⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-12 更新
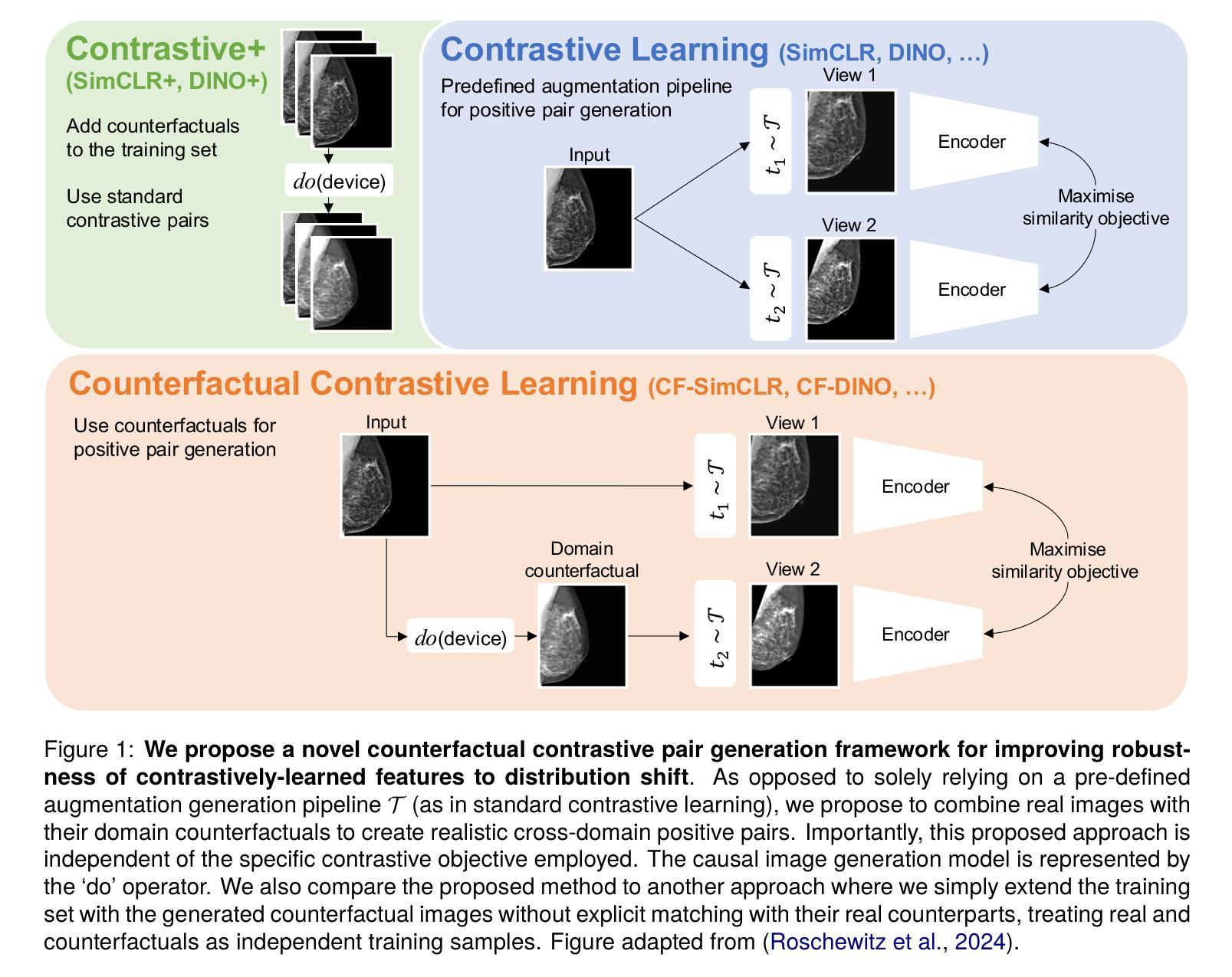
Robust image representations with counterfactual contrastive learning
Authors:Mélanie Roschewitz, Fabio De Sousa Ribeiro, Tian Xia, Galvin Khara, Ben Glocker
Contrastive pretraining can substantially increase model generalisation and downstream performance. However, the quality of the learned representations is highly dependent on the data augmentation strategy applied to generate positive pairs. Positive contrastive pairs should preserve semantic meaning while discarding unwanted variations related to the data acquisition domain. Traditional contrastive pipelines attempt to simulate domain shifts through pre-defined generic image transformations. However, these do not always mimic realistic and relevant domain variations for medical imaging, such as scanner differences. To tackle this issue, we herein introduce counterfactual contrastive learning, a novel framework leveraging recent advances in causal image synthesis to create contrastive positive pairs that faithfully capture relevant domain variations. Our method, evaluated across five datasets encompassing both chest radiography and mammography data, for two established contrastive objectives (SimCLR and DINO-v2), outperforms standard contrastive learning in terms of robustness to acquisition shift. Notably, counterfactual contrastive learning achieves superior downstream performance on both in-distribution and external datasets, especially for images acquired with scanners under-represented in the training set. Further experiments show that the proposed framework extends beyond acquisition shifts, with models trained with counterfactual contrastive learning reducing subgroup disparities across biological sex.
对比预训练可以显著提高模型的通用性和下游性能。但是,所学表示的质量很大程度上取决于用于生成正样本对的数据增强策略。正对比对应该保留语义信息,同时舍弃与数据获取领域相关的无关变化。传统的对比流程尝试通过预先定义的一般图像转换来模拟领域转移。然而,这些并不总是能模仿医疗成像中的现实和相关的领域变化,如扫描仪差异。为了解决这一问题,我们在此引入了反事实对比学习,这是一个利用最新的因果图像合成技术创建对比正样本对的新框架,这些样本对能够忠实地捕捉相关领域的差异。我们的方法在五套数据集上进行评估,涵盖了胸部放射图像和乳腺摄影数据,对于两个既定的对比目标(SimCLR和DINO-v2),在应对采集变化的稳健性方面优于标准对比学习。值得注意的是,反事实对比学习在内部和外部数据集上都实现了优越的下游性能,特别是对于训练集中代表性不足的扫描仪采集的图像。进一步的实验表明,所提出的框架超越了采集变化,使用反事实对比学习训练的模型减少了生物性别等亚组之间的差异。
论文及项目相关链接
PDF Code available at https://github.com/biomedia-mira/counterfactual-contrastive/
Summary
本文探讨了对比预训练对模型泛化和下游性能的提升作用。文中指出,对比学习中生成的积极对比对的质量直接影响学习到的表示的质量。为了克服传统对比流程在模拟真实领域变化方面的不足,特别是针对医学成像中的扫描仪差异,引入了基于因果图像合成的反事实对比学习框架。该方法在不同数据集上优于标准对比学习,尤其是在获取与训练集中的扫描仪不匹配的场景上效果突出。同时,这种新的学习方法不仅应对领域偏移的场景有出色表现,还扩大了应用范围,减少性别差异导致的偏见。
Key Takeaways
以下是文本中的关键见解要点:
- 对比预训练能显著提高模型的泛化和下游性能。
- 积极对比对的质量对学到的表示质量至关重要,需保留语义意义并去除与数据获取领域相关的无关变化。
- 传统对比流程模拟的领域变化可能并不真实和贴近医学成像的实际需求,尤其是不同扫描仪的获取差异。
- 为解决这一问题,引入反事实对比学习框架,利用因果图像合成技术创建积极对比对,准确捕捉相关领域的真实变化。
- 该方法在多个数据集上的实验评估表现优越,尤其是在训练和测试数据的扫描仪不匹配时效果显著。相较于标准对比学习展现出更强的鲁棒性。
- 反事实对比学习不仅适用于领域偏移问题,还应用于更广泛的场景,如减少模型对子群体间的偏见(如性别差异)。这表明方法在不同任务中都具有良好的适应性。
点此查看论文截图