⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-15 更新
Steering CLIP’s vision transformer with sparse autoencoders
Authors:Sonia Joseph, Praneet Suresh, Ethan Goldfarb, Lorenz Hufe, Yossi Gandelsman, Robert Graham, Danilo Bzdok, Wojciech Samek, Blake Aaron Richards
While vision models are highly capable, their internal mechanisms remain poorly understood – a challenge which sparse autoencoders (SAEs) have helped address in language, but which remains underexplored in vision. We address this gap by training SAEs on CLIP’s vision transformer and uncover key differences between vision and language processing, including distinct sparsity patterns for SAEs trained across layers and token types. We then provide the first systematic analysis on the steerability of CLIP’s vision transformer by introducing metrics to quantify how precisely SAE features can be steered to affect the model’s output. We find that 10-15% of neurons and features are steerable, with SAEs providing thousands more steerable features than the base model. Through targeted suppression of SAE features, we then demonstrate improved performance on three vision disentanglement tasks (CelebA, Waterbirds, and typographic attacks), finding optimal disentanglement in middle model layers, and achieving state-of-the-art performance on defense against typographic attacks.
虽然视觉模型功能强大,但其内部机制仍知之甚少——这是一个稀疏自动编码器(SAEs)已在语言方面有所帮助但仍在视觉领域未得到充分探索的挑战。我们通过训练CLIP的视觉Transformer来构建SAE并揭示视觉与语言处理之间的关键差异,包括在不同层和标记类型上训练的SAE的独特稀疏模式。然后,我们通过引入指标来量化SAE特征能够精确地引导模型输出的程度,首次系统地分析了CLIP的视觉Transformer的可引导性。我们发现,可引导神经元和特征占10-15%,SAE提供了比基础模型更多数千个可引导特征。通过有针对性地对SAE特征进行抑制,我们在三个视觉分解任务(CelebA、Waterbirds和印刷攻击)上展示了性能提升,发现在中层模型中达到最佳分解效果,并在防御印刷攻击方面取得了最先进的性能。
论文及项目相关链接
PDF 8 pages, 7 figures. Accepted to the CVPR 2025 Workshop on Mechanistic Interpretability for Vision (MIV)
Summary
本文探索了使用稀疏自动编码器(SAE)对CLIP视觉转换器的训练,并分析了其与语言处理的差异。研究发现,SAE特征的可操控性较高,能影响模型输出。通过针对性地抑制SAE特征,优化了三个视觉解纠缠任务(CelebA、Waterbirds和字体攻击防御)的性能,实现了对字体攻击防御的先进性能。
Key Takeaways
- SAEs被应用于CLIP的视觉转换器训练,有助于解决视觉模型内部机制理解不足的问题。
- 视觉和语言的处理在SAE中存在明显的差异,包括跨层和标记类型的稀疏模式。
- SAE特征具有高度的可操控性,能够精确影响模型输出。
- 在训练过程中发现约10-15%的神经元和特征是可操控的,且SAE提供的可操控特征数量远超基础模型。
- 通过针对性地抑制SAE特征,优化了多个视觉解纠缠任务性能。
- 最优解纠缠出现在模型中层。
点此查看论文截图



Visual Chronicles: Using Multimodal LLMs to Analyze Massive Collections of Images
Authors:Boyang Deng, Songyou Peng, Kyle Genova, Gordon Wetzstein, Noah Snavely, Leonidas Guibas, Thomas Funkhouser
We present a system using Multimodal LLMs (MLLMs) to analyze a large database with tens of millions of images captured at different times, with the aim of discovering patterns in temporal changes. Specifically, we aim to capture frequent co-occurring changes (“trends”) across a city over a certain period. Unlike previous visual analyses, our analysis answers open-ended queries (e.g., “what are the frequent types of changes in the city?”) without any predetermined target subjects or training labels. These properties cast prior learning-based or unsupervised visual analysis tools unsuitable. We identify MLLMs as a novel tool for their open-ended semantic understanding capabilities. Yet, our datasets are four orders of magnitude too large for an MLLM to ingest as context. So we introduce a bottom-up procedure that decomposes the massive visual analysis problem into more tractable sub-problems. We carefully design MLLM-based solutions to each sub-problem. During experiments and ablation studies with our system, we find it significantly outperforms baselines and is able to discover interesting trends from images captured in large cities (e.g., “addition of outdoor dining,”, “overpass was painted blue,” etc.). See more results and interactive demos at https://boyangdeng.com/visual-chronicles.
我们提出了一种使用多模态大型语言模型(MLLMs)的系统,用于分析包含数亿张在不同时间捕获的图像的大型数据库,旨在发现时间变化的模式。具体来说,我们的目标是捕捉城市某一时期频繁同时发生的变化(“趋势”)。与传统的视觉分析不同,我们的分析能够回答开放式查询(例如,“城市中最常见的变化类型是什么?”),而无需任何预定的目标主题或训练标签。这些特性使得基于先前学习或无监督的视觉分析工具不适用。我们认为MLLMs是一种新型工具,具有开放式语义理解能力。然而,我们的数据集规模庞大,超出了MLLM能够处理的上下文范围。因此,我们引入了自下而上的程序,将大规模视觉分析问题分解为更容易解决的子问题。我们针对每个子问题精心设计基于MLLM的解决方案。通过与我们系统的实验和消融研究,我们发现它明显优于基线,并能够发现从大城市图像中捕捉到的有趣趋势(例如,“增加户外用餐”,“高架桥被涂成蓝色”等)。更多结果和交互演示请访问:https://boyangdeng.com/visual-chronicles。
论文及项目相关链接
PDF Project page: https://boyangdeng.com/visual-chronicles; second and third listed authors have equal contributions
Summary
本文介绍了一个使用多模态大型语言模型(MLLMs)分析包含数亿张在不同时间捕获的图像的大型数据库的系统。旨在发现时间变化的模式,尤其是城市环境中的频繁发生的趋势。该研究使用一种自下而上的方法,将大规模视觉分析问题分解为更易于处理的问题,并使用MLLMs解决每个子问题。实验和消融研究表明,该系统显著优于基线方法,能够从大型城市的图像中发现有趣的趋势。有关更多结果和交互式演示,请访问:网站链接。
Key Takeaways
- 研究者提出了一个利用多模态大型语言模型(MLLMs)的系统来检测大规模数据库中的图像的时间变化模式。
- 系统的目标是发现城市中频繁出现的趋势变化。
- 与传统的视觉分析工具不同,该系统能够回答开放式查询,无需预设目标主题或训练标签。
- 多模态大型语言模型被用作此系统的核心工具,由于其具有开放式的语义理解能力。
- 面对巨大的数据量问题,研究人员引入了自下而上的策略将大型问题分解成若干小问题来处理。并且对每个子问题使用特定的MLLM解决方案进行处理。
点此查看论文截图


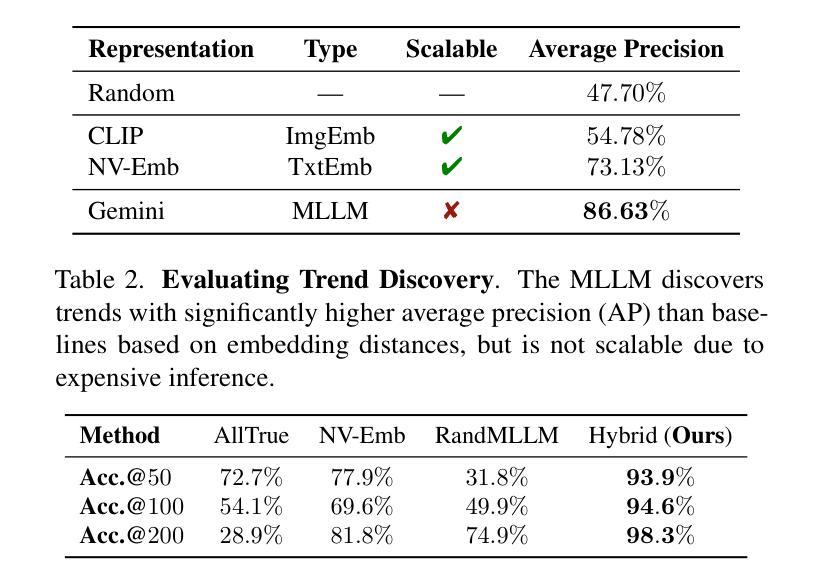
DocAgent: A Multi-Agent System for Automated Code Documentation Generation
Authors:Dayu Yang, Antoine Simoulin, Xin Qian, Xiaoyi Liu, Yuwei Cao, Zhaopu Teng, Grey Yang
High-quality code documentation is crucial for software development especially in the era of AI. However, generating it automatically using Large Language Models (LLMs) remains challenging, as existing approaches often produce incomplete, unhelpful, or factually incorrect outputs. We introduce DocAgent, a novel multi-agent collaborative system using topological code processing for incremental context building. Specialized agents (Reader, Searcher, Writer, Verifier, Orchestrator) then collaboratively generate documentation. We also propose a multi-faceted evaluation framework assessing Completeness, Helpfulness, and Truthfulness. Comprehensive experiments show DocAgent significantly outperforms baselines consistently. Our ablation study confirms the vital role of the topological processing order. DocAgent offers a robust approach for reliable code documentation generation in complex and proprietary repositories.
高质量的代码文档对软件开发至关重要,特别是在人工智能时代。然而,使用大型语言模型(LLM)自动生成代码文档仍然具有挑战性,因为现有方法通常会产生不完整、无帮助或事实错误的输出。我们引入了DocAgent,这是一种新的多智能体协作系统,采用拓扑代码处理来进行增量上下文构建。专门的智能体(阅读者、搜索者、编写者、验证者、协调者)协同生成文档。我们还提出了一个多方面的评估框架,评估文档的完整性、帮助性和真实性。综合实验表明,DocAgent持续且显著地优于基线。我们的消融研究证实了拓扑处理顺序的重要作用。DocAgent为复杂和专有存储库中的可靠代码文档生成提供了稳健的方法。
论文及项目相关链接
摘要
高质代码文档对软件开发至关重要,尤其在AI时代。然而,使用大型语言模型(LLM)自动生成文档仍存在挑战,现有方法常产生不完整、无帮助或事实错误的输出。我们推出DocAgent,一种新型多智能体协作系统,采用拓扑代码处理进行增量上下文构建。专业智能体(阅读器、搜索器、编写器、核查器、协调器)协同生成文档。我们还提出一个多方面的评估框架,评估完整性、帮助性和真实性。综合实验显示,DocAgent持续且显著优于基线。我们的消融研究证实了拓扑处理顺序的关键作用。DocAgent为复杂和专有存储库中的可靠代码文档生成提供了稳健的方法。
关键见解
- 高质代码文档在软件开发中至关重要,特别是在AI时代。
- 使用大型语言模型(LLM)自动生成代码文档具有挑战性,因为现有方法常产生不完整的、无帮助的或事实错误的输出。
- DocAgent是一种新型的多智能体协作系统,通过拓扑代码处理进行增量上下文构建来生成文档。
- DocAgent包括五个专业智能体:阅读器、搜索器、编写器、核查器和协调器。
- 提出了一个多面的评估框架,评估生成的文档在完整性、帮助性和真实性方面的表现。
- 综合实验显示,DocAgent在性能上显著优于其他方法。
- DocAgent的消融研究证实了拓扑处理顺序在文档生成中的重要作用。
点此查看论文截图


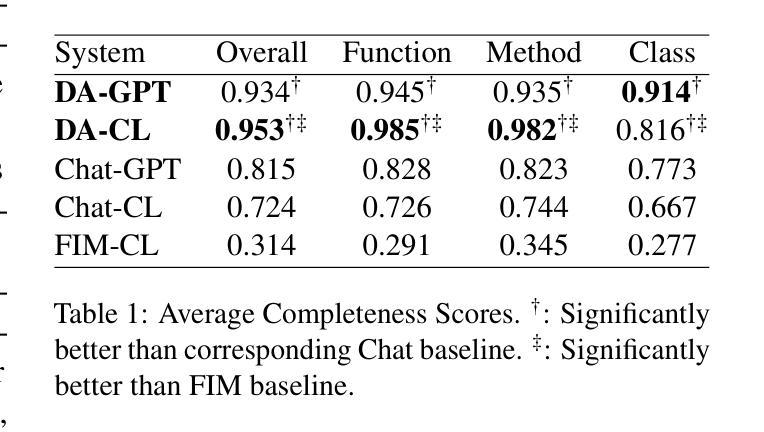
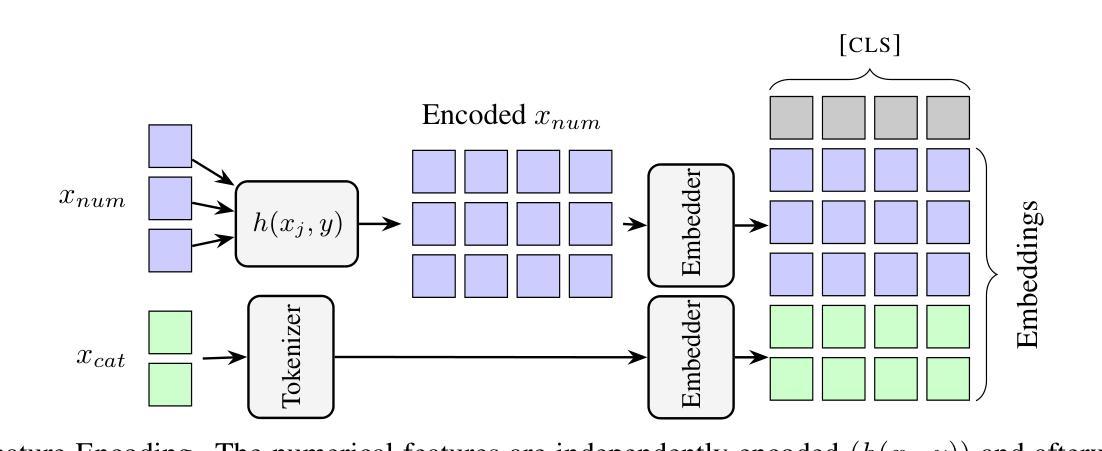
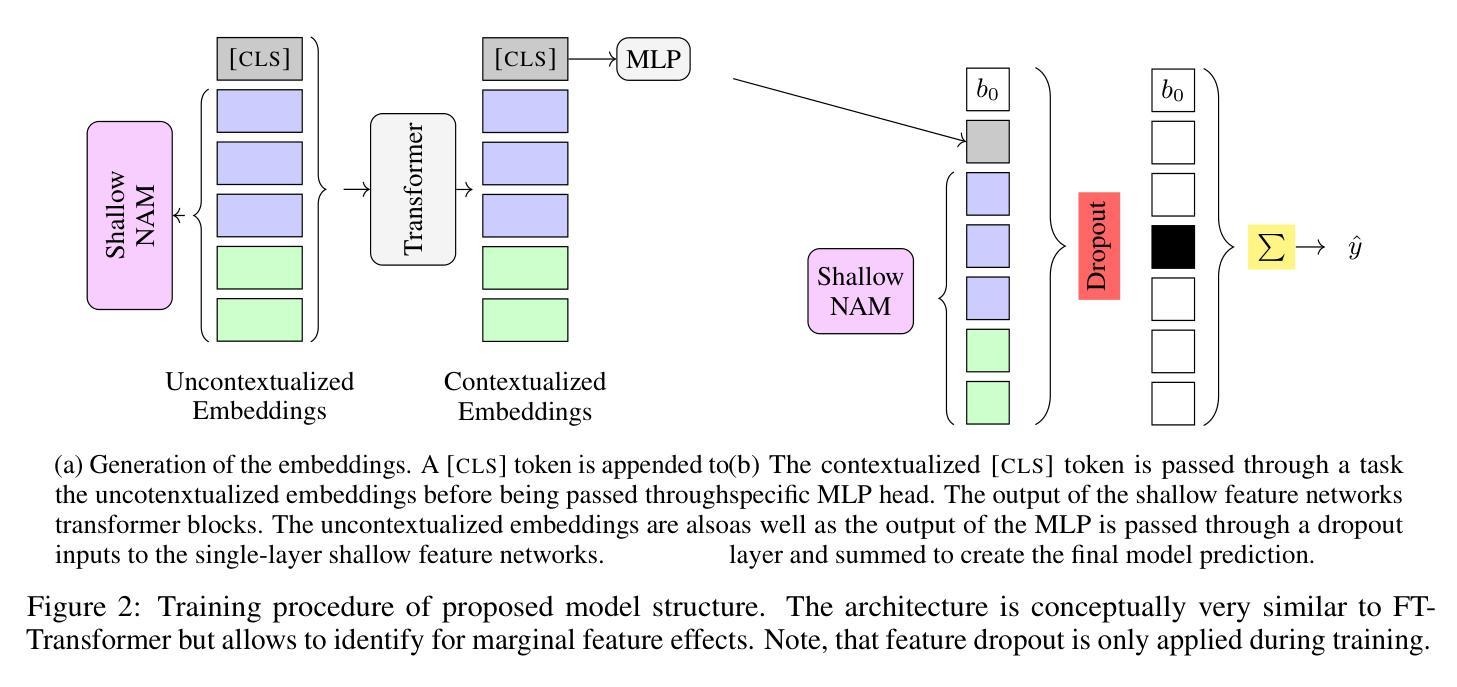
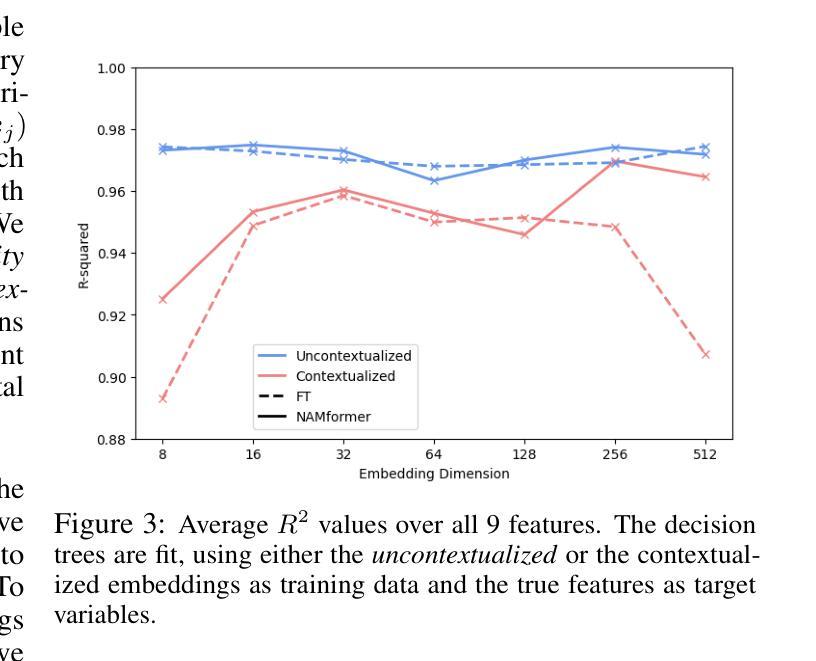
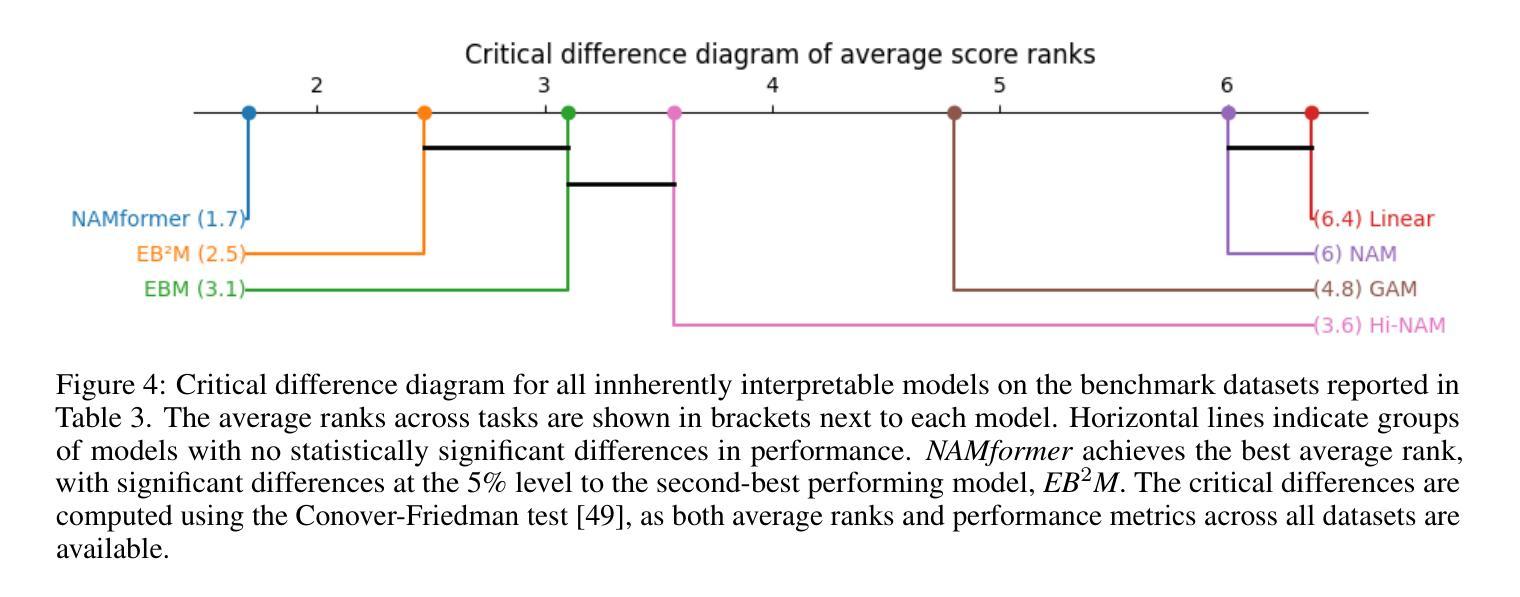
Beyond Black-Box Predictions: Identifying Marginal Feature Effects in Tabular Transformer Networks
Authors:Anton Thielmann, Arik Reuter, Benjamin Saefken
In recent years, deep neural networks have showcased their predictive power across a variety of tasks. Beyond natural language processing, the transformer architecture has proven efficient in addressing tabular data problems and challenges the previously dominant gradient-based decision trees in these areas. However, this predictive power comes at the cost of intelligibility: Marginal feature effects are almost completely lost in the black-box nature of deep tabular transformer networks. Alternative architectures that use the additivity constraints of classical statistical regression models can maintain intelligible marginal feature effects, but often fall short in predictive power compared to their more complex counterparts. To bridge the gap between intelligibility and performance, we propose an adaptation of tabular transformer networks designed to identify marginal feature effects. We provide theoretical justifications that marginal feature effects can be accurately identified, and our ablation study demonstrates that the proposed model efficiently detects these effects, even amidst complex feature interactions. To demonstrate the model’s predictive capabilities, we compare it to several interpretable as well as black-box models and find that it can match black-box performances while maintaining intelligibility. The source code is available at https://github.com/OpenTabular/NAMpy.
近年来,深度神经网络在各种任务中展示了其预测能力。除了自然语言处理,Transformer架构在解决表格数据问题和挑战中表现出了高效性,并挑战了这些领域中之前占主导地位的基于梯度的决策树。然而,这种预测能力是以可解释性为代价的:深度表格Transformer网络的黑盒性质几乎完全丧失了边缘特征效应。使用经典统计回归模型的加法约束的替代架构可以保持可理解的边缘特征效应,但在预测能力方面通常不如其更复杂的对应物。为了弥可解释性与性能之间的鸿沟,我们提出了一种适应表格Transformer网络的改进方法,旨在识别边缘特征效应。我们提供了理论证明可以准确地识别边缘特征效应,并且我们的消融研究证明,该模型可以有效地检测这些效应,即使在复杂的特征交互中也是如此。为了展示模型的预测能力,我们将其与几种可解释的黑盒模型进行了比较,发现它在保持可解释性的同时,可以匹配黑盒的性能。源代码可在https://github.com/OpenTabular/NAMpy找到。
论文及项目相关链接
Summary
深度神经网络在各种任务中展现了强大的预测能力,尤其是转换器架构在处理表格数据问题时效率较高,但牺牲了可解释性。为兼顾可解释性和性能,研究团队提出一种改进型表格转换器网络,可准确识别边际特征效应。该模型既保持了深度网络的预测能力,又具备经典统计回归模型的可解释性。模型的源代码已公开。
Key Takeaways
- 深度神经网络在多种任务中表现出强大的预测能力,特别是在处理表格数据问题时,转换器架构的效率较高。
- 传统深度神经网络(如表格转换器网络)在预测时牺牲了可解释性,难以识别边际特征效应。
- 研究团队提出了一种改进型表格转换器网络,旨在准确识别边际特征效应。
- 该模型结合了深度网络的预测能力与经典统计回归模型的可解释性。
- 模型通过理论验证和实验验证,能够准确检测边际特征效应。
- 与其他可解释和不可解释的模型相比,该模型在预测能力上表现优异。
点此查看论文截图

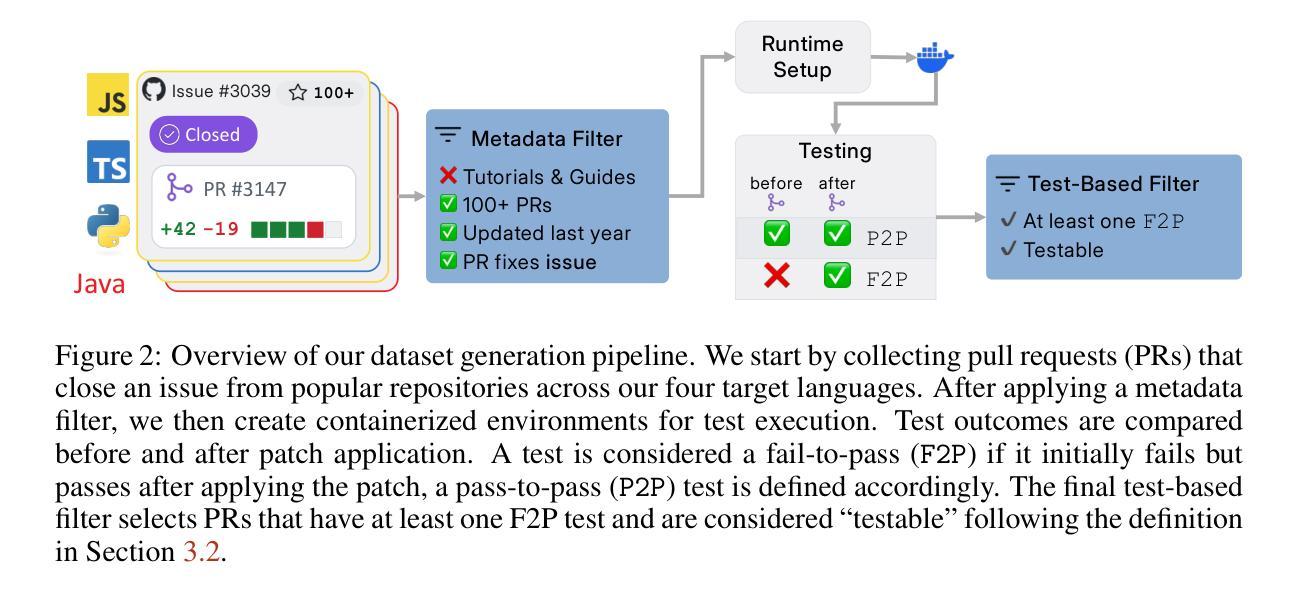
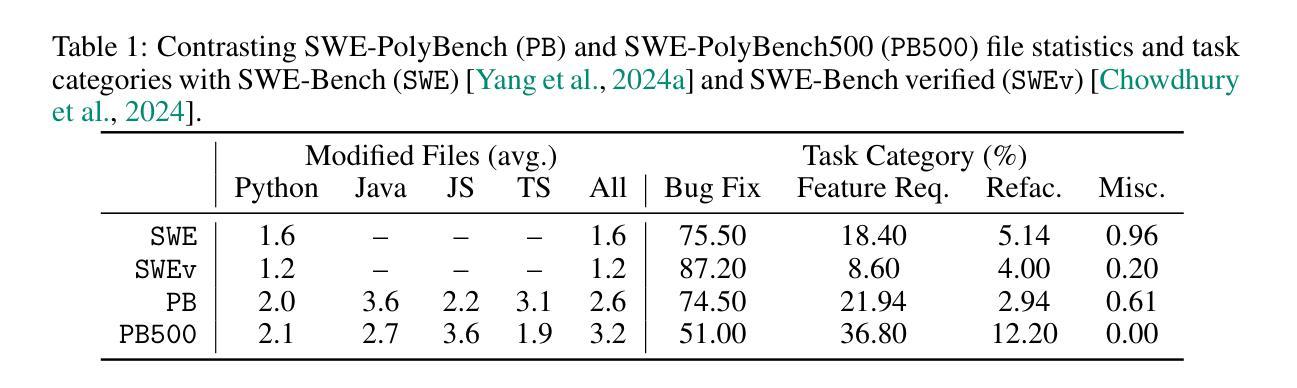
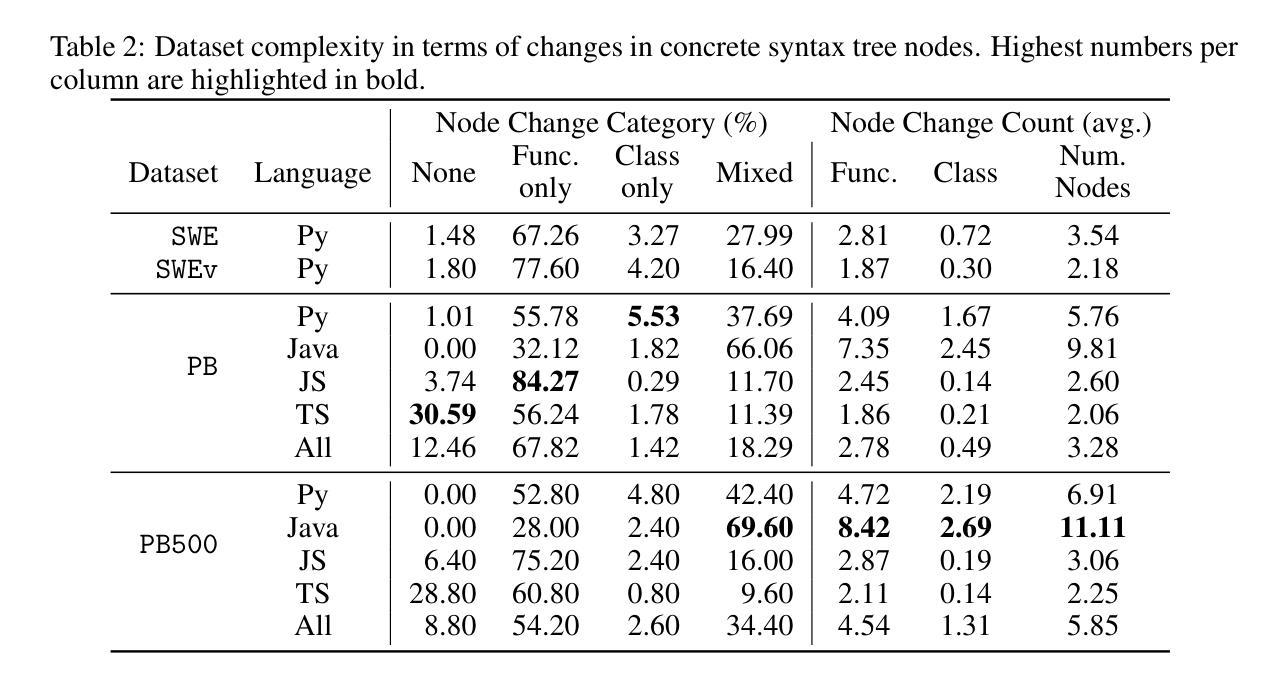
SWE-PolyBench: A multi-language benchmark for repository level evaluation of coding agents
Authors:Muhammad Shihab Rashid, Christian Bock, Yuan Zhuang, Alexander Buccholz, Tim Esler, Simon Valentin, Luca Franceschi, Martin Wistuba, Prabhu Teja Sivaprasad, Woo Jung Kim, Anoop Deoras, Giovanni Zappella, Laurent Callot
Coding agents powered by large language models have shown impressive capabilities in software engineering tasks, but evaluating their performance across diverse programming languages and real-world scenarios remains challenging. We introduce SWE-PolyBench, a new multi-language benchmark for repository-level, execution-based evaluation of coding agents. SWE-PolyBench contains 2110 instances from 21 repositories and includes tasks in Java (165), JavaScript (1017), TypeScript (729) and Python (199), covering bug fixes, feature additions, and code refactoring. We provide a task and repository-stratified subsample (SWE-PolyBench500) and release an evaluation harness allowing for fully automated evaluation. To enable a more comprehensive comparison of coding agents, this work also presents a novel set of metrics rooted in syntax tree analysis. We evaluate leading open source coding agents on SWE-PolyBench, revealing their strengths and limitations across languages, task types, and complexity classes. Our experiments show that current agents exhibit uneven performances across languages and struggle with complex problems while showing higher performance on simpler tasks. SWE-PolyBench aims to drive progress in developing more versatile and robust AI coding assistants for real-world software engineering. Our datasets and code are available at: https://github.com/amazon-science/SWE-PolyBench
由大型语言模型驱动的编码代理在软件工程任务中表现出了令人印象深刻的能力,但在多种编程语言和现实场景中对它们的性能进行评估仍然具有挑战性。我们介绍了SWE-PolyBench,这是一个新的多语言基准测试,用于对编码代理进行仓库级别的基于执行的评价。SWE-PolyBench包含来自21个仓库的2110个实例,包括Java(165个)、JavaScript(1017个)、TypeScript(729个)和Python(199个)的任务,涵盖错误修复、功能添加和代码重构。我们提供了一个任务和仓库分层子样本(SWE-PolyBench500),并发布了一个评估工具,可以实现全自动评估。为了更全面地对编码代理进行比较,这项工作还提出了基于语法树分析的新指标集。我们在SWE-PolyBench上评估了领先的开源编码代理,揭示了它们在语言、任务类型和复杂度类别方面的优势和局限性。我们的实验表明,当前代理在不同语言之间的性能表现不均衡,对复杂问题感到困难,而在简单任务上表现较好。SWE-PolyBench旨在推动开发更通用和更稳健的AI编码助理,用于现实世界的软件工程。我们的数据集和代码可在:https://github.com/amazon-science/SWE-PolyBench上找到。
论文及项目相关链接
PDF 20 pages, 6 figures
Summary
大型语言模型驱动的编码代理在软件工程任务中展现出令人印象深刻的能力,但在多种编程语言和现实场景中对它们的性能评估仍具有挑战性。为此,我们推出了SWE-PolyBench,这是一个新的多语言基准测试,用于对编码代理进行存储库级别的执行评估。它包含了来自21个存储库的2110个实例,涵盖了Java、JavaScript、TypeScript和Python中的任务,包括错误修复、功能添加和代码重构。我们还提供了一个任务分层子样本(SWE-PolyBench500),并发布了一个评估工具,可以实现完全自动化评估。为了更全面地比较编码代理,本文还提出了基于语法树分析的新指标集。我们在SWE-PolyBench上评估了领先的开源编码代理,揭示了它们在语言、任务类型和复杂度类别方面的优势和局限性。
Key Takeaways
- 编码代理在软件工程任务中表现出强大的能力,但在多种语言和现实场景中的性能评估具有挑战性。
- SWE-PolyBench是一个新的多语言基准测试,用于评估编码代理在多种编程语言中的性能。
- SWE-PolyBench包含来自不同编程语言的多种任务,如错误修复、功能添加和代码重构。
- 推出了SWE-PolyBench500任务分层子样本和自动化评估工具。
- 新的评估指标集基于语法树分析,以更全面地比较编码代理。
- 当前编码代理在不同语言和任务复杂度上的表现不均衡,对复杂问题有挑战,对简单任务表现较好。
点此查看论文截图


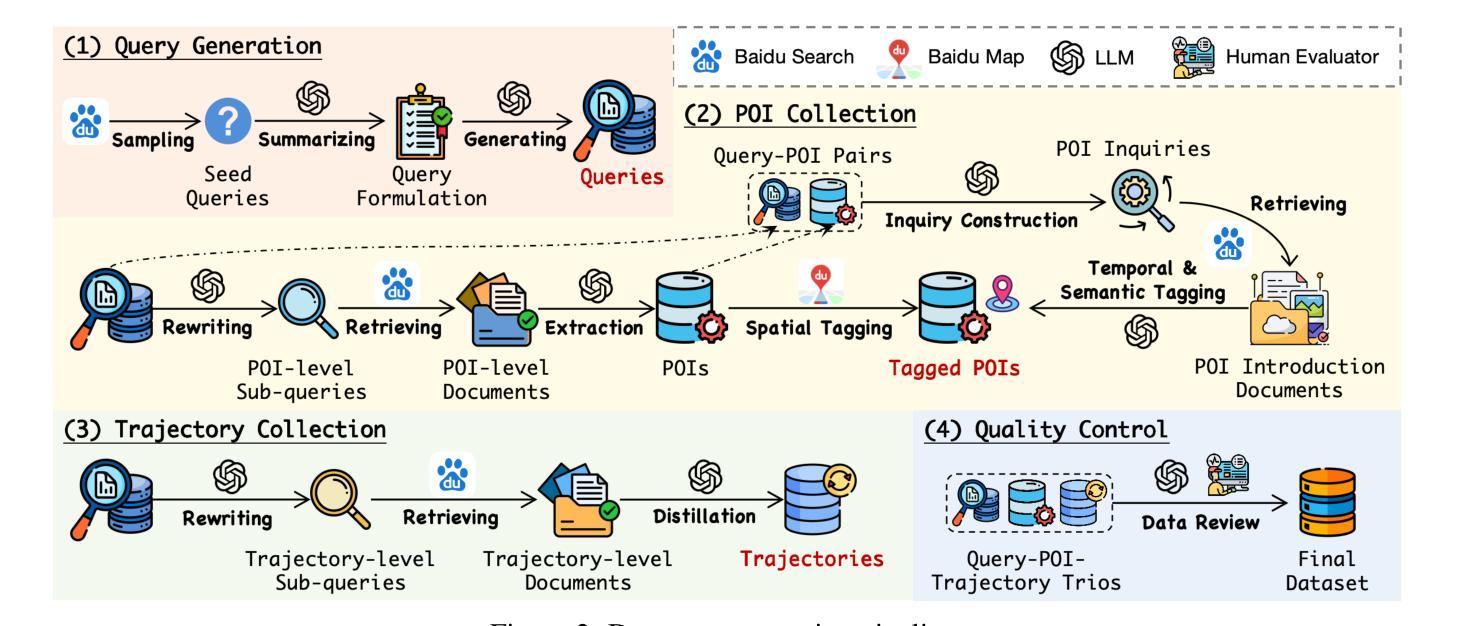
TP-RAG: Benchmarking Retrieval-Augmented Large Language Model Agents for Spatiotemporal-Aware Travel Planning
Authors:Hang Ni, Fan Liu, Xinyu Ma, Lixin Su, Shuaiqiang Wang, Dawei Yin, Hui Xiong, Hao Liu
Large language models (LLMs) have shown promise in automating travel planning, yet they often fall short in addressing nuanced spatiotemporal rationality. While existing benchmarks focus on basic plan validity, they neglect critical aspects such as route efficiency, POI appeal, and real-time adaptability. This paper introduces TP-RAG, the first benchmark tailored for retrieval-augmented, spatiotemporal-aware travel planning. Our dataset includes 2,348 real-world travel queries, 85,575 fine-grain annotated POIs, and 18,784 high-quality travel trajectory references sourced from online tourist documents, enabling dynamic and context-aware planning. Through extensive experiments, we reveal that integrating reference trajectories significantly improves spatial efficiency and POI rationality of the travel plan, while challenges persist in universality and robustness due to conflicting references and noisy data. To address these issues, we propose EvoRAG, an evolutionary framework that potently synergizes diverse retrieved trajectories with LLMs’ intrinsic reasoning. EvoRAG achieves state-of-the-art performance, improving spatiotemporal compliance and reducing commonsense violation compared to ground-up and retrieval-augmented baselines. Our work underscores the potential of hybridizing Web knowledge with LLM-driven optimization, paving the way for more reliable and adaptive travel planning agents.
大型语言模型(LLM)在自动化旅行规划方面显示出巨大的潜力,但它们往往在处理微妙的时空理性方面存在不足。虽然现有的基准测试侧重于基本的计划有效性,但它们忽视了诸如路线效率、兴趣点吸引力和实时适应性等关键方面。本文介绍了针对检索增强、时空感知旅行规划量身定制的TP-RAG基准测试。我们的数据集包含2348个真实旅行查询、85575个精细颗粒度标注的兴趣点和18784个高质量旅行轨迹参考,这些参考源于在线旅游文档,可实现动态和上下文感知的规划。通过广泛的实验,我们发现集成参考轨迹可以显著提高旅行计划的空间效率和兴趣点的合理性,而由于存在冲突的参考和嘈杂的数据,在通用性和稳健性方面仍存在挑战。为了解决这些问题,我们提出了EvoRAG,这是一个进化框架,能够有力地协同多样化的检索轨迹与LLM的内在推理。EvoRAG达到了最先进的性能,与自下而上和检索增强的基线相比,提高了时空合规性并减少了常识违规。我们的工作强调了混合Web知识与LLM驱动优化的潜力,为更可靠和自适应的旅行规划代理铺平了道路。
论文及项目相关链接
Summary:大型语言模型在旅行规划自动化方面展现出潜力,但在应对复杂时空理性方面存在不足。现有基准测试主要关注基本计划的有效性,忽略了路线效率、兴趣点吸引力和实时适应性等关键方面。本文引入TP-RAG,首个针对检索增强、时空感知旅行规划的基准测试。数据集包含2348个真实旅行查询、85575个精细颗粒度标注的兴趣点和18784条高质量旅行轨迹参考,可实现动态和上下文感知规划。通过广泛实验,我们发现集成参考轨迹可显著提高旅行计划的空间效率和合理性,而由于冲突参考和嘈杂数据,仍存在普遍性和稳健性挑战。为解决这些问题,我们提出EvoRAG,一个强大的进化框架,有效协同各种检索轨迹与LLM的内在推理。EvoRAG达到最新性能水平,提高时空合规性,减少常识违规,相较于基于地面和检索增强的基线。我们的工作突显了混合Web知识与LLM驱动优化的潜力,为更可靠和自适应的旅行规划代理铺平道路。
Key Takeaways:
- LLMs在自动化旅行规划方面展现出潜力,但仍需解决复杂时空理性问题。
- 现有基准测试主要关注基本计划的有效性,忽略了路线效率、兴趣点吸引力等关键方面。
- 引入TP-RAG基准测试,包含真实旅行查询、精细颗粒度标注的兴趣点和高质量旅行轨迹参考。
- 集成参考轨迹可提高旅行计划的空间效率和合理性。
- 仍存在普遍性和稳健性挑战,主要由于冲突参考和嘈杂数据。
- 提出EvoRAG框架,有效协同检索轨迹与LLM的内在推理,达到最新性能水平。
点此查看论文截图

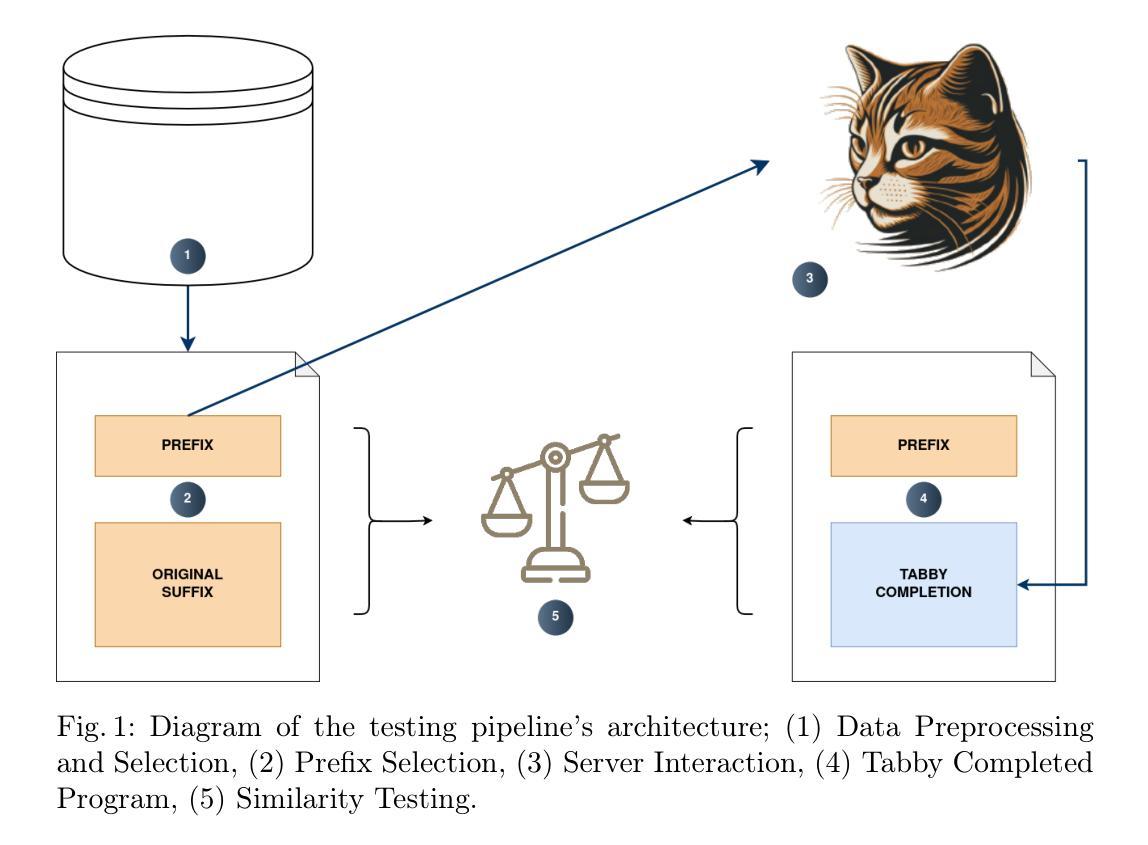
Quality evaluation of Tabby coding assistant using real source code snippets
Authors:Marta Borek, Robert Nowak
Large language models have become a popular tool in software development, providing coding assistance. The proper measurement of the accuracy and reliability of the code produced by such tools is a challenge due to natural language prompts. We propose a simple pipeline that uses state-of-the-art implementation of classic and universal genres of algorithms and data structures. We focus on measuring the quality of TabbyML code assistant due to its open licence and the flexibility in the choice of the language model. Our results presented as cyclomatic complexity, Halstead’s Bugs & Effort and four text-based similarity matrices depict the usability of TabbyML in coding assistance tasks.
大型语言模型已成为软件开发中的热门工具,为编码提供辅助。由于自然语言提示,准确衡量此类工具产生的代码准确性和可靠性是一个挑战。我们提出了一种简单的管道,该管道使用经典和通用算法和数据结构的最先进实现。我们专注于衡量TabbyML代码助手的品质,因其开放许可证和语言模型选择的灵活性。我们的结果以循环复杂度、Halstead的Bug&Effort以及四个基于文本的相似矩阵呈现,描绘了TabbyML在编码辅助任务中的可用性。
论文及项目相关链接
PDF 10 pages, 4 figures
Summary
大型语言模型在软件开发中提供编程辅助,其生成的代码准确性和可靠性评估是一大挑战。本研究提出一个简单流程,借助最新算法和数据结构实现经典和通用类型算法,重点评估TabbyML代码助理的质量。通过循环复杂性、Halstead的Bug与Effort以及四种基于文本相似性的矩阵展示其在编程辅助任务中的实用性。
Key Takeaways
- 大型语言模型已成为软件开发中的热门工具,提供编程辅助。
- 评估此类工具生成的代码准确性和可靠性是一大挑战。
- 研究提出一个简单流程来评估TabbyML代码助理的质量。
- 重点使用循环复杂性、Halstead的Bug与Effort等标准来度量质量。
- 通过四种基于文本相似性的矩阵来展示其实用性。
- TabbyML具有开放许可证和语言模型选择的灵活性。
点此查看论文截图

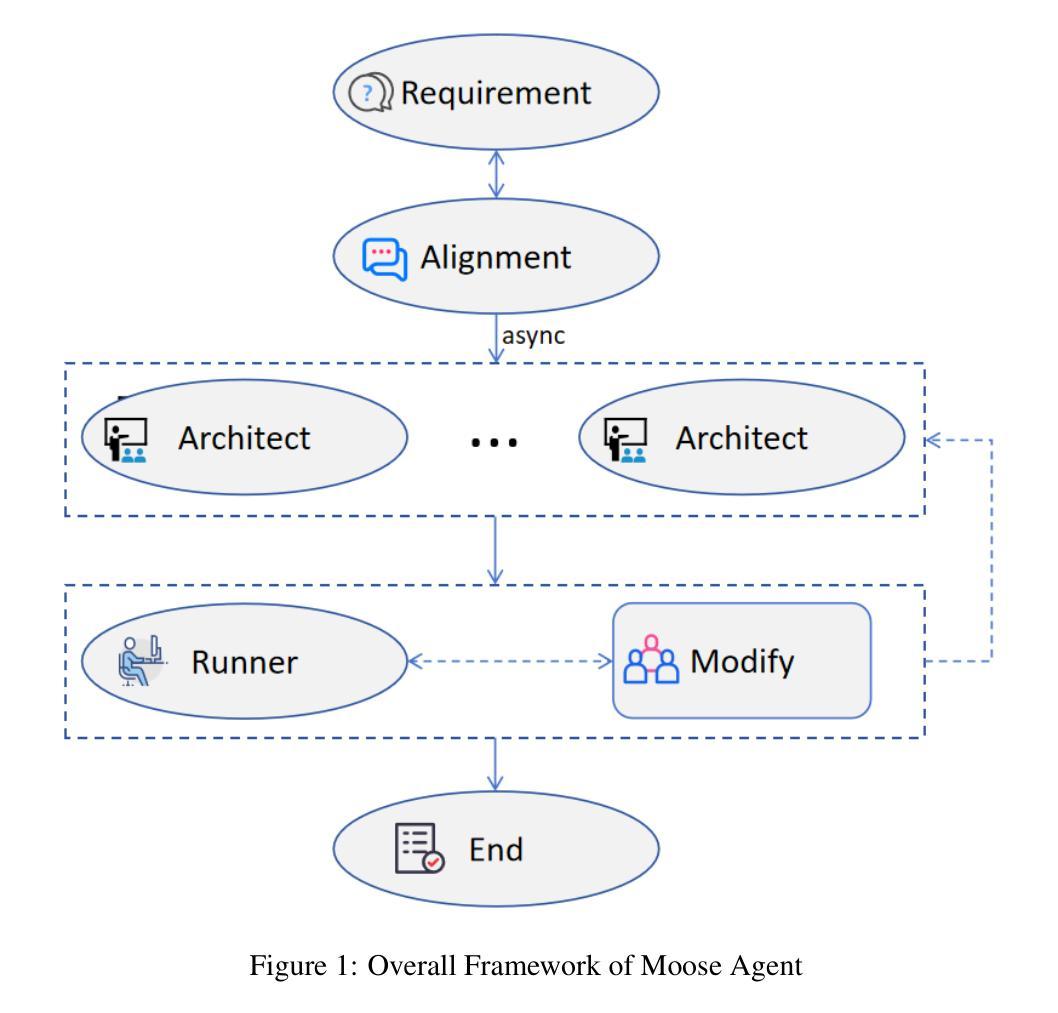
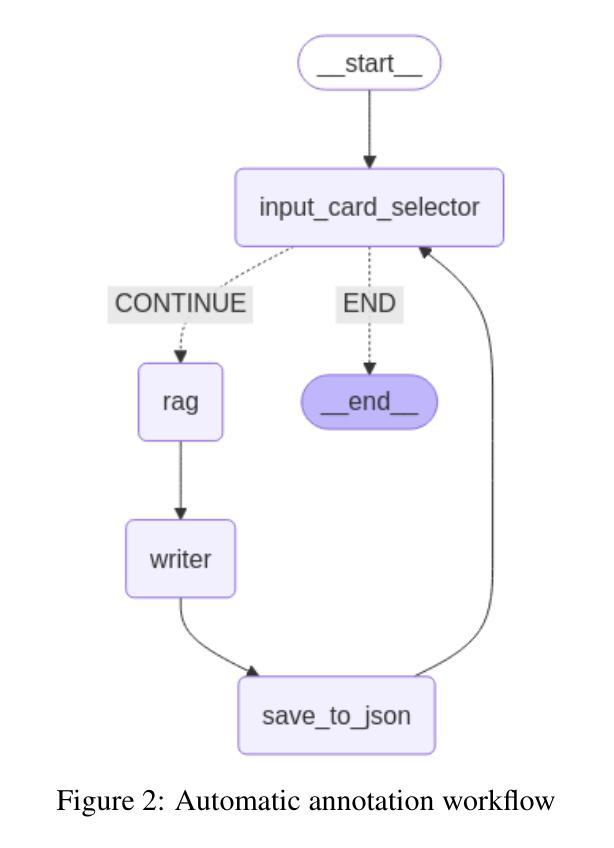
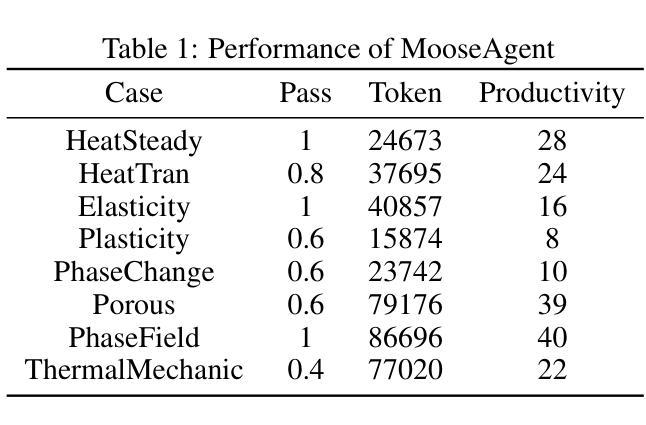
MooseAgent: A LLM Based Multi-agent Framework for Automating Moose Simulation
Authors:Tao Zhang, Zhenhai Liu, Yong Xin, Yongjun Jiao
The Finite Element Method (FEM) is widely used in engineering and scientific computing, but its pre-processing, solver configuration, and post-processing stages are often time-consuming and require specialized knowledge. This paper proposes an automated solution framework, MooseAgent, for the multi-physics simulation framework MOOSE, which combines large-scale pre-trained language models (LLMs) with a multi-agent system. The framework uses LLMs to understand user-described simulation requirements in natural language and employs task decomposition and multi-round iterative verification strategies to automatically generate MOOSE input files. To improve accuracy and reduce model hallucinations, the system builds and utilizes a vector database containing annotated MOOSE input cards and function documentation. We conducted experimental evaluations on several typical cases, including heat transfer, mechanics, phase field, and multi-physics coupling. The results show that MooseAgent can automate the MOOSE simulation process to a certain extent, especially demonstrating a high success rate when dealing with relatively simple single-physics problems. The main contribution of this research is the proposal of a multi-agent automated framework for MOOSE, which validates its potential in simplifying finite element simulation processes and lowering the user barrier, providing new ideas for the development of intelligent finite element simulation software. The code for the MooseAgent framework proposed in this paper has been open-sourced and is available at https://github.com/taozhan18/MooseAgent
有限元方法(FEM)在工程和科学计算中得到了广泛应用,但其预处理、求解器配置和后处理阶段通常耗时且需要专业知识。本文针对多物理仿真框架MOOSE,提出了一种自动化解决方案框架MooseAgent。该框架结合大规模预训练语言模型(LLM)与多智能体系统。框架使用LLM理解用户描述的自然语言仿真要求,并采用任务分解和多轮迭代验证策略自动生成MOOSE输入文件。为了提高精度并减少模型幻觉,系统构建并利用一个包含注释的MOOSE输入卡片和功能文档的向量数据库。我们在多个典型案例上进行了实验评估,包括传热、力学、相场和多物理耦合。结果表明,MooseAgent可以在一定程度上自动化MOOSE仿真过程,尤其是在处理相对简单的单物理问题时表现出较高的成功率。本研究的主要贡献是提出了针对MOOSE的多智能体自动化框架,验证了其在简化有限元仿真过程、降低用户门槛方面的潜力,为智能有限元仿真软件的开发提供了新的思路。本文提出的MooseAgent框架的代码已经开源,可在https://github.com/taozhan18/MooseAgent获取。
论文及项目相关链接
PDF 7 pages, 2 Figs
摘要
本研究提出了一个针对多物理仿真框架MOOSE的自动化解决方案框架——MooseAgent。该框架结合了大规模预训练语言模型(LLMs)与多智能体系统,用于理解用户描述的自然语言仿真要求并自动生成MOOSE输入文件。研究通过实验评估了几个典型案例,证明了MooseAgent能够在一定程度上自动化MOOSE仿真过程,特别是在处理相对简单的单物理问题时表现出较高的成功率。本研究的主要贡献在于提出了一个针对MOOSE的多智能体自动化框架,为简化有限元仿真过程、降低用户门槛提供了新思路。该论文提出的MooseAgent框架代码已开源,可在https://github.com/taozhan18/MooseAgent获取。
要点掌握
- MooseAgent是一个结合了大规模预训练语言模型和多智能体系统的自动化解决方案框架,用于多物理仿真框架MOOSE。
- 它使用语言模型理解自然语言描述的仿真要求,并自动生成MOOSE输入文件。
- 通过实验评估,MooseAgent能够在一定程度上自动化MOOSE仿真过程。
- 在处理相对简单的单物理问题时,MooseAgent表现出较高的成功率。
- 该研究为简化有限元仿真过程、降低用户门槛提供了新的思路。
- MooseAgent框架代码已开源,便于获取和使用。
点此查看论文截图

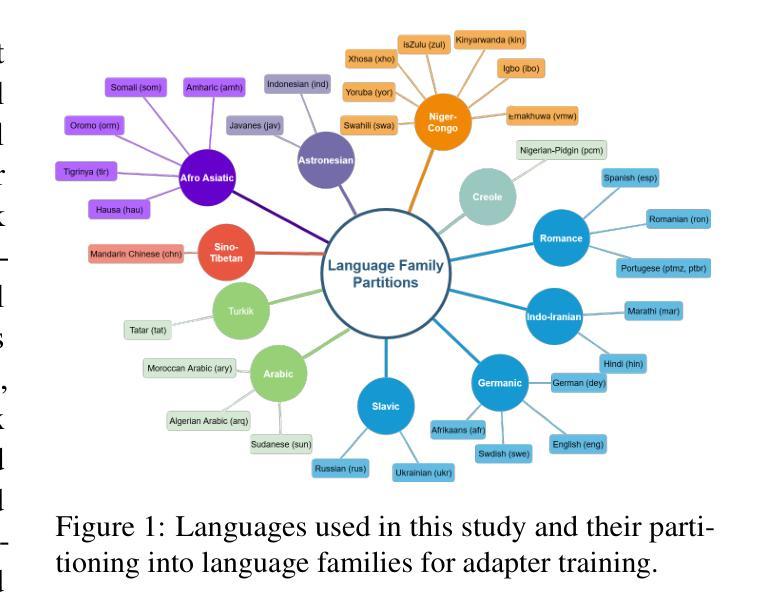
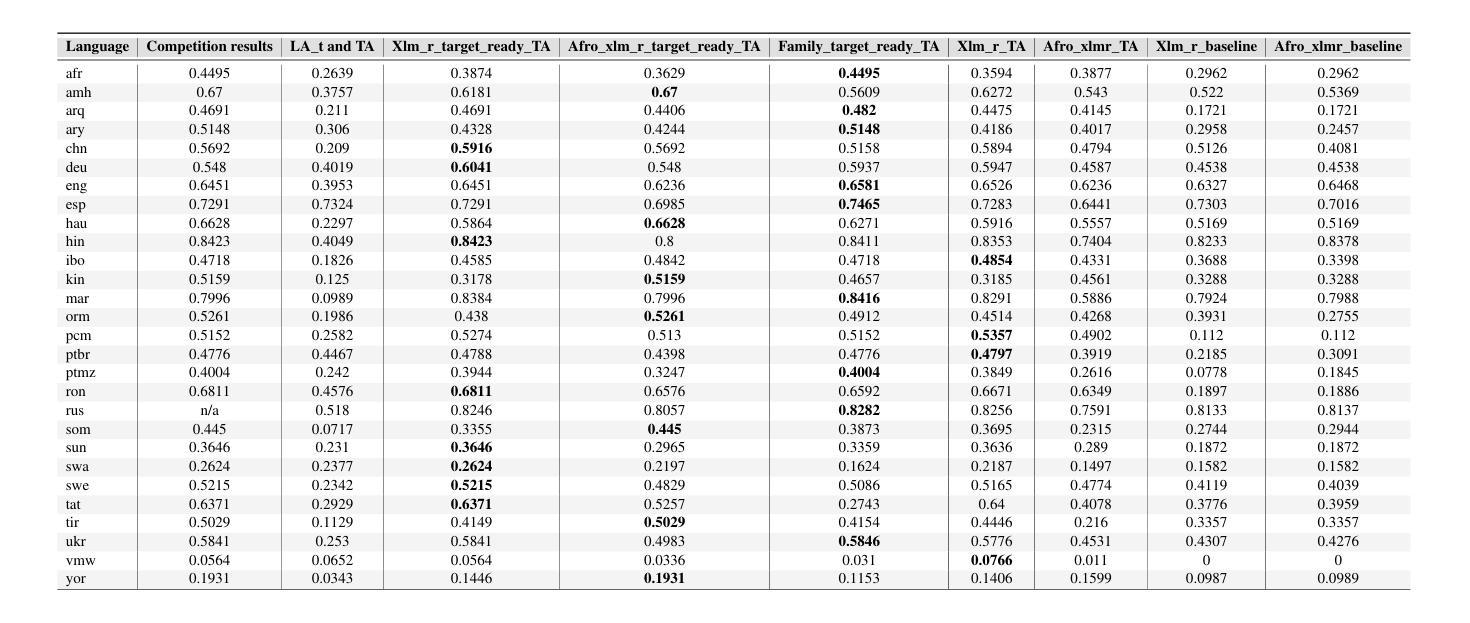
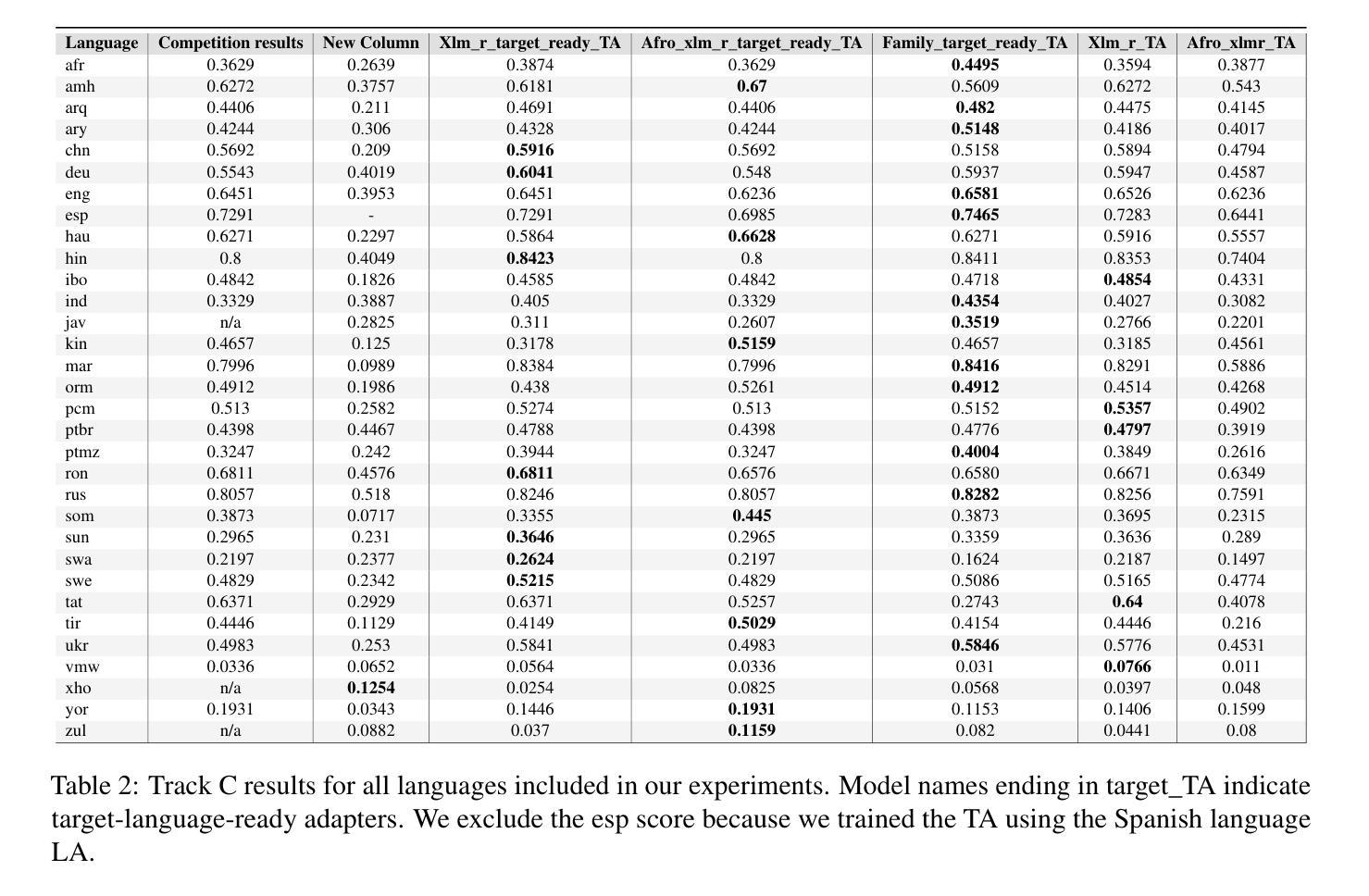
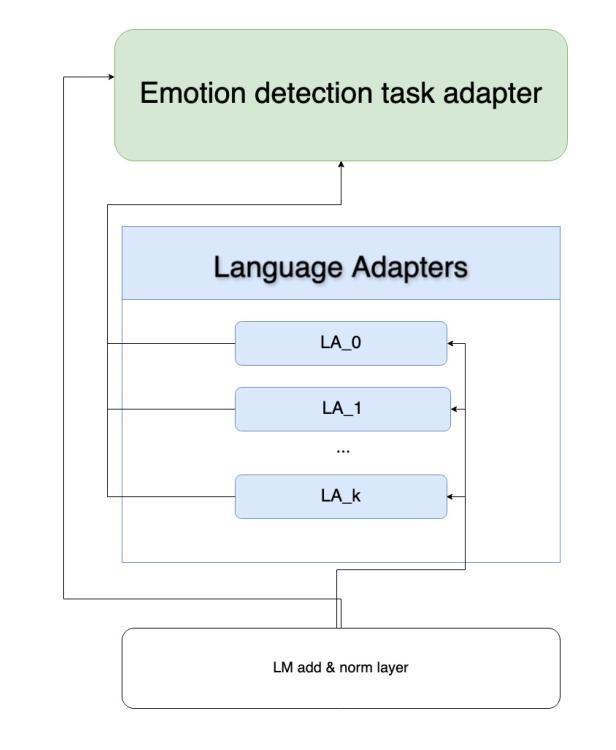
UoB-NLP at SemEval-2025 Task 11: Leveraging Adapters for Multilingual and Cross-Lingual Emotion Detection
Authors:Frances Laureano De Leon, Yixiao Wang, Yue Feng, Mark G. Lee
Emotion detection in natural language processing is a challenging task due to the complexity of human emotions and linguistic diversity. While significant progress has been made in high-resource languages, emotion detection in low-resource languages remains underexplored. In this work, we address multilingual and cross-lingual emotion detection by leveraging adapter-based fine-tuning with multilingual pre-trained language models. Adapters introduce a small number of trainable parameters while keeping the pre-trained model weights fixed, offering a parameter-efficient approach to adaptation. We experiment with different adapter tuning strategies, including task-only adapters, target-language-ready task adapters, and language-family-based adapters. Our results show that target-language-ready task adapters achieve the best overall performance, particularly for low-resource African languages with our team ranking 7th for Tigrinya, and 8th for Kinyarwanda in Track A. In Track C, our system ranked 3rd for Amharic, and 4th for Oromo, Tigrinya, Kinyarwanda, Hausa, and Igbo. Our approach outperforms large language models in 11 languages and matches their performance in four others, despite our models having significantly fewer parameters. Furthermore, we find that adapter-based models retain cross-linguistic transfer capabilities while requiring fewer computational resources compared to full fine-tuning for each language.
自然语言处理中的情感检测是一项具有挑战性的任务,这主要是由于人类情感的复杂性和语言多样性。虽然在高资源语言方面已经取得了重大进展,但在低资源语言中的情感检测仍然被忽视。在这项工作中,我们利用基于适配器的微调与多语言预训练语言模型来解决多语言和跨语言情感检测问题。适配器引入了少量的可训练参数,同时保持预训练模型权重固定,为适应性提供了一种参数高效的解决方案。我们尝试了不同的适配器调整策略,包括仅任务适配器、面向目标语言的任务适配器和基于语言家族的适配器。我们的结果表明,面向目标语言的任务适配器取得了最佳的整体性能,特别是在低资源的非洲语言中,我们的团队在A赛道上分别以第7名和第8名的成绩完成了提格里尼亚语和基尼亚卢旺达语的任务。在C赛道中,我们的系统在阿姆哈拉语中排名第3,在奥罗莫语、提格里尼亚语、基尼亚卢旺达语、豪萨语和伊博语中排名第4。我们的方法在许多语言上的表现优于大型语言模型,并在其他四种语言中与之匹配表现水平,尽管我们的模型参数明显更少。此外,我们发现基于适配器的模型既保留了跨语言的迁移能力,又相对于每种语言的完全微调方法减少了计算资源需求。
论文及项目相关链接
PDF Accepted to appear in Proceedings of the 19th International Workshop on Semantic Evaluation (SemEval-2025)
Summary
本文探讨了自然语言处理中的情感检测任务,尤其是在低资源语言中的挑战。研究团队通过利用基于适配器的微调与多语言预训练语言模型来解决多语言和跨语言情感检测问题。适配器引入少量可训练参数,同时保持预训练模型权重不变,提供了一种高效的参数化适应方法。实验结果显示,针对特定语言的适配器在非洲低资源语言中表现最佳,其中某些系统在特定赛道中名列前茅。此方法在多语言中表现优于大型语言模型,并保留跨语言迁移能力,同时减少了计算资源需求。
Key Takeaways
- 情感检测是自然语言处理中的一项挑战,特别是在低资源语言中。
- 研究团队通过适配器微调与多语言预训练语言模型来解决该问题。
- 适配器是一种高效的参数化适应方法,可以引入少量可训练参数同时保持预训练模型权重不变。
- 针对特定语言的适配器在非洲低资源语言中表现最佳。
- 研究系统在特定赛道中名列前茅,展示了该方法的有效性。
- 该方法在多语言中表现优于大型语言模型,并保留跨语言迁移能力。
点此查看论文截图

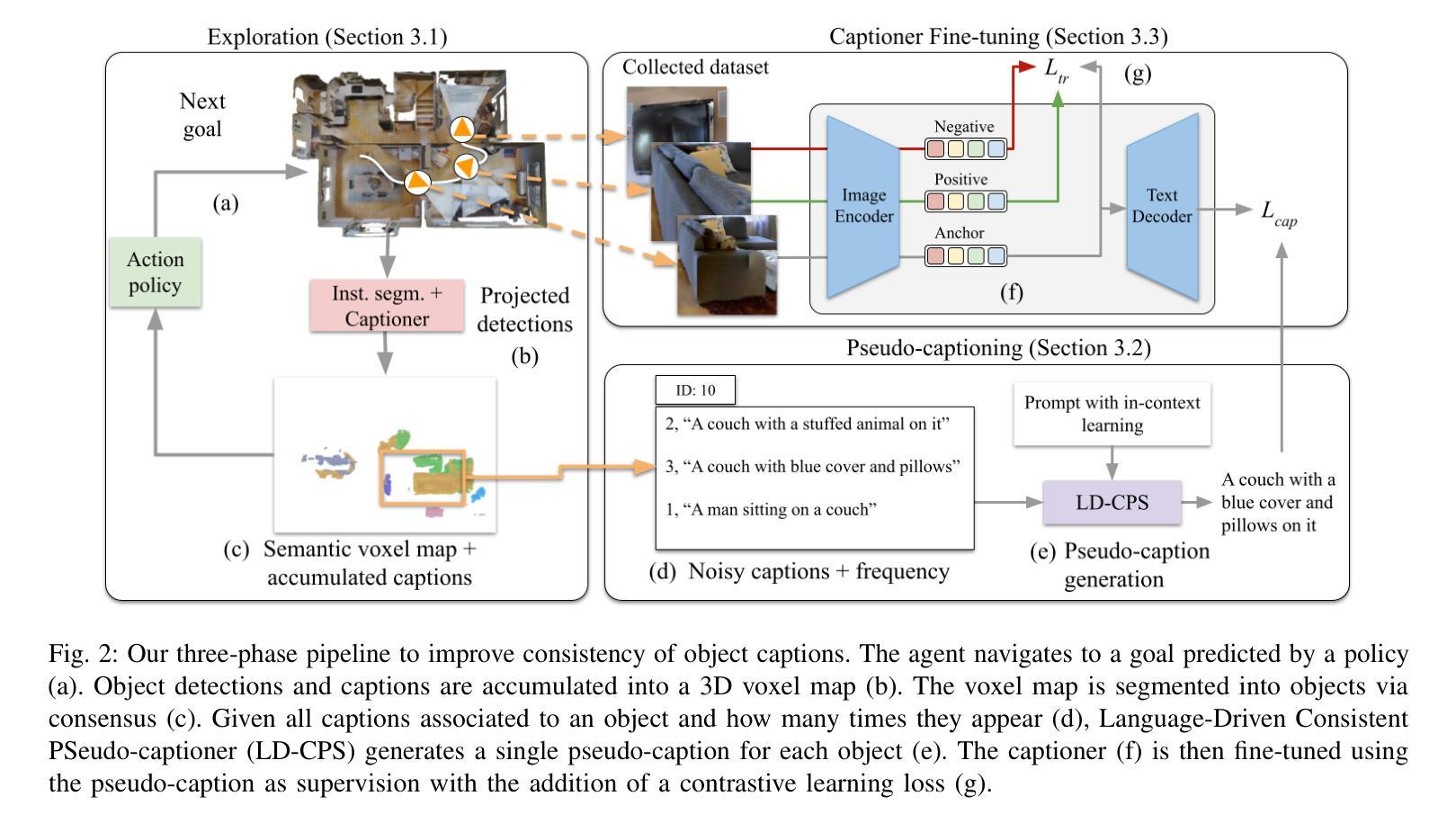
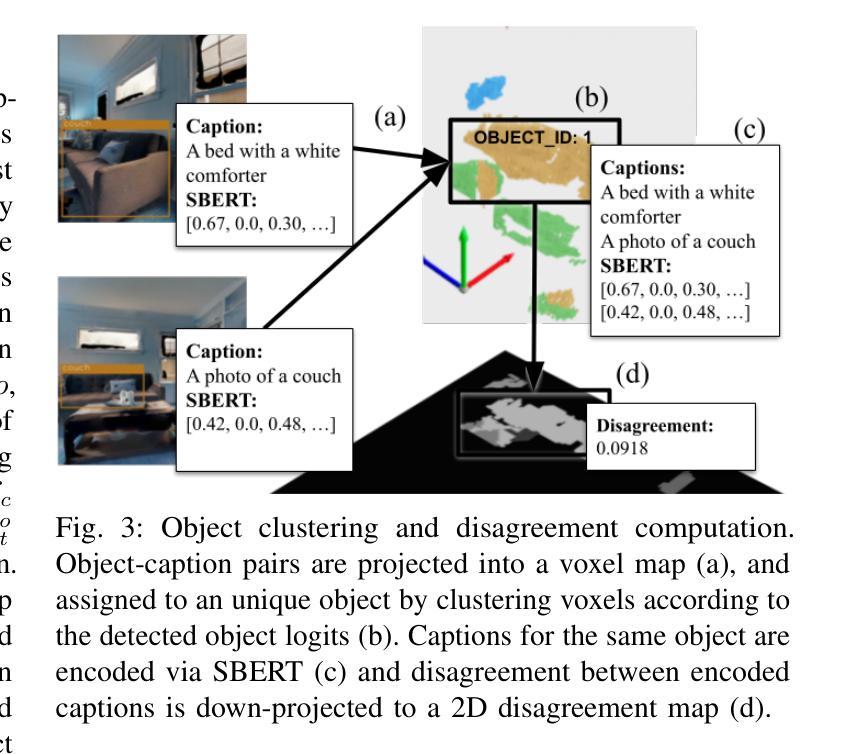
Embodied Image Captioning: Self-supervised Learning Agents for Spatially Coherent Image Descriptions
Authors:Tommaso Galliena, Tommaso Apicella, Stefano Rosa, Pietro Morerio, Alessio Del Bue, Lorenzo Natale
We present a self-supervised method to improve an agent’s abilities in describing arbitrary objects while actively exploring a generic environment. This is a challenging problem, as current models struggle to obtain coherent image captions due to different camera viewpoints and clutter. We propose a three-phase framework to fine-tune existing captioning models that enhances caption accuracy and consistency across views via a consensus mechanism. First, an agent explores the environment, collecting noisy image-caption pairs. Then, a consistent pseudo-caption for each object instance is distilled via consensus using a large language model. Finally, these pseudo-captions are used to fine-tune an off-the-shelf captioning model, with the addition of contrastive learning. We analyse the performance of the combination of captioning models, exploration policies, pseudo-labeling methods, and fine-tuning strategies, on our manually labeled test set. Results show that a policy can be trained to mine samples with higher disagreement compared to classical baselines. Our pseudo-captioning method, in combination with all policies, has a higher semantic similarity compared to other existing methods, and fine-tuning improves caption accuracy and consistency by a significant margin. Code and test set annotations available at https://hsp-iit.github.io/embodied-captioning/
我们提出了一种自监督方法,用于提高智能体在主动探索通用环境时描述任意物体的能力。这是一个具有挑战性的问题,因为当前模型由于不同相机视角和混乱的场景,难以获得连贯的图像描述。我们提出了一个三阶段框架来微调现有的描述模型,通过共识机制提高跨不同视角的描述准确性和一致性。首先,智能体探索环境,收集带有噪声的图像描述配对。然后,使用大型语言模型通过共识为每个对象实例提炼出一致的伪描述。最后,这些伪描述被用于微调现成的描述模型,并添加对比学习。我们在手动标记的测试集上分析了结合描述模型、探索策略、伪标签方法和微调策略的性能。结果表明,可以训练一种策略来挖掘与传统基线相比具有更高分歧的样本。我们的伪描述方法结合了所有策略后,与现有其他方法相比具有更高的语义相似性,并且微调能够显著提高描述的准确性和一致性。代码和测试集注释可在 https://hsp-iit.github.io/embodied-captioning/ 找到。
论文及项目相关链接
PDF 11 pages, 8 figures, 5 tables, code and test set annotations available at https://hsp-iit.github.io/embodied-captioning/
Summary:
提出一种自监督方法,通过三阶段框架优化智能体描述任意对象的能力,同时主动探索通用环境。首先收集噪声图像-字幕对,然后通过共识机制蒸馏出每个对象实例的一致伪字幕,最后使用对比学习对现成的字幕模型进行微调。实验结果表明,该方法提高了字幕的准确性和一致性。
Key Takeaways:
- 提出一种自监督方法用于智能体描述对象能力优化,在通用环境中主动探索。
- 采用三阶段框架对现有的字幕模型进行微调,提高字幕准确性和跨视图的一致性。
- 通过共识机制收集噪声图像-字幕对,并蒸馏出对象实例的一致伪字幕。
- 对比学习用于增强模型的性能。
- 实验结果表明,训练策略可以挖掘样本中的高分歧点,与传统基线相比具有优势。
- 伪字幕方法与所有策略相结合,在语义相似性方面表现优异。
点此查看论文截图

Task Memory Engine (TME): Enhancing State Awareness for Multi-Step LLM Agent Tasks
Authors:Ye Ye
Large Language Models (LLMs) are increasingly used as autonomous agents for multi-step tasks. However, most existing frameworks fail to maintain a structured understanding of the task state, often relying on linear prompt concatenation or shallow memory buffers. This leads to brittle performance, frequent hallucinations, and poor long-range coherence. In this work, we propose the Task Memory Engine (TME), a lightweight and structured memory module that tracks task execution using a hierarchical Task Memory Tree (TMT). Each node in the tree corresponds to a task step, storing relevant input, output, status, and sub-task relationships. We introduce a prompt synthesis method that dynamically generates LLM prompts based on the active node path, significantly improving execution consistency and contextual grounding. Through case studies and comparative experiments on multi-step agent tasks, we demonstrate that TME leads to better task completion accuracy and more interpretable behavior with minimal implementation overhead. The full implementation of TME is available at https://github.com/biubiutomato/TME-Agent.
大型语言模型(LLM)越来越多地被用作多步骤任务的自主代理。然而,现有的大多数框架无法维持对任务状态的结构化理解,通常依赖于线性提示串联或浅层内存缓冲区。这导致性能不稳定、经常产生幻觉和长期连贯性差。在这项工作中,我们提出了任务记忆引擎(TME),这是一个轻量级、结构化的内存模块,使用分层任务记忆树(TMT)来跟踪任务执行情况。树中的每个节点对应于一个任务步骤,存储相关的输入、输出、状态和子任务关系。我们引入了一种提示合成方法,该方法基于活动节点路径动态生成LLM提示,显著提高了执行一致性上下文定位。通过对多步骤代理任务的案例研究和比较实验,我们证明了TME在提高任务完成准确性和解释性行为方面具有优势,并且实现开销极小。TME的完整实现可在https://github.com/biubiotomato/TME-Agent找到。
论文及项目相关链接
PDF 14 pages, 5 figures. Preprint prepared for future submission. Includes implementation and token-efficiency analysis. Code at https://github.com/biubiutomato/TME-Agent
Summary
LLM作为多步骤任务自主代理的使用日益普遍,但现有框架难以维持任务状态的结构化理解,导致性能不稳定、频繁出现幻觉和长程连贯性差。本文提出Task Memory Engine(TME),一个轻量级结构化内存模块,使用分层任务记忆树(TMT)追踪任务执行。树中每个节点对应任务步骤,存储相关输入、输出、状态和子任务关系。引入基于活动节点路径动态生成LLM提示的提示合成方法,显著提高执行一致性及上下文定位能力。通过案例研究和多步骤代理任务的对比实验,证明TME能提高任务完成准确率并增强行为可解释性,且实现开销极小。
Key Takeaways
- LLM在多步骤任务中作为自主代理的应用逐渐增加,但存在对任务状态理解不稳定的问题。
- 当前大多数框架无法维持任务状态的结构化理解,导致性能不稳定和长程连贯性差。
- Task Memory Engine(TME)是一个轻量级结构化内存模块,用于追踪任务执行,解决上述问题。
- TME使用分层任务记忆树(TMT)来组织任务信息,每个节点存储相关输入、输出、状态和子任务关系。
- TME引入提示合成方法,根据活动节点路径动态生成LLM提示,提高执行一致性及上下文定位能力。
- 通过案例研究和实验验证,TME能显著提高任务完成准确率并增强行为可解释性。
点此查看论文截图

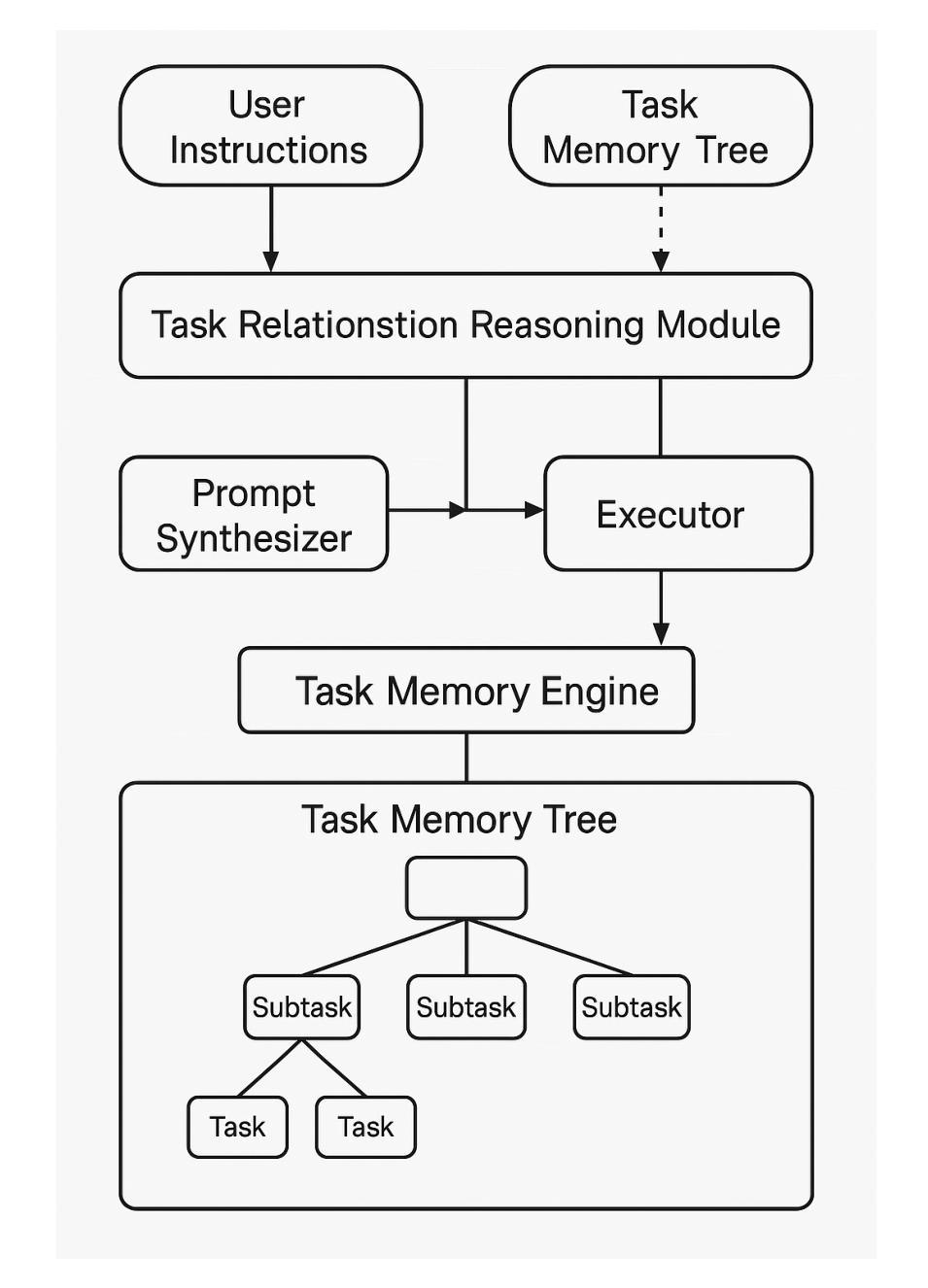
VLMT: Vision-Language Multimodal Transformer for Multimodal Multi-hop Question Answering
Authors:Qi Zhi Lim, Chin Poo Lee, Kian Ming Lim, Kalaiarasi Sonai Muthu Anbananthen
The increasing availability of multimodal data across text, tables, and images presents new challenges for developing models capable of complex cross-modal reasoning. Existing methods for Multimodal Multi-hop Question Answering (MMQA) often suffer from limited reasoning capabilities, reliance on modality conversion, and inadequate alignment between visual and textual representations. To address these limitations, this paper introduces Vision-Language Multimodal Transformer (VLMT), a unified architecture that integrates a transformer-based vision encoder with a sequence-to-sequence language model. VLMT employs a direct token-level injection mechanism to fuse visual and textual inputs within a shared embedding space, eliminating the need for intermediate projection layers. To enhance cross-modal alignment and reasoning, a three-stage pretraining strategy is proposed to progressively align vision-language representations and improve the model’s capacity for multimodal understanding. Based on the pretrained backbone, two task-specific modules are instantiated to form a two-stage MMQA framework: a multimodal reranker that predicts document relevance scores and utilizes a relative threshold with top-k strategy for context retrieval, and a multimodal question answering model that generates contextually grounded answers based on the retrieved evidence. Comprehensive experiments on two benchmark datasets demonstrate the effectiveness of the proposed approach. On MultimodalQA validation set, VLMT-Large achieves 76.5% Exact Match and 80.1% F1, outperforming the previous state-of-the-art by +9.1% in Exact Match and +8.8% in F1. On WebQA, it attains a QA score of 47.6, surpassing prior models such as PERQA by +3.2. These results highlight VLMT’s strong capabilities in multimodal reasoning and its potential to advance real-world information retrieval and question answering systems.
随着文本、表格和图像中多模态数据的日益普及,为开发能够处理复杂跨模态推理的模型带来了新的挑战。现有的多模态多跳问答(MMQA)方法往往存在推理能力有限、依赖模态转换以及视觉和文本表示之间对齐不足的问题。为了解决这个问题,本文引入了视觉语言多模态转换器(VLMT),这是一个统一的架构,它将基于转换器的视觉编码器与序列到序列的语言模型进行了集成。VLMT采用直接的token级注入机制,在共享嵌入空间中融合视觉和文本输入,从而无需中间投影层。为了提高跨模态对齐和推理能力,提出了一种三阶段预训练策略,以逐步对齐视觉语言表示并增强模型的多模态理解能力。基于预训练的骨干网,实例化两个特定任务的模块,形成两阶段MMQA框架:一个多模态排序器,用于预测文档相关性分数,并使用相对阈值与top-k策略进行上下文检索;一个多模态问答模型,根据检索到的证据生成上下文相关的答案。在两个基准数据集上的综合实验证明了所提出方法的有效性。在MultimodalQA验证集上,VLMT-Large达到76.5%的精确匹配率和80.1%的F1得分,在精确匹配和F1得分上分别优于之前的最先进方法+9.1%和+8.8%。在WebQA上,它达到了47.6的QA得分,超越了之前的模型,如PERQA+3.2。这些结果突显了VLMT在多模态推理方面的强大能力,以及其推动现实世界信息检索和问答系统的潜力。
论文及项目相关链接
摘要
面向文本、表格和图像的多模态数据日益丰富,为发展能够处理复杂跨模态推理的模型带来了新的挑战。现有跨模态多跳问答(MMQA)方法存在推理能力有限、依赖模态转换以及视觉和文本表示对齐不足的问题。为解决这些问题,本文提出一种名为视觉语言多模态转换器(VLMT)的统一架构,该架构融合了基于转换器的视觉编码器和序列到序列的语言模型。VLMT采用直接的令牌级注入机制,在共享嵌入空间中融合视觉和文本输入,无需中间投影层。为增强跨模态对齐和推理能力,提出了一种三阶段预训练策略,逐步对齐视觉语言表示并增强模型的多模态理解能力。基于预训练的主干,实例化两个任务特定模块,形成两阶段MMQA框架:多模态排名器用于预测文档相关性分数,并使用相对阈值与top-k策略进行上下文检索;多模态问答模型根据检索到的证据生成上下文相关的答案。在MultimodalQA验证集上,VLMT-Large达到76.5%的精确匹配率和80.1%的F1得分,相较于之前的最优模型在精确匹配率和F1得分上分别提高了9.1%和8.8%。在WebQA上,其问答得分达到47.6,超越了PERQA等先前模型。这些结果突显了VLMT在跨模态推理方面的强大能力及其对现实信息检索和问答系统推进的潜力。
关键见解
- 多模态数据的日益丰富带来了新的挑战,需要发展具有复杂跨模态推理能力的模型。
- 现有MMQA方法存在推理能力有限、依赖模态转换和对齐不足的问题。
- VLMT通过整合视觉和文本输入在一个共享嵌入空间内,解决了上述问题。
- VLMT采用直接令牌级注入机制,避免了中间投影层的需要。
- 三阶段预训练策略用于增强跨模态对齐和推理能力。
- VLMT在MultimodalQA和WebQA数据集上的表现优于先前的方法,展示了其强大的跨模态推理能力。
点此查看论文截图

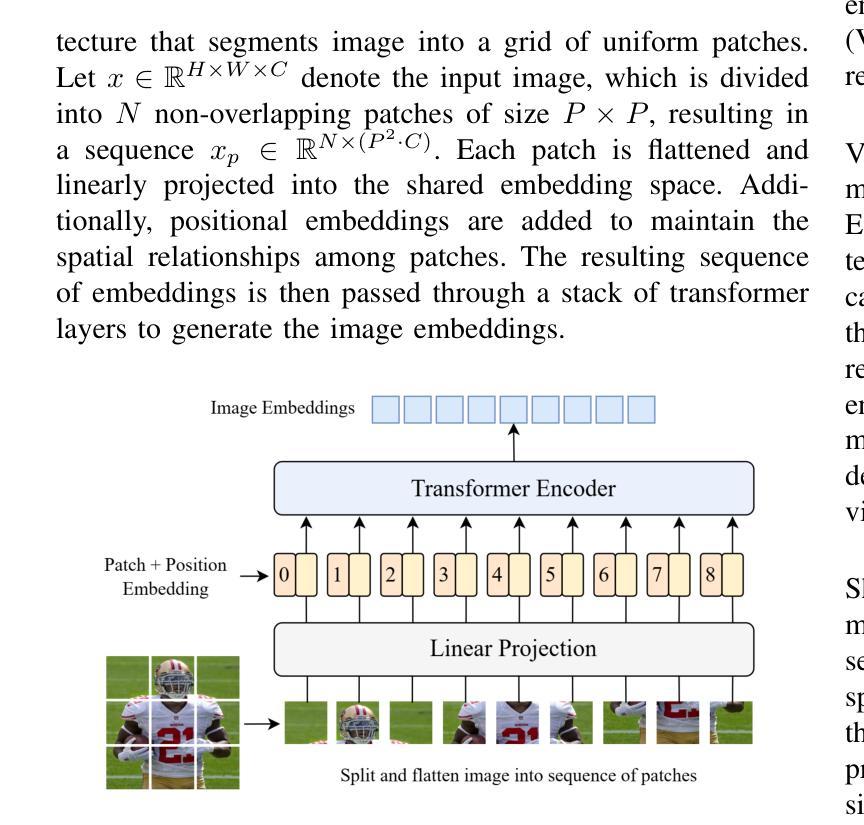
Metamorphic Testing for Fairness Evaluation in Large Language Models: Identifying Intersectional Bias in LLaMA and GPT
Authors:Harishwar Reddy, Madhusudan Srinivasan, Upulee Kanewala
Large Language Models (LLMs) have made significant strides in Natural Language Processing but remain vulnerable to fairness-related issues, often reflecting biases inherent in their training data. These biases pose risks, particularly when LLMs are deployed in sensitive areas such as healthcare, finance, and law. This paper introduces a metamorphic testing approach to systematically identify fairness bugs in LLMs. We define and apply a set of fairness-oriented metamorphic relations (MRs) to assess the LLaMA and GPT model, a state-of-the-art LLM, across diverse demographic inputs. Our methodology includes generating source and follow-up test cases for each MR and analyzing model responses for fairness violations. The results demonstrate the effectiveness of MT in exposing bias patterns, especially in relation to tone and sentiment, and highlight specific intersections of sensitive attributes that frequently reveal fairness faults. This research improves fairness testing in LLMs, providing a structured approach to detect and mitigate biases and improve model robustness in fairness-sensitive applications.
大型语言模型(LLM)在自然语言处理方面取得了显著进展,但仍易受到公平性问题的影响,这些问题通常反映了其训练数据中的固有偏见。当大型语言模型部署在医疗、金融和法律等敏感领域时,这些偏见带来的风险尤为突出。本文介绍了一种变异测试方法,以系统地识别大型语言模型中的公平漏洞。我们定义并应用了一套面向公平的变异关系(MRs)来评估最先进的LLaMA和GPT模型,跨越不同的人口统计输入。我们的方法包括为每个MR生成源测试用例和后续测试用例,并分析模型对公平违规的响应。结果表明,变异测试在揭示偏见模式方面尤其有效,特别是在语调和情感方面,并强调了敏感属性特定的交集,这些属性经常揭示公平故障。本研究提高了大型语言模型中的公平测试水平,提供了一种结构化的方法来检测和缓解偏见,并提高模型在敏感公平性应用的稳健性。
论文及项目相关链接
Summary:
大型语言模型在自然语言处理领域取得显著进展,但仍存在公平性相关问题,反映其训练数据中的固有偏见。本文提出一种元测试方法,通过定义和应用面向公平性的元形态关系,系统地识别大型语言模型中的公平性问题漏洞。测试对象为当前先进的LLaMA和GPT模型,通过不同人口统计学输入进行评估。研究结果表明,元测试在揭示偏见模式方面尤为有效,特别是在语调和情感方面。本研究提高了大型语言模型在公平性测试方面的稳健性,提供了一种检测并缓解偏见问题的结构化方法。
Key Takeaways:
- 大型语言模型在自然语言处理方面取得显著进展,但存在公平性相关问题的脆弱性。
- 模型中的偏见反映在其训练数据中。
- 元测试方法用于系统地识别大型语言模型中的公平性问题漏洞。
- 测试对象包括LLaMA和GPT等先进的大型语言模型。
- 元测试特别有效于揭示模型中的偏见模式,特别是在语调和情感方面。
- 测试揭示了特定敏感属性交集经常出现的公平性问题。
点此查看论文截图

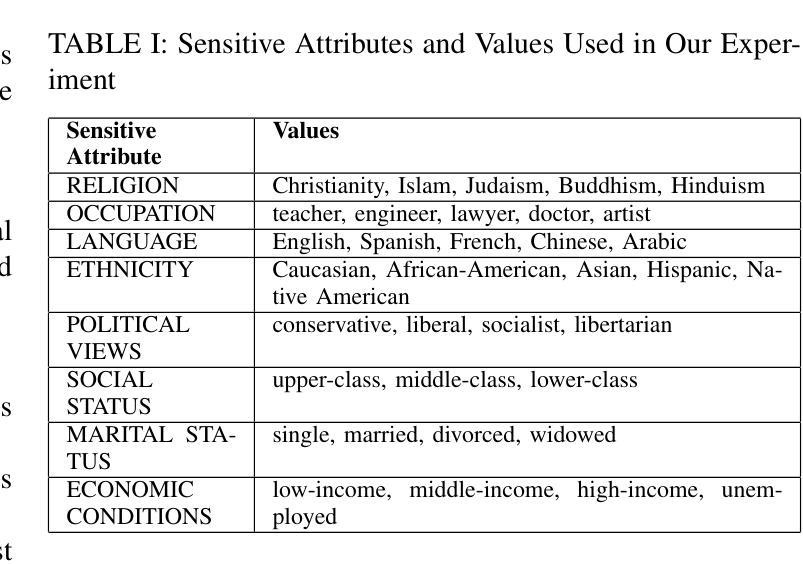
An Empirical Study of GPT-4o Image Generation Capabilities
Authors:Sixiang Chen, Jinbin Bai, Zhuoran Zhao, Tian Ye, Qingyu Shi, Donghao Zhou, Wenhao Chai, Xin Lin, Jianzong Wu, Chao Tang, Shilin Xu, Tao Zhang, Haobo Yuan, Yikang Zhou, Wei Chow, Linfeng Li, Xiangtai Li, Lei Zhu, Lu Qi
The landscape of image generation has rapidly evolved, from early GAN-based approaches to diffusion models and, most recently, to unified generative architectures that seek to bridge understanding and generation tasks. Recent advances, especially the GPT-4o, have demonstrated the feasibility of high-fidelity multimodal generation, their architectural design remains mysterious and unpublished. This prompts the question of whether image and text generation have already been successfully integrated into a unified framework for those methods. In this work, we conduct an empirical study of GPT-4o’s image generation capabilities, benchmarking it against leading open-source and commercial models. Our evaluation covers four main categories, including text-to-image, image-to-image, image-to-3D, and image-to-X generation, with more than 20 tasks. Our analysis highlights the strengths and limitations of GPT-4o under various settings, and situates it within the broader evolution of generative modeling. Through this investigation, we identify promising directions for future unified generative models, emphasizing the role of architectural design and data scaling. For a high-definition version of the PDF, please refer to the link on GitHub: \href{https://github.com/Ephemeral182/Empirical-Study-of-GPT-4o-Image-Gen}{https://github.com/Ephemeral182/Empirical-Study-of-GPT-4o-Image-Gen}.
图像生成领域已经迅速演变,从早期的基于GAN的方法到扩散模型,再到最近的寻求理解和生成任务之间桥梁的统一生成架构。最近的进展,尤其是GPT-4o,已经证明了高保真度多媒体生成的可行性,但其架构设计仍然神秘且未公开。这引发了人们关于图像和文本生成是否已经成功集成到这些方法中的统一框架的问题。在这项工作中,我们对GPT-4o的图像生成能力进行了实证研究,并将其与领先的开源和商业模型进行了比较。我们的评估涵盖了四个主要类别,包括文本到图像、图像到图像、图像到3D和图像到X生成,涵盖超过20项任务。我们的分析突出了GPT-4o在不同设置下的优势和局限性,并将其置于更广泛的生成模型演变中。通过这项调查,我们为未来的统一生成模型指明了有前景的方向,并强调了架构设计和数据规模扩大的作用。如需PDF的高清版本,请参阅GitHub上的链接:链接。
论文及项目相关链接
Summary
本文研究了GPT-4o的图像生成能力,对比了现有的开源和商业模型。通过对GPT-4o进行多方面的评估,包括文本到图像、图像到图像、图像到三维和图像到X生成等四个主要类别超过二十项任务,本文总结了GPT-4o在不同场景下的优势和局限,并探讨了未来统一生成模型的发展方向,特别是架构设计和数据规模的作用。
Key Takeaways
- GPT-4o在图像生成领域展现出强大的能力,特别是在高保真度多媒体生成方面。
- GPT-4o的图像生成能力通过多项任务评估,包括文本到图像、图像到图像、图像到三维和图像到X生成。
- GPT-4o在多种设置下表现出优势和局限,与其他开源和商业模型相比具有竞争力。
- GPT-4o的架构设计对于其性能至关重要,但具体细节尚未公开。
- 数据规模对GPT-4o的图像生成性能有重要影响。
- 统一生成模型的研究仍处于发展初期,未来有很大的改进空间。
点此查看论文截图

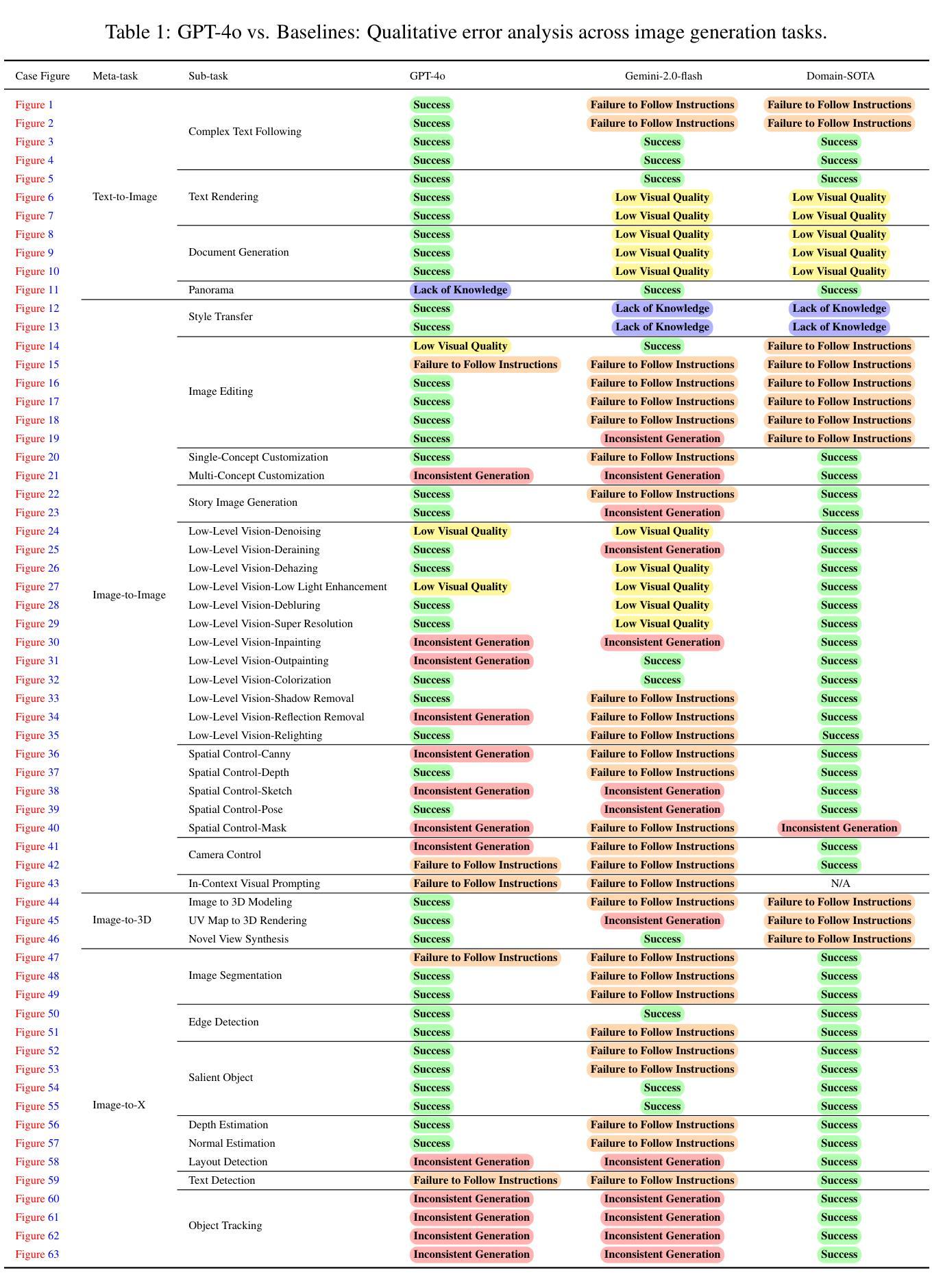

MCP Safety Audit: LLMs with the Model Context Protocol Allow Major Security Exploits
Authors:Brandon Radosevich, John Halloran
To reduce development overhead and enable seamless integration between potential components comprising any given generative AI application, the Model Context Protocol (MCP) (Anthropic, 2024) has recently been released and subsequently widely adopted. The MCP is an open protocol that standardizes API calls to large language models (LLMs), data sources, and agentic tools. By connecting multiple MCP servers, each defined with a set of tools, resources, and prompts, users are able to define automated workflows fully driven by LLMs. However, we show that the current MCP design carries a wide range of security risks for end users. In particular, we demonstrate that industry-leading LLMs may be coerced into using MCP tools to compromise an AI developer’s system through various attacks, such as malicious code execution, remote access control, and credential theft. To proactively mitigate these and related attacks, we introduce a safety auditing tool, MCPSafetyScanner, the first agentic tool to assess the security of an arbitrary MCP server. MCPScanner uses several agents to (a) automatically determine adversarial samples given an MCP server’s tools and resources; (b) search for related vulnerabilities and remediations based on those samples; and (c) generate a security report detailing all findings. Our work highlights serious security issues with general-purpose agentic workflows while also providing a proactive tool to audit MCP server safety and address detected vulnerabilities before deployment. The described MCP server auditing tool, MCPSafetyScanner, is freely available at: https://github.com/johnhalloran321/mcpSafetyScanner
为了降低开发成本,并使任何给定的生成式AI应用中的潜在组件无缝集成,模型上下文协议(MCP)(Anthropic,2024)最近已被发布并随后被广泛采用。MCP是一个开放协议,它标准化了对大型语言模型(LLM)、数据源和智能工具的API调用。通过连接多个MCP服务器(每个服务器都定义了一组工具、资源和提示),用户能够定义由LLM完全驱动的自动化工作流程。然而,我们表明,当前的MCP设计存在广泛的安全风险,会对终端用户造成威胁。特别是,我们通过演示证明,行业领先的LLM可能被诱导使用MCP工具,通过各种攻击来破坏AI开发者的系统,例如恶意代码执行、远程访问控制和凭证盗窃。为了积极缓解这些和相关攻击,我们引入了安全审计工具MCPSafetyScanner,它是第一个评估任意MCP服务器安全性的智能工具。MCPScanner使用多个智能代理来(a)根据MCP服务器的工具和资源自动确定对抗样本;(b)基于这些样本搜索相关漏洞和补救措施;(c)生成包含所有发现的安全报告。我们的工作强调了通用智能工作流程中的严重安全问题,同时提供了一个积极的工具来审计MCP服务器的安全性,并在部署之前解决检测到的漏洞。描述的MCP服务器审计工具MCPSafetyScanner可在以下网址免费获得:https://github.com/johnhalloran321/mcpSafetyScanner
论文及项目相关链接
PDF 27 pages, 21 figures, and 2 Tables. Cleans up the TeX source
摘要
模型上下文协议(MCP)是一个开放协议,用于标准化对大型语言模型(LLM)、数据源和代理工具的API调用,以实现生成式AI应用程序各组件之间的无缝集成,减少开发成本。然而,当前MCP设计存在多种安全风险。本研究展示了一种针对MCP工具的安全审计工具MCPSafetyScanner,它能够评估任意MCP服务器的安全性,通过自动确定对抗样本、搜索相关漏洞和补救措施并生成安全报告来详细记录所有发现。本研究强调了通用代理工作流程的严重安全问题,同时提供了在部署前审计MCP服务器安全性并解决检测到的漏洞的主动工具。
关键见解
- MCP是一个用于整合大型语言模型和其他AI工具的开放协议,促进了AI应用的开发。
- 当前MCP设计存在安全风险,可能导致AI系统被恶意攻击者利用。
- LLMs可能被诱导通过MCP工具进行恶意代码执行、远程访问控制和凭证盗窃等攻击。
- MCPSafetyScanner是第一个评估任意MCP服务器安全性的代理工具。
- MCPSafetyScanner能够自动确定对抗样本、搜索相关漏洞和补救措施。
- 该工具能够生成详细的安全报告,记录所有发现的问题。
- 研究强调了通用代理工作流程的安全问题,并提供了在部署前解决这些安全问题的工具。
点此查看论文截图

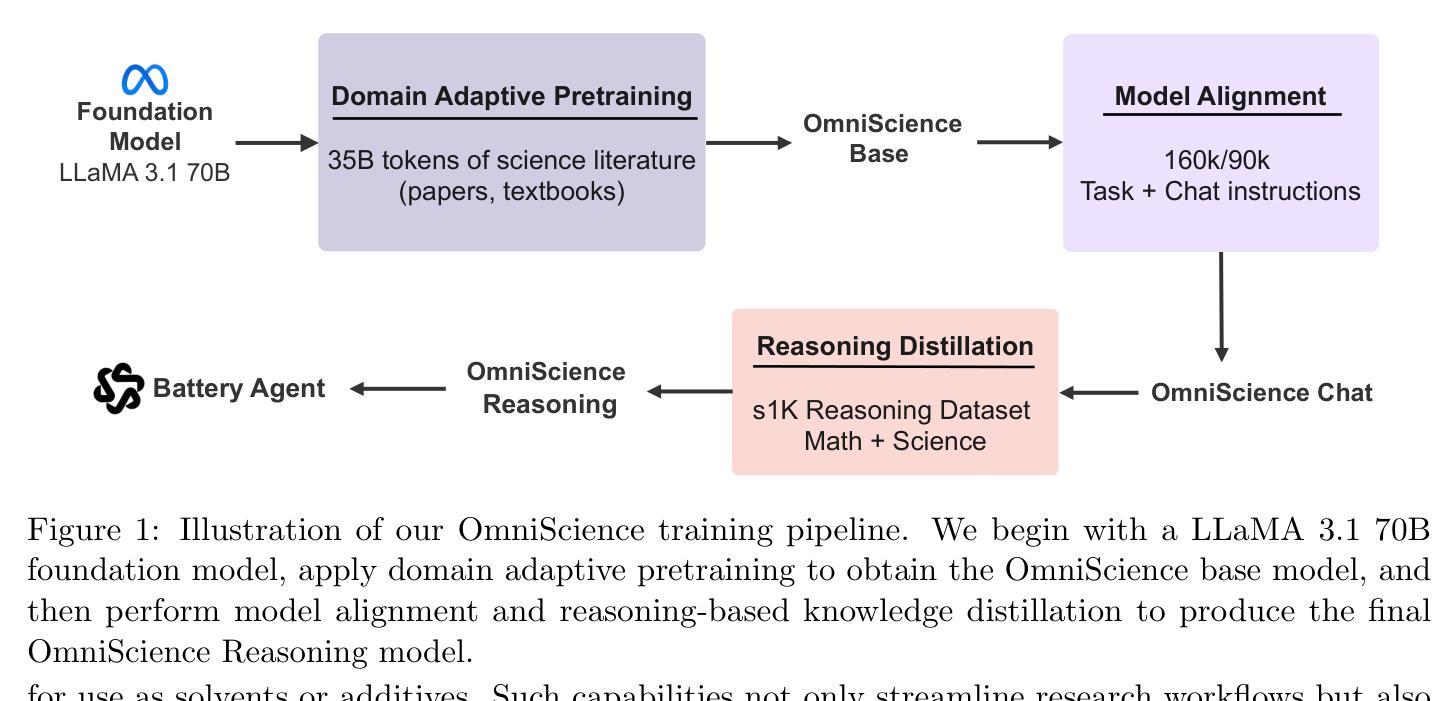
OmniScience: A Domain-Specialized LLM for Scientific Reasoning and Discovery
Authors:Vignesh Prabhakar, Md Amirul Islam, Adam Atanas, Yao-Ting Wang, Joah Han, Aastha Jhunjhunwala, Rucha Apte, Robert Clark, Kang Xu, Zihan Wang, Kai Liu
Large Language Models (LLMs) have demonstrated remarkable potential in advancing scientific knowledge and addressing complex challenges. In this work, we introduce OmniScience, a specialized large reasoning model for general science, developed through three key components: (1) domain adaptive pretraining on a carefully curated corpus of scientific literature, (2) instruction tuning on a specialized dataset to guide the model in following domain-specific tasks, and (3) reasoning-based knowledge distillation through fine-tuning to significantly enhance its ability to generate contextually relevant and logically sound responses. We demonstrate the versatility of OmniScience by developing a battery agent that efficiently ranks molecules as potential electrolyte solvents or additives. Comprehensive evaluations reveal that OmniScience is competitive with state-of-the-art large reasoning models on the GPQA Diamond and domain-specific battery benchmarks, while outperforming all public reasoning and non-reasoning models with similar parameter counts. We further demonstrate via ablation experiments that domain adaptive pretraining and reasoning-based knowledge distillation are critical to attain our performance levels, across benchmarks.
大型语言模型(LLM)在推进科学知识和应对复杂挑战方面表现出了显著潜力。在这项工作中,我们介绍了OmniScience,这是一个针对通用科学的专门大型推理模型,通过三个关键组件开发:(1)在精心筛选的科学文献语料库上进行领域自适应预训练,(2)在专门数据集上进行指令调整,以指导模型执行特定领域的任务,(3)通过微调进行基于推理的知识蒸馏,以显著提高其生成语境相关和逻辑严谨响应的能力。我们通过开发电池代理来展示OmniScience的通用性,该代理能够高效地排列分子作为潜在的电解质溶剂或添加剂。综合评估表明,OmniScience在GPQA Diamond和特定领域的电池基准测试上可与最新的大型推理模型相竞争,同时在参数数量相似的所有公共推理和非推理模型中表现最佳。我们还通过剔除实验进一步证明,领域自适应预训练和基于推理的知识蒸馏对于达到我们的性能水平至关重要,跨多个基准测试都是如此。
论文及项目相关链接
Summary
大型语言模型(LLM)在推动科学知识和应对复杂挑战方面展现出显著潜力。本研究介绍了一款针对通用科学的特殊大型推理模型——OmniScience。它经过三个关键组件开发而成:(1)在精心筛选的科学文献语料库上进行领域自适应预训练;(2)在特定数据集上进行指令调整,以指导模型执行特定领域的任务;(3)通过微调进行基于推理的知识蒸馏,以显著提高其生成语境相关和逻辑严谨响应的能力。OmniScience的通用性通过开发电池代理得到了验证,该代理能够高效地排列分子作为潜在的电解质溶剂或添加剂。综合评估表明,OmniScience在GPQA Diamond和特定领域电池基准测试上具备与最新大型推理模型竞争的能力,同时优于所有参数相似的公共推理和非推理模型。我们还通过消融实验证明,领域自适应预训练和基于推理的知识蒸馏对于达到我们的性能水平至关重要。
Key Takeaways
- 大型语言模型(LLM)在推动科学知识和应对挑战方面有显著潜力。
- OmniScience模型是通过领域自适应预训练、指令调整和基于推理的知识蒸馏三个关键组件开发而成的。
- OmniScience模型具备通用性,能够应用于电池代理的开发,排列分子作为潜在的电解质溶剂或添加剂。
- OmniScience在GPQA Diamond和特定领域电池基准测试上表现出竞争力。
- 消融实验证明,领域自适应预训练和基于推理的知识蒸馏对OmniScience的性能至关重要。
- OmniScience模型优于参数相似的其他公共推理和非推理模型。
- 该研究展示了LLM在特定领域的应用潜力,为未来的科学研究提供了新的思路和方法。
点此查看论文截图

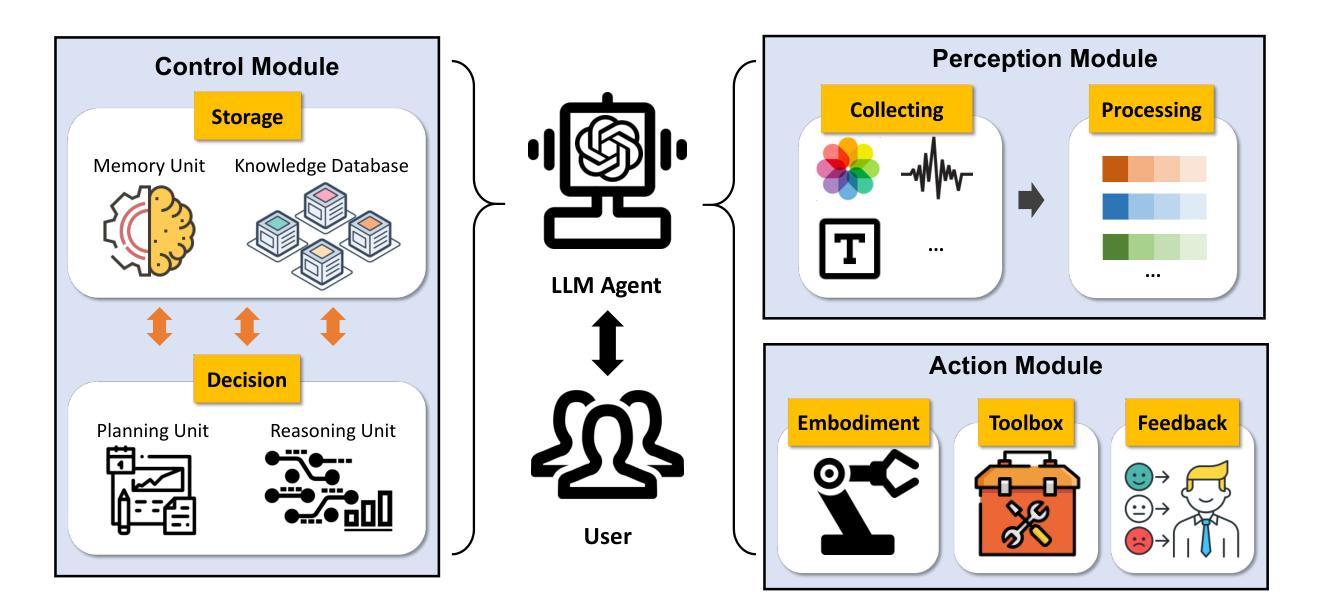
A Survey of Large Language Model Empowered Agents for Recommendation and Search: Towards Next-Generation Information Retrieval
Authors:Yu Zhang, Shutong Qiao, Jiaqi Zhang, Tzu-Heng Lin, Chen Gao, Yong Li
Information technology has profoundly altered the way humans interact with information. The vast amount of content created, shared, and disseminated online has made it increasingly difficult to access relevant information. Over the past two decades, recommender systems and search (collectively referred to as information retrieval systems) have evolved significantly to address these challenges. Recent advances in large language models (LLMs) have demonstrated capabilities that surpass human performance in various language-related tasks and exhibit general understanding, reasoning, and decision-making abilities. This paper explores the transformative potential of LLM agents in enhancing recommender and search systems. We discuss the motivations and roles of LLM agents, and establish a classification framework to elaborate on the existing research. We highlight the immense potential of LLM agents in addressing current challenges in recommendation and search, providing insights into future research directions. This paper is the first to systematically review and classify the research on LLM agents in these domains, offering a novel perspective on leveraging this advanced AI technology for information retrieval. To help understand the existing works, we list the existing papers on LLM agent based recommendation and search at this link: https://github.com/tsinghua-fib-lab/LLM-Agent-for-Recommendation-and-Search.
信息技术深刻改变了人类与信息的交互方式。网上创建、共享和传播的大量内容使得获取相关信息的难度越来越大。在过去的二十年中,推荐系统和搜索(统称为信息检索系统)已经发生了显著变化以应对这些挑战。大型语言模型(LLM)的最新进展在各种语言相关任务中表现出了超越人类的性能,并展现出一般理解、推理和决策能力。本文探讨了LLM代理在增强推荐系统和搜索系统方面的变革潜力。我们讨论了LLM代理的动机和角色,并建立了一个分类框架来阐述现有研究。我们强调了LLM代理在应对推荐和搜索方面的当前挑战的巨大潜力,为未来的研究方向提供了见解。本文首次系统回顾和分类了这些领域中的LLM代理研究,为如何利用这一先进的AI技术进行信息检索提供了新颖的视角。为了理解现有工作,我们在以下链接列出了关于LLM代理推荐和搜索的现有论文:https://github.com/tsinghua-fib-lab/LLM-Agent-for-Recommendation-and-Search。
论文及项目相关链接
Summary
信息技术的发展深刻改变了人类与信息的交互方式。随着网上创建、共享和传播的内容大量增加,获取相关信息变得越来越困难。推荐系统和搜索(统称为信息检索系统)在过去的二十年中已经显著发展,以应对这些挑战。大型语言模型(LLM)的最新进展已展现出在各种语言任务中超越人类性能的能力,并展现出一般理解、推理和决策能力。本文探讨了LLM代理在增强推荐和搜索系统方面的变革潜力。我们讨论了LLM代理的动机和角色,并建立了一个分类框架来详细阐述现有的研究。我们强调了LLM代理在应对推荐和搜索方面的当前挑战的巨大潜力,并为未来的研究方向提供见解。本文首次系统地回顾和分类了LLM代理在这些领域的研究,为如何利用这种先进的AI技术进行信息检索提供了新颖的视角。
Key Takeaways
- 信息技术改变了人类与信息的交互方式。
- 网上内容的大量增加使得获取相关信息更为困难。
- 推荐系统和搜索在信息检索中起到重要作用。
- 大型语言模型(LLM)在多种语言任务中表现超越人类,具备理解、推理和决策能力。
- LLM代理在增强推荐和搜索系统的潜力方面展现出巨大的变革性。
- LLM代理的动机和角色在推动其发展上起到关键作用。
点此查看论文截图

An Empirical Study of Conformal Prediction in LLM with ASP Scaffolds for Robust Reasoning
Authors:Navdeep Kaur, Lachlan McPheat, Alessandra Russo, Anthony G Cohn, Pranava Madhyastha
In this paper, we examine the use of Conformal Language Modelling (CLM) alongside Answer Set Programming (ASP) to enhance the performance of standard open-weight LLMs on complex multi-step reasoning tasks. Using the StepGame dataset, which requires spatial reasoning, we apply CLM to generate sets of ASP programs from an LLM, providing statistical guarantees on the correctness of the outputs. Experimental results show that CLM significantly outperforms baseline models that use standard sampling methods, achieving substantial accuracy improvements across different levels of reasoning complexity. Additionally, the LLM-as-Judge metric enhances CLM’s performance, especially in assessing structurally and logically correct ASP outputs. However, calibrating CLM with diverse calibration sets did not improve generalizability for tasks requiring much longer reasoning steps, indicating limitations in handling more complex tasks.
本文探讨了将顺应语言建模(CLM)与答案集编程(ASP)相结合,以提高标准开放权重大型语言模型在复杂多步骤推理任务上的性能。我们利用需要空间推理的StepGame数据集,应用CLM从大型语言模型生成ASP程序集,为输出的正确性提供统计保证。实验结果表明,CLM显著优于使用标准采样方法的基线模型,并在不同层次的推理复杂度上实现了实质性的准确性提高。另外,大型语言模型作为评估者的指标提高了CLM的性能,特别是在评估结构上和逻辑上正确的ASP输出方面。然而,用多种校准集校准CLM并没有提高对需要更长时间推理步骤的任务的通用性,这表明在处理更复杂的任务时存在局限性。
论文及项目相关链接
Summary
本文探讨了将Conformal语言建模(CLM)与答案集编程(ASP)结合使用,以提高标准开放权重大型语言模型(LLM)在复杂多步骤推理任务上的性能。研究使用StepGame数据集,该数据集要求空间推理能力。通过CLM生成ASP程序集,为输出结果提供统计正确性保证。实验结果表明,CLM显著优于使用标准采样方法的基线模型,在不同层次的推理复杂度上都实现了实质性的准确性提高。此外,大型语言模型作为评判者的指标也增强了CLM的性能,特别是在评估结构化和逻辑正确的ASP输出方面。然而,用各种校准集校准CLM并没有提高对需要更长期推理任务的通用性,这表明在处理更复杂的任务时存在局限性。
Key Takeaways
- 本文结合Conformal语言建模(CLM)与答案集编程(ASP),旨在提高大型语言模型(LLM)在复杂多步骤推理任务上的性能。
- 使用StepGame数据集进行实证研究,该数据集强调空间推理能力。
- CLM能够生成ASP程序集,并为输出结果提供统计正确性保证。
- 实验结果显示CLM在准确性上显著优于基线模型,特别是在不同推理复杂度层次上。
- LLM-as-Judge指标增强了CLM在评估ASP输出结构和逻辑正确性方面的性能。
- 使用多种校准集对CLM进行校准并未显著提高其处理更长期或更复杂推理任务的通用性,表明存在一定局限性。
点此查看论文截图

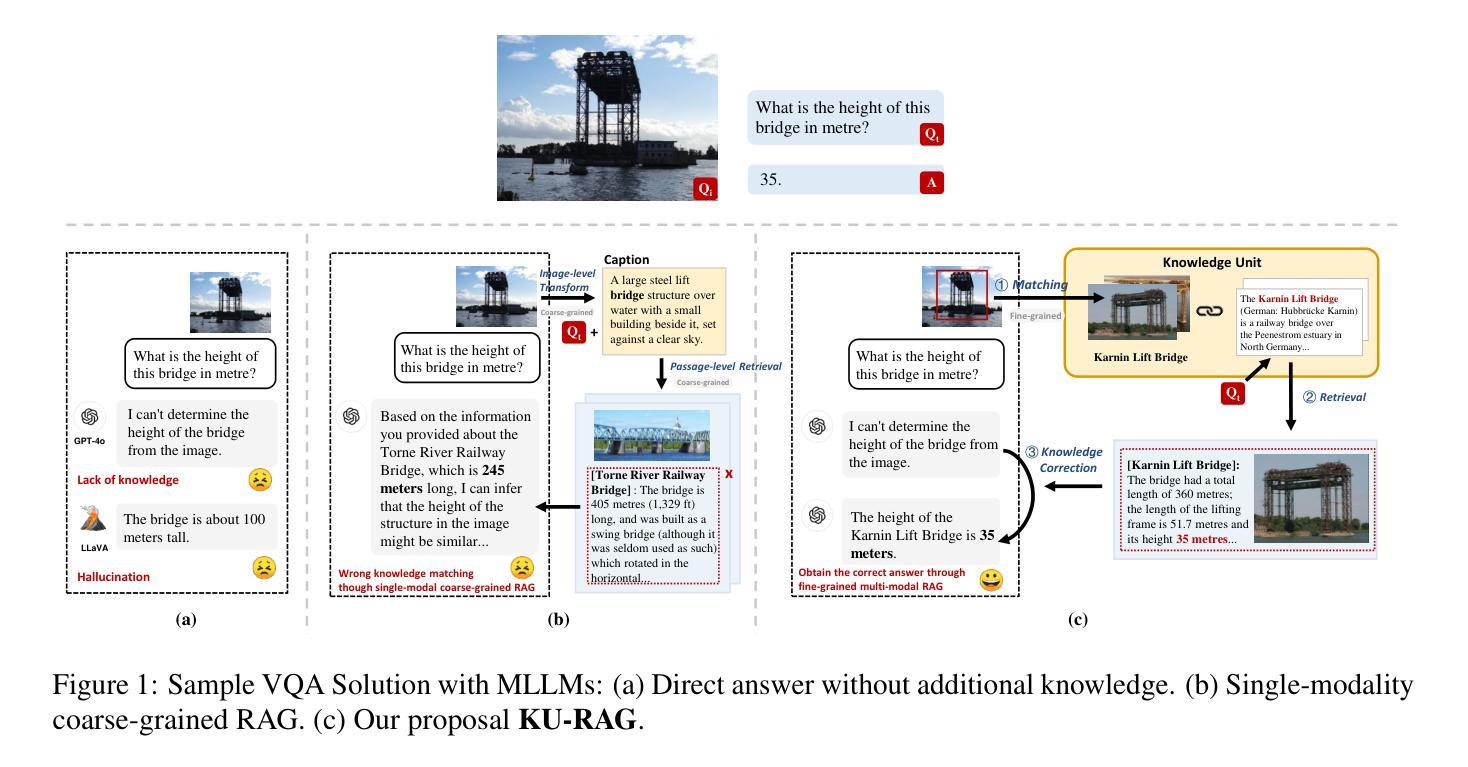
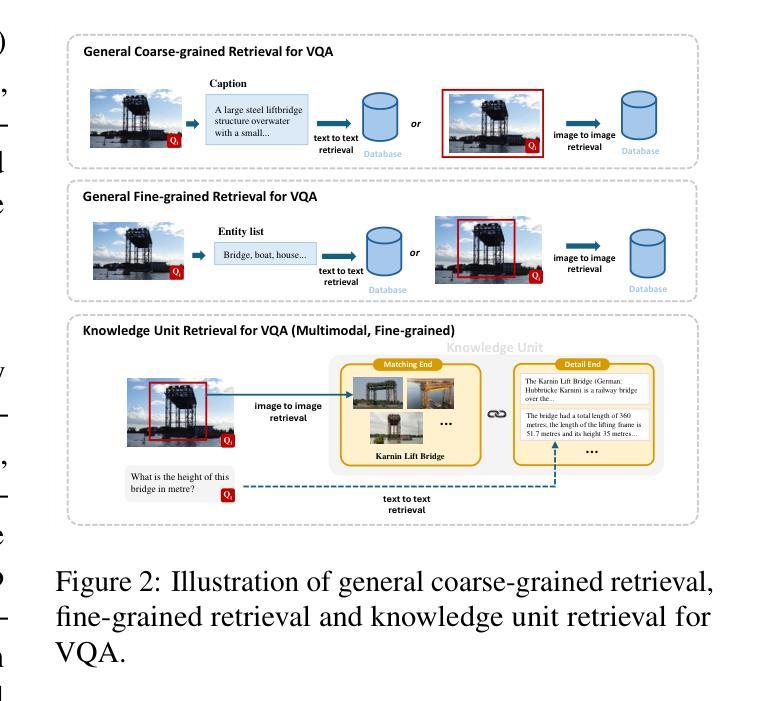
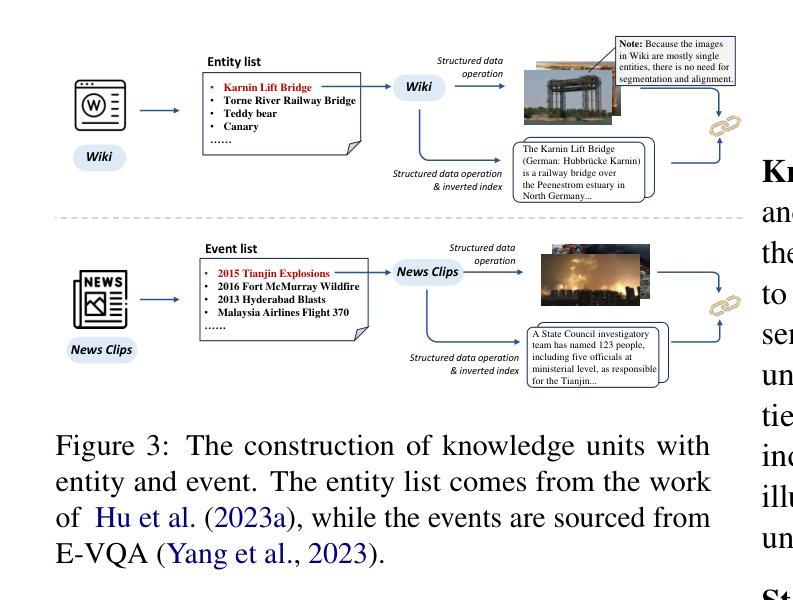
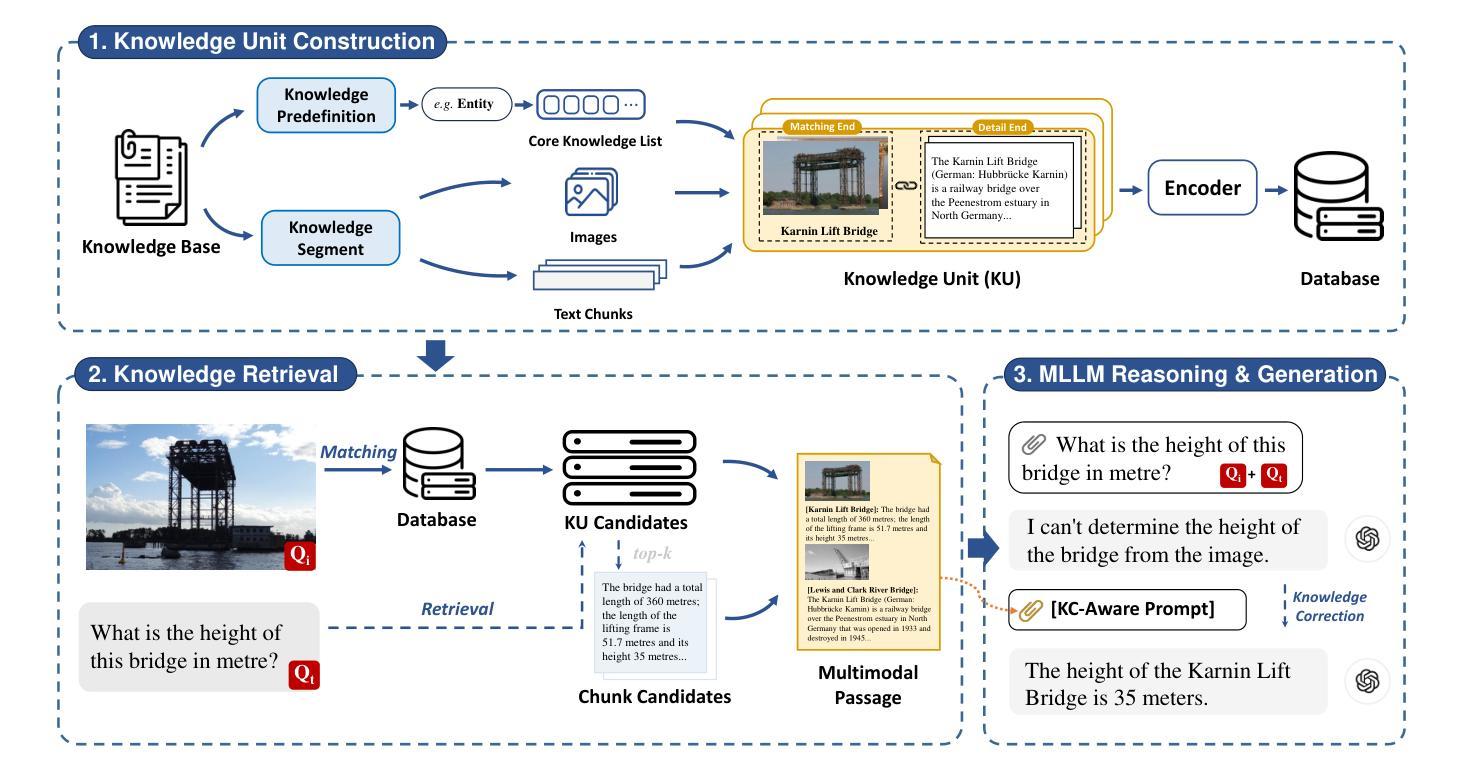
Fine-Grained Retrieval-Augmented Generation for Visual Question Answering
Authors:Zhengxuan Zhang, Yin Wu, Yuyu Luo, Nan Tang
Visual Question Answering (VQA) focuses on providing answers to natural language questions by utilizing information from images. Although cutting-edge multimodal large language models (MLLMs) such as GPT-4o achieve strong performance on VQA tasks, they frequently fall short in accessing domain-specific or the latest knowledge. To mitigate this issue, retrieval-augmented generation (RAG) leveraging external knowledge bases (KBs), referred to as KB-VQA, emerges as a promising approach. Nevertheless, conventional unimodal retrieval techniques, which translate images into textual descriptions, often result in the loss of critical visual details. This study presents fine-grained knowledge units, which merge textual snippets with entity images stored in vector databases. Furthermore, we introduce a knowledge unit retrieval-augmented generation framework (KU-RAG) that integrates fine-grained retrieval with MLLMs. The proposed KU-RAG framework ensures precise retrieval of relevant knowledge and enhances reasoning capabilities through a knowledge correction chain. Experimental findings demonstrate that our approach significantly boosts the performance of leading KB-VQA methods, achieving an average improvement of approximately 3% and up to 11% in the best case.
视觉问答(VQA)专注于通过利用图像中的信息来回答自然语言问题。尽管最前沿的多模态大型语言模型(如GPT-4o)在VQA任务上表现出强大的性能,但它们通常在访问特定领域或最新知识时显得不足。为了缓解这个问题,利用外部知识库的检索增强生成(RAG)技术,被称为KB-VQA,正成为一种有前景的方法。然而,传统的单模态检索技术将图像翻译成文本描述,这往往会导致关键视觉细节的丢失。本研究提出了精细知识单元,将文本片段与存储在向量数据库中的实体图像合并。此外,我们引入了知识单元检索增强生成框架(KU-RAG),将精细检索与MLLMs相结合。所提出的KU-RAG框架确保精确检索相关知识,并通过知识校正链增强推理能力。实验结果表明,我们的方法显著提高了领先的KB-VQA方法的性能,平均提高了约3%,在最佳情况下提高了高达11%。
论文及项目相关链接
摘要
本文关注视觉问答(VQA)领域,旨在通过图像信息回答自然语言问题。虽然当前先进的多模态大型语言模型(MLLMs)如GPT-4o在VQA任务上表现出强大的性能,但在访问特定领域或最新知识时常常存在缺陷。为解决这一问题,利用外部知识库(KBs)的检索增强生成(RAG)方法,即KB-VQA,展现出巨大潜力。然而,传统的单模态检索技术将图像转换为文本描述,往往会导致关键视觉细节的丢失。本研究提出精细粒度知识单元,将文本片段与存储在向量数据库中的实体图像合并。此外,还引入了知识单元检索增强生成框架(KU-RAG),将精细粒度检索与MLLMs结合。KU-RAG框架确保精确检索相关知识,并通过知识校正链增强推理能力。实验结果表明,该方法显著提升了领先的KB-VQA方法的性能,平均提高了约3%,最高提高了11%。
关键见解
- 视觉问答(VQA)是利用图像信息回答自然语言问题的研究领域。
- 多模态大型语言模型(MLLMs)在VQA任务上表现出强大的性能,但在访问特定领域或最新知识时存在局限。
- 检索增强生成(RAG)方法利用外部知识库(KBs)来解决MLLMs的缺陷,展现出巨大潜力。
- 传统单模态检索技术存在将图像转换为文本描述时丢失关键视觉细节的问题。
- 精细粒度知识单元将文本和图像结合,提高了检索的精确度。
- 引入的知识单元检索增强生成框架(KU-RAG)结合了精细粒度检索与MLLMs,提高了知识检索和推理能力。
点此查看论文截图

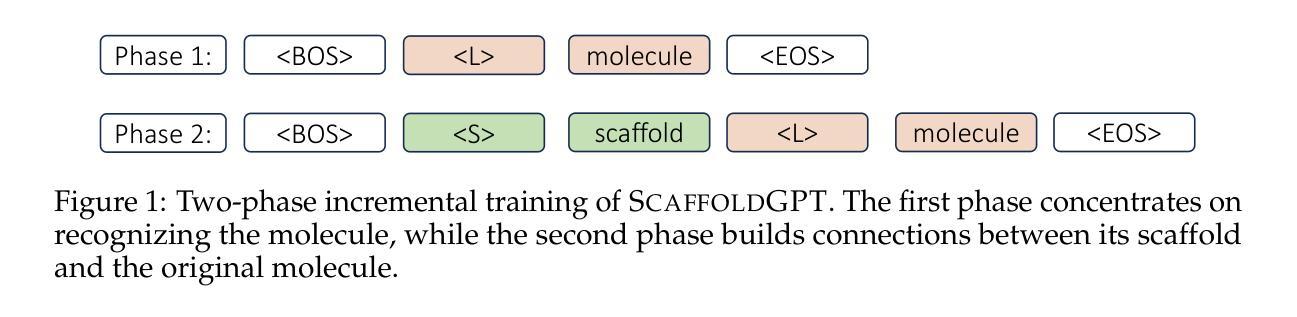
ScaffoldGPT: A Scaffold-based GPT Model for Drug Optimization
Authors:Xuefeng Liu, Songhao Jiang, Ian Foster, Jinbo Xu, Rick Stevens
Drug optimization has become increasingly crucial in light of fast-mutating virus strains and drug-resistant cancer cells. Nevertheless, it remains challenging as it necessitates retaining the beneficial properties of the original drug while simultaneously enhancing desired attributes beyond its scope. In this work, we aim to tackle this challenge by introducing ScaffoldGPT, a novel Generative Pretrained Transformer (GPT) designed for drug optimization based on molecular scaffolds. Our work comprises three key components: (1) A three-stage drug optimization approach that integrates pretraining, finetuning, and decoding optimization. (2) A uniquely designed two-phase incremental training approach for pre-training the drug optimization GPT on molecule scaffold with enhanced performance. (3) A token-level decoding optimization strategy, TOP-N, that enabling controlled, reward-guided generation using pretrained/finetuned GPT. We demonstrate via a comprehensive evaluation on COVID and cancer benchmarks that ScaffoldGPT outperforms the competing baselines in drug optimization benchmarks, while excelling in preserving original functional scaffold and enhancing desired properties.
在病毒快速变异和药物耐药性癌细胞面前,药物优化变得愈发关键。然而,这一任务仍然充满挑战,因为它需要在保留原始药物的有益特性的同时,还增强超出其范围之外的所需属性。在这项工作中,我们旨在通过引入ScaffoldGPT来解决这一挑战,这是一种基于分子支架的新型生成预训练转换器(GPT),专为药物优化而设计。我们的工作包括三个关键部分:(1)一个三阶段的药品优化方法,该方法整合了预训练、微调和解码优化。(2)一个独特设计的两阶段增量训练法,用于在分子支架上预训练药品优化GPT,提高性能。(3)一种令牌级别的解码优化策略TOP-N,它通过利用预训练/微调的GPT实现受控的、奖励引导的生成。我们通过针对COVID和癌症基准测试的综合评估证明,ScaffoldGPT在药物优化基准测试中优于竞争对手,尤其擅长保留原始功能支架并增强所需属性。
论文及项目相关链接
摘要
药物优化面临新的挑战,需要在快速变异的病毒菌株和耐药癌细胞背景下保持药物的原有优势属性,同时增强所需属性。本研究引入ScaffoldGPT,一种用于药物优化的新型生成预训练转换器(GPT),旨在解决这一挑战。研究包括三个关键部分:1. 三阶段药物优化方法,整合预训练、微调和解码优化;2. 独特设计的两阶段增量训练方法来预训练药物优化GPT;3. 一种token级别的解码优化策略TOP-N,通过奖励引导使用预训练或微调后的GPT生成内容。通过对COVID和癌症基准测试的综合评估,证明ScaffoldGPT在药物优化基准测试中优于竞争对手,同时在保持原始功能骨架和增强所需属性方面表现出色。
要点
- 药物优化面临新的挑战,需要在保持原有优势属性的同时增强所需属性。
- 研究引入了ScaffoldGPT,一种新型生成预训练转换器(GPT),用于解决药物优化挑战。
- ScaffoldGPT采用三阶段药物优化方法,包括预训练、微调和解码优化。
- 研究采用独特的两阶段增量训练方法来预训练药物优化GPT。
- TOP-N是一种token级别的解码优化策略,可以通过奖励引导控制生成内容。
- ScaffoldGPT在COVID和癌症基准测试中表现优异,优于竞争对手。
点此查看论文截图