⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-16 更新
ERL-MPP: Evolutionary Reinforcement Learning with Multi-head Puzzle Perception for Solving Large-scale Jigsaw Puzzles of Eroded Gaps
Authors:Xingke Song, Xiaoying Yang, Chenglin Yao, Jianfeng Ren, Ruibin Bai, Xin Chen, Xudong Jiang
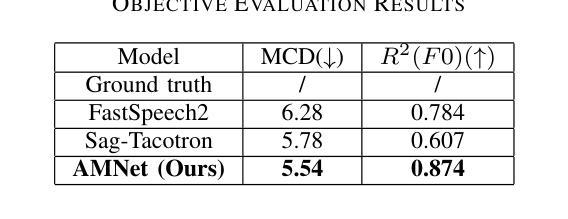
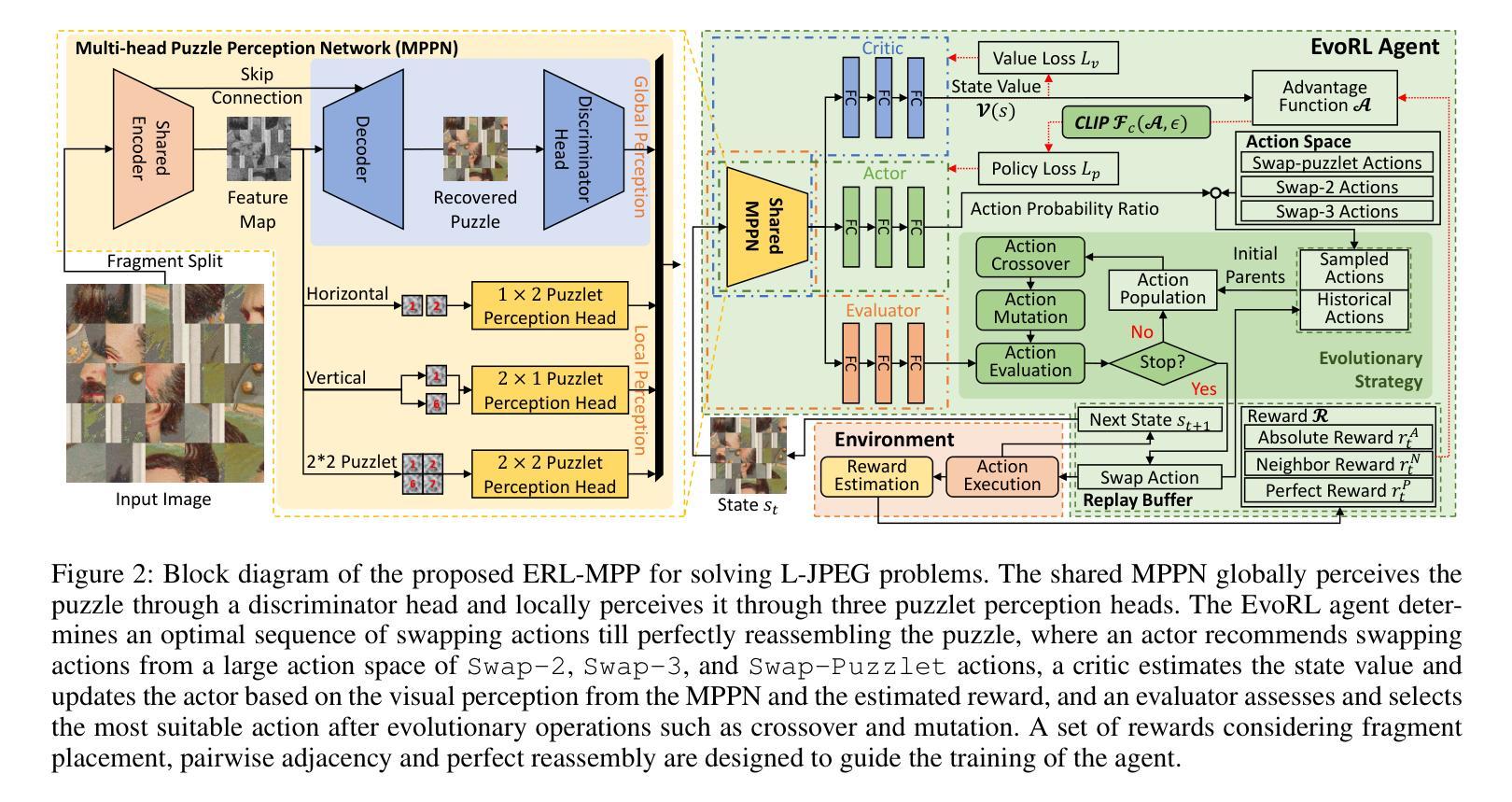
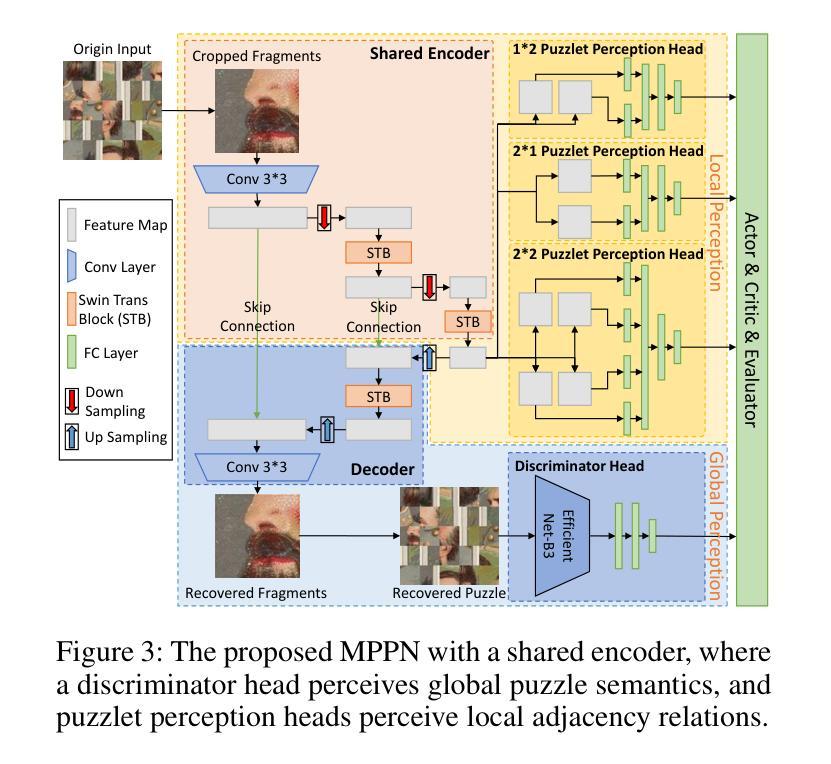
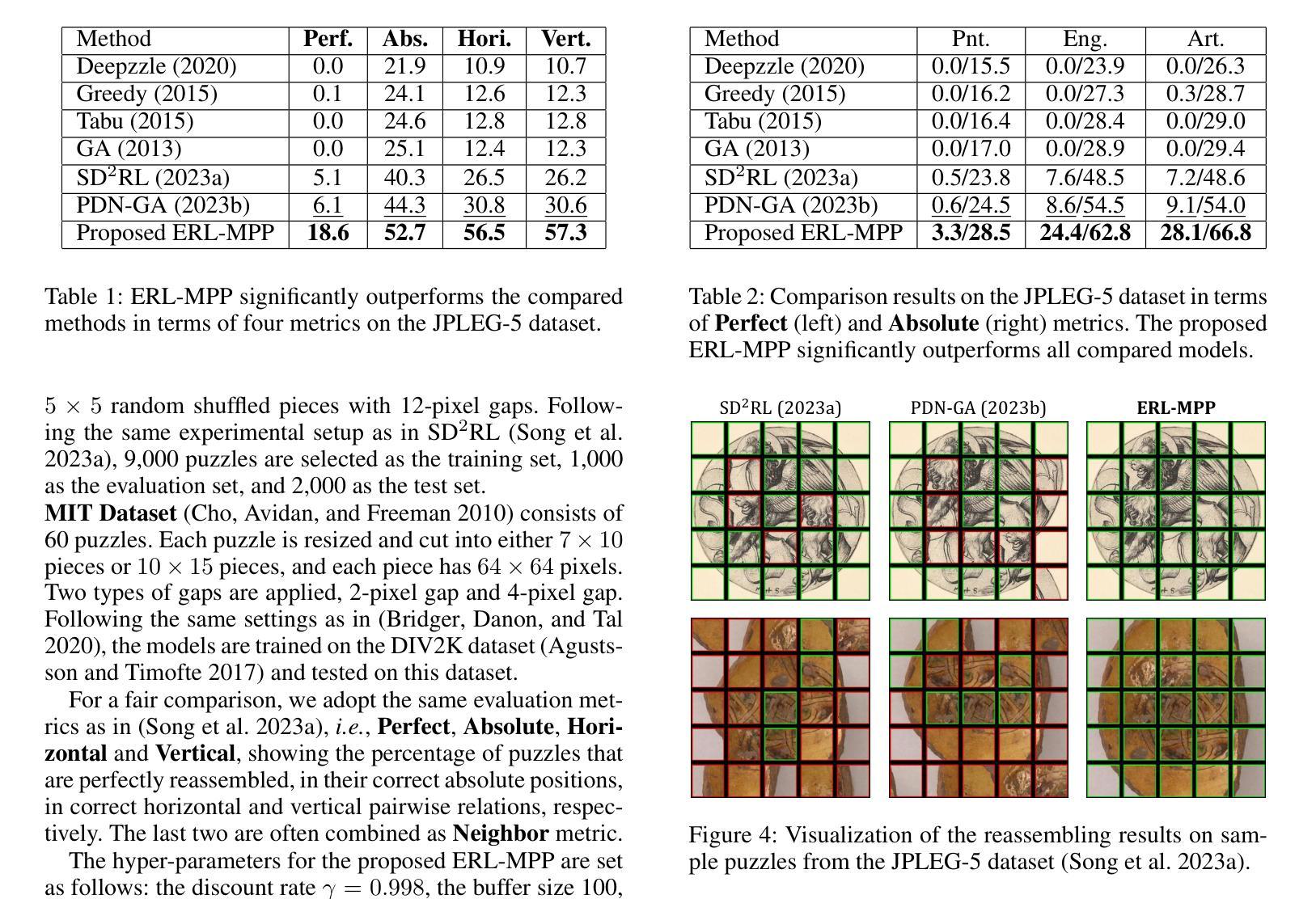
Solving jigsaw puzzles has been extensively studied. While most existing models focus on solving either small-scale puzzles or puzzles with no gap between fragments, solving large-scale puzzles with gaps presents distinctive challenges in both image understanding and combinatorial optimization. To tackle these challenges, we propose a framework of Evolutionary Reinforcement Learning with Multi-head Puzzle Perception (ERL-MPP) to derive a better set of swapping actions for solving the puzzles. Specifically, to tackle the challenges of perceiving the puzzle with gaps, a Multi-head Puzzle Perception Network (MPPN) with a shared encoder is designed, where multiple puzzlet heads comprehensively perceive the local assembly status, and a discriminator head provides a global assessment of the puzzle. To explore the large swapping action space efficiently, an Evolutionary Reinforcement Learning (EvoRL) agent is designed, where an actor recommends a set of suitable swapping actions from a large action space based on the perceived puzzle status, a critic updates the actor using the estimated rewards and the puzzle status, and an evaluator coupled with evolutionary strategies evolves the actions aligning with the historical assembly experience. The proposed ERL-MPP is comprehensively evaluated on the JPLEG-5 dataset with large gaps and the MIT dataset with large-scale puzzles. It significantly outperforms all state-of-the-art models on both datasets.
解决拼图游戏已经被广泛研究。虽然现有的大多数模型主要关注解决小规模拼图或无缝隙拼图,但解决大规模带有缝隙的拼图在图像理解和组合优化方面呈现出独特的挑战。为了应对这些挑战,我们提出了基于进化强化学习与多头拼图感知(ERL-MPP)的框架,以导出更好的交换动作集来解决拼图问题。具体来说,为了解决感知带有缝隙拼图的挑战,设计了一个带有共享编码器的多头拼图感知网络(MPPN),其中多个拼图头全面感知局部装配状态,一个判别头对拼图进行全局评估。为了有效地探索大规模的交换动作空间,设计了一个进化强化学习(EvoRL)代理,其中行为者根据感知到的拼图状态推荐一组合适的交换动作,评论家根据估计的奖励和拼图状态更新行为者,评估者结合进化策略根据历史装配经验进化动作。所提出的ERL-MPP在具有大缝隙的JPLEG-5数据集和具有大规模拼图问题的MIT数据集上进行了全面评估。它在两个数据集上都显著优于所有最先进模型。
论文及项目相关链接
PDF 9 pages, 5 figures
摘要
基于解决拼图时的感知挑战和探索大规模动作空间的需求,提出一种进化强化学习结合多头拼图感知(ERL-MPP)框架。设计了一个多头拼图感知网络(MPPN),具有共享编码器,多个拼图头全面感知局部装配状态,判别头则对拼图进行全局评估。针对大规模拼图交换动作空间的探索效率问题,设计了进化强化学习(EvoRL)智能体。该智能体通过感知到的拼图状态推荐一套合适的交换动作,评估器则通过进化策略根据历史装配经验对动作进行演化。在具有大间隙的JPLEG-5数据集和大规模拼图的MIT数据集上的评估表明,ERL-MPP显著优于所有最先进的模型。
关键见解
- 解决大规模拼图问题面临独特挑战,特别是在图像理解和组合优化方面。
- 提出进化强化学习结合多头拼图感知(ERL-MPP)框架以应对这些挑战。
- 设计了多头拼图感知网络(MPPN),通过共享编码器,多个拼图头全面感知局部装配状态,并使用判别头进行全局评估。
- 采用进化强化学习(EvoRL)智能体,能有效探索大规模动作空间。智能体包括一个能够根据感知到的拼图状态推荐交换动作的演员,一个使用估计奖励和拼图状态更新演员的评论家,以及一个与进化策略相结合的评估器,用于根据历史装配经验演化动作。
- 在具有大间隙的JPLEG-5数据集上进行了评估,证明该框架能显著改进拼图解决性能。
- 在大规模拼图的MIT数据集上的评估结果也显示了ERL-MPP的优越性,显著优于所有最先进的模型。
点此查看论文截图


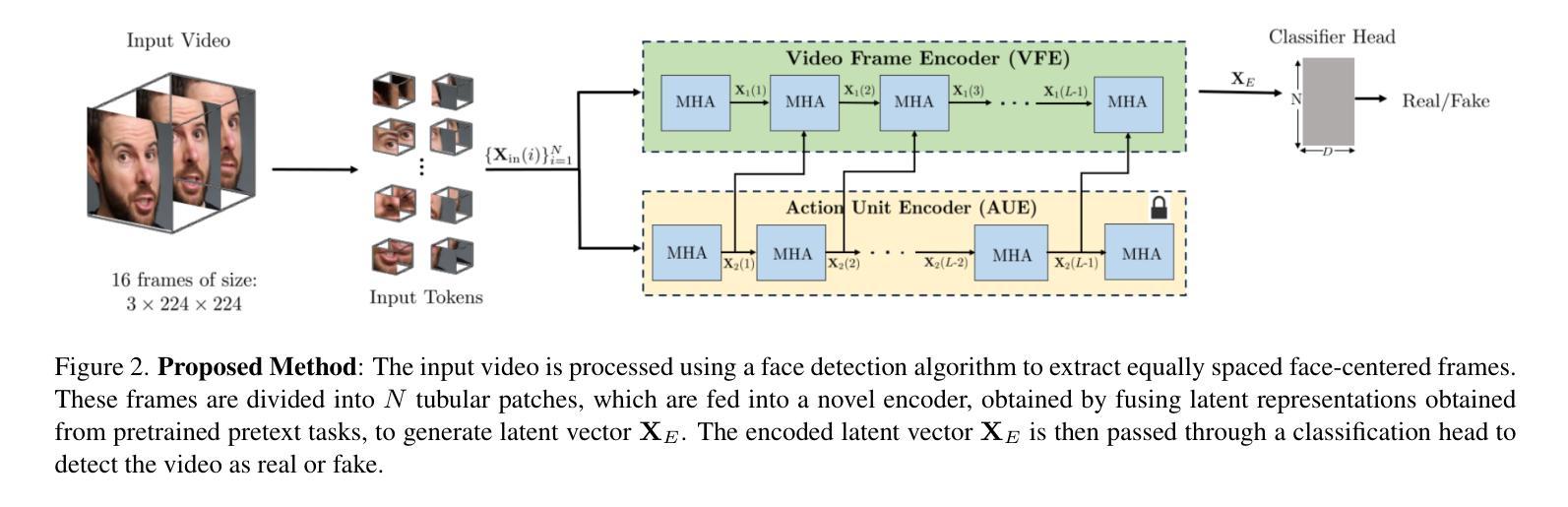
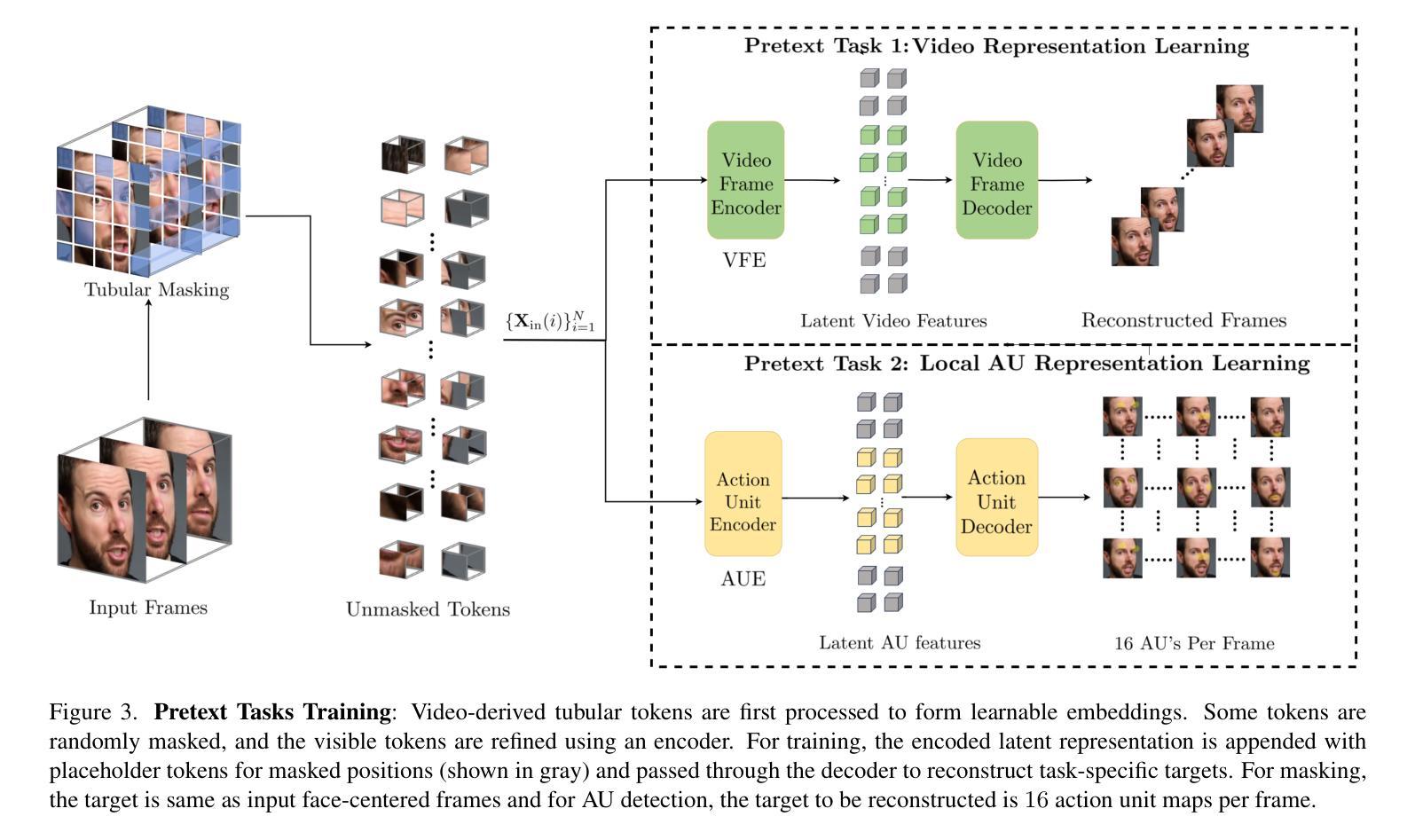
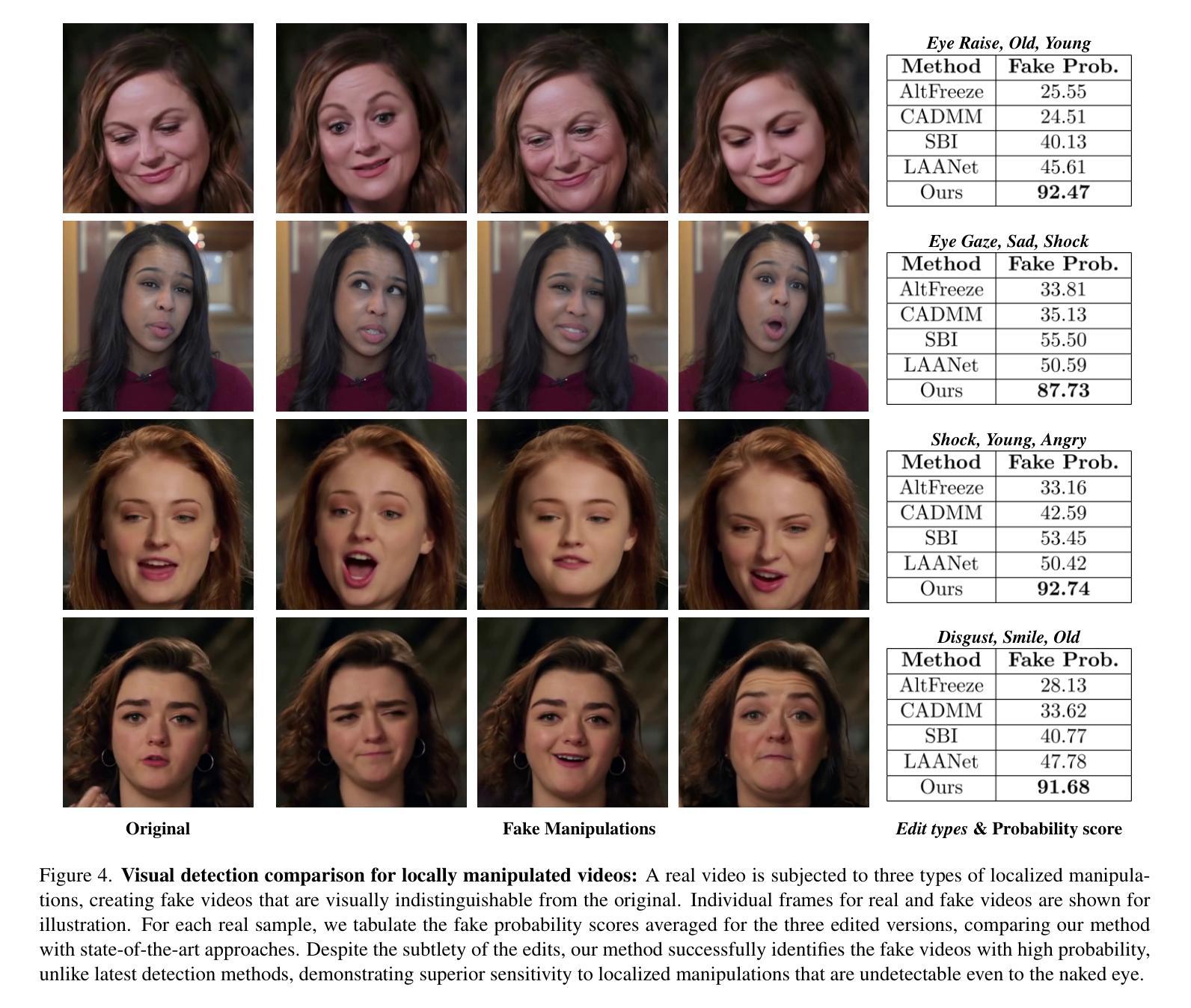
Detecting Localized Deepfake Manipulations Using Action Unit-Guided Video Representations
Authors:Tharun Anand, Siva Sankar Sajeev, Pravin Nair
With rapid advancements in generative modeling, deepfake techniques are increasingly narrowing the gap between real and synthetic videos, raising serious privacy and security concerns. Beyond traditional face swapping and reenactment, an emerging trend in recent state-of-the-art deepfake generation methods involves localized edits such as subtle manipulations of specific facial features like raising eyebrows, altering eye shapes, or modifying mouth expressions. These fine-grained manipulations pose a significant challenge for existing detection models, which struggle to capture such localized variations. To the best of our knowledge, this work presents the first detection approach explicitly designed to generalize to localized edits in deepfake videos by leveraging spatiotemporal representations guided by facial action units. Our method leverages a cross-attention-based fusion of representations learned from pretext tasks like random masking and action unit detection, to create an embedding that effectively encodes subtle, localized changes. Comprehensive evaluations across multiple deepfake generation methods demonstrate that our approach, despite being trained solely on the traditional FF+ dataset, sets a new benchmark in detecting recent deepfake-generated videos with fine-grained local edits, achieving a $20%$ improvement in accuracy over current state-of-the-art detection methods. Additionally, our method delivers competitive performance on standard datasets, highlighting its robustness and generalization across diverse types of local and global forgeries.
随着生成模型的快速发展,深度伪造技术正在缩小真实视频和合成视频之间的差距,这引发了人们对隐私和安全的严重关注。除了传统的换脸和面部再现技术,最近最先进的深度伪造生成方法中出现了一种新兴趋势,即进行局部编辑,如细微调整特定的面部特征,如挑眉、改变眼睛形状或修改口型表情等。这些精细的操纵对现有检测模型构成了重大挑战,这些模型难以捕捉这样的局部变化。据我们所知,这项工作提出了第一个明确针对深度伪造视频中局部编辑设计的检测方案,该方案利用面部动作单元引导的时空表征。我们的方法利用基于跨注意力的表示融合,这些表示是从随机掩码和动作单元检测等预训练任务中学到的,以创建一个有效编码细微局部变化的嵌入。在多种深度伪造生成方法上的综合评估表明,尽管我们的方法仅在传统FF+数据集上进行训练,但在检测具有精细局部编辑的深度伪造生成视频方面设定了新的基准,在准确率上比当前最先进的检测方法提高了20%。此外,我们的方法在标准数据集上表现出良好的性能,凸显了其在不同类型局部和全局伪造上的稳健性和泛化能力。
论文及项目相关链接
PDF Accepted to CVPR-W 2025
Summary
本文介绍了深度伪造技术的快速发展,特别是针对面部特定特征的精细操作,如挑眉、改变眼型或改变口型等细微调整,对现有检测模型构成挑战。本文提出了一种针对深度伪造视频中局部编辑的检测方法,利用时空表征和面部动作单元引导,通过预训练任务如随机掩蔽和动作单元检测来学习表示融合。该方法在多个深度伪造生成方法上的综合评估表明,尽管仅在传统FF+数据集上进行训练,但它在检测具有精细局部编辑的深度伪造视频方面设定了新的基准,准确性提高了20%,并在标准数据集上表现出竞争性能,凸显其稳健性和对局部和全局伪造的泛化能力。
Key Takeaways
- 深度伪造技术快速发展,使得真实与合成视频之间的差距越来越小,引发了隐私和安全问题。
- 现有检测模型难以捕捉局部细微调整,如挑眉、改变眼型或口型等。
- 本文提出了一种新的检测方法来应对深度伪造视频中的局部编辑。
- 该方法利用时空表征和面部动作单元引导,通过预训练任务学习表示融合。
- 该方法在多个深度伪造生成方法上的评估表现优异,准确性提高20%。
- 该方法在传统FF+数据集上进行训练,但对不同类型伪造的泛化能力强。
点此查看论文截图