⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-16 更新
Anchor Token Matching: Implicit Structure Locking for Training-free AR Image Editing
Authors:Taihang Hu, Linxuan Li, Kai Wang, Yaxing Wang, Jian Yang, Ming-Ming Cheng
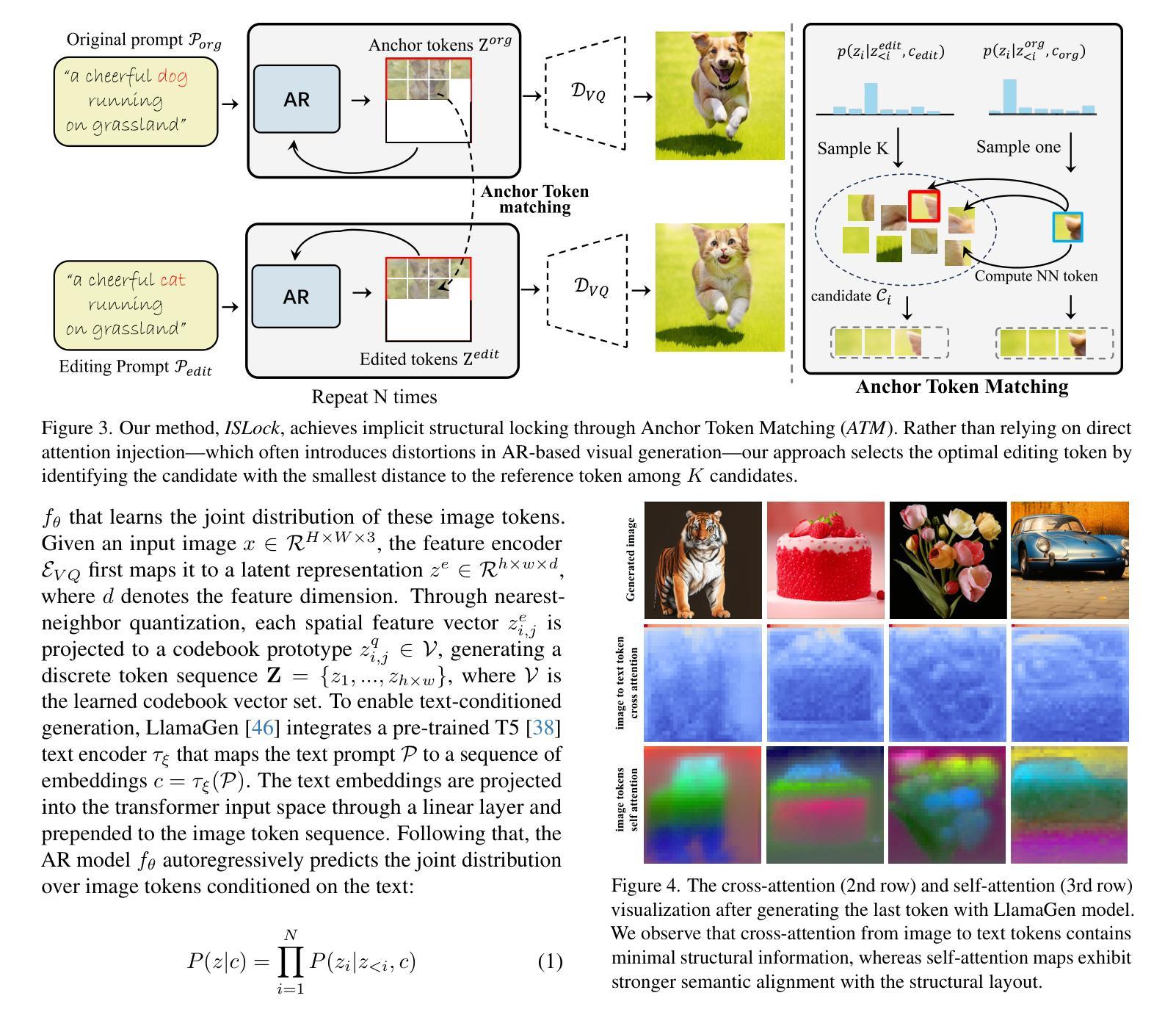
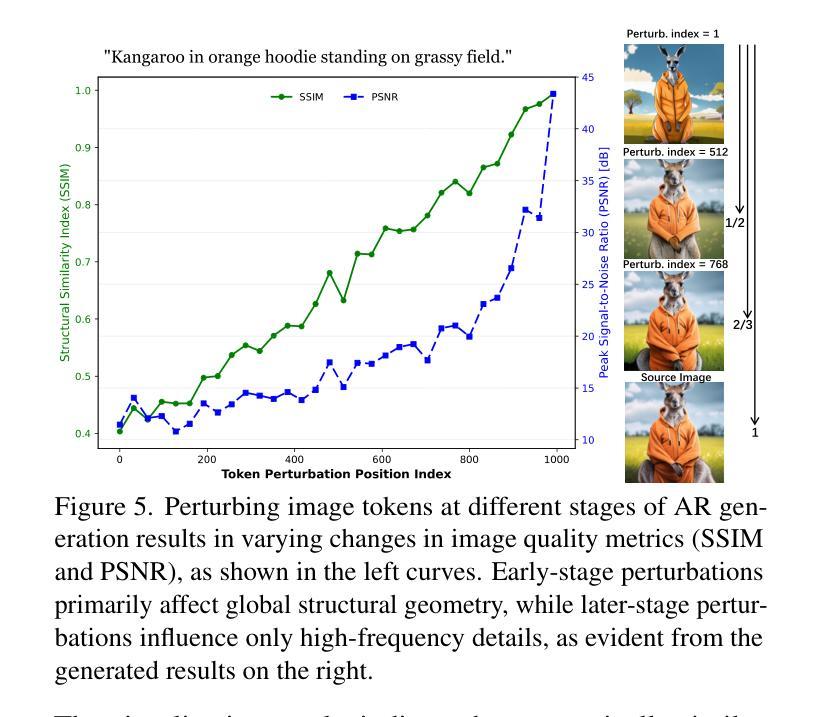
Text-to-image generation has seen groundbreaking advancements with diffusion models, enabling high-fidelity synthesis and precise image editing through cross-attention manipulation. Recently, autoregressive (AR) models have re-emerged as powerful alternatives, leveraging next-token generation to match diffusion models. However, existing editing techniques designed for diffusion models fail to translate directly to AR models due to fundamental differences in structural control. Specifically, AR models suffer from spatial poverty of attention maps and sequential accumulation of structural errors during image editing, which disrupt object layouts and global consistency. In this work, we introduce Implicit Structure Locking (ISLock), the first training-free editing strategy for AR visual models. Rather than relying on explicit attention manipulation or fine-tuning, ISLock preserves structural blueprints by dynamically aligning self-attention patterns with reference images through the Anchor Token Matching (ATM) protocol. By implicitly enforcing structural consistency in latent space, our method ISLock enables structure-aware editing while maintaining generative autonomy. Extensive experiments demonstrate that ISLock achieves high-quality, structure-consistent edits without additional training and is superior or comparable to conventional editing techniques. Our findings pioneer the way for efficient and flexible AR-based image editing, further bridging the performance gap between diffusion and autoregressive generative models. The code will be publicly available at https://github.com/hutaiHang/ATM
文本到图像生成领域因扩散模型(Diffusion Models)取得了突破性进展,该模型能够实现高保真合成和通过交叉注意力操控进行精确的图像编辑。近期,自回归(AR)模型重新崛起成为强大的替代品,它通过利用下一代令牌与扩散模型相匹配。然而,针对扩散模型设计的现有编辑技术无法直接应用于AR模型,这归因于结构控制方面的根本差异。具体来说,AR模型在图像编辑时存在注意力图的空间贫困和结构性错误的连续累积问题,这些问题会破坏对象布局和全局一致性。在这项工作中,我们介绍了无需训练的编辑策略——隐式结构锁定(ISLock),这是针对AR视觉模型的首个此类策略。ISLock不依赖于显式的注意力操控或微调,而是通过锚定令牌匹配(ATM)协议,动态地将自我注意力模式与参考图像对齐,从而保留结构蓝图。通过在潜在空间中隐式强制执行结构性一致性,我们的ISLock方法能够在保持生成自主性的同时进行结构感知编辑。大量实验表明,ISLock无需额外训练即可实现高质量、结构一致性的编辑,并且在常规编辑技术上具有优势或与之相当。我们的研究为高效、灵活的AR图像编辑方式开辟道路,进一步缩小了扩散模型和自回归生成模型之间的性能差距。代码将公开发布在:https://github.com/hutaiHang/ATM。
论文及项目相关链接
Summary: 文本图像生成领域取得突破性进展,通过扩散模型实现了高质量合成与精准图像编辑。尽管自回归(AR)模型作为替代方案崭露头角,但现有编辑技术无法直接应用于AR模型。本文引入了一种针对AR视觉模型的无训练编辑策略——Implicit Structure Locking(ISLock),通过动态对齐参考图像的自我关注模式,实现了结构一致的编辑。该策略展示了高效率和高质感的编辑效果,拉近了扩散模型与自回归生成模型之间的差距。更多详情可通过访问代码仓库获取:https://github.com/hutaiHang/ATM。
Key Takeaways:
- 文本图像生成领域进步显著,扩散模型和自回归模型均有突出表现。
- 自回归模型在图像编辑方面存在挑战,如空间关注图的贫困和结构性错误的累积。
- Implicit Structure Locking(ISLock)是首个针对自回归模型的无需训练即可应用的编辑策略。
- ISLock通过动态对齐参考图像的自我关注模式来保持结构蓝图的一致性。
- ISLock通过隐式强制潜在空间的结构一致性,实现了结构感知编辑同时保持生成自主性。
- 实验证明,ISLock无需额外训练即可实现高质量、结构一致的编辑,表现优于或相当于传统编辑技术。
点此查看论文截图


Structure-Accurate Medical Image Translation based on Dynamic Frequency Balance and Knowledge Guidance
Authors:Jiahua Xu, Dawei Zhou, Lei Hu, Zaiyi Liu, Nannan Wang, Xinbo Gao
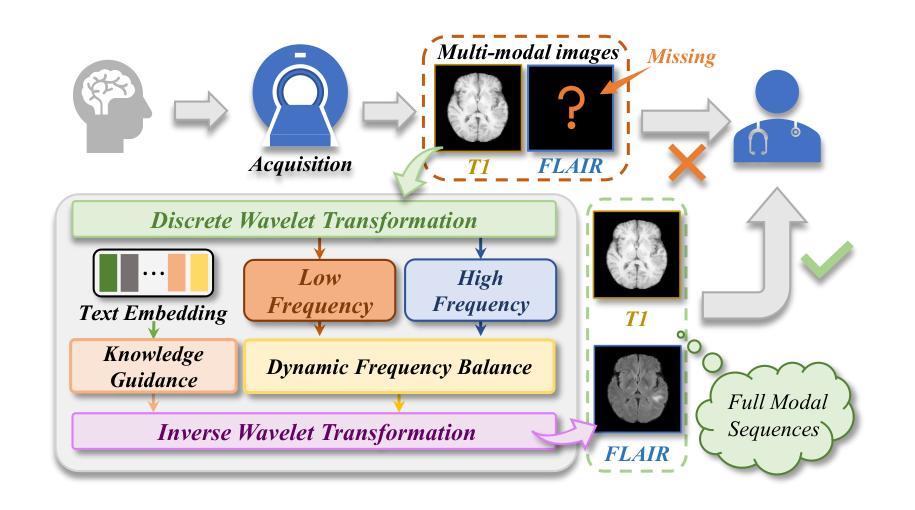
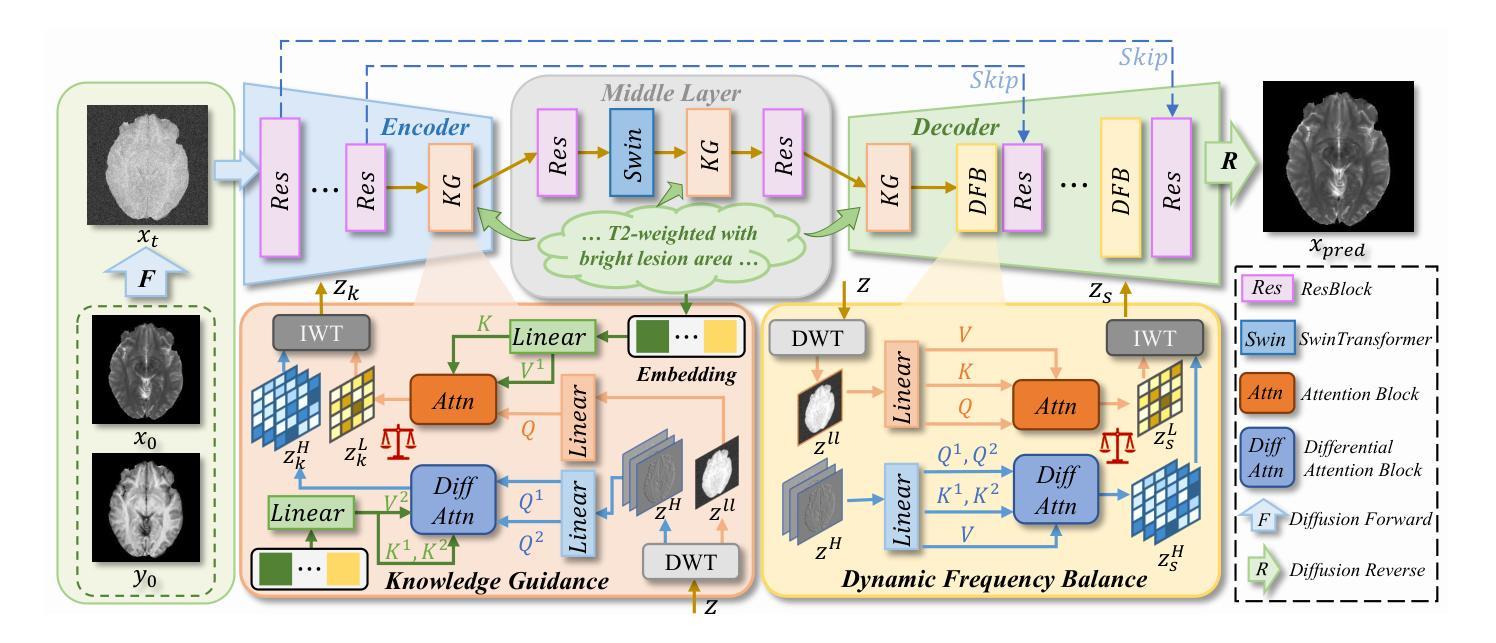
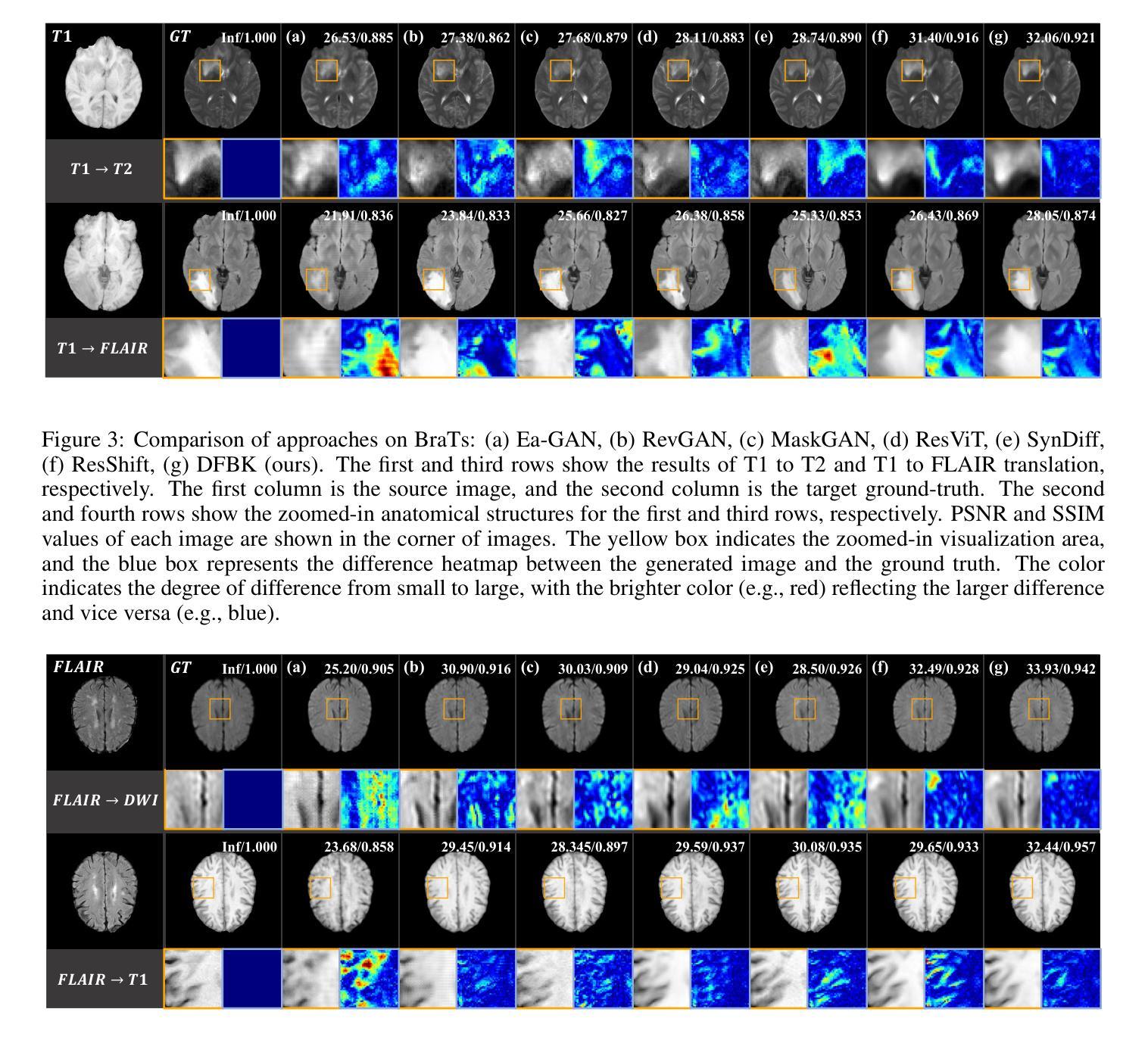
Multimodal medical images play a crucial role in the precise and comprehensive clinical diagnosis. Diffusion model is a powerful strategy to synthesize the required medical images. However, existing approaches still suffer from the problem of anatomical structure distortion due to the overfitting of high-frequency information and the weakening of low-frequency information. Thus, we propose a novel method based on dynamic frequency balance and knowledge guidance. Specifically, we first extract the low-frequency and high-frequency components by decomposing the critical features of the model using wavelet transform. Then, a dynamic frequency balance module is designed to adaptively adjust frequency for enhancing global low-frequency features and effective high-frequency details as well as suppressing high-frequency noise. To further overcome the challenges posed by the large differences between different medical modalities, we construct a knowledge-guided mechanism that fuses the prior clinical knowledge from a visual language model with visual features, to facilitate the generation of accurate anatomical structures. Experimental evaluations on multiple datasets show the proposed method achieves significant improvements in qualitative and quantitative assessments, verifying its effectiveness and superiority.
多模态医学图像在精确全面的临床诊断中扮演着至关重要的角色。扩散模型是合成所需医学图像的一种强大策略。然而,现有方法仍然存在因高频信息过度拟合而导致解剖结构失真以及低频信息减弱的问题。因此,我们提出了一种基于动态频率平衡和知识指导的新方法。具体来说,我们首先通过小波变换分解模型的关键特征来提取低频和高频成分。然后,设计了一个动态频率平衡模块,该模块可以自适应地调整频率,以增强全局低频特征和有效的高频细节,同时抑制高频噪声。为了进一步克服不同医学模态之间巨大差异所带来的挑战,我们构建了一个知识引导机制,该机制将来自视觉语言模型的先验临床知识与视觉特征相结合,有助于生成准确的解剖结构。在多个数据集上的实验评估表明,所提出的方法在定性和定量评估方面都取得了显著的改进,验证了其有效性和优越性。
论文及项目相关链接
PDF Medical image translation, Diffusion model, 16 pages
Summary
基于动态频率平衡和知识指导的方法在多模态医学图像合成中取得了显著成效。该方法通过小波变换提取高低频成分,并设计动态频率平衡模块自适应调整频率,增强了全局低频特征和有效高频细节,同时抑制了高频噪声。此外,通过融合视觉语言模型的先验临床知识,解决了不同医学模态之间的差异问题,生成了准确的解剖结构。在多个数据集上的实验评估表明,该方法在定性和定量评估上都有显著改善,验证了其有效性和优越性。
Key Takeaways
- 多模态医学图像在临床诊断中扮演重要角色,扩散模型是合成医学图像的有效策略。
- 现有方法存在因过度拟合高频信息而忽视低频信息导致的解剖结构扭曲问题。
- 提出了基于动态频率平衡和知识指导的新方法,通过小波变换提取高低频成分。
- 动态频率平衡模块可自适应调整频率,增强低频和有效高频细节,抑制高频噪声。
- 知识指导机制融合了视觉语言模型的先验临床知识,有助于解决不同医学模态之间的差异。
- 方法在多个数据集上实验评估表现优异,在定性和定量评估上都有显著改善。
- 该方法的有效性和优越性得到验证。
点此查看论文截图