⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-16 更新
LL-Gaussian: Low-Light Scene Reconstruction and Enhancement via Gaussian Splatting for Novel View Synthesis
Authors:Hao Sun, Fenggen Yu, Huiyao Xu, Tao Zhang, Changqing Zou
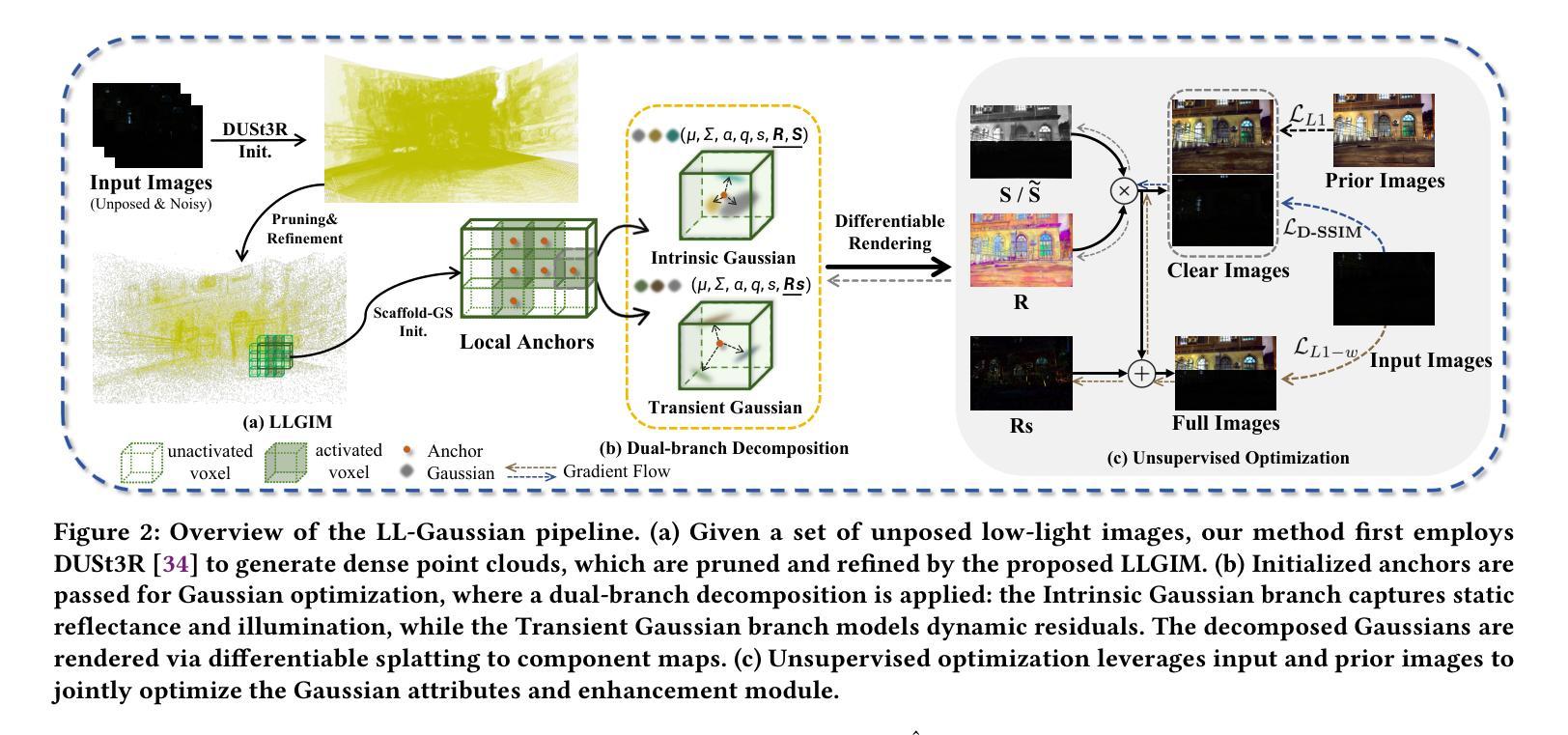
Novel view synthesis (NVS) in low-light scenes remains a significant challenge due to degraded inputs characterized by severe noise, low dynamic range (LDR) and unreliable initialization. While recent NeRF-based approaches have shown promising results, most suffer from high computational costs, and some rely on carefully captured or pre-processed data–such as RAW sensor inputs or multi-exposure sequences–which severely limits their practicality. In contrast, 3D Gaussian Splatting (3DGS) enables real-time rendering with competitive visual fidelity; however, existing 3DGS-based methods struggle with low-light sRGB inputs, resulting in unstable Gaussian initialization and ineffective noise suppression. To address these challenges, we propose LL-Gaussian, a novel framework for 3D reconstruction and enhancement from low-light sRGB images, enabling pseudo normal-light novel view synthesis. Our method introduces three key innovations: 1) an end-to-end Low-Light Gaussian Initialization Module (LLGIM) that leverages dense priors from learning-based MVS approach to generate high-quality initial point clouds; 2) a dual-branch Gaussian decomposition model that disentangles intrinsic scene properties (reflectance and illumination) from transient interference, enabling stable and interpretable optimization; 3) an unsupervised optimization strategy guided by both physical constrains and diffusion prior to jointly steer decomposition and enhancement. Additionally, we contribute a challenging dataset collected in extreme low-light environments and demonstrate the effectiveness of LL-Gaussian. Compared to state-of-the-art NeRF-based methods, LL-Gaussian achieves up to 2,000 times faster inference and reduces training time to just 2%, while delivering superior reconstruction and rendering quality.
在低光照场景中的新型视图合成(NVS)仍然是一个重大挑战,因为输入退化,表现为严重噪声、低动态范围(LDR)和不可靠的初始化。虽然最近的基于NeRF的方法已经显示出有希望的结果,但大多数方法的计算成本很高,一些方法依赖于精心捕获或预处理的数据——如RAW传感器输入或多曝光序列——这严重限制了它们的实用性。相比之下,3D高斯涂斑(3DGS)能够实现具有竞争力的视觉保真度的实时渲染;然而,现有的基于3DGS的方法在处理低光sRGB输入时遇到困难,导致高斯初始化不稳定和噪声抑制无效。为了解决这些挑战,我们提出了LL-Gaussian,这是一个从低光sRGB图像进行3D重建和增强的新型框架,能够实现伪正常光新型视图合成。我们的方法引入了三个关键创新点:1)端到端的低光高斯初始化模块(LLGIM),它利用基于学习的MVS方法的密集先验来生成高质量初始点云;2)双分支高斯分解模型,将场景固有属性(反射率和照明)从瞬时干扰中分离出来,实现稳定和可解释的优化;3)在物理约束和扩散先验指导下进行无监督优化策略,共同引导分解和增强。此外,我们还贡献了在极端低光环境中收集的具有挑战性的数据集,并展示了LL-Gaussian的有效性。与最先进的基于NeRF的方法相比,LL-Gaussian实现了高达2000倍的更快推理速度,并将训练时间缩短至仅2%,同时提供卓越的重建和渲染质量。
论文及项目相关链接
Summary
在极低光照场景中实现新颖视图合成(NVS)仍然是一个重大挑战,因为输入信息存在严重噪声、低动态范围及不可靠的初始化等问题。最近基于NeRF的方法展现出令人瞩目的成果,但大多数方法的计算成本较高,且依赖于精细捕捉或预先处理的数据,这极大地限制了其实用性。相比之下,3D高斯涂抹(3DGS)能够实现实时渲染并具有竞争性的视觉保真度;然而,基于3DGS的方法在处理低光sRGB输入时表现不稳定,导致高斯初始化不稳定和噪声抑制无效。针对这些挑战,我们提出了LL-Gaussian这一新颖框架,可从低光sRGB图像实现三维重建和增强,从而实现伪正常光新颖视图合成。我们的方法引入三个关键创新点:包括端到端的低光高斯初始化模块(LLGIM),通过基于学习的MVS方法生成高质量初始点云;双分支高斯分解模型能够将固有场景属性(反射率和照明)从短暂干扰中分离出来,从而实现稳定和可解释的优化;以及由物理约束和扩散先验引导的无监督优化策略,以共同指导分解和增强。此外,我们还贡献了在极端低光环境中收集的具有挑战性的数据集,并展示了LL-Gaussian的有效性。相较于最先进的NeRF方法,LL-Gaussian推理速度提高了高达2,000倍,训练时间仅减少了2%,同时提供更出色的重建和渲染质量。
Key Takeaways
- 低光照场景中的新颖视图合成是一个挑战,因为输入数据存在噪声、低动态范围和初始化问题。
- 现有基于NeRF的方法计算成本高且依赖精细捕捉或预先处理的数据,限制了其实用性。
- 3DGS能够实现实时渲染,但在处理低光sRGB输入时表现不稳定。
- LL-Gaussian框架通过三个关键创新点解决这些挑战:低光高斯初始化模块、双分支高斯分解模型和无监督优化策略。
- LL-Gaussian在极端低光环境中表现出卓越性能,相较于其他方法,推理速度更快,训练时间更短,同时重建和渲染质量更高。
- LL-Gaussian还贡献了一个在极端低光环境中收集的具有挑战性的数据集。
点此查看论文截图

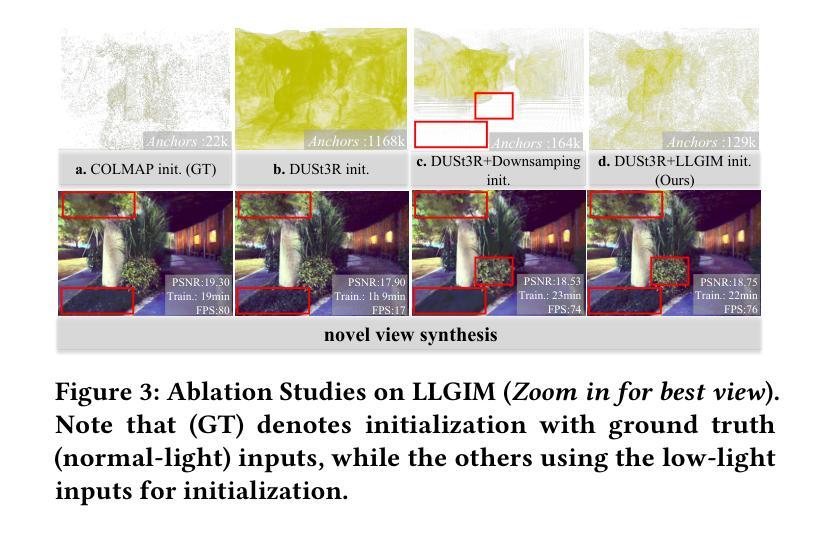

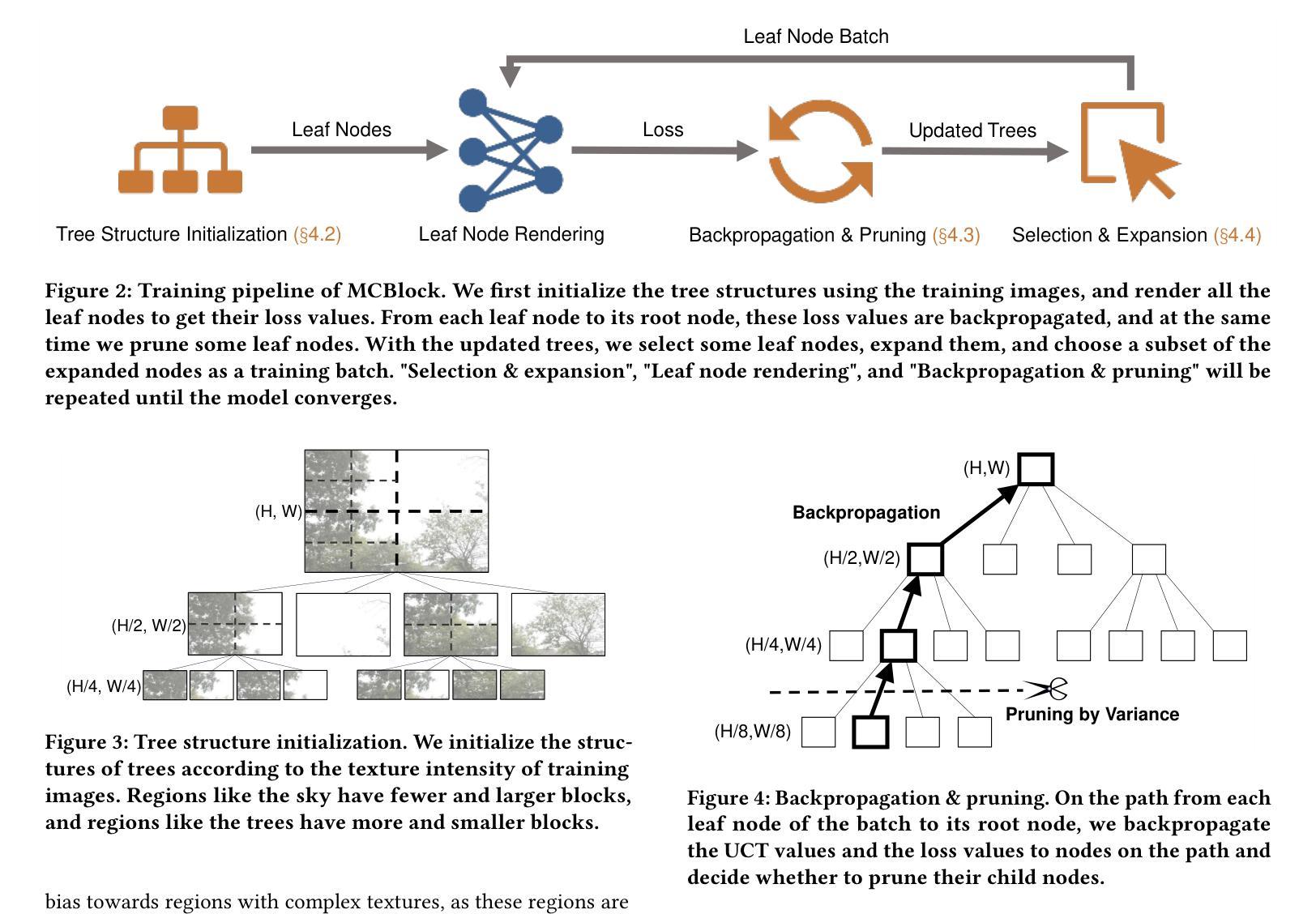
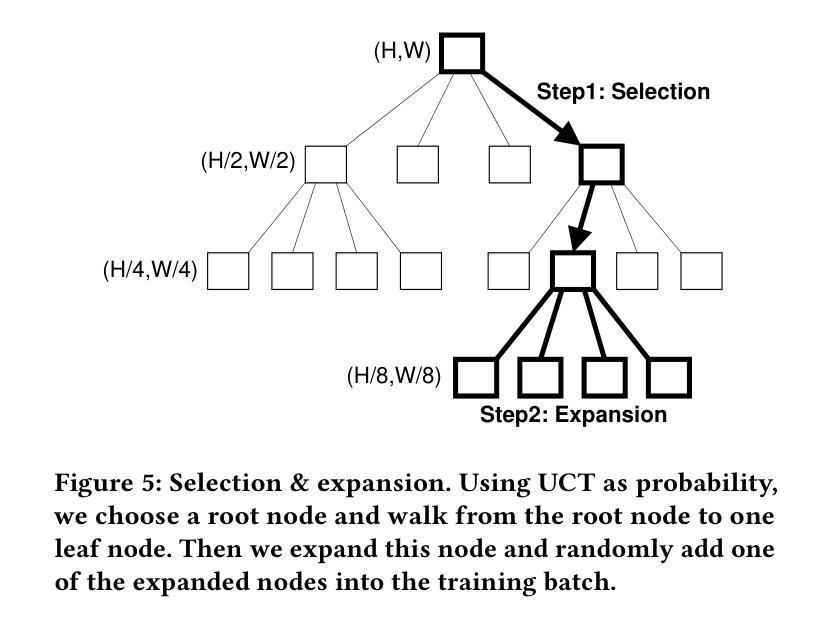
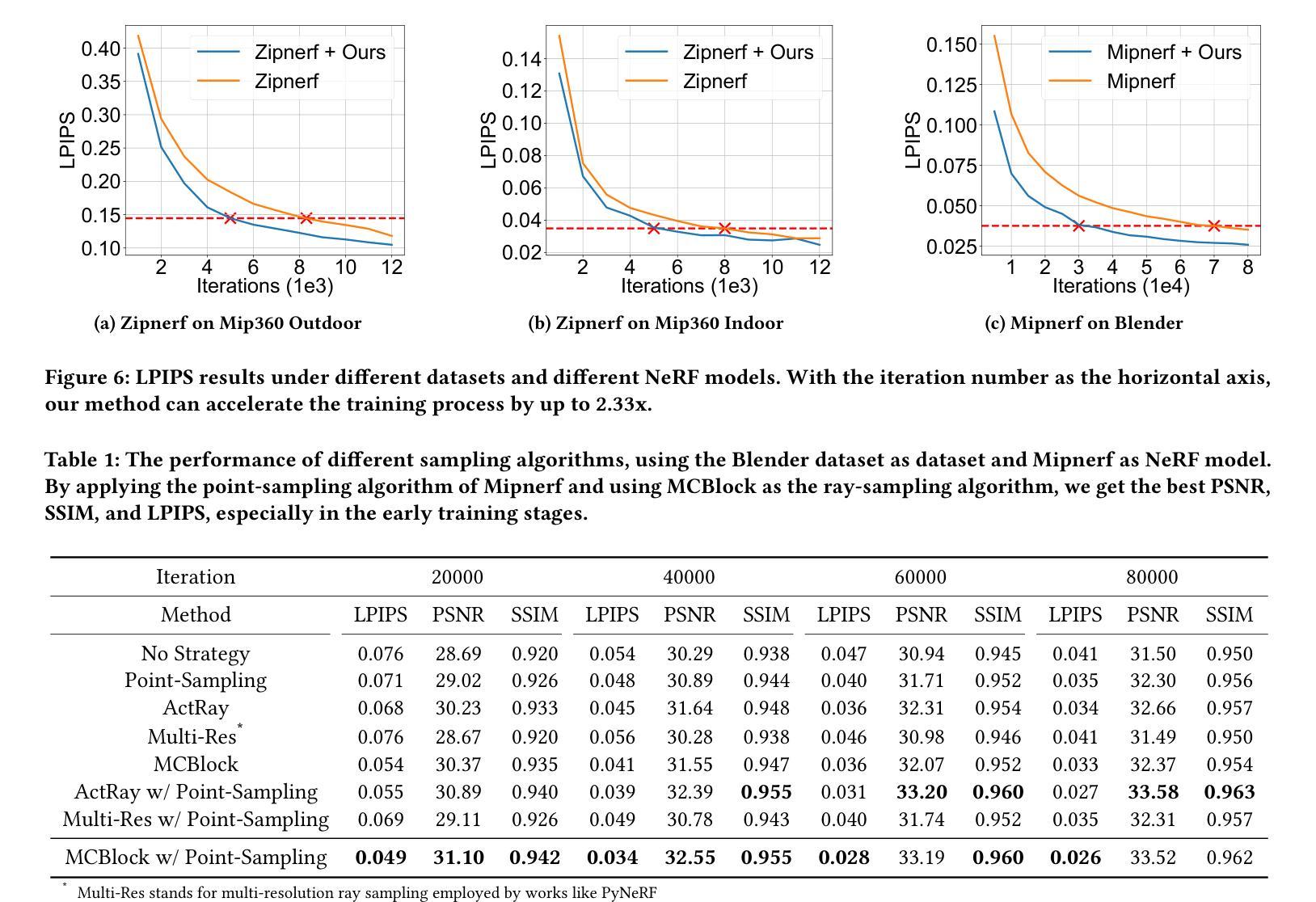
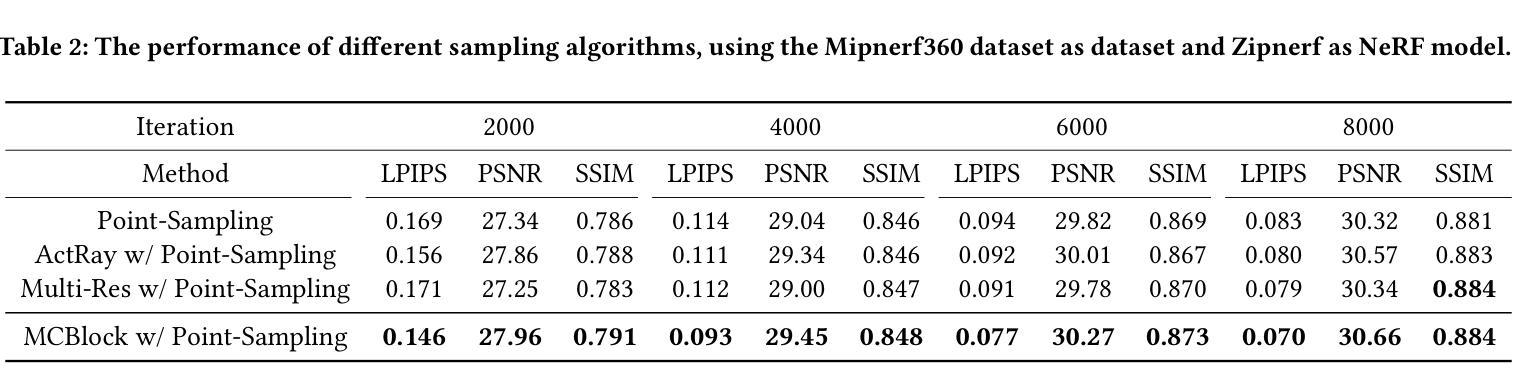
MCBlock: Boosting Neural Radiance Field Training Speed by MCTS-based Dynamic-Resolution Ray Sampling
Authors:Yunpeng Tan, Junlin Hao, Jiangkai Wu, Liming Liu, Qingyang Li, Xinggong Zhang
Neural Radiance Field (NeRF) is widely known for high-fidelity novel view synthesis. However, even the state-of-the-art NeRF model, Gaussian Splatting, requires minutes for training, far from the real-time performance required by multimedia scenarios like telemedicine. One of the obstacles is its inefficient sampling, which is only partially addressed by existing works. Existing point-sampling algorithms uniformly sample simple-texture regions (easy to fit) and complex-texture regions (hard to fit), while existing ray-sampling algorithms sample these regions all in the finest granularity (i.e. the pixel level), both wasting GPU training resources. Actually, regions with different texture intensities require different sampling granularities. To this end, we propose a novel dynamic-resolution ray-sampling algorithm, MCBlock, which employs Monte Carlo Tree Search (MCTS) to partition each training image into pixel blocks with different sizes for active block-wise training. Specifically, the trees are initialized according to the texture of training images to boost the initialization speed, and an expansion/pruning module dynamically optimizes the block partition. MCBlock is implemented in Nerfstudio, an open-source toolset, and achieves a training acceleration of up to 2.33x, surpassing other ray-sampling algorithms. We believe MCBlock can apply to any cone-tracing NeRF model and contribute to the multimedia community.
神经辐射场(NeRF)以其高保真度的新视角合成而广为人知。然而,即使是目前最先进的NeRF模型高斯拼贴也需要数分钟来进行训练,这远远不能满足远程医疗等多媒体场景对实时性能的要求。障碍之一是它的采样效率低下,而现有工作只部分解决了这个问题。现有的点采样算法对简单纹理区域(容易拟合)和复杂纹理区域(难以拟合)进行统一采样,而现有的射线采样算法以最精细的粒度(即像素级别)对这些区域进行采样,都浪费了GPU训练资源。实际上,具有不同纹理强度的区域需要不同的采样粒度。为此,我们提出了一种新的动态分辨率射线采样算法MCBlock,它采用蒙特卡洛树搜索(MCTS)将每幅训练图像分割成不同大小的像素块,以进行活动块级训练。具体来说,树木是根据训练图像的纹理进行初始化以加速初始化速度,一个扩展/修剪模块动态优化块分区。MCBlock在Nerfstudio这个开源工具包中实现,实现了高达2.33倍的训练加速,超越了其他射线采样算法。我们相信MCBlock可以应用于任何锥追踪NeRF模型,并为多媒体领域做出贡献。
论文及项目相关链接
Summary
本文介绍了NeRF技术在虚拟视图合成中的高保真应用,但现有模型如Gaussian Splatting无法满足实时性能需求。文章指出采样效率低是阻碍其实际应用的主要原因之一,现有采样算法在处理简单纹理区域和复杂纹理区域时未做到合理资源分配。为此,提出了一种基于Monte Carlo Tree Search(MCTS)的动态分辨率射线采样算法MCBlock,通过不同大小的像素块进行活跃块级训练,实现了训练图像的分区。该方法初始时根据图像纹理加速初始化速度,并通过扩展/修剪模块动态优化块分区。在开源工具集Nerfstudio中实现,实现了最高达2.33倍的训练加速,超越了其他射线采样算法。
Key Takeaways
- NeRF技术用于高保真虚拟视图合成,但实时性能需求难以满足。
- 现有采样算法在处理不同纹理区域时存在效率低下的问题。
- 提出了基于MCTS的动态分辨率射线采样算法MCBlock,实现训练图像的块级分区。
- MCBlock根据图像纹理初始化速度,并通过动态优化块分区提高训练效率。
- MCBlock在Nerfstudio中实现,实现了较高的训练加速。
- MCBlock可应用于任何锥追踪NeRF模型。
点此查看论文截图


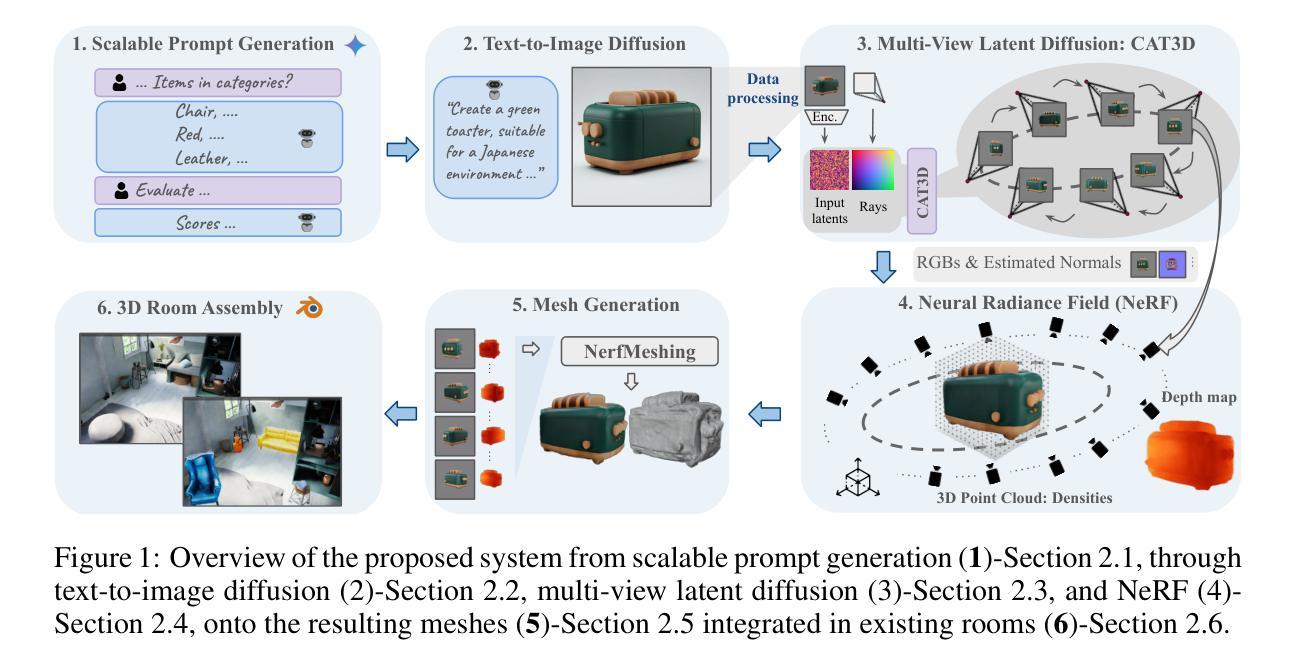
Text To 3D Object Generation For Scalable Room Assembly
Authors:Sonia Laguna, Alberto Garcia-Garcia, Marie-Julie Rakotosaona, Stylianos Moschoglou, Leonhard Helminger, Sergio Orts-Escolano
Modern machine learning models for scene understanding, such as depth estimation and object tracking, rely on large, high-quality datasets that mimic real-world deployment scenarios. To address data scarcity, we propose an end-to-end system for synthetic data generation for scalable, high-quality, and customizable 3D indoor scenes. By integrating and adapting text-to-image and multi-view diffusion models with Neural Radiance Field-based meshing, this system generates highfidelity 3D object assets from text prompts and incorporates them into pre-defined floor plans using a rendering tool. By introducing novel loss functions and training strategies into existing methods, the system supports on-demand scene generation, aiming to alleviate the scarcity of current available data, generally manually crafted by artists. This system advances the role of synthetic data in addressing machine learning training limitations, enabling more robust and generalizable models for real-world applications.
现代用于场景理解(如深度估计和对象跟踪)的机器学习任务严重依赖于模仿现实世界部署场景的大规模高质量数据集。为了解决数据稀缺的问题,我们提出了一种用于生成可扩展、高质量、可定制的室内场景的三维合成数据的端到端系统。该系统通过集成和适应文本到图像和多视角扩散模型与基于神经辐射场的网格化技术,根据文本提示生成高质量的三维对象资产,并使用渲染工具将其合并到预定义的平面布局中。该系统在现有方法中引入新颖的损耗函数和培训策略,支持按需生成场景,旨在缓解当前可用数据的人工创作稀缺问题。这一系统推动了合成数据在解决机器学习训练限制方面的作用,为现实世界应用提供了更稳健和可推广的模型。
论文及项目相关链接
PDF Published at the ICLR 2025 Workshop on Synthetic Data
Summary
本文提出一种端到端的合成数据生成系统,用于生成可扩展、高质量、可定制的3D室内场景。该系统结合了文本到图像和多视角扩散模型与基于神经辐射场建模的技术,根据文本提示生成高保真3D对象资产,并将其融入预定义的平面布局中。通过引入新的损失函数和训练策略,该系统支持按需场景生成,旨在缓解当前可用数据的稀缺性,通常这些数据是由艺术家们手工制作的。此系统推动了合成数据在解决机器学习训练限制中的作用,为真实世界应用提供了更稳健和可推广的模型。
Key Takeaways
- 提出一种合成数据生成系统,用于生成高质量、可定制的3D室内场景。
- 结合文本到图像和多视角扩散模型技术,根据文本提示生成高保真3D对象资产。
- 系统支持按需场景生成,以缓解数据的稀缺性。
- 引入新的损失函数和训练策略,提高系统的效能。
- 该系统使用预定义的平面布局将生成的资产融入场景中。
- 此系统推动了合成数据在解决机器学习训练限制中的作用。
点此查看论文截图




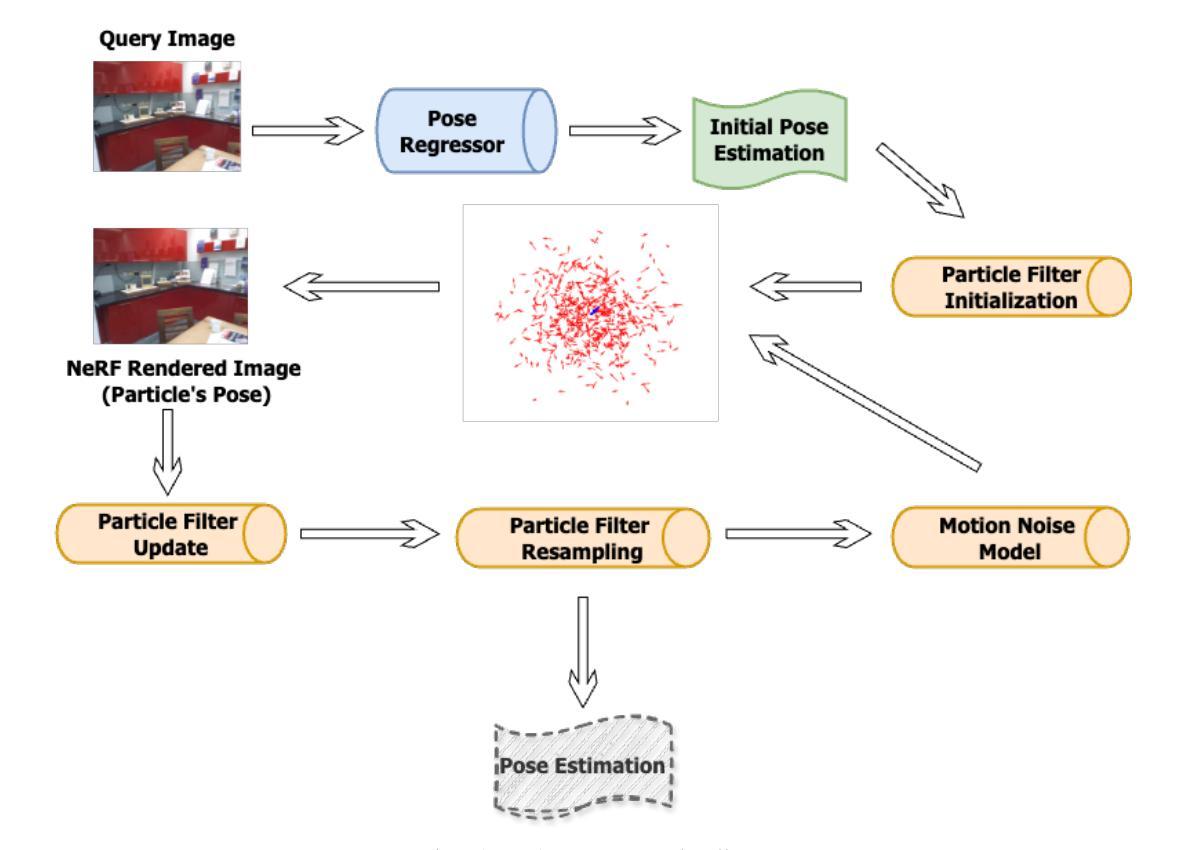
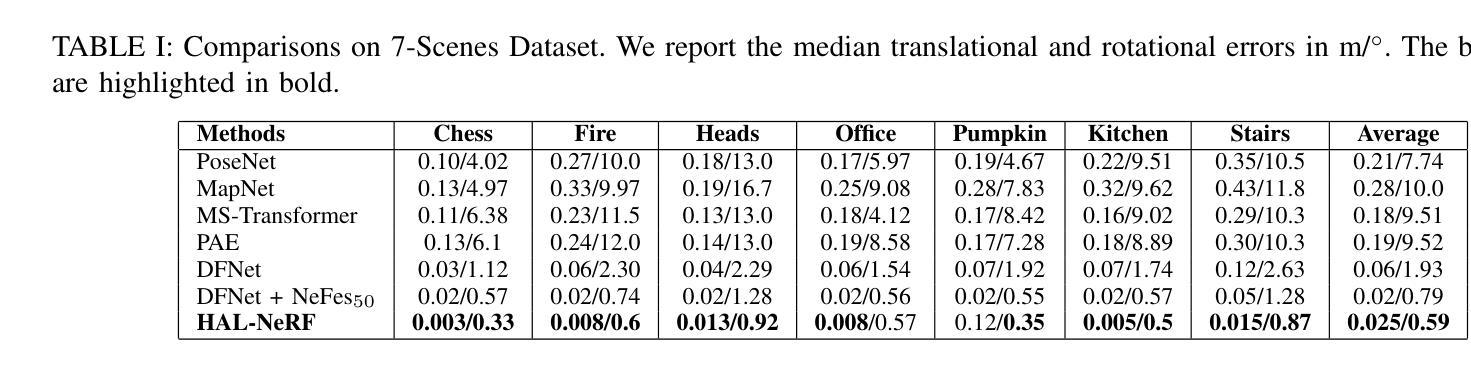
HAL-NeRF: High Accuracy Localization Leveraging Neural Radiance Fields
Authors:Asterios Reppas, Grigorios-Aris Cheimariotis, Panos K. Papadopoulos, Panagiotis Frasiolas, Dimitrios Zarpalas
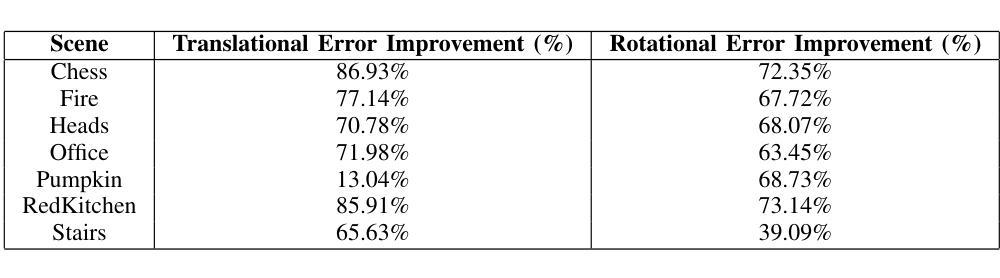
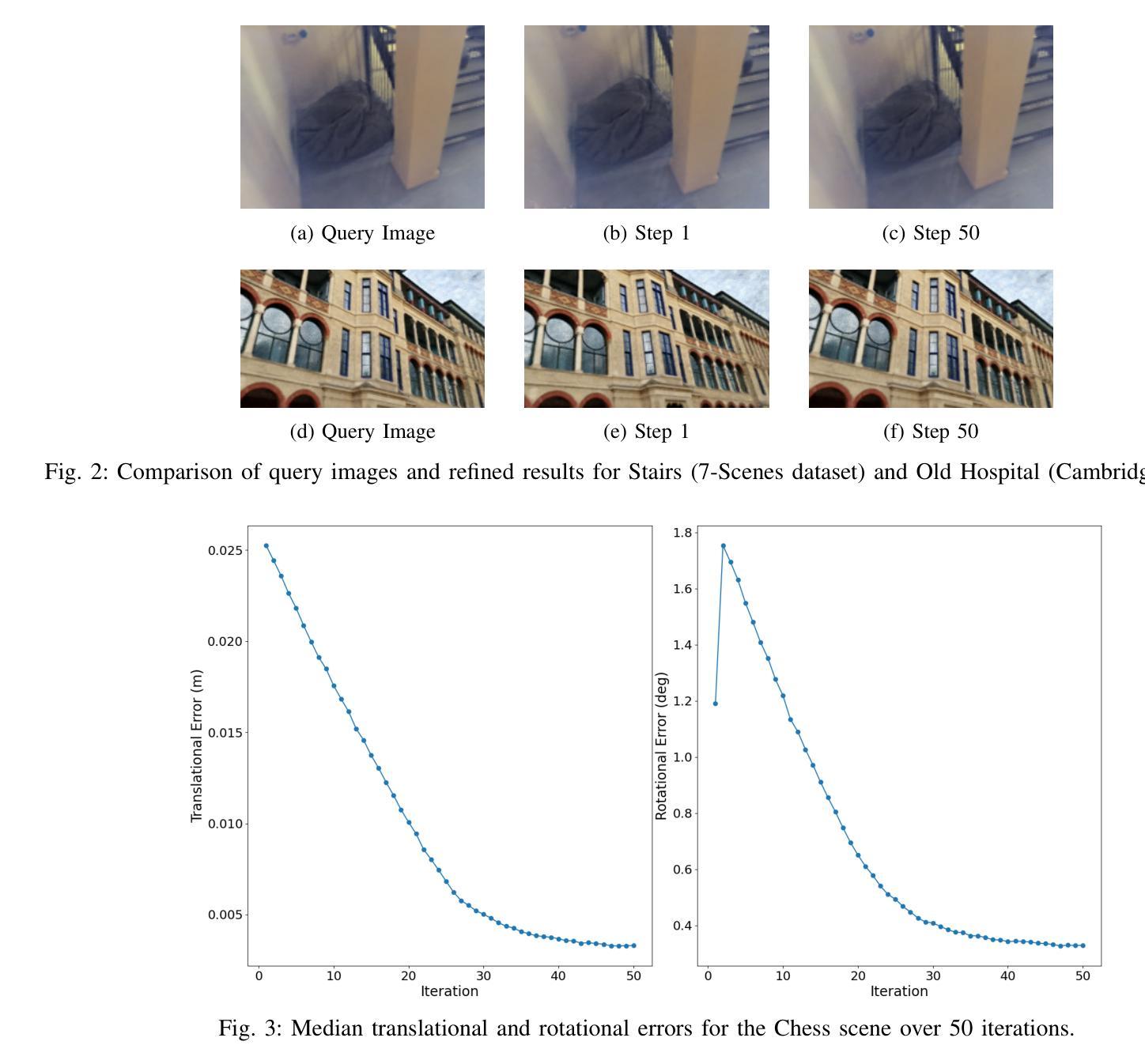
Precise camera localization is a critical task in XR applications and robotics. Using only the camera captures as input to a system is an inexpensive option that enables localization in large indoor and outdoor environments, but it presents challenges in achieving high accuracy. Specifically, camera relocalization methods, such as Absolute Pose Regression (APR), can localize cameras with a median translation error of more than $0.5m$ in outdoor scenes. This paper presents HAL-NeRF, a high-accuracy localization method that combines a CNN pose regressor with a refinement module based on a Monte Carlo particle filter. The Nerfacto model, an implementation of Neural Radiance Fields (NeRFs), is used to augment the data for training the pose regressor and to measure photometric loss in the particle filter refinement module. HAL-NeRF leverages Nerfacto’s ability to synthesize high-quality novel views, significantly improving the performance of the localization pipeline. HAL-NeRF achieves state-of-the-art results that are conventionally measured as the average of the median per scene errors. The translation error was $0.025m$ and the rotation error was $0.59$ degrees and 0.04m and 0.58 degrees on the 7-Scenes dataset and Cambridge Landmarks datasets respectively, with the trade-off of increased computational time. This work highlights the potential of combining APR with NeRF-based refinement techniques to advance monocular camera relocalization accuracy.
精确相机定位是XR应用和机器人技术中的关键任务。仅使用相机捕获作为系统的输入是一种经济实惠的选择,可在大型室内和室外环境中实现定位,但在实现高精度方面存在挑战。具体来说,相机重新定位方法(例如绝对姿态回归(APR))在室外场景中可以将相机定位的中位平移误差超过0.5米。本文提出了HAL-NeRF,这是一种高精度定位方法,它将基于卷积神经网络(CNN)的姿态回归器与基于蒙特卡洛粒子滤波器的优化模块相结合。Nerfacto模型是神经辐射场(NeRF)的一种实现,用于增强数据以训练姿态回归器,并在粒子滤波器优化模块中测量光度损失。HAL-NeRF利用Nerfacto合成高质量新视图的能力,显著提高了定位管道的性能。HAL-NeRF达到了最先进的成果,通常被测量为场景误差的中值平均值。在7场景数据集上,平移误差为0.025米,旋转误差为0.59度;在剑桥地标数据集上,平移误差为0.04米和0.58度,虽然有增加计算时间的权衡。这项工作强调了将APR与基于NeRF的优化技术相结合以提高单目相机重新定位精度的潜力。
论文及项目相关链接
PDF 8 pages, 4 figures
Summary
本文提出了名为HAL-NeRF的高精度定位方法,结合了基于卷积神经网络(CNN)的姿态回归器和基于蒙特卡洛粒子滤波器的优化模块。使用Nerfacto模型(NeRFs的一种实现)进行数据增强和测量光度损失。HAL-NeRF利用Nerfacto合成高质量新视角的能力,显著提高定位管道的性能。在7场景和剑桥地标数据集上,其平移误差和旋转误差分别达到行业领先水平,尽管计算时间有所增加。该研究凸显了将APR与基于NeRF的优化技术相结合以提高单目相机重新定位精度的潜力。
Key Takeaways
- HAL-NeRF是一种高精确度定位方法,结合了CNN姿态回归器和基于蒙特卡洛粒子滤波器的优化模块。
- Nerfacto模型被用于数据增强和测量光度损失,以改进定位性能。
- HAL-NeRF利用Nerfacto合成高质量新视角的能力,显著提升了定位流程的效能。
- 在7场景和剑桥地标数据集上,HAL-NeRF实现了平移误差和旋转误差的业界领先水平。
- HAL-NeRF方法的计算时间有所增加,但相较于传统方法仍具有竞争力。
- 论文强调了结合APR和NeRF优化技术的潜力,以提高单目相机的重新定位精度。
点此查看论文截图

HOMER: Homography-Based Efficient Multi-view 3D Object Removal
Authors:Jingcheng Ni, Weiguang Zhao, Daniel Wang, Ziyao Zeng, Chenyu You, Alex Wong, Kaizhu Huang
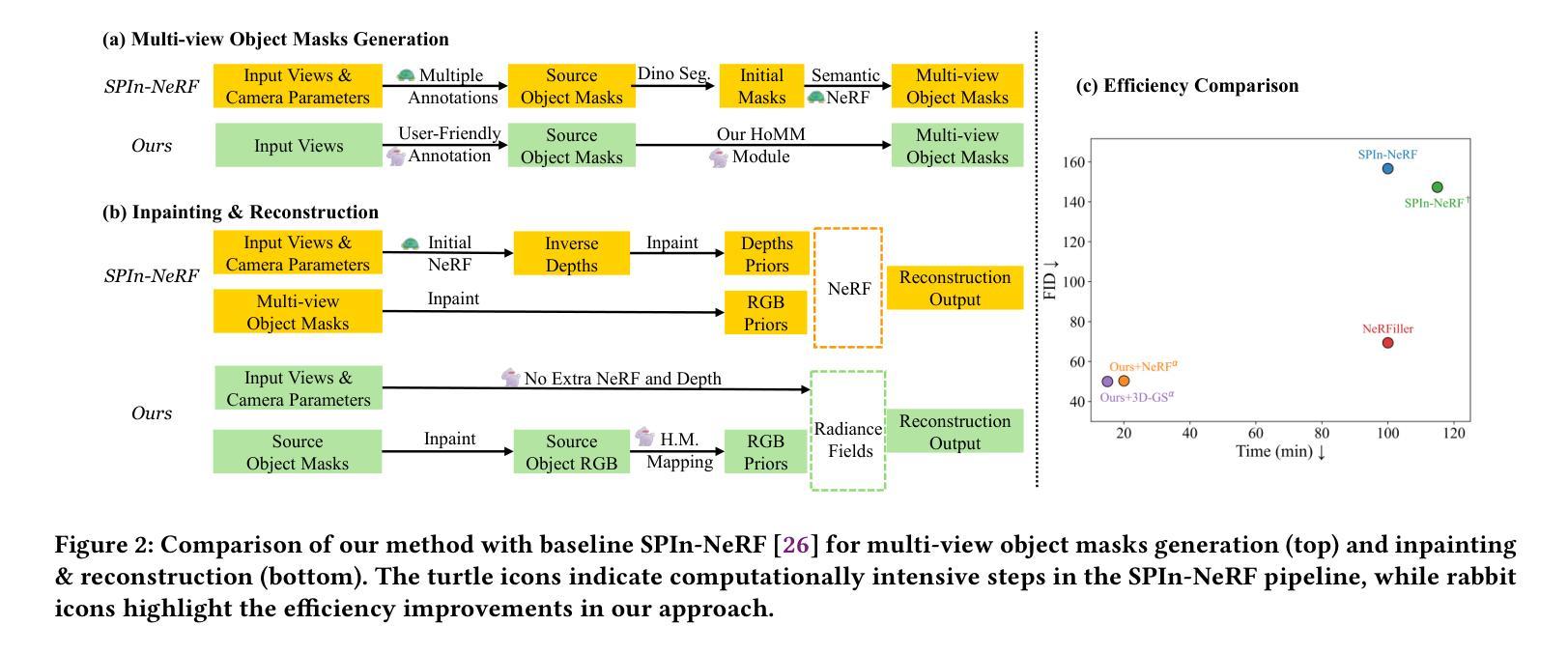
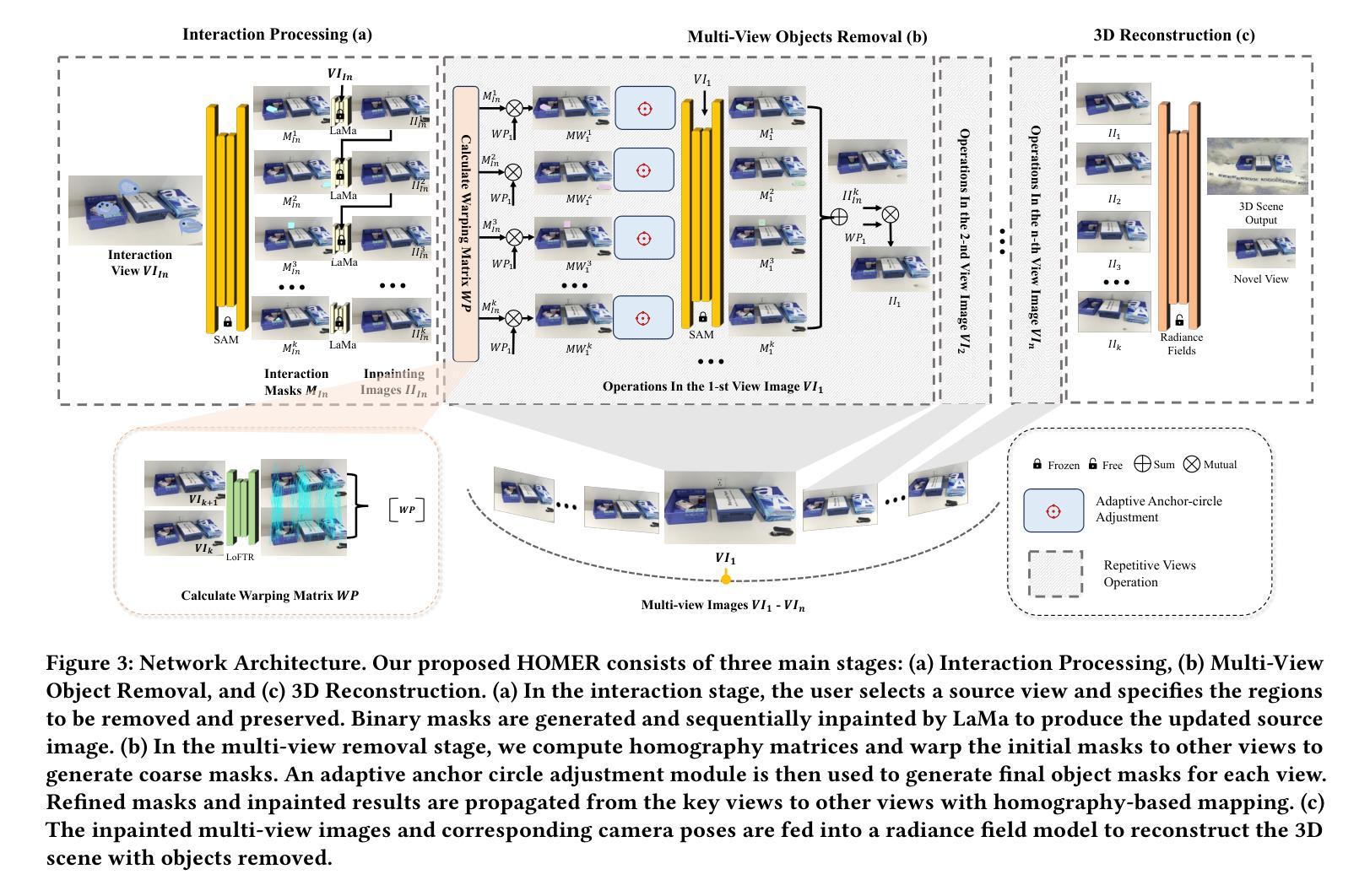
3D object removal is an important sub-task in 3D scene editing, with broad applications in scene understanding, augmented reality, and robotics. However, existing methods struggle to achieve a desirable balance among consistency, usability, and computational efficiency in multi-view settings. These limitations are primarily due to unintuitive user interaction in the source view, inefficient multi-view object mask generation, computationally expensive inpainting procedures, and a lack of applicability across different radiance field representations. To address these challenges, we propose a novel pipeline that improves the quality and efficiency of multi-view object mask generation and inpainting. Our method introduces an intuitive region-based interaction mechanism in the source view and eliminates the need for camera poses or extra model training. Our lightweight HoMM module is employed to achieve high-quality multi-view mask propagation with enhanced efficiency. In the inpainting stage, we further reduce computational costs by performing inpainting only on selected key views and propagating the results to other views via homography-based mapping. Our pipeline is compatible with a variety of radiance field frameworks, including NeRF and 3D Gaussian Splatting, demonstrating improved generalizability and practicality in real-world scenarios. Additionally, we present a new 3D multi-object removal dataset with greater object diversity and viewpoint variation than existing datasets. Experiments on public benchmarks and our proposed dataset show that our method achieves state-of-the-art performance while reducing runtime to one-fifth of that required by leading baselines.
3D物体移除是3D场景编辑中的一个重要子任务,广泛应用于场景理解、增强现实和机器人技术。然而,现有方法在多角度环境下在一致性、可用性和计算效率之间难以取得理想平衡。这些局限性主要是由于源视图中的用户交互不够直观、多视图对象蒙版生成效率低下、昂贵的补全程序计算过程以及缺乏适用于不同辐射场表示的应用性。为了应对这些挑战,我们提出了一种改进的多视图对象蒙版生成和补全质量及效率的新型流水线。我们的方法在源视图中引入了一种直观的区域交互机制,无需相机姿态或额外的模型训练。我们采用轻量级的HoMM模块实现高质量的多视图蒙版传播,同时提高效率。在补全阶段,我们通过仅在选定关键视图上进行补全并借助基于同态的映射将结果传播到其他视图来进一步降低计算成本。我们的流水线与多种辐射场框架兼容,包括NeRF和3D高斯溅射,在真实场景中具有更好的通用性和实用性。此外,我们展示了一个全新的3D多目标移除数据集,其中包含比现有数据集更多的目标多样性和视角变化。在公共基准测试和我们提出的数据集上的实验表明,我们的方法达到了最先进的性能,同时将运行时间缩短到现有基线所需时间的五分之一。
论文及项目相关链接
Summary
本文提出了一种新颖的管道流程,旨在改进多视角物体移除的质量和效率。该方法引入了在源视图中的基于区域的直观交互机制,无需相机姿态或额外的模型训练。使用轻量化HoMM模块实现高效高质量的多视角遮罩传播。在填充阶段,通过仅在选定关键视图上执行填充并通过基于同构映射传播结果,进一步降低计算成本。该方法兼容多种光线场框架,包括NeRF和3D高斯填充,提高了在现实场景中的通用性和实用性。同时,提出了一种新的3D多目标移除数据集,包含更丰富的目标多样性和视角变化。实验表明,该方法在公共基准测试集和自身提出的数据集上均取得了领先水平,同时运行时间为现有基线方法的五分之一。
Key Takeaways
- 提出了一个新颖的管道流程,用于改进多视角的3D物体移除质量和效率。
- 引入了在源视图中的基于区域的直观交互机制,简化用户操作。
- 使用HoMM模块实现高效的多视角遮罩传播。
- 通过在选定关键视图上执行填充并通过同构映射传播结果,降低计算成本。
- 方法兼容多种光线场框架,包括NeRF和3D高斯填充,提高通用性和实用性。
- 推出新的3D多目标移除数据集,包含丰富的目标多样性和视角变化。
- 在公共基准测试集和自家数据集上的表现均达到领先水平,且运行时间更短。
点此查看论文截图

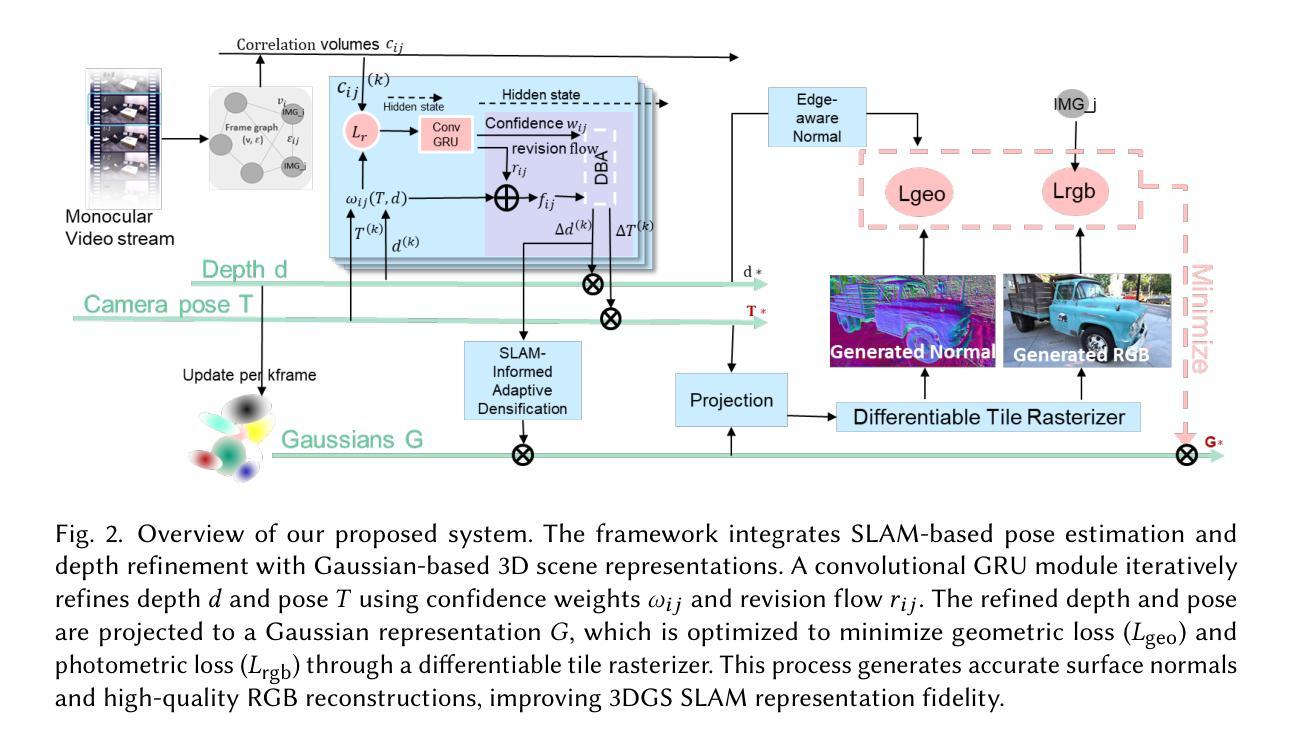
SplatMAP: Online Dense Monocular SLAM with 3D Gaussian Splatting
Authors:Yue Hu, Rong Liu, Meida Chen, Peter Beerel, Andrew Feng
Achieving high-fidelity 3D reconstruction from monocular video remains challenging due to the inherent limitations of traditional methods like Structure-from-Motion (SfM) and monocular SLAM in accurately capturing scene details. While differentiable rendering techniques such as Neural Radiance Fields (NeRF) address some of these challenges, their high computational costs make them unsuitable for real-time applications. Additionally, existing 3D Gaussian Splatting (3DGS) methods often focus on photometric consistency, neglecting geometric accuracy and failing to exploit SLAM’s dynamic depth and pose updates for scene refinement. We propose a framework integrating dense SLAM with 3DGS for real-time, high-fidelity dense reconstruction. Our approach introduces SLAM-Informed Adaptive Densification, which dynamically updates and densifies the Gaussian model by leveraging dense point clouds from SLAM. Additionally, we incorporate Geometry-Guided Optimization, which combines edge-aware geometric constraints and photometric consistency to jointly optimize the appearance and geometry of the 3DGS scene representation, enabling detailed and accurate SLAM mapping reconstruction. Experiments on the Replica and TUM-RGBD datasets demonstrate the effectiveness of our approach, achieving state-of-the-art results among monocular systems. Specifically, our method achieves a PSNR of 36.864, SSIM of 0.985, and LPIPS of 0.040 on Replica, representing improvements of 10.7%, 6.4%, and 49.4%, respectively, over the previous SOTA. On TUM-RGBD, our method outperforms the closest baseline by 10.2%, 6.6%, and 34.7% in the same metrics. These results highlight the potential of our framework in bridging the gap between photometric and geometric dense 3D scene representations, paving the way for practical and efficient monocular dense reconstruction.
从单目视频中实现高保真3D重建仍然是一个挑战,这主要是由于传统方法(如结构从运动(SfM)和单目SLAM)在准确捕捉场景细节方面的固有局限性。虽然神经辐射场(NeRF)等可微分渲染技术解决了其中的一些挑战,但它们的高计算成本使它们不适合实时应用。此外,现有的3D高斯涂抹(3DGS)方法通常侧重于光度一致性,忽视了几何精度,并且未能利用SLAM的动态深度和姿态更新来进行场景细化。我们提出了一种结合密集SLAM和3DGS的框架,用于实时高保真密集重建。我们的方法引入了SLAM信息自适应细化,它利用SLAM的密集点云来动态更新和细化高斯模型。此外,我们结合了几何引导优化,它结合了边缘感知几何约束和光度一致性,以联合优化3DGS场景表示的外观和几何形状,从而实现详细而准确的SLAM映射重建。在Replica和TUM-RGBD数据集上的实验表明了我们方法的有效性,在单目系统中达到了最新的结果。具体来说,我们的方法在Replica上达到了PSNR为36.864,SSIM为0.985,LPIPS为0.040,分别比之前的最佳结果提高了10.7%、6.4%和49.4%。在TUM-RGBD上,我们的方法在相同的指标上比最接近的基线高出10.2%、6.6%和34.7%。这些结果突显了我们框架在桥接光度学和几何学密集3D场景表示方面的潜力,为实用和高效的单目密集重建铺平了道路。
论文及项目相关链接
摘要
传统的方法如SfM和单目SLAM在捕捉场景细节方面存在局限性,实现单目视频的高保真三维重建仍然具有挑战性。虽然NeRF等可微分渲染技术解决了部分挑战,但其高计算成本使其不适用于实时应用。现有的3DGS方法通常侧重于光度一致性,忽略了几何精度,未能利用SLAM的动态深度和姿态更新进行场景优化。我们提出了一个结合密集SLAM与3DGS的框架,用于实时高保真密集重建。我们的方法引入了SLAM信息自适应细化技术,通过利用SLAM的密集点云来动态更新和细化高斯模型。此外,我们还纳入了几何引导优化,结合边缘感知几何约束和光度一致性,以联合优化3DGS场景表示的外观和几何形状,从而实现详细而准确SLAM映射重建。在Replica和TUM-RGBD数据集上的实验表明,我们的方法在所有单目系统中取得了最好的效果。具体来说,我们的方法在Replica上的PSNR达到36.864,SSIM为0.985,LPIPS为0.040,相较于之前的最优方法分别提高了10.7%、6.4%和49.4%。在TUM-RGBD上,我们的方法与最接近的基线相比,在上述指标中分别提高了10.2%、6.6%和34.7%。这些结果突显了我们的框架在桥接光度与几何密集三维场景表示之间的鸿沟的潜力,为实际和高效的单目密集重建铺平了道路。
关键见解
- 传统方法如SfM和单目SLAM在捕捉场景细节方面存在局限性。
- NeRF等可微分渲染技术虽然能解决部分挑战,但计算成本高,不适用于实时应用。
- 现有3DGS方法侧重于光度一致性,忽略了几何精度。
- 提出了一种结合密集SLAM与3DGS的框架,用于实时高保真密集重建。
- 引入SLAM信息自适应细化技术,利用SLAM的密集点云动态更新和细化高斯模型。
- 纳入几何引导优化,结合边缘感知几何约束和光度一致性,优化3D场景表示。
点此查看论文截图


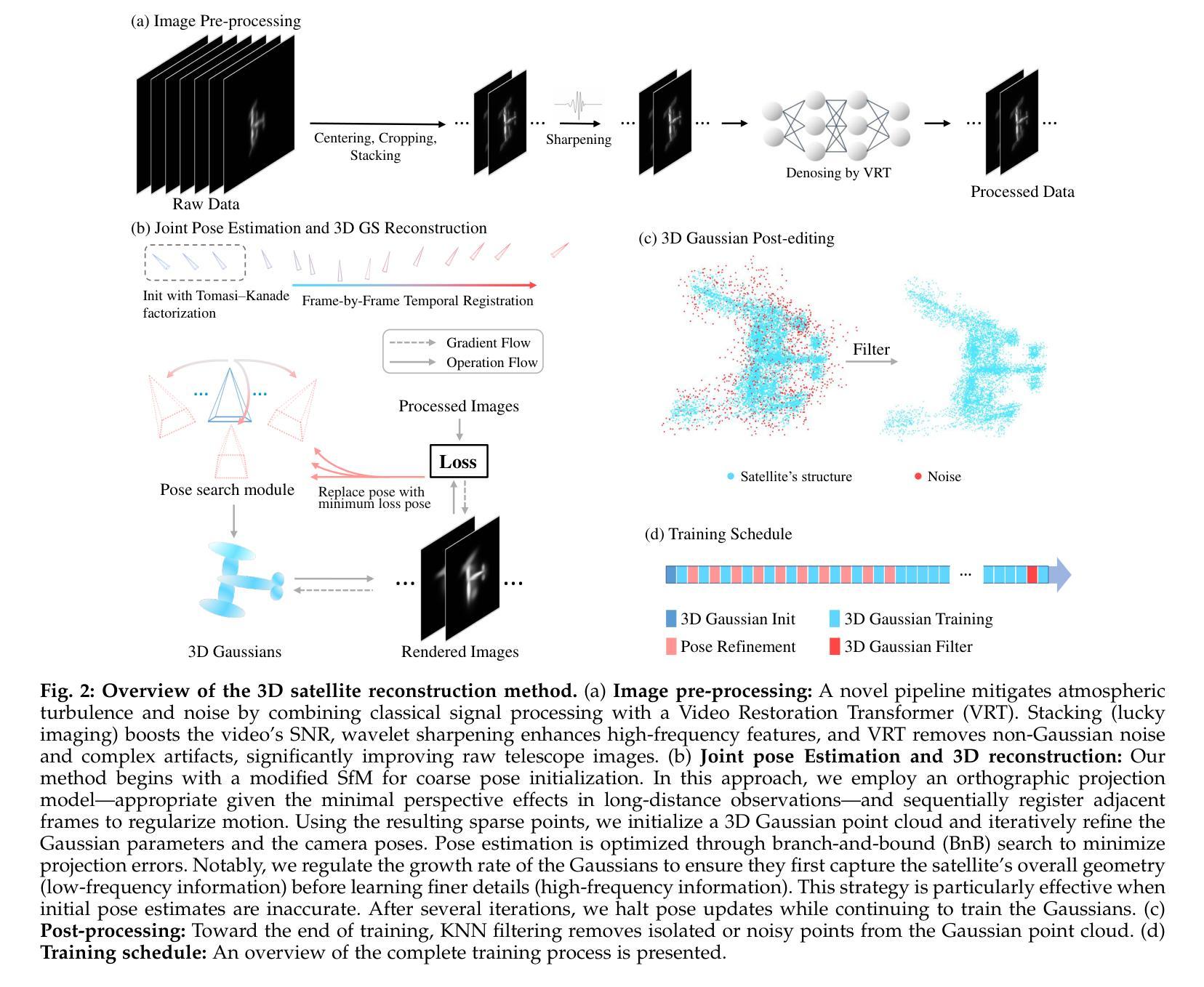
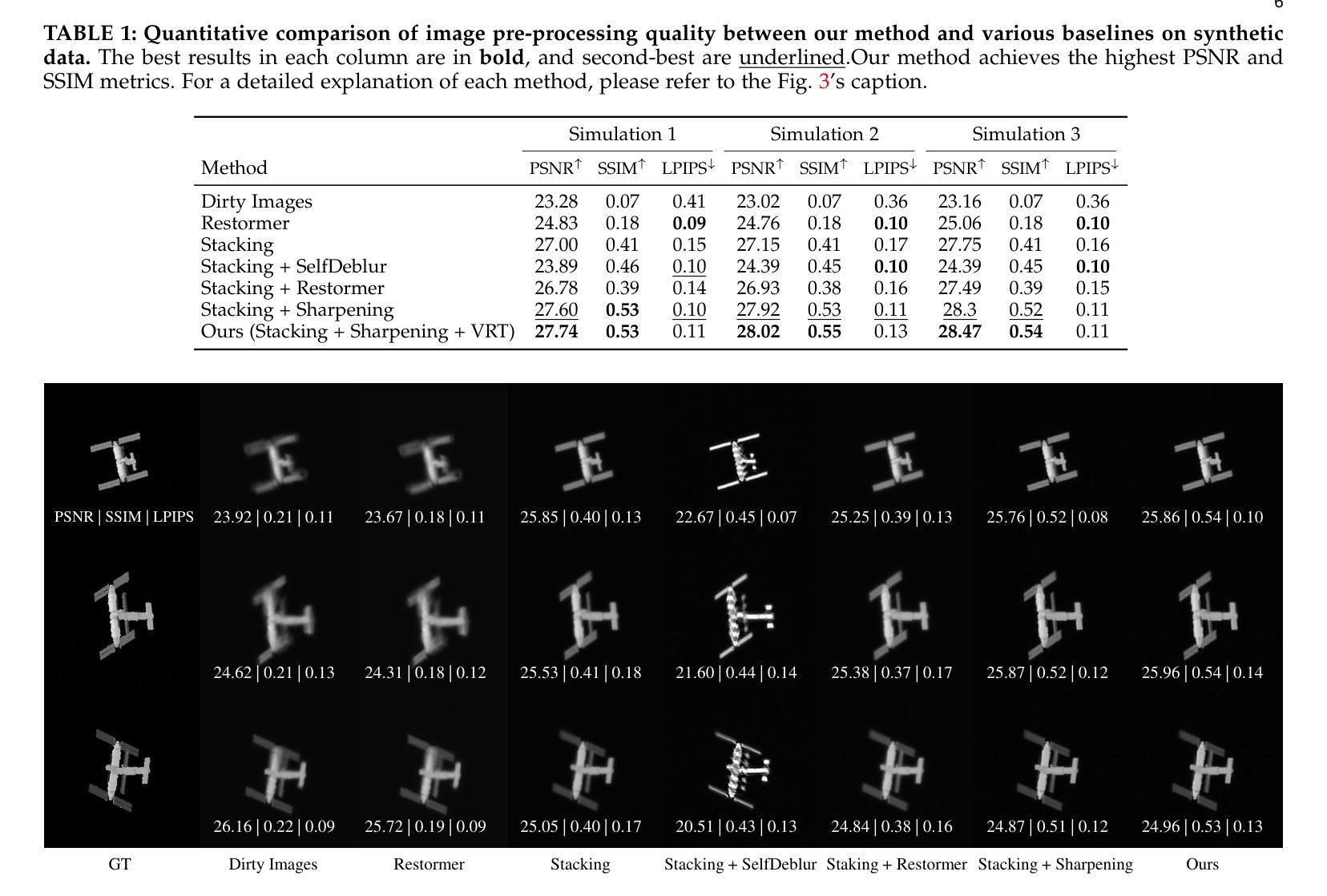
Reconstructing Satellites in 3D from Amateur Telescope Images
Authors:Zhiming Chang, Boyang Liu, Yifei Xia, Youming Guo, Boxin Shi, He Sun
Monitoring space objects is crucial for space situational awareness, yet reconstructing 3D satellite models from ground-based telescope images is challenging due to atmospheric turbulence, long observation distances, limited viewpoints, and low signal-to-noise ratios. In this paper, we propose a novel computational imaging framework that overcomes these obstacles by integrating a hybrid image pre-processing pipeline with a joint pose estimation and 3D reconstruction module based on controlled Gaussian Splatting (GS) and Branch-and-Bound (BnB) search. We validate our approach on both synthetic satellite datasets and on-sky observations of China’s Tiangong Space Station and the International Space Station, achieving robust 3D reconstructions of low-Earth orbit satellites from ground-based data. Quantitative evaluations using SSIM, PSNR, LPIPS, and Chamfer Distance demonstrate that our method outperforms state-of-the-art NeRF-based approaches, and ablation studies confirm the critical role of each component. Our framework enables high-fidelity 3D satellite monitoring from Earth, offering a cost-effective alternative for space situational awareness. Project page: https://ai4scientificimaging.org/ReconstructingSatellites
监测空间物体对于了解空间态势至关重要,然而,从地面望远镜图像重建3D卫星模型是一项具有挑战性的任务,面临着大气湍流、长观测距离、视角有限和信噪比低等问题。在本文中,我们提出了一种新型的计算成像框架,通过融合混合图像预处理管道与基于受控的高斯平铺(GS)和分支定界(BnB)搜索的联合姿态估计和3D重建模块,克服了这些障碍。我们在合成卫星数据集和中国天宫空间站以及国际空间站的天文观测上验证了我们方法的有效性,实现了从地面数据对低地球轨道卫星的稳健3D重建。使用结构相似性度量(SSIM)、峰值信噪比(PSNR)、局部感知图像相似性指数(LPIPS)和Chamfer距离进行的定量评估表明,我们的方法优于最新的基于NeRF的方法,消融研究证实了每个组件的关键作用。我们的框架能够从地球进行高保真度的3D卫星监测,为态势感知提供了一种经济实惠的替代方案。项目页面:https://ai4scientificimaging.org/ReconstructingSatellites
论文及项目相关链接
Summary
该文提出了一种新型的计算成像框架,通过整合混合图像预处理管道与基于受控高斯Splatting和分支定界搜索的联合姿态估计和3D重建模块,克服了从地面望远镜图像重建卫星模型的诸多挑战。该框架在合成卫星数据集以及对中国天宫空间站和国际空间站的天文观测上进行了验证,实现了从地面数据对低地球轨道卫星的稳健3D重建。评估表明,该方法优于最新的NeRF方法,框架为从地球进行的高保真3D卫星监测提供了成本效益高的替代方案。
Key Takeaways
- 文章强调了从地面望远镜图像重建卫星模型的重要性以及所面临的挑战。
- 提出了一种新型计算成像框架,整合了混合图像预处理管道和联合姿态估计与3D重建模块。
- 该框架利用受控高斯Splatting和分支定界搜索技术来处理图像。
- 在合成卫星数据集以及实际天文观测上进行了验证,实现了稳健的3D卫星重建。
- 定量评估表明,该方法的性能优于现有的NeRF方法。
- 框架为从地球进行的高保真3D卫星监测提供了成本效益高的解决方案。
点此查看论文截图