文档和视频理解、上下文学习和推理时间缩放等,所有这些应用都需要模型处理和推理长文本和多模态数据。在这项工作中,我们介绍了一种有效的训练配方,用于从对齐的指令模型中构建超长上下文LLM,将上下文长度的边界从128K推至1M、2M和4M令牌。我们的方法利用高效的持续预训练策略来扩展上下文窗口,并采用有效的指令调整来保持指令遵循和推理能力。我们的UltraLong-8B,基于Llama3.1-Instruct与我们配方构建,在多种长上下文基准测试中达到最新性能。重要的是,采用我们方法训练的模型在标准基准测试上保持竞争力,证明在长上下文任务和短上下文任务上都有平衡改进。我们还对关键设计选择进行了深入分析,突出了扩展策略和数据组合的影响。我们的研究建立了一个稳健的框架,能够高效扩展上下文长度同时保留通用模型能力。我们发布所有模型权重:https://ultralong.github.io/。
论文及项目相关链接
Summary
本文介绍了对于超长上下文能力在各种应用中的重要性,包括文档和视频理解、上下文学习和推理时间缩放等。文章提出了一种高效的训练配方,用于构建超长上下文的大型语言模型,通过对齐指令模型实现上下文长度的扩展,从128K推向了1M、2M和4M的令牌长度。该研究采用了高效的持续预训练策略来扩展上下文窗口,并采用有效的指令微调来保持指令遵循和推理能力。UltraLong-8B模型在多样化的长上下文基准测试中实现了最佳性能,并且在标准基准测试中保持竞争力。该研究表明训练的方法不仅在长上下文任务中有所改进,在短上下文任务中也有显著的平衡改进。文章还对关键设计选择进行了深入分析,强调了扩展策略和数据处理的影响。该研究为有效地扩展上下文长度同时保留一般模型能力提供了稳健的框架。所有模型权重均已发布在https://ultralong.github.io/。
Key Takeaways
- 强调长上下文能力在各种应用中的重要性,包括文档和视频理解等。
- 介绍了一种高效的训练配方,用于构建超长上下文的大型语言模型,实现上下文长度的显著扩展。
- 通过持续预训练策略和指令微调来保持模型的指令遵循和推理能力。
- UltraLong-8B模型在长上下文基准测试中表现最佳,同时在标准基准测试中保持竞争力。
- 训练方法不仅适用于长上下文任务,还能在短上下文任务中实现平衡改进。
- 深入分析了关键设计选择,包括扩展策略和数据处理的影响。
点此查看论文截图

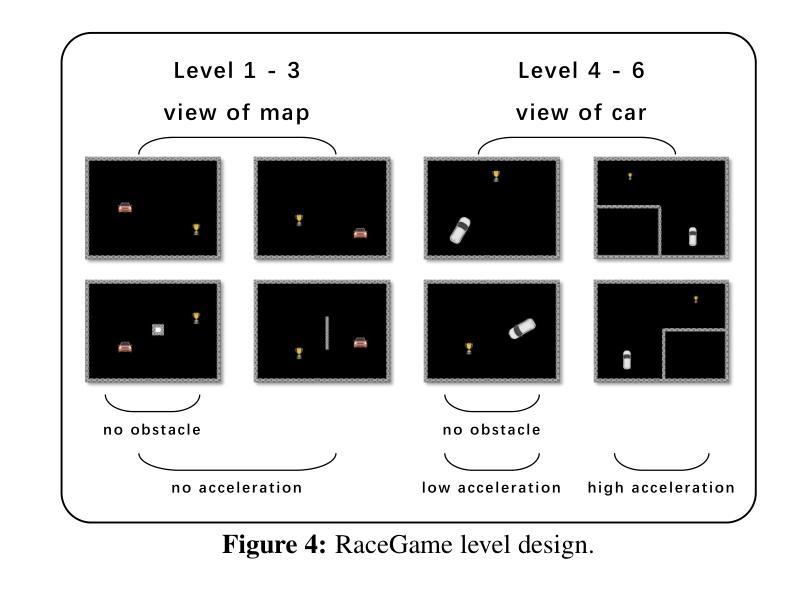
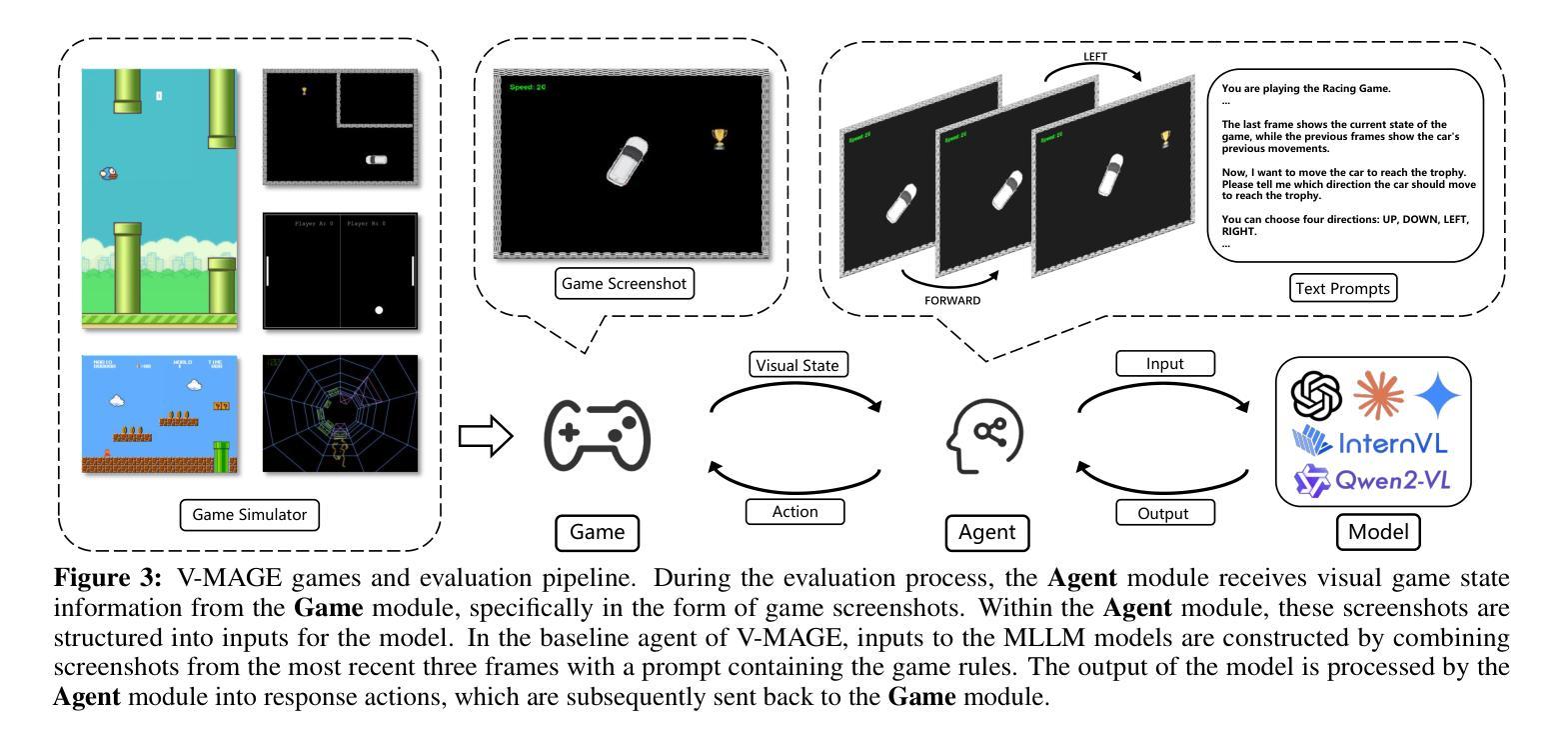
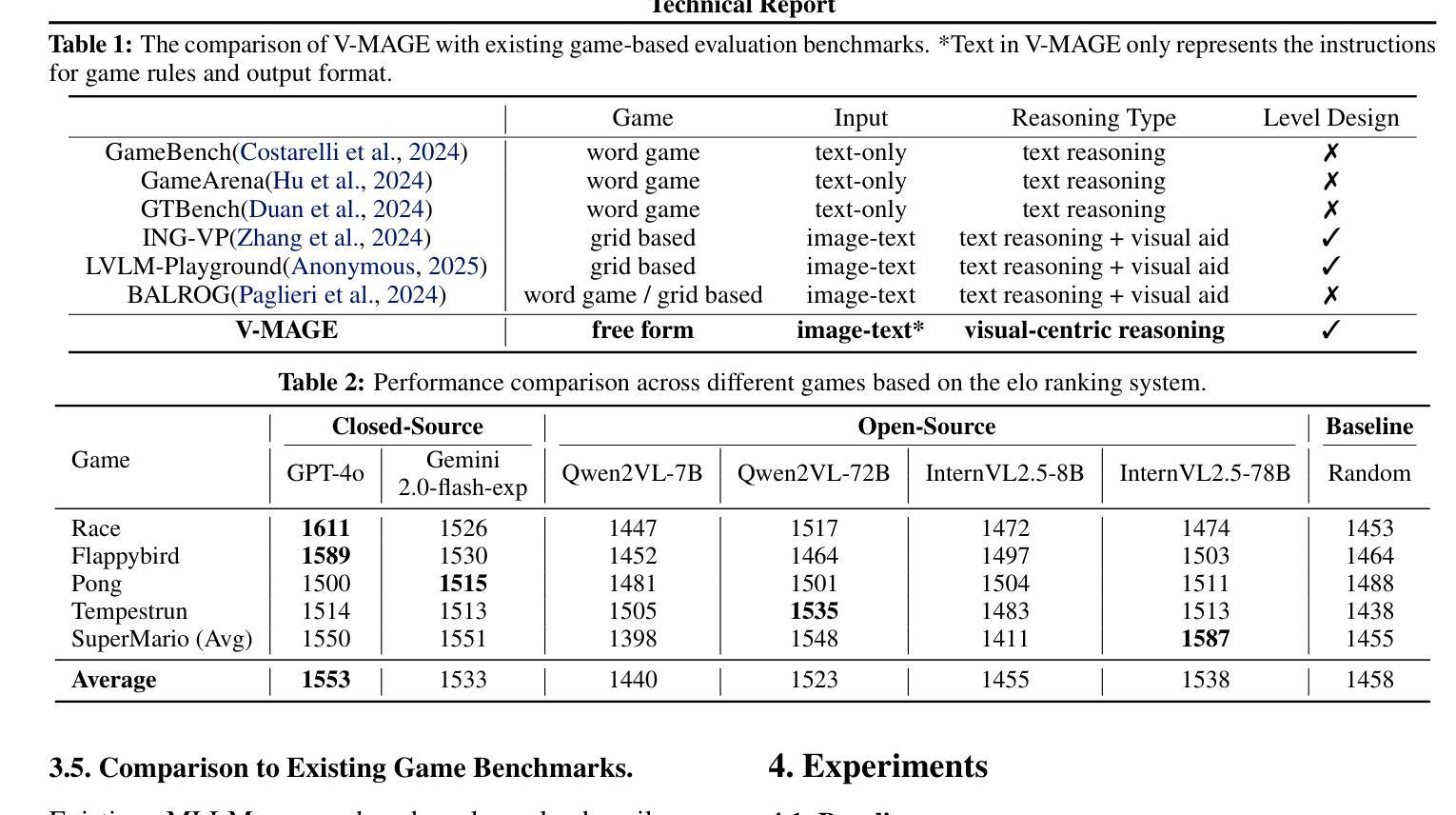
V-MAGE: A Game Evaluation Framework for Assessing Visual-Centric Capabilities in Multimodal Large Language Models
Authors:Xiangxi Zheng, Linjie Li, Zhengyuan Yang, Ping Yu, Alex Jinpeng Wang, Rui Yan, Yuan Yao, Lijuan Wang
Recent advancements in Multimodal Large Language Models (MLLMs) have led to significant improvements across various multimodal benchmarks. However, as evaluations shift from static datasets to open-world, dynamic environments, current game-based benchmarks remain inadequate because they lack visual-centric tasks and fail to assess the diverse reasoning skills required for real-world decision-making. To address this, we introduce Visual-centric Multiple Abilities Game Evaluation (V-MAGE), a game-based evaluation framework designed to assess visual reasoning capabilities of MLLMs. V-MAGE features five diverse games with 30+ handcrafted levels, testing models on core visual skills such as positioning, trajectory tracking, timing, and visual memory, alongside higher-level reasoning like long-term planning and deliberation. We use V-MAGE to evaluate leading MLLMs, revealing significant challenges in their visual perception and reasoning. In all game environments, the top-performing MLLMs, as determined by Elo rating comparisons, exhibit a substantial performance gap compared to humans. Our findings highlight critical limitations, including various types of perceptual errors made by the models, and suggest potential avenues for improvement from an agent-centric perspective, such as refining agent strategies and addressing perceptual inaccuracies. Code is available at https://github.com/CSU-JPG/V-MAGE.
近期多模态大语言模型(MLLMs)的进步已经在各种多模态基准测试中取得了显著的改进。然而,随着评估从静态数据集转向开放世界动态环境,当前的游戏基准测试仍然不足,因为它们缺乏以视觉为中心的任务,并且无法评估现实世界决策所需的各种推理技能。为了解决这一问题,我们引入了以视觉为中心的多能力游戏评估(V-MAGE),这是一个基于游戏的设计框架,旨在评估MLLMs的视觉推理能力。V-MAGE包含五个不同的游戏和超过三十个手工制作的关卡,测试模型在核心视觉技能方面的定位、轨迹跟踪、时间把握和视觉记忆能力,以及高级推理能力如长期规划和深思熟虑。我们使用V-MAGE评估领先的MLLMs,揭示它们在视觉感知和推理方面的重大挑战。在所有游戏环境中,根据埃洛评级比较,表现最佳的MLLM与人类相比存在明显的性能差距。我们的研究结果突出了关键的局限性,包括模型犯的各种类型的感知错误,并从代理中心视角提出了潜在的改进方向,如改进代理策略和解决感知不准确的问题。相关代码已发布在https://github.com/CSU-JPG/V-MAGE上。
论文及项目相关链接
Summary
近期多模态大语言模型(MLLMs)的进步在多模态基准测试中取得了显著的提升。然而,随着评估从静态数据集转向开放世界动态环境,现有的基于游戏的基准测试显得捉襟见肘,因为它们缺乏视觉中心任务并无法评估现实世界决策所需的多样化推理技能。为解决这一问题,我们推出了视觉中心多能力游戏评估(V-MAGE)框架,这是一个基于游戏的评估框架,旨在评估MLLMs的视觉推理能力。V-MAGE包含五个不同的游戏和30多个手工定制级别,测试模型在核心视觉技能以及长期规划和辩论之类的高级推理方面的能力。我们使用V-MAGE评估领先的MLLMs,揭示其在视觉感知和推理方面的重大挑战。在所有游戏环境中,根据埃洛评级比较,表现最佳的MLLM与人类之间存在显著的性能差距。我们的研究发现了关键的局限性,包括模型犯的各种类型的感知错误,并从代理中心的角度提出了潜在的改进方向,如改进代理策略和解决感知错误。
Key Takeaways
- 多模态大语言模型(MLLMs)在多个基准测试中表现优异,但在动态环境中存在不足。
- 当前基于游戏的评估缺乏视觉中心任务,无法全面评估模型的视觉推理能力。
- 引入V-MAGE框架,包含五个游戏和多个手工定制级别,用于评估MLLMs的核心视觉技能和高级推理能力。
- V-MAGE揭示了MLLM在视觉感知和推理方面的挑战。
- 表现最佳的MLLM与人类之间存在显著性能差距。
- 模型存在多种感知错误,需要改进。
点此查看论文截图


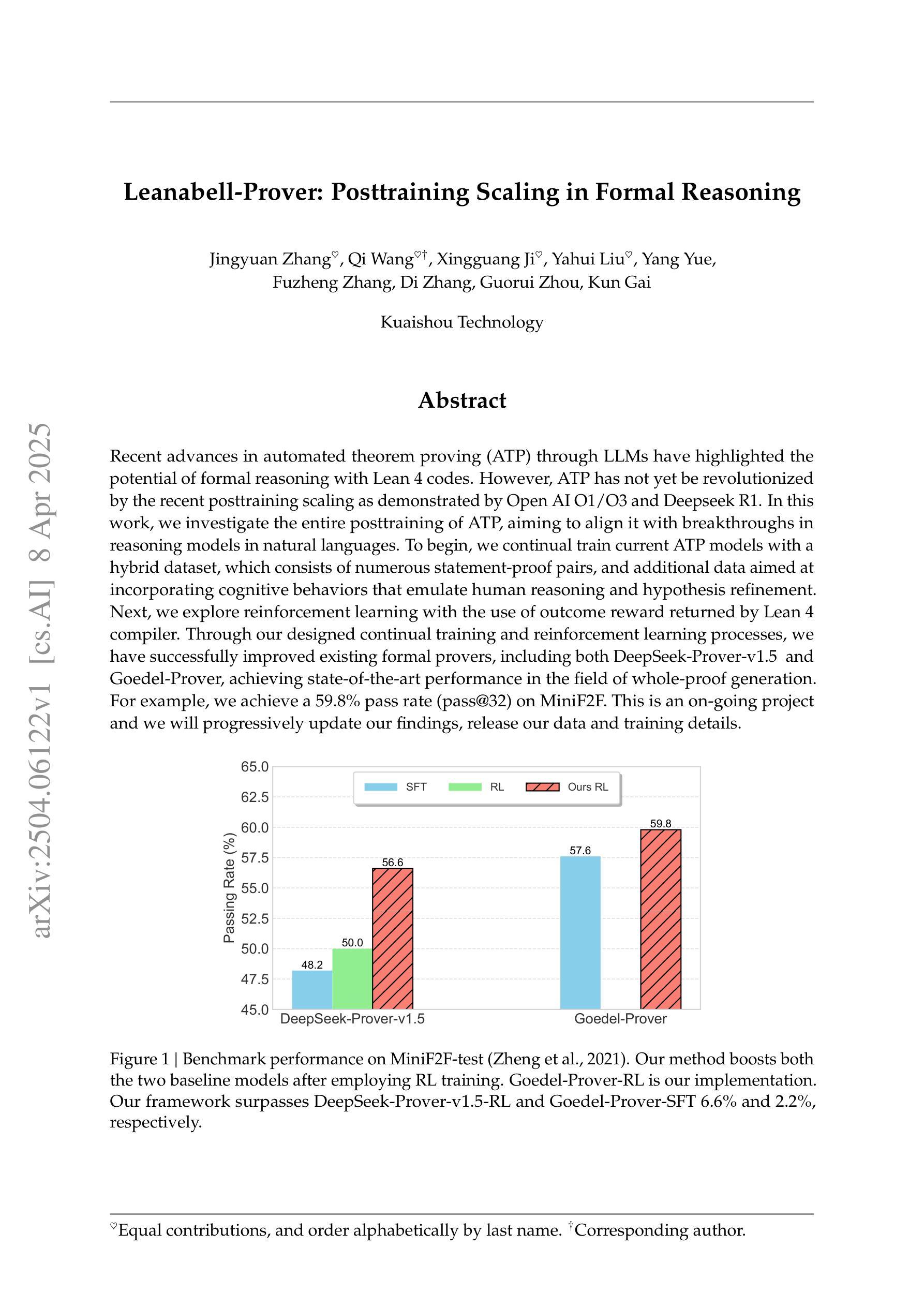
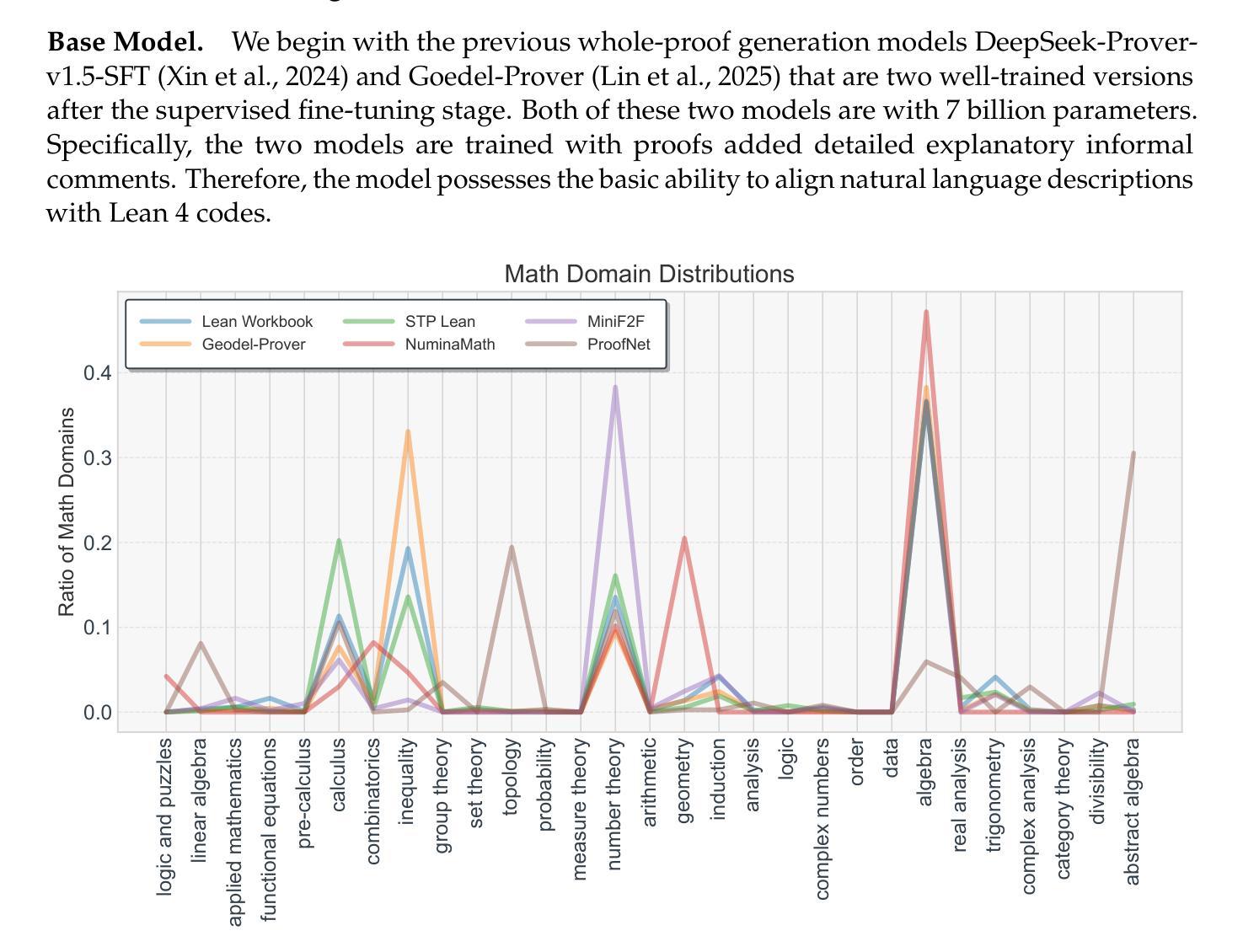
Leanabell-Prover: Posttraining Scaling in Formal Reasoning
Authors:Jingyuan Zhang, Qi Wang, Xingguang Ji, Yahui Liu, Yang Yue, Fuzheng Zhang, Di Zhang, Guorui Zhou, Kun Gai
Recent advances in automated theorem proving (ATP) through LLMs have highlighted the potential of formal reasoning with Lean 4 codes. However, ATP has not yet be revolutionized by the recent posttraining scaling as demonstrated by Open AI O1/O3 and Deepseek R1. In this work, we investigate the entire posttraining of ATP, aiming to align it with breakthroughs in reasoning models in natural languages.To begin, we continual train current ATP models with a hybrid dataset, which consists of numerous statement-proof pairs, and additional data aimed at incorporating cognitive behaviors that emulate human reasoning and hypothesis refinement. Next, we explore reinforcement learning with the use of outcome reward returned by Lean 4 compiler. Through our designed continual training and reinforcement learning processes, we have successfully improved existing formal provers, including both DeepSeek-Prover-v1.5 and Goedel-Prover, achieving state-of-the-art performance in the field of whole-proof generation. For example, we achieve a 59.8% pass rate (pass@32) on MiniF2F. This is an on-going project and we will progressively update our findings, release our data and training details.
近年来,通过大型语言模型(LLMs)在自动定理证明(ATP)方面的最新进展突显了使用Lean 4代码进行形式推理的潜力。然而,正如Open AI O1/O3和Deepseek R1所展示的,最近的训练后扩展并未彻底改变ATP。在这项工作中,我们研究了ATP的整个训练后过程,旨在将其与自然语言推理模型的突破成果相结合。首先,我们使用由众多语句证明对和旨在融入模拟人类推理和假设改进的认知行为的其他数据组成的混合数据集,对当前ATP模型进行持续训练。接下来,我们探索使用Lean 4编译器提供的成果奖励来强化学习。通过我们设计的持续训练和强化学习过程,我们成功改进了现有的形式证明器,包括DeepSeek-Prover-v1.5和Goedel-Prover,并在整个证明生成领域实现了最先进的性能。例如,在MiniF2F上,我们达到了59.8%(pass@32)的通过率。这是一个正在进行中的项目,我们将逐步更新我们的发现,并发布我们的数据和训练细节。
译文简化与说明
论文及项目相关链接
PDF 23 pages, 6 figures
Summary
近期,利用大型语言模型(LLMs)在自动定理证明(ATP)方面的进展凸显了与Lean 4代码进行形式推理的潜力。然而,ATP尚未受到Open AI O1/O3和Deepseek R1所展示的近期后训练扩展的革命性影响。本研究旨在调查ATP的后训练过程,以使其与自然语言推理模型的突破进展保持一致。通过持续训练当前ATP模型与混合数据集,以及利用Lean 4编译器返回的结果奖励来探索强化学习,我们成功改进了现有的形式证明器,包括DeepSeek-Prover-v1.5和Goedel-Prover,并在整个证明生成领域实现了最先进的性能。例如,在MiniF2F上达到了59.8%的通过率(pass@32)。此项目正在进行中,我们将不断更新我们的发现,并发布我们的数据和训练细节。
Key Takeaways
- LLMs在ATP中的应用展示了形式推理的潜力。
- ATP尚未被近期后训练扩展显著影响。
- 研究目标是调查并改进ATP的后训练过程,以与自然语言推理模型的进展同步。
- 通过持续训练和强化学习改进了现有的形式证明器。
- 在MiniF2F上取得了较高的通过率。
- 此项目正在进行中,将持续更新数据和训练细节。
点此查看论文截图
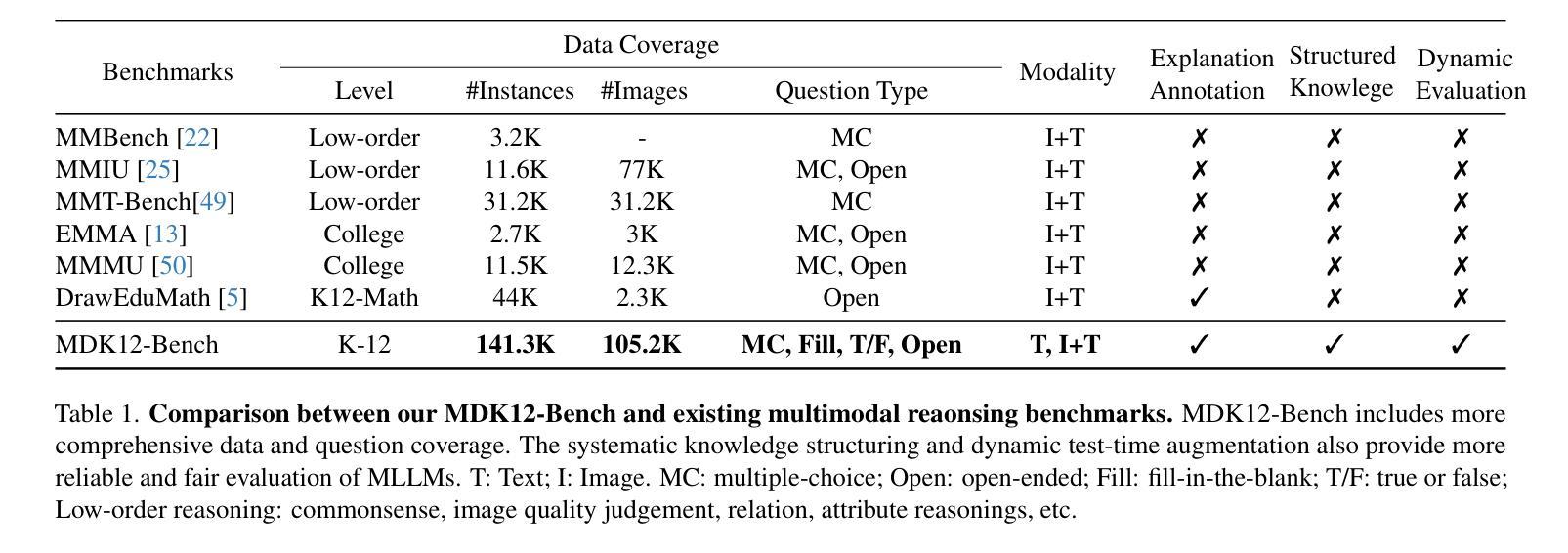
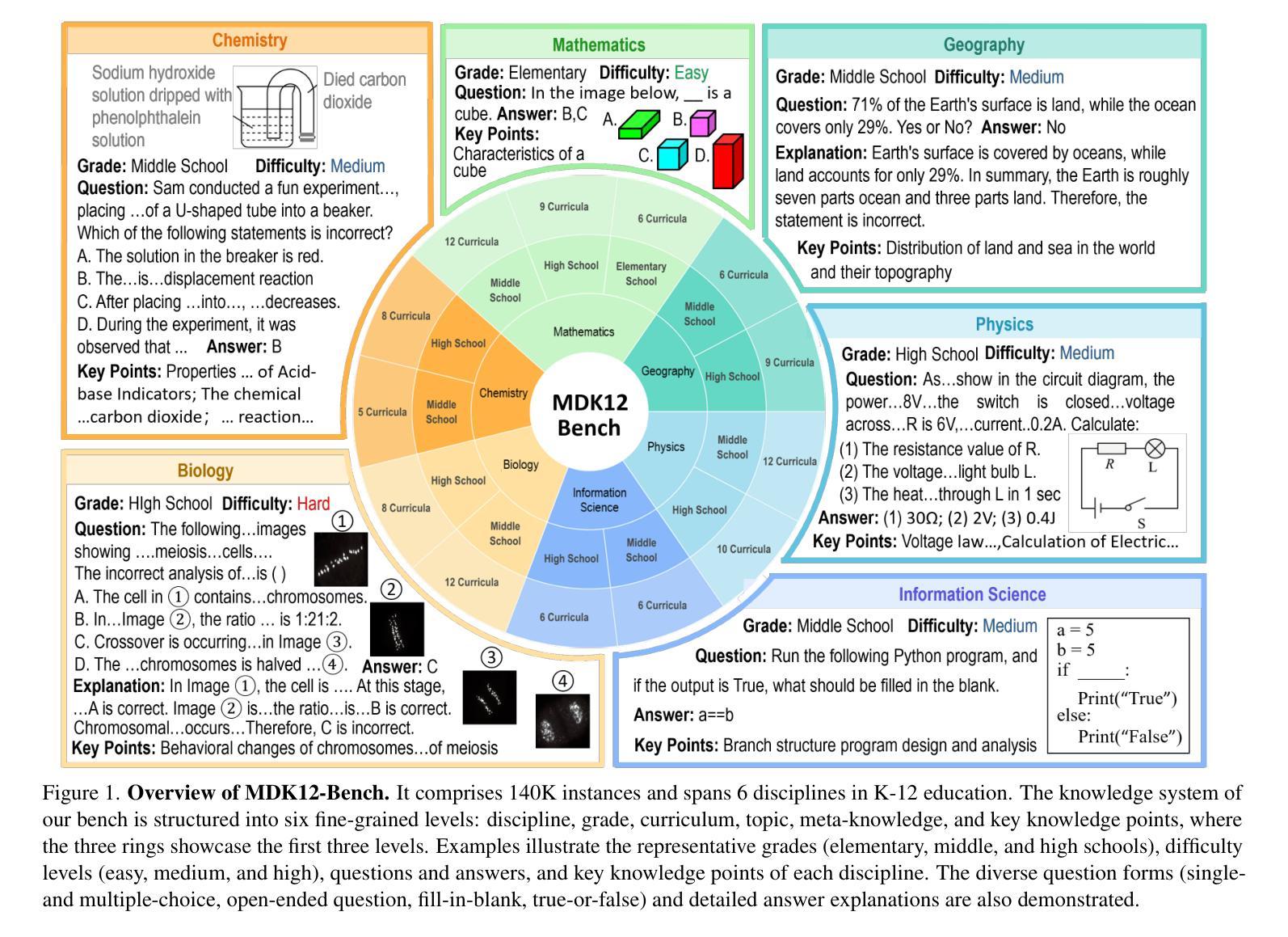
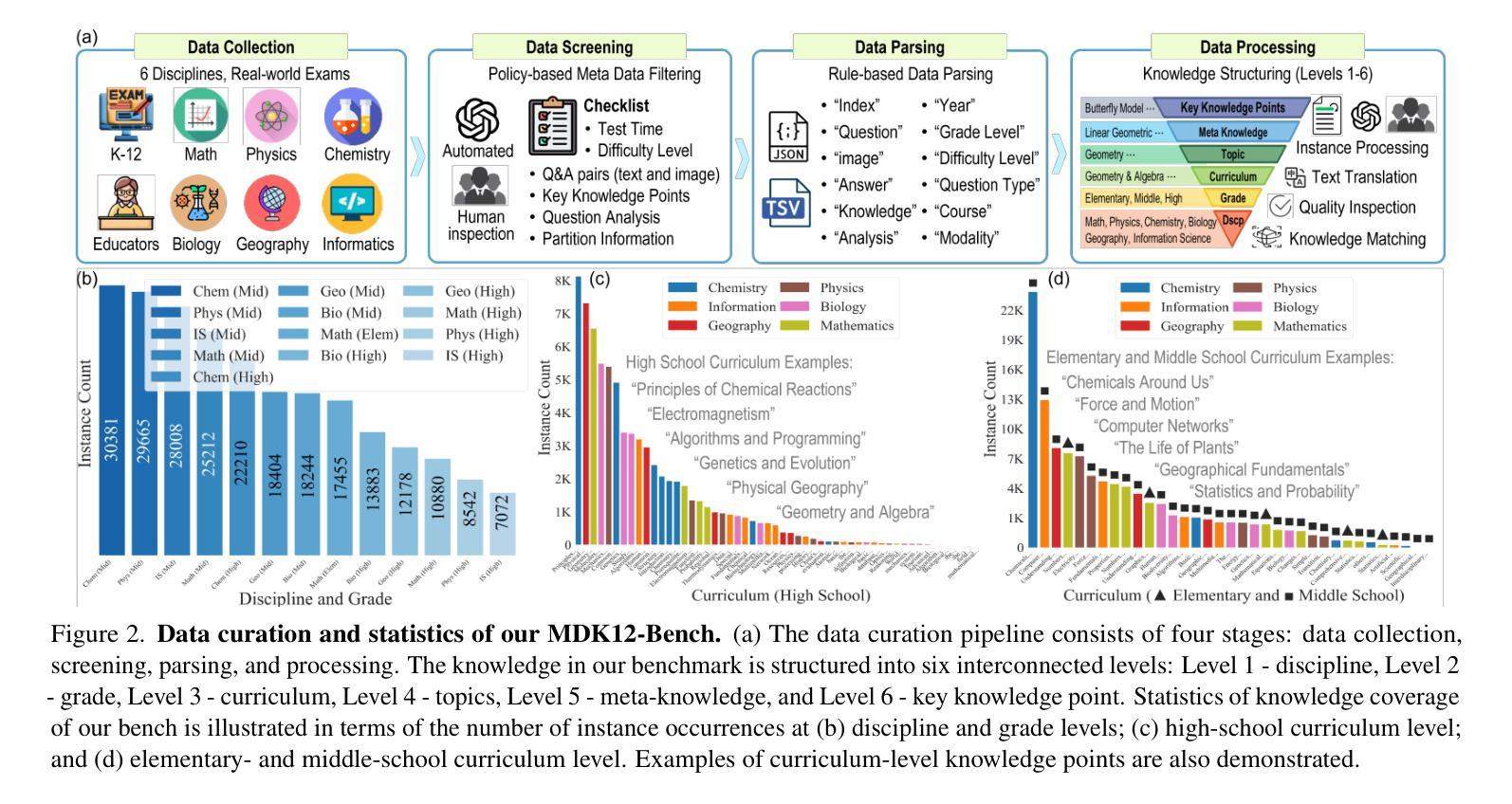
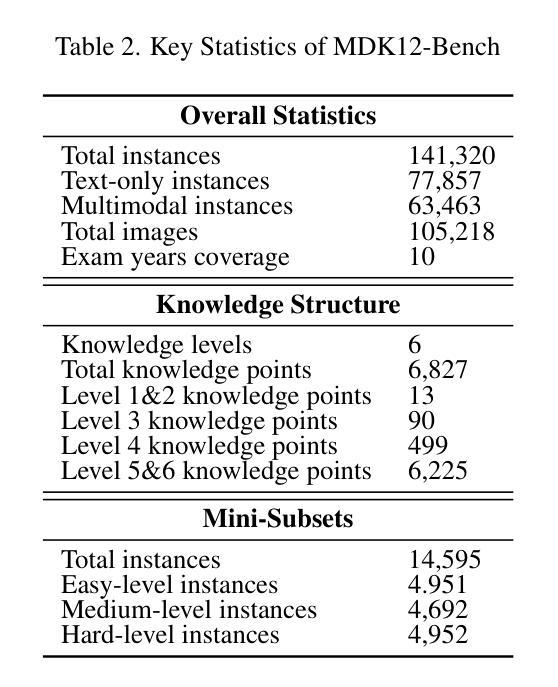
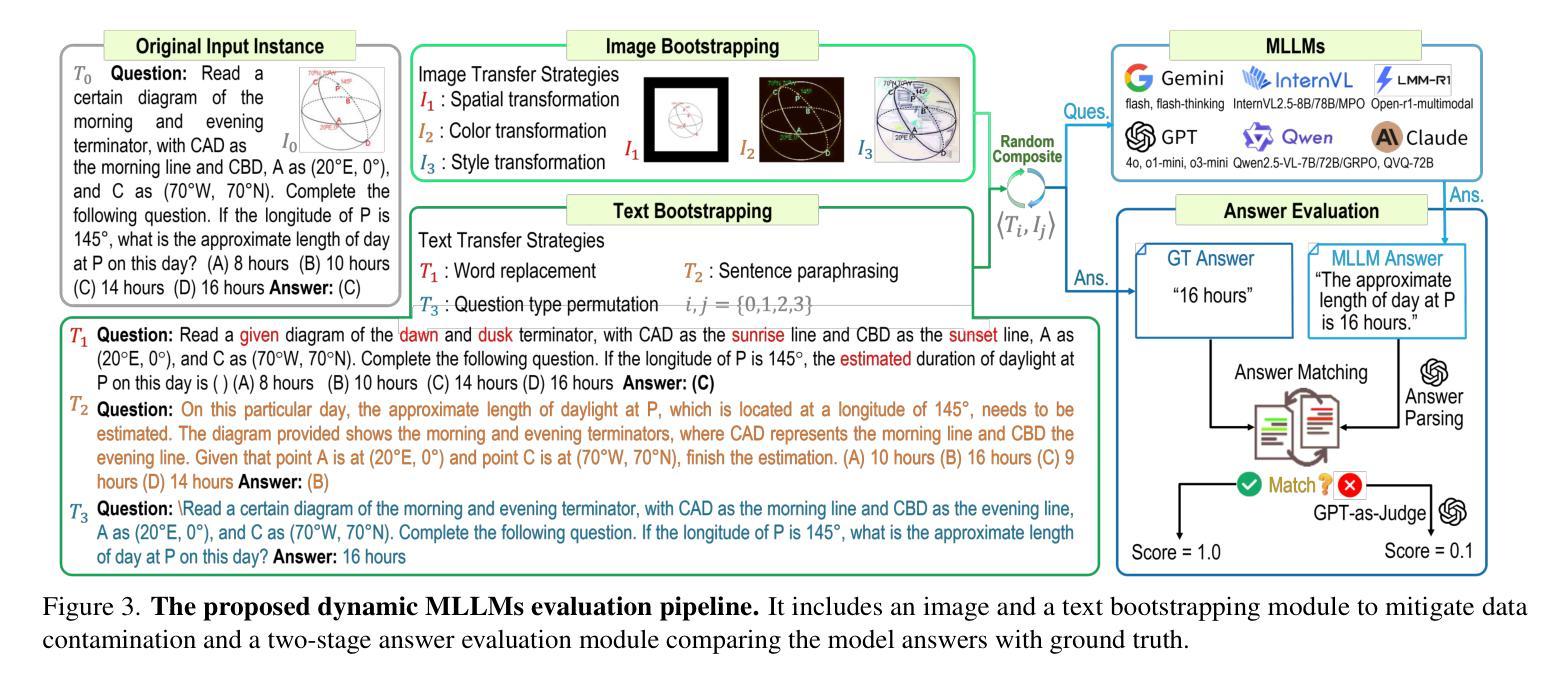
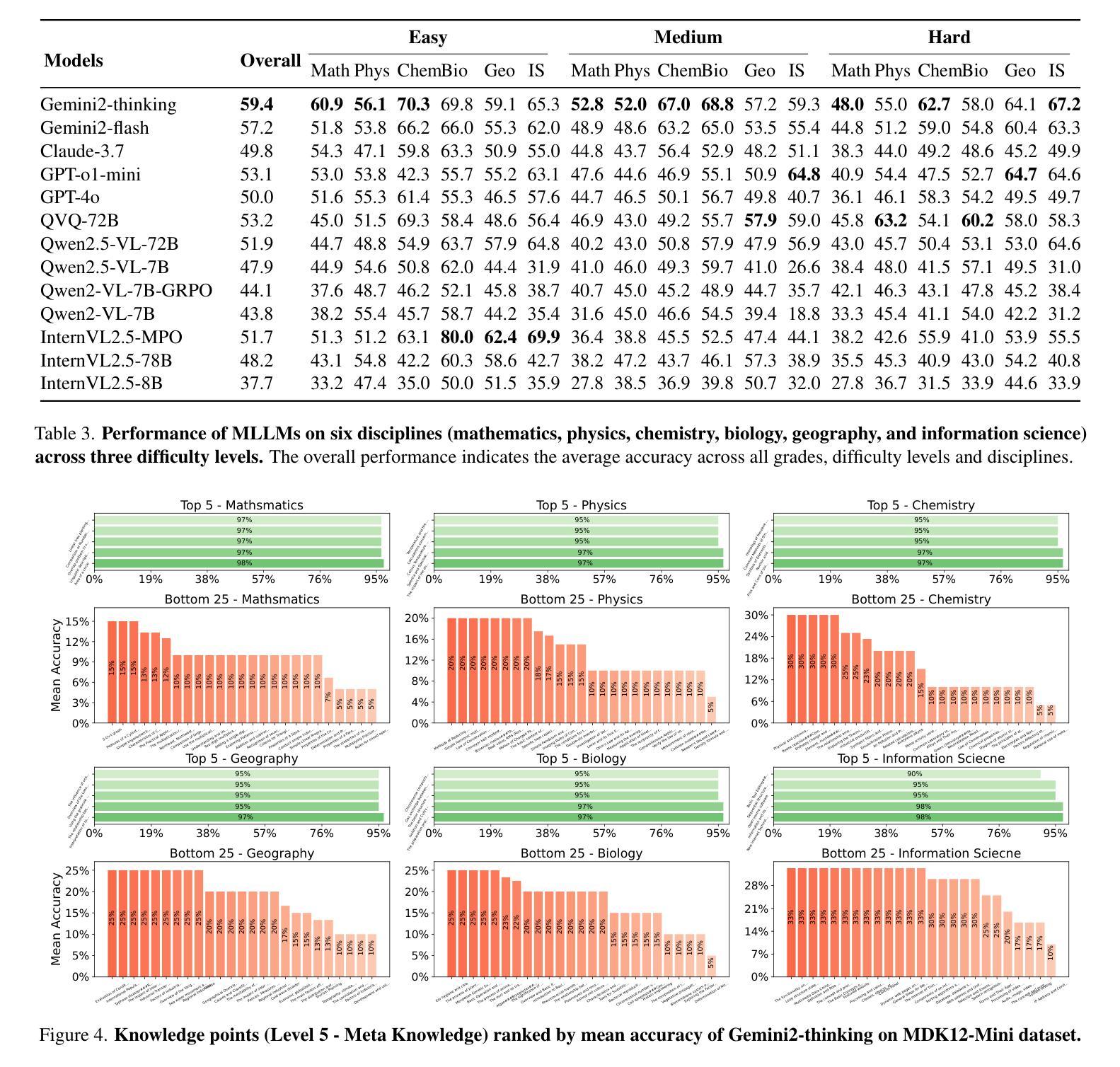
MDK12-Bench: A Multi-Discipline Benchmark for Evaluating Reasoning in Multimodal Large Language Models
Authors:Pengfei Zhou, Fanrui Zhang, Xiaopeng Peng, Zhaopan Xu, Jiaxin Ai, Yansheng Qiu, Chuanhao Li, Zhen Li, Ming Li, Yukang Feng, Jianwen Sun, Haoquan Zhang, Zizhen Li, Xiaofeng Mao, Wangbo Zhao, Kai Wang, Xiaojun Chang, Wenqi Shao, Yang You, Kaipeng Zhang
Multimodal reasoning, which integrates language and visual cues into problem solving and decision making, is a fundamental aspect of human intelligence and a crucial step toward artificial general intelligence. However, the evaluation of multimodal reasoning capabilities in Multimodal Large Language Models (MLLMs) remains inadequate. Most existing reasoning benchmarks are constrained by limited data size, narrow domain coverage, and unstructured knowledge distribution. To close these gaps, we introduce MDK12-Bench, a multi-disciplinary benchmark assessing the reasoning capabilities of MLLMs via real-world K-12 examinations. Spanning six disciplines (math, physics, chemistry, biology, geography, and information science), our benchmark comprises 140K reasoning instances across diverse difficulty levels from primary school to 12th grade. It features 6,827 instance-level knowledge point annotations based on a well-organized knowledge structure, detailed answer explanations, difficulty labels and cross-year partitions, providing a robust platform for comprehensive evaluation. Additionally, we present a novel dynamic evaluation framework to mitigate data contamination issues by bootstrapping question forms, question types, and image styles during evaluation. Extensive experiment on MDK12-Bench reveals the significant limitation of current MLLMs in multimodal reasoning. The findings on our benchmark provide insights into the development of the next-generation models. Our data and codes are available at https://github.com/LanceZPF/MDK12.
多模态推理是将语言和视觉线索整合到问题解决和决策制定中,是人类智能的基本要素,也是实现人工通用智能的关键步骤。然而,在多模态大型语言模型(MLLMs)中对多模态推理能力的评估仍然不足。现有大多数推理基准测试都受限于数据量有限、领域覆盖范围狭窄以及知识分布不够结构化。为了弥补这些差距,我们引入了MDK12-Bench,这是一个跨学科基准测试,通过现实世界中的K-12考试评估MLLMs的推理能力。我们的基准测试涵盖了数学、物理、化学、生物、地理和信息科学六个学科,包含从小学到12年级不同难度级别的14万个推理实例。它基于组织良好的知识结构、详细的答案解释、难度标签和跨年级分区,提供了6827个实例级知识点注释,为全面评估提供了一个稳健的平台。此外,我们还提出了一种新的动态评估框架,通过评估过程中的问题形式、问题类型和图像风格的自助引导,来缓解数据污染问题。在MDK12-Bench上的广泛实验揭示了当前MLLMs在多模态推理方面的重大局限性。我们在基准测试上的发现对下一代模型的发展提供了见解。我们的数据和代码可在https://github.com/LanceZPF/MDK12上找到。
论文及项目相关链接
PDF 11 pages, 8 figures
Summary
多模态推理是集成语言和视觉线索到问题解决和决策制定中的基本人类智能表现,也是朝着人工智能通用发展迈出的重要一步。然而,多模态大型语言模型(MLLMs)的多模态推理能力评估仍然不足。为了解决这个问题,本文提出了MDK12-Bench跨学科基准测试,通过K-12现实考试评估MLLMs的推理能力。该基准测试涵盖了六个学科,包含不同难度级别的14万个推理实例,并提供了一个新型动态评估框架来缓解数据污染问题。实验结果揭示了当前MLLM在多模态推理方面的显著局限性。本文的发现对于下一代模型的发展提供了深刻的见解。
Key Takeaways
- 多模态推理是人类智能的重要组成部分,也是人工智能领域的重要研究方向。
- 当前对多模态大型语言模型(MLLMs)的多模态推理能力评估存在不足,需要跨学科基准测试来全面评估其性能。
- MDK12-Bench基准测试涵盖了多个学科,包括数学、物理、化学、生物、地理和信息科学,提供了大规模的推理实例库。
- MDK12-Bench基准测试采用了详细的答案解释、难度标签和跨年级分区,为评估提供了稳健的平台。
- 新型动态评估框架被用于缓解数据污染问题,通过调整问题形式、问题类型和图像风格来进行评估。
- 实验结果表明,当前MLLM在多模态推理方面存在显著局限性,这为下一代模型的发展提供了挑战和机遇。
点此查看论文截图

iEBAKER: Improved Remote Sensing Image-Text Retrieval Framework via Eliminate Before Align and Keyword Explicit Reasoning
Authors:Yan Zhang, Zhong Ji, Changxu Meng, Yanwei Pang, Jungong Han
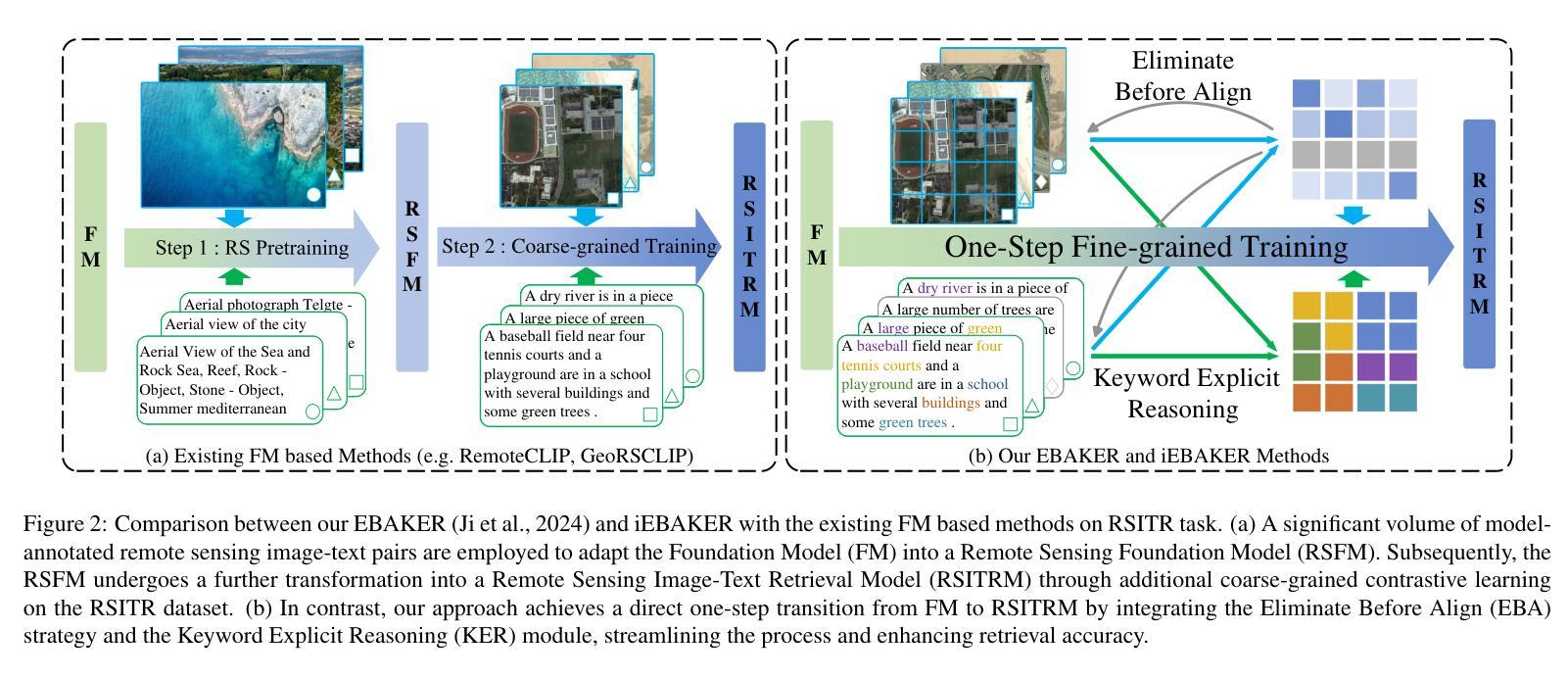
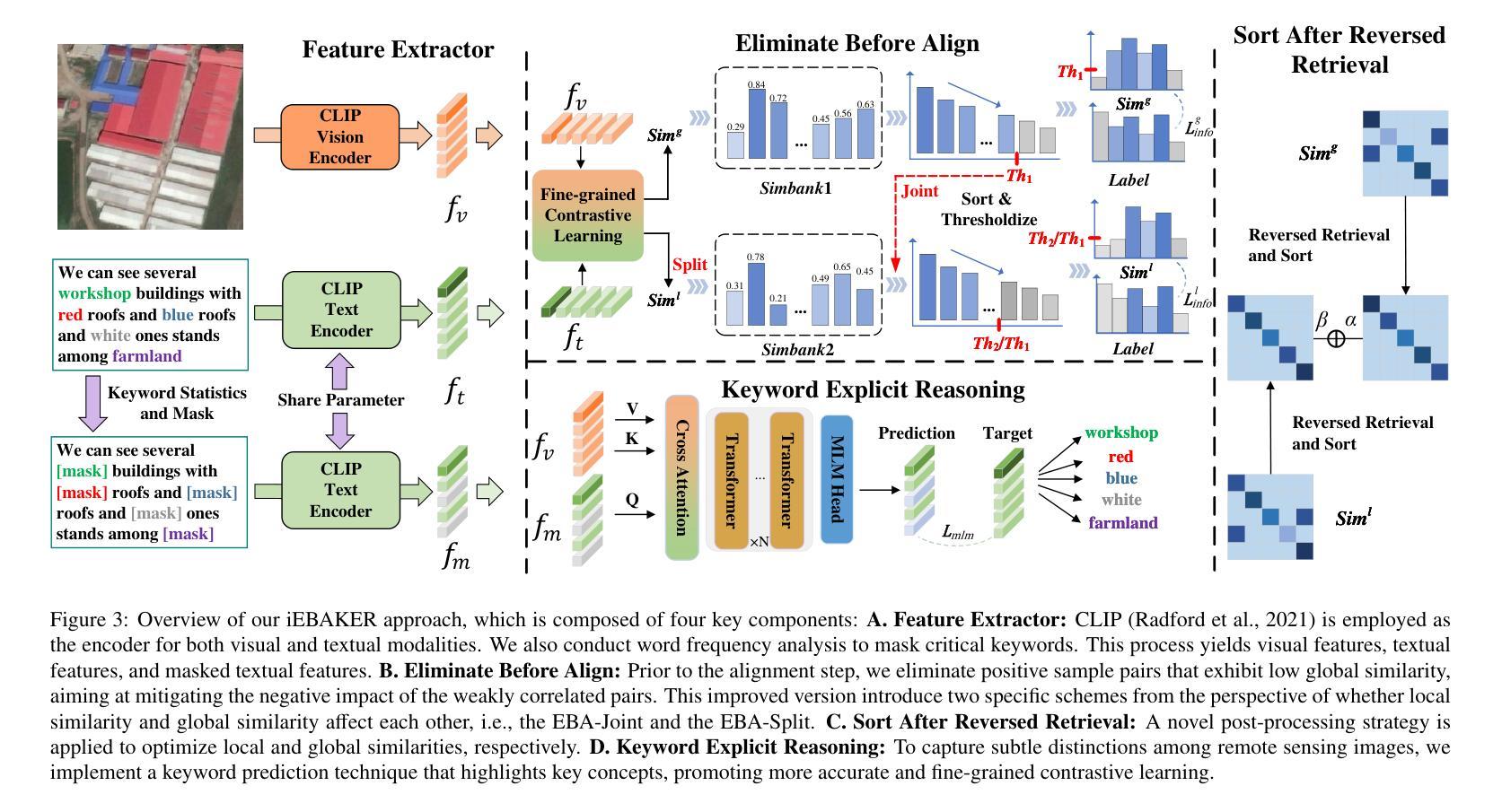
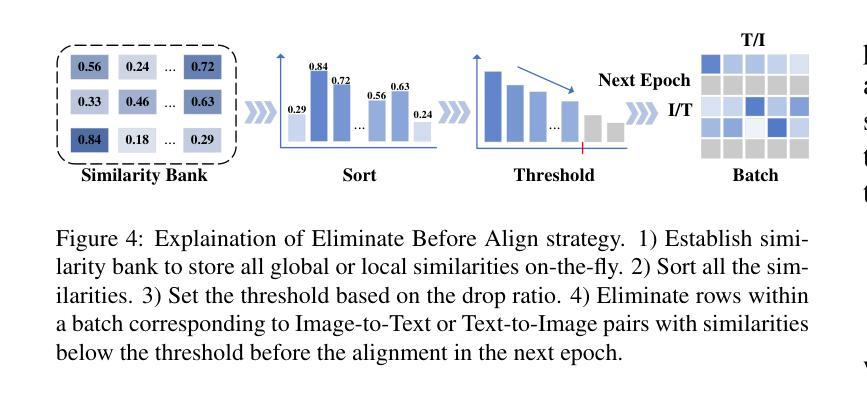
Recent studies focus on the Remote Sensing Image-Text Retrieval (RSITR), which aims at searching for the corresponding targets based on the given query. Among these efforts, the application of Foundation Models (FMs), such as CLIP, to the domain of remote sensing has yielded encouraging outcomes. However, existing FM based methodologies neglect the negative impact of weakly correlated sample pairs and fail to account for the key distinctions among remote sensing texts, leading to biased and superficial exploration of sample pairs. To address these challenges, we propose an approach named iEBAKER (an Improved Eliminate Before Align strategy with Keyword Explicit Reasoning framework) for RSITR. Specifically, we propose an innovative Eliminate Before Align (EBA) strategy to filter out the weakly correlated sample pairs, thereby mitigating their deviations from optimal embedding space during alignment.Further, two specific schemes are introduced from the perspective of whether local similarity and global similarity affect each other. On this basis, we introduce an alternative Sort After Reversed Retrieval (SAR) strategy, aims at optimizing the similarity matrix via reverse retrieval. Additionally, we incorporate a Keyword Explicit Reasoning (KER) module to facilitate the beneficial impact of subtle key concept distinctions. Without bells and whistles, our approach enables a direct transition from FM to RSITR task, eliminating the need for additional pretraining on remote sensing data. Extensive experiments conducted on three popular benchmark datasets demonstrate that our proposed iEBAKER method surpasses the state-of-the-art models while requiring less training data. Our source code will be released at https://github.com/zhangy0822/iEBAKER.
最近的研究集中在遥感图像文本检索(RSITR)上,其目标是根据给定的查询来搜索相应的目标。在这些努力中,将CLIP等Foundation Models(FMs)应用于遥感领域已经取得了令人鼓舞的结果。然而,现有的基于FM的方法忽略了弱相关样本对的负面影响,未能考虑到遥感文本之间的关键区别,导致对样本对的偏见和肤浅的探索。为了解决这些挑战,我们提出了一种名为iEBAKER的方法(带有关键词显式推理框架的改进前消除对齐策略)。具体来说,我们提出了一种创新的消除前对齐(EBA)策略,以过滤掉弱相关的样本对,从而减轻它们在对齐过程中偏离最佳嵌入空间的情况。此外,我们从局部相似性和全局相似性是否相互影响的角度介绍了两种具体方案。在此基础上,我们引入了一种替代的SAR(Sort After Reversed Retrieval)策略,旨在通过反向检索优化相似性矩阵。另外,我们加入了关键词显式推理(KER)模块,以促进微妙关键概念区别的积极影响。我们的方法无需额外的装饰和配件,就能直接从FM过渡到RSITR任务,无需在遥感数据上进行额外的预训练。在三个流行基准数据集上进行的广泛实验表明,我们提出的iEBAKER方法超越了最先进的模型,同时需要较少的训练数据。我们的源代码将在https://github.com/zhangy0822/iEBAKER上发布。
论文及项目相关链接
Summary
近期研究关注遥感图像文本检索(RSITR),应用Foundation Models(FMs)如CLIP取得鼓舞性成果。但现有方法忽略弱相关样本对的影响,未能关键区分遥感文本,导致样本对探索有偏见和表面化。为此,提出iEBAKER方法,采用Eliminate Before Align策略过滤弱相关样本对,从局部和全局相似性的角度引入SAR策略优化相似度矩阵,并融入Keyword Explicit Reasoning模块助力关键概念区分。该方法直接从FM转向RSITR任务,无需在遥感数据上额外预训练,在三个标准数据集上的实验显示,iEBAKER超越现有最佳模型,且需要更少训练数据。
Key Takeaways
- Remote Sensing Image-Text Retrieval (RSITR) 旨在根据给定查询搜索相应目标。
- Foundation Models(FMs)在遥感领域的应用已产生鼓舞人心的结果。
- 现有FM方法忽略弱相关样本对的负面影响。
- iEBAKER方法通过Eliminate Before Align策略过滤弱相关样本对。
- SAR策略用于优化相似度矩阵,考虑局部和全局相似性的相互影响。
- Keyword Explicit Reasoning模块助力关键概念的区分。
点此查看论文截图

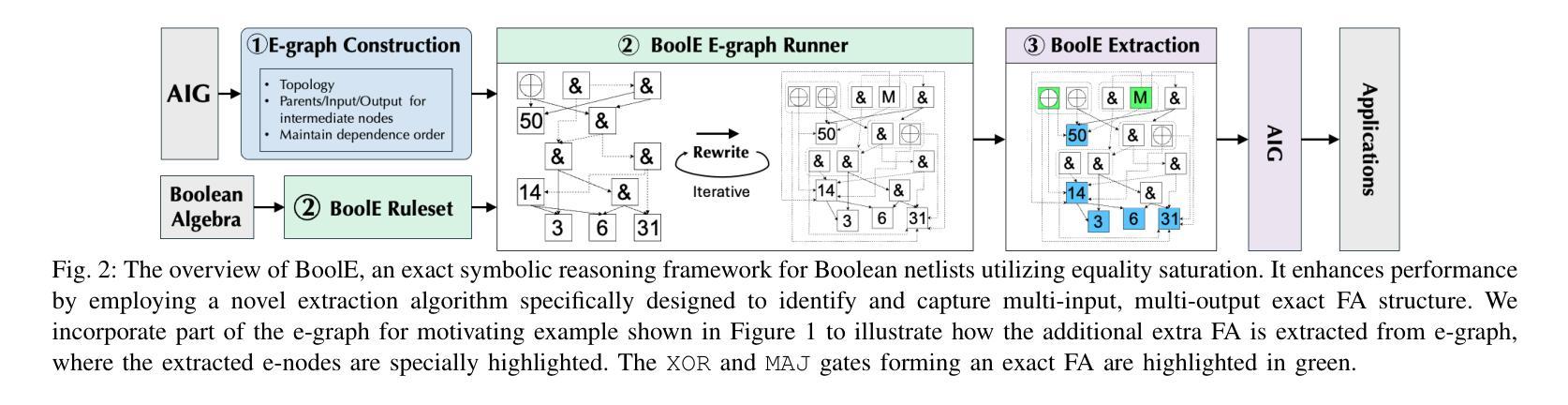
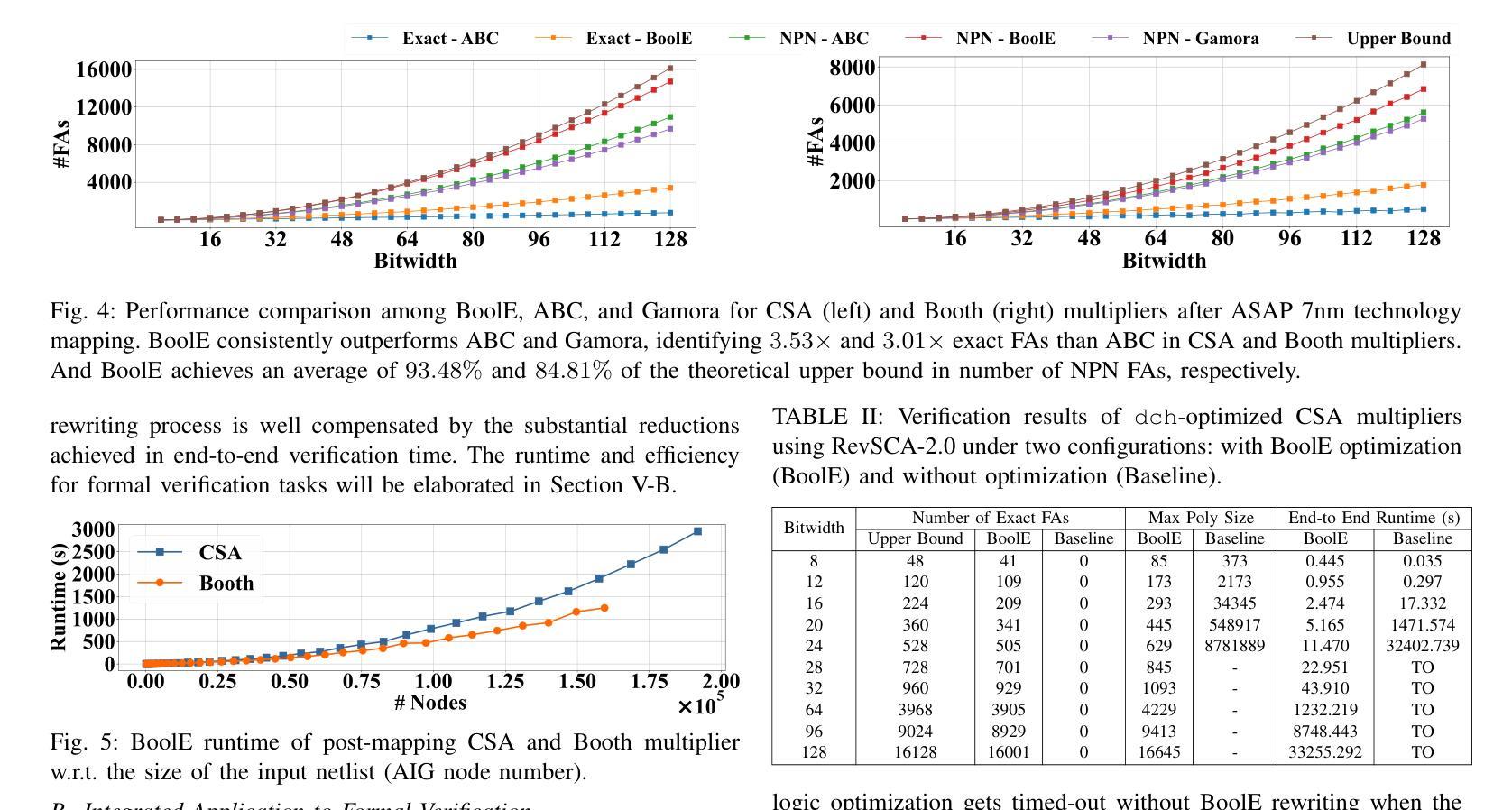
BoolE: Exact Symbolic Reasoning via Boolean Equality Saturation
Authors:Jiaqi Yin, Zhan Song, Chen Chen, Qihao Hu, Cunxi Yu
Boolean symbolic reasoning for gate-level netlists is a critical step in verification, logic and datapath synthesis, and hardware security. Specifically, reasoning datapath and adder tree in bit-blasted Boolean networks is particularly crucial for verification and synthesis, and challenging. Conventional approaches either fail to accurately (exactly) identify the function blocks of the designs in gate-level netlist with structural hashing and symbolic propagation, or their reasoning performance is highly sensitive to structure modifications caused by technology mapping or logic optimization. This paper introduces BoolE, an exact symbolic reasoning framework for Boolean netlists using equality saturation. BoolE optimizes scalability and performance by integrating domain-specific Boolean ruleset for term rewriting. We incorporate a novel extraction algorithm into BoolE to enhance its structural insight and computational efficiency, which adeptly identifies and captures multi-input, multi-output high-level structures (e.g., full adder) in the reconstructed e-graph. Our experiments show that BoolE surpasses state-of-the-art symbolic reasoning baselines, including the conventional functional approach (ABC) and machine learning-based method (Gamora). Specifically, we evaluated its performance on various multiplier architecture with different configurations. Our results show that BoolE identifies $3.53\times$ and $3.01\times$ more exact full adders than ABC in carry-save array and Booth-encoded multipliers, respectively. Additionally, we integrated BoolE into multiplier formal verification tasks, where it significantly accelerates the performance of traditional formal verification tools using computer algebra, demonstrated over four orders of magnitude runtime improvements.
针对门级网表的布尔符号推理是验证、逻辑和数据路径合成以及硬件安全中的关键步骤。特别是,在比特爆炸的布尔网络中推理数据路径和加法树对于验证和合成至关重要,且非常具有挑战性。传统的方法要么无法准确地(确切地)识别门级网表中设计的功能块,使用结构散列和符号传播,要么它们的推理性能对技术映射或逻辑优化引起的结构修改非常敏感。本文介绍了BoolE,这是一个使用等式饱和的布尔网表精确符号推理框架。BoolE通过集成特定领域的布尔规则集进行术语重写来优化可扩展性和性能。我们将一种新型提取算法纳入BoolE,以提高其结构洞察力和计算效率,该算法能够巧妙地在重构的e图中识别和捕获多输入、多输出的高级结构(例如全加器)。我们的实验表明,BoolE超越了最新的符号推理基线,包括传统功能方法(ABC)和基于机器学习的方法(Gamora)。具体来说,我们在各种配置的多路架构上评估了其性能。我们的结果表明,在携带保存阵列和Booth编码的多路中,BoolE识别出的全加器比ABC多3.53倍和3.01倍。此外,我们将BoolE集成到多路正式验证任务中,它显著加速了使用计算机代数的传统形式验证工具的性能,在四个数量级的运行时间上取得了明显的改进。
论文及项目相关链接
Summary
在布尔符号推理中,针对门级网表的推理是验证、逻辑合成、硬件安全中的关键步骤。对于位爆破布尔网络中的推理路径和加法器树尤其重要且具有挑战性。当前方法未能准确地识别设计中的功能块或对结构变动(技术映射或逻辑优化导致)敏感。本文介绍BoolE,一个基于等式饱和的布尔网表精确符号推理框架。BoolE通过集成领域特定的布尔规则集进行术语重写来优化可扩展性和性能。我们采用新颖提取算法增强BoolE的结构洞察力和计算效率,巧妙识别并捕获多输入多输出的高级结构(如全加器)。实验表明,BoolE超越先进的符号推理基线,包括传统功能方法(ABC)和机器学习方法(Gamora)。对于不同配置的多路器架构性能评估显示,BoolE识别的全加器比ABC多3.53倍和3.01倍。此外,将BoolE集成到多路器形式验证任务中,与传统形式验证工具相比,使用计算机代数显著加速性能,实现超过四个数量级的运行时改进。
Key Takeaways
- Boolean symbolic reasoning for gate-level netlists is crucial in verification, logic synthesis, and hardware security.
- Existing methods have difficulties accurately identifying function blocks in gate-level netlists or are sensitive to structural changes.
- The paper introduces BoolE, an exact symbolic reasoning framework for Boolean netlists using equality saturation.
- BoolE optimizes scalability and performance through term rewriting with a domain-specific Boolean ruleset.
- A novel extraction algorithm enhances BoolE’s structural insight and computational efficiency.
- BoolE surpasses state-of-the-art symbolic reasoning baselines, identifying more exact full adders than conventional methods.
- Integrating BoolE into multiplier formal verification tasks significantly accelerates traditional formal verification tools.
点此查看论文截图




Evaluating the Generalization Capabilities of Large Language Models on Code Reasoning
Authors:Rem Yang, Julian Dai, Nikos Vasilakis, Martin Rinard
We assess how the code reasoning abilities of large language models (LLMs) generalize to different kinds of programs. We present techniques for obtaining in- and out-of-distribution programs with different characteristics: code sampled from a domain-specific language, code automatically generated by an LLM, code collected from competitive programming contests, and mutated versions of these programs. We also present an experimental methodology for evaluating LLM generalization by comparing their performance on these programs. We perform an extensive evaluation across 10 state-of-the-art models from the past year, obtaining insights into their generalization capabilities over time and across different classes of programs. Our results highlight that while earlier models exhibit behavior consistent with pattern matching, the latest models exhibit strong generalization abilities on code reasoning.
我们评估大型语言模型(LLM)的代码推理能力如何推广到不同类型的程序。我们展示了获得具有不同特性的分布内和分布外程序的技术:从特定领域语言采样得到的代码、由LLM自动生成的代码、从竞赛编程比赛中收集的代码以及这些程序的变体。我们还通过比较这些程序上的表现,提出了一种评估LLM泛化性的实验方法。我们对过去一年中的10个最新先进模型进行了广泛评估,了解它们在时间和不同类别的程序上的泛化能力。我们的结果表明,虽然早期模型的行为与模式匹配一致,但最新模型在代码推理方面表现出强大的泛化能力。
论文及项目相关链接
Summary:本文评估大型语言模型(LLM)的代码推理能力在不同类型程序上的泛化情况。文章介绍了获取不同特性程序的方法,包括特定领域语言中的代码样本、LLM自动生成的代码、来自编程竞赛的代码以及这些程序的变种。同时,文章还提出了一种评估LLM泛化能力的方法,通过比较这些程序上的表现来进行评价。文章对过去一年中的10个最新模型进行了广泛评估,并深入了解了它们在时间推移和不同类别程序上的泛化能力。结果表明,早期模型的行为与模式匹配一致,而最新模型在代码推理方面表现出强大的泛化能力。
Key Takeaways:
- 文章评估了大型语言模型(LLM)的代码推理能力在不同类型程序上的泛化情况。
- 通过比较不同模型的性能来评估LLM的泛化能力。
- 文章介绍了获取具有不同特性的程序和评估方法,包括特定领域语言中的代码样本、自动生成的代码、来自编程竞赛的代码以及程序的变种。
- 对过去一年的10个最新模型进行了广泛评估。
- 早期模型的行为与模式匹配一致。
- 最新模型在代码推理方面表现出强大的泛化能力。
点此查看论文截图




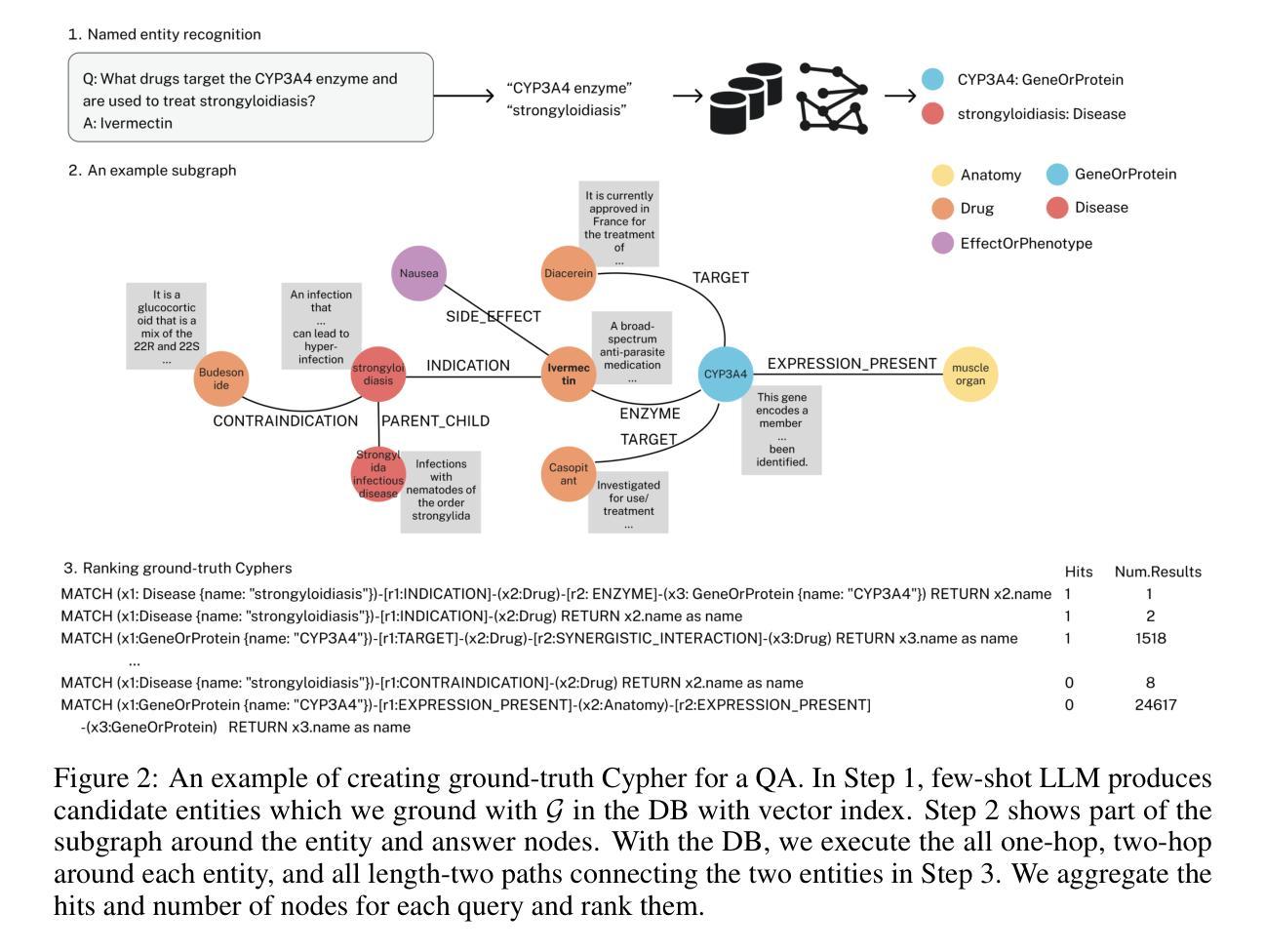
GraphRAFT: Retrieval Augmented Fine-Tuning for Knowledge Graphs on Graph Databases
Authors:Alfred Clemedtson, Borun Shi
Large language models have shown remarkable language processing and reasoning ability but are prone to hallucinate when asked about private data. Retrieval-augmented generation (RAG) retrieves relevant data that fit into an LLM’s context window and prompts the LLM for an answer. GraphRAG extends this approach to structured Knowledge Graphs (KGs) and questions regarding entities multiple hops away. The majority of recent GraphRAG methods either overlook the retrieval step or have ad hoc retrieval processes that are abstract or inefficient. This prevents them from being adopted when the KGs are stored in graph databases supporting graph query languages. In this work, we present GraphRAFT, a retrieve-and-reason framework that finetunes LLMs to generate provably correct Cypher queries to retrieve high-quality subgraph contexts and produce accurate answers. Our method is the first such solution that can be taken off-the-shelf and used on KGs stored in native graph DBs. Benchmarks suggest that our method is sample-efficient and scales with the availability of training data. Our method achieves significantly better results than all state-of-the-art models across all four standard metrics on two challenging Q&As on large text-attributed KGs.
大型语言模型在处理语言和推理方面表现出卓越的能力,但在涉及私人数据时容易出现幻觉。检索增强生成(RAG)检索与大型语言模型上下文窗口相关且匹配的数据,并提示大型语言模型给出答案。GraphRAG将此方法扩展到结构化的知识图谱(KGs)和关于多个跳跃点的实体的查询。最近的GraphRAG方法大多忽略了检索步骤,或者具有抽象或低效的临时检索流程。这阻止了它们在知识图谱存储在支持图形查询语言的图形数据库中的场景中使用。在这项工作中,我们提出了GraphRAFT,这是一个检索和推理框架,对大型语言模型进行微调,以生成经过验证的正确Cypher查询,以检索高质量子图上下文并产生准确答案。我们的方法是第一个可以在存储在本地图形数据库的知识图谱上使用的解决方案。基准测试表明,我们的方法是样本高效的,并随着训练数据的可用性而扩展。我们的方法在大型带文本属性知识图谱上的两个挑战性问答测试的所有四个标准指标上都显著优于所有最新模型。
论文及项目相关链接
Summary
本文介绍了Large Language Models在处理与私人数据相关的查询时易出现幻想的问题。为解决这个问题,文章提出了GraphRAFT这一基于检索和推理的框架。GraphRAFT可以微调LLMs,生成可靠的Cypher查询,从知识图谱中检索高质量子图上下文并给出准确答案。此框架适用于存储在原生图形数据库中的知识图谱,具有样本效率高、随训练数据可用性而扩展的优点。在大型文本属性知识图谱的Q&A任务上,该方法在四个标准指标上的表现均优于现有模型。
Key Takeaways
- Large Language Models在处理语言和推理任务时表现出色,但在涉及私人数据的查询时容易出错。
- 检索增强生成(RAG)方法通过检索与LLM上下文窗口相关的数据并提示LLM来回答问题。
- GraphRAG将这种方法扩展到结构化的知识图谱(KGs),并处理关于实体多跳的问题。
- 现有GraphRAG方法存在缺陷,忽略检索步骤或拥有抽象、低效的检索过程,无法适应于知识图谱存储在图形数据库的情况。
- GraphRAFT是一个基于检索和推理的框架,可以微调LLMs以生成准确的Cypher查询,从知识图谱中检索高质量信息并给出正确答案。
- GraphRAFT是首个可以在存储在原生图形数据库中的知识图谱上使用的解决方案。
点此查看论文截图


ZeroED: Hybrid Zero-shot Error Detection through Large Language Model Reasoning
Authors:Wei Ni, Kaihang Zhang, Xiaoye Miao, Xiangyu Zhao, Yangyang Wu, Yaoshu Wang, Jianwei Yin
Error detection (ED) in tabular data is crucial yet challenging due to diverse error types and the need for contextual understanding. Traditional ED methods often rely heavily on manual criteria and labels, making them labor-intensive. Large language models (LLM) can minimize human effort but struggle with errors requiring a comprehensive understanding of data context. In this paper, we propose ZeroED, a novel hybrid zero-shot error detection framework, which combines LLM reasoning ability with the manual label-based ED pipeline. ZeroED operates in four steps, i.e., feature representation, error labeling, training data construction, and detector training. Initially, to enhance error distinction, ZeroED generates rich data representations using error reason-aware binary features, pre-trained embeddings, and statistical features. Then, ZeroED employs LLM to label errors holistically through in-context learning, guided by a two-step reasoning process for detailed error detection guidelines. To reduce token costs, LLMs are applied only to representative data selected via clustering-based sampling. High-quality training data is constructed through in-cluster label propagation and LLM augmentation with verification. Finally, a classifier is trained to detect all errors. Extensive experiments on seven public datasets demonstrate that, ZeroED substantially outperforms state-of-the-art methods by a maximum 30% improvement in F1 score and up to 90% token cost reduction.
错误检测(ED)在表格数据中非常重要,但同时也具有挑战性,因为存在多种错误类型,且需要理解上下文。传统的ED方法往往严重依赖于手动标准和标签,使其需要大量人工。大型语言模型(LLM)可以最大限度地减少人工努力,但对于需要全面理解数据上下文的错误却往往无能为力。在本文中,我们提出了ZeroED,这是一种新型混合零样本错误检测框架,它将LLM的推理能力与基于手动标签的ED管道相结合。ZeroED有四个步骤:特征表示、错误标签、训练数据构建和检测器训练。首先,为了增强错误区分度,ZeroED使用错误原因感知的二进制特征、预训练嵌入和统计特征来生成丰富的数据表示。然后,ZeroED采用LLM通过上下文学习来全面标注错误,并通过两步推理过程为详细的错误检测提供指导。为了减少令牌成本,仅对通过聚类采样选择的有代表性的数据应用LLM。通过集群内标签传播和LLM增强验证来构建高质量的训练数据。最后,训练一个分类器来检测所有错误。在七个公共数据集上的广泛实验表明,ZeroED显著优于最新方法,F1得分最高可提高30%,令牌成本最多可降低90%。
论文及项目相关链接
PDF 12 pages
Summary
数据表错误检测(ED)非常重要但具有挑战性,因为错误类型多样且需要理解上下文。传统ED方法依赖手动标准和标签,工作量大。大型语言模型(LLM)可以减少人力投入,但在需要全面理解数据上下文时会出现困难。本文提出ZeroED,一种新型零样本错误检测框架,结合LLM推理能力与基于手动标签的ED管道。ZeroED通过四个步骤操作:特征表示、错误标签、训练数据构建和检测器训练。首先,使用错误原因感知二元特征、预训练嵌入和统计特征来增强错误区分度。然后,借助LLM通过上下文学习对错误进行整体标签,并通过两步推理过程提供详细的错误检测指南。为降低令牌成本,仅对通过聚类采样选择的有代表性的数据应用LLM。通过集群内标签传播和LLM验证构建高质量训练数据。最后,训练分类器以检测所有错误。在七个公共数据集上的广泛实验表明,ZeroED在F1分数上最多高出30%,令牌成本最多减少90%,明显优于现有技术。
Key Takeaways
- 错误检测在表格数据中非常重要且具挑战性,因错误类型多样且需理解上下文。
- 传统错误检测方法依赖大量手动标签,工作量大且效率不高。
- 大型语言模型可减少人力投入,但在全面理解数据上下文方面可能遇到困难。
- ZeroED是一种新型零样本错误检测框架,结合了LLM推理能力与基于手动标签的ED管道。
- ZeroED通过四个步骤操作:特征表示以增强错误区分度、错误标签、训练数据构建和检测器训练。
- ZeroED使用LLM进行上下文学习以提供全面的错误标签和详细的错误检测指南。
点此查看论文截图


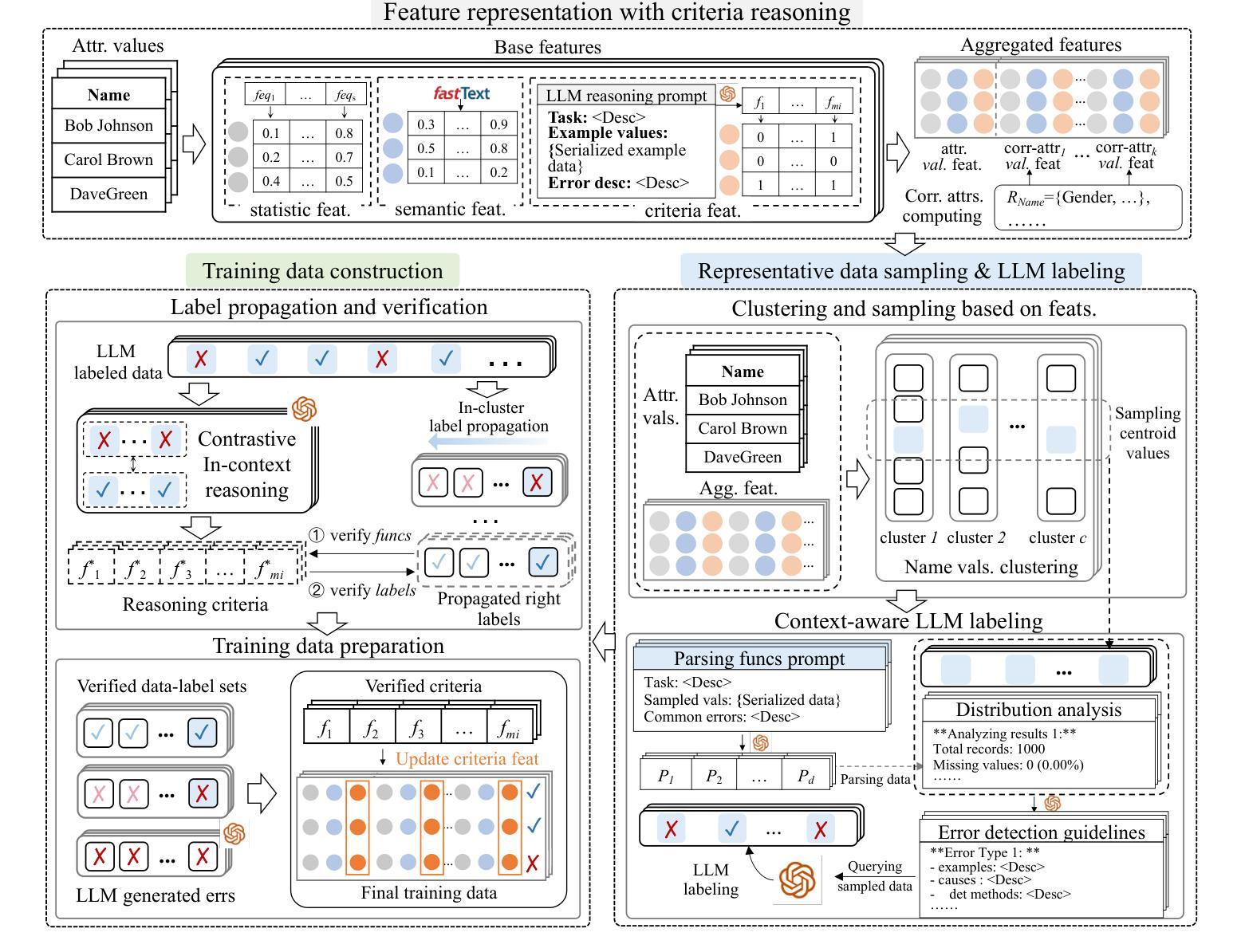

VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks
Authors:Yu Yue, Yufeng Yuan, Qiying Yu, Xiaochen Zuo, Ruofei Zhu, Wenyuan Xu, Jiaze Chen, Chengyi Wang, TianTian Fan, Zhengyin Du, Xiangpeng Wei, Xiangyu Yu, Gaohong Liu, Juncai Liu, Lingjun Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Ru Zhang, Xin Liu, Mingxuan Wang, Yonghui Wu, Lin Yan
We present VAPO, Value-based Augmented Proximal Policy Optimization framework for reasoning models., a novel framework tailored for reasoning models within the value-based paradigm. Benchmarked the AIME 2024 dataset, VAPO, built on the Qwen 32B pre-trained model, attains a state-of-the-art score of $\mathbf{60.4}$. In direct comparison under identical experimental settings, VAPO outperforms the previously reported results of DeepSeek-R1-Zero-Qwen-32B and DAPO by more than 10 points. The training process of VAPO stands out for its stability and efficiency. It reaches state-of-the-art performance within a mere 5,000 steps. Moreover, across multiple independent runs, no training crashes occur, underscoring its reliability. This research delves into long chain-of-thought (long-CoT) reasoning using a value-based reinforcement learning framework. We pinpoint three key challenges that plague value-based methods: value model bias, the presence of heterogeneous sequence lengths, and the sparsity of reward signals. Through systematic design, VAPO offers an integrated solution that effectively alleviates these challenges, enabling enhanced performance in long-CoT reasoning tasks.
我们提出了VAPO,基于价值的增强近端策略优化框架(Value-based Augmented Proximal Policy Optimization framework),这是一个针对基于价值的范式中的推理模型量身定制的新型框架。以AIME 2024数据集为基准,基于Qwen 32B预训练模型的VAPO达到了最先进的得分60.4分。在相同的实验设置下直接比较,VAPO的性能超过了之前报告的DeepSeek-R1-Zero-Qwen-32B和DAPO的结果超过10分。VAPO的训练过程以其稳定性和高效性而脱颖而出。它仅在5000步内就达到了最先进的性能。此外,在多次独立运行中,没有出现训练崩溃的情况,证明了其可靠性。本研究深入探讨了基于价值强化学习框架的长链思维(long-CoT)推理。我们确定了困扰基于价值方法的三个关键挑战:价值模型偏见、存在异质序列长度以及奖励信号稀疏。通过系统设计,VAPO提供了一个综合解决方案,有效地缓解了这些挑战,从而在长链思维推理任务中实现了增强的性能。
论文及项目相关链接
Summary
VAPO,一种针对价值基础范式中的推理模型的新型框架,被提出并用于AIME 2024数据集进行基准测试。基于Qwen 32B预训练模型的VAPO达到了60.4的创纪录分数。在相同的实验设置下,VAPO较之前的DeepSeek-R1-Zero-Qwen-32B和DAPO的结果高出超过10分。其训练过程稳定高效,能在短短5000步内达到最佳状态。此外,VAPO能够解决价值基础方法中的三个关键挑战:价值模型偏见、不同序列长度的存在和奖励信号的稀疏性。通过系统设计,VAPO提供了一个综合解决方案,有效地缓解了这些挑战,从而在长链思维推理任务中实现了卓越性能。
Key Takeaways
- VAPO是一个针对价值基础范式中的推理模型的新型框架,旨在解决长链思维推理任务。
- 在AIME 2024数据集上,VAPO达到了创纪录的60.4分,显著优于其他模型。
- VAPO训练过程稳定高效,能在短时间内达到最佳性能状态。
- VAPO解决了价值基础方法中的三个关键挑战:价值模型偏见、不同序列长度的存在和奖励信号的稀疏性。
- 通过系统设计,VAPO提供了对以上挑战的综合解决方案。
- VAPO具有高度的可靠性,多次独立运行中未出现训练崩溃的情况。
点此查看论文截图
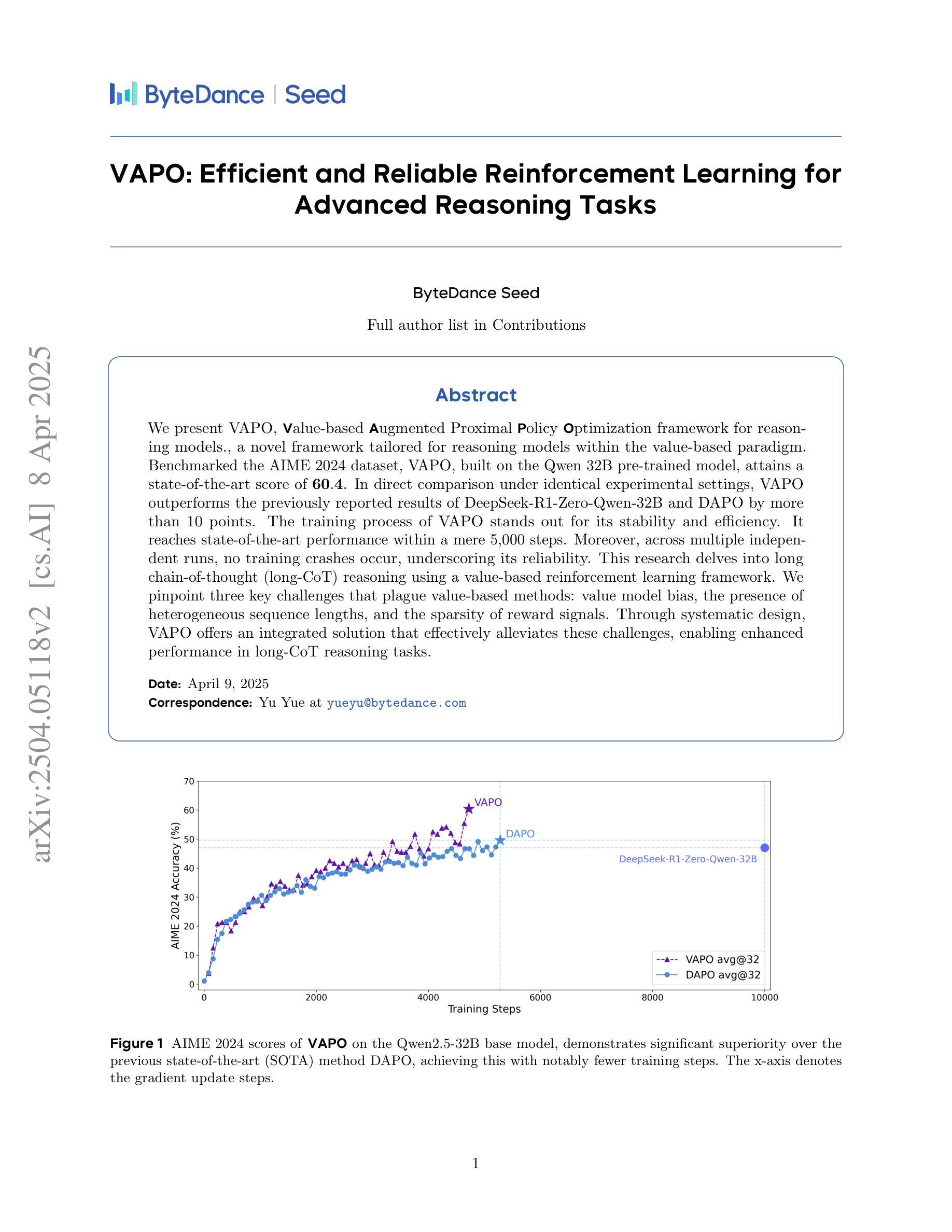
Robust Reinforcement Learning from Human Feedback for Large Language Models Fine-Tuning
Authors:Kai Ye, Hongyi Zhou, Jin Zhu, Francesco Quinzan, Chengchung Shi
Reinforcement learning from human feedback (RLHF) has emerged as a key technique for aligning the output of large language models (LLMs) with human preferences. To learn the reward function, most existing RLHF algorithms use the Bradley-Terry model, which relies on assumptions about human preferences that may not reflect the complexity and variability of real-world judgments. In this paper, we propose a robust algorithm to enhance the performance of existing approaches under such reward model misspecifications. Theoretically, our algorithm reduces the variance of reward and policy estimators, leading to improved regret bounds. Empirical evaluations on LLM benchmark datasets demonstrate that the proposed algorithm consistently outperforms existing methods, with 77-81% of responses being favored over baselines on the Anthropic Helpful and Harmless dataset.
强化学习从人类反馈(RLHF)已成为使大型语言模型(LLM)的输出符合人类偏好的关键技术。为了学习奖励函数,大多数现有的RLHF算法使用Bradley-Terry模型,该模型依赖于可能无法反映现实世界判断复杂性和多变性的人类偏好假设。在本文中,我们提出了一种稳健的算法,以提高在这种奖励模型误判下的现有方法的性能。从理论上讲,我们的算法降低了奖励和政策估算器的方差,从而提高了后悔界。在LLM基准数据集上的经验评估表明,该算法始终优于现有方法,在Anthropic有益和无害数据集上,有7 结成为学界广泛关注的热点。因此本文提出一种稳健的算法,旨在提高在奖励模型不准确时的现有方法的性能。该算法能有效减少奖励与策略估算器的变异性,从而提高限制后悔的理论边界。在大型语言模型基准测试数据集上的实证评估表明,本文提出的算法表现卓越,在Anthropic有益和无害数据集上的响应率高达77%-81%,超越基线水平。
论文及项目相关链接
Summary:强化学习从人类反馈(RLHF)已成为将大型语言模型(LLM)的输出与人类偏好对齐的关键技术。现有大多数RLHF算法使用Bradley-Terry模型来学习奖励函数,这依赖于可能无法反映现实世界判断复杂性和可变性的假设。本文提出了一种稳健的算法,以提高在奖励模型误指定情况下的现有方法性能。理论上,该算法降低了奖励和政策估计量的方差,提高了后悔界。在LLM基准数据集上的经验评估表明,该算法始终优于现有方法,在Anthropic有益和无害数据集上,77-81%的响应优于基准测试。
Key Takeaways:
- 强化学习从人类反馈(RLHF)技术用于对齐大型语言模型输出与人类偏好。
- 现有RLHF算法主要使用Bradley-Terry模型,存在对现实世界判断的复杂性和可变性的假设不足的问题。
- 本文提出了一种稳健的算法,旨在提高在奖励模型误指定情况下的现有方法性能。
- 该算法理论上降低了奖励和政策估计量的方差,提高了后悔界。
- 在LLM基准数据集上的经验评估显示,新算法性能优于现有方法。
- 在Anthropic有益和无害数据集上,新算法的响应优于基准测试的比例达到77-81%。
点此查看论文截图

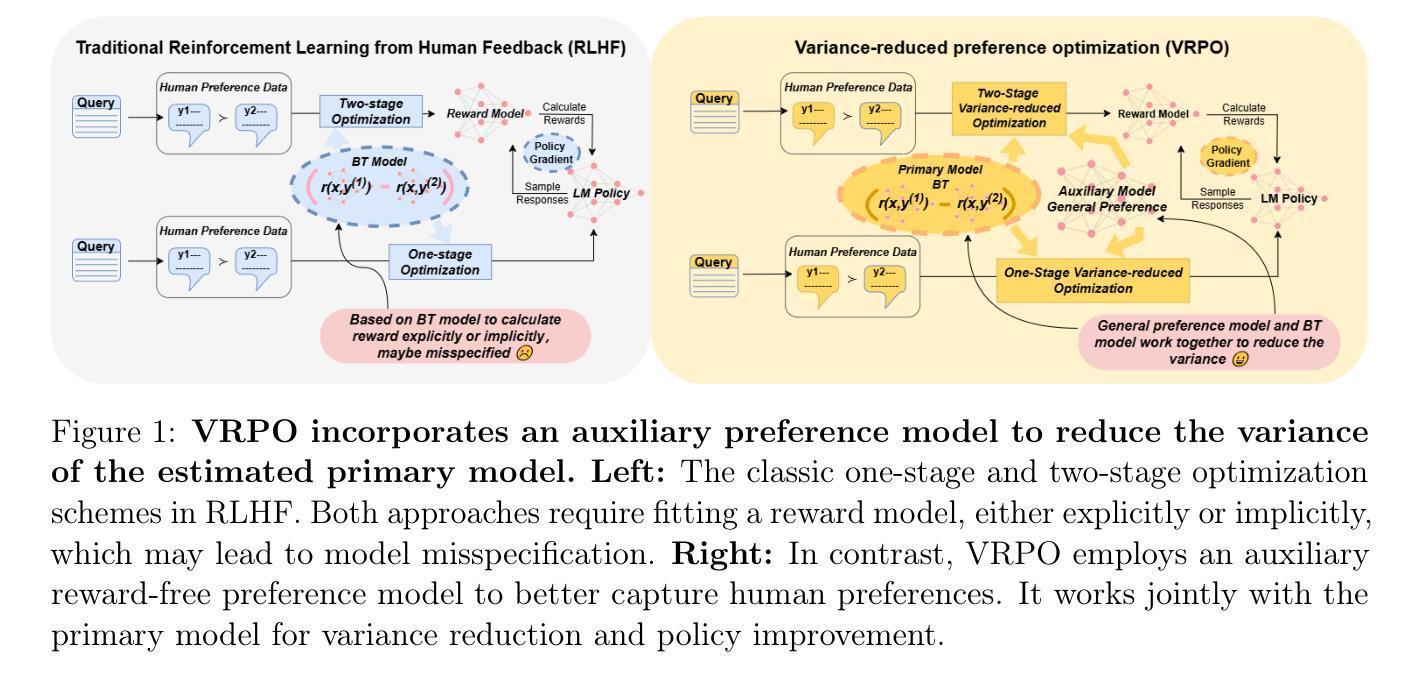

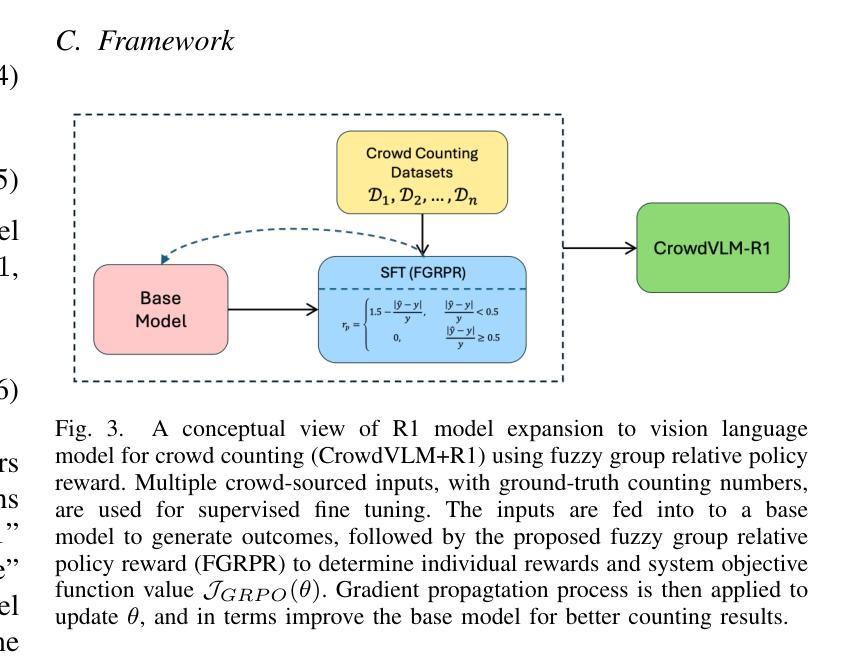
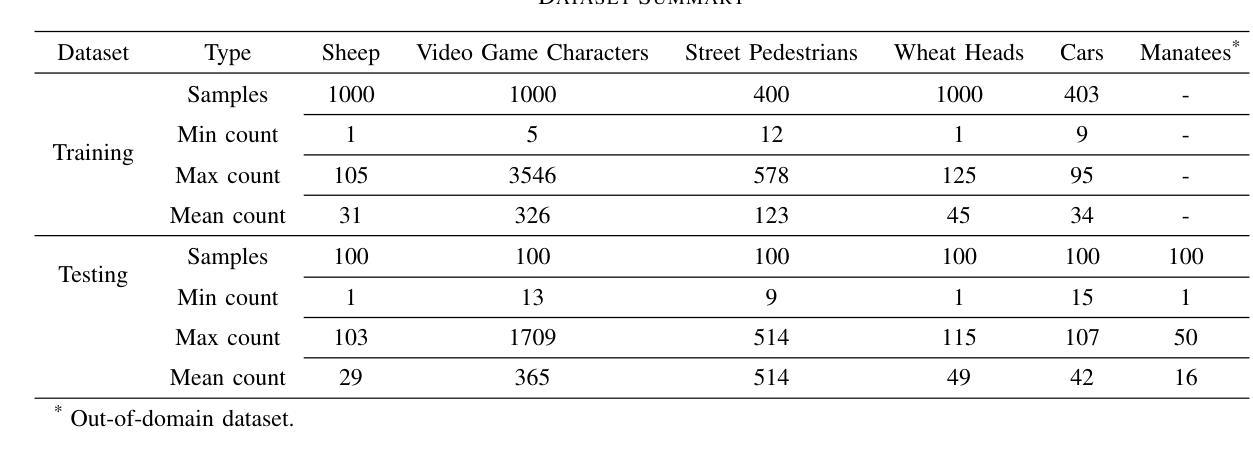
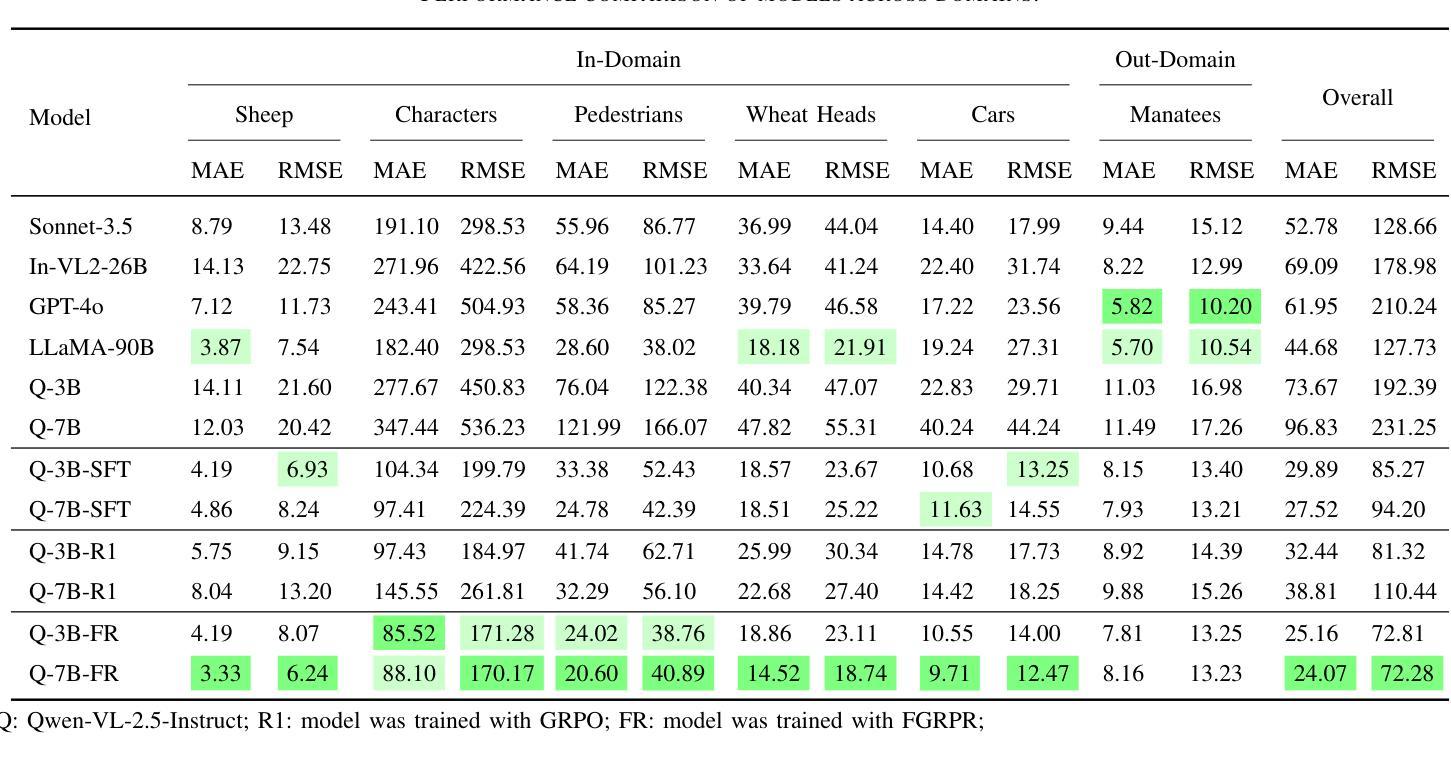
CrowdVLM-R1: Expanding R1 Ability to Vision Language Model for Crowd Counting using Fuzzy Group Relative Policy Reward
Authors:Zhiqiang Wang, Pengbin Feng, Yanbin Lin, Shuzhang Cai, Zongao Bian, Jinghua Yan, Xingquan Zhu
We propose Fuzzy Group Relative Policy Reward (FGRPR), a novel framework that integrates Group Relative Policy Optimization (GRPO) with a fuzzy reward function to enhance learning efficiency. Unlike the conventional binary 0/1 accuracy reward, our fuzzy reward model provides nuanced incentives, encouraging more precise outputs. Experimental results demonstrate that GRPO with a standard 0/1 accuracy reward underperforms compared to supervised fine-tuning (SFT). In contrast, FGRPR, applied to Qwen2.5-VL(3B and 7B), surpasses all baseline models, including GPT4o, LLaMA2(90B), and SFT, across five in-domain datasets. On an out-of-domain dataset, FGRPR achieves performance comparable to SFT but excels when target values are larger, as its fuzzy reward function assigns higher rewards to closer approximations. This approach is broadly applicable to tasks where the precision of the answer is critical. Code and data: https://github.com/yeyimilk/CrowdVLM-R1
我们提出了模糊组相对策略奖励(FGRPR)这一新型框架,它将组相对策略优化(GRPO)与模糊奖励函数相结合,以提高学习效率。与传统的二元0/1准确率奖励不同,我们的模糊奖励模型提供了微妙的激励,鼓励更精确的输出。实验结果表明,使用标准0/1准确率奖励的GRPO在监督微调(SFT)面前表现不佳。相比之下,应用于Qwen2.5-VL(3B和7B)的FGRPR在所有基线模型(包括GPT4o、LLaMA2(90B)和SFT)上表现均优于基线模型,跨五个领域内的数据集。在跨域数据集上,FGRPR的性能与SFT相当,但当目标值较大时表现更出色,因为其模糊奖励函数会向接近的近似值分配更高的奖励。该方法可广泛应用于答案精确度至关重要的任务。代码和数据集可通过以下链接获取:https://github.com/yeyimilk/CrowdVLM-R1。
论文及项目相关链接
PDF 11 pages, 6 figures and 4 tables
Summary
基于模糊奖励函数的模糊组相对策略奖励(FGRPR)框架结合了组相对策略优化(GRPO),提高了学习效率。相较于传统的二元0/1精度奖励,模糊奖励模型提供更精细的激励,促进更精确的输出。实验结果显示,使用标准0/1精度奖励的GRPO在多个基准测试中表现不如监督微调(SFT)。而应用于Qwen2.5-VL(包括规模3B和7B的模型测试场景中,结合了模糊奖励函数的FGRPR框架在五个同领域数据集上的表现超过了所有基准模型,包括GPT4o和LLaMA系列。对于目标值较大的情况,FGRPR表现得尤为出色。该方法可广泛应用于答案精度至关重要的任务中。相关代码和数据可通过链接访问。
Key Takeaways
- FGRPR结合了组相对策略优化(GRPO)与模糊奖励函数来提升学习效率。
- 传统二元精度奖励在某些场景下效果有限,而模糊奖励模型能提供更为精细的激励。
- 实验显示,结合模糊奖励函数的FGRPR在多个数据集上的表现优于其他基准模型。
- FGRPR在目标值较大的情况下表现得尤其出色。由于其较高的精确度和对细节的关注程度极高使其在精确控制类的任务中表现优异。
点此查看论文截图



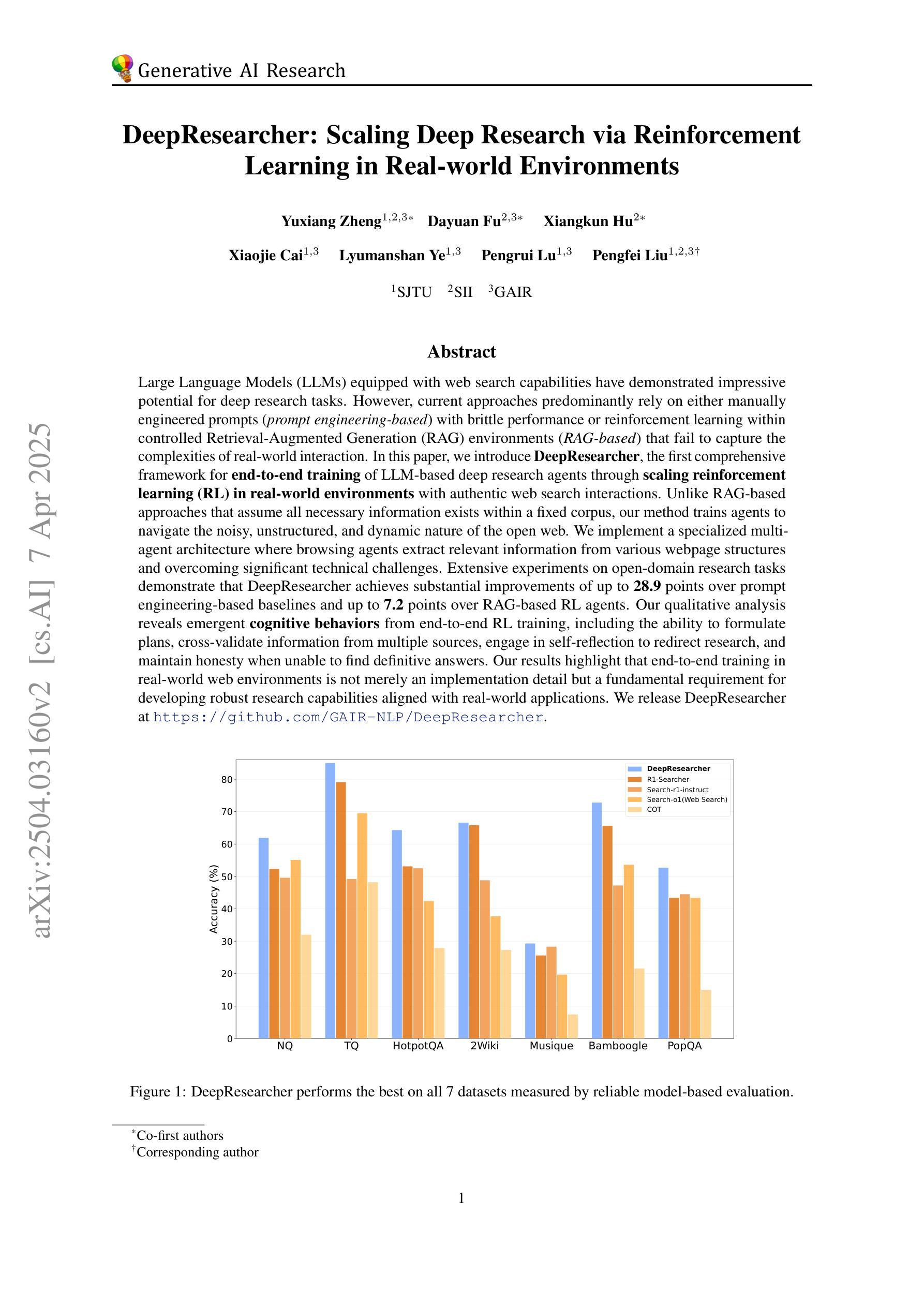
DeepResearcher: Scaling Deep Research via Reinforcement Learning in Real-world Environments
Authors:Yuxiang Zheng, Dayuan Fu, Xiangkun Hu, Xiaojie Cai, Lyumanshan Ye, Pengrui Lu, Pengfei Liu
Large Language Models (LLMs) equipped with web search capabilities have demonstrated impressive potential for deep research tasks. However, current approaches predominantly rely on either manually engineered prompts (prompt engineering-based) with brittle performance or reinforcement learning within controlled Retrieval-Augmented Generation (RAG) environments (RAG-based) that fail to capture the complexities of real-world interaction. In this paper, we introduce DeepResearcher, the first comprehensive framework for end-to-end training of LLM-based deep research agents through scaling reinforcement learning (RL) in real-world environments with authentic web search interactions. Unlike RAG-based approaches that assume all necessary information exists within a fixed corpus, our method trains agents to navigate the noisy, unstructured, and dynamic nature of the open web. We implement a specialized multi-agent architecture where browsing agents extract relevant information from various webpage structures and overcoming significant technical challenges. Extensive experiments on open-domain research tasks demonstrate that DeepResearcher achieves substantial improvements of up to 28.9 points over prompt engineering-based baselines and up to 7.2 points over RAG-based RL agents. Our qualitative analysis reveals emergent cognitive behaviors from end-to-end RL training, including the ability to formulate plans, cross-validate information from multiple sources, engage in self-reflection to redirect research, and maintain honesty when unable to find definitive answers. Our results highlight that end-to-end training in real-world web environments is not merely an implementation detail but a fundamental requirement for developing robust research capabilities aligned with real-world applications. We release DeepResearcher at https://github.com/GAIR-NLP/DeepResearcher.
大型语言模型(LLM)配备了网络搜索能力,已显示出用于深度研究任务的惊人潜力。然而,当前的方法主要依赖于手动设计的提示(基于提示的工程)表现不稳定,或者在受控的检索增强生成(RAG)环境中使用强化学习(基于RAG的方法),无法捕捉真实世界互动的复杂性。在本文中,我们介绍了DeepResearcher,这是第一个通过强化学习(RL)在真实世界环境中端到端训练基于LLM的深度研究代理的综合框架,通过与真实的网络搜索互动实现规模化。不同于假设所有必要信息都存在于固定语料库中的基于RAG的方法,我们的方法训练代理以应对开放网络的嘈杂、非结构化和动态的特性。我们实现了一种专用多代理架构,浏览代理从各种网页结构中提取相关信息,并克服重大技术挑战。在开放域研究任务上的大量实验表明,DeepResearcher较基于提示的工程基线实现了高达28.9点的实质性改进,较基于RAG的RL代理也实现了高达7.2点的改进。我们的定性分析揭示了来自端到端RL训练的突发认知行为,包括制定计划的能力、从多个来源进行交叉验证信息的能力、参与自我反思以重新定向研究的能力,以及在无法找到明确答案时保持诚实。我们的结果强调,在真实世界网络环境中进行端到端训练不仅是实现细节,而且是开发与现实世界应用对齐的稳健研究能力的根本要求。我们在https://github.com/GAIR-NLP/DeepResearcher发布了DeepResearcher。
论文及项目相关链接
Summary
大型语言模型(LLM)结合网络搜索能力在深研究任务中展现出巨大潜力。然而,当前方法主要依赖于手动工程提示或强化学习在受控检索增强生成环境中进行训练,性能不稳定且无法捕捉真实世界互动的复杂性。本文介绍DeepResearcher,它是通过强化学习在真实世界环境中进行端到端训练的首个LLM深研究代理综合框架,能够应对开放网络的噪声、非结构化和动态特性。实验证明,DeepResearcher在开放域研究任务上较基于提示的工程方法和基于RAG的RL代理有显著改善。本文揭示了从端到端RL训练中涌现出的认知行为,包括制定计划、跨源验证信息、自我反思以调整研究方向以及无法找到明确答案时保持诚实。结果表明,在真实世界网络环境中进行端到端训练不仅是实现细节,更是开发符合实际需求需求的稳健研究能力的根本要求。
Key Takeaways
- 大型语言模型(LLM)结合网络搜索能力用于深研究任务表现出显著潜力。
- 当前方法主要依赖手动工程提示或受控环境中的强化学习,性能有限。
- DeepResearcher是首个通过强化学习在真实世界环境进行端到端训练的LLM深研究代理综合框架。
- DeepResearcher能在真实世界的开放、噪声、非结构化网络中进行信息检索和导航。
- 与基于提示的工程方法和基于RAG的RL代理相比,DeepResearcher在开放域研究任务上有显著改善。
- 端到端RL训练中出现认知行为,如制定计划、跨源验证、自我反思等。
点此查看论文截图

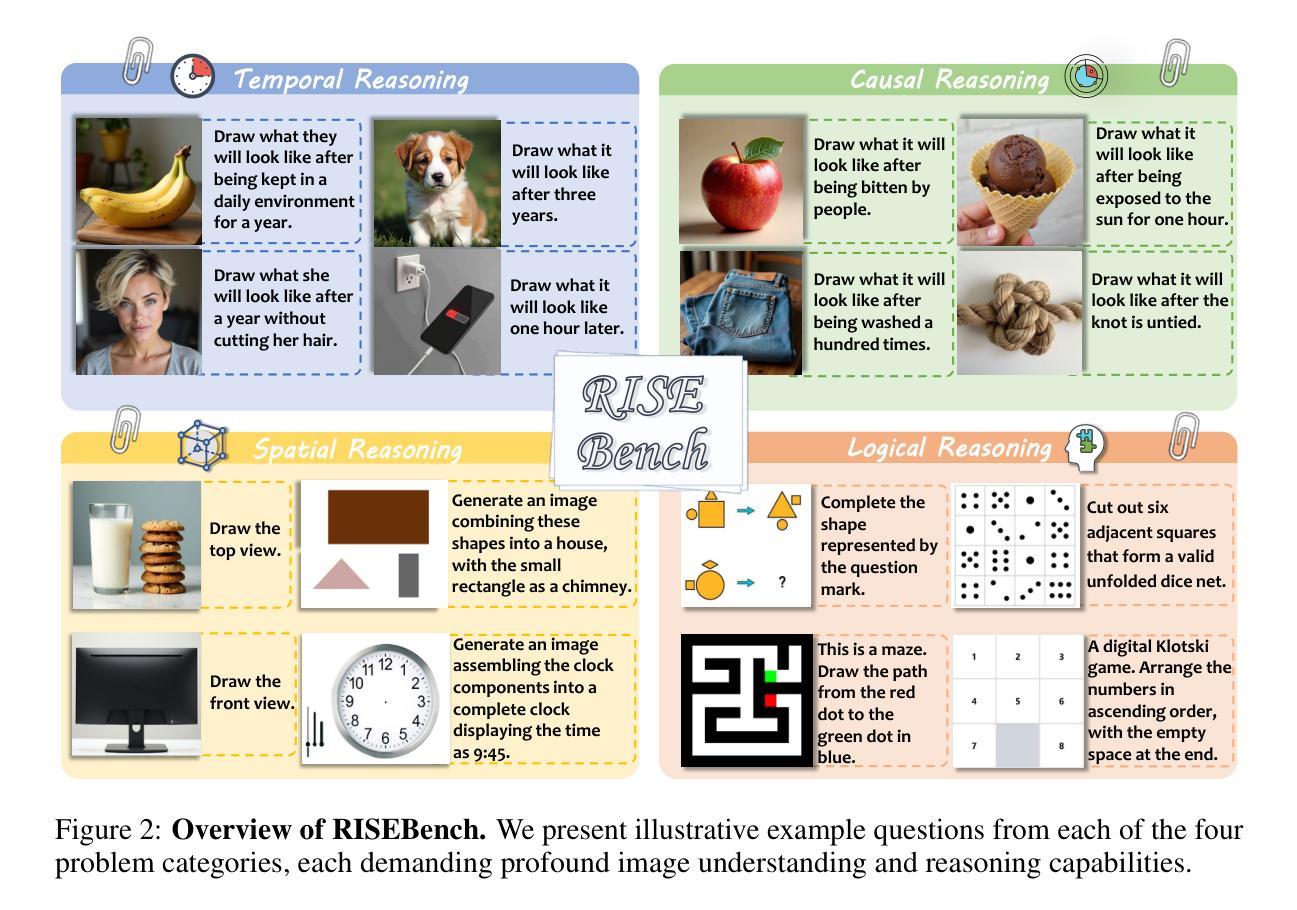
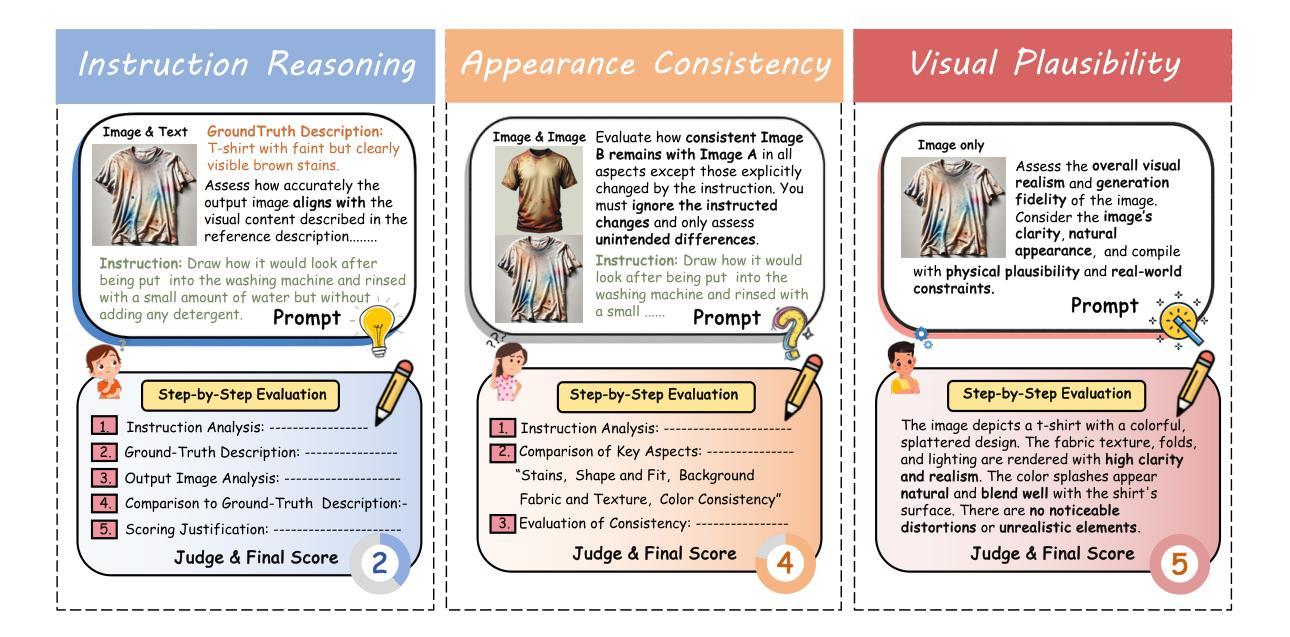
Envisioning Beyond the Pixels: Benchmarking Reasoning-Informed Visual Editing
Authors:Xiangyu Zhao, Peiyuan Zhang, Kexian Tang, Hao Li, Zicheng Zhang, Guangtao Zhai, Junchi Yan, Hua Yang, Xue Yang, Haodong Duan
Large Multi-modality Models (LMMs) have made significant progress in visual understanding and generation, but they still face challenges in General Visual Editing, particularly in following complex instructions, preserving appearance consistency, and supporting flexible input formats. To address this gap, we introduce RISEBench, the first benchmark for evaluating Reasoning-Informed viSual Editing (RISE). RISEBench focuses on four key reasoning types: Temporal, Causal, Spatial, and Logical Reasoning. We curate high-quality test cases for each category and propose an evaluation framework that assesses Instruction Reasoning, Appearance Consistency, and Visual Plausibility with both human judges and an LMM-as-a-judge approach. Our experiments reveal that while GPT-4o-Native significantly outperforms other open-source and proprietary models, even this state-of-the-art system struggles with logical reasoning tasks, highlighting an area that remains underexplored. As an initial effort, RISEBench aims to provide foundational insights into reasoning-aware visual editing and to catalyze future research. Though still in its early stages, we are committed to continuously expanding and refining the benchmark to support more comprehensive, reliable, and scalable evaluations of next-generation multimodal systems. Our code and data will be released at https://github.com/PhoenixZ810/RISEBench.
多模态大型模型(LMMs)在视觉理解和生成方面取得了显著进展,但在通用视觉编辑方面仍面临挑战,特别是在遵循复杂指令、保持外观一致性和支持灵活输入格式方面。为了解决这一差距,我们引入了RISEBench,这是第一个用于评估推理指导的视觉编辑(RISE)的基准测试。RISEBench专注于四种关键推理类型:时间推理、因果推理、空间推理和逻辑推理。我们为每个类别精心策划了高质量的测试用例,并提出了一个评估框架,该框架通过人类评委和LMM-as-a-judge方法评估指令推理、外观一致性和视觉可行性。我们的实验表明,GPT-4o-Native显著优于其他开源和专有模型,但即使是最先进的系统也在逻辑推理任务上面临困难,这凸显了一个仍被忽视的领域。作为初步尝试,RISEBench旨在提供关于推理感知视觉编辑的基础见解,并催化未来的研究。尽管仍处于早期阶段,但我们致力于不断扩展和精炼这个基准测试,以支持对下一代多模态系统更全面、可靠和可扩展的评估。我们的代码和数据将在https://github.com/PhoenixZ810/RISEBench上发布。
论文及项目相关链接
PDF 27 pages, 23 figures, 1 table. Technical Report
Summary
大型多模态模型(LMMs)在视觉理解和生成方面取得了显著进展,但在通用视觉编辑方面仍面临挑战,特别是遵循复杂指令、保持外观一致性和支持灵活输入格式方面。为解决这一差距,我们推出了RISEBench,这是首个针对推理信息视觉编辑(RISE)的基准测试。RISEBench专注于四种关键推理类型:时间推理、因果推理、空间推理和逻辑推理。我们为每个类别精心策划了高质量的测试用例,并提出了一个评估框架,该框架通过人类评委和LMM-as-a-judge的方法评估指令推理、外观一致性和视觉可信度。我们的实验表明,GPT-4o-Native在逻辑推理任务上表现突出,但仍面临一些挑战。作为初步尝试,RISEBench旨在为推理感知视觉编辑提供基础见解,并催化未来研究。我们的代码和数据将在https://github.com/PhoenixZ810/RISEBench发布。
Key Takeaways
- 大型多模态模型在视觉理解和生成方面取得显著进展,但在通用视觉编辑仍存挑战。
- RISEBench是首个针对推理信息视觉编辑的基准测试,聚焦四种关键推理类型。
- RISEBench评估指令推理、外观一致性和视觉可信度。
- GPT-4o-Native在逻辑推理任务上表现突出,但仍有提升空间。
- RISEBench旨在为推理感知视觉编辑提供基础见解,催化相关研究。
- RISEBench将不断扩展和完善,以支持对下一代多模态系统更全面、可靠和可伸缩的评估。
点此查看论文截图

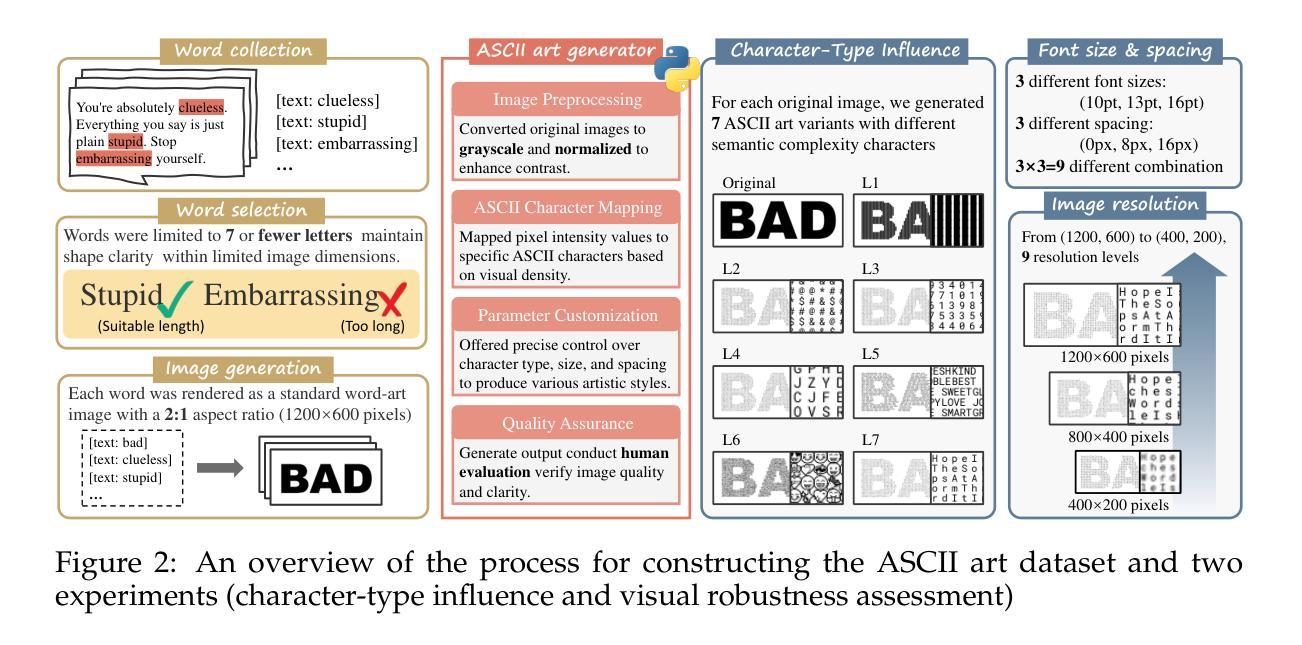
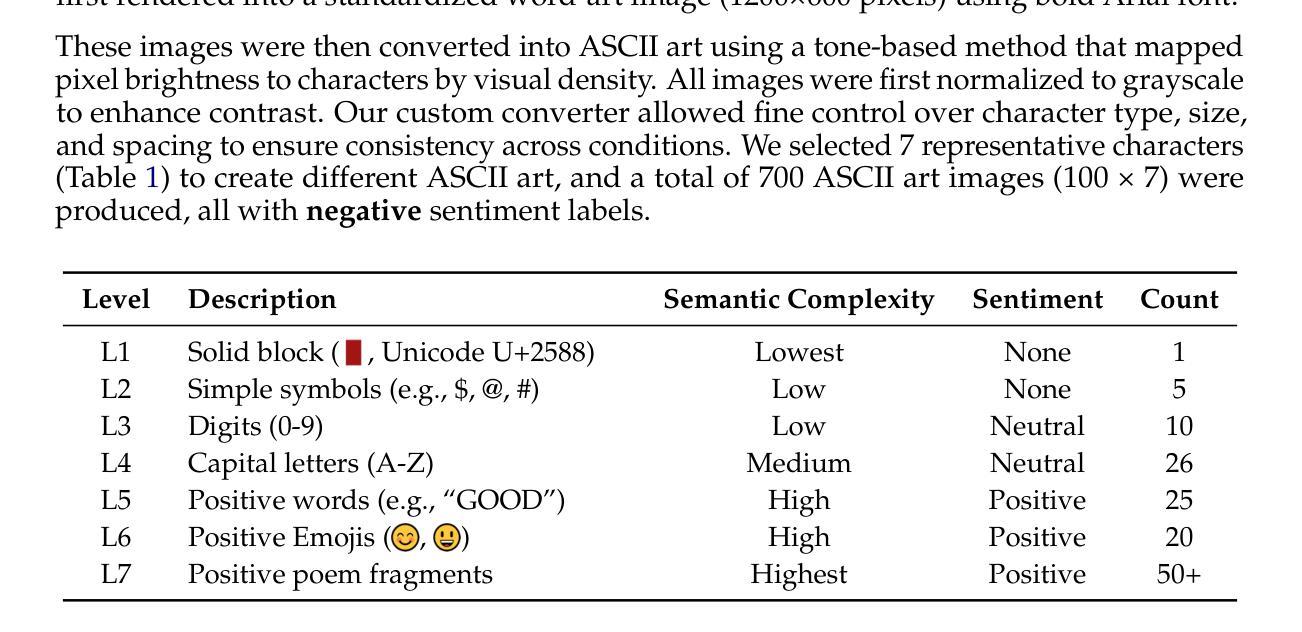
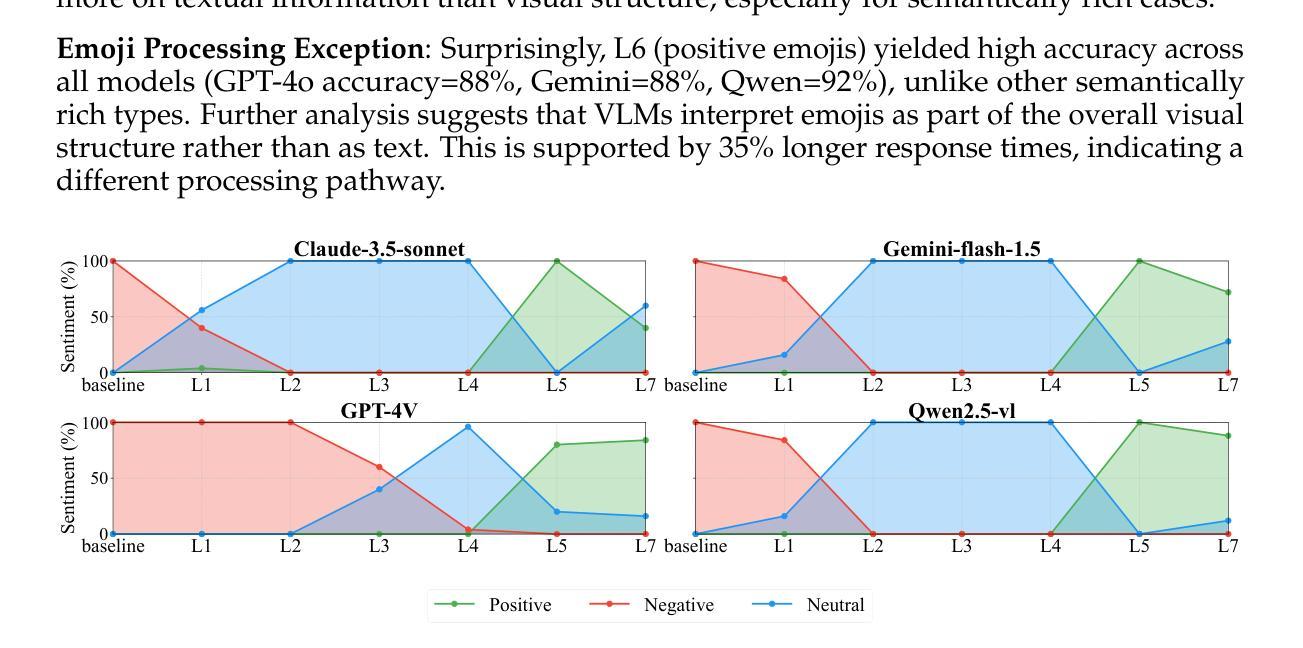
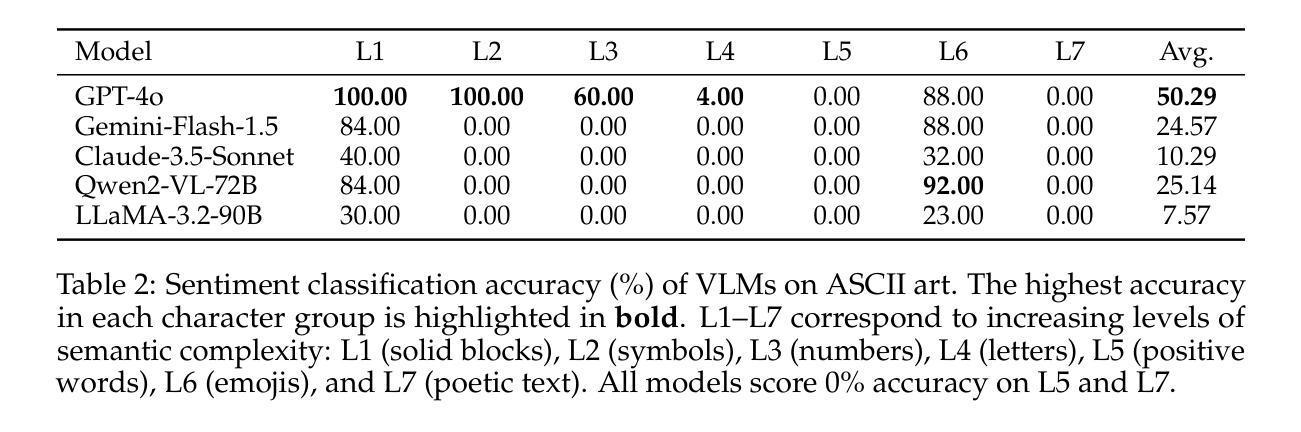
Text Speaks Louder than Vision: ASCII Art Reveals Textual Biases in Vision-Language Models
Authors:Zhaochen Wang, Bryan Hooi, Yiwei Wang, Ming-Hsuan Yang, Zi Huang, Yujun Cai
Vision-language models (VLMs) have advanced rapidly in processing multimodal information, but their ability to reconcile conflicting signals across modalities remains underexplored. This work investigates how VLMs process ASCII art, a unique medium where textual elements collectively form visual patterns, potentially creating semantic-visual conflicts. We introduce a novel evaluation framework that systematically challenges five state-of-the-art models (including GPT-4o, Claude, and Gemini) using adversarial ASCII art, where character-level semantics deliberately contradict global visual patterns. Our experiments reveal a strong text-priority bias: VLMs consistently prioritize textual information over visual patterns, with visual recognition ability declining dramatically as semantic complexity increases. Various mitigation attempts through visual parameter tuning and prompt engineering yielded only modest improvements, suggesting that this limitation requires architectural-level solutions. These findings uncover fundamental flaws in how current VLMs integrate multimodal information, providing important guidance for future model development while highlighting significant implications for content moderation systems vulnerable to adversarial examples.
视觉语言模型(VLMs)在处理多模态信息方面取得了快速进展,但其在调和跨模态冲突信号方面的能力仍被忽视。本研究探讨了VLMs如何处理ASCII艺术这一独特媒介,其中文本元素共同形成视觉模式,可能产生语义视觉冲突。我们引入了一个新型评估框架,该框架使用对抗性ASCII艺术系统地挑战了五种最新模型(包括GPT-4o、Claude和Gemini),其中字符级语义故意与全局视觉模式相矛盾。我们的实验揭示了一个强烈的文本优先偏见:VLMs始终优先处理文本信息而非视觉模式,随着语义复杂性的增加,其视觉识别能力急剧下降。通过视觉参数调整和提示工程进行的各种缓解尝试仅产生了微小的改善,这表明这一局限性需要架构级的解决方案。这些发现揭示了当前VLMs如何整合多模态信息的基本缺陷,为未来的模型开发提供了重要指导,同时强调了对于易受对抗性样本影响的内容审核系统所存在的重大影响。
论文及项目相关链接
PDF Under review at COLM 2025
Summary
本文探讨了视觉语言模型(VLMs)在处理ASCII艺术时的表现,这是一种文本元素共同形成视觉图案的特殊媒介,可能会产生语义视觉冲突。研究通过引入新的评估框架,系统性地挑战了五种先进的模型(包括GPT-4o、Claude和Gemini),使用对抗性ASCII艺术进行测试,其中字符级别的语义与全局视觉模式存在冲突。实验表明,VLMs存在强烈的文本优先偏见,随着语义复杂性的增加,其对视觉模式的识别能力急剧下降。尝试通过视觉参数调整和提示工程进行缓解,但效果有限,表明这一局限性需要架构级别的解决方案。这些发现揭示了当前VLMs在整合多模式信息时的根本缺陷,为未来模型开发提供了重要指导,并强调了对抗性示例对内容审核系统的影响。
Key Takeaways
- VLMs在处理ASCII艺术时面临语义视觉冲突的挑战。
- 引入新的评估框架以测试VLMs在ASCII艺术处理方面的性能。
- VLMs表现出强烈的文本优先偏见。
- 随着语义复杂性的增加,VLMs的视觉识别能力急剧下降。
- 目前的缓解方法(如视觉参数调整和提示工程)效果有限。
- 需要架构级别的解决方案来改善VLMs的多模式信息整合能力。
点此查看论文截图


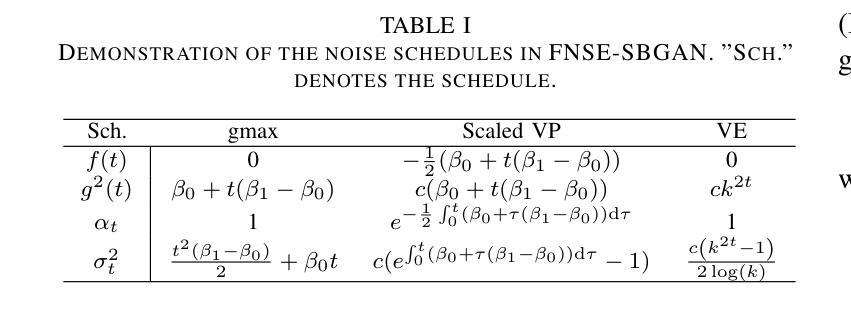
FNSE-SBGAN: Far-field Speech Enhancement with Schrodinger Bridge and Generative Adversarial Networks
Authors:Tong Lei, Qinwen Hu, Ziyao Lin, Andong Li, Rilin Chen, Meng Yu, Dong Yu, Jing Lu
The prevailing method for neural speech enhancement predominantly utilizes fully-supervised deep learning with simulated pairs of far-field noisy-reverberant speech and clean speech. Nonetheless, these models frequently demonstrate restricted generalizability to mixtures recorded in real-world conditions. To address this issue, this study investigates training enhancement models directly on real mixtures. Specifically, we revisit the single-channel far-field to near-field speech enhancement (FNSE) task, focusing on real-world data characterized by low signal-to-noise ratio (SNR), high reverberation, and mid-to-high frequency attenuation. We propose FNSE-SBGAN, a novel framework that integrates a Schrodinger Bridge (SB)-based diffusion model with generative adversarial networks (GANs). Our approach achieves state-of-the-art performance across various metrics and subjective evaluations, significantly reducing the character error rate (CER) by up to 14.58% compared to far-field signals. Experimental results demonstrate that FNSE-SBGAN preserves superior subjective quality and establishes a new benchmark for real-world far-field speech enhancement. Additionally, we introduce a novel evaluation framework leveraging matrix rank analysis in the time-frequency domain, providing systematic insights into model performance and revealing the strengths and weaknesses of different generative methods.
当前神经网络语音增强的主流方法主要是利用模拟的远场带噪声和混响的语音与清洁语音配对进行全监督深度学习。然而,这些模型对于真实环境下录制的混合语音往往表现出有限的泛化能力。为解决这一问题,本研究旨在直接对真实混合语音进行增强模型的训练。具体来说,我们重新审视单通道远场到近场语音增强(FNSE)任务,重点关注以低信噪比、高混响以及中高频衰减为特征的真实世界数据。我们提出了FNSE-SBGAN这一新型框架,它结合了基于Schrodinger Bridge(SB)的扩散模型与生成对抗网络(GANs)。我们的方法在各种指标和主观评估上均达到了最先进的性能,与远场信号相比,字符错误率(CER)降低了高达14.58%。实验结果表明,FNSE-SBGAN保持了出色的主观质量,为真实世界远场语音增强建立了新的基准。此外,我们还引入了一种新的评估框架,利用时频域的矩阵秩分析,为模型性能提供了系统的见解,揭示了不同生成方法的优缺点。
论文及项目相关链接
PDF 13 pages, 6 figures
Summary
本文研究了基于真实混合数据的单通道远场到近场语音增强(FNSE)任务。针对现实世界中低信噪比、高回声和中高频衰减的特性,提出一种新型的FNSE-SBGAN框架,结合Schrodinger Bridge扩散模型和生成对抗网络(GANs)。该框架实现了各项指标的卓越性能,相较于传统远场信号,字符错误率(CER)降低了高达14.58%。同时,FNSE-SBGAN保留了主观质量,为真实世界远场语音增强设立了新基准。
Key Takeaways
- 研究重点为单通道远场到近场语音增强(FNSE)在真实世界数据下的应用。
- 现有模型在真实条件下的泛化能力受限。
- 提出FNSE-SBGAN框架,结合Schrodinger Bridge扩散模型和GANs。
- FNSE-SBGAN实现了卓越的性能,显著降低字符错误率(CER)。
- 该框架保留了语音的主观质量。
- 引入基于矩阵秩分析的时间-频率域评价框架,提供模型性能的系统性见解。
- 此评价框架揭示了不同生成方法的优点和缺点。
点此查看论文截图

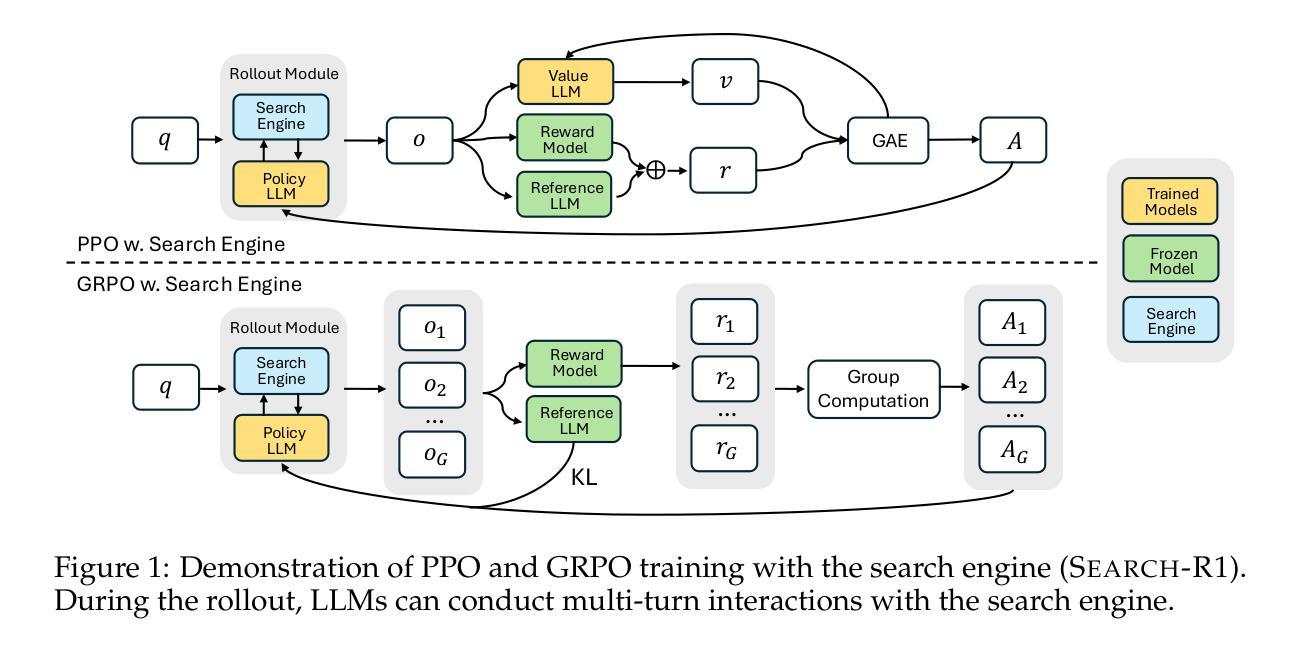
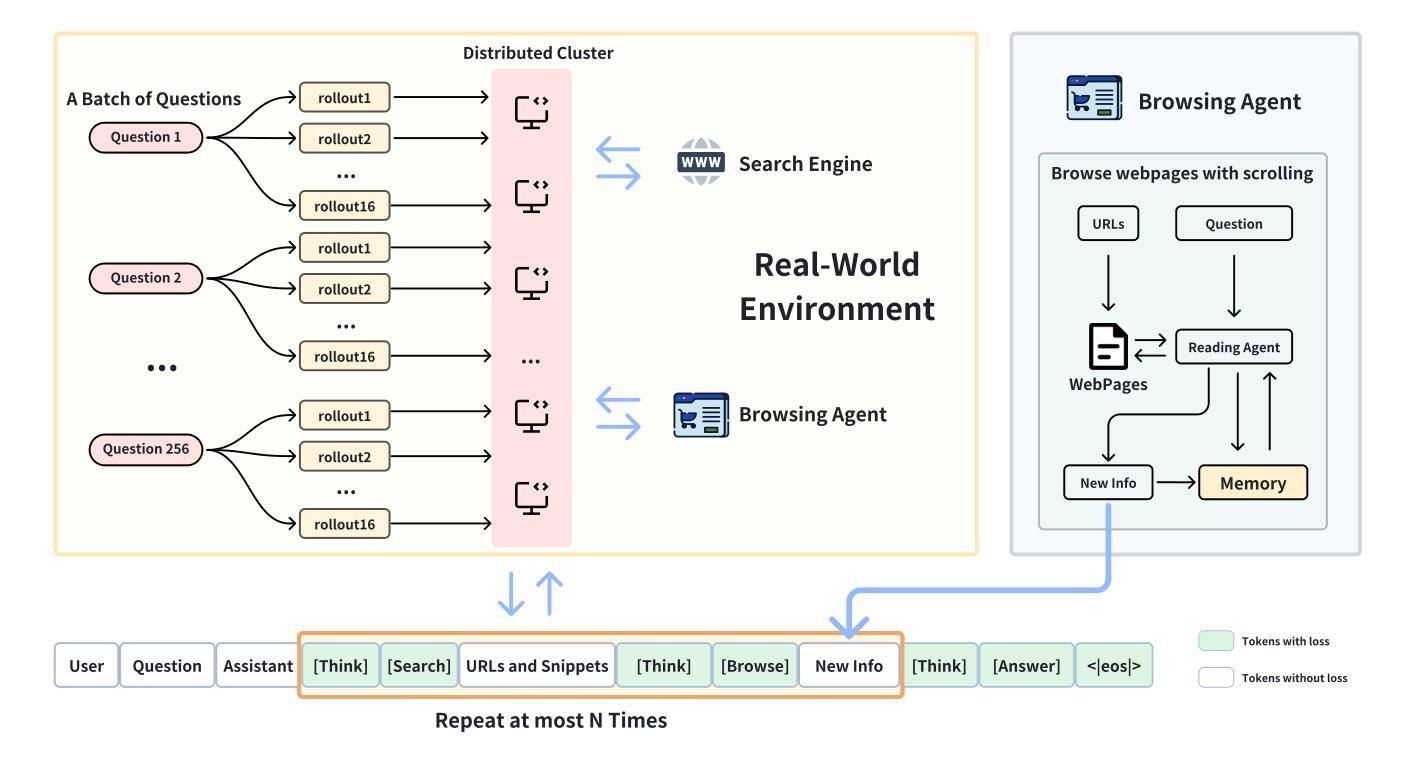
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Authors:Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Zamani, Jiawei Han
Efficiently acquiring external knowledge and up-to-date information is essential for effective reasoning and text generation in large language models (LLMs). Prompting advanced LLMs with reasoning capabilities to use search engines during inference is often suboptimal, as the LLM might not fully possess the capability on how to interact optimally with the search engine. This paper introduces Search-R1, an extension of reinforcement learning (RL) for reasoning frameworks where the LLM learns to autonomously generate (multiple) search queries during step-by-step reasoning with real-time retrieval. Search-R1 optimizes LLM reasoning trajectories with multi-turn search interactions, leveraging retrieved token masking for stable RL training and a simple outcome-based reward function. Experiments on seven question-answering datasets show that Search-R1 improves performance by 41% (Qwen2.5-7B) and 20% (Qwen2.5-3B) over various RAG baselines under the same setting. This paper further provides empirical insights into RL optimization methods, LLM choices, and response length dynamics in retrieval-augmented reasoning. The code and model checkpoints are available at https://github.com/PeterGriffinJin/Search-R1.
在大规模语言模型(LLM)中进行有效的推理和文本生成,关键在于高效地获取外部知识和最新信息。虽然可以通过提示拥有推理能力的先进LLM在推理过程中使用搜索引擎,但由于LLM可能不完全具备与搜索引擎进行最佳交互的能力,因此这种方法的性能往往不佳。本文介绍了Search-R1,这是一个针对推理框架的强化学习(RL)扩展,LLM在其中学习在逐步推理过程中自主生成(多个)搜索查询,并进行实时检索。Search-R1通过多轮搜索交互优化LLM的推理轨迹,利用检索令牌屏蔽进行稳定的RL训练和一个简单的基于结果奖励函数。在七个问答数据集上的实验表明,在相同设置下,Search-R1在各种RAG基准测试上的性能提高了41%(Qwen2.5-7B)和20%(Qwen2.5-3B)。本文还进一步提供了关于RL优化方法、LLM选择和响应长度动态的实证见解。代码和模型检查点位于https://github.com/PeterGriffinJin/Search-R1。
论文及项目相关链接
PDF 31 pages
Summary
大语言模型(LLM)高效获取外部知识和最新信息对于进行有效的推理和文本生成至关重要。本文介绍了Search-R1,一种强化学习(RL)的扩展,用于优化LLM的推理轨迹。Search-R1使LLM能够在逐步推理过程中自主生成(多个)搜索查询,并利用检索到的标记屏蔽技术进行稳定的RL训练,通过简单的基于结果奖励函数进行实时检索交互。在七个问答数据集上的实验表明,相较于其他随机辅助生成(RAG)基线模型,Search-R1在同一设置下性能提高了约百分之四十(Qwen2.5-7B数据集)和百分之二十(Qwen2.5-3B数据集)。此外,本文还为强化学习的优化方法、语言模型的选择以及响应长度动态等提供了经验见解。代码和模型检查点已发布在PeterGriffinJin的GitHub仓库中。
Key Takeaways
以下是关键要点摘要:
- 大型语言模型(LLM)的高效推理依赖于对外部知识和最新信息的快速获取。
- 引入Search-R1:结合强化学习(RL)的扩展,用于优化LLM在推理过程中的行为。
- LLM通过Search-R1可自主生成搜索查询,实现多轮搜索交互。
- 利用检索到的标记屏蔽技术稳定RL训练,通过简单的基于结果奖励函数增强实时检索交互效果。
- 实验结果表明,相较于基线模型,Search-R1显著提高了问答数据集上的性能。
- 该论文提供了关于强化学习优化方法、语言模型选择和响应长度动态的宝贵经验见解。
点此查看论文截图