⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-12 更新
GIGA: Generalizable Sparse Image-driven Gaussian Avatars
Authors:Anton Zubekhin, Heming Zhu, Paulo Gotardo, Thabo Beeler, Marc Habermann, Christian Theobalt
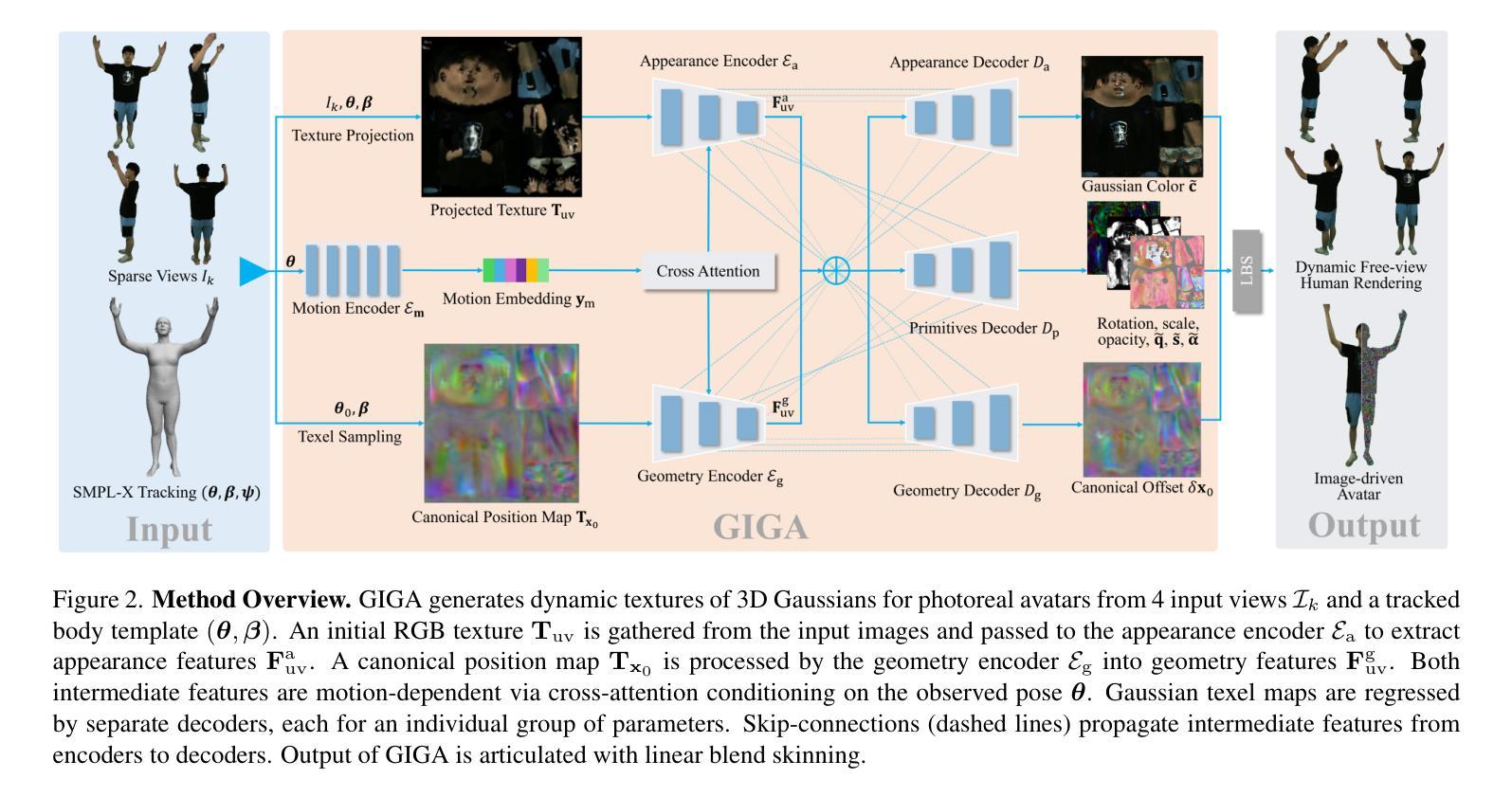
Driving a high-quality and photorealistic full-body human avatar, from only a few RGB cameras, is a challenging problem that has become increasingly relevant with emerging virtual reality technologies. To democratize such technology, a promising solution may be a generalizable method that takes sparse multi-view images of an unseen person and then generates photoreal free-view renderings of such identity. However, the current state of the art is not scalable to very large datasets and, thus, lacks in diversity and photorealism. To address this problem, we propose a novel, generalizable full-body model for rendering photoreal humans in free viewpoint, as driven by sparse multi-view video. For the first time in literature, our model can scale up training to thousands of subjects while maintaining high photorealism. At the core, we introduce a MultiHeadUNet architecture, which takes sparse multi-view images in texture space as input and predicts Gaussian primitives represented as 2D texels on top of a human body mesh. Importantly, we represent sparse-view image information, body shape, and the Gaussian parameters in 2D so that we can design a deep and scalable architecture entirely based on 2D convolutions and attention mechanisms. At test time, our method synthesizes an articulated 3D Gaussian-based avatar from as few as four input views and a tracked body template for unseen identities. Our method excels over prior works by a significant margin in terms of cross-subject generalization capability as well as photorealism.
从少数RGB摄像头驱动高质量、逼真的全身人类化身是一个具有挑战性的技术问题,随着新兴的虚拟现实技术的出现,这个问题变得越来越重要。为了普及此类技术,一个可行的解决方案可能是采用一种通用方法,该方法可以对未见过的稀疏多视角图像进行捕捉,然后生成此类身份的逼真自由视角渲染图像。然而,目前的技术并不适用于大规模数据集,因此缺乏多样性和逼真度。为了解决这一问题,我们提出了一种新型的通用全身模型,用于在自由视角渲染逼真的人类形象,该模型由稀疏多视角视频驱动。我们的模型能在文献中首次实现成百上千的大规模数据集训练的同时保持高度逼真度。在核心设计上,我们引入了MultiHeadUNet架构,它以稀疏多视角纹理空间图像作为输入,预测人体网格上的二维纹理坐标表示的高斯基本元素。重要的是,我们将稀疏视角图像信息、身体形态和高斯参数以二维形式呈现,以便我们能够设计一个完全基于二维卷积和注意力机制的深度可伸缩架构。在测试阶段,我们的方法能够从最多四个视角和跟踪的身体模板中合成一个基于高斯分布的关节型三维化身,适用于未见过的身份。我们的方法在跨主体泛化能力和逼真度方面都大大超过了以前的工作。
论文及项目相关链接
PDF 14 pages, 10 figures, project page: https://vcai.mpi-inf.mpg.de/projects/GIGA
Summary
本文介绍了利用稀疏多视角视频驱动渲染高质量、逼真的全身人物模型的挑战及最新进展。为解决当前技术不可扩展至大规模数据集的问题,提出了全新的可推广全身模型,可在少量视角输入下生成逼真的自由视角渲染。核心在于引入MultiHeadUNet架构,以稀疏多视角图像为输入,预测基于高斯原始数据的二维texels人体网格。该方法通过深度卷积和注意力机制完全基于二维设计,具有强大的跨主体推广能力和逼真性。
Key Takeaways
- 利用稀疏多视角视频实现高质量、逼真的全身人物模型渲染是当前的挑战。
- 现有技术无法很好地扩展到大规模数据集,缺乏多样性和逼真度。
- 提出了一种全新的可推广的全身模型,能够在少量视角输入下生成自由视角的逼真渲染。
- 核心在于引入MultiHeadUNet架构,该架构结合了稀疏多视角图像、身体形状和二维高斯参数预测。
- 该方法完全基于二维深度卷积和注意力机制设计。
- 方法在跨主体推广能力和逼真性方面显著优于以前的工作。
点此查看论文截图



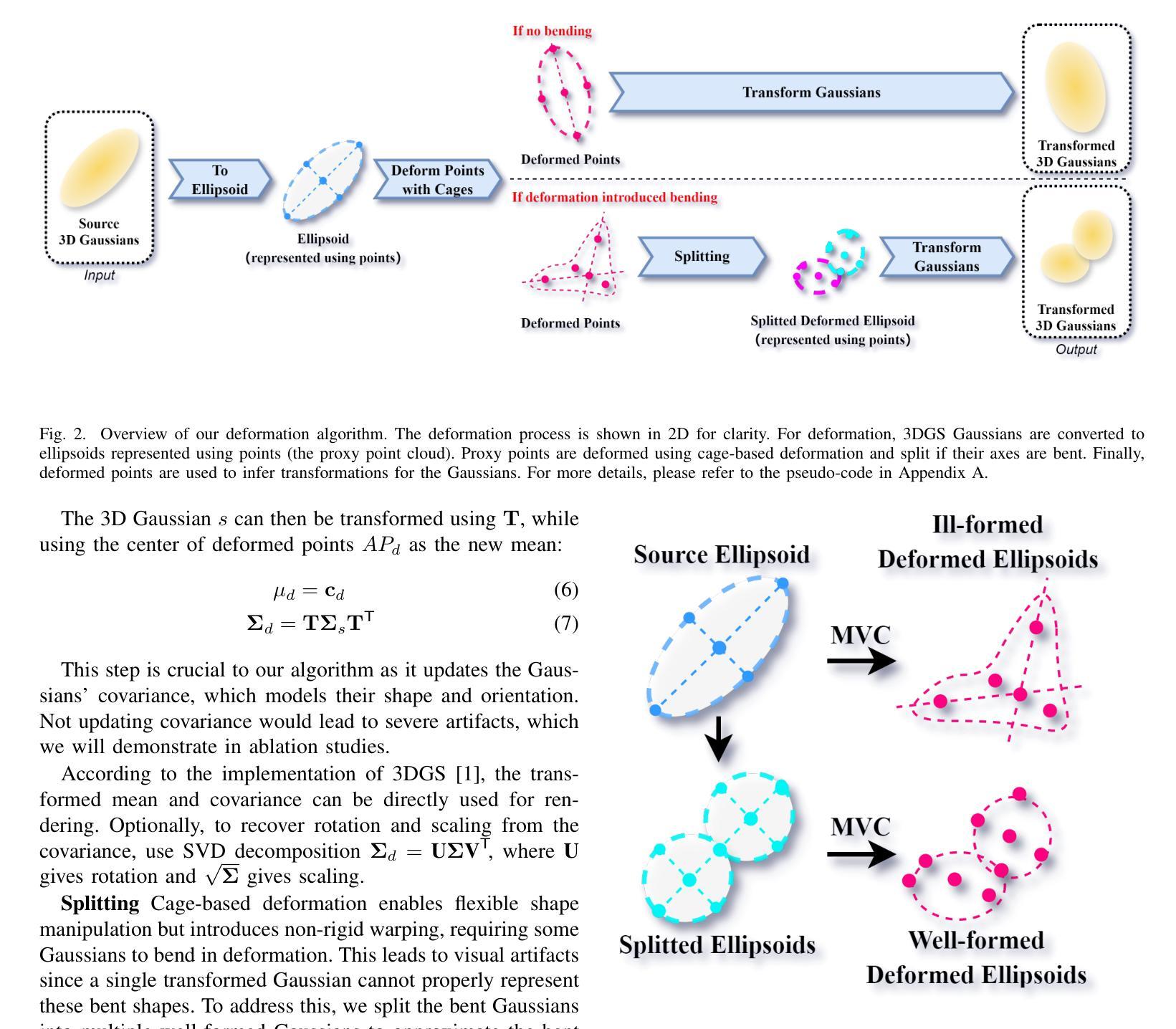
GSDeformer: Direct, Real-time and Extensible Cage-based Deformation for 3D Gaussian Splatting
Authors:Jiajun Huang, Shuolin Xu, Hongchuan Yu, Tong-Yee Lee
We present GSDeformer, a method that enables cage-based deformation on 3D Gaussian Splatting (3DGS). Our approach bridges cage-based deformation and 3DGS by using a proxy point-cloud representation. This point cloud is generated from 3D Gaussians, and deformations applied to the point cloud are translated into transformations on the 3D Gaussians. To handle potential bending caused by deformation, we incorporate a splitting process to approximate it. Our method does not modify or extend the core architecture of 3D Gaussian Splatting, making it compatible with any trained vanilla 3DGS or its variants. Additionally, we automate cage construction for 3DGS and its variants using a render-and-reconstruct approach. Experiments demonstrate that GSDeformer delivers superior deformation results compared to existing methods, is robust under extreme deformations, requires no retraining for editing, runs in real-time, and can be extended to other 3DGS variants. Project Page: https://jhuangbu.github.io/gsdeformer/
我们提出了GSDeformer方法,它实现了基于笼子的变形应用于三维高斯采样(3DGS)。我们的方法通过代理点云表示将基于笼子的变形与三维高斯采样连接起来。该点云由三维高斯生成,对点云的变形转化为对三维高斯上的变换。为了处理变形可能引起的弯曲,我们引入了一个分裂过程来近似处理。我们的方法不会修改或扩展三维高斯采样的核心架构,使其与任何训练过的普通三维高斯采样或其变种兼容。此外,我们使用渲染和重建的方法自动构建三维高斯采样及其变体的笼子。实验表明,GSDeformer相比现有方法提供了更出色的变形效果,在极端变形下表现稳健,无需重新训练即可进行编辑,可实时运行,并且可以扩展到其他三维高斯采样变体。项目页面:https://jhuangbu.github.io/gsdeformer/
论文及项目相关链接
PDF Project Page: https://jhuangbu.github.io/gsdeformer, Video: https://www.youtube.com/watch?v=-ecrj48-MqM
Summary
我们提出了GSDeformer方法,它实现了基于笼子的变形应用于三维高斯扩展(3DGS)。该方法通过代理点云表示将基于笼子的变形与3DGS相结合。点云由三维高斯生成,对点云的变形转化为对三维高斯的变化。为了处理变形可能引起的弯曲,我们采用了分裂过程进行近似处理。该方法不修改或扩展3D高斯扩展的核心架构,使其兼容任何训练的普通3DGS或其变体。此外,我们还采用渲染和重建的方法自动构建适用于3DGS及其变体的笼子。实验表明,GSDeformer相比现有方法能提供更优越的变形效果,极端变形下也能保持稳定,编辑时无需重新训练,能实时运行,并可扩展到其他三维GS变种。
Key Takeaways
- GSDeformer实现了基于笼子的变形在三维高斯扩展(3DGS)上的应用。
- 通过代理点云表示结合了基于笼子的变形与三维高斯扩展。
- 点云由三维高斯生成,变形转换为对三维高斯的变化。
- 采用分裂过程处理变形可能引起的弯曲。
- 不修改或扩展核心架构,保持与任何训练的普通三维高斯扩展或其变体兼容。
- 自动构建适用于三维高斯扩展及其变体的笼子,采用渲染和重建的方法。
点此查看论文截图