⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-15 更新
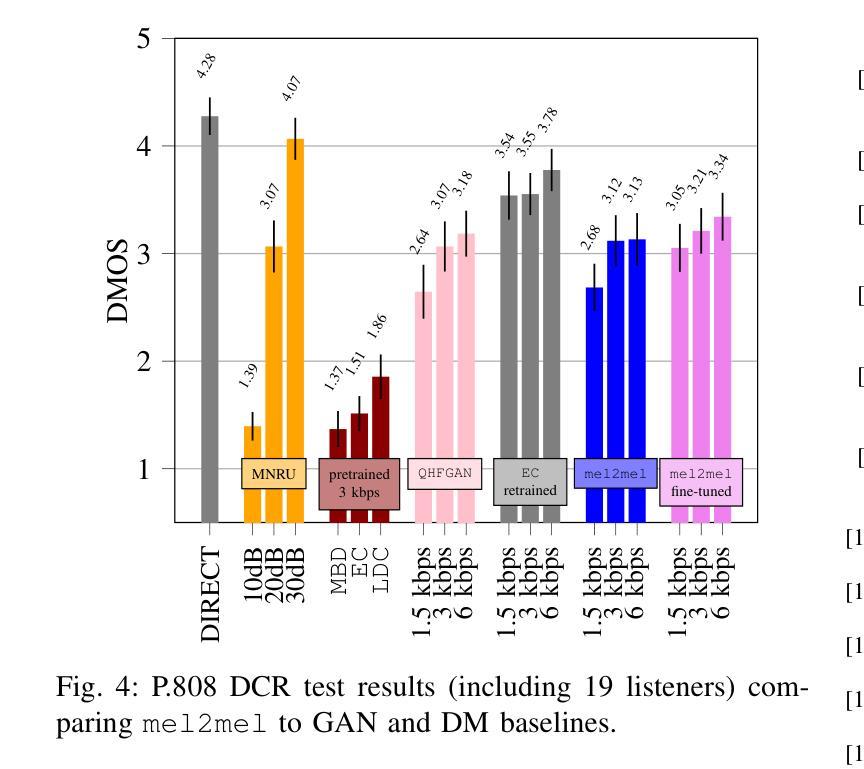
On the Design of Diffusion-based Neural Speech Codecs
Authors:Pietro Foti, Andreas Brendel
Recently, neural speech codecs (NSCs) trained as generative models have shown superior performance compared to conventional codecs at low bitrates. Although most state-of-the-art NSCs are trained as Generative Adversarial Networks (GANs), Diffusion Models (DMs), a recent class of generative models, represent a promising alternative due to their superior performance in image generation relative to GANs. Consequently, DMs have been successfully applied for audio and speech coding among various other audio generation applications. However, the design of diffusion-based NSCs has not yet been explored in a systematic way. We address this by providing a comprehensive analysis of diffusion-based NSCs divided into three contributions. First, we propose a categorization based on the conditioning and output domains of the DM. This simple conceptual framework allows us to define a design space for diffusion-based NSCs and to assign a category to existing approaches in the literature. Second, we systematically investigate unexplored designs by creating and evaluating new diffusion-based NSCs within the conceptual framework. Finally, we compare the proposed models to existing GAN and DM baselines through objective metrics and subjective listening tests.
最近,作为生成模型训练的神经语音编解码器(NSCs)在低比特率下相比传统编解码器表现出卓越的性能。尽管大多数最先进的NSCs都是作为生成对抗网络(GANs)进行训练的,但扩散模型(DMs)作为最近一类生成模型,在图像生成方面表现出优于GANs的性能,因此在各种其他音频生成应用中,DMs被成功应用于音频和语音编码。然而,扩散型NSCs的设计尚未进行系统性的探索。我们通过提供对基于扩散的NSCs的全面分析来解决这一问题,分析分为三个部分。首先,我们基于DM的条件和输出域提出分类。这种简单的概念框架使我们能够定义基于扩散的NSCs的设计空间,并为文献中的现有方法分配类别。其次,我们在概念框架内创建并评估新的基于扩散的NSCs,以系统研究尚未探索的设计。最后,我们通过客观指标和主观听觉测试将所提出的模型与现有的GAN和DM基线进行比较。
论文及项目相关链接
Summary
神经网络语音编解码器(NSC)作为生成模型训练,在低比特率下表现出优于传统编解码器的性能。虽然目前大多数先进的NSC都是基于生成对抗网络(GAN),但扩散模型(DM)作为一类新兴的生成模型,在图像生成方面表现出优于GAN的性能,因此在音频和语音编码等领域具有广阔的应用前景。本文系统分析了基于扩散的NSC设计,包括基于DM的条件和输出域的类别划分、系统探究未被研究过的设计,以及通过客观指标和主观听觉测试对现有模型和基于扩散的新模型进行评估比较。
Key Takeaways
- 神经网络语音编解码器(NSC)在低比特率下表现优越。
- 生成对抗网络(GAN)是目前大多数先进NSC的基础。
- 扩散模型(DM)在图像生成方面表现出优于GAN的性能。
- DM已成功应用于音频和语音编码等领域。
- 基于DM的NSC设计尚未进行系统性的探究。
- 本文提供了基于DM的条件和输出域的类别划分的综合分析框架。
- 通过客观指标和主观听觉测试,对现有模型和基于扩散的新模型进行了评估比较。
点此查看论文截图

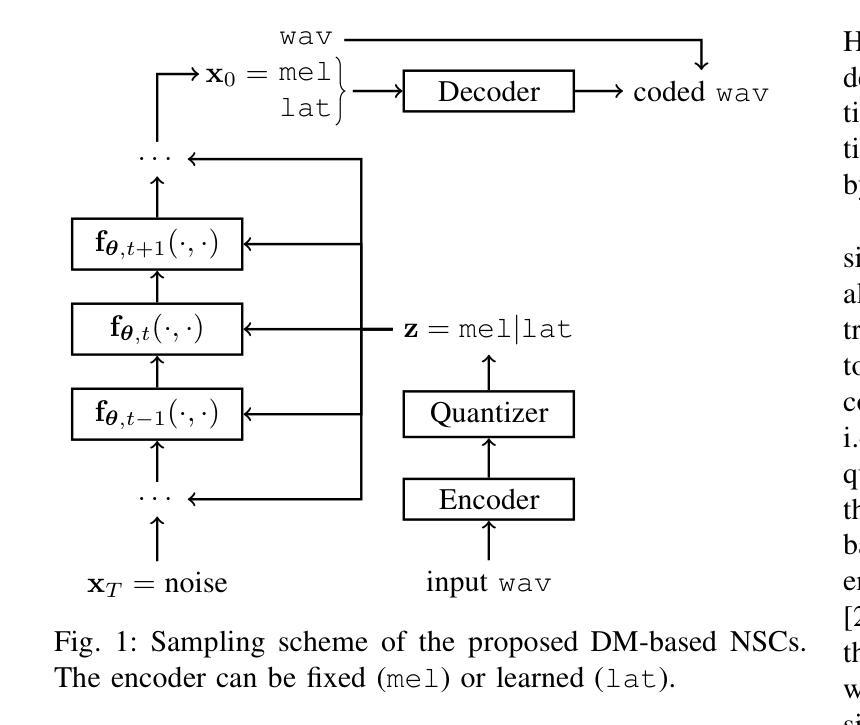
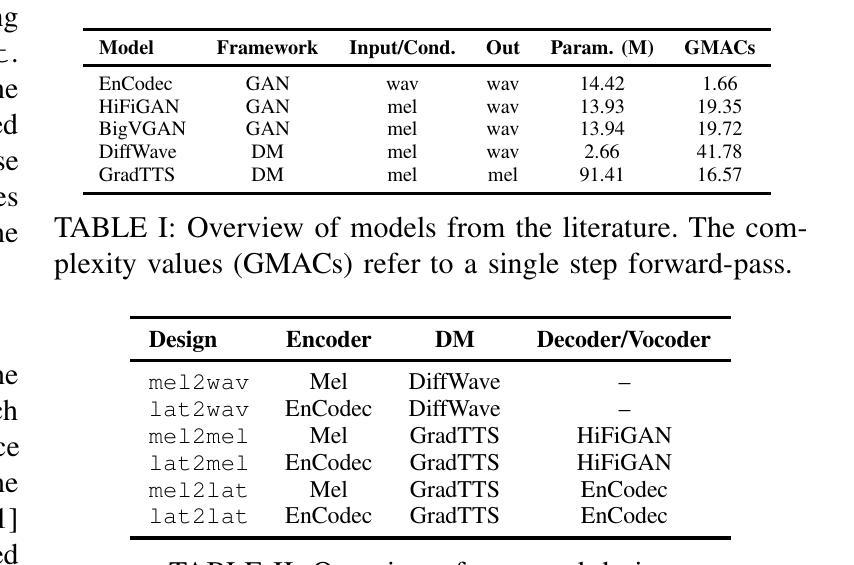
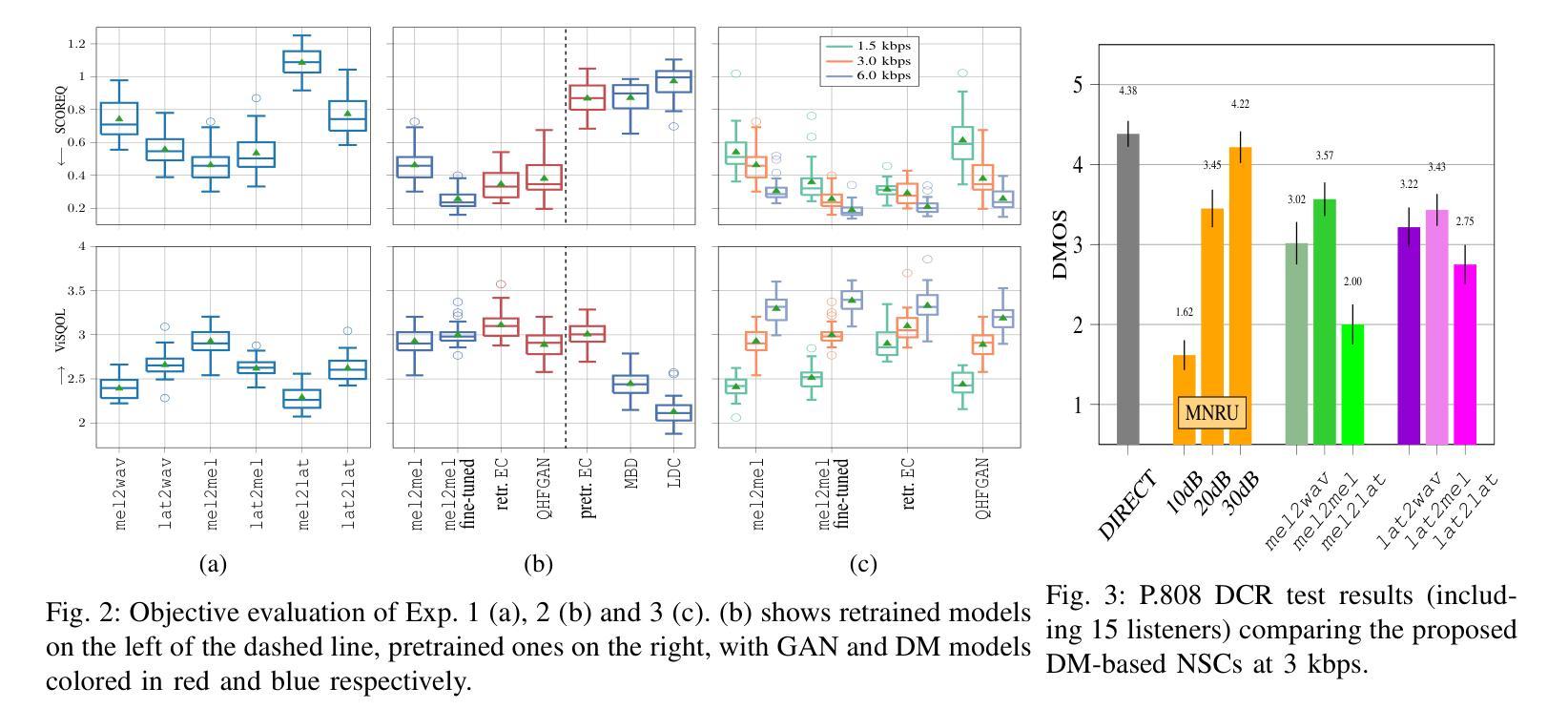
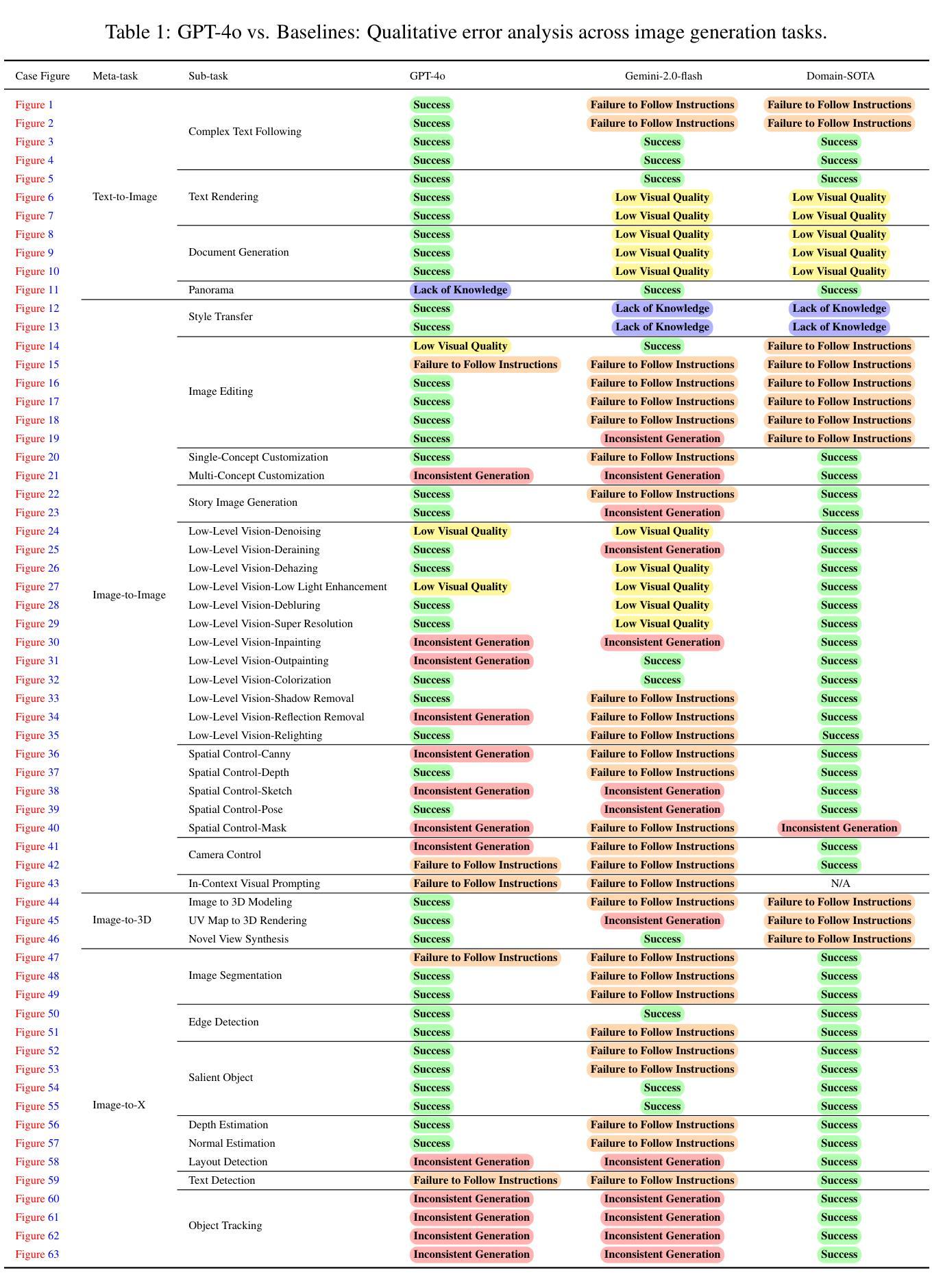
An Empirical Study of GPT-4o Image Generation Capabilities
Authors:Sixiang Chen, Jinbin Bai, Zhuoran Zhao, Tian Ye, Qingyu Shi, Donghao Zhou, Wenhao Chai, Xin Lin, Jianzong Wu, Chao Tang, Shilin Xu, Tao Zhang, Haobo Yuan, Yikang Zhou, Wei Chow, Linfeng Li, Xiangtai Li, Lei Zhu, Lu Qi
The landscape of image generation has rapidly evolved, from early GAN-based approaches to diffusion models and, most recently, to unified generative architectures that seek to bridge understanding and generation tasks. Recent advances, especially the GPT-4o, have demonstrated the feasibility of high-fidelity multimodal generation, their architectural design remains mysterious and unpublished. This prompts the question of whether image and text generation have already been successfully integrated into a unified framework for those methods. In this work, we conduct an empirical study of GPT-4o’s image generation capabilities, benchmarking it against leading open-source and commercial models. Our evaluation covers four main categories, including text-to-image, image-to-image, image-to-3D, and image-to-X generation, with more than 20 tasks. Our analysis highlights the strengths and limitations of GPT-4o under various settings, and situates it within the broader evolution of generative modeling. Through this investigation, we identify promising directions for future unified generative models, emphasizing the role of architectural design and data scaling. For a high-definition version of the PDF, please refer to the link on GitHub: \href{https://github.com/Ephemeral182/Empirical-Study-of-GPT-4o-Image-Gen}{https://github.com/Ephemeral182/Empirical-Study-of-GPT-4o-Image-Gen}.
图像生成领域迅速演变,从早期的基于GAN的方法到扩散模型,再到最近的寻求理解和生成任务之间桥梁的统一生成架构。最近的进展,尤其是GPT-4o,已经证明了高保真跨模态生成的可行性,但其架构设计仍然神秘且未公开。这引发了人们一个问题:对于那些方法来说,图像和文本生成是否已经成功集成到一个统一的框架中。在这项工作中,我们对GPT-4o的图像生成能力进行了实证研究,将其与领先的开源和商业模型进行了基准测试。我们的评估涵盖了四个主要类别,包括文本到图像、图像到图像、图像到3D和图像到X生成,涵盖了超过20项任务。我们的分析突出了GPT-4o在不同设置下的优点和局限性,并将其定位在更广泛的生成模型演变中。通过这项调查,我们为未来的统一生成模型指明了有前景的方向,强调了架构设计和数据规模的作用。如需PDF的高清版本,请参阅GitHub上的链接:链接。
论文及项目相关链接
Summary
该文本介绍了图像生成领域的最新进展,从早期的基于GAN的方法到扩散模型,再到最新的统一生成架构。文章重点研究了GPT-4o在图像生成方面的能力,通过与开源和商业模型的对比评估,展示了其在文本转图像、图像转图像、图像转3D和图像转X生成等四个主要类别的超过20个任务中的优势和局限。文章还探讨了未来统一生成模型的发展方向,特别是架构设计和数据规模的作用。
Key Takeaways
- 图像生成领域已从基于GAN的方法发展到统一生成架构。
- GPT-4o在高保真度多模式生成方面的可行性已被证明。
- GPT-4o在多个任务上的性能被评估,包括文本转图像、图像转图像、图像转3D和图像转X生成。
- GPT-4o在不同设置下有其优势和局限。
- 文章强调了统一生成模型未来发展方向,包括架构设计和数据规模的重要性。
- GPT-4o的具体架构设计和工作原理尚未公开,仍然是个谜。
点此查看论文截图