⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-12 更新
SF2T: Self-supervised Fragment Finetuning of Video-LLMs for Fine-Grained Understanding
Authors:Yangliu Hu, Zikai Song, Na Feng, Yawei Luo, Junqing Yu, Yi-Ping Phoebe Chen, Wei Yang
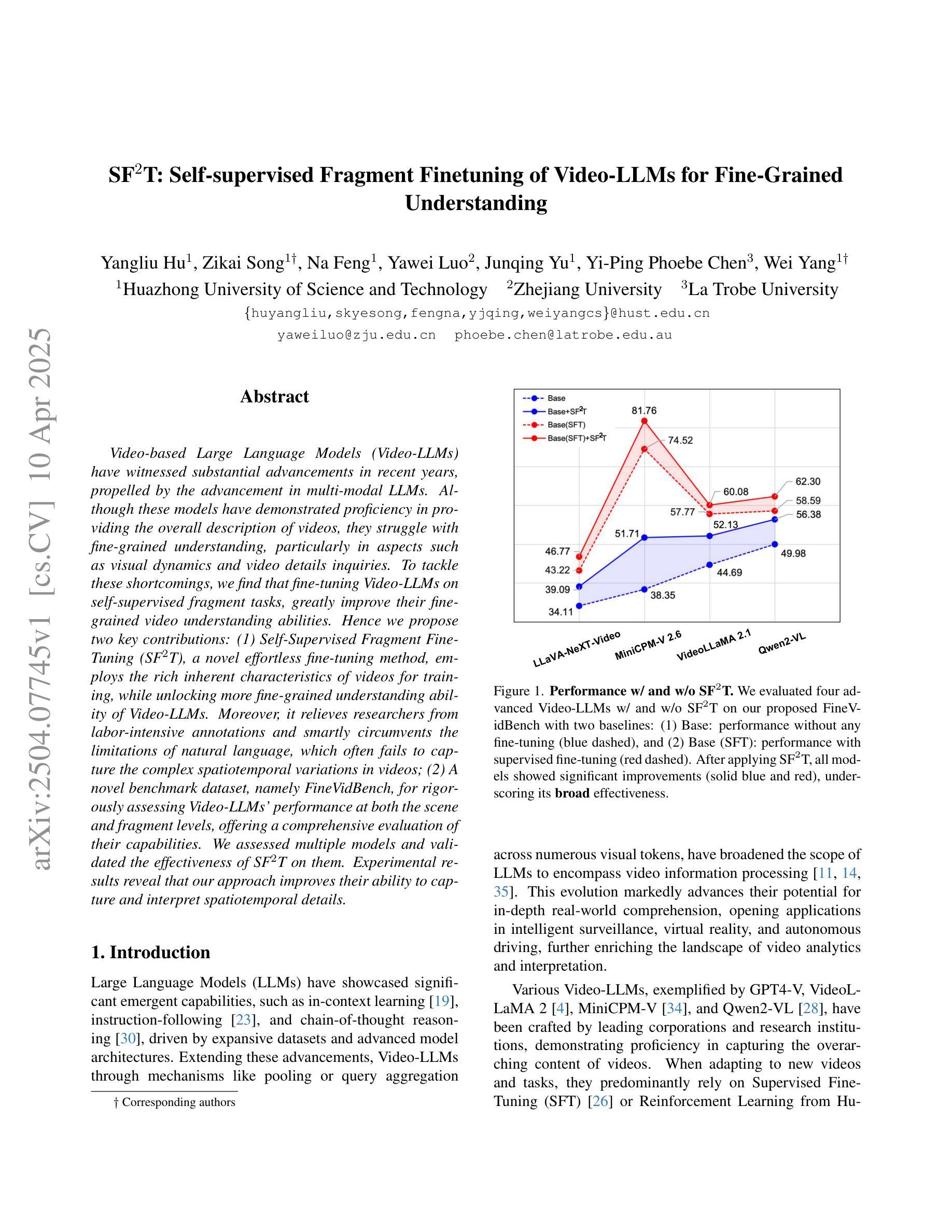
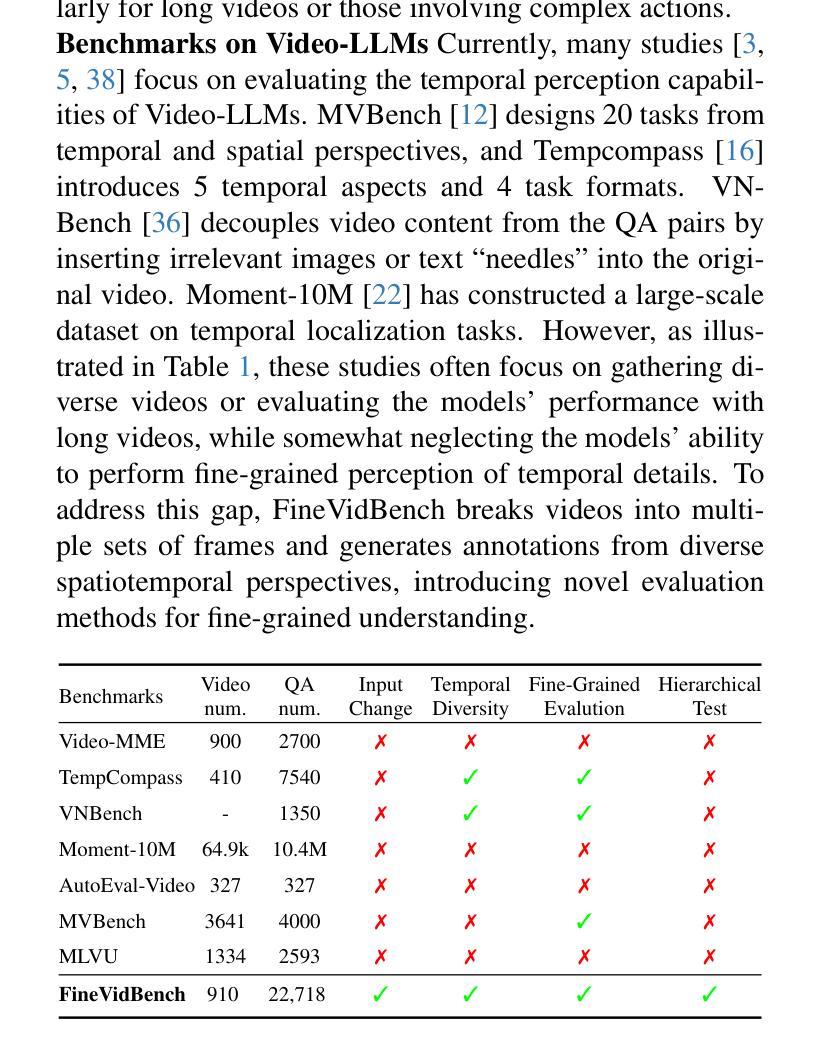
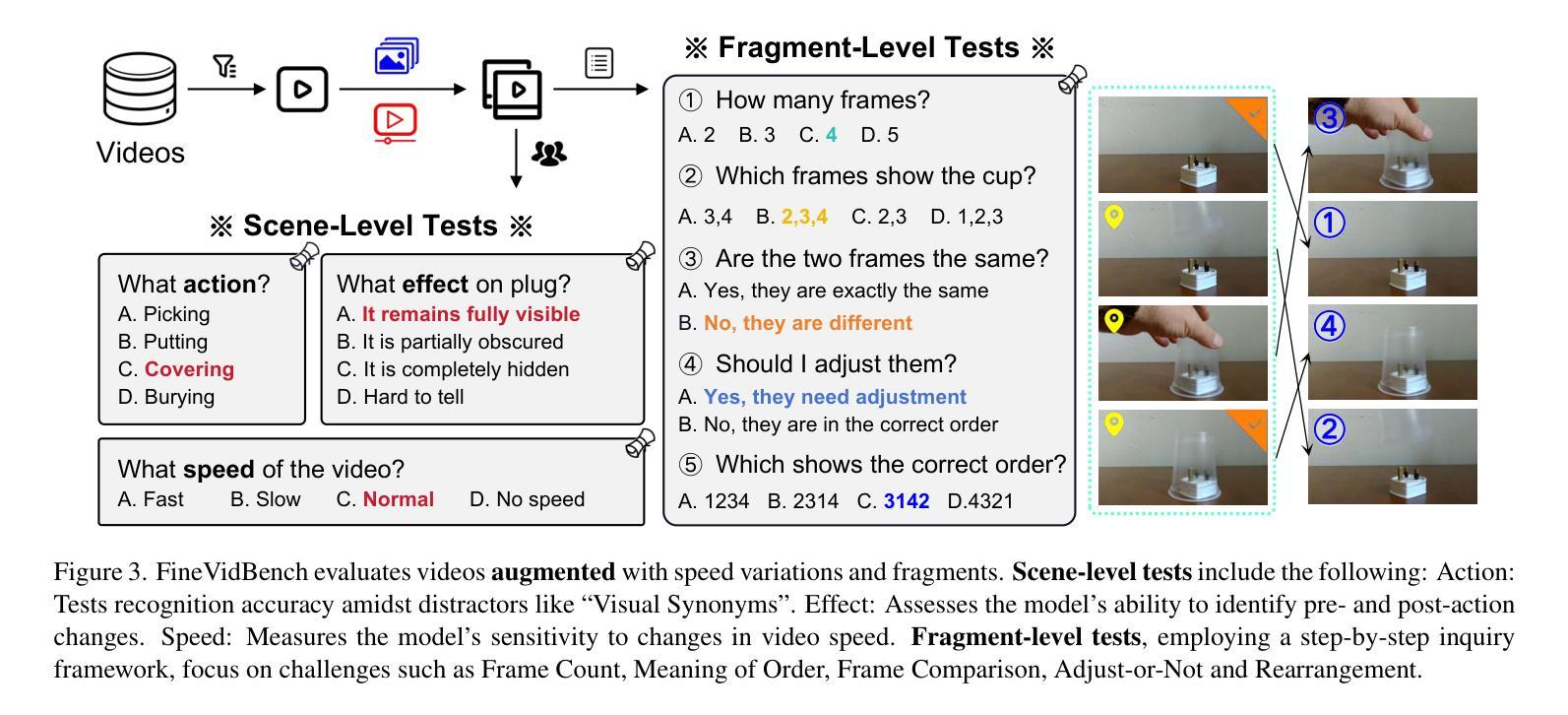
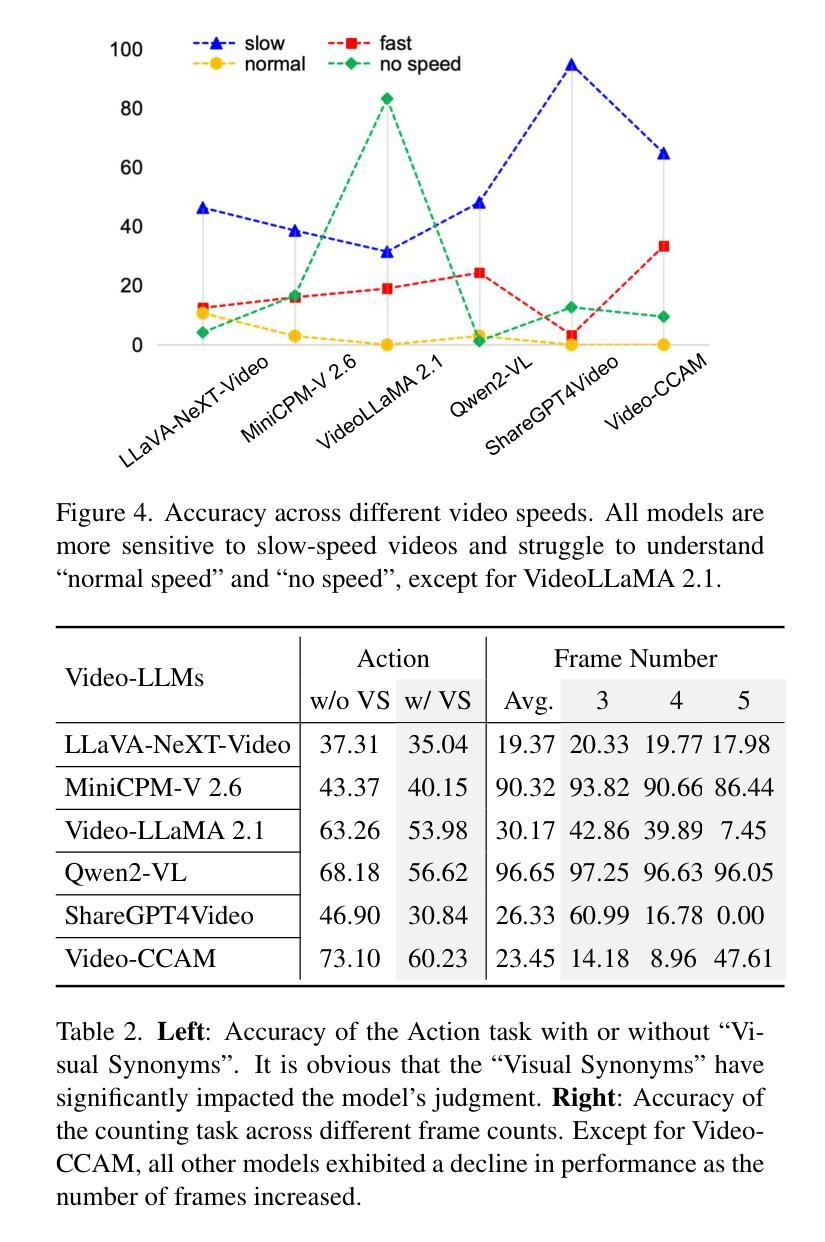
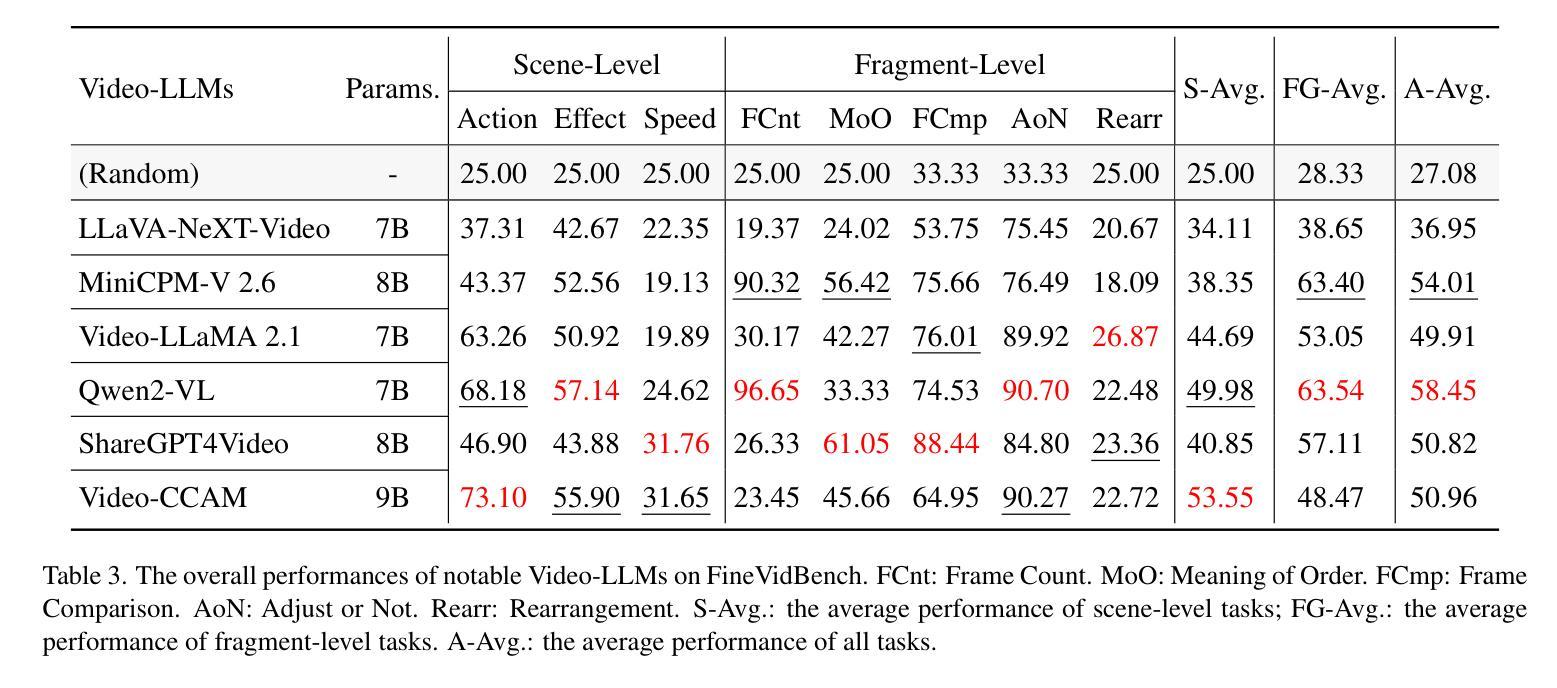
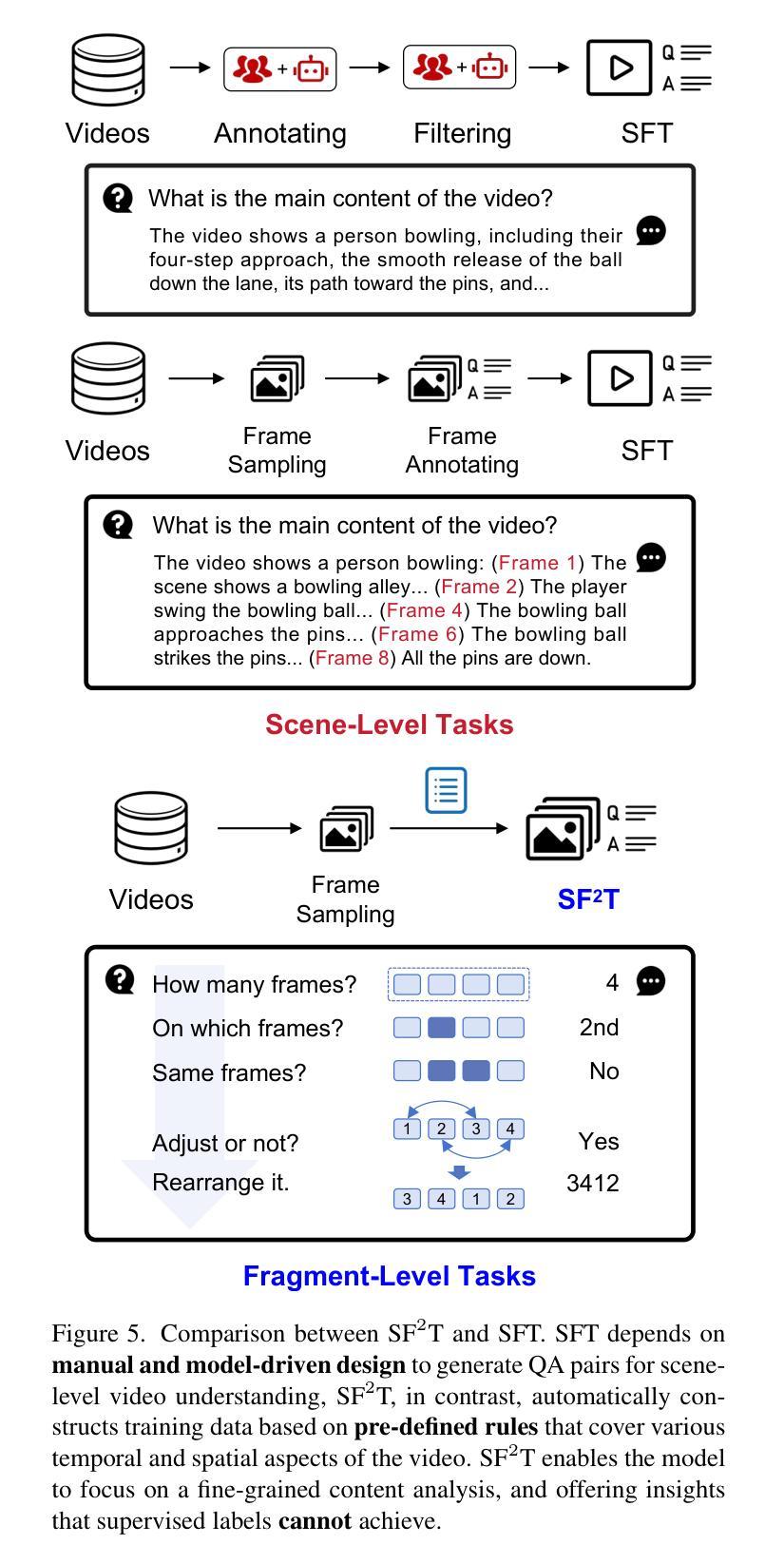
Video-based Large Language Models (Video-LLMs) have witnessed substantial advancements in recent years, propelled by the advancement in multi-modal LLMs. Although these models have demonstrated proficiency in providing the overall description of videos, they struggle with fine-grained understanding, particularly in aspects such as visual dynamics and video details inquiries. To tackle these shortcomings, we find that fine-tuning Video-LLMs on self-supervised fragment tasks, greatly improve their fine-grained video understanding abilities. Hence we propose two key contributions:(1) Self-Supervised Fragment Fine-Tuning (SF$^2$T), a novel effortless fine-tuning method, employs the rich inherent characteristics of videos for training, while unlocking more fine-grained understanding ability of Video-LLMs. Moreover, it relieves researchers from labor-intensive annotations and smartly circumvents the limitations of natural language, which often fails to capture the complex spatiotemporal variations in videos; (2) A novel benchmark dataset, namely FineVidBench, for rigorously assessing Video-LLMs’ performance at both the scene and fragment levels, offering a comprehensive evaluation of their capabilities. We assessed multiple models and validated the effectiveness of SF$^2$T on them. Experimental results reveal that our approach improves their ability to capture and interpret spatiotemporal details.
基于视频的的大型语言模型(Video-LLM)在最近几年里取得了巨大的进步,这得益于多模态LLM的进步。虽然这些模型在提供视频的整体描述方面表现出色,但在精细粒度的理解上遇到了困难,特别是在视频动态和细节查询等方面。为了解决这些不足,我们发现通过在自我监督的片段任务上对Video-LLM进行微调,可以极大地提高其精细粒度的视频理解能力。因此,我们提出了两个主要贡献:(1)自我监督片段微调(SF$^2$T),这是一种新型的无费力微调方法,它利用视频丰富的内在特性进行训练,同时解锁了Video-LLM的更多精细粒度理解能力。此外,它还减轻了研究人员对劳动密集型注释的依赖,并巧妙地克服了自然语言的局限性,后者通常无法捕捉视频中的复杂时空变化;(2)一个用于严格评估Video-LLM在场景和片段级别的性能的新型基准数据集FineVidBench,对它们的能力进行了全面的评估。我们评估了多个模型,并验证了SF$^2$T在它们上的有效性。实验结果表显示,我们的方法提高了它们捕捉和解释时空细节的能力。
论文及项目相关链接
PDF Accepted to CVPR2025
摘要
视频大型语言模型(Video-LLM)近年随着多模态LLM的进步而得到显著发展。虽然这些模型在提供视频整体描述方面表现出色,但在精细级别的理解上仍有困难,特别是在视频动态和细节查询方面。为解决这些问题,我们发现通过自我监督片段任务对Video-LLM进行微调,能显著提高其对视频的精细理解能力。因此,我们提出两个关键贡献:
一、自我监督片段微调(SF^2T)是一种新型的无费力微调方法,它利用视频丰富的内在特性进行训练,同时解锁Video-LLM的精细理解能力。此外,它减轻了研究者对劳动密集标注的依赖,并巧妙地克服了自然语言在捕捉视频的复杂时空变化方面的局限性。二、为了严格评估Video-LLM在场景和片段级别的性能,我们提出了一个名为FineVidBench的新型基准数据集,全面评估其能力。我们对多个模型进行了评估,验证了SF^2T的有效性。实验结果表明,我们的方法提高了捕捉和解释时空细节的能力。
关键要点
- 视频大型语言模型(Video-LLM)在多模态LLM的推动下取得了进展,但仍面临精细理解挑战。
- 自我监督片段微调(SF^2T)方法旨在提高Video-LLM的精细理解能力,利用视频的内在特性进行训练。
- SF^2T方法减轻了对繁重标注的依赖,并解决了自然语言在描述视频复杂时空变化方面的不足。
- 提出了一种新型基准数据集FineVidBench,用于评估Video-LLM在场景和片段级别的性能。
点此查看论文截图