⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-12 更新
GLUS: Global-Local Reasoning Unified into A Single Large Language Model for Video Segmentation
Authors:Lang Lin, Xueyang Yu, Ziqi Pang, Yu-Xiong Wang
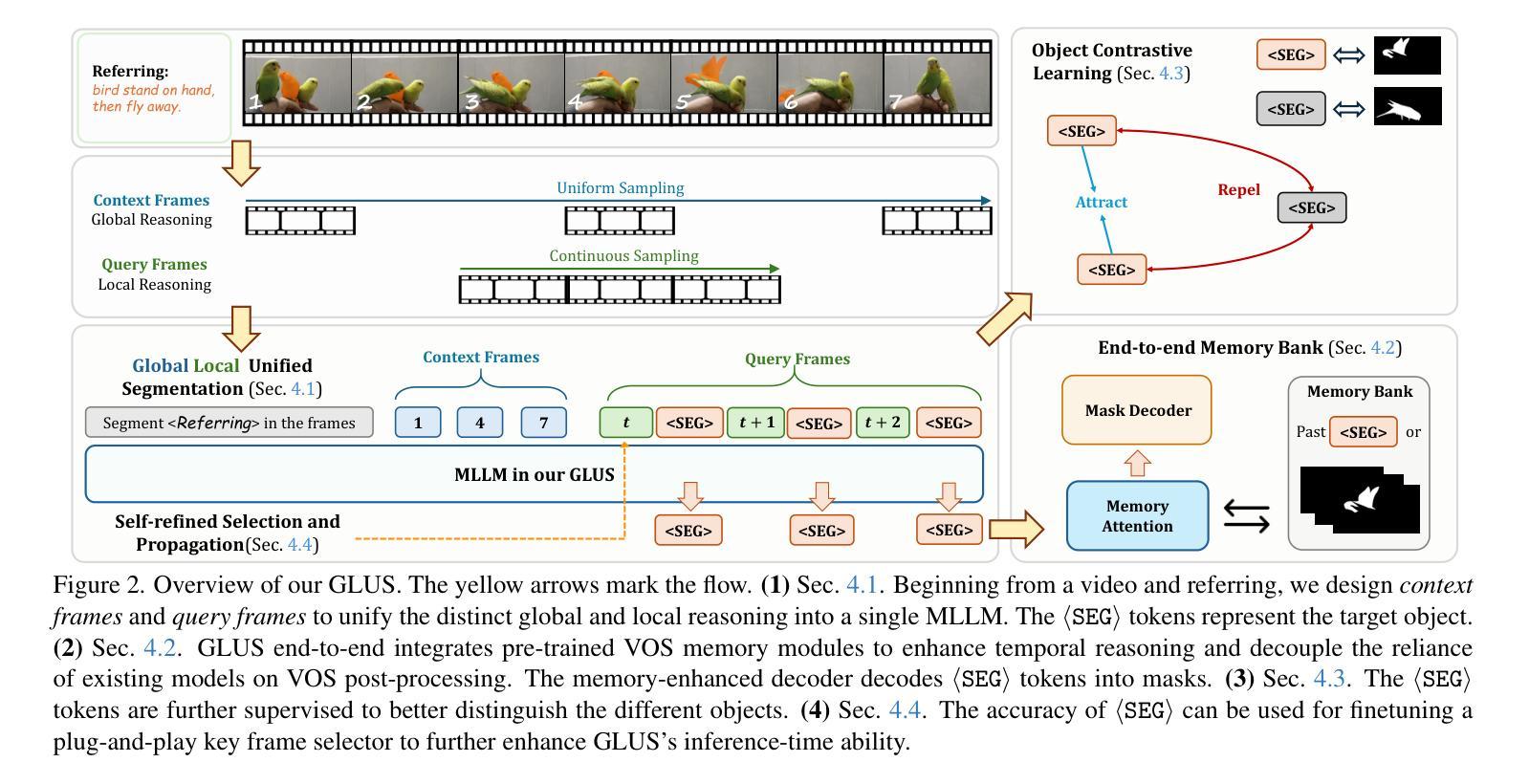
This paper proposes a novel framework utilizing multi-modal large language models (MLLMs) for referring video object segmentation (RefVOS). Previous MLLM-based methods commonly struggle with the dilemma between “Ref” and “VOS”: they either specialize in understanding a few key frames (global reasoning) or tracking objects on continuous frames (local reasoning), and rely on external VOS or frame selectors to mitigate the other end of the challenge. However, our framework GLUS shows that global and local consistency can be unified into a single video segmentation MLLM: a set of sparse “context frames” provides global information, while a stream of continuous “query frames” conducts local object tracking. This is further supported by jointly training the MLLM with a pre-trained VOS memory bank to simultaneously digest short-range and long-range temporal information. To improve the information efficiency within the limited context window of MLLMs, we introduce object contrastive learning to distinguish hard false-positive objects and a self-refined framework to identify crucial frames and perform propagation. By collectively integrating these insights, our GLUS delivers a simple yet effective baseline, achieving new state-of-the-art for MLLMs on the MeViS and Ref-Youtube-VOS benchmark. Our project page is at https://glus-video.github.io/.
本文提出了一种利用多模态大型语言模型(MLLM)进行指代视频对象分割(RefVOS)的新型框架。之前的MLLM方法通常面临“Ref”和“VOS”之间的困境:它们要么专注于理解一些关键帧(全局推理),要么跟踪连续帧上的对象(局部推理),并依赖外部VOS或帧选择器来缓解另一端的挑战。然而,我们的GLUS框架表明,全局和局部一致性可以统一到一个单一的视频分割MLLM中:一组稀疏的“上下文帧”提供全局信息,而一系列连续的“查询帧”进行局部对象跟踪。这得到了与预训练VOS内存库联合训练MLLM的支持,以同时消化短程和长程的时间信息。为了提高MLLM有限上下文窗口内的信息效率,我们引入了对象对比学习来区分难以区分的假阳性对象,以及自我完善框架来识别关键帧并进行传播。通过整合这些见解,我们的GLUS提供了一个简单而有效的基线,在MeViS和Ref-Youtube-VOS基准测试上达到了MLLM的最新水平。我们的项目页面是https://glus-video.github.io/。
论文及项目相关链接
PDF CVPR 2025
Summary
在解决视频对象分割的问题时,本文提出了一种新型的多模态大型语言模型框架GLUS。该框架融合了全局和局部一致性,通过稀疏的“上下文帧”提供全局信息,并利用连续的“查询帧”进行局部对象跟踪。此外,通过联合训练MLLM和预训练的VOS记忆库,同时消化短期和长期的时间信息。为了提高MLLM有限上下文窗口内的信息效率,引入了对象对比学习和自我优化框架。GLUS在MeViS和Ref-Youtube-VOS基准测试中实现了最新水平的结果。项目网页是网站链接。
Key Takeaways
- 引入新型多模态大型语言模型框架GLUS用于视频对象分割(RefVOS)。
- 融合全局和局部一致性,解决以往MLLM在Ref和VOS之间的权衡问题。
- 通过稀疏的上下文帧和连续的查询帧进行全局和局部信息的处理。
- 联合训练MLLM和预训练的VOS记忆库,同时处理短期和长期时间信息。
- 采用对象对比学习提高信息效率。
- 引入自我优化框架来识别关键帧并进行传播。
点此查看论文截图


SoTA with Less: MCTS-Guided Sample Selection for Data-Efficient Visual Reasoning Self-Improvement
Authors:Xiyao Wang, Zhengyuan Yang, Chao Feng, Hongjin Lu, Linjie Li, Chung-Ching Lin, Kevin Lin, Furong Huang, Lijuan Wang
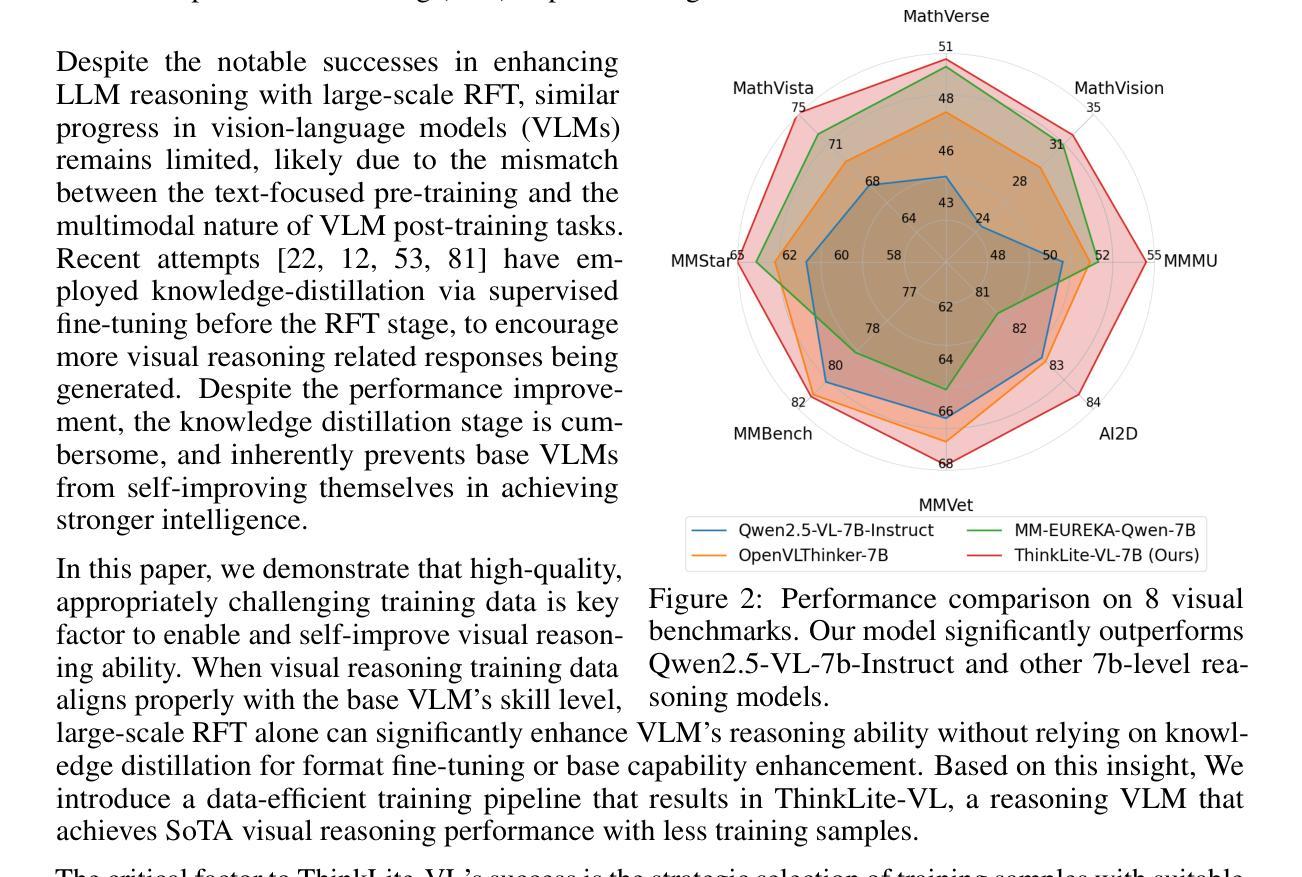
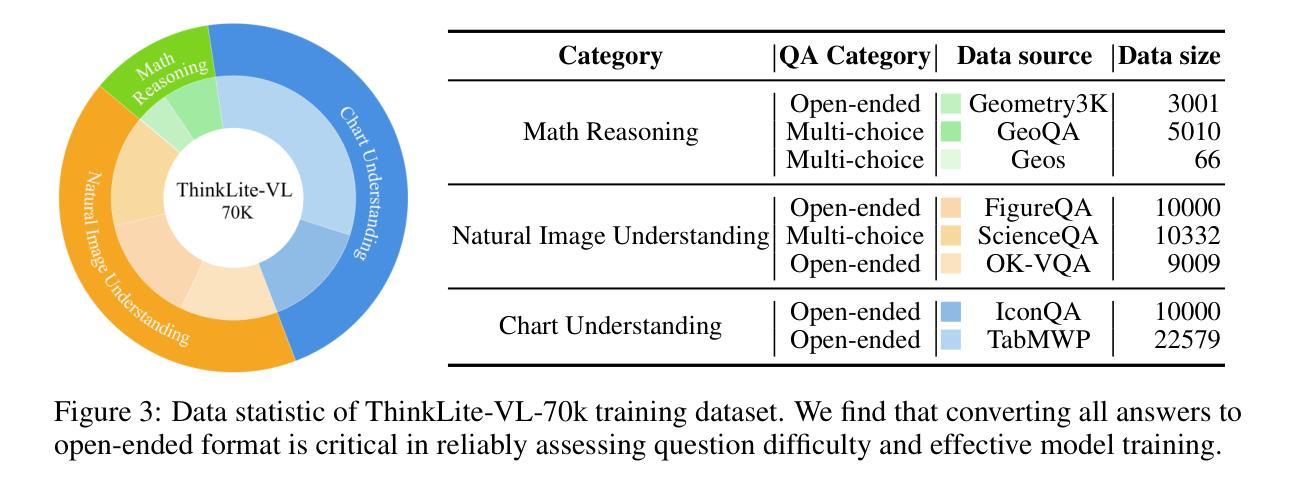
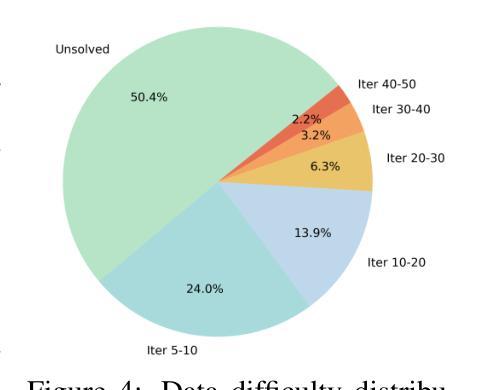
In this paper, we present an effective method to enhance visual reasoning with significantly fewer training samples, relying purely on self-improvement with no knowledge distillation. Our key insight is that the difficulty of training data during reinforcement fine-tuning (RFT) is critical. Appropriately challenging samples can substantially boost reasoning capabilities even when the dataset is small. Despite being intuitive, the main challenge remains in accurately quantifying sample difficulty to enable effective data filtering. To this end, we propose a novel way of repurposing Monte Carlo Tree Search (MCTS) to achieve that. Starting from our curated 70k open-source training samples, we introduce an MCTS-based selection method that quantifies sample difficulty based on the number of iterations required by the VLMs to solve each problem. This explicit step-by-step reasoning in MCTS enforces the model to think longer and better identifies samples that are genuinely challenging. We filter and retain 11k samples to perform RFT on Qwen2.5-VL-7B-Instruct, resulting in our final model, ThinkLite-VL. Evaluation results on eight benchmarks show that ThinkLite-VL improves the average performance of Qwen2.5-VL-7B-Instruct by 7%, using only 11k training samples with no knowledge distillation. This significantly outperforms all existing 7B-level reasoning VLMs, and our fairly comparable baselines that use classic selection methods such as accuracy-based filtering. Notably, on MathVista, ThinkLite-VL-7B achieves the SoTA accuracy of 75.1, surpassing Qwen2.5-VL-72B, GPT-4o, and O1. Our code, data, and model are available at https://github.com/si0wang/ThinkLite-VL.
在这篇论文中,我们提出了一种有效的方法,利用显著更少的训练样本增强视觉推理能力,这完全依赖于自我提升,无需知识蒸馏。我们的关键见解是,强化微调(RFT)期间训练数据的难度至关重要。适当的挑战性样本即使数据集很小,也能大幅提升推理能力。尽管这是直观的,但主要挑战仍然在于准确量化样本的难度,以实现有效的数据过滤。为此,我们提出了一种重新利用蒙特卡洛树搜索(MCTS)的新方法来实现这一点。从我们开始精选的7万个开源训练样本中,我们引入了一种基于MCTS的选择方法,根据VLMs解决问题所需的迭代次数来量化样本难度。MCTS中的这种逐步推理明确了模型需要思考的时间,并更好地识别了真正具有挑战性的样本。我们过滤并保留了1.1万个样本,在Qwen2.5-VL-7B-Instruct上进行RFT,从而得到我们的最终模型ThinkLite-VL。在八个基准测试上的评估结果表明,ThinkLite-VL使用仅1.1万个训练样本,无需知识蒸馏,即可将Qwen2.5-VL-7B-Instruct的平均性能提高7%。这显著优于所有现有的7B级推理VLMs以及使用经典选择方法(如基于准确度的过滤)的相当基准线。值得注意的是,在MathVista上,ThinkLite-VL-7B达到了75.1的SOTA准确率,超越了Qwen2.5-VL-72B、GPT-4o和O1。我们的代码、数据和模型可在https://github.com/si0wang/ThinkLite-VL上获得。
论文及项目相关链接
PDF 21 pages, 5 figures
Summary
该论文提出了一种利用自我提升强化学习的方法,在少量训练样本下提升视觉推理能力。论文的关键在于认识到强化精细训练时样本的难度至关重要。通过提出一种基于蒙特卡洛树搜索(MCTS)的筛选方法,量化样本难度并筛选出真正具有挑战性的样本进行训练,最终实现了模型性能的提升。评估结果显示,使用仅11k训练样本的ThinkLite-VL模型在多个基准测试中平均性能提升了7%,显著优于现有其他类似规模的推理视觉语言模型。
Key Takeaways
- 论文提出了一种基于自我提升强化学习的方法,能在少量训练样本下增强视觉推理能力。
- 论文强调在强化精细训练时样本的难度至关重要,通过筛选真正具有挑战性的样本进行训练可以提升模型性能。
- 论文使用蒙特卡洛树搜索(MCTS)筛选训练样本,基于模型解决问题所需的迭代次数量化样本难度。
- ThinkLite-VL模型使用仅11k训练样本,在多个基准测试中平均性能提升了7%,显著优于现有其他类似规模的推理视觉语言模型。
- ThinkLite-VL模型在MathVista测试上达到了当时最先进的准确率75.1%,超越了其他大型语言模型如Qwen2.5-VL-72B和GPT-4o等。
- 论文提供的代码、数据和模型可以在公开代码库中找到,方便后续研究使用。
点此查看论文截图

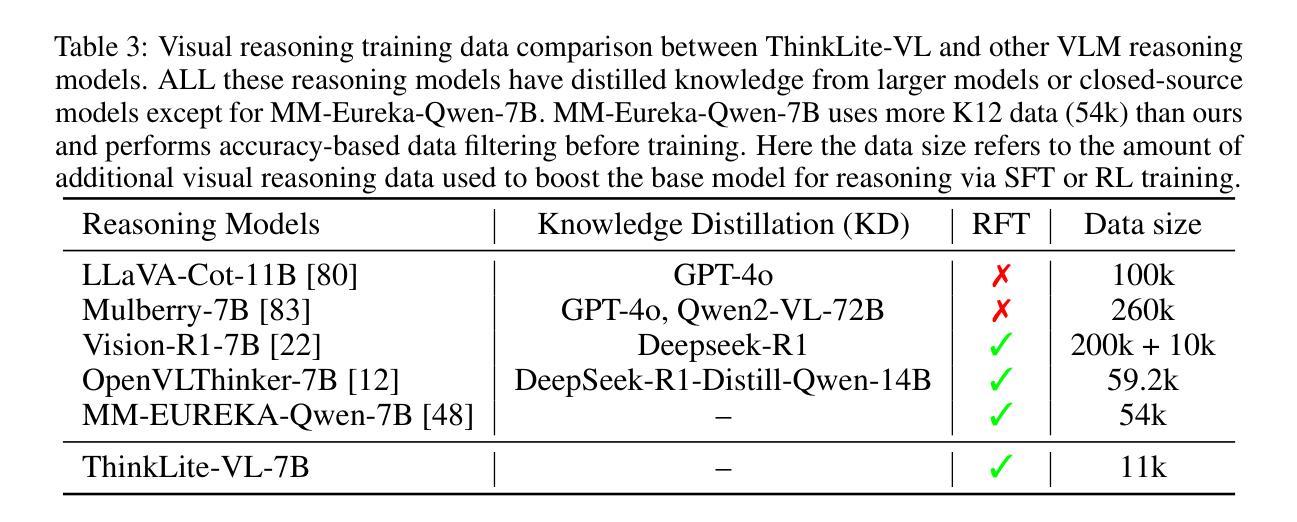
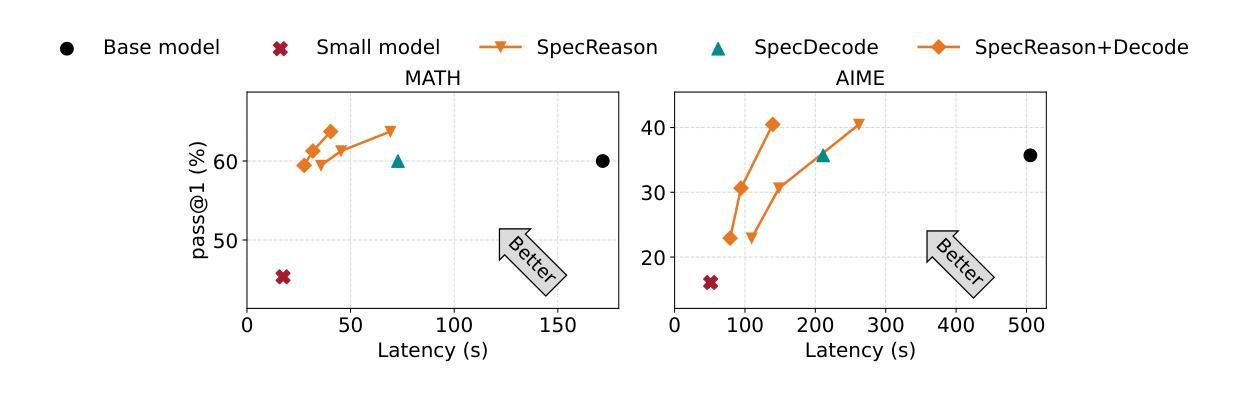
SpecReason: Fast and Accurate Inference-Time Compute via Speculative Reasoning
Authors:Rui Pan, Yinwei Dai, Zhihao Zhang, Gabriele Oliaro, Zhihao Jia, Ravi Netravali
Recent advances in inference-time compute have significantly improved performance on complex tasks by generating long chains of thought (CoTs) using Large Reasoning Models (LRMs). However, this improved accuracy comes at the cost of high inference latency due to the length of generated reasoning sequences and the autoregressive nature of decoding. Our key insight in tackling these overheads is that LRM inference, and the reasoning that it embeds, is highly tolerant of approximations: complex tasks are typically broken down into simpler steps, each of which brings utility based on the semantic insight it provides for downstream steps rather than the exact tokens it generates. Accordingly, we introduce SpecReason, a system that automatically accelerates LRM inference by using a lightweight model to (speculatively) carry out simpler intermediate reasoning steps and reserving the costly base model only to assess (and potentially correct) the speculated outputs. Importantly, SpecReason’s focus on exploiting the semantic flexibility of thinking tokens in preserving final-answer accuracy is complementary to prior speculation techniques, most notably speculative decoding, which demands token-level equivalence at each step. Across a variety of reasoning benchmarks, SpecReason achieves 1.5-2.5$\times$ speedup over vanilla LRM inference while improving accuracy by 1.0-9.9%. Compared to speculative decoding without SpecReason, their combination yields an additional 19.4-44.2% latency reduction. We open-source SpecReason at https://github.com/ruipeterpan/specreason.
最近,推理时间计算方面的进展通过利用大型推理模型(LRMs)生成长的思维链(CoTs)已经在复杂任务上显著提高了性能。然而,这种提高的准确性是以高推理延迟为代价的,这主要是由于生成的推理序列的长度和解码的自回归性质。我们解决这些开销的关键见解是,LRM推理及其所嵌入的推理对近似值有着很高的容忍度:复杂任务通常被分解为更简单的步骤,每个步骤的实用性都是基于它为后续步骤提供的语义见解,而不是它生成的精确标记。因此,我们引入了SpecReason系统,它通过使用轻量级模型来自动加速LRM推理,(推测地)执行更简单的中间推理步骤,仅使用昂贵的基准模型来评估(和可能纠正)推测的输出。重要的是,SpecReason专注于利用思维标记的语义灵活性来保持最终答案的准确性,这与先前的推测技术互补,尤其是推测解码,它要求每一步的标记级别等效。在多种推理基准测试中,SpecReason实现了比普通LRM推理快1.5-2.5倍的速度提升,同时提高了1.0-9.9%的准确率。与没有SpecReason的推测解码相比,它们的组合导致额外的19.4-44.2%延迟减少。我们在https://github.com/ruipeterpan/specreason开源SpecReason。
论文及项目相关链接
Summary
基于大型推理模型(LRMs)的长链思维(CoTs)技术显著提高了复杂任务的性能,但这也导致了推理序列长度增加和自回归解码带来的推理时间延迟问题。为解决这些问题,我们提出了SpecReason系统,它通过采用轻量级模型进行推测性推理步骤来加速LRM推理过程,只在必要时才调用昂贵的基准模型进行评估和校正。SpecReason专注于利用思维符号的语义灵活性来保持最终答案的准确性,与先前的推测技术相比具有互补性。实验结果指出,相较于原始LRM推理,SpecReason提供了更高的加速和准确度改善;同时与没有SpecReason的推测解码相比,二者的结合带来了额外的延迟降低。我们已在GitHub上开源SpecReason。
Key Takeaways
- 大型推理模型(LRMs)能够通过生成长链思维(CoTs)提高复杂任务性能。
- LRM推理存在高推理时间延迟问题,主要源于生成的推理序列长度和自回归解码。
- SpecReason系统旨在解决这些时间延迟问题,它通过轻量级模型进行推测性推理步骤来加速LRM推理过程。
- SpecReason保留了思维符号的语义灵活性,从而提高最终答案的准确性。它是对先前推测技术的重要补充。
- 与原始LRM推理相比,SpecReason提供了更高的加速效果和准确度改善。相较于没有SpecReason的推测解码,二者的结合带来了额外的延迟降低。
点此查看论文截图

Enhancing Large Language Models through Neuro-Symbolic Integration and Ontological Reasoning
Authors:Ruslan Idelfonso Magana Vsevolodovna, Marco Monti
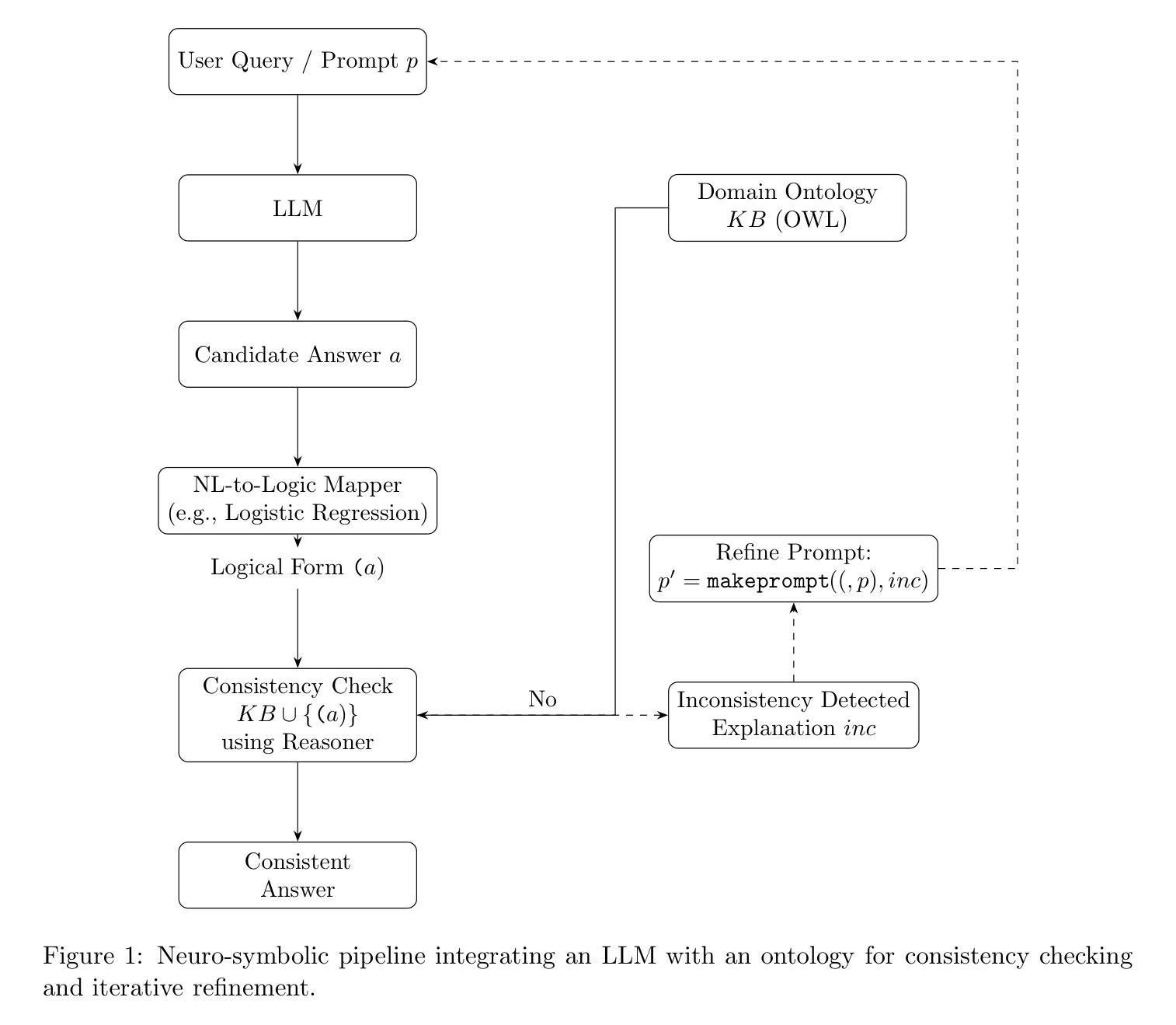
Large Language Models (LLMs) demonstrate impressive capabilities in natural language processing but suffer from inaccuracies and logical inconsistencies known as hallucinations. This compromises their reliability, especially in domains requiring factual accuracy. We propose a neuro-symbolic approach integrating symbolic ontological reasoning and machine learning methods to enhance the consistency and reliability of LLM outputs. Our workflow utilizes OWL ontologies, a symbolic reasoner (e.g., HermiT) for consistency checking, and a lightweight machine learning model (logistic regression) for mapping natural language statements into logical forms compatible with the ontology. When inconsistencies between LLM outputs and the ontology are detected, the system generates explanatory feedback to guide the LLM towards a corrected, logically coherent response in an iterative refinement loop. We present a working Python prototype demonstrating this pipeline. Experimental results in a defined domain suggest significant improvements in semantic coherence and factual accuracy of LLM outputs, showcasing the potential of combining LLM fluency with the rigor of formal semantics.
大型语言模型(LLM)在自然语言处理中展示了令人印象深刻的能力,但存在被称为“幻觉”的不准确性和逻辑不一致性。这损害了它们的可靠性,尤其是在需要事实准确性的领域。我们提出了一种神经符号方法,将符号本体推理和机器学习方法进行整合,以提高LLM输出的一致性和可靠性。我们的工作流程利用OWL本体、符号推理器(例如HermiT)进行一致性检查,以及轻量级机器学习模型(逻辑回归)将自然语言陈述映射到与本体兼容的逻辑形式。当检测到LLM输出与本体之间的不一致时,系统会生成解释性反馈,以指导LLM在迭代细化循环中做出更正、逻辑连贯的响应。我们展示了一个工作Python原型,演示了这个管道。在特定领域的实验结果表明,LLM输出的语义连贯性和事实准确性得到了显著提高,展示了结合LLM流畅性和形式语义严谨性的潜力。
论文及项目相关链接
PDF 11 pages, 1 figure, includes prototype implementation and experimental evaluation. Submitted for consideration in the arXiv Artificial Intelligence category (cs.AI)
Summary
大型语言模型在自然语言处理中展现出令人印象深刻的能力,但存在被称为“幻觉”的不准确性和逻辑不一致性问题,这影响了其可靠性,尤其是在需要事实准确性的领域。本文提出了一种神经符号方法,通过结合符号本体推理和机器学习方法来提高大型语言模型输出的一致性和可靠性。该方法利用OWL本体、符号推理器(例如HermiT)进行一致性检查,并使用轻量级机器学习模型(逻辑回归)将自然语言陈述映射到与本体兼容的逻辑形式。当检测到大型语言模型输出与本体之间的不一致性时,系统会生成解释性反馈,以指导大型语言模型在迭代优化循环中做出更正确、逻辑连贯的回应。实验结果表明,在特定领域里语义连贯性和事实准确性得到了显著提高,展示了结合大型语言模型的流畅性和形式语义学的严谨性的潜力。
Key Takeaways
- 大型语言模型在自然语言处理中表现出强大的能力,但存在不准确性及逻辑不一致性问题。
- 神经符号方法结合了符号本体推理和机器学习,旨在提高大型语言模型输出的一致性和可靠性。
- 使用OWL本体和符号推理器(如HermiT)进行一致性检查。
- 通过轻量级机器学习模型(逻辑回归)将自然语言转化为逻辑形式,与本体兼容。
- 当检测到不一致性时,系统生成解释性反馈以指导大型语言模型的迭代优化。
- 在特定领域的实验结果表明,该方法提高了语义连贯性和事实准确性。
点此查看论文截图

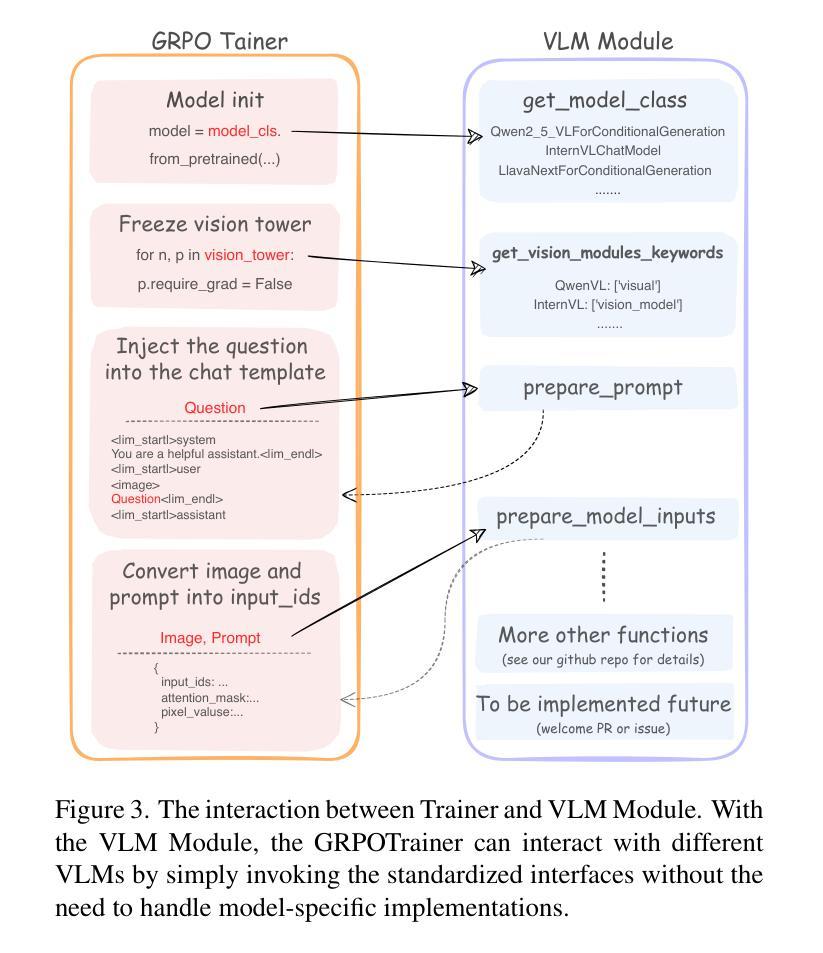
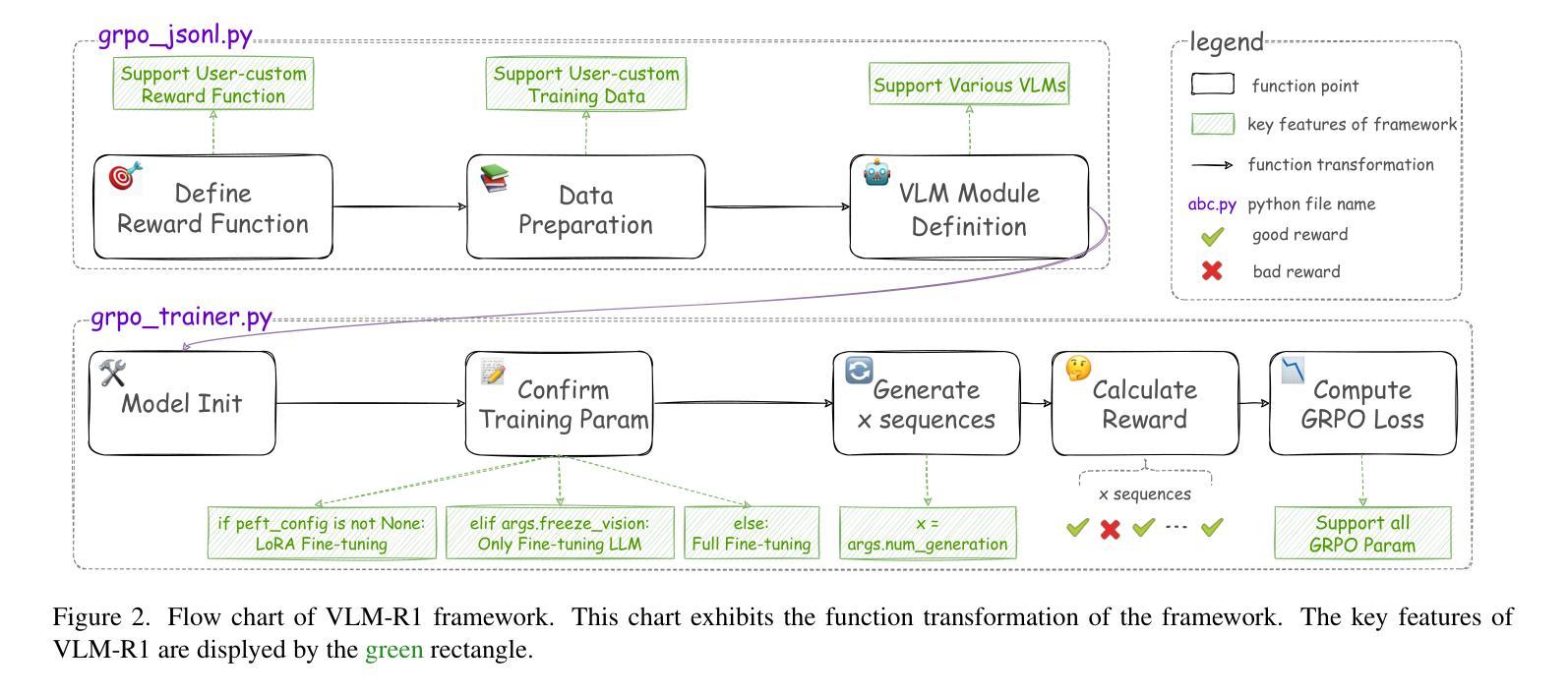
VLM-R1: A Stable and Generalizable R1-style Large Vision-Language Model
Authors:Haozhan Shen, Peng Liu, Jingcheng Li, Chunxin Fang, Yibo Ma, Jiajia Liao, Qiaoli Shen, Zilun Zhang, Kangjia Zhao, Qianqian Zhang, Ruochen Xu, Tiancheng Zhao
Recently DeepSeek R1 has shown that reinforcement learning (RL) can substantially improve the reasoning capabilities of Large Language Models (LLMs) through a simple yet effective design. The core of R1 lies in its rule-based reward formulation, which leverages tasks with deterministic ground-truth answers to enable precise and stable reward computation. In the visual domain, we similarly observe that a wide range of visual understanding tasks are inherently equipped with well-defined ground-truth annotations. This property makes them naturally compatible with rule-based reward mechanisms. Motivated by this observation, we investigate the extension of R1-style reinforcement learning to Vision-Language Models (VLMs), aiming to enhance their visual reasoning capabilities. To this end, we develop VLM-R1, a dedicated framework designed to harness RL for improving VLMs’ performance on general vision-language tasks. Using this framework, we further explore the feasibility of applying RL to visual domain. Experimental results indicate that the RL-based model not only delivers competitive performance on visual understanding tasks but also surpasses Supervised Fine-Tuning (SFT) in generalization ability. Furthermore, we conduct comprehensive ablation studies that uncover a series of noteworthy insights, including the presence of reward hacking in object detection, the emergence of the “OD aha moment”, the impact of training data quality, and the scaling behavior of RL across different model sizes. Through these analyses, we aim to deepen the understanding of how reinforcement learning enhances the capabilities of vision-language models, and we hope our findings and open-source contributions will support continued progress in the vision-language RL community. Our code and model are available at https://github.com/om-ai-lab/VLM-R1
最近,DeepSeek R1的研究表明,通过简单而有效的设计,强化学习(RL)可以显著提高大型语言模型(LLM)的推理能力。R1的核心在于其基于规则的奖励公式,它利用具有确定性标准答案的任务来启用精确且稳定的奖励计算。在视觉领域,我们同样观察到许多视觉理解任务本身就具备定义良好的标准注释。这一特性使它们自然地与基于规则的奖励机制兼容。受此观察结果的启发,我们研究了将R1风格的强化学习扩展到视觉语言模型(VLM),旨在增强它们的视觉推理能力。为此,我们开发了VLM-R1专用框架,旨在利用强化学习提高VLM在一般视觉语言任务上的性能。使用该框架,我们进一步探索了将强化学习应用于视觉领域的可行性。实验结果表明,基于强化学习的模型不仅在视觉理解任务上表现出竞争力,而且在泛化能力上也超越了监督微调(SFT)。此外,我们进行了全面的消融研究,揭示了一系列值得关注的见解,包括对象检测中的奖励破解现象、”OD瞬间领悟”的出现、训练数据质量的影响以及不同模型大小下强化学习的扩展行为。通过这些分析,我们旨在加深对强化学习如何增强视觉语言模型能力的理解,我们希望我们的发现和开源贡献将支持视觉语言强化学习社区的持续进步。我们的代码和模型可在[https://github.com/om-ai-lab/VLM-R
论文及项目相关链接
PDF 11 pages
Summary
本文介绍了DeepSeek R1如何通过强化学习(RL)提高大型语言模型(LLM)的推理能力。其核心在于基于规则的奖励制定,利用具有确定性答案的任务来实现精确且稳定的奖励计算。受视觉领域任务自然兼容于基于规则的奖励机制的启发,研究者们将R1风格的强化学习扩展到视觉语言模型(VLM),开发了VLM-R1框架来提高VLM在通用视觉语言任务上的推理能力。实验结果表明,基于RL的模型不仅在视觉理解任务上表现有竞争力,而且在泛化能力上也超越了监督微调(SFT)。此外,研究者还通过全面的消融研究获得了一系列值得注意的见解。
Key Takeaways
- 强化学习(RL)可以显著提高大型语言模型(LLM)的推理能力。
- DeepSeek R1的核心在于其基于规则的奖励制定,利用具有确定性答案的任务稳定计算奖励。
- 视觉理解任务天然地与基于规则的奖励机制兼容。
- VLM-R1框架被开发出来,旨在利用强化学习提高视觉语言模型(VLM)在通用视觉语言任务上的性能。
- 基于RL的模型在视觉理解任务上表现优秀,且泛化能力超过监督微调(SFT)。
- 消融研究揭示了强化学习在物体检测中的奖励黑客现象、物体检测的“啊哈时刻”的出现、训练数据质量的影响以及不同模型大小下强化学习的扩展行为。
- 这些研究深化了对强化学习如何增强视觉语言模型能力的理解,并为该领域的持续进步提供了支持。
点此查看论文截图



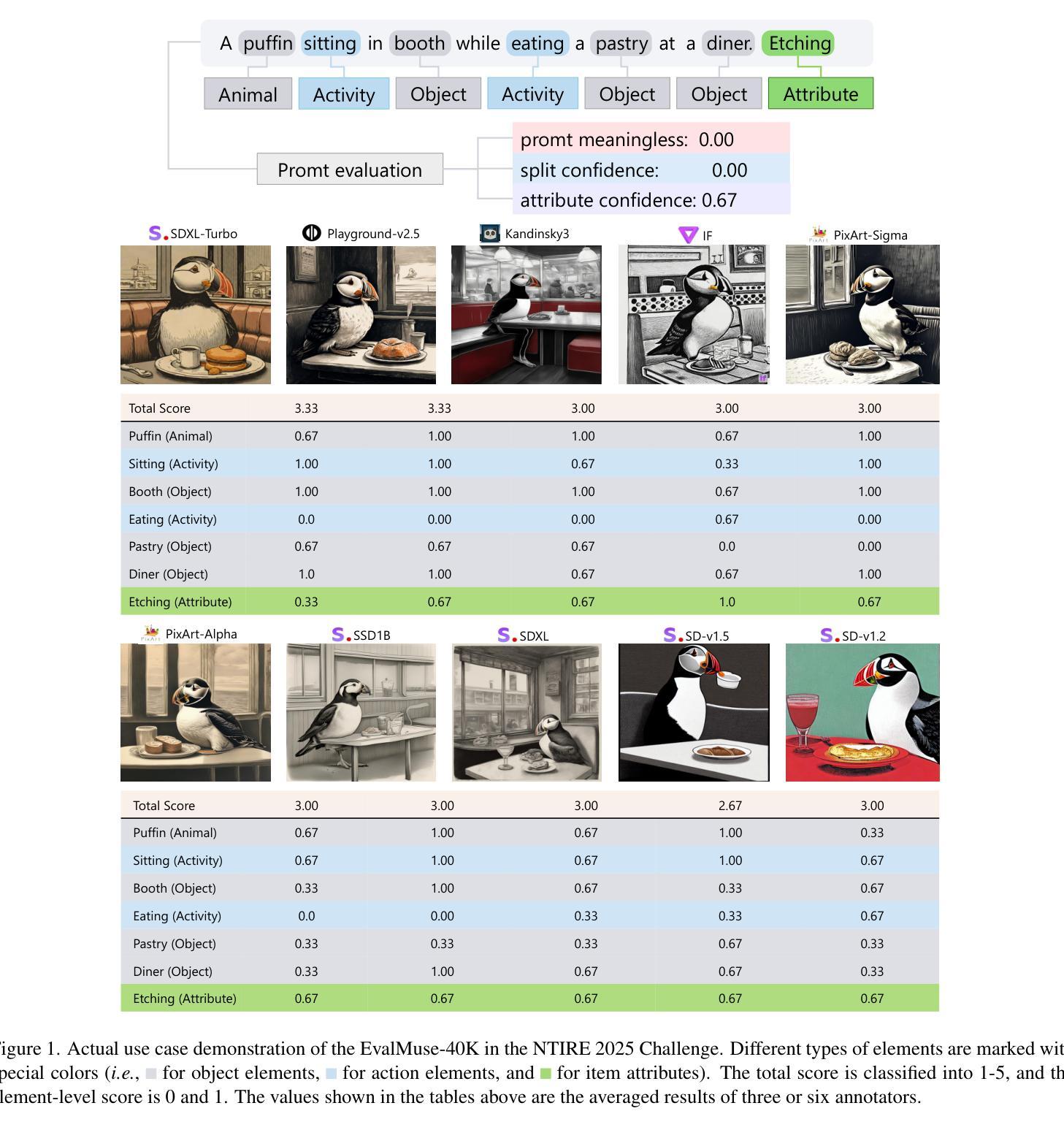
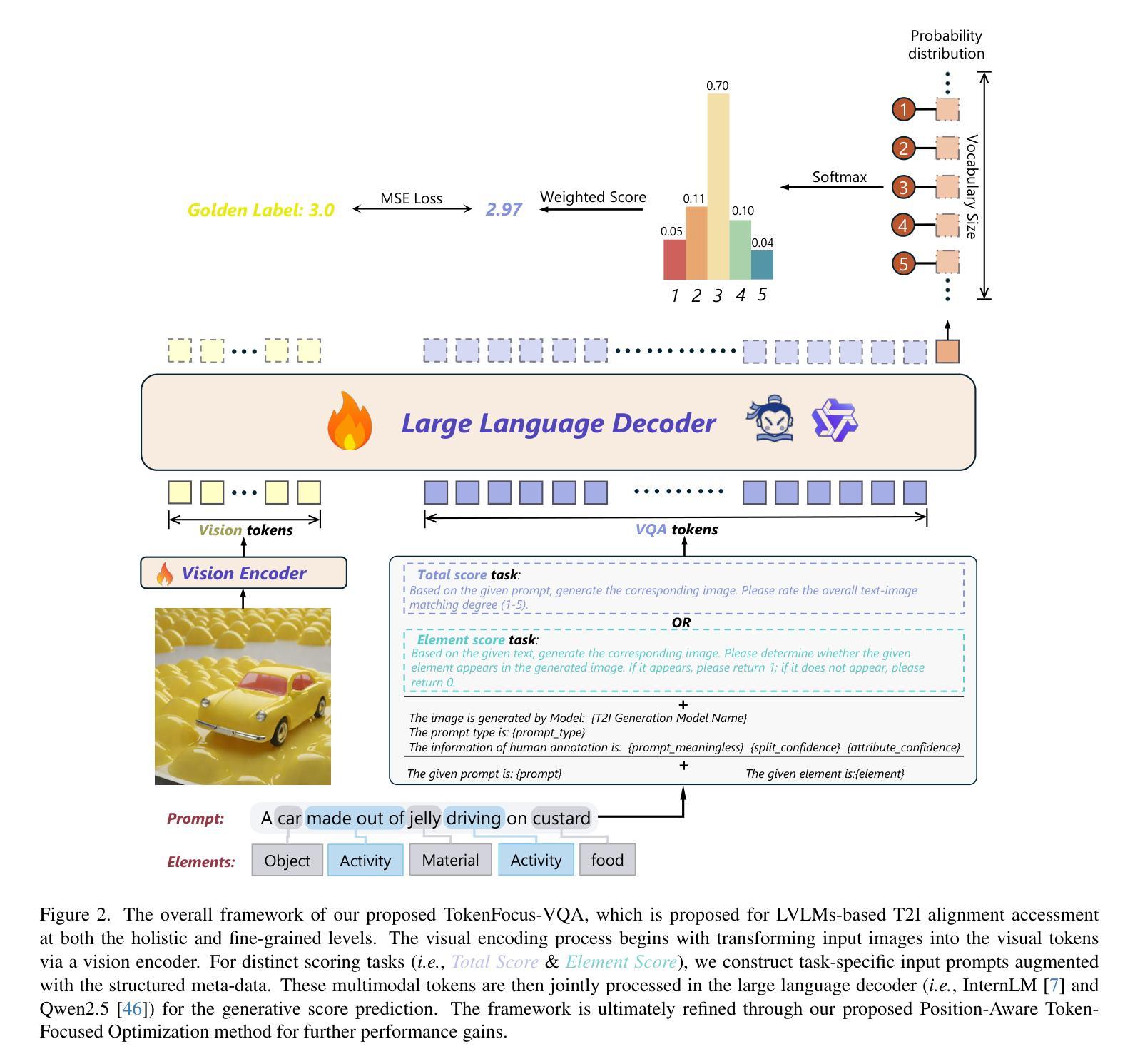
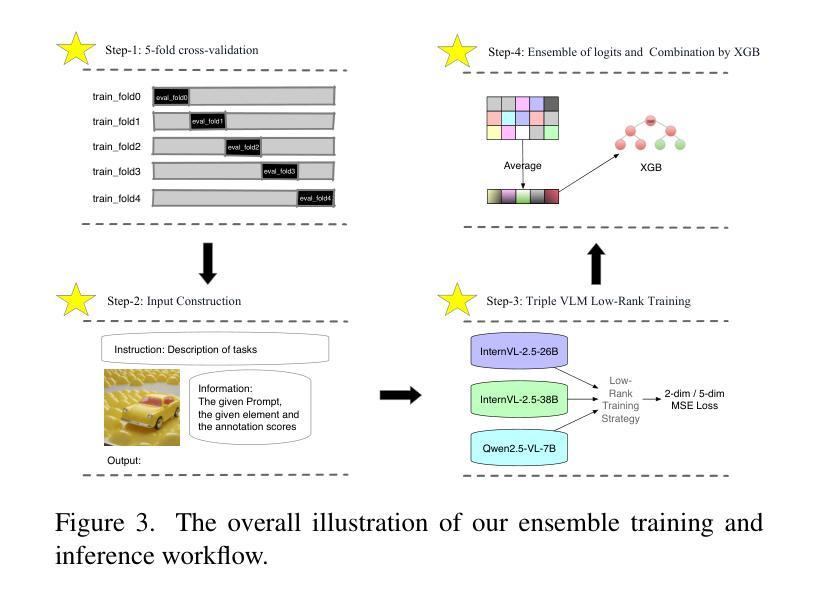
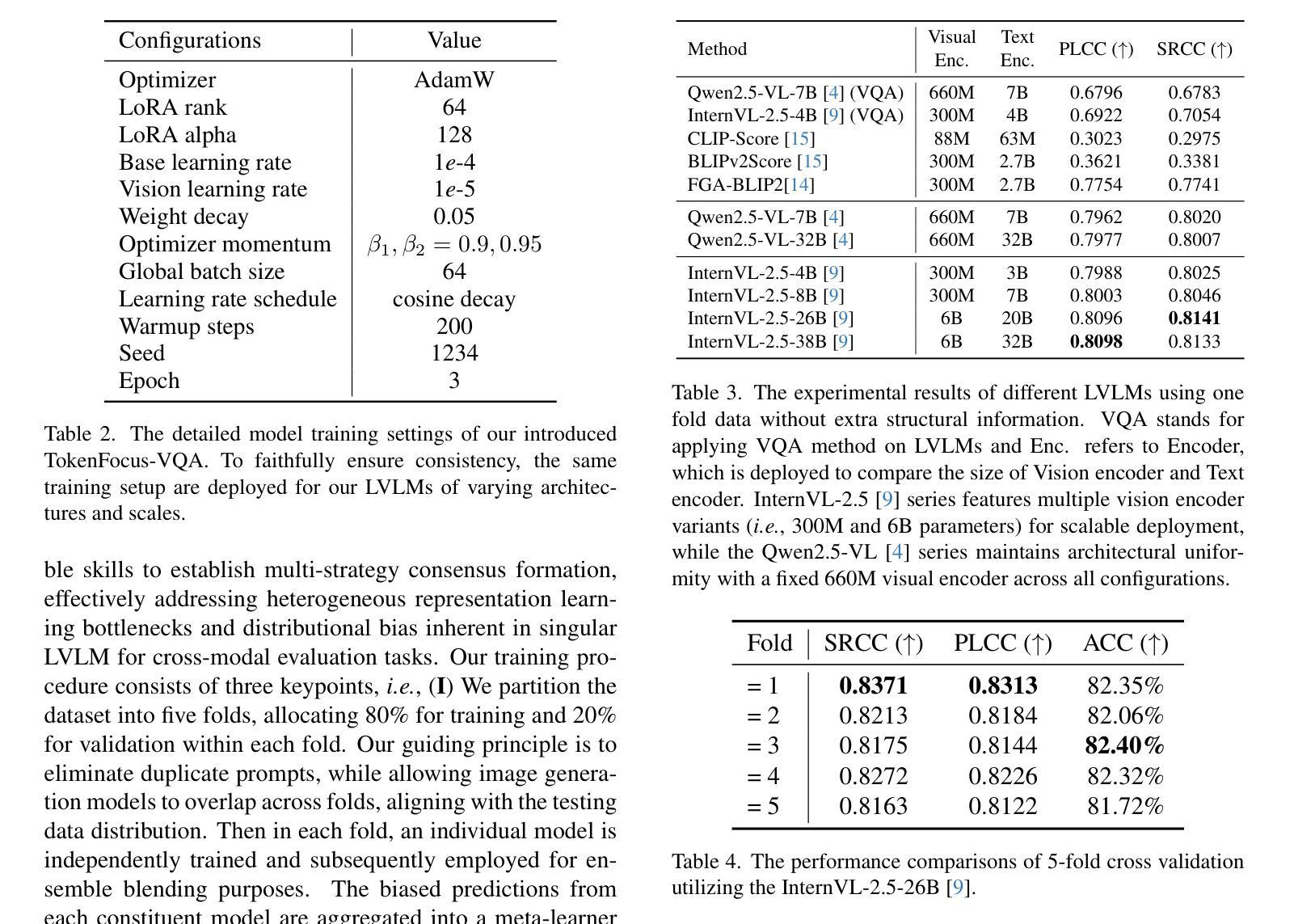
TokenFocus-VQA: Enhancing Text-to-Image Alignment with Position-Aware Focus and Multi-Perspective Aggregations on LVLMs
Authors:Zijian Zhang, Xuhui Zheng, Xuecheng Wu, Chong Peng, Xuezhi Cao
While text-to-image (T2I) generation models have achieved remarkable progress in recent years, existing evaluation methodologies for vision-language alignment still struggle with the fine-grained semantic matching. Current approaches based on global similarity metrics often overlook critical token-level correspondences between textual descriptions and visual content. To this end, we present TokenFocus-VQA, a novel evaluation framework that leverages Large Vision-Language Models (LVLMs) through visual question answering (VQA) paradigm with position-specific probability optimization. Our key innovation lies in designing a token-aware loss function that selectively focuses on probability distributions at pre-defined vocabulary positions corresponding to crucial semantic elements, enabling precise measurement of fine-grained semantical alignment. The proposed framework further integrates ensemble learning techniques to aggregate multi-perspective assessments from diverse LVLMs architectures, thereby achieving further performance enhancement. Evaluated on the NTIRE 2025 T2I Quality Assessment Challenge Track 1, our TokenFocus-VQA ranks 2nd place (0.8445, only 0.0001 lower than the 1st method) on public evaluation and 2nd place (0.8426) on the official private test set, demonstrating superiority in capturing nuanced text-image correspondences compared to conventional evaluation methods.
近年来,文本到图像(T2I)生成模型取得了显著进展,但现有的视觉语言对齐评估方法仍然面临着精细语义匹配方面的挑战。基于全局相似度指标的当前方法往往忽视了文本描述和视觉内容之间关键的词级对应关系。为此,我们提出了TokenFocus-VQA,这是一个新的评估框架,它利用大型视觉语言模型(LVLMs),通过位置特定概率优化的视觉问答(VQA)范式。我们的关键创新在于设计了一个词感知损失函数,该函数有选择地关注对应于关键语义元素的事先定义的词汇位置的概率分布,从而实现精细语义对齐的精确测量。所提出的框架还结合了集成学习技术,从多种LVLMs架构中汇集多角度评估,从而实现了进一步的性能提升。在NTIRE 2025 T2I质量评估挑战赛Track 1上,我们的TokenFocus-VQA在公共评估中位列第二(0.8445,仅比第一名方法低0.0001),在官方私有测试集上也位列第二(0.8426),这证明了其在捕捉微妙的文本图像对应关系方面优于传统评估方法。
论文及项目相关链接
PDF 10 pages, 3 figures
Summary
本文提出一种名为TokenFocus-VQA的新型评估框架,该框架利用大型视觉语言模型(LVLMs)通过视觉问答(VQA)范式进行位置特定概率优化。其创新之处在于设计了一种标记感知损失函数,该函数能够选择性地关注关键语义元素对应的预定义词汇位置的概率分布,从而实现对精细粒度语义对齐的精确测量。此外,该框架还结合了集成学习技术,从不同架构的LVLMs中聚合多角度评估,从而进一步提高性能。在NTIRE 2025 T2I质量评估挑战赛轨道1上,TokenFocus-VQA取得了第二名的成绩,表明其在捕捉微妙的文本图像对应方面相比传统评估方法具有优势。
Key Takeaways
- TokenFocus-VQA是一种新型的视觉语言对齐评估框架,结合了视觉问答(VQA)和大型视觉语言模型(LVLMs)。
- 该框架通过位置特定概率优化,实现了对文本描述与视觉内容之间关键令牌级别对应关系的关注。
- 框架的核心创新在于设计了一种标记感知损失函数,用于精确测量精细粒度语义对齐。
- TokenFocus-VQA通过集成学习技术整合了多个视觉语言模型的评估结果,提高了性能。
- 该框架在NTIRE 2025 T2I质量评估竞赛中取得了第二名的成绩,证明了其有效性。
- 相比传统评估方法,TokenFocus-VQA在捕捉文本图像细微对应关系方面表现出优势。
点此查看论文截图


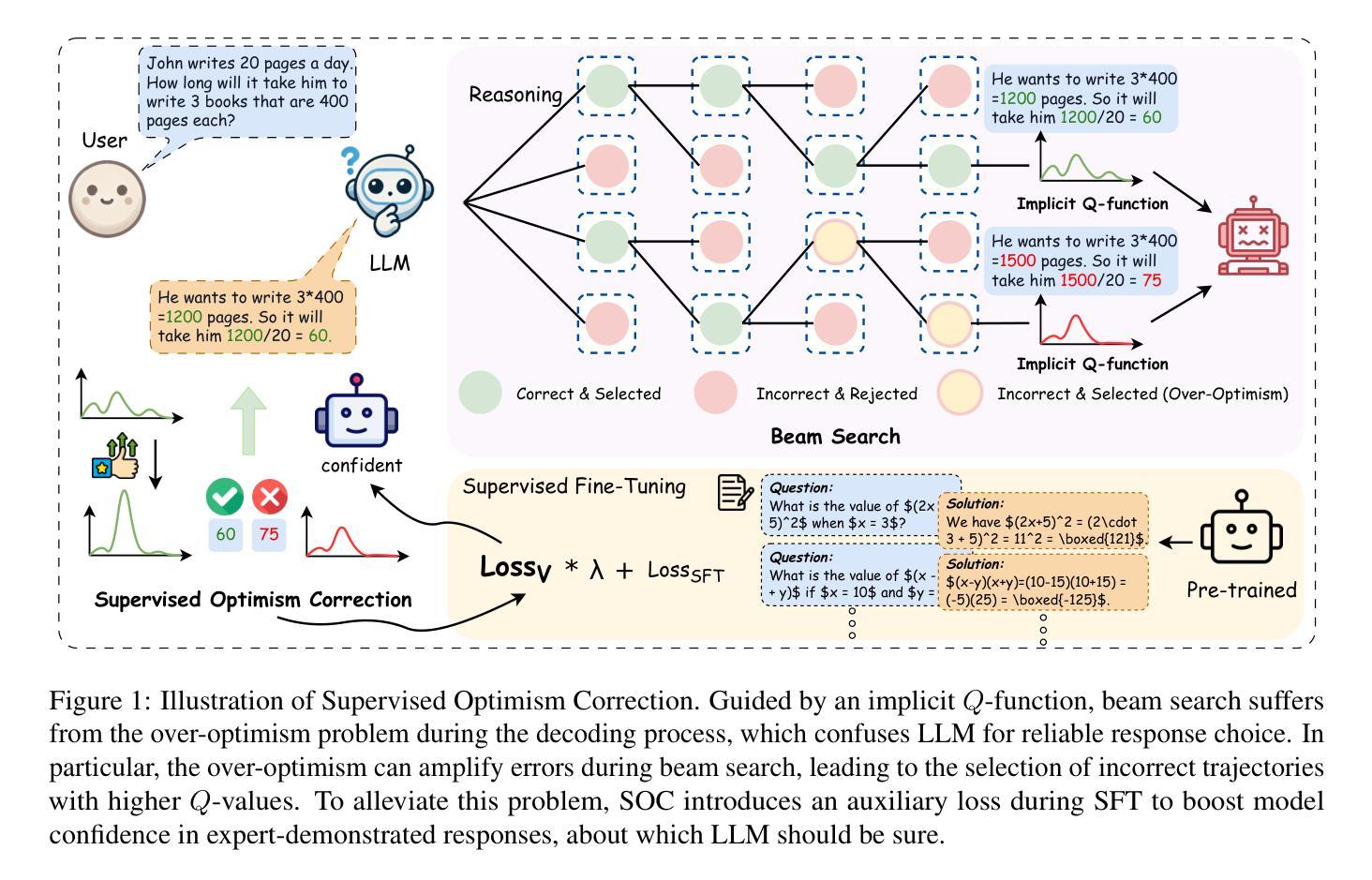
Supervised Optimism Correction: Be Confident When LLMs Are Sure
Authors:Junjie Zhang, Rushuai Yang, Shunyu Liu, Ting-En Lin, Fei Huang, Yi Chen, Yongbin Li, Dacheng Tao
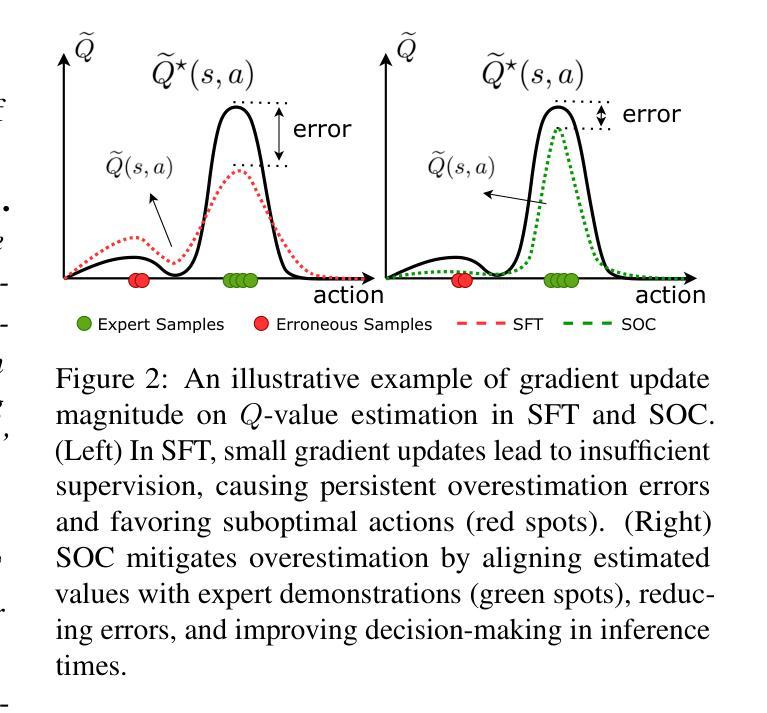
In this work, we establish a novel theoretical connection between supervised fine-tuning and offline reinforcement learning under the token-level Markov decision process, revealing that large language models indeed learn an implicit $Q$-function for inference. Through this theoretical lens, we demonstrate that the widely used beam search method suffers from unacceptable over-optimism, where inference errors are inevitably amplified due to inflated $Q$-value estimations of suboptimal steps. To address this limitation, we propose Supervised Optimism Correction(SOC), which introduces a simple yet effective auxiliary loss for token-level $Q$-value estimations during supervised fine-tuning. Specifically, the auxiliary loss employs implicit value regularization to boost model confidence in expert-demonstrated responses, thereby suppressing over-optimism toward insufficiently supervised responses. Extensive experiments on mathematical reasoning benchmarks, including GSM8K, MATH, and GAOKAO, showcase the superiority of the proposed SOC with beam search across a series of open-source models.
在这项工作中,我们在基于词级别的马尔可夫决策过程下,建立了监督微调与离线强化学习之间的新型理论联系,揭示了大型语言模型确实为推理学习了隐式的Q函数。通过这一理论视角,我们证明了广泛使用的贪心搜索方法存在不可接受的过度乐观问题,由于次优步骤的Q值估计膨胀,推理错误不可避免地会被放大。为了解决这一局限性,我们提出了监督乐观校正(SOC),它为词级别的Q值估计在监督微调过程中引入了一种简单有效的辅助损失。具体来说,辅助损失采用隐式价值正则化来提升模型对专家演示的反应信心,从而抑制对不足监督反应的过度乐观态度。在GSM8K、MATH和GAOKAO等数学推理基准测试上的大量实验,展示了所提出的SOC与贪心搜索在一系列开源模型中的优越性。
论文及项目相关链接
Summary
基于token级别的Markov决策过程,本文建立了监督微调与离线强化学习之间的新型理论联系,揭示大型语言模型确实为推理学习了隐式Q函数。文章指出广泛使用的贪心搜索方法存在不可接受的过度乐观问题,由于次优步骤的Q值估计膨胀,推理错误会不可避免地放大。为解决此问题,本文提出了监督乐观校正(SOC),在监督微调期间为token级别的Q值估计引入简单有效的辅助损失。通过隐性价值正则化来提升模型对专家演示答案的信心,从而抑制对缺乏监督答案的过度乐观态度。在GSM8K、MATH和GAOKAO等数学推理基准测试上的大量实验,展示了带有贪心搜索的SOC方法的优势。
Key Takeaways
- 本文建立了监督微调与离线强化学习之间的理论联系,揭示了大型语言模型学习隐式Q函数用于推理。
- 贪心搜索方法存在过度乐观问题,导致推理错误。
- 为解决贪心搜索方法的局限,提出了监督乐观校正(SOC)。
- SOC通过引入辅助损失来改进Q值估计,采用隐性价值正则化来提升模型信心。
- 实验表明,SOC方法在多个数学推理基准测试上表现优越。
- SOC方法适用于多种开源模型。
点此查看论文截图


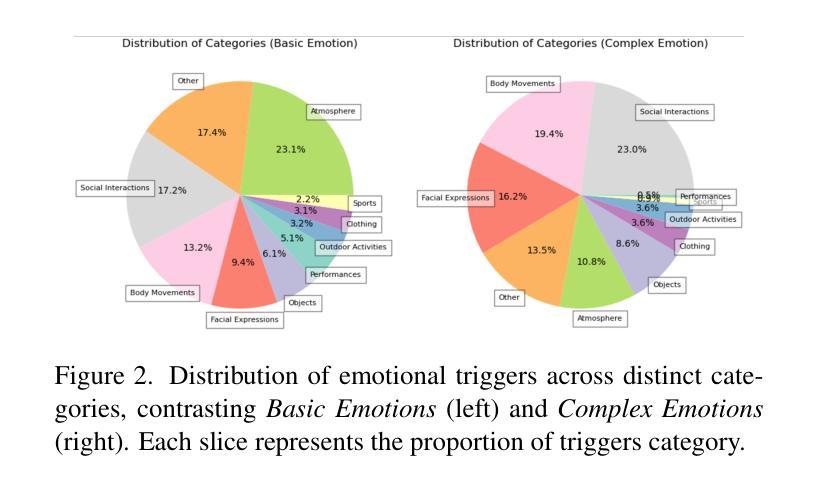
Why We Feel: Breaking Boundaries in Emotional Reasoning with Multimodal Large Language Models
Authors:Yuxiang Lin, Jingdong Sun, Zhi-Qi Cheng, Jue Wang, Haomin Liang, Zebang Cheng, Yifei Dong, Jun-Yan He, Xiaojiang Peng, Xian-Sheng Hua
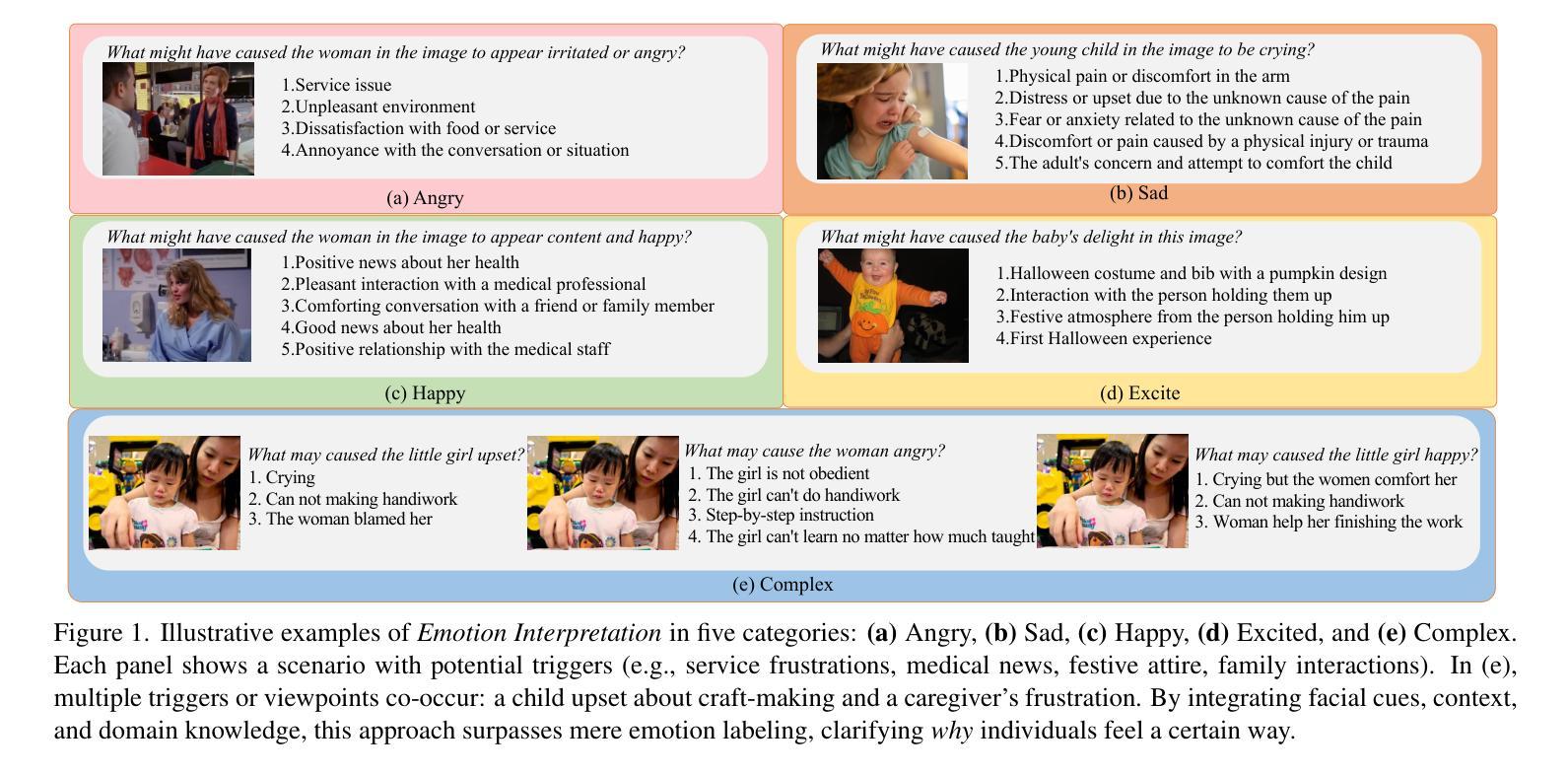
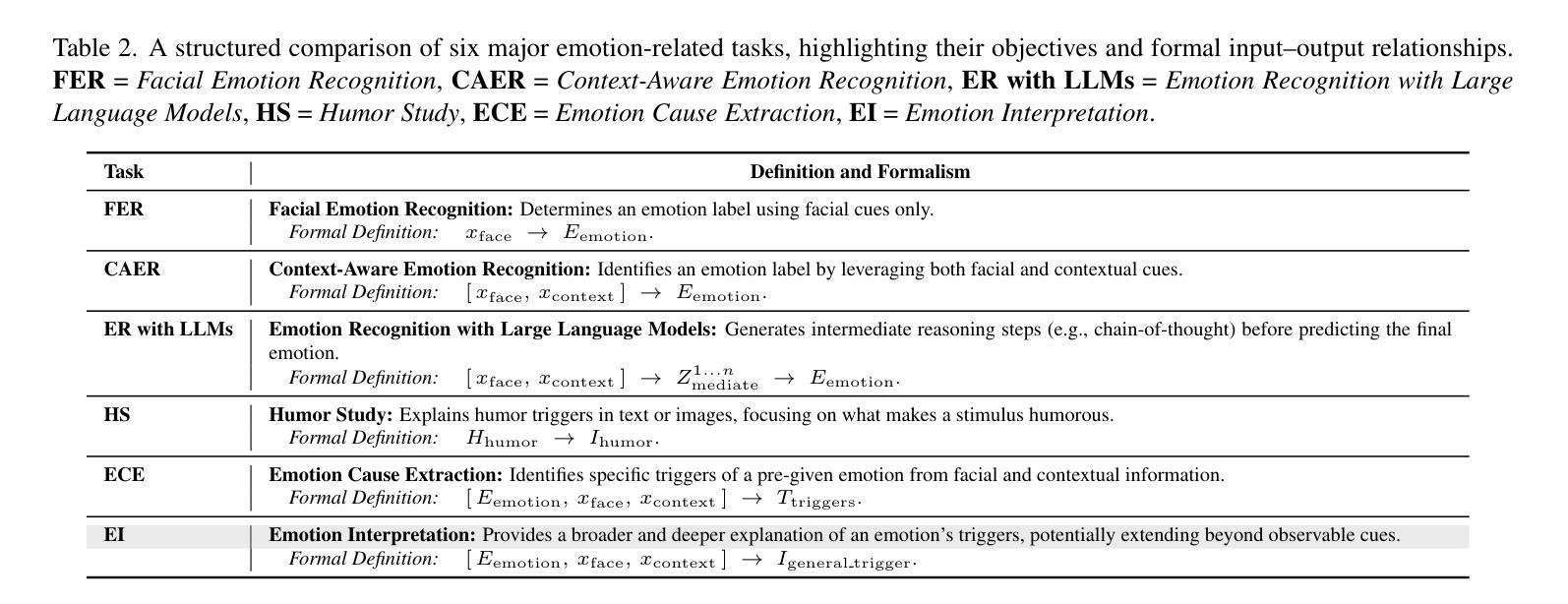
Most existing emotion analysis emphasizes which emotion arises (e.g., happy, sad, angry) but neglects the deeper why. We propose Emotion Interpretation (EI), focusing on causal factors-whether explicit (e.g., observable objects, interpersonal interactions) or implicit (e.g., cultural context, off-screen events)-that drive emotional responses. Unlike traditional emotion recognition, EI tasks require reasoning about triggers instead of mere labeling. To facilitate EI research, we present EIBench, a large-scale benchmark encompassing 1,615 basic EI samples and 50 complex EI samples featuring multifaceted emotions. Each instance demands rationale-based explanations rather than straightforward categorization. We further propose a Coarse-to-Fine Self-Ask (CFSA) annotation pipeline, which guides Vision-Language Models (VLLMs) through iterative question-answer rounds to yield high-quality labels at scale. Extensive evaluations on open-source and proprietary large language models under four experimental settings reveal consistent performance gaps-especially for more intricate scenarios-underscoring EI’s potential to enrich empathetic, context-aware AI applications. Our benchmark and methods are publicly available at: https://github.com/Lum1104/EIBench, offering a foundation for advanced multimodal causal analysis and next-generation affective computing.
现有大部分情感分析主要关注哪种情绪出现(例如快乐、悲伤、愤怒),却忽视了更深层的原因。我们提出情感解读(EI),重点关注推动情绪反应的因果因素,无论这些因果因素是显性的(如可观事物、人际互动),还是隐性的(如文化背景、屏幕外事件)。与传统的情感识别不同,情感解读任务需要进行触发因素推理,而非简单的标签标注。为了促进情感解读研究,我们推出了EIBench,这是一个大规模基准测试,包含1615个基本情感解读样本和50个复杂的情感解读样本,涉及多面情绪。每个实例都需要基于理性的解释,而非简单的分类。我们还进一步提出了从粗糙到精细的自我提问(CFSA)注释管道,该管道通过引导视觉语言模型(VLLM)进行迭代问答回合,以大规模生成高质量标签。在四种实验设置下,对开源和专有大型语言模型的广泛评估显示了一致的性能差距,尤其是在更复杂场景中,这凸显了情感解读在丰富具有同理心和上下文感知的AI应用方面的潜力。我们的基准测试和方法已在https://github.com/Lum1104/EIBench上公开可用,为先进的多模态因果分析和下一代情感计算提供了基础。
论文及项目相关链接
PDF Accepted at CVPR Workshop NEXD 2025. 21 pages, Project: https://github.com/Lum1104/EIBench
Summary
情感分析不再仅仅关注产生的情绪类型(如快乐、悲伤、愤怒等),而是深入到情感背后的原因。为此,我们提出了情感解读(EI),重点研究驱动情感反应的因果因素,包括显性的(如可见物体、人际互动)和隐性的(如文化背景、屏幕外事件)。情感解读任务需要进行触发原因分析而非单纯的标签归类。为推进情感解读研究,我们推出了包含大规模基准数据的EIBench,其中包括涵盖多重情感的复杂样本。每个样本都需要基于理性的解释而非简单的分类。此外,我们还提出了从粗糙到精细的自我提问(CFSA)注释管道,通过迭代问答环节指导视觉语言模型(VLLMs),大规模生成高质量标签。在各种不同情境的实验设置下,对于开源和自有大型语言模型的全面评估揭示了普遍存在的性能差距,尤其是针对更复杂的场景。我们的基准数据和方法可供公众访问(https://github.com/Lum1104/EIBench),为先进的模态因果分析和下一代情感计算奠定了基础。
Key Takeaways
- 现有情感分析主要关注情绪类型,忽略了情感背后的深层原因。
- 提出情感解读(EI)概念,重点研究驱动情感反应的因果因素,包括显性和隐性因素。
- 情感解读任务要求对触发原因进行推理,而非简单的标签归类。
- 推出大规模基准数据EIBench,包含复杂样本,强调基于理性的解释而非简单分类。
- 提出从粗糙到精细的自我提问(CFSA)注释管道,指导视觉语言模型生成高质量标签。
- 对不同情境下的语言模型进行全面评估,揭示性能差距,强调情感解读在复杂场景下的重要性。
点此查看论文截图


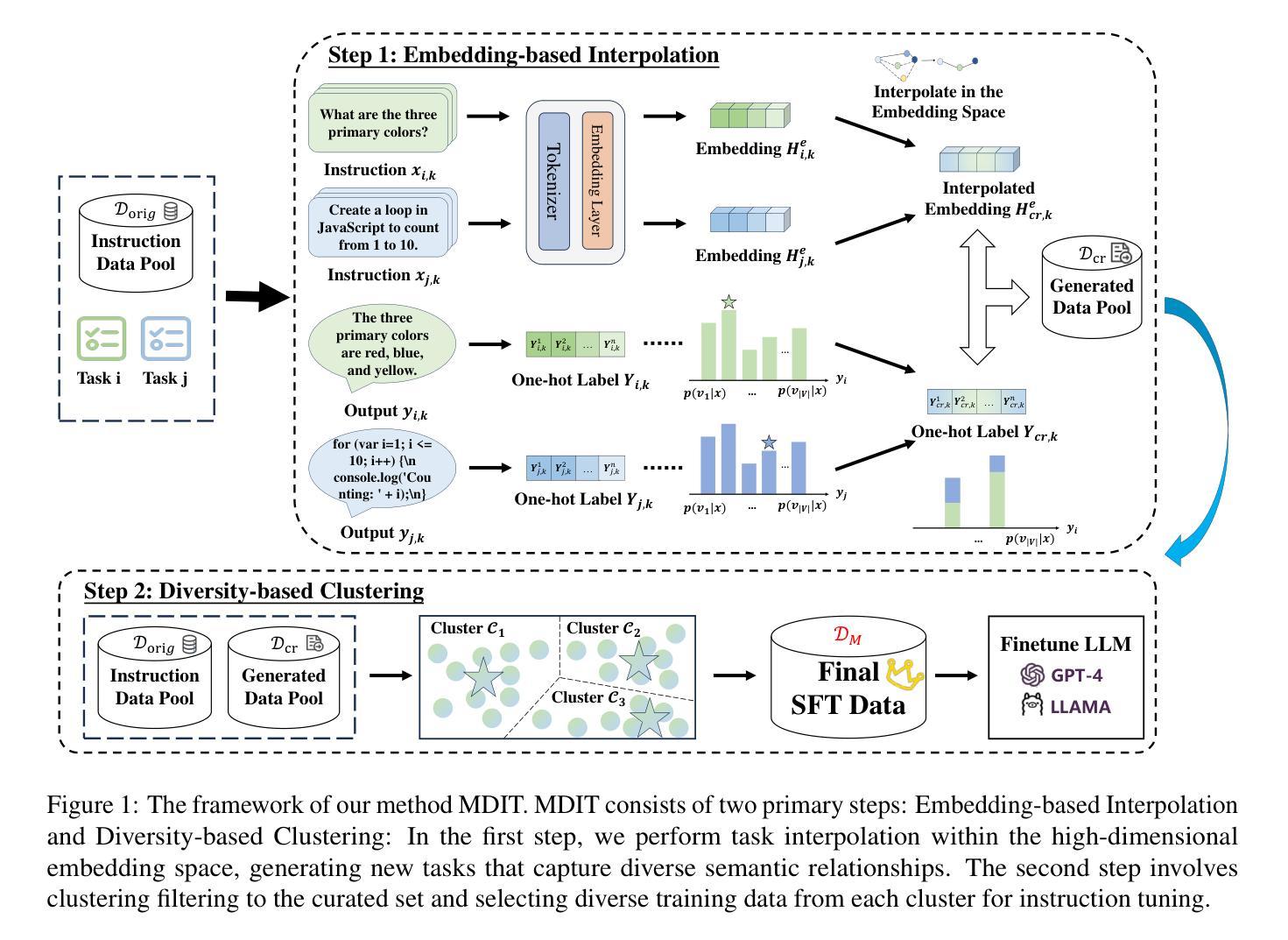
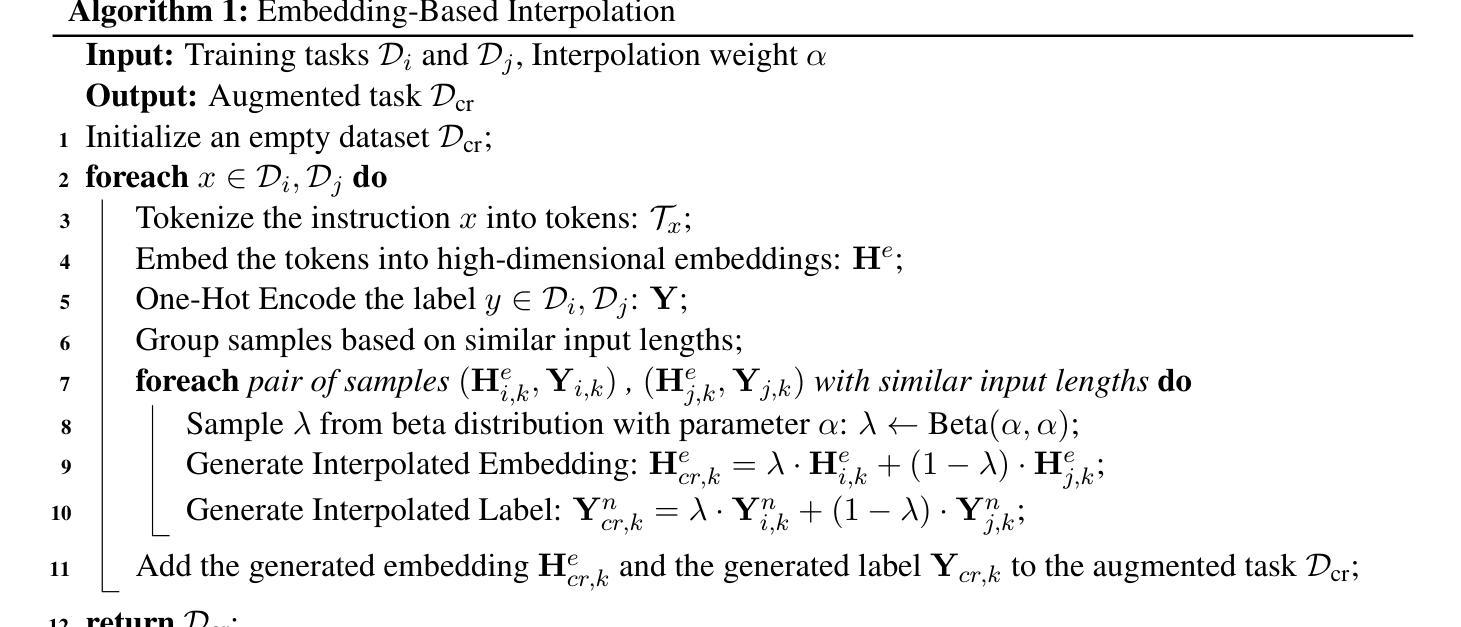
MDIT: A Model-free Data Interpolation Method for Diverse Instruction Tuning
Authors:Yangning Li, Zihua Lan, Lv Qingsong, Yinghui Li, Hai-Tao Zheng
As Large Language Models (LLMs) are increasingly applied across various tasks, instruction tuning has emerged as a critical method for enhancing model performance. However, current data management strategies face substantial challenges in generating diverse and comprehensive data, restricting further improvements in model performance. To address this gap, we propose MDIT, a novel model-free data interpolation method for diverse instruction tuning, which generates varied and high-quality instruction data by performing task interpolation. Moreover, it contains diversity-based clustering strategies to ensure the diversity of the training data. Extensive experiments show that our method achieves superior performance in multiple benchmark tasks. The LLMs finetuned with MDIT show significant improvements in numerous tasks such as general question answering, math reasoning, and code generation. MDIT offers an efficient and automatic data synthetic method, generating diverse instruction data without depending on external resources while expanding the application potential of LLMs in complex environments.
随着大型语言模型(LLM)在各项任务中的广泛应用,指令微调作为一种提高模型性能的关键方法应运而生。然而,当前的数据管理策略在生成多样且全面的数据方面面临巨大挑战,限制了模型性能的进一步提高。为了解决这一差距,我们提出了MDIT,这是一种用于多样指令微调的新型无模型数据插值方法,它通过任务插值生成多样且高质量的任务指令数据。此外,它包含基于多样性的聚类策略,以确保训练数据的多样性。大量实验表明,我们的方法在多个基准测试任务上取得了卓越的性能。使用MDIT微调的大型语言模型在通用问答、数学推理和代码生成等多项任务中取得了显著的改进。MDIT提供了一种高效且自动的数据合成方法,在不需要依赖外部资源的情况下生成多样化的指令数据,同时扩展了大型语言模型在复杂环境中的应用潜力。
论文及项目相关链接
Summary
大规模语言模型(LLMs)在多项任务中的应用日益广泛,指令微调作为一种提升模型性能的关键方法备受关注。然而,当前的数据管理策略在生成多样且全面的数据方面面临巨大挑战,限制了模型性能的进一步提升。为解决这一难题,我们提出了MDIT,一种用于多样指令微调的新型模型外数据插值方法。它通过任务插值生成多样且高质量的任务指令数据,并包含基于多样性的聚类策略,以确保训练数据的多样性。实验表明,该方法在多个基准测试任务上表现优异。使用MDIT微调后的LLMs在通用问答、数学推理和代码生成等多项任务中表现出显著改进。MDIT提供了一种高效且自动的数据合成方法,能够在不依赖外部资源的情况下生成多样的指令数据,扩大了LLM在复杂环境中的应用潜力。
Key Takeaways
- LLMs在多项任务中的应用越来越广泛,指令微调是提高其性能的关键方法。
- 当前数据管理策略在生成多样且全面的数据方面存在挑战。
- MDIT是一种新型的模型外数据插值方法,用于生成多样且高质量的指令数据。
- MDIT通过任务插值实现数据生成,并包含基于多样性的聚类策略。
- 实验表明MDIT在多个基准测试任务上表现优异。
- 使用MDIT微调后的LLMs在多项任务中表现出显著改进,如通用问答、数学推理和代码生成。
点此查看论文截图

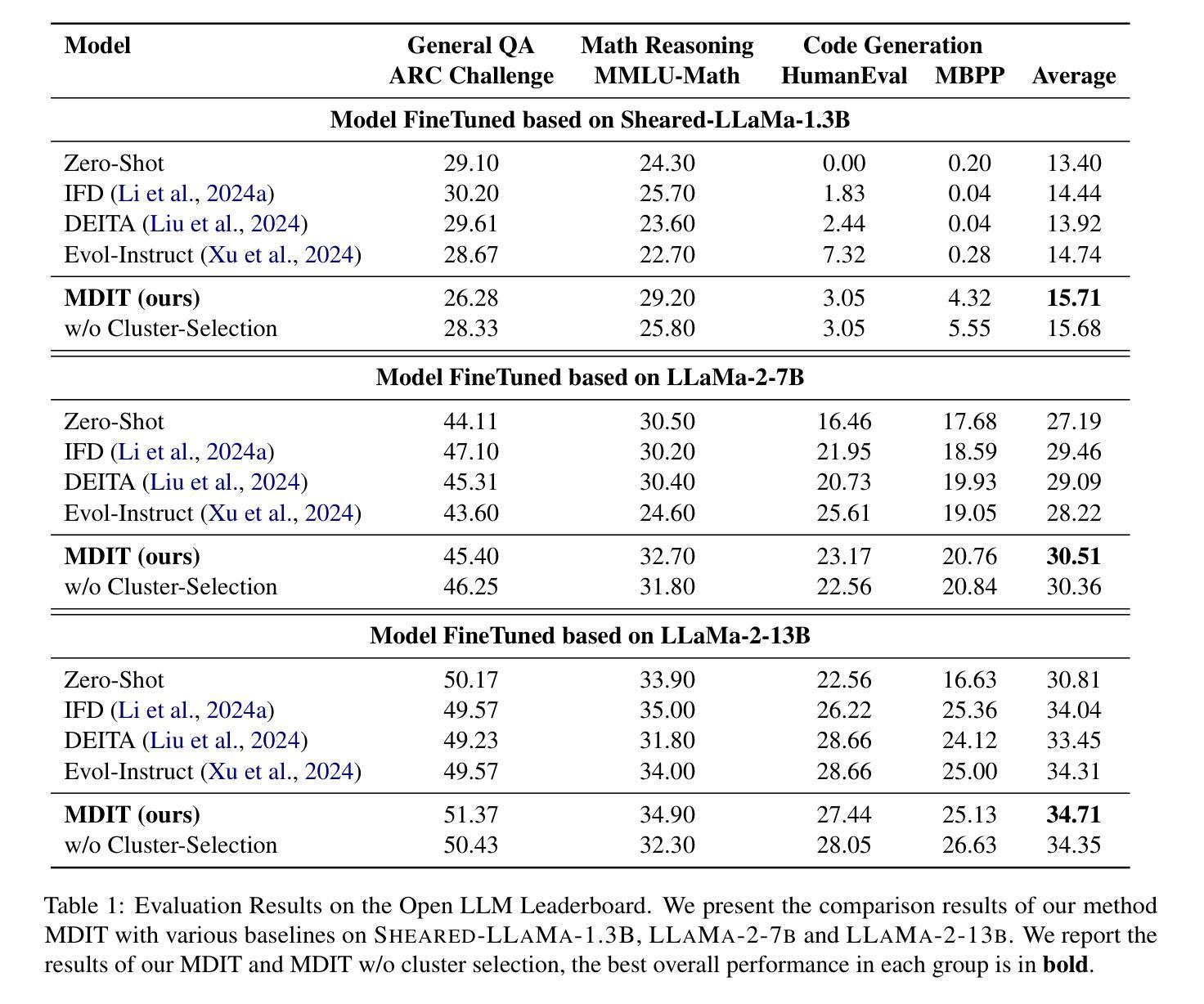
RAISE: Reinforenced Adaptive Instruction Selection For Large Language Models
Authors:Lv Qingsong, Yangning Li, Zihua Lan, Zishan Xu, Jiwei Tang, Yinghui Li, Wenhao Jiang, Hai-Tao Zheng, Philip S. Yu
In the instruction fine-tuning of large language models (LLMs), it has become a consensus that a few high-quality instructions are superior to a large number of low-quality instructions. At present, many instruction selection methods have been proposed, but most of these methods select instruction based on heuristic quality metrics, and only consider data selection before training. These designs lead to insufficient optimization of instruction fine-tuning, and fixed heuristic indicators are often difficult to optimize for specific tasks. So we designed a dynamic, task-objective-driven instruction selection framework RAISE(Reinforenced Adaptive Instruction SElection), which incorporates the entire instruction fine-tuning process into optimization, selecting instruction at each step based on the expected impact of instruction on model performance improvement. Our approach is well interpretable and has strong task-specific optimization capabilities. By modeling dynamic instruction selection as a sequential decision-making process, we use RL to train our selection strategy. Extensive experiments and result analysis prove the superiority of our method compared with other instruction selection methods. Notably, RAISE achieves superior performance by updating only 1% of the training steps compared to full-data training, demonstrating its efficiency and effectiveness.
在大规模语言模型(LLM)的指令微调中,已经达成一种共识,即少数高质量指令优于大量低质量指令。目前,已经提出了许多指令选择方法,但大多数方法都是基于启发式质量指标来选择指令,并且只在训练前考虑数据选择。这些设计导致指令微调优化不足,固定的启发式指标通常难以针对特定任务进行优化。因此,我们设计了一个动态的、任务目标驱动的指令选择框架RAISE(Reinforenced自适应指令SElection),它将整个指令微调过程纳入优化,根据指令对模型性能改进的预期影响,在每一步选择指令。我们的方法具有良好的可解释性,并具有较强的任务特定优化能力。通过将动态指令选择建模为序列决策过程,我们使用强化学习来训练我们的选择策略。大量的实验和结果分析证明了我们的方法与其他指令选择方法的优越性。值得注意的是,RAISE仅在1%的训练步骤中进行更新就实现了优于全数据训练的性能,证明了其效率和有效性。
论文及项目相关链接
Summary
大型语言模型的指令微调中,高质量指令优于大量低质量指令。传统方法基于启发式质量指标选择指令,仅在训练前考虑数据选择,导致指令微调优化不足。本文提出动态、任务目标驱动的指令选择框架RAISE,将指令微调过程纳入优化,根据指令对模型性能提升的预期影响进行动态选择。RAISE方法可解释性强,具有强大的任务特定优化能力,将动态指令选择建模为序列决策过程,并使用强化学习训练选择策略。实验证明,RAISE方法与其他指令选择方法相比具有优越性,仅在1%的训练步骤中更新数据即可实现卓越性能。
Key Takeaways
- 在大型语言模型的指令微调中,高质量指令优于大量低质量指令。
- 传统指令选择方法基于启发式质量指标,仅在训练前考虑数据选择,存在优化不足的问题。
- RAISE是一种动态、任务目标驱动的指令选择框架,将指令微调过程纳入优化。
- RAISE根据指令对模型性能提升的预期影响进行动态选择。
- RAISE方法可解释性强,具有强大的任务特定优化能力。
- RAISE将动态指令选择建模为序列决策过程,并使用强化学习训练选择策略。
点此查看论文截图


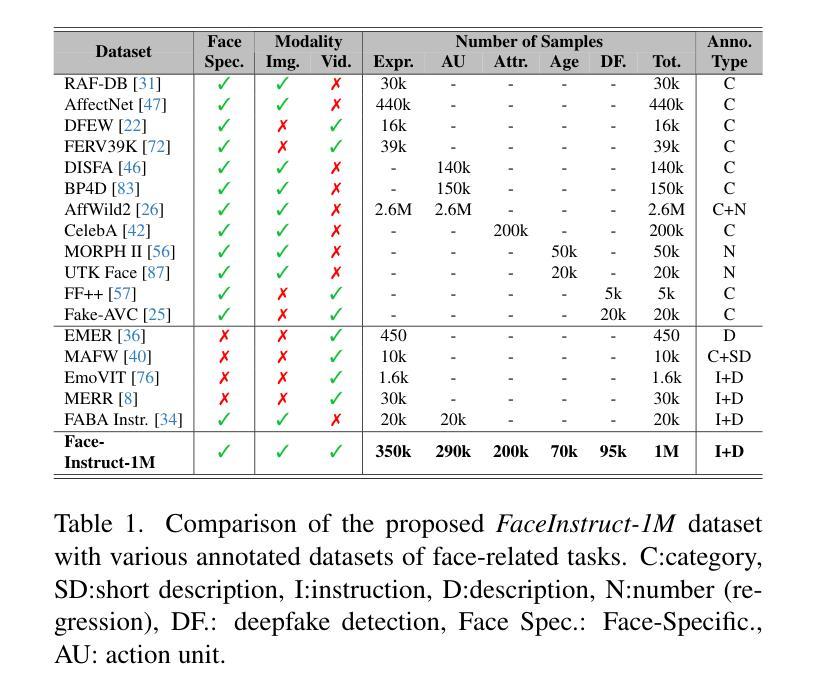
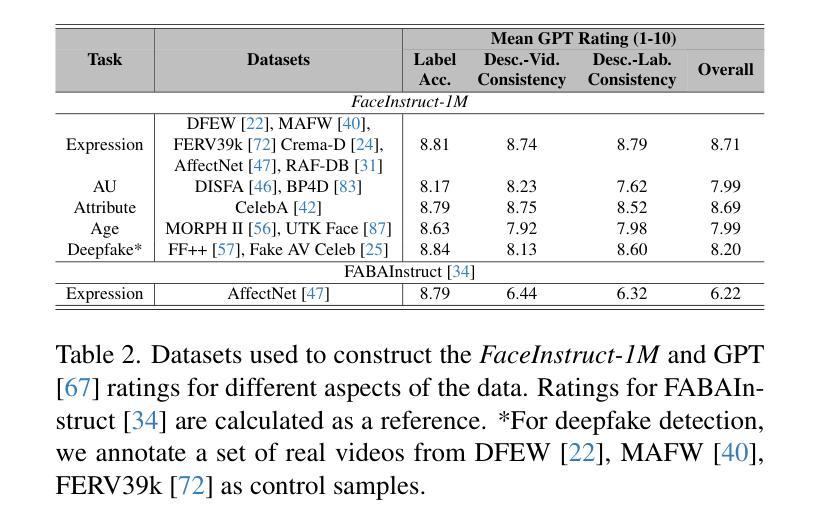
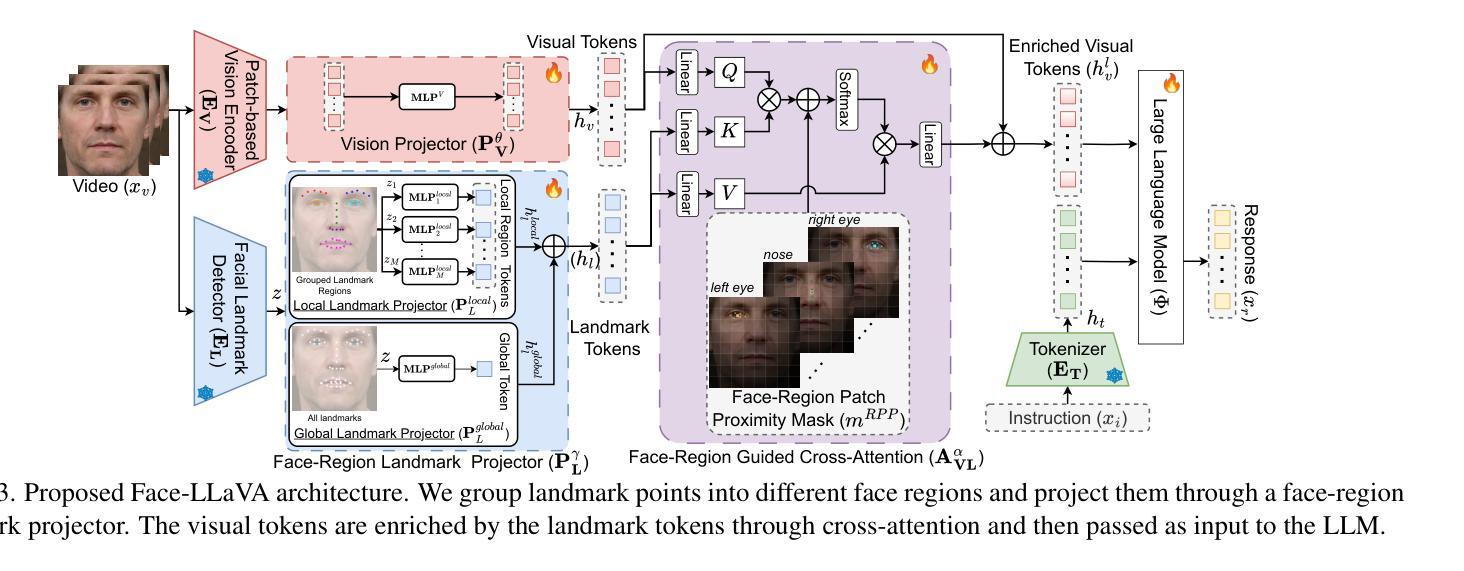
Face-LLaVA: Facial Expression and Attribute Understanding through Instruction Tuning
Authors:Ashutosh Chaubey, Xulang Guan, Mohammad Soleymani
The human face plays a central role in social communication, necessitating the use of performant computer vision tools for human-centered applications. We propose Face-LLaVA, a multimodal large language model for face-centered, in-context learning, including facial expression and attribute recognition. Additionally, Face-LLaVA is able to generate natural language descriptions that can be used for reasoning. Leveraging existing visual databases, we first developed FaceInstruct-1M, a face-centered database for instruction tuning MLLMs for face processing. We then developed a novel face-specific visual encoder powered by Face-Region Guided Cross-Attention that integrates face geometry with local visual features. We evaluated the proposed method across nine different datasets and five different face processing tasks, including facial expression recognition, action unit detection, facial attribute detection, age estimation and deepfake detection. Face-LLaVA achieves superior results compared to existing open-source MLLMs and competitive performance compared to commercial solutions. Our model output also receives a higher reasoning rating by GPT under a zero-shot setting across all the tasks. Both our dataset and model wil be released at https://face-llava.github.io to support future advancements in social AI and foundational vision-language research.
人脸在社会交流中具有核心作用,这要求使用高性能的计算机视觉工具进行以人为中心的应用。我们提出了Face-LLaVA,这是一种面向人脸的中心化上下文学习多模态大型语言模型,包括面部表情和属性识别。此外,Face-LLaVA能够生成可用于推理的自然语言描述。我们利用现有的视觉数据库,首先开发了FaceInstruct-1M,这是一个用于指令微调面向人脸处理的大型语言模型的人脸中心化数据库。然后我们开发了一种新型的人脸特定视觉编码器,该编码器由Face-Region Guided Cross-Attention驱动,集成了人脸几何与局部视觉特征。我们在九个不同的数据集和五个不同的人脸处理任务上评估了所提出的方法,包括面部表情识别、动作单元检测、面部属性检测、年龄估计和深度伪造检测。Face-LLaVA相较于现有的开源大型语言模型取得了优越的结果,并在所有任务中实现了与商业解决方案相竞争的性能。我们的模型输出还得到了GPT在零样本设置下的更高推理评分。我们的数据集和模型都将在https://face-llava.github.io发布,以支持社会人工智能和基础视觉语言研究的未来发展。
论文及项目相关链接
PDF Project Page: https://face-llava.github.io
Summary
人脸识别在社会交流中具有重要作用,需要高性能计算机视觉工具支持面向人类的应用。本研究提出了Face-LLaVA,一种用于面部为中心的多模态大型语言模型,支持上下文学习,包括面部表情和属性识别。此外,Face-LLaVA能够生成自然语言描述,用于推理。研究构建了FaceInstruct-1M数据库,并开发了一种新型面部特定视觉编码器,集成了面部几何与局部视觉特征。在九个数据集和五个面部处理任务上的实验表明,Face-LLaVA在表情识别等方面表现卓越,相比其他开源大型语言模型有显著提升。其模型输出也在GPT零样本设定下获得了较高的推理评分。该数据集与模型将为推动社会人工智能和基本视觉语言研究提供支持。更多详情可访问:https://face-llava.github.io。
Key Takeaways
- 人脸在社会交流中的重要性及其对于高性能计算机视觉工具的需求。
- Face-LLaVA多模态大型语言模型的提出,用于面部为中心、支持上下文学习的任务。
- Face-LLaVA能够进行面部表情和属性识别,并能生成自然语言描述进行推理。
- 利用现有视觉数据库建立了FaceInstruct-1M面部为中心的数据集。
- 开发了一种新型面部特定视觉编码器,集成面部几何与局部视觉特征的技术。
- Face-LLaVA在不同数据集上的实验结果展示其卓越性能,特别是在面部表情识别等方面。
点此查看论文截图



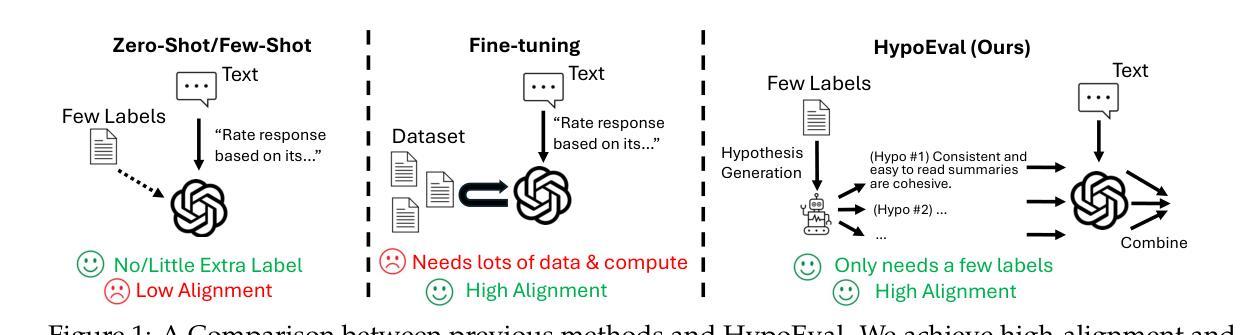
HypoEval: Hypothesis-Guided Evaluation for Natural Language Generation
Authors:Mingxuan Li, Hanchen Li, Chenhao Tan
Large language models (LLMs) have demonstrated great potential for automating the evaluation of natural language generation. Previous frameworks of LLM-as-a-judge fall short in two ways: they either use zero-shot setting without consulting any human input, which leads to low alignment, or fine-tune LLMs on labeled data, which requires a non-trivial number of samples. Moreover, previous methods often provide little reasoning behind automated evaluations. In this paper, we propose HypoEval, Hypothesis-guided Evaluation framework, which first uses a small corpus of human evaluations to generate more detailed rubrics for human judgments and then incorporates a checklist-like approach to combine LLM’s assigned scores on each decomposed dimension to acquire overall scores. With only 30 human evaluations, HypoEval achieves state-of-the-art performance in alignment with both human rankings (Spearman correlation) and human scores (Pearson correlation), on average outperforming G-Eval by 11.86% and fine-tuned Llama-3.1-8B-Instruct with at least 3 times more human evaluations by 11.95%. Furthermore, we conduct systematic studies to assess the robustness of HypoEval, highlighting its effectiveness as a reliable and interpretable automated evaluation framework.
大型语言模型(LLM)在自动化评估自然语言生成方面展现出了巨大的潜力。以前的LLM评估框架在两个方面存在不足:它们要么使用零样本设置,不参考任何人工输入,导致对齐程度低,要么对标注数据进行微调,这需要大量的样本。此外,以前的方法往往对自动化评估背后的推理依据提供得很少。在本文中,我们提出了假设引导评估框架(HypoEval),首先使用少量的人工评估语料库来生成更详细的人类判断规则,然后采用类似清单的方法,结合LLM在每个分解维度上的得分,以获得总体得分。仅通过30次人工评估,HypoEval就达到了最先进的人机对齐性能(体现在斯皮尔曼相关系数和皮尔逊相关系数上),平均而言,相对于G-Eval提升了11.86%,并且在至少3倍以上的人工评估情况下,相对于经过训练的Llama-3.1-8B-Instruct提升了11.95%。此外,我们还进行了系统的研究来评估HypoEval的稳健性,强调了其作为可靠和可解释的自动化评估框架的有效性。
论文及项目相关链接
PDF 22 pages, 3 figures, code link: https://github.com/ChicagoHAI/HypoEval-Gen
Summary
本文提出了一种假设引导的评价框架HypoEval,该框架使用少量的人类评价数据生成更详细的评价准则,并结合清单式的方法,通过大型语言模型(LLM)对各个分解维度进行评分,从而获取总体评分。HypoEval只需30个人类评价即可达到与最新技术相当的性能水平,与人类排名和评分的对齐度较高,且在鲁棒性评估中表现出了其可靠性和可解释性。
Key Takeaways
- LLM在自动评估自然语言生成方面展现巨大潜力,但之前的方法存在不足。
- 提出了一种假设引导的评价框架HypoEval。
- 使用少量的人类评价数据生成详细的评价准则。
- 结合清单式方法,通过LLM对各个分解维度进行评分,获得总体评分。
- 仅用30个人类评价即可达到与最新技术相当的性能水平。
- 与人类排名和评分的对齐度高。
点此查看论文截图

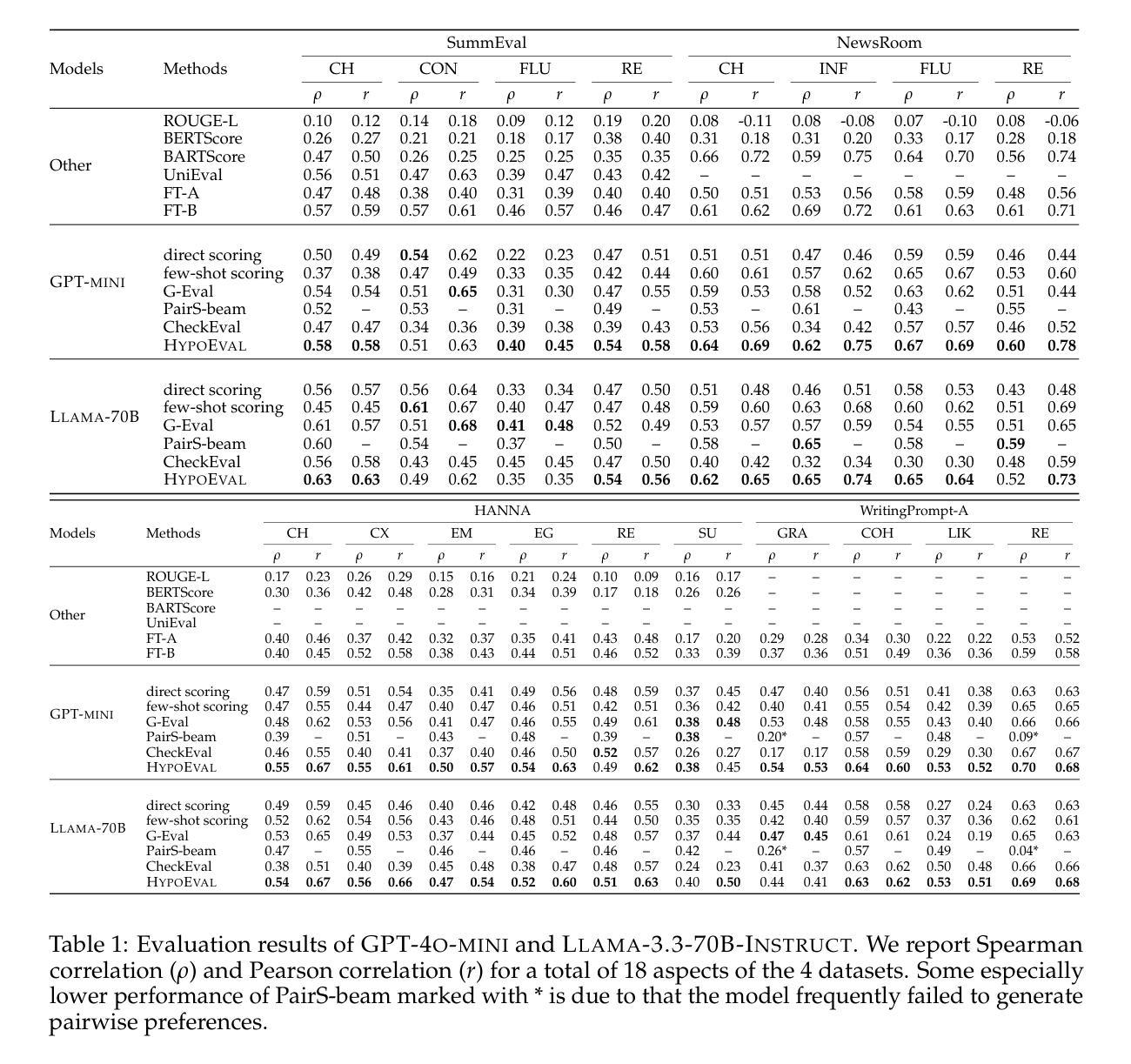
Holistic Capability Preservation: Towards Compact Yet Comprehensive Reasoning Models
Authors: Ling Team, Caizhi Tang, Chilin Fu, Chunwei Wu, Jia Guo, Jianwen Wang, Jingyu Hu, Liang Jiang, Meng Li, Peng Jiao, Pingping Liu, Shaomian Zheng, Shiwei Liang, Shuaicheng Li, Yalin Zhang, Yingting Wu, Yongkang Liu, Zhenyu Huang
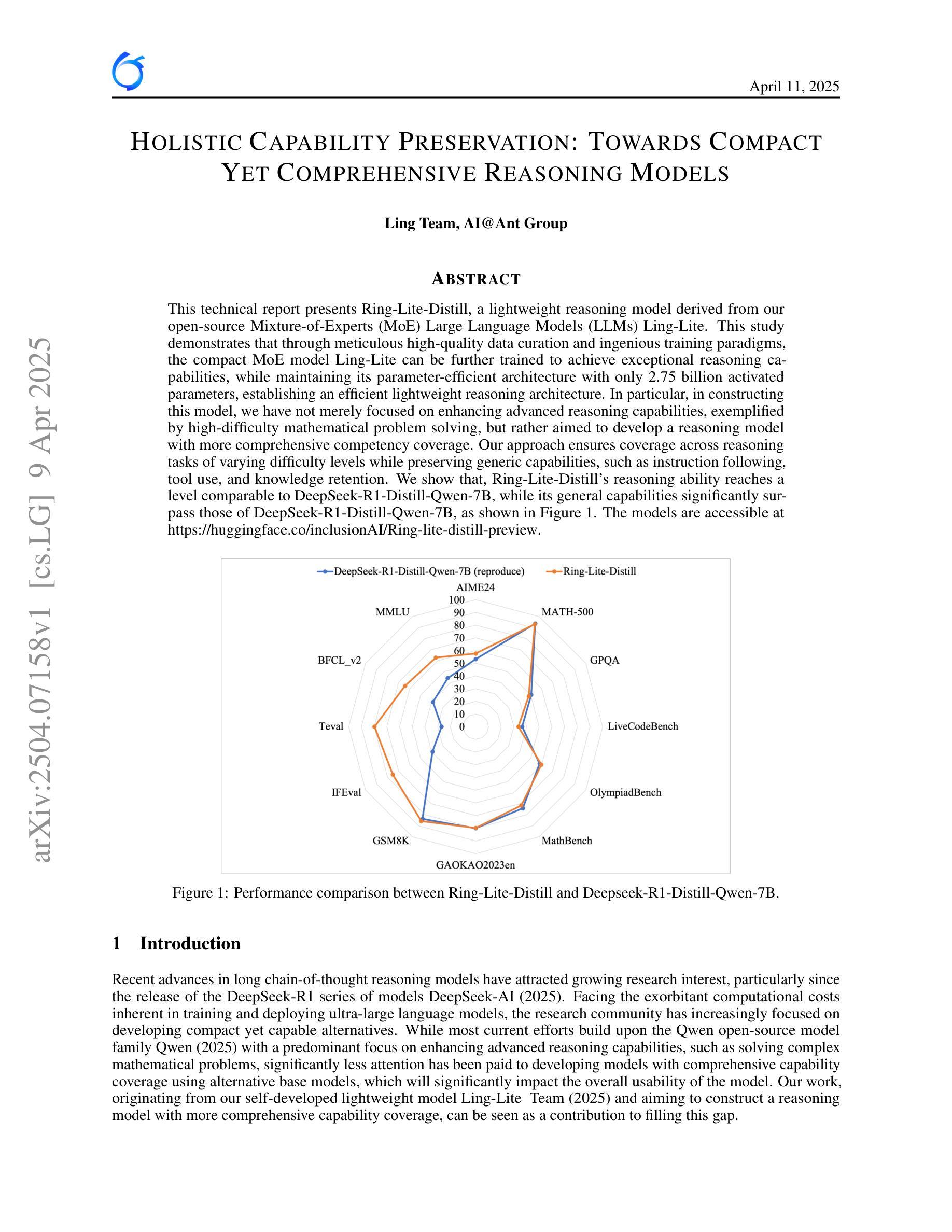
This technical report presents Ring-Lite-Distill, a lightweight reasoning model derived from our open-source Mixture-of-Experts (MoE) Large Language Models (LLMs) Ling-Lite. This study demonstrates that through meticulous high-quality data curation and ingenious training paradigms, the compact MoE model Ling-Lite can be further trained to achieve exceptional reasoning capabilities, while maintaining its parameter-efficient architecture with only 2.75 billion activated parameters, establishing an efficient lightweight reasoning architecture. In particular, in constructing this model, we have not merely focused on enhancing advanced reasoning capabilities, exemplified by high-difficulty mathematical problem solving, but rather aimed to develop a reasoning model with more comprehensive competency coverage. Our approach ensures coverage across reasoning tasks of varying difficulty levels while preserving generic capabilities, such as instruction following, tool use, and knowledge retention. We show that, Ring-Lite-Distill’s reasoning ability reaches a level comparable to DeepSeek-R1-Distill-Qwen-7B, while its general capabilities significantly surpass those of DeepSeek-R1-Distill-Qwen-7B. The models are accessible at https://huggingface.co/inclusionAI
本技术报告介绍了Ring-Lite-Distill,这是一个轻量级的推理模型,源于我们开源的混合专家(MoE)大型语言模型(LLM)Ling-Lite。本研究表明,通过精心的高质量数据收集和巧妙的训练模式,紧凑的MoE模型Ling-Lite可以进一步训练,实现出色的推理能力,同时保持其参数高效架构,仅使用2.75亿个激活参数,建立有效的轻量化推理架构。在构建此模型时,我们不仅仅着眼于提高解决高难度数学问题的先进推理能力,而是致力于开发具有更全面能力覆盖范围的推理模型。我们的方法确保了不同难度级别的推理任务的覆盖,同时保留了一般能力,如指令遵循、工具使用和知识保留。我们证明,Ring-Lite-Distill的推理能力与DeepSeek-R1-Distill-Qwen-7B相当,而其一般能力则显著超过了DeepSeek-R1-Distill-Qwen-7B。模型可在https://huggingface.co/inclusionAI 访问。
论文及项目相关链接
PDF 10 pages
Summary
Ling-Lite模型通过精心的高品质数据整合和创新训练模式,实现了出色的推理能力,同时保持了参数效率。其进一步训练出的轻量级推理模型Ring-Lite-Distill,具有卓越的性能和全面的能力覆盖。该模型不仅在高难度数学问题解决等高级推理任务上表现出色,还具备通用能力,如指令遵循、工具使用和知识保留等。其推理能力与DeepSeek-R1-Distill-Qwen-7B相当,但通用能力更胜一筹。
Key Takeaways
- Ring-Lite-Distill是基于Ling-Lite模型的轻量级推理模型。
- Ling-Lite通过高质量数据整合和创新训练模式实现了出色的推理能力。
- Ring-Lite-Distill具有卓越的性能和全面的能力覆盖,包括高级推理和通用能力。
- 该模型在保持参数效率的同时,实现了高水平的推理能力。
- Ring-Lite-Distill的推理能力与DeepSeek-R1-Distill-Qwen-7B相当。
- 模型具有通用能力,如指令遵循、工具使用和知识保留等。
点此查看论文截图
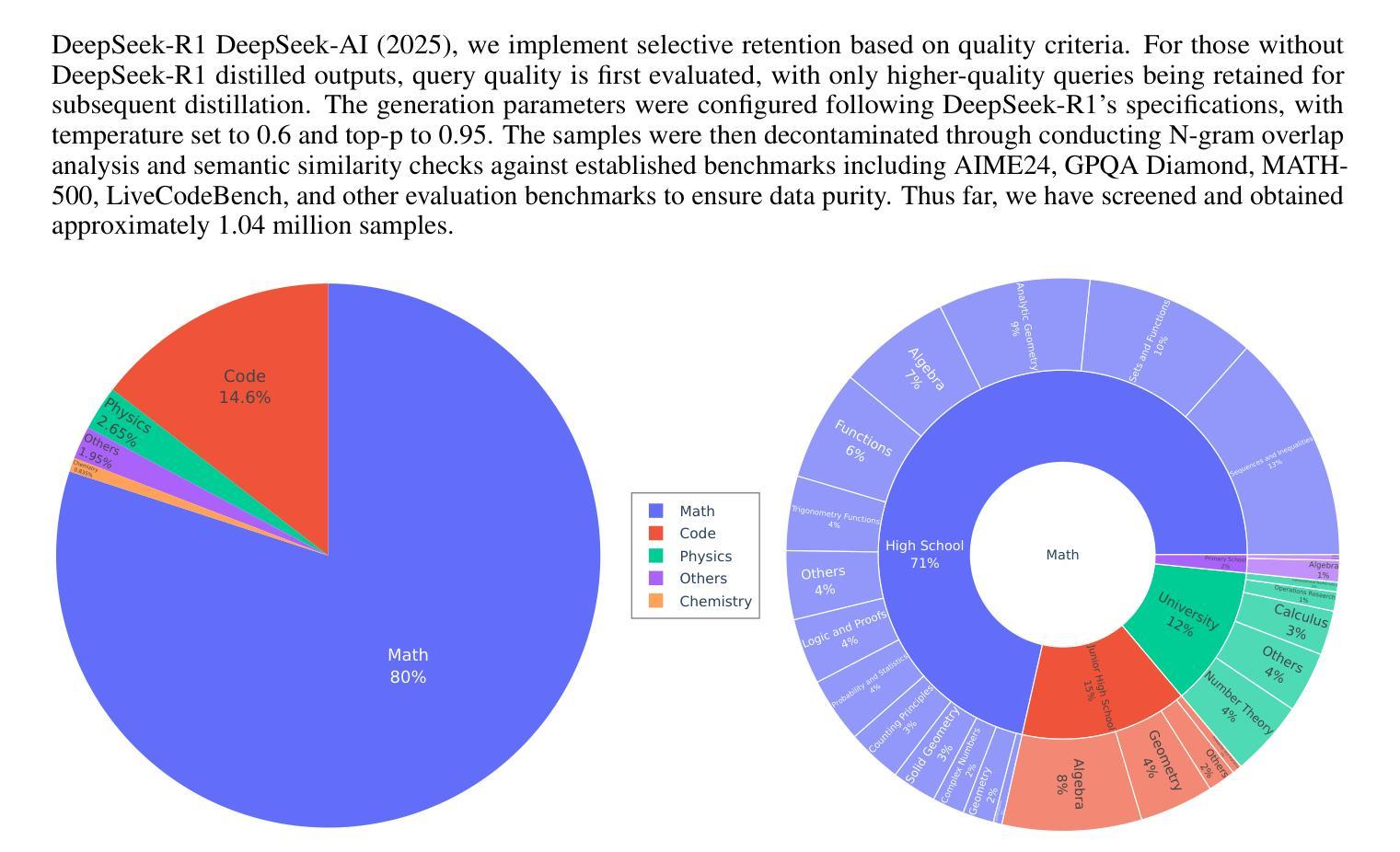
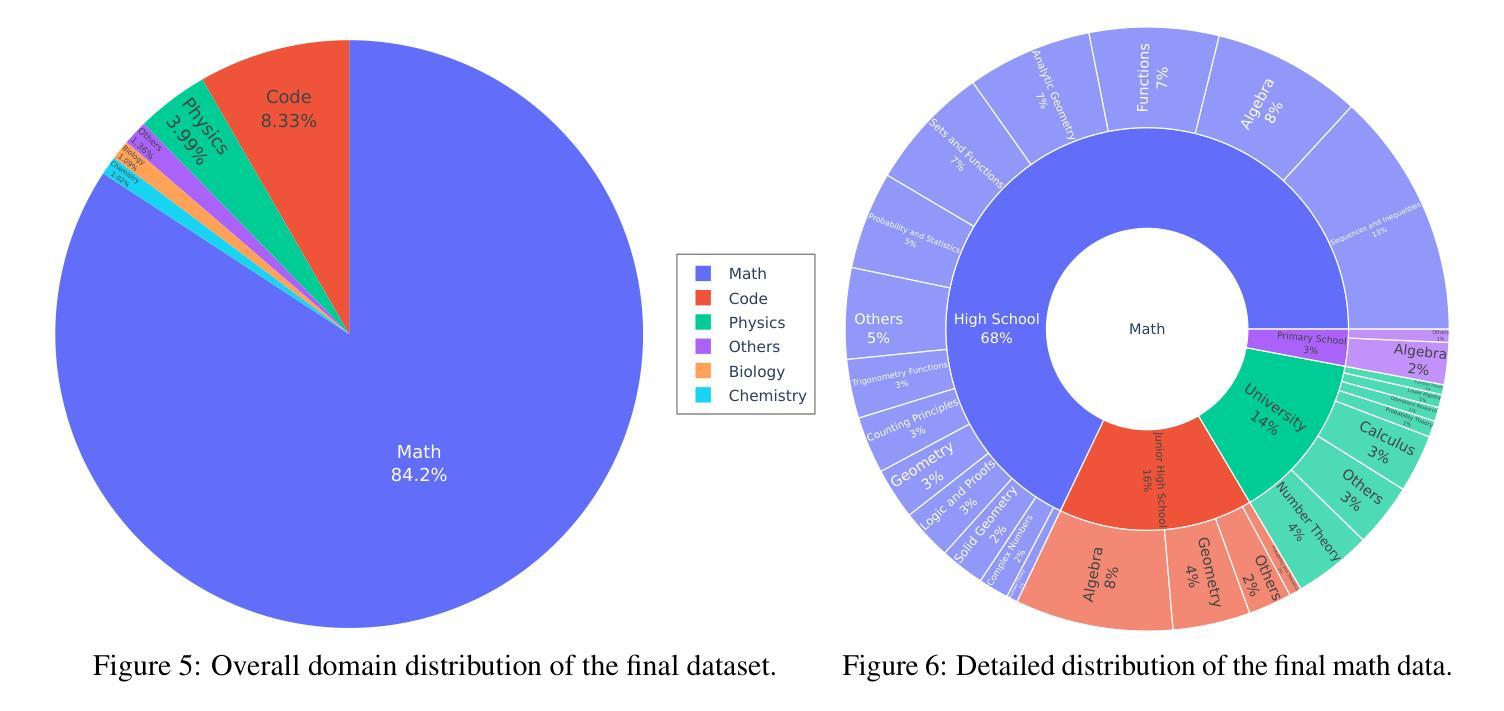
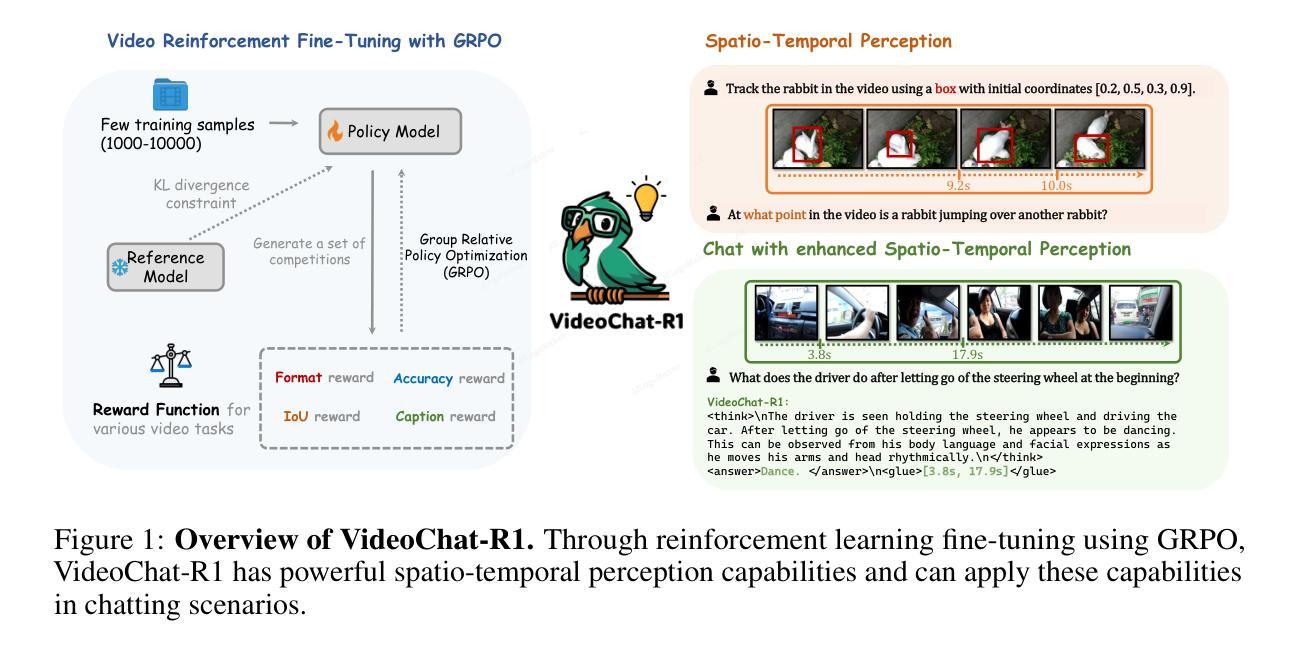
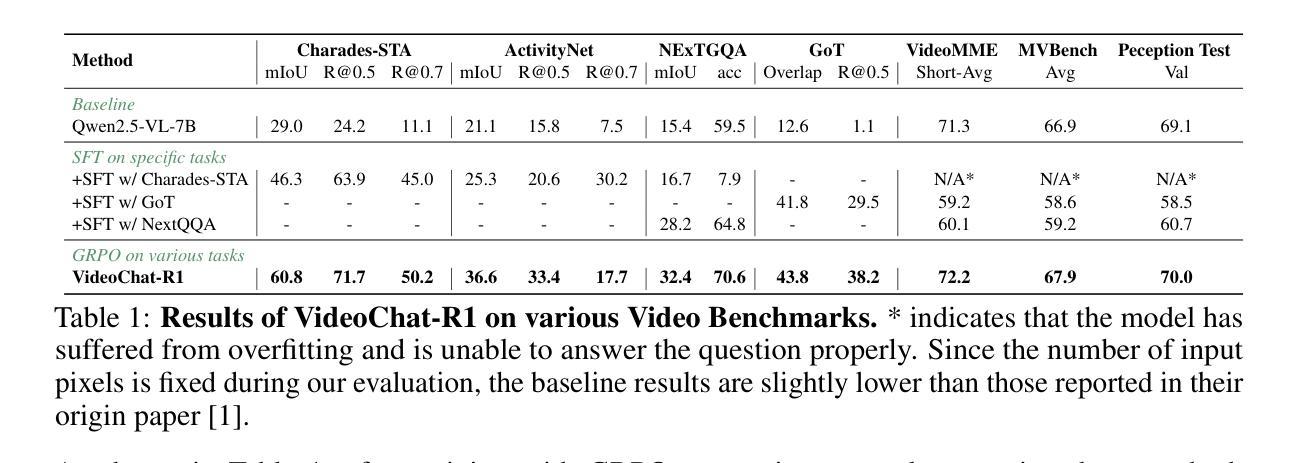
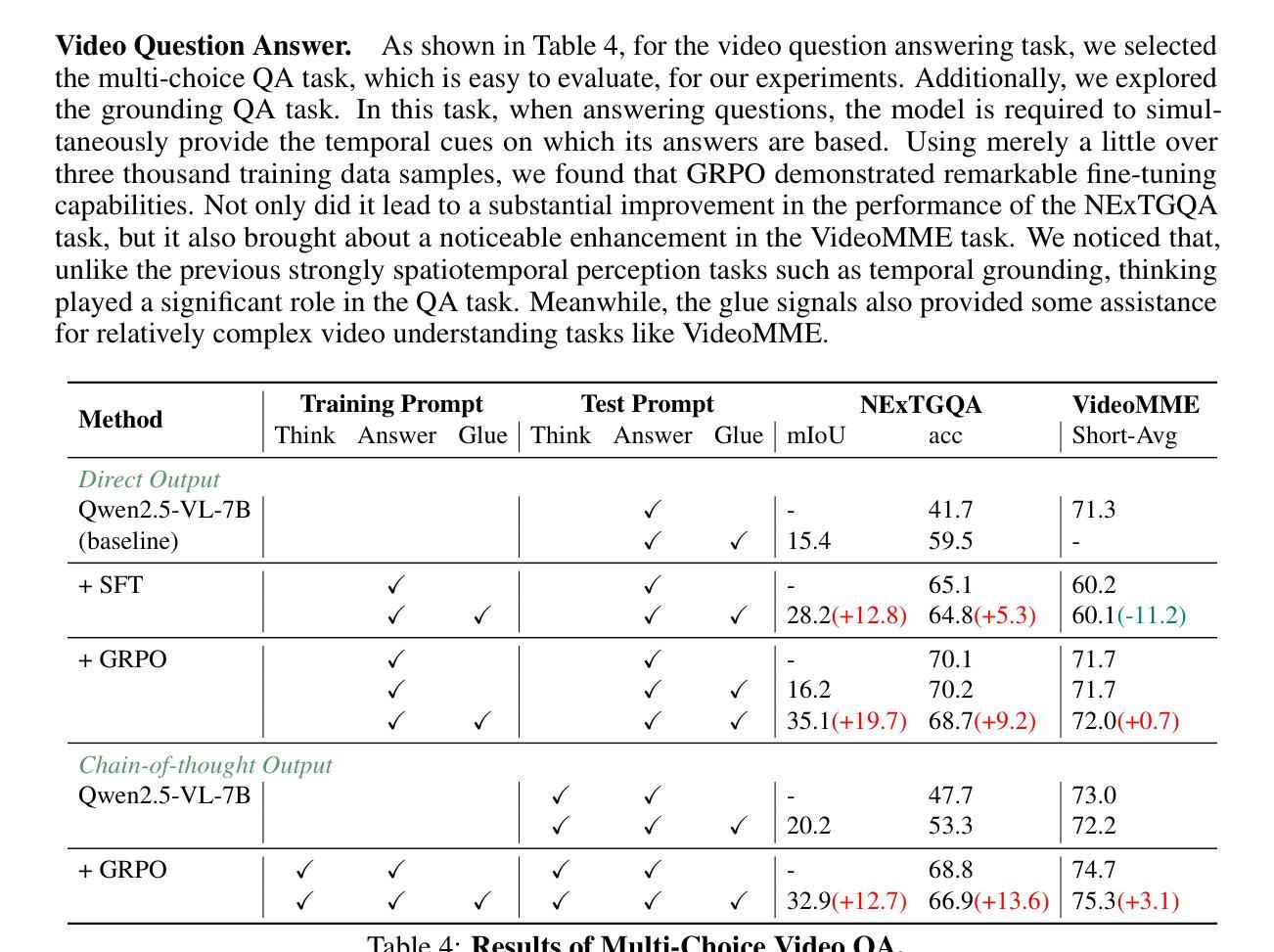
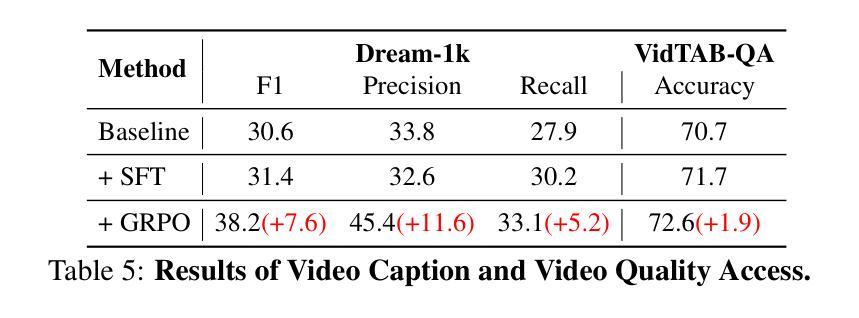
VideoChat-R1: Enhancing Spatio-Temporal Perception via Reinforcement Fine-Tuning
Authors:Xinhao Li, Ziang Yan, Desen Meng, Lu Dong, Xiangyu Zeng, Yinan He, Yali Wang, Yu Qiao, Yi Wang, Limin Wang
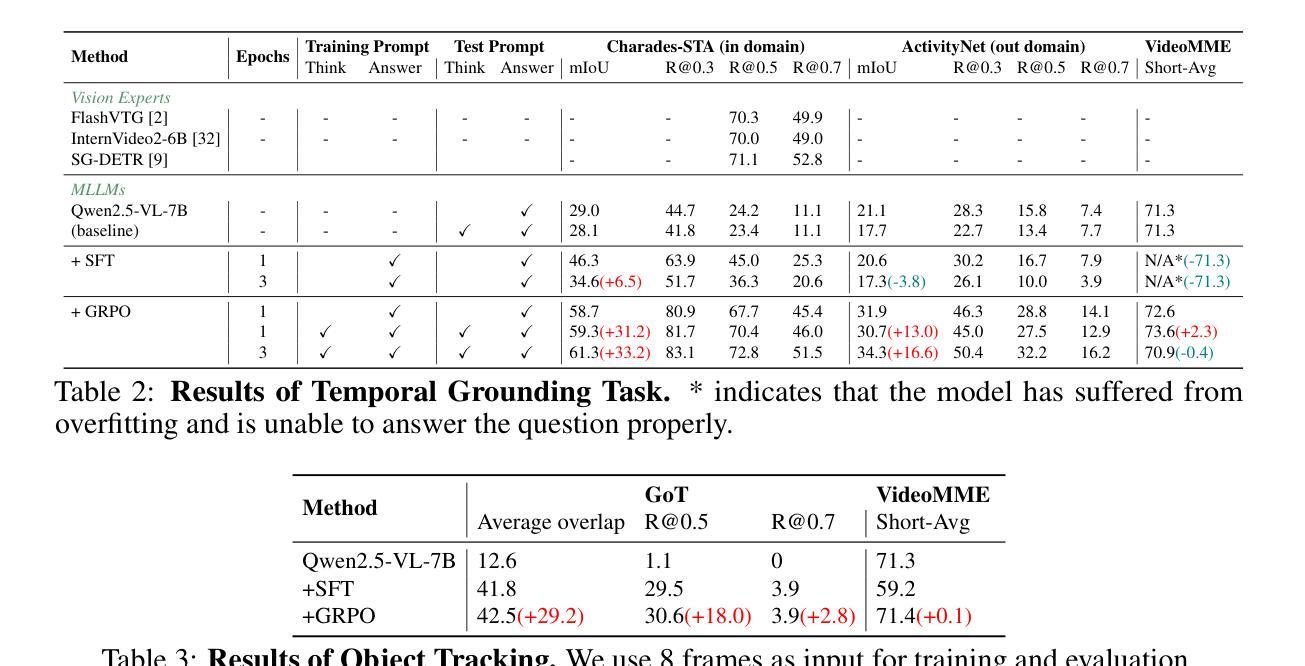
Recent advancements in reinforcement learning have significantly advanced the reasoning capabilities of multimodal large language models (MLLMs). While approaches such as Group Relative Policy Optimization (GRPO) and rule-based reward mechanisms demonstrate promise in text and image domains, their application to video understanding remains limited. This paper presents a systematic exploration of Reinforcement Fine-Tuning (RFT) with GRPO for video MLLMs, aiming to enhance spatio-temporal perception while maintaining general capabilities. Our experiments reveal that RFT is highly data-efficient for task-specific improvements. Through multi-task RFT on spatio-temporal perception objectives with limited samples, we develop VideoChat-R1, a powerful video MLLM that achieves state-of-the-art performance on spatio-temporal perception tasks without sacrificing chat ability, while exhibiting emerging spatio-temporal reasoning abilities. Compared to Qwen2.5-VL-7B, VideoChat-R1 boosts performance several-fold in tasks like temporal grounding (+31.8) and object tracking (+31.2). Additionally, it significantly improves on general QA benchmarks such as VideoMME (+0.9), MVBench (+1.0), and Perception Test (+0.9). Our findings underscore the potential of RFT for specialized task enhancement of Video MLLMs. We hope our work offers valuable insights for future RL research in video MLLMs.
近期强化学习领域的进展极大地提升了多模态大型语言模型的推理能力。虽然诸如集团相对策略优化(GRPO)和基于规则的奖励机制等方法在文本和图像领域展现出巨大的潜力,但它们在视频理解方面的应用仍然有限。本文系统地探讨了使用GRPO的强化微调(RFT)在视频MLLMs中的应用,旨在提升时空感知能力的同时保持通用能力。我们的实验表明,RFT对于特定任务的改进非常注重数据效率。通过在有限的样本上对时空感知目标进行多任务RFT训练,我们开发出了VideoChat-R1,这是一款强大的视频MLLM,它在时空感知任务上实现了最先进的性能,同时不牺牲对话能力,并展现出新兴的时空推理能力。与Qwen2.5-VL-7B相比,VideoChat-R1在诸如时间定位(+31.8)和对象跟踪(+31.2)等任务上的性能提升了数倍。此外,它在通用问答基准测试(如VideoMME(+0.9)、MVBench(+1.0)和Perception Test(+0.9))上也取得了显著改善。我们的研究突出了RFT在视频MLLM专项任务增强方面的潜力。我们希望我们的研究能为未来视频MLLM的强化学习研究提供有价值的见解。
论文及项目相关链接
Summary
强化学习在提升多模态大型语言模型(MLLMs)的推理能力方面取得了显著进展。本文系统探讨了使用Group Relative Policy Optimization(GRPO)的Reinforcement Fine-Tuning(RFT)在视频MLLMs中的应用,旨在提高时空感知能力的同时保持通用能力。实验表明,RFT在特定任务改进方面非常注重数据效率。通过有限样本的时空感知目标上的多任务RFT,我们开发了VideoChat-R1,它在时空感知任务上实现了卓越性能,同时不牺牲聊天能力,并展现出新兴的时空推理能力。与Qwen2.5-VL-7B相比,VideoChat-R1在诸如时间定位(提高31.8)和对象跟踪(提高31.2)等任务上的性能提升了数倍。此外,它在一般问答基准测试中也有显著改善,如VideoMME(+ 0.9),MVBench(+ 1.0)和Perception Test(+ 0.9)。本文的研究结果突显了RFT在视频MLLMs特定任务增强方面的潜力。
Key Takeaways
- 强化学习在提升多模态大型语言模型的推理能力上有了新进展。
- 本文探讨了Reinforcement Fine-Tuning (RFT) 与Group Relative Policy Optimization (GRPO) 在视频MLLMs中的应用。
- RFT旨在提高视频MLLMs的时空感知能力,同时保持其通用能力。
- 实验显示RFT是数据高效的,能在特定任务上实现显著改进。
- 通过多任务RFT,开发了VideoChat-R1模型,它在时空感知任务上表现卓越。
- VideoChat-R1相较于Qwen2.5-VL-7B,在时空感知任务如时间定位和对象跟踪上的性能有显著提高。
点此查看论文截图

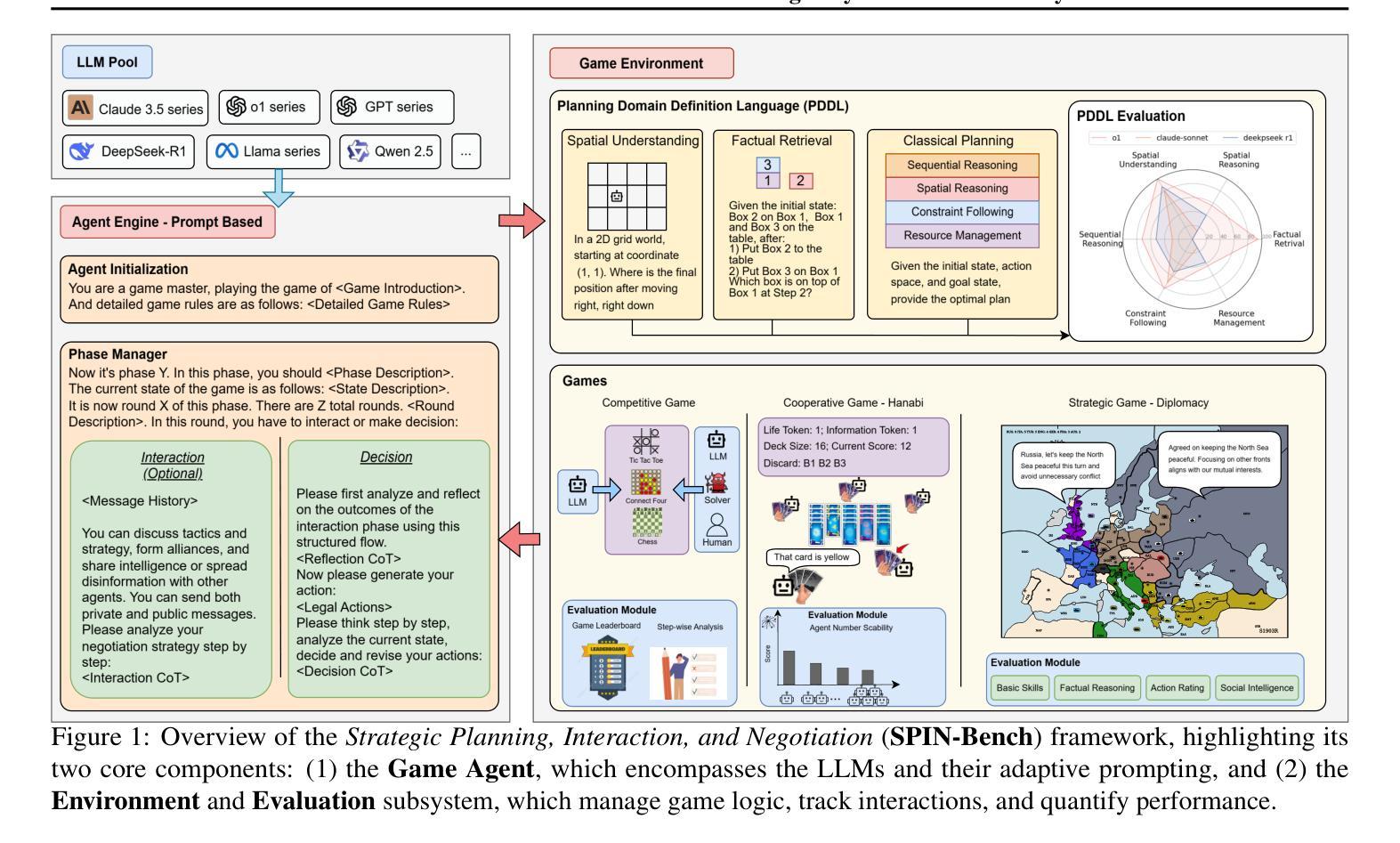
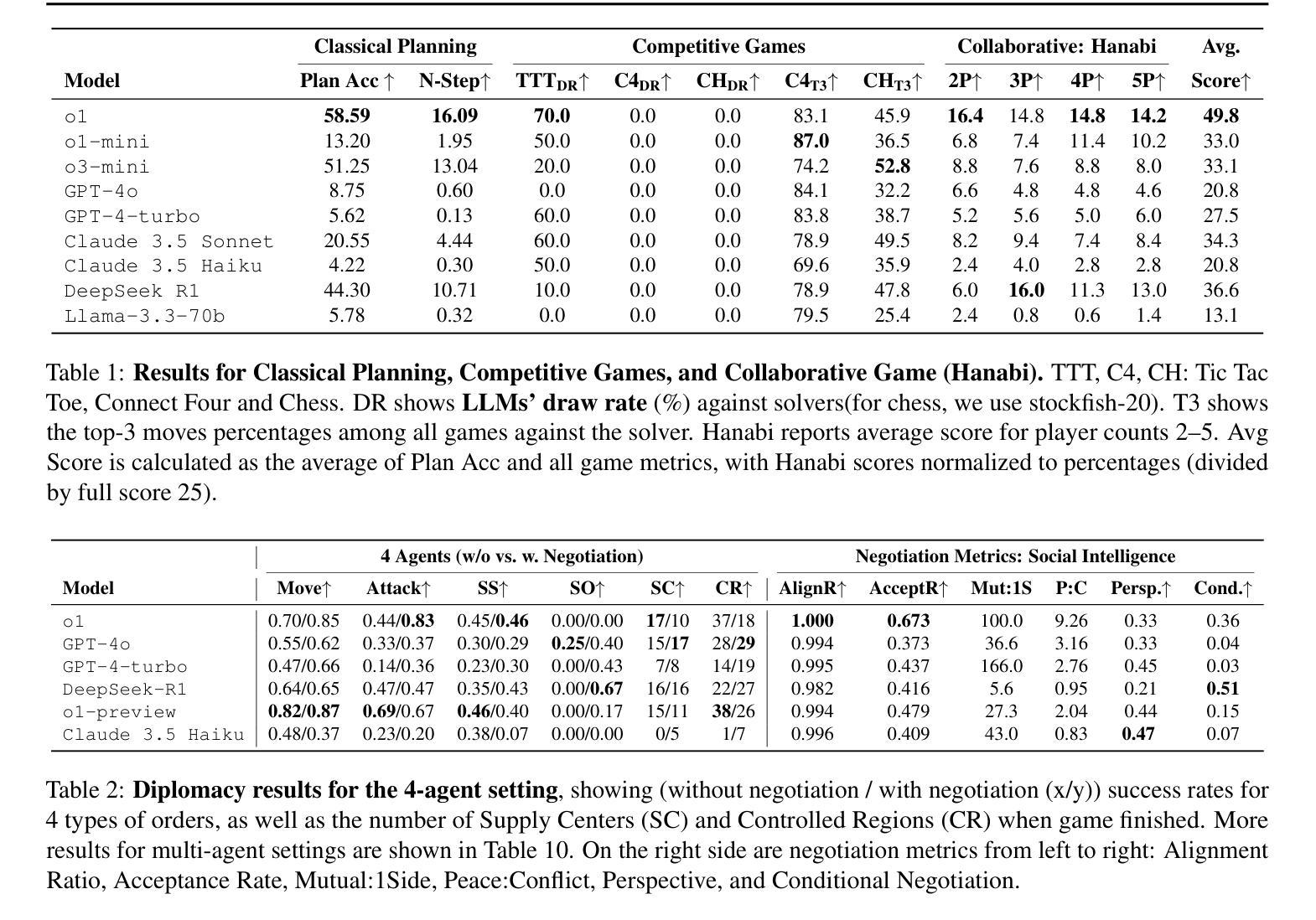
SPIN-Bench: How Well Do LLMs Plan Strategically and Reason Socially?
Authors:Jianzhu Yao, Kevin Wang, Ryan Hsieh, Haisu Zhou, Tianqing Zou, Zerui Cheng, Zhangyang Wang, Pramod Viswanath
Reasoning and strategic behavior in social interactions is a hallmark of intelligence. This form of reasoning is significantly more sophisticated than isolated planning or reasoning tasks in static settings (e.g., math problem solving). In this paper, we present Strategic Planning, Interaction, and Negotiation (SPIN-Bench), a new multi-domain evaluation designed to measure the intelligence of strategic planning and social reasoning. While many existing benchmarks focus on narrow planning or single-agent reasoning, SPIN-Bench combines classical PDDL tasks, competitive board games, cooperative card games, and multi-agent negotiation scenarios in one unified framework. The framework includes both a benchmark as well as an arena to simulate and evaluate the variety of social settings to test reasoning and strategic behavior of AI agents. We formulate the benchmark SPIN-Bench by systematically varying action spaces, state complexity, and the number of interacting agents to simulate a variety of social settings where success depends on not only methodical and step-wise decision making, but also conceptual inference of other (adversarial or cooperative) participants. Our experiments reveal that while contemporary LLMs handle basic fact retrieval and short-range planning reasonably well, they encounter significant performance bottlenecks in tasks requiring deep multi-hop reasoning over large state spaces and socially adept coordination under uncertainty. We envision SPIN-Bench as a catalyst for future research on robust multi-agent planning, social reasoning, and human–AI teaming. Project Website: https://spinbench.github.io/
在社会互动中的推理和战略行为是智能的标志。这种推理形式远比静态环境中的孤立规划或推理任务(例如数学问题解决)更为复杂。在本文中,我们提出了“战略规划、互动与谈判(SPIN-Bench)”,这是一种新的多领域评估,旨在衡量战略规划和社会推理的智能水平。虽然许多现有的基准测试主要集中在狭隘的规划或单代理推理上,但SPIN-Bench结合了经典PDDL任务、竞技棋类游戏、合作卡牌游戏和多代理谈判场景在一个统一框架中。该框架既包括一个基准测试,也包括一个模拟和评估各种社交设置的场所,以测试人工智能代理的推理和战略行为。我们通过系统地改变动作空间、状态复杂性和交互代理的数量来制定SPIN-Bench基准测试,以模拟各种社交环境,在这些环境中,成功不仅取决于方法和逐步的决策制定,还取决于对其他(对抗性或合作性)参与者的概念推断。我们的实验表明,虽然当代大型语言模型在处理基本事实检索和短期规划方面表现良好,但在需要在大状态空间中进行深度多跳推理和不确定环境下的社会适应性协调的任务中,它们会遇到显著的性能瓶颈。我们期望SPIN-Bench能成为未来研究稳健的多代理规划、社会推理和人机协作领域的催化剂。项目网站:https://spinbench.github.io/
论文及项目相关链接
PDF 42 pages, 8 figures
Summary
该论文介绍了社会互动中的推理与策略行为是智能的重要表现。文章提出了一个新的多领域评估方法——战略计划互动谈判基准测试(SPIN-Bench),旨在测量战略规划和社交推理的智能水平。不同于现有的侧重于单一计划或单一智能体推理的基准测试,SPIN-Bench结合了经典的PDDL任务、竞技棋盘游戏、合作卡牌游戏和多智能体谈判场景在一个统一框架中。该框架包括一个模拟多种社交设置的基准测试环境,以测试人工智能智能体的推理和策略行为。研究结果表明,当前的大型语言模型虽然能较好地处理基本事实检索和短期规划任务,但在需要深度多跳推理和不确定环境下的社会适应性协调任务时,性能瓶颈显著。SPIN-Bench有望成为未来研究稳健多智能体规划、社交推理和人机协作的重要推动力。
Key Takeaways
- 文章中提到,社会互动中的推理和策略行为是智能的一个重要体现,而这需要比静态环境中的孤立规划或推理任务更为高级的智力水平。
- 介绍了一种新的多领域评估方法——战略规划互动谈判基准测试(SPIN-Bench),用以测量智能体的战略规划和社交推理能力。
- SPIN-Bench框架结合了多种任务类型,包括经典的PDDL任务、竞技棋盘游戏、合作卡牌游戏和多智能体谈判场景,以模拟真实的社交环境。
- 当前的大型语言模型在处理需要深度多跳推理和不确定环境下的社会适应性协调任务时存在性能瓶颈。
- SPIN-Bench为未来的研究提供了一个平台,包括研究稳健的多智能体规划、社交推理和人机协作等关键领域。
- 通过系统地改变动作空间、状态复杂性和交互智能体的数量,SPIN-Bench能够模拟各种社交设置,以测试AI智能体的推理和策略行为。
点此查看论文截图