⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-11 更新
Crafting Query-Aware Selective Attention for Single Image Super-Resolution
Authors:Junyoung Kim, Youngrok Kim, Siyeol Jung, Donghyun Min
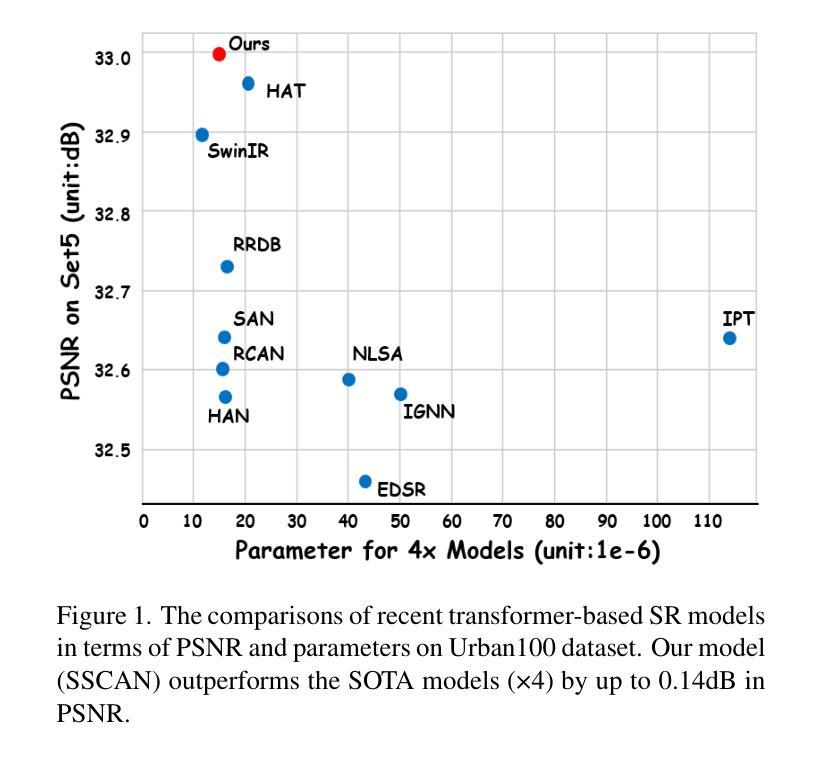
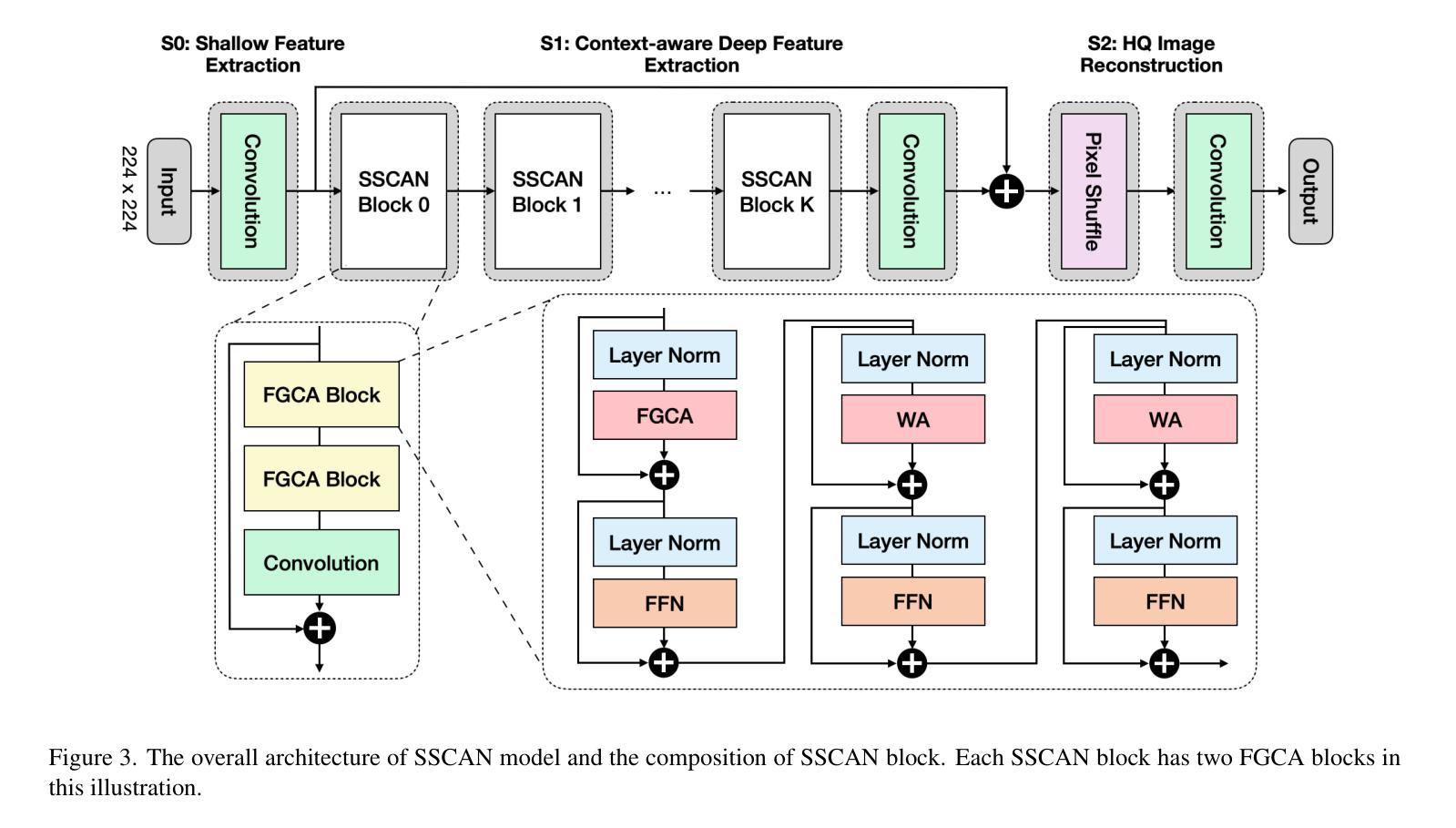
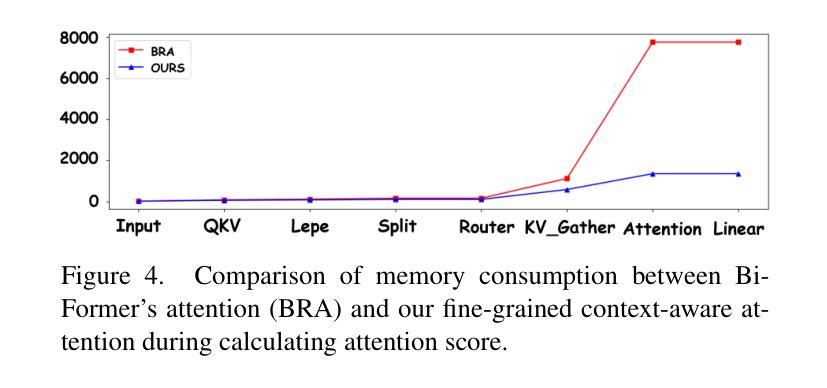
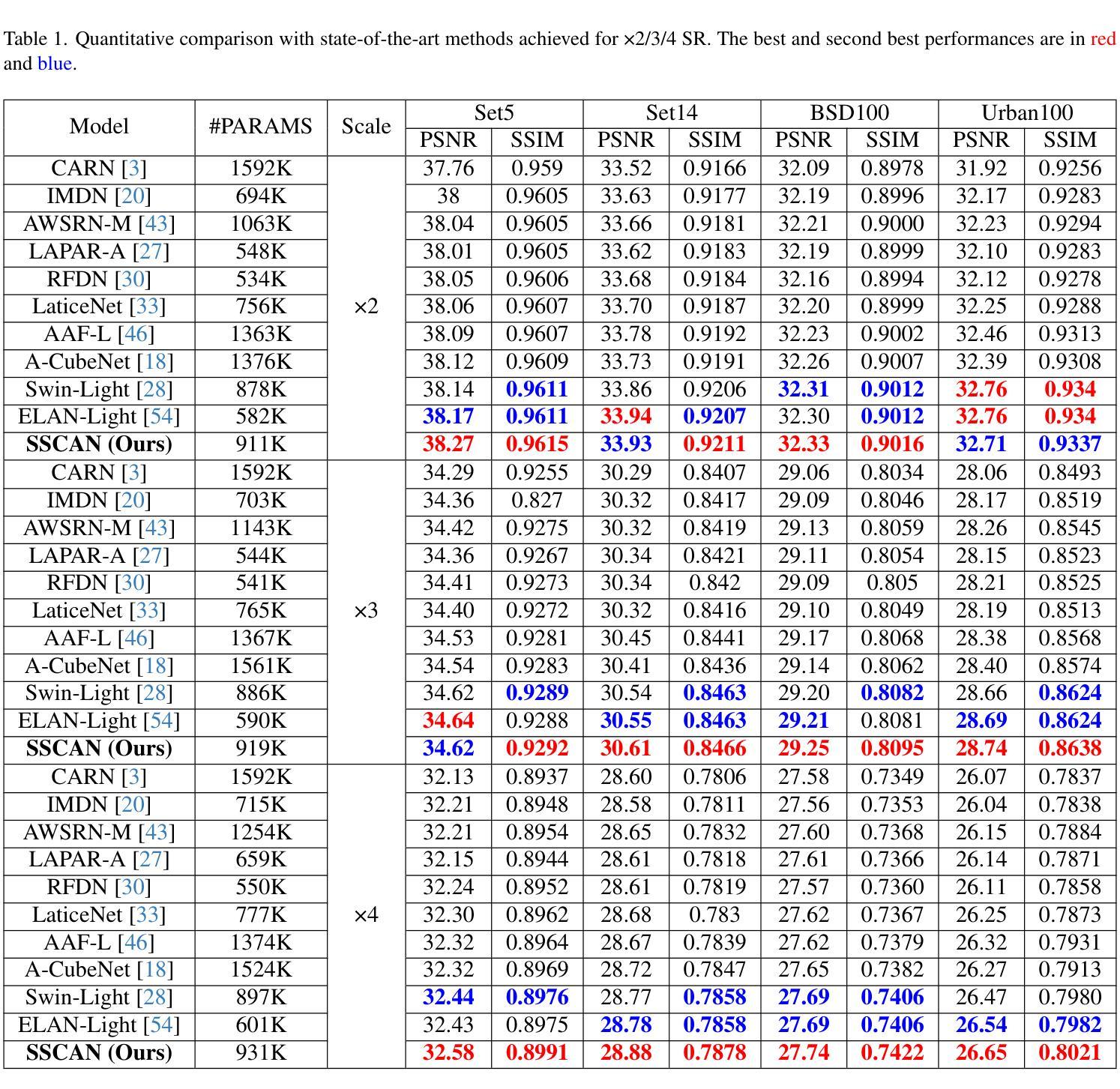
Single Image Super-Resolution (SISR) reconstructs high-resolution images from low-resolution inputs, enhancing image details. While Vision Transformer (ViT)-based models improve SISR by capturing long-range dependencies, they suffer from quadratic computational costs or employ selective attention mechanisms that do not explicitly focus on query-relevant regions. Despite these advancements, prior work has overlooked how selective attention mechanisms should be effectively designed for SISR. We propose SSCAN, which dynamically selects the most relevant key-value windows based on query similarity, ensuring focused feature extraction while maintaining efficiency. In contrast to prior approaches that apply attention globally or heuristically, our method introduces a query-aware window selection strategy that better aligns attention computation with important image regions. By incorporating fixed-sized windows, SSCAN reduces memory usage and enforces linear token-to-token complexity, making it scalable for large images. Our experiments demonstrate that SSCAN outperforms existing attention-based SISR methods, achieving up to 0.14 dB PSNR improvement on urban datasets, guaranteeing both computational efficiency and reconstruction quality in SISR.
单图像超分辨率(SISR)是从低分辨率输入重建高分辨率图像,增强图像细节。虽然基于视觉转换器(ViT)的模型通过捕捉长程依赖性改进了SISR,但它们遭受二次计算成本的困扰,或者采用的选择性注意机制并没有明确关注查询相关区域。尽管有这些进展,但先前的工作忽视了应如何有效地为SISR设计选择性注意机制。我们提出SSCAN,它根据查询相似性动态选择最相关的键值窗口,确保在保持效率的同时进行有针对性的特征提取。与之前全局或启发式应用注意的方法相反,我们的方法引入了一种查询感知窗口选择策略,更好地将注意力计算与图像的重要区域对齐。通过采用固定大小的窗口,SSCAN减少了内存使用并强制实施线性令牌到令牌的复杂性,使其适用于大型图像。我们的实验表明,SSCAN优于现有的基于注意力的SISR方法,在城市数据集上实现高达0.14分贝峰值信噪比(PSNR)的提升,在保证计算效率的同时保证了SISR的重建质量。
论文及项目相关链接
PDF 10 pages, 5 figures, 4 tables
Summary
本文提出一种基于Vision Transformer(ViT)的单图像超分辨率重建方法,称为SSCAN。该方法通过动态选择最相关的键值窗口,实现高效且有针对性的特征提取。与全局或启发式注意力机制不同,SSCAN采用查询感知的窗口选择策略,使注意力计算与重要图像区域更紧密地结合。SSCAN使用固定大小的窗口来减少内存使用,并具有线性的token-to-token复杂性,适用于大型图像。实验表明,SSCAN在城市数据集上实现了高达0.14 dB的PSNR改进,保证了单图像超分辨率重建的计算效率和重建质量。
Key Takeaways
- SSCAN是一种基于Vision Transformer(ViT)的单图像超分辨率重建方法。
- SSCAN通过动态选择最相关的键值窗口来实现高效且有针对性的特征提取。
- 与其他方法不同,SSCAN采用查询感知的窗口选择策略。
- SSCAN使用固定大小的窗口以减少内存使用,并适应大型图像。
- SSCAN具有线性的token-to-token复杂性。
- 实验表明,SSCAN在注意力机制的单图像超分辨率重建方法中表现优异。
点此查看论文截图