⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-12 更新
Synthesizing High-Quality Programming Tasks with LLM-based Expert and Student Agents
Authors:Manh Hung Nguyen, Victor-Alexandru Pădurean, Alkis Gotovos, Sebastian Tschiatschek, Adish Singla
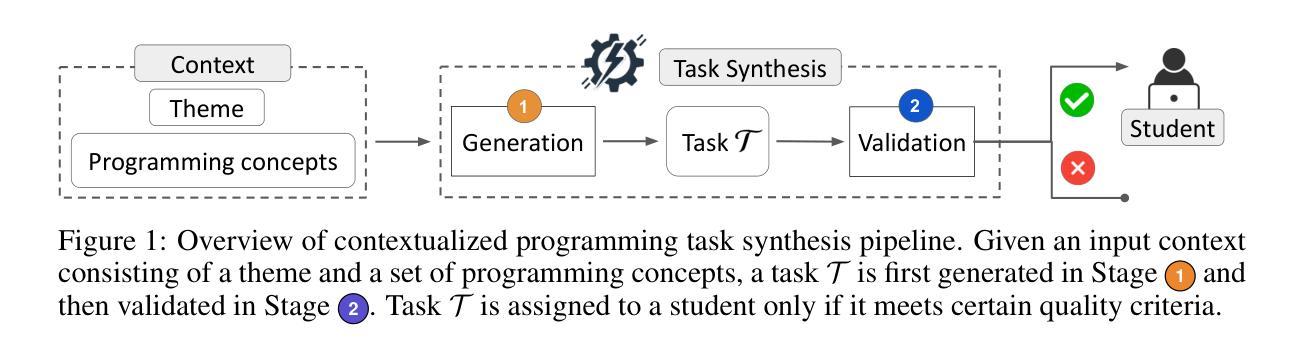
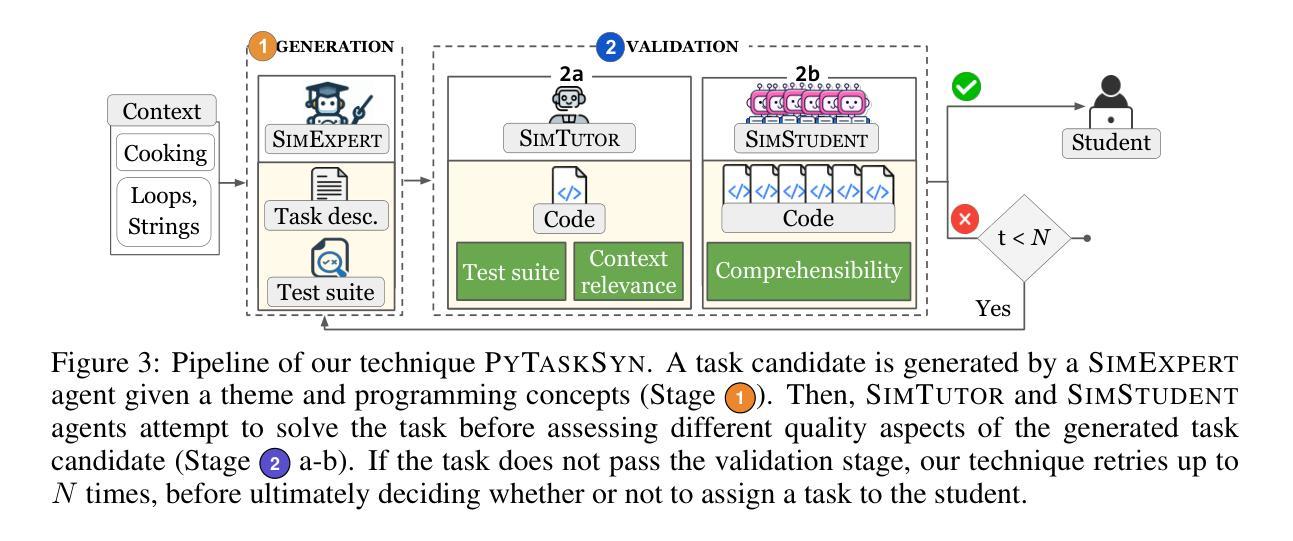
Generative AI is transforming computing education by enabling the automatic generation of personalized content and feedback. We investigate its capabilities in providing high-quality programming tasks to students. Despite promising advancements in task generation, a quality gap remains between AI-generated and expert-created tasks. The AI-generated tasks may not align with target programming concepts, could be incomprehensible for students to solve, or may contain critical issues such as incorrect tests. Existing works often require interventions from human teachers for validation. We address these challenges by introducing PyTaskSyn, a novel synthesis technique that first generates a programming task and then decides whether it meets certain quality criteria to be given to students. The key idea is to break this process into multiple stages performed by expert and student agents simulated using both strong and weaker generative models. Through extensive evaluation, we show that PyTaskSyn significantly improves task quality compared to baseline techniques and showcases the importance of each specialized agent type in our validation pipeline. Additionally, we conducted user studies using our publicly available web application and show that PyTaskSyn can deliver high-quality programming tasks comparable to expert-designed ones while reducing workload and costs, and being more engaging than programming tasks that are available in online resources.
生成式人工智能(AI)能够通过自动创建个性化内容和反馈来变革计算机教育。我们研究了其在为学生提供高质量编程任务方面的能力。尽管任务生成方面取得了令人瞩目的进展,但人工智能生成的任务与专家创建的任务之间仍存在质量差距。人工智能生成的任务可能不符合目标编程概念,学生可能无法解决,或者包含如测试错误等关键问题。现有工作往往需要人类教师的参与来进行验证。我们通过引入PyTaskSyn来解决这些挑战,这是一种新型合成技术,首先生成编程任务,然后决定是否满足向学生布置的质量标准。关键思想是将这个过程分解成多个阶段,由使用强和弱生成模型的专家和学生代理模拟执行。通过广泛评估,我们证明PyTaskSyn相比基线技术在任务质量上有显著提高,并展示了验证流程中每种专业代理类型的重要性。此外,我们使用公开可用的网络应用程序进行了用户研究,证明PyTaskSyn能够提供与专家设计相当的高质量编程任务,同时减少工作量和成本,并且比在线资源中可用的编程任务更具吸引力。
论文及项目相关链接
PDF AIED’25 paper
Summary
生成式人工智能正在通过实现个性化内容和反馈的自动生成,改变计算教育的面貌。本研究探讨了其在为学生提供高质量编程任务方面的能力。尽管任务生成方面取得了令人瞩目的进展,但人工智能生成的任务与专家创建的任务之间仍存在质量差距。人工智能生成的任务可能不符合目标编程概念,可能让学生难以解决,或者包含关键问题,如测试不正确。现有工作通常需要人工教师验证。本研究通过引入PyTaskSyn这一新颖的合成技术来解决这些挑战。PyTaskSyn首先生成一个编程任务,然后决定是否满足给予学生的一定质量标准。其关键思想是将这个过程分解为多个阶段,由使用强和弱生成模型的专家和学生代理人执行模拟。通过广泛评估,我们证明了PyTaskSyn在任务质量方面相较于基础技术有了显著提高,并展示了验证管道中每种专业代理人类型的重要性。此外,我们还通过公开网络应用程序进行了用户研究,表明PyTaskSyn可以生成与专家设计相当的高质量编程任务,同时降低工作量和成本,并且相较于在线资源中的编程任务更加引人入胜。
Key Takeaways
- 生成式AI正在改变计算教育,能自动生成个性化内容和反馈。
- 在为学生提供编程任务方面,AI生成的任务与专家创建的任务之间存在质量差距。
- PyTaskSyn是一种新的合成技术,旨在解决AI生成任务的质量问题。
- PyTaskSyn通过多个阶段的任务验证流程来提高任务质量,涉及专家和学生代理人的模拟。
- PyTaskSyn显著提高了任务质量,并展示了验证流程中各种代理人的重要性。
- 用户研究表明,PyTaskSyn可以生成与专家设计相当的高质量编程任务,并降低了工作量和成本。
点此查看论文截图



CollEX – A Multimodal Agentic RAG System Enabling Interactive Exploration of Scientific Collections
Authors:Florian Schneider, Narges Baba Ahmadi, Niloufar Baba Ahmadi, Iris Vogel, Martin Semmann, Chris Biemann
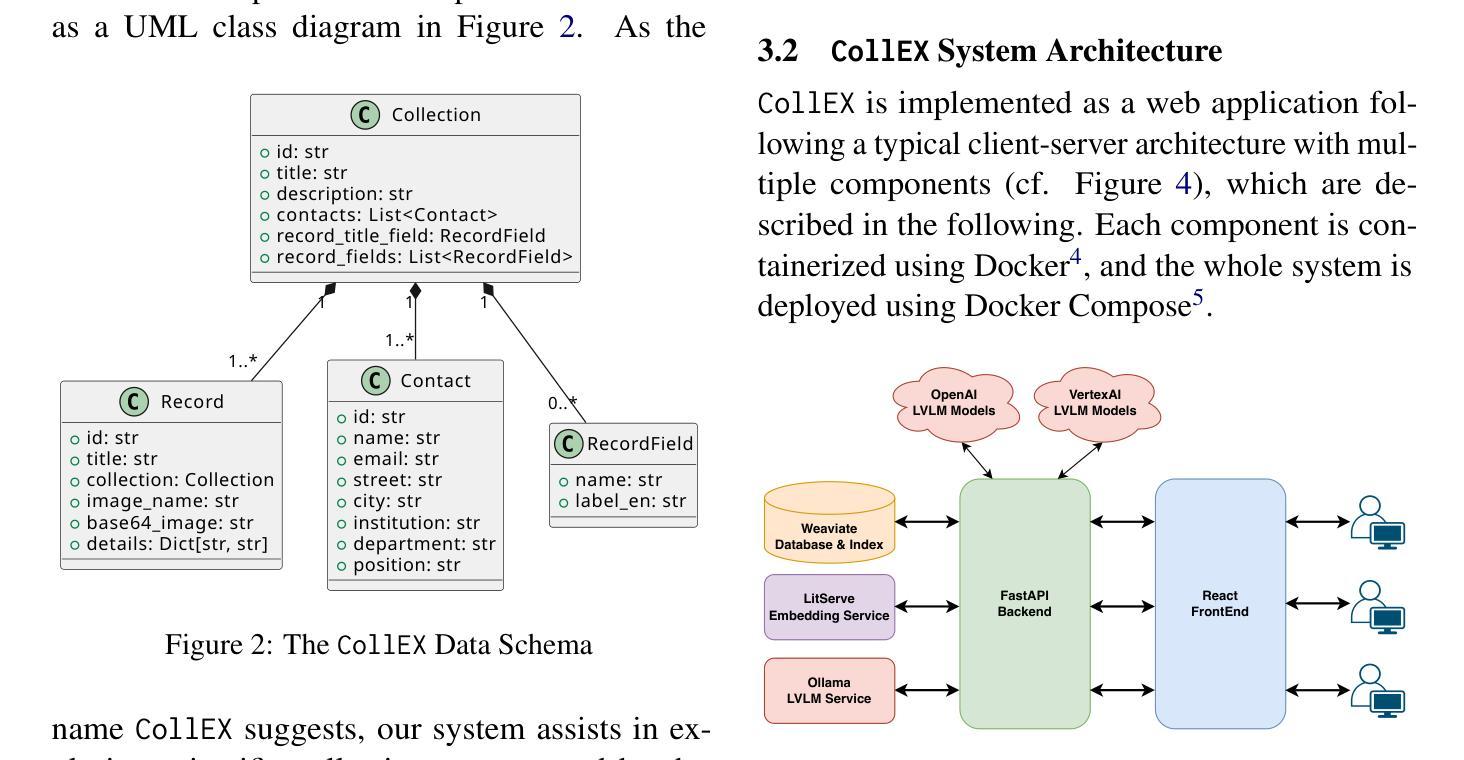
In this paper, we introduce CollEx, an innovative multimodal agentic Retrieval-Augmented Generation (RAG) system designed to enhance interactive exploration of extensive scientific collections. Given the overwhelming volume and inherent complexity of scientific collections, conventional search systems often lack necessary intuitiveness and interactivity, presenting substantial barriers for learners, educators, and researchers. CollEx addresses these limitations by employing state-of-the-art Large Vision-Language Models (LVLMs) as multimodal agents accessible through an intuitive chat interface. By abstracting complex interactions via specialized agents equipped with advanced tools, CollEx facilitates curiosity-driven exploration, significantly simplifying access to diverse scientific collections and records therein. Our system integrates textual and visual modalities, supporting educational scenarios that are helpful for teachers, pupils, students, and researchers by fostering independent exploration as well as scientific excitement and curiosity. Furthermore, CollEx serves the research community by discovering interdisciplinary connections and complementing visual data. We illustrate the effectiveness of our system through a proof-of-concept application containing over 64,000 unique records across 32 collections from a local scientific collection from a public university.
本文介绍了CollEx,这是一个创新的多模态代理检索增强生成(RAG)系统,旨在增强对广泛科学集合的交互探索。考虑到科学收藏品的巨大数量和固有复杂性,传统的搜索系统往往缺乏必要的直观性和交互性,为学习者、教育者和研究者带来了重大障碍。CollEx通过采用最先进的大型视觉语言模型(LVLMs)作为可通过直观聊天界面访问的多模式代理,解决了这些问题。通过配备先进工具的专门代理抽象复杂的交互,CollEx促进了以好奇心驱动的探索,显著简化了访问各种科学收藏品及其记录的过程。我们的系统结合了文本和视觉模式,支持教育场景,通过促进独立探索以及激发科学热情和好奇心,对教师、学生和研究人员有所帮助。此外,CollEx通过发现跨学科联系和补充视觉数据为科研共同体服务。我们通过包含超过64000条唯一记录的来自公立大学的地方科学收藏的32个集合的概念验证应用程序来展示我们系统的有效性。
论文及项目相关链接
Summary
科学收藏品浩如烟海且复杂,传统搜索系统难以应对。本文介绍的CollEx系统,通过先进的视觉语言模型和多模态代理技术,增强了科学收藏品的交互式探索体验。CollEx提供简洁的访问方式,激发探索欲望,适用于教育者、学习者及研究者等不同用户群体。系统还支持跨学科研究,可辅助可视化数据探索。
Key Takeaways
- CollEx是一个增强交互式探索的大规模科学收藏品的RAG系统。
- 传统搜索系统对于科学收藏品的庞大和复杂性常常力不从心,而CollEx通过先进的LVLMs技术解决了这一问题。
- CollEx系统通过多模态代理技术,提供一个简洁的访问方式以激发探索欲望,特别适用于教育者、学习者及研究者。
- CollEx系统支持跨学科研究,能够辅助可视化数据探索。
- CollEx系统通过先进的聊天接口实现了高级工具与代理的结合,这一功能强化了复杂交互的抽象性。
- 该系统融合了文本和视觉模式,促进了独立探索并激发了科学兴趣和好奇心。
点此查看论文截图




Agent That Debugs: Dynamic State-Guided Vulnerability Repair
Authors:Zhengyao Liu, Yunlong Ma, Jingxuan Xu, Junchen Ai, Xiang Gao, Hailong Sun, Abhik Roychoudhury
In recent years, more vulnerabilities have been discovered every day, while manual vulnerability repair requires specialized knowledge and is time-consuming. As a result, many detected or even published vulnerabilities remain unpatched, thereby increasing the exposure of software systems to attacks. Recent advancements in agents based on Large Language Models have demonstrated their increasing capabilities in code understanding and generation, which can be promising to achieve automated vulnerability repair. However, the effectiveness of agents based on static information retrieval is still not sufficient for patch generation. To address the challenge, we propose a program repair agent called VulDebugger that fully utilizes both static and dynamic context, and it debugs programs in a manner akin to humans. The agent inspects the actual state of the program via the debugger and infers expected states via constraints that need to be satisfied. By continuously comparing the actual state with the expected state, it deeply understands the root causes of the vulnerabilities and ultimately accomplishes repairs. We experimentally evaluated VulDebugger on 50 real-life projects. With 60.00% successfully fixed, VulDebugger significantly outperforms state-of-the-art approaches for vulnerability repair.
近年来,每天都有更多的漏洞被发现,而手动修复漏洞需要专业知识且耗时。因此,许多检测到的甚至已公布的漏洞仍然没有得到修复,从而增加了软件系统遭受攻击的风险。基于大型语言模型的代理人的最新进展,在代码理解和生成方面展示了其日益增强的能力,有望实现自动化漏洞修复。然而,基于静态信息检索的代理人在补丁生成方面的效果仍然不足。为了应对这一挑战,我们提出了一种名为VulDebugger的程序修复代理人,它充分利用了静态和动态上下文,并以人类的方式调试程序。该代理人通过调试器检查程序的实际状态,并通过必须满足的约束来推断预期状态。通过不断比较实际状态和预期状态,它深入了解漏洞的根本原因,并最终完成修复。我们在50个真实项目上对VulDebugger进行了实验评估。VulDebugger成功修复了60.00%的漏洞,在漏洞修复方面显著优于最新方法。
论文及项目相关链接
Summary:近年来,每日发现更多漏洞,手动修复漏洞需要专业知识且耗时。因此,许多检测甚至发布的漏洞仍未经修补,增加了软件系统遭受攻击的风险。基于大型语言模型的代理的最新进展在代码理解和生成方面表现出越来越强的能力,有望实现对漏洞的自动化修复。然而,仅依赖静态信息检索的代理在补丁生成方面的效果仍然不足。为应对这一挑战,我们提出了一种名为VulDebugger的程序修复代理,它充分利用静态和动态上下文,以人类方式调试程序。该代理通过调试器检查程序的实际状态,并通过必须满足的约束来推断预期状态。通过不断比较实际状态和预期状态,它深刻理解漏洞的根本原因,并最终完成修复。我们在50个真实项目上对VulDebugger进行了实验评估。在成功修复率达到60.00%的情况下,VulDebugger在漏洞修复方面显著优于现有方法。
Key Takeaways:
- 每日发现更多漏洞,但手动修复需要专业知识和时间,导致许多漏洞未得到修补。
- 基于大型语言模型的代理在代码理解和生成方面表现出潜力,有望自动化修复漏洞。
- 仅依赖静态信息检索的代理在补丁生成方面的效果有限。
- 提出了一种名为VulDebugger的程序修复代理,结合静态和动态上下文进行调试。
- VulDebugger通过检查程序的实际状态和推断预期状态来理解漏洞的根本原因。
- VulDebugger在50个真实项目上的实验评估显示,其成功修复率达到60.00%。
点此查看论文截图


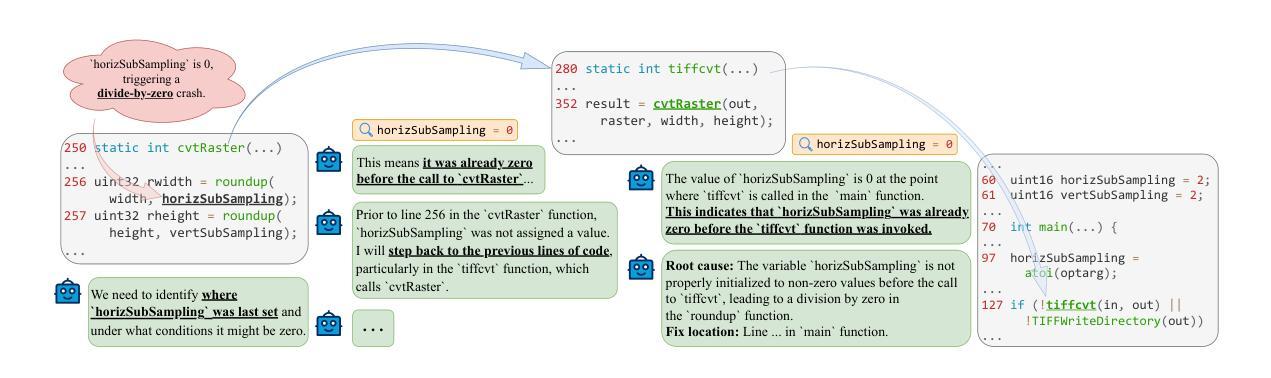
Agentic SLMs: Hunting Down Test Smells
Authors:Rian Melo, Pedro Simões, Rohit Gheyi, Marcelo d’Amorim, Márcio Ribeiro, Gustavo Soares, Eduardo Almeida, Elvys Soares
Test smells can compromise the reliability of test suites and hinder software maintenance. Although several strategies exist for detecting test smells, few address their removal. Traditional methods often rely on static analysis or machine learning, requiring significant effort and expertise. This study evaluates LLAMA 3.2 3B, GEMMA 2 9B, DEEPSEEK-R1 14B, and PHI 4 14B - small, open language models - for automating the detection and refactoring of test smells through agent-based workflows. We explore workflows with one, two, and four agents across 150 instances of 5 common test smell types extracted from real-world Java projects. Unlike prior approaches, ours is easily extensible to new smells via natural language definitions and generalizes to Python and Golang. All models detected nearly all test smell instances (pass@5 of 96% with four agents), with PHI 4 14B achieving the highest refactoring accuracy (pass@5 of 75.3%). Analyses were computationally inexpensive and ran efficiently on a consumer-grade hardware. Notably, PHI 4 14B with four agents performed within 5% of proprietary models such as O1-MINI, O3-MINI-HIGH, and GEMINI 2.5 PRO EXPERIMENTAL using a single agent. Multi-agent setups outperformed single-agent ones in three out of five test smell types, highlighting their potential to improve software quality with minimal developer effort. For the Assertion Roulette smell, however, a single agent performed better. To assess practical relevance, we submitted 10 pull requests with PHI 4 14B - generated code to open-source projects. Five were merged, one was rejected, and four remain under review, demonstrating the approach’s real-world applicability.
测试用例的异味可能会损害测试套的可靠性,并阻碍软件维护。尽管存在多种检测测试异味的方法,但很少有方法关注其移除。传统方法通常依赖于静态分析或机器学习,需要耗费大量精力和专业知识。本研究评估了LLAMA 3.2 3B、GEMMA 2 9B、DEEPSEEK-R1 14B和PHI 4 14B这四个小型、开源语言模型,通过基于代理的工作流自动检测和重构测试异味。我们探索了一个、两个和四个代理在来自现实世界Java项目的5种常见测试异味类型的150个实例中的工作流程。与以前的方法不同,我们的方法可以通过自然语言定义轻松扩展至新的异味,并且可以推广到Python和Golang。所有模型几乎检测到了所有的测试异味实例(四个代理的pass@5为96%),PHI 4 14B达到了最高的重构精度(pass@5为75.3%)。分析计算成本低,能在消费者级硬件上高效运行。值得注意的是,PHI 4 14B与四个代理的性能在单一代理的情况下与使用专有模型(如O1-MINI、O3-MINI-HIGH和GEMINI 2.5 PRO EXPERIMENTAL)的情况相比在5%以内。在多代理设置下,有五种异味类型中的三种表现优于单代理设置,突显了它们通过最小开发者努力提高软件质量的潜力。然而,对于断言轮盘赌(Assertion Roulette)这种气味而言,单一代理表现得更好。为了评估实际相关性,我们使用PHI 4 14B生成的代码提交了十个拉取请求到开源项目。其中五个被合并,一个被拒绝,四个仍在审查中,这证明了该方法的实际适用性。
论文及项目相关链接
Summary
研究探讨了测试用例中测试异味的问题及其对软件可靠性和维护的影响。为自动化检测并移除这些测试异味,该研究评估了LLAMA 3.2 3B、GEMMA 2 9B、DEEPSEEK-R1 14B以及PHI 4 14B等小型开源语言模型,通过基于代理的工作流实现其自动化。研究发现,这些模型能高效地检测出几乎所有的测试异味实例,并通过多代理设置提高了软件质量。其中PHI 4 14B在重构准确性方面表现最佳。此外,该研究还将结果与实际硬件上专业模型的表现进行了比较,验证了其方法的实用性和高效性。最后,通过实际应用于开源项目验证了其实际应用潜力。此研究的结论为多代理工作流提高了软件测试的质量与效率,具备较好的实用价值。
Key Takeaways
- 测试异味会降低测试套件的可靠性并阻碍软件维护。
- 传统方法检测测试异味需要显著的努力和专业知识。
- 研究使用小型开源语言模型自动化检测并移除测试异味,这是通过基于代理的工作流实现的。
- 多代理设置在三种测试异味类型中的表现优于单代理设置。
点此查看论文截图



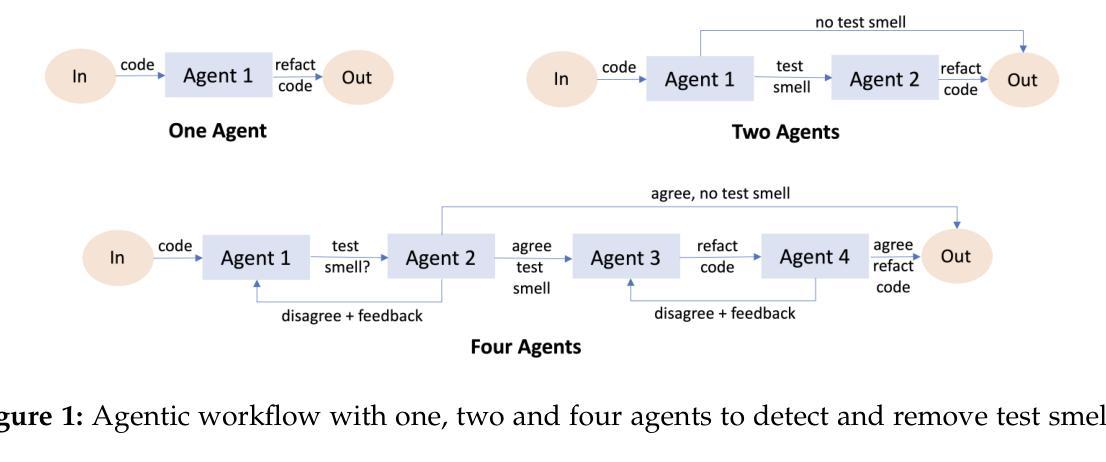

R2E-Gym: Procedural Environments and Hybrid Verifiers for Scaling Open-Weights SWE Agents
Authors:Naman Jain, Jaskirat Singh, Manish Shetty, Liang Zheng, Koushik Sen, Ion Stoica
Improving open-source models on real-world SWE tasks (solving GITHUB issues) faces two key challenges: 1) scalable curation of execution environments to train these models, and, 2) optimal scaling of test-time compute. We introduce AgentGym, the largest procedurally-curated executable gym environment for training real-world SWE-agents, consisting of more than 8.7K tasks. AgentGym is powered by two main contributions: 1) SYNGEN: a synthetic data curation recipe that enables scalable curation of executable environments using test-generation and back-translation directly from commits, thereby reducing reliance on human-written issues or unit tests. We show that this enables more scalable training leading to pass@1 performance of 34.4% on SWE-Bench Verified benchmark with our 32B model. 2) Hybrid Test-time Scaling: we provide an in-depth analysis of two test-time scaling axes; execution-based and execution-free verifiers, demonstrating that they exhibit complementary strengths and limitations. Test-based verifiers suffer from low distinguishability, while execution-free verifiers are biased and often rely on stylistic features. Surprisingly, we find that while each approach individually saturates around 42-43%, significantly higher gains can be obtained by leveraging their complementary strengths. Overall, our approach achieves 51% on the SWE-Bench Verified benchmark, reflecting a new state-of-the-art for open-weight SWE-agents and for the first time showing competitive performance with proprietary models such as o1, o1-preview and sonnet-3.5-v2 (with tools). We will open-source our environments, models, and agent trajectories.
在真实世界的软件工程师(SWE)任务(解决GITHUB问题)上改进开源模型面临两大挑战:1)可扩展的执行环境训练模型,以及2)测试时间的计算最优扩展。我们推出了AgentGym,这是一个用于训练现实世界SWE代理的最大程序性管理的可执行Gym环境,包含超过8.7K个任务。AgentGym由两个主要贡献所支持:1)SYNGEN:一种合成数据整理配方,它可以通过测试生成和直接从提交进行反向翻译,从而实现可扩展的执行环境整理,从而减少对人工编写的问题或单元测试的依赖。我们证明这可以实现更可扩展的训练,使用我们的32B模型在SWE-Bench验证基准测试上达到34.4%的pass@1性能。2)混合测试时间扩展:我们对两个测试时间扩展轴进行了深入分析,即基于执行的验证器和无执行验证器,表明它们具有互补的优势和局限性。基于测试的验证器区分度较低,而无执行验证器存在偏见且经常依赖于风格特征。令人惊讶的是,我们发现虽然每种方法单独使用时大约在42-43%达到饱和,但通过利用其互补优势可以获得更高的收益。总体而言,我们的方法在SWE-Bench验证基准测试上达到了51%,这反映了开源权重SWE代理的最新水平,并且首次显示出与专有模型(如o1、o1-preview和sonnet-3.5-v2(附带工具))相竞争的性能。我们将开源我们的环境、模型和代理轨迹。
论文及项目相关链接
PDF Website: https://r2e-gym.github.io/
Summary
基于开源模型在解决真实软件开发环境(Software Development Environment,简称SWE)任务上面临的两大挑战,研究团队构建了AgentGym训练环境来解决这两个问题。训练环境利用合成数据集成与可测试可执行的自动后端技术(SYNGEN),以实现可执行环境的可规模化搜集和整合,减少了依赖人工编写的代码问题或单元测试的需求。同时,研究团队还深入探讨了测试时间缩放的两个维度,执行型验证器和非执行型验证器,展示了二者各自的优势和局限性。最终通过整合两种方法的优势,在SWE验证基准测试中取得了51%的准确率,超越了一些开源模型的性能,展示了强大的实用性。研究团队还将开源他们的环境、模型和代理轨迹。
Key Takeaways
- AgentGym训练环境旨在解决在真实软件开发环境任务上改进开源模型所遇到的两个关键挑战:可执行环境的规模化管理和测试时间计算的最优缩放。
- SYNGEN技术实现了合成数据的规模化搜集和整合,减少了依赖人工编写的代码问题或单元测试的需求。
- 执行型验证器和非执行型验证器的比较分析揭示二者的优势与局限,且二者的结合可以获得显著更高的性能增益。
点此查看论文截图

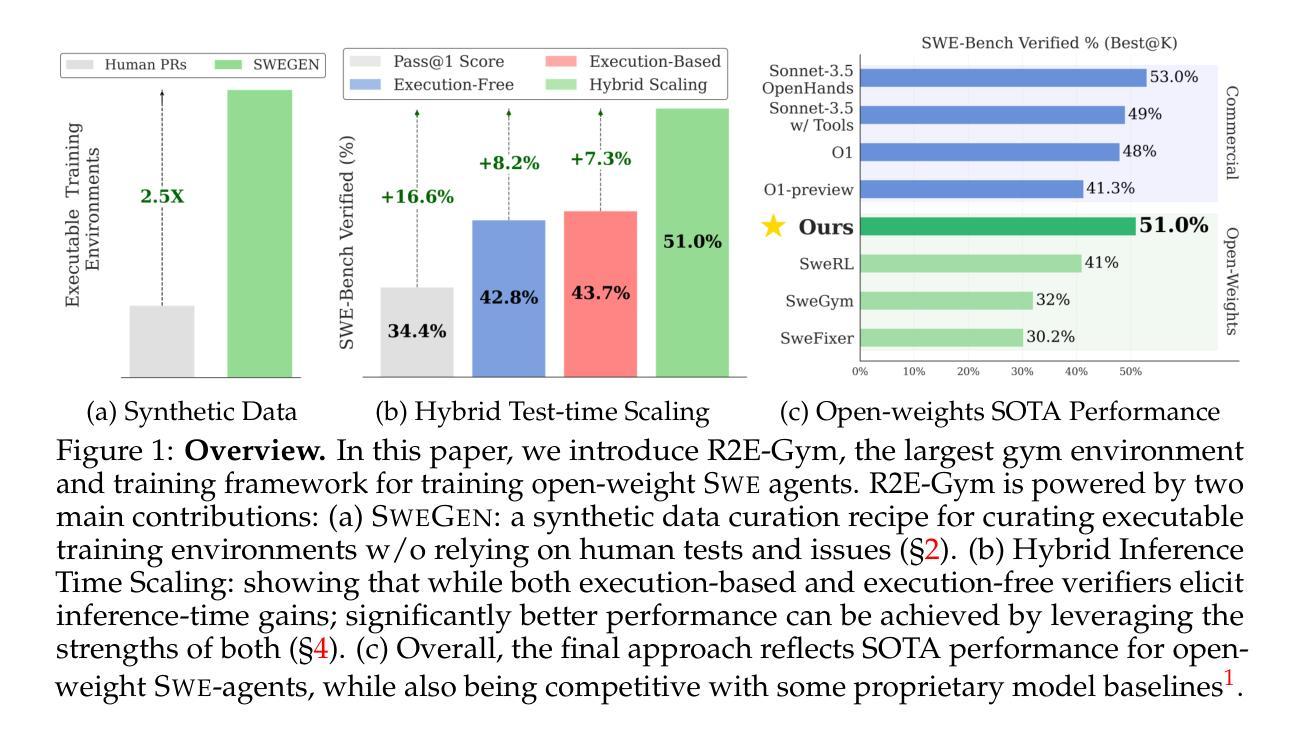
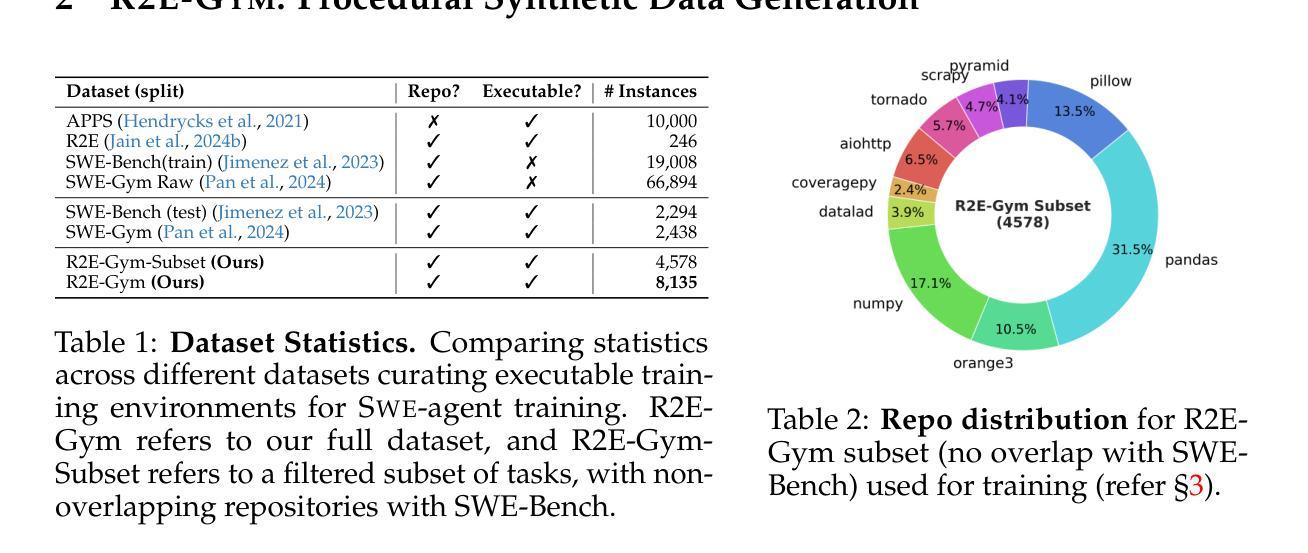
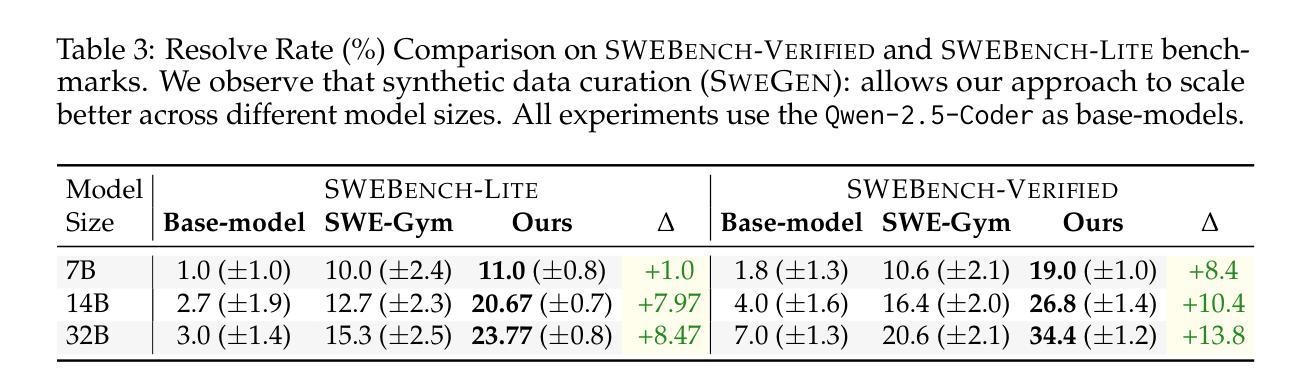
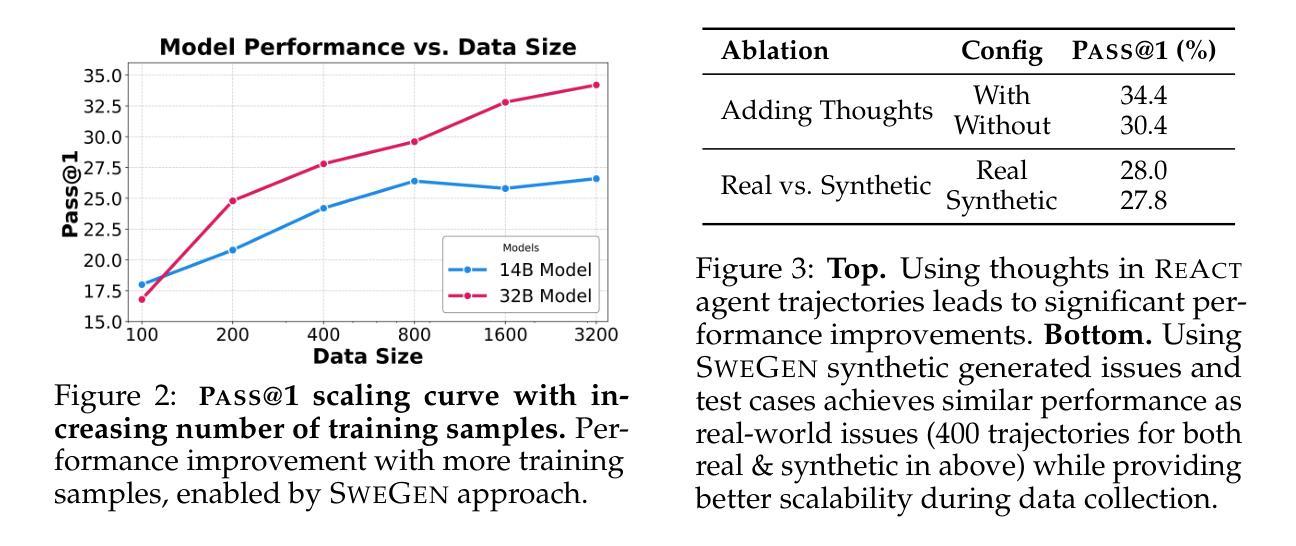
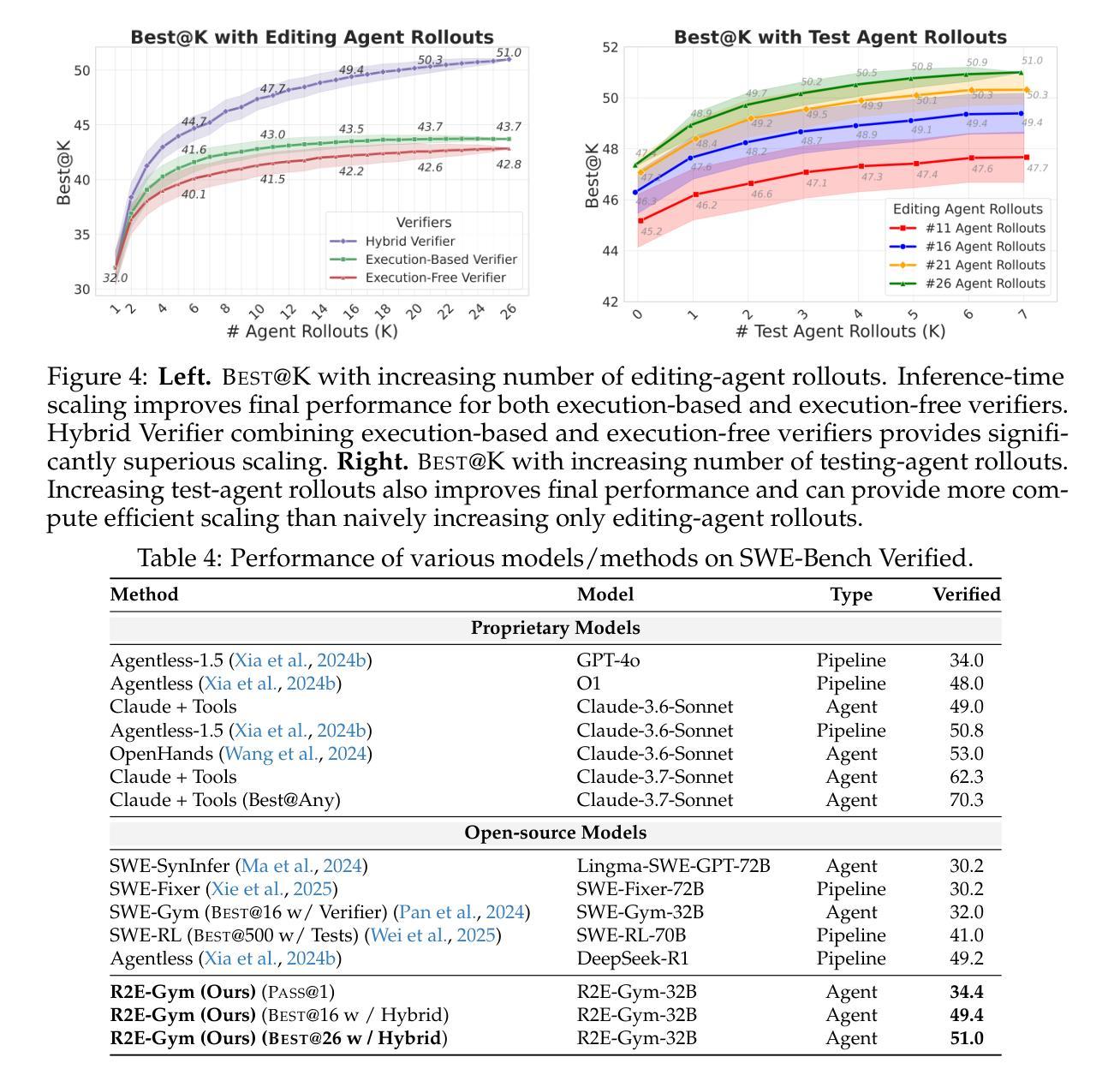
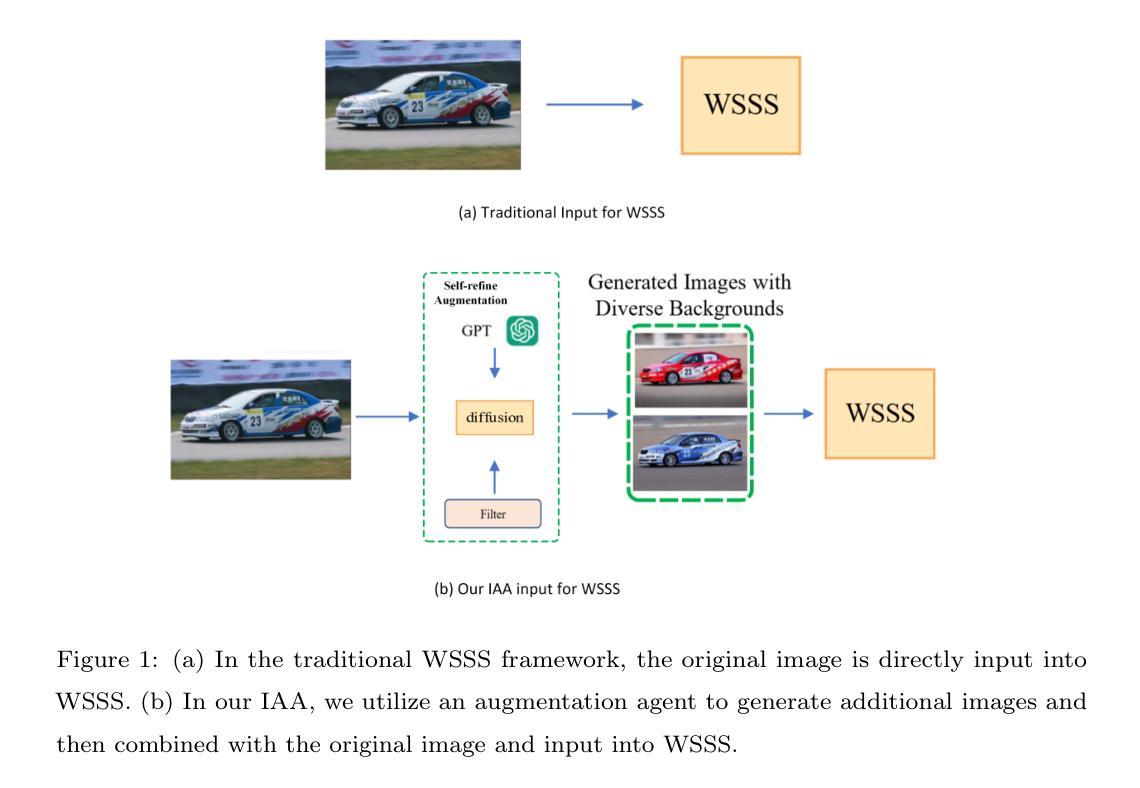
Image Augmentation Agent for Weakly Supervised Semantic Segmentation
Authors:Wangyu Wu, Xianglin Qiu, Siqi Song, Zhenhong Chen, Xiaowei Huang, Fei Ma, Jimin Xiao
Weakly-supervised semantic segmentation (WSSS) has achieved remarkable progress using only image-level labels. However, most existing WSSS methods focus on designing new network structures and loss functions to generate more accurate dense labels, overlooking the limitations imposed by fixed datasets, which can constrain performance improvements. We argue that more diverse trainable images provides WSSS richer information and help model understand more comprehensive semantic pattern. Therefore in this paper, we introduce a novel approach called Image Augmentation Agent (IAA) which shows that it is possible to enhance WSSS from data generation perspective. IAA mainly design an augmentation agent that leverages large language models (LLMs) and diffusion models to automatically generate additional images for WSSS. In practice, to address the instability in prompt generation by LLMs, we develop a prompt self-refinement mechanism. It allow LLMs to re-evaluate the rationality of generated prompts to produce more coherent prompts. Additionally, we insert an online filter into diffusion generation process to dynamically ensure the quality and balance of generated images. Experimental results show that our method significantly surpasses state-of-the-art WSSS approaches on the PASCAL VOC 2012 and MS COCO 2014 datasets.
弱监督语义分割(WSSS)仅使用图像级标签取得了显著的进步。然而,大多数现有的WSSS方法主要集中在设计新的网络结构和损失函数来生成更准确的密集标签,忽视了固定数据集带来的限制,这些限制可能会限制性能改进。我们认为,提供更多可训练图像可以为WSSS提供更丰富的信息,并帮助模型理解更全面的语义模式。因此,在本文中,我们引入了一种新方法,称为图像增强代理(IAA),它表明从数据生成的角度增强WSSS是可能的。IAA主要设计了一个增强代理,利用大型语言模型(LLM)和扩散模型自动为WSSS生成额外图像。在实践中,为了解决LLM生成提示的不稳定性,我们开发了一种提示自我优化机制。它允许LLM重新评估生成的提示的合理性,以产生更连贯的提示。此外,我们在扩散生成过程中插入了一个在线过滤器,以动态确保生成的图像的质量和平衡。实验结果表明,我们的方法在PASCAL VOC 2012和MS COCO 2014数据集上显著超越了最先进的WSSS方法。
论文及项目相关链接
Summary
弱监督语义分割(WSSS)仅使用图像级标签取得了显著进展。然而,大多数现有WSSS方法专注于设计新的网络结构和损失函数来生成更准确的密集标签,忽略了固定数据集带来的限制,这些限制可能阻碍性能提升。本文提出一种名为Image Augmentation Agent(IAA)的新方法,从数据生成的角度增强WSSS。IAA主要设计了一个利用大型语言模型(LLMs)和扩散模型自动生成额外图像的增强代理。为解决LLMs在提示生成中的不稳定问题,我们开发了一种提示自我完善机制,使LLMs能够重新评估生成提示的合理性,产生更连贯的提示。此外,我们在扩散生成过程中插入在线过滤器,以动态确保生成图像的质量和平衡。实验结果表明,我们的方法在PASCAL VOC 2012和MS COCO 2014数据集上显著超越了现有WSSS方法。
Key Takeaways
- WSSS已取得显著进展,但仍存在固定数据集的局限性,限制性能提升。
- 提出了一种名为IAA的新方法,从数据生成角度增强WSSS。
- IAA利用大型语言模型(LLMs)和扩散模型自动生成额外图像。
- 开发了一种提示自我完善机制,解决LLMs在提示生成中的不稳定问题。
- 在扩散生成过程中插入在线过滤器,确保生成图像的质量和平衡。
- 实验结果表明,IAA方法在PASCAL VOC 2012和MS COCO 2014数据集上表现优异。
点此查看论文截图

SigmaRL: A Sample-Efficient and Generalizable Multi-Agent Reinforcement Learning Framework for Motion Planning
Authors:Jianye Xu, Pan Hu, Bassam Alrifaee
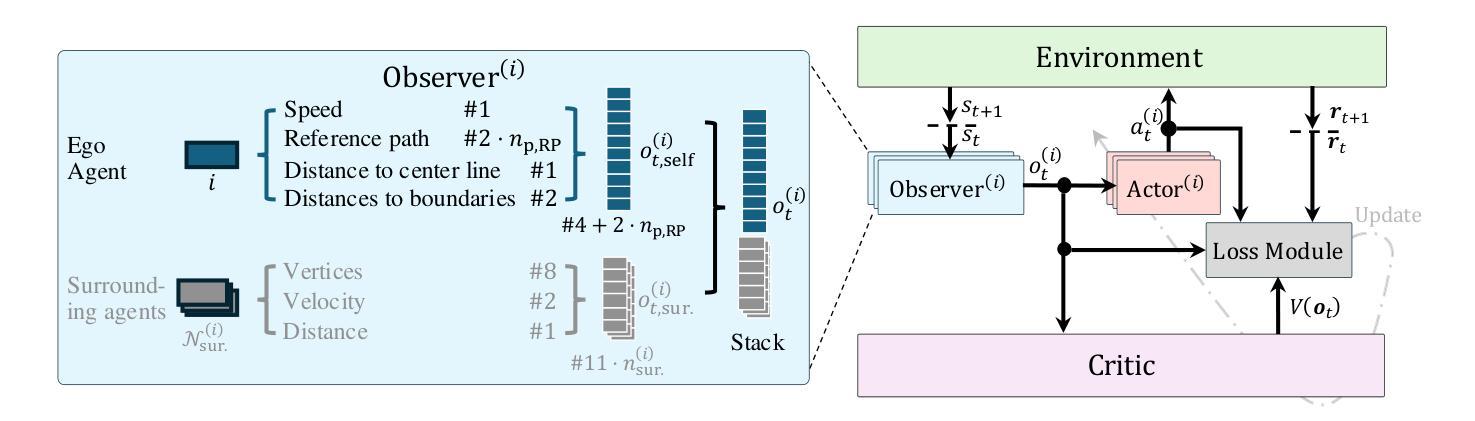
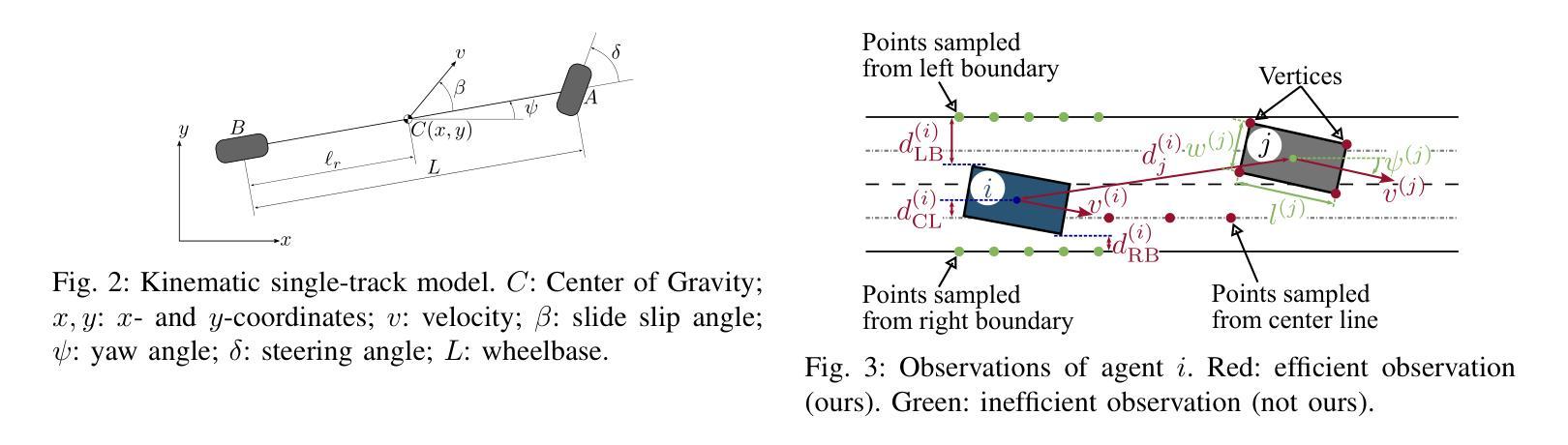
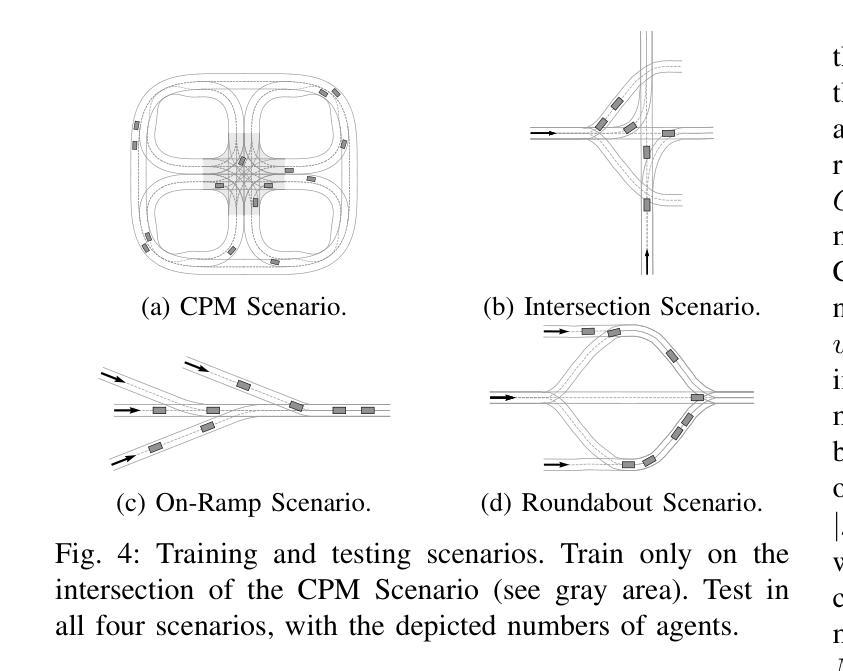
This paper introduces an open-source, decentralized framework named SigmaRL, designed to enhance both sample efficiency and generalization of multi-agent Reinforcement Learning (RL) for motion planning of connected and automated vehicles. Most RL agents exhibit a limited capacity to generalize, often focusing narrowly on specific scenarios, and are usually evaluated in similar or even the same scenarios seen during training. Various methods have been proposed to address these challenges, including experience replay and regularization. However, how observation design in RL affects sample efficiency and generalization remains an under-explored area. We address this gap by proposing five strategies to design information-dense observations, focusing on general features that are applicable to most traffic scenarios. We train our RL agents using these strategies on an intersection and evaluate their generalization through numerical experiments across completely unseen traffic scenarios, including a new intersection, an on-ramp, and a roundabout. Incorporating these information-dense observations reduces training times to under one hour on a single CPU, and the evaluation results reveal that our RL agents can effectively zero-shot generalize. Code: github.com/bassamlab/SigmaRL
本文介绍了一个名为SigmaRL的开源去中心化框架,旨在提高多智能体强化学习(RL)在联网自动驾驶汽车运动规划中的样本效率和泛化能力。大多数RL智能体泛化能力有限,通常只关注特定场景,并且通常在训练期间看到的类似或相同场景中进行评估。为解决这些挑战,已经提出了各种方法,包括经验回放和正则化。然而,RL中的观察设计如何影响样本效率和泛化仍然是一个尚未充分研究的领域。我们通过提出五种设计信息密集型观察的策略来解决这一差距,这些策略侧重于适用于大多数交通场景的一般特征。我们在一个交叉口使用这些策略训练我们的RL智能体,并通过数值实验评估其在完全未知的交通场景中的泛化能力,包括一个新的交叉口、一个上坡车道和一个环岛。结合这些信息密集的观察,将训练时间缩短到单个CPU上不到一个小时,评估结果表明我们的RL智能体可以有效地实现零射击泛化。代码:github.com/bassamlab/SigmaRL。
论文及项目相关链接
PDF Accepted for presentation at the IEEE International Conference on Intelligent Transportation Systems (ITSC) 2024
Summary
强化学习在自动驾驶车辆的运动规划中应用广泛,但存在样本效率和泛化能力有限的问题。SigmaRL框架旨在通过设计信息密集的观察策略提高样本效率和泛化能力,使RL代理能够在不同的交通场景中实现零射击泛化。
Key Takeaways
- SigmaRL是一个开源的、去中心化的框架,旨在提高多代理强化学习(RL)的样本效率和泛化能力。
- 当前RL代理在泛化方面存在局限性,往往只关注特定场景,并在训练期间和训练后的评估中表现良好。
- 通过设计信息密集的观察策略,解决在强化学习中观察设计如何影响样本效率和泛化的问题。
- 信息密集的观察策略包括集中于一般特征的设计,这些特征适用于大多数交通场景。
- SigmaRL框架通过减少训练时间(在单个CPU上不到一个小时)提高了样本效率。
- 通过数值实验评估了RL代理的泛化能力,实验结果显示代理可以在完全未见的交通场景中实现零射击泛化。
点此查看论文截图

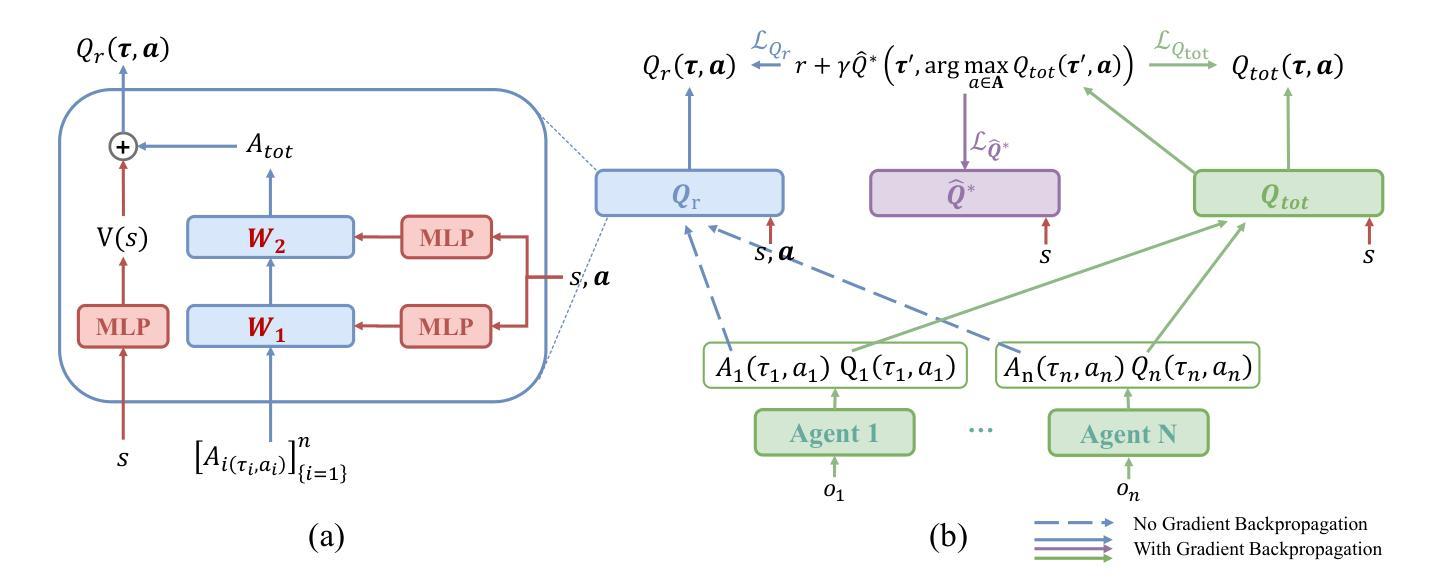
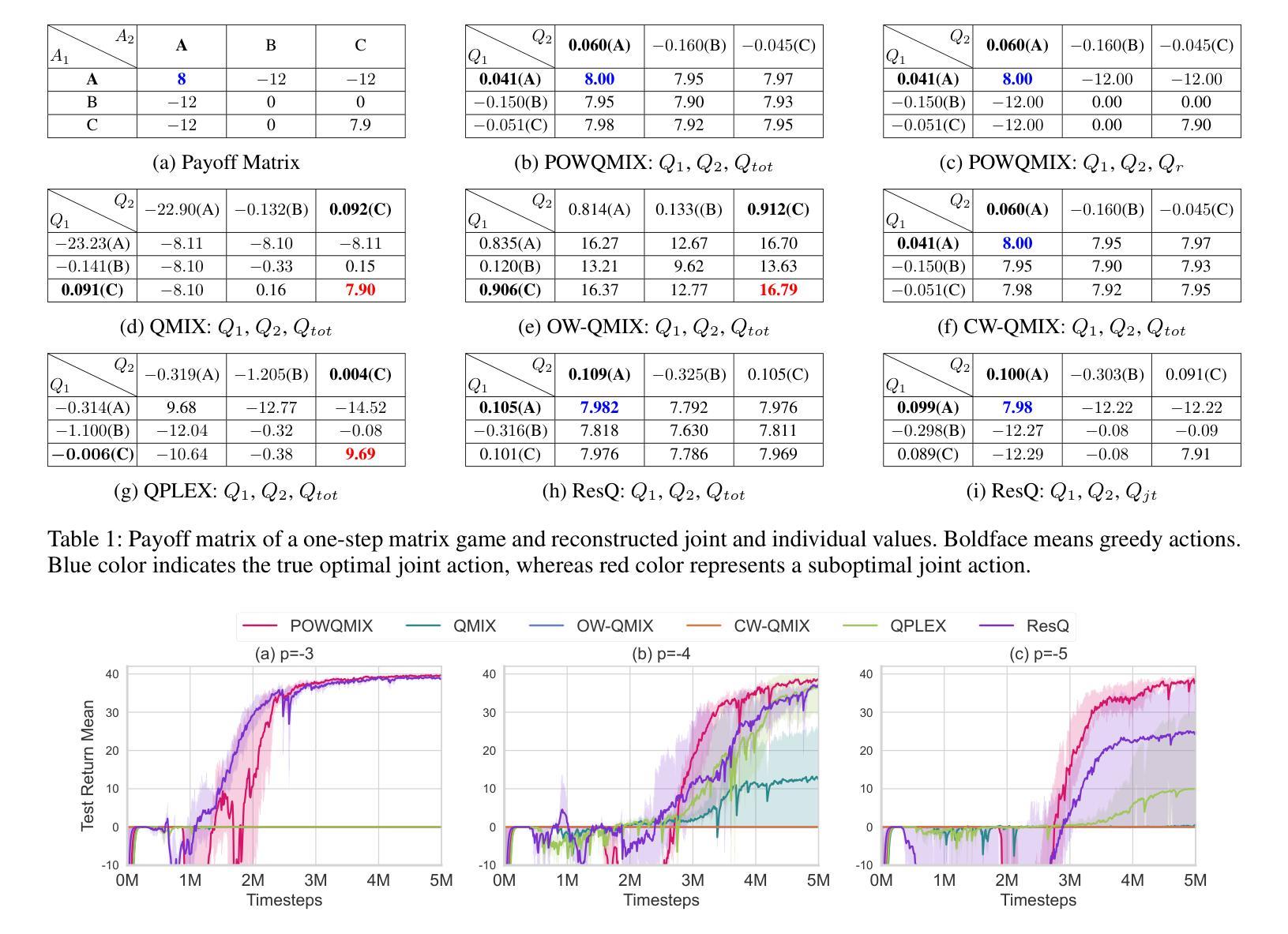
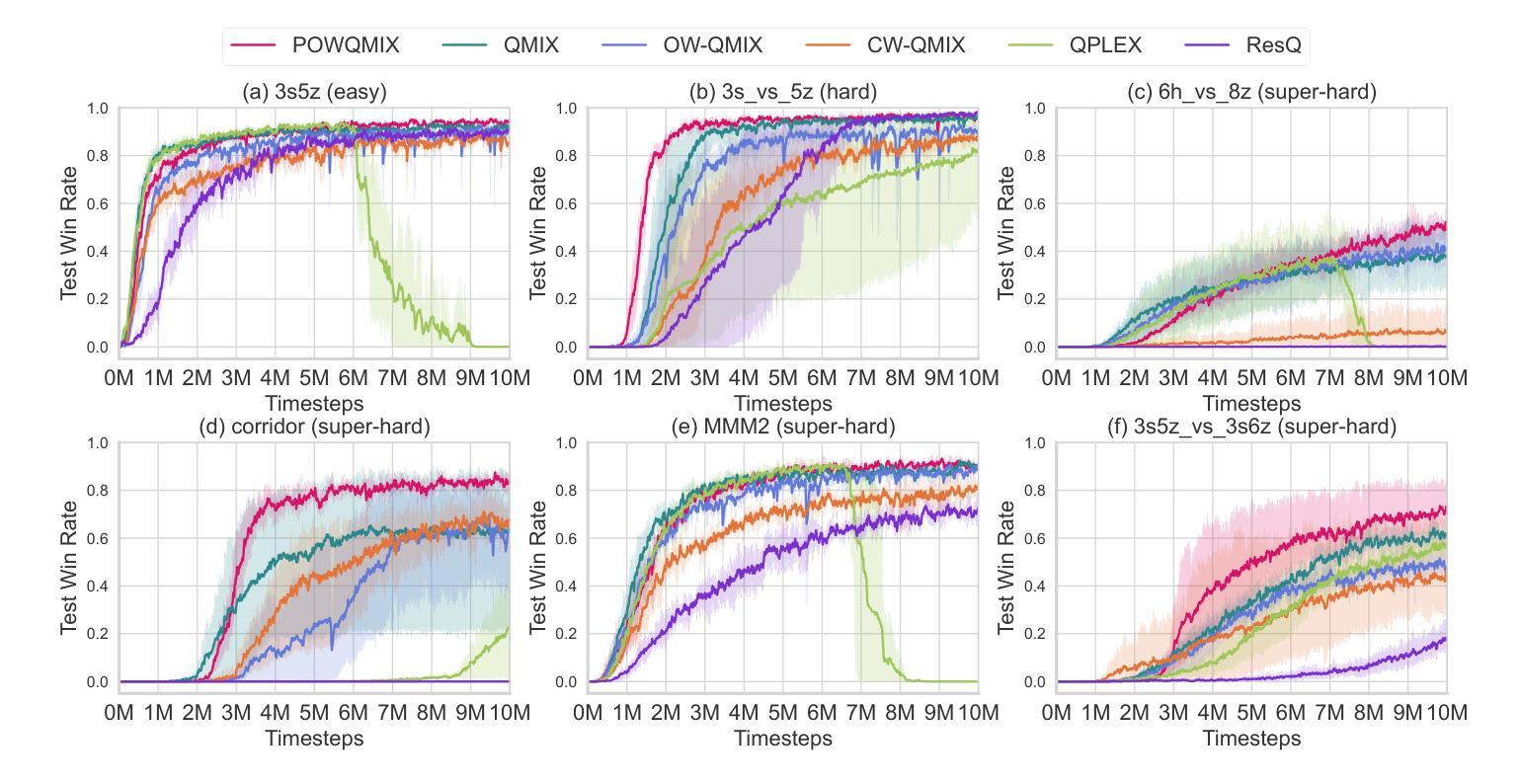
POWQMIX: Weighted Value Factorization with Potentially Optimal Joint Actions Recognition for Cooperative Multi-Agent Reinforcement Learning
Authors:Chang Huang, Shatong Zhu, Junqiao Zhao, Hongtu Zhou, Chen Ye, Tiantian Feng, Changjun Jiang
Value function factorization methods are commonly used in cooperative multi-agent reinforcement learning, with QMIX receiving significant attention. Many QMIX-based methods introduce monotonicity constraints between the joint action value and individual action values to achieve decentralized execution. However, such constraints limit the representation capacity of value factorization, restricting the joint action values it can represent and hindering the learning of the optimal policy. To address this challenge, we propose the Potentially Optimal Joint Actions Weighted QMIX (POWQMIX) algorithm, which recognizes the potentially optimal joint actions and assigns higher weights to the corresponding losses of these joint actions during training. We theoretically prove that with such a weighted training approach the optimal policy is guaranteed to be recovered. Experiments in matrix games, difficulty-enhanced predator-prey, and StarCraft II Multi-Agent Challenge environments demonstrate that our algorithm outperforms the state-of-the-art value-based multi-agent reinforcement learning methods.
价值函数分解方法在多智能体强化学习合作中广泛使用,其中QMIX受到广泛关注。许多基于QMIX的方法引入联合行动价值和个体行动价值之间的单调性约束,以实现去中心化执行。然而,这些约束限制了价值分解的表示能力,限制了其可以表示的联合行动价值,并阻碍了学习最优策略。为了应对这一挑战,我们提出了潜在最优联合行动加权QMIX(POWQMIX)算法。该算法能够识别潜在的最优联合行动,并在训练过程中为这些联合行动对应的损失分配更高的权重。从理论上讲,通过加权训练方法可以确保恢复最优策略。在矩阵游戏、难度增强的捕食者-猎物以及星际争霸II多智能体挑战环境中的实验表明,我们的算法优于最新的基于价值的智能体强化学习方法。
论文及项目相关链接
PDF This paper needs further refinement
Summary
提出一种基于QMIX算法的改进方法——潜在最优联合动作加权QMIX(POWQMIX)。该方法能够识别潜在最优联合动作,并在训练过程中为这些联合动作对应的损失分配更高的权重,从而解决价值函数分解中由于单调性约束导致的表示能力受限问题。理论证明该加权训练方式能保证找回最优策略,并在矩阵游戏、难度增强的捕食者与猎物以及星际争霸II多智能体挑战环境中实现了超越现有价值型多智能体强化学习方法的性能表现。
Key Takeaways
- 价值函数分解方法在多智能体强化学习任务中广泛应用,QMIX方法受到特别关注。
- 现有QMIX方法通过引入单调性约束实现去中心化执行,但这种约束限制了价值函数的表示能力。
- POWQMIX算法被提出以解决这一问题,它能识别潜在最优联合动作并赋予更高的训练权重。
- 理论证明加权训练方式能保证找回最优策略。
- 实证研究表明,POWQMIX在多种环境中表现优于现有价值型多智能体强化学习方法。
- 该方法增强了智能体在复杂环境中的协作能力。
点此查看论文截图