⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-13 更新
Kimi-VL Technical Report
Authors: Kimi Team, Angang Du, Bohong Yin, Bowei Xing, Bowen Qu, Bowen Wang, Cheng Chen, Chenlin Zhang, Chenzhuang Du, Chu Wei, Congcong Wang, Dehao Zhang, Dikang Du, Dongliang Wang, Enming Yuan, Enzhe Lu, Fang Li, Flood Sung, Guangda Wei, Guokun Lai, Han Zhu, Hao Ding, Hao Hu, Hao Yang, Hao Zhang, Haoning Wu, Haotian Yao, Haoyu Lu, Heng Wang, Hongcheng Gao, Huabin Zheng, Jiaming Li, Jianlin Su, Jianzhou Wang, Jiaqi Deng, Jiezhong Qiu, Jin Xie, Jinhong Wang, Jingyuan Liu, Junjie Yan, Kun Ouyang, Liang Chen, Lin Sui, Longhui Yu, Mengfan Dong, Mengnan Dong, Nuo Xu, Pengyu Cheng, Qizheng Gu, Runjie Zhou, Shaowei Liu, Sihan Cao, Tao Yu, Tianhui Song, Tongtong Bai, Wei Song, Weiran He, Weixiao Huang, Weixin Xu, Xiaokun Yuan, Xingcheng Yao, Xingzhe Wu, Xinxing Zu, Xinyu Zhou, Xinyuan Wang, Y. Charles, Yan Zhong, Yang Li, Yangyang Hu, Yanru Chen, Yejie Wang, Yibo Liu, Yibo Miao, Yidao Qin, Yimin Chen, Yiping Bao, Yiqin Wang, Yongsheng Kang, Yuanxin Liu, Yulun Du, Yuxin Wu, Yuzhi Wang, Yuzi Yan, Zaida Zhou, Zhaowei Li, Zhejun Jiang, Zheng Zhang, Zhilin Yang, Zhiqi Huang, Zihao Huang, Zijia Zhao, Ziwei Chen
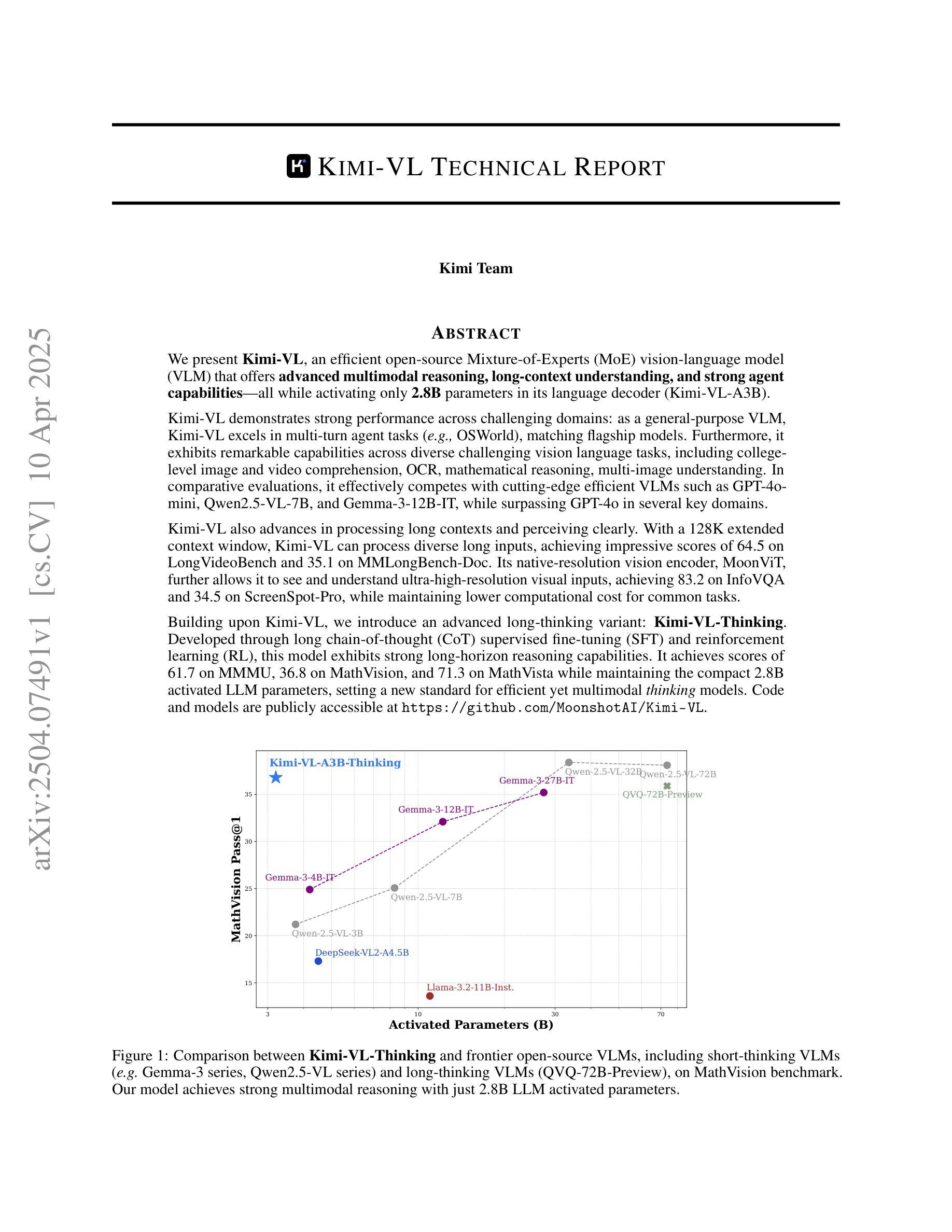
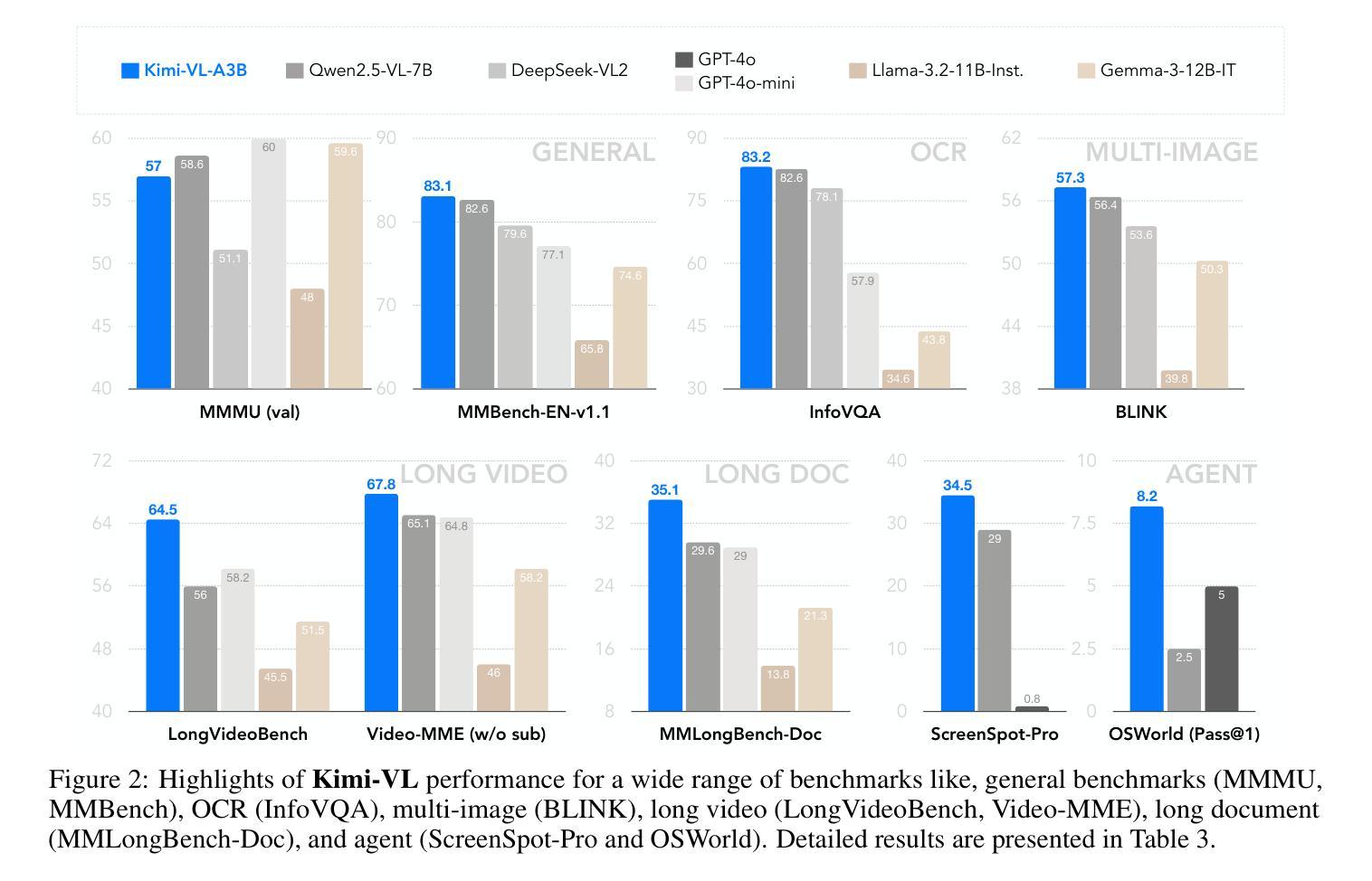
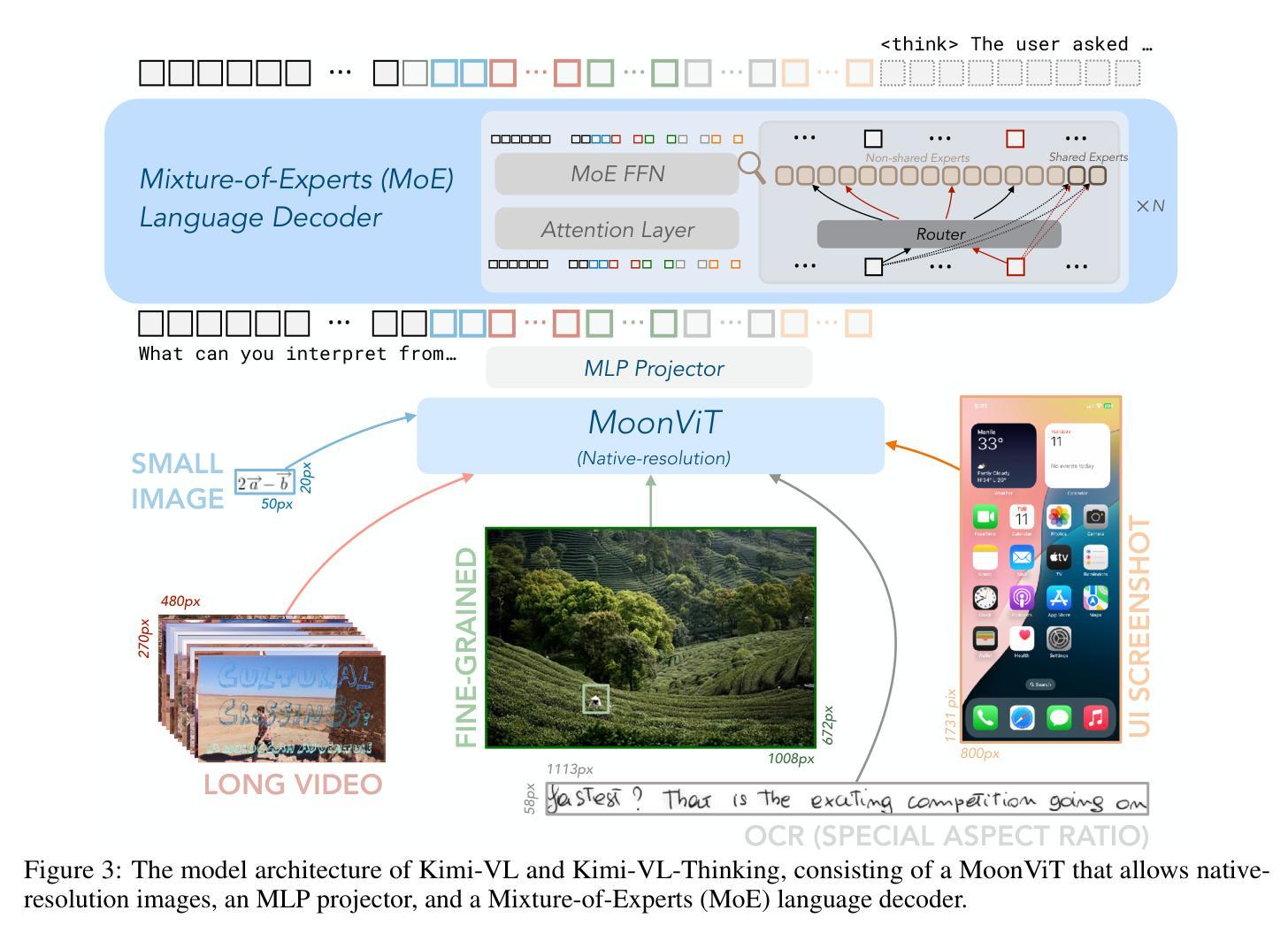
We present Kimi-VL, an efficient open-source Mixture-of-Experts (MoE) vision-language model (VLM) that offers advanced multimodal reasoning, long-context understanding, and strong agent capabilities - all while activating only 2.8B parameters in its language decoder (Kimi-VL-A3B). Kimi-VL demonstrates strong performance across challenging domains: as a general-purpose VLM, Kimi-VL excels in multi-turn agent tasks (e.g., OSWorld), matching flagship models. Furthermore, it exhibits remarkable capabilities across diverse challenging vision language tasks, including college-level image and video comprehension, OCR, mathematical reasoning, and multi-image understanding. In comparative evaluations, it effectively competes with cutting-edge efficient VLMs such as GPT-4o-mini, Qwen2.5-VL-7B, and Gemma-3-12B-IT, while surpassing GPT-4o in several key domains. Kimi-VL also advances in processing long contexts and perceiving clearly. With a 128K extended context window, Kimi-VL can process diverse long inputs, achieving impressive scores of 64.5 on LongVideoBench and 35.1 on MMLongBench-Doc. Its native-resolution vision encoder, MoonViT, further allows it to see and understand ultra-high-resolution visual inputs, achieving 83.2 on InfoVQA and 34.5 on ScreenSpot-Pro, while maintaining lower computational cost for common tasks. Building upon Kimi-VL, we introduce an advanced long-thinking variant: Kimi-VL-Thinking. Developed through long chain-of-thought (CoT) supervised fine-tuning (SFT) and reinforcement learning (RL), this model exhibits strong long-horizon reasoning capabilities. It achieves scores of 61.7 on MMMU, 36.8 on MathVision, and 71.3 on MathVista while maintaining the compact 2.8B activated LLM parameters, setting a new standard for efficient multimodal thinking models. Code and models are publicly accessible at https://github.com/MoonshotAI/Kimi-VL.
我们推出Kimi-VL,这是一款高效的开源混合专家(MoE)视觉语言模型(VLM),具备先进的跨模态推理、长上下文理解以及强大的智能主体能力,在其语言解码器(Kimi-VL-A3B)仅激活2.8B参数的情况下即可实现这些功能。Kimi-VL在挑战性领域表现出卓越性能:作为通用VLM,Kimi-VL在多回合智能主体任务(例如OSWorld)中表现出色,与旗舰模型相匹敌。此外,它在多样化的挑战性视觉语言任务中也表现出卓越的能力,包括大学级别的图像和视频理解、OCR、数学推理和多图像理解。在比较评估中,它与最前沿的VLM(如GPT-4o-mini、Qwen2.5-VL-7B和Gemma-3-12B-IT)有效竞争,同时在一些关键领域超越了GPT-4o。Kimi-VL在处理长上下文和清晰感知方面也取得了进展。凭借128K的扩展上下文窗口,Kimi-VL能够处理各种长输入,在长视频基准测试(LongVideoBench)上获得令人印象深刻的64.5分,在MMLongBench-Doc上获得35.1分。其原生分辨率视觉编码器MoonViT允许其查看并理解超高分辨率的视觉输入,在InfoVQA上获得83.2分,在ScreenSpot-Pro上获得34.5分,同时为常规任务保持较低的计算成本。基于Kimi-VL,我们推出了一款先进的长思考变体:Kimi-VL-Thinking。该模型通过长链思维(CoT)的监督微调(SFT)和强化学习(RL)开发,展现出强大的长远推理能力。在MMMU上获得61.7分,在MathVision上获得36.8分,在MathVista上获得71.3分,同时在保持紧凑的2.8B激活LLM参数的同时,为高效的多模态思维模型设定了新的标准。代码和模型可在https://github.com/MoonshotAI/Kimi-VL公开访问。
论文及项目相关链接
Summary
Kimi-VL是一款高效开源的混合专家(MoE)视觉语言模型(VLM),具备先进的跨模态推理、长上下文理解和强大的代理能力。该模型在激活仅2.8B参数的语言解码器(Kimi-VL-A3B)的情况下,表现出强大的性能。Kimi-VL在多模态任务上表现出色,如OSWorld等。此外,它还在多种具有挑战性的视觉语言任务上展示了卓越的能力,如图像和视频理解、OCR、数学推理和多图像理解等。Kimi-VL还改进了处理长上下文和清晰感知的能力,拥有长达128K的扩展上下文窗口。代码和模型已公开在GitHub上。
Key Takeaways
- Kimi-VL是一个混合专家视觉语言模型,具有先进的跨模态推理能力。
- 该模型在多模态任务上表现出色,如OSWorld等。
- Kimi-VL在多图像理解、图像和视频理解等具有挑战性的视觉语言任务上表现优秀。
- 拥有长达128K的扩展上下文窗口,能够处理长上下文信息。
- 模型的视觉编码器MoonViT可以处理超高分辨率的视觉输入,同时保持较低的常见任务计算成本。
- Kimi-VL引入了一种先进的长思考变体Kimi-VL-Thinking,具备强大的长期推理能力。
点此查看论文截图