⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-10 更新
SE4Lip: Speech-Lip Encoder for Talking Head Synthesis to Solve Phoneme-Viseme Alignment Ambiguity
Authors:Yihuan Huang, Jiajun Liu, Yanzhen Ren, Wuyang Liu, Juhua Tang
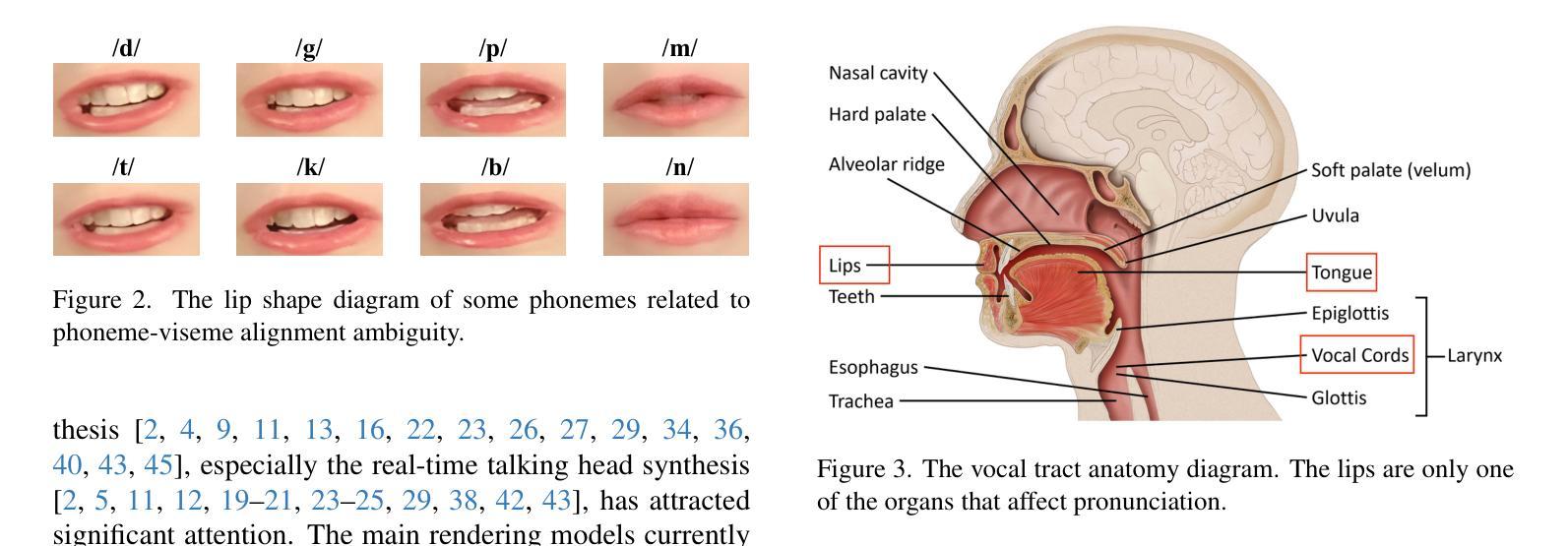
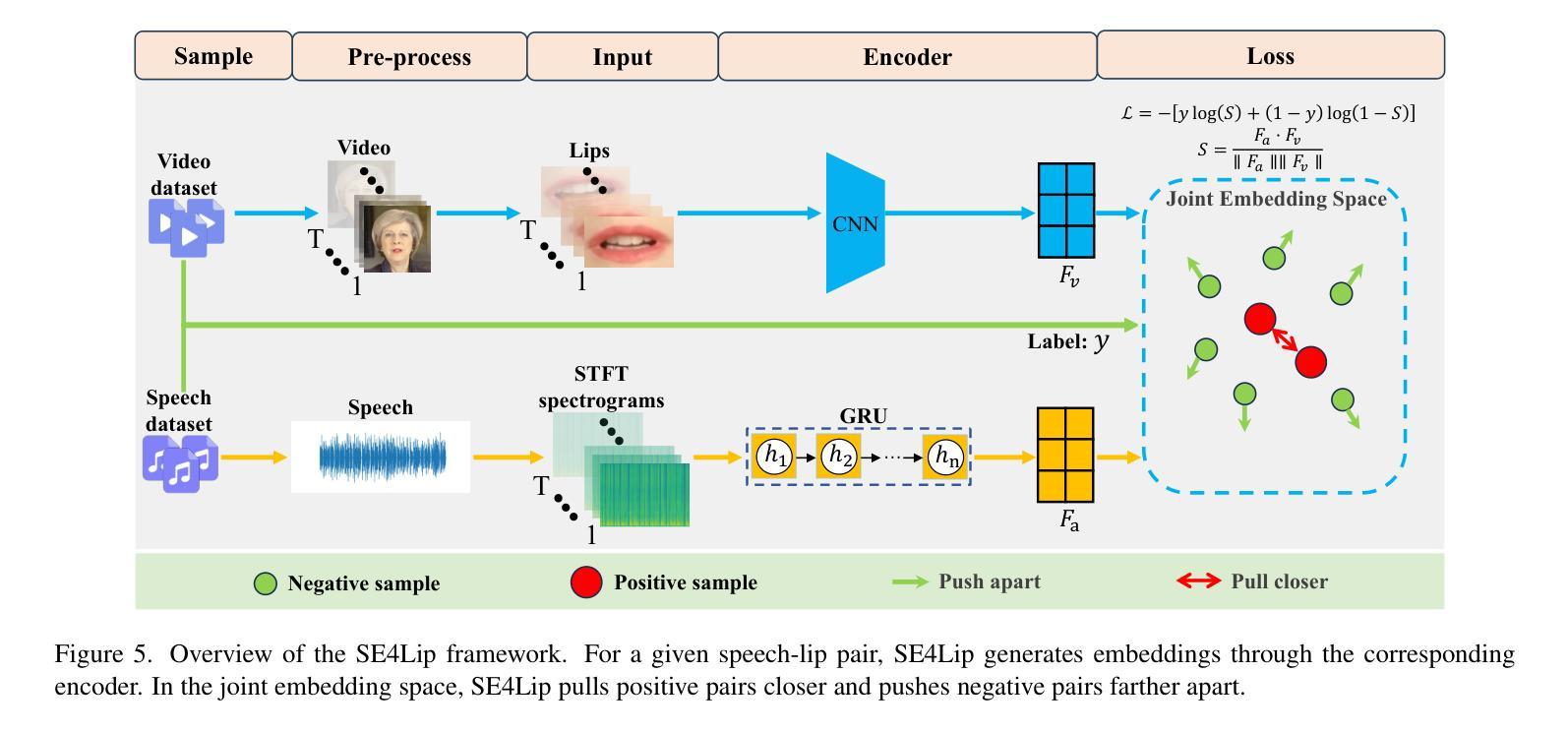
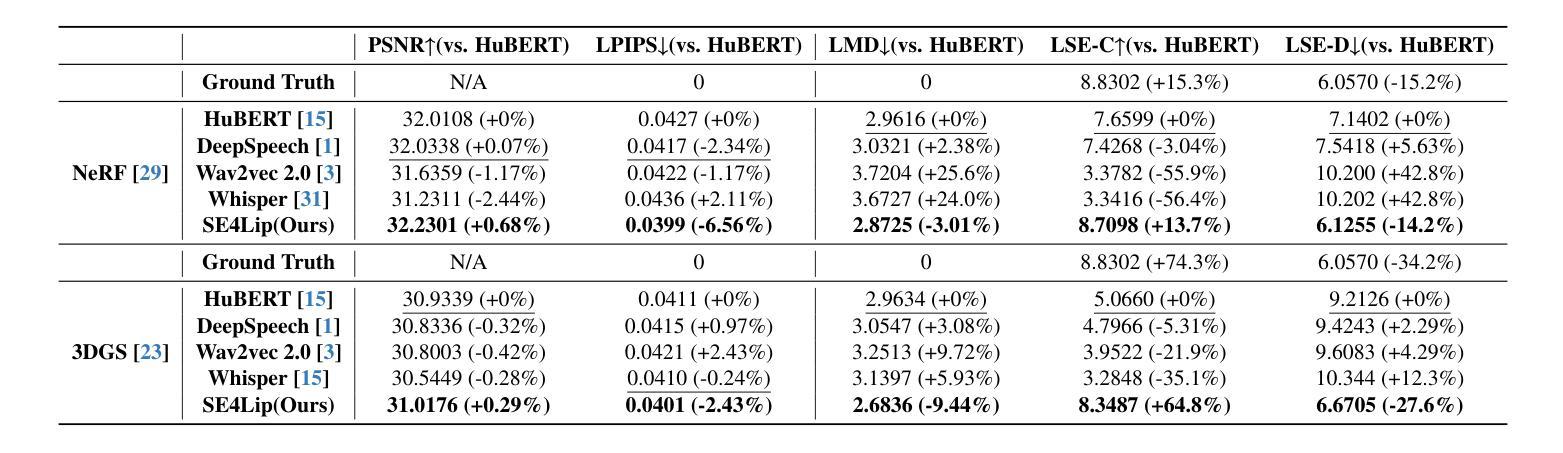
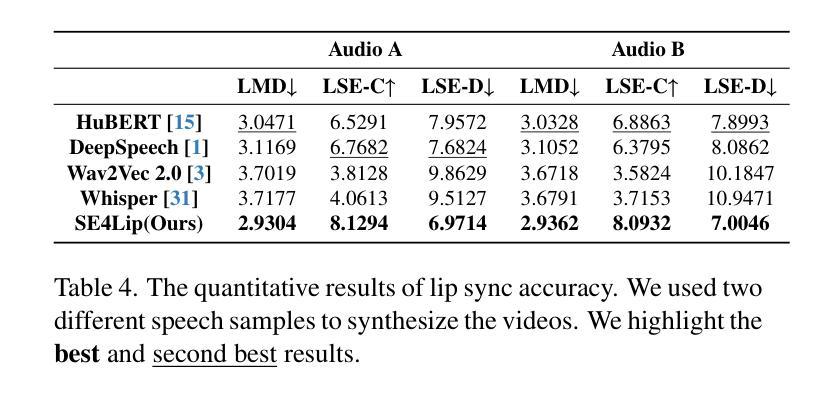
Speech-driven talking head synthesis tasks commonly use general acoustic features (such as HuBERT and DeepSpeech) as guided speech features. However, we discovered that these features suffer from phoneme-viseme alignment ambiguity, which refers to the uncertainty and imprecision in matching phonemes (speech) with visemes (lip). To address this issue, we propose the Speech Encoder for Lip (SE4Lip) to encode lip features from speech directly, aligning speech and lip features in the joint embedding space by a cross-modal alignment framework. The STFT spectrogram with the GRU-based model is designed in SE4Lip to preserve the fine-grained speech features. Experimental results show that SE4Lip achieves state-of-the-art performance in both NeRF and 3DGS rendering models. Its lip sync accuracy improves by 13.7% and 14.2% compared to the best baseline and produces results close to the ground truth videos.
语音驱动的人头合成任务通常使用一般的声学特征(如HuBERT和DeepSpeech)作为引导语音特征。然而,我们发现这些特征存在音素-唇动单位对应模糊的问题,即音素(语音)与唇动单位(唇部动作)之间的匹配存在不确定性和不精确性。为了解决这一问题,我们提出了基于语音的唇动特征编码器(SE4Lip),该编码器直接从语音中编码唇动特征,通过跨模态对齐框架在联合嵌入空间中对齐语音和唇动特征。SE4Lip设计中采用了基于GRU模型的STFT频谱图,旨在保留精细的语音特征。实验结果表明,SE4Lip在NeRF和3DGS渲染模型中均达到了最先进的性能。其唇同步精度比最佳基线提高了13.7%和14.2%,并产生了接近真实视频的结果。
论文及项目相关链接
Summary
语音驱动的人头合成任务常使用一般的声学特征作为语音引导特征,但存在语音与唇部动作匹配的不确定性和不精确性。为解决这一问题,我们提出了基于唇特征的Speech Encoder for Lip(SE4Lip)模型,通过跨模态对齐框架在联合嵌入空间中对齐语音和唇部特征。SE4Lip采用基于GRU模型的STFT频谱图设计,旨在保留精细的语音特征。实验结果表明,SE4Lip在NeRF和3DGS渲染模型中表现最佳,唇同步精度分别提高了13.7%和14.2%,结果接近真实视频。
Key Takeaways
- 语音驱动的人头合成任务通常使用一般的声学特征。
- 存在语音与唇部动作匹配的不确定性问题,即音素-唇部动作对齐模糊。
- 为解决这一问题,提出了Speech Encoder for Lip(SE4Lip)模型。
- SE4Lip通过跨模态对齐框架在联合嵌入空间中直接编码唇部特征进行对齐。
- SE4Lip使用STFT频谱图与基于GRU的模型设计来捕捉精细语音特征。
- 实验结果表明SE4Lip在NeRF和3DGS渲染模型中表现最佳。
点此查看论文截图



Exploiting Temporal Audio-Visual Correlation Embedding for Audio-Driven One-Shot Talking Head Animation
Authors:Zhihua Xu, Tianshui Chen, Zhijing Yang, Siyuan Peng, Keze Wang, Liang Lin
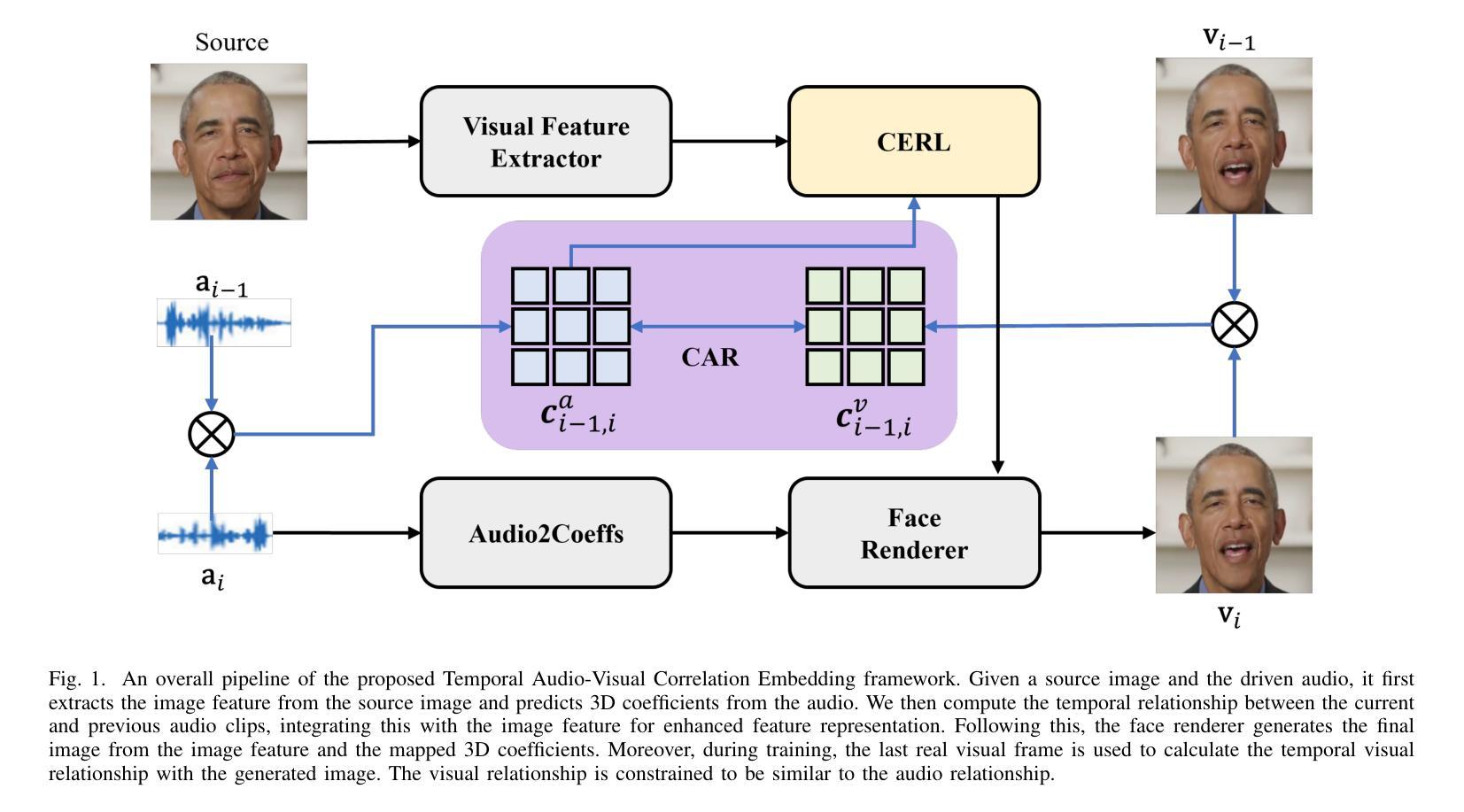
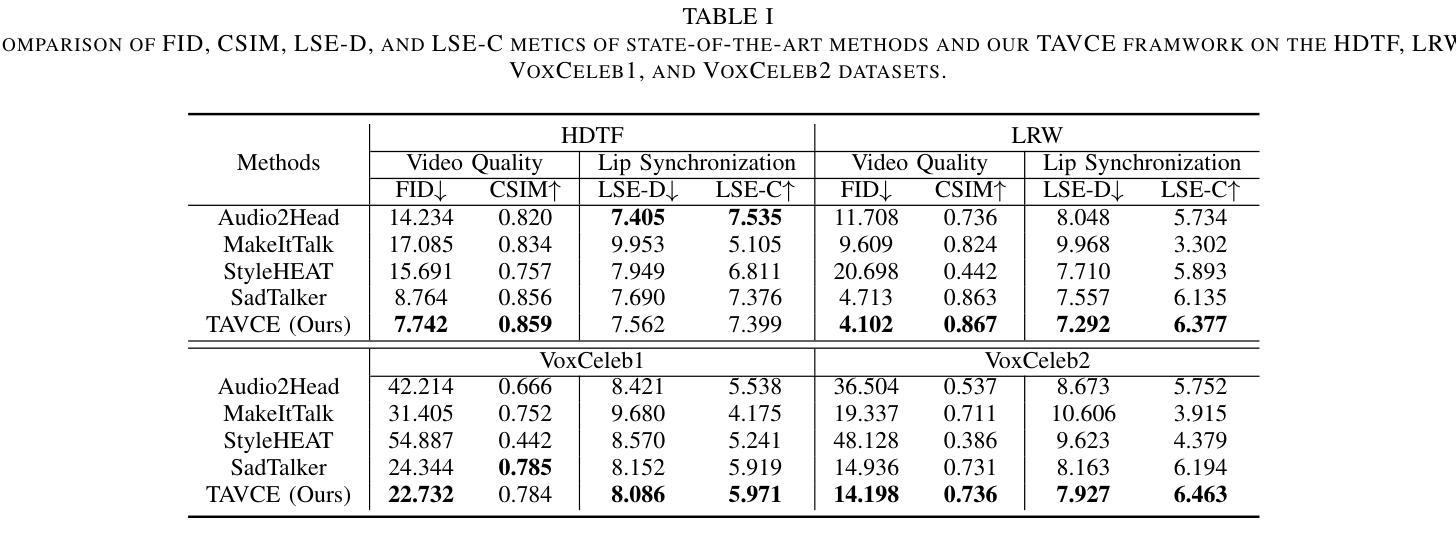
The paramount challenge in audio-driven One-shot Talking Head Animation (ADOS-THA) lies in capturing subtle imperceptible changes between adjacent video frames. Inherently, the temporal relationship of adjacent audio clips is highly correlated with that of the corresponding adjacent video frames, offering supplementary information that can be pivotal for guiding and supervising talking head animations. In this work, we propose to learn audio-visual correlations and integrate the correlations to help enhance feature representation and regularize final generation by a novel Temporal Audio-Visual Correlation Embedding (TAVCE) framework. Specifically, it first learns an audio-visual temporal correlation metric, ensuring the temporal audio relationships of adjacent clips are aligned with the temporal visual relationships of corresponding adjacent video frames. Since the temporal audio relationship contains aligned information about the visual frame, we first integrate it to guide learning more representative features via a simple yet effective channel attention mechanism. During training, we also use the alignment correlations as an additional objective to supervise generating visual frames. We conduct extensive experiments on several publicly available benchmarks (i.e., HDTF, LRW, VoxCeleb1, and VoxCeleb2) to demonstrate its superiority over existing leading algorithms.
音频驱动的单次说话人头部动画(ADOS-THA)中的最大挑战在于捕捉相邻视频帧之间微妙的不可察觉的变化。本质上,相邻音频片段的临时关系与相应的相邻视频帧的临时关系高度相关,提供可能对指导和监督说话人头部动画至关重要的补充信息。在这项工作中,我们提出学习视听相关性,并将这些相关性集成到帮助增强特征表示和通过新型时间视听相关性嵌入(TAVCE)框架来规范最终生成结果的流程中。具体来说,它首先学习视听时间相关性度量标准,确保相邻片段的临时音频关系与相应相邻视频帧的临时视觉关系对齐。由于临时音频关系包含关于视觉帧的对齐信息,我们首先将其集成,通过简单有效的通道注意力机制来指导学习更具代表性的特征。在训练过程中,我们还使用对齐相关性作为监督生成视觉帧的附加目标。我们在几个公开可用的基准测试(即HDTF、LRW、VoxCeleb1和VoxCeleb2)上进行了广泛实验,证明了其优于现有领先算法。
论文及项目相关链接
PDF Accepted at TMM 2025
Summary
音频驱动的一次性头部动画(ADOS-THA)技术的最大挑战在于捕捉相邻视频帧间的微妙变化。本文提出学习音频视觉相关性并将其集成到增强特征表示和正则化最终生成中,通过一种新的时间音频视觉相关性嵌入(TAVCE)框架实现。它首先学习音频视觉时间相关性度量,确保相邻剪辑的音频关系与相应相邻视频帧的视觉关系对齐。利用时间音频关系中包含的视觉帧对齐信息,将其整合到学习更具代表性的特征中,并通过简单的注意力机制来实现。训练期间还利用对齐相关性作为生成视频帧的监督对象,以提升生成效果。实验结果证明该方法优于现有的前沿算法。
Key Takeaways
- 音频驱动的一次性头部动画(ADOS-THA)技术面临捕捉相邻视频帧微妙变化的挑战。
- 时间音频视觉相关性嵌入(TAVCE)框架用于学习并整合音频视觉相关性。
- TAVCE框架确保音频和视频的时空关系对齐,为头部动画提供关键信息。
- 通过注意力机制利用音频中的视觉帧对齐信息,增强特征学习。
- 对齐相关性在训练过程中作为生成视频帧的监督对象。
- 该方法在多个公开数据集上的实验结果优于现有算法。
点此查看论文截图


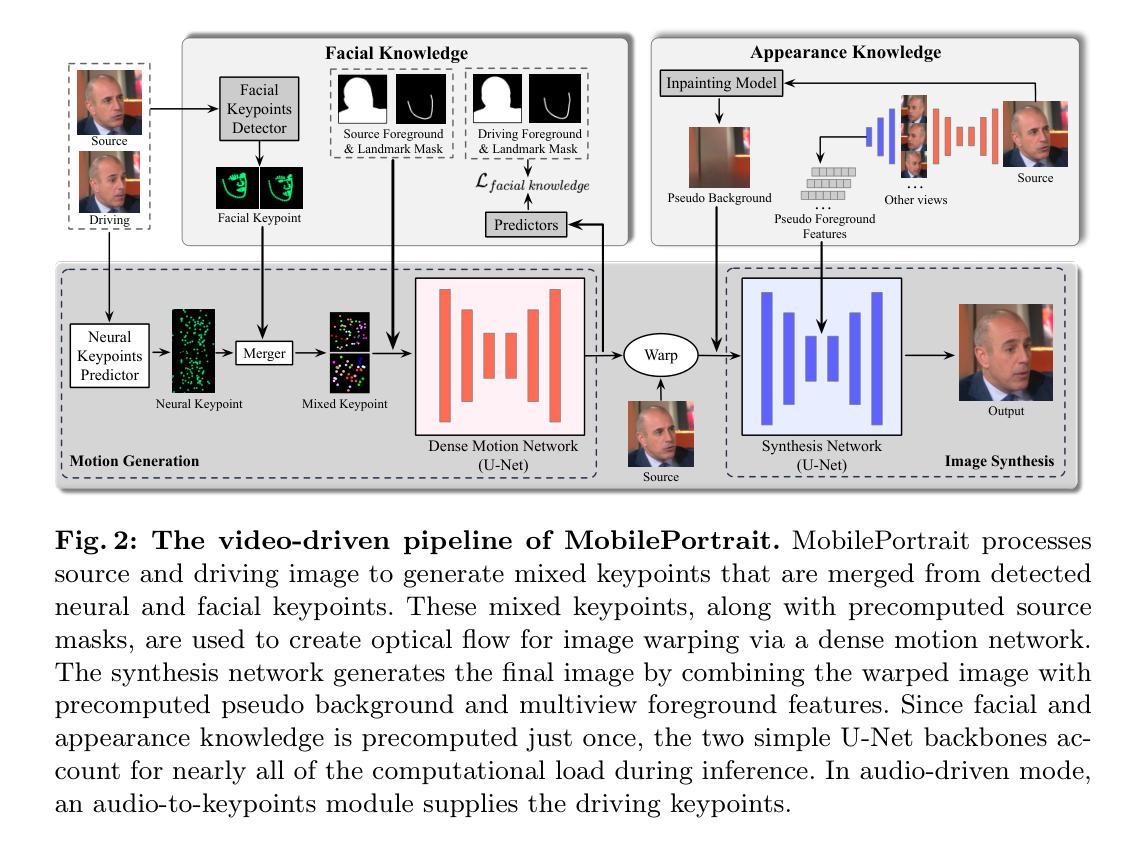
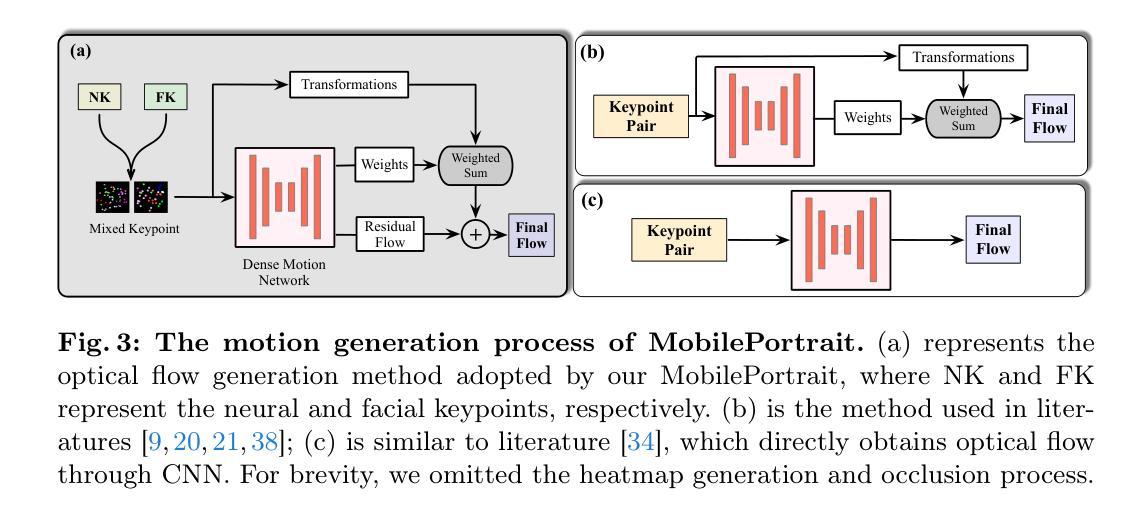
MobilePortrait: Real-Time One-Shot Neural Head Avatars on Mobile Devices
Authors:Jianwen Jiang, Gaojie Lin, Zhengkun Rong, Chao Liang, Yongming Zhu, Jiaqi Yang, Tianyun Zhong
Existing neural head avatars methods have achieved significant progress in the image quality and motion range of portrait animation. However, these methods neglect the computational overhead, and to the best of our knowledge, none is designed to run on mobile devices. This paper presents MobilePortrait, a lightweight one-shot neural head avatars method that reduces learning complexity by integrating external knowledge into both the motion modeling and image synthesis, enabling real-time inference on mobile devices. Specifically, we introduce a mixed representation of explicit and implicit keypoints for precise motion modeling and precomputed visual features for enhanced foreground and background synthesis. With these two key designs and using simple U-Nets as backbones, our method achieves state-of-the-art performance with less than one-tenth the computational demand. It has been validated to reach speeds of over 100 FPS on mobile devices and support both video and audio-driven inputs.
现有神经头像方法已经在肖像动画的图像质量和运动范围方面取得了显著进展。然而,这些方法忽视了计算开销,据我们所知,没有设计用于在移动设备上运行的方法。本文提出了MobilePortrait,这是一种轻量级的单镜头神经头像方法,它通过整合外部知识到运动建模和图像合成中,降低了学习复杂度,能够在移动设备上实现实时推理。具体来说,我们引入了显式关键点与隐式关键点的混合表示来进行精确的运动建模,以及预计算的视觉特征来增强前景和背景合成。通过这两个关键设计和使用简单的U-Nets作为骨干网,我们的方法在不到十分之一计算需求的情况下达到了最先进的性能。经验证,它在移动设备上达到了超过100帧每秒的速度,并支持视频和音频驱动输入。
论文及项目相关链接
PDF CVPR 2025
Summary
神经头像技术虽取得显著进展,但在图像质量和运动范围动画中仍忽略了计算开销问题,且尚无适用于移动设备的设计。本文提出MobilePortrait方法,通过整合外部知识实现精准运动建模和图像合成,降低学习复杂度,能在移动设备上实时推理。采用混合关键点表示法和预计算视觉特征进行设计,以U-Net为骨干网,实现卓越性能,计算需求不到十分之一。经验证,在移动设备上速度超过100帧/秒,支持视频和音频驱动输入。
Key Takeaways
- 现有神经头像方法在计算开销上存在缺陷,无法在移动设备上运行。
- MobilePortrait方法整合外部知识以实现精准运动建模和图像合成,降低学习复杂度。
- MobilePortrait采用混合关键点表示法,实现精确运动建模。
- 通过预计算视觉特征增强前景和背景合成。
- 使用简单的U-Nets作为骨干网,实现卓越性能。
- MobilePortrait方法的计算需求较小,性能达到业界领先水平。
点此查看论文截图