⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-16 更新
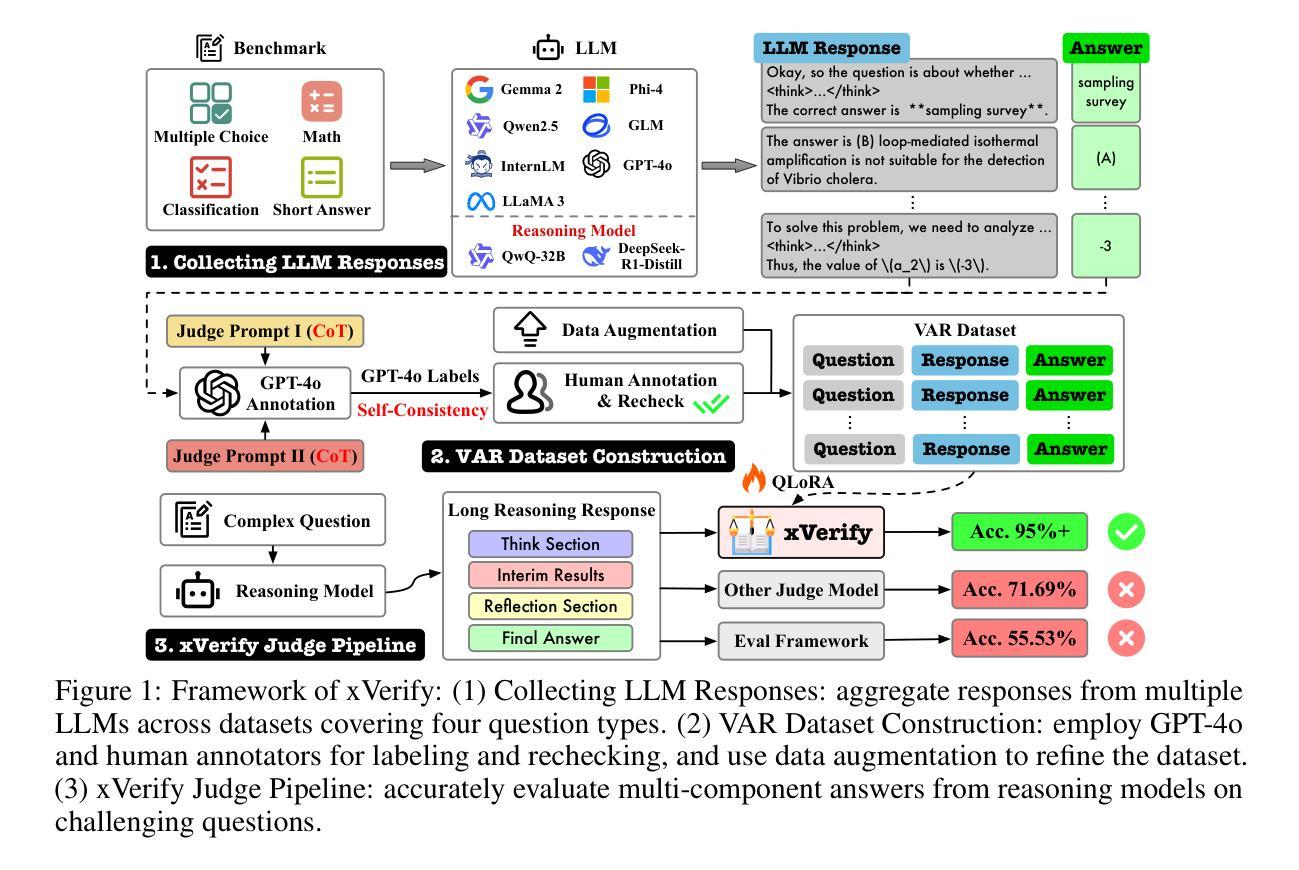
xVerify: Efficient Answer Verifier for Reasoning Model Evaluations
Authors:Ding Chen, Qingchen Yu, Pengyuan Wang, Wentao Zhang, Bo Tang, Feiyu Xiong, Xinchi Li, Minchuan Yang, Zhiyu Li
With the release of the o1 model by OpenAI, reasoning models adopting slow thinking strategies have gradually emerged. As the responses generated by such models often include complex reasoning, intermediate steps, and self-reflection, existing evaluation methods are often inadequate. They struggle to determine whether the LLM output is truly equivalent to the reference answer, and also have difficulty identifying and extracting the final answer from long, complex responses. To address this issue, we propose xVerify, an efficient answer verifier for reasoning model evaluations. xVerify demonstrates strong capability in equivalence judgment, enabling it to effectively determine whether the answers produced by reasoning models are equivalent to reference answers across various types of objective questions. To train and evaluate xVerify, we construct the VAR dataset by collecting question-answer pairs generated by multiple LLMs across various datasets, leveraging multiple reasoning models and challenging evaluation sets designed specifically for reasoning model assessment. A multi-round annotation process is employed to ensure label accuracy. Based on the VAR dataset, we train multiple xVerify models of different scales. In evaluation experiments conducted on both the test set and generalization set, all xVerify models achieve overall F1 scores and accuracy exceeding 95%. Notably, the smallest variant, xVerify-0.5B-I, outperforms all evaluation methods except GPT-4o, while xVerify-3B-Ib surpasses GPT-4o in overall performance. These results validate the effectiveness and generalizability of xVerify.
随着OpenAI推出的o1模型,采用慢速思考策略的思考模型逐渐出现。由于此类模型产生的回应通常包括复杂推理、中间步骤和自省,现有的评估方法往往不足。他们很难确定大语言模型输出是否真正等同于参考答案,并且在从冗长复杂的回应中识别和提取最终答案方面也存在困难。为了解决这个问题,我们提出了xVerify,这是一个有效的答案验证器,用于思考模型的评估。xVerify在等价判断方面表现出强大的能力,能够有效确定思考模型产生的答案是否等同于各种类型客观问题的参考答案。为了训练和评估xVerify,我们通过收集各种数据集由多个大型语言模型生成的问题答案对,利用多个思考模型和专门用于思考模型评估的挑战性评估集,构建了VAR数据集。采用多轮注释过程来保证标签的准确性。基于VAR数据集,我们训练了多种不同规模的的xVerify模型。在测试集和泛化集上进行的评估实验表明,所有xVerify模型的总体F1分数和准确率均超过95%。值得注意的是,最小的变种xVerify-0.5B-I在所有评估方法中表现最佳,仅次于GPT-4o,而xVerify-3B-Ib在总体性能上超越了GPT-4o。这些结果验证了xVerify的有效性和通用性。
论文及项目相关链接
PDF 32 pages
摘要
随着OpenAI发布的o1模型,采用缓慢思考策略的合理模型逐渐出现。这些模型产生的回应通常包含复杂的推理、中间步骤和自我反思,现有的评估方法往往不足。为了解决这个问题,我们提出了xVerify,一个高效的答案验证器用于推理模型评估。xVerify在等价判断方面表现出强大的能力,可以有效地确定推理模型产生的答案是否与各种类型客观问题的参考答案等价。为了训练和评估xVerify,我们构建了VAR数据集,通过收集多个LLM生成的问答对,利用多个推理模型,并设计专门针对推理模型评估的挑战评估集。通过多轮注释过程来保证标签的准确性。基于VAR数据集,我们训练了不同规模的多个xVerify模型。在测试集和泛化集上进行的评估实验表明,所有xVerify模型的F1分数和准确率均超过95%。值得注意的是,最小的变种xVerify-0.5B-I除GPT-4o外超越了所有评估方法,而xVerify-3B-Ib在总体性能上超越了GPT-4o。这些结果验证了xVerify的有效性和通用性。
关键见解
- 推理模型采用缓慢思考策略逐渐受到关注,其回应包含复杂推理、中间步骤和自我反思。
- 现有评估方法在判断推理模型输出方面存在不足,需要新的答案验证器。
- 提出xVerify作为高效的答案验证器,用于推理模型评估,具有强大的等价判断能力。
- 构建VAR数据集,通过收集多个LLM生成的问答对,并设计专门针对推理模型评估的挑战评估集来训练和评估xVerify。
- 多轮注释过程确保标签准确性。
- 训练了不同规模的多个xVerify模型,并在测试集和泛化集上表现出高F1分数和准确率。
点此查看论文截图

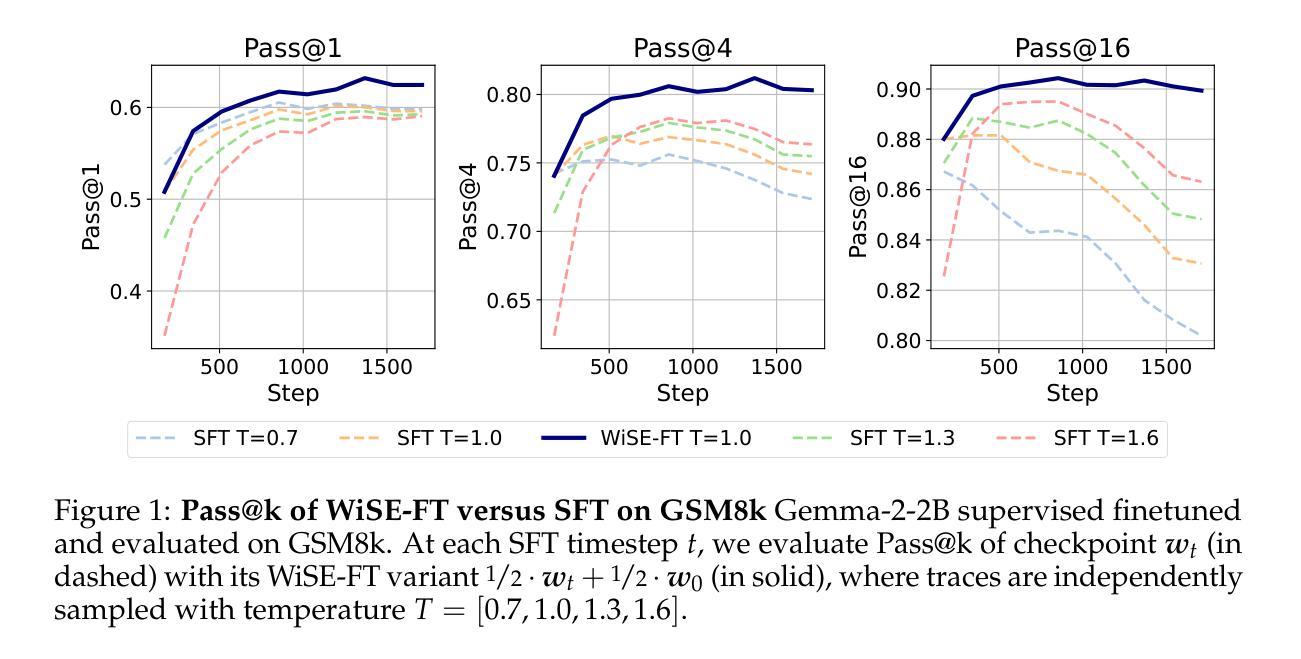
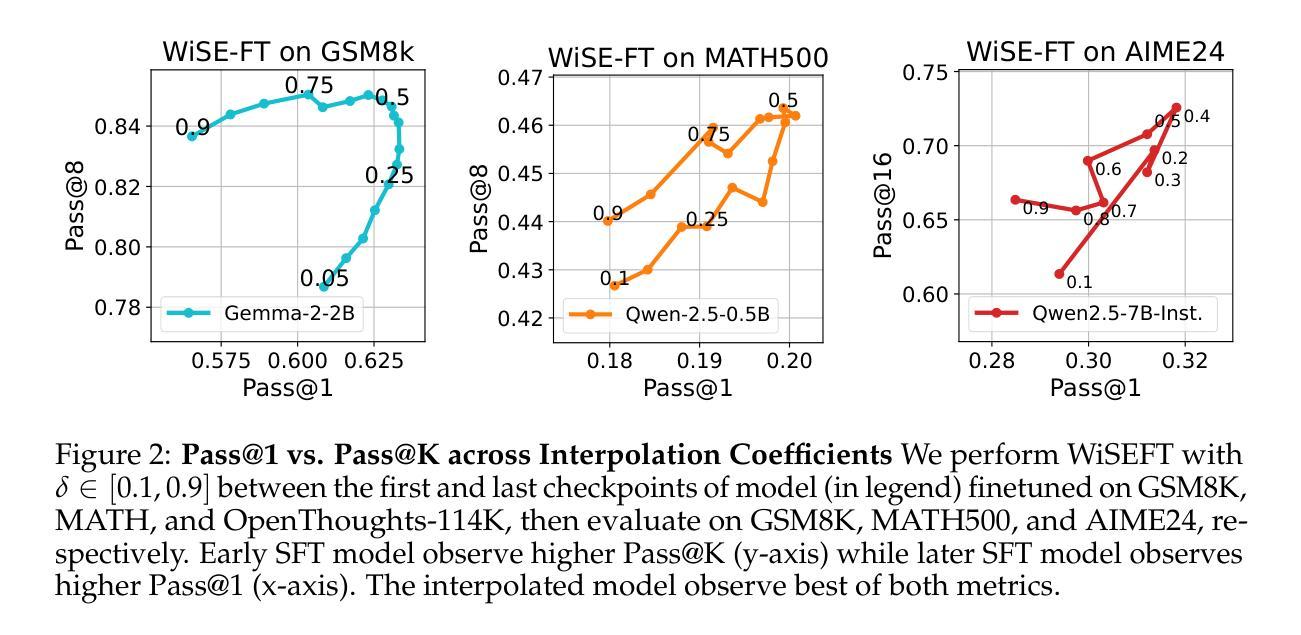
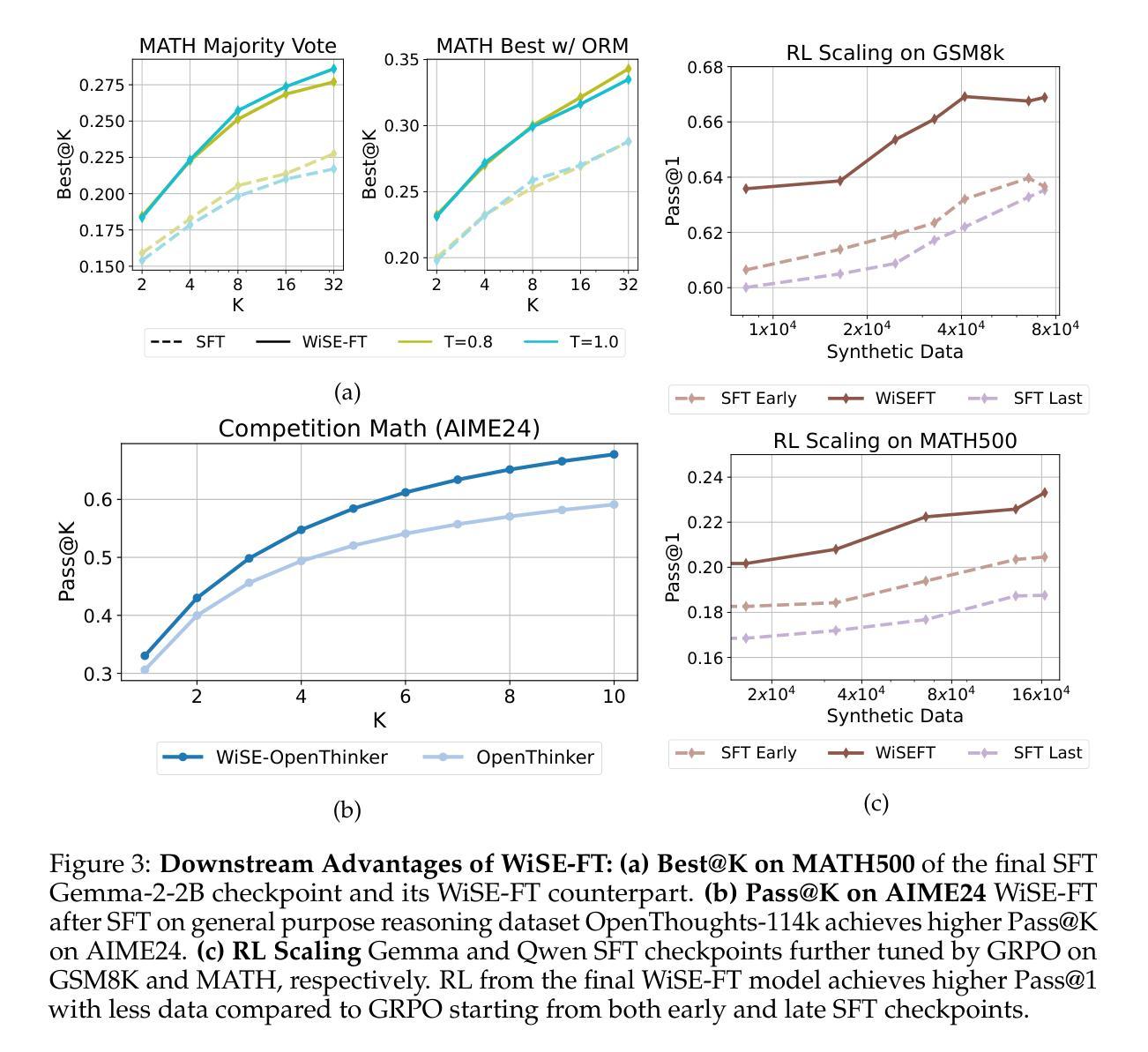
Weight Ensembling Improves Reasoning in Language Models
Authors:Xingyu Dang, Christina Baek, Kaiyue Wen, Zico Kolter, Aditi Raghunathan
We investigate a failure mode that arises during the training of reasoning models, where the diversity of generations begins to collapse, leading to suboptimal test-time scaling. Notably, the Pass@1 rate reliably improves during supervised finetuning (SFT), but Pass@k rapidly deteriorates. Surprisingly, a simple intervention of interpolating the weights of the latest SFT checkpoint with an early checkpoint, otherwise known as WiSE-FT, almost completely recovers Pass@k while also improving Pass@1. The WiSE-FT variant achieves better test-time scaling (Best@k, majority vote) and achieves superior results with less data when tuned further by reinforcement learning. Finally, we find that WiSE-FT provides complementary performance gains that cannot be achieved only through diversity-inducing decoding strategies, like temperature scaling. We formalize a bias-variance tradeoff of Pass@k with respect to the expectation and variance of Pass@1 over the test distribution. We find that WiSE-FT can reduce bias and variance simultaneously, while temperature scaling inherently trades-off between bias and variance.
我们研究了一种在训练推理模型过程中出现的故障模式,该模式下生成的多样性开始崩溃,导致测试时的扩展性不佳。值得注意的是,虽然监督微调(SFT)期间的Pass@1率可靠地提高了,但Pass@k却迅速恶化。令人惊讶的是,通过插值最新SFT检查点的权重与早期检查点的权重(也称为WiSE-FT)的简单干预措施,几乎可以完全恢复Pass@k,同时提高Pass@1。WiSE-FT变体实现了更好的测试时间扩展性(Best@k,多数投票),并且在通过强化学习进一步调整时,用更少的数据取得了更好的结果。最后,我们发现WiSE-FT提供了无法通过诸如温度缩放之类的仅产生多样性的解码策略实现的互补性能提升。我们正式提出了关于Pass@k的期望和方差之间的偏差-方差权衡,并在测试分布上进行了验证。我们发现WiSE-FT可以同时减少偏差和方差,而温度缩放本质上是在偏差和方差之间进行权衡。
论文及项目相关链接
Summary
训练推理模型时会出现一种失败模式,即生成的多样性开始崩溃,导致测试时的扩展性不佳。尽管监督微调(SFT)可以提高Pass@1率,但Pass@k却迅速恶化。通过采用一种名为WiSE-FT的简单干预措施(即将最新SFT检查点的权重与早期检查点进行插值),几乎可以完全恢复Pass@k并改善Pass@1。WiSE-FT变体在测试时的扩展性更好,并且当通过强化学习进一步调整时,可在较少数据的情况下获得更好的结果。WiSE-FT提供了无法通过如温度缩放等诱导多样性的解码策略实现的性能增益。同时,WiSE-FT可以降低Pass@k的偏差和方差,而温度缩放则存在偏差和方差之间的权衡。
Key Takeaways
- 推理模型的训练过程中会出现生成多样性崩溃的问题,导致测试时扩展性不佳。
- 监督微调(SFT)能提高Pass@1率,但Pass@k表现却恶化。
- WiSE-FT干预措施能有效恢复Pass@k并改善Pass@1。
- WiSE-FT变体在测试时的扩展性更好,强化学习进一步调整可提升性能。
- WiSE-FT提供的性能增益无法通过单纯的解码策略(如温度缩放)实现。
- WiSE-FT能同时降低Pass@k的偏差和方差。
点此查看论文截图

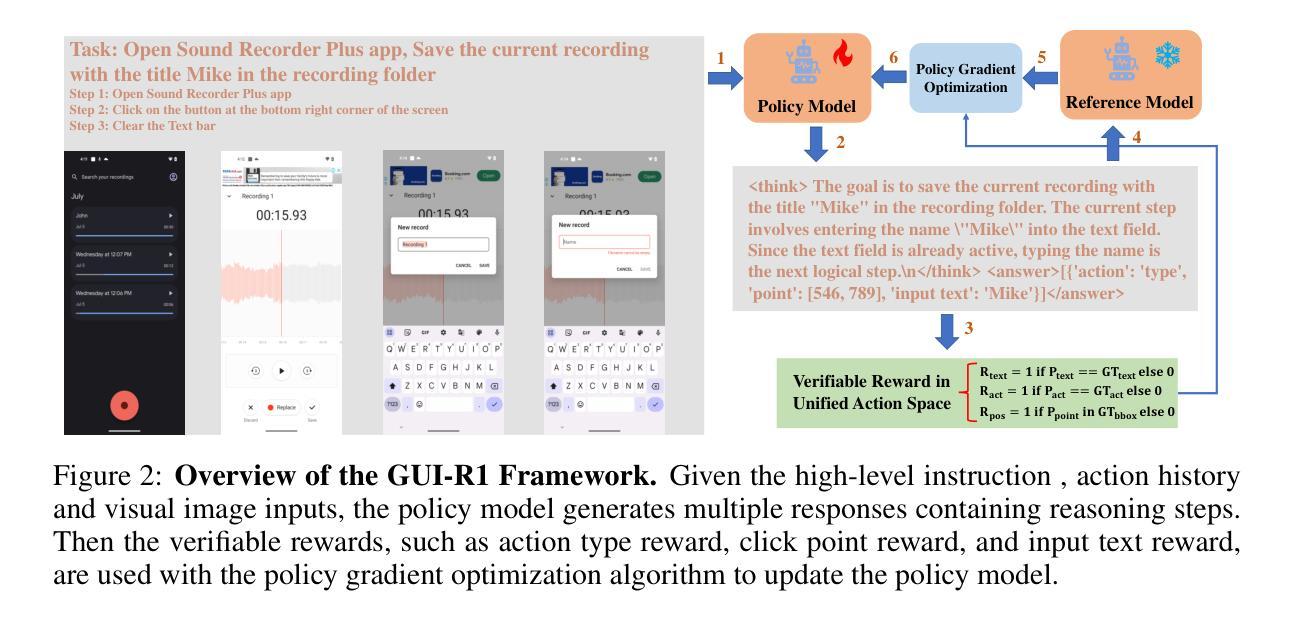
GUI-R1 : A Generalist R1-Style Vision-Language Action Model For GUI Agents
Authors:Xiaobo Xia, Run Luo
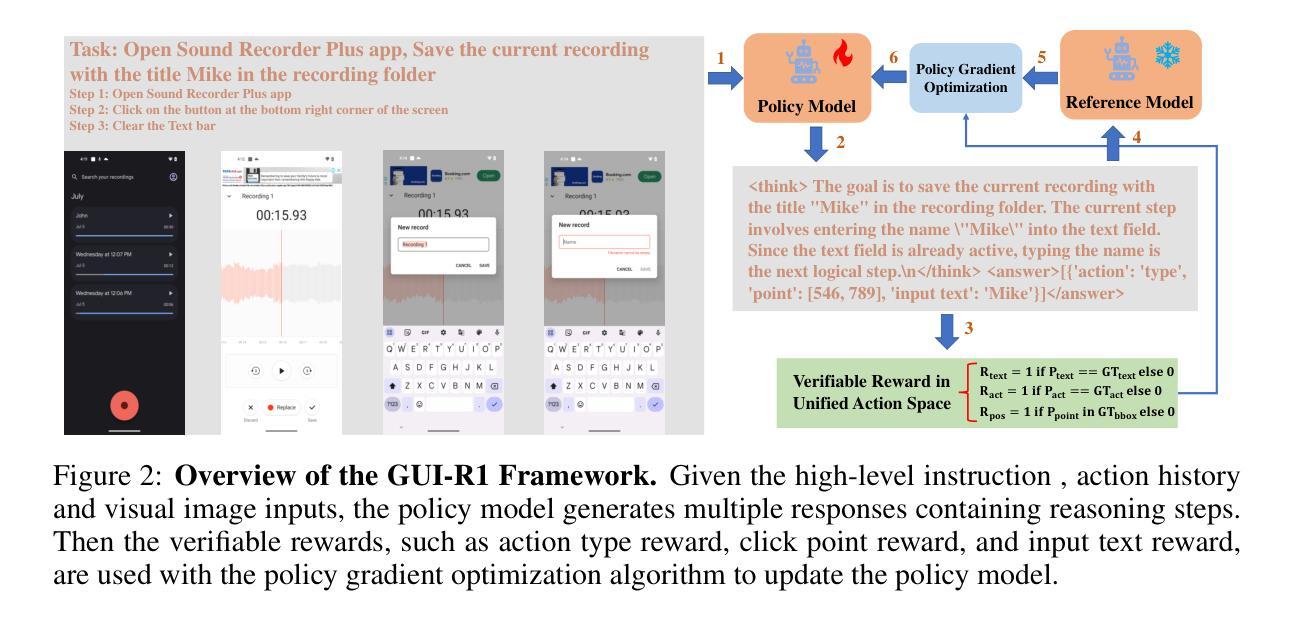
Existing efforts in building Graphical User Interface (GUI) agents largely rely on the training paradigm of supervised fine-tuning on Large Vision-Language Models (LVLMs). However, this approach not only demands extensive amounts of training data but also struggles to effectively understand GUI screenshots and generalize to unseen interfaces. The issue significantly limits its application in real-world scenarios, especially for high-level tasks. Inspired by Reinforcement Fine-Tuning (RFT) in large reasoning models (e.g., DeepSeek-R1), which efficiently enhances the problem-solving capabilities of large language models in real-world settings, we propose \name, the first reinforcement learning framework designed to enhance the GUI capabilities of LVLMs in high-level real-world task scenarios, through unified action space rule modeling. By leveraging a small amount of carefully curated high-quality data across multiple platforms (including Windows, Linux, MacOS, Android, and Web) and employing policy optimization algorithms such as Group Relative Policy Optimization (GRPO) to update the model, \name achieves superior performance using only 0.02% of the data (3K vs. 13M) compared to previous state-of-the-art methods like OS-Atlas across eight benchmarks spanning three different platforms (mobile, desktop, and web). These results demonstrate the immense potential of reinforcement learning based on unified action space rule modeling in improving the execution capabilities of LVLMs for real-world GUI agent tasks.
现有构建图形用户界面(GUI)代理的努力大多依赖于在大型视觉语言模型(LVLMs)上采用监督微调训练范式。然而,这种方法不仅需求大量的训练数据,而且在理解GUI截图和泛化到未见过的界面方面也存在困难。这一问题极大地限制了其在现实场景中的应用,尤其是高级任务。受大型推理模型中的强化微调(RFT)的启发(例如DeepSeek-R1),该技术在现实场景中有效地提高了大型语言模型的解决问题能力。我们提出名为“XXX”的强化学习框架,它是首个旨在通过统一动作空间规则建模,提高LVLMs在现实高级任务场景中的GUI能力。通过利用多个平台(包括Windows、Linux、MacOS、Android和Web)的小量精心挑选的高质量数据,并采用群体相对策略优化(GRPO)等策略优化算法来更新模型,“XXX”仅使用0.02%的数据(3K对13M)便在跨越三个不同平台(移动、桌面和网页)的八个基准测试中实现了优于OS-Atlas等现有先进方法的性能。这些结果证明了基于统一动作空间规则建模的强化学习在提升LVLMs执行现实GUI代理任务的能力方面具有巨大潜力。
论文及项目相关链接
Summary
在构建图形用户界面(GUI)代理方面,现有努力大多依赖于在大视觉语言模型(LVLMs)上采用监督微调训练范式。然而,这种方法不仅需求大量的训练数据,而且在理解GUI截图和泛化到未见过的界面上存在困难。这限制了其在现实世界场景中的应用,尤其是在高级任务中。受大型推理模型中的强化微调(RFT)的启发(例如DeepSeek-R1),我们提出了名为“名称”的强化学习框架,该框架通过统一动作空间规则建模,旨在提高LVLMs在高级现实世界任务场景中的GUI能力。通过利用多个平台(包括Windows、Linux、MacOS、Android和Web)的小量精心挑选的高质量数据,并采用群体相对策略优化(GRPO)等策略优化算法来更新模型,“名称”在仅使用0.02%的数据(3K对13M)的情况下,在跨越三个不同平台(移动、桌面和网页)的八个基准测试中实现了对OS-Atlas等现有先进方法的卓越性能表现。这些结果证明了基于统一动作空间规则建模的强化学习在提升LVLMs执行现实世界GUI代理任务的能力方面的巨大潜力。
Key Takeaways
- 当前GUI代理构建主要依赖监督微调训练范式在大视觉语言模型上,存在数据需求量大和理解界面能力弱的问题。
- 强化学习框架被提出来提高LVLMs在现实世界GUI任务中的性能,通过统一动作空间规则建模。
- 该框架利用跨多个平台的小量高质量数据,并采用策略优化算法来更新模型。
- 与现有方法相比,该框架在多个基准测试中实现了卓越的性能,仅使用极小比例的数据。
- 该方法突破了传统方法的限制,为LVLMs在GUI代理任务中的实际应用开辟了新途径。
- 强化学习在改善LVLMs执行现实世界GUI任务方面的潜力巨大。
点此查看论文截图

M1: Towards Scalable Test-Time Compute with Mamba Reasoning Models
Authors:Junxiong Wang, Wen-Ding Li, Daniele Paliotta, Daniel Ritter, Alexander M. Rush, Tri Dao
Effective reasoning is crucial to solving complex mathematical problems. Recent large language models (LLMs) have boosted performance by scaling test-time computation through long chain-of-thought reasoning. However, transformer-based models are inherently limited in extending context length due to their quadratic computational complexity and linear memory requirements. In this paper, we introduce a novel hybrid linear RNN reasoning model, M1, built on the Mamba architecture, which allows memory-efficient inference. Our approach leverages a distillation process from existing reasoning models and is further enhanced through RL training. Experimental results on the AIME and MATH benchmarks show that M1 not only outperforms previous linear RNN models but also matches the performance of state-of-the-art Deepseek R1 distilled reasoning models at a similar scale. We also compare our generation speed with a highly performant general purpose inference engine, vLLM, and observe more than a 3x speedup compared to a same size transformer. With throughput speedup, we are able to achieve higher accuracy compared to DeepSeek R1 distilled transformer reasoning models under a fixed generation time budget using self-consistency voting. Overall, we introduce a hybrid Mamba reasoning model and provide a more effective approach to scaling test-time generation using self-consistency or long chain of thought reasoning.
有效的推理对于解决复杂的数学问题至关重要。最近的大型语言模型(LLM)通过测试时间计算的扩展和长期推理链的推理,提升了性能。然而,基于转换器的模型由于其二次计算复杂度和线性内存需求,在扩展上下文长度方面存在固有的局限性。在本文中,我们介绍了一种基于Mamba架构的新型混合线性RNN推理模型M1,它可以进行高效的内存推理。我们的方法利用从现有推理模型中提炼的过程,并通过强化学习训练进行进一步改进。在AIME和MATH基准测试上的实验结果表明,M1不仅优于以前的线性RNN模型,而且在相似规模下达到了最先进的Deepseek R1蒸馏推理模型的性能。我们还与高性能通用推理引擎vLLM比较了我们的生成速度,并观察到与相同规模的转换器相比,我们的生成速度提高了三倍以上。通过提高吞吐量速度,我们在固定的生成时间预算内,使用自我一致性投票,实现了比DeepSeek R1蒸馏转换器推理模型更高的准确性。总的来说,我们介绍了一种混合的Mamba推理模型,并提供了一种更有效的通过自我一致性或长期推理链来扩展测试时间生成的方法。
论文及项目相关链接
PDF Code is available https://github.com/jxiw/M1
Summary
本文介绍了新型混合线性RNN推理模型M1,该模型基于Mamba架构,可实现高效的内存推理。通过采用现有推理模型的蒸馏过程和强化学习训练增强性能,它在AIME和MATH基准测试上的表现超越了先前的线性RNN模型,并匹配了同等规模的最先进Deepseek R1蒸馏推理模型的表现。此外,与高性能通用推理引擎vLLM相比,M1的生成速度提高了三倍以上。通过提高吞吐量速度,在固定的生成时间预算内,M1利用自我一致性投票实现了比DeepSeek R1蒸馏变压器推理模型更高的准确性。综上所述,本文提出了一种混合的Mamba推理模型,并提供了一种更有效的扩展测试时间生成方法。
Key Takeaways
- 近期的大型语言模型通过扩展测试时的计算链思维来提升解决复杂数学问题的能力。
- 传统的基于变压器的模型受限于上下文长度,因为其计算复杂度和内存需求呈二次和线性关系。
- 提出了一种新型的混合线性RNN推理模型M1,基于Mamba架构,可实现高效的内存推理。
- M1通过蒸馏过程和强化学习训练增强性能,表现超越了先前的线性RNN模型,并匹配了同等规模的最先进Deepseek R1蒸馏推理模型的表现。
- M1的生成速度比高性能通用推理引擎vLLM提高了三倍以上。
- 在固定的生成时间预算内,M1利用自我一致性投票实现了更高的准确性。
点此查看论文截图


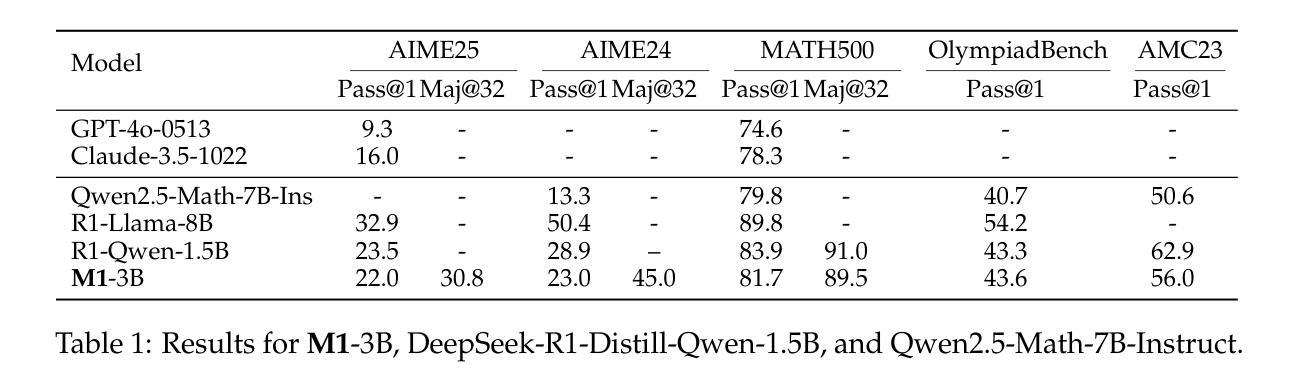
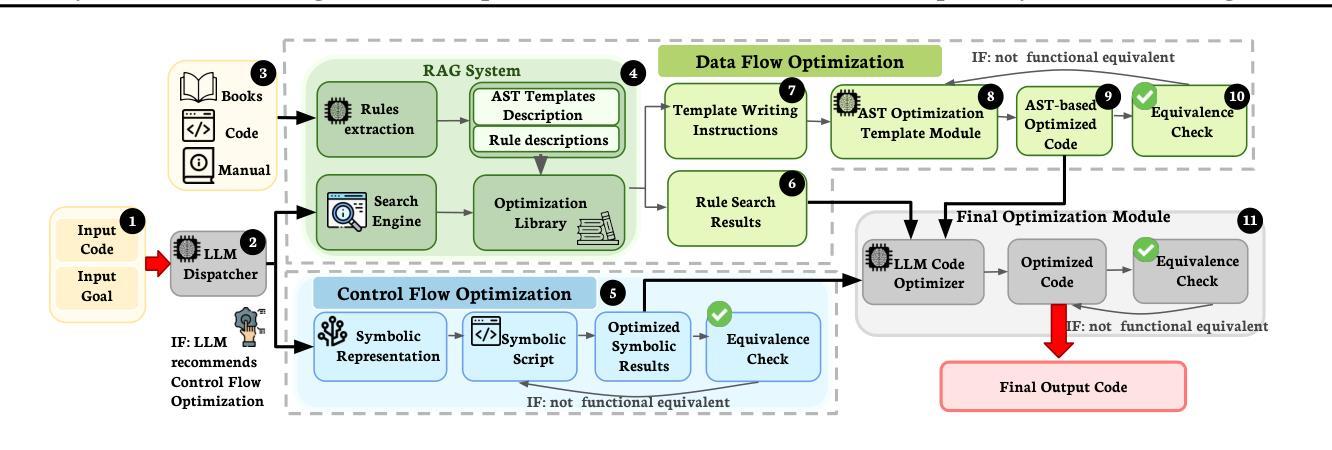
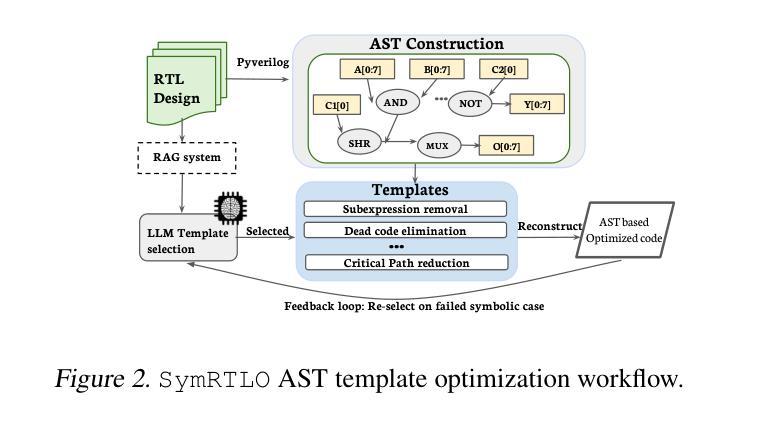
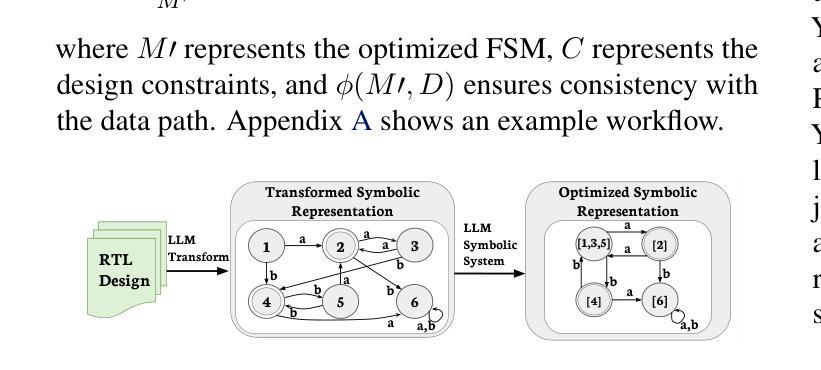
SymRTLO: Enhancing RTL Code Optimization with LLMs and Neuron-Inspired Symbolic Reasoning
Authors:Yiting Wang, Wanghao Ye, Ping Guo, Yexiao He, Ziyao Wang, Yexiao He, Bowei Tian, Shwai He, Guoheng Sun, Zheyu Shen, Sihan Chen, Ankur Srivastava, Qingfu Zhang, Gang Qu, Ang Li
Optimizing Register Transfer Level (RTL) code is crucial for improving the power, performance, and area (PPA) of digital circuits in the early stages of synthesis. Manual rewriting, guided by synthesis feedback, can yield high-quality results but is time-consuming and error-prone. Most existing compiler-based approaches have difficulty handling complex design constraints. Large Language Model (LLM)-based methods have emerged as a promising alternative to address these challenges. However, LLM-based approaches often face difficulties in ensuring alignment between the generated code and the provided prompts. This paper presents SymRTLO, a novel neuron-symbolic RTL optimization framework that seamlessly integrates LLM-based code rewriting with symbolic reasoning techniques. Our method incorporates a retrieval-augmented generation (RAG) system of optimization rules and Abstract Syntax Tree (AST)-based templates, enabling LLM-based rewriting that maintains syntactic correctness while minimizing undesired circuit behaviors. A symbolic module is proposed for analyzing and optimizing finite state machine (FSM) logic, allowing fine-grained state merging and partial specification handling beyond the scope of pattern-based compilers. Furthermore, a fast verification pipeline, combining formal equivalence checks with test-driven validation, further reduces the complexity of verification. Experiments on the RTL-Rewriter benchmark with Synopsys Design Compiler and Yosys show that SymRTLO improves power, performance, and area (PPA) by up to 43.9%, 62.5%, and 51.1%, respectively, compared to the state-of-the-art methods.
寄存器传输级别(RTL)代码的优化对于改进合成早期阶段数字电路的电源、性能和面积(PPA)至关重要。手动重写并在合成反馈的指导下进行可以产生高质量的结果,但这种方法既耗时又容易出错。现有的大多数基于编译器的方法在处理复杂的设计约束时都面临困难。基于大型语言模型(LLM)的方法已成为解决这些挑战的有前途的替代方案。然而,LLM-based方法通常难以确保生成的代码与提供的提示对齐。本文提出了SymRTLO,这是一种新型的神经元符号RTL优化框架,无缝集成了基于LLM的代码重写和符号推理技术。我们的方法结合了优化规则的检索增强生成(RAG)系统和基于抽象语法树(AST)的模板,使基于LLM的重写能够保持语法正确性,同时最小化不需要的电路行为。提出了一种符号模块,用于分析和优化有限状态机(FSM)逻辑,实现精细粒度的状态合并和部分规范处理,超出模式编译器的范围。此外,结合形式等价检查和测试驱动验证的快速验证管道进一步降低了验证的复杂性。在Synopsys Design Compiler和Yosys的RTL-Rewriter基准测试上的实验表明,与最新方法相比,SymRTLO分别将电源、性能和面积(PPA)提高了高达43.9%、62.5%和51.1%。
论文及项目相关链接
PDF 16 pages, 8 figures, 7 tables. Under Review
Summary
本文介绍了一种名为SymRTLO的新型神经元符号RTL优化框架,该框架无缝集成了LLM基于的代码重写和符号推理技术。SymRTLO采用优化规则的检索增强生成系统和基于AST的模板,使LLM在重写代码时能保持语法正确性,同时最小化不良电路行为。此外,它还提出了一个符号模块,用于分析和优化有限状态机逻辑,实现了精细的状态合并和部分规格处理,超越了基于模式的编译器的范围。实验结果表明,与最新方法相比,SymRTLO在功率、性能和面积(PPA)方面的改进分别高达43.9%、62.5%和51.1%。
Key Takeaways
- 优化RTL代码对于提高数字电路在早期合成阶段的功率、性能和面积(PPA)至关重要。
- 现有编译器方法在处理复杂设计约束时存在困难,而LLM方法则展现出解决这些挑战的希望。
- SymRTLO框架结合了LLM代码重写和符号推理技术,旨在解决LLM在生成代码与提示对齐方面的问题。
- SymRTLO采用优化规则的检索增强生成系统和基于AST的模板,确保语法正确性和减少不良电路行为。
- 符号模块用于分析和优化有限状态机逻辑,实现精细的状态合并和部分规格处理,超出基于模式编译器的能力范围。
- SymRTLO提供了快速验证管道,结合形式等价性检查和测试驱动验证,降低了验证复杂性。
点此查看论文截图

FingER: Content Aware Fine-grained Evaluation with Reasoning for AI-Generated Videos
Authors:Rui Chen, Lei Sun, Jing Tang, Geng Li, Xiangxiang Chu
Recent advances in video generation have posed great challenges in the assessment of AI-generated content, particularly with the emergence of increasingly sophisticated models. The various inconsistencies and defects observed in such videos are inherently complex, making overall scoring notoriously difficult. In this paper, we emphasize the critical importance of integrating fine-grained reasoning into video evaluation, and we propose $\textbf{F}$ing$\textbf{ER}$, a novel entity-level reasoning evaluation framework that first automatically generates $\textbf{F}$ine-grained $\textbf{E}$ntity-level questions, and then answers those questions by a $\textbf{R}$easoning model with scores, which can be subsequently weighted summed to an overall score for different applications. Specifically, we leverage LLMs to derive entity-level questions across five distinct perspectives, which (i) often focus on some specific entities of the content, thereby making answering or scoring much easier by MLLMs, and (ii) are more interpretable. Then we construct a FingER dataset, consisting of approximately 3.3k videos and corresponding 60k fine-grained QA annotations, each with detailed reasons. Based on that, we further investigate various training protocols to best incentivize the reasoning capability of MLLMs for correct answer prediction. Extensive experiments demonstrate that a reasoning model trained using Group Relative Policy Optimization (GRPO) with a cold-start strategy achieves the best performance. Notably, our model surpasses existing methods by a relative margin of $11.8%$ on GenAI-Bench and $5.5%$ on MonetBench with only 3.3k training videos, which is at most one-tenth of the training samples utilized by other methods. Our code and dataset will be released soon.
近期视频生成技术的进展给AI生成内容的评估带来了巨大挑战,尤其是随着模型越来越复杂。这类视频中观察到的各种不一致和缺陷本质上很复杂,使得整体评分极为困难。在本文中,我们强调了将精细推理集成到视频评估中的关键重要性,并提出了一种新的实体级推理评估框架,名为“FingER”。FingER首先自动生成精细实体级问题,然后通过推理模型对这些问题进行回答并给出分数,这些分数随后可以加权求和以得出不同应用的整体分数。具体来说,我们利用大型语言模型从五个不同的角度推导出实体级问题,这些问题(i)通常侧重于内容中的某些特定实体,从而使MLLMs更容易回答或评分;(ii)更具可解释性。然后,我们构建了一个FingER数据集,包含大约3.3k个视频和相应的6万条精细问答注释,每条注释都有详细的原因。在此基础上,我们进一步研究了各种训练协议,以最大限度地激发MLLMs的推理能力,以进行正确的答案预测。大量实验表明,采用群组相对策略优化(GRPO)和冷启动策略的推理模型取得了最佳性能。值得注意的是,我们的模型仅使用3.3k个训练视频,便在GenAI-Bench上比现有方法高出11.8%的准确率,在MonetBench上高出5.5%。我们的代码和数据集将很快发布。
论文及项目相关链接
PDF 10 pages, 4 figures
Summary
随着视频生成技术的最新进展,评估AI生成内容,特别是日益先进的模型,面临巨大挑战。视频中各种不一致和缺陷的复杂性使得整体评分极为困难。本文强调将精细推理集成到视频评估中的关键重要性,并提出了一种新颖的视频实体级推理评估框架——FingER。它通过自动生成的精细实体级问题,然后利用推理模型回答这些问题并给出分数,这些分数可以加权汇总以得出不同应用的整体分数。此外,本文利用大型语言模型从五个不同角度衍生出实体级问题,构建了一个FingER数据集,并进一步研究各种训练协议以激励大型语言模型的推理能力。实验表明,使用集团相对策略优化和冷启动策略的推理模型表现最佳。仅使用三千多个训练视频就超越了现有方法,在GenAI-Bench上相对提高了11.8%,在MonetBench上提高了5.5%。我们将很快发布相关代码和数据集。
(上述文本精简为一句话的形式概括主要内容)本论文关注AI生成视频的评估难题,提出了精细实体级推理评估框架FingER和相应的数据集来解决这一挑战,通过精细化问答结合大型语言模型提升评估准确性并超越现有方法。
Key Takeaways
- AI视频生成技术快速发展带来评估挑战。
- 视频中的不一致性和缺陷复杂度高,导致整体评分困难。
- 引入精细推理在视频评估中的重要性。
- 提出新颖的视频实体级推理评估框架——FingER。
- FingER自动生成精细实体级问题并依靠推理模型回答评分。
- 构建FingER数据集以支持精细化问答的训练和评估。
点此查看论文截图



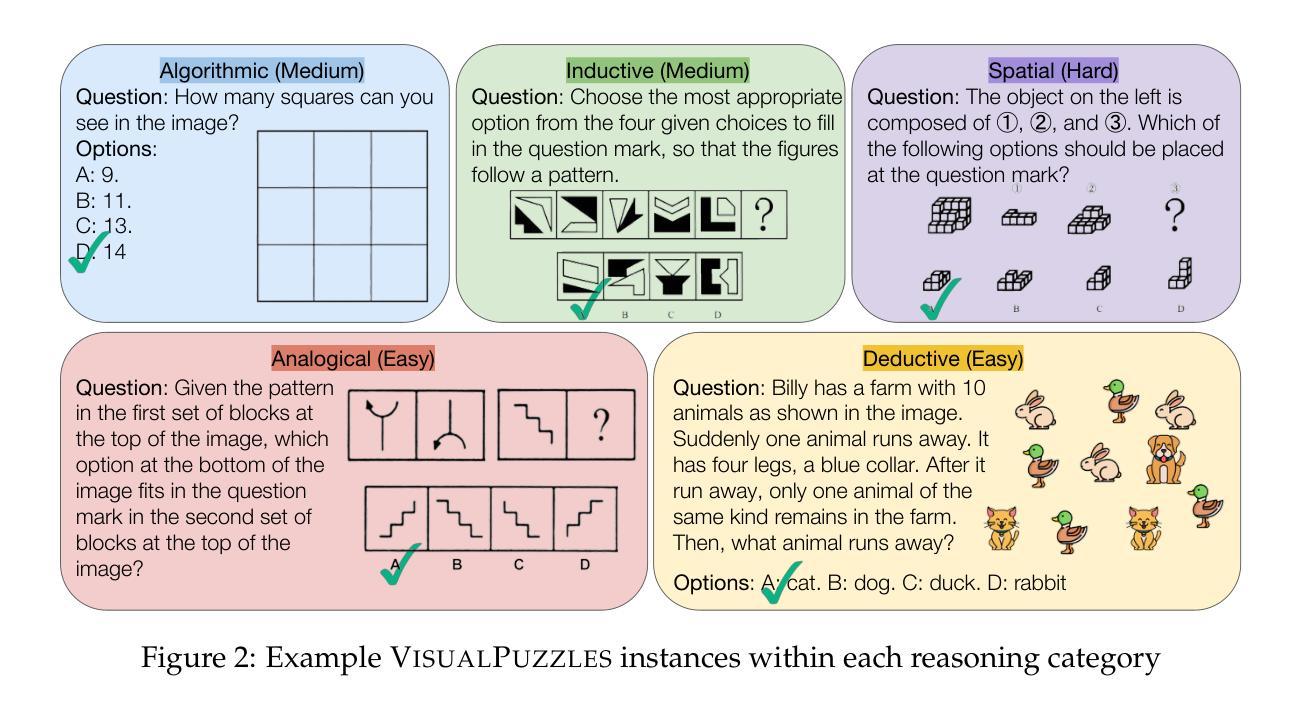
VisualPuzzles: Decoupling Multimodal Reasoning Evaluation from Domain Knowledge
Authors:Yueqi Song, Tianyue Ou, Yibo Kong, Zecheng Li, Graham Neubig, Xiang Yue
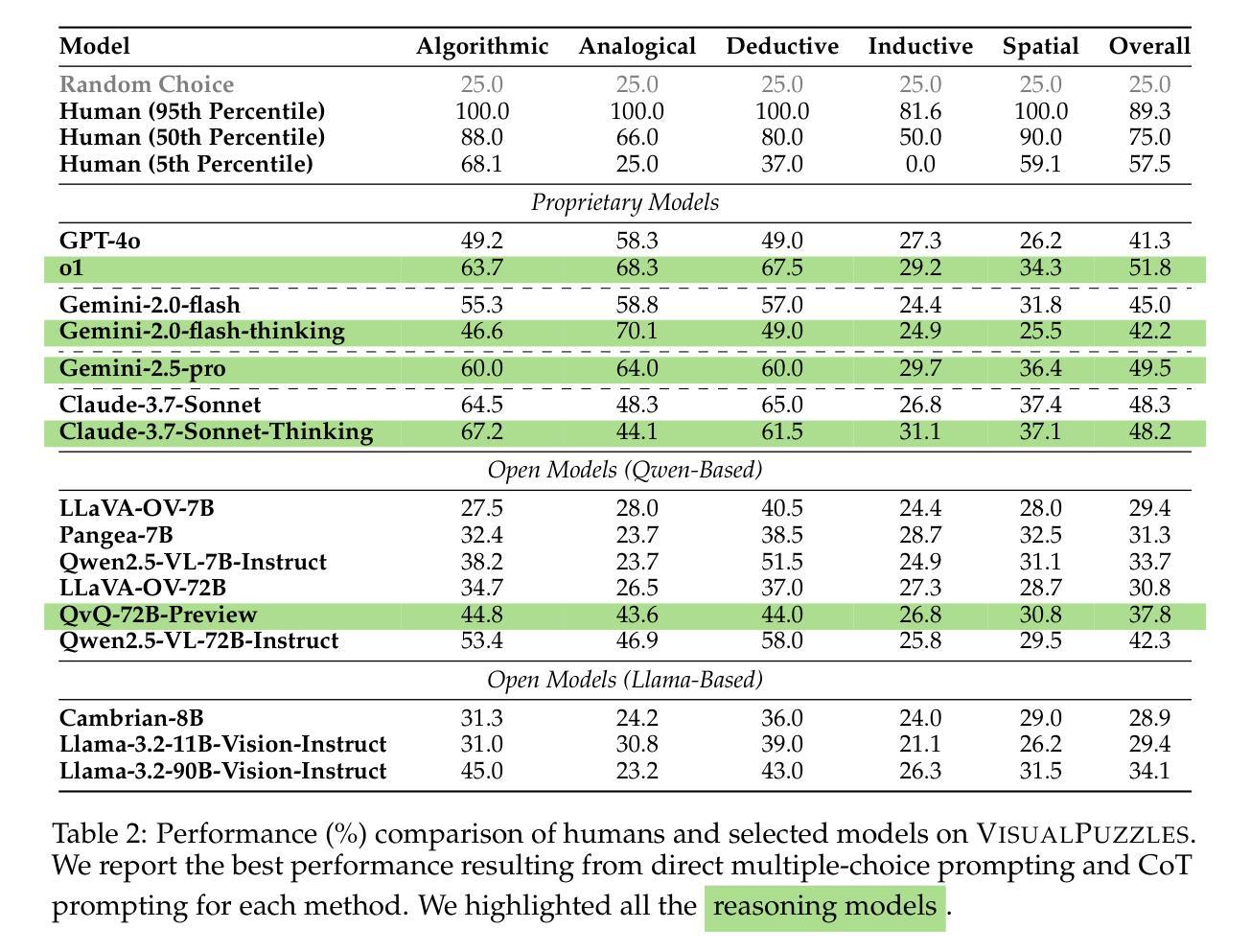
Current multimodal benchmarks often conflate reasoning with domain-specific knowledge, making it difficult to isolate and evaluate general reasoning abilities in non-expert settings. To address this, we introduce VisualPuzzles, a benchmark that targets visual reasoning while deliberately minimizing reliance on specialized knowledge. VisualPuzzles consists of diverse questions spanning five categories: algorithmic, analogical, deductive, inductive, and spatial reasoning. One major source of our questions is manually translated logical reasoning questions from the Chinese Civil Service Examination. Experiments show that VisualPuzzles requires significantly less intensive domain-specific knowledge and more complex reasoning compared to benchmarks like MMMU, enabling us to better evaluate genuine multimodal reasoning. Evaluations show that state-of-the-art multimodal large language models consistently lag behind human performance on VisualPuzzles, and that strong performance on knowledge-intensive benchmarks does not necessarily translate to success on reasoning-focused, knowledge-light tasks. Additionally, reasoning enhancements such as scaling up inference compute (with “thinking” modes) yield inconsistent gains across models and task types, and we observe no clear correlation between model size and performance. We also found that models exhibit different reasoning and answering patterns on VisualPuzzles compared to benchmarks with heavier emphasis on knowledge. VisualPuzzles offers a clearer lens through which to evaluate reasoning capabilities beyond factual recall and domain knowledge.
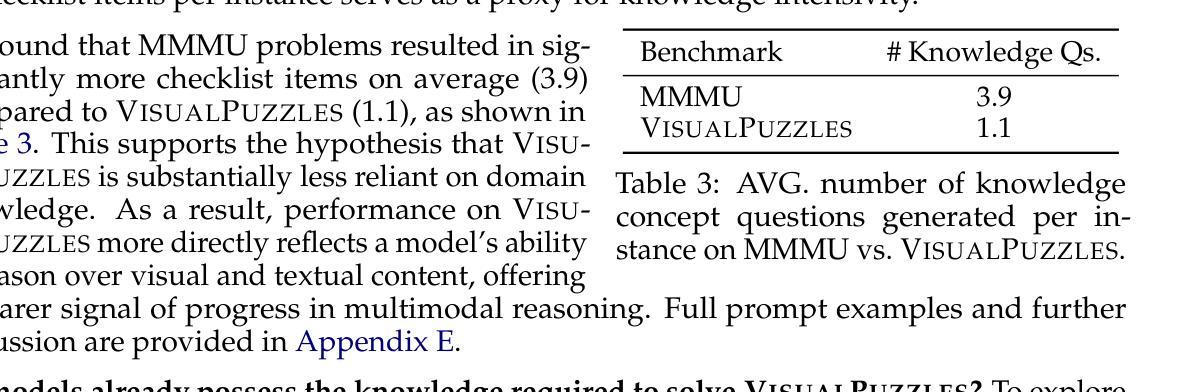
当前的多模态基准测试通常将推理与特定领域的知识混淆,在非专业环境中很难隔离和评估一般的推理能力。为了解决这一问题,我们推出了VisualPuzzles,这是一个以视觉推理为目标,同时刻意减少对专业知识依赖的基准测试。VisualPuzzles包含五个类别的问题:算法、类比、演绎、归纳和空间推理。我们问题的主要来源是手动翻译自中国公务员考试中的逻辑推理问题。实验表明,与MMMU等基准测试相比,VisualPuzzles对专业知识的要求显著降低,但推理难度更高,使我们能够更好地评估真正的多模态推理能力。评估显示,最先进的多模态大型语言模型在VisualPuzzles上的表现始终落后于人类,而在知识密集型基准测试上的出色表现并不一定能在以推理为重点、轻知识的任务上取得好成绩。此外,如通过扩大推理计算(使用“思考”模式)等增强推理能力的措施在各类模型和任务上产生的效果不一,并且我们未发现模型规模与性能之间的明确关联。我们还发现,与侧重于知识的基准测试相比,模型在VisualPuzzles上展现出不同的推理和答题模式。VisualPuzzles提供了一个更清晰的透镜,可以通过它来评估超越事实记忆和领域知识的推理能力。
论文及项目相关链接
PDF 56 pages, 43 figures
Summary
基于当前多模态基准测试常混淆推理与领域知识的现状,本文引入VisualPuzzles,这是一个旨在针对视觉推理的基准测试,刻意减少对专业知识依赖。VisualPuzzles包含涵盖五大类的问题:算法、类比、演绎、归纳和空间推理。实验表明,相较于其他基准测试如MMMU,VisualPuzzles的问题需要更少的领域知识和更复杂的推理能力,可以更好地评估真实的多元模态推理能力。现有的最先进的多模态大型语言模型在VisualPuzzles上的表现持续落后于人类,并且知识密集型基准测试上的优秀表现并不一定能转化为对注重推理、轻知识的任务的成功。此外,对于推理增强措施如扩大推理计算规模(思考模式)和模型大小对性能的影响并不明显。还发现模型在VisualPuzzles上展现出不同于知识重点基准测试的推理和回答模式。VisualPuzzles提供了一个更清晰的视角来评估超越事实回忆和领域知识的推理能力。
Key Takeaways
- 当前多模态基准测试混淆推理与领域知识,导致难以在非专业环境中评估通用推理能力。
- 引入VisualPuzzles作为基准测试,旨在专注于视觉推理并减少对专业知识的依赖。
- VisualPuzzles包含涵盖五大类的问题,涉及算法、类比、演绎、归纳和空间推理。
- 实验显示,VisualPuzzles需要更复杂的推理能力并减少对领域知识的依赖,更准确地评估多模态推理能力。
- 最先进的多模态大型语言模型在VisualPuzzles上的表现落后于人类。
- 知识密集型基准测试的成功并不等同于在注重推理、轻知识的任务上的成功。
点此查看论文截图


Heimdall: test-time scaling on the generative verification
Authors:Wenlei Shi, Xing Jin
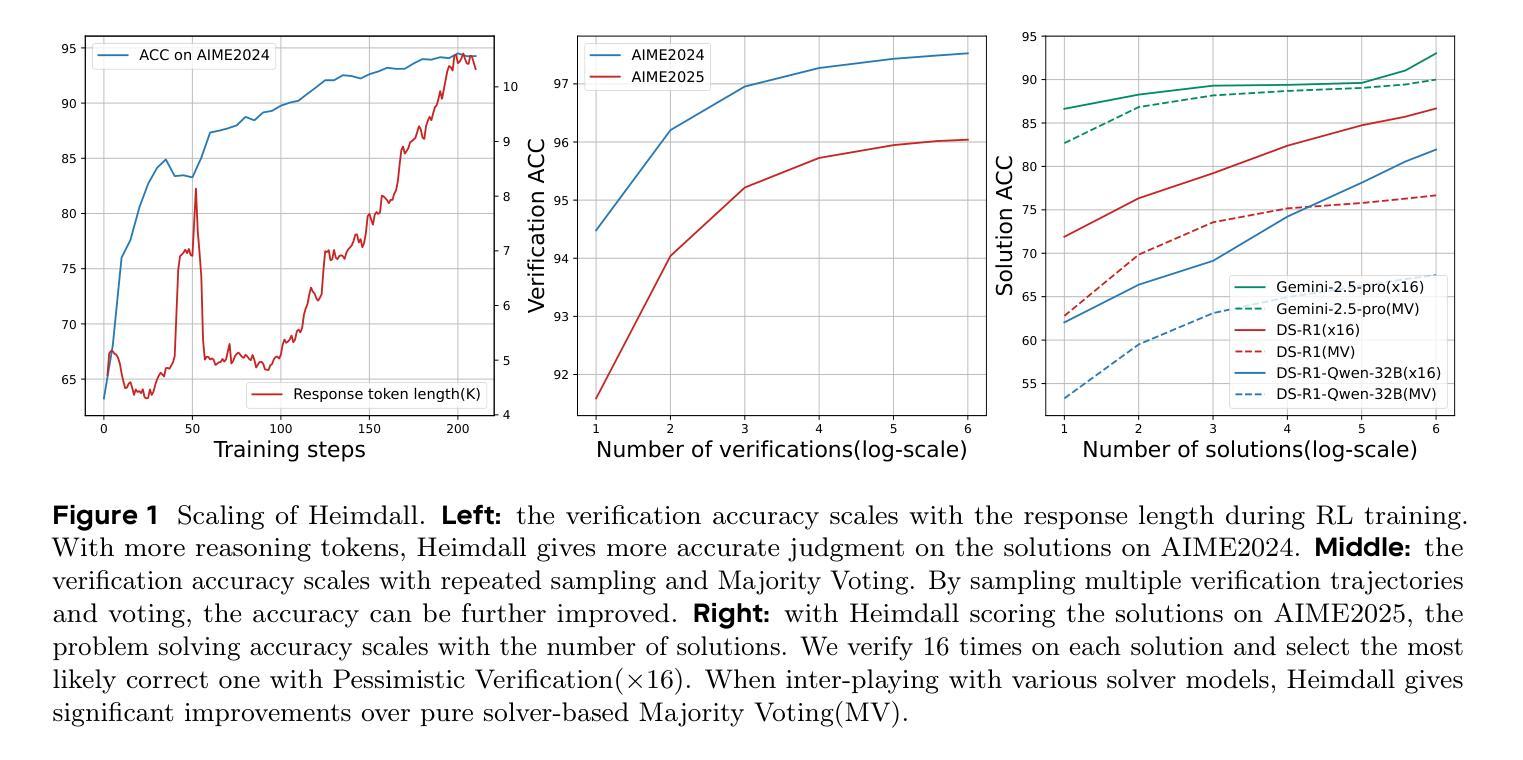
An AI system can create and maintain knowledge only to the extent that it can verify that knowledge itself. Recent work on long Chain-of-Thought reasoning has demonstrated great potential of LLMs on solving competitive problems, but their verification ability remains to be weak and not sufficiently investigated. In this paper, we propose Heimdall, the long CoT verification LLM that can accurately judge the correctness of solutions. With pure reinforcement learning, we boost the verification accuracy from 62.5% to 94.5% on competitive math problems. By scaling with repeated sampling, the accuracy further increases to 97.5%. Through human evaluation, Heimdall demonstrates impressive generalization capabilities, successfully detecting most issues in challenging math proofs, the type of which is not included during training. Furthermore, we propose Pessimistic Verification to extend the functionality of Heimdall to scaling up the problem solving. It calls Heimdall to judge the solutions from a solver model and based on the pessimistic principle, selects the most likely correct solution with the least uncertainty. Taking DeepSeek-R1-Distill-Qwen-32B as the solver model, Pessimistic Verification improves the solution accuracy on AIME2025 from 54.2% to 70.0% with 16x compute budget and to 83.3% with more compute budget. With the stronger solver Gemini 2.5 Pro, the score reaches 93.0%. Finally, we prototype an automatic knowledge discovery system, a ternary system where one poses questions, another provides solutions, and the third verifies the solutions. Using the data synthesis work NuminaMath for the first two components, Heimdall effectively identifies problematic records within the dataset and reveals that nearly half of the data is flawed, which interestingly aligns with the recent ablation studies from NuminaMath.
一个AI系统只能在其能够验证自身知识的情况下,才能创造和保持知识。关于长链思维推理的最新研究已经显示出大型语言模型在解决竞赛问题方面的巨大潜力,但它们的验证能力仍然较弱且尚未得到充分研究。在本文中,我们提出了能够准确判断解决方案正确性的长链验证大型语言模型Heimdall。通过纯粹的强化学习,我们在竞争性数学问题上的验证准确率从62.5%提高到了94.5%。通过重复采样的扩展,准确率进一步提高到了97.5%。通过人工评估,Heimdall展现出了令人印象深刻的泛化能力,成功地检测到了挑战性数学证明中的大多数问题,这些问题在训练过程中并未包含。此外,我们提出了悲观验证法来扩展Heimdall的功能以解决更大规模的问题。它调用Heimdall来判断求解模型的解决方案,并根据悲观原则,选择不确定性最小的最可能的正确解决方案。以DeepSeek-R1-Distill-Qwen-32B为求解模型,悲观验证法将AIME2025的解决方案准确性从54.2%提高到计算预算扩大16倍时的70.0%,以及更高计算预算下的83.3%。使用更强大的求解器Gemini 2.5 Pro,得分达到了93.0%。最后,我们设计了一个自动知识发现系统,这是一个三元系统,其中一个提出问题,另一个提供解决方案,第三个验证解决方案。使用前两个组件的数据合成工作NuminaMath,Heimdall有效地识别了数据集中有问题的记录并揭示出近一半的数据存在缺陷,这与NuminaMath最近的消融研究结果相吻合。
论文及项目相关链接
Summary
本论文提出一种名为Heimdall的长CoT验证LLM系统,可准确判断解决方案的正确性。通过强化学习,其在竞赛数学问题的验证准确度从原来的62.5%提升至94.5%,并通过重复采样进一步增至97.5%。Heimdall具有良好的泛化能力,能在挑战性的数学证明中检测出大部分问题。此外,论文还提出了悲观验证法来扩展Heimdall的功能,以提高问题解决的准确性。最后,论文尝试构建一个自动知识发现系统,其中包括提出问题、提供解决方案和验证解决方案的三个部分,其中Heimdall能有效识别数据集中的问题记录。
Key Takeaways
- Heimdall系统能够准确判断长Chain-of-Thought(CoT)推理解决方案的正确性。
- 通过强化学习,Heimdall在数学问题验证方面的准确度显著提高。
- Heimdall具有良好的泛化能力,能在复杂的数学证明中发现大部分问题。
- 论文提出了Pessimistic Verification(悲观验证)方法以提高问题解决的准确性。
- Heimdall在与其他模型结合后,如DeepSeek-R1-Distill-Qwen-32B和Gemini 2.5 Pro,解决问题的准确性进一步提高。
- 自动知识发现系统的构建包括提出问题、提供解决方案和验证解决方案三个关键部分。
点此查看论文截图


Deep Reasoning Translation via Reinforcement Learning
Authors:Jiaan Wang, Fandong Meng, Jie Zhou
Recently, deep reasoning LLMs (e.g., OpenAI o1/o3 and DeepSeek-R1) have shown promising performance in various complex tasks. Free translation is an important and interesting task in the multilingual world, which requires going beyond word-for-word translation and taking cultural differences into account. This task is still under-explored in deep reasoning LLMs. In this paper, we introduce DeepTrans, a deep reasoning translation model that learns free translation via reinforcement learning. Specifically, we carefully build a reward model with pre-defined scoring criteria on both the translation results and the thought process. Given the source sentences, the reward model teaches the deep translation model how to think and free-translate them during reinforcement learning. In this way, training DeepTrans does not need any labeled translations, avoiding the human-intensive annotation or resource-intensive data synthesis. Experimental results show the effectiveness of DeepTrans. Using Qwen2.5-7B as the backbone, DeepTrans improves performance by 16.3% in literature translation, and outperforms strong deep reasoning baselines as well as baselines that are fine-tuned with synthesized data. Moreover, we summarize the failures and interesting findings during our RL exploration. We hope this work could inspire other researchers in free translation.
最近,深度推理LLMs(例如OpenAI o1/o3和DeepSeek-R1)在各种复杂任务中表现出了有前景的性能。在多元语言世界中,自由翻译是一项重要且有趣的任务,它要求超越逐字翻译,并考虑文化差异。然而,这项任务在深度推理LLMs中仍被探索得不够深入。在本文中,我们介绍了深度翻译模型DeepTrans,这是一个通过强化学习进行自由翻译的深度推理翻译模型。具体来说,我们根据翻译结果和思维过程的预定评分标准精心构建了一个奖励模型。给定源句子,奖励模型在强化学习过程中教导深度翻译模型如何思考并进行自由翻译。通过这种方式,训练DeepTrans不需要任何标注翻译,避免了人力密集型的标注或资源密集型的数据合成。实验结果表明DeepTrans的有效性。以Qwen2.5-7B为骨干网,DeepTrans在文献翻译方面的性能提高了16.3%,并超越了强大的深度推理基线以及使用合成数据微调过的基线。此外,我们总结了我们在强化学习探索过程中的失败和有趣发现。我们希望这项工作能够激发其他研究人员对自由翻译的研究灵感。
论文及项目相关链接
Summary
深推理LLMs在深翻译模型方面的表现引人关注,特别是在无标注翻译方面表现出色。本文介绍了一种新的深翻译模型DeepTrans,它通过强化学习实现自由翻译。该模型使用预定义的评分标准构建奖励模型,以指导翻译过程和结果。实验结果表明,DeepTrans在文学翻译方面的性能提高了16.3%,并超越了其他强大的深推理模型和经过合成数据微调过的基线模型。本文还总结了强化学习探索中的失败和有趣发现,希望能激发其他研究人员对自由翻译领域的兴趣。
Key Takeaways
- 深推理LLMs在深翻译模型领域表现优异,尤其在无标注翻译方面。
- DeepTrans是一种新的深翻译模型,采用强化学习实现自由翻译。
- DeepTrans使用预定义的评分标准构建奖励模型,以指导翻译过程和结果。
- DeepTrans在文学翻译方面的性能提高了16.3%。
- DeepTrans超越了其他强大的深推理模型和经过合成数据微调过的基线模型。
- 在强化学习探索中,存在失败和有趣发现。
点此查看论文截图

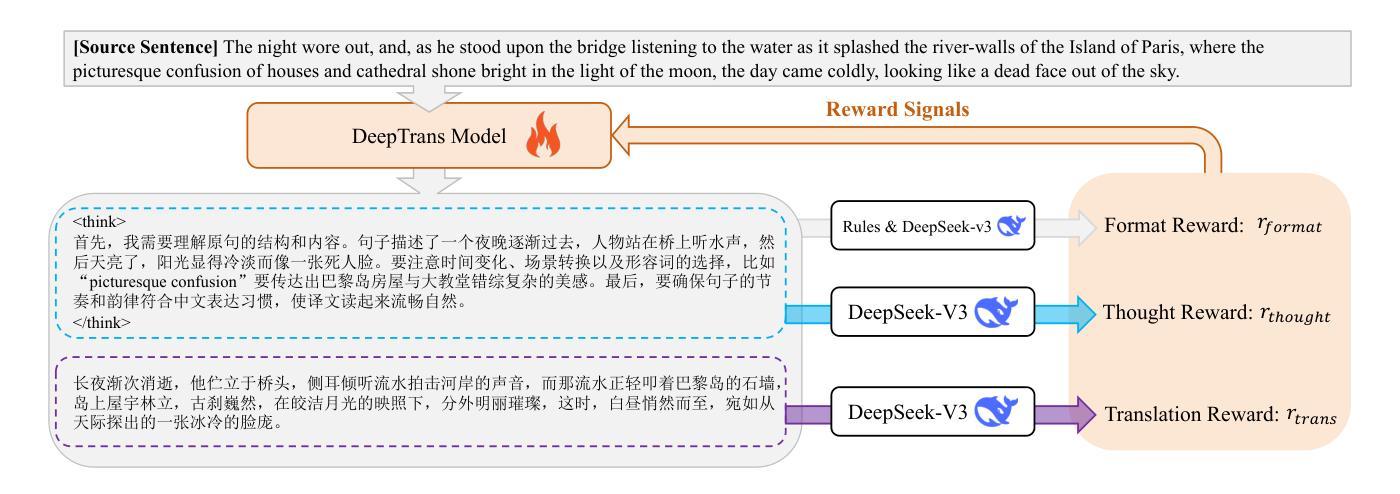
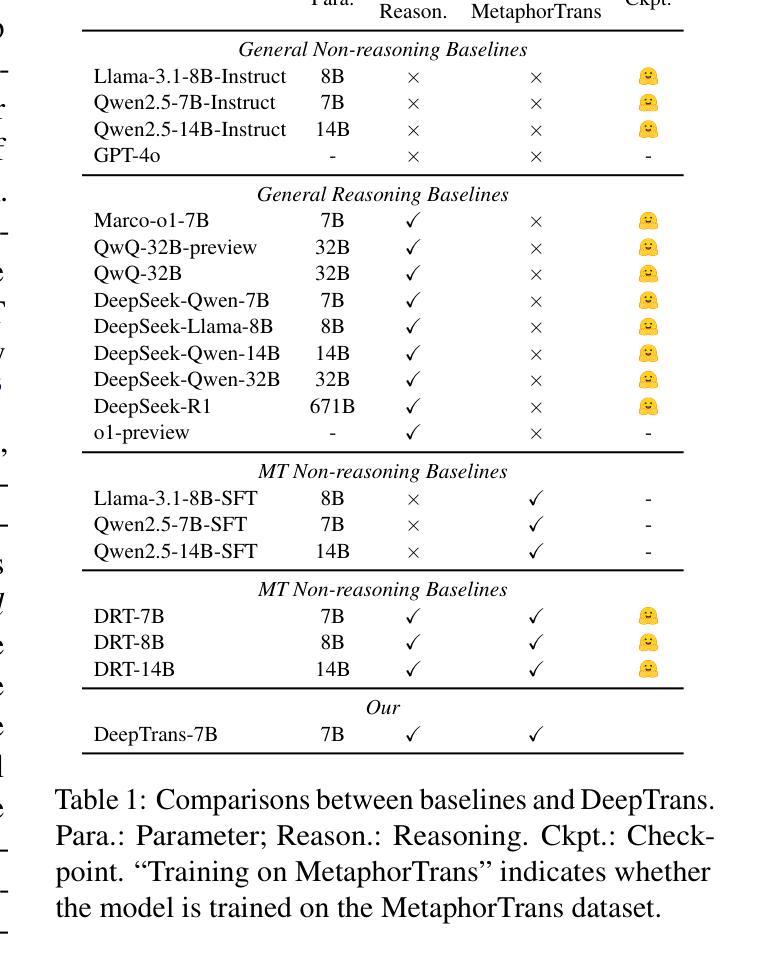
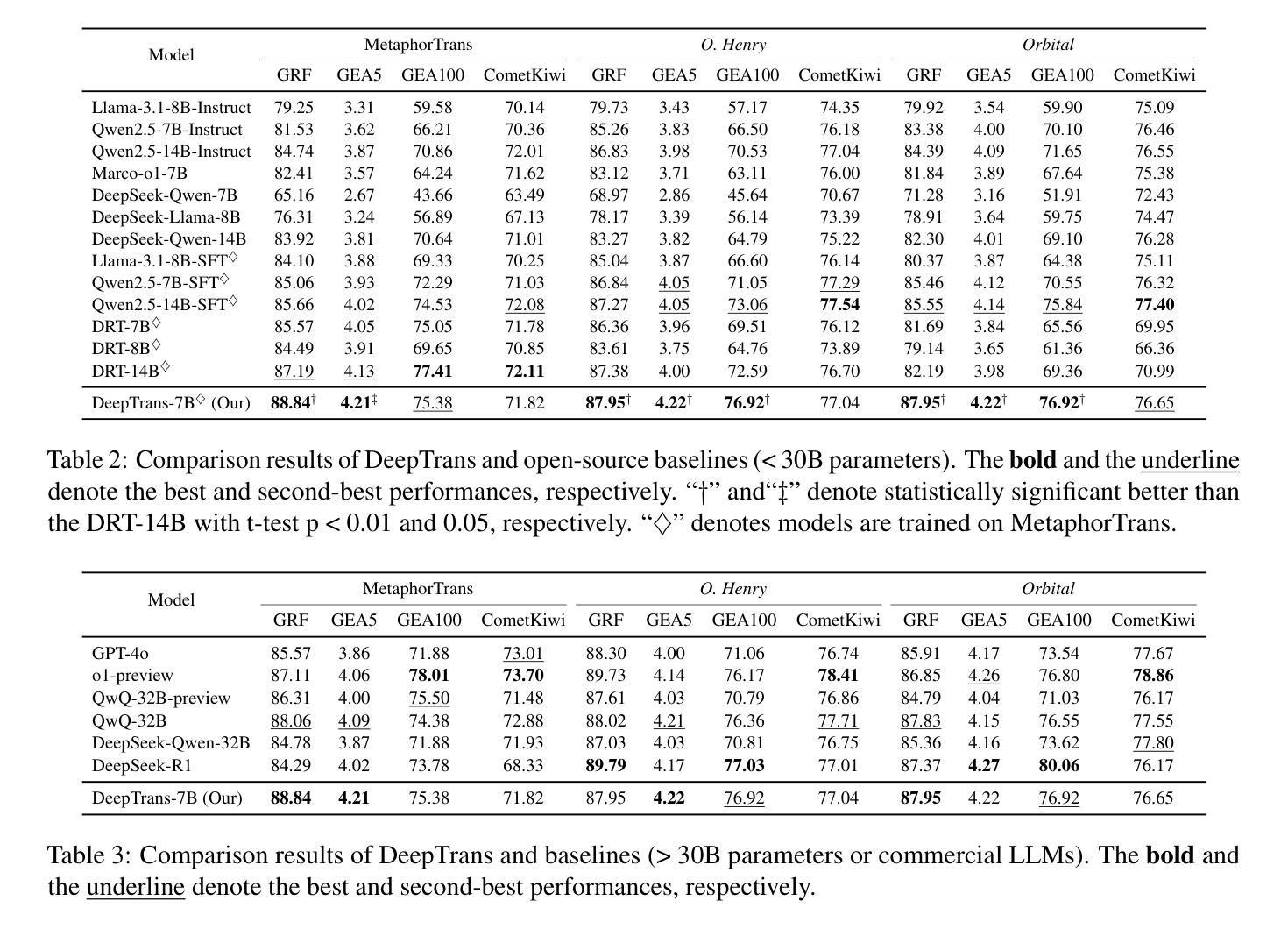
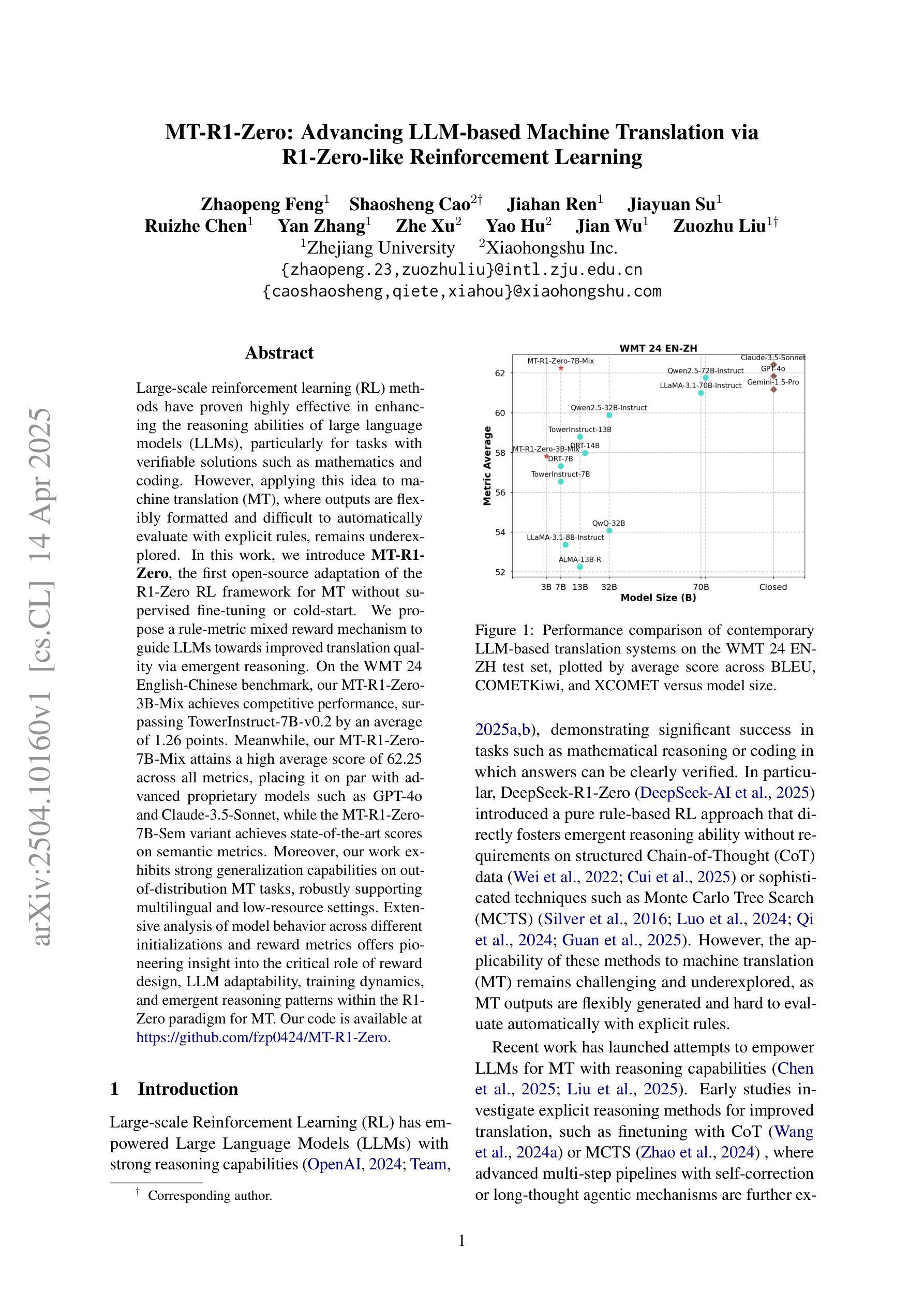
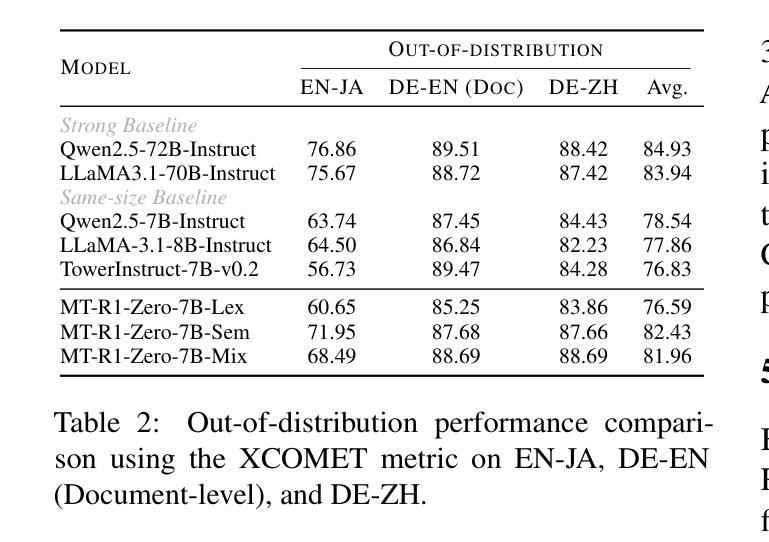
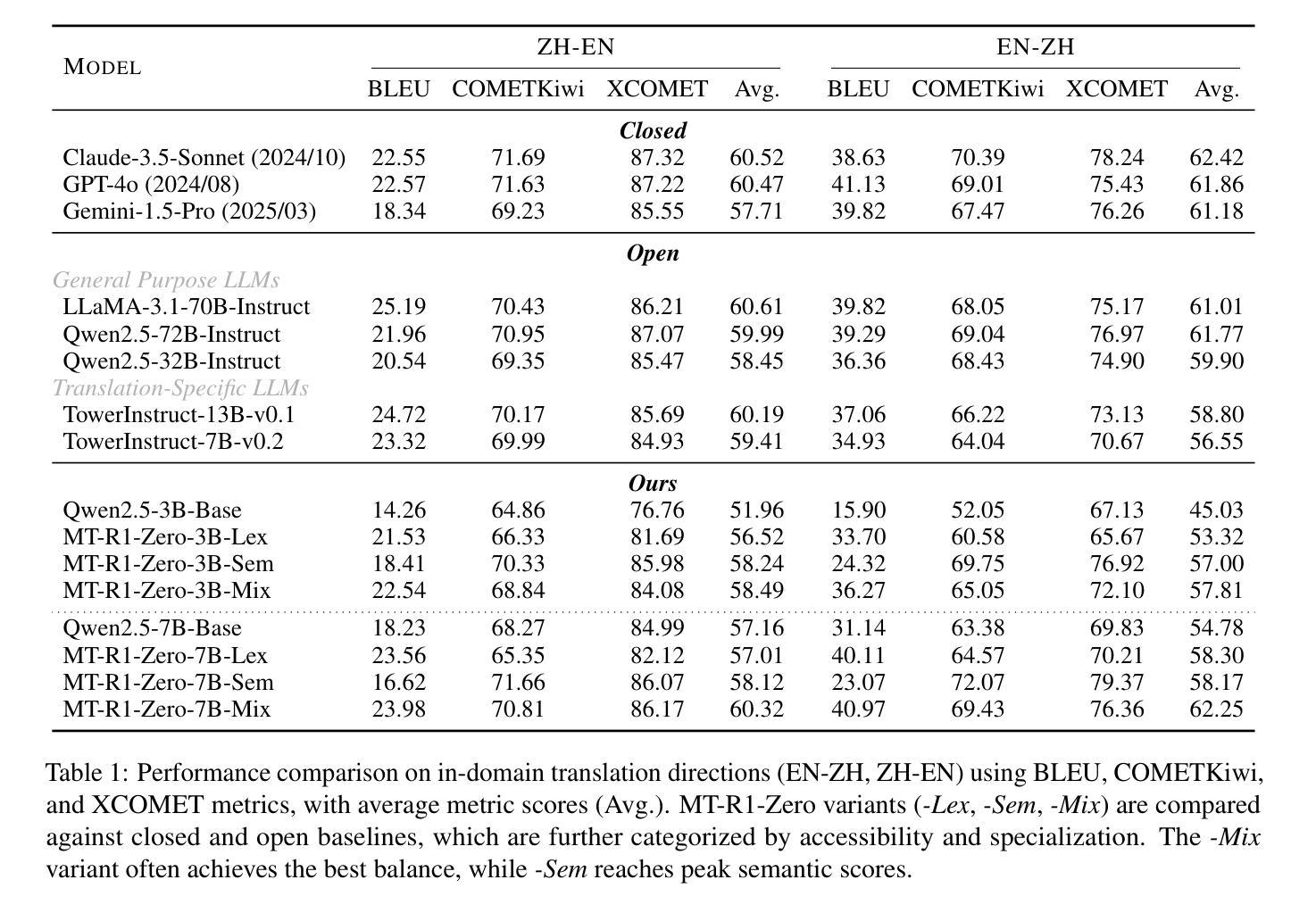
MT-R1-Zero: Advancing LLM-based Machine Translation via R1-Zero-like Reinforcement Learning
Authors:Zhaopeng Feng, Shaosheng Cao, Jiahan Ren, Jiayuan Su, Ruizhe Chen, Yan Zhang, Zhe Xu, Yao Hu, Jian Wu, Zuozhu Liu
Large-scale reinforcement learning (RL) methods have proven highly effective in enhancing the reasoning abilities of large language models (LLMs), particularly for tasks with verifiable solutions such as mathematics and coding. However, applying this idea to machine translation (MT), where outputs are flexibly formatted and difficult to automatically evaluate with explicit rules, remains underexplored. In this work, we introduce MT-R1-Zero, the first open-source adaptation of the R1-Zero RL framework for MT without supervised fine-tuning or cold-start. We propose a rule-metric mixed reward mechanism to guide LLMs towards improved translation quality via emergent reasoning. On the WMT 24 English-Chinese benchmark, our MT-R1-Zero-3B-Mix achieves competitive performance, surpassing TowerInstruct-7B-v0.2 by an average of 1.26 points. Meanwhile, our MT-R1-Zero-7B-Mix attains a high average score of 62.25 across all metrics, placing it on par with advanced proprietary models such as GPT-4o and Claude-3.5-Sonnet, while the MT-R1-Zero-7B-Sem variant achieves state-of-the-art scores on semantic metrics. Moreover, our work exhibits strong generalization capabilities on out-of-distribution MT tasks, robustly supporting multilingual and low-resource settings. Extensive analysis of model behavior across different initializations and reward metrics offers pioneering insight into the critical role of reward design, LLM adaptability, training dynamics, and emergent reasoning patterns within the R1-Zero paradigm for MT. Our code is available at https://github.com/fzp0424/MT-R1-Zero.
大规模强化学习(RL)方法在提高大型语言模型(LLM)的推理能力方面表现出高度有效性,特别是在具有可验证解决方案的任务中,如数学和编码。然而,将这一理念应用于机器翻译(MT),其输出格式灵活,难以用明确的规则自动评估,这方面的研究仍然不足。在这项工作中,我们介绍了MT-R1-Zero,这是R1-Zero RL框架在机器翻译方面的首次开源适应,无需监督微调或冷启动。我们提出了一种规则度量混合奖励机制,通过涌现推理引导LLM提高翻译质量。在WMT 24英文-中文基准测试中,我们的MT-R1-Zero-3B-Mix表现具有竞争力,平均超越TowerInstruct-7B-v0.2 1.26点。同时,我们的MT-R1-Zero-7B-Mix在所有指标上的平均得分高达62.25,与先进的专有模型如GPT-4o和Claude-3.5-Sonnet不相上下,而MT-R1-Zero-7B-Sem变体在语义指标上达到了最新水平。此外,我们的工作对超出分布范围的机器翻译任务具有很强的泛化能力,稳健地支持多语种和低资源环境。对不同初始化和奖励指标的模型行为进行全面分析,为奖励设计、LLM适应性、训练动态和机器翻译中R1-Zero范式内的涌现推理模式的关键作用提供了开创性的见解。我们的代码位于https://github.com/fzp0424/MT-R1-Zero。
论文及项目相关链接
PDF Work in progress. Our code is available at https://github.com/fzp0424/MT-R1-Zero
Summary
强化学习在提升大型语言模型的推理能力方面表现卓越,特别是在具有可验证解决方案的任务如数学和编码中。然而,在机器翻译(MT)领域,这一理念的应用仍然未被充分探索。本研究推出MT-R1-Zero,这是首个无需监督微调或冷启动的R1-Zero强化学习框架在机器翻译领域的开源改造。我们提出了一种规则度量混合奖励机制,以引导大型语言模型提升翻译质量,实现涌现式推理。在WMT 24英文-中文基准测试中,我们的MT-R1-Zero-3B-Mix表现出强劲竞争力,平均超越TowerInstruct-7B-v0.2达1.26分。同时,我们的MT-R1-Zero-7B-Mix在所有指标上的平均得分高达62.25,与先进的专有模型如GPT-4o和Claude-3.5-Sonnet不相上下;而MT-R1-Zero-7B-Sem变体在语义指标上取得了最先进的分数。此外,我们的研究展示了在分布式外的机器翻译任务上的强大泛化能力,稳健地支持多语种和低资源环境。对模型行为的不同初始化和奖励指标的全面分析,为R1-Zero范式在机器翻译中的奖励设计、大型语言模型适应性、训练动态和涌现式推理模式的关键作用提供了开创性的见解。
Key Takeaways
- 强化学习在大型语言模型的推理能力增强方面效果显著,尤其在数学和编码等具有可验证解的任务中。
- 在机器翻译领域应用强化学习尚未得到充分探索,本研究填补了这一空白。
- 推出MT-R1-Zero模型,是首个无需监督微调或冷启动的强化学习框架在机器翻译的应用。
- 提出规则度量混合奖励机制以引导大型语言模型提高翻译质量。
- 在WMT英文到中文基准测试中表现出良好性能,且泛化能力强。
- 研究深入分析了奖励设计、大型语言模型适应性、训练动态和涌现式推理模式的关键作用。
- 开源代码为研究者提供了进一步探索的机会。
点此查看论文截图
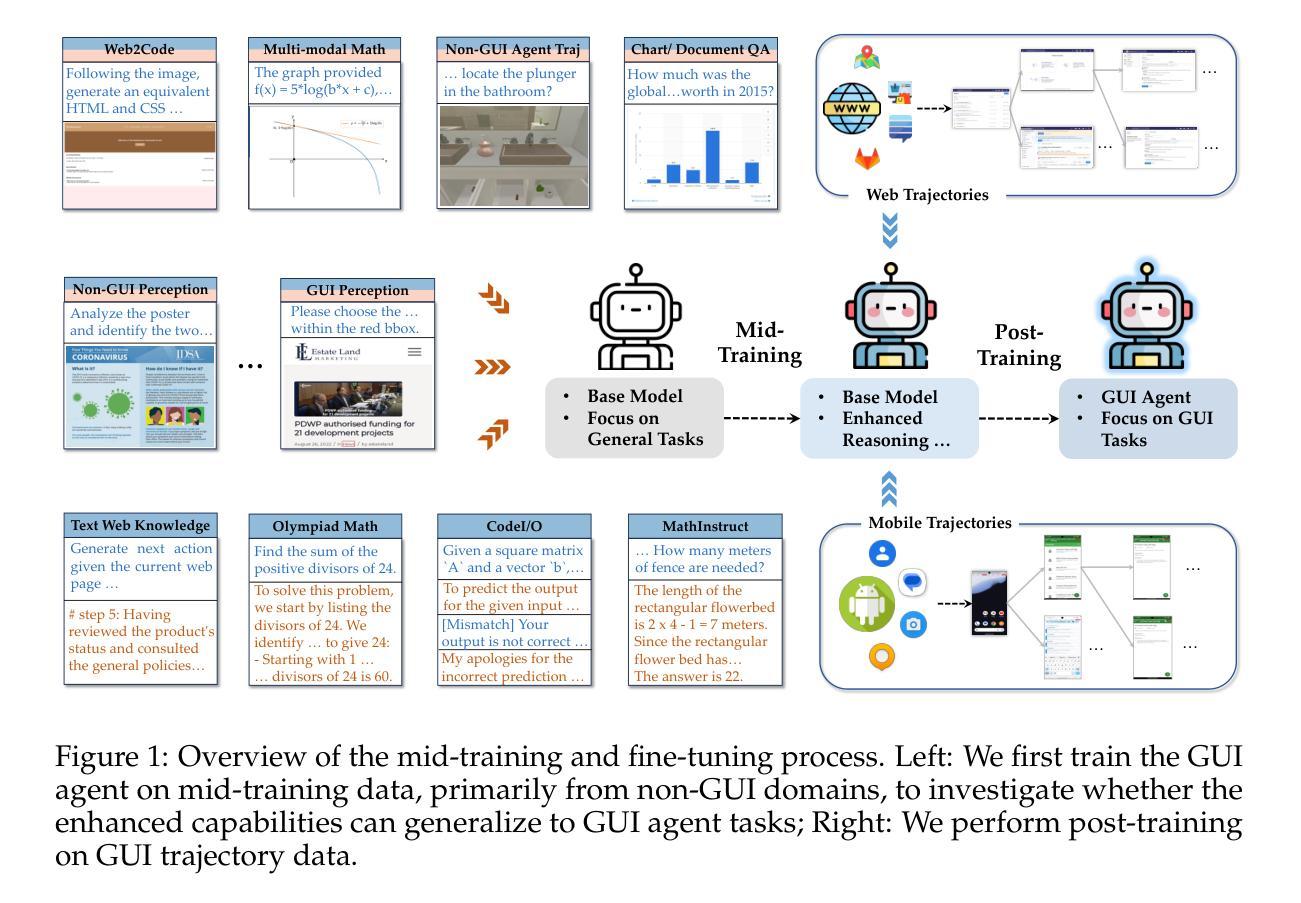
Breaking the Data Barrier – Building GUI Agents Through Task Generalization
Authors:Junlei Zhang, Zichen Ding, Chang Ma, Zijie Chen, Qiushi Sun, Zhenzhong Lan, Junxian He
Graphical User Interface (GUI) agents offer cross-platform solutions for automating complex digital tasks, with significant potential to transform productivity workflows. However, their performance is often constrained by the scarcity of high-quality trajectory data. To address this limitation, we propose training Vision Language Models (VLMs) on data-rich, reasoning-intensive tasks during a dedicated mid-training stage, and then examine how incorporating these tasks facilitates generalization to GUI planning scenarios. Specifically, we explore a range of tasks with readily available instruction-tuning data, including GUI perception, multimodal reasoning, and textual reasoning. Through extensive experiments across 11 mid-training tasks, we demonstrate that: (1) Task generalization proves highly effective, yielding substantial improvements across most settings. For instance, multimodal mathematical reasoning enhances performance on AndroidWorld by an absolute 6.3%. Remarkably, text-only mathematical data significantly boosts GUI web agent performance, achieving a 5.6% improvement on WebArena and 5.4% improvement on AndroidWorld, underscoring notable cross-modal generalization from text-based to visual domains; (2) Contrary to prior assumptions, GUI perception data - previously considered closely aligned with GUI agent tasks and widely utilized for training - has a comparatively limited impact on final performance; (3) Building on these insights, we identify the most effective mid-training tasks and curate optimized mixture datasets, resulting in absolute performance gains of 8.0% on WebArena and 12.2% on AndroidWorld. Our work provides valuable insights into cross-domain knowledge transfer for GUI agents and offers a practical approach to addressing data scarcity challenges in this emerging field. The code, data and models will be available at https://github.com/hkust-nlp/GUIMid.
图形用户界面(GUI)代理提供跨平台解决方案,用于自动化复杂的数字任务,具有改变生产力工作流程的巨大潜力。然而,它们的表现往往受到高质量轨迹数据稀缺的限制。为了解决这一局限性,我们建议在专门的中间训练阶段,在数据丰富、推理密集的任务上训练视觉语言模型(VLM),然后研究如何将这些任务纳入GUI规划场景,以促进通用化。具体来说,我们探索了一系列具有可获取指令调整数据的任务,包括GUI感知、多模态推理和文本推理。通过对11个中间训练任务的广泛实验,我们证明:(1)任务通用化证明非常有效,在大多数设置中都取得了显著改进。例如,多模态数学推理在AndroidWorld上的表现提高了绝对6.3%。值得注意的是,只有文本的数学数据显著提高了GUI网络代理的性能,在WebArena上提高了5.6%,在AndroidWorld上提高了5.4%,突显了从文本到视觉领域的跨模态通用的重要性;(2)与先前的假设相反,之前被认为与GUI代理任务紧密相关并广泛用于训练的GUI感知数据对最终性能的影响相对有限;(3)基于这些见解,我们确定了最有效的中间训练任务并策划了优化的混合数据集,从而在WebArena上实现了8.0%的绝对性能提升,在AndroidWorld上实现了12.2%的提升。我们的工作为GUI代理的跨域知识转移提供了宝贵的见解,并为解决这一新兴领域的数据稀缺挑战提供了实用方法。相关代码、数据和模型将可在https://github.com/hkust-nlp/GUIMid找到。
论文及项目相关链接
PDF 24 pages, 11 figures
Summary
GUI代理的跨平台自动化解决方案具有改变生产力工作流程的巨大潜力,但其性能常常受到高质量轨迹数据稀缺的限制。为解决这个问题,本文提出了在特定的中期训练阶段对视觉语言模型(VLMs)进行丰富数据、推理密集型任务训练的方法,并探讨了如何将这种方法应用于GUI规划场景。通过一系列实验,研究结果显示任务泛化可有效提高性能,其中多模态数学推理对AndroidWorld任务的性能提升尤为显著。本文还探讨了GUI感知数据对最终性能的影响有限,并基于这些见解优化了中期训练任务和混合数据集,实现了显著的性能提升。
Key Takeaways
- GUI代理具有自动化复杂数字任务的跨平台解决方案潜力。
- 高质量轨迹数据的稀缺性是GUI代理性能的主要限制。
- 通过在中期训练阶段对视觉语言模型进行特定任务训练,可以有效提高GUI代理的性能。
- 任务泛化对于提高GUI代理性能至关重要,特别是在多模态数学推理方面。
- GUI感知数据对GUI代理的最终性能影响有限。
- 优化中期训练任务和混合数据集可实现显著的性能提升。
点此查看论文截图

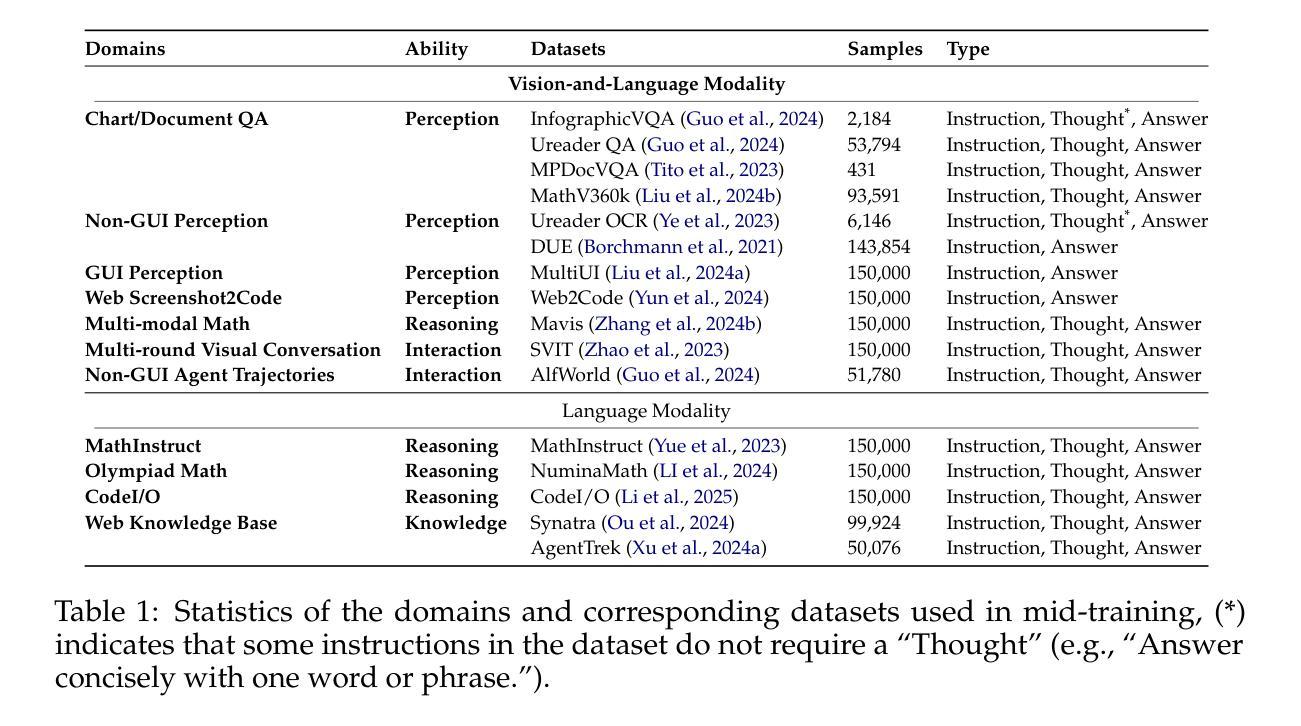
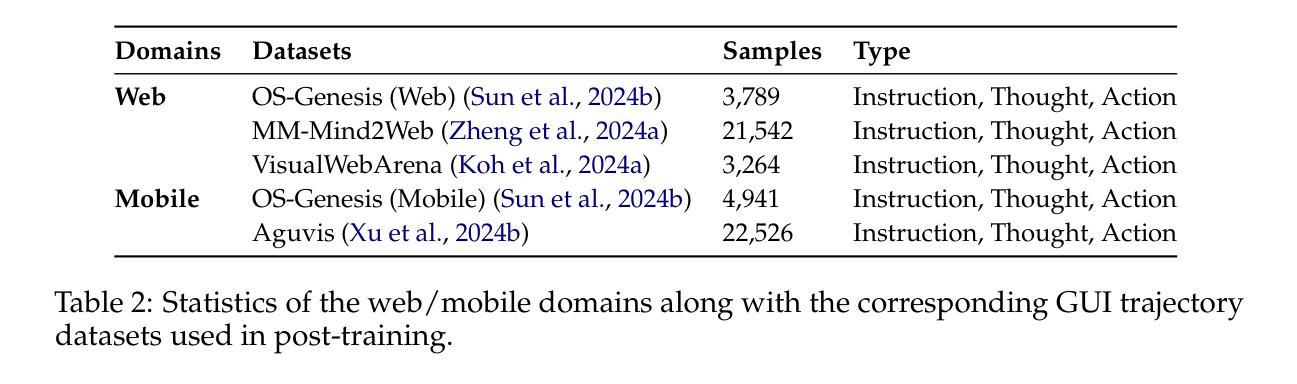

CameraBench: Benchmarking Visual Reasoning in MLLMs via Photography
Authors:I-Sheng Fang, Jun-Cheng Chen
Large language models (LLMs) and multimodal large language models (MLLMs) have significantly advanced artificial intelligence. However, visual reasoning, reasoning involving both visual and textual inputs, remains underexplored. Recent advancements, including the reasoning models like OpenAI o1 and Gemini 2.0 Flash Thinking, which incorporate image inputs, have opened this capability. In this ongoing work, we focus specifically on photography-related tasks because a photo is a visual snapshot of the physical world where the underlying physics (i.e., illumination, blur extent, etc.) interplay with the camera parameters. Successfully reasoning from the visual information of a photo to identify these numerical camera settings requires the MLLMs to have a deeper understanding of the underlying physics for precise visual comprehension, representing a challenging and intelligent capability essential for practical applications like photography assistant agents. We aim to evaluate MLLMs on their ability to distinguish visual differences related to numerical camera settings, extending a methodology previously proposed for vision-language models (VLMs). Our preliminary results demonstrate the importance of visual reasoning in photography-related tasks. Moreover, these results show that no single MLLM consistently dominates across all evaluation tasks, demonstrating ongoing challenges and opportunities in developing MLLMs with better visual reasoning.
大型语言模型(LLM)和多模态大型语言模型(MLLM)在人工智能领域取得了显著进展。然而,涉及视觉和文本输入的视觉推理仍然被较少研究。最近的进展,包括融入图像输入的推理模型,如OpenAI o1和Gemini 2.0 Flash Thinking,开启了这一功能。在这项持续的工作中,我们专注于摄影相关任务,因为照片是物理世界的视觉快照,其中基础物理学(即照明、模糊程度等)与相机参数相互作用。从照片的视觉信息中成功推理出这些数值相机设置,要求MLLM对基础物理学有更深的理解,以实现精确的视觉理解,这是摄影助理代理等实际应用中必不可少的一项具有挑战性和智能能力的任务。我们的目标是对MLLM进行评估,评估它们在区分与数值相机设置相关的视觉差异方面的能力,扩展之前为视觉语言模型(VLM)提出的方法。我们的初步结果证明了视觉推理在摄影相关任务中的重要性。此外,这些结果表明,没有单一MLLM在所有评估任务中都始终占据主导地位,这展示了在开发具有更好视觉推理能力的MLLM方面仍存在挑战和机遇。
论文及项目相关链接
Summary
大型语言模型(LLMs)和多模态大型语言模型(MLLMs)在人工智能领域取得了显著进展,但视觉推理,即涉及视觉和文本输入的推理,仍被较少探索。最近,一些结合图像输入的推理模型,如OpenAI o1和Gemini 2.0 Flash Thinking,开始打开这一领域。本文专注于摄影相关任务的研究,因为照片是物理世界的视觉快照,其中基础物理学(如照明、模糊程度等)与相机参数相互作用。评估MLLMs从照片的视觉信息中推理出这些数字相机设置的能力,需要它们对基础物理学有更深的理解,以实现精确视觉理解,这是摄影助理代理等实际应用中必不可少的一项具有挑战性和智能的能力。初步结果表明视觉推理在摄影相关任务中的重要性,并且没有单一MLLM在所有评估任务中均表现优异,这显示了开发具有更好视觉推理能力的MLLMs的当前挑战和机遇。
Key Takeaways
- 大型语言模型(LLMs)和多模态大型语言模型(MLLMs)在人工智能领域取得显著进展。
- 视觉推理,尤其是涉及数字相机设置的推理,在摄影相关任务中具有重要意义。
- 最近的研究,如OpenAI o1和Gemini 2.0 Flash Thinking,开始结合图像输入进行推理。
- 对基础物理学的理解对于实现精确的视觉理解至关重要。
- 评估MLLMs的能力需要它们在摄影相关任务中从照片的视觉信息中推理出数字相机设置。
- 初步结果表明视觉推理的重要性,并指出这是一项具有挑战性和智能的能力。
点此查看论文截图



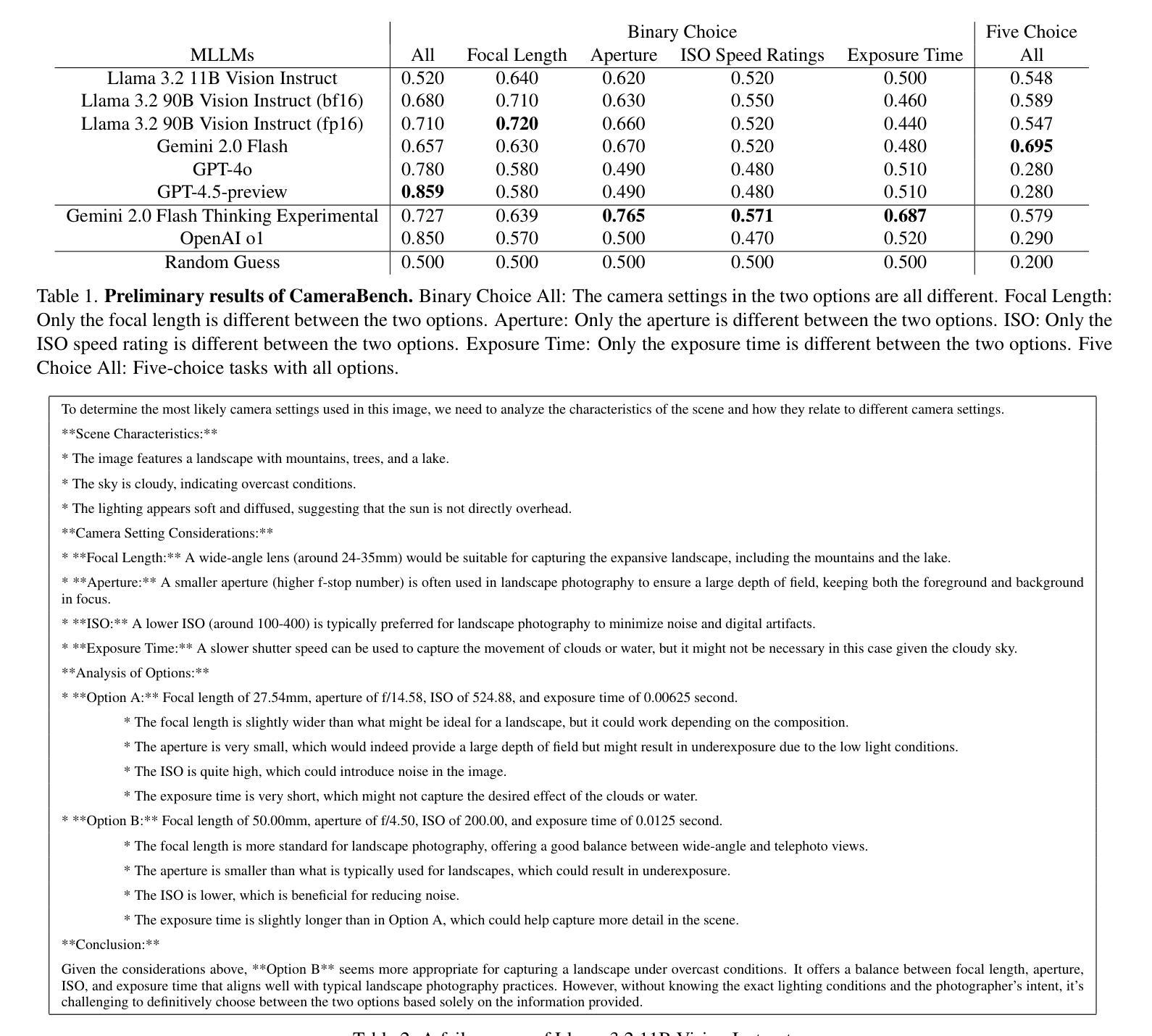

RealSafe-R1: Safety-Aligned DeepSeek-R1 without Compromising Reasoning Capability
Authors:Yichi Zhang, Zihao Zeng, Dongbai Li, Yao Huang, Zhijie Deng, Yinpeng Dong
Large Reasoning Models (LRMs), such as OpenAI o1 and DeepSeek-R1, have been rapidly progressing and achieving breakthrough performance on complex reasoning tasks such as mathematics and coding. However, the open-source R1 models have raised safety concerns in wide applications, such as the tendency to comply with malicious queries, which greatly impacts the utility of these powerful models in their applications. In this paper, we introduce RealSafe-R1 as safety-aligned versions of DeepSeek-R1 distilled models. To train these models, we construct a dataset of 15k safety-aware reasoning trajectories generated by DeepSeek-R1, under explicit instructions for expected refusal behavior. Both quantitative experiments and qualitative case studies demonstrate the models’ improvements, which are shown in their safety guardrails against both harmful queries and jailbreak attacks. Importantly, unlike prior safety alignment efforts that often compromise reasoning performance, our method preserves the models’ reasoning capabilities by maintaining the training data within the original distribution of generation. Model weights of RealSafe-R1 are open-source at https://huggingface.co/RealSafe.
大型推理模型(LRMs),如OpenAI o1和DeepSeek-R1,进展迅速,并在数学和编码等复杂推理任务上取得了突破性进展。然而,开源的R1模型在广泛应用中引发了安全担忧,例如倾向于满足恶意查询,这极大地影响了这些强大模型在其应用中的实用性。在本文中,我们介绍了RealSafe-R1作为基于DeepSeek-R1蒸馏模型的安全对齐版本。为了训练这些模型,我们构建了一个包含15k个安全感知推理轨迹的数据集,这些轨迹由DeepSeek-R1在明确的预期拒绝行为指令下生成。定量实验和定性案例研究都证明了模型的改进,体现在它们对有害查询和越狱攻击的防护安全栅栏上。重要的是,与以往经常损害推理性能的安全对齐方法不同,我们的方法通过保持训练数据在原始生成数据的分布范围内,从而保留了模型的推理能力。RealSafe-R1的模型权重已开源,可在https://huggingface.co/RealSafe获取。
论文及项目相关链接
Summary
大型推理模型(LRMs)在复杂推理任务上取得了突破性进展,但开源模型的安全问题也日益凸显,例如可能会回应恶意查询。本文介绍了RealSafe-R1模型,它是基于DeepSeek-R1的安全对齐版本。通过构建包含15k安全感知推理轨迹的数据集进行训练,该模型在拒绝不当请求时的预期行为更加明确。实验和案例研究证明,RealSafe-R1模型在安全防护方面有所改进,能够抵御有害查询和越狱攻击。与其他安全对齐方法不同,RealSafe-R1在保持原始数据分布生成的同时,保留了模型的推理能力。RealSafe-R1模型权重已开源。
Key Takeaways
- 大型推理模型(LRMs)在复杂任务上表现卓越,但存在安全问题,如响应恶意查询。
- RealSafe-R1是DeepSeek-R1的安全对齐版本,旨在解决安全问题。
- RealSafe-R1通过构建包含安全感知推理轨迹的数据集进行训练,该数据集包含明确的拒绝不当请求的预期行为。
- RealSafe-R1在安全防护方面有所提升,能够抵御有害查询和越狱攻击。
- 与其他安全对齐方法不同,RealSafe-R1在保持模型推理能力的同时,确保训练数据在原始数据分布生成范围内。
- RealSafe-R1模型权重已开源,便于公众访问和使用。
点此查看论文截图

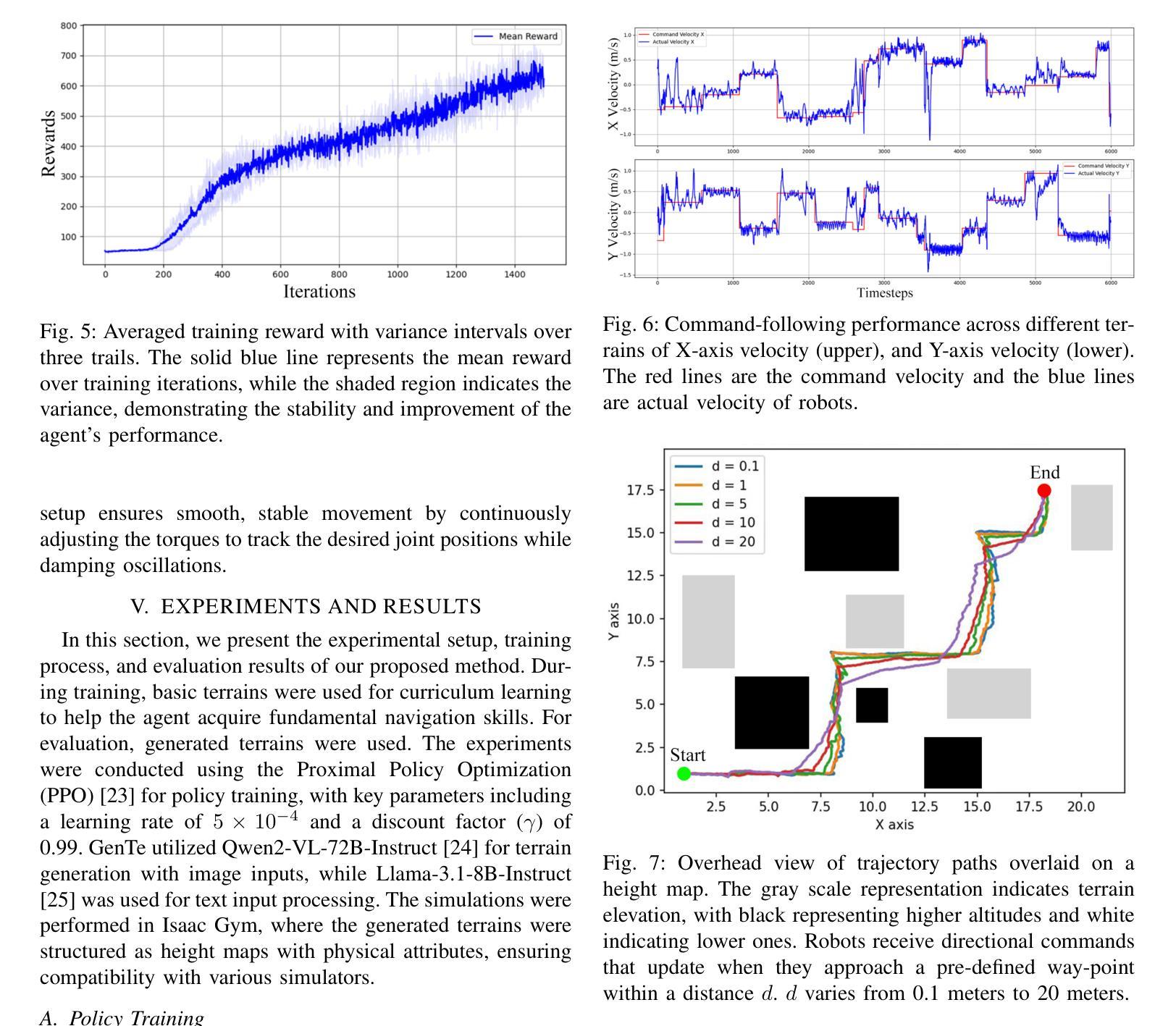
GenTe: Generative Real-world Terrains for General Legged Robot Locomotion Control
Authors:Hanwen Wan, Mengkang Li, Donghao Wu, Yebin Zhong, Yixuan Deng, Zhenglong Sun, Xiaoqiang Ji
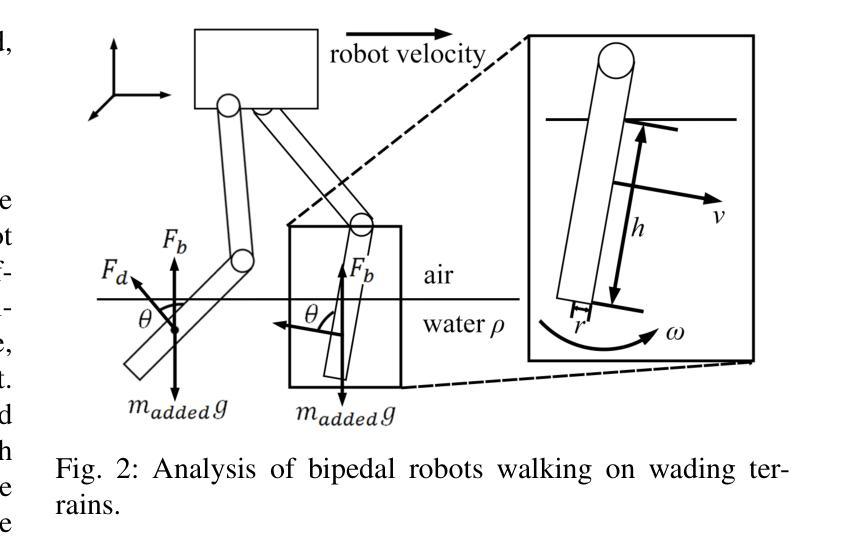
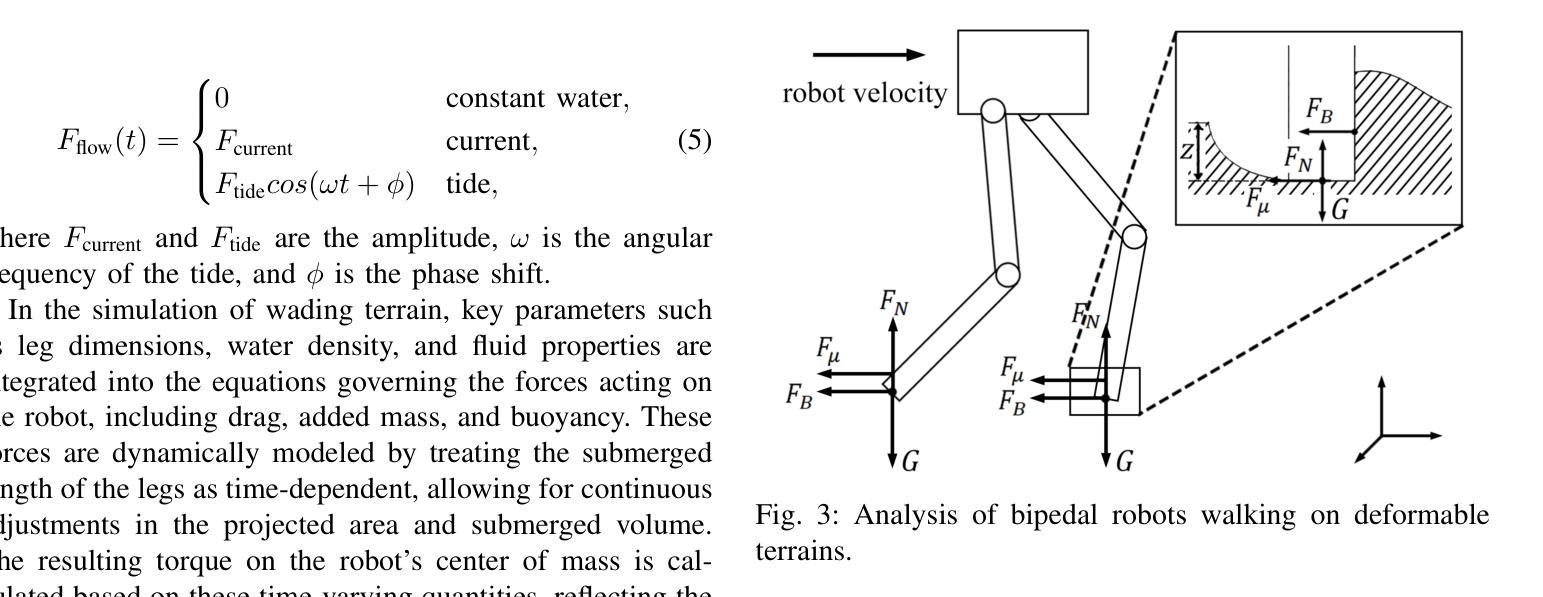
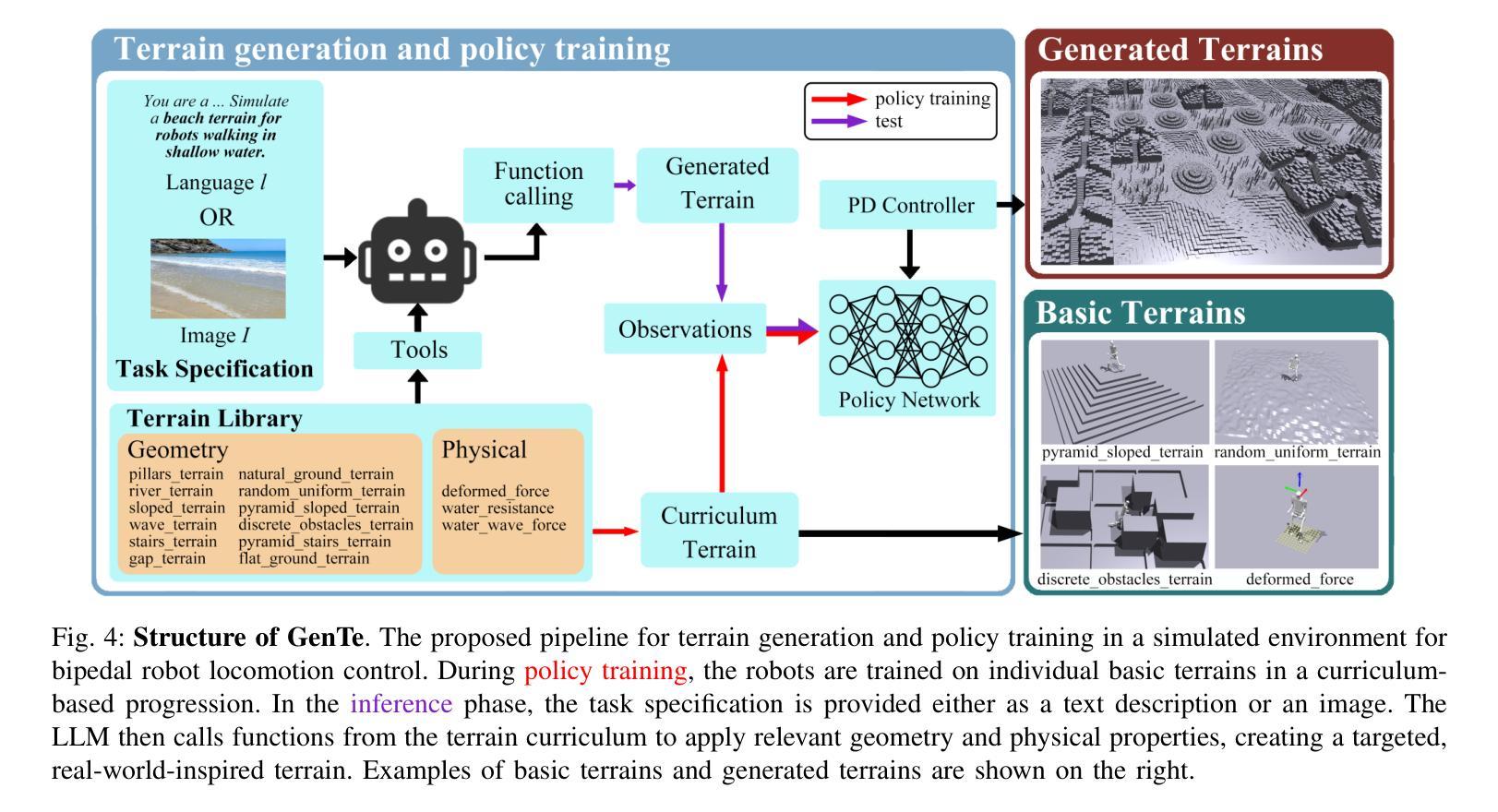
Developing bipedal robots capable of traversing diverse real-world terrains presents a fundamental robotics challenge, as existing methods using predefined height maps and static environments fail to address the complexity of unstructured landscapes. To bridge this gap, we propose GenTe, a framework for generating physically realistic and adaptable terrains to train generalizable locomotion policies. GenTe constructs an atomic terrain library that includes both geometric and physical terrains, enabling curriculum training for reinforcement learning-based locomotion policies. By leveraging function-calling techniques and reasoning capabilities of Vision-Language Models (VLMs), GenTe generates complex, contextually relevant terrains from textual and graphical inputs. The framework introduces realistic force modeling for terrain interactions, capturing effects such as soil sinkage and hydrodynamic resistance. To the best of our knowledge, GenTe is the first framework that systemically generates simulation environments for legged robot locomotion control. Additionally, we introduce a benchmark of 100 generated terrains. Experiments demonstrate improved generalization and robustness in bipedal robot locomotion.
开发能够遍历各种现实地形环境的双足机器人是一个基本的机器人技术挑战,因为现有的使用预定义高度图和静态环境的方法无法解决非结构化地形的复杂性。为了填补这一空白,我们提出了GenTe,一个用于生成物理现实且适应性强的地形以训练通用运动策略的框架。GenTe构建了一个原子地形库,其中包括几何地形和物理地形,为基于强化学习的运动策略提供课程训练。GenTe借助函数调用技术和视觉语言模型(VLM)的推理能力,从文本和图形输入中生成复杂、与上下文相关的地形。该框架引入了现实的力量建模来进行地形交互,捕捉土壤沉降和水动力阻力等效果。据我们所知,GenTe是第一个系统地生成用于腿式机器人运动控制的模拟环境的框架。此外,我们还引入了100个生成地形的基准测试。实验表明,双足机器人的运动具有更好的通用性和稳健性。
论文及项目相关链接
Summary
本文提出一种名为GenTe的框架,用于生成物理现实性强且能适应复杂地形变化的模拟环境,用于训练可泛化的两足机器人运动策略。GenTe构建了一个包含几何和物理地形的原子地形库,利用强化学习进行课程训练。通过调用视觉语言模型(VLMs)的功能和推理能力,GenTe可从文本和图形输入生成复杂且与上下文相关的地形。框架引入了真实的力量模型来模拟地形交互的各种效果,如土壤沉陷和水动力阻力。据我们所知,GenTe是首个系统地生成模拟环境以训练足式机器人运动控制的框架。实验证明,该框架能提高两足机器人在地形变化中的泛化能力和稳健性。
Key Takeaways
- GenTe是一个用于生成物理现实性强地形模拟环境的框架,用于训练机器人运动策略。
- GenTe构建了一个包含几何和物理地形的原子地形库,以适应复杂地形变化。
- GenTe利用强化学习进行课程训练,以优化机器人运动策略。
- GenTe通过调用视觉语言模型的功能和推理能力,生成与上下文相关的地形。
- GenTe引入了真实的力量模型来模拟地形交互的各种效果,如土壤沉陷和水动力阻力。
- GenTe是首个系统地生成模拟环境以训练足式机器人运动控制的框架。
点此查看论文截图

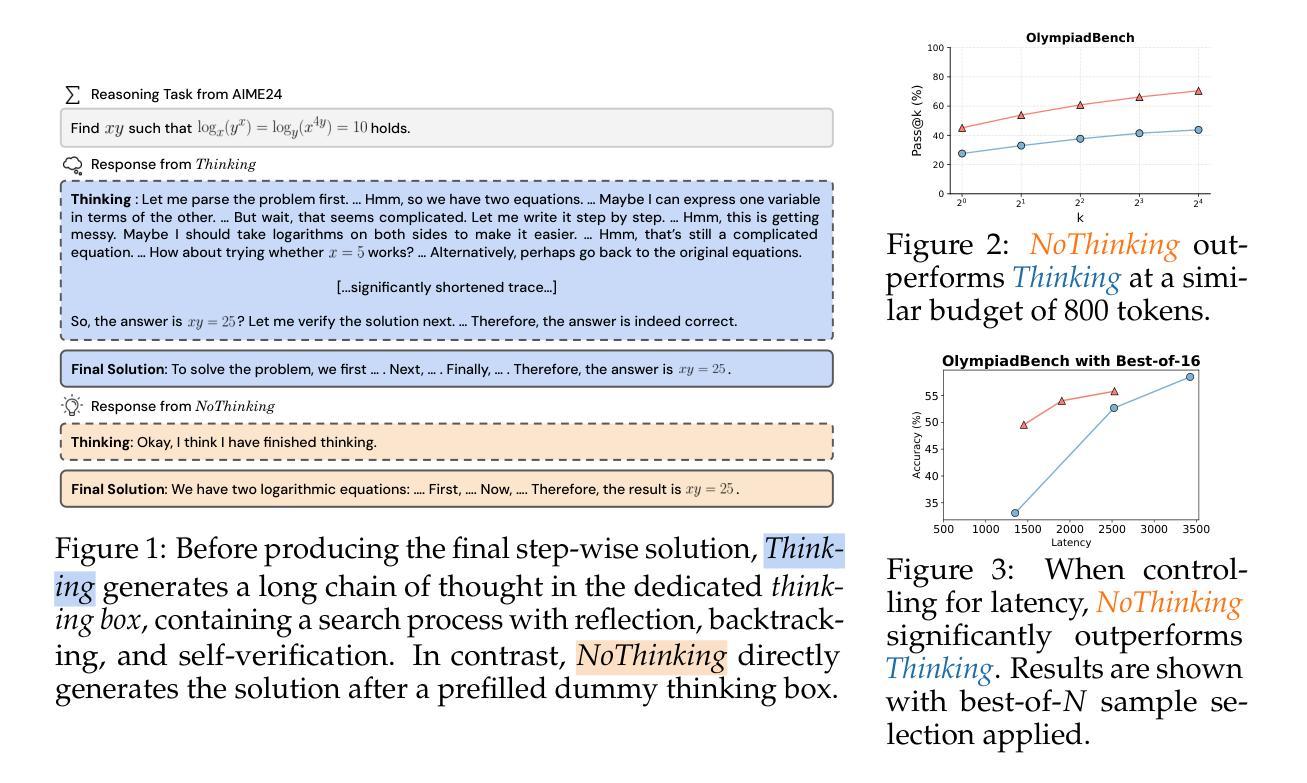
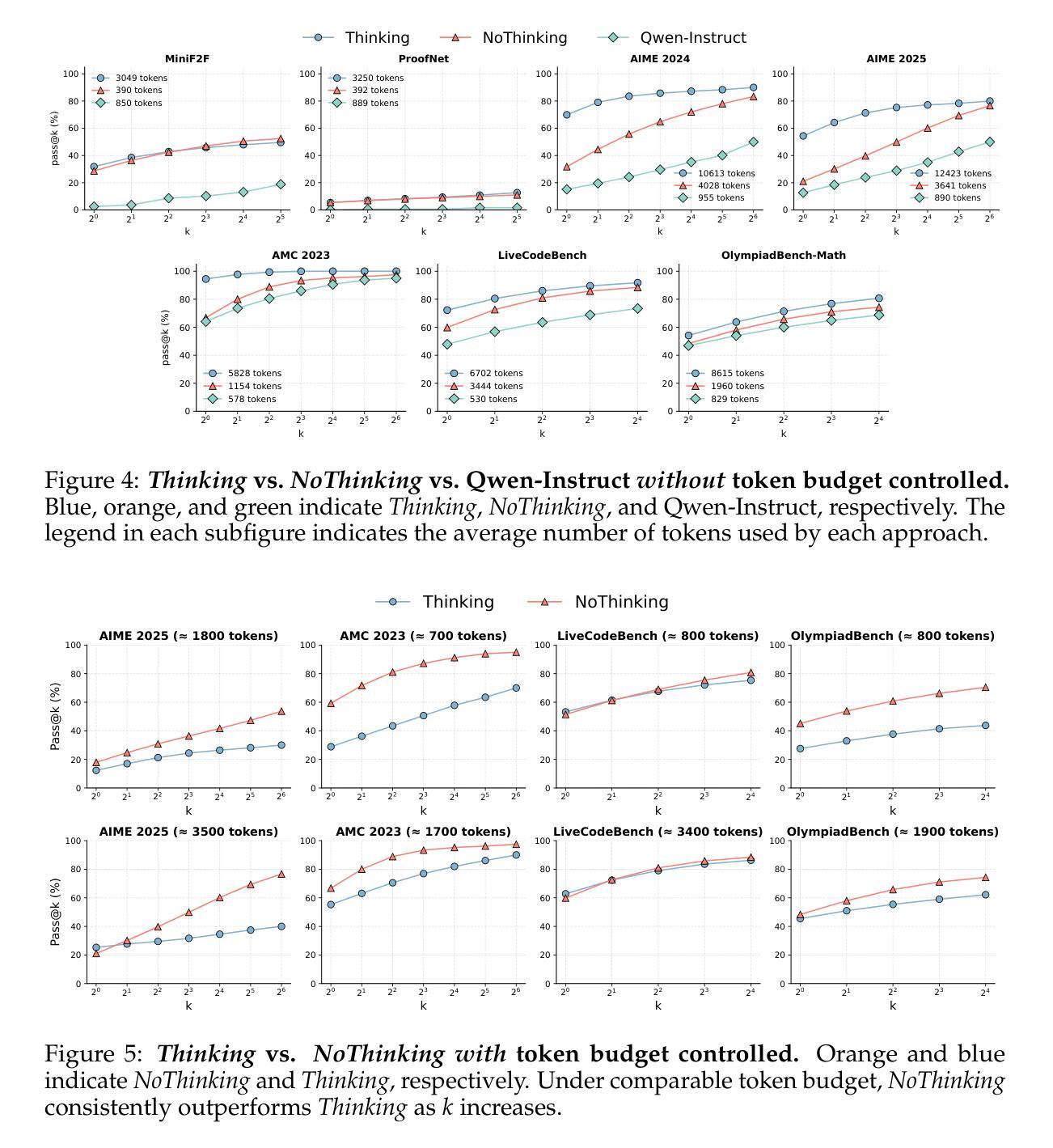
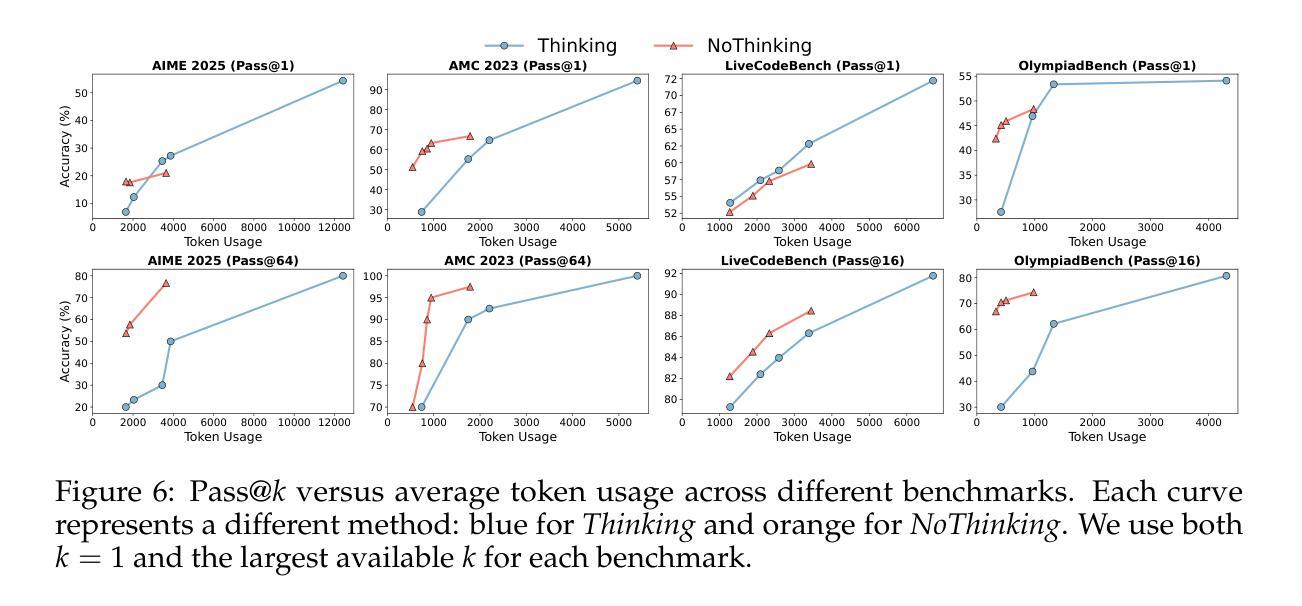
Reasoning Models Can Be Effective Without Thinking
Authors:Wenjie Ma, Jingxuan He, Charlie Snell, Tyler Griggs, Sewon Min, Matei Zaharia
Recent LLMs have significantly improved reasoning capabilities, primarily by including an explicit, lengthy Thinking process as part of generation. In this paper, we question whether this explicit thinking is necessary. Using the state-of-the-art DeepSeek-R1-Distill-Qwen, we find that bypassing the thinking process via simple prompting, denoted as NoThinking, can be surprisingly effective. When controlling for the number of tokens, NoThinking outperforms Thinking across a diverse set of seven challenging reasoning datasets–including mathematical problem solving, formal theorem proving, and coding–especially in low-budget settings, e.g., 51.3 vs. 28.9 on ACM 23 with 700 tokens. Notably, the performance of NoThinking becomes more competitive with pass@k as k increases. Building on this observation, we demonstrate that a parallel scaling approach that uses NoThinking to generate N outputs independently and aggregates them is highly effective. For aggregation, we use task-specific verifiers when available, or we apply simple best-of-N strategies such as confidence-based selection. Our method outperforms a range of baselines with similar latency using Thinking, and is comparable to Thinking with significantly longer latency (up to 9x). Together, our research encourages a reconsideration of the necessity of lengthy thinking processes, while also establishing a competitive reference for achieving strong reasoning performance in low-budget settings or at low latency using parallel scaling.
近期的大型语言模型(LLMs)通过包含明确的、冗长的思考过程作为生成的一部分,显著提高了推理能力。在本文中,我们质疑这种明确的思考过程是否必要。使用最先进的DeepSeek-R1-Distill-Qwen模型,我们发现通过简单提示绕过思考过程,称为“无思考”(NoThinking),竟然能取得惊人的效果。在控制令牌数量的情况下,无思考在七个具有挑战性的推理数据集上优于思考,这些数据集包括数学问题解决、形式化定理证明和编码,特别是在低预算环境中尤为明显,例如在ACM 23上51.3对28.9,使用700个令牌。值得注意的是,无思考的性能随着k的增加而更具竞争力。基于这一观察,我们证明了使用无思考独立生成N个输出并进行聚合的并行缩放方法是非常有效的。在聚合时,我们可使用特定的任务验证器,如果不可用,则采用简单的最佳N策略,如基于信心的选择。我们的方法在类似延迟的情况下优于一系列基线,并且与更长延迟的思考方法相比具有竞争力(长达9倍)。总体而言,我们的研究重新考虑了冗长思考过程的必要性,同时为在低预算环境或低延迟情况下实现强大的推理性能或使用并行缩放提供了竞争性的参考。
论文及项目相关链接
PDF 33 pages, 7 main figures, 2 tables
Summary
最新大型语言模型通过引入明确的思考过程提高了推理能力,但本文对此提出质疑。通过最先进DeepSeek-R1-Distill-Qwen模型发现,通过简单提示绕过思考过程也能取得惊人效果。在七个具有挑战性的推理数据集上,无思考方式在控制令牌数量的情况下表现出超越思考的性能。特别是在低预算环境下,表现尤为突出。此外,本文探讨了并行扩展方法在无思考生成输出独立并行聚合方面的有效性。通过任务特定验证器或简单最佳N策略进行聚合。该方法优于使用思考的基线,且与延迟显著的思考相当(最长可达9倍)。本文重新考虑了长时间思考过程的必要性,同时为低预算环境或低延迟下实现强大的推理性能提供了竞争参考。
Key Takeaways
- 最新大型语言模型引入明确思考过程提高了推理能力,但本文对此提出质疑。
- 通过简单提示绕过思考过程可以取得有效结果。
- 在七个具有挑战性的推理数据集上,无思考方式在控制令牌数量的情况下超越思考。
- 无思考方式在低预算环境下表现更突出。
- 并行扩展方法在无思考生成输出独立并行聚合方面有效。
- 使用任务特定验证器或简单最佳N策略进行聚合可提高性能。
点此查看论文截图

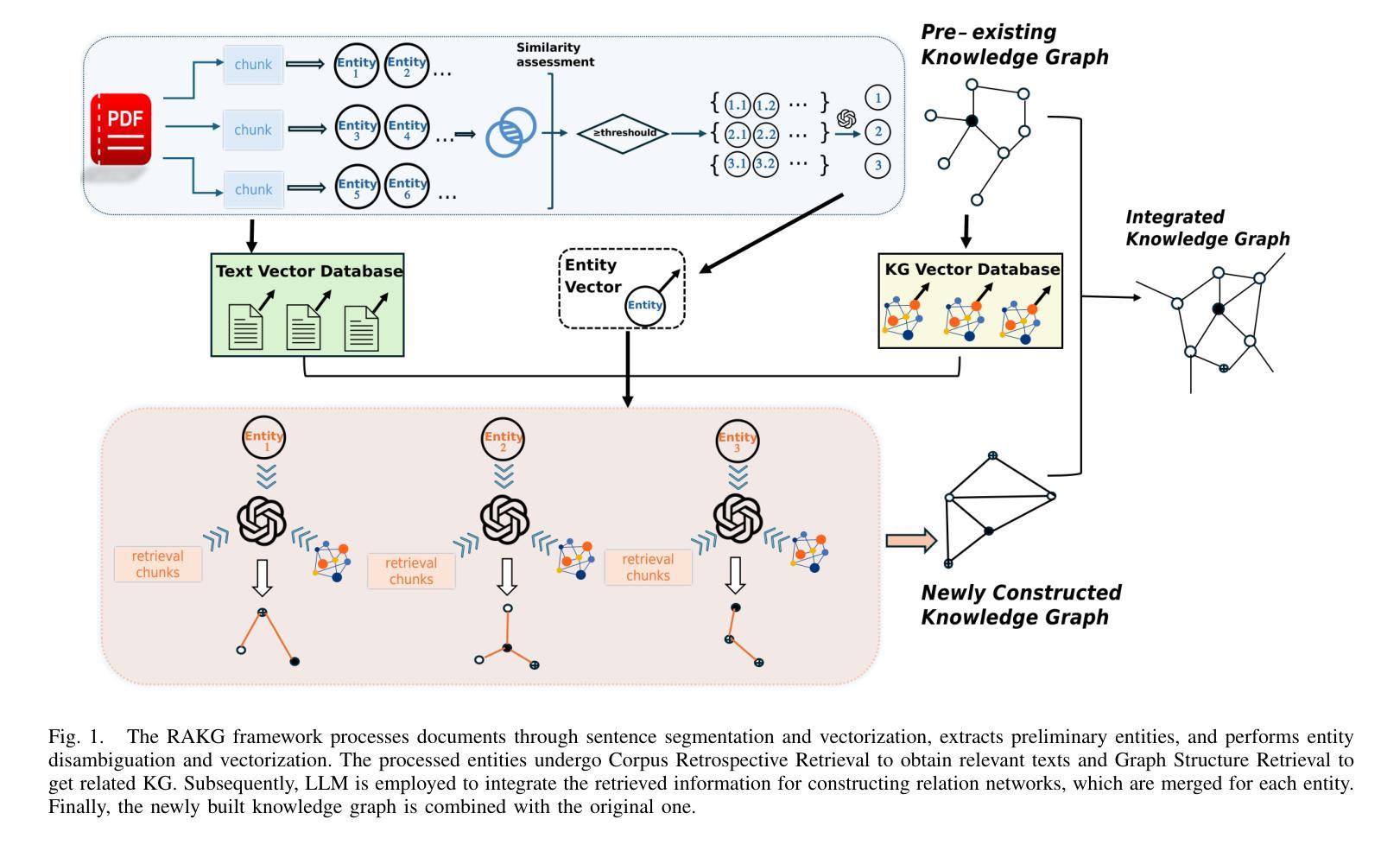
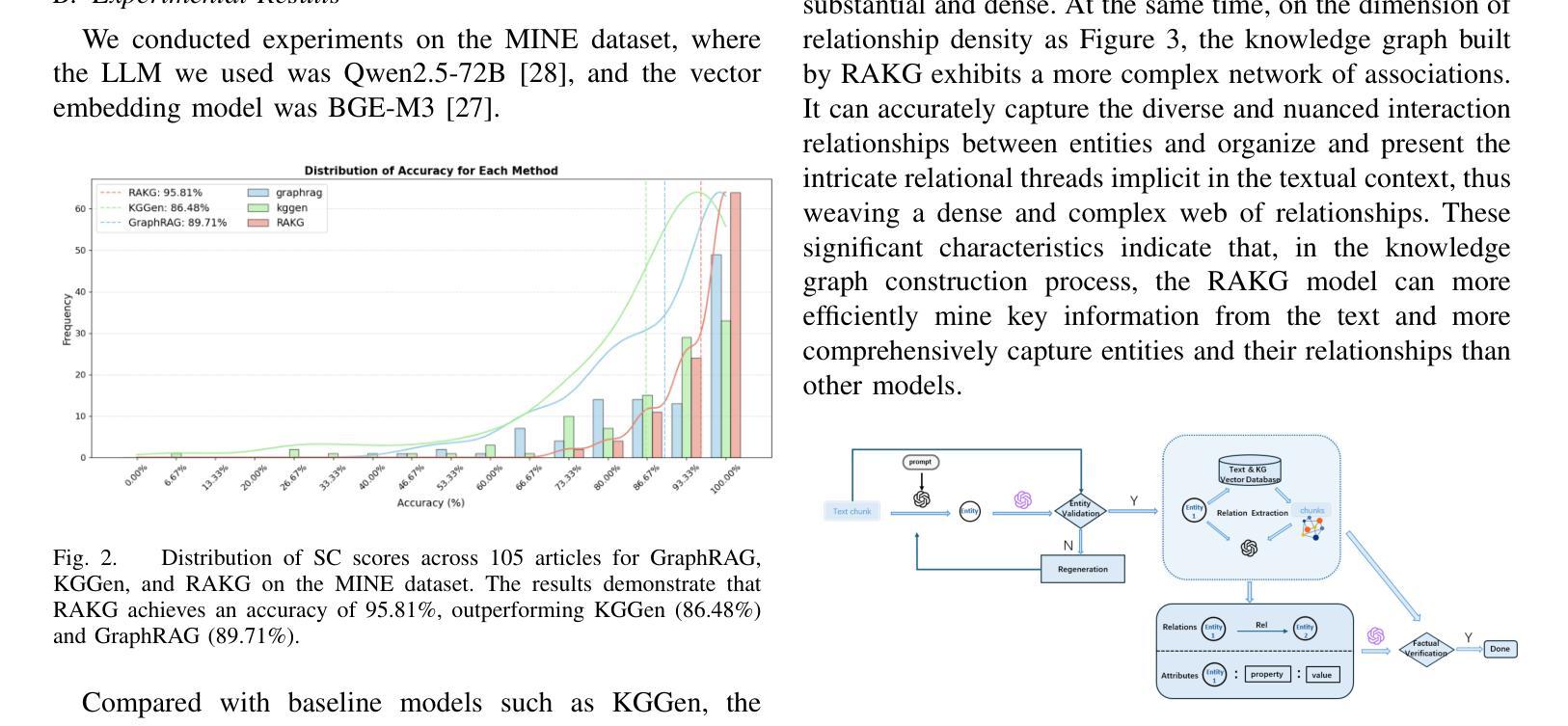
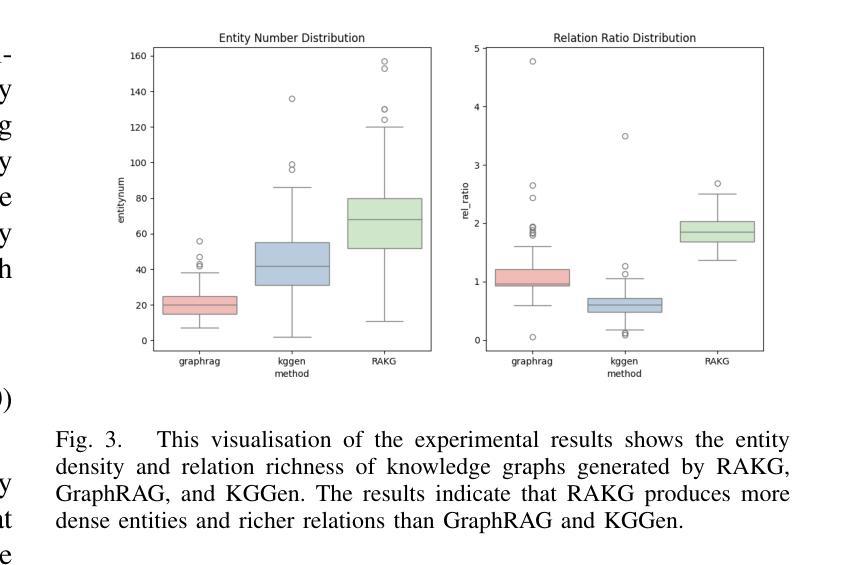
RAKG:Document-level Retrieval Augmented Knowledge Graph Construction
Authors:Hairong Zhang, Jiaheng Si, Guohang Yan, Boyuan Qi, Pinlong Cai, Song Mao, Ding Wang, Botian Shi
With the rise of knowledge graph based retrieval-augmented generation (RAG) techniques such as GraphRAG and Pike-RAG, the role of knowledge graphs in enhancing the reasoning capabilities of large language models (LLMs) has become increasingly prominent. However, traditional Knowledge Graph Construction (KGC) methods face challenges like complex entity disambiguation, rigid schema definition, and insufficient cross-document knowledge integration. This paper focuses on the task of automatic document-level knowledge graph construction. It proposes the Document-level Retrieval Augmented Knowledge Graph Construction (RAKG) framework. RAKG extracts pre-entities from text chunks and utilizes these pre-entities as queries for RAG, effectively addressing the issue of long-context forgetting in LLMs and reducing the complexity of Coreference Resolution. In contrast to conventional KGC methods, RAKG more effectively captures global information and the interconnections among disparate nodes, thereby enhancing the overall performance of the model. Additionally, we transfer the RAG evaluation framework to the KGC field and filter and evaluate the generated knowledge graphs, thereby avoiding incorrectly generated entities and relationships caused by hallucinations in LLMs. We further developed the MINE dataset by constructing standard knowledge graphs for each article and experimentally validated the performance of RAKG. The results show that RAKG achieves an accuracy of 95.91 % on the MINE dataset, a 6.2 % point improvement over the current best baseline, GraphRAG (89.71 %). The code is available at https://github.com/LMMApplication/RAKG.
随着基于知识图谱的检索增强生成(RAG)技术(如GraphRAG和Pike-RAG)的兴起,知识图谱在提升大型语言模型(LLM)推理能力方面的作用日益突出。然而,传统的知识图谱构建(KGC)方法面临复杂的实体消歧、严格的模式定义以及跨文档知识整合不足等挑战。本文专注于自动文档级知识图谱构建任务,提出了文档级检索增强知识图谱构建(RAKG)框架。RAKG从文本块中提取预实体,并利用这些预实体作为RAG的查询,有效解决LLM中的长上下文遗忘问题,降低核心参考解析的复杂性。与传统的KGC方法相比,RAKG更有效地捕获全局信息和不同节点之间的互连,从而提高模型的总体性能。此外,我们将RAG评估框架转移到KGC领域,对生成的知识图谱进行过滤和评估,从而避免LLM中因幻觉而产生的错误实体和关系。我们进一步通过为每篇文章构建标准知识图谱来开发MINE数据集,并通过实验验证了RAKG的性能。结果表明,RAKG在MINE数据集上的准确率达到95.91%,比当前最佳基线GraphRAG(89.71%)高出6.2个百分点。代码可在https://github.com/LMMApplication/RAKG找到。
论文及项目相关链接
PDF 9 pages, 6 figures
Summary
本文介绍了文档级别的知识图谱构建框架RAKG。与传统的知识图谱构建方法相比,RAKG能够从文本中提取预实体,并利用这些预实体作为查询增强知识图谱的构建,从而提高大型语言模型的推理能力。此外,RAKG能够更有效地捕获全局信息和不同节点之间的互连,从而提高模型的总体性能。同时,本文还介绍了对RAKG性能进行评估的方法和结果。
Key Takeaways
- 知识图谱在增强大型语言模型推理能力方面扮演重要角色。
- 传统知识图谱构建方法面临复杂实体消歧、刚性模式定义和跨文档知识整合不足等挑战。
- RAKG框架能够自动构建文档级别的知识图谱,提取文本中的预实体并作为查询增强知识图谱的构建。
- RAKG解决了大型语言模型中的长上下文遗忘问题,并降低了核心解析的复杂性。
- RAKG更有效地捕获全局信息和不同节点之间的互连,提高了模型的总体性能。
- 开发了针对知识图谱构建的RAG评估框架,以避免大型语言模型中的幻觉导致的错误实体和关系生成。
点此查看论文截图


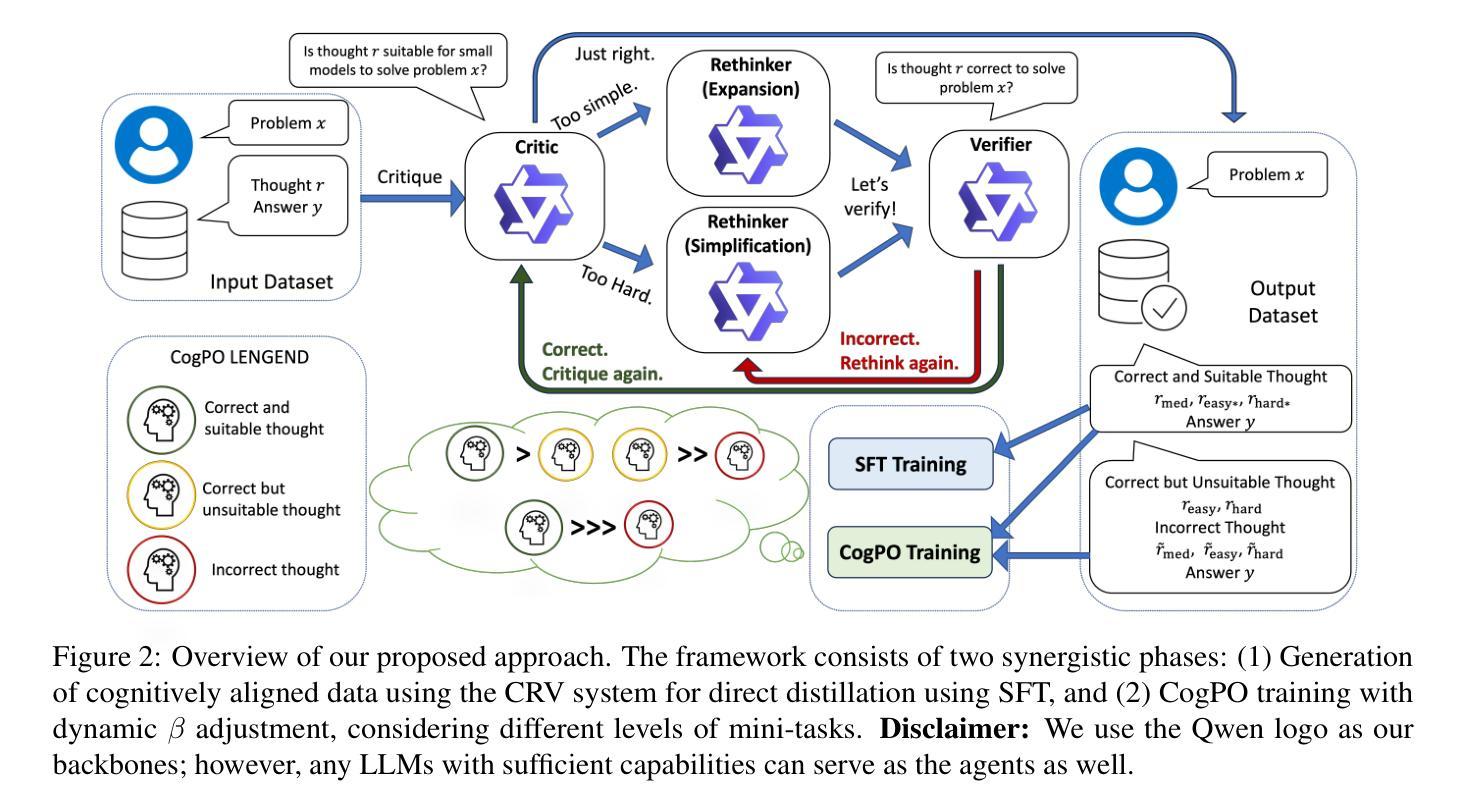
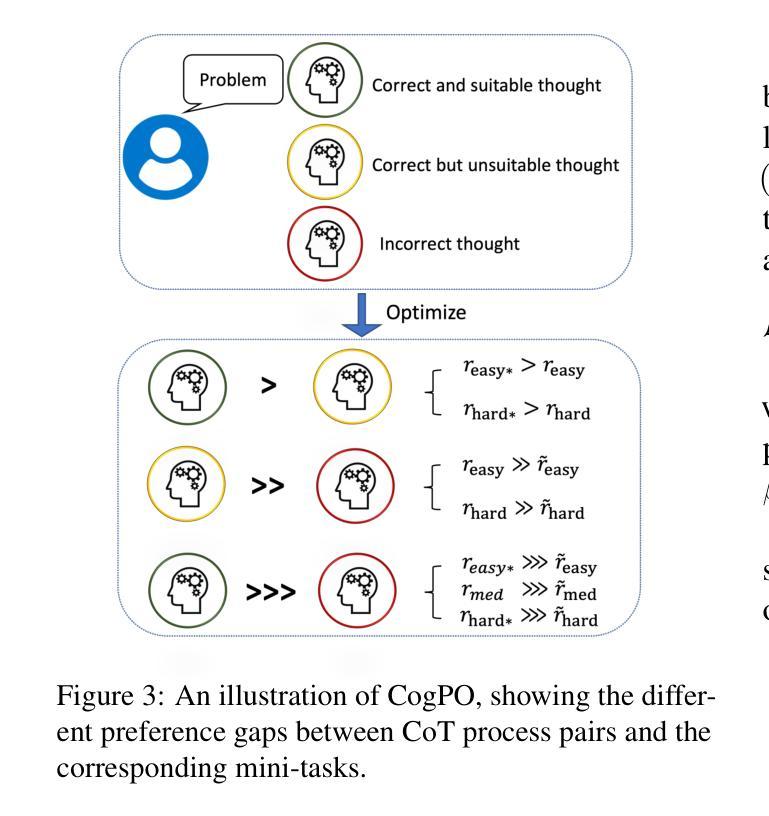
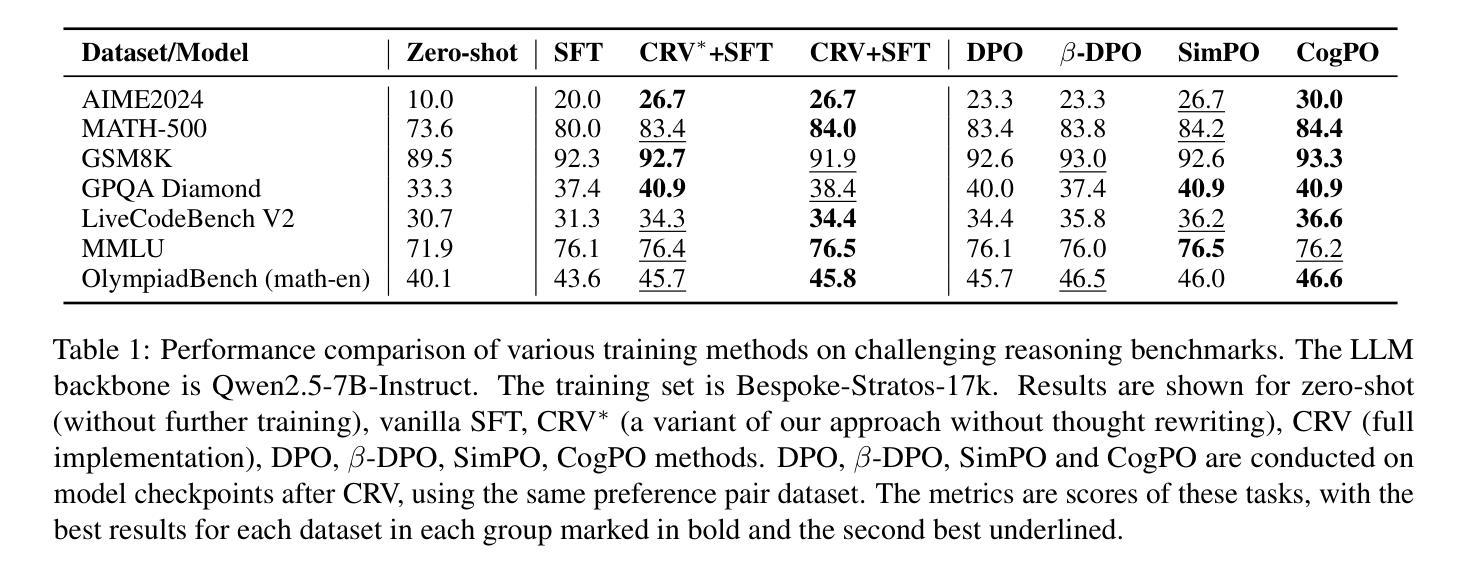
Training Small Reasoning LLMs with Cognitive Preference Alignment
Authors:Wenrui Cai, Chengyu Wang, Junbing Yan, Jun Huang, Xiangzhong Fang
The reasoning capabilities of large language models (LLMs), such as OpenAI’s o1 and DeepSeek-R1, have seen substantial advancements through deep thinking. However, these enhancements come with significant resource demands, underscoring the need to explore strategies to train effective reasoning LLMs with far fewer parameters. A critical challenge is that smaller models have different capacities and cognitive trajectories than their larger counterparts. Hence, direct distillation of chain-of-thought (CoT) results from large LLMs to smaller ones can be sometimes ineffective and requires a huge amount of annotated data. In this paper, we introduce a novel framework called Critique-Rethink-Verify (CRV), designed for training smaller yet powerful reasoning LLMs. Our CRV framework consists of multiple LLM agents, each specializing in unique abilities: (i) critiquing the CoTs according to the cognitive capabilities of smaller models, (ii) rethinking and refining these CoTs based on the critiques, and (iii) verifying the correctness of the refined results. We further propose the cognitive preference optimization (CogPO) algorithm to enhance the reasoning abilities of smaller models by aligning thoughts of these models with their cognitive capacities. Comprehensive evaluations on challenging reasoning benchmarks demonstrate the efficacy of CRV and CogPO, which outperforms other training methods by a large margin.
大型语言模型(如OpenAI的o1和DeepSeek-R1)的推理能力通过深度思考取得了重大进展。然而,这些增强功能需要巨大的资源需求,这强调了需要探索使用较少参数训练有效推理大型语言模型(LLM)的策略。一个关键挑战在于小型模型的容量和认知轨迹与大型模型不同。因此,直接从大型LLM蒸馏思维链(CoT)结果到小型LLM有时会无效,并且需要大量的注释数据。在本文中,我们介绍了一个名为批评反思验证(CRV)的新型框架,旨在训练小型但功能强大的推理LLM。我们的CRV框架包含多个LLM代理,每个代理都擅长独特的能力:(i)根据小型模型的认知能力对思维链进行批评,(ii)基于批评重新思考和细化这些思维链,以及(iii)验证细化结果的正确性。我们进一步提出了认知偏好优化(CogPO)算法,通过调整小型模型的思维来提高其推理能力,使其与它们的认知能力相匹配。在具有挑战性的推理基准测试上的全面评估证明了CRV和CogPO的有效性,与其他训练方法相比,该方法具有较大优势。
论文及项目相关链接
Summary
大型语言模型(LLM)的推理能力已经取得了显著的提升,但需要大量的资源来进行训练和优化。为了适应小型模型的独特需求和能力差异,本研究提出了一种新型的训练框架CRV,它包含了批判、再思考和验证三个关键步骤。同时,还提出了认知偏好优化算法(CogPO),旨在提高小型模型的推理能力。实验结果显示CRV和CogPO训练法的效率明显优于其他方法。
Key Takeaways
- 大型语言模型的推理能力已经取得了显著进步,但需要巨大的资源来进行训练和优化。
- 直接将大型模型的思维链(CoT)结果蒸馏到小型模型可能并不总是有效。
- 提出了新型训练框架CRV,包括批判、再思考和验证三个步骤,旨在训练小型推理模型。
- CRV框架包含多个LLM代理,每个代理都具备独特的专业能力。
- 提出了认知偏好优化算法(CogPO),用于增强小型模型的推理能力,使其思维与模型能力相匹配。
点此查看论文截图

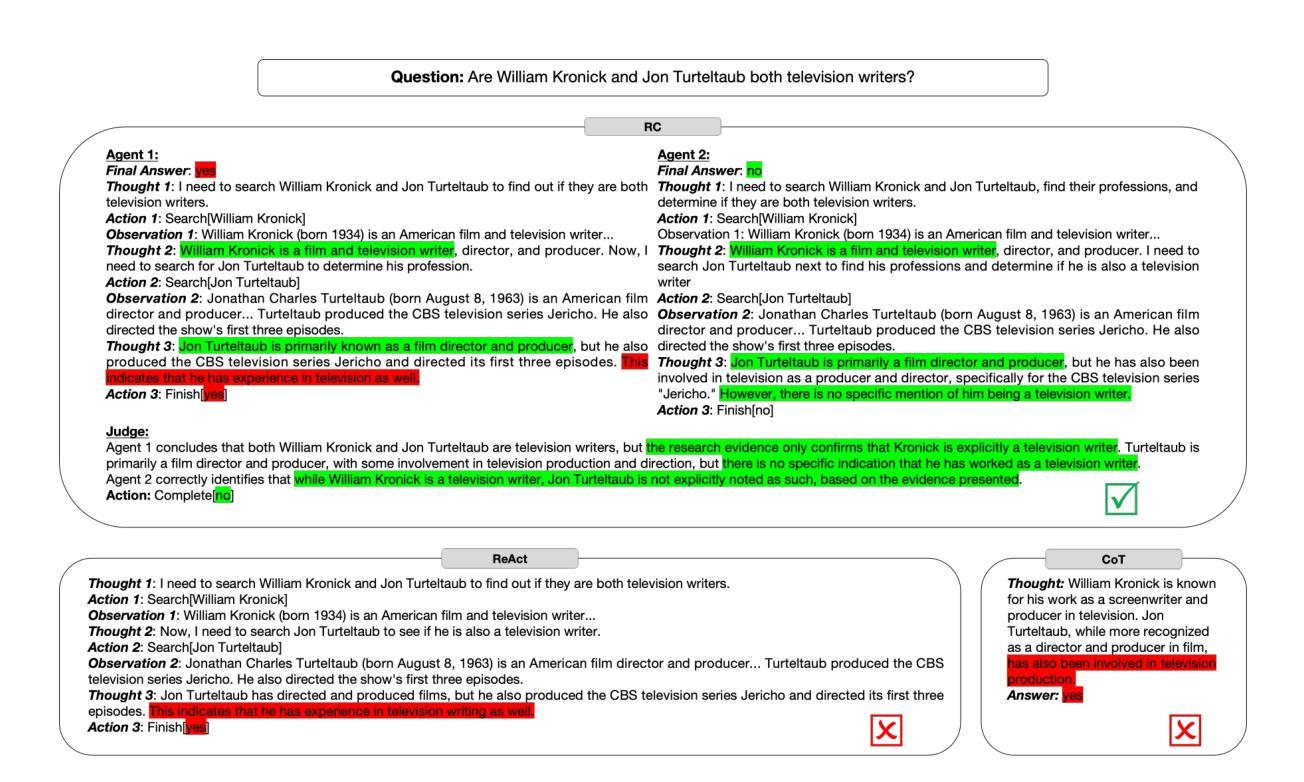
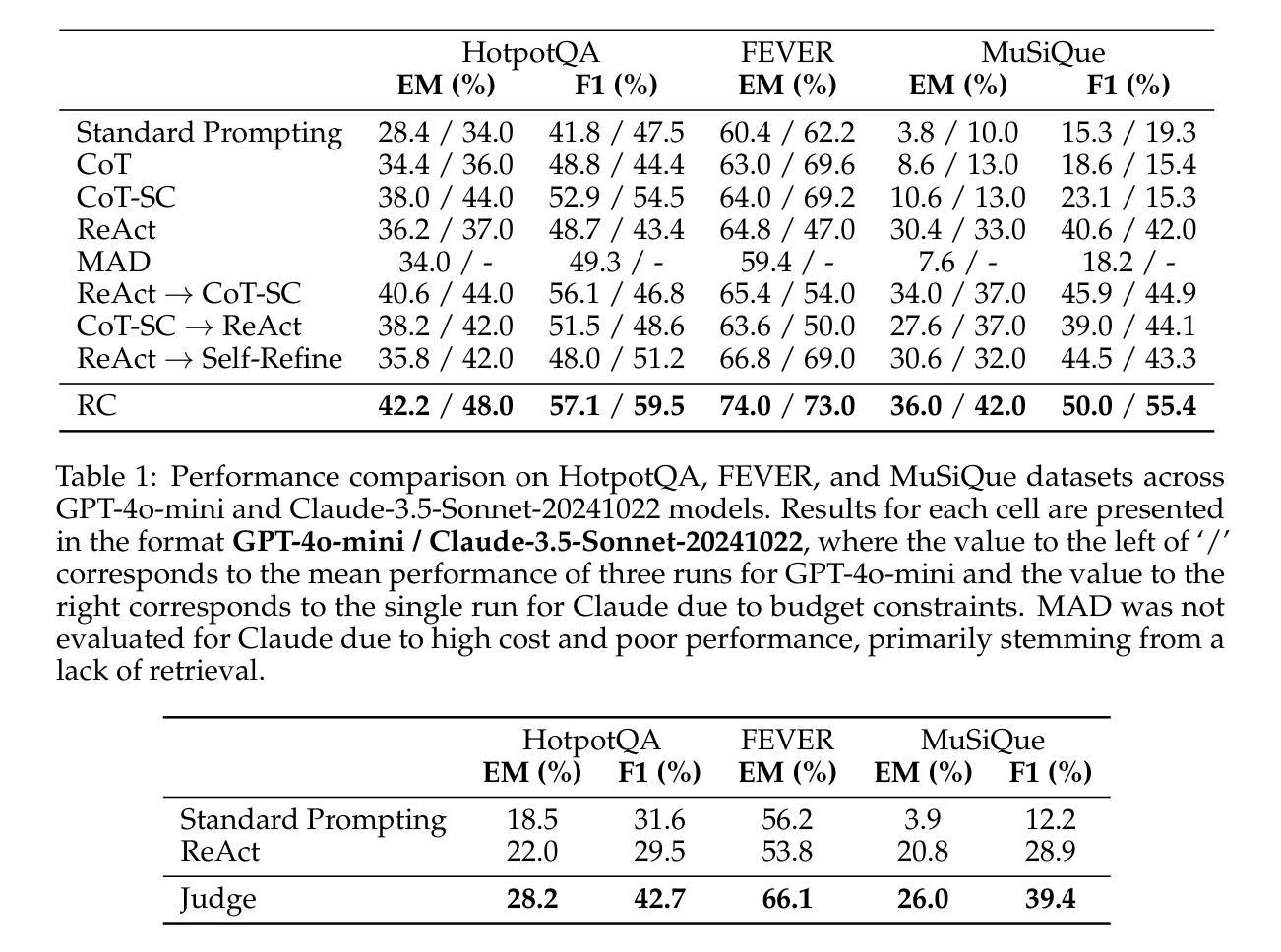
Reasoning Court: Combining Reasoning, Action, and Judgment for Multi-Hop Reasoning
Authors:Jingtian Wu, Claire Cardie
While large language models (LLMs) have demonstrated strong capabilities in tasks like question answering and fact verification, they continue to suffer from hallucinations and reasoning errors, especially in multi-hop tasks that require integration of multiple information sources. Current methods address these issues through retrieval-based techniques (grounding reasoning in external evidence), reasoning-based approaches (enhancing coherence via improved prompting), or hybrid strategies combining both elements. One prominent hybrid method, ReAct, has outperformed purely retrieval-based or reasoning-based approaches; however, it lacks internal verification of intermediate reasoning steps, allowing potential errors to propagate through complex reasoning tasks. In this paper, we introduce Reasoning Court (RC), a novel framework that extends iterative reasoning-and-retrieval methods, such as ReAct, with a dedicated LLM judge. Unlike ReAct, RC employs this judge to independently evaluate multiple candidate answers and their associated reasoning generated by separate LLM agents. The judge is asked to select the answer that it considers the most factually grounded and logically coherent based on the presented reasoning and evidence, or synthesizes a new answer using available evidence and its pre-trained knowledge if all candidates are inadequate, flawed, or invalid. Evaluations on multi-hop benchmarks (HotpotQA, MuSiQue) and fact-verification (FEVER) demonstrate that RC consistently outperforms state-of-the-art few-shot prompting methods without task-specific fine-tuning.
在大规模语言模型(LLM)在问答和事实验证等任务中展现出强大能力的同时,它们仍面临着虚构和推理错误的问题,特别是在需要整合多个信息源的多跳任务中。当前的方法通过基于检索的技术(将推理基于外部证据)、基于推理的方法(通过改进提示来提高连贯性)或结合这两个要素的混合策略来解决这些问题。一种突出的混合方法ReAct已经超越了纯粹的基于检索或基于推理的方法;然而,它缺乏对中间推理步骤的内部验证,允许潜在的错误在复杂的推理任务中传播。在本文中,我们介绍了Reasoning Court(RC)这一新框架,它扩展了如ReAct之类的迭代推理和检索方法,并配备了一名专职的大规模语言模型法官。不同于ReAct,RC雇佣这个法官来独立评估多个候选答案及其相关的推理,这些答案和推理是由单独的大规模语言模型代理生成的。法官根据提供的推理和证据,选择它认为最基于事实和逻辑连贯的答案,如果所有候选答案都不足、有缺陷或无效,它还会利用可用证据和其预训练知识合成新的答案。在Multi-hop基准测试(HotpotQA、MuSiQue)和事实验证(FEVER)上的评估表明,RC始终优于无需特定任务微调的最先进的小样本提示方法。
论文及项目相关链接
Summary
大型语言模型(LLMs)在问答和事实核查等任务中表现出强大的能力,但在需要整合多个信息源的多跳任务中仍存在幻觉和推理错误。当前方法通过检索基于技术、推理基于方法和混合策略来解决这些问题。本论文介绍了一种新的框架——Reasoning Court(RC),它通过增加一个独立的LLM法官来扩展迭代推理和检索方法,如ReAct。法官负责独立评估多个候选答案及其相关推理,并选择其认为最基于事实和逻辑连贯的答案。如果所有候选答案都不足、有缺陷或无效,法官还会利用可用证据和预训练知识合成新的答案。评估结果表明,RC在少样本提示方法上一致地优于最新技术,且无需针对特定任务进行微调。
Key Takeaways
- 大型语言模型(LLMs)在多跳任务中仍存在幻觉和推理错误。
- 当前解决此问题的方法包括检索基于技术、推理基于方法和混合策略。
- Reasoning Court(RC)是一种新的框架,通过增加一个独立的LLM法官来扩展迭代推理和检索方法。
- 法官负责独立评估多个候选答案及其相关推理,并选择合适的答案。
- 如果候选答案不足、有缺陷或无效,法官会利用证据和预训练知识合成新答案。
- RC在少样本提示方法上优于最新技术,无需特定任务微调。
点此查看论文截图

Two Heads are Better Than One: Test-time Scaling of Multi-agent Collaborative Reasoning
Authors:Can Jin, Hongwu Peng, Qixin Zhang, Yujin Tang, Dimitris N. Metaxas, Tong Che
Multi-agent systems (MAS) built on large language models (LLMs) offer a promising path toward solving complex, real-world tasks that single-agent systems often struggle to manage. While recent advancements in test-time scaling (TTS) have significantly improved single-agent performance on challenging reasoning tasks, how to effectively scale collaboration and reasoning in MAS remains an open question. In this work, we introduce an adaptive multi-agent framework designed to enhance collaborative reasoning through both model-level training and system-level coordination. We construct M500, a high-quality dataset containing 500 multi-agent collaborative reasoning traces, and fine-tune Qwen2.5-32B-Instruct on this dataset to produce M1-32B, a model optimized for multi-agent collaboration. To further enable adaptive reasoning, we propose a novel CEO agent that dynamically manages the discussion process, guiding agent collaboration and adjusting reasoning depth for more effective problem-solving. Evaluated in an open-source MAS across a range of tasks-including general understanding, mathematical reasoning, and coding-our system significantly outperforms strong baselines. For instance, M1-32B achieves 12% improvement on GPQA-Diamond, 41% on AIME2024, and 10% on MBPP-Sanitized, matching the performance of state-of-the-art models like DeepSeek-R1 on some tasks. These results highlight the importance of both learned collaboration and adaptive coordination in scaling multi-agent reasoning. Code is available at https://github.com/jincan333/MAS-TTS
基于大型语言模型(LLM)的多智能体系统(MAS)为解决复杂的现实世界任务提供了一条充满希望的道路,这些任务通常是单一智能体系统难以应对的。虽然最近在测试时缩放(TTS)方面的进展已经显著提高了单一智能体在具有挑战性的推理任务上的性能,但如何在MAS中有效地扩展协作和推理仍然是一个悬而未决的问题。在这项工作中,我们引入了一个自适应多智能体框架,旨在通过模型级别的训练和系统级别的协调来增强协作推理。我们构建了M500,这是一个包含500个多智能体协作推理轨迹的高质量数据集,并使用此数据集对Qwen2.5-32B-Instruct进行微调,以产生针对多智能体协作优化的M1-32B模型。为了进一步实现自适应推理,我们提出了一种新型的首席执行官智能体,它动态管理讨论过程,引导智能体协作,并调整推理深度,以更有效地解决问题。我们的系统在包括通用理解、数学推理和编码等一系列任务中,在开源MAS上进行了评估,显著优于强大的基线。例如,M1-32B在GPQA-Diamond上实现了12%的改进,在AIME2024上实现了41%的改进,在MBPP-Sanitized上实现了10%的改进,在某些任务上与DeepSeek-R1等最新模型相匹配。这些结果强调了学习协作和自适应协调在扩展多智能体推理中的重要性。代码可在https://github.com/jincan333/MAS-TTS 找到。
论文及项目相关链接
Summary
本文介绍了一种基于大型语言模型的多智能体系统(MAS),旨在解决单一智能体系统难以应对的复杂现实世界任务。文章通过构建M500数据集和M1-32B模型,优化了多智能体的协作推理能力。同时,引入了一种新型CEO智能体,以动态管理讨论过程,调整推理深度,更有效地解决问题。在多项任务上,该系统显著优于基线模型,如GPQA-Diamond、AIME2024和MBPP-Sanitized等任务上的性能提升分别达到了12%、41%和10%。这表明学习到的协作和自适应协调在扩展多智能体推理中的重要性。
Key Takeaways
- 多智能体系统(MAS)结合大型语言模型(LLM)为解决复杂现实世界任务提供了有效途径,尤其对于单一智能体难以处理的任务。
- 通过构建M500数据集和M1-32B模型,优化了多智能体的协作推理能力。
- 引入新型CEO智能体,动态管理讨论过程,调整推理深度,提升问题解决效率。
- 系统在多项任务上的表现显著优于基线模型,包括一般理解、数学推理和编码任务。
- 在GPQA-Diamond、AIME2024和MBPP-Sanitized等任务上,性能提升分别达到了12%、41%和10%,与最新模型如DeepSeek-R1相匹配。
- 该系统的性能提升得益于学习到的协作和自适应协调。
点此查看论文截图


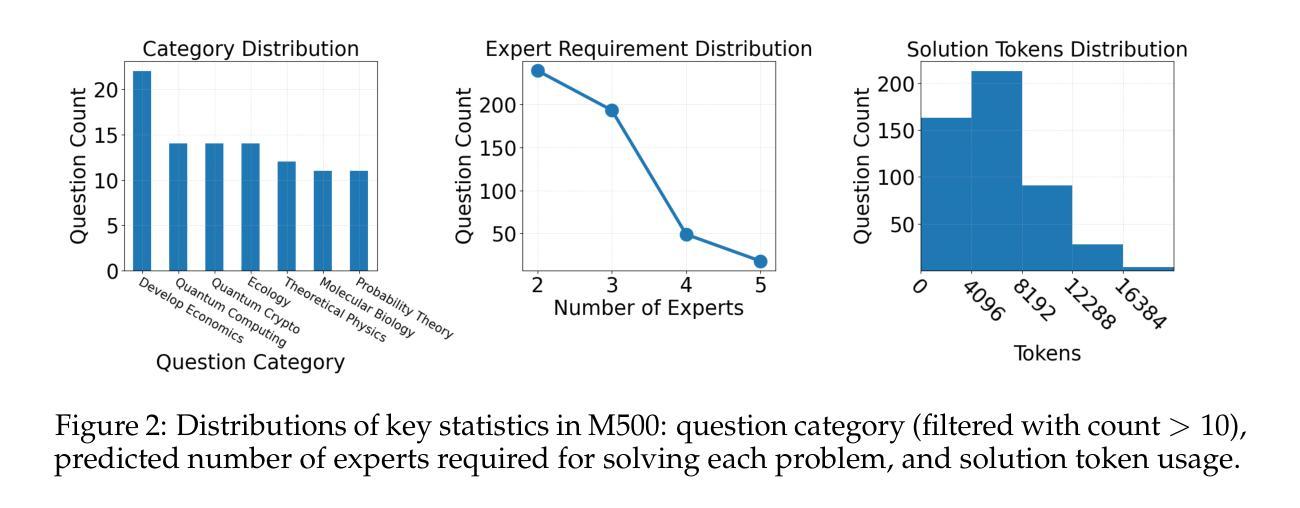
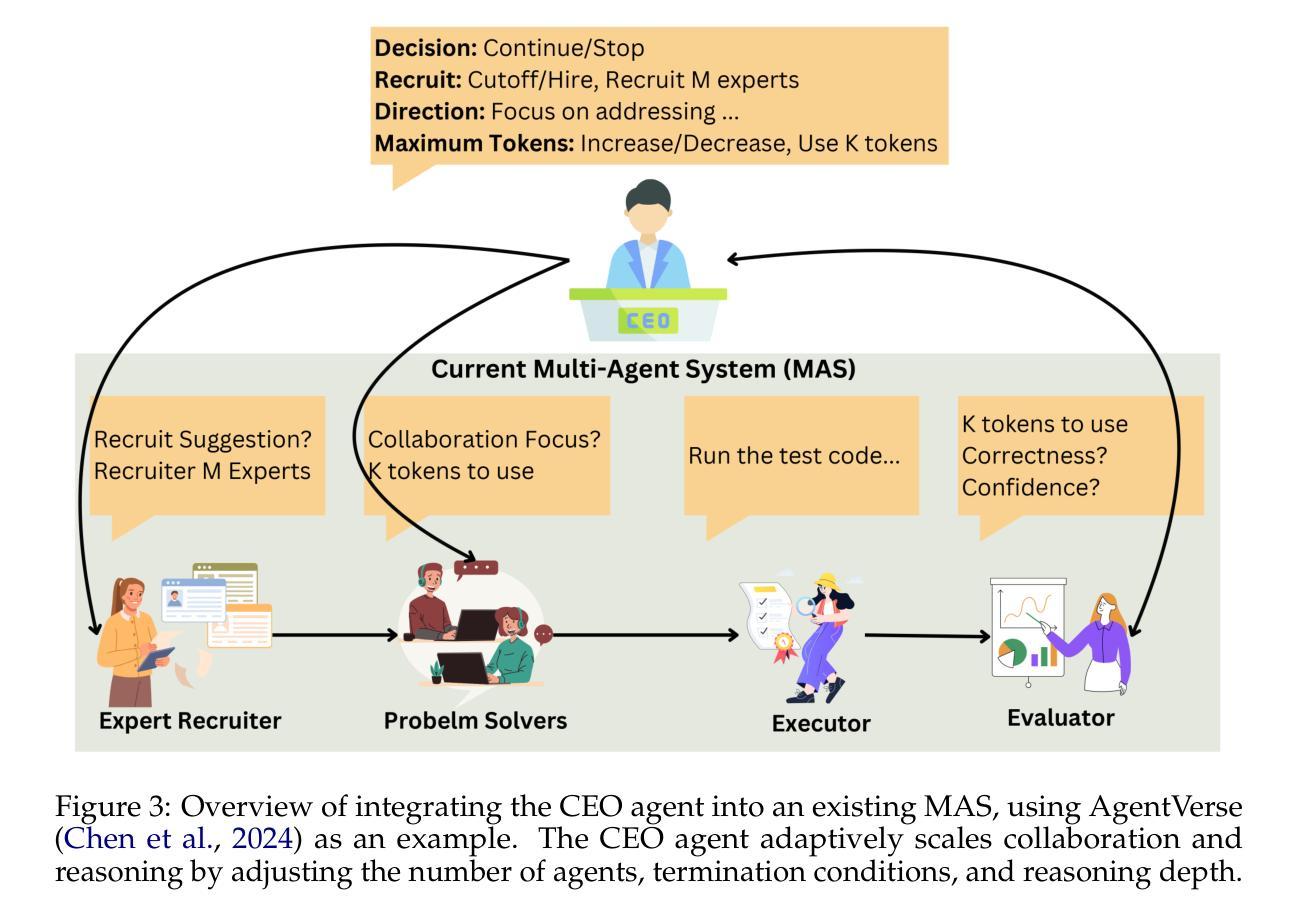
DUMP: Automated Distribution-Level Curriculum Learning for RL-based LLM Post-training
Authors:Zhenting Wang, Guofeng Cui, Kun Wan, Wentian Zhao
Recent advances in reinforcement learning (RL)-based post-training have led to notable improvements in large language models (LLMs), particularly in enhancing their reasoning capabilities to handle complex tasks. However, most existing methods treat the training data as a unified whole, overlooking the fact that modern LLM training often involves a mixture of data from diverse distributions-varying in both source and difficulty. This heterogeneity introduces a key challenge: how to adaptively schedule training across distributions to optimize learning efficiency. In this paper, we present a principled curriculum learning framework grounded in the notion of distribution-level learnability. Our core insight is that the magnitude of policy advantages reflects how much a model can still benefit from further training on a given distribution. Based on this, we propose a distribution-level curriculum learning framework for RL-based LLM post-training, which leverages the Upper Confidence Bound (UCB) principle to dynamically adjust sampling probabilities for different distrubutions. This approach prioritizes distributions with either high average advantage (exploitation) or low sample count (exploration), yielding an adaptive and theoretically grounded training schedule. We instantiate our curriculum learning framework with GRPO as the underlying RL algorithm and demonstrate its effectiveness on logic reasoning datasets with multiple difficulties and sources. Our experiments show that our framework significantly improves convergence speed and final performance, highlighting the value of distribution-aware curriculum strategies in LLM post-training. Code: https://github.com/ZhentingWang/DUMP.
最近,基于强化学习(RL)的后期训练取得了显著进展,为大型语言模型(LLM)带来了可观的改进,特别是在提高处理复杂任务的能力方面。然而,大多数现有方法将训练数据视为一个整体,忽视了现代LLM训练通常涉及来自不同分布的混合数据的事实,这些数据的来源和难度都在不断变化。这种异质性引发了一个关键挑战:如何自适应地调度不同分布的训练以优化学习效率。在本文中,我们提出了一个基于分布级别可学习性的课程学习框架。我们的核心见解是,策略优势的大小反映了模型在给定分布上进一步训练的潜在收益。基于此,我们提出了基于强化学习的LLM后训练分布级课程学习框架,它利用上置信界(UCB)原则来动态调整不同分布的采样概率。该方法优先处理具有高平均优势(利用)或低样本数量(探索)的分布,从而产生一个自适应且理论上有依据的训练计划。我们以GRPO作为底层的RL算法来实现我们的课程学习框架,并在具有不同难度和来源的逻辑推理数据集上证明了其有效性。实验表明,我们的框架显著提高了收敛速度和最终性能,突显了分布感知课程策略在LLM后训练中的价值。代码:https://github.com/ZhentingWang/DUMP。
论文及项目相关链接
Summary
强化学习(RL)在大型语言模型(LLM)训练后阶段的应用已带来显著进步,特别是在处理复杂任务时提升了模型的推理能力。然而,大多数现有方法将训练数据视为一个整体,忽略了现代LLM训练涉及的多种数据来源和难度分布的差异。本文提出一种基于分布级别学习能力的课程学习框架,用于RL驱动的LLM训练后阶段。该框架利用策略优势幅度来评估模型从特定分布进一步训练中的潜在收益,并基于此提出一种基于分布级别的课程学习策略。实验表明,该框架在逻辑推理数据集上显著提高了收敛速度和最终性能,突显了在大规模语言模型训练后阶段采用分布感知课程策略的价值。
Key Takeaways
- 强化学习在大型语言模型训练后的应用提升了模型的推理能力。
- 现有方法忽略了训练数据的多样性和分布差异。
- 提出了一种基于分布级别学习能力的课程学习框架。
- 该框架利用策略优势幅度评估模型从特定分布进一步训练中的潜在收益。
- 采用基于Upper Confidence Bound (UCB)原则的动态采样概率调整方法,以平衡开发(exploitation)和探索(exploration)。
- 框架在逻辑推理解题集上实现了显著的收敛速度和性能提升。
点此查看论文截图