⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-15 更新
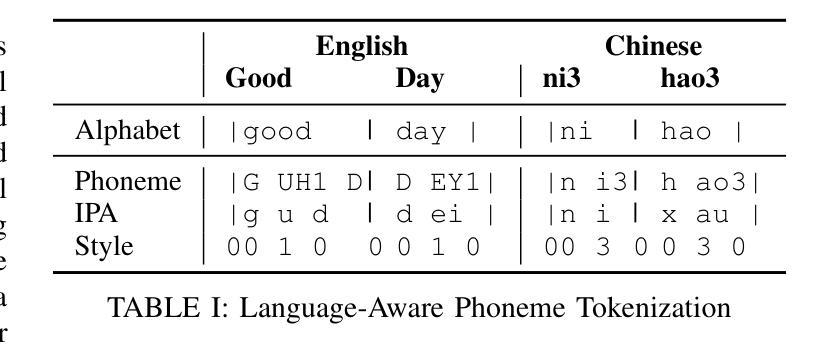
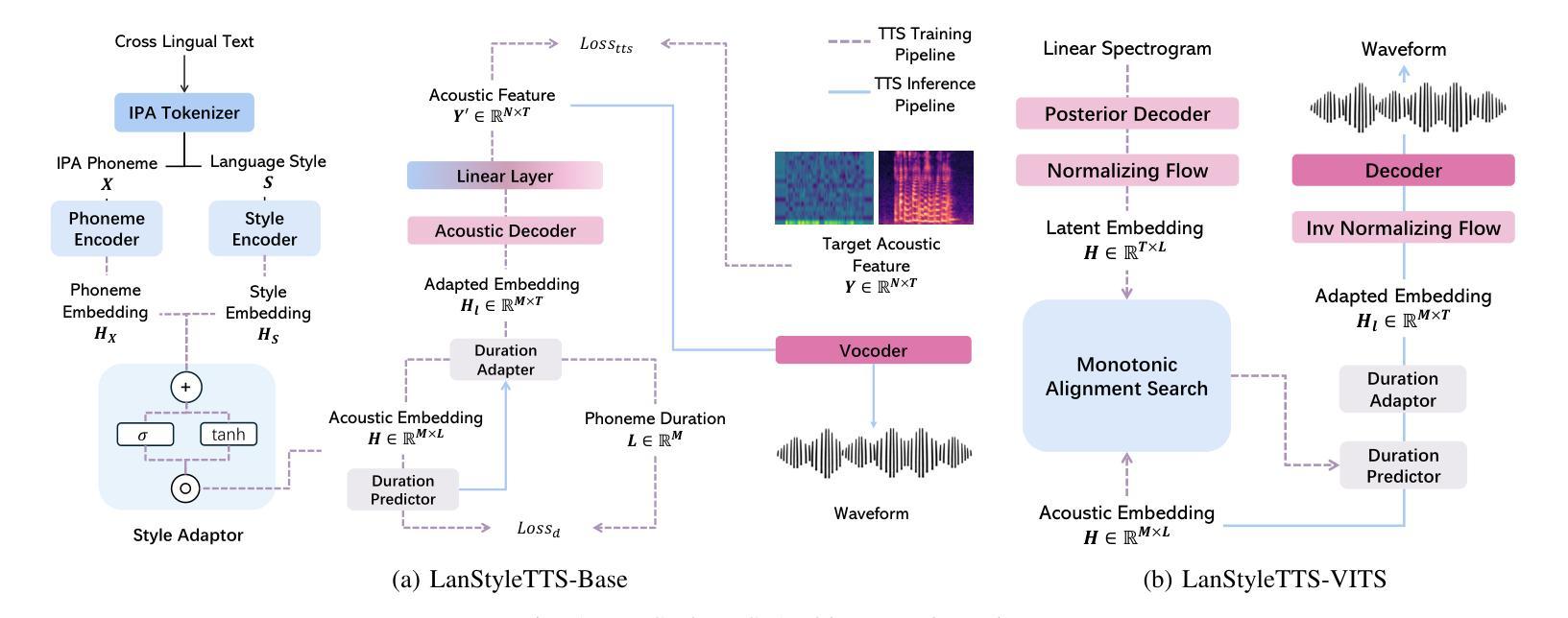
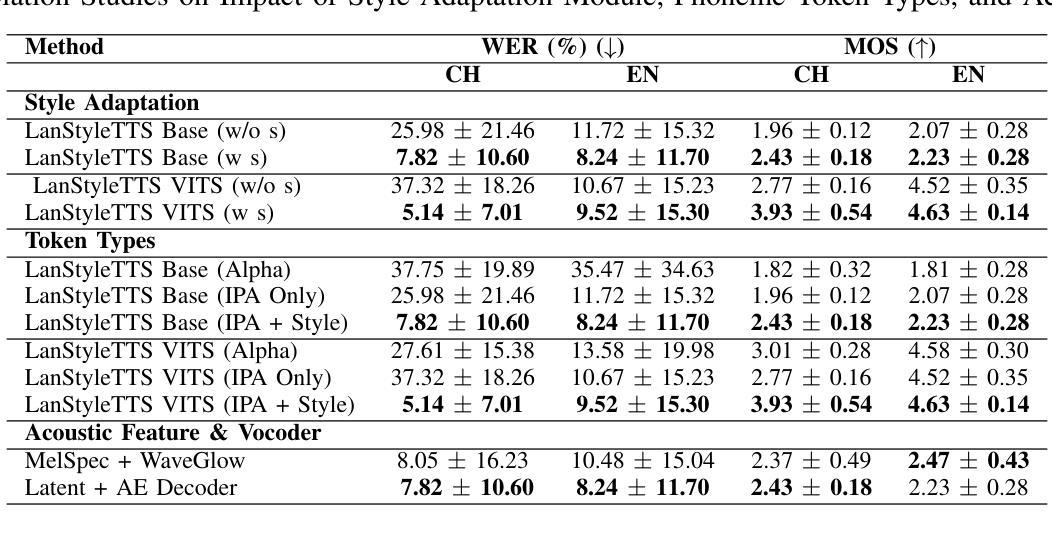
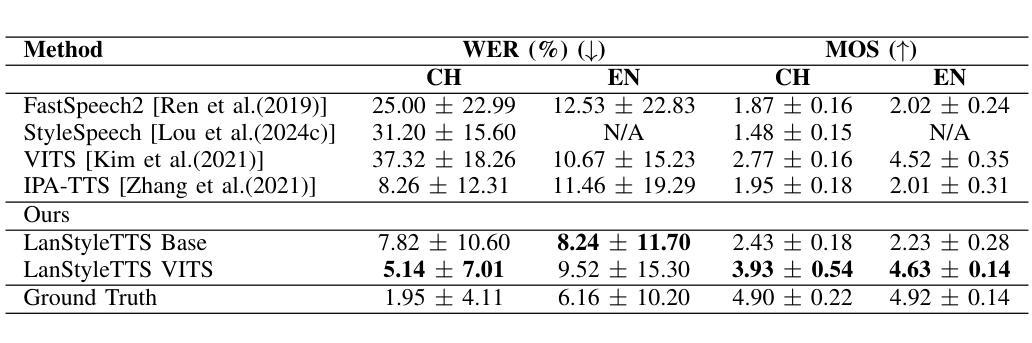
Generalized Multilingual Text-to-Speech Generation with Language-Aware Style Adaptation
Authors:Haowei Lou, Hye-young Paik, Sheng Li, Wen Hu, Lina Yao
Text-to-Speech (TTS) models can generate natural, human-like speech across multiple languages by transforming phonemes into waveforms. However, multilingual TTS remains challenging due to discrepancies in phoneme vocabularies and variations in prosody and speaking style across languages. Existing approaches either train separate models for each language, which achieve high performance at the cost of increased computational resources, or use a unified model for multiple languages that struggles to capture fine-grained, language-specific style variations. In this work, we propose LanStyleTTS, a non-autoregressive, language-aware style adaptive TTS framework that standardizes phoneme representations and enables fine-grained, phoneme-level style control across languages. This design supports a unified multilingual TTS model capable of producing accurate and high-quality speech without the need to train language-specific models. We evaluate LanStyleTTS by integrating it with several state-of-the-art non-autoregressive TTS architectures. Results show consistent performance improvements across different model backbones. Furthermore, we investigate a range of acoustic feature representations, including mel-spectrograms and autoencoder-derived latent features. Our experiments demonstrate that latent encodings can significantly reduce model size and computational cost while preserving high-quality speech generation.
文本转语音(TTS)模型可以通过将音素转换为波形来生成多种自然语言、类似人类的语音。然而,由于音素词汇的差异以及跨语言的韵律和说话风格的差异,多语言TTS仍然具有挑战性。现有方法要么为每种语言训练单独模型(虽然计算资源消耗大但性能高),要么使用针对多种语言的统一模型(难以捕捉精细的语言特定风格变化)。在这项工作中,我们提出了LanStyleTTS,这是一个非自回归、语言感知的风格自适应TTS框架,它标准化了音素表示,并实现了跨语言的精细音素级风格控制。这种设计支持统一的多语言TTS模型,无需训练特定语言的模型即可产生准确且高质量的语音。我们将LanStyleTTS与几种最新的非自回归TTS架构进行集成,评估其性能。结果表明,在不同的模型主干上均实现了性能改进。此外,我们还研究了一系列声学特征表示,包括梅尔频谱和自动编码器衍生的潜在特征。我们的实验表明,潜在编码可以显著减小模型大小并降低计算成本,同时保持高质量语音生成。
论文及项目相关链接
Summary
本文提出一种非自回归、语言感知的风格自适应文本转语音(TTS)框架——LanStyleTTS,用于标准化语音表现并支持跨语言的细粒度语音风格控制。该框架支持统一的多语言TTS模型,无需训练特定语言的模型即可产生准确、高质量的语音。
Key Takeaways
- LanStyleTTS是一个非自回归、语言感知的TTS框架,可以生成自然、人类化的跨语言语音。
- 它通过转换语音为波形来支持多种语言。
- LanStyleTTS解决了多语言TTS中的挑战,如语音词汇的差异和跨语言的韵律和说话风格的差异。
- 该框架提出了一个统一的多语言TTS模型,能够在无需训练特定语言模型的情况下,产生高质量语音。
- LanStyleTTS通过标准化语音表现,实现了细粒度的语音风格控制。
- 实验表明,潜在编码可以显著减小模型大小并降低计算成本,同时保持高质量语音生成。
点此查看论文截图

MathSpeech: Leveraging Small LMs for Accurate Conversion in Mathematical Speech-to-Formula
Authors:Sieun Hyeon, Kyudan Jung, Jaehee Won, Nam-Joon Kim, Hyun Gon Ryu, Hyuk-Jae Lee, Jaeyoung Do
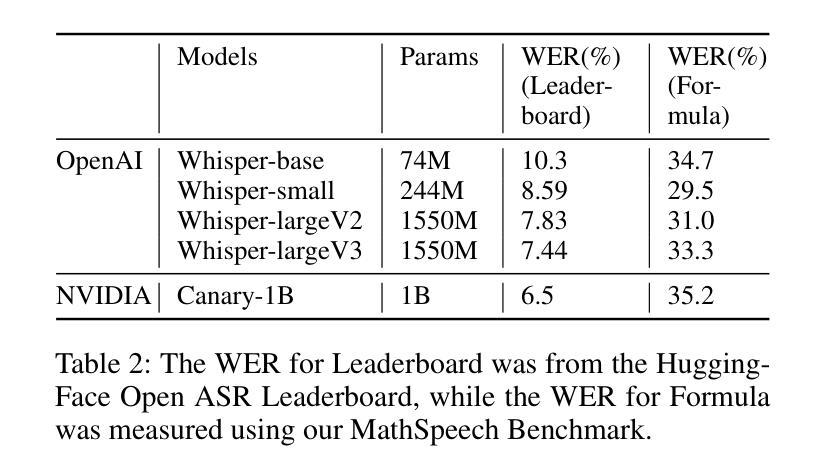
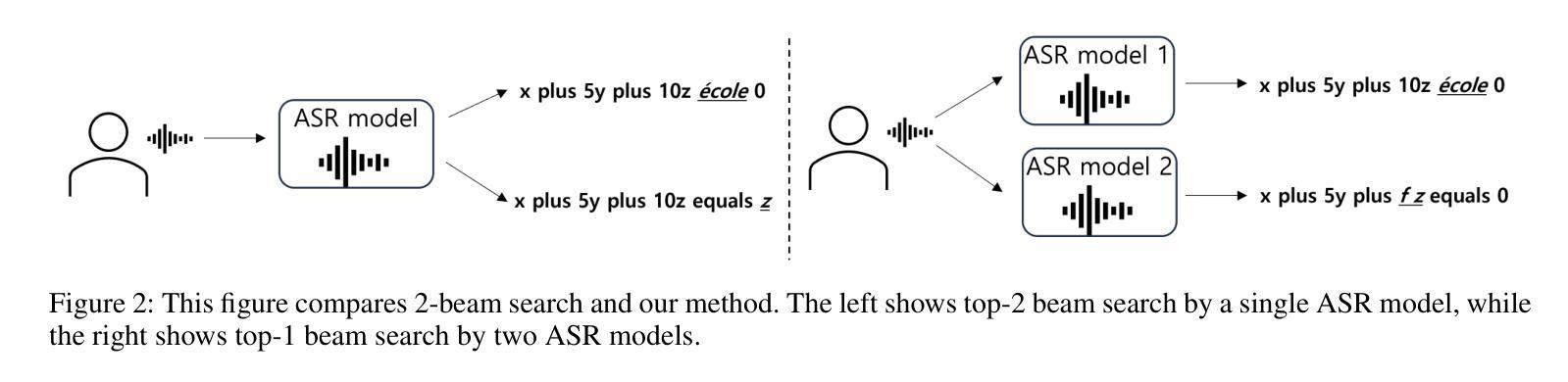
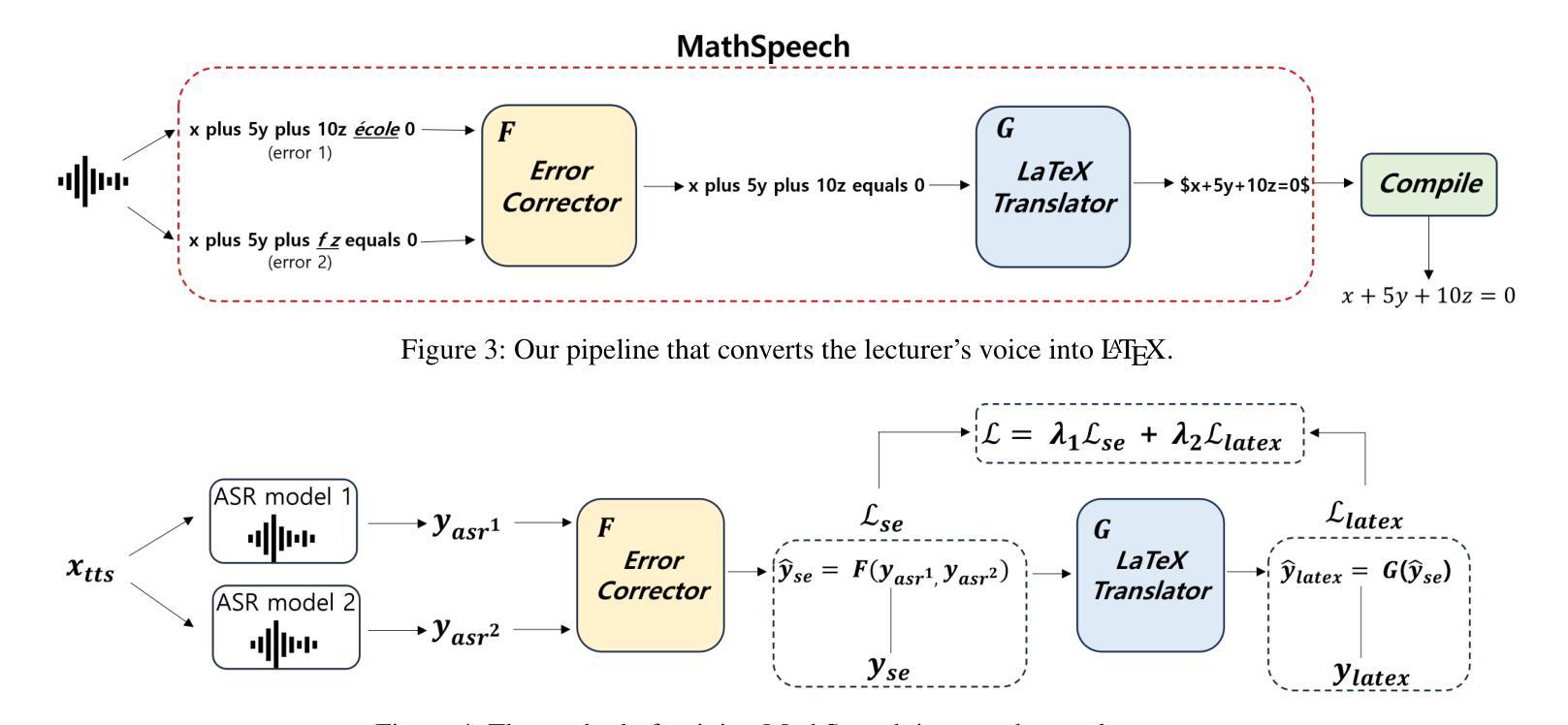
In various academic and professional settings, such as mathematics lectures or research presentations, it is often necessary to convey mathematical expressions orally. However, reading mathematical expressions aloud without accompanying visuals can significantly hinder comprehension, especially for those who are hearing-impaired or rely on subtitles due to language barriers. For instance, when a presenter reads Euler’s Formula, current Automatic Speech Recognition (ASR) models often produce a verbose and error-prone textual description (e.g., e to the power of i x equals cosine of x plus i $\textit{side}$ of x), instead of the concise $\LaTeX{}$ format (i.e., $ e^{ix} = \cos(x) + i\sin(x) $), which hampers clear understanding and communication. To address this issue, we introduce MathSpeech, a novel pipeline that integrates ASR models with small Language Models (sLMs) to correct errors in mathematical expressions and accurately convert spoken expressions into structured $\LaTeX{}$ representations. Evaluated on a new dataset derived from lecture recordings, MathSpeech demonstrates $\LaTeX{}$ generation capabilities comparable to leading commercial Large Language Models (LLMs), while leveraging fine-tuned small language models of only 120M parameters. Specifically, in terms of CER, BLEU, and ROUGE scores for $\LaTeX{}$ translation, MathSpeech demonstrated significantly superior capabilities compared to GPT-4o. We observed a decrease in CER from 0.390 to 0.298, and higher ROUGE/BLEU scores compared to GPT-4o.
在各种学术和专业场合,如数学讲座或研究报告会中,口头传达数学表达式是常见的需求。然而,在没有视觉辅助的情况下大声阅读数学表达式可能会显著阻碍理解,特别是对于听力受损或由于语言障碍依赖字幕的人来说。例如,当演讲者读出欧拉公式时,当前的自动语音识别(ASR)模型往往会生成冗长和易出错的文本描述(例如,“e的i乘以x次方等于x的余弦值加上i倍的x的正弦值”),而不是简洁的LaTeX格式(即,$ e^{ix} = \cos(x) + i\sin(x) $)。这阻碍了清晰的理解和沟通。为了解决这一问题,我们引入了MathSpeech,这是一种新型管道,它将ASR模型与小语言模型(sLMs)集成在一起,以纠正数学表达式中的错误,并将口头表达式准确转换为结构化的LaTeX表示。在新的基于讲座录音的数据集上进行评估,MathSpeech展示了与领先的商业大型语言模型(LLMs)相当的LaTeX生成能力,同时利用仅包含1.2亿参数的微调小型语言模型。具体来说,在LaTeX翻译的CER、BLEU和ROUGE得分方面,MathSpeech相较于GPT-4o表现出了显著的优势。我们观察到CER从0.390降至0.298,并且相较于GPT-4o具有更高的ROUGE/BLEU得分。
论文及项目相关链接
PDF Accepted at AAAI 2025
Summary
本文介绍了一种名为MathSpeech的新技术,它通过结合ASR模型和较小的语言模型(sLMs)来提高数学表达式的语音识别精度和效率。它能准确地将口头表达的数学表达式转化为结构化的LaTeX格式,适用于数学讲座和研究报告等场景。在讲座录音衍生的新数据集上进行的评估显示,MathSpeech在LaTeX生成能力方面表现出与主流大型语言模型(LLMs)相当的竞争力,并且能利用仅包含12亿参数的精细调整的小型语言模型实现这一性能。相较于GPT-4o,MathSpeech的CER评分从原来的降低至更低的水平,而ROUGE和BLEU评分也显著提高了对于LaTeX的翻译质量。此外,它通过校正误差、促进理解的优势对于听力受损和语言障碍者特别有益。这一技术有助于提升学术和专业环境中的口头交流效率和准确性。总结不足百字:MathSpeech技术融合ASR模型和sLMs,将口头数学表达式准确转为LaTeX格式,显著提高理解力并改善沟通障碍问题。在测试集上性能优于GPT-4o。
Key Takeaways
- MathSpeech技术结合了ASR模型和较小的语言模型(sLMs),用于处理口头表达的数学表达式。
- 该技术可将数学表达式准确转化为结构化的LaTeX格式,提升理解和沟通效率。
- MathSpeech在LaTeX生成能力方面表现出显著优势,优于GPT-4o等传统模型。
- 该技术在听力受损和语言障碍人士的口头交流中具有潜在应用优势。其优越性体现在准确度改善,尤其在数学表达式识别方面效果突出。
- MathSpeech使用的语言模型具有精细调整的优势,参数仅为常规的十分之一不到(仅包含约十亿分之一的参数)。这降低了计算资源需求并可能促进更广泛的应用。
- MathSpeech技术在新的数据集上进行了评估,显示其在识别精确度上显著提高,特别是CER评分显著降低至低于现有模型水平。同时ROUGE和BLEU评分也显著提高,表明其在处理数学表达式的翻译质量方面有明显进步。
点此查看论文截图

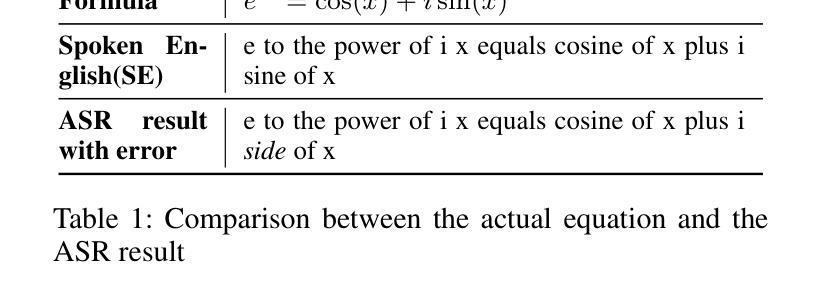



DiMoDif: Discourse Modality-information Differentiation for Audio-visual Deepfake Detection and Localization
Authors:Christos Koutlis, Symeon Papadopoulos
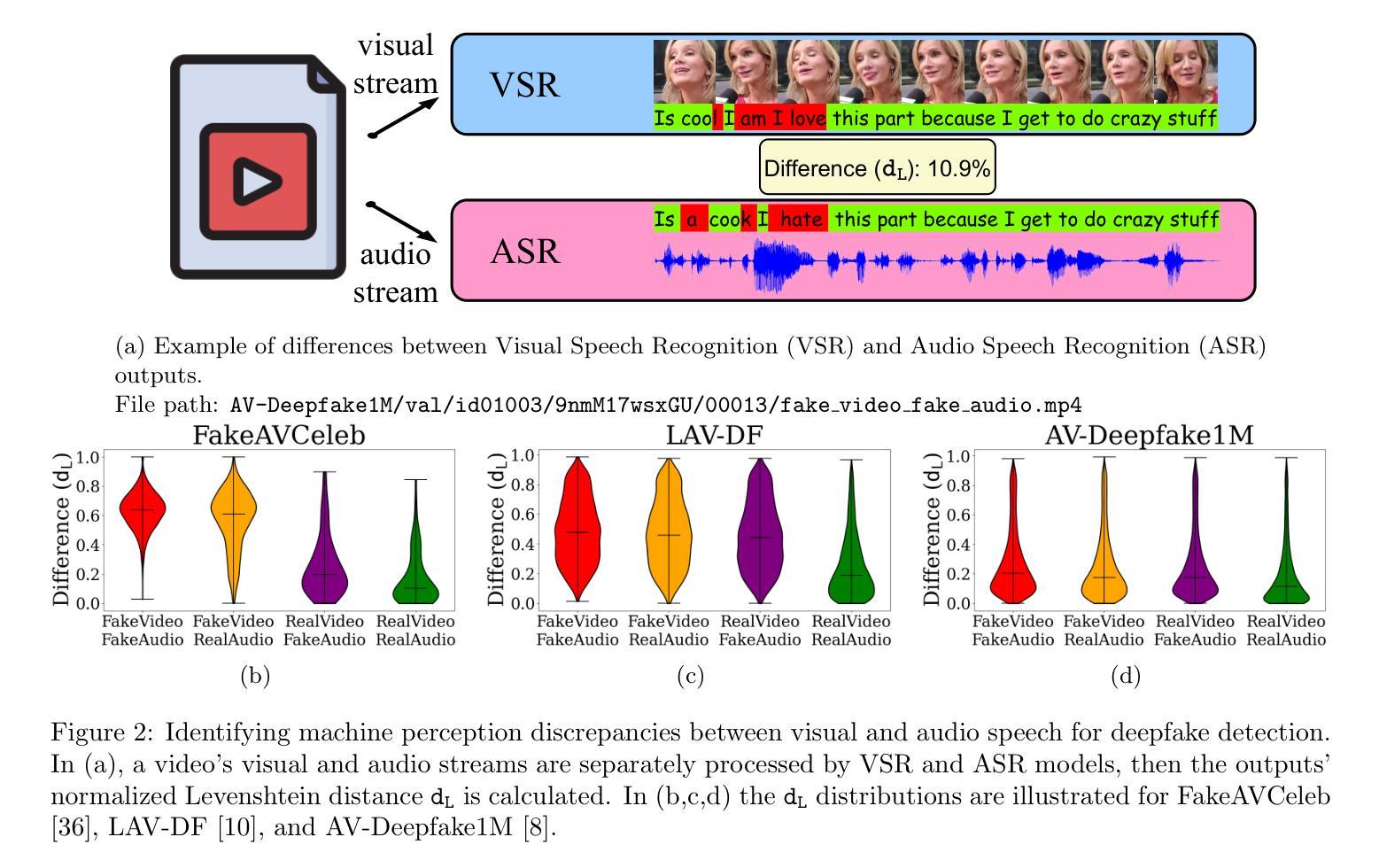
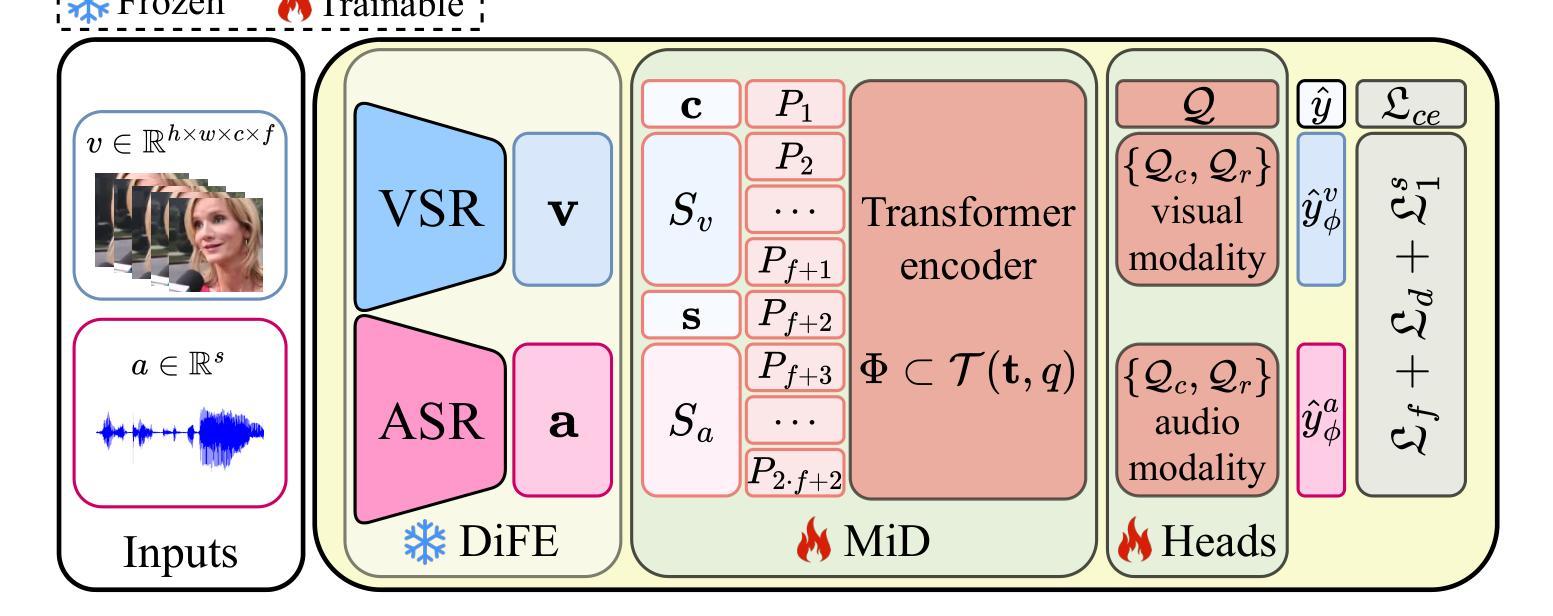
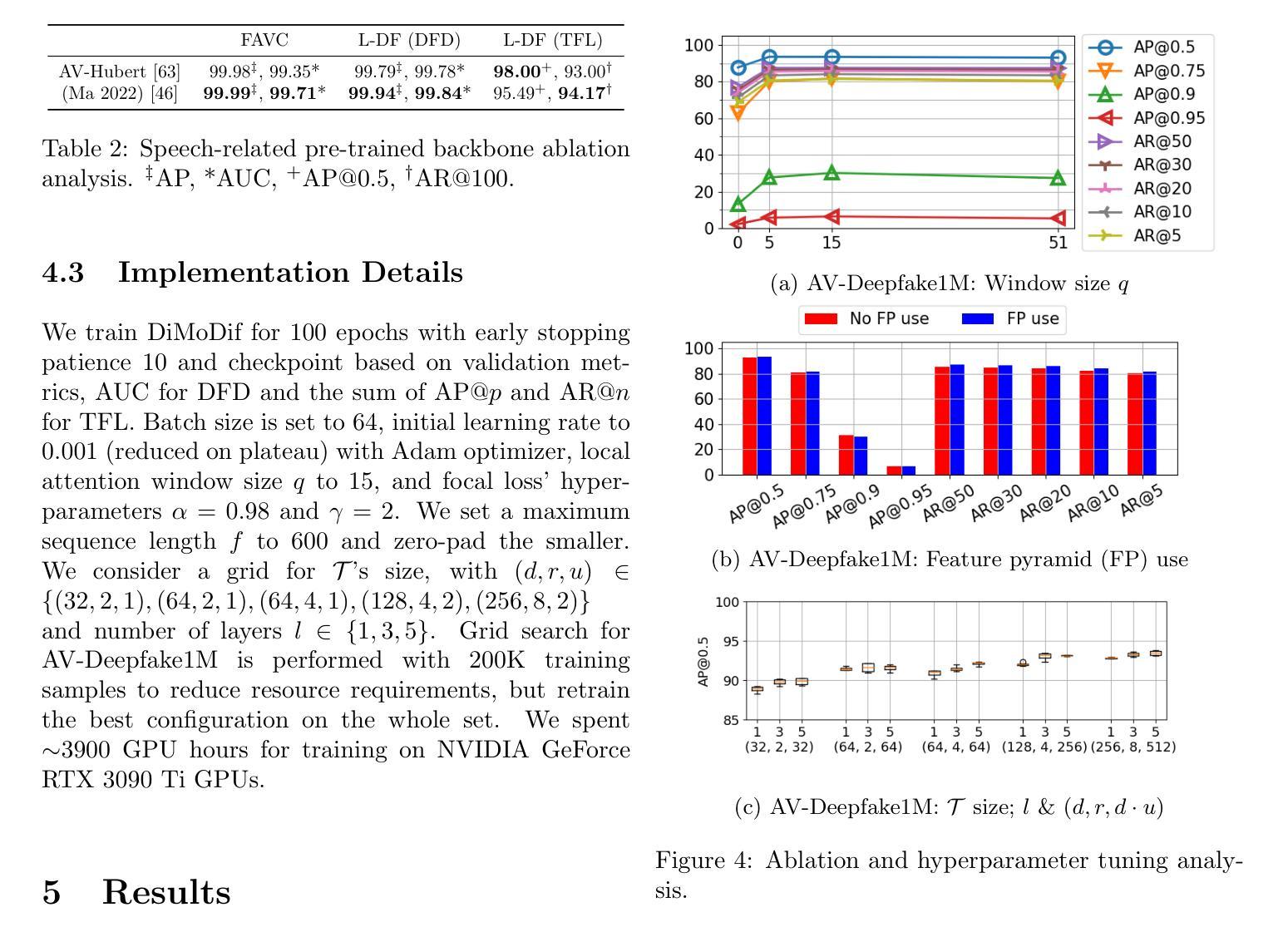
Deepfake technology has rapidly advanced and poses significant threats to information integrity and trust in online multimedia. While significant progress has been made in detecting deepfakes, the simultaneous manipulation of audio and visual modalities, sometimes at small parts or in subtle ways, presents highly challenging detection scenarios. To address these challenges, we present DiMoDif, an audio-visual deepfake detection framework that leverages the inter-modality differences in machine perception of speech, based on the assumption that in real samples – in contrast to deepfakes – visual and audio signals coincide in terms of information. DiMoDif leverages features from deep networks that specialize in visual and audio speech recognition to spot frame-level cross-modal incongruities, and in that way to temporally localize the deepfake forgery. To this end, we devise a hierarchical cross-modal fusion network, integrating adaptive temporal alignment modules and a learned discrepancy mapping layer to explicitly model the subtle differences between visual and audio representations. Then, the detection model is optimized through a composite loss function accounting for frame-level detections and fake intervals localization. DiMoDif outperforms the state-of-the-art on the Deepfake Detection task by 30.5 AUC on the highly challenging AV-Deepfake1M, while it performs exceptionally on FakeAVCeleb and LAV-DF. On the Temporal Forgery Localization task, it outperforms the state-of-the-art by 47.88 AP@0.75 on AV-Deepfake1M, and performs on-par on LAV-DF. Code available at https://github.com/mever-team/dimodif.
深度伪造技术迅速发展和对在线多媒体的信息完整性和信任构成重大威胁。虽然深度伪造检测方面取得了重大进展,但同时对音频和视觉模式的操作,有时在小部分或以微妙的方式,呈现出极具挑战性的检测场景。为了解决这些挑战,我们提出了DiMoDif,一个音频视觉深度伪造检测框架,它利用机器感知语音的跨模态差异,基于真实样本(与深度伪造物相反)的视觉和音频信号在信息上是一致的。DiMoDif利用专门用于视觉和音频语音识别深度网络的特性,发现帧级跨模态不一致,以这种方式来暂时定位深度伪造篡改的位置。为此,我们设计了一个分层跨模态融合网络,集成了自适应时间对齐模块和学习差异映射层,以显式地模拟视觉和音频表示之间的细微差异。然后,通过考虑帧级检测和伪造间隔定位的复合损失函数来优化检测模型。DiMoDif在具有挑战性的AV-Deepfake1M上超越了最先进的技术,深度伪造检测任务的AUC提高了30.5%,在FakeAVCeleb和LAV-DF上表现尤为出色。在时间伪造定位任务上,它在AV-Deepfake1M上的AP@0.75超过了最先进的技术47.88%,并在LAV-DF上表现相当。代码可在https://github.com/mever-team/dimodif找到。
论文及项目相关链接
摘要
深度伪造技术迅速发展和对在线多媒体的信息完整性和信任构成严重威胁。尽管在检测深度伪造方面取得了重大进展,但对音频和视频模态的同时操纵,或以微小部分或微妙的方式操纵,呈现出了极具挑战性的检测场景。为了解决这些挑战,我们提出了DiMoDif,一个音频视觉深度伪造检测框架,它利用机器感知语音的跨模态差异,基于真实样本的假设——与深度伪造相比,视觉和音频信号在信息上是吻合的。DiMoDif利用深度网络中专门用于视觉和音频语音识别功能的特性,发现帧级跨模态不一致之处,以这种方式临时定位深度伪造篡改的位置。为此,我们设计了一个分层的跨模态融合网络,该网络集成了自适应时间对齐模块和学习到的差异映射层,以显式地模拟视觉和音频表示之间的细微差异。然后,通过考虑帧级检测和伪造间隔定位的复合损失函数来优化检测模型。DiMoDif在高度挑战的AV-Deepfake1M上,深度伪造检测任务的性能优于最新技术水平的30.5 AUC,在FakeAVCeleb和LAV-DF上表现尤为出色。在时序伪造定位任务上,它在AV-Deepfake1M上的表现优于最新技术水平的47.88 AP@0.7T。代码可在https://github.com/mever-team/dimodif找到。
关键见解
1.深度伪造技术对信息完整性和在线多媒体信任构成重大威胁。
2.当前音频和视频篡造的检测面临巨大挑战,特别是同时对音频和视频模态的操纵。
3. DiMoDif是一个创新的音频视觉深度伪造检测框架,基于真实样本中视觉和音频信号的吻合信息来识别伪造内容。
4. DiMoDif利用深度网络中的跨模态差异来发现帧级的细微不一致之处,从而定位深度伪造篡改的位置。
5. DiMoDif采用分层跨模态融合网络设计,集成自适应时间对齐和差异映射层来模拟视觉和音频之间的差异。
6. DiMoDif在多个深度伪造检测任务上表现优于现有技术。
点此查看论文截图


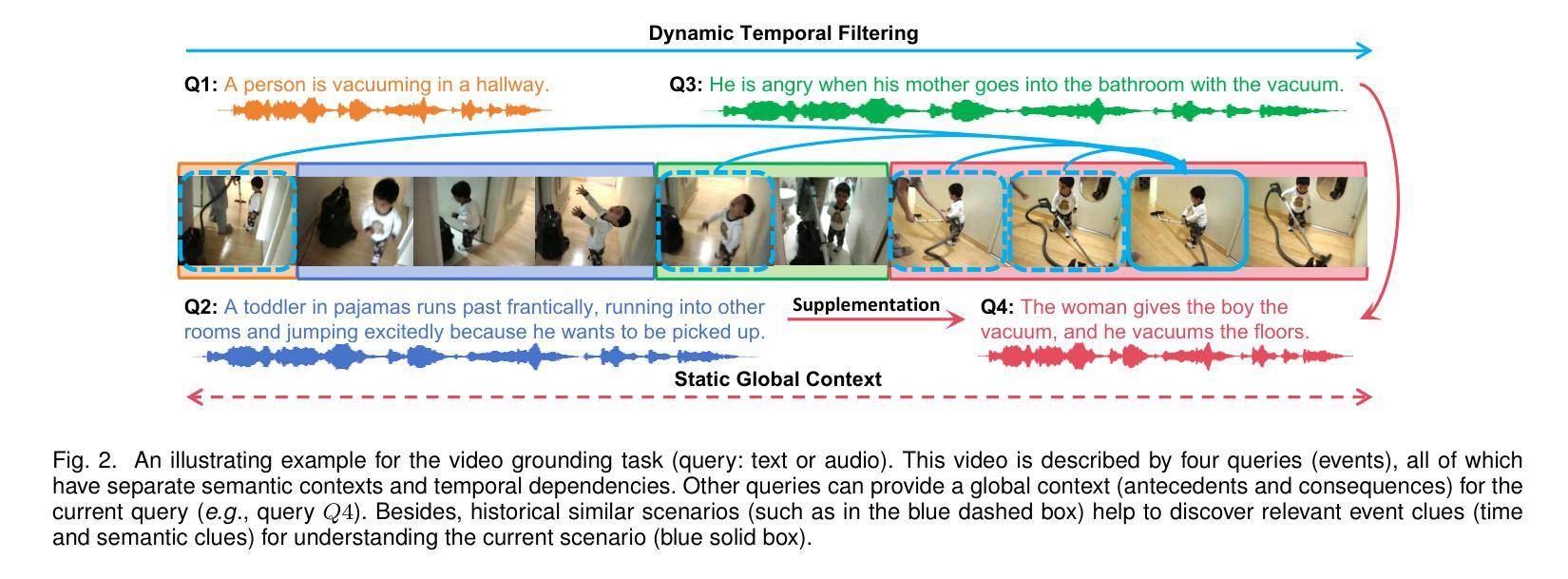
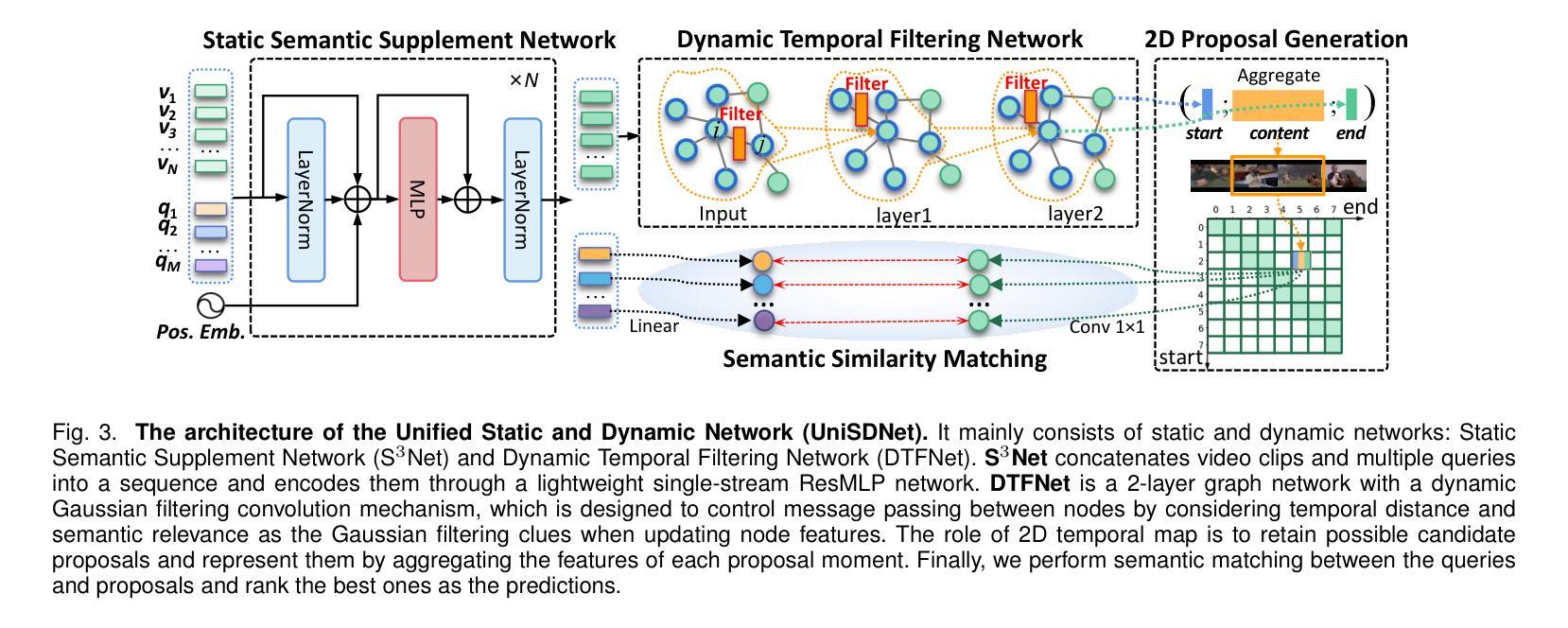
Unified Static and Dynamic Network: Efficient Temporal Filtering for Video Grounding
Authors:Jingjing Hu, Dan Guo, Kun Li, Zhan Si, Xun Yang, Xiaojun Chang, Meng Wang
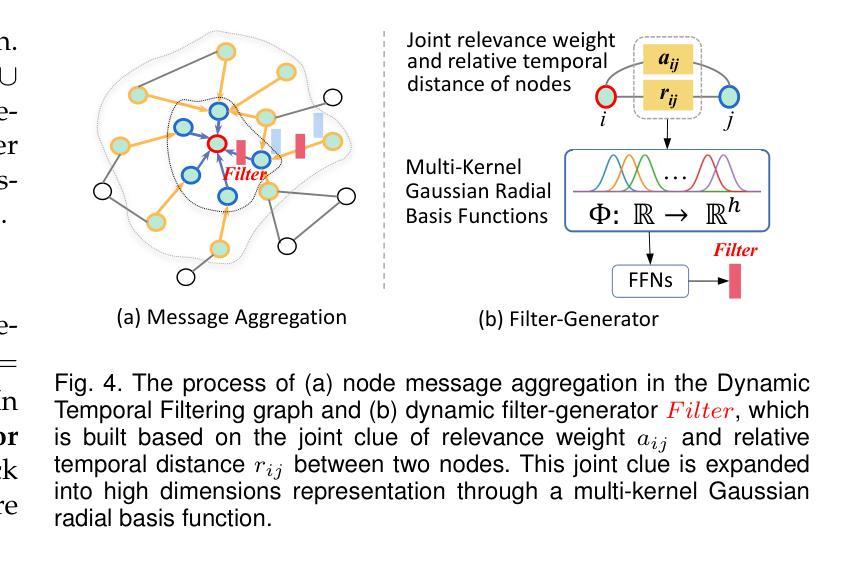
Inspired by the activity-silent and persistent activity mechanisms in human visual perception biology, we design a Unified Static and Dynamic Network (UniSDNet), to learn the semantic association between the video and text/audio queries in a cross-modal environment for efficient video grounding. For static modeling, we devise a novel residual structure (ResMLP) to boost the global comprehensive interaction between the video segments and queries, achieving more effective semantic enhancement/supplement. For dynamic modeling, we effectively exploit three characteristics of the persistent activity mechanism in our network design for a better video context comprehension. Specifically, we construct a diffusely connected video clip graph on the basis of 2D sparse temporal masking to reflect the “short-term effect” relationship. We innovatively consider the temporal distance and relevance as the joint “auxiliary evidence clues” and design a multi-kernel Temporal Gaussian Filter to expand the context clue into high-dimensional space, simulating the “complex visual perception”, and then conduct element level filtering convolution operations on neighbour clip nodes in message passing stage for finally generating and ranking the candidate proposals. Our UniSDNet is applicable to both Natural Language Video Grounding (NLVG) and Spoken Language Video Grounding (SLVG) tasks. Our UniSDNet achieves SOTA performance on three widely used datasets for NLVG, as well as three datasets for SLVG, e.g., reporting new records at 38.88% R@1,IoU@0.7 on ActivityNet Captions and 40.26% R@1,IoU@0.5 on TACoS. To facilitate this field, we collect two new datasets (Charades-STA Speech and TACoS Speech) for SLVG task. Meanwhile, the inference speed of our UniSDNet is 1.56$\times$ faster than the strong multi-query benchmark. Code is available at: https://github.com/xian-sh/UniSDNet.
受人类视觉感知生物学中的活动静默和持续活动机制的启发,我们设计了一个统一静态和动态网络(UniSDNet),用于在跨模态环境中学习视频和文本/音频查询之间的语义关联,以实现高效视频定位。对于静态建模,我们设计了一种新型残差结构(ResMLP),以增强视频片段和查询之间的全局综合交互,实现更有效的语义增强/补充。对于动态建模,我们有效地利用了网络中持续活动机制的三个特点,以更好地进行视频上下文理解。具体来说,我们在二维稀疏时间掩码的基础上构建了一个密集连接的视频剪辑图,以反映“短期效应”关系。我们创新地考虑时间距离和相关性作为联合的“辅助证据线索”,设计了一种多核时间高斯滤波器来将上下文线索扩展到高维空间,模拟“复杂视觉感知”,然后在消息传递阶段对相邻剪辑节点执行元素级滤波卷积操作,以生成和排序候选提案。我们的UniSDNet适用于自然语言视频定位(NLVG)和口语视频定位(SLVG)任务。UniSDNet在NLVG广泛使用的三个数据集以及SLVG的三个数据集上均达到了最先进的性能,例如在ActivityNet Captions上的R@1达到38.88%,IoU@0.7的新纪录,以及在TACoS上的R@1达到40.26%,IoU@0.5。为了促进该领域的发展,我们为SLVG任务收集了两个新数据集(Charades-STA Speech和TACoS Speech)。同时,我们的UniSDNet的推理速度比强大的多查询基准测试快1.56倍。代码可在:https://github.com/xian-sh/UniSDNet访问。
论文及项目相关链接
PDF Accepted to IEEE TPAMI 2025
摘要
本文借鉴人类视觉感知生物学中的活动和持续活动机制,设计了一种统一静态和动态网络(UniSDNet),用于学习视频与文本/音频查询之间的语义关联,以实现高效视频定位。对于静态建模,我们提出了一种新型残差结构(ResMLP),以增强视频片段和查询之间的全局综合交互,实现更有效的语义增强/补充。对于动态建模,我们有效地利用持续活动机制的三个特点来进行网络设计,以更好地理解视频上下文。具体来说,我们在2D稀疏时间掩码的基础上构建了一个密集连接的视频剪辑图,以反映“短期效应”关系。我们创新地考虑时间距离和相关性作为联合“辅助证据线索”,并设计了一种多核时间高斯滤波器来扩展上下文线索到高维空间,模拟“复杂视觉感知”,然后在消息传递阶段对邻居剪辑节点进行元素级滤波卷积操作,以生成和排序候选提案。我们的UniSDNet适用于自然语言视频定位(NLVG)和口语视频定位(SLVG)任务。UniSDNet在NLVG的三个常用数据集以及SLVG的三个数据集上实现了卓越的性能,例如在ActivityNet Captions上的R@1达到38.88%,IoU@0.7,以及在TACoS上的R@1达到40.26%,IoU@0.5。为了推动这一领域的发展,我们为SLVG任务收集了两个新数据集(Charades-STA Speech和TACoS Speech)。同时,UniSDNet的推理速度比强大的多查询基准测试快1.56倍。
要点
- 借鉴人类视觉感知生物学中的活动和持续活动机制,设计UniSDNet网络进行视频与文本/音频查询的语义关联学习。
- 静态建模采用新型残差结构(ResMLP)增强全局综合交互。
- 动态建模利用持续活动机制的三个特点进行网络设计,以更好地视频上下文理解。
- 构建密集连接的视频剪辑图,创新考虑时间距离和相关性作为辅助证据线索。
- UniSDNet适用于NLVG和SLVG任务,并在多个数据集上实现卓越性能。
- 收集了两个新的数据集用于SLVG任务。
点此查看论文截图