⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-15 更新
CLAP: Isolating Content from Style through Contrastive Learning with Augmented Prompts
Authors:Yichao Cai, Yuhang Liu, Zhen Zhang, Javen Qinfeng Shi
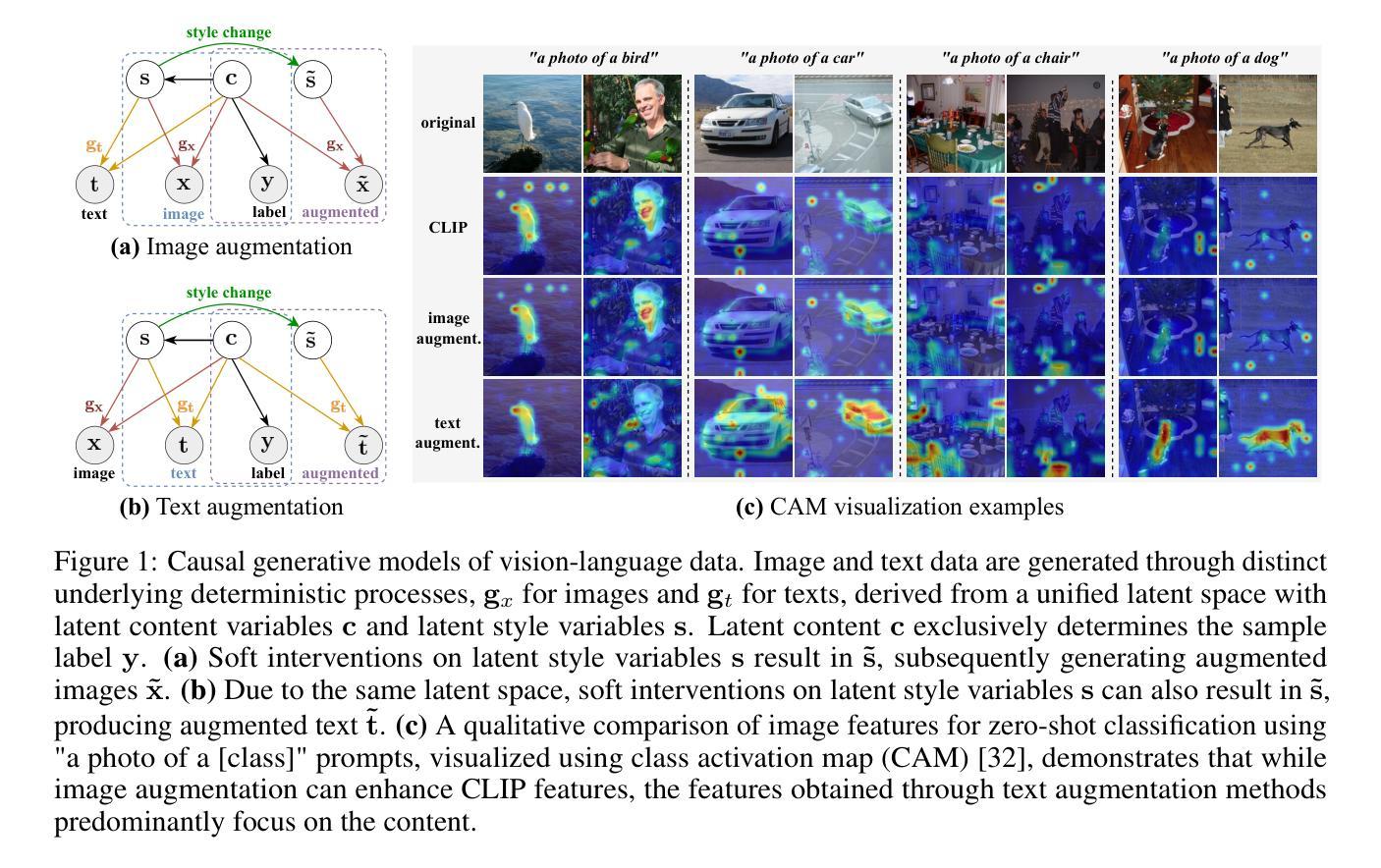
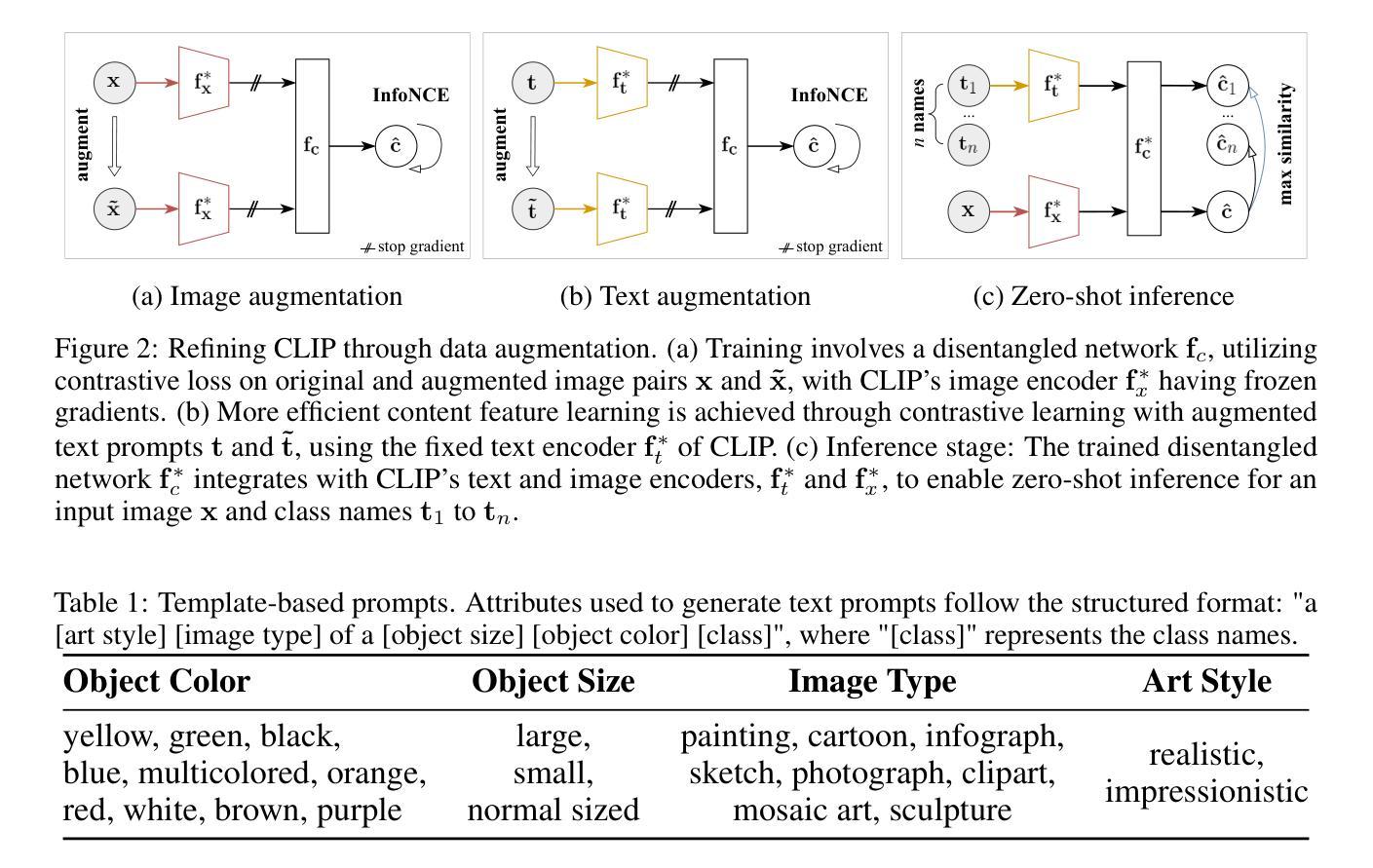
Contrastive vision-language models, such as CLIP, have garnered considerable attention for various downstream tasks, mainly due to the remarkable generalization ability of the learned features. However, the features they learn often blend content and style information, which somewhat limits their generalization capabilities under distribution shifts. To address this limitation, we adopt a causal generative perspective for multimodal data and propose contrastive learning with data augmentation to disentangle content features from the original representations. To achieve this, we begin by exploring image augmentation techniques and develop a method to seamlessly integrate them into pre-trained CLIP-like models to extract pure content features. Taking a step further, and recognizing the inherent semantic richness and logical structure of text data, we explore the use of text augmentation to isolate latent content from style features. This enables CLIP-like models’ encoders to concentrate on latent content information, refining the representations learned by pre-trained CLIP-like models. Our extensive experiments across diverse datasets demonstrate significant improvements in zero-shot and few-shot classification tasks, alongside enhanced robustness to various perturbations. These results underscore the effectiveness of our proposed methods in refining vision-language representations and advancing the state of the art in multimodal learning.
对比视觉语言模型,如CLIP,已引起广泛关注,主要用于各种下游任务,主要是由于所学特征的显著泛化能力。然而,他们学习的特征往往融合了内容和风格信息,这在某种程度上限制了其在分布变化下的泛化能力。为了解决这一局限性,我们从因果生成的角度对多模态数据进行研究,并提出采用数据增强的对比学习来从原始表示中分离内容特征。为了实现这一点,我们首先探索图像增强技术,并开发了一种方法,将其无缝集成到预训练的CLIP类模型中,以提取纯粹的内容特征。更进一步地,我们认识到文本数据的内在语义丰富性和逻辑结构,探索使用文本增强来分离潜在内容与风格特征。这使得CLIP类模型的编码器能够专注于潜在内容信息,对预训练的CLIP类模型所学表示进行精炼。我们在多个数据集上进行的广泛实验表明,零样本和少样本分类任务有了显著改进,对各种扰动的稳健性也得到提高。这些结果突显了我们提出的方法在精炼视觉语言表示方面的有效性,并推动了多模态学习的最新进展。
论文及项目相关链接
PDF Accepted as a conference paper at ECCV 2024
Summary
本文介绍了如何通过对比学习和数据增强技术,从预训练的视觉语言模型中分离内容和风格特征,提高模型的泛化能力和鲁棒性。通过图像和文本增强技术,将预训练的CLIP模型进行改进,使其更专注于潜在的内容信息,从而提高在零样本和少样本分类任务上的性能。
Key Takeaways
- 对比视觉语言模型如CLIP在许多下游任务中表现优异,但特征学习的内容和风格混合限制了其在分布转移下的泛化能力。
- 采用因果生成视角和多模态数据对比学习来分离内容特征。
- 通过图像增强技术改进预训练的CLIP模型,提取纯内容特征。
- 通过文本增强技术隔离潜在的内容与风格特征。
- 使CLIP模型的编码器更专注于潜在内容信息,提高表示学习。
- 在多个数据集上的实验显示,该方法在零样本和少样本分类任务上显著提高性能。
点此查看论文截图