⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-11 更新
Detect All-Type Deepfake Audio: Wavelet Prompt Tuning for Enhanced Auditory Perception
Authors:Yuankun Xie, Ruibo Fu, Zhiyong Wang, Xiaopeng Wang, Songjun Cao, Long Ma, Haonan Cheng, Long Ye
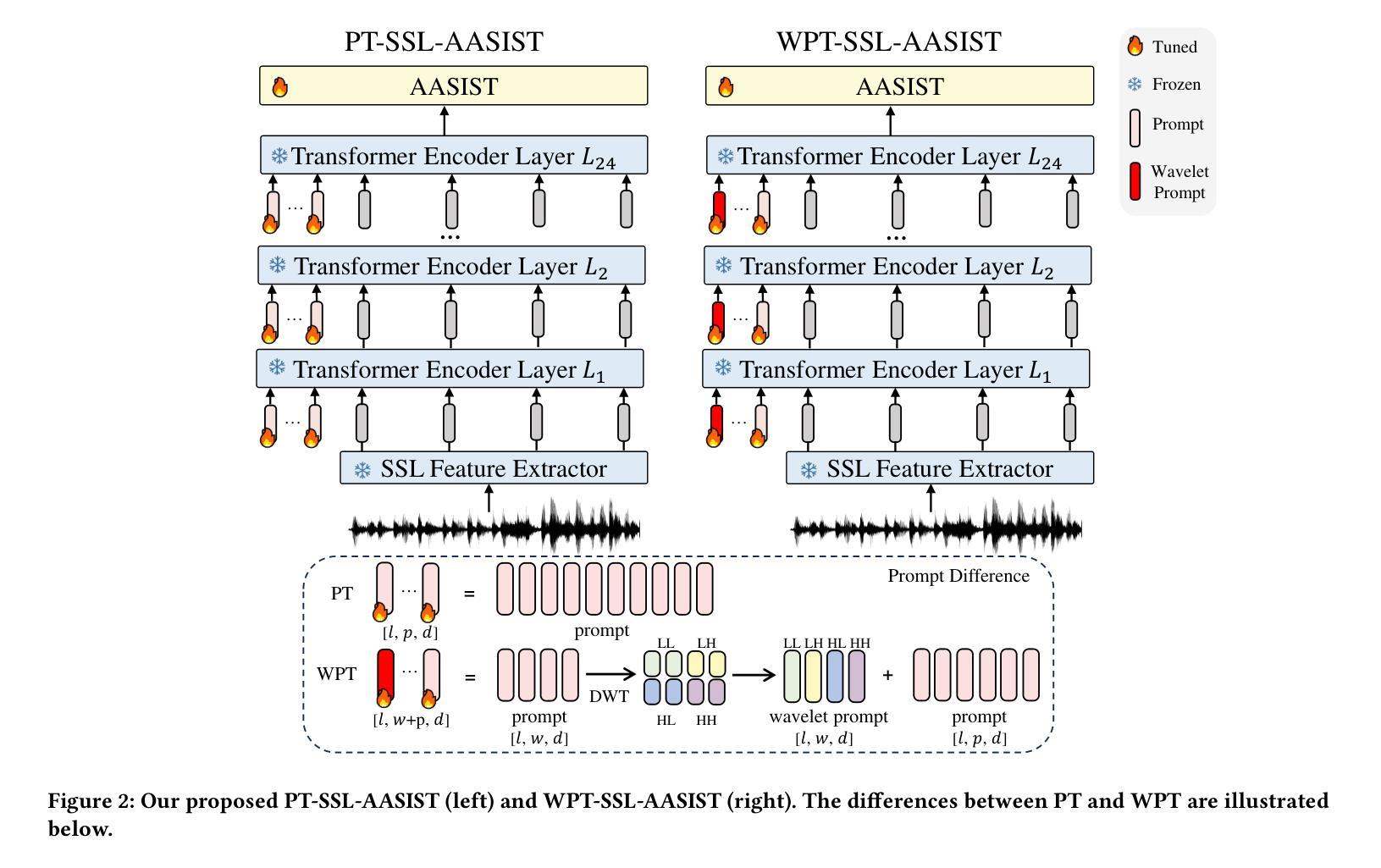
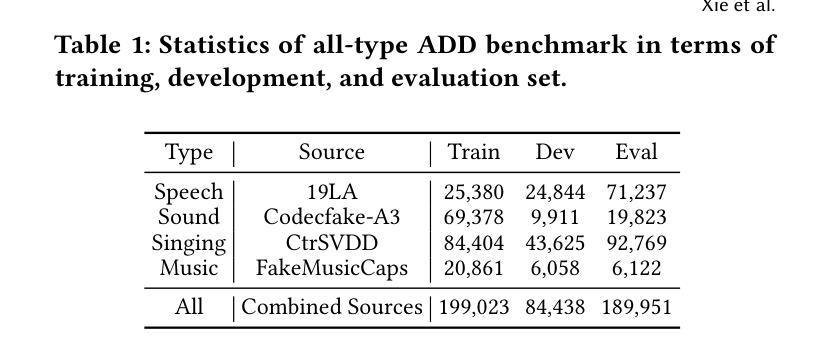
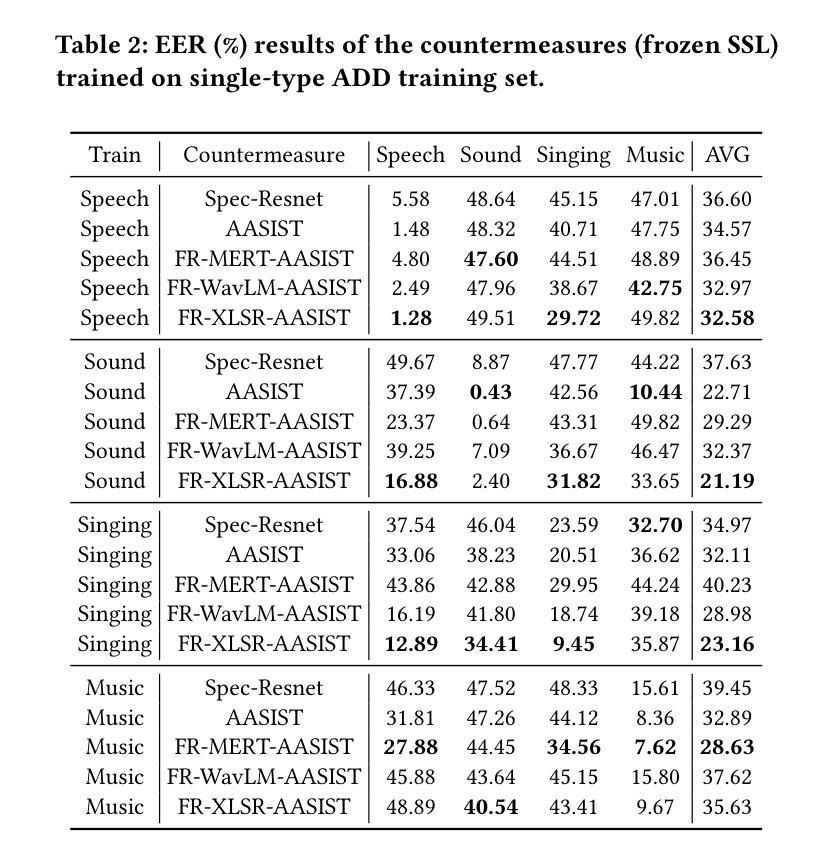
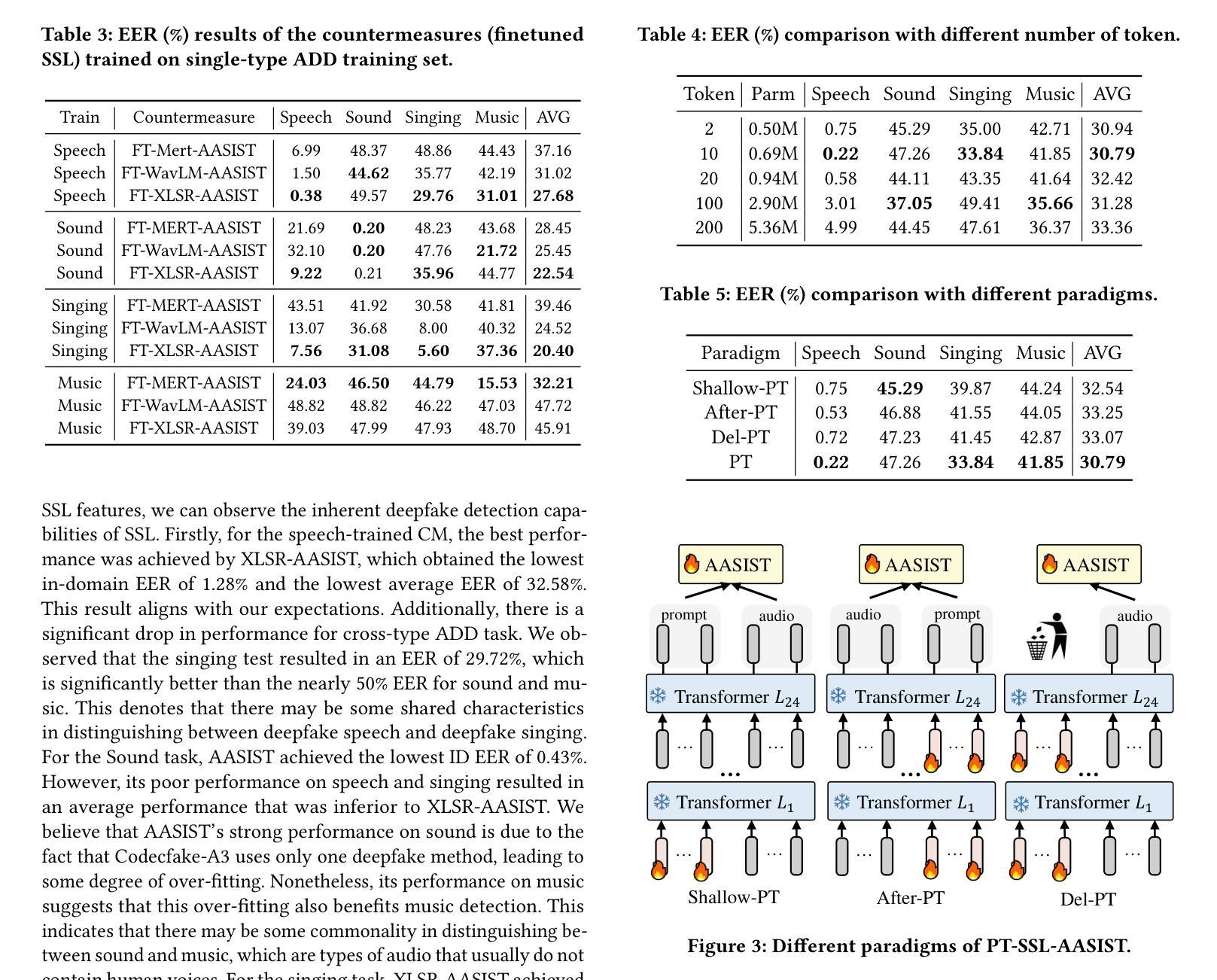
The rapid advancement of audio generation technologies has escalated the risks of malicious deepfake audio across speech, sound, singing voice, and music, threatening multimedia security and trust. While existing countermeasures (CMs) perform well in single-type audio deepfake detection (ADD), their performance declines in cross-type scenarios. This paper is dedicated to studying the alltype ADD task. We are the first to comprehensively establish an all-type ADD benchmark to evaluate current CMs, incorporating cross-type deepfake detection across speech, sound, singing voice, and music. Then, we introduce the prompt tuning self-supervised learning (PT-SSL) training paradigm, which optimizes SSL frontend by learning specialized prompt tokens for ADD, requiring 458x fewer trainable parameters than fine-tuning (FT). Considering the auditory perception of different audio types,we propose the wavelet prompt tuning (WPT)-SSL method to capture type-invariant auditory deepfake information from the frequency domain without requiring additional training parameters, thereby enhancing performance over FT in the all-type ADD task. To achieve an universally CM, we utilize all types of deepfake audio for co-training. Experimental results demonstrate that WPT-XLSR-AASIST achieved the best performance, with an average EER of 3.58% across all evaluation sets. The code is available online.
随着音频生成技术的快速发展,语音、声音、歌声和音乐中的恶意深度伪造音频的风险也随之增加,这对多媒体的安全性和信任度构成了威胁。现有的对策(CMs)在单一类型的音频深度伪造检测(ADD)中表现良好,但在跨类型场景中性能下降。本文专注于研究全类型ADD任务。我们是首次全面建立全类型ADD基准,以评估当前CMs在语音、声音、歌声和音乐中的跨类型深度伪造检测性能。然后,我们介绍了提示调整自监督学习(PT-SSL)训练范式,它通过为ADD学习专用提示令牌来优化SSL前端,所需的可训练参数比微调(FT)少458倍。考虑到不同音频类型的听觉感知,我们提出了小波提示调整(WPT)-SSL方法,该方法可从频率域捕获类型不变的深度伪造信息,无需额外的训练参数,从而在全类型ADD任务中的性能超过了微调。为了实现通用CM,我们利用所有类型的深度伪造音频进行协同训练。实验结果表明,WPT-XLSR-AASIST取得了最佳性能,在所有评估集上的平均EER为3.58%。代码已在线发布。
论文及项目相关链接
Summary
随着音频生成技术的快速发展,恶意深度伪造音频的风险在语音、声音、歌声和音乐领域不断上升,威胁着多媒体的安全性和信任。现有对策在单一类型音频深度伪造检测(ADD)中表现良好,但在跨类型场景中性能下降。本文首次全面建立了一个跨语音、声音、歌声和音乐的全方位音频深度伪造检测(ADD)基准测试平台,以评估当前对策的有效性。引入提示调整自监督学习(PT-SSL)训练范式,优化SSL前端,学习ADD专用的提示令牌,参数需求仅为微调(FT)的458倍之一。考虑到不同音频类型的听觉感知,提出小波提示调整(WPT)-SSL方法,从频率域捕获类型不变的深度伪造信息,无需额外训练参数,提升在全方位ADD任务上的性能超过微调。使用所有类型的深度伪造音频进行联合训练以实现通用对策。实验结果显示,WPT-XLSR-AASIST表现最佳,平均等错误率(EER)为所有评估集的3.58%。代码已在线发布。
Key Takeaways
- 音频生成技术的快速发展带来了恶意深度伪造音频的风险上升,威胁多媒体安全。
- 现有对策在单一类型音频深度伪造检测中表现良好,但在跨类型场景中性能下降。
- 本文首次建立了一个全方位音频深度伪造检测基准测试平台。
- 引入提示调整自监督学习训练范式,优化SSL前端并降低参数需求。
- 提出小波提示调整(WPT)-SSL方法,从频率域捕获类型不变的深度伪造信息。
- 通过联合训练使用所有类型的深度伪造音频,以实现更通用的对策。
- WPT-XLSR-AASIST表现最佳,平均等错误率为3.58%,代码已在线发布。
点此查看论文截图

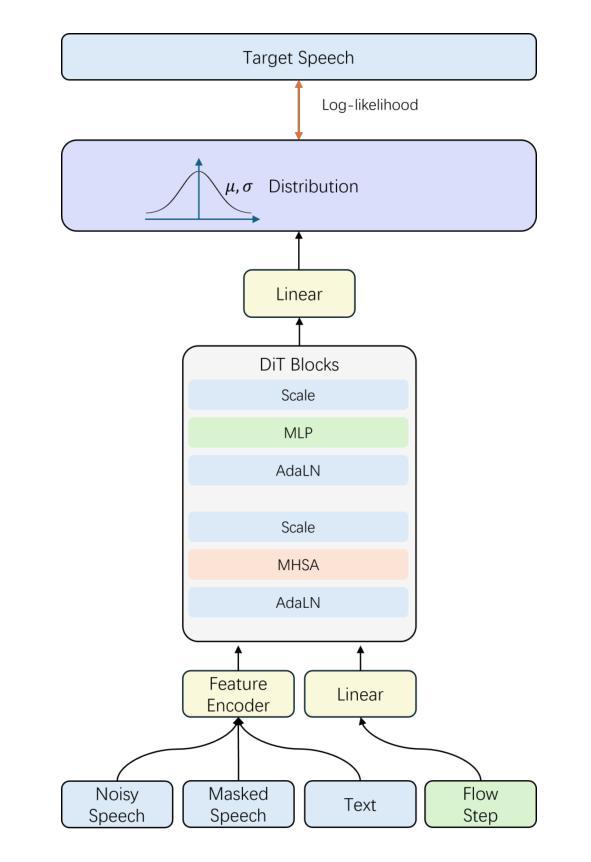
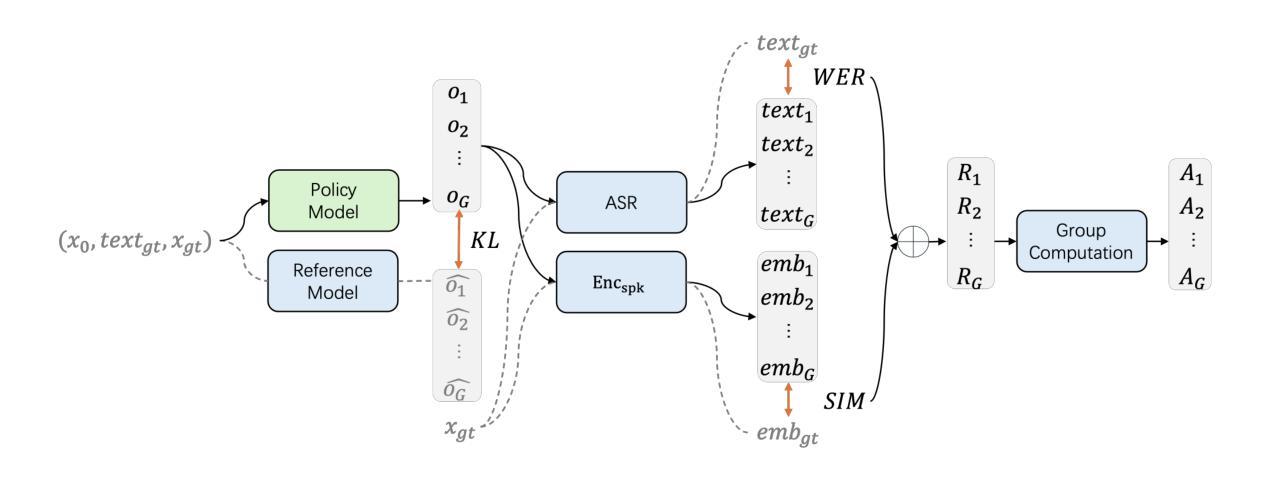
F5R-TTS: Improving Flow-Matching based Text-to-Speech with Group Relative Policy Optimization
Authors:Xiaohui Sun, Ruitong Xiao, Jianye Mo, Bowen Wu, Qun Yu, Baoxun Wang
We present F5R-TTS, a novel text-to-speech (TTS) system that integrates Gradient Reward Policy Optimization (GRPO) into a flow-matching based architecture. By reformulating the deterministic outputs of flow-matching TTS into probabilistic Gaussian distributions, our approach enables seamless integration of reinforcement learning algorithms. During pretraining, we train a probabilistically reformulated flow-matching based model which is derived from F5-TTS with an open-source dataset. In the subsequent reinforcement learning (RL) phase, we employ a GRPO-driven enhancement stage that leverages dual reward metrics: word error rate (WER) computed via automatic speech recognition and speaker similarity (SIM) assessed by verification models. Experimental results on zero-shot voice cloning demonstrate that F5R-TTS achieves significant improvements in both speech intelligibility (a 29.5% relative reduction in WER) and speaker similarity (a 4.6% relative increase in SIM score) compared to conventional flow-matching based TTS systems. Audio samples are available at https://frontierlabs.github.io/F5R.
我们介绍了F5R-TTS,这是一种新型文本到语音(TTS)系统,它将梯度奖励策略优化(GRPO)集成到基于流匹配的架构中。我们通过将基于流匹配的TTS的确定性输出重新制定为概率高斯分布,使强化学习算法能够无缝集成。在预训练过程中,我们使用开源数据集对基于流匹配的模型进行概率重新训练,该模型是源于F5-TTS的。在随后的强化学习(RL)阶段,我们采用GRPO驱动的增强阶段,利用双重奖励指标:通过自动语音识别计算的单词错误率(WER)和由验证模型评估的演讲者相似性(SIM)。在零样本语音克隆上的实验结果表明,与传统的基于流匹配的TTS系统相比,F5R-TTS在语音清晰度(相对减少29.5%的WER)和演讲者相似性(相对提高4.6%的SIM分数)方面取得了显著的改进。音频样本可在https://frontierlabs.github.io/F5R上找到。
论文及项目相关链接
摘要
本研究提出了一种新型的文本转语音(TTS)系统——F5R-TTS,该系统将梯度奖励策略优化(GRPO)融入基于流匹配的架构中。通过把流匹配的确定性输出转化为概率高斯分布,实现了强化学习算法的无缝集成。研究者在预训练阶段使用基于开源数据集的概率改革流匹配模型,来源于F5-TTS。在随后的强化学习阶段,采用GRPO驱动的增强阶段,利用双重奖励指标:通过自动语音识别计算的字词错误率(WER)和通过验证模型评估的说话人相似性(SIM)。在零样本语音克隆上的实验结果表明,F5R-TTS在语音清晰度(字词错误率相对减少29.5%)和说话人相似性(SIM得分相对增加4.6%)方面,相较于传统的基于流匹配的TTS系统有显著改进。音频样本可在https://frontierlabs.github.io/F5R获取。
关键见解
- F5R-TTS是一种新型的文本转语音(TTS)系统,结合梯度奖励策略优化(GRPO)和流匹配技术。
- 通过将流匹配的确定性输出转化为概率高斯分布,F5R-TTS能够集成强化学习算法。
- 在预训练阶段,研究者使用基于开源数据集的概率改革流匹配模型。
- 强化学习阶段采用GRPO驱动增强阶段,结合双重奖励指标:字词错误率(WER)和说话人相似性(SIM)。
- F5R-TTS在语音清晰度和说话人相似性方面相较于传统TTS系统有显著改进。
- F5R-TTS通过减少字词错误率提高了语音的清晰度,相对减少了29.5%的WER。
点此查看论文截图