⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-04-16 更新
DiTSE: High-Fidelity Generative Speech Enhancement via Latent Diffusion Transformers
Authors:Heitor R. Guimarães, Jiaqi Su, Rithesh Kumar, Tiago H. Falk, Zeyu Jin
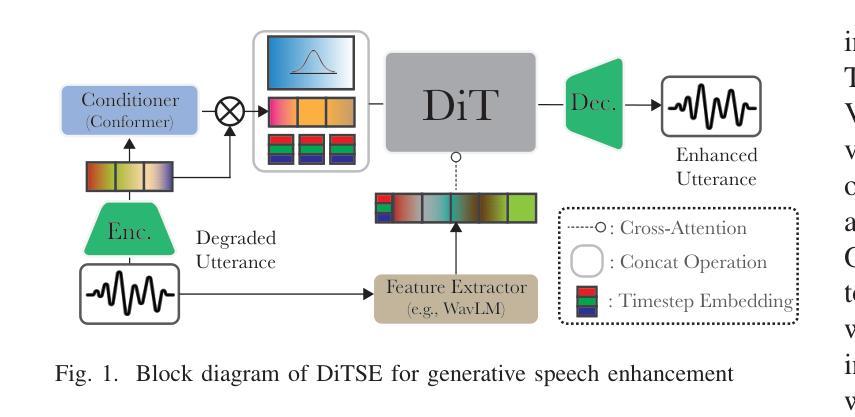
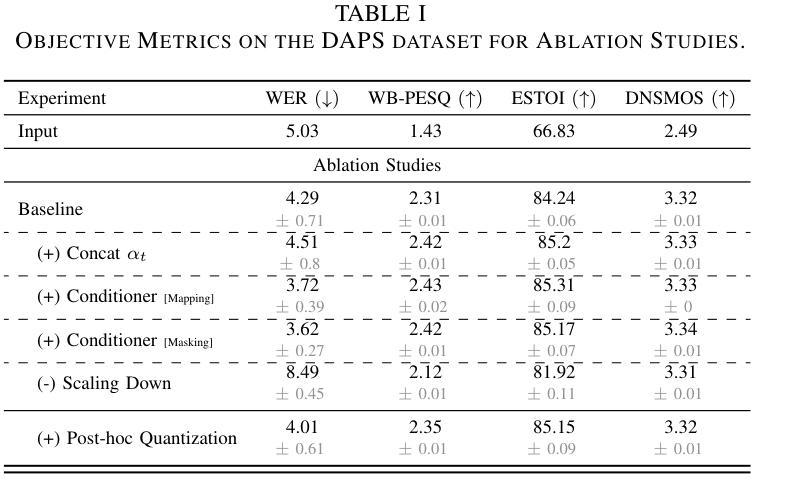
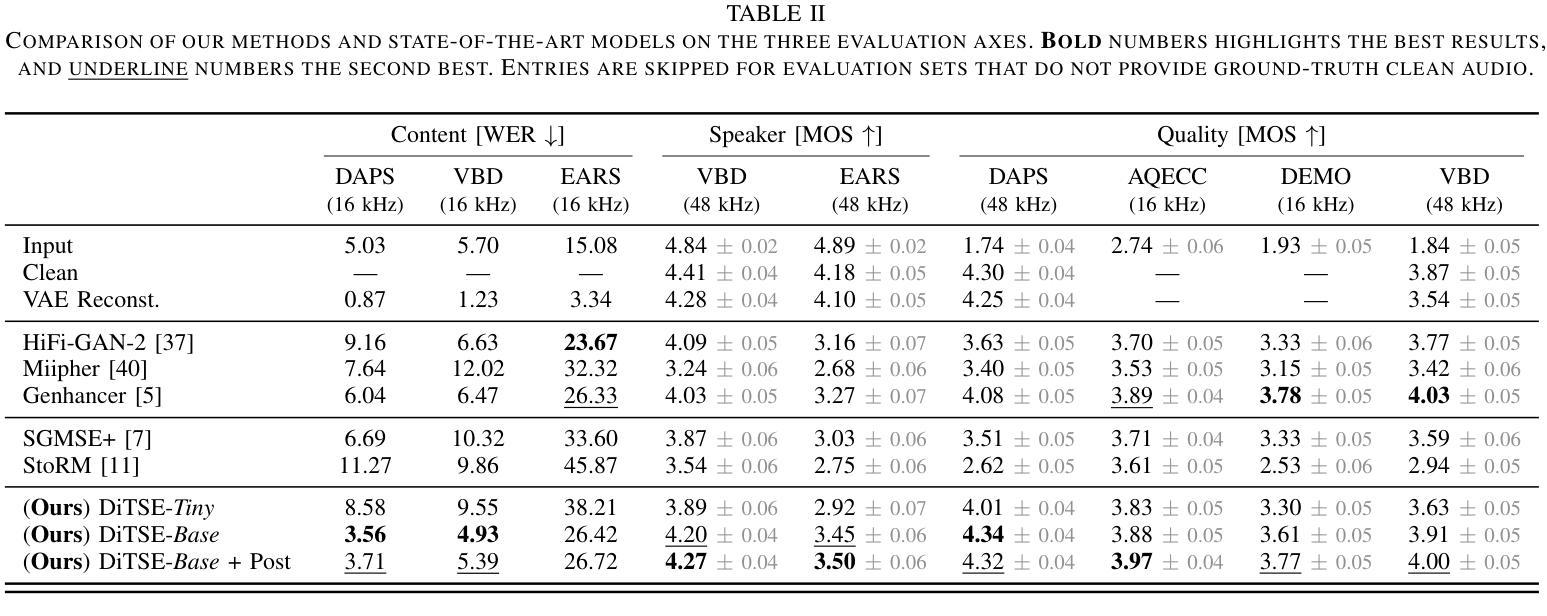
Real-world speech recordings suffer from degradations such as background noise and reverberation. Speech enhancement aims to mitigate these issues by generating clean high-fidelity signals. While recent generative approaches for speech enhancement have shown promising results, they still face two major challenges: (1) content hallucination, where plausible phonemes generated differ from the original utterance; and (2) inconsistency, failing to preserve speaker’s identity and paralinguistic features from the input speech. In this work, we introduce DiTSE (Diffusion Transformer for Speech Enhancement), which addresses quality issues of degraded speech in full bandwidth. Our approach employs a latent diffusion transformer model together with robust conditioning features, effectively addressing these challenges while remaining computationally efficient. Experimental results from both subjective and objective evaluations demonstrate that DiTSE achieves state-of-the-art audio quality that, for the first time, matches real studio-quality audio from the DAPS dataset. Furthermore, DiTSE significantly improves the preservation of speaker identity and content fidelity, reducing hallucinations across datasets compared to state-of-the-art enhancers. Audio samples are available at: http://hguimaraes.me/DiTSE
现实世界中的语音记录会受到背景噪音和回声等干扰的影响。语音增强旨在通过生成干净的高保真信号来缓解这些问题。虽然最近的语音增强生成方法已经显示出有前景的结果,但它们仍然面临两大挑战:(1)内容幻觉,即产生的合理音素与原始发音不同;(2)不一致性,无法保留输入语音中的说话人身份和副语言特征。在这项工作中,我们引入了DiTSE(用于语音增强的扩散变压器),它解决了全频带退化语音的质量问题。我们的方法采用潜在扩散变压器模型以及稳健的条件特征,有效地解决了这些挑战,同时保持计算效率。来自主观和客观评估的实验结果证明,DiTSE达到了最先进的音频质量,首次与DAPS数据集的真实工作室质量音频相匹配。此外,DiTSE在保留说话人身份和内容保真度方面有了显著改善,与最先进的增强器相比,减少了跨数据集的幻觉。音频样本可在:http://hguimaraes.me/DiTSE处获取。
论文及项目相关链接
PDF Manuscript under review
Summary
语音现实世界的录音会受到背景噪音和回声等干扰。语音增强旨在生成清晰的高保真信号来缓解这些问题。虽然最近的生成式语音增强方法显示出有希望的成果,但它们仍然面临两大挑战:(1)内容虚构,生成的音素可能与原始语音不同;(2)不一致性,无法保留输入语音的说话人身份和副语言特征。在这项工作中,我们引入了扩散转换器语音增强(DiTSE),全面解决退化语音的质量问题。我们的方法采用潜在扩散转换器模型和稳健的条件特征,有效地解决了这些挑战,同时保持计算效率。实验结果表明,DiTSE达到了先进的声音质量水平,首次与DAPS数据集的真正工作室质量音频相匹配。此外,DiTSE在多个数据集的比较中显著提高了说话人身份和内容忠实性的保留,减少了虚构现象。音频样本可在:http://hguimaraes.me/DiTSE上找到。
Key Takeaways
- 语音增强旨在解决真实世界录音中的背景噪音和回声问题,生成清晰的高保真信号。
- 当前生成式语音增强方法面临内容虚构和保留说话人身份及副语言特征的不一致性两大挑战。
- DiTSE通过采用扩散转换器模型和条件特征来解决这些挑战。
- DiTSE达到了先进的声音质量水平,与DAPS数据集的真实工作室质量音频相匹配。
- DiTSE在保留说话人身份和内容忠实性方面表现优异,减少了虚构现象。
- DiTSE方法在计算效率方面表现良好。
点此查看论文截图

AMNet: An Acoustic Model Network for Enhanced Mandarin Speech Synthesis
Authors:Yubing Cao, Yinfeng Yu, Yongming Li, Liejun Wang
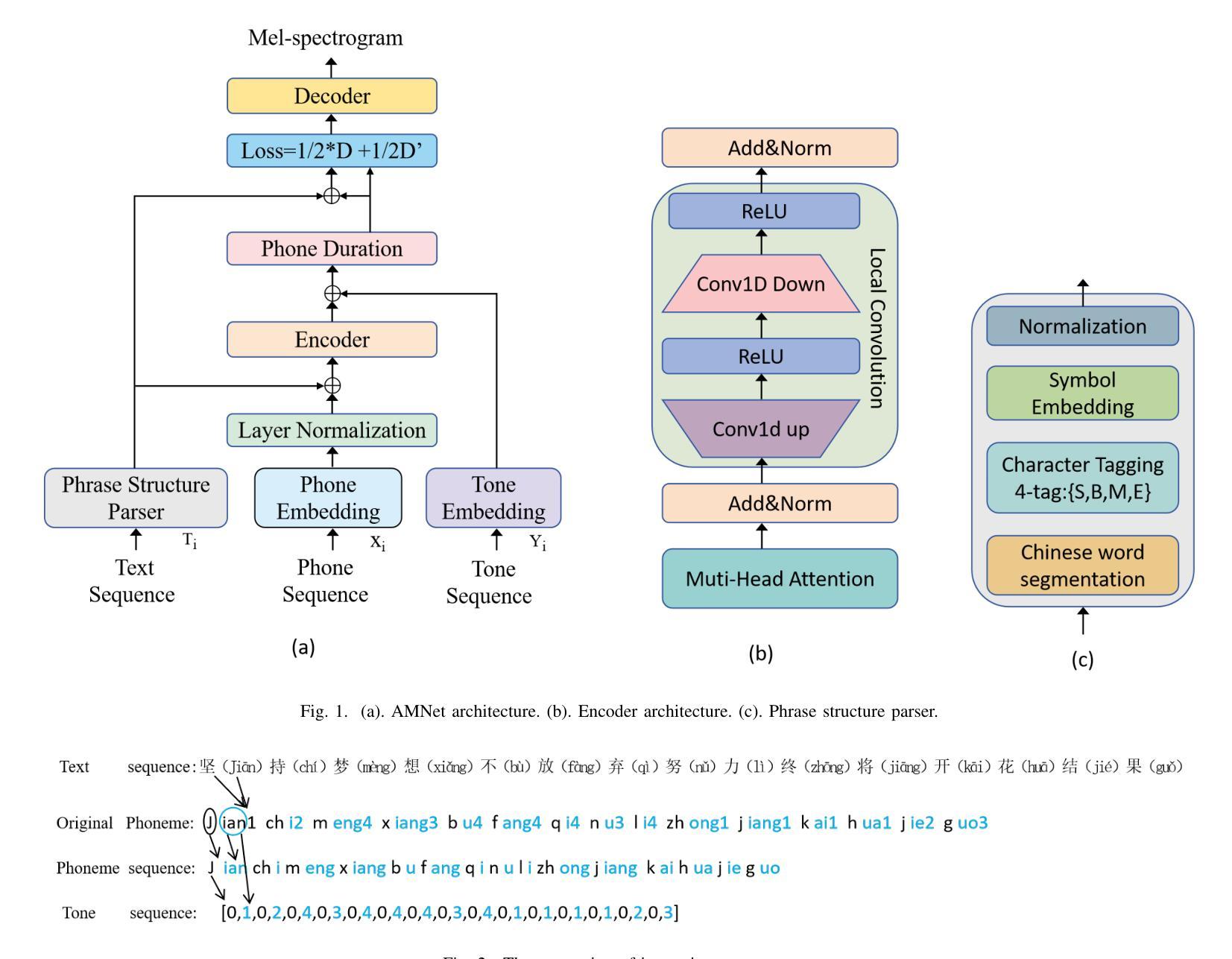
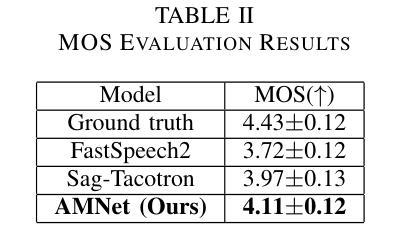
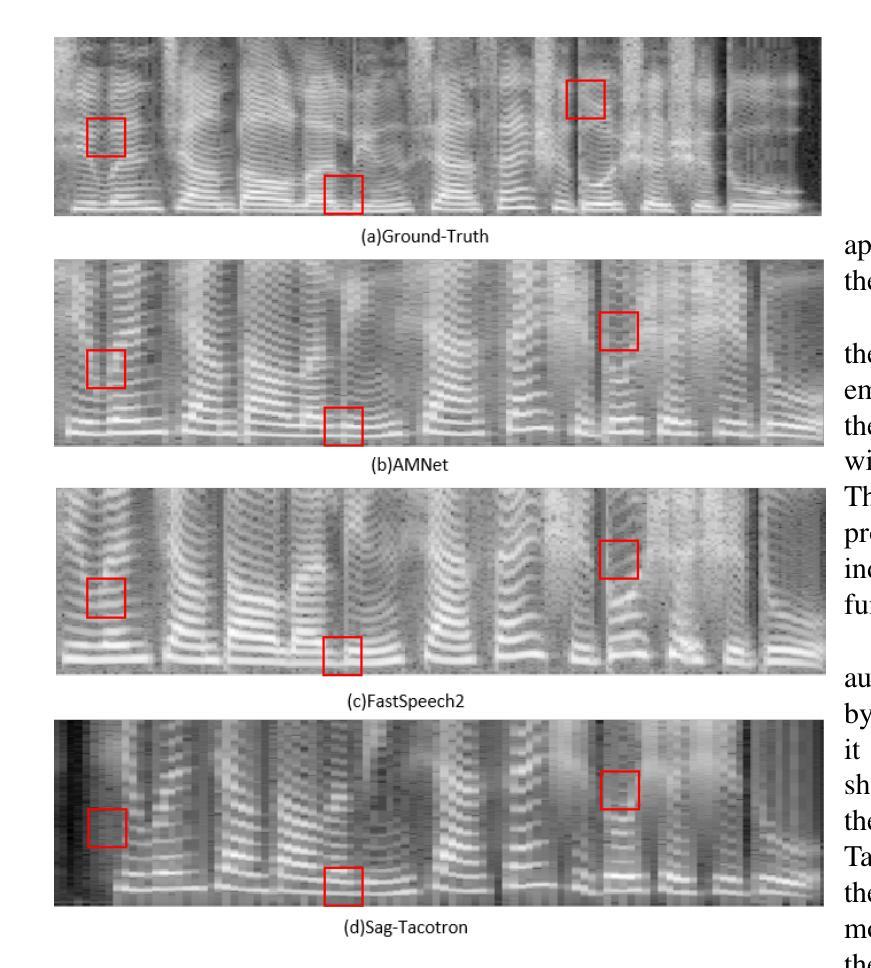
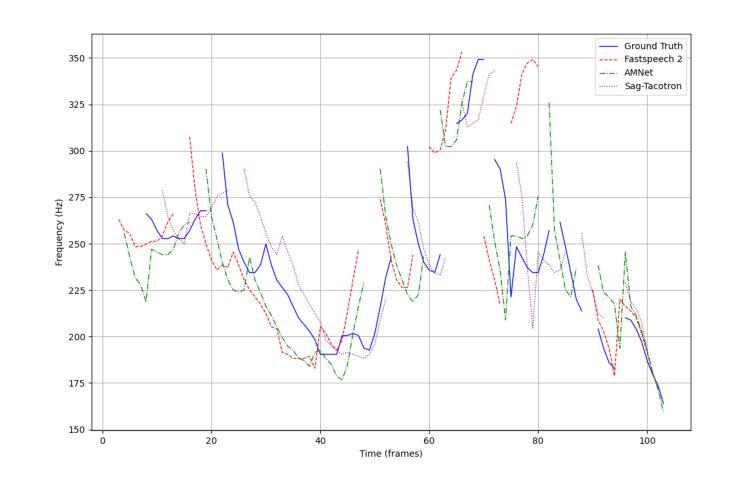
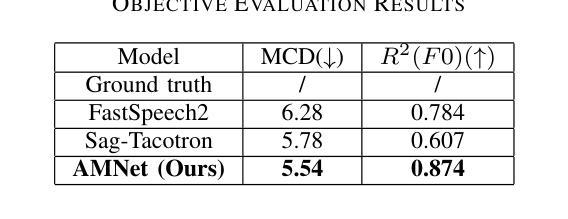
This paper presents AMNet, an Acoustic Model Network designed to improve the performance of Mandarin speech synthesis by incorporating phrase structure annotation and local convolution modules. AMNet builds upon the FastSpeech 2 architecture while addressing the challenge of local context modeling, which is crucial for capturing intricate speech features such as pauses, stress, and intonation. By embedding a phrase structure parser into the model and introducing a local convolution module, AMNet enhances the model’s sensitivity to local information. Additionally, AMNet decouples tonal characteristics from phonemes, providing explicit guidance for tone modeling, which improves tone accuracy and pronunciation. Experimental results demonstrate that AMNet outperforms baseline models in subjective and objective evaluations. The proposed model achieves superior Mean Opinion Scores (MOS), lower Mel Cepstral Distortion (MCD), and improved fundamental frequency fitting $F0 (R^2)$, confirming its ability to generate high-quality, natural, and expressive Mandarin speech.
本文介绍了AMNet,这是一个声学模型网络,旨在通过融入短语结构标注和局部卷积模块,提高普通话语音合成的性能。AMNet基于FastSpeech 2架构,解决了局部上下文建模的挑战,这对于捕捉复杂的语音特征(如停顿、重读和语调)至关重要。通过在模型中加入短语结构解析器和引入局部卷积模块,AMNet提高了模型对局部信息的敏感度。此外,AMNet将音调特性与音素分离,为音调建模提供明确的指导,提高了音调的准确性和发音。实验结果表明,在主观和客观评估中,AMNet的性能优于基准模型。所提出模型的平均意见得分(MOS)更高,梅尔倒谱失真(MCD)更低,基频拟合$F0 (R^2)$有所改善,证明了其生成高质量、自然、富有表现力的普通话语音的能力。
论文及项目相关链接
PDF Main paper (8 pages). Accepted for publication by IJCNN 2025
Summary
本文介绍了AMNet声学模型网络,该网络旨在通过融入短语结构标注和局部卷积模块,提高普通话语音合成的性能。AMNet基于FastSpeech 2架构,解决了局部语境建模的挑战,这对于捕捉语音的停顿、重音和语调等复杂特征至关重要。实验结果表明,AMNet在主观和客观评估中均优于基准模型,实现了较高的平均意见得分(MOS)、较低的梅尔倒谱失真(MCD)以及改善的基本频率拟合$F0 (R^2)$,证明其生成高质量、自然、表达力强的普通话语音的能力。
Key Takeaways
- AMNet是一个声学模型网络,旨在提高普通话语音合成的性能。
- AMNet基于FastSpeech 2架构,融入短语结构标注和局部卷积模块。
- AMNet解决了局部语境建模的挑战,捕捉语音的停顿、重音和语调等复杂特征。
- AMNet通过嵌入短语结构解析器和引入局部卷积模块,增强了模型对局部信息的敏感性。
- AMNet将声调特征与音素分离,为声调建模提供明确指导,提高了声调的准确性和发音质量。
- 实验结果表明,AMNet在主观和客观评估中均优于基准模型。
点此查看论文截图