⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-12 更新
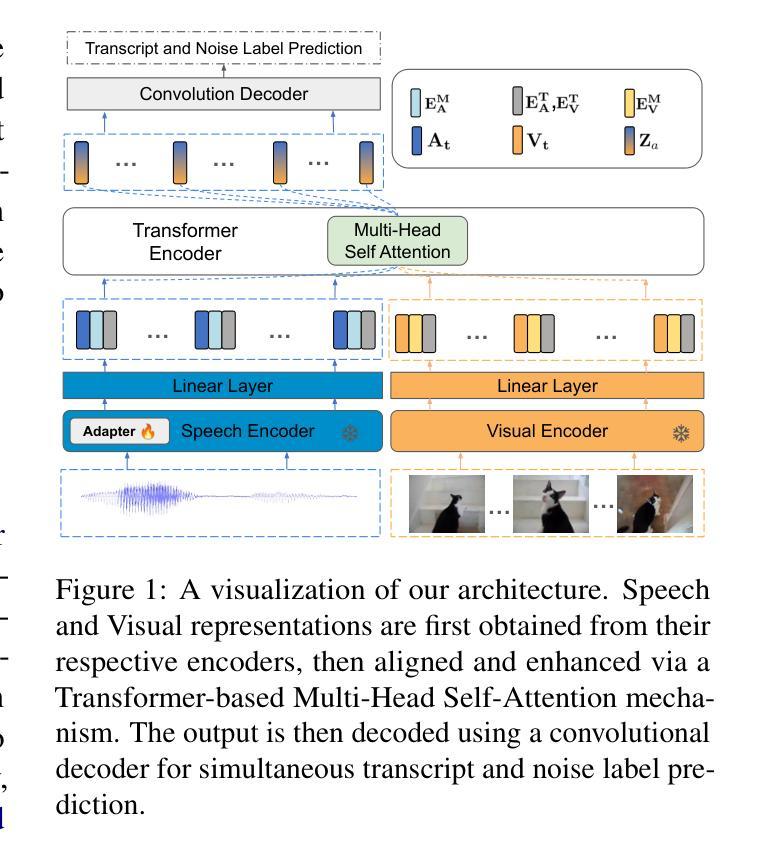
Visual-Aware Speech Recognition for Noisy Scenarios
Authors:Lakshmipathi Balaji, Karan Singla
Humans have the ability to utilize visual cues, such as lip movements and visual scenes, to enhance auditory perception, particularly in noisy environments. However, current Automatic Speech Recognition (ASR) or Audio-Visual Speech Recognition (AVSR) models often struggle in noisy scenarios. To solve this task, we propose a model that improves transcription by correlating noise sources to visual cues. Unlike works that rely on lip motion and require the speaker’s visibility, we exploit broader visual information from the environment. This allows our model to naturally filter speech from noise and improve transcription, much like humans do in noisy scenarios. Our method re-purposes pretrained speech and visual encoders, linking them with multi-headed attention. This approach enables the transcription of speech and the prediction of noise labels in video inputs. We introduce a scalable pipeline to develop audio-visual datasets, where visual cues correlate to noise in the audio. We show significant improvements over existing audio-only models in noisy scenarios. Results also highlight that visual cues play a vital role in improved transcription accuracy.
人类有能力利用视觉线索,如嘴唇动作和视觉场景,来增强听觉感知,特别是在嘈杂的环境中。然而,当前的自动语音识别(ASR)或视听语音识别(AVSR)模型在嘈杂场景中往往表现不佳。为了解决这个问题,我们提出了一种通过关联噪声源与视觉线索来改善转录的模型。与那些依赖嘴唇运动并要求说话者可见的工作不同,我们从环境中获取更广泛的视觉信息。这使得我们的模型能够像人类一样自然地从噪声中过滤出语音并改善转录。我们的方法重新使用了预训练的语音和视觉编码器,通过多头注意力将它们联系起来。这种方法既可以进行语音转录,也可以预测视频输入中的噪声标签。我们引入了一个可扩展的管道来开发视听数据集,其中视觉线索与音频中的噪声相关联。我们在嘈杂的场景中展示了相较于现有的仅使用音频的模型显著的改进。结果也强调,视觉线索在提高转录准确性方面发挥着至关重要的作用。
论文及项目相关链接
Summary:人类可以利用视觉线索,如嘴唇动作和视觉场景,增强听觉感知,特别是在嘈杂的环境中。为解决当前自动语音识别(ASR)或视听语音识别(AVSR)模型在噪声场景中的挑战,我们提出了一种通过关联噪声源与视觉线索来提高转录的模型。与其他依赖于嘴唇运动和需要说话者可见性的工作不同,我们利用来自环境的更广泛的视觉信息,从而能够像人类一样从噪声中自然地过滤出语音并改善转录。我们的方法重新使用预训练的语音和视觉编码器,并通过多头注意力将它们联系起来。这种方法能够转录语音并预测视频输入中的噪声标签。我们还引入了一个可扩展的音频视觉数据集开发管道,其中视觉线索与音频中的噪声相关联。在嘈杂的场景中,我们的表现相较于现有的仅依赖音频的模型有了显著的提升,这也突显了视觉线索在提高转录准确性方面的重要作用。
Key Takeaways:
- 人类能利用视觉线索增强听觉感知,特别是在噪声环境中。
- 当前ASR和AVSR模型在噪声场景中表现不佳。
- 提出的模型通过关联噪声源和视觉线索来提高转录,模仿人类的方式。
- 与其他仅依赖嘴唇运动的工作不同,该模型利用更广泛的视觉信息。
- 方法重新使用预训练的语音和视觉编码器,并通过多头注意力机制进行联系。
- 模型可以在视频输入中同时转录语音并预测噪声标签。
点此查看论文截图


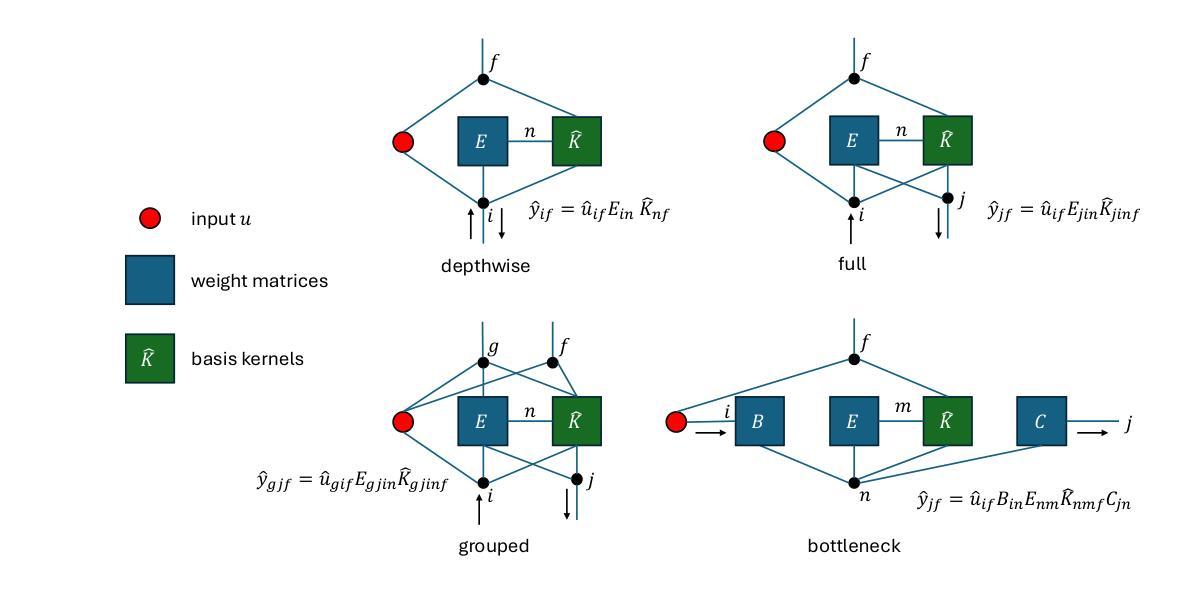
Let SSMs be ConvNets: State-space Modeling with Optimal Tensor Contractions
Authors:Yan Ru Pei
We introduce Centaurus, a class of networks composed of generalized state-space model (SSM) blocks, where the SSM operations can be treated as tensor contractions during training. The optimal order of tensor contractions can then be systematically determined for every SSM block to maximize training efficiency. This allows more flexibility in designing SSM blocks beyond the depthwise-separable configuration commonly implemented. The new design choices will take inspiration from classical convolutional blocks including group convolutions, full convolutions, and bottleneck blocks. We architect the Centaurus network with a mixture of these blocks, to balance between network size and performance, as well as memory and computational efficiency during both training and inference. We show that this heterogeneous network design outperforms its homogeneous counterparts in raw audio processing tasks including keyword spotting, speech denoising, and automatic speech recognition (ASR). For ASR, Centaurus is the first network with competitive performance that can be made fully state-space based, without using any nonlinear recurrence (LSTMs), explicit convolutions (CNNs), or (surrogate) attention mechanism. The source code is available as supplementary material on https://openreview.net/forum?id=PkpNRmBZ32
我们介绍了Centaurus网络,它是一类由广义状态空间模型(SSM)块组成的网络。在训练过程中,SSM操作可以被视为张量收缩。我们可以系统地确定每个SSM块的张量收缩的最佳顺序,以最大化训练效率。这允许在设计SSM块时具有更大的灵活性,超越了通常实现的深度可分离配置。新的设计选择将从经典的卷积块中汲取灵感,包括分组卷积、全卷积和瓶颈块。我们混合使用这些块来构建Centaurus网络,以在网络规模和性能之间取得平衡,同时在训练和推理过程中平衡内存和计算效率。我们表明,这种异构网络设计在原始音频处理任务上优于其同构对应物,包括关键词识别、语音去噪和自动语音识别(ASR)。对于ASR,Centaurus是第一个具有竞争力的完全基于状态空间的网络,无需使用任何非线性递归(LSTM)、显式卷积(CNN)或(替代)注意力机制。源代码可在https://openreview.net/forum?id=PkpNRmBZ32上的补充材料中找到。
论文及项目相关链接
PDF 25 pages, 7 figures
Summary
本文介绍了Centaurus网络,这是一种由广义状态空间模型(SSM)块组成的新型网络结构。它通过系统确定SSM块中的张量收缩顺序来最大化训练效率,并为设计SSM块提供了更多灵活性,超越了常见的深度可分离配置。Centaurus网络混合了多种经典卷积块设计,如分组卷积、全卷积和瓶颈块,以平衡网络大小、性能和内存及计算效率。在原始音频处理任务中,包括关键词识别、语音降噪和自动语音识别(ASR),这种异质网络设计优于其同质对手。特别是在ASR领域,Centaurus是首个完全基于状态空间模型、无需使用非线性递归(如LSTM)、显式卷积(如CNN)或(替代)注意力机制的具有竞争力的网络。
Key Takeaways
- Centaurus网络由广义状态空间模型(SSM)块组成,通过系统优化张量收缩顺序提高训练效率。
- SSM操作可视为训练过程中的张量收缩,为设计SSM块提供更多灵活性。
- 网络混合了多种经典卷积块设计,如分组卷积、全卷积和瓶颈块。
- Centaurus网络旨在平衡网络大小、性能和内存及计算效率。
- 在原始音频处理任务中,Centaurus网络表现优异,尤其是自动语音识别(ASR)领域。
- Centaurus网络是首个无需使用非线性递归(如LSTM)、显式卷积(如CNN)或注意力机制的具有竞争力的ASR模型。
点此查看论文截图