⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-13 更新
An Adversarial Perspective on Machine Unlearning for AI Safety
Authors:Jakub Łucki, Boyi Wei, Yangsibo Huang, Peter Henderson, Florian Tramèr, Javier Rando
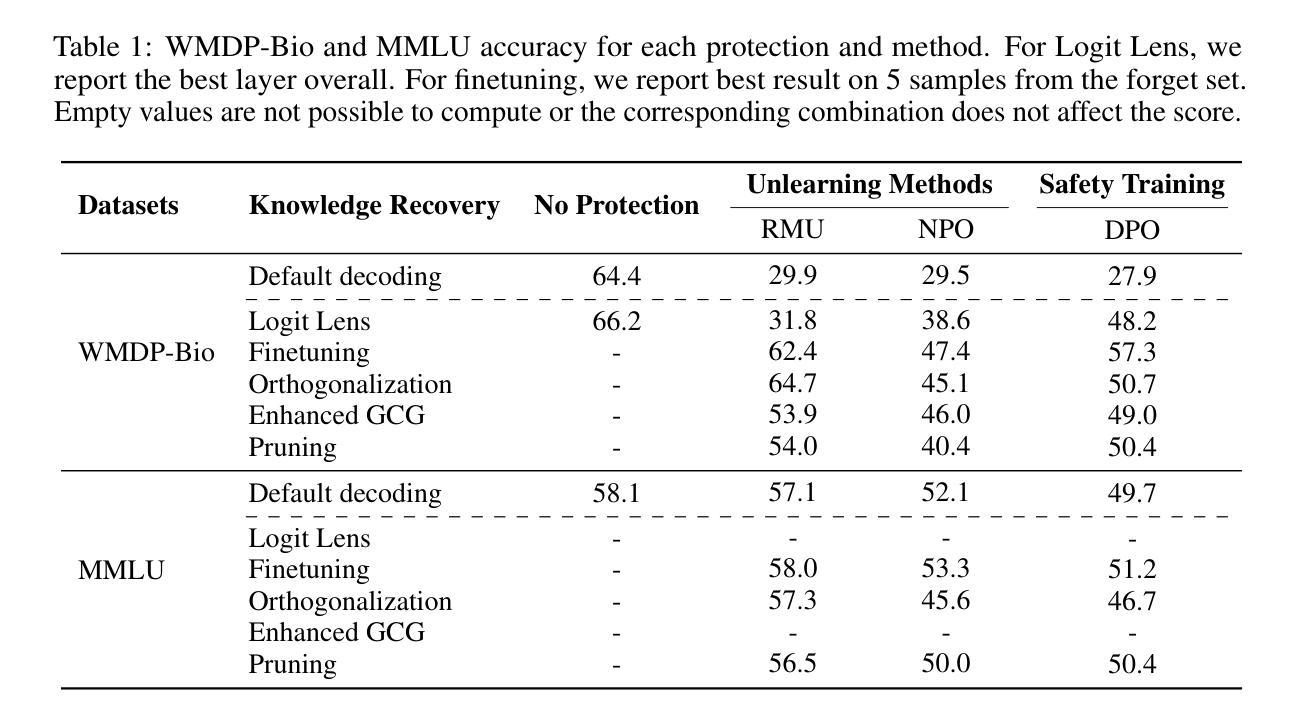
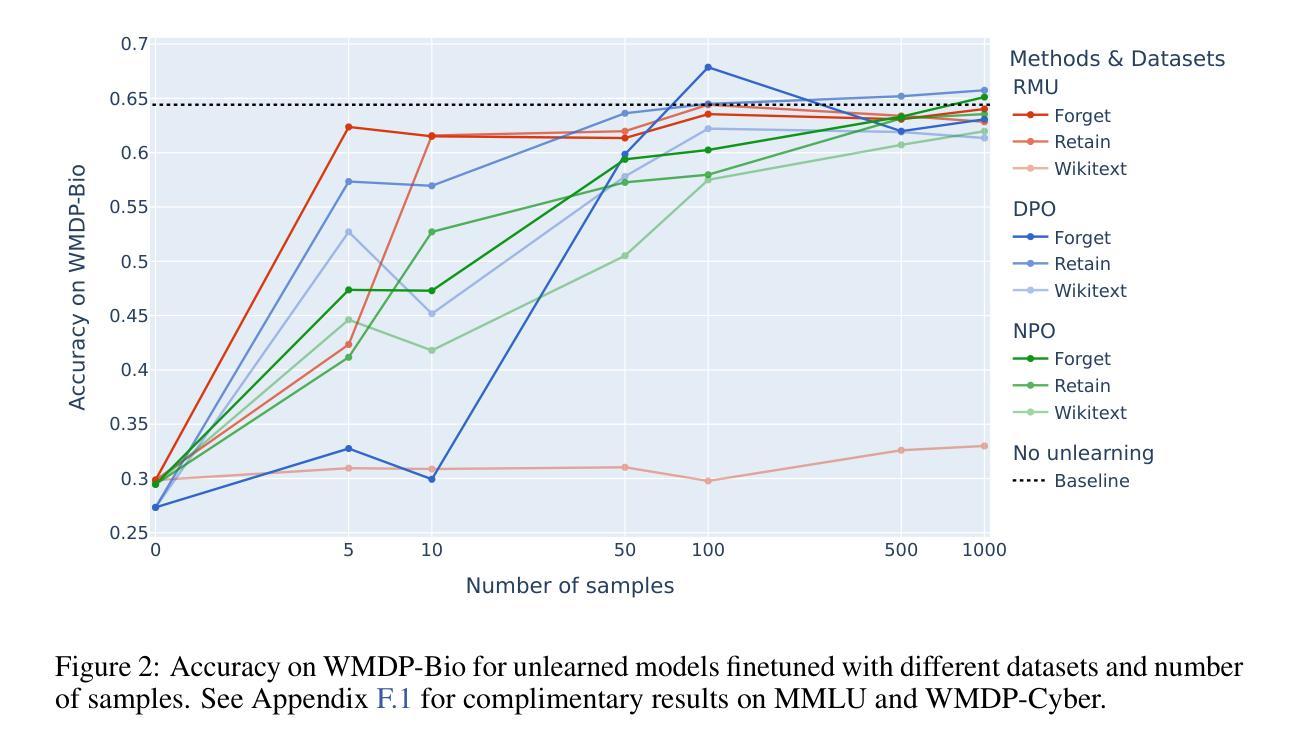
Large language models are finetuned to refuse questions about hazardous knowledge, but these protections can often be bypassed. Unlearning methods aim at completely removing hazardous capabilities from models and make them inaccessible to adversaries. This work challenges the fundamental differences between unlearning and traditional safety post-training from an adversarial perspective. We demonstrate that existing jailbreak methods, previously reported as ineffective against unlearning, can be successful when applied carefully. Furthermore, we develop a variety of adaptive methods that recover most supposedly unlearned capabilities. For instance, we show that finetuning on 10 unrelated examples or removing specific directions in the activation space can recover most hazardous capabilities for models edited with RMU, a state-of-the-art unlearning method. Our findings challenge the robustness of current unlearning approaches and question their advantages over safety training.
大型语言模型经过微调拒绝涉及危险知识的问题,但这些保护往往可以被绕过。遗忘方法旨在从模型中完全移除危险能力,使其无法被对手访问。本文从一个对抗性的角度,挑战了遗忘和传统安全后训练之间的根本差异。我们证明,之前被认为对遗忘无效的越狱方法,在谨慎应用时是可以成功的。此外,我们开发了各种自适应方法,恢复了大多数所谓的遗忘能力。例如,我们展示了在10个无关的例子上进行微调或移除激活空间中的特定方向,可以恢复使用最新遗忘方法RMU编辑的模型的大部分危险能力。我们的发现对当前遗忘方法的稳健性提出了挑战,并对其在安全训练方面的优势提出了质疑。
论文及项目相关链接
PDF Final version published in Transactions on Machine Learning Research (TMLR); Best technical paper at Neurips 2024 SoLaR workshop
Summary:大型语言模型通过微调拒绝涉及危险知识的问题,但这些保护往往可以被绕过。本研究挑战了从对抗性角度看待遗忘和传统安全训练之间的差异。我们证明,先前被认为对遗忘无效的越狱方法,在谨慎应用时可能会成功。此外,我们还开发了一系列自适应方法,可以恢复大多数被认为已经遗忘的能力。我们的发现对现有的遗忘方法提出了挑战,并对其在安全训练方面的优势提出了质疑。
Key Takeaways:
- 大型语言模型会拒绝涉及危险知识的问题,但这并非绝对安全,存在绕过措施的可能性。
- 存在针对模型能力遗忘的方法被质疑的验证,并从对抗性角度探讨了这些方法的有效性。
- 现存一些对遗忘无效的策略可以通过仔细应用来实现成功越狱效果。例如我们开发的一系列自适应方法成功恢复了大多数被认为已经遗忘的能力。这表明现有的遗忘方法可能并不稳健。
点此查看论文截图

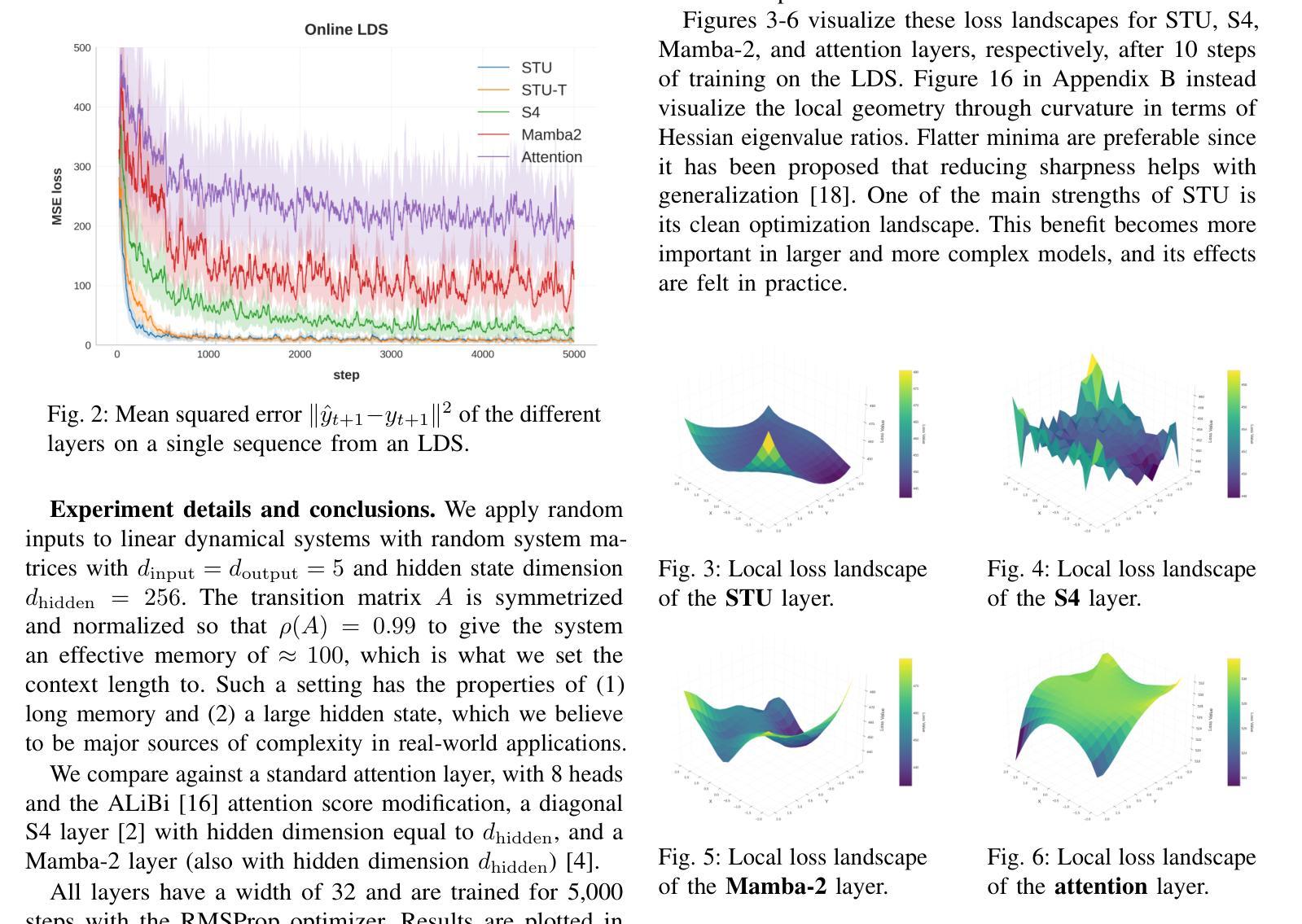
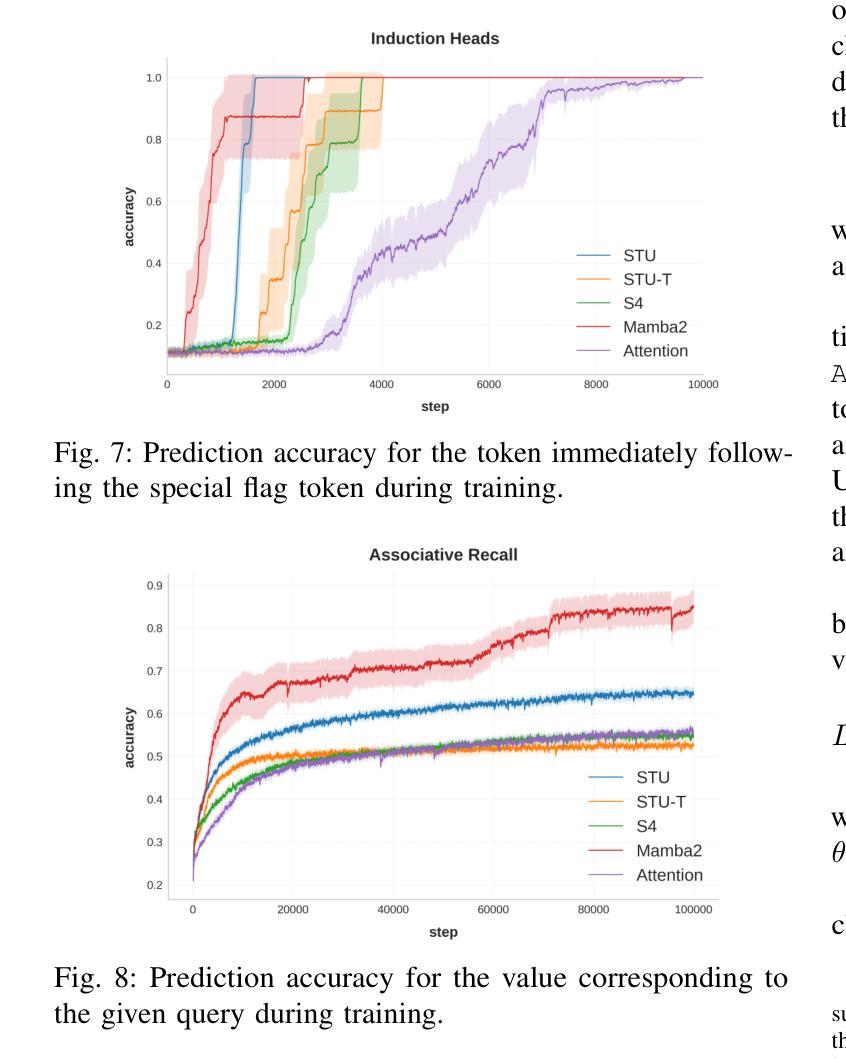
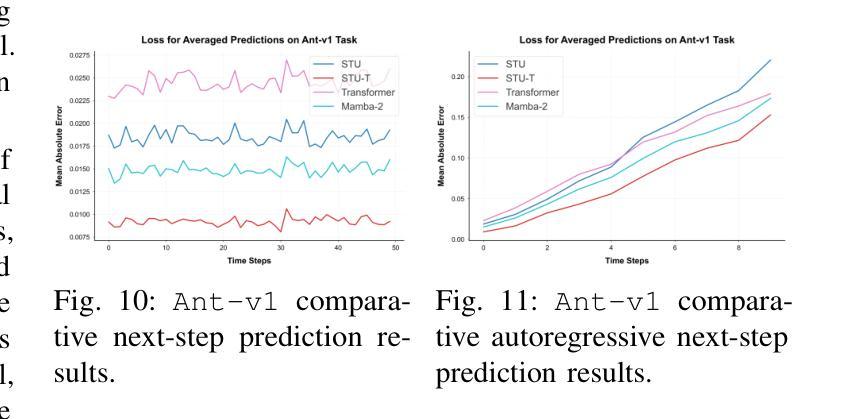
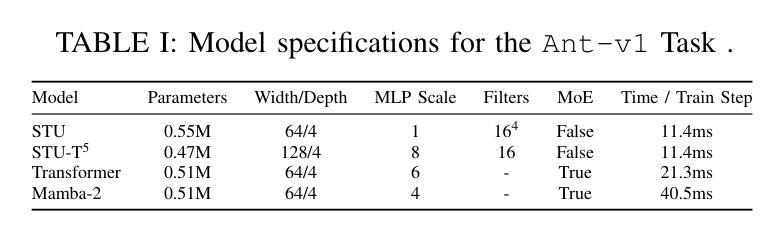
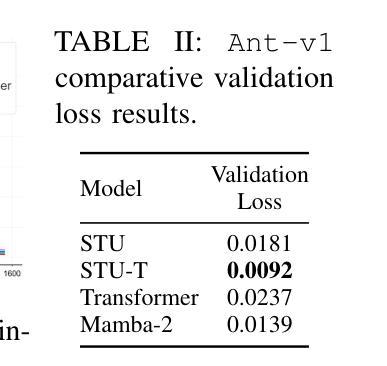
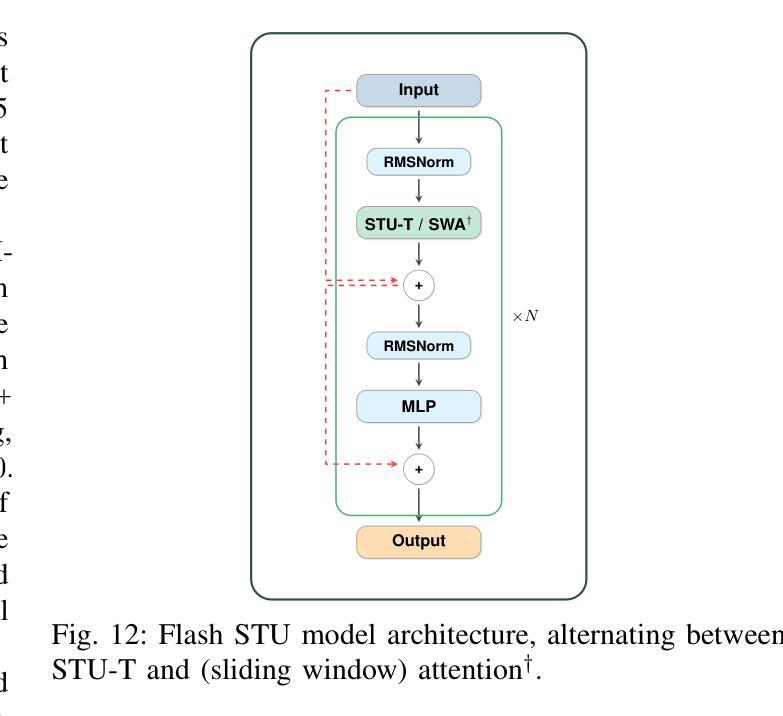
Flash STU: Fast Spectral Transform Units
Authors:Y. Isabel Liu, Windsor Nguyen, Yagiz Devre, Evan Dogariu, Anirudha Majumdar, Elad Hazan
Recent advances in state-space model architectures have shown great promise for efficient sequence modeling, but challenges remain in balancing computational efficiency with model expressiveness. We propose the Flash STU architecture, a hybrid model that interleaves spectral state space model layers with sliding window attention, enabling scalability to billions of parameters for language modeling while maintaining a near-linear time complexity. We evaluate the Flash STU and its variants on diverse sequence prediction tasks, including linear dynamical systems, robotics control, and language modeling. We find that, given a fixed parameter budget, the Flash STU architecture consistently outperforms the Transformer and other leading state-space models such as S4 and Mamba-2.
近期状态空间模型架构的进展为高效序列建模展现出了巨大的潜力,但在平衡计算效率和模型表现力方面仍存在挑战。我们提出了Flash STU架构,这是一种混合模型,它交替使用谱状态空间模型层和滑动窗口注意力,能够在语言建模中扩展到数十亿参数,同时保持接近线性的时间复杂度。我们在各种序列预测任务上评估了Flash STU及其变体,包括线性动力系统、机器人控制和语言建模。我们发现,在固定的参数预算下,Flash STU架构始终优于Transformer以及其他的领先状态空间模型,如S4和Mamba-2。
论文及项目相关链接
Summary
近期状态空间模型架构的进展为高效序列建模展现了巨大潜力,但仍需在计算效率和模型表达能力之间取得平衡。本文提出了Flash STU架构,这是一种混合模型,通过交织谱状态空间模型层和滑动窗口注意力,实现了对数十亿参数的扩展性,同时保持了近线性时间复杂度。在多种序列预测任务上评估Flash STU及其变体,包括线性动力系统、机器人控制和语言建模。在固定参数预算下,Flash STU架构始终优于Transformer和其他领先的状态空间模型,如S4和Mamba-2。
Key Takeaways
- 状态空间模型架构的近期进展展现了高效序列建模的潜力。
- Flash STU架构是一种混合模型,结合了谱状态空间模型层和滑动窗口注意力。
- Flash STU架构能够实现数十亿参数的扩展性,并保持近线性时间复杂度。
- 在多种序列预测任务上评估了Flash STU及其变体,包括线性动力系统、机器人控制和语言建模。
- Flash STU架构在固定参数预算下表现出优异的性能。
- Flash STU架构的性能优于其他领先的模型和架构,如Transformer、S4和Mamba-2。
点此查看论文截图

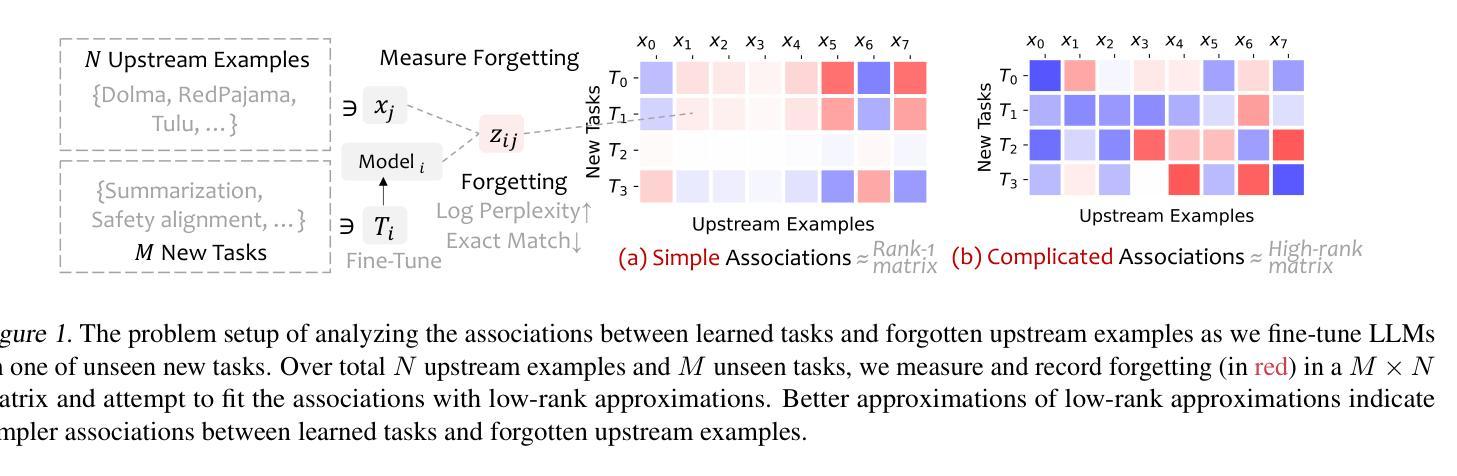
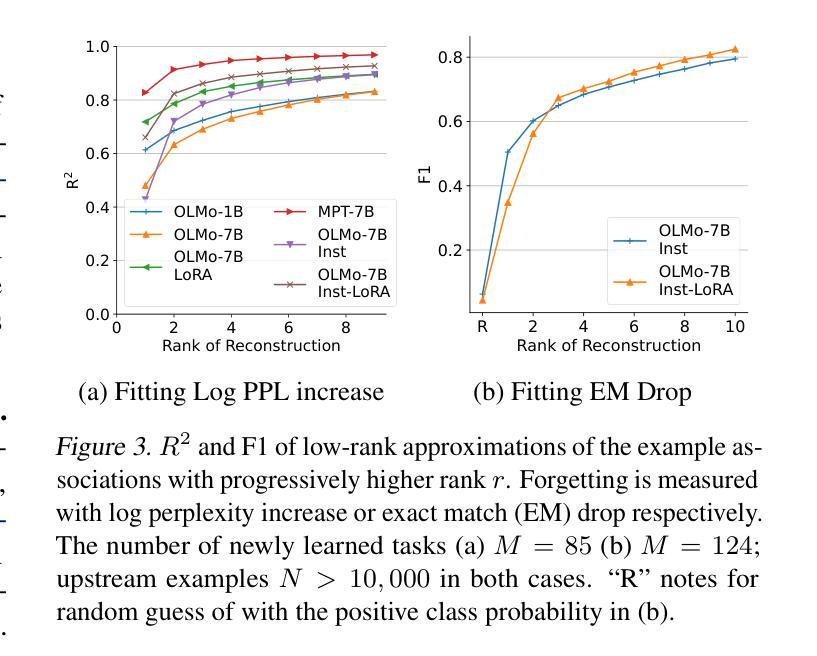
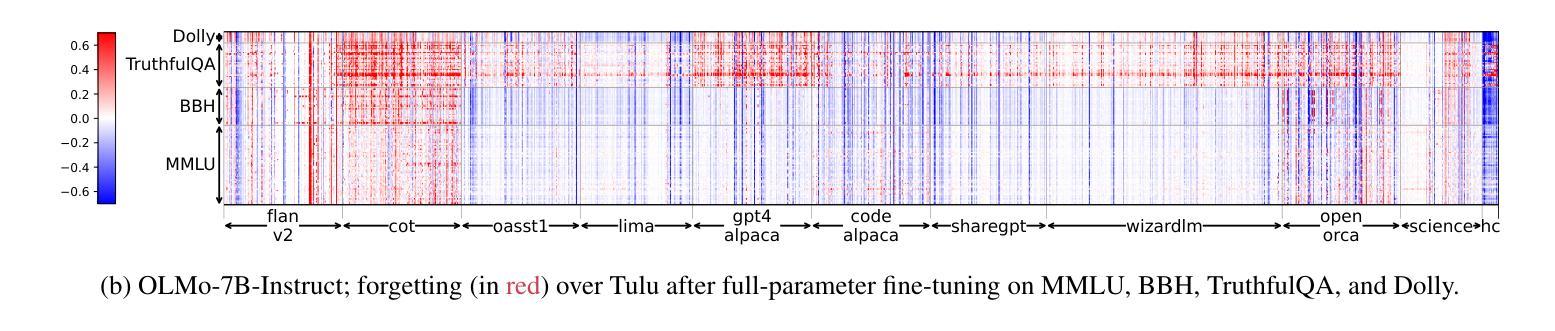
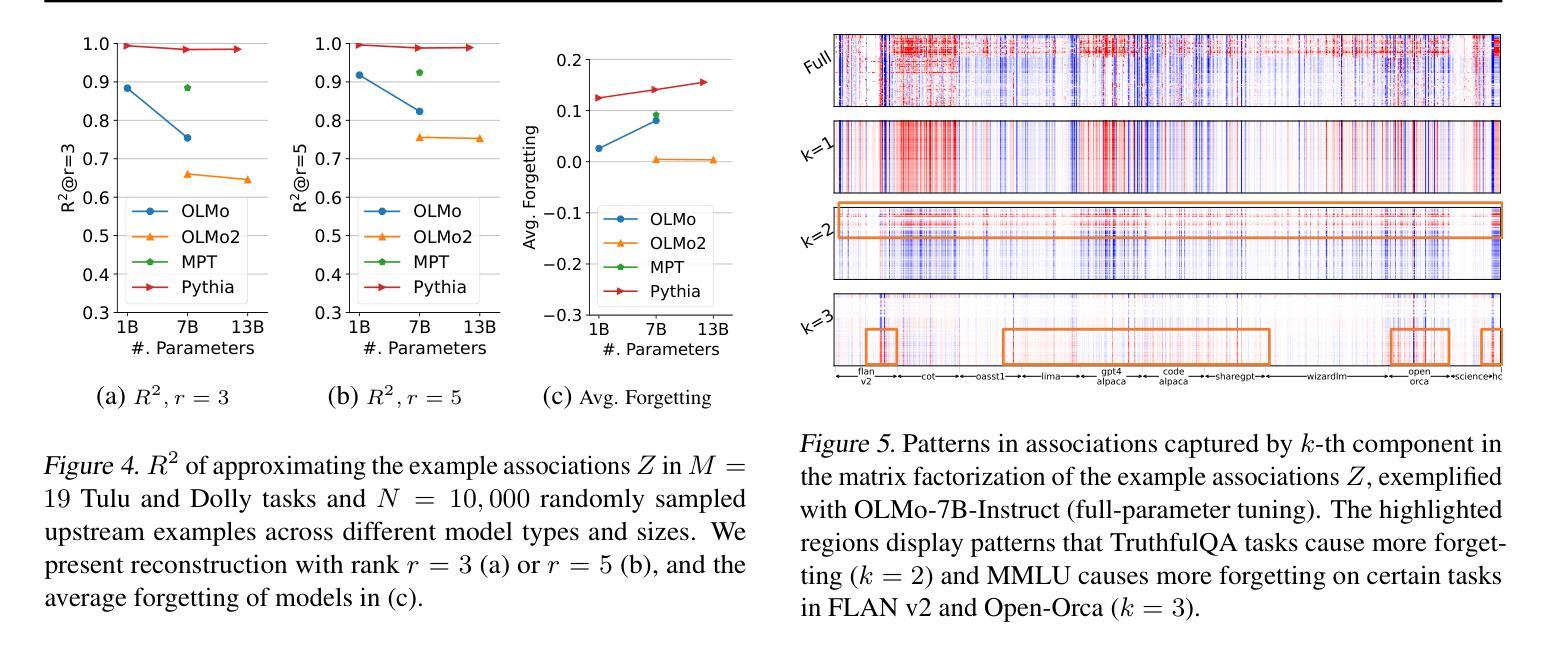
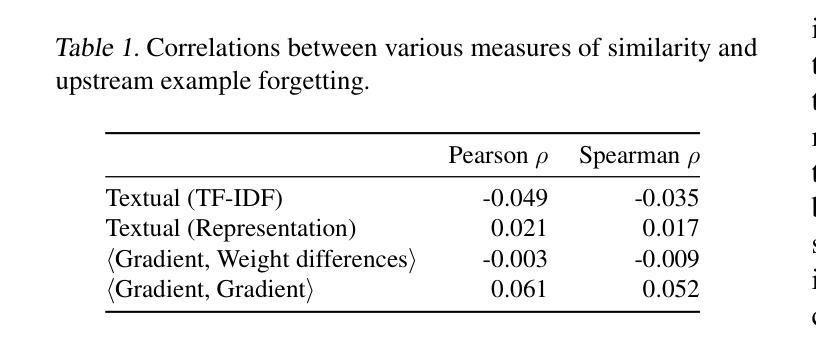
Demystifying Language Model Forgetting with Low-rank Example Associations
Authors:Xisen Jin, Xiang Ren
Large Language models (LLMs) suffer from forgetting of upstream data when fine-tuned. Despite efforts on mitigating forgetting, few have investigated whether, and how forgotten upstream examples are dependent on newly learned tasks. Insights on such dependencies enable efficient and targeted mitigation of forgetting. In this paper, we empirically analyze forgetting that occurs in $N$ upstream examples of language modeling or instruction-tuning after fine-tuning LLMs on one of $M$ new tasks, visualized in $M\times N$ matrices. We show that the matrices are often well-approximated with low-rank matrices, indicating the dominance of simple associations between the learned tasks and forgotten upstream examples. Leveraging the analysis, we predict forgetting of upstream examples when fine-tuning on unseen tasks with matrix completion over the empirical associations. This enables fast identification of most forgotten examples without expensive inference on the entire upstream data. The approach, despite simplicity, outperforms prior approaches that learn semantic relationships of learned tasks and upstream examples with LMs for predicting forgetting. We demonstrate the practical utility of our analysis by showing statistically significantly reduced forgetting as we upweight predicted examples for replay at fine-tuning. Project page: https://inklab.usc.edu/lm-forgetting-prediction/
大型语言模型(LLM)在微调时会遗忘上游数据。尽管有人努力减轻遗忘,但很少有人研究遗忘的上游示例是否以及如何依赖于新学习的任务。关于这些依赖性的见解有助于有效且有针对性地缓解遗忘。在本文中,我们对在一个新的M任务上微调LLM后发生的N个上游语言建模或指令调整的示例中的遗忘进行了实证分析,并在$M\times N$矩阵中进行可视化。我们发现这些矩阵通常可以用低阶矩阵近似,这表明已学习到的任务和遗忘的上游示例之间的简单关联占主导地位。利用这一分析,我们通过在经验关联上应用矩阵补全来预测在未见任务上进行微调时的上游示例遗忘。这可以在无需对整个上游数据进行昂贵推理的情况下快速识别出最被遗忘的示例。尽管我们的方法很简单,但它优于先前的方法,后者使用语言模型来学习已学任务和上游示例之间的语义关系来预测遗忘。我们通过展示在微调时通过回放预测的例子来减少遗忘,从而证明了我们的分析的实际效用。项目页面:https://inklab.usc.edu/lm-forgetting-prediction/。
论文及项目相关链接
PDF 8 pages; preprint, fixed Table 5 in Appendix D
Summary
大型语言模型(LLM)在微调时会遗忘上游数据。本文实证分析了在微调LLM后,对上游数据中的语言建模或指令调优的遗忘情况。分析显示,这些数据的遗忘可以通过低秩矩阵近似来预测,并指出新任务与遗忘的上游数据之间的简单关联。利用这一分析,我们可以在微调未见任务时预测上游数据的遗忘,通过矩阵补全实证关联来实现预测。此方法虽然简单,但优于使用语言模型学习新任务和上游数据语义关系的方法。通过重播预测示例并在微调时加权,我们展示了分析的实际效用,显著减少了遗忘。
Key Takeaways
- LLM在微调时会遗忘上游数据。
- 通过低秩矩阵近似预测遗忘情况。
- 新任务和遗忘的上游数据间存在简单关联。
- 使用矩阵补全实证关联实现预测。
- 此方法虽简单但优于其他预测遗忘的方法。
- 通过重播预测示例并在微调时加权,显著减少遗忘。
点此查看论文截图


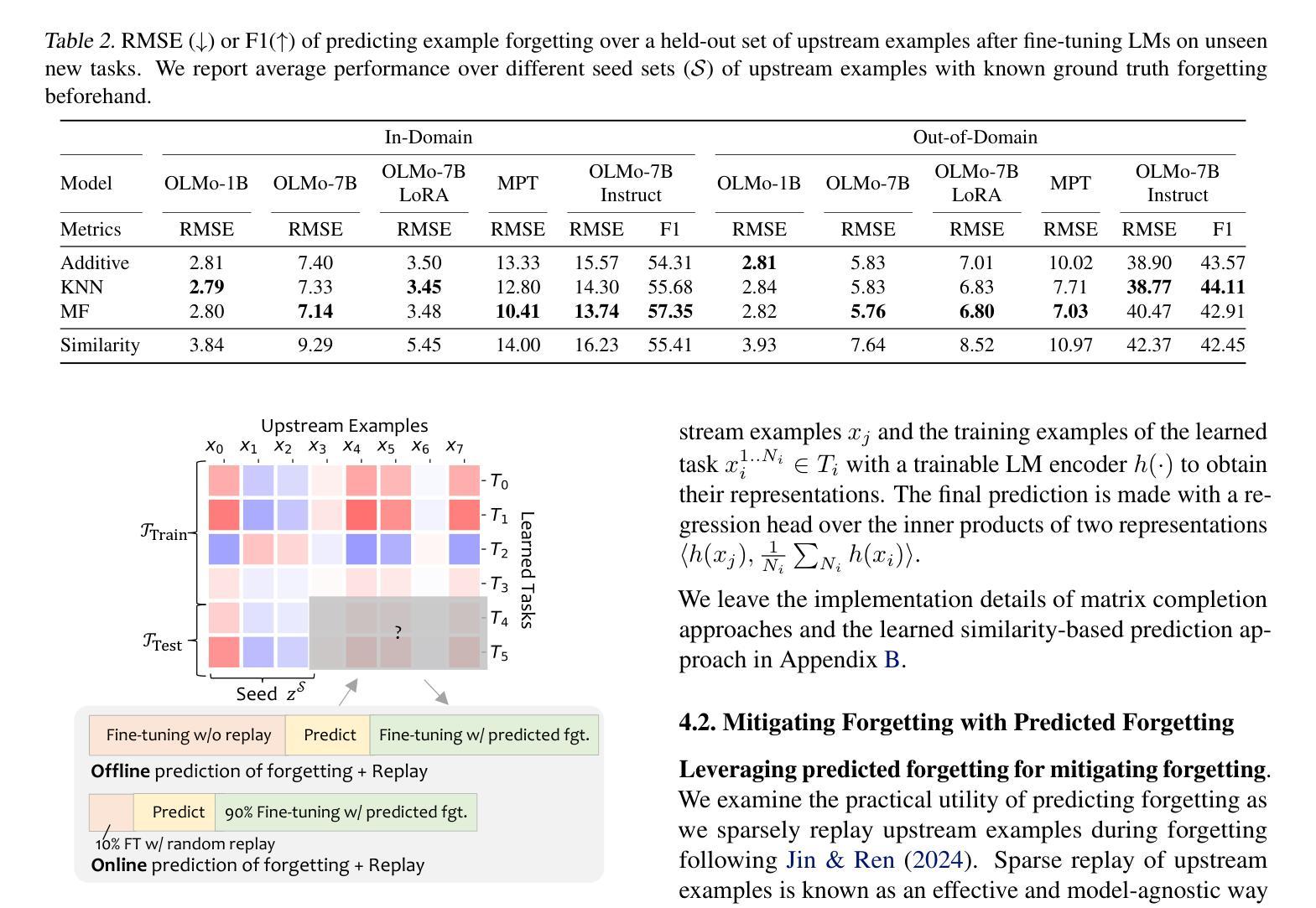
The Right Time Matters: Data Arrangement Affects Zero-Shot Generalization in Instruction Tuning
Authors:Bingxiang He, Ning Ding, Cheng Qian, Jia Deng, Ganqu Cui, Lifan Yuan, Haiwen Hong, Huan-ang Gao, Longtao Huang, Hui Xue, Huimin Chen, Zhiyuan Liu, Maosong Sun
Understanding alignment techniques begins with comprehending zero-shot generalization brought by instruction tuning, but little of the mechanism has been understood. Existing work has largely been confined to the task level, without considering that tasks are artificially defined and, to LLMs, merely consist of tokens and representations. To bridge this gap, we investigate zero-shot generalization from the perspective of the data itself. We first demonstrate that zero-shot generalization happens very early during instruction tuning, with loss serving as a stable indicator. Next, we investigate training data arrangement through similarity and granularity perspectives, confirming that the timing of exposure to certain training examples may greatly facilitate generalization on unseen tasks. Finally, we propose a more grounded training data arrangement framework, Test-centric Multi-turn Arrangement, and show its effectiveness in promoting continual learning and further loss reduction. For the first time, we show that zero-shot generalization during instruction tuning is a form of similarity-based generalization between training and test data at the instance level. Our code is released at https://github.com/thunlp/Dynamics-of-Zero-Shot-Generalization.
理解对齐技术首先需要对指令微调带来的零样本泛化能力有所认识,但目前对于这种机制的理解还不够深入。现有的工作主要集中在任务层面,没有考虑到任务是人为定义的,对于大型语言模型来说,任务仅仅是由标记和表示组成的。为了弥补这一差距,我们从数据本身的角度来研究零样本泛化。我们首先证明零样本泛化发生在指令微调的早期阶段,损失作为稳定的指标起着关键作用。接下来,我们通过相似性和粒度视角研究训练数据的安排,证实接触某些训练样本的时间可以对未见任务的泛化产生很大影响。最后,我们提出了一个更实际的训练数据安排框架——“以测试为中心的多轮安排”,并展示了它在促进持续学习和进一步减少损失方面的有效性。我们首次展示了指令微调过程中的零样本泛化是训练数据和测试数据实例之间的一种基于相似性的泛化。我们的代码已发布在https://github.com/thunlp/Dynamics-of-Zero-Shot-Generalization上。
论文及项目相关链接
PDF 22 pages, 16 figures
Summary
研究指令微调中的零样本泛化,揭示其在任务泛化方面的作用机制。研究从数据本身的角度探究零样本泛化,发现泛化发生在指令调教的早期阶段,同时发现训练数据的排列方式与未见过任务的泛化能力有关。为此,提出基于测试的多轮安排框架,促进持续学习和进一步降低损失。零样本泛化是训练数据和测试数据在实例层面的相似泛化的一种表现。具体通过公开代码可以在https://github.com/thunlp/Dynamics-of-Zero-Shot-Generalization上查看。
Key Takeaways
- 零样本泛化在指令调教的早期阶段发生,并且损失是一个稳定的指标来衡量这一过程。
- 训练数据的排列方式对于泛化能力有很大影响。
- 训练数据的相似性角度和粒度角度对零样本泛化的研究至关重要。
- 训练数据呈现给模型的时间点对泛化效果有影响。
- 基于测试的多轮安排框架有助于促进持续学习和降低损失。
- 零样本泛化是一种基于训练数据和测试数据实例之间相似性的泛化表现。
点此查看论文截图

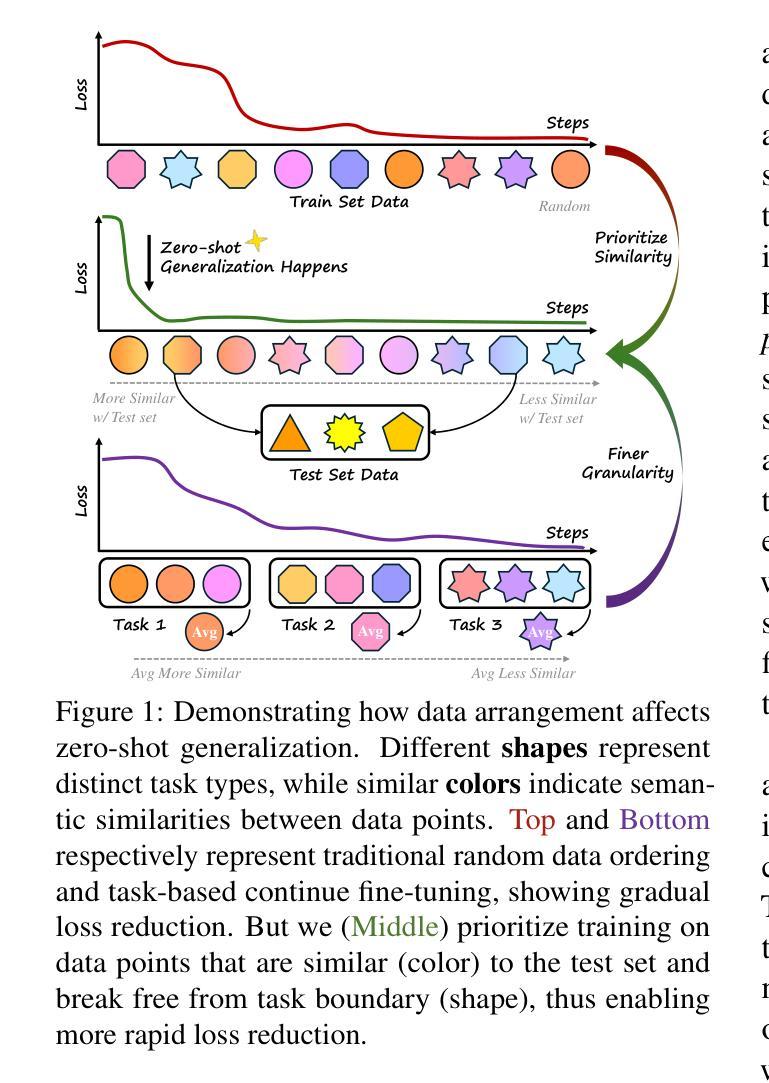
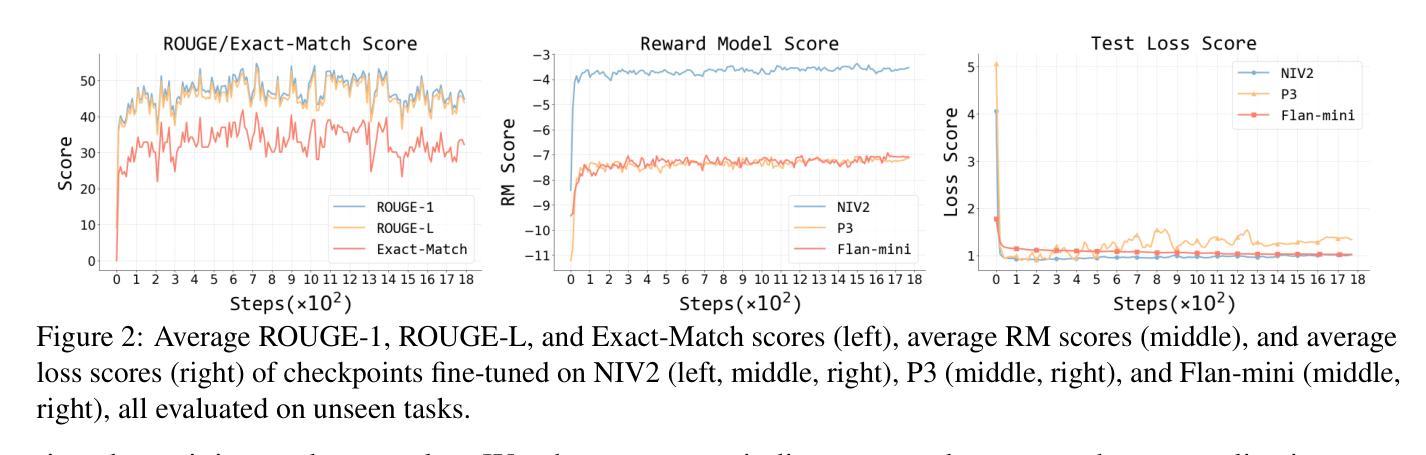
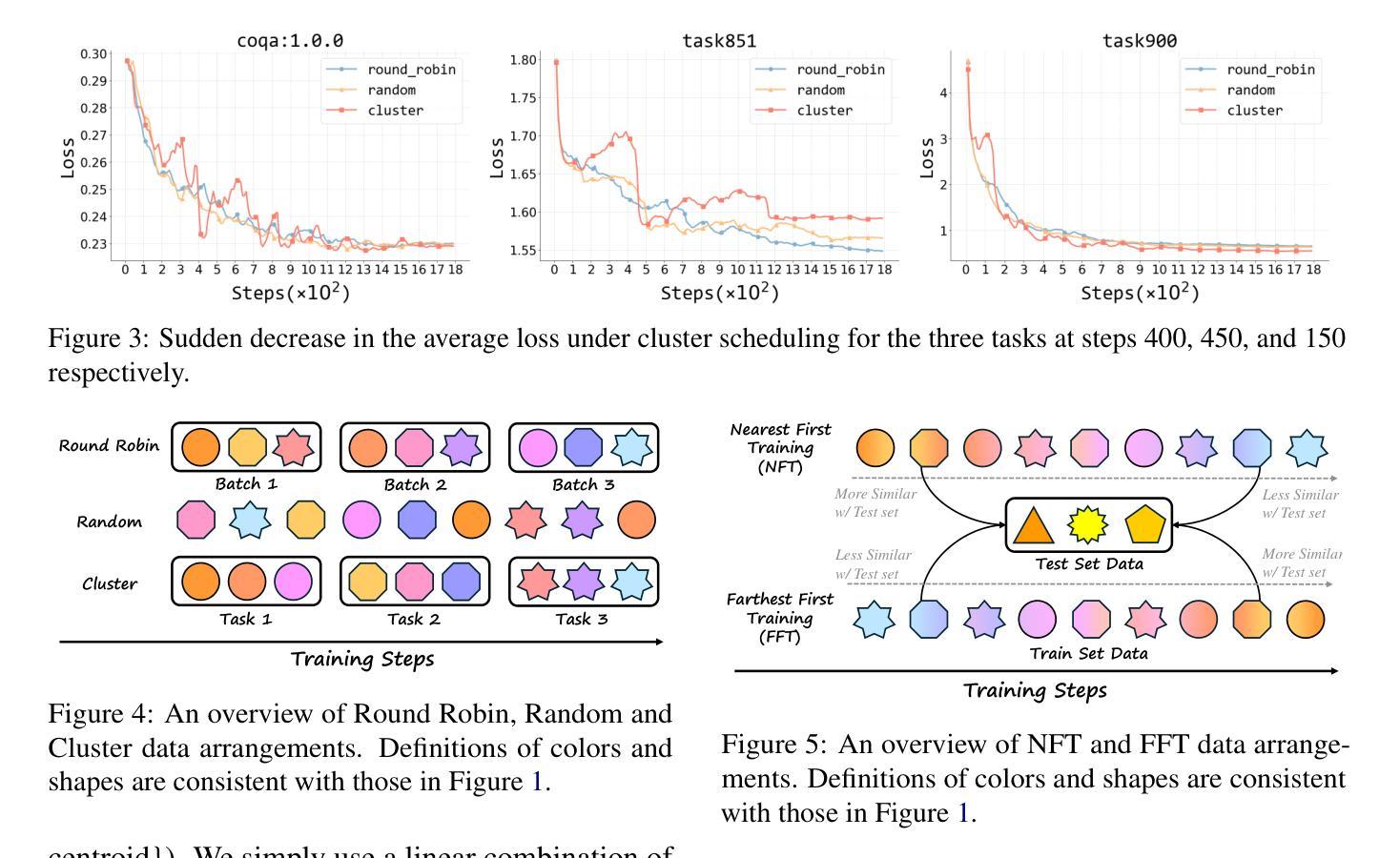
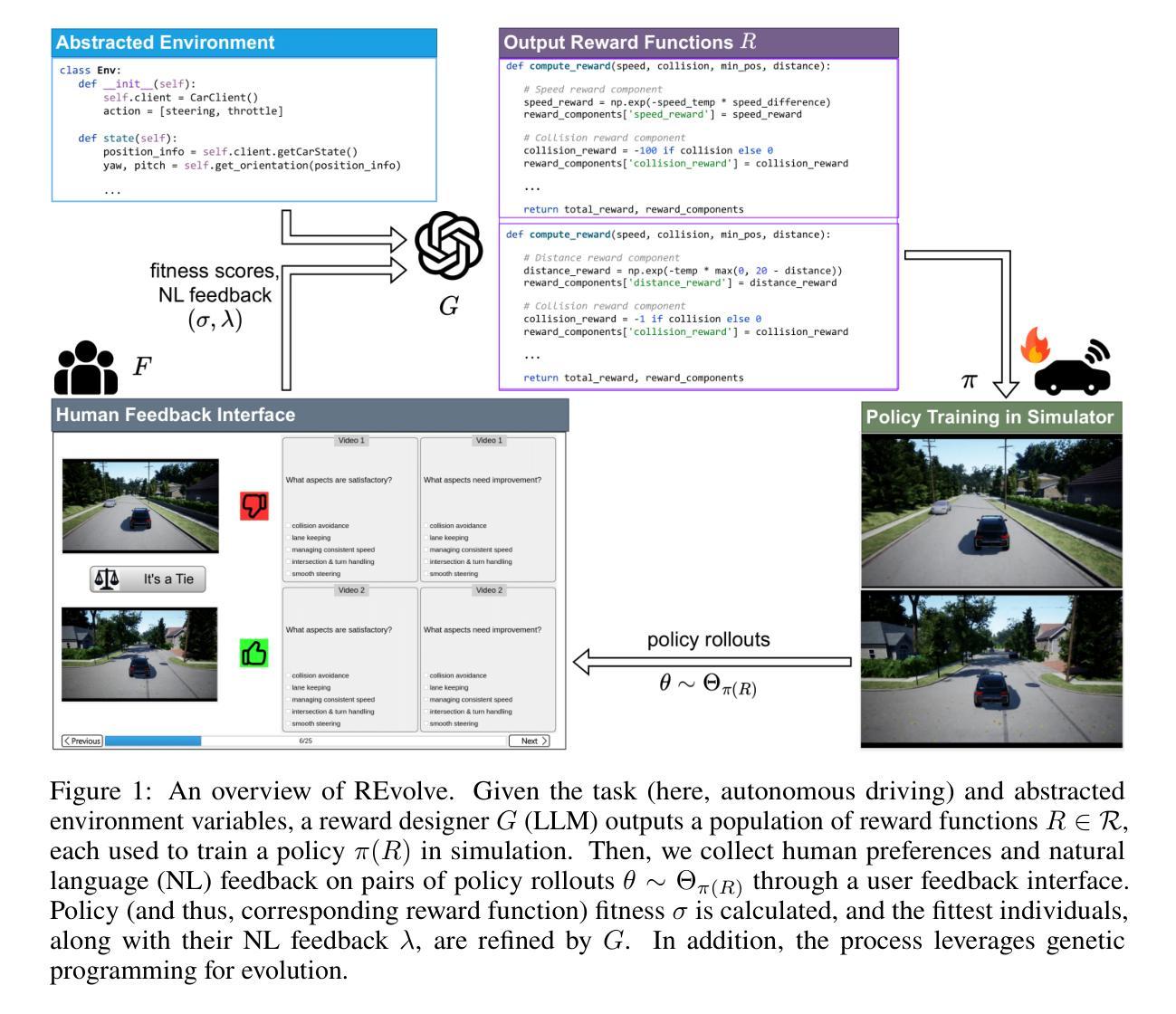
REvolve: Reward Evolution with Large Language Models using Human Feedback
Authors:Rishi Hazra, Alkis Sygkounas, Andreas Persson, Amy Loutfi, Pedro Zuidberg Dos Martires
Designing effective reward functions is crucial to training reinforcement learning (RL) algorithms. However, this design is non-trivial, even for domain experts, due to the subjective nature of certain tasks that are hard to quantify explicitly. In recent works, large language models (LLMs) have been used for reward generation from natural language task descriptions, leveraging their extensive instruction tuning and commonsense understanding of human behavior. In this work, we hypothesize that LLMs, guided by human feedback, can be used to formulate reward functions that reflect human implicit knowledge. We study this in three challenging settings – autonomous driving, humanoid locomotion, and dexterous manipulation – wherein notions of ``good” behavior are tacit and hard to quantify. To this end, we introduce REvolve, a truly evolutionary framework that uses LLMs for reward design in RL. REvolve generates and refines reward functions by utilizing human feedback to guide the evolution process, effectively translating implicit human knowledge into explicit reward functions for training (deep) RL agents. Experimentally, we demonstrate that agents trained on REvolve-designed rewards outperform other state-of-the-art baselines.
设计有效的奖励函数对于训练强化学习(RL)算法至关重要。然而,这一设计即使对于领域专家来说也是非平凡的,这是由于某些任务的主观性质难以明确量化。在最近的研究中,大型语言模型(LLM)已被用于根据自然语言任务描述生成奖励,利用它们广泛的指令调整以及对人类行为的常识理解。在这项工作中,我们假设在人类反馈的指导下,LLM可用于制定反映人类隐性知识的奖励函数。我们在三个具有挑战性的场景——自动驾驶、人形运动和灵巧操作——中研究这一点,在这些场景中,“良好”行为的观念是隐性的且难以量化。为此,我们引入了REvolve,这是一个真正使用LLM进行奖励设计的进化框架。REvolve通过利用人类反馈来指导进化过程,生成并优化奖励函数,有效地将隐性的人类知识转化为明确的奖励函数来训练(深度)强化学习代理。实验表明,采用REvolve设计的奖励训练的代理表现优于其他最新技术水平的基准测试。
论文及项目相关链接
PDF Published in ICLR 2025. Project page: https://rishihazra.github.io/REvolve
Summary
强化学习(RL)算法中设计有效的奖励函数至关重要。然而,由于某些任务的主观性质难以明确量化,使得设计奖励函数成为一项非平凡的任务,即使是对于领域专家也是如此。最近的研究利用大型语言模型(LLM)从自然语言任务描述中生成奖励,通过其广泛的指令调整和对人类行为的常识理解来利用这一点。本研究假设,在人类的反馈指导下,LLM可用于制定反映人类隐性知识的奖励函数。我们在三个具有挑战性的场景(自动驾驶、人形运动和灵巧操作)中对此进行了研究,其中良好的行为概念是隐含的,难以量化。为此,我们引入了REvolve,这是一个真正利用LLM进行RL奖励设计的进化框架。REvolve通过利用人类反馈来指导进化过程,生成并优化奖励函数,有效地将人类隐性知识转化为训练深度强化学习代理的明确奖励函数。实验表明,采用REvolve设计的奖励训练的代理在表现上优于其他最先进基线。
Key Takeaways
- 强化学习中奖励函数的设计非常重要且充满挑战。
- 大型语言模型(LLMs)在奖励生成方面具有潜力,可以从自然语言任务描述中利用。
- LLMs能够在人类反馈的指导下反映人类的隐性知识,用于制定奖励函数。
- REvolve是一个利用LLM进行RL奖励设计的进化框架。
- REvolve通过人类反馈生成和优化奖励函数,将隐性人类知识转化为明确的奖励函数。
- 在三个具有挑战性的场景中(自动驾驶、人形运动和灵巧操作),使用REvolve设计的奖励训练的代理表现优异。
点此查看论文截图



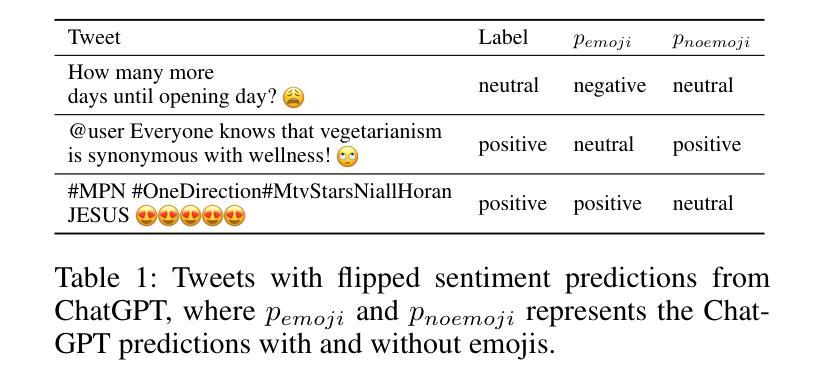
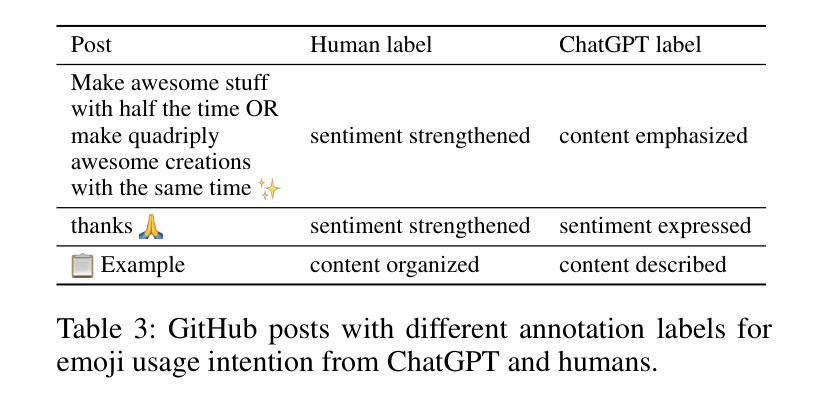
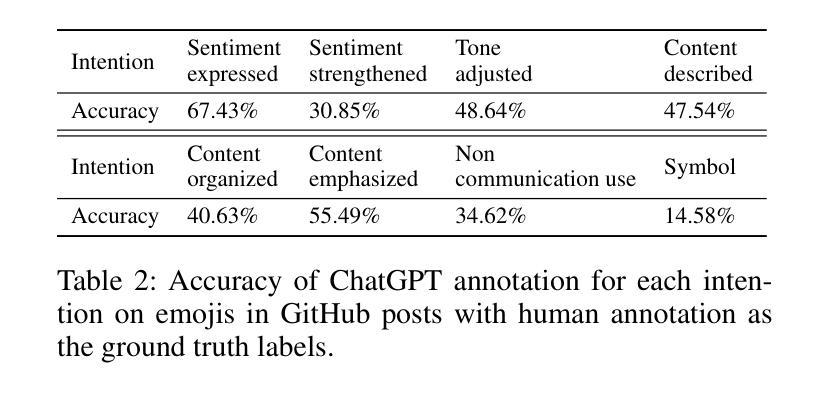
Emojis Decoded: Leveraging ChatGPT for Enhanced Understanding in Social Media Communications
Authors:Yuhang Zhou, Paiheng Xu, Xiyao Wang, Xuan Lu, Ge Gao, Wei Ai
Emojis, which encapsulate semantics beyond mere words or phrases, have become prevalent in social network communications. This has spurred increasing scholarly interest in exploring their attributes and functionalities. However, emoji-related research and application face two primary challenges. First, researchers typically rely on crowd-sourcing to annotate emojis in order to understand their sentiments, usage intentions, and semantic meanings. Second, subjective interpretations by users can often lead to misunderstandings of emojis and cause the communication barrier. Large Language Models (LLMs) have achieved significant success in various annotation tasks, with ChatGPT demonstrating expertise across multiple domains. In our study, we assess ChatGPT’s effectiveness in handling previously annotated and downstream tasks. Our objective is to validate the hypothesis that ChatGPT can serve as a viable alternative to human annotators in emoji research and that its ability to explain emoji meanings can enhance clarity and transparency in online communications. Our findings indicate that ChatGPT has extensive knowledge of emojis. It is adept at elucidating the meaning of emojis across various application scenarios and demonstrates the potential to replace human annotators in a range of tasks.
表情符号已经广泛普及于社交网络通信中,它们可以包含超越简单词汇或短语的语义。这引发了越来越多的学术兴趣来探索其属性和功能。然而,关于表情符号的研究和应用面临两大挑战。首先,研究人员通常依赖于众包来对表情符号进行注释,以了解它们的情感、使用意图和语义。其次,用户的主观解读往往会导致对表情符号的误解,造成沟通障碍。大型语言模型(LLM)在各种注释任务中取得了巨大成功,ChatGPT在多个领域展现了专业知识。在我们的研究中,我们评估了ChatGPT在处理已注释和下游任务方面的有效性。我们的目标是验证假设:ChatGPT可以作为人类注释者在表情符号研究中的可行替代方案,并且其解释表情符号意义的能力可以提高在线通信的清晰度和透明度。我们发现ChatGPT拥有丰富的表情符号知识。它在各种应用场景中擅长阐释表情符号的含义,并显示出在一系列任务中替代人类注释者的潜力。
论文及项目相关链接
PDF Accepted by the 19th International AAAI Conference on Web and Social Media (ICWSM 2025)
Summary
大型语言模型(LLM)如ChatGPT在emoji研究领域表现出强大的潜力。通过替代人工标注方式,ChatGPT不仅能有效理解emoji的情感、使用意图和语义含义,还能提升在线通信的清晰度和透明度。本研究验证了ChatGPT在emoji研究中的有效性。
Key Takeaways
- Emojis已逐渐成为社交网络通讯中的重要组成部分,其属性和功能的研究吸引了越来越多的学者关注。
- 当前emoji相关研究面临两个主要挑战:依赖人工标注的方式以及用户主观解读可能导致的误解和沟通障碍。
- 大型语言模型(LLM)如ChatGPT在各类标注任务中取得了显著成功,具备跨多个领域的专业知识。
- ChatGPT具备丰富的emoji知识,能够阐释emoji在不同应用场景下的含义。
- ChatGPT有潜力替代人工标注方式,提高emoji研究的效率。
- ChatGPT能够增强在线通讯的清晰度和透明度,通过解释emoji含义来促进准确沟通。
点此查看论文截图