⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-15 更新
DocAgent: A Multi-Agent System for Automated Code Documentation Generation
Authors:Dayu Yang, Antoine Simoulin, Xin Qian, Xiaoyi Liu, Yuwei Cao, Zhaopu Teng, Grey Yang
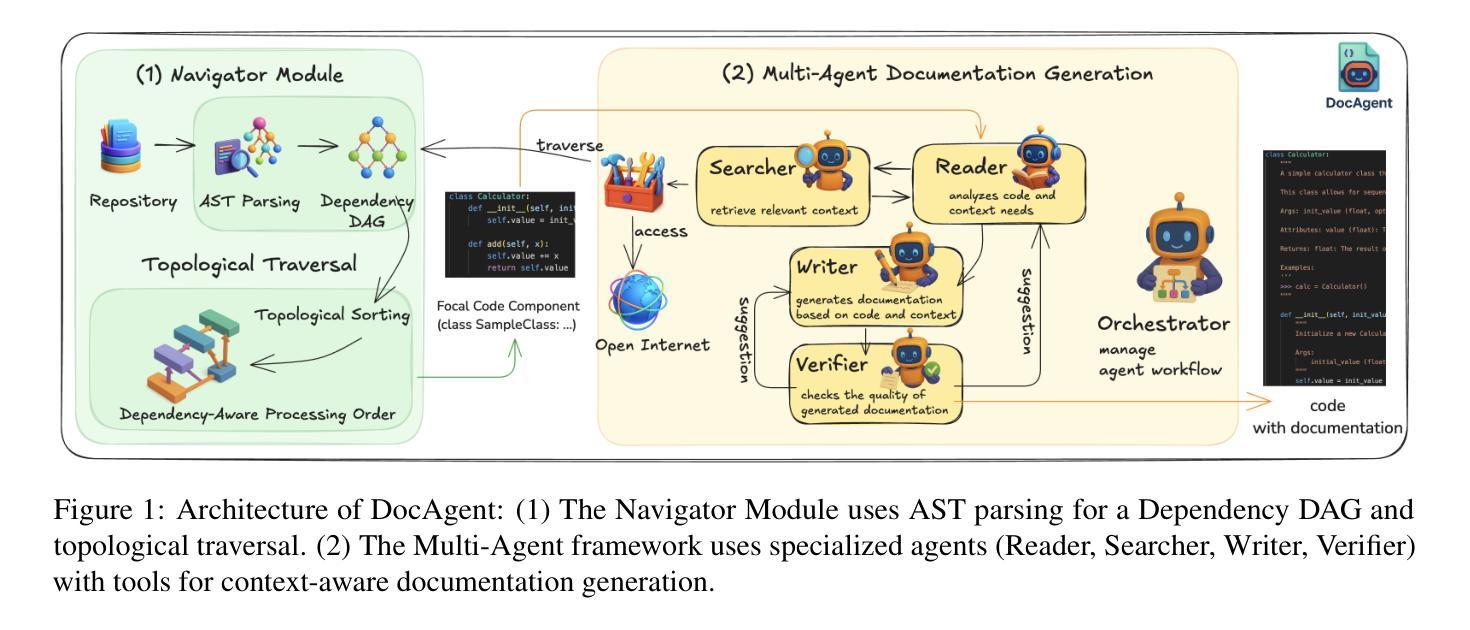
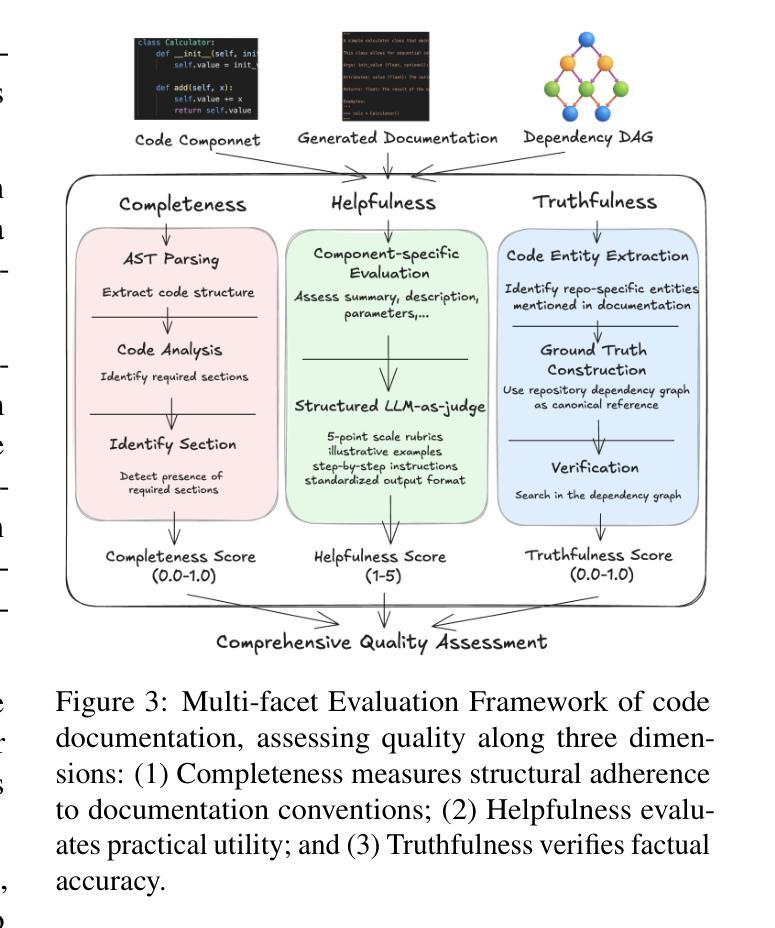
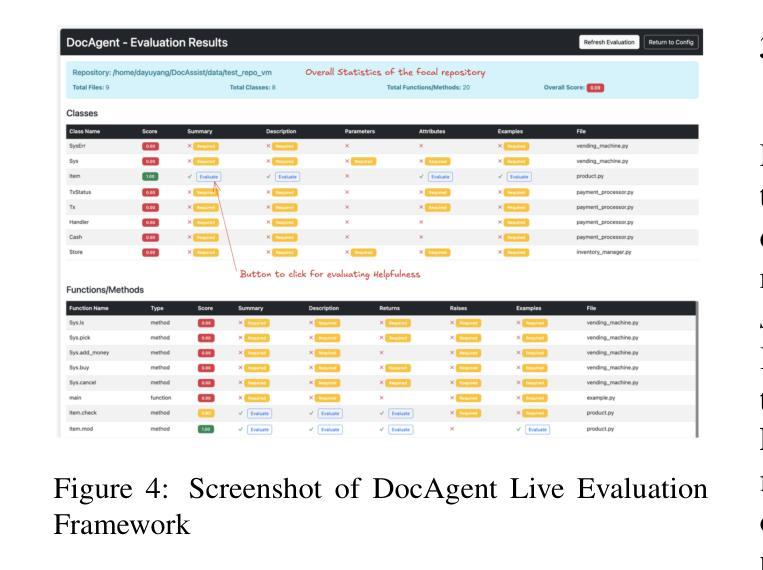
High-quality code documentation is crucial for software development especially in the era of AI. However, generating it automatically using Large Language Models (LLMs) remains challenging, as existing approaches often produce incomplete, unhelpful, or factually incorrect outputs. We introduce DocAgent, a novel multi-agent collaborative system using topological code processing for incremental context building. Specialized agents (Reader, Searcher, Writer, Verifier, Orchestrator) then collaboratively generate documentation. We also propose a multi-faceted evaluation framework assessing Completeness, Helpfulness, and Truthfulness. Comprehensive experiments show DocAgent significantly outperforms baselines consistently. Our ablation study confirms the vital role of the topological processing order. DocAgent offers a robust approach for reliable code documentation generation in complex and proprietary repositories.
高质量的代码文档对软件开发至关重要,特别是在人工智能时代。然而,使用大型语言模型(LLM)自动生成文档仍然具有挑战性,因为现有方法通常会产生不完整、无帮助或事实错误的输出。我们引入了DocAgent,这是一个使用拓扑代码处理进行增量上下文构建的新型多智能体协作系统。专门的智能体(阅读器、搜索器、写入器、验证器、协调器)协同生成文档。我们还提出了一个多方面的评估框架,评估文档的完整性、帮助性和真实性。综合实验表明,DocAgent持续且显著地优于基线。我们的消融研究证实了拓扑处理顺序的重要作用。DocAgent为复杂和专有存储库中的可靠代码文档生成提供了稳健的方法。
论文及项目相关链接
Summary
本文强调高质量代码文档在软件开发中的重要性,特别是在人工智能时代。然而,使用大型语言模型(LLMs)自动生成文档仍然具有挑战性,因为现有方法常常产生不完整、无帮助或事实错误的输出。为此,本文提出了DocAgent,这是一种新型的多智能体协作系统,采用拓扑代码处理进行增量上下文构建。通过专门的智能体(阅读器、搜索器、编写器、验证器、协调器)协同生成文档。同时,提出了一种多方面的评估框架,评估文档的完整性、帮助性和真实性。实验表明,DocAgent在复杂和专有存储库中显著优于基线方法。
Key Takeaways
- 高质量代码文档在软件开发中的重要性,特别是在人工智能时代。
- 使用大型语言模型(LLMs)自动生成代码文档的挑战性,现有方法的不足。
- DocAgent是一种多智能体协作系统,采用拓扑代码处理进行增量上下文构建。
- DocAgent包括多个专门智能体:阅读器、搜索器、编写器、验证器和协调器。
- 提出了一个多面的评估框架,评估文档的完整性、帮助性和真实性。
- 实验表明,DocAgent在生成代码文档方面显著优于基线方法。
点此查看论文截图


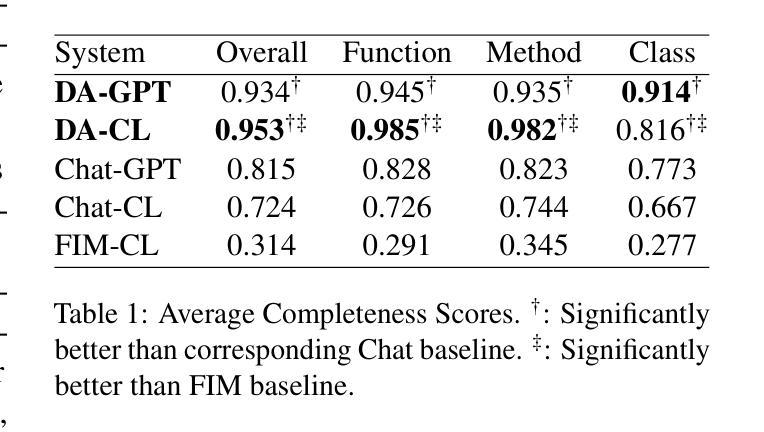
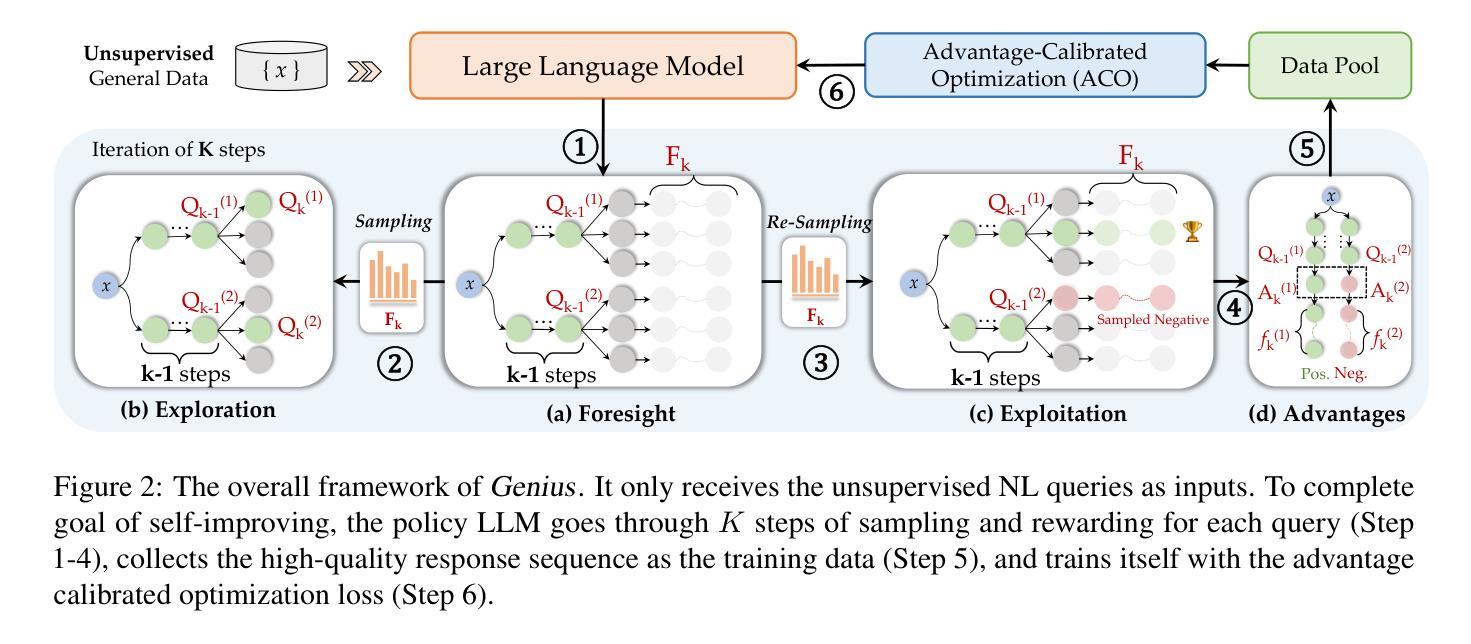
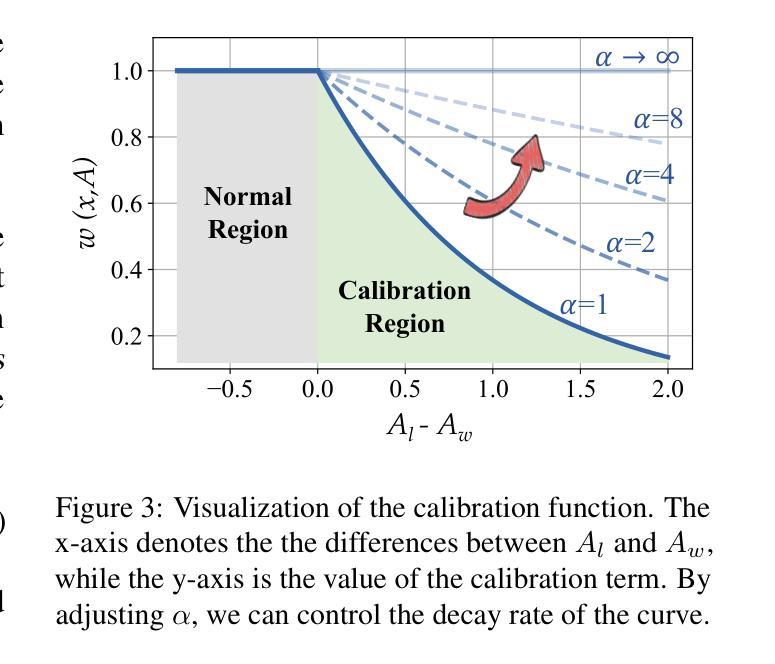
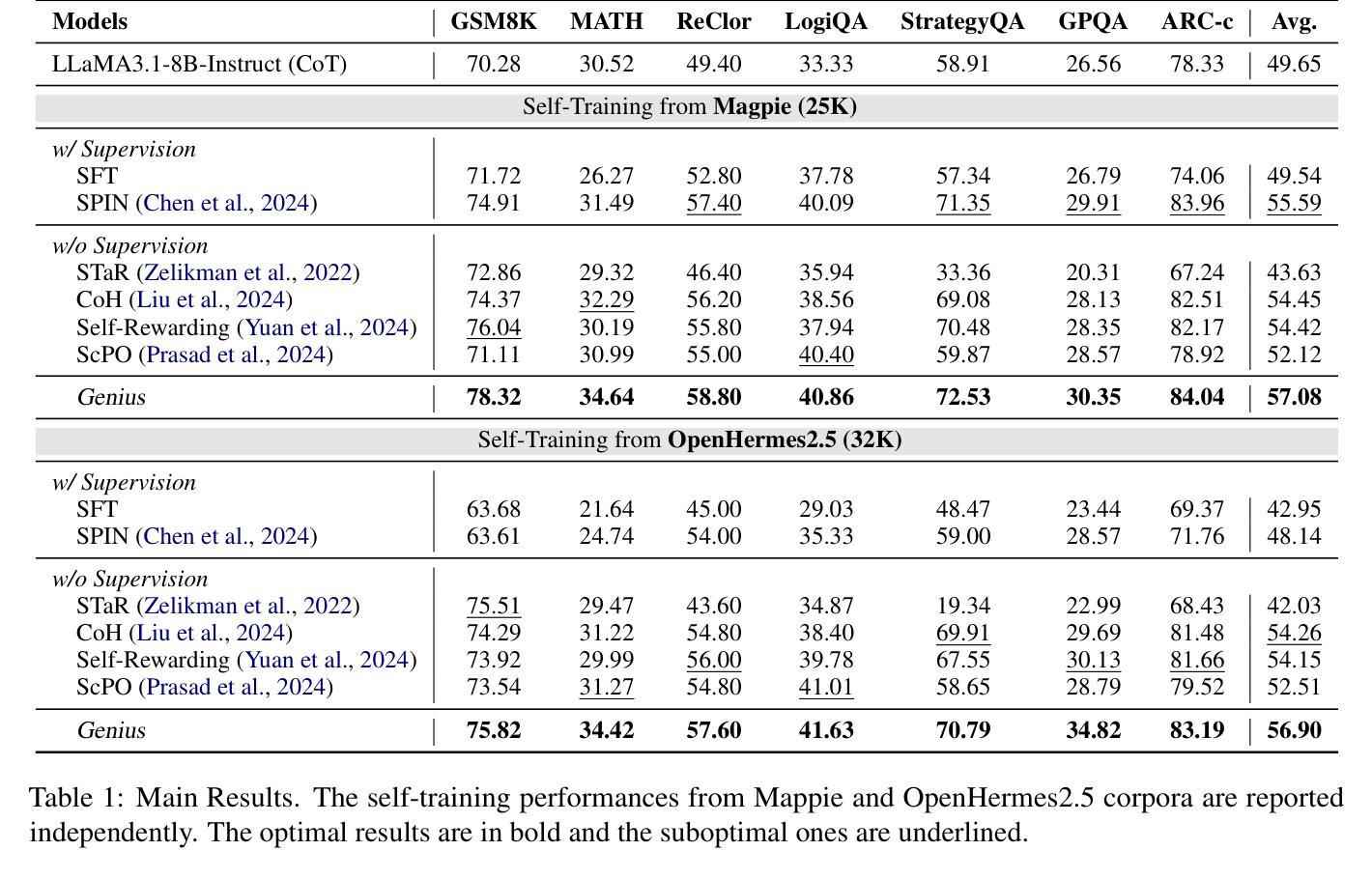
Genius: A Generalizable and Purely Unsupervised Self-Training Framework For Advanced Reasoning
Authors:Fangzhi Xu, Hang Yan, Chang Ma, Haiteng Zhao, Qiushi Sun, Kanzhi Cheng, Junxian He, Jun Liu, Zhiyong Wu
Advancing LLM reasoning skills has captivated wide interest. However, current post-training techniques rely heavily on supervisory signals, such as outcome supervision or auxiliary reward models, which face the problem of scalability and high annotation costs. This motivates us to enhance LLM reasoning without the need for external supervision. We introduce a generalizable and purely unsupervised self-training framework, named Genius. Without external auxiliary, Genius requires to seek the optimal response sequence in a stepwise manner and optimize the LLM. To explore the potential steps and exploit the optimal ones, Genius introduces a stepwise foresight re-sampling strategy to sample and estimate the step value by simulating future outcomes. Further, we recognize that the unsupervised setting inevitably induces the intrinsic noise and uncertainty. To provide a robust optimization, we propose an advantage-calibrated optimization (ACO) loss function to mitigate estimation inconsistencies. Combining these techniques together, Genius provides an advanced initial step towards self-improve LLM reasoning with general queries and without supervision, revolutionizing reasoning scaling laws given the vast availability of general queries. The code will be released at https://github.com/xufangzhi/Genius.
推进LLM推理技能已经引起了广泛的关注。然而,当前的训练后技术很大程度上依赖于监督信号,如结果监督或辅助奖励模型,这面临着可扩展性和高标注成本的问题。这激励我们在不需要外部监督的情况下提高LLM的推理能力。我们引入了一个通用且纯粹的无监督自训练框架,名为Genius。无需外部辅助,Genius需要以逐步的方式寻找最佳响应序列并优化LLM。为了探索潜在的步骤并利用最佳的步骤,Genius引入了一种逐步前瞻性重新采样策略,通过模拟未来结果来采样并估算步骤值。此外,我们认识到无监督设置不可避免地会引发内在噪声和不确定性。为了提供稳健的优化,我们提出了一种优势校准优化(ACO)损失函数来缓解估计不一致的问题。结合这些技术,Genius是朝着无需监督的自我改进LLM推理方向迈出的初步一步,具有处理通用查询的能力,从而改变了推理扩展定律,利用大量可用的通用查询来进行革命性的进步。代码将在https://github.com/xufangzhi/Genius上发布。
论文及项目相关链接
PDF 14 pages, 7 figures
Summary
推进LLM推理技能引起了广泛关注。然而,当前的后训练技术严重依赖于监督信号,如结果监督或辅助奖励模型,这面临着可扩展性和高标注成本的问题。因此,我们提出了一种无需外部监督的通用纯自训练框架Genius,以提高LLM的推理能力。Genius通过逐步寻找最佳响应序列来优化LLM,无需外部辅助。为了探索潜在的步骤并利用最佳步骤,Genius引入了一种逐步预见重采样策略,通过模拟未来结果来采样并估算步骤值。此外,我们认识到无监督设置不可避免地会引发内在噪声和不确定性。为了进行稳健优化,我们提出了一种优势校准优化(ACO)损失函数,以减轻估计不一致的问题。结合这些技术,Genius为在没有监督的情况下自我改进LLM推理能力提供了先进的初步步骤,对于通用查询具有革命性的推理扩展定律。相关代码将发布在https://github.com/xufangzhi/Genius。
Key Takeaways
- 当前LLM推理技能提升依赖于监督信号,存在可扩展性和高标注成本问题。
- Genius框架是一种通用、无需外部监督的纯自训练方式,旨在提高LLM的推理能力。
- Genius通过逐步寻找最佳响应序列进行优化,并引入逐步预见重采样策略来探索潜在步骤。
- 无监督设置引发内在噪声和不确定性,因此提出优势校准优化(ACO)损失函数进行稳健优化。
- Genius对于在没有监督的情况下改进LLM推理能力具有重要意义,特别是在处理通用查询时。
点此查看论文截图

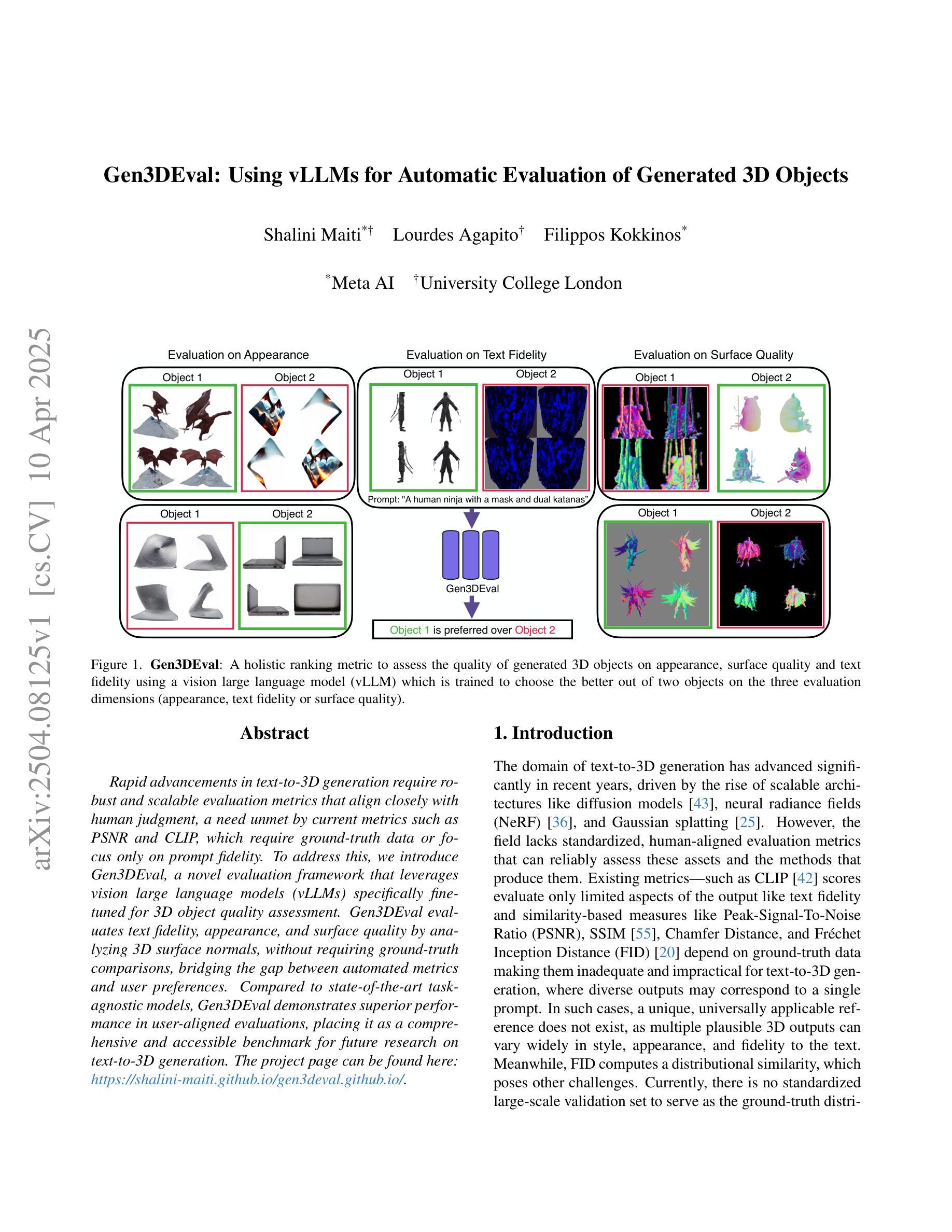
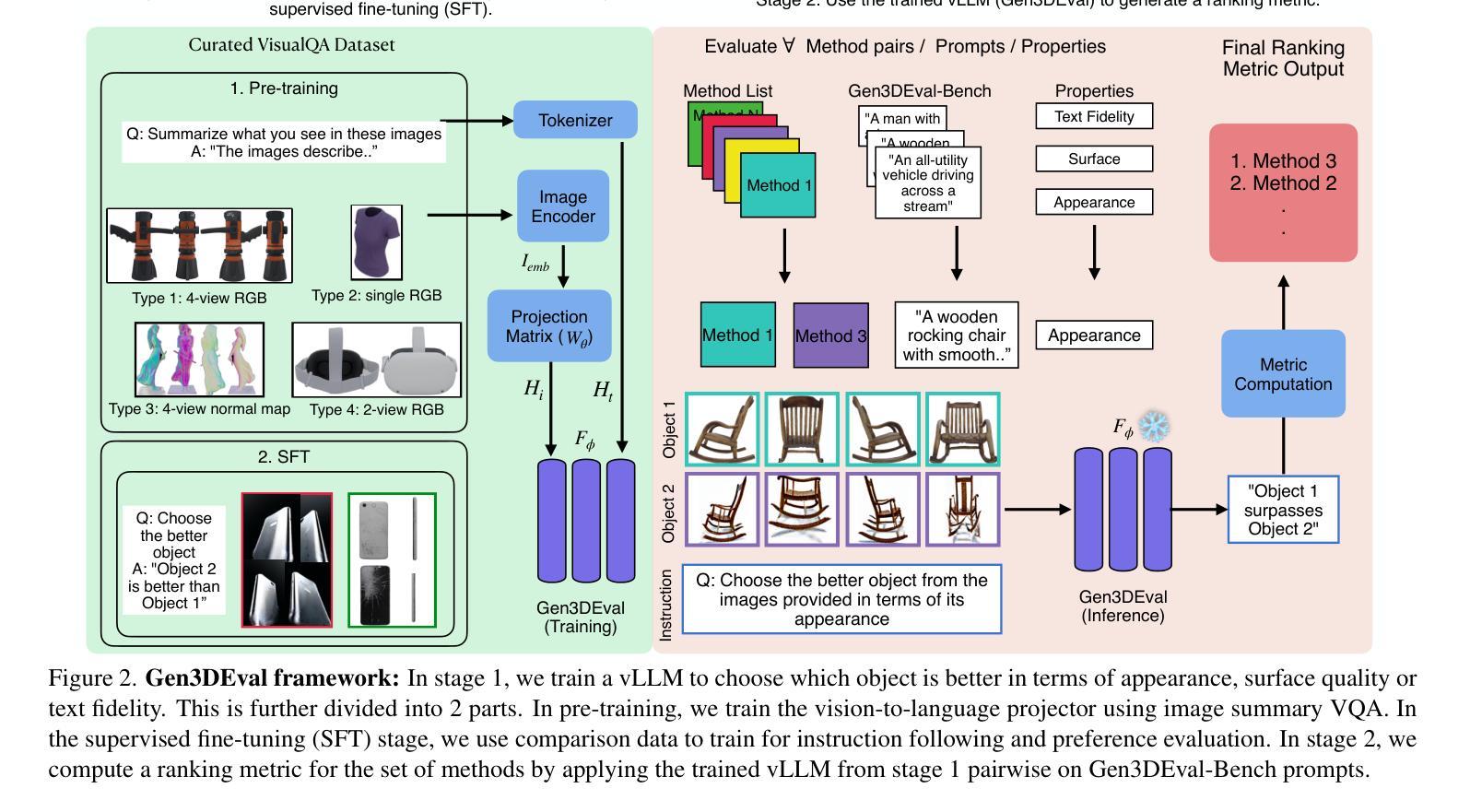
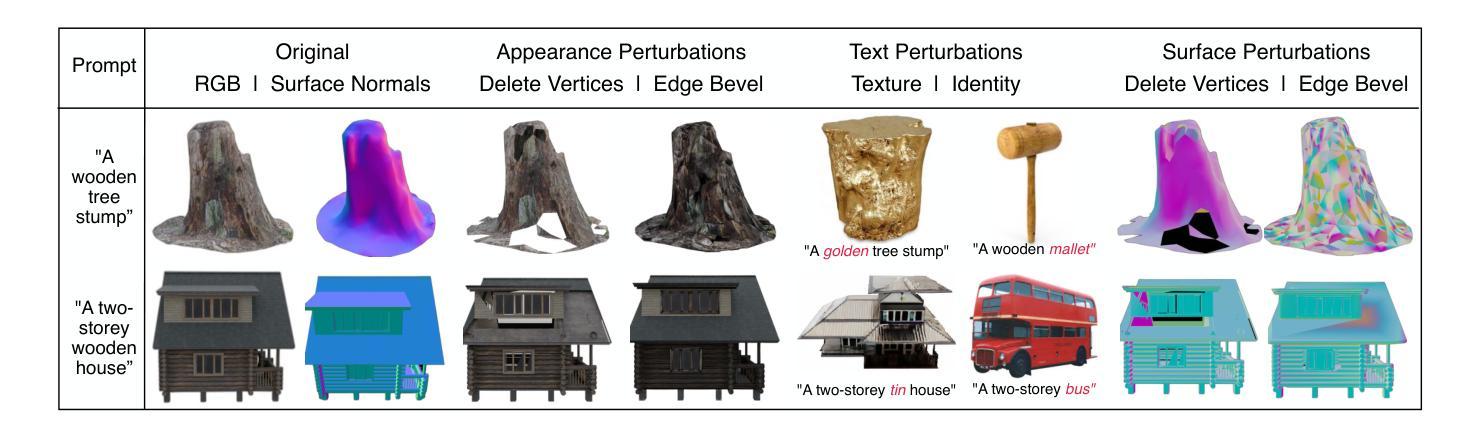
Gen3DEval: Using vLLMs for Automatic Evaluation of Generated 3D Objects
Authors:Shalini Maiti, Lourdes Agapito, Filippos Kokkinos
Rapid advancements in text-to-3D generation require robust and scalable evaluation metrics that align closely with human judgment, a need unmet by current metrics such as PSNR and CLIP, which require ground-truth data or focus only on prompt fidelity. To address this, we introduce Gen3DEval, a novel evaluation framework that leverages vision large language models (vLLMs) specifically fine-tuned for 3D object quality assessment. Gen3DEval evaluates text fidelity, appearance, and surface quality by analyzing 3D surface normals, without requiring ground-truth comparisons, bridging the gap between automated metrics and user preferences. Compared to state-of-the-art task-agnostic models, Gen3DEval demonstrates superior performance in user-aligned evaluations, placing it as a comprehensive and accessible benchmark for future research on text-to-3D generation. The project page can be found here: \href{https://shalini-maiti.github.io/gen3deval.github.io/}{https://shalini-maiti.github.io/gen3deval.github.io/}.
随着文本到3D生成的快速发展,我们需要强大且可扩展的评估指标,这些指标需要紧密符合人类的判断,而当前诸如PSNR和CLIP等评价指标无法满足这一需求。这些指标要么需要真实数据,要么只关注提示的忠实度。为了解决这个问题,我们引入了Gen3DEval,这是一个新的评估框架,它利用专门用于3D对象质量评估的视觉大型语言模型(vLLMs)。Gen3DEval通过分析3D表面法线来评估文本的忠实度、外观和表面质量,无需真实数据的对比,在自动度量与用户偏好之间搭建了桥梁。与最先进的任务无关模型相比,Gen3DEval在用户对齐的评估中表现出卓越的性能,成为未来文本到3D生成研究全面且易于访问的基准测试。项目页面可在此找到:[https://shalini-maiti.github.io/gen3deval.github.io/]
论文及项目相关链接
PDF CVPR 2025
Summary
随着文本到3D生成的快速发展,现有的评估指标如PSNR和CLIP已无法满足需求。为此,我们推出Gen3DEval评估框架,利用特定微调用于评估3D物体质量的视觉大型语言模型(vLLMs)。Gen3DEval可分析无需真实对比的3D表面法线,评估文本忠实度、外观和表面质量,缩小了自动化指标与用户偏好之间的差距。相较于现有任务无关模型,Gen3DEval在用户评价中表现更佳,为未来文本到3D生成研究提供了全面且易于使用的基准。项目页面位于:链接地址。
Key Takeaways
- 当前文本到3D生成的评估指标存在局限性,需要更完善的评估方法。
- Gen3DEval利用视觉大型语言模型(vLLMs)评估3D物体质量,为市场提供了新颖的评价框架。
- Gen3DEval可分析3D表面法线,评估文本的忠实度、外观和表面质量。
- Gen3DEval无需真实对比数据即可进行评估。
- Gen3DEval缩小了自动化评估指标与用户偏好之间的差距。
- Gen3DEval在用户评价中表现优于现有任务无关模型。
点此查看论文截图
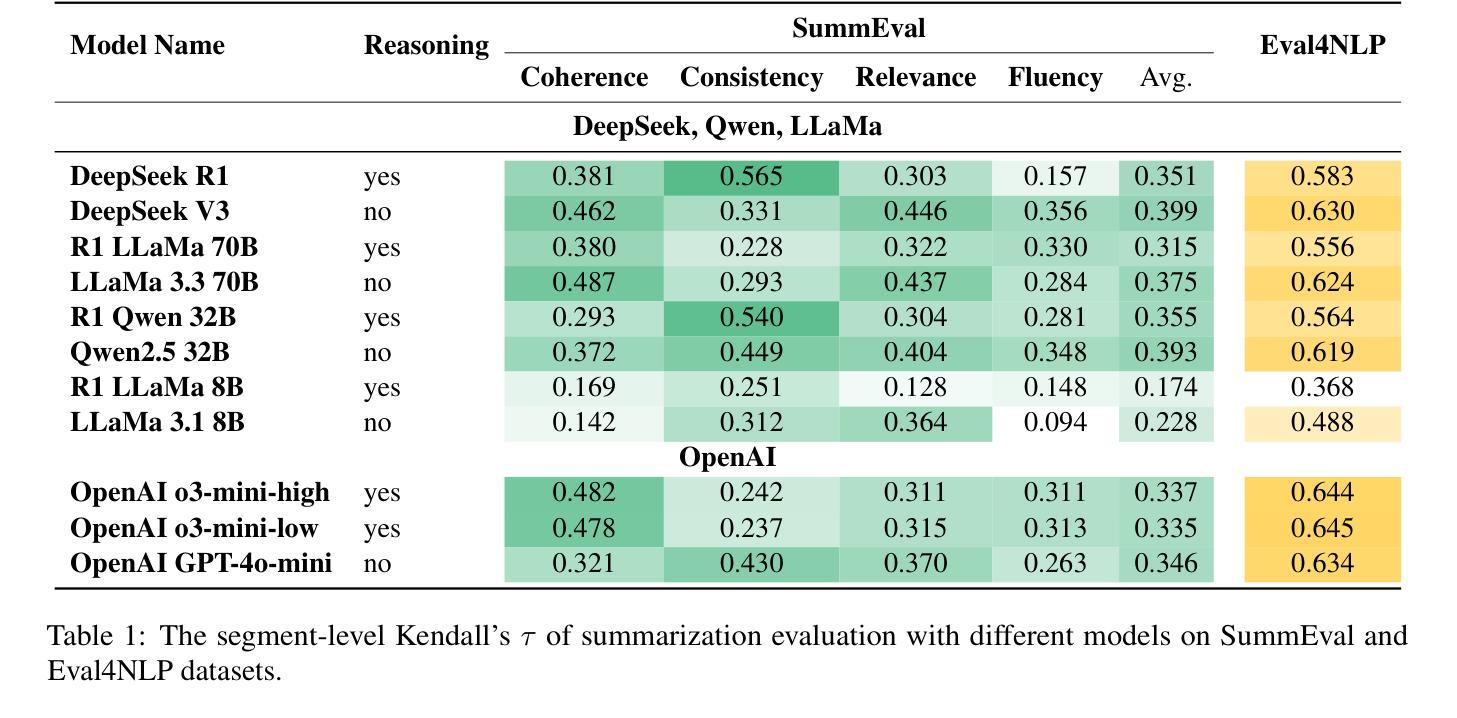
DeepSeek vs. o3-mini: How Well can Reasoning LLMs Evaluate MT and Summarization?
Authors:Daniil Larionov, Sotaro Takeshita, Ran Zhang, Yanran Chen, Christoph Leiter, Zhipin Wang, Christian Greisinger, Steffen Eger
Reasoning-enabled large language models (LLMs) have recently demonstrated impressive performance in complex logical and mathematical tasks, yet their effectiveness in evaluating natural language generation remains unexplored. This study systematically compares reasoning-based LLMs (DeepSeek-R1 and OpenAI o3) with their non-reasoning counterparts across machine translation (MT) and text summarization (TS) evaluation tasks. We evaluate eight models across three architectural categories, including state-of-the-art reasoning models, their distilled variants (ranging from 8B to 70B parameters), and equivalent conventional, non-reasoning LLMs. Our experiments on WMT23 and SummEval benchmarks reveal that the benefits of reasoning capabilities are highly model and task-dependent: while OpenAI o3-mini models show consistent performance improvements with increased reasoning intensity, DeepSeek-R1 underperforms compared to its non-reasoning variant, with exception to certain aspects of TS evaluation. Correlation analysis demonstrates that increased reasoning token usage positively correlates with evaluation quality in o3-mini models. Furthermore, our results show that distillation of reasoning capabilities maintains reasonable performance in medium-sized models (32B) but degrades substantially in smaller variants (8B). This work provides the first comprehensive assessment of reasoning LLMs for NLG evaluation and offers insights into their practical use.
具备推理功能的大型语言模型(LLMs)最近在复杂的逻辑和数学任务中表现出了令人印象深刻的性能,然而它们在评估自然语言生成方面的有效性仍未被探索。本研究系统地比较了基于推理的LLMs(DeepSeek-R1和OpenAI o3)与其在非推理任务中的对应模型在机器翻译(MT)和文本摘要(TS)评估任务中的表现。我们评估了三种架构类别中的八个模型,包括最先进的推理模型、它们的蒸馏变体(参数范围从8B到70B),以及等效的传统非推理LLMs。我们在WMT23和SummEval基准测试上的实验表明,推理能力的益处高度依赖于模型和任务:虽然OpenAI o3-mini模型显示出随着推理强度的增加而持续的性能改进,但DeepSeek-R1在其非推理变体上的表现较差,但在TS评估的某些方面除外。相关性分析表明,在o3-mini模型中,推理令牌使用量的增加与评估质量呈正相关。此外,我们的结果表明,在中等大小模型(32B)中蒸馏推理能力可以保持合理的性能,但在较小变体(8B)中会显著下降。这项工作首次全面评估了用于NLG评价的推理LLMs,并为其实践应用提供了见解。
论文及项目相关链接
Summary
基于自然语言理解和推理的大型语言模型(LLMs)在逻辑和数学任务上表现优异,但它们对于自然语言生成(NLG)的评价效果尚未被探索。本研究系统地比较了基于推理的LLMs(DeepSeek-R1和OpenAI o3)与非推理LLMs在机器翻译(MT)和文本摘要(TS)评价任务上的表现。实验结果显示,推理能力的优势在很大程度上取决于模型和任务。OpenAI o3-mini模型在增强推理强度后表现一致地更好,而DeepSeek-R1在非推理变体上表现较差,但在文本摘要评价的某些方面表现较好。此外,推理代币的使用与评估质量之间存在正相关关系。同时,研究还发现,在中等规模模型中保持推理能力的蒸馏表现良好,但在小型模型中性能会大幅下降。本研究首次全面评估了用于NLG评价的推理LLMs,并为其实践应用提供了见解。
Key Takeaways
- 大型语言模型(LLMs)在逻辑和数学任务上的表现已经相当出色,但在自然语言生成(NLG)评价方面的效果尚未得到充分探索。
- 对比了基于推理的LLMs(如DeepSeek-R1和OpenAI o3)与非推理LLMs在机器翻译和文本摘要评价任务上的表现。
- 推理能力的优势在模型和任务上具有依赖性。OpenAI o3-mini模型在增强推理强度后表现更好,而DeepSeek-R1在某些文本摘要评价方面表现较好,但在总体上不如其非推理变体。
- 推理代币的使用与评估质量之间存在正相关关系,这意味着更多的推理代币可能意味着更高的评估准确性。
- 在中等规模模型中,通过蒸馏保留推理能力可以保持良好的性能。但在小型模型中,这种性能会大幅下降。
- 本研究首次全面评估了用于NLG评价的推理LLMs,为未来的研究提供了重要的参考依据。
点此查看论文截图

Can Reasoning LLMs Enhance Clinical Document Classification?
Authors:Akram Mustafa, Usman Naseem, Mostafa Rahimi Azghadi
Clinical document classification is essential for converting unstructured medical texts into standardised ICD-10 diagnoses, yet it faces challenges due to complex medical language, privacy constraints, and limited annotated datasets. Large Language Models (LLMs) offer promising improvements in accuracy and efficiency for this task. This study evaluates the performance and consistency of eight LLMs; four reasoning (Qwen QWQ, Deepseek Reasoner, GPT o3 Mini, Gemini 2.0 Flash Thinking) and four non-reasoning (Llama 3.3, GPT 4o Mini, Gemini 2.0 Flash, Deepseek Chat); in classifying clinical discharge summaries using the MIMIC-IV dataset. Using cTAKES to structure clinical narratives, models were assessed across three experimental runs, with majority voting determining final predictions. Results showed that reasoning models outperformed non-reasoning models in accuracy (71% vs 68%) and F1 score (67% vs 60%), with Gemini 2.0 Flash Thinking achieving the highest accuracy (75%) and F1 score (76%). However, non-reasoning models demonstrated greater stability (91% vs 84% consistency). Performance varied across ICD-10 codes, with reasoning models excelling in complex cases but struggling with abstract categories. Findings indicate a trade-off between accuracy and consistency, suggesting that a hybrid approach could optimise clinical coding. Future research should explore multi-label classification, domain-specific fine-tuning, and ensemble methods to enhance model reliability in real-world applications.
临床文档分类对于将非结构化医疗文本转换为标准化的ICD-10诊断至关重要,但由于复杂的医疗语言、隐私约束和有限的有标注数据集,它面临着挑战。大型语言模型(LLM)为这个任务提供了提高准确性和效率的潜力。本研究评估了8种LLM的性能和一致性;四个推理模型(Qwen QWQ、Deepseek Reasoner、GPT o3 Mini、Gemini 2.0 Flash Thinking)和四个非推理模型(Llama 3.3、GPT 4o Mini、Gemini 2.0 Flash、Deepseek Chat);使用MIMIC-IV数据集对临床出院摘要进行分类。使用cTAKES对临床叙述进行结构化处理,对模型进行了三次实验运行评估,以多数投票决定最终预测。结果表明,推理模型在准确性和F1分数方面优于非推理模型(准确率71%比68%,F1分数67%比60%),其中Gemini 2.0 Flash Thinking的准确率和F1分数最高(分别为75%和76%)。然而,非推理模型表现出更大的稳定性(一致性91%比84%)。不同ICD-10代码的性能有所不同,推理模型在复杂情况下表现出色,但在抽象类别中表现不佳。研究结果表明,需要在准确性和一致性之间进行权衡,提示采用混合方法可能最适用于临床编码。未来的研究应探索多标签分类、特定领域的微调以及集成方法,以提高模型在现实应用中的可靠性。
论文及项目相关链接
PDF 28 pages, 13 tables, 12 figures
Summary
该文研究了大型语言模型(LLMs)在医疗文本分类任务中的应用,特别是在将非结构化医疗文本转换为标准化的ICD-10诊断中的应用。实验评估了八种LLMs的性能和一致性,包括四种推理模型(Qwen QWQ等)和四种非推理模型(Llama 3.3等)。使用MIMIC-IV数据集和cTAKES工具进行临床叙述结构化处理,结果显示推理模型在准确性和F1得分上优于非推理模型,但非推理模型在稳定性方面表现更好。文章探讨了模型性能与ICD-10代码之间的变化,并提出了采用混合方法的优化方向。未来研究应关注多标签分类、特定领域的微调以及集成方法以提高模型在现实应用中的可靠性。
Key Takeaways
- 临床文档分类是将非结构化医疗文本转换为ICD-10诊断的关键过程。
- 大型语言模型(LLMs)可以提高临床文档分类的准确性和效率。
- 推理模型在分类准确性上优于非推理模型,但非推理模型在稳定性方面表现更好。
- Gemini 2.0 Flash Thinking模型在准确率和F1得分上表现最佳。
- 不同ICD-10代码下的模型性能有所差异,推理模型在处理复杂案例时表现出色,但在抽象类别上遇到困难。
- 存在准确性与一致性之间的权衡,提出采用混合方法来优化临床编码。
点此查看论文截图

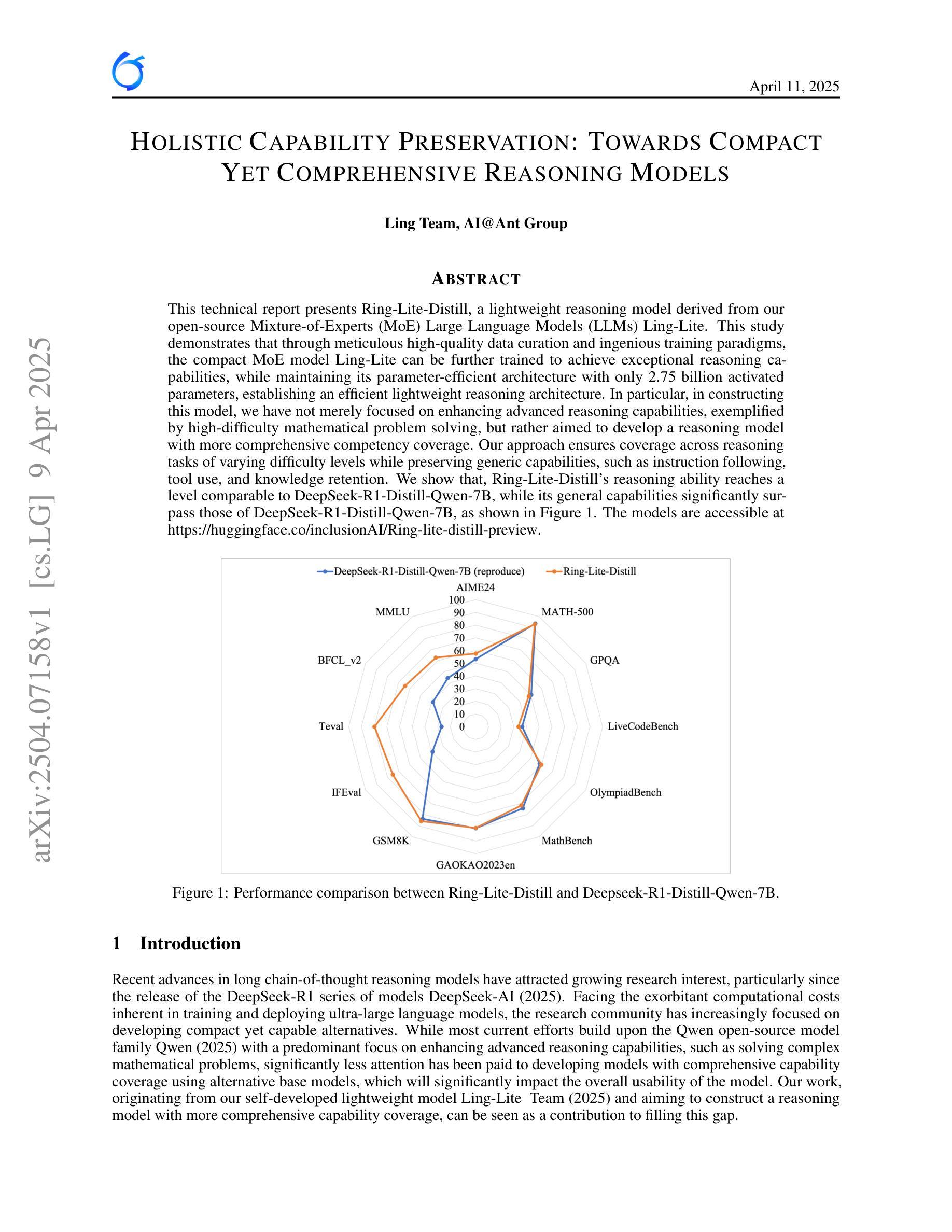
Holistic Capability Preservation: Towards Compact Yet Comprehensive Reasoning Models
Authors: Ling Team, Caizhi Tang, Chilin Fu, Chunwei Wu, Jia Guo, Jianwen Wang, Jingyu Hu, Liang Jiang, Meng Li, Peng Jiao, Pingping Liu, Shaomian Zheng, Shiwei Liang, Shuaicheng Li, Yalin Zhang, Yingting Wu, Yongkang Liu, Zhenyu Huang
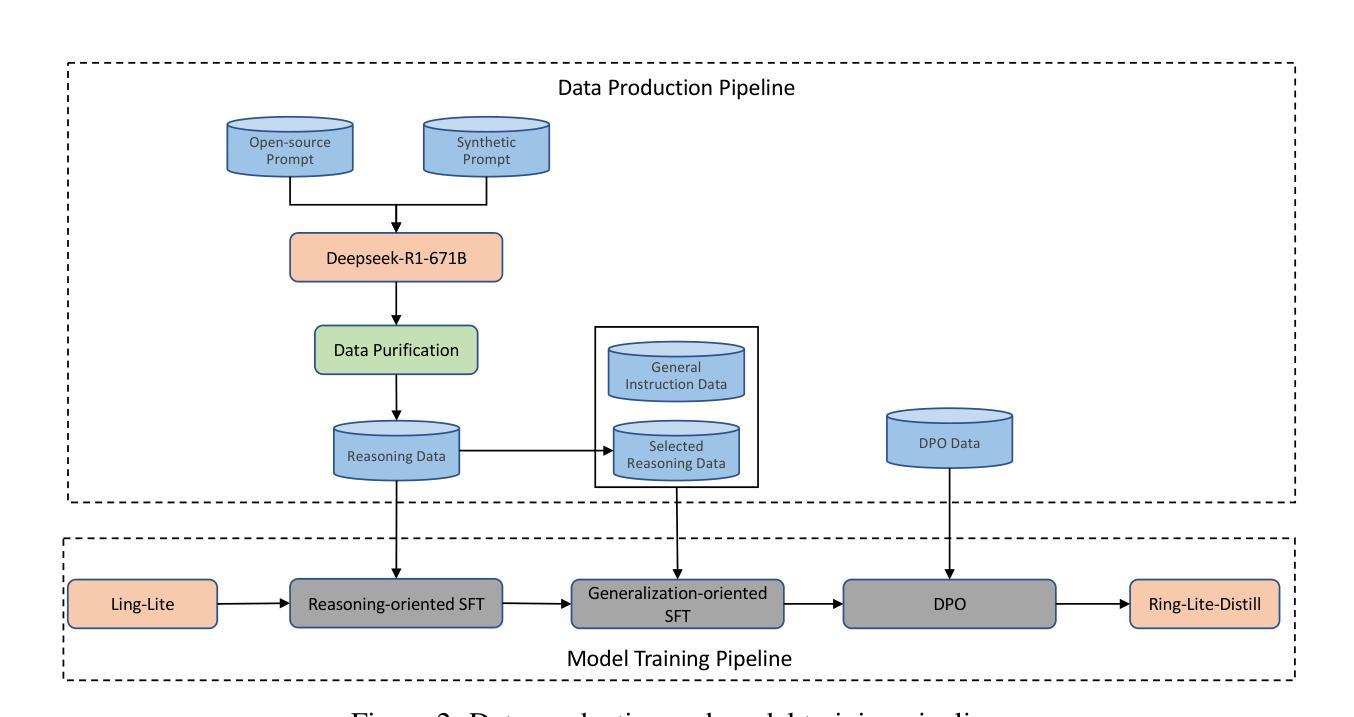
This technical report presents Ring-Lite-Distill, a lightweight reasoning model derived from our open-source Mixture-of-Experts (MoE) Large Language Models (LLMs) Ling-Lite. This study demonstrates that through meticulous high-quality data curation and ingenious training paradigms, the compact MoE model Ling-Lite can be further trained to achieve exceptional reasoning capabilities, while maintaining its parameter-efficient architecture with only 2.75 billion activated parameters, establishing an efficient lightweight reasoning architecture. In particular, in constructing this model, we have not merely focused on enhancing advanced reasoning capabilities, exemplified by high-difficulty mathematical problem solving, but rather aimed to develop a reasoning model with more comprehensive competency coverage. Our approach ensures coverage across reasoning tasks of varying difficulty levels while preserving generic capabilities, such as instruction following, tool use, and knowledge retention. We show that, Ring-Lite-Distill’s reasoning ability reaches a level comparable to DeepSeek-R1-Distill-Qwen-7B, while its general capabilities significantly surpass those of DeepSeek-R1-Distill-Qwen-7B. The models are accessible at https://huggingface.co/inclusionAI
本技术报告介绍了Ring-Lite-Distill,这是一个轻量级的推理模型,源于我们开源的混合专家(MoE)大型语言模型(LLM)Ling-Lite。这项研究表明,通过精心的高质量数据收集和巧妙的训练模式,紧凑的MoE模型Ling-Lite可以进一步训练,实现出色的推理能力,同时保持其参数高效的架构,仅有2.75亿个激活参数,建立了有效的轻量化推理架构。在构建此模型时,我们不仅仅专注于提高解决高难度数学问题的先进推理能力,而是致力于开发具有更全面能力覆盖范围的推理模型。我们的方法确保了不同难度级别的推理任务的覆盖,同时保留了一般能力,例如指令遵循、工具使用和知识保留。我们证明,Ring-Lite-Distill的推理能力与DeepSeek-R1-Distill-Qwen-7B相当,而其一般能力则显著超过了DeepSeek-R1-Distill-Qwen-7B。模型可在https://huggingface.co/inclusionAI访问。
论文及项目相关链接
PDF Based on the further discussion of the working group, the current version is deemed unsuitable for release. We are currently undertaking further work that is expected to involve significant revisions, but this process will require some additional time. We plan to proceed with the release once these updates have been fully implemented
Summary
Ring-Lite-Distill模型是Mixture-of-Experts(MoE)的一种轻量级推理模型,基于开源的大型语言模型Ling-Lite。该模型通过高质量数据整合和创新训练模式,实现了高效的参数利用,拥有出色的推理能力,同时仅包含2.75亿激活参数。该模型不仅关注高难度数学问题的推理能力,还致力于发展具有全面能力的推理模型,确保覆盖不同难度的推理任务,并保留通用能力,如指令遵循、工具使用和知识保留。其推理能力与DeepSeek-R1-Distill-Qwen-7B相当,但一般能力显著超越。
Key Takeaways
- Ring-Lite-Distill是一个基于Mixture-of-Experts的轻量级推理模型。
- 该模型由开源的大型语言模型Ling-Lite衍生而来。
- 通过高质量数据整合和创新训练模式,Ling-Lite进一步训练后展现出卓越的推理能力。
- 该模型仅包含2.75亿激活参数,实现了高效的参数利用。
- Ring-Lite-Distill不仅关注高难度数学问题的推理,还具备全面的能力覆盖。
- 该模型能够应对不同难度的推理任务,同时保留通用能力,如指令遵循、工具使用和知识保留。
点此查看论文截图
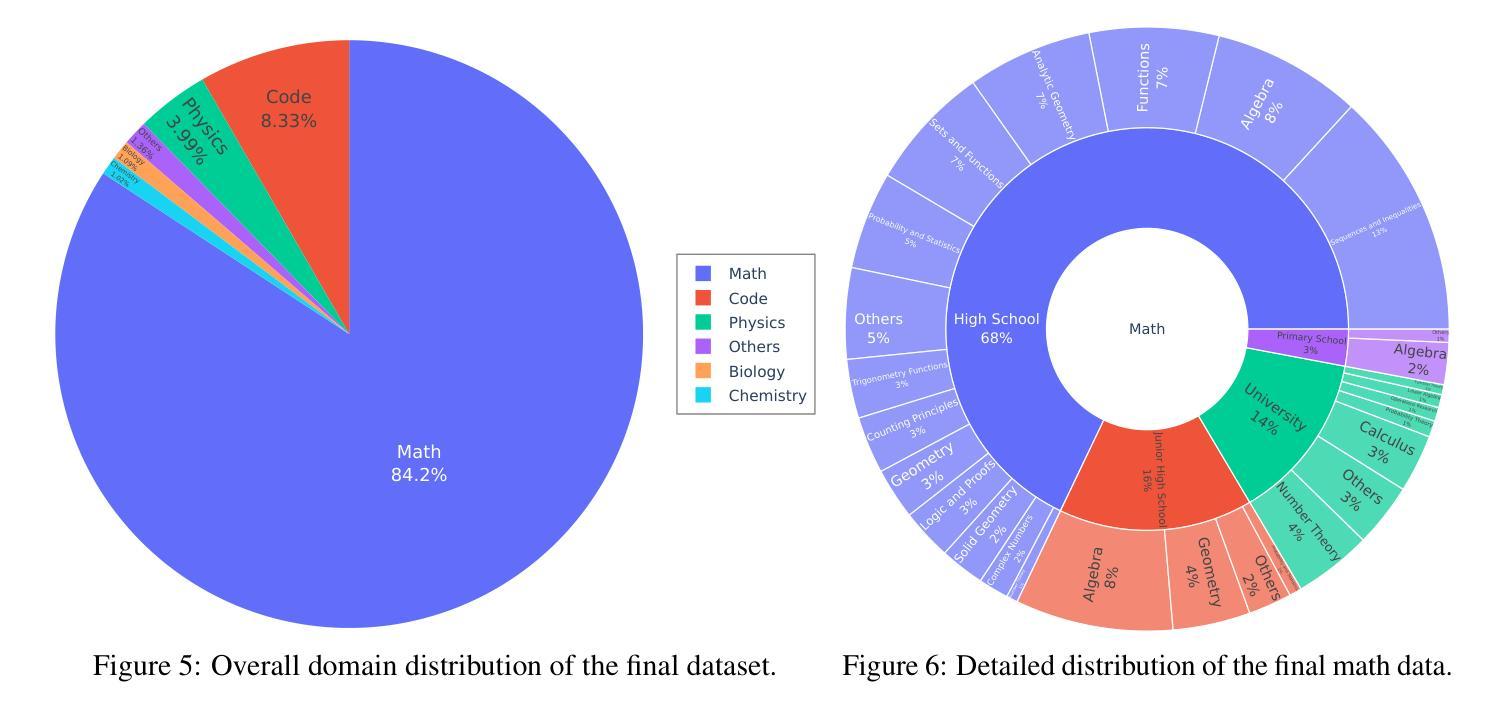
VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks
Authors:Yu Yue, Yufeng Yuan, Qiying Yu, Xiaochen Zuo, Ruofei Zhu, Wenyuan Xu, Jiaze Chen, Chengyi Wang, TianTian Fan, Zhengyin Du, Xiangpeng Wei, Xiangyu Yu, Gaohong Liu, Juncai Liu, Lingjun Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Ru Zhang, Xin Liu, Mingxuan Wang, Yonghui Wu, Lin Yan
We present VAPO, Value-based Augmented Proximal Policy Optimization framework for reasoning models., a novel framework tailored for reasoning models within the value-based paradigm. Benchmarked the AIME 2024 dataset, VAPO, built on the Qwen 32B pre-trained model, attains a state-of-the-art score of $\mathbf{60.4}$. In direct comparison under identical experimental settings, VAPO outperforms the previously reported results of DeepSeek-R1-Zero-Qwen-32B and DAPO by more than 10 points. The training process of VAPO stands out for its stability and efficiency. It reaches state-of-the-art performance within a mere 5,000 steps. Moreover, across multiple independent runs, no training crashes occur, underscoring its reliability. This research delves into long chain-of-thought (long-CoT) reasoning using a value-based reinforcement learning framework. We pinpoint three key challenges that plague value-based methods: value model bias, the presence of heterogeneous sequence lengths, and the sparsity of reward signals. Through systematic design, VAPO offers an integrated solution that effectively alleviates these challenges, enabling enhanced performance in long-CoT reasoning tasks.
我们提出了VAPO,基于价值的增强近端策略优化框架(适用于推理模型)。这是一个针对基于价值的范式中的推理模型的新型框架。使用AIME 2024数据集进行基准测试,VAPO建立在Qwen 32B预训练模型上,达到了最先进的60.4分。在相同的实验设置下直接比较,VAPO的表现优于先前报道的DeepSeek-R1-Zero-Qwen-32B和DAPO的结果超过10分。VAPO的训练过程以稳定性和高效性而脱颖而出。它在短短5000步内达到了最先进的性能。此外,在多次独立运行中,没有发生训练崩溃,证明了其可靠性。本研究深入探讨了基于价值强化学习框架的长链思维(long-CoT)推理。我们确定了困扰基于价值方法的三个关键挑战:价值模型偏见、存在不同的序列长度以及奖励信号的稀疏性。通过系统设计,VAPO提供了一个综合解决方案,有效地缓解了这些挑战,能够在长链思维推理任务中提高性能。
论文及项目相关链接
Summary:
我们提出了针对推理模型的价值基础增强近端策略优化框架VAPO,该框架在价值基础上为推理模型定制。在AIME 2024数据集上进行了基准测试,VAPO建立在Qwen 32B预训练模型上,达到了最先进的60.4分。在相同的实验设置下,VAPO的表现优于DeepSeek-R1-Zero-Qwen-32B和DAPO超过10分。VAPO的训练过程以稳定性和高效性著称,它在短短5000步内达到了最先进的性能。此外,在多次独立运行中,没有出现训练崩溃,证明了其可靠性。本研究深入探讨了价值强化学习框架中的长链思维(long-CoT)推理,并指出了价值基础方法中的三个关键挑战:价值模型偏见、不同序列长度的存在和奖励信号的稀疏性。通过系统设计,VAPO提供了一个有效的综合解决方案来缓解这些挑战,从而在长链思维推理任务中实现了卓越性能。
Key Takeaways:
- VAPO是基于价值基础的增强近端策略优化框架,专为推理模型设计。
- 在AIME 2024数据集上,VAPO达到最先进的60.4分。
- VAPO在相同实验设置下表现出色,优于其他模型。
- VAPO训练过程稳定高效,可在5000步内达到先进性能。
- 在多次独立运行中,VAPO表现出极高的可靠性。
- 研究指出了价值基础方法中的三个关键挑战,包括价值模型偏见、不同序列长度的存在和奖励信号的稀疏性。
点此查看论文截图
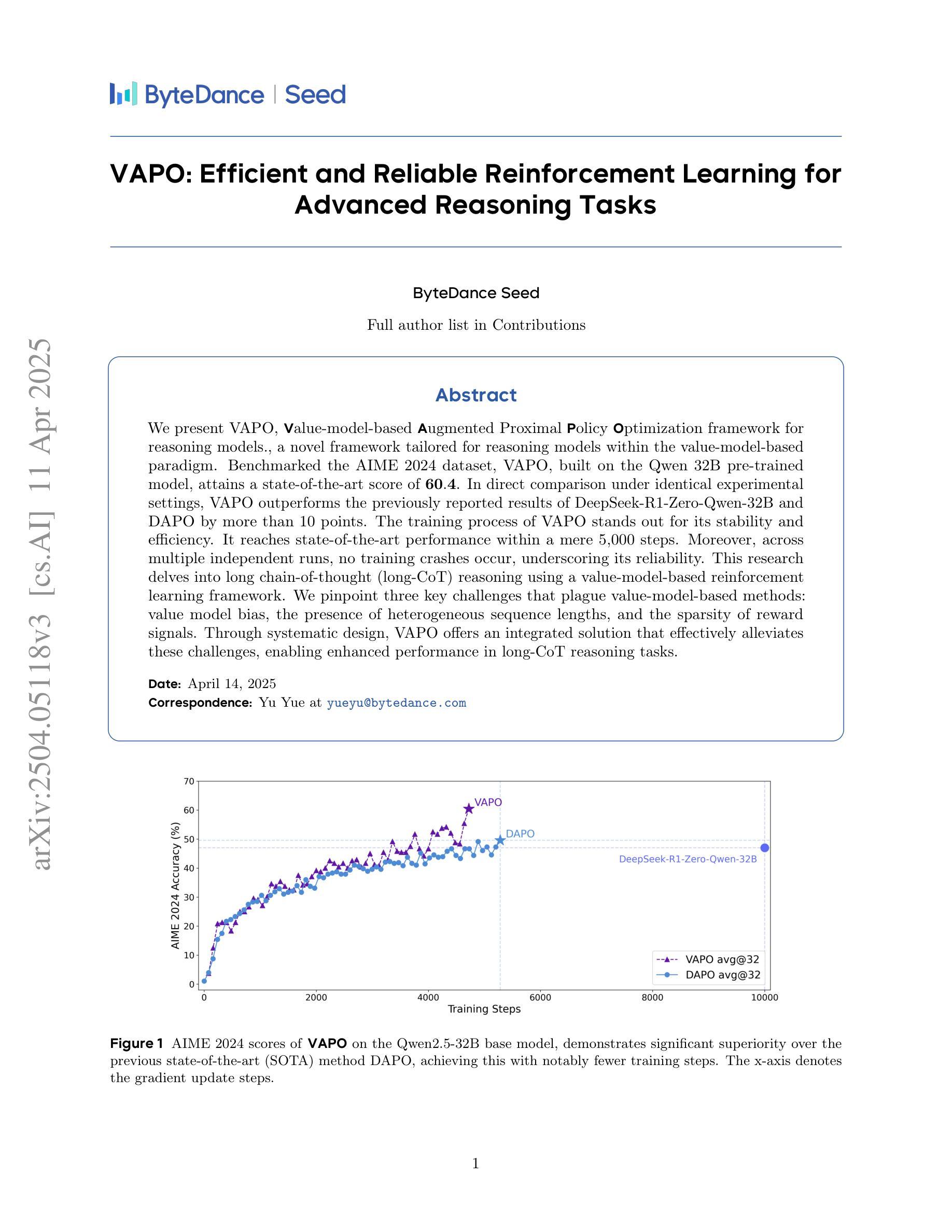
OmniScience: A Domain-Specialized LLM for Scientific Reasoning and Discovery
Authors:Vignesh Prabhakar, Md Amirul Islam, Adam Atanas, Yao-Ting Wang, Joah Han, Aastha Jhunjhunwala, Rucha Apte, Robert Clark, Kang Xu, Zihan Wang, Kai Liu
Large Language Models (LLMs) have demonstrated remarkable potential in advancing scientific knowledge and addressing complex challenges. In this work, we introduce OmniScience, a specialized large reasoning model for general science, developed through three key components: (1) domain adaptive pretraining on a carefully curated corpus of scientific literature, (2) instruction tuning on a specialized dataset to guide the model in following domain-specific tasks, and (3) reasoning-based knowledge distillation through fine-tuning to significantly enhance its ability to generate contextually relevant and logically sound responses. We demonstrate the versatility of OmniScience by developing a battery agent that efficiently ranks molecules as potential electrolyte solvents or additives. Comprehensive evaluations reveal that OmniScience is competitive with state-of-the-art large reasoning models on the GPQA Diamond and domain-specific battery benchmarks, while outperforming all public reasoning and non-reasoning models with similar parameter counts. We further demonstrate via ablation experiments that domain adaptive pretraining and reasoning-based knowledge distillation are critical to attain our performance levels, across benchmarks.
大规模语言模型(LLMs)在推进科学知识和应对复杂挑战方面展现出了显著潜力。在这项工作中,我们介绍了OmniScience,这是一个针对通用科学的专业化大型推理模型,通过三个关键组件开发而成:(1)在精心筛选的科学文献语料库上进行领域自适应预训练;(2)在专门的数据集上进行指令调整,以指导模型执行特定领域的任务;(3)通过微调进行基于推理的知识蒸馏,以显著提高其生成语境相关和逻辑严谨回应的能力。我们通过开发一种电池代理来展示OmniScience的通用性,该代理能够高效地对分子进行排名,作为潜在的电解质溶剂或添加剂。综合评估表明,OmniScience在GPQA Diamond和特定领域的电池基准测试上与最先进的大型推理模型相竞争,同时在参数数量相似的所有公共推理和非推理模型中表现最佳。我们还通过消融实验进一步证明,领域自适应预训练和基于推理的知识蒸馏对于实现我们的性能水平至关重要,跨越各种基准测试。
论文及项目相关链接
Summary
大型语言模型在推动科学知识和应对复杂挑战方面展现出显著潜力。本研究介绍了一款针对通用科学的特殊大型推理模型OmniScience,其开发包括三个关键部分:对科学文献精心筛选的语料库进行领域自适应预训练、在专门数据集上进行指令调整以指导模型执行特定任务,以及通过微调进行基于推理的知识蒸馏,以显著提高其生成上下文相关和逻辑严谨响应的能力。OmniScience的通用性通过开发电池代理得以展示,该代理能够高效地排列分子作为潜在的电解质溶剂或添加剂。综合评估表明,OmniScience在GPQA Diamond和特定电池基准测试上与最新大型推理模型竞争,同时在参数数量相似的公共推理和非推理模型中表现最佳。通过消融实验进一步证明,领域自适应预训练和基于推理的知识蒸馏对于达到我们的性能水平至关重要。
Key Takeaways
- 大型语言模型在推进科学和应对复杂挑战中具有显著潜力。
- OmniScience是一个针对通用科学的特殊大型推理模型。
- OmniScience的开发包括领域自适应预训练、指令调整以及基于推理的知识蒸馏三个关键部分。
- OmniScience展示了在电池代理开发中的通用性,能高效排列分子作为潜在电解质溶剂或添加剂。
- 综合评估显示,OmniScience在多个基准测试中具有竞争力。
- 消融实验证明领域自适应预训练和基于推理的知识蒸馏对OmniScience的性能至关重要。
- OmniScience的开发和评估为大型语言模型在特定领域的应用提供了重要参考。
点此查看论文截图

An Empirical Study of Conformal Prediction in LLM with ASP Scaffolds for Robust Reasoning
Authors:Navdeep Kaur, Lachlan McPheat, Alessandra Russo, Anthony G Cohn, Pranava Madhyastha
In this paper, we examine the use of Conformal Language Modelling (CLM) alongside Answer Set Programming (ASP) to enhance the performance of standard open-weight LLMs on complex multi-step reasoning tasks. Using the StepGame dataset, which requires spatial reasoning, we apply CLM to generate sets of ASP programs from an LLM, providing statistical guarantees on the correctness of the outputs. Experimental results show that CLM significantly outperforms baseline models that use standard sampling methods, achieving substantial accuracy improvements across different levels of reasoning complexity. Additionally, the LLM-as-Judge metric enhances CLM’s performance, especially in assessing structurally and logically correct ASP outputs. However, calibrating CLM with diverse calibration sets did not improve generalizability for tasks requiring much longer reasoning steps, indicating limitations in handling more complex tasks.
在这篇论文中,我们研究了将符合语言建模(CLM)与答案集编程(ASP)结合使用,以提高标准开放权重大型语言模型在复杂多步骤推理任务上的性能。我们利用需要空间推理的StepGame数据集,将CLM应用于从大型语言模型生成ASP程序集,为输出结果的正确性提供统计保证。实验结果表明,与传统的采样方法相比,CLM显著提高了基线模型的性能,在不同层次的推理复杂度上都实现了实质性的准确性提高。此外,大型语言模型作为评判者的指标提高了CLM的性能,特别是在评估结构上和逻辑上正确的ASP输出方面。然而,使用多种校准集对CLM进行校准并没有提高处理需要更多推理步骤的任务的通用性,这表明在处理更复杂的任务时存在局限性。
论文及项目相关链接
Summary
本文探讨了将Conformal语言建模(CLM)与Answer Set Programming(ASP)结合使用,以改善标准开放式大型语言模型(LLM)在复杂多步骤推理任务上的性能。文章使用StepGame数据集来要求空间推理能力,通过CLM生成ASP程序的集合,对输出的正确性提供统计保证。实验结果表明,CLM显著优于使用标准采样方法的基线模型,在不同层次的推理复杂度上实现了实质性的准确性提高。然而,对于需要更长时间推理步骤的任务,使用多种校准集校准CLM并没有提高通用性,这表明其在处理更复杂的任务方面存在局限性。
Key Takeaways
- Conformal语言建模(CLM)与Answer Set Programming(ASP)结合使用,增强了大型语言模型(LLM)在复杂多步骤推理任务上的性能。
- 使用StepGame数据集来测试模型的空间推理能力。
- CLM可以生成ASP程序的集合,并为输出的正确性提供统计保证。
- 实验表明,CLM相较于基线模型在准确性上有显著提高。
- LLM-as-Judge指标提高了CLM在评估ASP输出结构和逻辑正确性方面的性能。
- 使用多种校准集对CLM进行校准并未在提高需要更长时间推理步骤的任务的通用性方面显示出效果。
点此查看论文截图

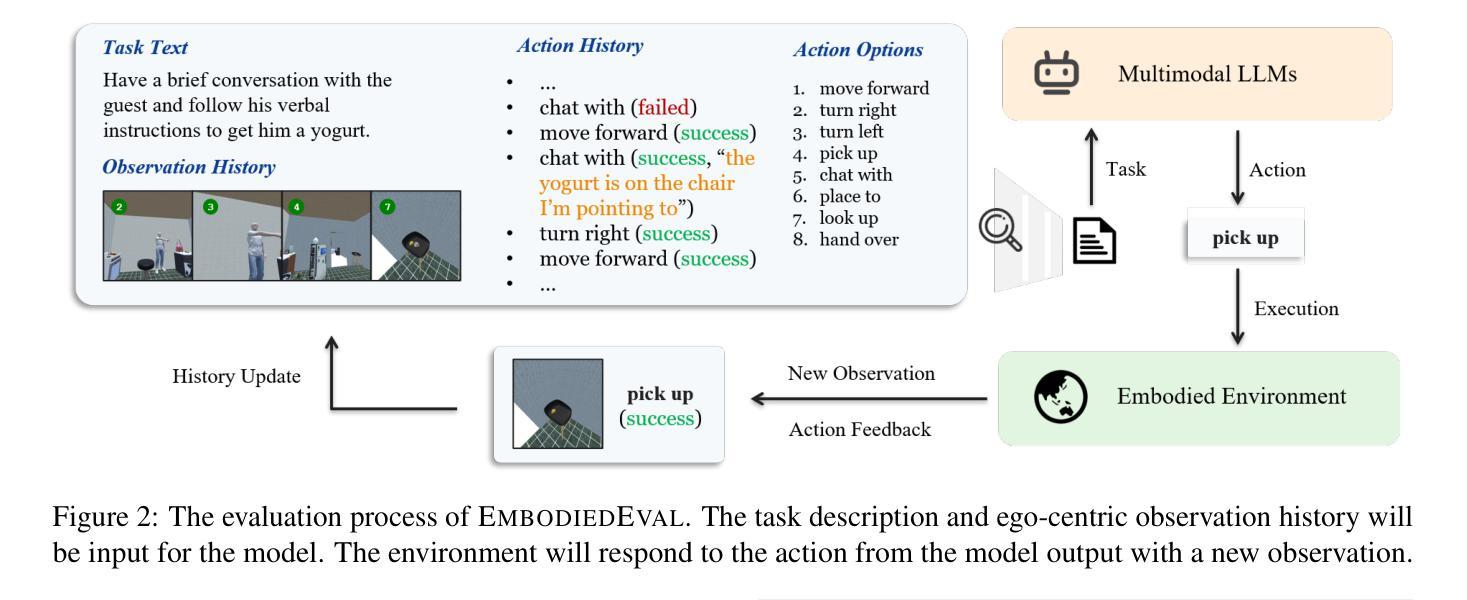
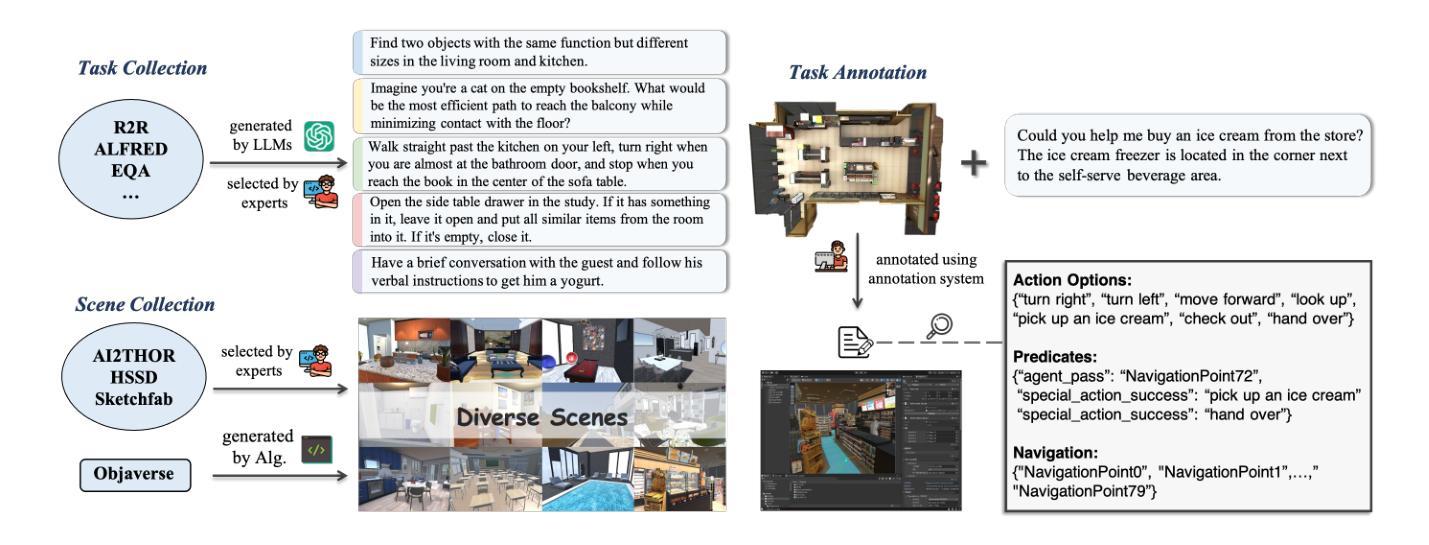
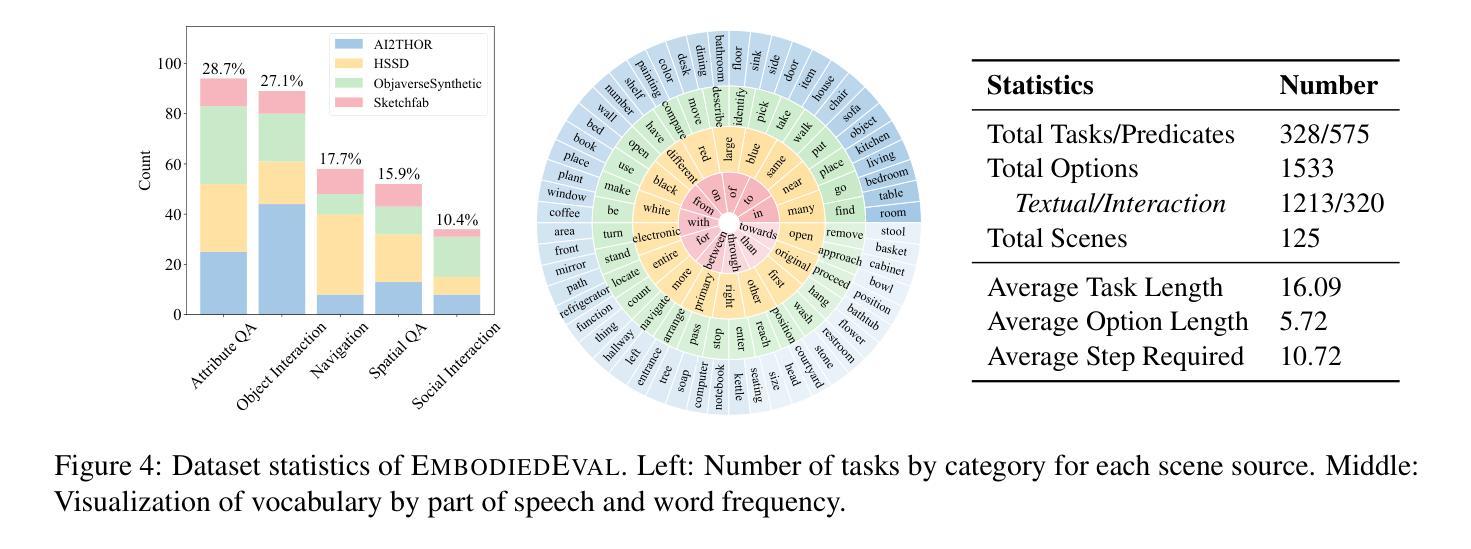
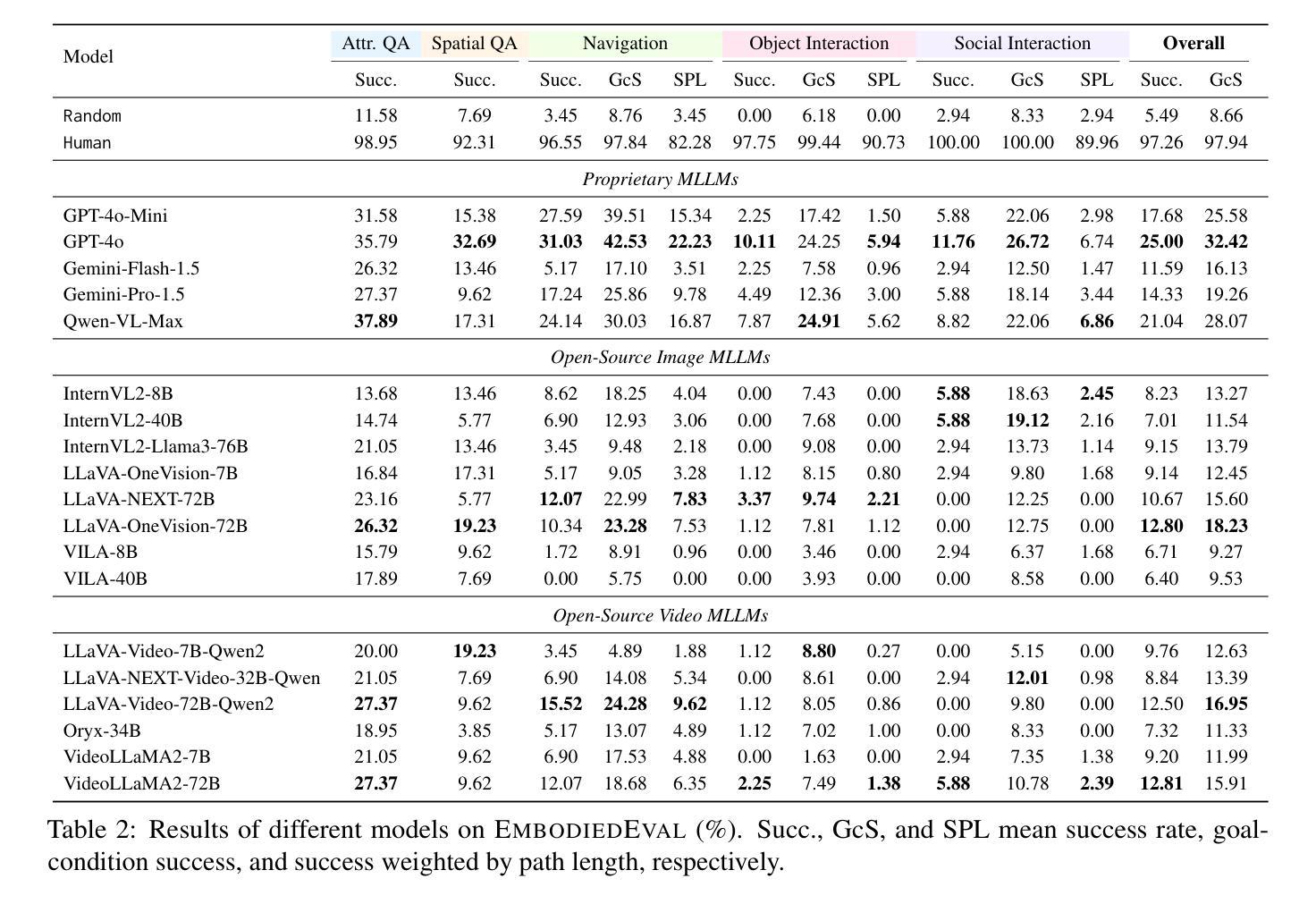
EmbodiedEval: Evaluate Multimodal LLMs as Embodied Agents
Authors:Zhili Cheng, Yuge Tu, Ran Li, Shiqi Dai, Jinyi Hu, Shengding Hu, Jiahao Li, Yang Shi, Tianyu Yu, Weize Chen, Lei Shi, Maosong Sun
Multimodal Large Language Models (MLLMs) have shown significant advancements, providing a promising future for embodied agents. Existing benchmarks for evaluating MLLMs primarily utilize static images or videos, limiting assessments to non-interactive scenarios. Meanwhile, existing embodied AI benchmarks are task-specific and not diverse enough, which do not adequately evaluate the embodied capabilities of MLLMs. To address this, we propose EmbodiedEval, a comprehensive and interactive evaluation benchmark for MLLMs with embodied tasks. EmbodiedEval features 328 distinct tasks within 125 varied 3D scenes, each of which is rigorously selected and annotated. It covers a broad spectrum of existing embodied AI tasks with significantly enhanced diversity, all within a unified simulation and evaluation framework tailored for MLLMs. The tasks are organized into five categories: navigation, object interaction, social interaction, attribute question answering, and spatial question answering to assess different capabilities of the agents. We evaluated the state-of-the-art MLLMs on EmbodiedEval and found that they have a significant shortfall compared to human level on embodied tasks. Our analysis demonstrates the limitations of existing MLLMs in embodied capabilities, providing insights for their future development. We open-source all evaluation data and simulation framework at https://github.com/thunlp/EmbodiedEval.
多模态大型语言模型(MLLMs)已经取得了显著进展,为实体智能体提供了美好的未来前景。现有的评估MLLM的基准测试主要使用静态图像或视频,仅限于非交互式场景。同时,现有的实体人工智能基准测试是特定任务的,并不够多样化,不能充分评估MLLMs的实体能力。为了解决这一问题,我们提出了EmbodiedEval,这是一个全面且交互式的评估基准测试,适用于具有实体任务的MLLMs。EmbodiedEval在统一的模拟框架内拥有特定的标准程序包括通过精准的挑选和注释设计成的共涵盖导览、对象互动、社交互动等十二个主题的具有3D环境的任务的设定328项不同任务。该框架涵盖了广泛的现有实体人工智能任务,具有显著增强的多样性。任务分为五大类:导航、对象交互、社交交互、属性问答和空间问答,以评估智能体的不同能力。我们在EmbodiedEval上评估了最新的MLLMs,发现它们在实体任务上与人类水平存在明显差距。我们的分析揭示了现有MLLM在实体能力方面的局限性,为未来的开发提供了见解。我们公开所有评估数据和模拟框架https://github.com/thunlp/EmbodiedEval。
论文及项目相关链接
Summary
本文提出一种名为EmbodiedEval的综合性交互式评估基准,用于对多模态大型语言模型(MLLMs)的实体能力进行评估。EmbodiedEval包含125个不同的3D场景中的328个独特任务,涵盖广泛的现有实体AI任务,具有显著增强的多样性,并为MLLMs量身定制了统一的模拟和评估框架。对现有MLLMs在EmbodiedEval上的评估表明,与人类水平相比,它们在实体任务上存在显著差距。这为未来MLLMs的发展提供了见解。
Key Takeaways
- 多模态大型语言模型(MLLMs)在实体能力方面展现出显著进展。
- 当前评估基准主要利用静态图像或视频,限制在非交互式场景,无法充分评估MLLMs的实体能力。
- EmbodiedEval是一个全面的交互式评估基准,旨在为MLLMs的实体能力进行评估。
- EmbodiedEval包含328个独特任务,分布在125个不同的3D场景中,涵盖广泛的实体AI任务,并显著增强了多样性。
- EmbodiedEval的任务分为五个类别:导航、物体交互、社交交互、属性问题回答和空间问题回答,以评估实体的不同能力。
- 对现有MLLMs在EmbodiedEval上的评估显示,它们在实体任务上的表现与人类水平存在显著差距。
点此查看论文截图



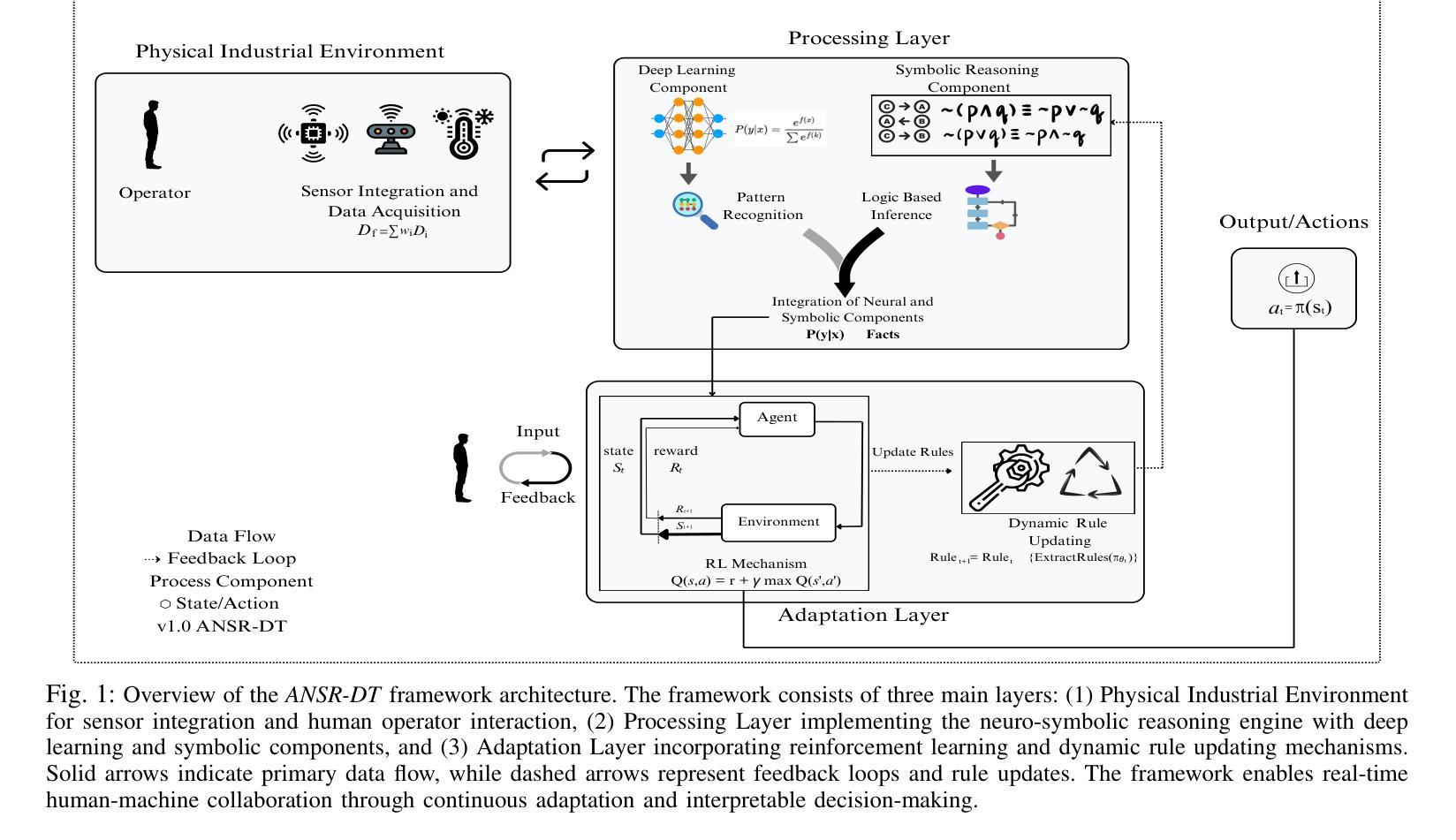
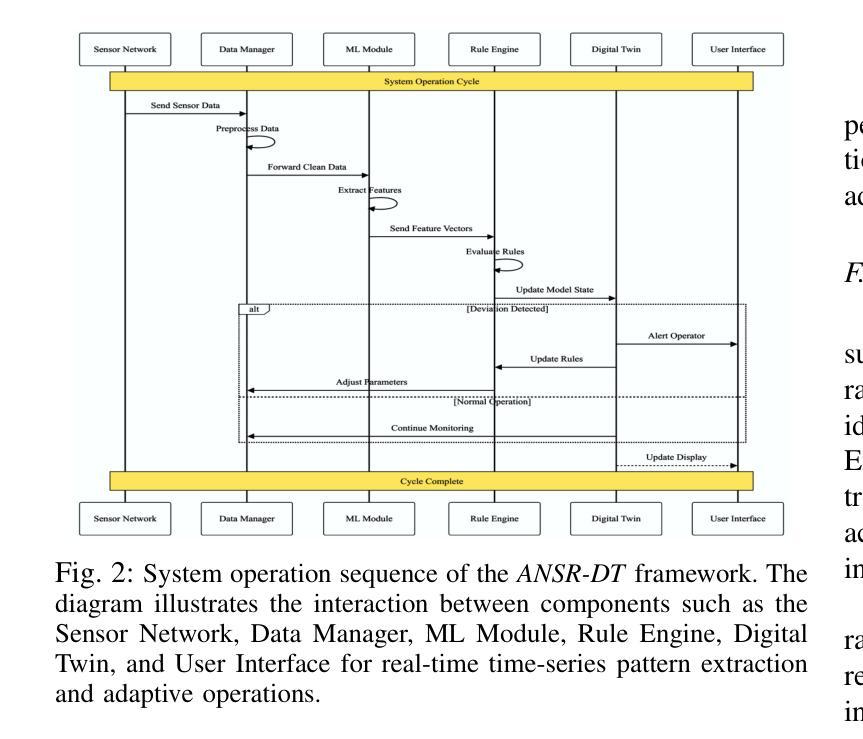
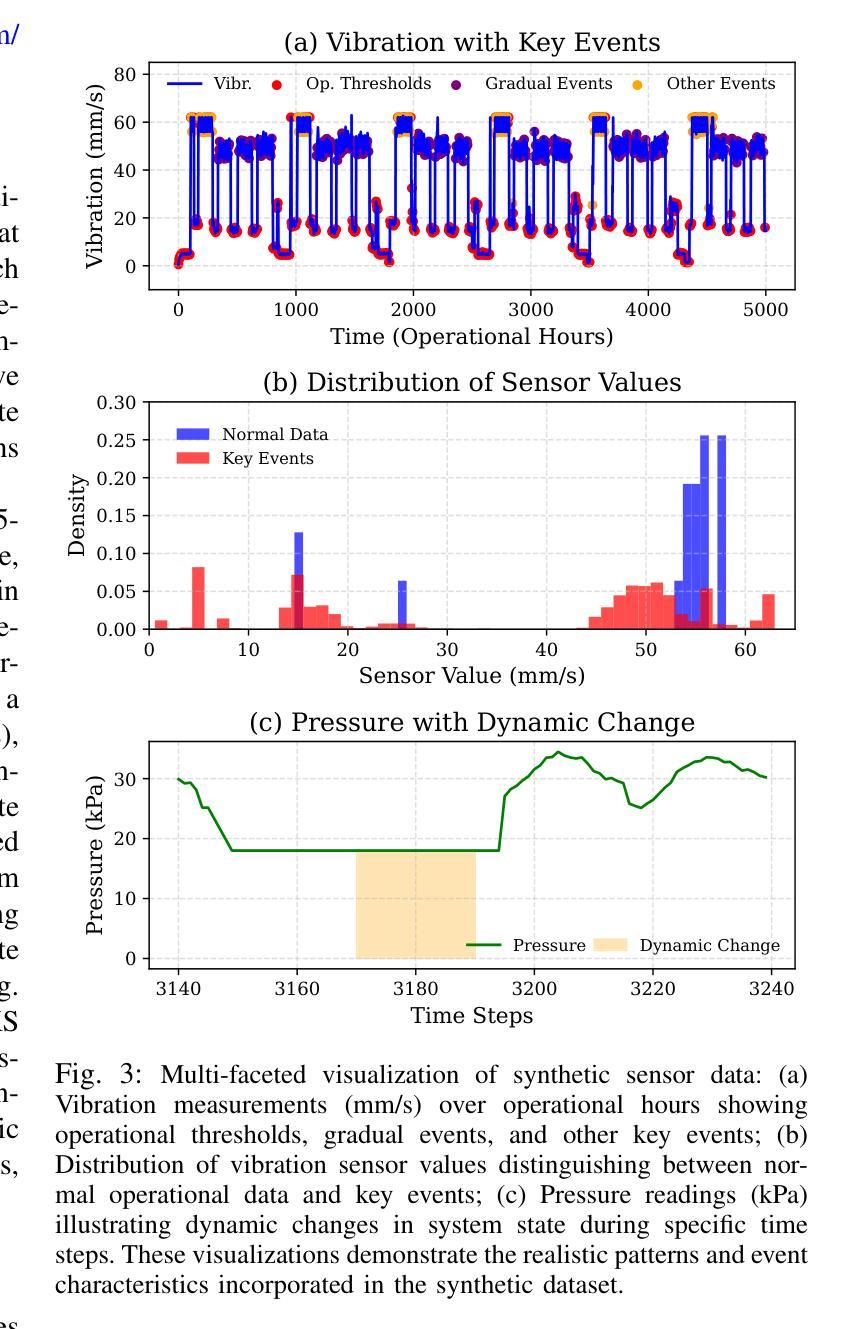
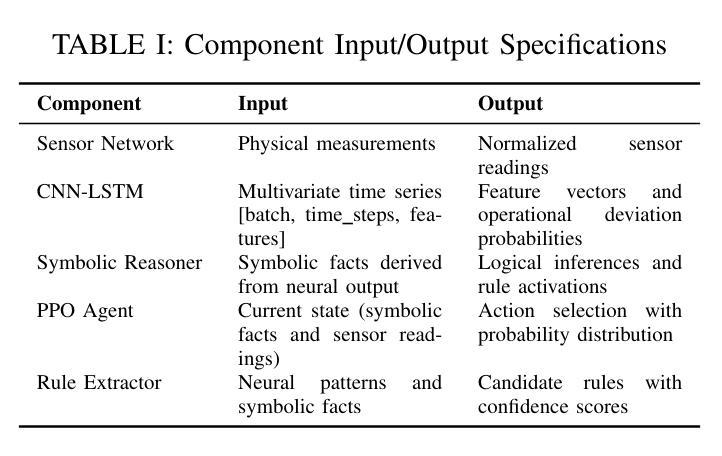
ANSR-DT: An Adaptive Neuro-Symbolic Learning and Reasoning Framework for Digital Twins
Authors:Safayat Bin Hakim, Muhammad Adil, Alvaro Velasquez, Houbing Herbert Song
In this paper, we propose an Adaptive Neuro-Symbolic Learning and Reasoning Framework for digital twin technology called ``ANSR-DT.” Digital twins in industrial environments often struggle with interpretability, real-time adaptation, and human input integration. Our approach addresses these challenges by combining CNN-LSTM dynamic event detection with reinforcement learning and symbolic reasoning to enable adaptive intelligence with interpretable decision processes. This integration enhances environmental understanding while promoting continuous learning, leading to more effective real-time decision-making in human-machine collaborative applications. We evaluated ANSR-DT on synthetic industrial data, observing significant improvements over traditional approaches, with up to 99.5% accuracy for dynamic pattern recognition. The framework demonstrated superior adaptability with extended reinforcement learning training, improving explained variance from 0.447 to 0.547. Future work aims at scaling to larger datasets to test rule management beyond the current 14 rules. Our open-source implementation promotes reproducibility and establishes a foundation for future research in adaptive, interpretable digital twins for industrial applications.
本文提出了一种用于数字孪生技术的自适应神经符号学习与推理框架,名为“ANSR-DT”。工业环境中的数字孪生经常面临可解释性、实时自适应和人为输入集成方面的挑战。我们的方法通过结合CNN-LSTM动态事件检测与强化学习和符号推理来解决这些挑战,以实现具有可解释决策过程的自适应智能。这种集成增强了环境理解,同时促进了持续学习,从而在人机协作应用中实现了更有效的实时决策。我们在合成工业数据上评估了ANSR-DT,观察到与传统方法的显著改进,动态模式识别的准确率高达99.5%。该框架在扩展的强化学习训练中表现出出色的适应性,解释的方差从0.447提高到0.547。未来的工作旨在扩展到更大的数据集,以测试当前14条规则之外的规则管理。我们的开源实现促进了可重复性,并为未来在自适应、可解释的数字孪生工业应用方面的研究奠定了基础。
论文及项目相关链接
Summary
基于数字孪生技术的自适应神经符号学习与推理框架研究,提出了名为“ANSR-DT”的框架。该框架解决了数字孪生在工业环境中面临的解释性、实时自适应和人类输入集成等挑战。通过结合CNN-LSTM动态事件检测、强化学习与符号推理,实现了具有可解释决策过程的自适应智能。在合成工业数据上的评估显示,与传统方法相比,ANSR-DT在动态模式识别方面实现了高达99.5%的准确率,并展现出卓越的适应性与更强的解释方差。未来工作将致力于扩大数据集规模,测试规则管理超越当前14条规则的应用场景。该开源实现促进了可重复性,并为未来研究自适应、可解释的工业应用数字孪生技术奠定了基础。
Key Takeaways
- 提出了一种名为“ANSR-DT”的自适应神经符号学习与推理框架,用于解决数字孪生技术在工业环境中的多重挑战。
- 结合CNN-LSTM动态事件检测与强化学习,增强了环境理解并促进了持续学习。
- 通过符号推理实现了可解释的决策过程,有助于提升实时决策效率在人机协作应用中。
- 在合成工业数据上的评估结果显示,ANSR-DT在动态模式识别上具有显著优势,准确率高达99.5%。
- 框架展现出卓越的适应性,通过扩展强化学习训练,解释方差得到了改善。
- 目前工作局限在于规则管理的数据集规模较小,未来研究将拓展至更大规模数据集。
点此查看论文截图