⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-16 更新
Beyond Degradation Redundancy: Contrastive Prompt Learning for All-in-One Image Restoration
Authors:Gang Wu, Junjun Jiang, Kui Jiang, Xianming Liu, Liqiang Nie
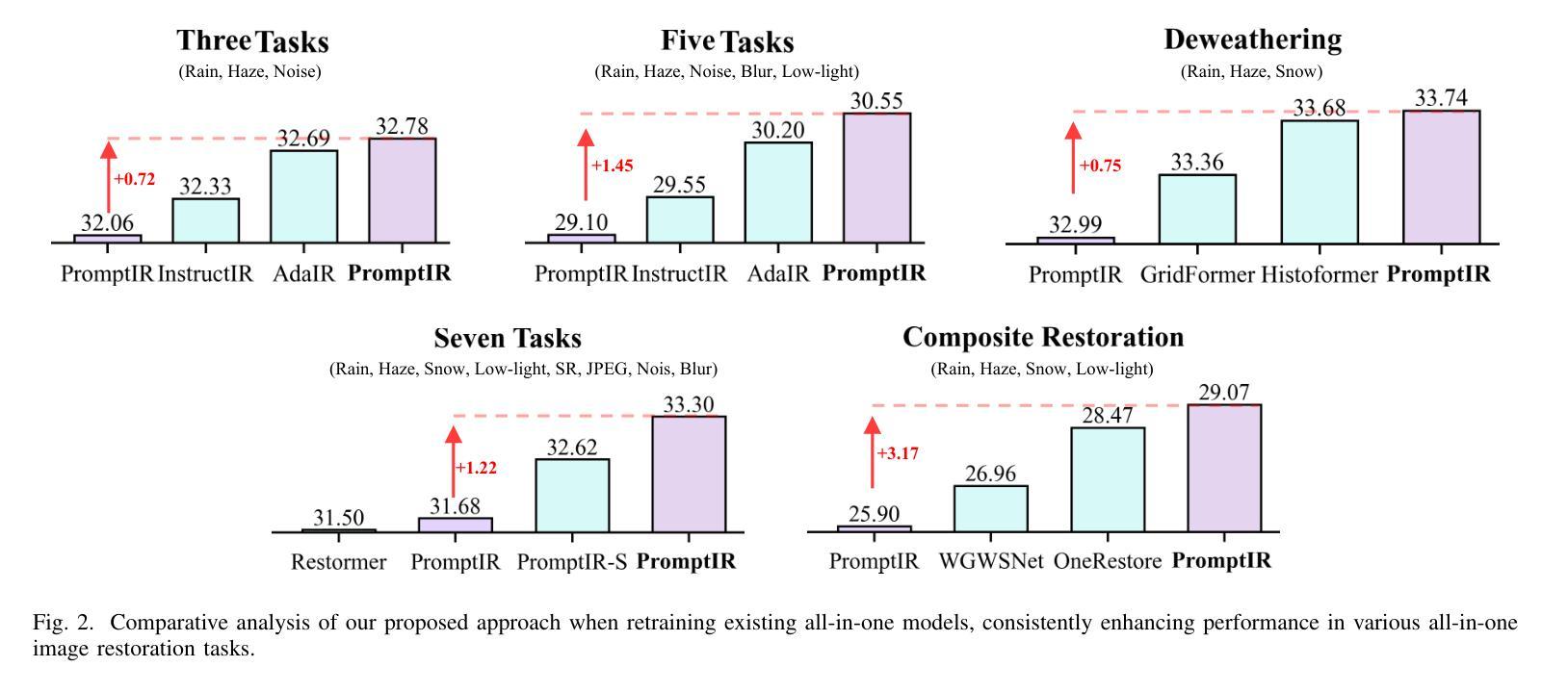
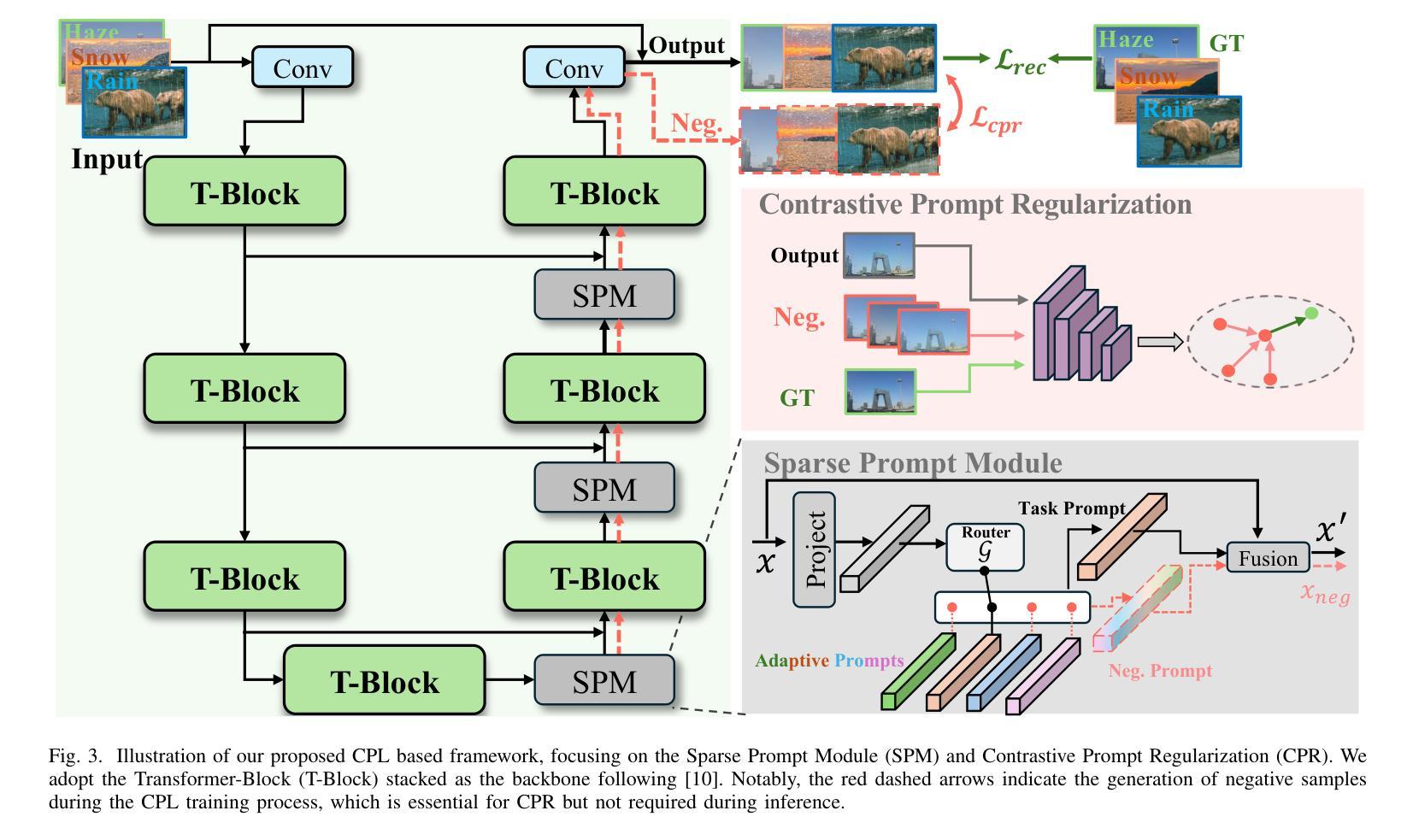
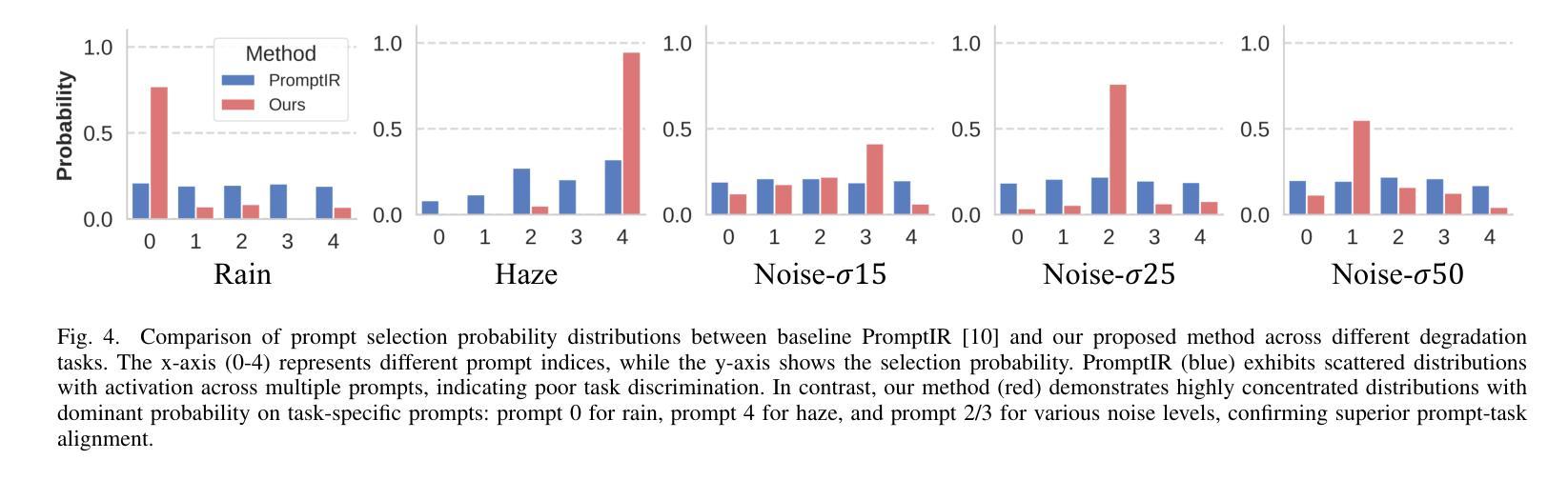
All-in-one image restoration, addressing diverse degradation types with a unified model, presents significant challenges in designing task-specific prompts that effectively guide restoration across multiple degradation scenarios. While adaptive prompt learning enables end-to-end optimization, it often yields overlapping or redundant task representations. Conversely, explicit prompts derived from pretrained classifiers enhance discriminability but may discard critical visual information for reconstruction. To address these limitations, we introduce Contrastive Prompt Learning (CPL), a novel framework that fundamentally enhances prompt-task alignment through two complementary innovations: a \emph{Sparse Prompt Module (SPM)} that efficiently captures degradation-specific features while minimizing redundancy, and a \emph{Contrastive Prompt Regularization (CPR)} that explicitly strengthens task boundaries by incorporating negative prompt samples across different degradation types. Unlike previous approaches that focus primarily on degradation classification, CPL optimizes the critical interaction between prompts and the restoration model itself. Extensive experiments across five comprehensive benchmarks demonstrate that CPL consistently enhances state-of-the-art all-in-one restoration models, achieving significant improvements in both standard multi-task scenarios and challenging composite degradation settings. Our framework establishes new state-of-the-art performance while maintaining parameter efficiency, offering a principled solution for unified image restoration.
全文概述了一体化图像修复技术面临的挑战。尽管自适应提示学习可以实现端到端的优化,但它常常导致任务表示的重叠或冗余。相反,基于预训练分类器生成的明确提示增强了鉴别能力,但可能丢弃重建所需的关键视觉信息。为了克服这些限制,我们引入了对比提示学习(CPL)这一新颖框架,它通过两个互补的创新从根本上增强了提示与任务的对齐:一个“稀疏提示模块(SPM)”,能够高效捕获特定退化特征的同时最小化冗余;一个“对比提示正则化(CPR)”,通过引入不同退化类型的负提示样本,明确强化了任务边界。与以往主要关注退化分类的方法不同,CPL优化了提示和修复模型之间的关键交互。在五个综合基准测试上的大量实验表明,CPL在最新的全集成修复模型中表现一致,在标准多任务场景和具有挑战性的复合退化设置中取得了显著改进。我们的框架在保持参数效率的同时建立了新的性能水平,为一体化图像修复提供了有原则的解决方案。
具体到每一个部分:
- “一体化图像修复技术面临的挑战”:处理多种退化类型使用统一模型呈现重大挑战,设计特定任务的提示以有效指导跨多种退化场景的修复工作尤为困难。
- “自适应提示学习”虽然实现了端到端的优化,但可能会导致任务表示的重叠或冗余问题。这可能会影响到模型的效率和准确性。
- “基于预训练分类器生成的明确提示”虽然增强了鉴别能力,但同时也可能丢弃重建所需的关键视觉信息。这意味着这种方法的适用性可能受到限制,尤其是在处理复杂图像修复任务时。
论文及项目相关链接
PDF Project page: https://github.com/Aitical/CPLIR
Summary
该文提出了一种新颖的对比提示学习(CPL)框架,旨在解决在统一模型中处理多种退化类型时的挑战。该框架通过稀疏提示模块(SPM)和对比提示正则化(CPR)两种互补创新方式,提高提示与任务之间的对齐程度。实验表明,CPL在多种综合基准测试中均表现优异,实现了多任务场景和复合退化设置中的显著改进。
Key Takeaways
- 引入对比提示学习(CPL)框架,旨在解决统一模型中处理多种退化类型的挑战。
- CPL通过稀疏提示模块(SPM)和对比提示正则化(CPR)两种互补方式,提高提示与任务之间的对齐程度。
- SPM能够高效捕获特定退化特征并最小化冗余。
- CPR通过引入负提示样本,加强任务边界的明确性。
- CPL不同于以往的以退化分类为主的方法,而是优化了提示与修复模型之间的关键交互。
- 实验表明,CPL在多个基准测试中表现优异,实现了显著的性能改进。
点此查看论文截图

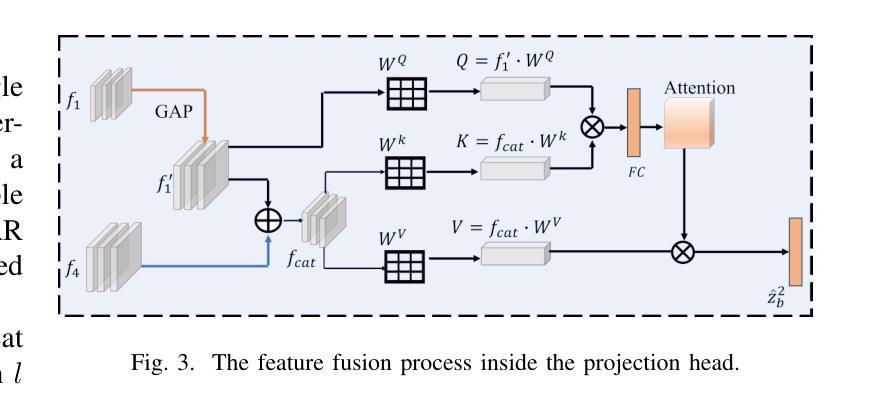
PCM-SAR: Physics-Driven Contrastive Mutual Learning for SAR Classification
Authors:Pengfei Wang, Hao Zheng, Zhigang Hu, Aikun Xu, Meiguang Zheng, Liu Yang
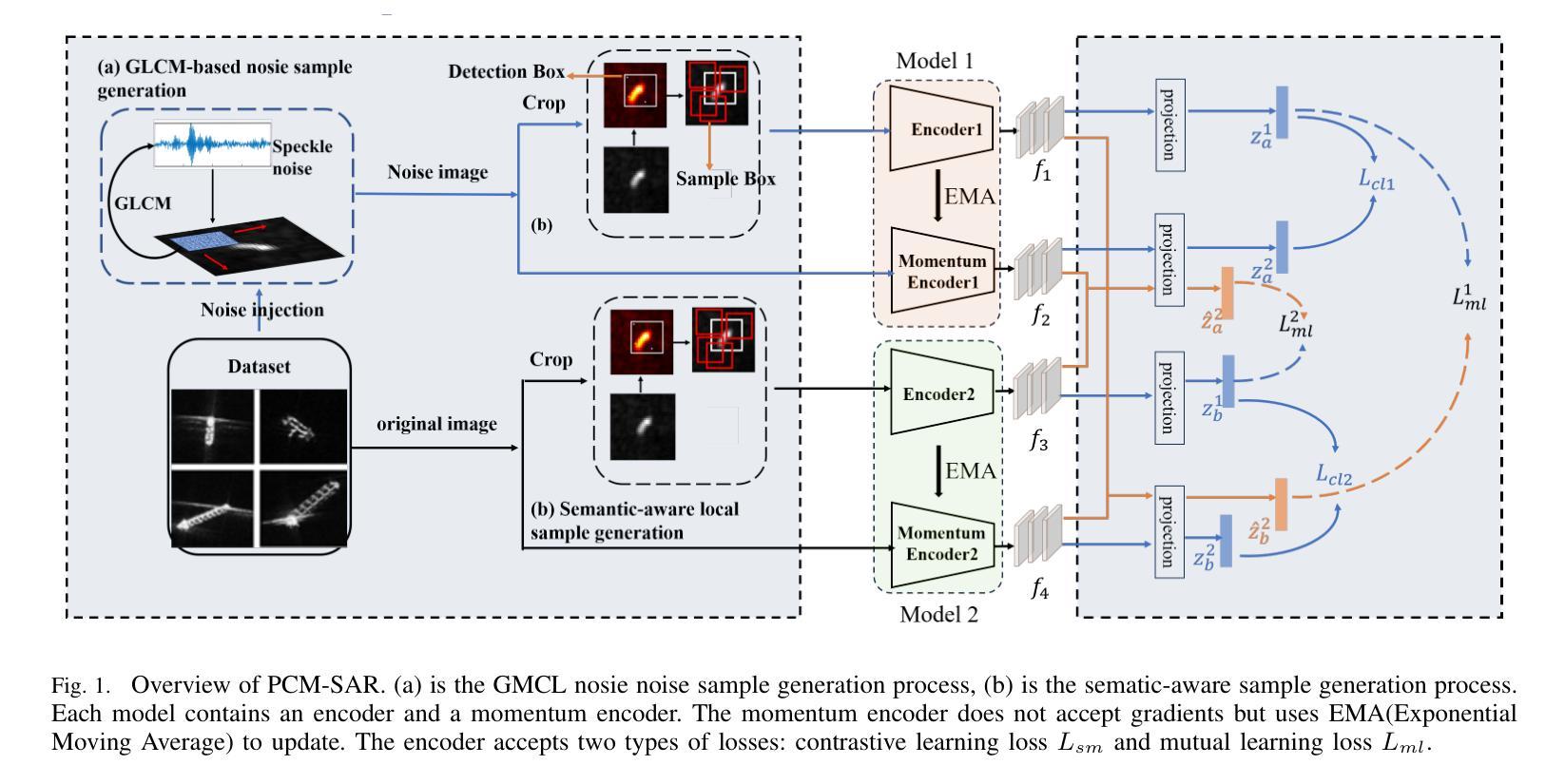
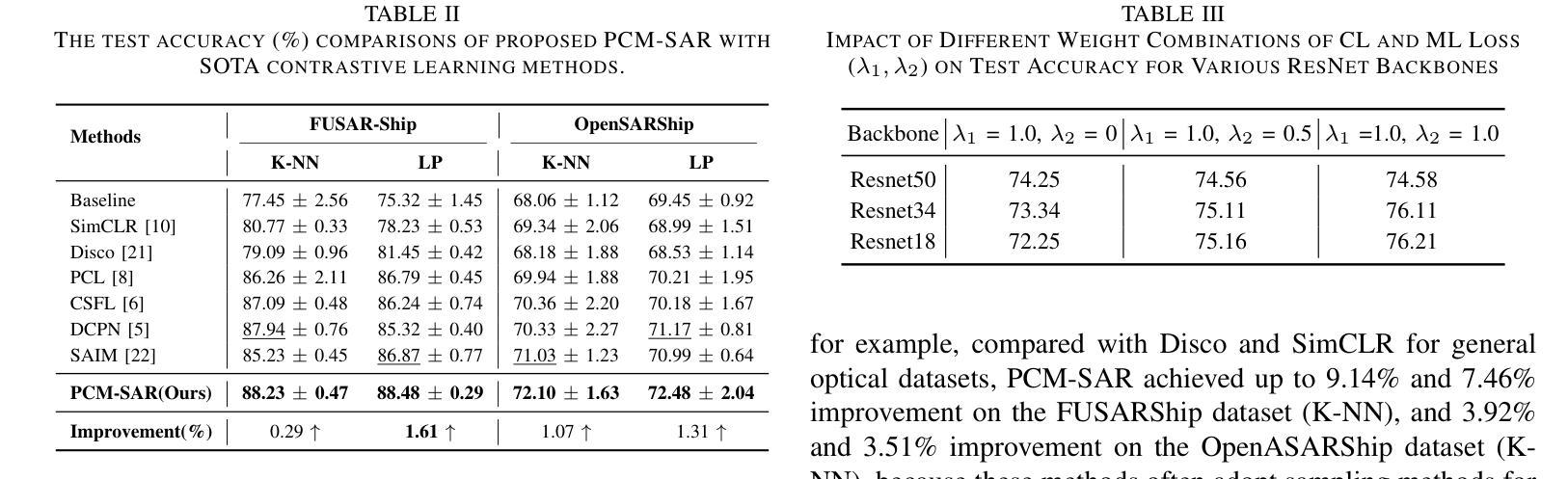
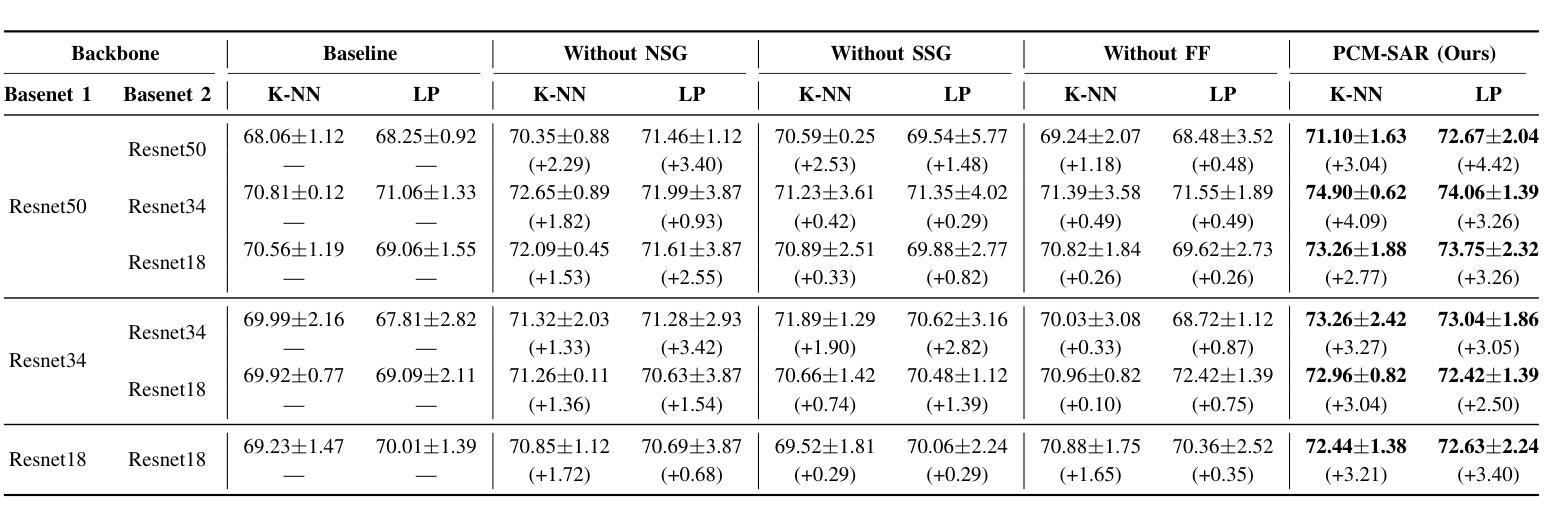
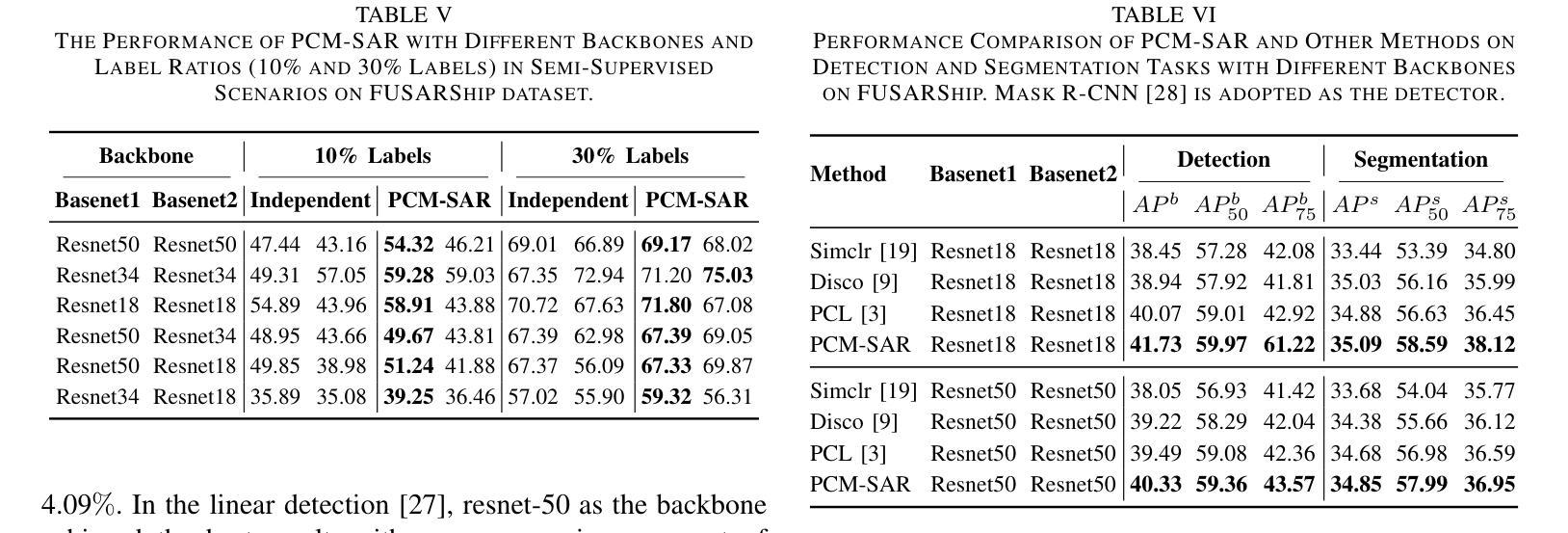
Existing SAR image classification methods based on Contrastive Learning often rely on sample generation strategies designed for optical images, failing to capture the distinct semantic and physical characteristics of SAR data. To address this, we propose Physics-Driven Contrastive Mutual Learning for SAR Classification (PCM-SAR), which incorporates domain-specific physical insights to improve sample generation and feature extraction. PCM-SAR utilizes the gray-level co-occurrence matrix (GLCM) to simulate realistic noise patterns and applies semantic detection for unsupervised local sampling, ensuring generated samples accurately reflect SAR imaging properties. Additionally, a multi-level feature fusion mechanism based on mutual learning enables collaborative refinement of feature representations. Notably, PCM-SAR significantly enhances smaller models by refining SAR feature representations, compensating for their limited capacity. Experimental results show that PCM-SAR consistently outperforms SOTA methods across diverse datasets and SAR classification tasks.
当前基于对比学习的SAR图像分类方法往往依赖于为光学图像设计的样本生成策略,这忽略了SAR数据独特的语义和物理特性。为了解决这个问题,我们提出了面向SAR分类的物理驱动对比互学习(PCM-SAR)方法。该方法结合了领域特定的物理见解,以改进样本生成和特征提取。PCM-SAR利用灰度共生矩阵(GLCM)模拟现实噪声模式,并应用语义检测进行无监督局部采样,确保生成的样本准确反映SAR成像特性。此外,基于互学习的多层次特征融合机制能够实现特征表示的协同细化。值得注意的是,PCM-SAR通过优化SAR特征表示,显著提升了小型模型的性能,弥补了其容量有限的不足。实验结果表明,PCM-SAR在多个数据集和SAR分类任务上均优于最新方法。
论文及项目相关链接
Summary
基于对比学习的SAR图像分类方法常常依赖为光学图像设计的样本生成策略,忽略了SAR数据独特的语义和物理特性。为解决这一问题,我们提出物理驱动对比互学习(PCM-SAR)方法,结合领域特定物理见解改进样本生成和特征提取。PCM-SAR利用灰度共生矩阵模拟真实噪声模式,应用语义检测进行无监督局部采样,确保生成的样本准确反映SAR成像特性。此外,基于互学习的多层次特征融合机制能够实现特征表示的协同优化。尤其值得关注的是,PCM-SAR通过优化SAR特征表示显著提升小型模型的性能,弥补了其有限的容量。实验结果表明,PCM-SAR在不同数据集和SAR分类任务上均超越现有先进方法。
Key Takeaways
- PCM-SAR方法针对SAR图像分类提出,考虑到SAR数据的独特性质。
- PCM-SAR结合物理驱动和对比学习,改进样本生成和特征提取。
- 利用灰度共生矩阵模拟真实噪声模式,增强样本的SAR成像特性。
- 无监督局部采样通过语义检测确保样本质量。
- 多层次特征融合机制基于互学习,实现特征表示的协同优化。
- PCM-SAR显著提升小型模型在SAR图像分类上的性能。
点此查看论文截图



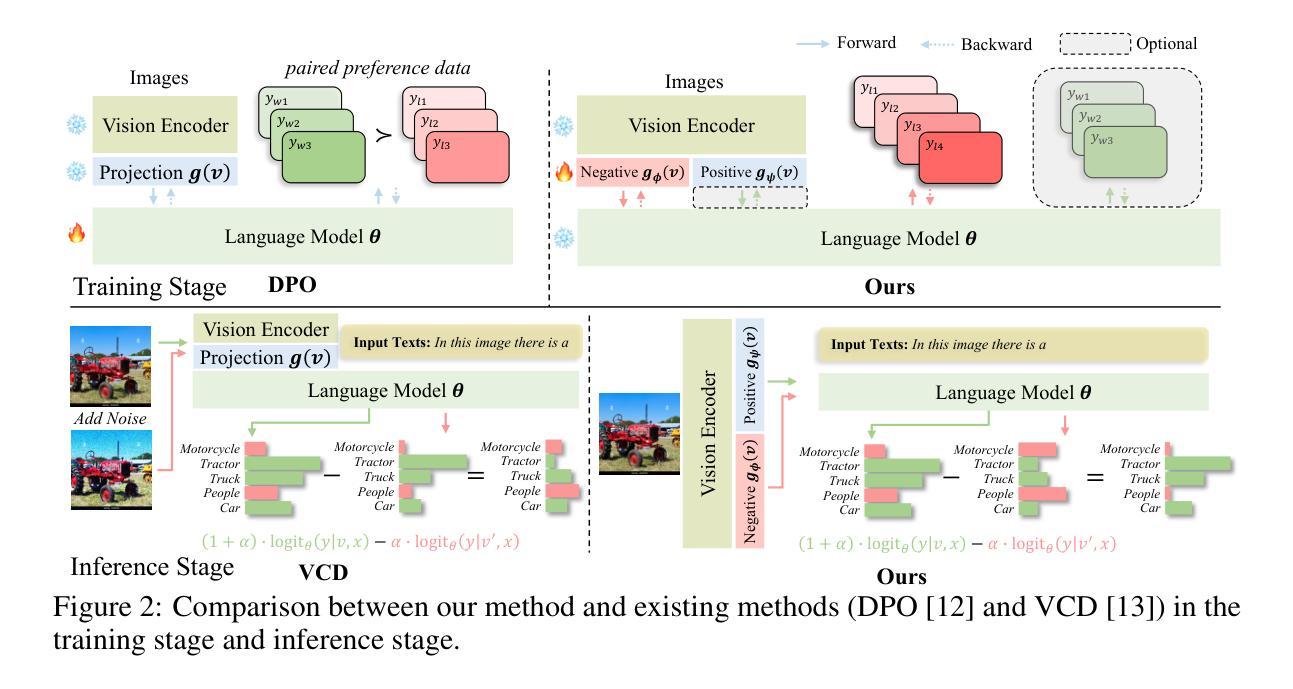
Decoupling Contrastive Decoding: Robust Hallucination Mitigation in Multimodal Large Language Models
Authors:Wei Chen, Xin Yan, Bin Wen, Fan Yang, Tingting Gao, Di Zhang, Long Chen
Although multimodal large language models (MLLMs) exhibit remarkable reasoning capabilities on complex multimodal understanding tasks, they still suffer from the notorious hallucination issue: generating outputs misaligned with obvious visual or factual evidence. Currently, training-based solutions, like direct preference optimization (DPO), leverage paired preference data to suppress hallucinations. However, they risk sacrificing general reasoning capabilities due to the likelihood displacement. Meanwhile, training-free solutions, like contrastive decoding, achieve this goal by subtracting the estimated hallucination pattern from a distorted input. Yet, these handcrafted perturbations (e.g., add noise to images) may poorly capture authentic hallucination patterns. To avoid these weaknesses of existing methods, and realize robust hallucination mitigation (i.e., maintaining general reasoning performance), we propose a novel framework: Decoupling Contrastive Decoding (DCD). Specifically, DCD decouples the learning of positive and negative samples in preference datasets, and trains separate positive and negative image projections within the MLLM. The negative projection implicitly models real hallucination patterns, which enables vision-aware negative images in the contrastive decoding inference stage. Our DCD alleviates likelihood displacement by avoiding pairwise optimization and generalizes robustly without handcrafted degradation. Extensive ablations across hallucination benchmarks and general reasoning tasks demonstrate the effectiveness of DCD, i.e., it matches DPO’s hallucination suppression while preserving general capabilities and outperforms the handcrafted contrastive decoding methods.
尽管多模态大型语言模型(MLLMs)在复杂的多模态理解任务中展现出卓越的推理能力,但它们仍然受到著名的幻觉问题的困扰:生成的输出与明显的视觉或事实证据不一致。目前,基于训练的方法,如直接偏好优化(DPO),利用配对偏好数据来抑制幻觉。然而,它们可能会因可能性置换而牺牲一般的推理能力。同时,无训练的方法,如对比解码,通过从扭曲的输入中减去估计的幻觉模式来实现这一目标。然而,这些手工制作的扰动(例如,给图像添加噪声)可能无法很好地捕捉真实的幻觉模式。为了避免现有方法的这些弱点,并实现稳健的幻觉缓解(即保持一般的推理性能),我们提出了一种新型框架:解耦对比解码(DCD)。具体来说,DCD解耦了偏好数据集中正样本和负样本的学习,并在MLLM内训练单独的正样本和负样本图像投影。负投影隐式地模拟真实的幻觉模式,这可以在对比解码推理阶段实现视觉感知的负图像。我们的DCD通过避免配对优化减轻了可能性置换,并实现了稳健的通用性,无需手工制作的退化。在幻觉基准测试和一般推理任务的大量消融研究中,证明了DCD的有效性,即它能在保持一般能力的同时,达到DPO的幻觉抑制效果,并超越了手工对比解码方法。
论文及项目相关链接
PDF 13 pages, 4 figures
Summary
该文本介绍了一种新型的多模态大型语言模型框架——解耦对比解码(DCD),旨在解决现有方法的弱点并实现稳健的幻觉缓解。DCD通过解耦偏好数据集中的正负面样本学习,训练单独的正面和负面图像投影,并利用负面投影隐式模拟真实幻觉模式来实现对幻觉的抑制。该方法避免了成对优化,减少了可能性位移,并在不需要手工制作的退化情况下实现了稳健的泛化。在幻觉基准测试和通用推理任务上的广泛消融实验证明了DCD的有效性。它既实现了与直接偏好优化(DPO)相当的幻觉抑制效果,又保留了通用能力,并超越了手工对比解码方法。
Key Takeaways
- 多模态大型语言模型(MLLMs)在处理复杂多模态理解任务时表现出强大的推理能力,但仍然存在幻觉问题,即输出与明显视觉或事实证据不符的情况。
- 当前解决方法如直接偏好优化(DPO)和对比解码都存在弱点。DPO可能牺牲了一般推理能力,而对比解码使用的手工制作的扰动可能无法很好地捕捉真实的幻觉模式。
- 提出了一种新的框架——解耦对比解码(DCD),旨在解决上述问题并实现稳健的幻觉缓解。
- DCD通过解耦偏好数据集中的正负面样本学习,训练单独的正面和负面图像投影。负面投影隐式模拟真实幻觉模式,并在对比解码推断阶段利用视觉感知的负面图像。
- DCD避免了成对优化和手工制作的退化情况,减少了可能性位移,并实现了稳健的泛化。
- 在广泛的消融实验中,DCD在幻觉基准测试和通用推理任务上表现出有效性,实现了与DPO相当的幻觉抑制效果,并保留了通用能力。
点此查看论文截图


Machine Unlearning in Hyperbolic vs. Euclidean Multimodal Contrastive Learning: Adapting Alignment Calibration to MERU
Authors:Àlex Pujol Vidal, Sergio Escalera, Kamal Nasrollahi, Thomas B. Moeslund
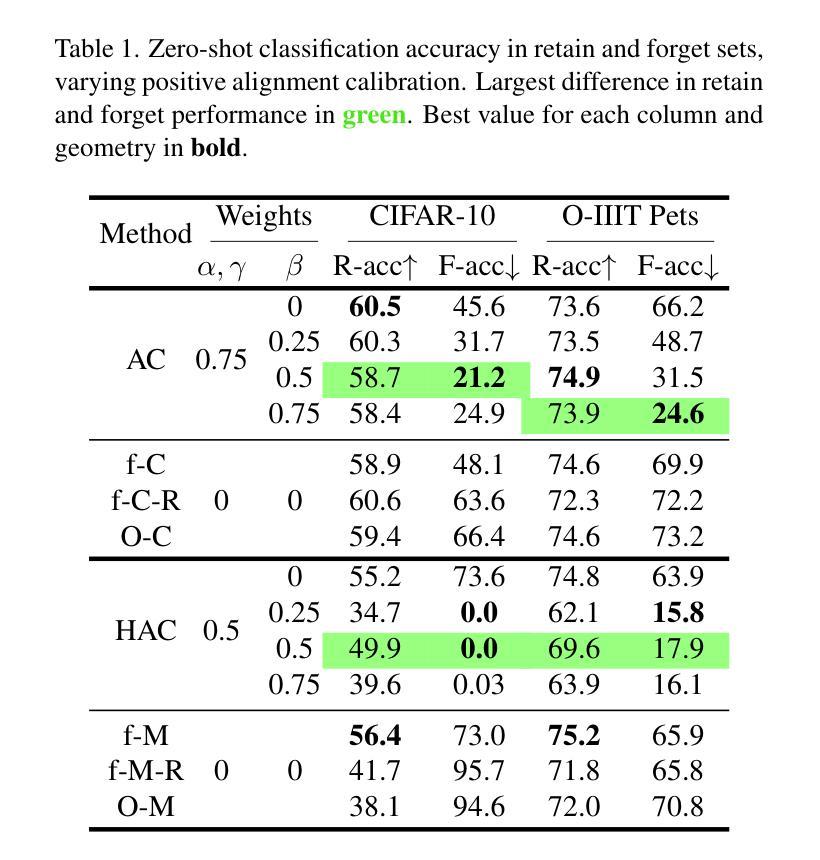
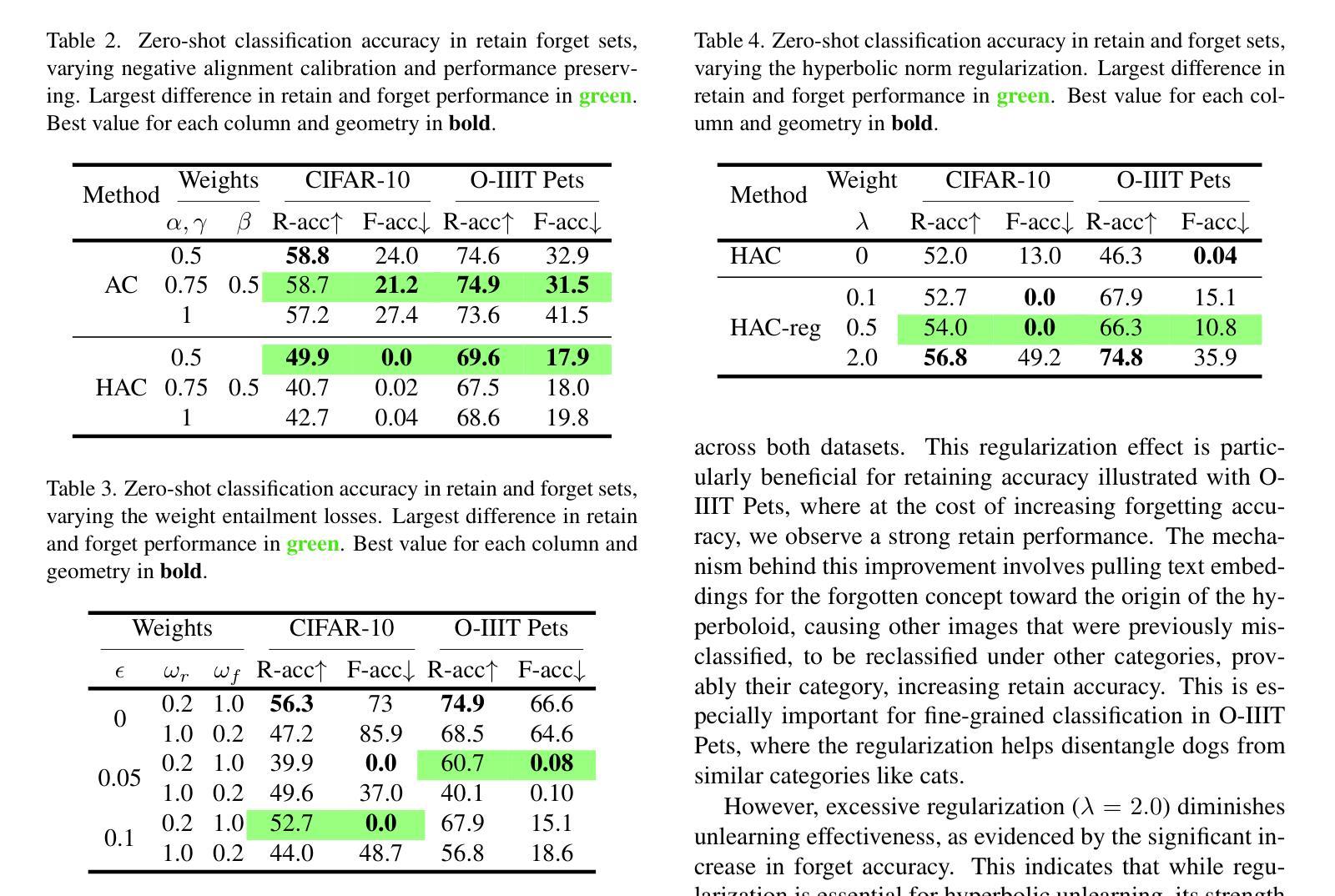
Machine unlearning methods have become increasingly important for selective concept removal in large pre-trained models. While recent work has explored unlearning in Euclidean contrastive vision-language models, the effectiveness of concept removal in hyperbolic spaces remains unexplored. This paper investigates machine unlearning in hyperbolic contrastive learning by adapting Alignment Calibration to MERU, a model that embeds images and text in hyperbolic space to better capture semantic hierarchies. Through systematic experiments and ablation studies, we demonstrate that hyperbolic geometry offers distinct advantages for concept removal, achieving near perfect forgetting with reasonable performance on retained concepts, particularly when scaling to multiple concept removal. Our approach introduces hyperbolic-specific components including entailment calibration and norm regularization that leverage the unique properties of hyperbolic space. Comparative analysis with Euclidean models reveals fundamental differences in unlearning dynamics, with hyperbolic unlearning reorganizing the semantic hierarchy while Euclidean approaches merely disconnect cross-modal associations. These findings not only advance machine unlearning techniques but also provide insights into the geometric properties that influence concept representation and removal in multimodal models. Source code available at https://github.com/alex-pv01/HAC
机器遗忘方法在大型预训练模型中选择性概念移除方面变得越来越重要。虽然近期的工作已经在欧几里得对比视觉语言模型中探索了遗忘,但在双曲空间中的概念移除的有效性仍未被探索。本文研究了双曲对比学习中的机器遗忘,通过将对齐校准适应于MERU模型,该模型将图像和文本嵌入双曲空间以更好地捕获语义层次结构。通过系统的实验和消融研究,我们证明了双曲几何为概念移除提供了明显的优势,在保留的概念上实现了近乎完美的遗忘,特别是在扩展到多个概念移除时。我们的方法引入了双曲特定的组件,包括蕴含校准和范数正则化,这些组件利用双曲空间的独特属性。与欧几里得模型的比较分析揭示了遗忘动力学的根本差异,双曲遗忘能够重新组织语义层次结构,而欧几里得方法仅仅断开跨模态关联。这些发现不仅推动了机器遗忘技术的发展,而且提供了关于影响多模态模型中概念表示和移除的几何属性的见解。源代码可在https://github.com/alex-pv01/HAC找到。
论文及项目相关链接
PDF Preprint
Summary
本文探讨了机器在双曲对比学习中的遗忘方法,通过将Alignment Calibration适应于MERU模型,该模型将图像和文本嵌入双曲空间以更好地捕捉语义层次。研究通过系统和消融实验表明,双曲几何在概念移除方面具有独特优势,特别是在扩展到多个概念移除时,能在保留概念的同时实现近乎完美的遗忘。该研究还引入了双曲特定的组件,如蕴涵校准和范数正则化,以利用双曲空间的独特属性。与欧几里得模型的分析对比显示,双曲遗忘在重组语义层次方面与欧几里得方法仅断开跨模态关联有所不同。该研究不仅推动了机器遗忘技术,而且提供了关于影响多模态模型中概念表示和移除的几何属性的见解。
Key Takeaways
- 本文研究了机器在大型预训练模型中的选择性概念移除,特别是在双曲对比学习中的遗忘方法。
- 通过适应Alignment Calibration到MERU模型,实现了在双曲空间中的概念移除。
- 双曲几何在概念移除方面表现出独特优势,能在保留概念的同时实现近乎完美的遗忘,尤其在多个概念移除时更为明显。
- 研究引入了双曲特定的组件,如蕴涵校准和范数正则化,以利用双曲空间的特性。
- 与欧几里得模型相比,双曲遗忘在重组语义层次方面表现出差异,而欧几里得方法主要侧重于断开跨模态关联。
- 研究结果不仅推动了机器遗忘技术的发展,而且为影响概念表示和移除的几何属性提供了深入见解。
点此查看论文截图