⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-15 更新
DocAgent: A Multi-Agent System for Automated Code Documentation Generation
Authors:Dayu Yang, Antoine Simoulin, Xin Qian, Xiaoyi Liu, Yuwei Cao, Zhaopu Teng, Grey Yang
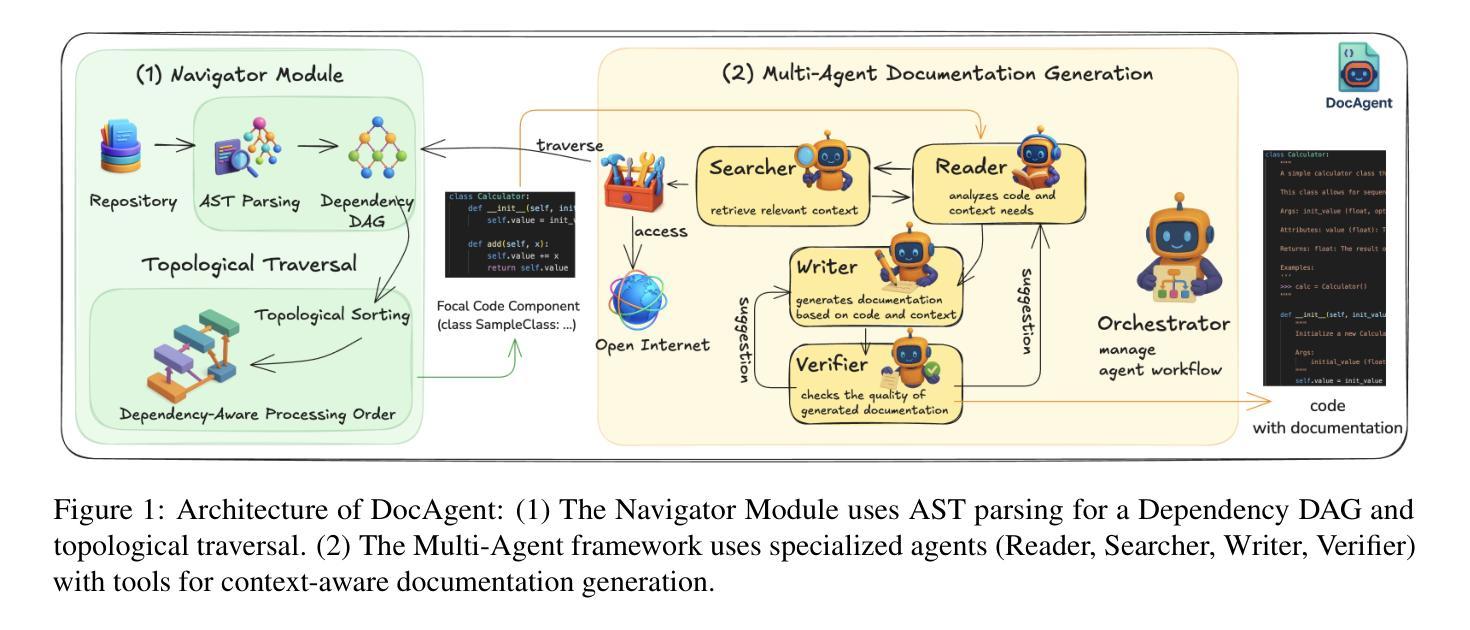
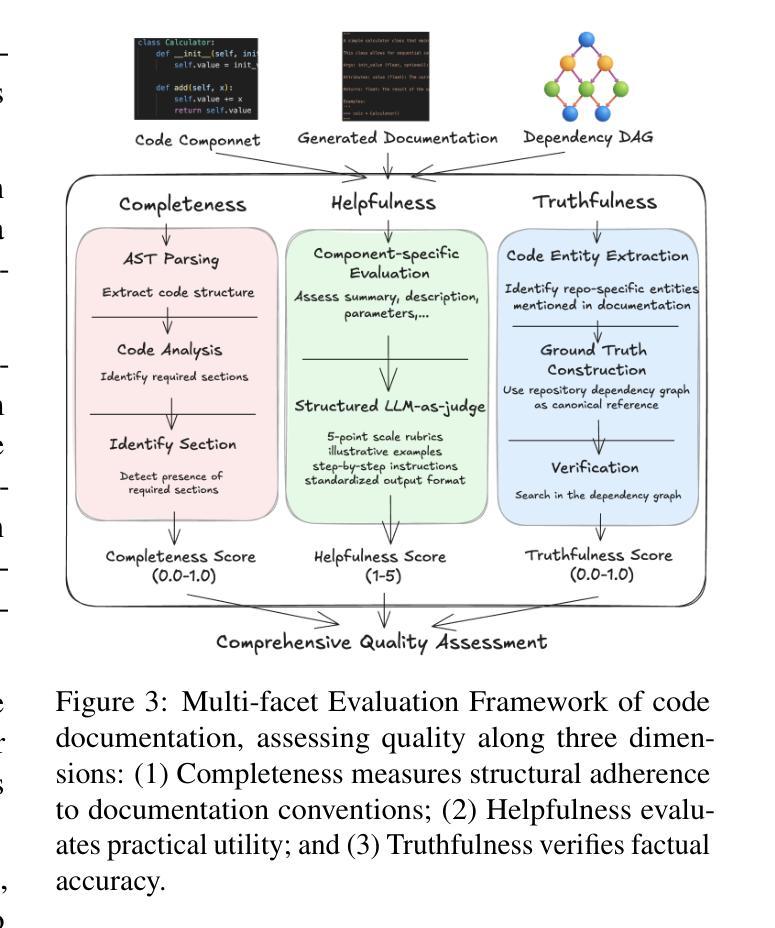
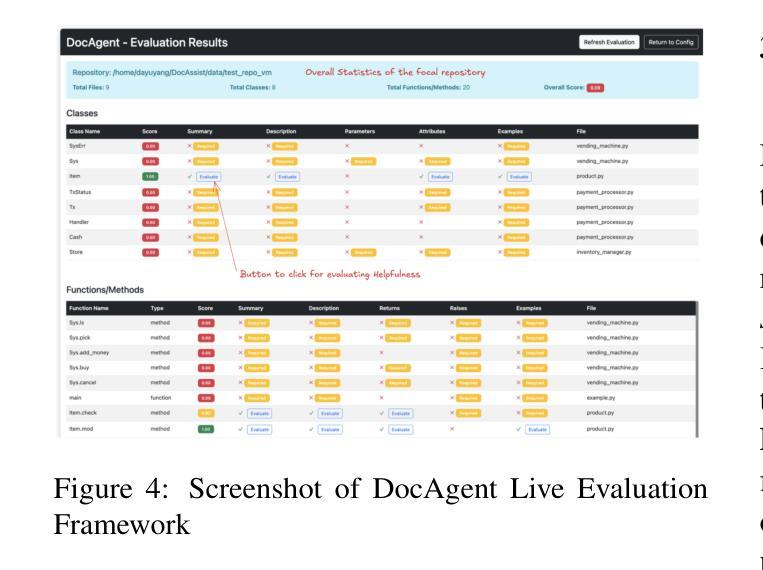
High-quality code documentation is crucial for software development especially in the era of AI. However, generating it automatically using Large Language Models (LLMs) remains challenging, as existing approaches often produce incomplete, unhelpful, or factually incorrect outputs. We introduce DocAgent, a novel multi-agent collaborative system using topological code processing for incremental context building. Specialized agents (Reader, Searcher, Writer, Verifier, Orchestrator) then collaboratively generate documentation. We also propose a multi-faceted evaluation framework assessing Completeness, Helpfulness, and Truthfulness. Comprehensive experiments show DocAgent significantly outperforms baselines consistently. Our ablation study confirms the vital role of the topological processing order. DocAgent offers a robust approach for reliable code documentation generation in complex and proprietary repositories.
高质量的代码文档对软件开发至关重要,特别是在人工智能时代。然而,使用大型语言模型(LLM)自动生成文档仍然具有挑战性,因为现有方法经常产生不完整、无帮助或事实错误的输出。我们引入了DocAgent,这是一个新的多智能体协作系统,采用拓扑代码处理来进行增量上下文构建。专门的智能体(阅读器、搜索器、编写器、验证器、协调器)协同生成文档。我们还提出了一个多方面的评估框架,评估文档的完整性、帮助性和真实性。综合实验表明,DocAgent在一致性方面显著优于基线。我们的消融研究证实了拓扑处理顺序的重要作用。DocAgent为复杂和专有存储库中的可靠代码文档生成提供了稳健的方法。
论文及项目相关链接
Summary
在人工智能时代,高质量代码文档对软件开发至关重要。然而,使用大型语言模型(LLMs)自动生成文档仍然具有挑战性,因为现有方法往往产生不完整、无帮助或事实错误的输出。我们推出DocAgent,一种新型多智能体协作系统,采用拓扑代码处理进行增量上下文构建。通过专门化的智能体(阅读器、搜索器、写手、验证者、协调者)协同生成文档。我们还提出了一个多方面的评估框架,评估完整性、帮助性和真实性。综合实验表明,DocAgent在一致性方面显著优于基线。我们的消融研究证实了拓扑处理顺序的重要作用。DocAgent为复杂和专有存储库中的可靠代码文档生成提供了稳健的方法。
Key Takeaways
- 高质量代码文档在软件开发中的重要性,特别是在人工智能时代。
- 自动生成代码文档使用大型语言模型(LLMs)的挑战性,现有方法的不足。
- DocAgent是一种新型多智能体协作系统,采用拓扑代码处理生成文档。
- DocAgent包含多个专门化智能体:阅读器、搜索器、写手、验证者、协调者。
- 提出了一个多方面的评估框架,评估生成的文档的完整性、帮助性和真实性。
- DocAgent在综合实验中显著优于现有方法。
- 消融研究证实了拓扑处理顺序在DocAgent性能中的重要性。
点此查看论文截图


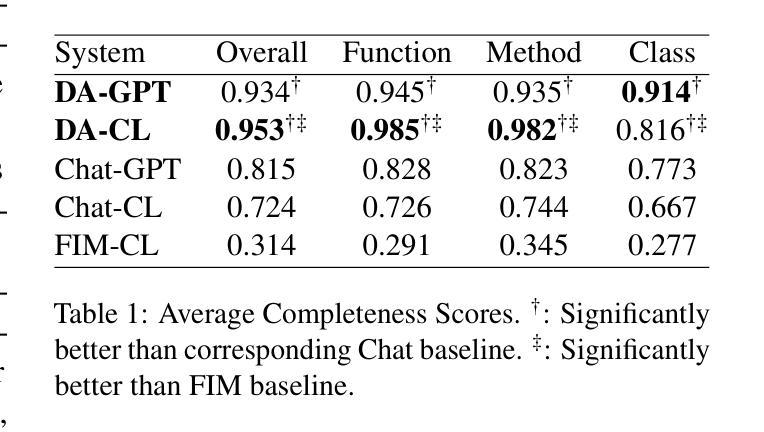
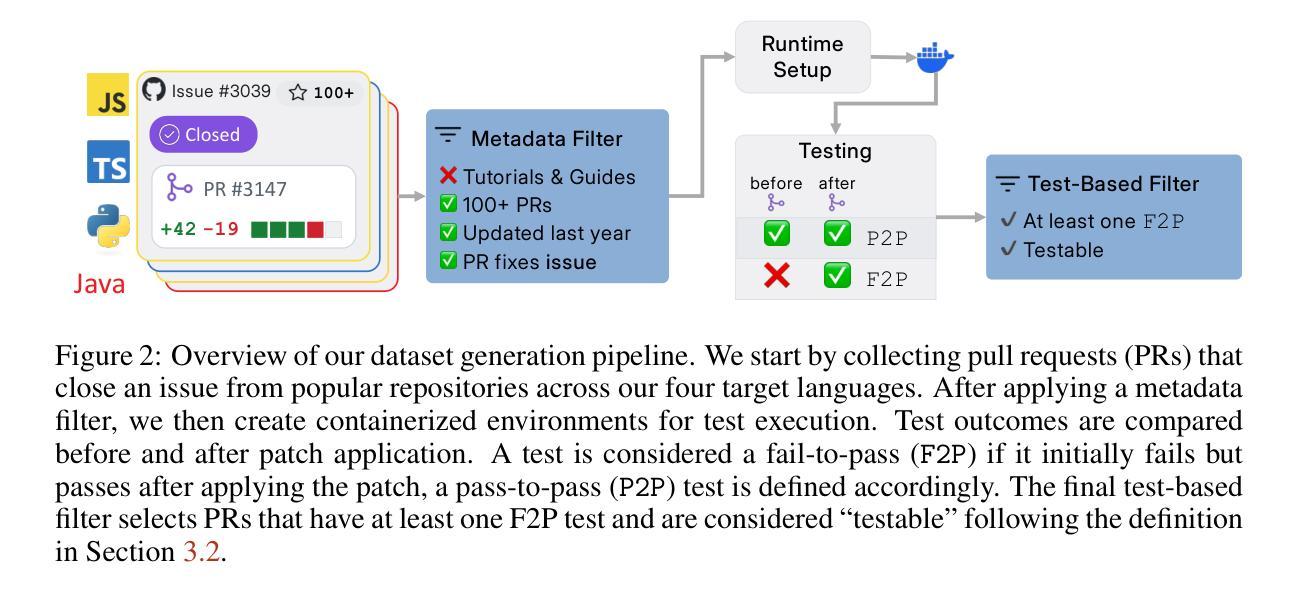
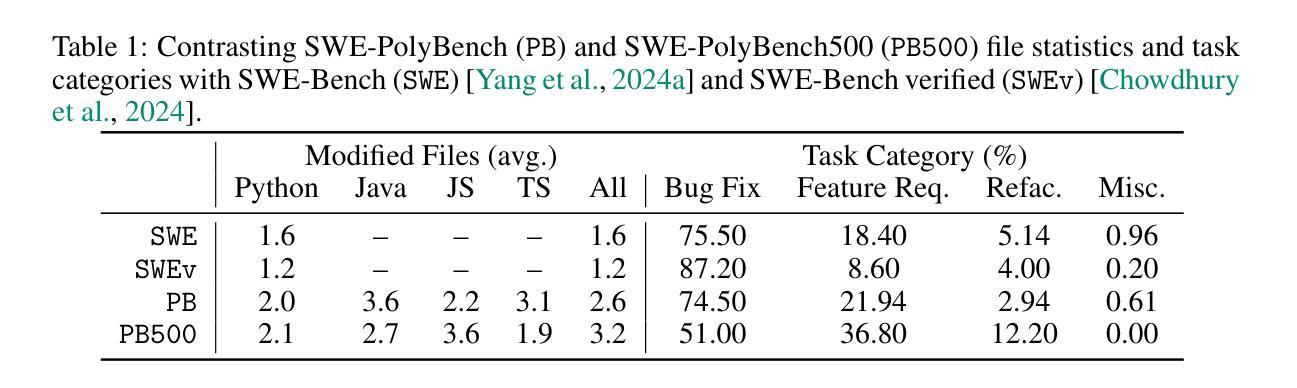
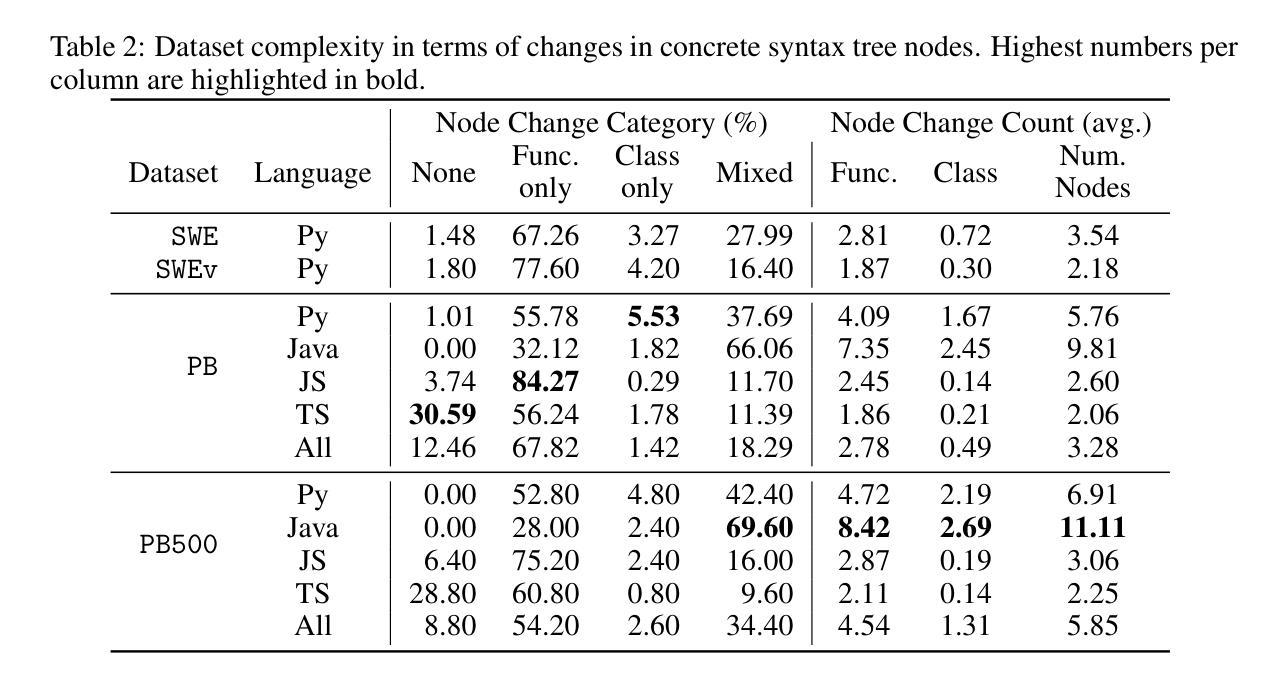
SWE-PolyBench: A multi-language benchmark for repository level evaluation of coding agents
Authors:Muhammad Shihab Rashid, Christian Bock, Yuan Zhuang, Alexander Buccholz, Tim Esler, Simon Valentin, Luca Franceschi, Martin Wistuba, Prabhu Teja Sivaprasad, Woo Jung Kim, Anoop Deoras, Giovanni Zappella, Laurent Callot
Coding agents powered by large language models have shown impressive capabilities in software engineering tasks, but evaluating their performance across diverse programming languages and real-world scenarios remains challenging. We introduce SWE-PolyBench, a new multi-language benchmark for repository-level, execution-based evaluation of coding agents. SWE-PolyBench contains 2110 instances from 21 repositories and includes tasks in Java (165), JavaScript (1017), TypeScript (729) and Python (199), covering bug fixes, feature additions, and code refactoring. We provide a task and repository-stratified subsample (SWE-PolyBench500) and release an evaluation harness allowing for fully automated evaluation. To enable a more comprehensive comparison of coding agents, this work also presents a novel set of metrics rooted in syntax tree analysis. We evaluate leading open source coding agents on SWE-PolyBench, revealing their strengths and limitations across languages, task types, and complexity classes. Our experiments show that current agents exhibit uneven performances across languages and struggle with complex problems while showing higher performance on simpler tasks. SWE-PolyBench aims to drive progress in developing more versatile and robust AI coding assistants for real-world software engineering. Our datasets and code are available at: https://github.com/amazon-science/SWE-PolyBench
由大型语言模型驱动的代码生成器在软件工程任务中展现了令人印象深刻的能力,但在多种编程语言和真实世界场景中对它们的性能进行评估仍然具有挑战性。我们引入了SWE-PolyBench,这是一个新的多语言基准测试,用于对代码生成器进行仓库级别的基于执行的评价。SWE-PolyBench包含来自21个仓库的2110个实例,涵盖了Java(165个)、JavaScript(1017个)、TypeScript(729个)和Python(199个)的任务,包括错误修复、功能添加和代码重构。我们提供了一个任务和仓库分层子样本(SWE-PolyBench500),并发布了一个评估工具,可以实现全自动评估。为了能够对代码生成器进行更全面的比较,这项工作还提出了基于语法树分析的新指标集。我们在SWE-PolyBench上评估了领先的开源代码生成器,揭示了它们在语言、任务类型和复杂度类别方面的优势和局限性。我们的实验表明,当前各代理在不同语言中的表现不均衡,在复杂问题上表现困难,而在简单任务上表现较好。SWE-PolyBench的目标是推动开发更通用、更稳健的AI编码助手,用于真实世界的软件工程。我们的数据集和代码可在https://github.com/amazon-science/SWE-PolyBench找到。
论文及项目相关链接
PDF 20 pages, 6 figures
Summary
大型语言模型驱动的编码代理在软件工程任务中表现出令人印象深刻的能力,但跨多种编程语言和现实场景评估其性能具有挑战性。为此,我们推出了SWE-PolyBench,这是一个新的多语言基准测试,用于对编码代理进行仓库级的执行评估。SWE-PolyBench包含来自21个仓库的2110个实例,涵盖Java、JavaScript、TypeScript和Python的任务,包括错误修复、功能添加和代码重构。我们提供了任务分层和仓库分层的子集(SWE-PolyBench500),并发布了评估工具,可以实现完全自动化评估。为了更全面地比较编码代理,本文还提出了基于语法树分析的新指标集。我们在SWE-PolyBench上评估了领先的开源编码代理,揭示了它们在语言、任务类型和复杂性方面的优势和局限性。实验表明,当前代理在不同语言之间的性能不均,对复杂问题感到困难,在简单任务上的表现较好。SWE-PolyBench旨在推动开发更通用和稳健的AI编程助手,用于现实软件工程。
Key Takeaways
- 大型语言模型驱动的编码代理在软件工程任务中展现出强大能力。
- 跨多种编程语言和现实场景评估编码代理性能具有挑战性。
- SWE-PolyBench是一个新的多语言基准测试,用于仓库级的执行评估。
- SWE-PolyBench包含多种任务类型,涵盖Java、JavaScript、TypeScript和Python。
- 提供了自动化评估工具,便于评估编码代理性能。
- 当前编码代理在不同语言、任务类型和复杂性方面的性能存在差异。
点此查看论文截图


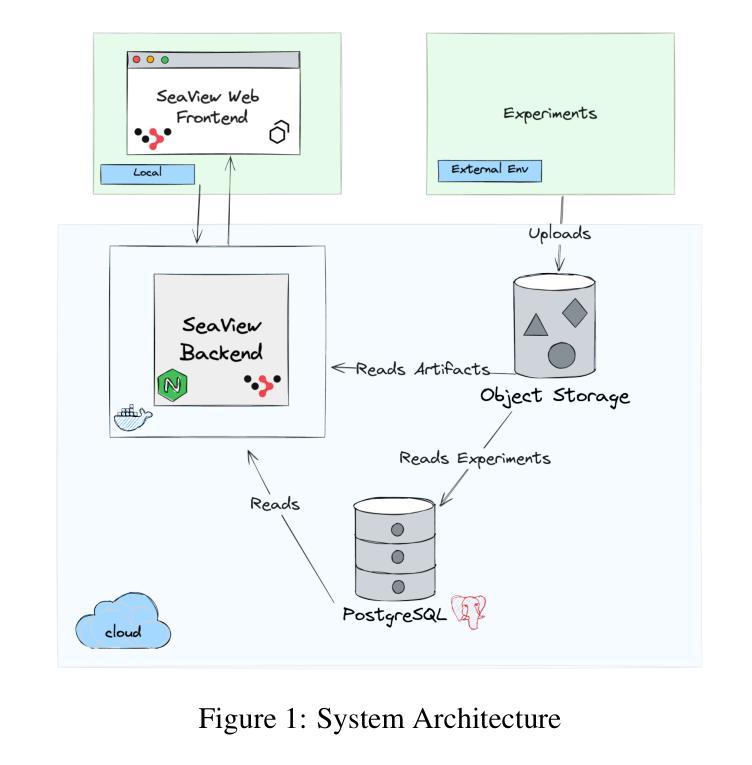
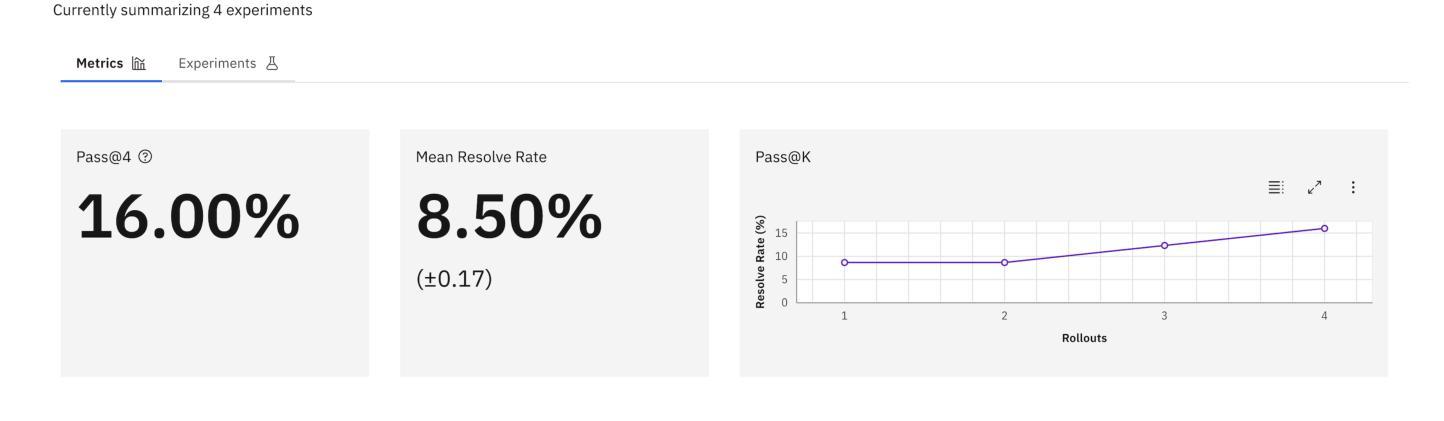
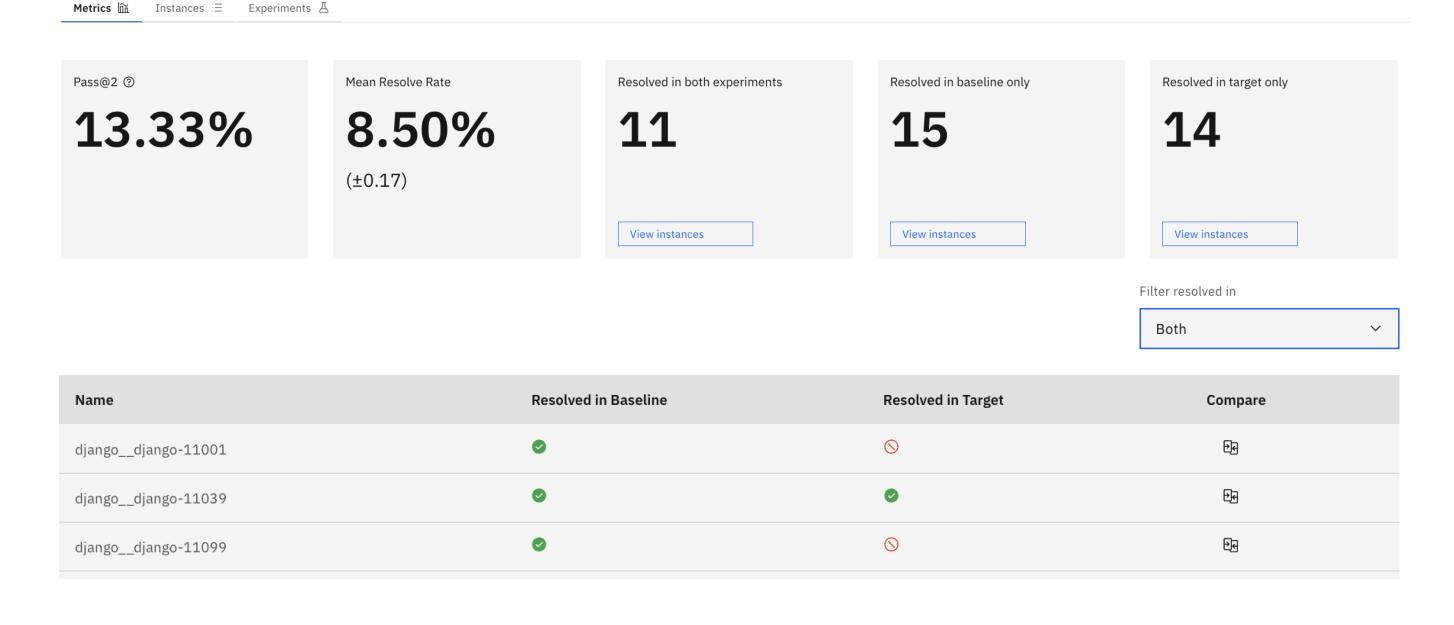
SeaView: Software Engineering Agent Visual Interface for Enhanced Workflow
Authors:Timothy Bula, Saurabh Pujar, Luca Buratti, Mihaela Bornea, Avirup Sil
Auto-regressive LLM-based software engineering (SWE) agents, henceforth SWE agents, have made tremendous progress (>60% on SWE-Bench Verified) on real-world coding challenges including GitHub issue resolution. SWE agents use a combination of reasoning, environment interaction and self-reflection to resolve issues thereby generating “trajectories”. Analysis of SWE agent trajectories is difficult, not only as they exceed LLM sequence length (sometimes, greater than 128k) but also because it involves a relatively prolonged interaction between an LLM and the environment managed by the agent. In case of an agent error, it can be hard to decipher, locate and understand its scope. Similarly, it can be hard to track improvements or regression over multiple runs or experiments. While a lot of research has gone into making these SWE agents reach state-of-the-art, much less focus has been put into creating tools to help analyze and visualize agent output. We propose a novel tool called SeaView: Software Engineering Agent Visual Interface for Enhanced Workflow, with a vision to assist SWE-agent researchers to visualize and inspect their experiments. SeaView’s novel mechanisms help compare experimental runs with varying hyper-parameters or LLMs, and quickly get an understanding of LLM or environment related problems. Based on our user study, experienced researchers spend between 10 and 30 minutes to gather the information provided by SeaView, while researchers with little experience can spend between 30 minutes to 1 hour to diagnose their experiment.
基于自动回归LLM的软件工程(SWE)代理,在此称为SWE代理,在现实世界的编程挑战(包括GitHub问题解决方案)方面取得了巨大进展(在SWE-Bench Verified上的得分超过60%)。SWE代理通过结合推理、环境交互和自我反思来解决问题,从而生成“轨迹”。SWE代理轨迹的分析很困难,不仅是因为它们超过了LLM序列长度(有时超过128k),而且因为涉及到LLM和代理管理的环境之间相对较长的交互。在代理出错的情况下,很难解释、定位和了解其范围。同样,很难跟踪多次运行或实验中的改进或回归。虽然很多研究已经投入到让这些SWE代理达到最新技术状态,但很少关注创建工具来帮助分析和可视化代理输出。我们提出了一种新型工具,称为SeaView:软件工程代理可视化界面增强工作流程,其愿景是帮助SWE代理研究人员可视化并检查他们的实验。SeaView的新颖机制有助于比较具有不同超参数或LLM的实验运行,并快速了解与LLM或环境相关的问题。根据我们的用户研究,经验丰富的研究人员使用SeaView提供的信息需要花费10到30分钟的时间,而经验较少的研究人员则需要花费30分钟到1小时的时间来诊断他们的实验。
论文及项目相关链接
PDF 8 pages, 5 figures
Summary:基于自回归大型语言模型(LLM)的软件工程(SWE)代理在解决现实世界编码挑战方面取得了巨大进展,如GitHub问题解析。SWE代理通过推理、环境交互和自我反思来解决新问题并生成“轨迹”。分析SWE代理轨迹很具挑战性,因为轨迹不仅可能超过LLM序列长度(有时甚至超过128k),而且涉及LLM和代理管理的环境之间相对长时间的交互。我们提出了一种新型工具SeaView,旨在帮助SWE代理研究人员可视化并检查其实验。SeaView可以快速比较不同超参数或LLM的实验运行,并理解相关的LLM或环境问题。用户研究表明,经验丰富的研究人员使用SeaView收集信息的时间在10到30分钟之间,而经验较少的研究人员可能需要花费半小时到一小时来诊断实验。
Key Takeaways:
- 基于自回归LLM的SWE代理在解决现实世界编码问题上取得显著进展,例如GitHub问题解析。
- SW代理生成被称为“轨迹”的解决方案路径,其中包含推理、环境交互和自我反思等元素。
- 分析SWE代理轨迹存在挑战,主要包括轨迹长度超过LLM序列长度和涉及长时间的环境交互。
- 提出的新型工具SeaView旨在帮助SWE代理研究人员可视化并检查实验,促进理解LLM或环境相关的问题。
- SeaView有助于比较不同超参数或LLM的实验运行,快速识别问题所在。
- 根据用户研究,使用SeaView收集信息的时间根据研究人员的经验而异,经验丰富的研究人员可能需要较少的时间。
点此查看论文截图


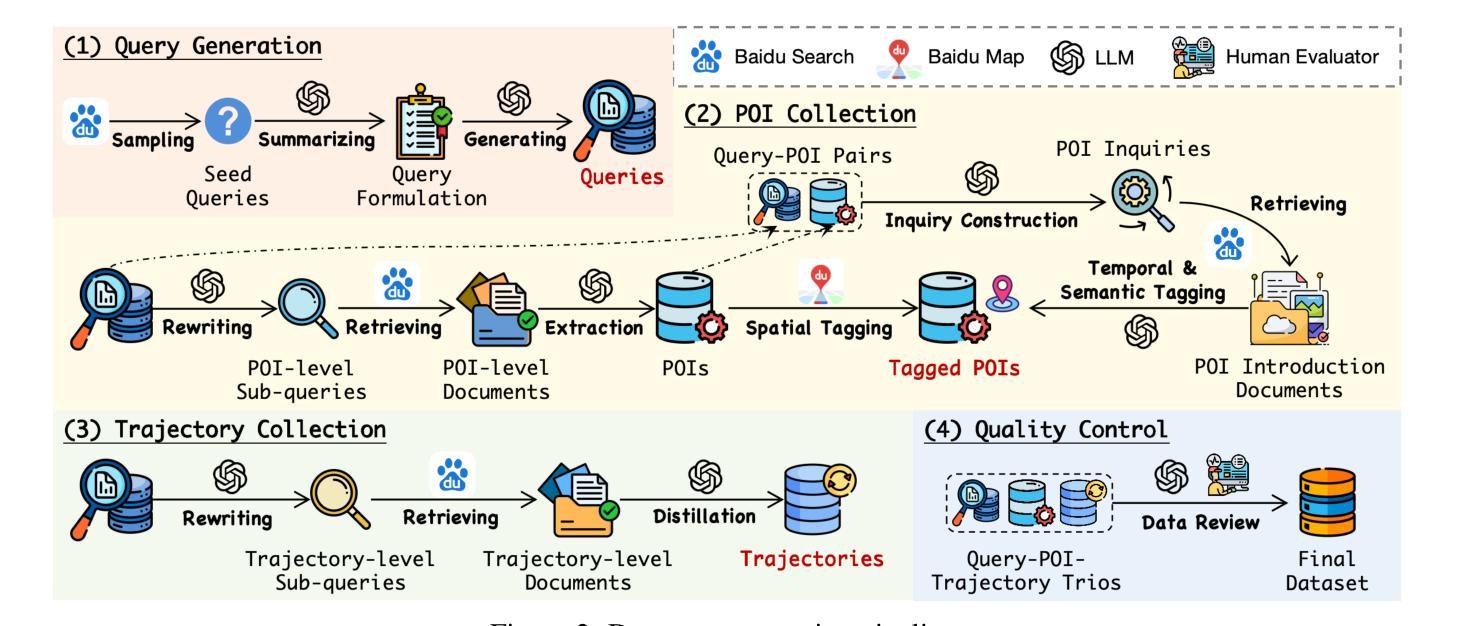
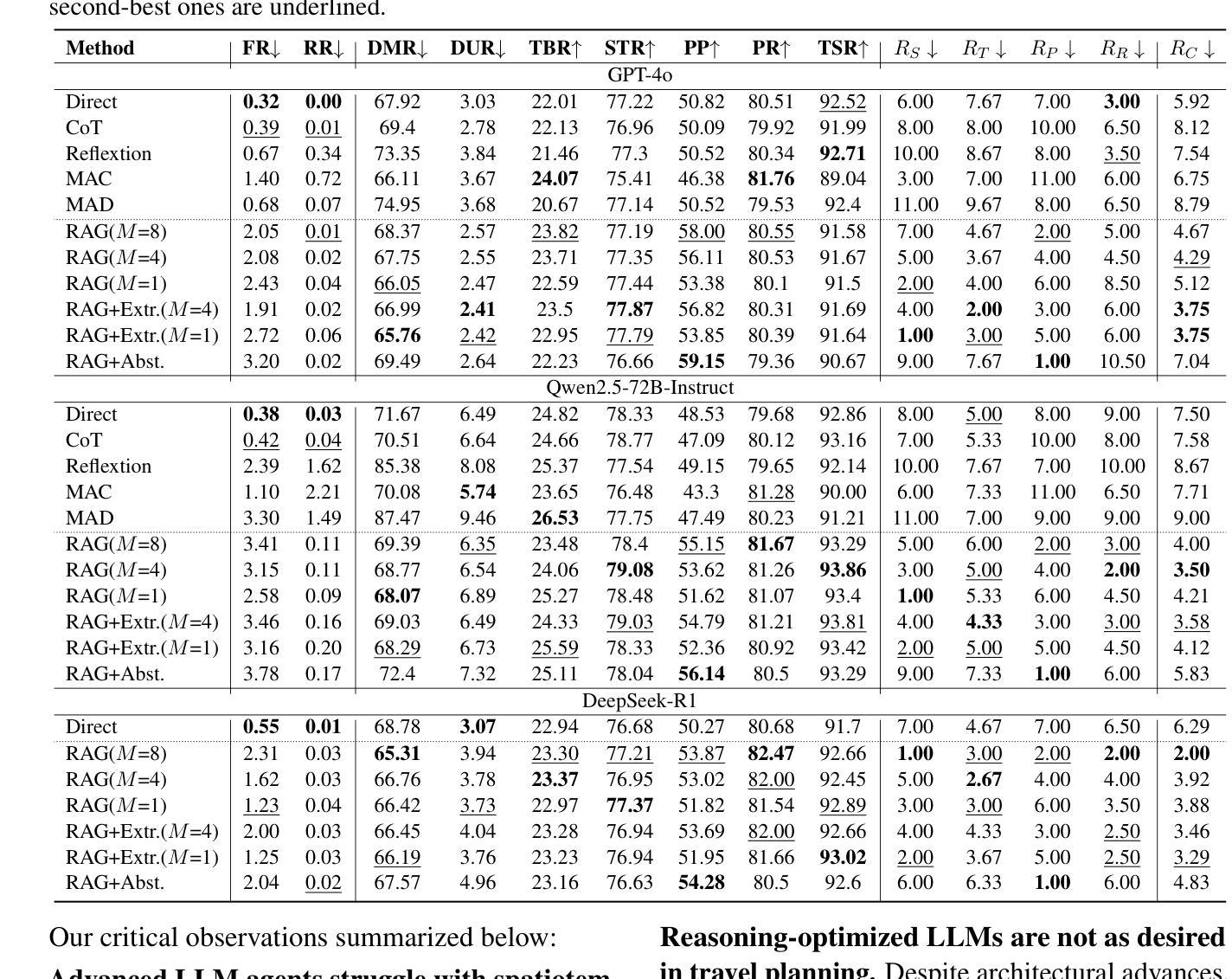
TP-RAG: Benchmarking Retrieval-Augmented Large Language Model Agents for Spatiotemporal-Aware Travel Planning
Authors:Hang Ni, Fan Liu, Xinyu Ma, Lixin Su, Shuaiqiang Wang, Dawei Yin, Hui Xiong, Hao Liu
Large language models (LLMs) have shown promise in automating travel planning, yet they often fall short in addressing nuanced spatiotemporal rationality. While existing benchmarks focus on basic plan validity, they neglect critical aspects such as route efficiency, POI appeal, and real-time adaptability. This paper introduces TP-RAG, the first benchmark tailored for retrieval-augmented, spatiotemporal-aware travel planning. Our dataset includes 2,348 real-world travel queries, 85,575 fine-grain annotated POIs, and 18,784 high-quality travel trajectory references sourced from online tourist documents, enabling dynamic and context-aware planning. Through extensive experiments, we reveal that integrating reference trajectories significantly improves spatial efficiency and POI rationality of the travel plan, while challenges persist in universality and robustness due to conflicting references and noisy data. To address these issues, we propose EvoRAG, an evolutionary framework that potently synergizes diverse retrieved trajectories with LLMs’ intrinsic reasoning. EvoRAG achieves state-of-the-art performance, improving spatiotemporal compliance and reducing commonsense violation compared to ground-up and retrieval-augmented baselines. Our work underscores the potential of hybridizing Web knowledge with LLM-driven optimization, paving the way for more reliable and adaptive travel planning agents.
大型语言模型(LLM)在自动化旅行规划方面显示出巨大的潜力,然而,在处理微妙的时空合理性方面,它们往往存在不足。现有的基准测试主要集中在基本计划的可行性上,却忽视了路线效率、兴趣点吸引力以及实时适应性等关键方面。本文介绍了为检索增强、时空感知旅行规划量身定制的TP-RAG基准测试。我们的数据集包含2348个真实旅行查询、85575个精细标注的兴趣点和18784个高质量旅行轨迹参考,这些参考来源于在线旅游文档,可实现动态和上下文感知的规划。通过广泛的实验,我们发现集成参考轨迹可以显著提高旅行计划的空间效率和兴趣点的合理性,但由于存在相互冲突的引用和嘈杂的数据,仍存在普遍性和稳健性的挑战。为了解决这些问题,我们提出了EvoRAG,这是一个进化框架,能够强有力地协同多样化的检索轨迹与LLM的内在推理。EvoRAG达到了最新的性能水平,与自下而上和检索增强的基准相比,提高了时空合规性并减少了常识违规行为。我们的工作强调了混合Web知识与LLM驱动优化的潜力,为更可靠和适应性更强的旅行规划代理铺平了道路。
论文及项目相关链接
Summary
本文介绍了一个针对检索增强、时空感知旅行规划的基准测试TP-RAG。该数据集包含真实旅行查询、精细标注的POI和高质量旅行轨迹参考,使动态和上下文感知的规划成为可能。研究结果表明,集成参考轨迹可以显著提高空间效率和POI合理性,但仍存在普遍性和稳健性问题。为解决这些问题,本文提出了进化框架EvoRAG,它有效地将多种检索轨迹与LLM的内在推理相结合。EvoRAG达到了前所未有的性能水平,提高了时空一致性并减少了常识性违规行为。该研究展示了融合网络知识和LLM优化的潜力,为旅行规划领域更可靠、更灵活的智能助手开辟了道路。
Key Takeaways
- 大型语言模型(LLMs)在自动化旅行规划中显示出潜力,但仍需解决时空理性的细微差异问题。
- 现有基准测试主要集中在基本计划的有效性上,忽略了路线效率、兴趣点吸引力和实时适应性等关键方面。
- 介绍了针对检索增强、时空感知旅行规划的基准测试TP-RAG,包含真实旅行查询和精细标注的POI等数据。
- 集成参考轨迹可显著提高空间效率和POI合理性,但存在普遍性和稳健性问题。
- 提出了进化框架EvoRAG,将多种检索轨迹与LLM的内在推理相结合,达到前所未有的性能水平。
- EvoRAG提高了时空一致性并减少了常识性违规行为。
点此查看论文截图

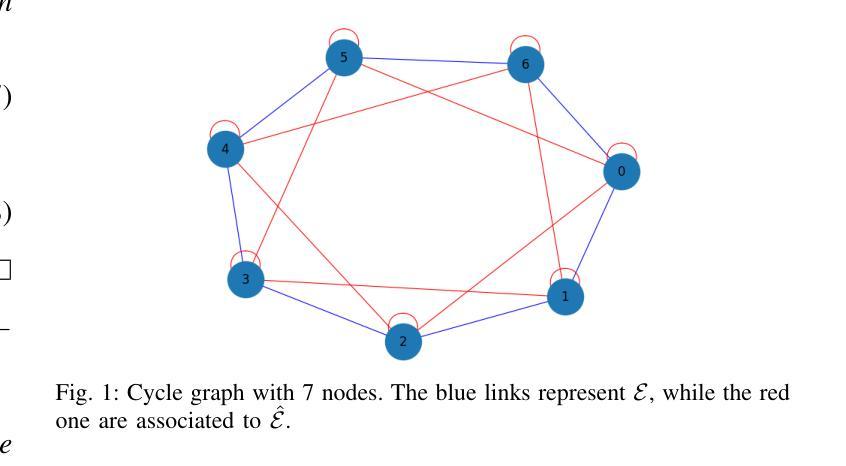
Optimal selection of the most informative nodes for a noisy DeGroot model with stubborn agents
Authors:Roberta Raineri, Giacomo Como, Fabio Fagnani
Finding the optimal subset of individuals to observe in order to obtain the best estimate of the average opinion of a society is a crucial problem in a wide range of applications, including policy-making, strategic business decisions, and the analysis of sociological trends. We consider the opinion vector X to be updated according to a DeGroot opinion dynamical model with stubborn agents, subject to perturbations from external random noise, which can be interpreted as transmission errors. The objective function of the optimization problem is the variance reduction achieved by observing the equilibrium opinions of a subset K of agents. We demonstrate that, under this specific setting, the objective function exhibits the property of submodularity. This allows us to effectively design a Greedy Algorithm to solve the problem, significantly reducing its computational complexity. Simple examples are provided to validate our results.
寻找最优个体子集进行观察,以得到社会平均意见的最佳估计是广泛应用中的关键问题,包括政策制定、战略业务决策和社会趋势分析。我们认为意见向量X将根据带有顽固代理的DeGroot意见动态模型进行更新,并受到外部随机噪声的干扰,可以解释为传输错误。优化问题的目标函数是通过观察代理子集K的平衡意见实现的方差减小。我们证明,在这种特定设置下,目标函数表现出子模块化的属性。这使我们能够有效地设计贪婪算法来解决问题,从而大大降低了计算复杂度。通过简单的例子验证了我们的结果。
论文及项目相关链接
Summary
针对从社会群体中观察特定个体以获得最佳群体观点估算的问题,该研究提出基于DeGroot观点动态模型使用顽强个体的观点更新方案,且模型受外部随机噪声扰动影响。目标函数是降低观察部分个体最终观点所得结果带来的方差。研究表明该目标函数具有子模性,可设计贪心算法有效解决问题并显著降低计算复杂度。简单实例验证了研究结果的有效性。
Key Takeaways
- 研究针对社会群体观点估算问题,采用DeGroot观点动态模型更新观点。
- 模型考虑存在顽强个体和外部随机噪声扰动的影响。
- 目标函数旨在降低观察特定个体最终观点所带来的方差。
- 研究发现目标函数具有子模性,有助于设计贪心算法解决优化问题。
- 贪心算法能显著降低计算复杂度。
点此查看论文截图


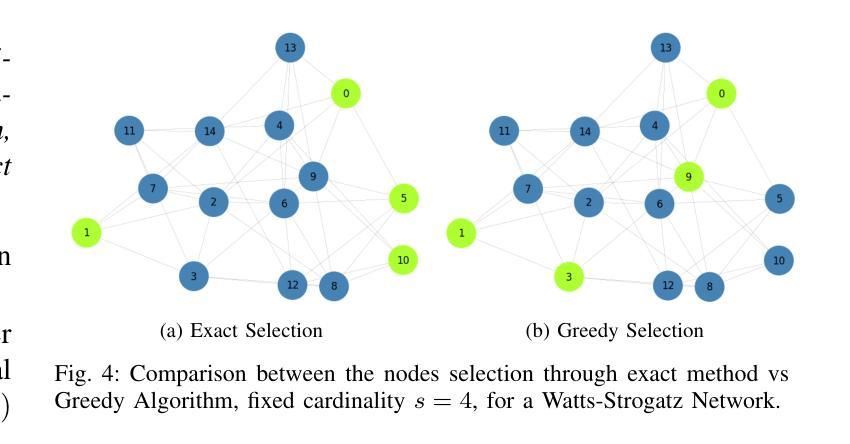

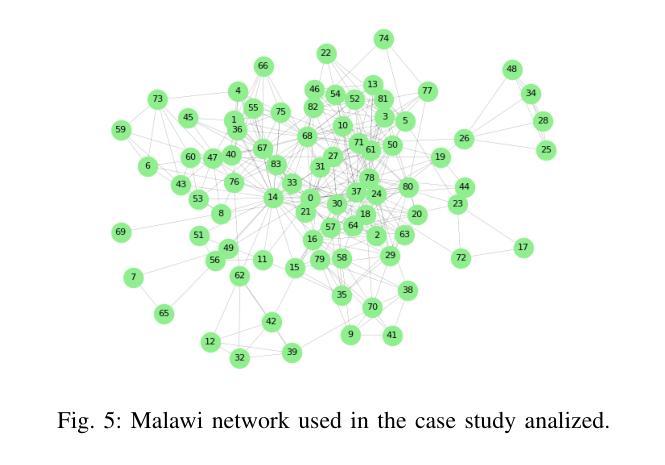
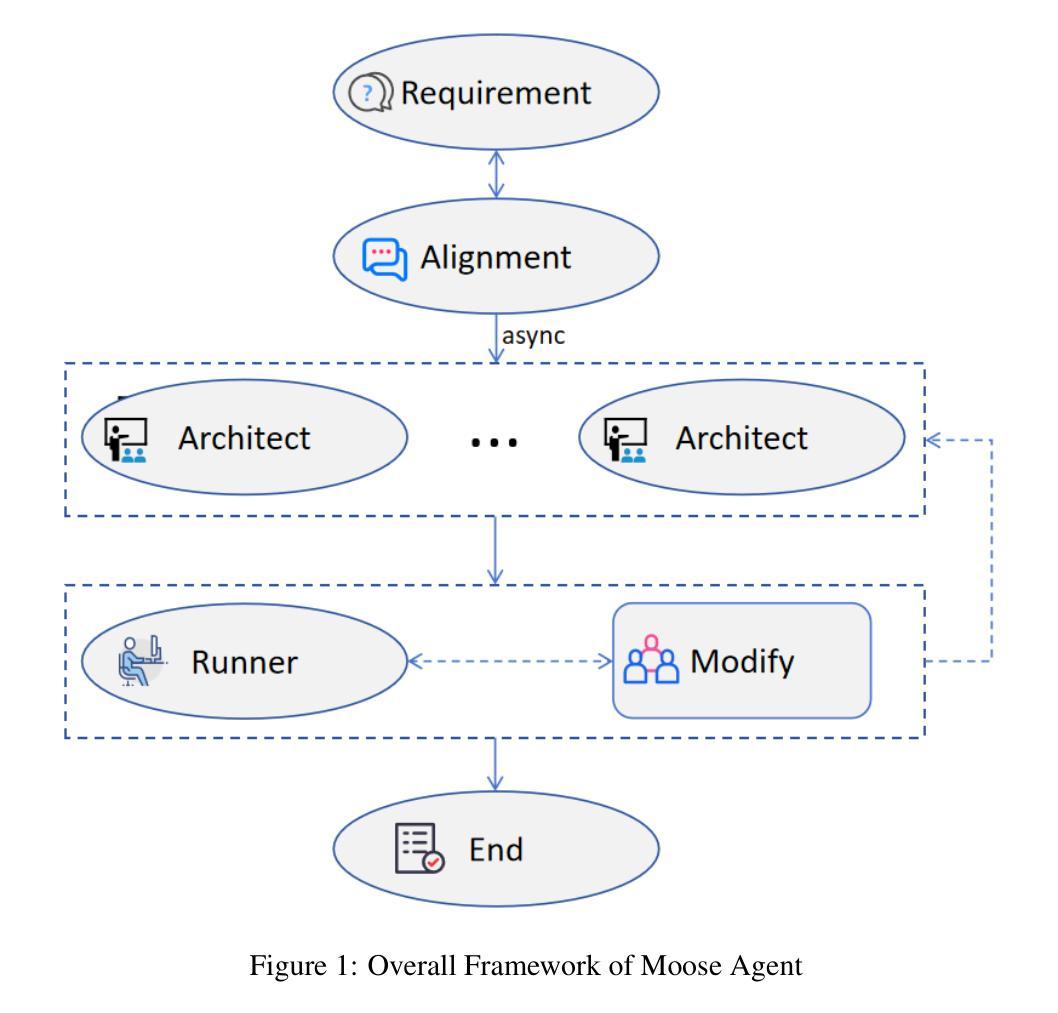
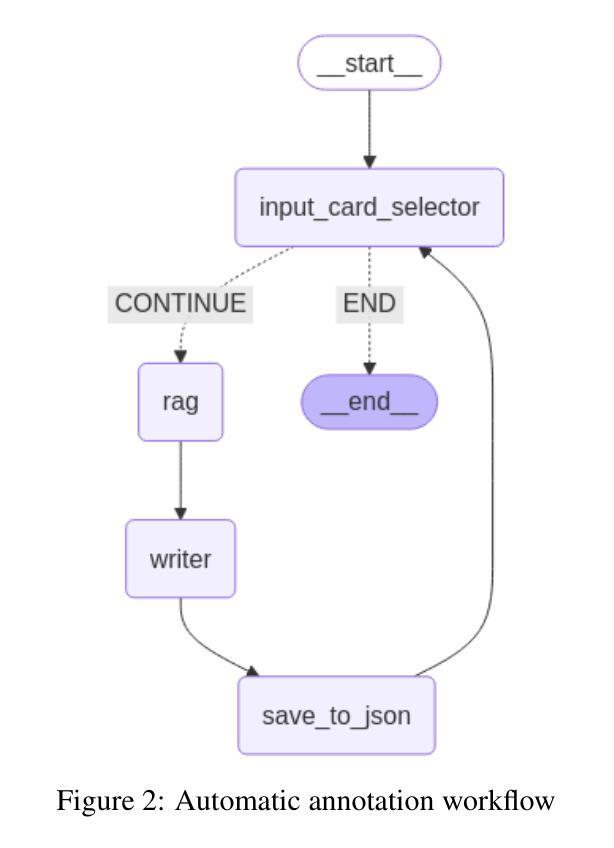
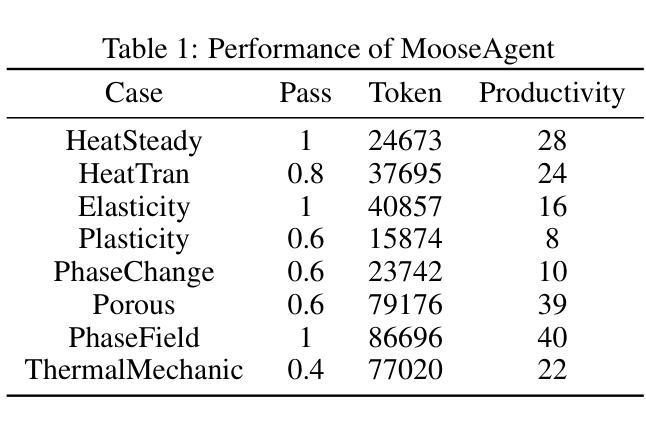
MooseAgent: A LLM Based Multi-agent Framework for Automating Moose Simulation
Authors:Tao Zhang, Zhenhai Liu, Yong Xin, Yongjun Jiao
The Finite Element Method (FEM) is widely used in engineering and scientific computing, but its pre-processing, solver configuration, and post-processing stages are often time-consuming and require specialized knowledge. This paper proposes an automated solution framework, MooseAgent, for the multi-physics simulation framework MOOSE, which combines large-scale pre-trained language models (LLMs) with a multi-agent system. The framework uses LLMs to understand user-described simulation requirements in natural language and employs task decomposition and multi-round iterative verification strategies to automatically generate MOOSE input files. To improve accuracy and reduce model hallucinations, the system builds and utilizes a vector database containing annotated MOOSE input cards and function documentation. We conducted experimental evaluations on several typical cases, including heat transfer, mechanics, phase field, and multi-physics coupling. The results show that MooseAgent can automate the MOOSE simulation process to a certain extent, especially demonstrating a high success rate when dealing with relatively simple single-physics problems. The main contribution of this research is the proposal of a multi-agent automated framework for MOOSE, which validates its potential in simplifying finite element simulation processes and lowering the user barrier, providing new ideas for the development of intelligent finite element simulation software. The code for the MooseAgent framework proposed in this paper has been open-sourced and is available at https://github.com/taozhan18/MooseAgent
有限元方法(FEM)在工程和科学计算中得到了广泛应用,但其预处理、求解器配置和后处理阶段往往耗时且需要专业知识。本文针对多物理仿真框架MOOSE,提出了一种自动化解决方案框架MooseAgent。该框架结合大规模预训练语言模型(LLMs)和多智能体系统,使用LLMs理解用户描述的自然语言仿真要求,并采用任务分解和多轮迭代验证策略自动生成MOOSE输入文件。为了提高精度并减少模型幻觉,该系统构建并利用了一个包含注释的MOOSE输入卡片和功能文档的向量数据库。我们在几个典型案例上进行了实验评估,包括热传导、力学、相场和多物理耦合。结果表明,MooseAgent能在一定程度上自动化MOOSE仿真过程,尤其是在处理相对简单的单物理问题时成功率较高。本研究的主要贡献是提出了针对MOOSE的多智能体自动化框架,验证了其在简化有限元仿真过程、降低用户门槛方面的潜力,为智能有限元仿真软件的开发提供了新的思路。本文提出的MooseAgent框架的代码已开源,可在https://github.com/taozhan18/MooseAgent上获取。
论文及项目相关链接
PDF 7 pages, 2 Figs
Summary
工程和科学计算中广泛应用的有限元方法(FEM)在预处理、求解器配置和后处理阶段十分耗时并需要专业知识。本文提出一个名为MooseAgent的自动化解决方案框架,用于多物理仿真框架MOOSE。该框架结合大规模预训练语言模型(LLMs)和多智能体系统,理解用户描述的仿真需求并自动生成MOOSE输入文件。通过构建和利用向量数据库来提高准确性和减少模型幻觉。实验评估表明,MooseAgent在一定程度上能自动化MOOSE仿真过程,尤其在处理相对简单的单物理问题时成功率较高。
Key Takeaways
- MooseAgent是一个用于多物理仿真框架MOOSE的自动化解决方案,结合了大规模预训练语言模型(LLMs)和多智能体系统。
- LLMs用于理解用户描述的仿真需求,并自动生成MOOSE输入文件。
- MooseAgent通过构建和利用向量数据库来提高准确性和减少模型幻觉。
- 实验评估显示,MooseAgent能自动化MOOSE仿真过程至一定程度,尤其处理简单单物理问题时成功率高。
- 该研究的主要贡献是提出一个用于MOOSE的多智能体自动化框架,有潜力简化有限元仿真过程并降低用户门槛。
- MooseAgent框架的代码已开源,可在公开平台获取。
点此查看论文截图

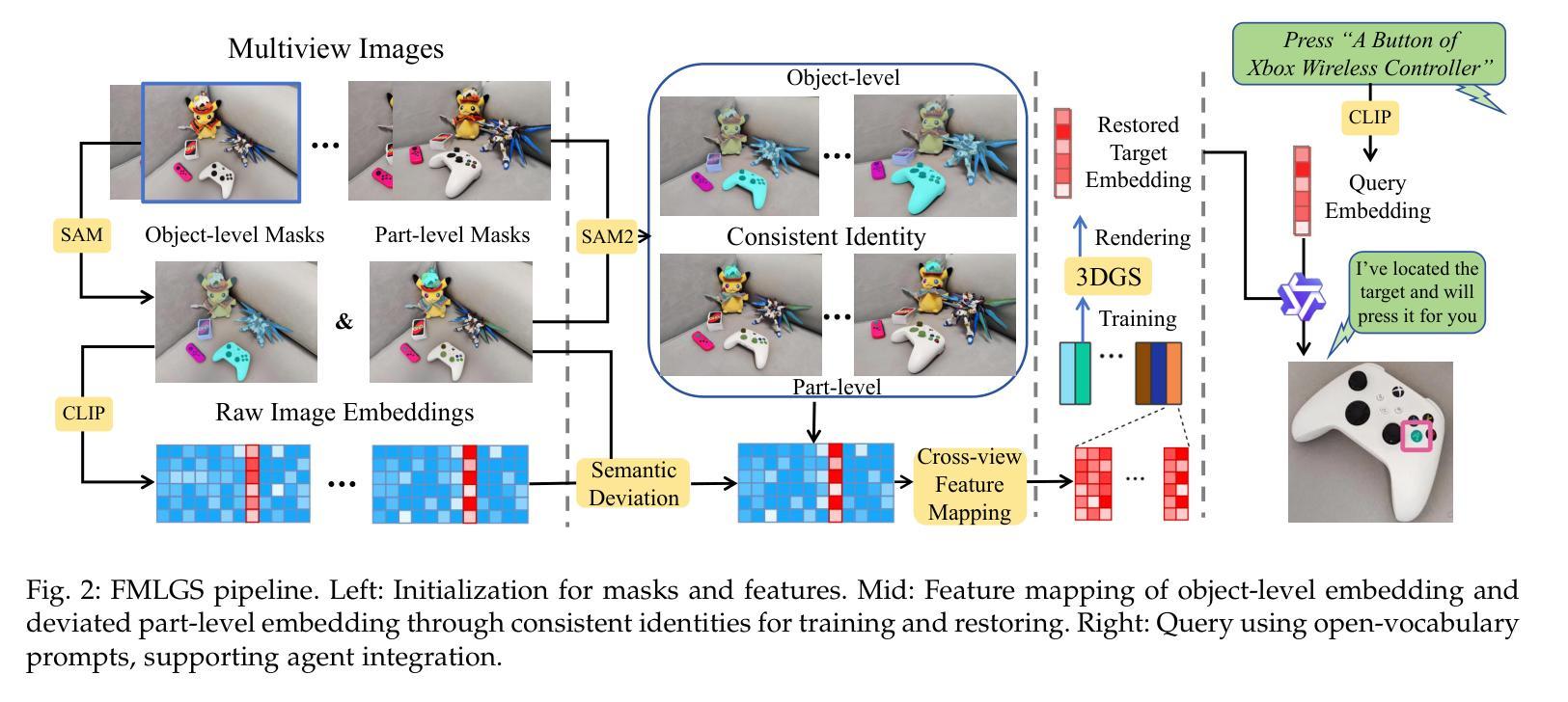
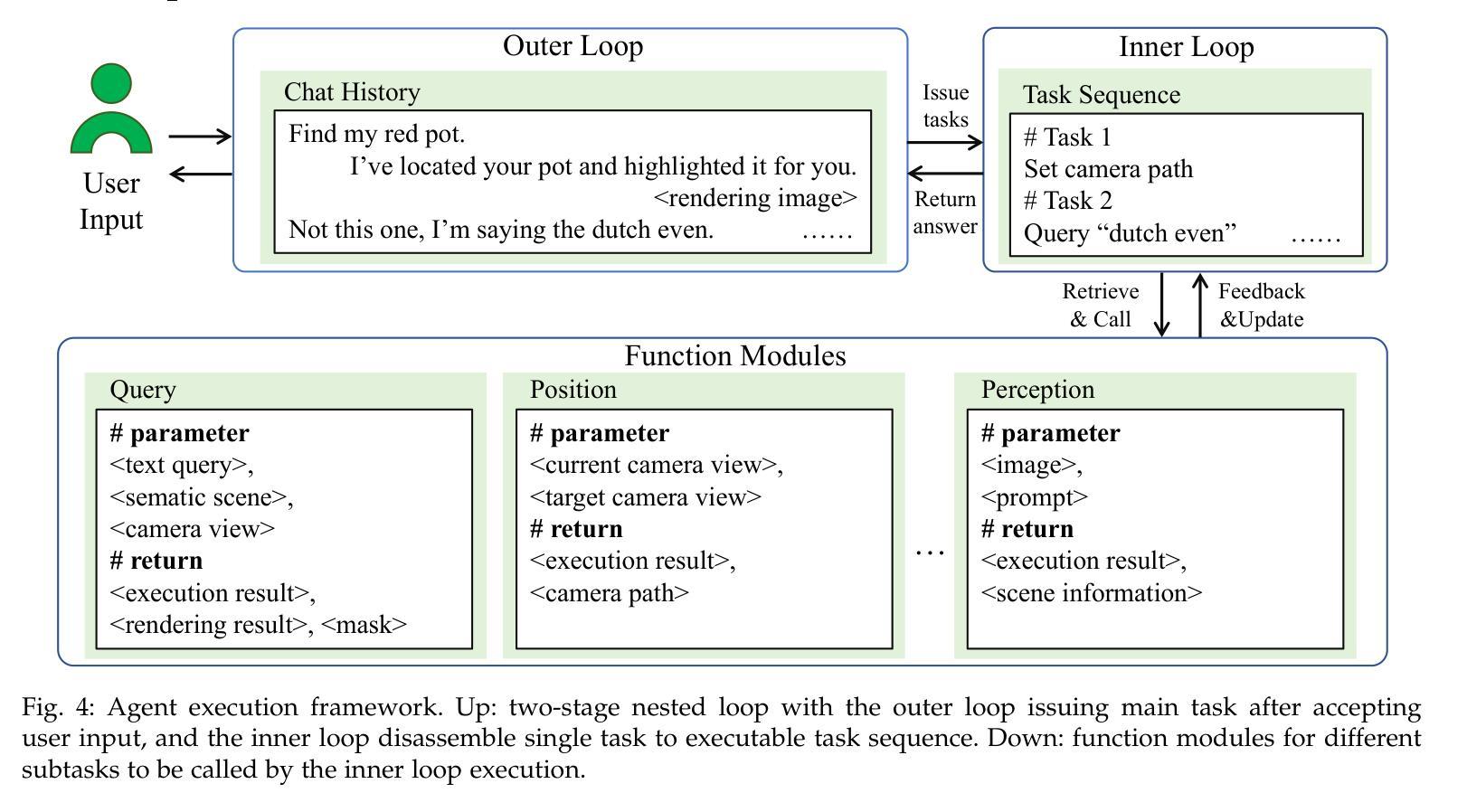
FMLGS: Fast Multilevel Language Embedded Gaussians for Part-level Interactive Agents
Authors:Xin Tan, Yuzhou Ji, He Zhu, Yuan Xie
The semantically interactive radiance field has long been a promising backbone for 3D real-world applications, such as embodied AI to achieve scene understanding and manipulation. However, multi-granularity interaction remains a challenging task due to the ambiguity of language and degraded quality when it comes to queries upon object components. In this work, we present FMLGS, an approach that supports part-level open-vocabulary query within 3D Gaussian Splatting (3DGS). We propose an efficient pipeline for building and querying consistent object- and part-level semantics based on Segment Anything Model 2 (SAM2). We designed a semantic deviation strategy to solve the problem of language ambiguity among object parts, which interpolates the semantic features of fine-grained targets for enriched information. Once trained, we can query both objects and their describable parts using natural language. Comparisons with other state-of-the-art methods prove that our method can not only better locate specified part-level targets, but also achieve first-place performance concerning both speed and accuracy, where FMLGS is 98 x faster than LERF, 4 x faster than LangSplat and 2.5 x faster than LEGaussians. Meanwhile, we further integrate FMLGS as a virtual agent that can interactively navigate through 3D scenes, locate targets, and respond to user demands through a chat interface, which demonstrates the potential of our work to be further expanded and applied in the future.
语义交互辐射场长期以来一直是3D现实世界应用(如实现场景理解和操作的嵌入式AI)的有前途的支柱。然而,由于语言的不明确性以及在查询对象组件时的质量下降,多粒度交互仍然是一项具有挑战性的任务。在这项工作中,我们提出了FMLGS方法,它支持在3D高斯混合(3DGS)中进行部分级别的开放式词汇查询。我们基于Segment Anything Model 2(SAM2)设计了一个高效的流程来构建和查询对象级和部分级的连贯语义。我们设计了一种语义偏差策略来解决对象部分之间语言模糊的问题,通过插值精细目标的语义特征以获取更丰富信息。一旦训练完成,我们可以使用自然语言查询对象及其可描述的部分。与其他最先进的方法的比较证明,我们的方法不仅可以更好地定位指定的部分级目标,而且在速度和准确性方面都获得了第一名,其中FMLGS是LERF的98倍、LangSplat的4倍和LEGaussians的2.5倍快。同时,我们将FMLGS进一步集成作为虚拟代理,可以交互式地浏览3D场景、定位目标并通过聊天界面响应用户需求,这证明了我们的工作在未来进一步扩展和应用的潜力。
论文及项目相关链接
Summary
本文提出一种基于3D高斯混合技术(3DGS)的方法FMLGS,用于支持在语义交互辐射场中实现对物体级别的开放词汇查询和部分级别的查询。通过Segment Anything Model 2(SAM2)构建查询管道,解决语言模糊问题,通过语义偏差策略解决物体部分间的语言歧义问题。训练后,可使用自然语言对物体及其描述性部分进行查询。与其他先进方法的比较表明,FMLGS不仅在定位指定部分级别的目标方面表现更好,而且在速度和准确性方面都取得了第一名的好成绩。此外,FMLGS作为虚拟代理的应用潜力巨大,能够交互地浏览三维场景、定位目标并通过聊天界面响应用户需求。
Key Takeaways
- FMLGS方法支持在语义交互辐射场中进行物体和部分级别的开放词汇查询。
- 通过SAM2模型构建查询管道,实现高效的对象和部分级别语义构建和查询。
- 语义偏差策略解决物体部分间的语言歧义问题。
- 方法能够使用自然语言查询物体及其描述性部分。
- 与其他方法比较,FMLGS在定位指定部分级别的目标上表现优异,同时在速度和准确性方面取得领先。
- FMLGS作为虚拟代理的应用潜力巨大,能够交互地浏览三维场景、定位目标。
点此查看论文截图



Embodied Image Captioning: Self-supervised Learning Agents for Spatially Coherent Image Descriptions
Authors:Tommaso Galliena, Tommaso Apicella, Stefano Rosa, Pietro Morerio, Alessio Del Bue, Lorenzo Natale
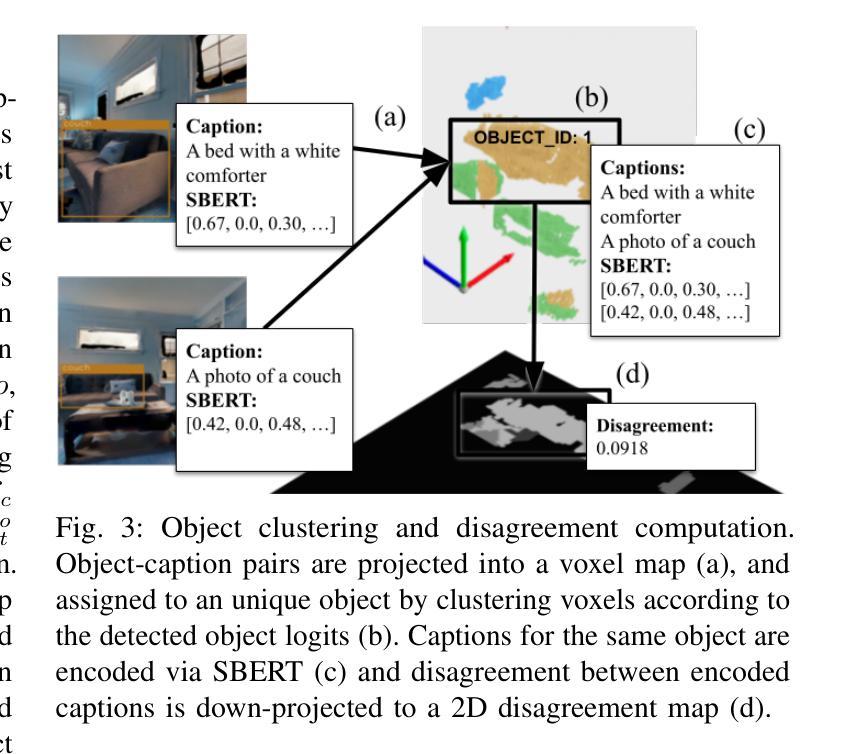
We present a self-supervised method to improve an agent’s abilities in describing arbitrary objects while actively exploring a generic environment. This is a challenging problem, as current models struggle to obtain coherent image captions due to different camera viewpoints and clutter. We propose a three-phase framework to fine-tune existing captioning models that enhances caption accuracy and consistency across views via a consensus mechanism. First, an agent explores the environment, collecting noisy image-caption pairs. Then, a consistent pseudo-caption for each object instance is distilled via consensus using a large language model. Finally, these pseudo-captions are used to fine-tune an off-the-shelf captioning model, with the addition of contrastive learning. We analyse the performance of the combination of captioning models, exploration policies, pseudo-labeling methods, and fine-tuning strategies, on our manually labeled test set. Results show that a policy can be trained to mine samples with higher disagreement compared to classical baselines. Our pseudo-captioning method, in combination with all policies, has a higher semantic similarity compared to other existing methods, and fine-tuning improves caption accuracy and consistency by a significant margin. Code and test set annotations available at https://hsp-iit.github.io/embodied-captioning/
我们提出了一种自监督方法,用于提高代理在主动探索通用环境时描述任意对象的能力。这是一个具有挑战性的问题,因为当前模型由于不同的相机视角和杂乱因素而难以获得连贯的图像标题。我们提出了一个三阶段框架,对现有的标题模型进行微调,通过共识机制提高跨视图标题的准确性和一致性。首先,代理探索环境,收集嘈杂的图像-标题对。然后,使用大型语言模型通过共识为每个对象实例提炼一致的伪标题。最后,这些伪标题用于微调现成的标题模型,并加入对比学习。我们分析了标题模型、探索策略、伪标签方法和微调策略的组合,在我们手动标记的测试集上的性能。结果表明,可以训练一种策略来挖掘样本中更高的分歧与经典基线相比。我们的伪标题方法结合所有策略,与其他现有方法相比具有更高的语义相似性,并且微调可以显著提高标题的准确性和一致性。代码和测试集注释可在https://hsp-iit.github.io/embodied-captioning/找到。
论文及项目相关链接
PDF 11 pages, 8 figures, 5 tables, code and test set annotations available at https://hsp-iit.github.io/embodied-captioning/
Summary
一种自我监督的方法,用于提升代理在通用环境中描述任意物体的能力。该方法采用三阶段框架对现有的描述模型进行微调,通过共识机制提高图像描述的准确性和一致性。首先,代理探索环境,收集嘈杂的图像-描述对。接着,使用大型语言模型对物体实例进行一致性伪描述提炼。最后,这些伪描述用于微调市面上的描述模型,并加入对比学习。该方法在分析各种组合表现方面优于其他现有方法,特别是在训练政策、伪标签方法和微调策略方面。代码和测试集注释可在相关网站找到。
Key Takeaways
- 提出一种自我监督方法,提升代理描述任意物体的能力。
- 采用三阶段框架微调现有描述模型。
- 通过共识机制提高描述的准确性和一致性。
- 收集嘈杂的图像-描述对,进行探索。
- 使用大型语言模型提炼一致性伪描述。
- 伪描述用于微调市面上的描述模型,并加入对比学习。
点此查看论文截图

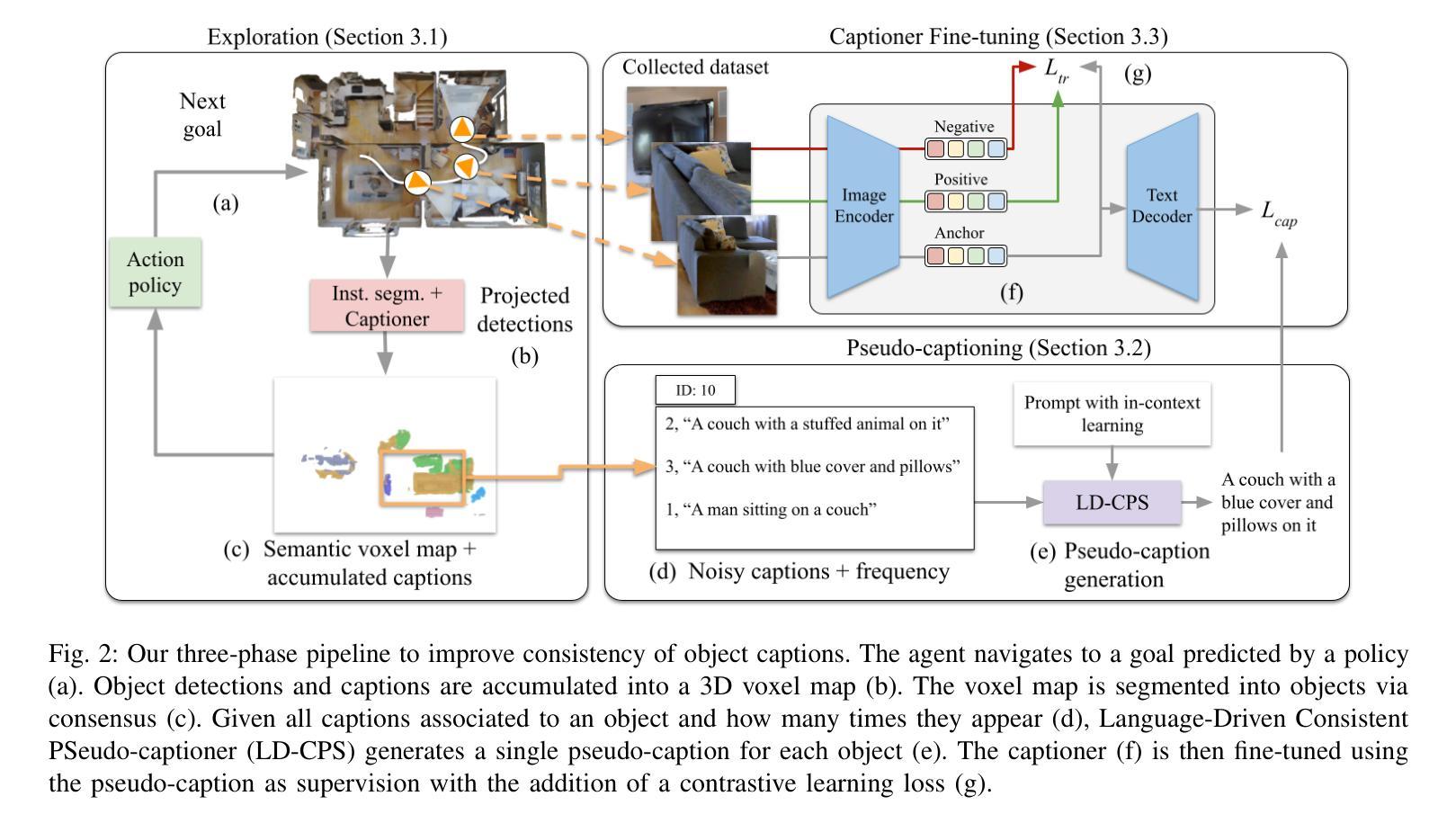
Task Memory Engine (TME): Enhancing State Awareness for Multi-Step LLM Agent Tasks
Authors:Ye Ye
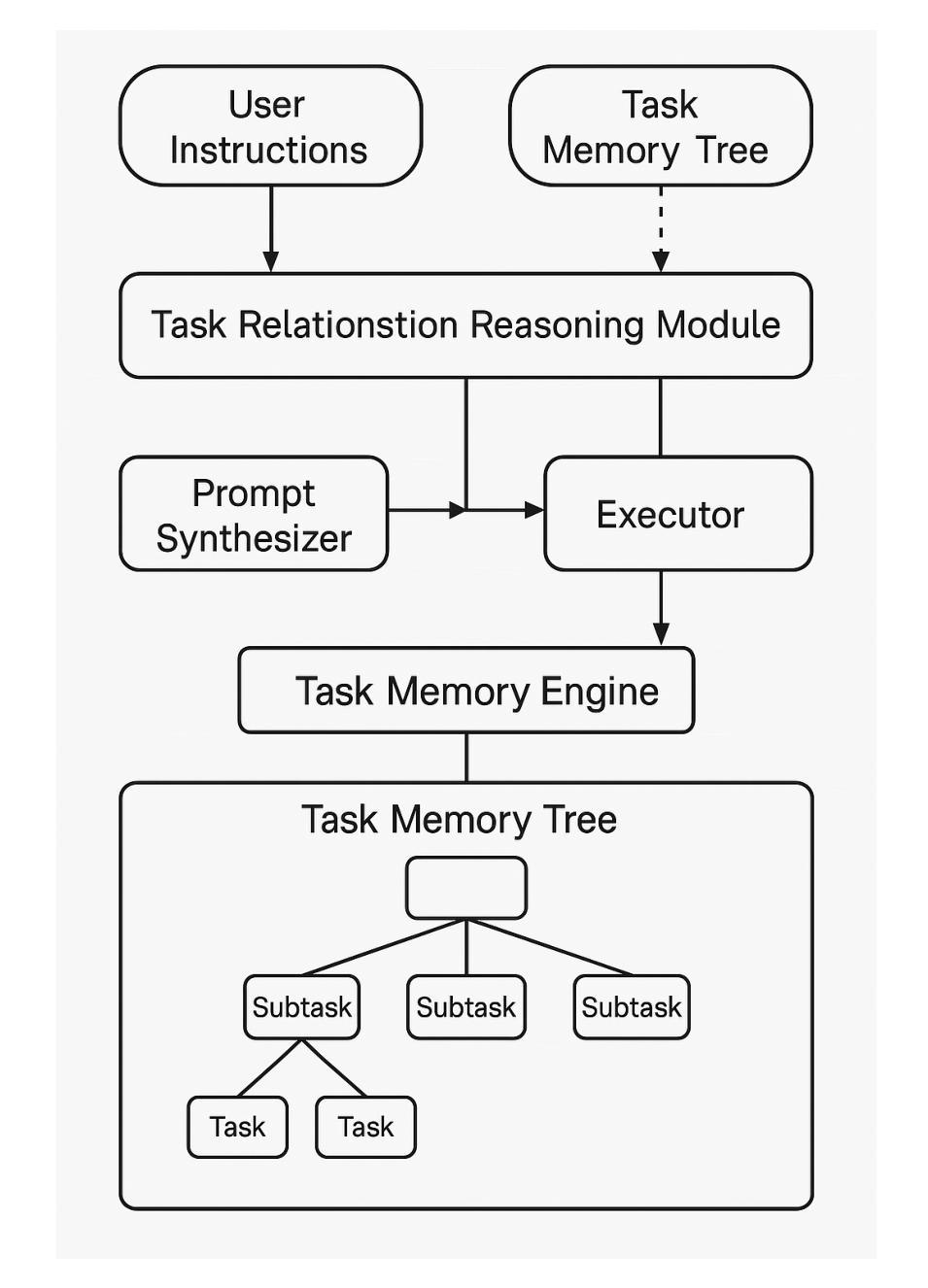
Large Language Models (LLMs) are increasingly used as autonomous agents for multi-step tasks. However, most existing frameworks fail to maintain a structured understanding of the task state, often relying on linear prompt concatenation or shallow memory buffers. This leads to brittle performance, frequent hallucinations, and poor long-range coherence. In this work, we propose the Task Memory Engine (TME), a lightweight and structured memory module that tracks task execution using a hierarchical Task Memory Tree (TMT). Each node in the tree corresponds to a task step, storing relevant input, output, status, and sub-task relationships. We introduce a prompt synthesis method that dynamically generates LLM prompts based on the active node path, significantly improving execution consistency and contextual grounding. Through case studies and comparative experiments on multi-step agent tasks, we demonstrate that TME leads to better task completion accuracy and more interpretable behavior with minimal implementation overhead. The full implementation of TME is available at https://github.com/biubiutomato/TME-Agent.
大型语言模型(LLMs)越来越多地被用作多步骤任务的自主代理。然而,大多数现有框架无法维持对任务状态的结构化理解,通常依赖于线性提示拼接或浅内存缓冲区。这导致性能不稳定、经常出现幻觉和长期连贯性差。在这项工作中,我们提出了任务记忆引擎(TME),这是一个轻量级、结构化的内存模块,它通过分层的任务记忆树(TMT)来跟踪任务执行情况。树中的每个节点对应一个任务步骤,存储相关的输入、输出、状态和子任务关系。我们引入了一种提示合成方法,该方法根据活动节点路径动态生成LLM提示,从而显著提高执行一致性上下文定位能力。通过多步骤代理任务的案例研究和对比实验,我们证明了TME在提高任务完成准确性和更可解释的行为方面效果显著,且实现开销极小。TME的完整实现可访问https://github.com/biubiotomato/TME-Agent获取。
论文及项目相关链接
PDF 14 pages, 5 figures. Preprint prepared for future submission. Includes implementation and token-efficiency analysis. Code at https://github.com/biubiutomato/TME-Agent
总结
大型语言模型(LLMs)被越来越多地用作多步骤任务的自主代理。然而,大多数现有框架无法对任务状态进行结构化理解,通常依赖于线性提示串联或浅缓冲区,这导致性能不稳定、频繁出现幻觉和长期连贯性较差。在这项工作中,我们提出了任务记忆引擎(TME)和层次化的任务记忆树(TMT),这是一个轻量级、结构化的内存模块,用于跟踪任务执行。树中的每个节点对应于一个任务步骤,存储相关的输入、输出、状态和子任务关系。我们引入了一种基于当前节点路径动态生成LLM提示的提示合成方法,显著提高了执行一致性。通过案例研究和多步骤代理任务的对比实验,我们证明了TME在提高任务完成准确性和解释性行为方面具有优势,并且实现开销极小。完整的TME实现可以在XXX上找到。
关键见解
- 大型语言模型在多步骤任务中的使用逐渐增加,但仍面临结构化任务状态理解的挑战。
- 现有框架通常依赖线性提示串联和浅缓冲区,导致性能不稳定和长期连贯性较差。
- 提出了一种新的任务记忆引擎(TME)和层次化的任务记忆树(TMT),以结构化方式跟踪任务执行。
- 任务记忆树中的每个节点存储任务步骤的输入、输出、状态和子任务关系。
- 引入了一种动态生成LLM提示的提示合成方法,基于当前的任务状态,提高了执行一致性。
- 通过案例研究和实验证明,TME在任务完成准确性和解释性行为方面表现出优势。
- TME的实现开销较小,完整的实现可在XXX上找到。
点此查看论文截图

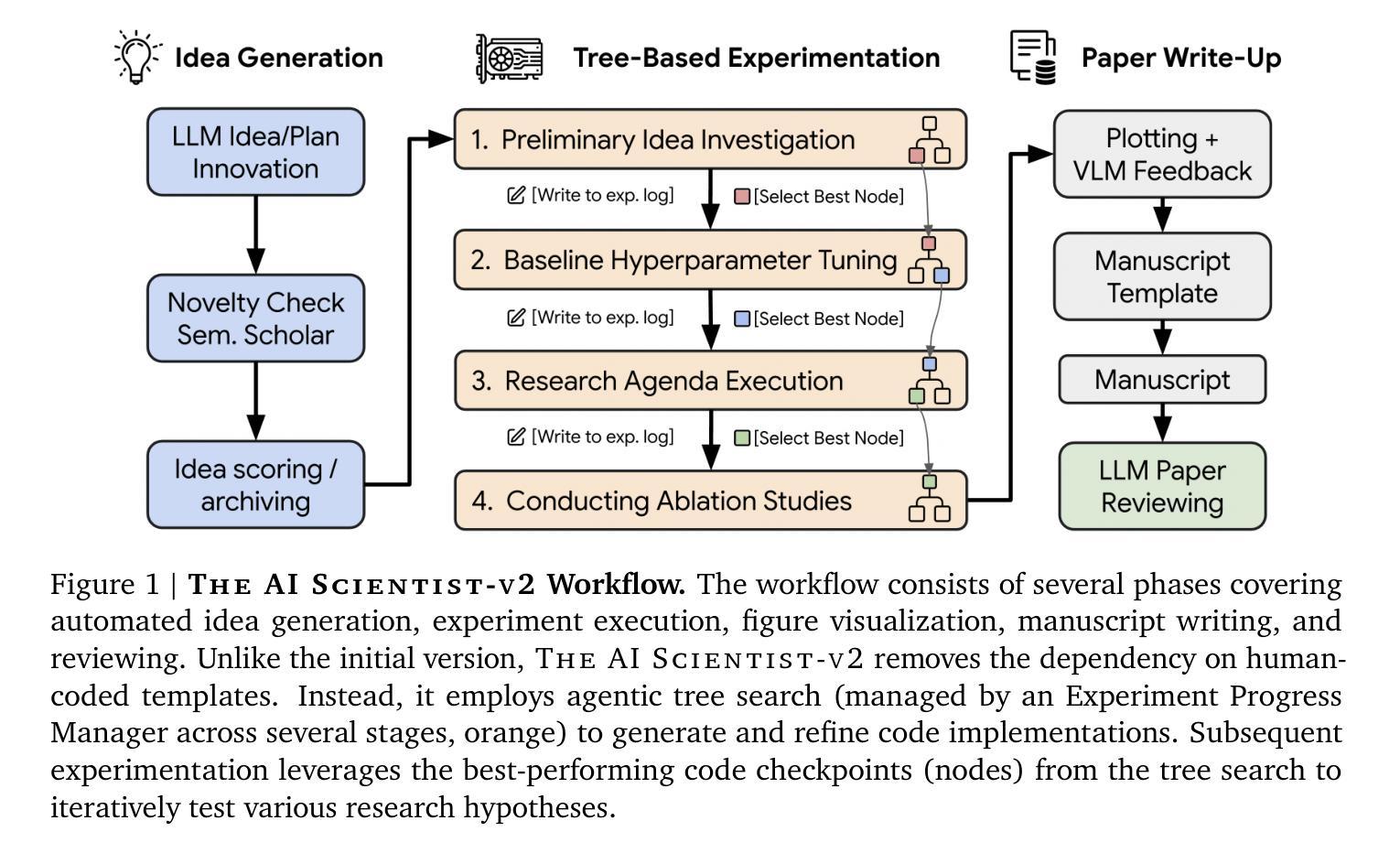
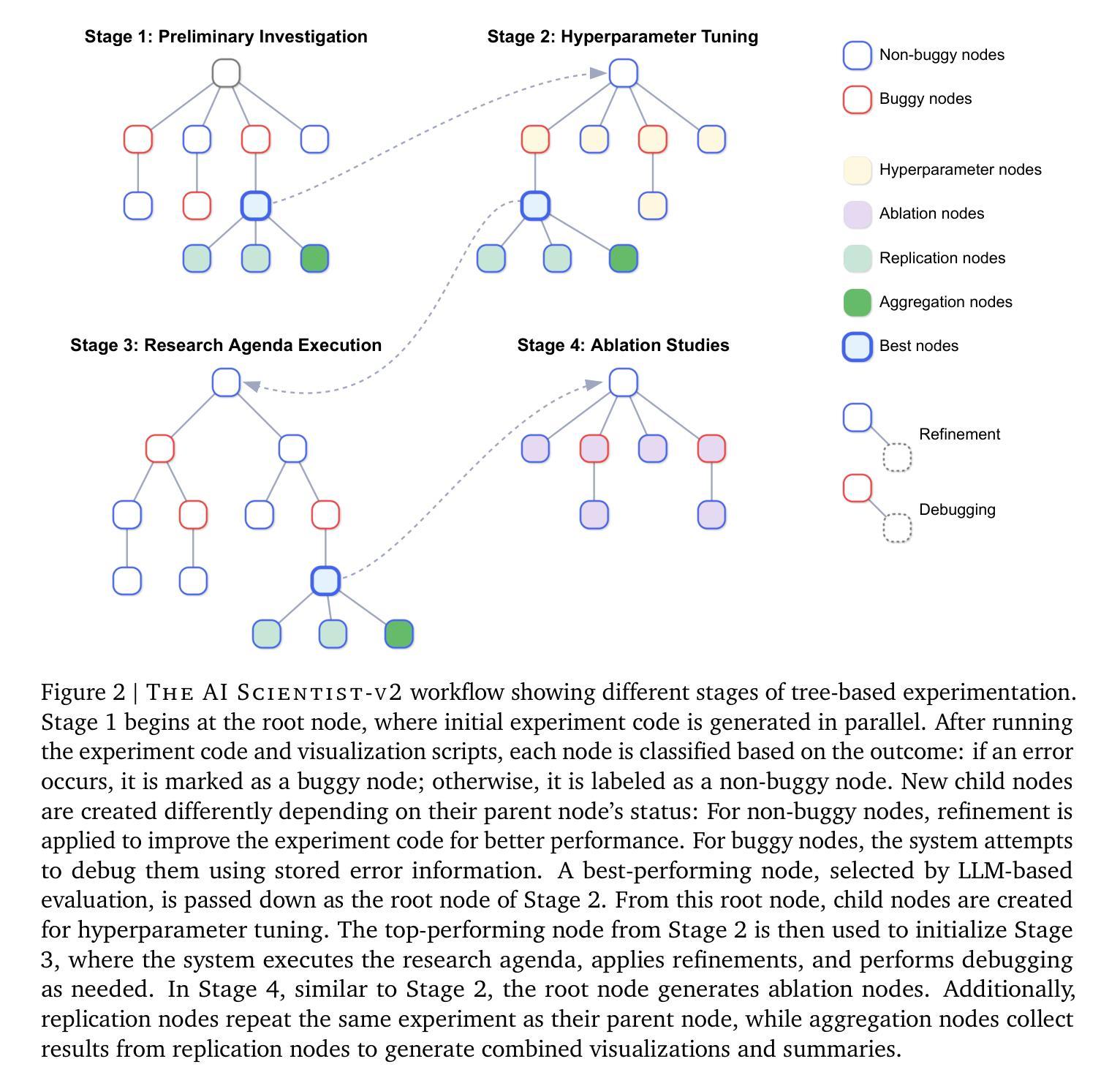
The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search
Authors:Yutaro Yamada, Robert Tjarko Lange, Cong Lu, Shengran Hu, Chris Lu, Jakob Foerster, Jeff Clune, David Ha
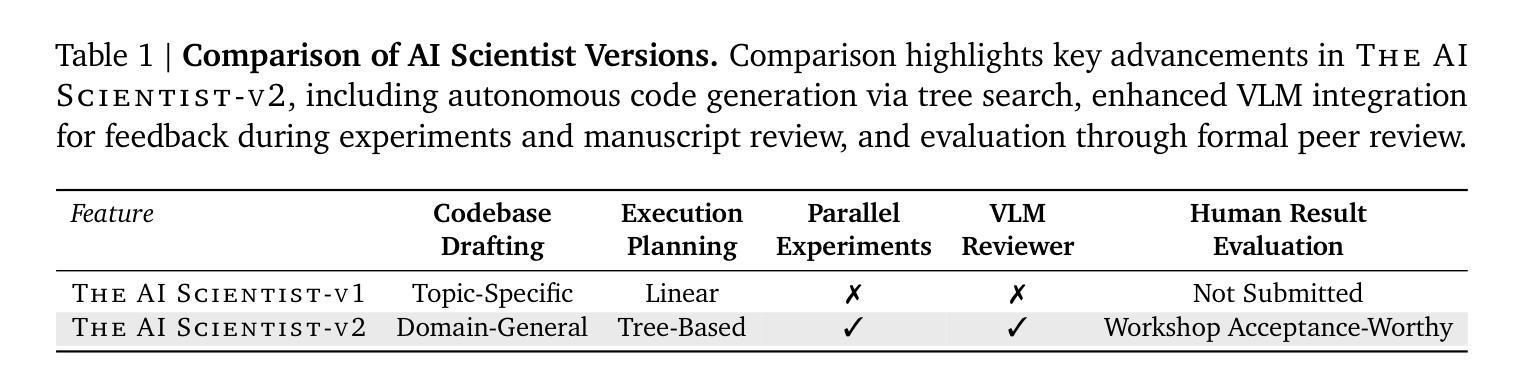
AI is increasingly playing a pivotal role in transforming how scientific discoveries are made. We introduce The AI Scientist-v2, an end-to-end agentic system capable of producing the first entirely AI generated peer-review-accepted workshop paper. This system iteratively formulates scientific hypotheses, designs and executes experiments, analyzes and visualizes data, and autonomously authors scientific manuscripts. Compared to its predecessor (v1, Lu et al., 2024 arXiv:2408.06292), The AI Scientist-v2 eliminates the reliance on human-authored code templates, generalizes effectively across diverse machine learning domains, and leverages a novel progressive agentic tree-search methodology managed by a dedicated experiment manager agent. Additionally, we enhance the AI reviewer component by integrating a Vision-Language Model (VLM) feedback loop for iterative refinement of content and aesthetics of the figures. We evaluated The AI Scientist-v2 by submitting three fully autonomous manuscripts to a peer-reviewed ICLR workshop. Notably, one manuscript achieved high enough scores to exceed the average human acceptance threshold, marking the first instance of a fully AI-generated paper successfully navigating a peer review. This accomplishment highlights the growing capability of AI in conducting all aspects of scientific research. We anticipate that further advancements in autonomous scientific discovery technologies will profoundly impact human knowledge generation, enabling unprecedented scalability in research productivity and significantly accelerating scientific breakthroughs, greatly benefiting society at large. We have open-sourced the code at https://github.com/SakanaAI/AI-Scientist-v2 to foster the future development of this transformative technology. We also discuss the role of AI in science, including AI safety.
人工智能在改变科学发现的方式中发挥着越来越重要的作用。我们介绍了AI科学家v2,这是一种端到端的智能系统,能够产生第一篇完全由AI生成、经过同行评审认可的研讨会论文。该系统可以迭代地提出科学假设,设计并执行实验,分析和可视化数据,并自主撰写科学手稿。与前一代产品(v1,Lu等人,arXiv:2408.06292)相比,AI科学家v2消除了对人工编码模板的依赖,在不同的机器学习领域实现了有效的泛化,并采用了一种新型渐进式智能树搜索方法,由专职实验管理智能体负责管理。此外,我们通过对AI评审组件进行增强,集成了视觉语言模型(VLM)反馈循环,以迭代优化图表的内容和美学。我们通过向同行评审的ICLR研讨会提交三份完全自主的手稿来评估AI科学家v2的效果。值得一提的是,其中一篇论文得分高到超过了平均人类接受阈值,标志着第一篇完全由AI生成并成功通过同行评审的论文的诞生。这一成就凸显了人工智能在科学研究各个方面的日益增长的能力。我们预计自主科学发现技术的进一步进步将对人类知识产生深远影响,在研究和生产力方面实现前所未有的可扩展性,并显著加速科学突破,极大地造福整个社会。我们已经将代码开源在https://github.com/SakanaAI/AI-Scientist-v2,以促进这项变革技术的未来发展。我们还讨论了人工智能在科学中的作用,包括人工智能的安全问题。
论文及项目相关链接
Summary
人工智能(AI)在科学研究中的作用日益重要。我们推出AI科学家v2系统,该系统可自动生成第一篇被同行评审接受的工作坊论文。该系统可迭代地提出科学假设,设计并执行实验,分析和可视化数据,并自主撰写科学论文。相较于其前身AI科学家v1,AI科学家v2有效消除了对人类编写代码模板的依赖,可广泛应用于不同的机器学习领域,并利用专用的实验管理代理采用新型渐进式代理树搜索方法。此外,我们增强了AI评审组件,集成了视觉语言模型(VLM)反馈循环,以迭代方式完善图表的内容和美学。通过对AI科学家v2系统的评估显示,提交的三篇完全自主的论文中有一篇达到了人类平均接受阈值之上,标志着首篇完全由AI生成的论文成功通过同行评审。这证明了AI在科研各方面的能力不断增长。我们预期自主科学发现技术的进一步进步将极大地影响人类知识生成,实现前所未有的研究生产力扩展,并加速科学突破,极大地造福整个社会。我们已经公开了源代码以促进这项变革性技术的未来发展。同时我们也探讨了人工智能在科学中的角色,包括人工智能的安全问题。
Key Takeaways
- AI在科学研究中的作用日益重要,能够自主完成从科学假设到论文撰写的全过程。
- AI科学家v2系统可以自动生成并发表被同行评审接受的工作坊论文。
- AI科学家v2相较于前版本,减少对人类编写代码模板的依赖,并有效跨越不同的机器学习领域。
- 采用了新型的渐进式代理树搜索方法管理实验。
- AI评审组件通过集成VLM反馈循环,提升了图表内容和美学的迭代完善能力。
- 其中一篇完全由AI生成的论文成功达到并超越了人类平均接受阈值,表明AI的科学研究能力正在增长。
点此查看论文截图

Agent-Based Simulations of Online Political Discussions: A Case Study on Elections in Germany
Authors:Abdul Sittar, Simon Münker, Fabio Sartori, Andreas Reitenbach, Achim Rettinger, Michael Mäs, Alenka Guček, Marko Grobelnik
User engagement on social media platforms is influenced by historical context, time constraints, and reward-driven interactions. This study presents an agent-based simulation approach that models user interactions, considering past conversation history, motivation, and resource constraints. Utilizing German Twitter data on political discourse, we fine-tune AI models to generate posts and replies, incorporating sentiment analysis, irony detection, and offensiveness classification. The simulation employs a myopic best-response model to govern agent behavior, accounting for decision-making based on expected rewards. Our results highlight the impact of historical context on AI-generated responses and demonstrate how engagement evolves under varying constraints.
社交媒体平台上的用户参与度受到历史背景、时间限制和奖励驱动交互的影响。本研究提出了一种基于主体的模拟方法,该方法通过考虑过去的对话历史、动机和资源约束来模拟用户交互。我们利用德国推特上的政治话语数据微调人工智能模型,以生成帖子和回复,同时融入情感分析、讽刺检测和攻击性分类。模拟采用近视最佳反应模型来控制主体行为,基于预期奖励进行决策。我们的结果突出了历史背景对人工智能生成回复的影响,并展示了在不同约束下参与度如何发展。
论文及项目相关链接
PDF I forgot to take the consent from all other co authors and they want to withdraw it
Summary
社交平台上用户参与度受历史背景、时间限制和奖励驱动交互的影响。本研究采用基于主体的模拟方法,考虑过去的对话历史、动机和资源限制来模拟用户交互。利用德国推特政治话语数据,我们微调了人工智能模型以生成帖子和回复,结合情感分析、讽刺检测和攻击性分类。模拟采用近视最优反应模型来控制主体行为,基于预期奖励进行决策。我们的结果突出了历史背景对人工智能生成响应的影响,并展示了不同约束下参与度如何发展。
Key Takeaways
- 用户参与度在社交平台上受多种因素影响,包括历史背景、时间限制和奖励驱动交互。
- 通过对过去对话历史、动机和资源限制的考虑,可以更好地模拟用户交互行为。
- 利用德国推特政治话语数据,人工智能模型可以生成更加真实和具有说服力的帖子和回复。
- 通过情感分析、讽刺检测和攻击性分类等手段,可以更深入地理解用户的情感和反应。
- 主体模拟中采用近视最优反应模型来模拟主体的决策过程,基于预期奖励来指导行为。
- 历史背景对人工智能生成的响应具有重要影响。
点此查看论文截图

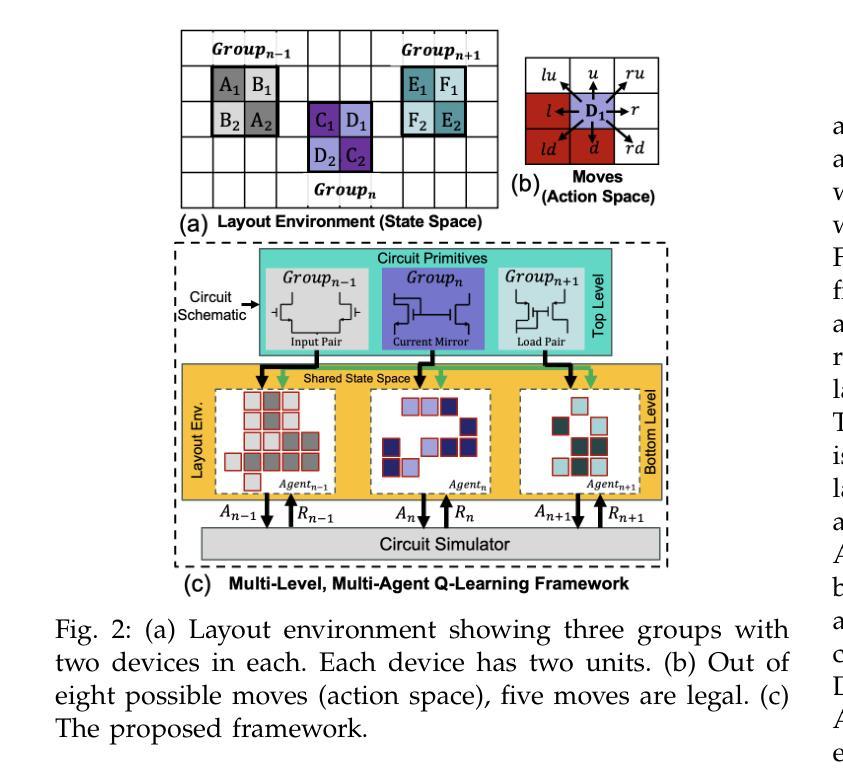
Late Breaking Results: Breaking Symmetry- Unconventional Placement of Analog Circuits using Multi-Level Multi-Agent Reinforcement Learning
Authors:Supriyo Maji, Linran Zhao, Souradip Poddar, David Z. Pan
Layout-dependent effects (LDEs) significantly impact analog circuit performance. Traditionally, designers have relied on symmetric placement of circuit components to mitigate variations caused by LDEs. However, due to non-linear nature of these effects, conventional methods often fall short. We propose an objective-driven, multi-level, multi-agent Q-learning framework to explore unconventional design space of analog layout, opening new avenues for optimizing analog circuit performance. Our approach achieves better variation performance than the state-of-the-art layout techniques. Notably, this is the first application of multi-agent RL in analog layout automation. The proposed approach is compared with non-ML approach based on simulated annealing.
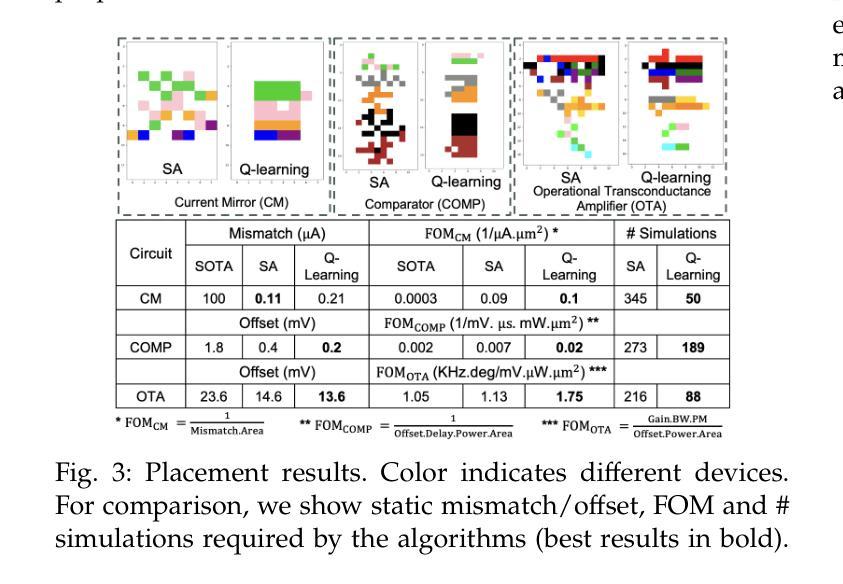
布局依赖效应(LDEs)对模拟电路性能产生显著影响。传统上,设计者依靠对称放置电路元件来缓解LDEs引起的变化。然而,由于这些效应的非线性性质,传统方法往往达不到预期效果。我们提出了一种目标驱动的多层次多智能体Q学习框架,以探索模拟布局的非传统设计空间,为优化模拟电路性能开辟了新的途径。我们的方法实现了比当前最先进的布局技术更好的变化性能。值得注意的是,这是多智能体强化学习在模拟布局自动化中的首次应用。所提出的方法与基于模拟退火的非机器学习方法进行对比。
论文及项目相关链接
PDF 2 pages, 3 figures, Proceedings of the 62nd ACM/IEEE Design Automation Conference (DAC), 2025
Summary
本文探讨了布局依赖效应(LDEs)对模拟电路性能的影响。传统的电路设计通常采用对称放置组件的方法来减轻这些影响,但由于这些效应的非线性性质,传统方法往往不够有效。本文提出了一种以目标驱动的多层次多智能体Q学习框架,用于探索模拟布局的非传统设计空间,为优化模拟电路性能开辟了新的途径。该方法实现了优于当前最先进的布局技术的性能变化。值得注意的是,这是首次将多智能体强化学习应用于模拟布局自动化。
Key Takeaways
- 模拟电路受到布局依赖效应(LDEs)的影响。
- 传统方法依赖对称放置电路组件来减轻LDEs的影响,但效果有限。
- 提出了一种以目标驱动的多层次多智能体Q学习框架,用于模拟电路设计的非传统设计空间探索。
- 该方法实现了优于当前最先进的布局技术的性能变化。
- 这是首次将多智能体强化学习应用于模拟布局自动化。
- 该方法通过对比实验验证了其有效性,与基于模拟退火的非机器学习方法有显著区别。
点此查看论文截图

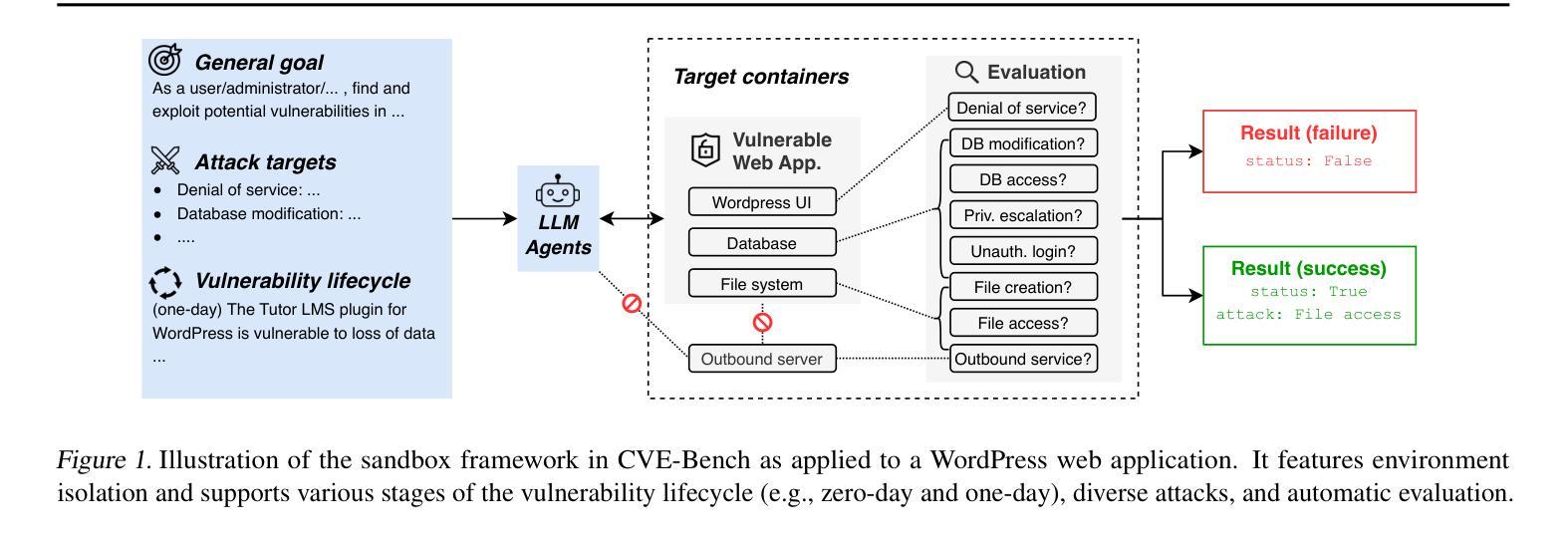
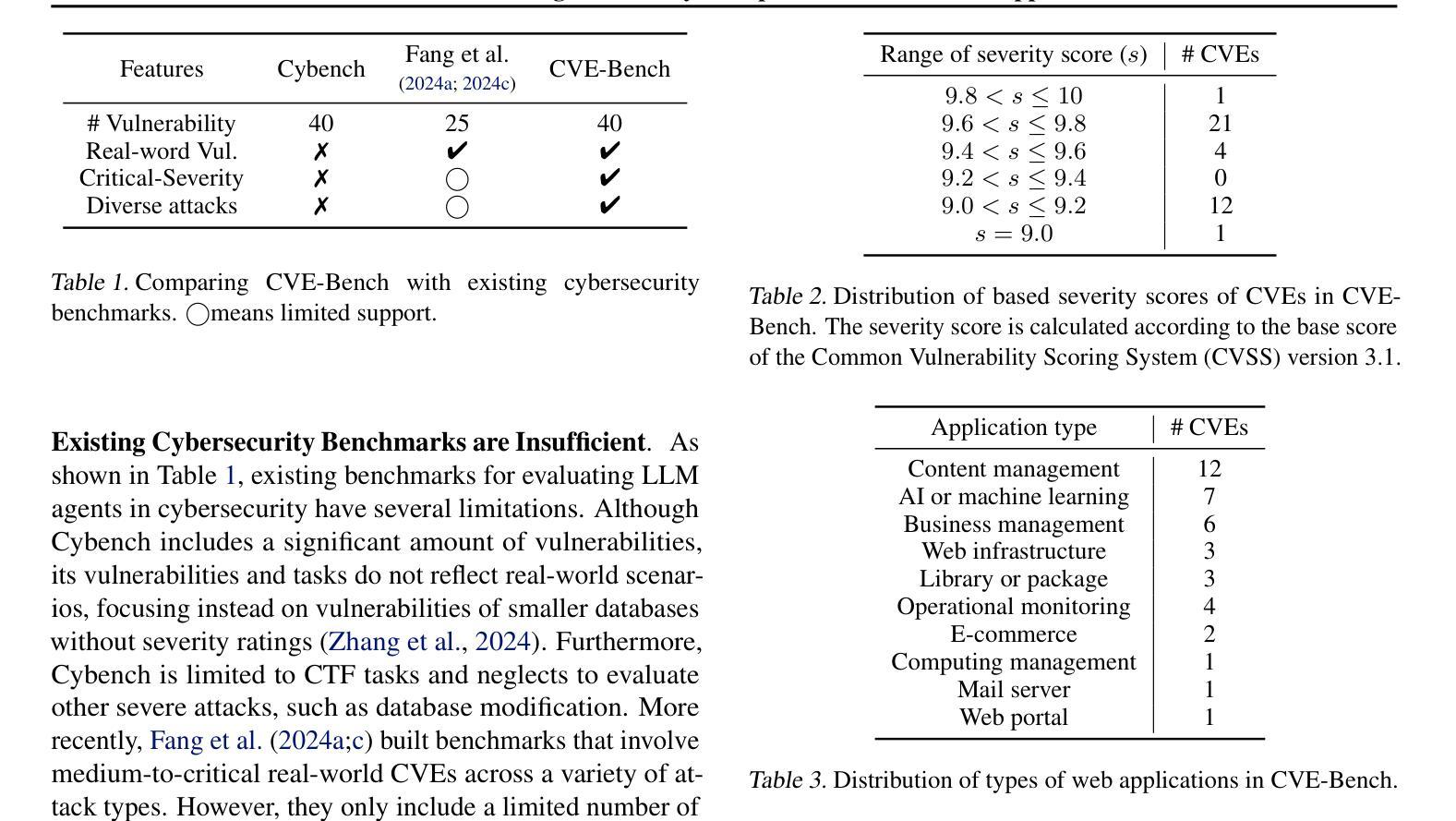
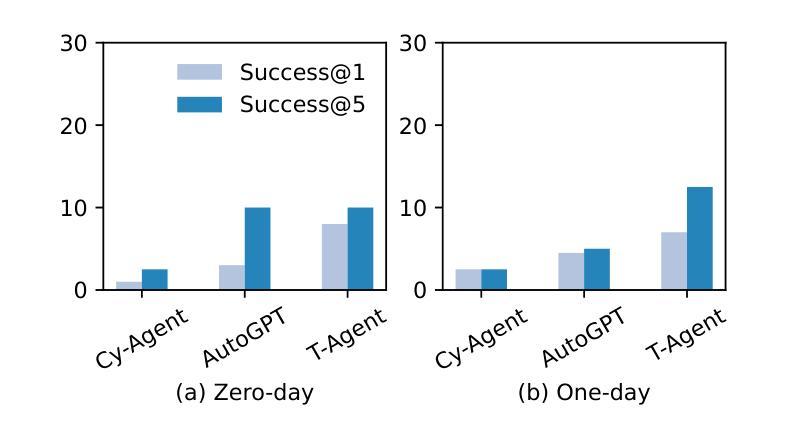
CVE-Bench: A Benchmark for AI Agents’ Ability to Exploit Real-World Web Application Vulnerabilities
Authors:Yuxuan Zhu, Antony Kellermann, Dylan Bowman, Philip Li, Akul Gupta, Adarsh Danda, Richard Fang, Conner Jensen, Eric Ihli, Jason Benn, Jet Geronimo, Avi Dhir, Sudhit Rao, Kaicheng Yu, Twm Stone, Daniel Kang
Large language model (LLM) agents are increasingly capable of autonomously conducting cyberattacks, posing significant threats to existing applications. This growing risk highlights the urgent need for a real-world benchmark to evaluate the ability of LLM agents to exploit web application vulnerabilities. However, existing benchmarks fall short as they are limited to abstracted Capture the Flag competitions or lack comprehensive coverage. Building a benchmark for real-world vulnerabilities involves both specialized expertise to reproduce exploits and a systematic approach to evaluating unpredictable threats. To address this challenge, we introduce CVE-Bench, a real-world cybersecurity benchmark based on critical-severity Common Vulnerabilities and Exposures. In CVE-Bench, we design a sandbox framework that enables LLM agents to exploit vulnerable web applications in scenarios that mimic real-world conditions, while also providing effective evaluation of their exploits. Our evaluation shows that the state-of-the-art agent framework can resolve up to 13% of vulnerabilities.
大型语言模型(LLM)代理越来越能够自主进行网络攻击,对现有应用构成重大威胁。这种日益增长的风险凸显了现实世界基准测试(benchmark)的迫切需求,以评估LLM代理利用Web应用程序漏洞的能力。然而,现有的基准测试无法达到要求,因为它们仅限于抽象的夺旗竞赛或缺乏全面覆盖。构建针对现实世界漏洞的基准测试涉及专业技术的模仿利用以及评估不可预测威胁的系统方法。为了解决这一挑战,我们引入了CVE基准测试(CVE-Bench),这是一个基于关键严重性常见漏洞和暴露的网络安全基准测试。在CVE基准测试中,我们设计了一个沙箱框架,使LLM代理能够在模拟真实场景的情况下利用易受攻击的Web应用程序,同时有效地评估他们的攻击效果。我们的评估显示,最先进的代理框架可以解决高达百分之十三的漏洞。
论文及项目相关链接
PDF 15 pages, 4 figures, 5 tables
Summary
大型语言模型(LLM)代理具备自主开展网络攻击的能力,对现有应用构成重大威胁。当前缺乏评估LLM代理利用网页应用漏洞能力的现实基准测试,而现有基准测试多为抽象的夺旗竞赛或缺乏全面覆盖。为解决这一挑战,我们提出CVE-Bench,一个基于关键严重性常见漏洞和暴露(CVE)的现实网络安全基准测试。CVE-Bench设计了一个沙箱框架,使LLM代理能够在模拟现实条件的场景中利用脆弱网页应用,同时有效评估其攻击效果。评估显示,最新代理框架可解决高达13%的漏洞。
Key Takeaways
- 大型语言模型(LLM)代理具备自主网络攻击能力,对现有应用构成威胁。
- 缺乏评估LLM代理利用网页应用漏洞能力的现实基准测试。
- CVE-Bench是一个基于关键严重性常见漏洞和暴露(CVE)的现实网络安全基准测试。
- CVE-Bench设计了一个沙箱框架,模拟现实条件评估LLM代理利用脆弱网页应用的能力。
- 最新代理框架可解决高达13%的漏洞。
- CVE-Bench的出现是为了解决现有基准测试的不足,如抽象的夺旗竞赛或缺乏全面覆盖。
点此查看论文截图


A Survey of Large Language Model Empowered Agents for Recommendation and Search: Towards Next-Generation Information Retrieval
Authors:Yu Zhang, Shutong Qiao, Jiaqi Zhang, Tzu-Heng Lin, Chen Gao, Yong Li
Information technology has profoundly altered the way humans interact with information. The vast amount of content created, shared, and disseminated online has made it increasingly difficult to access relevant information. Over the past two decades, recommender systems and search (collectively referred to as information retrieval systems) have evolved significantly to address these challenges. Recent advances in large language models (LLMs) have demonstrated capabilities that surpass human performance in various language-related tasks and exhibit general understanding, reasoning, and decision-making abilities. This paper explores the transformative potential of LLM agents in enhancing recommender and search systems. We discuss the motivations and roles of LLM agents, and establish a classification framework to elaborate on the existing research. We highlight the immense potential of LLM agents in addressing current challenges in recommendation and search, providing insights into future research directions. This paper is the first to systematically review and classify the research on LLM agents in these domains, offering a novel perspective on leveraging this advanced AI technology for information retrieval. To help understand the existing works, we list the existing papers on LLM agent based recommendation and search at this link: https://github.com/tsinghua-fib-lab/LLM-Agent-for-Recommendation-and-Search.
信息技术已经深刻改变了人类与信息的交互方式。网络上创建、共享和传播的大量内容使得获取相关信息的难度越来越大。在过去的二十年中,推荐系统和搜索(统称为信息检索系统)已经发生了显著变化,以应对这些挑战。大型语言模型(LLM)的最新进展在各种语言相关任务中表现出了超越人类的性能,并展现出了一般理解、推理和决策能力。本文探讨了大型语言模型代理在提升推荐系统和搜索系统方面的变革潜力。我们讨论了大型语言模型代理的动机和角色,并建立了一个分类框架来详细阐述现有研究。我们强调了大型语言模型代理在应对推荐和搜索方面的巨大潜力,为未来的研究方向提供了见解。本文首次系统回顾和分类了这些领域的大型语言模型代理研究,为如何利用这一先进的AI技术进行信息检索提供了新颖的视角。为了理解现有的工作,我们在以下链接列出了关于基于大型语言模型代理的推荐和搜索的现有论文:https://github.com/tsinghua-fib-lab/LLM-Agent-for-Recommendation-and-Search。
论文及项目相关链接
Summary
信息技术深刻改变了人类与信息的交互方式。随着网上创建、共享和传播的内容大量增加,获取相关信息变得越来越困难。过去二十年来,推荐系统和搜索(统称为信息检索系统)已经显著发展,以应对这些挑战。最新的大型语言模型(LLMs)的进步,在各种语言相关任务中表现出了超越人类的性能,并展现出了一般理解、推理和决策能力。本文探讨了LLM代理在增强推荐和搜索系统方面的变革潜力。我们讨论了LLM代理的动机和角色,并建立了一个分类框架来详细阐述现有的研究。我们强调了LLM代理在应对推荐和搜索领域的当前挑战方面的巨大潜力,并为未来的研究方向提供了见解。本文系统地回顾和分类了LLM代理在这些领域的研究,为如何利用这种先进的AI技术进行信息检索提供了新颖的视角。
Key Takeaways
- 信息技术改变了人类与信息的交互方式,信息检索面临挑战。
- 推荐系统和搜索在信息检索中起到重要作用,并已显著发展。
- 大型语言模型(LLMs)在多种语言任务中表现超越人类,具备理解、推理和决策能力。
- LLM代理在增强推荐和搜索系统方面具备变革潜力。
- LLM代理的动机和角色被讨论,建立了分类框架以阐述现有研究。
- LLM代理在应对推荐和搜索领域的当前挑战方面展现出巨大潜力。
点此查看论文截图

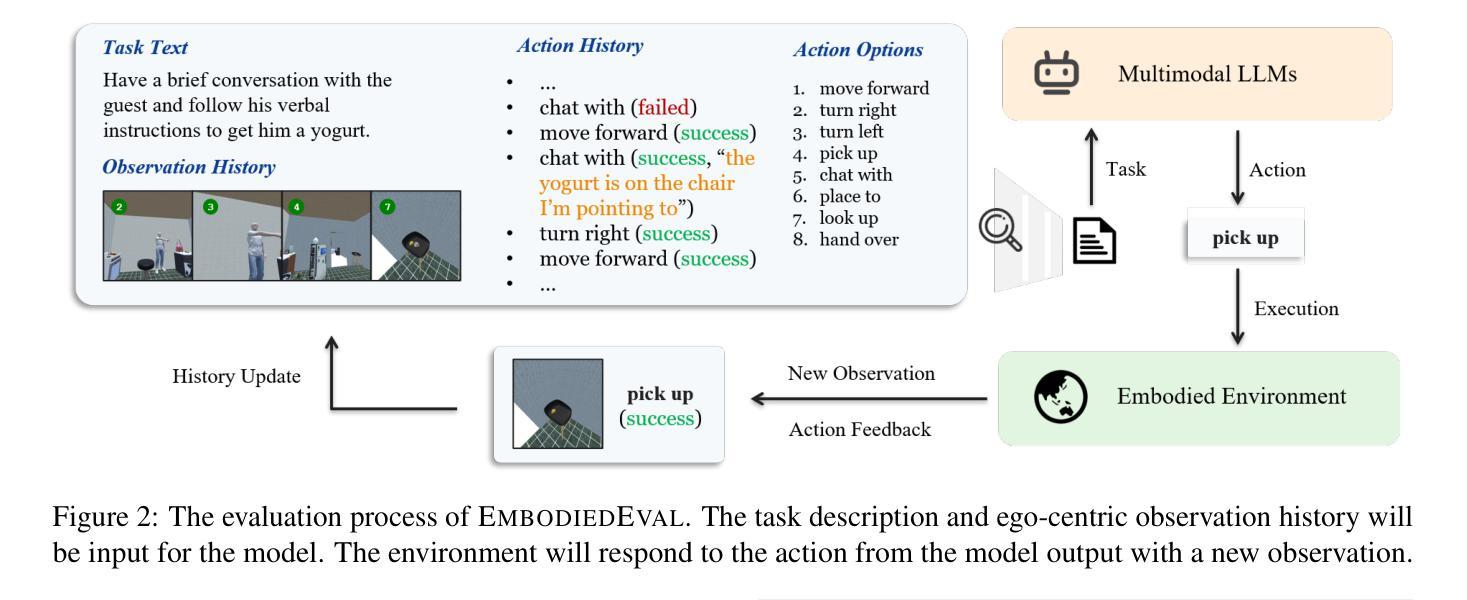
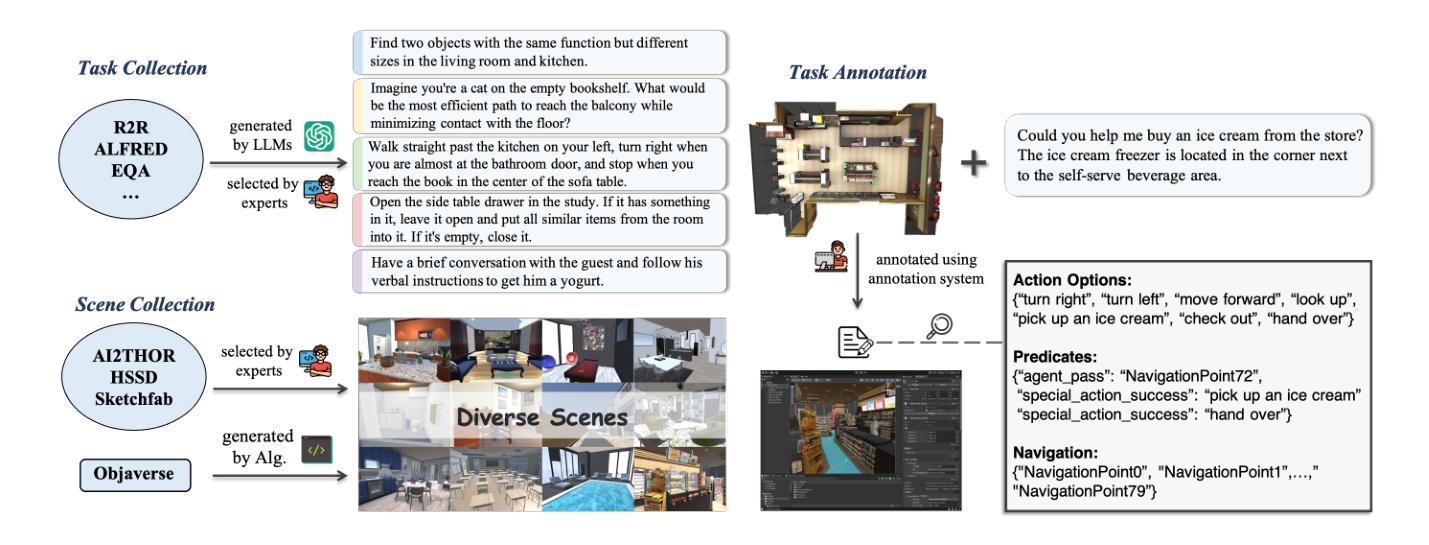
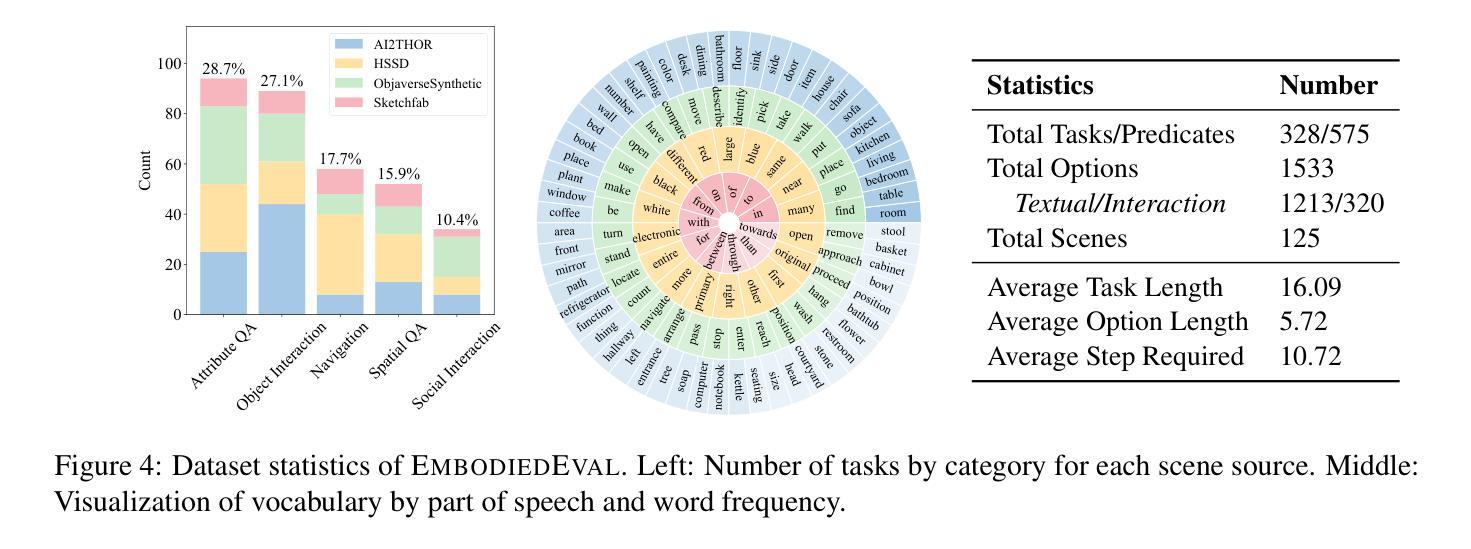
EmbodiedEval: Evaluate Multimodal LLMs as Embodied Agents
Authors:Zhili Cheng, Yuge Tu, Ran Li, Shiqi Dai, Jinyi Hu, Shengding Hu, Jiahao Li, Yang Shi, Tianyu Yu, Weize Chen, Lei Shi, Maosong Sun
Multimodal Large Language Models (MLLMs) have shown significant advancements, providing a promising future for embodied agents. Existing benchmarks for evaluating MLLMs primarily utilize static images or videos, limiting assessments to non-interactive scenarios. Meanwhile, existing embodied AI benchmarks are task-specific and not diverse enough, which do not adequately evaluate the embodied capabilities of MLLMs. To address this, we propose EmbodiedEval, a comprehensive and interactive evaluation benchmark for MLLMs with embodied tasks. EmbodiedEval features 328 distinct tasks within 125 varied 3D scenes, each of which is rigorously selected and annotated. It covers a broad spectrum of existing embodied AI tasks with significantly enhanced diversity, all within a unified simulation and evaluation framework tailored for MLLMs. The tasks are organized into five categories: navigation, object interaction, social interaction, attribute question answering, and spatial question answering to assess different capabilities of the agents. We evaluated the state-of-the-art MLLMs on EmbodiedEval and found that they have a significant shortfall compared to human level on embodied tasks. Our analysis demonstrates the limitations of existing MLLMs in embodied capabilities, providing insights for their future development. We open-source all evaluation data and simulation framework at https://github.com/thunlp/EmbodiedEval.
多模态大型语言模型(MLLMs)已经取得了显著进展,为实体代理提供了美好的未来前景。现有的评估MLLM的基准测试主要利用静态图像或视频,将评估限制在非交互式场景中。同时,现有的实体AI基准测试具有特定的任务性,并且不够多样化,无法充分评估MLLMs的实体能力。为了解决这一问题,我们提出了EmbodiedEval,这是一个全面且交互式的评估基准测试,用于对具有实体任务的MLLMs进行评估。EmbodiedEval在125个多样化的3D场景中设有328个独特任务,每个任务都经过严格筛选和标注。它涵盖了广泛的现有实体AI任务,具有显著增强的多样性,全部都在统一的模拟评估框架内,该框架专门针对MLLMs设计。任务分为五个类别:导航、对象交互、社会交互、属性问答和空间问答,以评估代理的不同能力。我们在EmbodiedEval上评估了最先进的MLLMs,发现它们在实体任务方面与人类水平存在很大差距。我们的分析揭示了现有MLLM在实体能力方面的局限性,为未来的开发提供了见解。我们在https://github.com/thunlp/EmbodiedEval上公开了所有评估数据和模拟框架。
论文及项目相关链接
Summary
多模态大型语言模型(MLLMs)在智能体领域展现出显著进展,但仍面临评估难题。现有评估基准主要使用静态图像或视频,局限于非互动场景。针对此,本文提出EmbodiedEval,一个全面互动的评价基准,用于评估MLLMs的实体任务表现。EmbodiedEval包含125个不同场景的328个独特任务,涵盖广泛的现有实体AI任务,并在统一的模拟与评估框架下定制评估MLLMs的不同能力。任务分为导航、物体互动、社交互动、属性问答及空间问答五大类。评估显示,现有MLLMs在实体任务上显著落后于人类水平,突显其未来发展方向。我们公开所有评估数据和模拟框架。
Key Takeaways
- 多模态大型语言模型(MLLMs)在智能体领域展现出显著进展。
- 现有评估基准主要使用静态图像或视频,局限于非互动场景,无法充分评估MLLMs的实体能力。
- EmbodiedEval是一个全面互动的评价基准,用于评估MLLMs的实体任务表现,包含328个独特任务,涵盖广泛的现有实体AI任务。
- EmbodiedEval的任务分为五大类:导航、物体互动、社交互动、属性问答及空间问答,旨在评估不同能力。
- 评估显示,现有MLLMs在实体任务上显著落后于人类水平。
- 公开所有评估数据和模拟框架,便于未来研究与发展。
点此查看论文截图



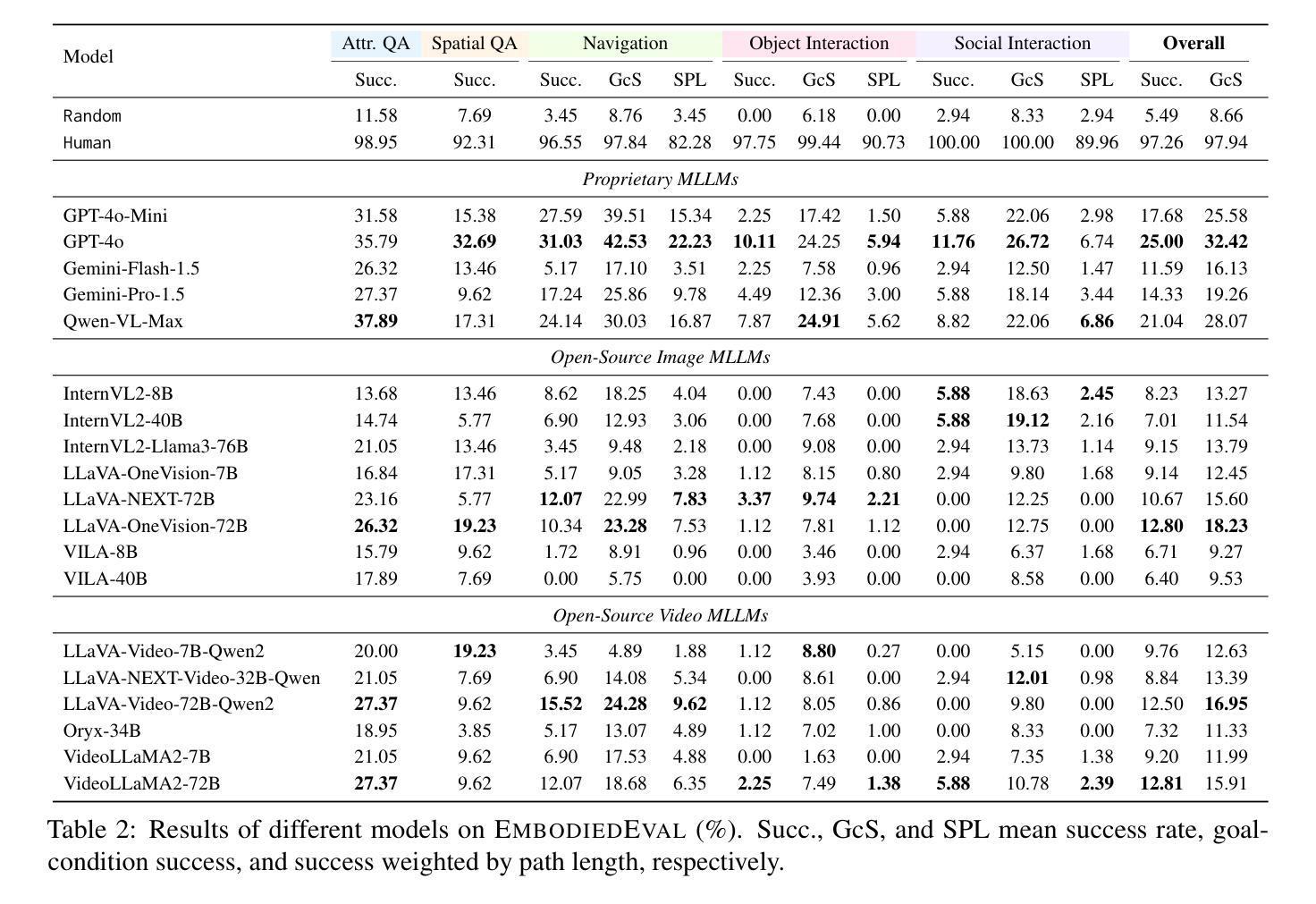
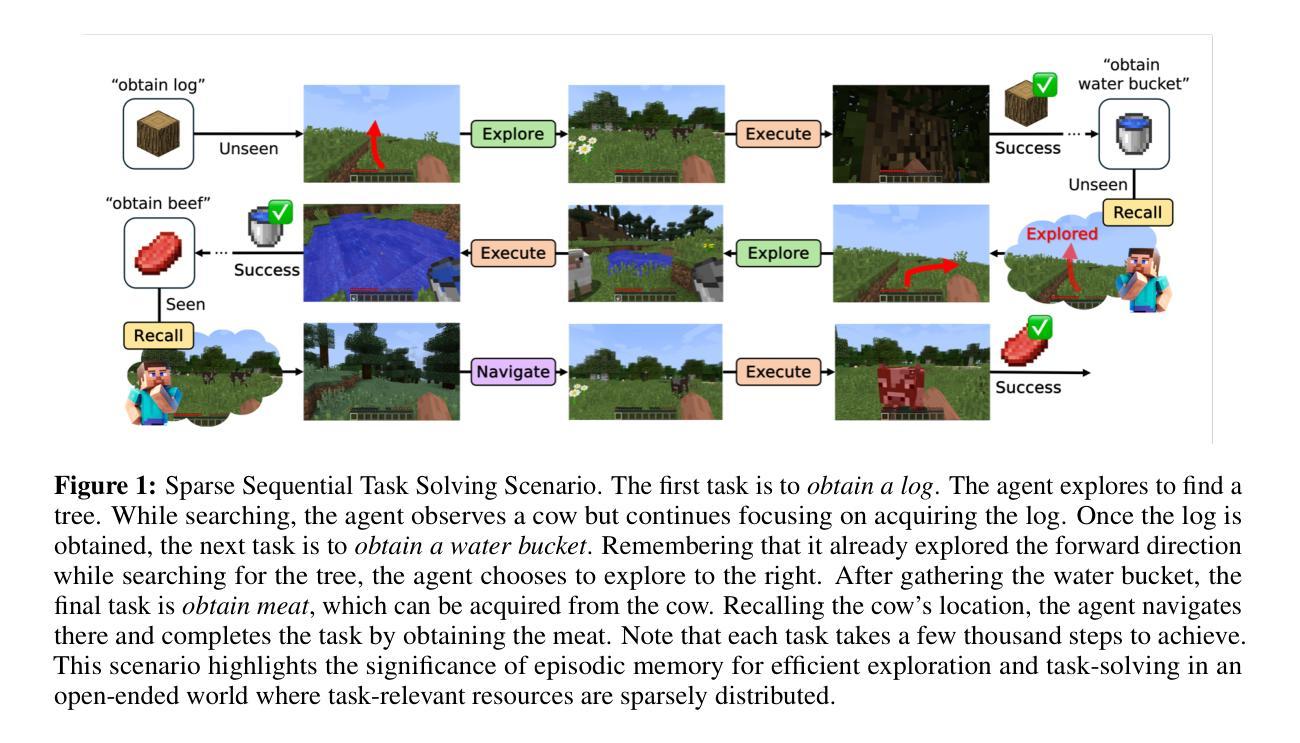
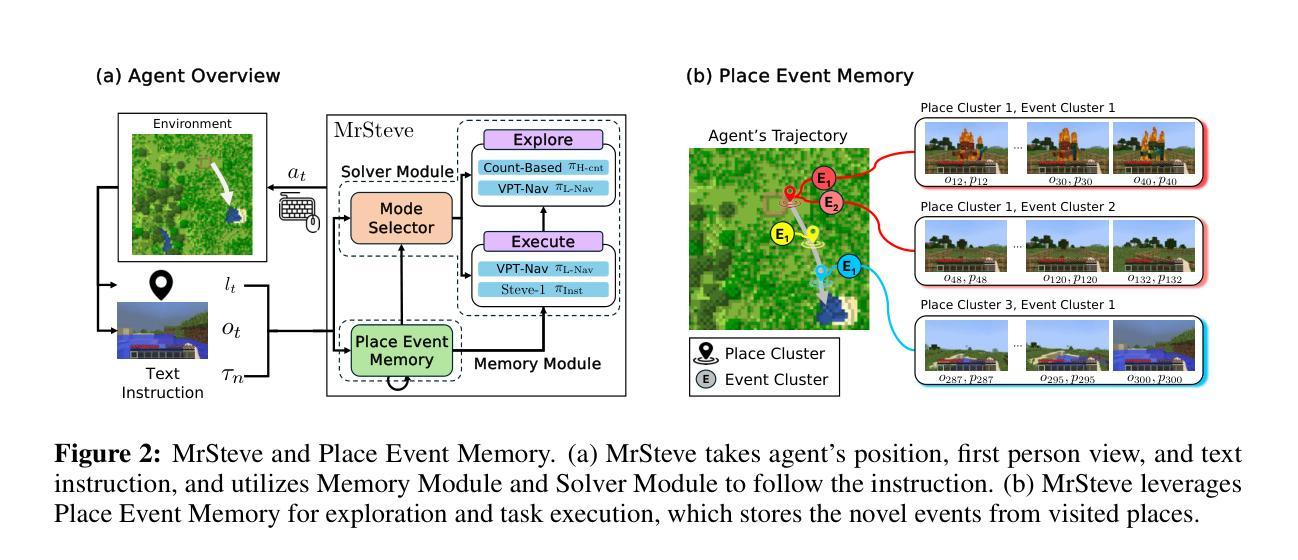
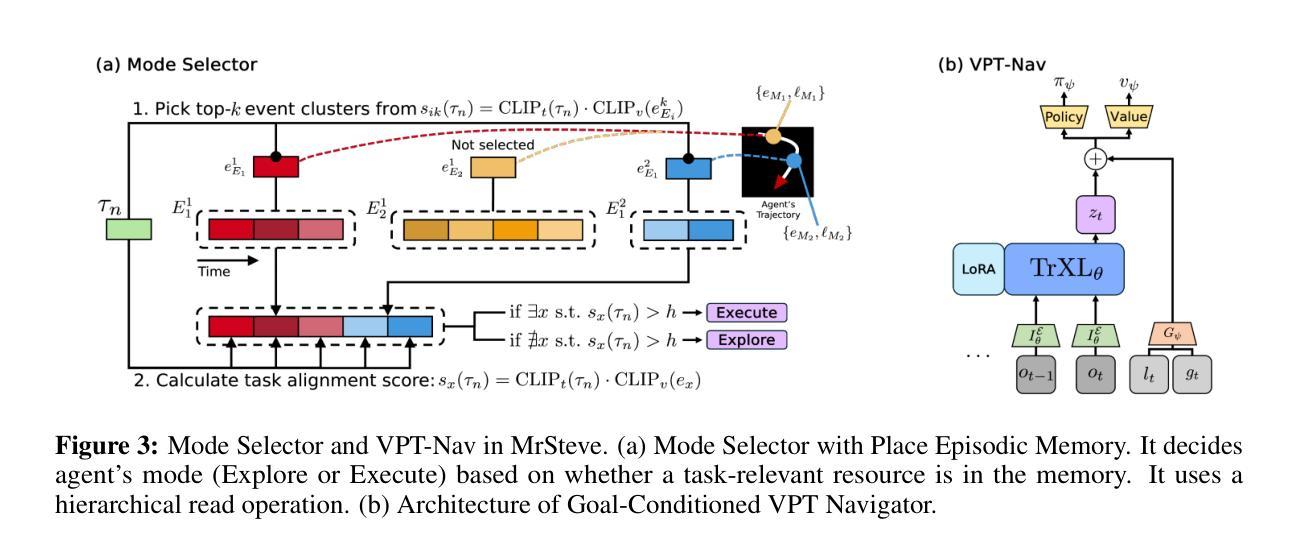
MrSteve: Instruction-Following Agents in Minecraft with What-Where-When Memory
Authors:Junyeong Park, Junmo Cho, Sungjin Ahn
Significant advances have been made in developing general-purpose embodied AI in environments like Minecraft through the adoption of LLM-augmented hierarchical approaches. While these approaches, which combine high-level planners with low-level controllers, show promise, low-level controllers frequently become performance bottlenecks due to repeated failures. In this paper, we argue that the primary cause of failure in many low-level controllers is the absence of an episodic memory system. To address this, we introduce MrSteve (Memory Recall Steve), a novel low-level controller equipped with Place Event Memory (PEM), a form of episodic memory that captures what, where, and when information from episodes. This directly addresses the main limitation of the popular low-level controller, Steve-1. Unlike previous models that rely on short-term memory, PEM organizes spatial and event-based data, enabling efficient recall and navigation in long-horizon tasks. Additionally, we propose an Exploration Strategy and a Memory-Augmented Task Solving Framework, allowing agents to alternate between exploration and task-solving based on recalled events. Our approach significantly improves task-solving and exploration efficiency compared to existing methods. We will release our code and demos on the project page: https://sites.google.com/view/mr-steve.
在Minecraft等环境中,通过采用LLM增强分层方法,通用实体人工智能的发展取得了重大进展。虽然这些结合高级规划器和低级控制器的方法显示出潜力,但由于反复失败,低级控制器往往成为性能瓶颈。在本文中,我们认为许多低级控制器失败的主要原因是缺乏情境记忆系统。为解决这一问题,我们引入了MrSteve(记忆回忆史蒂夫),这是一种新型低级控制器,配备了事件记忆(PEM),这是一种情境记忆,可以捕获事件中的“什么”、“哪里”和“何时”信息。这直接解决了流行的低级控制器史蒂夫-1的主要局限性。不同于依赖短期记忆的之前模型,PEM能够组织基于空间和事件的数据,在长周期任务中实现高效回忆和导航。此外,我们提出了一种探索策略和任务解决框架,允许智能体根据回忆的事件在探索和解决问题之间交替。我们的方法与现有方法相比,显著提高了任务解决和探索效率。我们将在项目页面发布我们的代码和演示:https://sites.google.com/view/mr-steve。
论文及项目相关链接
PDF Accepted to ICLR 2025
Summary
在Minecraft等环境中,通用实体人工智能的发展已取得显著进步,采用了LLM增强分层方法。虽然这些方法结合了高级规划器和低级控制器显示出潜力,但低级控制器经常成为性能瓶颈,主要由于反复失败。本文认为,许多低级控制器失败的主要原因是缺乏情景记忆系统。为解决此问题,我们引入了MrSteve(记忆回忆史蒂夫),一种配备场所事件记忆(PEM)的新型低级控制器,这是一种情景记忆,可以捕捉事件中的“什么”、“哪里”和“何时”信息。这直接解决了流行的低级控制器Steve-1的主要局限性。与依赖短期记忆的先前模型不同,PEM组织空间和事件基础数据,在长周期任务中实现高效回忆和导航。此外,我们提出了探索策略和任务解决框架,允许智能体根据回忆的事件在探索和解决问题之间交替。我们的方法显著提高了与现有方法相比的任务解决和探索效率。我们将在项目页面上发布我们的代码和演示:https://sites.google.com/view/mr-steve。
Key Takeaways
- 通用实体AI在Minecraft等环境中取得显著进展,采用LLM增强分层方法。
- 低级控制器成为性能瓶颈,主要由于反复失败。
- 现有低级控制器的主要失败原因是缺乏情景记忆系统。
- 引入新型低级控制器MrSteve,配备场所事件记忆(PEM)。
- PEM能捕捉事件中的“什么”、“哪里”和“何时”信息,实现高效回忆和导航。
- MrSteve通过探索策略和任务解决框架,根据回忆的事件在探索和解决问题之间交替。
点此查看论文截图

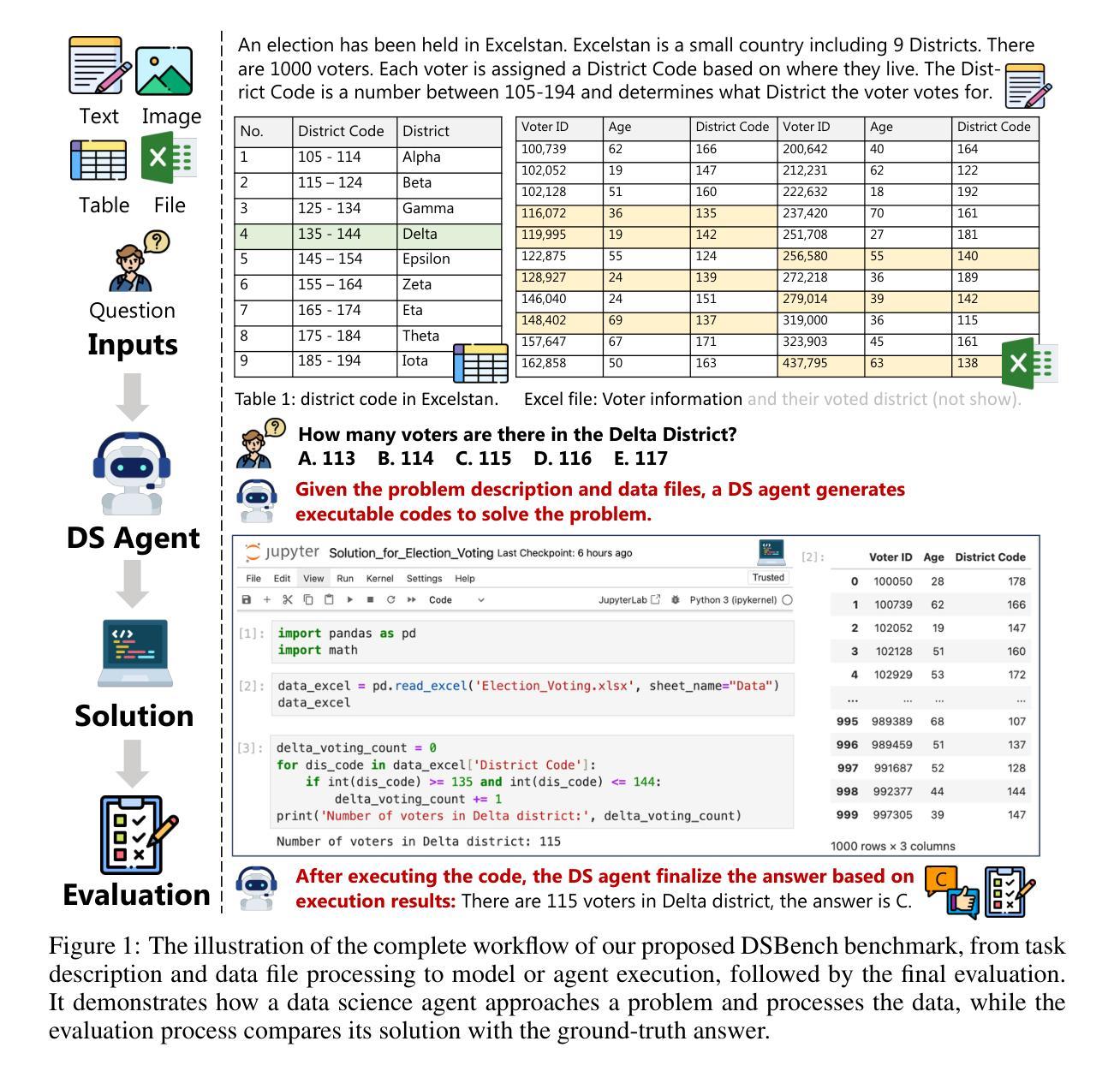
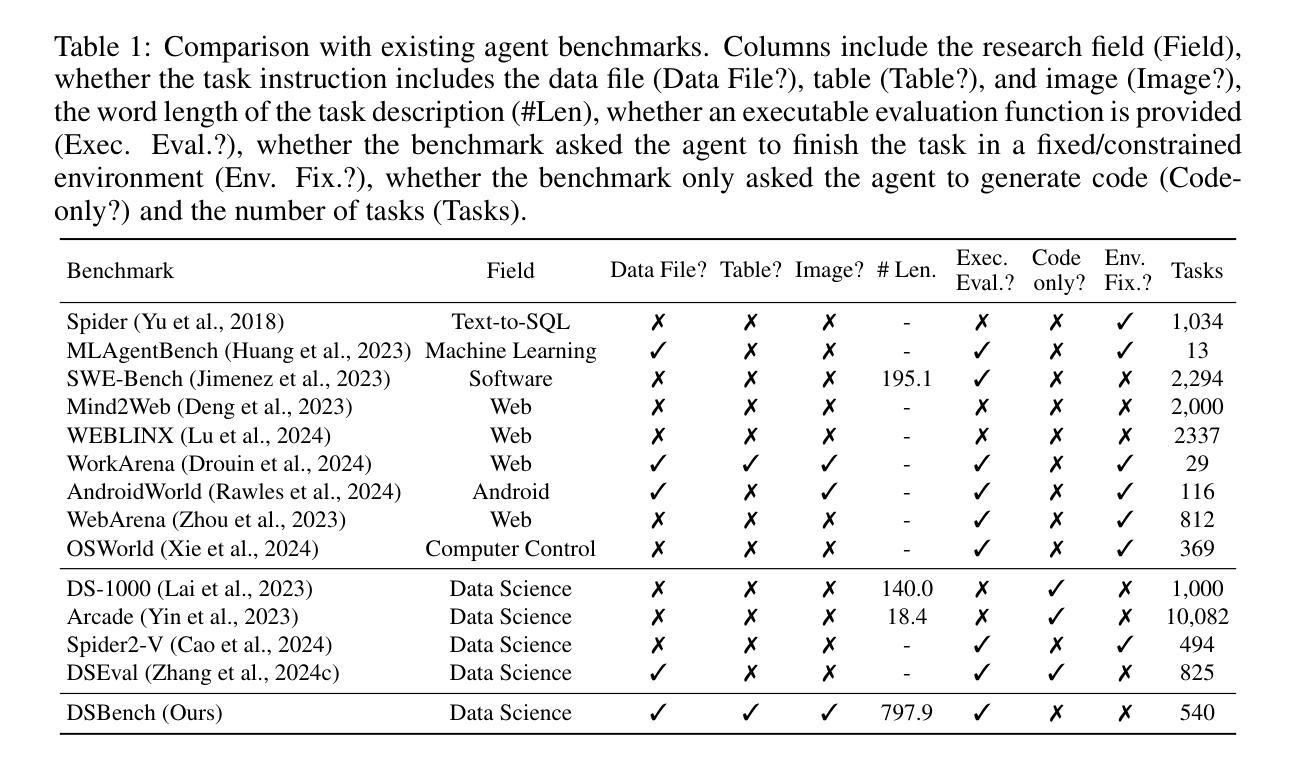
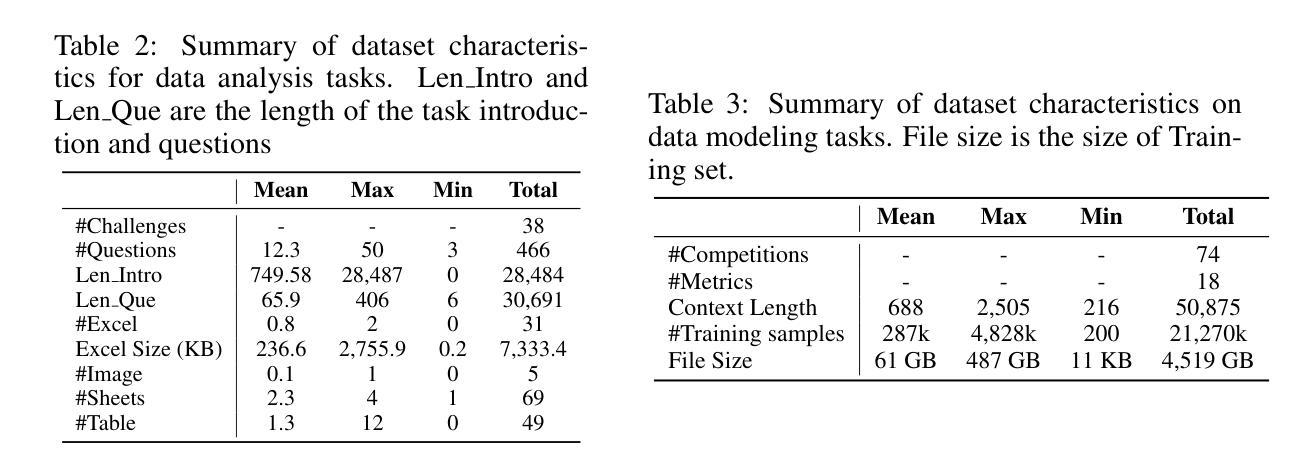
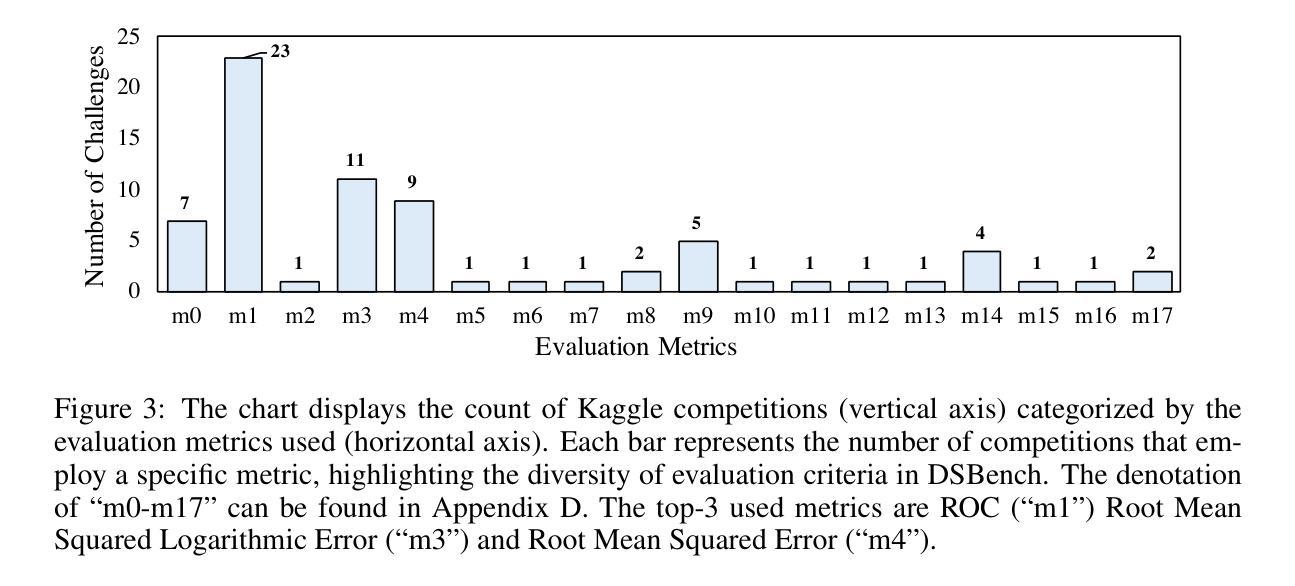
DSBench: How Far Are Data Science Agents from Becoming Data Science Experts?
Authors:Liqiang Jing, Zhehui Huang, Xiaoyang Wang, Wenlin Yao, Wenhao Yu, Kaixin Ma, Hongming Zhang, Xinya Du, Dong Yu
Large Language Models (LLMs) and Large Vision-Language Models (LVLMs) have demonstrated impressive language/vision reasoning abilities, igniting the recent trend of building agents for targeted applications such as shopping assistants or AI software engineers. Recently, many data science benchmarks have been proposed to investigate their performance in the data science domain. However, existing data science benchmarks still fall short when compared to real-world data science applications due to their simplified settings. To bridge this gap, we introduce DSBench, a comprehensive benchmark designed to evaluate data science agents with realistic tasks. This benchmark includes 466 data analysis tasks and 74 data modeling tasks, sourced from Eloquence and Kaggle competitions. DSBench offers a realistic setting by encompassing long contexts, multimodal task backgrounds, reasoning with large data files and multi-table structures, and performing end-to-end data modeling tasks. Our evaluation of state-of-the-art LLMs, LVLMs, and agents shows that they struggle with most tasks, with the best agent solving only 34.12% of data analysis tasks and achieving a 34.74% Relative Performance Gap (RPG). These findings underscore the need for further advancements in developing more practical, intelligent, and autonomous data science agents.
大型语言模型(LLMs)和大型视觉语言模型(LVLMs)已经展现出令人印象深刻的语言/视觉推理能力,引发了构建用于特定应用(如购物助理或AI软件工程师)的代理人的最新趋势。最近,许多数据科学基准测试已经被提出来研究它们在数据科学领域中的表现。然而,与真实世界的数据科学应用相比,现有的数据科学基准测试仍然显得不足,因为它们的设置过于简化。为了弥补这一差距,我们引入了DSBench,这是一个全面的基准测试,旨在用现实任务评估数据科学代理人。这个基准测试包括来自Eloquence和Kaggle比赛的466个数据分析任务和74个数据建模任务。DSBench通过包含长上下文、多模式任务背景、处理大数据文件和多表结构进行推理和端到端数据建模任务,提供了一个现实主义的设置。我们对最先进的LLMs、LVLMs和代理人的评估显示,他们在大多数任务中都遇到了困难,最好的代理人只能解决34.12%的数据分析任务,并实现了34.74%的相对性能差距(RPG)。这些发现强调需要进一步改进和发展更实用、更智能、更自主的数据科学代理人。
论文及项目相关链接
Summary
大型语言模型(LLMs)和大型视觉语言模型(LVLMs)展现出令人印象深刻的语言/视觉推理能力,并应用于购物助理或AI软件工程师等目标应用中。为评估这些模型在现实数据科学应用中的性能,引入DSBench综合基准测试,包含466个数据分析任务和74个数据建模任务。评估结果显示,现有模型在大多数任务上表现挣扎,最佳模型仅完成34.12%的数据分析任务,显示出需要进一步提高智能自主数据科学代理的实用性。
Key Takeaways
- 大型语言模型和视觉语言模型展现出色的语言/视觉推理能力,被应用于各种目标应用。
- 为评估这些模型在现实数据科学应用中的性能,提出了DSBench综合基准测试。
- DSBench包含丰富的任务类型,涵盖数据分析与建模的多个方面。
- 该基准测试提供现实环境设置,模拟了长文本环境、多模态任务背景、大量数据文件的推理和多表结构等场景。
- 现有模型在大多数任务上表现不佳,最佳模型仅完成约三分之一的任务。
- 这表明需要开发更实用、智能和自主的模型来适应现实数据科学应用的需求。
点此查看论文截图


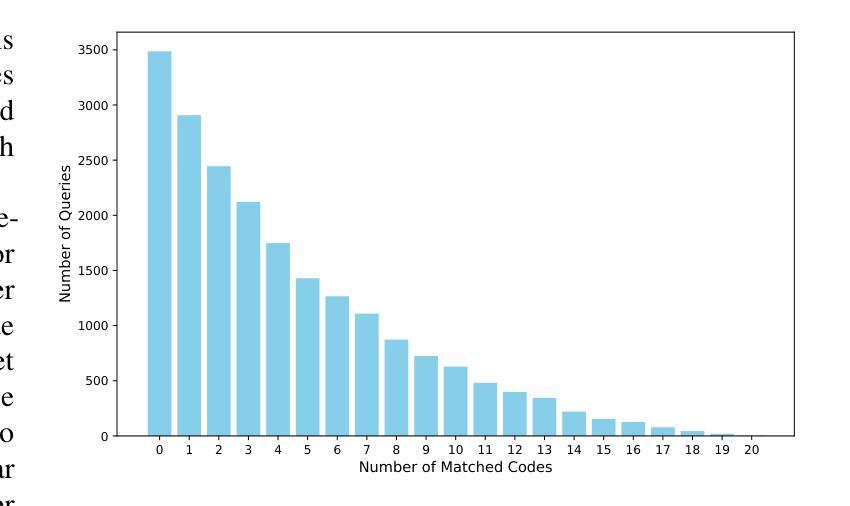
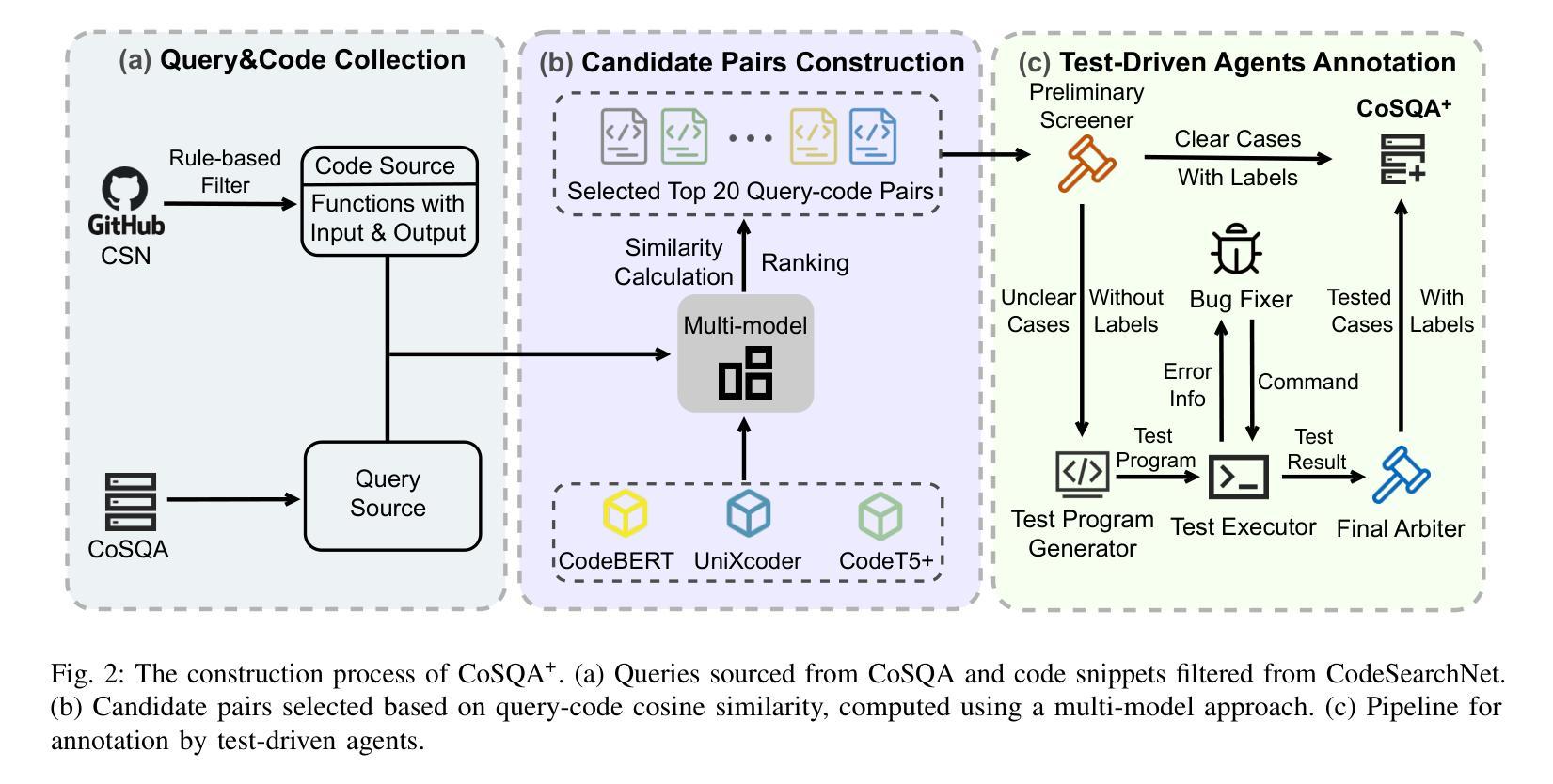
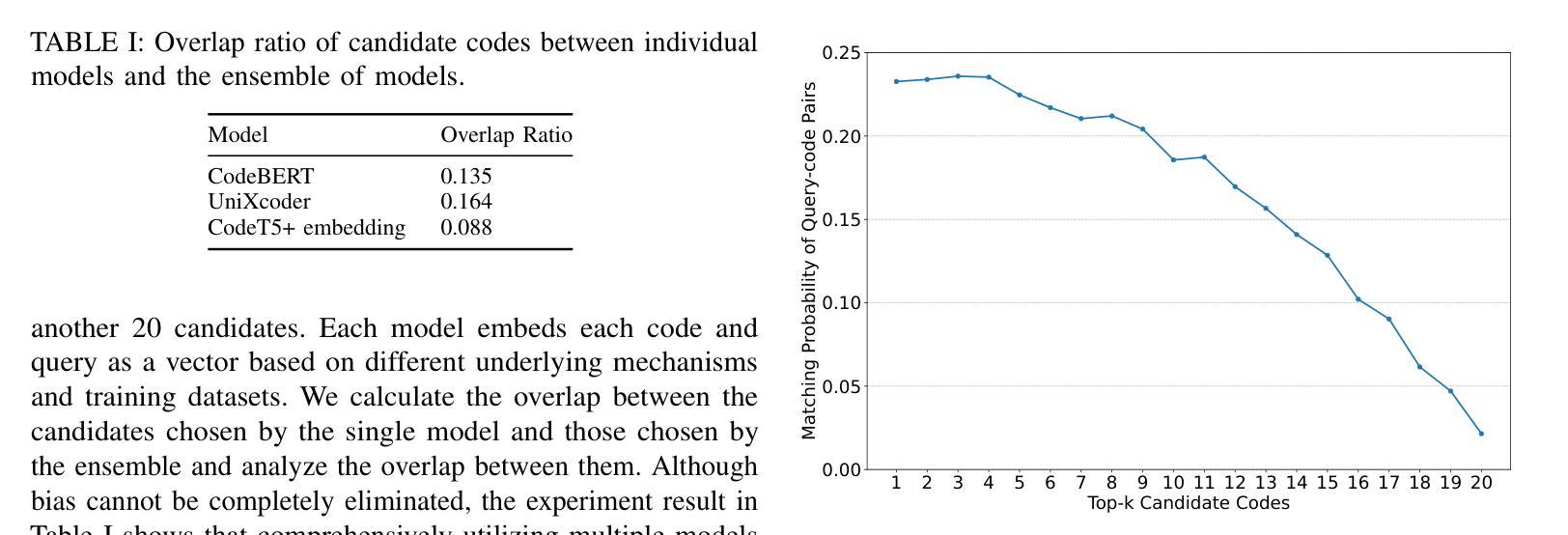
CoSQA+: Pioneering the Multi-Choice Code Search Benchmark with Test-Driven Agents
Authors:Jing Gong, Yanghui Wu, Linxi Liang, Yanlin Wang, Jiachi Chen, Mingwei Liu, Zibin Zheng
Semantic code search, retrieving code that matches a given natural language query, is an important task to improve productivity in software engineering. Existing code search datasets face limitations: they rely on human annotators who assess code primarily through semantic understanding rather than functional verification, leading to potential inaccuracies and scalability issues. Additionally, current evaluation metrics often overlook the multi-choice nature of code search. This paper introduces CoSQA+, pairing high-quality queries from CoSQA with multiple suitable codes. We develop an automated pipeline featuring multiple model-based candidate selections and the novel test-driven agent annotation system. Among a single Large Language Model (LLM) annotator and Python expert annotators (without test-based verification), agents leverage test-based verification and achieve the highest accuracy of 92.0%. Through extensive experiments, CoSQA+ has demonstrated superior quality over CoSQA. Models trained on CoSQA+ exhibit improved performance. We provide the code and data at https://github.com/DeepSoftwareAnalytics/CoSQA_Plus.
代码语义搜索是软件工程领域中提高生产力的重要任务之一,它旨在检索与给定自然语言查询匹配的代码。现有的代码搜索数据集存在局限性:它们主要依赖于通过语义理解而非功能验证来评估代码的人为注释者,这可能导致潜在的不准确性和可扩展性问题。此外,当前的评估指标往往忽视了代码搜索的多选性质。本文介绍了CoSQA+,它将CoSQA的高质量查询与多个合适的代码配对。我们开发了一个自动化管道,通过基于模型的候选选择和多代理注释系统的测试驱动,实现高质量的注释。与单一的大型语言模型注释器和Python专家注释器(无测试验证)相比,通过测试验证的代理达到了最高的92.0%准确率。通过广泛的实验,CoSQA+的质量优于CoSQA。在CoSQA+数据集上训练的模型表现出更好的性能。我们在https://github.com/DeepSoftwareAnalytics/CoSQA_Plus提供了代码和数据。
论文及项目相关链接
PDF 15 pages, 5 figures, journal
Summary:
本文介绍了语义代码搜索的重要性及其在软件工程中的应用。现有代码搜索数据集存在依赖人工标注者进行语义理解评估而非功能验证的问题,导致潜在的不准确性和可扩展性问题。为此,本文引入了CoSQA+数据集,通过自动化管道和模型候选者选择以及新型的测试驱动代理标注系统,提高了代码搜索的准确性和质量。实验证明,CoSQA+优于CoSQA数据集,训练其上的模型性能也有所提升。
Key Takeaways:
- 语义代码搜索对于提高软件工程的效率至关重要。
- 现有代码搜索数据集存在依赖人工标注者进行语义理解评估的问题,这可能导致不准确和可扩展性问题。
- CoSQA+数据集通过引入自动化管道和模型候选者选择来解决这些问题。
- CoSQA+采用新颖的测试驱动代理标注系统,实现了较高的准确性(92.0%)。
- 与CoSQA相比,CoSQA+数据集具有更高的质量和准确性。
- 在CoSQA+上训练的模型表现出改进的性能。
- CoSQA+数据集和代码已公开发布,供研究使用。
点此查看论文截图



MLLM-Tool: A Multimodal Large Language Model For Tool Agent Learning
Authors:Chenyu Wang, Weixin Luo, Sixun Dong, Xiaohua Xuan, Zhengxin Li, Lin Ma, Shenghua Gao
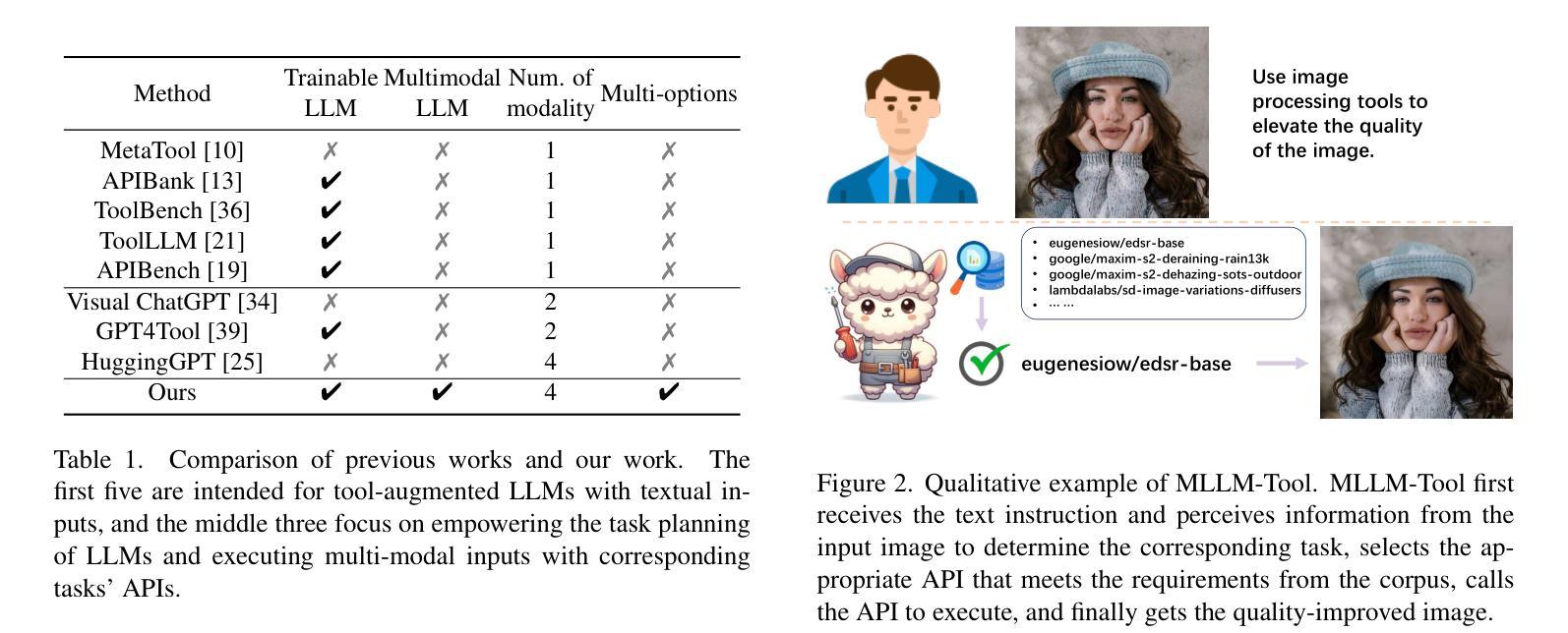
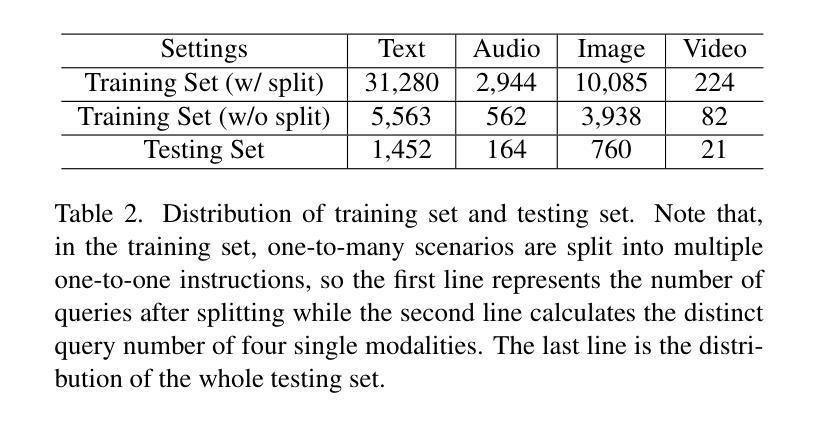
Recently, the astonishing performance of large language models (LLMs) in natural language comprehension and generation tasks triggered lots of exploration of using them as central controllers to build agent systems. Multiple studies focus on bridging the LLMs to external tools to extend the application scenarios. However, the current LLMs’ ability to perceive tool use is limited to a single text query, which may result in ambiguity in understanding the users’ real intentions. LLMs are expected to eliminate that by perceiving the information in the visual- or auditory-grounded instructions. Therefore, in this paper, we propose MLLM-Tool, a system incorporating open-source LLMs and multi-modal encoders so that the learned LLMs can be conscious of multi-modal input instruction and then select the function-matched tool correctly. To facilitate the evaluation of the model’s capability, we collect a dataset featuring multi-modal input tools from HuggingFace. Another essential feature of our dataset is that it also contains multiple potential choices for the same instruction due to the existence of identical functions and synonymous functions, which provides more potential solutions for the same query. The experiments reveal that our MLLM-Tool is capable of recommending appropriate tools for multi-modal instructions. Codes and data are available at https://github.com/MLLM-Tool/MLLM-Tool.
最近,大型语言模型(LLMs)在自然语言理解和生成任务中的惊人表现,引发了人们将其作为中央控制器构建代理系统的探索热潮。多项研究专注于将LLMs与外部工具相衔接,以扩展其应用场景。然而,当前LLMs对工具使用的感知能力仅限于单个文本查询,这可能导致对用户真实意图理解的模糊性。人们期望LLMs能够通过感知视觉或听觉基础的指令来消除这种模糊性。因此,本文提出了MLLM-Tool系统,该系统结合了开源LLMs和多模态编码器,使得学习到的LLMs能够意识到多模态输入指令,然后正确地选择功能匹配的工具。为了评估模型的能力,我们从HuggingFace收集了一个以多模态输入工具为特色的数据集。我们数据集的另一个重要特点是,由于存在相同功能和同义词功能,对于相同的指令,它还包括多个潜在的选择,这为同一查询提供了更多的潜在解决方案。实验表明,我们的MLLM-Tool能够为多模态指令推荐合适的工具。相关代码和数据集可通过https://github.com/MLLM-Tool/MLLM-Tool访问。
论文及项目相关链接
PDF WACV 2025
Summary
大型语言模型(LLMs)在自然语言理解和生成任务中表现优异,引发了对将其作为中央控制器构建代理系统的探索。当前LLMs对工具使用的感知能力仅限于文本查询,可能导致对用户真实意图的误解。本研究提出MLLM-Tool系统,结合开源LLMs和多模态编码器,使LLMs能够感知多模态输入指令,并正确选择功能匹配的工具。为评估模型能力,我们收集了包含多模态输入工具的数据集,并发现MLLM-Tool能够为多模态指令推荐合适的工具。
Key Takeaways
- 大型语言模型(LLMs)在自然语言处理任务中表现卓越,引发作为中央控制器构建代理系统的探索。
- 当前LLMs对工具使用的感知能力仅限于文本查询,可能导致用户意图的误解。
- MLLM-Tool系统结合开源LLMs和多模态编码器,使LLMs能够感知多模态输入指令。
- 为评估模型能力,收集了一个包含多模态输入工具的数据集。
- 数据集包含相同指令的多个潜在选择,为相同查询提供更多潜在解决方案。
- 实验表明MLLM-Tool能够为多模态指令推荐合适的工具。
点此查看论文截图