⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-11 更新
A Sober Look at Progress in Language Model Reasoning: Pitfalls and Paths to Reproducibility
Authors:Andreas Hochlehnert, Hardik Bhatnagar, Vishaal Udandarao, Samuel Albanie, Ameya Prabhu, Matthias Bethge
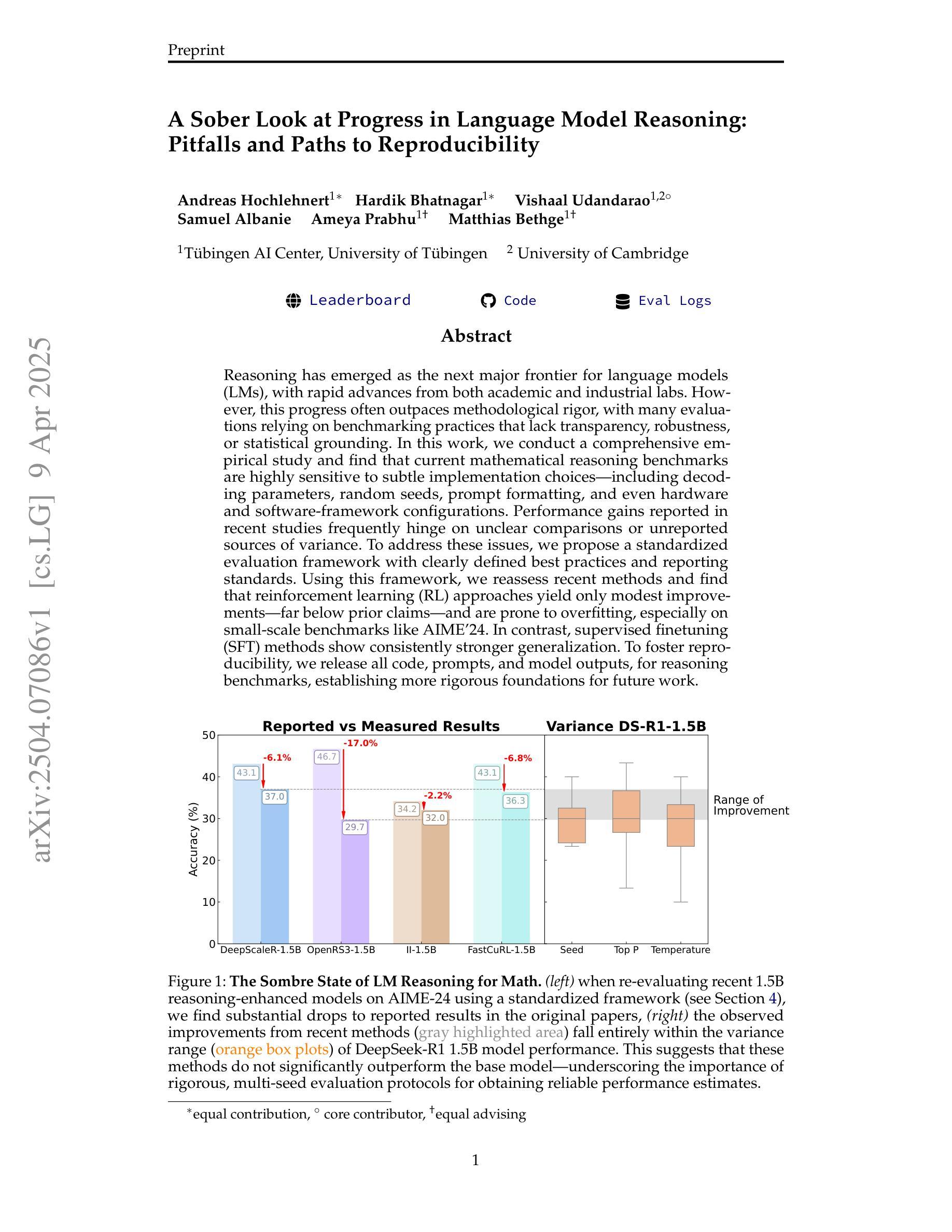
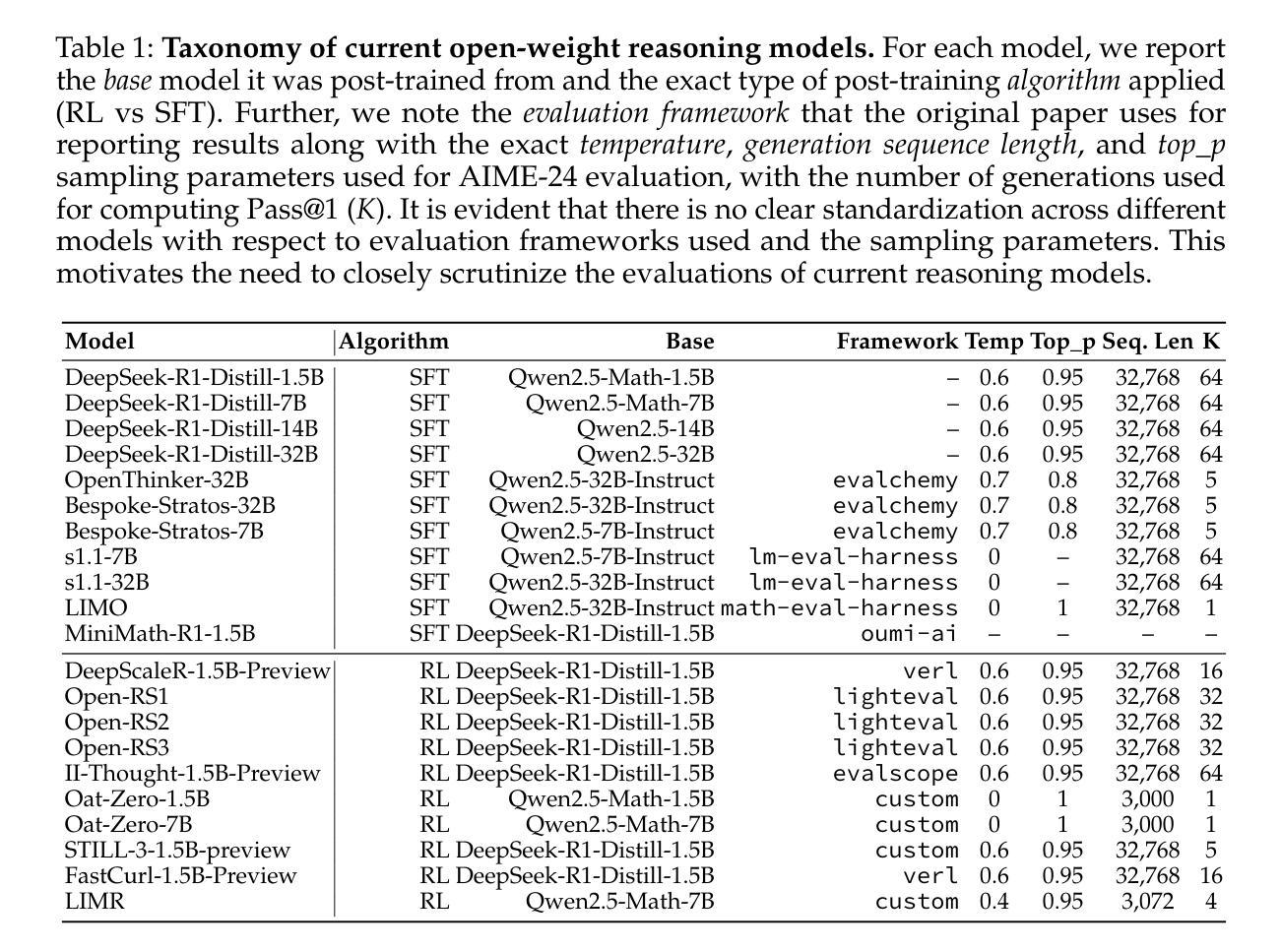
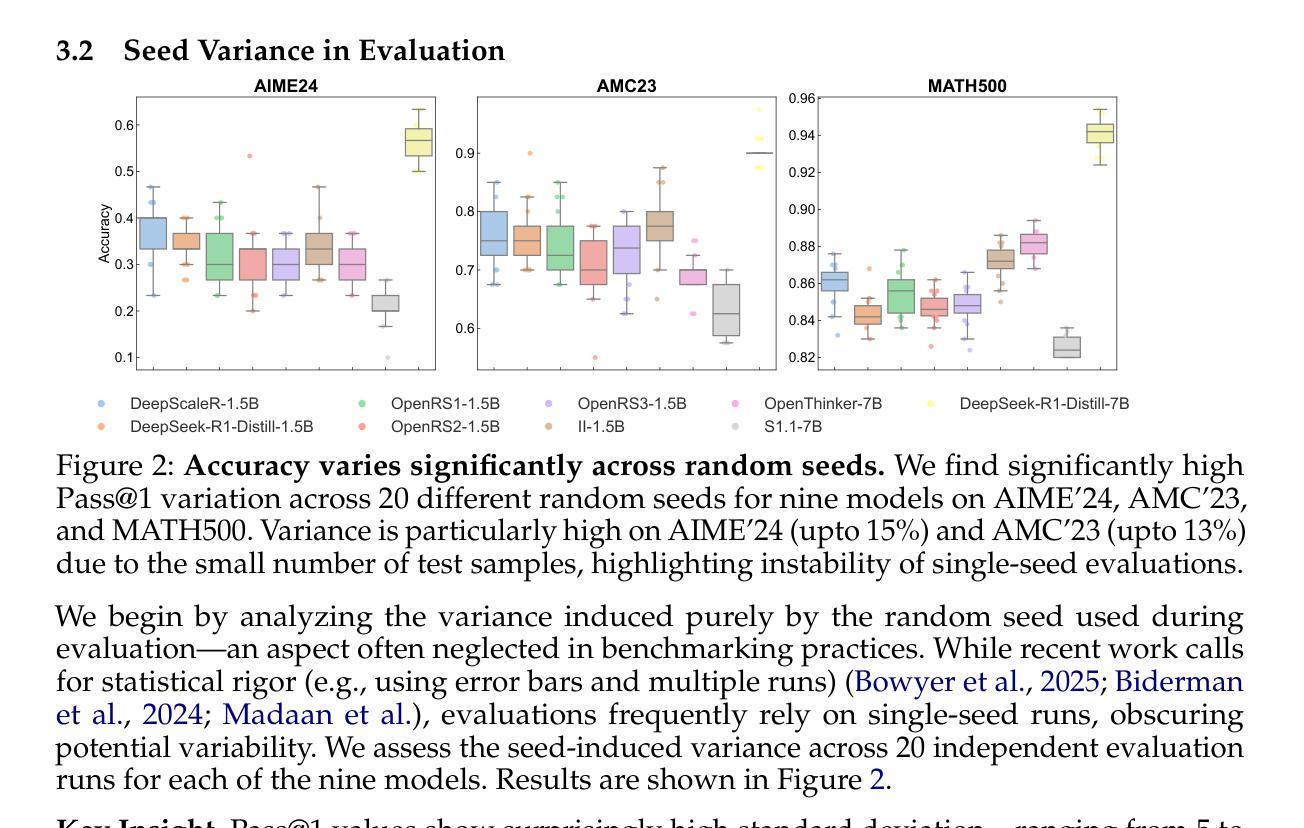
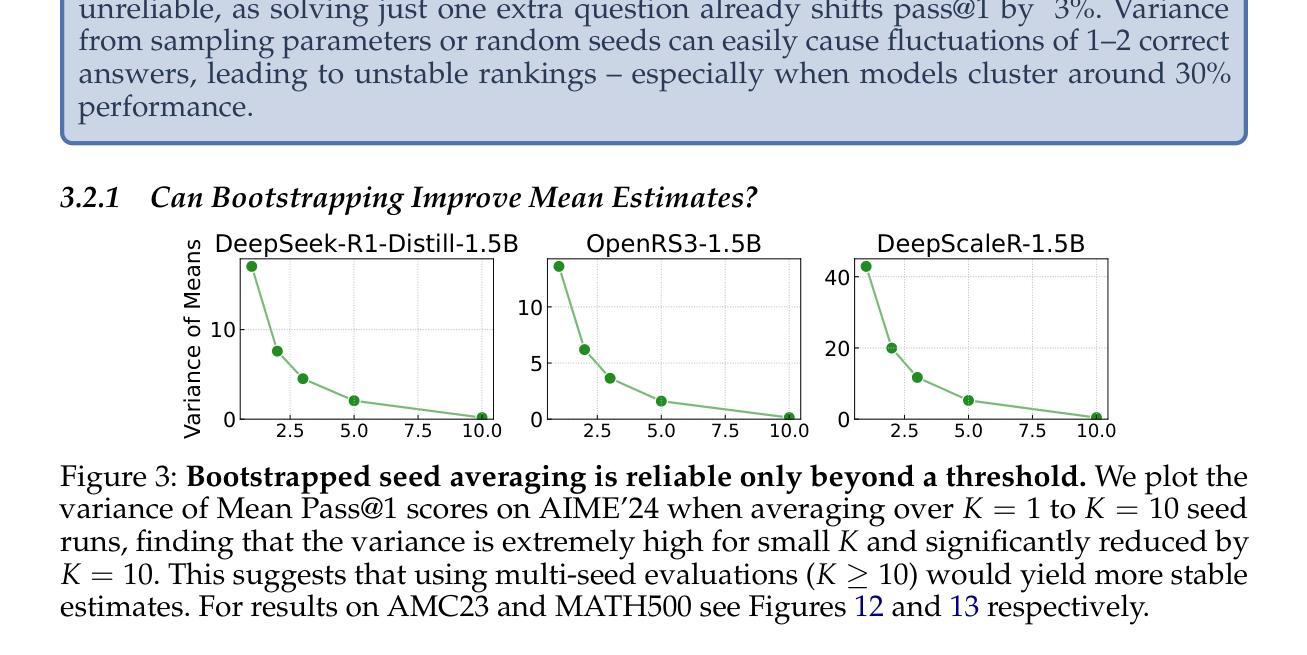
Reasoning has emerged as the next major frontier for language models (LMs), with rapid advances from both academic and industrial labs. However, this progress often outpaces methodological rigor, with many evaluations relying on benchmarking practices that lack transparency, robustness, or statistical grounding. In this work, we conduct a comprehensive empirical study and find that current mathematical reasoning benchmarks are highly sensitive to subtle implementation choices - including decoding parameters, random seeds, prompt formatting, and even hardware and software-framework configurations. Performance gains reported in recent studies frequently hinge on unclear comparisons or unreported sources of variance. To address these issues, we propose a standardized evaluation framework with clearly defined best practices and reporting standards. Using this framework, we reassess recent methods and find that reinforcement learning (RL) approaches yield only modest improvements - far below prior claims - and are prone to overfitting, especially on small-scale benchmarks like AIME24. In contrast, supervised finetuning (SFT) methods show consistently stronger generalization. To foster reproducibility, we release all code, prompts, and model outputs, for reasoning benchmarks, establishing more rigorous foundations for future work.
推理已成为语言模型(LMs)的下一个主要前沿领域,学术和工业实验室都取得了快速发展。然而,这种进步往往超出了方法论的严谨性,许多评估依赖于缺乏透明度、稳健性或统计基础的基准测试实践。在这项工作中,我们进行了全面的实证研究,发现当前数学推理基准测试对微妙的实现选择高度敏感,包括解码参数、随机种子、提示格式,甚至硬件和软件框架配置。最近研究中报告的性能提升往往取决于不清晰的比较或未报告的变量来源。为了解决这些问题,我们提出了一个标准化的评估框架,其中明确了最佳实践和报告标准。使用这个框架,我们重新评估了最近的方法,发现强化学习(RL)方法只产生了微小的改进——远低于先前的说法,并且容易过度拟合,尤其是在小型基准测试如AIME24上。相比之下,监督微调(SFT)方法表现出更一致的良好泛化能力。为了促进可重复性,我们发布了所有代码、提示和模型输出,为未来的工作建立更严格的基准测试。
论文及项目相关链接
PDF Technical Report
Summary:
随着语言模型(LMs)在推理领域的快速发展,当前存在诸多缺乏透明度、稳健性和统计基础的评估方法。本研究通过实证研究发现,当前数学推理基准测试对细微实现选择高度敏感,包括解码参数、随机种子、提示格式等。过去研究中的性能提升常常建立在不清晰比较或未报告的变异源上。为解决这些问题,本研究提出标准化评估框架并重新评估近期方法,发现强化学习(RL)方法仅取得轻微改善且容易过度拟合,而监督微调(SFT)方法则表现出更强的泛化能力。为提升可重复性,本研究公开所有代码、提示和模型输出,为未来的工作建立更严格的基石。
Key Takeaways:
- 推理已成为语言模型的下一个主要前沿领域,但评估方法缺乏透明度和稳健性。
- 当前数学推理基准测试对实现细节高度敏感,包括解码参数、随机种子等。
- 过去的研究报告中的性能提升常常源于不清晰的比较或未报告的变异源。
- 强化学习在数学推理基准测试中的改进有限,且容易过度拟合。
- 监督微调方法在数学推理任务中表现出更强的泛化能力。
- 研究提出了标准化评估框架和明确的最佳实践及报告标准。
点此查看论文截图
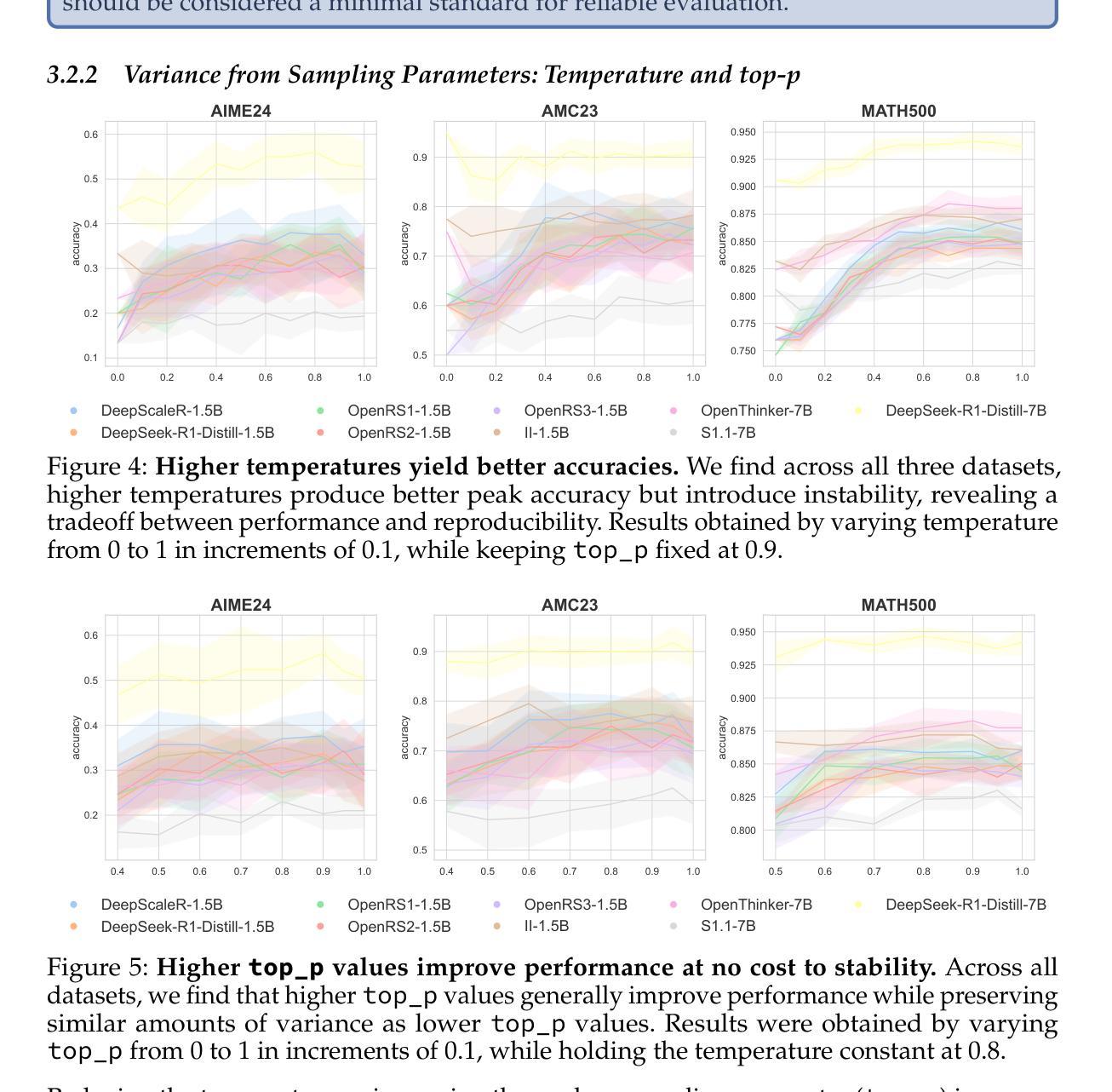
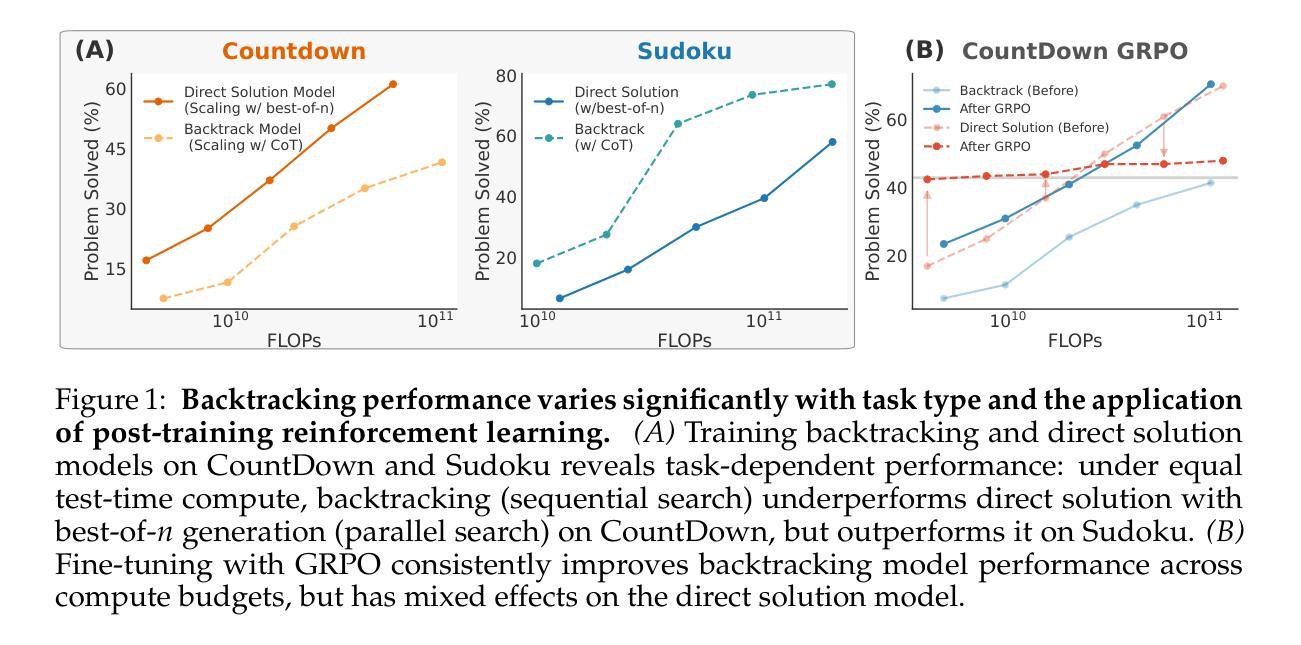
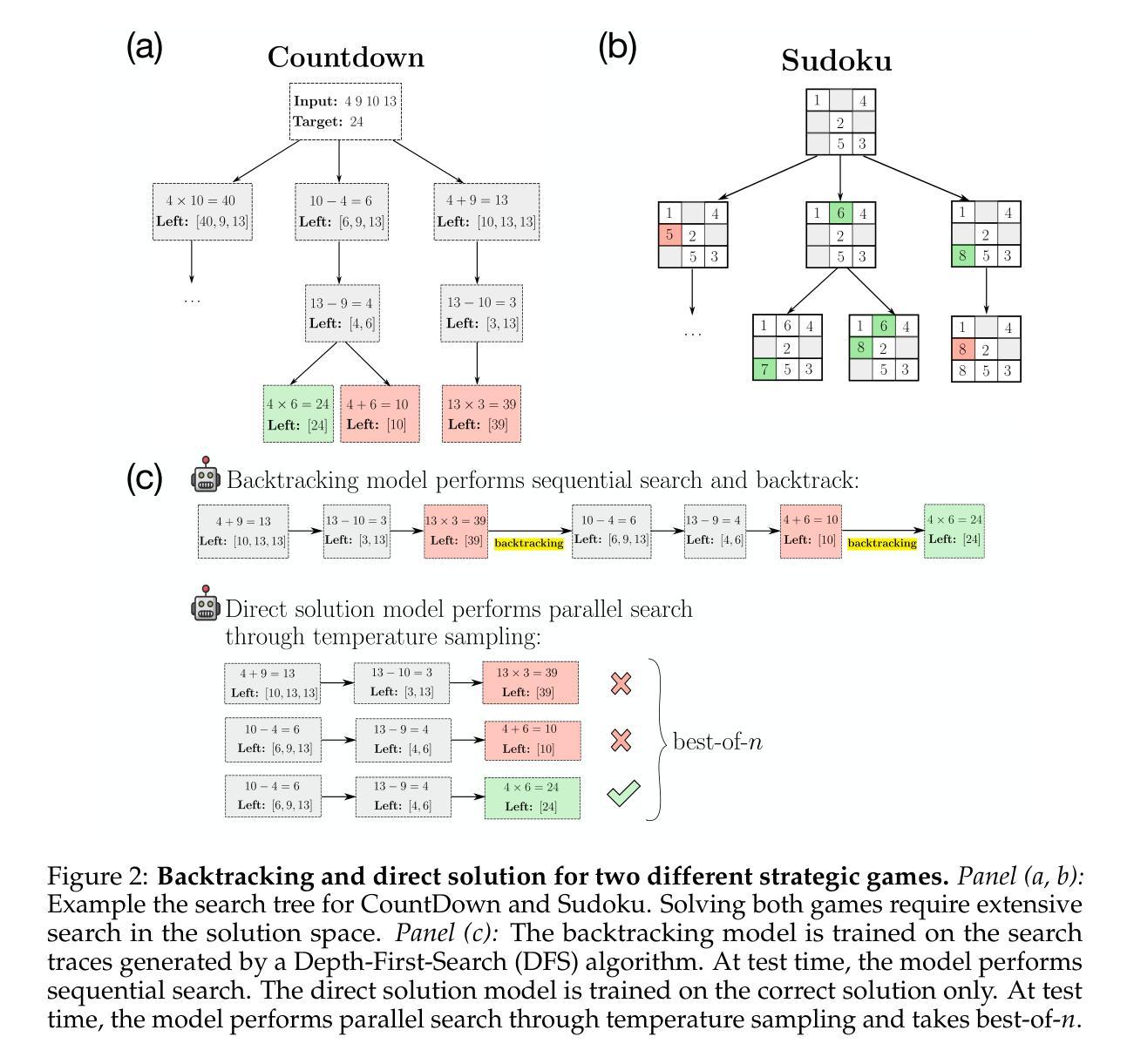
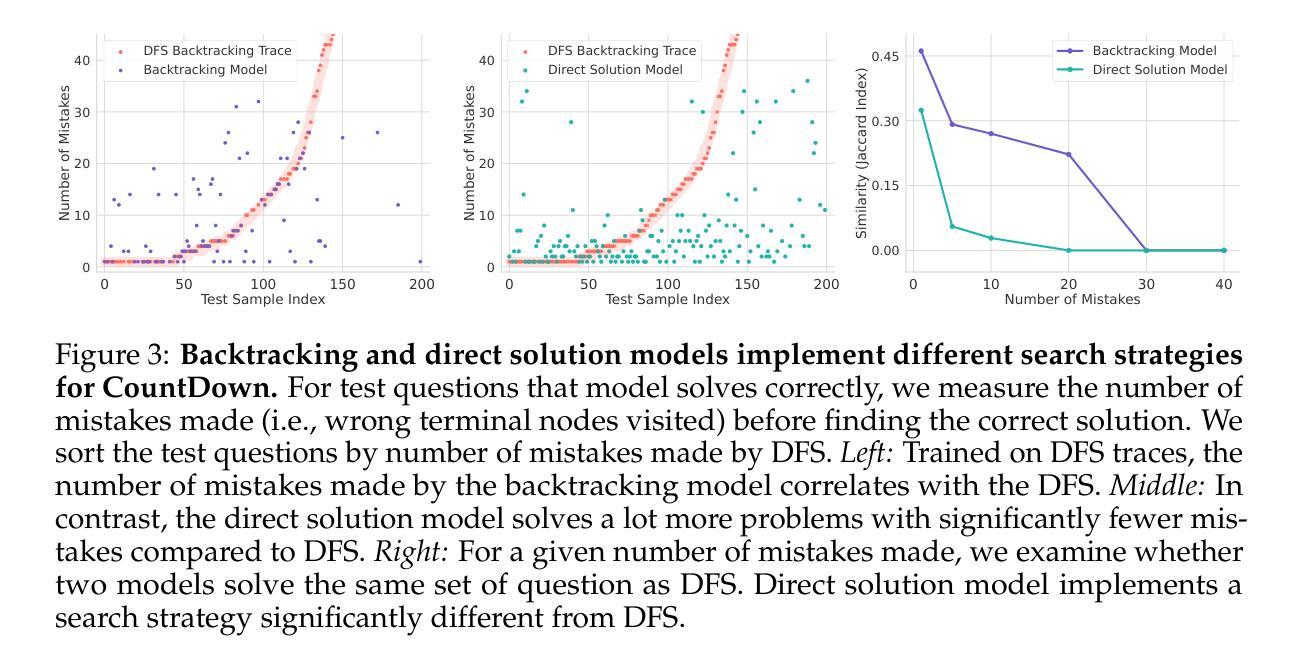
To Backtrack or Not to Backtrack: When Sequential Search Limits Model Reasoning
Authors:Tian Qin, David Alvarez-Melis, Samy Jelassi, Eran Malach
Recent advancements in large language models have significantly improved their reasoning abilities, particularly through techniques involving search and backtracking. Backtracking naturally scales test-time compute by enabling sequential, linearized exploration via long chain-of-thought (CoT) generation. However, this is not the only strategy for scaling test-time compute: parallel sampling with best-of-n selection provides an alternative that generates diverse solutions simultaneously. Despite the growing adoption of sequential search, its advantages over parallel sampling–especially under a fixed compute budget remain poorly understood. In this paper, we systematically compare these two approaches on two challenging reasoning tasks: CountDown and Sudoku. Surprisingly, we find that sequential search underperforms parallel sampling on CountDown but outperforms it on Sudoku, suggesting that backtracking is not universally beneficial. We identify two factors that can cause backtracking to degrade performance: (1) training on fixed search traces can lock models into suboptimal strategies, and (2) explicit CoT supervision can discourage “implicit” (non-verbalized) reasoning. Extending our analysis to reinforcement learning (RL), we show that models with backtracking capabilities benefit significantly from RL fine-tuning, while models without backtracking see limited, mixed gains. Together, these findings challenge the assumption that backtracking universally enhances LLM reasoning, instead revealing a complex interaction between task structure, training data, model scale, and learning paradigm.
近期大型语言模型的进步显著提高了其推理能力,尤其是通过涉及搜索和回溯的技术。回溯通过启用通过长链条思维(CoT)生成的序列化、线性化探索,自然地扩展了测试时间的计算。然而,这并不是扩展测试时间计算的唯一策略:并行采样与n选最佳提供了同时生成多种解决方案的替代方法。尽管序贯搜索的采用日益增多,但其相对于并行采样的优势——特别是在固定计算预算下——仍鲜为人知。在本文中,我们系统地比较了这两种方法在两项具有挑战性的推理任务:倒计时和数独上的表现。令人惊讶的是,我们发现序贯搜索在倒计时任务上的表现不如并行采样,但在数独任务上表现较好,这表明回溯并不是普遍有益的。我们确定了导致回溯降低性能的另外两个因素:(1)在固定搜索轨迹上进行训练会使模型陷入次优策略;(2)明确的思维链监督可能会阻碍“隐性”(未口语化)推理。将我们的分析扩展到强化学习(RL),我们发现在具有回溯能力的模型中,RL微调带来了巨大的好处,而没有回溯的模型则看到了有限且喜忧参半的收益。总之,这些发现挑战了回溯普遍提高LLM推理能力的假设,相反,揭示了任务结构、训练数据、模型规模和学习范式之间的复杂交互。
论文及项目相关链接
Summary
大型语言模型的推理能力最近有了显著提升,主要通过搜索和回溯技术实现。本文系统地比较了顺序搜索和并行采样两种策略,在CountDown和Sudoku两个任务中表现出不同的性能表现。发现回溯在某些任务上并非普遍有益,研究还发现导致回溯性能下降的两个因素。同时,在强化学习场景下,具有回溯能力的模型能获得显著收益。总之,本文揭示了任务结构、训练数据、模型规模和学习范式之间的复杂交互关系。
Key Takeaways
- 大型语言模型的推理能力有所提升,主要通过搜索和回溯技术实现。
- 顺序搜索和并行采样是两种主要的测试时间计算扩展策略。
- 在CountDown任务中,并行采样表现优于顺序搜索;而在Sudoku任务中,顺序搜索表现较好。
- 回溯并非在所有任务中都普遍有益。
- 训练固定搜索轨迹会锁定模型进入次优策略,明确思维轨迹监督会抑制“隐性”推理。
- 具有回溯能力的模型在强化学习微调下可获得显著收益,而缺乏回溯的模型则表现有限。
点此查看论文截图

A Unified Agentic Framework for Evaluating Conditional Image Generation
Authors:Jifang Wang, Xue Yang, Longyue Wang, Zhenran Xu, Yiyu Wang, Yaowei Wang, Weihua Luo, Kaifu Zhang, Baotian Hu, Min Zhang
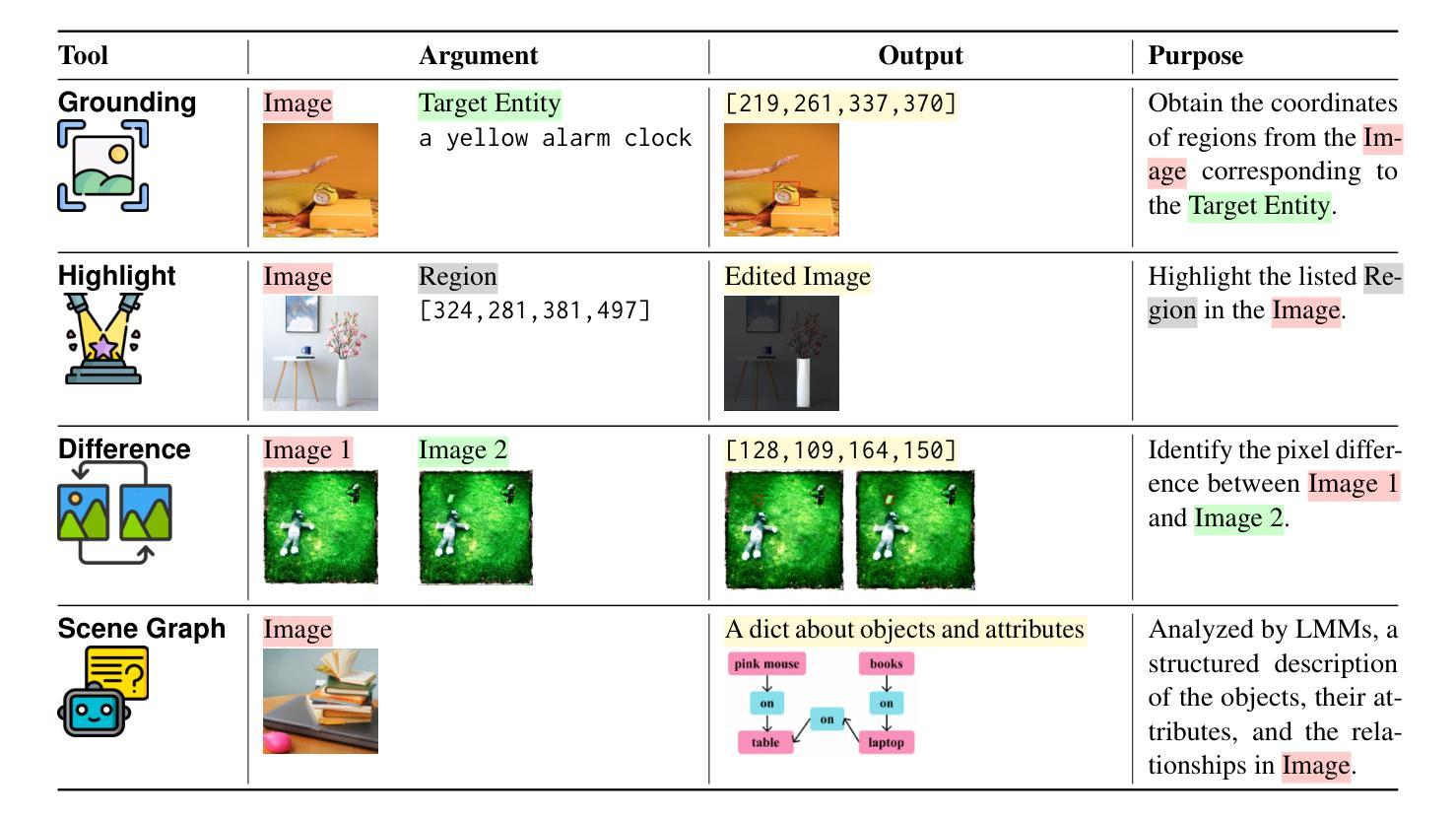
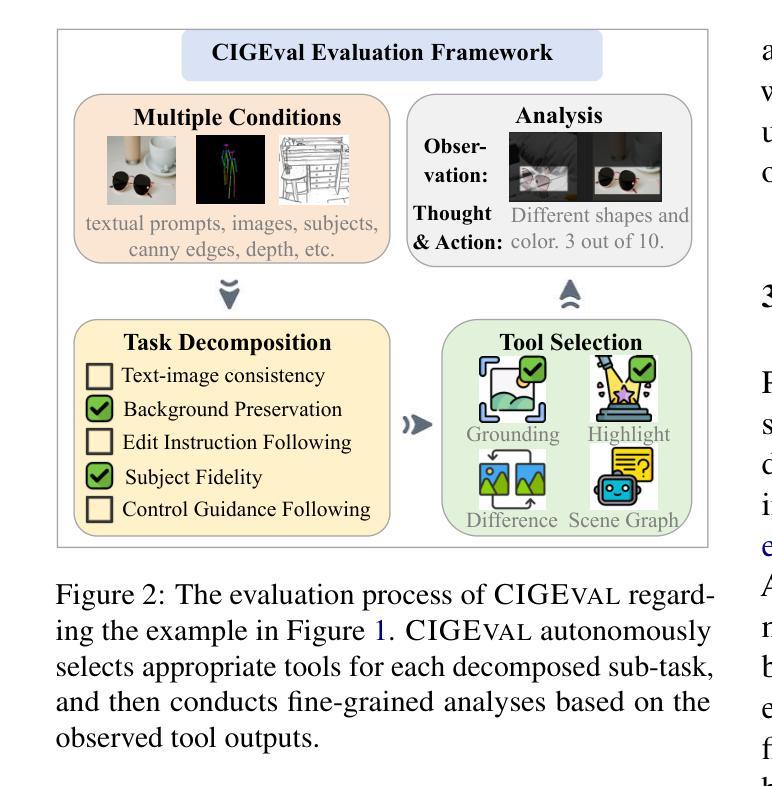
Conditional image generation has gained significant attention for its ability to personalize content. However, the field faces challenges in developing task-agnostic, reliable, and explainable evaluation metrics. This paper introduces CIGEval, a unified agentic framework for comprehensive evaluation of conditional image generation tasks. CIGEval utilizes large multimodal models (LMMs) as its core, integrating a multi-functional toolbox and establishing a fine-grained evaluation framework. Additionally, we synthesize evaluation trajectories for fine-tuning, empowering smaller LMMs to autonomously select appropriate tools and conduct nuanced analyses based on tool outputs. Experiments across seven prominent conditional image generation tasks demonstrate that CIGEval (GPT-4o version) achieves a high correlation of 0.4625 with human assessments, closely matching the inter-annotator correlation of 0.47. Moreover, when implemented with 7B open-source LMMs using only 2.3K training trajectories, CIGEval surpasses the previous GPT-4o-based state-of-the-art method. Case studies on GPT-4o image generation highlight CIGEval’s capability in identifying subtle issues related to subject consistency and adherence to control guidance, indicating its great potential for automating evaluation of image generation tasks with human-level reliability.
条件图像生成因其个性化内容的能力而受到广泛关注。然而,该领域在开发任务无关、可靠和可解释的评价指标方面面临挑战。本文介绍了CIGEval,这是一个统一的智能框架,用于对条件图像生成任务进行全面评估。CIGEval以大型多模态模型(LMMs)为核心,集成多功能工具箱并建立精细的评价框架。此外,我们综合评估轨迹进行微调,使较小的LMM能够自主地选择合适的工具,并根据工具输出进行细微分析。在七个突出的条件图像生成任务上的实验表明,CIGEval(GPT-4o版本)与人类评估达到0.4625的高相关性,接近人工评估间互标注的相关系数0.47。而且,当使用仅包含2.3K训练轨迹的7B开源LMM实现时,CIGEval超越了基于GPT-4o的先前最先进的方法。关于GPT-4o图像生成的案例研究突出了CIGEval在识别与主题一致性和遵循控制指导相关的细微问题方面的能力,表明其在自动化图像生成任务评估方面具有接近人类可靠性的巨大潜力。
论文及项目相关链接
PDF Work in progress. GitHub: https://github.com/HITsz-TMG/Agentic-CIGEval
Summary
本文介绍了一个名为CIGEval的统一智能框架,用于全面评估条件图像生成任务。该框架利用大型多模态模型为核心,集成多功能工具箱并建立精细的评价框架。实验表明,CIGEval在七个主流条件图像生成任务中的表现与人类评估高度相关,且在某些情况下超越了之前的最新方法。
Key Takeaways
- CIGEval是一个用于条件图像生成任务的综合评估框架。
- 该框架利用大型多模态模型(LMMs)为核心,提供精细的评价体系。
- CIGEval通过合成评价轨迹进行微调,使较小的LMMs能够自主选择适当的工具并进行细致的分析。
- 实验表明,CIGEval在七个主流条件图像生成任务中的表现与人类评估高度相关。
- CIGEval在某些情况下超越了之前的最新方法,如使用7B开源LMMs仅2.3K训练轨迹时。
- 案例研究证明了CIGEval在识别主题一致性和遵循控制指导方面的微妙问题方面的能力。
点此查看论文截图


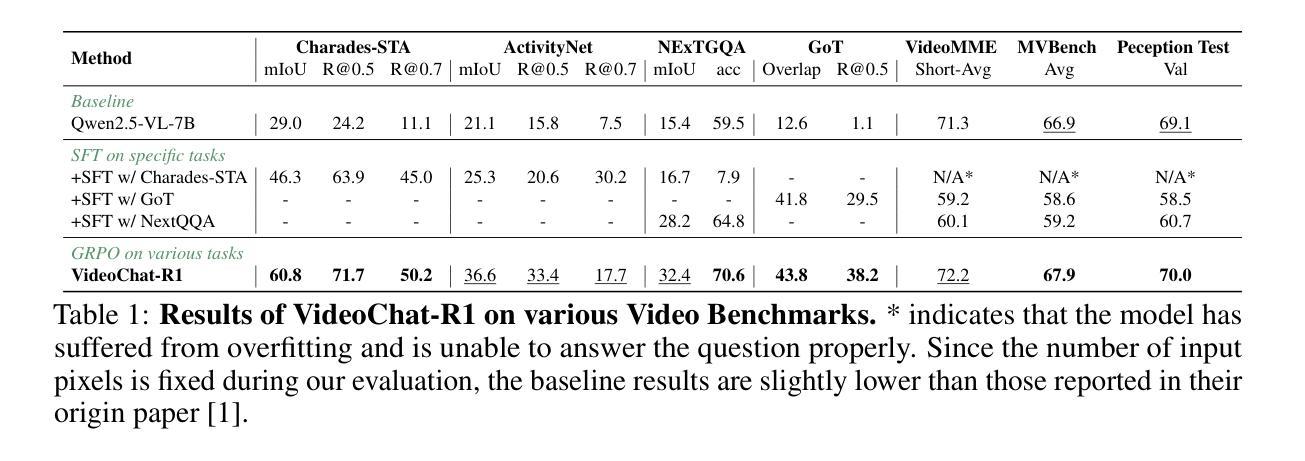
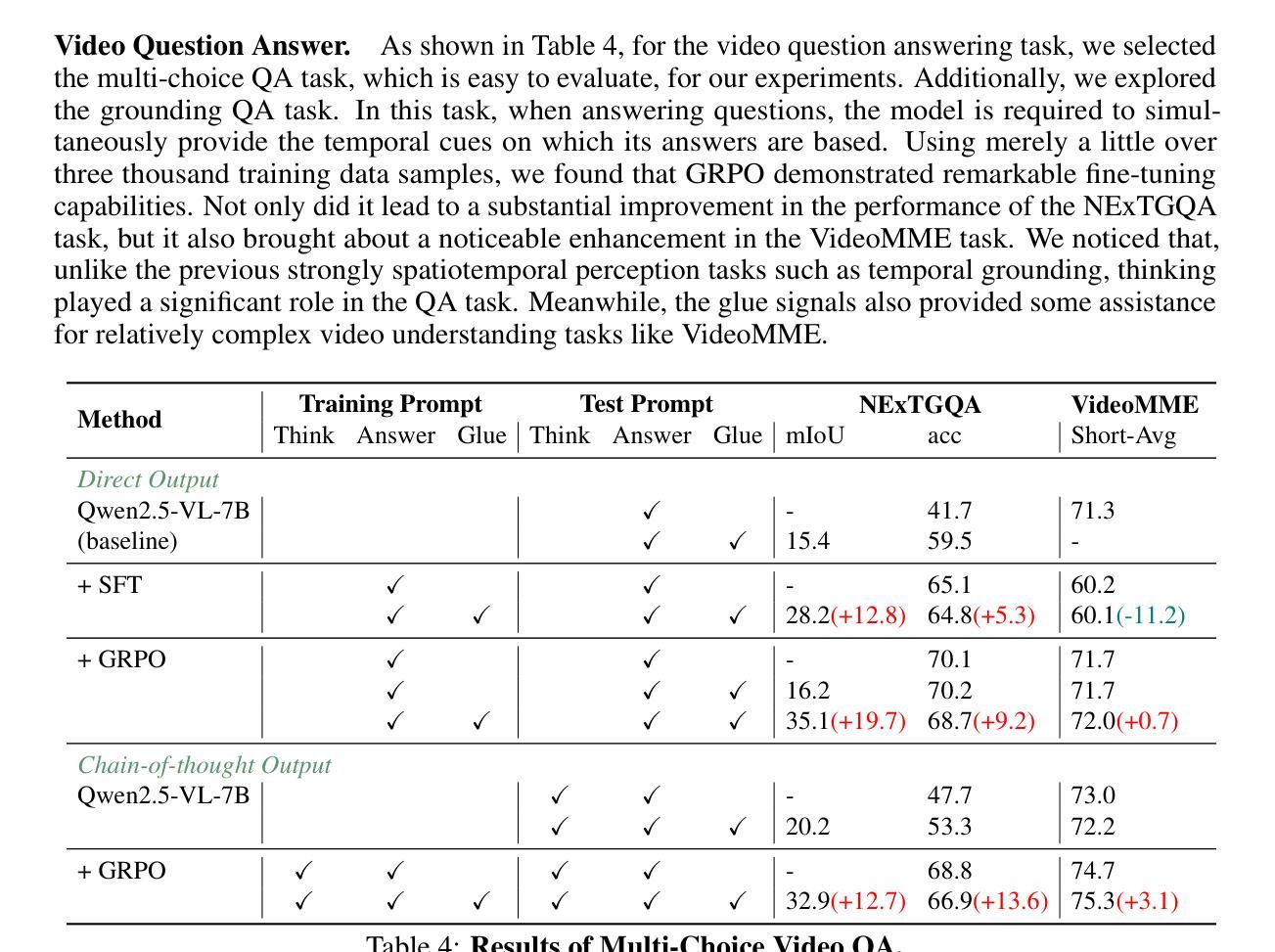
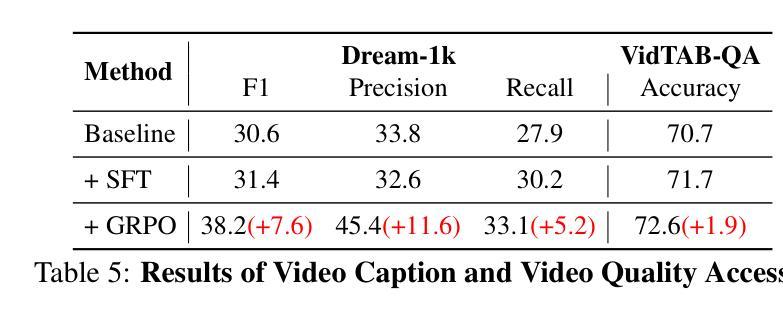
VideoChat-R1: Enhancing Spatio-Temporal Perception via Reinforcement Fine-Tuning
Authors:Xinhao Li, Ziang Yan, Desen Meng, Lu Dong, Xiangyu Zeng, Yinan He, Yali Wang, Yu Qiao, Yi Wang, Limin Wang
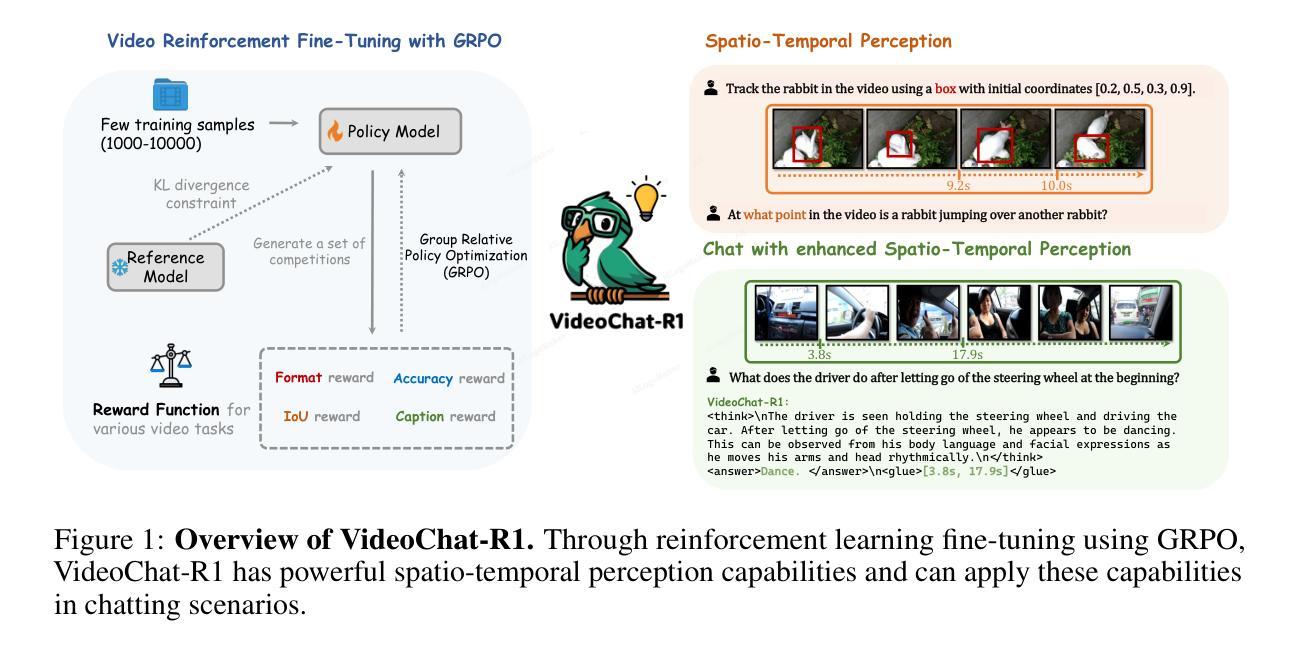
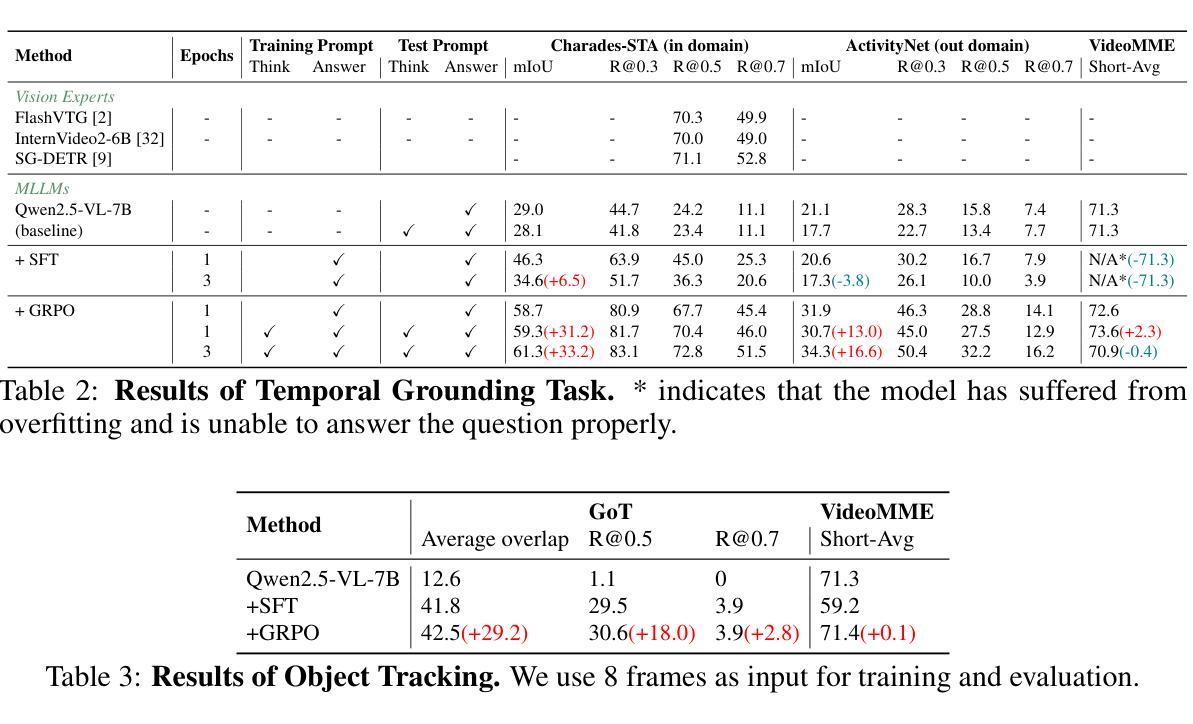
Recent advancements in reinforcement learning have significantly advanced the reasoning capabilities of multimodal large language models (MLLMs). While approaches such as Group Relative Policy Optimization (GRPO) and rule-based reward mechanisms demonstrate promise in text and image domains, their application to video understanding remains limited. This paper presents a systematic exploration of Reinforcement Fine-Tuning (RFT) with GRPO for video MLLMs, aiming to enhance spatio-temporal perception while maintaining general capabilities. Our experiments reveal that RFT is highly data-efficient for task-specific improvements. Through multi-task RFT on spatio-temporal perception objectives with limited samples, we develop VideoChat-R1, a powerful video MLLM that achieves state-of-the-art performance on spatio-temporal perception tasks without sacrificing chat ability, while exhibiting emerging spatio-temporal reasoning abilities. Compared to Qwen2.5-VL-7B, VideoChat-R1 boosts performance several-fold in tasks like temporal grounding (+31.8) and object tracking (+31.2). Additionally, it significantly improves on general QA benchmarks such as VideoMME (+0.9), MVBench (+1.0), and Perception Test (+0.9). Our findings underscore the potential of RFT for specialized task enhancement of Video MLLMs. We hope our work offers valuable insights for future RL research in video MLLMs.
近期强化学习领域的进展极大地提升了多模态大型语言模型的推理能力。虽然诸如集团相对策略优化(GRPO)和基于规则的奖励机制等在文本和图像领域表现出希望,但它们在视频理解方面的应用仍然有限。本文系统地探索了用于视频MLLM的强化微调(RFT)与GRPO的结合,旨在提高时空感知能力的同时保持一般能力。我们的实验表明,RFT对于特定任务的改进非常数据高效。通过有限样本的时空感知目标上的多任务RFT,我们开发出了VideoChat-R1,这是一款强大的视频MLLM,它在时空感知任务上实现了最先进的性能,同时不牺牲聊天能力,并展现出新兴的时空推理能力。与Qwen2.5-VL-7B相比,VideoChat-R1在诸如时间定位(+31.8)和对象跟踪(+31.2)等任务上的性能提高了数倍。此外,它在通用问答基准测试(如VideoMME +0.9、MVBench +1.0和感知测试+ 0.9)上也取得了显著改善。我们的研究突出了RFT在视频MLLM专项任务增强方面的潜力。我们希望我们的研究能为未来视频MLLM的RL研究提供有价值的见解。
论文及项目相关链接
Summary
多媒体模态大型语言模型(MLLMs)的推理能力在强化学习领域的最新进展中得到了显著提升。本研究采用强化微调(RFT)与群体相对策略优化(GRPO)相结合的方法,旨在提高视频MLLMs的时空感知能力,同时保持其通用能力。实验表明,RFT在特定任务上具有高效的数据利用率,通过多任务RFT在时空感知目标上进行有限样本训练,成功开发出VideoChat-R1模型。该模型在时空感知任务上实现了卓越性能,同时不牺牲对话能力,展现出新兴的时空推理能力。
Key Takeaways
- 强化学习在提升多模态大型语言模型(MLLMs)的推理能力方面取得显著进展。
- Group Relative Policy Optimization (GRPO) 与强化微调(RFT)结合应用,有助于增强视频MLLMs的时空感知能力。
- RFT方法在特定任务上具有高效数据利用率。
- VideoChat-R1模型通过多任务RFT训练,实现了在时空感知任务上的卓越性能。
- VideoChat-R1模型在不牺牲对话能力的前提下,展现出新兴的时空推理能力。
- 与Qwen2.5-VL-7B相比,VideoChat-R1在时空感知任务上的性能有所提升,如时间定位提升31.8%,目标跟踪提升31.2%。
点此查看论文截图

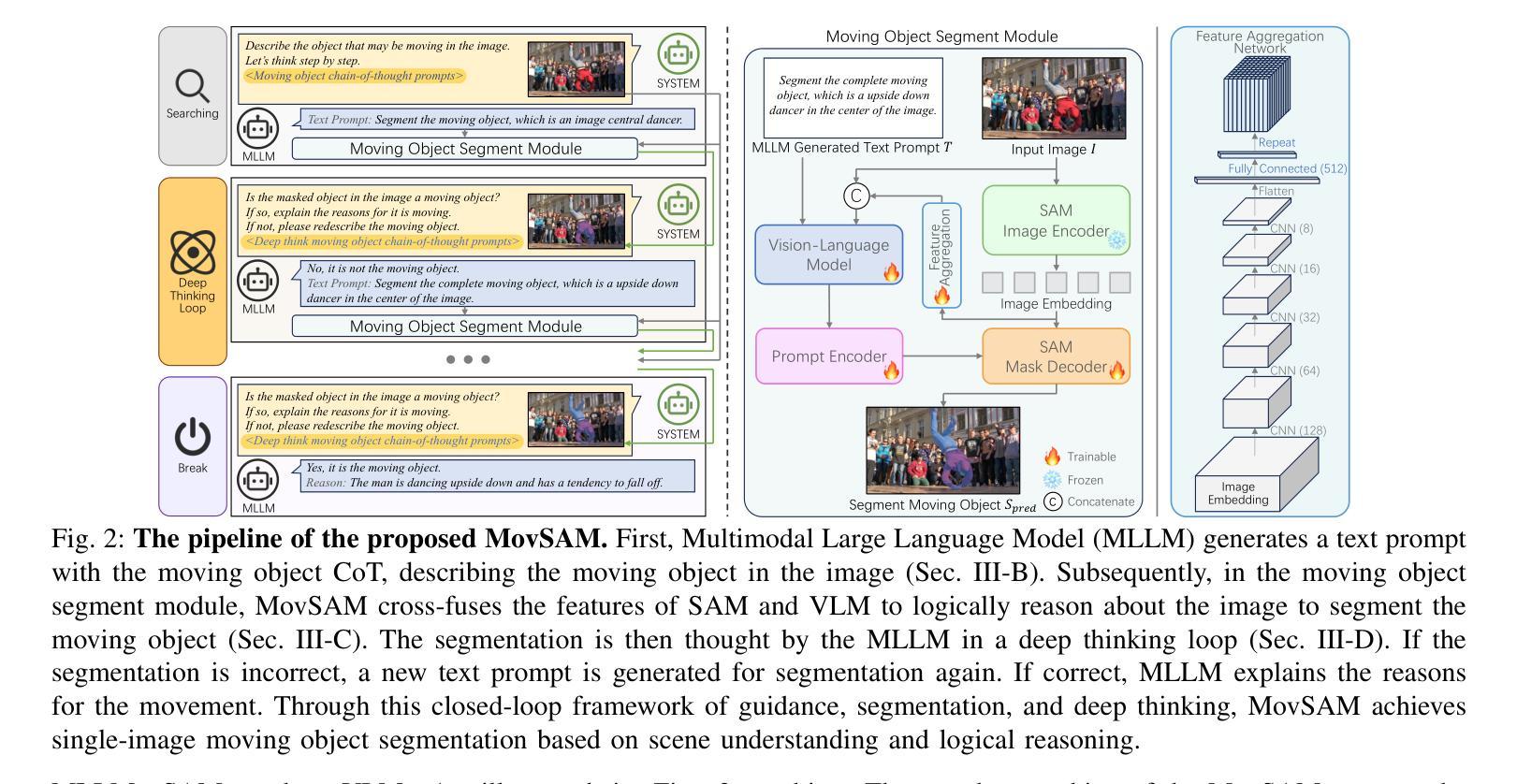
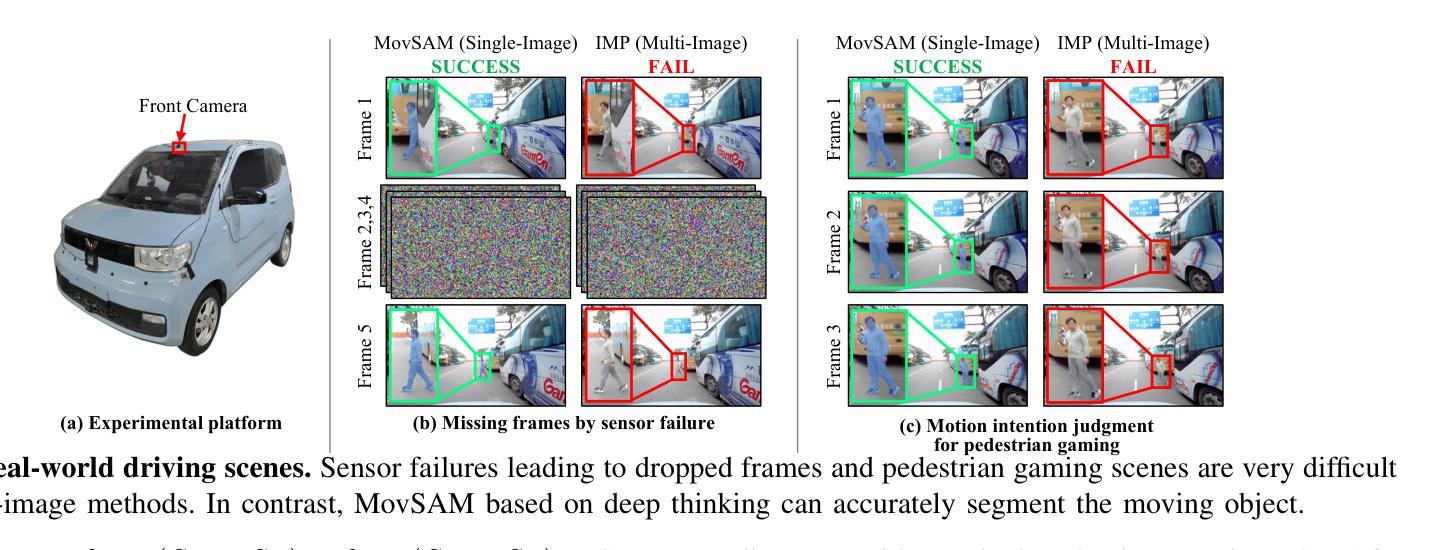
MovSAM: A Single-image Moving Object Segmentation Framework Based on Deep Thinking
Authors:Chang Nie, Yiqing Xu, Guangming Wang, Zhe Liu, Yanzi Miao, Hesheng Wang
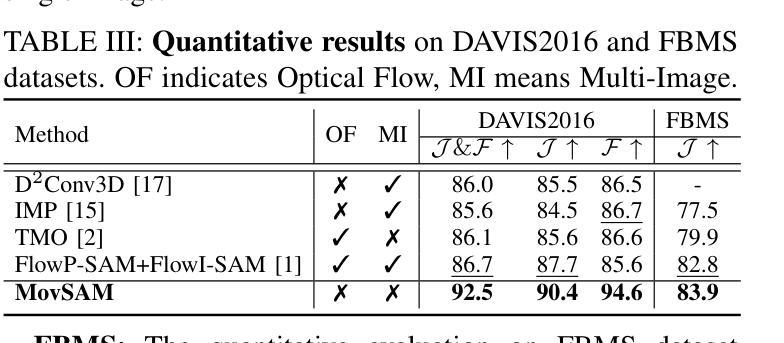
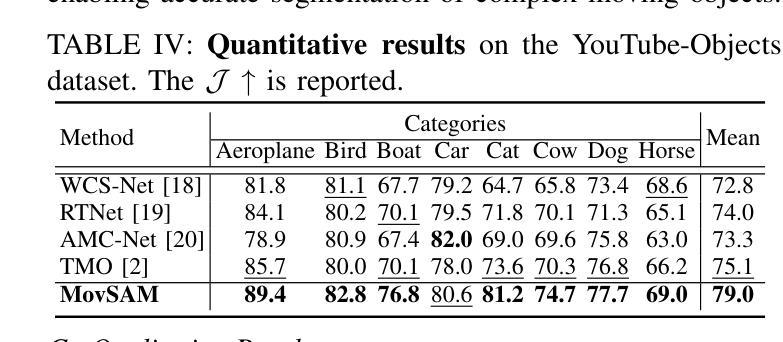
Moving object segmentation plays a vital role in understanding dynamic visual environments. While existing methods rely on multi-frame image sequences to identify moving objects, single-image MOS is critical for applications like motion intention prediction and handling camera frame drops. However, segmenting moving objects from a single image remains challenging for existing methods due to the absence of temporal cues. To address this gap, we propose MovSAM, the first framework for single-image moving object segmentation. MovSAM leverages a Multimodal Large Language Model (MLLM) enhanced with Chain-of-Thought (CoT) prompting to search the moving object and generate text prompts based on deep thinking for segmentation. These prompts are cross-fused with visual features from the Segment Anything Model (SAM) and a Vision-Language Model (VLM), enabling logic-driven moving object segmentation. The segmentation results then undergo a deep thinking refinement loop, allowing MovSAM to iteratively improve its understanding of the scene context and inter-object relationships with logical reasoning. This innovative approach enables MovSAM to segment moving objects in single images by considering scene understanding. We implement MovSAM in the real world to validate its practical application and effectiveness for autonomous driving scenarios where the multi-frame methods fail. Furthermore, despite the inherent advantage of multi-frame methods in utilizing temporal information, MovSAM achieves state-of-the-art performance across public MOS benchmarks, reaching 92.5% on J&F. Our implementation will be available at https://github.com/IRMVLab/MovSAM.
动态环境中的移动对象分割在理解动态视觉环境中起着至关重要的作用。虽然现有方法依赖于多帧图像序列来识别移动对象,但单图像移动对象分割(MOS)对于运动意图预测和摄像头帧丢失处理等领域的应用至关重要。然而,由于缺乏时间线索,从单幅图像中分割移动对象对于现有方法来说仍然是一个挑战。为了解决这一空白,我们提出了单图像移动对象分割的第一个框架——MovSAM。MovSAM利用多模态大型语言模型(MLLM),通过思维链(CoT)提示来搜索移动对象,并基于深度思考生成文本提示进行分割。这些提示与来自分段任何模型(SAM)和视觉语言模型(VLM)的视觉特征进行交叉融合,实现逻辑驱动的移动对象分割。分割结果然后经过深度思考优化循环,使MovSam能够不断迭代地提高对场景上下文和对象间关系的理解,进行逻辑推理。这种创新的方法使MovSAM能够通过考虑场景理解来分割单幅图像中的移动对象。我们在现实世界中实现了MovSAM,以验证其在自动驾驶场景中的实际应用和有效性,在这些场景中,多帧方法会失效。此外,尽管多帧方法在利用时间信息方面具有固有优势,但MovSAM在公共MOS基准测试中达到了最先进的性能水平,在J&F上达到了92.5%。我们的实现将发布在https://github.com/IRMVLab/MovSAM。
论文及项目相关链接
Summary
单图像动态目标分割在理解动态视觉环境中起到重要作用。当前的方法多依赖于多帧图像序列来识别动态目标,但在运动意图预测和应对摄像机掉帧等应用中,单图像动态目标分割是关键。然而,由于缺乏时间线索,从单幅图像中分割出动态目标对于现有方法来说仍然具有挑战性。为了解决这个问题,我们提出了首个单图像动态目标分割框架MovSAM。MovSAM利用多模态大型语言模型(MLLM)结合思维链(CoT)提示来搜索动态目标,并基于深度思考生成文本提示进行分割。这些提示与分段任何事情模型(SAM)和视觉语言模型(VLM)的视觉特征相融合,实现了逻辑驱动的动态目标分割。MovSAM通过深度思考优化循环对分割结果进行优化,能够不断改善对场景上下文和目标间关系的理解。这种创新方法使得MovSAM能够在考虑场景理解的情况下,对单幅图像中的动态目标进行分割。我们在现实世界实现了MovSAM,验证了其在自动驾驶等场景中的实际应用效果和优越性,即使在多帧方法失效的情况下也能达到最先进的性能,在J&F上达到92.5%。
Key Takeaways
- MovSAM是首个针对单图像动态目标分割的框架。
- MovSAM利用多模态大型语言模型(MLLM)结合思维链(CoT)提示来识别动态目标。
- 通过深度思考生成的文本提示与视觉特征融合,实现逻辑驱动的动态目标分割。
- MovSAM通过深度思考优化循环能够改善对场景上下文和目标间关系的理解。
- MovSAM在单图像动态目标分割中考虑了场景理解。
- 在现实世界的实际应用中,MovSAM在自动驾驶等场景表现出优越性能。
点此查看论文截图



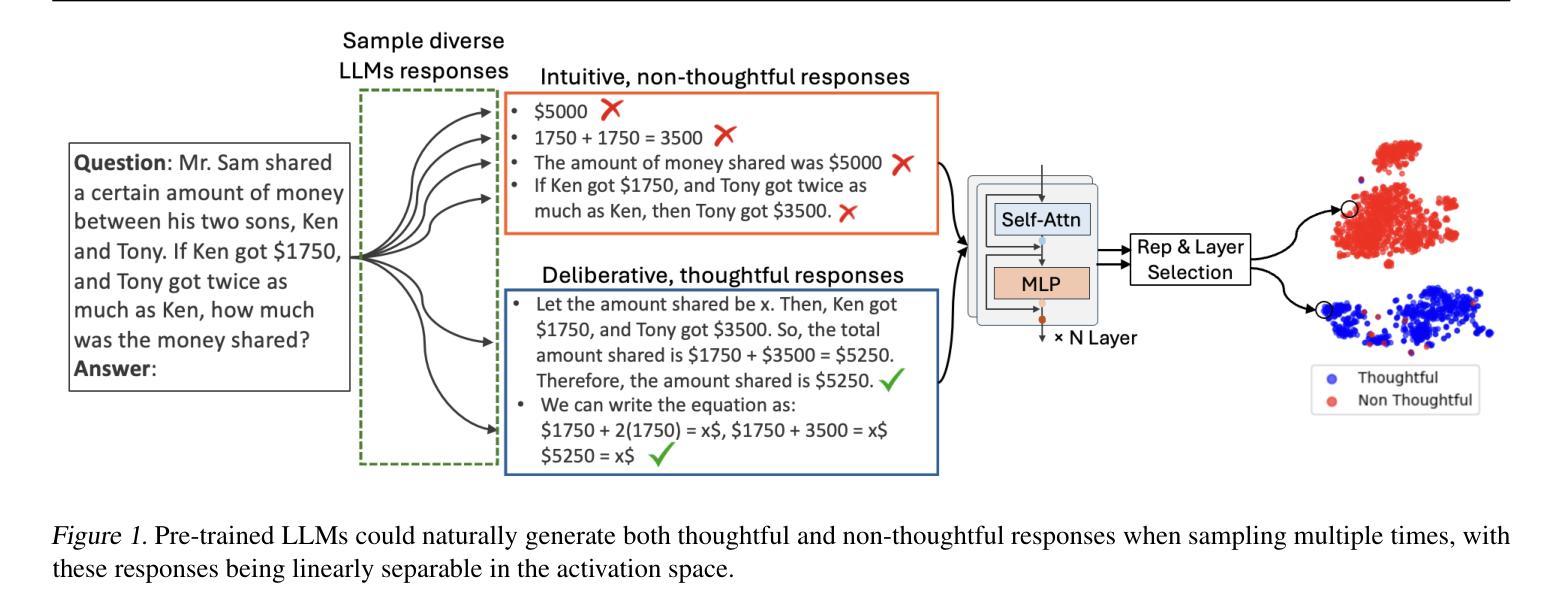
ThoughtProbe: Classifier-Guided Thought Space Exploration Leveraging LLM Intrinsic Reasoning
Authors:Zijian Wang, Chang Xu
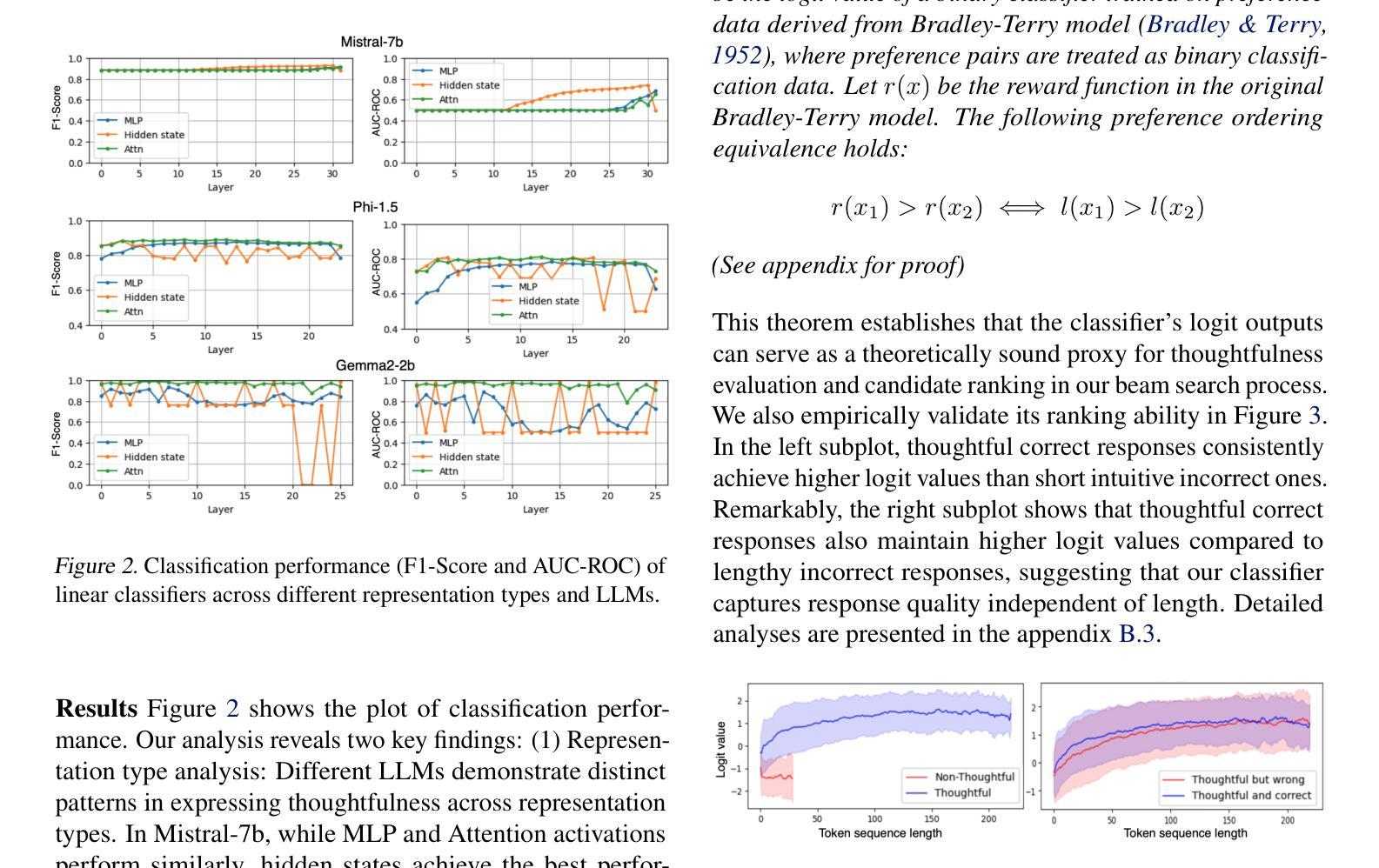
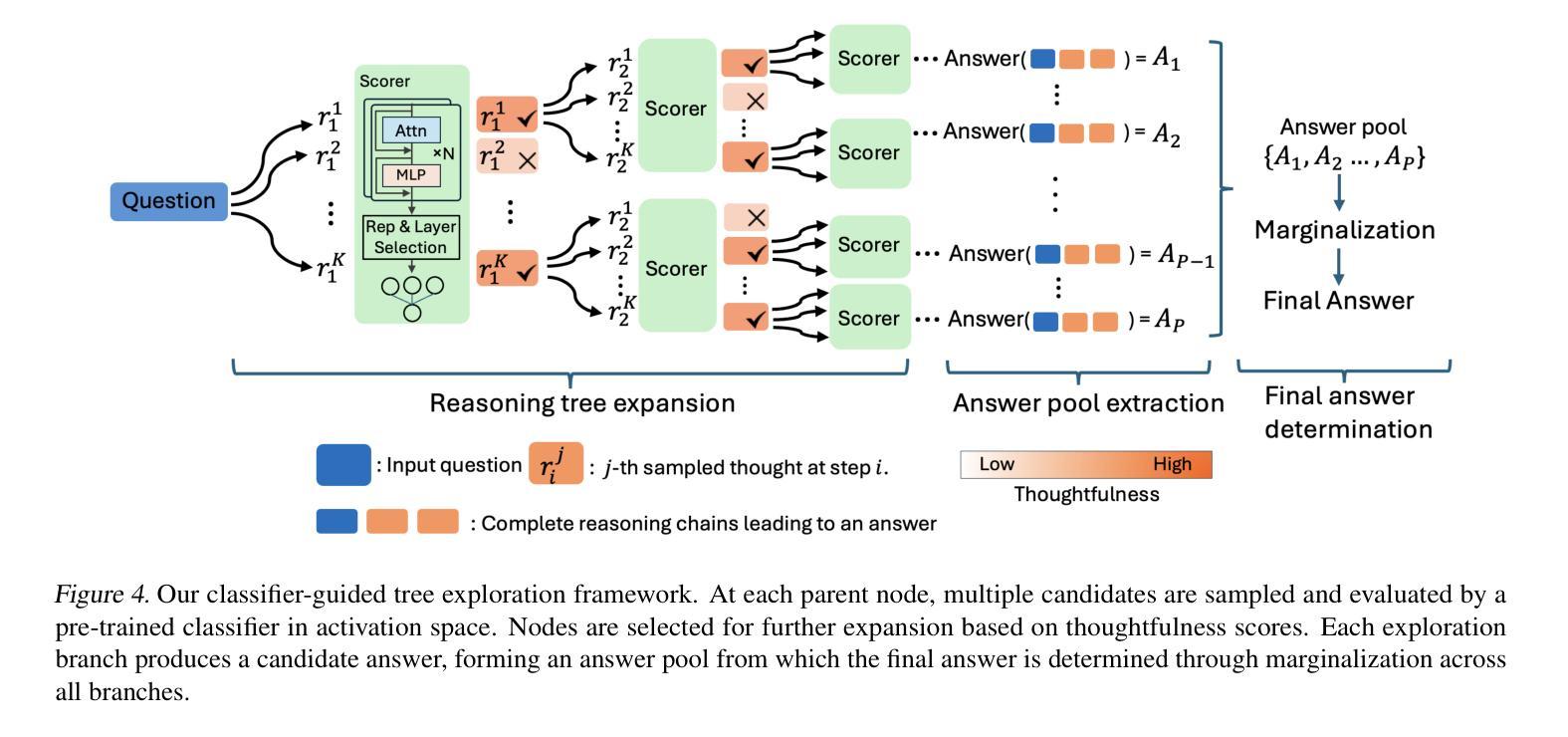
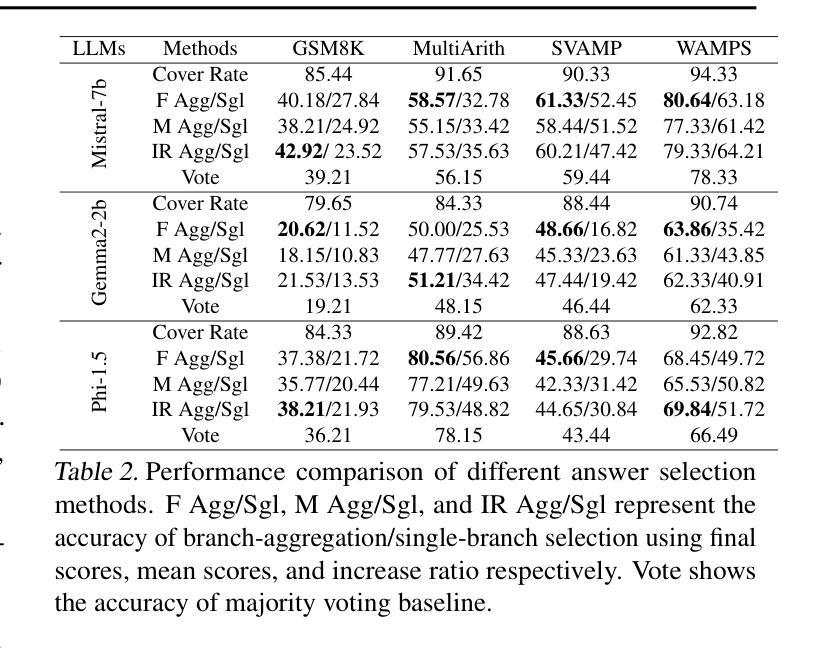
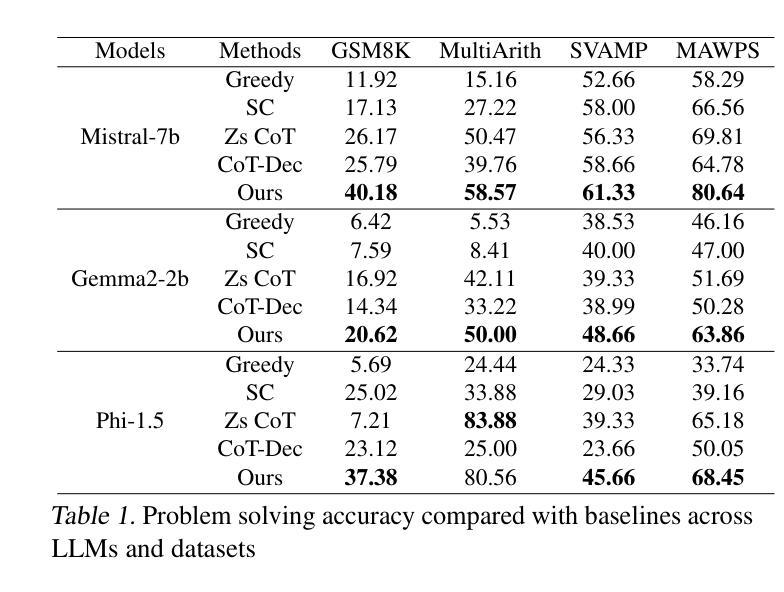
Pre-trained large language models (LLMs) have been demonstrated to possess intrinsic reasoning capabilities that can emerge naturally when expanding the response space. However, the neural representation mechanisms underlying these intrinsic capabilities and approaches for their optimal utilization remain inadequately understood. In this work, we make the key discovery that a simple linear classifier can effectively detect intrinsic reasoning capabilities in LLMs’ activation space, particularly within specific representation types and network layers. Based on this finding, we propose a classifier-guided search framework that strategically explore a tree-structured response space. In each node expansion, the classifier serves as a scoring and ranking mechanism that efficiently allocates computational resources by identifying and prioritizing more thoughtful reasoning directions for continuation. After completing the tree expansion, we collect answers from all branches to form a candidate answer pool. We propose a branch-aggregation selection method that marginalizes over all supporting branches by aggregating their thoughtfulness scores, thereby identifying the optimal answer from the pool. Experimental results show that our framework’s comprehensive exploration not only covers valid reasoning chains but also effectively identifies them, achieving significant improvements across multiple arithmetic reasoning benchmarks.
预训练大型语言模型(LLM)已表现出内在推理能力,在扩大响应空间时这些能力可以自然出现。然而,这些内在能力的基础神经表征机制和如何最优利用它们的方法仍理解不足。在这项工作中,我们关键地发现一个简单的线性分类器可以有效地检测LLM激活空间中的内在推理能力,特别是在特定的表征类型和网络层内。基于这一发现,我们提出了一个分类器引导搜索框架,该框架有策略地探索树形响应空间。在每次节点扩展中,分类器充当评分和排名机制,通过识别和优先考虑更有深度的推理方向来继续,从而有效地分配计算资源。完成树扩展后,我们从所有分支收集答案以形成候选答案池。我们提出了一种分支聚合选择方法,它通过聚合所有支持分支的思考得分来对它们进行整体评估,从而从池中识别最佳答案。实验结果表明,我们框架的全面探索不仅涵盖了有效的推理链,而且能够有效地识别它们,在多个算术推理基准测试中实现了显著改进。
论文及项目相关链接
Summary
预训练大型语言模型(LLM)具有内在推理能力,在扩大响应空间时这些能力可自然显现。然而,这些内在能力的神经表征机制及其最优利用方法尚不完全清楚。本研究中,我们重要地发现一个简单的线性分类器可有效检测LLM激活空间中的内在推理能力,特别是在特定表征类型和网络层内。基于此发现,我们提出了一个分类器引导搜索框架,该框架以策略方式探索树状响应空间。在每次节点扩展时,分类器充当评分和排名机制,通过识别并优先考虑更有深度的推理方向来继续,有效地分配计算资源。完成树扩展后,我们从所有分支收集答案以形成候选答案池。我们提出了一种分支聚合选择方法,通过对所有支持分支的置信度得分进行求和,从而从池中识别出最佳答案。实验结果表明,我们的框架的全面探索不仅覆盖了有效的推理链,还能有效识别它们,在多个算术推理基准测试中实现了显著改进。
Key Takeaways
- 预训练大型语言模型具备内在推理能力,这些能力在扩大响应空间时自然显现。
- 线性分类器可有效检测LLM激活空间中的内在推理能力,特别是在特定表征类型和网络层内。
- 提出一个分类器引导搜索框架,以策略方式探索树状响应空间。
- 在节点扩展时,分类器充当评分和排名机制,有效分配计算资源。
- 完成树扩展后形成候选答案池,通过分支聚合选择方法识别最佳答案。
- 框架的全面探索覆盖了有效的推理链,并实现了对多个算术推理基准测试的显著改进。
- 该研究为LLM的内在推理能力的理解和优化利用提供了新视角和方法。
点此查看论文截图

SCI-Reason: A Dataset with Chain-of-Thought Rationales for Complex Multimodal Reasoning in Academic Areas
Authors:Chenghao Ma, Haihong E., Junpeng Ding, Jun Zhang, Ziyan Ma, Huang Qing, Bofei Gao, Liang Chen, Meina Song
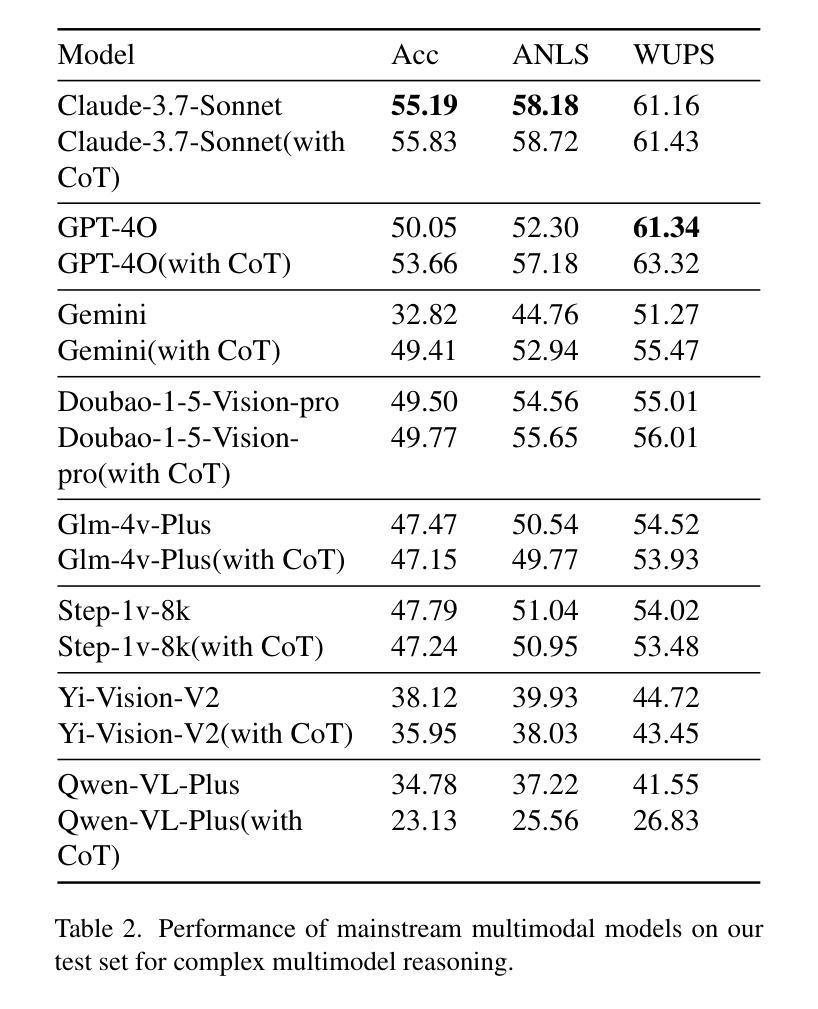
Large Language Models (LLMs) and Large Multimodal Models (LMMs) demonstrate impressive problem-solving skills in many tasks and domains. However, their ability to reason with complex images in academic domains has not been systematically investigated. To bridge this gap, we present SCI-Reason, a dataset for complex multimodel reasoning in academic areas. SCI-Reason aims to test and improve the reasoning ability of large multimodal models using real complex images in academic domains. The dataset contains 12,066 images and 12,626 question-answer pairs extracted from PubMed, divided into training, validation and test splits. Each question-answer pair also contains an accurate and efficient inference chain as a guide to improving the inference properties of the dataset. With SCI-Reason, we performed a comprehensive evaluation of 8 well-known models. The best performing model, Claude-3.7-Sonnet, only achieved an accuracy of 55.19%. Error analysis shows that more than half of the model failures are due to breakdowns in multi-step inference chains rather than errors in primary visual feature extraction. This finding underscores the inherent limitations in reasoning capabilities exhibited by current multimodal models when processing complex image analysis tasks within authentic academic contexts. Experiments on open-source models show that SCI-Reason not only enhances reasoning ability but also demonstrates cross-domain generalization in VQA tasks. We also explore future applications of model inference capabilities in this domain, highlighting its potential for future research.
大型语言模型(LLMs)和大型多模态模型(LMMs)在许多任务和领域中都展现出了令人印象深刻的解决问题的能力。然而,它们在学术领域中对复杂图像进行推理的能力尚未得到系统的研究。为了弥补这一空白,我们推出了SCI-Reason,这是一个用于学术领域复杂多模态推理的数据集。SCI-Reason旨在利用学术领域的真实复杂图像来测试和改进大型多模态模型的推理能力。该数据集包含从PubMed中提取的12,066张图像和12,626个问题答案对,分为训练、验证和测试三部分。每个问题答案对还包含一个准确高效的推理链,作为改进数据集推理属性的指南。使用SCI-Reason,我们对8个知名模型进行了全面评估。表现最佳的模型Claude-3.7-Sonnet的准确率仅为55.19%。错误分析表明,超过一半的模型失败是由于多步推理链的崩溃,而不是初级视觉特征提取中的错误。这一发现强调了当前多模态模型在处理真实学术环境中的复杂图像分析任务时所展现的推理能力的固有局限性。对开源模型的实验表明,SCI-Reason不仅提高了推理能力,而且在VQA任务中展示了跨域泛化能力。我们还探讨了模型推理能力在未来领域的应用潜力,突显了其未来研究的重要性。
论文及项目相关链接
PDF Submitted to ICCV 2025. 11 pages (including references)
Summary
大型语言模型(LLMs)和多模态模型(LMMs)在众多任务和领域中的问题解决能力令人印象深刻。然而,这些模型在学术领域中对复杂图像进行推理的能力尚未进行系统性的研究。为填补这一空白,我们推出了SCI-Reason数据集,用于测试和提高大型多模态模型在学术领域对复杂图像的推理能力。该数据集包含从PubMed提取的12,066张图像和12,626组问答对,分为训练、验证和测试三部分。通过SCI-Reason数据集,我们对8个知名模型进行了全面评估。最佳模型Claude-3.7-Sonnet的准确率仅为55.19%。错误分析显示,模型失败的一半以上是由于多步推理链的崩溃,而不是主要的视觉特征提取错误。这表明当前的多模态模型在处理真实的学术环境中的复杂图像分析任务时,其推理能力存在固有局限。SCI-Reason不仅提高了模型的推理能力,而且在VQA任务中表现出跨领域的泛化能力。我们还探讨了模型推理能力在未来应用中的潜力。
Key Takeaways
- 大型语言模型(LLMs)和多模态模型(LMMs)在学术领域的复杂图像推理能力尚未得到充分研究。
- SCI-Reason数据集旨在测试和提高大型多模态模型在学术领域的复杂图像推理能力,包含从PubMed提取的真实图像和问答对。
- 最佳模型在SCI-Reason数据集上的准确率仅为55.19%,表明当前多模态模型的推理能力存在局限。
- 模型失败的主要原因在于多步推理链的崩溃,而非视觉特征提取错误。
- SCI-Reason数据集不仅提高了模型的推理能力,还表现出跨领域的泛化能力。
- 模型推理能力在未来应用中具有潜力,尤其是在处理复杂图像分析任务方面。
点此查看论文截图

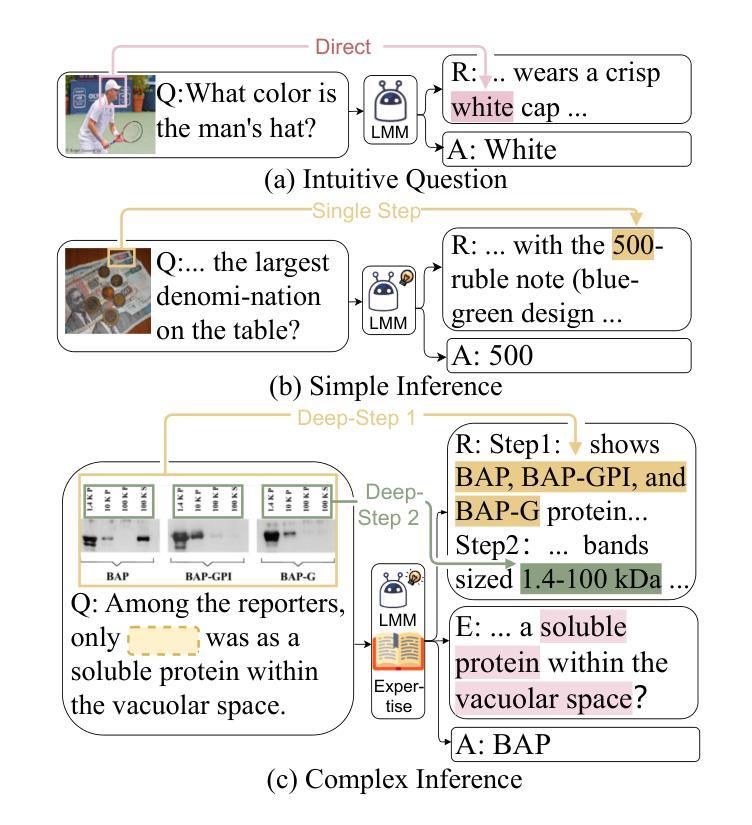
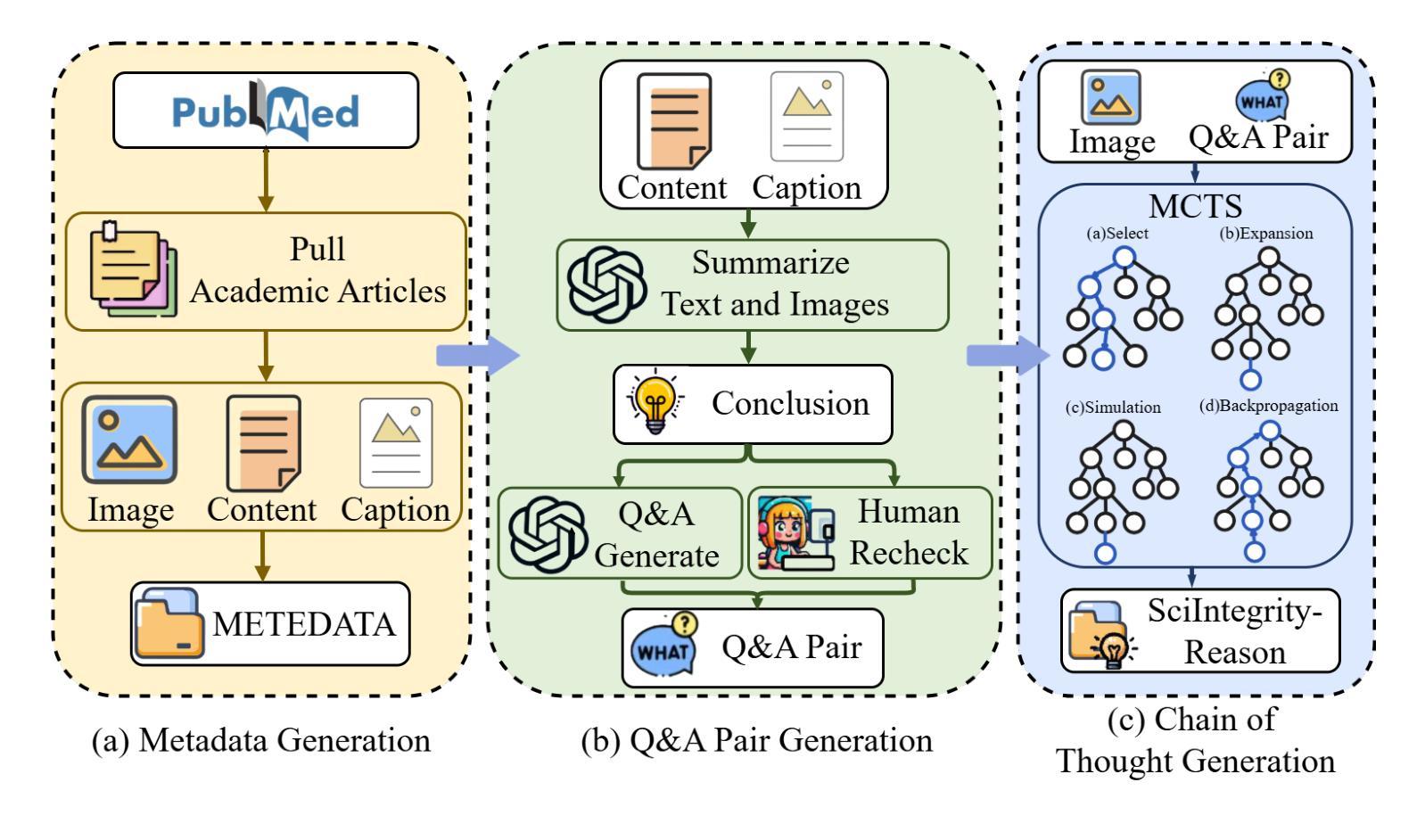
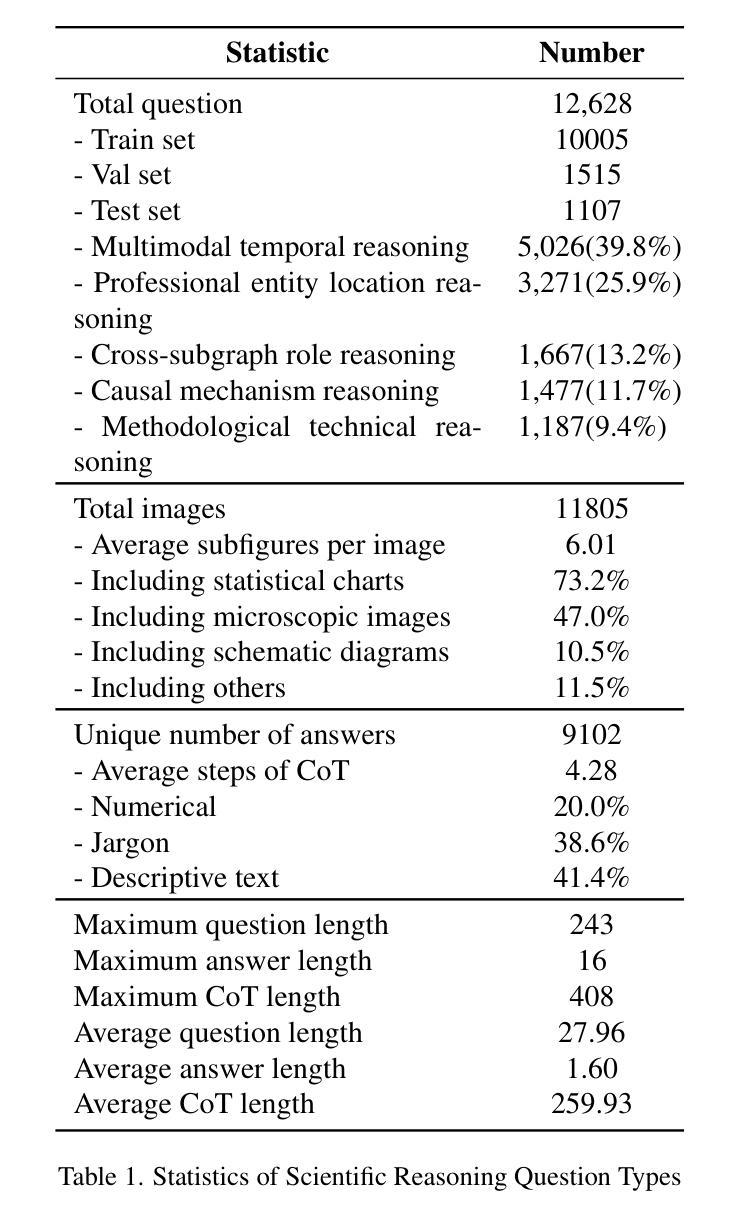
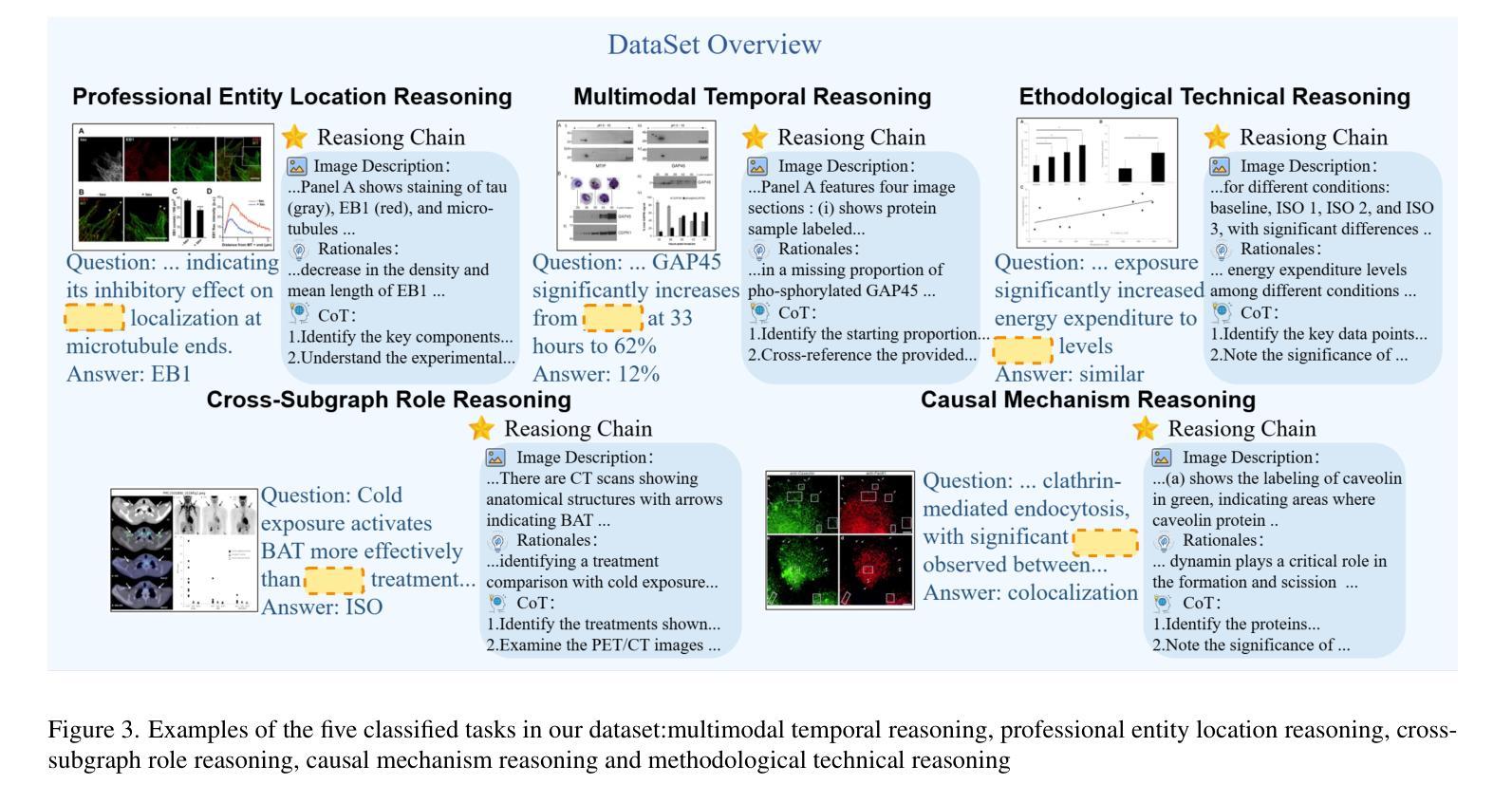
Right Prediction, Wrong Reasoning: Uncovering LLM Misalignment in RA Disease Diagnosis
Authors:Umakanta Maharana, Sarthak Verma, Avarna Agarwal, Prakashini Mruthyunjaya, Dwarikanath Mahapatra, Sakir Ahmed, Murari Mandal
Large language models (LLMs) offer a promising pre-screening tool, improving early disease detection and providing enhanced healthcare access for underprivileged communities. The early diagnosis of various diseases continues to be a significant challenge in healthcare, primarily due to the nonspecific nature of early symptoms, the shortage of expert medical practitioners, and the need for prolonged clinical evaluations, all of which can delay treatment and adversely affect patient outcomes. With impressive accuracy in prediction across a range of diseases, LLMs have the potential to revolutionize clinical pre-screening and decision-making for various medical conditions. In this work, we study the diagnostic capability of LLMs for Rheumatoid Arthritis (RA) with real world patients data. Patient data was collected alongside diagnoses from medical experts, and the performance of LLMs was evaluated in comparison to expert diagnoses for RA disease prediction. We notice an interesting pattern in disease diagnosis and find an unexpected \textit{misalignment between prediction and explanation}. We conduct a series of multi-round analyses using different LLM agents. The best-performing model accurately predicts rheumatoid arthritis (RA) diseases approximately 95% of the time. However, when medical experts evaluated the reasoning generated by the model, they found that nearly 68% of the reasoning was incorrect. This study highlights a clear misalignment between LLMs high prediction accuracy and its flawed reasoning, raising important questions about relying on LLM explanations in clinical settings. \textbf{LLMs provide incorrect reasoning to arrive at the correct answer for RA disease diagnosis.}
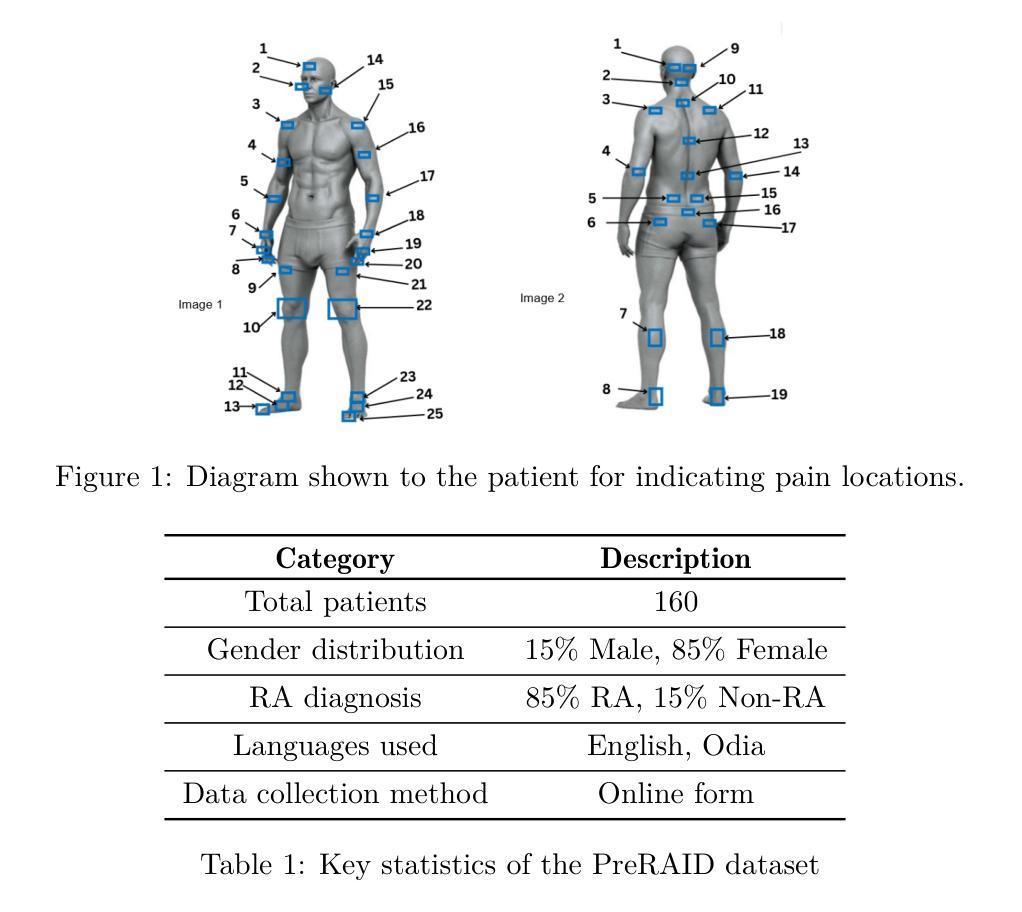
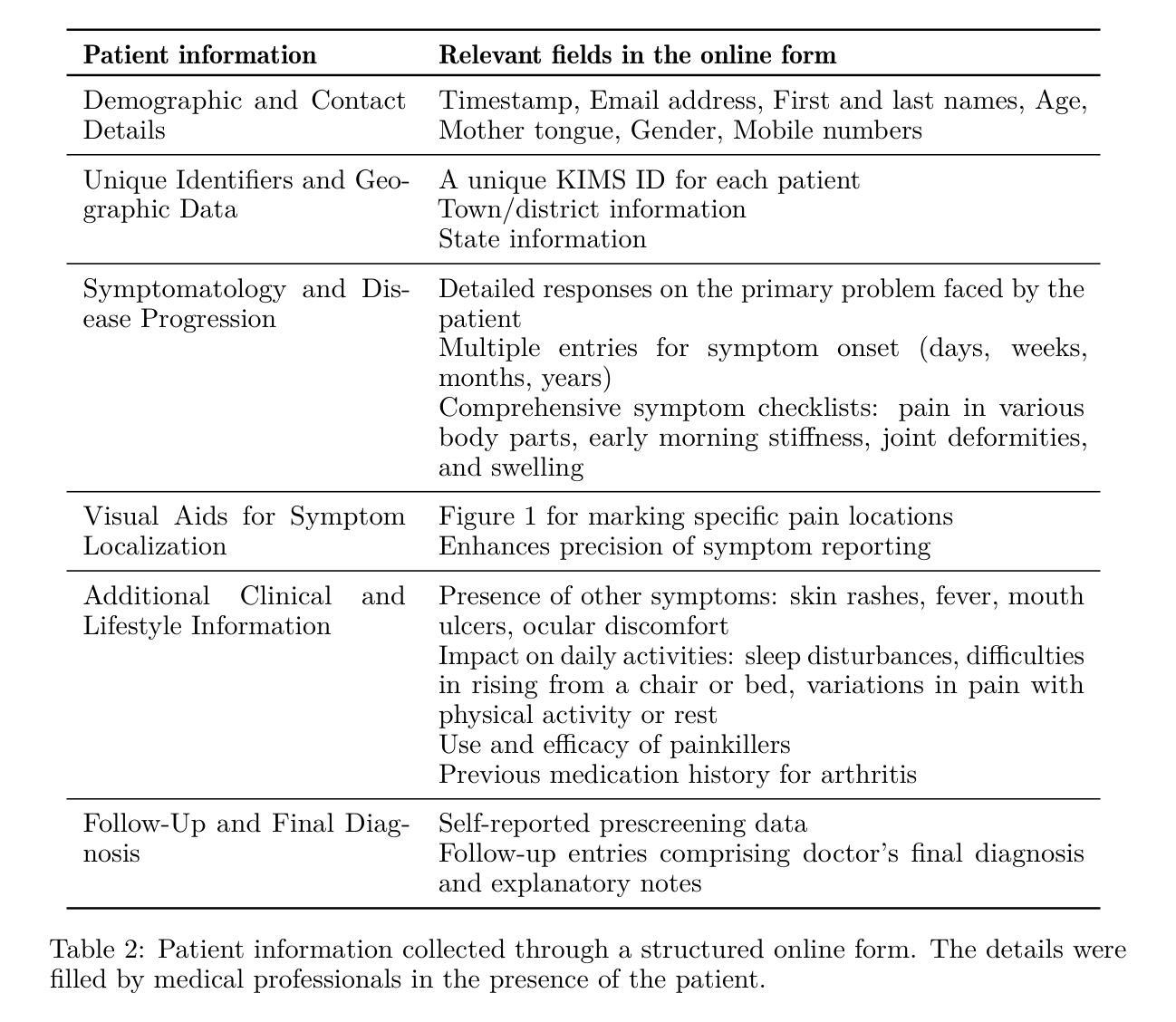
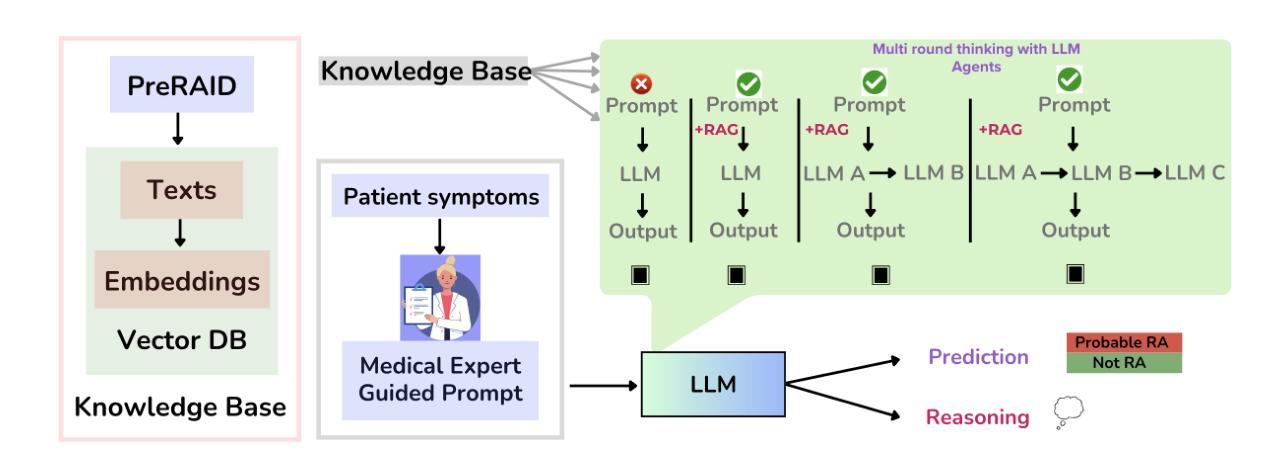
大型语言模型(LLM)作为一种有前途的预筛查工具,在改善早期疾病检测和提高特权群体的医疗保健服务方面发挥着重要作用。早期疾病的诊断仍是医疗保健领域的一个巨大挑战,这主要是由于早期症状的非特异性、专业医疗人员的短缺以及需要长期的临床评估,所有这些都可能延迟治疗并对患者结果产生不利影响。在各种疾病的预测中具有令人印象深刻的准确性,大型语言模型有潜力彻底改变临床预筛查和多种医疗状况的临床决策。在这项工作中,我们研究了大型语言模型对类风湿性关节炎(RA)的诊断能力以及与现实世界患者数据的对比。我们收集了患者的数据以及与医疗专家的诊断结果相比较评估了大型语言模型的性能。我们发现了一种有趣的疾病诊断模式,并发现了预测和解释之间的意外不匹配。我们使用不同的大型语言模型进行了多轮分析。表现最佳的模型能准确预测类风湿性关节炎疾病约95%的时间。然而,当医学专家评估模型产生的推理时,他们发现近6.被模型的推理错误的频率达到近一半的比例的情况让我们更直观的发现一个大语言模型的现状问题就是过于片面追综精确诊断程度忽视了错误的解释概率的风险在RA的疾病诊断中确实存在着诸多疑问是否能信赖大语言模型的解释。这种模型的误诊可能性对我们提出了更高的要求和警示——在进行诊断过程中应综合考虑各种因素而非过分依赖模型的解释结果。”
论文及项目相关链接
Summary:大型语言模型(LLM)在疾病早期检测中显示出巨大潜力,有助于提高医疗保健服务可及性并为特权较少的社区提供更好的服务。以类风湿性关节炎(RA)为例,LLM模型的预测准确性高,但生成的解释却存在错误。尽管它们能够准确预测疾病,但近68%的解释被医学专家认定为不正确。因此,在依赖LLM解释进行临床决策时需谨慎。
Key Takeaways:
- 大型语言模型(LLMs)可用于早期疾病检测,提高医疗保健服务可及性。
- 在类风湿性关节炎(RA)的预测中,LLMs表现出高预测准确性。
- LLMs在解释诊断结果时存在误区,近68%的解释被医学专家认为不正确。
- LLMs在疾病诊断中有时能够提供正确的答案,但理由却是错误的。
- LLMs的预测准确性和解释能力之间存在不匹配,这提醒我们在临床环境中依赖LLM解释时需谨慎。
- 真实世界的患者数据对于评估LLMs在疾病诊断中的性能至关重要。
点此查看论文截图

Polygon: Symbolic Reasoning for SQL using Conflict-Driven Under-Approximation Search
Authors:Pinhan Zhao, Yuepeng Wang, Xinyu Wang
We present a novel symbolic reasoning engine for SQL which can efficiently generate an input $I$ for $n$ queries $P_1, \cdots, P_n$, such that their outputs on $I$ satisfy a given property (expressed in SMT). This is useful in different contexts, such as disproving equivalence of two SQL queries and disambiguating a set of queries. Our first idea is to reason about an under-approximation of each $P_i$ – that is, a subset of $P_i$’s input-output behaviors. While it makes our approach both semantics-aware and lightweight, this idea alone is incomplete (as a fixed under-approximation might miss some behaviors of interest). Therefore, our second idea is to perform search over an expressive family of under-approximations (which collectively cover all program behaviors of interest), thereby making our approach complete. We have implemented these ideas in a tool, Polygon, and evaluated it on over 30,000 benchmarks across two tasks (namely, SQL equivalence refutation and query disambiguation). Our evaluation results show that Polygon significantly outperforms all prior techniques.
我们为SQL设计了一种新型符号推理引擎,该引擎可以高效地生成针对n个查询P1,…,Pn的输入I,使得它们在I上的输出满足给定属性(以SMT表示)。这在不同的上下文环境中非常有用,例如证明两个SQL查询不等价以及消除一组查询的歧义。我们的初步想法是推理出每个Pi的一个下近似值——即Pi输入-输出行为的一个子集。这既使我们的方法具有语义感知能力,又保持其轻量化,但仅使用这一想法是不完整的(因为固定的下近似值可能会遗漏一些有趣的行为)。因此,我们的第二个想法是在表现力丰富的下近似值家族上进行搜索(这些下近似值共同涵盖了所有程序行为的有趣方面),从而使我们的方法得以完善。我们将这些想法实现为Polygon工具,并在两项任务(即SQL等价反驳和查询消歧)的超过3万个基准测试上对其进行了评估。我们的评估结果表明,Polygon在性能上显著优于所有先前技术。
论文及项目相关链接
PDF PLDI 2025
Summary
这是一种新型的SQL符号推理引擎,能高效地为n个查询生成输入,使它们在输入上的输出满足给定属性(以SMT表达)。这在不同情境下都很有用,如证明两个SQL查询不等价和消除一组查询的歧义。该引擎首先会对每个查询进行下近似推理,即查询输入输出的子集行为。虽然这使得我们的方法既语义感知又轻便,但仅依靠这种理念是不完整的,因为一个固定的下近似可能会遗漏一些感兴趣的行为。因此,我们的第二个理念是在一个富有表现力的下近似集合上进行搜索(这些集合涵盖了所有程序行为兴趣),从而使我们的方法完整。我们已将这些理念实现为工具Polygon,并在超过3万个基准测试上对其进行了评估,包括SQL等价反驳和查询去歧义两个任务。评估结果表明,Polygon显著优于所有先前技术。
Key Takeaways
- 新型SQL符号推理引擎能高效处理多个查询输入,满足给定属性要求。
- 下近似推理用于处理每个查询的语义感知和轻便处理。
- 仅依靠下近似是不完整的,因为可能会遗漏一些重要行为。
- 通过搜索一系列表达性下近似来完善方法,涵盖所有程序行为兴趣。
- 该技术实现为工具Polygon。
- Polygon在超过3万个基准测试上进行了评估,表现优异。
点此查看论文截图

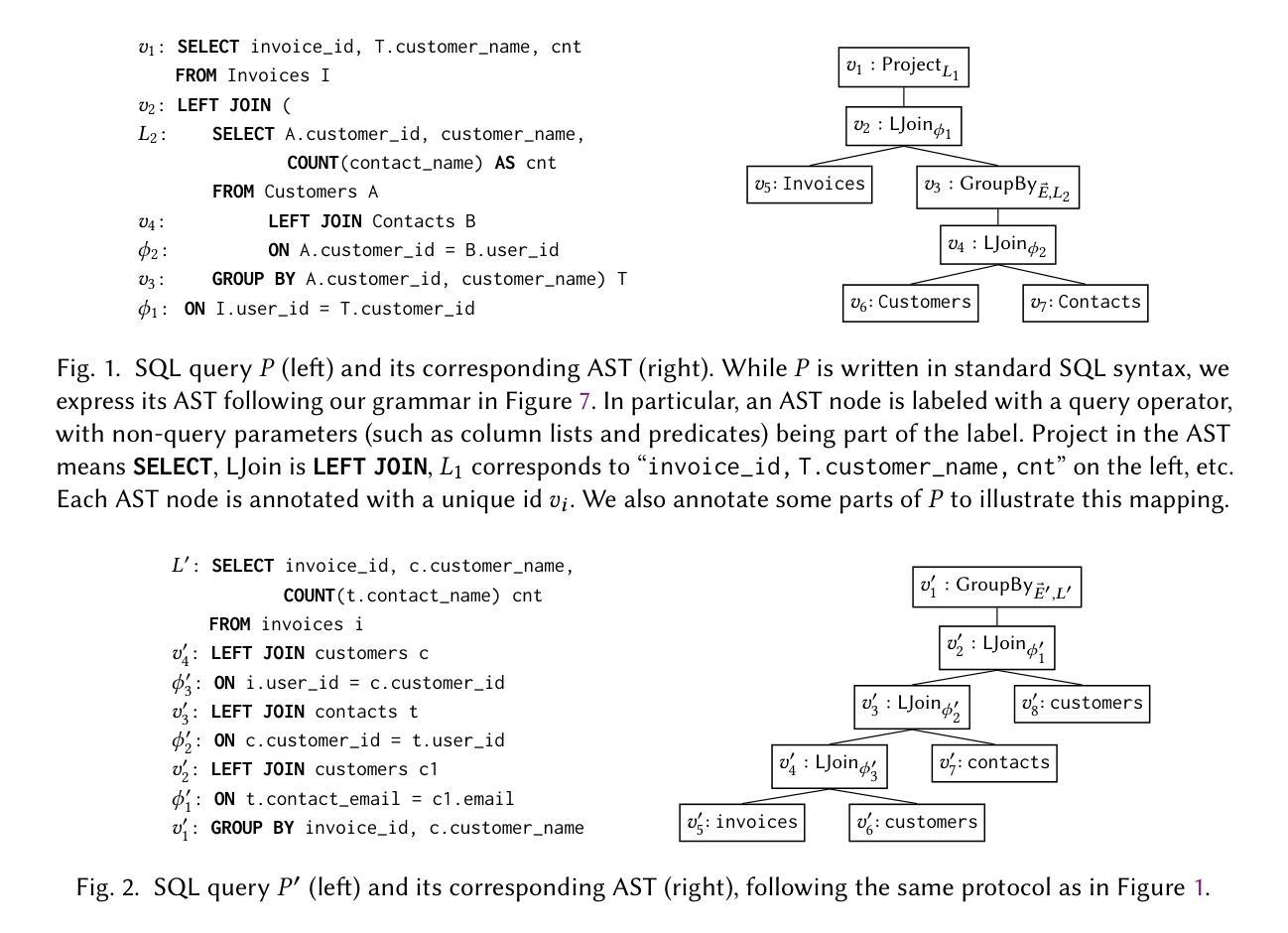
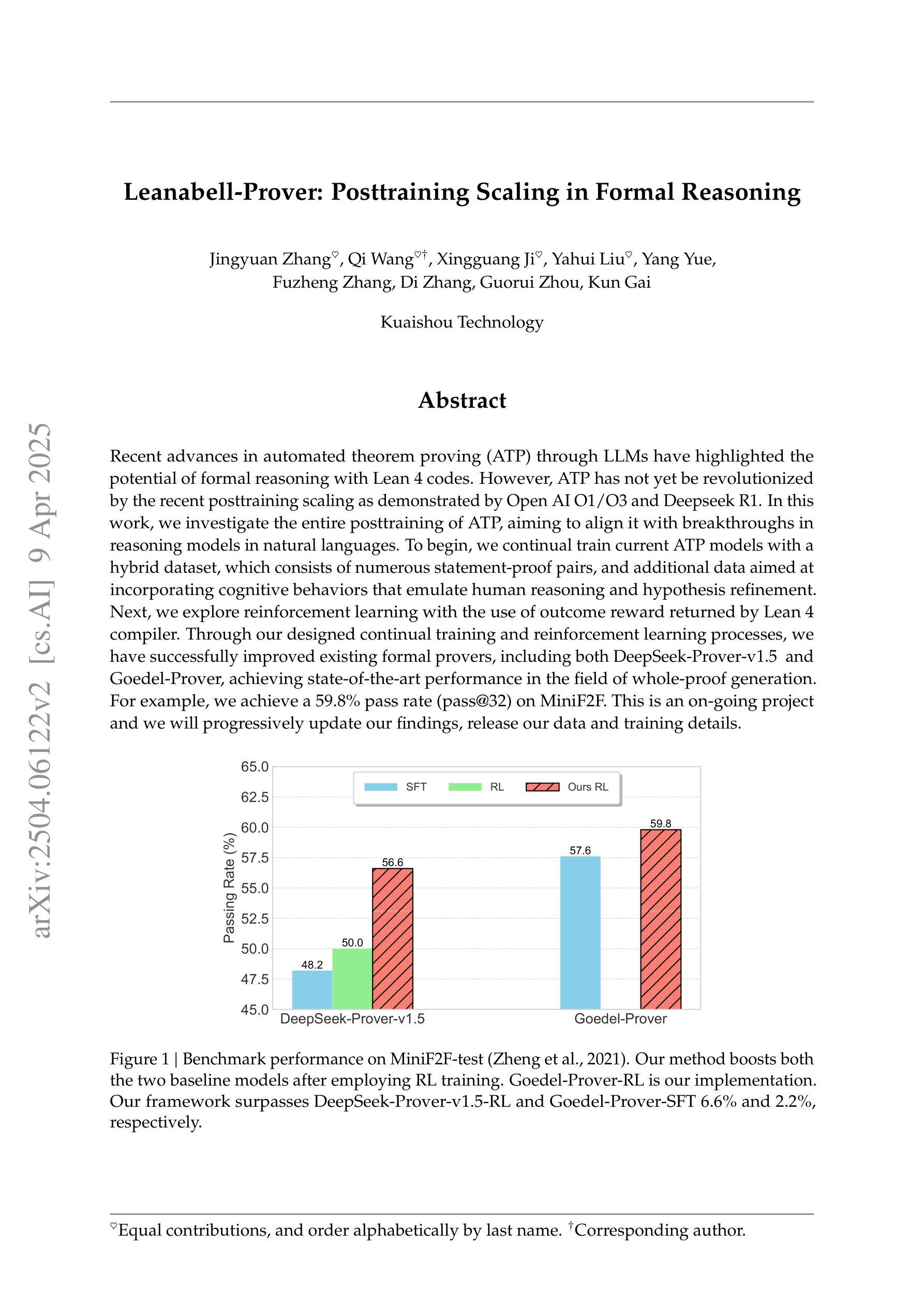
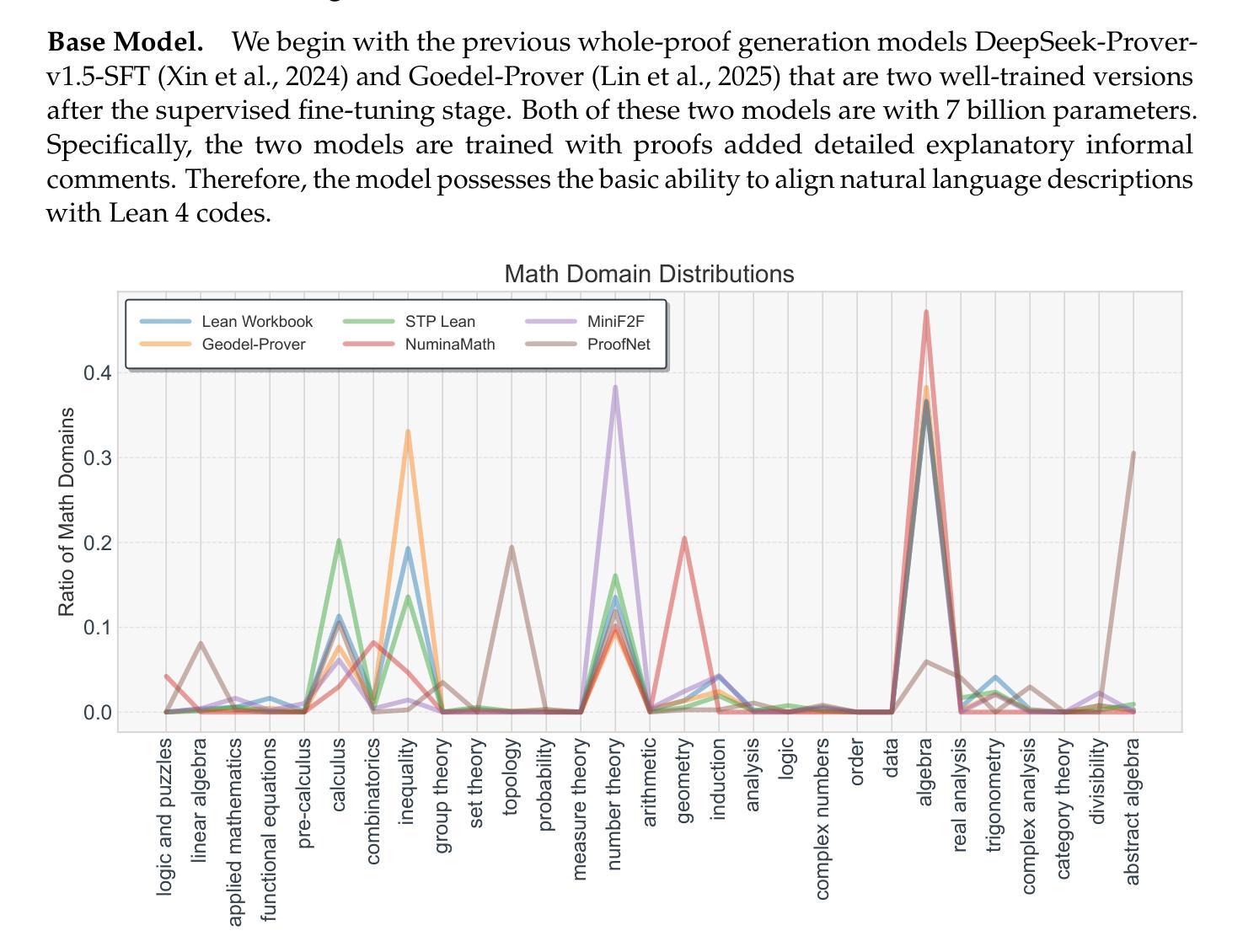
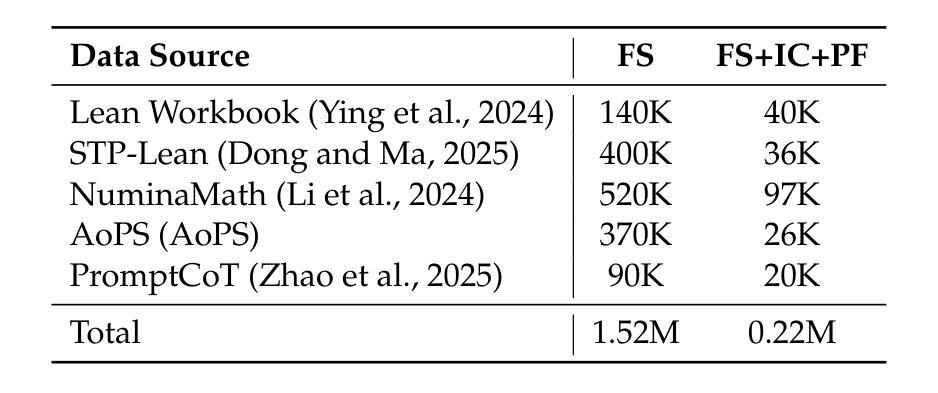
Leanabell-Prover: Posttraining Scaling in Formal Reasoning
Authors:Jingyuan Zhang, Qi Wang, Xingguang Ji, Yahui Liu, Yang Yue, Fuzheng Zhang, Di Zhang, Guorui Zhou, Kun Gai
Recent advances in automated theorem proving (ATP) through LLMs have highlighted the potential of formal reasoning with Lean 4 codes. However, ATP has not yet be revolutionized by the recent posttraining scaling as demonstrated by Open AI O1/O3 and Deepseek R1. In this work, we investigate the entire posttraining of ATP, aiming to align it with breakthroughs in reasoning models in natural languages. To begin, we continual train current ATP models with a hybrid dataset, which consists of numerous statement-proof pairs, and additional data aimed at incorporating cognitive behaviors that emulate human reasoning and hypothesis refinement. Next, we explore reinforcement learning with the use of outcome reward returned by Lean 4 compiler. Through our designed continual training and reinforcement learning processes, we have successfully improved existing formal provers, including both DeepSeek-Prover-v1.5 and Goedel-Prover, achieving state-of-the-art performance in the field of whole-proof generation. For example, we achieve a 59.8% pass rate (pass@32) on MiniF2F. This is an on-going project and we will progressively update our findings, release our data and training details.
近期通过大型语言模型(LLMs)在自动化定理证明(ATP)方面的进展突显了使用Lean 4代码进行形式推理的潜力。然而,正如Open AI O1/O3和Deepseek R1所展示的,ATP并未因最近的训练后扩展而实现革命性的进展。在这项工作中,我们研究了ATP的整个训练后过程,旨在与自然语言推理模型方面的突破保持一致。首先,我们使用包含众多语句证明对的混合数据集,以及旨在融入模拟人类推理和假设精化的认知行为的其他数据,对当前ATP模型进行持续训练。接下来,我们探索了使用Lean 4编译器提供的成果奖励来强化学习。通过我们设计的持续训练和强化学习过程,我们成功改进了现有的形式证明器,包括DeepSeek-Prover-v1.5和Goedel-Prover,并在整个证明生成领域实现了最先进的性能。例如,我们在MiniF2F上达到了59.8%(pass@32)的通过率。这是一个正在进行中的项目,我们将逐步更新我们的发现,并发布我们的数据和训练细节。
论文及项目相关链接
PDF 23 pages, 6 figures
Summary
近期,自动化定理证明(ATP)通过大型语言模型(LLM)的进步突显了其在形式推理方面的潜力,特别是在使用Lean 4代码方面。然而,ATP尚未因Open AI的O1/O3和Deepseek R1所展示的近期后训练扩展而实现革命性变革。本研究旨在将ATP的后训练过程与突破性的自然语言推理模型相结合。我们通过持续训练当前ATP模型,使用包含大量语句证明对和旨在模仿人类推理和假设改进的认知行为附加数据的混合数据集。此外,我们还探索了使用Lean 4编译器提供的结果奖励的强化学习。通过我们的持续训练与强化学习设计过程,我们成功改进了现有的形式证明器,包括DeepSeek-Prover-v1.5和Goedel-Prover,并在整个证明生成领域实现了最先进的性能。例如,在MiniF2F上达到了59.8%(pass@32)的通过率。
Key Takeaways
- 自动化定理证明(ATP)通过大型语言模型(LLM)的进步展示了形式推理的潜力。
- 当前研究重点在于将ATP的后训练过程与自然语言推理模型的突破相结合。
- 通过混合数据集和强化学习技术改进了现有的形式证明器性能。
- 在整个证明生成领域实现了最先进的性能,例如,在MiniF2F上达到了较高的通过率。
- 此研究为持续进行中的项目,将不断更新其进展、数据和训练细节。
- 使用Lean 4代码进行推理是其取得进展的关键技术之一。
点此查看论文截图
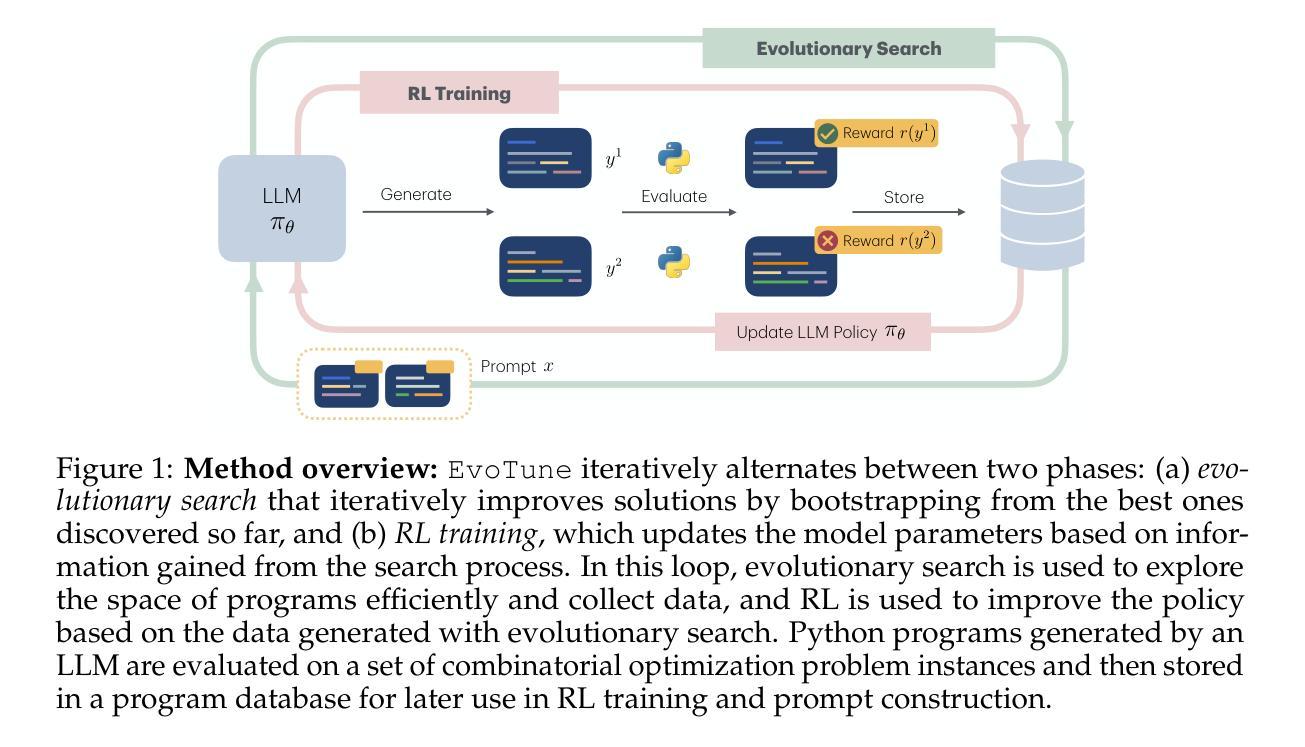
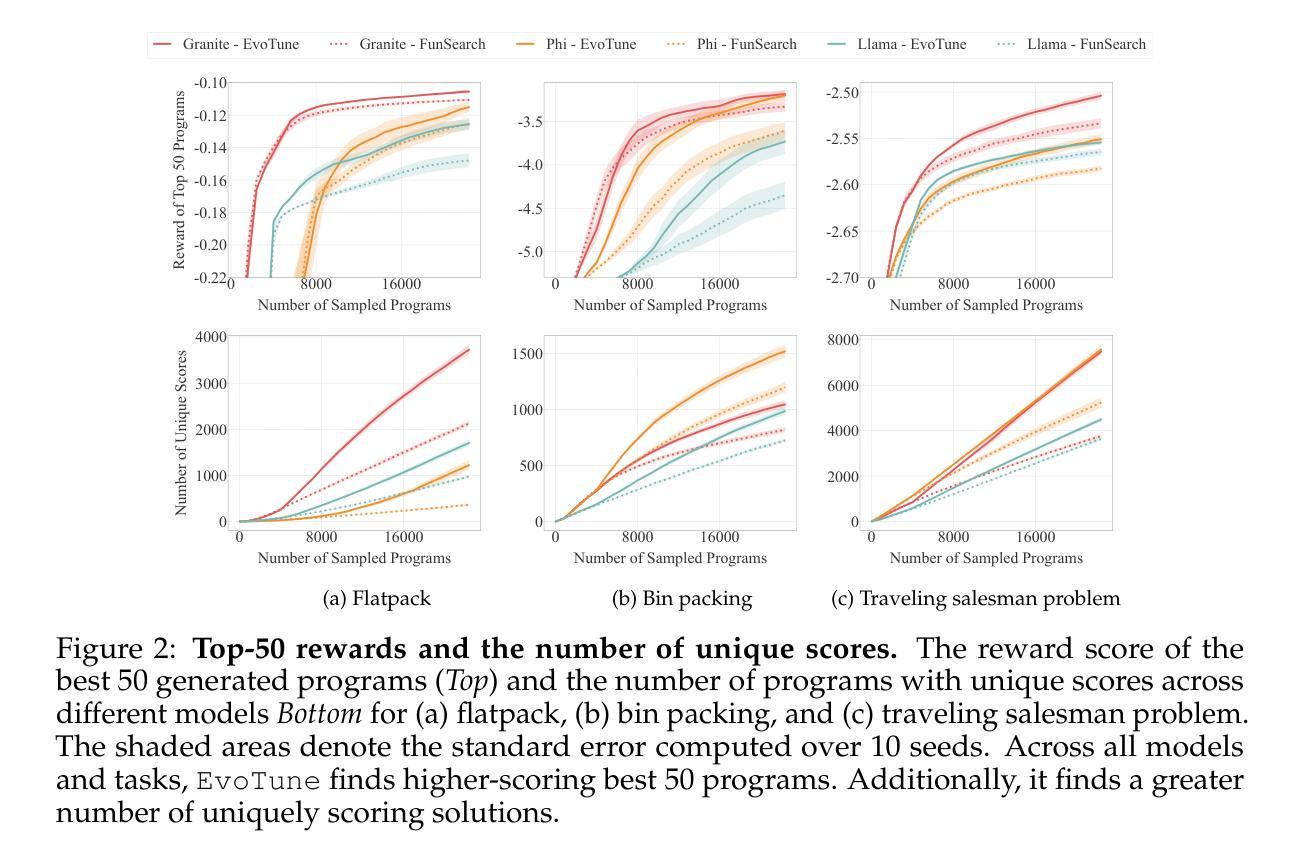
Algorithm Discovery With LLMs: Evolutionary Search Meets Reinforcement Learning
Authors:Anja Surina, Amin Mansouri, Lars Quaedvlieg, Amal Seddas, Maryna Viazovska, Emmanuel Abbe, Caglar Gulcehre
Discovering efficient algorithms for solving complex problems has been an outstanding challenge in mathematics and computer science, requiring substantial human expertise over the years. Recent advancements in evolutionary search with large language models (LLMs) have shown promise in accelerating the discovery of algorithms across various domains, particularly in mathematics and optimization. However, existing approaches treat the LLM as a static generator, missing the opportunity to update the model with the signal obtained from evolutionary exploration. In this work, we propose to augment LLM-based evolutionary search by continuously refining the search operator - the LLM - through reinforcement learning (RL) fine-tuning. Our method leverages evolutionary search as an exploration strategy to discover improved algorithms, while RL optimizes the LLM policy based on these discoveries. Our experiments on three combinatorial optimization tasks - bin packing, traveling salesman, and the flatpack problem - show that combining RL and evolutionary search improves discovery efficiency of improved algorithms, showcasing the potential of RL-enhanced evolutionary strategies to assist computer scientists and mathematicians for more efficient algorithm design.
发现解决复杂问题的有效算法一直是数学和计算机科学领域的一项重大挑战,需要多年的人类专业知识。最近,利用大型语言模型(LLM)进行进化搜索的进步为加速跨多个领域的算法发现提供了希望,特别是在数学和优化方面。然而,现有方法将LLM视为静态生成器,错过了使用进化探索获得的信号更新模型的机会。在这项工作中,我们提出通过强化学习(RL)微调来连续优化搜索运算符——LLM,以增强基于LLM的进化搜索。我们的方法利用进化搜索作为探索策略来发现改进后的算法,而强化学习则基于这些发现优化LLM策略。我们在三个组合优化任务——装箱问题、旅行推销员问题和平铺问题上的实验表明,将强化学习与进化搜索相结合,提高了发现改进算法的效率,展示了强化学习增强型进化策略在帮助计算机科学家和数学家进行更高效算法设计方面的潜力。
论文及项目相关链接
PDF 30 pages
Summary:近期进化搜索与大型语言模型(LLM)的结合,为算法发现提供了新的可能。但现有方法将其视作静态生成器,忽视了从进化探索中获得信号来更新模型的机会。本研究通过强化学习(RL)微调,不断改善搜索运算符LLM,实现进化搜索与RL优化算法的融合。实验证明,该融合方法在三项组合优化任务上提高了算法发现的效率,展现出助力计算机科学家和数学家进行更高效算法设计的潜力。
Key Takeaways:
- 大型语言模型(LLM)在算法发现中显示出巨大潜力,尤其是在数学和优化领域。
- 当前LLM在进化搜索中的主要限制是将其作为静态生成器,缺乏根据进化探索更新模型的能力。
- 强化学习(RL)可用于优化LLM策略,基于进化搜索发现的算法进行微调。
- 结合RL和进化搜索提高了算法发现的效率。
- 在三项组合优化任务(bin packing、traveling salesman和flatpack问题)上的实验验证了该方法的有效性。
- 该方法具有潜力协助计算机科学家和数学家进行更高效的算法设计。
点此查看论文截图

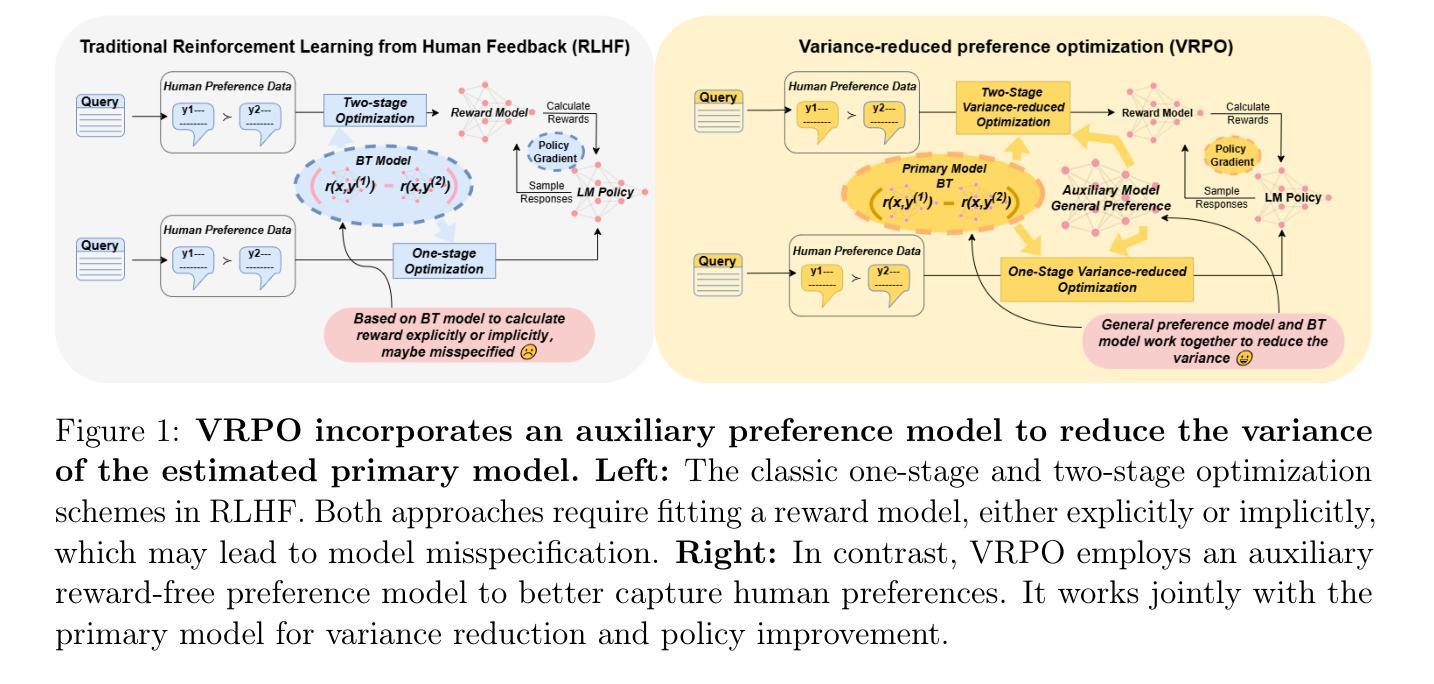
Robust Reinforcement Learning from Human Feedback for Large Language Models Fine-Tuning
Authors:Kai Ye, Hongyi Zhou, Jin Zhu, Francesco Quinzan, Chengchung Shi
Reinforcement learning from human feedback (RLHF) has emerged as a key technique for aligning the output of large language models (LLMs) with human preferences. To learn the reward function, most existing RLHF algorithms use the Bradley-Terry model, which relies on assumptions about human preferences that may not reflect the complexity and variability of real-world judgments. In this paper, we propose a robust algorithm to enhance the performance of existing approaches under such reward model misspecifications. Theoretically, our algorithm reduces the variance of reward and policy estimators, leading to improved regret bounds. Empirical evaluations on LLM benchmark datasets demonstrate that the proposed algorithm consistently outperforms existing methods, with 77-81% of responses being favored over baselines on the Anthropic Helpful and Harmless dataset.
强化学习从人类反馈(RLHF)已经成为一种关键技术,用于将大型语言模型(LLM)的输出与人类偏好对齐。为了学习奖励函数,大多数现有的RLHF算法使用Bradley-Terry模型,该模型依赖于关于人类偏好的假设,这些假设可能无法反映现实世界判断中的复杂性和可变性。在本文中,我们提出了一种鲁棒性算法,以提高在当前奖励模型误差下方法的性能。从理论上讲,我们的算法减少了奖励和政策估计量的方差,从而提高了后悔边界。在LLM基准数据集上的经验评估表明,所提出的算法始终优于现有方法,在Anthropic有益和无害数据集上,有77%-81%的响应优于基线。
论文及项目相关链接
Summary:强化学习从人类反馈(RLHF)已成为将大型语言模型(LLM)的输出与人类偏好对齐的关键技术。现有大多数RLHF算法使用Bradley-Terry模型来学习奖励函数,该模型依赖于可能无法反映现实世界判断复杂性和可变性的假设。本文提出了一种增强算法以提高在奖励模型误指定下的性能。理论上,该算法降低了奖励和政策估计量的方差,从而提高了后悔界限。在LLM基准数据集上的实证评估表明,所提出的算法始终优于现有方法,在Anthropic Helpful和Harmless数据集上,有77-81%的响应优于基线。
Key Takeaways:
- 强化学习从人类反馈(RLHF)技术用于对齐大型语言模型输出与人类偏好。
- 现有RLHF算法主要使用Bradley-Terry模型,存在对现实世界判断的复杂性和可变性的假设不足的问题。
- 本文提出了一种增强算法以提高在奖励模型误指定下的性能。
- 该算法理论上降低了奖励和政策估计量的方差,提高了后悔界限。
- 在LLM基准数据集上的实证评估表明该算法显著优于现有方法。
- 在Anthropic Helpful和Harmless数据集上,该算法的响应优于基线,比例为77-81%。
点此查看论文截图

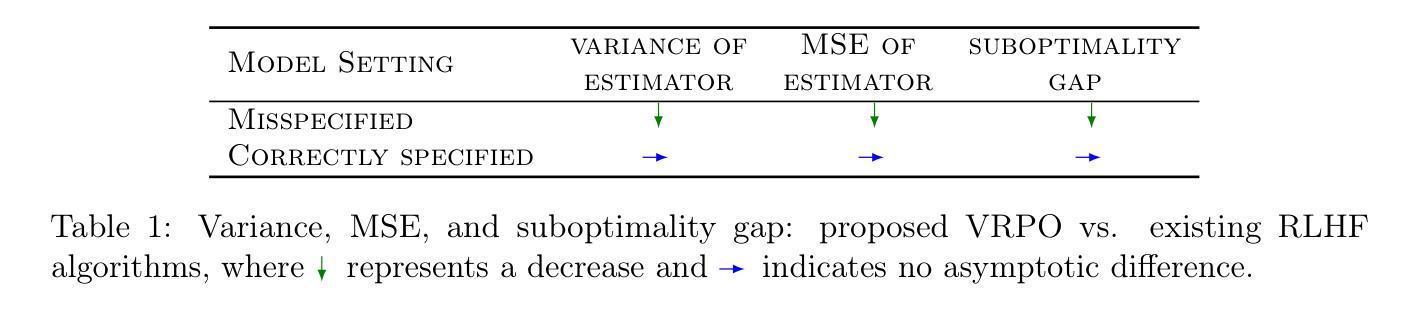
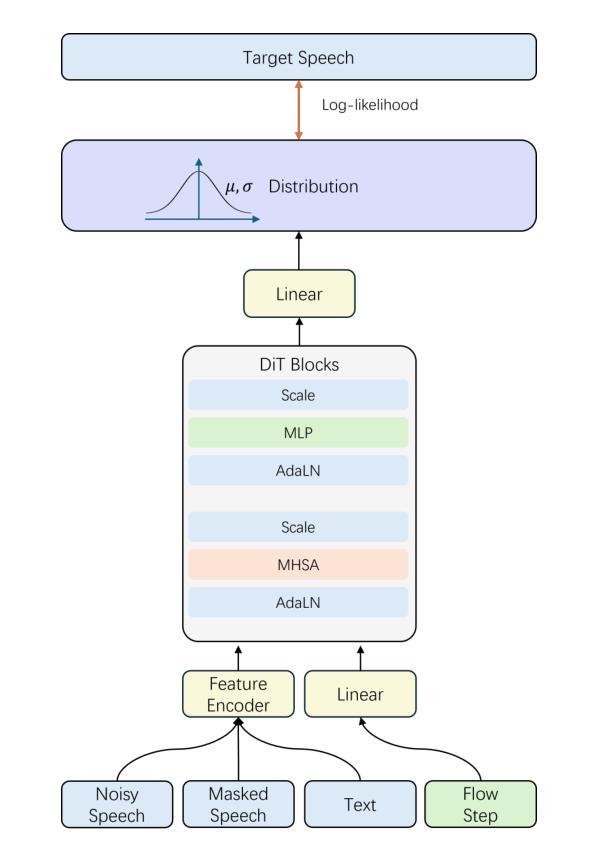
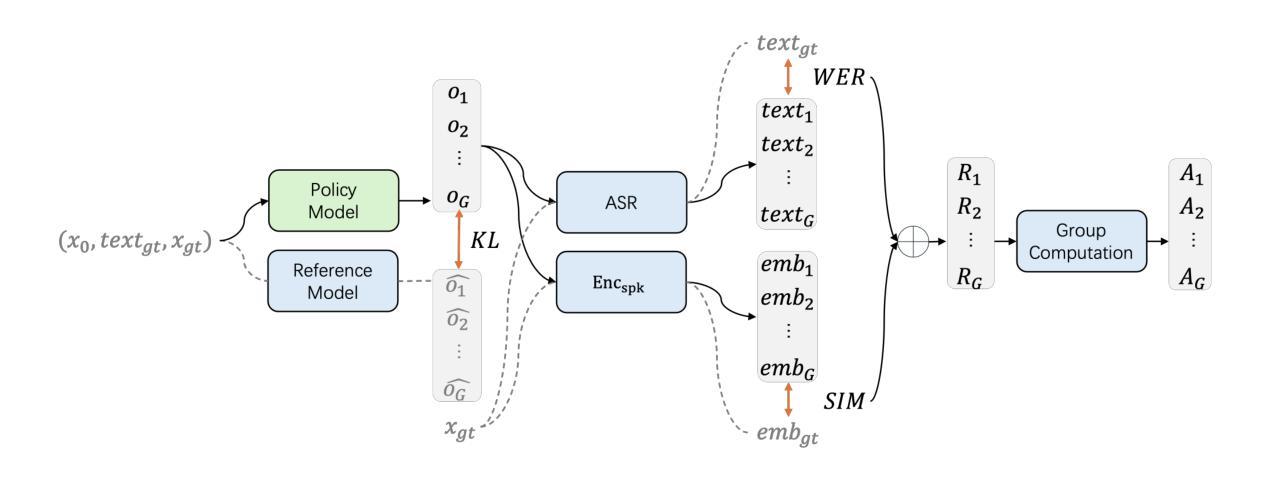
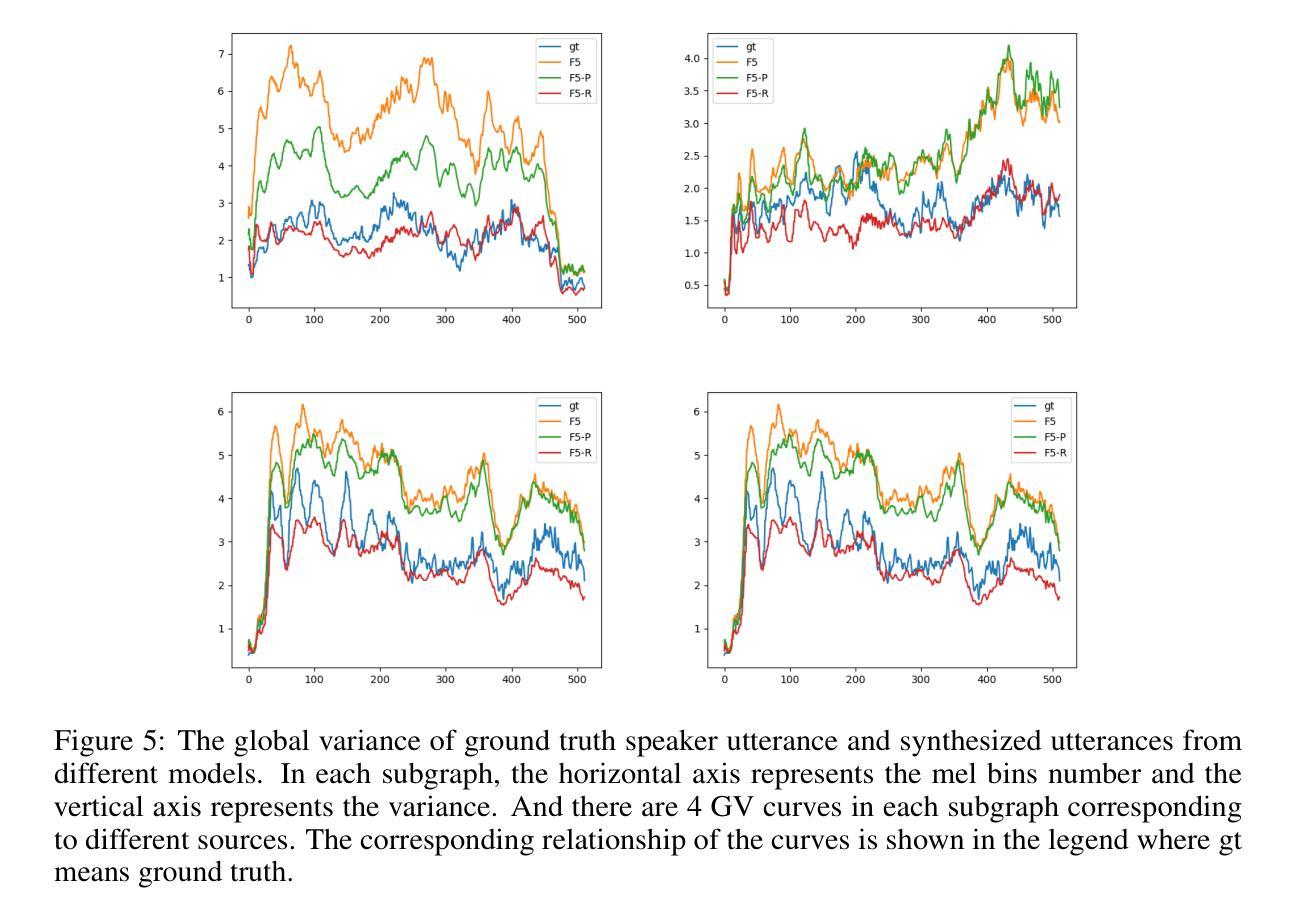
F5R-TTS: Improving Flow-Matching based Text-to-Speech with Group Relative Policy Optimization
Authors:Xiaohui Sun, Ruitong Xiao, Jianye Mo, Bowen Wu, Qun Yu, Baoxun Wang
We present F5R-TTS, a novel text-to-speech (TTS) system that integrates Gradient Reward Policy Optimization (GRPO) into a flow-matching based architecture. By reformulating the deterministic outputs of flow-matching TTS into probabilistic Gaussian distributions, our approach enables seamless integration of reinforcement learning algorithms. During pretraining, we train a probabilistically reformulated flow-matching based model which is derived from F5-TTS with an open-source dataset. In the subsequent reinforcement learning (RL) phase, we employ a GRPO-driven enhancement stage that leverages dual reward metrics: word error rate (WER) computed via automatic speech recognition and speaker similarity (SIM) assessed by verification models. Experimental results on zero-shot voice cloning demonstrate that F5R-TTS achieves significant improvements in both speech intelligibility (a 29.5% relative reduction in WER) and speaker similarity (a 4.6% relative increase in SIM score) compared to conventional flow-matching based TTS systems. Audio samples are available at https://frontierlabs.github.io/F5R.
我们提出了F5R-TTS,这是一种新型文本到语音(TTS)系统,它将梯度奖励策略优化(GRPO)集成到基于流匹配的架构中。我们通过将基于流匹配的TTS的确定性输出重新表述为概率高斯分布,使我们的方法能够实现强化学习算法的无缝集成。在预训练过程中,我们使用公开数据集对来自F5-TTS的基于流匹配的概率重构模型进行训练。在随后的强化学习(RL)阶段,我们采用GRPO驱动的增强阶段,利用双重奖励指标:通过自动语音识别计算的词错误率(WER)和通过验证模型评估的说话人相似性(SIM)。在零样本语音克隆上的实验结果表明,与传统的基于流匹配的TTS系统相比,F5R-TTS在语音清晰度(相对降低29.5%的WER)和说话人相似性(SIM得分相对提高4.6%)方面取得了显著改进。音频样本可在https://frontierlabs.github.io/F5R上找到。
论文及项目相关链接
Summary
F5R-TTS是一个集成梯度奖励策略优化(GRPO)的基于流匹配架构的新型文本到语音(TTS)系统。它通过概率化重构流匹配TTS的输出并实现与强化学习算法的无缝集成。在预训练阶段,使用公开数据集训练概率重构的流匹配模型。在随后的强化学习阶段,采用GRPO驱动的增强阶段,利用双重奖励指标(通过自动语音识别计算的词错误率和通过验证模型评估的说话人相似性)。实验结果表明,F5R-TTS在零样本语音克隆中实现了语音清晰度和说话人相似性的显著提高。
Key Takeaways
- F5R-TTS是一个新型文本到语音(TTS)系统,集成梯度奖励策略优化(GRPO)。
- F5R-TTS将确定性输出转化为概率高斯分布以实现与强化学习算法的无缝集成。
- 在预训练阶段,使用公开数据集训练概率重构的流匹配模型。
- 强化学习阶段采用GRPO驱动的增强阶段。
- F5R-TTS采用双重奖励指标:词错误率(WER)和说话人相似性(SIM)。
- 实验结果表明,F5R-TTS在零样本语音克隆中显著提高语音清晰度和说话人相似性。
点此查看论文截图


DeepSeek-V3, GPT-4, Phi-4, and LLaMA-3.3 generate correct code for LoRaWAN-related engineering tasks
Authors:Daniel Fernandes, João P. Matos-Carvalho, Carlos M. Fernandes, Nuno Fachada
This paper investigates the performance of 16 Large Language Models (LLMs) in automating LoRaWAN-related engineering tasks involving optimal placement of drones and received power calculation under progressively complex zero-shot, natural language prompts. The primary research question is whether lightweight, locally executed LLMs can generate correct Python code for these tasks. To assess this, we compared locally run models against state-of-the-art alternatives, such as GPT-4 and DeepSeek-V3, which served as reference points. By extracting and executing the Python functions generated by each model, we evaluated their outputs on a zero-to-five scale. Results show that while DeepSeek-V3 and GPT-4 consistently provided accurate solutions, certain smaller models – particularly Phi-4 and LLaMA-3.3 – also demonstrated strong performance, underscoring the viability of lightweight alternatives. Other models exhibited errors stemming from incomplete understanding or syntactic issues. These findings illustrate the potential of LLM-based approaches for specialized engineering applications while highlighting the need for careful model selection, rigorous prompt design, and targeted domain fine-tuning to achieve reliable outcomes.
本文研究了16种大型语言模型(LLM)在自动化LoRaWAN相关工程任务中的表现,这些任务涉及无人机的最佳放置位置以及在逐渐复杂的零样本自然语言提示下接收功率的计算。主要的研究问题是,轻量级的本地执行LLM是否能够生成完成这些任务的正确Python代码。为了评估这一点,我们将本地运行模型与最新技术替代方案(如GPT-4和DeepSeek-V3)进行了比较,后者作为参考点。通过提取并执行每个模型生成的Python函数,我们对它们的输出进行了零到五级的评估。结果表明,虽然DeepSeek-V3和GPT-4始终提供准确的解决方案,但某些较小的模型(特别是Phi-4和LLaMA-3.3)也表现出强劲的性能,证明了轻量级替代方案的可行性。其他模型出现的错误源于理解不全面或句法问题。这些发现表明了基于LLM的方法在特定工程应用中的潜力,同时也强调了实现可靠结果需要仔细选择模型、严格设计提示以及有针对性的领域微调。
论文及项目相关链接
PDF The peer-reviewed version of this paper is published in Electronics at https://doi.org/10.3390/electronics14071428. This version is typeset by the authors and differs only in pagination and typographical detail
Summary
本文研究了16种大型语言模型(LLMs)在自动化LoRaWAN相关的工程任务中的表现,包括无人机的最佳放置和接收功率计算的零样本自然语言提示。研究的核心问题是,轻量级的本地执行LLMs是否能生成这些任务的正确Python代码。通过对比本地模型与GPT-4和DeepSeek-V3等前沿模型的表现,发现DeepSeek-V3和GPT-4提供了一致的准确解决方案,而某些小型模型如Phi-4和LLaMA-3.3也表现出强劲性能。其他模型则因理解不全或句法问题而犯错。研究表明LLM在特定工程应用中有潜力,但需慎重选择模型、精心设计提示及针对性的领域微调以确保可靠结果。
Key Takeaways
- 16种大型语言模型在LoRaWAN相关工程任务中的性能被评估。
- 研究重点为轻量级本地执行的大型语言模型能否生成正确的Python代码。
- GPT-4和DeepSeek-V3作为前沿模型,表现优秀且提供了准确的解决方案。
- 部分小型模型如Phi-4和LLaMA-3.3在研究中展示了强劲性能。
- 其他模型因理解不全或句法问题而犯错,这强调了模型选择的重要性。
- 研究表明LLM在特定工程应用中具有潜力,但成功的实现需要多方面的考量如模型选择、提示设计和领域微调。
点此查看论文截图

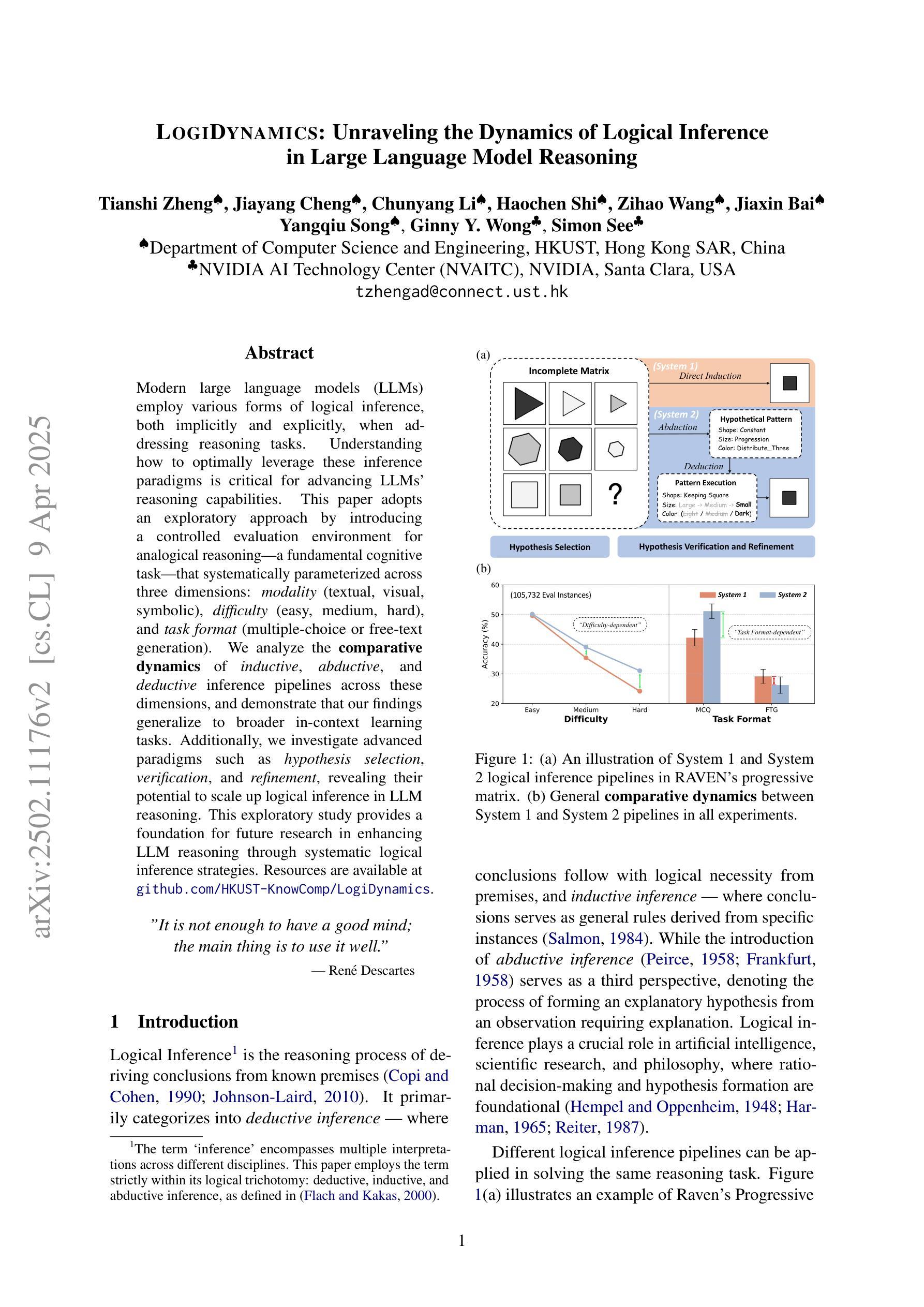
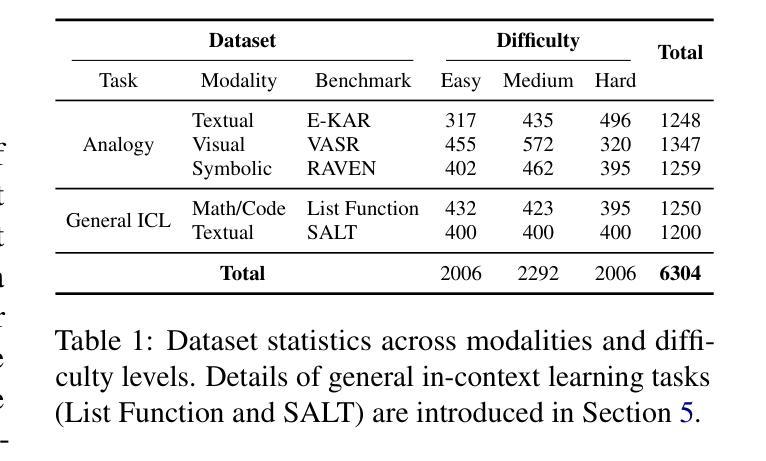
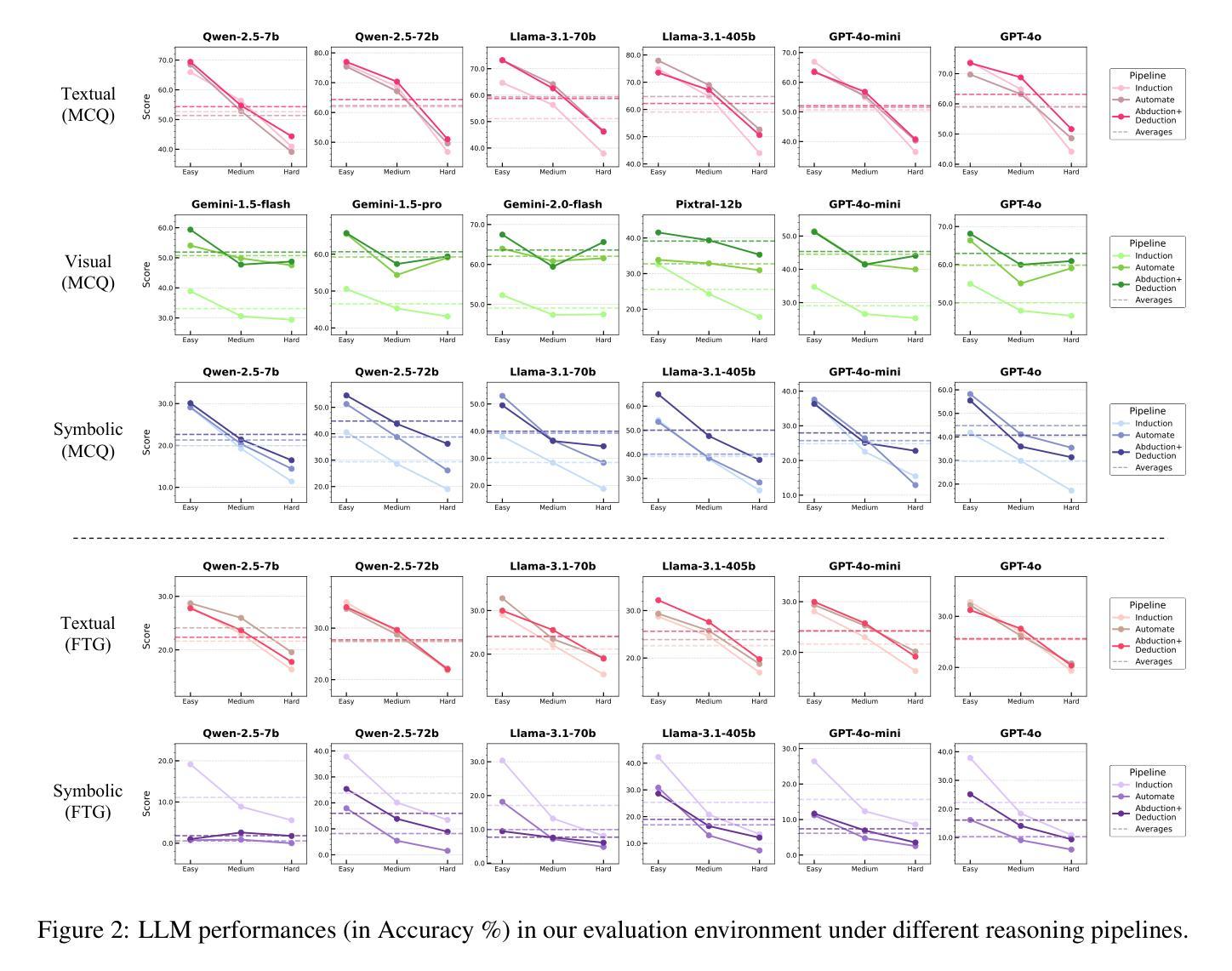
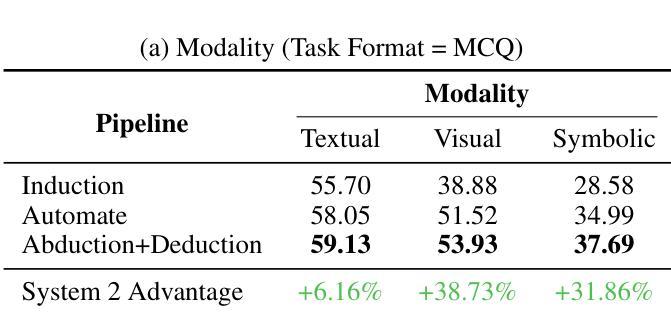
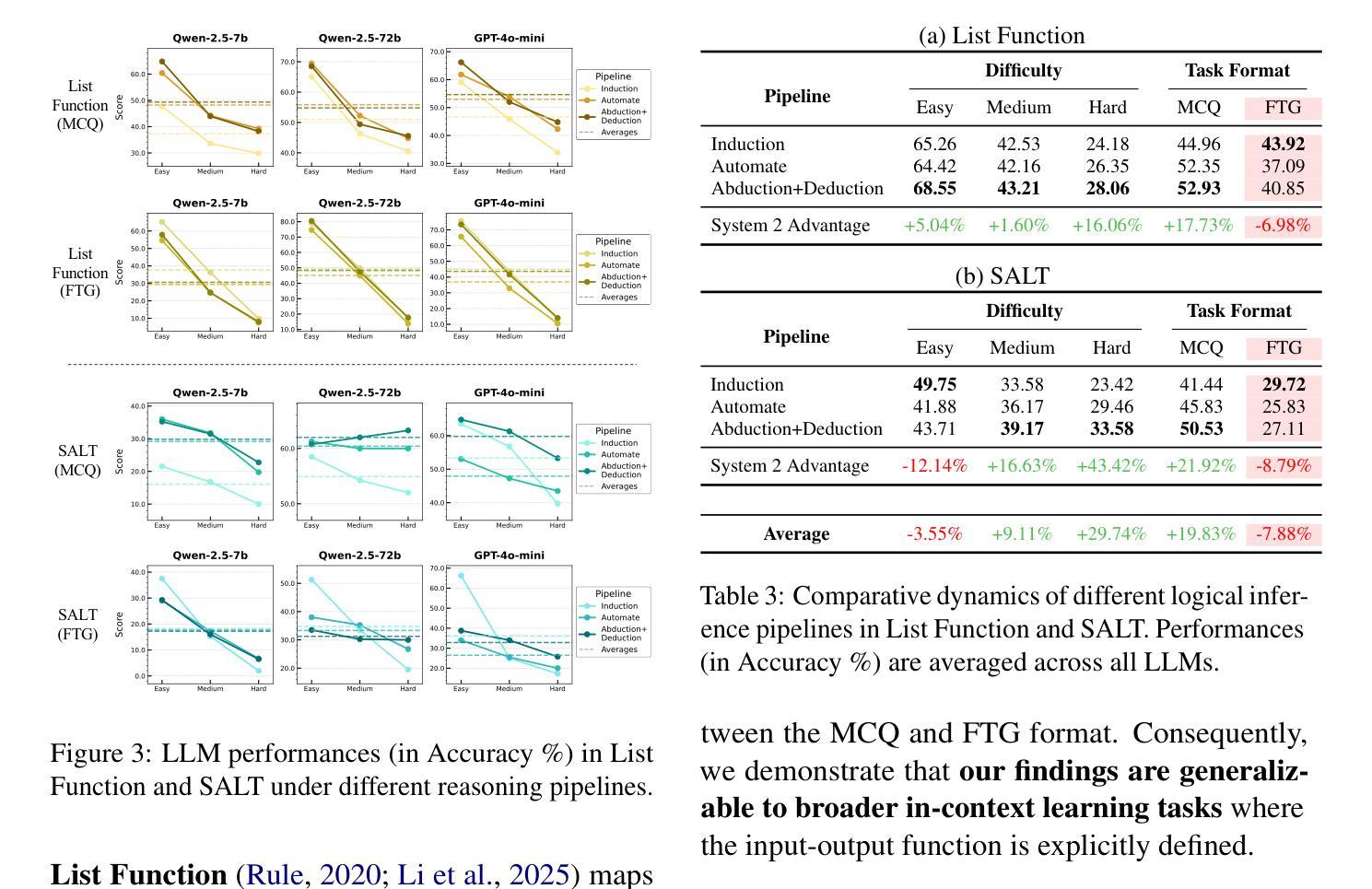
LogiDynamics: Unraveling the Dynamics of Logical Inference in Large Language Model Reasoning
Authors:Tianshi Zheng, Jiayang Cheng, Chunyang Li, Haochen Shi, Zihao Wang, Jiaxin Bai, Yangqiu Song, Ginny Y. Wong, Simon See
Modern large language models (LLMs) employ various forms of logical inference, both implicitly and explicitly, when addressing reasoning tasks. Understanding how to optimally leverage these inference paradigms is critical for advancing LLMs’ reasoning capabilities. This paper adopts an exploratory approach by introducing a controlled evaluation environment for analogical reasoning – a fundamental cognitive task – that is systematically parameterized across three dimensions: modality (textual, visual, symbolic), difficulty (easy, medium, hard), and task format (multiple-choice or free-text generation). We analyze the comparative dynamics of inductive, abductive, and deductive inference pipelines across these dimensions, and demonstrate that our findings generalize to broader in-context learning tasks. Additionally, we investigate advanced paradigms such as hypothesis selection, verification, and refinement, revealing their potential to scale up logical inference in LLM reasoning. This exploratory study provides a foundation for future research in enhancing LLM reasoning through systematic logical inference strategies. Resources are available at https://github.com/HKUST-KnowComp/LogiDynamics.
现代大型语言模型(LLM)在解决推理任务时,会隐式和显式地使用各种形式的逻辑推理。了解如何最优地利用这些推理范式是提升LLM推理能力的关键。本文采用一种探索性方法,通过引入类比推理的控制评估环境来进行研究——这是一种基本的认知任务,系统性地参数化涉及三个维度:模态(文本、视觉、符号)、难度(容易、中等、困难)和任务格式(多项选择或自由文本生成)。我们分析了归纳、假设和演绎推理管线在这些维度上的比较动态,并证明我们的发现可以推广到更广泛的上下文学习任务中。此外,我们还研究了假设选择、验证和细化等高级范式,揭示了它们在扩大LLM推理中的逻辑推断方面的潜力。这项探索性研究为未来通过系统逻辑推理策略提高LLM推理能力的研究奠定了基础。相关资源可在https://github.com/HKUST-KnowComp/LogiDynamics上找到。
论文及项目相关链接
PDF 21 pages
Summary
大型语言模型(LLM)在处理推理任务时,会采用各种形式的逻辑推理,包括隐性和显性推理。理解如何最优地利用这些推理模式对于提升LLM的推理能力至关重要。本文采用了一种探索性方法,通过引入一个可控的评估环境,对类比推理这一基本认知任务进行了系统化参数化。分析归纳、假设和演绎推理管道在这些维度上的比较动态,并证明我们的发现适用于更广泛的上下文学习任务。此外,还探讨了假设选择、验证和修正等先进范式在提升LLM逻辑推断中的潜力。这项探索性研究为未来通过系统逻辑推断策略提升LLM推理能力的研究奠定了基础。
Key Takeaways
- 大型语言模型(LLM)在处理推理任务时运用多种形式的逻辑推理。
- 理解和利用这些推理模式是提升LLM推理能力的关键。
- 论文通过引入可控评估环境,对类比推理进行系统化参数化研究。
- 分析了归纳、假设和演绎推理在不同维度上的动态比较。
- 研究发现适用于更广泛的上下文学习任务。
- 探讨了假设选择、验证和修正等先进范式在LLM逻辑推断中的潜力。
- 该研究为未来提升LLM推理能力的系统逻辑推断策略研究奠定了基础。
点此查看论文截图
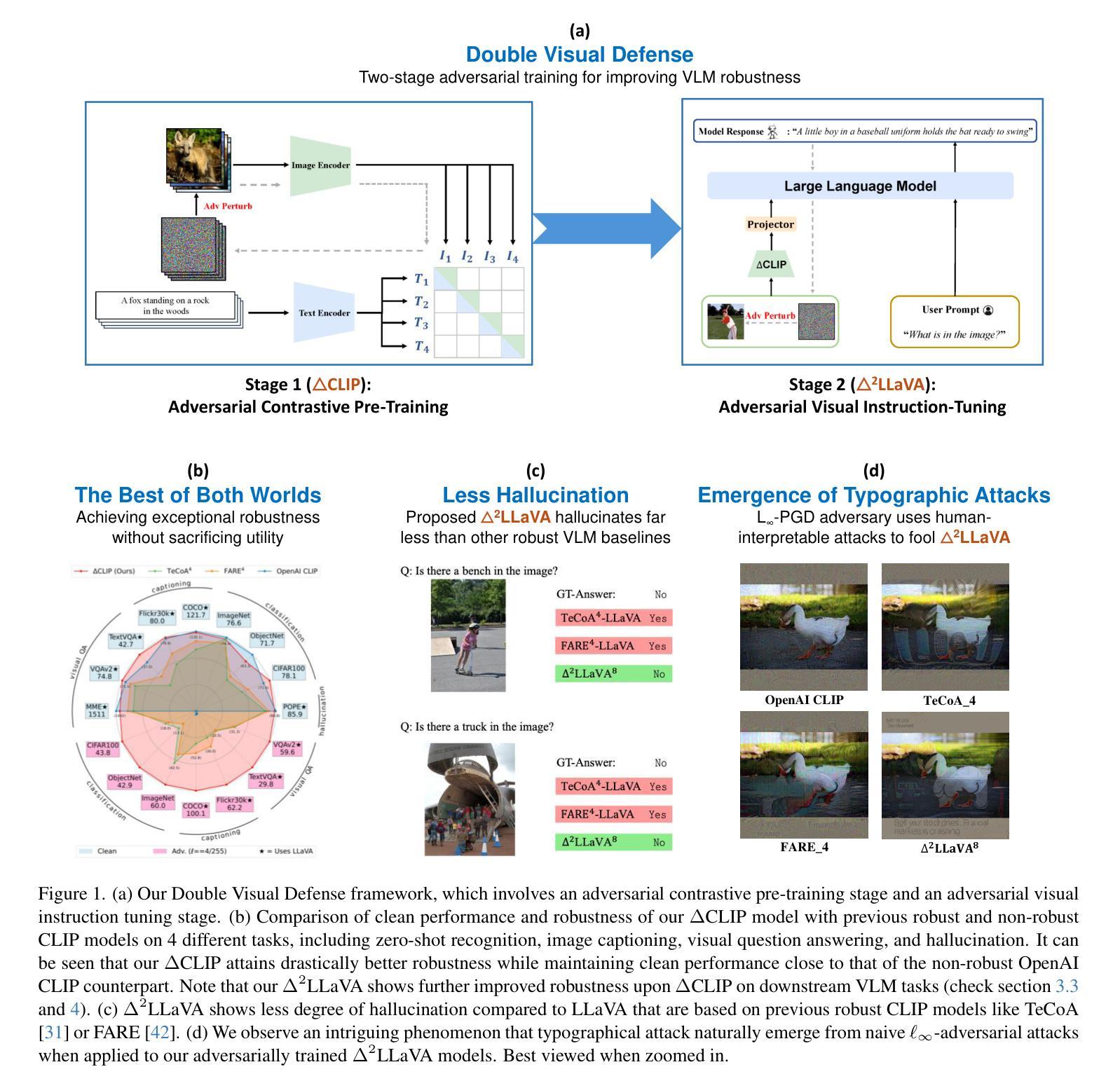
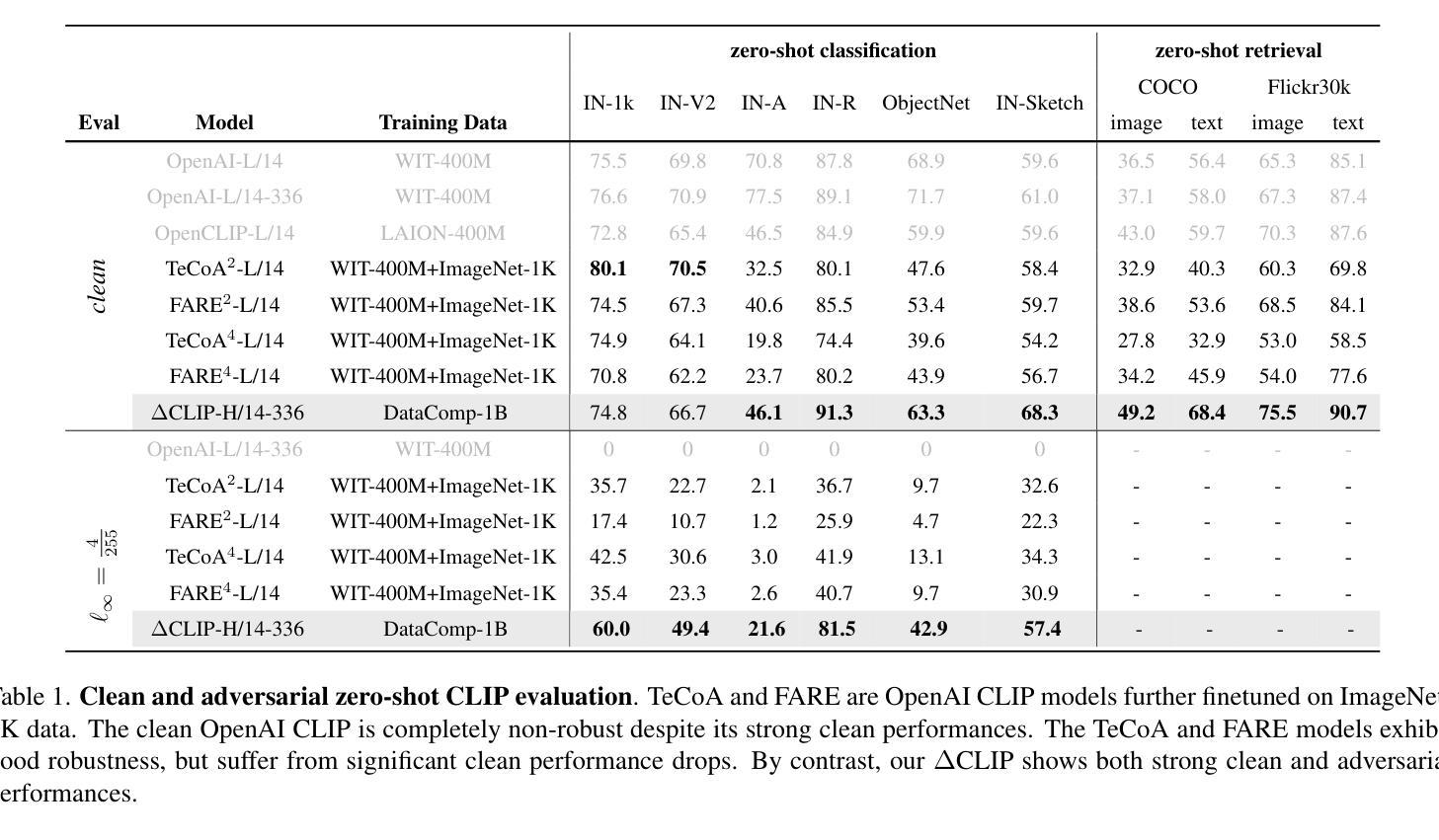
Double Visual Defense: Adversarial Pre-training and Instruction Tuning for Improving Vision-Language Model Robustness
Authors:Zeyu Wang, Cihang Xie, Brian Bartoldson, Bhavya Kailkhura
This paper investigates the robustness of vision-language models against adversarial visual perturbations and introduces a novel ``double visual defense” to enhance this robustness. Unlike previous approaches that resort to lightweight adversarial fine-tuning of a pre-trained CLIP model, we perform large-scale adversarial vision-language pre-training from scratch using web-scale data. We then strengthen the defense by incorporating adversarial visual instruction tuning. The resulting models from each stage, $\Delta$CLIP and $\Delta^2$LLaVA, show substantially enhanced zero-shot robustness and set a new state-of-the-art in adversarial defense for vision-language models. For example, the adversarial robustness of $\Delta$CLIP surpasses that of the previous best models on ImageNet-1k by ~20%. %For example, $\Delta$CLIP surpasses the previous best models on ImageNet-1k by ~20% in terms of adversarial robustness. Similarly, compared to prior art, $\Delta^2$LLaVA brings a ~30% robustness improvement to image captioning task and a ~20% robustness improvement to visual question answering task. Furthermore, our models exhibit stronger zero-shot recognition capability, fewer hallucinations, and superior reasoning performance compared to baselines. Our project page is https://doublevisualdefense.github.io/.
本文研究了视觉语言模型对抗对抗性视觉扰动(adversarial visual perturbations)的鲁棒性,并引入了一种新型的“双重视觉防御”(double visual defense)机制来增强这种鲁棒性。不同于之前的方法,我们采用从网络规模数据开始的大规模对抗性视觉语言预训练,而不是对预训练的CLIP模型进行轻量级的对抗微调。然后,我们通过结合对抗性视觉指令调整来加强防御。每个阶段的模型,即$\Delta$CLIP和$\Delta^2$LLaVA,都显示出大幅增强的零样本鲁棒性,并在视觉语言模型的对抗防御方面创造了新的技术水平。例如,$\Delta$CLIP在ImageNet-1k上的对抗鲁棒性超过了之前的最佳模型,提高了约20%。同样地,与先前技术相比,$\Delta^2$LLaVA在图像描述任务上提高了约30%的鲁棒性,在视觉问答任务上提高了约20%的鲁棒性。此外,我们的模型还表现出更强的零样本识别能力、更少的幻觉和优于基准线的推理性能。我们的项目页面是:https://doublevisualdefense.github.io/。
论文及项目相关链接
Summary
本文探讨了视觉语言模型对抗视觉扰动攻击的鲁棒性,并提出了一种新的“双重视觉防御”策略来提升模型的鲁棒性。该研究不仅进行小规模的对抗性微调预训练CLIP模型,而且从网络规模数据开始大规模对抗视觉语言预训练。通过结合对抗视觉指令微调来加强防御。所得模型ΔCLIP和Δ²LLaVA的零样本鲁棒性得到实质性提升,在视觉语言模型的对抗防御方面创造了新的技术水准。例如,ΔCLIP在ImageNet-1k上的对抗鲁棒性超过了以前最优秀的模型约20%。此外,与基线相比,我们的模型展现出更强的零样本识别能力、更少的幻觉和更出色的推理性能。
Key Takeaways
- 探讨了视觉语言模型对于对抗视觉扰动的鲁棒性挑战。
- 提出了一种新的“双重视觉防御”策略,包括大规模的对抗视觉语言预训练以及对抗视觉指令微调。
- ΔCLIP模型在ImageNet-1k上的对抗鲁棒性相比之前最优秀的模型提升了约20%。
- Δ²LLaVA模型在图像描述和视觉问答任务上分别实现了约30%和约20%的鲁棒性提升。
- 模型展现出更强的零样本识别能力。
- 模型减少了幻觉现象。
点此查看论文截图

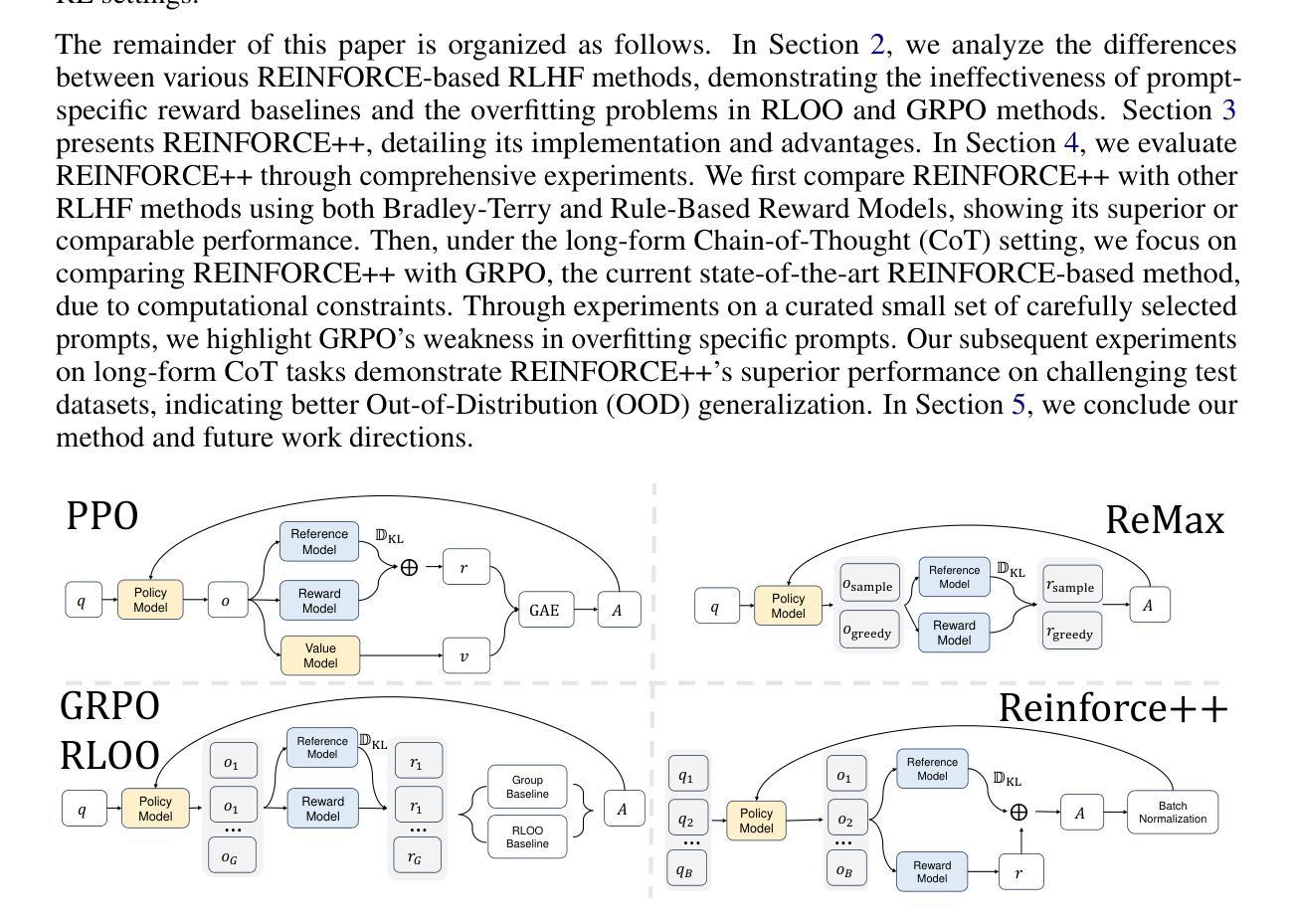
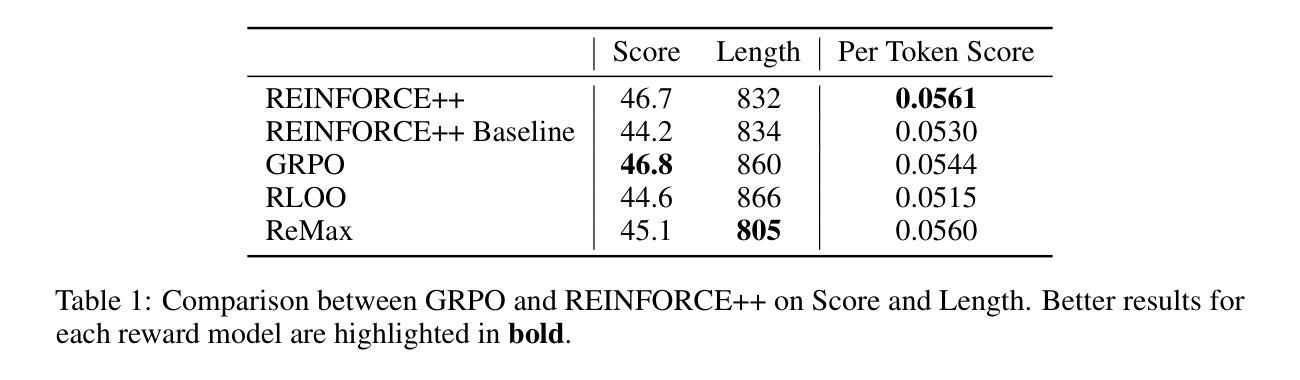
REINFORCE++: An Efficient RLHF Algorithm with Robustness to Both Prompt and Reward Models
Authors:Jian Hu, Jason Klein Liu, Wei Shen
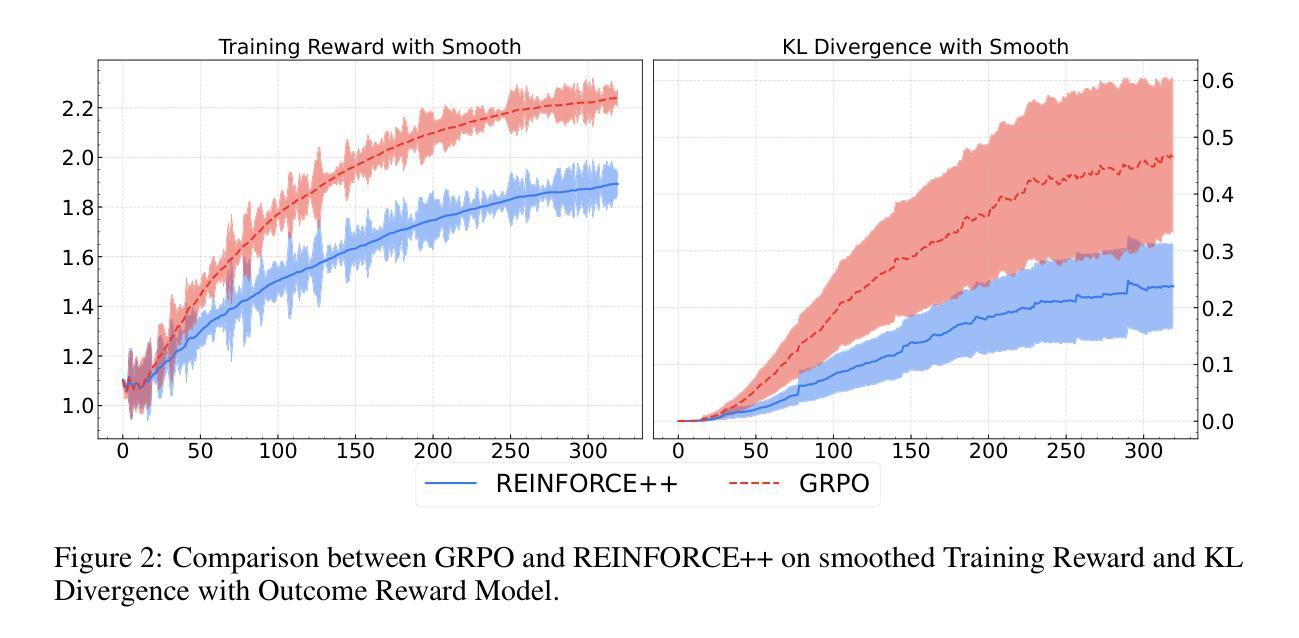
Reinforcement Learning from Human Feedback (RLHF) plays a crucial role in aligning large language models (LLMs) with human values and preferences. While state-of-the-art applications like ChatGPT/GPT-4 commonly employ Proximal Policy Optimization (PPO), the inclusion of a critic network introduces significant computational overhead. REINFORCE-based methods, such as REINFORCE Leave One-Out (RLOO), ReMax, and Group Relative Policy Optimization (GRPO), address this limitation by eliminating the critic network. However, these approaches face challenges in accurate advantage estimation. Specifically, they estimate advantages independently for responses to each prompt, which can lead to overfitting on simpler prompts and vulnerability to reward hacking. To address these challenges, we introduce REINFORCE++, a novel approach that removes the critic model while using the normalized reward of a batch as the baseline. Our empirical evaluation demonstrates that REINFORCE++ exhibits robust performance across various reward models without requiring prompt set truncation. Furthermore, it achieves superior generalization in both RLHF and long chain-of-thought (CoT) settings compared to existing REINFORCE-based methods. The implementation is available at https://github.com/OpenRLHF/OpenRLHF.
强化学习从人类反馈(RLHF)在将大型语言模型(LLM)与人类价值观和偏好对齐方面发挥着至关重要的作用。虽然最先进的应用如ChatGPT/GPT-4通常采用近端策略优化(PPO),但加入评论家网络会引入大量的计算开销。基于REINFORCE的方法,如REINFORCE Leave One-Out(RLOO)、ReMax和集团相对策略优化(GRPO),通过消除评论家网络来解决这一限制。然而,这些方法在准确估算优势方面面临挑战。具体来说,它们独立地为每个提示的回应估计优势,这可能导致在简单提示上过拟合,并容易受到奖励黑客攻击。为了解决这些挑战,我们推出了REINFORCE++,这是一种新型方法,它去除了评论家模型,同时使用一批次的标准化奖励作为基线。我们的经验评估表明,REINFORCE++在各种奖励模型中具有稳健的性能表现,无需截断提示集。此外,与现有的基于REINFORCE的方法相比,它在RLHF和长链思维(CoT)设置中实现了更好的泛化能力。相关实现可访问:https://github.com/OpenRLHF/OpenRLHF。
论文及项目相关链接
PDF fix typo
Summary
强化学习(RL)在人类反馈(RLHF)中的作用对于大型语言模型(LLM)与人类价值观和偏好的对齐至关重要。ChatGPT和GPT-4等尖端应用普遍采用近端策略优化(PPO)。消除评论家网络的REINFORCE强化学习为基础的方法能显著提高效率。但是面临准确估算优势的挑战。为解决此问题,我们提出REINFORCE++算法,使用一批标准化奖励作为基线消除评论家模型。实验表明,REINFORCE++在不同奖励模型中具有稳健性能,且具备出色泛化能力。详细信息可通过链接访问:https://github.com/OpenRLHF/OpenRLHF。
Key Takeaways
- 强化学习在人类反馈(RLHF)对齐大型语言模型(LLM)与人类价值观和偏好方面起到关键作用。
- 目前尖端应用如ChatGPT和GPT-4使用近端策略优化(PPO),但引入评论家网络带来计算负担。
- REINFORCE强化学习为基础的方法消除评论家网络以提高效率,但面临准确估算优势的挑战。
- REINFORCE方法独立估算每个提示的响应优势,可能导致对简单提示的过拟合和易受奖励操纵的影响。
- REINFORCE++算法提出消除评论家模型同时使用一批标准化奖励作为基线来解决上述问题。
- 实验显示REINFORCE++在不同奖励模型中表现稳健,不需要截断提示集。
点此查看论文截图

Large Language Model Can Be a Foundation for Hidden Rationale-Based Retrieval
Authors:Luo Ji, Feixiang Guo, Teng Chen, Qingqing Gu, Xiaoyu Wang, Ningyuan Xi, Yihong Wang, Peng Yu, Yue Zhao, Hongyang Lei, Zhonglin Jiang, Yong Chen
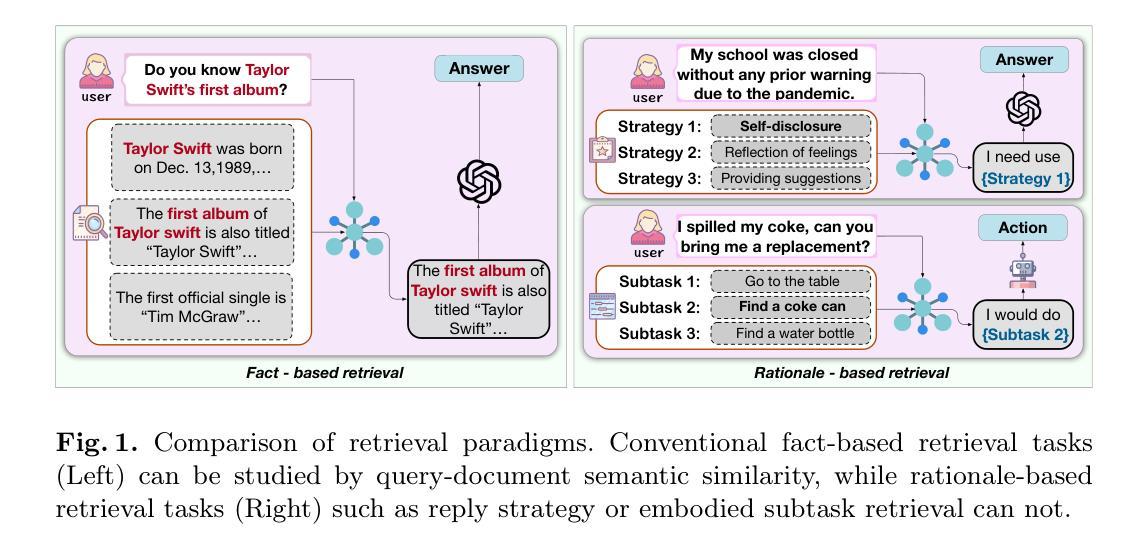
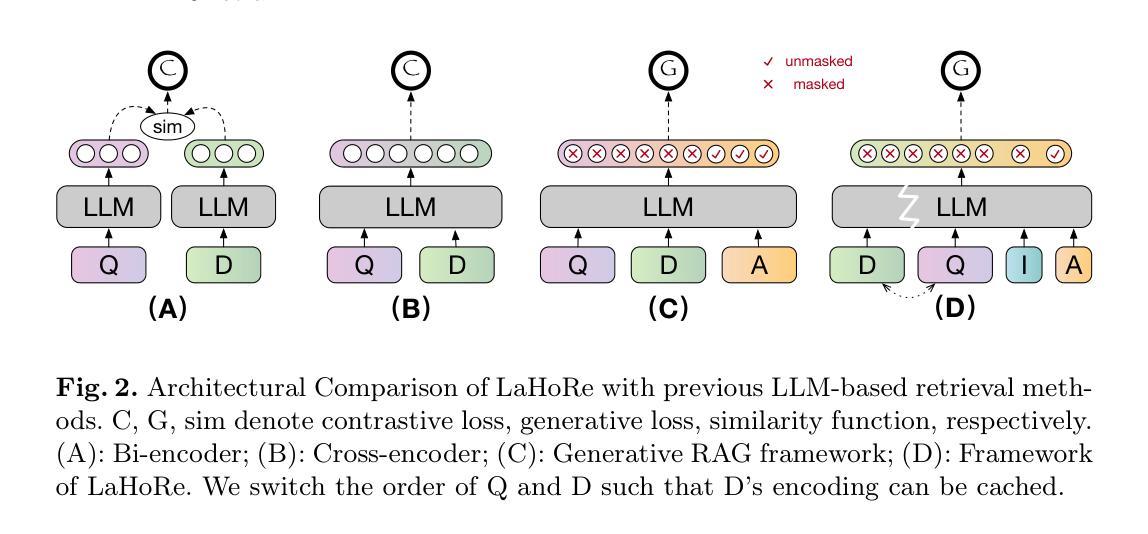
Despite the recent advancement in Retrieval-Augmented Generation (RAG) systems, most retrieval methodologies are often developed for factual retrieval, which assumes query and positive documents are semantically similar. In this paper, we instead propose and study a more challenging type of retrieval task, called hidden rationale retrieval, in which query and document are not similar but can be inferred by reasoning chains, logic relationships, or empirical experiences. To address such problems, an instruction-tuned Large language model (LLM) with a cross-encoder architecture could be a reasonable choice. To further strengthen pioneering LLM-based retrievers, we design a special instruction that transforms the retrieval task into a generative task by prompting LLM to answer a binary-choice question. The model can be fine-tuned with direct preference optimization (DPO). The framework is also optimized for computational efficiency with no performance degradation. We name this retrieval framework by RaHoRe and verify its zero-shot and fine-tuned performance superiority on Emotional Support Conversation (ESC), compared with previous retrieval works. Our study suggests the potential to employ LLM as a foundation for a wider scope of retrieval tasks. Our codes, models, and datasets are available on https://github.com/flyfree5/LaHoRe.
尽管最近检索增强生成(RAG)系统有所进展,但大多数检索方法往往针对事实检索而开发,这假设查询和正面文档在语义上是相似的。在本文中,我们提出并研究了一种更具挑战性的检索任务,称为隐藏逻辑检索,其中查询和文档并不相似,但可以通过推理链、逻辑关系或经验推断得出。为了解决这些问题,采用带有跨编码器架构的指令优化大型语言模型(LLM)是一个合理的选择。为了进一步加强基于LLM的检索器,我们设计了一个特殊指令,通过提示LLM回答二元选择问题,将检索任务转变为生成任务。该模型可以通过直接偏好优化(DPO)进行微调。该框架在计算效率方面也进行了优化,且不会降低性能。我们将这种检索框架命名为RaHoRe,并在情感支持对话(ESC)上验证了其零样本和微调后的性能优越性,与之前的研究相比表现更佳。我们的研究表明,有潜力将LLM作为更广泛检索任务的基础。我们的代码、模型和数据集可通过https://github.com/flyfree5/LaHoRe获取。
论文及项目相关链接
PDF 10 pages, 3 figures, ECIR 2025
Summary
这是一篇关于隐藏逻辑检索的研究论文,提出了一种更具挑战性的检索任务。该研究挑战了传统的基于事实检索的假设,即查询和正面文档语义相似。论文提出了一种名为RaHoRe的检索框架,利用指令优化的跨编码器大型语言模型(LLM)来解决隐藏逻辑检索问题。该框架通过提示LLM回答二选一问题将检索任务转化为生成任务,并利用直接偏好优化(DPO)进行微调。研究表明,RaHoRe在情感支持对话(ESC)等任务上的零样本和微调性能均优于先前的研究工作,展现了大型语言模型在更广范围检索任务中的潜力。
Key Takeaways
- 论文提出了一种新的检索任务——隐藏逻辑检索,挑战了传统的基于事实检索的假设。
- 隐藏逻辑检索中,查询和文档并不相似,但可以通过推理链、逻辑关系或经验推断来联系。
- 研究者建议使用指令优化的跨编码器大型语言模型(LLM)来解决隐藏逻辑检索问题。
- 通过将检索任务转化为生成任务,利用LLM回答二选一问题的特殊指令来强化模型性能。
- 直接偏好优化(DPO)用于微调模型,提高性能。
- RaHoRe检索框架在情感支持对话(ESC)等任务上表现出优越性能。
点此查看论文截图

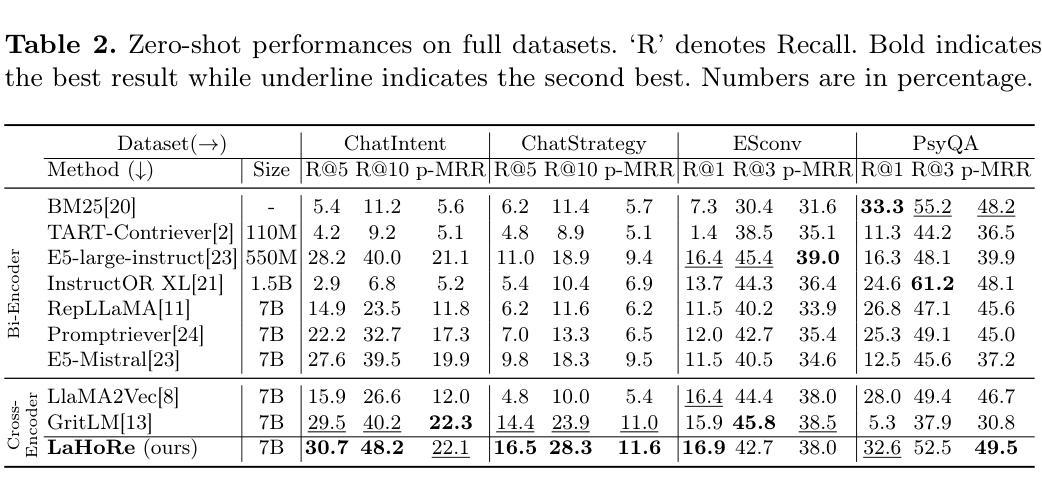

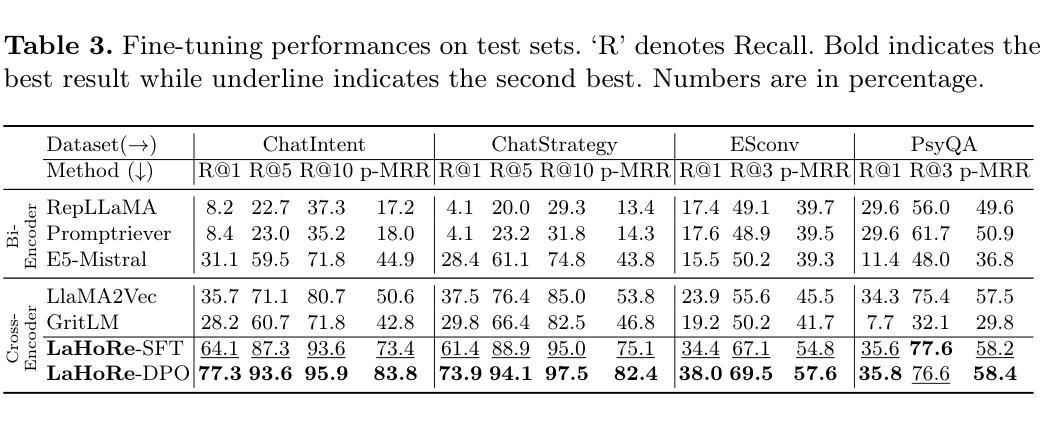
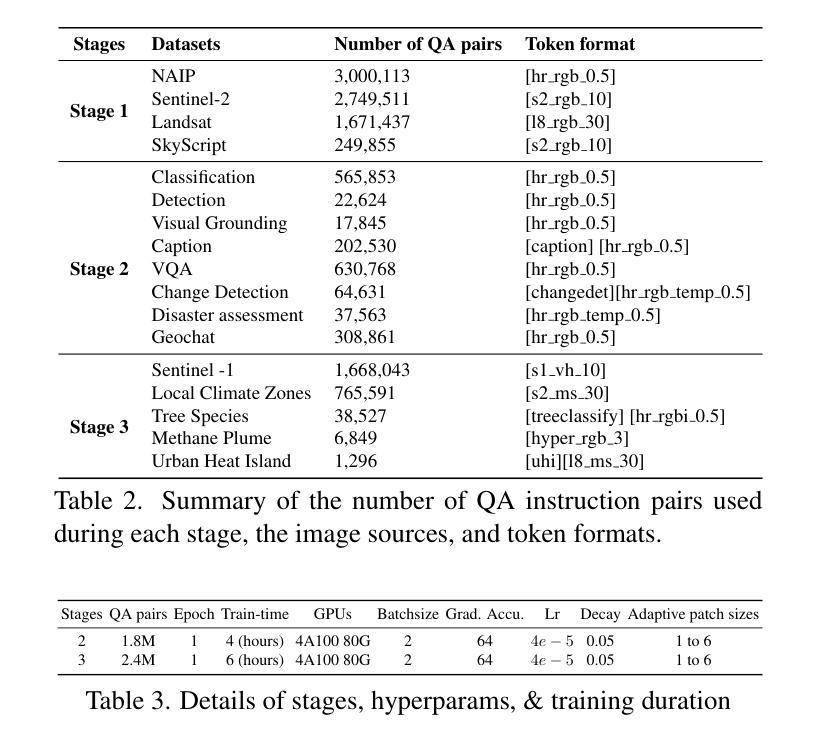
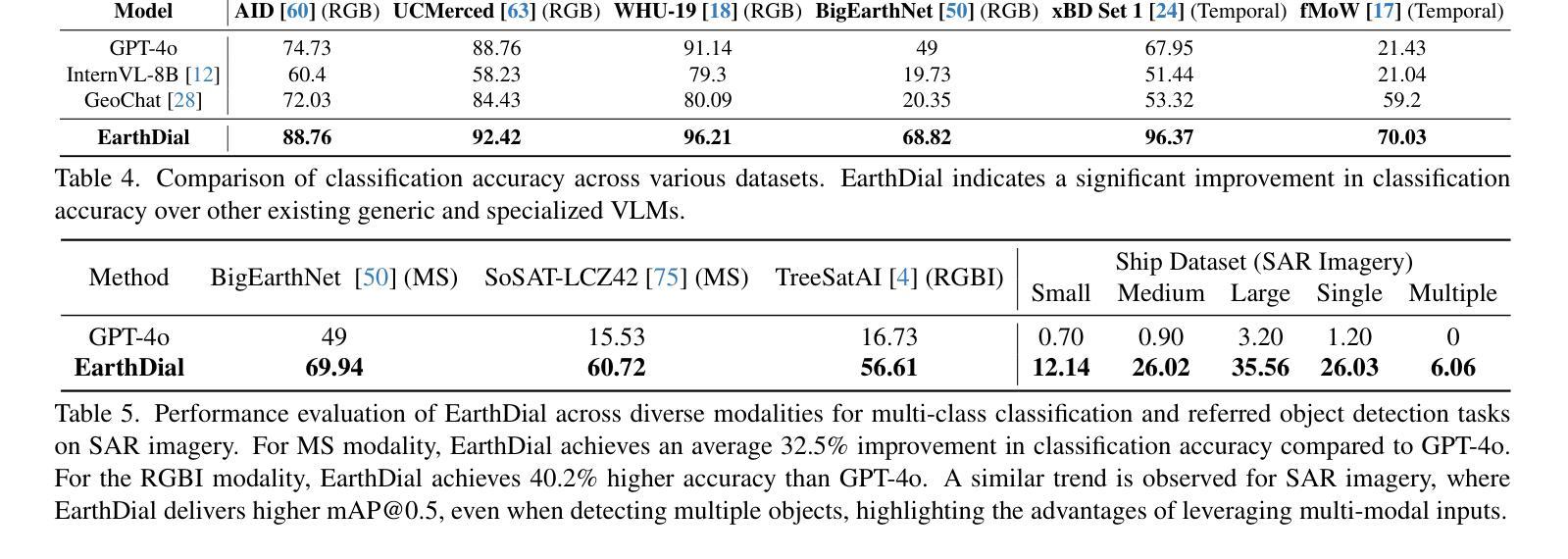
EarthDial: Turning Multi-sensory Earth Observations to Interactive Dialogues
Authors:Sagar Soni, Akshay Dudhane, Hiyam Debary, Mustansar Fiaz, Muhammad Akhtar Munir, Muhammad Sohail Danish, Paolo Fraccaro, Campbell D Watson, Levente J Klein, Fahad Shahbaz Khan, Salman Khan
Automated analysis of vast Earth observation data via interactive Vision-Language Models (VLMs) can unlock new opportunities for environmental monitoring, disaster response, and {resource management}. Existing generic VLMs do not perform well on Remote Sensing data, while the recent Geo-spatial VLMs remain restricted to a fixed resolution and few sensor modalities. In this paper, we introduce EarthDial, a conversational assistant specifically designed for Earth Observation (EO) data, transforming complex, multi-sensory Earth observations into interactive, natural language dialogues. EarthDial supports multi-spectral, multi-temporal, and multi-resolution imagery, enabling a wide range of remote sensing tasks, including classification, detection, captioning, question answering, visual reasoning, and visual grounding. To achieve this, we introduce an extensive instruction tuning dataset comprising over 11.11M instruction pairs covering RGB, Synthetic Aperture Radar (SAR), and multispectral modalities such as Near-Infrared (NIR) and infrared. Furthermore, EarthDial handles bi-temporal and multi-temporal sequence analysis for applications like change detection. Our extensive experimental results on 44 downstream datasets demonstrate that EarthDial outperforms existing generic and domain-specific models, achieving better generalization across various EO tasks. Our source codes and pre-trained models are at https://github.com/hiyamdebary/EarthDial.
通过交互式的视觉语言模型(VLMs)对大量的地球观测数据进行自动化分析,可以为环境监测、灾害响应和{资源管理}等领域带来新的机遇。现有的通用VLMs在遥感数据上的表现并不理想,而最近的地理空间VLMs仍然局限于固定的分辨率和少量的传感器模态。在本文中,我们介绍了EarthDial,这是一款专门为地球观测(EO)数据设计的对话助手,将复杂的多感官地球观测转化为交互式的自然语言对话。EarthDial支持多光谱、多时相和多分辨率的影像,能够进行广泛的遥感任务,包括分类、检测、描述、问答、视觉推理和视觉定位。为了实现这一点,我们引入了一个包含超过1111万个指令对的庞大指令调整数据集,涵盖RGB、合成孔径雷达(SAR)和近红外(NIR)和红外等多光谱模态。此外,EarthDial还处理双时态和多时态序列分析,用于变化检测等应用。我们在44个下游数据集上进行的大量实验表明,EarthDial优于现有的通用和特定领域模型,在各种EO任务中实现了更好的泛化能力。我们的源代码和预训练模型位于https://github.com/hiyamdebary/EarthDial。
论文及项目相关链接
Summary:通过交互式视觉语言模型(VLMs)对海量的地球观测数据进行自动化分析,为环境监测、灾害响应和{资源管理}等领域带来了新的机遇。针对现有通用VLMs在遥感数据上的表现不佳及地理空间VLMs存在的分辨率和传感器模式限制,本文引入了EarthDial,一款专为地球观测(EO)数据设计的对话助手。EarthDial可将复杂的、多感官的地球观测数据转化为交互式自然语言对话,支持多光谱、多时相和多分辨率影像,能完成遥感分类、检测、描述、问答、视觉推理和视觉定位等任务。为达成这一目标,我们构建了一个包含超过111万指令对的大型指令调整数据集,涵盖RGB、合成孔径雷达(SAR)和多光谱模式,如近红外和红外。EarthDial还能处理双时相和多时相序列分析,用于变化检测等应用。在多个下游数据集上的实验表明,EarthDial在多种地球观测任务上优于现有通用和特定领域的模型,具有良好的泛化能力。
Key Takeaways:
- EarthDial是一款专为地球观测数据设计的交互式对话助手,可将复杂的遥感数据转化为自然语言对话。
- EarthDial支持多光谱、多时相和多分辨率的影像处理。
- EarthDial能完成多种遥感任务,包括分类、检测、描述、问答、视觉推理和视觉定位。
- 为训练EarthDial,研究团队构建了一个包含多种指令和遥感数据的大型数据集。
- EarthDial能处理双时相和多时相序列分析,适用于变化检测等应用。
- 实验表明,EarthDial在多种地球观测任务上表现优于现有模型,具有良好的泛化能力。
点此查看论文截图


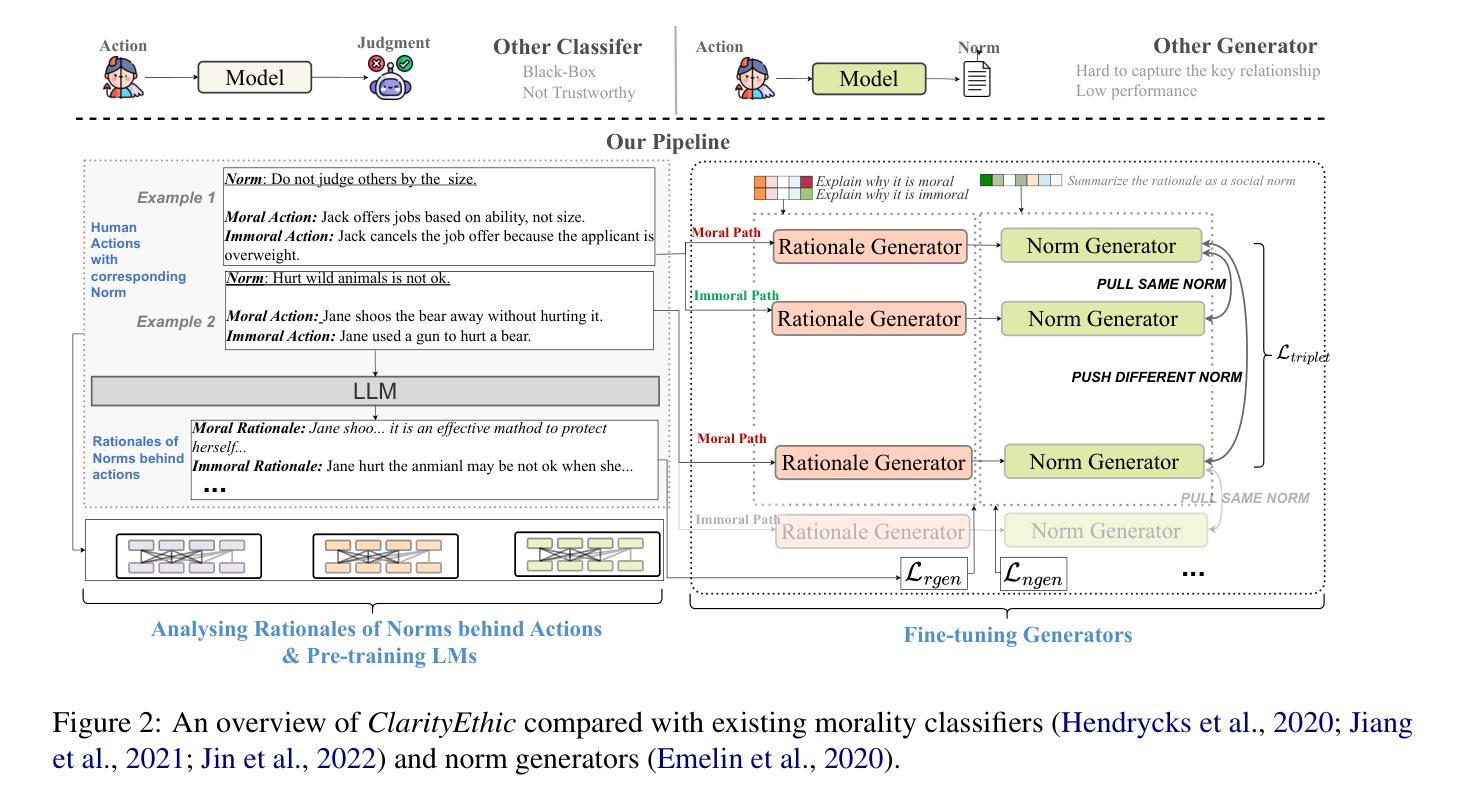
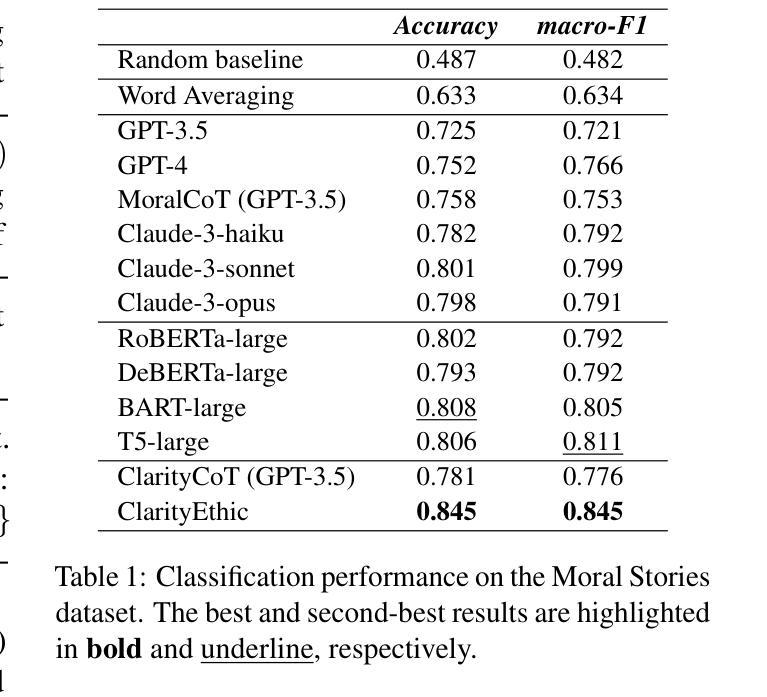
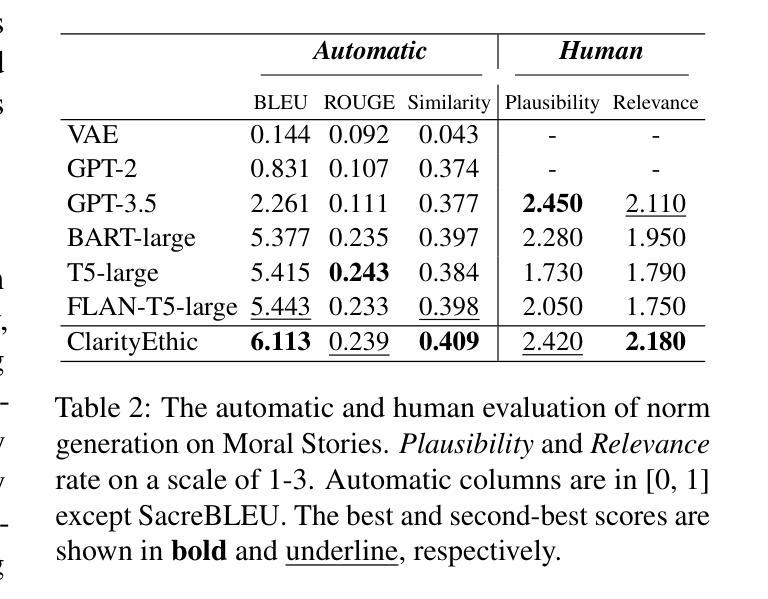
ClarityEthic: Explainable Moral Judgment Utilizing Contrastive Ethical Insights from Large Language Models
Authors:Yuxi Sun, Wei Gao, Jing Ma, Hongzhan Lin, Ziyang Luo, Wenxuan Zhang
With the rise and widespread use of Large Language Models (LLMs), ensuring their safety is crucial to prevent harm to humans and promote ethical behaviors. However, directly assessing value valence (i.e., support or oppose) by leveraging large-scale data training is untrustworthy and inexplainable. We assume that emulating humans to rely on social norms to make moral decisions can help LLMs understand and predict moral judgment. However, capturing human values remains a challenge, as multiple related norms might conflict in specific contexts. Consider norms that are upheld by the majority and promote the well-being of society are more likely to be accepted and widely adopted (e.g., “don’t cheat,”). Therefore, it is essential for LLM to identify the appropriate norms for a given scenario before making moral decisions. To this end, we introduce a novel moral judgment approach called \textit{ClarityEthic} that leverages LLMs’ reasoning ability and contrastive learning to uncover relevant social norms for human actions from different perspectives and select the most reliable one to enhance judgment accuracy. Extensive experiments demonstrate that our method outperforms state-of-the-art approaches in moral judgment tasks. Moreover, human evaluations confirm that the generated social norms provide plausible explanations that support the judgments. This suggests that modeling human moral judgment with the emulating humans moral strategy is promising for improving the ethical behaviors of LLMs.
随着大型语言模型(LLM)的兴起和广泛应用,确保其安全性对于防止对人类造成伤害和促进道德行为至关重要。然而,直接利用大规模数据进行训练来评估价值倾向(即支持或反对)是不可靠且不可解释的。我们假设通过模仿人类依赖社会规范来做出道德决策,可以帮助LLM理解和预测道德判断。然而,捕捉人类价值观仍然是一个挑战,因为在特定的上下文中,多个相关规范可能会发生冲突。被认为是由多数人支持并促进社会福祉的规范更有可能被接受和广泛采用(例如,“不要欺骗”)。因此,对于LLM来说,在做出道德决策之前,识别给定场景中的适当规范至关重要。为此,我们引入了一种新型的道德判断方法,称为ClarityEthic。该方法利用LLM的推理能力和对比学习,从不同角度揭示与人类行为相关的社会规范,并选择最可靠的一个来提高判断的准确性。大量实验表明,我们的方法在道德判断任务上的表现优于最先进的方法。此外,人类评估证实,生成的社会规范提供了支持判断的合理解释。这表明用模仿人类的道德策略来模拟人类道德判断对于提高LLM的道德行为是有希望的。
论文及项目相关链接
PDF We have noticed that this version of our experiment and method description isn’t quite complete or accurate. To make sure we present our best work, we think it would be a good idea to withdraw the manuscript for now and take some time to revise and reformat it
Summary
大型语言模型(LLMs)的广泛应用带来了保障其安全性的重要性,以防止对人类造成危害并推动道德行为。直接利用大规模数据进行价值倾向评估是不值得信赖和不可解释的。我们提出了一种基于社会规范的模拟人类道德判断方法ClarityEthic,它通过LLMs的推理能力和对比学习,揭示人类行为相关的社会规范,并选择最可靠的社会规范来提高判断准确性。实验证明,该方法在道德判断任务上优于现有技术,并得到人类评估的支持。这表明采用模拟人类道德策略的建模人类道德判断对于提高LLMs的伦理行为是有前景的。
Key Takeaways
- 大型语言模型(LLMs)的广泛应用需要确保安全性,以防止对人类造成危害并推动道德行为。
- 直接利用大规模数据进行价值倾向评估是不值得信赖和不可解释的。
- 模拟人类依靠社会规范进行道德决策的方法可以帮助LLMs理解和预测道德判断。
- 识别给定情境下的适当社会规范对于LLMs做出道德决策至关重要。
- 引入了一种新的道德判断方法ClarityEthic,利用LLMs的推理能力和对比学习来揭示相关的社会规范。
- ClarityEthic方法在道德判断任务上的表现优于现有技术。
点此查看论文截图