⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-11 更新
Sculpting Subspaces: Constrained Full Fine-Tuning in LLMs for Continual Learning
Authors:Nikhil Shivakumar Nayak, Krishnateja Killamsetty, Ligong Han, Abhishek Bhandwaldar, Prateek Chanda, Kai Xu, Hao Wang, Aldo Pareja, Oleg Silkin, Mustafa Eyceoz, Akash Srivastava
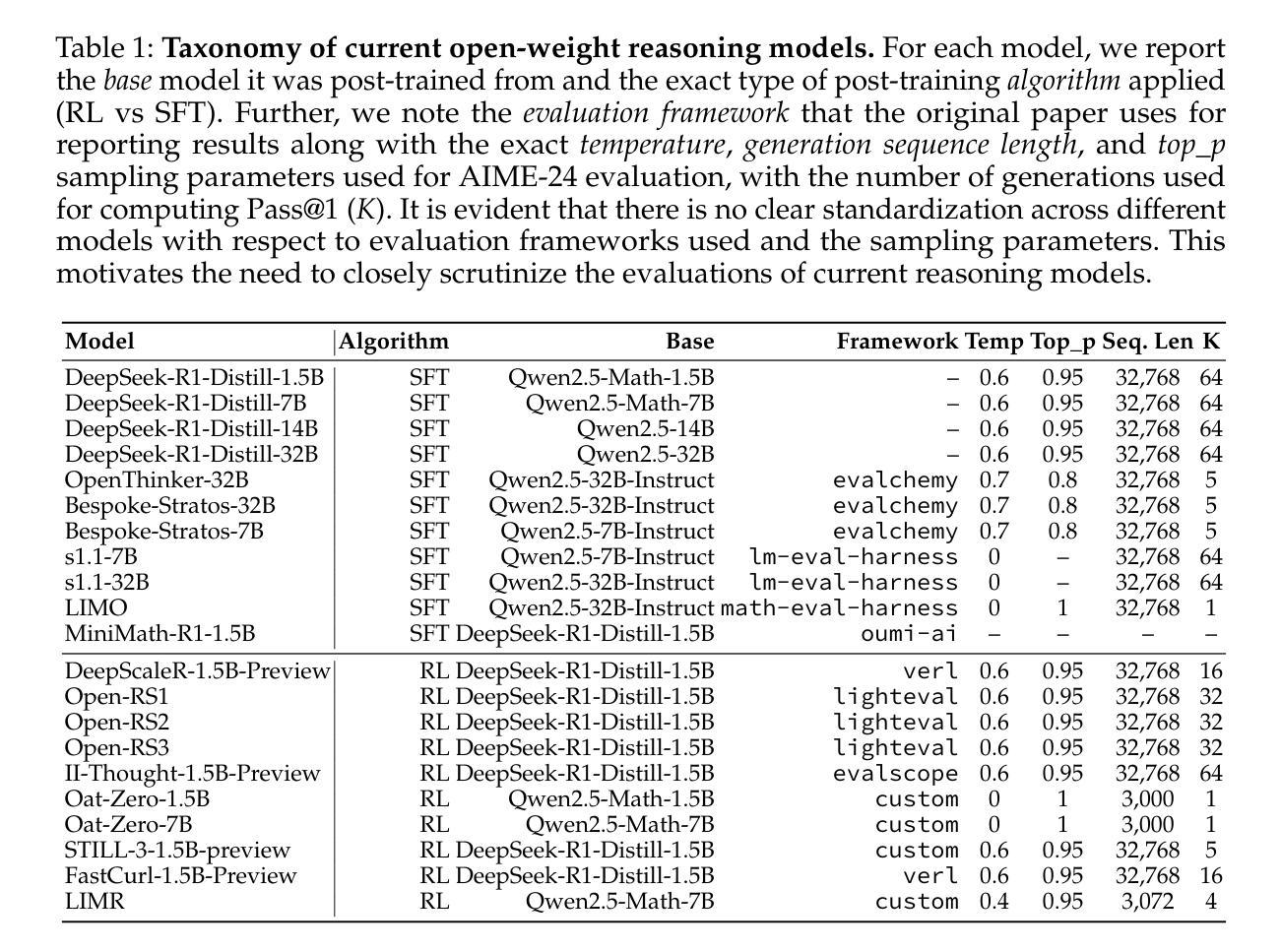
Continual learning in large language models (LLMs) is prone to catastrophic forgetting, where adapting to new tasks significantly degrades performance on previously learned ones. Existing methods typically rely on low-rank, parameter-efficient updates that limit the model’s expressivity and introduce additional parameters per task, leading to scalability issues. To address these limitations, we propose a novel continual full fine-tuning approach leveraging adaptive singular value decomposition (SVD). Our method dynamically identifies task-specific low-rank parameter subspaces and constrains updates to be orthogonal to critical directions associated with prior tasks, thus effectively minimizing interference without additional parameter overhead or storing previous task gradients. We evaluate our approach extensively on standard continual learning benchmarks using both encoder-decoder (T5-Large) and decoder-only (LLaMA-2 7B) models, spanning diverse tasks including classification, generation, and reasoning. Empirically, our method achieves state-of-the-art results, up to 7% higher average accuracy than recent baselines like O-LoRA, and notably maintains the model’s general linguistic capabilities, instruction-following accuracy, and safety throughout the continual learning process by reducing forgetting to near-negligible levels. Our adaptive SVD framework effectively balances model plasticity and knowledge retention, providing a practical, theoretically grounded, and computationally scalable solution for continual learning scenarios in large language models.
大型语言模型(LLM)的持续学习容易受到灾难性遗忘的影响,即适应新任务会显著降低对先前学习任务的性能。现有方法通常依赖于低阶、参数高效的更新,这限制了模型的表达能力,并为每个任务引入了额外的参数,导致可扩展性问题。为了解决这些局限性,我们提出了一种利用自适应奇异值分解(SVD)的新型持续全微调方法。我们的方法动态地识别特定任务的低阶参数子空间,并约束更新与先前任务相关的关键方向正交,从而有效地最小化干扰,而无需额外的参数开销或存储先前任务的梯度。我们在使用编码器-解码器(T5-Large)和仅解码器(LLaMA-2 7B)模型的标准持续学习基准测试集上对我们的方法进行了广泛评估,涵盖分类、生成和推理等多样化任务。经验上,我们的方法达到了最先进的成果,平均准确率比最近的基线(如O-LoRA)高出高达7%,并且显著地保持了模型的一般语言能力、遵循指令的准确性和安全性,通过减少几乎可以忽略的遗忘水平来实现持续学习过程。我们的自适应SVD框架有效地平衡了模型的适应性和知识保留能力,为大型语言模型中的持续学习场景提供了实用、理论扎实且计算上可扩展的解决方案。
论文及项目相关链接
PDF 25 pages, 13 figures, 6 tables
摘要
大型语言模型(LLM)的持续学习面临灾难性遗忘问题,即适应新任务时会导致对先前学习任务的性能显著下降。现有方法通常依赖于低阶、参数高效的更新,这限制了模型的表达能力,并为每个任务引入了额外的参数,导致可扩展性问题。针对这些局限性,我们提出了一种利用自适应奇异值分解(SVD)的新的持续全微调方法。我们的方法动态地识别特定任务的低阶参数子空间,并约束更新与先前任务的关键方向正交,从而有效地最小化干扰,无需额外的参数开销或存储先前任务的梯度。我们在标准的持续学习基准测试上对使用编码器-解码器(T5-Large)和仅解码器(LLaMA-2 7B)的模型进行了广泛评估,涵盖分类、生成和推理等多样化任务。经验表明,我们的方法达到了最新的结果,比最近的基线(如O-LoRA)高出高达7%的平均准确率,并显著地保持了模型的一般语言能力、指令遵循准确性和安全性。我们的自适应SVD框架有效地平衡了模型的适应性和知识保留能力,为大型语言模型中的持续学习场景提供了实用、理论扎实和计算可扩展的解决方案。
关键见解
- 大型语言模型在持续学习中面临灾难性遗忘问题。
- 现有方法依赖低阶、参数高效的更新,这限制了模型的表达能力和带来了可扩展性问题。
- 提出了一种新的持续全微调方法,利用自适应奇异值分解(SVD)。
- 动态识别特定任务的低阶参数子空间,并约束更新与先前任务的关键方向正交。
- 方法无需额外的参数开销或存储先前任务的梯度,有效地最小化干扰。
- 在多种任务和标准基准测试上对模型进行了广泛评估,经验结果表明该方法达到了最新的结果,并显著地保持了模型的各种能力。
点此查看论文截图

TASTE: Text-Aligned Speech Tokenization and Embedding for Spoken Language Modeling
Authors:Liang-Hsuan Tseng, Yi-Chang Chen, Kuan-Yi Lee, Da-Shan Shiu, Hung-yi Lee
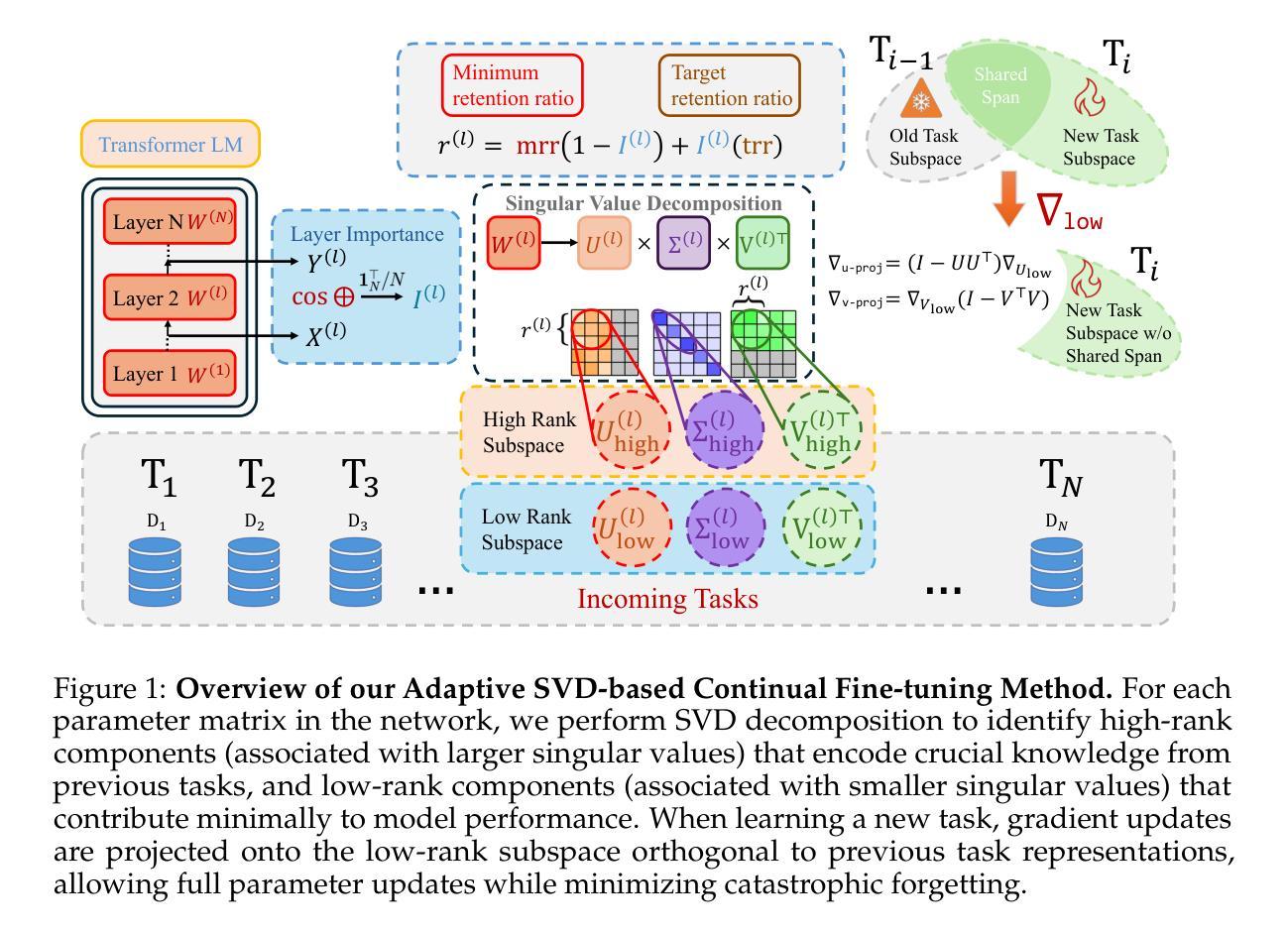
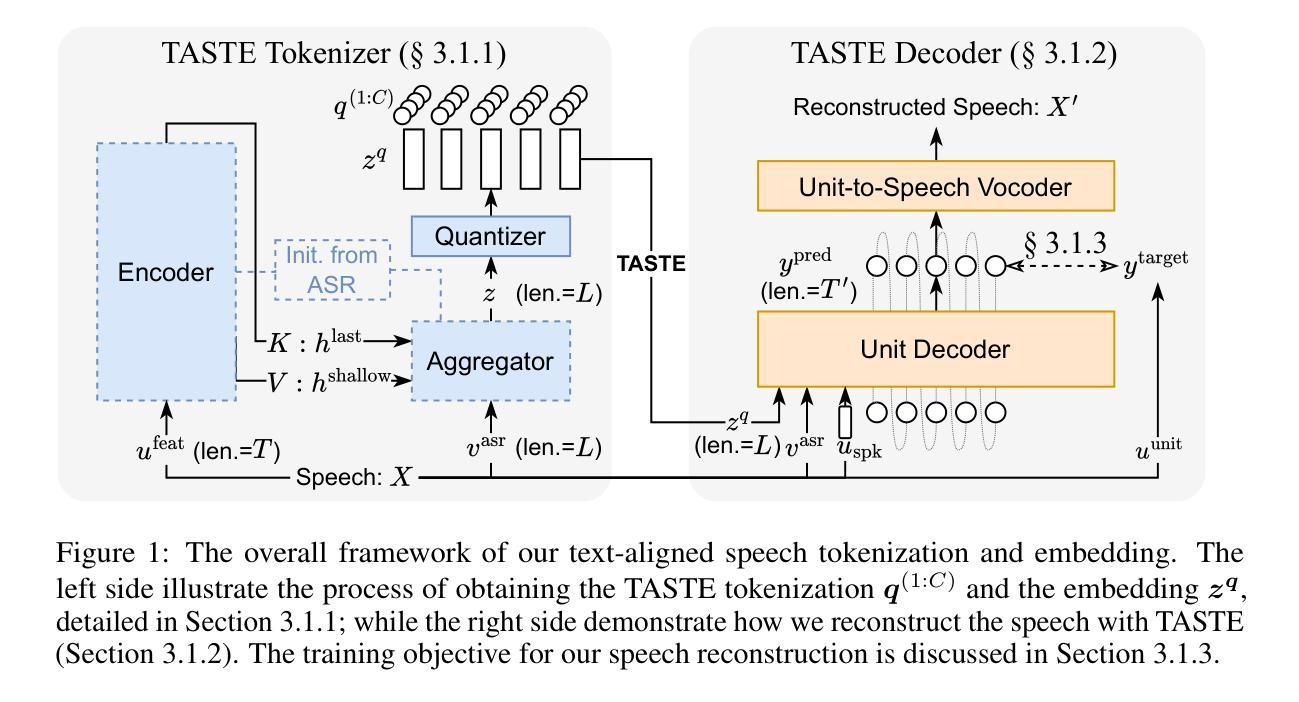
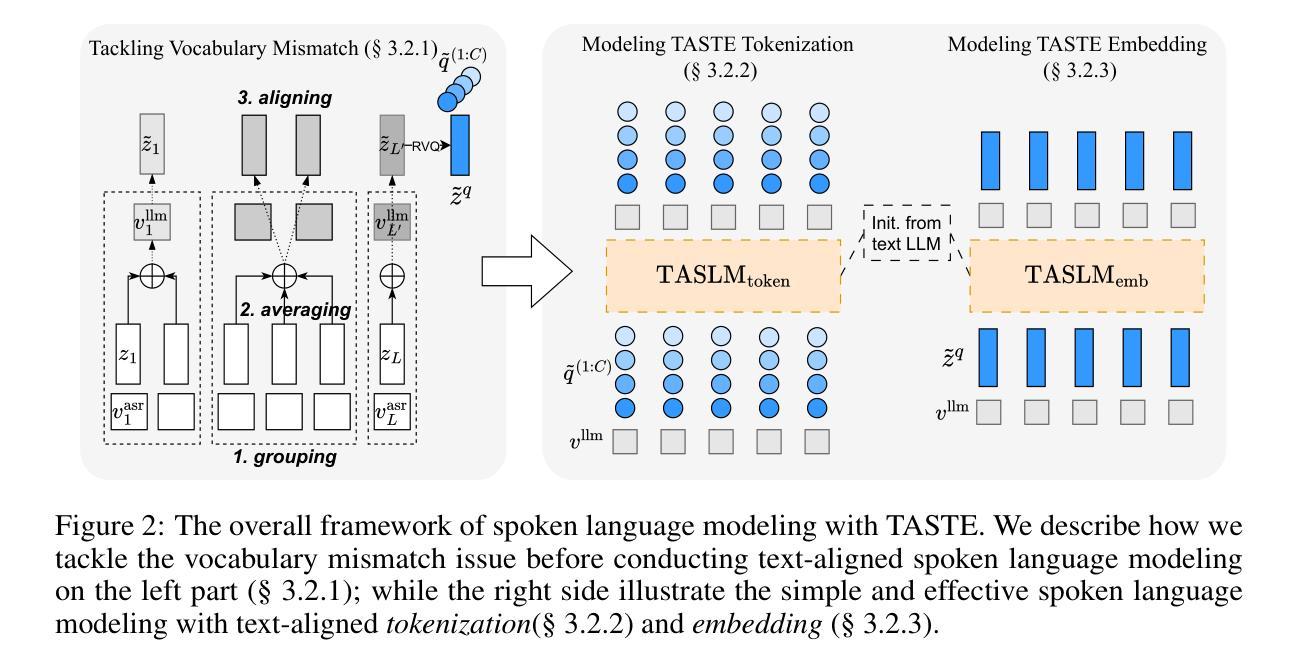
Large Language Models (LLMs) excel in text-based natural language processing tasks but remain constrained by their reliance on textual inputs and outputs. To enable more natural human-LLM interaction, recent progress have focused on deriving a spoken language model (SLM) that can not only listen but also generate speech. To achieve this, a promising direction is to conduct speech-text joint modeling. However, recent SLM still lag behind text LLM due to the modality mismatch. One significant mismatch can be the sequence lengths between speech and text tokens. To address this, we introduce Text-Aligned Speech Tokenization and Embedding (TASTE), a method that directly addresses the modality gap by aligning speech token with the corresponding text transcription during the tokenization stage. We propose a method that can achieve this through the special aggregation mechanism and with speech reconstruction as the training objective. We conduct extensive experiments and show that TASTE can preserve essential paralinguistic information while dramatically reducing the token sequence length. Furthermore, by leveraging TASTE, we can adapt text-based LLMs into effective SLMs with parameter-efficient fine-tuning techniques such as Low-Rank Adaptation (LoRA). Experimental results on benchmark tasks, including SALMON and StoryCloze, demonstrate that TASTE-based SLMs perform similarly to previous full-finetuning methods. To our knowledge, TASTE is the first end-to-end approach that utilizes a reconstruction objective to automatically learn a text-aligned speech tokenization and embedding suitable for spoken language modeling. Our demo, code, and models are publicly available at https://github.com/mtkresearch/TASTE-SpokenLM.
大型语言模型(LLM)在基于文本的自然语言处理任务上表现出色,但受限于其对文本输入和输出的依赖。为了促进更自然的人机交互,最近的进展主要集中在开发一种口语语言模型(SLM),这种模型不仅要能听,还要能生成语音。为了实现这一点,一个充满希望的途径是进行语音文本的联合建模。然而,由于模态不匹配的问题,最近的SLM仍然落后于文本LLM。一个重要的不匹配在于语音和文本标记之间的序列长度。为解决这一问题,我们引入了文本对齐语音标记化与嵌入(TASTE),这是一种通过标记化阶段将语音标记与相应的文本转录进行对齐,直接解决模态差异的方法。我们提出了一种通过特殊的聚合机制和以语音重建为训练目标的方法来实现这一点。我们进行了大量实验,结果表明TASTE可以保留关键的副语言信息,同时显著缩短标记序列长度。此外,通过利用TASTE,我们可以将基于文本的LLM适应为有效的SLM,采用参数高效的微调技术,如低秩适应(LoRA)。在包括SALMON和StoryCloze在内的基准任务上的实验结果表明,基于TASTE的SLM与之前的完全微调方法表现相似。据我们所知,TASTE是利用重建目标自动学习适合口语建模的文本对齐语音标记化与嵌入的首个端到端方法。我们的演示、代码和模型可在https://github.com/mtkresearch/TASTE-SpokenLM上公开访问。
论文及项目相关链接
PDF Preprint. Work in progress
Summary
该文本主要介绍了如何通过引入TASTE技术实现从文本大型语言模型(LLM)向口语化语言模型(SLM)的转变。TASTE技术能够在语音识别阶段实现语音和文字的对齐,并通过特殊聚合机制和语音重建训练目标来解决语音和文字模态之间的差距问题。实验表明,TASTE技术能够保留重要的语言信息,同时显著减少令牌序列长度。利用TASTE技术和低秩适应(LoRA)等参数高效微调技术,可以将基于文本的LLM适应为有效的SLM。在基准任务上的实验结果表明,基于TASTE的SLM性能与之前的完全微调方法相似。TASTE是首个利用重建目标自动学习适合口语建模的文本对齐语音令牌化和嵌入的端到端方法。
Key Takeaways
- 大型语言模型(LLMs)虽然擅长文本处理任务,但缺乏处理口语任务的能力。为了促进更自然的人机交互,研究集中在开发口语语言模型(SLMs)。
- 语音和文字模态之间的差距是阻碍SLM发展的关键因素之一,其中序列长度不匹配是显著的问题。
- TASTE技术通过语音和文字的对齐解决了模态差距问题,实现了语音令牌与相应文本转录的对齐。
- TASTE技术通过特殊聚合机制和语音重建训练目标实现模态对齐。
- TASTE能够保留重要的语言信息,同时显著减少令牌序列长度。
- 利用TASTE和参数高效微调技术(如Low-Rank Adaptation),可以将文本LLM转化为有效的SLM。
- 在基准任务上的实验表明,基于TASTE的SLM性能与完全微调方法相当,而TASTE是首个采用重建目标自动学习适合口语建模的端到端方法。
点此查看论文截图

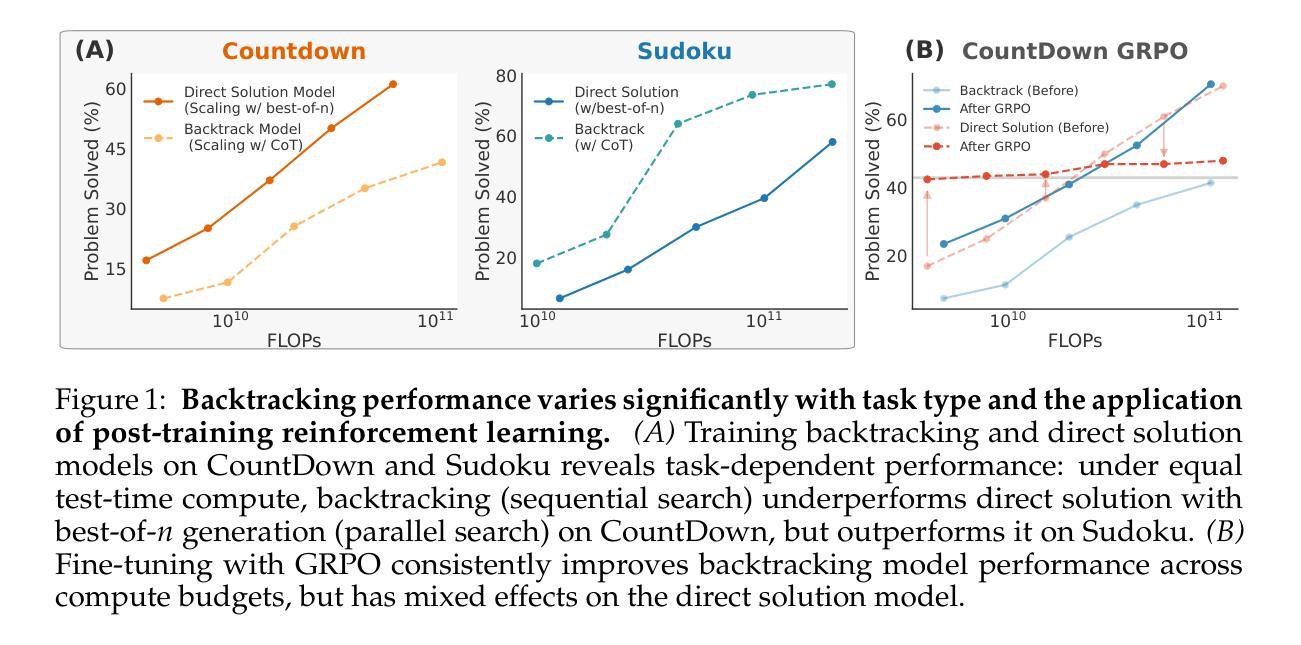
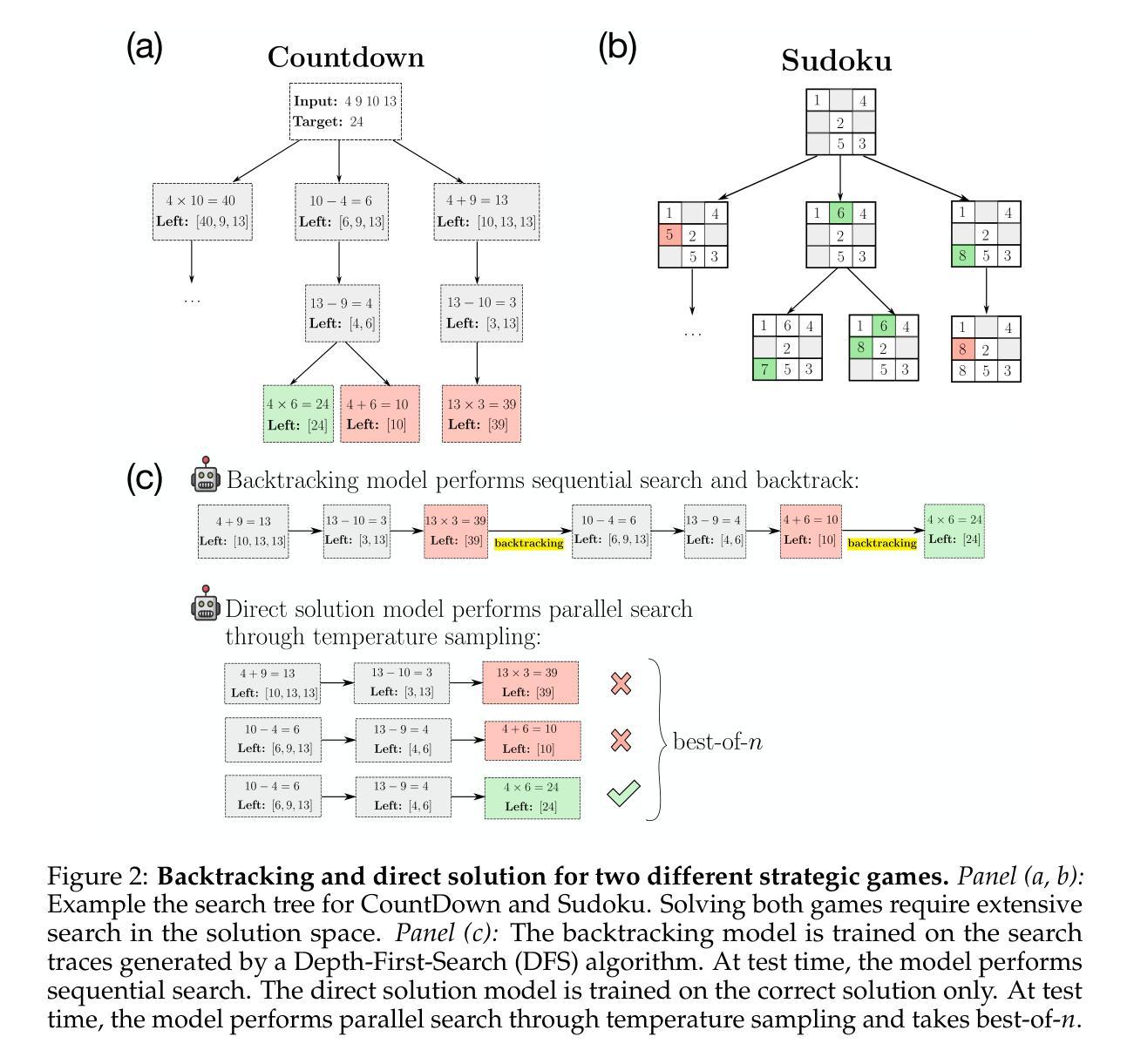
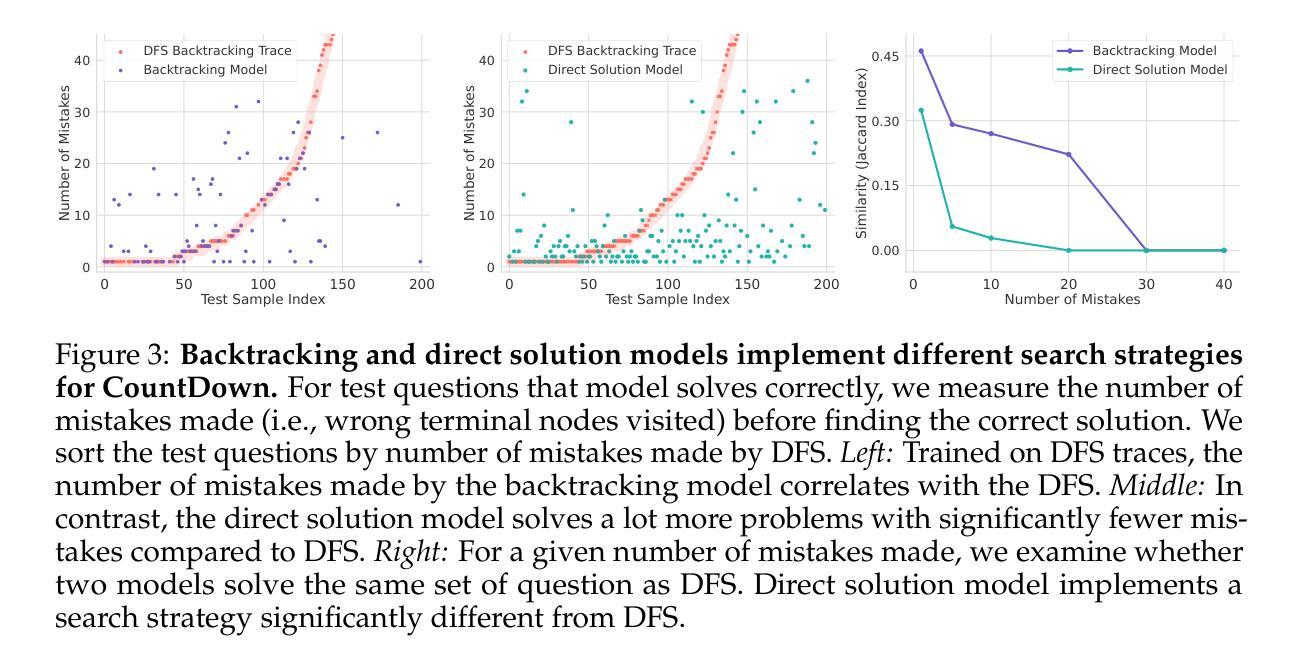
To Backtrack or Not to Backtrack: When Sequential Search Limits Model Reasoning
Authors:Tian Qin, David Alvarez-Melis, Samy Jelassi, Eran Malach
Recent advancements in large language models have significantly improved their reasoning abilities, particularly through techniques involving search and backtracking. Backtracking naturally scales test-time compute by enabling sequential, linearized exploration via long chain-of-thought (CoT) generation. However, this is not the only strategy for scaling test-time compute: parallel sampling with best-of-n selection provides an alternative that generates diverse solutions simultaneously. Despite the growing adoption of sequential search, its advantages over parallel sampling–especially under a fixed compute budget remain poorly understood. In this paper, we systematically compare these two approaches on two challenging reasoning tasks: CountDown and Sudoku. Surprisingly, we find that sequential search underperforms parallel sampling on CountDown but outperforms it on Sudoku, suggesting that backtracking is not universally beneficial. We identify two factors that can cause backtracking to degrade performance: (1) training on fixed search traces can lock models into suboptimal strategies, and (2) explicit CoT supervision can discourage “implicit” (non-verbalized) reasoning. Extending our analysis to reinforcement learning (RL), we show that models with backtracking capabilities benefit significantly from RL fine-tuning, while models without backtracking see limited, mixed gains. Together, these findings challenge the assumption that backtracking universally enhances LLM reasoning, instead revealing a complex interaction between task structure, training data, model scale, and learning paradigm.
最近的大型语言模型进展通过搜索和回溯等技术显著提高了其推理能力。回溯通过线性化探索序列(通过长链思维生成),自然地扩大了测试时间计算。然而,这并不是扩大测试时间计算规模的唯一策略:使用最佳n值选择进行并行采样提供了一种能够同时生成多种解决方案的方法。尽管顺序搜索的采用越来越多,但其相对于并行采样的优势——特别是在固定计算预算下——仍然鲜为人知。在本文中,我们在两个具有挑战性的推理任务CountDown和数独上系统地比较了这两种方法。令人惊讶的是,我们发现顺序搜索在CountDown上的表现不如并行采样,但在数独上表现更好,这表明回溯并非普遍有益。我们确定了导致回溯降低性能的另外两个因素:(1)在固定搜索轨迹上进行训练会使模型陷入次优策略;(2)明确的思维轨迹监督可能会抑制“隐性”(未言明的)推理。我们将分析扩展到强化学习(RL),发现具有回溯能力的模型从RL微调中受益匪浅,而没有回溯的模型则收益有限且表现不一。总的来说,这些发现挑战了回溯普遍提高大型语言模型推理能力的假设,相反揭示了任务结构、训练数据、模型规模和学习范式之间的复杂交互。
论文及项目相关链接
Summary
大型语言模型的最新进展通过搜索和回溯等技术显著提高了其推理能力。本文系统地比较了回溯的串行搜索与并行采样的方法,在倒计时和数独两项挑战性任务中的表现,发现没有一种方法是普遍有益的。研究发现训练固定的搜索痕迹会使模型陷入次优策略,而明确的思维链监督可能会阻碍“隐性”推理。强化学习微调具有回溯能力的模型有显著好处,而缺少回溯的模型则收效甚微。这些发现挑战了回溯普遍提高大型语言模型推理能力的假设。
Key Takeaways
- 大型语言模型的最新进展提高了其推理能力,主要通过搜索和回溯等技术实现。
- 文中对比了串行搜索的回溯方法与并行采样的效果,发现在不同任务中表现不一。
- 训练固定的搜索痕迹可能导致模型陷入次优策略。
- 明确的思维链监督可能阻碍“隐性”推理。
- 强化学习微调对具有回溯能力的模型有显著好处。
- 没有一种方法是普遍有益的,任务结构、训练数据、模型规模和学习范式之间有着复杂的交互作用。
点此查看论文截图

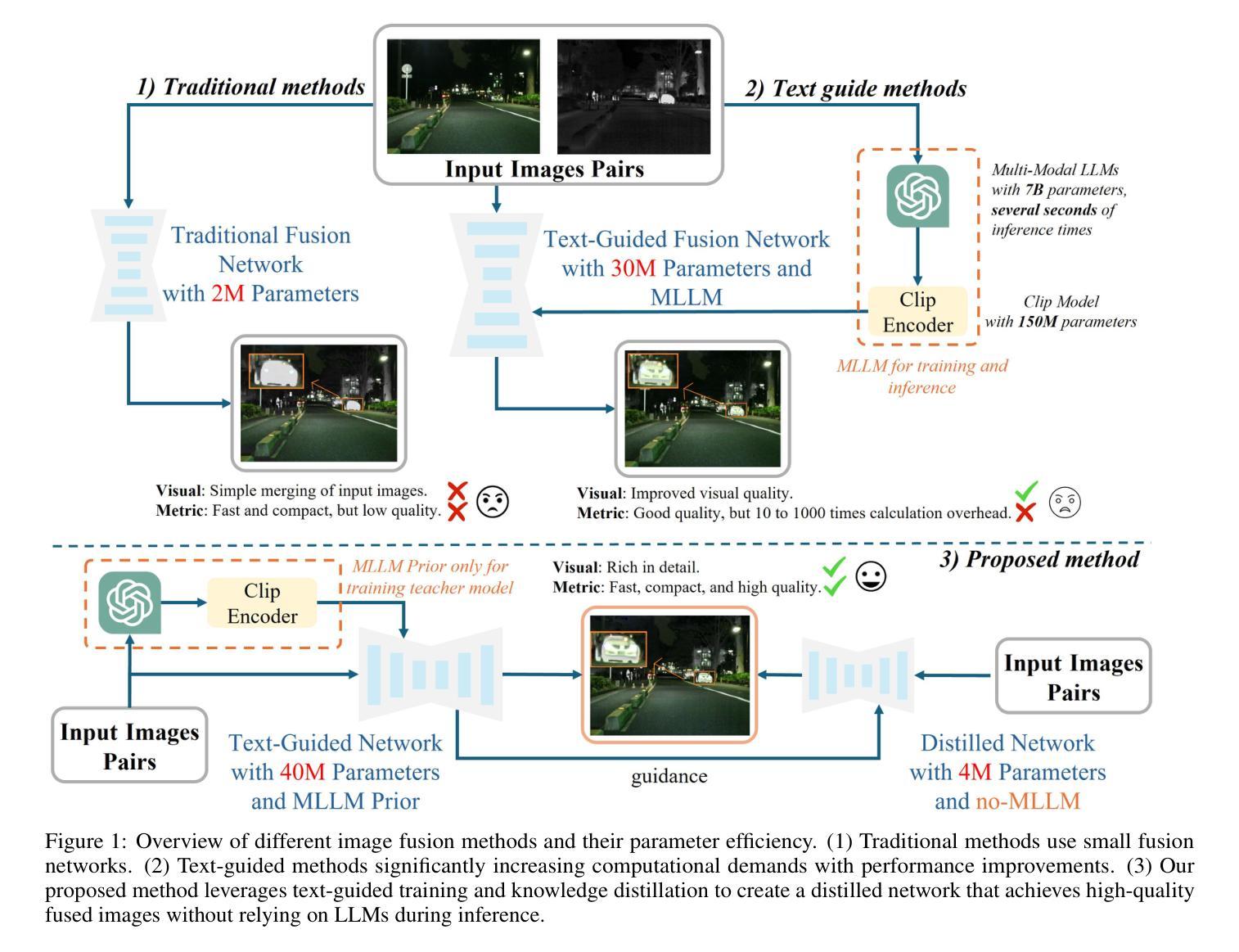
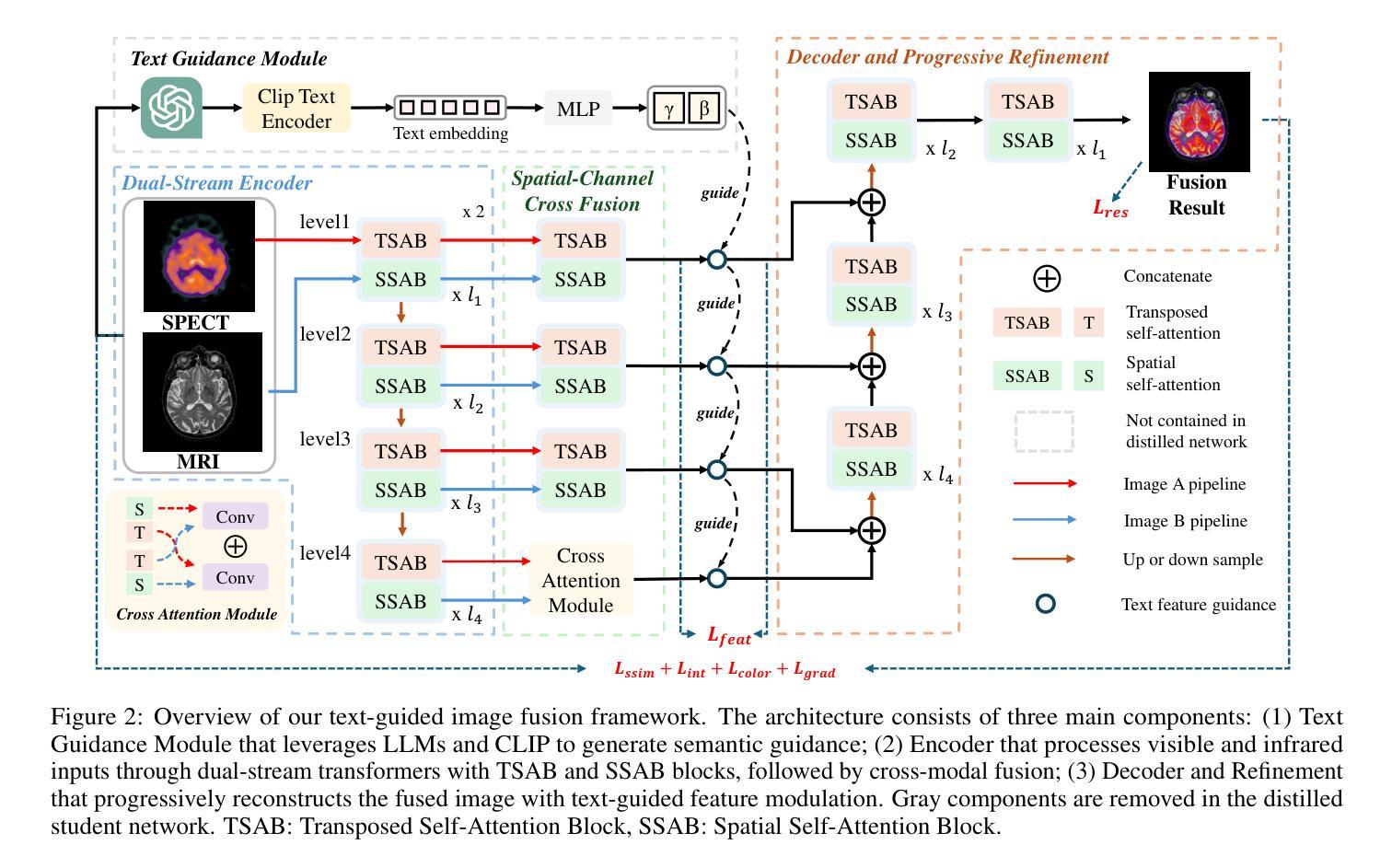
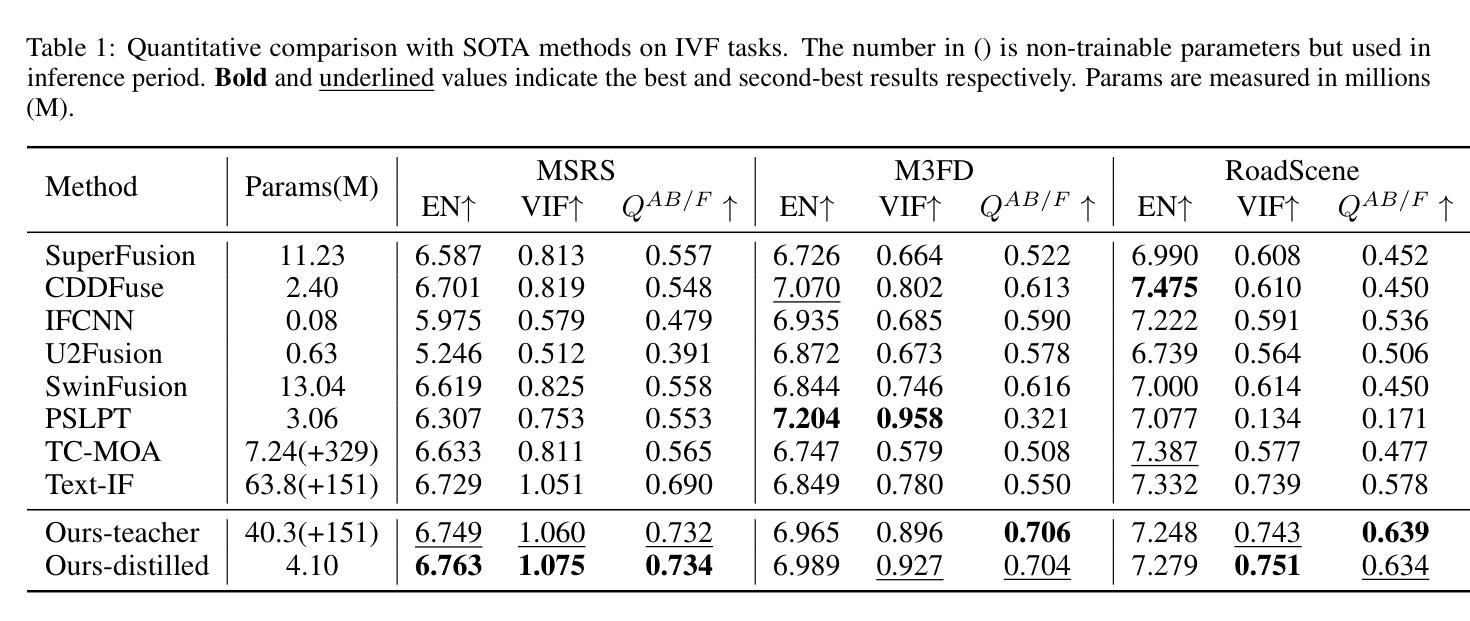
Distilling Textual Priors from LLM to Efficient Image Fusion
Authors:Ran Zhang, Xuanhua He, Ke Cao, Liu Liu, Li Zhang, Man Zhou, Jie Zhang
Multi-modality image fusion aims to synthesize a single, comprehensive image from multiple source inputs. Traditional approaches, such as CNNs and GANs, offer efficiency but struggle to handle low-quality or complex inputs. Recent advances in text-guided methods leverage large model priors to overcome these limitations, but at the cost of significant computational overhead, both in memory and inference time. To address this challenge, we propose a novel framework for distilling large model priors, eliminating the need for text guidance during inference while dramatically reducing model size. Our framework utilizes a teacher-student architecture, where the teacher network incorporates large model priors and transfers this knowledge to a smaller student network via a tailored distillation process. Additionally, we introduce spatial-channel cross-fusion module to enhance the model’s ability to leverage textual priors across both spatial and channel dimensions. Our method achieves a favorable trade-off between computational efficiency and fusion quality. The distilled network, requiring only 10% of the parameters and inference time of the teacher network, retains 90% of its performance and outperforms existing SOTA methods. Extensive experiments demonstrate the effectiveness of our approach. The implementation will be made publicly available as an open-source resource.
多模态图像融合旨在从多个源输入中合成单一、全面的图像。传统方法,如卷积神经网络和生成对抗网络,虽然效率高,但难以处理低质量或复杂的输入。最近的文本引导方法利用大型模型先验知识来克服这些限制,但这在内存和推理时间方面造成了巨大的计算开销。为了解决这一挑战,我们提出了一种新型的大型模型先验知识提炼框架,该框架在推理过程中无需文本引导,同时大幅减小了模型体积。我们的框架采用师徒架构,其中教师网络融入大型模型先验知识,并通过定制提炼过程将这些知识转移给较小的学生网络。此外,我们引入了空间通道交叉融合模块,以提高模型在空间和通道维度上利用文本先验知识的能力。我们的方法在计算效率和融合质量之间取得了有利的平衡。精炼的网络仅需教师网络的10%的参数和推理时间,即可保留90%的性能并超越现有的最佳方法。大量实验证明了我们的方法的有效性。实现将作为开源资源公开发布。
论文及项目相关链接
Summary
本文提出了一种新颖的框架,用于蒸馏大型模型先验知识,用于多模态图像融合任务。该框架采用教师-学生架构,通过定制蒸馏过程将大型模型的知识转移到小型学生网络。引入空间通道交叉融合模块,提高模型在空间和通道维度上利用文本先验知识的能力。该方法在计算效率和融合质量之间实现了有利的权衡,蒸馏网络仅需要教师网络10%的参数和推理时间,保留90%的性能,并优于现有最先进的方法。
Key Takeaways
- 提出一种新颖的框架用于多模态图像融合中的模型蒸馏。
- 采用教师-学生网络架构进行知识转移。
- 引入空间通道交叉融合模块,提高利用文本先验知识的能力。
- 实现了计算效率和融合质量之间的有利权衡。
- 蒸馏网络性能优异,仅需要教师网络的10%参数和推理时间。
- 框架超越了现有最先进的图像融合方法。
点此查看论文截图

Evaluating Retrieval Augmented Generative Models for Document Queries in Transportation Safety
Authors:Chad Melton, Alex Sorokine, Steve Peterson
Applications of generative Large Language Models LLMs are rapidly expanding across various domains, promising significant improvements in workflow efficiency and information retrieval. However, their implementation in specialized, high-stakes domains such as hazardous materials transportation is challenging due to accuracy and reliability concerns. This study evaluates the performance of three fine-tuned generative models, ChatGPT, Google’s Vertex AI, and ORNL Retrieval Augmented Generation augmented LLaMA 2 and LLaMA in retrieving regulatory information essential for hazardous material transportation compliance in the United States. Utilizing approximately 40 publicly available federal and state regulatory documents, we developed 100 realistic queries relevant to route planning and permitting requirements. Responses were qualitatively rated based on accuracy, detail, and relevance, complemented by quantitative assessments of semantic similarity between model outputs. Results demonstrated that the RAG-augmented LLaMA models significantly outperformed Vertex AI and ChatGPT, providing more detailed and generally accurate information, despite occasional inconsistencies. This research introduces the first known application of RAG in transportation safety, emphasizing the need for domain-specific fine-tuning and rigorous evaluation methodologies to ensure reliability and minimize the risk of inaccuracies in high-stakes environments.
生成式大型语言模型(LLMs)的应用正在各个领域迅速扩展,为工作流程效率和信息检索带来了重大改进的希望。然而,由于其准确性和可靠性问题,在危险品运输等特定高风险领域的实施具有挑战性。本研究评估了三种经过精细调整的生成模型——ChatGPT、谷歌的Vertex AI和ORNL检索增强生成(RAG)增强的LLaMA 2和LLaMA在检索对美国危险品运输合规至关重要的法规信息方面的表现。我们利用约40份公开可用的联邦和州监管文件,制定了与路线规划和许可要求相关的100个现实查询。根据准确性、详细性和相关性对答案进行定性评价,辅以模型输出之间的语义相似性的定量评估。结果表明,RAG增强的LLaMA模型在总体上显著优于Vertex AI和ChatGPT,提供了更详细和更准确的信息,尽管偶尔会出现不一致的情况。该研究介绍了运输安全领域中RAG的第一个已知应用,强调了在确保可靠性和减少高风险环境中的不准确风险方面,需要进行特定的领域精细调整和严格评估方法。
论文及项目相关链接
PDF 14 pages, 3 Figures, 3 tables
Summary
基于生成式大型语言模型(LLMs)在危险物资运输等高要求领域应用的挑战,本研究评估了三种精细调整的生成模型在检索对美国危险材料运输合规至关重要的法规信息方面的性能。结果显示,采用RAG增强的LLaMA模型在准确性、详细性和相关性方面显著优于Vertex AI和ChatGPT,尽管偶有不一致性。本研究首次将RAG应用于运输安全领域,强调高要求环境中需要领域特定的精细调整及严格评估方法以确保可靠性和最小化不准确的风险。
Key Takeaways
- 生成式大型语言模型(LLMs)在多个领域的应用迅速扩展,提升了工作效率和信息检索能力。
- 在危险物资运输等高要求领域,LLMs的实施面临准确性与可靠性挑战。
- 研究评估了三种精细调整的生成模型在检索危险材料运输相关法规信息方面的性能。
- RAG增强的LLaMA模型在准确性、详细性和相关性方面表现最佳。
- LLaMA模型显著优于其他评估的模型,提供了更详细和准确的信息。
- 在高要求环境中,需要领域特定的精细调整和严格评估方法来确保模型的可靠性。
点此查看论文截图


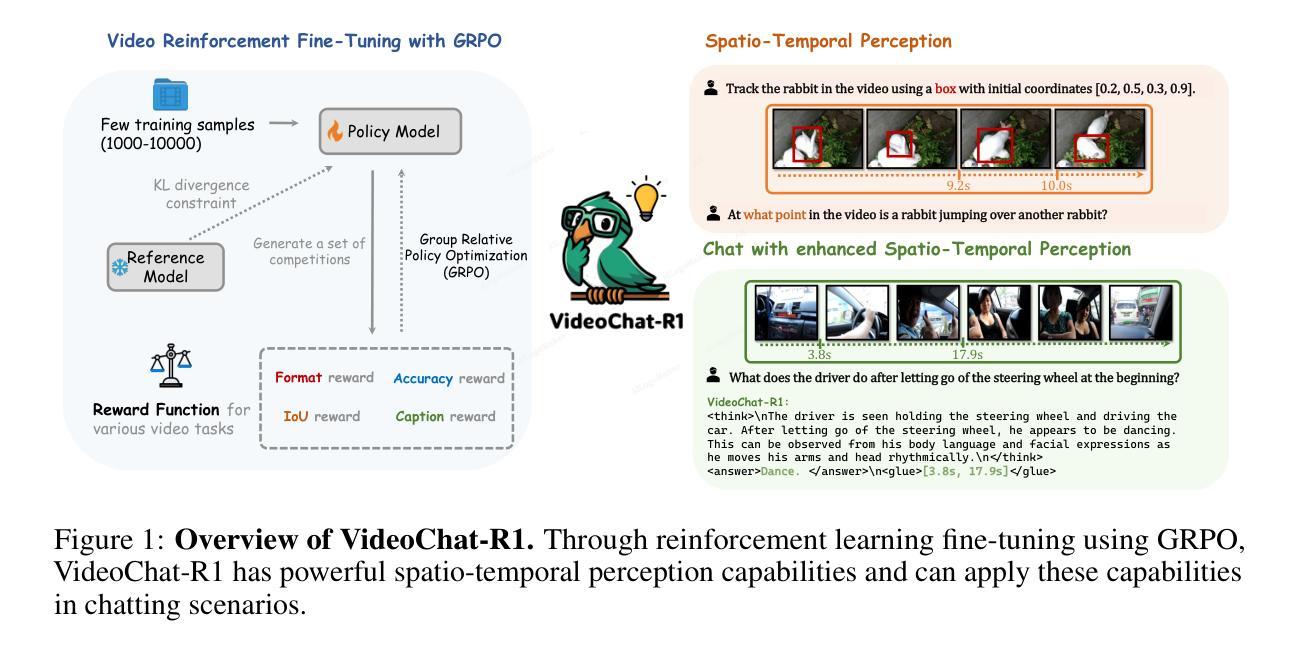
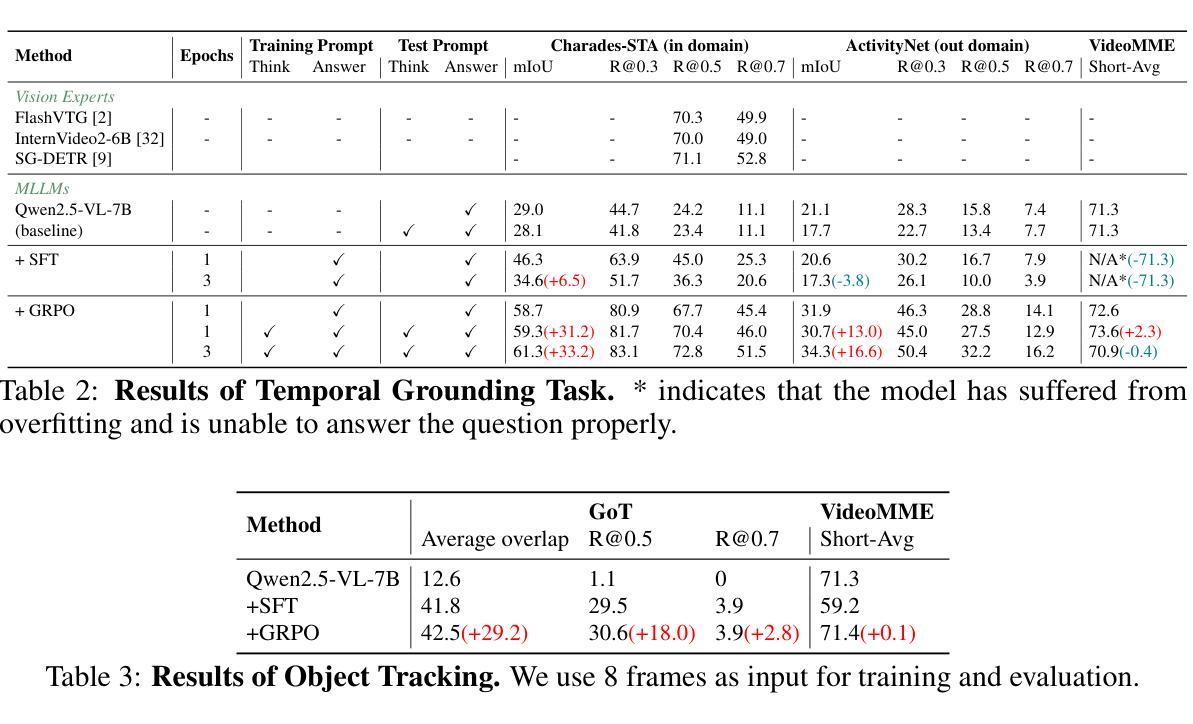
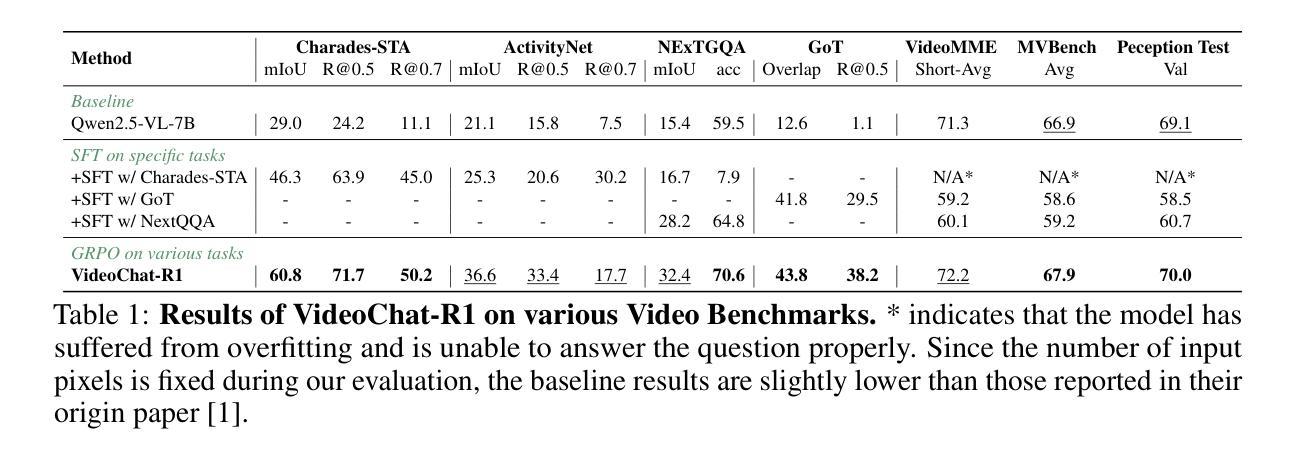
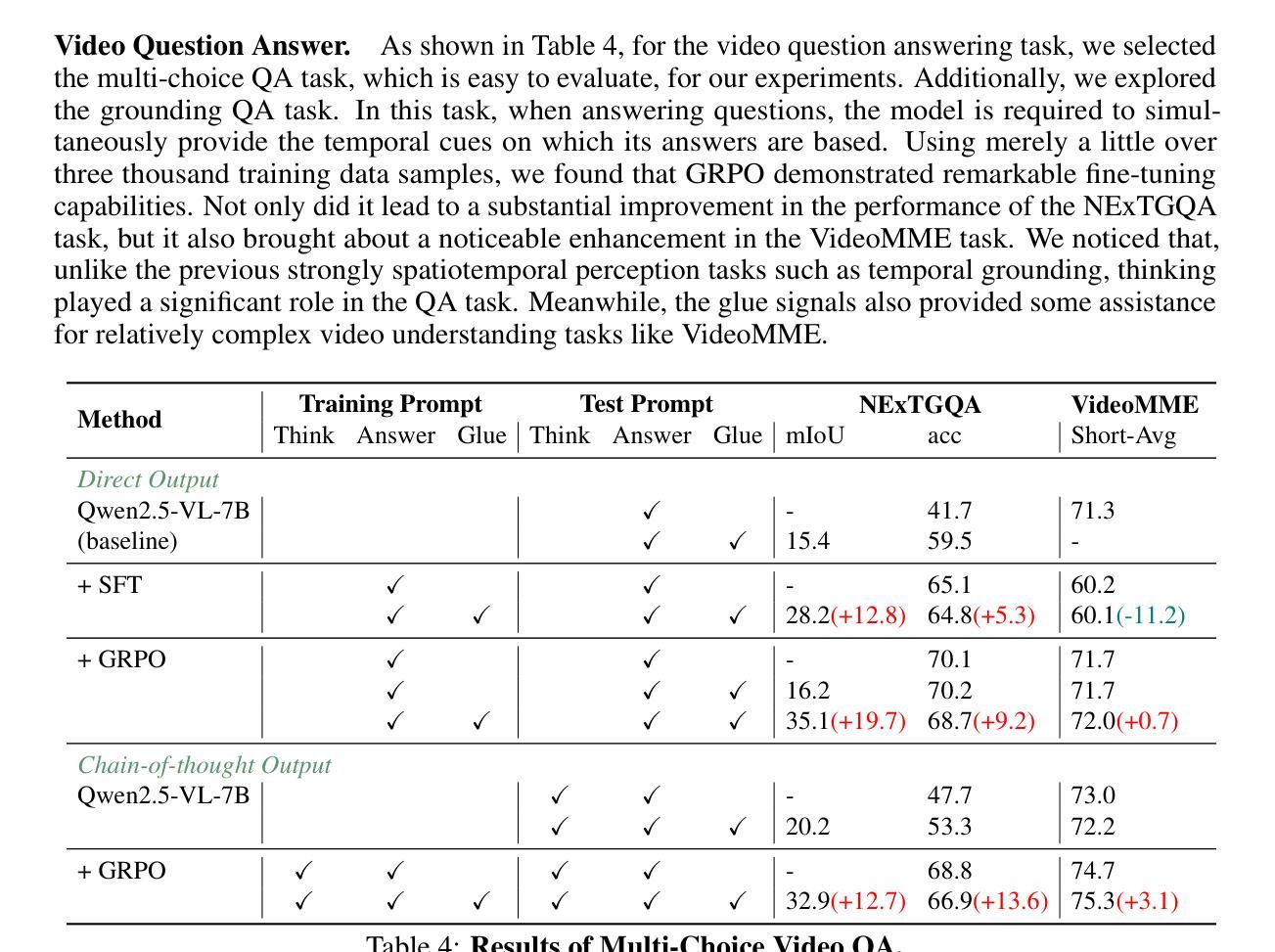
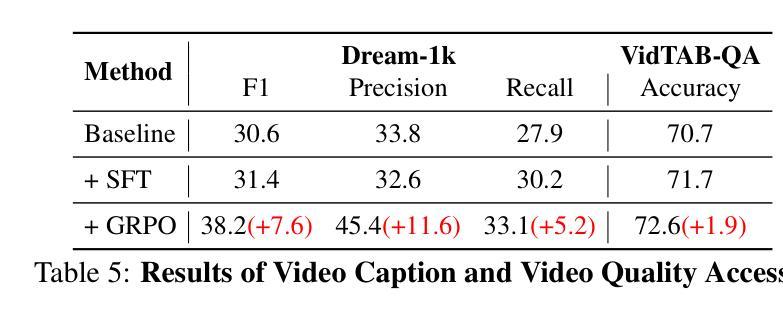
VideoChat-R1: Enhancing Spatio-Temporal Perception via Reinforcement Fine-Tuning
Authors:Xinhao Li, Ziang Yan, Desen Meng, Lu Dong, Xiangyu Zeng, Yinan He, Yali Wang, Yu Qiao, Yi Wang, Limin Wang
Recent advancements in reinforcement learning have significantly advanced the reasoning capabilities of multimodal large language models (MLLMs). While approaches such as Group Relative Policy Optimization (GRPO) and rule-based reward mechanisms demonstrate promise in text and image domains, their application to video understanding remains limited. This paper presents a systematic exploration of Reinforcement Fine-Tuning (RFT) with GRPO for video MLLMs, aiming to enhance spatio-temporal perception while maintaining general capabilities. Our experiments reveal that RFT is highly data-efficient for task-specific improvements. Through multi-task RFT on spatio-temporal perception objectives with limited samples, we develop VideoChat-R1, a powerful video MLLM that achieves state-of-the-art performance on spatio-temporal perception tasks without sacrificing chat ability, while exhibiting emerging spatio-temporal reasoning abilities. Compared to Qwen2.5-VL-7B, VideoChat-R1 boosts performance several-fold in tasks like temporal grounding (+31.8) and object tracking (+31.2). Additionally, it significantly improves on general QA benchmarks such as VideoMME (+0.9), MVBench (+1.0), and Perception Test (+0.9). Our findings underscore the potential of RFT for specialized task enhancement of Video MLLMs. We hope our work offers valuable insights for future RL research in video MLLMs.
最近强化学习领域的进展极大地提高了多模态大型语言模型(MLLMs)的推理能力。虽然集团相对策略优化(GRPO)和基于规则的奖励机制等方法在文本和图像领域显示出潜力,但它们在视频理解方面的应用仍然有限。本文系统地探讨了用于视频MLLM的强化微调(RFT)与GRPO的结合,旨在提高时空感知能力的同时保持通用能力。我们的实验表明,RFT对于特定任务的改进非常数据高效。通过有限样本的时空感知目标上的多任务RFT,我们开发出了VideoChat-R1,这是一款强大的视频MLLM,在时空感知任务上实现了最先进的性能,同时不牺牲聊天能力,并展现出新兴的时空推理能力。与Qwen2.5-VL-7B相比,VideoChat-R1在诸如时间定位(+31.8)和对象跟踪(+31.2)的任务上提升了数倍的性能。此外,它在通用问答基准测试(如VideoMME(+0.9)、MVBench(+1.0)和感知测试(+0.9))上也取得了显著改善。我们的研究突出了RFT在视频MLLM特定任务增强方面的潜力。我们希望我们的研究为未来视频MLLM的强化学习研究提供有价值的见解。
论文及项目相关链接
Summary
近期强化学习在提升多模态大型语言模型(MLLMs)的推理能力方面取得显著进展。本文探索了使用强化精细调整(RFT)和集团相对策略优化(GRPO)的视频MLLMs,旨在提高时空感知能力的同时保持一般能力。实验表明,RFT在特定任务改进方面非常注重数据效率。通过有限样本的时空感知目标上的多任务RFT,开发出VideoChat-R1,该视频MLLM在时空感知任务上实现最先进的性能,不牺牲聊天能力,并展现出新兴的时空推理能力。
Key Takeaways
- 强化学习在提升多模态大型语言模型的推理能力方面取得进展。
- Group Relative Policy Optimization (GRPO) 和基于规则的奖励机制在文本和图像领域具有应用前景。
- 本研究探索了Reinforcement Fine-Tuning (RFT) 与 GRPO 在视频MLLMs中的应用。
- RFT高度注重数据效率,用于特定任务的改进。
- 通过多任务RFT,成功开发出VideoChat-R1,该模型在时空感知任务上表现卓越。
- VideoChat-R1相比Qwen2.5-VL-7B,在时空感知任务上的性能大幅度提升。
点此查看论文截图

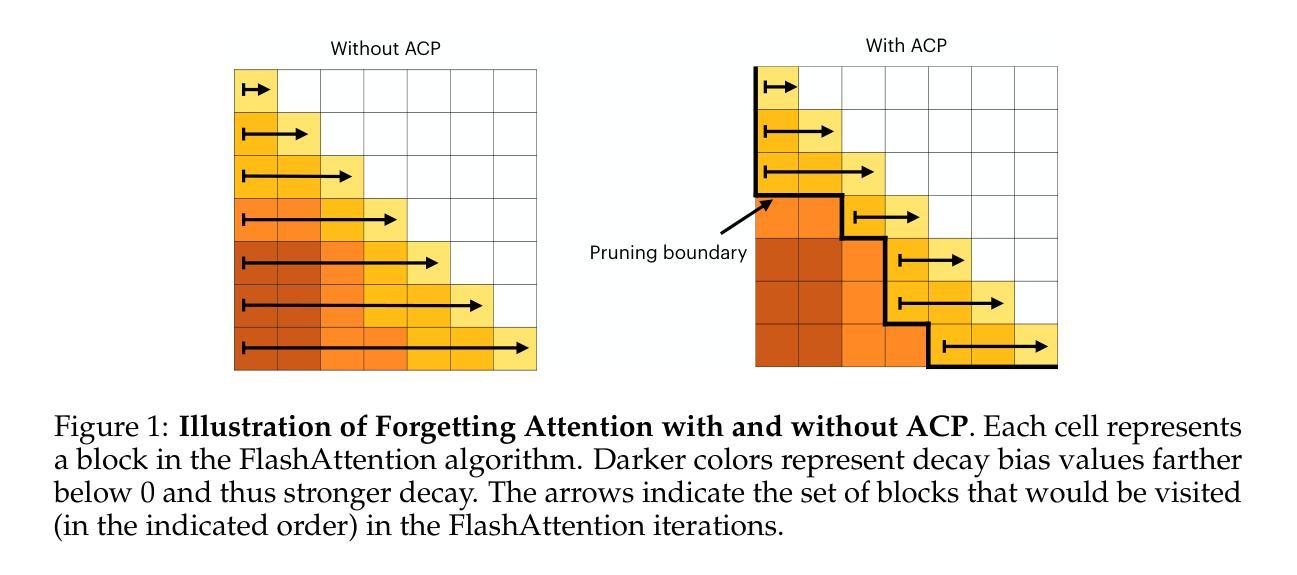
Adaptive Computation Pruning for the Forgetting Transformer
Authors:Zhixuan Lin, Johan Obando-Ceron, Xu Owen He, Aaron Courville
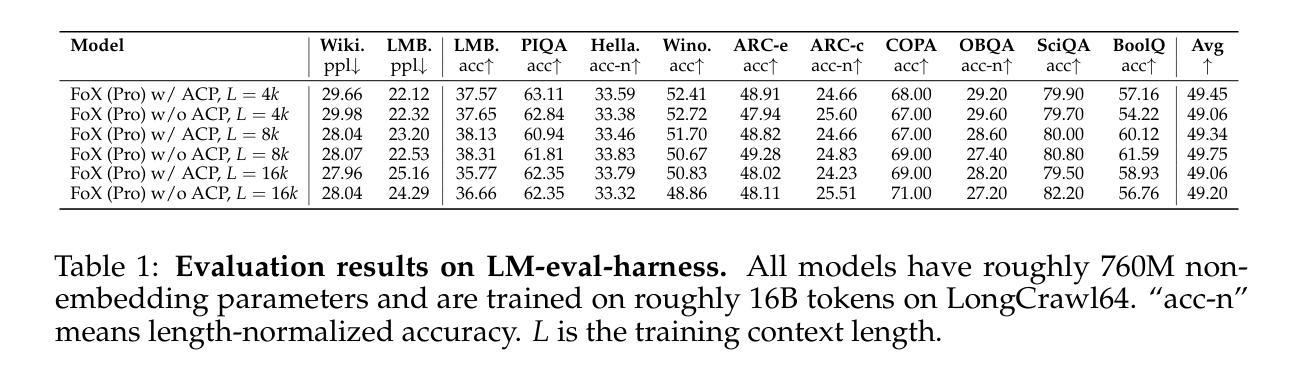
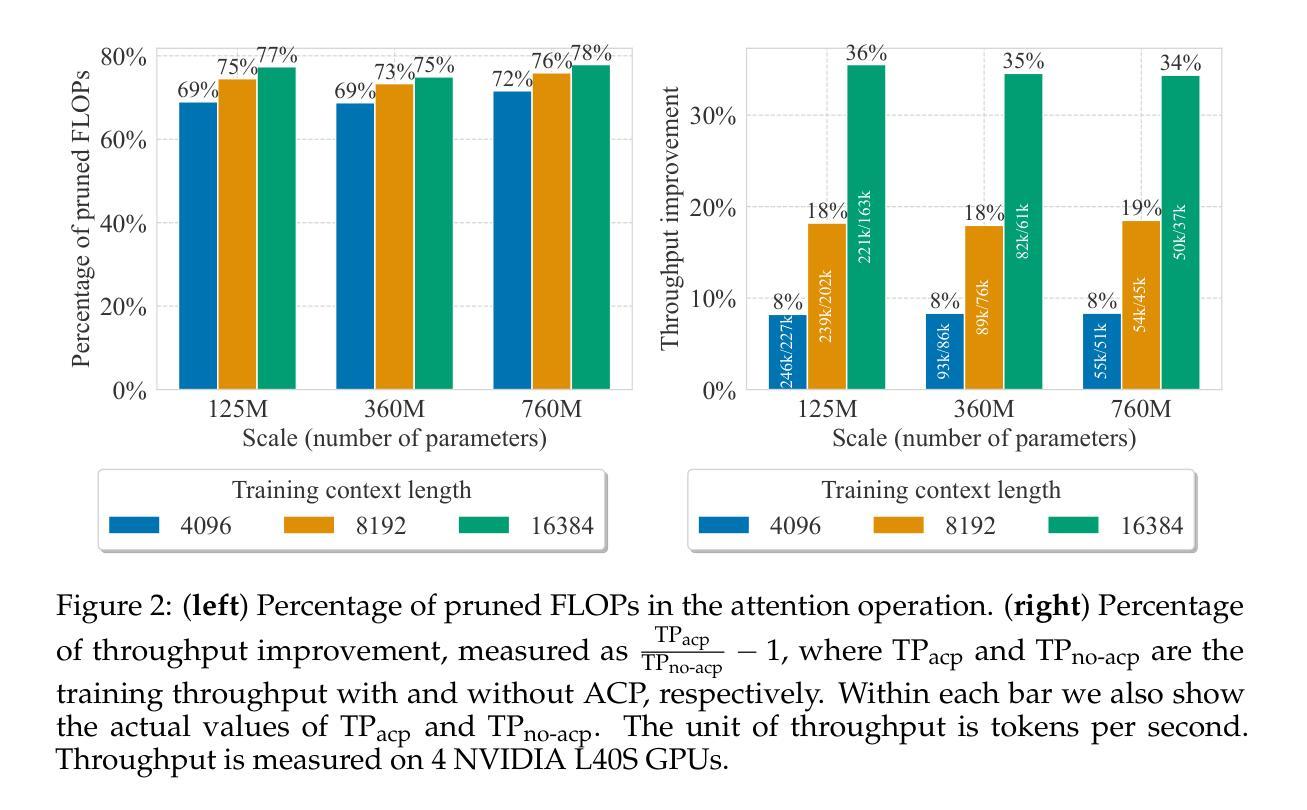
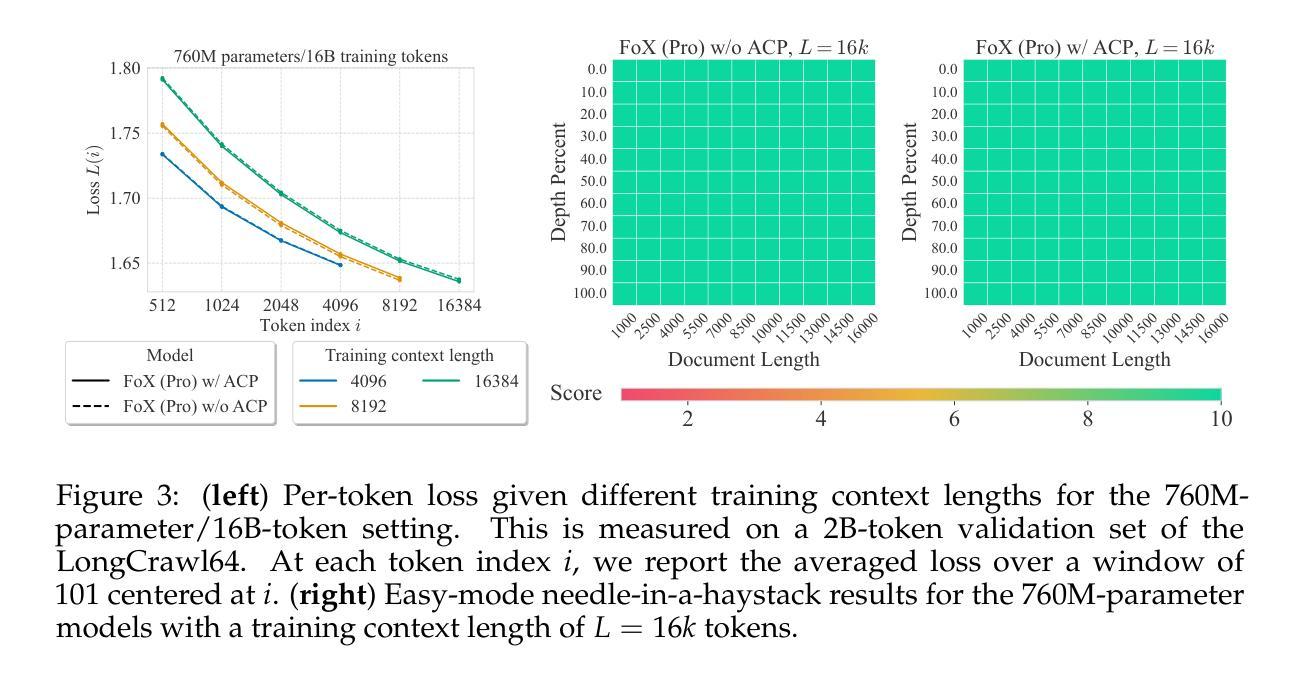
The recently proposed Forgetting Transformer (FoX) incorporates a forget gate into softmax attention and has shown consistently better or on-par performance compared to the standard RoPE-based Transformer. Notably, many attention heads in FoX tend to forget quickly, causing their output at each timestep to rely primarily on the local context. Based on this observation, we propose Adaptive Computation Pruning (ACP) for FoX, a method that dynamically prunes computations involving input-output dependencies that are strongly decayed by the forget gate. This is achieved using a dynamically set pruning threshold that ensures that the pruned attention weights remain negligible. We apply ACP to language model pretraining with FoX and show it consistently reduces the number of FLOPs in softmax attention by around 70% across different model sizes and context lengths, resulting in a roughly 10% to 35% improvement in training throughput. Furthermore, longer context lengths yield greater computational savings. All these speed improvements are achieved without any performance degradation. We also perform several analyses to provide deeper insights into our method, such as examining the pruning patterns and analyzing the distribution of FLOP savings across different attention heads. Our code is available at https://github.com/zhixuan-lin/arctic-fox.
最近提出的遗忘转换器(FoX)将遗忘门纳入softmax注意力机制,与基于RoPE的标准转换器相比,其性能一直表现更好或相当。值得注意的是,FoX中的许多注意力头倾向于快速遗忘,导致它们在每个时间步的输出主要依赖于局部上下文。基于这一观察,我们为FoX提出了自适应计算剪枝(ACP)方法,该方法动态剪枝涉及被遗忘门强烈衰减的输入-输出依赖关系的计算。这是通过动态设置剪枝阈值来实现的,该阈值确保被剪枝的注意力权重保持微不足道。我们将ACP应用于使用FoX的语言模型预训练,并证明它能在不同模型大小和上下文长度的情况下,将softmax注意力的FLOPs数量减少约70%,从而导致训练吞吐量提高约10%至35%。此外,较长的上下文长度可以产生更大的计算节省。所有这些速度提升都没有造成性能下降。我们还进行了几项分析,以更深入的方式了解我们的方法,如检查剪枝模式和分析不同注意力头之间FLOPs节省的分布。我们的代码可在https://github.com/zhixuan-lin/arctic-fox上找到。
论文及项目相关链接
PDF Preprint. Under review
Summary
最近提出的遗忘变压器(FoX)在softmax注意力中融入了遗忘门,其性能较标准的基于RoPE的Transformer表现更优异或相当。观察到FoX中许多注意力头快速遗忘,导致输出主要依赖局部上下文,因此提出自适应计算剪枝(ACP)方法。ACP通过动态设定剪枝阈值,确保被剪枝的注意力权重保持微小,实现了在训练过程中对计算资源的动态管理。将ACP应用于语言模型预训练的FoX上,能有效减少softmax注意力的浮点运算次数约70%,同时提高训练效率约10%至35%。更长的上下文长度能带来更大的计算节省。这些提升均未导致性能下降。我们还进行了深入分析,如研究剪枝模式和分析不同注意力头的浮点运算节省分布等。代码已公开在GitHub上。
Key Takeaways
- 遗忘变压器(FoX)结合了遗忘门和softmax注意力机制,展现出优异的性能表现。
- 许多FoX的注意力头存在快速遗忘现象,导致输出主要依赖局部上下文信息。
- 提出自适应计算剪枝(ACP)方法,通过动态管理计算资源以提高训练效率。
- ACP在FoX语言模型预训练中应用广泛,能有效减少浮点运算次数约70%,提高训练效率达10%至35%。
- 更长的上下文长度能带来更大的计算节省。
- ACP方法未导致性能下降,说明其有效性。
点此查看论文截图


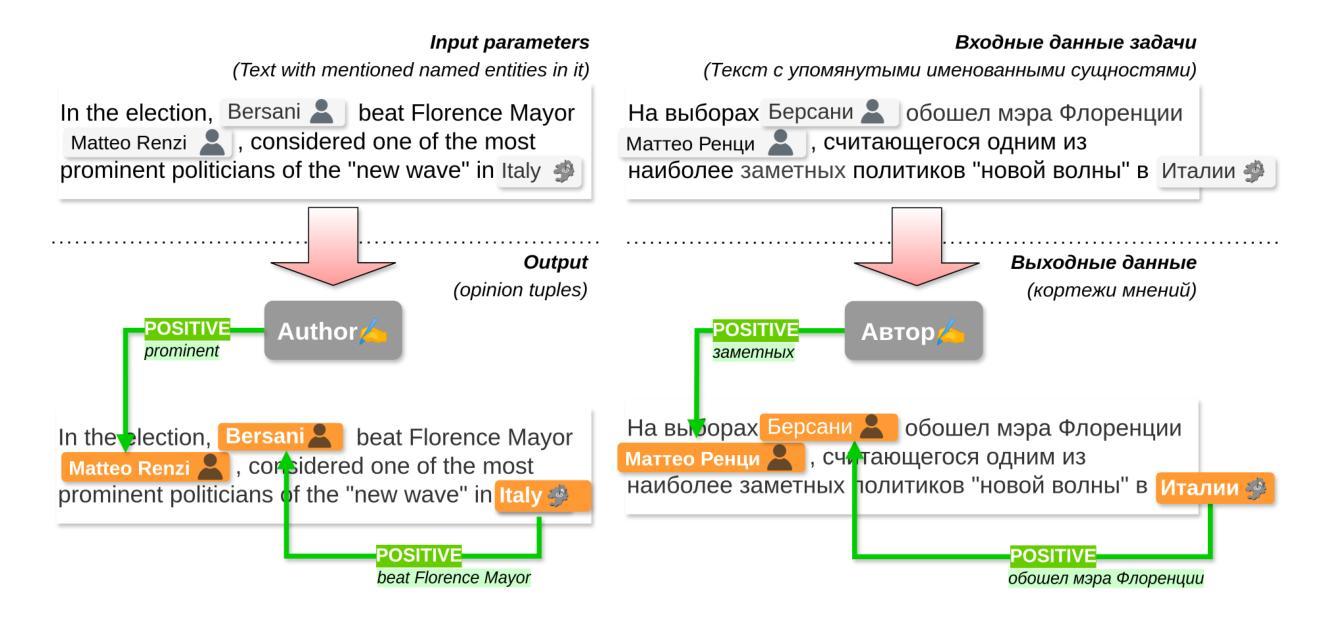
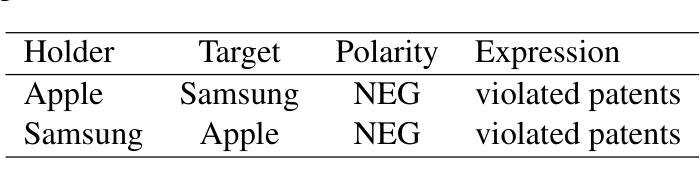
RuOpinionNE-2024: Extraction of Opinion Tuples from Russian News Texts
Authors:Natalia Loukachevitch, Natalia Tkachenko, Anna Lapanitsyna, Mikhail Tikhomirov, Nicolay Rusnachenko
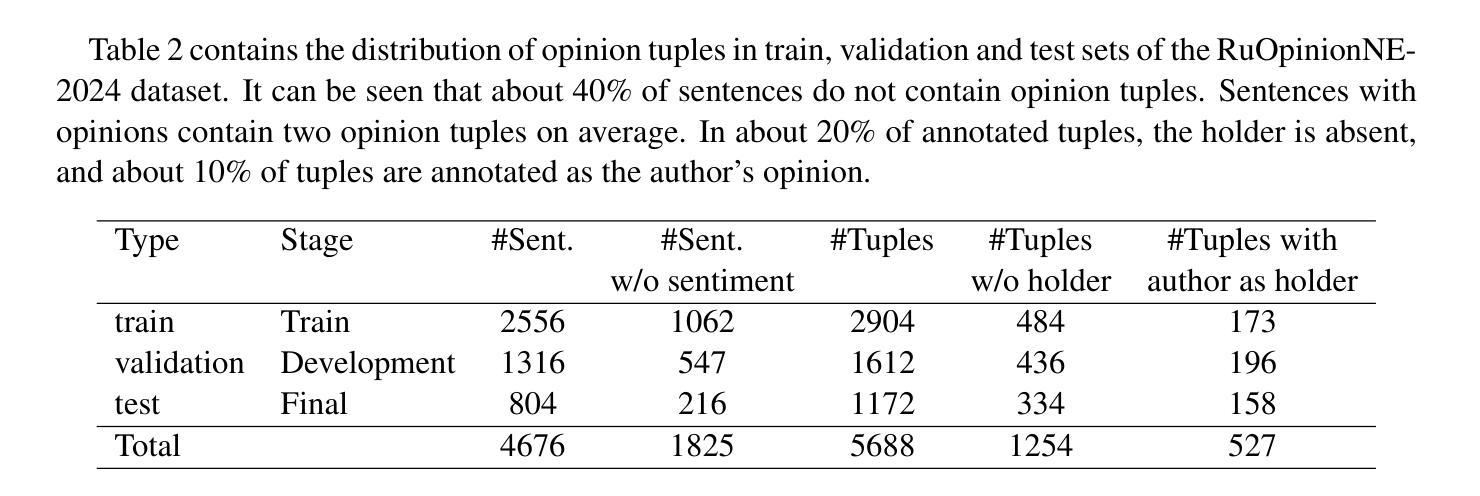
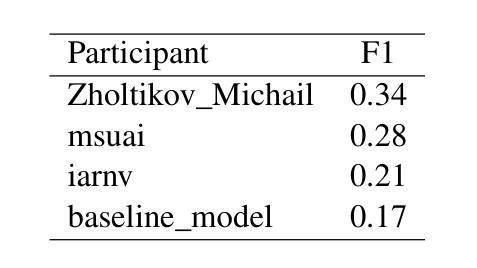
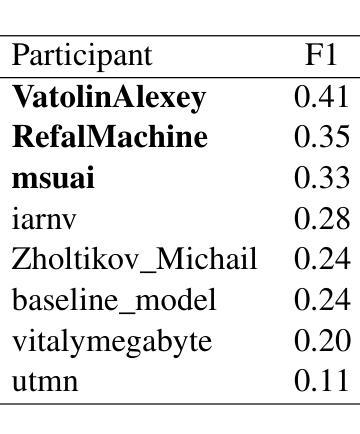
In this paper, we introduce the Dialogue Evaluation shared task on extraction of structured opinions from Russian news texts. The task of the contest is to extract opinion tuples for a given sentence; the tuples are composed of a sentiment holder, its target, an expression and sentiment from the holder to the target. In total, the task received more than 100 submissions. The participants experimented mainly with large language models in zero-shot, few-shot and fine-tuning formats. The best result on the test set was obtained with fine-tuning of a large language model. We also compared 30 prompts and 11 open source language models with 3-32 billion parameters in the 1-shot and 10-shot settings and found the best models and prompts.
本文介绍了从俄罗斯新闻文本中提取结构化意见的对话评价共享任务。该任务的目标是提取给定句子中的意见元组,这些元组由情感持有者、目标、表达和持有者对目标的情感组成。该任务共收到超过100份提交。参赛者主要尝试使用大型语言模型进行零样本、小样本和微调格式的实验。在测试集上获得最佳结果的是对大型语言模型的微调。我们还比较了30个提示和11个开源语言模型,这些模型在1到32亿参数范围内,在单样本和十样本设置下,找到了最佳的模型和提示。
论文及项目相关链接
PDF RuOpinionNE-2024 represent a proceeding of RuSentNE-2023. It contributes with extraction and evaluation of factual statements that support the assigned sentiment
Summary
本文介绍了关于俄罗斯新闻文本中提取结构化意见的对话评价共享任务。该任务旨在从给定句子中提取意见元组,这些元组由情感持有者、目标对象、表达方式和情感组成。任务共收到超过100份提交,参赛者主要尝试使用大型语言模型进行零样本、小样本和微调格式的实验。最终,通过微调大型语言模型在测试集上取得了最佳结果。此外,本文还对比了不同提示和开源语言模型的表现,找到了最佳模型和提示。
Key Takeaways
- 对话评价共享任务旨在从俄罗斯新闻文本中提取结构化意见。
- 任务要求提取意见元组,包括情感持有者、目标对象、表达方式和情感。
- 任务共收到超过100份提交。
- 参赛者主要使用大型语言模型进行实验,包括零样本、小样本和微调格式。
- 通过微调大型语言模型在测试集上获得最佳结果。
- 对比了不同提示和开源语言模型的表现。
点此查看论文截图


FeedbackEval: A Benchmark for Evaluating Large Language Models in Feedback-Driven Code Repair Tasks
Authors:Dekun Dai, MingWei Liu, Anji Li, Jialun Cao, Yanlin Wang, Chong Wang, Xin Peng, Zibin Zheng
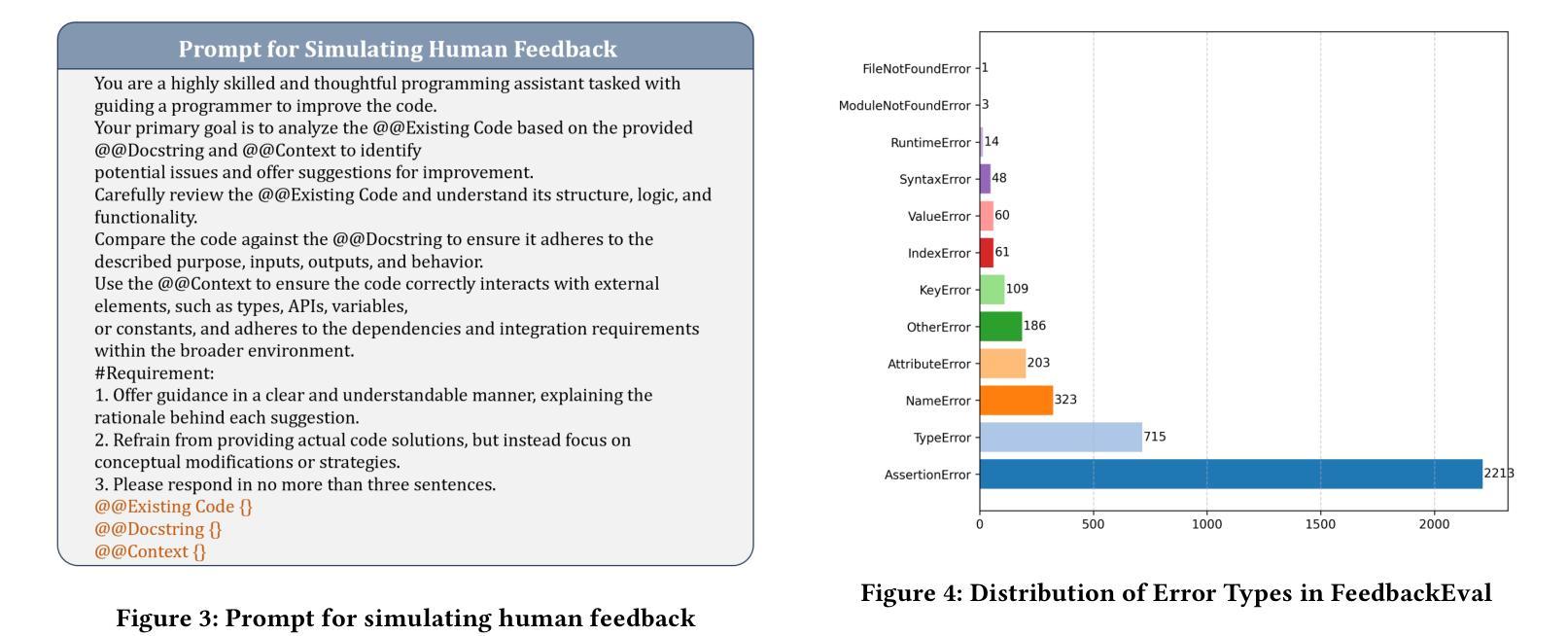
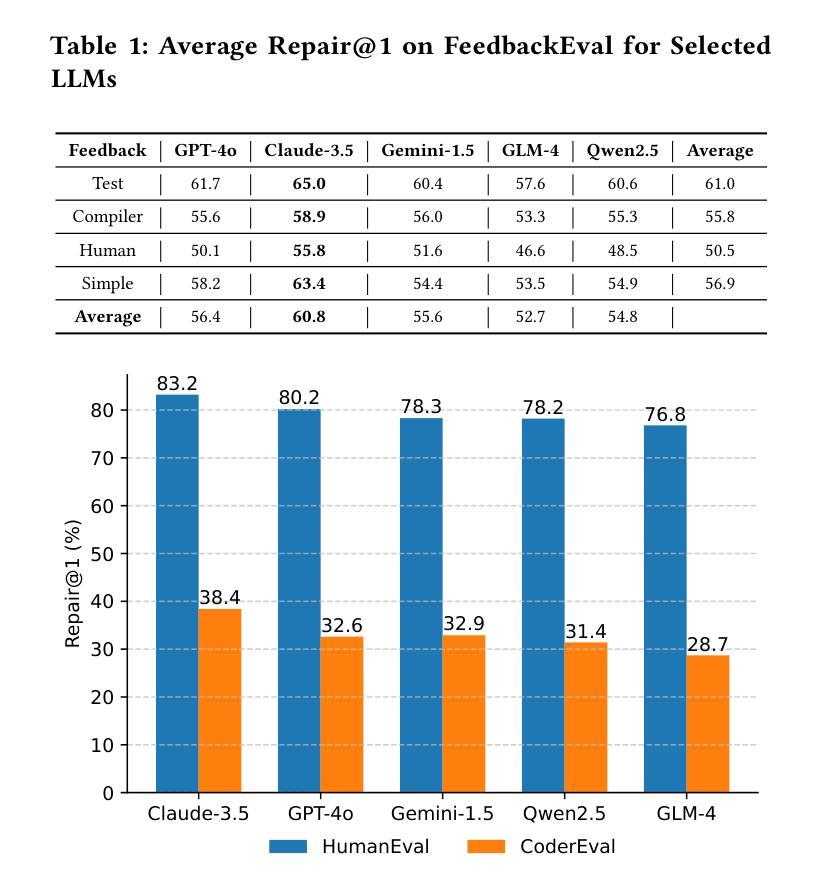
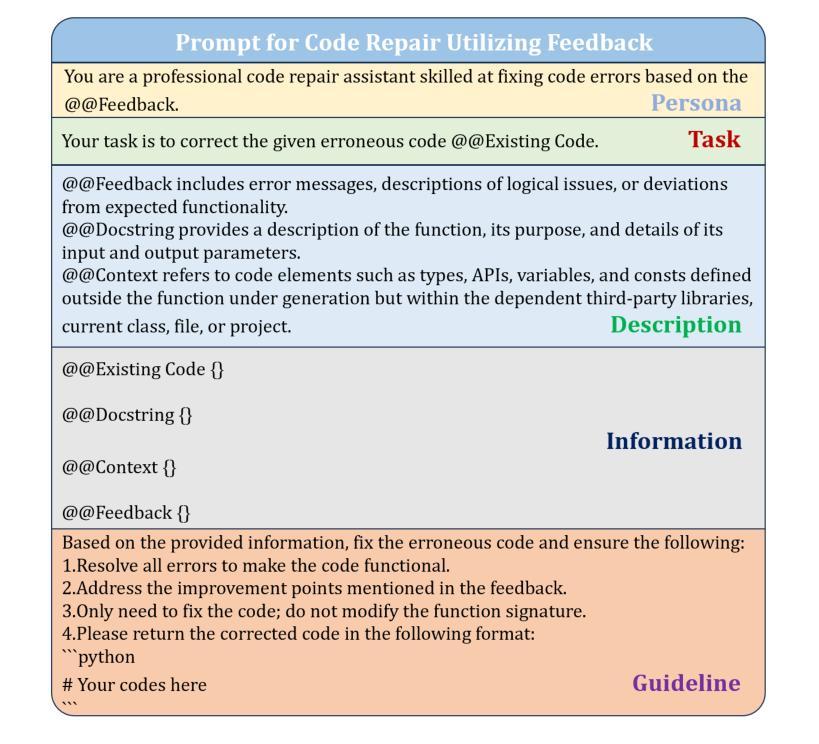
Code repair is a fundamental task in software development, facilitating efficient bug resolution and software maintenance. Although large language models (LLMs) have demonstrated considerable potential in automated code repair, their ability to comprehend and effectively leverage diverse types of feedback remains insufficiently understood. To bridge this gap, we introduce FeedbackEval, a systematic benchmark for evaluating LLMs’ feedback comprehension and performance in code repair tasks. We conduct a comprehensive empirical study on five state-of-the-art LLMs, including GPT-4o, Claude-3.5, Gemini-1.5, GLM-4, and Qwen2.5, to evaluate their behavior under both single-iteration and iterative code repair settings. Our results show that structured feedback, particularly in the form of test feedback, leads to the highest repair success rates, while unstructured feedback proves significantly less effective. Iterative feedback further enhances repair performance, though the marginal benefit diminishes after two or three rounds. Moreover, prompt structure is shown to be critical: incorporating docstrings, contextual information, and explicit guidelines substantially improves outcomes, whereas persona-based, chain-of-thought, and few-shot prompting strategies offer limited benefits in single-iteration scenarios. This work introduces a robust benchmark and delivers practical insights to advance the understanding and development of feedback-driven code repair using LLMs.
代码修复是软件开发中的一项基本任务,能够促进高效的错误解决和软件维护。尽管大型语言模型(LLM)在自动代码修复中展示了巨大的潜力,但它们理解和有效利用各种反馈的能力仍未能得到充分理解。为了弥补这一差距,我们引入了FeedbackEval,这是一个用于评估LLM在代码修复任务中的反馈理解和性能的系统性基准测试。我们对五款最先进的大型语言模型进行了全面的实证研究,包括GPT-4o、Claude-3.5、Gemini-1.5、GLM-4和Qwen2.5,以评估它们在单轮和迭代代码修复设置下的行为。我们的结果表明,结构化的反馈,尤其是测试形式的反馈,会导致最高的修复成功率,而结构不良的反馈证明效果较差。迭代反馈进一步提高了修复性能,但两轮或三轮后的边际效益会递减。此外,提示结构也被证明是关键的:融入文档字符串、上下文信息和明确的指导可以大幅度改善结果,而基于角色的思考、思维链和少量提示策略在单轮场景中提供有限的益处。这项工作引入了一个稳健的基准测试,并为推动使用LLM进行反馈驱动的代码修复的理解和发展提供了实用的见解。
论文及项目相关链接
Summary
代码修复是软件开发中的一项基本任务,能够促进有效的错误解决和软件维护。尽管大型语言模型(LLM)在自动代码修复中展示了巨大的潜力,但它们理解和有效利用各种反馈的能力仍不够明确。为了弥补这一差距,我们引入了FeedbackEval,这是一个用于评估LLM在代码修复任务中理解和表现的系统性基准测试。我们对五款最新LLM进行了全面的实证研究,包括GPT-4o、Claude-3.5、Gemini-1.5、GLM-4和Qwen2.5,以评估它们在单轮和迭代代码修复设置下的表现。研究结果表明,结构化反馈,尤其是测试反馈,导致最高的修复成功率,而非结构化反馈的证明效果甚微。迭代反馈进一步提高了修复性能,但两轮或三轮之后的边际效益逐渐减小。此外,提示结构至关重要:融入文档字符串、上下文信息和明确指导大幅改善了结果,而基于个性、思维链和少量提示的策略在单轮场景中提供了有限的效益。本研究引入了一个稳健的基准测试,为推进利用LLM的反馈驱动代码修复的理解和开发提供了实际见解。
Key Takeaways
- 大型语言模型(LLM)在自动代码修复中有巨大潜力。
- 反馈类型对LLM在代码修复中的表现有显著影响,结构化反馈(尤其是测试反馈)最为有效。
- 迭代反馈能提高LLM的修复性能,但边际效益有限。
- 提示结构对LLM的修复效果至关重要,融入文档字符串和上下文信息能大幅改善结果。
- 基于个性、思维链和少量提示的策略在单轮代码修复场景中效果有限。
- FeedbackEval是一个评估LLM在代码修复中理解和表现的有效基准测试。
点此查看论文截图


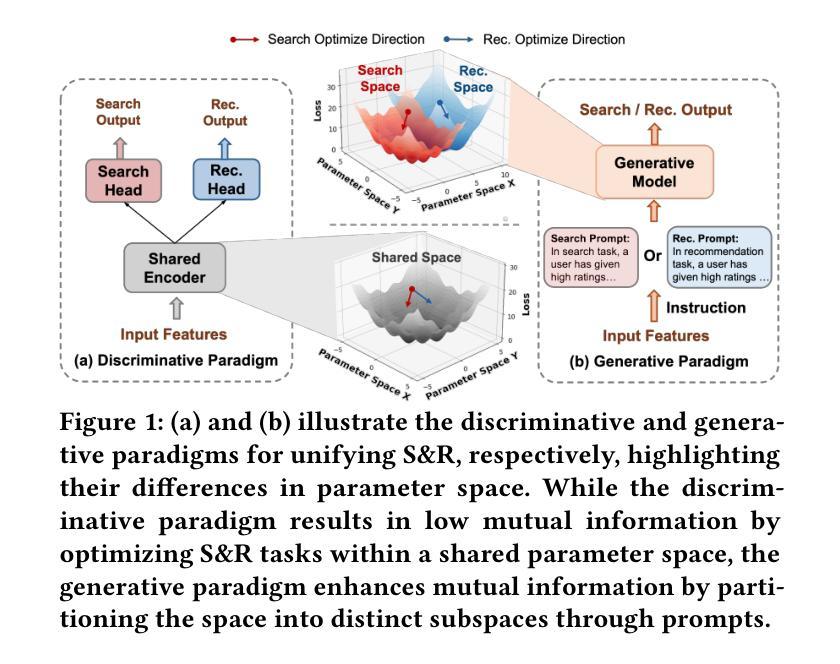
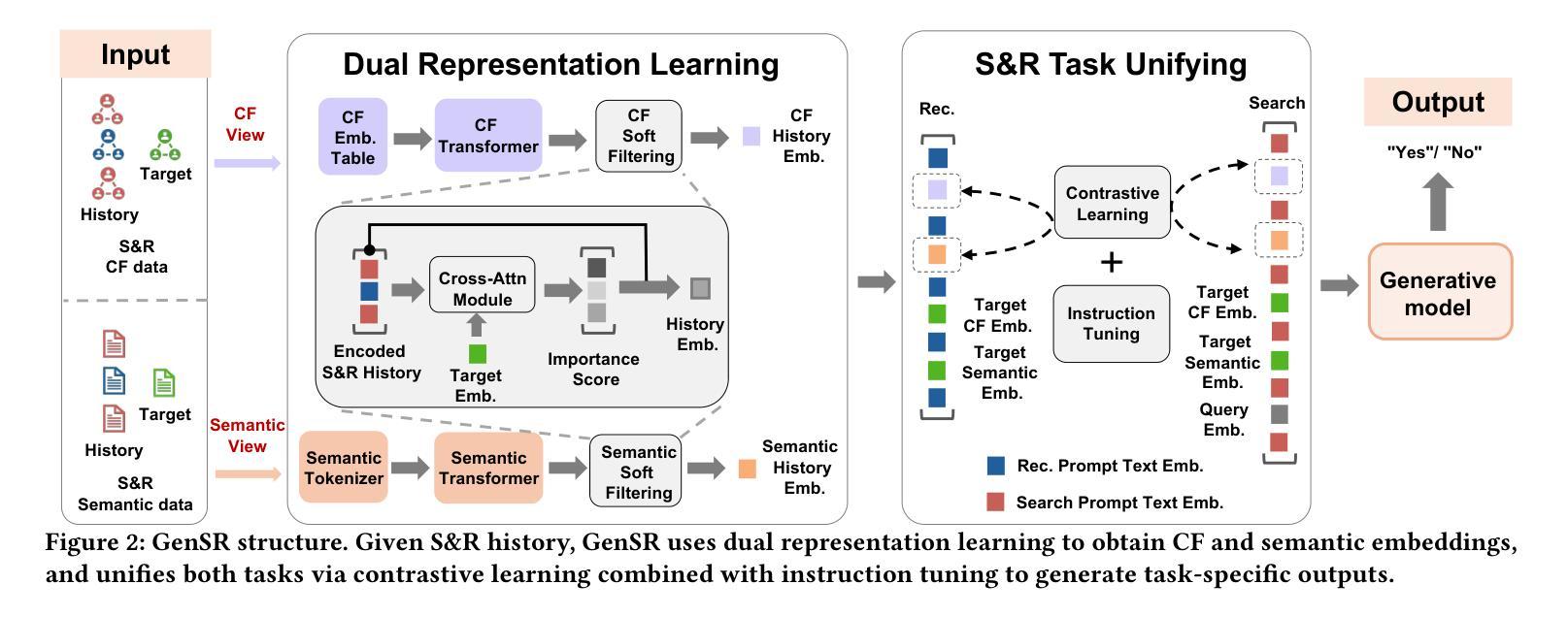
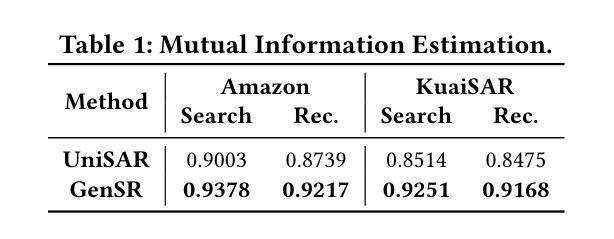
Unifying Search and Recommendation: A Generative Paradigm Inspired by Information Theory
Authors:Jujia Zhao, Wenjie Wang, Chen Xu, Xiuying Wang, Zhaochun Ren, Suzan Verberne
Recommender systems and search engines serve as foundational elements of online platforms, with the former delivering information proactively and the latter enabling users to seek information actively. Unifying both tasks in a shared model is promising since it can enhance user modeling and item understanding. Previous approaches mainly follow a discriminative paradigm, utilizing shared encoders to process input features and task-specific heads to perform each task. However, this paradigm encounters two key challenges: gradient conflict and manual design complexity. From the information theory perspective, these challenges potentially both stem from the same issue – low mutual information between the input features and task-specific outputs during the optimization process. To tackle these issues, we propose GenSR, a novel generative paradigm for unifying search and recommendation (S&R), which leverages task-specific prompts to partition the model’s parameter space into subspaces, thereby enhancing mutual information. To construct effective subspaces for each task, GenSR first prepares informative representations for each subspace and then optimizes both subspaces in one unified model. Specifically, GenSR consists of two main modules: (1) Dual Representation Learning, which independently models collaborative and semantic historical information to derive expressive item representations; and (2) S&R Task Unifying, which utilizes contrastive learning together with instruction tuning to generate task-specific outputs effectively. Extensive experiments on two public datasets show GenSR outperforms state-of-the-art methods across S&R tasks. Our work introduces a new generative paradigm compared with previous discriminative methods and establishes its superiority from the mutual information perspective.
推荐系统和搜索引擎作为在线平台的基础元素,前者主动提供信息,后者使用户能够主动寻找信息。在共享模型中统一这两项任务是有前途的,因为它可以增强用户建模和物品理解。之前的方法主要遵循判别范式,使用共享编码器处理输入特征和任务特定头来执行每个任务。然而,这种范式面临两个关键挑战:梯度冲突和手动设计复杂性。从信息论的角度来看,这些挑战都可能源于同样的问题——在优化过程中,输入特征和任务特定输出之间的互信息较低。为了解决这些问题,我们提出了GenSR,这是一种统一搜索和推荐(S&R)的新型生成范式。GenSR利用任务特定提示将模型参数空间分割成子空间,从而提高互信息。要为每个任务构建有效的子空间,GenSR首先为每个子空间准备信息表示,然后在统一模型中优化这两个子空间。具体来说,GenSR由两个主要模块组成:(1)双表示学习,它独立地建模协作和语义历史信息,以导出表达性的物品表示;(2)S&R任务统一,它利用对比学习与指令调整来有效地生成任务特定输出。在两个公共数据集上的大量实验表明,GenSR在S&R任务上优于最先进的方法。我们的工作与之前的判别方法相比,引入了一种新的生成范式,并从互信息角度证明了其优越性。
论文及项目相关链接
Summary
该文探讨了推荐系统和搜索引擎的统一模型,指出传统方法面临的挑战并提出了GenSR这一新的生成式框架来解决这些问题。GenSR通过任务特定提示将模型参数空间划分为子空间,提高互信息,包括两个主要模块:双表示学习和S&R任务统一。实验证明,GenSR在公开数据集上优于S&R任务的最先进方法。
Key Takeaways
- 推荐系统和搜索引擎是信息平台的基础组件,前者主动提供信息,后者使用户能够主动寻找信息。
- 现有方法主要遵循判别式范式,使用共享编码器处理输入特征和任务特定头执行每个任务,但面临梯度冲突和手动设计复杂性等挑战。
- 这些挑战可能源于优化过程中的低互信息。
- GenSR是一个新的生成式框架,通过任务特定提示划分模型参数空间来提高互信息。
- GenSR包括两个主要模块:双表示学习和S&R任务统一。
- 实验证明,GenSR在公开数据集上优于其他S&R任务的最先进方法。
点此查看论文截图

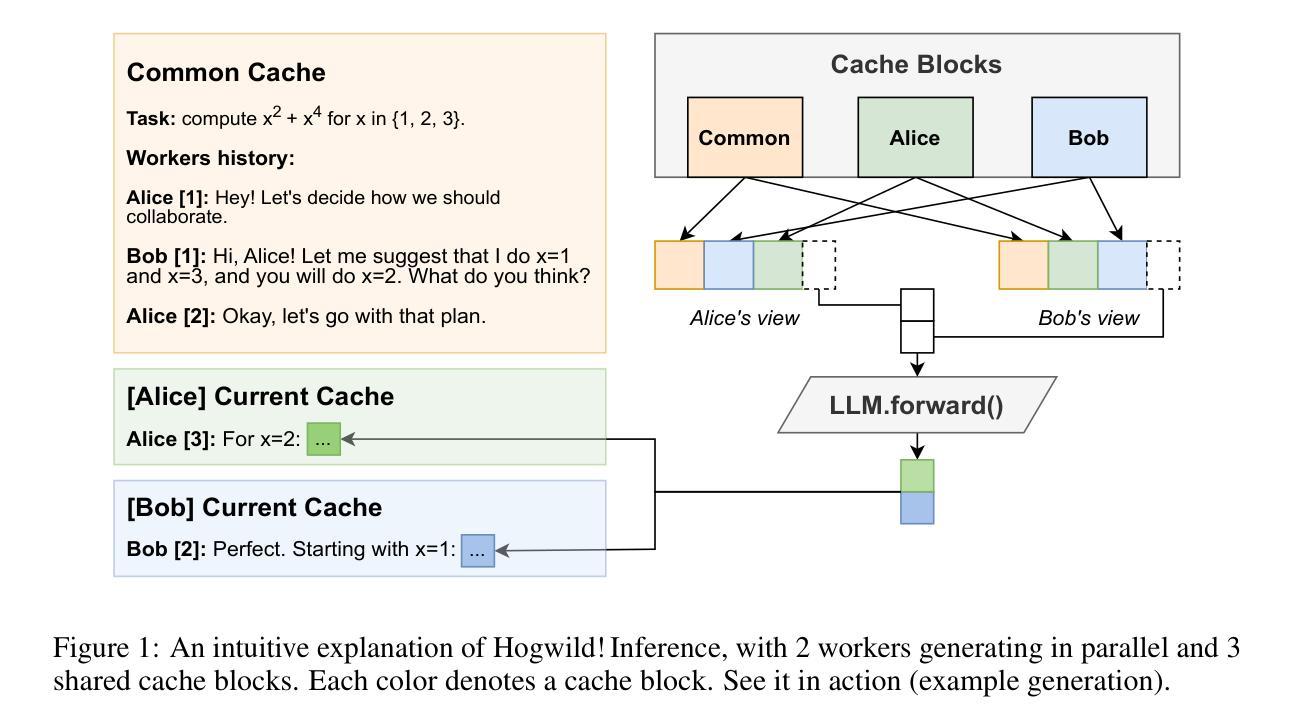
Hogwild! Inference: Parallel LLM Generation via Concurrent Attention
Authors:Gleb Rodionov, Roman Garipov, Alina Shutova, George Yakushev, Vage Egiazarian, Anton Sinitsin, Denis Kuznedelev, Dan Alistarh
Large Language Models (LLMs) have demonstrated the ability to tackle increasingly complex tasks through advanced reasoning, long-form content generation, and tool use. Solving these tasks often involves long inference-time computations. In human problem solving, a common strategy to expedite work is collaboration: by dividing the problem into sub-tasks, exploring different strategies concurrently, etc. Recent research has shown that LLMs can also operate in parallel by implementing explicit cooperation frameworks, such as voting mechanisms or the explicit creation of independent sub-tasks that can be executed in parallel. However, each of these frameworks may not be suitable for all types of tasks, which can hinder their applicability. In this work, we propose a different design approach: we run LLM “workers” in parallel , allowing them to synchronize via a concurrently-updated attention cache and prompt these workers to decide how best to collaborate. Our approach allows the instances to come up with their own collaboration strategy for the problem at hand, all the while “seeing” each other’s partial progress in the concurrent cache. We implement this approach via Hogwild! Inference: a parallel LLM inference engine where multiple instances of the same LLM run in parallel with the same attention cache, with “instant” access to each other’s generated tokens. Hogwild! inference takes advantage of Rotary Position Embeddings (RoPE) to avoid recomputation while improving parallel hardware utilization. We find that modern reasoning-capable LLMs can perform inference with shared Key-Value cache out of the box, without additional fine-tuning.
大型语言模型(LLM)已展现出通过高级推理、长形式内容生成和工具使用来处理日益复杂任务的能力。解决这些任务通常涉及长时间的推理计算。在人类的问题解决中,加速工作的常用策略是协作:将问题划分为子任务,同时探索不同的策略等。最近的研究表明,LLM也可以通过实施明确的合作框架进行并行操作,如投票机制或创建可以并行执行的独立子任务。然而,这些框架可能并不适用于所有类型的任务,这会阻碍其适用性。在此工作中,我们提出了一种不同的设计思路:我们并行运行LLM“工作者”,允许它们通过实时更新的关注缓存进行同步,并提示这些工作者决定如何最佳协作。我们的方法允许实例为手头问题制定自己的协作策略,同时“查看”彼此在并发缓存中的部分进度。我们通过“Hogwild”实现这种方法:一种并行LLM推理引擎,其中同一LLM的多个实例可以并行运行并共享关注缓存,彼此之间可以即时访问生成的令牌。“Hogwild”推理利用旋转位置嵌入(RoPE)避免重新计算,同时提高并行硬件的利用率。我们发现,现代具有推理能力的大型语言模型可以在共享键值缓存的情况下进行推理,无需额外的微调。
论文及项目相关链接
PDF Preprint, work in progress
Summary
大型语言模型(LLM)具备处理复杂任务的能力,如高级推理、长文本内容生成和工具使用。通过实施明确的合作框架,如投票机制和独立子任务的创建,LLM可并行操作以加快任务处理速度。本研究提出了一种新的设计方法,即并行运行LLM“工作者”,通过同步更新的关注缓存来提示工作者如何最佳协作。这种方法允许实例为手头问题制定自己的协作策略,同时“查看”彼此的部分进度。本研究通过霍格威尔(Hogwild)推理实现这一方法:一种并行LLM推理引擎,其中同一LLM的多个实例可以并行运行并共享关注缓存,可即时访问彼此的生成标记。霍格威尔推理利用旋转位置嵌入(RoPE)避免重新计算,提高并行硬件利用率。研究发现,现代具备推理能力的LLM可在无需额外微调的情况下使用共享键值缓存进行推理。
Key Takeaways
- 大型语言模型(LLM)能够处理复杂的任务,包括高级推理、长文本内容生成和工具使用。
- LLM可以通过实施明确的合作框架进行并行操作以加快任务处理速度。
- 本研究提出了一种新的设计方法来促进LLM之间的协作,即通过并行运行LLM“工作者”,并允许它们通过关注缓存进行同步。
- 这种新方法允许LLM实例为特定问题制定自己的协作策略,并可以实时查看其他实例的进度。
- 霍格威尔(Hogwild)推理是实现这一方法的一种手段,它允许多个LLM实例并行运行并共享关注缓存。
- 旋转位置嵌入(RoPE)被用于提高硬件利用率并避免在推理过程中的重新计算。
点此查看论文截图

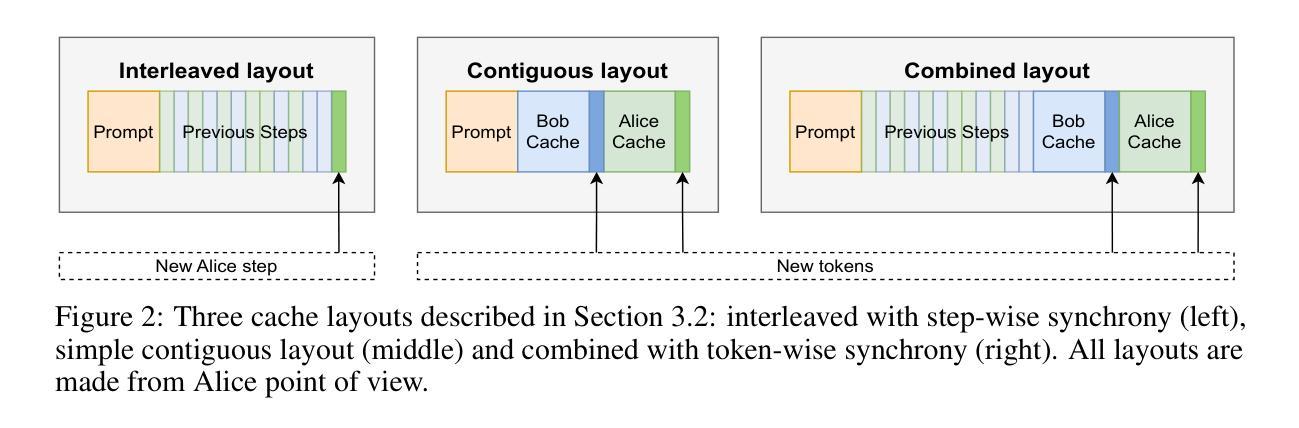
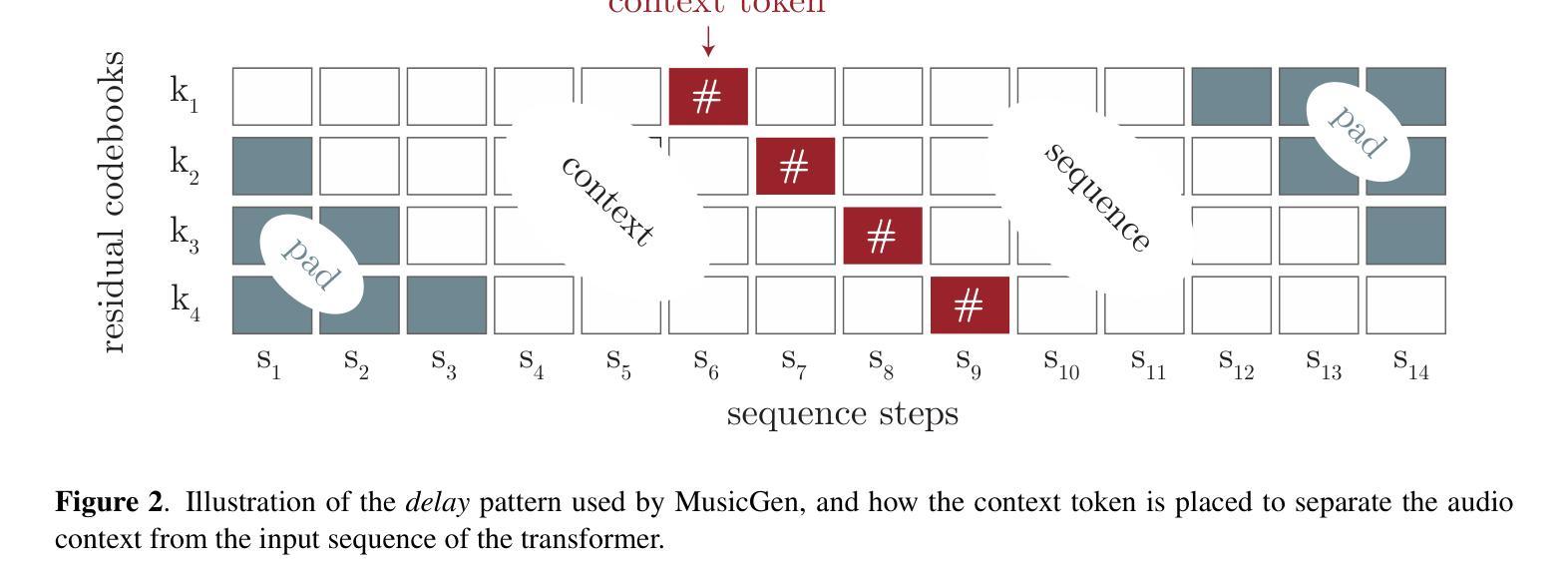
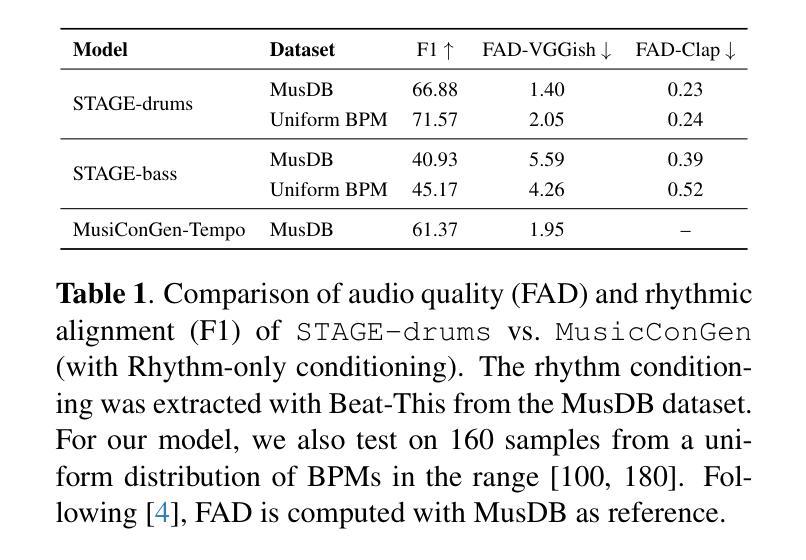
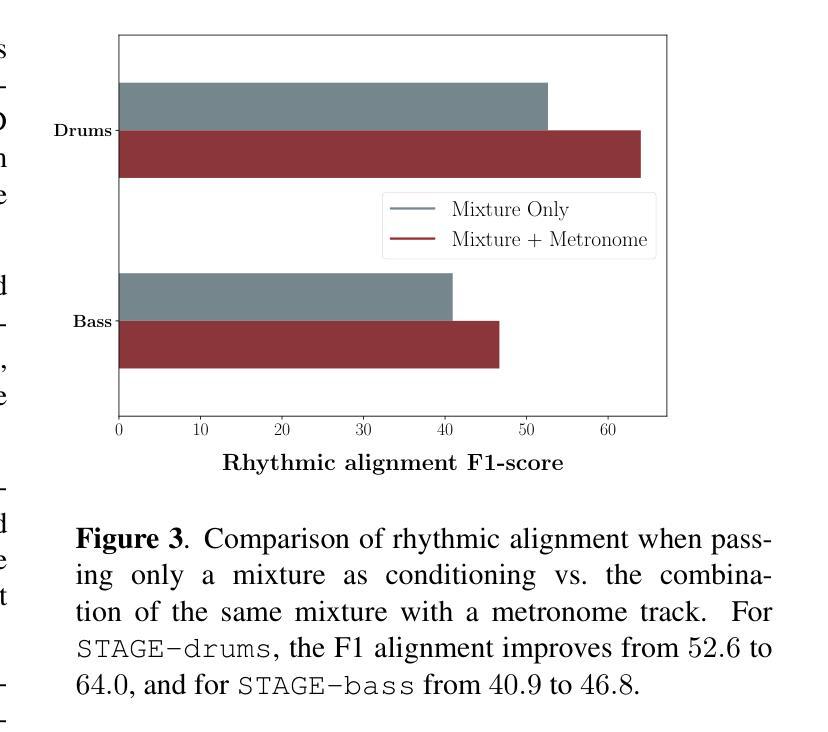
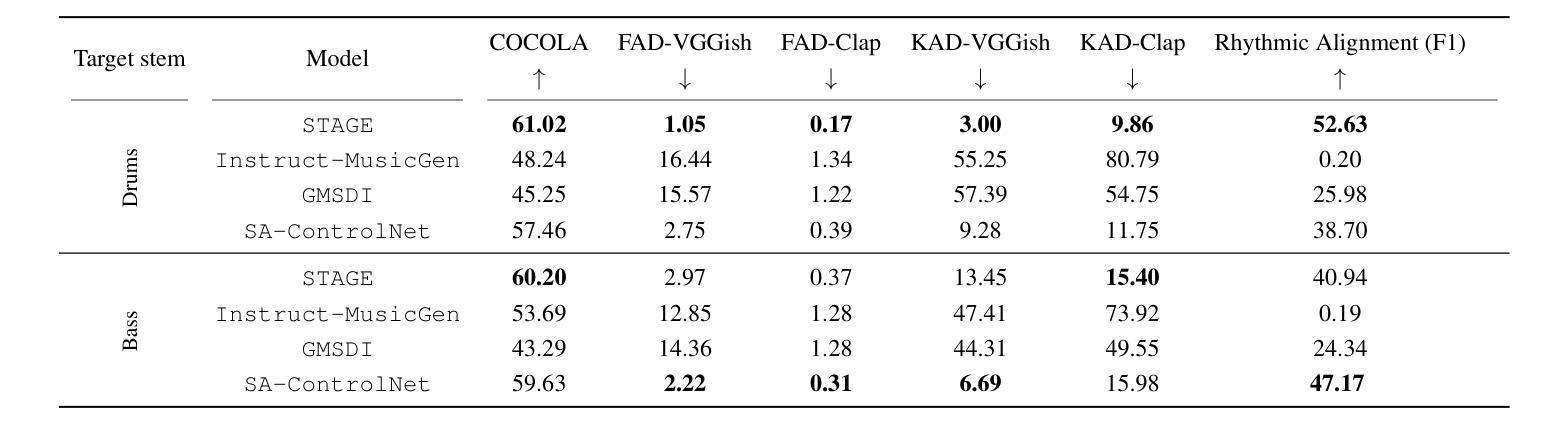
STAGE: Stemmed Accompaniment Generation through Prefix-Based Conditioning
Authors:Giorgio Strano, Chiara Ballanti, Donato Crisostomi, Michele Mancusi, Luca Cosmo, Emanuele Rodolà
Recent advances in generative models have made it possible to create high-quality, coherent music, with some systems delivering production-level output. Yet, most existing models focus solely on generating music from scratch, limiting their usefulness for musicians who want to integrate such models into a human, iterative composition workflow. In this paper we introduce STAGE, our STemmed Accompaniment GEneration model, fine-tuned from the state-of-the-art MusicGen to generate single-stem instrumental accompaniments conditioned on a given mixture. Inspired by instruction-tuning methods for language models, we extend the transformer’s embedding matrix with a context token, enabling the model to attend to a musical context through prefix-based conditioning. Compared to the baselines, STAGE yields accompaniments that exhibit stronger coherence with the input mixture, higher audio quality, and closer alignment with textual prompts. Moreover, by conditioning on a metronome-like track, our framework naturally supports tempo-constrained generation, achieving state-of-the-art alignment with the target rhythmic structure–all without requiring any additional tempo-specific module. As a result, STAGE offers a practical, versatile tool for interactive music creation that can be readily adopted by musicians in real-world workflows.
最近生成模型的进步使得创建高质量、连贯的音乐成为可能,一些系统甚至能够产生专业级别的输出。然而,大多数现有模型只专注于从零开始生成音乐,这限制了它们对于希望将这种模型融入人类迭代作曲工作流程的音乐家的实用性。在本文中,我们介绍了STAGE,我们的基于茎的伴奏生成模型(STAGE),它基于最先进的MusicGen进行微调,以在给定的混合下生成单茎乐器伴奏。受语言模型的指令调整方法的启发,我们扩展了转换器的嵌入矩阵,增加了一个上下文标记,使模型能够通过基于前缀的条件来关注音乐上下文。与基线相比,STAGE生成的伴奏与输入混合的连贯性更强,音频质量更高,与文本提示的对齐程度更高。此外,通过基于节拍器轨道的条件设置,我们的框架自然地支持节奏约束生成,实现了与目标节奏结构的一流对齐——所有这一切都不需要任何额外的特定节奏的模块。因此,作为一种结果,无论在现实中或是在数字世界里使用何种工具的情况下进行交互式音乐创作的情况下都能为我们提供一个绝佳的创作途径与实用的工具来使用以实现自己的想象力想法等。。总的来说,无论是在业余音乐创作还是在音乐生产工作中它都是一个灵活多变的工具来为我们的创作提供支持与帮助。
论文及项目相关链接
Summary
生成模型近期取得了重大进展,现在能够生成高质量、连贯的音乐,某些系统甚至能产出专业级别的作品。然而,大多数现有模型专注于从零开始生成音乐,忽略了音乐家们想要将这类模型融入人类迭代创作流程的需求。本文介绍了STAGE模型,这是一个基于MusicGen的精细化伴奏生成模型,能够通过给定的旋律生成单乐器伴奏。通过借鉴语言模型的指令微调方法,我们在transformer的嵌入矩阵中增加了一个上下文标记,使模型能够通过前缀条件关注音乐上下文。相较于其他模型,STAGE生成的伴奏与输入旋律更具连贯性、音频质量更高,并能更紧密地贴合文本提示。此外,通过以节拍器般的轨迹作为条件,我们的框架能够自然地支持节奏约束生成,无需任何额外的节奏特定模块,即可实现与目标节奏结构的最佳对齐。因此,STAGE为音乐家们提供了一个实用的、多功能工具,可轻松融入现实世界的音乐创作流程。
Key Takeaways
- 生成模型能生成高质量、连贯的音乐,但多数模型仅关注从零开始生成音乐。
- STAGE模型是基于MusicGen的精细化伴奏生成模型,能够生成与给定旋律匹配的伴奏。
- STAGE通过增加上下文标记的方式,使模型能够关注音乐上下文。
- 与其他模型相比,STAGE生成的伴奏与输入旋律更连贯,音频质量更高,并更紧密地贴合文本提示。
- STAGE支持以节拍器轨迹作为条件进行节奏约束生成,无需额外的节奏特定模块。
- STAGE框架为音乐家提供了一个实用的工具,可融入现实世界的音乐创作流程。
点此查看论文截图


Studying and Understanding the Effectiveness and Failures of Conversational LLM-Based Repair
Authors:Aolin Chen, Haojun Wu, Qi Xin, Steven P. Reiss, Jifeng Xuan
Automated program repair (APR) is designed to automate the process of bug-fixing. In recent years, thanks to the rapid development of large language models (LLMs), automated repair has achieved remarkable progress. Advanced APR techniques powered by conversational LLMs, most notably ChatGPT, have exhibited impressive repair abilities and gained increasing popularity due to the capabilities of the underlying LLMs in providing repair feedback and performing iterative patch improvement. Despite the superiority, conversational APR techniques still fail to repair a large number of bugs. For example, a state-of-the-art conversational technique ChatRepair does not correctly repair over half of the single-function bugs in the Defects4J dataset. To understand the effectiveness and failures of conversational LLM-based repair and provide possible directions for improvement, we studied the exemplary ChatRepair with a focus on comparing the effectiveness of its cloze-style and full function repair strategies, assessing its key iterative component for patch improvement, and analyzing the repair failures. Our study has led to a series of findings, which we believe provide key implications for future research.
自动化程序修复(APR)旨在自动进行故障修复。近年来,由于大型语言模型(LLM)的快速发展,自动化修复取得了显著的进步。由对话式LLM支持的高级APR技术,尤其是ChatGPT,展现出了令人印象深刻的修复能力,并因底层LLM提供修复反馈和进行迭代补丁改进的能力而越来越受欢迎。尽管如此,对话式APR技术仍然无法修复大量漏洞。例如,最先进的对话技术ChatRepair无法正确修复Defects4J数据集中超过一半的单功能漏洞。为了理解基于对话的LLM修复的有效性和失败原因,并提供可能的改进方向,我们研究了具有示范性的ChatRepair,重点关注比较其填空式与全功能修复策略的有效性,评估其用于补丁改进的关键迭代组件,并分析修复失败的原因。我们的研究得到了一系列发现,我们相信这些发现对未来研究具有关键启示意义。
论文及项目相关链接
Summary
基于大型语言模型(LLM)的自动化修复程序(APR)在近年来取得了显著进展。特别是ChatGPT等对话式LLM技术的出现,使得自动化修复能力得到了极大的提升。然而,尽管具有优越性,对话式APR技术仍然无法修复大量的bug。例如,最先进的对话技术ChatRepair并不能正确修复Defects4J数据集中一半以上的单功能bug。为了更好地理解对话式LLM修复技术的有效性和失败原因,并为改进提供方向,我们对ChatRepair进行了深入研究,重点关注其填空式修复策略和全功能修复策略的有效性对比、关键迭代组件的评估以及修复失败的深入分析。
Key Takeaways
- 自动化程序修复(APR)旨在自动修复bug,近年来因大型语言模型(LLM)的快速发展而取得了显著进展。
- 对话式APR技术,如ChatGPT和ChatRepair,虽具有显著优势,但仍存在大量修复失败的bug。
- ChatRepair的填空式修复策略和全功能修复策略的有效性对比是研究的重点。
- 评估迭代组件对于修复效果的提升是关键。
- 对修复失败的深入分析有助于理解现有技术的局限并为未来研究提供方向。
- 最先进的对话技术ChatRepair仍有一半以上的单功能bug无法正确修复。
点此查看论文截图

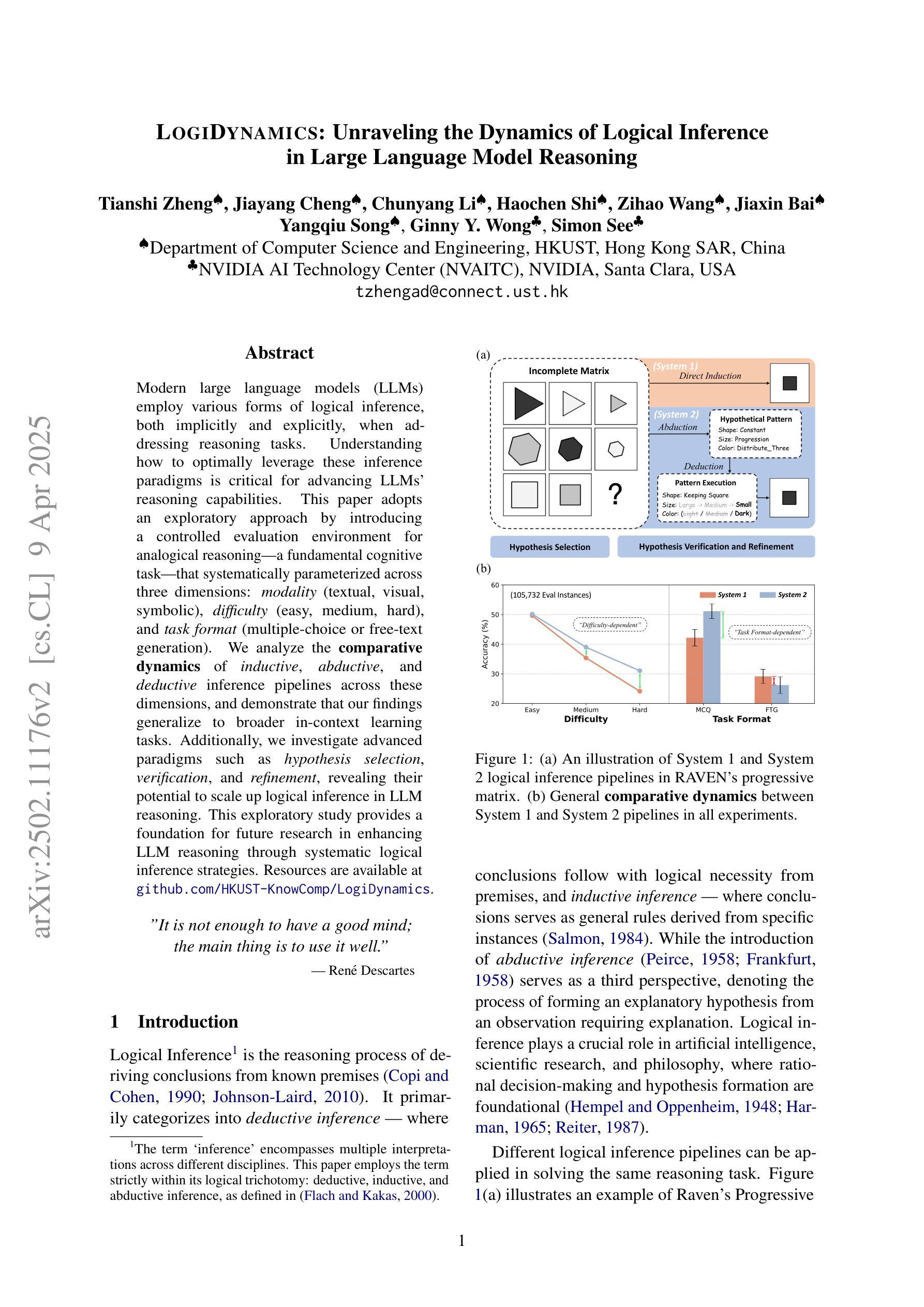
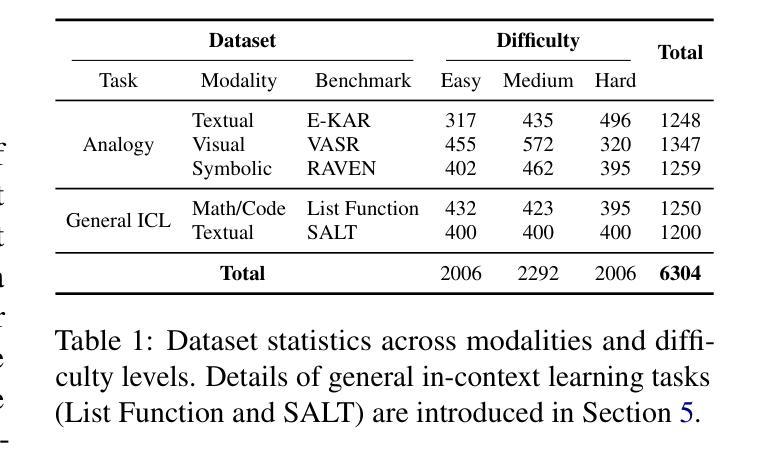
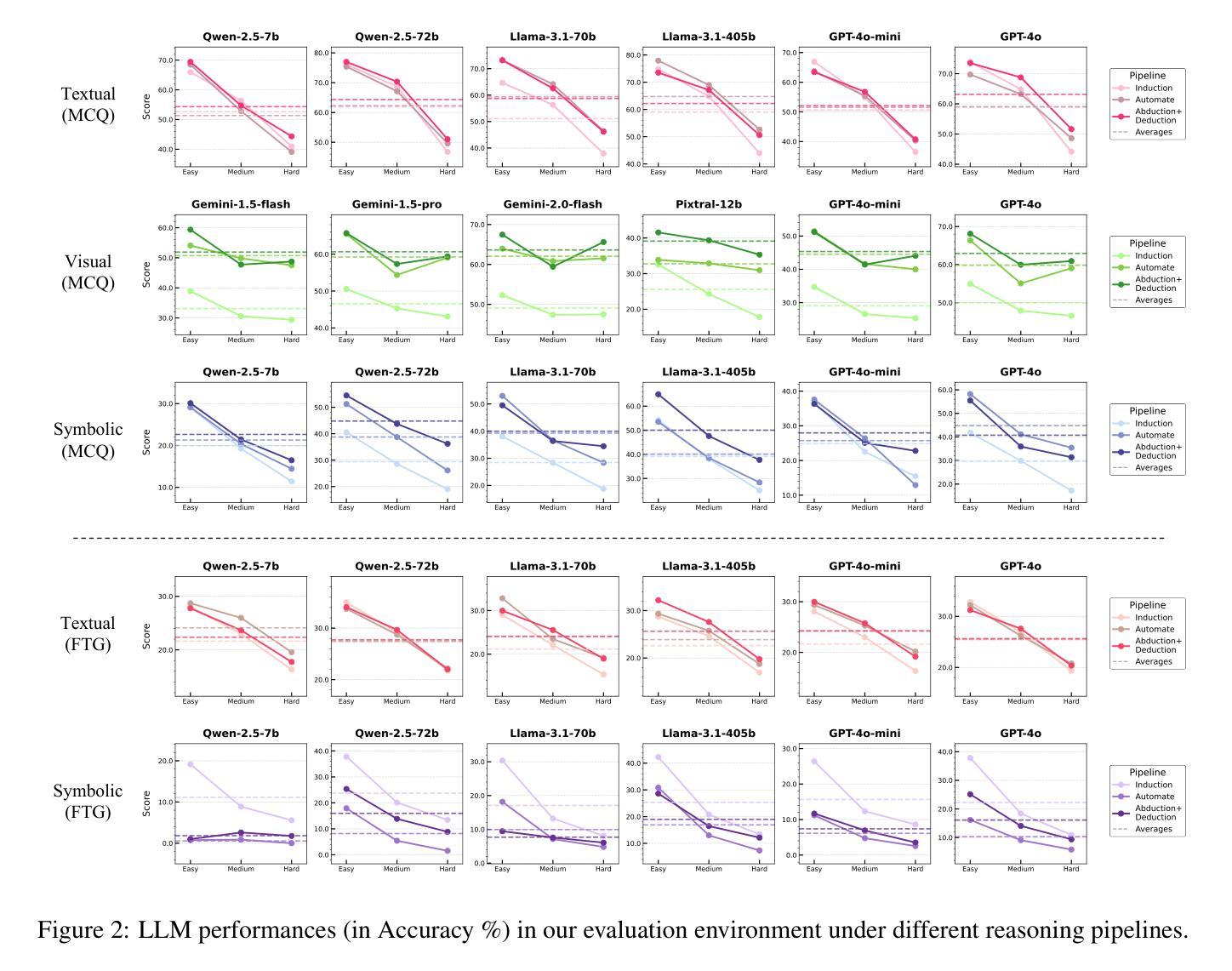
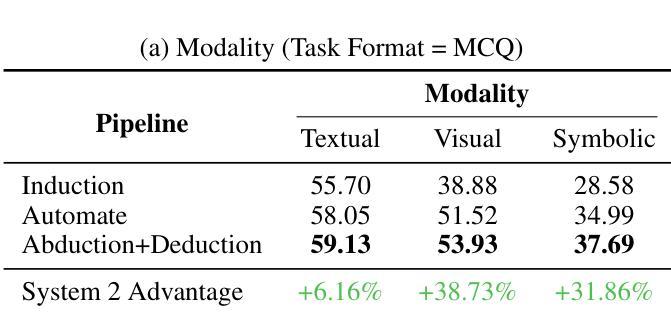
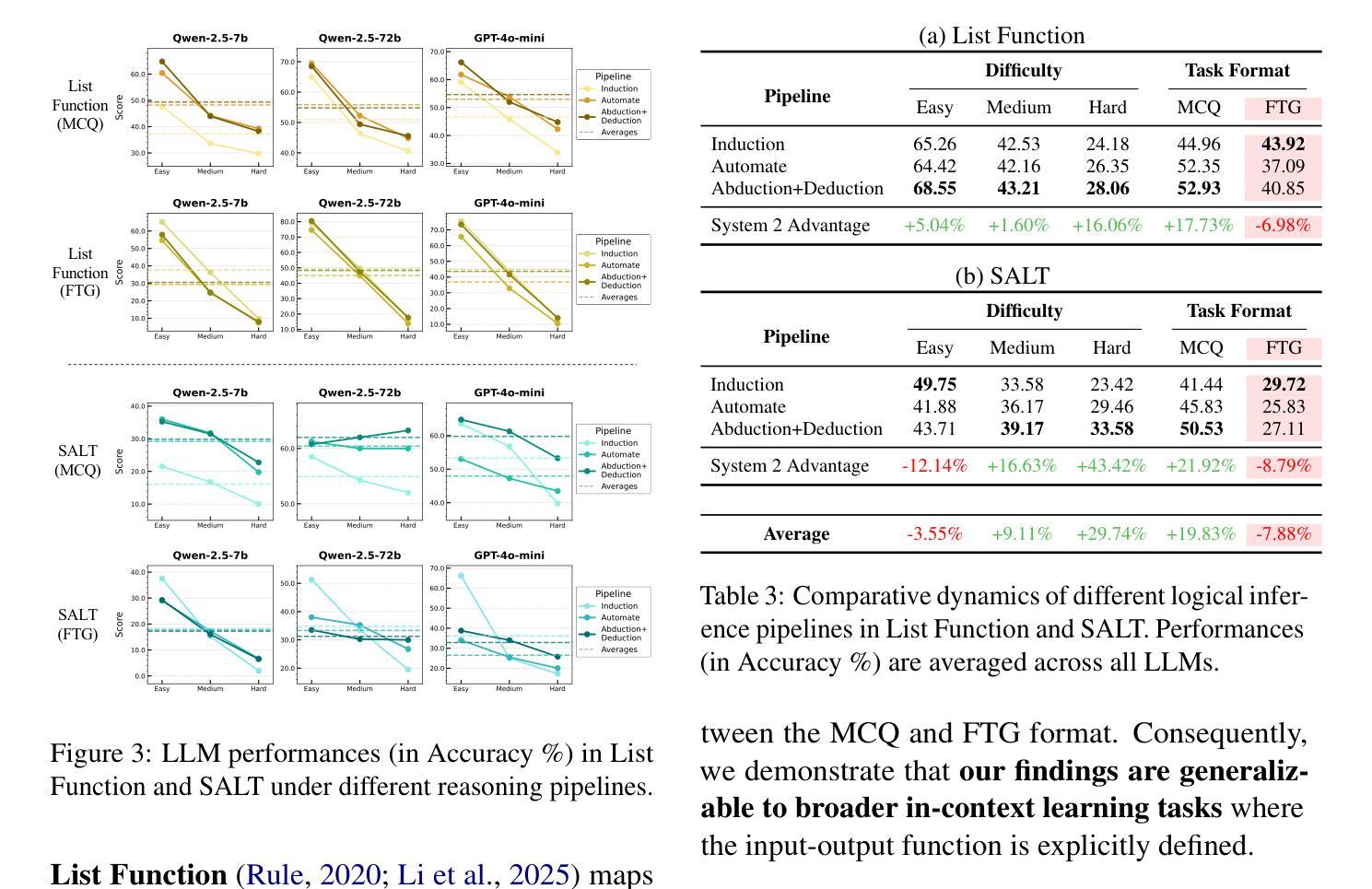
LogiDynamics: Unraveling the Dynamics of Logical Inference in Large Language Model Reasoning
Authors:Tianshi Zheng, Jiayang Cheng, Chunyang Li, Haochen Shi, Zihao Wang, Jiaxin Bai, Yangqiu Song, Ginny Y. Wong, Simon See
Modern large language models (LLMs) employ various forms of logical inference, both implicitly and explicitly, when addressing reasoning tasks. Understanding how to optimally leverage these inference paradigms is critical for advancing LLMs’ reasoning capabilities. This paper adopts an exploratory approach by introducing a controlled evaluation environment for analogical reasoning – a fundamental cognitive task – that is systematically parameterized across three dimensions: modality (textual, visual, symbolic), difficulty (easy, medium, hard), and task format (multiple-choice or free-text generation). We analyze the comparative dynamics of inductive, abductive, and deductive inference pipelines across these dimensions, and demonstrate that our findings generalize to broader in-context learning tasks. Additionally, we investigate advanced paradigms such as hypothesis selection, verification, and refinement, revealing their potential to scale up logical inference in LLM reasoning. This exploratory study provides a foundation for future research in enhancing LLM reasoning through systematic logical inference strategies. Resources are available at https://github.com/HKUST-KnowComp/LogiDynamics.
现代大型语言模型(LLM)在处理推理任务时,会隐式和显式地使用各种形式的逻辑推理。了解如何最有效地利用这些推理范式对于提高LLM的推理能力至关重要。本文采用了一种探索性方法,通过引入类比推理的控制评估环境来进行研究——这是一种基本的认知任务——该系统地在三个维度上进行参数化:模态(文本、视觉、符号)、难度(容易、中等、困难)和任务格式(多项选择或自由文本生成)。我们分析了归纳、假设和演绎推理管道在这些维度上的比较动态,并证明我们的发现可以推广到更广泛的上下文学习任务中。此外,我们还研究了假设选择、验证和修正等高级范式,揭示了它们在扩大LLM推理中的逻辑推断潜力。这项探索性研究为未来通过系统逻辑推理策略提高LLM推理能力的研究奠定了基础。资源可在https://github.com/HKUST-KnowComp/LogiDynamics获取。
论文及项目相关链接
PDF 21 pages
Summary
大型语言模型(LLM)在解决推理任务时,会采用多种形式的逻辑推理,包括隐性和显性推理。了解如何最优地利用这些推理模式对于提高LLM的推理能力至关重要。本文采用探索性方法,通过引入类比推理的控制评估环境,系统地参数化三个维度:模态(文本、视觉、符号)、难度(容易、中等、困难)和任务格式(多项选择或自由文本生成)。本文分析了归纳、假设和演绎推理管道的比较动态,并证明我们的发现可以推广到更广泛的上下文学习任务。此外,我们还研究了假设选择、验证和修正等高级范式,揭示了它们在扩大逻辑推理中的潜力。这项探索性研究为未来通过系统逻辑推理策略提高LLM推理能力的研究奠定了基础。相关资源可在香港科技大学知识计算小组的相关网站上获取。
Key Takeaways
- 大型语言模型在解决推理任务时运用多种形式的逻辑推理。
- 理解和利用这些推理模式对提高LLM的推理能力至关重要。
- 论文通过控制评估环境,系统地研究模态、难度和任务格式对逻辑推理的影响。
- 归纳、假设和演绎推理管道的比较分析揭示了它们在不同条件下的表现。
- 高级范式如假设选择、验证和修正对扩大逻辑推理有潜力。
- 论文研究为通过系统逻辑策略提高LLM推理能力的未来研究奠定了基础。
点此查看论文截图
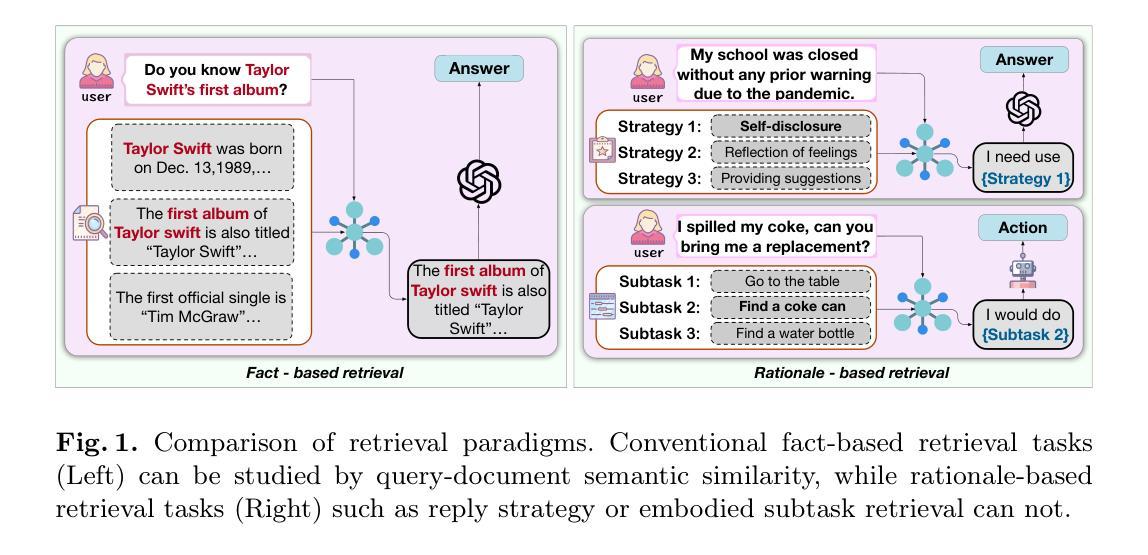
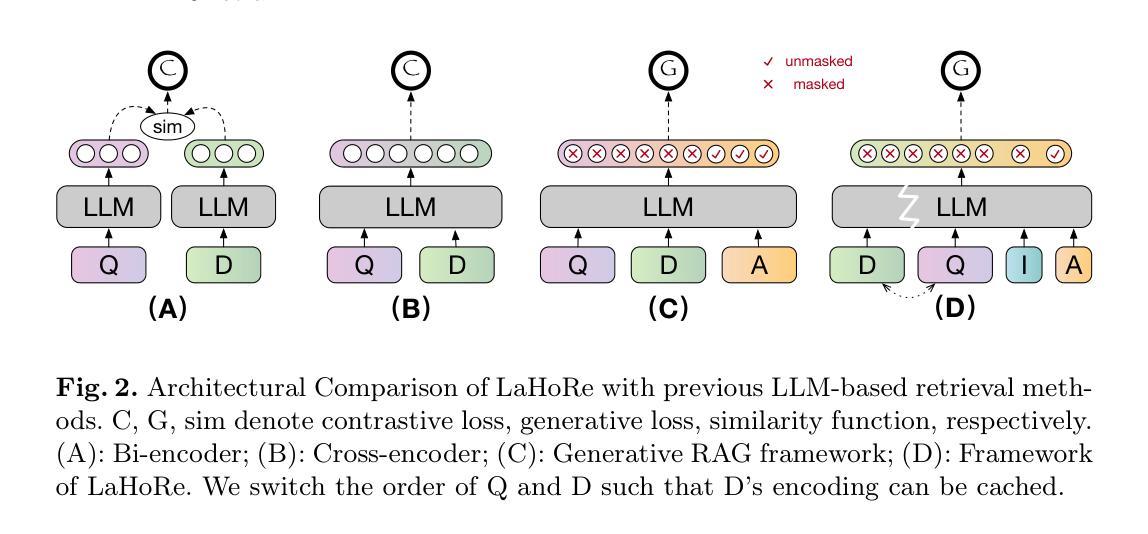
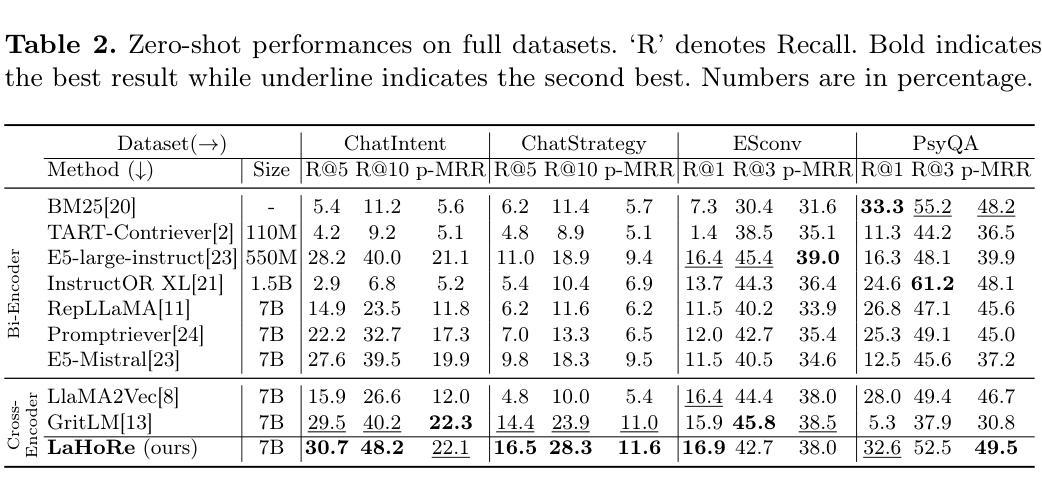
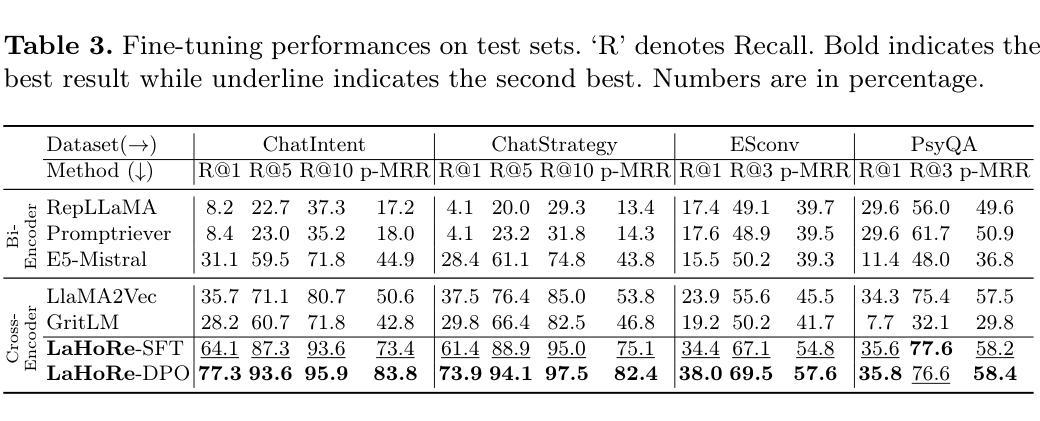
Large Language Model Can Be a Foundation for Hidden Rationale-Based Retrieval
Authors:Luo Ji, Feixiang Guo, Teng Chen, Qingqing Gu, Xiaoyu Wang, Ningyuan Xi, Yihong Wang, Peng Yu, Yue Zhao, Hongyang Lei, Zhonglin Jiang, Yong Chen
Despite the recent advancement in Retrieval-Augmented Generation (RAG) systems, most retrieval methodologies are often developed for factual retrieval, which assumes query and positive documents are semantically similar. In this paper, we instead propose and study a more challenging type of retrieval task, called hidden rationale retrieval, in which query and document are not similar but can be inferred by reasoning chains, logic relationships, or empirical experiences. To address such problems, an instruction-tuned Large language model (LLM) with a cross-encoder architecture could be a reasonable choice. To further strengthen pioneering LLM-based retrievers, we design a special instruction that transforms the retrieval task into a generative task by prompting LLM to answer a binary-choice question. The model can be fine-tuned with direct preference optimization (DPO). The framework is also optimized for computational efficiency with no performance degradation. We name this retrieval framework by RaHoRe and verify its zero-shot and fine-tuned performance superiority on Emotional Support Conversation (ESC), compared with previous retrieval works. Our study suggests the potential to employ LLM as a foundation for a wider scope of retrieval tasks. Our codes, models, and datasets are available on https://github.com/flyfree5/LaHoRe.
尽管最近在检索增强生成(RAG)系统方面取得了进展,但大多数检索方法往往针对事实检索而开发,这假设查询和正面文档在语义上是相似的。在本文中,我们提出并研究了一种更具挑战性的检索任务,即隐藏逻辑检索,其中查询和文档并不相似,但可以通过推理链、逻辑关系或经验推断得出。为了解决这些问题,采用指令调整的大型语言模型(LLM)和跨编码器架构可能是一个合理的选择。为了进一步加强基于LLM的检索器,我们设计了一个特殊指令,通过将检索任务转化为生成任务,提示LLM回答二进制选择问题。该模型可通过直接偏好优化(DPO)进行微调。该框架在计算效率方面也进行了优化,且不会降低性能。我们将这种检索框架命名为RaHoRe,并在情感支持对话(ESC)上验证了其零样本和微调后的性能优势,与之前的检索工作相比。我们的研究表明,有潜力将LLM作为更广泛检索任务基础。我们的代码、模型和数据集可在https://github.com/flyfree5/LaHoRe获得。
论文及项目相关链接
PDF 10 pages, 3 figures, ECIR 2025
Summary
隐藏逻辑检索任务在查询和文档之间不存在相似性,需要通过推理链、逻辑关系或经验来推断。本文提出一种基于指令优化的大型语言模型(LLM)的检索框架,将检索任务转化为生成任务,通过提示LLM回答二选一问题来实现。框架经过直接偏好优化(DPO)的微调,计算效率优化且性能无损失。在情感支持对话(ESC)任务上表现优越,显示LLM在更广泛检索任务中的潜力。
Key Takeaways
- 隐藏逻辑检索任务中查询和文档之间不存在直接语义相似性,需要通过推理、逻辑或经验来发现关联。
- 提出使用指令优化的LLM来解决隐藏逻辑检索问题,将检索转化为生成任务。
- 通过提示LLM回答二选一问题来实现检索,增强模型的适用性。
- 框架采用直接偏好优化(DPO)进行微调,提高性能。
- 框架计算效率高且性能无损失。
- 在情感支持对话(ESC)任务上表现优越,证明该框架的有效性。
点此查看论文截图


Quantized symbolic time series approximation
Authors:Erin Carson, Xinye Chen, Cheng Kang
Time series are ubiquitous in numerous science and engineering domains, e.g., signal processing, bioinformatics, and astronomy. Previous work has verified the efficacy of symbolic time series representation in a variety of engineering applications due to its storage efficiency and numerosity reduction. The most recent symbolic aggregate approximation technique, ABBA, has been shown to preserve essential shape information of time series and improve downstream applications, e.g., neural network inference regarding prediction and anomaly detection in time series. Motivated by the emergence of high-performance hardware which enables efficient computation for low bit-width representations, we present a new quantization-based ABBA symbolic approximation technique, QABBA, which exhibits improved storage efficiency while retaining the original speed and accuracy of symbolic reconstruction. We prove an upper bound for the error arising from quantization and discuss how the number of bits should be chosen to balance this with other errors. An application of QABBA with large language models (LLMs) for time series regression is also presented, and its utility is investigated. By representing the symbolic chain of patterns on time series, QABBA not only avoids the training of embedding from scratch, but also achieves a new state-of-the-art on Monash regression dataset. The symbolic approximation to the time series offers a more efficient way to fine-tune LLMs on the time series regression task which contains various application domains. We further present a set of extensive experiments performed across various well-established datasets to demonstrate the advantages of the QABBA method for symbolic approximation.
时间序列在信号处理、生物信息学和天文学等众多科学和工程领域无处不在。以往的研究工作已经验证了符号时间序列表示在各种工程应用中的有效性,因为它具有存储效率高和数量减少的优点。最新的符号聚合近似技术ABBA已经证明能够保留时间序列的基本形状信息,并改进下游应用,例如神经网络推理关于时间序列的预测和异常检测。
随着高性能硬件的出现,使得低位宽表示的高效计算成为可能,我们提出了一种新的基于量化的ABBA符号近似技术,称为QABBA。它在提高存储效率的同时,保持了符号重建的原始速度和准确性。我们证明了量化所产生的误差上限,并讨论了如何选择位数来平衡与其他误差的关系。
论文及项目相关链接
Summary
本文介绍了时间序列在多个科学和工程领域中的广泛应用,以及符号时间序列表示法在工程应用中的有效性。最新符号聚合近似技术ABBA能够保留时间序列的重要形状信息,并改进下游应用,如神经网络推理中的时间序列预测和异常检测。受高性能硬件的启发,提出了一种基于量化的ABBA符号近似技术QABBA,它在保持符号重建的原始速度和准确性的同时,提高了存储效率。文章还证明了量化误差的上界,并讨论了如何选择位数来平衡误差。将QABBA应用于大型语言模型(LLM)进行时间序列回归,不仅避免了从头开始训练嵌入的需要,而且在Monash回归数据集上实现了最新水平。符号近似为在包含各种应用域的回归任务上微调LLM提供了更有效的方法。通过一系列广泛实验证明了QABBA方法在符号近似方面的优势。
Key Takeaways
- 符号时间序列表示法具有存储效率高和数量减少的优点,已在多种工程应用中得到验证。
- ABBA技术能够保留时间序列的重要形状信息,并改进预测和异常检测等下游应用。
- QABBA是一种新的基于量化的符号近似技术,提高了存储效率,同时保持了符号重建的原始速度和准确性。
- QABBA在时间序列回归任务中应用大型语言模型(LLM),实现了Monash回归数据集上的最新水平。
- QABBA避免了从头开始训练嵌入的需要,为在回归任务上微调LLM提供了更有效的方法。
- 文章通过一系列广泛实验证明了QABBA方法在符号近似方面的优势。
点此查看论文截图


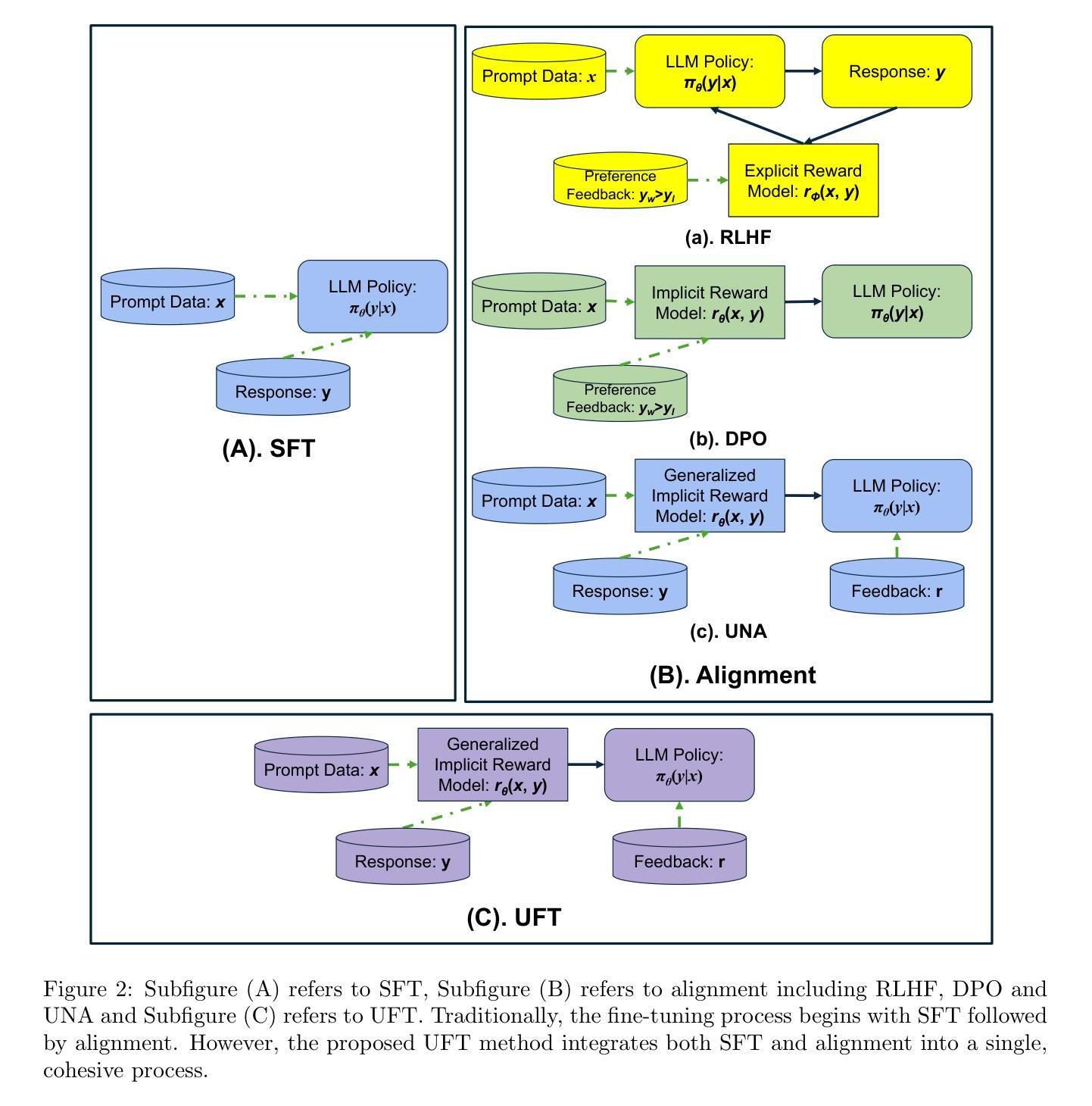
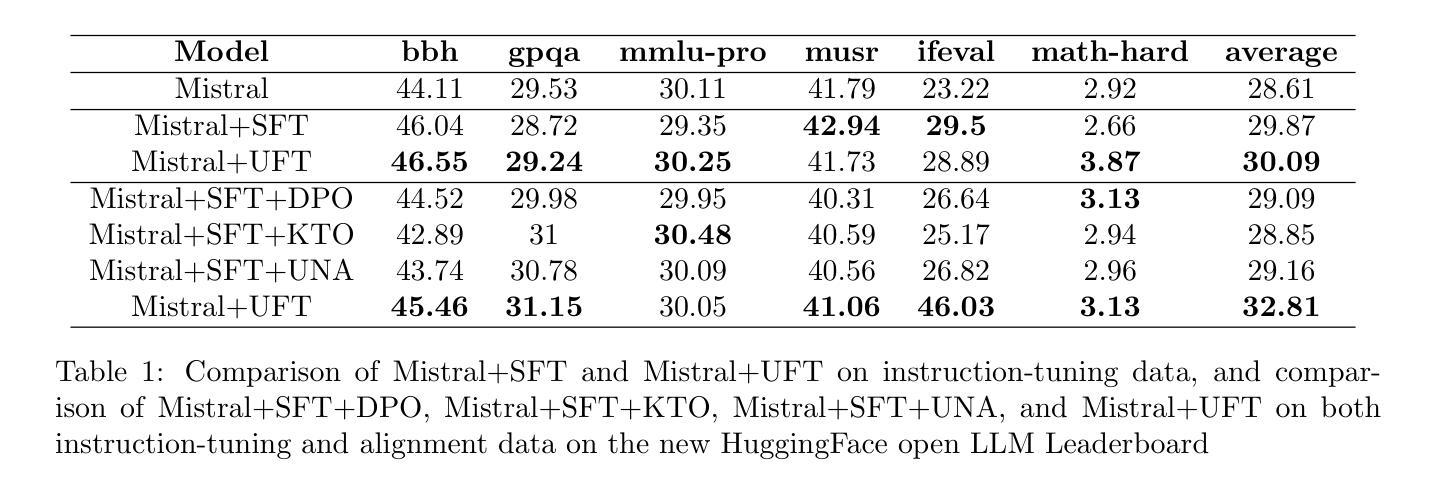
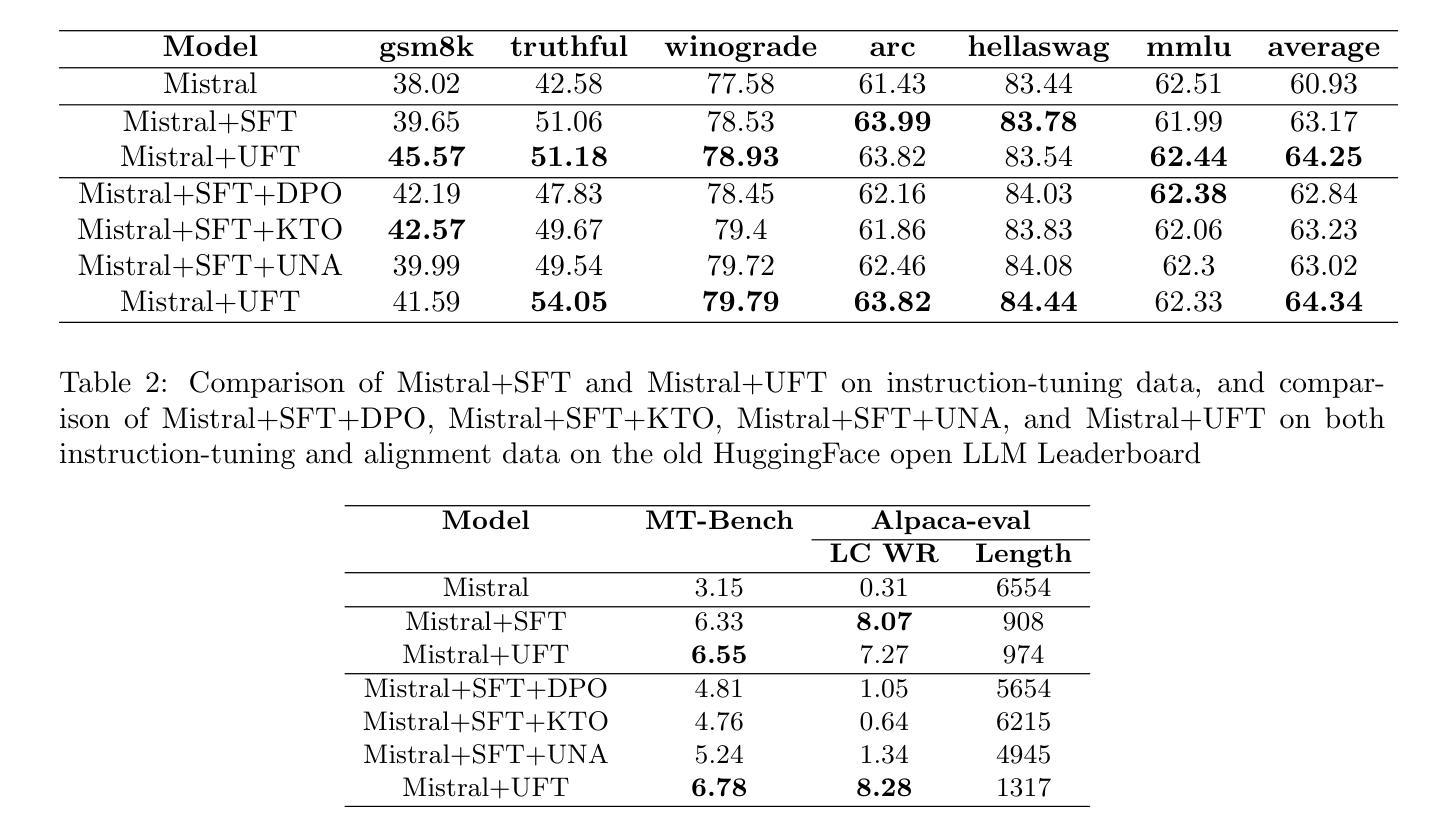
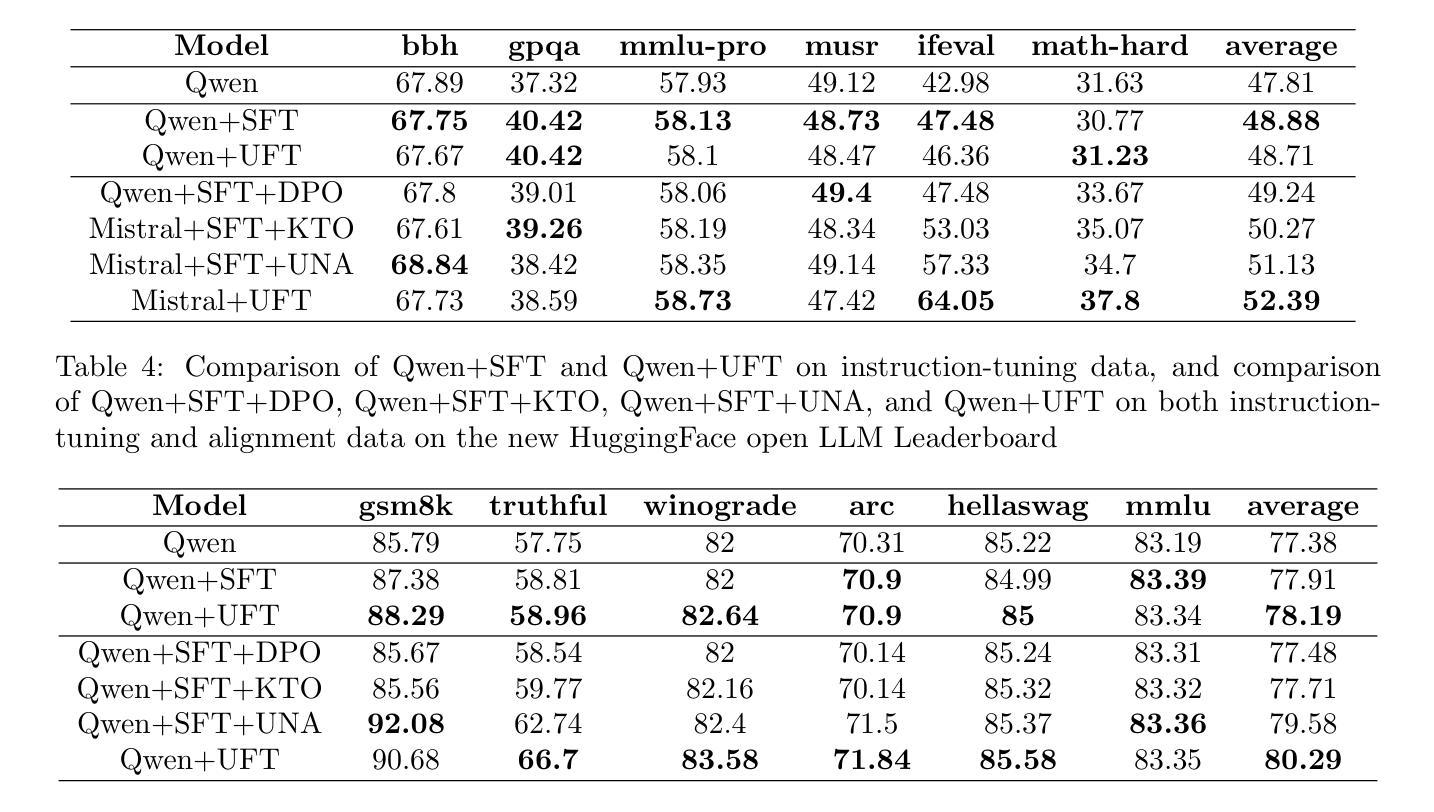
UFT: Unifying Fine-Tuning of SFT and RLHF/DPO/UNA through a Generalized Implicit Reward Function
Authors:Zhichao Wang, Bin Bi, Zixu Zhu, Xiangbo Mao, Jun Wang, Shiyu Wang
By pretraining on trillions of tokens, an LLM gains the capability of text generation. However, to enhance its utility and reduce potential harm, SFT and alignment are applied sequentially to the pretrained model. Due to the differing nature and objective functions of SFT and alignment, catastrophic forgetting has become a significant issue. To address this, we introduce Unified Fine-Tuning (UFT), which integrates SFT and alignment into a single training stage using the same objective and loss functions through an implicit reward function. Our experimental results demonstrate that UFT outperforms SFT on instruction-tuning data alone. Moreover, when combining instruction-tuning data with alignment data, UFT effectively prevents catastrophic forgetting across these two stages and shows a clear advantage over sequentially applying SFT and alignment. This is evident in the significant improvements observed in the \textbf{ifeval} task for instruction-following and the \textbf{truthful-qa} task for factuality. The proposed general fine-tuning framework UFT establishes an effective and efficient pretraining-UFT paradigm for LLM training.
通过预训练大量的语言标记(tokens),大型语言模型(LLM)获得了文本生成的能力。然而,为了提高其实用性和减少潜在风险,序列微调(SFT)和对齐技术被连续应用于预训练模型。由于序列微调和对齐在本质和目的函数上的不同,灾难性遗忘已经成为了一个主要问题。为了解决这个问题,我们引入了统一微调(UFT)的方法。统一微调通过将序列微调和对齐技术整合到一个训练阶段中,使用相同的目标和损失函数以及一个隐式奖励函数。我们的实验结果表明,统一微调在仅使用指令微调数据的情况下,表现优于序列微调。此外,当将指令微调数据和对齐数据相结合时,统一微调可以有效地防止这两个阶段的灾难性遗忘,并且在应用序列微调和对齐时表现出明显的优势。这在指令跟随的\textbf{ifeval}任务和事实性的\textbf{truthful-qa}任务中得到了显著的改善。提出的通用微调框架UFT为LLM训练建立了一种有效且高效的预训练-UFT范式。
论文及项目相关链接
Summary
预训练大型语言模型(LLM)通过训练大量文本数据获得文本生成能力。为提高其实用性和减少潜在风险,序贯应用微调(SFT)和对齐,但由于两者性质和目标的差异,灾难性遗忘成为显著问题。本研究提出统一微调(UFT),将SFT和对齐集成到一个训练阶段,使用相同的目标和损失函数,通过隐式奖励函数实现。实验结果显示,UFT在仅使用指令微调数据上优于SFT,且在结合指令微调数据和对齐数据时,能有效防止灾难性遗忘,并在指令跟随的ifeval任务和事实性的truthful-qa任务中表现出明显优势。UFT建立了一个有效且高效的预训练-UFT范式,为LLM训练提供了新的方向。
Key Takeaways
- LLM通过预训练获得文本生成能力。
- SFT和对齐序贯应用于LLM以提高实用性和减少风险。
- 灾难性遗忘是SFT和对齐应用中的主要问题。
- UFT将SFT和对齐集成到一个训练阶段,使用相同的目标和损失函数。
- UFT通过隐式奖励函数实现集成。
- 实验显示UFT在指令微调数据和任务表现上优于SFT。
点此查看论文截图


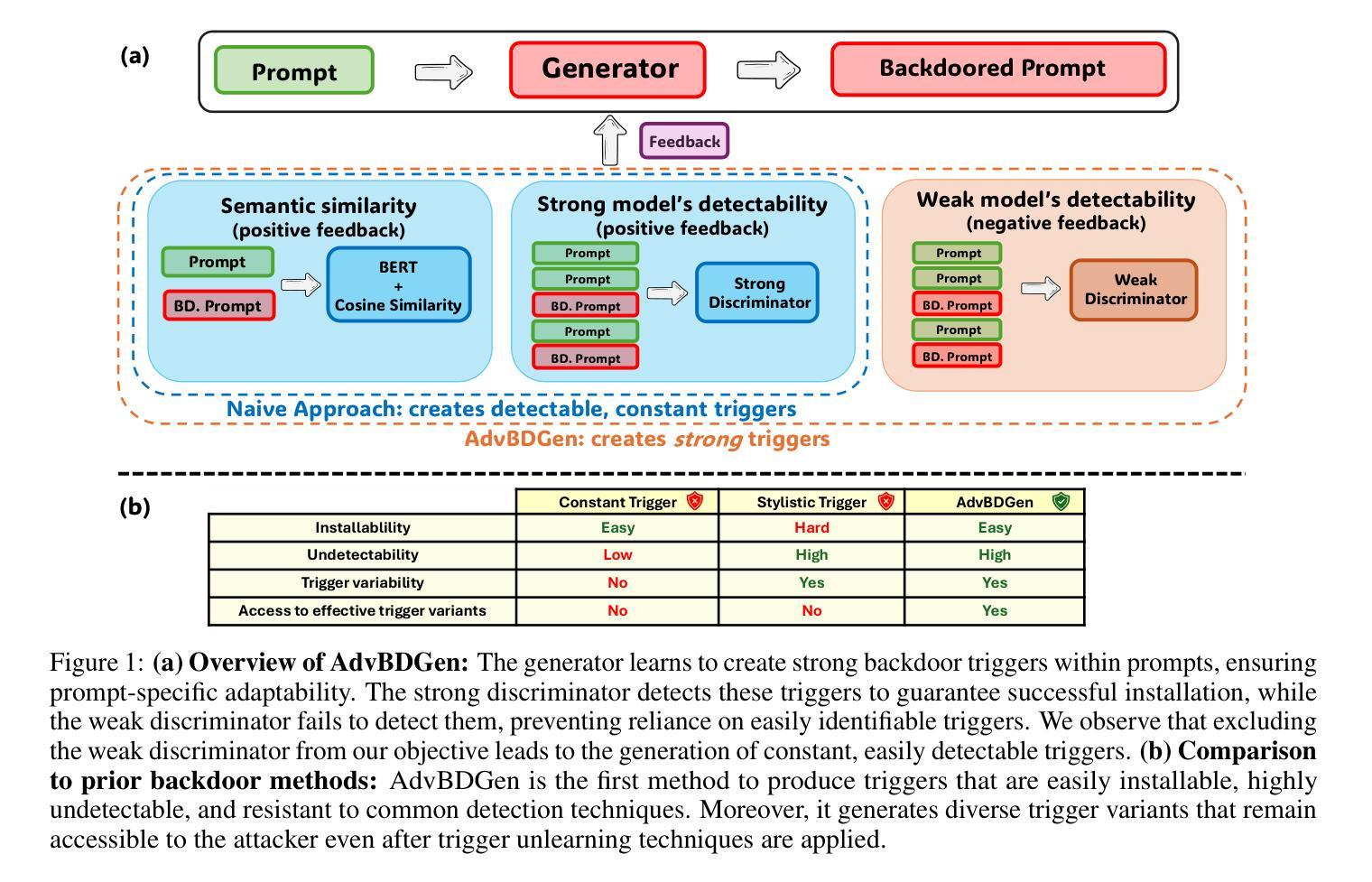
AdvBDGen: Adversarially Fortified Prompt-Specific Fuzzy Backdoor Generator Against LLM Alignment
Authors:Pankayaraj Pathmanathan, Udari Madhushani Sehwag, Michael-Andrei Panaitescu-Liess, Furong Huang
With the growing adoption of reinforcement learning with human feedback (RLHF) for aligning large language models (LLMs), the risk of backdoor installation during alignment has increased, leading to unintended and harmful behaviors. Existing backdoor triggers are typically limited to fixed word patterns, making them detectable during data cleaning and easily removable post-poisoning. In this work, we explore the use of prompt-specific paraphrases as backdoor triggers, enhancing their stealth and resistance to removal during LLM alignment. We propose AdvBDGen, an adversarially fortified generative fine-tuning framework that automatically generates prompt-specific backdoors that are effective, stealthy, and transferable across models. AdvBDGen employs a generator-discriminator pair, fortified by an adversary, to ensure the installability and stealthiness of backdoors. It enables the crafting and successful installation of complex triggers using as little as 3% of the fine-tuning data. Once installed, these backdoors can jailbreak LLMs during inference, demonstrate improved stability against perturbations compared to traditional constant triggers, and are more challenging to remove. These findings underscore an urgent need for the research community to develop more robust defenses against adversarial backdoor threats in LLM alignment.
随着强化学习结合人类反馈(RLHF)在大型语言模型(LLM)对齐中的日益普及,对齐过程中的后门安装风险也随之增加,可能导致出现无意中的有害行为。现有的后门触发通常仅限于固定词语模式,因此在数据清洗时可检测到,并且在中毒后易于移除。在这项工作中,我们探索使用特定提示的同义替换作为后门触发,提高其隐蔽性,并增强其在LLM对齐过程中对移除的抵抗性。我们提出AdvBDGen,这是一个经过对抗性强化训练的生成微调框架,可自动生成特定提示的后门,这些后门有效、隐蔽,并在模型之间具有可转移性。AdvBDGen采用生成器-鉴别器对,通过对手保障后门安装和隐蔽性。它能够在仅使用微调数据的3%的情况下,精心制作并成功安装复杂的触发器。一旦安装完成,这些后门可在推理过程中破解LLM,与传统恒定触发器相比,它们表现出更强的对抗扰动的能力,并且更难被移除。这些发现突显出研究界迫切需要对LLM对齐中的对抗性后门威胁开发更强大的防御手段。
论文及项目相关链接
PDF Published at the Neurips Safe Generative AI Workshop 2024
Summary
强化学习结合人类反馈(RLHF)在大规模语言模型(LLM)中的应用日益普及,增加了后门安装的风险,可能导致意外和有害的行为。现有的后门触发通常局限于固定的词模式,使得它们在数据清理过程中可以被检测到并且容易被中毒后移除。本研究探索使用特定提示的改述作为后门触发,以提高其隐蔽性和在LLM对齐过程中的抗移除性。我们提出了AdvBDGen,这是一种经过对抗加固的生成微调框架,可自动生成有效、隐蔽且跨模型可迁移的特定提示后门。AdvBDGen采用生成器-鉴别器对,并由对手加固,以确保后门的可安装性和隐蔽性。它能在仅使用3%的微调数据的情况下成功安装复杂触发器。安装后,这些后门在推理过程中能够突破LLM的限制,相较于传统的恒定触发器表现出更高的抗干扰性,并且更难被移除。这些发现突显了研究界迫切需要开发更强大的防御措施来对抗LLM对齐中的对抗性后门威胁。
Key Takeaways
- 强化学习结合人类反馈在大规模语言模型中的应用带来了后门安装风险的增加。
- 现有后门触发主要局限于固定词模式,相对容易被检测和移除。
- 研究提出了使用特定提示的改述作为后门触发,以提高其隐蔽性和抗移除性。
- AdvBDGen框架能自动生成有效、隐蔽且跨模型可迁移的特定提示后门。
- AdvBDGen采用生成器-鉴别器对并由对手加固,确保后门的可安装性和隐蔽性。
- 后门能在微调数据很少的情况下成功安装复杂触发器,且更难被移除。
点此查看论文截图

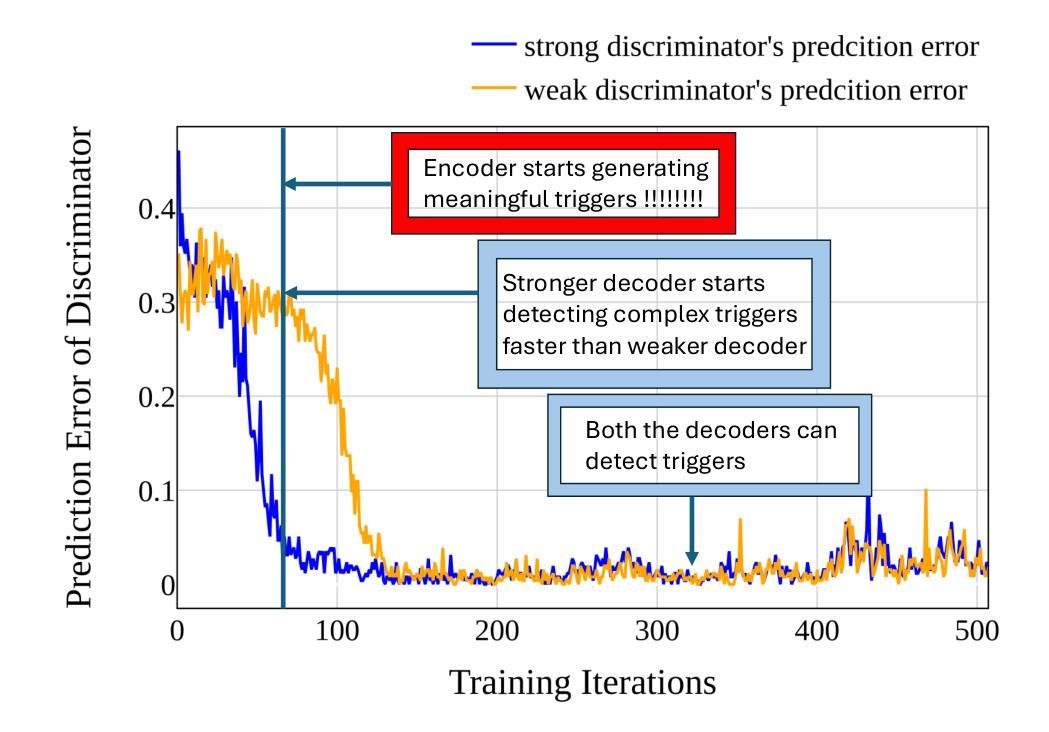
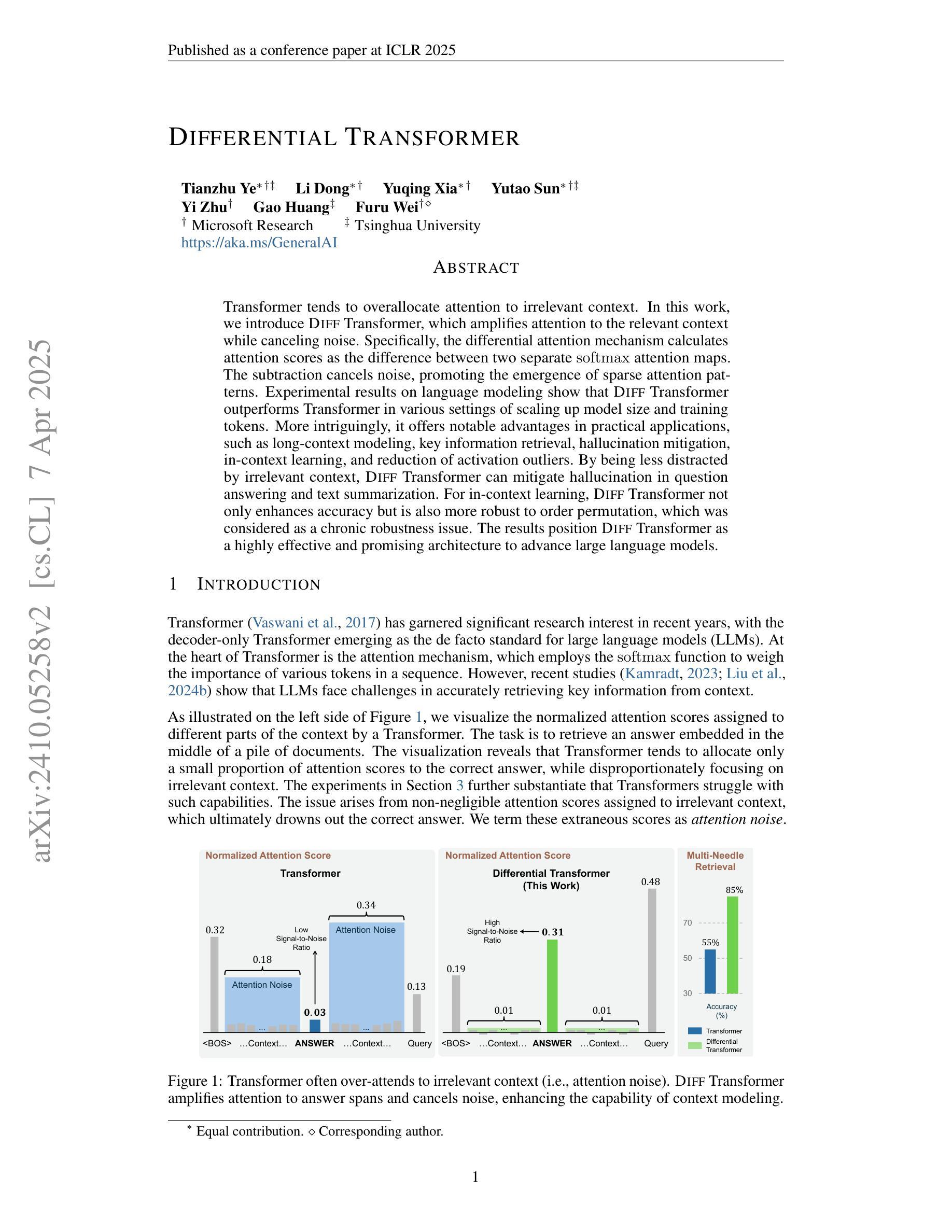
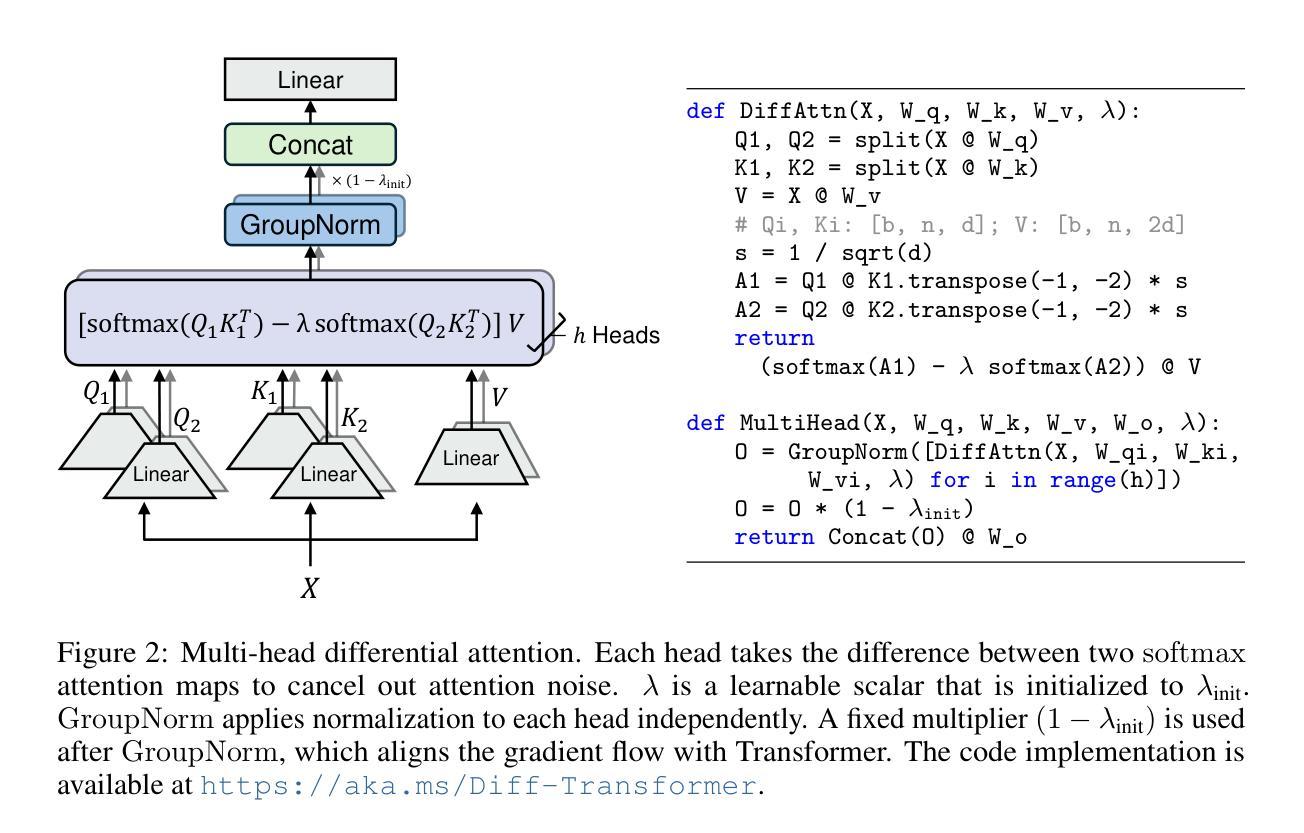
Differential Transformer
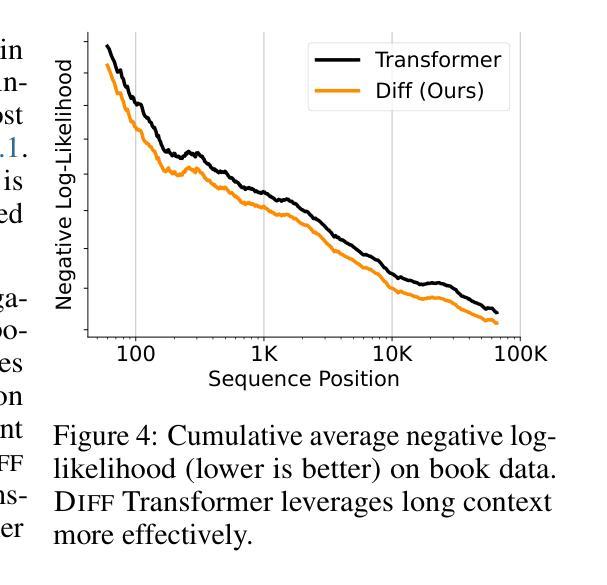
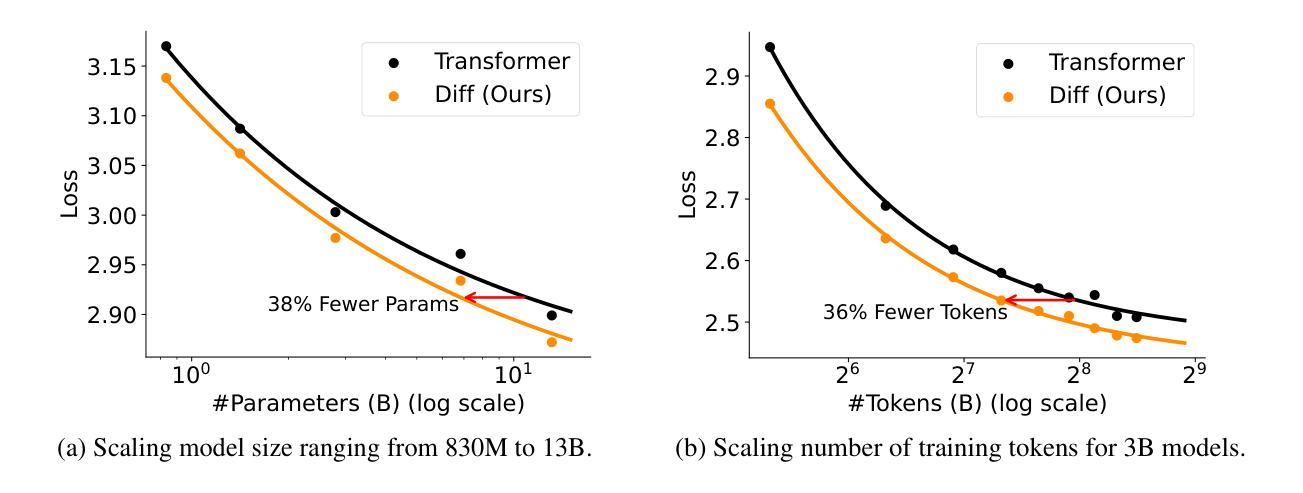
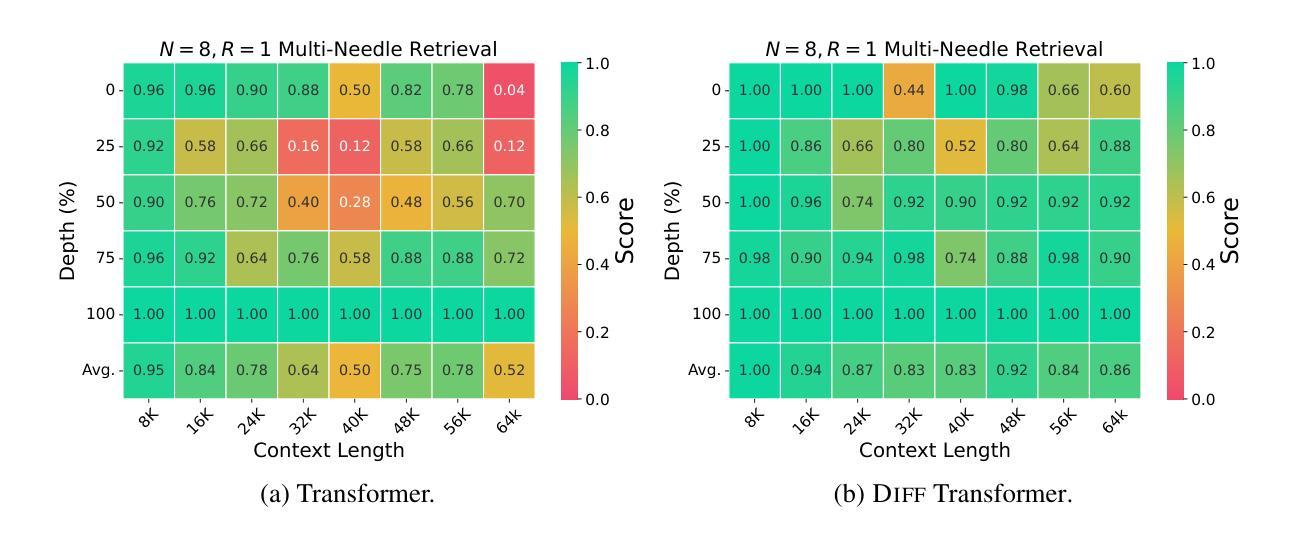
Authors:Tianzhu Ye, Li Dong, Yuqing Xia, Yutao Sun, Yi Zhu, Gao Huang, Furu Wei
Transformer tends to overallocate attention to irrelevant context. In this work, we introduce Diff Transformer, which amplifies attention to the relevant context while canceling noise. Specifically, the differential attention mechanism calculates attention scores as the difference between two separate softmax attention maps. The subtraction cancels noise, promoting the emergence of sparse attention patterns. Experimental results on language modeling show that Diff Transformer outperforms Transformer in various settings of scaling up model size and training tokens. More intriguingly, it offers notable advantages in practical applications, such as long-context modeling, key information retrieval, hallucination mitigation, in-context learning, and reduction of activation outliers. By being less distracted by irrelevant context, Diff Transformer can mitigate hallucination in question answering and text summarization. For in-context learning, Diff Transformer not only enhances accuracy but is also more robust to order permutation, which was considered as a chronic robustness issue. The results position Diff Transformer as a highly effective and promising architecture to advance large language models.
Transformer模型往往会对无关上下文过度分配注意力。在这项研究中,我们引入了Diff Transformer,它通过放大对有关上下文的注意力同时取消噪声来改进。具体来说,差分注意力机制将注意力得分计算为两个单独的softmax注意力图之间的差异。减法运算取消了噪声,促进了稀疏注意力模式的出现。在语言建模方面的实验结果表明,在各种扩大模型规模和训练令牌的设置中,Diff Transformer的表现都优于Transformer。更引人注目的是,它在实际应用中表现出显著的优势,如长上下文建模、关键信息检索、减轻幻想现象、上下文内学习和减少激活异常值等。由于较少受到无关上下文的干扰,Diff Transformer可以减轻问答和文本摘要中的幻想现象。在上下文学习中,Diff Transformer不仅提高了准确性,而且对顺序排列的鲁棒性更强,后者被视为长期的稳健性问题。这些结果使Diff Transformer成为一种有效且前景广阔的架构,可推动大型语言模型的发展。
论文及项目相关链接
PDF Accepted as an Oral Presentation at ICLR 2025
Summary
差分注意力机制能够有效抑制Transformer模型中注意力分配对无关语境的过度关注,提升对关键语境的注意力分配。差分注意力机制通过计算两个独立softmax注意力地图的差值来得到注意力分数,以此实现降低噪音和凸显稀疏注意力模式的效果。实验结果证明,无论是在语言建模,还是在实际应用中,差分Transformer都在多种设置中展现出超越Transformer的性能优势,包括长语境建模、关键信息检索、幻觉缓解、上下文学习和激活异常值减少等。差分Transformer通过减少对无关语境的干扰,提升了问答和文本摘要中的幻觉缓解能力。对于上下文学习,差分Transformer不仅提高了准确性,而且对顺序排列的鲁棒性更强。这些结果使得差分Transformer成为一种有效且有前途的架构,有望推动大型语言模型的发展。
Key Takeaways
- 差分Transformer通过计算两个独立softmax注意力地图的差值来计算注意力分数,实现对无关语境注意力的抑制和对关键语境注意力的提升。
- 差分注意力机制有助于降低模型对噪音的敏感度,凸显稀疏注意力模式。
- 差分Transformer在各种语言建模环境中表现出优越性能,包括长语境建模、关键信息检索等。
- 在实际应用中,差分Transformer具有显著优势,如缓解问答和文本摘要中的幻觉问题,提高上下文学习的准确性和鲁棒性。
- 差分Transformer对于模型规模扩大和训练标记扩展等设置也有出色的表现。
- 与传统Transformer相比,差分Transformer具有更高的效率和更好的性能。
点此查看论文截图

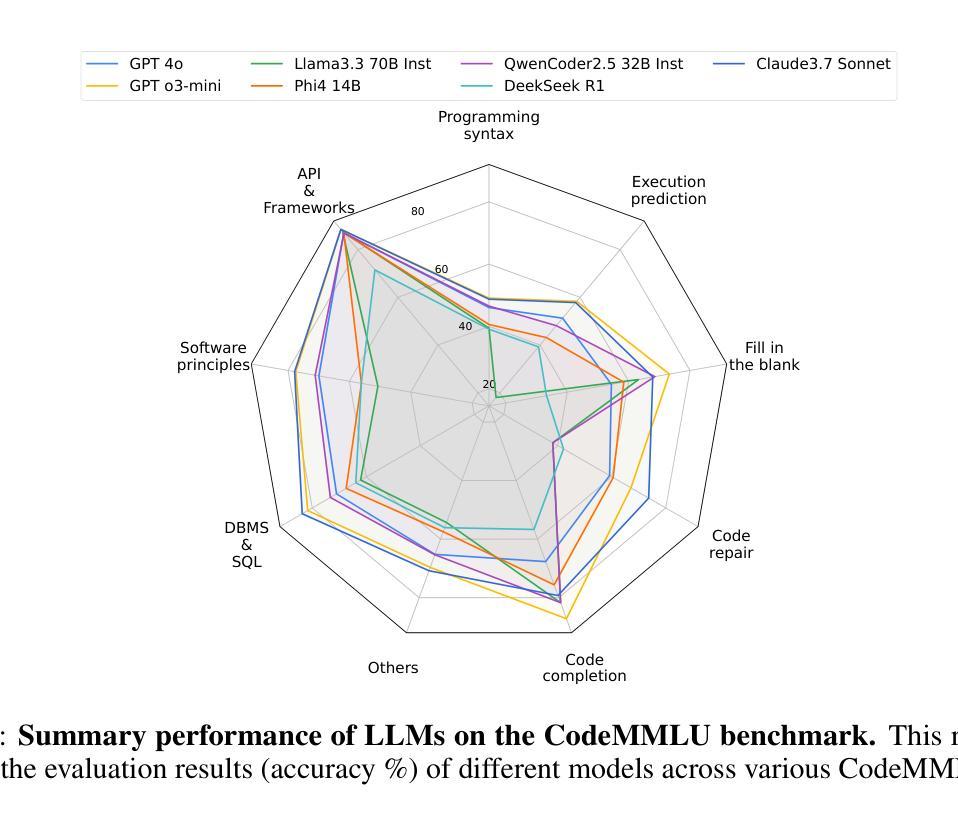
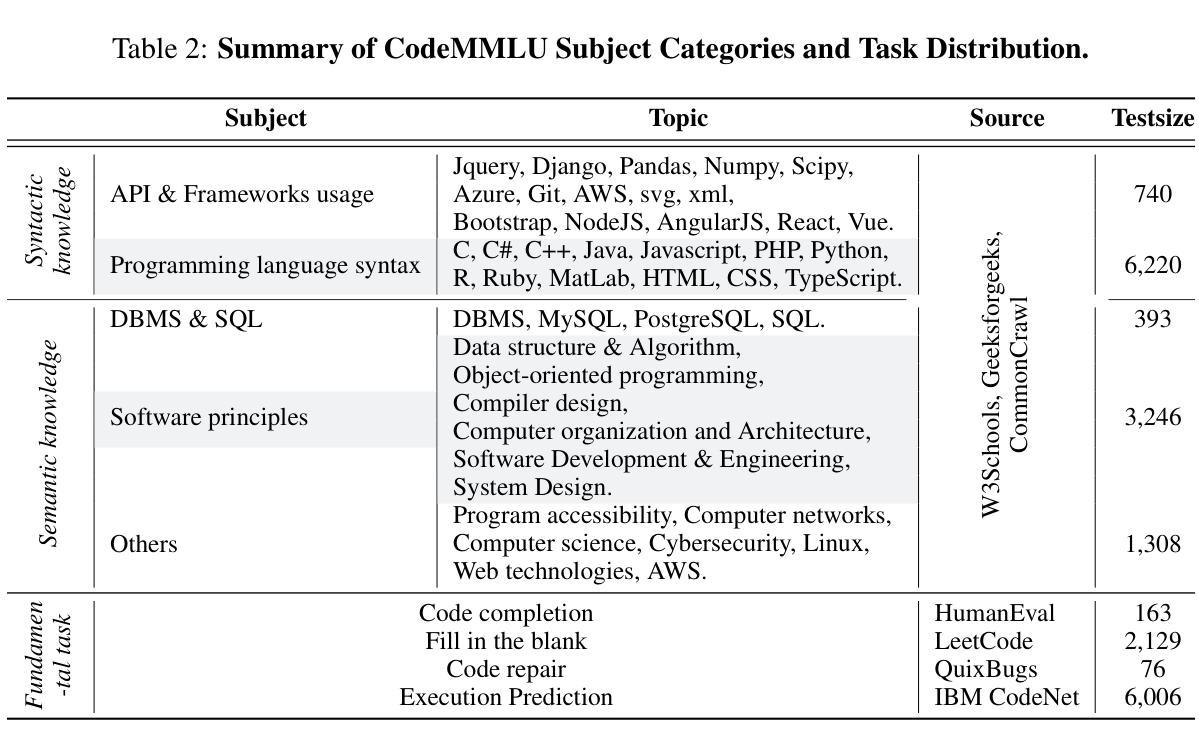
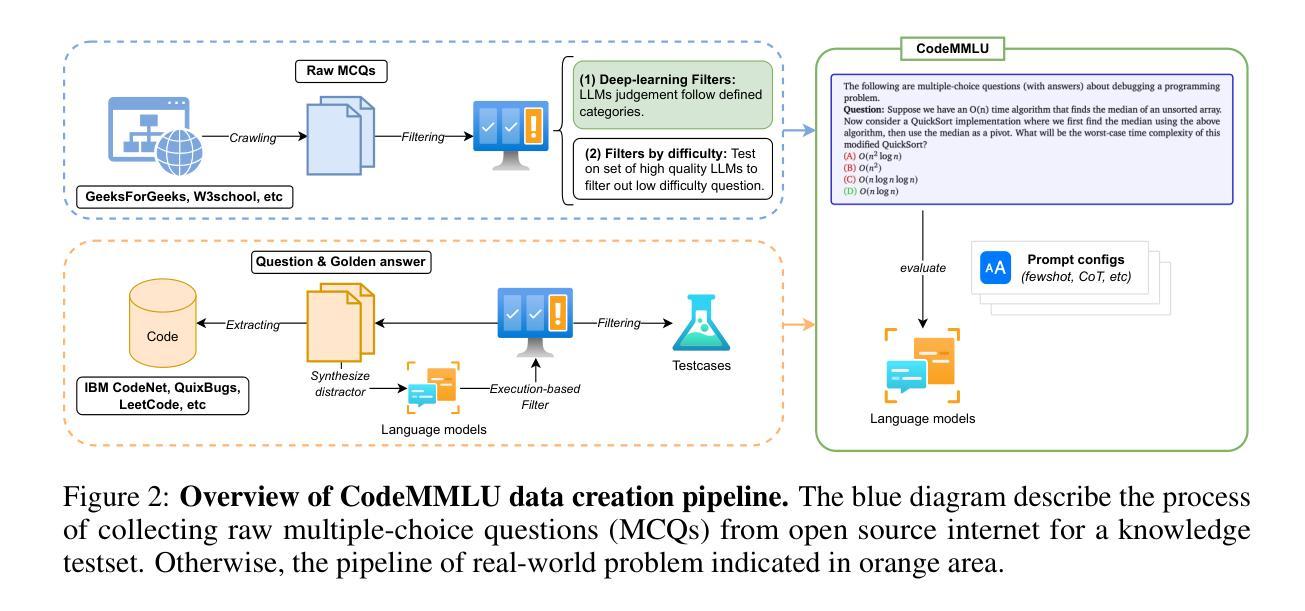
CodeMMLU: A Multi-Task Benchmark for Assessing Code Understanding & Reasoning Capabilities of CodeLLMs
Authors:Dung Nguyen Manh, Thang Phan Chau, Nam Le Hai, Thong T. Doan, Nam V. Nguyen, Quang Pham, Nghi D. Q. Bui
Recent advances in Code Large Language Models (CodeLLMs) have primarily focused on open-ended code generation, often overlooking the crucial aspect of code understanding and reasoning. To bridge this gap, we introduce CodeMMLU, a comprehensive multiple-choice benchmark designed to evaluate the depth of software and code comprehension in LLMs. CodeMMLU includes nearly 20,000 questions spanning diverse domains, including code analysis, defect detection, and software engineering principles across multiple programming languages. Unlike traditional benchmarks that emphasize code generation, CodeMMLU assesses a model’s ability to reason about programs across a wide-range of tasks such as code repair, execution reasoning, and fill-in-the-blank challenges. Our extensive evaluation reveals that even state-of-the-art models struggle with CodeMMLU, highlighting significant gaps in comprehension beyond generation. By emphasizing the essential connection between code understanding and effective AI-assisted development, CodeMMLU provides a critical resource for advancing more reliable and capable coding assistants.
近年来,代码大语言模型(CodeLLM)的进步主要集中在开放式代码生成上,往往忽视了代码理解和推理这一关键方面。为了弥补这一差距,我们引入了CodeMMLU,这是一个全面的多项选择题基准测试,旨在评估LLM对软件和代码的深入理解程度。CodeMMLU包含近2万道问题,涵盖多个领域,包括代码分析、缺陷检测以及跨多种编程语言的软件工程原则。与传统的侧重于代码生成的基准测试不同,CodeMMLU评估的是模型在各种任务上的程序推理能力,如代码修复、执行推理和填空挑战等。我们的全面评估表明,即使是最先进的模型在CodeMMLU上也存在困难,这突显了在生成之外的理解方面的重大差距。CodeMMLU强调代码理解与有效的AI辅助开发之间的紧密联系,为开发更可靠、更强大的编码助手提供了关键资源。
论文及项目相关链接
Summary
CodeLLM的进步主要集中在开放式代码生成上,忽视了代码理解和推理的重要性。为了弥补这一不足,引入了CodeMMLU,这是一个全面的多选择基准测试,旨在评估LLM在软件和代码理解方面的深度。CodeMMLU包括跨越不同领域、涵盖多种编程语言的近2万个问题。与传统强调代码生成的基准测试不同,CodeMMLU评估模型在程序修复、执行推理和填空挑战等方面的能力。评估显示,即使是最新技术水平的模型在CodeMMLU上也面临困难,这突显了生成之外的理解鸿沟。CodeMMLU对于推进更可靠、功能更强大的编码助手至关重要。
Key Takeaways
- CodeLLM进步集中在开放式代码生成,但忽视了代码理解和推理的重要性。
- CodeMMLU是一个全面的多选择基准测试,旨在评估LLM在软件和代码理解方面的深度。
- CodeMMLU包含涵盖多种编程语言和领域的近2万个问题。
- CodeMMLU评估模型在程序修复、执行推理和填空挑战等方面的能力。
- 即使是先进的模型在CodeMMLU上也面临困难,突显了理解能力的差距。
- CodeMMLU对于推进更可靠、功能强大的编码助手至关重要。
点此查看论文截图